diff --git a/.circleci/config.yml b/.circleci/config.yml
new file mode 100644
index 0000000..9456918
--- /dev/null
+++ b/.circleci/config.yml
@@ -0,0 +1,161 @@
+version: 2.1
+
+jobs:
+ lint:
+ docker:
+ - image: cimg/python:3.7.4
+ steps:
+ - checkout
+ - run:
+ name: Install dependencies
+ command: |
+ sudo apt-add-repository ppa:brightbox/ruby-ng -y
+ sudo apt-get update
+ sudo apt-get install -y ruby2.7
+ - run:
+ name: Install pre-commit hook
+ command: |
+ pip install pre-commit
+ pre-commit install
+ - run:
+ name: Linting
+ command: pre-commit run --all-files
+ - run:
+ name: Check docstring coverage
+ command: |
+ pip install interrogate
+ interrogate -v --ignore-init-method --ignore-module --ignore-nested-functions --ignore-regex "__repr__" --fail-under 50 mmseg
+
+ build_cpu:
+ parameters:
+ # The python version must match available image tags in
+ # https://circleci.com/developer/images/image/cimg/python
+ python:
+ type: string
+ default: "3.7.4"
+ torch:
+ type: string
+ torchvision:
+ type: string
+ docker:
+ - image: cimg/python:<< parameters.python >>
+ resource_class: large
+ steps:
+ - checkout
+ - run:
+ name: Install Libraries
+ command: |
+ sudo apt-get update
+ sudo apt-get install -y ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 libgl1-mesa-glx libjpeg-dev zlib1g-dev libtinfo-dev libncurses5
+ - run:
+ name: Configure Python & pip
+ command: |
+ python -m pip install --upgrade pip
+ python -m pip install wheel
+ - run:
+ name: Install PyTorch
+ command: |
+ python -V
+ python -m pip install torch==<< parameters.torch >>+cpu torchvision==<< parameters.torchvision >>+cpu -f https://download.pytorch.org/whl/torch_stable.html
+ - run:
+ name: Install mmseg dependencies
+ command: |
+ python -m pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cpu/torch<< parameters.torch >>/index.html
+ python -m pip install mmdet
+ python -m pip install -r requirements.txt
+ - run:
+ name: Build and install
+ command: |
+ python -m pip install -e .
+ - run:
+ name: Run unittests
+ command: |
+ python -m pip install timm
+ python -m coverage run --branch --source mmseg -m pytest tests/
+ python -m coverage xml
+ python -m coverage report -m
+
+ build_cu101:
+ machine:
+ image: ubuntu-1604-cuda-10.1:201909-23
+ resource_class: gpu.nvidia.small
+ steps:
+ - checkout
+ - run:
+ name: Install Libraries
+ command: |
+ sudo apt-get update
+ sudo apt-get install -y git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 libgl1-mesa-glx
+ - run:
+ name: Configure Python & pip
+ command: |
+ pyenv global 3.7.0
+ python -m pip install --upgrade pip
+ python -m pip install wheel
+ - run:
+ name: Install PyTorch
+ command: |
+ python -V
+ python -m pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
+ - run:
+ name: Install mmseg dependencies
+ # python -m pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch${{matrix.torch_version}}/index.html
+ command: |
+ python -m pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
+ python -m pip install mmdet
+ python -m pip install -r requirements.txt
+ - run:
+ name: Build and install
+ command: |
+ python setup.py check -m -s
+ TORCH_CUDA_ARCH_LIST=7.0 python -m pip install -e .
+ - run:
+ name: Run unittests
+ command: |
+ python -m pip install timm
+ python -m pytest tests/
+
+workflows:
+ unit_tests:
+ jobs:
+ - lint
+ - build_cpu:
+ name: build_cpu_th1.6
+ torch: 1.6.0
+ torchvision: 0.7.0
+ requires:
+ - lint
+ - build_cpu:
+ name: build_cpu_th1.7
+ torch: 1.7.0
+ torchvision: 0.8.1
+ requires:
+ - lint
+ - build_cpu:
+ name: build_cpu_th1.8_py3.9
+ torch: 1.8.0
+ torchvision: 0.9.0
+ python: "3.9.0"
+ requires:
+ - lint
+ - build_cpu:
+ name: build_cpu_th1.9_py3.8
+ torch: 1.9.0
+ torchvision: 0.10.0
+ python: "3.8.0"
+ requires:
+ - lint
+ - build_cpu:
+ name: build_cpu_th1.9_py3.9
+ torch: 1.9.0
+ torchvision: 0.10.0
+ python: "3.9.0"
+ requires:
+ - lint
+ - build_cu101:
+ requires:
+ - build_cpu_th1.6
+ - build_cpu_th1.7
+ - build_cpu_th1.8_py3.9
+ - build_cpu_th1.9_py3.8
+ - build_cpu_th1.9_py3.9
diff --git a/.dev/batch_test_list.py b/.dev/batch_test_list.py
new file mode 100644
index 0000000..c4fd8f9
--- /dev/null
+++ b/.dev/batch_test_list.py
@@ -0,0 +1,133 @@
+# yapf: disable
+# Inference Speed is tested on NVIDIA V100
+hrnet = [
+ dict(
+ config='configs/hrnet/fcn_hr18s_512x512_160k_ade20k.py',
+ checkpoint='fcn_hr18s_512x512_160k_ade20k_20200614_214413-870f65ac.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=33.0),
+ ),
+ dict(
+ config='configs/hrnet/fcn_hr18s_512x1024_160k_cityscapes.py',
+ checkpoint='fcn_hr18s_512x1024_160k_cityscapes_20200602_190901-4a0797ea.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=76.31),
+ ),
+ dict(
+ config='configs/hrnet/fcn_hr48_512x512_160k_ade20k.py',
+ checkpoint='fcn_hr48_512x512_160k_ade20k_20200614_214407-a52fc02c.pth',
+ eval='mIoU',
+ metric=dict(mIoU=42.02),
+ ),
+ dict(
+ config='configs/hrnet/fcn_hr48_512x1024_160k_cityscapes.py',
+ checkpoint='fcn_hr48_512x1024_160k_cityscapes_20200602_190946-59b7973e.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=80.65),
+ ),
+]
+pspnet = [
+ dict(
+ config='configs/pspnet/pspnet_r50-d8_512x1024_80k_cityscapes.py',
+ checkpoint='pspnet_r50-d8_512x1024_80k_cityscapes_20200606_112131-2376f12b.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=78.55),
+ ),
+ dict(
+ config='configs/pspnet/pspnet_r101-d8_512x1024_80k_cityscapes.py',
+ checkpoint='pspnet_r101-d8_512x1024_80k_cityscapes_20200606_112211-e1e1100f.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=79.76),
+ ),
+ dict(
+ config='configs/pspnet/pspnet_r101-d8_512x512_160k_ade20k.py',
+ checkpoint='pspnet_r101-d8_512x512_160k_ade20k_20200615_100650-967c316f.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=44.39),
+ ),
+ dict(
+ config='configs/pspnet/pspnet_r50-d8_512x512_160k_ade20k.py',
+ checkpoint='pspnet_r50-d8_512x512_160k_ade20k_20200615_184358-1890b0bd.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=42.48),
+ ),
+]
+resnest = [
+ dict(
+ config='configs/resnest/pspnet_s101-d8_512x512_160k_ade20k.py',
+ checkpoint='pspnet_s101-d8_512x512_160k_ade20k_20200807_145416-a6daa92a.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=45.44),
+ ),
+ dict(
+ config='configs/resnest/pspnet_s101-d8_512x1024_80k_cityscapes.py',
+ checkpoint='pspnet_s101-d8_512x1024_80k_cityscapes_20200807_140631-c75f3b99.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=78.57),
+ ),
+]
+fastscnn = [
+ dict(
+ config='configs/fastscnn/fast_scnn_lr0.12_8x4_160k_cityscapes.py',
+ checkpoint='fast_scnn_8x4_160k_lr0.12_cityscapes-0cec9937.pth',
+ eval='mIoU',
+ metric=dict(mIoU=70.96),
+ )
+]
+deeplabv3plus = [
+ dict(
+ config='configs/deeplabv3plus/deeplabv3plus_r101-d8_769x769_80k_cityscapes.py', # noqa
+ checkpoint='deeplabv3plus_r101-d8_769x769_80k_cityscapes_20200607_000405-a7573d20.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=80.98),
+ ),
+ dict(
+ config='configs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_cityscapes.py', # noqa
+ checkpoint='deeplabv3plus_r101-d8_512x1024_80k_cityscapes_20200606_114143-068fcfe9.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=80.97),
+ ),
+ dict(
+ config='configs/deeplabv3plus/deeplabv3plus_r50-d8_512x1024_80k_cityscapes.py', # noqa
+ checkpoint='deeplabv3plus_r50-d8_512x1024_80k_cityscapes_20200606_114049-f9fb496d.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=80.09),
+ ),
+ dict(
+ config='configs/deeplabv3plus/deeplabv3plus_r50-d8_769x769_80k_cityscapes.py', # noqa
+ checkpoint='deeplabv3plus_r50-d8_769x769_80k_cityscapes_20200606_210233-0e9dfdc4.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=79.83),
+ ),
+]
+vit = [
+ dict(
+ config='configs/vit/upernet_vit-b16_ln_mln_512x512_160k_ade20k.py',
+ checkpoint='upernet_vit-b16_ln_mln_512x512_160k_ade20k-f444c077.pth',
+ eval='mIoU',
+ metric=dict(mIoU=47.73),
+ ),
+ dict(
+ config='configs/vit/upernet_deit-s16_ln_mln_512x512_160k_ade20k.py',
+ checkpoint='upernet_deit-s16_ln_mln_512x512_160k_ade20k-c0cd652f.pth',
+ eval='mIoU',
+ metric=dict(mIoU=43.52),
+ ),
+]
+fp16 = [
+ dict(
+ config='configs/deeplabv3plus/deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes.py', # noqa
+ checkpoint='deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes_20200717_230920-f1104f4b.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=80.46),
+ )
+]
+swin = [
+ dict(
+ config='configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K.py', # noqa
+ checkpoint='upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K_20210531_112542-e380ad3e.pth', # noqa
+ eval='mIoU',
+ metric=dict(mIoU=44.41),
+ )
+]
+# yapf: enable
diff --git a/.dev/batch_train_list.txt b/.dev/batch_train_list.txt
new file mode 100644
index 0000000..17d1993
--- /dev/null
+++ b/.dev/batch_train_list.txt
@@ -0,0 +1,19 @@
+configs/hrnet/fcn_hr18s_512x512_160k_ade20k.py
+configs/hrnet/fcn_hr18s_512x1024_160k_cityscapes.py
+configs/hrnet/fcn_hr48_512x512_160k_ade20k.py
+configs/hrnet/fcn_hr48_512x1024_160k_cityscapes.py
+configs/pspnet/pspnet_r50-d8_512x1024_80k_cityscapes.py
+configs/pspnet/pspnet_r101-d8_512x1024_80k_cityscapes.py
+configs/pspnet/pspnet_r101-d8_512x512_160k_ade20k.py
+configs/pspnet/pspnet_r50-d8_512x512_160k_ade20k.py
+configs/resnest/pspnet_s101-d8_512x512_160k_ade20k.py
+configs/resnest/pspnet_s101-d8_512x1024_80k_cityscapes.py
+configs/fastscnn/fast_scnn_lr0.12_8x4_160k_cityscapes.py
+configs/deeplabv3plus/deeplabv3plus_r101-d8_769x769_80k_cityscapes.py
+configs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_cityscapes.py
+configs/deeplabv3plus/deeplabv3plus_r50-d8_512x1024_80k_cityscapes.py
+configs/deeplabv3plus/deeplabv3plus_r50-d8_769x769_80k_cityscapes.py
+configs/vit/upernet_vit-b16_ln_mln_512x512_160k_ade20k.py
+configs/vit/upernet_deit-s16_ln_mln_512x512_160k_ade20k.py
+configs/deeplabv3plus/deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes.py
+configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K.py
diff --git a/.dev/benchmark_evaluation.sh b/.dev/benchmark_evaluation.sh
new file mode 100755
index 0000000..68dc272
--- /dev/null
+++ b/.dev/benchmark_evaluation.sh
@@ -0,0 +1,41 @@
+PARTITION=$1
+CHECKPOINT_DIR=$2
+
+echo 'configs/hrnet/fcn_hr18s_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION fcn_hr18s_512x512_160k_ade20k configs/hrnet/fcn_hr18s_512x512_160k_ade20k.py $CHECKPOINT_DIR/fcn_hr18s_512x512_160k_ade20k_20200614_214413-870f65ac.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/fcn_hr18s_512x512_160k_ade20k --cfg-options dist_params.port=28171 &
+echo 'configs/hrnet/fcn_hr18s_512x1024_160k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION fcn_hr18s_512x1024_160k_cityscapes configs/hrnet/fcn_hr18s_512x1024_160k_cityscapes.py $CHECKPOINT_DIR/fcn_hr18s_512x1024_160k_cityscapes_20200602_190901-4a0797ea.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/fcn_hr18s_512x1024_160k_cityscapes --cfg-options dist_params.port=28172 &
+echo 'configs/hrnet/fcn_hr48_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION fcn_hr48_512x512_160k_ade20k configs/hrnet/fcn_hr48_512x512_160k_ade20k.py $CHECKPOINT_DIR/fcn_hr48_512x512_160k_ade20k_20200614_214407-a52fc02c.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/fcn_hr48_512x512_160k_ade20k --cfg-options dist_params.port=28173 &
+echo 'configs/hrnet/fcn_hr48_512x1024_160k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION fcn_hr48_512x1024_160k_cityscapes configs/hrnet/fcn_hr48_512x1024_160k_cityscapes.py $CHECKPOINT_DIR/fcn_hr48_512x1024_160k_cityscapes_20200602_190946-59b7973e.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/fcn_hr48_512x1024_160k_cityscapes --cfg-options dist_params.port=28174 &
+echo 'configs/pspnet/pspnet_r50-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION pspnet_r50-d8_512x1024_80k_cityscapes configs/pspnet/pspnet_r50-d8_512x1024_80k_cityscapes.py $CHECKPOINT_DIR/pspnet_r50-d8_512x1024_80k_cityscapes_20200606_112131-2376f12b.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/pspnet_r50-d8_512x1024_80k_cityscapes --cfg-options dist_params.port=28175 &
+echo 'configs/pspnet/pspnet_r101-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION pspnet_r101-d8_512x1024_80k_cityscapes configs/pspnet/pspnet_r101-d8_512x1024_80k_cityscapes.py $CHECKPOINT_DIR/pspnet_r101-d8_512x1024_80k_cityscapes_20200606_112211-e1e1100f.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/pspnet_r101-d8_512x1024_80k_cityscapes --cfg-options dist_params.port=28176 &
+echo 'configs/pspnet/pspnet_r101-d8_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION pspnet_r101-d8_512x512_160k_ade20k configs/pspnet/pspnet_r101-d8_512x512_160k_ade20k.py $CHECKPOINT_DIR/pspnet_r101-d8_512x512_160k_ade20k_20200615_100650-967c316f.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/pspnet_r101-d8_512x512_160k_ade20k --cfg-options dist_params.port=28177 &
+echo 'configs/pspnet/pspnet_r50-d8_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION pspnet_r50-d8_512x512_160k_ade20k configs/pspnet/pspnet_r50-d8_512x512_160k_ade20k.py $CHECKPOINT_DIR/pspnet_r50-d8_512x512_160k_ade20k_20200615_184358-1890b0bd.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/pspnet_r50-d8_512x512_160k_ade20k --cfg-options dist_params.port=28178 &
+echo 'configs/resnest/pspnet_s101-d8_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION pspnet_s101-d8_512x512_160k_ade20k configs/resnest/pspnet_s101-d8_512x512_160k_ade20k.py $CHECKPOINT_DIR/pspnet_s101-d8_512x512_160k_ade20k_20200807_145416-a6daa92a.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/pspnet_s101-d8_512x512_160k_ade20k --cfg-options dist_params.port=28179 &
+echo 'configs/resnest/pspnet_s101-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION pspnet_s101-d8_512x1024_80k_cityscapes configs/resnest/pspnet_s101-d8_512x1024_80k_cityscapes.py $CHECKPOINT_DIR/pspnet_s101-d8_512x1024_80k_cityscapes_20200807_140631-c75f3b99.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/pspnet_s101-d8_512x1024_80k_cityscapes --cfg-options dist_params.port=28180 &
+echo 'configs/fastscnn/fast_scnn_lr0.12_8x4_160k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION fast_scnn_lr0.12_8x4_160k_cityscapes configs/fastscnn/fast_scnn_lr0.12_8x4_160k_cityscapes.py $CHECKPOINT_DIR/fast_scnn_8x4_160k_lr0.12_cityscapes-0cec9937.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/fast_scnn_lr0.12_8x4_160k_cityscapes --cfg-options dist_params.port=28181 &
+echo 'configs/deeplabv3plus/deeplabv3plus_r101-d8_769x769_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION deeplabv3plus_r101-d8_769x769_80k_cityscapes configs/deeplabv3plus/deeplabv3plus_r101-d8_769x769_80k_cityscapes.py $CHECKPOINT_DIR/deeplabv3plus_r101-d8_769x769_80k_cityscapes_20200607_000405-a7573d20.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/deeplabv3plus_r101-d8_769x769_80k_cityscapes --cfg-options dist_params.port=28182 &
+echo 'configs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION deeplabv3plus_r101-d8_512x1024_80k_cityscapes configs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_cityscapes.py $CHECKPOINT_DIR/deeplabv3plus_r101-d8_512x1024_80k_cityscapes_20200606_114143-068fcfe9.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/deeplabv3plus_r101-d8_512x1024_80k_cityscapes --cfg-options dist_params.port=28183 &
+echo 'configs/deeplabv3plus/deeplabv3plus_r50-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION deeplabv3plus_r50-d8_512x1024_80k_cityscapes configs/deeplabv3plus/deeplabv3plus_r50-d8_512x1024_80k_cityscapes.py $CHECKPOINT_DIR/deeplabv3plus_r50-d8_512x1024_80k_cityscapes_20200606_114049-f9fb496d.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/deeplabv3plus_r50-d8_512x1024_80k_cityscapes --cfg-options dist_params.port=28184 &
+echo 'configs/deeplabv3plus/deeplabv3plus_r50-d8_769x769_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION deeplabv3plus_r50-d8_769x769_80k_cityscapes configs/deeplabv3plus/deeplabv3plus_r50-d8_769x769_80k_cityscapes.py $CHECKPOINT_DIR/deeplabv3plus_r50-d8_769x769_80k_cityscapes_20200606_210233-0e9dfdc4.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/deeplabv3plus_r50-d8_769x769_80k_cityscapes --cfg-options dist_params.port=28185 &
+echo 'configs/vit/upernet_vit-b16_ln_mln_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION upernet_vit-b16_ln_mln_512x512_160k_ade20k configs/vit/upernet_vit-b16_ln_mln_512x512_160k_ade20k.py $CHECKPOINT_DIR/upernet_vit-b16_ln_mln_512x512_160k_ade20k-f444c077.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/upernet_vit-b16_ln_mln_512x512_160k_ade20k --cfg-options dist_params.port=28186 &
+echo 'configs/vit/upernet_deit-s16_ln_mln_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION upernet_deit-s16_ln_mln_512x512_160k_ade20k configs/vit/upernet_deit-s16_ln_mln_512x512_160k_ade20k.py $CHECKPOINT_DIR/upernet_deit-s16_ln_mln_512x512_160k_ade20k-c0cd652f.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/upernet_deit-s16_ln_mln_512x512_160k_ade20k --cfg-options dist_params.port=28187 &
+echo 'configs/deeplabv3plus/deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes configs/deeplabv3plus/deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes.py $CHECKPOINT_DIR/deeplabv3plus_r101-d8_512x1024_80k_fp16_cityscapes-cc58bc8d.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/deeplabv3plus_r101-d8_512x1024_80k_fp16_cityscapes --cfg-options dist_params.port=28188 &
+echo 'configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 tools/slurm_test.sh $PARTITION upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K.py $CHECKPOINT_DIR/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K_20210531_112542-e380ad3e.pth --eval mIoU --work-dir work_dirs/benchmark_evaluation/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K --cfg-options dist_params.port=28189 &
diff --git a/.dev/benchmark_inference.py b/.dev/benchmark_inference.py
new file mode 100644
index 0000000..5124811
--- /dev/null
+++ b/.dev/benchmark_inference.py
@@ -0,0 +1,149 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import hashlib
+import logging
+import os
+import os.path as osp
+import warnings
+from argparse import ArgumentParser
+
+import requests
+from mmcv import Config
+
+from mmseg.apis import inference_segmentor, init_segmentor, show_result_pyplot
+from mmseg.utils import get_root_logger
+
+# ignore warnings when segmentors inference
+warnings.filterwarnings('ignore')
+
+
+def download_checkpoint(checkpoint_name, model_name, config_name, collect_dir):
+ """Download checkpoint and check if hash code is true."""
+ url = f'https://download.openmmlab.com/mmsegmentation/v0.5/{model_name}/{config_name}/{checkpoint_name}' # noqa
+
+ r = requests.get(url)
+ assert r.status_code != 403, f'{url} Access denied.'
+
+ with open(osp.join(collect_dir, checkpoint_name), 'wb') as code:
+ code.write(r.content)
+
+ true_hash_code = osp.splitext(checkpoint_name)[0].split('-')[1]
+
+ # check hash code
+ with open(osp.join(collect_dir, checkpoint_name), 'rb') as fp:
+ sha256_cal = hashlib.sha256()
+ sha256_cal.update(fp.read())
+ cur_hash_code = sha256_cal.hexdigest()[:8]
+
+ assert true_hash_code == cur_hash_code, f'{url} download failed, '
+ 'incomplete downloaded file or url invalid.'
+
+ if cur_hash_code != true_hash_code:
+ os.remove(osp.join(collect_dir, checkpoint_name))
+
+
+def parse_args():
+ parser = ArgumentParser()
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('checkpoint_root', help='Checkpoint file root path')
+ parser.add_argument(
+ '-i', '--img', default='demo/demo.png', help='Image file')
+ parser.add_argument('-a', '--aug', action='store_true', help='aug test')
+ parser.add_argument('-m', '--model-name', help='model name to inference')
+ parser.add_argument(
+ '-s', '--show', action='store_true', help='show results')
+ parser.add_argument(
+ '-d', '--device', default='cuda:0', help='Device used for inference')
+ args = parser.parse_args()
+ return args
+
+
+def inference_model(config_name, checkpoint, args, logger=None):
+ cfg = Config.fromfile(config_name)
+ if args.aug:
+ if 'flip' in cfg.data.test.pipeline[
+ 1] and 'img_scale' in cfg.data.test.pipeline[1]:
+ cfg.data.test.pipeline[1].img_ratios = [
+ 0.5, 0.75, 1.0, 1.25, 1.5, 1.75
+ ]
+ cfg.data.test.pipeline[1].flip = True
+ else:
+ if logger is not None:
+ logger.error(f'{config_name}: unable to start aug test')
+ else:
+ print(f'{config_name}: unable to start aug test', flush=True)
+
+ model = init_segmentor(cfg, checkpoint, device=args.device)
+ # test a single image
+ result = inference_segmentor(model, args.img)
+
+ # show the results
+ if args.show:
+ show_result_pyplot(model, args.img, result)
+ return result
+
+
+# Sample test whether the inference code is correct
+def main(args):
+ config = Config.fromfile(args.config)
+
+ if not os.path.exists(args.checkpoint_root):
+ os.makedirs(args.checkpoint_root, 0o775)
+
+ # test single model
+ if args.model_name:
+ if args.model_name in config:
+ model_infos = config[args.model_name]
+ if not isinstance(model_infos, list):
+ model_infos = [model_infos]
+ for model_info in model_infos:
+ config_name = model_info['config'].strip()
+ print(f'processing: {config_name}', flush=True)
+ checkpoint = osp.join(args.checkpoint_root,
+ model_info['checkpoint'].strip())
+ try:
+ # build the model from a config file and a checkpoint file
+ inference_model(config_name, checkpoint, args)
+ except Exception:
+ print(f'{config_name} test failed!')
+ continue
+ return
+ else:
+ raise RuntimeError('model name input error.')
+
+ # test all model
+ logger = get_root_logger(
+ log_file='benchmark_inference_image.log', log_level=logging.ERROR)
+
+ for model_name in config:
+ model_infos = config[model_name]
+
+ if not isinstance(model_infos, list):
+ model_infos = [model_infos]
+ for model_info in model_infos:
+ print('processing: ', model_info['config'], flush=True)
+ config_path = model_info['config'].strip()
+ config_name = osp.splitext(osp.basename(config_path))[0]
+ checkpoint_name = model_info['checkpoint'].strip()
+ checkpoint = osp.join(args.checkpoint_root, checkpoint_name)
+
+ # ensure checkpoint exists
+ try:
+ if not osp.exists(checkpoint):
+ download_checkpoint(checkpoint_name, model_name,
+ config_name.rstrip('.py'),
+ args.checkpoint_root)
+ except Exception:
+ logger.error(f'{checkpoint_name} download error')
+ continue
+
+ # test model inference with checkpoint
+ try:
+ # build the model from a config file and a checkpoint file
+ inference_model(config_path, checkpoint, args, logger)
+ except Exception as e:
+ logger.error(f'{config_path} " : {repr(e)}')
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ main(args)
diff --git a/.dev/benchmark_train.sh b/.dev/benchmark_train.sh
new file mode 100755
index 0000000..cde47a0
--- /dev/null
+++ b/.dev/benchmark_train.sh
@@ -0,0 +1,40 @@
+PARTITION=$1
+
+echo 'configs/hrnet/fcn_hr18s_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION fcn_hr18s_512x512_160k_ade20k configs/hrnet/fcn_hr18s_512x512_160k_ade20k.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24727 --work-dir work_dirs/hrnet/fcn_hr18s_512x512_160k_ade20k >/dev/null &
+echo 'configs/hrnet/fcn_hr18s_512x1024_160k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION fcn_hr18s_512x1024_160k_cityscapes configs/hrnet/fcn_hr18s_512x1024_160k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24728 --work-dir work_dirs/hrnet/fcn_hr18s_512x1024_160k_cityscapes >/dev/null &
+echo 'configs/hrnet/fcn_hr48_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION fcn_hr48_512x512_160k_ade20k configs/hrnet/fcn_hr48_512x512_160k_ade20k.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24729 --work-dir work_dirs/hrnet/fcn_hr48_512x512_160k_ade20k >/dev/null &
+echo 'configs/hrnet/fcn_hr48_512x1024_160k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION fcn_hr48_512x1024_160k_cityscapes configs/hrnet/fcn_hr48_512x1024_160k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24730 --work-dir work_dirs/hrnet/fcn_hr48_512x1024_160k_cityscapes >/dev/null &
+echo 'configs/pspnet/pspnet_r50-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION pspnet_r50-d8_512x1024_80k_cityscapes configs/pspnet/pspnet_r50-d8_512x1024_80k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24731 --work-dir work_dirs/pspnet/pspnet_r50-d8_512x1024_80k_cityscapes >/dev/null &
+echo 'configs/pspnet/pspnet_r101-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION pspnet_r101-d8_512x1024_80k_cityscapes configs/pspnet/pspnet_r101-d8_512x1024_80k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24732 --work-dir work_dirs/pspnet/pspnet_r101-d8_512x1024_80k_cityscapes >/dev/null &
+echo 'configs/pspnet/pspnet_r101-d8_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION pspnet_r101-d8_512x512_160k_ade20k configs/pspnet/pspnet_r101-d8_512x512_160k_ade20k.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24733 --work-dir work_dirs/pspnet/pspnet_r101-d8_512x512_160k_ade20k >/dev/null &
+echo 'configs/pspnet/pspnet_r50-d8_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION pspnet_r50-d8_512x512_160k_ade20k configs/pspnet/pspnet_r50-d8_512x512_160k_ade20k.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24734 --work-dir work_dirs/pspnet/pspnet_r50-d8_512x512_160k_ade20k >/dev/null &
+echo 'configs/resnest/pspnet_s101-d8_512x512_160k_ade20k.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION pspnet_s101-d8_512x512_160k_ade20k configs/resnest/pspnet_s101-d8_512x512_160k_ade20k.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24735 --work-dir work_dirs/resnest/pspnet_s101-d8_512x512_160k_ade20k >/dev/null &
+echo 'configs/resnest/pspnet_s101-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION pspnet_s101-d8_512x1024_80k_cityscapes configs/resnest/pspnet_s101-d8_512x1024_80k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24736 --work-dir work_dirs/resnest/pspnet_s101-d8_512x1024_80k_cityscapes >/dev/null &
+echo 'configs/fastscnn/fast_scnn_lr0.12_8x4_160k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION fast_scnn_lr0.12_8x4_160k_cityscapes configs/fastscnn/fast_scnn_lr0.12_8x4_160k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24737 --work-dir work_dirs/fastscnn/fast_scnn_lr0.12_8x4_160k_cityscapes >/dev/null &
+echo 'configs/deeplabv3plus/deeplabv3plus_r101-d8_769x769_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION deeplabv3plus_r101-d8_769x769_80k_cityscapes configs/deeplabv3plus/deeplabv3plus_r101-d8_769x769_80k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24738 --work-dir work_dirs/deeplabv3plus/deeplabv3plus_r101-d8_769x769_80k_cityscapes >/dev/null &
+echo 'configs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION deeplabv3plus_r101-d8_512x1024_80k_cityscapes configs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24739 --work-dir work_dirs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_cityscapes >/dev/null &
+echo 'configs/deeplabv3plus/deeplabv3plus_r50-d8_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION deeplabv3plus_r50-d8_512x1024_80k_cityscapes configs/deeplabv3plus/deeplabv3plus_r50-d8_512x1024_80k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24740 --work-dir work_dirs/deeplabv3plus/deeplabv3plus_r50-d8_512x1024_80k_cityscapes >/dev/null &
+echo 'configs/deeplabv3plus/deeplabv3plus_r50-d8_769x769_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION deeplabv3plus_r50-d8_769x769_80k_cityscapes configs/deeplabv3plus/deeplabv3plus_r50-d8_769x769_80k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24741 --work-dir work_dirs/deeplabv3plus/deeplabv3plus_r50-d8_769x769_80k_cityscapes >/dev/null &
+echo 'configs/vit/upernet_vit-b16_ln_mln_512x512_160k_ade20k.py' &
+GPUS=8 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION upernet_vit-b16_ln_mln_512x512_160k_ade20k configs/vit/upernet_vit-b16_ln_mln_512x512_160k_ade20k.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24742 --work-dir work_dirs/vit/upernet_vit-b16_ln_mln_512x512_160k_ade20k >/dev/null &
+echo 'configs/vit/upernet_deit-s16_ln_mln_512x512_160k_ade20k.py' &
+GPUS=8 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION upernet_deit-s16_ln_mln_512x512_160k_ade20k configs/vit/upernet_deit-s16_ln_mln_512x512_160k_ade20k.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24743 --work-dir work_dirs/vit/upernet_deit-s16_ln_mln_512x512_160k_ade20k >/dev/null &
+echo 'configs/deeplabv3plus/deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes.py' &
+GPUS=4 GPUS_PER_NODE=4 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION deeplabv3plus_r101-d8_512x1024_80k_fp16_cityscapes configs/deeplabv3plus/deeplabv3plus_r101-d8_fp16_512x1024_80k_cityscapes.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24744 --work-dir work_dirs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_fp16_cityscapes >/dev/null &
+echo 'configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K.py' &
+GPUS=8 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh $PARTITION upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K.py --cfg-options checkpoint_config.max_keep_ckpts=1 dist_params.port=24745 --work-dir work_dirs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K >/dev/null &
diff --git a/.dev/check_urls.py b/.dev/check_urls.py
new file mode 100644
index 0000000..42b6474
--- /dev/null
+++ b/.dev/check_urls.py
@@ -0,0 +1,101 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+import os
+from argparse import ArgumentParser
+
+import requests
+import yaml as yml
+
+from mmseg.utils import get_root_logger
+
+
+def check_url(url):
+ """Check url response status.
+
+ Args:
+ url (str): url needed to check.
+
+ Returns:
+ int, bool: status code and check flag.
+ """
+ flag = True
+ r = requests.head(url)
+ status_code = r.status_code
+ if status_code == 403 or status_code == 404:
+ flag = False
+
+ return status_code, flag
+
+
+def parse_args():
+ parser = ArgumentParser('url valid check.')
+ parser.add_argument(
+ '-m',
+ '--model-name',
+ type=str,
+ help='Select the model needed to check')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ model_name = args.model_name
+
+ # yml path generate.
+ # If model_name is not set, script will check all of the models.
+ if model_name is not None:
+ yml_list = [(model_name, f'configs/{model_name}/{model_name}.yml')]
+ else:
+ # check all
+ yml_list = [(x, f'configs/{x}/{x}.yml') for x in os.listdir('configs/')
+ if x != '_base_']
+
+ logger = get_root_logger(log_file='url_check.log', log_level=logging.ERROR)
+
+ for model_name, yml_path in yml_list:
+ # Default yaml loader unsafe.
+ model_infos = yml.load(
+ open(yml_path, 'r'), Loader=yml.CLoader)['Models']
+ for model_info in model_infos:
+ config_name = model_info['Name']
+ checkpoint_url = model_info['Weights']
+ # checkpoint url check
+ status_code, flag = check_url(checkpoint_url)
+ if flag:
+ logger.info(f'checkpoint | {config_name} | {checkpoint_url} | '
+ f'{status_code} valid')
+ else:
+ logger.error(
+ f'checkpoint | {config_name} | {checkpoint_url} | '
+ f'{status_code} | error')
+ # log_json check
+ checkpoint_name = checkpoint_url.split('/')[-1]
+ model_time = '-'.join(checkpoint_name.split('-')[:-1]).replace(
+ f'{config_name}_', '')
+ # two style of log_json name
+ # use '_' to link model_time (will be deprecated)
+ log_json_url_1 = f'https://download.openmmlab.com/mmsegmentation/v0.5/{model_name}/{config_name}/{config_name}_{model_time}.log.json' # noqa
+ status_code_1, flag_1 = check_url(log_json_url_1)
+ # use '-' to link model_time
+ log_json_url_2 = f'https://download.openmmlab.com/mmsegmentation/v0.5/{model_name}/{config_name}/{config_name}-{model_time}.log.json' # noqa
+ status_code_2, flag_2 = check_url(log_json_url_2)
+ if flag_1 or flag_2:
+ if flag_1:
+ logger.info(
+ f'log.json | {config_name} | {log_json_url_1} | '
+ f'{status_code_1} | valid')
+ else:
+ logger.info(
+ f'log.json | {config_name} | {log_json_url_2} | '
+ f'{status_code_2} | valid')
+ else:
+ logger.error(
+ f'log.json | {config_name} | {log_json_url_1} & '
+ f'{log_json_url_2} | {status_code_1} & {status_code_2} | '
+ 'error')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/.dev/gather_benchmark_evaluation_results.py b/.dev/gather_benchmark_evaluation_results.py
new file mode 100644
index 0000000..47b557a
--- /dev/null
+++ b/.dev/gather_benchmark_evaluation_results.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import os.path as osp
+
+import mmcv
+from mmcv import Config
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Gather benchmarked model evaluation results')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument(
+ 'root',
+ type=str,
+ help='root path of benchmarked models to be gathered')
+ parser.add_argument(
+ '--out',
+ type=str,
+ default='benchmark_evaluation_info.json',
+ help='output path of gathered metrics and compared '
+ 'results to be stored')
+
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ root_path = args.root
+ metrics_out = args.out
+ result_dict = {}
+
+ cfg = Config.fromfile(args.config)
+
+ for model_key in cfg:
+ model_infos = cfg[model_key]
+ if not isinstance(model_infos, list):
+ model_infos = [model_infos]
+ for model_info in model_infos:
+ previous_metrics = model_info['metric']
+ config = model_info['config'].strip()
+ fname, _ = osp.splitext(osp.basename(config))
+
+ # Load benchmark evaluation json
+ metric_json_dir = osp.join(root_path, fname)
+ if not osp.exists(metric_json_dir):
+ print(f'{metric_json_dir} not existed.')
+ continue
+
+ json_list = glob.glob(osp.join(metric_json_dir, '*.json'))
+ if len(json_list) == 0:
+ print(f'There is no eval json in {metric_json_dir}.')
+ continue
+
+ log_json_path = list(sorted(json_list))[-1]
+ metric = mmcv.load(log_json_path)
+ if config not in metric.get('config', {}):
+ print(f'{config} not included in {log_json_path}')
+ continue
+
+ # Compare between new benchmark results and previous metrics
+ differential_results = dict()
+ new_metrics = dict()
+ for record_metric_key in previous_metrics:
+ if record_metric_key not in metric['metric']:
+ raise KeyError('record_metric_key not exist, please '
+ 'check your config')
+ old_metric = previous_metrics[record_metric_key]
+ new_metric = round(metric['metric'][record_metric_key] * 100,
+ 2)
+
+ differential = new_metric - old_metric
+ flag = '+' if differential > 0 else '-'
+ differential_results[
+ record_metric_key] = f'{flag}{abs(differential):.2f}'
+ new_metrics[record_metric_key] = new_metric
+
+ result_dict[config] = dict(
+ differential=differential_results,
+ previous=previous_metrics,
+ new=new_metrics)
+
+ if metrics_out:
+ mmcv.dump(result_dict, metrics_out, indent=4)
+ print('===================================')
+ for config_name, metrics in result_dict.items():
+ print(config_name, metrics)
+ print('===================================')
diff --git a/.dev/gather_benchmark_train_results.py b/.dev/gather_benchmark_train_results.py
new file mode 100644
index 0000000..8aff2c4
--- /dev/null
+++ b/.dev/gather_benchmark_train_results.py
@@ -0,0 +1,100 @@
+import argparse
+import glob
+import os.path as osp
+
+import mmcv
+from gather_models import get_final_results
+from mmcv import Config
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Gather benchmarked models train results')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument(
+ 'root',
+ type=str,
+ help='root path of benchmarked models to be gathered')
+ parser.add_argument(
+ '--out',
+ type=str,
+ default='benchmark_train_info.json',
+ help='output path of gathered metrics to be stored')
+
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ root_path = args.root
+ metrics_out = args.out
+
+ evaluation_cfg = Config.fromfile(args.config)
+
+ result_dict = {}
+ for model_key in evaluation_cfg:
+ model_infos = evaluation_cfg[model_key]
+ if not isinstance(model_infos, list):
+ model_infos = [model_infos]
+ for model_info in model_infos:
+ config = model_info['config']
+
+ # benchmark train dir
+ model_name = osp.split(osp.dirname(config))[1]
+ config_name = osp.splitext(osp.basename(config))[0]
+ exp_dir = osp.join(root_path, model_name, config_name)
+ if not osp.exists(exp_dir):
+ print(f'{config} hasn\'t {exp_dir}')
+ continue
+
+ # parse config
+ cfg = mmcv.Config.fromfile(config)
+ total_iters = cfg.runner.max_iters
+ exp_metric = cfg.evaluation.metric
+ if not isinstance(exp_metric, list):
+ exp_metrics = [exp_metric]
+
+ # determine whether total_iters ckpt exists
+ ckpt_path = f'iter_{total_iters}.pth'
+ if not osp.exists(osp.join(exp_dir, ckpt_path)):
+ print(f'{config} hasn\'t {ckpt_path}')
+ continue
+
+ # only the last log json counts
+ log_json_path = list(
+ sorted(glob.glob(osp.join(exp_dir, '*.log.json'))))[-1]
+
+ # extract metric value
+ model_performance = get_final_results(log_json_path, total_iters)
+ if model_performance is None:
+ print(f'log file error: {log_json_path}')
+ continue
+
+ differential_results = dict()
+ old_results = dict()
+ new_results = dict()
+ for metric_key in model_performance:
+ if metric_key in ['mIoU']:
+ metric = round(model_performance[metric_key] * 100, 2)
+ old_metric = model_info['metric'][metric_key]
+ old_results[metric_key] = old_metric
+ new_results[metric_key] = metric
+ differential = metric - old_metric
+ flag = '+' if differential > 0 else '-'
+ differential_results[
+ metric_key] = f'{flag}{abs(differential):.2f}'
+ result_dict[config] = dict(
+ differential_results=differential_results,
+ old_results=old_results,
+ new_results=new_results,
+ )
+
+ # 4 save or print results
+ if metrics_out:
+ mmcv.dump(result_dict, metrics_out, indent=4)
+ print('===================================')
+ for config_name, metrics in result_dict.items():
+ print(config_name, metrics)
+ print('===================================')
diff --git a/.dev/gather_models.py b/.dev/gather_models.py
new file mode 100644
index 0000000..3eedf61
--- /dev/null
+++ b/.dev/gather_models.py
@@ -0,0 +1,211 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import hashlib
+import json
+import os
+import os.path as osp
+import shutil
+
+import mmcv
+import torch
+
+# build schedule look-up table to automatically find the final model
+RESULTS_LUT = ['mIoU', 'mAcc', 'aAcc']
+
+
+def calculate_file_sha256(file_path):
+ """calculate file sha256 hash code."""
+ with open(file_path, 'rb') as fp:
+ sha256_cal = hashlib.sha256()
+ sha256_cal.update(fp.read())
+ return sha256_cal.hexdigest()
+
+
+def process_checkpoint(in_file, out_file):
+ checkpoint = torch.load(in_file, map_location='cpu')
+ # remove optimizer for smaller file size
+ if 'optimizer' in checkpoint:
+ del checkpoint['optimizer']
+ # if it is necessary to remove some sensitive data in checkpoint['meta'],
+ # add the code here.
+ torch.save(checkpoint, out_file)
+ # The hash code calculation and rename command differ on different system
+ # platform.
+ sha = calculate_file_sha256(out_file)
+ final_file = out_file.rstrip('.pth') + '-{}.pth'.format(sha[:8])
+ os.rename(out_file, final_file)
+
+ # Remove prefix and suffix
+ final_file_name = osp.split(final_file)[1]
+ final_file_name = osp.splitext(final_file_name)[0]
+
+ return final_file_name
+
+
+def get_final_iter(config):
+ iter_num = config.split('_')[-2]
+ assert iter_num.endswith('k')
+ return int(iter_num[:-1]) * 1000
+
+
+def get_final_results(log_json_path, iter_num):
+ result_dict = dict()
+ last_iter = 0
+ with open(log_json_path, 'r') as f:
+ for line in f.readlines():
+ log_line = json.loads(line)
+ if 'mode' not in log_line.keys():
+ continue
+
+ # When evaluation, the 'iter' of new log json is the evaluation
+ # steps on single gpu.
+ flag1 = ('aAcc' in log_line) or (log_line['mode'] == 'val')
+ flag2 = (last_iter == iter_num - 50) or (last_iter == iter_num)
+ if flag1 and flag2:
+ result_dict.update({
+ key: log_line[key]
+ for key in RESULTS_LUT if key in log_line
+ })
+ return result_dict
+
+ last_iter = log_line['iter']
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Gather benchmarked models')
+ parser.add_argument(
+ '-f', '--config-name', type=str, help='Process the selected config.')
+ parser.add_argument(
+ '-w',
+ '--work-dir',
+ default='work_dirs/',
+ type=str,
+ help='Ckpt storage root folder of benchmarked models to be gathered.')
+ parser.add_argument(
+ '-c',
+ '--collect-dir',
+ default='work_dirs/gather',
+ type=str,
+ help='Ckpt collect root folder of gathered models.')
+ parser.add_argument(
+ '--all', action='store_true', help='whether include .py and .log')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ work_dir = args.work_dir
+ collect_dir = args.collect_dir
+ selected_config_name = args.config_name
+ mmcv.mkdir_or_exist(collect_dir)
+
+ # find all models in the root directory to be gathered
+ raw_configs = list(mmcv.scandir('./configs', '.py', recursive=True))
+
+ # filter configs that is not trained in the experiments dir
+ used_configs = []
+ for raw_config in raw_configs:
+ config_name = osp.splitext(osp.basename(raw_config))[0]
+ if osp.exists(osp.join(work_dir, config_name)):
+ if (selected_config_name is None
+ or selected_config_name == config_name):
+ used_configs.append(raw_config)
+ print(f'Find {len(used_configs)} models to be gathered')
+
+ # find final_ckpt and log file for trained each config
+ # and parse the best performance
+ model_infos = []
+ for used_config in used_configs:
+ config_name = osp.splitext(osp.basename(used_config))[0]
+ exp_dir = osp.join(work_dir, config_name)
+ # check whether the exps is finished
+ final_iter = get_final_iter(used_config)
+ final_model = 'iter_{}.pth'.format(final_iter)
+ model_path = osp.join(exp_dir, final_model)
+
+ # skip if the model is still training
+ if not osp.exists(model_path):
+ print(f'{used_config} train not finished yet')
+ continue
+
+ # get logs
+ log_json_paths = glob.glob(osp.join(exp_dir, '*.log.json'))
+ log_json_path = log_json_paths[0]
+ model_performance = None
+ for idx, _log_json_path in enumerate(log_json_paths):
+ model_performance = get_final_results(_log_json_path, final_iter)
+ if model_performance is not None:
+ log_json_path = _log_json_path
+ break
+
+ if model_performance is None:
+ print(f'{used_config} model_performance is None')
+ continue
+
+ model_time = osp.split(log_json_path)[-1].split('.')[0]
+ model_infos.append(
+ dict(
+ config_name=config_name,
+ results=model_performance,
+ iters=final_iter,
+ model_time=model_time,
+ log_json_path=osp.split(log_json_path)[-1]))
+
+ # publish model for each checkpoint
+ publish_model_infos = []
+ for model in model_infos:
+ config_name = model['config_name']
+ model_publish_dir = osp.join(collect_dir, config_name)
+
+ publish_model_path = osp.join(model_publish_dir,
+ config_name + '_' + model['model_time'])
+ trained_model_path = osp.join(work_dir, config_name,
+ 'iter_{}.pth'.format(model['iters']))
+ if osp.exists(model_publish_dir):
+ for file in os.listdir(model_publish_dir):
+ if file.endswith('.pth'):
+ print(f'model {file} found')
+ model['model_path'] = osp.abspath(
+ osp.join(model_publish_dir, file))
+ break
+ if 'model_path' not in model:
+ print(f'dir {model_publish_dir} exists, no model found')
+
+ else:
+ mmcv.mkdir_or_exist(model_publish_dir)
+
+ # convert model
+ final_model_path = process_checkpoint(trained_model_path,
+ publish_model_path)
+ model['model_path'] = final_model_path
+
+ new_json_path = f'{config_name}_{model["log_json_path"]}'
+ # copy log
+ shutil.copy(
+ osp.join(work_dir, config_name, model['log_json_path']),
+ osp.join(model_publish_dir, new_json_path))
+
+ if args.all:
+ new_txt_path = new_json_path.rstrip('.json')
+ shutil.copy(
+ osp.join(work_dir, config_name,
+ model['log_json_path'].rstrip('.json')),
+ osp.join(model_publish_dir, new_txt_path))
+
+ if args.all:
+ # copy config to guarantee reproducibility
+ raw_config = osp.join('./configs', f'{config_name}.py')
+ mmcv.Config.fromfile(raw_config).dump(
+ osp.join(model_publish_dir, osp.basename(raw_config)))
+
+ publish_model_infos.append(model)
+
+ models = dict(models=publish_model_infos)
+ mmcv.dump(models, osp.join(collect_dir, 'model_infos.json'), indent=4)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/.dev/generate_benchmark_evaluation_script.py b/.dev/generate_benchmark_evaluation_script.py
new file mode 100644
index 0000000..d86e94b
--- /dev/null
+++ b/.dev/generate_benchmark_evaluation_script.py
@@ -0,0 +1,114 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+from mmcv import Config
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert benchmark test model list to script')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('--port', type=int, default=28171, help='dist port')
+ parser.add_argument(
+ '--work-dir',
+ default='work_dirs/benchmark_evaluation',
+ help='the dir to save metric')
+ parser.add_argument(
+ '--out',
+ type=str,
+ default='.dev/benchmark_evaluation.sh',
+ help='path to save model benchmark script')
+
+ args = parser.parse_args()
+ return args
+
+
+def process_model_info(model_info, work_dir):
+ config = model_info['config'].strip()
+ fname, _ = osp.splitext(osp.basename(config))
+ job_name = fname
+ checkpoint = model_info['checkpoint'].strip()
+ work_dir = osp.join(work_dir, fname)
+ if not isinstance(model_info['eval'], list):
+ evals = [model_info['eval']]
+ else:
+ evals = model_info['eval']
+ eval = ' '.join(evals)
+ return dict(
+ config=config,
+ job_name=job_name,
+ checkpoint=checkpoint,
+ work_dir=work_dir,
+ eval=eval)
+
+
+def create_test_bash_info(commands, model_test_dict, port, script_name,
+ partition):
+ config = model_test_dict['config']
+ job_name = model_test_dict['job_name']
+ checkpoint = model_test_dict['checkpoint']
+ work_dir = model_test_dict['work_dir']
+ eval = model_test_dict['eval']
+
+ echo_info = f'\necho \'{config}\' &'
+ commands.append(echo_info)
+ commands.append('\n')
+
+ command_info = f'GPUS=4 GPUS_PER_NODE=4 ' \
+ f'CPUS_PER_TASK=2 {script_name} '
+
+ command_info += f'{partition} '
+ command_info += f'{job_name} '
+ command_info += f'{config} '
+ command_info += f'$CHECKPOINT_DIR/{checkpoint} '
+
+ command_info += f'--eval {eval} '
+ command_info += f'--work-dir {work_dir} '
+ command_info += f'--cfg-options dist_params.port={port} '
+ command_info += '&'
+
+ commands.append(command_info)
+
+
+def main():
+ args = parse_args()
+ if args.out:
+ out_suffix = args.out.split('.')[-1]
+ assert args.out.endswith('.sh'), \
+ f'Expected out file path suffix is .sh, but get .{out_suffix}'
+
+ commands = []
+ partition_name = 'PARTITION=$1'
+ commands.append(partition_name)
+ commands.append('\n')
+
+ checkpoint_root = 'CHECKPOINT_DIR=$2'
+ commands.append(checkpoint_root)
+ commands.append('\n')
+
+ script_name = osp.join('tools', 'slurm_test.sh')
+ port = args.port
+ work_dir = args.work_dir
+
+ cfg = Config.fromfile(args.config)
+
+ for model_key in cfg:
+ model_infos = cfg[model_key]
+ if not isinstance(model_infos, list):
+ model_infos = [model_infos]
+ for model_info in model_infos:
+ print('processing: ', model_info['config'])
+ model_test_dict = process_model_info(model_info, work_dir)
+ create_test_bash_info(commands, model_test_dict, port, script_name,
+ '$PARTITION')
+ port += 1
+
+ command_str = ''.join(commands)
+ if args.out:
+ with open(args.out, 'w') as f:
+ f.write(command_str + '\n')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/.dev/generate_benchmark_train_script.py b/.dev/generate_benchmark_train_script.py
new file mode 100644
index 0000000..6e8a0ae
--- /dev/null
+++ b/.dev/generate_benchmark_train_script.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+# Default using 4 gpu when training
+config_8gpu_list = [
+ 'configs/swin/upernet_swin_tiny_patch4_window7_512x512_160k_ade20k_pretrain_224x224_1K.py', # noqa
+ 'configs/vit/upernet_vit-b16_ln_mln_512x512_160k_ade20k.py',
+ 'configs/vit/upernet_deit-s16_ln_mln_512x512_160k_ade20k.py',
+]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert benchmark model json to script')
+ parser.add_argument(
+ 'txt_path', type=str, help='txt path output by benchmark_filter')
+ parser.add_argument('--port', type=int, default=24727, help='dist port')
+ parser.add_argument(
+ '--out',
+ type=str,
+ default='.dev/benchmark_train.sh',
+ help='path to save model benchmark script')
+
+ args = parser.parse_args()
+ return args
+
+
+def create_train_bash_info(commands, config, script_name, partition, port):
+ cfg = config.strip()
+
+ # print cfg name
+ echo_info = f'echo \'{cfg}\' &'
+ commands.append(echo_info)
+ commands.append('\n')
+
+ _, model_name = osp.split(osp.dirname(cfg))
+ config_name, _ = osp.splitext(osp.basename(cfg))
+ # default setting
+ if cfg in config_8gpu_list:
+ command_info = f'GPUS=8 GPUS_PER_NODE=8 ' \
+ f'CPUS_PER_TASK=2 {script_name} '
+ else:
+ command_info = f'GPUS=4 GPUS_PER_NODE=4 ' \
+ f'CPUS_PER_TASK=2 {script_name} '
+ command_info += f'{partition} '
+ command_info += f'{config_name} '
+ command_info += f'{cfg} '
+ command_info += f'--cfg-options ' \
+ f'checkpoint_config.max_keep_ckpts=1 ' \
+ f'dist_params.port={port} '
+ command_info += f'--work-dir work_dirs/{model_name}/{config_name} '
+ # Let the script shut up
+ command_info += '>/dev/null &'
+
+ commands.append(command_info)
+ commands.append('\n')
+
+
+def main():
+ args = parse_args()
+ if args.out:
+ out_suffix = args.out.split('.')[-1]
+ assert args.out.endswith('.sh'), \
+ f'Expected out file path suffix is .sh, but get .{out_suffix}'
+
+ root_name = './tools'
+ script_name = osp.join(root_name, 'slurm_train.sh')
+ port = args.port
+ partition_name = 'PARTITION=$1'
+
+ commands = []
+ commands.append(partition_name)
+ commands.append('\n')
+ commands.append('\n')
+
+ with open(args.txt_path, 'r') as f:
+ model_cfgs = f.readlines()
+ for i, cfg in enumerate(model_cfgs):
+ create_train_bash_info(commands, cfg, script_name, '$PARTITION',
+ port)
+ port += 1
+
+ command_str = ''.join(commands)
+ if args.out:
+ with open(args.out, 'w') as f:
+ f.write(command_str)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/.dev/log_collector/example_config.py b/.dev/log_collector/example_config.py
new file mode 100644
index 0000000..bc2b4d6
--- /dev/null
+++ b/.dev/log_collector/example_config.py
@@ -0,0 +1,18 @@
+work_dir = '../../work_dirs'
+metric = 'mIoU'
+
+# specify the log files we would like to collect in `log_items`
+log_items = [
+ 'segformer_mit-b5_512x512_160k_ade20k_cnn_lr_with_warmup',
+ 'segformer_mit-b5_512x512_160k_ade20k_cnn_no_warmup_lr',
+ 'segformer_mit-b5_512x512_160k_ade20k_mit_trans_lr',
+ 'segformer_mit-b5_512x512_160k_ade20k_swin_trans_lr'
+]
+# or specify ignore_keywords, then the folders whose name contain
+# `'segformer'` won't be collected
+# ignore_keywords = ['segformer']
+
+# should not include metric
+other_info_keys = ['mAcc']
+markdown_file = 'markdowns/lr_in_trans.json.md'
+json_file = 'jsons/trans_in_cnn.json'
diff --git a/.dev/log_collector/log_collector.py b/.dev/log_collector/log_collector.py
new file mode 100644
index 0000000..d0f4080
--- /dev/null
+++ b/.dev/log_collector/log_collector.py
@@ -0,0 +1,143 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import datetime
+import json
+import os
+import os.path as osp
+from collections import OrderedDict
+
+from utils import load_config
+
+# automatically collect all the results
+
+# The structure of the directory:
+# ├── work-dir
+# │ ├── config_1
+# │ │ ├── time1.log.json
+# │ │ ├── time2.log.json
+# │ │ ├── time3.log.json
+# │ │ ├── time4.log.json
+# │ ├── config_2
+# │ │ ├── time5.log.json
+# │ │ ├── time6.log.json
+# │ │ ├── time7.log.json
+# │ │ ├── time8.log.json
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='extract info from log.json')
+ parser.add_argument('config_dir')
+ args = parser.parse_args()
+ return args
+
+
+def has_keyword(name: str, keywords: list):
+ for a_keyword in keywords:
+ if a_keyword in name:
+ return True
+ return False
+
+
+def main():
+ args = parse_args()
+ cfg = load_config(args.config_dir)
+ work_dir = cfg['work_dir']
+ metric = cfg['metric']
+ log_items = cfg.get('log_items', [])
+ ignore_keywords = cfg.get('ignore_keywords', [])
+ other_info_keys = cfg.get('other_info_keys', [])
+ markdown_file = cfg.get('markdown_file', None)
+ json_file = cfg.get('json_file', None)
+
+ if json_file and osp.split(json_file)[0] != '':
+ os.makedirs(osp.split(json_file)[0], exist_ok=True)
+ if markdown_file and osp.split(markdown_file)[0] != '':
+ os.makedirs(osp.split(markdown_file)[0], exist_ok=True)
+
+ assert not (log_items and ignore_keywords), \
+ 'log_items and ignore_keywords cannot be specified at the same time'
+ assert metric not in other_info_keys, \
+ 'other_info_keys should not contain metric'
+
+ if ignore_keywords and isinstance(ignore_keywords, str):
+ ignore_keywords = [ignore_keywords]
+ if other_info_keys and isinstance(other_info_keys, str):
+ other_info_keys = [other_info_keys]
+ if log_items and isinstance(log_items, str):
+ log_items = [log_items]
+
+ if not log_items:
+ log_items = [
+ item for item in sorted(os.listdir(work_dir))
+ if not has_keyword(item, ignore_keywords)
+ ]
+
+ experiment_info_list = []
+ for config_dir in log_items:
+ preceding_path = os.path.join(work_dir, config_dir)
+ log_list = [
+ item for item in os.listdir(preceding_path)
+ if item.endswith('.log.json')
+ ]
+ log_list = sorted(
+ log_list,
+ key=lambda time_str: datetime.datetime.strptime(
+ time_str, '%Y%m%d_%H%M%S.log.json'))
+ val_list = []
+ last_iter = 0
+ for log_name in log_list:
+ with open(os.path.join(preceding_path, log_name), 'r') as f:
+ # ignore the info line
+ f.readline()
+ all_lines = f.readlines()
+ val_list.extend([
+ json.loads(line) for line in all_lines
+ if json.loads(line)['mode'] == 'val'
+ ])
+ for index in range(len(all_lines) - 1, -1, -1):
+ line_dict = json.loads(all_lines[index])
+ if line_dict['mode'] == 'train':
+ last_iter = max(last_iter, line_dict['iter'])
+ break
+
+ new_log_dict = dict(
+ method=config_dir, metric_used=metric, last_iter=last_iter)
+ for index, log in enumerate(val_list, 1):
+ new_ordered_dict = OrderedDict()
+ new_ordered_dict['eval_index'] = index
+ new_ordered_dict[metric] = log[metric]
+ for key in other_info_keys:
+ if key in log:
+ new_ordered_dict[key] = log[key]
+ val_list[index - 1] = new_ordered_dict
+
+ assert len(val_list) >= 1, \
+ f"work dir {config_dir} doesn't contain any evaluation."
+ new_log_dict['last eval'] = val_list[-1]
+ new_log_dict['best eval'] = max(val_list, key=lambda x: x[metric])
+ experiment_info_list.append(new_log_dict)
+ print(f'{config_dir} is processed')
+
+ if json_file:
+ with open(json_file, 'w') as f:
+ json.dump(experiment_info_list, f, indent=4)
+
+ if markdown_file:
+ lines_to_write = []
+ for index, log in enumerate(experiment_info_list, 1):
+ lines_to_write.append(
+ f"|{index}|{log['method']}|{log['best eval'][metric]}"
+ f"|{log['best eval']['eval_index']}|"
+ f"{log['last eval'][metric]}|"
+ f"{log['last eval']['eval_index']}|{log['last_iter']}|\n")
+ with open(markdown_file, 'w') as f:
+ f.write(f'|exp_num|method|{metric} best|best index|'
+ f'{metric} last|last index|last iter num|\n')
+ f.write('|:---:|:---:|:---:|:---:|:---:|:---:|:---:|\n')
+ f.writelines(lines_to_write)
+
+ print('processed successfully')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/.dev/log_collector/readme.md b/.dev/log_collector/readme.md
new file mode 100644
index 0000000..41ea235
--- /dev/null
+++ b/.dev/log_collector/readme.md
@@ -0,0 +1,143 @@
+# Log Collector
+
+## Function
+
+Automatically collect logs and write the result in a json file or markdown file.
+
+If there are several `.log.json` files in one folder, Log Collector assumes that the `.log.json` files other than the first one are resume from the preceding `.log.json` file. Log Collector returns the result considering all `.log.json` files.
+
+## Usage:
+
+To use log collector, you need to write a config file to configure the log collector first.
+
+For example:
+
+example_config.py:
+
+```python
+# The work directory that contains folders that contains .log.json files.
+work_dir = '../../work_dirs'
+# The metric used to find the best evaluation.
+metric = 'mIoU'
+
+# **Don't specify the log_items and ignore_keywords at the same time.**
+# Specify the log files we would like to collect in `log_items`.
+# The folders specified should be the subdirectories of `work_dir`.
+log_items = [
+ 'segformer_mit-b5_512x512_160k_ade20k_cnn_lr_with_warmup',
+ 'segformer_mit-b5_512x512_160k_ade20k_cnn_no_warmup_lr',
+ 'segformer_mit-b5_512x512_160k_ade20k_mit_trans_lr',
+ 'segformer_mit-b5_512x512_160k_ade20k_swin_trans_lr'
+]
+# Or specify `ignore_keywords`. The folders whose name contain one
+# of the keywords in the `ignore_keywords` list(e.g., `'segformer'`)
+# won't be collected.
+# ignore_keywords = ['segformer']
+
+# Other log items in .log.json that you want to collect.
+# should not include metric.
+other_info_keys = ["mAcc"]
+# The output markdown file's name.
+markdown_file ='markdowns/lr_in_trans.json.md'
+# The output json file's name. (optional)
+json_file = 'jsons/trans_in_cnn.json'
+```
+
+ The structure of the work-dir directory should be like:
+
+```text
+├── work-dir
+│ ├── folder1
+│ │ ├── time1.log.json
+│ │ ├── time2.log.json
+│ │ ├── time3.log.json
+│ │ ├── time4.log.json
+│ ├── folder2
+│ │ ├── time5.log.json
+│ │ ├── time6.log.json
+│ │ ├── time7.log.json
+│ │ ├── time8.log.json
+```
+
+Then , cd to the log collector folder.
+
+Now you can run log_collector.py by using command:
+
+```bash
+python log_collector.py ./example_config.py
+```
+
+The output markdown file is like:
+
+|exp_num|method|mIoU best|best index|mIoU last|last index|last iter num|
+|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
+|1|segformer_mit-b5_512x512_160k_ade20k_cnn_lr_with_warmup|0.2776|10|0.2776|10|160000|
+|2|segformer_mit-b5_512x512_160k_ade20k_cnn_no_warmup_lr|0.2802|10|0.2802|10|160000|
+|3|segformer_mit-b5_512x512_160k_ade20k_mit_trans_lr|0.4943|11|0.4943|11|160000|
+|4|segformer_mit-b5_512x512_160k_ade20k_swin_trans_lr|0.4883|11|0.4883|11|160000|
+
+The output json file is like:
+```json
+[
+ {
+ "method": "segformer_mit-b5_512x512_160k_ade20k_cnn_lr_with_warmup",
+ "metric_used": "mIoU",
+ "last_iter": 160000,
+ "last eval": {
+ "eval_index": 10,
+ "mIoU": 0.2776,
+ "mAcc": 0.3779
+ },
+ "best eval": {
+ "eval_index": 10,
+ "mIoU": 0.2776,
+ "mAcc": 0.3779
+ }
+ },
+ {
+ "method": "segformer_mit-b5_512x512_160k_ade20k_cnn_no_warmup_lr",
+ "metric_used": "mIoU",
+ "last_iter": 160000,
+ "last eval": {
+ "eval_index": 10,
+ "mIoU": 0.2802,
+ "mAcc": 0.3764
+ },
+ "best eval": {
+ "eval_index": 10,
+ "mIoU": 0.2802,
+ "mAcc": 0.3764
+ }
+ },
+ {
+ "method": "segformer_mit-b5_512x512_160k_ade20k_mit_trans_lr",
+ "metric_used": "mIoU",
+ "last_iter": 160000,
+ "last eval": {
+ "eval_index": 11,
+ "mIoU": 0.4943,
+ "mAcc": 0.6097
+ },
+ "best eval": {
+ "eval_index": 11,
+ "mIoU": 0.4943,
+ "mAcc": 0.6097
+ }
+ },
+ {
+ "method": "segformer_mit-b5_512x512_160k_ade20k_swin_trans_lr",
+ "metric_used": "mIoU",
+ "last_iter": 160000,
+ "last eval": {
+ "eval_index": 11,
+ "mIoU": 0.4883,
+ "mAcc": 0.6061
+ },
+ "best eval": {
+ "eval_index": 11,
+ "mIoU": 0.4883,
+ "mAcc": 0.6061
+ }
+ }
+]
+```
diff --git a/.dev/log_collector/utils.py b/.dev/log_collector/utils.py
new file mode 100644
index 0000000..848516a
--- /dev/null
+++ b/.dev/log_collector/utils.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# modified from https://github.dev/open-mmlab/mmcv
+import os.path as osp
+import sys
+from importlib import import_module
+
+
+def load_config(cfg_dir: str) -> dict:
+ assert cfg_dir.endswith('.py')
+ root_path, file_name = osp.split(cfg_dir)
+ temp_module = osp.splitext(file_name)[0]
+ sys.path.insert(0, root_path)
+ mod = import_module(temp_module)
+ sys.path.pop(0)
+ cfg_dict = {
+ k: v
+ for k, v in mod.__dict__.items() if not k.startswith('__')
+ }
+ del sys.modules[temp_module]
+ return cfg_dict
diff --git a/.dev/md2yml.py b/.dev/md2yml.py
new file mode 100755
index 0000000..4c2e129
--- /dev/null
+++ b/.dev/md2yml.py
@@ -0,0 +1,272 @@
+#!/usr/bin/env python
+
+# Copyright (c) OpenMMLab. All rights reserved.
+# This tool is used to update model-index.yml which is required by MIM, and
+# will be automatically called as a pre-commit hook. The updating will be
+# triggered if any change of model information (.md files in configs/) has been
+# detected before a commit.
+
+import glob
+import os
+import os.path as osp
+import re
+import sys
+
+import mmcv
+from lxml import etree
+
+MMSEG_ROOT = osp.dirname(osp.dirname((osp.dirname(__file__))))
+
+
+def dump_yaml_and_check_difference(obj, filename, sort_keys=False):
+ """Dump object to a yaml file, and check if the file content is different
+ from the original.
+
+ Args:
+ obj (any): The python object to be dumped.
+ filename (str): YAML filename to dump the object to.
+ sort_keys (str); Sort key by dictionary order.
+ Returns:
+ Bool: If the target YAML file is different from the original.
+ """
+
+ str_dump = mmcv.dump(obj, None, file_format='yaml', sort_keys=sort_keys)
+ if osp.isfile(filename):
+ file_exists = True
+ with open(filename, 'r', encoding='utf-8') as f:
+ str_orig = f.read()
+ else:
+ file_exists = False
+ str_orig = None
+
+ if file_exists and str_orig == str_dump:
+ is_different = False
+ else:
+ is_different = True
+ with open(filename, 'w', encoding='utf-8') as f:
+ f.write(str_dump)
+
+ return is_different
+
+
+def parse_md(md_file):
+ """Parse .md file and convert it to a .yml file which can be used for MIM.
+
+ Args:
+ md_file (str): Path to .md file.
+ Returns:
+ Bool: If the target YAML file is different from the original.
+ """
+ collection_name = osp.split(osp.dirname(md_file))[1]
+ configs = os.listdir(osp.dirname(md_file))
+
+ collection = dict(
+ Name=collection_name,
+ Metadata={'Training Data': []},
+ Paper={
+ 'URL': '',
+ 'Title': ''
+ },
+ README=md_file,
+ Code={
+ 'URL': '',
+ 'Version': ''
+ })
+ collection.update({'Converted From': {'Weights': '', 'Code': ''}})
+ models = []
+ datasets = []
+ paper_url = None
+ paper_title = None
+ code_url = None
+ code_version = None
+ repo_url = None
+
+ with open(md_file, 'r') as md:
+ lines = md.readlines()
+ i = 0
+ current_dataset = ''
+ while i < len(lines):
+ line = lines[i].strip()
+ # In latest README.md the title and url are in the third line.
+ if i == 2:
+ paper_url = lines[i].split('](')[1].split(')')[0]
+ paper_title = lines[i].split('](')[0].split('[')[1]
+ if len(line) == 0:
+ i += 1
+ continue
+ elif line[:3] == 'Before you create a PR, make sure that your code lints and is formatted by yapf.
+
+### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
diff --git a/.github/ISSUE_TEMPLATE/config.yml b/.github/ISSUE_TEMPLATE/config.yml
new file mode 100644
index 0000000..aa982e5
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/config.yml
@@ -0,0 +1,6 @@
+blank_issues_enabled: false
+
+contact_links:
+ - name: MMSegmentation Documentation
+ url: https://mmsegmentation.readthedocs.io
+ about: Check the docs and FAQ to see if you question is already answered.
diff --git a/.github/ISSUE_TEMPLATE/error-report.md b/.github/ISSUE_TEMPLATE/error-report.md
new file mode 100644
index 0000000..f977b7d
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/error-report.md
@@ -0,0 +1,48 @@
+---
+name: Error report
+about: Create a report to help us improve
+title: ''
+labels: ''
+assignees: ''
+
+---
+
+Thanks for your error report and we appreciate it a lot.
+
+**Checklist**
+
+1. I have searched related issues but cannot get the expected help.
+2. The bug has not been fixed in the latest version.
+
+**Describe the bug**
+A clear and concise description of what the bug is.
+
+**Reproduction**
+
+1. What command or script did you run?
+
+ ```none
+ A placeholder for the command.
+ ```
+
+2. Did you make any modifications on the code or config? Did you understand what you have modified?
+3. What dataset did you use?
+
+**Environment**
+
+1. Please run `python mmseg/utils/collect_env.py` to collect necessary environment information and paste it here.
+2. You may add addition that may be helpful for locating the problem, such as
+ - How you installed PyTorch [e.g., pip, conda, source]
+ - Other environment variables that may be related (such as `$PATH`, `$LD_LIBRARY_PATH`, `$PYTHONPATH`, etc.)
+
+**Error traceback**
+
+If applicable, paste the error trackback here.
+
+```none
+A placeholder for trackback.
+```
+
+**Bug fix**
+
+If you have already identified the reason, you can provide the information here. If you are willing to create a PR to fix it, please also leave a comment here and that would be much appreciated!
diff --git a/.github/ISSUE_TEMPLATE/feature_request.md b/.github/ISSUE_TEMPLATE/feature_request.md
new file mode 100644
index 0000000..ec59b78
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/feature_request.md
@@ -0,0 +1,22 @@
+---
+name: Feature request
+about: Suggest an idea for this project
+title: ''
+labels: ''
+assignees: ''
+
+---
+
+# Describe the feature
+
+**Motivation**
+A clear and concise description of the motivation of the feature.
+Ex1. It is inconvenient when [....].
+Ex2. There is a recent paper [....], which is very helpful for [....].
+
+**Related resources**
+If there is an official code release or third-party implementations, please also provide the information here, which would be very helpful.
+
+**Additional context**
+Add any other context or screenshots about the feature request here.
+If you would like to implement the feature and create a PR, please leave a comment here and that would be much appreciated.
diff --git a/.github/ISSUE_TEMPLATE/general_questions.md b/.github/ISSUE_TEMPLATE/general_questions.md
new file mode 100644
index 0000000..b5a6451
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/general_questions.md
@@ -0,0 +1,8 @@
+---
+name: General questions
+about: Ask general questions to get help
+title: ''
+labels: ''
+assignees: ''
+
+---
diff --git a/.github/ISSUE_TEMPLATE/reimplementation_questions.md b/.github/ISSUE_TEMPLATE/reimplementation_questions.md
new file mode 100644
index 0000000..c82397b
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/reimplementation_questions.md
@@ -0,0 +1,70 @@
+---
+name: Reimplementation Questions
+about: Ask about questions during model reimplementation
+title: ''
+labels: 'reimplementation'
+assignees: ''
+
+---
+
+If you feel we have helped you, give us a STAR! :satisfied:
+
+**Notice**
+
+There are several common situations in the reimplementation issues as below
+
+1. Reimplement a model in the model zoo using the provided configs
+2. Reimplement a model in the model zoo on other datasets (e.g., custom datasets)
+3. Reimplement a custom model but all the components are implemented in MMSegmentation
+4. Reimplement a custom model with new modules implemented by yourself
+
+There are several things to do for different cases as below.
+
+- For cases 1 & 3, please follow the steps in the following sections thus we could help to quickly identify the issue.
+- For cases 2 & 4, please understand that we are not able to do much help here because we usually do not know the full code, and the users should be responsible for the code they write.
+- One suggestion for cases 2 & 4 is that the users should first check whether the bug lies in the self-implemented code or the original code. For example, users can first make sure that the same model runs well on supported datasets. If you still need help, please describe what you have done and what you obtain in the issue, and follow the steps in the following sections, and try as clear as possible so that we can better help you.
+
+**Checklist**
+
+1. I have searched related issues but cannot get the expected help.
+2. The issue has not been fixed in the latest version.
+
+**Describe the issue**
+
+A clear and concise description of the problem you meet and what you have done.
+
+**Reproduction**
+
+1. What command or script did you run?
+
+```
+A placeholder for the command.
+```
+
+2. What config dir you run?
+
+```
+A placeholder for the config.
+```
+
+3. Did you make any modifications to the code or config? Did you understand what you have modified?
+4. What dataset did you use?
+
+**Environment**
+
+1. Please run `PYTHONPATH=${PWD}:$PYTHONPATH python mmseg/utils/collect_env.py` to collect the necessary environment information and paste it here.
+2. You may add an addition that may be helpful for locating the problem, such as
+ 1. How you installed PyTorch [e.g., pip, conda, source]
+ 2. Other environment variables that may be related (such as `$PATH`, `$LD_LIBRARY_PATH`, `$PYTHONPATH`, etc.)
+
+**Results**
+
+If applicable, paste the related results here, e.g., what you expect and what you get.
+
+```
+A placeholder for results comparison
+```
+
+**Issue fix**
+
+If you have already identified the reason, you can provide the information here. If you are willing to create a PR to fix it, please also leave a comment here and that would be much appreciated!
diff --git a/.github/pull_request_template.md b/.github/pull_request_template.md
new file mode 100644
index 0000000..09d5305
--- /dev/null
+++ b/.github/pull_request_template.md
@@ -0,0 +1,25 @@
+Thanks for your contribution and we appreciate it a lot. The following instructions would make your pull request more healthy and more easily get feedback. If you do not understand some items, don't worry, just make the pull request and seek help from maintainers.
+
+## Motivation
+
+Please describe the motivation of this PR and the goal you want to achieve through this PR.
+
+## Modification
+
+Please briefly describe what modification is made in this PR.
+
+## BC-breaking (Optional)
+
+Does the modification introduce changes that break the backward-compatibility of the downstream repos?
+If so, please describe how it breaks the compatibility and how the downstream projects should modify their code to keep compatibility with this PR.
+
+## Use cases (Optional)
+
+If this PR introduces a new feature, it is better to list some use cases here, and update the documentation.
+
+## Checklist
+
+1. Pre-commit or other linting tools are used to fix the potential lint issues.
+2. The modification is covered by complete unit tests. If not, please add more unit test to ensure the correctness.
+3. If the modification has potential influence on downstream projects, this PR should be tested with downstream projects, like MMDet or MMDet3D.
+4. The documentation has been modified accordingly, like docstring or example tutorials.
diff --git a/.github/workflows/build.yml b/.github/workflows/build.yml
new file mode 100644
index 0000000..628a9ca
--- /dev/null
+++ b/.github/workflows/build.yml
@@ -0,0 +1,221 @@
+name: build
+
+on:
+ push:
+ paths-ignore:
+ - 'demo/**'
+ - '.dev/**'
+ - 'docker/**'
+ - 'tools/**'
+ - '**.md'
+
+ pull_request:
+ paths-ignore:
+ - 'demo/**'
+ - '.dev/**'
+ - 'docker/**'
+ - 'tools/**'
+ - 'docs/**'
+ - '**.md'
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.ref }}
+ cancel-in-progress: true
+
+jobs:
+ build_cpu:
+ runs-on: ubuntu-18.04
+ strategy:
+ matrix:
+ python-version: [3.7]
+ torch: [1.5.1, 1.6.0, 1.7.0, 1.8.0, 1.9.0]
+ include:
+ - torch: 1.5.1
+ torchvision: 0.6.1
+ mmcv: 1.5.0
+ - torch: 1.6.0
+ torchvision: 0.7.0
+ mmcv: 1.6.0
+ - torch: 1.7.0
+ torchvision: 0.8.1
+ mmcv: 1.7.0
+ - torch: 1.8.0
+ torchvision: 0.9.0
+ mmcv: 1.8.0
+ - torch: 1.9.0
+ torchvision: 0.10.0
+ mmcv: 1.9.0
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v2
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Upgrade pip
+ run: pip install pip --upgrade
+ - name: Install Pillow
+ run: pip install Pillow==6.2.2
+ if: ${{matrix.torchvision == '0.4.2'}}
+ - name: Install PyTorch
+ run: pip install torch==${{matrix.torch}}+cpu torchvision==${{matrix.torchvision}}+cpu -f https://download.pytorch.org/whl/torch_stable.html
+ - name: Install MMCV
+ run: |
+ pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cpu/torch${{matrix.mmcv}}/index.html
+ python -c 'import mmcv; print(mmcv.__version__)'
+ - name: Install unittest dependencies
+ run: |
+ pip install -r requirements.txt
+ - name: Build and install
+ run: rm -rf .eggs && pip install -e .
+ - name: Run unittests and generate coverage report
+ run: |
+ pip install timm
+ coverage run --branch --source mmseg -m pytest tests/
+ coverage xml
+ coverage report -m
+ if: ${{matrix.torch >= '1.5.0'}}
+ - name: Skip timm unittests and generate coverage report
+ run: |
+ coverage run --branch --source mmseg -m pytest tests/ --ignore tests/test_models/test_backbones/test_timm_backbone.py
+ coverage xml
+ coverage report -m
+ if: ${{matrix.torch < '1.5.0'}}
+
+ build_cuda101:
+ runs-on: ubuntu-18.04
+ container:
+ image: pytorch/pytorch:1.6.0-cuda10.1-cudnn7-devel
+
+ strategy:
+ matrix:
+ python-version: [3.7]
+ torch:
+ [
+ 1.5.1+cu101,
+ 1.6.0+cu101,
+ 1.7.0+cu101,
+ 1.8.0+cu101
+ ]
+ include:
+ - torch: 1.5.1+cu101
+ torch_version: torch1.5.1
+ torchvision: 0.6.1+cu101
+ mmcv: 1.5.0
+ - torch: 1.6.0+cu101
+ torch_version: torch1.6.0
+ torchvision: 0.7.0+cu101
+ mmcv: 1.6.0
+ - torch: 1.7.0+cu101
+ torch_version: torch1.7.0
+ torchvision: 0.8.1+cu101
+ mmcv: 1.7.0
+ - torch: 1.8.0+cu101
+ torch_version: torch1.8.0
+ torchvision: 0.9.0+cu101
+ mmcv: 1.8.0
+
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v2
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install system dependencies
+ run: |
+ apt-get update && apt-get install -y ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 python${{matrix.python-version}}-dev
+ apt-get clean
+ rm -rf /var/lib/apt/lists/*
+ - name: Install Pillow
+ run: python -m pip install Pillow==6.2.2
+ if: ${{matrix.torchvision < 0.5}}
+ - name: Install PyTorch
+ run: python -m pip install torch==${{matrix.torch}} torchvision==${{matrix.torchvision}} -f https://download.pytorch.org/whl/torch_stable.html
+ - name: Install mmseg dependencies
+ run: |
+ python -V
+ python -m pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch${{matrix.mmcv}}/index.html
+ python -m pip install -r requirements.txt
+ python -c 'import mmcv; print(mmcv.__version__)'
+ - name: Build and install
+ run: |
+ rm -rf .eggs
+ python setup.py check -m -s
+ TORCH_CUDA_ARCH_LIST=7.0 pip install .
+ - name: Run unittests and generate coverage report
+ run: |
+ python -m pip install timm
+ coverage run --branch --source mmseg -m pytest tests/
+ coverage xml
+ coverage report -m
+ if: ${{matrix.torch >= '1.5.0'}}
+ - name: Skip timm unittests and generate coverage report
+ run: |
+ coverage run --branch --source mmseg -m pytest tests/ --ignore tests/test_models/test_backbones/test_timm_backbone.py
+ coverage xml
+ coverage report -m
+ if: ${{matrix.torch < '1.5.0'}}
+ - name: Upload coverage to Codecov
+ uses: codecov/codecov-action@v1.0.10
+ with:
+ file: ./coverage.xml
+ flags: unittests
+ env_vars: OS,PYTHON
+ name: codecov-umbrella
+ fail_ci_if_error: false
+
+ build_cuda102:
+ runs-on: ubuntu-18.04
+ container:
+ image: pytorch/pytorch:1.9.0-cuda10.2-cudnn7-devel
+
+ strategy:
+ matrix:
+ python-version: [3.6, 3.7, 3.8, 3.9]
+ torch: [1.9.0+cu102]
+ include:
+ - torch: 1.9.0+cu102
+ torch_version: torch1.9.0
+ torchvision: 0.10.0+cu102
+ mmcv_link: 1.9.0
+
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v2
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install system dependencies
+ run: |
+ apt-get update && apt-get install -y ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6
+ apt-get clean
+ rm -rf /var/lib/apt/lists/*
+ - name: Install Pillow
+ run: python -m pip install Pillow==6.2.2
+ if: ${{matrix.torchvision < 0.5}}
+ - name: Install PyTorch
+ run: python -m pip install torch==${{matrix.torch}} torchvision==${{matrix.torchvision}} -f https://download.pytorch.org/whl/torch_stable.html
+ - name: Install mmseg dependencies
+ run: |
+ python -V
+ python -m pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch${{matrix.mmcv_link}}/index.html
+ python -m pip install -r requirements.txt
+ python -c 'import mmcv; print(mmcv.__version__)'
+ - name: Build and install
+ run: |
+ rm -rf .eggs
+ python setup.py check -m -s
+ TORCH_CUDA_ARCH_LIST=7.0 pip install .
+ - name: Run unittests and generate coverage report
+ run: |
+ python -m pip install timm
+ coverage run --branch --source mmseg -m pytest tests/
+ coverage xml
+ coverage report -m
+ - name: Upload coverage to Codecov
+ uses: codecov/codecov-action@v2
+ with:
+ files: ./coverage.xml
+ flags: unittests
+ env_vars: OS,PYTHON
+ name: codecov-umbrella
+ fail_ci_if_error: false
diff --git a/.github/workflows/deploy.yml b/.github/workflows/deploy.yml
new file mode 100644
index 0000000..ab64085
--- /dev/null
+++ b/.github/workflows/deploy.yml
@@ -0,0 +1,26 @@
+name: deploy
+
+on: push
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.ref }}
+ cancel-in-progress: true
+
+jobs:
+ build-n-publish:
+ runs-on: ubuntu-latest
+ if: startsWith(github.event.ref, 'refs/tags')
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python 3.7
+ uses: actions/setup-python@v2
+ with:
+ python-version: 3.7
+ - name: Build MMSegmentation
+ run: |
+ pip install wheel
+ python setup.py sdist bdist_wheel
+ - name: Publish distribution to PyPI
+ run: |
+ pip install twine
+ twine upload dist/* -u __token__ -p ${{ secrets.pypi_password }}
diff --git a/.github/workflows/lint.yml b/.github/workflows/lint.yml
new file mode 100644
index 0000000..7f7a309
--- /dev/null
+++ b/.github/workflows/lint.yml
@@ -0,0 +1,31 @@
+name: lint
+
+on: [push, pull_request]
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.ref }}
+ cancel-in-progress: true
+
+jobs:
+ lint:
+ runs-on: ubuntu-18.04
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python 3.7
+ uses: actions/setup-python@v2
+ with:
+ python-version: 3.7
+ - name: Install pre-commit hook
+ run: |
+ pip install pre-commit
+ pre-commit install
+ - name: Linting
+ run: |
+ sudo apt-add-repository ppa:brightbox/ruby-ng -y
+ sudo apt-get update
+ sudo apt-get install -y ruby2.7
+ pre-commit run --all-files
+ - name: Check docstring coverage
+ run: |
+ pip install interrogate
+ interrogate -v --ignore-init-method --ignore-module --ignore-nested-functions --exclude mmseg/ops --ignore-regex "__repr__" --fail-under 80 mmseg
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..2c1ffb5
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,119 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/en/_build/
+docs/zh_cn/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+data
+.vscode
+.idea
+
+# custom
+*.pkl
+*.pkl.json
+*.log.json
+work_dirs/
+mmseg/.mim
+
+# Pytorch
+*.pth
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
new file mode 100644
index 0000000..90f7eba
--- /dev/null
+++ b/.pre-commit-config.yaml
@@ -0,0 +1,51 @@
+repos:
+ - repo: https://gitlab.com/pycqa/flake8.git
+ rev: 3.8.3
+ hooks:
+ - id: flake8
+ - repo: https://github.com/PyCQA/isort
+ rev: 5.10.1
+ hooks:
+ - id: isort
+ - repo: https://github.com/pre-commit/mirrors-yapf
+ rev: v0.30.0
+ hooks:
+ - id: yapf
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v3.1.0
+ hooks:
+ - id: trailing-whitespace
+ - id: check-yaml
+ - id: end-of-file-fixer
+ - id: requirements-txt-fixer
+ - id: double-quote-string-fixer
+ - id: check-merge-conflict
+ - id: fix-encoding-pragma
+ args: ["--remove"]
+ - id: mixed-line-ending
+ args: ["--fix=lf"]
+ - repo: https://github.com/markdownlint/markdownlint
+ rev: v0.11.0
+ hooks:
+ - id: markdownlint
+ args: ["-r", "~MD002,~MD013,~MD029,~MD033,~MD034",
+ "-t", "allow_different_nesting"]
+ - repo: https://github.com/codespell-project/codespell
+ rev: v2.1.0
+ hooks:
+ - id: codespell
+ - repo: https://github.com/myint/docformatter
+ rev: v1.3.1
+ hooks:
+ - id: docformatter
+ args: ["--in-place", "--wrap-descriptions", "79"]
+ - repo: local
+ hooks:
+ - id: update-model-index
+ name: update-model-index
+ description: Collect model information and update model-index.yml
+ entry: .dev/md2yml.py
+ additional_dependencies: [mmcv, lxml]
+ language: python
+ files: ^configs/.*\.md$
+ require_serial: true
diff --git a/.readthedocs.yml b/.readthedocs.yml
new file mode 100644
index 0000000..6cfbf5d
--- /dev/null
+++ b/.readthedocs.yml
@@ -0,0 +1,9 @@
+version: 2
+
+formats: all
+
+python:
+ version: 3.7
+ install:
+ - requirements: requirements/docs.txt
+ - requirements: requirements/readthedocs.txt
diff --git a/CITATION.cff b/CITATION.cff
new file mode 100644
index 0000000..cfd7cab
--- /dev/null
+++ b/CITATION.cff
@@ -0,0 +1,8 @@
+cff-version: 1.2.0
+message: "If you use this software, please cite it as below."
+authors:
+ - name: "MMSegmentation Contributors"
+title: "OpenMMLab Semantic Segmentation Toolbox and Benchmark"
+date-released: 2020-07-10
+url: "https://github.com/open-mmlab/mmsegmentation"
+license: Apache-2.0
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000..38e625b
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,203 @@
+Copyright 2020 The MMSegmentation Authors. All rights reserved.
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2020 The MMSegmentation Authors.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 0000000..e307d81
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,4 @@
+include requirements/*.txt
+include mmseg/.mim/model-index.yml
+recursive-include mmseg/.mim/configs *.py *.yml
+recursive-include mmseg/.mim/tools *.py *.sh
diff --git a/README.md b/README.md
index e08bcfb..8b59bda 100644
--- a/README.md
+++ b/README.md
@@ -1 +1,70 @@
-# kneron-mmsegmentation
\ No newline at end of file
+# Kneron AI Training/Deployment Platform (mmsegmentation-based)
+
+
+## Introduction
+
+ [kneron-mmsegmentation](https://github.com/kneron/kneron-mmsegmentation) is a platform built upon the well-known [mmsegmentation](https://github.com/open-mmlab/mmsegmentation) for mmsegmentation. If you are looking for original mmsegmentation document, please visit [mmsegmentation docs](https://mmsegmentation.readthedocs.io/en/latest/) for detailed mmsegmentation usage.
+
+ In this repository, we provide an end-to-end training/deployment flow to realize on Kneron's AI accelerators:
+
+ 1. **Training/Evalulation:**
+ - Modified model configuration file and verified for Kneron hardware platform
+ - Please see [Overview of Benchmark and Model Zoo](#Overview-of-Benchmark-and-Model-Zoo) for Kneron-Verified model list
+ 2. **Converting to ONNX:**
+ - tools/pytorch2onnx_kneron.py (beta)
+ - Export *optimized* and *Kneron-toolchain supported* onnx
+ - Automatically modify model for arbitrary data normalization preprocess
+ 3. **Evaluation**
+ - tools/test_kneron.py (beta)
+ - Evaluate the model with *pytorch checkpoint, onnx, and kneron-nef*
+ 4. **Testing**
+ - inference_kn (beta)
+ - Verify the converted [NEF](http://doc.kneron.com/docs/#toolchain/manual/#5-nef-workflow) model on Kneron USB accelerator with this API
+ 5. **Converting Kneron-NEF:** (toolchain feature)
+ - Convert the trained pytorch model to [Kneron-NEF](http://doc.kneron.com/docs/#toolchain/manual/#5-nef-workflow) model, which could be used on Kneron hardware platform.
+
+## License
+
+This project is released under the [Apache 2.0 license](LICENSE).
+
+## Changelog
+
+N/A
+
+## Overview of Benchmark and Kneron Model Zoo
+
+| Backbone | Crop Size | Mem (GB) | mIoU | Config | Download |
+|:--------:|:---------:|:--------:|:----:|:------:|:--------:|
+| STDC 1 | 512x1024 | 7.15 | 69.29|[config](https://github.com/kneron/kneron-mmsegmentation/tree/master/configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py)|[model](https://github.com/kneron/Model_Zoo/blob/main/mmsegmentation/stdc_1/latest.zip)
+
+NOTE: The performance may slightly differ from the original implementation since the input size is smaller.
+
+## Installation
+- Please refer to the Step 1 of [docs_kneron/stdc_step_by_step.md#step-1-environment](docs_kneron/stdc_step_by_step.md) for installation.
+- Please refer to [Kneron PLUS - Python: Installation](http://doc.kneron.com/docs/#plus_python/introduction/install_dependency/) for the environment setup for Kneron USB accelerator.
+
+## Getting Started
+### Tutorial - Kneron Edition
+- [STDC-Seg: Step-By-Step](docs_kneron/stdc_step_by_step.md): A tutorial for users to get started easily. To see detailed documents, please see below.
+
+### Documents - Kneron Edition
+- [Kneron ONNX Export] (under development)
+- [Kneron Inference] (under development)
+- [Kneron Toolchain Step-By-Step (YOLOv3)](http://doc.kneron.com/docs/#toolchain/yolo_example/)
+- [Kneron Toolchain Manual](http://doc.kneron.com/docs/#toolchain/manual/#0-overview)
+
+### Original mmsegmentation Documents
+- [Original mmsegmentation getting started](https://github.com/open-mmlab/mmsegmentation#getting-started): It is recommended to read the original mmsegmentation getting started documents for other mmsegmentation operations.
+- [Original mmsegmentation readthedoc](https://mmsegmentation.readthedocs.io/en/latest/): Original mmsegmentation documents.
+
+## Contributing
+[kneron-mmsegmentation](https://github.com/kneron/kneron-mmsegmentation) a platform built upon [OpenMMLab-mmsegmentation](https://github.com/open-mmlab/mmsegmentation)
+
+- For issues regarding to the original [mmsegmentation](https://github.com/open-mmlab/mmsegmentation):
+We appreciate all contributions to improve [OpenMMLab-mmsegmentation](https://github.com/open-mmlab/mmsegmentation). Ongoing projects can be found in out [GitHub Projects](https://github.com/open-mmlab/mmsegmentation/projects). Welcome community users to participate in these projects. Please refer to [CONTRIBUTING.md](.github/CONTRIBUTING.md) for the contributing guideline.
+
+- For issues regarding to this repository [kneron-mmsegmentation](https://github.com/kneron/kneron-mmsegmentation): Welcome to leave the comment or submit pull requests here to improve kneron-mmsegmentation
+
+
+## Related Projects
+- [kneron-mmdetection](https://github.com/kneron/kneron-mmdetection): Kneron training/deployment platform on [OpenMMLab - mmdetection](https://github.com/open-mmlab/mmdetection) object detection toolbox
diff --git a/configs/_base_/datasets/ade20k.py b/configs/_base_/datasets/ade20k.py
new file mode 100644
index 0000000..efc8b4b
--- /dev/null
+++ b/configs/_base_/datasets/ade20k.py
@@ -0,0 +1,54 @@
+# dataset settings
+dataset_type = 'ADE20KDataset'
+data_root = 'data/ade/ADEChallengeData2016'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 512)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', reduce_zero_label=True),
+ dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 512),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/training',
+ ann_dir='annotations/training',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/chase_db1.py b/configs/_base_/datasets/chase_db1.py
new file mode 100644
index 0000000..298594e
--- /dev/null
+++ b/configs/_base_/datasets/chase_db1.py
@@ -0,0 +1,59 @@
+# dataset settings
+dataset_type = 'ChaseDB1Dataset'
+data_root = 'data/CHASE_DB1'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+img_scale = (960, 999)
+crop_size = (128, 128)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=img_scale,
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+]
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type='RepeatDataset',
+ times=40000,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/training',
+ ann_dir='annotations/training',
+ pipeline=train_pipeline)),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/cityscapes.py b/configs/_base_/datasets/cityscapes.py
new file mode 100644
index 0000000..f21867c
--- /dev/null
+++ b/configs/_base_/datasets/cityscapes.py
@@ -0,0 +1,54 @@
+# dataset settings
+dataset_type = 'CityscapesDataset'
+data_root = 'data/cityscapes/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 1024)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='leftImg8bit/train',
+ ann_dir='gtFine/train',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/cityscapes_1024x1024.py b/configs/_base_/datasets/cityscapes_1024x1024.py
new file mode 100644
index 0000000..f98d929
--- /dev/null
+++ b/configs/_base_/datasets/cityscapes_1024x1024.py
@@ -0,0 +1,35 @@
+_base_ = './cityscapes.py'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (1024, 1024)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/cityscapes_768x768.py b/configs/_base_/datasets/cityscapes_768x768.py
new file mode 100644
index 0000000..fde9d7c
--- /dev/null
+++ b/configs/_base_/datasets/cityscapes_768x768.py
@@ -0,0 +1,35 @@
+_base_ = './cityscapes.py'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (768, 768)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2049, 1025), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2049, 1025),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/cityscapes_769x769.py b/configs/_base_/datasets/cityscapes_769x769.py
new file mode 100644
index 0000000..336c7b2
--- /dev/null
+++ b/configs/_base_/datasets/cityscapes_769x769.py
@@ -0,0 +1,35 @@
+_base_ = './cityscapes.py'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (769, 769)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2049, 1025), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2049, 1025),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/cityscapes_832x832.py b/configs/_base_/datasets/cityscapes_832x832.py
new file mode 100644
index 0000000..b9325cc
--- /dev/null
+++ b/configs/_base_/datasets/cityscapes_832x832.py
@@ -0,0 +1,35 @@
+_base_ = './cityscapes.py'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (832, 832)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/coco-stuff10k.py b/configs/_base_/datasets/coco-stuff10k.py
new file mode 100644
index 0000000..ec04969
--- /dev/null
+++ b/configs/_base_/datasets/coco-stuff10k.py
@@ -0,0 +1,57 @@
+# dataset settings
+dataset_type = 'COCOStuffDataset'
+data_root = 'data/coco_stuff10k'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 512)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', reduce_zero_label=True),
+ dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 512),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ reduce_zero_label=True,
+ img_dir='images/train2014',
+ ann_dir='annotations/train2014',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ reduce_zero_label=True,
+ img_dir='images/test2014',
+ ann_dir='annotations/test2014',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ reduce_zero_label=True,
+ img_dir='images/test2014',
+ ann_dir='annotations/test2014',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/coco-stuff164k.py b/configs/_base_/datasets/coco-stuff164k.py
new file mode 100644
index 0000000..a6a38f2
--- /dev/null
+++ b/configs/_base_/datasets/coco-stuff164k.py
@@ -0,0 +1,54 @@
+# dataset settings
+dataset_type = 'COCOStuffDataset'
+data_root = 'data/coco_stuff164k'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 512)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 512),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/train2017',
+ ann_dir='annotations/train2017',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/val2017',
+ ann_dir='annotations/val2017',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/val2017',
+ ann_dir='annotations/val2017',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/drive.py b/configs/_base_/datasets/drive.py
new file mode 100644
index 0000000..06e8ff6
--- /dev/null
+++ b/configs/_base_/datasets/drive.py
@@ -0,0 +1,59 @@
+# dataset settings
+dataset_type = 'DRIVEDataset'
+data_root = 'data/DRIVE'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+img_scale = (584, 565)
+crop_size = (64, 64)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=img_scale,
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+]
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type='RepeatDataset',
+ times=40000,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/training',
+ ann_dir='annotations/training',
+ pipeline=train_pipeline)),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/hrf.py b/configs/_base_/datasets/hrf.py
new file mode 100644
index 0000000..242d790
--- /dev/null
+++ b/configs/_base_/datasets/hrf.py
@@ -0,0 +1,59 @@
+# dataset settings
+dataset_type = 'HRFDataset'
+data_root = 'data/HRF'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+img_scale = (2336, 3504)
+crop_size = (256, 256)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=img_scale,
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+]
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type='RepeatDataset',
+ times=40000,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/training',
+ ann_dir='annotations/training',
+ pipeline=train_pipeline)),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/kn_cityscapes.py b/configs/_base_/datasets/kn_cityscapes.py
new file mode 100644
index 0000000..e15ad34
--- /dev/null
+++ b/configs/_base_/datasets/kn_cityscapes.py
@@ -0,0 +1,54 @@
+# dataset settings
+dataset_type = 'CityscapesDataset'
+data_root = 'data/cityscapes/'
+img_norm_cfg = dict(
+ mean=[128., 128., 128.], std=[256., 256., 256.], to_rgb=True)
+crop_size = (512, 1024)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ # img_scale=(2048, 1024),
+ img_scale=(1024, 512),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='leftImg8bit/train',
+ ann_dir='gtFine/train',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/loveda.py b/configs/_base_/datasets/loveda.py
new file mode 100644
index 0000000..e553356
--- /dev/null
+++ b/configs/_base_/datasets/loveda.py
@@ -0,0 +1,54 @@
+# dataset settings
+dataset_type = 'LoveDADataset'
+data_root = 'data/loveDA'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 512)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', reduce_zero_label=True),
+ dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1024, 1024),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='img_dir/train',
+ ann_dir='ann_dir/train',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='img_dir/val',
+ ann_dir='ann_dir/val',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='img_dir/val',
+ ann_dir='ann_dir/val',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/pascal_context.py b/configs/_base_/datasets/pascal_context.py
new file mode 100644
index 0000000..ff65bad
--- /dev/null
+++ b/configs/_base_/datasets/pascal_context.py
@@ -0,0 +1,60 @@
+# dataset settings
+dataset_type = 'PascalContextDataset'
+data_root = 'data/VOCdevkit/VOC2010/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+
+img_scale = (520, 520)
+crop_size = (480, 480)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=img_scale,
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='JPEGImages',
+ ann_dir='SegmentationClassContext',
+ split='ImageSets/SegmentationContext/train.txt',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='JPEGImages',
+ ann_dir='SegmentationClassContext',
+ split='ImageSets/SegmentationContext/val.txt',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='JPEGImages',
+ ann_dir='SegmentationClassContext',
+ split='ImageSets/SegmentationContext/val.txt',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/pascal_context_59.py b/configs/_base_/datasets/pascal_context_59.py
new file mode 100644
index 0000000..37585ab
--- /dev/null
+++ b/configs/_base_/datasets/pascal_context_59.py
@@ -0,0 +1,60 @@
+# dataset settings
+dataset_type = 'PascalContextDataset59'
+data_root = 'data/VOCdevkit/VOC2010/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+
+img_scale = (520, 520)
+crop_size = (480, 480)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', reduce_zero_label=True),
+ dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=img_scale,
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='JPEGImages',
+ ann_dir='SegmentationClassContext',
+ split='ImageSets/SegmentationContext/train.txt',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='JPEGImages',
+ ann_dir='SegmentationClassContext',
+ split='ImageSets/SegmentationContext/val.txt',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='JPEGImages',
+ ann_dir='SegmentationClassContext',
+ split='ImageSets/SegmentationContext/val.txt',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/pascal_voc12.py b/configs/_base_/datasets/pascal_voc12.py
new file mode 100644
index 0000000..ba1d42d
--- /dev/null
+++ b/configs/_base_/datasets/pascal_voc12.py
@@ -0,0 +1,57 @@
+# dataset settings
+dataset_type = 'PascalVOCDataset'
+data_root = 'data/VOCdevkit/VOC2012'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 512)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 512),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='JPEGImages',
+ ann_dir='SegmentationClass',
+ split='ImageSets/Segmentation/train.txt',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='JPEGImages',
+ ann_dir='SegmentationClass',
+ split='ImageSets/Segmentation/val.txt',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='JPEGImages',
+ ann_dir='SegmentationClass',
+ split='ImageSets/Segmentation/val.txt',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/pascal_voc12_aug.py b/configs/_base_/datasets/pascal_voc12_aug.py
new file mode 100644
index 0000000..3f23b67
--- /dev/null
+++ b/configs/_base_/datasets/pascal_voc12_aug.py
@@ -0,0 +1,9 @@
+_base_ = './pascal_voc12.py'
+# dataset settings
+data = dict(
+ train=dict(
+ ann_dir=['SegmentationClass', 'SegmentationClassAug'],
+ split=[
+ 'ImageSets/Segmentation/train.txt',
+ 'ImageSets/Segmentation/aug.txt'
+ ]))
diff --git a/configs/_base_/datasets/potsdam.py b/configs/_base_/datasets/potsdam.py
new file mode 100644
index 0000000..f74c4a5
--- /dev/null
+++ b/configs/_base_/datasets/potsdam.py
@@ -0,0 +1,54 @@
+# dataset settings
+dataset_type = 'PotsdamDataset'
+data_root = 'data/potsdam'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 512)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', reduce_zero_label=True),
+ dict(type='Resize', img_scale=(512, 512), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='img_dir/train',
+ ann_dir='ann_dir/train',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='img_dir/val',
+ ann_dir='ann_dir/val',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='img_dir/val',
+ ann_dir='ann_dir/val',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/stare.py b/configs/_base_/datasets/stare.py
new file mode 100644
index 0000000..3f71b25
--- /dev/null
+++ b/configs/_base_/datasets/stare.py
@@ -0,0 +1,59 @@
+# dataset settings
+dataset_type = 'STAREDataset'
+data_root = 'data/STARE'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+img_scale = (605, 700)
+crop_size = (128, 128)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=img_scale,
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+]
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type='RepeatDataset',
+ times=40000,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/training',
+ ann_dir='annotations/training',
+ pipeline=train_pipeline)),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/datasets/vaihingen.py b/configs/_base_/datasets/vaihingen.py
new file mode 100644
index 0000000..c0df282
--- /dev/null
+++ b/configs/_base_/datasets/vaihingen.py
@@ -0,0 +1,54 @@
+# dataset settings
+dataset_type = 'ISPRSDataset'
+data_root = 'data/vaihingen'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 512)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', reduce_zero_label=True),
+ dict(type='Resize', img_scale=(512, 512), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='img_dir/train',
+ ann_dir='ann_dir/train',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='img_dir/val',
+ ann_dir='ann_dir/val',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='img_dir/val',
+ ann_dir='ann_dir/val',
+ pipeline=test_pipeline))
diff --git a/configs/_base_/default_runtime.py b/configs/_base_/default_runtime.py
new file mode 100644
index 0000000..b564cc4
--- /dev/null
+++ b/configs/_base_/default_runtime.py
@@ -0,0 +1,14 @@
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook', by_epoch=False),
+ # dict(type='TensorboardLoggerHook')
+ ])
+# yapf:enable
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+cudnn_benchmark = True
diff --git a/configs/_base_/models/ann_r50-d8.py b/configs/_base_/models/ann_r50-d8.py
new file mode 100644
index 0000000..a2cb653
--- /dev/null
+++ b/configs/_base_/models/ann_r50-d8.py
@@ -0,0 +1,46 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='ANNHead',
+ in_channels=[1024, 2048],
+ in_index=[2, 3],
+ channels=512,
+ project_channels=256,
+ query_scales=(1, ),
+ key_pool_scales=(1, 3, 6, 8),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/apcnet_r50-d8.py b/configs/_base_/models/apcnet_r50-d8.py
new file mode 100644
index 0000000..c8f5316
--- /dev/null
+++ b/configs/_base_/models/apcnet_r50-d8.py
@@ -0,0 +1,44 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='APCHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN', requires_grad=True),
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/bisenetv1_r18-d32.py b/configs/_base_/models/bisenetv1_r18-d32.py
new file mode 100644
index 0000000..4069864
--- /dev/null
+++ b/configs/_base_/models/bisenetv1_r18-d32.py
@@ -0,0 +1,68 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ backbone=dict(
+ type='BiSeNetV1',
+ in_channels=3,
+ context_channels=(128, 256, 512),
+ spatial_channels=(64, 64, 64, 128),
+ out_indices=(0, 1, 2),
+ out_channels=256,
+ backbone_cfg=dict(
+ type='ResNet',
+ in_channels=3,
+ depth=18,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 1, 1),
+ strides=(1, 2, 2, 2),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ init_cfg=None),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=256,
+ in_index=0,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=[
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=64,
+ num_convs=1,
+ num_classes=19,
+ in_index=1,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=64,
+ num_convs=1,
+ num_classes=19,
+ in_index=2,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ ],
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/bisenetv2.py b/configs/_base_/models/bisenetv2.py
new file mode 100644
index 0000000..f8fffee
--- /dev/null
+++ b/configs/_base_/models/bisenetv2.py
@@ -0,0 +1,80 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='BiSeNetV2',
+ detail_channels=(64, 64, 128),
+ semantic_channels=(16, 32, 64, 128),
+ semantic_expansion_ratio=6,
+ bga_channels=128,
+ out_indices=(0, 1, 2, 3, 4),
+ init_cfg=None,
+ align_corners=False),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=128,
+ in_index=0,
+ channels=1024,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=[
+ dict(
+ type='FCNHead',
+ in_channels=16,
+ channels=16,
+ num_convs=2,
+ num_classes=19,
+ in_index=1,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ dict(
+ type='FCNHead',
+ in_channels=32,
+ channels=64,
+ num_convs=2,
+ num_classes=19,
+ in_index=2,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ dict(
+ type='FCNHead',
+ in_channels=64,
+ channels=256,
+ num_convs=2,
+ num_classes=19,
+ in_index=3,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=1024,
+ num_convs=2,
+ num_classes=19,
+ in_index=4,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ ],
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/ccnet_r50-d8.py b/configs/_base_/models/ccnet_r50-d8.py
new file mode 100644
index 0000000..794148f
--- /dev/null
+++ b/configs/_base_/models/ccnet_r50-d8.py
@@ -0,0 +1,44 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='CCHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ recurrence=2,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/cgnet.py b/configs/_base_/models/cgnet.py
new file mode 100644
index 0000000..eff8d94
--- /dev/null
+++ b/configs/_base_/models/cgnet.py
@@ -0,0 +1,35 @@
+# model settings
+norm_cfg = dict(type='SyncBN', eps=1e-03, requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ backbone=dict(
+ type='CGNet',
+ norm_cfg=norm_cfg,
+ in_channels=3,
+ num_channels=(32, 64, 128),
+ num_blocks=(3, 21),
+ dilations=(2, 4),
+ reductions=(8, 16)),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=256,
+ in_index=2,
+ channels=256,
+ num_convs=0,
+ concat_input=False,
+ dropout_ratio=0,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ loss_decode=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0,
+ class_weight=[
+ 2.5959933, 6.7415504, 3.5354059, 9.8663225, 9.690899, 9.369352,
+ 10.289121, 9.953208, 4.3097677, 9.490387, 7.674431, 9.396905,
+ 10.347791, 6.3927646, 10.226669, 10.241062, 10.280587,
+ 10.396974, 10.055647
+ ])),
+ # model training and testing settings
+ train_cfg=dict(sampler=None),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/danet_r50-d8.py b/configs/_base_/models/danet_r50-d8.py
new file mode 100644
index 0000000..2c93493
--- /dev/null
+++ b/configs/_base_/models/danet_r50-d8.py
@@ -0,0 +1,44 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='DAHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ pam_channels=64,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/deeplabv3_r50-d8.py b/configs/_base_/models/deeplabv3_r50-d8.py
new file mode 100644
index 0000000..d7a43be
--- /dev/null
+++ b/configs/_base_/models/deeplabv3_r50-d8.py
@@ -0,0 +1,44 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='ASPPHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ dilations=(1, 12, 24, 36),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/deeplabv3_unet_s5-d16.py b/configs/_base_/models/deeplabv3_unet_s5-d16.py
new file mode 100644
index 0000000..0cd2629
--- /dev/null
+++ b/configs/_base_/models/deeplabv3_unet_s5-d16.py
@@ -0,0 +1,50 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='UNet',
+ in_channels=3,
+ base_channels=64,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ norm_eval=False),
+ decode_head=dict(
+ type='ASPPHead',
+ in_channels=64,
+ in_index=4,
+ channels=16,
+ dilations=(1, 12, 24, 36),
+ dropout_ratio=0.1,
+ num_classes=2,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=128,
+ in_index=3,
+ channels=64,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=2,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='slide', crop_size=256, stride=170))
diff --git a/configs/_base_/models/deeplabv3plus_r50-d8.py b/configs/_base_/models/deeplabv3plus_r50-d8.py
new file mode 100644
index 0000000..050e39e
--- /dev/null
+++ b/configs/_base_/models/deeplabv3plus_r50-d8.py
@@ -0,0 +1,46 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='DepthwiseSeparableASPPHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ dilations=(1, 12, 24, 36),
+ c1_in_channels=256,
+ c1_channels=48,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/dmnet_r50-d8.py b/configs/_base_/models/dmnet_r50-d8.py
new file mode 100644
index 0000000..d22ba52
--- /dev/null
+++ b/configs/_base_/models/dmnet_r50-d8.py
@@ -0,0 +1,44 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='DMHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ filter_sizes=(1, 3, 5, 7),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN', requires_grad=True),
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/dnl_r50-d8.py b/configs/_base_/models/dnl_r50-d8.py
new file mode 100644
index 0000000..edb4c17
--- /dev/null
+++ b/configs/_base_/models/dnl_r50-d8.py
@@ -0,0 +1,46 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='DNLHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ dropout_ratio=0.1,
+ reduction=2,
+ use_scale=True,
+ mode='embedded_gaussian',
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/dpt_vit-b16.py b/configs/_base_/models/dpt_vit-b16.py
new file mode 100644
index 0000000..dfd48a9
--- /dev/null
+++ b/configs/_base_/models/dpt_vit-b16.py
@@ -0,0 +1,31 @@
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain/vit-b16_p16_224-80ecf9dd.pth', # noqa
+ backbone=dict(
+ type='VisionTransformer',
+ img_size=224,
+ embed_dims=768,
+ num_layers=12,
+ num_heads=12,
+ out_indices=(2, 5, 8, 11),
+ final_norm=False,
+ with_cls_token=True,
+ output_cls_token=True),
+ decode_head=dict(
+ type='DPTHead',
+ in_channels=(768, 768, 768, 768),
+ channels=256,
+ embed_dims=768,
+ post_process_channels=[96, 192, 384, 768],
+ num_classes=150,
+ readout_type='project',
+ input_transform='multiple_select',
+ in_index=(0, 1, 2, 3),
+ norm_cfg=norm_cfg,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=None,
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole')) # yapf: disable
diff --git a/configs/_base_/models/emanet_r50-d8.py b/configs/_base_/models/emanet_r50-d8.py
new file mode 100644
index 0000000..26adcd4
--- /dev/null
+++ b/configs/_base_/models/emanet_r50-d8.py
@@ -0,0 +1,47 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='EMAHead',
+ in_channels=2048,
+ in_index=3,
+ channels=256,
+ ema_channels=512,
+ num_bases=64,
+ num_stages=3,
+ momentum=0.1,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/encnet_r50-d8.py b/configs/_base_/models/encnet_r50-d8.py
new file mode 100644
index 0000000..be77712
--- /dev/null
+++ b/configs/_base_/models/encnet_r50-d8.py
@@ -0,0 +1,48 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='EncHead',
+ in_channels=[512, 1024, 2048],
+ in_index=(1, 2, 3),
+ channels=512,
+ num_codes=32,
+ use_se_loss=True,
+ add_lateral=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_se_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.2)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/erfnet_fcn.py b/configs/_base_/models/erfnet_fcn.py
new file mode 100644
index 0000000..7f2e9bf
--- /dev/null
+++ b/configs/_base_/models/erfnet_fcn.py
@@ -0,0 +1,32 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='ERFNet',
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ init_cfg=None),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=16,
+ channels=128,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/fast_scnn.py b/configs/_base_/models/fast_scnn.py
new file mode 100644
index 0000000..8e89d91
--- /dev/null
+++ b/configs/_base_/models/fast_scnn.py
@@ -0,0 +1,57 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True, momentum=0.01)
+model = dict(
+ type='EncoderDecoder',
+ backbone=dict(
+ type='FastSCNN',
+ downsample_dw_channels=(32, 48),
+ global_in_channels=64,
+ global_block_channels=(64, 96, 128),
+ global_block_strides=(2, 2, 1),
+ global_out_channels=128,
+ higher_in_channels=64,
+ lower_in_channels=128,
+ fusion_out_channels=128,
+ out_indices=(0, 1, 2),
+ norm_cfg=norm_cfg,
+ align_corners=False),
+ decode_head=dict(
+ type='DepthwiseSeparableFCNHead',
+ in_channels=128,
+ channels=128,
+ concat_input=False,
+ num_classes=19,
+ in_index=-1,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1)),
+ auxiliary_head=[
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=32,
+ num_convs=1,
+ num_classes=19,
+ in_index=-2,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.4)),
+ dict(
+ type='FCNHead',
+ in_channels=64,
+ channels=32,
+ num_convs=1,
+ num_classes=19,
+ in_index=-3,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.4)),
+ ],
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/fastfcn_r50-d32_jpu_psp.py b/configs/_base_/models/fastfcn_r50-d32_jpu_psp.py
new file mode 100644
index 0000000..9dc8609
--- /dev/null
+++ b/configs/_base_/models/fastfcn_r50-d32_jpu_psp.py
@@ -0,0 +1,53 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 2, 2),
+ out_indices=(1, 2, 3),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ neck=dict(
+ type='JPU',
+ in_channels=(512, 1024, 2048),
+ mid_channels=512,
+ start_level=0,
+ end_level=-1,
+ dilations=(1, 2, 4, 8),
+ align_corners=False,
+ norm_cfg=norm_cfg),
+ decode_head=dict(
+ type='PSPHead',
+ in_channels=2048,
+ in_index=2,
+ channels=512,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=1,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/fcn_hr18.py b/configs/_base_/models/fcn_hr18.py
new file mode 100644
index 0000000..c3e299b
--- /dev/null
+++ b/configs/_base_/models/fcn_hr18.py
@@ -0,0 +1,52 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144)))),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ channels=sum([18, 36, 72, 144]),
+ input_transform='resize_concat',
+ kernel_size=1,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=-1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/fcn_r50-d8.py b/configs/_base_/models/fcn_r50-d8.py
new file mode 100644
index 0000000..5e98f6c
--- /dev/null
+++ b/configs/_base_/models/fcn_r50-d8.py
@@ -0,0 +1,45 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ num_convs=2,
+ concat_input=True,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/fcn_unet_s5-d16.py b/configs/_base_/models/fcn_unet_s5-d16.py
new file mode 100644
index 0000000..a33e797
--- /dev/null
+++ b/configs/_base_/models/fcn_unet_s5-d16.py
@@ -0,0 +1,51 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='UNet',
+ in_channels=3,
+ base_channels=64,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ norm_eval=False),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=64,
+ in_index=4,
+ channels=64,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=2,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=128,
+ in_index=3,
+ channels=64,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=2,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='slide', crop_size=256, stride=170))
diff --git a/configs/_base_/models/fpn_r50.py b/configs/_base_/models/fpn_r50.py
new file mode 100644
index 0000000..86ab327
--- /dev/null
+++ b/configs/_base_/models/fpn_r50.py
@@ -0,0 +1,36 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 1, 1),
+ strides=(1, 2, 2, 2),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=4),
+ decode_head=dict(
+ type='FPNHead',
+ in_channels=[256, 256, 256, 256],
+ in_index=[0, 1, 2, 3],
+ feature_strides=[4, 8, 16, 32],
+ channels=128,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/gcnet_r50-d8.py b/configs/_base_/models/gcnet_r50-d8.py
new file mode 100644
index 0000000..3d2ad69
--- /dev/null
+++ b/configs/_base_/models/gcnet_r50-d8.py
@@ -0,0 +1,46 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='GCHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ ratio=1 / 4.,
+ pooling_type='att',
+ fusion_types=('channel_add', ),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/icnet_r50-d8.py b/configs/_base_/models/icnet_r50-d8.py
new file mode 100644
index 0000000..d7273cd
--- /dev/null
+++ b/configs/_base_/models/icnet_r50-d8.py
@@ -0,0 +1,74 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ backbone=dict(
+ type='ICNet',
+ backbone_cfg=dict(
+ type='ResNetV1c',
+ in_channels=3,
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ in_channels=3,
+ layer_channels=(512, 2048),
+ light_branch_middle_channels=32,
+ psp_out_channels=512,
+ out_channels=(64, 256, 256),
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ ),
+ neck=dict(
+ type='ICNeck',
+ in_channels=(64, 256, 256),
+ out_channels=128,
+ norm_cfg=norm_cfg,
+ align_corners=False),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=128,
+ num_convs=1,
+ in_index=2,
+ dropout_ratio=0,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=[
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=128,
+ num_convs=1,
+ num_classes=19,
+ in_index=0,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=128,
+ num_convs=1,
+ num_classes=19,
+ in_index=1,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ ],
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/isanet_r50-d8.py b/configs/_base_/models/isanet_r50-d8.py
new file mode 100644
index 0000000..c0221a3
--- /dev/null
+++ b/configs/_base_/models/isanet_r50-d8.py
@@ -0,0 +1,45 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='ISAHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ isa_channels=256,
+ down_factor=(8, 8),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/lraspp_m-v3-d8.py b/configs/_base_/models/lraspp_m-v3-d8.py
new file mode 100644
index 0000000..9325824
--- /dev/null
+++ b/configs/_base_/models/lraspp_m-v3-d8.py
@@ -0,0 +1,25 @@
+# model settings
+norm_cfg = dict(type='SyncBN', eps=0.001, requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ backbone=dict(
+ type='MobileNetV3',
+ arch='large',
+ out_indices=(1, 3, 16),
+ norm_cfg=norm_cfg),
+ decode_head=dict(
+ type='LRASPPHead',
+ in_channels=(16, 24, 960),
+ in_index=(0, 1, 2),
+ channels=128,
+ input_transform='multiple_select',
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/nonlocal_r50-d8.py b/configs/_base_/models/nonlocal_r50-d8.py
new file mode 100644
index 0000000..5674a39
--- /dev/null
+++ b/configs/_base_/models/nonlocal_r50-d8.py
@@ -0,0 +1,46 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='NLHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ dropout_ratio=0.1,
+ reduction=2,
+ use_scale=True,
+ mode='embedded_gaussian',
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/ocrnet_hr18.py b/configs/_base_/models/ocrnet_hr18.py
new file mode 100644
index 0000000..c60f62a
--- /dev/null
+++ b/configs/_base_/models/ocrnet_hr18.py
@@ -0,0 +1,68 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='CascadeEncoderDecoder',
+ num_stages=2,
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144)))),
+ decode_head=[
+ dict(
+ type='FCNHead',
+ in_channels=[18, 36, 72, 144],
+ channels=sum([18, 36, 72, 144]),
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ kernel_size=1,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=-1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='OCRHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ channels=512,
+ ocr_channels=256,
+ dropout_ratio=-1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ ],
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/ocrnet_r50-d8.py b/configs/_base_/models/ocrnet_r50-d8.py
new file mode 100644
index 0000000..615aa3f
--- /dev/null
+++ b/configs/_base_/models/ocrnet_r50-d8.py
@@ -0,0 +1,47 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='CascadeEncoderDecoder',
+ num_stages=2,
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=[
+ dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='OCRHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ ocr_channels=256,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+ ],
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/pointrend_r50.py b/configs/_base_/models/pointrend_r50.py
new file mode 100644
index 0000000..9d323db
--- /dev/null
+++ b/configs/_base_/models/pointrend_r50.py
@@ -0,0 +1,56 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='CascadeEncoderDecoder',
+ num_stages=2,
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 1, 1),
+ strides=(1, 2, 2, 2),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=4),
+ decode_head=[
+ dict(
+ type='FPNHead',
+ in_channels=[256, 256, 256, 256],
+ in_index=[0, 1, 2, 3],
+ feature_strides=[4, 8, 16, 32],
+ channels=128,
+ dropout_ratio=-1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ dict(
+ type='PointHead',
+ in_channels=[256],
+ in_index=[0],
+ channels=256,
+ num_fcs=3,
+ coarse_pred_each_layer=True,
+ dropout_ratio=-1,
+ num_classes=19,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+ ],
+ # model training and testing settings
+ train_cfg=dict(
+ num_points=2048, oversample_ratio=3, importance_sample_ratio=0.75),
+ test_cfg=dict(
+ mode='whole',
+ subdivision_steps=2,
+ subdivision_num_points=8196,
+ scale_factor=2))
diff --git a/configs/_base_/models/psanet_r50-d8.py b/configs/_base_/models/psanet_r50-d8.py
new file mode 100644
index 0000000..689513f
--- /dev/null
+++ b/configs/_base_/models/psanet_r50-d8.py
@@ -0,0 +1,49 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='PSAHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ mask_size=(97, 97),
+ psa_type='bi-direction',
+ compact=False,
+ shrink_factor=2,
+ normalization_factor=1.0,
+ psa_softmax=True,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/pspnet_r50-d8.py b/configs/_base_/models/pspnet_r50-d8.py
new file mode 100644
index 0000000..f451e08
--- /dev/null
+++ b/configs/_base_/models/pspnet_r50-d8.py
@@ -0,0 +1,44 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='PSPHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/pspnet_unet_s5-d16.py b/configs/_base_/models/pspnet_unet_s5-d16.py
new file mode 100644
index 0000000..fcff9ec
--- /dev/null
+++ b/configs/_base_/models/pspnet_unet_s5-d16.py
@@ -0,0 +1,50 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='UNet',
+ in_channels=3,
+ base_channels=64,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ norm_eval=False),
+ decode_head=dict(
+ type='PSPHead',
+ in_channels=64,
+ in_index=4,
+ channels=16,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=2,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=128,
+ in_index=3,
+ channels=64,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=2,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='slide', crop_size=256, stride=170))
diff --git a/configs/_base_/models/segformer_mit-b0.py b/configs/_base_/models/segformer_mit-b0.py
new file mode 100644
index 0000000..5b3e073
--- /dev/null
+++ b/configs/_base_/models/segformer_mit-b0.py
@@ -0,0 +1,34 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='MixVisionTransformer',
+ in_channels=3,
+ embed_dims=32,
+ num_stages=4,
+ num_layers=[2, 2, 2, 2],
+ num_heads=[1, 2, 5, 8],
+ patch_sizes=[7, 3, 3, 3],
+ sr_ratios=[8, 4, 2, 1],
+ out_indices=(0, 1, 2, 3),
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_rate=0.0,
+ attn_drop_rate=0.0,
+ drop_path_rate=0.1),
+ decode_head=dict(
+ type='SegformerHead',
+ in_channels=[32, 64, 160, 256],
+ in_index=[0, 1, 2, 3],
+ channels=256,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/segmenter_vit-b16_mask.py b/configs/_base_/models/segmenter_vit-b16_mask.py
new file mode 100644
index 0000000..967a65c
--- /dev/null
+++ b/configs/_base_/models/segmenter_vit-b16_mask.py
@@ -0,0 +1,35 @@
+# model settings
+backbone_norm_cfg = dict(type='LN', eps=1e-6, requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain/vit_base_p16_384.pth',
+ backbone=dict(
+ type='VisionTransformer',
+ img_size=(512, 512),
+ patch_size=16,
+ in_channels=3,
+ embed_dims=768,
+ num_layers=12,
+ num_heads=12,
+ drop_path_rate=0.1,
+ attn_drop_rate=0.0,
+ drop_rate=0.0,
+ final_norm=True,
+ norm_cfg=backbone_norm_cfg,
+ with_cls_token=True,
+ interpolate_mode='bicubic',
+ ),
+ decode_head=dict(
+ type='SegmenterMaskTransformerHead',
+ in_channels=768,
+ channels=768,
+ num_classes=150,
+ num_layers=2,
+ num_heads=12,
+ embed_dims=768,
+ dropout_ratio=0.0,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ ),
+ test_cfg=dict(mode='slide', crop_size=(512, 512), stride=(480, 480)),
+)
diff --git a/configs/_base_/models/setr_mla.py b/configs/_base_/models/setr_mla.py
new file mode 100644
index 0000000..af4ba24
--- /dev/null
+++ b/configs/_base_/models/setr_mla.py
@@ -0,0 +1,95 @@
+# model settings
+backbone_norm_cfg = dict(type='LN', eps=1e-6, requires_grad=True)
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain/jx_vit_large_p16_384-b3be5167.pth',
+ backbone=dict(
+ type='VisionTransformer',
+ img_size=(768, 768),
+ patch_size=16,
+ in_channels=3,
+ embed_dims=1024,
+ num_layers=24,
+ num_heads=16,
+ out_indices=(5, 11, 17, 23),
+ drop_rate=0.1,
+ norm_cfg=backbone_norm_cfg,
+ with_cls_token=False,
+ interpolate_mode='bilinear',
+ ),
+ neck=dict(
+ type='MLANeck',
+ in_channels=[1024, 1024, 1024, 1024],
+ out_channels=256,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ ),
+ decode_head=dict(
+ type='SETRMLAHead',
+ in_channels=(256, 256, 256, 256),
+ channels=512,
+ in_index=(0, 1, 2, 3),
+ dropout_ratio=0,
+ mla_channels=128,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=[
+ dict(
+ type='FCNHead',
+ in_channels=256,
+ channels=256,
+ in_index=0,
+ dropout_ratio=0,
+ num_convs=0,
+ kernel_size=1,
+ concat_input=False,
+ num_classes=19,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='FCNHead',
+ in_channels=256,
+ channels=256,
+ in_index=1,
+ dropout_ratio=0,
+ num_convs=0,
+ kernel_size=1,
+ concat_input=False,
+ num_classes=19,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='FCNHead',
+ in_channels=256,
+ channels=256,
+ in_index=2,
+ dropout_ratio=0,
+ num_convs=0,
+ kernel_size=1,
+ concat_input=False,
+ num_classes=19,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='FCNHead',
+ in_channels=256,
+ channels=256,
+ in_index=3,
+ dropout_ratio=0,
+ num_convs=0,
+ kernel_size=1,
+ concat_input=False,
+ num_classes=19,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ ],
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/setr_naive.py b/configs/_base_/models/setr_naive.py
new file mode 100644
index 0000000..0c330ea
--- /dev/null
+++ b/configs/_base_/models/setr_naive.py
@@ -0,0 +1,80 @@
+# model settings
+backbone_norm_cfg = dict(type='LN', eps=1e-6, requires_grad=True)
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain/jx_vit_large_p16_384-b3be5167.pth',
+ backbone=dict(
+ type='VisionTransformer',
+ img_size=(768, 768),
+ patch_size=16,
+ in_channels=3,
+ embed_dims=1024,
+ num_layers=24,
+ num_heads=16,
+ out_indices=(9, 14, 19, 23),
+ drop_rate=0.1,
+ norm_cfg=backbone_norm_cfg,
+ with_cls_token=True,
+ interpolate_mode='bilinear',
+ ),
+ decode_head=dict(
+ type='SETRUPHead',
+ in_channels=1024,
+ channels=256,
+ in_index=3,
+ num_classes=19,
+ dropout_ratio=0,
+ norm_cfg=norm_cfg,
+ num_convs=1,
+ up_scale=4,
+ kernel_size=1,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=[
+ dict(
+ type='SETRUPHead',
+ in_channels=1024,
+ channels=256,
+ in_index=0,
+ num_classes=19,
+ dropout_ratio=0,
+ norm_cfg=norm_cfg,
+ num_convs=1,
+ up_scale=4,
+ kernel_size=1,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='SETRUPHead',
+ in_channels=1024,
+ channels=256,
+ in_index=1,
+ num_classes=19,
+ dropout_ratio=0,
+ norm_cfg=norm_cfg,
+ num_convs=1,
+ up_scale=4,
+ kernel_size=1,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='SETRUPHead',
+ in_channels=1024,
+ channels=256,
+ in_index=2,
+ num_classes=19,
+ dropout_ratio=0,
+ norm_cfg=norm_cfg,
+ num_convs=1,
+ up_scale=4,
+ kernel_size=1,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4))
+ ],
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/setr_pup.py b/configs/_base_/models/setr_pup.py
new file mode 100644
index 0000000..8e5f23b
--- /dev/null
+++ b/configs/_base_/models/setr_pup.py
@@ -0,0 +1,80 @@
+# model settings
+backbone_norm_cfg = dict(type='LN', eps=1e-6, requires_grad=True)
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain/jx_vit_large_p16_384-b3be5167.pth',
+ backbone=dict(
+ type='VisionTransformer',
+ img_size=(768, 768),
+ patch_size=16,
+ in_channels=3,
+ embed_dims=1024,
+ num_layers=24,
+ num_heads=16,
+ out_indices=(9, 14, 19, 23),
+ drop_rate=0.1,
+ norm_cfg=backbone_norm_cfg,
+ with_cls_token=True,
+ interpolate_mode='bilinear',
+ ),
+ decode_head=dict(
+ type='SETRUPHead',
+ in_channels=1024,
+ channels=256,
+ in_index=3,
+ num_classes=19,
+ dropout_ratio=0,
+ norm_cfg=norm_cfg,
+ num_convs=4,
+ up_scale=2,
+ kernel_size=3,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=[
+ dict(
+ type='SETRUPHead',
+ in_channels=1024,
+ channels=256,
+ in_index=0,
+ num_classes=19,
+ dropout_ratio=0,
+ norm_cfg=norm_cfg,
+ num_convs=1,
+ up_scale=4,
+ kernel_size=3,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='SETRUPHead',
+ in_channels=1024,
+ channels=256,
+ in_index=1,
+ num_classes=19,
+ dropout_ratio=0,
+ norm_cfg=norm_cfg,
+ num_convs=1,
+ up_scale=4,
+ kernel_size=3,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ dict(
+ type='SETRUPHead',
+ in_channels=1024,
+ channels=256,
+ in_index=2,
+ num_classes=19,
+ dropout_ratio=0,
+ norm_cfg=norm_cfg,
+ num_convs=1,
+ up_scale=4,
+ kernel_size=3,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ ],
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/stdc.py b/configs/_base_/models/stdc.py
new file mode 100644
index 0000000..341a4ec
--- /dev/null
+++ b/configs/_base_/models/stdc.py
@@ -0,0 +1,83 @@
+norm_cfg = dict(type='BN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='STDCContextPathNet',
+ backbone_cfg=dict(
+ type='STDCNet',
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False),
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(in_channels=384, out_channels=256, scale_factor=4)),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=256,
+ channels=256,
+ num_convs=1,
+ num_classes=19,
+ in_index=3,
+ concat_input=False,
+ dropout_ratio=0.1,
+ norm_cfg=norm_cfg,
+ align_corners=True,
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=10000),
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=[
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=64,
+ num_convs=1,
+ num_classes=19,
+ in_index=2,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=10000),
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=64,
+ num_convs=1,
+ num_classes=19,
+ in_index=1,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=10000),
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ dict(
+ type='STDCHead',
+ in_channels=256,
+ channels=64,
+ num_convs=1,
+ num_classes=2,
+ boundary_threshold=0.1,
+ in_index=0,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=True,
+ loss_decode=[
+ dict(
+ type='CrossEntropyLoss',
+ loss_name='loss_ce',
+ use_sigmoid=True,
+ loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=1.0)
+ ]),
+ ],
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/twins_pcpvt-s_fpn.py b/configs/_base_/models/twins_pcpvt-s_fpn.py
new file mode 100644
index 0000000..e772275
--- /dev/null
+++ b/configs/_base_/models/twins_pcpvt-s_fpn.py
@@ -0,0 +1,44 @@
+# model settings
+backbone_norm_cfg = dict(type='LN')
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ backbone=dict(
+ type='PCPVT',
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/pcpvt_small.pth'),
+ in_channels=3,
+ embed_dims=[64, 128, 320, 512],
+ num_heads=[1, 2, 5, 8],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ mlp_ratios=[8, 8, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=True,
+ norm_cfg=backbone_norm_cfg,
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False,
+ drop_rate=0.0,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2),
+ neck=dict(
+ type='FPN',
+ in_channels=[64, 128, 320, 512],
+ out_channels=256,
+ num_outs=4),
+ decode_head=dict(
+ type='FPNHead',
+ in_channels=[256, 256, 256, 256],
+ in_index=[0, 1, 2, 3],
+ feature_strides=[4, 8, 16, 32],
+ channels=128,
+ dropout_ratio=0.1,
+ num_classes=150,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/twins_pcpvt-s_upernet.py b/configs/_base_/models/twins_pcpvt-s_upernet.py
new file mode 100644
index 0000000..a48e1a9
--- /dev/null
+++ b/configs/_base_/models/twins_pcpvt-s_upernet.py
@@ -0,0 +1,52 @@
+# model settings
+backbone_norm_cfg = dict(type='LN')
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ backbone=dict(
+ type='PCPVT',
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/pcpvt_small.pth'),
+ in_channels=3,
+ embed_dims=[64, 128, 320, 512],
+ num_heads=[1, 2, 5, 8],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ mlp_ratios=[8, 8, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=True,
+ norm_cfg=backbone_norm_cfg,
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False,
+ drop_rate=0.0,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2),
+ decode_head=dict(
+ type='UPerHead',
+ in_channels=[64, 128, 320, 512],
+ in_index=[0, 1, 2, 3],
+ pool_scales=(1, 2, 3, 6),
+ channels=512,
+ dropout_ratio=0.1,
+ num_classes=150,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=320,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=150,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/upernet_r50.py b/configs/_base_/models/upernet_r50.py
new file mode 100644
index 0000000..1097496
--- /dev/null
+++ b/configs/_base_/models/upernet_r50.py
@@ -0,0 +1,44 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='open-mmlab://resnet50_v1c',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 1, 1),
+ strides=(1, 2, 2, 2),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='UPerHead',
+ in_channels=[256, 512, 1024, 2048],
+ in_index=[0, 1, 2, 3],
+ pool_scales=(1, 2, 3, 6),
+ channels=512,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=1024,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/upernet_swin.py b/configs/_base_/models/upernet_swin.py
new file mode 100644
index 0000000..71b5162
--- /dev/null
+++ b/configs/_base_/models/upernet_swin.py
@@ -0,0 +1,54 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+backbone_norm_cfg = dict(type='LN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='SwinTransformer',
+ pretrain_img_size=224,
+ embed_dims=96,
+ patch_size=4,
+ window_size=7,
+ mlp_ratio=4,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ strides=(4, 2, 2, 2),
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=True,
+ qk_scale=None,
+ patch_norm=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.3,
+ use_abs_pos_embed=False,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=backbone_norm_cfg),
+ decode_head=dict(
+ type='UPerHead',
+ in_channels=[96, 192, 384, 768],
+ in_index=[0, 1, 2, 3],
+ pool_scales=(1, 2, 3, 6),
+ channels=512,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=384,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/upernet_vit-b16_ln_mln.py b/configs/_base_/models/upernet_vit-b16_ln_mln.py
new file mode 100644
index 0000000..cd6587d
--- /dev/null
+++ b/configs/_base_/models/upernet_vit-b16_ln_mln.py
@@ -0,0 +1,57 @@
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain/jx_vit_base_p16_224-80ecf9dd.pth',
+ backbone=dict(
+ type='VisionTransformer',
+ img_size=(512, 512),
+ patch_size=16,
+ in_channels=3,
+ embed_dims=768,
+ num_layers=12,
+ num_heads=12,
+ mlp_ratio=4,
+ out_indices=(2, 5, 8, 11),
+ qkv_bias=True,
+ drop_rate=0.0,
+ attn_drop_rate=0.0,
+ drop_path_rate=0.0,
+ with_cls_token=True,
+ norm_cfg=dict(type='LN', eps=1e-6),
+ act_cfg=dict(type='GELU'),
+ norm_eval=False,
+ interpolate_mode='bicubic'),
+ neck=dict(
+ type='MultiLevelNeck',
+ in_channels=[768, 768, 768, 768],
+ out_channels=768,
+ scales=[4, 2, 1, 0.5]),
+ decode_head=dict(
+ type='UPerHead',
+ in_channels=[768, 768, 768, 768],
+ in_index=[0, 1, 2, 3],
+ pool_scales=(1, 2, 3, 6),
+ channels=512,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=768,
+ in_index=3,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole')) # yapf: disable
diff --git a/configs/_base_/schedules/schedule_160k.py b/configs/_base_/schedules/schedule_160k.py
new file mode 100644
index 0000000..39630f2
--- /dev/null
+++ b/configs/_base_/schedules/schedule_160k.py
@@ -0,0 +1,9 @@
+# optimizer
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+optimizer_config = dict()
+# learning policy
+lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
+# runtime settings
+runner = dict(type='IterBasedRunner', max_iters=160000)
+checkpoint_config = dict(by_epoch=False, interval=16000)
+evaluation = dict(interval=16000, metric='mIoU', pre_eval=True)
diff --git a/configs/_base_/schedules/schedule_20k.py b/configs/_base_/schedules/schedule_20k.py
new file mode 100644
index 0000000..73c7021
--- /dev/null
+++ b/configs/_base_/schedules/schedule_20k.py
@@ -0,0 +1,9 @@
+# optimizer
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+optimizer_config = dict()
+# learning policy
+lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
+# runtime settings
+runner = dict(type='IterBasedRunner', max_iters=20000)
+checkpoint_config = dict(by_epoch=False, interval=2000)
+evaluation = dict(interval=2000, metric='mIoU', pre_eval=True)
diff --git a/configs/_base_/schedules/schedule_320k.py b/configs/_base_/schedules/schedule_320k.py
new file mode 100644
index 0000000..a0b2306
--- /dev/null
+++ b/configs/_base_/schedules/schedule_320k.py
@@ -0,0 +1,9 @@
+# optimizer
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+optimizer_config = dict()
+# learning policy
+lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
+# runtime settings
+runner = dict(type='IterBasedRunner', max_iters=320000)
+checkpoint_config = dict(by_epoch=False, interval=32000)
+evaluation = dict(interval=32000, metric='mIoU')
diff --git a/configs/_base_/schedules/schedule_40k.py b/configs/_base_/schedules/schedule_40k.py
new file mode 100644
index 0000000..d2c5023
--- /dev/null
+++ b/configs/_base_/schedules/schedule_40k.py
@@ -0,0 +1,9 @@
+# optimizer
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+optimizer_config = dict()
+# learning policy
+lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
+# runtime settings
+runner = dict(type='IterBasedRunner', max_iters=40000)
+checkpoint_config = dict(by_epoch=False, interval=4000)
+evaluation = dict(interval=4000, metric='mIoU', pre_eval=True)
diff --git a/configs/_base_/schedules/schedule_80k.py b/configs/_base_/schedules/schedule_80k.py
new file mode 100644
index 0000000..8365a87
--- /dev/null
+++ b/configs/_base_/schedules/schedule_80k.py
@@ -0,0 +1,9 @@
+# optimizer
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+optimizer_config = dict()
+# learning policy
+lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
+# runtime settings
+runner = dict(type='IterBasedRunner', max_iters=80000)
+checkpoint_config = dict(by_epoch=False, interval=8000)
+evaluation = dict(interval=8000, metric='mIoU', pre_eval=True)
diff --git a/configs/ann/README.md b/configs/ann/README.md
new file mode 100644
index 0000000..30a59c3
--- /dev/null
+++ b/configs/ann/README.md
@@ -0,0 +1,69 @@
+# ANN
+
+[Asymmetric Non-local Neural Networks for Semantic Segmentation](https://arxiv.org/abs/1908.07678)
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
+The non-local module works as a particularly useful technique for semantic segmentation while criticized for its prohibitive computation and GPU memory occupation. In this paper, we present Asymmetric Non-local Neural Network to semantic segmentation, which has two prominent components: Asymmetric Pyramid Non-local Block (APNB) and Asymmetric Fusion Non-local Block (AFNB). APNB leverages a pyramid sampling module into the non-local block to largely reduce the computation and memory consumption without sacrificing the performance. AFNB is adapted from APNB to fuse the features of different levels under a sufficient consideration of long range dependencies and thus considerably improves the performance. Extensive experiments on semantic segmentation benchmarks demonstrate the effectiveness and efficiency of our work. In particular, we report the state-of-the-art performance of 81.3 mIoU on the Cityscapes test set. For a 256x128 input, APNB is around 6 times faster than a non-local block on GPU while 28 times smaller in GPU running memory occupation. Code is available at: [this https URL](https://github.com/MendelXu/ANN).
+
+
+
+
+
+
+
+
+
+
+
+
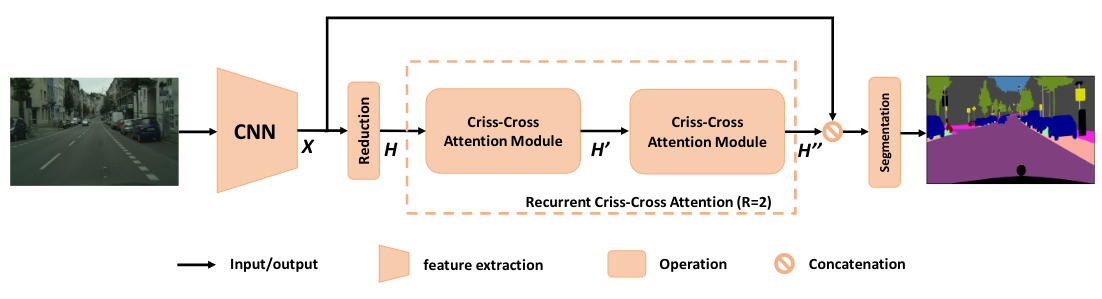
+
+
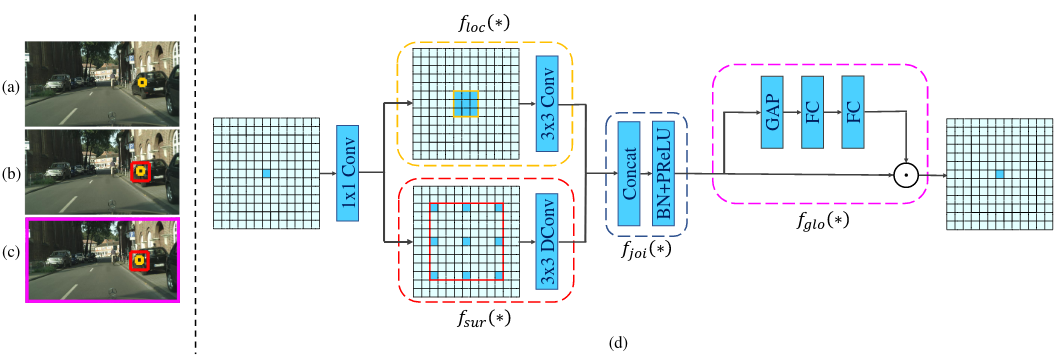
+
+
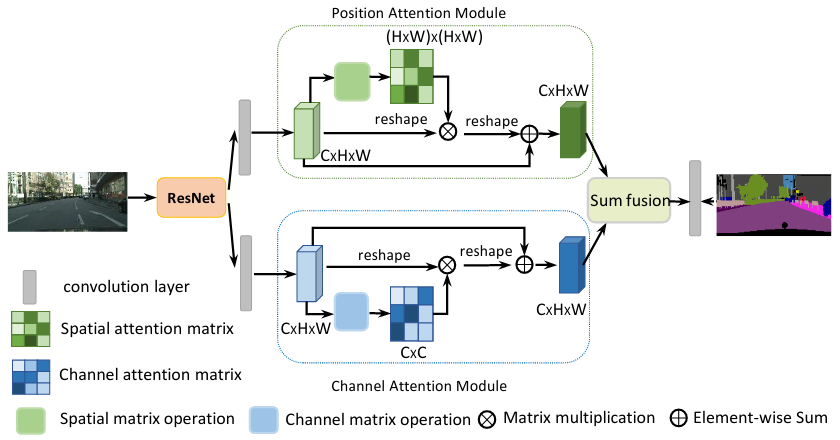
+
+

+
+
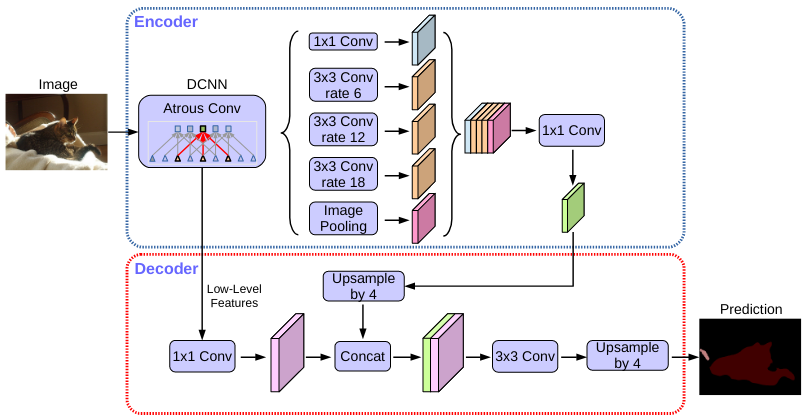
+
+
+
+
+
+
+
+
+
+
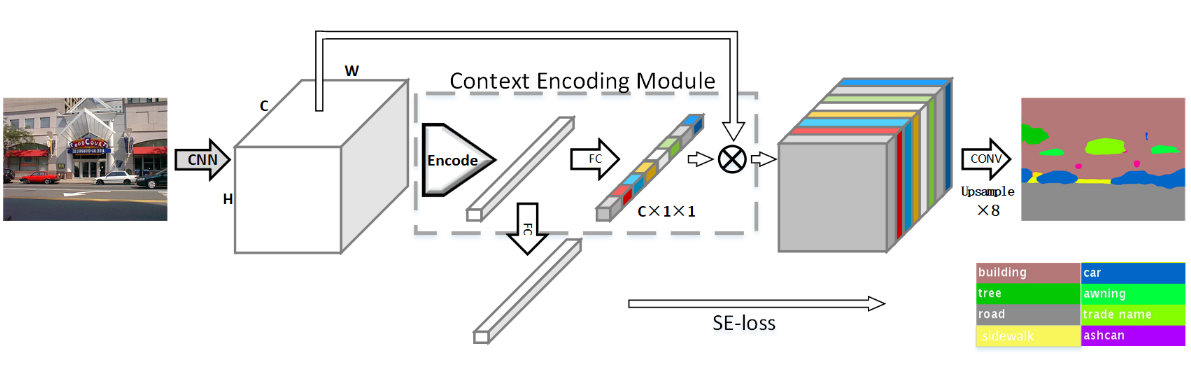
+
+
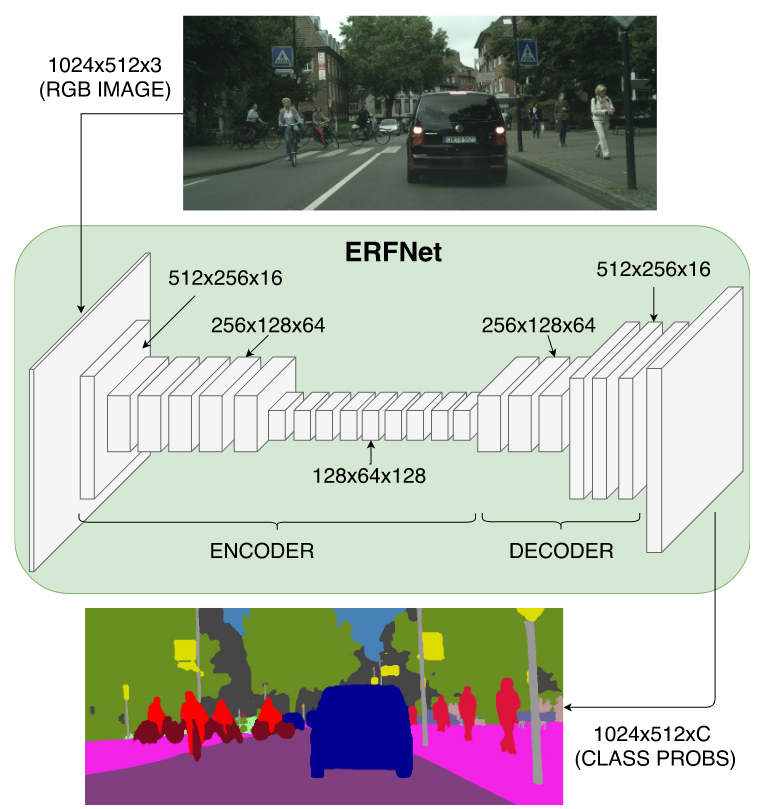
+
+
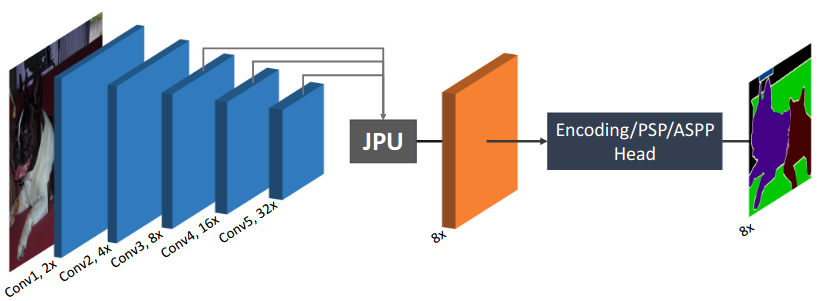
+
+
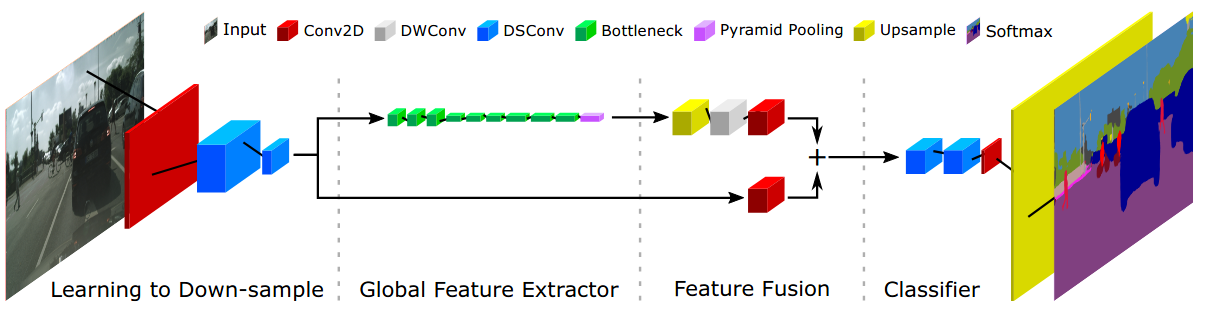
+
+
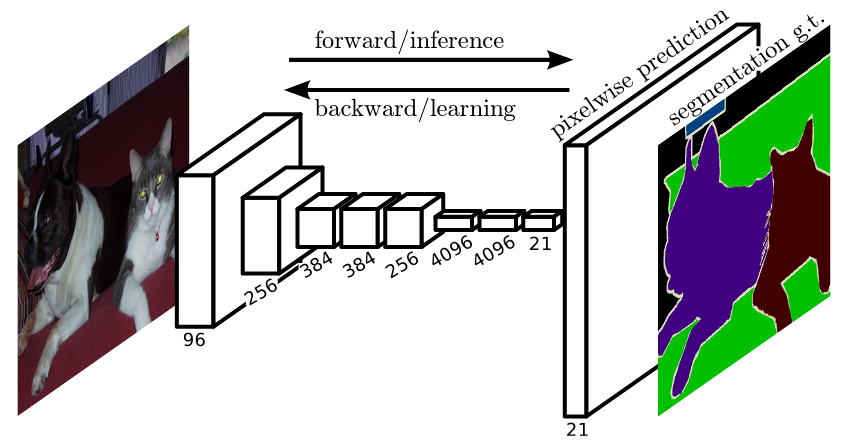
+
+
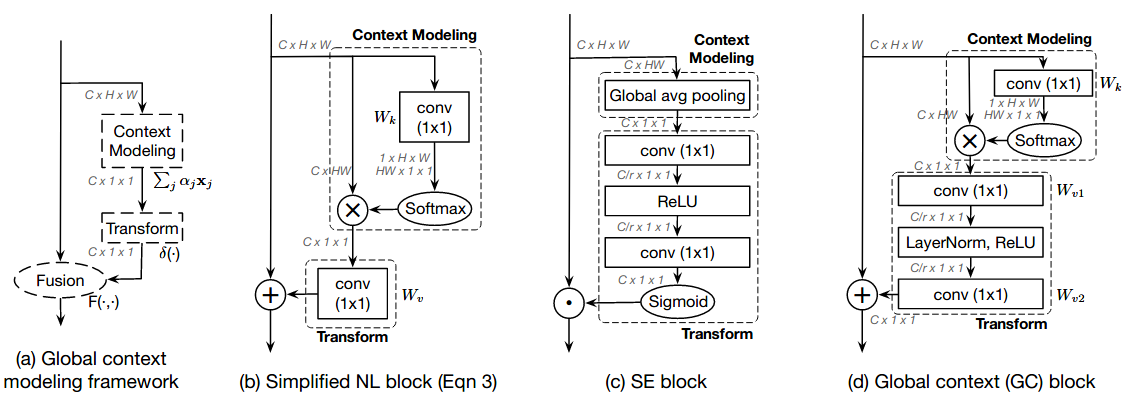
+
+

+
+
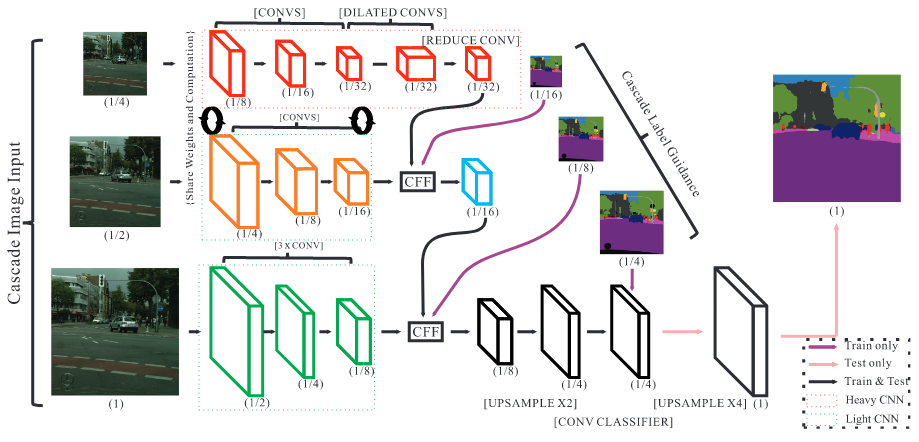
+
+
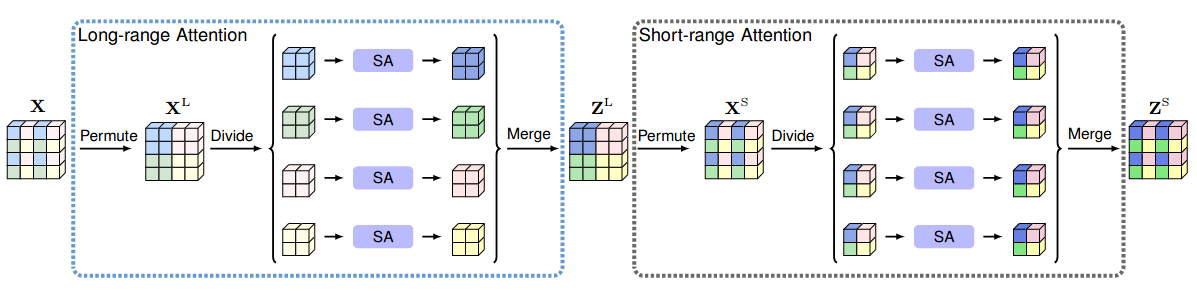
+
+
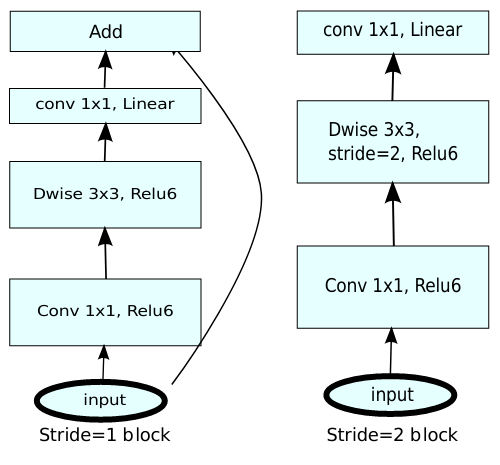
+
+
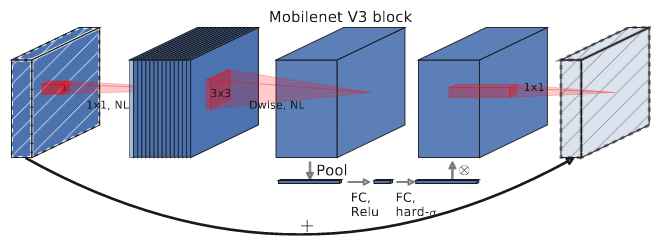
+
+
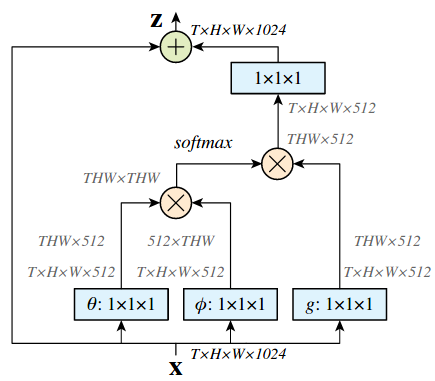
+
+
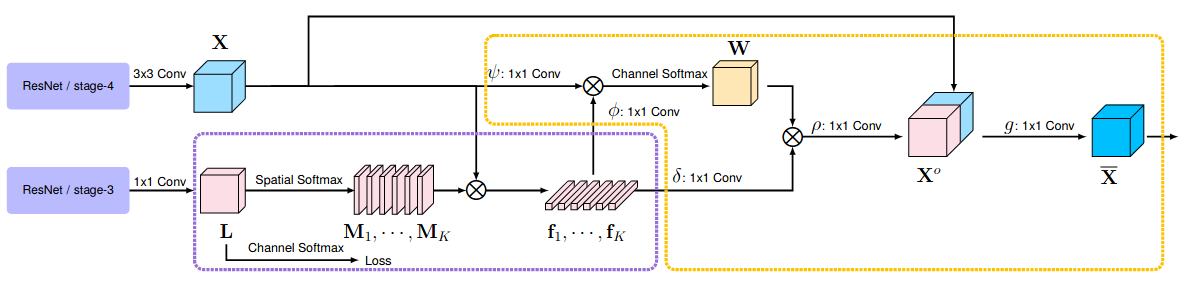
+
+
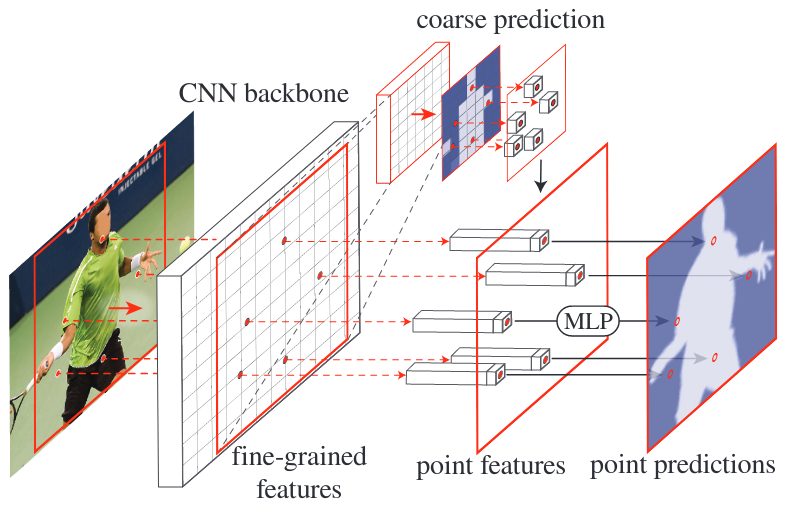
+
+
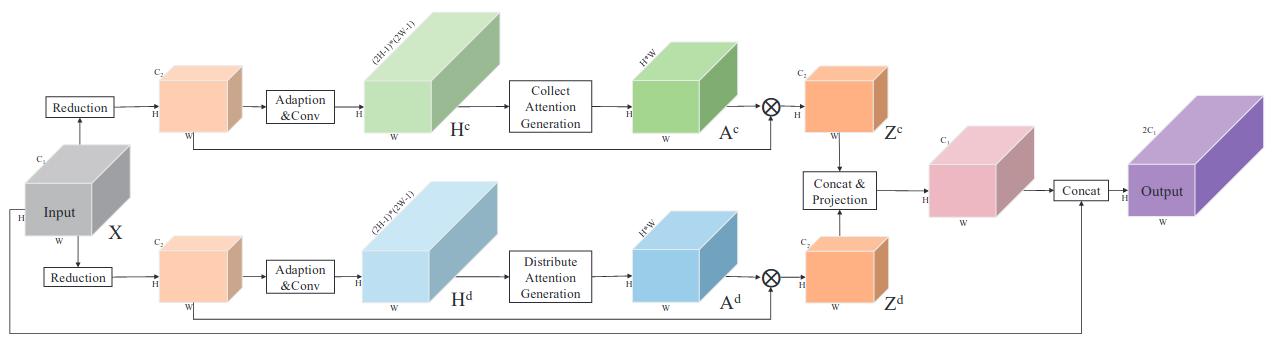
+
+
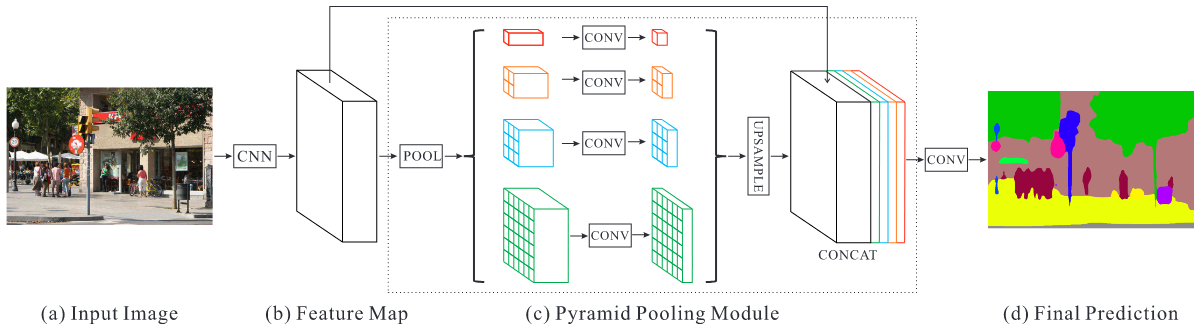
+
+
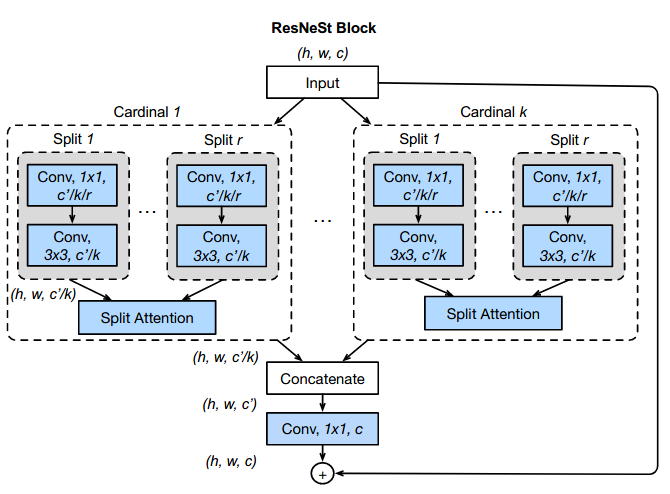
+
+
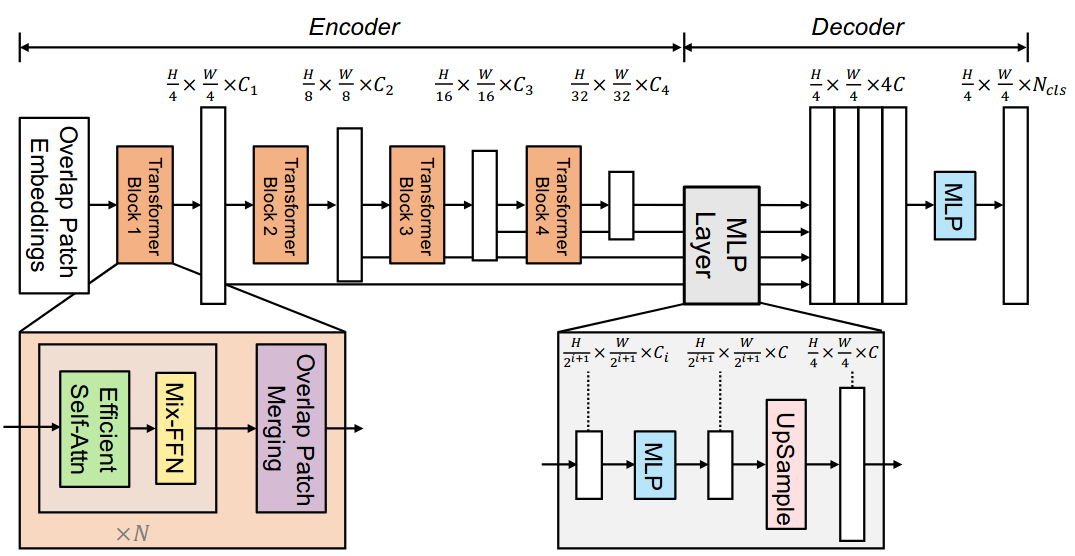
+
+
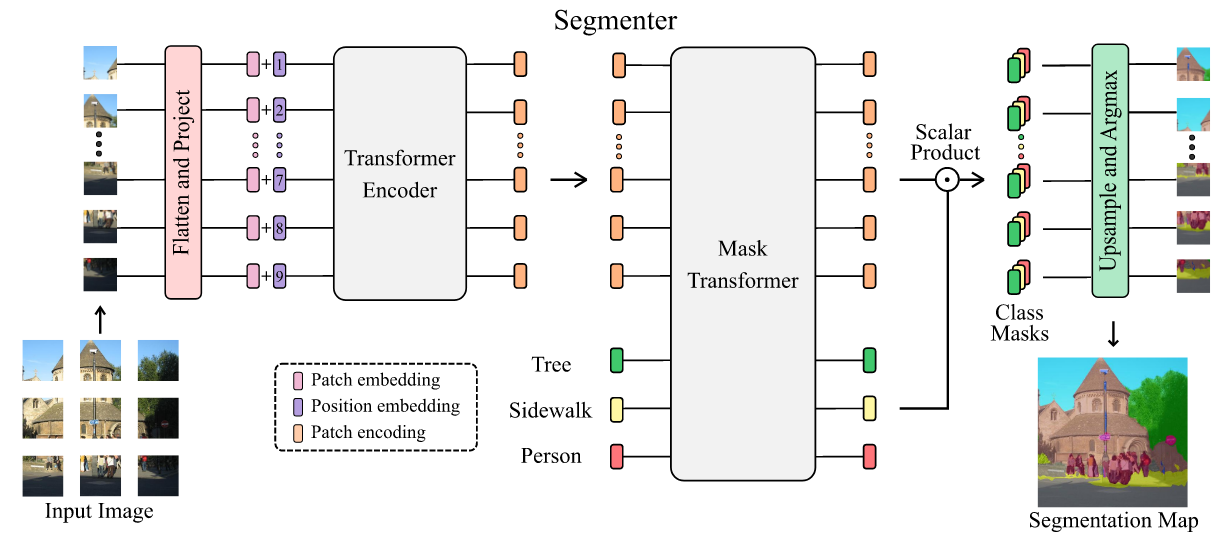
+
+
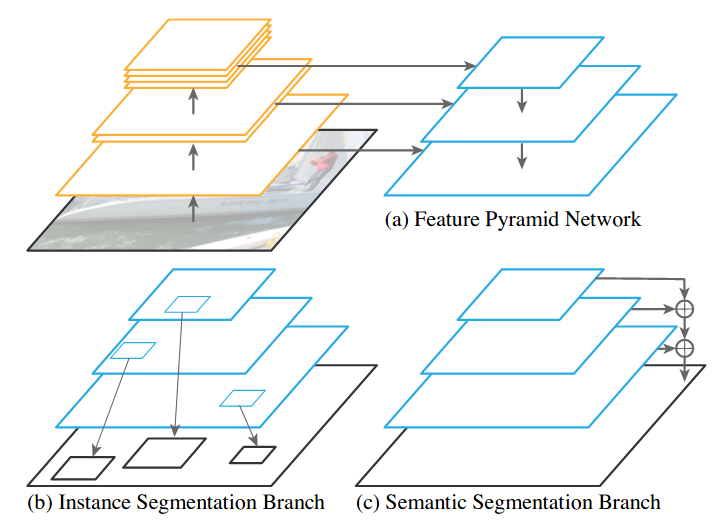
+
+
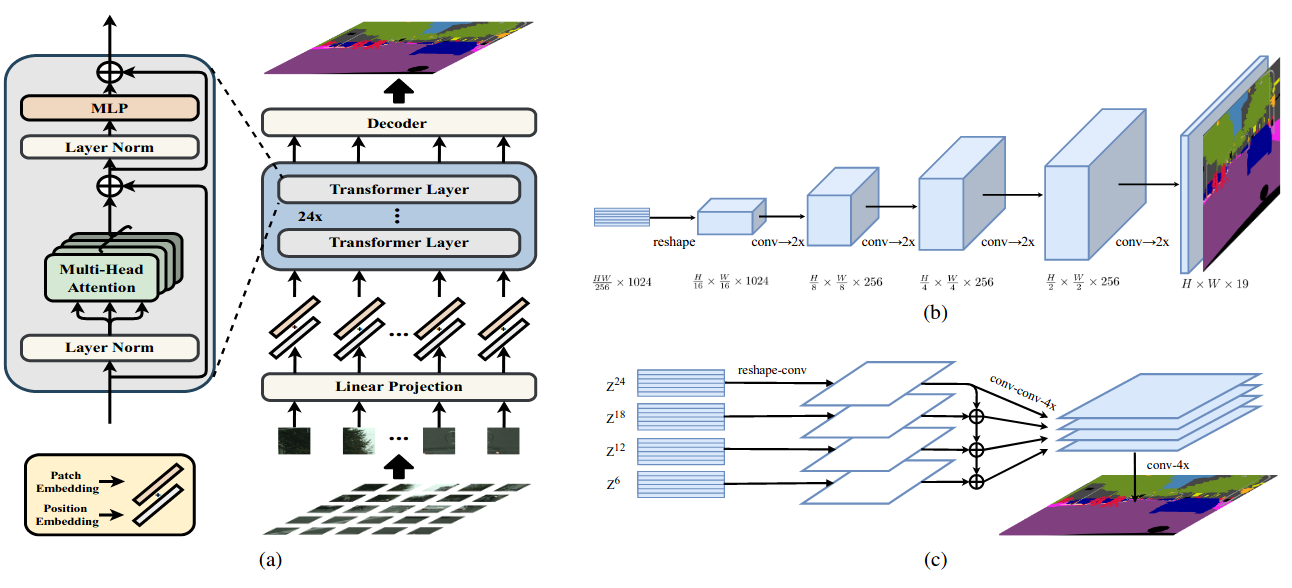
+
+
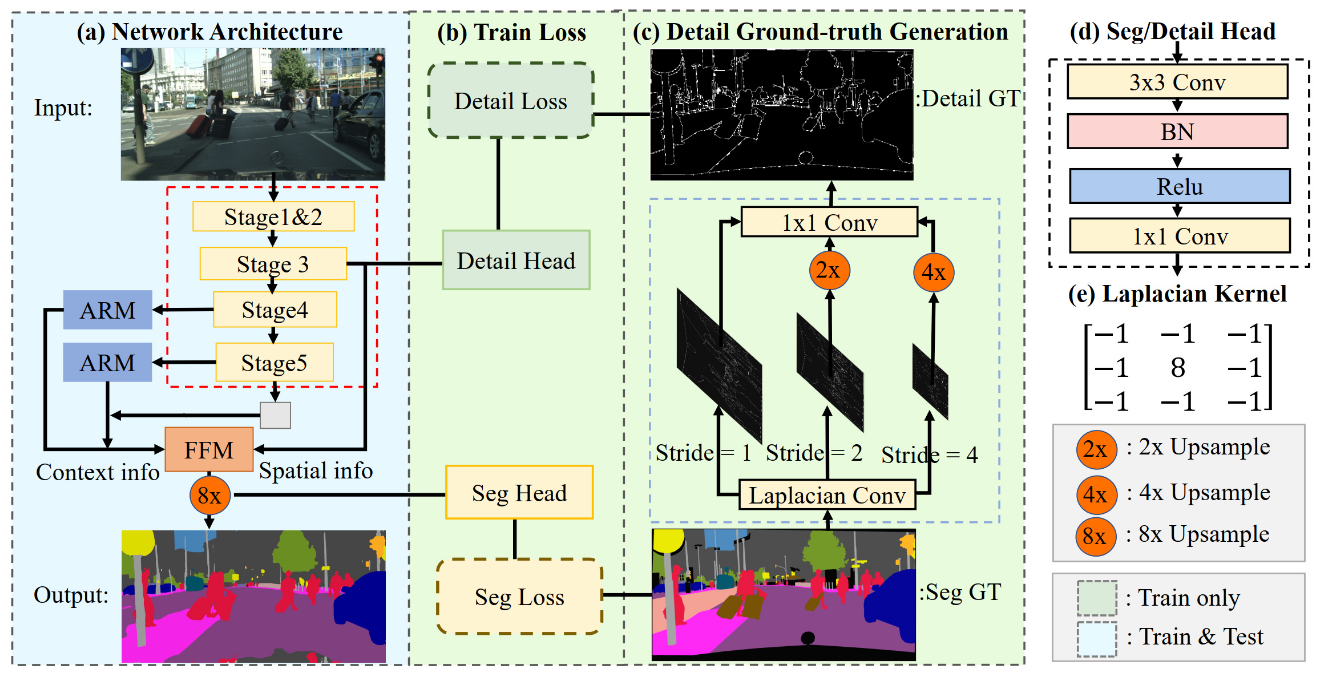
+
+
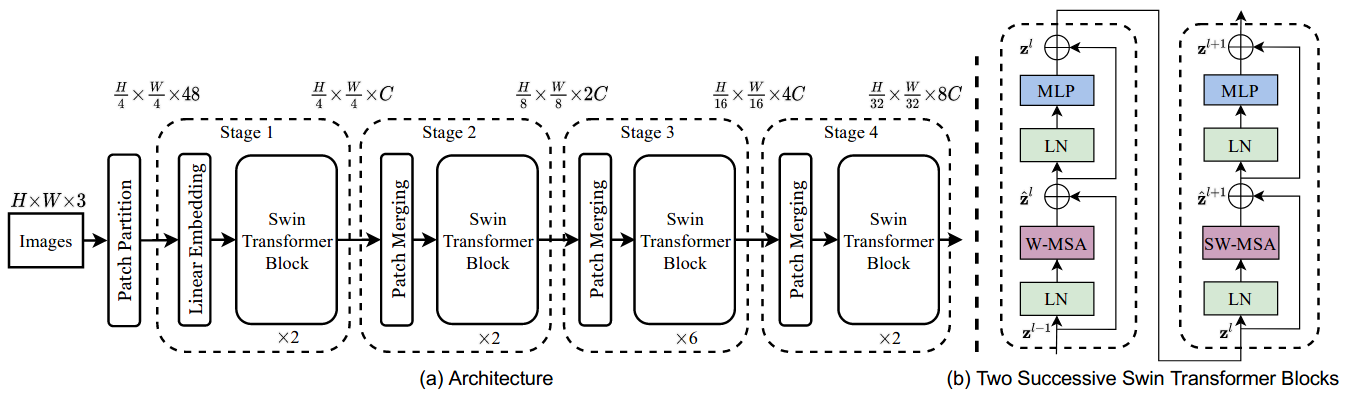
+
+
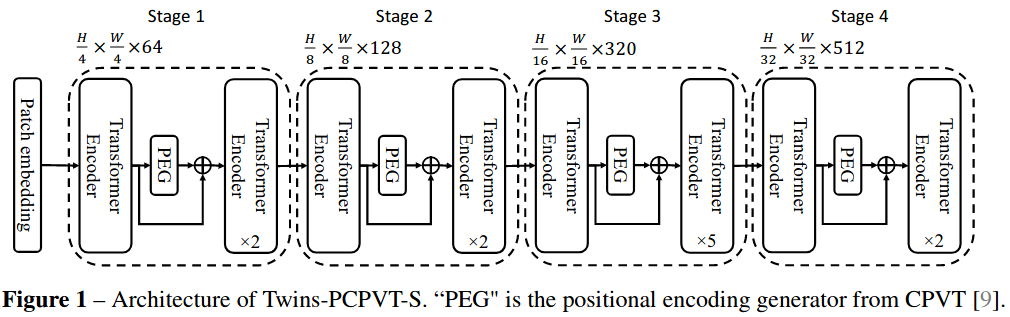
+
+
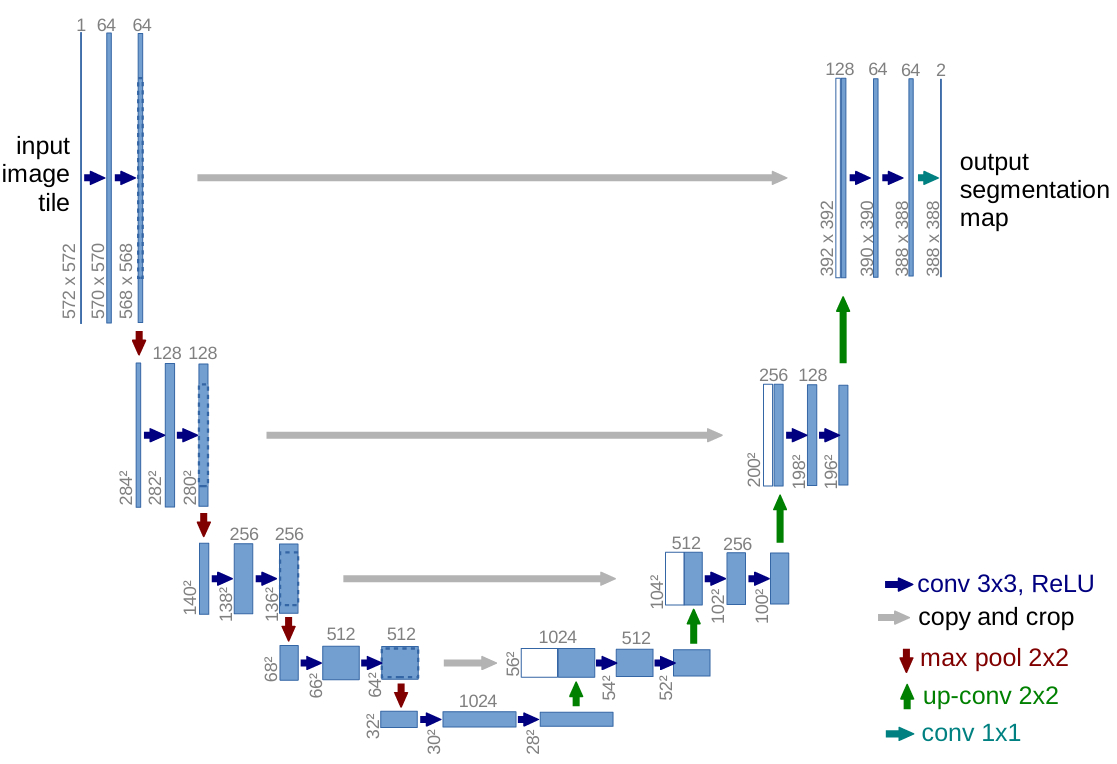
+
+
+
+
+
 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FVmnaxFJvsb8"
+ },
+ "source": [
+ "# MMSegmentation Tutorial\n",
+ "Welcome to MMSegmentation! \n",
+ "\n",
+ "In this tutorial, we demo\n",
+ "* How to do inference with MMSeg trained weight\n",
+ "* How to train on your own dataset and visualize the results. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QS8YHrEhbpas"
+ },
+ "source": [
+ "## Install MMSegmentation\n",
+ "This step may take several minutes. \n",
+ "\n",
+ "We use PyTorch 1.5.0 and CUDA 10.1 for this tutorial. You may install other versions by change the version number in pip install command. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "UWyLrLYaNEaL",
+ "outputId": "32a47fe3-f10d-47a1-f6b9-b7c235abdab1"
+ },
+ "outputs": [],
+ "source": [
+ "# Check nvcc version\r\n",
+ "!nvcc -V\r\n",
+ "# Check GCC version\r\n",
+ "!gcc --version"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "Ki3WUBjKbutg",
+ "outputId": "14bd14b0-4d8c-4fa9-e3f9-da35c0efc0d5"
+ },
+ "outputs": [],
+ "source": [
+ "# Install PyTorch\r\n",
+ "!pip install -U torch==1.5.0+cu101 torchvision==0.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html\r\n",
+ "# Install MMCV\r\n",
+ "!pip install mmcv-full==latest+torch1.5.0+cu101 -f https://download.openmmlab.com/mmcv/dist/index.html"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "nR-hHRvbNJJZ",
+ "outputId": "10c3b131-d4db-458c-fc10-b94b1c6ed546"
+ },
+ "outputs": [],
+ "source": [
+ "!rm -rf mmsegmentation\r\n",
+ "!git clone https://github.com/open-mmlab/mmsegmentation.git \r\n",
+ "%cd mmsegmentation\r\n",
+ "!pip install -e ."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "mAE_h7XhPT7d",
+ "outputId": "83bf0f8e-fc69-40b1-f9fe-0025724a217c"
+ },
+ "outputs": [],
+ "source": [
+ "# Check Pytorch installation\r\n",
+ "import torch, torchvision\r\n",
+ "print(torch.__version__, torch.cuda.is_available())\r\n",
+ "\r\n",
+ "# Check MMSegmentation installation\r\n",
+ "import mmseg\r\n",
+ "print(mmseg.__version__)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eUcuC3dUv32I"
+ },
+ "source": [
+ "## Run Inference with MMSeg trained weight"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "2hd41IGaiNet",
+ "outputId": "b7b2aafc-edf2-43e4-ea43-0b5dd0aa4b4a"
+ },
+ "outputs": [],
+ "source": [
+ "!mkdir checkpoints\r\n",
+ "!wget https://download.openmmlab.com/mmsegmentation/v0.5/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth -P checkpoints"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "H8Fxg8i-wHJE"
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.apis import inference_segmentor, init_segmentor, show_result_pyplot\r\n",
+ "from mmseg.core.evaluation import get_palette"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "umk8sJ0Xuace"
+ },
+ "outputs": [],
+ "source": [
+ "config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'\r\n",
+ "checkpoint_file = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "nWlQFuTgudxu",
+ "outputId": "5e45f4f6-5bcf-4d04-bb9c-0428ee84a576"
+ },
+ "outputs": [],
+ "source": [
+ "# build the model from a config file and a checkpoint file\r\n",
+ "model = init_segmentor(config_file, checkpoint_file, device='cuda:0')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "izFv6pSRujk9"
+ },
+ "outputs": [],
+ "source": [
+ "# test a single image\n",
+ "img = 'demo/demo.png'\n",
+ "result = inference_segmentor(model, img)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 504
+ },
+ "id": "bDcs9udgunQK",
+ "outputId": "7c55f713-4085-47fd-fa06-720a321d0795"
+ },
+ "outputs": [],
+ "source": [
+ "# show the results\r\n",
+ "show_result_pyplot(model, img, result, get_palette('cityscapes'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ta51clKX4cwM"
+ },
+ "source": [
+ "## Train a semantic segmentation model on a new dataset\n",
+ "\n",
+ "To train on a customized dataset, the following steps are neccessary. \n",
+ "1. Add a new dataset class. \n",
+ "2. Create a config file accordingly. \n",
+ "3. Perform training and evaluation. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "AcZg6x_K5Zs3"
+ },
+ "source": [
+ "### Add a new dataset\n",
+ "\n",
+ "Datasets in MMSegmentation require image and semantic segmentation maps to be placed in folders with the same perfix. To support a new dataset, we may need to modify the original file structure. \n",
+ "\n",
+ "In this tutorial, we give an example of converting the dataset. You may refer to [docs](https://github.com/open-mmlab/mmsegmentation/docs/en/tutorials/new_dataset.md) for details about dataset reorganization. \n",
+ "\n",
+ "We use [Standord Background Dataset](http://dags.stanford.edu/projects/scenedataset.html) as an example. The dataset contains 715 images chosen from existing public datasets [LabelMe](http://labelme.csail.mit.edu), [MSRC](http://research.microsoft.com/en-us/projects/objectclassrecognition), [PASCAL VOC](http://pascallin.ecs.soton.ac.uk/challenges/VOC) and [Geometric Context](http://www.cs.illinois.edu/homes/dhoiem/). Images from these datasets are mainly outdoor scenes, each containing approximately 320-by-240 pixels. \n",
+ "In this tutorial, we use the region annotations as labels. There are 8 classes in total, i.e. sky, tree, road, grass, water, building, mountain, and foreground object. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "TFIt7MHq5Wls",
+ "outputId": "74a126e4-c8a4-4d2f-a910-b58b71843a23"
+ },
+ "outputs": [],
+ "source": [
+ "# download and unzip\r\n",
+ "!wget http://dags.stanford.edu/data/iccv09Data.tar.gz -O standford_background.tar.gz\r\n",
+ "!tar xf standford_background.tar.gz"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 377
+ },
+ "id": "78LIci7F9WWI",
+ "outputId": "c432ddac-5a50-47b1-daac-5a26b07afea2"
+ },
+ "outputs": [],
+ "source": [
+ "# Let's take a look at the dataset\r\n",
+ "import mmcv\r\n",
+ "import matplotlib.pyplot as plt\r\n",
+ "\r\n",
+ "img = mmcv.imread('iccv09Data/images/6000124.jpg')\r\n",
+ "plt.figure(figsize=(8, 6))\r\n",
+ "plt.imshow(mmcv.bgr2rgb(img))\r\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "L5mNQuc2GsVE"
+ },
+ "source": [
+ "We need to convert the annotation into semantic map format as an image."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WnGZfribFHCx"
+ },
+ "outputs": [],
+ "source": [
+ "import os.path as osp\n",
+ "import numpy as np\n",
+ "from PIL import Image\n",
+ "# convert dataset annotation to semantic segmentation map\n",
+ "data_root = 'iccv09Data'\n",
+ "img_dir = 'images'\n",
+ "ann_dir = 'labels'\n",
+ "# define class and plaette for better visualization\n",
+ "classes = ('sky', 'tree', 'road', 'grass', 'water', 'bldg', 'mntn', 'fg obj')\n",
+ "palette = [[128, 128, 128], [129, 127, 38], [120, 69, 125], [53, 125, 34], \n",
+ " [0, 11, 123], [118, 20, 12], [122, 81, 25], [241, 134, 51]]\n",
+ "for file in mmcv.scandir(osp.join(data_root, ann_dir), suffix='.regions.txt'):\n",
+ " seg_map = np.loadtxt(osp.join(data_root, ann_dir, file)).astype(np.uint8)\n",
+ " seg_img = Image.fromarray(seg_map).convert('P')\n",
+ " seg_img.putpalette(np.array(palette, dtype=np.uint8))\n",
+ " seg_img.save(osp.join(data_root, ann_dir, file.replace('.regions.txt', \n",
+ " '.png')))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 377
+ },
+ "id": "5MCSS9ABfSks",
+ "outputId": "92b9bafc-589e-48fc-c9e9-476f125d6522"
+ },
+ "outputs": [],
+ "source": [
+ "# Let's take a look at the segmentation map we got\n",
+ "import matplotlib.patches as mpatches\n",
+ "img = Image.open('iccv09Data/labels/6000124.png')\n",
+ "plt.figure(figsize=(8, 6))\n",
+ "im = plt.imshow(np.array(img.convert('RGB')))\n",
+ "\n",
+ "# create a patch (proxy artist) for every color \n",
+ "patches = [mpatches.Patch(color=np.array(palette[i])/255., \n",
+ " label=classes[i]) for i in range(8)]\n",
+ "# put those patched as legend-handles into the legend\n",
+ "plt.legend(handles=patches, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0., \n",
+ " fontsize='large')\n",
+ "\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WbeLYCp2k5hl"
+ },
+ "outputs": [],
+ "source": [
+ "# split train/val set randomly\n",
+ "split_dir = 'splits'\n",
+ "mmcv.mkdir_or_exist(osp.join(data_root, split_dir))\n",
+ "filename_list = [osp.splitext(filename)[0] for filename in mmcv.scandir(\n",
+ " osp.join(data_root, ann_dir), suffix='.png')]\n",
+ "with open(osp.join(data_root, split_dir, 'train.txt'), 'w') as f:\n",
+ " # select first 4/5 as train set\n",
+ " train_length = int(len(filename_list)*4/5)\n",
+ " f.writelines(line + '\\n' for line in filename_list[:train_length])\n",
+ "with open(osp.join(data_root, split_dir, 'val.txt'), 'w') as f:\n",
+ " # select last 1/5 as train set\n",
+ " f.writelines(line + '\\n' for line in filename_list[train_length:])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HchvmGYB_rrO"
+ },
+ "source": [
+ "After downloading the data, we need to implement `load_annotations` function in the new dataset class `StandfordBackgroundDataset`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LbsWOw62_o-X"
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.datasets.builder import DATASETS\n",
+ "from mmseg.datasets.custom import CustomDataset\n",
+ "\n",
+ "@DATASETS.register_module()\n",
+ "class StandfordBackgroundDataset(CustomDataset):\n",
+ " CLASSES = classes\n",
+ " PALETTE = palette\n",
+ " def __init__(self, split, **kwargs):\n",
+ " super().__init__(img_suffix='.jpg', seg_map_suffix='.png', \n",
+ " split=split, **kwargs)\n",
+ " assert osp.exists(self.img_dir) and self.split is not None\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yUVtmn3Iq3WA"
+ },
+ "source": [
+ "### Create a config file\n",
+ "In the next step, we need to modify the config for the training. To accelerate the process, we finetune the model from trained weights."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Wwnj9tRzqX_A"
+ },
+ "outputs": [],
+ "source": [
+ "from mmcv import Config\n",
+ "cfg = Config.fromfile('configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1y2oV5w97jQo"
+ },
+ "source": [
+ "Since the given config is used to train PSPNet on cityscapes dataset, we need to modify it accordingly for our new dataset. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "eyKnYC1Z7iCV",
+ "outputId": "6195217b-187f-4675-994b-ba90d8bb3078"
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.apis import set_random_seed\n",
+ "\n",
+ "# Since we use ony one GPU, BN is used instead of SyncBN\n",
+ "cfg.norm_cfg = dict(type='BN', requires_grad=True)\n",
+ "cfg.model.backbone.norm_cfg = cfg.norm_cfg\n",
+ "cfg.model.decode_head.norm_cfg = cfg.norm_cfg\n",
+ "cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg\n",
+ "# modify num classes of the model in decode/auxiliary head\n",
+ "cfg.model.decode_head.num_classes = 8\n",
+ "cfg.model.auxiliary_head.num_classes = 8\n",
+ "\n",
+ "# Modify dataset type and path\n",
+ "cfg.dataset_type = 'StandfordBackgroundDataset'\n",
+ "cfg.data_root = data_root\n",
+ "\n",
+ "cfg.data.samples_per_gpu = 8\n",
+ "cfg.data.workers_per_gpu=8\n",
+ "\n",
+ "cfg.img_norm_cfg = dict(\n",
+ " mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)\n",
+ "cfg.crop_size = (256, 256)\n",
+ "cfg.train_pipeline = [\n",
+ " dict(type='LoadImageFromFile'),\n",
+ " dict(type='LoadAnnotations'),\n",
+ " dict(type='Resize', img_scale=(320, 240), ratio_range=(0.5, 2.0)),\n",
+ " dict(type='RandomCrop', crop_size=cfg.crop_size, cat_max_ratio=0.75),\n",
+ " dict(type='RandomFlip', flip_ratio=0.5),\n",
+ " dict(type='PhotoMetricDistortion'),\n",
+ " dict(type='Normalize', **cfg.img_norm_cfg),\n",
+ " dict(type='Pad', size=cfg.crop_size, pad_val=0, seg_pad_val=255),\n",
+ " dict(type='DefaultFormatBundle'),\n",
+ " dict(type='Collect', keys=['img', 'gt_semantic_seg']),\n",
+ "]\n",
+ "\n",
+ "cfg.test_pipeline = [\n",
+ " dict(type='LoadImageFromFile'),\n",
+ " dict(\n",
+ " type='MultiScaleFlipAug',\n",
+ " img_scale=(320, 240),\n",
+ " # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],\n",
+ " flip=False,\n",
+ " transforms=[\n",
+ " dict(type='Resize', keep_ratio=True),\n",
+ " dict(type='RandomFlip'),\n",
+ " dict(type='Normalize', **cfg.img_norm_cfg),\n",
+ " dict(type='ImageToTensor', keys=['img']),\n",
+ " dict(type='Collect', keys=['img']),\n",
+ " ])\n",
+ "]\n",
+ "\n",
+ "\n",
+ "cfg.data.train.type = cfg.dataset_type\n",
+ "cfg.data.train.data_root = cfg.data_root\n",
+ "cfg.data.train.img_dir = img_dir\n",
+ "cfg.data.train.ann_dir = ann_dir\n",
+ "cfg.data.train.pipeline = cfg.train_pipeline\n",
+ "cfg.data.train.split = 'splits/train.txt'\n",
+ "\n",
+ "cfg.data.val.type = cfg.dataset_type\n",
+ "cfg.data.val.data_root = cfg.data_root\n",
+ "cfg.data.val.img_dir = img_dir\n",
+ "cfg.data.val.ann_dir = ann_dir\n",
+ "cfg.data.val.pipeline = cfg.test_pipeline\n",
+ "cfg.data.val.split = 'splits/val.txt'\n",
+ "\n",
+ "cfg.data.test.type = cfg.dataset_type\n",
+ "cfg.data.test.data_root = cfg.data_root\n",
+ "cfg.data.test.img_dir = img_dir\n",
+ "cfg.data.test.ann_dir = ann_dir\n",
+ "cfg.data.test.pipeline = cfg.test_pipeline\n",
+ "cfg.data.test.split = 'splits/val.txt'\n",
+ "\n",
+ "# We can still use the pre-trained Mask RCNN model though we do not need to\n",
+ "# use the mask branch\n",
+ "cfg.load_from = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'\n",
+ "\n",
+ "# Set up working dir to save files and logs.\n",
+ "cfg.work_dir = './work_dirs/tutorial'\n",
+ "\n",
+ "cfg.runner.max_iters = 200\n",
+ "cfg.log_config.interval = 10\n",
+ "cfg.evaluation.interval = 200\n",
+ "cfg.checkpoint_config.interval = 200\n",
+ "\n",
+ "# Set seed to facitate reproducing the result\n",
+ "cfg.seed = 0\n",
+ "set_random_seed(0, deterministic=False)\n",
+ "cfg.gpu_ids = range(1)\n",
+ "\n",
+ "# Let's have a look at the final config used for training\n",
+ "print(f'Config:\\n{cfg.pretty_text}')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QWuH14LYF2gQ"
+ },
+ "source": [
+ "### Train and Evaluation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "jYKoSfdMF12B",
+ "outputId": "422219ca-d7a5-4890-f09f-88c959942e64"
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.datasets import build_dataset\n",
+ "from mmseg.models import build_segmentor\n",
+ "from mmseg.apis import train_segmentor\n",
+ "\n",
+ "\n",
+ "# Build the dataset\n",
+ "datasets = [build_dataset(cfg.data.train)]\n",
+ "\n",
+ "# Build the detector\n",
+ "model = build_segmentor(\n",
+ " cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))\n",
+ "# Add an attribute for visualization convenience\n",
+ "model.CLASSES = datasets[0].CLASSES\n",
+ "\n",
+ "# Create work_dir\n",
+ "mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))\n",
+ "train_segmentor(model, datasets, cfg, distributed=False, validate=True, \n",
+ " meta=dict())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DEkWOP-NMbc_"
+ },
+ "source": [
+ "Inference with trained model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 645
+ },
+ "id": "ekG__UfaH_OU",
+ "outputId": "1437419c-869a-4902-df86-d4f6f8b2597a"
+ },
+ "outputs": [],
+ "source": [
+ "img = mmcv.imread('iccv09Data/images/6000124.jpg')\n",
+ "\n",
+ "model.cfg = cfg\n",
+ "result = inference_segmentor(model, img)\n",
+ "plt.figure(figsize=(8, 6))\n",
+ "show_result_pyplot(model, img, result, palette)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "MMSegmentation Tutorial.ipynb",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "pycharm": {
+ "stem_cell": {
+ "cell_type": "raw",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": []
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/demo/demo.png b/demo/demo.png
new file mode 100644
index 0000000..1e82d7a
Binary files /dev/null and b/demo/demo.png differ
diff --git a/demo/image_demo.py b/demo/image_demo.py
new file mode 100644
index 0000000..05e1a79
--- /dev/null
+++ b/demo/image_demo.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser
+
+from mmseg.apis import inference_segmentor, init_segmentor, show_result_pyplot
+from mmseg.core.evaluation import get_palette
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument('img', help='Image file')
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--palette',
+ default='cityscapes',
+ help='Color palette used for segmentation map')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ args = parser.parse_args()
+
+ # build the model from a config file and a checkpoint file
+ model = init_segmentor(args.config, args.checkpoint, device=args.device)
+ # test a single image
+ result = inference_segmentor(model, args.img)
+ # show the results
+ show_result_pyplot(
+ model,
+ args.img,
+ result,
+ get_palette(args.palette),
+ opacity=args.opacity)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/demo/inference_demo.ipynb b/demo/inference_demo.ipynb
new file mode 100644
index 0000000..2f86f20
--- /dev/null
+++ b/demo/inference_demo.ipynb
@@ -0,0 +1,150 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "mkdir: cannot create directory ‘../checkpoints’: File exists\n",
+ "--2020-07-07 08:54:25-- https://open-mmlab.s3.ap-northeast-2.amazonaws.com/mmsegmentation/models/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth\n",
+ "Resolving open-mmlab.s3.ap-northeast-2.amazonaws.com (open-mmlab.s3.ap-northeast-2.amazonaws.com)... 52.219.58.55\n",
+ "Connecting to open-mmlab.s3.ap-northeast-2.amazonaws.com (open-mmlab.s3.ap-northeast-2.amazonaws.com)|52.219.58.55|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 196205945 (187M) [application/x-www-form-urlencoded]\n",
+ "Saving to: ‘../checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth.1’\n",
+ "\n",
+ "pspnet_r50-d8_512x1 100%[===================>] 187.12M 16.5MB/s in 13s \n",
+ "\n",
+ "2020-07-07 08:54:38 (14.8 MB/s) - ‘../checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth.1’ saved [196205945/196205945]\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "!mkdir ../checkpoints\n",
+ "!wget https://openmmlab.oss-accelerate.aliyuncs.com/mmsegmentation/v0.5/deeplabv3/deeplabv3_r50-d8_512x1024_40k_cityscapes/deeplabv3_r50-d8_512x1024_40k_cityscapes_20200605_022449-acadc2f8.pth -P ../checkpoints"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {
+ "pycharm": {
+ "is_executing": true
+ }
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.apis import init_segmentor, inference_segmentor, show_result_pyplot\n",
+ "from mmseg.core.evaluation import get_palette"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {
+ "pycharm": {
+ "is_executing": true
+ }
+ },
+ "outputs": [],
+ "source": [
+ "config_file = '../configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'\n",
+ "checkpoint_file = '../checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# build the model from a config file and a checkpoint file\n",
+ "model = init_segmentor(config_file, checkpoint_file, device='cuda:0')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# test a single image\n",
+ "img = 'demo.png'\n",
+ "result = inference_segmentor(model, img)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "/mnt/v-liubin/code/mmsegmentation/mmseg/models/segmentors/base.py:265: UserWarning: show==False and out_file is not specified, only result image will be returned\n",
+ " warnings.warn('show==False and out_file is not specified, only '\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAA20AAAHFCAYAAABhIhFgAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nOy9W49sS3Lf94vMtVZVdffe+1zmzI0URVKiLJkWDBiGZfhBMiDJ8ovhV9sfQE/+AH7yB5EBPRqG/SLAgAwZfrJhywRhQTKoi6nRcIYzHJ7bPvvS3VW1Lpnhh4jMlVXdvc8h54x4JFUAe3d31Vq5cuUlIv5xS1FVLnShC13oQhe60IUudKELXehC30wKf9IduNCFLnShC13oQhe60IUudKELPU0X0HahC13oQhe60IUudKELXehC32C6gLYLXehCF7rQhS50oQtd6EIX+gbTBbRd6EIXutCFLnShC13oQhe60DeYLqDtQhe60IUudKELXehCF7rQhb7BdAFtF7rQhS50oQtd6EIXutCFLvQNpl8IaBOR/1RE/j8R+YGI/De/iGdc6EIXutCFLnShC13oQhe60L8JJF/3OW0iEoHfBf468FPgt4H/UlX/ydf6oAtd6EIXutCFLnShC13oQhf6N4B+EZ62/wD4gar+UFUn4H8A/vNfwHMudKELXehCF7rQhS50oQtd6F976n4Bbf4S8JPm758Cf+ldN2y2G91dXdHFp7sTY0BEmOf55HNFQUFVyZrJOaNZ7V/rRRRAAREEkCDEGIkxIiKPP1QECQFVZZkXcs7elBJi8EZXCiKIiD3mqRcRARE0Z+Z58U5BCAHrxnpnEAEBQShvUn4rr6aqqGYQIYiQFVJKAKQle/vr3aULD7slSBA0QxAf2TMnrCpkyvfekCoSbG7E+5NzrsNd3qPMhXpDWvrjbdjzbORsPsrz/UoJhBBQzagqomsXCIKcjXh77/qZPVfVR0LWUQlhtV+UngrSrCFB0XWtqPdXhK7rfD3U0azPW+bF77SGFQgx2FoJAgrLsvg82t0xBltr3r74i3Z9t/bTr00pkVLycV+vF7H1jfh68Hka+g6R0Aye36dqbyxCCPh7ln9n45gzS0rklE9euczAOrunc5LVBiB2HcPQ0+2eIbFjeMe+//koE3UmS4++wz51ujv+9aSvN56itKloGtktL31ulWmefV0UBrWuh8dJTvaifRTYbAbnJzAvC5vNhkP/3YZ3Cee32d5WUjJe3XW21h/yuyoMzu4+//5Pnr6eQJinGvny93QW9M7PT8SsfF19/jrosZ39VTv3dXODVV64pCSQkTQxTyMg9MPAPE+klDkeDpWvg8vnZiJUV/1GkJX/NnJYfe+FEBrebN9JMBmUc0ZEGDYD8zQ/OnnqMkJEiF0EIC2JECMxBFJaTvQREaHveyQEqtArdD6s51P0Lmb85NQpKSVyzibLyniFImdX/QRMDom/U+ECdWx9nE/ZjFR5n13fyinZeIRgcvzRDp/pJGijI1lbpg4KXdc7vxJUM8uykJO6itRutNLjd63tP8rabdt7atAf4xPyJd+fX/sYv33quV/Wl6c+excPLzpZ9nlfcYN93cqhx/Rk10mz67e+psq6UCDGSAjxUX65dtf19frc9Xktvfri9eeq+tFjTfyitKUvJRH5m8DfBLi6vuKv/Cd/lfdu3gO0godCXSc8e3ZNP0R+9vHH9fPCuDRl37CJaZ65vz9w3O8Zx4W0ZDSn8kyQwDD0XN/suLm5Yrft6fotnCjdBtRUIt12gyq8/OQlh8M9OWciiefPbpCuByAliBH6rqeLEQmFgwUkONBTUAkQInGzYb+fePnJJ6ac58T1rqff7hBVcGY3xEDXd2XAbKJ9srOa8jzNM9M403WRYeiYcub1qzvmaeF4f0BIaE6oUpX4IAGJAdQArgBD37GoAawhCkGVLCtQQ2FWWJISo9CFQOgiOWWGoaff9IQQmKeF6f4ORJiTEkOgj7YhUs5kVdKSMCgjdDEYqFElJ2dWaveFrgNVA58ixAARtXfXjCA2RtsBkYA6CEEzQaIzx2QAHkgpMy+JOZlg6aIgOdP1kc1mKCuzMs4qGBUIgTkpXTDQmnNmnBL0Gz788AXPb65AOnu+j9u0LLz67HMD2imxAHMOPLu5ZrvrGYaelJRXn37GMi8cFyUI3DzbcdwfyctCFwOx61AJfPTdj7i+vrb3AjQrb9++5e71W5Z54niciTEQ+8g4JYYh8uy9DwghcDzcMY8jsd/y7W9/i6urLV0QpOvICuNxZFkSMUS2uw1dF9yQUIRZB7rY2kuJu9s9b97ecjgcieJrvI8EFVKGUIBbsHnWnE3Jp+Ojjz7iV379T/PBn//LvPfBR+ziOvY8+O2PR6rKPL/lO/KScfNL7PPm3dcDC5mIEH7up//LoafEpDY/v0xFfTegenitizsDRzmxvP4pv/nybzOmkWWa+fjjn3H39h7NxpPTkr5UkQ9BXNiZ5hm7yK/++p8hxsiyzHz++Uu+98u/zA9+9b+ta7IIzKJkwSqA53nm9vYNb29vGbZbXjx7wXYYvP0TdOh9e9i5VuRnbQxVrGszKUSx70/H6bSNcxXrMfWn/aztT6u0n/fzsc/aHqyGIG3uMcPXQ1p7Ye1Sr1sNOKdtnQCHJ/tilKoyfdpSozNVIPhUM2UO2vu+jB6OdwaElBZC6B4AIchu1JJqEC3vv177tHKcc3JDwcPvbDxXo+TzsCe+/jF/8JMfk4h89L3v8vs/+F1+8IMf8fmnnzGNE2hiGDr6YaAIlpwS87yQcyKEQOwiAdzgZtxrnBdyVq6f3bDbDhwPB0SVeV44zInrZ9fsdlvubu+RvuPXf+3X+OSnP2GZJ3DgpQAOLsbjCF3Hiw8/IGrm7ds7uu3A9e6K6f6OeVlIKsxzot8MfOd732W7M56bpslkfXhESdcMzXhpTid/Pxy3dl1nlICQePPmlvu7e+Z5JsaOfrNhs+kJoaPve4bNYAAO5XCYAWWcRhPtIsTYUQyKMUb6PhAEJEYQQVPieJw4Ho/M88Th7pYQIy+e3zD0PYgQKngr7xlO3nfOICSWlDgeRsZpIsTIdrvl/Q+/zfP332MIwv7+ltdv3pKmRBwGgpjOI3m28XK+VaFl2Rf5lOOLBAd9Dd47WetPrePHuJX9DATbQXUucnN/bt65pYcGh4dga32WljGMtgdD1Xsf46Tej8q7AjzG3ySgCuM0Mk0zOS+m0y6LjW0Mph9DBWRRFRUhp8Q0jhz2e8bjwpLh+vkVu+srQlKmeUKi8OzZc3bbG0IMrvdwCroBXUam/QHUMMkp3l+v+x//+7/z44cvYfSLAG1/APyp5u9f9s9OSFX/FvC3AD748AMNUtCt4o4jnxepSkKZjHWdBEJQsootFVX6fuDmJjD0kcM4MR9Hljk5GhZQGIaO6+stV9c7YtfzcNECZMZxZr+/J4RAWmZymjDYwAlajrHsmlS9GNb/dfFotZacCmURaaSRMbAnyZmVoAQRUjXAFM8iiHsUcspUq54EEAPD4szFfo+20bNbxiWQsqJdIBd+IAY4MxigBJAIwRRy8bko9sOq49dRtY2V0dqWBEGTWbyyZEIwJSGEQD90pKSkZUFSInYR7aL10YVoUNBW2VIgBkK/QViYp4mcMkGMhWS3KGrd2kqQYHNRx7AwN2dOwbxd1Vrpc7W+k02bCuRlYcmZGJINtYTKmEQCmhOCCwdZQfzqWgtIEoIUQK51SWZnWrkoEQ52SyNV0Q2CRAO6V1dbYjwyHifevvqC3c0zdtfXSBCm48TnH3/Ms2+9z3vPn9P7nG22G8I8Mx1HpiUQ48aYGY3n1ZezhMDuekfKsGRlGQ8GZJeMhg7I1aqc6xYIEMuWSGz7juvlNVG+y6xlrdr7dwi5WLvqOjIRbZ+d+/BOyUZe2eVbuj6whOCWh6dJgIiQ/N74rwhwg1NwJs3Prw7HGqF39t7noM5mqZkHafa9CDH2iBtWiif2yxTsnLUaugQxPqMZMCB30wckzdVTGyiWf4/vL4DB11zfdbx48T7DsOHzL77g4/0nvHj+jJubG4JEui460Drz2Jd3bvSJshVPAEVzbTp7t3b0VnVnnZ3HwJk2v1tfWgDUzIt/Xr5/CO6M35j35HE50gKxU5C1Ar28btp63en4PJzQP2pu/DnwWj01D68ta7nwowcqoX94+rkBMOfczec2LjH2j/dLFZGzSa7tlXFfPOIhPvV676BW0fTdpDBOC/v7e37vRz/i5WefMU8TaKbvonmtHEgnVTdsZkKI1da8rg8Y04LmzNXNNdc3O5aUiTGiOVuUR/WomfKfkyDSVWVZ6oZmZcAW0oIQkQDD0DP0A1EKwCv6m78iAjmjlUc8wk8fUa5VHprMQghI7MwQlNK6Vproia6LbLcbV7zNIygSCLLOUTg3CIggDeiQErETVjmvKSHdmZp8uolXOXxCZTwCipBVgOTP9NFyHlTkWp6OvDqOjId7lnm2NZ0TyTpnup08WOiNTtkCm1bfbLotuJWplRqPrfeHFNTaliYqqfAZbRhj4VEW+LN6fs/HSMT0wjIOKhYtFqSDYMZ88zanE11y7fM5+LMXfNKAFIwXmL5p4DJIRMXfSRUJDtKBeUkcj0emo+lSy5JM/sRIcJ0LIGbbE0EVlYwQHhifTqP+DIeIv3vxlLdev3fRLwK0/TbwGyLyaxhY+y+A/+pdNwybgW9/9BHH/eSLIDeWt3UhqCrJJ98WvVZhKp15kSRlQt8TBLq+Z+x7E2IK8zKxzJmb6w273ZbQ9TblAloWpEBROnNeePnZS/KyoGqIO3Qm9FNWg2+qvpnEUXNZnMXi0EoaA1dlr8QgLGkpcIdHN04Fs4KKNEzRv8ZBRTArG8kYZS7exeB98YEKIVQFX0IgpbxaSzFwWbeFrn2lgF5rFDBQlEVOLYth3V6rEJCqxIsohMCm6ziOs7mqcybEYj0XYufANyXI5vmQYLwmN2NUvDkKaFY6CQzb58R+5rC/tfnyFyuCI5hsW0MTADz0o4ZlipJyBm0+yxlVnwOKAIU8JZKWkFAlEAwIFsYszR708EUf0EbBfhi+UnmZg2yD1dFn28e10csKGI/Rwihjf42EwPEwsX/7BvSKrhs4piPjkkifvSSnxLc+/MgELzDEgG42HI8JyUd217tV2GpmjcwUui6aQpAX7nJimUeTB8uMR32ereuMJEGJTMcj98c915//iJdvXxE++nMEDNReba5AleX2c7j7mL7rid/7Tfq+Y5zMovW8230JY1Myma3u6bsbxndc2ZIgRPQEuP2rA92MWjF8qpL/0ZTqp9t3XuGbx34ERA3yFi8Fmh4IzuLoii7QU+OiyinX0Ktz4TVc3bAkU2BUwsoD1IF8yiuUrFZ4Ybu74qNvRd7e3fEHn37C7vaW73/0bUQ2zhfXXXgu4wtYk+ivs6yg4bHr1/F5x9i5DGtDsU/et4wrp6Aq50zr6jsf19UjROX7qzft8RX8ZaD+3Hv51b18Dyk3XrZ6b/tZwxbPvZZwqoo+9sSH3VAg8XTKfvnuoRIpYipRSjMhdITQAjNFSOuieIROrz+lVsHNeTHF1AdA8sQf/uQnfPbpF0zH0cJ7+45hs4YZ5pwtTSNZeFYXTfZmFIKZa1POLFNid7Xj6npHWhZ224H7eSIndVBiiqmEM4+gajUrlJCvAjLace66aCkBISCaT2BoI5FdCQ51j2V1mV0mfVkswqkVZI3huoQ4DkPHZrPjcLhnTKkRoQWUG7ALXUd0kBLO5MOJp1xcHonpE1KvCUwZtuuV9piUfA37+DzYfw5+s+GCEnJajSvFMJ/X0bEHrvvscNyzLJN77k1PSW48qLrtktawJ13TNVqvmYhWXfZJIGZhX9a2GjctRnpVyESCrGuhjIU6mCnvrw56RUrEwilXWcH6Y+CK2m91HRIRJHZ0AiqRnJZmFnhwv8MelLLTxdfPw1e29VzCUS0FxfE2khLBwVgWSPPMeH/geLTokZwSKa2hrNAA0KrrBbQB4Ke6nlFA8Vc6eZsyMlLH5N30tYM2VV1E5L8G/h5mivrbqvqP33VPkEDf9xyZmnZsEZgHxt2WQFC3NtidINmVaLOYhBhMge/MOhVDrNYzkWtUMzF2BA9tlOIueUQcaEpkDRzuj+uHU8dmm5nSwpA9vtsXbq890TgGq1uioE8FLcxyFcz2Vosp5I/tscL4iiXZEo7AgahIYCihPwAaWOYM3qcgggYbyxgDsYK2WC0mKUn7OArQMpXIvXi+/VKC2K/DVRayCgYE/bnF8lIWYcxKWvkWXd/RS2Q5HgwALUroLSQPsVjxebKnZm1Uzgb05KYPZqnIpKR0/ZabZ5F5umM8zrBkZ6blHSvUtXUmZf1YOEEU34CtJVCkUT5WYZfTwus3B2KM7HYDUSEE34bSQKzWwkZh/+KeOb9KGjVDTAgHDNxnYF4yKblMi0LUVTiAeV+XJbM/zuy2HdfXV8QIx8PC/vaerpuYjxNKZpkjOb0kp8xH3/oWw2DvvokW6nEc75kPmee7awPNcrpDRIS+Czy73kJO3L5dLBTO/f2hKsXRlqxiRoLsFq60cDwekOOBuz/8PUQCz54/Z+w3oMo4HUjzxNXumv74mtGV8c8+/4zv/Xt/nfeu3ieEJ9iXQs4z8zwxDIPpaF+BfFdW4JYcJn/ToJs+8ftT17y7LX3n3+UzXf9YVbNs6zyTyT7IoRuqBHpKsW/sVifPqECh8jLziB/mkUkVXQ4srDmywY1QtU1vNJT9pCYHPnjxnC4ov/vjHxLzzEff/iU2fVcNHVlN7Be9qvYDkFQ76DzmVGdzLtf8vSpMxeO4KlTe1/y4UbK2UT1bLv/E7inv2gKpFeSdhj2ee+rA5GgBdfnBdY9TO4ft7097Bp9uVyiGN63v/y4P29p++X4BngZMpxQp3qmmV2c/Cz0EcYW3pDQRa/g2ID+fD36N5OiApcr1aRx5+flLpv3BUjBiOAFsmpR5WshpIUiwaBkxA2H0tRskkNJssmOIzKrc7J4Ro6VgKB7donoCjhUY82xrLgQzUGZFHWu4pk5gIeuChC2aFtLQ0VV9xo0Rmlx2FeFM1YXsXcI6L/06rpoTEuIKbHMiDBu2uyu2Q09WZV4sHymEdc0LLtcFYghoEJZGbJsibQzJ+E4ElhNQFxx0iCElurCukOBAJcjZqssKse5sTqCFtN7pAisSQmnYDeoqhBgRFfIyETzMsoToBhTpohljwQ23RcU/1a/KZ1pCh5AT/uCL72yj5TNDiI1DfGAeKWBzhUfliet7N3yv8m8H9A7ICv+0rphUCRIsOqOsI0/dEXwpnRmfss+D+JoUWmBolFKqhu7izTJDS1mTzitFCJLJ0cyzyzyx3x8YDxPzNFXjeT63JElkhU7S8GAhakSjcE6miwdynGE++7IYGt9piF7pF5LTpqp/F/i7X/X643jkDz/+mJvdjSkIuorBat335EEJiuZg4TTSTOiJsFVC7EwJdk3dPCy2HEMItllcE7WFFBA5dddnhXm0+Oe0JM+nmJmnzP2bW6btaLHQbinIcebZ82uieOihFpuweabOY7ULMKJYp0+SJwSkFI2QuqgrkPANGYIQckZKGIAkt7ZYnp0ECy0U3PoUA5T394UdYzJMmdfNKQhRXZy5NqMi1mZVsIq1rhRNEUTdvxKkYuucc93TReEqOWl1s2JCJ3Shuqo1JcxFXhdWGThvy/LUooLkZHH3ofM5jmx27xG6I9PhnjzOJ/wqa7BYadSZW6jPyEoViiVUKAQhqvV98XEKDlLTNPL5pyPXL254dn3N0Ft8tGrjZVRFiwsKCmRbO9R4jX32SRgDVTNR1nUMGRIkcSYXVk/vlJTxcCDnnqvdls32ipyPHA8TyzSZB9HHMGfh7RevWJaFDz/8FrtNT4zKZugQrjmMB+7ynmfXV816XUlCYNhs2KXMtMDd3S1RDbjFoSOGzoVhrMJvmhKqmR///k/phs9QlHm2sIO+sxzSYqQYD/dcDQNXu4EQO2K0HIlP/sHfI/7Kb/D8l/5dpN9yTpuY+VBfsvQDIW5Zlq+uZvmqtjWCupqo3+g8ty+J/HwUiD32+XmI5FMArlDlSXFBsu35LtpoIRGRfApwGv3iHKQEN5xI6NyYovXfkkGmI3/h7n/ifzn8VfoY6YIJQctNDeteku60uJQq+2nP8ThyM9zw4598yn7OfPTBc3abKzPgucehBOGUHJI1h6pY8/F9qrbvWAGWrZDi7Vvfs/1lBVUm41ZQ1+pS2ljqC/9RD+nR2s76e5mL8GBMz8FUSsuTIPHBPH/Fzx77vHoInZ+Vvq/h1l/dS2ftld++qrpSJ+68Jf93DvweesfKOBlgO5/Qd3sxYR2D0/E2D5tqJoSOnH0+xDyPaUkVlAybnlg9bJaLtszJZE4M5ilw+340q6CpENlrAqiy6XtShEOaTUZkS0UQzRT/l6g9bxMNIOqs1bJa3k4Fus3gAGqg8/ZDtpEoYWMWCmmyOxNMAaHaO6p8q1685hlSDPP+Hn1vgC3GjrQsvHz9mvv7A1ebHtPV1MZQ1YF0IAQvEOEuryAdFl1jhpkgQsklym5ADeAFS2zs+pBRLSDYlXEfu9L3lDMJM8Jq84a236TxyHj+mXrchqzaeohC3PQ2XiWlIitL0Qucf5LV5rqksPjzypjS/LauzbBe99g281tE7V+Stq2zix5Z46sasCosp+GZa95d8WQWvugZ0WiIhBjoPEw5CGgwnTT4eOcHj1YP0aw9OXv/YhAxXli2heJG+dDX/lqobAYyaZ652x85Ho6kxSMVTu31/tOcHZ0DaanGflsjqfQtaU27aV286cssUzS5pO+gP7FCJCekLV4vnbbByDkQJQF9vVBCmyBcgrojeIhIiBHUQJg6akeaZ9SiI2XSiwJt4KrkiJWKlWuVPIMzeUkc95lpnCnxqDFG5s2GzXZgGyNSEEtxYyO2EuIqICR0QFd7UL1oTlkzeLiGKQqNcBapK6tUSCtovu9gcoZfkmOT3xMlmHUjCISI5Ozb3K7NyT1rQQ0U2MMpoYugRFk366rIN/3GvUSyKg/1klws5IJohGCueEQIXaDr+2IzYi5WP3Hhos7w3XOTRSz3yN9tGY9MxwO7Z88ZNhtUe0LY0O8COY7k/b0BQYFAtry2MrOeI6D+jNwAs+xFFQpjDoIpkmIewZyVvCRuv3jNeJh57z1L/i4Mq3qptGUwYoVpMItPyVbLeqpUmQfOx5qM+rrqAiwpF1ltAtw3vqoyHyfuU+bqemOJ6mX6vCXLS7sipZm7t/csS+ajjz7gercjdB1DFwg6eDXWbAnZNiK0MCGEwO5qx5IDeZkZj3tSzoQEQx/NQFKspyhdVwSUhfJmlN49nLok0uFI7DsrVnOcOSwW7tv1GJiUwDRN/P6P/jm/KpGb7/8m0u9o6aPNkdd3B+70ijxu2ac/OptzUwkJJRVh8CcM3M6ZufI0YHsqR+38+8eeUbzDj13R5lOpr7UVi5z35vFWnlb+qdzfDB3ZQKHnjP7uP/tn/Oj2e+Shhxi46j0fOXjBIt8Pfd9ZroK/fcoT+8MdLFYZ9fd/+JpPP9nx4Yv36fue0G/IYnErQ7AqbuVdSzRCFztidHd9iGaI0AXbldAFA38KaJvzARZ9Iadh56Vd21sr6FRWUFPCjqCm9FY+v+aQnAPvwivWMFFqy2asKukFpsiuRtKi3J6oRY08Ksq2NJ+fg5PyJGn+le9Ds+oey097as39celhW6e865RKbtNj++VcMX4q7NJC6nPVTaAd/5yTz2sk54VM5jjOLKXKc04EUWIfa1GEnK0CcUqJGGWNlCkai/9XinCZcVHZDgOqwqvPXjFszCMWMENfbNenG3BhVbytSFkB/db33XZLHAbPoTOjRUqZw+HIMk3EEH0nUGVo+aMYOUIxVjS6dlaTw1VPEAOsV7sdIfbc3t/x5ouX3N7tif2AbnoPv/cInIr+OkTMsB4CVecraPF0NgRp51BtnFWELqgV0gr2DiGsqSVVKkjhU22aTkFC5bviFYcasqiCklH1ypMCEqNF9iRlScmAc9EX3L2X5pklJSIlDDw02Zrtujxfp+uOCq4v1dVbDCuCm5vkbE8LNc+hWqLW9qWEpp5sl3YH27VF8ksB1yLuPexNby6FpUIJiVUWzYzTRJ5mNy600Nif5NFQq37djIJqXU+qjYEonVdHDaR54XB7z3GcSEuyeZL2Gqohoes6YtfRb7cMWzdyFEeHFobmoFkBL8BXwf1jnjQ5nS97p4eXtfTNAG0Cd4c9OcHzZ9d1Uz9QUpSqeUqzicydLNXCFGKw+O1w7jj1+1qXhi9WzbICLVYPy7AdyHPPPLmnRmvg8kkSeloSi1dKe/beM55dXzXevCKQM2RbnDEUpKqoJtRLNRbLwPrOuQrZdQwiHhuJOsOJ0RaWeRF7ukHRZcHqbVg1SPPMrVUBxa3V1W7onM6sCGshgfLw1shRXr1uOh/bFEsun/VH1S0f2UI21xE2QGRKvc1VKEcwYApFFFOai9k7BzHZ6qEbrXZgVTCVaZxZli8Ytls2VzdstjtEOrpth3QDevuGtD9g4airtc3GtrXUrMU0ggRyqSaJjVv0vmiwTd5FYV5mjvd3vJwnbl5cs7u+Iqf0QGmzsbT7AmtJcrMI+ZC7hSarWu5PwCpreahqoijta5Wi1v4rQF4WxvtM6Ae6GMiiBK8co9kS2q+f39CNI8f9kY8/ecn7336f969uiAIxdnSRdR17L2MQkkbMamlVPZ9dD0i64q0mDocD8zQhAbabLcn3Z0lkzjmZh3KB2HdI79bZJBBNGQgi1Qq3ZEXnBc0HY5wBOlU+++RHyIvvc/3ero7ti26mY+YwHXmz+T7yxwBsLQVXRZLt3m9UnltRDd7laXNodfL3V3mDp+RGC9hMGVJCgLSANgxCBB4TUqu1vTwnYjGIZ6FsDcNLKUEXefb9v8x/lL/DF8uG+9QTdeZbm8nAf85M88KsgZdjzzwZyokCvzTMTAH66MpZFsb5lvDmjq4zz56QyJpJIRBCR/JKsCWywditkJcZukAMnYcRuZFKhKGPnioiaCdEDUTNxNbAVQBZiIvcBVsAACAASURBVB5+5mF8At0wuNLWKBoi9KFjiEKW4FWO13GNPrt9tFLTwY9G+XgcGCXSZSWJ1XwzILDmC1Ul3XlIdG23VY5Owq3qxJg3okaJ1HzwFfTVXOCmLTnjgUU4F1b+VQBbu3be9VnT/NdAZczsr6/iJDwvBGNH1oBqQCSwLAtv396xfPY50zhSxq8fTDEEB2wpsyTzjIUuunfZlFspVaBR83T73Ids8zKNE8t0RNhgAUE2UCqn75NzYnavX+ul0AqKhLjZVq/BkhKx79gfjszTRH++zUUpHq2i+yMNO9BMSTHQM14Uuo5h2BJCx9vbt3zx8gvub++Y54VOI1yVVAJ5ZHJdmsua+S6exG5GzTJ3az67yVAlEiy3273pmRKavKAysBZrc8jX8jaROif+gqy7yHLhJVju+5IWUjLgFcMp6Cp1BkwPDGg2vWaeZ6Z5ZOgiXQyUgM9yq0iwnP+TNIC1L0HxFJM1xy5Qtu0KiQoMrakfTTSU8edVwzg/Qmfdg0X7WPuQshC6SAyxAjUP2aprvdDxeGR/2DOOE0PXs4ni41va1Qftf5k0a8HoSSs1mqrIxKITi0eHrYwldh3d0BO7aEbBGE6wXaCtcgm4J46GH1a5eTJN2ixlxyuPgbuGvhmgDXOxz6EUzzBQpNoACNRzkoqqYhuCBhSZt60kOa+gBmyZSYxo8QVnkBp76gAjF8Sf6Toh5cjVVY+mrZX+XOaKrO1MLN8l6iGEITDPE+PxSBcj/bBh6NdFLMUfDXY0QH366l9UCt4u9xT7fm6muzAiV8oUBxkO+CTQ98KikRiVJB7H4EqD/fPzRWRlHGV8s2ot4ME6lCfbtG5sogWXiBCcYa6Iu9ksUja6F/ionsOS1yU1Vh+x7/PJdiz99s6cJ/VWUtKijPsD03Fkud5x9eI5gYGu3/D8/Y+Im9fcv7m3q7OSY1FgSj5e6ZeQckb9vBQkOJOnWuFCwKpcihBDzzIvBt5u71jmpXpnsjPLtsNtiKTg4Z6uFGdntOV+y7GjMj3L4QnkvNr8LLTA4sTLyM1LphcXyIX5+TiO93sg8+y9F4QQ2N8fePPJJ/Bd5f3tTV3T7RyCWSItv8R75mOxu9paGfhlZpom8jwzS6AbLM8piwkWCZmYk1kLk7DZ9uSUmZaJ49FmfQiWlxYkkscFFVhcqRGUOW2YXr3h+M9/i1/9i3+N3eYGEWEIiWU68KP7Hd9+/u4y/19GZQzLTk11Jk6F7ddJj+mDjymfevbTfn+3NrkG8xRF/XQPydnPk7Yf1VS9Elfy3IWgxHja2mlOFLRyzSj51vJCTpUXZY9aMx4VCPz7f+6K35n+LNtpR8lLeN7NfH848ofjhvtk3rXva6xnVaoqy3xgs7zhV577mZtLYjweQMyDNi3JK9PNLCkzzs5r1fnrMXl4kikg0zKBTiiweP6PaIYFjvNCyokQO5MZebQ9m5WjK4/qY7FoIHbFWh9QMX4tsOavSb/KgAL+mOvkCOYti8VjInieXqTz0YzSIRIJ243xHM3EENh0wpLNMNJFIQyD83G4myOv8xVsBsK80HWRRQJZhJ0Dxzan0HIIy+8ZNLrCR630WUJO1X8+VnSkXSePflf+02YP6Prd6X54sgUsr6lzmQlPe8+a9r60v8FBylPFSIz/pjRxuN/zyQ9/j+39Szp34PZdR991ZqBUrADCZCF1IUZPu/B9olr3R1EeLSVLXE54DrWC6IRqT8Ll9ql2b4qrZkTT6RmrxeNSQITrGsuSuH97y5wywxCJ52OnoYL9gLAQIAtrjRbnO95+q1T3nelLX7z6mC9evuWwHzmOE8u8sIuDr7NS6r/oguU9OiRMJznMOWf6rq/K+lOFborWpRrp+1X30iysDTYGCV9GJSIAYi1E0ipOxRCeNaAsFXO4r9v1KvF0HvEiTbafFxHmeeTu/hbJif76ijbeo3ADVYWkls5Synk3IZIZq8g8l76zqswnhjUHFbUCes39L0CpzFNTLKZ53fN9m739buit4qIm8HD0FqylnElL5vb2Lct4ZJxni9a5Cmxikzu2Mj3r/4m18jQUNITWuOVvUAv14eNoBucQBZKF3BY5ZB43n/Ng9SCs3oLn3DVG7BWsKtXN24zvGojihmmXwCc5d+W9lAb8P07fGNAW26pLxbrpv6r44YmhhI2UfIfs3rTi3SkHHSqaLO/N2siUajkAImvYYYkBtmIQ3obY9uy7yLOrHZDpgjJNkWlarJok9kh1q1HOhrSHGHm229B1Hd0DORBtsTfueur0xZNPitXU/nZwimAhcsWKtS5MLQLT8+j6boME8/zlcaxjEdxLZB6uVYlX1XUPtMYM/1M9niV0PQmhwxZYF09t/dL8X6gk0atvhvPcKJ8Um8tQIKy6Q9Nz3rRYr0ByhX8WslTXeDOq5oLk7s0dh/2R5x+8oO+vkBC4vn6ffrjmcPua+Tg62LEcxIy58lX9sEQb8dXLKsV7q5V5BXHPmyrSd0QPAWVZmDPEPlKhVShu/eLCZ50HV6hQs9zgpdCrgqMFWJvQCpLZxMBRLPw1IuRgIaddNCC1jDOkkk8ZmsILSlI43Fl54Zv3X3B1c8X+9p6XP/mY/K0P+ODFewb6oZ6ZV2YhpURXPKhQPQTb7Zb0LPPmzRsP+5ms0lnfeZnqcvSC5e4cF0UOE5vtQAiRIS+ukKs/Z/FCRDa+5XBLXUYLU719w6f/+H/jl//i3yAOV2SU28M90g1snlSevjpJ85uY2P2XwjTfxbaL4eD0s3cz+vN2z69/l8K7hurq6RdCtc6TkkcrrCMWhNU73gjVItxFaK53Y8mDDti+6YLthU/SC0r9GQEOMvAv5mvLf+gcpKD1fEtVO85C9X1+5hX2tM/ollrAIDRFPApfD9IWDbL33srCd4YDKS+gtg7naWKp4dOwTKNXm7PS5JoVHVctUlVJmhiXIwUxpGQVARVlXLJXADRlPWta+W/TH8kzWTqCZI+icp7jnGYNZfS5k0jW9bzSQCBKRuNAqUpr8klAE0EnOsmE2JOwMzk3oaPrA3Pc8mn6gDgMDJ1wNViVxdgP9F4BNIfe+4HnHrmcqpzwdC18VSrDEJr7whNtnK/p9VOA7uxIEx9bLWN8Si3IPO2znniYnwajiqqdrXbc3/N7//Qfcv97/4Dvfvs7xK0Zl2IXTwDbPJthrBQQKznsgqkzIsXav4KIqtgWywDr5+WonBBKcKWthQIsiomw6pAhVGVcdEEzzHnh9vaOJWWGIRBbj6IbvNutmytAbHKtSlGIcuZYNPOCLgvznHj99gteffEF8zjZETSzhT0OvR3xpFVXWgfaQOW8gqrapeB6z2NzYhTRqneQLYe290cU3NqCtayZlKm5hBbhVdZFAaKncw+uI/i5b5Z+ES3UVToDBqpITgRV5iVx2O+5vbtlmWaur7Y+t+s5gutaNn1AwQtDFkTj10lmpnj4v9w48TiVXasnf9U/aGWKXdfF3r2HnXkx44a2YqnmzDJN7Pd77o5HlnG0iLV5IQO73VVjLM7NE9sN6FxOqdeuRoBMqe8Alo5SDOcGTk0fi1J4IWsFY8mVPyO2RiWY/jT0HV3oSDnVuRbBwubFKhE8quMGM1yEFNZ9Ia7tFmbZGDmfom8MaCuuy0e+ocSlLsWx5cJwfxzpHAH3/UA5X0UkErpkVv3C3NxDI51aiEJVP8uG02bTFWZmVS2fX18z9j3jOHLYHxgPYodbptXNXxZj30c7v8StllASFv15mszbV+G3C1ptF3x5z5J8GivjyFpghE12WRvFCiYidF1H0oWgVk0zh4C65dly8E6ZWhGlFiREFfq1O1rGSdCc6lko7RyVPjTyY91YYu9SLftna7JsBhCzUgprQZOS9xWEoMESucXCJuNZO+rztoZ12AVpXnj16Uu2Vweubm5gs6HrejbXL0j5DbpMgK7lmsWAZsmRkSqJpT4jeC6bHdxewhqyWc3qLi7Mxt4jdJ0VWlBrqYBTKQy1WtItdLQvB1zjAsHnyax/lttXMq6CiNUgjYEQpZZkzimD5/GJGHhKXjraFoAwTwt3r95wdX2NZmWaJj7/xA78fvH8GSknA8ohkAkcl0QvZuE3IBhJaSaXfbrMRBHmnNBFmQ578mLV+qZloSvxdBIIcWQ/wjRviu3LjBjuXZASmtnw63lZkK5D0sI4L3z2+i3Pf/z/8N73/20Syhf3C8P2g8cZ589B0YWRzfiaPbT+/8enczZ9HuraXnN+7VcBbGuO2xPPO9mURcF+uMFOwisVasBJNiEcmjWMh+XlypepeSghNBMq5SiO0D6qUuFQPx0/JGsmNmC8ZVPrfasy0/Jg/wQp/DSsWrgVjiq5fKbcrPvTPh/p+P1l58/1PJa+KHTGInSrPI8TL+J8krdmY+yjWsOMMs/ibAbJlEg52/gkOxg5eXj6nJR8XOqcTDobyEsLc/aiKckKZuWszCkzLzMpZVLyswqakH8L9U5Mal5SdCnDgBL84Fk/wkQWEGEUk5lZE4nAVfwECT05JLSzc7TC9pqr3YZhs+Fl/JCuHxhiIBK5UysgoZSc5VPw80DH/RJ6UNBNVk9eLe5Svmu+L3QOrgqAO7+ufCbuuWp0KzeQtiAC58WPATdTuOd55sf/5Lf42T/6+wxxYzKkGkVwLJPNw6YmBzovlFHSPXK20uJ9OSNNpIb1tWNZ2F9KAoPx1RKeWXdpVSDU1qmseVrFuFxC0+Zp5G6ayVNiO3TrwDWh/Harpxao5ceFlCzvro5pCe3siH3PdtNzOIwsSyIfDty/ect8HBkPI/O8IEHY7LbcvHiPLsbGYyvrGlLjPSd1KtrRL/p3CVsrvXElv/I1CSuI1+x82FI4rB03GrpR2OavrBEzBK1GqYbHYXzHxn6yitCq5kHtBmJngCJp5njYc393x/FwRDSxG/yg8FrIrj0HzPY2qOestXy1vMda8+B0Wdo4rJVnnfs9CRoaWNboK83XTdPB6hUEq1VQikOpmjFrniYOhyPH/R3jNLPMi/1bLH9TCaScUNaaDiYf1F/86aSAtUjTCt4q5Cw8WGJd+xoCEiMhZ6/m6dFruUSQrLl7MUSCF1hrrZBVA86Bp2zF4sb1amwyAboOW1Ub361NfGNA22l5dU+NLKWbAdRzrNwcO6dsSDebBavrmnKxxTwSHJzJurBL2uXastaN0C6E4gFWNdf1ZrCQxi4Gun7muD8wT77A8gqWNpuNeSVONpC/AELOC+O4ePnWBNXDx4NrRdRCGdrEYVE/X1GrZToEOWEQMUBO5jmKQUjBD3csVoPClULJSzjdzMXytlbHccUqOMMPTdldtNYfKODB5lPdO7cWokDzyTzXipPSCkdqzmBZvCswLd9Zb7OIV1gs0y1+/sZq2V6ZOhzv9yzjyOb6iqvrGwSxs/qWuYLqAp5KbH+xmNcdpVrXoYiFbanXGy+erJUBUnekqnop2kgXxatLekW1s0pEZS6aopGg5jBTpXpNy44XH28JAQl2lEPf2wGVYZrMW1ksqmK5g5sYmCY7Jy8GYR4X3s5vTSFIC5qUt1+8ZpkWpnmE5N5ShCV5MZqqshszCs06Uk+6zz6pR6wIhObM7AaOjK8pVYhW0OTq6hlK5+V5ZNWCzgSJGXEycV6IsWN/+4pnL3+Xw/yMP7zvuPnw5wuNfIoKl0j+7uthJD8/FcFSWjwHaXry+0PBWjyYwmpJf4y7PLjvfGwfa7sqhKfvasV4IoFmv/qitG0jtRoovkYKK24LFLVWfYB8IpSVRMc/vP8LDEN5bunXw/epoOCJ0jHlliDnSgysxpM2h6u0e84ni0W99SIKt3nDbT5ffy2EWGdyZCSKoJ23IWvoeO2PNgkBmvnlfiKKgb8SeohmknuhcaU5pWz5oMn/+bulnEh5Bs2MSzL+58+ak4WJ5pQY52S8YLbOLLowLgt5nplSAp0QlLc+WhL3vInZwqH6j9ntrthsOq6ePSf070G34VW6ck/P46X723ktdRAqBC/KcTOa7YSsyvL6s4COmq/cAKoTW1DTbhGP+kj75Yt13TWFxXh8PZb3GaeFP/jh7/Cz//e3ONze0z0rOsl6UU6ZZVns/aN4lVRqkZusypxS9bypi6VSVc+MyKVAlUfsaF4Bndo8F0/DCijMc7Qo1VRhhYCM54+jVSBGM33vc1e2r3jxlTqODiSxnO3FwYaNvc9ojAybDdvN1uXsHgXikmvlxhADIVk4Wt8P9OX81jo/4XT4vJx/620B6nEgti7MY28BLScraZ2oB2tiBTSmX1k1ZHu/bNX/2zV3Jq7K2bdZzRNTwNPQ94RusPxWEss4cnt3x3g4ojnRd5HtMNB3PX3XOR8Fq3J+tnZ8BJqVeIoGHvymZ588JnHa/bnyrYx4Pm/T2klXXH8NYmfnOWDLOTOPe8Zx5u5uzzLPzPPMMieWZWFZkldQzZRwilPnSj7ZyzZHcvLzpPBdKWZYVAk3spSiOIU3FA+2BtPLyMlDQ0t+YUktwXWs4HJMauSstpOuWMh868JvhuZE3kob9ilP8o+WvjGgLXi+kKpYiFgtg+/gCVcmVKml/jWgJCvUUAdqBV8B9YpYsC66bKHnTbhku/gLH1uPWSsKb0fXeSx/sLKfyzQxz+bSV4XNdmCzGXyBrDlABoBKWBwc7g/c39+T54Xiss6hna1msps2ihKhhtoMv1TFAQcMDm7xU9sBg/6nBU1wy1xoBFcQa0+97ahKllDPoev6jnm05NQCxEr1KmP6ptBTAKdILaQRPVcthlAP1T21yvvAi6la5bBwlbQuZk0e6od/VqyDJqz6zhTEMM/uCX24A+Z5YX7zluP9nn678zFZ47hNUK+hHDUkIuOHjJpHrlphEAvNksJUQhncat0r7aZ54TgmpiEjEXabDfg5gidMvlEX14hyC4kSEmhX0VwxAoUgVsAj9O65jMQYzEIuK6ouDC2IsNn0zOPsc2gFQHJz+qPmzHI82Nt4+ToBhmLxVeh88Qy+9hZ1ZtVUBCteiZAyoetrAE1E6bKFOEdZzSk5JWYHv0GEac5mVa6KvQG+lBbm0KHjxOG4Z8ozr29f84H0xOHXTooff11kwdgrrJlR/MTHd9af+6qkzT8e+Wm/fwWQ1fK0szZPrmsWXhtlUJLQW8/aY88pe7coK6HdR80bVSDn89eazVBqmfuiqNdwQD/Soj2I2wxWUt+rKOLnY1/uKLJT4KR41PnbPOWZfSx/sRbaKEooLeBYFQd1HluOMbDr1nDMV8vDIyvattAyTuvxCUcd6FwBLu8Q/SVVTD4IgoZyTtLpyJTUgiBUr0EQywXv/J2eh4nn0Q55JhfFNzMuE4f7e5Z55Hg/cjzuuR0X5mn0XNZEHBPKyH13z5sewqcvGa63vHj2Hu8//5C3+YZZdvQxUqsjN5NSgbuuc1cAWwvGfHJOi2cU3ikP5zP4Z+UMsRKW3hbeKIpcGXuador8XKNawsmaa3S2E1JV5nnk0x/+U372j/4v9vcHckoc9vfs7++4utqZZpJXD2kMka4anR06ZAufjV1ks9uYZ7sYQnzus2Ll9invSg2fLSt1tZWsOVfrgKqX0acq2lnNMxIxw3Rpq7SXl4wZxu04F6oxsvGcq4XjBzLdYDlNXdeR0sTr2z3j/p7NMJA7K0a22QxV47GCZWsJqKIfnunJJ9Tq7RoaY2zRl4LJzpQ8cqIYSnwMNUHXr8q9Acs13z1K4WpywgtqPpiUESohir5+KblRHSH2pjMtM/f3t+zv9yyTFRwZhp5+sEq2BSisRqLT4z3KbHIyK85nKx4QHw7nurV40GNtrWvhtK0WqK17JGZlaa3L/s4lFFr1yDwK9/f3HA8HK6wyzV68r3jYkjlA1O4seaFt+O46t65bVX6qdUzK9VVeaGOcq5EcRXPzPeygLZef2PFOyd+3HKkk4lFM5dis5JhNVwfKA9SlFria/UiHNgusCE1TK4vxrWGAT9A3BLTZmVHr79SSq6pYOGHvkEtBl2RDriuAUc10IbpCWBRnE4x2ynwpkporiIt10zebC0DFFV0BD0GwwQ700jug6Eh9b4BGYVwWttEry1S2hgFLBStaYjlAyzhxeHvPMo0GZLoetgP9dqCn48RjWDdDyXvLtXzrg0P/fMEoQBoZuo7NbsNCZsoLUrm2eYhMuc/V8qPQMB5nZnktXxxDoOsD6GIKWC6LemWGli8HmoUQ7biErIp4XltuGFs7/9U6JmbxkGJCdIWlXEczs0ENSKVkhWMk2Pk1eFWgZS7llE8GCRSW2azJXRfpYzlsMTB51dE+BiQt1ldXcEqeSNOV0pyXBm7X0/q8mhosIJoYD3uWac/8/MZCEh0MroreKaA1MBiNOWSIIZNzrCEx6uA6xKJciws1s1ZaZT8/aqH0JwSEjmEr5MlCTgtoN+VGG03f/MKqll+RPYwg2FapCkwqB/emYiAoSpGzySrlfQh9UIKABjjs9/TDjtjZelp8GCOJpJmYO3JK9t4pgWaWtEDf8epN4Ob6DR9/8gnzvPBrL/40w/YZ193VWr2Pr4eKn2DOiSiBoy50RLqyfut1f9R2jR4ofXw5MGv/PveuFXEOpyCt/F3XHWuo7nl7xXunFah42yJ0URilMhZvd+28CTRxYKX1vtNZOe1XSquyAEIg8dde/H3+j8N//ACEtmzwEbWi9uWcE6xvvf71FHBTihxpxsU7Ia0mfP4MWcesBXLnQO9JKvq0n3Oiqozac8wrTxQRJFFn68HKK6Ko5BBVoGKN1xGIq7f/FTteZ+c9NZc8kENGNg72vqX8Sn9Hn4/c399zuL1nf3/Pm7s7xvFImo5MUyDGzDLu2b++ZXP1is31jm9/+CHbeMXP0vtmBKOrRU3KbJysYVkBx/kcLSlX0FrkyFOKaFvd8imrfaECBh9MSVXaz0faQ3+lWZO6sMwTn/74d/nhb/893n7xhnkcTU7GYhRxj0CyggyhVBFEDYRbx5nnhRgiz5/fEGNkOh7sTChfhIIZ70LSakQBO56mr0zJC8j43NvZZTbY0ce3rOuS+xwQNt2aRyaynnsmAurrQxHEqzhHWTP1S85OCIL0A5utmbnmaeT17R37N2/oNzuGHpPdbhTX1DEva9GLImsrMKo9aubXdaQKpk8myMFk1vV7sFSMCtQzaECC6XXFyFO9vv7u6qDN7i8gcpXf52spxsCSlRCVhIcNBuVwvOfN2zvmw54Q4GrTs9lsiH0kiBlecTCxtt2Cs2aiT5aqrnpA5T+PrdezXLHmu0IV8InUsMjWkJVCu1uLgLe9k5bM/d1bjuNkx1vMC8sysczZQsKTpWrkE6OcRxWx5vKvcoMK2GpExMnZeBY+XIDaaohpdU6/zvd2EHOaSOwszFsN2pZ07GLcsccFRCJRxc/IXgHbiTqePdIsylpQrxrnK0P295LqqSvb8V30DQFtnMSBtYuyJhLmTDd0LKrs93t2wwDiBUHE47y7shWVIqIr2q+Ta9YTaujl+UZb7wV8w9hDyvllOLDKeWXqz7qdV/Dyw7ZVLZlxXWUGgzxmN6dMStazvIzklNAAV1dX9H1PDNEYdl4FVSkVkiv3OptggYiVf9VsgjVI4P333+e+v+ewP/pIrIplbn63g7rVgRVetAJfTDY2Xd+Tp8XaKHpaPGWi9Q9fpF20Dq2xxhnVeHLtyVlzrOEV6zqgKsRZTCpmByHF/Z40k5Zk4RSbgdhFunlmcq/bqixZP3JWy+moQiczLxZitP3gBtGJ5Ec9FAuMumX6RNirktLiIStUkOLLB6GJgxcrqkBK3L16wzxNa4XIBhS2v0v1QmeyLmh2a2e2AA0RQVOqMf0KJvxiXIWyhEa4GqOKXQcamTw2v85fAdYezirqawLPoFMLlZKm3+mszxnoRKzypq0uC9OdFqTkYvgC1iAwZy9xPZGlh5KvIJnC9jKZeYG0T4h6cRc3riR5y09/8ns+xj2f/Z3/jps/+x/yG3/mz/Ptb/0S0cOLvk7g1ktkxoTOp4dXfHB9w3W3e1Lxf4pOlY7z7x5n4S2geqwdaADaCVh4pK1isXwAY9a/z4EbDl6CBCQMwOwed7GQoUYRKHkg9n5ih9/ie70kpldFwM6KLPHpNRcY6J3ft+qBrWUfO304v+2150rekyDnEWqFchG0qxZ0Cj/b8W6tv+vXD5/3tLVb1h/NJTW/o34vheU+uf5E1vO4zkPI1n6tBa0UCCHW8CITCi4vPNf20/y+9f0Kbp4t/Klwz6+lI/e3b7m/u+X1m1tu7+44jhPoTFpec7x9xdvXn/HivQ/56P1bxu37LPGaMfcgfR2vk7LqDeht+22/r+vpnDefjjEePq8P2jgH1S2gewwESkU3p/cH9MyIoLz95Pf54f/5P3P36g3LtBDEPFZdF09WnqpaOGQQjy7y42AUxsXm49mzK/rBqu0GBMIqG4ryGHxNWq5bcNlj63YpYYFF128U+Sxr1UdE6hmuIrbPSzGyqshinjjTwUKV4/bezQjk4t8RutgxTplxHLl7+5bjYc88J6Tv/fri+QjmYSugJZZwuVNqg5hP9LmSG60tfzGesvgZvut+9r3g6R8GZm16Qxerm1dkadalrAp2LQzS6CotEBKPJPDzGLsuMk8Tr9685ri/J2hmO/QM/cCw6eoRO+ZdVAwA+Rs2xecKaGnBlK0jf67ieq7PQy252DKTNtSyWRAlvK2ZyeDyXRpv0IOd5oOimlmOR6Zxz70fWr1ME7OHQCavuquNXthSDGe9dCPBKtLWlZDVZE7tZyg9s75Yl05lYVkTppev+rRdWzZHqHyvcPggHZ2ns0Sk1tB+oPu6UCrg0YY0uHNqxSTNhK1j+SXi6BsC2hSGdfPYuLpFJwO23dhuN9xcX3N/f18tgqZEeIZYUkSyWyUc7RvXAS+vWhlwUeAFLEHU+wFYJcbCkKGUly7r2dovlpVVAIYYkVijZe27ZqErZrlRtbK5WrxY3Rvy8AAAIABJREFUIZCXxHh3YD5ODNsNu92O7vqKnLOdwUZj3VCtcdLWn1CFlWLWjcPdPX3fs+x6QoDdZmDTd+aWTslC21gXigKST8P0iqKlrqDNSyb0vu1No7YLixWoZVRVySubZS1ef55JUqLDy++mC4V1gxVF0ZuWXObJpZTPZQjC4TCRU6bf9Fb9se/pFWZdHCSvVI6TqO3V9zY+fXX1HstwZDnsScts5yQVQZlMEc2+SKxsstKG3BAEXeyNrTS6D5WYi31JdrBjiHbuU+1Eo+hVJcTXmikFqa5LS3gpZ4vomrkpgWKhrLkEDryCmDDsOjsiY6r7Tr1/oSLPVvGvvMQVt+CKYzkSIeKhorjfujEbVUUsrEIlhkBfAL9Ajh2iwnazsXBUFAkQfWzV96hOkJP3GQcPqpYbEJQ+wHKcef07/zv/4os/oP9Lf4P3P/xOVTS+LhIReg28nkau+g1TSmy6bIeFr6r9V6YHoOvsk6cB3Nnf7/CmnVO1TjbhkE89r55ZJu4hUIHgHtxg3p6TA+vRBrD5iXcSEcmuyPmZfa6gGH/1A5/zVIGbVXft11ZXneHEI92+YSvw302nXv/HRknPvreQoqo6PXpdGaeTcdfHZ1AaZdc33aMVCB8CrSfAxBP0OCg5jXxow6DqGIcWDBWlh7N74D4P3OeeD7qJ+P4Lrl9kXnx3Tz684c3rN7x69Zq727cs80LMiZfHP+T46iXXH36LD997n274kDDsuMtXD6rcnQO2FXiGRysDPjYuhZ+WMDltvntsjE/mhDb8/RSsnYQYs669nBP393t+8H//r9zdHTyNQum7QNcXHxReWdOV+m793AoVOMfSbGdU9j1IYHd1xX6eWZZlfXCZmGZvCBbCXlInoigTrj94EambzRXjeGRKix19IWLeBgcDtUEpsizWvVlBqjS6g+ha9RTznKlihTZS5jgeub2943B/z3QcSTmzub5iDZi2e0LsaiGcoHYYuYUZn871+b5fDdwlpFCds9ncWcp8PC1copzIhiKzLezL3rfWo2gVcbz9xtN2TkVHy2oRPvv9nv3+nmWe2PQ9Q7ehH3ovIhYfeHY0t2GXZe+FOuXhZEBcIhYgRwnbb3Uzf0fxiKazkdRmLQX3xLXQGDk3gJ6vf6lzMM8LeV6Y21SiRq98jOGWo6jKE9tLWt5Vxig66CqvUsr1F+9i9W7pqqGqel0G1wlKlFAQ8YIu6x6vVc1FiF2saRrtsK3BoOtwBDxlqGAAtDphtIzVYwamJw14Rt8Q0OaDg1DP4QJMoIDF84tVFyqVtZYy8eYFSMvCcbaQqd3QE7vOjQVm+y3t1XwIVwBzWlANxCgOEm0TuupLtVCohc1pWgECrAw7xOguzjbOmbriFAsVTNnymWInZA9bK+BtnhMhJdKcyLPF+Hb9huvrDdthUxMbxYtYNJpDtboUQTxPC+NxYZomdrsNu5tr+n4gxsiyZCQncwf7Csv+xu1mqXu3jHN2TxaFqVkfQi3l6wy6WFv85vbcvHWubVRKVabgVrDgG8TerVVk1rXyqJLqmpyEQJ4XxsNopZJ7WwtZIeepAgYRalWgUu7X7GC2eZd5IuUdMW6I1z1LOpLvj1ZMBCil+9cjbwpYM8tRwZIKzqTUN7cznCD00iFgVSqbnMYSalJUXRGrlmn5CoWNuftdjRlkLWErFMllP9qkxeyn2wQrIR1jQPFjMtI624IY0nOAlT1vUMs6E7PY5mCKfnnRBLXyUlkPVcOWtPbcw48FmDClP8ZA30diUJ7dXFULcbVCqed+qtJ3C2lZAM+5yLkaIoxnCJvthmmc+OTHP4Ag/Dt/5T/jevee53fIiar+88A4EeGjmxcc5pGuHxDBi+P80SDbadmNFTB9uaftq9FjQK70/7zNx67RspjLdboKUDugmmq8kRCQ3HiXcaEmUPIrxT01pZgG5FpuGUperj1NJLoSPNteCjaDWvnIOg5t8Yo2D6q95ssA3QPw9cjnj+lnrYJxXsGwvefUWvwojDuBz095eqri8aDN8uTTTrYetvU6edB+20Yxva39b5/XKlBr379YhtrWIFs2N+/RbSf+re+85tWrl7z89GNevb5jSTP7w8z42Rfcv33L9uZzvv+9X+GqH7mTZxz1/2fuTXdlOZI0sc/MPSIy8yz3kpesItlFVnct3QNpRgIGgiDphyQIEKA30APoHWcEQYCkwYymW5oButVbVVfXwmKTxe1uZ8vMCHe3+WFm7h558rLYoz+MKt5zTi4RvpibfbaPJwDtzcpVH2Lef156/tH97ZEErhy6/OyV2X5NmdmMwvrd0nmL+3OiofsCiBZd+OQv/xQvv/pSi0uItqIYxlhDTvWMtHsFU4A1uIdXBOxycxhG/T6kKZIO8sUAvtMakebG1eJezbBIHLC72GHOBc8//wKcVUGqhuaOFjzHlKqoN2xkdJG96BhruGo5pVcUoBDu7+41lPbhHsf9Acu8aOE2fQhgzeard8x+CgTzvCBMEwJ39I4WjwOcgGFiM2ifnoaOdk7OSK1ADgFKAcXYMIw0OY56MrR4TIiekoPuSb7OWuL9fr/H3e0t0nxEJOBis8HU5a0BsGrRjo4UT2o+m+LRHlcKqBUtOmE0NeyuU1ROL1p90aNwtJUQ6m0NaxhmEquoXS0lpDQGDzk1vuD7w1YZnAIj5IAFeX1m+l05U7hD0PHvanxsP70xNq3et+90sJHMmCFoMsKWCiAzDKMZOlCfg9WaE0WAredcd4/V5+AqNdWaC445Uem2+/LvUdJOr++M0hYLwYtjuAtRLRj2d1FvQTFBlUvWUp3QBdCmqAkjMw4Q5OOMKQZM0+SUVK+q4JSM43FRZkuj5UI5WNES5VIUcLbFZXgDaRFzpbPrGCtRC9tl1P5epKGCQ9BGxBDBfJhNIVQmWAoBknE4HDDPM4gjuFxhfCsauA2QtFQCfLTfhrcVwAvSnHBzOOL+9h7TdsL26hIUNLE/nwA/FSKwENBOgBmxlVKQSsLo1VKtxLu3uoSYNzNYeWgvk88MKtYigdULkUuLsSYiFFgzWFPee29cDQyVxkx8hfv9BGSVF5FzgWBBHAYtHJMY50zYJWtCd/HQ2bLg4SaDGZi2F4hhwDBcIFxvMB/ugXlWAczab2ZJqjhoXgXZPbPmWwKgECwH65G62YWHrYGgH/AqmME1P5CtemSRAogmszCohrUSqUXVvWouyYhsL1Rj1VwSEc/IboIfpgRnQLjli7iABghRG8LUfWq9ajoloFO8K98zYc/SrFfRQBFCwOGgxQ9ijBp2eqJclJyR5gVLTmpwgW1pyZViHuaCYSoYw4DMGZ/+8ufI5Yif/PiPMbz3n4LDoG1CpogxTAiw4jeN4DrqWl/nXiUibIcJCwpIlAccJWOiaIBj/d03sWg5+a3PH5PV5/5xTL5+z85yAwXyxsGsvAc96ukREmCggtb3Ii0QpQq/tKfJiXCTx8GdDvaydmG323lYn/NRVeIYLVymV9T0S30eSnuE1HYp7i1+fCzfpPa4/UPOfLZ6hszzEsyDnHLXrNhWnqh50tpe+L2oFhJpz9CFO1W03Yvg4yh2/ryoy1rJehxeeKoEPVbczr/fe7tWStAZYpolYM4BoAEpbLF79y389Nk7ePH8a/zus3/Aq9sH5GMCcsbxeMTxfsEH77+DZ0/fxefyDBnDo3v68/px+Eo1QOefwUop8tdA6jEqRUx+r+faE7vOMz963qkHuyqLIpjnA37zl3+GT/7m3+F4NJ42aIEJ5+0lZSTzvrXVJjB16QmMhoeYEeOAw36P7WZsSpXNh4gQCpA9XNSEigTto5c93NGgOCPjbr/H7etbBCFVJqF56bmcgH07t0qnJocd/BaLKLKzRCBEYlBW76HWETAP+rLH8eEOx/0e85whRTAE7xmrYNfbL7mXo55xy2P2nrT9Fdk9+lXQtPxarPeNbX7c3du/JgIM7GdOFV0BICXZyvUft7Bxi7xq7/SMkpBSwv39A+7uX0OKYIoDNpsB4zC0AiPei7QR4ck5PVUIXTE4LX8llaG5MUPtEzYfaeOCeKqM4z0YhuvuJ6sVrEpoxcMGQsmIoeHnZhjnOGAkRqYFKWckM/yvlKJOLhBpFA76WffgCMpDXZ4AzchQ37c1XBuU9LNu3IUZFbXKZYA7Zuoudh421REYMWrtAEmo+Nm3WrqIBTXmK2/R3H87dQGQxcf4Zvn7Tdd3RmkTq2/uzJODrBqKqk6gRSckZ2QHelUL1w0cB3VfpiXhMC845oxIjM00aVy0EyURgKzMpBJyL5SSKWJszyaIBIByDUdkfy6v7TVKJC0ZU0kggFg73W+nTa3Ux9Dqiupx05/ZQKg26ku4vQ0Yxwnbi63dv4W9MREWaXkd+roSWwxADAQSBQ/3N/d4uNtjmEaMIwHYNWAEdeUKe75Rdwik/RQIUmGMwPqU1D8tudUtfsjKiDlAqGDJWttqjAFZaK1Dnd7PQIc7njs7ps7TfqpAsNy6Wu3CvkFaKMGFSR/G0aLDzUsEuw8TpCTcvHiJYdpjd/0Eo5Xe3VxcoUxHzHd3KFm/xUEVDrFQLyINlS2WAyC2P16tyidHIIRAdf9PmbaWxhZjvoSlkIYWhaBMBg6C25SlwO4HVRax1lOpFCDEylADOlDZ3ciXMXSV2ajSgrTv+M/q1vDcom6RQVYJzi3DGkbJMFDP0N5ttg9ZtHl7zlkrbhbBcb8AMuua9x4g1UI0rMcs1+NQQFkV/WkcQTzj45/9DA9ffwrwvwLFEdvpApsf/5e4enoNgLCNAW9dP8W4vVZIT6yKHMH+9umQS4QTWtVQycWEaKSAY0mYWBU3zxw4IfH1GnbqmEBQrNl738up8SjneSdAHI89J32OmodQn7638uScAJlHr598vpDmg/rA1PAij77qY/TQtGJC3xWekguChUXnVJRXs1mIit+D6/KfCupTVuLevOYVAfpGTs4za8XKdjRrfpw/o+qZ3f3rnGwz3EPO1YqnYdAiyuNr5TpoIRv3jotY4Ybe+kztGUWcD7TiU6cgps5v9R5177Xfz+WQnOZ0re9Lj/kTmhxqfedaCKFU8NeuRQJeY4fXtMMH7z/Bk2ffw4svPsEXX7zA7f0tJAkgt/jlr2/wzrPXePb9B1xfPcM/zFcoWLf0WVm1zZNxWgmvt7q3c2IrbDQaang2wZs9g4wvrZS31WrZGLjRRVXkCpZlj09++Rf45G/+bxxutTlyiIxxGmtBq1R7ZTrg9bBN2zf3nqEPhCNkyRpWN8aOMKkaFBT/9muATvkRIBcUIaRlxvPnr3DYHxBCwDBaLj4EWSySyHi9pxHkJEDgZojxjxA0ioMJ2c5aFtEesTnDE63dFDGOo/U4PaIUsZ6ibozRuRO5QdOMAd35Wu+E/XQjPrWmxSgwAwig+dmWSnJ6F7Kw7hWNN1rT24XaroA6pVhMVuhITiKDXN5JQWDBJg6IISIOATGEqrDV1JGuUlwzuvgtlZ8ImnLAKFXG54IOx56c++4lcQ+zDZMhyNRCSUEEYm0XJCl15N/xHVGg4SjARozmHPHzZRgjKBWjaISPBDW++hxFrFqxe71BEC/5Xxehyb3HgknfF8cmj4wr7fvtu62fLgEt5LejjcYr7FuBMATtFywUrMKltovKMN7sxjuFqkjUvIAAEFkLmBQRy8MzmXgSMfFN13dHaQvOVMVowhMnLSxR37US9mpNhBVfAGDWMCBlqSXJjQUgzTNmCBAGCIDtSM1sCuhmVTrQg1ZKQUqlWsaIAArmXROrXtldawFlzN4r8ClX08MdBwwALrFFCIzD/T0O+yOWJddyrDlbKTArbLE/JMzHI3aXm0a0UqyruofiOSDyqpAqyNiYQhQFS7kUpOMR6SCYjxlhiBqeiXWIVk9oMLBTKwrWOevPBmT9dVOu+t57dg2BLUxUGYzfI9TeI/7I5nGjnnHU0EnSWO9+PDAFqg7HmSzAZiEpmdAOeBPIYvMt0EIILtSX4xG3z7/G9vIS0+7SQvgGLV2frRW5KK1x8N5umvjN2jCvE6ImPL18vluCINUCCqAzYKBj3IL5cMDdnXppmzXfgYV9lqn2U2NhBCareufPqx+v+WsOEg2FaoSyFEjwEyStvLgpZNozxi239EgQZhEFm1JW+W1ujVUUUCy8QwUPBw1BSvOMaRqQUsLrm1uknKBpv3mlwDiwECYIGJfbEdNmwjRtcH9/MKOiYIgRl7sdXr26wzRtIPkW93iNzYt/Cfr+2yCOeCDgbrMDvf8niBxB0xXG6VKL84SoxW1iwNXmEtGBS7eHHCyBHoRFcs3zOJQFA8dWzQpOd76rsjp3rkQVCJJkvL6/xf52DylFK52ODA/74RhAoqXBvcVDCOExxuzuvfKy+eu9u6ofntPKiaayUggDgeKAQMGK0+BRmEujDPfAK6fTQgvSmvqy5pgoD0yV+FVZmbU3WAsaXoEa5Vf+h+6JtsCgajRxJetUMPbTVD4PcG73Pb3I7tOEezvhbiHuB6fhdY/vE9DzWK/A2wGOaizpsn0MQDelsjv73fPqmtTxrtcHQPXInYYO9jnSNphHYGntpQur36XjNTWM7sSl8Q/HHSLv8MEPdnj69Ct89tkX+PrFF5jnGYGAF59/ivv9Hh/8IOG964IbXOCIDQqFVVVHN5KFEOt8Hl8OjPrcPQDgdThtPR1q6HOLfOkOqD83hNj9LVB5p704n//mb/HFv/9XWG4fVGELjGkarZCCoCQ1RgEtJ7PycTcIGx5i6eQymawVQhLqzpWYh//k6NueDQG1oIcaoQXHeYbkghgCxsB1HZVtuYLQnlAKTPErlZdr1L9XFPB/CAWuYAEcyeSA1PnFIWIsugYZlicEsnu1xV4ZIVyB7iFJ2xU9tKrRNCplVOM6KFhYpbiwtw/p94oUMAUUyViSGv8hXnRFxxDYsZaHdvervfZEBwGyyVURxT1htwFgRVaqQur71IqYUeUD7kkncxAICgF9H0cY7vXsit5j3IdGEhHAAipWyM1eq42LSBUXTaeISstmfKIaCtjPt/rnVsaRhqeaksXEVvhczy4LKn/hoPWsqXSmRaYz57gZjtx71htjAKx47DnDFGSNUU65uyuNvYyuPXQBEKz/Mun8smRQaTyZmFBI6c3173omzagtZ9pQifGY87zr8fUdUdqoI9T11eeTMRPGIWAaJ+yPR30fJ6QkGYIAdymHGNUlWwpKOmIcB3PRajJ8KaXbuqa6LJZTNgwaPKVUYmN0b41b/MQsi+z3QFX0ig+ykrhakIZBwy8jK9Pa72cga7hAkmCeOOvBUjIe7u9xcbXDuBkeMTOPN4a4T8qtS/paIECCNjFWL5JYo8MFaV4wWHLlqXWc0Y8favX280u+3k3pcQVJQLUdgH+mt1qSAZQ+yqFtvc6J7cUu4MEfWOdVANM8pDGBDjCy7wMr0H1kbXXrRn/wCc1CCJgRoeD+5gbLfNQQ091uVca1wGP6HaBZz7MiNl5bI3HAabRh4Z51at0cnQHWvDUilJJx8/oO85JwcbXDZhhQ4+xhSbT2s2EBRiEPIaw8x2SghuLUXCRygOiVOVFpvMqIDuyskCKad5YJoNLiw4mpKm61iA1IewyFgBAZwrUjDspxD7ncIcQIETXUbDYRyIwiBYclaRUqIVxsJlxeX2KzvcJuO4JQcJgz6LBYTz8CgTGNBC2/nbAZBzDUY353vzcFOODh4QB5/m+w213i6Qd/CNldIRfB58sWHEdspwHjByMyBewPBzwcj9jGEaVkbLZbLfBCDA7APC+Y5xlDHBFCwhCielWltORvBkhMcHqYm7R8lHme8eWnf4Or8m9QlgWIjBS15LBwAIYBMEVt3F3iQP85ZPPTWk313HWqrNWd7TWXtWxeffaRF0ZTzFC8jlYP/kwRQzV0ldryw2mtf6gUUcu4GzbsuSBWoZayLdpaA3IMFj2x3I16qEPS1x1UmeHnVHwGT5Yppyvl+PfEi3myxt9W6J6GGr7xe37ubOzOaftPO7vzIXkpemCtfLGDDbuPyFrBPKfn12E1FrZS8vS5577Znm/fQh9eCAAhqOfiy3yFy8sJH/34Gm+9/QSffvJbvL57wCER8sMRv/3V3+Pd9+7x3jvfBzZP8UVWzzif0YJ7r3OvdNYQ9P6zrsi5AkuCUNbhb3a3mv6g8uXNfa1KyXjx8iV++f/+H3jx/DnmeQGzetiC5aFLKWqgLaKhVmY081DonAs4Ui0iocUwWj9V7jfFZJqJfr0H9Yp8A84kauDMEFX4shqBYgjVOKwk4kaBdt5rOXZBzf8uXUUFhVrmwenkgsUa2bmpVGEGpogQg/au4tCFCnluWIZUI65050+q0QTibMt4RadcGypS4+Kj81VUOc7Oe/Q1NQhmlJwRwojIoY5bozhc6et5qI9BunPByIzu3lDF1ItnkXnnTsb1WGFrey0eLmhnlXOpPXX7a30ufXBNqSJT8AFBYQIh6H5Y3iMxAxxR0gJkaDuDx+YAX93V4DVE1k+Nry0BHMDFMCgTSMxbZUpbsR5fHp/hRi42z7kXQlrzHsdU673wypHfxJ9c4bMFrXzd8ZtNAG6EcNrT3EPqalvY3oidGxGw+R7E7w2cJFdLowFxj+S3kxt+fUeUNqkFF4DGbE6vGBjTOGKMAXPirupfI94QlCFQkdrsQUDIoi7ZyKM25V3UKpwsrCKnjBBdoOu9nP8oUzQ2bqCVHAGDIaV3kfs3/Tttjh2HAxGg+bdavGCMGv4hAg3rPByQUsZACmiJGQ/7PeI4VoElgHqbIG2sJNUqA0K1AmQjnOBKZ9D8Luqbq0or3U5nSr7GGJCImpm3DkK0bHtnXUGlUfOcorRik7UAyCO+hXrQxQWVWvdqf4ET0tBpMTyE0IVPz6xgnggHLlmakAwQi7tXhhYCY9oMKDlgmZcqsJgI6TiDcsbkSljR+OicBMnAJkq2UA+qUkR826sy60LHwUUDCACQS4EHcXhOWyv/XHC4v0dKC9LVhTYktXDIYqAgcNfIgWjV1qE9hqrwq3qwvykFXEM79dUeBANatyRwC+libsn54ptvaEdEwaSHBlWrrtEbhBVwlwzJGcv+oN7fOCjgAePq6VOQhbvMhyMOxyOIB1w/ucJms0EuwN39HstRywqfchBmxmazw/5wwGERXExaO/X4oMafBEYgwWazwdPrp5jSHrg9oJSM66SN2y/4KZjfAyHieDjg5avXuIU2bAcxFkkYAIhkTGNEzgIeRjx76x1cX12CETFQhJAgG+jJdv6KhfUQCMia15SXA/7k2f+KcvcLyCYjl2RAwgCnEFAYWBbEssU77/4WL/l/QZK32/k0On0kFyoOO2c1OH+demR8XYOhxmoMcdpiaP8wB+xUdVN49Tlgrew4OK6h8WZdLQYeqUZkdOqetN8JjWaZGSnlmpNZTbEGLqh7qACtkpcLcWlgsb9OPT3+k8wg5nOta3oqBmg9Z12Oc+Ci4wo+HvupBSvWiqnfsd/ues7skPdqcg9ZT+dJ1OYitJ6CRyHICljiZE3W89OwVmeEbXEWMF7miAee8OEHG+y2W3z66Wf48uuvsRz2QAj4/LNPcJiP+OD9gj+4IHwyX1ZPF2B8qHRAzf3/b1Cqa5ANNcDGEI/XbmtSh+mArt5pNV9XEI/HA37zp/8S+5cvcLS2ONM01DYD2fJxSyktL4ganpNSrGF2XCs6NXyuhZ09usj82KUp5QCsCMQI9Yaq4hYh4HHQqsX2nDVyaXlt7pmqBk4zotSrhgJLK2hVWiGSkmBRU3W54YZNZraQcYLkgCKkBeSQAYpgWjqeApUPIhXvOeQQsLrGe6VNrOqi57A0IQyQltJv4N9y68YNDocZhIwiA4RQe3yW0rdLaDRMpCkPYejpvs8zc8lqCgsERMHT5UwWnq5+zx/0PmIKRMVkogpxMRoqoFpFstj5ZANcdTRdqUwKDLYQxBgYYRgBUiMBM2EuGWwRZ+5dbfy/dIYQVXS9RU9PSWT/EgmEA8hCIFkMtzLVc6DfNc8es7U9sADCKgrWYdH9eTz15LtydM6+4twLzsPsOx7W3iWDNAUa0LBRinVLramEHWNqdLYeHODeOgEIvZ7Q5oVUgPjmCqT99R1R2mgd5ma5aqs4emeuISDEiMvNBssy16pxDhiZe02gT8hWQtkfFu3/AUFgtTgVgZYkzQGDWalLVQhRAbMSp4WFlQJhLchArKVRc2EQS7dfBYRg4Nf9VhrCJyQoJSBGdUtP40YBdskYpoxxGlFywXY7IsaxegO0elpUIARlfil7YqcRXyBveF8b/EV2hcCUN1bmUpMnpXnh9M+W+yK2/pGB3TBimY9gYiTjkxMqW63/NouFE38LjUoCDH1nePTAyy0bjCLN8lLPIhOCjTGblaS6y4G63zX8ykBuDQUkQoRgbik4Gg4IqCexaMheCAG81dzItORWjpetCI4pHLnof8s+4+lbVxg4YzkcIVALYuvkYTTM1prCtFYKAEq2cFE/DUBaEsj2lUgFKMSUo5yRjgvu8g2W7WalXHtvPZetRM1j2qXaWJlpWxNfRxtDcMsQa283RmeVP7lCx5CiWc8V8KnVtbamqAm+3rzb8tpYq5uBvZJlwcEAerAiKIEmBWnBh5wQglLdw/6Ih4cjJJdGrWcYn1tAN5sNDvt7LEkbxvKoLHAiQjoekHLCy9ev8Gz8PgIKUAp2lIG84HAz4+3bXyOGiPF4j226wS9uBtw/ZJ2nuTlCLPivf/R/4c9++99jt9vhbgNcXzP2B7W4D0OEELAsx5p38fBwh8+fv8b11QWe7C616BAdcbl5gZevMhgZeU6g2IrtuFcVAJYk2MbXeC1J99HTc/q1OCPAxMHLuffOSLyVZdMqY4WgZcjVuKKN1yvvNsHeMEivMtjfVc41QJq9cigxooVvuaCt3gayRsGn4zQazDmfPLdddV3MuHCqlDwGCOcd905lAAAgAElEQVS/f7q+6kEqtfWBoGlQeuZPhmocT1jOrndvMV7xVDesASfRIg0q9hcDFTwUU4q7nazj6zi+8oRHc3cQqjL7tErgm8bvYM9lw+n6zhLx68NTbC+v8NM/vsLF5SU+/d2neLg7gOaE5599hmXJ+OgjwYeXwO/SdV1jQuclBVCYUNLK1r9SSpynOqZoc5eaBwmgenuJWm6vG0NLR7MigsP+Ab/403+Bz3/79zjc7wERbTsT9SyUItXDxkGLL60UMyiPHMZo3jd7jvNsJlRXElm1O1bQ6CHqplKgVTlUYyaHoOfTPjNtRkg2r6FhzarpGZ/uczoBIJlO63tO8MJNihNq7zJAIyikyatcEqwlrb7PauTWnGq7MZuXrhoimoB2WlVM5ikBRoMOmCkAyFrROuv3vYDRCUXCdUsmwWxxbDEG3N3f4eH+Bk+un2qhrZIgHE3JpJWxpg819xDsNYtwHAU8MuifiicBgFYhsi6Ul9uvrFQ3SwQaJsktWoi6sDsPRXXe0wxtyjM4RlAcgFIQA2OcBo12AbAsgnlOOM6pnqdTD/ZjL5aG3PacQM+KecxKazvgXrRi42bj4VpqjTQXcuUZf8x3XbbocsjZ99ApcnXcUPJezElRnJbsfYPEPalUQwMCYYgBYwxAIFDug5OlzuV0rKuraMqID9kdBwBAUc30Cl8e45f++k4obQRgCAE5LeYuV+MWmzVCP9M2R/NHBtPGgXlJyIuWg57N6l3jee1QD4GBMeJwXDBEwhijlqoWYE4Zc84oKSEzY4gaQkliDQDZbRVqVUjLgsOcIVKwmUaM44i2w4AHBsDCNJuFokvcJjLlSoE8TElSog6IMZhFIyBa2fp2ebJ3RvK4chGNuVYKawChavh6yGPkqqh6Iqbz7JL7Q0r10NqgIWBsxggmQRwjsGhhkRZ+w7WXk3vrfN+KFScBlFlCxDyl6xhl8b4oACict5TkLgQydDlORFwZVsVk8DATVbyzH15WJpWJgJJRJCJI0ZC+OOh4c8YwaONghjY+LUUq6Mm5YF4EuZApVgW7y6cI0wGH+3vkJanybOFYZIcSaOGcFYdVClNFJw4ByXtZGSMTaEXMmkqdC9LhCCHGwKqIK8hSZUo06qB6EJoFvmeIHsLmYauwSkcwBmJMUDoGWZmcvl6kQs+6x75tDhQcFBB3Ia/GoNY6OSMVwTLPmKYRgXit+NbLwMWS67kjO/Dn4sZ12BqSMI0b3D/swWHG5cUECREDAbzRSnXbacRblzsgiCrsrGw5pYRf/vVf4vBwxPbiAm+/9QQ/2syYh47mhRAjMNCC//YP/3cgBIxccMUf4m9v/yfkvCg9hoCH+zvQMONw/B1uvvoSz1+8wothC9r8BM+e7PE//LP/B19+eYcAnWMGY3DB7evrYIk8Ib3Lz5UmUE5R/DqsZP3mynvSAXp/r/98doDQWRmlgmkDcSH0VplzG2M/188uUlYRGMeUQZFW1LtCS51Fnaglmj+e0/rZ54TkN73WAxf3Gqv3xIEIr97vv6MxGo/XvnmJHq+33//U0+l9IWvhE5sPd94iSBdO5n8bQJEzpOH8oSrzj1eh/STnAVIrV/ZzavPSSAn3zJ3O2YYNgHFEwMvwLj76wwlXV1v8+uNPcfvqFQSC25sX+OXPH/Djn/wE37smPC9XKFjnYwEAshoppV/ffjwdjZxViu0K4RzoR8UWqkgUzMsRv/7bP8Pnv/kF5v0eKAXD6PhC+XxaFpSUwQREK2vvchfQ9jnDNGLc7YBl0UINZkRV/YfbmJ1vF/fOA16hWsG8nT8O2Ow22Oy2ODzcqyGNVf5zIN/CSgPOh4t5QVypFCIEO1tCZPKneVqrwuhKBpsczxn5kXzzs2lh1eRg15UcXxX/xmrh23tStDiN39yKFimGSfYMW7NGYAbCdV0zMQYGlpzw8vkrSE7YTROGcQRRhLcn8UfwCfNSUjJ1/wR31J3tFCb4elF7X0QQSJWH0p+tOubmF6oyuBbkwXlZ1xXUceSsS6HeVbORgqYR0xDM8Cw4zlq1/OHwAAJjF7zQjp3hXgb0c1yhF1PY7Llq3HBc4WdVUwiKDUz8HPZV1q3OTuhIwHFp8/yZnWGVQ/04hN+Ahho4BGogLgVMBbk7hbCqx/VQkHlBCRDr5VyoIFKAR9EJKc7SSJDUyVv3LrexcWBIOpcf2Mnpb3F9J5Q2v168fIHtdsIu7joQQDAHiF51DRjEevA30wgZB0wpI6cZkGw5UYxGaIxxiJiXBSmppycw40gBBalakNyrkksG298lF0zBinvkgiUVUFE9fTnOWlwjDKqMoAG4Kvx86JVxRNTQFhJos1lSJbGL39XP6tjrnCsTUMHMgDZ97vpGAC0PqWd9evDdM9jGB1NEGsyysbKDMZuPHRYOAy53GywpY56PXS+Kbo8Eq9cq66lCQqwy3Ll8g34mrVBDvW3x8CapjMC/pRUXuftWXXwFNOQhfaKWgaIJt2oF0v1NktSr5rlBNGjiuLSYbUAgWfvWCamSvBweUK4uEOIG26uI5XBAur/Vio3dfvpeKNP3/DV/PbT1Mk5NcOauoQwlC5IxbwbMs6aMyanNb+kWZZRWlKHmCviYPAfUwWDwMQCSBJkaDfu5JGqhkbq2LaTNmaZWzPM1s/eKK6q6B+xKNKCVS0XHmucFmEabCzfAUbxPDDVzt9MuK/U+Do5sxKPK+4DLC8LDfo/yEhhGxiFriXliIB2P2G4iNtstCIyFYLxEtHgKvMl5Qc4JkmwPAEwckVLBZ5/+N9r7UQg3d3dAWhDDvwZB95FEK4eG8SUYv8IFz/jgyR4y3uDTu9/hg/gbvPpaUFLLlXAPZZtzR9vSwqRr7qQp1f38v831TXlKcvLcgA4UEQGkFcKqsYq51mNqgr5TtGxoDqb6IiYOuoagzwhdAaje61Q98atw9AZeT683WTJPFVIfXFUT6w+qv/v3qsX73D26Z0p3PzV8cP29f1avNBUrlNUHxhFRDd2qiolXemWu4e5vmi91Z7LB7naJUC3S0bHt7jv6r2Iyy42FVDDTK0RqiX+TJVrv15pdEx7KiJfhKb7/3ogwXuLj33yMVy+eIx8zjsdbfPKrv8cP/gh4+xp4Ider+xUL3QKJFQl4HIK7er69rLTmc5VH52Ylk4HaiiTnBV9+9lt88Yuf4eHVDXJKGIaAYRx0PYpgWRakpEXBOAbLAe1oqCqR3MJk67h1zR0897JOOp5Nzvv9XiDEEJAC4auvvgJDwZ7iZI+uMdYBrCmgLpWBVvE2GT5cDydW5UyjOCyzjPwfqlZ3kZo6BOVLpYXGFemMHD6SAu3X5p5ZH4/xQghgbT8EAIob7jwPHaiGe0X1pxuvCh4V7A/3eLi/wxACtldXiMOIEAe7X1OuEQIomOfelXZZj0lsvR576dn2cH1GVNmgDqk0xc4Bgv7aRaJRsKbYnScSOGnS3GEUECREBAaYIwLLKsUmF/WsPewPeNjvcdzvkXPBxXYD4bHRwGouOFHjunVwnlTngio7lZ0bryzUeD6o0iyx0+dj3q339/SK9ev9z8ffAxwT13kwNRxkf+teW8Bk7ddn2JAj4hBrLt4p3OU63+LLUXmJY3EGkLxQTh/a7tgYb5ZN/fWdUdqICp48fYJxnExz9Ulp77LIDhhtowNQ46Wg4kP7mOhrwcCVWHEAB68xDlZqFxWAZ1PAFOq0fLFcCo7HGYBg3AzAMEKgTbJj1NCD47JoqfcQUZnVGQ3GbXP+TuuhIdYLzvmdM2+vrOdlgH1Ubq104Sjd6/a8ThjBDonootbD1AOQ2sxaBL3hpncrCwTzcUbCA4Qirq8vtTFkYBwXZZaPlDc7yA2s9cKfDGR2jAq91aQ1Ae3Tkq0UgVaoIkLoSks7g6AzAIdd6YZlJJLz8nZYXfEBoNbIUUsRw5gkQcNp+7wVnwNBy9K/fvEc28unmMYR0+4KHCJKPiIdDvB+a5UqKhhojKUtkjF4mwOzgvwYWN3zKWsOhNagA2BhT25Z16XomIBUUHvK3B7lvPn3bVF7a1cVEjhhMETwElYOeqqS0dEinCkyq+EjBm0W76yPNIZ+WY4QXNh49Tycs4bX+1Jbz25B23VC1xwidtstDocD0uEILhrSlkSw8A0mZrzz7JmWoQ/aPFokA3NCLAJaZi0UFALScVaaGCJkCmAExEwoyCAGBg44Lg9YloIsGpZNWSt45PsN5vmPgXkGU8Jm+zmu5IjnX/4QH33wHCnd4ggB8qKh2N0euqJNBMtjNA+LJ0PL+rStl+w8LZx6QtR4sF73/n0mbZ7KaIKvlulX7NwkvO2Vi6g1EG1sy638pwVHanPjb1DGVnPuwr1/39V7xup8+yWTbs3QlK3Kt4h/r+D9JoHcr/Wpl6vfqzcqhG9USk722eam9Lya3kpPIcCqDVeJsfop3efa62YotDdOR1SHSFSBvEtEPlGu7koAUsAHzzSM+ePfRnz55XMsywPu7vf4+De/woc/LJCLLR7nfJFP4PF61D/Wr1dl2XvkETTqx/fV/u7XUkTw6vmX+NW//Re4+ey3WOYZMWovNl/rnDJy0jznKs+CRgMwaVuR1pePMMSIRTIkCzxkyw02deB1HTWNxKtruwFWiiCXjP3+Aa9fvgIRaZVoB//U1CNHBAJl3x7qqO93VYN9A8VvYB0PTfHIRfnaKZ91QUTIpuz0qRwaaSQMBArd+QqApHWrGma0fo1mDKyg29CbWBIt0IjSfi+lWPSW5l4/3N/j9uY1QISL3RbTMGAYRojlv9v2aSio8xHDpEUE1qa0wxqGkuqhMnr2Y9ftH9Ep/9LIqQK2KKQ27no7PyuCprABVrBmfTU6p+rF4hC0tULQYhq5FCwpYb/fawXzwwHzvCAtCbkIxhiBaXAbQBtQt3cNKTfDs/Mo5mBYsnEIcq+4eEiks3nnU2weWEKvtPVyoueBzfN2KsO6deu8juLKHsE8pHWVTOH2z3fyj0hTcqLms/Vywqevv0qdA4B1RSi7Y3ZnwRuuUxn9pus7obS5kLq62FrujGurAljrZgfOvcCo/wggxQ5JUAIaGHBvC220a/2cEwIK4sCQkmuFQFe3FPAVBCmIABazpE9jQIiDLXwxa551sV80PHOKA1q8tV3meWsFSYwBOuekYjzQNfvQvk0RoBZyA1BX+MEJRkMk/d5FXE41tujveSNlydlJtFnM6lJa2EApWjjCK/oYI1lSQZrvQET4CguunjzBNAwIkbAss1kWlMgLdBsrO6sFOHxIxUqmNwHIzCdJ9Kjv9VcXFFLnB1g4ZlWmTBD539R62WjRKGc8Hiqkh458F0hzDV1pQ9KwWw/prL2famSSfu5wd4/lOOPi6hq7yyvEaQOIWraW+wcce8uoAyhxoW3zsP8xkVnQ3FrTrFIxMIqHmfp73dzbAp4HuI9YxynjcyulZh2syoOvPuc5IEZLRXGD9n9jVgFnm+rZIh5GSQAkFQyTgY6i+RAFhDlr8QR9Wiv/DgdYbiDoj4MZHjZxg8NyAKAV3SBScxv7+XKI2EyjVmZMCmiC0UAUgIs1jXcDCgCOAfOyYH84YP/FF6BhtKgOrQYXl6PyGBOOAKGkGXQ8IMZBGa6oxF9SBuWihW1CABCQjz/Uyq5zwN/97AMcDkdM48d46+nPANKqpL6DAoskzgV5FqQ0o5S8KhxRyKpVii/feU/Q6XWqYDwOeeuUNxuP70+MsRZf0LLgBX16iVhJ6VVtWHJvjN4/chPShVRp1lDs8+NzOlgpaqcA8mQejyeNppzR+hl9+ErvRXIrqjF2BbLfsHbdY85eLdD4vHImBiKrfeeM0v3Gq0NgpQ+htKt3Xvu9O/zYjX6Fh+2nr0cH0di9Bmtl00Re99z1evoD7mXAPyxX+PBtwTiOGAfGJ//wBdLygPtbwae//nv80U83uNq8g8/yE3uqj487wfZ4fU6NeoAailevM60+X7h4IilKSrj51b/DX/3b/xP718+xP85aPn9orQBSykgpgYIaNwJrKwH1gjVeSOLyRj2FpWgkj/N1B7dNzOirTgsVwle6L3i4vbOUCcY0eA+2JucJliqgzF1lP1v4rhnHS9tMA8JS+bzv6ZzUGDyOA7IwcrHoE+fvQftfSWneEd9/j1gQaI9Tkf6cBfSFDogJ025j62ehZ9BcYs+nVUMgTDnwEE/3jKg8XZYFtzevcdw/YBgGXGwn8DAhsuUqUViRjC4Bt8V3cO9rU9ZAXKQZIHSu+r4WSGzymBi1GIenzTi+1cmZSkQMrlWm+ygVqntEZrhrw/BYk6BJOjFgGMc6nnlJeNjvcbi7weEwY5kXLMuCZU5Itnf5YqdyvMuDX596qXNpfTAJjlXUgN/WgakVHlfDusDb6lYjCQgs0Nxwe1RBa42y5nV9z0otuiJYp6T55/wuFROu5Fb7WDshPg9UBXvgiEBaIMeVxYx2HpoS1wnfE97DrJW8dZy0Cret+O1bXN8JpQ0CA2gCSF5tNiAWeoHqScgAgoVLFdK/I/sCO+NtCkGICth2JEAYFBRaSe5cAAqMaHvL6PpssTLbxQBWjEE9MGbBZFIPTipAzBkh9IA5oJGQWFaOeoYgWIUBFVhja8uLKCBNTAcjSLFQwGIxzy2pVV2x6uXR9mTmKyTBGIE5UVM6gK4/iPaCU0tiG0cu1ozbxgoYCLKkSzbXdCnA7as73L66xXY74OLpWyARpJI1NCqnelRg/U/IqwtWLbGFo2jYpSqVgTR3TEyg+Iy1+iChiHpj2mWeSRFIyRiGocvXaB6yYHMBaWioQJkKC0A5YzQPVi6iTF8KhqCHMWcPQdV8shAYGQwu2udGxKsAmnV6WXD78gWO84wnb10h8ASOEygewEvWUr1ozD2lBDPowH2BLijZ5iFSwCiVgTKzlo/3VbD1iZGbhbkYlPJ/yOiMSmVNTMAQ1PMoYmE7ELMiNguvgnD9WZurtuOr97PPq5BUBToQrFCgcqsAVKtjiBFDCCoUi0C82b3RZ066zzk7LXpYZ/fgeojaH66wAaq0zfMB47BBGAblEa6gEyEOE0pQJYMMAEAKXs0JT6ad5TQCKWnKv0hGmAqQCuZlRj7sVXiWor0ge8q0sLYxao6qn0OywY8UgPg4b2a0n8stIciA+fhP8LtXP0HcTVjAmDYv8c73/gLMM0gWFdrMePWScZgShl0HPKUBWeD3KC3d+zVcr6JFu98ZwRJCQIgByTxhu82IZTOhhoD49+1gFmghKCJSOvNwGDY+DKrhZaqoHIE0q6LNbxZuzfjRgfPOOtsrBMpdu9DE7qqKbf04dUJ9rcDVZ9tnHzdOcZDdKzhvvhr3bYpbVUKpkxt2w3+MEi421379XEmuR8qNEw2vv/ES+1wLOa9SA4DKa6fu1TOZUUx2BVnnfZ+W8j9ixGfLE7x3OeFHP/5jhDLhiy8/xcPxAXe3L/HxL/4KP/6Tf4p3rglf5evKd07nfk5JO734xANyGrbkdJBSweuXX+Ov/vzP8fLjj5GKeuO9p6saKwokJTUKckRkrkWbkuWBD8YTtGiYYD4ecX9zhyEwOLrBVFfajXVEZKX6GZkEsy70el8EQMmIMWJgMzQGa7NjZO19JrvJ6p7BFDnznhfWPHERVO8SSGX7/rhgWTK25lkkyViOsxmlzFhGBBI1FLd0lQB0ecoBXDEfd2e0csqgdKHFwGI1tq/zrLgawHWd9NwkmpFRcCEjgAiIIJJguLzEMI4YYgSR4iIwuf5q+6j3I4a2Y7Lztuqv5mHRDIgodiMBai44NUpCB8y1yA21KLl2ABVj6btVkauqhPcirC1iqljpLveBqQkoQMXMcc7YHw64vbvDcpyRDgcsKamyNi9IKVmF3rCKuJLKZ2yoLhdMto+GPF1VFPHWS44bHY8b/8ouW1TWgj0Uu+VJxiDGp/vnNyN3JVsiMwZbzVhq57V9zNQjYXhWMUz5JsOiJNRFcDgPdEODefB7/ouMWmZOgL6Sb+0f7EDUbptFo+pqSkwnU76twgZ8R5Q2ty6lrFb2WvrQTo43cUxZrQCRpMYpc1sTqJsZ8Pwa7xWm4QHaj8QBZyjawDWQKitJDCh6ZcJckHIGcwESIQXGELW89f1xwWC9pXLOmOcFS07YjCOmwRrpsqlXRtwKQbA6Yc3aBDv8Zm3Wd9uH0AvrzgtpHFhEkARahc+0/3kuWFI2pQmre3nyuAA1wR0m1IspckHD0a2sfQtzJDupgYGSCh7uDri/+xwhBkybEeM0YJk9FMLXMneHToFkFg/sozodIh1PzkkPNLfD6GFDmq0mOk0QsuVxBDIB6IDcGawpqa6wkCXtsykWSkCsFi0QhhCU8ZL1sAkRYPVwUGnhEgMRME2QoMpvEEFOqVqYiIBl/4AXy4zLi0sMmxEUAmIWHEXDUKMxjRgDcjb7i4XRKIxV2ohE2sdMpCrdADDAGZj3QRPktCCOkzFFFZaBK2kBfk/Wgj+q7LkSIyagmgUJphDAjA21V41ddZfF7me/O0Csg7WKlMkYFYuAi4CCh5c6QNL5SF5Q8nIWkK5ecvdANTWaoKzlqgUlZxzKA7a0A4cB7ikhIjx9+jbefvYEm6FjhXFCjhd45513QGHQ4jNzquC/WEnr43JAkqS0mDNyTsgpKx9LGVISNnLQNbezKSwgy4mVUqyKma8k1fUSaeeSoGHdyEAYB+Tle5j3f4jLq1+AeVCjCBF+/vk/x+a9K1xvpFrye+j9bQG+fhjGSpoQfNPHpmnCZrMFyhFFBNvdDpvN0BSmnGpKYDUXdCxeLbOszkZL8m5NpAuODw9AGCBlPquA9crUaWhhry01z2Cn+EmbW/NUt59nPTMnqoy84fc3fWb1+u9ZX6AZd0qvBPvwv+1+9s8TsdYv3RsmE1xHP40qPV1SwOJKDPm4TOmv4K/RY0U71FKwWClrzuP6+T7kAb/MEc/igD/8aQAo4/MvP8VhDri5u8fPf/F3+IOfRMSLHTKN9b4aRrcOuzy9Vt7UR8p7P1t7jQk3d7f4m3/9v+Gr3/wcEjTHaJoGqy5YzFOuOdAhNM8NEZBKwXFJ2I6N3/SPcXDIFqUgEGvrgxqO2E9FXKkoYgqVRmF4OfcQ2IqHoPJpIcv5dpkeWA2z3GsAZvA1zz5BYZkUQSoF+72Gh49TxLSd1BBKQBxirfJYclbepA9Wxd75NBkoNp6vZNnmxuRywegRLuXqxkCbYbd1c9omZOQkKDJrqXkQSlQ5GmPEdrfTs80BFKkuPkFTEFzBYtsHqTnpYpEbpdJKMcWuKiqVhtb895T8HodIrqhB9+sMb6jf640kzg+611pCjo759c0D7h/uMT/scVxmpFl7lqak3rW8pPY8aQkTrjDVu4pGNEmdPJC6aKPVGarj99W1eWlVkqqccsdzFf8yqtfLDAUErKp3uhIItPzS9shePvjeNvkAIq/rXvGsVOOE8ysYJrZqrwMQwwCIOjbE9txj/3oZxE7nhhXZcHoWLTjkuN8/fypPft/13VDaSkFZFkjwEENgJdWLlqaXAkh2V3H7yNnLBUVP+GwlygXgaYQUy1UpRWN8lwXLkrAkj+vTxYzM2I6xMrci6pqNPohckMqMuRRIGQBWspvGAWQNBQGYogWsz52XekXHuNvZl+7zfolj25NLCYBRs6yIq8VGgBpy0X+1WmD1BrXaj1vkekWz4nmo8hqifj6VgrwsuJ8XHAeNnQ6kAiWLOqa5gkCdZ+ielwoQRKzfWGOGRYzRiyBrKxDTGtoiSc4oSZUBQBUt9+ixgeuUM6JEJPu8iBl72DyVwpgpI6YEsURfAFhCQKBi80vWq0XAKVu1oGK0UKwVRdCebZbjF5iBnLA83KKkAZILUhEcZ0GKEdOoHgcUzXXKpWhxE2hVzFw0rJdzBiBYUkEMgDeb9PCAItAmzRkarhJmXKSEq6sdSslIVjAlBDbmJ0hZ5zIQUAoZXWtFTHU/K0MrArXUGijw8stkjJFMWCiY5qrcV6uY5Tp40rwansw7Dmk0KpqwH4Mq0CWp9a8vYtLovGNyOvkGDk/zmOz+aV6Qyz22m8va2D4MEeNuwvfefQ/X2x3o+gOAI2jYQrZP6y08DKJYNdlSCnLJGFMriyywPky54JgTaBGMnLELCcWMTSkvmPOMS+wRylG9/ZYTC2Qsx4Cv5wm5JByXAy7LCywpa96mr/d8BBGwm+6wGe4NlABxGCrNrSpunYTH/r4wwUcKj332PIAgzLTBV/GP8eTJHY7zc1BewIUgZGUPClAY8CbbpJ0gAdA6tJibdRmkhroigvu7W9ze3OPqyVvYbHbV0+YKVk8aj5UpecQn1yGyZ+bfAbhvA/T/oy6xsb3x7RYi7X/3z63f7XFhN7bzhg6lYfdkUAeAKtjtlK+a6ySPUsMqSG2K72oA69dOFLa6b93fK+W4+2xfpIVAeJE2KBH46EcfoXDCl59/jSURDjev8Pp3H+N7PxjxMH0PCcGa9mbNZ2d6tFQe7r1+Xmedpw5m+HxByDnh7vUNyjLjagq4iwN2g3r3ShEz3GgEBoWoBjdfMxKIFGy3A7bbLXLKiJGt6q/m4w9RW1yEQBbyRQAXDd32vmZW/o9DQMiioNOU3wxBCIMiAdX+zDhqBdIMCxNFFFZPDhGBo5b/pyIWzgnN5enAs/a6LVjmDBLB9ZMLXFxuISmjLAsWgbYzKUUxjRciASw8UJSflwQmxjAEFA6IQY3ETV8s5ozR9RFopE2pyboWzunubSlgElMACpIIGAUUtAJzShkyDQCs8rX1+Gu+9p7A23zV89bXdNQoEA6k0Vv2mlhuttPQ+csVAXQAzhWh/nPSKUrSDe0cv+h5mam2K51Rz3I6HHB/OGA+zFjmWSPMUlb8kkuN1HDFXtvsGIqsScmtAbuO0c9EU6J65bQz8cNV7lq9PBXFxaTKWzQDjt+JA2OIXYVG9DKo41n1sSenWwCv0O5roPi2KL1LVsWQyQTnX1kAACAASURBVPZUJ8a23kQMBDX4BNJq7sSK69ch0xZZYXxEc0A1tYhIlVOBwikOZoi0KfQ8VSDqNQLcEnZmr9v1nVDaOCbg+neg8n2IXGLd16JdJrqacgMFcGLVg4hCFTj+DTErvJgiVhk4s5bgtAICIRcMw4D5eMQ8zwr+Fq+qCNXOi+nUwfp2Sz8qC5GbZyt4ocRSiBEjYxxjHXszOHWWI1HrO5jM6uRjbRt4Vlmzv4tYPLCtSY0zhlYZ8zWpzZB75c2Ft5/KHqxBvW8Q0Zh3Zi01bEnQ2peaNO9EWjx7sDh6H7IzIgJqb5lwatkEoCEGLTdQBaYXOOlAmH03VDpY36lWcWK7F3l4i6417FmNI7cwS4+FZ269ZBaL1azJ5GJCAhpOoAnOQBgGMAeUpBUoAQ2t5JSx5IIlCYowypIxbbcYtyPm/R3y8QjnigXkhS2tSqF7bS3nz/eQvQWBh6KqYlVSwd3NHdKyYNpsFADD6iCRIINU2dTYNHh2kaaeUUvYbqSve2/MpFhoB9n+rEIXbD9WoWi0Vh38OyEESDBLKExJlYQ4DJBSkJYFYYjqiRcB5dwqevZXJzckG7NmAhUgRMZmmnC/LDjuDwZcLxBCRAhjnQee/AC4fh9uIenFQHBQSYwTHejRMATALAlj7c+oAkRg4RFSMFIGS8ZUsuaAlASRguUooKR8ZF72yPcv8Ku//ltc0AHPhhkegsEMHJYF22VWpVSAr159iBv+EE/HYcX03wTi3+SNWk3ccQM30Hr62VlG/C6/j//i2du4vbvBw11GzosCSbFCFiWjlKYsCtDyN6DAp1jijpihZskZ+4cZx/0Bwzji6Sbi7befgRKfWFzXc/qm3Ls3ztfnik5hOqExMkBy+tTHvOebX/dnnI7Rx+meFfWMn89tOx1X/5lvUsb7d7wHmY+1FWItLcfM+KfTXcOPndnELYy9pbF7fVU0xuRvP3b9/zeDlH6NXucNML6Hjz4CkAd8/uVnuD8e8PyLLxHHLd77g4Bp2uLX+w0Oy4InO0boDHFOI/v9HpvNpr7WlMZujeAQXvlyhhYmuz/scfX0HQzL+3iLJ8zlCCkZh/0DXry8tcJmGiLlcligLSviwNhd7JDM+JOKGcpIK1GWXJBYUDJMaVOekVK23q7Z/isWQq75vnU/K/4hlMBASubZMCohAIcZEmNV9GIp2reUVH5wsSiXlCtxJAH2hyOWeQExYbfb4ur6EiSCGRnJvIFUxAxk2hIJIYCyhvaTyQGVNWbkWgrAAzgvAAYF05ZDXwpp9AqprAvwKBNTVDt1ClAPh4SIzQQ8HGfcvXoFYsLl7kJzZK3IBFu+bRVRVVQJuswrQIK1L2l0LKKG1JK0uriFgdm587C7xkTbcxTHnJzCzhjWzlmj+yY7zp2FUw4jpnR03EBXphSU4wHLnDAfj1jmpJFDEGv/ZOsNN5Awlpqr1+bSQkdlNY82vzbfvoufOmsFMCO0mBwErOn8ykOh+5RyxuA1KaossrVi5+uEGnnWCy5XWF0iV7EltsNqvNbgJjXkA4pzJasSLmRGAmIQhaqUgxkIakgoWb3qxbzPsW5fNoWTECAonRW1wLGAQgm2eZ0UPv7G6zuhtIEEYVoQkrhJBmf5eCmgnFVTr5q41Ka2bnFa3Tpo3DCtzc/toNrrHFUJGbHBMKilKoYjDvOCpWTc7WfsNhsECIYxoqSMglhL93qYWrEy5xQC9sejNmmWgNt5QeCAzaS9MgCAeoIjVIVN31u/5fRXraLdZ0s3aYHqguRM1wpJ6D1dgWvWi/q94tZVdkmlAi7lVkSkuKKi1hiwNvsObCF8wkhcVr5SBwQny1/5Qa1cuXpD/2Xqk03PICZoz7ZApL1OeobmBUPsbiw9OKD2L7fvEXkPGqoWFbKwNgKBoV4wka6HDzMQtOF4iAHJrKcZESQFxWLtNUyhqNereBuLjBgHDE+uwQ8P2N89WL5P3TCQ5fkUW48ay25ro4CiEU0koAQNTTo8HLDfH7VHoS3qm4w4rq/7EpecLWzUvKseJuN0IaosouRH9wHalgoxSLJW/TSDSbEQ1WVesNmMUCaHZlARXfF5TtgEZZoAupy2teDy0Pg2hmJ/qyFnu92AIHj16gb3d/dIacb11VNAtjrQy++DOoVtNZ/zy3V+De3n1DJ5dE1t/G6KEgDJT5vAYLcg7LRRvZgn7+72Cvyr3+H18QG32YU+8O7uc/zonc81V5KBVw9v4+++/O/w/odPNaS3rgOtfq4UlE4ekxl13OtR/SzdZ4MVMlJQ0INz4NP5A7wT/xN89CHj/vVLfP75DV7e7JvxyR6HkjplYQ0I+vUCzCCBCELBZjfg6Yc/wp+m/3FlJDhd/LMKS6d0rh55urHOj9604342pM3fA6n6r1TvVf9V6kDzmet03GowKY/25NFn5WQvfs+1UmI7JUtg5/qEQXgoudiY2udFrWVlbbA5ZS4V6Po8urmc866dVcTb4O0zwE2egOl7+MEPC+blAct8wJKO+OJ3n2AaGN9/9x1cPiR8fbxCAOHyYgcE9dyJaM+0Fy+f4/r6KUJkbDdbBFbzH5/ylm5zGYSL3Q4/+cmPkD/6EPnzn6Ec7wAISjri/v4Of/3//SW++uprjQAppeZSO74PYcRSBFMccJiX2uNJ+35q49+haGakpyUAljYQtMKgCGlE0Jyr4dgrGidRoCgEIGuLjCyk1Wp9VtarjQiQwFgA8xbpHhMBeclV9hUQ0jxjfjhAiHCxu8Tm+gpLEQQBxHKGUtEKrwmo3hsQAcELhFRqA8S86RBIEkj0FdcIEiICBTUsimhES0bBIL4vlRIBEHIJCFH39tXNPY6He4zjhItpwDhNVuCuyc6VsaSntJXhQZWTUsSchmZYtHFnEeXXlQk85h1kfKnJxcd5Wfp6Z0QhAhfN3Fg6LPYffwmIA5gL4jCg5IKcSm3RIEW0v52PEYDWGNAPtPE6D+q9bo/ni0791RoUVM3wXqisFA0zrOkWPXsWoBR9hrY16fEhagGX+nrFj3Iy3nNXw78EaDSYG8sF3Zkz4K16m8LECmL1ZzbHQPGzWlcPAAqCWC0EoBr5pRtHmxedI503Xt8NpU20NG5KGeNKX6M1GkM/6RZ/DzvYVVO3uG+xqml131f82ImU2nsEhIGt0pG6wOOwoOQEh1YhBow54pj22rurlFoUQsvettLyOWcEYoQQNKxgmbEZY8MNBWoFs+IpcnIKOoPNGlS4vO0ADmz+DRQRYOWKq0fQhWT3gJrTVr8llsumi6Y9l1pxFhAsJp4sVyoiJ2tmyW3AnoROgLnaO8IUqfsag3mAWENBijTvWd1v0WIU0V2JPTHUUDgBlebq1nGShoT6s1d5PrYSRazSYVvUvucSAWAEA/QeUoNqAWOOoDhA5gNKKRgGA83WvKvuRj2YAqYFUhj7+z0CA+N2h2G8AF1HyM0eJR3hzAeiDcCdhNmAbfVAVjSp0/YEYmbCGANSzlqQhAitWt8JnVnvY2lLaTmjniunwt0LDmgp8KIVLB3IidJK6WjJP+d9owAtIKSeMLZE/FawR5swt3HNhz2GQfMO+zy0/pjQikUojUuhWtRH+UHEZrvDdl5wePEKh4cC5ltstmppF9KQzPNi9x93uSA4vXpd6fQLPTAkKKgCAeM44u233sWru1vkNKMsR1AAvnr4AX7+5T/HP3n/LzBlwc3xXWTeWRhHazbcK2WrB6ApavoSrcZRz0vHN92K++h+AIQC/vzwTxG2gh/9yQESAuLwHPd3RxQhRC5I5YyLklDjRBiAOudZ82PHAdvdJXgYEK9/gL9+8j8j09TGslowV6Aev+6Lv5pvD9ikvXZaiKL/rN9u5dWqoOHx1E6v36ewef5W3zpAn+veljc869vrbPV5zfDXeZXl8dr4a+556/OFPScFaMpZG1Kn7JDlqHQK2psU4155W4VUdlP1129kh/euvo8PPzrgcJjx+tULzIeMX338G7z8+ktstwHfu/wBXh6AzWZaNcqeU0Le3+CT/QG7iy2eXRU8ubq2HKumDpxCBpCWpr+eriCToFz9V/q5+R75q59hHL/G1cUlXr98bV51sVB257uCLAXjMGrfLPJIlX7dLfWiUyzqfQxwllIs34qsR2eDCAFS5ZdVOEM18hYBBbY8NcUFJWu5ebbKM+zthpg1h65oSCCKgELEOI2YthNKKRgjg+OAbJEXkbU9k3qNXDHUSAChtrJKUz5nm6cZVpQPRwAZan2mCvmbwr/eFAEBsuD+YY/bmztQKbi6uMA4bTAE5SegFgXyJvoiQq3Oqz1BBTywFgDLpYZmr47cSmgq/1pfa3nl+6k/dX16JcN/ZlLDnhqOQ82X7D3kp/d705UtoiZErXheUsayeLVOzYHMaB495r6YTzsFp4pn/3sbg+5p88qR4iuyYmfU4Rf4nhBAnYyvIfCej+kY1oQSrZVcx1U6jtOx+gc6XCLZ9olqJfJznnaCyQXE1XzFvIUksKiw3LCvuFuDTdlXw32ywdQzUPWPf/z1nVDaigjysnTa+3kizCAt126AspKJxo45V19/6RSnn14d4NVQSlQGx6yJq4i6TBzU2jxExrIEHOdZizoMAYek1iwPcYkEHEUs0XMAseZHrQCDKWz98NpZkTafRqsVZjF7Un83VeqS1hHA1MroNouPEqjninmoUa3saJ7O0xAe728CE0ba8BgAWXEMGxsFrtWdvMcPRD2PgFoEq5ApQIwjtlMECDgsfWArjGE7oCxtkqUlKCtINyDCQKvaVBHmGsydXFXxJ5h1mxAQTZkwwWLJo4U8dFX/bon4ln8hpSrtS9FeOWQatoiLHb8K8rLHzcsDpuOM3eU1hnHC1dMB8+FeizesCEJXxY+9Cm6yvD/Uda5V30xIxqACS1NBzWtoDNPJDFAh6vkO2a3qpGfTy+C7FSoVW4/SQpE9x86NBKpAtnWvyp0Sovp/a9UotSwHE1AlLQCAtCxIOauXx3LX+lw+fa7vsy4CeSNYB6RMoBjARXNMXXgf90fc3x/wjtMB/v8rbOeuHvgRUMODqAMhDeRK3TsGYxxHfPCD9/Du8R3ksuDh8ICUZrx69RqfvPwpfrj9Eu/kW9y++kgdvsEsoJ3RAcBZZQRoCgGtFH+q76GOaA2oe09JDxj+/f6f4T/bDrj68Q/xg/f/FstRK8QFAkJJSDy0ZxNrie3QxkaKRA0wBnyS/gjjMOJT/BRFri2k2weKFU9/0+ur+Z5RpntjgM/v3Ge/rW50Cgj7e/b3bh659Z1LD0ZEw2nq/c4M4putyuevyld6Y52HnHbK3GNZSvWz33h12Q2tcXLbmpUB79z4Tj7/pjnsZcSzd97H+3cHyLzg5d0NcGTclTsEusJ7zxJyyFWp9+uKF8ThDr+5EWD4PnLKZ5/BJ4OsZ5b6cREwXoCf/QThcMBmHDBME0padG9qbhc0ZNvD7kkBs0jjl+286p1VN6YmfwGt+pey5uUytBsKGl91/gZR/ip2P7HwY1/fqryThw3WIaqi5R/vcEMNSiHCFAKIg1YcTMmKjOjnSTSPVciqMTtdkQ9E567OErZiDejeNzjv7YC8OBepnMiOY3wLSsLd3R0OD/eYhhGb7QZDDNqTzOjPVhYVb1XvTMfpxIpddHsuWUM8H1XmwSmuoDMK2/nz2YdErsbSPmEyLGghG9Z55LQAKG/kUetntOPLnu5BAgSTE4Fh2jQAaf3kBI+L3XReNrxRCe0lnefOPl6z+h3qjPzU3qse+6DYxeW537c+Z7X0HTLu9AfPsyfux6br3s9IF0kNxl5YpuoiROBIiOTGeHNgQMv3n6jwtqdZ14lZywOwwZPOKFRxdJcjZ6v7jXgV+I4obQRoHCmr4sTRF7mLw4aBTheuuZj7vdemT+7r77Xb6evmPugMYA2MG+dxJc6JqAdCagmesCyzMhNmzOkAt4iWzBoyGAIg2sOMYkTw+qx1qK5gtDFrnxR9T3GoP9cBnX2znaHzwq0KTa2I5EwJQHXlimn+q3CBzuOlzL7rz8UMBqtrvRSwOkHq43yZowl1VdocDnfx21BwcjjMiOOEeDkgxIAwJPOOtjYPIFdAzntcuTvSnuTpZ5iLQMKJZdf2UxVH/g/UvVmTJcl1JvYdd4+4S2ZWb9ULCgQJgENiaBppRlzmTTLJZNJf0F/Tw/wGPci0mYkmyWSSaSRwSGGIoYYEiKW70d1odHVVLneJCHc/ejjnuHvEvZmV1Q3KegLoysx7Izx8Ped8Z5U4gUZQPWftJLZ5EKKfc7XyEiQIWjRzKEW8vfdAcmXOTdMYNDU61HLJzDjudkjThM3FBVbbC6y2G4y7vS5WLvuSYASyCpikHWRlek4JjYEumRPrhJYMAGPVETxVBmBAWoB7mglsc0ssUI9NfXbmYqd7MpU5W+5RBWiz4G3Zdy5IzR7ScQ/DiE23EgvfGS1jbXIudFfaqADbe4R+BXJyDruuA7sA76u7RPPY/a95xH3nvrPxP0SOyxrrPHZdh2fPnsmSsCQ5GKcJv/zol+CU8Yvrf4YPLn6IHLZYu5VkUIVajB6SeJurZNe7h1ksBYOlm/KS4fz18Y+wwvfx/pPvl2QPDoDnhOhCERZranezKHPZQ3KqPD4a328mfN43R24GcGaWNHOHPMEc87621wmIKkIkz87CUit+dn4W95V3KNi1ObB1Lver0nAuNZ4T6r7aZaCs6ewcuBVJ5fz1kJB4MrdUAVuhwC0Ztj4t/m4/O3effUYg3MYeE23x/gcf4Hg8YvfxiGnYIyWPuynicJxwud0jFg8J2btvdyM+zhlP8gHX0zTzDmithPdZBGfj1DXk9Rug1RNwF7BebzDu70rRbAMFABUrRrUmUPkO1IgH6lJpcoi4wmdMw1Gs6cbPuVoEiUiEwMzKx8h0WdID5ecmE5nAyGgTaKj1o6HpAEqiCuecpsln7PYHvHG1lXI/CtwEqLYt6bstu2UzTrsnc80QLTyMJZufut6bdwlyEm6v8RbSbyATEIhxdXmJvu8UrIkAXeqI2hoQney1c6dLFESqVCIAC/kj8zKu6/xeaUH5q+61GRGrWAdyAY4kuQsAxDjdQ9Ir0ZiFvDDq+dM9Z/HZjkjqvJK5xNpMcLW03dPN2VkvdO5Ubqq4mApwLncVer6YH5LPvHcIQSxnplSobXJRMBg1ADe020BBEd6KMDzruwMUeNGczpbxiJVXCmtLCA4rICWg5LicXZyhafZUjs9AlnOTyBTdzVCXjz+CaX8jQBtDBpORVYtVJ01XQ39tNGItsQPmKIaN4DUCXDMXrOj3pBOgxQZS4u2ae9SM2/eduneJ1WPLvcYrCWFJmSWWyHlMMcLFjNAt+rzgSFIlXolkVi2dshHOkup4RnAakGJCN0PiT7zLGKfqKkGgmnabudb7QCWWksRC7vZN8HJ1qZHjQmBJK4y5kOxQXWgASQKRtIxDex+BkFPCNB4wDCM4jbh88wn6rpMg6yT13tAwtaVy13RmrWxGBHERU0Zk9W9mB6EAR7bJKJM4A0QaI1c0Qnr+i3VNQajtMypaVCnI7TzV4qQ6/85J/TcXvICxaSqC1DQMSNOEcThifXk5A0RQupNZbWVsm0cFYCqsVkAVoyTMKMQ36VpmxrjbY5omwAGbVS/zq7ww20Q2VLQkINF90jmaCTrnGJIIHq4IE3OCTYBzGkfSAEb9LKsriHMkcW8ssQThJI1dWdTS16LksH2iE8KqXOl6D8dA6DsEYsSUAY7nGv3/7WpJ/0xoJLXuQ9hA7wNCCHhyeYX83lNM6Sn+cvgdjOst3r5Y46133kHf95Ux2Zls2Rk1gtzDMun9/X1IeAdhxBofTd85/TI140uVdtzX3kzQf4iX2XD1DFsMrlt4DFj/7F4DfS1gXYJXkRHuEZWaflthZmHqp4lSTPEycx1svpu/EGe/n3lpfFUgtwSiDwqQ9zVR+cbpl40igKqnRPP18nb9ORel52fCTvbp/O1zj/dXKzz79gfY727xm88npDRhOuxxc32NN0IHuNi0xfhk3GDYZ/xi12PtRiTzkKHHA7baf6WNqOrJmFmsM5xq8WBU63QFsnPxrUg8JY57TjNdCFitulJkPqfcnA8FakllKCZRvqlFhZzEh5GeDxE6UWLP7F2sPFEUH9YBKoYmAnAcB0zDhDhFvPPuO8hR3unYAj1I+BskDrxa1wBJFpdVzqYiV1d6rV5EusfkeUK/WmG16pFSlFlTF07WuVlvNqqsolmiota7qN1Pdf0w+9zuzwXIzPkJcgUQhbeTuOObkHKqyMEjL4euD4ALktyMJFlX3zvEKQmPbvp/nwXv7FXmwGvIi8krsleSBOqVPVompDZQlQhcE66YlW1pNdRPURuqm3mKERkeoZu7ILdumVJTWD1sVJnVOiFUmQSq4Jc+GKizfavQXr5vgLbszcVVBBGSZCMOcMHD+yDym86/2Ios5njRRAsWWOkAGkV36RrNN9FrXN8I0Aa0jAkibTfJFUxyZc3WUivJSzpxQLdFzshmxqQzmPXc4WlusgLAdjPRmXuSFvHTvJ7kxJWpU//yxFIkMyUpbmkujAkZzq3mB7p5l8ChRlhwQvhsYYmS3aaxcPKnZBC0OTQ3NCpJH8pGpGaegOLikrMBODs0KMGh3ommoQZnKgjUkgfOtxkF6zEtFhbtu/RJg5qzAQ2Co4wpZdzd7HB3c4v1xQbby62kfeegta64zeh+4qbAQAn4lqlsJYR5+nMww/wHHauvt6gP9TkqTEAcRHxp0lEtiupKgWaN1crQOm8Z5DoQmRW4KTZN9ZwSZ/g+oOs9xmFEnBK8E2Y1DQM4TujX6yKsMAyYmb3R3GWEoHEG2M+8kuo9ORVCZMUsmRjjMOLw2YS33n0DmKoyxJFYSGvqWQu+nhPYImDY8bznah2PnGUfVYImtVIagcUaNQ198MhTdYsl70ump7qk8nJPkhhorojQlp0kaJmI0AUPYilQa/14Hfn3dUXcliwvSbQNN88+q6DBNXNjv3Qu4Dvf/g6evf8MAHAYpJD4qu/Q972ksaF6zg3Kz45BIwwuSNBv7brXctf0pHXbtL1kiqKT51RAaJyZGpftKiiZkmLm3r1YtaULaHsVaxh41u7ZMTZ7rbVYnrTZKI7a/tt3+sErr/uEsse4SLaujwxIvUBe7oxmXGf2w/Id5+6bATai5uv7YdDJ+pz83f7bCt+yVn973eMHb1zgW+9/Gzc3e+z3L5GmiNvra/SbC4TSA7kmdvjZ4RJEA47HI4J3D67zYy4HQs5ibRqGQ/nMWAwBmtaeyqAsNrycUnKacbjuCVYwRsGXzLnEwOFwFIuazYideeVvrJmoLUsdJ5FEMokXEDNXeYfV5ZwURBmjKnxcrHwgUU6kwxHTmOCCxNC64OFJEjqQ7XURB1D0lhYzTtVCYvJJO/OZWcNQ5A6/WmGz6nH15InKVVEyQVZmAQIjdD3Mc0j4bm31VWvLQI0VowrbRVnOKgsApmwEGJYd8LSlV++jE1dsJ+WkvAtgIoSug/cOoA7eReyPI6ZhhzTV0i+PfYddZr00QYo0VwEU6Ft8pAqVZbjzNs+PcQ7YToHu/AkGOOl2oJnSva6Zh3cdGB7gWMENtY3JH8WZ9SwNbARjMkW+jDs0TJVMyZ507xJEQc+WDMWDgkPU9mOScbqsMuQZoCHlQyQWslqrgyrT5XxlTeL3utc3A7QxUGJTZNfgxPcYGVJ4tdkYbIoPB6IMLokMuC6uyNZy+3JyFxJVwYfnpCujow06bl2FssZiBNXUIEcwA+MU0XmHmLKkLtfA3qLxLgehmQuIYI+ikVMNLgOZuBTuNv1hNWI1WkiSei8gAoKJf3JjSlKXzrEeFO9K6lJq3MxSqqZgSzKR2d6kwn22OC6Zi6R1TZgzcpSsT+b+RmWOubpCOHV1Sozj3R7D7oB+1WG1WQveXBD1ZpqadVuw+eaPrPNGREIImYGUS00XmRDxUSZi1JlyWtPDlxSvICqZggqm0bs9TKMnKYUpkWw8yoXeAAJcUqJiIVutejiXkJOUCMgpIyXGMv2vjdni12bFlxsN8T2zBOOi8qysie8Yt89flPptQEO4Lb4TAua9awByyQp3vyBpk2OszTRbknTUoQ9+DqitvZzUxdOBvNRFsmKmKaUzo5QJSeyKRVwEVDGnMwDD396RuJyAZ1q9c+z3H+pqGVkrzN4HMk4sRST+9aEXhcKq7x98Tzsua2mZNsL+PQe07gNfD10PgaLTfi5AKhHSmb1fe1tpb055to6tReoxFpOlAq0Aqa+IXpfukicgR8dqXguvamvZ1/vO2utY3YrlgQlMy0RGFVDYz/LeJYA1Nqj0op3nE0sDaBYfds7auASzy+/uWxMG4zdfPse3N5d4+sFT3Oxe4OMP9xiGAdM0YTwe8QQTJhYaD6iL32WP6S5ifXEB33eFz953LfvQ/m2CXgg9CEGACAGAgzOX9EYDbMDIYofsu+12i3feeQdffPGbBrfp2dDHMzOmGDGMEevOlV6zyhPtDDLXkjwC/lD4lI0CnpCmiHGY4Fcd+lDSOKrFSmi3JZPqQsBmvYJzR4yqQJXxOVEsw0AfAM4iqGqtNiIHUpskgzThEp0QX4bEwU5E2FxcYdUH7Hc77Pc7rPtO1otMqb7wIgBmf8/aJbV+NvRiycPKd0CzI5fqUAnLSEzKk6vxYHnNFDuorqOs8wvyUvDWefguIATL2sgYxj2GwxEvbq9BU8TFdotV58++x97VhjsAc3pkSkxnxgYF6tn2IDV7rQHFKDMye9tsX5/SumZlmhAJB0Lwnbi/ljW026j8JL9CFcqpjoXq2EqjqOs1I+mVycJOrMmu1lCr7DNArEcXcKZolhZcCMgxwnuHRA7ZiSXYrGiOaokwS1BSeIILMrGx4b4Nlnid65sB2qBCaDbj7xw5MSvRlxNWH9JFXAYD1kaBssrLvVcWt25Wkmc63gAAIABJREFUAObiO7uHLUUTaXVzR4vnlHSymGC9ZsXjzFiHgJwYY4zgnCSwVdMLM7UvmqPEamzk8p5ckq3oD5uSlmFqOzkTfCexVSVRCDMAqQcn1qs2m6AyEMdSH4YF8CwJ2oyxNZveXDo8iUsh62dUiMg8/kRcGDNcJgQvg83skFLCeBwwHEe44BHu0SrZ0lriAsv9t4QKmvJCCbQSgcLg6lUKe+uZCk4kfQtaNfO4a1IHwyyQhkaBCshLqYDaV+cIaRJLMTRBCBEQ+oBpWMTsGbBt+pkzY0wSF+eDB08TxGKFhnhxYbQn8V02M4RStiGDkLKk9zdwWYLauckaCrPksWYLmx/FatlSgZrnrI6IZolcjGEzACapsSNgFgWkEVEpj2HDkFXxYB5PaIFl45o9wI0bBAOAB0hcWSyx0LmMXP+Q1zlq9RjL1P3t3Qfa6/cAGoXEqeVHpooLg4QBjNcFbDNa1PYBZz9vT61dbQ3Jc/THxuv82aiCr3S1Cjjp7+M02idt3PMZobpjtpfNsVtA6ZP7XsccfE/fTsQuPnXnooXwOQOYtBgj1X1bXf7mgti5cTmcZshc/s6Fq9HJ5+2VOCNmwufHgD98y+GDD76FLz7/EsMo9cyGwwFP4kt87t8oSW9WfY+LzQoxMTZX24am134sz8e56+TMsiVPSKKQKrxBlcuqPRaAU6SGM+2ihi8YLVbN/G5/xDgM6rKlPXZm4ZJRWB1NB1Tlm7Wj1jcT8OOUcDwMQGZ0q1MFEFONrc/CxOC7DjRFuClqfxuFmrabMgFUswk75XW1OlEtVFyShRSgIEp7sf5k3Nxc43C3k5JJ634mmbcKYHn9Ayv2gDKobdNicQFVYi9iaYocUZwV1fOoWOHaJq1frriMknMgJzVKg/cgR+i7gBAcYmIMhwGHwx63hz2mwx7TkOC8w3q1lhS7D1wVRJ35zv4hlLVCM+8Owvsd1cRypwKzfVrjc9uZsfsqSyVx022SG5FzIB9AuSZbkyRU2hdLk69nyOgLc+1VOVsmt7a9aJR3tXtc7sXs87r0ZSxO6Zh38J1YQYOTer3U95JUj/Ynsje3XmCKGGdRrYYjHrgsX8JD1zcDtBEgSFr+ZC0FbBa0JpAHb7/9Np5fv8QUR9gicGMVMNrUtmvFoc2lEWjObyMVFwyjveCksUqym0Xg1PgmS4s7ex+gCy5AU54lOMfwjpEhCTe09RmLKH8QCtApckRBcK0EXwV6Yx3WYgpqTUsTslcQCQFqpJYwMYxRYQaVQcqYnG7cEs/WLhYnSLV4c6eUeyTjFMHDLHhSWwW2V7mukwAZVxg/SFK7uuCRs9OivLn4BNfXNxPO0PTFBPRUvnZUU7mKA0oj1J7gZEEwjkh9/SVDZswOIRjzrgTL3EoINSOivZeUICtymxO15ry293olBnkSt8FSm05pEruaakViEQljBC6eXMGvBoy7A3xusoQCp4e+7BPTJhnNo2I1y0AhNMUFVZUTosUVhm9isikNSM9eAoowAsjntYgpab/kS6+MSt4hW1tc1xOISxJenSurR9ewc8t+Y2tTBgSwFX7X4u8tIWVy8M7iOcR11Ls2tum3f72OqH2/uLFknO03c8DWCpItwHl0H5Szm6ICWDLB09/tb+vhnFq0/ZFrKbRjcX8ZWXOLM5VB84ITa81Mq/xql8GTdzda47btzPlsBs5Xtf9oN6ZHdPO3Ec92FlSesRCcAKRCr+hkbqz/Atb0nBduQufbw0N7/eHvZxau0hfGMOyx2yU47/H0vXfw8vYOyBN2ux0+/OQT/O7vv4lf5ycAAEdeM/M5bLugPEJBTE7iWXAiqN8/5wbIRaE1SYmfHJVGVr5k9F0ER3dCp438UhZvGiFtTpN4ZIxjRJwiVsFrsWhU+UctaRKPVmO6cja5R8eo8gUzY5gihsOIzBmXl5sSow/V3aj4VDmggSpyErdZtXQAs2T2LpQ6q1uFA5LWZyQbZGlQ51Y/51raIDMhpoS73Q2m4wGrrsPFpkcfQnGjOwfY5vOpoRjmGcIW3jCnYwY0i7LI2jdVsIWq8HmvH1fFyvbtOtQMqzMayaHrBHR67+FCQN8JYHWOMIwRv3n+AuN+j2kYMI4TpmlCjIyuC1i6Hz50VTHJeKRYOYF57JiBNkdaWkgEKGuljMWWSB6p5+70snE3EZst7bLPijOd9aO24D1h1Xl4B4ysbsZFfuTmtbY5m/bb4MsyEdVrj0FSBUMbKXKLyWqKAJ0ToLZZrXGxkZIhRISUEvIwIcdRe9C8W7USUsdOUv93qiRRgbH0w7pWzgBzxaGvuL4ZoA1qwWAjxACK3kgu88nvug7eeUwQITvJlyKItcXvyKwcArrY4mE1CLbVyM80Zu2PAuG1vTLJrAJhDT6t90GAhP5NSv2o6woLk7pZDMoqjDvoZ4A4MDSWDGWY5Q/UTSjNNcBRXUB8lP7HCBAyQhfgfCejjAlWWw7Mpe6WCfG2ecSFToVmnf+UsvRNBWIEqoxCx82Qsgyka2rTYgGvZr2p2eOEyTiWcUs/GM5xEdZtKco8L2gFQ+rfOLVESoTbZBtLLDxlulRgNLBnQNJJliD9U4NbzSKomiADp1n2WqmZppog01A5sww3fTbrlaTalRpi3jkEBfGTm4rFp+5FASwpSaFT0aBK3RtyHn13BR9WOOxudV3TiQWx7k1hWsU5QBmoBaizFnhjoMT9ITMyZUmoQ1SYGqERHM3lFMYozE20+d3WyaxnALymlZbtpEwjZ6QY4UKo58f2pI6dgMZCrT3mOl/lsKtW25VzK2vqFUiy9q+UpfgHvlp2a/8tWTA3n8+3+72+BK945/mnatIEmt17auWw6x4rIFXWbY5PLbycC+3L9u93eavKjupS1PbpoWetX1/nOufet/z+VcDJEpOU/Xtff7m2/3Wtaa97lZimIr9V4dcAUQs67DwWPqaXCdHnLGZAXe/Hgre5qHim380pSSkhpYTPXuyQdgOueI93nr6DX3/2Ka5fHhB5xGcff4pn7z7Ft1Y3mGLC3eYDeO+wvrjAe0/fg/ciBr28vcZnL17gg6dP8eb2Umk/N++s42kZka1uCJJAoiiBmvmkpg6VqaQVrcxYmjchOtQU4wCkkPYUse37YqFiVaShsbI5yzrJWucLQi8p6wgU4A1xwnE/As7h6q038cblJcaj1p5VXp6dCrOk/WShRCUEHLWLRGbty5Un5qR8zxaOIDWtqlcHaOmOJ8rJ3X6P29tbODCeXGywXq/hGlfwskepOWMLhRIzw8UM9PP6oSL/c0nvb0PJbErPOSRhVWovyYqJh8Ua3Qjhc2Fcilp7ciAviS363iOxJKxLccCXL69x2B0QxxFxGhGjxJ3HGEHOo1v3MzB+H407pSHLTpu1V+dbx2Dg1QCkPNl6YrWyuMhoZ9s/w9nKGhlAdpJhPPL8Oa81/bwL8E5jJAmoggLOEgVu4jHbLswU7gruqsJ65gdUbnOOsF712F5eYbvZoOukTM0UZd+yC+g8YzgKzSBOhUIATRkDFSTLvktcFB1m9dbpqDPwSLb1jQFtRVMElJSuduXs4CkhwWJ6ZFMQAaRCbSKHkLK4zOiimXWgLOg5TaMSpNlm0MPH+q8kPtEvVItAFi/MQKkR1WgtGxokAm9mKS4IlGBEdjV2j5hLMLO5cXBZVMmgBJjfbAtpz7sGdJ0HJsngaIACAJJaNpi1QCcEUMyKbLP45BI3qZIBdMEh5oyYVaZPwgBkil19R5KNnLSwtYa+VcDgHFJxuzPii0arqNY/EyZke1giLAFGsGoYmNUNIpPbjfBaogKgAFVknWuZUJjgn1OqlLgspQka8lanafLZFnJBRDIF8X5NRRICpQQ4eV9mUv/mIMBvURdmfqm4TjXFsyMGxxF3tzfYXmzRdT0un7yJaThgOByAqWZKI6K5pakZkWjOUZmns6BrFEWI0DJSoFoLhbc8mFgKejNUOKBq4refLYMphedBsDLzOWU7ViLQFAurEWKazXNOXMD0zBxjB79dD1YFV87iZ04o698ynPtY0Ne9qnh5/rtWQKXFZ8v+tH2sv58Kwq+6lvWnattzK0orh7SWz2W/7P3zfp+fyVf1twjJVBVeleK3clGjLW/72+41pThLwfvc3w+CyAXfqHEj9wtQjwJsj71+25sS2med0NaF8+Se0oUmLo3qZ3MA1rZhgu987I+dC27+PTcBKoPh5vYO159+iP7m77H3Ad/57ncxMGOzXeHFlxmEERwZP/6bv8N3nr2LiYE3rkZ8/vmIfr0R7wEFEaPWhYzKv2w859yEWWWGrFQx54RhHMAxgqmDQxQlWdGokrpMZjjOACSN+Ez/RJDSQF0HVg8VU/4RgNV6pbUsqZQjyhqCkIlAmZE1sy+Da1ZGq+Di5J7DMOE4DHDe4/LNK1xebJEsnTyRxBUrnTYnHyaqJiWar7Rk6BV5InGtgZUzC8+GK8pQch4+l4wFIEfoeo/tZi3ZglPCy5cvMA4HrFZrbPuA0PdwPsg7dU+24KScx/pB3bsaA9bSzGqFrFktG2m+ubfGr0PPy2wntmLjUtEzQxAAkxQml6QXPWKKGKcBtzcvsbvdYZoiUhoRJ5FnnfK21WqFqzcu8fTdd0XOSRGzLOoPXg1wYo0rhCma1YPGLU5a48ZYp/gcEGy5Wsu9bCpPfMnK1rE+tLzbeydxbonVg03aC85J+MayG4UREMxNtS3hdZ7h6piaMwly8F7Ca/yTS6y3F1iHHiHIdymJott5D+8IzAljTJJ9O5qHjuIRJDBYkg6CmvAQk+dJRc1cx97I7oDIQue8H9rrmwHaWDaLO+msDYiVmACcIjglpElcIcDAcYg4Dkf0wSP0PUIICF4sLF5PVmUg5xgsTqSlIiuydrCezgIyynfZfG71jjYlDIkmICtBKJFOTYZMAkoykNY03erXiRjMVLRBNTK5dlz8qlEEZtOqZGZwSnC+Q+g7gCPSNAlIsaLazgmRN/DMGRm1sDJo6TIFOLXU5cxSlwzWlBJuBTcVaNdptiDnnFQgsLg9fR8ZoG00aIY/GDUrofALsa0RiWn9jasV7u4y4jiVHpv3uSMBy+aCCEBc/BR/MVvOSK/En0Hk1GW1sRwRodTkkA5DliWB4Ksmy15iWry6M1DqyJAk58hs2ULLDQqss4JiWSfvGOP+DkhHdJtL9KstVptLOCLsbm5LAfNcHctngN56xagaYCgRzToJZbVUqHOuWk6TWkpLeyXQvGqRTpiY/nQ+IHSdZkmzNXGIrXZaNbzU5qZvCHx1byHRPubKxCQGcREfCIiCRDNP8rxrv/VryVuWfOQsP3mgvZY1Lduv93y9QbXxbu1l/V6Kz/P3nfbonNvmfdc5wCRCRbPmTf+M7BLqvm1pU9OIktgqqGRwSbZUcQsVr5vXcat86N6vYu178N3tInyNq571eZtLF7Olq2nbDfvNRPdTaDVf+dn78dhh8MmZ4eZzuw5f/ALjL/4av7r5HBdvXOHq4gJvvfUWbq93JbFWoojj7hbPv/RYrXp8vrsFdg4vjm/iOIzoNgEMQtDkDH6xk85bCAWwMTMSRxzHATc3N7i+PWDTewwRJYlXLsqkFmigFPK1xfDe4+LyEtfX10hxaOLUuCYIwXwCpfizgjhP1WVSV8YZ2IK8izT+jZzHZitKv5wZoetEeUapCO6i3JWD4QywEImVQkM/bCwwCx81FnHLFIzc1IQjZZmSKO1ydYH1ZiOWvZxBzOhzxvrqCr1lUYTyoEaBbLzN6rAt6VSN5272cwvulnuarH/6LEmMtJUeMjaUG3kEUK+k0pxSkzNnn0ESCwXG4XCL/W6P29sdhuMROUZMk7i+5szwwWG93YJihzfffYp3336CfrXG8XBEihHnTxHXcZY5aL4uHigqf6ryvsgkpoAqYTHzuHWi+c/5RWffayYJhih2yx5iyeBc4uDVQEMspSNMluL8KoUXK4G3ztUx1L7MB9BmW69T49CveqxWa7jQqWiXQV4yoxIgxoopIsUJcRwxDuNMWdB6S2hgV+0XGAQJg0kqt5isuUxe5bzKpg9c3wzQphepexkW4M3SrzMzjuOEwzBK5jASwpQzYRpGjEdG8AN85+H7Hn3XYRM82HkhVASxkDUkmcXrSn5fbFD9S/1vxdqWzWxk8Wy5xjgxz5qu71Ctw0zD3arY9OPM4nbXCkZEUkZACEPVOIvLmJJ0c5csB4uqxcnuZdaskwQfeviwkkyFcUAcx5L233iI1zgvw6vV2kLti3TcbXKK6kNuTEv6qP7n9px+Jx46GczSZ/VCLOMoAoHOFzclA5IRGrYDAMSYsN1u0fU99vsjjodjBYxEoJxhBasZbmaJkj61a6THrQU8xQJl+0WBJflK+FD945kzMjkEkiQ2WSmZrZHVknJuWT58vg+zPuO9x2Yttf+mMWIcrzH2B3TrLTZrD8tVI/vFwVxOWxxVmDrJZLdCs5w/qaVjhblt7cW90hhXjQOzLFzOzoftVVtHcFlL59Q92dRQLX3iynTK3mOppZZiBGevcYB2/yk4rG0V6cVmowxemJJ8nPUcfT3I8+rrtyFzP7aNh6xGj73OgbVXtTsXbpfC+tIqc/r9ufaW4M/60vYT7flctkHzp1u3ZdMFG/g7uQ+2RR8Y81cAZ9bRAtJaVnCuvYVUes7a8MrXlcOv43V13O09RQsOVEB3Znbvh2WzR0++r9EwvLjf6M8SBC7VAyb0qCL05hMkiiDy2PYrvHjxEpfbNYKXJFzTNIHIgzBhGDOePXsXm/UaKX2Gf3NgHI8HXG22IACr1QYrf43NatXCq1kv2n5nZsQ84XAc8OHf/xgf/vB/w3B7gzQdSp/nNJ0q7ys1WLmABDDjeNhjGo4zEcjWiXXtbDswq7s9GvqlQqDjXN0o7XNUwdV7KSHgvUfXdQu+R3MNqcoFJ6ebdYAG5MzUYfsTVPgMFe+UqvQM6y26rsPtOCAfRlxdrBBCwPbJRUnWcS5OVZSI8yQ6xoOsW0vX/NkqWJv2TOnvbMjyj4XtaOGGtkUbvr3/QVrAGYfjHrvdHvu7O4zHI8YhIsaEOEkoR0oZm6sneOvNSwTvcLef4MMa6FaybkTIbu49U5o3JebiPM8H7rTUEpp7K4AANJeBWz5rBolX0xtza69K67YVky/kb9ObWziJWf8cieXNOwJyDc+ZxSdmUabbdjN+DjKw18yByWJtjxYgM0POpJRW1tpqGRKbmiJiShjHCYfjAWmawCyeaPO8BnIOMgG1mIf4LjGABAexkqo8lGdJNGbz9ND1jQFtOWewU4JghKKwVQDIyOxwOI64ub2DA+PyYltqiwnzy4hTRpxG0GHA0Tns+oC+X2Gz6hCcB5iK9sYWuPgKi6QLKYJW9doGzERTxU0cG8HKwmmVv9mYBFhBGK1VI9BbLAZEbpTlbQthl/iQwji1jwb2CoWpW3F2zIxg54yYxW3UKbjKVp+HgK7foFtdYBiOiOMB1mG2Q60corpPshwkzQwldE2TWZhFTO/1Tlwm5TDIhi6xccqolI2Uel9FtnBUlsBAg7M10PeY7E46DzklfHm9w3pKuLzcYv3WFVYXW0zHI0CqZfFOAapZ0mp7YNVWNkzHOV9eIltDDmslnFQ1VvqPjSoToQ16Xl5S3NIBnjTI39azXkmzHzrVbHoP+ODhvEMIhGlKGEep7ZbHDsiMKTKSA1xncWgmIBQRtcwrEWT8LSPQTGAyHumjpbN1ypwdiWXQ3Kw8KfjU97VWA0Kd09AFbcNmjyWIv/yNArSqABkxTQMyVihfN2PA7O/G9UAkXLEK671xYoSg+1XLMbRzfgo3MPsOzfePEZnb9kzYeqjNV/Xj6wI/eVcrePC93+Fkx9wPruznQxa2h6xtj+nzrG2qO7r2ts7bV3lXWadGWVQaXlwG6oyGu8Uzy3056z9VIaS8+L6FVUG9WB2be+d1Rc+/96QtqmtlbS9umc1x2//lfbin29Xp//57CvB4aOBnnk+qMMqI+Pc3/wb/5Hu/xL/46QTvnVqNIn76i1/iB3/wj3EcR0zjqLyDMU0DXOhxefkEl09ucOG3uNhsEHMU3qTZq4tL6+IQpkZplTgic8bPfvq3+OjDn2D82Q+xuz6I62Ohe5BYZKNlxYOAQJqZWFy2NawgZ3G7UnrIvuZEzpb4jIu4UKaJ1aWsuvFxKTCdCRjGCZ4ZXd8LHjNxMjh0XYB3ToRQArDck7pXY+LiwTFbM851vux5bSMxI4jPZOHRkmjEiRwVE55/+QLD8Q6X6y0crWX/hK4As3N0sI2Jb8ESq1BsYO1eClCU4KdUgjA/I/N6bCqnPUhaGmVlCyinA25eHnDYHzEctRzFMBZldb/q8ea338b7b76FruswDQP2wzVCYHSNtvUhWeL8d2f6bNZQzQZS+LRzCr4bF1trV5XVs42h+yDDq8tvMwsFRcnlafH4rO9VRnAuwIegYU5W1J0aWXH+DlNAV+S2HHMrL6vMWSCFuD4G7xD6Dt45xHHAmJLUfFa33nEccDjuEYcJnCPgHFb9BssdlrMmrVJfLZFxNUZUC4VX0YQLXFi62f+74R4JY2JmFahB0FwCu0SvkRKQxoj98YAuOHT9Cs4z+lWHNB6btOFJao+liOkwYOcdur7Hqu8FwHWdWLUsdm62kdoNSMWSBtSJlT4Dxc3x7ETTLFvszHICccNg/d3IPDOQ2ww5vgNSKoJ3S6zJE5DrJixaDhBCYEz7VD6PI4MPIzZXV/Dea8wXYYwSA9Wv1litN0jTgONBwFsEw6s2wFzkMpFs9oavZxVJHImmxEBWUrc55IzMAa7RklldOKMHUr+uuiEYUKyWG93QDbJr42vM7YdixN3LG9zd3OHyjSfoVh261UpA3TjNBSsIA2qz07Z0j5khR7dqd+y9zjvklCqYFfQD3whUAeLGKXtb+urYaro0oBgVREtxeIuUEDeUxECnhC0lCV52RPC+h/cZoAiXEihGTCkjZ0JMwOpig/U64Ljfw7FmpyliJjUi8JzAwnvZcwxQtmB2c+214O/7hf+WeSy1fWItFKBrRu5yd7a00R6JWQk9AyljnCJSYoTGmifnYbmiwOzQKROlFECU4J1aqB1kXZWBJ+1Ly5IWrc6u5Vvb+1v92UPy+EPf3wfalgLx173us55R8++5Zx5qDzgvjH8VC6A9Y4DnnLVuZiXGfO7OWeruG8dyP9M997Uva70nljKCg9RAemjIZt2alQOg+p293zIkL+Sl+TPcnLflBibMMmCei2OjxXP3zY+RrSYiaPbg+cIGrz4L9c7TtbTnYor44ovP8M7hX+Hi6Yc4DM/xn//+S/wPf/MWOGccDzuwD8j5iOMoGd5ySsiOsN/f4u/+5kdwnHGMGe+//S5efHGBLvRixRiPuLj9NW6vJMvkarVqyAsjcUJOGfvhgC+++ALPP/0Iv/w//mv4nDHFpIpbV3gRm3I3y7iYWWu1ZniVYmXPSOIkYnPNR41r12UnVTbOEp+pwswE0eL1o3w0Z8Z+d8Q0JWy36ypGQemwM0dQApGAQgMGzoRgMg8JiJWnebUtkBgzLHRDz2TKcDmhiJjlUMr3d9OIm5cv4WLGk60kGrFnfZMxeil3tfGkJ5YkA8xEmMtpza6bCff303mZVg2LKPKYyR42kbx44PSP+m5JQBanCXmK4DGqRUi9Zy4v8M6bb2O1WUvZpBjRed8Aj4YWzEc9U5DedxGp292CtjB8VVrr53Oww2WbLVosY3VN6YNTRHb60exrR1IHV0EaeUIfQqU9VGn+zLUbwuYzS4bwQpS0T+2+mblIKviTswg4PyFgQOd3+Gd/8hGmccIUBYfsd1v81V+9K6FFOYGzZC8NXQc4hynqviigS2LlXQLYMxIYgR0s1KatEQjIeSk2n8Rw/lReOnd9I0Bb0WqxiZL6eUHrrP8XAezZt57h73/6Ewz7I7xaQlJiwPUIjpE5gbO43LG5wqUMjhlpnJDiCpdXDr3r6iZ21JQBaN8PaGQc6g3ceDcSwHQSJ9Mq++W2JuZNP0qoH5iLX71kgyFPzUad2edm1h77KfIoK/1SRpES4pRABOxeRnR9j7BawYeu1KqKUUz03nlsr94AOCEOB0zjAMs4RUTwRIhmqWTWmmytgKMbz5v1DfWQNPdZ8HfK0GBfeQcX9YMREMbMHWBBdGUeZSM7IoSgqVkz4/bLF/Bdh/V2LUBVxyFrYdkjATh3hgmob7KCcvYkCSlZIFUuGYuoAkZds0JbyJJ06D3MpUC5ptmAFS0133zM9og4mHhLX88MzgkpOcCbEKYayZTEfTUm2ffsMY0T6PIK66sOx+MB0+Eo68jquNIwwKrFIxUitL8ETCwLRYTS9wwJp2RdJ0scY5rg6q7BlaGr5oxJmJFjI6+SIpfbtWVzxVXrbEzglECdbwqZnuEIDFRxUrOUMSNS1KZr4pcEhzSMyNMeHAdw6NGKqvfxmuXn7d8tS381+a3PLNt7qI1zn71KGD4HeB62slm7rweylm21/y7fsYwRqrv+1f1q+3+fFUjaun8dTkFabbMFY5lOLY6Sp3f+97Kt8p4lQFp0qlopME9mhQawlrik5hm7b/EdUHkDuWr5bvsCVOtgK4Ke32+n67IQWQHw2fvmdyz/nu/H+ee1LbsrM+P589+Af/bf4DL9CH/58wPWvcfl5QX+9Du3+Itfr8DTiLuXL/CznwSs1tsitHFmUMo47I+iJOSE/S//Fp/+8P/GZrtFcMCUGCNWeHdgfOf7f4SgGn/WJA43ty9wd73DJz//EX7+478CXnyOzFHzFGtssvWcja4qPWwCUo2vacQ5gFborlYRhnqTWKmFJuFWWwaFCMXTx7DFOE04HkfElND3HUIXYCvtyPaMvdOL27oCAgN9JWNyWSMo71iCIpqtUb15bv1hOAxTxG53h+PxiD4EbJ6sseqDeLRQ3YNL9zwDZGZBPLfDiGq2f6ToAAAgAElEQVQpkbKvue6m8vOM1cb4E+szZoUT4E0w+yRQedv85Y28uACYdq/zDqu+RyDC6AjpKEpkH7zmczBZgkChK+c6g+Bx/7W0atln98bWVWIj+1SV7VJImqpM3NCH07basZ3OR5GJ1JKYmxMuoRGVdhOjWIm9d+rVVpuXbKsmFzTtsyRmkzOFRoap3Zn/qTgADMaAyycv8f77n2N7cYdpTHjxRRY5o7xjhz/7k+cgxRg//uv30a06DMctDgeTIasfE5iQOMNzRGYH1gzZDlPNPdGc7YIJjE7YOF5xfSNAW7nMUgPbCg1hKYuSS/IB0/AgM/b7CWma0HUquDuPBluobC7FDIMWnC6CdvuOImRzJbwu19/R4IZmY9032WJib+5t8YdTS6Jqc4rgwhDpFw6gAHAsxFhu0tlRYd/SchhYkP55MdemjJzM7QNIMSGnI4bDEaHvELoeoQ+gfgUiyepoJQFct4ZLCTlPtetFGCet5aZxaWpdk35UAUEYit3TBBCrxoqxmDs+FYJNRSgAkOuBL8KQurRk+cs7VxJnMGfsb3c6V77MGVn2SoJYAvUAOXU5IhXLTiUs+ZutL23XrTI7eQEhbDF6QiYcCcByJZMuofxP9/5i82jwrroxkoDr4yGh6zv0nRBA075ZHRqhJQnjfof9KmC13qBfb9GHgGk4Ih4HBdEEr/7rEvSuLZkQgPrTq6tOcUklYSSmlZ35djdrU9aJJQNT1ybp0csyomYSJQtl0/qK9R3kkXNCTBMC+iaQ+CFAoYxeXUBkjgEXCCnq3OcRh+mIw4tPMRy+RHf5HhxciWFsxRrdxieAYPldQxJm95zsacx31jkS0f69bIfO3D8f/cNWrceCsfuA3EPWtmULr9P2Q+9cfvcYy925TJnn3vHQeM61YZ9ZH0oMXBMYL2T8DDimal0r4JbEBbL92xox4d8sZeaOZtZ5OYP6nb7LhNulgN32YT6O+69l/1uA+iqg9tg2l5+d+z7nhBfPP8c/93+D46RJtNAhpQRwxv7ugONxB86Mzz77Nd7/4BkuL7YYx1HaywpgnYMnjwkd4jhgx8BmvRJ5YbjGdPscOSckTogxYn884ri/w0/+r/8Jd8+/wN2vf4o0CjA2+ZJJRUvNfGuhCS1Nt3OcAXjKaC04LeAoykCbCZ4nsbJkB3ZvaV3B6ZCkYHZOGavNGttNJ9abhrd6QrPXGt5UeEGVm6y4tgjWNg55n7jI17VyVHta6thqnylHDPs7pGnC5WaFvl9J5j4rFE7n9+psAuuPAsgKrGpcI8/R2/Pwoml+Ns8mh3LJ+jeL55+1DAUO57gDYC6QRAQXglqIAB+zJOjQkjoASt1UayslQkS1wJ49NwraiE55a9sT614BpzWHtnxelAKkxpCZH8yZVlsuubxvLsjNlHg065VYASE0y7lOy2ZIEjyLOjqpMFBBAkBnopPOMVQGOGcchj2+//u/xNtvPcc4JOxva9x/ezlHiFOGuZD+4A8/Rug8bneX+Lf/7wdIsa+AC2Z80GeVRjOxWAMpWAeaPipPU5nzNBHj+esbA9rOE32d+QV6XnUeq/UaMSeknBFTBnIEpwmRZQXt8LrgETqv2e6kLpZ3cmrEYmCUQNnvbEPJBk8xITMjuEYL8ApITGVDcdmpBK5SL+Qw13HWMTvnNIufJrVn6d9cdDNukZv2rFuEYNn5Tqa1xlJMw4A4TnBHB+f2CKse/WarxUGbEgBEIE2gHTNKVh9z/yAlWGQ1Y5r/ElOxtpkWyQR8iT/Stg3EKGCwxCbQEgCnE9uOyG7l+h4W/3kHD+c0lm+akIoLi/lzNzFfbPF+7TSfYSTUgBtUoaol4myZIbXLAt5bWyNQ9Pdap6xtQlaYyhraWuTMwJTAKSNPHt06VF/0UlJcLGU5Zdy9eIFhtcfmyRX6fo3OAXGKQNQ80M0alwBMoKBsK6ydAXHLnM9EJd10bq+hWN8kO6YJIFqGQUFucR/NArKSUlCrJy9W8IQ4jsB2K+DLATm3/V9mNuEyJobXs1ZdOwGJIRmPI37293+Ljz/5EHHzBP/Bf/Rf4uryEh5U3Jfb2Ekbb158NnfIvJ+VLU9xs+QnggbjfBvt9dD3jwE1dt/rXI+9/3XbfZ02zQL1VZ9/6Pv72n0IZN5vXZqpHk+em9GWchTrZyX5wuLdM1fHZk5a0LekW1o4pBGgHp6LFig/Zq6XwPoc0H5onnJJZFE/b8+cJLySETiOorgFw7leP3cg36Prhd9fX7/ExcUWIQREDQPIDPRdh3Uf4INDv1qBQSosM4YhYv/8V5h+9SPEzT/H9YvP8dP/53/F7YvnuPvsIxz3GYQMT66x+FvMsZsXfp6tYx1WZuBmd8DxEPHWE64DJAVHS+ChirPcJjybTRCXDF7MwHQckVLGer1C3/eSCMuLNwaxNFfsRs7BeVnflA2AKe231aKavMJW07xKWAVRQuU+s3XNMiYpoemwWvXo+x7eB7XqtHxyuR8bKkg0KwNV4qyAajkzq5rNH9fEFfZM+x6TF9r9RUXZIe8XfbrIYeXT2ZltMlxT+90pVXfOw/sEkEf0kqXTQxJfzCyXIMmi7QI4Ezo85prPXesWaP127SZkIOdJgFHzDEH4bfDmovh63KfyWfte+TIDILE+OUD2jPFiJ+EmgMTGB6JyjszLq1gOTR5oD0GRew2QcvncKE6GQ0wJ3/ndj+D9S2xWL3HYm+xxfnQhSK1jM0YwM8YhYt1f4w//YABjg7/6y2/V+tBNxs2ShR0QZTtHUS6YvM716FqN3KR5G/6diWkzJqO0Sz4DMCfzmtzCE578/i2G24zxbiXBvOpXS1ps2lwKODOC9yAvQcA+hFIRPkMK+TEDGWdqXxCQYsYwRvTBIyUGxyTBtc6VpBVzp8X58+UHywa2IyJAJi/OmiRAIWZddJqDNXWpaGDaWe2OWHXUBTEQiB1SiqKRbDsGZYQxISEhpYhhf0DXd1hfXMKFAHYBoCgETjdiZsJxkkDjVecA5+AJUl9LZe/W+iIau8r6iyBSiCcQWs0yEXwfkKckqYIxx2pFC1U0G65aXbUNi0PMucbRUSBwSpg0tS6IJA2vARSo6wCLhoQhhcDFcudkhzSgymiWWEsXwkb7u6MKSjMDSwKrwpvRVMH6QqwyoaQ6LuPQHZBSRj5M6Lug4RQOwTMm0jT4LPekvRTt7C+ucLmVzGhJCVFx/8nirOscgZICajJAKevVaTraWnyzpv+3dRE3yVOiQ0TogtcSEgJgM9TtK7sCEKFrKudK4w2VsE5R3FKLa8+McJ+J9FLgHocRtOoA8gB1AE1l5nPOOB4m3Fxfo9/u8C//+/8K/+SP/2N88P0/AVOAJ6kptwRl9XcunxWL5+KeWZfO/H3u3leJyKe76PxFs9/PC8+PFcpf51q2+bAl6+E4vaUF5uuAwa/6/GPAnrSPSueASgga74ClG1Vp4x5F4BKA3WuN4PNtVuGt6c9rXI+Z/3a977Oi3bdnmRkxJwxpgCexGnoKIAIiK90jB/IO77/zBt7yT/Gl0o/1dgsXIHScGeMwYXTAkwuPFKXm2na9QoqpCvk5AW4tQrRaFIr7epqQDtf41c9/gp/93d9gd/MlhtvnuL5jIA5CqzmLi7z23xGBk4ytX/UCZooQr94XKtkwM25fPsfxMKHXkkUmvZX9QjWGkXV+SD0divIOqtmPrEJjFZYdEbogyjwGsNms4QkY9ofZyhCJs3icJry8vUOeMlYe4u0wS3LDleE1IguDkZPWjWVxP012f32yZAQkIoTQKTjyNSSA7jtdZ/ZRC7wMIDfzsmwnqycIUM+GZAzOda5NSegcyAVYHTQGS4INIgXT+fT4LGSS+dlWrtBY3x05kDMA57UmGxfqEVMSeUNlO98xJmaEMr7zMW3tu2vH5nKW3gSbqAYDq/KDyp6lLgi75GW7pWm0Baq53StNq/YK52TOpfavQ05KEVyVeySbqUOGlN8wryrRSTS8axYu0763ccdtiQ0zmEd88K1P8c5bH+N4jJjGhyPDvad7SSVnxmZ9gA8D/pP/9IjPP3+Cjz58Vt4r+5HgGYj6GZksk817aLYU0ns9xq+KT/xGgTYAzSKry1hmcOMDmzJjGDOm6YDsRmDNGK6fKLytWR3FWqViuPdwQQ3M3iHrdwzJAlU7AZTI8WbBcsp4fnsHHzw2fYccAhIyVp1sMkuzPsdP5TS3jYMzzTKB+SKCMxwxEgOJaha+QvCtjpk+R5DgxXnRCUJkiGBMsvEYjC4E9AhIKSPGWPx2uRF0jWn5IAk2psO+FBg0d4mYNaibrUo80G83WHWEKUYwEijFGQN3JAWpE4uWoWS1UmIgxBCz+XYErSBPyFoQm0iJbcqldpwvRFuzSypj8KiJJUCEyAZ2BdQ7z2CtZM+cgcRITjVaROg3a3hHiCpSmyVIgARKQK/wsayu4aa79GUdy/Ln6uICoBRNr1vD/OkXVKKgVX0OEAseUUnNyykjx1SZmPdwBITQISdSpiBzEQ877LKUd4hJrKYhOLjOA5MwqCacTd4YJYjfYhBn9B+YMYQlsWFGcaG1B10f9BmnezhCYs9yIV6y2Bm5qffnSPZYzgmdCygsmug8YDMhLDPyYQ/vL0GdLxvNkxNFDWcMU8ZhJAxhjwti/Ov//X9EZuD97/1T9H4NUF3d5VVkrrPf/sNe85Nf+zHvC50FRedA1UPAzb4/K3Q395y7/Nl+1T5/1avt8339/20A0nOulPdb45ZPLPlA06aS9RmYMV5izB98whvPiUXtffddBrjqnq1z99jrXuD1wBy3YG75LuHBGS9eXuOTj3+C760P6DcbXGy22K57fDS9gdSv0YUOwXX40999guHiv8DvvfW/SHyQd/jkV58ILVE6H+OEGD28C/jkk0/w/e/+XkPUVEmZElIu6i8kUxzlhOPtNV785nOMw4jMDkiT1jZzypddVeKQzOgJHST7zl4r7x6ORwCMdSf1oKCAy84HQ3icEs3iNVQmX1fQFFvZUfEOck54tfcezBneO2w2koBEXESlT44EmKWcsdsfcHtzh3gcsNmskZ1YwAw0EqMmwamdgPXEeQdOTsQQ5+AtxAIApwhyPQC17BlYs3lrwNqpN4s7T9cx34PFDZV5xlSNN5XP27XR90OXxeqlwgUQsdT2S0ktUzbb5k1RwaEoozU9V2sNp2Uv22FRifMCoVgbc2Zw5Jl7JBEhTtJq8AEpiqvefVdV0LRcicrps85J1moPHxymMeqzlnRfeLMrfiYN1bE/Z3uB2ukscyHzSnXM5aZKr9peyR8B7Loi15lXVAknaV/ZPFiXWPI3FCWXyjDvvHODP/zBz3F9s8fxEE/qtN1/PczZU8zIaY9n35oArPDpJ+/KvimKbpVVGSAEZNJ4OkY54+22TyAgZpwr6dBe3xDQRqUOlF1WP83MrWgIlwAPsZaE1Z1oRxCkOKavVgsgwFGG9x5ec/Of9fttiKEBKlZiZcuWkrjXxcNRXS47xBAQgpcikEGSlZS0/XZ2SjooLpuoVb5aqURAEpPY+3Ix9eszyy4X3Df/zpP6AAfJSsQqHEimHIeVX4F7qXuVEiNpAgsiktSn3iNa3SoWcEMKlnISYb+1Ko7DhL7faobGhBQjKI6IcSoCt41DLCzqSpCkeCFyTVYyow/MxZ2uEAGbXy5LVn4pyTTASKh7BRArHgNCAFjq+xVsXmKeFBxAND6XV1schwk5Rb1RNEBZtSQWpG0k0TlzPrJ10Z8z0D4Xt4CqgYRz+rt2/YwW0ZHEoHnv0AXxg488lSyM1QtdiIbrAkJwyCmLKw8DlDLGKSEleRmFgPXFFcbjLeLuCNasq9bd7MRdIecqds+Jsq4nSOWi+jcDko6aoBmxksT96bzEzOquY4yQK6PWmFObyX61kpIN04TkvCg/OOkanhEjFwByHCNWXY/iDOIAJC1j4Ai9B1zKOMQBfSb85Id/jo6Ap9//Y3h6mExy+XkqBC+F2XPffV03wqUwf0Ir7n3uDJA4eZZnPyssqW2/qvdLwGsnwZ593WyYr7LgPWZcbTuPvf+xfVq2tXSRnIEwMkognxltLa41TV8cLA6uNFToVttuESCtjSLMLft8bq88PLfL+L4lEHto7y/jAO0apxFffvkcF/EONzd3GL94CccRnQdy6PDL+B62mzUuLy/x9vuMdy6f4r2n/yHc8RP85vNPMUWHz3drEDmE1RqYRLkDAJQJWcv8pCSzm3NGHEekFBFjxBQnjMMg/GscsL+7K/VYyeiariDnJLyAaxwacVbLkVCXWmbFElygLL7QGrEiFlmh+d7WU1Kt6/pY1kbCLNOfgKBGmFCwJfTWYbVeA2C8fHGDoFn57H1EQBwnjOMO43EU5ap0uCihAd2HzqmXzqknQWZY0kzErECOJFZfZi+X/b/kie4c3S5jO00hXwDYAogtPXcKtjhjgeLZ32rlcUGsPEHCDOI4gRFF0awZhh0VX67SDozftWfC+Pn8xJd+ylcelmWUVXKXeRbPlaByG7OwqQCGowzwqT/X8uyXXAFsWb/RWMtsL0uPHFnxc8DiM4ikvA/nCeDOdA2za6ZEuG8J2UBtwzF04xG5EjLvYK6QBO9ZDA0ELQul4RpVi1z7YC6SPF/f1h0WkER3f/iDD3F7e8DxGBHjw4DodS9mYDhO+Pa3P4MPwEe/+h0QQumuJJHJIExwKutIt7kqprMYMRKz1u2LD77zGwLaVDDXTEXiDtYMrjkAolgXSd87Qt8H0NOMww6obmZGFHKxjrhFAgS2fxrGJgedy0a14sRyxSKs5omRpgmDCr196OA7h75fYRWkaCUIUu4NSmPKSVl0ghqxRQ/UWXdL7VP1lrQTMUc8JSBe547IamNBgZoI5L4LcIHhk8c0aWyA91pGQITnEnOXxW87s2gyciPE5iSuky5HAQuhQ+hXcGlCiiOG4yhWLa6WsaTMRtZafOmTkxgimwdC1aDlFqShOcDG6LjGWp1q7PRW5S6eWbN2zs3fhdnkhN3tHeDExYRTApuBRq1ldX8IETdBgFtfa9PSsd5DzVLN+kcAtQHbdUxL7bwjgg+SaMcHL+AzZZkn2Ha2uWXNSmlpnQGLWTP3EAZjvx+xuXRYb64A1yMedxgOx7L7nAFGrSNXsncVZlFBmPMeMaUiWJD22YBwyYZVBBRjg9JzU1TYWEG6bkTYrMX6mTWBDDm+TxE7X3u9KQ8HuIu1MD/IOSeIoohYXINjEkB/BIN2jB//yz/HH4Hx3vf+VDWg5spx6gqWmRFTROdCyWh77rrPdWze7ceDBrrnd2n3t3ctxZDHtH3fOF63ncdej3nfY+7/uu8+v8a1H6beOSfznOvr7B6a97qetCo6tsJr27/XHe1jXUlf1311fj8QnMfVkwvs3e9g/PgvsD8cMBykvlp6+n0M+QhOjDEmfDYcsPpHz3C7eR9Puy9wcXEFpj1+cX2Fro9wzmO96goxJe8R+hWC99jv9/JOBmLOIE2pvt/tMe52gNIq8xCAusVDNeYpCTgzFmRnwhJumBs5WxZHqFLKXPS9pFcXHZ0rHvUm3Mr90jATNM6gZhVmbc/2TtsHq2kGKHhywieGYUSKCd7VyCgiB6aMEDyQA3JvHkmubrbKisGoGYOJUMoFAWJtIHUnDBDeDkg2b5EqSF399QwUvn9uj8jbjL8sBXADZwbelvt9CdTa5Fhlvyl4kfn3cF74vPG143DA8TiJm6gLkpRNhTdTOOaciqLZkfUHi4PanvgK3sg8ZUj6kCzrMubntuA+BYEMoPOECVxCEKoL5hKI1s4QUXGDLCFI9p4yby3gA0K3wnq9AbFlXJ7PowFkK/VUZ3853y2FM3lB4kcntiRJTi1/ajRw6haqSuZxOp9cxcYqBl4FqYvX55zxe9/9TAqaH6bfOmCr7wHGIeLZs8+xuejw859+G+Sy1PTN0g9SgTGmLGWZooWkiNV/Sow4iXzO+UyoVnN9M0DbXAYHQzKuzG7QzcNFiwNQTmB0WF0muABwNjRfQZgh+4L0gcZ0WgVwhqY0TyrUmTuYI/jgsN5sMY0D0hjBOWqmQCAPA6ZhgHcBUz/BXWywulirG1szhHv5mIAop0cnqXRPaN3/VANbDp8AEAaQ2IClEjwIUQ7BoV/1iFNUxRTDhQ7OC/CaJtGchSDCeIpRCUVDDGyOimZFDx5PAjQ4YToMGDrCantRCIdoeh261Ra+W+N4HMBxkExJldLKe4xxadYtO/uWgpcUmKBYd4yhVVDDgNaoaaa60XbammdzS23Mz6SxEdm7InAM+wN2t3foVj1WmxXWm3XJemmWQ2b53XsC2LzS5++z+wHVHEFjLgGAI4B+sTUqkBTQBfjMM+dzYfgEr9pa5whJg73NTceAjg/iipigNWHUlEfQtUbGdNzj+a8/w8UbV+j6Dda9WIyHu72Ilgo+TUudcrFjqiayjtnpPQ4GaPU/IlDO6EJXxqtQUBmzMCImJ5ZdiIDgdMsbmOOcMcaMfjtncieXaea4zi6lCM4ZXuvScDYtp5z1EAK22w3ubl5is73EOA6g0OMv/uf/Fn/2nxGefvePYfGrxuYyxFId44ScE4ZxwsXFJVbUJCR4pODbXq+ydsyGisoaX8U2gVOdUStanG9//v5XxZ895mozbZqV+KE2X+UG+ZCF0O4w9+hzbT72al0RX/+5Fl6dArZ2nyxBGTfPVZm6EYaE4DX74IwrK52bp9NxLMd4n8vpQ9frzI8DoQsdnly+gcvbD4Gn72GcBuzu7nB9/SV6t8f3/70/w7rvkQFcvPy3uFhv8LPnB/yfH7+Nf/r2Nf67fx0KLfahr0k5YgYFh08/+wy/++wZiA5Kj0XRtd1c4q233sbN7S0oWGy70hUFF9l3oBwRc0Z2oc4OWYp/sX4yA5RZBCrV0ppnibmu+0ACojKwWgvH//L5c6w3W/SrtU4eS4mJZN4fDY5SnpNSxjBO6PsOjhiWEF6sgBZuoCncyZJU6Xw7KYcDBZG+I6z0e+edeBpx817rBOuuZRTgCQD73S28yiuRUXmwa5Ka6JwBVGUIA2SNom6mRDUrFBg0RnA3V4SVVhsLm/1tbyvdb+4nlQedD/CrLTqfIAkmJtztD7i7vQFACFeXMi6/sCMTYHkTRA/c8uaHzkWlcK45H8ZPSg+ZJWGMfuIDIxIhkC95FyyUpaUo7WhbAFfBm6ulAxqQaQXlybnimhnjgDge4TvNeLicRGuC2nOu874ozyRnoJ0/au5jje8jrC8usF6t0Qcv85oSKEe4tmYtVWBm77F6gsWzQPuZU0ZKERfbL3EcxtdwifxqV5wSjrsBbzy5QeIPQOzBMWFKY7H6S0mmiGmckJKUMIpRvNME3sgBIvcQUP2mgLZ6AnWPkCayaG8yYiJZpjgxEDxiTMg8wvFaMu5Yc7qARCjZaSpxOH+4ZCNSc8KBOEYM44S72yNWK8lamTkjjoPEUelBdrr56iFphreQimwTe6pHudb9UdGCSBJtEM0AW8FSjmrcl7aAlllzwKrvIZnzJCB7GkeAxV2062rVducZOatVKGYFfqIRkYxdWTRoZUwJKLXrGLubW0lgstmgX63RdR1ijMhRNuv24gLABVI8YtzvkUmJB8nceSIED3CSJCxZi2+bZs0RJMYszQkDmTtIM+GegVQYjSxHYOlxScPiPZAniAXMwSMDOatLrliqOpYEFuPhiF3YiXWrbIvqgmt1ywDShDhCyOciIzSwljQw2pwZbX9wPbT1DWXPWLkEiWXz+p8rcZ+O1P9bBTPREkvaXsFETmI3UwI5qQlDOZfzNA5HpC9GbK+22FxewHVrwB2LIEkQl0xABBMrBh8U8FjMWc55FvRtnzMA9h5+ZdpebdcRus5jtVrjeNhjfxiQpcogPCs4J6DvevzO7zzDp598iimOzTzdc/Fi9nXfTqlJH9DcElPC/nDE7f6IJ29e4fZwAHUe426Hb7//Hg6f/BS3XY/Ve38AOCBQwDhOcM7B+6B+7A5rLeK+FFu/jhvkq0DfUiyyn27xWcsG6J7fH5rVh9nIV7vafrbJpQ3MzcW9VnQ6/c3uPL3XxOxTMPMQWK2tv/6anW+rESwXgGoJ4E77cApcH7r3oXvaqwWDy2dad81zffgqV3m2WWijpRfbC+Tv/QmGX/wQE2dcPbnC9uICb7z7u3BvvwVH6qJ3WCPHjF8/3+FHP/0V/vyz34CnhPUmafkTGVVJ5MGMcRzUomGeEIQ4Rfzms1/j809/jZfPrwHOxbVcaHGeM3FeCKRQoZUq+AAYl9s1vJeaaFK1R5S7TCZg1lh1clSTYum0ZM1yTSpIixAOAZEMTDHhMIjs0a17eJYYeQGbYilz8hoRxH2rMpDLuQomuz6UtShhC8o/2eLJdV4SN0K/7os4jeI+afNbwIfxlwRzqiwxgWotIyLJhNyJj81M6UtU3gEDbI0id3mdZIlsrVY2Av3MdT36VQdHYuW4vTvg9uVLDMOAFBNc34n5xEPivEkzDzCX1PNLGnpCidjWuMnySgRYaQe1tkWyXpabJAxDrWVxIkzHEa4XPiOOI1z4btsL2d+lBzAAt2SXZR4yTLBo5pTBHDGOIzrVoZulz+awtMfmxsuqJzWhuwyltF+6BJGUfC8uqZeXW2y3F3BOAOI0DOj6HhS8ZIeOWhy3nfiWUbSgciZjM/7RH3yCrrvB3b6Wo/o6F5HkAEjptD1m/Yxv8YN//Ev81b96F+NxxDhOsgYFNer+T5ZrlSUW1DuV6dyJhXl5fTNAm110KuwWC0axyjBC8AjsEPrqh1w2xuynst3iytUwJWr2UwPSUSx0shAhSFaqaZKSAqJpIXFPC3KvI4kfC6FT4kqYKZnsnSaIqrAc9RBUBikvNo0WQKrJ4XlbbGPicmDKF8wAZwTKmGwnM1DSkWZGZCm4KTTeiUUjJhRxgqUvxUhLDkQaP+RIrRSVoIMljV0RxswAACAASURBVHycbjH4I8ZNh9Cv4TsBGDEmSGB0gAs9cj4ipVzSthdXN6Ji1XPOIKweCOlGEfbBAiBs3UgBTFSm3NJ18xD2RIhaiBowImMzJyZ2By8xcMGDUkJ2HiknTGOG7ztNypIBFormbH+R/BQ/bLEfENX1zGhgGjOII4BVIfieirhRsjMyxJWTbJ9yJaLeO8msqfvVu7JlAEgKYecF2PksVtX/j7p3a5IkOc7FPveIzKrqntnrAQEKMJA8PBfJ+KB3mclk+usyvRxJL9TlHFEAARDA4rY7uzvT3VWVmRHhenD3iMisqp6eJUitAoad6qq8xNXdP78mf4cFIQNqYS1Z1+fp4Yg0zRjGUfeLA+IYajru5qLS9rRJOQry2xArsWdmjMEztJUVk4i7PcbDAUKMKRXINFudI31IfY+9e57OKKn5fFc3TfYsbdtGoHGApAQp7pazFb4YHAPuDns8PZyxuxuRl4LAEX/445f44je/wUf/9AU++fcP+Onf/C0+/uhTK8khKMtiRFaJiCo4CoJnpOvaSy1oW+H4uft8/8jmb//M3efL9/jzL6/ZzmTprrngmzfuudX6ZwjWz3uuj/Wswy2d7XcGVvl/bwOb69DmJcD6pYDlOXBzDQheCHzd9wR3lW/gffts6a59aWtxRpeuvv1ztjFsH6p42Pa5iGBJC2KICH18OQEpC+Yf/B3K6Wvsl7d4HXcIP/yPnWBI5o4G7CJhlIRAI+Y843h6Uq8YU2pJKTWerEjBP/7iH/GXP/yL9jLJkJKVlpTS0vf3AtZG3ryUpbqda0JlFoDh9fdIFZEOVkqx5GBsQjeqpUNfYrvDC2UTVDlNGpuzzFowm5nw+uM7jCGqYpT09Wzu4/oQc8Fzy5sLlVwNkaowZUIJBqtSNk8WWg18nbERWNKsSlkRBA5VeXlNF84hmiu+Clyt+Lb+rRY0rlabbb1PZ2ps8hiKqBsnsAJ/vbjVF+B2LysHjgrKSbOMThMe3r3D6XTCMi+aK6EIRrDNwZouVUd+6mVJaXihA4tN+e+yp9U5rXPUrqsAM3u5JwGLIAZGISDGgOJhCB2fW8fL4+I7T0rillbuZsnpSlWAm6yiuDJqYWghBOp4cDfmOifSKHNTYjSw2I+vCEGYEULAp/evMYyj7j/RWK5xjLi7v4fkhPl8xtN5QqTSHI0aA0D1KNo2Uhk354JpmjDuM3J2UHl5+XOtDwMBgN2OMe4ipnPCNAmkdLFnUpARMR3PePz2HR6+2Zk1TemQv1xsA4XAlsneC4ozPPlOys+bBb8XoI2gPqx9NXb/pbHm7rADAGkaew7RCjQyJDcHEwVNpjuj9v0lM1WtlgaaehydHXJpQqEUQZaMYPXP5klTrQ+7wcztARzcFYGrpsWtSaBKkwFokesZBQPYUspTlWbYhi5i1grGRa9rOn1aFzb2Jujcynptiv0bQoC7LxSWWlRaQavPg828Ee0QAopk60+urH7Vr7zg/JRApwnDTot37/Z7cIiWbMZmnNWSqt8Z+OW1kNkDgN4K1b9S4VE7FETUshWJNGutCDg3S5ATKM0wKtUVVZ9hgmEIYIudLBbnV+fXJogs9iES1NUUUi12dSVE0JcEKCLNakdNfBLb7+6PH4haWmQbmzjDMMudKzqyAKPNqfNctqyPpSvcqmdNVHAgIIQBKXEraC2C8+nUiEwnYYsRYy/n4IzU+VPda/VfH3Cxs6AMXmx/gYBpmrE73CkgJpMorCg2U5ekxPZtSQvSso74FIgmDaCus92v7WOpinGwgLKtIQQoGWmaNRPqvNh+WMAgLBjx5re/xtPwI9x/8m8wjnuM4w4AgaM+fzpPiMMAArAsM3jcd3N+KewWE+ze79p3u71EfH7fNVXguHHf9rdeOHrJu7f3X3vurXf0/++BTA/2+u++iyXzuXYLyP1zLKfva9d2xK0C4S/9HXh+T32IBe27uIhWUCjAPJ1xmia8un+NsMZs+PbttzhPZ0yF8Pruxzh8+hkABSIFBTlnvPnd7/Fqv7MkIgWSF+RlQZnOSBbv6jtDxNy7QWB+whgjPv3kEzhDDqwugjGagsVqvta42Sp4oyb4AFx47S0YBPLC6KL/shjQNLlGQR9jiB67W1qQWJ0nVB4MYOXGX5aE8/EE4oBXr1/hsN9hWZZ2LhoaWAnuFUR0MkITwq2wdZZai9PZlBZ0Frgrr5BaGSKzlmQIEUAyTyP1ysldYi59u9Jl3wPOr5o8Zud7W5y7R38GNOvJ6K6tPMHfYc9VHmiFwslDLsQyFRdM5xOOT084H484TzOWJVnyB8G43+HTj+4QnL9K61/tlaxpFtd1wzOtWx+bBx+nzoEN1xKRlNLxKkjN4K3rt3YJfa5J3VQ3frf17usL5nnBEiIwhgqQ/LfViDYgroFEPzRyMScijBxNZmdds2jF1SVnnKcJkhOm8wmnKeFujDW5YJW3/F0XWAFV4fLq9RP2hyfkTTnaD239fRoTl7vYuO5HjiBSK1xaNAOkKoLYakgavfBEQYZZ2EBrmTNKmSE5X5Xn+/a9AG2AH8BeQAWUMF5GPORckJYEZjO9CzXB3mPJdBegUDBBk6/XUrOYMoGm38+VTKEeLGa1tokIEFwg1vfEEGvmqFrzC0X7hHYYqZROgyVIueB4OoIEiDFi3I1gYowDW9FqPwB6yOtCimpHmhbDyNnGAuIuEC0VrVuozEJGSth0fGU1Xk9Bz6IaC7XTaL81Q60e5hIC8gL0WT9dy4ICzOcJaVatyW6/w7AbAKirJUGBhoCQs9L2cT8gRiDnZK6nFfe6N6itmFS3xEZQOsCQpc4N4ESRkJi6jGCNwZIBuAjPEKWZlZSouMZWwUque0ypnTPgECLG/Q5Ukj3FE517B1a7HdIlc1EiznX6t8Sx/6sKEkyI1g/n7dvDXplpd6h69sNBNTvjEI1p1Z1Sa6b1Wrbe9bGUXM34TIQIYGmvbtfXs+JWPgL5dhHBPE34+s0bdTv20gjGiB0Q66V6HqQUzPOCYdSCuRpQ3rsQXjnjRKCBQcgocOCrew9VccDY7/cQZJTzgoACjvd4fYggRAzDj3D/1z+xovUK4nNeEArjeHzA6emIEAcQM4YY8IMf/Ah9AeS+9S5nHwIA1u5r299uty0wayBn/e+HgLcteLr1O7COWbvFjnpw1gt02354u9XX59jdc79/6Py/5NprwOY7yg7fuR+33t+SXW1oxjPP3rpPfrCrpFl7eg8Hb6UU5DQj5YzD4YDXd/cQCJYyQ4rg8XTC21//Z/zyH/5P7F/f4ZuvvsSbb7/FvMyQMCKXM86LWPZkQfaU5ZboIZeMh4cHBW0+hhAQY6iWmSUp9e9Tu6txpymqnG/08xncFbAOqwnjfYIQwIROKchF61DqpY2uekK2Gktlz1QlEmMcRwwWFtKepz3x1XRrUuMVjbfAwagrw6CgpJiikEQgrLJQywAmVXnIgVXeoaJhC6FlQWTJKM5jCoCcASu1REKVmV9LMrJqfbr/vphYF35S578DMwQAlgnS54yDyn95meFKx+U84enxiOl8xjTNmsxLgDhGfPLpZ/jsL36EPD11mFqVnKAmK6YiN+RJ75f+h6zPpTJ3l9m2xoR2Y8mWKq3W/ZCuKLNUmcjH71QzGBj0fq09y3Txe6ynif/IgJklQxP10NF4eIsErkpnf8Z1GnGRmd3iswSoSeWYCAMPGHa7Ku+nLJA0Iy0J52XG+XRCmiZQjMAYq/IDYhlVHbgbs9BzY/KcyQ6H/RP2+xOOp9LJMMAwDoCkVdHslzRmQhwHDeMpUFdt9z4K4+paEYBj0DqzlvXTQXdNxlaAPC9mbc/1nDGzevc90743oK01cyfr65N0bF9MyMrZTbBq0l6mGSRR3b6MWGlRR52AggKmgGwpk7fZiwSa+cgVEyJW6ytoys6qFaEGlpi0QGJhttpoBiAs61NAR/dW4EK/K1NCSgsWZhyPR4TAeH13wDAMADEkBMTNOZAiWOYFjkyVZrfNp19r3Y+cNE5rToJADVhpEUmuzKqPkepTsRIRYmQgZ+RipQE4QKsuEoYA7EYFoGleurINBgpccBcB5QWYijFnLW4gonRdxCwsHDHev0LKCWU+IacFRbJaHAHkwoicQcTKKH08ohmd0LkLVkuPEVkt0s1GqNyaxRaonYEiNVEK+SbQ7VhT0rYkJM58VNh4engExwEhEsbIVbtzXfz0dyQwjd2eapuDzR3I94xncIQzVbBVCqK6lz0pSKnvsELcrNbflQ7U6mnkLJp9FRYkW0SZrqSVllcJiwBSzNdeWzYzfoYKNnnDJMTAf4CAYjA3HdS50/cWPH79FnF31r1migQXeIjEhBsNqhdmnKcThvF11bT2wmRBF3fQnTlnOJra2l182/IQaVKRaXrCuLtHSgs4TzieGX/3d3+F/f4e43/1U8zDHUpJmBcg5wWDRIS4x+5QsN/fYRx2iDFiy9gqI73YDTbH/Rm+csUWsPVXCK4/s/+9F2y2wOh9rOva73Lls5Oqsvl96+xxDQjK5rfteK65Z14bcx8bdw1IXvtev1uD5/7va5+/r+05oLjdN+vP5iVgT7jlFtnPxeU+Xb/94vcOQChpbs90QPTR/R5x3CE8/grzH97g6eGIX37xG/z+i98gPh1BgXH86mucHp4QEHC3v8N5OuL87qRa7GGAq0SyELjWfxQUO4VOmlXbrcq1lJLxQnIk4+yj9tOBjCp8WqIxcoGBPEGaCZlMq/lwAIiiViwvEQDAlG/qCdInvyA0N7dgnhNLWjR2nAek6VS9PgQwV/qm5GUyodnlE1E5p/KJQAglIOeEDM00SEVQWC2BZLnuiWAeLKbYY+Cjjz/SZ82Lupp2e4xJNrvB3PSsX15DFwS1AqaisWvP1Gfbtm26e5BmVNb+qXyjmfkKJCUDPh4jDwxMWExOJFblOQW1PiYQtGK67wDfOaRCOAGSBaU0Fa0Ns52RPseBK9CpW9lOq9zTpt7t28fHzFikWWFMxKxAH0ANpdDnyOp+f1GveM3ksmn/MoFnuNQHmex9UVDS16Apxy9aQ5Z1dKzSApY5AzKj5AVzyjifzzidTpBlATEwhIj9EDQZjLlq8srKytVYoPGrUvsmIliWYhjB3YZF6w5LRil21pgwjAQOA+bzjJz7/aqyqbcYgdFC8odRgeEiY5MHASBPAAGlvIKUgiXnmgjQDSrNwJHME0o7PQwRcTcixvje+PHvDWhTILG1HDlYa0IrSLM58mKHLYQWp9Jp8FgYhQQsuQp2AlSNmfsNEwwRd1YF7ZAmtSipoCDUheEOnKmwzYjB65/495YRr3NZaBtYPyrDIFAmrQWWgZQYX08LKBB244j9/gAMQVP2h17/p64KmgQhIaV2cJW+FwT2g1egscaWVMSIpY+jEXgy31+qR4tNstYCyQHCglwEHPR9kRkihCESYowoRTPh5FQqAwyBkK2YM7O7WTJSKkhLQRZ3YQXyMmFZRoQYEQ6vEfKCvMxIy4yyLB7gpivZgwciBZNoDLn6PHdrWkQ0g2LxddJUrCLqihioXa5Ys9PowImnWQj9INpzl9OEN+cvsb/bYdzvEIcB7lYKmFaLsGZjHQODaZ0U7BAsWk5/L11G055x2jjdldfRn7tbsmcx3FBVPw/MtncJ4CXpeyrAWfczxtDOTGUUBoQscQx3zxexQqEEK26vwflNO2bH2c96KcYgUJlb3O1x9+oVjo9PgLNNYqRlUWHsitaWDEi378za2K7QfciNMenaq/9+GPeYl4TBYjFSXvAPv/hH/O1Pfor9J4+IH9+Z66pmqxuHAeMwIsRPdH9cgRK3AFN1Gaq/X+d+1wBbz+Rl8ze6v73dytC4IXkXf19rt2DLLXDm92wBWf++7TO38sH2Wdeuea5v1/r352rPgcF/ybYFaA0EPT93tLm+/217/a13XbcQuz9GU1BsQRyRxn3WeBFybwXBiAnTr/4e355ncCn43R//gK9//wUWIex3I2g3ala4pCVkKGgs6p4Z092E5elonRMwErgj/zllLNPSBGexJFJBEx6UrEKw8jRNTFW4xS1XHVZQwTiY50ypmakb74F5uRj6rYKy17/0Gauu3z4XQOURNcGWKyKF1WWPADaLfoiEslCVkKQ0S0MfgNfHFSntWAu/ZJQ7kAISEUHJLYkURfVSapYUwWBxztN5wjzNiGhlAUAuh1CrwQqj60Z3dW+YqoAI5Nrp9wC2614oquyLHhsEoOSMaZrw9PiA8zTj/u6A/TjArV8xRtCBkFLGAi3XE6p1U4XpnKn3ztR6fKKKazbFvdhGco8m39MX8V/SYgmrQuBqDSCbx44HCwgZhMhA8VANOBZqJ5qIEIQscKWBzH7OiohmPneR2e4jUwgM+wH3hzuEOIAlA55+/gZxa66tHVezve+K6HoFR4yHiJITjtMZS86Yp0ktTiUhDhHDfkQcBnAIFgfvStzWAR83cQNuPfEiStjtTk2+MkVLjAExAEkCgq0XMYHl+bpode7sOaUUk2FVEJQyAzRoJ3hEjBkhzJjOjQA1a5/2mQgIUWX7YTAlbymQxQ0yt9v3A7RdypVVGydeBbldqtYr2xSSE7JYYUha76zKxHqCuElJChTNUmPvIyO0rhUjIhSjJzXdNzuR1s3EvO18cyeone5e6RbtMA5aSDCxjsMGJhk4pwlpXvD69R3iMNg49BkFmi2QI4FDRCyLJpnoTOWecZItw6KOm2q/iDyGkKolxwm6By5nIUvvSyZvM4gFw26nRSBZNZcplxpTNIwD4iCYp7Rat1KkBViKxn0RihIGHlFSRiLTeHZTGcYDwrhHTBPCeUZJblYudRzKJDp9V6VXVIGTwLUdOkfUbSsBNK2uaAbPQoRoewPuBlGBmq+jLaoxVw4MRsH56YT5eELcjXCLkV9PhBpb0D/LrZHVslZT22qGzgpAXFuDTcCzSwLOLHoCxlyDn5tmkkGkNfmCJdoh9mBw+3/Xp17Qgpg1q+5pqa4Pa9/3piQJpPvINcmVyRhwHMYIgWc0E7N+evruqH3UK5SZLjOWnADECzcbB3GCxjhKUR/zbLJMYyLkiwNmwul4RNzvgQGaDABATmec3gFfff0t/urfRhwOe4QwYIyjxaKGOv39vr0Ghj5UqL/lDrn9fF3Ibr+79am/tv+94PZzgGZBuwawbgGWa0Chn6P+vdt+X+vHtX5fm9PtOry03QLMPVhxkH0JYJ6/7xIcNcDzXSx36z75O9q7nmP5z/32kti4a325PXfX3k8oWUtk5JowouDp29/hD//5f8a3X/4Jb958hWVJCAB2w4Bd3GG3HzEvC5bTGcLupmeeJjEgDBExxu7dJrAJICljOp9x2O3XhFeA1/f3OBwOalm3bLtJ1KLfj6p6IdphV27Tu8iRKW30pepNZlZ9o9u9+/oqcQe1f3IuSClj4E3qb1F6FccRQwiYpwWRd6gZ+8TDCdwSaM8k1jpkJmOJhQeY+0G1oImVLfAbIzGSAFwMVFkai1KKFiRfMqZ5wnw8qyVjHOEwrFl7/KU+bz1Psd0vdteNrXcrVMDPud5WlKeZ8nCaZ5yOR5yORyzThEKMw2Ff3ytZNBuyCfJFFCQRMaiWtLHEZKRJSQSqTG21zUyZveW7/vlyJKsEME0+3JweQa33qo/WuqeRNM7wMhnImuJl6ufM+HDHzrVuqlnTcl73gYBxf4dXn3yGyITp+IA0pfaai9a/e80VyOSvYrw/C7AsC5ZlxjTNSGnWfAGBsR8DYhgQLD9Fzb2gKdm7vAWocobv2S0zkiK4v5vw13/zDd6+kwqOmNXYk3LCMmtcGjMwjBE8MIYBICqmIF8Ptuq9rRi5yzcxZIAjRA5ISWVa5Bmff37CT37yiF/+4pM676XWOgYgJvcMWrYJOWv5jaBJWv7/kT1SoLW4SFbAi6CFDSvOMs2PlILX4a9xxC9U20aWiEQC+tNfugxuAtMc2SzWrS/AKtDUpAm3bJvixJUjKzGqj7m50GSLHZkbxKiIqFVqyQAJKEZEAUrKBgKCaoNqPJ0SBdeUaPZGnYseiHotjiyCaUoQKZqp0QRtZwRKcDwjkWmNVi6pNhlWhNkBCIegGXSmhDAMWJYFBC1UKla42835ECNU1LRr2Zgmkbu3as0ckgV5SXh6mxGGPQ6vdohhQM5JnxcGHO4GlDxiCmecjycvOqDZL6nFTfn8+4Fp26dpqTTCSS9yG2YpUrNylozq4kKAZvGCEcQKmCzZh9GOaIk0Si5YpgUUAgbzya/xEEQIxDUDlv9WOkarH2yeBJa5UfsvrtnVhaugVedUk8v0rrpOcLgyk0qB6pwhKIEUKpWIu8az+mJ3c+igsU824n+7y8sqS1YwImyizpbtxDiowsKZjPVxSTNCMp8EEVMgCJAz5mnBsFOQns2PwZME2ayigngC8rSA4w7ISX3Iu8ItRIQsBeCgCUXGARgC5uMJd3cjlpTw5Zdf4dPf/j/46Ac/xrjbgTvaspG92nM34+yXdy10+Pe3BeDtM/tRAtcT+Ny6b/u5v+fa/d7PrevhFsz1z9p+ls11/b+3vn+u3Rpj/75rv7/vGe3axjfW91wHbv2171/DFRf5TsCt3X/5zD9nqwLsM+O+vOdy7lbOckQokrEUYHr4Fn/65d/jj//0M7z7wxc4nycQAfvdiBj32O2iJs3iiGR1IM/TCcfjI86no6ZNl1xTzpeqebf445IxzwuSBfj3PSLrSy2dYq4WHksUuJEJr4bqswAor2Vyzwa/Dg2U9BY3MSAnAohTQl7V7IIIspUAoNCATMM8VHlO8RPWHS4hlaP8PiKATBDUWnLr2PMm8JhiC85HpfJul7lgYGCeZ0zThLRksGRE1qRm7sLuLxZ/Rwe6qh22qJu91+iklC2t//rkVmU7rrcV/ZCC8+mEk5WOmc5aPzcVQbC4NgdWbAloYH0IXMxFkmsBbZ9vsbUjBztwq1rXj42Q10CT81mTKbrx0RXhMCNXxS7BeHZJFSxLffY17tEA+2Vf9PpewctE6n1ihJwIECKEuDPXUqDWN17tUVT+72NsskB/ulQhMy1JSyksE1LSsIvIjHEcMIS4Kl0E8jj45kEjuDLXvi7tW2wNNu4FNezUuhqCDZUYzJq5PETW74URBj3HAYy05Co3afgOVHnMNp82p644KkVphvBY5yCEgGGMWse3oCay8xp0xZL2RG5gjVzBvTUCbdr3A7RZ6wk7oQGsKpp0GrI9fYqHrNoljkowSlLpmckLKa8JKooH2wKleK0wYFVfol97IlDoxUztYwChpt0xwka9L7Y9g6GeeLeWYElJC+uJAQYm7Mexpi4OIajVoVoEWiC05Kxp6alP1ABjKPo554RlNiIeFFS4UC1AS6EP01ia9gkG3ohIwYVrCou6XcYQsHABDxHpfEZekrnahQ5PEDxPP7EAxAgMiycSLOLMpR1+kYI0a0Dqcn5CHEaMd69qLRki0kDjYQ8O6jpZTFuzM2Ls24S6tbwQnsVjjPQAFlJXWM86WWPXqnXSQK1YMhLQinCr+wqs0LYReLfqCZoWzjoW9gcMgRDHqHFgFuR7DeALADBr2RsW22NifUHl2zoU05Ya/+szZa5n2pwvqSUJqXEZKAg5K0E3Qi5Emrq6bvtO6LT9j0pkAbfiEoCBgCEE28Pc4dFcQSNHRl40YNetfpqDVYl2tqB7MYBNgTHNM+K466ynqPXStOua+wzie64AKDhPGefzjDHu6hiYgDEwjtMCogHLUpDSCa9fH/Dw7Vvs719jSQt++Q//BR+9fo3P/5v/HjQ0d9wOx7d56dZvy2Jl9f0aqPV/++f+0VtWfY22XAMnPci6dk0P+giXroRbYLV99vb96523fkYfn+bjKbico/5Z197TP8PveY7dbcn7S9p1y9rzT7kF9F5y70v79Odst8CY7z3p3smVw6wBWd+viz1t9DSLpqdPX/0Sj79/xG9+/wXk+ITT8QHzdMbucI9hfw9GwW43ouSkZXSg0boimhRqOp5wfPeAh3cPcFVCKRrr60K189Q0zapYFEut3QYHsAlea1ZuQExQoAKeYZh6nUl/q9nzz7kIRmpK0H6pKhWuz1lbxQBgiAG7IVa3SPH4OKCmofcEEX4q3G0LgnWtWqAqMmu/sTlLpMrLMA54dTjg8d1brfaSpWW9BJBKQZ4XnJek6ehjxGgeQCpI29y7Yt0JPTNyKqgpFl2mc4XXonKMZyP2/bJKotHtwR7GNRAD5DTh7TdvcZoTprOueckZHAOG3QEhhma9orZbPbsnw+Pv+7cSvPZfKdnyE6zdDbtpvdFuU6XODwcAYVn06mJ8LjBjsUQ6FUAyN5fFK28W8Wvbe+uUc7un31OtAHsASMMlcg3ostn3x1X+38Dadj60FeQ54fR0wrIsCATsYwDvBsRAFr5jzzdZs/a4Z6ZdqIPGXLqc0nWvm+ppSUg0IwswDKSKHvOGSouCNWZNekcGkgVapzgtCV7sm6i5QxJpCJCIYJkWc3MO5gEEaDhShghD8gSiiDAE7Pe7arzIOaMULeRelpbILZiFzeWwluf7dvtegbZ+BRTNM2oApIMSEwhrnaRckESwLFkJs2XBYSEgFkjRNOOBWpUKqhkR/J81cb2UHMyNLJf1hrKLV/VmrDUh6FJUcAsTLFDSNWgOluKgFjaPS/NsUu7mKKVYhkmYhrE7qIbG3Nri9NFDhlzIZpvLOlRmyKLByBoTFGwcpCFg5Mkt1iKmEjaFtVpvQkEwc0YpCTXDDgSgANjGBdwyopa80geBSkHJwJxPmM8nUBhw/9FrZeRey8bipYZAqmEUTU6z6h/RhaDKTCAD985YvNC3uO+CyFrb4WAfaFi92yMVk0Fj3iyGu1t3qXOt2cEW0LBDHEYwFU1Ksom/c2KGItVHnUmQpGl/e4EW3qftVrb6H/2jBTBNLlVi4Sn2AUbmTsUMtWRmEa2z4oy1i6rYVwAAIABJREFUFESL7/P4coJYILy5CoSg36cEigzmqPuegmo0a5C7neksVZjxszowI4dGHHWAbEBuHezuY8mS1RIGT2qk6jKNVcmYz2cs+z3AQA5ksa3AXQw450WLjgbG27cP+IvPP8ebb95hGAdMpyf8+r/83/jkP/x3WuKDNdbDBdlbovQWjFwDJrfb81DkpeL7c9f1FrMtoNre3wt8twDkLeCF7vst2Or70P/+HANb7f3N8/r3bsHin7u9xAL15wBr/5LNx6COcG3ut3tAuuuB6+ANaN4Bxc6oFMHT+RFvv/gZfv6//0/49o/fYLdM2H/6OcIYMYw79RLJCcMwYtztMJ3OWIrgeD5iSTNiAQgZWQrOs1rQAgEpJ+V53JLUC8TioRMggjBoNrwinh3SLSc6qNEsPQSz5tfPbmnqIUOFXzXmyXmDXqAz6X+rt4LObTHezYSqNPbZOx6PePPN17X8TO9B0yvgWjzV+hopBYEISwEKdwrwKrSTeRFRdaUUIhwOd/jB53dYpjNODw+YSkIMWjC7kIALgYtgWRaMzObGFlZhIaKdhJ8yTQii/wukArdbUqSXO4bQzr/IVZdpvU+zgRZQrY8lpZPHhJALUFLSGnJJuWbggGEY1AvGhKGq4HYXReZaC7XYvNQyApYunAg1gyMzq6uidMCrJzYmj7WmX6o7bWvbZHjRjA8ZJg+aT67YehJktd7+Yuk8cYDmvtevvVs1AaCIrotb5mrylkgYBrPymXzVvaZ7x/Xxdculz2bgMFpCkWhz3XldbRPJ9ICtj1f3PRFc2KrMQbr3AUsu4CD4H/+HL/HwOKiHT9I4Vs9QHgIhJUEIGTxEcJCacCREjbfjVssdIkAcg3msqQJZ90ZGySPGnbo5gvS8GMAAhQFhHDSuv2juhMzQWnzB0ioQmUxOFQMIMa7AifU+ef7nf71WY34uTqysPlbTLLfkIICARG0nuQiQtbg0srIgd4lTFzUj2bpD0DQHsnqbgOBFn8n9XGtX6Mbmba34nncB1GmL2P0iVVtHRGZGVQ1W4FgDQzezBEcbOWfNmMnRgEPXD9GEI1LWYorYRvEr2cYfLNCHmMFihFHUsqaH2uYVnmDC+6a1bjQ+zQR/Cw7lwCi5okSArJgjqbuAd1djqSICk6X6v0xnIDnh6dtvcCTC7tVrBGYUO2nZx1sKWFizhUqHXDYSoogBAXM3UHCqSdh7Bl01q6Z17YPa/TATecygvqgPQvbabm5OF5trATCfzjifFtynghAJwzDo3Ph+dkkCOvfsDLdr1aLUrafOJzWNsH93Q2KvxIJZgZS/um5WHWwRwWKxFn2bL553+cU4DBjGAAGjSAbQgofJBIjC6tbJ5PDHBcYMkfbO5hIkkLQg5+Q9rusEcXteUxaIFAxpRpJXIHJfcgVcrg1flgQmYB8CUlaVZwwBX775WhMCQTODklmje6bi89YLsltAswYSLS1zHznzoRaUl4G+9/++vW4L3m69qwdjvUDv12/BGV5wLXV/97/f6uu1598CgM+1567ZWkK37V8LkL3PWrfdP7esZ8+1HrBt2/V1WPfJz2CBCr5zmvF4esLbP/waX/zTL/D1z/8XcMrY7+/A4yvMWXCQUul+IUYqQDqfMZ2OePv2HabjI6yKDna7vRZCPh9RckLKGfM0Y9zvwdGACATLnJBmA2yWrKzRVzJFnI05BOzuDphPU+WlNY5GB1lHWkqLYScisCVvKmiui1v3Ob2WUTwBQZUFjKfaS0KMGHf7mp6+vnsjqDObxwwarW/AEqsyAx4OIYKW0t/4lwDY7wYQRTwdjzg+PmApBY0jAsHKKREThlHjtHve0xK0WScc3JqCjSRXkLsCKZ3AToBpldFcStHJNDxoLb0QkeYFKSeVA+1w1xijccBoiVQmMQf5GCAlI6WMGByuW+08UZdYklBj8rV11E9KDUmQep+Bv22GzA8gA1X+6b6LpLJcILXyFtH3evK4Js1L+4ekhbXQ+oliWaKl5+e+25gsvtFyIwwD7u/vcbfbqSwtsgp32bZt3Nzl+BSgK6Dp+QjVu1YW1yvv8O/a3kLdYyZ0VkygeycgxgH7/YDj0ZQuTChJ93wI6sqYkhbzpjlj2EUwCpbF9nG47EeaF0jKGgcpBnKJQbGNRYExoUiEOpx1e4hUcc5QXACvDAY3MpFf2e55pn1vQBsATPI1dvI5mO/rYvZ7o8+QmJdU/bcLBeQiyMsCDgViAckhRgRuIMAzRzrwIwdsbs0DuvmSatlyACWWPt3jgKSz4xCpP6xr6Z5rDjr9shp3Z0Q/BLJYOYKLIA7yqACpZKS0QGIEh2SWPnOZsx3e0r3n1Xvr4aGOCNTI4bLytVZtnqW1bRK9EubgG62zbtbgaQJxqgylCVgKVtX8Lxbsrc8LHDGIgqmUitXB0Pu8CGrOGTKfsAjUPdT2BTMQzcQspMRbtWWpcSfrh2ozTAvqB56oxm41n2W9o98rxabKA8ttm9QRUi/5idEUA63eDbfYpZTx9PadprcdB8QYVrtGLMSzqpFgDPhKjaO6vqAuSc9W7NW9H42ptug1HVtgrXFUfdMrVyFjpB4PuD0o+uw+XrASW4amgra55ZryuRfR102HqsHyFcBLWd3BxMjQWo0xRP3N/N/VbTSYC0NLapIsSyZZ8hCCBwYzOACn8wIpC+7v7xGC1oCjoGszzZNqenkACODHP4E+/6n1V6pWeb0WLuatARzVeb+9hv9ft35lZfP99m9vWwvdJnrm4tPaqew2ULjVBC2OeHPsVn271uf3AZJbsWn/GuDsOavd1u3wFojrr3vpfvJntHV8edyebFa4SEEqCW/f/BG///n/gT99+RXOX/4cNGfswBg/eo1xHFFSwdPpjKesSYBQiiVh0GQlKJqdsBRTnpKm6M5LRspF64CmpKCpA2FpSVimyQBbK2D79PSktdo+/bjbIIQYAyRllQ8gqMyh/teUk1JD2C+EzLbfOuscoElJ/AIDhEIqvwiAOMTKS/a7PT797DN88+YNSpqrMOjPrt47xliZCV7n113A+tgiKQQOTpNRZZkiWis1Z8HT6YzjwxNOpxNYVIEbmCyWWp8dghUKj6FapFZjr+Cq/VDsfJfKV6kKtgRUvlwsC3CvaWQOuoONpw/jAAFwPs/IKemTS+ctQyrDhcCIMSLHjBwzEjTMRMQSxlB/XpzvBRDlVYIsn69iLvwOJr2uWOXz0kSnnkGtvZ6uA5Ltvmk7zaU+qWUTinmIiHuaoAO2QM2iWPmNuKxnCmd/OgGesEWKprw/7A+4u7/HfndAGMa6l1ye9LFWY8mmv5ef+8GZQrhTljTxWjSTN9zKtDlP9W+3Krsct3kX+eMEQLA0+ppJ1E1oceAa6tIKY2u30pwQAoGr/CVISdTqCU3zP44DYBnks+QqBzkt0DJWBTl7zJy7Xbc1IGa1cnNBEndx1XdURRl5fO316fT2vQJtc3mLzDOGcld9DnSdmp86uemnA3CaojZr7Yqg2noV7qhu2SytpK1ulWAH3gOSrROdTClmKfHJLLRmgR5x0m8493Kj7hB7P/Xwox0Ga+wgAnqouKYRVvCmY9fTQ0TYDVGrxs8zhhAQd1ovou+HAziuaoo1oyWgcYEMR2io8U3aM6h2SWqpaIZASqqudJZpBO7i5mmC3QXDD6ozFCbrRwjgrK4iImrVBBiRGRwEIlEPQkr6LAJSB5iYNH7A0/S7P7DGPEVwGNRVZJ6B5Qw4yEMTTEQ88Uj9oqXldWLj7+xW3ZN6KGHvfuvXXJpgmbqvI2kMQQlWYiBnTKcJC3eunN1zBEBhLSrpmSwJxdLOhj6zs4J0qz9SGb1lMuVunjzQ2c8SeayjZWNS14kujtTN/hdNO8rcGHIDbsZ8fN/rTnI4BnidFauj6NptnziBPYvqoamlPQgFBUBaMsRC03zERQpyn6Y4oGnElwQJ6spQGFrkuxvXNGXcHTJmAUYrYbHkjBgi5pSQTyeUeQGevgQMtPXLdattAdv28/ZvWVGq68+6/msjXzds9DebT0VPBq81Qnd+Nn14Hxjq773Vttdv393LSGVzfd8f6X67Bupe0m6Bt3+J9tzeuOWCeA2s3frt1ve3xlZspVwd8b55c5tDKgnT7/4Bb775A371s5/h4cvfQ1LG4W6HYXfA6XwGDyOGccRSjljmM86nM05Px+o9Id5PF8qrwAbs9jvkpFa0xWqDKt/T3bDMC9I8o+SsNY/c0lQKTscTTscjPv3kYzgv1QQkjCCWBdYFVBdSZeMq7/0T1EQdOk/6uS9l4LuRiJA1LRpEBOdpQZ4TdruhPay3PFVivZ7jjrXUVdK6oy4LudLKC4FvYsNIXQg9duv09Ijz40O1QnGM5jkjmtiNTcFncUVeAsgVdDWBhLWUS1PmGv13ul7Is1saqKnzdoXGmQsmm/J9mRc8HU+YzhOGGDBaivQmM9k6+VpyQPSsg97Hjs+v3kkMojUlIQoVWFYwJMp3gNKAIuhShyoOIC7XDzUWsV/Qxh0ycv3OZa3z8QyBuvcyM8ZeDnb6RNrnq4DGZTrVetjrBBwiPv3hDzFEBaXjuKuJvHJekJYFuWaX3D60G+yN1se5kVmormWY1v5fgra20cUjbC7fK+06ldOlAn5mPUdpWurSX4u9K5YkhIMpcU1+iZEwDITdftT4twKklJBCWiWVK0tWt0nztmKWGrOnCQPXRqIMrTdXoLK+D6NQUUsrcDkXm/a9AW0q6ANcq0krW2YiTdbQEQH0i6xoACDzexa1zMQ4dPWZNNjSgUnVXpBaLkTTOplWwRkEmXaFEGYT/Bhw1773CSgucFcFkvonNP6TUyUkxa73g6gWIxVPsxQM7rpmQx6GQecla3ZNkLoA6MblGsTa3DicULuQ3KF5A4ZkRG5F3OyAV3cAgQVyanxfjIwU2Nww3dXOfNYtZolYNR5eaLJ3oyHSA52zZtFxlxqHeWpm9jgonchiACCXNndkjK+miBWNdQTU2krjPSQVyHQGlhnIpQNrVO3vfQp4bA94xy2doft+bAKytIVHJUn1NzJwQ8bwfY1SNvegXilAqIZQtyCRNNcctvkswuuuClArb9Z1NMhERjixaVXAUKbChFrXzJ9SE5bYPgBQAbp+1nnz10Znlu56a2uloJjMbcaObke8+7GklPDweMK//5u/1aGJRpDp8SzIaYbgrsZfqra5sxCYggTE4I9foSzSnQtluAoj1VIcWTM7HY8zcBiw2+3AIMzzjHGIKAI8LSfkXBAsHfQ2LkFn8rYAfq09d00vqL0EOvTAq2/vE7pv3YfN99vnbPnprfeo6qxXCLVx3brnGijcbvVr77x+XTvvcqUP+pkuvtM7Xwb1eoBzCxx9V2vdd7n/ljXsqqD8zO5aqzvb81bPF8FpOuNPv/h7fPuz/wtPj18hLxn7IWASAQ8jCAWBBFwyMjGeThNKWlCs3I3G+8rqmd0L9Z9qBWixUwXK2nJSIKeJsZQmlKLJS2qcNrlKlyCWGIWYzGWRTIiXlVWrzxjs7+y9LcgUq9rnLgZOxIQ0aFIlERzPM1Ip2N8dsN/vkOe1k3mVcUwxTWapE/++/uv7AVawe2sJQe2zu4mhMLgk5cuSUeYCYsYYGYDSslJUKZmz1qJyzw0x/iowxV7tAtWSLxAT0CnDXccJhIDcpU1Bx1ubXAcKRt8JCBHjbsA8LTgejzgdn3A6Tygp49X9HcYYwCFUntmvD3PQmrYhaNkWzypdmY17zzjvgTJaKgADS5rx+PgOQZbKK7Wos7l7buZYyuZEXixB+6Iv+UDkYSnr/c6mJDUMgDRpFkyOjN1hD46sbnr1Zf3bTY4h1O/99e6FxAaWMgpSDtjtIgbLXrgsGo6QpxPO5zOIgCFGE714865bHKk7F76+/ZyR0ckqY0ndE6twA7HEIy48dK+rawlgSRnzkjAvGcO4R9hbrLk/Wy5FuWvN5UVvITCGXUQcRxQJIEqgIWCMmoayFM3+PheraSgLMgJiZHz51Sv86pcfKRA0Och9hcjlXrfIeTZ3eU8gW9e+N6ANdVB95zXzIBUlBA4MnNACqCAOAMIQMI4BIaorVCFCrwqhYJkTTGiusio6MAXVSmjhTO2NCtiE5KJNtwe3R0b7uN3g0D5GI8QCIESzqikwdZO1WgHaHERSYs/BzfSwYEYNooQIct1wZCmFjYjDiltn1UI4a+7Zt6a+1557CmNNx6+jU1pMteC8FyEnBJCENv8VTLNWsQ9NAA+VwEIPZ9EF4BiwGwc8nTKOpzNCjIijEVsIKKqbWk5igMCyZXZxTspAjBGLoCyzklfWWIV5UQYS44B4eAXaFWA4oZzPyLMGNBfRwqIlC8LQ1pJhJQrqzNkrjYkFaXGSG2XsSuCobtLi39taGEELBhrc7E6mkizOMWEgzSNkob8FzmBqFqjKClfMvduCm+9W8QjBnutMGh3Qsj9a4LklzKFL0l2FFD+nhAriRVzI97tsvB1hF7iRXZnXu2/e4vSjM17dH+wNxYAWzG0qg0OEx7L0x46h8WcMAoYBc04YuOLITuxBDUoXKCMuuSClBSEM2A1AwQIaP8bD4yN+98cv8OOf/LfYDeOLwdS2XXOn7CjIld++23te0q6N4dq7NrzzJmi61q5Z527fd+XM3biyp2cbPXZ37zWot/6Lrvzmp6pRzvXzLq2jvcvnGmT578+5P16OSbo5lot9sb5nTQO293yotfCy/+2/Aeot0D+/iCClBYcf/DUO6RHTwz1SSvjm6zf4+u0JJKqAHMcBUhLy4zukaQJANalFLlRBAWBAwfjt1j2rcjJS9yVmYD7PKGmp7knKEjT+O5B6JTgfa+tkCYvMusImIrgFbwvYvF91NvwarNfNG/scFa1BmnPG3at73L+6B3JqsXPdu6rlCFAXMhFIlo3Hh/WfFG9UrkIaO9x4AePu9SvsxgHvvv4WGZrNkYyXxBAgBAMCUhXVLkSrowO5tq0J3E7XobRTLI15n/Iql86CZcpl31Emviqo4oBAhJwXraeZM96+PeP4+IDT6Yx5mpHSAuIB9691Xd113pWvVIU55ScBgkxQJTsMaJsy05XCRBrDRFnlRAZDlow/fvFbfPbZx9iNLgyYx5bkain013nyLbciPWslqZYu44sVWPnqqTeRqxV8/xYpkCSQlEGDJ1Tx8a4lui119XAet5v7O4cw4G4fTO7JWKYJS0pIacEyTZhzxmHcIToYX2GKnvL7/m/8HB3Aq1ZjoO6b/u8eUPUyAIDVXjLxDiWra++8JJzOs9YMnNX69fqjAfeWhZotdn2/F8yzJhF5aav0Q0wmpAyw731ASNd8WTKWBZq8BAUxEJgHQDQesQ+PIxFLYseqBOgExmZvs1l9D8r8foA2Ut/udN5BBg3w9NUUP/i+0BDsxhFhvENYDJV7LJVoAWchQeACKowhSCOq2WuRdIxTur8FANQtAKQFDau7Y2iWN88gWLXskYFUKmG78Lvq/6rvVpSd7Qc1Aesf7l8tbpZBB9icaHQuojXhhb3JLRw9AykFq3RVbV90hMQARalpJpUIFzAg6qVObH7P0L71QZRE1MAauX+umY6doJEWoXbw5xY098tO54w4RnDwjJQBJXkEllTfZAeWTiaUoelYHh+PKEWLgMdhAMeInBNSMrAx7rVg9zwjLbPVxikokTU7pQgocNXkwTS1PlZN1ELIBHARJBjAqpoA1PVTq67ND2tNN69VJ0LVQuXjdw2u7xEQIZj//hADmK22iRF0B4ECJWhqUHZrZ9t7vuuqa+5qr9lVld5LX+VM94HTGT8P9Ze29oDqJUBaQkE8MyUsdgFiGST9LnNlZtV0duHzdb0///TTLjur7TViBNaznlIx1wa0NMawrFPZ1izoE7lkFBngNQ91LFx1DsZJFUCL4DQtYGTc3+/BYEzTCYfDDr/69S9x9+N/wg9/8u+eZ9I32ksscXTl32vg6p/bmrhwu63FgMvPzz//EuBce/6HPrsXEfzzddfLlzPr0oGQ5nSG+vflk9eW3a0160OsYtt5MvFz1f/+mmuukXT1rpc3X6GC59csX+kTM+PV/WvEOCJO/wb0+oDz+YSnpxOGcFbloYyIXn+MGXh4AgG1lEySrAlHOqFQgCYLiKzmmgOr10kIWKZZ02iHgCGoVSFnjY1m0oQTzTOgCfrOx5V3KfjQ39ZgrCrPRGOy++/rbFGjkeQ5Zb0GLGt8FgdVVLp3Cjq6058Ef7+6a27WoQeJXRxxcaDVPWfY73AfRxyPj5pluYi6xCGixsCbRY/YlLjOI4xvqQWIagkmMf6om0WqTGXhXyvrhodBlwIEat4kFLSkUYgBcdiDpOB0zCh5wXyc8PD2Hc7TCfNkSaHG0ZLNRKyoYFFhuMpFTssdfTv3s8QVLjN4qx4z/fSCVOaptMBOXI3Z930JrKCFy3LS1qT9QPBaf+2b9TiWecbD4yOYA/ZjhO/WJWn84243ABjqOy5jzEw+rVk1ba1YQEKAtJq+TATkBfOiWUHn6YxlmTTZmAjCOMJjst6XzVC7IdXaWrUIdY6u3ePyEXT/OWCT9W7PprxeckZOBdM0Y05ZaxxbuSxi1vwVofOow0X+nhe3UgTLnLEQAGjMWwxkhhIbVtHYNy01QgBHxDGiyIAvv7zf6nlM+YKaO8EHSYB5EmoI0kvEie8FaCsL4/Tla+R5RBkCMKIKjddqqHEA7sY9dvcHLNMMAZmpWbPDcClgCfU4uXFj7X/c3P1WTI4ApwICXZytFWXVbqDifvJ7gcuvDgZUHAhWIu2E3wR2uiKKVOFUnEB0faD2myb0EPcKWPVnvTuo3qqMrBszEdgSQQgFCHsBU65l6dzdzAlyfbbAAobJBCxqbokNbfmgavFCdgZnhCdfaDpLHXuLc5JK5ABBSQlTSpiZEYYBMUbE/aEGpQPAuNshjiOWecZyPNa51Trv5iNPqNnv++76tJXqUmnM1bEWUDVcxYLE/d8eIPXPY4sPbILAep1KyUgFONwdFASJA2TvwsUmh1PcGkNgi+yWpVqnxvecEV/ebBrymDtCtUATESI2dNkYpmJY2/FWf02g6fedyKtrUx+UZ8TWmCQT40c/+pG6lcIBlrk+EEyLniBFGUzg0NWX6QVLtSeXnBFgWcOgwH8pOobm5qpJB5yVn6cFu/0AkGDkgLwsyE9nTG++AH7y7y6Zb52G50AKbf5uvd2eyi2oElzGq72vbcHN9p3YfH7fM17+3sunXlqnrgilL3r2ZTM7zQrU9GLTc2N8H0C7fd/1az/0e29qLdyu1uUzbgE3bdfsbref0/7+sL5efaYIpGiSoMenR0zLAq1HRMhLPdkgaGa/nBYMgRHv9ureaAmYLldPR0XQORrGAeNuByLSIspJY3lD1Ni0UjSjsGMiwErSUPfcTqiutTg3E7H1TAimDF0J5g5ygPXuFnG/8fo9m8fBMI4oy1xT4V+edFqBs75VS88GVBA8PF0HomVwCt68/ROmadGSRdVzw85JZ90jA2xq9ZSqgCvQQsw1cMX4umemBIAszSXfwZNPsUYzU50F4ohht8MQdT1SmnA6nyBJ+0eecEPUuybEiN1uh2EcLzJqi/PfztKlXikMsmQb3gctRdTRQDKe6+h99eAOeULBQzOINXlJ+nV7hkC6Al7lWuqeYZ9FcHp4xJMIOAz47PNPDZ6pMtbXcv2OzX4B1FW1o6i+F/xcioi5vRa8e3jAsszIy2KhF4zdMGCIXuxZroznkkqs2rXxX/muKZy7+em+LwKknLGkgnnWuns5FZsLWMK+YAWuNaszsUa7i3B9JxMQgomhH0TOBGlJ1ULHDBBnCw/S87Ys5qLNASHqvpuniN9+8RGG0f0qFKpXCqBC10quJ6CG+NQYkmfa9wK0SWYsT3tUKxT1m9quMTZUBJjngmArEDwGjjSrlPowBwQm80uzzQCAgtVa659rwK0J26XVovLr3N3x1qKnAgkalOgp8IX6vrd/FWM117iegjSrlSZOIRMsi1TvtTovIPW11tJizspaB73fLVAbraYMWWyV+9OSZccMESTZCJtagpSfiA1f3TQYZFrDNpEN8HlclAnam0kQuGbTugwnjmS4T7UlQQMIQZkq+KnMVbiro+JuR9rPDKi21i1Q2YSIaQKfz4jjiN3dHUKMWofGizeaxrGIlktYkmokYwWiNg/GpHuZyh0u6vJ0kjHJep2LSAW9QGOECVgRsTpbNiYRda+Z04w8T9jfDTgc7lW7WgSxKQbrPLtfd9Vu2nM0EUkDZRrv1gM0D6bTaxwg+z5i0SyUAtR6I6G0QWucYQEhaLkC8T3Z3gcDc4Q+jkV/Dx5gz4wvfvc7/NVP/8p+zagxI3DrYq5bP1vspLsSEVvhUCeQuWiNPI/LYEIg62evoSNCNnlLoJk+52XCq7s9AkVQLshTwrZtXcqutfdZnFzY7mkGXXz+cJDTb8vrgOf2b00s8f9uQcFlf14q8PfP9SetLZG3wcT6rbSaq/XzfQx+3+35u9Xv0r3zQ1wNn7OOXWtrjvX+5z73nAbeLp9/zToIuO37/c09U/xZIoJcMuY//RxP3/wegURL0hjNLrlo7ayoJVmkwJIkAbvDXms0mmX+quxbvyTEcdSMgiKaAj4p33VQlosKXEqA1a0tsgtRqHS5B2/VxR6otbrW7ph6XakgrUs6gka7iwASYC7+aEwXzvOo1nhECM1drwrXbX7VOHLptePn0eOUfCEcIyYRoBQ8vn2Hp4d3gNVvg/GinNWy6bwv54JgBa4hgiwak6yp5HWuCqlMo1HFAFlpnQpemVBSAcLa3X1Fd0QQwoBxv8cwqHL0+PiE89MTpjlhv99jHLQ+7TBElFzAIWhduBgrsG5Z3nxx2onU2r4ag+SL7Ym2xAGatJg2v79vree2JlW+yPXSKhfZglTXP2C1b3wGXAZwDgFI5y2jV2Zzn40jmozRr7ugZp9Ch7OMAAAgAElEQVQm9Ay/Ubnt2S1FrDSB8rElZUzLhDIvyJIwcsQuRsSoCVw4Bng93mat66f6Gf7VGQxaWs1+LtcWQClFvZZIj4ha07LxW4tPzbnKeswMHqImqyO27JqElDLyPGMYF0jYa1I7UotjLoIhqFJ6mtdj+ZBWCiB5AUoChXH1W4ythMT/+r/9Zf1+7XkBwxUK4zI0JMdDcNh+F7pY9ov2vQBtICAOWsuJKMJoWz3wpaIdVOFcU/2KuhpgxLgbsbimJQRk6t27gD4FestACJDjONM0rcofGm1YrhQ01J/bYaGs9ct6FlmNSNtV6BZGnKhvpDMGLFkKgNA7jkHT5gu6NPw6Po3x8YyMze9bRPkD0EACQSxQ1wkhIKJ2j1q8nPRdZIRd7xdNLBLsaWwDpGAxRCbWkLpTSM4ABwvGRj1MILRSAkYUA2uSiqo9IUJmrnFlPhgSNSUnZ7LiyVw0zkrrcbT6fA7gchLktGA6PiHGiPHuDnHcVbO+B3RDgNO5oOwC9p++Qk4LsCSU0tK9woSwKrRst4egvj8Yc9OsVMr4ywaoaPdpIzJRZwFShiQlI+WEt9/MeHh3xhCDxpgUz2pp4quNify5vh494KSLHqzmuf83BEISL0RNKEEL2ZJtZvKMjaQZMikEyxqmxdlLKZrVE6VmHmtxAJ0wWXSz6jbS2n0pLxjF3EIg0AprRYu2pgTJ0qzP1f0j1OsFASOAE2vhepmKZnMjTeTSB/bbrrZDY1XUBJCsNEcDiLXgZilFXTc357vTKeMlTVafBa7bLmZRdndcolDLa2zZ9ZUVvABpAlxl9dd6Sbjubljqb+te94D1paBmCyi8T73Y3v++jVlb39ufQbF9Qpt+Xl55q22tWSTmPknvB19b8L4FYZeW1nZ9uvJsTwTyIWDRn7ehJu8d+YXQt3l3faKodSWXjKUsWM4zztMZ07dvkM4nrXeYFiRLNHJ8elJQlRm7oAL/YbcHiDFPS0v9DlRAVDtUh908UpZ5wjIvkFxa8gnnKVktbBrPXUBxwHjYIy+pjdAEZlQgsBLVlRZ1fCcIdG08G2UH6lZWNwJKMSWYCxmdC59daHRP4x1uKj88NgMKMjJgrvLKdcbQ3IS8/qnKSyrFLNOCwGqV9Ix3Hr+Wc6tN6oWUHQ8VQOusIgOkcT1sAC7UJGnrXU0FmszM2KMUARW1ilC1nunc5ZzxdDzj+PiI43nCfDpDiDGMo1pJoM+KwwDJCZGDKXNJE7Nck6s6wMRECK6oJBU8xORBgsWvUwNTJKtN1j2z8SYiufTUAlXZok6GXbPO8Oj7xE6gabhXYqXJCP5MQUsp729z6x+h1cNd7xu3cLaOKlhLOJ4mTNMZUhYECtiNI4Y4IjoYBtV92ca+3t86lJ5q9+Nr/+rW14Q+1VMOZWXt8+RAKRetAZsL0rxgXtTtETYXHCOGMVreh3ZmUs44zRPKotG1xKGGzkBC7XdKggTCfh8AFkzn/J2BG0AAD5A8AxRAHDAMnqEdOJ8jjk+DVvPavEOYqjVNw0aURuXu0T6/7wu5+H6ANmi6bWKtrSXeLVLiAVhQqxgahQqwrw47hHHEN7+7A0BgLtXlkF08kZbpibqUwkABKHYnvwcG9nISqx7fC2KAqdK6W8wET4QawNQ/qxeOjVk4oKnnoHIKfz11gYyCyjYJWkU9G2CoZ7mJZrmoJSXEgDwn5KIlK5jXTNwFGxfuGZaIwuYkEpk2w4AcrMi2tIgnBRVk4pEYXTYrGVBj69zk7VkTW2ICFcCZAVgdFPVucGe1fo6VsAiaiyPq/FmaYxAOhx12uwHzvGBZsjKonrgCWJYFy9u3atoeBmVIHrRsSlABkIUQxjtgUMCWlwlYFluoy/gRQTuwngJfTARs8oJnckQV0rbuAt2wu4cLYgiAFEQm5FLU5ShsM4J2STVERWoQVVBXze+r/cvY0gr/2eMeuEvnH4oVULcvyOqcuFAvZLX4bD5IVHNbvMSG2FHpa98AStAss6vOE+E3v/41/sN//K+RRdfYM2AFm4OVtls3MnLJVjpDH54jg2I0y7qvHSGwWu9qpk538xEFwcEKEzkhfTxOAD/g/DQh5YQhxLqml3PXucO+oKn1IuFe3mBYHjGdTyi54DEH/CndQeIdPn51j9eHV/Ci3FuW2a/bVhSUzXV05R5va3DUA47boOd97pCXvbruxteLgz1YWJd2v3zi9r3XANv72hZoydXvL+ftUpRZX39DLN+85XrjK3dtQdRLAN16Hbf7dTvi2+9WYKCFs5+ejng8HzEyA2nC6eFblOWMmYD54R3yMuN8Oqm7XSCMQTM4ZiFMSfPDESXzzLgxD7ZpPUujZIt9c6WYZ2izekmAlz2hym+CgZ7+Dc7T94cDjsej8XAAm7UDgMW/8yy/pnhrMm53HskBv/FYM9lXeGbue93QUGmFCauuZKurUzasoBQUCAIRZgAsajVLSa1BEerREqMmOHO3zlJEa+ExWaFtS+9vwBLMiKTyFrMWJvY4HC0po32ECaGVD4vBGGrySKH1OSkAKC94evgWD09nTOcJ86SJw/Z3d/XaDJhLbdH4es/46woyy/atjiBUAU9v3dM1YZv/oLW2rgFz3VgX66ifreeSUTYp9Ylue7G12K5OqOt6VlV6HQEWf3cX114V6r5uFa2iA2x+tz25V3jA1qQswDJhCIz9/g4hqmeJ1hJjvA8kNCDXv2t7jWdQ9bFJ/VdMOe81eCVnzCnjPM3IOev/k2UchWXVNGt0iFqHVbK6XGeLZ1M+rtb1ENWFNoYBlEVlc6K63jkXzLNgGBm7XcA85yo3f0jTeMEESAbHiGjFtT1Xwn/6T3+pIJVIZXTDEGQ5IYRUzqAs3fkWBPMq0vPzfjr+vQFtul+7NEid9opYa4RURwGx/ww77O8P2B8OePz6VJ8DoJnSnVQ2CVS1RjBtfq0Rptf2wAr2uaYJr9Tg0mUBxF3wkyiyQrd5twPuMyvBiUjTMqnGxbpcXDBHmx82gSc742BY7j7ACUrZiC1tSPAATv+6EhIL4tJuB9SoE2piQsoFCdlqF7rAvB6j16Bw3W4RWlkGm2uFBRbXUgpORKmuvb/bmdiK8RJMs9bcRTgOGCNj2I1Y5gWzudDk1FvKYNbIDJnVz5sG2xOlACWhZK0RI4PFGnLAsLvDMKqbXZ7OKGnjJifd3qm0dBsHsRnE5s/ic24/FGq2B48VGwIjglGyMlt1k4Tui8DqDsOtIHY9N6t3d/3ZtGyghnQ71Ayqer1ZC41hepyioFlTfYy+/kyWwEBMMDICX0oBe7rvvluk4eAXxeql1VKhwJpuC67FNWu5bUavZacdCaq5hcUsMtn6S01U4u+mrh9rhqXM8nQ+q0BkGmC9tK3g1r6hJ3ul9lm1XrAZZMby9ku8PT0ChRAYmFLAnAh5JLy6O1QS0PH81bJu347u+v7z9ruXtcvN2+yKdPFd37Yqo5e0l7pZ9td+qEUKaBYlfc61UdpvV9T81962vZe+Y7/0WZfjep9FsyVVuT6DHzKvV/skgjQn5Le/Q3z6Vr0d5ic8fvlbHE9ngAUDM+bpjLTMABgcB43pkVJd9jK51Z0vx9PLutIJqsSqmCRCiGzGLDHrkcc5m9xmwI1jAOZ0oQEHCJ9/9jmWtKy+VRfvpoPtaaSTr2aNRQNbIGgMt9SsJAoomisjiwURELp43cs9RwaMXI/UW8k5iAqf8P5RFfyjATRXDFZxilXRVVJGCEGtHkQWRtOEfbfUFfI46xqcAlfIqvWQ4DXhdNgaMOa8zkupeB8U5Arm84TpdMY0LyAi7Hc73B12dd3UeYdXgndnpgQ8w6gLa5v10a3TrGSBA4YQUSuBit3nfcba+rIWnNnAoSle62asL7JnbgRu6j8IthnFqXsaqPdUAMRyM/QEWkFs6PIZNPm4p0BiRc3EYg6JAA4Rhzu1agemmtnZQd5VJvGCtn339iHF3BNzKpizJhFZ5gU5Lche5qgbm+cyqLw5JcznGbkkS0anHjVjCAhDUMA2DBgCg2NAGAOYgkWQkWZIpaRKlJKRZy1jcTgE5Awsy+2skppkpBuVCCDJlPw7lRdRkLJa1mOkphAnwy0EPbie6RRqGMkU4JZHEGpcpp+f9+G27wdokxYQGqIKQi6GNSHbBD6dEcQYsKSMr/9QgGnE3SvG48MZZEUsa9Com+bQwIq+8jprrgYZgiYh4Qa82lMctGltETV5olNP6zX9gVg9wX17OQBY9Hqn4iKqQawHQplQFXSpEWgXKp2oAFTroQXLVAUsNgasJTzvFPlblLkEm3txVYTLrGSuCSh4WhLSeQGD6uFxxtZKm5vAbsK5CuAK5IqbyTU6rs0OmXaUmxuBEJm7SUYRUXc0aUHXpcgq5NADjymoVjAOQBgG5JSxLDOWOWFZ1Px+7XAonzDr7jLj+O4thv0Bu8MBIp5ZjBHCgGEPTE9Hi1FTBh8tfsE1kKUUY1bcaaOaMBBsPX37MKmVtGci1b3QmL7zqiiEHJTZugtpyRnn4wkSBgz7HZaU6qbu6bM3KWZdxdrS53vCtake3F09eZlq3IafIuniIOpk2m9JOoWIPcXfViAt81kt5L3drP6Sbq1gLrUlIcYAkY1blY/Bz8NuRMnF4jXcatwR2P49/Zvdomp7WTh23WkMt0jBeZqQUkKRBuaZB7y6u69ZMK8J276yzIzDbsTHr3+Iw+6ALBG/OR3wY1EXMA5DFRS3LPMaUOg/O9Wq64W1Re2SGvr3tPn72hsu23OWnZe03j3Rn3fLQrT97n3v21rC/HM/P32rwqlf2yk1pPsOMNdR2vZT//td5qFxqpePa/3ef15br4H9KwI6fgl+91vg6cFckTLmecY3X/2/1L1NrC1Zlh70rbV3RJx773svsyozK6uc1VS52o0lN9hqM2isBgvJIzBSDyxZYgTIkif23J556ikSEpIHyHjCzwwjwcAgIVp2Iyg3YMoN3dXVld31kz+VnS/fuz/nRMTeezFYa+29I865772qtqUiUi/vvedE7Ni/a61v/X4KCgFvPXuC+7s7dd0OZCnUCSmpMoaCAQJX0D3eAQAeC03mNlyMVmvyDEmpJo8SEavTat4X5lbFu0NewTC5haJ9W9O4A/U9/aVslpsFhGyehJUumnWtWoKqKAnjuU5T3C0fdfN5FkagAZ6+n7lkc/RRulkTrlXaS7XfOatC0kGcxuoyRKts17GRdkTxGDT5WBHSGDwHdOJj7Oh+D142NWydJqKCSbZOURwwTrlm/R6GETEEcGj8Qt02A6pDryk+DdWYHNQFwNiRa9jOk3T1cKjfUK0WX+ut/26U3flmXRjs2rjATzfgrUdBe9rRvdnmue+LACikQGaaRpN5I7Z5ELo+V9BtT1N7JzNhGIbat0vWHJVNGhh+zOLj+4CYTCbxz+19orFp65qwrKulxV+RU6rhOzBlfIzRYjsZgdgscQn5tKKUUmVx9pppkTCGATEGnQsLowkE9egKKkVRNRCYD1gBCjO4qDs3scZwxquAnFtJAPeMAoC8c+sIQQu+q6wmECmW6IjhLqDixbFly++4yxtqW1JXxs9eF/P6/x9LG6mzXUYz75IEyzTHZsp0sVZMEB7wpfBL+Pj0h5CjZqiKAWbCpxbQ12XA0X0lhuTVJUCt3lQPSo/liJUQOiXwjUlgBVylfqgp/3fX5shK94E5R28Pt00EEbxux4YsdDTHAadbJ2IAUrKCmCDEAZizCxlioMemgkwYMlCmwNJLJqg7YJOXt2KTGChLa8GaBIGhhNZdII24VcZEmikMxgBdqAlQ5kEoyDnVOmm+cUUIwowYuG5q8vT4gFkDnfEpU8lQi6TyS41zKFFTPedcwCIYeQKHCOCEdfH4BgeJ/VIQND1uQV61LMB8d4vxasLh5gmGGJGz7kkxaVgEWLNmFwtsGTfFYgCMAexBkR/ekBKyWVKre2G9TzQdsyEuM6AhOCgR3w1tT+WcscyafOXqasQwjShFLVQc9E53ewUETGIxAFT7ti+c7QzQrWXkX/R9dVToQktnpfIkAaVIswCb+8rp/gGCghiizueGE1Adp4ZwuIDUCOyyrBiGATArc0Uo7LF0jFQKxvGAeUkg1roqPdcTF6NU8wDJflhs8A4qSQXAIpp4oUis1kWAsKYF//yf/R/46P/8H1Ey4er6Bt/8ha/im3/h1xGvrzHxaMlR+nd3vSDCOE24PlzjMB5wKhGhXG/ic/fiR7+n+p8dKdtce8ca2n1+Joi4gLn7/Jy9SNee/l/p+mVwtW9jf8cl6+WbWoiaU3JLXHN+TwNavXub98utKZefdgFWZ8bfU+PoNme90dQ9AKILP/vvevts/723dQ6o6aeeK+Dc0rjpJNqLe1fkvMxI8wlFBPO84P7+Di9fPMf93RFX1wc8//wLzdg6ThjGSS1qAFJW2uuFo/3Y1VfKrt+EKuC7JW2Ig5b1KKjx7YMl0xBhdde288qg6nnjgpHrI93lvkBj4UtWZUtVrNb5aTuJ0OLFW59hKfG3Y6lrz6Sx4B2VdZFgs6qCWnrHZQ8iWMgDIKXgdDwBAkSLi3HeIh3J8j6FwecBHkBeLQIkVMvErKUlxgistVu1OHhGgHp7BLRt7YrjQpYN0evBStvLgtyEfJ8X0RqzwzDoTaxp/4W4JlxrMdy6ZsxdWZbuFGxkKl/L8wWwSdGENO0+O7XVhR6Vn1EITRasyyLoXRKl9kGqfFMsZABQuZG6HAebLU2bH3Wx6t4kgeQV81JQEBBCafurf76THzeADcCZZc9lpougwAFue8R53aWQjVK0DppYhlYRYC0F66oK8WVJWJcFJXeWYLemmeLG31FKQTqeUFKp86tAjMBDxDgFDGzlIYIZCLglSiEbq9h4yeottjnR2FYRgReOoqxhWDCacjiESvBdCePDDqy0I2dBSjrmZOFHgMrLLiJEXrFgrCIIsxYHL7537WznTaZDqOtzKcDQqxEev34uQFvVlklGtjgROROqUA+ja69GHvHs+hnmNOG0JgUQzkcvEU5vyyNAO+LmmV1aqjt7klEPth7cuuVqA2R+q4W6VejSjrqQWzM9XbBStM71QkLrNNn4xYg5B+1bTlYHDYKSszJGIxjTFLEcW29rPCAa0dFX+g7V2iC1BpndXIlwLmrdgpVWYFQtI9n89ASFzcyth8E2so3D67ysa0bJwBi6zGGVQJtrLFCBmYPN3DGgIh4F2bRIRITj7T3m06zZqqJZuUQzUhE1lwh/JotUzaBqXRqxLVIwP5ywnGZM04ir6ysIR00ZIWJmcgAkePLkSg9yWpBSNiKszKR3kfRtmp1J+N8IICR4YLIL7GzasAItHOoL05Nhgmb+Kqwa2NP9Ax4eTnV+ITsxVHQ/kQk2yO7K2AgNUgaNsRPGpbrHkDFFF5DqGdioPf195JNptxTrL9Tldl7UBdN8gbJQB4iAd997H/f3d3i4v4cDqXVNQBZcX1+rssM3OlCZFJFa2hrD0jEMUf3bm6bfT50xeVipnxqDouOaDhOOyxGneUEIATHEOtYoCXff+y3I/IDjKUOWB5zeeYK77/0mhg/+LPjtr2AapjOB+zIoIHx4vDqjEf7U3kqG3d+XPtvJ4J2A1b/3Ul9ef8nmpzG1R+7t+7LvU8E5GPlZrr4fbiVjI1b78bjlTJ/YCX6vfEcDSA7YLlkInbB1LOHsJ3U/qX/Wrks9+mndHF93v5Lr83vOLJwlIS8POB6P+PzFc9ze3mG5e4nj/T1AgnmeISiIHBEhGMepzZBobLCW/Li81p4cQcTKzzChlIzDdAAHRjB3pLRmAwJsxZ6VL8YYLIadLKGQ1THrxuPKNAoR67wgrcli+EiFwG6TEjS+nXcEVwTVZY32kr4tpNNXD7HQOWa0iMHumaJWCrGY9QZENCbXrQw5Z5SsdLhUeooK3ACn35Zmnkwh6EAZHvNpyjxpvShFE5KJAGzGF18DCweu8hiboOvKRB2gYJPQjXSOCul7iFTZG6JaKTa1Qnsg5ePvZNyaDKQHW/1PG3fLNEmQwBWgeSKMZu5AlV+05jGZfNOnzrekI3VSt1erQdoSYGy3dJMT61890SPzEEIADxGBI9KaEMuCgQsKWU29vkXaDtzVgI3e7s6wdHO5ZyYV/W7nsfdaceVwzgXLuuI4rxZjtpgrp7SyBNDxsFunQqjNSilWMzchrbkqRzgwYhgQI2OIEUMMiDFY6QGfP7W6EZwfQxUcJiOWbjMo0G8zlnIdLAAtQSJJwKweAgRBCNLJR3qV5OBSP00lVqVtP2FEhF/7tR/hf//2v4L7u5s6f8myXDqcEY6AaJZrtOkFTJl+5mZ74fq5AG3SC+G2uZg8SBLQYTUiEDng2dNr5DIh3T9otpas6L+IZoWrJm1Uu5Ra2DYpF7E7XE2gbn1rf1eNFhrx0wQbZuK0zd8UIMoYVJb0g1FPKYBggi9VwOLdIIL6uhYFUT2zca0J7CC7x6xmqHLCsLXsXJj11iJhSwSVOsFfUw8EUY0faM862yETiCxDlVmvNC+J1vwIQWvnFbO0iFhbQt08e/YniwLqGS052CRLJuGfN4AgkAoYybJoHu8fcIIWcB+GWLP9eJtMSqx7//w4aOCyFKmmeiLCEDUV8XKaEcKCkgVpzUjJiqUnIAnhMB6AcQKnhHWZkURjJtitt90KKKNwwRE1gYcziWJgr+ziICshriO3swNziYgMlFyzo7q1TEEMtaybu70i+1+6tRSiWmSVRMAF5t6gRSLZYiUYVkQcpC6WRSxLmahPI1CZJwfGxIRMrUKVykaX9i9151HnMqcF85Jwfa1pwlyIkH3Num7Rcwn1XIl08ZSdJaHeLh1vg+D+7han289x//wTCN7V/V2A65AhP/ldpNM97h9WlDTjlAMebj/H3Yu38HT8PsI7X0OzAPlZPRPdAAAv0vDGAOpVJ/0x0NdTpP3n2+fbPO77fA65LvXtklvj+bu2gKXv2WPvPm+v/8b3UR/Z607Z+znp2wfOgctFILNjrv6eVwGjyzvaaKHRrrPzR6+a3cfec7kPj7//p4N/5fgF7j76XXz88Uf4/PYLxJQ18dOSkNcVKWtijPHJoHEgwVyiRekbh4DjskJrOjrfNQHIUr4LNHW/8m3VoH3w9a8D0IzPOakK0euEBvY4LW3D3f0ArvUbRbaCERGh5AX3L1+C7FkxoAOhVlbH+r2Zyyp02Wkm489V66iCWa0ttjmEYspeVEAgAJYl4fjwoNYoo7saLSGa7jxGtUz5+5hAxQAoOtmFmhAYmC3konNL9/U23hMI1b2ySkwu41dRqjJc9ZawJFtkfNJB+GZj2fiKTyJRjWEqqaCQJRpx7wNRi9Yll1kHUE15369FZxXqvmCYglyAxu20Ha40RqxZqqWaHPCquZIrmOvXvfbL1nq/r7rewSkbWQIVVUwGDOOgsYbkvh9mXYzmxUPqIkp0Tm/6tj2u3T9rfXHvtdLfDreitaQp53RVRJBzRkpagHv2NPzLijVl5GqV0p6HISCaRUwtjha6kdQYU3Kp5xhEmGJAiANiYIRxwBA8BCBYaBhVl1nUuekXCFWe8f2xDWXq18jXrd0bWMCWITWXiLu7bwBScDh8DOYHk68tOQoBCcHowRlw0IsDfuVXPsVv/MafrLIYjDa05G/GCw1ASy5VyeD75o8N2ojoPwfw7wP4VET+NfvsywD+awDfBPAhgL8qIs9J3/afAPj3ADwA+I9E5Lde9w7A3KYMrfdXUwI0NltEE3PMy4qX9/dV8AoxgsytDVAaJcLV3CkC1bqJB2q2ySeCJnKo6qptHxxtC0sFlpVIBpP8k/azpkWwDSQETRjilkDrjMaaUYe6mzBPOinwjQ8DRc0drgM91o9oPrdEapY9W0sf1pkUR0ociNrGlwIRMxurn6jSanu+4p7u0Augrnyd25yUYrHLVFO9EzMoZ2VItoFrHSRrpxjw6pOP6Kt6J0wnv74Q7afWkWtuaAK1RFKMZmlrY5cNAdBfGRoLgKB7RZNm5o3fs3Y0V5ACqF92SStkiMrMecDhekAaV8g6Iy1r13Opa19jCCFAR2B1jjoA0f1CtqY7Rx3tCRkQjQERqjlcszLZUlS7hBAgQQWaXgvt7bvLILG5xkA1rcUzIZFZAY1os5WbABFCVocitdjqqnlwP7o921wOsYlx8bErAw8VWHEr+gZmKDA9zsjHB+QpYBhHkBXghDThNRfFit6Gj22TYAgdgCN7B5rArnSEQHnFi09/gPV/+0fI4YAkmlvuG3/iK3jvyQE5Z0hOJigVfPrJJ7i9u8dXfnHC019ccTW18qriexPV4ab25SfLWPfu/nqdJeoxKEXdT9l9/hiI2Vigdm3q/tz2+1Ibl4Db5bv7Wdi36UC3d8PE5ve9e/FFKCI4q0H/ptce2PVuyXtXy0vvPTvPHUg7B7bWnqDSqMe63a/V3gXzsavtv9dfG6WOKP24e/mAkjLeOlzjxRdf4PRwQlpWPe/MCNMIHgYMw6hKPOPvApi7FCP1iQBMkAlRXczXNVlqc30uGN2WXLTIfRFEA30q4LknwlYNQkSacRIdeyebNSlIJy0urEk6kgItnxVp/N7LlPTd1XvMukC0eacLwgTUmF2nfTWLLrQkTH1S0TssbLZ+ViUV0lACikGTPFSZRU9HHa/3oQMTBM3A6rKD81pVsFkqfMsJkKHlc7LY98WsdU4fBSgoWFed13GIrUyQ75edjNHTHrKQDKrWS5sBn7fuXykqO1HflmX4bbF22mbjWrCxA803U9PQwxKoCTd+LyaDMHHNxuwvZKdeRA04bCjU9lS+Suh2xV+2EJ5oLr2usCHWemlBJXl9P0NBKQEFlmSspxodUKwuhps+OTNtf/qZ8rWqmZbtuzVlzKcZp2XGshSktNZcC37WgGKJ0BR4hxA1o3QRrOtiVk2YfCQqi0yDATsNf9E4PV27ENUbplpeqUfde+EAACAASURBVIXE1BXdgZoaTtWBasB59ZayuezmSnsmQRwiYhzw4x/9Odze/wmEyDjMP0HgW7z91m91B6Xt+3171lWViy2ZCqw/YSOp2j2BasxclX0ugv3L15tY2v4+gP8UwD/oPvvbAP4nEfm7RPS37e+/BeDfBfBL9u9XAfxn9vM1Vydw1wXrhXibEav1IQCODzNuX97i9vkLRCZwZMRxwOHqGtM4QUA4WSV1PRAaEAhRgsmgFtPmhxtQQmCSSNvHJuR1nF7MDFUPc/a+ub5E3QuLD8cAm1FwlJRBZEHEIsZqLaU5qSk/y96y0mIABMbIq0bRtRDq30uylUwubgXef6q5WQua0MzWJ7GiahLYKaR3yeisFUpmMqIC08SRMiVqCScIqAczsMaCocv+BxdkSGOhmKEJO30cVBPyIDiDsnljP+jU+qg0jkAcQJFV+9YdDtdyO/MEqz81mZbIzfs5GSCyRCmlAhDTDhbdAfNdAqQgTlfK/sxUHw9PkMotZF18Adp+6061ZhFKKnxVhtOOhvN+ou267nQNbe3Jp6O5AJ5OCzIIa8o4XI2qOXU8BO+P7ktOQBli9Q1XsMOIuYHLbBoxFp2XlQmDWxQ75UjfpzbiTgtoP4g1y+P8cMRgtfR8itQ1VycgEFuQcQZLwXw8YTyMQKENM2Ly8ei7c8mN4PsZ9rMKMgVHgwhkkg4bkMvrCZ/94Ls4nrT8g3DA+vHvYPnGt7As9yiWjU7TDQPCCfn2U5QXPwK+8i00EUvbzyXXmm9SMrYpnc+vc/fKLTjqv5eLu6Jva3v5dtw/tdmmO1i1B0d78HCp/5fvfRz8nVkkxUGHoIop1PXpgnWsOqR136l7k7e97df+s/MYOBMOLCPpfggbOnNhRs766GewgrQt0+9jz3aP2H3SKbfO98el536ay+cq5wyOAYfDhHWZEeKAEAgIjEIagzUdJsSgdZZcK1qyYM0FgbfFmQGlndEE5j7xRckeX0bKg2zOma10Ckgz5oaAnLMZ86m5S5LHULfNUWOASPlCCKxh6VZyRPK2zLgrmOrf4uCbtrRsJ3TpsG3PsJVEFi1b4smj+vdo2n2y50qVicRkhFIEa844nRas84xxjEBRcdUBrnueaAFf5xfN+iKeBcveTEXqfSANQwi2j0AqmAYTvwQu1Gv8UikFIUZkCCJ54R9tLKUCTKhjNBLqb22osdJm+2MD9lDH3nhYk57ZkkpJ6b2OsKHnvrd8LRyU6rx0rpj2X04rioyAyT4wC6wHydSO+ZqZi9927f33Rkm1KU22kVKCJsow9zkIKATjAdQsTUQAicoQIXSKgUYVpFo2qL3b5nTDR3aPElCzTHo7YkaP+Tjj5e2DJjIjBSJxDNXQkVMyRYQKYyUnzEkLmruqXF1gI6YwmBVOgZ3KdGZRNMX6Boh1BeqEWp1aX9cGoHuLYn3g4vr7Z+MIjNdXGIeIcVDPoADC8uEHJm8GLOv7KPkdLAvhK+/+0zp5Yn0TNz5Y+8xkMqKtc84qJ1O0dbAyRtqJ6lUIKC5QYNuFG73mei1oE5H/hYi+ufv41wH8O/b7fwHgf4aCtl8H8A9E3/y/EtHbRPQ1EfnoVe8IQ8DN0xukZVHNORqiFXFh2TdfgZSAtK6AZFxfjTgcDhjGEfFwwP06Y11X3Nw8weHJE5RlQU7rGUMtEARQK9Le7fdziYU2G1t/Fni5RspZCSY6jRtRxUyV/YppggOBhTU70lk9MmNUUrpjSdZnbO6q/aFtC4yCQmbBs0POwUBeJ/jw2Thh2i9ts8CZPzBYnNEqgstZUl1oR+sPMygn25Tq8+3LUOo8djPUrQOLZopUkZiq4KwFKglEuVptPCaSs1XiiRFMQeOYmEDFg1TPXS4A0kNg37mrYrLA2Bg63+iSLfhdZ4aJkT1lMCJiZDAKci443t4Cd3c4XF8reLNsS1IEKauGNKFAxoCRlY1sxGBBS73VH/Kur4JWu4q4ATL4o84DKxozYccImuSM9Zhxun9Q/3Pu011shXRmjV9guJYNyB4nZ/dGGOGHIIogBbc/ksUYkLkwyzbLpL+jSIulg7omDVWa0M88saq0zQOXBqhkjEQ4PZwQmJGKZpEj00jHEJBtSoMJasuSUKAZPqcnN1jnI7gbeQ8lfOeUIshZkNeEsio4K5Tx/PmKu/vfw7KsVZPp9afieFArQMkqjHZuHO6GchgZXz8c8WLp3/444HrMAtcDOF/FLX3xSdsDsfa9u0Q7bD1//rwfLubKRXjy6uvcQrR9vl8ND10su/urUL4TsPtrX7vNQchF10hrx93u92Cs7ASiKhSjc3/dAag30aT2fdg8azPQi2zU3e97dLv+2zb9/XuguhecHrsIlr2QLCFADMAKjOOAI5nCjpqr/jAMtbakCoUrSlox5xnMhFQSotHXEBhDYcwpa3wQs1rICLU4c8oJY3QXd6ryqScnECZT8LlQpeCjJkWgLUjazE+RJlxJ2ymuCe8VR0Q4W9NNLJMRX1cGlk5B6opLYq4//bkwTJiub4B1Vndze2MBUFLBaX5AyVqvahxiVdj6lvWEId7HUhmBXkyElTyGTaxQUEEAV96Q7WEhtY6KZaISEaRSMC9rzWZ8dXONZ09vsCwLljWheklYxspC3MCUQD0x6oS3n1U86xK8bBQeHNBMHd3OJ9Xo9tavnsMTAKSMZT1hCF3MGQSQUJX2JB2N6xbZ+xUIVVNclXu1P6+6toIlEVlxc+OdHdCuViYThIgAjgHMg7rFBta6oZUKeGd7gNj/3I/H/nRlqoWplFIAS88/p1yTiYC14LmXDpCi7sppTepuLH1YkylROGCYBgyRMcRBLWoxmhxlrsIdmeGutMP+XAqa1a2nTLodG1DeyjdWGkCyyg8jI8QJ4zRgGrUfCK0PLEBaFoR4AperTj5kpHyDzAMgWYErFXDoXDZV1ITvuPs7wT/+jfdBnBEwINj5ckMEACBrTeLSD6gf8x6EXrh+1pi29zsg9jGA9+33DwD8oLvvh/bZGWgjor8O4K8DwPXNNb7ywddQ1oS3v/Y+jl88bA6vPVHBAEHrItwcJozThEUIp5e3+NI44Us3T5GWBXAtexxRWN0myCQ2Z/oA9NB1BLVqxXrkj+7o+SayeCltglRj40zC7nPBUs82o3CpbTihFssOIjXZjzNQ7xCAja5BPxMDLO5r7QwKkrUvVejvwZEKU+w5hTu3TKV9xeKVlBhVzRcECW4LU+vWWYIBak4JTGKBoGSMicCw9LDdIXMi1W9Rgse32Ua32Eam0oFF/cX/JhOONAGrAzzb/D3NBEyI1n6JaXCr777XDqlAWvsSIneN6Prqo0YgiBBI3fgciLvG6nR3DxyPOBxGTNOkdTpKQc5AseyTVzfXKEUBQJkXAGvddALa7E9fZzJrajFiWrXr5Gtg6+3rLgKNHWxZ0QIThhBRcqoaxXoy6isbw3ZRlHIryAqb58Kt0HbMBcnKQIhrKosG+ortVWGuZ7yIWRw7t1pIMU06WeFum3tRSyTZGvsOpZIhq1oLx0DKWNYMvmIghh0h9Fg2tRiq0EBYlhXjqO6NlNzNxLecCmSa+VRUqHP3XdOclyJY5lOnHBD7vkDSjDLcAE+/2k6VCAoKUta0yGVgBZCiSpufDvb0ozsX3HvQ2V/9O5wEKSA6vx7rT1+AefuG1wEx2fT1Td7n+/zSVWfsNRO3Z4yPulBWutKZ+V047kFcN+geuPVt17HuLHVvchXrR9NW2I9Kvi/Pcf8uV6bgFfO3v86sihVIFnjYfymCXGYAGp6wrAtoGCBLQhiiKYMYa8pYlxlrSlqna101bpkJcZoQYsDh+hp3L28BqBLD63XqpVrxP/zDH+BP/eK34Nr2GINaLayffu7IQAeTgjmNO2dQbEWWgVLdIpXVEAoCag0yb0ekgpS6Bc6UfzZnnjlXya0qan3+ilrXBACFCLKU6b0r4XvvfBmSV7x4viDUwsT6/XyatVB2YEzjoEWI7XLXzerlApjXDFpSESYrm2PZlo0/MNRN1ULoW3wbN2BSBDjNK+ZFvUSGw4T333sb11dXmtp9noFuf+eksUKeRVmEQKSZijMxmDKcPQuo3bMTdQgm6JvrvU8V2RrUUBgNOtKxV2W1XqlknOYVYYKFRujaEeUqQwixAn5rFyJWFkGTjVEnjza5r9HW2l/qpUVBnwyDLf5Q5QS3tDUAVmWmEFUJQYSrw2i8iuvZPScdj5/nnhah63cpWrM25YJlTUjLiixAssQiIpoDgEDVMqgxpDqmOAwKqDw/gRVjn65GTMNgSUgC2MoUBLqgGGK3baIC1U3f0azHPS3yf0UItfYeYJkfC0AZwxjx1rNrddskU+aI0lLJBdniJqVoMrz3v/qb+MEP/lLdN8KkCeeuJoCAz35yhZScQ+qclpTUImrj+O3fftfWVt1FhbwW9G5Q/cpJp4t4w+uPnYhERIQei/579XN/D8DfA4Avv/uOQhNLFDGHiFKUCHRPbJ5nIYRhwLxm3N3eYTmdcJwzvvrVdzFd3WBdV4wkWv29AOu6NK0qUYuteQPe6ZmI+gQWtTtiwiOhujrqZTUcHLxRT23QYrX64GCT1JURK8VX5mSktwNyNYOtaY36RVclH6sfuO2aUoAQtjoZD8oHNDHFAqrZnWBgkP3AkFsOO2ZFbOCITZpygtKIpj9bHIiBarzQxvmTHBKiEnPuhQ5Sgq5ZKKXex0AFfsHXyA41qqXN/Z6hTNoCixsTIIhkS0SCmgkR8PocqqHrtT4OgpSAqBWy5KatIxA4RISgVp51XtWFlkgDsIutvTFEjhMiR3AYMU4LTsfZgumzgTLbPPpy0yjZXiCLvSoNkFXBwrI5CjXg5S46qh0DAgWNxbPYPcCAIDVNL9l6lQ5Ekq2ba42qgBBY48oICO5+4XV/un3eNmzZ/O10ru7jDUVrTM73gACQEGq/ci4IAkTRc0Gs2SN7n3d37dB9ofE108DqmgggjoMFoC91/KhMx+demnKJqAIKhjI8zfBWUAphteQMHrxfRAX/LBlrSpiXFfdYccQD1nXFNKqjUaMMlwDXZbJ7WZy8/Gx/7x6obQHX48/L7t43hSOP9fOShehSH36Wy8GLA6hLoLEKOpXGnwM97Ldkx5w3Vj6ycdJuXJtfm0DzJqBuL4Rt+n2B+9c2nb7CacQr7t0JexV8FgEjqFtRDJiPD/jJJ8+thhG01IoIwhARKSBwQC6aiODh7ogiCTmL1X8sLZaGlM6OVweAqMbZBotZq7EjFoNKxrMCE7KfzW7OmVk/J0aIAeM0oph1oI9rcaDRW6sA1ARYTYuv9/MrJCxXNHoM3GZfSEf1WLPlzsuCvFFOi5VrmbVMjdF6iM5XJEIYhybcGyht23RrYxKgAk+VEZymu7XClL0iliC3Jb3yz31PqO5JvQQON1e4eXoNoYCX9w+Y5wV5TcaaCMliiiV3limfDjEQWunpbg6ZNdNyHcFWsNnMfK+syL3jMLWvSUFzNj7fgI+fhWIAbneka2hKQaixMh0YJJj7LXCGNC+eqyagm9NSjb8lWHIWKxQvbLGb8JwGgHqYieZUuEgb9ujA39voWC4FKRfklGsNtZTUalbMYssc1GOIuSpNURIygGEcMNRkOBougVwgOdd6tDEGxGFQudtEBQWglval6/ur+ITv796t18dT6dxesSkFy3rCsiwaGzio+ymRmCJUwWouBdlLdIkX+Q71vS4TTIcBbz8b8fFHT/Dh997DurisTljXjONpBceAadKakCEUDGOCwLNVX6DJO/rR/+mKlX9ZlrZP3O2RiL4G4FP7/EcAfqG77+v22SuvkhOWh3uEOGCdV5SUVCh1t4moliyCasuGEHA4HLBKQRwnAPcopeB0/4DbF3egMCCXjNNxtqLIqp0XKMIOuzxQ/cSdTZh97haUdth18bwdT4zXODftXKBQz7xIJyBJAhC2IMfFIH+34rdqWTGKoaCu8zMvm8QlnRbvfDhnl4imxS0m3BdRMKIEq70DTvy8NdK+iw+unz8/dCakss2Pg6LslAxk4EW1gCJqdanMSKBuIEzqv+/aFulcGoprvknvvSiomGWk9jNX4U1ELSgssLg4gdfxIKtDR5Y32TW4PlSVIwSCoIzNCK6YS56b06t/PBR0MREkF6R1RjDnf45RBZ7DiLKsOB3nbh7cbVYZSM1WJwbKHayKxw+IIyu4RqvUz51diNbhQb/3fe76pdTnN6mFLbNHH0vgwE21uYJioEsTBAU7AyYEkKYA9zFccjfRfeOf+Ub0vSFVEKKUPXAFHFmLegIYpQCFMC8rQhy85+rLb4qU6tJmypmStHAmDwE8DCgoTQizPuVSGteFy2cKBO0UGgHW85FSwXr/EsvzH6Nc/ynNqEeaNS2OEUyMgKQ+/rt049r+qyHLq9zi+usxEHj+uVz8fAvWGgDatnX+2+v63Pfj0lNOR/hMQHr8ciVdzzi9dXdtdJpGnUKuxfycA7BLwKzfG+cd7+aMaDNvj43xUTD7GnXs/vv9uPea7j2Y6+/r27oEojVTMCOlhPm04OpA4KBHMC0J08011IVSQdvD3QOWdcEwDCDOKEk2SlCnSTEGyKCWBvd80Fkr1g9VOxHrmoUQwDmrNavS9eZuFgatCTZNAx4eTshJ40VFLHbOeSvO5ClLqNKE9EtzvZcXGt01cNmRLr+1rCtePP8j5FQQTSFpjcEtPD1oYmtrHIfd+qL1ny0df/UUcYGjKTo9eVQWTx9ve43aONwaEdCy8FY+FxhB2SLSuuBuzRbfrTe5q5xaFJ0y157o2OFZms352s6zvsNkD5ib5saDyQft7yjVo8XHqSDK49/MetoOsp1RG3OL0+hxmH4cAAy10A4yuMblt3XW/a9tei1hP7tbGtrWy2rKSuNb0azR1S3P52H3XCkZp2XFNESMtP2uvWvLNJy2rUmfTSlhmResKVclCBOBOGAIZGn6A4YhYoyq2A5MWA9RE86wWti0zE2AiJWnSAm5eMkpL1vQXB/3Lo5nZ2YHyJoF8vz+vdW/rYfJYZbgp+SiSXq4oKSM1RKpCDRpDtnc5JoBtc6aNagxuVdXB9zdvYNhuMYwtFuOJ81YzYERhmgW7oRQvLyEbdVXZLPsryqSvcH1s4K2fwjgPwTwd+3nf9t9/jeJ6L+CJiB58bp4NkDNmvcvbiEiuJ4OIIoQK9a3vQhk1iUhQggRNzc3OEwj1pRwOi5Yy4IvPv8MgGavuskJcRgh0GB/1TY1SspEymlEWgyY4SZnacwBV09vIJFQTouddwcNBq7MZ1+JUr8IJhCaW5rvtdARE6kwyES/AnCACsW5SYaejlb680kaNLyKxkoVySaP67YPUQsD9oTJL3YLDp8LQu1MdMyJGVS62u7SzNbbqJfuXeQEyUQVsdguoj2JOesgMyMQKyOnYrVrtFyvAhibjyKq9bGJb2DKGblNnh1OZcTSrXF3GwpYTONIClzZanRtNPDkcXlmhbVtlEtz6xPJWFZgHELHMH2sbBa/jPn+DhSOmA5XoKjuEKBg1rHTZj1c7NtMsjHtnigW0VgK8WACVHmmpmauIXMd064CpmXnAoDMGvcnABJhUzuNclHXkdji4Yq1WbXjdZLd7bTLLGnMGVVZ0ZiNBI0RhOWu1NeKCnCNB1s3BZrslEBMGOB6WnO3TSec5qNqCwNhhjMJtcx1s6eaxkAQq3t4NR4wz4vOje2dtM5Y1lWtq+5/ZKSDRMyazFU4CJHVRXK51z1l+4lsLhnA1XSFaVzwwMcqwL9KiO+vN3F521rOmjDfqkU1MLFPi+/f+GeNZr3Zux/rT99Wfddjlgw0JZBTFAdxe3DSz1sfe1bb7oRpUNtzfs8euOyI1flYXgGo6tkqxnvEPuuWdb82b7TmcvmZS89XCixtfvpnuZ7NBnLP7nOgYgq1XAQlrUqfAXgdrJQzrmNUpQcD66LuVSp8Fi3o3I9dTJHHRm8D14LOKJqBLSPVFOPH0xGffvopqmVrIyTrgrp72TAO6hLHWvfJPRdqojMoa6hCbKfpFjZ+TS0ZQt1nzt9NFjG/GmwKMHcgQXZ7KwIYRs0wXMEZNDpaqD68E3Abb3N9JzfGVUUXn2ciU3oxQMWz95p7ZCktSx+rnJGKui9W90nWn5Goxj+BPMRas/8Ra0p6sXqkACGOA/LarGzKL7a8SGCK9JoZUtRbxWQKVQy4tcuFfrU4qmaw0WvdkwyuceGELr8I3FGpkGfIdE+rUsETS9HC3sOIZ1dPMZK6dgIFnozf1169X5vl0sfZrDT1zd1+8LOpb9QSGFyLRddFrIpZPXtrKjgtmqeBmDEGwlZs7wRBNHkspYx5zViXFad5tXpqRhmIDHi1mEqOAWMMGCNXt1uXNYdhwDAdNGFPpxwphTEUrSOHLNUVWUUxrufzfB93vaeO3lCvVLKo6gsgrbe21RPvShqfH0lY5lkNGeJeLdAYd18NQjfnUs+UK/FP81v4zv/9b+KTTz7b9t8MSq5oYGJNQcgt+2Xw7KgkABd0ZEHlL+9/KpbF9Hycj11vkvL/v4QmHXmXiH4I4O9Awdp/Q0R/DcAfAPirdvt/D033/3vQlP//8Wt7AAA5o7y8U0H8yzNopOoLD7hWWwmtQFAyY1kWfPTJJ4bsJ0zTFW6uPUZG44bm+YT725eWLjgq6IBgCgEFhIyi/rc82ITBRL1ugUiZ0U2IeHK4Ui1JWXE8req/D3SE1CwaGx5iAqgFHfdABwBSYUSLa6PQCx8Ambta8SyXRLUIZgVmBOTciEi0A1koAHKsMXq7+M/6Ds+KpJqBlpWFIKbNQs3+J0VN60kApYom2EmxI6Zk0wvYKj+yWC9jxLV9UfDn7qEOijYTDwDmq68mfADganIXn0/ynuioKiHWxzWhQqfxcEHZqRKTao1apiJtwTNRkhEjTUKS25uM8NdHHHiImKAQgZQtZbKgxKZBIgKGQQUJFX4K5vs7CAjjYcIwTtDMkz3hcyuPvjLYHLglVgG4u+nBCIu6CuY6NzrXunpS3SB9CJXXdXvUwX0gQuyEAwFQmDRIHNoHr3WEIhi8TesTo5i7cHuf/iybDJptf7fd4KK6CyU6z/ZdLsAQQIFVIFyKCUcCjfFMYAADZSwPK3S3ulsW2mAAS9NrcR0BCAVYLIOo5FwFHc0ky2DOXTtVMjOGpec3syDkiJQzllWzghZ4odlmQ0giWArXSTCyABf8/mVdl6LnLn22FfTb9bP2rQeC6H6CdpaeDpD1z/bAqsZs+X3WsGpRqf59NqxHPj9jnrJ9/yvvvfB9pW2d8K5Dbda3S/O4cVfs3rOxmGELsPbtnVlHu/7UOXvFfPdAt0hBEXWrKmlFThkxDhDJyqtywXCYEELAYTwghoAV5npXDLSZt4QCpVKFrzofbJYNcOOlCChrRsoqyJOIZtNzd3izumVSRS8zQDE0BWMIoBABKeoNEZoiiNHAmo/Vja2qB5TGL4onG0OH3LDx3akg1Ph1sdhbbzsMI549OSCJ4O7FS4D6cWJH9/o90NbdY9jq1iWl08W9UaRToxpvqLFtwem/gdUiSF7HrgJwtYaFjua6codZZTMOGsNdilo6OQPF5AzN9SAVuGrcfeM1qHKSgpSUCmKIEHMR1Ogp41KlgCP7ZGz2dlOI9EmBqCoKz+iLeB4A5Y9AAWLE1XTA1ZMbjIMJ9SVpAjtsr6Yw9fNcAFkBNKWlu9cp3W4J6mB5K+ti2hz4HEHcfTFhXVesy4wiGSjQLIxDRNiF6HiMeil6Jtekxa9PVk+tKiOCuj0SE2Jw90fGEBgxuvuiJovrx+jhFcTtmeoWCg0xYQBBsoY/WIbLfs57MLZ3M68W3p1yohFkXaONW+TufqEAX/A1Ab/5T97Hn/83fl9lXzt/wRLiMJv8EXTMV0Os/IYJWOYTSi5aP44DjmlAzjsDA5HKypWWq1yzySLJZPybVFbweURTEAFQ763uep1rJPBm2SP/g0e++ksX7hUAf+O1b90/B1TtClIGRv3QbQpMlsRDVJOVMzCfTjg+PCAMA4hH8GCF8MwywkPAGCLIiMKaNSNOSRmnlGvQaSDSQsreE2fw3UVQq14YAkJOIB5BVyMO04ScFog6EYJo5+oFb0sU5HjeevuMYG548HS17qgGAAHu5ogOSpxlnek2MZtbFVFAZNYaFENEKal+70KCP+qKuprdByqIM6nroGb6gxEnTUARASyrT44zf4sz7ARyN3VnoFkfbEMr+Oy81mtqdvuJBlZAyiiKCeIOywiqnfX6MIBUX+zaN/Ff7ZkiBmbaPHimTs+O2AsQIKr39+AJUHcRiJg7pmUzMu1ZGNQ2tVG0dVo4ZsI4BIxTQC6EkjNSzkgp43h/xPH+iGkaK4LxeRJRwiQiePL0Svu/zmqFFCBY56s2EIRkigOGEnfwzqXV9mytoVTnzgQY77tldyyuoaOWbZOy1j30Nc5BBbTo+7+bBsN0VVnqTi1OnH3MrsX2cStxVaLnzwpQa91lqxlE2DFxMISkPuduxArPVp0CbsJXLAreCoudC9NMG0Pn2ifphib13Q4W6tqJIKUVx7uX+KM//H08++ov4vrZl0yJBLgiZy2CT5YDnlRBEZurF77bG7efvcm1b+fxe5RVNRbdz+jjQOOnfWcvWOkHWwF4A0D2Glc+//yscezX6vyex9zd/oVdj7y7B1sbUFiFzgZO93PognUP0vYAbduFHQij8+8uWtc23SqYH074/KPv4+7FF7h7eYtkz6wnTWZwmCaACCEGBSSIADFEUpcby8qpDLF2xc+W8nuztHitUBA49+N36wzVzxqgUVa7rEkTfwyDgsWUNGGS9HOxFRF9zIGB4gWbyfmE1OQLOgJ7dwc62WiUywC5e17XDJCcMa8Jx+Os7mW9orZbX88MQkZj0QGxKmNkr40JrECNGSNT6HqNTp85CU7/9L5UCtaUkFLBOAREispHQMg1QuASmwAAIABJREFUNRFqsjMid9+27Nek8TsaW2g7RARepUHJOFXRqi8tU0rRguw5gUWLsV+Hq26+VH44i3l+5Ii20BVUz5ZOtNf/swFWanM7jiNurm80s2BVEqtywePZq9Du2Ql1Ni/TC9Fz0t5PKuGRe+c40GD1zllXpKzui+u6QqyGbQiMMU4ITIgxauhENWSgkxkKlnVBWrN5p+l8MTHioOcwhIAQVOaJISDG7twY/yQoz+3r7Oq6mezoJQc6Fg2fDdL4oKC+uqZUb3TKXR738/V6urtVMp0BPgFAXbkHZeYa98nG5TlaBmtoaRAOgAC3dwOef3bA175+D5Rv4DBGPDwkVdya5XG+1C0VftDccFVGhGQti+Rz77NIgBSq4ihRkzHdE8i7vge1l64/diKSf9EXVd9C6CYvHQ8nqodlnRc8/NFzUGAtmBwVoAzjCI4RPAxmttT03hQDxsOk7ZUCSaoxHGpmQL3EuUon1CvYyiCKGMcJOWdEFpRsoMZdxIz8e2wMqGeCnUXGrtC73tm4KgvZpLhEFWIZsIyBHWI3sOC1I3RzaPrlcRxBHHF9iFWDVSztPNAxcMcf5O4Pftisd/65adz2uWfqMRfUtL6V3xsggGWQqjopcQJONTXxRvduGkgmQTKiXyOGjFEW6XVcqC5/SkhCzzngXgia/0PtHUa2dlGOXfyHaVDAsOB2ZyLGxEXaoQUQAyEG1fqCgHXJDXQAFpxrLoHMCHFQAbgExCLIZcW6imZ0zLlqqfwcu7k/ZUbhgBgHxHHAkDOOx6MKccbc+Uwc3q6ZWxHrfhdzEXCpp20NCIBUkZJqkiMIhV0wQWsnq8k/iLpTxo5IAZ7Gw11HrPSGZU1sOi0xfUUnQMJospiF0EGPXeu84vY0Y4gB14cJfYpTt4CrEOZ2RmjmSvT3AZn9N0Fzl1LhJ0MwXV+ZJr65b/fwxd1vnKkBmk3t/mHGh7/zHSwQ/Om/8JdxdX1ThQJxpml/VPcbk3aaUN2sYFWAgwv3rY1LQngP9qi7p5+j/vI29+CsiSI/O8CRs7f33+m1cWu0+eg6r5+Xx1pptK1sAHy7LjHHN3FPufQMEW1qHj3WbnWL9C0u5SyezpNtPNYXV3D21rI9+PO4vI3bjc1d/77WqJ8NnL+bYPEguvNePP8cP/7tb+PlTz5BWldkIpSUsaSkSQqYMY2TWaPMMuYk3fqYTclTBa/ufap0Yzv+2mkhdUOOofNkQTsDLhAGZgzThNPDEdnm8nR/xO3tEZJWHN55p3LZ/vwAzk93Z2JDu2zhOoVWxWSymzfqXOM64BYCIc0n3K+zetCI0unS3eN0uZa2MHq+dyUDuljiInWdAFRBvO47EAqhWv5KFqxrwpqUP10/ucbVNFn9LU2UFZhqce0irdSPep5Y/dQa19VkD6091vieCKprsMaHCyAFKWU8PBxB0MRPUs9GN+OVJKrSV3bjb/d17nTUxZy7ezo1DxyfY4SAUDIye6iCJqybTzPyumCaBohwBeL2ZNsPliehCO12je+Hbdy5dkf5Zc4F83JCzitySsZTVXkexwnBZAgPe3CZckkZOWfMS8KyrEgpQzrrtXqoaYmAYQgY2K1kXk5ge7Z9n/Q0tX6HdjRrOItZ5JR/Z5PPbKE6q5FzjG3M3b51nMu53fctGczlq5eLAJdTNHwihIDpMNVYfQIsYYre8c+/8x6O9wNevDjgiy8e8N47fwbTOGNessXmKR1/990HzPMRz59f7d7eeMomzKFLeObSZfUkMHk3W7bvysOMVhRwja991fVzB9o++vGP8f43vglG0EXzStf10uQFBAApoawC0IKF1Mows1o5ZBgwHkaEQf9RCJp5CcVcIxiCgBANnHUB7oJsghMUcEBwPB4RhhNubm7g/qzMWiwQad0UyiyF1bdWBH2RcAjAlr/As0aFEAAWc6FoIIaEUBhAdvAoQCnmzu2Bvqj3wwmm1+JiNXUPMaCAa8p5txqcarYnc93IdiDF/cphrgxiIjXcfIOaTn+LKhVMmqBaSw1K0zipv7POiyeGqaMrbqnqhEPxpB6omQ0LGCxWh85AE4gMxGrfsnSEBI3HbnpLdVaNkME5TnNicIBawfAFIQ82ZrLsnMTqIlCtURYbUFDdBojQgsfNxUeEUVIBFyDEhGL17c5pnhIlKRllXSAckACEEHH99G1gPWE5PsA4ti9NXSPhBuVc491tJFM27BiibMceiyAHxmpCR3OfEni6bIgmzektf3UgfruJmhnSmGL/aj9C8DYMwDIgGjSHXjNIRJhPC+5yxv3DCW8/vcZYa+sIiDXGpllmAXGGS937qQtwByBwAUXHl8oKtR5s2yGIH0Wd637MAEqe8XAi/PC734FIwi//xb+CcZyqCyy5oEc+TcX6IrVr57Gg7VI+ILvPOu18B/b2fJouPNsvxdZdsgmCDr628HnbVi8g+3eyvbn2ney/PRA5Gyg6sLQDN28SH/AoIOrHdkELfFEz7LziNRrSvv+b+LAdQPL39Baxrc2gCYL9c70bY9/OfunqnNp9dQ7JvhNsNogD5lIK5uWI0x98Gw/HI+6PJ6yLxnpm9eLSmBEixGG0fpEBGNQMc727Xx3zBolRFXC9Vlju5t1Gr/FUHMG8AkFjSA7XB9zd3luMnApBZdV4dw7K+8SUPkrrBCjAB7/wC/j97/4ePImVO/z3U8pm+aqZdV1x2K2OVEFStoxHpLqjFSoIVjvUQbSPqwEC1KzBAnO92q+5v9NkFJeMvDC2C5JiEqJbSUiA9ThjTRk8RDx9+y08e/sZ5nlFSnfq78OoJXGSqDweSBOVabMMV4qSfe9KXe1Tc5u31bIO1dWDiGhsVYxanN3d7Cs9tym0CVE5QECRTQCmtm9EvXRkV08R1u8YY7OSsiahUZyr6ehTWnBaV9wfj1juH3A4jBjHQROylQxQ0P1bN6xUHldVWmeEuR1EIkIqgtNpxul0RM7quhhBGC02MAatPxg6Q0I2ASivBSknrOuMZc7VehpYcy6EqMlBhiFiHNjqkG7VamJ0Z6PYuyAc7ek1wRLE+ZyZ5xFbpmWxe9jkN5WtDNp503ZWuCq19ClCQPVA21yNM3kIz15ZdekSEdzdjfjud9/BN7/1GUpKSKsmNwQJvve9b+Dh/hlOD0qfYgA+/+wJ5ocf4p133oOG8xitoud47yvfwdtfWqtnmc/dvK5Y5hUSgrnUCr797a/i7i7gvfeO+OVf/vx8OCZXF2qyGQnwj3/zA6QlGH+/4E23u35uQJu7M51Olur/UYbbtFcxRg3QBBAs0KcUTUGKecHp/gGIAQJSK9xhAA8j2EDcEBg5aRCmFKtxQoBnfAOgG0oESRLub+9xd3ePcZxwNY2IwwQpCUtZ9Hk7BIUASoQwBLBo7JyDKzEt/kABMjLyk1ILFZYSQEV3B5EgFJh2Sl0kNeaqKGAj09o0fxMlhN3+1w2u/6bIGGNAKgpqpshYsgBFGSp15iqtFqXZgDSbvQuKRqjEYpR8ipwwOXOSjExUg8EJVN1R3c9XCT1htYw+IY4bYMQWlB7JXC+YlImVpEGcRaobSG+5U2FLLXchCPbnu8VTEczkpqZ0SwPtgbbVhYId1KOCWL88Rq8WuAZqOuYQ3L3V5pQ6FycHx7nbZqL7BYUR4ox19v4qWcxCGK3fBCBE4Hh3h5RWxPFKtYVs8XkckFOCCGG0dPuGSgETAIrNe8maxKXXiFHJzdzqYzMhxcfpmvwNYNOBGnhTC1uxdc+iAM7BIuUEMNUaRuhn1mVVOyuhJjlxYZUwEGH1zKYCLKVgzBmt/p5mA01EGFCwpqIuOEBVKBBMf1PXT89T6JhIKMDKShuYA0RWDNRlSgNZJirZaNaYpGZtq3JFKViOR0QCfv87/wwC4E//6l/G4ekT1bTVVLAK3oSwSYvuzK8KRva/bYzHmcxSPyjorDO+H6pwv1nuzbnZU+KeqTfgJmf3bPpQP2+29HKBxhevnyPbNvfCah/Ltr/exMXkMSAmJFoiZD+eXZs/i0Xu4nNNNqkTW61tm9s6ELeXqtDO4+a7vm27Zx9bV/vk4K10gpFs5/n+4QE//Kf/Az798YdqHeCAlPX+lJIqSGNEHAbEAOSsqf7X5egaNSu2XCCi5TBilM17NCmGKvXIrP2K6fTEqhXHLT1a6NbPckkZp3Xtkpo0XjJdReSkwu66rAiBIWQxsCSYLERCVMsGMqVZfz48qyMZL3DlVJ1OQQs4FgeY3d6qwrGmxefQlTPp39XTXgOeOZfqql0v74c03hvaVwBUHspFLD6NIWC1tomAYsTh6Q2mMeL+5S1KTgpY3SXTeTwBOYlZVZpFjY2FVj6pptXqfprXhFQU0DnrVPAuBgSgKeSHQYu01z1ncYM2MR7u4LMiBsj7jVzcO6IEECmgieOAm6trXN1cg0Aoy7G2qp4/BQmCZZ7x8uWt7lMIxjBoUWnoPvNcm27pDBWhmaLOQPLmfNU1NUhTEuaHI47HGQRgCgPCGCwhCapiWKCsNxVBXtV1dbUaaZ5cJgTGOETj2wFxCDgMwcI1Wj9V1CDbB3v6bHF3HW7TMWJ3kc21jludVLiuwUphC/7q3rvgh0F+UutK1t97flR5iykyNgCSCK+i7USEkgnf+92n+M7/FXFas/HtAjDpfhg1jq1Xfy6W6GWYRpDN9cP9Le6X58r7LYLKS2RdDYKra+0/IUEI+LV/60PFn6ZYdm6nMoE6HGOzPQSSCv7iv/1dcGQEr+tGwD/67x4d4s8PaPOLw9a9hFkqHQRQT3/ggA8++AAffvihfmxF+NiK9tbUt5aBMqeEMi+QcguKETToZg/DhGEaEWJACQFEUV0uES2rUYAQcH0VMU0jktW3eHl7BNFdFajU310tHr4XQmTtb7bzy4Cr3wsBh0PEdHVALoK8LljTimX1eBlL2W9CINnYCwLIspFU4k7udietzpZZEI6nBcsiuJsCbjiq2XgYICVjLUkTh5hQTzWgUrPeMLMJnxZPaAez1pjbL0v9o6VyB7wem4I9j/8SKAOIgZGKQPIKkcn67g21NtwoX4O2SSqjKkCNp1Ih2mMLt0WVq5manDLsBTPfc+7C5+DOmJIxMgesVTvqphsXJogtQ5C+y0kTwerF2IuK1QsJVk9Oiq9zbEJ4L4GJgoAQde9KycjzjDQvoDDi+uYAgQUzF0HKQKGA68MIyUr4VfjTDUo+2D3wsj3l0yM+d/Yv+/yJ1Nu4SC1qSjZB2X4vtCPgprEkNODfGRVqXIGIgqpvfOOb9qXGBhAR1gpeBJIyxsNoyV8IFNRdujF2dWNGLkAqkBAReavdI9FYjcC58hIhc5V0tbXFXUDMRblbywZipApTLqioddzBEnA8PuBwOODHv/f/gCjil/7cr4KuvoxhiMa0TbtO1MXVtL1wEahU5uf9MDpzBrl2z1z4Wo/G1gLZg6xOVNkxoe55nLNn/6z//LE+9dagjWUIbwaYHgN5jwIv1wTDrazeYRe299bBnbRjf78JYNz3q7oIAhvh/XI/cRmcXZps/3PvQtovxv73Kly3Z0pRxeL984/xxU8+w3x/wrxYUh2BKd4II2tWvCEOOB4fsJxOemaIEIeAOExqzcmE7DUrd2vq3lpMnbWI3cKu2eECB0yHA7KtUxi0RuOynECdhWfjHWC1I6MVV3bwIYABt7aWNe7I/ucz4fooqSfg/CImZKhSyXl2n52yiGA+LRiHAHfKry315FdQaXP1dAE2SaOMAGnffPk6y63Gq2UV+AEcQFo+qWjbbAqu07zovHCElHUzJ0WAyIQUCDk1QN//EyEtz5C18LeqmItagcxP3IEeAFMaAhoXJ+Cg/E55rUA127nOvypgWxy1Sx9kyk9IqZb+Yu8ahwFXN88wHa707OaMYtlNSy5YloTTfMI8Lyh5RQwBV+MBcYyIlqxDvZaKI5UzXiWQroZoO5B9PHIPDGIMuL4+KHS2OESNJfeQlYQ1C9Ka7cwl03WoonUYRrNMaiKYweLUmFsimx589fufO56qe5nrAw62Nzy49tqtQ2ZpNrmJSQGvu3vvY41BXar/DdC6fG6q18TubFH3vbe1p+V7Ws/sWTlja7P2hWurZX+OadtXEdI6qyb3cAz6vI/Fwjc2XtUObEWqNx0TI5cZDqKV1CjxSfOClBMCBlBU63HgLQbaXz93oO1yjMIrmKAzS4snKNUdqjFbJT7tgMm6gnLGMgPACXPUApwq7AUgDhiGwWpoRBRWRjRwwHgIkEOACMwfWeteIKtG5DQvYFar1jBEaLq9fgS24UxNRSEgkiDGaxxEsK4zckpNaDcQWmfCixR3TM6LFuvmdMFKgdbplLDMGZ/nBS/jLWIMGIZR0w1bnRNGQE7r9jCQZ5ii+re6jbh/t0m13RopAfU2bF1gWrEiNQuoZ0AqUiDEFTecr3LLtlR3BQVAMlyHWeWMjYTZCKU06gl36ewTkfhUahsKdsgb9UNcrW1b8LER1G3eNBtQ/4xrjAUgRmRVOmeoRtNr1bHH9KlKd1PDCGigiVgBodbsUe2xa7SPd3eYhoC8ZqRV38c5AeGAEEfEUeNOkBZINuDpA9kfu+5v9wv3eDqgMe6QC3JQt5/EBtjI96wgW2ybvkehN0XWfVwTgmArGEu/Xl1/TIARbOXl+jURhhiQjBg39yJ9/3L/AISozL5zh66WVAioAJnQ3IxscvoajKEAuaYnkw2oqu6WdUM7Q5Tqry4FOJ1OWDPw4//3txCOf4R3f+nPY/rWr0BIkwOEnFBIC8buXQX9TG4YJbo4THRAZ7+srwA8vg2ke57EmYyc3afzYpa2PTCvS6azL3BXxm3vzlwbu3HuwcPZ/XsgBZ/y7dw065LvncYbdo2fz8/ufY9+53/vhIqL7pTYP3auoX8MUAONR25m/Kwrj7+3t9j1gs9lq6Vmo7s/3uPh4+8hz7fIuUDyArGsrwRREDCooiSvM9ZlxnS4VkDl+1cyci5a1HdN5k6ppyxwgJTUTSlVrfN+fsZpxNtf+hI+/+K5JsOIURVXLhQ1ql+vAAIPqngdYqu5yqz7YE0rUs4aR2TPsDEWowAX12JPh6r12JV1VbkEBWEp2dduR6KOidVlsZ/dmnCr/1gJIKx/prAuaIo/tdBoogpixtXNtXoC5WKxYVaHKwQMQTPv5qwKchZUcMiEGte21xGoAcb4IlGVDVxe0Oc7yadbR11bB+OxtryP2RN0MX6uCKtz4O9Seax0ewbMAA+QrPxxXWaQleNJ5gZZcsIYCcN0XZN1EHvoi8UamwU7UFuVV0da2Tib9G77ARV4AspTUy4oadXU/GupLpMuPzAFjKMWsh8CYQiEEGPNw9Doabt8uh+jN+exgGc3+C9oQM5ouDSPK6K2ts7bWybtRpket4z53Jgc62UGuvlqNa7O3SfPQOJubL5XOLCW8CG1FEZPFAINMwGagr6OpZ+KXJRWScFIE9ai56mYIoAtsRFB5Vs2uZ+EKp3OVq6qSEFZ7PmqhVE3b8nFMksz4mG8MF/t+rkDbdv1dUFZIFU3j+3MdpeDm6ph9yxPDtY6gurF9QBBWQrKmgEs+j0TZtIDQoGBUc3l4zSpr35UwT+GQf2QxwwWwVoS0rxgnWcMTZEBwEFl5evWvYJpIEjg2r8ogxKgXKygthYJZLaUvT0w8c3az4E4cVRiZ/WPUXLGkhOWk0DkXomTxVTFGGor1aIlqBYslKYvEtEDNkTNeshGRF2I0y6VSsxFNJjcaWmIGlckIIiZocWCws40Jib0OgZT/+5kGkjT3gGVmTnjKjaXgbuilW1HKVN3xGKDcgczIQsk7dROJKr51WxELqTre4qvhbXlYJCIm/toHVYvKAqWZYbcZkzTqAUfTSsLUuUDh6aJ9XguBwfuLhQHRhwCchYsx1mtWDmhFAZz0uLdKWnCEwqYpogyRqTjCeucLgprwgywWPp+qhusnqusAYQi0NokzNVFNOfG0iKptU18rkl32DAOuLm5xlIEx5cvNQU36mNVW6z/toLpV9//SrWu52rds3fb+rmQSMVSnlDA+197D+vbb+Gjj3+oRJYBYit0TqWujVhAO5MYYGrxkS5IZwZEdO8z/Dt9N4k701iTZNpfcehi9wshrTOODxk//PD7eDiteOvqgPz1fxWSzAU4yNZd0IAgm5C21zT2Ql7zACjdfkH97FKR6kuCiNQzvfsMPcByd0bU+nO9e2Mnj14Ekxc/q/S5+3t/7SRmt5Z4fKw9uGUql8BJ106f9GHz3gCtddXRXKo0TvcO7frTjv2uDxeuqmmu7b8CbD3y+aX4vtdZJV/1vYgqPj67/QKffv93cfrwd7CsSd2yphGBgTVGLKcjRFT7n5YT8iy4fvIEV9dXyGkBQDVOerXaUWlZIaZkrSPtkkkINBtbR1gNQJmgaEqQeVlR1lVBhdGnakVzEGTnT8u20Nabx+YsubXNLpZm3bLbNgLxdq47C4b1bZu91kiUaPblYRwa7648wvbsDqv772QySw9mCMoTWxlosbCBgvk0I4lgHEe8996XwDHidHePObsnQQFIeQ4sBbxIUWuiZ9k1cOjyADMjwGMBfVzS7oHxUaINWFMWInVsDuya+6rR3mrlbuAmGK11yYdFIMJVmV15ElmKEJuwIRAkLXg4rXg4zUBKuLo6YGSNIb+eBgBjrVVWrbk2uPqT90f3Fee43x/cUz3/VeWhJWXMy4p1tXgrDRQDs4bxBOOpwxAxRU+13yVX6eawf8frFEMuG27uffQZ9/qByRz2CbXSD5B9HeVuKl5J71xqe9X32oe+vTODTPddDXupw2IcDhNG0XT/7fyqQNe3UVPLSP9uNNkwJSBoCFVaV32iZPXOE0FKGZCCtGaE6YAY1aWXhbU+JZsyP3kHyXIWWBxgMO9AERC3zNiPXT93oM3dCETM5RCu26hJPc8uP7zOrKsJv/tM14vq/cXqkrjGbcPMPbQkmTB5f8RKhGNgYBi0Avo4YjocMI6DAZEA4gEcNMOkxgWVpksQ6bz9CHnNWJcT7u7v8ezpE7AFcKsNiVHKCpgWjg04qL+9MXRBFSJ5F8jZCLsKVZr9MIDFg6hsrEU33HpSbV3gbfyQAyq3N7hPs04Dg8cRN9fXKHnF4sxgA0yoblJ7nbacM4hY0+8Sg1Nz62xjMIBoBy0LauwQIDVAvWpCHdxLhqwmBGFLYgnKq2r9F2MGKpgWizsrhjkbkPZngwUwE5lGkgkEyxwqdvQrldf7gsUEcpeIhA285AyU46yB8qyFYMdx0ExXHVGlIhB2P3xBKipkxOjpiANCKC5JVitdIC0l8PDyJcZpxNX1DdaiBC6LClJrBsauflw3U23fip2xGscFR5LqxGKFWkMuDfAzwatCNOWCa+Im8DDhaQwYCXj58iWY1c2xWhEcCDXJFwLgcDhUAu6CEFlg2rABmGSZYfR8H26e4t3330eJE370w4/AuTRa00EKrXWkezWQAFJaxjObGscTYmvBxqBJ8o4dkT7v9zt7MHIWSGNb7h8W3H7/D3CY/gn+dRwxPH0LgKDwCuERmZLKr8UmlwAOAYHDBnz1QK7stJMO3vq/91f/fQ+kqqDsbaNZ/tQR2plfAzq0a88/3//d1CWqxDo/sGfdPG/LQNFGUO7BkyefQAe2vA2vsvI6sLPLb9DORmu3ufh0QssFUFStfLSd10va44tjd373UwK0N76nCjH6cygFb18F3B4iyjpiNld+KgBKQWTVW6c1IVLE1dMnePLsmXLspLGljY4KSskN6HZ75lLX1AW3y1RIOl88RE2EtJwQuvi1Ns72e2fvwGc/+QzT9Q2ePH0Kt7CDGWEY1D3Z15Db7vWlqno8avNYLKGJf696FQ0FCMG07X0Yg6hcQuZZsVcqunJGZZ8mpHN9sY9FoGWxjD8Y7SsGZkUE4zThybMbpEJI9w//H3Vv1ivJkpyJfWbuEZlnqaq7994kZ9jCYKZFDShBEkZ60oue5ufph+hZAgYYSBBACSI4IkfsZu/NS/btrv0sGYu7mx7MzN0jMk91c56u4uLWOSczFg93c9vtMwVjsKFES2VXGWYIiaYDFKsJ92dHApKtcRFvsu1yTg2tAutrGriiTG4XoynGzqaJWiqYG6Wqh5W6p1zJ3lzrgtz3fJ0Xsv5uwDIvmN6/R14WMBGujiOiyYkQvGzCI2J0cQ/q0zueKGKlF90+7X5r2VHN6BBRB/ycMubTgtkaZTurCiFgGHTeOUQMgTEEgvcd7Puy9WMk6mnvibHv9sTOp3TZXqt8qTFfnytFn2RzFEgFzNBufk8bcBcegqbPX9Drq7XYdMk+8FLlHLUWWf4qpRRLi5SaCq3IrNzKZnA+VwAsdNzfzTghk/URLMhZ1NkrwBBC3cMAYxg8040MGE+do31qKJmOWd/BHNRsOka21hAfOr52RhsA7GsKAtOmrq1jAe2z0hbvLHogTQGtqX57IY+t0uO/ez2XKs8FlDLWR8FKhMcY1PsUA8arI8bjATweANEwbCoFeU063lw0BROonpNSCu4eHnB/d4fDMCIejziOA3JOyLlUaH1hRkFAZO9J5uNUxSmLIV1B+2hVbxUBHCK8F5Ul7KliyQpJH8W7wet8rVnvkkvBELXxYs6KdlkEViCujTWLIVyO8YCRWdP0kjVZNIIvyrV0jBZeDxwUxSsXq/1h5FSXuwq/XjgQdbUG0uriKgyxnRs5aD8tM3BdKEtWRaHYBCgZiAlZFTY1BYMDPMXB6UVBHPw6rWtyxCwxGnUb32wnOMt3JtE8hqQAViB4V2kpwHSasZzmDQvz6KGDwcD6FD7en8DBDL0h2JrEKvAiO70FFClYpgnLNGMYI47Xt1rTmEw0xgGH4wBeZ3BKwG5fqLFuaJ8uOIt5oi2hu0Yd7aCihebJBaptWoF6nx7u7xCPB7AIhuGAFx89x7KuePfmLbKBC/lenOcJ4+G63851iCSApIyVtS/MDKlxAAAgAElEQVSKGjG57g1vXH3KBR8PAzgOSEWAsmLIGVISUAad5wIIS90nzmc2CiBrI3aY4AwVTMBqV9xcMYPEC5eLEU8wOhaBgQgVFNIGxb/8xc9xvL7Gv/oX/wIpDfg8/iP+9lXELAGP718BadFnDQc8//RbePHiBaLV0Fbld8cZVWip8OjTKy8abdTu0fPPXNTJEqqDC1Ww+Dt6c/RtO4KW2tkffWSQ+nOeMNLOMiW6azdE8cTRO142nwOg3MBP+s/Pb3L+zaXzHBypKj9PKFR1zLR9h43Bd2kYXRTxUlrQxbTQ/4RDav834JOPP8W1nHC7fB/P7u/x+KMfKa9fk8lQUzwCA8OIq9tniOMISQnJDWZxXqnpXhSCGtNkmRLVIdcfxi9Ja+U8vUzT3RZQXjFE3hhT23ewX1jRjGtj72pcGy9mxkCaBZKsBt7lT6cy2/1lM+/9Um/mne16doOiWluIALIjJAJYlgXD8Wh/tVRD1WX0PHWUoBXWdU4EzwyRbDzXwBBAhHVJQPEaKgaxwv0XMfHIVCM7JAlFNG2/kLfSkQr/n9xqMiC0ftIDa0uYXLqMqM06Kl92cDIxxlrIlFDnJ1Web5lBjV6R36u0k0Xrx+fpEafTYtGrhCFEHK+uEIeAIcaWzunrL4Q94I83xW40pPgIDizm/L1+X7TuCeJOJzXUS1FwnmlZsS4J67pomwtSehvHqFlODIQhYrB60ODOGNrWQfPOeHPD7dKh9Lh/rxbM8GtVbFHTV2jzZvW6uiI7YmeBdSjOG15IbRCXB0hAS3l8gi9u1kB2Y/e940GRrmUTewfR7p2hzyNHF7Wf+9E56A6q48T2cBwwRrG2VFo4oejghFxUF2Am5FRqv+M2p7qupYg2j2ftURyjt6ew3UH6BgWCeCELpj++lkbbXpC13/UfEVTUuUspIR869mkovkB+r81Cw42By9IgpAwgoywrTo8THoMKpBCD5qUStQafRUBBa91ijIgGlHB9PGJdV6zLjHle8GgeRaImULTnxgAaByXPYgRmHjbPdj97n46YA5mHz9ooeL0OERA8x1ZEQVGKGQtC7VlBhaOUglQIWBMcc6UaC6WgQu6Spo8FeDqXDlGKFrAWZ8Kgs22rOdOWnOaKj2xFgQvU4Loede9fdOxnSgu50WjWnGuatslrDVSTHN2hsLyeRuJfBfLoqD+CWrEpKUMprtQ7nDs0JK85+OrlpMiQpO1MtfRPW60TUGsxnT7ZTZGivcnSmsxwU3ND0dWgBi8TIqwAW7QBdT49YF0TStZJzWkF8xF0vEEoCXldAAHysgDU7TUAQaz+jhkJUI+0eXezeY5gc5lFEAQKdFPMk25F3sMwoCwL1mVBQUDKwPHqGmld8O7Ne6h5p3T4D3//Jf74T3+g982lWfV1afyZ5gXtFYBOuHkfuCEyloWAUgzFTaOPj6cFgQXHo+J0qvOBu76F2DqUxASKew6rYl/g0dwaXFfJq6elYu5/qbJrlRU4Cf7+l7/CVTzgeMUYhhF/+5Of405ucf+7X4HmRxylID//HH/0w/8G1z/8c9DVrU1HQYixRt56A6yiUtqRkUFG+ympgRtjQKaMVtBp75YL5nXFOIxNoegO3z0aTdyLfLF5b0bR3lisBiK1v5803HrjjVEdK9JO2r77xsizddh9fgnB0mVMu+Jp/WNvOG1Uuv29q6b0gffrFRPpZ9FuYWtwNh/7+1+Qixdl2YV3gWwjYP7z5W9/h1evX4JDRAwBJa0G9qiK6nA84Pb2FkOMIBEsOWM6TQqoIIAgKKjEptDeUmlLsZVs89jS1DU65zDny7LgzavXHXx4P8XbcXsEpxo4xaM4rSqazVHHTPD0PjLeXRP/fH3NANWplvaZyVIyg4RtHlutp9V+2v1DZ5N8+Y+/wQ+ePatGIaNFUqoGaIq4y6hSClLRaALY2IkZiMU0cIZGcrT9ghoRrqjXXpJQh6UiD7YUwQAokiqMb2ZpNdBgF26V2KvLvCOvRmrGE6U5jWFivY8mOj2oMtvPvmeo+Hq7vtMZdSVjnR9QMnAYAoZ40J5lQVNAa0pst0cub4XtfhfTwZwOSTSW10eGRYA1FytFUGj+edb+a+5kYQ44HAZdD/aG14zI1BlkjYZ63eXSOJ9yyOx8RRePyqtqCqeuyrkm5nNQpwUEQ0m/MK596u6Th5z/cckBdXHM5C2LnDLONchie/o8hdKMuQsOSwDmsCjIklGy8iQFNSGjvYIDOYa3HiEqUCEJQIc2siKq7/t9jYA1wk6kdaSmI9byGQJe/fYGp4fhQ7P39THaXHhG6qbEXtaJQNA2nL/pmcK/N8ouHD24x1lEjjzast3kZwpAZ/17igNlTYnMy4J0mtRIIPVCCzMCItY1YSkn9QgQrEdJRBzHWrekBoRG21LOFmYllCGqIu88xJk5M2BtA7R/CcN1xMBAYPXT6f25Kr0ES6sQy+tVHRVMQMoKOxsCqoCRnBXpKCfMk0bvTqcJQwwYxgHDOCiUssCMvBbZhBnCFaDDhFA25udeMDFB4sKiKpD7lSb1nOplncFmZ1s1Ure97LXb5fWeRYBgBrBms0jLyXevkgn06pLaMASnWa8lZHgvP5B6pHpflKKSUhVYPFgRNEhTWOq5AhAbPHUlXoBKFbaVxxliJEdrsu4pLpZGQqwComT3fJeKNpqWgul0QhwVnSqMVxAxo03QQf0rLXuTbTLFQFN3FMCjzYtdY7Rb50nRAkCkArWEosW+ecHyuGqdmtFLIWWWn33jGxut273BhPY8ASp6pSsPxFxpDVBjPYZgESOPgamwIhKcloQBGSFGpckQDD5cB99EknS0VqnL2RXwhKfMo+s6L1q4XOmkCPKScLp/wP39HU4nxrKs+PIXv1RFsyiKVQIh3r9H+d1PkH/3DNPnP8Dbt2/x+PAen3/re7i9ftaKuo2fKOx3MboTzMuKIehefZwnTGnFJze3IA4oksEgXMcfQ+SE0/QAygWH4Qa5/DmIhouC9RI37iNqTxtiulwVgOpptq33cV5U/NczznBhbbbPdB7rc+SHo+bvTDz7n3dq4n5sevDmftv6uDPvs/HhM1nljgAC6sZ3g66mg7kxoeeRMHqe1FkWmzH2srE37N3ZdR5xFJR1wpsvf4x3b94gLwtIMmokThRQIQbC1TjgeDyCCVjXFW9evwHWFcTAuiZQEBwPBzAJ5nlRntjrjRtVT+fdXyOOBwxrsu19juTnyu7+8D3n593c3iIOA0ybaM2aIwOeAWMykXra6lKrdrYxap+1D+kcdrFQvYvNfE9VW0Xdo7YMAOyyCViWpC0XjD8G0zGU9jQlXyH4GSGoo5GgfDjBFO+q2FPVU9S4aGjPAFU+W6ARPAddcH3M6ZtFjUw2IC5vC1RE+p7L+hk6w4Sgwr+uke61noMyWxooaZSV4FF/Xwx9j+PxBodRatudAjJI/So8a6rq01Ho7RqSG5xQ51fKCqYjVS4w5mXFsswG5NJqwdjSbmNgxMBWRsOG9N0ba72xRWaU+zifGqt/9hTNXeBWnQw7v+f+PtvrK2lv+hl/YAQfshp/71EVW7jT1ZuH+7cfPKQ5Cs+cOHV4bb+KKHLn6XHGdJqQVm2XlFLCuiYFJYyEGAa8u7vCz37+HP/sT17jMD5WA2yZF6R9er7LYVtPsUUehoj376/w619qGYS3NiIAr18fcTr9/8Roc9EYei+DckRTPD3FETvefk4yv89gq/VslxitCdEzEnYPZ1/82j1vX8PQp3vo2dl6kWiqoSwrIIJVBGuMKEEVyWGICAdTnmPEYJt8GEIL3+oDzPkjVREUEVXKo0a8pIjm4MK4PQfnAttxErRpNXeF1OKlHlJ7UhVTGnIuyIUACsinGbNvEPMaxRgQD0eFmM9Fi4lhNWS2iIwW+bg6HnD/sKixEQg5m8dzq1ZXEVo9jtBEOIhVCzlog20QJqk6j+dl+8L2UVX1tJoRolYXXJ/QiSggr/Wrll9jIF5v4NHR5hUyQWrGoPaB03o0r7UKVnAcovYSydmBMNr7llJq3RYz9HcB4sAgazau06pGrBo9FpFyUI9SrCkZtXFBNGqXBdP9HSiMGMeI49UI72uyKTZkApXeiNPUXZ/XKKKZ7fbOQhZ9K4LoU1ekRl8ZwMoBLIwhHiAE3J8eddiidBgPEd/57rdx9/5R58Lml0W0B5xAo3gpAbk1a4eo04EtPQuAGUkwPcXuwwwHFXHnxLokzPOCm5ujotsRI1DVsQGoM8QZ7T7CtBEqhKqA5FJQkvMep5l2nhTdv6WoN/enP/kplnlBqyoFVggwPeDN65d4+euf4PGnf4Wf/fSXYCp49dnn+PZ//W/x+WffVmXNBOw0L5jXCcKE62HEsi6IV0pPx0PENf8lDvk9UICcMqZ5xnxIiIFwmh9BuWC8/gQP+CHYRcaZPrAVjvujulN6z0k3aZeu6yM/bba7e+3O700svfZMWACwiHdnnvWruFWfPYGuKdhnkbWdctJH7i4pFx4l426+Nin5PnbXW6RzIu0NMf+9Csazh23GK0CXV7wrD3CFseORxRBe59MDfvPzv8VpeoTryWxpekIMjsDx+oirm2udJym4f/sGyzTj+fPnEMl4d/caxBm3t7d1IzFZ8ahs14lIzChvPDAGxkrGbXcOs0vrAKgx5SUDKSVEZhwPR7Cl5xPU0MilgGRFzgVhHCzC1anFT6gTVeQTbShNyxk6gAMzTsjJbhMoEhCTGTy2Ls7TyI0GvXMqBfO8YF0zhiHg6uqqKrW+hkWUJwYo+2YDHCPpeo8WwNO8AIPlhzp0vU4qlYIgWl9jYgQMQSaY480faWngbHVONVonyGJ1w6yuPZEEJkNorDK0KdN9baI7dMeoCXilAPO6QErGtTkGVIS1+RmGUVMVSfdQrVCqpOHnXjBo0M7xKJpHXFNKmKcZp9MDpmmCFE01LUVQStJaToODH6KhPbL2EXb4+UtGmv+8ZN+0Ne2Vvi132l0BNcaeMvL8jMY71Tzu37z/TNDP00VwDCdvbGezN4yekguX0jfP7+96TW9kdqVBtvbKo1vbDtIb1vtu9PMnjof7E25uZ6xLNr4HzNOC6XHG3335BdL8mWak5YDTFPEf3lzjYTqhcMTNMWKeHzHPCaBQeaM6VVpatmfbDWNEWBnzHGrwph/fhQSCzfG1MdpciPXNdp3JNBn1hOFmxx4e/9LRf39JUXCDbO/RhI+lv8dOcD/1/H6oEZ1iYd+VnEFZU+PyPGOeJgWvCIw4RoRhwLpGhLBqmiQp6iOb0tpqBkQjc7Na9ot5EPMcFH1S9H+vqQncIoqOlkUm6LPV0HFgBDMQNVc7q9eIgSRAMLhdn8+cFEVHHmdwYByGoMaaMdKUHXYVQAggIQyHiLEQPv3kI0yp4HRSrxVQQFZ753MYmCuHCNQida70qnFiOfr7ZqSb1bjk4S4oKGDp0yebYh1C97cIhMkcsB1BiqP/mJHMjFKyGsQuvOHpkVzTX4lZwWxkRX1BMyYKMyBF2wO40cXAMAxgZuR1rU1dtYaCrUbXegfGUNOPNJLVDEYBIacVJQtYJiSJOOW1Gay2B3yuinkOmAiUMrIUCDOGXLR+zQ8H+WCgBLYItq2VzZmnPzEJKEREhhYRu2ApogZVHBS9CZruE0RbCTj9g4BxiMawBYELiAKCoaEBAKcF8QI3VK+sRaItYi1QZa7kgmnNGIYIHrWGUwCMQli1SWCn6rvytKM3Adg8+8uyWm++DGLtsQNChwztKHvK59Z1rnOhBrZGAVLOePXVV3j3/gFLSoh5QimCl9M93v32f8LrP/qX+OyH/wM++uQzAIK3795jmk54fhNA+e8Qp5/j2fU3MIYRc5nxPj/i7n4CScHNsxd4/+4f8Ks3r/Di+XMUYXzyyceY1wlD/l+Rxn9ba0V7pVp1/Q8ZXudTA5uuJw22zhO6scjapa2GzM7rlZLt4zx20Oaz3WV3YwAtOcvHsL3mLFol/X17A6RX1KR+61E4V0r8qOiUVpdUz9s9zwdFFyf1/KjP7pyLAgEYoEK6fiy1MLV0z1umB5R1BZUMDkH7aoqYwkGInuQh2htpWlYsxLi5vdaeqGKRD6utcuV1zQXHOsBS23CINHAbL+wHVDcIUCVav7s8x3XumZFzwem0oGSpjgqIApFVJboUSCHkVSNYGklBfcbeTvaf+8/8YM9uqBcbK+3OcXAiXwsyA03EHGECeH2VAlAR8rwizSuG4wE3N1cQSSjZVXFWQKyenqthhZqyHwlYSJucA1tl3JXdXARsa8DmfCOooc65OYv95WuPXLJdZnsyiPU7gyAZYUkpiNTqhQBgCBEcvIceqh9CRKO4p9OEtMwACW6OVxUR+9KhyMNGE51zRod62WhC56gQlOr8TkUwzQum04x1XczfQaAAzVLJBRwjDoM62GPU0pjBZFNfk7Yfb09H/c/9OH1UnSl04TP9+zxKjupw6h/stHh+dqMe2n0Ocmdox6uo+04a9/fr9+9x2Xjam3y750rLaNs7uPRnOdv/l/jBh0uoBOu81gCD4ytAVA+Y5ojHhyscIts+AJZlxP19QmZFIV0nxuk0Iw5R36iYY94MuJRzdSgM44ADZINMui/R+tDxtTDaBMAMINQNVKCZs7xTHKnjdrRtEwZsCOo/eSx7o+sSQZiX0oWpiGhh9RO5sgAM3YnAhwHj4YCcM2SakdekBb9OXEBVwJES8rwgAShR07pCDMAwgIeIIUTEIXYogp77rWkTJBmOoxLIGbQqp/us8Gp7wMEUrLYtJeSulsWBD3IWcDavgJCplKbIdp4qEUIqjjRENdVPsqIuUgwYY8AjZTAKhsA4vLg1JikIkk3Z0OvFR2uDZ9tF5HTitOJw73UZt+oNW31adiQTT0eAeiW1l42/j93D/tGaOc3zV/VOuWDgNqPehLHmVpN6g/TEYKexoXZqn5xLaXXF9kSwWq76HjwgBCuuzoxk0WOpiFIMsbSSGANK1pQmN+Q8MqppiuZ1t0iUo+25Ip6h8P0sUiPImbmmSUIaPPZepIinaJYCbXausNE6N7Z/rMAXYMTQ1omsqLikZDmsjNtnz3Hz6SfA+/dYFjVwiRlrsf5/piCCyNJdLb1C+ihIJ8hdPSdShp1dQdHvp0VTJK7pqN7kwFjrTmtCGZVGt4enXuRcFObcJWYpoBDNCWSKV9Fm6yULiI3fdSzNo8oigmlZwektQghYRRXF6QGYJ0L6yV/jzf09vvuDP8d4dQu6eoGr4dd4Rj9BmgXLuuDu7h1ub58jrTNCLnicZ0QGlmVCWjNIGBxGMEdVfB9OGI+EML5Clk/boDrjjUCbFgWVEOpkAAWa3oS6p6ilRl44Srf5nPWTzXkFZ6i3J1tRN7ZqSbo+s1Mr+jqwnZnVD3f3ClSf0qtFmxfcXG9j2MmlvXLz++/UXdelCZ3VbDxhSF66lz6PtuhBm84bmsExLzP+4f/5d3j36iuE4y3G7pn6fgFhCDgcjpX9DsOA4/EaLNrImAN3mRUwOtHsiGacs8n9ltpb64ZcsRV1Gv79l38PVxW2Nmzj1aZxIa0rJGccr64024p0D3sKHcHAMKJGrh4fHk12bVECL0UwNoo2UJGoNYblb9rdxXi3RgA7Rc2noBKGOVbdmCAyMCgCWQQ9ras6+aieAggQIJrdUHlUmz+PFNc68Mq3lRdnOMSHOR4NvMjKb9WRtRloM0zYjHKKtkNEIKRp2ZEZRazO2vYhszldecTxeIUYgJJXlLQiF3XcLvOMXBKYdW3GyIjmqGxz30scV3pVmQe5w9V+2rz0k+2OnpIzUspWj5awzBNSKSjZZWUAB81E8IRLDgFXxxFXx4MiMFcnPupY/Bn+d//7Hv3x8rE3ap7ilReMn42nwInANb8+3d/GjXO3W13pDQ/Te2jZB9C35SFCrf/c871LNahPv4/fr5UM9QZc/32f8n4OJHM5yraVUdt97mONY8Qw6B4jQxWvHvPuXPVTCEJkhMHKL8xeoUAoKevzWOvHB3PC92Ppf/6+42thtBURzFmVbGXuCnhQBW9vUfhBlnrVHWebo3eH/ROPzT3QjLnNZ2fezwsbxz7yJs5xGDBe3wAgpGXG47s7wEAESslIy4qQsmLyiNZaERroSVpWlGFVkFUi8GHEs49uQTxUBhCYEYeIEZZO5zNJ1FL5bHgRqFDy/k6B2Rr7Ato7pb2IojYq12eDEuQaUG9eLiJRwwGaJiHFPXKWNmJRkpILHu5PWKaCackYDrHWSa3FcBM75UMAdNkZBl7Y4MxFxNJVGgNiIvRpSzAByExIZrT1LQTq387kuUtjq+st1Qgmmw8HVuk3Idkmr30n0VISpDOemge60ZCmS+nvhRkjs3pIc0ZgRWtjZhRKWwMVaqyVJJpWG6Mqp2nVZxBrdIvUOA1W/Fih0bup8oiDiNQ5lG5f+T5xA86VsP2uq8IUgkSC0VCcmFnpo1cgmCBZaYsM3IfIlDwIDscjIIL51RsIlIa4J5CeXmwgKVtdF/OmT5MIoQgDUIREH2cVBh4VWBJyzri6Phg8r9Nfoxl9z45vGTP3foQAagNX4YDb51cbg0UEOB4OdQ3VGNa2DZV+ew1fBIEzhsNQlUBKCad7IP3q5/jJV79GOD7H9/7Vv8b3/vjvkTPh7uEBgYHTuuKQVkzThPd37/Gbl7/FMUZcPTzg4f4BEEFOJ4zHW5SckEDgtOCW/hIT/nOs+QvlJz6XAhSDtPtQqiOBL35+iU9vvKQZcC9xcxC4grY3JHwX7c0hQqWyXuKi0UqL7PQ/sfmsg+mAbLz525J4rfnS7xX5TiB5K5w/pI55umS7325edp/3111Svqj7bvv2m4srLRUB3n75Y/zyxz+FrILDkCE1TVx5QwEhhoCrmxuNIueC0+Mj3r97i8+/+ByOpQEiK1HpleumNrZ01p4eOsXaLJNcPHWfKiCC30/cQQOt+4psTszAKldKxvRwj2X5CFfXXd1IVfigtWO5HyecMPYzdXY0I6zAsRe7R7RXq+/XDBxXmwEo0nERrUE1Hi1ozjYvQWAOWoIgAKPA8T6LeGmDqeekNW06N3pOMOVaSGVo9PUQQQAhS4GnnEm3hnAjo7N/vN6WAyO5zHLl17KjFDgNRgP2ZWDcXh1BnHGa1GAbo5XD5BUxBhyHUUEbmNUR7eymKuO9k3i/Ij2Vu9Gie9bHvKaMaVqwLAuWJaGUBE+yIg4I0WvMDJxCBEGCAmoNEcfjiNHryPfOkp6GLhx9uuTlg3zisfFe2Pu0zK5u3/Rvvnlwt+901rpZke11uztpVFQAh+in0JyPekbFdOvXYSMHan3a0zr77zvUiYuz8/33fVbC/hn7zzaGG9xB2PoIN9my651mekFg0myzGPDs9gYCMR2iGY5EhJwXpFSAkkGw7LDUovn/lDkAviZGmxOnQGXzl19+iT/64z82RsWbULqfLjBAAgB7+/1DisDFp+8WD0DdEE4ET1rm3KXgXXqefaQQ6WR+K0bgCBwY4zONJByvrwEihYadJ6AITqcZyFlTObLWGDERkIpGZkRQphllPSIcVAgV0Tq2nLOhxgmYvN+aDsfR5vdDrszPdnMwIeYRGpPUzrsBWHSpeMG9ErvYu9bUtCECIC1kRjNcUilYUsE0LShC+Oo3v7W+JVrjRcyI41B7cgW0iA42hqZOdBZBhKaAojgy1TbCJrYWvi7sMPZW6B1M+aRuayjbFIO917t4MXGdN6cjQNN8TAg2SGH36Ms2QkxUvb5PUisZ/YgZwHDhzYp8SG1tdXT6XWAF1QiG5pazGmz7m4eo4y2rNuPOm7spNz4bn9gcWpV5LFrvwKVbI79Dv042b6H3Sop70NgM/a2qSmxRdyUwnOYFyzxXOuTAXe2d1LlnW5vSrffGKCUHmDFhVr3v9p85QByAZ10zxlTwkBaMMW4E3wc9pg4+Yo3sOTBSCRiG0Zp1tuNwPFQFTqDRtxohpyaeCWTtNQTLqgpqcGeFCJZZ05Tp9Aa/+g//J/Ljc3z+RxrxTKngzevX4JLweD8j5Ql5nvD2viCtBWldcDge8f7hEc8Q8XZd8Y1PP8P19TVIHiD5Nzgtz3F1PKrB/IEk/A+npfTLfJmHbh1xzWzS/yx1vlOO9kZOo4qmMbsh4fMJvw8MTMH7WmwMN591qeveK1EeeTX1ofvOoys4S6V+ynDysRDtd2H7ff9Zm6NLSarnz6nz0hlHfle/QykF+dWvEIcBU1ossqMRgiUVpCwgShiuDxBD1ZvmE968eqlRBA6gXKxmmGufRyKNdmXLDqjvKv2MFLfm6pyUIuYYkNbk2Y7S3fv0OEEgiPEASQnEQeG2ATxOE5Z1xRUMpCRvZfu+9UBVfi/s7Trf7vCrYynmzKAKbiP1Z0NyZSKLnqMaQUTak7SIIBrPC7Rd8xCCInhaOrejU+9r65wP1t+tECyXxntpRyxap1UQmJGpuUdEsKn7hRTkdcFSBMjq0DL3RCVMkqYXmBQx+0NlRAgBy7pY+mPCMI4Y4kFRtW+u6o7TF2JzqPQOt2a4EdXV6ia0M0tsXUWAJWnN8nyarMm18mCXw15OUFNldQYQY8DhcEAMA5a0ok3tljYuRdj23334aGv2tMNAqsFGlk77oUyvp7nNU+e6Max8VpGgrSZcttGsAm6I1jBdifjs/Z+Kev0hx1NX+Ri5M+gunoMtSJR/bgNU2yMrFoSC5QlKKjVY43jhxRwyIWhWkDopSHUsPgerEgGCRBROlfY5C/LZmX/4/HxNjLbOWi6Cx9NUlTsA2syuaOAegAreIliK4GTABsrMGNE0QyfgP2QSnjLY3OtoN2rE19W0XQy9BlZocjvHHlI9UE3FJoRhMGheTY8jOiKTEk0SwvFqREkJy2lCiIx1zlZ3o9DrSmyiefQ2N35/ghci25glAtDaKDKBobNKEAoI5NFEnc8sWkMQiUGGJJFUetbIkQhq/4WgXLsAACAASURBVJw2oQZXb4I4qNsKlnmvDFGsALwq2dF6h82YT1NdO2LdEAxtKC/uK+SAYsnHwZAdHQ9Qe+cxSiRgGMFp7fr8NWNDBMgS1EhLpSpxFdGvex8gVENJcmNoDvyhKGVNqexVts6cwF7VYkM4JLYCbQZYCIkY0Ws4s9ZwjUSIHJBBVgNnDgMmiwx2YopaSggHRiluDBltGMANAMQ4AKyNnrMAlHPtw+ag9TmX6hkciiAHrz/p3ooIxVMtpb2pkCNZ6ghU+bK0UFqQS0bOC2JhBempc9d+MvmcBozDEWU+uZ7TKdjY7MksZnqL4PHxHvfvjwp7XVRZ1PQUjR4TdQ/sHm7ia2OAz0tBIPWaWctZFOng8LsUbgAdGh3MUPSalfbAdVU0uBBaFC8ASAyQkDbDDQ31spSsvbJyAXJBYcYwBAVygmpjpQBSEu7fvMOP/+oRb14FfOc/O+L+/h4vXrzA+3dqjD5OC9ZpRhhGzI93yDkjkOBwdY2UE24OA9b5hHfv3uL29gbr+tcgjMj4UwTEDbLXB400VwKCgCVURarnkWI/+2WQs/vK7uf5N9vFNH5rBlvN6t2My67qLrv02aXDTbX2GhcuyO08P7x/3qXDU+P6aNRW7TKV1g0Oke67C/fb1ff4yNv3nRImGo24n0/46rcvcX+aEarSLEjrgmWZwBwh6wrCDUrJWOYVb9++w+k0q9ONutSm+lbm/Crb9RS7fykCqTu7GLojME0T1mXV/m+7BdGEW68V1TqSOBxwdYiYSqqOBXVGZnApCEF7ZQEAZa01Xde1yj4W0Zpl44DcKVQbunHnULcOvr8FGrIRJzrjCUTqaNJG2FINHL23QfAPUXs67taH2WRiCIrUODfgBWZAksn9qmd0s1xUT0hQ3kheAy6CdVVHWMoN5zjAAFWC1sspq1Gj7vFxwrrMCBzw0UfPAClY89ZoyGDlwZ1joBSt75nnGWmekQowjhFXh9jqgaD95DRSvafojVl64Tv/6SnQSsspZSxrwnw64bSsWJcGRhdjNE6ubRHysla2FJhxOA44Hq8wHgbEOGga5V0DuNor233ao+sJxeDj/zCjxd5DunclQp/aWGWeuEH6ofs1zvEhniZiYHPCSGlBLgXjMEIgWKYZMgriMGrtOdr7ewdQ592lWBYWehknm/nw393ht5f5eivTDTsjEiAFP2pPrOd+SPZ8aNbFnLq5mC4dGGN8xDe++RcocEAvnXcCIJINWI7BQjVN2d/DI9b21lUXK7b/maB69IXF6GXpU8fXxmjzg5z5FGXggZ4myAztkZXcgkhZDQRD0SMAo8lEAgy16MOeBiJqICR2TX/UJt68RbHanLPpBN4JwyLVmp+XCYEjIgckzhDirrbHxhoGjEPEQgERjKurI1BWUDxASsF8OuHh7gGyZ852jyJUOwHsoVo9iphNORfRKKfnzvsdfUv1kKUwhb8kG6srY90wOgefpZBliNWKxWEAS4YsiqYjAEpGbXBduPWWkiLIawIFBosy9Gb4tjlWkBr1AIkxpwMFfPHxLR6uR+0XNC/2bp6IBzVUVce1WkADZRHdcEKMsvPueZ1UnUtL/wRa8pdHbLR+0LztolE2S8aDsxIKpigA8DyD4Cb15jXN8LHebr4+LB1SVv1H1zzYWtWUFjvL08BIREFtiFDY6IWg8PnF0gOLbFI5sjeJNyTExISV0JDgdkpxhvVs696jJ5acVrx8+RrDeEBgqhD3zvz8VAFpPSAxhGNHZAACY8lZlSRShTFQ0XReSUjzjF//4meQeKzXuUcZRvN1PWyqWgoIbaI4kTzl1iI0FDaOmF6oqtcR1aBHsRo+o4lcVKHIKYGH46aNQzZ6UAVeFFGz7iv9JcZQ+8ssqyCyIpjp0z1TgCHzgq9+Rri7e4/rF4/I0wmffec7WNcFb16+RMkZ4zBgXjMCA+PhiDgOIGEEKrh7/xb3D494f3ePMQgS/y84FMF49c9xiMPvh7xyeiBS4ItKozsBJS162cRy/0lb8kpCZzKOumtg69AMtrZ324X6WUuz2rpa2rPd8bFV37fOu2bAls011cjqxrmXIL5/ewOvN9bq753i048E3fcfnhN/36bgahTNgXgKyv0bLI93kHUBotbhnqYFDw8nBIE5PwRDDFiWjHfv7jCfZo2CbQxCl7+mqEGjFhXNtY1Gx9cp+SLaS9CNi+072i8lY04ZKSXcPrvGn3zCGMeA7z6f8DAX/O7hiOFQ8PlNxg8/e8BPTvfA8QqBFpRC+CL+ElfyGr863GASxrtkymuBOnXgw+oVMZtJacBegMowgQJ98D7nwJQ3Jm29knNRo8gcfiFs11dLaPSTvKMvdSwGFK9dJzXClNc4Oil16dvq3S8AIkQbZYOQc8bDwwNOpxmSM4bAoBCQUcBFN0vOGYNHMkz2RUsNq3WkRVMsU6eHEsxxVHUAM/geHpBFcHUccBtil7LeHIGbkhNLpa/lCugMAkv9bAZUqXrWuq5YUsayrFofZ85WGDaAG4U5F+SkQCNkqafjEHE8RAzjAXEYEeKgafrMIFp0DW0tzyNtODueNti2fO3yd91c+FGjar5fnrh3ZZQ+d+6YNz7WOdtENz5KWZFXjRZnCxCUQmDOCLHpgeqL7CvhnrYIe37Vl49so129i9tfs1SgG71PzzO6fbi/n558zsV7h2DV8QlEBYfxHjkTQlzxrW/+HyCstdGLYhQ4Dw/opYfA0o5rhN3mwBifZ4m4gV27/Pq6UBv770+Z/RoabYC+iwg6A2vLsIS6BBRjYL4YnnDhP1MFmACoZAVUoEbCtc6rPts1xCY0ziJs9n1FmrQB7w28s4O64k8pyCUhxEGJMiusrOQVgRh8dQVwAHFECGKMGFgRMbDms49XwDzNBjLhjMyND/Xaa38TVgHbMxh7lRCoRUD6V1cNE7lYJIss1cMM2t6DAA61mSigCIXFvD8FCo+uhcqwqF/e9KARYpB5ooUJQQoiFJVSDcpiiqk+whklk9Y4ZNg727ZnMtRLJlCMuOaA43hAzivmZdX5SqUqVQQFJqkw+ag7DM6W2hrqx55xx3BUSKpgMzaL+h1r3QeshoyMifppLTqoHpsQA0oCStJ0UGKCeNi9Gi92rT+up7uOIbodQjauXiFQQ0XnmGtNnZuTur6eytOENVVAARGDfwbpORb13aZ+ohbZ96kJW2Vc/81rwnSaMI4HBKM7Oqhhdprn6qlclxklJ5CbgM7/UkaQAqGAaHMNCpW1lrzg8WFCCLOO17eBaPTX16TITuFlhtAuat+tsc+nt87wT7Wm0yaku58KR03qJku3GQdzBDAbmM1WTHt6SskFwWilRqGHCCTd/7pORRtnVwXHBZkK5YevIso6YownvH31GgjRUqJ0TWNUVVMs43QYIg6HK9y/f8S6nDBNJ6RlRhbC8fp/xu23/kd88cm/PkPUbeTYlIJuEqpXdjMvdcTYXaOzsBfA/rsn68jFM7u55L1q4woD4FKAqXsm+TlbRWILavL0QdVR1lfB9d+3td6pPfXzi6n7/jIffHbLNunuVr/zWmBPoS8WfU6WDiYlg99/CSozlHY0XWyeTvZeBeM4YFkT1pTxcP+AdZpwdRwAk8cKdZ01qjVEbdFBnmonOBxi44mboxlv/n1x/rI/UzT1fwwLfvBFwUefEP6r754AZOR1tfYqE0IkpLXgYU74Qn6EuPxMHY9FASjucsa/+fY93k4j/vLLF/hq2dLKdglks2a6HB2dOy+ogRFfe71iWTPWZUUWwWEcVFLUSJwphgZWIARFEt3IIAdTURoVtEfWtYe7kUrdFwytk2dRXcJdCvO0qGOUYJFD3VU+/GD8JwTSDIkYMI4D1pRRQJjXbKi2Rfllp78RWcsgaXNzczUCZGBpFdTB6VNMnPXywmnE6df1rgJIS7FNKWFZVyzzimlesSwrxJzF6sRTWSoimlpelK6ZGeM4IMaIwxgxjoNC9zMbAEkAOKqeQzAEZaeLFgHaO9T2v2+PrQzp17YRmxtHPe9wJWBPgWc7Y/dxz2v7x+jnnl4MwLKbVACQZOSskdmUC2JOyGL9+EQDA43nurTa6s1AAyF5sqYN+/0mm+va2Lgb9/ad987gtuOotkzpZUc/ISFM+OKL/wvLesD11e8QmJBFM39Un/W8NLuPaFZSKTZ2Uef3drCqW1eE405vcNvFny82N4qw/WHD7WtitDVP32bhsCE1VcgZtW/Y3pjr/tArzFtVGQaABNkAWTDpJDjRRNptun6Y1AQJgE3Ptqo0ffA1W95vCKF6Xd0AESlYp0Vhkq8Jw6ACkFgQO/CEmmZp8+V56GINKpkZ4zDqpuuV5SIobMaR79xuzisNdZLAa48YGi0pRZ2uqt5rzWGFBbYFo67xOTNVRCpVbgkQqn3WNtuOujSUbjMLPKzeMwdP7WwMX0Q9xPOakN+8xzivOBwPGMexesmEAuaT9fzy6CFE00U6dc+N0BZFNIHhBlfpfEz+HbCJyvmcCkoNjUcrxN4zKa3zMIU8MMKg54YQzPsllhrD8FID1wdcSNO+QAG61sQBRHnDpAHrGVeNNjIjyxmfnVeRBFD73/ldztVQ1D0SxKKV6kU414CqoLO1DAHBInXJ6DjEAXEYkFftoRQjQCgoaYFHSwu1mSRTp0MgDIza3sKPIUgFBQkcqmer1B5GXWmcHSzqFHAFGt3P/p2k2ydMWpfSHl3NYL8TjmNAjAOuj1dN+coKhhLiOVuu/V4IqrAbPTk/ikHrMEJs7nqnbfUL6joKBI+vD5DMeLx7xO0XCrU9rwX3j4+IISDlgpubGxwOR6AkTGvCadJoy930iEOIeHFzi2fPbnAz/Byl/Bk8Fa5qBOjGIOd0eclgA3rqPP+r7Zq2Aba7drsszkH6hLunz5Pd38Znu3v0xldVri8oZXsZ5imQPcx/f5e9IrFROy7NHTYnuBW3+3hf37Kdbx2P8sB5esCrV6/x7u4dUtJ70ukl8qufYZpXTYcnIOWs+zHNOBxGKOR/wP39A9I8YTxEEDGyACCF208lQ5gwXB1RRGuY07xoZok5G8VkTaOBPsHfvdxlQ1ffuJ3x/Y8ekYUwBEagBd9+vuL6JqNk7aHlKZi5FFBmLNOM+/tHlCIYQsDNYQBIgYzWVdONn4/AF89W/Pb98GF9+oNLUjZOHFVA9I9lmjEvCRwCxuNopQPb6z3jw9Fj+3qs/cGkZQOaxdEGKFXnaQ4eJuVPNTJIwOEwgqCoiCCVLxnaV9Mjo374upr6oSmeydLmhWrKp79QqfyyfqQGGcX2QU27vTy/54bQdqfkXLCmjGWetb/ktFrZBSl9sraCkVKwVlRkAXPAYYyI46CGWozaTiZw5WVkRiURWUYQdTIAtezysuPhDzn2C+oTdb7QzSl/qa3U5Wu2n1N1flc9jNDKXJwLmtwmA/FRkMCkkdQYrF5za5woynuuz7poGO3epdahbdb1ghEGNNnin0kbL7qryJ2T8AIVqsTXtM3z0YkAKY149+6fIxfBOMwI4529UzPUAKXpYP0rU1a90evcdKxbGt7QjAOsgeot9/Mk8vszVr4eRpuYQmjT7+AAukA1qxsCQ8O3PBc3Xp9ipM1D4QtlREVNHBe0qJwq6RVbwSBDBGPvWbHzAGzCtsRcowHAljAvvC5iPIC4ICcVKjwOuHr+HGEYkecZEEEMBKYAoVTDKo58dDpNkHmCLAtyjBARpOxQwQQaBpQlacQpMlIS68vVBHrJWjNAZli5J66UhhDpMiWJkW/0+rW2GUpO+kxuUTudD6kgHwCsv4oyw8wFSG70KNSzXmdznXUhKEsVbJlgKWlqOCUT9C6IMhROPqeEZU14eHgEQIjjgPEwYDweFCafXBkwA5MMsVBQDWGPRvlmd/S/ymRMODFXnAlTiqkp+Lvi2CItHbURaSNeZsI4RgzmWAjW2HmZA3LJatSFiJyBIRLYjLxxYOA4QOa19Uuxefb37BkYquAhkOQqnAC0aKFsFVIRMxyg6TVZAHHErC5iwKYQVE+ueZC3Ueqi+bBW10TQGg24M6G4kWxK1zIbaIHe+/39HdI8aWsG6edPU3ukZI3UEcAxoBRgiEAoOsosqoAKsbVa2Do3+nWunxLqePpzyN/PjKde9b/oSIIZAyXj9ctXnYKgStX19Q1evPgERMD3v/99/OKnP4Mn9KpRpPu2ja1xfiLjSc7f2JQ5ZqAfF4DpIWI5CR7eFtx+c8Zw0DGlJYGJ8OrVa7x+fYcQBPFwQADj84+fIcSA+/sJ7x8e8eLFCzy/JhT6G5zKv7RUU/q9KehV4BJUecC5yJb66WYVfCa6sxtvv6woPDWWdg/anNfHxKg7u+0ZAGfeUEI/ku3I3Vjrz90+8WxIT6phZ8/r9+iHz4Tun6acQYB1XfDq1z/Gl3/zF7h7uEfKmupL6RGQFYPVd1fAvxC0V2hoqehpWvDRpx8j54TH+xNyyhgOBzw+3OH+7g4hRIyDwmevD/dY5kWjuTAZ1BkRyg/M2WK05Gzrv/3+Hb7xMQEkGClhDBnDOKoDBkess2ZeUAFg6f+1Lh6k0a1cMDLh27dHzQIhwh3rfporr8QlO/jDBttO1nsLGgIMqMQUYpPRx+NBHbdSWpElGZ25M9bvAzOQcvc8oooMrSxAao1641VqnADKcpNNemCuPTVD0B5jrkB7fV5F8Db9igEEC1XzEPX/JdkopaIxEmlqtoIy61swMRLcQb2rF7/gTNjPuU5lZ1SUoq1YlgXzNGFeUjU6tS2LqrUpJeSal67rczxGHIYR42G0VNCIwFTTM13f2WRNEUPAm/UV01khrX7t/NjuYuIAj9JsdqvxdRMkZxMg/edmWMuGGLbz19eR+b/iqchGh1I1lXbkpFHZJRXMy6oZUSVjXjR1/ngY4DK6iNWVEc7u1BtZ/dj2+nApqn8ytbq1Om+2Dnua6P+WznhTDhsQWevlBZrWm1YF5DvEgFg3h+pmPey+SMDDw3exrMDDwxeIccY4vkfOP8HL393g5toyMVwjlMZDC1AxBSC9g7zNt79vP0fWBlj3pBDyXmd44vh6GG3YhmelW7sinudqcZVu0VxJgTF6nSAXuVtvRFVc8dQGczaHLTw8gMWKvhhADIxoG4xybuiRtIsSdlG4/h3VGaDKTeagBZ+WkjIwIxxHnCwFUaHFixluxRhFM7jWadaUqYEwDCMQBoTR6vpAiEFRGLmmizWFqgKUmHARi+bUwxqMrt4LppQaSdM5cqLtim1BNUJVshJ31CI5sIgZWQVJAAKDgmAwQ0AbvIrBJQMS9BpXFrJsGRFgCmouhgau7xwspUHvq/VwaZmxzjPu3t6Zos2domAeNRu3FO0RyMy4vhohHIBiEZgizchiroA1YtdeVFatiFVrm2zu0TkNiuDAC771fMZ/+Y2X2svLipcCEWIcMS8rrq6PGCKjQHuTlayGDwXgr39zjZ//7oAlB5zuHnHSAjN40T9ZbVu1N+1fJgazpT0Sb1gvs6dQQR0kvhZkwh+wlEhll1wKcgzVobISYRBgVeLZyCJVpoCaPkYtDaKkbE4UqYxxzZ4FbgMogKzZCuS30bRxiOCiSI+UNEYmB4fBVgGbSQBYLZgUEEVdFbamAmJMVVCdCIQLfMMFN0zuukLsX5uQ2hdJZ0Oj1JNabQITMLC2/uAQMI6j8UA7gwxwwWrCQrCqmdIEVy6aukImoYUVfXcDE2dKmWRCPgUsv4hgNi+qCWGBIA7As++8xzBMiGPAeHXE/fu3oFJQiPHq7WvcvngOpr/CKhPk6s/APFhj9+a8aLWBaOHxfqK6XzdGz2a+qRr4Tx87Jan7tzMVd3d46n477y6267/Pxtgbar0Bh/77gD6jq37nFxKwbbz8xLG//2WVUd9hHz1elhnzMkOkYLl7i9/+zf+Od69eKlqaedrhCkQgrDkjiCjSaThgGAes8wKBoKyroUMq/RAzwFoj9HCfja8IDldXNVukAOCiCMee2i0w77+9EZOPgxBJ8MNvvceffLHi+vYaLEApwdIvBcuyoIj2ZDuwAlJVYBCoQTPdP2CZV0CA58cRAuAmBkTWSB3njOS13BtB3pTlszXYzasqZS1K6FeoXDSZHgiUVWcYhoiSUj3fZWsjJLOYVHtFqQ4Oqnd3vS+LptOrgu6MW+uFc1oxLwtSygYKYvzdZKZHkrzelgkQQ9ZkptoWAAMhiANmaXomhwDF8kw2Jxla82OrWgIyVB+gy9PoLwtAEAshb4IbGo1dlwXLmjDNK+ZlRk4JVlJt/WtVlc05I6+TzjmrPjCOA64O0VIgtbREW6+0dF0tsUENBLR1s7HtDJFiJR5PW/J7buC62/58f1HCdkfvv/f53BtrJoGl1eOeGzpuNGmAQMeiuozWYBpCOxPKuuD9m/d4PM12rWIFxI/U4a1Grel8AAIKgLIdtTssaOtUvcQ/q95FTbcno/d2O6u3rQ4nf2+Gp2Jr0CJhygXLsiCntYJ1MUfw82cIA5k+JhuDjZhwdT3i5mqEyIKUAtZyi5Se4fH0ApEfDCiwdtpVhzkJhqhAfQyL7FPeLKEHBfydt/PRlrjYvP4hx9fGaPNjv6mZpVlTfoJtllwExXauWDi31S14XY5NXBWET2+yNomdsJaWHlWgKHqLfc9ALf4lRm08Sjrwdg8bn8CMU7uvFCBLg+bP0n0nWqytEQ8gxoiUk3rAYsD1zRUWEjzcP1YLfhwGjMMAAWm6BwkON9eIgbDMWZXnYullRYENSucNLCRapGsekGyeBBKFbW6xUNg4lZkHatE6MENSBnkfMAFyStVjVkgBRYCsQoJaLSAxG0w/qicW3Bv0O23GN0Bxg8IjEIJ4GDGMg6aO5oKUEtKaUHLGmlKtA6zRCyjjLtQav0Yi8DhqbnxJHXyJ/ptyQSDDs5TOm+6REzQnqtfbuUtBAKBkfHG14L/75mscBoIsAYchIhY1WnPJmO7vseaMZZoUFdMipzEENYiF8GdfPOKH3zhhTQVfvVzwv/3sFndpqAYIerpES+FrGd+9nkCVKTbLUlQRr5FlZUSeIisCZEdngwl4Eax2m+2Wo7rW7hn156o3uXRj1CtOp3scDzcb5blwUJCi3cFFMCBgHCMWma3gXp8bRFMMuQgkEBIiBpCGSoMJ7R3jLNTQHJ0/eBRR931Tn/T7qoKhbxRc375azp26bbJaxR+qkVMdEc7yCICw9T7S9YnEyIwKLBRjRIiE6hqwa9X94w4wVNoUq3+rhqq9AnNAWgre/uIFrl6seP7NBev0AOrQrab7R/zoR/8vnj/7GB+/eG+gSh9hyp9rZCUOCO7pd1rLbb33VLEnlb0K04TeJR7ezm41zu3cbYLk9vo/xLvpZtLeQJMLf29Nzd3T8lOjAHZ+xhol6p0SfXr4hhX6z6fO9eyKUvAwLfjtr/4O92++wvLVTxQ5lBRFtz8354KHxxlSMsabI8ZxwGEYME8TYMYRMxAPR0yPj1AQCO0xVoi0GXKMIEh1HBIHBM7wgq9Ohdm8i+8gAfDNZyv+2cf3mE6AlPv2nqaIOkhJKQWHQR0w9X5mwCynGVkEz48DUARHZhxjwPdePAMA/MeXb3CfChaTF/2xMY67xd1vZeebRbytjvIbBFb1n5Q2KUgFtnDIfjbDAOaY0IgXmq9FRPtClW6ehBxqyKJjXa2dKerrPGOaZk0JHaIas1ZKAY+ukdU/M9U0bDZQjlrzC9VzObhhwwjDiJuD0SgsHZ36ubconBnRrUUObfSD/kgsCAVYRBXuZVkxTQvWZcFaijmD1RjzipHs75MzEAKGw4hhCDiMB/3d69vNEe6OWsBrJp0n+X7RZ2gESHnoPmOKydI/nySIdi/9qkMXvsgB9pwD23Osz5nefjtpnnlUH21Dcb3Jo2qaDaXAaIVUx8yFFRdgTVjWBdPDCafHBXGMiCGCpGBaVttS3hLHx2MozPDEdZVlT73J2ZvJdvfXbBXpyxSM50vRVMTiUV1Fi01ZAYiKAfzlnGvAwOVFCLlWdhIuyR7Cs2c3uL291vpM20ccAsbDAVIWeHW8A5NI8VH3b3B+9J+K6ZUts6+dsK8B/NDxtTPaNvQoW8Kvh2lz4zDg6uoa9/d3GqkBTAfytC1TUFjzpjW/1AoZSWq9juItnD9rUzzYhSlcYdP0fxUeXPRvBaXQ2w+uMLGiSSlhKppdKVGVLg4oWJWR5ox5msBJc955DMiiodYQAqg4FGRAGAkHusE0zVjnBaf7e2UsIYJDwGApD4c4gG5HXN+qkic5I6UVKSeI5fGntKIkM0rEhavRkyl2ZHNQsinT1BRAN1JINNpUuveua9h7UYC6K7UeL1uqGzdBZXNP0LRKVQQMEl5kkxrHHUM2PVejKN5jJTBGHjCO2oTY+6/ktCp8bypW6C6oDSRKwWlOOJDODURLuqW04ngnOGcErpgWcxaIz43PnTQjzifjv/j2I1BWfP7sE3z39gqffPJxFRB3a8KPfvsSr16/wXKarZHnYFFS96IL0pogIpjWgo+uEv77P53xuxNjVYsaP3tz0FeycXt01Ui1zbXn76MT/vaLCKoC5MpFZT5OKGSomJ0BS7ILrBgpFPF9ahE+sgf5+NDqPe/uH3B7+6JOW2tELiY425QKQ1sylGZik5lDSawusPCeozTapDodcIARX192IdgpG0193gnSblB9lFU6mpF2cv1J3b2ozoJ9Lf6Z3qGAkAzdh0NQ+H+01FJnc+KCwl2x9q0uqRgrdKGh92XLChAQ5vcj7okAfoA36RUA87yAY0TOBfN6wqfp34P4iJf338SL2xt88ulnWOlPIRjAHAF4eswWZbX99Lod58ZbI8nZQpN0rpC0xetr6BoQiCsF+/V+un6gqVVtXnZLdXb0n7Htzb0wFivP2j7j8j2AnRHWGaKuIO2VBfdptmuKKWeaJibphMPDl/hE3uAob/EyRjzMb5HWdZO+U4rCfOeUcHt9DFiamAAAIABJREFUhZubKwQmxEB4WBPioPWm66w9ruZp1vcsAioFx5ub2q5Fa3VDe2dr/0KWxbB9920qaf1MBGWdMZdYU5IhnqrU0AOLlE5ZVcOnlAKOAWEHp70KcJ8Ft0FBFrwm/DLwi8/ndq73c6+nbpU5b0nUPmlgQqKTjVpo7zTNZJkMRneiaXVqRFiGg/UDdadMFnU01qcR4eo4ICV1WipYFyErMIDNkZZh3D67QYgB6+OMZV6QLW0ebgySrltVriWDx4hIWh+wmswr1UDXUYTQv4MPTerf5IYtLFunZDwsCdM0YZ5WJJO9YgaDljEUlFSQrX8ssaKFDtdHDGPEOAwIMSCEwUDLAO/xpr93XLTbL82IbCBeAFlzc51Pz6bRVMe832xbQqgCtF1/zjg+tPubZNk4hYEzXuZtBqqDpx8WFEAmi+pRmt2VsWbdVylnrPOKtNh8k8HYM0AUEXOBp7W685Dg0S8C1dwYVP3R9+bmXXa8TKN1pns4eBapYZbNwaoGmfYBlKI9RnPOcJRQ3y99bazPQXUS1JHQdox+qPe1OjACGUbDGXBVk8fSzfHedt8ffs0eq2G3THVOfp/x9rUz2ojQZqBuLsGZGxLAMIy4ur7G3d0dmsAHfCochcibM/visG1GJkVtMt608dq52rhPLZF+P6IpHQKtjctGOAzTccm8QsagvbGzpxZSsFxpY8p5XZCFwCIYSJlZLgUxOuPrGgD6/Kwr5vf32og3BhAHzIFBwwCKETEO4BgUrCAGDDFgFEIx2IxSFBmsiGCZZ0XomxakOVXm6+FwIihQBlBRlHrF1ueEDDZQTCms8ycKSy4uCdkEPWmdVJXHQFXsqqrSe7B8c/mGcKbWa1V1k0hnqFDN46fjAQKFlH58OGnKj2gPugTG9O4ed+/vQQSEqGmXuRQtzM8CihHO4IkZYTxYTr1lPitmdMc0duldxAAzvv3px/jhZy/wve99B+PHzThJIvjW5x/j//7Rz/B3X71B4FINNoXoj4AUsORKdwXAx88SPnuh9XxCCd/9SCOfKa14fEz4d/9xqEoxbBm0bxvVKE5vcsAiORxV/XDlTLw5rjFOMGOQVluRyOlYxyalGS8la82EON0QmXqTqmBwBUrA3d6GRWbPvbQ6WgYFVKNN+n9Z6z43dXCElnZE/X2pesbqOIy+q6pv/ETXtdG5pjpwSykFay+4jjzbjVo2gGItWN8+UEVJrftOJ7quG5MD+iiCHnNzJtT1I+MzEMu7bwqUp8HB18AEcV8B55+f3g1YVsHzb951OiGBU8bMgOSCQIzbFxFD/hvM7wvu+FPE+FMAAYfjFTD8AGv5LoYYzV/WpbC5wl/XoTu69SJWJxvBeLF41FHTfQW2z/eGMXrBSm3+OwNqrz4ZVcB7nF0Spn6ddH9r2lRBtwp6BIBKu/cF8t0cWlvcRtI/Ud+5rVn/fXXM+LuIYDo94u39A/Cbv0F5eINTWg0oJEFyqaBMDpaTc0IyYJvDza32abTa18M4IFiPMxBwmmZNlSNBGBTAg6vBxtVAuTRvun2kKlJax4Xm9ILgd3cRv4gjvnMzI1kvte3RZH+rpfJvdJrG4wFLLpjXjBc3BxBpXetv7+7xlqj2DfX7sBuBRE+uUx2HuJOri9rYPLpzqVfymFxGqkyhnHcKuTMSczoaCbiRA5OTTue9MZENIAtmoIVhQAgrsvfpJFiGTaUWXN3cIA4HMAFv0htgWUFgiGjbZCHVFfwdSy5IOSvgUp4xTROWJYEJlhWgO0LbJUjnCFSpXh1YRdPEl5SR1gXzvGBZEtY1VZ4HslTXYq0f7N5MhHGIOHi9egwavWQy4K2WxeF74tKua7XTF3akCEBcdb69UXae6GHaew8C1POyXn/5A7iAG2JVvhIu0H6jF033RzWEIIKUC9ZlxZq0rIKYEYLqggAwzzPWacbidYFGO2lNGMYjmBglhDOjUeusdW2UF7f3Jljk9dI7ubyDAIZenYug5IxSkjnRc82O0ihqNoNe6jy67KgGout39pnXlOr5sPIIshTiupk28wegRmKrh4EurBGRRR430sUyrno5o/Iql+0zbEhbpO1/wvG1Mdq0/oOqtXx+dBJ2o3Q1bwlt16J9VprBAeQaIaiZBpWBmgc4hEqgQaR54PSuegl6Zt5Etof9YytEAUJAIQvNC9TLFYFcVs1rDwOICEM8gp6x1g6YYA4MpDXD0WlcwVvnFcvjA2Rd1BAk0Sa7uQBY9R2t/8nqxDlEcIyIg6YOclA42xADohkgx+MVihTMy4y3L1+j5FyZtdc7VGRA25nEXQ57t4H8ILJUglSqMHClmKACfs2MgTQVrJQCyUV7hbWFBudSPdgE9Sz2wrD3YnifmoqkTJUAqpEA86wMI2NMGWlNlQ6U6SszySJIiQBZwUFTx6p3h7wWA5aCAVwdIlJu0Tu13zIEmpqgKF5UtZYxBvzR976D4RufA9efAMs95OpTyHqPT04zfnB9wJtPPsHj+1fwywABlWyGBNUI3rIkhGyeWmKAF9zyowr3ATiOC/7N9xh/8Y+fbBRNZTmWwtl5hJzwKSo6IRUBmddamJEBq3c0+rO1Sn5fURCb2N1LPbctpaOI9kvzJAtfYxcCUkqlK6cZMmOowQgJZF0hw9DqTLFXd6nWVvafNjp1A9yU/oIaGnUHjD9/c7l4LYxyBa7CWeoUblm/VdyWxkXqFX1xNPrIpdT7+LBcaJFPLVnNgkWDQVTnyp/SnFDnnlB9nzbu6nwh5cv/H3Vv1mPLkp2HfSsiMnPvXVX33LGb3W2yu0VaBmRTsGQLkDw8GDb84if9S/0GwQIIQbANkDQkkQbNqdlkz3c495xTw96ZMSw/rCEid9Xppt+uEjinqvaQGcOKNa9vrfcRb8oRH3z30Y1t6znFjfF4f8bh8IC6rcghYnv7Dh/fVsQYcX5g1PrXuDl9CKQT+PS/IdA0HN2XlZfrFBrYGmhj6tHAY8CRGkf1yDyvzwyHhv1nXUEajFbAFa9xD0djbdwHu8KQVuvpS607GnigjRdm/Rtee65IjPME2Ju0mrLz9PAOP/nf/xWeSgFQwLUipAmtZFwuZ1gWCtR4TjEiHFTqsNSuYUoojRCWGUTWw4nAtWJeFpD2e6ytIKSAKZE6WEZ6UsMhRkllauwAVdcTsjYiaw24XxPChzNoy96e4DlCpjzKwKG872kFpnnCkivuH5583wIErKLoV4tm3vz+d57w5X3E5w9J0hTV6csqTFxJHR9rxp06X5nSno9iOHFmcBG5gv3jH/0IP/jd33uuyXFXkMF2HvpngvK/ytwbdLPVpQHQCElUhNrmglsM3AogzgkBjPO2CfJybSIPQvC0R1DQ9ggNVArKKsAuJUu+7zwlcCREiqgk+kJjAX2yfnVSqi+8vOSMyyXjsq7Y8oZS2OWxya6aC6qWhIQgZ2paJiyz6C8pRalH1HY15GBinS+QMY2RsMa/BCkNcMfMXirKggb/y/bY7tpPHNxQ3+9fr1nebapRxAsMwEtqdiKYd9MYCy2YGaWR62SlZmSLnIeAKUYcjydMkwB/bTnjcnnC48Oq0TWLTtt4hKbilHBzcwTzhDhFVCJ03E+JBO9nM86S3cnAbCOVMdZaUHKWVMSyoVYxyO07TQMnJQvSs9UOMksNnjSWH6K+GPiH8eHhpy3i6D63AZuD2mUEnvN5sk0wvfHZfj5/ZX/0Oy1du24jE2opkI7l1Hnkr7m+MUabCBr9zTaZTeAFBBqK9+Xt7ugG9VZVpsy4d2Vv+e6eOCj7jApqlmnfBYwpJqBOrK6IK5nKuEUwJ3Rh40RjikSp4FRE2JCgLmIS5oMAxCkiTLcIqSBvZzFwKALYgGYHlYHWUGrD+fEsPZquFAa7qLU9Yk2pqO2MCmCLUsQZlhlxnpEmASOgKSGGiHma8dFnn+Lx4QHnt/dg3ntOJBVRc5pNSAzKkS9tM2W7udIrgtWALlhzx9GRL0ng7+1ejRmhivelez4Go5mgKSiqqCosseTpW9Nyfn7wuKcZWVNEyZeOYlQEQkREaCbkRDO2vjMpEKR+m1BqRdsKlkmiQq02gBtaVrq1QmelHXHWNCRipGkSRK/lBpSOqBQBzr7eEUC4/wqRodD/QG2EGJqP39in9Z8ZFaTOTqTG4Vt3CT9cL/jRm7nTBgk9WGuGiKvYNvc1rwYWQkBkoXnxBMr3bV8TBIjElIkoCyNrTT19wRma6oxVlQtmSzeWPd8JuNHDxgNNhiBeuyvnQa2Sux80OkgxwOpFgwQ8UUvFzWkWRTRLmq/1RZNmqsMp0z0uW+6AOTSyfPUu6/orvip2lyo3g9noRoAI4wZw7coB6Z6QqGpB5+fp9Sz7T8xI8zSsXV+ycfymVNJ4dp0+Lb0Pnbe2hrIC22NAWBqidFhGWTe0yjgcCl5/0TAvMy6PT4hpxeePj3j14QnvHt6i8oTf+rRhXs748PR/4bH9CwQHLeh89/qSNREjzfeagkIt9/V2h87gQe33G+jJ7rnfin6OeK+AXI/ofSJ1vJ+NY1TAmK2W9NpYu1bc6Op1G82oJA0GP+/fAbB7dmsZ5Rd/ipgKyuMT5lnQ//K2oZSyu3PXMQNSIkwpodaCFCEaoddfA/ePG7baMC8TKEQcDieRaQtwOp4EFZl078baVaXZQIriGqXeR0DFxEQB7+P9f/rLE5YJ+NbNhlcniQw0BeQxBMpxNRnQGj09xwRQlM///PGC2xjx8WlBZcbDmnHWfnNpEgS6QFBHeuelysYdfEjmI58z1yYbqBVkvYQHRZDhw1/tMEjTwaBK6zPa6NKu+V535bMhgLl0eogi76hJlCwSkOYJ07KAWsW6ZtSqZ5wb8prx5suvcT5fUHJV4DAB/oqtCcAMqyOqVuStutM0hqDJAkGd5wHF4Dvc4BCwp1IkgtZaxfl8Rs5bHwcF6fsFyYqqmu5vWTGHOeGwzJiXBSmS1tCrobbLYQt43iqr82TTK0l7srJtqG0kCJr7p5tgNXp9H0Y/sv1q7Xj69+zd63P9spG2A4BzKoDLtmd3YUhbnMbIiutQ6wZmBWFLEcfjEdM0qZ4liNpPjxc8Pjzgclm1pAI7/dBXUZ39REC1XoFEjgxdKxCiZMC4Vnp1/kZe3kDSjuEstYm1Vcl4GUoYHGG3KWgYS7mQg55RX6sYu8zc1YsDu7YXtoayE+aSHsc4rCwzammwxgXMANem6qIqCbt76yz9wBoHJY+k2377My2LbxhfRXOD7e97fSOMNr76baxLsKPBLqSkpF7rehFiRJoSPCSPYdG5p3v4ZQs/CHYbgIU2k3mp1XsVYLZXGIwx+Y8BsAKdSMG1Ao5wBxUg1XzM67mtF0xNcnQzCXgAOCrCH4GQUEsU71gIyBRdYNgqHQ4zwkcfYn18xNPjk6BxYT/NFCNy6a+ODXBZeieIJ+t8EdAIgqRUxghKEYEClhCA44K8ad2dOPJhnekDyZpXRs/3JmGsTQ8gQY0w7uN3pVoXS+4jBhGrx9MYpBeoJjGgLELao24afRgK0sW0tvQRdoPx+miwjjfAGjA2j9IRIKmBEG9RJEnTsObhxep+SNIQynnDJSbkddV+a9GhdnmYO6A1iohATKAidSGhFTBXhHJGymdQnHZFq601MXxYZtdad1ZU9UhZTrqxp+6BUgHaGl5fEv7qyyPC5NSixq4Z5iRe5dYVjdYYIan2o145UmO4kaQab3YviNFXr5hn1XEF+1tbZJCSRjAz1VOINeUjZzFEd8NVyOsUUTY1JpVvxJQQmJFz1tsxIjHSFKV+y4y6VgF0wJaUAsqaJV06Bim6DxGQ0+HCNAaNYKCnKZlTwNw1wqUkCktaBi06Q/N9MQNhpMWas0CmTxNaqWhZa02VJoWGKxBIAQwG45rlvAVIdHOakkbQ9yq/q/utnwujd0uvsTQThgjx1ppEdreI+5/cIH2QcfPZGTQTahPkvuMScLk84rKekVJCYsa6Vbx7W1EKcLw9Ik4zzucHNP4ZwunnSPN3d/16dumS+lOEsQI5cP9cj7J1Q0ze695tHu4Fxs6ow+7bwMuBG10v8bg8N7xtL68MRN2O/QZjLLC/HgFj3KWXFL7+6ZeUPFIFj/d3YUZ9eot3b94CYcY8Z8zHEwIxas6Y5hnMjJzL7p6m6CzHBdvlgmVZJDNDddtLzih58/kfDgcQJIIyHQ5IU/K0v9YsAtL3sw0ORZabKN8yKrUsih6R/+Of3WFZEv7p9+7lbNSK5eaIms/47vGtp9y2sfEwQ82d6G0zSqn4Ohc8akPpTY0+cc4EfPmQ8JiDIkATEEzOX++zPiJo+rHt985RIpklLAcJ5kfr9fLKN1rD/f09bm9vYQarUURrAGGvvRprHf1yBq5hgEZEDIoTPvzwiJgmPNy/k7YH5uhhxsObN7Aa7UABrdnvkoYsstloHCqXpYcogkWT9b1aQalnKZWccT6fUbYN57MY2tDyDngtM6RFi8LNG9pjSlH7p00Ik+hCUdMeR75klNpYylC6Mqd8Q7ObRAVow95YCQc8QtfPYD8EgfcZP/K5FxRsVwr7+d0baJ0n7A2coR5r90lIHX+T3sKSwtwzvlidJ0RS6nE4HDBN0WtHW2vIuWBdV5zPF1yeLija73TPY19IXVY6L+sGrlXk6dECGNq6iSXLCGTyp+t3urr+e0AD54yyruLwZa07s7Il4OVUU9sjwJG67dxc7VRvvzXoeLIlwzkzjfBK1tjvgiRt72vbK7n5fmh++Drwg5wNkxXjLirP08wik7T+7hXQwW+KsgHfEKMN6N6GfqY0JK0J3T33uPluMbMSdutnxr7ui6nC39QmZv/uNaEZI6tmNOgtpyC5qqE2IAbEgTBMEITQPZugDk/aa97YhVXdBAQEAKgxclSPUS2eYhJqRsuM6RDd8x4VuolZ0leWmxNCSjivGTFvO6NNPCIvaCH2pv8+KjkA11XnoP8pw56ZkYWLgYPUBYYo+fGsksU8TtwYVaxYgTg2pqQRSFYDjkLwvmKk30MwkApZseAROjtY0IO3U1evVJ1Bedoxzq487P7W55sH2DyJgKbfBqkHaFqXFIlQ2HYVAnxRRXC0ynh8PPd7AtrweKAPSN3bHCJSBO7fvsPXX73Gx7c3QiMGSzsQZz3cIN+/1WbPEhKmGLWGoUcQ5Bxd73tfD/NeXvOGziy0+mBwZuyuEYwEmqDIjBa7dxVEAgBgyvTombZzomsJllowY9rmiWcvbGkqKAYUR/seBr5hrxMpzK+0OdBewZLqymIkWhRRcuWTI0GFQEgpunOFIsDUsByPghJaa/egwQz2gLsP7yTVK2cZg0Kfj2q4fUslrpAmMbh2emQiLMuMaUoIMWA5zDgelx1NC7/Z76pdtSjcMQOoBVk9/SnFriS5MmwkYanj7M8h+5976onYpTLvQITybsZTI5x+sGlajnjxp8MMcEUp6pUtFU+PGfPdHW5Dw+XxNUqVuqTj9Edo6X8Ahc/GE6vDukp7sdev0YRfvEYlS4rog0aBr9ds3B+YoapgIa6QYlj0Z+McXtulQr00SNq9ZqMZRnv18+93dQkDN9zc4dEqHr/8Cd58/jPkbZM2KLUiLROWwwmlZtSSkDdzTAzqFvfaoePNLfK2omgj+hCkQfy2KZz/NEndayBpMxO1qTGbt3oYrDo5ekqWvkV91cQd0RVdm2NtwB//9M4dOaePPgBdHpE/YvzuJ4/e0NuMqCbFvt2Tb8MgQr7qmyTPYvzd1xMe1giKXV9jxq6li4x1iKTqa92wV+VSLC43eggdRdGWgwG0UvH111/j7vYWlqremECsDh+TSYMjzQeiaiBDeK2AdMnvIQTMy4KtZOTaJNuApZa9UvC6fxuMsDc5ESH21jhE4mhMPm5yh5HNXVKCyZnx4+Mjnp6eulNI1wxawyTRVUIKActhESfTFDVCFJB2ja5lcPu0916rZo7WPjoa/+y/8Hgu98qyBe7dMGCjxP0JbbzfPyMQpwHdL2bj+e9JRdfP1Wq1aHI1FsdiKRXZ6vhIHN/TlDDFyRuBG2iZGVrrtuHydMZ6WXFZN+Q1q7HX97F/x4zIZ+wNQmoNVAlylPfRbLs8JduW384qjWcjKI6A9Ey1Wvhm+t+VJ0v0maF/8jg4deIQeuZX1weoQ+crLZOCdEnk/GqiatiD5ZykpLp3JIkmEjly/PgdW5/rK6jextd0ZXxskAu+ljE8u89vur4RRhsBe6MHALThMhrtDN1R7BFpOF2jSWG0WBW5UA7jsJA7b2i3fv0lewjYPQimGAMAWsUUusJKMWgkTgjAUuksIGEKQWvSJNqYnL1ec0HihIaGrTwgTpP0biFCOQOXywW1NESawEEiCOZxIWv4GKIaEXLNKWIr1Q/UlPYRt7/X1TUAN2AmADmK8mOgAc1CPUSSfqL7IGmR6kk1hqSIWB7NsTepp9AFIoRE7tVkVXKdqfnrDCaSyJNtm42Few2Uz4V70eqOu9pOqEcVFT0iGbUZeVPFDxDwFeN0CFo7QEiBABJvWAymAChjbE0iBbB0P6CUhmkRT9pDCvjDn32J/+XuTjyKhwUA0O7f4vUvfom/ff0GWFep82NI+m0DWtAocOiRtZcURQrkiIu1RvzRT26V8Y2fZauQH7+6v52lmerk2DyU2i8sgYUOWT21LGmDkbpvKTSWpulmhPj+dWHq3mPdm8yMwoQ4fNLP9SiEWSKNMUaUnJFrBafO4qhACrKZEeZJ70UWcBr4kNQzitLXwE1yztMyS+1IE6O5tYZWCh4fzvjk4w/wqNDTMUZJXyQBS6IgChCpIDRENJuMe+CIcDhIH6wYAtLxiNPNSVaGJD3FC3aGvTJ5uW4FRIRL3tCKCMO8bmgtIqXJlZ4xtz/ogjutsqU6q8PFnzAuMwPEKI8J734x4+a3HsDMOG/F00iWZRKjuFXcffSJ1IFWRowLHjMBlbHk1zjcXNQEvjKKWDy5gYIDj4ihi64YYG807Q2lTrzMLEhzg4l2bQzuenM2Yxn7FEd5gkUqJdJnfPzl6/oAXV9XykokcQBdOfxqs9rt5/diwNPzvX6XLZOh4emrn+IXP/p/NB1tA1jBIlqTXkON9hMwBZMkp4Uo4HRzA6aAyoS8rZij8JP5IOmFOCbNeuiQ6ilG5FaEDke2oWe2tooYJMXV5IQY1qNy0xdX6NOUbqF4k9ClEr54nPB7n8nZCOrZkHR6Bipj3fZRBlvf0Vizf//o22d88Tjj9ePAO6422SNlg9MIuKpZUQWTyZoh28kbnotrGlajwPTLJul8xNDsmL7XlpLI+rnOSqs73R4fz3j79mtcztKjLpE590nr8hoiwaNvAT2DhZukrDZ1FFpGil8hSAsQnQPHXprQlRwCWIBtuBav6U4p4rAIovOkJRkhRu39Nta6dPqU7Tcjbjx5Jl8sKiuRPLChQMqeOEz7jt4bmOOwyZYBxA54ZSnBXWHvxn6zs9ZMfwnDe6b/9A0WJwKczpsiIhqEfW0FtbACmkXMyyStUwzUh3QOSkfSi4zxdDnj8nAWYJFcOxCXyTZ1vD2PqgFd7pL7VAjQfnyaXlktta+JMyFEB+vxB+nZvOaJBAbHKHgKeiZaq2hWjhS683UkHRvgWK/mzmJSHcLTrs1Yk5Y4vQestEmScxIGBwhpWVF/LoW+RhZhDyytc3ardn1gyYwz+YMGsB04XyEYlgO4n9VnxvLf4/pGGG12WWhX8oMVvj10gd7nd70gWnM02iVWdKOCx4EP+IqkghkMBJAs7niNer79nc2DwACaIj+R1h6hewAYmpo1eOMqFFUPYtEzKWaeGiCsHk8Ye3+SyFfeMjgGxNpQ3mWU5SLpdwyEWsBRwSEYyKVimRIaM7J6a2S8e4H1//cKMYgSGTQPvwr8Kmr1fm/E4tWMgVC1gJdDABoQWh3ajUh0yoRfIN6tMyDraXU1dnC8lx0A6d0htWUAPNxuIn00+nwjbf7Yv0S6b42l2DVREK8NkRsg1QSn8kxDwBShKUwuoonwgTDyyoDIa4nyNNWyai14umz45RePwOkRaA3/+k9X/NP/7Du4PR4BAA/nM/7k736Gv339FpfaBJWSG9jyQ5nd6IhuO4u3h4jAtODudkI63IFDwL/+jwFfvpVIckqy7iyV9l3BsOadNIB8uDYoi2YR6dAYRRUG6KddnDAjWcSJG5i7y5rUiGVo1A8AEbsdIrZzV76XacYUjX51j7UGz9AkWHQzaR7LkiI5tYYx6YtIUpEFPlhJxox5+4DRBQKiMv8QtH4NJKnYOrZiFfK14vXXb9WDqKi0qlDO84yb02ycCJe14PLwJMAOejaMZgEghoS8bginI5bDhPm4gCSs2gUWS61FGIrmGQFhyl5feqGMqgUBZZPeWdM8IVByQeGqrwpp659kuhZxE9qKGvVyh4UKHjCeXlfkdcLtd85CA8x4dXuHwsBlXXG7TLg5HUBxxmkOqK3go9sbLPMRH338Hay0IPOeN/nFouR4PZFttK6lqlhuRomyOXx58GyOCp7chnt9m0bj7PfdEMwKGr+r9xMI9r16sn/e+PP6Ls+NPa6DcegGI3Sf+xyujTp75s7BxYzzZcVP/u7HePv5z1EqI6UJCfB6FSjgUhzAW+x+knI1Y1lmMEWU9QK0iqhKXkDTtGPC9tVbfPBb30OGwP632qQXZuu9k5hF4ZTonypVGkUaQVz2TnebpxwzjW8jBOAwi1PyQCsOdw3/3Q8vKCsjThKB6C1cRKhEkvPa3NGj8whBamQouOJ4mBqmgL2iPqy3fTsAXvBp94xgRakbp9GG7aNuVOlLYqN1qHJqDetlA6UgezS8Z+NmlnrAljOgkRQznFkVw/XpjPXp7BGHaUrC81VmCbR5RIPIa2o2O0Ve5F7zRCRREfMZQRXeUeEmlnTCqmBjAnDREBigJCAih3nGYZkRU5CIbIjdQFCDqjtKVHn29R9pXg1WyeF0PcKNe6AkGUafAAAgAElEQVQ7+wcNmVTwC69m7CICYNkrdTw4lTQghHFXO/1U1YOsBr/yPjbDLK2Hqp9d4bPSammTVhsVQAyY5gmH+SQ1pyEq6upIX/Ks1qS+f90yzk8XrOeLGGqDXjr40n293nf5+TO1wn5llqhokfYPNMiqAEhf32E1dk+6oldSWc/M4FDARZCHofpiRxs32SOyMfgZ1KBIFPsgJEvVtoi8Au5YGr3LcnMkvTDvwT3kkVp3hJLv97MiK/Oy+mz3dOr8ntVyEcXqvevfb9tlxa+7vhlGG5F3WwfgxOFaPNmCBVh9iBxaGohyf+0iLajDgbf8Uj1Ela/uMT5QmcigGHRvC4+/Aix92nxnjU/UhsrZGUapBTklQeeqcjC3wI5YaIwrATvGT2CQ9h1rDNB5E09/ziANoRf1xM0pYs3al0UNLJ+dKtK2RrL8Ly/iLk9Yc4qljiZoWkPEPE9Ow5aqWmsTzj4g/zQ0BwaBrmWt8j418/x1hi38woqFR2HeCTtoDrukbaGnpBGMO7rS9dIM/ZZaWwWrKWSgqYJBKvANLIU1fY65oejnCJAayybzixb5sgairixA10LqkZgZ/+5Ht/iX/+gRj+cVP23Az9/+JT4IskIrBTwCyFpwHNRwcb9CqaAk3iCuMr4YCVNMeKg3eFcP+OrxgL/46aeoYDw+fY3KRWbOjNCaggUK06RAirx4xWA0FEWBwLUNkPfw9kKNyI1ekFSBJavjVG8Zhb6R5M6U0GvBRzQh3bHGDZenC3Iu3mdPlpvdeJIzDU8XobyhUOhMU+mgkDXOZYkKN6EhHtKIWfobAGTcxmR4lPOXMyo3pGXBFAtmSPoFIDV0tVRM8yznrlSkGJDiZESJVEUpqKy1uf5s7RGTpM8iEWGaZq1J0ygtGliIQIAVBmHSAERKWJO09VhikPqVok3sa0O+bGhTkzSQIHWyrF4UInYk0p0xpHKs6z3kirAodYynNwTQjJtvb1p7kRHijFe3d5gi4+n+HabjEaf5DjFOaApGs/LvYG2fdEMRA19WsTnyJiVV/8ujFma0oPOPneI0UNX4inEFATWxu+3TrvdC9Pr3UciSG1ndiJKfPaXrNwtkk1vGe7sIHNaG+zNfumOtBU9Pj3j45V/h3V/8IUptSHFCitQVHWbPQBE8CHLFP6SE480RU1S497IhxYDChCZeHgUIUKUyaO0Xi0K1rgXgsyAXny8OxNQ0VbC1im3b0GoGhcm1kL3BPCQTsZxLZuA7dxteHQr+8XfuJXLWtL/pky7UAtHsWt5tmYEhXDsHxLAkiW4TK3KdvwmKqWvAMPp3VQ2WtigyUNYjxCiOKuX9ZN97wQC0mnmGlBp0OmgI7uiSe4E0ZbE1PDw8uMNXrGFJ3w8EFI1GJeOrUdKDoVGTQFb/zogwBGB1g7ABG0mUW3g6BqRAEXj6SASLhKn8ro2RS8a2ZRBJq4Wb2yOWeUYMwBSjZoaoIRgs9Xqvz/Wz9LIyO9azmiEGwJXnrix3nc1Pi9847A1zLcXo0bOqDgfgEE7PQE6apqEKrDv7EA1J1FopVW0ILk4KdWDEiHk54Hg6CRqi1jv2/RcaqK14zV+tFVsu2NaM7XKRHmYNzifsspTXnX7qq6Wv7afiZVWke8wk84jK/+n6Dk63SktkUdZu0NqKuypNpCm0oizVGECqT1hz+MisYIDa15a5nxuxrjzqKIb6VZ2ojZKGlFoDrMHzz3VDt/Nsr1/W3hgd6K/vsSAXkzqj2XEYbP19T1TlEd1J5cHV2o/ZHBQauP36lMlvhNEWAuHm7igKFElBaZqi9qmxhR7zfjuFxZQENr8BlnfbvS0vWbeWrrEnW7fwX2QQxhhw5UG4uobd6HTGPXqhJmfZClblfFGNNUHsEYYWg8HY9rS2QHBAFE/nIoCjKHFUJcLDrSFrVEZC2vLkFANKbSDlPJJrPxCv/k0vvHa1GLYQkOhT9yYQST1DTFHtAoW9byYM+wGpVoeoe2UHm83qYqtAYfUckerSvXdR41G916myMHQ76F3Hu1bdOgNvdriHg27XrpKKOvAJAN8TZ0xsO27hcatuEIMoN2Nilqopn4+BsNWG/HRGJGCFAEmMCIj2+cos6VvcBNgji5EVAnnNFQXCn/3qDn/3cId5irg5kY+SyNKpoAXrZsAHsDa43O04+X+yLh5t0ZeY1dBlVGOeDHDoiIkMQZm01huBIWk/41a84DhglrrM7SLAFnb8xhPYFdm+pTVNAsZRFXlxENIJrAiXsh6RJMo90oXIepmP0IDcOsWIAkZoghYaVRkShZWAlBwg4bAcsIlEB1sBPViMJYb2IhpSWECY5gRKSXoIEoFo8EQDHUbc6a3Toihvaoyx5egnpBBQW0Uulo0gvGiaxJustfjqoRcFtLl6wwPLG/2S9rfsZ2Hg7VcJW2GE72+4LAuOtweEwNi2VfowtYrjHHE6fYB5XmR9a5Ua1iYNXluTNZ3S5IYcc0/Z6amwnf90OtAaDPe8+jtu1Nnf/VzCjTVfUyj/4JeSNq+vKyOOr1/rwnsnV8wBxPs5yFvk3+u6qNCX1YDZaNvueZayScjbBe/evsGbv/wjMGtzYq6IcRZHRAjIecN6PuNyEXAAB9ggq3klnJ/OIG6Yplmj4EEjK1XS4mIEus6uKxiBdkHNEZdVgEkOywGXpzNKrTieDjidTsjnFSU3pEmcKIxR8RwVKWU7U0QrFf/kW1/iMDPKNsw8BOEvw5qbtWeyfls35PxyiYDtkUToeq82TEna4RwOokTWKqizACzBe6QRSS80VVYzTpTQbEiGzltKQakFLWdxxFzVn7cQELlBellJtKrFhAhGjFGBmcQpa+UbTRFVg3iw4Iqz7lEAJOsFkqbOJPIkKBMw2RaH+nJJEfOF8npjZjHYjI8Ks9ZMoiLoj8sy44MP7nBzc9D69QHky9Mbyfe461+ysvszr0MgeP0zD0aeXbs/x7M1Kuf2OgNQZ0DTiHAtBduWsW4CS19yxuF0g3k+AmRoqPL9kCT6VDgoSFtFqQU9qgyAKyhEpBgQ44IYh3Q9NvpRJ7XqSZI6KLpTKRV527DlirJtIjdeQDPqa/eiKO2feeH1MLxhWsvY485oyOSN7wkFr1v3tXenxpUeAd9gkW3RonaqkBCQqpwQS9lv1NBM/pGsT6AO+W99TF1ncYvfdEoT4OSPd1oY9dzxF93bNCXc3B5xuTDWp5cXTsYlRr2lFgOdPgC40+bXmQ3Oe3/D5+z6RhhtzOKhYXRvvyOWMWAZwNdXCBHzsmA5HYXgtbjVa11YwAfYw/4YDLZhYXWlxEbhFxfOwEZU1EMYz2jkdCXc9fFrAwGuBskfrYOe2Mc84kaaN0z9NempFpCCemYQQFE9vMg7xs/MbqhNUeDO92vO+/Hrz2ZRp3FzgB08q03B1MfxMPTcZF0rkkLWwCZE5JrUu1CLeLPQrO7EjAuNAJj8BYEDI7r4gRqF3UsU2NJhroqHuXvhZcQW9eq7AohhKJWUFlkdlC3R8Jy+2rhnwxIyC3JgALlC2oi0ftxwzIApinBvTMiVEUlSPCzt3uUKA9D0rdIawlY1qgKkSZSmoB4s8c7LDf7x98748sd3OlfrmiaM1pwZRJZ2BJin7BlvUm/WLmt4ICUrJgaggCLigSt+HlRhUAW1BUKyNWxNcvxHD9nuMZLbfzgcsOWKw2Iu+XF4/RuVOyJd1GL2pnNgCNoku/NgVIr1yaR7x9ilVdrRaXq2pxhB3FBZeFWMkjIZYtCms1JYXxUIwKK08oywG/M4WyKJBrx7eIdPPvrYAVierQ11D2Y/x2J4hSSIkQ2ECqmvS8sk/a1YjGuy6Htgv6t4O7s8I1vnMEZzOj8TmpFYZAgRuRQ8fh1x+uwJTPeSckUBhzliXTckJmy5YcoXpJhEKcVPUfm3sOZb/OqL1zgcF7y6u4ODmvqzCOCr9iXKPzzqp0bx87qv9/ythtnzz3X+73v2gux56eL3fq5H/G3sAHBtsI2vuVQhEoXQ/t6N5hr4RK40LXj16hXmb38bJT/hcs563wAQo5SMbSviTEgRsQlgCQC0WlAykPMGag2n40FljaTdRjAqRcRkSpjR85CWxEDNG2JMiPOM080RXAvyY0EM0YF2LK1PhbLzaF8rYaggkhq5UiWLwzFT7atgGEJjbYzMvEOAZkD7QL3/qqVAeojyAK5BQIiY58X3gVQBLE0g7//Zf/NLUCyIFPAXf/kx3ryWeuRai6DXsjhBgqWCghyWfF2lx6rUz/QoRQO6IqiOH3eOhYA0JQdYUfMGZMBOJreCps0DuwbhwpvhvYGZFXE2CDtwKgpW/2P3sOf4LIYTA1nrKWImbbkCIMTkoDRBQ3M00OzoH7WoiaOBDGdlzAjaOVUtFZEGgfkeg2X8jEfCKmPbLljXDet68QbTNRdPrwUDaT5gyxtSlRqynIvoZi2LU2rLDgwyTTNCiO74kOEGc6kAMMOsiKOsSc0016KOwoiaC7Ztw7pmlFw0nf/9POjaWPOl2Kt2LjeCygDfg92H5LKyFHEYsAdQmuo2hocsdEqDc1u/DwsyyP5FUvRoAQGQIIMqbo3EoHejDkLnpTUBhNJBmi4cYkCKUctXLEK5T/EE4EadOSNeIg2rk2X7rur5aZpwezoAZR3qCAGjy3268j7YcX3x8L9ZD8AL+xR4R8rvu74RRhuYUbYMQDa1bEKs9p7VxZBO2VTyECM++OBW8oiZsVUh8FYLmoaTrbs62PpHNQfJaINx15Vkg2i/Nt664DUP6Qh8YteYSys/lXB1LsJk5D7yvwom/d0OJ1EDl+oHH3B2rLJSvJ4xJcRAupHszD3FgE09i7kOBbG6nmOKpDHD0eJ/6TIvo40Ghuw5GMSunppG7MrKTtN2g4hScsS+cUy1FBG0Bg3d2Mle7CiFZw1iKDSbnw7NjDe4P6erYM7o0fcBbAZN96C2BoTAPiY7+AKHLwZAQZDmoZreUC1dAdhHAnW5GEBh6XtDDEzRBwUA7mRwb94Ahw6SOkhwf50AJMs31yhDrhVLfML/+sOfIc3qLQ4R/+bPFnx1T9iaLxNqC57C6hxjUCDk0FQBYMFVfgjbWgMGMtNUyafGiK2hJIUgdgcBCYAJGrhlwGGYu/I99kMjIgEAGep9AGhNXEDTNCgiScdM04RaCi7ns0Tu0QuEeQdEsE9BEJWWUBDABh1YtBIhRfeUE6ymlVBbxbZubrSZEXX7wUlrEvapGwzsHSJ26kfDs1SUTY1sQs/r332nC9rusRaGH1Uwpii1ewGMkCYcIOvaak8vH2cv42RFRhv241oZcukmz22skRf9+Fd/fcJHP7wHt4ZlnkA4YJkSbm5vULYNX64bTseCj17d4Q5PuI1/hLKd8WH8GnfLHWL6Z6j8fQSYM2rgLUTIJePduzeIacLNSeDR3z7c4+Gy4buffQsz8TM+Zr9bw2nhdWNk4/08r+/6bzbcrtPN9x7U4T3lD53r7580KqrveZB/w2l7+DwRy5lPE+b5BjWfcSnSOqJsK87rBjGyAkJYUCMDJifRpDEvNxzmWdq/AFAVDA1B3AGGlKYZEabKW69EtIbDYZbMmTR5+4lpSqLQhggE/alcMpC1CRFislVndcj+j//gHhNllPUl+SyX1PsIJKsZbCBBZS2loJT2/EsQuS/4QDy+qGdM9y1IfWvNGb/7w1/i+z94wjQVoBYcb2/x8Ue/RKnAH/zB76BVjWLzy8Z5XCZBZF7FODb+wrrSSwpwlke2AyqjWFAEK1dwzkAQ+yWQAoq0KhqSGsDim2EIGII6bUi4eaIg/Eznar0dmZqjZ0u+gjpdSdr5AMrTIXI7ThOmKP1mQ4o4qTgxOeUozFeK6n4TDEDEKfnqnBrs+8DBXMtlN0rGc2QPrAxwI4kwXy44X87SNywXtGrgbs1P5OiqqqXg/v6dlLq0jEoRU4hY5gUpJTfYXDcZyEd+anugVjyw0BqDFUW3MaG0ipI3nJ827aHGXXXSq2l2yvt0NN59YTi1pBYPLJ3zSpbqvXmIMjclSFlC60U83lm+aXJD5iE0avvC6HoTqHd+DRQEQbyyI/UCARwbYCnBQenM8zZJgNdCkChdDOKYGRSrYMBo1usREogxZ6RioEnIhdn57MA5JY2YAjhMWtfJfSNHZW64iNidoe+7SB2Mxo+elS2Zl4bs1L3/+kYYbQxJo/D0jJBwuaw4HJYulrSmStZPEnhqEW/V5fwEAAgpYZ5nxHD0vOmmXsSq4A/crBmhhcPlsIrHQyNzmlZlhCxjhCtlve5Kfh/bFTxn0HsrPIQeNu44ipbCwP6s7sbqB2mnunEA54a8Sq+cFAIipE4oEaOszZ+7U0+vFIJRsRjHaVG63T7Voa8GRnXDFMlhHeTm/RPDvT3aSGYgyRqYUgWQFM0r8p+lDYgRLgZ5q5L/XNQYN2+LeLFCh3fVH7t6xL4UcIXHmDu0PkijbtYLK3iNyXDEQ8AcxZgpzGIUNBGcVVNbDIlLwAF0bETaxLHhf/7dN0ikXuL63BssawIt4pVBx0FNYoILYBOMBHF8EMRrXomQA+G//+2ASwb+zf97h7VJj7hlnhFTVJhsXK0RwYoaYtcT3UBz+gkBiRklaq0M911OVdI43Y1LQG4NMzMOWp+h+Lp6DlmL2W0E3L2MosENA5HXZwJWBlrVWhkGlmVRT3dTuq1AiIipF9ePhrvwTEaHKtSnB7K47t5pABEqZStYWRoUx0C4++BG0CtbQ0xJZIoyaWfY5nFsnfYBuJE3GrFX8lVGonJqjEp4uq2eKavvi4GQUsKWC2JMKGVDr7XSPVbZdJ3QYkah8bXWLL1prDdirfuQ75Yc8PYnN4g/eEIIAU9PGyhVZJxxmAPmANw/RByWIy6XJ4SY8fjuHktqAK9o5Stw/C5amLVuT1deH3jZCt49rgj8hIU3LKHitD6gHT9BGhSnl+p1X1Z29orhtWffOPIV53BF4dnevOD4crCbK/7h3xnHcvWsUd70+/UxyW175JxZok21CJLovBylmfFWkNcVRNKT7Xy+oG1FazaDIvaJIxM143A6YllmBx7ZTZYiIld1gvZIr9EU63aFECVrhsQ7LracJhEGkTESRdTIh/JINXN3hgxAuLQJr6IgMTbej8nXp7GgOzN2NWTTknCsCx4eLy/vAQ/rOL447JLMreJ3vv8F/sHvvsHhsKC1iK015C2DYkUIwD//5z/Fv/2D7/k3Yz8sXXuE8ATSqD3qvh8Y0iT9O90ekQhdq1WanatCWUuV1EnSljQsSiexZKVUiEIZ1XtkdXAM+U6EZL1AlcoQAihJg+aUBAFW0tJoqBcTPS1EM/x7lIMAHA7Wp1IzhPS4AF2+C72aDDHFfNyRgOegQAPIxw5SnDopqBIuNePiBJe6soKnywWP7+6xXrLLkdHQsRqqpsZmjKFHC0PAPM9I6fZZ/RkAtDY4MZRuJJOkoDbRN7k2EFethWsolZHLhvVSBGjuBX6yWxGfsqVcj4tmzzRjGXujB/2MCAnK4bII9Whg9vvJXomBo6fQvjfosXZeLc3W5JdxsoaIxupcxRCjDdHB6dCkBYWIPZbyHsv8GfRYKx9y3Zb6fEoRgWo9IFlTTBnA6Q5Y4tL1+OHnjo+40Qmczxd8/vnnO53Iv0vSHqjUujPY1J9r5ZG+BqNrLoDdITPSkYEt7dOanl/fCKNNFlp+IWK0uuEXP/85fvDDH+j7Ft1y7icL1xpOpxNef/Ua9w8PUh9mnh1liCEGRM2DndMsAuYAQBVDNpSpJiAFgsi0oVZVRqrAE7fG3YBiMQTNixaHfiZ2oMbJieCVv7peThAm1pUJ+V1SWPxQDt6iZ5xieK+oATN0t5BaOEg9EQEOAhggRkDga2WkX9cGGwCvh/Phq7bnxE/DQeDxc8NYyVVU/5BAZzNIEYD6GTJlltRwIU0NUQMuZ9Rc+6KSpMGxaQD63d7LS2++c4fpD1c0LJ7br6qMgJwOVf6CUTWNRBpuy62lTkaL0J2xstcnmjICQ0DEyCyfX2bQRVt/dW5UAGn8mhaPm3e4Gxg6gtYQW8Y/+S7h//yppBQzScSv5bKHxDaGz9zja7ZItrakHkxuyL7mSgRE8Ii4DqJxQ2Lxtj49PKI0mVMDQUM2LkRcwaWAVgrgtYzAqw9f4atf/QpmrCgOGIrWADxuGcsq/X/i0OyVitQs+HLFhI6SKTGENhAgRwMAgTNZl0lmVIWAlIIDutQqyG+sfet6yqnSAEF5lL3UN8jSOYTZj8LTR2ycr78yKEGg3hMQZP1pWKG0AxAt8kd7BWnYNtnmrhDvn9bHIkanKbnCd8GS4sxg5NLATyvagREwgc8PmOcPcffxJ2BmXJ7u8fXrhuX0AbhkXGpGY+Du8A41FDCWjqbnLgrg5nDA/K1PUUrBJ9MZSwiot9/CG74buiDQMA/sfn9uuD2PzI3X80/L/0R4MWXJnDv2LPc07zy6ux189kSL0Nvlj9F7DHg+u88an4uBwNb2Im96rjO4iZNzWy/qYOJdkb9BcB8PUncWtNjfoN/7CJXReWQCSJGkBb0p06wGwAC9zYLwIPRCpI4NkwOdpwh/VPmILgf/+Gd3+K++lfFffPwgIFZVnLEdEZK60Ud7XR4AYrK2J+/ntfYsY2d2X0AiLsfbDf/wH34FUEApGUXXMa/SJ7WWgvNatdxDznFjchS8BijyK4HShFjZyxpsH29ub/H0xRf+GoNRmRBaRd2ypIBuYgxwbZiSodwFV5w7ncpzmXp/OGY1wlT3oBilDyYB8zQhTAIWpKkmeqdRrxFiqR4h5J1YNS7FDCynIybIc4LJZv3bdAIDsbFv+zNs9u89u0p9Si/buqGCJVNlkCUMdcDXhlZEeBtvuUYLR4w4LhOmecbhdMTxuCDF5M4qm1evfTR9QFKQ2Y0FLdVRsDUBJWnIpaLUilwkFbO9QIvvm283MMd1HJZr/Fvv06qOuT1PvXu/yiHPeIknMsjTdnfv+lbw0A9N74OezWXtiaSfoNyPCKha+jKWnohM6TJG6KxJyuhIG9xRYcfMMSspCmp8j7Mb13k3bzs72nKMiYb59Iw5yWYjxKrZPDvnFZ6xdQNhY9aQ09WjRVYQJOz4fv4EfFOMNnSdvnsQhoGromGbbO8yATVXRdNZuwFEln4Xeo2cE41C/BrYhyk0ISgqTQRmhcZV5JPSqgMMWISu1Sb/moVhq6a1tWcb8ryGrs/Pfu/GWx0Oi6U/yQKRGX9u5NH+lNJVFA2i0BawGldqBBEUtUcFaKtqyImCGV84rAA06kiuhOB6n4a/rlN/bHz7T3ZN8Woa/ROkIX018giQ/lFBDnGsAmLQv2sCdzjAdlPjIy9xK32fxoc784TXbfEAdEBQecttl+MsSFL07OgRJComyyfjK7mAw8uNK8fLHAR2QIRxQuGim6aHth6tI/IdGMmkVRG2ovAwKlUETKIQar2X7a81vrQqgzE5kiERvN1a2t9q8Upri752RB2br2wbtnWVcVJAmicEEi/y9VKkecIy96d/67NP8dWvfuWG8bj2zA3buuFcG45LwjGd4JiTiYAWNErYKdWHDmXMw74zS3pQ0/EboE7ORXohNqBtEoGylgylFlCT5t5j9MrYvthUtiEsii6pwnw64YMP7nb77nWVQD9773G32KsCYiSiTgxFk6NjKriOSc9YG+et94peM2BOCaUrhp+Z4GmpGcwBLSdsDzPoLmNbC45zEmWdG7b1go8/+Qx5mXE+P4KZ8LSu2M5nvPrwIxz5O2A+dr7HQt/G20IgzPOCaZrxdV2QuOEYIqj17AentV0qqi73kCLpazby0+HnuAfueDMeexUUv87A2O3JwJfJ/7cVtlNqajZ2PwdVwVmS2EujQj3Or+JyWfHmx/8Rbz7/Fc7v3mErBTkXrJdVskhUkQRB07psoSuOhwMOxyPilFyG4mpOFg+kEIepaGKU1nyZ8SaNzeVnbdKqQvizuu12DjU4janmrfy2Gxh/8stXeCpHfPt0wQ8/OquHXRRkaXExrDAD1Iazw3DUw/eKAJMXz94n1FKR1xm/+NVn+J3ffgtmRmxAQwWlBC4N85Rw/2bFuq5Sj8rQLIIu6Eida9PNAgqE7bH0fSTChx99hNdffSl6hiE4Erru0Zrw1iCo243ZpaNkhqjzklS5HgSA8eI4RUzzBIqT1LOFiMqShlq3jK1k7VHZDR+nA7a6LDjKous4DHUGADFN+OSwOKn3NeD9EXBdwq5uNLhh1OB9YPtiWbSM0Ljisq4S3YPSD6wkRnnIcIZ7UEj47zwnHA4LlsOCeVkwORiUyJTiuh27o9+NP2ZvIWDyoTZx9tfSUHJFrhU1VxQ7e+81RF+6BqwAhnUkcJo1GaGVE+5wrsye1jjq135X7udlP5a/z5jsHuxbKN/sqdJdZrU9DdoeUR9XcKEj32lmALuu3BS3glHr2ZGWDbQvTaS8hnp0wgzq9xhBI0fz/6kvoK+Cj1vjcDbZXGUmhGENOmZA/84LlymPgRASAxwBktTfZ46Eq+ubYbSZsqyr1v2q/QOSzztG2+Sy9BxrsO06N/ccV4eYVVesNaW05wrQR3BEmmDQ4UYABKQ5gZBg7SWZGZUVirVIlKKUilaKejd6qNYUwdE7cm3IjdcYou6HbFQ0rnKb9ac1HFQw8Z0Cw8Pn+qEmdHHJQG09lQPiXZ1U0Y5kQCwDw+Erghz1d/DAWfqr+zkb51Tjo9EYzd/dy7Zds8rgy2dzc+YuB2ErFevDkyjOKtxC6qAQO2bJvHutMaS3XutRUoNcJlsbthRk0u4GXbFxQ3xHw+rxoqs1cE7xMi3sLhOaqqyJABalxvLka614yQD0ejJuviYGSfxUNlg8f9KG4kHThYFeVAwiGPLLxBDk0qDPtOcwvNB+lBChijg1XVdQDS3K3ZAvF5RSUVlTecYzTiS9cEL0CINtv9HmCkmPhEEBgwDt+2i3ilT2aFIAACAASURBVEFqLioX6b1DGQKtYEFCU9qvhJs9S2tjc6nYLis2BVEhIiAqaJD+nZsA8Iz3gEYexGgTNSsEmV9rQIWANBwOhx0PsP9Hhf86ZY6oRzAIQNAoPpQP2jgtqg3AbEVYauVorJEdMOpCVt4bacvGIs1yAwFoG0qLQJmxLIwtV2znDYdXMwI3rE9P+Dx/jqfLE/K24rjMyAx8+um38erVhwgxav3jnn/5PlxtzNoaqM2+Ol1RwHAeu/fVv2rKrN7fjdbdmo4KTVdQdpLJDPmr1+z+tbYRMR77epmBz9u6X71jY7XXGjfcXy5orWJmcWjEMIFZeilxK3jzN/8en//lf8B6fkQuGefzilYKqFakGHHecm9xEKKPb9LebCkJkAIrwi8pKBggdCXrawqR7FUpDcvhgBgJT4/3DpMt9CXnsORi9p07SYzf7yQ+X60G9fVoDPzNVwf87HXEn39+AgAcp4r/6ffeYds2bFXKH6B18B0JldzQtNi7bHcbjAPdz4GGnOcSkOYZl0vG5z8P+J3fBlKaME0R21qQizSSD8uE2w8z/vPf+wJ//aNvCzCTGiljGn5TgyIrvw52zlhpNwRwkT/GsoGYBEFS0hKFl3hqJKAtPLR2R4S+t9OJKWCKERwFMj2lhEYBedtQLytq1QwidYTt5q9AYczi+BvTAHcXS8ZSAzBNk9A2mwQRju36He2/1zmtrb4ajBq1bCDNdiHVXAmhyTsxCPqxOS0J8Mg7Q2REGQwHhuzn6faI4zwjWa2lnt1apTXOzino0RyAWI00tWilbk0cdjlLXXJTecaNHQjOnC6/7hr1PENFHxfLz6ID40m7Jy8puErfvJZnMo4rPQy/oY5WvyM8UHWjoUZRnwQ51XbPYdRafuGtQUhSBK3+FQywpWA2iJMvAmSTYgMikblN04Q0zdoCQ85V44asjcr3YoIQpwhOBHcmoVPauFCSoSefczlIV7RqVwwgbefAqnmD+j5fr12/SdsRQmvGKwkIL9fcjtc3w2jTq282edYQA+DK0oi68W6xx+yUlzwJ7p2oY9jUoh39aUL7phIFR4jqId2wM+S8R0QAiAKWRZQGG0PT+rlaKqxvWTPCaoO3hrsH5aXrum/NPt2nz8EWr+kYpG+GYPz0uoznK61cGWYQNmYU0Yy85qZAIx1LAGLqRchjHZ/ezFSLLnz97sOzfPAqDMmFlU+Jrw6Ua5PUmQY6c7NUD8eMlE1AzlWUOgPtCPJ+StZeIShgBFSZhR5AGXUIwYutGUCpEi0IujfWOwg6R/a1HBbg2brv02eftoAP59/AxYe7sf4naH/Bz0OgIfXyJcVT93StM7YmaktTDSoGSC2E7w0JQ1ZDniloHTr7IAoAthonjSixCUxmJCgCowqWFoM3niWW3i40eMQIhHlKYngWaRZgy2fpvAA8zaNprZqhXPn6NKvL6GA7zhxZ+hqCGaw1dq2yz3nYIiR9vFVROLtVJxETIaWA0hhJGvkJEEsDqFacDjNuTkdMicAhIgXSInrCaZmRAqGU0uGrmcDWT8nWWcfe3Flwtaeu6joRSlNgjJ+FnjH5vVatB7Kzo9+zcyqKXzfkzJgj55n97PHgxiWS9iV1ioiVEUJCSow0FYR5QQgJh5s7oGVc7r/EthZMy4ySM9YY8Hh5xKfhYwAZgnbaFShZn/1ZMn61l459H6XAvKfmvO8+u+uF90bjzrys/vfVOXtmZDIPvEAXFq1Hk2xxnS88vx+jyzlRRANmIjyeL/j6/ACkA+5ub3BcJuTtgjd/+yf44s//EOenFefzBdu2Sd1TiNpcvdN5StHrQ6Z5kvrHSWqJQ5jAQ2XpS0u15YzW1HiJYlBY+nEpkr5naUkxECIqghoXgUgcCyHpE1iVN6sqYadbeX8/hrVG5It8r3LAH//0Fr//7TcAF2SuCLk6P2jcgFzce1+tV6M7ska5avrHtdxkX6fpcEAIPVV9XibEFLE+nVFKwZQCjidxgnlEXc+01AQ1vP3qKzGuUlJ0TjgyI3TcchaFv3KrGrnvmR6gnlJt/DIBaCT11DGKs9L6RpIOA0EQCh8vT57Z4Ijb7qiT3xtLex5H+nzPJfwlSBSzaZ2ogYrobcUhrDzD+hBwRXc8Ahb58qIgRzoWhEFmQq4F+ZzBreHmdEQISY1viURa42XT6BStDABhmiPmw4zjQQy1oH0vW2soWVIcBdiMgFZ1LBVNHQ/E1QGtGgvol8DyF0V6NOeGlQ50Jd746Kiremsg5bnWexa1R/f6+Xt5/RMRGoUeaevs3Z+92yvj7yAfx/Bp39HRWdTf84HvXE9CW10/H2WmLEgEai9NYAoCiNL0WX43LZVJjMgT4iRlSCU3oSu9e87FEWHdsc7k8s7nrdgC7g9Q/n19tgFISmwDmDbQC5aRf8cMTYKjtsrzWz9jVxepYwWQcpOmzn4K5E4hgMA1Pv/y1fWNMdrM8+bbNygzMZoyoYYI9gZb93DDPSHPL3u9h9ztskaTcvWibh1ZL8B1b7UstnRaD55iYn1sBIJdBCA5UwXAzeuGzIPCgzHnofbdvz52dmWuvz9MT2nSjoxV+mid1lWqkClh3aAaAtp6AFRNQQyEaT547V6pFecnKeg271R0bz4g/aUsbGzjtHo1E8rDoPWZwsCsvs1fNnvNCAJX2+fzDiQ56yGGvl46pjAoVSVXtHXTehBStD1x/7YmCg5DkBoFAESN/sBgDuBaERAs5upjI1gUY1C+1CDGe2jz3/3oFv/yv7xgzPx43zXwIy8iN6SK/nX1BOq8U4xY24T7dUYIAf/H377Cmhum1MP6Kcr+MYtS7wa01a6BYemeImvVeFYkwjEhwHK3C0SYCNIiY6qCuiheX3JksmL6B3WDwRRZSUGpKCrXXUgMtQrMDE4R2KTQ2dDrHEIY6IqCXhXS5J7i5EIAEBqpRiNXgs++Z2MFpBA5oqfENRBqKZjThHlWZ4DCP8eYJGJxuWA+LJjmGR7qkm0DwJjnhFqbn1dzaPTnDvQwNJj1e5Csm6yPjDMMqWpSy3oNvAHZQXOKqFJhW9FrEQDzmI92JRhy5sCYYkJIhO0+oZyB4wdiFGx5w+PjI9a8oSpYDK8ZecuIhxtMrxK+eP0a3w7/Abx8Cg6f7hC+hkc5/QWlLxmrRSNeEMfDfV4y4GwNOiVg976BZ3TghIFD2We6Hv2MN3fDT+iWDOUMqqjrOWz+fRk599v7XAIBh+WIZT6g1A/RasblcsabX/0S7778Bb76q/8bT+/ucd42lE2At1hrV0MISDFhniek44Kb0wnr+YJcxCAIUdpXSJuKgBZEJlG02hLyyFWrDSlGxFCxHE+S3sxw73u5rMCrD1R2ivH2re99D/OyiGFHhMPtCa09U+/g7j8jxGGtiQhzavjWafX9/hfffwtiASJgsPdxQinQ0L+uMTvP6PuiQCzm8B/5BvY0brTSqqRgxxRRuSCw1bZGZEW9nuYEcJN0uCoyVJD8BG1YUtsV5Ijh6aqKMKQ5cEGQJYc2IfvSCavhU8MkiuNO5PWMoL0tTQaXKoAplk7qNMrQOixN7WOrEWova6DoxqLQlPAVEGOrjJU3tcXIz4OhV7q6TNzP3aBrQVtxSOplA7RPI7eG+4cnbOcLcisohTHNM47HAwIECCm6Hii1fX2lxIA8HBIOi6See6pd2UCtOl0zCJErmEQHsMyIwBINyrli3aR5eMmKTt46NoHppmUw1pyEeP/TdaZAPXCg6gPv9toI8Dl/s0+kqMBYjXv0+oW9u0Y8Hw3I/p29kSiALvv7NBg9U1fQVMcJ6K8Zvw3cMz9k3IOhFoKWcnWDl5TX1CL6Wi3iXKBoMm2f+SEqZsDhuCCGgLxlXC6r8Iy0bxfjmSa6nrbWFAJiSJhiQwvoodphH8YdYG5Ik+K2N3a+Pq5xT2u91tNs7a/28z+V5tpiGA0F+1e0ZqjWciC6te0K8+C+GI2362cAPRr2665nqYxXxaKdb465uaO3REKl1kONFIDC5hlCwKTROk/bsUnqg2uznN7mdUjW20oidYZ2KSeuKVPpB7CPuSnIgxhS+qzhoIG7Iurec6iiYd8ZJ0+CYpW3PCymzVWJP143CA8O1zr29PADpAaUc4erg7Kf0bMNE0WCAU49uuIM1z0v7Id3NIhbg6fXxkDAIjWNMSVMy6yf6ZFRTyHRouPa2MFQxuQnG700DJa0r/WyoefiD3vwG67dFtj4d8hQ8lOeJQpEA+HPfnWD+23GL95J/yDx3Ept0ATeRXCAnuZJIE1x0r/bcKZUwYistRbcp9BaF5ZjI3K3n0bmNSjQblj30JO/lyjIGYz2DCCvmwXxdoQh+g4hXLE2HsaYiLBuGTQRmBeMke9Sini0mT0lVnQOlrPAsp+NI0KMOBwWPF1W5MuKGKWYekoJzCxRDm16D2wASKITJUsKFwxqwQYoUN6+VrZQRM/2yeel/7wy6coxoLfdfdr5A9k67xdSWImkWCdIdMfoeox0A7pnU9LaGn0tRHArIAgS23FKaK3hzZuvQbCGwA2MimmKaDXj8d0bfHL4DNvlCSn8OWq6QwjLzpnhxhKxIrIymjbyJer05gruCxyjjfR3tWbm8ezzlE/VVgY6thTXbqyNct0MrVzyAGAwXH7cn9c69M9ej3HYGx4/D1y2Da9/8hd4/aN/j4d3b3B5OgsSndZbW7pYTBHL8YBlnnE4LpgOBxCCtoDI/nwiLR+IQKjKk5smDBIDtfT5KpDS7e1JlPYGBFZIcwoKXV5RKntARZpcb8jrhhaiyqWwm63LJOyOtu5Jw+9/+x1++PEFzGJQX1aJujPYZS8b31J6pUDIdaj5He5ZawWRRKZqVfAhc3Sy1S8R3KEbzKgCWA1FxIC4zAjTBBDhk1rx4aszfvYzAsWAwyw8QaDKk/aCM51FiGhbVzw8POJ0POpztf+V1S/uFBfRF+I0aV2+pn4m+b0ywKVga03QlkvxOm+Tly7PtNWD6RQvsxqjC6nVnZKi06akaWsRtTWUdRODn660/J0TQ/5jTRdn5bGtFdQsSIqbphmmlHB3muVzpXgrIDmzFv3rewNmN976MrHOjz0zw6LYwVNoqZfJgMAUXb8T/hgEdXXNeHp40jHoObTkiGu98UouyU8pv4mDjlRrlfRapWGrvRT1IAxzvDbc9rxl3zvsavd+jY6x15m7weDzcwTh8cmsqlp/5nU03GQNA1LLygofQgN/pUEe2bpdGWR2b0ZTtHe4YOsqECFOhDhPmKOA1cm99i2TQCbJjAv3ycoZUUe0Zh3c3t3h4eFBn7Bf0PlwREVwHXmUtc8d9NTPHbqePu6LRLr/E4q02cXN0gr0by1GFiXP6toAQDwKbMYAWAt+4cbbeF17LWzBxp/jZ39dKoC/ZQz96pJHiXQ2QbxL0QtChAKQgoHpWk1dlPorhYwPIXomOCAIdbVVcJHDbsLZjAj3rrKoXtyuCMgOHw9BactkGJRo8S5T/6ztDbMbn24EmWeuScG01wxCGE+IpDC6EafjjDhNIjQY4FYkXdGK1m2RR48nv0+YqGdDK9vN+0OQeiFL0WCd9PW+Mro3JGio2gW9PtcYLaB2A1uuvgi9UgoaJA2JTMAP/HVOAYd5wtoa1uENm2IIQMDzlgIjPdk+7BRyKFo+mzeJ1VtEWOaEf/s3H+CnX08aER6/tU99IGdsatg3dEh/kJcjODJeFToY6yaB57bnKLYLgBn9HJqzoZ9BMRJNCbaocmPCdr5IaqGmSJJGDchy1wdFTIZDyqyvFV2t42tN9io2MO/hw+8fV6A1zPOEwyxNgM3AlD3o9VFpmnDzwS0qS2QhMgNbRkqSqlLyhvX8hPkgLUhKZZRccToumE6S6uQoZnrfm5tb3NyccFm3/tz3s6K+7gRYzc7xKI4GRxk0byhMaQC40e4G3XeghrOuP8WAkALIItheXyOfDzHi7u4OKUVcHp8AbqAY0BAwzQtOR4nQ5CJF2zF0iPAA4DgnbA24XM746svXeHp8wu3NV1in7+DTz34bRJPzK+ENQ60oS1SjaQq0TfWlq0fHBrqHOhlsnSBNkR8fH4Fpxs286P0rvnz7DpGBjz78ADFOIEj0qbaCEKQg3ustmbGtK+IhonnGQafPqnRP7xnvdXrltTLmkX8iPD7c4+u/+ws8vLnH5fwkYByunApdU5DI0zQfcDgeYE7PLmuDn0UxSHodVGOAWnFQgGbyqFVN94HyRhYFTGfawDg/PiCkJP8AkAxN0WAB7OqixjRn449GtDCdB//tb32J3/4gI2fuNUZGw9aQyUdh9CzPvVzeD6veWtMm0EYcwo+gshSu1MoNkjpdp2nWPQuCEqlFabe3G25vz6BwwjxFSARJ21qnhLZl1VfknkwBuRQ8PT3idDyooQYFkmhAC5LSrSAmaZoQUwLHKA3LY0RrDXnbsNaMWhlcqrSeYUu13WfxiDPXeOTzWhrJEum6SyCAtOee1RdJpo18WoITndjttPnziDTKL/Ko1IaSN3Fu5Q25FI2qCG1xYxxujmiHCSkCcUqIZRLwF2YxaJQ4RH4EHVuX9Vyb8jPshGdvRxEcrEP9EyiQVH/Tqwx4pNWGmrM7Lex2BrPv60Z49hk70zEGHE4HLbFRa29lZC5d99LImyFLdn2U+kBV/ffzNvAe+86o317X5wLdPFO8PYyZCsw9YiS6eNtbbXpj1Zy0xg/OW4wMbNTkbUnkVQt2dIyKHntzw0eNZtO/WhEHy2gZS4ZH7wMomQLxGQjYeI1oA+NnBJG8oLaGxAlTmnB7e+tGG9CnL3OXMxd1kjsLg6+/YPvYda7WrnE4ntstL13fCKNtZLCW8tN1TB4gN/dKotPxIP16KhpgXpZOiuTCyT4rv/ecWP/kYDn/GvvtxcuMSkfeI3JYX2B/iIwpWm0QYOkaZsCR9HKhgJAIKUSAEuI0YT4cQCEORpUw6bpJX5JSWwdGUYRDQ7x8ZhwQXBFxZVGZhyUO+PpB+4ZNQIJ48hCFMdfa5D0bE3eBYOiElWckU4KZcbkUlHxxxDvx6FlaWYTVpcgtNf3ravAG6ihGmEXrOrqasTjb0HH6IXQjRgy1hsIBVNt1O+m+gSAQsdSDBUIuDcfjATc3C9at4OHtI0ounlpbWvVic1ZvjtPhwISfM/pBmWFtxaA1GSkGsNJM3OD59Lau//V3H/DLtx85HTd0AWOpHJL6qAKwqVIfgkdKyAxrQ5mztW2SRpMBh3QG0FNdxg0iwHqmBGJtiilX9jmaImpf75+R/mAdSv1vf/xjSdVt0j+uDN5hF5i1gGlCacLkdMt83gxgiuapCFK3p06IkjO2bcMjEdI84fZ0kF5GwZwYvUjfI+tEmOcJE2u0Fox8WYEt4/+j7s2fJEuS87DPPeK9zKyju2d6ZmdnscBosYAEA0EQpCSaLjPKTCaZ/leZJDP9JjNK1GGUSIEEIEIUAewusDM7uzvX9lWVme+ICNcP7h4RL6u6F/pFNnpjPVWVxzsiPDz8+PzzkgTx6S0IGbUVCaux06CPCjKNMYJiBOb1wThunBKXCeIK3dHAFWN3fQNJCYQZ05Sr0QmBsb6JTWGnG6lJIgGbHlfeuF3lQmWvv68QgzYvnieUpJ+XYkbolKqTz9GiyqvWAV5dHzCMEZQLXt1rPdDpGPDq1YDv//CPkctvAlCnyEQORM6it+B8OuGAGe8HwjeLwplCGBtcHVr35lHrTYDBnCERIKelCupxOeNHP/4xPvrgCQ4f/yYAfY4v/vrfYH/9FE+fHFQ6acC6TljXFYfDdTWqHLJW17idORtsaYtOokpQ0K97JmshUlLd2DmMm6ydXodwdX2D733vuyjPDrg/nvH6zWss04TT+QjJBSmvuL65hawJ46BNgH3+sxsNPse27wRS5yMDgCh9+bQkoCRdA6LvqQxv9xIpBUNk7IaIYRjBISBaTRWjaAYI6rgGWH25GPHFxmDZImb853u7M0qJ8F1AgEqY5JnSlJO2EiCyRiGkULjysA+mH94LVARWj55QEiGFgNPdfdNGRPjJjwlDHPD111d4c7fH02cT/t1/8CWI23r64ucH/M1fW687qF4kg93rOGVrqcAIUKZdd85/8fNfIK0rYgxG0CUorL0nh2EwGdL9OYmiDqaUakDKs2nK0SFwg7vAmzqXykQZLThcx5wbEoaCE3dVg0nv2QIUkTw71QW0LNBcBasKhgClYEoZ63rCPGlj62StG6Q0Aoka6DY7oF7enMSwy6CMGjSe11Rr8xTmP6NIgGTSwAAFg8w2+KLOc8FqTMowJ9bHz2apBgFhcuZyAhD4kSaa7sB2D17lCwBCbGgrf6ZhPygE2RzflLQ+bruJ+rne4og8YqRuArzS21D2GreAfH+v/hz+LO2K0n3GMlYC9OHZxz8t1QZ04pbOKNdvMGkgUaBtiPxc7nwSo29aKrBAd3VaPcPayqX8Gh7QUwgJV2dzq23UXl+XBfOq9t9AR3z11VdVFi7HPueEdS0IV9HGXxuI/y38rs2YAW1+NLP6bjKSb4XTpkdb6ASNiC/LisN+hCaww4UMu4Js3vjmXFLUU++iwpfXImpetwg6YgT7lLPZPDIJphf/VselB63f7b6ctx43dffdZ0lciQVqkEttW6ARdo66KfM4INCoVNhiMIIiSKKtCiTnFkEyp4oALClDZs2WKTmHCqrg4bMyEQID6yrVqCbS+kP/jrdIqIqM9D7dSPejiFLfOzRS6v9QDWI2titXeL6h+5gVoUZnzAwUzZZpn41Si9B9/P1Q5dQyhj7OkUMrIvf7qSIq9SVX6u4IrXYaDgysquhT0dYU0kenRH3K27HUh3WI6qW8PfybjGI+VC3FDEhiyLwiM6GAcTUW/Of/zkv8rz95huMaqjNeU/cigFCFKxS7Nyltziq8Wtqc9bczdhhFsk0nAw/CeAXWCoEEhVq2CnJprLXhVqdCcP3kpkImalsDU/6516Xmm5AHO0SdxG4rqr8Fr7fQbbwWFCuhS7Aa0wJZk5JlWGAgmr4RqAO9TBOQVzVa2Pq6eASVAzJnBGmwPSbr2YQmN+1grEV7RcKcWXhBP3S/qbJTv1E2G2BwuQhaa0JBI8/qMFgmlQklA9FRafJIcbZ18GYOlXiJmeE9CPv7VlEJChWJweZVs/6UEwDSDXFazVhhZBDe3B1Bw6ioAREcwmB1TEDkFQFvALy31Z+i4zhNMzDf4fn4EvvphPl8hTcp4vmTW4Swt80fNdvYVLtn0Ak5JxAx1nXG/ZvPNcO+/gmG45+j7N7DafcHwPh7gAiupv8O43iLofwXEP4Bcir41a8SptMLfPSdW1xdHZALIHhmzr/D7pqOcBgY+2v+SDWIpHfoBATrumKeFQZIY8LNTh1GZq+zLRh3I+arG1wPGkg7H+8Q9iOGw06zOZIQOOJcTJeLO3yCIhF5TdssdikozJA1o2R1BOZ5QlqTZswsc9jbq0SamdDgooBDxDAO2F9fWY2wG/UBkGxtQKAOIHsQQIVa/D0P5AB1bNw5W5elfucShhQCgRxKLejWkSCGgDW93XFziDxiMERFAWWvr9I5ZAbKLPizf3ljLuOMV78C8nyNP/i7LzEOGTkLXr68AoLWEaPuO1JtjqpPTSb6NewQTrYsd4gHxBjrxiUCy0rNyNmEyQLEArEMZJMthfNrM+dSWm8wNjhgsJ/wn9C9XTNVqmvDOGodE7WsbOBgNcQEyVtSNa9aDp1Wmc5nvHpzj2VeKiqoZDHiIwtYRyUK2Y0K+xzGAdGzeQTwELGP3oOSsK5LI1FxB5MOCCwQFpSitkDKCWWVavdsoKLue5gT4jaRy19JOgZkinccB6RV9bTPqWeO1Juget62RnzN275HDCJz/kLE3lo3lFzAJaPSZKO3Ff0CvueavKCtaQ/Q9oe/JiJtLQpwSYLnNm3vsKGJZbVP7NPQDBec/LE6u+RDWW9E7RF45SBTzV76vtPQJP2zVm8dzAIuVD+vUyXVfu/vzHujkn612oXdk8KtOP9OsfnTirxWolOKFzC0z/vPYRgwp1n1Evt8bu3SfuyciISwnae+XvXXOWzAt8pp64SRtPbn1auX2H30kerf0vUL6b7h89EMMDMsa41c9/lupKofYX/5gpRqkunG/jaHrQn2xfn7e/rbudyb87bz6B8P6aQTVrtxZ00ENQeu1aFxazbOBI5K88vECGPEzl4nexAmwrwsePPyFeZzizw/OgBkDJo86H4klr3L7nQRgjk9LM1BZnJnqz+ZKq4QAkq2Taf7gBK3AFgzFlqrsT8MEcNuaNFYU7C5bvQWVXQse3m4GHTstgpQ0KKuVB0S6r5z+QBiCh2YTmdM09xghAaDTSlvVFEIrW7pP/nhPYbQEH6P9flr9ZIwAhz9oxJ62Lm8NKTkjGnS7MaOCf/g+6/w2asDPn+9x5Idhulz1TYup5tuxcU6PYS+uLZlmurnGAC4Re6yWjnCVhfHDHCo8Mf6XB3bkmfTy8XY6suMOASjmu4nrzd47fOlwMGtTHbeuplR29zNCVGkfDtlDRKQbTSsGb2SC5Y11c8EDmAhzOcZKSksdbDvidEvl3VVcpNSKnyk5Eey3FXyCNPphNcvX+H6+vqB7KHWC5L7VO2r6D5qxAscIg4H1r+vBbMTgBSxdh20/W5nRNZovs0TxAqtfZsk17jUiB9yMuNdXVtdgwCReJtke/YMosFgzdoDMzBjLepISgEoHRHSn2KN/6itF2l2+M3NE3zy5ITj8QrDboendIV9OIB5aOPb7Rcud2q0JpQimOczkD/Dm9df4Otf/GNQEkhJKDnhxdcLXr9+hZurf47duMM5zcjniOnuz3E4/AjrnPDZjwMkf4UnccRBbjCfF5zl7yBDAApY19/F4XCFYRihtPe6QPs6Rt+xWo2OwnMAdUCur68gIljXbLTuYuQdmgE7H+/w1Re/QDi90sbuy6qBB1LmuxBHGwSCSDBD4z3bawAAIABJREFUzVgB84pkwSwKAV5xITmZjhNM04y8prreAwcUYhAtdWyr0Zy17QDZ9YLDJjdH21PI9o2KFjEkRrXVNrqWIUi6p0mxbMlDna6MbBEshELai1RMhx0OO8h5rqxzl8fGyBZtPSI2Xg4TlyyovaAoAFIQA+HrL5/i1fdnfPfjE87nAZ9+9jFi3LAn+WDp9+watcm16dTzecK6JlAMONzeKiOg9axLRZEz2cabheHpBTKHXKRD0ljmCKLsgjEIJJD2BYXCDSObswYtTdCMoCF/jDWSoCyXqZQawPHMFaw3VqbS6YRuHDsDmmPEMETteQsNuBVkQNS4dobT3X6PIdp1iIx5uzTCk+I1rbC+Xd7btvWP89Y3dT/dOGdmT1ogwFEgUoO7/sFm6D15eg0YLBVpxf3rOyTrzQsAwQjosu+n9fl728Hk3+Wh1gBBIfslW+Z9+50+oHN5ENB6n0r7ztuOOETEQTuXSkraLqurYydynX3xRWkwbbF713ltNh8Z62fNVPZ7iNvl3R6vMyZ+ehuPYlw8piMsAN8/f0XB2bl1r/a9gdyIacMMbJhZLx6rOXjuUPuxIS95eOTcbN63H22v9JP0NCPVft289m6/4dvhtPnkuqcpeEiA0ZYbHht8FwH/6ULTxoPqwkZ9rwlS3Ro2dXFoq6b7SW7g1FOTUZE3B+Xx4y0L4m2f3vov9lrn0NVXWzTT70VlpTlymqXzRqeWqQsWsQqOAYYuxir4/vzdte1zITACCOtqGzW3BU0w54K8kLud6sHQiWhfOaulsmF6MB/vqjHsa0BgDpdmdjSq6HWQDxSoL9JuettAWyrd3+zfataxnawpIzJYk4ixmFHDlotN6qVz78fb2j/0mQaH9/nY1XpPeL06d0a1Hs+vFjy/WvGdmzP+lx/fohTBuB/bI9QT+oZSTE/KxpAHYNityxs3oJIADGW11OgfQ0jUONjtGzwlZ3MejNWp5LbGQGaQSZ33vK5aIxRiG7t6y7T52+W1jpI9QykKx2LWZrWzG27kkbVW00NmvfSwXJcXJb8okADsdyNunt5inhfkV29aBo0AUMB4fdCsXVrNUL/0svzD7VCzXseyrXU3cvV3esxh87NZ1NsXsOq2gnG3x5K81lQAbwfiu1pd43pSP4Nm6ahBTvz+6iGAaC2niLZrKEKIVzNoWJCKILDAtyqVCUAJKhwKIoAQ1vMEGQaEqMZrGM4It75eqDpsviS/yQdc4Q4hjhhpjznp/bV1JJDaT0mfR2vWvsaLL/8n5PMZkn6OtE7I51N16BlAXmYgLbg7A8cQlcL+dMTPfvpTUFQZCvOvUAT48pdPcHodsTsccDz9Y8zLjDiOoPgXePb+J3j64X8MZkHOCt/Meamj1+pV2viv84pUcm3wKyLIxIglG0NZRsoJyzzh53/1Z/jl3/wFaJoxXF1hiCPGwRzv0EEMbW/NxQgfUsZ0vMdyPgFQ0iXJRWF7Bt1qulzJYugC8slbNVPvP+VVs5vcsfheHNVedadNTOrIqxa3EHiH9P3rb57hP/jkiJIT1kXbCpSOEEFUlMyRkdZzzWCfIYa3Om2dRFfHWiwAF4D6sAJtlxBjRAwFf/B3fwVm4MOPAq6ur3F1YPz+30n4m59cYVmV5ANF90lfbBwCAsEYOwMiB0zTjOP9vUK9dtqrMRclIoPoulJQWFHYp6WPmVlhk1abWIrR0K8rSH0iSECDWoZsTOjBIJrWSMDWiDsUxJo5Bwg8RAzQXn4ggFjZMatGsA3uYR2R1xyqzRFDRBrcXtHZKSIIkRGj1qQNQ6hNk4kYa1an1RklvY2SQzxT1sYs3MJvNRDietTRRu7MeduHZk51uhvNJoAAHAc8ffq03us6SS1l8aPA9uPOdnlUtsQCwqbzHI5acsY8r/DsU/v82yRU77Pu/ZAHa9EPf90zfI7eEgRdxEkhot5pARewz8s1rOrE9yIPOqDZevWF3mZum0y1q00eK/cYPdx3WzunaqQAjzwrYSt7FbLrMlD6Uet3OEC0dxc4DiDM7dxdeU2/e/tr6zzXut5mv2x+rb5CP4/Vbi/lcSX6a45vh9MGM5bsvw2skVghdRZlFHi0XhUY1QjP5YPTxWbxyMZRv/cIRKv/u5uBPlrfTi0VSud9pB47pK71v+0kvc2Ib7fV34obeZUBkAhhAPbjgEyEZUnK9OdfsPqx5qCyFeb3Etefu3kfHHTB0+xpY9tQWMxgUGeiOASAZHOfDj3wvnjMQHokGwbabgNuWKMzdmp7AiLHdepC8YwZuePD7RyXjlhntPaRpI0+v3Ts+vsyRViyGolir1UmJCZEtvYVnTI43IwIZUFKaXu+i2uVIg1Db+fUTFuDCNT7h+K7/XP2Dr73ZME/+sEr/JMfP2mZx6KOn4pO6c5vgsVQUhJv7VAE2TJq1DmZZA+kuU07rOn2KityKdqraYjgELXFAgIkJ2vqSjVCbL53ZTZLWLu6i20tlogAMQJrqvPNZHUZxP3SVYjeulqPvlaLEVi3+damAgardWPG4JwGWXHsOZmB6Sxg9WIZCIeAwTMrMSKLIGW5LGrCY1tCP5eV1p90jT0M4uj6qlnPjRPW12RI1V0CQUYAS+42WNTzENwY1Ih6MFhyoKI8g7YRuY5dlhU8JECAnAXIC+LNAo4CrUFViOUuMtacsCS97zgou2Ky3mVh0P5RgODl6yNubgXT+YRxHMF0QB88kFzwJgUMRlqwpgXLyhhiF/mxuTufTnh9f4/IjPfGf4kvP/sJjm8+A6V1S9IkAqVuU/nJ2eBRRZtC55Tx6uWLGpX1gMDp/g3WE3Dz7BnmecG6LFimM4bxL7EMLxGff4Dz+tuQIohDhpisMVE1PO/vXiGEAVc3NzieTvjs8y9w2A9ISWnjd/sdfut7HyEExpoy0jLh7quf4cWP/k/kJeFmP9SgkHotVk7AbpUKpCxYZsE8zThPE+bThJRWRA6Q3R5CZSsP1Z7oYYoKyS0Uqg5NItjZuhRbE/vDCI4DBKsRNHn9XIM0EgdQeGRfdkO/TQw8KPTpqyvcpSt88uSM333/NeLuGiyCaVkVrpZz5+65nhS4oUegWsP8mC5nc4R6A6/qQ/udmfD3/j3g935vBTNwe6s08lrfHJBzwfvfERAS/vIvnSDH7BnWa4xPbjDEAQWMP/x7X+H2dsE0TRUaWYTxz/7372MfqJI4FMsEAaob16zMxcMAjEZMAgCclRW0zItm+YuADW4oZC2TWKrTxkRNn1p9cBy0bpCszU9gNgiZ6wiFu2fJVoMJ31g39bBOOuJ7NQdGDAGFAApAoYghBByudgqJ7PR8SgU5r1pmUbLaNUWqznMbwGenlNaqQElWMmD9L0NUeyVbSwad5kZg5w4HXO7csfCXnCRNBMnYdLtiAA1WmL71XmuPyZeUjOk0qaPM2htsMHbdytzJD7/3riOjqqIHNuHmkdz+gkCSknFJdbylJpa0vEC5BLzmtu0R29q4/jLbx71wc8jzge3tIg5nbXtJc3z8Og5n96958M7et39VZW1sV3P4mDb3plsXdY/VyjXIyiksVmG2cfus79YFXDkaHnMi/V4ufQUNHtrfJsb+5/+viEgAj8qpoaVoK9bmkFEHsxTfKIG6IRtSltRfqH2zlC2p1TNsh7t9/+Hvevy6gXtg8AM2ubxZcNS9V6MNb7P6H9wRVb0h3TNfXp/o4VKpZyGFpY17pXh++eJNbX4qEFAWUNSi4iGQ1jJIbiPl9w3v/dHuX3uxaZQw+aZmDinZxsZMKCVYtqs92yZqA1TWH8HanV/fZ8sM1Gbexo7oz6l46lKVbi1N7Td86SJCF3PnrzWl0I5VBJQymK1vlphz1o+1yeQ4DtjtBnVd3alBewZb2vCwUjFYRowjKD1mjOPB4Q3amyGv12FFwKgyybq55e5Zm94gXA8ZHvjQmj/vi2ObeWk1VPW65PuaILkcXuLhuzHp3yEjHxlCgEgBFwHK2pJ1kRDCgBAIKSs0TGl3NSq6rAuuhmvEGGuUNGWFhvkg1fgqa+YYxYMoHmnTTzDT5jz+r591bpYqXOlrk3UGF0ExneO+FxFVmKcfa8ngXFDciVcLR1VT6eW/mkoXI6dnC5HxySef4NNPP9XvdpvN9hzt1xY53uqNFrmEQZ68/kCbxNfAhp2PUYyUQqrsVIhss25Qcsbr12+wzrPplnZx7Z2m0Lc1ZTO+xHoiakuK/WGPURJKEjz/6DmyDLpeSHB69Slw/ScI8R/CezZtnx3mNM746suX+MXdhCf7Hfb7AeMw1tv84pe/RFn+Erf7L/DTNy9xvLuHSK5y0ctycSYdY78tIhDTmST6dwEgpCQibg7MknF+8QpMQGRGoICcMu7vXuLnP/3vMTDj9fz3cS7XGHd77COBSbMv19dP8PmnP8Xt7sd49skO+/WI3flThAlKqJMKUniOf/PqP0TJK5bzivTZn4EZWJYF+/0BFAJKSqCovQcJhMDWF7QUSFrw4tUZkjKmedGMaFd/K2hQMu8+A6M9ZyZomaU3/yWQJJzmFcva+oGWkrEu2htpHEZrUK/uGoOQmzuGSpbRB6M6ad7u1A0eXgrw6hzx5niFP/t8xO5qj5uQ8J/+4CvsBsJizlgq0pobF61v14AOEGOspCP1el6rFxgiUbk70PZfhxIXAB995w6/9f17pHwACuHFC83olopxV/31O78NfPnlb+D1i51m1IaIOIx1b3z+/AV+69/61DLPjN3Ox0Z1/d//ox/h//7XP0SaskIJRWvAtLGwNnJmJsQnt3A4uJhsEhEigFAEKQZjENW2M4C2a+EYKuFZHe2gsu81dCIrPBsvBchFA7ClLLavKNzX9YcpmzqfIBijpGobDozdYQeQ1j+KtGDdsiR10qzGte75vdlkcqMtQ9QhVbIsrckuAgzjAMqC3dXB7Avtw5pT1iBRSsiZOhsHaiPYXtHXYtXHIEIMCtW8tA43j+tG+NvMPBENYjChFMIwND2tRruApKEK2rO/5aQEYy+kmlV+7NiYPUWq/HS3tXHsKtt5yWjexeXnBKn0Do1tPnVd0eakl+Yv+bpyRnj7QLWr/BykMqdlIRfD4Htc76yxs7Er6qxvMbW5n+4ky7Lg889/jtubpwCsXMVgcf3urDY51VISM2jf6TBv5MjvAQBir+XsCu92PfRrv/4j/18cLerdXiLsDwfcPLnBvCSsk1gSpZEleL3E9rtunBQ4SQnMnG9ztx0ZsVaBVejQhE7esRB8oD3tfHnmynr5YFVDNxL7+4Ejga0C3LoAfs+PvG7nYilagFtf1gwPB0bJ/mSkQTCLLgDWf6oSh3RGvylDB3fU61irAnXOLkbGMw9kxeZETeDJWd10OTExEL1hojtn5ngzQaCwD68t14XcrsUGzyRgwzylcrXNrhFfKIZuCJX7x0gzckJJwHSeQUwYHErCQRulRiOE8dYGNVKjTqZHIwUNaqN3zjZ7sI2W4RmhX+fP6yNRjciQZXV1mDtICBq00K8KWOYkcos0w5y9ENToywUUGaEIMES4/LNozRZyUkVr5710PR4YXKQyxkNEHAeNhBuUUki0PXkBAMfyFzAUxuuyt8wLgsHTiLR59XyezQnS87QapmI49DbGtfRX1IhTp1C/k4pgNJkr0iKBKkcK2fUxZfIIqh4bII7DwCzKKylhXVXfLMtaa0nFNqBaA4Rc5bOdremgUp3PptSFuCus1ter/riYkC3MRmtCdmOEiK4k7YHWdFeFTpPK7DgOGMf41iCWy1CeE44pW/a0yUMughDU2fJm5wzR/o4hYGSGlKy9nZhwur/DR9/9Pq6uDphSxu31eyjjb0DCYIE7hXeKaI+knDLW5YRlfYX51f+GYb7H3aszTjtgR4ycGO89f4ZxfY11mXA8J5yOZy0rktbHpx/fYG5GLgJiheNa+2KF/EJqppeg5B9uqMCghUUasdR0OmGeziqr5edY0gphQjEkQgoD0uGAcL7H/THjL94wUi6Yl4xzyfBm9KF8gbD8twgQTF9eYZ1inXsmwpIykAsGGCmRZKSi62eaZ/05LchrMsNTTPeo3heBEaUUeJbOMzwCwrjbYxgU8VIESkxisFi2oM80zVgXJTZxo8mdoSzcdBMsEFCcqKXJPDa/9RaajTi1e9KAHeOUR/zPf/0Mv//REc+vApZpNqZRG4uiDuW4G3E47FAIWGaFsCc6YJZrW9QJO9zjz375BF+fFWzHru9srTAUzJGL1gNxHA2OGVAkITIjUjG4GuPq5gqCm27RaOZ0nTOWJUGdGuD2yQ0gKwgBS8o4nc549izhh7/zJf70j58irasS9pQCr7VXh9fboNheC13OxAG0G8GDOafRaszRdBWRM1Tzxm5sCtxrneykKErsJFKnxZmufebSmhAgyIZe6PWb2zs5C3JejDXS69BcNrp9SyyzRrbuPGipbyGMETe3V9p3MDDO5xn3pxm7ccCyroiD9+vyOu52brc1BBflLpW8TR7Yfp75Cf3n0Qz1Pvj7tqNtVVLRSvUcTOpwAkjLWjNoFSHhDko9F1W7yhE37yoj6c1fJgJMB+Xc3L029O6clofe1luOB6BmGxi3drqK7K2YuS0rLWvabGM9b6ne8OaC7kXpnw+csXYb6uJ337k4QggYxwGbOtnufL3Dpq+Vdk1HTknbP/tr906j2/b6jwAShCgoSXUVh4KS392r7dvhtJHbz22QHL7kVLnjGHG4OoBDhEAjLdP5hDSvVXG0GjXdfuv8dEZmM6Vhe62ow+ZGzoVj51Ch6ky81ZGTzXe8+L7fdnz6dZ677Et9twN21DALjAWtGdr17gRmCKG1Fuivgyp38MapWx/PHKmOfpaYQFqQ1Izw+gDtSfx8fp8dSVZ1nihwY+R8xPCrz8KEYAaE4/71fFJr44rYHPHFmPmU+Up3wxNSC6vrs/a/1+u333xRe0S5iEDWgpwECam7prIThhAwjCN2+x1C8IhhroxaZIK9HXaxmTajcfM07z7UttmqOzHH12ygzUFEiFHpjmMM+JvXT3BMA26eHOBNwXOxzBs8o8aQLmEsIuCo46GflZrCvnTUNoqN1AhkcyyZBJFVJnzicymauRKryyuAWJRVqaMBFmU79eswE8bdiGW2Zpi2szFQqZyb4Dsdvz9LCxyIaBasd0DdQN6MoX2erFjfQ40Ec9JK1g1TBJkZ2eogg72X1wSSAB64boQFDvHsN0OXRjHqawFKxssXL8xJ1/VZa3Qe28TgBqb1qKsLw8aCNKPeIrfdJsRel6tDF6AZsR6u5J9vASWtSdMxuwhaielKM3iHoEYtWWsFRkFOK9JMGlnnHYQPKGBM0z2W6YQ7+ggUP8aeizE9EkqxBqilYJ/f4P71He7lF1jKPShPmM9HYAIWZsQ44u7NHY73R6RF+yhKKeao6dg7DFgogFGUzr44lFRraUikwWHsKNKyBN4cGaWgsJiTIJrRNN1aWchEWUdzykYGs+DF8aSZgiKYyVWl3l8WAQdnX9PvXz+/A+OA+dUeLr0sWh9BkrGuQMkrpmXF+TRhWRYjyGkNgZ2aXffOUGWvyYPunxxWxFEzRZIT1lnr8Rju8Bbc3d9Brm8xT7Puz1LQowGadrh0wAiERi702A7RTHnTlY8YjwLBN8cB//Sz9/E7HybEcsYQVvzuBxM+f7XHi3vCnDK+8yzit9+fjPRB8HX5bZxwgzf5Pc3GlAV0/jk+f72AyZpR+x3bMhrGjI+/d48YogY0jEBDM/SD7uEWoQ+DGoJ3RTPSJVvzaMu0JMt0OBTtzd0EZsbV9RWYGEkKUso4nydIl813O0aniutwNuQAQCFgvLpSWn9b16V4qxlCXQLo+Rb0BYYgpQySAs5KGgK5qKsOJh+RwaysolqfOFeIrO905olhXmZMp7nqXUd4eG9ZD6a5c8IxYIgR+92gmbIiNYsoonX1tzfXGKIGTuY1g3iFB5VdVxGjEkD5XlztuX4D2+jj3jLAQ6flLYGs7cuegXnLZ7nbP1kDz8y+P7Z1U0nDHnOcitSL9vLx6GHj6vsZGzatbIXAPtv2RSV+2Zyk+1yr6dreBep9iX/OgjOeqVJq/86+Jg3Q++9v2+P6edkmevxH9Twf+eZjZ9TzPH/2DG/uz+hiEpenbo/tj0e+j/Rn72SIUNdPHQvLYjrKp1gttkhLqrzr+FY4bbpeqD60iECyRu5Od0p5PAyKS+aoG0wQwbJGYE5wS6M+LpH1nzKBJGoTCcA/qREcu6o04W/GsZ/O2M8E5gx4XZ2ppX5h1t+baiA7h4OPRNo7lyaiJoJs4rnPEz7ESKunrkQK7A8EQmP08M/5rqjv1+imeEZINZluBFTHE76o6qBczBsRKHY1N9RFG4AuC0ft+nVs2hgRvP8LVS9Lo4ClMnVVeKY/Rv+7iBWEEtiUD7FlFh9TdNTq8PxcynqmmBg10mDP4AZwQfEmpSLISY2zyAnADgQglxX3b6buURkUCOOgrFkhRCBwzVjWQv+3q9nL267jXsSyXyJNju2aMRJ2+xGD1Tl88Trir355jRfLAWsChqFTICZgUgrSagZxytbAXaV0GAPCOLZNwTS4O3bO3CT2ezCtV1ymxPDrBAyD05UDVDyLqht+ZgFntk08w4EZcV2RU7KajYAf/OAH+Oxnn2JeE5Az0pJaX7PeFSflTKnoK9KIGotgFM2kAZZhqmNMtQ7xYvThG46vaZGMu/v7asxTKdq7KBesSCgp6XNMSaEdrHCzaVpwdzyDS9k4ic4mBwrYjQdAIl69eqVPJbB13pS934/fffFJKasazcRQMh09OCgRA2c0aAZZphuojKm1h1Bn+ABQ57l32lyjEWPYjbpGrMF8lRUBGBmFInKSaiyGELCLQZ1QCih5wTyfcTxP+PjD93B7+yG+Pv8+nhDpOLLCdnNOOE0zxvwv8OLVT5Hv7xHGjPPxiGmeEQJr36ZUUAohl3vkdTHyG4HA+tpZtId8wzXCErGMaGB1yCCCJOrASRELOniwy+ZBNJMDGIwQgKBoawvbJ8SUo2v0LT26NP2aS93UETSr6OyKYlEJZsL+2YLp5a7qsnG3Q8kZ5/MZaxEs84JlnpXGXgTjbqeywxa8YCelaoQlVc5Y+4B6PTAHXbMlq7yGrH3DGLov3b8+4upws9kjlnVVuLg5vr6nkjgBRN+bbbvaNqZV990HAY5qnLMLOD57NWBdIpgyXixP8fLIeHW3YllWfPaK8bMXOzx//gHiuMO9PLf+XgkcGJlHnORDgH5Rr6O95Bo8c38QfPydI66vPsCz95/peuAAKqUFMS1QMU0T1nnFMiuZEmDwWhFEtHrbkrPCkFkJYSr9vSFfqt4pYpBlHZ3cGesEQErGkhJQpLIuE1nwSNRxcfIDTzBrYLRlDZQxV1szEJGWqdgYxwAwRzg6RxE8XO834yHDt6snImWCDKzN2SEqI+u6asYwaNlDIIUxFgrY7fe4vt7jej+CiDF73aI7p5XYRf9xdRwsq2aEJUSkstvtDe68ZadEuLD5fF3Vo3OIO+l8cPTS7CL7uM/Wnf/X2umu6x85nwfF0Wq9Lw//TrObSIMy7hyzQphLDdq95Ya6Aan1V0RdtHT73ToWvobd1rD10T6nk+H6TW+T6vncRvXkRYFsB9nXJ7bnrGtx43C2/bJ/RU9VaumEuhnbcZCLV8I4gOZWTqS3XB793mPnaHPyjjF/5PhWOG2Aw9q2lN/JOpSHqI1/U1JjDtCUbkrYTG49esGpM3IpUI+50zaKD1xtskjEhbG7cSKwEbb+ngjd+/CV55FpdQYMtafvuyNh3/BiYe6EsyPMAiAV764R+u3C9rFFFzWv2SaBZbPEspsdoQLag8kmakTqSDnumdXQrgvelD2BLHOj97UlXNJYnLO66bkcoKh010m6+3E6WHI2TD+NZuWqw8qNYjgEtkWIR49+jES8PtIcIovMZYsCdn64ftecwho10ZPohmNRJRFVpJOTXjDjsBuwvzqAmJFLwv/wV3v8Z594VOmhY76ZL9/kPYpvLxQx/kNjYou7HfbXV/gff/I+TgsjZWAtbDTN1qvH4CgOkaKgzF0gDULknJVQYVlt3rlGKiFa7zfa9TMaoSTBm/LC1jJhKQnn9YTrXUCM+zr2zE2BFo5gYRQuiKLrW/sLiTGEJZUzKZB1xfHuDnEYMAwDhjhgSglY1zpObA55pba3e1rWFcEIYuIwIIsZ1gKwQWzdaZcikNCtGa+xsOckESznBcuSEK0RvF9n2A2QMWKaFpRl1f47YQCBkEtGWtaqajYWM4B50dq+rSI3OEX3N3DhQJFubMfjC+zGW3AYTGds6zBddVEmYGh6Jlp7A7Zei8xK367jo30zHxoGagqFIWpWlBhlXW0OtAWHy2wRAlKy5uKMVIqS0NgmXpYZ12PEfn8F5gNux98EQDif73A+n5GWbzDgn+KbN3f43vtPcTp+g9P9PYgE05qAlLXH0xAwTatS++ekKWhfP+S63G/fjQ9ohkwM2ie6xrwuSgSKsJdmPKnuEYNDmhBJMCPVMgceHrKIdEBo2VLDnAuoW99qvCozYAFzxGrjT1IapHVYcf3RCcdf3UKK9qGazhPOxzOWNdeGwSDr2ycG7y3ajkIj7bBMoAWjmBHiAGJG8sAMsTkVQOGgsP7dYP27iglTB7EwMZ7u73G4utIWLCXBy2eULEIHsBgsK4TQ7S2dY1b3QanbYqkYJ/+cZQ06gh8RbY77zbRHKQnAqgECGvD1iXH90YcgjLpm+kAhHDJ8sco6w4qJcLjZY3/YaebbMv0CgmQncskIQYMYOWcU9aPMSWaEQSGQiylNla0Bz55co0jAeZo6UiYHjwkU/JrBwwBCQYTSvPuK5BCxZ627UnIny9BwUFmM1hvNZLoPzugvDIJR7UczkEnHJQ6m38hJNqQGe3xec3ZYIape6oMTwzAA0CyeFCU38ZYKHIBAmr1bbD8PTpIB5R2hAAAgAElEQVTi+78b7xCLDvqZ9f6FFPqvWesCKdWoquUYzWbzYDsqoYRmMw0Sb6FyPXEPYXnLBo1mNgZY0PcRO7yq+i6w5aZorZN+y/n79dH0hcP7t6vibfcpxTOOvZ1qdarUvW7zWA2Szgb0l3sn0I3JYmNYs5z1HvsnMyfP/BsPuLt+bhDW/iksO9efxwfNjWKzaUOFZfv1StW/29FpOsSLo4gJkdjM81I/Vc/U7X/EUZmRq/dFmi1jqckDHd9urO0nM1fSoXpPvt5/jQP3rXHaYMayiOKYS86VgjgnWI8OQhh1pRYESJkxLWjYec9QmSAVdJkM6uO/QBUSAJBixbTqvKiABnurg8Qo9aLi5E3wKhwBjfYewIaK3T9R7f6OSAMwBkd08IPNXRYtAIbzFOmhEDw2djeFByRrBOzBD5VlV+juOJA5sGgrz2S+TzlcRi62U0W2MJ1FyYx6U+Zkgq3ZBYK1DOpGoduY7brs91EtIhixhCpsZe7ztgTdgvSNXVzVmrIxR4p63GY3qvr4rqi0IXcpBQ4UYjNSyGBugDqBxUyuYAXcfQPuIopRZ6/fKFKplJ3lalkzDrYw16Xg1XHC1+8JPrxquOh6f3WoLMIaTM5Za0RWh5UUh8ISrq9GYH+Df/H1byDtr7DfKVvcAOD26TUCB0gRHE9n3N1plkipvDulmbVvVjzssdvvsawrnDXRld1g419hLmLOzgOFI7p5loIyhkoMxGbYShMBm1dtbB0ogC1Dy8wIlqUSAf7yr34EWF3Eepo0MsZBswOisBpnQWVodF9sHCkycipYimCXM0KIKFAynvCIxPclZy5F7OeFwupyWUFUkChqVLp+oQBJs2wclY0NZviOu521Z/BRsisI1HmuDlm/ZTTd5k6C/5/tbcoF53kEyYo1K1ztar8zVjwPNOh5eOjxOXpe8gjjpS6qDKMP6xH8vjgwBg6gIYDkDM3Uw1KuLatfcsaUi0HzgBiH6sS/+PIXICR8+NEPQKLQ0F35E9zd/wWm+3ttZrqs+Hx+gzKro0bB5KsITqej3gvYYKaoWS41Flxuu2ebGNgbdEwEwQIUnp0Qq1P1b2RbbyEAIDes9XqqT6yGpgBisGov7C9kRpPJtq8nslpFgdZfsAACRsoJKRmzKaBw4qDjuHs6Q8A4/koDmvO8WGZGH1ANGAZbPROsOS2bPiERzXy06d5ImdrGbG6mzpUbP77HVCPORV6aRC7Tiul0j3lRJySvBTxE7HZ7gLR/pcPfKcKCf4/T8dNG7k3vEMHLGwioTih5rXSMSLmAhqjOpumqu/sjbm+Hbu/QLG6olHHdQHTw6qv3nuL994DbZxOGnRHdiFZBMxMKCSCMECMCAyUpjftxUue2ZLHsp5LAPL09t0sJcP/mDkUIKQvWeTWH59BGgEwXxoAYBs3Me6/LOlABQFJntXPQKskbszrcvr7JA6YqGyFov02GEpFoE2totlcEkKT2dhEsedV5tfYC66oENzmZbdTVx6vdFCCiCBoEHa9gWVzPtoAZAwBJuZ+JrSwQAQHVUXcUk9tZ27Ik08e24GvgxhwKhii7oAAiisIovZ4AkItluqU5o+86SovGPeq4+XxeLrraB81eDkTwvET1nWhrQfWnY1ANtrgfUR1T0XHKOSOnjBBV92+JsbrbEVT9qRcsF0HDduMb//mR89S67Ef6KraoiNtKbrW356o+4eVg9sPncg4gb+ooPUvH9XLofxNYQIQw7na4DRHrklB4e/7LW9bLi+r7Xvoom263JAOwcRjdvvXH7p1b4gIp765nA74lTpuIKjhdGGKKxqN3WkmcU8Hx/owQZgC64NOaUItifZ1JM6SrSWSfMR3dzZfDVRpxOvk1/XvsGYZmpAKEYRyRFo3m6rksmgszZGpPGzOGTPhE3NSC1eH5N8zJuDCWpKOjrP5BFw0pKdkmUCqWXmuy+kiDHiEI1u7rJil2bdsUqpJDsw/7ufJxqefkuujaAoQ9szFTsSsNe9bNZ2xuelZGd+Dc0WPA0+Pt8akpsDr3buxYNE7QOd12TnInExtDTPvFNedKp1nhasKEQNoUG8hNHvhyZes1i9VgMQdjwlLFFczRTgLEqgyBf/KjW/xHnwDff7YgBqpU6EKoLJMAIY4RwRxrD2qAtL+qEIHCiJf0Xdyv38U63ODJTg1JEEPyiuurawjpJslxwPF4wuk81SbswtazjMwhJ1X0gQjZjdPSCoVVl5uTbrvEk5sFRQjH4w6N/F+N0pwz8mrMWURVnn1D6aG5BKl1n2GIusn4dQOhJCW48PUvizYKDrsRwdYemwPtJC0MgIsHaaUaKs0c7JwYkKsexd5f2HJwg9GhkdDsIFgzG2QGf8kF+6u9rnWiajyCdMz12h53VT2kRpRe5/b2Fnd39xcrsN1MvXepIg4tG9To8fl0xhAZORfsBssKZzHIajHSF9dTqPqjZnG3W2jHNGd/A0bS4muLMYwDCgeFxFogq7ihSACJR0L1vVwW7OIOYRiQhXB3dwTHL3BO/xU+ePoMwxhxNY6YiUEcAazIpwkAgbEDckTOL0EQBES4jqkQ8Dp0giAFSSLW46gylgXTiz2G5xMEwO56VWZIj4ISVaPQNbcHAHRZ2pp3pjEx2nGTGx8vW4Y2ZrRVG65wSY2AkgWIrGyMq/alYo7QyEmTgiLA7tmElAvS1zs4dB+AepRSQMYQqIauNtAmg3BqG49tZNcNaEdUMFoUXMSMe6+57B3f7J8zuUkrjm9eQAS4uX2KnBJSLgqL3WmPyJyNwr5ujt6epT2jdHr7sYO6a+q+x1bb58gcM6ZyMec14Ksvv8L19S1AZEiKAsq6FlxOuBSErLyXYusxLSvO54LT/RFMjKvdHnGnRlZO2mNrHLhCT9dlxf3dEfdvwsZ6rkQEUNgeWVY1VSizYNgN9Zn8+QKpELl+KMWYCBW8oHJiOjfGaE4bVTZGt63cTokx1j0JHMHWDsCDYyAVuVwK8johp6yoh5R1PqvdIXWOqK4XD0ds4DWWme6yMP2ebjpSA6JaP/3QnegMOAAaNNlC0kpHNqU2VzH0C9dgjVyez/SEa/MqbnWjawH6arQ/IpKm4jb3vXG6/JTUnE7A3i9qd3hfzNJ9V0tyvGcmbdsjMdXO2v05VQ82x8CDbqVkIKEibqrDI/4dsozZ44fbPw/061uOIlI5J2ofZiLrTS8X1TydDhFczP+vd5gvj0pMJ5eyeDlL+pLv7VyN4Hbly2+UvGrLDWnv29fbN+rG3Bk7/RO5TAkA6UiF3nF8S5w27fXTjBeDApFG2FUJFMzzZNFLZ0MMhqmmDelEC6N2GoG2C6Y6VOZMhBbKAPUftvcd/ucHEzSib3UelUKYyepOzCk0D6FXULIqvjrEYEa+RQEJqPUSPtGEqqT9IRQ9oO8zTBFnv9d+ZC+MAzToYB9t8ntksW46vWPjwyD+W9Nm7hy3cW2pba+N8c2/d9Rk8xNoSpKq0iNwJZGoGcLSjNQqO3YWzfRAsxtmtG90e4XiPb7w+7osj3V4jZFwgNo8HT2+UyXLxSmZQcbcqRS1wdjUuGaE+/sGlDb3jz+/wedvVvzeRzM+jA2aIAX45fpbSDLg+/LXKIEQo0Zz/4/PbquBICAkDJiGj7A/HBBYc7Mpr8irNsZd14wwOPwlIhfB6V4zIt6+IY4DDp6ZISCUAjHDXsYBeVma0eePDCBCcHOT8Ud/9DWSEE6nEX/+rz5EyQKOWtNHKMoC6VkHLZ3QYn6D3TwWSdTsgEJAmTTrTlGzUWwGpCyrrQeVgSgAkjYoYIMtCghJBJQdLmfzRABRxwaFtllSdUb6KfbM7qV8bcdEYlQIZsrgEKv8SU6Y12Rrii6CMYKb6+v69/MPPrxw2h6MTvvb9B6Tk4pYBrtkrGvGEAI0+GFZtu55XRargqxrX/BogBUNKsLk5xGDKGkgpxp0KJuMt9chuTOU1wzIgnIWrCDkknB3f8RqTv7HH3+MdZ6wzGfAHGEBEEmz4yTJ5KNAkBFJswO5PouBqogRdyNoHTF99VRrgM4zuBQcv7oCAKSbDAoJhw+NiKI+uxkzhkuv2WV3uz14YPyzBj7UmhkmvbuiuiSSCkjjbKNWrE7aVkJy0qizn9dsneAbHRn8TRjD0wny9U6DBWYI6f1xJRup0Vxj82UOmrErWoMIsdMSgSTrePr6YCWbQGlQc2eGJSagMhKrESekLRuIo9bWjqPOf8oIgc0o1/YcUmnyvTa3P8yMFuDSNKywxn7tMCMBEGYs84zlbsUQo+rzQWvFCKgIjpSKlXjp/p468UcI1XgrpFHH+f6II2ecjifsDgewGWRLynjxq19hXQs++OA9XB320P6EHnBzyKw+h0gjqAEBec24Px4VQs0NWlYP1rY5DIW8pjUjw1gXReu22sQIxJwTdTgFMHIkDc2WWi7RO4RaQ2wlAVn1dDHnTJtZm+NXtGRAe3x5yQSMmVj1nWQjj/LAjOtPzz7ZXi6mO7K0IIEOlAezO2dH3P5yy63z7N1iMJy7+L4tUnW8twoShhF2uZ638zhBVnX0UDGtzOVBNkrIA0/4tcfmq253bWwiU1OW8u5r79o9OamTO2y0uYBDF6v8vsOVqvXq1h7ocu+CXfdv4yI5zPTSGXnnIWpbSc2UUs2SPXQBu/XQ2QZ08Tnmx5/YxaPPxW4+WZ06wXxeMK1KJOfIrwfn6g7vIwt0cvoOedAt8rFAhO4bgRVe+euOb4XTBlNu5nPWxaAKr/XIku6BScyIBmFdM86nczUGhkGVZMmKURfXmDWC3U+5OYr2Qst0mZCYlJRu8yeD/cQYa28WT+2W0hYNQaPp3OFuCWy9c/QumKkWyZNYyrq7txgCxv1oDF/b6S6i40ZFUNghbnQh0NRJEjdrVB8W4kYjoTmK2Aqf/+oKepOhMNiaswG5k+vfZ/L+PC2K589WM3yo07NRZhzYsjhe7Jy76/ePKFXJCCyCq1geNEjf5dNs/yrY7Hu1AJsjIYpG7yiwOQlUZWNr9Cq8JBuWPkTWSKVIdVR8bkTaOAKEOQd8+jLiq/sR+8FHCHj//ee4evIRhBhfH0d88/VXGOKA4WqPN/NQM52lCKZF8L3vRggKEhhBBOucMc1J2ThXRhiqoCtdddGanIIMHgQ5BJynGSyq2CGi3Agk6sDE0GWX3SBVE3W/S3j+YVKTlTKef/CFNthmxhAC/tk//w2cp2wQZAJbxoeIINzBg21cihfNqyDVjT4Qt6wBKa1zNgeFCaBSkIkRxeql/J8Zy15cqag3M2bhsLYLYX/00DkLrDWNYANLktXSAbVoWnWUrYVOp6R12ycH3bNrZBWAFHz+s59fXFs2/3d5cp0j4iaNZ4u331SK73at7buq7JTB0zKUb9vU/dREGOJgzqm2hGB4jrWDj3ukP4s1k9WxKOKR3oJlnpW11WozpQhevvgKx/WM9Poe03lCg4IKEgoECyDKOcZe78qa2TCUKbxTjwCgwNiNBHy04vUXCnvKIHOzCpZjhBTGtAhuPzpWfUxAJZ9yFapGoVTnvuR+Q5ZmqBZUtj0pGRIDlHxHDNNnxr3AnCm9WW3bogGGgW5wG36Is3yKlV5BiupUsf51xVpdsEG4USybfGFYus6KVgagxCr6XUAz4LVdiy5wFNJGCFKysfcxUFL9yOappb8Qax2nO0vkCxBV81f57USwmVae/dAIvWxkWf+IHFHSCgFwmmYMpI5tgNalMMzpYiWqcEdBTCczMSIXrIsSwMRxRNztgZCs7yBVuD+JgFhAISpaIM1AGBEZGAdWB3HcAayBOgKBLGAUos5/Ngp6giAwEAMhI6DkFbuh1XC5vIagjd4rWgVQYh5bYcyh1e+IqD4yP7hczI/qpAApGYUI67pgtbW3rkkzaaVlAitJj404B4XaOvy/EiJV+Lk6bgXafoI59LOre4gb+YTa62qzj1p9WYOUtf2q2mRiTpNLiVCFD4shU7yeXcnANLur458B6mrOq0Q2feYSJi7Q0su3/q5ZoAqSN91vxFd43DAHAGLGMMY6z96CCBbgSmtC6BasOzJ+3Vbr3Cl3UpKXJK3cwE/hwfbLrcwdNosT1drDd2572zPAV6j4BaXtR0VKq3kUbQuSxe3DNn+tBGR7ZgC257c3bYvTEfd95dIWfOQ+eyyN/7wYQXhpVEkJmRgMVvutG5B6q5sASUGWgvgWgKigZW/9bh51h0XlmDhDunZdjx3fEqfNDxXiEAKurq/w8cff1fEijU71KoQCKSPZmlGyMt8RMZgLBmsWyqvVE3RXEKgDVmqVo2LjQxw0UlkloHvf4GN1sy7WZDEqZC6tCygwJHXZuD5yaILllOL+GjMe7z/RxRLiOCiMwe/NhLaHcqScsb6+R+0ZxmRNhZpAb/qlUFPyJL743AD3lHKLovkG4kZYU9g6Tqnoxu/mafbKMHKDnHQHwXahVOH1++EBJOYQMLWMF3ULnbZKxeGcwTxPgtfSOWKnLVmvsRFzjnt3LjBVtkQqGinMMQClKTQlVVFKfJdLFZO+NovUKCtuFABSLBscuuia6AYWY4TIqpFnJpwTYUptc9ulA/ZWbXXOB7yZtOfZaL2rarsG357LCpHo5rf2EgoBQyCsUTNiEL3P/W6/kRWXhzcv79Djz/35d7sBh/2APhJc5Tkwbp7d4oMPn2vNJwc8/4gAb+bOwH/54Qv81//NBxYZ9snVqGgga+AeA2I15AUshJKl1pPq/NUJRX8U0ShwHAaMNsbsUUigZsD7uslVGDuXcY/mGSsnirQ6N9IgQrZaC72PAqZwARls7hREGd6GEKpjx8xq9KHJgf/U+KmRAdhba0oPtUMLP6NWc+sIwCa3tuloTh3V78paQKPVkvT6rjOXAWjtX0oYY9jU9l5GnT2rXlQMqiXGzNaLSWux3OrO2Vq0B81gSylISTMvOs8JJBkDR6TTGel0gog6IYuRPQSrk1hMvrI9Iwmwr82i1RFfc1ZDFQU5D4BMWI4TltMBIto4XUSdoyz63HI34J6vcfXBSWGyze2rYyQWiRdzepizBTi4wos4+DzlOropib2uU1aQwaT1nqlonVkqMBZVIPAB7w1/CAIwZW3arXNqc1U0AxICIxIhE+nVSEm9vY+mquGgjkdFSbhcQPs+Wh0yfF+qoqUszVQKwFLrwKpRy16L1ow/NRb1XD4fcAOd+u5FsjGefU30Uhaj9gRd5rm+wxDcvX4FjhEBhAFSHfbATeYJRQOi3ZFT0kwkF5QMxHFEIMJiBmE25EwxArJiuiTNCeeT4MnTYsy0ilJ479n7dbyKN2O3daFtV3xNt70CEOwGxnjt9WO2z1vaIOeMMfo4qbMXrLY/DiPioC0HAm+rcTmoAYgiyFK0Hli0vUsWZTktOeN8POu9EWE6z6pvTaaItA43Rr0mwFVmypqwrsnKMXpH3Uo+uJvnrVSY3NrrWoRY9+GqgULEeNAa5RCC1lUawQWzwpLJnMRa91v1W6nrPo5sbJvmCFtgxLwMEBWweGC+2WvFl7ntc82k6/Z5iJHxOGRa4FV4hfpBeeSwYF0JjCABQmI92QRiAQjerA9sxm0IjDW32lKVjs6pof47l9/v5sTtO3no1G2u++hrqgOKGNrFz3kRjPELSa2Js1kubbw3jhuh7l2VXM7+9aVDve6gaqtv9ztyR1/cTts+P9C7cUAMAUMAUkqAjPAMjL9fEEAds4SuC4UKNbvOaWja2GmQ8ZF6vssxJQEhvNXh9+Pb5bSRRcmiZst2+1GNWiLM01xre/xgJtAYcHVzg5cvvtG1CxWowAo5iSYYjgkGgARggBp5SylIYinwjr4WeEygTRhJazQ4NNpe3SPNgBYX3cucLdVnMPdC75f1s60fmkEDa/rYcex2sqCRRPEHdueENJpV9KRtUKECGwfG3L3aF3LXbKP9q4yJaM5hfVAfHPsR2VmpfDNNAEbDkMJY99qC88hcLSx9i5Sq8ew9f3o1YPVN3eZesrE/smY3duOAORSILLoZVXikH1KNSK/V4jq8zZBxQoJQjfnWyLtmIMwJCszY7Ufd0IzMAwIUy7Z6JsD2DBCgzKiiFhwHBpJuPF5TpvVCVA2dLvDUOU8OUSiQtALDCBR15qMSQoKYkOcJc1YDIsSIcReMxciHQ51IJkHKDyel5AzBzjEtWzOfFPolIWhQxHePONr7gjhmfOfDFb/6ZlRWtZxBRTc5d4RpKUg216Q9FcBlUIICDsY+Z4GDclH/CjNgRKw9AJAWzcRIKZDqNLvcNIhSf/ROiWfQCJrFSzyArDBOaza1NiCSGjYoRZuW6nRhHJUxkrg1F64XlNb/hnz5US1fRq71dy7lerNbRwubc9b3SBVDBZ148IIADKFu2J0wbe7La1NAjJSVdOByoTZTS7+Tk2ZsYxghwRxvmxop7RuttZA50VbbVxvOQirEUUxXBEKtfxIiLAJj+RQ4W6465owlKYxP67cUblgjwCWBhDDcTBiOjPnuCpqR1+uWlCv0fH6zw3DI2D9ZdF4669Sh79r7r7UH8EFlDiAqULdfNjLKRlihgSjRzAWKsSRbHVIuNmiC94c/NN0BlFWQUlGCCNubis+xR7o744aZDE4PgBgDezDOrT2/Z6mBBhSgsLEVFwEbk5SqGqo9Bqs8CQElAFjh5EupFMtU+Yhx3ZJq5secuMcOAtU6ZUCvmXLb/91MZNLgnhLtODKDbD5dtJ2YCDX4en11hTkVPHn/PQxBHZE3d9rPb50XpHVtJQ/k1wSOxwH/1796D0/fO8J73BXDrpai8kis8rCcJ4zxGuNuUNlm7c3GpAQh0zlimUfc3o4gaP1iloLBeuhBBMPI2O3VeRnMgdJstMIjUxIUThhFEKxGuxiSp46vOdfnOWE+T9iPsSI0OIaauXaII0GRAIAgxqi6y1lnqK3jx7IyyjjpYad+Pt1o9jlpATS9Ra77nNs7LmulFEMvutPX11+hsmB61odj0H2smnKKuul9AA0W9VkaN85F90K/Y9NTvVviD9+rWiYviXFdRG913DgGq01vdt04AqtoXz7p5HtzTTvWitBoa9hu0y7Z7w/9XLWauAxdM5u9bmPa9d97uEgdvaDtsAxG3elZ/W4XtOkdNiKDpgFtVm0PNCcYnoAgt322o/Eo+oMIPaMp7K7URpYaZNt4iHYHJIIyrUjnGYUI4zjW+ZV6Jgu8uY4nwhCNfwCtzKKZyqrDfEqkPC4PLaBK7/T1/fh2OW3V+NAtIeWClGaQQ2YAXXwCSC7gkpFLwfvvPcWXv4imaNoRaGMiIQkUPmF/K1EB1QhfLVrs5GFDdV5fs18qdIhq1AnonBG7uq8Boe0iccMdAnh/VvHwgzltJvMtcmCWPJmjJvX1AOLUxs/37moE+r03ZeIbg9Qx75QrudLaxEz0qcz2dKOgZnws6rrBaqMZVPV5u5NcKgWvq0D9nt5LZb3cuAq+j3gFCZQliAOubm5xYMb9m/tKgtDjlEvOWOa1krdIp2OLCAZmUAwKbUwOoVOlUFA6I7spfoHVG+Ss88kKUSxMG4hsf3gtmYgxWLKADO7hSq/i8ju5q8/fRYRzypjWFYcxIa8FKFL7R5EI0jIhr/ocYRyQ2aNdLYtMUjDsRqQ04fLIWZscK1VzqTLgSvF0POPNXWNEIxRk8VYVgrSs+N3fOeGrLz5GKWp8UhHNGucGn2WLSkMEWDJSSMhFo+cAFAZijZKbDOhcKMxY24WQfbauRtfZZuhdzp8LrL8uvXK36QtO3NDvNP2kkrKkDYM22h0Gr89QQommJqR9He0eNM7h/dserr13H1asblBS+JiUjgUDUIc7ErabsbtgHeEPczWWmJQAxF8HAH8YnStlTlwmNXbH2wtd1x/9mpcuE0pigTCVhdX6gnmUnIkR4A3hjVK/SK09AQFJsrEI67MUHwi3tSwyxgLsbzOwEJak+iuvWkdmhYyqy7rRIfH4mGjNl2hbCpcV1/vFvFVd82UbrS9AoWK2g8HMSJ+51jbDgjt2625ooXTtRHLGKmreudEKgjnApTZsZjNlAzXyh35PlEeMHw8eNnRLN35ek8stP0IMZU4kpXWfJ0Y6Z9Sm3caw2KzahmjR7M6WRfVhRL3fJxxY6brRa6ffvlrU2RcgRLAFcxACghDWNaFkoCQLSlhWoMHl9Z7dMAOAN29G/OkfryCs+N1/+2uwke0kC07GMSKlghcvnuA4DaqfxYw2gTFVAy9eXuPP//wa//4/vMNhr+PHApR1RSHCeWJ8880zPH16UJ0rwLIsWKYFc0pIawITYdzvoDWMSpjl6BYSox43nUc5IU8Tsgzgw95QKgSy3rdsdV/onG0dgn6/uXQh2ry4LlUZs8BanUFY2tltFB0rDgHwjFXRIgqqOscZwJsDLjaOjoqot2frhkNAjAYzhe5vQo7Ros156qbXP4td30x51FIIt1fqB7mTYR+H7twiD1+zsfKssY+Zjz2HABhai1Fj8XjY6qX9LmI2WJbKHAlo8qNvn9Xuo7WC6N/bdkGRzbBI93r3l+ko06cNEG+rs0El4TYkyXa83XiQ9lnXoT495MksvO0wfWDnzpIRH3NrRNDAnD3GqslnFg12ZHiJQKj2bP/k9ZtkdcHi5w0axHNmFeoRaf0Y1rerXfz/5viWOW2mrI1FKKdkxbmokUaIRrRSIcg06QbKTWHUjYRoS7/dHYEUTsMilf3s4Z248DRHst1iW4kcrI7gQeNZ/0g7gzoG0j4nLXor9X+9IanXVUiLNmq+3DxBvqG0pHQlu6j7LW3EFORpY3uXA0BSjR0vW26GFXw/86eC1EXQXiNslaMb4SBV9pshBCotuxv/IQaUlKqjWJe+G26PzKZnEtzIhTWOHcYRCAFxmJE7h9f9pkQMrAkbSkqCFcjqnF5dXyHljPNp0ns02Fnv/FXnorsjH1ryfh/JHCfycbIxqspAlQ4H0t5Z1JxVDjrvYhNQSiAoNAkAACAASURBVFFcuznIAnXclNVrxYsXb7CbC6JBQVfp14AuoGIsh2vOKKmx5BUAeV2x2+8xnaatfjXRK7lg3I21DxSTkviUQBjsX9shCLFTeojU1u+aMMSAw/UIEGFdElZjQs25k22OlW3Mj5wyypo2BkW030UEIQ7Invk1Y0c3IoXA+rqvReguhxTQK3SdZtcoui5D19ajEnEwofVA1Ixr4IB1XVACg4rmDotnBiEIkRDZiq7MwBLRTSpEkxMtNkDPUurQ5EuWMDeC1Ghi609luqW48yZaG4MCWgg0OEMoNQ3hhpw7LeSGTNtMma1uGEoiEGKwhA1hGALWlMA5IRgNv97+du363G2zj6LwaCIUcUilTzEbtGtbL1Kz7UURA8gZmjoBhD1ooZfwBiUSFK093q7YXZ/x+ufPkJKRK3TrdLheMFwvdfNtrSNs/ZdmnOqrrgGbzLgyyB1KhEAoKYP/H+repdeSJEkP+8zdI+Kcc+/NzMp6ZFV1V0/3aERJwACkFgSHBChwQQkQIYA7rbniH+BC/AnaciVAO3GnPyBIIggIkChxJE6PhB71TE/PsB+aqaqurqqsvI9zTkS4m2lhZu4e596qHu1KAVRl5r3nRHi4m5vb47PPgrMlisEXrc5GvPm22KNUFpyspNZp+qx1fyegRvG32QCy8ZNGnR0+6A6vKK0/YHquMpu2vUjQzJsE2Pc6NEck7McrpJRwetAGzPDAk7Q5ckPeQ4XwFbXzzgNHVWd0M3tZnVyNdtSpevIiGy6KQ1RFHXQA+XyGDEooFq0+bBy1Dm/hWUkyRBQyb3bJ7d2I27sRAYIvvtwhWvby7Xffw+GwBwP4xc9/geNxwvmszjhDoZggUYbgccA4Dvjy9YQ/+Dd7/O3f+8sGmSXC//mH7+HhOOD16wksGafjCXlWxkbxuiYRhfQ7I62ogU+SteZR2Oj7AZGCBME+AGS1eiA9A0JU45RLAQeFo4dilehFyUU0IMYNYuhrVwMSKpPKkkxVLsn2ip+dj9aGDXFBMFp2cwKslyOC94bjajfVHVbPBDtFXUahiClCaxvg8On2aVTPwAPmatd09fcuYmZ7eA0Yuqf6Z1qjeIMhuza4fGfzRKpK71oLVL2LCnTv5ro+rX4a0LPXHZ3oDI1oTh+69653cYe37snNPx+NWS7Wu/+ZwJED9qwskNTpDfuwQxWfEAF7K2utItvP1Lu4/da9R0OVOERV/xkevUCVEHTuYdXGJgaWAQ1giPWO22JcHl0hViBalXc7K/ogT+eY1JW7vG8NVP3/raaNbHPbDOjPrEmZkCpNANW4KKUgpYCU7DCWFhHbmDQilRmqhoKCHfC2RZP/XJ/anrMdnEUU9Al+VMYYIUU24+4vsx3V6K0Mat0hVqMy3ca0lxAWoyfXMQSxzUhtCzQ7omXLaoamg0kSpQoTZXQNSc1wU/uRgIvNgWYztnfye3YHd9NBYtAdag5l/271DtubElHXK6s3Fppj+tQl4g6gzlUpDHABnPyDLrMKbpBjE7FT5RIs8h2wP+whIlhWQVkXAGqgF3IxUkfH6x30A953T38vti7+jOjOpQ/HyTVCsGibOlWBgOubZ1orIc2ornNqWsojZ6LCheO9Ntj1Fenx1f28VqiJOQo+P4UZ+yFhDEEhaDUSCBAFI5VBpf5nCKyABPurK7z1thdKB4CKQmNtsk/zik8+eaMQNGbMixoBz9++wcuXzyAQrA8LZi6YzwvKmrEyI88zlmXVlgsR+Oi3fgv/9s//rCpdzz4Mtt6lo+F340/nbZsx17nLEIu+B+JGBCBbaRN4xF7lTYJCsQYRXB12mOesgSAizCIQgxfleUEpBbtJDcFIgkKEm2fPDcLjT1EqTYFgmnabyCygeoN6uerEtr+cftsPsY3cm6LwmhmtbXOdajqtDypBj7ZwsfO8DjakZIaaZVRCwJDI3tNbiUgzxGOo427seQ3S4oyloW9zYvLGwiie1eozzTbOQLFaY04OhWJqwHrPqdPDCCVAovZbA444nQYwq0EeghtCgjAwQuQqRyDP6Ktxl8UaFFvwztsEaPZHZ897XOvc82bR9HBPFeJboOeLZ88hXrtn0DtR+KaxHZhjag5NoJqA19rpAFlXIHl/QyXy0PYgnUiQBmIoJTtDNWPh3VBtYXXYbkWKZkDdWRj3Iw7TDkMMBtnLKMtSzygrZ1ZKehJIcaglKimI/9vFtDfHq9UFglv+inqwr1xsBmf2jEH1b0xJg0cdzDwQkLmgLBlyMn0RR8RhQBpHEK1YlwXR5qg8QaHKIHz+xR4pBrz97rsgehunk2AtBZ9//pmNsoBIMATCMI0YhogIMlKPARDGV19E/Mt/8R0UAKuxMs5zBHMGr+dKre9BaAFhzaUGPQVmz1TbMNTzlgTgdcZyewfOBTQMCPs94hARFj3vQrQMW4z67iMBUmomgHO2vd70qXS13m46iWgwDtwFAuu8EVpdT/seTKf2SIBK0nEx31Llr/9Z+0fo5BWAZkKMERPGeulD8W4/NQjT7oiayfWfkJ1zRB3J0uW10ZDoe5A+fgdAJJgMiwW0tzbKU4Z9+2k7BzwUZOahtufBtqfvdgB4MkshpoOAx7aSsNpUTyEnyDPo/llLLEi3T1twbjsH/g8SKLHYk/DBTik8ehWBk/r0OuNRcMd/R/Y7s0n6Lc0gxDEh7SfQvHy9o9aPTErTPe6UitV1eu9b+Hmpl9MJSgh1n1TiHyLgNzhswLfMaXtSygE1vnuHzf8U87s28LGWAvXPMfSw8i8zeUoTABr+um6J5i9o5IravfvifTd845AsStuUkQa+esfkYiP45q1FLe1jvgGbawQTCjdqLjDPFJCCbv5q7PXPE4VOuMPfGyEQODq5G8c3iezFJuo3uEWt+lv1H5PNqB4rh8v7yGb6yJmuuxurc0BkBzSgxooIzvOiDmC3XjWDSdCsYuegSvefX16vMIwBECNN8MLlNrn6/26wlXWP7JmRmuMZGlZbP4sKdfWIojvOMQYMY2tq7HPmRmxt4m1fD9FZvTqVLReHB7mR17WR6NYla0QAL997CeaitOmiNW4eba1YChuTFLZslb17YXiBrvoQUg/iUopCF0kN0iUXfPH5Hc6HBS+eX2N3s8f1kCr7Ws5a9/b82TWyPWOIAct51ueHiBQDOCWFQrLOCwFAKYgioOQRSHN2uDee2+HsvX36WkmQN0o2Y8FkqLBmXvKalXCAWBmnSNdmFSWRGMcRsi7IhTGNCasRmeTzSWGe/dLY+lztd8reaQfCBlJh1nPVHyFYnxs9cL0dgUZ+m0B7g9MKhnbCCZddETXO/d/d3vAARxMpje5ztqyYMeJy0QglBcI4JFBUYBOrN+tK0Q4nNmY9+46tR141UpuCuw26HiVbsMwGUopm8OrQo8FzQmfgm6FFtYAiQEghhsSEEhhUBM8++goPn70NXqMyYBIw3azYvXus7y9QuGPslOhaijqBkQAUhKhZCt8X3h6g1nVYXZDaqRa9p6JpP7DVR1KVN9/383qLQG+bMUQNQh7NCDEmypCaI4wONh09C9zJk5KeqEPKLBii6ZCQQChY1lLbDsDG6tBRgZK1MKtTysx4/dUbPLu+QsmM4/0JSy5IoWBdVggXzaQvKygE5MKY5xk5FzAX1Q2i2eNqt/ne8D3pxvSww82LBXlNOB8DohtOdTe35CECIQ5j1fvuCAh0/w5prPJeWGvUZbagpsCaqpvtYPfdPMl0tMKhk/YnFEYYIg6HSQmghgGRDOIaA9IwIKSIIVg/xxgNebDi9RevcX8/a0bL9opHfD0YXYoyPEbf8U15tQ0aghIwiSMcEsYXzyAAlnlBGlId/5gIg5GlcKwmper4FLWthmhtWymKfNJJcyNe9xXgel7q3y/tuWrEwiGi+m6ozp/J/oVZUI1we9xFrl0/EzpjVxigiFaJprqnZ0i0bXNxqXSEi58RYE3MzaJ7Cpp1cUnn0NZnbkat68tm0wlg8hq1BQqAi6907+tngP3dnqXohG++njK5yII6m6d0dsUjJ66zqapuMI3WHxQeBFLbLQKc61x45k1/pwP3IEFvN/r4qtnph5q0cXVWcr3CE+PejH3zO4F3ahYAmQhRqEMSPB5T/V4nC77GNTEDanW5dgN3si+d/xYo/Qa72K5vldMmolE/DYyqk8IUQBRbQR/MaCgGvRmon1u4VU4hIO5GCAjBDqfgBhkp/S+jebvb7/sktrUNQftjoY+K2ESnGLtIK5lt0QTNjbHqFVRj+XITuUdhAucGvkcIXchhEWjSuYhBM0NCxnYjBgTurkCC2NMxBtqOkboxuNdZF+aJxerWw50N/bFbiW0eqd6vOTaXN9WziYxNs93/Ub8M6v+sIIKmZMygFXj2iqqP4QpIqiXquQCDhMGdIX1IKVoYvi4ZUhg0ehatTVpl2rR3ilZAXUpnRMMcZmrmo+9j2IFONlday2aR2KCOWKCokWtX1CKb6E2Fk7oV263fozhItwQiXbTa3seVhxZzBxQBTucF5+NJacJDqPCsIqIZamg244P37nSsAFphTFtLV74C3edsZB5SCu7ujjidF9xc7XHz/Ar73Q4pJOziBBojrm8OuL07IYaAd14+w4cfvAvOBcu6orAWcJe1YM0FKUY1tFKyegmH69g8MaOELp/jGlkUhh1IWQR9Tf1s7LOd6pgT9ld7xCHh7s29rWHAAIWJFmhkdj8OdieVnZQSdgc1JvU5emc3Dq9uritVuGf8+mzxJhtW3AFtG2MYBhApmYBYrZEbQ4+2Ul0fNZx73QRRch7xViGdCDELIEVrg4wZU6P/Vq8FH6PZZW7EQHdtiC0LB9FMFaB7tmbpTF9zkeqkOYKKSB031xs+H5UPxOYppZY1FZRGluRlfoGQIvDhXyPkhz2++PiM3f6EwzsnzIsdoiCDJaPW+EkxU8VIktiZZ6H3ZVFCLYIYaQQUqttxCAgEwsFq86xEkLw5t2eFCa/LnwDl38cUXpo/2ltGuvZO2IAUTI/p/VmAaHPMLJBSlCTEtmgyx8PNn5JXuF5VB0gdhFI0Oy5FSTTAGghkEcx5xfLlLc6nGZGAdVk06CIZ8+mEsxGqqGIQzMcH5MI1wEaxZQxcvi8vCgElAx9++Bq/+7uf48svd/j0V8+QAvDJL6/qcaJipvN9c33CO+/fIQiQc8DHHz9DMgr9weCmIg1uGohQ1oz5eAazIPn5CyM1c3n1XSAAzGGbxkGDMqIkaC+e3yhMMCbElLSvbIhGUKNny7LMWE4zzqcFp+MDci6IQ1J69DW7EBsrru1jFiSvhyrsxxhyXlFKqS1GPHtZxAJq/p4sWOZFHe41Q8ahwVihaBWFew8aRBDNsgS737oWpYt/dJ4b7L00p2fj3FQHhSB9mLw3oi/tDvhZuc1Q+972cxTwIIeNqY9WQfUXS6lBk4CW0BBsPtrsLNc/aC6pv2uwd4tBWxTqkbudi6eN/Et7b3tFg4TOPGtGfTMX/RebzeMQ/ctn6VReBpjbOxK0DrXvO9nu3en6Ry9h9o6beXUlZeOI9JaVK2S3ktRM6ewXr78rm0c8GoCaDxeZznpmXc5O9wzqPvvkGpFBc7UGPhdGiLJ59lNrKVBUD4VtYLyasAaV5IsbNLn1z5G1JvkG4eiub5XTtimWR7fIxsbGzBeTp5Tm7JE406NCiokeplGdKY9EaDWwbTCtQ8u3D9soVT+cbg5TTBivBtUJ0ZLnVpXrkTyNNjtBQoMawYgoWKQpMi9WNONRrIYhGDuUU/xTcOEHtJOQc4W1DVNEgBA1g/CkeD1x2SFQU+UbQ6B3yAB3FB2z68q2fd6iWtLuU0eyvS2qMWcP6X3ZEEKF0rgxUueBmkLd7EH7d2V8hH5uGLRVQl8fyNIIS9xf7UlaQncP/9Odsto3pn68KQCxwZClzbiY0keDevh7t8nVv0vHd1uheTbIh+MJb27vcHP9DIuT7Ihn8LaKL1BHdvJ1DpuP1h3qztCvIzKZi86+xQKipRp9wfCcua4RzKAp+J0fvAbwDmIKWEvGeZ4RQ8I+7UBB2c1SVKcoi2etuR4iec24vb3HeV6wP0y4ubnG1W6PKwzVLyECxmnE1bU2Q3bWUnVg1InJXHC8P3YRU43gezAIUQlmUo289vNf1XibHRfSejfPnAaMY0JKEbdQ1ra1LIi7CVOHDvAvX13PGNIJv/pkBwqjsnhezL9AdY2uo5FO+BjqWN2h8YMB3ZqK0nhbtkub7xoExWjoxWvFsuqjMFxyvdlnQ8QGauIESHZ5go+XVQkDuI23sJpmXjflYR0BQEL6aq5LzOGKMdQecuzELcZiGqOn1brhODmReSnbfkMGK0eoRASQliR2sgHPSIYx4+p6xjkfkYYHX3g7T1pQxs8aZlTSG/Ji/FocowZMLp5ZMN0gqL0sq/agVpMUjJpdiRBN5xnpz5E/xi6+Xfe+vmMdZpOzOkVqbCuiQOHiEqyZNZmsi5YcOJGHGONjTM04BQTLumJZNUOeqv4G5sz43ve+wuHqjB/93x/gdDzjMEXEIWqN22GH/X5XnQ/XTcuasczOzuiQrOZo9NBk5ZkRvPrghOcv7vD++3cgAl69WvHuu79GKYLnVy/wkx+/ZQEtzdBPuzN+93c/w3uvBGsuOD1kXI87TCnhZz97C1Q+goQtYoC4oBxPWB+O6rD6GtmVBjtPTBRDJExTwnTY4+rmGtPhAFpX7A973Lx43sHklS6/lILjecb54Yg8rzjPswadrOZ5GCNevHiGdcm4u71DXlcUEWNVNa0TLKthZENBgHVZ1ZlirnZGII3nKLmN1YN5ptfOxCiCaRqrXUUi4CVDPNBptZEkQF5X5DVrywVn4nOZgwZnmBnrvKizC8+yXECdLw8lChDJlRTt4pfdZt1C21k6NE7nWqmdohEZss1RitYCEnkHNd2VZIRi/SI7y2E9waWJSD+6QIQUIlbkJy0uDfw9/g1d/GnUK9XJcXvma2vS6i01SLOKGItpyyL3l0gL/tTvOyN3d95txmif9715eb/tz7bB+gqJvxwJl2r3qK1O2BQ5Mjo28b7edTtfl7f1uerHUN+z+7vWI2oGttpHF06SnnfaAqbaUY+VbPsZC9ZlQYiX7XN0zbyucRNwsNd+DF992sF+6vp2OW3oJ5vgRA4UdFNSb2hHTatz13vDf982OwxaoAYnRVIWNDtESs6PBPPRxHVSo48RxNp4L8C315ACBjFHU1wetwvBYEjRw3RdlYkthVYE3BwTqkaGKkirm7LIxVoySlblGKM1+ObWz6nWBT4hBBvZAywl3TI3lZSgq0HzM7fzFgFRnR47auXNc3qHpi5Gu6cGSJ7YEN2wm7FKdVxPO6X6cz+M1HLZVPz5U1sk7YJBqW5S37B2V7I2EMUi6nADx5W5Pw5UqZP79Dh8TLJ9lBpkVKng9Tldxq8wcmbMxxn7cdl+GUDzQvzHVOf8N15m5JMzIdo+ab9XrII4AYhHNYPNdGFlpyoMDgr5LCXgD//wPfzd/0SNwmVdcfurX2O8ucGQRqs342ogavYFSIGQuyxFLgCfZqzLitNxxu4w4YP33sFbRVRJQvDm7oR5zTiMI2JIWMngls4aKEAcBzALHo4nCBHGSqRBVsOqDJOIBsEkMhY+gmc8SYBCQR12Nzr9QCI1jooAQzDImCnqtTDi8Qixniueab46POCwP4FlZ7TyFskXg2bY5wJpT7LL1i49dLNb+UfLS4A5jMFqS3WzcsmQsjYxSvr8mgUL2z2mEf4GNaFAraCfYEYQIKIQtzQOKrelgDs94XNHFrRSRJQYQYr1wDISCIfCcWHbUWwkI+ryMbznmBrPoPYYEm1WzEWqwS2kcE22FhVOVud1qNqnUPBw9wYhJCCtWAojrNqHK7OAVjYmYmV3DUQKTRQjZ0Dbe+RENRTtfJKaSQ9atujbT+e4m3uBtIbAYJQC08uMLHc4lr/cGDGqe+phU2UhF0YuOv5oY9AzSTqj3nQPqfPrJteldHER3M9HkBGCIWodZhEBl4y3337Ay5f3+NEfvQIBmHPBNE1gYYzTDsM4grnUfmcg6jIXLkNuREOdS6coJGCeC+ZV8IObGb/1/YeqhIZhQAwB87zgt77/FSIKfvzjdwAhxFjwt37vU7x4ASTrNUYs+N5375EC4S9+eQUaU6XOp6BTGFKwNjhbY1CgJRBTUhnFfsThcI3dOGAYB4SUcHV9jd2QUHLGznqr6j6MeLh7gy9vH1BOZ+RStJTCHCiCBRyJMO72ePWdDzHFhB/96MdY17XLBFKth1Y/SOePiUA5azaaUPVyDAHZapH6S7pUr8SAdVmA5Ps7VsEUa5BdbO3kBIPGl6oKxyFtAt4UA8bd0KDk1YjRP3X4AZeKzVEEPaGOvrIb/653++9sLQHZHMgqycWyisuqgf3dNIIogKmgkqS4leD2o5/t4iOx/U3bUTCr7tfzojkyT53AT9n97Zf+pfY2gbRuvq5FHVD7d0/sozrS5hb+Hts57edJCiz93r83dffs5rN77pOX23FuIzxhnzHFFjjoHaFucrTxOxq7sic6ykUdel34utBdRrGz2+p3GiqFLVjov6NutGI2eK699552BC6s2E68pVsvfy7MzqJHd7qUXQm9nHyzHfctc9q01iZAYWfTpEpxWZXeVsSwMU+nEFDDJh4WoWCFsKQRfUHtAyRcEFKqNKt1BNImrX+MJ6SkOnvR6KQTQKwGY9RDTgyuRQTDrTdDn5mx5rUaikMIoBiUNW8tGPcThmHQ4nyyaEdQ2EprIKsECFEYy3xCzqVlzkSjb42A4evdHHh0gEWZ/eoqwM/XjTBeOoLaJ6vNXfV7tk/ZaqtOMXf/AwCkEODEgTV6QvSk4PeXqxW2WqWSNVIZT422vjnE9o/QcPhCRiiiL4XAmiLnUixW0hy50I0pdE5Pryj9vm7YbubCNrNH08chQVLnMAWCwvlEeySFgHGI4EK4q2QU27kgo2rWoTTY7JOXj7NTP/Vu/l4hWNTfMifSviwgUAxa1O4/Ltrj8KuvYP0LI/bjDtMH74DSYOyqgpwjfv/3vwPgBNhBmDtGrho1JYClILNgWVbkuWDcPdfs6Tjg7uGIjz/5HC9fXOHZzTWCRVAzCZLVHk7TiCgBYYg4r8UcJ0Immx8QwjIDYUU+qYyfTFmPU7LxaLYJnCtZhtaGtgxKMhkW3ewWGCKtCfIopBlEv/psj08+nTAMVDPDDV7idoLVOuFiD3R/3xZ1Sx0Pnvg8YI6MfS7bRCsYyprLBg2iiBmw3c21/pB1LyQipN1kRDICEINCAK8ZHAOGQfU1rZqFhEV5RQv9lP0WzWnxWgp3lovp4RgDhjSgSEEkzcoWAWLHnuvdop0Om8UNEo0iBwjgtYxFAxAkioYQsoADC8ZR16yUrNmErPVuagORZc+U2CEwIEWJNarWE9exghSTOu+FoaQyOs7K9CsBgTSrwcKI1jeQC2p/JrcD2p7Q+fHv2PaotrIHG2Js9a3CbKgLbGXL9/sTutRVsbVIr98qRUDOpiLmWIpnUgU//IP3UMrbADJiStjvRsQYsc7zk88RW3wy3ejkMgBAXDBOI/K8YIwBJQS8fnMLFgbnGSWzNbQF1nVFMfjimgf85Cfv1DcJMeLFy4CRAJy1ZdD+MGIOhOWhgBGVHr0/E4qytnEvYtB6thgiYorYPbvCi5cvkcahkWW4wzUOiOOEoQievXiOw5cvscxnnE73uL+9x/GrO5VFw0p56aMIIzlBTyC8eXOHh9tbO8t8rozoqqIKqM6Dks5obWQ/2z3LYwtMb0xFZZ4EIKzw33yazWwK1TljY4DdyIqNKw6psQ+bXJXMGMYRu13EUvT8aM2SzTDvbheDINckDNl50yCrXIoxyjou2hEGdtbZfGxMDNZm1afTWXumijJTV3tKLhBbW5+ovaP9jIyB2K/iPR2tBUdDALUbPFVbJnIB6iKgFUx092fGWrgFOi7W7fLzvj5e/lLnopfv7r1U16OPT+Mp+fimq9rI1r8xfD31Sb2b66/6uO53wV7rchSeUe6/Uh1ruBzoXTYOo/0iQCoZjjy10P5xEaxLrnO5qTeD1HOmltZczEVDdPm+Rg2Buc6zv0DckexmgCKD2BqqP0F61F/fMqdNr8rUEyK86IaLwhrFTzRpVP+Xl9TwK4MQaxYrs2CEwSwZT3jT7Q5yMXHCAgFjzbk+X8Sa+JK2k+4XT+EuwQ5+UhgXa4bteHfUaFgMWE6qSFwRreuKmKJm0EQhN8M4Yp1nCAuGKSEmjV5O04gYB8RxQOYMWANc8aLZ7h208LcZit7rsNYweZbCp27jgHksVP/e76KIbaZtazxeKo12B988jnsWwMHi+ls/2E0Wvt5ps8wUVLkG0Z5Eu2kEjYMVwguc0tqhbp5ZFGNG0+ClGpqqiBjn4z0kJsRY82jWa09fRZQ/vc2Nv+/lUOu8myxJqxVgLpWSPQyXc2WGRVBmpY8/+dSc7a73k81Ndb82Gm07FP2xHTBfQ1JEpJT1u90O83xGLmu7H4uy4psD4HVIXhsyl4z72zuEmOrzwzoDtCCEgI8/PaDkBiN4KhLoQQYuAuICCYRlVTr2NCQ90FkV7O3rO+yGEdeHgxoz1ZkiDIhgEowpIUVtEJ2LIBo0MpDCdTYF7FDIEOx9RARrXgBSGmCiiCHF5iiUgtUgmdHaRMSodP8hAGQGd7T+UAztSTUN2jj6MvhUs90Xa9KKwjeraT/b0Ag9+qzPcXeOa7YnmCHXGyrhQv6EtfYnFJCwOjgUcb9mQJyJkIAYtK63OhCx3qvKXGj6ZfNuQEdZbqncvjEPWVa2eNRVjViBBgK8d58H6pyq3k/EnLs5jTq+YvqWC2OeBcPgfcOokXYENXajzZFYJoNgxE2iRB6+/4g00OBy0wAcBtGEGt1e/yAiKIXqzzeiIFy3v/ebmsIz3KTvYc5/ZDVvxxIhRQAAIABJREFUqJl6n8geJuRqiAi1VYHoa6m+t7VTRKcjO3ReG6TKbux7AtoyQ8oKATCOCXkFmAlXV9pLzKe+iGz2kut7tnOQCMqkmAUZUftrEWMMBCoF9+cZd5mwZsGHH57x2z94g4CAvGatsbJnjWPEl59fm2GmZwWTWA1cBrjVyIch4Y//7AYffz7gxfsaiPH96sESigkyJAwhYBwHjIc9Ds+ucX3Y2x5P0Mw1ILDa2TCC4oCcV8zzGZ/85Sf4i1/+TFuTMFtmV/dhEVgbDMtyF0ExBAKzOaPGag2QwfKp6XqbT22+jsqUKuYQSWmna6s76zbExTXuJlzdXOF8PGvdIjQYDFAlXnF5aKgX/VlecrWhiIAUdR4pBlBKkDx3Mv3Y2fi6q7BgLauuTUqAtW12m7sa9q5/ukuEtUl5ychrqfqw1o2jtQLQEo3mVPaOwGXMs4cRBluvcUjWu5TrueWj6VkF+vs5WyrX/cuajDBHUlhb2jhbY39mA1pnuZYnwHU1EEKbtXJ/AfW8qSeFIhZlq5OJvA1M60NX7+/fY65s0iJAkEbCp6NtOSyBIEhRyKFs7yV2ZjfaW0CYLg6JruzJf9IHLdECAVtbx0iWNkzEF5+5+EvwIJqgsZ5WG0W6iayT0sZT19ic98627nXo0xeB83a+v+n6ljhthtG+MFeYlehARVbaTiUDpPik2Y/dy6gCUxgU2MgcoA3zuBgznW6+yqombdP1guyTzlAFKVYg7IrXP6sMVMYgF0khEKUgr+q952WpB7o7nD1Uwe+hAVLbtCbM3jQ8iGA9MdaY1SEEsNsZAUAulUjA6cE1EqUvpO/bV/n45QLlktsJz6V8kteitSgBBUKIAsmEbhvUddluL4JHWeuS2Rxrvd/2eR5Jq/ZbB0NoGOKtxhWz8sZpxLDb414eUJZcN9JmND4Qqyd0peFY/DgMoJSQT6U+xg/PzbuaEUbQurxhHOphSmTRUO8zA1jtCCpBwcYBCwQq6lSTk5oIIZux46j8WjgeYjVg2rw+Xos2VjFDb7vfLhUeM2utxLJWuCfIawAv+oRZTcTta8Gf/vGCd957reyKUKKDzz/f4+H4Aukne/zOmxNkVYKEUhh/fEUmV4473+49sUikvnO/gIIlMx5OZ4z7CTtKFvHr30SdtxICBhIsoUCmhLMYq11IkJJrsKU+x+4PkDqg0orSSzFDQLTW9rxkzGtGCFQP8pAihpQQLWDDNXIqGHeDZTGNtKjuP+rkSuryeX2Kv08tPBfRe1BUp743kL2m48IhNYmBU8+FtIX6bk/wpnuc2piCtkYJnbOtSeKgtYpGdUwE8DKC14TmgJE5Bb632+t71sKSzPp0J14Q3yN6/HqvSicUYVYCF6eyL74XSacn2hyCCGKGUIhKHELiBjCQBv17ACpDo8PS3V7z2jUOLTou0nHBmEHje1nVe9PzWvfXwcAINbvYxNrJD/roLW1q9aq+YbGxBiuIb02Si9PrA81ElaZXYd8Tg096gEyZC/sxNqi+8hARQhwQLKN8gkIV3331CmVdcbx7g2VdzWF0J03lW/eP9pRkBIAShl2CLAuGIKBlwfHujPOScZ+B2cp4h4GwmyJIlK3yXDSqTsL42Z/f4M9++o6O3+C95/OKn/50h7/2O2ckg28vWfDrXwOf/XpCAWFeC8ZQMO4m7HY7kGg2+abs8N7772KaJhwOB0y7HShEMBesyxllmRECYcmC83xGPs/IhXF8+Tbee/8VhBmvv3iN11981RniUh0xzQpprzaAIBxqIGqZZ9y/eaPOJvR8cwp3h077ZvVazMxeG+x156j1TU6o5GevG/M9UUgaFAkR/f4ENMZsAiEAQfV9GgZ1iguDlxWAtw0ikztgmpRIZTmerObVWRe/2SDtbbn5dEYpjDQmTBNQJsZArh+pGseNnE7/X4lkrN2K3pHs3a3Ozv/d7zkfg+BRkoOs6YjXstbvmD1EhC2DoD3xqbyTT/E6LyavUZEJJCjrqnuDNeBBBGRjzG3Gv9oBvf0fvazC7AWqjep11rX3H1V96lB9Rxr4vGs9fKo9ADVxEGowIKVU5785F41Dobl023mqM92XIbmxbY6Qw+KridiOv/ad7d3qvkIIj2pPN9/8RrHr3Uu/r9og7I1uth4tOmnp9DMMpdJQOE6IVJ3ui0jAZo465++v4rh9K5w2gsEWnZvD3VZyoW0RvDYRaBGFarCg/ikiyMcTiM7VgWHhdoCFAO4hJag6y+7RQSbbqVyjqGLU1pCuwzyzwQWD9pgquRtTO6i9+aRuwnY42iehvVOiwor0xvocH1ApWmBcNJJHhs2P5CxmrXeVGva9ce6WfXOItL4mtpe3jdPseqpz2pwfM7C9RoWaMq2LCtSIYqWuk/bLTeAHm6/VOVGGwy38of2uWptWZ+GGh0WMQaieYGcA6T87ZUcAvBmpaEYFANIwIg0JR4tCJutlVN/HRuyGfg/r6F/I1Vr9vDupMCXBYlanO2/qYKchYJpGTLsRgNWD9fUAxnSoB7bUejGPkH7d9lc5r/nN+hbiY2MNQBRz5nulFkzRZhEkl31zYOZzwI/+r5c43DwDC/C9j76L+XzCL37+Bj/4csRHxyPKbDVVUGKYayH88AYVnurrUQ8T2s4vgNqstxStb0spID57tqmvJFDNAXt96ZAI0z5iSgPOyxm3p8XgnIMZ9JrRI3NMWhChKWOVHctUSxfphqBk4GRZ/eBF/FHh3iko/XioghyqzqmOZnXkYE5sd0SYvAe33QAIQtOV9XPAmrNCuqoz3+9/uycDktm9rnpVA74GNNzpAWQtlXXN21gUM0gDKbQsGiNgnhNCHoCk0fZ3vlzx2//2pHVVpI5PChF/8oMRr9/Sfm/KkNccaKJuPFGhV1S83smDK0Dn1SKIGp3uzAUBKCkZFbuBy7aePVJD08XWVkTrPsjgoh48U/ZXsZYWTrsu1dmthCJWmO6VddLRdlaEkBic2wJEvRMIas66rrVglXsc+dP6ngJ1UK1wTWWFUPdKIGW2iykgpdQV4pM6nyIoJSMEhYLHEDsIsGij6ZQQ84pB9hhSREpGCmUkMZ6ZoTg1fZsGaxq/gIgwW5/CabfTmlQzTk9LAcuKMRH2YwFRwXzKKEsxOKyeaSl5QIcRisJlD6MatqUwfvmLazCrI6TtRID1nPGnP0n47kcLDvsdKBC++vyI/+N/f4U3bwY47JnI2Dxt+8Qh4cXLdyBhxLJklHXG8f4WQhE5FyzLjHWeUbISf+RcUIrC5FIacH1zA+aCX/zs5zgdT5p1TpoRLsxV32sD3+Y8icFOxWtqQDgMCcciWLzxtDSjm8wWKLVmrdlILs+My0ybPwvgdoSrFrGzUJETLXA2poR1XVWKBarPSAOQ1a5hq5kFNPgRowYySjbD1+VxawBfZnGa8AOSs7aDMCgjH3bKBCxS7TLNUHu5QruPmFKtAV1rZzAMCTGqjVNr30WaDdJMiUcX+dCaMt58BWhtIaT/zuNbKeIKgIAQImn/QJvHdSnVyK/kWpu79qUKaHJh9pkiO1w90sYWaVm7fnD63YoyMBQKBapoCTLH3CH021mxUXmvtN7+u5xDCooyqLoUF/drCbeq16uthnr+9nbf1mauhtbmvnZU+KewBbH2n1N9O6aIUhiRrEDBN8OT3/FTHE1IiDbPJN9omzN6a339VZ01v74VTptuQDNkRbtrHE8nfP7rz/HhRx9CgqbIRQqEqa2nWJ1DUHgFBctIQTf3mgviBeEEQ6NTkcgKH/XwrVhnc9uZRVmdeu9YpMOKKwsWlSf8/Kw1CoCRdcRoiq9hqZNYBDdo9ASAMUfaZglO+Q14LZ8XfJaijTVZoL2oYM4KO1627UmNJOu4A7jlkl3Aq3nfftZnpZoJuVW0Zru3LWoOotTPmSJB3NyvMtdd4NAJqEZmvR8BHqMLG8d963BwN1ixnkWn01nHUrj73sYvtS938iFKWuNkAoXdQe/G2U2uR00deKGHlRaag1rNmzc030QbbWfvpklnpXA93Ji0ZmGaJuwPe+wPe1CwSE5xBRhqJg51BO2//up1I7mR64q7I+hwhyKbTMc0QGTutSkAApeCaNF8VVwKNQsp4nhKuD+PEBG89+4rPNy9watf3eLDNyfMQM1yuxL+4Aj8/Znwp3vCn++o6kh3sEPU3OKnv/oM3//eR+jlVKDMaZ999hqv39zj5nqPt54/xxSTsebVt0YmRmRCIcFhmDCMCfsD43w+4+E0Y2VGSslw7cWYCbmRNkBJkUKMZiDpKU7Uw8kMGieeGWHQIkgp4Oqt5x0dd/FZg1cRmYsKSGkHthso/soidV+7gZqS1oL2BxgA0x8CP+h1L3aWR2r3DI8OZHQODoNW1qyOCMQalHt7CQ12Rs1KC1SHuuMlAUMW/Ef/6xukAqSFNfJOJm8h4G++XvA//51nOB9athAQ5CwVMRA6veCHfjBjR6EsQEikxB3UHfI6nQrrJVL6c5PBISWM46iBtg5u1Eh9jZ1CBAxtb8HY0k0Hotp8WVxwRQDviWn1S2y942qU2xfUN2sfIESDOfZX4YIsx/odZ9sjEkSKeOu7b3D/8Uvt4UWE/Tjg778hTBKBlbCuBf/jTcACQQna68uNB2J1bIP1DEMaUEg19+H6GW7GHQKAN/MJp9sHsLXJWTMjrwyZ7/Hpp4zDfsR8WiCUwEwIGUBROOO4U2O/FMGyMNbzDEojCghxp3o0DgNKFqRScBUKJEXkzPjLXxL+6GbAf/DvrZbR1bM7CJDPM06nqAEED2KCcPtmwv/w332I/W5CEcF6XnB7LxBRopCbw4g1S4NVi+qwh9MZX37+GXIWY2VcNKDja3M6q14o5oTFWLNdQEGKAQ/394rKsbO6C/coUYjCdlB8n8FsAzFhJoWoS4D2cSsMloJEAQgEEnXcSmfYV+PQnhZDQAlAXh1q6YZ7+3wIAQ/HI3aHfbUbmqFMiMNgNa1aX7wez0hDssySIOfSWiHZ/fNaQB4oKFu57s+ljS1xYbD6q2gddGtSXJ0HQ6hQVfHNRWp7X1ESaUwYUzLHdPuoFnzbwsfbYG3emCq7d/9ClSwWGjuphjq28MjtyxEQtJ9nP5gQAoR1XzpBTn2UtGzeZX2hD8bPnerUijvWWhKgP7N3eOIWyollDLZO8GR6Wg0rwCut2/nns6/ts4ge37uGfB2tQdt6XPFxMarDuYlL955Y53zpnaX+a/PM4GP0NaJN4qJ5cb1hF5CGhCELhGJD6vd6vf9uP3f+f/vd5Vl6efWEL35LMrtT+BLE+fj6VjhtgBcpCjy8zSyqVFlrW2IkcAmQKG39TMdpDdNO677gRrxi2IMVdHoz4cKMEYwsgrWPZNth6sZJydqbKw0JFG0FmbHOipduE94krN9Q7oBx0YicMnW1Pl8esQ4ApmpAw5SRMr2VXCCk2Z2U3LgWq8soRoNtjkJR1RZiQEhGrmLpMt84Wq9BJslQw7ZG8MxheEo2qzC2Wodt/iUBVOA0rq4c9LW6+hRpDiFdeBdOlND8R2rwB1euHuG63BSi6+qOJIs2D/W0e1/LZ3+pP5OqFgTk7h8TpBQsS9bMwcXj3FjcOK02PwHKImgv+xsvb1mhDW5D/Q4XxrJmzEtGLhmFBdMwYF4WSAwWPOjhhF0E6XJypf6v13327z6jZDYhM7hk8LpsiGYEDUkqzNakHlrDYAcH3MgmhVgkIUxLqSxmzWiQ2qh4B+CvHwPuBuDXA20+x0Uw7ZISHdp7imVIxCKvMQasc8aXyz2WpeDZzQFDCIjjBKfbJmasBuJfiTCQRl6vrq6w3+9wOs2Yl4w5eE2SGKwpo0AdE20fAjCv8LqhSG1fK2uryvCQAoZk9W1xsCivEi+wReeJAO4ajurECg7zgpR2IDSW2Uu5y7kgL2fQ/oA0DvB6TGalYpfAGBC6w8ozqd3qZ1HyJBfiPiPvcx0TAEJeFjAII8QgKcacaMbB+XxSx5akOranz67xn/3ZJ9gvgrKsyNJtGlFjIgF4ds/qtNWJcFISqS0AHh2a0gxuCYScXSMRulgGYBk6lpYd8J0P60nFWecmDoM6eJYlFS7Ia0HubBECah0N234PIoo0QINCazpDHXMRVKKQOkry/dhZetKWQFxX2j+oa1vg89fDd9JOHeedAH/zHvheiKAEBNGekUkE/+CLjC+D4Ic7xm2KWO0cIWZMMSINA+acrf5aMO0OiGPAcv8GFALOX97ii9dv1GGJEcNuZ/Bh4OH+hBgThJSMhUKCIxd0PxWQFJRlwTwX5AxEWbBixO0D8OwKSAeClIT5mJEADMiQIMg54M1rwjwzaEfG6glMZsTnRUsWyAJPKSWEGDBOE0JMiCFiOd+D5QFjGvD2ey/x8Scf491XH5oDwFY+ITje3+PzX32pwYUYqzsgpEy3+5c3EMwombT+Zs0YJOL9999HjAOQDSpdWTE72QlaM5sgKDF2jrPaPRWsJcDdXBR2G6MGFliz027sEzTw6/EGtyuHadQ2CxDM58WcNkLvsLXtJBbooArH9S0ah1TPSaIEIENgsLriMmzZdoW4IATCaV4wyljrNKk7YfvLz+Wnofyk9emxg18aA6FDHAy42WWQCAXq1KYhIQzRmEMHv6NBNe35NRCp/9UYnw+lHxJZRn0zxBbk7K+a+ZMWlqvvbP8TC3ZpPZvqU0ffaPZ6a1i0x7Qymn6exhitVRJpjXxxeeImg1V5tPMghog4pOboESE0RvyWESKz97pg/HbyAKDV9V1evTVo07n9nNm+1barw2x2jMI+lazJZb3xB5DNjRtPenYwTFxsjLIZr95ouydabe8YIzZp3GZoPfl+/vvex+t9vUff6X8hqLwGZKzd33R9a5w2P6xBUFhK1Oji6f5UDzttlNwtuQkJM+M73/0u/uTHb/xmuoAhIh72Gi02oU05Q+YVIefq9Tv2GtkLxVsat3ghs2WoFJ5vG8I2Jjx6hs6INiWpGbenFGaTgRACvIm0Rq41pS8ikLKocVKCRs/F4RAqhDmXpgBDIwAgI9MQUsdAB6v1L4YjtME0AxiARtADodFobaNQfVap1bUIOlJ6eKbNN1JbMWkO02V0TajVWnW/8jtVGKAdBJvvktT5IxAiAdMwIA1JiWNqNk1QFZ/PP2nU0kksIAr0CaS9roZImGNSo6MNBlQjfZ2hC6q1B+TKwecVW2dJjTmyTIJDVanOts9bIL1XRMB7r17hlz//OWq9EnWKysZVn+9r2kURO5+1KRZtkGIEKzrWnAuOD0fknJW0pwqAva05TUWU1UycIc+gbBINrhMC3joXvLwvtWdNLzfF5Hgkr//SxwwxoJBCipgL5vMMPhy2is7miFkUnhHUkVzmBXk3QaQgZT+MALBS/DsMlMakxh0RKAjGMSkDXAg4ns44n2d1jNur65i9po2V5p4isNp7pxBAMWIaIw6HvVJiEyFa37Uigrv7E073D7X2iU0OXFxUTiKGYQ8i4Nefv0bdg9VYd6MHSGnAbprqnhMwHo4z7u4f8PzqgGm/Q/SoI8TaC9gLDbYvC4MKICloD8pumuMYkVcBrwrlXg3eikBa7yhSD5wUA9KYNLMPrbHVABRjMYq4/gxk0XYJf+OHt/jv/+MX9UjfZAQ94OLjrnLkUGK9fx9YKsUyJ5AGR0R3gpI1N54XxBghMWqArv0a4v02RfvNsenwdkCHqtfYxtcTeuhgHEFhRiisho18UL4htR2GB1QY5rwJVwIGN2aEL2BO3m8JAVNh/PVzwqtMOJUZw0jgVVvEKNQw4HkR/N2Hgv/tsOLnoaAIYb8fqh4JIsjram0eCjgMABOWZUHm4vE+RBg0SARrZiAohDCao1PX2JwihRzpz4eBUIo7HCtWIby50yb0gbXxtxRGFF+/gDe3e5zPZww7DeQMAYjCeP/9e3zx+gYQhb4FIhyur5TEIgaEFIztVNdiyQVfvr7DOE149z1ARGGe0fSHrrs6OpqJcSdBETqvX9832YSSRux3e5Q1g5M6FlwPFzdVldGyErXYmVO7ropmdcl6WIKV/VCDqL3h2uDi9axxUTDx5sKYFw0EeUYUwJPZ9BAI4zSqvREIaRgN7eSBFw0+EzOGkNQhsDNFSUIGjGZOiO2HGB0dQVoLW0fbLj+b3GZBye0liEApYowBwxgRjX24vmO9h+rxYvvFyblijIiD2k8UYoVrb17ebU27z4WP1P2D2j+l+6r9s3SBIP+0f9b38eYSdSXIWsE4OYre13o/siCEpx1sJd4LFqjUeriYNBBPpIiuklfwsmLJjEjR5gZgMr1YZUZtG4IGnBztoTpVTK9oHamT6G2dtSaX4msKuDLs1sktxu1sUDeXXmYEQc2MAQbx7mTfTcOtw0PN4e48brXNqatTdAuUutZQPhLAg2BKOGj7r4qJVNncLmd3mPmfRBcy0eUF5ethkAFqc/fHwtdd3wqnzTNEvSAQBIEEOWdoc8lQgcNSax9U0ZZLpkf7M0KMOSpY2YAonMFglFkuvmOCKY7/t80iRer3uTYJ1EtRUF4v0b+UOREujxcKE2g/K4VrKl376ABIevh5poO5VFRb3TTixcbNkNG5kToEN9fABWEYkFLAtvbd7lUKaIj90Pv/NdlGQwW7kdE9pTe37F6hTkKvoHqjq16t/OzxnJFtZnOw+siHoGHUfYzcFb7WQm1p9+5fqje0vMQhwrMlEUMioISNs9jYpPwQ1X/HQJAY9fnuHV1c/TGWM7csI1qknYjw/PkzvPXyLaRhwLIWM96k/ge0wy9QU5Bw1+TCiKzGqzl7ZPiOYEeJzxVDqfZbf6e6cPrdEGqvNnHyOlZ8w0BU577KkV2Ttb9Y1hVrpYpWeDBxwO88CL54FszA5crgVHLBsqxoWQqqzLG19pRgGaCAnDOQolbZsAAxeJxY15aNGGhZIaHB7yhoduzZ9QFDijifF8ync609atFZ0ahtCBWqHEIAi0bsSybc3R6rXDx7doWr62tt3rvMOB7PT+gD3TlEDjtVfbIuK0oxECWhyrHvH4cPBbVYARaIBJS14OHhWI2gXdJG2xwIkIiSc4U1KZJAny9Z1Ck3QQwWCHAYVy5GCEKxwvgKASFFhKTHidJgO8EC2/J4ncbFG/c9jvzdAKuVDZuAUn+5CuudOSJyjhUQxDIA9lyD/IYUWusAc5YpQIMOBCy3B3CO2L99b6XEgg6AXR1m/Xg1u+tYmjDC9plCjoagTb61UwGBixpg7N66f40sg8DuDPs+7+ZNzBE0pIStHA6r4MNZwGCEELEujLwsyjYnQAgjCIQUAvaJsBfGMRB2hx3G3VT1aLZm6TkzzssdeF1r5h8pIXCDwI5DwJQGMEVlEDXYdD9Y5oKSMzgQ1nXFWowkRYC8MpiDIk94wUCEGRqIda0VwHj13i32+xN2cQc2ZwIM/Du//QV+/CfPOuIaYJ7PVW4CKSmYknuojM3n2YIGDMqC9XhC3I1VB9cMZg2o+cu4+YV6QBERVs64vbvDu4c9yMnNzFokm6eYkuojUgbOkCLAwVoNuMR6zY3Y3lMGy5MoodnusMM0aTsgEeB4d4fzsm7GFs3ZEQFyafuKCBuYsYkn9rsJkUibrIPgdB1FtPYOQRETZEgnZ71GYcRpAElRmKqdaMOQEAmYa62v6Srfp/7vuq+7M9X+C4YgCgYD5VKQSftf5lJ0L4vWhuXCWM6z6l1mdTZjsCypnkVuuG9O4s5eaDMu3e/agNxuF5szZjszWaoudgesicrG0Kg/unBfq31Q3OYEmnPcXWIPJyLsxr0ShSRDJ5DCboWVXVLGAVLmqg9BwNLiWgDMwWNGIgYobsZOjtrwNG512EzTSINrAupYKRh/+3aXl+r2PgmgyrfiDy7svTaep+1nuyt6QHlDIDUbuN7SbcftSjW7BqxnQe5aWZkcNN2ATm66AX7N+5KgBowEGhS7fBUKVOv5H43ties3Om1E9BGAfw7gld3tvxaRf0ZELwH8twC+D+DnAP5zEXlN+nb/DMA/AHAE8I9E5Ie/6Tle9+OvXw9lw/pq7w1Pb9hhZU7LJX15JWtYM9bsHet1MrQR9bY2QUQ9a/K0KqNJCbNSCLP/kx/Nac8CeTF3CqnKT6Kbn7yYBTHqBu43bo1YBKrR46oQXQEa8xfxVjHEGIGobEDjbgAhG047W98pAJDaWNQe2O2UjasI1OPFjVivYWnjrdGtzpnwWXqaWCRo9Vu/yWBKzuRY7IdkI+i+3Ir6oZGh4/GE86oMVzFcCggqbhvQiHGxMfs7sgDn0xlCyva0rhmRBu1JKbACbGpKvc6LYvwVX96mpM2d22ZWlxGC1rhwi8oSdD73hx12u52Rf7R53cAQ/biRNs+9vPv8uNLtS3Hru1anzxWrH/TOZtqtq/8rBsT+N6QwLA6kBj0F/MUvfo4Xr094NwYciPD8+Q0YwOv7B+RyriQT/k4vz4zfy4w/+GhST6CDVNb1la5BsL+3GBmPGWIP5wXJ5D0GQuBoA2dIVoIVGZKxVhA4s/bggjkRIzANEWUJWIBKFONNeIkIbPAnd0SYGWFQGOSaGUC2eQAk503T3keX1c7tDjvrASkVak3C2uTWpzno2sYUq+HZ79JAGuEWFpyXgmFdcb4/gW72yFl7gwm0l2GMLcPi2VOXGkc3MBPuHmYsa0FKscLIfM8H27MpJQzjACnZ2jqgspntdiNIBHPXBwfQgz9Caz+qYWUy6AamG3xFNju+yqhZUQBQ6w8FSsdPphfEo1TBZQ3YTSPGYUJeVmRoNm3+asL5yx1AhP3bOicMGGmE6Uc2J8p3qjkwVR9D4Zlwxy4oM18khcSPkxIqcNDP8lp8BnRu0RxbXxo/FwlAGgYMg8LP1GnQoFjKwN+4A+IUwDkj54zjeQExW9ZBz6EYA8IQIEF7i/r66b3U4Wcj5Dmf77Dm1bJPYrWuUIeN2YwRW2tY+xJfH9Hm24ULlvOM04On7tIlAAAgAElEQVQiZoojQ4LCAbUPGmFIGgRYi+A8Zzj0ub9CiojTWJkERYC4uDMmlVF5Oc91AlNK6rSx61wl3nDUnYhgLRmDDEjGxKcQcEEypdjqmNn6fklF7iCoI3P/cMRbBmVm0+U9oiTZ+xERkDMQAogLhhQx7faKthkG5HmpNe61TtKDGjFi2E1IMYEIWOYZdJzhpjBRUB1c2Mia2lpcRvhrQC1EEOkeg82fGpqacdwRsEaru40RQ4wYk9oTaVTzcc2MzDY3RroiOUNibOf2hS3Tr+kIgkElIBK24yPC6XTG0XqiVSZSy+BWWbIAWkoRY5yq7STcIZHMwapzUkfRgfcIVg8tzR0gsz39hCaBhMeOXiCqevpxpVV9+3qfzVxwCwo+Xbem3x2GAdM0mDOdFEVFuvZk8B8aR2DNCCZH+eJ2ZDaZmkB+zktbK+iZtTmthqGr66NHMlWDDXY+XepqdrCouM0kNYtdr7B1zho6sVlG7qT2tmknWXCYqT6zmoTN5pL2DpsJgZLnLPOCNWtPUoxh84xvckj7+/SXy1R7i+bM+TrofBCIGIEJ5Tc86a+SacsA/omI/JCIbgD8ARH9CwD/CMC/FJH/koj+KYB/CuC/APCfAvh37b+/BeC/sj+/4WXVaNdGeP62aqARgBSD9RmzMzqQZr/so5X+WRxWov95IbA3quZSsDyxIVyp6IHJzSCHb6BivZjdOXr07Ro1UgdKN6Yyqulmqj3m/krX5TPau6BY1CyGuugCQlnWasTFpCLWR5A4F8RDwIvra8jVVXVQtB5OD2knCSEbu9S6C5O7Krnki4YhAOMugjmCIuqm6edGzx3vV/fYiwlEGBIgQSGJIlKpuz1jBFMycAfVHfeqDPRnfhAN44RxPyGvq0Houk0nqDTggMfRm2EkFLSfTik4nZQ5kq0fi0ADAR41DbHNBbPYfBaFflm21A+ganwZvDHGiGVZUUruFJJ9TrSe6eF00sh1FmXs+4aojk6mHn41GlQjmv7q1AxDXwM3mH2tQBgCIR0OWJYzloWBJSvlN+khUN1FUiZJgcIaxd6z5ILz6YxlWTBOA54d9khRmZl2MUCmAQ/nxbJUQIgJ4z7h/SHi+TjgOM9a91EKxnHAd7/7HbBo5n1DwWfrRaYfAtToqo1jiRBYI4sxJOT1AcfTDD4TKCYzRBymqsoUM4Eoo+RV220Q6RoUi6zCHAVjRg1E2F3t4QXPKbW5FRYUUoiRQ7a3h45urv1+RM7ZevS4rrBsUb/Oln3hXBDHAdRHrNTWsPeQCmv1rCWzsgQq+5saCRStjma1gMXghqvgeF51/kKw6Le9VDBD36BNMSUcpgQhwlqaHGmTdlJa86BtAYrVvIUUMe0npCHh/HDG3/nXd/hXf/tZFWaFPLYp8mhsq0+1WjLpIOkme+6YsTTSmwolK9bHcRwx7CYN4h0Jt5+8hSENYKxAIOyvXuJ8vsXqUDPA9qiNxGA5TFT3mI5DKtW/N0AGGUuwMMDaGiFFAsVoAT3viguD5rXDHABiYaSkhlkgQgqxBgwq1AzAM2P3W2atZVLo3ohxGrGuubI/AgDHCI6EsGbklXE8KRyYggY7NOgB8Lpi1fAznKVLYVUBKBmnh4IsEfsparsbK4qR5YjT+YyyrHaOq8KJMWi2xDJppIoRtQ9mPUdVT/q8/vSnL/HBd17jxVsJDosmAtY16b0vswUmR+rcsgV3g8lJje3XwJrXkRRzRkNKaD2r7DOFahP0QAp3pcKgZJmXons8l9LVuKojVEqBkGZ5RQS8aK+7uNvj8Ow5UoCyUp7O1QYKMUKYDYoYdS95X7fLc6AGeQW8rhcGpMBJs/ydHa2ga0OgISEyAGbkwihrwWI6aH+9x7Dfq20VmiFb9+eaEQujLAqnr80TO9XFcMRE1vPODFXVp9peBhZ00cbirjsIpaxasx/IHFbqyDJU5td1hZCe0cua9Zxasjpyg0LffTxWaeo3qEa9H4c+T81eaEiiqn/IZalJXY8ecpunZt/Jp4TVKbRZcbKlbLXtX3c5smQckuo+CkjDoP18zXlFtPKZEJCmEfDghSiTbu5sgiDKkuz/ARrs9mAI4QKiybZrpH9vG1uVNanPq3aayYnawl0QptpvbXoEMFh7J2bdLQEgVAb49sVgY5WarDAYqd/CIzQAmAJiZy/WP5mRVw1MlSIYeuISG0A9Q+pZwta+p9m5j5aQTAdQAHc1eT5UEUFMBZwTak3db7h+o9MmIp8A+MT+fkdEfwzgOwD+IYC/Zx/7bwD8T1Cn7R8C+OeiK/aviegFEX1g93nyCkSYhog1Z+QlgzkixUFT3OSF8s3YJI+uUJ9s7Yq4obCpNQYM06gYa1ZlFnMxRaGOUV+30hS43sXvBrSatd7Dx4Vg95dniBRCphLoZAxfd10EEC5+154XjA1IDV51RmtvNqNf7ZV2ILJ+HuqIiTWBrbAvYYALCqFJUz+E3tvxGSZFq4YYcXM44Hq/19oFFqylqGIWd1So7kqyCNVlNDlEpZTmqytwKcbcWOBpVHWmqNaOENCi7y2kaGuvTu04jgCRMpX1LyJkinirEWqUTNQVHMcB++sDTucTbt+cNJI4a23bMEXMs8MASTNwAAiMZPuY84rlJABp9lSDV5pZi8KQ4nBbhbhx8aywOj2n04L1vGo7A27GoIpCWwsxOFq/XG54f5189leteOpkL6aIaZoAAUqZK7xFBMa2KuAQQCIYTEEzSGG4ISBzwenENSqdhcGZAbZ6iagNqVWJhVqEHQT4e58Cnw7AvxkJ91X4WpajtgARoHF2G5zODrfqKdv3M+teRFSmWYggs/ZwzAhKJ88FUjLmOSM52YvOsDlBoYNheSZFaZJXgyn5FEZNo+qhakEcgjQ5z56V0MJ5jZCrfHjgpFkZmqnRwIVFfEMACbBmDRKkoNldCgGHw0HJWdZiwTCysVGVb7hR6bM7kEIjTTcWC2GoDaABBs4F5BmDShCgztp5WZV90FnEYGywar0gxoQUrLZnGLHfj5h2O4QQcZ8mnJc7HF6vuH2WjOreivV1FNXIc/9GAMuOd3IsDS3gLL9iskyA9Q4kjLsJCAllGbA8jLj9+ACKAQ7oCkg4f/YWZH+y+WvwoFAdQG8Xo8GxAELhYu1TLEuZVcaJnBk3aAJZBFE0y9TXIDNzvV+lPuh9+6Cvv4uEFdEcAXPaImEYUm3MG5MSSQwxIpmBR7ZH427E83eucZoCZqv5HcwYHKe9NbFXPfNw+xXmlZFLxrIs4PPZltTg+6VgQAbYW9kISFaUvGCMAbKfAOgZlUsBZzbmY91bg5HorLbWec3Yqiyq5+Lnnw1474OMIaiBe/tmxL/6X95HCLEzdtq+ISLbf+jOR7UNDvsrNUStRvX+9lZ1ge1j/2ytlbZUcARhFQHAKKLG9PVuh5dvvVRj02QiDBMOhwnTkJAL4+7NHTIKKDSSDjVmtO4rpIRlWbGsxYINlv0SC+cJawPs7E2LBGVZ9Oz2M8FnwGSUgs+dvjNzOyNEUMtMgsPaI4AQEczGCCEgHXYYrw9a/1uZYYHazByEyeqs1pP22CMLmDG7bgYgeg7f3z3UVhGuiygotDYGsT5lWpsb7IwuResmhRlnrPAszziNqktFsJ5nnOcVwtrfzUna1ChO1W4ELAPjdlK1lUTbg3RnRj07u7n1n4VWLAvPxPaBYf9qJSzbmGQGDc4C5hkBjW38m64YA+KQ9D3MnqPgGUe299S9EIcBZc2QUiqo6NKpiLA5YdWXVSaxzV6ZkdU5tA2d5VdtsC0CFFTCQIHbF54RRw3E9FetPbPAaU3AVCdZxyIUNlDb9jutoacuOKMcCV7Hrm/wyC0KoeM80GcoORVD3JC7nDgPfHXtpAD3JWhje/tfL1EDvUyVNYKCZiHlYi8/df1/qmkjou8D+A8B/D6AV50j9ikUPgmoQ/f/dF/7C/vZxmkjon8M4B8DwDiOOFsT32Y4djVPIiDrm9Aivm0h1RfK3c/0EIwRGKahPXRI2kTTa9BKwXI8d6OSR579NoOmAgvf7Nv3ga+EZr801S9QowHZhbWndN2IHtwZArw3WTNQyQxEYaOUd+EqXKOSISgUMg3al4e9h4tBLwDRQuFgPU/0t0jMWIYVsmoRq2e49DKiBDJjoq8fdDgFqRHppA5q+ETkYlFL0tqPWmvn02hT7kZwTBGHw5VCkpghJWMpuauLgY3Do9pbBqd2jOi/pK4HLi6tl/SF1q3tBmK3KjGBYoJR0Sgxx7pW0oplUdgQurUUK7ofdwnnU8a6ZOwOA26uBzw8ZCyrRrOYyepGCmIQpBgwnxUyqBAvxanHFLUfnzfrhlQyAFRonEDIs2tex9ZPsP/0Yk7sI0xdw1VXkiBtP+FyGAhSqDnOLbphxc7WcDtqJikFAocIWrU+Zl0yhkENqFUUpuwU+ACMIpu1CBuCV0j/L3Nv8nPLlp55/VYTEXvvrznt7fJm2pl22WVjZbkaXJSqVBQlBKhmTEBigBBiABIMGPMXMOIPsMQQCSGBVCCVagADoHBJYMumXG7TTabz3rzNab9mNxGx1noZvO9aEfs7NxsPkDKuzrnn29/esSNWrLXe7nmel78h8Ju9aDIBhzMFx1JqEFKDm3bxbU4sGcQ6N2y2V1hZKbjQdO/1fDbHXeuXZCvdYGQAVNK0Ve+7GN6RZ9bEnY20ZdbFK2z54mJHzoXD/mAOi423OLo+KsSv9kuCFoSqaIoZQVPE9NYW5DSOxifSaxs2WzabDSKZKZX2Pl8NbRGtvGVtvuoMOibRIVYtUHqcMM+pZXIFrVhWKK1yR1ROe0rqOHhnfB3UofUY5DsGnChcdbsd2Gw3GtjkxGYIfOh2/J0/nfjNX/DcXHvL9tYZbNBUM8hSlmp+TWbVeXx2OOWwSZsb6vjsdlecbnfMxw23r3qKiaZIUocTlzntJ8rYES6XPcFbOxrvgzWANYUyamWvVgr0udWY2Nt+ngVqn8PK2es6awrvHSnpsy6lIGUx3mJtL1K5o+QZ74RgyqRzMQhzEcQEN7oYW7KsiDburRQAEWE7dAx9T8ofInQ6T2ZdSykXnjx5aw6Q5/rJM62S5JnT8cTNq9ekaaL2vwol6K4SAs/HE986vaaUwnF/5K33/NF2R8r6nH3QfllCNI5qYLi4wjvHeDzofiY0CG9LxthA/MEfXDOnW7797QNv3vT89m9fcn+vc6qt9+aA6QanQ7Mk+upu+LWvfWzcdWmbofcRMTGvmuhcTaZm26SIeRs6N4vtHfoZx9WjS0ueOkuqWPIqhNXpbA/LpkZd1EEMwRNQiGuDh9mcSrMqe9ZZXtfAAlXTORH7DhEhzWt/ZTWfzCGuStb1HDlrhavmbYeh4+Lyks7WkCZEfEtg1MC++jMhdsisAafm19aVFF0p8zgyG0S2BUAx4ja9jpkLWpEX8+EM4TSXrD6EgAuOzWZgiJrMTKlAiFzf7Rk9pC7a85ZFiv9BlKDDuvTpVWe7RWE6Xiz+aJ0rNQheV8JXJ1R9gVJMwr8+n2XcHaZbYH5CSTSV6x93VMSDN+5eaHxLbevUdWqfUy7QBRg6mB2+CMzpbA68Mxirrz/jGpq9Z8WzW+zq8sEznYG43PSadtHOvQ6E6jow21WKFVF9tb2r59Ou76tuYO33cRakayxpvrCUM7/gQTSt1yALcmL5incibxWJs5ff8UV+6LW+e6iNN17rT/D+nzhoc85dAv8j8F+KyO0ZnlVE3KLM8BMdIvLrwK8D7HY7mab0YDDte2t/NgHnlHyKLcLaL+Q8flrDHAvF1M7EoEy5io2InAUDesofXpl49/UaZC0TuJKWW1ZA1lwr5X1UYy2g/JWycB8qrEzvwrXrqRDIgL5vblCIhTelm6deU7IGwYAqUaXE8XRintNivFYlY3WeMpK16lMbA9e1K2653zoK60mt/ASPixpA9w5mHxBmkmHRYVl2bRmuojfvPV4K750yP3eEf/GoY99pFj+lWTfm1Tnceo+1F+rCEb1tcirtebe54Tg7DyzOXg1IqBmjohndNCvMophoSEqFu9uJIg7v1YFcUJ+eac4ICeUOZU6nhBNn/XwMVx3sekohp4IfHJPBBWPXKQk9eDZdZJ9mfMkGA7DnVco5nMLgmzXRs2ywFgBUiyGa/HCOM/WxNkLtoaoT0P7pPJXYKe2Zr8ZQNHhbuSUG6VHOTjT+UhFhHCdm63Ok8D8NRIM5mXX8P8qBv1c8v3Gt17s4GitD52j3c5aZ46uCNrQ66LS5Q5vWVIc+NthW/VVtoOwsYMKtVsJKEKm+39veVIfszO/znhiEi4sdThJzWhrnSqzX6um60O7NOc+w6Y2fpwqytaWCuFp1d8xJ4W+hbcPqdA+D4IaBXDI+JUqawT0wXM7ucaYOsiqoAlKyJX/qxNJ9RqDtEziDWvkIORMdBrVz/D8ffcTf/95f6NQRVQzM+yP700wfoN8M1usp8uEsvH90vL12Wol0FRpt1UdfYS+VIC9LUAYmRS5Lb54zR12D3WHoCXSkmw3ZlIgdKrogokCDUgqH/T0OR+c7wmZi6YumY/AQdgyLM+ODU8XO+mwdmsxIheOLHZcfHnFOK3+x67UvkAjRZzoPp5TIxStkLgs5jTjviX5DwjGVE7sO5rrwgNsfbCiiVZgFRgxlTsxB21Jg/SP/aL7md19+zFEesybx6yEcj7u2Nzx//jk+ZILzbIaBQ99r7zGnfd3i0ONy4l//5BM248yj8UTJhTkljs4xPX+P7+wuybnQ9T1PnlxzPI3cvt2TCsRelU97yfRDx+HuwOl4XHiTK16ZZOHP/uwJz57/Cq9fHbm/e9ue7sPeVm3J2ZhUp7ImPqpTWL1K77wmIRwtSbWG4gJNsTf4FQ3DqX11QNd1BCf87Le+xWeff46k3KqnKlhWDNJr3y2FNM7cvr2lXF1DKU1FNztVnI1dt/SEKwUJviEFmt7/6tkJxRK4NP6gzk1MpY+WgCmrwEOKtgjAL02Z55RVNRU4HE+kOdH1GzaDtvQ4HQ/0m00L/rqhI1pgWYPhltuzrwrek4NCl1WdT/0hbU1Q2Gx7YtzANCEILnQMcUPhyOF40oErtYrvKaI82UdvDsT7kW1J7DvPFDUp5INvY/eQttH2NFh53qsIo71L9/oWHDtDDISAc3P7aF69J6XM2pSuk6GY7yRWPPDy44M25zSBGzzgg4nDePPZFkg4WGII8D6QglBkXeWyqSP6vrC63wo5fmdOPQxgWPu5dfiWZEK93uZj+9Dsb7uQOhoiZ35I8xFlQc69Oxi0eVzXIJZMaLbY6bXbLeh5f6II6isgigYb5ew6V3B9m9s1wfLjvmbtp9YXlir4j7/Gnyhoc851aMD234nI/2Qvf1Fhj865j4Av7fVPgW+sPv51e+1HHjVjsMC8zmF0+ls0oxwc06yVOf9gkOv7SxFIucEd1u8pqHwvrCBxZ+c457S9G2QvAgr1qBlS/bzDBwFrwlmdQnXizCB4T4yePBeThF6yrDmV1ULXzwezEqU5DEuQWVXWnLOmlmLQBKcBVwHGw4mDZYHaNa8EOtq9rQeiZZyW51H/mufEmzc37Tr9arU0jodtlEpQ9S371TKEmiKmFOF0PHFxe+Cvvspc9B3DdsNtdLq7WKXJ1SDZLbfhvN5HMLhCa6ArqFPrtVm1TgxvLRpqcL52XF0L3qsjqlXNWcUeSrHg02uVYrLviZodrc5AEd3AppGWnUtT4X4ewTu6GJfeU3bkIuTjXN1k3cydZlZzmnECsVOilP7n7PoM2mrfW43tVx6rlNB6P1tP7Jps0A3Rmeyza4ZGqxCNRdgqlILyTMP6fLm0DL/uZZ4uRnKekKSBdC7VuDhiH+iGHikwTxP5pJn5Z27gHxw6vvdwndu6dKHydHRcvK2D5dGun7Oj4Jmcx3Umu8zi3Hd9z2zy01XoZF29aT//iF1Zs6i0c9dGwK4s8zLGwKMnT/DRMx2Vd3AyhTvvVM0vxkgqmc1uw2a3Nd4jhBhbtjYL7DY75awZ9zZLMOddK9wmtaf94rrAjHI4JU8mrKHDo5L/dhOpgFHvgnea+c+12qbV/JQLcy4ENADMKeFjpwK/JTdu4auLS1tHpSU2Ys7gJm0Tsj8w9D27iwu8j/z1TxIvd5kXG8Ay4ZVP7EOHmIpmybKQykXFJZCCiwobxOYcaPNpsT07Z8cnfxxxMpqxFBN6cU3AJTvdNH0BP3n8AIj2T3LQoDzRB5Io1E+hvg7lTy0w3VwKOTvGm0fIqWeeMm++v+WN31IePeXZe+8pPyVBkpG7FzeICO99EPnWzx4AePvmhtu3r4llw2X4Fm/l9/DDQHmTuf2sYzyO/P1PJyaX6KLy5EoR5fGUog6kc02B+ZbIi7se5w44F82GZkLs6ILj9q6nlAQi3L39kH4z8tGHnxKiCiGMpxMhWlCaEv/osx8wvHlDGhN3tid1zjF4x9958YL9B4Hvx0hKibt7U1X1yquBmVIcaZ5bYiTECLOqxQYTGBIxfltxnI5PmeYbvL9BMlwGjwTHQWr1xxm3VxahLe9VqRFn3GAY+g6kEDqVlZ+OI9fX1zx7+pS7+zuzbYszJdnhQjAOriYZS8r0MdAPvforLtD5yDxOaKVToaWgfMaapC1SofxCmhKH+3t2u406/4q7NMSJNOVWFS3ZgAlHNDjtSsm4VJvwwPt2zhunONs+pQIkNAij/tEcs9qgKS09ROcpMZ2OVkXXoNEZP7ELCo90lnSuKr1YEq6eXRd/YOg65nHUQL62ZcjKaxSiVr6d0i8cmSJKdYiVFpImSsmKEkC/881u4NmXb5RyMCbyNmtgZzz7NE8KGw6Ly3suICfNYXf2vIGz4L3t8c3VWUctNkcEqn6BtKrOUrkRSeS8+JbacoIfezjv6Xrj8xHavFz7ACJFk23BM8+JdBotKA7gc3N2W8KoqrGLrNQrfZs60hxwha2K+QUP6Rh1rB54VIsveP5qO/ead73c5/L76uvWo6mfrpK11efyribnNQlgAOPV1Z1fbXG+tSBZVH/tZxzFx/O7eRClPvxEVcF84KRQUNrC6p3vfP4nqbKuj59EPdIB/y3wByLy36x+9T8D/xHwX9v///Hq9f/COfffowIkNz+Kz6Zf8iAbUeXS37kWddA2mw39bmB/c6DqQHoHwzAwmiCH8mNUdWzN5X84PFUiOp2943z61TGtgWV93/lYr5q3OkEbDsjZZ7SprhA7Z0RHrzhyC0K0J5fCMlrlxvWEIEZgrpj/81JqKUVJqV0wKWExWKKeq/PQbXpAVdVK65m0brWw3GyVyK6Taf23q069bZZnFdfV2KySHMuQrWMk1kGjMO1P/OqnR4rznLY9f+P7iX/8PHCqwhP2qbZBVfWoxstzLbOmZIWCdwEhr5xs81BrwHcWyeuLWU9OEI93nr4b6OLMMERm55ZqjtD6KbUcmm1SXaeCGwUo2dQkWbJPzUhgcBMUGlh/VUTwJVuftFol87QMnRnVRa2tns++Y3kgbX2ss3FK6l7Bj1fHko2zql3jLtEanCM1vFweqbf5mARCKbjg6UJAJGsfMAS8BnfdEKHANM6WzAg4F7RS4lQhb54m5nFmnmZk7OiOE2w3qwyeZtBzLkQHPoYzTkFlBjkzmG1v8ZZRlxVsyjmwtee9JkjSrL3nahxbx9W72oLdqhfrpeNqiqOeV4OedUW02kGVAHe40Cmsfs4t6HaS8UErRj44U03T59gDU1YDrLBHMQNVjANauaBa6dfnlZWk7ZRzmmxOVShkXdNtLsS6t6gx8pEGxcbU46TCr0P9nOAk2Z6iaoWI0A1RuW6ptGCzIQpEA6lpTOz3R7bbrVbsshnMB4kFrfA4qjKrC1E5Ds4cJAskQlAnMATH1dUlm+2G01E47meOnz/i6vLaklqO25s7cnH4nFQwhhoManB7eHXJRVeIMePi3OYCzuG7jt7mgHdOFRIJ9BttcFzmwJtXiddfXrHdXbDddLy4vGj75OXVY+6OBVKiHNWBznJJ9IUvXgY+f3mJC4B8wN//5hXz/l4rFBPIGJnePIJyoGTPxnl83xO6QHGFznV0wZOmxJRVWGO4uKD0PYfTlrvbO6Z5bmNccGy2lzx9csFhf+L29hYkt638u999zDe/CVeXEMIJ72E7z/zdTz9lezhxvx+RnFsL0GzPoXeOJ9PIn+cdGUfKnuggF+W6jW9rtfgSKR3eF4ZeKF6rRCF4Dqcdr189Q0rGOyHPG1Ka6OIjYu/pho5pnClFE7Tb7QYExvGeEAuhQMEzW/WXFux45aOeTpZ4VMRI7Dpi3zV4eE3B1Oy/whmdBvchEHdbto+vyVNiqn1ki5DFRKmyUHcGbA1EczhrMrDt/zgNhlJiHCetONvenYuKU4Ha/FpZXufqShFOJ5V7b6JfD13M1Z5VaQKCoZDMjkkR49kmXAxcXe1w1ypgpglKoe86Sk62b5vdyemd5KFZEEDRDDE4XAkcc8H1G7ogTEXTSSKF4DdsLnsO+xM5ezZDYNsPZ/eQSmKeJso46Z7dCT6ogrGnnFVcglMulMTQhH6aE14zBfUK3erfq+1HHoyhlKLVbB463UvD87XdWX/d8swWleB6rT/Mfw9B7ZL3QRE+zmk/Y6fwx8WO0vh9ataselYWf1VkLfRR/YLqU9pc9cvFtM+5QKUpnbkNsjTxfsCGsxGp7Xuk+QyCrN6wen0VRzdbXsesOW4Oivow9YOyMv7q+6ppyqsAtJhvG9q11ftrjrvarbzybB74R8vPjsqnV4XSpT9lfY+g8N6zFijtPs9fq8WnH4X2q8dPUmn7e8B/CPyuc+537LX/Cg3W/gfn3H8CfA/49+13/wSV+/8TVPL/P/7xX7Hgx2sVwX4ASivr45QnlqsSFxWWptH1xx9/zJ9/97vtrGIZqujqtospIp0fazf64QL8YQvp4WvvvOcrPiRiwYbLRmZ2Vi20SUJw2gcAACAASURBVMVyITWg8SQQp05XW1w0p7AGC8EyOs5pfzHvQtskcsnk/REwZ9HgTSEEtpcXTV0TyxpPaWY8HJtUdoNYoM5tDcSaQauOr9RnZk4+smrm++6Yr6RC+Wiv2P856mYUS+HrJ/jTzulmQX2eDoprRq5+Zanfleu4ZqTM5JQZx4mKR68PQuGT6ew5nUnYA3MujXu12Wzo+0WQoDm1LDBdbwGb945QilUnWHEubBQr0Bt9f/G0zbMezmkANM0q3z0MvbZucPW92Hf6lWKemIJlafK8602gnn6TEx8fCyFqdWAOji+24ey79fHUqp5uKtktjkddK8GqCb5u7H4R3qmwUW8VRvqMO2GVH0coSw5Oe9OUJvSxtp3dlHn+Z5/z5sl1e45r/PhioCunDRr01i2vY4IaXezI03SeKLLnUzOIvfHt9I9bpnb13Jpx8fjaL8AZj8tI/Ej95GL4U0qM04yfPV5gnmec96RpavLNk/VCC86R5tSgVQCHYgkpVFV3dCpA4b1nThrszdPMOM4E74ghUIoqqKWsmH5f1KnxQR1EQNVJ0cRHXed4DOZoga5XsajjaEGza0OgYiXOacItdFrZoTAMA8OwIRlMPedatbY9xcYtp8J+vyfGjmc/KLz6KwPFWZBt87itm5W9q0gDQTmDDml75xADfTcgp2vCacP8asSjynVVjc0Z767KTxdWkB2Doe8/v8IFYfvsqHPBUAxD3xP73nhphXTw+BhI0rGfIze3TzkWx+trFZrhJAzdpBBMccTTxM3bN6TjxHSraoKVqzJNierk+LhhyM/56x9t2Gy2zG+3pPEx/QDjqNyy7XbLtuvJORGjtp7wOVfMMCEENpuBl5vn/P74HiXft/00WDY+Z7U1WqXVoKaLgXHOUDKvXlxwe3PFbquO8bdefZfHb2+RqLDYbBkJo9jhvTrpf/f2ln/O3yRdPEZcR27rMCA+UpwqamoGP1jj6UQpmTwLffR88L4GLV2BP/p9IbOD8oHy57KQEeZSEBc47rWvY9ffcn19Yh5NWdlP7DZ3On1yJk2jiYksHFIs8Rcqn5easKl9A6u9sTy/CJcXF/i8SKvXPVdSVpRIDcbMifYhmEqeM7vl2r7tHGw2G8bjkVF0v6jrLMRAqYm8uqmsDhV9UhvoQq2IgKXUmqOoQZmJ2NR9tCIEmiOKCvsUaddee1K6rtOf00yek+7/Uas/zlsrmJUISavQx1UAXIxr7wTfdZrEzgnJM6AQ5hA0kRc7XafBa/9TQYguEqrNOo6Iiwq99EI/C/GYOF0MeK8NukUKMXimcUZSbkm9d700HY+YEt1pZtwOK+i6jfNXcdXMh3tob2vgtvj+ts+Uc3v/8HHWqlIphdpUW5UKdY3QEsA1AHIatNUKrChn25WiMNdV8NF82rNr0jMFa3tBmxuloZp0bsSl4vXghB5Z7PfqnivFoKy/sppnWX6sl6JV+HM023kSwsa5QIyuWqx2DotRzf9cmYvV+Grj9wdOqa1n/b2tcKmu2vLeJaFpwZlzXzGP9PgqyLbYmLVY0f7Iyh/5UcdPoh75z3j37urxb37F+wX4z3/sN3/F0WB2qxqpSCXcG9QsJ8rhoLjp1QSRB+dx3hN6R2eOfS4FqgiBva+IMGZdzD/8mjwP52j9jorZPSe0Vq7HQmYudVEXofbEEFlq4rk6ldAmlsPpRlhqtsYMuCllLYV8m2TeLd8RoauNsr0z4r5KmWYR5dY568dTCb7OHB6T0P2qR75c4xJstQVTg7hV+UqrHNUxWz77MDAG+MV9wUeTsY09eM+39wW3dfzJsJrdsgRKInXrte+WBjBkOp0QyZSCZizzuuKm17PI8X7V9BbGcUZu76hzb7Wmz0a/GGywGkXvFH9ejKfo7DsqhFSHQ+dMjAGiclrqb2tQ7INvTaVbw037/lwyMilkJsZANnEGhdcaL/KhYhEQi/DtG+GjYsIxDkoX+H0cn+40B+XEKr4mbuMecEcF3lVw8otICZbRjiEQY4Eg2qYjwVyy9mYKjpxdq64hynNABCsU2Uat6yt20RBP5assbZub3sHQR6Awr2AnxRoRV3htiN4CfKhOSUtBumVdgQaifrU+26ZrG/dut8WFoP24YqgPGOxa55TUaBVtWr6/u9fnmU1FT2pQp8e8UygPAmmckSrdTDW2ej0pBoL3Cs81GBm5ME8T+7t7Yuy42PZM40S82pFSYdOHljBAQJJoNSdWlP5yeKmkcIU6uhiVF2eKexp8jfis84+kFeLWpkAKv3Z7x3bTs7+lVcYrrKvNdrdAcFNO/NyfJ/7kWwNS4Tv23pyEENR5rAksX02YQKHQO+1fRCq8+SwwvnRI8Wx3nnmcVPHW1z5dgavLK3LJpHliOh41QGHZu6QUiIGc4PazjTrvAB7GGOk3G4btAEUY74PCWg3+/mLYQB+4jB3H48jpcIC+B4om2XJiPo4cT3pduj4Ks9Sx0okR8SQ3czwISKHsr+l618RufnkKbPtgXD5VCM5FA8/Qd1xtNgpdDVUu36Ctfcfjqwt2Fzvw+rvNENntItePr3AUuhjYH1SOPUZ1HFP6Ba6n13zj8C8ZTyOh04p/daoq97TzntgFdpc7fv6Dn0cun5DzbPZaWwrMc+F0PDKdTkzjkXnMkGZS0d5fLoshD0oTJComxhHdKpkCYImWKpSUypa79JgxFVwphJjYhs94/33fOOT1giWLwumdfl8qmd4qxs4WnvfKK41OxU/EOUIXef7smSac0D5wa7TbCiPS9qiiWTATlLLkQMnkkkzIJqkQUiln9IxgqryLq752Yu17vLahaQmp5qHToI4impxQ0adlLzBLqn9c3YsNgZJF1Wi9XwIR23NOhxOui2z6wYLQekHn+4nyEjMSoqIDREwp0iMEvK8boY5730VySWfnWNtAna8biniGL490XUcWx+WUCDdHDlOi73tCGNlfDcxDxzxPJsBkMPo2g5Y0YMiZqxe3DMkxJ8frx5u6xbSxXviB77oP9bUlmfhuQOYcq0rd+eedJeKKSKNhxM4UMes88m4RkDIfUXl+gdD3hCJtPeSULPhrLvD5NTefzDWBvErBqde3+CdLIFp/WZVZYUUncrTE6xm33PzmKsC1dD+Q6trp60aQb76oQT/tlM3nfzjWZ8+heslOzpL2ta5XAbmrDywJhqBUiNqjswmvNS2IunaWwLL5zFJtWl2pX30sASHaDOCHvfHB8ZdSj/z/6/AO+qFrzuoCZXL0fSRG7UuTrcn2POc2OfRPzcIufViqkzUbvyI61S+K7rzZYPcgIlsTzOvi6bq4Cjr0gp0zvLYpBenvDLJnD3V3sdPFV3+XC3NOzKepKbKpA6Sn947WcwqAsmyaVOfGtalRrxhQydjoHF3nKcUab5rCF6gz2QfNhPhSTIjEW98mM4x8xex/uKEoIL8O1pn4Sl1g68m6BCrr30lTWhOBXz04nl0OdEElmut4Bu/42widS/yhn1uz5aWypONcqysEb0BodWKHoWdMGTfS5LCbetE66KjnYzW2osqAw26rDXgnhW/4Kq2OnC3WmkCoO5XYWEXbsGvVV7+rOqvnY6zjVeFeqOHabBARptqSwcb5b305MmQNzj95/5JPN97UzR7uXucBSBB4b8wU38CixCI8Pnk+2apBDs5bw+118O7BZbPvBhXEnBJfq+SLrEG9fodKnN8cTg02U5vgSsvs2oZvcJ8WHLvK3czsXt8zfvKC09efMx2PegV1bmkUxfuT8O19YtfBP3seUBp9DYgLiOLOnUOrgQ0mtVxvndewuvMirUdecbSqV5VbLzkxnU7E6LnYbTGmnEGYNDiTbC2cvRrgedKKu8MhTgOkZVktVT7nXGViLo/TazCtkNAVgVkEJNseoRtKdhp0aoBTcLIyU84SKjYfK1RSclEoq2Vtu+Lpvef+cNBstvUtHKfZ9ja9VoVie/I4N3L51w93lDRbki23QKOwjCOoMXRo4FvA5rJOEhd0PL0rSPEq8mEYF+/EGlc7fOiRUgj9wN1Lx+lNoNtE/FZhasFrheF4mlvPMu+jSTwnpimRilhPP08uhYJjsEbm85wUrhaVWF9EVV9Pp5npdCSlbPB14c3miteHG3y/4/33tgwbrare3e9xCP0wUEqv7VpypngPHUjtIVQf0gSews088ccvD3z74/eQoIqluRRiCHyUCgFHltzsj8fmk6xgRSjEdJoTIUQ+/vgjnj99rBV8HPv9nuPhHpFCyAoRn/NEdBZoF08oQsTxQSx8I068ygUpE+tj6IJymCtEth+4un7E1G/Z72cO9wemcWR/f8/pOJPSrCqK0twsXDQlQWsxEYLy6UKIVLh4cAYTnCeStb6QogFryRmZBUTRFt57QhfI6X2+8bPa9mOxT+YwmqOb58Q8TvRdf74XSN1frSWG7ZXRWhOBJodqa5Y1ZMwbF1VzORkfIsX4s5ITs4E+hk2PzEmTNt7TBW9CSA6KoiO8+QXiPc5lltBQTF3SFDDFg2ilbvGtaLoKury0GteHwHbTI5Yg18SQJplzmhmT7mOx7bk1SanJk2gBRUnGfa3mrXF56z1YaxjbO1VBsWg/TAo+RELO2joE5f+mBJ0r1uerJiV0fm7uR65v9sz7mWQ3Kujz39wlhD056bjFvuP4waOV2ZV3ko9Pv3yLmzNhzogPxP3E4/HE7cfPDBVl4lw10Uf1eywwXtgIrULWEtosv3PWu2udvF8f2hPW/FATasJ8jsWTknoXjR/unLP1DGmcmkbC+qiXkkX94ZpkWXpeVoXQOl8qLNGfP8tVELWIgmGJoVpkcMZ7N2+h1EiXpQpWT9WCRGl1m9ZbELcEeizfox83X3DlouPcUgGTauOXNjIVbXbu3lbHA03k2Loptp/WW26P0vZptdGrc7SnU/eLlU/WgtMV8usvefxUBG0CZ6qJ4PBipFMpzGmZkBUhs/QYWnFzHlQWvLMG18GTgOwdYV4gcQIcU2LXRZNkXjZloBnqhdheCby+GcJSlgpLWS+cGDjc788mhbN+JmsIWGgZP2kwQNASeG18XYMDFTmQBu2p2QPvaxNSq/RYKrikwlwU7iGoulWMS4ZMihhJWt3M0ibag6ezxCY60fwCG2lGza0/ce701kBTYwA15B6Fam5D4Pks9CLa0oBFoALUmPztFPlb0vO/XWZej0dO0J6JglSUq1NrkBSTxO0HupC5f6Ok8m7oVK1xFRzUB+1YnHABI8lrYKm95Qw+9mCO6FcuvIKa5axGsjoGxdMC9XXVps2NagRsAxXncF1UhaiUETzPTsIvfz7TxdI2OZczf+3lif2HW15YE/f1Wc//LfyDlwXvI84JfYya0fWOIIWINoIGjNdjXIuCBfmrPY0V7GCdSlwlXELX0W89IRaOY5X0XwjUDfpW6vhVmKEF43bKUoR8GHF3J+TtPf2c2BShDJHBWnpcJOHX3maCwDBN/Fu548sIv/G0OlRmVHMhGX9smZ9LouGr4AnSiPawHXrG5JhLUaK8c9omIyXG2Rp5e79UJwFxnnHOeK9jGbwKoRxXEFrdEiqaIKNCoNJ4jXV8g3MQPX0ctHm7Bba1V0+Vy/DeM/Qd2+2WsB1MXl5alarOv4xZTlkCBm9BEt5RnCeJME+qoJiyNt+dk+7LtVG3A3L2TDbfa2/Mzz97yeU8U/ICiazJLkEWaLZOCkSqVL63vV57E3XxOb1LuLjB9Rd0Q2CeCve3Nwy7yPXFBXGY+PLzL5nuLhhvHP3W011tyXOmlExKmWl0lDHy8tU3lmRbmPn4g78g9le4+UhCuUPO9umcrd1Hzm0uuSKErspuC6cKW3MqEHMSTy6ZYLywaRqNkwey6oVJ5f9R2/2aoEpda1ul+KVSOJkj57KQnAbBv3Qz8WQqZA9pnttcaBlz27R3secogf9l+lli2DMM2rbkeNzz+WdfcJwyzCP39wdEFttifvaZkxqcg/CGm8NbRApplXDA6dqOHrrgQRzdsGXOwvF04HicePv6rbb4EYXGDcMAUedB9AvjBBRRELwnemfVBl3vXjVVAOXNJqtMLg6lJlpzmpmmkel0IM+qQvxbvwX/8B86fFQPzJmIjQE7WXY4NMNuytPVI09F8Dnhu86QLwbH9eoUHgGp2RCE3pvYlAjeKUy5pNEgxDb1redeToGCBjDOe/qLjb1BJfW982y3A944b2/mdCZk4VNhsw18OGwJP3jBzdt7wm7g7hvPudsfqFWEuuNl9JpL9Djr7edqix+3rFcvOja6T1coZCDLDD7w6LMbuD/QnUYOu4H76x3UjirU79PvTMYx1JMrHFJKpQFogmkcCx6t2ntxHEoBk1jHglGRQDiOXEwTswgSIsFPxkdW+xK8x/XaY44kfPDinlfPdsaxMsEgS2Q/erNnGDOPn1wTnOPzz14wTnu881wJlF/cIUETSjXJvrgCOl5ViKoFNO7cpug/tb2LD47xVAPf5RlqMJsU4uzVh43WM0yruWpvxZAL8zQxi/IzO4O0e6DMqek5VBPdaEgiTYijJkcfBhhrU+hdWRIq6wBUZ2qzn2D9MDUyWoK3lfK7ttbhzNd0nnMoI9VMLZ5GaWW5c5+zJnhrSLf+v1QhMK96yEtyRSzhqZW02Xqp1k+n5KzfrpxX41aDk8WCZbH+l6trWz7xbmi4vr/1GP8k0Ej4KQnaFul2W9jGGQAagb2Lhnt3ji6C8wpD0l5gKoe+4BjNubYHWQMy7z0lBFzRJsZTLmv/ZQml61napKgGLDAMvWW49dzzNDON4wO5VA2gSiUlG8wsehAXmKfU+qv5EAw7vgRn7eG5VRXAXvJ+ea0GbzF6MMWylEoL4nAGaypCQXl0YbvRZr7TAjtY6l9ClbbVzXkJbsE2bzyx4p7ttZoBqlmG9omWlavfo89a4UmOD8bCR4fE5TFzBOUR+KUPVAKiVd6cc/zbd5FXfss/7U8mJFDa10Rz9MTRJLSXDJFmmPNhpOs7HS+0aadetjROSzth64+33MMZL64dy4a7PDdMDWv1+UoErkPEMrZLwFYDPpu/uTBPiTRNOIGuQPS+EUa8Bc+SqwkM7Vw1u9eIxfbv6CBGfYZDHynSkXPhZyZ4exK+v1NOWipaSdGmn9KeW6gODBBsQ64ZrSCi4h323jIlrpNnlspB1HmSpc4xhVUUFkjnesIsmTXlKL736Sv8Jy9Jp5Enm8i/fN8jlxe6X9xrA/BcCkfJdKMj+8iZ0tUD46kJ++WZreOH9j60qFMTJlmUY0PRLHjnob+4xOHoNhuGPmggLIIna+bd7qIqqQbv8a5jfHu/NOVerfFpTBTV/GCa5lZtd86Rg8eL0PXOKkLLBZeixegKe8U5k6XWpBS+kFNiTkm5HqvPeuA0zUhOdH2vqpw1UIxeK43AIdUg23RDz3IXS3+mGDxP00wnWm0sq/1NM55VZRHqDqQo44LH8/6bxIuPVE1v6Af+/Ld/lTx6fOiY6RFXeYCFGKHrBn7+V/6I4C9INx2b+MKy9cZjuU3c3sH3vvgQ311wcSmEKDgXcKnj+9//Jof7A7/w5BPeH/aMRXgdl8FRxVfPPEXSaSA4R0/P3m9IqVDkgEMdrbtuyxgiLtWEmSBZq1UXVxdMJ4MIiuP6+pLLywvaomp7qa6ZlDM+KMcjRt8y4uM889g5LpLajjlpYFqSqkWqgKruaSFqoNOFwnscuAteoYWlMB4nZMoEH5FY2Ox2hnao/NC6djSB6oomFfzhFZJmLU6FoKR/W8PFKvVzKXRDx+5yp3yiUyadTpY00X06dp011a0Q2WVNlsZbL0xZnX3nstk87eclZBWccpHQq9ukIlqJoq2p2nwuOS/VXn/AUhbNAa4IGliqD76JgqkzXnBE8Ty+PZA2gvedJSW1pUtJykV0ttZ3pwk3zsxotSR0EObMuO2Ut+M9rgjdJpiAj84zijq6nfVYxHv606xKii4SPn1BuN0zPr8izVOr8Dx9fU//5S3z0DEVoQuejfeUL+9w28DBw+xcE+fwVvHBKRxfiwerUMt5c/SjwuBWe0ZOidNpZDY7cT1s2J8mhrsT2/3I4YPHygu3al5xei+d1wFOWPJOkrLuipBLxkmmFFW3lKJVNynKLffR44NQSqQ/zlzeHskinE6TCqk4DeJzFi42fbP9mKpoSJn3P3vL4WrHfLnBiRDnzKP7o/K5Li/ptzvefvkZDqHzDvEwbnokFzrRpIIPwVBRZx6j+YmLzV1TIvQxxuYz1X6iuref859CUEpATllbawQNgAqWNLE8Xi5CVVIWEy9L86TBSgxILs1mp5SpvTzX4nxg7o68GzgU81uKUWxAFnv6IInd/CCbRxQLeGo2+mwk6hmWsKbBI7WguvhB9b0PbLPymauPLxS8JqzQuR37Dh8jodPm7bHrEJwicASFH9u1dU6aorwDKJl5Ek3eRW/rxa2/XDUYCnQCrl70OpK0AsU6EK4jsA7SK+e++kc/Lnj7qQjacMqfEQSMAAhwOBy5ujgx9IMZeZM8dergBwXFM0+5OcTN+XHubEMWZ8IHIswGfRnOpNqlfW+TUxVa9UoHczVp7TryChJTDw0yTD0qpcXIbDcG71wgG9ttxHeR8TSS56QiFsGro+A1u+K98eTQxVOzJedNfZfxcd4TO98yQDhnPbO8VY00G+uEFfxSb1hp6MWCSFpGaYk1dDKK9yzKjStirSzE2zrJa2BUnchvHTKbSfjmvZLNj6XCOux6azbHKf8uxmhVQs9u6PgZN/AnPkOqgaeRUesCWWLeJrsuWatl8zSTg8Ju+yGqw5Wr8VjGoaa61xh6qX+Z0uCSiaRdebvf5a2WddVXVkOxOqRd/8LP1B5vJc+t0uK9I4ao/EwRitMm1nqKcsa9XOJ+15IGP3Nw7IbA1eVOoaImgpNtXjgfjLMQ+OLFI16+7cil001RnpgQiqOLHRUe3LZjKY3bh1O56mmEcByBk1Y3S0a8aDsMsKrn0gdsnbRYwy+wikHXRQ0Mx4nLWfilFyPf3QyMlxuKG60HmTnqwJ/FwjjODENn8JI2Xd5lJwtodcevnsH6ueq8SrkY9LZjtxkY5w+Y82NC7OjDBdvLPafjl+Q0Qu3JR02AFAgOZ1lRVjAUUEOds2W0SzaBhtCqcbrB6Yh77+3P4iRokspaiITQDIF3dQQ1CNwfTvRDz27omxEnOnrXo9wShaZNSVrQ6Y1jd7jLvHy502s1tEvfn7i6uNMssCU2vpZmfu3FCza5tLYQIrQKm2sZW9fWhS45haD+yu+f+N8/3hFC4MWnT7h9e8TTEToBb+IoFDovuDJTpsSf/s7Xcc6x254ITjgl2E2X3NwIX//ic74xj/zJPDF78AH6oSd4DQLKPPHe9IZvv7rheZfZD57/44lvMua4yP7+CeO+534/4ELk4mKj2eSU6TrILrHdZniisFdviZXCov6JcUscQp4nNputOsxnvGi1MdM8cnd/QnImBMcwdHRdT9f3DAK//OrI1e1Edl6z6ga1xHukQK49ykjklOkk86/5z/mu+xpjtnU6jsROBY5y2PD0+pLtZkMMERcCXWciUHitjpTEOE08erXHnwKbPrLZbhgPI0erJKqqrae/uOTJ06dc7C44nU7Mh1n/XxZKQDVR3iDtVfm4BvZ16a1IA80BzUmTr87lliBTPrmNpy2ZhaejsLN5nhnHiX4TjJfZls9q0a9dca34HQ5Hhtf3XM2Z4TDCMTHMS0UyRk+SgD+duHp9S0mZ7c0emTOnLM3JjDFyd70j9IGL7YY8ZWbnmcicrjZNUl6A0HXs5kI/ZnY3J+ZxwntPnmeKc1x/8ZZs/ketHGdXcHNq4iZzygy7Cy7nzGtfeHU1IDXp14KGoNUfZ022cSowZHDU+/sDKWkblsvLC4beq7y802TW6WrD01FpKjIrRPXyxQ2l74jiSddbpmkGZ7DLWtOwgNHVBGQRiosEp+0EiiiFRWPXguSECs+qamIRrZTklHUc0MRV1+l553k2IaZOESwp4WPg8jQTsxCsEbnfbDVBTObVFy84HjTxdrzaMneB/PSC66465V/Bh0IhvGqanf28wGbXRt85dJ1aQJxNxTfG2t9tcfSdo/luaZpQCSr1ZVTlW8Vu6DzzNFJmDdy6vqPbbZhm7ddY+8Y5zISgfMLomsdlSYvK86sXXjm+7x51vdXkd2v0YL7ceXCyGqtqxnDtDSs3qy2/6l/V9bX4WQsi7IwfJ4s9cQ6uiyOeEnJM+gnzV7Jou5Hqv4gIues4Pf9AE1OIQXY16XqcErteE5+lBqw5M40T05gIXQDpaKpaiLkL9TqXOytnY1Knxppqc+7Xf9XxUxG0qdCCwUOca5vW8XjgaNjybA5QzqVt2I18z8P4nbZIMjSeBEnlaNf43z6Exq8q1ZA8ONkyiNqf7McN6lJ1Wn6epkRKB1uwFU5ZGMcRRppyVCkKxYoRw5urA7a73BH7jv3NHXlOi/BIzW7bPVdBjtB1IJo9cybr7+xevChHp8yZ0/74zugpJnzhQSx/r4bWSvPZGnicNXpeZV/c6uE45/jmPvOL+wJz4TjNzKexcWcWsuuq8mTwAO+1yfDV9QXfTh33neeT5YK1+CTnk2GdtVhiAEdJhVMaiX2kGwZCiNo3plamalbFeQ2SfF7uZTVKS57o4Wt1wdbrsPetxqERfWtPHdvIzJ3FeRUp2W4GRp+YTlP9sFZSLbj3zhGBX7nJ/J9Pwipb7Oj6wHY7qOMtwi/uZ7oO5lwrZJX7F/leueSPjs8o9PRdjw9XhDDQ96E1hQ+hx5FNDdIqTzb5QoBc1OjpZQqnKfOb+YZf5p6PZG/zu5zBiWtVd03ZX4I2G1MRrSyGgE+J4BXq+74PPL4p/M4Wct8TO21M7pxjcvDicWQwZ8Z7T4gGpZqFYs22XPs+g7zYZNdm7yagEiOXVxfEzYbjYeaTv3gKOdFvOrr+OfitVScid7dPePrkJW290pHLTgAAIABJREFUNc9UidRFqogOzdhUzoI6nKX1x6sLL6wCzmDZ+Bi8rm0bK4dC0rLvQVITDDjsjyCZy6trPIXoHLsYm2Ji9pEYgnJlQqfj7HRedduZ4WLi9uaSN3cXOApzgmHbs9v1zNJB7Ilu5vISnj35nPsXf87f/M6f8Ajh4nQildyeuUKPF+7c+WFrrxSCD/RZ+Ct/uOe3nn2Lv/jjn8FLT3HC0A08efpI+1GWwv3tHYe7ERcypTimaeJwFLrwnOwHTuWKTCL2L/lFueX/mj80+GMhDsp1ds5xmhLvl1su84lJPFed55v7wp9uHXlOvL35WfJ4QSeCYyKnxP40EZxjFwNu/oDbw4n7uwzcwjPl0Tocp+OJUjJOhNNpVrXJUkjzSDcMWol0S2sI75RrNx2PzH8R6eSCKXi+CIH/+3OhTM/4R/57XN7O1qTeYLS59ourwltZnQRLFO4PRzYy8a0c+U78gDKrwE2eE4eUSeLpt9eErqPrO2okU5NIVfVzx8y/Id9BRBj6QRUEU2q8G92PHRdX12yvrpjSzP3Na6T0TKeJOWmFS4VEROF4ttSddwalpc2XWtQNtaGxJRbLnBGEXDyQ2jpvQaDREVRxUFekC4F8GplzIYo/42er4wnPnj0j5VoBt2DrB68YXt0wnDKbITI6hehPx4nDd77P43/lW8xTJk8j/N53eP52z2lKHMvSW7UlWbzn8WkmFs+ORMBxf79nnBO744S3gAXg8bOOrThidkwU5jTj+o7gtTdintPCpzbb0oWg9tlVmGtg6HV/uTocuHm8M7TDMjbeewKOEEygxGynonZUECkXbTPQKv9BxUL8xQYZetyX96Y+aBsXjqubE2F8xeZuyzxOHJ9c4732qE3BEweDbkeYfRX/SXgfkWzBTWeVbuPjeqdms4uZPgjTqEGrCnss+8pswWyMqizprTdn10c6U2OepTCdRtIMIwdtI5ALYx+5v7xk6iPiHRsRVYGuExULNCwp4P2SpAELvMyHOS+rCDEEai895wI+KGTeh0CIWl3LuTQ/M8YIYloO2gxVg9uUrLKrY6LIA6EfIn3UIMIFxzhlVTK1y3HiyNT9po6XUV5spdR5vw4m6r9KqWiuYrztJfHv6xsdLfFaRP0asbkmInhR+2PIfKOjrLwsEUrlV2JB/kOTITQ7osJLRmmZMrsvX5PuTjBO+r3V/ojyx2tfQVd9183A/Muz7V069vl+T/r0JenZJX0X6USxG+IccyqMY2JKM0Pul7TjqmdB8wGtqKFQSnubnFfVighpzswpG7rphx8/FUHbOtfqvEIrwur3qagEMSlrZgEhFWDO5mAtS6lmpOt09KAKjFZhyqsM/lnp1f5fq2vnzQOXtbdUA5b3v3t8ddSc87sP490HVCuNC0QxOG1UXGFGpYj1WMII9dX2GMzD1c0vU5LDR+uVVCfPPOP7zq6/Bl3n99nuZL2u4Ux+XCwArlmzd8IXqUtOF/BHx8LPvZoYZxX2GMfac+5HH/VZTJM2VL9+dMVVHxS6kjPOq+pXzdpZ+uQsu4VllOq6kiLMUybNR4ZNz8XljsPhSJ4VmqZyzgrTreV+11YcWj2rX4HCaLy3zVhKG4slo7wmpqrISsqLCMf5yFU+pgZGVWWqlEytU3gzFi54snc8nnUDCCGQfeTi+pJXL3+Oz75MFiQ5flBUZMElFTDZbgY2G4XLEno617eU1q5Xx0vFGwo5OXKY2vUdzy/XbiO3F/qgG1v2W9LFM+L4JTnNVFhki6/b5oU5XIuoyRK4LYtNQqD0PX7Y8ufDR/xe+Ih4ukJw/NMPbAu3z03Zgv8EY4Lb+0IXHYfjkd3mj/FhT/HRpMcDzne4oePySST4wBcvPmIeO3yaEf+Mi/iE1AnPvqHzQ0nc5tiKJh4Op8zps5/lww++A5RmjIoY7t0pKKsaeBVb6un6TmVTctEqhzl4mpiy/c/XSoKzRIwnF697oUFVs0wK7UggORmS1tMNWbOL2bMZdtDv+PLNXyX0A7vtFp9CXWzgI65kcjpwOk5MkyAeUh455pHYQfAdswyUAmNwcOgo09f4z6Y/4O14YkyZybLGa2jkWmSqPn9dIHUtKPyuc45HN4n7GNjfCU8eR0KANE+8ffUK3ES3eUrKyv/tNleE0HP3xQ8IXc+zxx+y3ezYPdqSUuLrl694ensgfhbo4wYfe7bbHSE4yEJJdwaRM57h6LgIAdnApz/4GsIGJ5mxZGarzpR5ZkyFMHRc7rYa5EsPL5/TX94j/cSYCofDDUMX2DiQaIqy3rO52BFiwGXlbWiCy+NcwbvC5s0lh9cK45+joi+mvfb9Gro9hynRhdrAW/ec4J06uiU3Z6mUwnS0nqbO8+9+7cQ/32z5o1cq116SCm9sLh5xsdlxOsyMhxFtbLzimLkC4vDTay7ffp/bVGCcmWdNpCx2w5Fy4tWLL8AlfIj8B+P/yq9v/h3mcSQlg0W7wjRlQtR1EbrVHNR256pwnAsUTWz2XcBFsQAyk7LHk8jo3punURO8YeHvkJUl5lEAeTHpelW8cc02mKYim80G7yOJTHeY2H7/S/Y3d/RFGLYDKReK6DPL08j85g1z+hlO00xAOL14TRJITiGTsSZJBFwM7HYDgmO/PzGOiT6CzIkggrs7qIhLAXxgOKndH3NmTGr/x4NCTNd890W9r6jQjHF5fAjELhisUOFjjz97w4sPHlNSMZ6m8WpzggLOKAliCZcQva1PUbSEfWeIHcPWQUp03vP6gyt2b27oYlYOX4a72zu6Y+QxDp9mnh5f8vbrzzHHDSQjpiDpQNEfKfHR5284bDo+j5By5sJQSgDOyFiDTEQf2E/TKvmnLRXC0LO96GDOzLPO0YgKqxxPJ6Z5Voffwemk1bi+74ndQNkFTh88InjH1vanruvRYKYmVqk5jbMjAMWxcMnA2odU2+/atToURZVnpRXU5EjsIs6nltzUPVFRKRroFCQVplm51BK8Jmu9Z4i1BYz2pAs+qACV91b5cxSpAdySkHec9xN7WJjQoCIxVvuDockMKaOIpEL0Dh86nH2nJkI0uJumRNV0UL/Q/l6Vn9YhYoiefrM1P9LhVtdXg0IRIU/ZFF8DKRXEz8S7A9NhPPe5pSKdZPnZ7BPHE3f/7x9y+dd+yV4v5NPE8MUbum2PXGz1XpzCeOeUyTnhSu2fmEghEr1jnCeDNVeOujCNs46V+eWanFSaipioV7w58Ojtvml4/LDjpyJoExy+KTU565GgTXa3uy2XV5ekrBkRFTOwlbIi+z84YYvgAXCOKEIaOvoiTL6QZ3WE93Ni28UlaPEOyqLg10754Gu+Olj7y7/n4fsV5qD96LyHlIpOxIOVgUXlakWcQY1qdqI2Z9ZMvG6aYhl4AZM9TeNIcrAzQrfdNY15szK8y99LYF2kIHmphtTP1aBR3+yXf1pWocwJ3pw4vtWFtPBbVlexGnPnlk2lBnY5CYf7vTrLjx4pr5Fkn9ENuOHuRYzv2MKntsPWbGwNbhWaOrO9uiAPhek4qohLFuZxVCeo3Z2009VamnOaKQvRI6Iy/TarDdZsuHPLvokUcqnVtoqFXu7fmbBJMaU3h9k3WLiTAvOUmchED30XeZw6snR8On3Mm0+fk6YJHzbEPpr8fqQfevChZVAPpSCzUOaM49Sed5GsWUDLF4l39KWz+63GpxgUSshS8GWpkE2AOHUi/0X/da42X/Ds+BLvC5Q6P1dNxakZyzqPl1rMAr8FJ4XXu/f5J+GX6fue3eWlZsq85/Z4VDhIwZI0TuFozmAfnUOk53gS3r79Jk8eP+b6egcENpsNzilPrR80I/9zjxcYslbiHOM48vn9S3IpJOebcl4VGZqS4/Hjx3zyg2/y4fvfo4vWq86BF1NtFcPhW9UAXb1q/LLCG6vAhfbcoRnlUgriOsax5/Xrn+H2LlhFPoBBwrwJGWl7EeMEfxnVWRS4evSYwUWGrZDSxGF/QCRTcmzr0nuPj4U0BQ7HIzZxceKYszCGoFBXmTkdJ+4Pb/j3Nr/D8fClhh/tmdUKek2sLeunChq1faDu53YNuxC5dh0udJxSYethPI70sdMWC12hiwNhp7CllGa2ux3X15c8enrJ5ePnfPMbX0Nm4fFf3PHEvebibkscHnH9aMujq0eEGDne33PxxWv+1fjS4ketTHXF4aaBnDvmLPRDR5mTOe26ZpDCy3HikAq7iy2XFwOXg0f2V7z95DVfPH2B6xMSHPFyp4iLXPlDRZOQzuNctL1A94acE9NBKCUgXvulddHjSuapnMjTTG9l4cqXC6aIeLanmkjTODskJJ48f4+td7hXP+BwuCC9vWfEU1zg8mrH8XBQTrEyOW3f1L0MoHjhP3W/wdt5UhimrcmUdEut1XPnHcf7Iy/mL+i7Dhc7prTXKltRaHcQ1BFLkIrHl5nQdzhURThLRtIyXTRZpkqLlCoF5shSUB5TwVC8hFTIBvmm7jNeIZ7zNGtmXqTZsQZJc+C8ENLM8fUNm++/5NaSw8NGURmU2Ro1O+URjRMUweXM4TSzLzpyGmxmprkQYtCAMc0c9hm8Vv3n08gpC5tNT+cdfRcRcRyP2lj7/v5Inidcmhm2W6akz7PrO2QsYOq4a0U/QfB9Tz8MdKUg88Th7W0LamIXTVUafFS1EH12We2581rdjxFTceDy8TUlJVwI9JbwLUWTyTInZu8p5oQq1FHI04gPgc1WHV7vHX5/4uKTN7x9ftmQRlVFmjnz5NWeR8OEbC+4HA98cDxx++EzuNrggxrBqoD95PNbDqcTh5NC/2IXta+lcRddCRQnFO9JvdJjRKCkmpA1SGZKbfz6GDjtBrwhNirb3zlhtNYrIoXT/nSmkKjjoXazmNiZJFkKCtWu+0LzJiwAKKWQx/GsULDWCHCnUWGhc6aLHTjPNJ2Y5oQv2hojCkt/0NV5nPcMXWQ+nnBOOeneBKvEDFNNWKzbS6wPZ3Z8HkfE6D51vIpRHFSFsyav9T3V3xILatb9ORuqqn7fV/jKPgdiZ9y/+pbVh1QxUmzcpQWDCjXtoRyZTycKqjxbkzNrzQhEZYS897gVukxS4f43f5cQOqaUmU4jJ+fxTHq9p4ltSjx7eWAaM4dr7b86HUcEYXuxYzCBw5IKMk1IzqqGOxWuPn9jhQ2FL1+GoInbGJE08aOOn4qgzTlwQZ2OIg4nCZw6P5cXF8bF8vikzT8RCK4ad4v8/z/m3uzHsiw77/vt4Qx3iIiMzKrMrKpmd3MwB0GiZZuUAPPFgmFYgATYguF/wK/+8wzLAgw/kDAsywJEk1aLk9jNHqqrsiqHiLjDGfbkh7X2OTeyhqb01AfozqyMG/fes88e1vrW932rVOMHHh1ctT9bKUU8mRTlWBxukIe4eNSU91Bg+MpE/rqJ/U339R97lcKCklf6oFVMxFArFKKpqzo3Q6F4SQJW+wOWBZG0Uaf1jegFrIGUv7JevvV7FyjmMVVwGYvleVQK1Prv7Wnm+68HFXuWrx2/rybJj0WZskEYpilwcwq0GwhIEJz1l+rnxhgx08Sadtb0o6571cHpJpBS4Xh/pN907K/2DOeRQmGepAmzU5SyojXrLiNUr5zFnapmVGZ5zfq3Uup3RB2oLrVbSpkz670W1R1SNziEOoQxQqfKckAnK5Wi33ud+aP5BSPP8Y3n5skTNn2HdV43PhEgxyjBtDxLSbxqWX+5q+pkWmTJVRGvq8J4lNakwaa1cvg7Jz3ScszEJJXR7W7HefNb/E7scWkijBPn88T9/UFgyeVTZQOuh2V5NElkDfxN85Q/9L8JiBgcLKkE2RjthTC8ZOkBVAquiBFPHBP+uuGDZ08ZzrL5Cr3DMI8jGMuYooIB8tkhgzGe/X7D4XSkWK8JdcBYT4qyLk3VOeZEComuu+XnPx/54NmneD9KoKGs/5Sh6Hev86UkSa5SraarzsEYs7ys5EzKlvP5BafTd2m6ln5boLBYo8cimHU1n8gqTqcImjePEwZD2G4Y5gjW4a1nPg2EPOiaExvzzXarVD1xi3POcZ4mfNtRTKGkifM4QCl8FL6gjF9wmh7kgF56qa2rxVqrdJS8LnJ1EBXDh7KAKSln+s+OfPDZW6L9kN3TK6ZxQnxxIr2zQJJ2C5OALiGJrmgcJuYx8NHtLXvXs28i339iGV8n2qblycsP+ei2w1rPMRiOpUhPMe+VqSDr5KPo2bx+jndXGJIYb2TRwC33JtA7KUVymnnRBn7lRn42bwp/9u4Wtxvom5YyGz6zhZJEY3Y6jWp+oxXyAiWJPms6F+a7hpIMWEuMkZIEyf9v2r8hxUjbi+ueon0ydIU1gDKC8soWkolz4Pj2Nee7t/yOd/yb+T9hwHEOiauba5yBKQTEjlx1TRpcGj1Yf4vPSXMgxUzTOC2QVmZI5RMUkW8qhdqkhE2ZX/c/5V+XD3R9Su/J5SxImSFamgKYFR3PKUvZwtiFmiemNUZaaaAJWSranLasRg1CCxETqlLUOCkKqLY40a1TUYAUy37f8f2YOZ5m3tVYIBemYSTPk8QSFUQyIquoeqCq84kha+Bv6ZyhayTUmqYg59M8U4pZ0Pa+9cK6KVoRsdIGYTgeySLiYlRphrUO13hMCJBlrKwmUzEECRST9Cp1RjVhRft4qnayOhSvmj7Zg4pBKvQGjLPYLIYWXdeSmurcucZHKQlol7MktqeXt7R//RneqzzDWqKyhJrWy3x6947NcGS83ZOc4RwjLmb2bw40EUrbE+O8gLA3r94yd56w61UuAd1pZAoz52kWBgKWEKMCp5BjYjxPlMbwcLtj2na8+PweMycFP1M9VhbtfQyRYddxuN5ADMvpXVhdbkspmJKZ5lmTHEMto4rb92NAOl04ftREWfblsn4H6hLOXxNbCm2utivyfSaOM+MwCQPDqw46JNoW9Vdw9F0rVTkF9je7zUIXdY3HlYh26GUVz3x9XGatwyulO8Ga7JayaOPlm0o1rGol1+pv1UlevL/Gd+VyHV4GQBpnZWQ9VyD3K6jUxe86K3tg7S8rJlCGqC1OjJXnYaxQrdf3McveJRMC1R3Lw2jPM+ddJ5KB0yR+GO9ONCkTjcG8fmD75QNunPCzmEy1bSNAjXe0OdJneb7VnCTEpBRoQ9s1oq92Fpx9rL//muuXIml7/3osyssLDcw1LaRI5dIuz9g8AhceBfq2FKIeaBLUXLwO6Nxq1HmpQ3r/Mu/Nrb/dffztXveNn5dXB8RS5FCw1pJSpDZU1E9aqgF1UFZ9lNxTRaCaxot4PiV83ypFTzYm2YQlwfWLFfW6VuoGVhMR5yw3p4k8hYVqcbzeYFqvfsxrAodR5PHRPT5Ojv82V86JaZ754N1A17Sc9Ns/OoKNIKx914G1gpDlS6fQCyMERcAwEiBMp0ESAKBtPdvdVjjO50GqGTU4ySu1sSDBkS1Gk2cdrwtQwBizUCplL9CnUx7PV9EZaLU5r8Ft0cZUKQsVNMGS60ica/mj8iv89OZXeN53NE2jPX7kSrmI9iRLYJiXCoi8QXWJK2XVJ9Z7qA2jJYBnqfBiHLa5GHlFr7M6ukZF4Ixx/FXzCf/V7cSNC9zfPRDil9osdkWIWT91GdtadaxAy/9nX3KaIjGclVvvaLseYwpjSKQs37FpHFYROIMETg/ziRhn2u6GgiWEwN27d2IjLhEbKUehBalWE+PZXj3h2dNrYuqJCT64veLtXSGEWcABnXONbzHWcDzP3N5syfman/74wPMPj1gz1SGStek7cd6zVaOhQnHVoi2jYFbROcby5s0LYnzCk1v73j4pQWvJhViymtWgPY2S9GfT5/P27Wua8w7fdXjf024lAVrBAw1AQgTVTc5xZiyZrmmErjWNxJQ4nU58Uu75b8Mfs5neEZR6Vg1H6vz3TbMEcNI/an3c9dyuFXKZQ0IFQvu1eeeIzoGRoHc8j/S7PU1tLO4c3ipYE2fOxwN/+dd/Trvd8fdvDObLf8fpdOIf2MSfTi946QZSnumzpTcP/L2Xid25ZThJP0HnG6bdDU9vNtycWx7uB4oF6y0hZjZ9K420U+J0mnHO859/r+fFfm002/eFf3CVMeYaY4QOvWfkB+aeeZ6Z5lnBNau6UxkWbzPpriW9ayglAAZTGoqVICaYQL9phUZVELv0VDP7stCxcrlAoIsEcEMRR8Gm9ULtCQHnG7ZboZHKdxAapOhA9DnqXvn75c9I4xlpGSIodIkGqr5F96zF8CpKUuW8578Mf8G/Ks8WIDHrHJE+hAlDJkxZzx090C2QJbjMOfPd9CO8hbtyzRf56WJ7vsTGxmGsDKTonFf9LEYSuJiS7KeqC7fOYp0hxyTTLUdSHrEp6feXYK4o4IWuR8Ec3LI/SqIsiUrbCh3RezGe6dtWaFGlsN3vyMYviWtBXCgZz0zngahni3WWvmvIzlC8MJHCPEMUvZ0YI8h3aPpupX0ayNqo27Ue33cY3adMzjS5sD9OHPYdKWWmEJmDJBwYI1XDkrFJqmfOu8XQBAON97T20qxtraRbK3QvtPH8dDoxpEzXOKwXnWTB0I6BZo6kTYOJmZs3D7ghgiaG5Eg0UjVyvqH9+Vummw3T9RZj4MnrA6Uk+sYJRRhHaDzzFHQaGLrWErYtPL2mK4Xxwxu2P38ne1uMy35Y9VZhmnn34R7GUZJcLc1YI03UK3BK1fKj4ECN9S/+93XX45zkFwPXsndKTFDHOYbIOZ6Yp1kMhIrIKEzOlBiJIZCSJPU2yzngvaPdbyghcj6PhBCwzgkTaf2kr//S+qMldlL5TU1g6xkkVOyCwyz9fut4mdq0/puUMF9XFfnKYJT3ozxgjcEk1qz06tXa/+vu61FlOq+tDGRPkn2mBk6VRVS9G7rP3jHPMyEX5nJh1qdyh7Zt9L+Fhh2D9iiVRpAr+yQXjHV0mw6vjdTRJO6reu/H1y9N0iZNqgveOumhXAPALL3EnPEIqq4buoW2qV3ldSBYNxFyBudIxqihgFCHjBOL25wyxIhvxRZ1fbgX09jUhfbY2e6bEIn194TKtHCwzbpg6++tAb0iX4pOpAVhr4iWXfjF8jMrqIFJODUvyEkW59q/7fGt5JR4+uqe0jqOz2+W15j8+N5syux/8iXDtiN++IQLddE6PrpDXc+J/cNEPgykmHC+JUwBczzjGoe52vJwu5ekCLi+P/NXdlpoqa7Ab7Z7KsT5TdP0fRqlzO3Mn9iZh1LpO+h7mIVOZozqtxrP4gaog762mFj/r+jkyUZpANrYdZmDMVMt6tfNSMeuJj9F6A6Veli1WsDKJ8+Xc40loa2XiNAjcQ70250EUFp5cu5y7kmwV3Ub/1v4Fe5vv8vNzX69TyCn1aSg6CYdMqKTLBZLJn1Dg08Q/ZVU19QASF8q3mGJgsxJgzT3XRC0pIBDkqDKec//On+H/+n2FfM2ELOCCkvirhvdI/0Til7Lhj3PgcN04DTPdFdbhnGmaSNtW7i5vqZxZyY/choHpiDfpVJbaRu6RpBoSmG/3/HZF2/pd3tC0qap1mCKY54ncnZgsqLUmXma2LQth/PEpu+5ucq8uzsQCIRYsCaRM/R9wzBMwIa2a7l7t+GnP3mB8YHnz38GmvjaHLm56jkRGYdZ0PmUF+pR1Xpdrs/PP39JCE/YbltA9sUCmCLVzcs1k1UnYK08Kwl6NXlPmfHhSNfN7PdgGukj9nCa6DpHv9nhnaeQiMkQi+F0PjPHia1vhfpjDU3bcGWvuL3/lNvwTqtNF5U0pALQdZ0mLWubkeo2ZRRtLYpwGsF5FEQSPQS2MiRkLrYaoArFyeObVqnMA433hJgZxyP3P74Tw4VN4ln4KWGe+F458i/ffkZ8IkdfXwzYE2dX2I3z4mLrvGHylv2V43e3Z/6fsWEaZ2m6bUS74duW1onhyO9+lPnOrVVgp67TmgyzuOB9nx27KfNn42s+LRMlF5wD6/QoLhBipsyQYydjZFG7fcOcEoFI0KSg8Q3WZjWAWOdK1oSg7oepQDaF1hj8pqdtW/rSM04zTdfhnWeaRX5AgVgyRE2IxElD9ZiRXLI8g1IocwWxyuXRuQBi9Tkqh+kR6JdLwZX1O4cMLatRkbWe33U/ADvJZ9nCLg5gYF88LxADgJGGH6Tf1N/JS2PmoiCXnKJVz1118doeQPd+by3WS/Ipz06qG5a199ZSCWalh7V9Qzmcefi//g3TIAGx13lPKZLwxMQwBTnTvWeeJsYwaNImumlr/eL8WSuFSQM73zlZtzFCEtdpSsZ3W77/mx8zjANvvviSMMZlXEHogo5CVPS/ArMGaKcA+x4QQ5NpGEnF4DpPTpmQMq0x4iOQNe6wQuWtNvbGGDa7jSSL9YDW7xBDZLPdLDb+JWem8CBnmAKb13cn9vdy5jWpiN+AAesNtun1LM0452kJNIczB29wYybO4h49hSCGM7YsGmHrRG7gvCPV9kTGMO069qaQYxJnwJw12FZgsMZOKWszCAUejMH5mnHpfNdmzku1HZbA4qvVsjX5QsHX+l6Pf85XrsukIGeRCIFKCVRI2iBrO6vhRhojR62EN9bi9lu6xpF1bI7HM+E8XoYd33pVfX0N1KojtSEvawMUZhEh9qPWEEb7UpZ6Q/Xe6jeoieDlzxXBuiB6yhO5cC1/ZFZ2cTOxcRxudpiHg8ZxdT8RydECLMEjG//w7p7508/wHz2nGMP27/024w/+itC3GC+mh28+ekLz5oHNacTYRjSDTs27XC1yXHwZpUDPSZ69y9IKLGpV1bnaQuviTs23P5lfmqRtdRS7iKjrIW5kwlovgv2UEo6Ma1vMNBCmoK81GmhrGRIwbbNQw8TAQaxOTV7t4nWbXl0Y9ZL5o9v/ewP5TZW31cZaERrnpDpRk0nqIbVmVpelZFd7XGB0Ia+v897hnCBV+6stbdtKIkDh/s29IqKCuJpc8Eq1unl1ZkOhS54nnx98XTgoAAAgAElEQVSAwusPr8llFgevIij/zc/vmIeZm5hpZvm82cLd8+sl+y8x8cGrdzQqVp6nQM6RFGZSzLhS8AX8w8CL04QI4YvQdq432CzJwzDM/HF4WHLCWjk0Bj62HbdWewstFZd1rGPOHGq1CaP9ni6SS7NSVZx1jx6W0Tf7umVh1H43F/BWbKujSIuXmbkE06yIDVnqYE+/uKPJhXHT8HCzldd4qyJg6VtUClhTsCEDSsVrG7X+TRhr6HzH1dU1H3/8iSS5Oi6JgulazKwiamuwbccfxo94tX3JrfZ7SqmIxW9MRJNQyB2AmJNW+AyUQEI3MSO0HlfXTZEDsDgjwVuRgCvnIu05qu6uZApxnc4XA5sSmCw92HzjeTAbDqlhu92zu7ricH+gZoFWtRPWmTXRqhu1sdKfDknC4hzYNq2sqSzIat82eLfnXgW+796+w7WN2DAXoR0aZ5nnxDDO+KZhv2mFYpJk0w9xJk7zEoSWUgjGYhi4O/TcXm/oXOHLd/c8udrReEu0hlAkfSVFxikzh8wYIsVYMp7z6ITWG17yySevKSXhMDTWsPENownLnMpKk6x9zPptTwyRMEPJvRgLtA3xQgsIMynWoVdHRIkEZY4YQ0mJVKL04NNmwrJapO3Dbtvjug1Pbp6w3+8w7UbWTU6M40DOgfRupuvEhh8g55n+/m/4x8d/RdAqjVgmy27rmo6uayRgKJmSzSOBvu5+y7qGi/1Ok//WRjxpCW4rTdkuAIbM9eE8EueZ3IoRwTwVpiniN3tsOUGYmM4jyVj+6fav+CL82hKIO+8YYsuYDSlK0+zbJ9fMm424dFr4/Y9G/uRVw3Ae6RwYEi6PlFL4nQ8LL66cNsT1ut0YrfjIEWsR2qWj8GJzxbO2J9TqBiz914omDZ/3kX+3sxjfUHCEFIkh8o/MT7guE9PoKDGRulYHT6neRahvOKmOrCeqBpTSI4Ku7+jMhl3p6NoWMaNYKbpGdXsL8FQrD8jaSBimcSaniCmq8SsVMFuTMsMKEj0rD/wT++f8L/yOJlIarKaMJ9KQ2ZUzv2X+gmwcpRjcOEvVNYg7ZdSA35hIUwaMMTQZ/gv+NZ+Vl/w8fULJjlXisE6udV2jzAvRfpacCSmSEzSNAbTa01iM8xiyMB+0KtN4MQCqmuQ4z7hDIQ6jVC63G0AMCpwV592s+26/ERfFfD5LgtI07Dc9Q0jELA6YsiqlOjEOAwWL9S1d2/DJ974rxiK24PsdeTjz+U++YDrPazCq4x9TwitaY4xZXP6KF3dJWwrTOEPSPbHr5Pi0Rns4miVqdk7cg+u1MIAuPlOSXLBOALZER7fpOQ8DvunwxmglPuMMWNV5u6aR5KiASZmSwPhCjqMm2JBpyDmxf3Mix0BCwLQwTAyT7D1N1y7P3VnHlDOvn2xBK4SUwqtne67PIwUF/AuUIkCa3E9hNRKrG6z+8Jsyq+VnhsVb4L2rgpLy2q++3bcVAer4VlDmUQGhQPEer+60LbKXkCImRWzfid5eK0G+8XTG8I/eZY7HkT98Uj/g2z9/yTPXOwJTWxy8d6/rj9cbpZotVQeGelpdJE51QDTGuoySNdzh64zr1M8GYSUUQk54a+jblv0OYm4evf5xUnUR28dEmYXJgbW47YZshN1Qk2d2HWH7IbPO3eevHpZ7fv38GmMtT794kDlUkP3fRmwWUyU0VvXeqKlcqds3p+ue081WPugH3/wofnmSNlA02FKy9j0zkIslhUzTWA3mkh6MXntLNWAipRi6ruP5ixe8+vxzpX850jyTm0YW/yXdUD/TpFTl1ljDVxK3b/3OC+L0+N+tffwPUvhbk5KaXFwmb7Wa9ljDVR69plIXm7Yl58I0z3SzbMxtSKTO0YaIm6Ephd3rg4iuYyK1LcFGvNr/3352J8Gjq1QlQ8iV8mFpWou3DkLkxWd3FfgQhMdU10sVVlpP2zWch8RwPIr2ZA6LY2VBbGv7TnRRxVi6rjCVvLpnKgpkDHyaZn4WJxyG77segJ1xeAyJwmdp5hwd/dSAMQytBW3MPQ2zzKUswVwys9xj0yiymS7MSeTq5kjfNtim5XQcxDp302AoNFYClIRZ+qjVxK8bRSzeniauRhHfppzxD5EPThMWuPvwinHbUTlg2xDxMbF/fRTXNe8ZPnnKsGlXR0EqgidjLvxoz4Th4fsvePrDzzHGEIzn/04v+ff+JU93ezEumaPOl6TVlkqvlQDZIQ3q0wU4VRu6OuMxS8NyB0Yr36kQSw0uV0RfAnCLkSNUPkfnfyoZYQ2J+2GMidHCP5+e88/832jList1Ypb1UfLqnlqbVgqlQNaH8w7vG23/oVS+nIhYjNop99sdx9NAKxG2VJ+QIHkcz2y3nu225e7uhG8s4yxBT1I616IhbZWumCJfvn3L8HBH0+0IfUfXbwhhpkkzMTrp+QWC0s+zuEs5R7e/YhrODKctX3z+jJvbV6TpxEdfZPbZ8sebVctWDSpkH7G8fP6SH/3oR3z5+iUh9RRjOJ5GOm9IxVJKWoJfa9WEyJhFB6xLa7FQr8mNAXLbsb9+wsuPX3KOhTxN3FxtaJpW9YKSJB/JnBrH1LYM0xnNlzgfHvif7/4PpcOu+5dzooHo+l4aIiP6R++dVH0X1m/N4IzSbuqGiQYJln9ofsZPzUteTbfELIfqXOee8TROrMiNRZo6F0MKiU1TeHFj8T5wePOOYxxlJpWMKxnrezatJgDWMG22vDkeeX73OSlnHrLl0+0TpcVk2qbwe58EnBEQLhdDLnHZz0NIpDLTt1LhMBcVCUl+K7VaAvPe92x7cxGnyHwXWmtmvy38xsfw128dP74znM8DPp65KhOUREmFaCCPI945xHDGKD1WxPWNt4RkFgpQNkLfE3DT4m3D85uOlCLjNFBSoe02ZBdVnyPrIGmA/bwcsNOJcZ6ZBzFCqDTiy4RtWddFtr1UpN5oc8aahDGFtm246j1X5Y7DeeRl+CFbN2NyJruGppWqwqAOeWCIISFN3a0aHqjNunM0tvA98ykmW35ePpY4AqGZF52XsmdlruwBa55gLnD86n9cCpjsMMXiEvjGkYExSCuO7W6Ht4XxPDCHQI5gcGK2srxZkfPMWq2cO4bToHujZbPbUoDxPOC6nqsPP6C8fkNtiCrGDkoYTQk04T8dTvz4/NcY6/nwo4+4yfDTH/5wsbyvlSNjhZ3grJX+sI1Ud0oWCUPKhXYM3Lw7MUyRuWRS12IvtLS5iObNGiNNi2PGINT9altvK5W7ggYVNC2yb4zHge1uhxmDmGY0Ts5U5+SMyEIzNVloYc7UdiiFnGbmkLRxuFTqwjxhSiYZi3ROL8uYlSIavlLkfHDO4hrRpNvGa6sIWauyJ1atrgJlphZ8FLxfHubjAF9A4q/PcGQPNo90bJfXJSBVY4g65/5DL2OsVMhbDzGRQzXEMmvTbgNd34r21BiK6s//08Hx8XbPW9/Q9cJ+Mt8S+Jbl/+BxdieZ3KVu2ZT3ftGsvyMJmjqRXiRmOjiPA2mNex9hwabaMNTYSKiXNba5/ODTpmG83rIJArvXr1JKAWdVG50vwPd6O0YBdChkzruWcdsqjHORdFuJbV59cqsg0nKHfPHxk/UTU2b/sy+xNc5VIAtnQffP7AupdRxuto+KPt90/dIkbbXZnliFmnWQ1WK2FA/FiJ1vq4FtBtdYzGyx9rG153LjuWCiiLXTxcS0wJwSjdVGt9YuG/d732x9qBdXrYL9olImXKBSWlZ/VNZ99Gf9fPkz5wtKnurZjJG+QW6O9MNMexhoMXhribdbdnPGjJKoWE3ukrrfpJRo2mbp5RNDYkqTDlc9IOSeYkhkdZz0Kjh3GJpGUMOchMfuVIBNMbSdJ4WGcUjStHqWKlHbSlUu6MQteph32w1dNVGxFoyIbnMSJ7RE5sfjTAyRW+PpjSVQeGcT28OIGwK29fhtK1x2Y9g4RaSOE/48s725wh0GcipLcCi9siRBjCHxZE682FxzGiIPx0AYBw4h4fHk26TPoqARKPtU6GJke3cmR6GmZmdonAc18LA6xk/eHLjPhWHX0Z0mrt8exUVQJ1Epme2rO47feSp29kkPQLVcds4uVJuC4W1n6RrDLln+z/lD/tw+5Wa/wVrPHJI2GIekzy4XizNZkuVKQ1MK4iMLmpKkkmekcpkpdI3HtY1oPXQzsbWK4wy+umfRsCBvyFry2YArRE1Wcyk8HA7czZE39i3j+SwaD9ZAz2iWKq0c1mRTuOCGT801R9vhvF+qPSFGhmHk7u0bmral9Q3jNNFvew7HIzFU11XRvzkjWi1hIon2M2eDMY4wjcSYqUrATMHmQjHiRta2nrfDzLv7M/M8sr99RiqZtusoaDuEkvE2Yawjx8A8jUCmbTumVLh72DOHyAc3P+dXvxj59KqBrZe+WCktbSAW37JiGIeWeWoxQNvUoMzQOgvGXTTjlTWEaouEDitr1HqLweGso9n0uq9lxuFIzonWOUYS05yYw4g1QpksSRqTxmxFfwc0zkoSPkzkVGicoVhJHNq+Y7MROqS1jjRJNbcojWYNjssSDSz6t4vpaJGgvOsafvVZw6afKEYgggz87OD5ZCdNtFNKlF5McJyTQPXFleV6YygxMRyOlOyoNYx6+bbTykahiSe6MNDvdozTzHAaSEko1jiLNw1Lv0VNQivBjhooOUfjvRpIZVAHYDAUq1RJ1Ray0KuMNDGuwWQROrxVauO2lQD5o53j990bnp1H1VH5BYkuun5yEc1vKQKAWmskYCuqeVZ9+DhMvKNwcA9Mdss8zxzOZxKWGw1uc5J+QSmLTiqnzN9Jf8F1PjCOs8xTrQyuz5KvxhsFAoWcCnYYOZqBUznxtH/Ds1z4qHzKHDM5R0JCXSNlXGJUTayTpKNpPDFI/60QpRdh2wpwVwG17/JjTJ75cfzO46AQ6NKBl/kVL5ov2TS/hzVqPVBjaW0bEwkUk0k54YDeO4Iv7K73WIquadXu1LxP45dSxPAL4+g2G0lunGccxKZ/GEa6rmF/tWM8j9pAuuBSEmdSpS9LX6eMyUKHnIcBZ6UHW4iJuzdvONwbzspmqfvoYvGP9Kf1zmJzITlLt99h5pnjMEEubIaZzWkkZjjfbOHGEFtpT1DNKRbaVsnicFsyphiKW5OQWpGFIo7FMWGdNoPe7mlaTwzSUzBnaWlSkjgsUgrWC5BYEXOxpHekGKX3XcxYAlOQ6lE2TvXeaoSxzLWMygbJKZBSYZ4DnVfAhDUvkGK0ppniYIMxme1h5HS7XSZyoTxORC6uR7Prb5F4Pdbur7HmtxXwllebFXgQjbCn2/ZK+Y9EZykxYW1ZYoDa+kCKppW6p1Q8a4U+6yI5Jo3jvvl7VBrxZdEBvrrcH//OOoqXA1Rqa6Z1YB4/mPJNm0n93KIJ1jcNmuzH531Hc2fxMVGJ2TXBF6aRJpulSAxgV9OUUsBuWroXz5jM4+pejd3W0+DR/13kngKUHa633Jwm3vshIHtF0Z6Ya8L27ZPhlyZpW7Viemg5WTB1oqdsRVSrDnHSy8ep6BoenxoXD4SvGmDUa07SkDbmQlM3cFAu9Tq431Tu1r99JXH7emONle74SHf2+Dc1qavmC2XdNFkttF3K7N4caYIIhwMyF9pXgWjE7Wk4nLH+wiFHEaUwzQTjkP4osmmuYvUiv4M0XJ1TlsaUXg5y13qaxjOMIzlGkY9nsCYxnGc5TGehqvrWkZIkLrnAPM9LQE7WviHe4hptKqnucSkHTIk0fUtjDKaI+8+7IlQGQfHVGa8U0hBojme18xV0UVyxYP/kihfXT7mfEg8PpyX5ds6y3W2gZMZxZpojb8wd4zjjnWGz6Wliprw7wfWJ4arnw/szZg7kkukyNCVTkAamzjl1d4uSYOlzLkCJkc2XD7QPHh+ilOCl9qD2yBZyYff2yPHpfhGTv/zoYyrNN6fV9vZtZ/j8iefu8xf8MD1l13e0XUcuanNcNzoNpDIWwYoTBTUuuKBYvD9vbW0rYbM0Rg5lobzVqqnVlg5VGmydI5u1gS26jow2iY1RAo/TcebN6Z639i2H+4cF4VyA+QXukv0g59VxyjvHF/4Jo9uwu+5VyyfV5hhn7g+Jvp3ZX1+TZkF1MeLW1rZutZU2hhhmvnz1OWbbsXE9YQ4YL/uItVad54XymBJ0jdxH73tc09Jbx7MPn2N8izOOKQV8M4rjVE4YcwXOc7qPDOcZm2fa3Z7Nfsvx/sDhYUccXlL4EcYYur4RpN4YUilcPblWi2LD1e01ff8BOW7BQte2OlYC6FCqagogrXuRQb+fx9hEykr/jFH0O84Qg5jCvH71in675Xw6cpfvxTXOWA7TATuJac0UDV3JhDBzmBNTjFSb+cYbjJN923uvDc7FxWucMxgxMJkKWBsXk5SLXW+dt+t2iXGe+bu/za/+6m/wHeeXyk8uhe8OsG91JZlOXeWUyWDWYDOkxNWVxUxyMkjhQqqpVs8SSsGPZ67jwO7JDf12w+eHgb5r2e22hBhXowuKhusG6Vu23oh3DuMcMUSqzhPWBuiigwnoboqzSkHMQqUUIwuHcUn6NoXAj15NPNw/8F+3P+ZZeiAZcY6t9tSukcbBOKTZbkpqZCROgdZmTSarW6kF7RNUcuQ+HAnTLE5mxnL39h2iBcuroYxWcc55ZLK199HKHLnESC8e6vrXXAgqR7iyr/kd/2fcphOboRCtobUW03iYAtZC1ztCqBVOLw5yRWl3eLS1HqIHZ3EqNTnj24ZfMz9jYyM/TN/jO+4zbuwDJSYaO7FtjvKsitCCVwMTpZWaGt7LfZ2nKIYgfYN1hfEkujVSpmk8m03HeV5pqDkXwhyxvrbzECOmbreF8yAGNOOEb7ysgxiFomgMrmmI57O0QrBaldtf09rC6TwxDhPBSjI5HA9SHYKlf2tdN/WsMFbOTmuMWMIXSRBLTHre6vllCleHMyZEHgzk/UYddPX9ZZGQoybqVs5XHEv/rlwSNkP72RtNouXrzNMgvbsUxKkgslDt5X2Tah1Tylqq0YQs1cbNaosfM5cUxDhLhTEl0e5iHMbkBSghZ67uToRdv2wqRvd2Y4xoB60l5yjMj1K4Ok2atF3uRebRnxKXvTfp6zn2DWYba7KD7k+PTci+zYxtCeGsWd4/pUIMmb41WOdprSHbsKwFqPHehGs9rojWs5TMv98Ubo6J82lkSkLxtvCtucJi8mguCgtl1Uiu22NZkrCvS+jWfCZL8lbHowjA+H7mWMetXP7212aX6/MwBmr7mMPtTuiKWgBJqrF/lDwZNUvRyrE4dIPre/oXH3B4/fq9j1pj6gVcXT99ea4VcH40TfRzqwynRNHOmm8b/PeuX5qkTazroYYgCxqJAesgR3K0yzf22uNonoI0hTR2HZsFeV4Tt/evOtkM0KvL3uXke6w7++arJlfLRxu4FBVevHL5YqsZxcUCeDTpzFcWs/wpVTdnDV0BvASmKaTqMiBfIEhl0aJiVQ2As46rRQ0MrAQSJiUBYozTw6Pj6smOGALjaWAeRkqBeZpxzuCduGXNMdB4R0boQTFK80Dfqtug2to7VyuFsijnOZCCImgGNYcxxCR26c4awmKqUlbxqY5DVJ2XTUZRtaSVM6sJhrjy9H1LSpH99TXjHDg9HImzBFRhChduZ4bRDtqb24MR969hnOFvPqNzDl9YyuwY0THlFCWZMcLnD1mamjqljlQahc8ZN8yChCMIkWFdwJRMMwZIsnk++/KBq7+7laQ0ZoqZpUeXug69c4afxB7vJcHE28V9MGJxqDsk0gA6q+akEB4BITIZJVhDxzqp/sEVu1CK61XvJxcJHOp4x7xWUGswJy0LqvFFohQ1AbGJbBMphEfrq1BU16gboVIU6xC5xmGbhlIc2TodR4MpaXEaPByOUDLn00jG0xiYwwS+xzSi/SlaGZlC4PjpnfRS8T05jIRs6Tce14oBhNN1YazB5BlvtvhuB/NISjOHhwfevrljOj3w3e99D2McOLHHFmrjM0wKjONMJ93KdbgdIeyw255d37O1zSLWNhZEwCbW/cPR8Nln14SUgUZoSznomOpzqU5uS/IjQU7bFnxbmIaZeZqYVXxfGodTcGwcRl69+pz91bVU4rueq90TAQucYY4PPLw7EebAMQfyHJhm2T8cmcY7XOv185V+Oow0jafZ9JgSCbMkdyHE1XWtRnVlTfQfaw2kN9Dge05ZwJsKEBgMz67q68SZqxiLXVqRSHJibSG5lvHFJ7DfsP3yM3zTMvU9X1hLThLQTvNIuD/wzHm8t7gCOxLl7SuOzXe+cgpIwKbBilnrd957ghpjGS7F9RJ21LVX9/KUDUWbNOcslDaMUAEpojcaj0f++/iX3KSZpLS3HBKzkX24qQ6/S/xjLyqXoiN01RbfSlW2aRu2zhFOE/MIxUkrBpsTcxInxqJ7bVEdbkH6olVDJqrhE7U9wOOramCrvlH2D8tVk/j+dsQWOa+9d6rBBNMURpBzwULXimOfNfL9hpTIcxQb+1ap9jkzxyT9qgqYGGlL4SU/5Rmf41PELgZMhQqwrw7ATqbLAkpVwLQ+bGj6jQDFwwQ5SbW3FPl+MYoOuJ7Xuh5zSJwejqxGU4YUZuY5LkGhAbrOcLi7w1pHv2lxphBilmS80equc2BFbrDZNMxDZgraEHs5wxToUrpVbQ/UNuJSSUrMD2eMs/Rtw4SYa1XdozEFhonrz94xfL8hWNF3liDV5tbJesLWtgYSr1gjPbBKcjz5/B2H84T1jpLEZdJZo/R1MXepc3vF1g0x10WiYxgzxUvvvdqNTwAESfiq5jkEBS7cum8IYIF+R8/GiBkdCmQ8/fKBucYVyIOuv2+902SjxoNr8v54/VcARieI7mVfI7e6WA9yj7mgFOWLdfILw8zylT1ILqeVM9H0CVtpndvPx8zf/WziT78L8wd7nEnkmHmbE/fTyP/ezQxBWDTO/uK0Yd2e61+++humvrBkFqHg8pPL8/4i8VoAVR4nbPUjlr989X1gHdv6c2ed7DyuIWwFZDAai8Rwsf5sZa/VPLAshiIiV1qyAS5T06Q/c3atGJqLV8p/67/kslBPq+t2pc9udhvaVk3F9Bbe4z997fVLkrQZzXLTYiTziEKYI67T5nhGeptYYxjGkTTNULJShi5+xQjFyFoR5tdr1sNmTpleq0rFrHTM9wGUb0NAVgDGXLyu5tuWou46cjBfvpYF6a2UG/lYs7ruXCzqellrub69pgP824HhdF5+vurlgFLwbcMHH31I37WCsqfI6TgSRqFrLUgPBed62r6Rzu3DROMMm36Lv2q47+45vX4nATUQxkBgAmNJOSuFISyVuksHTOesHK5azUuzCIKttSSEp+69NBUEtH/OKkwGcYDqNr04OtbJr6dqTOXRGFknTUF9I5/57u0db17fEWOQe1UEyCm3fh03o0kEFBuxSrPabUXvYV2DdeJCGUJUnr3q/yiUqA2MG3GIrBqjWjkh10NqRcpW1ok8+XaOPP/Jl7St5cmTPbdP9zwcR45REmaTZXONwfLzT18SUst+2+GblhxFS5VKxpik5u0eUxKJx7Th9/V8ZqEFy5WTVLnje46S3rrVbGB9MYtoW7gFMpfNqnUwJSlXy7BtC/8k/IXMAxl8/T5l0XQuTqrW4hBEylpDmCOn+cTRjlx7T+slEEilukoZhmFcGkGXIlVcELChKWZ5X+8952FiOAVO8biYr6QC89Dyne/9ilBEiyQlm77DuULbeuIceP36DYd3b5bK4wdPN1hrGc4DTd8SrWPX9jgX6LYbsnG0Do7nB9rWaqGj4V+6P+B/KN/j77yVtWsNfOnf8JdPf7QeFzkzjRIkbzd2SYpSlIp2LtC0Hu+90LJYKTTOeXKMhDAzngfdRGRscpKkO8TI4XBmOE9gDJvNlvNpoKjL2jicpU+Q6gadMarZEoqg0eReAnrpZZaiJUfp0xS1j+Th4Szat+WcrvTPqjF+DFplhALrvQGs9uCyy95ZFNCr7qJGXUzlPQTA8baQPHSbnpy3zJsddB1/8/QTXJG5lYxWtz74gLfblps4cMqZ4eqa11dP8UmorjX2Nkh1oWorloTTOYyzazPosu7HNXWBql0WGrHROWmNmDXlLMFwpTIba/jvup/Qp0hKEgjZXO3mCziPb8RBeJ5XpggGpYNLVbAkSEWovtlIovMQAg/DyJg8Rk01rBGjrhCCuE0q4IKR8/lfuN/m15t7XpY7xjlClrVJto/2hcvKqbFSl+y9Y2sNZ2tpjLgo5ihU+Lmuy8azK4UpCGOkUfbFOYrjY9Kec40zFOM0XpazIFWwImaK5lAtovOJueCM0AWdauGarpUYwUigplItSiiM58x0KJznIOfbcMa3QsFPChC3Xce263k4nSWKeoSDJcYQ5exHNe5FqFAL66eAb9XZOCW8s9L3yTqSOlfG88iTJ9dsOs/D20jOiTAnbNPQ+0ZA1yy6rRjiomlb+ofJE8A1jtIaSJkwToQCU87SM/Ui3vGNZ9M07L448OWLa2bnFvfHaBwhyv7e+mr0IsFvmCb6v/5cwLIs2j9yIWa5j6bxAqgYme8la5+9CkgjYF0tkIGAA1JZg2meZN0lSdgsUk32NixBmHR79Bpv1SQv4N9Ftg6m2ys+eHOUaqExkBLegM+RVAoTMgdTKtx+dsebj54sSZmhnmWPk6eaptfc7RfmXlwmPn/7awHwv0Z3VnvHJnWHlqRa22aUTBsS4f7AnYv0alyXYuZfbALzoO5Vvyhh08ppZYGtwcvFa0q5cIy8ZIiBLSsb5CsAWP23NXNaBsnohitzGmrwZC7GRNpe6PdjnfPWeQUTIq8/uuHpj19rm4cLOndJsg9fAJ1hnrHqcJ6zUQ12WcwE610scfflECyfLnPbx4wJke2rezlrqqlOKbRdw+Zqu3xHN0eu7s48PLq/3XsAACAASURBVNnyi6bIL0XStqCPpVS+nfJyhQ4YYwHjaDqHt4WcozSaDBFDZCnZ1pKsHvA4h99tLipXhjZFiFlsUvVzi34HkzJc6GxKEZSpivLrYGZFMmqi5Bt/MZFXml7bb5VysQYoOWemSWgsXeuX966X8455ClJNoppKrNd4OmP7noMxy8Mzprqqrd8rp8SbL17T9h0KKK0BT5ZqmHMGcqbrN+yur4gxckh3TPPMZz/7VIxBqAFFpqQoG3cpQFySJFh1ewCmZt7Oif5CbbGPx5lpONN4SeYE5bIUCiEIN923zTImq/Wz6BlCSIthQeMFTQlzWNCSuphSkH4lgmbqpps1YfNuoUU5qxvhRWJcFAJNKdEUT9s0bHdbNtstzkkD1Ddv3nI6DaohERpPKUIjMUii5pwBr3uDt4ybVl3ECpvDSC22LpQuBJxqsKQ0EvOg3H5FbfRFh+MTxrnQ9B2b3U4sd6nU2bJoLEoO68Fdd8YaMOvBKbuf2mPrRlYK2gJD5/oSbFYNyzoXK51Ifg5OUdhKp0wpYorox0rKkviltCT5IDzyWmFb0Mism76x1B6Y1lqurq74oH8KdnXas6YeptLzLYXAPM2Qy+Uts72+5eOXT8EIReR8HmlMwu/3WCcOciVFbj/4kI8//gTXNFKVcFYPAM/9/T3WWzZdx/X1Ts0QwPuW0xjwTcd+t2W76fFNyxwM282GXBL3d2dyCEInSom+6fhnT75P10viLcE77M0NT8Mz/jz8kImJzbbHOBHgh2kkTZPShpKitoY4B2nAewEeWWsZT2dmxQm8AiExSu8p03gBWlIm5ixBvnWUciI9PFAbt9fpIzodgzWRp7yRhDFFPs2Zj3IQTXAuOO+1KozoeKrzqG5AuQichZHnXvRzrLFrolMK1kTm9gnHza1G02tVXIKCokEaiI5Uom45NgrWFXzTMMyBmDKv2z3l41/X5NgsZ4IgvIa27Ti2H/LFfOKu3zMX8NU86iIJWZLpUqvlQmm3mHV/QgGxAhhJMDNmTVAVLJPG0IVcxKEWEmubAHF8q41lC7WJ+xoEFSPBWoqy59XepZeGB7UVji2QdC/OpfDjdKUaMifJsdp0l5yZQ1Tmi1AkXWPxXU/btXTNjisidhiJITJNswAERgyA8sUGUXs/+sZzu+1pDGxMy6ZpsQiDIoOwFkqR88yI/i+lRLKGOUSpBtT9BiipEIZBrNiN+YXuYb4Gpc6RG49rW5pNz1SkAbk1UIzDGNFkjePEcZjIKUuPwnFWYLfq4jOmt4ylULRHW50ZdX7FFElx/beK6juztqVxTio7vmkEdEmRMFXjFaHyuq6n61thn1AI04zve9q2YbvfYkrh7RevpQqra6zkLK6/JRONo7+6kp6YhyMjszI20P3XLFbl1ago9x3Xn91xutkyeUvedDyczgynAUqm6Vqur/ds+pb57YH8+o54GmiiVld0by65UFsyWmup7MfVKXwF6WSOFzWFM4wh6TPJQjdFYjPRoTnISbR1yO/JI4gU7dPpnJinhDnRvD5wO0StpLEySKyA+1nH2tZgPBWacSZstP1K3QHqsioXz9U8xmR/0fUfkbOtScZ7/5bTTAgyPug+VhBdo82ZsfP85MpwNnB+GJjbiK8995StVH8vw8UZfPF9dT+uIYiEWWW5+cv7X6tlsBQi4ZGtvn75NSRZKx+P/6Qu6/W/63jL31f65VrkWefxKrcStlKYZ5XuaB/c+sspsRgWlUIMAR/FLMp6aX8h+6pdPtMuX+T9pynPyaVMO85s7k6U88g4SzxvkGStUR31eDoT2wZvJSZxc8DFRPJfx9Rbr1+KpI1S+5UIVeTyMhgokRxnii2EbBVxEdRH32CpBOl/ylx0Dtc2zHNg07XYxutBVpZ+QiVlQQlDIk+zaI5qsm/sggDWjQU9YIxWCeRBtBjrBbnK0qvIKJq3WOcacdSTEqkhJ0fbSTuCAos9MsiGEyPae0fHwdQqnFjHx33Lk3FaEA5jDUXpT3JAODCWGMsy8byz+MaJO5W+cc6Zw8MDx4eDbnw1EBD7eeeqXawlFnCuIEi2TN62a+h2vThGTlrRsmYxr9huOrbbnrbvOE+vYRDzDzTA817Gt2kadrsNKWc1IxFudh0b9P5Lroe30bzQLcEKGVJJZFZaXaW7XCbuthRc18pz0blXdNzaxuMaT5wnod6WzOk80nZH0RMZw6CmLrL5iDkOIPo7NRCYppmmbej7jtA2HD64olpORwu7u7MivLK75Zwl2XVmGd9GEVyj5ipN2/Lsg44P7xtNbg0mF+lDWO9XqYIlCRXIKBfDLL2wJFCvldGYRe9kSxb6XEp4r3TJXHsfKmUIo20s7EIDdd4JpcCWZUM3SNVPKLm1B4mK4q0DJMg3ijzV7yiHvTyjookfVoAD5xusFxOdVKQCsKjojCXFIOY3uTBPURDxuo6tZ5PFObUA4zhDjtw+/4DNdsswiqMiuaXbSNLVKHhQgZkQE6/fviNOZ1zriSli1cxkHGbRDl5dEaaRh/EExjLFxNs3rxnPAykL7cYrvXijQTBGhPe2WB0CS/+q46M3HzA0E//i/KXoOVIFr8Ql0lqLs26hHtdxLFkO5JzSaq9/mbvnog5eMnbWWbq+wzkntOWYlr5+lSp7SVfd2CPfNX9J23qKN/zQ3tIS+L7TNWeE/jyNkyQxpdLQdG7oWq5JYU0MZd9aD0LnHOb2KW/3z0EpXNbWhM2sGjYc0stQzGpAA7dcKMXTNo4U52X/WE6V2lNJqwVZ1/AX7W4FFCoYWBNF1uCgVpZqsCa9qKR6aa3odUqpiVpZAB6922X8U45gai/ES8ZG5tXR8m+n5/xBOeG1llSPPBlGpedUe/56d+Yiga3vViQoRSsc/zbfMmaHLUka81KDpILPmVDyGsjlgnpq80f8Bv8j/y9t52i8siOs0BxzEpfY99kp0oJALdr9LT/yv8b3zM/YpZME9MaQdU76FHHGMOVM9pYmO+m5iASCVdtGAaPn7yV93jtDtzRClivo+IwpY+JEmQPxdKa0LUU1yMYoHZuCt5beWebGkzHENItZiOpO65yepllpgqvuvK436ywxiOaqacSIyzcNlIsG3xpLpCIeV41vYA4Sd+h3maOAPACu3bDddzSu0dYnkc2mw3vPHJU9o3FUyUVEEDkzHI5aeSkatBtIa5skzAXglhLTMOBiw3acyU+2hP2Gzln6u5NIMayhP03s93vsF2/Jd0dwDrdpKYn1PNYhqT38SsniQrkEvGaNoy4eWFYaa9s2xFl1SMbQbQWALxrg5RSZBunhVylnteq+ZBlaLZ7ngLNWTeflvAzGcf30mhwT091hgah8Nly/PXJ4tmfum2VPKhff8X1NWwViflFathaS/sPTt3oWC9usEMaBHNbKatO1+EbOSW9gNPCDm0AYR0ySympWcNw6J8BPiuqYvO4X1c8hX4IhCzChsY65vJc1+SrfeFuaSF0ydUyNm3Tv+rqsV2MYi9RTnBOmiCT7Vs8Ph1mlfOhkwzqD9R58ENAyFwWMH4NLAjTLf0v8Kj4LS1zy/kNY/qrjcQlU5czV6wP2OEgFfA7KFpKeur719H1D1xjmkIlxFjdUY/CnM9clk/23p2W/FElbQZpeusa/N0grEuRqSb5OLmPISXRTsvlBrWhlKkVNSt6C4EriUQOGGkDkAjar61r9VM2EJUYQCmBWytdXIA8M0xgwVnjFSwUDyzhOULK+tW42iogJ7WlcnncNZqp5AwtacIHQJknAQowYb/CdY3OaBHY1kuBaa2katzReTDHohFFURDfUpO5btbqSoh4kmtAtzcFLwu5a+k1HypnhcFaxqyRT0zDh+5Z+s8FsOs6nEYqgrAXZWNuu5cs3R84PZwm0qmObt1gvlvKSpFha3wg1LTtilI7yUDcsFjvjnCQp9N4yz6vejVIXUw2w5LLWiP6uiFZGKndRDmNtwi3PXuyIc2ERcRsrFLswB/l3LZnLc5P3zrkoPdEuz66a5pSLcacUTl3DthRSSUuwZEAqXGsrnHV9KAgRY+R4zhwezutGUysievDWDdzpJmGtGrxoeV5cI6XhKzkKImo8TZmZkxCbaj+XlAo5BrWLF9qr1cbCfd8t/UuwlqaRqmTdSEuBYmUMnBcakNUkPercjDE9AiWWZO2irQBFAiCZz5m59lEDff4e4z3j6cRwOpOj2LDvNi2u8fi2JcTMftczh4jzDafjiZyl39vD/I4YZlKQYOeJUq2Xam+Rjf48BamgmkLnLWGaaJpG3O5iELfIXDgcT+Q4Y53l7ZdvGaZZDoBSlGYLbduybT2brtGgyeouKGNnreNFeE6ZM38w7viR/Yul3YcxGqAYR9vrs9KqMyhyPMwUKg1EkzOl+BU542Sv1AR7miSpSVphWXblVMhotcUaTIn8Vv9jOt/RNp6uEyfPVxZu08DzMHI8nTkdB+nRVxJZaboCdtVE5xI9vUxU1ixzs99gdxsJypd1rG6MC8payEX2XWEDxeW95lmSnH67kaBsFiqV031AAAvRv1oFfsIcvrq7axNZRQF1TlxQAXX9r1yMKkSvAEQN6o3+mx70ekvWNGy3LdYKEDBNQRIkCndD5s/OW/6hg6ZS7EpZDQs1oU7m0mBBDGASRg1X9LUaiFV6sMkNyRriFLAG7dcpL46Fi/NTgDnnHTnO/Em+5h+XxJPeCs3ciCuat0ZcXfuG0zgzR9HVWiMAT7/Z8JYd/zz9fR7KhodyzX/m/xRXEm2KlK6hWGnRY4Gb/R7rDfPhxDjNarZlMGpAJACXULKdJpgJoUA2CrbUy7nCoMGac45t49h6z8kZrViucYHBYHPGURTkMWqk5Og6j+kk8ZpDIswz/abD+bUXaB1vZy0XreT1/JJkwjmvIIFIN0oMBAxF1xpoDGMK8+GeU2zY77ZEpIIX4khKWWUFrTJiVrZClkCEnKRJ+jAfcboXeytrp+saiWk0ABAjDtF1pZiI0wRtS39/5ioWdtse028ITs6QJhrsYQDjmLb9YipCjovRiGzpsld773DGSy/FvHT8YyWnmf+fuTf7tSU7zvx+sdbKYe99hjsUWRyKpChSA1uCpW61BQ9oNGC0bdgvDRgw0H73/+U3+9lPNmDYhmHADcPdUtsSW2qRlDiqyJruPefsIYc1+CFiZeY+VSSlt0oO995z9pC5poj44osvqPk3oeBDq+txhhCcnbWeOWk2O8219UNj9NJIsV3oxLqAOWdCI5nxPKhNtjktAKHl1TtfJE8XLsczs1GhyZkQE7cfPvHmi3ekNiznqNY9bTI1mxl+fnZ81lWroz7tR/76SzPC1hZItFaw3kYBLRVqG3a7G/pOtQaiTHp0bcAUbeIuCt6W6/NM11AFujc+1JVbrgtNC4A2P2brRut41XkGCziRBWDevtJeYP7S9QvEiarqOs/+5mAgoli8pL50KsruarvGBG/Uj/WhwzUqqJdzJiZVpH0uxlafc9sUfH0u4dkdreOx+YwXHz7BZSAeL1Z7qUBmV+18KUzDxK7XUq/D3nMZC10jzJMwlkhzHhEX+VXX5yJoA1FRBylLIGG7VzNWTdCJWpBKNjSUDaIo6+fVsVfVokoBw4I+Td+Ti/VDyWgnrqIoV13cdUFsiv63qfF1YV+nM50Tfus7v8M4Rn7wgx9c/dwHT3/Y4YLn/HhUBTbn2O96CIFxmInTRNN4o6cYDzZvF5j+OVPoDA2v/bMwQ+6D3xjsVaTFif7fwpNGMyeK7AmlaRX5tAykOEeaZx5N8arb9YuM9HgZmebIeJ6sP1qxXjrrvX7y8cTx6UTMBTEHSwzdb5qG0DVMU+aw76gtDZqivYYYB1LSInMQCBoELgCH1bhUasmKFNliqCieMwfVxnqKhQbNWKSkgiTaf8kxxxkIpDkzm1BK1xlNokDjA13bMg4jKUZVZgrCNEWiOf7iHZINRbS5q/eWS8YVFhXHKqih8yTM80xfKuVG7L+ZgiPGmcspczoaXmjZM9nUdMa5WH8dPcTEeVtLxZwWt6iLee9ALKCSfkO3lQVpEnbL+osp0oSwzFOll9Ws49oD0a3F3c5oXh5eeogPSYNlExlZ1VSvN/FaCKz/9iFwOOy5Dy+Wn4kUxEOKhY/PZwTh/p3X3N/udN+iConpeNIDO87M88Tp6QwpkeeZeZ7VERR15ufpwvF4ZJ96pRiOEx9+8oZUZl7dvWAfPO+//3OmlMko9W6aJxrfEscL86AKcRdrtJtzYZoyXedx5pQVMv/t3bcRa5ZXpJ4vRgdGLGh0fKk/0AXHYL9TpTSl5E7nmameRTYq6zC6ZTR1fCu6qGDXdDHRoOCJWUUSvGMJ9kUcyeqrugB/sP9rXjSDqmWOQZvtBnWOI/Bdt2e+PMLDqCBZSRQ8wrw4qyJrDzrdT1ugTBbxnv3tnubL7/FnX/7DJfvhfdCsRg2cKOS4vj/VWoXFQYBpGpSitwEvYsqb1i8FJ2EddydUZnBVEd3Wo1fgCFN1rT0VNTNe93j9U1grOeq810/ZugCZYRhxzvosrZATOSajutV3lo2Y0ebcEKMJhrA4I+IKJVsgsgGDBdRxnRNzCsxFRSuCrTsNYsC1DXc3e17cNrzz6pa+D8QhMl4Gvs/X+FLIfPmj9ym7lnJR5sGr+3uarsE9nHj7eFpsVmgCza6la15wfLqBGLnQ86/TH/IPm+8S3IgM6lTT74gx0nWtUngHFeAgpsW+ZaogjY5VdNoiJAPR+yt3WOpoL2MFst9BG2hKMfaLOq4q0mW2f06IUe9vbrShfC7auN0LeDfb/oauC8t3iuga8k5LAKoC7lZcrJ6TOWurGGJGmCjFE9B7yqidbHcd2TnGaWQcRgWlwD47kJ3QdB3uMuoqNhZFytc1ySkXJhRw67oG8YHGShNElAFQAYfSZKZxJKasYMFlYBwm5hgX4OUiNZtdtJWPUT8XyCdf+0jOC9lAwd3tjbUSEbqupW1bnFOf4nw6QckEyap027Z0uwPzPHEZRqWBL99REJLt02J9MjfBelDbNw0TKSUuxzNN45f9L/PM8c0bJCtYUxD6xjOMBhzOSelz+dM1XNv6KdnsbCygK9tFuL3Ksw/6e11CG/R71XRsKoGL+gg1oeHbhjYJQRJPLiCNW33JogJ1batnQ0pW0lPPZqnPZAkT7zZtZdCgR67Bt/Wp7MAs12Nk1mkN8rYDVBfJs5G5+nQnlCbQtg2NCSpls3HOVFCh9uLTOmpyofEwi4mNOEfwQQO8TY9GH5T1Jve3dN98z+ZwhRDq84g8u6lS8LnQPV3YfXJksv7EAE3X0HSNahqkzGiAf86Z82UGaczvUp0haQslOaZSno3qp6/PSdDG4nl471c00q44J22oW/nSa+i2oO5shtiRycWrUEaKiMtM8wyzDVylRWalANW/51Trk2oqd43Gn2/CNYi7Rir0cgvdJoTAOCoaWWOPeVQhi5QrTS0zjBPFCp+3MM5ibM1IrwehULoWGSI+FwtOteh6jokiukm1fYGp5Ng6zUULs5egwNLAobFFZps6eBX0iHZfcU6Ml1GbPTdhOX8qelQFC67HSUjTjARtwO29Z9cG2q7FNw3dfkfTdvjQkrxnmkfG8xEfhSaAPzilHqVMISBoAfxkaec6VMWyRyoNbMihWCbCCqNiVupELhDHCWm1IWpt1DrPs3KbvbPeR5U2AnPOSBYSiXEaKdQ6wkwaykIBWY4qEe35FfJ6qNe1xEqxtSHkUwCPgpbLwVidQ++hCea85myCoSsdqO2Fw95x/yLgQseHHylS6URT87tWabMlZ1VgdZWWV52aCpoIRQwHtXWbyVShuJoRqpScqhaXTVZ62b8mJQ6O/5K/4oPjZSkI1u+7OgWv1nz9jFKK0nztvmqNn/NO1f5kIiXY7Vpu9x3jNHF6PAGmXJkL8zRRdh2Pjycuw4h3qiBZCovzMQ4jw/nMz37yY/r9juADj6cT8zhy2O8ph2TS9trXLKZCmrU/W2Lm/Djx9PC09F6igj4E7u72NI1nHIwukSE7zfRshBTt/KqP7xQd9425BtetSNbx0b8WfYsig4rOLCIIuSSy7Yu6aXKMJBGatqEJLX3jePdFY3Vp3hzZzFe6N7ycCuRAiolxOOH61uZPjWHOmXmYaawNgdOufxgpzwK2ssk2rVMuTmjajsPtnnz3inJzz3e/8gekNDM9fkweJ5rO7qu/I+xvqNUs9cpUAZb1x6lonaMPDZPUInTrwWPZTc3UFRM9aSgLVciCu9rXyC5nQMgVcFDPoLLS+9c9tbVRlWKpdExF7JUJohQarvei98tzKfqzPm8pMFwuzJMqyy4Ndc2+Yd+5Cr4oWBCzICnpOU/Rvp1Ns5wzrRN8cNzeH3j33vOP9n/D/a4Qmp7YD6TbiWHe8fPHM3/T7XnrHd8siUPJNA9HGicM0QACWe+VVMg+Q0qquEhhCC1/Pn6L33PfY89MdJ5wORNCQ+h6pPFc2qAN52ejcdv+SwYSOQtQimgdfIyJuTpd3uEsM+mco3MZ6Tu63/8tVXHUA37xyzb603quzxG372n7luA9o9mc0DiatqXbFQWgsLnZOHYisNtpdj/HSNM2umZzBUOD1WlZBaNTdVUvgm8CgsO3DafzRW1VRuvvSiHUQM17ctTazQW5+SXXkmURT8xlobM3zlOsDKIOhDivjKBxot/1C3gRU9JowZxfF9R/KGNcQYSs/dy0e7Es+zHFTJwjTdfShAbftvjW04SGcY6UpLRsUKDB+0DftQq25WitmSKocL1m0AxcVHvTrvu0QIoz8xxxbdCehkXtxzwnXPC2XzKPH3+sgEexsgHWOvumCRyK49y2BmBydeoIm7rYzXUNQn7mbKxByt8hflNTYiJvG3CzJiGwe8iC1TWCT4XfPha+8lHk/22FH+xDNet4ExeSEGgQvEsWyFqm0sptauP6Oq/PbzUbiPTs6dUnlBpUXoU+y5/ACpCsA/epZ/fiNLFSRTyyV9q/6S0Up9TyskRUQo7qqyTQ84bqA5soT2lAVkpot9ux27XkvjfFVruXuqbXxzJbXWjGiIuJ+w/eMk2RyziZXZHldSkl5mgiXmm1e8NpYNdr32nTQmROWodN+vUh/eciaHNO6Pe9OdnOHNrVUJacibOpayGaSlEFg81hZepwgmaSgJyy0k3QWqdFdMSctGKF1mv2TZfVYvzr9/89gZH7+3ut9+mF169e8f7Pf05FYOfp0xziUgqTOZAi2mDUWcDhvaIn1VkTYcmUjHc96TLRjOp4ZMs7l6xCBXXRiZe1gXXJWge1qCxliknNixMwGWDnNNsW51nHxTnLDsEcMwUVk0hzMk/zesPVnhdgQYlR7prgcSFoc9YAXd/Sdh0ffPjWArEZrKFo1zZ0t/d6OMSEk4aUJ85PJ1yM+LZV7r6hG/WSzVgBpv6j+aoSk9IIU2bXqAz7PM0q2281Ei4XKFmDuaA1blJUpWueJ6AKmqg107owpWtoLZaOV2FtlLqIlaTC3XEwp6oG4VrXcDWEDlxTF6AsQVGKSWsCK6YpshTG5lK4PTj+6B/v+Na3X9B3Pd/988KPfmzrwMEij1pYs5BGV8lO9LBNBoyYY1f3jBbxYk6i0W9L1J+Zs1ipmZXsUiQgwZFy4c3bB6WxeUdOG4e2rKCEPfCydpY6jaKFvFpLYLWmQalt0zgvhvJ0PmtdnhNrVFtMfSpzOl0Yp0kfv+iamGNexGiKCMM4M8c3PD090TTtInhyPl94+3Dkxz/6CXke6Xed1S1l49lrz7gpRhpX6zSEZJn7pmloGqc94WBBMkVYWAOUNZNSpdRmU20stqcak9dX6rBSgvaHllokXQ2jWEDgg2ZFU0ocH08IcLg54L3j8eFIobDf93zrHcfd3vPVOzsTcgLJzHPG+xekjz4mDY/MkyrVXYCYioJpweO88Leh5Rsc9YwWCz/F4aXFSSHO4xqAUG9Uga2bmz3Nl97j+1/8Dqf+DqEwf/hjju//iJIzreg+Trt7ulfv0t6+pt/f4JwVfm5EPq7dqkRtpFodn2DZ5myGtZQqZZ/WEZTVsZI6T/Vfyz6tlPPnzoauh8y1syMVJLPMmH7OClRcgxU1A535f8ZXtA4g8y33xCsZ7FUOVd/PqFSHgY6skGcF1Ip9SS6JEkxK3zmyeGtWHxZb8c4+87tfOPK1mxO3TUtKEzGOzNPEcDnycB5h1nYvTRv4rt/T5MQ4D3wxTwZYrI+SC9D6pVn7WFu05MRT2vFT/5pvu7MKXYng2w7XtGoLZGNH7AyMVRzgymO0jGJMHI3ivzBbQlAKXc7svvouzasXpHEkO6PEb24X1onIOePrOFnwl+eJlB1i4i1zisRhVPqfK3SN9tW0fs2ayS5Z5zulRaQrCRScypGbrxNLgaCiSMMwko8n7alIIWAy/qUgXtkwKSUtwagAmAXKK+WQBVCr+7TbdQSvpQclF7JXerVzta+gXt5DNODzy93vsJNbYqONmIsAzlt5SaE0dc/AWE68P/2lqm5ai4+SEnNiKXOp+7BrGl23c2KKEXlxS3k8UsZJ/Y4si21wRcsncl5tpjO/L8eoNtKEfSoTpOIcImpcG+9JpgzoncNbg2opWds5zNrM2wcxFWXPy+PI9OpmDc6qvVpWzFquoyP/WYHM9tLZec7Y+rtfstnbZnNxywKu3/27p8I3zzA64TuPM3/tVZm0CX5Zb1W8bLn96i+KsmPEK50cUSElubpRfV4nZq82vyuy3mMN2p3YO1Zjr+dj2YTBtje2WbeUE3FWgZyUEr5tVJU8NFqv5oToHd7q3b3pYpScFJSMmZu3TwuoLgb21rpIVZINSKNnmXix+sjqJ5UlUBc7f9rLzOGDB8owcZpmbTlUVA22845xTlpysBnj7ZVS5nSyOmsR2qKKuKdBe9cJv3pBfC6CNrEsT13AYbuQ7WCQagS9WyTVl+iXKie7Kjgiq/GqtR3FR4b7lAAAIABJREFU/l4LEWuWq9YFlcJVgeLyUVvE8O9w3d/f4b2Qs+fFy3tO5xNPT088j6F1fRpHXyqVRTNmxcal8YoWX9VnoRslmOEvUizgWB3fKjZSC31x2HdsnifX4mtMsUvRsLV3y/XhogGC9gSLs35uFT4p8bpfjCZF1eDGXJBJ68DEORyi8vjB83Q8M33yoHWBaBPu2Zqsjt7hH0+4UJUxC1OciVPEB0frGibLYu72O0Oey4Kce79yv3N2hspBzJkQo9YqJm2GKqLyrl6UildsnFNKjFOm69rFsdLAWdXWgnPEZDVcJdOEKktuTkRKC2qfVfOA/vGyIu+1hsEWa/LuV2/ZZ/7h0qOrFJoG/tE/dNzfJU7HM9Mw8PKF8P0fdIS2RVJBFsEGE7/JrIfKKs63XDVoKaAOaIEgSlee06xiFU7wOFJJtE3Dru/p+h2q7OoRF/iD6a9xHyrJr6RPixXUMVv3xadBADEnCTKtdCZLnhEfuDnsOD0dGc6DFv3Lutedc6SYGMq4jNVWaa9iP1obpqiXdwWXEnkaKU7pqsfHN1o3lzNt22gtidVAqEpVIqWML8Lt3YFxnImXSZ2CWbOB05xpGuF/fPgh/+LmN9ZzJ8M4R6P/2GJwwjEP2vurqIjAze0BEMZx4ulpRNAmv6/3hfdu4xWfrxbtlwKnWfh3U4t4rXfdtY7f/7YW2TcdvN5ngtcA5Pnc5NPHlHjBOWGcIl3fstvt1IGeI8NZHfW32fE1EULJKpO/LKoamNdwdf185zxd3/H9V+/ib77IZfcCAeKHf83lg5+QhlH7N4agxfWPHzM8vaF/8Zr2239kQhBsFm1FXCFIsbKnqGAVBdmwILI5fdUu1DFbMrk18ERR+epKlOI+nRUT3f/1XrKBNLLZTwWtuXJOndfgnQF20bRJqkCKZX7HkRQT/yq+sncX7toLL7z+3fu1gL6KIdWWVQtVVKoLsDpCJWf+sf+QH+Uv8xgjaa51z47fv/kZX9vv+WoT6Qh6zpfEPEWOD4+M4xlK5nLJeKdCHQhM4vgLeiiZd8p1TUZJicv5Qmr26uznaUHXb+TIK/mQUYz2CLSHnpwTl0EVeg93t+Sns47T8hAYS0CATGeKitU5pChgE6dRHahSbavlrJuwiJ/8qvM2mVqyiJDHEZcTjsI86FnSlQLjCMnTiIBzpKS2bp4mPf9E7Ui7oTa2Xcc0zZSkrJFpUFaAbwIOVaBrBBopBoip45tDwLUKJs3jhAuRw90Lmr6nTAOPj09M00zNArku0IRGwZ6SwVVGip2N3uHEMvnmbOtj6NoX5/hS+9u8dF+Bzta/rKBUhQV0zBNTmflq/C1yKfzF6f/gND1o1ivqObXUWntv/kCh2++YHh4Jr+8VgB0no9zrZDpr9F1FfupeVcxUQeiqiFkoWsssQvZZSxWSIEXogiei4i65FPIc8X3HThSQ9WKKxy4s53kuCv57p+NTy1uXtV3KAgqvwM4vvzanM58ytr/kEsGEl9wCwgCL+m4uGjS4NQvAN85ZW4qIrqt5iiSfaHy3+MPzPC/sMrDMtLN6+OAWhlZhpfQuN/SZD1fASjlqn0DDEZYnvqpXu0aqNp+xBnclZaY4cTmdufnwgcNux83tAe8nW7Mwdw1P9ztKKbz44AmfVGq/sfrH5jIxVzaQ3ZDWuyn92DVqq0IIFKuHqxPVnmde/uKRtq37OJNPA9NlAhOeahtrBxUTg4H0Ipoomab1LNz6NPM4E7tA0wamWZ97NgHDX7ciPhdB2yY+W5B3qJN9vUBKwVDgWoxYeb2VerP50JyJaVYlveoZGRKSN9+zdbLXoP/693/fSw+xTAgNX/vae/zN3/yQYRiXwLSiRZoB0UPJbwrV63pe72ETPKEB3v7hQhiiCUVU3nxZEKEqM0zBmorq5zv7DJzDI/RdwxTjlcTq80LNFWEuSyAsbpUZ3m5kWeZmHU/NJgRSylzOFybvETea4EVFTlV9TKXiRVW14kgedI5dKRYg6cYbzgPzOCtNMWS6XU9K5yWo0gPIglhDpCsSFlPm6e0jiFtS7yVnSlAJ7JQzxKgGetQBDCGYMEp19ATvjE5gVJxsY1/QtH0uEC6RL/zkjaE1WtOWy7pBMyZmUpTzfb4UwlOynj7G167OoRnjLRq1zlLh7k4NUEqJxgvnS4AkSm0rqwONGbiMHWJli+HBsqsq3bFmg5wgOGJSulljzaTzPHC4f0nXd7RNR9v2DMMFiDjX8s5wVqpgLvZcq5O83FP97mLrzJx8EaFrG1KKjOOIbxpa3ygFYVLFOLFsl1iGs96uDx7falZUe5yNpFmdmsvpQujaRSXVeesVWRyvX7zk/v6GxzefMAwD45zIwwWSOl6aRMmLccpGN931Hbte6V3TlJb9Ps/RMn6JOMP30gMnN5Ite6lAkray2N/tleY1q+PSNgF3u9MaMnPE+76l6xqCgz9+T5u6N65dzgcAnJjCpCLr3/pydeJVdr/x3dWZtdRDAXOMxPFE/OQHNF4WSeRpnrk57Lm9PyxnWJ2vlAqvngrnjx+UAouQilIJvUSV8NbdaHOvdT//ur2jbTp612qG9KMfkIY3jJPWPoZSll5K6qxDuhyZPvwe8uV/gNgYYqhzsf3UGDVqOp8NDXdr9mG7f8oKiq11ajV0rrVIVZYf3ZNFyLXWhW3AxuKoiGwZjdWoCd1O9wjAeD4pCCfb897Oae8p0hjQou//38Yv8cX+wr2bV0VIQGUv9L42J/GzWNaC1Zx5J1zomXnInpxm3vM/4yvhkS92O16ERNfdE0LHPJ9JMfH4ySOPx5MKGhngMTMzj9PCXBnFcRFnSc/qmgouNHRtyxfLE/9J+rf8T+U36HY7/L5jXybunMM5bakyjIlmt+NyOvH49kjoeu0L6B1lUklu7z2h69j1gRAjs3jaXWd98iLFe0qc8a2KhpRRVZabL7yi/8ZXka6jd8JljOS4Ebpa5mBzqlrNeBVBW4YyZ5J3BO9VNRQoUenTwVqI4BwR7QPYhQZJxoiJCd+p3Rkvk4kmaPY3JK07Dk5W0RnRap3kHK5tcaFhmiatb3Mt0+UCGNDkA2KAddN4Drd7Gh8QgWEcOV8GFX1zjs7KFYr5AsIqckNJCJmvd3/IffiyZnPqjlD0wcZtk1Uh0BJ4x/8GQuFl+y7/1/G/53IZyIz0u15LFQxMFlF6+2LbxHHzh9/h6f/+NwqkF/1Zzot0CAavg8DcNgxNR/OLT0xNXGsxdc9aMJ6LqXGvNGifKx1Qa9xDo30uRSar5S/LPvHCOu8bRzVba4H1qsyZ6xrST12l2NKqmXR+9evrLhKvKtIFZKFgy1IzCaiqei788UcXZHezfF1OUf2MUgxQSMaSitfBWErat9JZXb6BHDV4W2yy1fTqGF3fadUHqqUVao7Ul9PHfhb1bsdl8/e6unJM7D56ov/oAYkZFyHN2gvQWe31vgnsHs/6uVFr12Wa8Uml/s/J2qUvYAQggf2+o5TM5eHC7n6nDeS9Ixq1Fxx+jnTDRJgd0zwRx7jsLXGe1jkyZSl7KKXYetI9DDBNq0BWvWJMjEPEB89h57g8qAJ1cNvz+7Ovz0fQlgvDZVijbNRRMTt8jViWQjXNa5C2dWC3wUYmz3GxnDFpIa5W2GidUg1GaiPMxXGp6e5fu6H02gZj+lmqSKlKSA3f+ta3+OEPf6j1UGb0coZmiiQnlMZv0F0WYY363FWYwTmHTJH9ZeLwcMa5q1IH3UTOLbvJ+dUZXzeoXCvpuBYXAmWKGkBu6tKWZpmo2+KMvlGKoli+8dpTLiuStogemOHWLJk5SjkynvWg0CbYfjGQtelsETU64mWp+dNDstYxmLiFCClGGlMcHS8jBeX7rzx39PlSXpqa1uyjeEecE+JsjrM6ScHaLCjVROfQO5jGmW6nKmopK1Lnismwl2KUS2u5YIjlnBJijUadrYXq0VU0WJxgK11rWMSRsgdpKWjLgW2txZpmvs6ymR0ww6FzMM1w2Avf+Q58969mdQ7KFquz4KysAZLlIjYuV1V0uq4XKGg2xYknRbh78Zrb21umOKH0hEjbNszR4c5vmIcHbcIc0+Lg/mre/7JU8SGws9rHRpQSMaeRmB2h1YN3HCaarkWDh6RUIzSDr/tRTEm2LN89jpMpWmoT2TEZIu8Cc5x588knzOMA4gkeLucL/a7jdFHj7oy6XL9zzgXX79i/uCXPM9EMqqvEdVQEIqdIxnFuB1UuFa+94ER4ao589/A9u0d9z3/+lYBIY8Oxybov0v2tNQm1vV6D+krFQunO/adQvGugRdZ/MAxnzj/+c9oA/e0NIo7z6WjNuhMplkWgZ302CHcv+VLX8faTN5yOF1yJZGnsPjWoziVoc2pX+P/cgdTvObQtwkyZz8TpTMqR/f0tp6PuxyCOedSspfhA2wZSHIiXI0UcyQyobSzAgwTmmIiVNv4M+KrPvf5Z6UJi+1XYVFywouNV0bdQSi3uN3W3zbypCqS7CgxTKpzOI4OocNM1OHa9L3ed4+XLnqfHwjxP5FQYreebvihbICoGZCodVVgduSvQUwKUSM7qwP2L3Y/4H/Irfjd8Hx8CTd/Rtp75fOEtsL/pEIHj2yPH8xPTrOd0SsWanqOB0sZm/ruw5zbP3OZVFOJyPvHwETQ549kzl8L4+ER7OXPPB5waC1y94/W771Jy5ng8M0wJ5gs3h4Z2v6fpOihFhT+8J8XIVFSNtbVzIDfCFAvBBUqKxBiJudB6rRGj7xCjhyJpGR/ZaOEtc1iKNsSOUW3KrLVb1Tq62mqhFDBZ72q0w35HaDvmGHHBIdO0qEmmmDg/PWmj51JovKfdiIPVGjKx7I6yUyA7T9P3+kwxKrV3mpmniV3XgHdqv3ad/i6ppyQWkLVNS0pwiRdjGmj23qFZKlfrXYtmmZz3tK7FS0BPFhsft1LlNris3ntFLBBav+OuecVw/gnOeRO3UlXqYg8q4ojjhfDFl7Rf+xIlw/1/9I84/8l3kaGexyw10OtaFmLryW3QGvRUJbTF/tBsUaEoNRVTfjRaZJ4UfI0pk4JmWXzjEQMVBfW5vIM2JRKByjhZ8A/z9arQFwI18/7LrtVfLc9+9tnXgoWXslQ2VDeivm+pjbcfNlOmtJmENkTXYELIMTMacL2I+ollnm291Qq0bQ/txblYQmfZBFZ2S7buaz9DKabIvjjGNl7I1TNtEbJFHqQOjwj+6czt2xPZWhTErCq/EWVmVQbZUpEq6hcFpy2qnPc0kqFYv+GUccFzc9NTSEq7nDPzSTi+faI7ncEk9+PDW05/+T0o2i6kAgOhVREfctFyijkukIL3KsLmRPt2LgmBJamyMlnGYaLtAmeBOWPKuL8+3vicBG2rJCsYh7zWJbnNvK8A8vLwFU1JpVxTG209BOfU0KMSvtur0qEyxidfoFFboJuP+6zgrd5P3UDOCbv9XhGloEVJtV6oUPjNb32T733ve7jTjBs10Ll9c2ZsPcO+Q0Q433Sf/pIY2Z3HxbzcvTktwV09y5Q+prSFUvu6OJVmjykb7cqEOdqgyF6MzOPEOKgcdinZxluWk6kJqmIppSBWa9fuew6HHd1uz5wyl8uF8XzR+sGszbpd45mq2pNXdTdFyd0ykCGoClDKUHs0dX6jYBkTOWpWJMaivWgsKOv6hhjXxqYRPWy7rllr8rJKHtdM1jpXKyXGiaqTDlPcOFyCC956yigal0vUFhN+bcgqdZEtgY2JRYhYKh3KnGi7GnZZwOS0V9xakyHmZ1vrAOuVpZmW1TcXBMnWzsJUnYpFgIKQ0sjHH8O7X/RQtFm05MQ8T4yjOgiLYEFd0HZwGiSgIIkrLJzBZ5cidibeQiGbQWz7HVOMDMOFUjJdf8PNfg9l5jfHn/I6PvFBvD7E6nx81lXnqcob4z1t23F/eIFzup5TUmrZnCbuXtziRTidzpxPFw32rPhYfSpDF5Ol4ESN8tJ2oOj8OafS928++gTxqDCFrZM4J+5vd+RsKmppHZOUVX21847j20fmeV56wtQmujXTu9vvCE3ge+/+iOtKtM0gw6c9omWlbQaprmM2BmFr0YvWfpRnH7XYStH1hBlsESjzif7yU/xdv8gjd63nHDWjMA0X3r71vHx5SwirvHqh8KfhwO+L8OI1SAgcHwYVepJg2SAhSMQd9vy13/FmKtzGiThNlPKGcnxDjLP2VfKOu9sbYpo5n0dSVuGM3WFP17ZISpx/+l1y2NO883Vyt8N7lJorMI7Doga5PHcNTktdB6uzXIfbmdO3XjXoXkexFE8hGlCiP6tA1TpHVneNft4SbJtwRj1v1iAyL+9zUvjtd1v6vuPh1PHJ2zM//XjmS/EtO1/W4LyGRrVeeetcLUFq3ev1nFen7ZHIP7z7Ca3fq2yMdwzDxCXNcHzi/nxDCMLxfOJyyVZLZopz0ULaOS3f0XatUuDePllBvf5njoW3jyf2jUfkkYYn9nKmTyNf9j8mzroO+5f3hMZzPh65PB1JU8Z3Pf1+x33bcjmdmIaR4TIu1PyYsta2TPozBFyxsHbj6Df7He3Le8J+t+z9OqMONmp4QtzYh1K0T5o3p6vd9ziEIZ8pJnyFzaVGw5ph8zct+33H5aLsEMSr8FUpyJzwJStFtmawxBG6FkqhdYJLCbwnTvOShZWuI+NUIMXObN8IpThjpWRC05CnibZrmKdIjGkBNn3w7HYdaZ60ps2e33u/HA51FcY50e56PUOFBWhjA+4s6/m5o7Rcju90/4xflP+Opa+i6LqYp1lZNTkSh5m2bfEG0hYv7L/zLcZ/85d2T2LgxHquXW57Hu73el/7jtbqCIEly9lY7XwRnV98wAVPsJp/bTKdmXxU0MuyTFpaoqsjFXj50ZGP3muX8UHkSjG0FLQ36Cbr9cvA/s8wqb/yqqCg/seZX1tWoSsLtmqNY86JOUeGy2WhB+cUiRNE8mL/y+Y+pSYYlrocPZRUdKlaKDsjNw+13SNXace6qTaXN3/FRkHHIZerMbT2i9ZqS3/Tny4kEQPK9buSgSfXd2FndsE0HML6azsnXRBC4+jalhS1hCQaiHx6milPJ5ph4vAPvoXvOsa//YA0K6Oo1kKLVx97nKyXac2MB2919NYOpMSrejbnHF3fEoJjHmZmA/jP55ED6qO3rVvP6l9xfS6CtnptaSpl63jUS1hUAa/eVxHLa+FCgCWpf/UxthgrFei6oHm9F/jVFMlqcNdxFu7v7tnt99brSZRDnguOjAsN7+xviT/5GD9Vgw/dGGkuWrjoh956Uq33Skx05/FqfD7rfhW5Y/HICihFCqfBU0UhmgYvKgxSsqrmlVJofNCGzYbuBSteTikzjxOUjBdH3wTu7u7Y3x7IGU7nnqe2IT88Mp5Gck44O2BqfzBQdNd78C6orLmo9P8wRi06L5liaobVOVh2p6jyT7aebjkmQtMwWKsBnANr7prySjmrnPPn8+9ETIksG7K21jRqfZinmGBBss2p4i6rk1pFRkrRhqwuOMbLpIGCAKlo7Uupgbsumupw1XyWcx6xjGids2zIzpobMQRLTEK7a8wR1GyothyAH/5N4b2vekgQZ23YHceROBldwYvWaImqka0RC1Bbj2Zb3FXYZ7PGKhUqGVInknj9+iUiwuVy4enpzDyPiDtxc9gvbQymYVDK3K8J1j7zEqHtdhwOe9rSAInoWkqMDE9vOJ+OhOAVDSsJyBsQIy9zPE+q5AayrHMVOalZbhbQJsdo9X66k7I4pjkzjfOqClcS4mDXdaTSMF4G8jxyOl3MgK9iP/MUmcaRpm2RAL/5atLvFkWbqzOwGe1qUW3218Di+djwWefCs3+v/yrmI1pW1Ryp/PAzKhXXxxM7n2l7fc5CoQme3e0N2anTeD6d8a5w//JeM/FFax8z8ENp+SM/8uL+Di+Ot588rucpHnGFE45Pmp7eZULb8vDwyG6/02XnldLpnDc1zILIqMIhWaklh72jbRukXEj5SDi+T760hNffwAukHEm10N6ioy2t+FOBso1ZdSs0cyZW6G/9F69C37R87ooRLy6I/bG4RgayrdnQug9y0Tq3aytlgR6Fr98Xyp0wvHPg619IvJsykr7Fi8cPENv3ixjFYjs3zY1ZBU0yAS/rWvlFGemLkOeZJCi1t+uYJs/D45Hx/BbnUTYB1TnTfVMVmCv1R0TY7XccDjt+Opz4rfTmysEbTBhrF97yTf99DjLQSFzO3BwCN3e3kDPD+UKMEXHCzauD0oyKZkzO54uCIcsQFx4/ebCelDa6YoSEUhbWiOx69r/xHiBM47Q4XJRC2UxdZSo4p73uStGaJoeAV8e4KkZVVgV2jhQgiRBKYRpHQt8R+o54ujAk2N/c6L67jASjrInV0zvvaZqwUtFT0ixfsV6yTaBpW6ZpVhXHnGm7wMt3XlEQnh6OnC8DhJbabFxZOKpWGQz9LiXTdi0pjxas2XlguXpxjjRGXAi87L/M6+brtjVWv6tsgAq1AesAlmpLFoUKWdAQwUTUvDanT3FeqPKSEsHsw5yFaRwZL4MuaZvXOuY5Fz7pbkhGez3ddDTDjKRaYlEQayOQp5lqzqpP6ZyzNkETw+nEfC4mlNYwTdalueIrMVJmz+7xwvl2Z+cE6KKxESiaDXyuQPLc//7sQEMH59fZw5LzCumYXd4mH9fwR7SOs2wCixj5rYfCn935RSysPoeavLWUJtfs7AIAbh5kMUfP/fIKChXTr7cBF7c+l/kqmwFcozTWk9gZeCIivHhzJDye1Z9LqpRdFmprpc9e3chSwwiRWp8sXv9s2sDhZkecIoOdIznl5SwGSH/7C9I047qG+f0PUbzY0wZ9rtnOjRLNFwue0Ho8QkyJebpWUPfemWq6ZsFDG/BOiMcBKMzjzCkr40qmGR/CM4XoT1+fo6BtY0QXNBS4MkC6FlKpdVnrz0CDr5ubW+5uTzwdnxajuc2sPP/KGrgFILJBlJb7+fXe5daArB9tKjSlLEElFG67nscpLRmA6iA7C1Zuh3iF/jopiDhy15BivqIJbKk1S+BpUJk4YZ5mTo9KgaiGJYkqI7Wdon6VYif12NZoh5zQGijLdrRGiUhZZY6HYWBOmTnOjPNMHEdtxpu1sLoWua5NgevGRmtSkhqJvmsZ50IcRpzUol6TpHeiAUwpSONpxTEO2ldtGjK+6HwlQ11z1HqhxXBsrtoDyokK3QRRQziMk9JETWBFHcTaN0uVLjNKc0zTjFjvo1KRKZGNw6ABmPfqbOZUTE544+5t1rarB6MUkyDXIVIU0gKcdUvoPXlncryaAa1N0edZVfK2alDeAkQpxZ7L3MaK0En9/GIHY9nGCc/BMgpKMRYsc4oagOEy8lH8kGm8kOwe5vHM6XTkt/eJb4cPOJ0uxhVf1+xiC34NuJRTZDifOLsTT+lomTdR1aYceXo8k4sqt21KTxa6KpgSqjVFV1q1uwIHVztWFnWpkmpZNRSrK0rikIzJor+g6wLn44npMpOK9fQ7DxunvJCmmcnUpELTkBG+sL/uKfSZEGyN26SeS5Wsun2N7ddSA2wzqzUgBKUAV7pKzdAIyHgkP/5MjWscLCso3L68Z7d/h8sYefvRz5mmibePjwzRcXNzgwaxj5xOZwpw//Le9rfe0iOeH/merzNwc3vD09ORZAXZuWgvpz+dHJd44ebuhqbvefroLaXA/vaANJ4cE5fLhWkamcYZcmGelV6bcySPI3f3e/aHA+JbxjhQ5oH49sec+dqKUC9OQx2f1Z6IZChu3ReAiLY6WPwOvWsWp7RsnAU701WhrgIza+3PMv6LMfvMUHFzr9fB96JYB/SN4+uvAF4xAR+8fsXNcOILbz/k4e0T59N5AbquHUVZgjjn9PND0HtMlm0oIty+fsX9qzvicOHtw4U4R+IcF8BL1+GKvNe+ZeK80sZ9MIEAz5vdATk/IGy8SlQt3jvHq3C2n1TbA7cvbun7jvPpzHy60AfP4fUrbl7c8sHPP4Jc2B92tMEhSenxHoiiNPqMBlcxJS07cNp7Ljg9Z10baF6/YJrjwjyp9eNSDBqTvOy5UqxXqO2lhDDnQmtBHGI0/JTIJo2eAEmJKEI8nThPiVev73HOE6cBdgel4LeFOAuNQzPMzms2+nwhWjmArysmZ1Wq7HrLsDgO93cc9h03hz3DZeCjj94wnM7McyK0La5oNiLGyDDonzeHndqbnGmbRs8jr6UNswVH/f2ttk2YRvrdgb2/4eBeL15QBqPX12BjCwWJni9L2eeyyUC0blJLCvTnwTnwGRFtL1BLMKiA8e2B7ptfJf/sF4vISLa6Wg2SVASsiJBCwD+N+JitZZId7BW0rY55ySBh+Q7nBFJkmCLOi9XX67rYdi5KKfOVp1u+mf/Js40LGLX0LAP/++7/1Hh1Q8P/rKsGQwoa1iBl84LNOa5/k6sMjNbTGQhkNeY6dIXfPWb8MDLtTBXbsv9fneC7Xij52ddsvkP9t6QME7QWuWTzQR3YIXIVLElZBb0Eo8cWrdF1eRMgKjRhj7bWQVcffD2fhcPjhf40wMV6A8Zo6r7rmhKxfqJVNNc2btM2zOO89I4FEK992PaHHfM4M54v5i+t9ZFbvG3+8BPrY6c0SLEzZprSch42XaPAr1Eu55jNZ9OPUVXKhr5vTOxHGC8z4rOKDZnwn/oypuwumGLnc8/r+vocBW161c1VUEpTep49exZe16OjOqqn4xNPT49X6MBnfk9FYe29kZrdqQ1gPztge24Ur/9eNxV4V4zvv7mPlBaFI3GeJoRlUdcaM03/rgsubRCUT31Pyle3WbOQ22Auzur8N01jCy4tDl3MtshKjfRYlKU0HjFZ99mQjgKuqKDC6XgmlTPjMJhwR1IDlDO4sNzWdfa0opZay3a5XBRty1obIJr+sYBgfWZ9FFXM0y7zhTmjUvtpdXbqYRmsBsCJugVTYTETfEjUAAAgAElEQVQ0db2McwJfaPsGZ9mzpvF0bUNBuAyDZqKKBg21xjAZrSQVaFt0U1eJ4ZKNR29BYm1kLbq2XNNw+8f/Hk9/8mfkcbI1AfOUcJ09dyn8efkD/niGpq0AltEnqQ3U4XS+6AhVNGyzWtM0IoZMAVzmonUQxdE2jsM+KFWhCMMwMk4qYiD1EN24lurQ1swcm+ylZrBC8JyOT7puo9ZqiW+0xibN4GfS+Q2X88UAmE+jir/MvlVnN6fEeD4R+4lSJu3TkkQdy5jQ6KowjiqDvxSWb84+VYtV2qzzDsFRzElTZwJ7dgHnydN0ZSSc6NqnQHYOT+Ty+MAJx3kYGU9n8C2d0ZF13y1PuNxHnCOvQqJrAy6UjcGtReWbd9SxstooluDts67KmV9/4uzeBWdvt8xsAaYj80ffZ5onhmEkjrNRveDDDz6mbVrariG4zDBmjk9H7l6/MEq5cP/injcfP3A8juTyqK072kATAkmEvw57OhHelYHDzZ7HN49aNyozJxpO6NkyTRMpdsQUOV8KBEc+FcbLoCqx3quSWevZtyrrHFNmiolffPhEeHvi/uU973zhC7Qh8HQ8Mn3yI+T+PWpGe+s41DneBkdXNZ6lZs2WCguqJ1rB5BUU0pC+Khiu76tntFKpa72FuRCLP6uYlADOMsRrGL8VMFnEVerclcLQ7Bh8R5My+ylyuQxKu6xnQVkzbOprrfdYAZqYCq5r6PuW4oSf/eR9hvOggLlTKfj1WfS7q9R+LhDahiaoSNBh3zOcjoS2o+v7enBsABq1S20TuO1bYi7sgwrTpBBoX7xUMO58om0bDi/u6G7v+Nv3f87TwxN918FBxUrI41Ie0Nj/xDtoOxJwHiZySvRdy94oWc67tf4M9d8XjuFmJRSK1dFvKPROe4INU1RwhMKuVcdryIF+1yoN3gnxMjI7debSOPDxB0qlbja1f9g6wIm27phGpWXDEtRkgSSO4rTtTBZhvKhw0le/8R6dD/zoRz/i4aM3dgaqY901iupfMmqkcmK6DJxKoeu7RVHZeVW9dUGQ3nqlApfxQrPfc/A3NNLrGWRjLbD0w1v2ygIs/DLkLROCY5qsWbZT4Secp6liFoALzbJGpLYGOOxJQdWHC5qRLqXw8cu9UknNGROBh6+9wxd/+ma5XzGK465rGKfENM/We1Lf5pyjC54xZbzH6o+usy7byxfHXdrjaTfLpVCt5YtU+G+O/5X6ONtFZYfGpz61tgAqZfFJypXNBW1jkJe1Xtfo/3z/v6qgCIIUR5sd/+nTPyOXpOunK1zG/4Wc3QL6vWz/M/7rN4FC5k93f8b7zc/tu9yVD+ldDzjIwuBHC2rs4MNZcmAFkwqCXIkwWVBd3yIs1Ps6DgvDbTmrgJJwWdhdJnafHJe+wDnNRiIQ66Xpl8DRaQmvBrXO07Za0141F3JSVVEnPTe3B0qKnE+aYVv1Ej491zVgC1azPpgglgg0jdMWKXacjlNUf4Tr5R+awP7QIakQx4jftQQHp6dhAYWarqFpW9qu5eb2oL5wzKsK/i+5PmdB2+osUjJv3rxhv9/TtR1rqsIOtWfRmAI/bnmZfMZkrN+imY0aQetyhOsa0rI4QL8sSPtln10f5eq1JavRzdq0M8dEdDPOBz3vLFtUnWJxz43eaviy1YctQ4YFJNvNXdZ7ySmTnQaEMcExnpRSg8naJutd4rVfi0ed2JQyc7I+R3WcLcMznC5EYBhngsPQqTVL6ZxXNUVZBUCwMa7c75IyQ9Q0drUxxQ7h0DZMWWcmm4R4znkxqvW5SsEcO0+/7xkMcY5FXxecIMETAAmawZuiPneJCUZomsD+sCOEwDDOjOO4ZC5Tmq0Hj6dIlZw2KqWJtDjRrE8NDOom9t4tGWEP9L/3Lcq+5/aP/4Djn/xb0tNpybCmohSZczkwxpZ/+S8T//SfhmXuMUQopcw4KpJRGzlWwyAUxiHzdGy4v29omszp7PnuX0Sm+UKcM+7+ntP5TNe1zNNMaBrmaVicvCXYrqakZGCmiCNsgyAr6D0cOoo4xlGRVKRQkjpVCQ3MT6ZAtzWIWnO4rm0fVDBknqbrwxwd63GKtOcHYu45Z1X3HIaBaRg3NFWl4oYmLL36bNWiymHOqBWCOGhDQ0xVIGbdW23jdf3YnKrzr2uz23XEeeL4OJKLKXVGPdCDBALVIG2cM9aaRUfh974ws+865gxePC44y2pUp+HZ4VGDgs8ocnd27tU9VgO3pebJ9p2+TiAO5OnC8W//QmloozZnbpqWpm2W7GOh8PR0IudEjpm2a7i9OeCdZ5omgvfcv7zl7cdvuRxPDKcT/a7l/uULM57wF2HPyxLZ9T0nfyTmxFscf+r25mTqehuGC9575mni8RN1rkQ83W7H/tDTeKWNFVFApipxxpRIMfHwyRseH0986ctfJMfCmI60hwkfan2wOZmLU3R9Vi6CYqZUV0hL891qrNXhVnVRDXw12FpZBDY99TymhgDW31I+PXfL1Jo1cyKrgNPG9pTnHs4CSApD03G765Val/Im8K/gyPX3lsKipuxDy+HVS0qceHjzYJRzb86ireMq4OQqAFXIybJ0c0Tahn7fk1LizdsjN7fCzaFXRd+8Fn1WtsmcMlO2nmdm7t2uw3cd59OJOCe6/QFpe37+/i+Yjid6U4HMaabb9aqcOEfmlKzfnfbgCqAtgQ49x8vEeYr4RsWl0jhzOg0qRpDzojYLm/HNmgsoThZKnQhKEbYm6MMU2fcB3wbiFBdwUyRpLblAI9YTtBSmQRWSb1/fKJBkdiOVjMtu3Z82/wgUr3QrQTOJoWuJ80zfH/it3/4NRDx/81ff4+HxCecc/a4hzgq65KIiX+KgawM5qdjGOE5aN9M0hKDKrpRC3/b4JjCNA5dYeNl8gZ2/5fd2/wwnfg0qqmu2mcvr1fXsvLL3OQNDnROmOWrtWn2NAa1Cxm2Niw18Dp54d+DpnVtyVQU2Z371h6yowHvmvsXNWlvmfc12OYSoAKpbFR9FoIQAacKHhjmOgMrA59pbdXM/D+V9fjb/Gd9o/2jd306ztLmA+IIr1U7UcTBAORdtCf78CHiupLg5P66uDebkBP758b+4SmQC0Lir13ftP9c9vKGuVuTnP87/ATKur5XN+ypwVIB/dfhTzlwoaf3dL5pfPLtljZ6WRkUi17ZXllN3fQglOCzgV8kZeTzz6u0FEVEl86jlKAqm1x7DKnSiJeKroqVz3lqGCfNotN8WUox437K/2VFy4ul4Yhwtw2a+5HKbIps1omfDNM5L4rgJToNGpzWvY8ykqOus75TyOI+RadL1F2dlP/VdQxlnzqdxOZ8LmtVVMb7A7vaAE8dlnJhMIOdXXZ+zoE2vYgeo/uPqF/qnoZNLLl5YKQ7PXv6Zj1801W5vXWh/n2VYf12Q9lmXVAepSqOWtbZiWbpFVbhynq/vx4yQ1lOoI18bXV/xb2UNhBaxBmTj+GG/c0tjzdnU+ygwj9o2oTYGVIddle7mqTDntCBymq41oRIL9LRySCBnslh3egu64rw2EK9j4e0+VFFQs3K51HozCy6rA4RmUfSqAUpemkjXk6Y2aPZBA6cUoxnQlZJZRGgbNfqh1Sayl5OqZ5E1sNrtOnxomGY1wsF7ppRQxobSXLuuxXnHPM+Q9Xlcq9mIUrQAmKKb0TnNDlSHohQtaO76Ftd5XH9D851vc/qzv6zLkVLgId/w/fQbzNLhSzJpciilFqhW570YwmnNLTfz/fAIP3tfePlOi1CQCeZ5YDhdKAjnp0dEhEvjtR+eV1W+ugb0ftbPK/XmRAje05hMtGalG3adouqtDzwez+p05qhrQmTNaJftAbkG5yJi6zNQKNpWIcarvVdKYRwGvpx/QJ4SH8WdBWgVwCiLMqTFr9TG4fV5xHn6feB8Ui65F+F23/N4Htc5MrpYE7Vua57nDXCictEp6doeh2mlsNq9atY4PTs0FOHuugZxgXdu4LBTakSOibFEGLcB3ub8WEfs6mzY1v3WPXH1Fikg3vaN/kJEKPOZ4YMf8PjmI4bTmeADh5sDbdcSmnY5d6oy4kM+Mk+6Bodh5IMPPuLly9d0bcM8z4QQuHt5x8PbJ6Zx5nS8gDhevX6p0t4UfuJafnPX0/Y9MZ74K9crjcyQ05QSp9O8ZjdyhlzodoHdrqPrVKCJOS5tWpxzuODZ9T0lRuZGBTTe/8lP2R8OeCfktz/BvfwGElpA1jYnn+EV5RoH5XoG271QqbR1DaxZtIoWV0DAvI/lO8SecRX0ubYtNU6owdES6NtZmhf0Wq72zvPrze6WF5dHQhNUCMrW3PpFqmScSzJF3EwSR9f3vL7rebwcVdijmBqqKeMKaB+4pU7M2RpXMajqJPVdC0V7DFJgmka43fHB/o53Hj6mMgO8cypBT6KdR87imWLENw23fU/KiePTkVTgdr/j4e1bLqez5ihzwjcN8xjp9x1jMatg53spKPXZOQXiRNi1gRF4nGeaWXD9hJvm1W7WOavzIlClmCVnYi5EIJTCZZisxlvXXb/rSKUgoaGpnxKCqjV6rzTNcaKAUVGhbXsocLlovzlnTcO9yasns4+UgqTMnPR5mr7TszQ4vvGN92jbnh9+/3scL2f6fU8QMfBC5yll2PtAahp1pIsyUrTRtVKOVWDCkQVOOYMXQtvysnmX3+n/CTfupVLlRMWVsmzc7o3fsV1j25+smTmhcR3vdt9mHP9CWR1hYtd3uq+oAasGS2HXLwIbucCwa3j7+obglAnjRYiuIO5ZyQwKJjy+2vP6PJCS0umcBc8xJWsgb2ei02BPWwkI2u7AgLymZRqGpY6uZpaFFbjYfnNtoq58QAtWpa4sC+IEawS+sauANii/FgVZn2tdmzUZlms7Dyn4hX2znQcb9avgqyz3svifcn0SLtV59oH1/f/h9O8vd1LPoH+b/4oslf6mD6qPvp57Ja93pUClfX7KZDv4SoGjP/Gj9kf4pwvd+28ZwRTF9Sx2JsFfNRbE7HztV1eKDlrOmThNJsRiZ7NztH3Hrtfs29PjWWn29iw18VEp3wrMmxCcBe3OaZsn75TOm3JhnJMx4tR37A8t5LV5veTCZdbPHy8zlEJMmTla32RTKEfWGQjOkaaJaZyZpvhrQrbPVdBWH6JcZXau0Amp2lju6j0VXb4ybfZxDUZ9fP5tcm0My+b/l5/VoIO/W/C2OFVAqZ2Kn9GZnifKrxzaGo9ZENb2QYvv57QGY6IbMDSeftfa71Xhphber0OwOnsxKXWsZM041PGqDkl1mELbUhrNVDmrn8Kcb+xwzNmaeVe0rLAgi1s6TC2YXWlbQknZ1A+90Xmug9XFIbVNU7NJpb5moz7pgseLHqZKUXSEtlGExjnaviVmQXIiTok0JwTHzd0Nj49PxFkPcxcCKSeapkGcmAoXNk5rA9uu62gbr+he8ErDc56cI17c4lQqiLCum1zAv/OScnOAop934At8rdHC+DrxfzqOHPPFUveZUvSAqj2C1MytbSEy5ar2uZiDF2Mm4eg8CFoYO88rz9iJYx4x1DmpwIqtmNVYXFOFRQSaQmgV0S9okfbxoqqmS/BEDeYLe4n8UfiANF4DCVvsJTSBptUmz6UUpG3+f+rerVeS7DoT+9a+RERmnlOnqrq6+sL7TSIpkSONRVAyBraswTzYMAYG/GLA/8zwi9/9Yhsw/OCxDcxIA3vG0hiCSFkSRUqUmuzqrsu5ZWZE7L2XH9Zae+/MU00ZfmoHwa5zTkbGZV/W9VvfOsGGi78ouPFlXjDPC5YcZIdZVpocHEq3djKYvSoqroLcmrSWwijeKKBRxywlrWnUegEz4lkVbikFd9e3QoBBsgeTYeNZYLQ3N3uMmxHPnm7x688KSpE1FoIwtE2hIEIKlsm5tj/Qou6w8ewO2xv9/qr7pds3RKhMrPV3ACUdMb/4CW4++RiHecE0RVxcXCIOY1W4vTwtDIVTORz2M8ZJIM0vP/kEF492GGIUIqFxwOXVBW5e32JZFhwPR9zd3uLRo0fw3uGjMOGbaY9hiPgLN2LvAsgrLC41aIk9rNOIekpc4Xn2WQ0MESHEAdvNBiVnHJ2DCxGH+wPub+8QhgjQK/hHH6rTZjdhGMzUTCUiD+qCf10MSfdc21tUu883Y6maXJqprVFmMpOJqhw+P4iaw2gHK1FAg0IWGKib7cYneku+7MNnqHIuZ9eX5sOP33mCX/A9DvevpW64MDYOoDFqo+5WHycsuR4M6VmZcwEcsN1tMI4R16+lznS7mzSYUfDy8jE+uHsDhhI/eImM34JwlwqOqsu2G4HmHfYHHPcHPHryGI6A5TgLGUeWIGOIA5aUMGICDQHrcRa4vkby06Jz6IWQimLAOAQccsIhF2wUVi91vy1rbRBqB9JSBJK2KzpeRdvnFABxs8E0DfDKMCiEYQVrlkAfISN6af3ilhWTk1qaeV5xf30DFyPmRcg3huhkNWn7GscsDqcTuJmwNXuQD0gFePe9d/H02Tv46G/+Bne3d8JA6wR267NkiCOU6IMZwzhU9FDIQt+f1lWcNa2lCdEhThHkPLbuMb6z+X1s/ZMaRIAZy2j6zJy2mmE+FR3d4pYsSKQJz4dv4pPNT1HAUnbgXJWhnLM8YxgRLy8kiDsfkeZV5GouKCSQMUlCn96MCJodF8dI7A6PZVmltYoGeQaFjVZ3igAOHrSIE+c9ae2TZDVRitSNZ9TsCHS+zPExNE4BoBUEVU83vmg52UN7onbjKDnGdm4v8d8mNWxuudpT3GRDDXjbekaVF3XE+jmETXKbt9N62naC/dUB+M30nRaIOn0duRS3mkc2B9JkiMlT1VlLnnFxTPjo1R9jVbhoWoQNNgyhOsrGGVCdOedqUEvek2sbJmjQ0WlAiblgnlfkdFZn1dna0TedU0rr0+dDQByk3vS4CqO3D1JCk0uBj5LQSMuKpTCmzYAQPUgTFusitXXOSZaOvHV1NXtWggUpZ/CakNdUmc9/1fG5cNrIES52I+ZFIiSAeO++aik5zIM2d4SIq5Ilb1quO985ZJQHDpuDwrNAraiYzrDI3fH/xmGz56vRYjV6+wwad969nW+foXvVGAM2FxsQGHe3BymuBWrUQYxNIQXwY8TLT15r35HuQXV1CHOdQPwiEdgTWLMSvWFozsmq+F2YwrboOwkjGxdIHZl+z5OQMuS1sYh5T9XxNuIHed8VXDRyAhIYB1FnfHc1OSSR2eiE7nWxHhlOIvRrkqwIeQ8fBPNu+GZmh2ka8fjpE8QYcH884PrlNUpKKDljWYCrq0vs9wcUJVYJmy02u0GcpZKRUkEMvvbimucVuSShfdXM55ql9w53i6QKLdYJ0FDcsNnAjaNkTwkY3A7vxA9hW5gBbNInIJrhKOP3/v2AE9oJjdqXIoYMw53UbHF3/6JZozkXpGytMGRvSHNwU7yof7eASf+ZOUQAYE02iboiay7Y7w8n0cfqJJWCggWP+QYHI6Eoll1ra2sYhqp4iSSD2ZzF/t0KcpZsai4J7aC6N0IMoDVVK5iL4Do4Z6nJ9G1N5lRwe5yRllRhdoAI6gLZgzFGHPaH2haglILDYcG0GbG92MCHgP3tHsejZO+YgXVZ8PvfvsR2IgQu4CpihYSl6cm+NgS1vq45W+3fE2VsRoOeavPTs+oKbKSryeKC9eM/x+2r11iWFZeXO1xc7NQAacaFZYzMGIkxIq1Js9Eb+EC4vzvg7uYO0zhid7GFDw677QRi4M3ra5RccH93hHMel5c7XTOS7T76hJUBKucSWe4dYsA4jaI4c8LxMOMiGHEACUyHWVqZjAGDBw5JICcxRGAr+/K4nxFDxPDyJ3Affk/H5bxOwBwjc/a59loDDOihv3T91upgnf1oxkirJVOlLIqqO4vq+iagtq+p89vtQ3tOrk6ls42jYyaS42eP3sOXr69VTrd6k3qdjq7dvnj96hVeLm9k55cMD6nP5Zxxd5jruzcDSTYuax3rMI4YxgFHjV6vy4zddkKJASVnbC/EwVlSQugMyj0cJH8msmV79QilsGTZCrC7uMT+7gbrKv3VnDas5pLgfMA6Lxi2Wxzu9mDt2MsAMkkPxKSQ+ZgLOEld2/1hPp22Xu6RjbHuRZsvIqTCIGQQeQQ1/GMIzQ5hnTGr7SKn13TwPmLUfmkoGfNKcLlVC6/riui99BhUuedKRpbwE+Ac4jgiMxDjgPffexeH/TU+/eQThHFEDF7avWvAcmRgTRnTFCQj46QpuyOpEYsxYE2DEG8ti5D6wCPEASF4XPhHuJre1fGU4OypndI5PACcb7XJ3I2luBE6liAQA+/Gr+DLm+/j5/hTlHKHw/09gC2GGKUVCxwCF1g/OQnqSKsfsUMssybzxJ190jZiq5d2JHbCfpZ1H4eIIXqd1lNqepluUui8GOzROZFTjuCgJRXHGT/Nf4LH8UO8E74o3/elc65Ud7LJdULpRQ6TQkwtmK/BFmrbktrWfnhU09actO57MDhz70Gro0Sup0Y6Oarl0byIGuSzmlw7sTpuBGEGB5SC//QBJbBeJNvW2bUnNcT67BtMeDxv8FHnUJljBu/hY9ASE7kWMZAoa2se6a1KJEFoAqF4uXDhIIRgBWqHJsQxgFZhAufc7ldKwdJHke3/CnE0dFvOBeN2xGYzVPhkmRNAkP5+SZFwqtusIXkcogxeKbXNi9m5RmKUEytJkPkPn7EG9PhcOG3OEYbtgDBGHPazRK/rSvGnRhwBIIsethRwwyD3GrVUR6xis0nx6gaf0tqIh37ZaRjCDM1/8F2YEUpRo73An30mTk5AzukkwuG1+HbaTvDOY54XHPdH7RliXelRizIBgYxdTQPCsAEnidznvFTjty4uRm2qXAgSvVIiCahw8l4WVE6NThkuCwkJkRamB8Efd0o4F679aiy7pjwnsqEqSw6E1ngQBysrnKb2sMpSR6J2tTQkhWRzQggo7CpRBxEhjgN4FohaLloDErwI6GFACBHLKn2JhjjCB99kiJPI5MWjS2Qu8JD2AxbpAEyIs8BUFCLhiCQL1K+OXATT7cQYc+QQ3Ihvjr+L5+GbGqkGXkwv8ffulzD5RCMBEyFor7m/Sff4o/QSIXgsc4ancrbeRCh752BEWxYRsueRhvMejgooL2AizMdUI6sPs13yuzPmIrLsqFdogKT8gza6F/iVRqE0cs6FkZQ4qGgBsPUKDOWAJRxRSgeVRXPYpnHA4AlrEfx6GKJSL3uB5XHv4MnzPqYFH2HTYfrJZKwEAL3XHngGLdVmqU7qHkkfgBwhOod7JeCo9ymMZS0IziPlpM5Qm4WSM/b3RwTKiJhxOQJTCFiLx3YgfPs5Y+tWUBKDqo+aiciy+rP6F5lbse7rO9XvUMvewxy46tC196+OgsxEPR/MKMs99nf3OBxmbLZbddiUZKJ3JJnRDzoXUUQxBoQhgiDZlfs7ae3ADFxeXcIRYXexBZeM6zd3SOuKu9t7hOCw22zqnDrvQNkMpSZPSynqlBUE57B9fAkw4/b6FoeDxzQpRJKhzo70gLQAk8muOAiDocDAZkybFXE9gsYtLOgBNbOqg0teIvkaTGnGD9AJQhg5Vj9r52uwjiFasOMcSibZnoLejHob/LGGUojAxcyyBo12xDLLDGTnEaLsU9uDD68mTy6Zloybg9D8k5emu7soe+P+sNR3KAUgH7rWI2JQx3HE5cUWh3nB8X4PQGD0+8OCOI04LivcxVYgsfd7JDBCzqAgRphneYZhM2K73WCeZ6zHGZvdBOcK7u73ggjRWmvkgrysmC5GLMcDxu0GYRzBR3HGMrM0u4UwRlYjqQjsL7i1Gwa16gugxYayC7oieNsTnoDMAt0bN4PUZgUHTgUFhKz63BFrr0NgLQUpLQiD6Ju0LNjstiAiyf4UNQRByCljGAJQGAUFvrAECJjhhwgmh7RmPH33CpvtDn/3058gFWCMrjJBkwY8nfOIAZoR40o0Ys42CAjRYes9jiT6YM0Z83HGsHuE39r8p7LufXM62pqtha6VdEKM8rb+TfKcODEK4fPw+Ob4e2Bk/L37MZZlRi5FA3AFXJI6b6dETFllN5cC9mIHVk+BDP3DVZcxASk4OHbt2dRwFpNJvsuVAEUzdGbLKDu39CCFslJztTnIF7U9Zc048hJSYXEcSlNU0OVQHR6CyYtmERoaq8qbB16VBt5Y12qVCmSAAbmO6lPRbZ2H1a5sVmxzp+tpVB3tNu2ETm1VDVEDUt1VrQ4Tal+KXKdO77W/E/pz7DOZD++dsK2TkuRASk2GYAkGAE7sw1KkBQdTezYiwJOwiW40i5s4IWWGj1Gh+DPKmmqT7Pp+GoQZv/whNr/2NYCAu3/7p0ivr0GsMGbvsN0OKLngcMyYNgO890jHJCUvzmM5LlhSVhh1QIgRefRK+iTwdKfIHO+kXnRZFsS8YNCSGteRSX3W8blw2rgog54zT72l5EnhD2cOPYBmyDFphRvhJOpfiCDbKiOVgtG3aCmzFlSz4FSJzBAFSnH1nOaEt8X2q2oM7Djff4DoiaTCyjkpeJZsQ5B6Jx+wrEkLstd2rS6yakIqZ8bhMMP5exAEZmaQRSJC1E2jZV9CJdwNpNRkkPSwICvolQ1o88B6T3IawVUrxSsTpWUU1zV1DhvXn0P0ADmUo9Cd5yQNjuMQ4GNAXsXA8MFJWpks/Q81GmWTO+8QiOGK/OyDx7oKnBHDoAWnAcMYEEKEj16iS6oQSgHGcRA6WxJigJwz1uOCzAwr/ezhnUIsAjH0dc4NntH34cipwAcSaCWJEnjiv4Dn4Zui5EhFFZEa7PLdm8e3eP3sGu/84gkajE8caSkqFyfQVxkv85GU1hpo5Dm9Yz5uCZeXwKL1auNAeP+DEZ9+EgQWmE8hqd5rNEvH1TJdp0QeKiidEGb44GsNmdWBGYmO9W/iUhCRkNCgkQUo1pcAACAASURBVCfRQRJI0LqKEyzCOnSMet1e6pTQPx1/ib/aX+ColMR22LPU+k71DErJtfF180dkvNKZIwldMzkxEq/Iy4L3LzLS6PDqKPBF5zw8ZXznfYcPHxUwPDICXuwDvnRl4+pAWrlvWfEWicTJc8vvLYN+nlkzZUwSUpSf7V9CJ8/sCwK6sT/mwxscX/wE97f3GGLAbrep7FS1ELw+iBoG5kzpvI7TKHubARcCtrstUkrY7w8YpxGbzQQiwqNHFygM3FzfYl1WXL++xYecwFG+9ywSfkm+lfDpvPngsbvYgcDYXGwRYgQKY9pscdwfQRCopmXbHAkhT01AUQMjheix2U64vd1jPs4YX/8M+OA3TxbSCQybuRqiLbvWBzdKtwCrOYomHN/ieFUjy+oD231PhloNvmY8vf0wiDhpGoFZ7XFl/IUTQyfEgGWe0bLhTVlWZ1+Nq7/HArcdMI5RnAmCBBKHAbGZcQIpG4IEYyB7dNqOWNaEw/1emlsrTPZwkGbmxEDKGZvNhON+LyRTJBmkaz/AwcNFj6fPn8E54Hg4oHDBdrfFuqxY50X6yXkPIgkaMgjrukjN67Iibib5e0oSKA0CY6ryhRsKJ47CjmkbRvZSq4mR0ac2WmwGpiJJvMMQB8kaqz4Mtb2KwPgtcJzXGX4Y4AqQFqn7HIZYSbOsj5PB/420B+uKhTU/HgPIB2QNWF5dXSKvC968vpFWPbLgdAk2p4VsX5cC5/X9qck4kyWbzRZEM8pxxvG4YAgJuLThsfXSHH3WzUGE6vDYQrfAsNkTbQPYOm+Igm9N/wQMwkf4M4G5L6uc6R3o6pEECWogUha5lDoos6aSmslnaBm4ItDDQsDN5YirTxcwE2IMyKXgsD+ilAGDUavr86V1lT52lvlnQaYE7zUXLHs3JcY4TXg8PMfGXdY6YVlerq4Vg/Dp9JwE+/ogTA0Qwp/atyp6m/y3zG2TEXacjjTaeWcMfL0mZaBCMSUL1xxtZvuu7pPqXPX1uXxyreoUUntGcyDbvZvMMzldETcQkpHdbsJyXHCYV9HfTslr9DnELtcgkhO971QHZi2F8ZqACUqml4xTAVJPW2HvFkXXl6h6dxyqw0ZEuPjt72L/r/4tps0gLXtWY1V3CK5U2/e4rCjHRYeMxFkLQoS27ga8eXqJzBlJ23/trve4vD0CRAhe+BLWpSDuImIMYi+/BYnSH58Lp41ICnZLYQSl5qW6EErnpMnCqTU9pcPIfqbKk6U/ah1FfxZB4h6jl7BFgUURTusAWtNOW8hn7EI4u+g/cFjkwGn/iGEckYzWfBEst9CSkxQDq8I1HdM7VXd3e6G4jxEpN0cvqXL23msvjW7DlYe0olbYKUpJnBU4Qkncfoc4A4QiG0Hpo51mFGoRqEWeVXk7L/UQNfsByWwNozDRcWH4EDBEISohVcz3d3s4jc4IsYdDYsZikKgYsdlMAttUIhqBDnIVIMsi9M9ZncwGSZXJsgarwQmmHRD6X2MxHKdBm54SCjt4KsqMpjVmnqqAiDHCh4Cb9AJ/fvyX+FL8PjZ0Vee8d15KMRihXCeXUp0fMZY7QpU2cQBbvVtz2NBde7fzeO89iUo6R7h4FPHVrzrc3Gg9FxeBFamSr3VVrOOlVPWkWqeSeTBjXVfktQnDUjJyEshmYak/qE/LRSB/VYGfZqyIJMOGIo2LSSOpKa3IuatTPQuQ9AGM3uFyJA3RpaG21ZhJAX7JBc4V5BTaHOQELipgSQ0p05x5xThFfO09h28+J5Af8eKepOE2EYYAvHdhiphRmPDVSWC51fERVddFLOns3/6d2rudQyHrO1PnsNkYfKbMs4ALI9++wP3tLbhkTBdbzVoDpM2hz+NPdQwArEoGZPV4Yvd6hNFh2kzS0PfuXohMvEd49AEeP3Io/Oe4vb7FPC94+uk19k8eIa0F76YFUxlw4P69gGEccfX4UXtPNV7GcUBOK477g8BdQCpPnMSrW0QNIHNuBLrn9zMOhyN2jxLc3Sdwu2ed8XPe+1PNrmowUpWHAMlarnVe6vh03vL5GjUjty14VoOlu+ZZEOGz1QabtVdntt6NpDj/2f0bcJaC93Ozqi2Jrr6ExBmL2w0uLjYoKWFJ0j7Dp6LGPVf0hMDtCJmBaRQEw/3tAYOXLEApGcRe2srkFTF63B6O+GjaYRtuQCnDO8LBBfwijMKm+PgSu8tL7O/vcfvmDsdlwaPCuLvbg3PBIUmtrdXwABm0JuwutyCIk0pB+ozlwgJlUhQIgzFp/ciyrELmUfuAKUsnAacFlW0+AUayj5w0Yhb9RwrJEgORihhjjoQZcVmTOAZKNV6YJUus18opSWPwCqES5mjyDpZUBIkeWpUF8dHTHcbNhP3+gJQLovNdhMlM7mYwF2atKzE5V1Bsv0FLQRxJEDMXLMuCu/s7/PTiT/CN7T+GIx1vFoiksXRbPSCcZnmLXrEGaU2vNTIfk1DFQgCF8Y34Q2z4CV6kn+Kj5f8W2T0NCB+8i3UVWyCnDBTRkSllzQgLRJUISpZTquMKACga7K1EFJJ591r+cLw/YA1O5b3MY0oZLgbNpHiQy8jrCj9IDy5mIFktOAHv+C9h5552oRDUz87371tZ28n2uzkxaFfiPvtlsqPpjHMnsN2XTlUObJ8/dN7a7eqKAdV/1WqyAEAX4KrXoJb0EFIQC+30z8gPvmdELoCsIRkDte8pSJaySOLEkTheMYaOeA5qz3ALUrDYLwLfZhQSJz2Q2GNik0htWz9s5BQuqnLCnrWfCkADNUNEiEJQktMR82HBZjchDEI6dDyqrR681LR6wuR2+Nr4A/w8/h1+dvka2exqiMN+/3gHOIfHNwcwqc08H1GmET5GML0N9Xd6fD6cNifeNKEAwWNyXvqHKGuQHZbGtNqDk5cjangVQD7UE0v3JzvmlBHUQx+8Uc4LY9SpcQmI8UUPbvEZb/MrP+nfxyj293f3tZ+aQSWHaYQfJ+Rlroo26+K3iE4z+kVYl5wRnEAHQZLZCkMUNirNduHMMLRebyFGjJsJTB5lOYpg32xAIOz3e6RlQYyyiPOaKw0/OamDaPTtvUOdUTJjHALiNICKLHCJJgCBCobdhPuDNLh2juBKweCdMGPFAQbwZb2mU0OcNCKSc1HEhGLaASCt6sygRrJzKUhLQikZ4zRovylozYFQQI9DQM5Q1qJQG26aoWZKj8iDWFh+vHdg75SqVZjLDv4WiX+C+/UFuDg8Cs/x1P9GNRZkHbRsrrM50WkRxWf9n5rhxxDjxJg1xehuDg6RwE4dokSqtAYyZWEqRcnayBGoxBcaIbXMYq3JLLkxqrLc3RhBmbUnm2IST5MMp2Zjcwy03sAJW2SMEeuy4rZ4/A/zl/Bb8TW+u94oicipIdzWq9UstP4zuqTred47zGvCui5nbQasZYRdR6Nw2ni+sMRMnRMY0TfedfjWM4cYxfn9UmRxpAF5Z6sUIKNFMqXbM0P1Cu9ULpwrxZNMm73UWxy1+uIsjsBpEELXT7XpJBhwPCxaVB01IAbdr/YlNc67AJ8YTKuwxyqE2Vd7kTBtJhz3B8zzgnVeELYb8PgIftjhyZcdyk//FHe391jmFW9eX2OYxtbsPEhGVSDHrmbqqI6bHM47bLZb3N/f4/b2HrvdDuZb2Zry3ohF1AhQyvMhBhyOC/K6IBxvgN0z+S49dFQ1XI8K/akwymaQtFP5M+KD1Zyp55EaUHx2Rv8ba+2rZeNFwTfn0Q4ZGa6BO3lOxrv3r/Hkzce4fnODtCzdUzcn0wIZBRGeREYF7xEGCVogeNDq4X2C90XlqzLqkUIOnccQAkpOONzciYHkCaXIPXMpGIaI+/sD3Dhgf5zxevcI711tsaaC4ANiHPDuo+eYpgHOSXOM25tbHOYZqTAO84r5/l4aZcMwCYKIAQAqwM3tARcXO+SUMASPWUdyTVozyoxAUkPJuWC/Fow736xoGxqNJ/WZUJNzgKLwSIw8CShpYlen35uRqn39lnmRDDGRkhqtmKZRSUukgXNW6KqhFkTOSRDQsBsM4Kg9w3YXogNzKji+eqWBXDuvM0bbH5ELIzjZ9zVYWxq81Q7HQAwehQPWOeEvXv8hHAFf2/zjU9nb3c/kWgvsqH7STBfZ4tTxo7ONVpiBzHjP/xoebz/AF+P3JFA4JPxteY3jYZbsWhEd+KXjF/CPXn8XRIS9u8cfPvo/xLmy2p+6hyB7lgmP6Qt46o74mP8a07QBsRBMzccZKSXMaVWZQfjO7g9wFZ/hJr/AXy1/BCLJvlkvT6Nt9N7LvLE4i+qPiqy3oIq9+meYf3W0ehnHpGWqBqfmzp2ya5leeKhD6hzJhU8shV4h9DVvp9rZoJmSVbRnI2VntOdpLlfTU9WOtNfvdF4DyMrdnOvufPYODCmByUWJVpSZ1kjgqv+pexFcQIWUMESQU2CBGwZFAond0eQvgRCCw2aKIKfB3CXhbUfVx0ZatmY4TSYc5gV3N3tldgfIOzy7/DJ+8+IPJLFDBAePLT3CM3wd31mOgHIP1DgLgHm4wY/j/1i5HErKahtJS5nyQEGdHp8Lp+1qKfhPPi7InIFVNtnNZsAfvxsAaPaBW5G4RFikdqfXoRVHy9DMclsggYCkRunoCC545D77gSaUa72Ds15SrPex650aF9BbbfcLLm4OwPPPftdKf8qMZZ4VziIZsTgNGgUqUsDoHOB9ZffzWvDlQCjENSLN5FCKU1YqbZwsODNROrrIXce8aIdt5pIz0poRIqsSLIg513vmVEBIcFF6SyRlrIxDQC4OnOVnwGE+HMU4ZILzAtW8cg48BKylYAUjxKiFmh7DZmMBTjE0F4GzZu4EBzcqVmOHLKVgnmeA5DNLp6d1RVqTQNkGwRazMpEFT4hKb55LhoOAIHJmpCVhGKOwUjqB/JAj6QsVfK0NkwkXKC2RwxA9pmlASrkWdjvnsJQ75JKxX1/j9eEOPn8BtQ2EwQZZ7QfWmhri0zqoTjMzuLZJOK1Paw5z0QhYCA6smVAiiTxCafiXJYGch4OwJ2IIABM8Oc04iSROte9Tb6hSXY8GTznXJfZohc6dL90DRAhDwLquuC0BL/KI/zk/xwUf8QV3f3IN8U/4RGH9l9Nf478+fOPkfsyMZU0IRXq9GaFRP0apdM9WGPOyYAgOm8nD7aSlw9XO4x+9l9p45lMmx2YQt4DOCWLIIp1nxBfmlPTv0jujgBYvE9XsJyrMEuhlTlOS1dzvHPi2HlAyluOMkhOGcVP3/2ldAQDyYM7mDQBAhWdP06AMXgRrzg1A69wGLHd7HJcFm/e+BjddyLNdvounX/4uyk//DIc3t5iOC1gZ2cgLFNqo2Z1zGCtJgCIQqphi+EAYpwk3b25BuIMLDj4L/be3gEq3DiTYIcEhLgXZYObdPqrMjDr2Mhaurns7r0ICCeIxwJ/M38MssBnT5gSf1iqeWNdqiTh36mSby2amzykhgEyaOXaP7l5j9+Lv8Pr2Hqux7T14JkNl6DoBgyD1E6Uw5nkRaKUP8M6BedW9n+WV64pnxEC4vdtju9vCU8GyiIGUC4MhjLsWAFmXjI8z8OzqOb6Wj/o0HillvLq+x9PHV1gP97i5vhWkAjlspoDlXomCstVJO/jQ1p1zhGVZpHVMLhg3EfNR5lgCl9InMxLhrjBSWtDMYR3KnkFBa9tqdrXX6ySsl1HJEBhtrhKAXICUGGk9aFBDdPWyrvAaiJ6XBakwhhiR5hUrCKo4AEiQzcdgqwKpCD14iAM2mw0oJ8zHGTf397KeIYatQfahawUgRYBoDXaSoKIFR4QPyxxXhX56j1gKSizYHw/4i9t/jYk3eC9+E8rxXBnvAILjXO0NMdpb4IEUJkm6b6hb7nX1E0AhwAEI/grbKCQ0h7jHL8I1llUye0K9H3EZd3gHT0BMeFae4MPX74Ocwx/t/g1e0ktYs/RSxDG9yDv84PYHcBH4Zvwn+JPlvwNRQWSGG0ZgYOzcY3xv+x/r2Ai9fKEVQx7AMSOlBWtKGNyA4AluGkAgPPdfx5fC9wHOqC14CNWpYHVajAKqyqVON5t4bTbE6R7tqdKpbffO0XuoQ3qZdeqmtdCPuJc1lybOon2/6hTXTRJqC61emrwt+3biHJ4HJk+p39vpTCDr34tSbQ5SZzkEW1/2fvo2OpZes6AlM5wXAqthiIICAmoCpLkDMkZh8NgEqT0rOSPntoeYGbwkYAiaFCk4HmapZ6VB17ckOdg7xDHi8fY5fnjxnyO40L2frMed/g9AhfHLfYA9PMa4w5L2cLxg1ZKX0Vlrp/8fOG3EQs1PDMzHBcuSMO0XfIFH3D8vgG8sW00AtAzM+WFqjiUsD3aEVf94VOIIJgu2Ce1qNYm6TSby9dSAJki6v8cvA8BmP+PxqzvQu+8KdMO+r1/35ISNyp8ac0HZ0aTXGGC1Tfv7A8jNku4vBc5BYYYagWRWKlGpP0rLjKgKhpiF4r4wlrLWWrLMjdSkN/ShY5XWBVyEu3YYB2w3A2bFnQ8bIfNIa8IQg/RzOy4Vpjhsg2ByAbgwAGWVptfeI0aH5AB2ArOKqnBkY5xmVsRPa78TGK7rWVSUHdAYpEgxwKUULLMorDBGhEEyObzKddZlBZFAsYT9MUtjYSJIT6uieH2PaQyYSWCgpOyPfZLdB2G29Jqet4xGCMpAtRhEpIDYwWPARJfIRMgsBoAjwTSPg6yVjfOIwaCssoqthYApwN78a6u87QIJqgoDqBjEVIWAMCapUoTACT1Y4SRB/TKBeGbvMB9mnEMv+3t1W+WtMqZ9x2oq6OQzgVkC/+3hS2AU5VZ8+/XOHUN/htuv9TulNGPDIoJAi4CywGCc7rcPn0S8cxXx1cdJGg6DQZRxwjBW79s5n1X9nRvjp4rtfI+dKjVp6UCdoyY90iDKy7lOHvXqmDtF3ozROlf6HWYg3fwS8/0bOCLEnj5fHbcaLQVg0JeUpAY0pVXlS9A1jpNoL5FXDL7WqqpONaNkePw+Hn9wgx+lhN+9+ViZcxnDFBSWZgpYxjrnVq9ScptvqdNlOA8JNqxCzBHicDpHDMl6ECRYozCo1BWdN0OoPqjMRBeQgDp+8qt4j6X+TV/yZP21NSDTXTTS267fhr2tR4O3F7ZZPDWy7CecsLXKv5vjHm4+4PGLn+P2bkZ+a9RYAmMxhioPjGGPvAS4LLsj0GIHZoc1M5AlM7dwxjKvCMEhRpL6tFywrLM4BrkFVDkXzMcZnLPIDgDXN3f45QBsjzfAuuIWAbcXT/DoybsAM968vlaIkQ59FmoI60sl3Ati0FTDlRx8Ye0pJ7JymQVyKKQRQHaEu2XFcV5l/XgSdmkd1Aor7+ZcHA6DX7V9653oMJsvFZRgSHDtuN9jTgXDEJD3BxBL0132Hnd3B6BkxGnEssxgYvggAc6gLJQpZYxDVGcXWFkyHRcXW1iLkjcvX+D1mxsMw4DYNaHOde3o5uRca8yMrY5MVugzW/yN7P2Cx0DSKnJeVqw6hsaQLPTp6tSSGZVZnTOG8Z3a3tIVBetv2C1HzVi168vfAI4TLpdLvPY3FQkwTiM204hplLZGXCQITCD8/v531Tlv+8Lkj4u6lxzh98b/QiF8VNeUzLg5JGLNPeMv4tv+P8RfHf4QqVxr4Ehk8jvxA2z8Jb49/UfWuu3UHiBSNnK7LqkG0lyo66noekmO+v26Ad5Wj0Ynv+nfOplvf+P6H1iG6cH3Ou/u1D2EboNWywoSlkjuril3MNn94E3Onr3dpL+GXbvKWEabR1LEna6zprfP7mYBkpIBctI3dEmY51kCQFpi0p5F30yZYSTo7JoPwQyeF+x/9JfYfOurKMuKcZDkRM4Fx/0i0+4chsFrv+EBP7j4z+ApqM0uSQFCAbnWE9De0eD3hYERO3wj/i7+bPkXVVekJSFuQi3F+lXH58JpK8xVAM9ZGlsyF2xvZix3C/jJdHJ+Lcx+cCVCo1mWQS7OA6M0A3ZcBOKBxiYJJjircSg2iYr97nc6mrIV+0+EzrhfENeEi5sDSBljwmYE+QAyp08X6QggvrqGCwFgKeAOQ5RFo1BHK5gkGRgAQlkbR2FFlAaABakUpGWVqGQRGtM4BjgvTbQzszArZmGIDNE/qMNr0DqqRp+wsTlcXl6AopcFPA5C3LEklJSxMmEYA9xmFCd7XpDWFTEEqTdxDnEYVbgwUmasqYBZHTR0BpTWdskmk/HPWeq7CFLjGLyyQk4T7m73lRXLoD+ukLCAKitYXhPiNCFuPY6HWXr+MDAOEpEBEdYsMKA4BMlKsbAlmiwJMSjTUEbKBTllNdO5wj5Sag1/zQlNqxj9MXqFvxKu3FN8OH4bP/cf1+bLwUt/EGdKBZI9KEoKgrq+O+Oim7cqzepnunD0ObhoB5hqa+pnhAazIVEteRbnO3iPzAXzslYoG+tYn2e73nZU50mf6Pvh5YNziASa1eryQjVX7XPgVOGf3zaA8d1wgx+lqxPniFnrRL3QAR8PxxODl0vGtJ3w/pXDs4uAb77rAGKsCWeNQU73yen4s8qG9vdzp/T0XU6dtUqy4jTAoVF3p0qOyPR4B9tCP8NOx+dhtrXJMF2TRdetM0YunMxj73ISiRGcVqm7WdcVw2ZXg0m9oUIQUy1onU/OBXn/BmH3VAI2+qzj1XNc7a8RD58qKYOvjmFzOkVpl2WtRqXchMEKkypa+ygJEgI5qVPMqryJZB57HMopTFuemtGPWctYWWTE6tZOxt0CRN1Ris3rgylHncTuHqhOgjnJ9Jadq5/rz3yyv+VaRMDl/gZPXvw95tt73B3FWbEcUffQGMcRu8udtCZZs86ZZpCdyJiiDqHA+RZhdtQenigFKwSxsNns4IiwJqVlVwiPPbe090CltE5pBTmP/f0BPzoQwpLwLM84RmC72eFiO+Dm+gZvXt9UUidiqWeblwSTfkHJb0q31p2TPSPwJsvIdftAR+5aWTCJZO3Hr3yhOwcA9xkhc95P147pF7j2WZ073WspZ6lvOUg/Jmh9L5TMyQE4zhL4DDHA+QAPOcdrjICJ4KcR67wCOWOj/e+IWAlI7jGvwjSZi1MQkTA6m9Nv+keyQDpehVC86JUm71H3CEgdKQAhiA7+ZPlrvBu+iIBt3QaF+/Us+0XsoIKCooHTzhg3R6QKM80+M4NrsJt0XxQMacD7v3iGN1+61e1HmNYRj26vEIJQppdcAHZdDy1gpFMHjGHOUq8Z217t/Jr6uQVFPwy/jhADbjevAJY1Ro7wYfw2Jrezx6rXrC687uf+M7t+Lx+qzdP9bsFZlejdHu5qausXuDrcOhPdPNLJefI90xNtrG0N9P/2IqxLiTz4Ww+67t/kRO701zgXXw/ObUiCWhcJHfcqQu1Zz+xW1Qu5FHh4rOuK+bhiTVpiBGgPReUK0PZQ5/ryXD/z4Yjjj3+CfHOHtBmlIXuQ4LnX2laof1F7+OaMxVpolALvCHFycM7DuQxp4KcWHikRDDMiBwTvsDoHUEFeF/Ck556RwJ0fnwunjRk4aFQsp9aT48ki2ZO9YmZ6wfO2Ok8ANbICiM/jzSju61DQKWMVKqYUmWRRQB3JXiGYQrt6eQdXhKzELwU+GfqeMX/0AukrH2J88liEdl2B3IzK6DGEiKxRKqkrK9pU2CIBskXiEPT/UQycLPRpw+BRknj3ac2IwWGIQYRILkipVBhdVMikNViWReGAnHWROIEuaWbGETAMAxYIvnyZFy2gFjhdzoRlZoRhwDAEHPZHrEmiNIEIKJLZM2NFnFEWpyRnrV+zpolCG79q4TkXrrVkKWUsSZ2PAgw+YBgjlsOM6asfYnz3Kfb/14/BEHiVD+2dCzPGUYreb29nOCStX5J5jIqbDkpDzVqbwCyEG8yoPTqsfwZpNNQ8a9aIo2gVOXeeF3gGBjcprMdo+kXJWkDh8uYCj68fSdbNEXzRf1kgG3/6pwW/9VttlTPbGmv/1RV/8vubNwU//3nG174eWhQnZRz2RzVSOjpkmO2R656ACtFzCKYd1nfr/HhIMw58P7w+O4frPioA/rflvaZE6hOdX/ctThsxvhuu8aN0dXJfi7YKTJeEOCWl+szeE96/8vj1ZxmbOON4PM/I0Zm2tb+3e5vR/TZH7e0ZNTl64h8zJKuiP4ucnh5NOXJhKUYpXTbHDgs46XUYrfk4ujE8yQSevYGtXy4Z02aDURsJt/UiF7L7Wt++kgvW/TWGvIBDy4DRdIU4TfjL8RLfyG/gY4D1zrP75ZRwe3sPYxYLMWDcThJcKwXruqrTGbDO0j/M+whnGQdqMC15f2oLgRpsS2+o9zaH2Pa1fVfNPvt+m7CzwdYh5w6y383Hg8qRk3NOgx/NPTM40Nna0Wce1wXP33yMdHOLw+2tMN9lMdTREWMRAdN2wsWjLYKP2N/vUbhzEk8g8g1aa8QjzlOtLRFVUnB7fSvQXZXLUxyxUUN6WRd1YgX2vS6rMOo6qXPzYcS7Tza4Ot7icDdjmY+4fnONTz+RnoHCRCuK9/7ugJyTOjcOJQsyJZJkaJyTfmMp5c6INESBA7zNtRm4VtPnMX7xfcxa94bO4YRe423zCzTocy4sLVV0tgqz1EzWPq/6d13bIUjtfckFcZTArCMNyJESejkhYNjvj3Be5HUcRmy2kwQ4mCVbBlJEhMxZ6xEnTb1lryv5SWFl2uMK658GBynjkjmt9azc3j+EgCXP+Hj5Gb4+/QAXtH0wGg+MXpizoeUbBGQbI9Vzzgh4SLL1nFYwBbCWd8iwsdRbQ4KE5DziccDjmwtYDwep+/a1hr/WeUH6uFJtIq9ytZNvVc7x2Tt0wbfCjA/9r4GnU/nda1cTH0ZkAaqgQmEC5+47nV4Bmr16srsVLcSuBQKMSMdx0ZYeJpxOSxFO1U8nydWpYNi1xGFuTi3Q2HbbOFSP0PSDrj1bI7ZSHh7U3u8k3NxycAAAIABJREFU4PoWr61+o9dppRKHyfpstWyfZedIqYyU7uS8Yl3ls6EmQFrtumMnvQyzkKaJfdNl2LjZdulWSjOICMf9AdZrLcQghCTe1zIjBwlO5X3CmpK8lTZot2A9kdcgiqoQUC1psvvYWi0lV+eV6DQ7e358Ppw2AuY5Y10lwt+K0oF3fvR3mK8ukDdjfcnKnsj9trSLQaMK6n3Z5qKOkEQtHrnGQ2OTuYAzndSyAAAXxtWrW0z75aSY2NK73jvk+3uUeUWBkjhVWEZjA1yTLFQ/UIVAQOEeORcgQzujC2HH8TjLazjt9ZKyLAzvqmP65OklQE4gKtoQ0vqwiZA2Eg3ptcQgHO727eVIU/uOhKCFCGkuig9uQso2dcoFaX+E95I5ycTot1oSwDCKZp+MsdIcYVfJDaTuLTBjLQWMAmTGODlMU8Td3YwlZTDPAjWJQTbHxQ7uncf12RiCUQ/enCltiDhGXD4VFikfAggKuXJi/LG+i8x7rguEiJBzQkkaMCCp1Yg6pQzLWPmaPTN4jtEIW688r3C3PoIyrAHTMpxIc9J16sjh1atm3AKo7I5NQDcB1iuH45Fxd8fSR0co9rTwdv0Mp+BkCbzddumO0xq1Xoi3Z+obQJ9DBAExBJ33+OHwKf4sXSEz8IP4Eh/6fbW3T+8p73HuDFl2qQV2M1JqTug4BPjNWFsa/PCLK8a4IDhI76u3RbQIqNTHFlek7sOT3x86aJ/luJH+jRR2YxaAKChdv1poXaoCeyiDxGFrjoUMjdUd0qmaM6UA1HYd/QM5cy/UwGEGpmkSOOUwKM2/7GtvhpD5P7q/gKK1IUUf7xSWAgDXThjCci5I3DlGEEU2DBHjNGEcPB49usAwbVGytBQ4HmUeRA4uYEjmPqWEIQ5nDpGtBYGrGMmDfSh1rHJ/AUBwfe9mmL1lA5w4AqSGJXWyFSpb5WEs6UDdmMnprO+ixBDkzuq0z9ejjGDIK778yd/ieHuL5e4grJ6m29ByC847XF5uMV1cCPzOgmAQHUXNcq0v3faW1qYpHNwHj+1uQiZGOkrv1LQw8rKCna/rGSTZr7DZYApR1sWy4v5wRD6uuHp0gatLhwkLpgTcvbmTmrQxYrN9KpBwVGmG169v4Mjh4slODVPr+aT3Yq7EnAw0GFQVXuo8Fcb+7l5JRKjNk851Qx5Q2z9vO0hqZMjWjAYxGEBWQ0uY77SXKgHkBTLFWVAXznvEIMgbq7122h6mlIJ1WeDcCmbC9mKUiD6A4CKSZTW5IBfG0Efc0PYbEbRvmGTbuCSsy4yIESU4OHi0Ju06ELC9IAZn8kEzEm8fCvmgoG8pbQEQmSNWeL8sCmICArQ9jM1RUMlK7TmIarsCAGJ0W0uGLqgijnnvNMl+lJ6mpPIT2vrJlnrbVVYuY4E3T+b8UXWgbM2dLIFaQ6gmUP/mKoOJ29+JLBDStLX9XOWekzH3zGBihfWrIwmA4eA1OymjFNT5Jdn6bXnKtewdAUDtG4K0PjoRcCjCBVFBnKj2ckuoml5RG5mgZSKo72XjKfGWrlSoCdLuAan+KKfoqHD31zr9nRS0Td6/LUPIygpAviCEQdiLg/Rmy2nFrEgOrzKhZEWjFUF7LUvC/v54wiZ+XifImSuHQU4Zy7JiHAVunrng6/QfYL5NYDiEcRBEWCA4H7vAdqd/2a4twYVn4av4cPgufnr8EwBGAmfS/C12SXd8Ppw2FlIOoxiuTgJQU4auX5Vi4QCczwxNrhtOomy+7hpWo1j6e5wanm9T1OfOnGPG5atbDHdzLTRtEVxIhDIEpYttGT0zlsjL4g6Dh/dOGQAZxQsEEETIRChpbfUdZpAza38syQyl0jDcaV1RUsL1zR7b3QYpy1jmnGU4nC0W1OcpuWCcJuTNKE6ZZu84Z6G990GiCMtRCT1aNs7gXEI9n4XcoTprDrSd4L3Hcn0jhaJO6gJSLjVzBUDgg8FDy/tFpThCyRIXWteMYYjYXm5wuDtKPyB9lgrhgThvfHuv6WsAHAXS5a0nCOA0OreuqUJtLBpjDobBsKTWzCuVbIBzCduLCcc1SwGrijtHJhKlTqo4h1RWDENAWqU3mDASOmQkzLxXZX0q9NR26wwo7Q3nkn5gGstKnG0T/Kr1K5JVuRNOzv9Vxz/ksJHtofoMnVNpilCDFOcNLOt5qhnJO1z4hKduwUveYPL6qCfRumaLWSTOjoiCC0q45dDWNjMAaab6dAf89vsJ5Eqt+yeEbm92kBZqcBcztO1p0f9qb0AGF/1spw1k1Q12fajz3xSEXafpuWI/VIPOHDdrwdAc987w7J61H2dmicrnE+fCvq6RV3M0tDXHpHApM0LtONGdehi0bdqOCEFqDFx1IZpDGMcBfA/8uAS8gRixbMXnBIQQsdmMuNhtME0jckk4HI6Y57VGHR3JvojTKKx8XjI0pSj7avPNYJFYAErxLc6lDKHD6as02I8ZKp+9DzRybRAv5l8JZRFjrukk6u5WczZiZaGadp2xE3ICLQu+/OJnuLu5FUMjKxlEsf5gcpFhHLB7fAl38Qh/f/kO7uMG3/n4Jwons+yMRpq5SHCDC1xRGQKppRJDTNgXaRwQQ8S9u8fNzV3tD5lXaRLdBwL8/QHLZoM1JVkDakB/4XCNkRxSLrgoGV9fFvzNNGCzHeDJYeueYCl7LDiAWPpdLvMMLlxrpOsCUP/K2z5gbT3D3GpAIe8TuGAdIsbNRlu+tLpo1iCbGElSy0wQ2Ge/J+Rsh2UR5mWnHiqZD0mkgdOi2WB6YLAxS7+2ZV4R4oAYxOFx3ldDLucCJoHuT9OAkS4x0ga/vfnn+DT9Lf7d/f8kwVhuRFi902NrYF0WMMQOEfkByRh4BzdUaaTDadlGDQ6BEAcZ+315gws8rcZj1TFEgDkC3VgDTp1frT0kmytx4JM60QzR9RYkImrs4DmLvCSFtTEV5DEhrlGetwA9etnGGKBWgmpOhTkKdBoGIV+9MtucVRD0df7nB6m8FPS11ArCSIbUYSK9H/fyQ5/THDrLnIIZyAz2BOP1lEfW8a6O5ml5TtG5Io8HzJz2nKJnmuxt82RDpxlPavBI6s9lQxRZ+ZCMUXUMq4jiqitP/27yBDVbR4S+cLh74E6/8glfR3eOXVzuCRJTKKeEPGekKH2PyQnHgI8BwQvTrdMSJYIEWHIRhy/Oi7TpmBVSacmStxymS6gUzKVgOa5gFJTJIWzFYfQhVHZ51Erh/gXMaZFxRGF4FxBcVL+GRbBpMTfT29ehHZ8Lpw0MhfLIL7XoGMDLb7yPNAS4zoorIIUnNoPVKLsrK40ZYmzwNtRV1dYydZEqWb7OERCCCnU9nxkXb/bY7pezjWCbSBsAei+bifkhfFM3tfce42bEStJzKJJi9rVPVCnddXUcnPMw7C9IGRtzkUhfFsd1nhchDVEHr72hMJSBgJIUwndcJKKj0EQxtn0tbGYw9oeDQi26KCXQosy6e6qQYvne7nu/DreZsPyLf42ckgg1a2rZ1ek0CBIhgwDvNEKk64GFCtXHgIvLDQ4HaWC4FsBtR/jtBuQIT3/4fdz8y3+j35HnKKVI9kyjfowCFNYxK7XWxzknBuDgJetW5DvOBBIAOHHipuCxzEkcLwjk0ZlEUGFpLRxC1KwiERIDb8pL8Ou/gnvnQxQvzGbVEWHGWoC/XG5hmeMYlVu9ZlDqsL3F/+KTwMWZD3ESGfv/cvSKsN+XNoeWQaxujq6Nb9IN3Nm5zPJ5dB4+RqQ14Z9vf4H/5vCN2vagyYH2/O291OBlxnM/498b3+BfrQqxJJmTdx4FXO0cfv1ZhnexRulbBgwAN1jCybtxe34bW/vZggRtXNo17feTzzqDx57PDHxXx7F6m2cWR3OyzLHnqrhQa6z6ZVHv3T25I8IYA444NjkHNTQI1Uhn1r6QJHu0dybPG53387kuovzGcYBBbuTNqD03M8ZR58GSxyyBKgrCersoDTeBsRwXHOe5yjK1UDBupEa2lILoSTMX7W25UB3DlFYsx0Vh4R6NNMbAbZ1s1/+f2xRvG1uxN7k5K50TLc+iWQbqIPydHLf7nY4ro9GPyprwYDw+3GF78xL88iVe3x9rzzx7ByO0cs5j2gzYXe7w6slzfLp7ap4r3gxbEG7qdWVeCN5pU/uUMQynwK3CQFoWHA6HGvmdD0eJOiuqAmsWO0rZm4mVpp2loB4sE80M7O9XpGGSwN26ghVunwtjQ1v89u6f4dP1b/BXyx/hWO6Rk8D9Zw08ppQrskYylKQkJNZXUcfaVBJkXRcAcAHjOOL+7g5eoeG2rln1ha9ypa0B8zss0JvWLL3DCEoY1NgTx2lAyBIcJu8wDoPWTUP1jLDjpWwsvg7W5sG5Tm6UIr2pvMe3pt/Fs/AVMAjPwlfwfPg6rumPkZNk3UJXKmL6gSHIj6y12ikJ+YxXJmOuTl6b51M7QxAh6wz8ePlf8Xz6GpwGTB5AyE+OHsrVuYXiXYN1zA1QZDqhBnX0mtaexmbjfrvHiw9e4sOfvafPy7WvHtszyScncgfUWrCYY9Jv7f6ebENoOtxZ1rpzZrh0GSiBexZ7VVsvpqKrSO+vApUTEhQRMVGaIDB7qNeVnX3aXUUdOxtHQ0dw0wuwdUtVBlTdA5MCVB2Zh6YEV+eR+vcj1PXTZujc0ND/2L6xz+uAd+/TJkECCs6BUtEMql39fJ2pLc/iYA9jxLJoy6ey6OVMzwr7qPdBanCdQahlEcYhwjmPcZOR1kWct2XBPLc+x9LmBsq50LgWgKIQ/hGb7Sj30HeTfwOsF50O6ckicxpI7Z/XQexAcabfNjGnx+fDaTs7Chgv8oz3/Sh/sAJb+UV+B4G5iQDbdI5c7b0EKOGIDoID4Xf2vwXURqfNMOrBKXd0wI82fw4ujIvrA/yaMM4JxSAnbEZo+34pBVgTohJ+2IYii/BxQUnAvJ8x74UgwUg4iCT75YUiU6LeJEYNs/SN6sWAFeOyNoYm32CHFZ5k4xFMhDUjsiiJyTBN1SkjUrKSbBhjoVJNi0cpVs9G8DECcBLd6LI//Tojko0BQGpSFOrpvIMPsqhrpNPkmjLzxCgKT5gnXTW6p2msdPf+yRXc40fioKaEZUn1egx5t5zlHXyQBuY5ZRyPsxgfqvScl/ooB03zewJxy7wxC6xzmRf4SeG5zBLBqUaTsmeVgqiCNKrMzJkBKqBUcP+LFxjeuQC/E2H2JSACcuGM//34aRV8zgOcq3kJg4LUwdW1ZfPZZ21MgMiaLiLcqQmRbpbqdyrLJJkxqYahrkdZ7xKNOiVlMC3VzoGSNPxgeFHV8nkErjDDSHI3WPFPh1/gOR361zv5nn23vy+Rw3ceMV5gxOZRwOAFNv14A1yMAMHXd3zw8k2XdgKX0OuJFsl9eJw6aO2CLQoOwPXkIk7/bepXnMRSDXywRcz1vBrUOFXK59Fg+649TDEDBIDbPEbcvAFd78WIs2ekFtCyvxm86WSuWPsv2Vqxvc7C5LiuSdsBBPjdU8CPlZCAGUi3L7AeD1iWjB/HHV4qbHWYBmw2I5z3OBwW5FWM2yUV5HXGugi8HETaBwvwzmGaBtzd3GE+SnbOB989rxAEFWbMxxUpZVxcXgDOg7bvVsIGeQExoJmpGeqWQ2fjEu7qo/q5P+nr1RladY82g6bODXNDenR6hu1UM5YgRsIXXv0c76wH7O+PeL0/IueOHbJbe+MUsdlucPP0PdwNG1xvLuuaKQB+uXuCD/gXFV0gDKEeQBYSJSVi6mMHaV1xd3+P42EGkavo/kF7W65rgtd6w2wBllzgh0H0EivEUo+UClCAeZ2xLAueMGF3PODVvOLL4+/gng/Y4Dm+kH4HPz7+L0gsBth8WOB2DrOSJBEZLNXVn0XGqayqbIVU9cfFo8dwjqQWklXPCtQGDTZn8tQIfOSaPgQUXcdxGAC3ahcdc9i0tYQPkrVSQjAjaPHkgeDgA9W9nZPVv6jNkE/hWeuyIOexylxzPJz2q5VSBam91hiTLgkh4olDhGcppyhcEKLAMr2NGQnpmtgQWg5BUs9NziEGjwMJFNksK5NZ1qT44Y7oNweq7IEPcEGaHRfVHdYqxk6tq6QPULYt0wxmPnUcUd+92zfV2jdZ3F2acMJ1II4JP3gR7n+qzkPbx718r06w/r2NC50qrs5Zrvu+u07p5HtzOHVNkpQw24uYM9OybMZiXq3gk6Pe72y8z4bqVI5Bxv1E8xGdzFUduqrOZP2dO1qdpJPPzEZB2xPkzMaDsLqbfXHucJ/obO2f6zwKF0UfmP6SjHdNKJQiz5sBhrTBWOZVSeSgfAMOJQQ4JROpffqgaATnql3tnPRQHieDMZsTrP4GUFvWnIxRN2dVQ5i9RVRh1s6FhxN5dnxunLZ+nRcA1yXhPTecnqCSqkYbqG0usDpozuE3lm/jy8sXH9hcxMDjfIVesXY7pp6XXcbFTcbP5j+BX4QyP2XWTMzZg5uBZd8tEDjF4QhyDwsKje3Keo2ZcWAEFzF45JQgxcWl4uFTzlhTFmIANZJrXd1biCPIEcYhgoKvlP9mnBkkkEtGGAes8yKBsSDF36WwMDZuJ6Q1acG9wzgFOB9FKZSC4KXI0yJg/Ti44DCNG9C91Nl5B2HOCgExRBQn28xXgxeqiFsETu0BcJHNVEA1G0alAM4jF9YIrm4uCLTSMmnjNIqiDbLhSu7rHJ0WlYoBbaxcogRMuQPLmoF8kOhuDIBzovRKAZVcX11S6QVG/+rJ1T5XK64Rwx5EV+qIdUsbDQrHDKDQqdxHM9bPjXbLhprjReQ0SmTwFxGKw1irIVpW4YFwsOeSuiokbvTYZ0EK6FgZs99brnTye+87pZwRNbKc1iO+61+Lk8sBwHLigNZtX5Vmy+69G1f88FnCfjuCHkAKmpR/6PC18e0/ehhF/uy/V2dNBXbvHFa2xWpANPXTHAHSjI383eAosvbQlNeZQkVtNv+WZ21egPwbt3BhwLQZMB+FTMhvFB4DPnl35taT0sB7pZsD06uyVhmH/REpZWy3G5VDIwo7IJdag3P38pc4vnkD7wgfIaKMAVfbCeM0wUcP7wM22x1effIpbu/2gJOaBHtlW3fFnDeW/pXWo5GV/IjBanzK/tsfjiI3hwCGA8cLYaOtorrbAB1stNa0woz4k9FscwB+8DcxivTsOkf6OZnzDjXy9AqnVqGcXAr4449xF1WuFj7ZXrk4xAhcXO4wbQa8uniKl5dPkdh1xlyPfugDEAxHRZrXpiOO84xpkog0M1BSwu31He73e4CFNCuDMY7aM8wRvA+1RjoXNYocYxo3ePXqBi54hOCrkbalGTkn7PdHMAOPPOGdKWING3xl9xtwmqnZ8rdwdfkY/+7w32ugTBzvy0db5C7LaPuNlSRLanRc3TeADNswTXj8eIfXr66RCxB8UCdTBAo51LrEXnKw1u7EISA7h8IO201ELqHqDNZ1w1zgvDBBF8cIlf6bkYpCFZ2wKZPuT9L5CN5rQ/AuQKI6pAXfxMSzHnprFmc7hFCdVRgNv/3ODJpGxCj12qHqBZNF0jTdLBNbH95Lv1GnWfga6LMlzacSvfkZcpKQXLUMPZWCkhNWiFNo42KyvD9E5+rN9LNiRT4MSG80AEbQ0K3t0wud/b2zDcFA6XQEgWqLJVYPhk7ezC4h8MZaEmnyu0tFFS0yI3cKOT8VGr0VT9VxpJMYqAraWpP2cKxsfFqmsf33xDGjLtvffW4/v5XITwUkUzu3H5F2bTv93IbufrKgSBf8fOBcqk73Vbk0Mh2qLDWn1+8wPZJEIEJxktF1BLWDxf4TUnHfrX2Zq3VdcTzMwnkwjfDBCZKBpNWVkCCVyqB9OkSEL0/fw1V4D+awnXyOJofUjURPdGhjkc0F9y0IJfWuGZ9lh9jxuXHagOZFewDfClu8KAtukCA5G4miOuZu4vovS6T9q+uX8KXjB+hjFjblhc+XuUbV7PqQ+x/TNT7a/5+gvGJeUjNKuw1ktTui3aygQvqapFwQCsNRE7793nNak2WtDgSVVFDAGKYRQxGIg9VdHQ9HNGx0ATtxxKBOak4FpzBPcVAM226DG2LAZhqwLhLxy+sKF7WAMxfwKoX7uWQc5gVhGBBDEIcvBkzbEey9EKNAlJYnh6QL0mnPOQ0hAMzYXE4Yp6HC3+rzQQz+zOdUrGL0GeGCd6IQcs6SvmYAi7Q0CGrU5VVgixRIjYAVRISo/YWILQLS3d9JHSJ5L9lIRkcFR3AuYPCyRkouWJZVp1igRSZ6nbOSXhlj8g73y4L5sGA3xcrI6fXypJRzxRUkV+CLw3/15i/qtRkAnBTC2sIReCdEmKNB58xPaDU8Ag/OiQAO7fsZWBeL0n720duORF0dFFps4jRGYY5I27sA8Af/D3Vv2qNbcpyJPZGZZ3mXqrpr39srm91UkxQXiZJIjSQSnNFiSoLgGQsayPYP8M/wXzH8wRjAhgEJMDwwxtBIMAWMpJE0kkiRFFex99t9t6p6t3NOZvhDRGTmeasuNR9bh+xbVe9yTi6RsccTzbu4TYf8un1GonqGdCYpecv1Aof9oMX+V/tN1d8/sr2QIqN1Cbss+ejoe3OmaoXT9X1hBtdVFeCasRQjLH/dUh242hM3F4mihHFeA1MsZil5hggJM46LoKsjPvV7V8an/KzWGRI59IsOu90Bh/0BLiNbVWvlHMBTMcar2rtcjF3NRYTeHmCg61qkZM6Vqvk8BMxknxKmJLzh9PQU/f034LoFQvAI4zn44j3sV0tcXu5ABHRtm1NUTcZZQbknSYHNCnpCdkXbOm0vN4jThNVqhaZbwD/3ybwulU1TGU8AEQusebajGMcUUf9+VZWwszM3hPNhMeXTATlLBMUdK98R+ggxIsWEi/0BXdsgeMIwaryTCIuFw/rsBNPyFN+6+TygBsuczmUOn3j0Ni6MftjSbwQFktjjsB9w6Eb0vYEkSWopJ0vjk0hwv+glEtN4rBctUpyksTQDh3HCol9gt9mBmbE+WaIJHi0twZywjo/B4x6Ik8poh8+HiM/c/F14X6DUHRGW/DJ+efX7+NvNv8c5zrHfDwjBY7lcZnQ1cVIWKG1R9AzYQ6OyXY/Tsxu4eHKB/WGP/qzX+QgAVmis9+CE/dZaTZQaLyRR9qQ1SUTbLtSRipyeyCT9mMRxJan9hhjJKWVFNCZBhRZ+FTMNxpREIERRXJtG+nQ659AE6RElPJiwXKzRLxYYLi5wOEzoOgach2UHWVRafjgBy3I04y/1ea8NC1lCAjmH0DSAOmv+av8H+OLi387Q7sBRcjeyU02NNHNSVK/pJHMrlZKhQfPPlFevKKukdauOXan9oiqr5DpWmOWF1hybzEKlN2ZnECqLhPOpJyHIbDi6GkFXmVLi8jCpdSsARTl9uhaoswEystNGjbT6MrCRDJREFl2T7yZCyeA6WrMrBtbR35gZZCVFtDb2qPrOFamY9TdcwyXnz6Xq39kAhUHp7axti/QHJScO7KJfV/PLxf9qDJE4qZ2uvzivAWb5XFRkypgkuuycpVMWQ90F4QfTGLF6+T7C2Sl23/0hUoW+Xst95z36cIJAbaaFPK38l7mV9PdratSctsYgBS+KED2WY8pRvmddHzGjzaYsk9hDmKzTtMR8JQYM9dboJmt3lA02oCIpkqiOEGU58Fmu6q0ICU+mdzBOg+bnX6/MlTMjFC/Ghc/FoMIwKqI1D5R6CCKTaDqkFbZEWC56nNxY4/x8C2z3Mk7nCqiFE2MiKnoaqUHBKYl302mUjrWua4qZWRGksLtbdNLIeBRPJk9JkZYY0lvGgRJj3A+4xCW81vdFZkzDhLDws55PZlsQOSw/9RqaszWICKc/+xns/+ZbAlrp6hS7YiwnLYRg7W0j3gaBAU9J0j77vtUImTwoaSSLbE0ZYEiIu3EOhynlvWyCR+MEWGFMku5p29k00koB3mkfGimEFiWAYRC7iQUqNqYk+qFL8OblqdIKkXUzniHTmVKWjBbUu/vk9gVOLp/i7rs3xetCIiwtBVQMGyX1WgagRD+ukiZXgk9XgcW7ZN7O68j5OsfClTtz+WnpDGZI1SjiJzTilIZiAFQGEVcLkgvTHSE0jbb6sFQD8zSqkEpzZTgllrQjFcbAPDXUjFmdXTFiKq/fNatQreFVpnmsUGQGbfVl5qVkSEFx9SlxvszFZ63s1Os7N4qfPU5RXBJmSpDWlWUAEQKa2x8HDRusVgvsdns07Yi2a1Xg1feq1+/IoLMxJnGe7Hd7TT9cIYQG7uw+/Pp28SxClPB2scaN+y+pokDwJ8/BLdbwbYOTxQIh3ERa9JimhO1uh8PuACKgaZorHlKL/7GBC1R7HJnBacJhe8B+f0DbdeiXPcLt10HQul1jyjMHEfTcQfmz8WtdiyM0znrvr9uVrKNpqhBzFHmkA7WehzOGkVdMzuprT97B1DY47A9I+4NOVIRdt1ji9GyBYXmKH954vjybGOb+Lgq2prgZTepZBY8APG4tVng8DdhsBKjCGqWTpqRbNsBi0UuxvXNI44TN5gAXI2LXo1kscNovJaXycoO2bdE2Lc78PXy2+xp8/ADx0R/gcvMIcVJIdpaSgcYHIDhF33Mqn4EbeA6fXf0qvuO+jsf+ITaXWzgPdH2P4BVtkx3Me51r2Z1ElUIr4ADb86d4en6Jvgu48ytfRApeoq3eo+86hOAwTQHDPmbQmnpjQ/AIyw6Hw4RIDq5pgBThVI47b7Vi6oxz4vB0rLAyjsTgQEDTSjbLfj+o7JQNMYhvEGF9uhawrpRwnj7AbbwEJA8C47Xui3iw/BF2l5cYhwnDOKHX/oRX40260UTaHaTmMYUnZ2U08/AK9ArICLxFfyKAQkYjzJGe/wqhURtzchRr2VDen8+CZ7W7IEuDrc4T5jZLmVO5n6QPzpGYK3trzheq8Vr5CutakI5ByhFgxnpOAAAgAElEQVQVBM94Y86YUMcQKWiNPYvLOK84TtPszZkBV/NlMkOFoVFezjXSti4Z6p6s4o0Ku8k10mUN5jlNZoTNDS/7u95lk8tUUR8ffTLfSVlvTg+vDB0A6N0Zlv0ZDocPMaQETlDwO4eQgWOqMbHSMaujiSA8PnNvZHTm4Ansjc0m7TUseq9ksUnJjiNgsWzhTtdoXrmPw2YLPDoHHj6egXEBwKo/wyqcVTRIhZ7rbbXVML2foPqNWQGMpbuBNiywc3s4illvj+kYzGR+fWSMtlqxIniE8AZOEbE6v49H9wccSMxwU/zk8M6dFKZs0xFhlIeU9ASQHU59SxXxt6dv4NvbP8V4GGdMToqGvXjI2IpKLbwpSkpisZat7qFuuWPIT1wxa28RHiZ1uCQs2gY4OxUGPgm0c9Jc/qYJ8MFjHA/5gNp9u64FvMdhpw11yQ6WrG2j9WQxAaHt4PaC0GVC3YpkvfxTwDq0f0yKEdMgPYBCG0AbVRpj1D2IszSelKbc74zNGFGmZDzSEDRnTNI+nyRd8bAXkAIBT3BiweSzL784L8IzQnoDEbP2zDA0KlEEqZHwt4TkrT+QCVCoss3VIRS4VwFFKKH2JvgMJc6Z4elwbH4g7bNSaKw0aJV6tykm/OftQ+zjhFFTjaZkjcWL8Di+7CXrnVS/tloS7t4VTsWJEV3C2Rnhxg2Hx4/jzLAxA8yMr/pR1xkPV2u5MBsfEeG1sMUrYVsZedUZ0++kmAT1NDFG9boRAcElOOcz+qelIg2HIRsM2YBj7XtEJYJLNB9j5gHlkNtOHc2jfq0oNMUjbGeEBJlLz68h82Uxdq0CU0Rf7WGWcbrq7+O1nys2tm9c0SYpuqilYxaDqxiuBIDO7mGFKKiM+x3IERaLXpRN0sbb1GS6B/mCaoXMRbDfH7C53GAcRpzdOMPp6Qm62y+BTu4JD6yWnUDA2UkZez4gWq9KhGmasA9niP1tLNYX2F5upJ/gIqFtFSGyWphyi0oZYcZ0GHDYH3A4DGj7Dqv1Es3qFuCbekHntGD3NEXHDDXda+Fl8z2opqfy4+ouq81WqRAVXeh4Ue3tzKDSq2lCTgF1JGd0seqxWi2xWZ3hndO7mZZEHF4j6wBwFB4+V7mAOEW8tD7BB3GP890eu+0ObrWQ2kQfwBCni/cOy+VC0q1VLWLvwG0rhf4hwFHC44ePkWLCYtHibvsxfKL9FXgEJL6Hyf0UpvEtdRqJERHagM45TS1U/mBpfACea16DCx7fCX+CR/QIm8s9xjFhuezR9B2CQeqniMQJPrRau+0wHiZ8+MEj7Pd7PLd+Gc8vXseuWeAC0i5C1lPT4p0icObU4LKT7Yv3wD8YsNtLts1q0YGdKtV27NUBh1SlNKkXq9ZBmIFhnLTVidBu13dYLsXbLuBjojxyYvzj/q/BiHit+ZIYKwR0TUDXt9jsBhz2A5qmQQimGluUSPV+dXCAWOp+ksq07Fg6omsG4JpKnzhW0u1jdpArfpnPYzkQWdHVlEkzTAv/qwyvbAAWo4JsjXVsbAAe9hLzEUWXM5YbpOvr5ixFPpO4MrkctUP+qJ5JXS8g16GJ/qLGZEyVQg6Q9ioEYV4zZwAnzELnNd9Qfcf0GWO7DORIzTxkWnSfkiKJwlNsenav4/nakMrtqntfI/Rnn1Mmn7jeHv1lLlM5j0lpsyYZ43sAnmtexwfj97Bpn2DcDeq0Fp2XvczBUt/zzVFkm/1h7ov8GF0IEY3yalK8i1w44qWGeRoiphCwfvE+hsOI5uMvwb+SsP/2DzC8/T4kQ8ih71b46bOv4n73OohURzDdoFqLHLM1IVxlRqEa4/PNJ/H+8B1cuieaRszwjb8WGbS+PkJGm8zIOcJ68RWE8BLuEMGdE55O39fVr3aeK6IGF0IqVAQptKXZITe5Wf6SzxIRfjT8Jd5P3xCCwbFiKlDilJKk4xnjt1CmWu6cvDaSTKDk58nDrN4mra8wT5mlFY1DxIcfPkG3khST3eGQidaMxBQj4jRW47LHlxQsW09TxgFC2waEfoEURzjv4bsl0mGnvXmEKH2QOToWhMmkGohzBHZOC0UZbdPAeZ9h3bNHzDwEamjGUVJKWKN+k9aTea15kAJ7DSWLxJiN3weP0HgQiwGcyJRVypvjSQpPU0zgKSKEIP25VPlnMlh+oRNSxSHGCIpGMFrjoAXewjRFkHjv0TbSwwhqVNpYZaplD4y2qjIZnb+E6P04iUAiMS7HKeI/bx9jO4yIMSJOEn1JnNCZvlmx1eqx8EFQNW2fzcC7c5dw/3mJYiYGiBlnp8DZGeHRI2TjBpgbB7VOSyRKa11HVu+L8fbagdI44Le7t7Dmw+x+eW2onPGUzLFgyE4OrlHnh3diHDuHD1c3cGO/waptkKaI7eUWKSnNEHLqaTFEqRovz8Z9vJZHo5spWfWnSqSQ8lo7zdIQOtTorNKPy4eu5i2VYK/e85qLL7RH2QC1mj1HvtzG0Erz3L1Cl88HnOdo0h8A3biLdPcuTh98Hw8/eIjLzRZAwtnJGk3j4JtOzx5B8nIcyCDyIWlw0zTh8nKDzWaH5WqN9ckC7e2XQavbgEZxY73vRh+VoAbUSNJ6oCmKIovlHSxuA4QfYbfdYrfdI04JfduAgjiq7B5Z+UmMcRoxTqPU600Jy0WH5XqNZnkD7uxFkBltuh6iVOnwNFIjyPRz550MvxBOMeJRnZ0KLIKNhioKO9K1CjPmoqQVIsu/vn36HF457BGaBmkcxDhiYL1eY7M+w7snd5G8L/R3zUUa2Z3iJOesMvYBsTUa73B6doLUeGwvN9hugdV6ibYNOASPaZzQtQ36JsB55dJeWmaQb9H1DcZhwoePH+EwDGjaBjfoRbze/go6twYnOd9N8IqUrBH/BExTxOryP4Bv/D4SN2ASPl63T7jTvIrGdfgv9H8jtFvsNls8fTJg1zbouh5t28ATMCVGSiPiPmG/P2A4HEBEuLO8h8+vfx1rfxP/gB+C1BA1j7yBpjiS1N85X2N0L97H8ON30bcBaRyAZQ8ki2AUBGVJ9y4MlYCcLi+Q58Lv9rsD4hQ1I8bh5DM/Bfzj2wIUxYzNdgekBApiIL81fBOvNl/K6sPr/S/hyfoB9odHOBwOEo1eSJ2yAGuVHU5GZwnZgSyRGC4Npamk8ZHz8OQwKGKrI4c3ui/LWoBnjZPFKe4qtlMMhxk96nNzrS4L4FdBnC7RN6dngu1cGfMwA1ONGDEGqnNJagAdGaFZL2KUptc24CODLf8o7Bq1DXrFYXONA8cicrISEZKep7dzBEqcx+10LnWcys5nbewQisF4fFkvt6NRFBj/Ssm1J5S5XHdH7WHMLE5nV+0pbLx6t+MaPFmUGdcsn1fLSktCjmaRh8IAmq5DGEaMkZEcY5wmkJPaT4OGyqMtIll001Qlv2a5R9V+S7RVSjI8fObZjGmISFEyu2qnsPMO3SsvYHzvQzTB4TMn/xKn3V3c6V/WfSLlwYVWynqXOdqY8tqzpfcXmg0hAKOURznv0RxF946vj5DRJukGq/4r6PqXoWxP/p9IO1VTJXR1wSpCATOe3D7HyeVT3HxwBlRKKXBVabNcU+aEf9z/Db57+ecgL9GYFKWBnxg0QtTjFCVVxDsgSUG3pflNGhly2nON2c0NtirlKhfYq7JjClrTBIwxYfvoqUbGPFJkGIrhNEZYf5w6GpCSFFeS9pyon2NM3YUW1HjEaURH0mB7m0bEw1Br4IjG5B0hpohxmCSypIicw2FAu+zRtAHDXhCfzHDN/Ew9QFNMUiiq47UccR6jlgLZHpPARnN1D1ViJfLnpSCfYjF2VYENjcdy0WfGURcWAyT93QCwooYN44jDbgAngSJfLju4IMqdJ8GQKwZMgncsqGlTqWuLIvUBIljmlXmRpzghjrIuKTGGUfsqMaFhhuMkvdtSwh89fRs/Ot/joE1wC+MHwqJIlMyjOOHjrzo8eEB4/ITQkB3fhAhC4ghE1hRUvZd6wByA/379Ku41i5mxBYjB//fDU/zJ7j2deNkDcEHIlCdJym7fNmBH8Jzw681beMFt0U4C0808p4U5wy19jkLr4Z1H07yAvv2iOCcUAfZB9wgPl+/hyekdfPrhj3BAEeomHBIDL20eYVyuMYZKQa8ug1Y3tMBcg1bRa25ZQC4LAYmslzPrNV3TadoTQYB1DEwI3uMnsVo7lVLWVKPGAdM0YooRnqM6cUTZngBEphz1KZEwy+1XZ4fmx8sNFZwoGxSsRljA5M4Q2ku4w4jzJxc4HEacnJygbYE4DcpDq4URVQKb3R6Hyy2GYcBitcBi2YKX97DnHths5Bwk5c8G924qHZFCMButCuIskUT+gxnM/YtYLnuMj97E4bDH44ePMQ0DvKJEejVkkwETKTDTNI1wPuD0bI31yQkWL3xOYGHN4K3FRvZGJzB57SlnfM/UU4m6j8NYlCqNsPdtgCcWRxBHJHZw2mzYlAanKkaCy6XOJWon0mo8jPMaZKNR75EWZ1jtlxjjhP15RNN4nC6XWK4XGNcrtKvFkQpjzyhyLsaIV97/kaAN1luqLR1caOCbBt3d13CWBqQf/h02F5eYhhHLkx437tzAOA5SdxHEYRgUzTdRAHHExfklnj69RPCEmzdOcNLcxWfDr8FxK8qUD3A+gbteHHyjOhoB7LcHTOM3cbH5Ayy6X0fXd1itFgjkUZKNgDN3Hz+3/G/x1/yHaEPAYThgvz1gtz3XuswKlxyS/h8ah1Vzgp8/+TdaV8d49e9ewn/57N/PFCuOCdM0AiRp+JRlKuDI45W/v4+1+x38hfs/sN8NSDGi71rs9wc9g4DTVgdzY4UA4io9irDVs5N7uHmP7sXn8cLJZ/Dij58DAFx2F/j6g3+H7XaPcb/HyIw/T3+IXzz91yAQzsJ9/MLJ7+JPdv8OF5eX2O32CMGhbUKWeZq4CUAif6SOGAZjSlBjQGqBGQp8AoZvO/TLBR59uEFk6Wm1pucwxSiIrKaUZmNBAVQq5EKL+pQSl3L+oWfPDAOuziGY6i6FeT+Z08w+0K+WS42BGjSjNtbyi+bMzymD1U3qzwGldEbfq7f1utZZc90SFQ/mrAOZYewQEdmJQZ3va8l1OmczotXYz/edj9qmVbO3WjXOb9SzLWsr/DfLB1R7pntcP2v23PqhtRFmtGeK0OyhBGs3VxuQ9fWpxVfxV/wE4yIibbYaDGAcUgT6HsE5WATTbsyuXpvrDNGyKJwipilhHKXVCBha50ZonKRpr375C+Dgs/7S9i26sxN8wv93eP7N59D5lQZPasP3qhFcVkV0r7JUhU/ZsohT1MM1Lfz+gEmR2xH+GRhtzjVYn/wM+ubzWbioDxoJwCv/8AK+9dPfB3BEmPZTtGIAAHtGcnUMzqohZk/MB+wyPsTj8R185/JPMQ0TiIBu0aHtWkwGPW2Fttpkr23bqkhVhAcnl71CgBgJksNaECQZAIUA1zVI+wGWBkgsiuJIJJ44ClifLhHagPOnexx2G2loCihRaXqllwPgtcYsHkEIk3rNGVEg+uOo4waa3iM9KYwwxYhRoXnF0yC4juMwIEWfa9swRbSLDqENGPaHLAhEu1cjgAlxYkxT0ggEtG4MeWzeBzCRAqqU/awjhJZK6hzDBYeGHaht0XRN7sUCVsQgZfFJ6wIYkCbZ1geENA3mMElapjEqcSPDgaS2rGbE5Eqag/bYccseFC2fnOE8gRUxLyrARoGtlfHfb97AzfAC3nUPc8pkHCN+0d9GpAs8oJ00DCIxMpx3+KV/4bGjbSHZJEqlbxzutB2WTYf/af2G6u4GqZxw6bZ4c/8OYif7GJJDs+nwO/09nC3W9Qkqaw7gy/0CXz69n40sS//LRo8aLX96eIBvD08xjhM2aY+vth/gDX8u6bx5/1gjUlKvtlj2aP0ppBowArgEa+F3jlxhRGJg0bboVz0uVmucdqcgACfjGunx+UwxTTEhHg44u3OG2zdPMDadKteu2sJsfaOk9pjhVSl8VXMUA3SZfR/C+M1fyhCHBMchRw0BS+1NGqW07xfVwzzylqok6V3VRsiDZIyaGpgdS7ZlDFDF3/J75gACIZry6QwSOmGcGFjchRsnnIQO2/YJdudbHPYPEUJA2zVo2zbzksM0YtztMQyDRGucw+17d7HoO7iT+8Dqrsw3St2vpLQUNcE8u945EANDLHWOQs5mEBEMIp5oBW5vguNjrE7WOBwGDPsROAwFFhoVXwgNlicn6NoWoV2Abr2B/cggTABJo1Ikg4lHdnbJdRX0BlVtWJ1mJS1YCLtdzPJJsiOQ53rlclZ/ZSopACQk+FIHWbxDogykiMMh4nxieLgMnrGfItKQcD4k7PYDamUhkxnUGGU5tz5GVa01skEelCLIB4AEut8dRnC3xMmLn0Z48F1cPj3H+ZMtnN9jueyxXPVoQitZCszY7/bYbHbYHaS5dr9YYrFai/F965OIuwZTGhEOQCAnaW2rXwZWH8KPf4Hkbori7z02i7tYLX4d3jfSc08dRFFTDc0ZucItfK7/TXz/8J+wc+do24P2PpuKcq1p4otwgpaW+PzitxDIoseAH3yW1ykx2o1HYIcmBXRpAaCkVpMj3H3nBm5tboHDhFVzC8P0IZ4+eYr+/nNSnzYOUi/DANS5K4IIqEI0ABjD4YDdTlr8NF2LsFpi+QufRbNt8NIPXs6672lo8dnF1/BXF/8XJmhvuPOEaRFzFmZPN/HFs3+NPzv8IS735wABy+USwVepcoqASuDs2NSMtqxUs4K6gAguNFj0DeI0Yr/dAAws6UyygVCML2jP01QrqtlgJW2oXsuWmqcpcIxSbKlvo5pFZz1tzvHmZkfR95D3/1h3rnVkyv+k+fevuejY4BCrqzhWnvE9G8Isw+aI1yU1eIuOqNLEdB2ivNa2FqCrRnH9zDLU+cB4SjMjzpyk8j3bwco5rfefW6ZWFVf4IB9bh1TGa5+xxZjr6XImKvZavQcE9PiF1e/h6+l/QYoRu90hl4Uf9gdwa03pkfUTs/TTNcxXRCoLXARLsOMwSFoxp4S277BoF/hY/3N4bfHz+G78Y4x3bmK7GwRkT/e8DT1O/A0sm5MyX4vu6ryZ5wQ1q3Ej5HIKIZArQ8XnFr+Fr4//K4LfYtIshKb5yWbZR8RoO8Oi+1mQETYpGpTO9R8/9c5c17QDRIVg6iJUu2qBVpSJsnrvjz/ENzb/L4bxkJkUK8PsuhZ+IU2tx3HUlEaHlCJa1yF0CqUfI6T5tRg4UGWJ6u6LeQiM5uYp+pdfwPa7P9K5W5SKiqEyDRj2AW3bYLVsMOxJw7dj/qzVIgHIqFXH8KR2pZiw2+zQaEPSEVI7Z7D2tmycBPnSaaNw8YooKIR3mA6jrPk4om0C9t5L75XszTelNGWhJW1lNDqRKibknEJDF6ZBjQlOp+mavnhUGQCsaXZeToxT1LQORQqaptwaoVkvpRGpQi4nJEX0lHFETVsMzhU44JmwMbKTNfKLDos3XsX4rR8Aea4yP0nxkEhAylFQB0oBr4dfAQCcxw5PcS4RWefQNA1+99ZrsKNeCmMdtj/e4e8/+93cN8/2vW0Dfuf2i7gRzvSsAGCHQAQEh1vDKcKPPd567T1MIeK5t+7g/lt3xJt8UsZs9Vnyt6aHKmeuvf/2vi3Ib+I1/EZKeLK9xF9d/B0+gQ8xTiiR1IqWiQhN26Dv72PRfgmOThDjBvvxP2GMH2TjbhjfwX7/ltCgO0Va3sC5fw5EHc52l4gxSl3bDLgjYZxGXG62OL/YYAwDDBI6qWC0FEnx8orn2QRKrq8gBtjyHY0/lGfIMhTUquQIrRo2c3ZtBpYq62QmnoMZ1o7K+oAUcVHp2owcu4JGt+XJdfRXUO9QvWavA0kVIUmVTtlFzjndlVfPgZZ30fs30bQ77C8eIY4jDts9Dgp8YfWl0Bl0fYe2bTG5FS65h0sL4GJTZp7Zbp16K7+MCuFv9yvcV73aWaNQ/tzcBNobAL+Frmc0iy3SYZPp0TzTzhH86o7WmQK8vosxAcRTVvqzkC9WdKbjq6oOnmF9yWXtD0RTMGCfck5yShf0/KSEUk5ee1ev59HMDKdRge+dvYCX0rvwhwGH4YDWR2xcwIP+FLPQ/pUx2tzkZ2iC1j0pL1aEu+EwYOwCXnn0Nt68cQ9P+zXaW6/ipHuK3eN3MBxGbDZ7bC73otjr4C2FKwSPxeoE7e1XQIubSARc8iX+evG3AIAX3fNoRg8aPW5Mp3A3/ht0oUdafCXzuZWnDOaRI/6xGLP2PwLhzN3HF/p/g7emb2LPT4AWlZ+lZAzcDq/iZngZlY4qZ48sNU/25qXv3cPp5VpkFhVFy2QxA0BgEDp8bvk1fBP/EQ8u38TDDz7E3bu3AddiOgyIueeaUWWCI2mFQADiNOLycodxnND1HbquxfJTr8G1klp6vr7EycUqK/nrZoUTdwsX0wNQJLzRflWycWCKIuNm8zxeP/sCvvHw/8OwP8A5h8Wik1ZAtXFRRQQsopbB15yD10yXpuuxWi7w5OFjDIcRvgn4VP9rOE7AQ5bBNc3a+ivtaQSPiHL/KeG14n4nNRlKna6mR87FjYB1QbiuU2PCyB6o9/7ouu71IrqAojaWK6fuiUVxJTPLsi2ueV6OLpbFKB9lhnA6w1nU1gdHkci8kFyiszLHYog7hji/aTZyHcM1Q9NafYuOHr9vbOLY3Jj/du2Es46cP8mZM8jvbv48o+2s4xFQG6L5c0y407yKB/33EWPC/iDOKWZgGCQzoWmk9QUfG5hcRkvquLSSlBiF3w2HATFKY+yXVj+Ns/YmXmm/AOc8frr9Nfz48bvYLd6bGaKLbYe7b9/J6wwg81+T2/VMGYVcBJqU5COmhqCmPdEXCIDXrDo3RXBkbeL97OsjYbSJV7gwiVK7YYbbnIHM0IaOCIDp6DDIuzPiZTDe3X0H3778OvbjttzPhL2e1dC24kV3Dkk9ys47xBjRBg/fBAyqrBqUaNMENaq42sF6sph5jfPLTmq4yBEwRkzjBO8cpqqBrM2zLuS09XA+ANoGoP6saVQJLEoZA2kcxfszTWJwqFfT0oO8l0bXRB5TarHoW/i2xeV0jpQidvuD1JsFjyF7nMn045lSYd4kRwR4SbfxPqDtgnj427Y6xPkfRRWD5uEnZULi0R8fPES4dxvd7RtInDAMg6CLkqZiJkZoFdrZW2+XORMyTy5Y01+PlaBKAWIdfzSur6fQjAMThI6twTmjaTy6RY/e91gsFwAS+kWHc0U2attGvdkLgXxN9YOllk4akY/5wDtHuHV5AzfiqXhjzM5U682W/s62Q/92h6EdcevBDVAnghOg7LUVQVmUFAKycZszxCsnCANVo+OAu6en+NXlz2Cz32MY3kRS1M4pJgWYUeVseQ/r/ksgOlHyXCC4L2Ca/gLT9ACzBqrOYbPZYpwmLJ9cgF1Atz3Hg90Wh/3VyIgYfJMwZDiQKynDNnzKKQ0Vu9Qznor7We5Hcs7jFDNNXmHOmpIDokp5cGKkcanBECVZ+FdpOsy6l5WAPKIz+/1wGADLxKp4mnNVUTYq4zNL4SPvrL53bIjRyYsIywMWixtq10XEp29X42KQC3Cnz8MUY7e8lc9n/XwR42VWFp0tKdH500Vw5X+OTF+tFWpuviLkN+7B4272MSkCd3DL21ma2rrYbc1gKze2UVepm8BsLbMqdawcVXKk/HpcVUJXv3d8cV3zVo0hP0ONF+fxZHWG53ebjBJ8xPCrB8/loL3z/uoWnh8OCMFjynJBIxmK0ouUcPvpB3jSLuAWNxC6UyzbJRbaF3O6+AA87GyCICKEs/ug0IF8C3SnaqCwlgLI3r3ZvQN0QBMDHh/WuLe7jX79VXhCNrIBi7YU9McypQoYhDR7ghkvtZ/NtJXnWimfzCnD6gv+lFgTEyfAObRtwM1HpwjbIDXNZOBg8iCrv8pj4IQeJ/hU/xVM0x/h4eYtPPzwA6zPTtA0AQ6SMl9nkSQ9a9M0Yrs9CGhIG3Dn5Hm83H4e/P4K754+wdhOeHzvKU4uVjDAjtP+Hp5f/hQuNo/QeIe2bzMoQXWEcH/xOt5f/wAPLt7GfrMDmMVw877QecXaWJ045dzK2odAWC9bbLcbXJyfgwG82H8avVsqPZfvX3dl1Z2rh+nfUbxQufGSOFFscKWnm8jRq/e2fq2ad4Caa5a6t5oQys9iJCCHGM3RPzuh5hzQUtd8lIAMJnSdoVTTSaVhzteGLN26pg15pslY26ycaVBPxPDvISUbSPoukSBTEj2T3YgYuP79wr6O+E9++tXNyPpBfpdn716ZO65uTX0fAFdCGp4c3ui/DI+At/nbSJw0jXx+h+ikRUBxCuhqGnouSzlRSiw4CuMoiJExoe1avH72C/jU+pcQ6h7QAJ7/8R28+6n38yo458AzEMfZrunP8uwC619F4uxfRzmKyzBWaWeF8PHuF/Ct4Y/hxwkxcnZePev6SBhtwNFG66G7zpuovEAOnCkESglGiNaAGeSywiQfoPzjaXoPA++lT5c+E0QKNSow8WmK0pMlMUKrufokNTcE2dhu2WN7scM4DPAaIXqm6FYiY0bp58GmRApsvfce0UfNJ5f6FIMknnkmSDyVXS/NAPe7w9Gjao+WVF6YlBvGiOlyB0unIi9RMo4R3hXPqvcecJIi17YBoQ3gScafpggfAmgYNYKhDAjqIXOEpg3qTWV47WljY8vk76C9amTcyfpoQASvnVkBfiFBXbzYYLrcor11AwTJ0U+xALEQkQhVrbWzQup8sMFotRfOOIxoulbaQUCEbq10G7uylW/u3IR/6XnEBx+qC7PKC2fkHm5t26IJHp9f/haCF2SzoI0UiYDTpye49fgmQghKSyYkhBZX0eHFd+7jzXtvwxpvOwDrwwprrIBGPHPWD8gYrynR3a4FtgCywWaKJQIpvWkAACAASURBVCoFFnm9Zq9B0kWLeNFidJRUX8AjNDfR9V9FihvsDn8CxoApRhwOA8bDCOeWWHRfRkqrnNabEoPjEi79PNL4R2Bs8oCclyavzhHCuEd/scE+CiO7olyrZ8XQpqYpAlQcCNmRoJ93Oc2wKOYlumXGDP0EJUVpITFGjkXgZEVh3m+wKNG18Kzonwu4xbFTphb0c3ALujK28vfRd6pnyHqI44bqe/glXLPI306rs2rsJII/9GWSs+fW4y182OqMrG7Xe3/FyKyvIgDzDWyqOsY10K9Ax0ZSxUuuvHbN5xg0n/vx+7Vy/Awltb53+YTN/SrXP34lc5PM/2p6rJRBYly2S1ye3MCSE+Ad/vH07hXHElVjPR7xk26FF/QEE7RnETXwNMF5YNF5LLqAFsALm0d4a3ETAMGvbsNG165vKrhU2RNqetQRRptP/kA179gkPG3PsVvs4SePT52/hhQneAU0cVR4TIrW19QjpgmHYZDXnAdrA20wY6qfcbT39d5GTVnkxCBmvPGN1wBitENAmJqcpsVlByRtEJTR6kgj1z3O8NnVb+Cv4x/g6fZDHMaItu+xWrRYLBcYI4OjKIjDJLDiw/6AYZzQNAFn65v4/Opr6HCK8XxE/3dr/MPP/EgcpWyueMlG+dj6c7gZXkHwHl3bFMJBGe/a38YXbvwW/iz9n3h88QH22z1SSugXvcoaWw/7kkbrbLWZQX2LxXqFcRzx9OFT7A8D+mWPm83zaLiZox+iPu81AdYpdFw+lzVbbQlkMOcZvVuly7OsDgUqqvVB+6Ouo6uYhw1IdEBLYWCLdM15+uwrlWwvtXa20nT0vWKgpNk3r+OQFmFTJHG2TnPmKC21c+Wq1oNc9ZbKJUjJC4ME7M6+UUP/Z7ODZA+Pruu479wcuf79+Sv1C+V51+QulIshdOhKBLFedwbQUI/Xu3+ByBPex/ew9zscdgOmcQQnSVMPjUecWPQFa7lkd9K9iiliHCPiOGYHbL/s8fGTL+CTKzHYjmUq52WWd1zyePl7z2s5gupJ16+AyHCbP6npQUfzM/Gmnt6alT8XXsO33dcFdCVOmOI1qfvV9ZEx2mzhGJh502aCSldOlKuKqZjiFDkbRYkBSilbwHUEjhno/AKLvkdME8ZBFomIEIKgJKYEKcYmQtd3iNOEtm2QWIoYY0pwCvl62O3hScKcMUbExPBmXJaZ6MEjlMQPSzmxrvDVvFPCdrPBQA5Je6+RGpUZEpUZ+52EfKejKBugxZZE4t1UxiGGqR1SaKNvUR6dpqy0iw4hBIzDIAajpkw2XcAhpgzMQo7hgkccOSPfyUJK6t9yudBtklSivMdqhDJH8Y4mBWWJglJHnNB3LfrgEZzD4KVOKTIwjRHNC/fQvSgF3MQWHS0M1nuHrmsQtEebfBAAXC5EtXqrcRBvTtBaBSMoZmSUT2itFDmH8eETTO+8j6Cpm8waFWTGYZwwTQneaoT8EutwWxROZq2vE2O9iQFtbEzrAVLd+FmMvCY1pQUMGEkh7g1d0CtncHnURZAIE5olYRh3UbqsaMU59QQZ6zYjj3PUG5CzaIXtSIJyCbRgbtA2vwOkhMYltD4hthM4AeMhABCwm2h0mxjRtQiLX8Mw/j/wjUStnXP4/q0XMZDDcBixb3Z49dHbWKa91A6ypNNav0JqA3584z521MBp2kKZW2GuRJTz8aXWo0zfDOKyguWy92oDK6Oh4fgrR/egsobHwrCuOy1bc9X4OP69vmoDpQRp9UwT5RTd8hzKEf7je+Zz063/yXFmKqscJHJvmXNJky38wFXC8Hg6zDVYzD897+M1mH3nGZ873oF6/54VRbj6sKKe2l1nZ+0Zzy3vVp81JUFfqb9v0fvIwI9Xt/HKNKGdDthL19lMi9elGOU7sih3MZb+noA2hIY4MM7PL3G58SBO2K8YY3OqWSKuGPtugXL6jXHMlbOsN+dx0IzuiAhDM4GaiL/pvoWbuxM8f3kfPAHLIPJBfKxivMQkKIvDMIKI0DZBlBmXMOnYrS5YlD8FtfFWkjA3xCRdi7HeL4qBkRXNqtI1GwksCLXZ2JdXW17hi+t/iz/H/46L3Qab80vst4L0xjrXpOUFk+SLY7VYY708wZdOfg8N9ZI1khjdtsHq6QIv/eg+LMwj2SRA5xa4s1jgcJB+UtL2QkfOxbm5cKf48q3/AV93/xuenD/GYT9gmiIWixZNI3WIRLauMm9Wudcului6HoftDudPpIn5sl/i1cXP4F54HXWpg83fnInIFCGCyeSGpT2SRjVnBGJ3YtPdYr6PI+VXhkJGBEYEsyCkmmO5pu0rB65ixin3aZ1jDtZn/tjW46PXzFSx10oGpXJzmq/CdT/LiDR7hRQ50nidGWGZKmtjRjR/+V7hG06fyqoPyLpDgPrys0kjO8eYiyj3n3kJ6zWpeAoz+MqKXc/rZqusVnuJYFfff4bcKYvHCNTh04t/hUQjLpuH2LRPsdvuMQ4Txomlvtr7bLDZWOU+kpo8jRHWYiQ0DU6Xt3B/+Qo+tfgKHPlSezlbBtONZI0njnjrtffwyW+9ivrDZk9UnfCqBXCgWZCMZz8yT+FiADKAQB1+dvXb+MvpDzGOMfckftb1kTHagML4az3IqbJkxGD53XZ4rrsEil+iAhONGClimTq5ty7Ya/0v4nF6F08O76mCq8qgD1kopikhskDch7ZRhU0eGqN492OUxouhVSRJAwo5HpR5J7lEroZhyvURU2T4KA1ODXr38RNpJF0LaHKk1rpcKaZc5F8L9MzcsqIGgeyHeDMJADyXBoUEdF2HpmsAlp5Mg4KlCJoeSbohSX8lC1E3Icg6KVyqrTGzNvcmCw2LwjHFCeMotYCSFVfVEmiqnFcABbFYkqBiajPRDI6hSrHzDv2iwTi63Fuv6wQdbcaVk4SdU4wAQdM7HabJ43Kzx5kPENAYtZIIii4ntGH1IiacJeqkyiuk99F+twcAdF2Dpmnw2eVvIFCbU75mChZVijeR9MYzNsCMsd/jndfeAzaiwDmIJ5qdKasu38eUpqI2yb8lxaVivqK/5SbwUucyG9aMPYu3Ub2F+XWjR03VIwDJKQgLAYlAaABK0jQ7pZyHft6eg5zHe8sHuGguQfS65OyrUuCipsN6h261wDvLT+DVp++jSyP6aYRzhMtuieQ8LhdrbFc3UFKby+zzul7zs76uRH6uUYiPvfhsysQ1kZu5elCP5+prc6OKcRxN+knXLEVcytnyrdOsOuKZd4DJ/hnPuOaq16h43NWTTNBoCGdUTHcsFOm67AO24erezRV9e27+3jXTqQ1XU1h+sq0nz6mzL2Z7mG8k58Q7U16LwSLKEwDiqqzCvPJX51eUIsogSXmrrqM9WQQAkmL2gxNzTtnTOcuXHAmonlHT2a5fYZWkJrtWMMzxAyJ4AsbVEstljxKRv7JsZf2AfM6MH+Tt5iJL7EvMCu7DDPKEx+tLPF59B1Oc8PrT1xBigzVOZGaWeaI8XvoHEqaUFLJX064JQlMKMEOksoddlpEyLprTEEpqbDHK5HnFaNDPJUKpNZVPUgr40vJ/xOP2Lfxg85d4uHsXl2kv7ysIFQCEJuC0P8OnVl/Fc82rQAISaePcmJAmxsf+9iXwMiFZTTsn5GQYPVfDMKJtFTjJGrZXaaMOHb50+nv4G/r3+HDzLsZhwmaa4JsRXd+izTXhcl5dCGhCgzhFfHj+IYb9DtOU0LUdXuk/g9faL0LqslNZt4oYsrFQmSjGe606na/hYVxERmUIGI0LFuUYo9TycI5ZzMoPys2u/lq/XZT4AjZHNlpmM49mJ8XaQtWcuuYtuZpFf5rjrjYY6o9kHlONzMHk9lweMPzMWLR7zCJpCh5in7IIWn7NZDkg70Wpr7S7ZTfL8URyo+f58804P3Y4Xifp5PU53zkGHLkuk6e+Z+mXC2W1Dp9b/BZGPuDb/j9i0zzG+eGhRLDHSUsYMNNrJArJgofhHIJvcHNxD6fdDXxu9TV4l3soZZrK2W4AKBGWmx77cAARENMEwW+29MfjyastwPV8rJyrnJUZrZl+DFROEBlU61ZYN7cx+PeQpn8uzbWvSyvUvXSelAoKo9W3j4NLapzoQQSwbfZ4s30Hr+9exSJ15swBWJhhhl4G5aa+RBCEqpSykbLsGkSIIScIj4TDMGEaJrReDJ6Y5ilSM2biSjykvXsL8YOHcOMGEVJbI1DgEZzU45ISxrFEAEUYqaHiSAwMIkSNwj3Ta68eGZ00wIzEUefrpLATANRzPg4R4zRJlMmJ8JL84EkVNMI4JEjLg5CbTAtgRon2xWmSSJ2mpwTIgToMkyCXaY+7oE2uJdqmeGchAE76c0hTbokajkhXCJqI4JsG06QKI0HTSqjkyqvXKEbxYtheh+DR9YTd7oDdZov16TpHMSXl0xWGozfzJ0vg5hmw2eXDOMWI3XaPaZzQNg0Wix532pexcGuBsIdFqUxRrP+rpSI04jhhiiNimiSaxSUKHaeIaRwkNTV7RAt7tZo1ud2xr1EvYx5GE3ORU/1uHKlmymLEG0qmRXwNvZLBs6ajQzfgYfNIaNcR3unfy0a6RwDAICaEo2r0el3eW7yKPh5w47ABgfBgdTPn7BvX+Inpcj9Bk6+NBDtHV5wfNu+jtShKTH0/e/Z1BtBcuNl9Z6BrR7t2PMb6e/bp3H6MKkWqehLNHlvzCRUrqqBFc4xdM3Qicdo0oQU0YmNKrim9uZVBpRcTJM1S+JoJZn2O3jsxFIHzmHdpI+5QvzbTBgAADhIRT1zT0LUqnZ6hCdNUpwXp53V/iaQe02u/QLqmjYGaTGU3jOBBQJXyZtzKoQBtZAWrUv6kX6E0Hc9gJWyCvd6QSonK79m4ymAYHu/ceRE3L5+I0aaf7VLEzd1FXr/oPTarMzRNm1fIVUyEbT5qwNZ0zXm9AGTPflFwiCA1GilplEXH6gIa5/GjW2+hnVrcHm/jbHOKxRQAdhijOggzSIlG+PW8JVZZmWnGxqFNrjMcuNKH6RZkq2VeevuynvlUr3Sho8TQ6IQgHp7R8/jZ1W/jneY72PMldvEC7w3fEdgJcvh4/3M48bdxAy9inKZ8LwP+AokqN41TpdDqeebChT2R1tKr3K+dJzruntb4zOpX8W33J3i4F8MtjhN204SDytiyjsIvUlT57j3arsNry5/Da+0Xsy6U97VaW1uOQnJmOMh8LJmvUGRmhEWG6DzndCMTNvZvdGJIr7LlarT81zq1jow1uyxr5PjcXL1+wntceF8e3zWfNkMQKDx9dtcMcDI3eY4lhPxu6boybsq/FRlfHL5Gz3Y/kcXOeUDT+pNmJznntdxH7mVlKfnJVOnXx7KOZtyvjJtQoon1+4QcbCm3qAwa3ZtSxgC01OFzi9/Ek+ZdPGnfwZuHv8FhEkeD1Lla9pr850j07FVzgpcWn8Hd5uM48bfzSMRwqsbLnB2wYfC49+ZtPPr4U4Ak+DJEacUTFFei7E11no2pQAZQEt+NlvNy5cvN3pO7rvxNvNh/Ghf7B5jiPxejDZjPTF+9Lk+2kk35IJjMtPOYU/ES4yJcYu8PWPLCvimfTaXozzlC8C4TcFZA1BqP0wTfNkhOFFT7DBHA3gOc4EMDjEnh2VkO5DVz6u7exLBawl1sMY1m6OkhZ2mwZ7/PomxEVX8zVzHZ+Wfq15jFYPBO0ItS3RYAovhDIdCnKBEwjiJkncH1x4g4CJEmBuI4YrL7Bi9w/BRyk0+owTSME1j7pIXGz1oSAIJC1jQNyAH73VApvAQXgrRvUP2HU8K4GzQlrygyzIzhMOJwkKhgaAKmmBD3A5rGq0dZ1mGcJkwRCI7Qtp00MtRG6MNuj80lYbFaSl1hjIoCKo8y9Ca/WoLOThA3OzAxppiwV2h0R4ST9QL3Fy/jk4uvoMEJMlslZE+XbG0RIMwAUkTihKg9RXgi3H7zBt6996HQhHNYbHucvXeCKUrNo6/SBBwJgigbmh5JulBJxE0Vy4cdEqVIE7NGq3XnHBWemg7JqRig0hA86t8JlCRdNrQNfrh6E4MfEH3EBW3yvnryoKxVVcr40TGZCy/C0PR40PRFQQOunK0r6XK1klMZY/XFprDh+NxcH3l6dlqaKc41KzYvt75CAMF4DFXGGmlRo91bDZmYrh0zPCH4gCZUiq0qgs7g7ZUHOo2IxRgBjdqLd1ccQuIskb5kRBUAxDUXJ8YUxxLBIFIFukL945LCVRRuVZUJsFqhrGOgRKhM0ckjIFMyUTH3+e4BEqUV3fBI6RAmfeW7FhFhlLHWqKFgRpoiavzHaqfmdFW9/pOuBMzoKZO/yaoEpDRdnWZej+pM5vEDxSFXT1MWd2Lg3cUZsCg0HTjhYnmqnyck57Btl4D2oLxODh87Nq6sSd7nanJc1omoZBHUkQbnPGIX8X73Pi66czTJI8WEcRjx3P4uzsZT2UIWimUqq4BkqIjIQt9o3pxS1k7DUawHJccNgETryp5mpVIbSOf9IdMvGBnQgwgvdJ8GEWHkPe73r6ti53C7ebHQA0vElFjqpckTvPNwoiWLQ0PHw9XzAJHJbFvMnAHp8uYrGuGSbuGT3Vex7y7wjcv/gDFOmKYJ0yh9DG0PiGzdHXwT4EPAJ/pfwCvh83KGZ0YRl2crKm71YG0SbdEgjesQZQAx0vnY2hpwhMnvrN9APljbUVa/KG10kir8jFLDVMhs9gfPX+ej1+dC5Rmyghl41mm2Q8vXvHx8H/19xs+OhnL8+fL8Sqed/SzGEF0ZS45Pwsy7FCfEBHhP6IOHM33A+ezI4CR1xylFDArm5kwWGS/Je1WPdc7LjI7nke35xxlXli6vT+Yh1SbZ2T9z93HW3scp3UPChIfTm3h7/OZsGMyMj7U/j1N/Bw4tbjb38+tCb4VH2jJn3QvA6Ee8//JD3WLBl8CUME7CC4hQmtIfPTfvoXh3ROc2Tasi7LxnOnCbsRHqnfBx3Ox/gHH6x+tWMF8fGaMNwFwYQQ2GIyK295X3zqggq5waCSBVZEhz5pmjKLLMiJwwTlNlCROk+NPgsas0EkeyeU5qu6TQcRJDLkja3hgZLg1I0byaKMK0nhMhb+a1EP1EaLsGIwGTpkmW9MGEmCQlUGrB0jNh/mU55akOCcxOBVEFf60KVpykDi8Ej7bxoDaIN2PS8DAkmgRmbY0gQngcIlJM0jzVPEZk3hKboxhS0TmM4zRTSFISIwURGWzF1qwNAS4oCIsiAcU4lT3RZ00xYhwGMQ4dwTdBjIhphHOSBqnHFnFKAEc0bcBZdw+fW34NPzj8GR647yMlYLuV5tDL9UK+J2cQoubOmXNKCSNHHDa7bHCenqzQdR06f4Len2o9mik0VDiGUnGpvWBYHUEIXpoRc8Ir770I1zd4+tw5mhTwUz98FQ0C0AlVEYDkSTGqaAYTQoDihpBECS1N1sBYSHPsMzOulVb15HHMNZpWHJ44qaEGWESAPOAbj2+efSs3mx5oNFEOp8kzMPOwMlbqpEtjbFnp53LW6y9aGlk2tYgzOJD9Ewnw+RiW75nj10QLuRwfkAhDvon8PcWI3W5C7TxyjtD3LdquE+Urz4EyQpgpiFafSCSpUVzVyclHiyMjsSs9/rJ3+aqyTFHbVUwTPEmua0q6lmR+XY2Ac8rACjDj2vnKKDVlN83OZlEVkJ8/TRNcVIAilPEDpAaiVpKQwPowi5I6jxDM98n2LwSv9zOpGgGqKRo5qj+/GA4JcB4MlwWswP+GDEpAGo2L0ZqPlzTOet4GuQPKVABy4rRwJDwH7HTe9fiiAh+pYaCOOyKHGuY/d6vS9Td4gtkgKuFu9HJV3ZPRms3G8KjreEw+WiN4o3GY488FGFjXcg6TBkPu8648jdkkQfmMsRXb3mNQ5Dw2/a4oOOacEJ6XYsIUR+y2e2yS1OKhJ7xz9h7eTYYuK87EcUpIkfAzF58G+bIijovDg1n4WmRTbo2OU65zB6QnquOo/bOUI1g/ViLAmqMrvc5YdxUNCEho0OKWf1mNthItsyi2J4AowbPPiqhAk3PmGbXiavtv9JM3NMOJ67kz7w4xVu4MPZ/hi6vfBwC8Ofwd3tp/Q3iQko3VzXduhZ9d/g5AjBYLOIRCMLpcOZJeUV023Yyf6BvlV9MrbA0lakwoCJEZWyDTeznTbHODSQapdXfsxHBOU+blTvcoj/X4eHAlN2YPKPKgeqmcqivOuOPvl0gyUzlbMqUqOlg9Z2bs6L6XmHu5rui49diOdMkc0am+ZNoe9H3nlE/HpGA1QltN26BvOySOiClhu9+X6BsByVpW0bwG7qpjzAZDpccdVZn6JW96Nh9OmslStwdg04b0CcZczCEI4IZ/HgBw5p/Hx9qfqeYs56GhBaC8gBUNXbUvzAnBFo3t/5h8xHa1E8TmlIAgsiROE6KCJpGTsc/2k1DxHgVbY5GBTuW/0UFK4vSx7ycSViLTlKj551dfwyHs8Adv/s941vWRMdrmNSOcN1pfmHkgZwdldhdllaZ7MeN0OsHH9x8ThsmAdcP43v5PcTF+kL/lFC7X5Il4ICR9kLQWbBhHtE4g6of9AE4xW98pJUy50a6OhsoBzweLURl9pVG2aasE8YxE9SqVqI+lRtr62LpQVkCsxiinfJqnR/vIEEmqBOexWdqlHA5OLPVkjVNDTcfgAHJOG13LTx+sUBhwOh5LI2G40l8NkmYaJ1NiaGaEDodRD5msd99L4/Jhilh2LWICxvGg7QoYTdtmVEhSTwknoG0bLFatgIWMMcPi2qZOg6RrEhht1+HE30TnVvjU4leRDgkf4ocAWBr6PjrHYrlAqzV8IMm7t6M/xgn7/Rbb7YA4RnhPWJ8usOg63Ayv4PXmK9JPLtOv8rNYFeiyyn6nKX6qfDMILjAAjyY1eP3tV8BvKztjBuUTK4TlTV5xiaXlx05Wm8AgK25VUBdi5GbIWZFQxSpq81WjpZQsxUnWex/2cIEQQsAHi4d40D7MzJE5wnxIjhysFxKpkmbiOGvFmU51zMQZYSmBS2FvDVmtNOsqIdy1ASFIjztRDBOiCp5sQKgQk3qV4jlmJE3HIQDiWEgpYRylF9xxtJ8TY787aCNOHF2V5mPqh57DbIxSeTblfytiUcvyOk+wnG3KHx0RMa/QsJ8RUHCFUkVlb1kzcPN0z1Mi53UXxQhwzsM7QtN1WK1Wggyr25hYFG5SoCRyXmuUoghPqpSYJM26hX/UzWuVfo68omVcBpJR7x2QO7E6M4nKehj6oTSqxk+8crrMNe95JzRqNbVEEGdG+YT8SIr85YXGIgNBHRmcUlFkNEzUmKGnyk9ul6DzuDbTRA1BMb4FKTnBegeqGUDaZxMyJ5dNA5NxUosdo/Ffa9lxTEeQqpsKzY5B8M5Svoyfs6b1mONFeppyvpWcWSlTM9njQEGiXWMY4aYJ7IIa/Ql2Mjy8/MuMcZzwjfW3ME1TBpX63OYNeAoAM8IQ4NiDNNWrNHwnpVXKMisBOTJUoxVKSYHUXIOSRvlkRI7JOBMAYDLDNtOs0LJFxZyDpAYDIMTMoZ2HaG0wQ8hIwBwfgDOjhGUcMkCVE6xRv6RpzVqT19ISLjF+qvkSPtF8yRA04CEyDApmVbsbGJwRoBPVr6lOUhkMZprNHTHFkEB+b64UQx0lKad+2X2tXquiu8RILuKD+4+wvuhx48MTpFzOArVVGeBJWu2oc17vimdex0bcP/V69fKMQx8xEj76vTa2akkwf6A41Mr5LjV4dmUk69ow09+56gFX68kmP7INToREwvsSItKUMEwHXG4P8HoG7Ax7bcfkmOGcykQg9wgk1XWhETug6Jh2nvNY1JhhG39Vz5V/cjU5dXJleQS2ElZ1gpixSyAmNOhVV4GugQRiGKlaxoT5yhfLQfbQdBpCokn0Hp0rW8/IFDEOB4lGKqaC1Jc6QV1n03sInCS4IbKSAHWoW99G6Z3q8phMF4wozrdAHbyhxj7j+sgYbeaeSlylCujrtW1fvTz/O/9ruffGXIB7wx2AitKUvT4mFJwr6I1kJKBs2ZUHJmbs9wcFtJhEmdWc19A0mEZJPwQV5lF71ctcATtVZsRIHZsaXE6UXYmoMRyTeodTPti1YSaNmsUojTHN3jOF2JRGp+7TJoiR6h2B4eBIIlWiTDkRWgrcQSGgb7VxMUiMVe/zesaYEC3N0/RxkpRIIundRTEheH+lcSCn4uH3Xnu/jQnj4YDmbAVGwMX5pbRdaALIO42YFYJo2qANgAU+v2uLcg9IEfjhMCBOEU3wWPRrfLL/l/keP939Gr7Nf4z3Ft+F8w6H/YDtZoctE0IjoXICgL4FkvTm2VzswQx0XcBytUTbtbjbvI5P9/8qK91CBSZ1WRlQtUbZTV0LL2hxrAjnLIpo3q7dFFsDVUhsTJazMmxXUs+uI8oeULURZ15w4fl6L07g7K52SCHhafcUznm81b+Pwe1hCpptOJE6OYCMcCn6XlXzQNZ82tKPLG1OTySbcs+YJo2Gq6EyM2Ls/KujY4qiNJq3CxVi6Vz0lnS961K9dHV1jZ/xtm5vWWKu1uKq0lueQ7O/swGfXyvZASUyUYSifcc+T0pn5gw5vjfI5RTuZ02kMm+O5l/eMYOLiNG0Hdq2QZwGHAZJp/Qk621rloweqhrX2Qoor680etR7YyfB/wT9q16zogTpWVMhL/K8Ui7z3tv+m2bDmRatzqw000YWqAC0b6Qqpmyfm6l0Qs81m7MzYnszAwQo45/LMr1XVuvmn+Mj+rJ02xmtVUJS5IsaGzrfen5XRBQX58DVFK6Uowy1Kn/lvOTpKW3CUrXnAIMgiWq5IEiRPhvYpgxqHTcDQzNhnCKa2GTe98OT7wNoEWPEnYtb6CZR6DglnIwr9LGDpYX1TcCggAZyiE1WKK/NNUtlByTiAzuVArZhixb1NplnVOcvz4+qfmu2piyyxOJ+gwAAIABJREFUlqg0vTYnr8kP1rpy05yVVi2qYUAdxAUExWVSVmedrq+duxIJkNfB0Fo8JQSq6Z5AWk8nPJpyFreZrUmtCIIon86cLyLSitLPE2bsESJnjAeGbUB32WAIBzBHIBKacw+3cRijcISULGposkCzSExR1wh/psvKwWNy12SSvqinq9SXzfjUEd3PAgv2L1cJfcfppXz0WRmxymjLEzH6Q5bdc/7LkJrGIpMsQltJD/2o7F1SHZiJ4TwLJgQ8wCF/3zZ15qwDl0ionTvda/ELJCARYhqgeG7woRHEdRuv0jMZDaDihfaRrKMAIHMMR2QjVPUX6aVY6jHNwZI06yGqo8n4XopsOYxljsxHzAazweSMlxFYPV5hWJ3PdOxpjKCYwC2pnFNnDyFH5u1plprNJCnRnKD9Y2s9KWXbgJFA2dkOCZzU6sozro+O0UammM4VHGFmigrFRxE3KgIwxUp4Ui0r7OCWg0D5gPDxuSyHxm6QGHApvxwnxjQOwhpIhHjUhp7JDk59O74qzA7vPMDw5DyHiZ0q7wkATxG+UsgsuuUcgUkAUGrDJ0fCdC0szF0rfICME66kWraNR980GMBIWs9ijJuZK0Zvh4zzkpA1rNbFmxSEIis/ukfmqam91IlLnY6loQLIDa6HUby1UwQuL3cIbcjzBKT2JpgHl6Sv13LZIwRB3iSQHpJy8MZhwmE/gAD0ix6vLb90hZH+VPcrOKP7+MD9EA/8j5GmCeMwYhwnHA5ymG5++nWAgO7+XcT/n7p3+7ktSe6EfpG51t7f951Tpy5d3dXV1d12t5tu3/C0B2MxmvE8WFykMRIvg2Y0EuJhpPkD+AfggReeeAGBRpqHgRcLDUIgEBJGjASMACEb1L7IHrsv7q6+uauqq87t+/ZeKzN4iIiMyFxrf+e0x0g1S1Xn23uvtfISGRn3jHjvfaRTwWs3b+Knr/4yAOCT0xdBIRlsz8xHPDNFiZ0fQzayPBpPxZt/uJFxIVKV5UB+E7qsmLESQrbC1RzaMuFAY9AVj42mgDVrXiLkOeHPrt/D7XTGmgven37c8IAra/0SVyZJ8UcUe1ZPS2AsOu5GUq3/F1x7Z9esLQDt7AM6yEufvWLGw984rr2eB1q0GZc+xXv3aXju/nk2xjTKx8ybvykwoT7Ucpxv38YuXQi0dHw1qeeKkmS7PUwT7s4rbj/6COb59ffJ8XlQMHs4tG9N4ebu1xEmOv5xgOSs7xJsx/Mk4c6979gdDv272iGvlzDaLnSV/FwgeUPdLFsGwF189EvFioCF+/MxRbQg4kN4Ugdt7dlvTajcxZmI37y9B6NDxossFDTAIjxr7UR6aDhvnm5MhGkyw6EKRQQ5TwsxrM7ThGmaxQK+ytnedfX+33vlQ1h4VWXGo+UhjlWiN6aUcDzM+MTj1zBhUv5T9XmFWyuPo3uNAGYLkSSfV1BWbT4AXGkZANZWWr3CTAQUKy0QI3K4KWqNJ2ufVVUjW0UaFsoUoBWQ8+XZMxAWpbuUWD14esdkLjuLa5ERrMqc4U0oXiwKKJmZBpHOmqO2FRNuOOSKkCVkISZwEv53/OiABx9c4/GnnmirFdfvH3D4cEah2mznJgBLmDJpSQddG63TKUZ/4cMZEgLcpL+2N7f7P0C1ebloeHa7U4yXDQqeLDacuYb9u7/dVezkhlOCZxKt5FjXmW5hqp+Ngdvv1gL0PVIZu0FCWgulTALH8rnJa1LHtnmTJ5cVwZptNMgVPhlvkfx9wGmzGFdE4ZJSD278M5kGhm/sCY1MpCmlYlX6nMZ1MvmDAk3vyKITQSqEz37906ifr/jo9WeYKOPN77zR3qmltkQjpMeo2tajwJ+tTZZT48RFs9yS5nwIsRNqIKnF5sRb2rFzfWyUNlvA9n1QfgDfF3F/cOUWVy/WKxcG+ohj+8x4f/1TvLd8s91LOSFNqRFqy1xEGtYjfQqBWBYNy6i1nT+pldRSAPcuXBBHmRnLR09R786dYgHdjqVUSWeqYUayiE6YIuGJ40oargizXrFY8tjaMIEKAqNyXoGccUyEfJxxnjMIGXMWd3op3PqpDCxa88cKiOdJQs1KYZSlYMvYuaXwNdjoje6ZlOQcFzSssZ4XTZ4APH78FIk0QyYY6yIb5fT997C8/T7yZ96ChXyiERGBD0GUwHUtePb4GarW2ZsPE96kn0Yp7tkSJpXwqfRlvHZ4B5+fb/G7t/8DpnzCfMWtttjNZ98Cg3D1idfwlbd+A9ePrzGnCVf0SHCpACtWx5kgZrGOZV0qEsnn5bw29LSUIfIeB7+bEUM0XKlVQndMOLS6XGad4lCM2ohxR9gtxkS0LAmJnbIU+ibg9x/+kaTgB3CX7sAZW4JiwobO0cItaxNALig6cD92hE9rcnhv9FT34RgDo2zj6xWH+xQZ7/flryjQbt9/kQLXC/oSNtqtUP9mGP/4bj+m7f671M7WkBQ9nD5iZrHSThPhvFYkWvHg+oDzPOHu9oQSioBe9lrGMQ0CUMCnUYGz/i+2v6OM94JHEG12x3Z5vO3O5j0b4SXchgtqcDx5EWy2OIGGVC5ihZ7J1k/5F1HztGz78vFeGsV9eOVt7ICjayPt4KB90OQI4b6d/TRPSIUoMXe3UofpMM+4OhwAFFR9XuQmDXPU7L+1Fqyl4nQWemo0jkiefXq8xWN+1kSlRAkfvPoR+JUs/Qf6/AuPvwLR90rLHm1HC5glAzJNSWp0IuHu9g5rISBxq5VFqGDyM5+kckxtylxQ0BqNQhuDgIsbbzThtFb27NS+aTwKROe8VomiSLUCVZSVBFLlVDxlicTwIx5jFTItpZ0K6rbuNm4bn5uLY7hcVEwCyijiMtmeMI+Mh0aCPe/km99/A09efYa7V+5wfHyFT/3gTTmPC1dDDKao1EIum9Jh41Otk21fsCjHmRh2TlbgWJuh0UYfemnTaFEQ4OGZPeUvKOjWCvdvWaIZmYvyxM3xBu6+7cqScV8PtDv0YLOAQnyQTF3miBKL/WUmgAk16a8sETXT5DQ3jsg/6ujNMBPkeUvSYRIEJyClqTVhRpzKLvvYyGo1I4J+NuVd5f8WyQO4cYC0Xi8rwE0iYgtRlSvXCV989/NY/mxFAuHq2ZUkcdItZ+UzYskpm5HZximRRCjBulBcV4XZ97rKb7UiTUmU1n+elDbbGE7UGWAjHowv/c7n8Ud/+RtYD2vHMkkFSzAwEZDThE/88A28+aPX9fhMgJBtG05Y+A5nPmkbAtQcCMAa6r3QNCGTeMOKejYQigQDEDe0ecOMyELiyCMfI2gSg+sZeOVGwjRuT425l1XORwFALUWLO+vGrJK5T/YCN0TwnWBCvzKnlubXYKXhlyTM4EyEelpwkwjz8YA8H8RKlkgSf5SimZ6EfKyagGQpBSlZ0WnCcj6Jl4NjgW05mzEfJmE0CzqPUBSop8OMwzwJUy4SblpYSx1IAp9mZCcS5k7LGbwsbW2LJslo4QUKhrVI7bT1vCDnhIfXD/FLN7+Bia7D2lEgqowDXeNA1/hXHvwdWLwzVM34WvojrFXOEF2nV/GAHkpyGOs7CucNswGQMP93/vBTOP3iHYgJn//mZ4RgaIhWUYLSxMIYllvXZhUWO4EyYQXoUnSj7ySloYbjaEyboIrugZAmCa997/BjfPv4XQBA4T5hDBjNiNEiu/QghgkMvq5bodbWj9tZFbeKRc9Me43vV7Yu3XM2dkl43b+2+gA3PLbxx3vy9wXKaZzTTtdtX3csdIRb//2SUB2Vusuwkd6Y41+EeQb6y+IRP1xf4dHDB1KLUffY6bzg7nS+mJbYh2xet73QlN1JeGgOepBtRYwo2uzNMjb7IhY4vrm/nqMwd/mZcc1erud+54RPvlAA0BI+jf02C3f7x/bJ5fFuxjDsScelEer9O/fD2A0p3a/s9+3S5HWgWvB8WfH89hbNs8AsusGF4TB70jJjA/KO9S5iYmXGU7obYm/lhd/+xO8FocIUNol4qGD8/Ec/g5s0YZoqllXooSTrkjNyTGLcBEut0ZkzwEnyGoDBmpCIiaT4tQwajATm0hnqwIw5SaKW03nd7Dfjh+uifDSUK7LASNJwWC9lXcFF1OAl7MsEKXEhEes1ZKD1sjls5XhSbjzFBmImuKSlezzzpt1LrQ1C8vN1CIZyMA7nGV/+/S9CzmgCqYazsBtLGUxwlLFR1rA1QiEGyI0n8rhwHkqlncO18FBXLmzYirM7tLv7StBWU1NEennPcM8VMBFp+wDHqJ6ZoyDuZTNnOa9Ispbuf2wtxfNm9teCRsWkqkdxOELH1T9R7KQd6FtN8YqwN3jF/AkbS2boganJk67nG8wDrySAkIGEVvtPlDKZv5ylbYJkkzuo65d9odrX+Bu1x2IJcmbgyEepc8cAjjbNni/E8HijTYqKqowtkrUziUxr8CH4uWoike0LgGAJkczxZSvHxetjobSZUGhfWswryXZPmPGV3/si3v3SD9orLvRY1qqE43LAO996CyZLNX2Ggs+NJAvZmOkqFvNkFOAs79SyYjlLxsFlrViLH1iW/kVZyVncnxNRS5QBvRd4CXJKmKcZa85YybMhmQ6WkhAf1NIYp22yKJxJhJRkumxHtlN/mNUtDYSbB9cSfqiJP1JKKABuVdsnlrodoKQFsOUU6GFOmI9z8zRb/bvKjLpIenpYhjMFMBFwdZyBVx5gWST98HlZcb49w4SJNGWgSoX729Vc4tw2VM7ChMoq5wdbbH+VkJmEJPHWulMs7hqAutslJPJ0d9YC3Ef89INfwWv5bTmnp4RHPJEm5nj4QufGVmJcSoGFA6xLwbp4OmVjUvo4zPUtYxbsIwZ+5ms/1SkEiqH6VZhdrQyUVft0YdrSRouVqWpIgStmjdonUiHC8SclwpzlnOSzq+dIifCd4/fwJEs6fks84tzCvWAJpEk8/BoVlqajNMGvf44ag+uv3VC6HSUpXp1xZxjDvvzI3Xg6xkq4cM8figqO7cVxDvcJrtE7GH+LnCXej5+t0O3L9BfPIcV5S8he6dqP/cZnAaFBx+MRr776ihizqtCZZal49vy5MNEOQnE+tp4pYFCEHYfnfSwmZO+FLTn8muzeZhnHYcLWxlhlfbbx7Cky3MHjksLc/x7xr8fFS9dorY+JR7xth28fkmdj2Y4PZpgkauFrl4wKo+HjPvzt90fkLfvrGNuP+Odt9f14KGefRdAEdUsRT0AXVhrb7Q0fwzrqv6wKnAwr7jN/a9XkLA2c1jpJH7//2p+08Vro8GY+WlYj54y310/htbtXnLYq/q0FuDpkPTbAOC0Lrp9dIRuPT0BiuZ+yhmIt0CQeAd4EPS8kkRtYC+bjAVOmluUUTbRPBjmFttFklbhqRS1Co1ey5FhC9xuUlRYgrGPl0mBYqsom1qcabQzkpKn9a/J+TR1gzZ5MOtZkPBSsJXr93JkrcIrHNAFUW2IXNzT065tIDNetdmLWogUkvJXIhOqqb7scF1ZYoahGgB3NjmH4b2e0Im+L4cuNCtgq6N+YwbbfpwSjc+6xldsDjwC1PaQrJS23PWyJTACnR6zn4cwIbbhv+9PoSjjvqr+OxcTj2Iz3m8zlV8hYTCT4AZOFZexZo8Xa2eFQc1EUdtvnJOGLCl85eqSNVa2DTKosq1GBWZIsOb3pRtaKdYu33AScCGvxRJMldNPnKhImlvHpqZ3horaHPGtzabCou2fw/Pp4KG3ollsXQGGom3U+z/jpP/hcB4CouAF6IBFirhMhVqwKlq7dZOWJzSol71vI3yhALuuKepbzWutaFPkU4EBLpzzPU8tqOOWM+TCJZaFWCV+IihuLF+t8PqMs6yBAAbVKmv12li2MkxvBUjgRWpryFkppoZ2mkAA4TAnzlLCsRdtWgp3EklaIME9SP2tdK86nM+pakAAcr46YDjMqV9RVEGxVeBT1Btaqaf9NJCFNjnKYcF7FIuTjkpSzAiPWgsy+FyTc0dOKr1PF+aQMi4V5Hw52+BUwN7lckulwWQsWTTwiGSmPePXqk3g1v+VhRDVgTmCoRoZ6QQBomS/0oKkpWt1TcV+zC2YmkG6eab2Zl7c2j4Y5zYzhc1hbsI+0tWO427KOknp/BdcfHx/j2XSHQhXfP/5ARqWZIZudjW20FmK8DUHshbQ9QdYFNH8ngHnzvN0TnG05se5RgpyJyXgvKWpxPP7u2FY/RhN0LwnvLgw7nLq7e0rozvd+Dtvfbc1HgTp+3wrKvSC636aREO46t99zJlzfXOGVVx4gG/OgirLe4fb2znEwjCcqG/2k0/jL5qk9oX/vIsSTHReeIT3TOzzRGHnXc6/ImzDkty+FqbBpFds7F3EGbdTBlw4geIfG8e723bft4opTmqQTsiiBPXjtj2/oP+zv1t+uoaBXpMKdQF7H9+Le3OI7gObtMQOXeWOM6pG5S9h5e2o/ROFRPSwMWGZS2SeWoMf6I4w4YWP0PaV9YyuktitNrdbr9+b38L35PQOCwoRg4a1J6Uhl4O3DpyUzpR5vIDKeJ7A5r0VC+hUezZjDEuKVsoZ7JsKURdEy3nHAjLfOb/oQIF6Aw5T1LDmwrqWVwFhLBUrF8eoAEGFZF6yVJawSGqYGBqrWkqzc1iOlBE4Fq0jyoCTJVDIlVEvI1XiEtFZVAPcaLwCQ1PitiRsMnZKG6Nn+JKPHCaTeU2Lo2X7Htb09VbVOnqRdJ2Pc0tZmacO4G93fEcfJVU8PyVUcDmOxjIw9TYo0Id4h751r/zv7oQprsY2XI7zdXyePmxJsHjgSWEJhGYDVTtFRAjXPtbTLKSrTQO8KD3CjLSUysY30/aprmiiWQvGotjTNApfmIbV10L457N9QbkCycrvS2cbe1RTyJSAipHZUlxts7H4TwaHrmEjEQSVEiQVOMiTZ6KmNJfJcHRcDgJXhAXJvH99cHw+lrRHn8BNRsAP0f+W+/a9pxJNtJruv1osgUMjy2nmeHJQFQXA7vCrJGwl11U2nodiyxaJFmjAfDpjnCdM8t9THgkzGjICoxBOCxUcZlSgpGrutcfSA35MwAmEyFh4HIklJnzNub0+t4HcUAowxHADg7gTSdxhotbcoJ02jO2FZV0l5fzqDa8V8nJH1nBOYsNaCWrTwLDM4ZKq0uZES4NN5Qb0743jIWM4LVlVQU06t6HVKCXQQIlm1fo6XChCmk5N43aqVR9CJBVlBzniVKmmglbkxS1mCq+sjHhwe4eevfx0P85u+Dhvhx7IQ2UwYzW/Nlp5cNyEDLZU9xedjg9QYbhMwAjFnlCYYMkOLVgNErLWL5MdoiWpEWK0/NmDWcEc5HzhJqYqc8a1H38aaCoiBJ/QMzyFlE1hrejkMbRzumTMDxb7w6L/2Xo3+qe2e9t9HQa7zKFwQ4LdW+svj8jXZayvuRm+rVzTHeY0MmroxXVLW9q5eUbnfSzd66MZ29uo0WrujN89oyvZZEfCnQ8aD6ytc3zzENKlRZV3w7PYOd7d3WkvRhd4Ig5eZd+sT0W5rfPPCHGHMDVrQ9/7LFNcXXz1sRuVpbGFjeAj/tk87eH2579h2/16E5wgVq68o93pBcLwscsH2d/R4jcLKnnEARm8D/l/2zlGDfYPV3sybEuYJB/q25K8pJa64OU8HCJQTrm6OOOYJbqA0K7oo74nkexN/uaKsC57fnVCWsPpN8DMi0M81JTtxHATSNjmDISOAO+BhlF6oyTomExh/+P7Nj7r5u3WFXPjr+vNv5nVTKRf+RfAj14Rn5Ta0L21OSQx7ldkVL/3MBFxfH/F2fQuvPn9FShkpr11rkVTrqYocxZASBiw1Dc26wllr42E0TpBmGTYVIaN5m1iUOKLUKo4JflCbj0QNeP08OUvNsLNNVWHCDElrT+o18d0CU/FRqwbCSLmYpLjusqFFKwF+EktkQW4KFEOzcrUQQX/Kcc94Lqu8Co5eI50dpfa2DLb6mrJH0plh00YkqldP6yPe6a4K9Muf8ZMYITLCZkoU3qmtvd63bcd14Dho7xC17JGsbVDD6ZHnOuztsrIeslRaYxNWK9hn6PAaYGAiAPnK+6E3XSt7T+XyXvG08h2s5YeolbhItSITUJHEmGBLFTGNqJULIR9GTxv1SNLL8tCPhdImm6+hv/7VuHpEYU83VbK0/kM7lBrRNNGAiAciqinJQ0aZWiPmaNYhrc92vDqicsVaCspSNFOkjO1wmHC4OoJIiBDIMkgGJg9FeiWsImBnTIcZp7OERyadp1lJ17DgU0qtHhAlc7dX5CRp+/NhQmHG6e6kGZt65p+JMCVhammeMR8PqGCczyuW0wqgYqlnVI2RXs7iUZymhOlwEAWveO03LlLLolg5ABXypynhcJw185cUsn7y9BaHqwllXdr5vGkWRTApwzDrWqKM/pizXKVIGGITTnPGUhlrLZjBKFxwe3unXkt5JCXC8eogXsJ8wJyu8DC/qbimVlvqFXBXBDnsrJCljwlf/P2fwh///Dfwye+8gZuPrmQ9K5pVxdqHWiSJoNmtLLxSGIAp6w1/GcKsih5+r7ULXrD8UYbjIAtvISATKBPmeUbOGc/mZ/j6g2+DACy0YGWvr2aTjWQxhm6YpdXXoCeLL/IqxTC2rbgZ2t0RbJug2mBD3d84qr22e4FTR9918zLCdHy/++UFz7+Y2Mb5XHrvPkUWMCGvwpI+jAL0OF//bs+6Iif4UNtvec547dVXcTwehJZxwboWPH78BHencweBKIyOa/WycDDbU1yWOM/x+/Dotl27z0HI2b1UaB3o5O5zjIYM9sie19MiKWy/bNcxyhO+ZjLufU9xa2OAaZcpf5BLpD3lfAM/7daG74elPeSkocfZ+xRT72f/mah8GO/olNTQvuG4ed1McLVyJKe7E6brjAfXB61ZJ16iUhYJ2U8SYeLnKjNwPGK+OuLpkye4Oy0asmf9yT8ie/Rjbut/EXI78sgFKPTg24ZbG4XWHQuThxVAQ2MIJSQCfPWsNEE8Ch/mJ8Cws7p2d0b8uD7BB/gI+VpreyZLyBd4ZZhURsZfevYLneC+uxNDWnYRi+wpC19z2iK/UfCcyLhbZBRXiSoJqdNTOIuYKGuNQm+fubbazRlRSapa90vPXqWEKQHTNHfJ1CpXVNazYyGaoAveGWUZreFbagFlqSkK1uQWyA5JFkW4jXVYEw9WHVbLwlC17A0lC91EyxBJLfQxKCRcu2pvbelI18VoBTOoFhRIZJrI4ErLOGQNJTTcs+ggGIRVmGc1qFRI2H0ynBi0OIrftQyI1b+VhDoabeVWqPau8TZOABXrX/d6q90IRGmIoUYDpeVtfkp3lAG7csluIID+9XJbgG8a5wFWIsOe59YXmtI8xHhtro+F0gYYwCxDi3hb2mebRMdEOBCsHhC2QUUGjACQzxNd4ZhvcDedwOLHR6kshxyZARKCzyQei+PhiHU9Y52rZDhcFmUIWRGbsei5rFIZU1k1RjrMj/VAcyLcnU84nc7tLFiaJhA0S6ESspahMWckjSGe5oxSC853K+Z5xnSYAUqYZ8a6rFiXtTsDM+WE49UBdJhUscySdpQZ00xYzlprDkA5Lc2SmbLUJgMqlrOMSbJaasV3PeDWFLZ5wvXNUUMadb4kCtezp15EfJoyrq5m5CkHIcgtOtQijKHFjRec7yTMkQiqiF1h+sxbOH7+Hc28JEw5TxNyIuR5wjRNOOZrXOeH+Nnjv4oreqW35DJCbD4giUKSxrcTwNtNwwBueMbxcMAxHUX1V1TrjYhC8VgVv3VV975TV4C5ncUzj2t3kZxJs/oiosB5OOwpL1imink+4MnVE7x7/T0oh9aENRwIQBSk3Gpr9ND2iAnzo8JlazMMsFPw9hQRGuDyMmFwMSRrL0zQCS2Hd/baudhFu/+SRi1cEv79fbo4tz0ld6vcxLn06fwbDLrv94Vu9u3Zd5mvKhZBaE5Ems5/xsNXHuJwOAIQI826nPH4yRMsa90wkTF8bm+dbbz3KnK8/3UfOr2QMgrEGyHmwmXFULdjiVKHt+qwi96vft73GSF6b0t/38Z9adSd93kcZnwO2/l3LRJdvjf01ylV7WkVJS4oWPtrLGdfIv9t49zZL5c81bL/axP0JMJBQonKueDJ8hR3z5/jeHWFq6sDQOK3WcuKZSWs66rFzQHKCSlNmNKER49ex4N1xfl0i9N5AdWKUq0I8dYjfR/cLkDzBc9fwmy5tzV87WE3oYtj4xBSR7o+QOMnDHox4WNZ+VpXCVFLUg6olabrxa0ef3nB//Xod4bxRnrlKTR8bqZcov1D6PllDCK0ZG8EK26vD1qoo9I5w3lTwqX/MHcSo/FXb38OmSalhbnjlQCwcMXCC9bzGbUybnDEhEnqnkLqnlnmZhllMJJan+qRq4kgKWkIEvkqCQmm5MxYxqxZyQMMiNRbSZrQo1oooXsxmSWkVo7BAHme5XiNwc6ba+OsHIs72+LWlgRXitA73ERVVeOzKt4NOXQMBM38aLTP1leXq7KFxFpvABdJUuNxhsr34Sjr8op5V6uMp8kupPhmqRwJvFrH/VEGkwGYWaOW7DyjFdg22mvvBJqgClmsPxfb25IO1vqG28gYazNnavO6JHPY9bFR2uYpN2VtjwlQAEybVHusF+IkNNHOCRlBceC/Of0UPjl9AY/xYVOSaq1ILMWgE2XkXLEujOV8xvE4g+YjUiqYJgYfD2iIAGjxYAjyrHKmjtlDJMMsZKOskoADQAsXJEDOYi1y7oyIcHU8IM8T1rVIVsUiSmMfemmfa9s4TWmbM+bjjJQnGZO0LOGYLN60WmorM0BJ3e0E1FV+N+JgikCtXmct5YT5MOPq6iBKniKzrReIUNaiBcclU+Q8zwInI7i2udqmlxTOy3nBcnIl9Hh1wOce/hymfMRyOOIuJ/BakecJjz73aazvf4g3ps/hmB4AAF7Pn8Ynpy81QbUthRJFOiKZAAAgAElEQVQM8UJC1zCFDR9wSf+1MJu0ZrzxZ6/h+rmlFaJOWmK4UFjaGT4O59LQCqFK6lpnRxYyAxY8irXmUs6gTHj/+AGmnPHDq/fwfLoNY2ANq+3bg9mLxJwj5NbKBITwFFjfoH5/Xbguedjibw0H4IrX+OzeNd6KynavHMRnLxM6fy4wniEu/+UVuK1QGcfZPAdG4Ll/x63gfbhaVA5ie3t/Lyu/OwJdG3P864I25YTj9RGv3Nwg5RlJz1Te3d3h6bNnkmSIHZf6NuPnhM5zfGE9OiG9G7nOLagJWzH2/tn2v11e0Et5uRyVoiKRuu8mRCCs20gzur5qvRffL91zXqce1PA8EGBjeBR/uwT7vf6xhfU4Jm8t0PXQwrj3+/mkHicuKLB7eB/vEVTQA0Aq1IkAJ3h3XgqW9Tlub+9wdXXA4TDjcDzqEQAN5WeAyxnreivnnRKJ14IIx6Oc3TqfFizLAjBZxFIYX6/IRTjsL+9lGmew6/fMzhPRUNUE6svtYdyn5G9s+MKwFqJQMZCyZigVQ7JHQFGPX61hb4e6SI0trWhKvmGU4Xbkoa1gcd+U0ct5zqKUV4CLll0i8/xEGdEaFroSeZD1yVzwO1d/gKyer5ySlkPIgXkVSB5w4Rtvnz6Jq/UGUsYCjZeXVaKxWjkdwM/dtT3MTRliEOz4Q+P9MNgYzadBITBYcTefCHEGGo+/4iNeWx81ZbbRvsYPCad8hw/z40DnfT0+sbwO4uwrzzLCVQ3eHpKpEVe2rmYkCky690KOn7nHLaiizc4ZkpquPXGHPFcgyQJbJAmCEmuzJIYf/eCQZDs+5/tLvmvSH52XZSdv9J+DTKdgkzyGblQw3YKZUVb3m1aIxzSmNLQxyfv/HGSPlPA6OWQYyYzebb+bpu2/ownLPVOh9pr8sdj/QAqINFNjVc9R2KfQ7IUpYdU09GmeUFZN0JjcUwS4hg+wnidKSHbwoLnmEQbvlqTr6yOOVwep4VVkA0D7z6rI2kastYArY8oZhRnLsiBNCae7M6p6dKL1szJwOq9IicXDpmnacyKpQ6NFsWvR8wCcAkOkViDZCETVkJOUM/KUcJgnTPMEIjkX19LoM1odsVqcCHNlnM8L8pTQDsmzWG64iLezllWKdet8QIT5OOOnHnwVX7r6VSRMeD9/iD/l74LBSFPG6z/1C3jlMfCJ/Fkc6UFbF8mAKQqXZR8iQGPmgWLmnkEw6/gtQePlGViBt/7wTRBpPTYN0eDq+MlEEk7KZiF2AZ4BAUwKSpJ2kpSZVpLPeSLcHk740dUHmo6Z8KPD+zbI1pYRwJH5mxKvAXCtv2ShKc7Xw5a4X3u5ZA0fr/s8QTF8YM8i5aO6X+jZf9fWUz8ixOO3/iK12La3HfK+oDlee8pU720Zxd/Q7zCYkSHH9zvlkN0D2Xk0aCv86h0ArAmTEo5X17i5vkJOaqEtjOd3t+2M7FbI3oNF753pYbJ9x0M5A47s4e/QyyXFoFMed97bu0bv0CVP2fh8814rHvHOs5cUsVHgN2Zu4/YPdq6Cwl7plSMDlmKEC+TD/MeVG5+pl5E+tBHfMG66D+dLymmD3wueTWT8YFgbcmUDQIOP8V6DTSkVz549x+ku43B1xGGaAQDruggfr6VZsokYq/YzTROur68kq/Nywu3dWbIxSm+BNox7DI1XmhCHtk602Yd9tIDBc/y8t5fivXGPjeGVEXa459oqVQw7qkFaWw0dbm3HNc7JZbW9/jbjpL0nQ3udZgwwKk4LkJXnGv4S92NtLwzjJK6o5ModM8u5/HLGujhDzClbkEsbc85Sn+/d+c+AqW6BG/arnUujWprsVoombqseWioqGg/jvnBx/8XFz7AXbF4Kw2s+4vX1kcg+WZLOoGr9XO33Lt3ho+lxgL1fH56fYOoDsttApiwOjloZq2bgtkcSeZTbyLucP9PwuwHbkSIq2YniLgj7gVJLuAcAP333WXG+RGgxOodEykLXUkpqHE8uopueYXhMyUM3GaL0QXiW7Hn1zKkBhqsrleLJVNmPa8NXM5eT0baOr7scfel6odJGRFcA/lcAR33+HzHzv09EXwDwmwA+AeC3Afw7zHwmoiOA/wLAvwTgfQB/i5m/dX8fYQ3tNE8jRpeFpm3oCcebDXH23k8ETFOWtO1kKdQrKNuZN1Hq1mXB7e0JN3PGNE9yGL+1HQm5LE7SkMpi4Rw7fQvu1vAFWnh5BVgUv+vrgxQPZWiWx6p9QyrA14K6rkgpaZijI66kCSasi3joLIumIIh4x0qpWM8xeyXABOREuLm5wjxPWNczTqfVCWTVRCEpt9DVUhigovAwxKwAF7DCKiXZaMv5jFJKqAPj6+iKIbdNmDLheHXE529+CV84/Ap4TSgoePiDazx8cIPHbzwFV2Dma7yVPgMwvMabMiDWDdMsI8bk26oZg1U8sYxCDD3tS2pyrc2CYrBiiMdqnjLmaQIoSYmI9axZtTRxA1iS3BDUlR/Oaqo1nxJJyG2e8MePvoUyLSi54o5O3qcSg4A2JucFmlmNvoAotTBdI+sbZW2XcTq/7HF8fMhguL32LIH9/f7N/tE9oXf4fXfrm+0qKgLbcAUXlffGN851fMY73gvlcm8IBWHThYRRWRhhtPVKesa46HUzYdW+x7FHPOnHLXQrTRmvPXqlhRSLUaHi9nTG8+d3zdDSz2uA0kZYjPcio+89ynvztc32IsUsztcMMPFc3t61URC7fi/h9h7+xfCYsMYQohBp2XZ+27a0IfQCmOGkCQhbBdAVAadZ4zbYSxgdWu6+j2PaKIj2dHuBNg28yHser63n2NtkWDKmfq80uRRWB2yLH/4sYVkLyvM7nNJZU4YXlHB2TUKqLAoBYF7B9RnIzlW3efKAy1q7zXBPx5mSinidUue4mrQGLPmE29yj8u6A3YVc126ja2ENbJ/te29daN7QwyAc17K/jtsmd6l+116/tfboaFzbbrQ9gpoIx6KsrUNb+0qP7U0BsvE/yxvQQjTHATBUwfL1AYBSJWO2hRsSCFOWoyEpSXkGuyx3RkKWAD7mJkOJ4qbRTcuKYnjBMWg77mIdp2Xe5Mi/ENCFGqW165ROeO/qPaSckfRIingEV5iXSBqIaaH8ev/wwQamRslTSs3I4lFFKmPgEmftw+qhawF2RbanL2FtLtKXHlGezs8bRWyz2U4NRBSOYsUjWZq9PAHQ75KkRhUq0cDU+KNRetZ9kGPlfCRjKQCXBXaOso2n/9BfLyClL+NpOwH4dWZ+SkQzgP+diP5HAP8egP+YmX+TiP5zAH8XwH+mf3/MzF8ior8N4D8C8Lfu60AIlw3WBGeDcmT2OzH0UZiLChSAGBIpBJhgFukvHf8KPlx/iNPd98C1YC0FqWSJfyfxqM2HjKI1xg6nBdPVEXaC3lPYO0EWuiKfEjkiCbEW166mDYJ5X87LivNS2mYGAcfjjPkwN4S+mmfkRDjdnlxBq5AaEVRhHh0iOZ9yuJrBkHCPsq6iPIWrltIOUMrZOTk/ty6SCON0d8Lx6oBXH76O2/MZp+d3LZzT4NkpqyDJfliBaE+tEAXyeHUAQUsFLGtrq1vGwLwsm+b18RHeyO/gC+lfBhUpQAoQckmYFklxLKVovE+L4G4b0TJ/hc4SSZFTQtJCiRoCOpxl02OI4pkrFZzTZvOnRksZpZyxLqxMgjVxjOBhM+ZoDT8i8XyuqYpX7XiHrz/4U8HR5JnVUCU+vPGxEEhtyhmgIZfsBNUEC9NFe0/MJbJq99snV/KCELIRTInE+hmJ1sUrWq7vocXYEawjEzfu1azE7ca98+l/vwwTv7cviJlCaMJzT5cqiML5zmEeo/IRn9t6M/ef7du+LOhVJJApfgTMc8Zrrz6SSAJFjlorfvzREwkN20hKlxSb7e/7z+3j2hZH+J57/e9NAB0F2AvXZpzQMxfUK8J7/Y1r1StvLni6ZNAh6WaOe8YJ3wccDCwewranQNkzUfA0r9Q4kt257Ywuzrv1tjEM9Cw3PrfnnQSgWQn79iL/MFHQwrpG48RIU/yzeJhjxmE7l12KRNAUKkFAlX5LwCNrr6wtjQW2+9r6pTaXtsqjwsrVnwnjd7gNa7nXRgdp91r4nPtnmtBvRp6OC/fv3Gvo7i7CPg7H+y+QLq2HDa7s39+SDwsvpMbH9p+/RAN1jGZgorBucTCDccBhFUZSGQXcGcfPCyGdpYZsYgApnkMT75zwYFVMrF+yYuYTZkjmWgvHrcxAqR7SOwj6GjHZz3HAR/udwVjlwBhoLeBOOfOQTOa4FyJMAwzDxZCImRq+u7GyG1n3JoNNSA4/cqNn48w8EyftpRmID7ZXn+fb9nPXf0AaspvWvpaJ4QqgmAKnjw95NcygxIymuFFyr509I4IYoc4EhBqpm6tI7eeqwqbIoffvqxcqbSwtPNWvs/7PAH4dwN/R3/8hgP8AorT9W/oZAP4RgP+EiIhfMJLO+jhq43aHPEaUwi72NwOzUeWPW4ixe+7ECzMhU8Z8yDjdrahVzl9Nk8YzM2Ga5EzY+XTG3d0ZN1myPnKtLVvhWqQgp9U0sjGYMmfjG+NUEyXkWeLHa1FvVq2YDrNaRWTHumAOTLNkZyx6xi1aS6T8gCh7RITX0zvga+BZ+QDPl8coEr9o0EZCAs2aoCSLZ3OaE7CIRemjD59gXVYcr6+luHatmKeMlVlSBdmG12BlGW6VVMsA0jzj+OgBcHdSa4WkGM45oRYNBW2uZFnPaRLvJuWEV/Nb+Es3vwHCBIaGfrJQRvEmqaK6Jtw8u9Z0vaSw9UQZVYmEbT5mlmKITJJZiC2UMQFcxYPGtjEDZiVX1AGPZ16YkdaEqzrLJmVRvLvsbST4QCRE4MPpsZwHnCZ8+8F3cZtPugcgY1hrwCTnNhz2h1l80NoHMuWtIkSGb/33ywrO9vc9wc0nZ4eTsfPM3pYfz5BFATH8yuNYDOdo+3Dbc6MSEYWdPaEgEFk3uyDC5hI8LiksrDjqNKqtWiPI0VM2fr+vz0vep0sKkPDDqnIJIR8OuHlwlIL3RQoATznhdD4HYaSNFHGttorpy197lvCfpJ091mHei8YDdsa2J+iLl93X5bLyuIfzUYDfCqMR7iPuj/vSbeK9x9KmRPASIPZ7WwOQZr+1luCNswhHUZAarx5X2eSmC/AY57e3lltY+PrgnnAf+b3uwmtU1nx+cSMza01TTVLS+s9aCJp9tfcUy3hVFptaWz+T5zeKjsCYOgE0eC5eOn13xBefd5TCa1Mae6HafuoMjW0dfby97+USbd4K5pfWuh8nwh7cp+Ndi+zRT05X9vZRaGjcG32DQ4eXcbff1ZbobWo4UcqKUqJCzAEEEd/8PoFRCoCVm6Ruj6cpi1I2JaQ8YVKZgJJGkbl1xs6S6G8k8qUmFFnWBbxWlRNV7sGw7oEWdGNvtMHwv1+jaMjoeWj0wvXzH7muz3ofn7Zcuh8m7H1SXAoENkC9e8VFGJWL4ryGCW4wW40bBAp0SY8XkECsMnsOhCC2x76N5gq3FyN5gsivKSVkjUgjoiZ72T4ukFBdofEVddWkPyDUsg4Oku31UmfaSMzGvw3gSwD+UwBfB/Ahs8aiAe8CeEc/vwPgOzInXonoI0gI5Xsv05cjj37r9mWME/dDgDtsxO8PaGMIRgDenr+Cx+t7Wt9LNN5UCmbNUEUQy/S6JixLwd3zOzyaJ+AgSkzS+vHeIzoMaZ6WOCHohrPNUauf+yJZzPPdGSWrdq6vFXWpg7nFRdv87fzb68dP4xPT50CU8Nn5qwCAH6/v4vH8A3xn+RoqShgDmss+kvg8TaL9rxVPHz/Fs2e3Wv9rljAASdSqSib8DFqpyKcVxyrer/zqI7z1hV/G8etnWOAGmIEEfB9/BKLnqihJ/5+dfxFzOrSt/vb8s1CtKlBcPdhOktmTGcjnhLe+/abya3mw6NyM7hAAVEnmwaznvAgq/Dg+VKVuEk1pOKYbWt3bUREnXTOuLMXXp6QGgQROrGmFxar2/Pgcj+enoET43vUPYBYfCZ3Qvx0OBxLBFpRgkqKzIIEHNTjab+0gPQ+8jztUfMlrywxfJADZ+Mb7pkCMz+/v93sY+tDP3px6YWh/XPacWR23bXAngMbfX0a5irYoiZdXxR4RJrRpI97f9tFaH0crHe28drw64HA44HR7h9NpwYOHD5DzhOfPn0tIZC3ocC6M32jufYLopbn8RVwRd/aVqcv9jt65Pa9nNKht5ECXeJSfcLeXhocv46vRjfAONfXK52WXyRNRjolzSmpYHKnG+NyLfje+1Z+scdj018ut7UsJ5F17+/tubEM5ZrdGJmTK2RENq1ceYePvPXj78LbQ8abwtnFp2Jnif1RAe+W8F1pHL63RbX9FFpZiwWL93WEW5JgLsLQ9wR3iUreWNAjhY6SSd2c8yZuKgn30Ovbz7WHa0+54lGQ7/s14Nsr7/jsvd420wuWpyox6XgY06OmffNsOgKsc8RBZTJStFPCHWMSWcj5hPQtu5URiJJsknBJJ/aEiuesxFsUHVcwSEY7zjJprC88sK2DF7xpcYank/1mufu4uZ4+8KUSKyS/hb6Qr9v3yHjee2O7Gxd4gvCpVQf4SIdYe971i/Y0QiSNme5d7OdHG0WF3UP649RXaqoyFV6yrzjxJqa6Us0R1ZcncnrOElFKYN0GyxycmCe+bMkpetrAK10spbSxxaV8lotcA/DcAfvZl3rvvIqK/B+DvAcAbh9d3NqcK0+Sf46JEhU1UMXOp+YFxIMS6NwJs/QPvHH8OmWb8v+tvoa5nMFcsy4oEySYkGyfhcDzgVE84nRc8efocDx89wHyYsSwreF1ASC6IDQTbCVYyWCJlcfcuS2mISYmQpyzFq5dVMrftMCg/2GjeqQTKE27ya/jy8dfwIL/e+mEAr+V38Hp+B6+kt1CD2cBSubIlF4F8f1Y/wDdP/7fIflqbDsxYkxTe9kLzfv7MmWJFS7xChNfSp/GpwyddINa5vD69g1JPLfabEuG19BlMSVLoWqy0ual9DdEUYYtH/tw334ZqTzArutX3SCkK86TCTlIrtQg8VYuZSxpdfVTP5nGtbYwNvcJa2MVEWAtjSnImkLJ69tKErz/4JjgzTvmMu3wnWUBb7RITQ7aXk0BS2uKlA7K64kPpGsR6Me23ob2Riu0pI+35XYVkEPh2+MSeQjZ+TynpXLbCsuP8DrNsQsCLGVQvcHR3dp+Pwvx9StPlUKb+mb3P1mYUBEavW+zXwnq38AQsK+kYXtkETQ21lsxoGQmMu2dPcV7kjOvp9g7n01nLhJQggDqjJT2Tex8cYomCl1LYTMp4SQXg/na3AvgIwwaP3TW7L6zyEg7v7NcLbXR97kyB1RgTqYDjbcAhhpzBUiGKiH6ivdAPdE9ZMRoTlJXAr8SnkDSD2948fI69kGs8vN9PMWywC5MMfXrb4fOFOfkjmiodCVSrKLbKB1o7vF0/2zdEJCH+ymeTTQH7OCj8xMRD6mhOm2cHc6XqDf8p/rq715PyNm8/Cq0Og8jn2qcG9+7h9ltnzKMgRnYeGZe9torjHl3wufe/j/CLQv4OT7Ext4LqezT9Po7X9727/8PrjS6H/Xff1opRTh5Ox82gQpqgImnf55UBLLDs6J1co2NLUw4Fvq1tvUcJ85w0YZ8n5jC51jxztVQvZ4QxULZXrLwPYFsaq5//lq5K29TlbYj41t709kYYDkqeS+16vyGTPwOTDeNM2gu7DD/0gB5lbC822kDtu426YSj3Izaa2ZpkS+zEICacSwUWTXVEpN63hDRpRF4jR6z9OeK/QLz4ybJHMvOHRPSPAfwVAK8R0aTets8C+K4+9l0AnwPwLhFNAF6FJCQZ2/r7AP4+APzUg8+zM6T41GVmbcSswbsJ6yLmMosyYAs8Wg6MaL2WP4PjdEA9FKznVYo5a9d2NmjKCXw84Hx3wt3tHUqtuLm5xvH6CjgesawL6p2FuHHrc1yMlmQFZFUqAYinbJrFlVpRJWkFMxjiTWItGGup42ut4l3LCVOaMdERv3T4GzjyNepqjMs2tiiIr+fPKkS5bWoQyaGslJC4ooLwRnobwIpvr7+LOqnyWERhKOdgAYgYTZD6aMdZOxUlsB1WHTbj6/nT4GkkH+RMkjSbohK2nCWCQBQWgAvjc995G+989y3M5wlIdk5NN2YrxmqEMW4I+b+sax8nrZtSEr7InA2vmuBh7RM1uCYQUiYgE9KUMU0ZPz48xreuvwMAONEiQnFhUKWWOSimZ+hIqwrkopv7ehdNApOzEf3x3IIzAWNoRB1ZCQaEy0rFVgnw37feFto8x5bTeEdAtAmWsu7+vne1vUSRFgfGsREkENa++3V4ph/7GJo4KlL3wewnuUb4mtJjmV91VF7E9oLy4DKoh1cyQz3MkrVsThL+U4qE29SitYSY9fzayMTjHP17VGQvzaXBDU7zdr1vQ7v3GQ3uU45b2xeMHvbMvQrfjjA7Pt5D6DJOS38RbsE6q6ReLOvyflS4eaff2LYPkwDaMnXBm95X1k0gvn/hin4/whCKa/x2/J3G5/r2LylfMRyrw109e2lH4LbL3yTVC4aV+JucXfPabmwzafJBnJ+JBhR4jymxZIlGbH4t+kMiQQxeUmWqb7utSdsfmzsBruMZShGmKSyiw47CMxH30N13ePDQ1wayu8rdHn3t3+qvfhxd6zvvdMjZteHwYf+RXLRvIZZtzKGPTvPred/+XJpWsLnf1kUfoCZ3KkYEWcMaKSwyCkNygbtCZzjez9/WsYKR5xlznpGSlmYiOZfcz0+8cUnpciWPIqilYl0XLEuVCDJNBscDnPdoyGhwsN/j3w5eg6IXjYZxfnG2MbJgz4tpre9TWQ5oRM2Y5XR0oD/D+50SGsdHO9OxrgYWaZQgRm004qHPx/1lWctrrVgB0EKhrZ0xgpBUMb90vUz2yE8CWFRhuwbwr0GSi/xjAH8TkkHy3wXw3+or/51+/z/0/v/CLzJNQ0fftPaREEeCLxvWiaggCgcebBYkrkrUwm4cEzkc6Bpfvfkb+F38Fp6UD6VGGDMqLzjMGWmaADByllph52XVei4rru7OuHlwg2maQFeQw89nEUglc6DEu9oBYRhZrwWdlwGy2YgATqkdF5WYfD2gyBYmIbVKUs445Af4F6//DbySPyku9lpFUcoET4MQSKMyITPTkKoMlQFOplDM+EL+FXzh+Cv4vbv/Cbf5KVY+4W59IkojEbh4Ae+H0+vIeUL6zKuYPv8ZmSNrH5FIWFYq0gO3NgxVPnIK1qdOGARqdcJRmZEmYK4JXDJSjkLDFp+ihVxKEAgQGGgxSDV4Cw1OVvfFRVE0AZvIXOCE83FBmjK+ff1dfDg9bkSpqpdOpuIKpeBCYLzaYQ0HyLkyUpVgVhHoUqhjiOHqzwdEgXiP9PXK7PaKVvD4mzHj+4VsPzO5JwDoVHXUvXDvQ+/n2JTFYc5RUL587c9xVDY2wucAm/uF/3FEP9llxL9jAnIHvRA6js3wrBfMjEnM09QphEIYfZBR2dvMZcCjSzPf9T4gnB3dVbxe7Klsvb9AcQtPXrziHDsPj/zQN8EmVDgOduLuIHj764rNTaew0HwNrW7Nm9TY53d0Y8o4J1cm7DttMxHYnUsQGNp88cWbb+PuYyCc2d7ayPW5Ae722VoxD5jvf7LWd5Ux+9zTBx3lrrJgIeJV94J5pBqHVblBVu36+ojDYUZufImxLlqvyTzKJHwShFbyRYp5F9ydzljWBWV1GYN0LowoGDt9JIr14Hq6KLKMe1gTWZp7KzROXpS3jF7QYd0j/W4oFHhHWMWulZfYq9t3Qr/t2sc/SyJjBmkExbUXA/cVAX9IZaWUEWmMKUw7DepPrUBWh5syD8n2aB7TbOFuYJSWVI46umFvc4ODr5/DJ8q5GidWIefayhnP6AxKhHmaMc8TskbuJKXFlvnSDXtexJ5oUo9cBfMB67ridFo80d1wXWJr97G7RveGhwg9HdrIEdjymxeiV5QjmtzU9zkQyd022ptxiTf0NvZ56dqJfNF/DdVGijvKUs1juDNOJkZdTvcN4KU8bW8D+Ick59oSgP+Kmf97IvoDAL9JRP8hgP8HwD/Q5/8BgP+SiP4EwAcA/vZL9BHPEA+LP260eBh8tDraZvMNsVfkmhsxFOR8NL2Fr1z9Gv6w/m94fPtjzSYpi5MraziaEJh5FpCty4rnz29xd3eLeZqQ50nSC2tqYasGz2B4NszamFPL8EdCcKUGGrWCjATbFJLEgzSjSqKET8//AgiET85fxCv0iVavS8L5GMypMRSDExG3bHEd01OAiG5YkXNqBOcXrv51AMDj8kN8P/2RIJrSKoPdF4+/isxXeF6e493nP8Dp5iy2TKvbZgyb5HlLEMJEDUakgb5Jx2ohoOIpNSGBYJbY2io1cqudh1YMsU8AY0QRRBrKKeEDJZjdGjiUsbfjcYnaBkskdVpO04Inh6ciBGRWj5qfM7Ri5HGuDe8M+dofYQaVoe+LlyolQk0keGeCDA/KhnFh+x40t3vFs47u3af4jBbjMPYIMxhx7hnC/RZaF5SasQpNxNkM1DwJrWG9v7UWXu5v7D3C86VsSoPlse9Y/xmJ+aBsdZbCnWfGRi95t/aUOAmfFdo4WX1HdkFInunbT6F2dFTUxrb3xnDpSjQE5ITMgTKGlxMCC/t54UtjMGF4r+0NoxzW2qGCwPS3vAaByfrv6J8NrzbjYVNjRg/YiOO+Br4WQQAkDIvk7+4pRT42Y5IvsSmUmG9FIh9jvMMDru8pjK7Q9U3EMdu4SYmFJd3YKmxxv8Z11SeUt4zCsuFIDAO3/gVPg+CcCKfTgloZh+MBc86yX5NYyUmPERAscZeeWYFmO55nHI5XWJc7Ud6W0s6gy76/3zBkVzV+BxVyA6+Lxb7nLEK7JIFirUyzs5pIyo4AACAASURBVHoKG24wj2tgcJP2XZWNsN+2Z/D9i7jM6EThX2X6O92rHNHtvSjMZG9pl//YEQk0cs2hZ+vW+iXSowjke0xPTer4NJw3zmDAUYR7l76bvCDjYamYVBmncsLpdNYacVMzPAiIuK2nJCdxammeY+M3+9EiofeeHPVfuPvT5NfdK/Jpfcv5lY/bdqrJv3v4xP0/O+OKNA4AbRa7f2MkweO1BwMKf3ea38gPutE6VrGzJz0ofqf/l7heJnvk1wD88s7v3wDwqzu/3wH4t19+CHb1549aoJAuXFzYaF3TT+29biyICIzNPR0vAMYnps/jZ6//On6v/s+4PT/VkCLx7FQtJJjkHxWKgLIU1LXgVBakpTRlM5/OmCs3RdSUBus354TDnIGUdA6rhkdJ3CvpuESXSSiV8Xr+LN6avwgG4TOHrzhymBJUGClnhY/UmjBoiFerj+n1+fcyZ7/lBH6P0ifx6vFTpncCeUA4Ah48ucHDxzc43ZxRwUiqOKashSZzkDnYiz6bVVp+EwWueQkTQNXlDks20hJ3KMEvVWkoQYqCkgn6AndWBY01gWZncRoIkCUOsVj6SYusv3v9fdQD45wX8agZ0azc1ks4YBoIl0LSiKjCXOYsHpCibYiinYKy1zOC3sJM4b4/23bCDgFugi5xECVtUWjzXmR845wCydwVxC/K5kHQjsLV+F5vaDEhhjYbecs/XiykjpZPb+uSELx9vwudxGZYLdzxZYa0F6p5XxiaN9oLtym5Mcjb4wvP786sPdutiTTWwWXPGwm0E63bJsNc7u/flDFuZxosfMjoa2zrRUrgHizuM1J0nsym4InQLbcutUH2pLdoNIH9mW4VRikx/tyFQfp5I2OD9xsowhyG/b13+VP7z3km3D2P2Utc96DuVpHZ7nu5d7lPpxnbCIHYTgtpI4l4GWkeM3A+r1jXgjxlHA4z5vmAo/IdQgJlyVIsBZT9/JEUbiYcr24wH66wLCuWkyhwtejKGd0JHTL6PRGVdCLPy9sgo3xk0Zxia8Nr6lbdPsnesRA+CvyfrTHh/ZWHZaJxqBHiG/hv+c3L4QcZHLq1t3GNuHiZz+zxgbhf7Znm7Qw4QwQc5gnzlMFQD1YtUlfWjKeKL0WN2yBqMB3ptv1OO6HMPpaRdhmNC3tNEw2VdW3F3g1MhjdJE5zk5JFA+7wNaBZ3fUbOMksStbVWKWu0A9sO3vvTeYnLsTOasZpyuXtdokixPYIpbE7pou/foiCoG8HYUpeMk8zUFmh6oNPjeDqeNorGTYgiH+DefF8strTrJzrT9v/31QuIsa7E5WeHX9EJr8YYmtAXnhsPXhLwiflz+Oor/yZ+5+l/jfNSsJxXUGGr36qKW/+aFNa0s2fiqi6lSl0E49nm+dNBHz/3NtYf/RjrR0+0HdlIpTLARQtYJ3z5+FfxaP4UmCWM8yo/aHPv5MHKwOTCmonzzcOF7ELwQOSYuSlGHhDIPbGOCkKXEDNQdZhnia2xFnNNms2jksEojJ2lE1LlDkRtkyT2jI6JhOZUX+K2GKnq+yShhwQ5k1agRTS5SuQEqVePxctntbMBamckKWUcDhNyznieb/FHD74JAHhOz1FQxJO59EQgKmscsl3GcAsTGrnK2cFaGQnCUOWcWmqCqcO0F1Bf9Hl4o31qa9iUDOreFe9lrxRGgWYUfvoF3BOcGwAGIdvuRWGJvI+N9Sy2+DJU7QJ596kPym5/Tu8+JeA+YTUqn7vvs6T2vRR2GUMjXxSG2Qul2sbmvW14ar+G41z8jIaMwVvaUyiBcAZvR4nzNOUABlwzg8kWb4MZoVN04qx8LpeUxt4AcGktfc7R67ARRneUqf4HK80R96vD1PDO50Yui5rArv9EG3VrzaWQ8Ovl+e7M1CayuzVGD6TRgA1su/n3tECCSPaExLh5t+sQ9+Q4pxdevBXzElHwNO170o3G1BDxQqQGupZESzOwnyuWZcE8nXE8zDgej433VY1sqcon5yRKHGkYMhFhnmfMkyQxW84n3N4tWNdi7M7hAGNjasDssMDW2CNA7KhFrKJAmoTKlvkSXCkAvQuHbEip7TF76St28dfpSr8WPt72I8Yr7ozoZcUgQ+hAd8dvfNpu+5EGi0QZ+x/abQrCtv11XVuIpoGp6vxqLb0AD4dNU97Y+L5Fd23XwcKKe5iEdbY2h1mY9NpYZJuzyBSUEnKS5Hk5Z4WrG4/7qDUZWNIxF5Z2a5UzcMtasa5ncHem3+HUlP92mfFjK7OocDd8bxwhwGE/NLfjp0T7z3F/z0SMPjoiNqr9DcYii3iy9yjOh0O0xQ7t2Vy7hDz+RpefvUCr4/WxUtrsknm4JWxLhPzzxpPGkh3NkndwfFIppqxzJF7e6KP0Bn7tlb+LH5z/BH/y/P/E89NTTYetzZNtXkt9CjB7FkjZx6FfZrSzepYJ6OqIX3z0G/jjZ7+Fpd4BxKiZceY7UGV8+vhlfOnqryLR1Kycca3tc9vwWWujjavdCgP6yw1HrC3VFJplQZvkboPpBgoZFBHeF2YiCkhlgLjilQ9v8PZ33xRvotKppOtkiUWM2di4XGnxKWQoE9U0uO0B3WiZCJwZtUDjtgUqcl6i4nQ6Yz2vAFkGpgn5kEFs1e6BNRdgysg54/tXP8QPjz8SQRuEigKupRXjTUlCVBsQgnwZK967V43tBzBbQhHoGTWv59XzrnHNTZg1/BIiWRGLuL9I6PFwYLu2Me6RMffU5D5lxe47ozLM3BN644obYZbfR/I+Evfx2jKQ/d/8961A+uLvYzu0+dwJhRfuxWv0BlwK67PvlxQUgMOeoZ379r19Cj9WIAh7e+MeFSDz4u2FG25hsQ+DPcW2MczI2+4xTHibdg6U2nPNOMLxOe/J4GAKp48/3rfPSq+lxa3wEy1Y2xG6yMIAun3aTbS1OLzey0JGn/XW6O21+W+acUC07pqy381/Pxy3a6O75Fkxil3yTIddHITYPm1+hP/9Eotx3igY9+8aX+n7784rh34ZQEoFxHbmmNtALbRsWVYsS8HpfMaD6yOm6aA6XmnG3BOzJPMCUEkMgqT8JueMfPMA01xwOp9wOp/1nBxEeOYqpXSyGBzPq9Nkx0Cn3X0Y+ojb8bnYgu9Jb9FbGFe3ebhHisz9u+KR2F5mSGq4zc7fN/QiLNhIx3ZaVvninkc2IwoUzkSwgIs2lsqQtPvDu3ZEI3petmOkhrZkcubuVMYfHE7217NzqxF/dz5+1QrwsmBdVpySZBOfpoOGU1IIqYwrjnYezmWPhGk64shArQeUsuLuvGA5ycl6k2u3+7mngT09in8Zfu4uzMaOKY2ygmJfossZriM4Ysghtyy3frxlb3zSf5R5DD5bmWDb8g7NHsb057rubViuj6XS1jIs7l6BAtjTqiRZhkFL2d7eaBYCva+AYbZ3LT5YBSgGPkU/g08++CL+afoneLZ+gA+W72kCEUNgt5oRCK9Nn5VwwETA9FCUhIgAqvGQTm9KE3714d/s1uiPT/8ElVd85eqvKwoOthJjrDoJ6pi6X91cL9yTz43SNAG5CWVRG1GBhrKNhdq5NhO2uVYcn82Y35hR54rpcEBKEzosZGpW+BwzpTC1c94dY6m2Niq/hHARW6tFk4hYzTmDEyvDLY1BysYutWKmGXnKWA8Fp+mEb9y8iyV79k+pQ16V8Uq4ZO5XM4hkjWr4dDp8UpgRIeWMPPmiCbGU72Nx2M0abdaPuyjVS14eF9oUiwJ8Lz67IWL71yWBfZ/udMjU/jYG11b20lmuvRHs/bhPN+7zpr2Ut0JGu2H2UWF7UejY+OyLPAvbMEwrBO/9R3zovGXd0F1oc6PLaOKJQrBbiq1vOxf0orBRHwt2n99T4Bi0Wd/7YNkJDPqlX1+f884ouzHG5zrFIsJcP8X7Eb7WzmaoJq0CMNeFr4EJC/2+oIHsmgAsMIpC0/2SwQsV5d099hISw948YVzAdvFO2wEUezjhSsZOjzu0aFTMbCntvFIc79iWwFjXszJABUxSELdbXxUSagVOpWA5LzgcDzgcr3DUBBHMrII9ScOlCAwIqElkg8oSwXFzdY2rwxHLcofnpxXrsmKpDKwV2XQXNn/faDY1o2CcnAucUzbjgtwvzJoA2TlWpAM9DAdQRb4SIUjUrX1csxEn+OKPaPiMqACJhL4/njCgDZ3Y6aZvQBDCxSbtfeyqo+t7bZH+N/AtwgZ395TT/X1lgij06IlW0r0g2PVRAdKmzF/XvDBqWbGciyQuyRmTZhk3OaPh2FBux8dMMAyccwYdtDSVLFA3lZFe7K+DRRH0fD3CLcIrQmbTUgt5i88FHowmKIbeX0TPwriZu/B+gqBkIqn9W6uZ7mSv95JBf70Mf7943U/aP0ZKW0fULzPcSFQtHBEGIO7E6PZce77rS76V2iOvIa3gI+HL138NKy949/w1Z7qOtfoi4fOHX1avGOMb87v4EE/0+FejFoFj69kTy0ao/3/l+q+1R1uoIsWuRoGsF2xccOmJs32ObYyQIk2WIpEYg/JAe1+4CRFEBKSEtz94C4fDFcqx4Hh3ACU9YxeUNmqCSm1p+jX1h3jTtB5ZFJBstMLcq/zVGHyXeUiUGPteJZFBnjJS1gPkU8Y0T/jRg/fBmfFseo4Ppo8cQPCNiiyH8HoFeLM1e6VIvYGdwJSksGJHsBzo4fd+p9paRcH9PgH4vuea0v0CZWKE+fDU5XtBsGz9RSYYvnaKQ9d6wO3wa2uBg3Bmvxr+dU/rcztC68sqWbseC2Ou+ndsa2xnX9mgzd/LhL2fR8N7o3Ej06jcDFXdQXvFWwu/9ZTT1CiAK2vBqjkoE0A8M7Ez9ghvmIXa9pT1NAoyl69LBoio8MSxgEPo0s4+Gcfb7ecggSlGOC7D+tujoZfH7nu8Fwqatd76H9qL+4NZHqlAUzT25hW/v3DeO+OlruMd3L9H+Gh7qG+t+0yELpxv9/2LffjZIObWYnd/86qeD68K45RIswY7PW9lBeA8vaq7163zFDtFZeDu7ozzsmI5HnB9PGI6TJIhWo0P0CzMXFdwQcuizLYLCDgcrpBywXlZPLMfM1BDoO2gILU9anMOCgnAWAtLHb22HsZbRoX4HkFyWHoxWBLKWjv7Q/dKxx+9maYAtG4ZXApqAub5CEJFKZGn9CHaNkuDxXagf06B2IfTzSHOIyw5VD4PtLR/b0snub/fjXm4NtNw2hD89C4/BlmwH0sYg2xmyZRd5Tyc3WtKVmvPjovY1qehNQIhYZ7D2Lk2OsRsmbct5N2Ga7zL6Fa/rm1KG5mC/R7F36Khsgdh73l+MV/x0PueJnJIBGd5ZhgabdXh9ugT9AkZX459udHtL+76+ChtZAL95Ud62hMFur3mKH5p8cmG14ZYVtCTAM8oqmnVTAzIOOJnpl+FhQPYptldDGbNKsW64NyUOWi/mSQ0L+cUkDESKwTs9FCQ2F97hlnj3NGeMQLoxKhNbGzB/xIcHQesjHhuw6p6dixaLQmEN//sjSiC6L8kyUsYoAo4MyEpjUAVtWqsvloHTTgWmJk3rbZmLYTDaI14B8QbVmsBmHC4yjjSAXUGvnHzpy1L5UfTEznXEBVqm32Ds7RfgwWUFQC7wnqwZHmoUb9ubY1N2NqBszMvvy4JNGMo255CIjgbGMDFdnrBeosnI75vCbGP19vltueoyaq7itsIk0YE2yB9DIPwHEcyKtcW9rR3Ju4+z9FFIZL7Z7YWVXTf9xRru297dGRckUFZuJ+ft/BQWlHkqMEKzIrjod8Gc25txrNLcV/3wv0+vMYrWpIj7dmVONF71O5TBvYU6T780WvcdUpS18YmLUq8uzM+ezww5oZPRgQMvv7A3jSaoExKzUJ4N7XMSgPO2E6NYUSdcu6YHnFnT3EjIoePCYIqeW9DIXUOF3B579o+09OD+72yih96vtjbi3ul663dMzoaZYXG+wJv6t7V/ZEMR5VftnqlOt4S2iH4PrOEEDaSWipOtycs5xVXVzOujlfizeACi/KR82uScdL4A7GF7RfUKkaQ43FGKQmn04rKpRvzHu5y+NdlCoGJzNv3WtzzDlPbgxHAvofjVZnBa+/B7ylD+BT3hOFXUDYYwFoZvCxg89ykjDxNO8wgzpQ02VfgR8P2ufx6XN9wa9ivW37kfd0nj+51yhrSSBRKNw1t2iV7VOUMZvekskVUuEfQ4nyEZtsaUmix5zO2Z2rLHhdxw8PqiZKUkEp5k+3az76jtQeOvFTKTC3LilLM4M5NiRujCPrxDTKO/WN8395TGpgaF7fZunxIehzKDUgvWDQCYHs60DxzMkRS1klFHS1ugPH9LcMHg3S9/DmXT4axXUb9i9fHQmkjsrTtGi7DNCysLWFkrrZowfpuhLsJr+4OboF1BkDKneJjDLLF2w+qPbW4i8DgmENEm5+ZSynJUWfJyYuqCGLFrgnAu1/+AX72a19AOtvBUQ8V8m6F1dgmcxhsEaIjxMaYm2VcasSZIjFAv1uHMBv/klLgE2JpyUEpsbm7581+47AJVYDJpPXSEpYiTM4uI1qWz6RWV9Ys9NHm2hEUUqafJZRxognvH3+M7159r03qRCtM2PMQh448tN/cNuIW3qQ8qFbz9IkQlluGzOT4ZyvVmIptaCUQITtkr1TrGJwvXRR8XjYUL35nZCSqXV82DnnIlGLnYjHkrY1ZBtCeNUEzKQ7GUIguPCTMa2dCHVH2LqiDaezaxkdko9u+G0e+G5q3I6iOv3eZINszdRAETEi93/DUvx/p2/a91ocK20kzywbkiNtHU5K3b0FJcAOUw7A/07W3MpdC6Aw+/X3afa6NZYC9z7GHv3nhgfvPMozrYl7G0ZvWiioPsI7jHj3NA8rqR24cfE+haBTDFEgyFmHpbxWzGSLMG+Fi2y+2RtYShdZ9PsILqH03ZXu738LvO2B0eFj90O09N3b4M/vrv9MB9YLVeJO162Y8YFsn8ZKFWftbvWYga8u2SA6TpH07DTD4UuMhjLDOAZ62Zk2gNsNGa1/ofmGgVAlxfPbsLmRrplayhmFK2njGt/cYC1/hNgavzQa9ryOmDfcPbXDjmU6HzJiHBifDB6MHUUK4z6DSc0WEdvv3wiR8/bSp6TADPLnxNazbCJ/Ys0JsoObRM+f7BW0eTg9YeXZKfo59Q/e0CUGx/bN63YMwVIxQcRpigXTcxuHTdcOT5qRschm3CaSG66J4iUzQ40QP9wCHDkkiLYm0Uer/lkWyu6VUwVoWilKW0MjkfGIvKoS5ApRxlVPD31Kq1ios+pvL8xGvJwrrqkNeTLfk/SMSyXDuAv1u9KYB2xckivObJv5c14YRtPYp8Apgu5f+Wa+PhdLGLPG4bs0y7oiNLGEEqdYLwhg7LAnq5SJC0TpaZqmObbuCw+ptq6DELRuiZCQkUFICSgCnJAWjQ7FuIxbU9o10ojkMtU/ZhJ/7p29hKpNk2rBNpXVguJ1/M5IaGST5H0XOiKNGGQgaU8+EhNz2sh0eM6JgJeTM6m7on4xI5pBTUidRFeZk/SbqY4HjBme0RB6lVqzL6spYh9s6FpbClZWBuCnauulE5JDthLv5DtOUwInxrZvv4KP0VNfMMruZkq1MNIph7PgUXf694sVoVlh4mF2e57bmTiM9dt4Vtvi3R+Ze6AkMHf2z+wTz/u/OtEJ/KBcUiiEhiVE2iryXxuE702JWHH+JQ8ltZEN3PMCjCaH21vhOvO/P7Cu5e79tn72kWESvWM+w+6sXtHxu8floPfU2to0JU2U9MK696hrYyMQL3DCvtcTVBaWmKegujuOICpML/2Ph5588Nt/hZYaofVyNHh/3IhKYXUHYwuUy3vdz8r3dNr+uX9yf0ThowrHQREkL36V96PhREIaUOJJ9aXMWvtGSBwfBzsZk9KlTJzqYKxx13C1Dr7S0gfcejCIst/d6ZSzMtoUXOm/bvy7hsVHWscsoBMY1s75cqJXxSrkajxdoVML4eUT3wP98vqqA6cJbG+qkVoNumKP2K96wEFYGAigD3d6sICasq44F/Vj6XE+BU1CPhxGCHS3UNWD4+AH3ljfcdg7UYBcXxx6RyBYTOAkltFG7dbb3Ot9Gg5OtTVPehjkQu7rfTbHJWgoPijAJPKV7hdveo6Z6jLS2p6uu9osSQsZXN+20VtBlQwr0Ynv1/Lqj9UEBq2Fd4FJt+96o0w7f4bbW1B31sznZPL01G0R8bjvq+IblOWFenXaBQSlhnTLmLGUQcjYaEdpim4PRB2k9TwlEE9Y0af1gKVC+rmIsTspnKjQZihkZWuNpsyf6PsM8ovjUzdIxth0JifReYbt9nbo/MmfqAO2kzouyb7q+j112OBH6fdF74fpYKG12eSy5EcAkNaWM8AUiP1q6gcaetS2Fg4ZApERd3R8DtrmEJdzCiJARL3GXWvy7pAfWlNZVLQdKTJtMS4RXHz/E04dPUbDqPPSmCkcpZUyHA/JpcuEzQEEYg4wxURoNoU4ojSBX1kLQoYlIdMhr7exBvaXBCnXlItNj+OHodn/Ab3NfAwBqRa0FpQClFollr86cozdVFCJuSmCPuQzLeNLCSWfGR8cnmKcJKSd84+bbqLDi4tJGrawHbS38lds6xqaFcKkHjxgtT5ymbuamvAg8kp5PM2LKAdkife+6YWdGnWB0jxTU3xnDU7oJ7Pzu9+6Xtfc8Oz60nvHFZrnBpLdWuqU5tm0Khz1pZSBGT7rR7bH0wJ5gI7+78HP/1S8S1/2wrUuC7qV+7ldmfMa9skab3/oxtMjsNl4/1+HMzAQm60lmOXCMxge2uGMKTTsZQ/0+ifMdlbuth217RQXMxjbCqwnCHMQv5nvbN5zpzt7tzM8A0MMoeCxgMGZEsGmlSFQIf/H3tmtnilrrWuFHphi0ealgY1nSYh1H4w1xl+makzOdADO0Z/e8lSOs9p5JMdlGWJMIe1+/LVRfRoGPyk8bK/eYGPu9rw8zJo5tR+OH0efRIOL3dYl3zmxGJa8TBlW241pDdhMrzCxyQGLWMjQBj5yNboTk0PQF2rwjuQUlYjQk+Q1v38hqU6y0CTc4ashs4FX+TIj0adgf5MzQpXuQ9uim/LUEPtFL51FF9nQwdgzfI55GuMi222EMyidFXnE6iGEuXWsdHdH1DkdmIoHy7WgwcoXR5IFOwden+giMS2ecwjv38hVto9vbCOu2//x+G/H9cKdUcKkotOKcpJh8Sl7rj1kzTzN35V1cCQw8Y5gpGx+G4pyVegohnC4bqAOjDX0QDIYZO58KuNJa1e9mLCoFcalaaGRo1ekBXV6Tkf1shzXcM57ncl2XQZP2X43Xx0JpI0I7b8SACO/MYIhbu5rlmEKYQZOEtY2gaHiYkCE3oeWJbUCW91PKaDYklkUlZHm+WlijEoIkaevJiIb1bMisjPyd997CR194gvVgpQAUBRTpXvvxIzwsD5CnHJCKmnBDPikndiYMBJg1ZpOpD6kDwCkhD5s7BsI4EwegdeYioa9t0w1bXhWZSOpEiKyodUUpBWW1kEYnEA1fuc/2aMSsEwj/P+bevMmS3LgT/Dki3sus6m5SpDSSRqZzZDOzspk17ff/AGu2a7Y2u2MzuiVSw1MkRfZVVZn5AvD9w28EXnbrvwqyK19EIACHw+EXHA4Sz+jl0tDahs8vX+GLx69w2Tf0feA3189dcR1joI+hG0mzIZL2u7j3CxWe9NT6gLTKKaurUwjjSYlKAnTm19MVBtv85t4Mn7nBeZ+CC5tv1qVKXbm84D8JE303ZnDVoXGvwQqbMaRzr3ByuFSPbVa4qsA2f6kZ2me8vbbKsIaV/G9WdFcrE7OS+22ubLCv3lm//J6NqYdq0FrgUaJaAh+xZ9Y7VsaLeOYZqSgi9CUgmZWhM57WHQVQaCrfwHnb8v3i2fw+VmfmcgFj5VTpt/P70pgrDtWIQdA4+QtXSErDRMnRZPxZKsxKqc6EKIdJrSODLSuwIcA5l6udOj2f6Xo23iyMaTaiV7RPsDP3JlXwzjhmJTBDyIkmLYTJnIEm+eK7mF8u40y++h60IpEKbDNfcxgnxT+XocnK8t6TrLZBYSFquhqVcNL0fDaSYDjf8+j11bbDkMorP/ZBCsMugAVwxv0sNDSeKuxWqaHKKS3zBSS+UPn0a2zNDD+hS6td1+IWvHE2T1arrl6H6UmU9B2HJ9Fbgib0EJ7epV4noSIOgIkvJZnf2uY03wiaQEz2yB/dTE/FZWYnTM4rMq8PfWSS2TavJ76TOhQgJuPkzHrjXZS/V8Z+OmG8Wpa1QO+M3j1uMbiY6m62kEHU4niqRmjTtp490UK4b8KB2y2hiTbFKaok7OqgkbNudO8OzuSFrgJ+00OJCG1PsjDp2XflfCaAhQF5VjCN91XexWBfjScFrk3RLvP1URhtpphADZ9W+kagTYNHlMERxcGHIVfzYAbxcwOareq0xVlmAGAeuMG+8sYAuDE2yckkhxAQgM5olmud7GEwCIuH/vO/+RMQOoalpTahzozLy46H2+WU4jbCGMWgsVOUhG+dQ4mSbYfwE0j6/IHN92GJEqEHglIwREDOAiEYPlO39H1hvKRhl3o/CBhHR+839EP3oGXNW6/BGleOoSGlNWCK8mRvDdfrBT/87o9xe7gBIBzbDcd2OLx8DIxu4QejnMOzuixEa7Ugno8JkDBZw6QpMPKbjJFkuKNYqdZ4+F0HDSMx4LMCEgY0J6U/GKWUWdDxqiH7lYalMn8u7w0MF9BaxsNzEqSG0Tn8bVakylOO0LECxVT3qg92n5VBICuR53pPVVHAO4fxZVhW4WZ15S3jNMFOOL2vY1hBCsjT6mSab82JzMKJjQaa06QJWGGPupJjK2fkOklyPlj1wVPG6Mm5Ma8wVtzE84zbwP03rUreN3jXBkI+T3AVSgRUZTCMjhF4QOB/ZRBa2Ew2WE4h065BYRjewAAAIABJREFUmAKoJGVKQarD9zXUlnJXE7XGeDMAnuRQ6rwT2GolbV6JmWmbmf3ohvquzps5GmA26O7RQEarBJemDpAQolHTyoZy40wznM6rCSj9w+kqsHn1Nhasv/V5bt+7H2F4sAgfUydYgmUlLN8mdAMRY9skOyVbZWlOQuWtyMUG3VIFU9iS5l/+nEefXZE1gFazyHGY6jP5ZoeCp7Xeonx61Y6SpF6TydHE1xCrUmDOrWoZS9Ge11sYyUz3wnEf2oe1F6WdepZ9h89tk5t1/nsxnmWG8kJAnfYaXaTz2SPhkGiIkxwC3BgIOQ1jNk6HEsHFiuPoS+FfRUbM45/n6WtJls56zoyn5eN7bPlEEYYHmQvbvuOyX9C2ppE09WvnZan+Wb72IWGU3A8cfeA4uvM7dpwkjkkZg+TjMXfBxir3hIhA2ybHcxCjj45xG5JAcNuK/ltwHIpHrt3rDYmh71bDMPEwd34kPfSbro/EaIMfTgkGsNWBL3an0kxjBm/kyrELmMGSnYvSJKIU957pPskmIgJvIbAJEiwDIuwMsIYfZiM4ppzvDMBQL9z+9OZ+V4lAW6x8sRLdgHgazNvtQscYgSY0yawtE8lQQhEl53AClU9FaM6bbGcSSbvoHA9WpjPjppOr29400TLAaKqwGK+yTEJmsGndLvwhBtIOtIsYa0/7M/72u/+Itm1iuYN1LyKDb+x1+t4TAFl0rSZsvLSQSZ3kJH3bbC9j2vy6mjc59OasrGQlZvYc37tqGaJ4Zs9zM1EuGODasLCeTyGKXlesbGaBtWozrpWGhDQBcl25i+cKQ6XK/V4zqjnUxARrVH9/xOcQvShh6lAOtT7j0X7n+2o8RG/WMPBUdtnD6bf6ctWBZXwtQpsUX648pfmWxpxaHX/z78hwqJg7KeQUCuuEg5XCPl/3aKeWX3vaHQMevja3D1TGffoSlf4yjc9tGEzTCqPTIXkdgbNagc3w8s6UvqySJ4U42h5J9bN+adssdJlXnYmSinrqT3ybx2hlzNk4RHrumfbO172VuPxsbdyThKyXzJB5fA3mGN9E/RM8ud5AwT06MgO66Eyc6/EBC1wjmnDlXa0dM9YJ8H3WvZvOMHTrhO6bsuRCrvhXfuWgZV5fUBqd88WbKsSsaz5XV3KCMrypTgNgsEbYJLz4qKhRWQ8pj+1e0rZ9EzRbFdZFp3MfkPitP7W62cfPasx7w/wrrXfWZSpZa/I1K5tp1XnABibL3sjFj+5hr4aY3L4RhfFUxeXsBDHQM1+KHs/PYs6dnQ/35uw9npj1I6pFC97ufW8wZiJMvAq6J60PjHFDvx1oe8O+XbBfGvZt9/2gVcfJJCGIYQZaY1z2DcwXALoPrjOO46YGXPCbURHmZDzzhGbn+uYXJLy3kURPNGqgbXLcv4YOmh+ssSirx+mptnvXOf0tjDW7Pg6jjXTDLxPYs1ssi+ngsIetTQ4TzCtQSZ9E8/AKFc5pP6xPLJuPmg3P6jsNCod4diap36089OVb/W9MHqbmsFNpgyAE5se8Kg5McUAW7ElZkXmhBYa1lUMwAhZDxIB5Q22zqIY6HkNW1AY0FFGYlTBu8Y6aZ2oMTXjhsxXYQKDW8GF/Rr907JcN+w785vFz/Orh1wApvhlg7uK5HAPdU8jGQNqED2amEigzIzaspkO3EUpNM2mcxlBlkI9rvVYMMyvGhnNN97pgIvm6b5RFB+bVtOppm+nKcCN4ygYmUU3zbjQyw+chO6GJwhFZS07CJJUt31R4GdbuWQE8tVBgiP7PqwnzN3nOfVM43qqOua7V+6x4Stl7fVg/r+90vPQhkezdvGwN+9bQ9otuBFclF4ynp2c8Pz3jOJIhByD24q5XQ6jcz32oeJ1XF7/tatk9A3h2EswKlNHGvLIWBuU4fZsaXd7OBqOJ49ZaWZ2vcAYfBarSFDVB60mwsCkgylEpOQq1j4L/pnx78sp6+zj9VvVS/7Uwrdzt84ra2ShH+httGs7n1eKV0TvX42No++8S52Q0EFnmzHMdGTY2Jd34emk7eMprBpvBLIpdCmJxnKQ6TTao3EzSwf+Q9yXWFkLK6upLY01YoyOk2zLc7qBojCgSSlQZ5aPpCkhRk7l8AXBdY0k2ScJr6c2Ev9BXWOE7nVlHMQ/MQZHUqsL3zYgM3KZkV46b6KWbxGzSeZK0Sa8pNKBwGVQo8wfwkVJgDZPMAOWkEZxw5fQUyKtRO5IpO8vSgF3H2eekVZj1Cj6P+XTZVGRPzR9YArpEW7Xmapx9E2CeMDi1Nq806oDNugSACPGcZS+nepKGlGTPYMa4dfRbx8uzZvHeN2zb5lk75T/91o/VMh40fMwJjG3bsA/GuGwanhnHC7wcXSK2vD8xASj9Dt4X4yVfpLK0CkdUqqe0wOEf2/gaJwhMTWSF7JzAVI4A8YzwkH12Hl76itKg18dhtDH0sGQOmiL5j0ZCgmWeZ5aDKFuimhXdJtqjphvS/L0qQZQ+UMFDYPAcnlIUltSkEa01mZhbttqF3KsKsGUBBptLmQFoVycNwspKLHnsucuX18WQZC7peW7TOKTws9gbNgBw77j1Ae7dBVGeAO75GEMzBaXxIRVUW8O2N/z87a+w7Rs+f/gSHy4fRBE1XLEwyz5SwhLOmMpMJEQocnsIDww5468eFNlM+/qkqPgJwfVaeS735wQ5s1D1+r/ls/Vlyo1BMcNILnjzKmHAk7+Py/buFKPCO1nxXr+1MRtJ0OfDmOPz+4bSN3TZ+5KEzaSsrsp/20vz+VSYcKK2E6zrJvKXszBMPCQrUkS4Plzw9vENrhfZTyHhulJX7wNPL094er6hHyLgR9JHIrMgp7pXV3CD141Sq5tO7++v5ry2mpaiBhZtzYZi0PiZvmkiaNKyvormimJwyzwOxeBSnEQ764BfZZWLuRRlmp49VkR6KjA7ebIC5Hx/0sPMadc0rCQU3zPeZpyenQ+8fF/L5FWwaZwNo6fnVZbJ1RDqOkr5dIP5OtMk3yuajLXgMZq7CnmVxfsDFCPTZ+jMs/XvyPXm3ui8DWeY9Ndgkm+kfKbEPO+5tBQ0vwrjt1unK6LTapgXy/x+5meFrqq+4fCZA6JUofMxGzEQx/e+73h8uGLfdtxenvD0fKD7WV1RQ+hLLcbCawoaXvfejDLReRbYKXjKypmP2fwBn5Xq+CbzJZv/Y6pCIzXAmLPuppF69WLAczik5tG2hquG6m17k7T/zO7E5m7ZsWt7te5ZO5EGgkdm2X7voul3joKrvN5pmgeOQ84qdCf53rC3zXWwlVMpH1dhlxyxFP3btg0XBg4+ZGuPJujKtJojHBjGM/0OptFJeG/IF3YmEiA4LVqdiTi9TeMxqHAsJ6fBwgPAwOgdHYRtY3BrCzo6Xx+H0YaMAP0LuFHibgXzJKtlRNmNkSq4a7AWV51a+dx0dS8I+CRmCqflKJf5N3KGxvC9uCFB5Ik3/BsXmNqGZ7I09qg40JltQqgc3JdYqkPCjI5gig0pLnhSCKzQ6Br22Lsk9mDo+SbR78Gs8fnDE4k489W+NwJo27FtDV+8+RK/fvO5/H74CqDmfRrMQJdVuT5sxW5MTED30OmkXRk/InhGCB8r25p4UCgU4jA8J2UrMfhgdYHR8LTlcqEovGbUWbl/y1VDHfPcDxhDQa1XrLiyT5sZbzKkZ2Yu/TZmCr2ralfg5rxSJ1s9CLFrIX6NEbDNqz1rBnemcX/DQQtLHCSB8G1W9WorVUE0gZy9q/lvhmlu27qVfbFzv1zBIsK+73jz8Ih939UT6WlzwaPjw4dnvP/6a/TOPo/r2J5Xfs90Pqlik0G/wnXAfY4isLZyOE+uooT5cGDhNWNxfnXfyIsV+LMxZDt3gid7N/x75TGFN1o/Ueo1w3ACrNTjbRBXhSgpHUW5ANzAyGGVppQWp8dkYOa+znPhdXrPc68arjl0clas5nqr4WXzZL2Pjjn20uWr0AzOBr2UOdNDXtmIxCpwWbUKMbMeM2JaRabWeU6Y/FUhn9on5XEnGh0MtFF4mTkGxoRn71euM+Fhxo8pehE1pFL0xMOlLy6n/D0vadA5Mos8KJEdanBujbDRwMbAbYjZIpiRUXh8uOK3vvsWj28fcHvqOG7PHmoYOKVoO8NRdJFgVAY/efk0BjovzxLE9s9x9MsK0PJG0JIHIl0RiZLHOgzrMWTP1RgDaBv2LU/2rHjn5/E78+SRo2NY+rzpfBldEnTYKlVrDR3Qw9ttTqbQz4yrbFmg/Ey4xNT/Fe+4x08Wz5nTmXJK/4PBPNBZDlUfLEbnAGIFrig77Lh3+aTnA4d8EX5s/Nv7bqXS3PCItuQQMIPdTp/wlcs7CiIpnQT5TjzAePEdTMG/M+2JMNBkO5W230ymv1YHPiKjzc4Lw9C9AJa/AwTsCSHzRIcSLkM2JybZXOaqDYCvzhkDyyws/eMCHD4gNvAe3UwSDNfBaMiMqk4Pmj2vDpIZPNFG7Vm+p+ktl2yQZhDSMJKQtoZ53205mQDuCgMzeIhHpGsSEfa8rYodVm+HHlCJMUq7BIjx3IB923B5uOB//tbfYdDAaAOd7FwYaB1aFyS1NnGESsxXVvKkj6b8wWEc+pcaYZsOF651JezdmRVZ8GeBakBkBSJS0ychGzsb1w1843VWaohif0FVvgOmWXTld37GTfQSWWhkwTTvHVCKKv1mlwO8kIFJ8TKhl3kx4O9PqxonGjiHeNWVmDsoxNzfsyLomChKqHmGV4ZJVjgWLS6MioA5f5+VkgRHa7her3j79g0um6VWFhwendFvz/jw9ISnp0PChnU8JjZYDfNk2JoieX8OBE2s54byFHcynUPu5t+1v2bCR131fQjpeJ6VvTVvmDs9O1/yu6wyrfu2ehkPLVxGFLbKs5vGQXpITQkvkgEwGdUcC6JcmJJlOM3GX55zYr/Fu5OMSfzhNUdF0Ookb2hlWJxX2k5yqtzH6orTByLqIbefjeWY/2vYoh1O/CdwZAbr7KXPyjYc3yIr7JzQ1ILDWmSICRwdF4G78gObYxV/hJ7w15odBi8gekJsYoxBeHzcse97GLcKyGsGeAl5N52gdxy943br1QhLuA1YQxFmZBqKjvUObDthu+y4Pb8AgzHUwCMCnp9f8PkXjO3Lr8GaQKKPwLhJEeCsAzlk3qYRPBUSELO3GkJWo0d1YKbfNOONt5yVqjTm5E2Hvki1OvuIgUYbmIboHBQRPKdkZZSfpTGYeF7gQa7jOHAo7XEXFZ8SPTgXKTwfQAlJlgGVsc1wUZT32vLcC53sxFMR8y3mYCw+kCry7GXlr54Q4M+YdesLMzaWVSZAnDu0NezNdClJ9mN9F3DkrETW8lJ/nAFHrYGZ0HvHrR+grrorZyec/OPrQQ1AT866hK2z4J/41KSYEQF7a+K8SHzGIgkN2wzSSBoT6FRqv3d9PEab/1AmMuArYMWh5Mqf/LDVHp9kmYitPCNW5YAwBhiAC1wlPAqW4BKCIg48gQlmApPuARt14ILp2mCxKy/OFJTZssePJ7ihhlETtmR+Y2G1UdKXjxvFkQWMSJyiFQ4jxCEZH4/exWPvTC3jJY5aOCm8rWEj4Ng6ju2GbdtwXAf+8Ts/FAbWdGWFk+94iDARdLIaX5mRJ2JdoFGB8/vZY78Ke6T1fCoKfzUkBIyW3nvmPkNiRQMqRSCMNQrS8nuOXhblOVWzMgqywRaKT1VO7LIn9w2aKBUiVJl0PlgUSW7drdPK6zgm+IrTLF1EpNm5ytMJ+igLfPP+N4Ofpqe1brkGmuaCDUGzDFPzudpAeuyI4OCsGFbBR17Oy9u7Ux+Up2wbHh+v+PTxDbDtCOYHEWwdePf+hqcPz4iVJackmLIZI5qFI7BtBD+bidfOhDAYlq8LHu+tkBXjDRFhsFakUs2ucI5kOJz3WOXypU6axz+NPeX2qxBxw4JTjBmd6yjsXPvZaI5Lo+Dz6Zyn6F+aG9P+L5N3oTDHnLLfM41W2BZ7/BbXfccFXJnJXZoN89fnobnxms8fr+ekKZfWMTuVXPGbFELnW97nXEu0U3RMnG6mvqVx1jpyad/rxfD9JhE5s27GEnNV/gUUZ5BxLdUviICjD1wuhMtlV8cNoUfavDjWJje3ww19VV0xcAEx8HK74flFkjiEsR0OuNJTfWjGE9HmxszoA08vB56PG9og1UfI9SlmxvPTi+Jd9t56cs3MJ5Wmy/EkNpaBkdCb9Cv53ewuj2Lid9XY5mKE2JdUz5KFtU2phJWOiB8zFErbWrChoYaLYkVuSbc12os9ytKGwmIKmn/FkOgkiv5yVJajJHIkSMyfiqNX5agnl7Fkbfa8NGpP01/C4JFmEFTxSdEpgK5uJ57eNux2LrDrV7IKt0ESmWybGDWyztLwlt94zogsYwDk9Ol4195BomMGHsYFzOJMOG4dt9FF12G4eg8gjhpQUBxzr/HWiUYMca01UGvYADD3wr/y1VQfuqev3Ls+GqPNhVeDr7hRRt7EJSO1PJA4UZS1dxBDzPbM2bEBvmzj50Iog2CKush9oQjyQxlUHwoXxnYFYfgTd8lJG64gMsp+bT/vItXPYGdOsLTeqd/GMELv0MyLo6MfQ407gh1KzlrG4JQkIqMYauSbR4Ox/OvDb9D2hq8ev8bnj1/KOTUg7LSLoadGtC2JY0SYHud/zHM60wFy2TMxW4joRub5t+czxowjTgrYLGy9XkfbHXgsz6d/cQdyqKzR/iXOYKQa7SlzZfYQiVxzhCoGQ/Y3ZAqhvbP24HQVcAYTj5hepXObI6CarYzjJhTKCe50ZVjiN53eW5hXVrQCzvP12oqBMMu0edtpoCqy5o+l6fv8t8JhYb/nMq8ZASe1gm2/A0XaaOdREp//+HjFm8dHtE33/4xos/cD79494en5WbAZ8VwFN+b1zvwy4y3C3qx/33zlfQZ2X1c6z33NjrS5HnJagyqIK7zHN/eUjGoEzfSzrtPpkcMzr1ALTkGpvpnn5D02OpfdCE6rwVZyIaPsQOtiAGYHCef5XHGR4ThfNNFjrdP6vhqv0v6prbhKHxdjEkpo1HYeNsVOguO84mb3C6gok71xjio7XLSikFnIOP32zLnm1qI+czBF+1zUjAIBK1SMCV/AnArSVuvUNyPqSB94//4Jzy83vLle8PD4kMqKscOtY3ADcxd8JghE7jZxKIDwcL3icrngdrvh+XagH8f9o3HSgLUW9EbM2DZJjMTMHl4T/ddy9pBrXYVX+RfKn7Pib+gB3TmZPL4zbm615rkcK3vWfKYpOTdWZMZa73AH4HxMSIFjbm/CiRtSymmIEly0zD8QdGEZV6v8nPlMgXkx/zKuKl+oMuv+HJv7W3l/boUhORUaSY6GTQ/j7izO+lsfOIYlpqBareGYRbv6nZff1nMhJVxS8iFs2PYd+7bhz17+GA+4Fh3FVu2IxMAbGPi7t/+EX++fi05FG7Ym5/1eLgPXLrkTeh+4HV0OEudEjbMHacJg6bsJdRYn/mXbsO0NtF/BYBwvR+0nkLdklrHI06Y4NhbXx2G0ZRqzWxN0gMpbToemT5Ml7W0TA22EcWbKVJosJK4zsxt0dS1CVawuU4LcSeBCAAAnRXA1odKcGSkT04l2FcSWuIMZP3XoKCTT6GGhW9sjjKXRJQSxa+xwnXAR4iQp9IcbtE0FxH7ZdZl6w48+/Yl71YgIv3z4Vx8DghxM7m3pYYWMWGmL+XlfyQtkxCTBJGBkRY30HL+s4GWEn69gfxaQNL0oQE23PDPtDE8ihYmhybMRsPHE4P2slsKaF2DcEbLlfXiiM4qrgm7Mv/YNDnfCkwJk8DYb66RYmQIWINR2Kh7WymgRHycmtR6YNS+j8ttwUWmLtS8ZX+vL5sZr70+tU7wTOmvTN6m80tNl3/DmzVs8XmX/p6X5h5731PsN799/wIcPz/6trLrSst5QhLIHdw4jfU0Y8KnMiq6jH+dnNcQvNpYXQX/HIFsp9Kv61leezEaDOYRZn5sBmbusRB81LHgLTwr6nSt/H2IqFPlwBGQveRbYdfxWRvIpXLHgIN0RfQMtB+epRt1ZUQtP8VmJPN/XlTGpv6V6znAwV2X3PP8jbEnqyf3PPKXSgNQLFZPKH9OgWnMzWLZCHis4IWuZJ53TBEFBPwMa1sVKO618InM9bIPAc78deNc7nm8db9484Hq5Supyza7dGG582LcMOY6n2X5ijZQhanh8fMTDA+N2e8GHpxe8vByxBcLnRJI4/ir4OxkxqxwzY9i/zPSrDwg5JVWmx9RfH606jkAuY3WkkeC0mu16UvpecePZrRf1mq7nKh0FTs/Uh3JWGDOrYh11ObTL5mJulZgAW6FKQuTMs9e8Np6/PoctI7SfLZjalu9yqC58vG1O5jo49SCys5KH9JNvMWBwZ3STxRNU0mWB93u37+B7t++C0PB7t98pKCNTTBpho4an7YZxGdi3TfMVmEzQZHy6b/5PvvpDfOf6GX55/Vd8tX/tfRkshiC1hn0b2PcLxugaUixJQYb3e75mXqN1dllJu4HR9x0X3rATYdOsz5Jo5NtfTQ3f166Pw2hTHAUNCokY4wzGgdAwYVMYwTSVsiRJZPIOaYx0Y6ixJlQpIVDmsZ/ggNF4xLCXl3miYdJd7anet8wI1HgkD3tTYaD7vNx74MUnkre6jLB6R2dgHAdGH3qu2XTwonrox1iEPWpbjQjbvuFyveI3bz7Hvzz+CtQa3m3vy77aMQZIFUsx1rjOxpVykz1uCbezd3ueLK3VMII04ovrnnJiqZZtlYdeL57ANUVByKsKmvV39e2YQwImpUN6XhOGzO2/Yj9UAZjqnBlMoC8cITO98lS4tbwmEcKmKqJRSYHVX85z4l4/Ys9aFkSvXfeMhm9qZ3qyaKsqj6sqy/joA59OU722n8HCaVsjXK47Pn3ziG2/Yttjcg0GBkta4w/v38v5NDjjMKG3vKu8ghJO787M6bvcBpd3YaSfD3W9p8Bng2tVfjZK7q0GZePtvkDNv+vK1qo/ANC2Db1300ZQ4pmxmntr4ynTicOY5EOhI808Eopq5YGV5iqe5j5Xh0iC8tW5Ye2FI2Y2ulwZzXNyMqhzW2Hc5dCuOq+jbWm/mbI4KUnzilvmcVGHfZfxl4q5Jp4fZxoFYl9a4pOUHCMm1yi+J+akZKfmilMi4TCBnaWH0WYZZ06O2sEY/QXHccPD4wPePL7BZsmJBoFIlH1qsrrGRNhGd/k2hpk5jK6keL1c0dqG1p7w4fnmTlGaeJygTsOznUYMn+EYKrLY9BWu/TTc2L4j0ReKCuc6luPSDEPDeUDpg1RDLONsR3a4uDjiHWJK2UCttxTwlJA4tnBtieUIw0X+HT5nolWX4zakCT+ZJLQGxZQ8pARP7nlWcb/pCmNLMep0qmNsS7uqUEdEl+ggZgvzyNwpKysUc4KBP3n6Q3z3+CzJBim7EaMP4F+u/4qfX38BJDzZtY8df/H+P+Oh77iMDSDLkmzw6V8mcGcc6KA+0G83EGQ1zwywRg1tsxVUxk4bfvf5+/ju7RO8oON/fPI3kvuAdEFDt0kQJA+CfN8xjg1HP9A1+UuikmlAba4Ttm1LRiHwfDCO/gJqB0xeeFcU7673e0U2x4DRkI4zWF8fh9FmV2aGdnp8ImTYRNTz3CTcUWZd9oSKV0pnyIBzyeKZmNf6gdhb5iFkatDotGRUTy8jLWVyique09ISgao8k/qMMNxIE+9Es2ILbc3m3BhDkoccHZ059tSdIAT4GBjcPT14a8DWNtAG3OhAA7DtF/zVb/0teIfHB+f++HEAQzMnwTw0OeSowuAT32XrHLYm/1pfG6UkDHnQz13Sn1JuUiGRUVcEY1HiUMqVGqZyiyKFiYYQzgp/hcegLd/pX3Os3ItemVrWNpNAnd4aRrLi6hgN0nboahVVYS2jxSa7s/LxDQhEUlB8/xCdxmflJfSWvR1Gxe18n968qtxX2splrZ1l+N/UvXkv2dxWxo0pLw+PF3zy5lHnnyKGGgYPNDCenp/x7v0HHMeAcysT9lkhrMAVnJ8N3xpGlPuf+1JXg8+4Aep+rRk/udy8Id/KfFNoZa4rPxeecw6xqwqD9bMaln7mlI2tYrb3jntGwmwAz3ivhob852cQEUIeJAFtWUgDt9ZuzCdYLyi1lxSt4jCY6Pb+Kly+cpl0NlIynOcxyiska7rIZWb+KQaqKMxBl3MIbf4+48IQkI3i6G9KQKAoEnkdQMiqiNZC1QE4Y8jLkugUY1jiGKEZzvJOBHvMm9RnyvBbRuTW0vsI1XO+Qupf5lh5HEzo755wvNzwyaef4nrZk7Tjoliy49qR6oTJAIbynzdv3uB6veLD0xNuN8mASIZjh5tc18o8szhZkw6b8Rg8Uf4Ohp9LErJ0nlvsv7n0sIZClk8w0+DZoctcP7PiflwvJGmHON8m+UJZp3GqAjDi0Gbk+rh+n7DDanwUnmSUYynrU1deFakrEQgusDqdcszpwxGSqiHRk8dIRxkoPI0IAzl5DmMbGx75gv/67i9AtGGLlHy1Xm3zj55/H3+A3wUT4//57L+DNxt9wl9+/V9wYVmJOhhoW+hBmSJ8Uiv8fQz0EWtX27Zhv+zi1AB87tjoNRD+41d/hv/+6V+j06FPp+0MoaD493mMUsnKM5wXWVn5O5jj7KTJOEsKT1pEUfZAEr32TdfHYbRlniej7uciSFy5TqlhU4CDWJ0TyFAPMiMrIZNyO2qPL9Ll5hW3YFVBiMaoSMuCq3IXLI4rP7K2OTHphapHALYUT23iwpl4H+iHZmDkLowfDOYQQOKpMoIQZtlI4n2vlw23/Ybnyw3bNtAvHf/w5p+jP0mBGwOR2n+wrgQalBnmSfgl4W4rhvIohVPMwkXryYo5AxoKeUJTyCNtUOLEQ4oUR1xSxuZVy/ru3M7qxUoxKYrAvbom2PM17nxjjKWs1c2cAAAgAElEQVTWabHyXgrzmMyVmFIhRqFk4uL8aZZuk+BygZ7LKr3NMM99CwUwCoSBa49mIfct+4V745ZnboJ9Ae981fezslLLCV8Ox5KQLoWyzaFYikeu4c3jFQ8Pj9i3Bnc0KU8YfeDl5QXv333Q5AFIOFZK56hvBfiZtjh9P3de5oxl3GKcDaJSU1LY5HDqdUIXKdfKFl+iODB7vapyP/wvr76evuVTQJwSxdmwLOG8YBBlb3ngaEZtEe7pWR6H0I/Z+bvVI/1W6GxvhzovCLZHMdp2pRkxYqzyTYS78ketd2VkrZW+s7FrcHLC9Wp8at/rmMnfmrjBV3f1tyi192hU8LteRQ26zaI091H2W8H5XN72SYj9hEUp9n/gOKzGSm4jyVZCwRkonZOYYGan1dBC3aHHUgLJYPPxMuBTwhFm4Pml4/b5l3h8vOLx4Ypt21ThHjiSXDPNYUD9rmSrROS8nIZkPNz3HcfthqfnHDIZ8JPSpc9rx4tpAaGkApzGpo6XcLnmZShhNCvFcPnNGW1Afu+4hc8hJDiz+9h64tWluZWNfHse0VQyNnbWq+BNoLZs4QBh89DXuBZmozwnct6diYkA7A24XHYMiIxwI5cZt0MMlMINVN7IuMZjqDPdEn6EYRp9NV2ZtH1xMjU1Qm31Vlafttbwye0zgAfaJt/8ycsf4814A7qSD3Cs4gkybP2wMUDYsEGOifgMn+EL/hq2KvoVfYXv9e+CaHOj0KoJPq7wK54bgH4cOPpwQ9v2aY5uuM5qjdR5pQv+81d/jr978094omdwoddAkOM56VZlRLPOZ/TozCDz3cwN1vqN3YWeDRBtaDQWdFSvj8Nos8t7ooJM5kkw2RyXyygZIeWSBBVZR+EJo9NwBc0D5SycUDSN8RDANuE5Mjkp8RYl3p+T/RECKmGW537LfJMl7DEkKYj8HSFU7QOHT7w+lpbf2CBDJt++bfj12y9wXA40anh3fY/PL186M2oarjOY5ewMa2vUs1Zy/zJuzg9CMWB9FwJIfvmyPFn4QmKYWscspOtFLkClXgqJhVCqjNfC+HsC2RyfS8WfTCaEwcHEaQPpPeNMj2G4k91x1V5RJhYKjQn/bHgwUJP0ZNDndNTIxjAQScfPsEd/5z1hXjvyr7Vn/6xcm5AI+ojQrvVKR+2L10MBTJQLmim9mepNtZ6+q22bMmzjMfGLZX3scibYuVRIjbDvG96+fYOHy8XrNKEyxsBxHHh+fsKHl45+697GLATOYYW5P4GPVXbRc13K1+5PsvRtbTcbCmeDLeCwtoynrOjl24S53st6mdsZbMrpokSZc9aHeWVK3lXjJuqwuRk4Y5g30LhVjhwdEy1522Ygg1xRUmJwYS0HaWudpvxTHJ5OgLimp/GofQncWBm7l76MUFPo/nisowcyLYw731n/y1PkhEkZr2t+SfG3DG3m5AqDzr1ioNnULPiX5zFXuTSd4bJumzIXLiwYA4ZtRY0XE+i+GmHcOgFl+h4DblRBZBmx4Utej9Hx4f0TXl5ueHy44vrwgH1rqGs+0bStkFjW6SyHrcz1csG+73i+3PDy/Cz7eiwfwKJOhsn1OCvWNZLyjZUxR2+k5mN7SyJkE0Wnr+dW8x2HPp9loFqVuS4Lwc0DpOaO1zUfLxAQkNchTk8d6EQgRGmcEoxAtOtrjk7K2qbi4ugHGgEPD1cAjOOQ5BV7E8NwJAxE3YLFy/WKy2VXWQwctxe8PN9wO2KlyR0xOv5bk8Qc277hoT3g399+F7RV3YMHwH3gD55/DxfewV11tQuljngnEYsoIfeExGOB5X87/hz/7ZP/6XrhP+8/wu98+X2wHjU1Bov25HpBzaJJpFnTW8PWJLSTIHvB7TzEIBdSffaQM+72Dd/lt/iPT3+Cf3j8AZ7aS50zBPAgAEP0wrZpfgfnEHUEjMerjo6imycqKhOOTryU2oatMTa22XR2Gq6uj8toA0wbdH371Auic5Y7msqVn/cYAjzMEhxTnVM9bkR7uTSd01z3JAKmvKmCPy+tlgnvnhxlRIMllrbbeWlmqEVbQQSkxB5hilCCYOip8Zcd7x8+4EdvfoZ31w842g2EpnyHNasjq+IYXtZ1WE0I2Sx67lKpAhvZ05obaKvLWOjgWCKX8YlxWF9prPgMDlgYEBrMIi5042uek8AJcqL8uN57NUYRhqBqpNpqi+OvKLm5Hm9ElUxTsEzJcbGJUAGq8lLrmmG8d6lCiIq/akCmcMbU19yX2qcU/8+c5GJ4G1djOhty1YDMH5wIDzEGdHpfjeTEgk/aCZdx8PO44i081jcp2a5EUPWmEgGXywWfvn3E/nBV9pDcFEw4+oEPH57w/Pzi9J+FvK0UrK4Ma+31mi7qtxkPtHw2GwP52zmkbr5s9fheyN29Nkyw1aJGY/HeH5Q+rBEVRvm8ag0YrnJf5nlrij0VHEUImNBNnCWVOGQqafW1kqHP/pJH69tqanRHIUy1oSBoNkhVC4HN7fVYxzdlVejfeJWV9PNbmMIVsOU59m9ps66jzLRfZH6es7Z3S2V00KRg0lXDmc4VvGJcmnwvbRpn0/K+eho0K69y/YnenToUW6ooFnYWSeoweseHD0+43Q5crzsu1yuYB47OLgPZHb0Sd9UseochGfma6AG2Yvd43bHvm2SafH6RfT8ceLLWTTE1XSTzG+ZwxppTYuAAj5YWvknnSdCkzp4J/5QqT4qWD0gta/QlctskmZTJOZ/rPm0Z8+H1zRxUEO+a4UTkY6hhtHCWhIQmVB3D6kir79jwfDBu/RmA6IAgwFbCjTJcF3X5QehHR4Os1tHlgsu242gHmDvMoWS4Duev/P4P7/8En7ZP8FvjO0XfcacHh7noodf2MkcyMMsZhIY1F14Mag0/vv4MX21fo1PHvm8+fxoI//RbP8Bvv3wPv/38fYwh2Rx77xiKA1l40DFlCY0kQiTM81V2OEFagr5xHBi3G26943hp2PcNn94e8WfPf4S//c4/YjRJaCJjKSuanYG2XXB5uOKiRw6g0LmuRpJGgqnO3vsRiUzSKvl8FRp3o58ylQWeX7k+DqMtM8Kkd8nWsIQEYwrGCF1bQsosqe+iai0rhpcxHCQm7NUjTXglBElSowbHnJCEAcZwz0dGtiusxmgUNtZ6bTWrj4He7dBpdgNsxs/QCTM4rHvDxXZpaO0CIsb/evsTfP3ma7S2YRDjaAfMS8RmDOp+OE5454zLE/bs2UItZKCQqRnAJB4RF1ZEKdzxjrAuwjzFtrvgpLmww8bz0Cg/pS0zUcD32ixXByjVZdwgCeVpOmaBZvdZOHODZvKqeYwtZGq9ciJ/RYHPAiW3GYbMHJ562pxfsaRQWGgUn0bUmKLPm5NCGLfUclumpKiBabLW4MzKYg4pdEES45sNZr5DL2tDPmg0133vmo31XK/hORRaFfxpn60LOP3QuUcj7I3w+HjF2zdvsV8uUxdI0yF3fP3uCcftllTaBZDehvxz4uvMGkZu+KtzdUVr/mZC5L1VtWgqDjQ9raguvl0ZfvfCIXOX77W9vs7PaxgfYNlcMz3zkJXQRG6F3uS5Mcm8ggqffx490OJsq5iTpPgyQ0vCj2x4XL9xvKSkCiH0FtR/5n2Z52WOTOWburJd+urOodrOeXwqbzkbYNbz86isDPH8rBjk82VyJjlwXC4UHj1hJ41r6J3aVy+zxnB2GtaVfgo6cJ5asTDzkVI3137U/kzzExTJ1BJs/ej40A88P99wvUqSkj6APg494sfGuaO1DdsmdR1HRydZ/QdklcIy1tH1Aft+we3lGS+3A8cYINOrHNdyldDinMecyFefLExaeKPqPJOOESt1Sda6TmEroaokO5az3CLXj4gAwgSwQOu6ylDGTYlYXCr6xExOR2cMDljBw6RCLsZPx6G1dOQCTX9jj6cctmyYqfw1AQIw1MBhPBODng+IYSMJlsxZwSwhxFGPfPeP7YfYaAPtYlQ3Ilzpgr/88F/cMKH0EQOywrXJ5qMGxnFIYpl8fCgT8P+9/R/oJKbIjW5gzZ9ofJYgJwr+5vIFvti+wtYJnz59B6YXdw23bmAMbn70FJHIzbYDl10Or+4jR31A9ReWObPvkomRgYMZR+94y5/gL7/633E8PuOvH/8et9sNx3HIQd+toV0vfnRBI6Nrkr13Ly+gXVan960BG7BfAB4XMTpvB176gX7IWXDlDMqJGVbnbvBej0x65fo4jDYg06IQt+KLiOLsTi86q6qEuafCN6Yyrm+R7kE1JmDfDBA3MLGmSKVQMmlSGkwxydkjwjUb9drAWcZGhhpqckZEtz0PJH2ysZS9AAwehzo9gil+2D9IpsfLjh9++hN8uH6QzFLmHQZAsDMiSA+3ToahYzFNOITykpd6DZ6CXmXKUcZ9yWk3aVJyDIWhVZRhkTplKpeBng+wS8ZRRjnA9SRU67dVyQFP6QYj9ZlSfbmNs0IyE1sVtvHOA2NUEROlkTCva7mhEyIxDvaGeCctk+Z9FJ5DWM8Kb8aBteciy+9WCVF8P5WOe7Oze7xO9jqrbR1zxz12rqQITlpr4BN3M6XDcDSHXZ7xEDCEJ315ZfqmGOuV0hceIoUBJqXgfXc2q7yFiPDpZ5/izeO1CGH7M3rH0+3A09MHHLfDj+twYkzX0CWr1UoSAR4WmFeGViFtUn8+f+j+ylfFZeV7K4PNvj0bhjn0dG3U3TMmZ4Mw97leXKZopbN8f/4EgO4zM5okSJa4wFVWIHP7hfZdB6Oom2PcbIZlmVTmoZb1MCblF3IepwI89z71eQ6NnMd+9VGIk/urpbUOnn7PsyXmP8AnHuIOjRN/Ta3RVKfiUkXx1E6W2/VdoSur15W6s9PjNQeCGQ0eFsscso5krxIbnTOqYzj/TX0vdYNc3znFJVJEHPkef0VKV64zjgNH77hcLrg+XHG5PGJcJOTaQs6a8SXdq7Tve50TRCDNlijJkt7g+jBwu93wcjt85c35HjM2aprtUh1G7qgLfo8U2TNg8sN6bngV7JijT+98VOPooOBpjl8vLw8iMQu5LuQhx9aybx+YVxGTrHEpRz7eSMNTZ3DAivTLIypCwVA6RNTnvfWBQK6ISxv5RTZpdQycH4kWKWIn8dkkDUVu6DFNzOAufWxE+D/f/F/4d8fv4Peffs9T+O/Y8YgHCUUkMRlufeDlONBHx4f2jM+vX+N/Pf4kxibRv4SpqgMv8YYGoA/G/7v/Df4T/wfsY8cA48ePP8XvHN/D7/TfFtQNxnBFjtEPju0riReYU04SDu3YiLGpiaOcAU3l8fbygD/FH+Mfrz8AYcf36C2oNfCuK7LE6EfXlWdZ0ZTnDQcP9EN4e9s2tCYredu+46qLIrfjwHHrOPoBZtsiEPhfsttveX08RpsiG9DVGJmJoRBHtIczhqSuykRYyRgjHk3fWDJWm6KUqNmYbnBLE7YIWBzhVP74cw2xl+QdtqLGeg6E9SnF4QOAxvZ6iI4yoMF6eOG24evrO9yuHf/82Y/QNg17IBLFkHK3GLEnLuoKXE+x/7n/6dbeCT7OrEqqMq8M5U8SfhKl+uhVJheJY+ohka4GuDK6UtRNALCspiIYdTp3+XTVSTMpPVP2uShzVpyh8JWx9C/I5MdCmaIEaQNSGBxzSwYeAI15NuUljMQwtNx4TdIsH6Zq5WLc4DQTisVK0Yu2rEw2pOIrcv2z4Kb0K5hrFpgNwKB4XyGev12vns2GQoQZmOAqhb1XprOHcp2L0EQG0tfO1s6ZRohkf8LD9YJBDWBJgcxdVnWOMfD0rAlHek0AMLsVWOd+0q5KO2ALCSKHeWnckc0vIFJkn5XUeWXstfDIVR1zuOw87qurthF0luvN9JIpUfCQwgV1fr1mAMaKOxLfShpgfBVwUDYEgv4TtIn2g7aQ+jaGeKpHor3S69kIbi1N5bam+zVDDLinvpwF5Fxnxr81Mc/JeQ5megtnyRyGaaw4PMmVbnKbM9QRWmpPQwbPo2dKPlm9zKn3jKwMrzDkPfX+h45hBoo1H20HDqLmxE3TXPAv2SRcrPDkvahhdLoU1DwlFP1PY3O7Hei943rZ8fDwgMubR4BldcGMmW2bHEgI2c3JQSBRYYTWHrDvO263G24vhx+YXELk7XfWP/JzWGgdOT2b8SIObasnjelkvM8BZzlMMw+YZN5LZTmpADnjsVMISvliyLu0jK0INsIRdcW1isyzTBfgWePRh5x11ntOk/NlbO7k4Dj3BmV2GK9zh5CNfZWRA8Avr7/Gv+y/0j4PfKd/B//+9u/APPD9999Ds3zqRPjNw+f4q/3v0ZnQP4w6h7WNTfec9XRmsPFR0uQ7f/PpPwQtMPA5f4nvf/l9bLpvjYgkUf9m+vmkayVHnQ0tg9xoJOWjRlG3ARxdsmq2bcP/8f4vcdku+HH7KX52+RcMlv3lYwwM6NYdBqjfgC4JA9vlisYMScREkIO8CWhiwI0rox83HEfHrR8YPfTye9c9DSxfH4/RxpiSPUxc2a6zfL+bCdL0rjIbKf+0iRMch3Sp35Nw8MShZ6ABz9jDkBWtMeLQPZEbHEwpef2ASPvJmjFIYBa2sm0NP377U2AH9n3D19f3eN6fsdMG8cKmzgw5LmCY8ecTZFY8Kz6S6KzeUedHPOFfJxtFulcPQYJFs1ccL0RiGReL6S3rQIoDOxpkdWXPWOafWZex3/dyGSxUZVUSqtKR4To/53oYfH5j5LVQ8KU+oxHzxASBZxIUsrExMhjigExTLmw195ykZ4ZrFnu1fDWsIitbO9Vb6Wv2YhtznlfJ8tWTQrxW4CqsGS/5aikrgCRaiHJZ4cuidbVnjJ2IUNqNKUxWlXY/4Ltcdrx98yjHV8BOHJG6+tHx4fkZ799/kBCK0u6djIdmMBRQjPCnFaQ7lxkcrxu7p9ZL3XVFJo/len/ba0b2bFBUA+DbXone/ZZcOTMQ6xmIOk6sSpxJdNTwIQCxwpYMZut54S/RjRhPDh5idCceZoM55rg5cioGGGU+z5crunbW0moM85z5t+A1mshz+ZvCVCufm/u3qCfLoCLTbSWFa3m9ROGhCf9cZrUodJyU4qlJ25+uoU/yfEDi2QNO4xt2xmI2vLKBXt/VcFXvT8YV5hGvCg4bsEl+2zA7n1QY7KBsIsLRZXXgOA5crldcLzs2XQlg/zbkjYT0Gj7YlWyBUZKutX3H1houlwu6Zrg9bsdZV6BsmqRVf6h8VvhNHzJzKlgaA2iFrwZGEAiwMc3zrRasjzg/D2opZRKdC682HhZf+AOKcmR1ca6ERTei+M5LJl7kq7WYokKSUyDgS3yEGvwoLJ57kvkyTfdnxHo9CoeJNd86w0Cjhi+3d/hy+xoEwu+2d+Ahuum+EX65/yta3zA4Mp+fwt/VONwvTWWE6T6h58H0T44R+vlnv8CfPv2h0+4gxg8ffwQw43dvv41P+2fBadJ0sfUQItvOAEyhenhpz/jl9dcQJybw95cfgED4ur/H09OLnPtGhO16xYVkYaE1gh2JYPPQI44Uv50lAY+NxrZtEhU3dt3/xuhdz1TuPdFY4OOb7PePx2gDioR1DyU12ddGhJY4BQPybCWwXI6nZW7YvCddTQuDjZCW4RWLhSfbZF0wCWbLIjP8cGtw9SgYUAwC964KOnuGRiNaUMOx3/B3n/4Ql13On/iwP+mB4KKIt9RjS1ZiiUvyfrgayqlgZG0D5af3M+q2kC3L1KPj0iQUwp1lkFWS0JXUcKsuFxEyWi742TlkMX+Wx2ClnAp4SYiTblIdWYlACD3/LjMvY6ZKI6jDvtpnEcrprGhzmXBVucnn9AAWNttzJ6PXLlizkWjDm2Ol7XM3YLMDwgR0NDqRMVejhcN8XjGOUHyT/JqQE0LZGJBmhLIQyHRWm5VfXbZhXSpKB1BPq8b3Vu8yHPV9mFjrsDLro08aZFqxflloRlbeHh6u+OTtIy77rmewQUJMGOjHC94/v+Dp+cVXvrMxn22PFUoYrmumsU7f3e1L4MmEaf67uuJdhJTVi9x4lyx1xl9r/VZXHBHA03hn3kxefn4HNcak7ro/FAjW5mli7SHI9yDmlbJQrCzkLc79ga6OwsLcRp6D+q0imRF70CRslF1+5KCBRgS2uaDfkoY7m/LpvEq+KLg2gRTCXfvBEXI0r5JXWnaETM/OtC3g2Rjm9nAa1/ma6W411jG82nYxOms/5+/MCWr876yjx1zK+3LljQDnuqvD59ygyBtLIW7f+Fl/8qjmxcxZsBLuQm0IZn3CWuJLjolcXR7ZyuQElkZxSLm2f7sduB0dT23Dp5++0UO1AzfbRsDoyuXYFVIbEh6yJ2fQ5vt7iDZct4aHywW349CzJLvCSDWzso+bdyJwkDgc5fGm9BoMpLDT/IWNV7X9K07sSchC7emMfA6aWDkVI5wxysoQsIEoLU5TSODOhlZCRNZFDWaiVAUp76m9njwb8paCaq67rKJ2Flj7yHpN7rj8bgTfckEE9C75EjiXY89/C0B05J/tv3K9hEDgw/BuY0I6rSmaSwOc6TDrMARCax1jKH6Y8LPrL8Bg/OnTHwEA/ubtP+Dz/QsQgC8uX2EfG/7r+79A4zM9bLpPj5S2iQi3QxY0/vqTf8Bze8G79sGB+JfLr/R7Bt0AHOKolj2hEv7Y0EA0JPKNhMlLfgio8+QG9mOA5PLQZ30kyXB2DJK5E2eFmrxdMYl6fRxGG0HDn5OQhljWFjZCdYSFMJxzo8imMNa0zlTGY84x1CAcnr7fp0NDGJDGyJyjKQFb5pjRhcn59FGiREQR57T98lIptjXwpQPU8KNPfoYvH7/Ctm9AAw7qONpA47RXjVkP1DYFaMGIDBWz9ZOFpTGjjDudsPJTcUfQOOY0Lk6UcfZKxrvIxrUyeFL9ksDmAnI8H9SwZaas4xf2fVbSAPSocYykcAATvqoxVj32NbRwJHxw7nBK6e2ZMpMQtn4hMRXva2qTnGYBcxO5UpAMIOt/nHuUItW5rhB621RVQBcbickRQc+AitXbKsSqd2y+Zhpc7pPx36E4xz3SPXvIojlUzqs38V2hIWXY65UdEaS9Swaomuk5YKnG8EAJ2TVPhQmmBM/18Yq3n7zBvl/k+84Asca3d7x79wEvt1tRMqqgmbDi/Up06kPNixXPPEdSz5JxtlK0763AGUQB49noszJ9ALbX/V44Ze5nrn8uM/elhFwCCMdC1BErKrHKYfVkfEe4XIZfObXI4Gg9NDcDJOiRIuzGrK2i6BWFLHpjWc96F4dd21K/0q+ygd2fsv4/UlzHqkjGWcZNxaPDd5pz9l3Q28qwz+Gz4rTgUk126lQYDAn5cPa0Ps2odZGidUGWbU5zm+ZshmHouBuGPaKi8HB5kM07Ln9jfxrrBmmeRstlQprEzBkmGzeTcVxhZusDK5rq2Bh+LPEHxXkArtvYyElZc0RIsoevv36Pbd+wtX3i3Qzws/zioLuu++eHnudmefO9ftT9SYVfTlic+Wt1UIVxF9EuUZnRA7tikCGI30UWWA0FuVneEPyYDQ55cSLbxPPkR+yzCGdBneeVp3fvo3/TuxAvxfiAMM1hcnhsJTXOu8zzW015rWMDcByHZA3f5Pw90nnsSfJyx3QsxKgZ6ExyxlvuChl8EzoRsmmcxkTfp33gQJrboNgVVGS2jVubnjF+evkFfm4GFcUK1lOT89b+78/+G5iBP7j9Hn7/6XcBAt7R1/jrx7/Dnz79Ib5/fA/7Tnj38B7//J0fyTYlPUqBekDN4LTwILJ9dCnUxxAHRRpypwEk3gqAeaRQ48WV5Ikt3NTx/ebr4zDaUImXIWkwxYMzysS0GSZ/KmosQ2RkEjKkhl/MLXyWVuwZpbrRS7US8gjWxCEa+ujAGBWqMgAbDFnuyfvUJLa24eXhkHPTrhv+4dN/EmWAGjbaVVgpQ/O0/LKUGkqIdQYhD4uyklCFMp3SA554G6kSSmh7K8L6/KvFLcu5ZBaOcl47s6KEPIweepQsR7FjyRkeQTMIIa+okoELRoSxMrMzi8xomBk47k+JWZHkCY85HCzeGV0F7JS+9/5Zv2etW7915Ve4hKJTGHsEn/Lp27i3/hIStZ/76GVyJ4Lh2OKV7++avg5lbH6TVS/rxzQnZ8F2lrvF8AIsFDNCx0w5yHicDbgYcx942F4Y6xugKyKTEeh+jIK6GuhbvIjazNBzGx8eLvjk7Rtctl32vOhB9DwGXm4v+PD0jJebhkLccbRokylFDSeUBu/LdKb2Qq3g7iVz1Bwwtjl8tUpm9xlHq1WW+CZa4bRpeDbwVnXm+/gm+iLjMqUGPvU4FMAgpVijyM6gLAvcG072Tuc613Bn5qwkZbhkEKJK8u9X3o2hiRfa5prYBB/XTxmy8DfgWS6JqDiRMhZc9XP8VUI7491wNpd9PZTWx2hBx9nWtTkVoWQ0QRoIEEV6xG5iDrlmMBYd4Q5bdFmu/UCm29TnTE8hy72WNM+kbOFzqfrg9ymMOdOA9UM1m9gj56/BrOYgn0etyG6VEw6tG/f5UHEKRX2IEdaPDqLbfbrI/U/47l2dw4ZYxYKfIQgKueUym1Odlab8vc83KE+r/H/uuQ2qfJbm6dQXW7HqinOZl7FSDoyUgC6a8RxgEy35o9lxd7oYG0Tna1uTc1obAZcdG2nmQQxw7+jeaXXgIJw5NUWcQpxkmjtMYA4TobODrezA7XiexjOHULKjrY9I3GIqSEF7iNETbk6r+onfGw/eN3GUHINPeK2NJF7o+oDcGAcfSFE3rJRHguOuURI/vv4UP7r+VL5ngfEHn/wEP2w/BSwb5S302hCp0TkHk0LniMg7Y2z6j9sY03xlBmhMPBburInIVq2XVhrzgrGm66Mx2gB4Dw0ZsYoAwD1UYZmS8cVMcco8wEAvg53qQipP5EcvWWg3q6E01BKWpeZRkgbYX5tTEqY4PGTR+9IatomTqg0AACAASURBVK3hl4+/Bl8Gtm3DV4/v8PX1vQhw2hxeMzgtKcnwUMsCcVxU/iQmiOmD8JSxEX0mN9JDtiloErBVo0mJ0/+1YnDJR5TK+WqLLvVn0qzm3SRAkiKtoFVxOgtpiLE2k/5MF7PBNdeVpy5PzoDXLp7gLy2kyR42U9COK0saqhVaCqdayO/tdUv3ohylFSLOdVcGJb+Tgpven1bocnk2FjrjNeHB2uUEfciNE+4zUKuVsbzSdO/Kym5R1SaNyJh8wdMkMARGXtS96Kv+3TbC9eGKT95ISCQAkJ6PxMy4HTd8eHrBy8sRq/mTLlLaMnpJyumrcMzfl3fSZ8v2WIQjdPRNO/Y+0+n7fL96Z3WEUU3L7wP/7Pf3Vv7udrY4P4If5W6k3pRfbHWoymP7Ttgz+3AqG6vnjar7hFnCY1gVg3vajpB7pcvSnQpsrYOzggqRAYMixBj3aJ/qPJsamZ1H2aiKMvmb9fiT/8vLslI+ShPlB3OnOT1KK7uYi3HiXZkPZR1B6uAYcVeOoiRP86187AZpPMl1RRsVbnnJcx+5SodoV56bcVXD47gkS3O5OxjQI1okw7U4eBwnzgyUwjnOPWXrl8v+6SJCPtcPub7aRVWvXpF5URo226IfecWOY/5l/N7l9yFMSGV04khI2mKC/Q5NGhAz0K/wWjeUFlOaGThYxoi4Q+0J0AuDNfSmHwPH7SbJOCBRLZd9BzbZAUUF5MqLHGi2GbfYoG/zuPCFqb+cy5Zpd6/Tr4nfxadiCBKAQw2bgRYyyNtXgMic/XFcTvA+73L0mGtbM5wrjUFQIvvQhnfaIgaaz8mmimZemSRFFDWjt9CFVNk9gbTtW41Oaw2k6f8lZJsQ67aARySZl+uE0/P1kRhtCUyGhJ+AZQ9bkTMLAZRGaRCDRjAHZ5rGhHN1/kyYmRlcXbMtRpZH+yALATHQAGWmqR2BDcBO+MF3foRta2jbhq8e3okBQ6HAEKDG2SgrcxiJ2XPAb00s51FFYSrLbqgZKRruxGCEcX9gZEU+K2WGM8WVCsyzfjWZThRPqkde25lxfPcK0WrL2E7nC2NN2pvgmgRNDRvTsBdVLvIqmU1wqTuJ1pRVzL4LSIPx5DCyiZgBWIyzYqTJamdONhJ9KeK//D4pXmmMjQc5FEUpq3XE+4ynRAv+74yPDJcx5PRFwkMYERXm1GIRujyVq3R5FvgBL89EkFtw2ILhJxUjGRiZzn1MseFyaXh4uODxesW+7ciMaIyOp5cXPD+94KYJRxKJRH00gZgm95n3GCDfxNLPva2GfKX91yTzvbDJvOoxl5+Nu3v1VQX3tT6punSnCN/5fNJRDPCgG1WyrMSsIEkYYssUJquTQw8msQE1ZZTT10m25HngKZCdfwXgQgtm4Cg1MUTEm0A/8TT43K+eXQvb5mk+p3mlPy2cu+hTqfw8zrMhPmP7HjXN9ds45NCi/H2MU+KrPFIdHKVNgS8yaQVJDpdVw33itfecVyYV8hYODbICZerh2Cece2YKWkCWZJo/13pamh9KY+z6BkDUXWHM4bgiixoIsr+dTU6Zw9t7kvpr9Jjg9JJZaGg9lMbsfEWfaMZ/mqjscnbm3zon6TwOlnCl4i+Fr2psVnYWCC4nGiPjUyG789iYMn+Pp9jkZMUL6RgwANKkL02zxPbeQdwAlkOjb7dDj3hSnOoRDEXH4sCHPLeELRY6mBO43GOK6Y8zpUq9CUWnaeL6jzFdjufktVAqm8adSHToY7gRyVCjiCc2phPd5aHxPXDdDqU/Mo/2eXyqMGGHavdsj2IfktWRIQd0U9P/ADQ9B1nsAbELaGuStMeMNEqY5+BX1k7bxCCX4wVk7jZ93ojB6nbnIUdzyHaHTbK7Jnzcuz4So40TNwdoqIfCMQIdfD09fAR3LklykmQYlPYXcSKxRAudB/iw1PixomWZ/EyBM2PKwx4BeEyZldkY+77jF5/8Gr98/BWwNfRLxFkSElFqff3WT+n4T+zwJHtin81YMM9QFqpXkugccEcJh5r3Z6mMUcIjIOGQgicxlNsiLNEZbHpmfHtA0qcuhfvMQPK9yp8qz2oBC2c5G1r2XcRFh9EYYVzBmCNcYQ2b1Z9CReMxjHBbCyVN2smFFWavPzMd9jrqN1FGBIYhwhGygDW1dkf5y99UxWp+eH5XxyhWPc/hdpye3RP8NcAmVVvLcMZlwgklwVfuXwndzfjVfo2kK+dWCEDbGG8fr3h4eFCPWl0N//B0w/sPT2Vf5NzbeaUqVJEYn1iJTfB9y2sOz5DffPrtDqSFQXdfOVu/e20V7X5dGbPlCyXrNcy2B9eFg+IxlLi4ZL8mdDHBJiOl78NNEyud8tz3ziLxW2Y9pBeoikLtB2tzBp7hZSD4xskpIB0ElL6Zs4oUr7MsK1grxrDVb0p/Xm2299VbnPl1dlI1PeDWDPMcZjrDMs/uOZQ5X5n3nPCQ6gfbmYRWX+KLNk2yJlW/dsiKc4bDVAmOAf+V4X4t+oK1kPNj6LxyHCclxuGxca1hvAFPlT+zEdMo6DliVhhgMegaWW8yHwiKt5qSNEy0Ee3YCp2zbMrhkvMGwxj5cDtneRwRPpUGY8Lauosbb1MLKprjNjXjM5EynnPZLFli5axKBuHndsxONMtIxOGN295oUnyPIRkCQ5c4pMxGuDw8oGkklrEYArA3xCJB5l0sTt3LvuPoA0cPfbLoE5TGlBvcOYSYzB79pUQm9J9533wFX3OeYtU5DURpqZYk3M/S8id+OZcvirj+ydwz+DBLzgiGrFoRFYhDRpy4ZIwN7Jw++a61BuySDfX2ciASq0D2cWpmTGKNtDs6eAO2ndCQHTKcuyjtHJLjYtwObJq9lSCHexM3SeoDViOwYd8a+mDdE65J2xaZpPP1kRhtqCNGZpjpKxtRcLAJlaYaNTBVBA8FkLLyZhBjHB1gSSJiGc1WDBU8JP5Y97MZIE6cO+HlckPbNuwb8Fff/XtA04TKXOgBDovwH6NrnPgdVneaPVkhsCdUJRyzbow3ZQRC3Gkm+8oLCU7aJICazcmJB8eeFL1XfuaO38xd7iiVs4fSVsrO38yezBkOAcAUpzAMzq3RAm9AKA2sY8LG9NBcdNbwxfTcG4sELFK7GNGy+Tx7tmdh6WuY3ifn0JPHPb67Z7Bl3Nj7oImTbLH+QPetTaipin0Bx8ffVRBOQnHSGldK2Wykrb+pSsXMgM+OhAzwmEbbcJphl0evHI9ygntukhWOh8uOx0/e4Hq5wNZhmEXovhwHnj4843a7pVWc9bVeBZEV4bMCfF9hrGrfeh7eC3PM99XJwejD4vojtHT+/l4o4yrc9Z7RFvsgZrpJfwmYP8+KbhaeLkIKAFBBy34oKyEdFD7SuoCWs8xjgERdxL4WlTuD3XscbWRuJ0yyBqLHyvHMK9wQYYgjyti8tjmcvwRfWaGfkqe20NHE3AtNjDz2QYMGI+nZfr13/872hgaZWx0Z/0q9Wu9rToDcKRNljbLRrHTYCBvPK/DZOx3zv2i/wRQStC7tA18UOM/7r1y99Smme4s415aVOMOHdEZIKNEsn6W7OxwVXkIT45g4vnVkEajZ3DWQkoFPgQLBpynyXNtNylOEhtqXIY0tT0BOp24reg6PKgfVeRMtlhBDBbywfZfBI+kLr1ypI2GOT3gtLJF9jDGV9RXJNGfX7U081rqTDPOzHGSgScbBRvvEzAiHxf7ZAeUJZ2MAL7cj6cDeTPA8R6kY+qH76flhGedgn1/FKZvgAQBqsiokB7QbURtjSbRVcBN1+J4trdGySINW+Kl6gFMfM7h33I6OwcC+E7YtmWxUx8mqDRVOabgRGsfCi1XQGoH2ht7hUXZ9DFAnDCJcLzvaptuXKDLMG08j7484SazxwZpJvr+AgTh8ewPGod9ujH3bQLThsgMgW32r0Sqr6+Mw2owL6A2nML0Q2qzheVQHxumIHYnW6Qg9tEPtIi1+YvfwZdyUQt8oW6q0tKEN7x7fo186bpcDP3nz81BoVMFnsKacF+SPwf67KKZ3FJ56vaIUuYYRMEaMLi0/dQXNXruAgeO02vgRbuYYi3lb5mn2MBaP/tSdORzejD9j7vO+CyQ6MGNxyTz1myzUos+hOBjkbqwxAzx0v8hIZRSeXBslRUafBvzzRKvwxZkogafzJeEs1SDGdO9iOX2TYSWHc26nQhgKxHl1JRREV0JSXTmEw+rIddoXxZxIjZ/DuRK81tqSDioObSO17dvIK8+TyFzgMGDP/VgpxkTKeC873r55wH59kHmiHx5j4Pn5Rc4wOnpdYVvwX+MDBPjZXU7bQJkDZ9irgLP9APk6zcHUp9cMKCsr7PBMP6uy956vwuqyQ8T4St4Hl8fX++iKP/wbrxOZfhRPp5rSrDey0vli6fyjbMbZUOUt7TdSXsJsKZ/TfOBozVZZOMmqYUdfLLwBmfKzkSBTnVzhMRjXqz7sbceVs97NToLAXRxXUMd0FQbrziZEuvD6br7OylktZitU0S9pN7ASa1bzPHAzoM6JExhUKGyGzTmMAhdsIhm6bsSz/t+8l8Gzgx4NL0pZ+Xe5OBRs11k8vZ4o4M72ooPmHHBZz6zHHyXZ7jAr/kgS2LgjpuWd0TG33ADMmKkg6qu8Ehh4nKhFWw9DtKK/EgP53qckdKL6aKAwbPh8xlRs7gZDzjgzWFy6c+1HrWNyOq/mUfrlZrOd9ebfyhgsrwVajGRY2yy6ltVr4xKUCR/RzGuK7LVHdaJwfkkE6pKPz2fOnT6fOXd6QeQLAgAlx4MZzxNv8H9Uz4fQ9bY1CS+0sGHXuZF0/tyHcJAzQQ/1Vueuhg8TSEIit4ZtG46z0NEZQ+lxllFm4AEkZ7A9bLjuF+ybjnM/8Hw78KIhorZARHRgaw3bvqER0AnYWvxW8CIs9c71cRhtOAsLZg6Zo4xEskP6fJhpXQ2k7kk8OBlMaeb6JPDQxGSFZ3SJoraBd+Ann/wMrTV88fAVXrYbAELDVqjWDrbWw7fC+Cvux/OA5AnDWAiPKFQUc1cQkkKW+5jL1tryFDO86CSxTwiuDjKShyIJDxuT+coC1AWYM9cQwTP/JZgQ1Pq9XwluR6ezLjdaArthZLoxwBqrnjBBijPGhJ9kSdbsPoZLu4tjBSwEydPVJzzXew6S4FRXUtSjjjm+Od+EsM1vcj3ZEPB9H9OVld545iqS17ySNyY0IlrZxoO1fTrBVRU7W3GwrE7nFZOiqKdxzl52nstNfTPFhlKljFCsSDsj+CIfFzPWAODhesGbN2/EO5ZgP/qBl5cXPD29oB8HjB7X8nkKvzrBGjDO3mp7Nu+DWo9qvLfx+MZVjgRjhum1UMmYZZPw9fkwjxXS/TTeKhidn7Eco1KdCLVvlUYM9jpHJDJhqMKW+DBHeeO3VTNSAXyCe+6tyRbC7PKSKuRdQ4oS8I4oBnX5W3AmfCREhdLuxMeNLuw8eaOfKkcnfFGmzVDzosw81nXVt77L++aCR8zOhRxiWPmgl1L4qSC2tjvx8tSxCIHO9VVZRYnR5i/t+/w8jyY4rTKkdm21SIyf6CezSTdh4DUUsPJ3xw9imKWEpfRn5AjUoH9OglM7Tg6V6CFc+YbJOc3er3Uz8vExzKzHLiUea30+zV/AskZanXVE4DzZ8Lxkh4YEG58sx7M8qCKj/M6reIYFQqKRE9vKBo71N9NAjVuwDseMCAWAqFbveCwdDh6U9UAZwknHA8OOB/K6dZhJXmHzFbB8LNDUTdclrb3ocQYvB9YuwPA3GTsx9RIWMz4yzenDYYYWbLxC9uZxsEoIDdTEHUn75ostQVOJPrx9lRNQd5KdbQzBE5dw13TWMQOwFP0E3VrUXB8t+obCMMZAP9RhvMsq2vW647JJH59fBvglvsm4P0bH0TuIGtpG2Lcd+6VhaxpKmQXbneujMdpWukc20HI5wYMw1N4Zo8uekjHs4OrqTXYmklJx50N6GwCz3rdG2PYdXzx+iZ+//QW2bQM34P3+wRmBnBzGsJCR0Ydmekyraa6wJs688pjYpEwokKQk8tuPOzYhQFVoeV0LxTYQOylVtictTVuBh+pniSGaEpZLry9jGLKv0HHgma+sp3asAzxmfphygvOKm2RyU0UqKR5usKXZX/ZbpO77YdVaQV49DIXMPsj4rIrOjINwChCIanpyhq1cJDIAYIeHmjFRjCaI08GW4Kunp15nmRp7V+yrLPey4kSL58wV0lC+YzxOypmVn4RuMFh7X889M5+G1XluE15XDmWugqfCv9AxEKJCy/g+Q3naWinqSo8IzobH6463bx+wNcJxSHKR3mUF/xgDvR84jkVGr4JvgdjJz/FkPXllRq2UpmX9tXxWmr7tNRucr63SFV42v3vFSIzwnVhRyXXU8MHKv7jMl6yyhVrlOQs0zLDM+cSfS7+NG5IqWJm6/Kf+IIDahlhhS3MDNoeUVwfViROAQnH2QKx05h4tYCOiEtprCouwhcqNynxw5wSX3UeCA0toUCTPhOs0dxdyJJSR9VhXelgWga9IvnqdJ3WBWvnr3YhkJ2oOsAnIm6P8U6JIguBwc8jokWkz7QHzYWMr7rXOCmDpvekMrHxpKsMmfKycgtzUWs9qr8nnofiqSftEBjs1SvY1lQ3k04ULLbQ0wzJkE43kd85zzjDbHDCclApmGfiqk6nqBlVG6/tJjMuYhGwWmDMP1h+1I+n5LPtjJd1hoLRix7kWbSfVfQ55Dw7Wmeue/wTKGDydMToXKsw74Leeuy4x6zGKsMKzqtPG2JT3iaN3rMdTWXyC8dAGSfxBRICulHFrurWYJQQSejSyTqLLZcdl22RFS+VsH9A8Fwqt6oOSt4KdV8m7jp02XB8esBGh9wNt28G94+l2Q9czIQz6fSfs+wMASRZj6mMYbGWYJEHVbtQkDpCXW8cxCG0wnp5f8Pxy+OHrMT+0ogEwdYwBHLcD9CIJafZ9x+WyFR1pdX00Rpt7r4wgdbYH4bIPDkPS+Y9b9zPT2BQtZY9E0CXMWAGbk340AMc+QJsYav/82Y/x9fVrtLZhEMt5Hvzi7kzWhjoOjEOWXK2Nu1JpYizLogxAswgOOxslSV8/SHeloXmdquzOzAZngTH/Loab8ptB8Ill6UtXxuIgRj5K8KRQKhOfmTdUOYcKCuHd5EpPIXIb1cSDqtFgfUpC1NuoYnAwuyHkxpYLGiQcZ2UFMC96YWiOu9y5UI8m1csFeTLnlXWe8do8NKey1gCRfPNyKP5WI/kHJ1KbBEcWnnEfiqa0l5QLaCy4MUvAz7QKkiUtZ8I3vm+m3aTECAZXGI5VPcjzlsDaXuAQiDYCrxV+/z7RTl7xmNiq4GfIfpLbbeDzL24Aa5bZCamzgrGapisYKBXmeLAsX+jAvi9lZkM3cD/DUVfxZtjnduvzutpHJxi8L+lZdpBlT6LAGPNpHVaa8cGlX5zGPJiNriiIFgzhPax8rKUZy4XmbBWeCJH1a9g5VQJz5XNB8EShBIQjSHlb8rBXXmSKWyg/Tfc12D+xMmh8McYz/+u/XHZi+g7opqSFYHH+kFhAwkfMWSIbR14+j2pX86CGxRZ6ZNaQserYyv3xuknD/xRdOcFf5j25bxMgcCOtzKfzHMkyQLhqKqvOHBBpindA9pwBsgcNaL7XzNqzMZYexoHJaS4br1zpEcx+Xh8gOgKrwpqlEYE9BI9ZjiralKZsrATdshVAdC2Gr+wW/BnOAj15fHDCOTtFK8gZ/GrQqj4jBnCtY0mMiSrkV+x5MzgsFL/0I9M6bDR1lnJSps2YzWQ6tRt4sY4HcUr7VIvy+evaU/b5aTpQdvCcDfz0nUWcgZeOCqOBusJMp3Gs3STftnvSB5V/dmbQGLpyVaM+mvfBKwQz48bs3pTepUIaQyNYLEqG9Whk8rwPL42wGXhNj2dJWaFszrfWNKQ48abBOI6O9x9ecL02XC9XPG4H2pUA7Hg/DvgAEaOhYcPAfr3iYdvwoqGNo9gLpP9nyRnRgE31pefnZxBuiOiDAU44nFmj8WQwO90e/cBxdDw/p+MC7lwfh9FWhFn6rRkdB0EOtu7d94iBOYVlQe8z0cihhlVhEOF82264XW/YLjv+/rN/kk2iyTDqpCtdNul7HAHAmhLUQyy/YVKY98uX4BO82cE4eplGAg/lKQDPCllQt1C85uu0CM8WupaWf62MeZSm89kyDov3hSuMLoDNO4hQaJDAZw4Du4ieLAz8I1kqByQNKyfFD0jMaUptXHGQWiEguVOUF2cFiFQE8RIHAueEN5jRHEwvIDh/73hczE9b2axiMvs847kJ42qIZFpzqVYMtvwtVBBUL2jUEQ4Ro/kU+ugKqXmgw0uUDwG28nZ2UFbmVs4AUwJtpcD7TbVvzFZXwGww1rrsdxoVSkbHNJ9lrhPAHTeN/2k2vlTrjTlufUVRQjNPkvLjZHRZfWt+Pc/FMF5mI8zgWTk4anuzwvT6ZasLBWeprjyer9RS+i1GQB2fMMrW33o5V3ryfM+hclnRSiOgEpMA3ceqb6Y5IorsmoYsDMr5uq9OSyGjE/uOeXjijswfZvjyvBN70Qy+ebVbD+q2qat0E6paZqKpHQA121RSLNK4LJ1zC+3QcUe2ZhgcyuaSraS60yYnz0h98zmVFit8BGd4fHw5jVe8rIZkkkUun9mrIC9oNFKV50KgOqczo0wYjH+NJ6VXVPoZEiZrdJTp1Mbcno2ISrEjBYrs5Ay5EgUThh30m+ZVI8GRrUgLLO00FwG4gWXV2iHe4SDLMgpwx196TPZMvxkW67bkdYjpyNPDwlFtDDKtFymPqnl5j/TfNAfYJVt6E99JEhYz7KqMMT40YE6dUMSl+qDFxL1LPxeTNfA4D4h3scz21DfWKXnmKzO668hN1Wu/t9awbYxD7RxsDbsSylC+13uXA75zZapTE4B2iXDDtjVHRiPZY1giCUx2uf64kreRp6JtBOIN1sMxeqyAMf5/5t51SZIlOQ/7PDKrunvmHC0XC2IBGLgAIQAkQJA/pPd/CRkkmUiClABiAS5tAe7lzHRXZYbrR/jl88isnrOimWxyz/ZUVcbFw8Pv4RGBbVfsukH7gr139H2PUygBO+hl2/B223DdbljbYnvQPGg7aC3NqsxgcnxprMIa7ajxEs6fmIci2+GMhe1BPX++DqfNJLx7ybCDPHxv2t73encZbHwYRhUAoI9IwBziaW3ct7MsC3728t+gq+Dz5RX//ekXGJNBR7Y7HH0+QETr8fomaJP5TCF49EYOYHglg9k+uyC2/gViubgn0uyEeVN3ZPnijBnhpyhnQYv4PP8u0uIeurl8guOKJsF7GCAg6cDGh7pTN4+PGdYa8GgK6DevV+mCnC3/jccg9JuWAhXkCG1KDM4jkmfMGCsBRWQzBPVJZ7/OS8pjN8hPOvM+2TAo7VYxHv/GUOZVPLFIb601K/FUMDVVtipwho8V7fibdz1PpqscaWqC/tRRqfUZEWYwPghqJN0mj5dVv4DcLp2fDMHoJhwkMrCsTAkqEU6GInIBbw7wicF0/tRCFW7WnK4QzsfLv1XH7xyOOV15xtcMlwjixMOzMbw/Vinwnr0fgbs8qnnuu/Q2N8EF2JoC4wTD/nH5QtaDDgVltnlSSh4iRLQAHOiVAz3+Tzp6bnRpyG61E9zc+Mr0VzLKSA7WVVEEfIy/M/yw8zSjiVNXCyqjgffMv6PhxQ4qt9beyQyqOlVPPk/ZDOJ2UOIZqMHSYvALMkWQDMcsZmPSikvFUBXuDEFtW0PYCdQmAFpcRgEtxqDwE0R53GzsTex4sBmElvN4VZj7igCMGeBOY4/oaNguQB7Yxbii1hXFaYCjkpSvsw3r6oJVgm3gWHBmiQgFG6OfmcYCf1zQy3nPlSgmaWf/eQCR8GOkn+nu1c4YtOAtWYo0xGQIaPTc+6Cji93rBYWdPt6xB22NjJOw9kjWzjof1H8OnwCU/F7qdIVIx/P1ivYy0vZaGxkIr5/f8PZ2x2YOePGdm4zTEltDW0bqX06Iw2s4NnwF21uAIc6tMAcN5Nj5/cIHzaCK3hc4VYUN3/uAUwTaFjuAinE0Zu/trePmZ8W7XmC0KeltOVKNY/HU/iRe7tO73/T5Opw2wI7I7OPywV4dJR9gc8UB2N0Nmsa8E41hZ1kWrEvD2/Mdf/fxp5Cl4ZeXX6HHhZjHI5zVTppUHcxxml4EkIJUmg2kfFAUwZ4qRVOAijlo/k6Iac6eo/V3QjT5+A3vGkCNUYsIuh9D7PA7g7RcOQv1Nxk1RxvK54TmwOuNPKVTwlSkAZAHyxwNcgXGCiMbJY5fN6zI+FEakuOnMA8eMAohUynCnRVSc2ashdnPcaMhBMJAn7oZzXCM0v96NJWMvwLxMZ0w6QdRJlZFylhTaQh4ThVaVlXZMDszumm8OegZCITDS1pA2EuOap6HnuXSiGSMebRfsCxzfDe7P4mtxON3F7Hx243fTx1kx1UcyFOFbwQRBMNg1xOYclgBTN7RVUuznXPmq8xGdR3pjBFebWMuIMOi9C2F3ub0lwrrY1WTq7H+52z1K42cUISq05grXx1xkxFakbq69aied3ieRkoq1+6/YmfGIYpUXZb7QDjeUESKf3eDw+W8FzD5ERflhgNvTcbBJC0MhKH7jnPs8AkQhyIVrnd5qDMeHBe1Dqcda4ydaaGuliYczuP+U+VlII3rs8BAdTBnMFmaJ+2UvR+qKHeW+XiD15GBKaXWhHE0S8u8TiRpYHLi/ZTLUBdDtrbYkJ+nEoejMjl9VUHYPX7WfuAzSOehBqNymmUj6EBZECxrzdH0i+NjLAqyVZLn5pXQkBnsKQUNMD6TeZMXGI+G20lhJq6n8Z/QD1xW+8SeEVpFFFyfR/AOvMVUDHKJcgSVDdfpzbOEqLwi9niNcWU4V/2Yfy9IOBQA11VwvbRxumATdN1wvwOvbxoBZvlU/QAAIABJREFUdb++pyYlJuSMOrYhuNCZzgqZ1hr63vF6u+N6BS6LQnfgvu24bXtkPI20XBRbT5qg2WXjfGpk7wMjmkxn+9qcDsehTX6S6Hbv2Lc9Li4vgYB5pGKn+sLmdNG472/MkZ04rZk551laft5FvULM52rQlsKDzhZEEMBtvXGf3gJRNefa6EELxkerJHiYm2X699HzVThtvXe8vd2DaN1ZC0FpEzgO/dgPl0r7ClVbFqyXBcvS8B+/+c/4fH0DmuLe9iCKQVg2UXZvW6RcIlTXCa/rmaxwAEi65G9JMMk2gkHQQ/6cTA85b2d9CZVLohgtn6aRkCApjpKrHzZgFCWKdiw3KWawsHQU5ErCexdjcfQvZDHI8CJKnuc7N7seh5vtpYMfETE3GrzsGcekuVIcyGw7c467suslNUpJeIvfpDob8yqjr5IeravZYJrGTfoSULvQ24wH+DRUYZ31OFI5nWymGils53OfRgpcEIcKqWlaxXGg8TL8PLaib4nvxqWyll4Y43Re8P7ZEDqqstFu0vn7G38pTYUUNLceQXFWKGSTIKr6CYK+unY0Ah7aGGfvvyDded4Kn2p957/P6Zc5xprwOzszXFIPY0gjP1eIDOd+DHOhX4crZVNrdaApK/J3P6lXaKnm3MH1CH4P+TCMiLGKLmGE+hgHLM14q+xvdr6ntuOob99n0egaFpdH8JSrlnSiiac4veyAM8cNMktDfEwuPV13OV/XOXvk9M9yJViv8OqkdwN2bvSMpjMNtgRH3Gk1meqJZQywOwU5VkNztEsCAwPvIkwbru8cJzZHbmBWlV2ll+PR2necN95MBtJf5nA1GSsyHjCNvYosm9QdFBduSTsJzGM7pPZu6GoS2+cSV2JBT6NJEajQzmsDXmxccZdVHV2xI+K7kAwPPKHwBsNb9OPUh2uHXXvQ/7xC6M7Nqf4OytG4Fgp+x1j0JfBR+Deud3gkupxKcP25bgZgUuPldgL1eeC6U3qmQMeZCV2xXxRoDU06mgDNlh2GLrE+zjwvzUUPD1SGDjBnawQWbN5CNtWES8i4x+zz5zs+21yqOSViGWyqY/Vtlz7mtbdxIbUC69LGPZik7/q+oeuO1ta4bgT7qOupgYqxB3nfd9y3DdIWrNdLOG7nurMGBMQMoCgpvl95KfvkVRWtK7Ztw7Ztdvj72FOnAwUxlxoKbs/eZawoPq0rlnbBvm+43TZsupszK/Bdox7T0AM1zaN5/HwVThuQdy4JgL03NGyhVPdtMwYm5pORStFXoF8Vyyq4XW74qw9/jbGaZIJJTbroiAaMU2563Fmyx2lQHGlngkiuLUGeE+03iEZIcHl1Vy5JbLHZsPJ7tvUATyx+4iykEJzsnM31JmEs/I9M77UyrzJGDJ+VtaMt9eiepqmXsnsS5Cx0p6NCayCOETp1GHUxjCTCIadOlZQUrivcGfWhKGk0AimnNg2HpQwgy+k4FzP3EtBYomuei2yHdMT0sFBHpTGG6UzZEZyeSuHC3uV4jfkgjFV26ADaSyG5gjIlOuKI9GlkJHCHsSpn7BTtu1EkyBSJVEInytMQ5ClmLi/8FV8ILIWps27gWoBymiCLhImUz+CvTyqVagz/f3vUEm0m4E/g4FU0hEMgMg4JUcIH1aJPxz14aTCfG5ZF1Ej2GypLZ6ydE0CsftlUeqRzvJvSbCgwMAeW0nHqlraJJCwA5Y7LUangxPdvjCKsL0zqapbl8XPqrf+v926Ltx7ttUNQ3LjqNR3fYeudLh1WXxXwFZyGxS+jVjV5Pq/YJ8/4SMMQSWwR3vzQIceJHAJocCPmLKARSOhxH2GOSQBK0+7+m+HR9+w57Qp4HhGGaOCQfp/HOlbYUxa4/E/aSploE4KyBGF6RJYqIwGul2/8GP2U6enAqfYx7Bi7K1cNPRaBAw8AeCDNT2JhCBjMjlg5G/VSxpQAGlw0a+BpzvSJXnxOxNL6Zr0Sw/QsEXpr/FQM1FmXS+LMB+kiOeFMnYNpHD7dou1036XDONN56GD11j3wQeOPfnicBWz4i6OJ4s5hpQNug7R5abz3jk3tcI77PWUGACwCaIOGIxEICtxXveyygMZicPTxJ9Wyz1U2WcYYK/2tDYfGGr2sDX0f5bqd3r53xb7fsWEEp1oTuy5HsW8b9l2hckdbVixrw6U13KG4bxv6Xq/gEsFYVtx3tH0f/Nhc90mBtC3NUw7yDdH2kPv9oHeXRSBygTRzOHsfAQQFREd2D6RhWcROnx9z0owm7287fr19xrIuWG134yqDJnc+eYhnmkE4I90Hz1fjtPmz9w7tGzY/9p4G1myyfvH8a+hFsSwNv3z6Ff7x+gu4ERkKAKkw3eHb1ZZLdbw7KCB6whgAUA64EKWjcdOgCHlSpOhgBDlEiun7OzbbnCo4f4/4nYjlH/t+KoFKpjJkMHKCI0SXK1f7I1XQxqsifH1jvTtnD6KC0yC93cRt6NIy36Wt4NwHDwmd6adjW6Ts6ZdRjoGKjxOOor3Z6LRSBySkQ5Ij16mEl6sCyA2uNErqBtdDsInBkfqKGw17ZFYyp9Ik1BKVnAX6+08oDDn+zvu53IkczsTciNk0VlaVjiAOo0PSDmpGo3SpY0lzm2EnHnEejgW4E6Tz5b+818GVRE5NGkbnxH3AFmYaSABnutFD+ZkqD/tdPdrZe0Zei+FQNUmJY5Dzwzx0nFc3uI+8Nz9cJj8fRlEMdF95U9U4+vy9J+Wmz4XvMunM9GTY+Oidzgxn6mnH7khkhLwEymaCVyfLnuPYTc4qxp1EQgUJW4pKt0xCTpZjOJ7Sfc6pGZeiwEHgowZNQhSbY0yIzBuOonxqwuN8e72GekNmwpbzDdMnox0PwKvDqkc6czxUxQHEaYAG0GBnFzJZfjjClY81Tib0wxN8fm3ewbJKpjHPXM96UVMuBMysgwbcvEKYHG9/SxaEf659PNLF6seuuz3UWtEbfJeWNBl34kaB/Lfu+zW8y2PdW+v4vORUzCosWnB5rEo4Txxk0Sh4sG8CFslV0giMDMIKeIico1k35R5JF16zY2enjD04SOdBRncCwp8Asow9W3HPb+/YrWzTPODD56uK2JwTYx7qxWi5nLycDVT+5NVt5vkcsQfFh5NlRSRtFB2DAGQsjvTexyK3dui2j9U62bBeVuhlhUjDsqzmIBlM6uvvQ3e9yAU/3H4LUOAf1/+OO24Fl0qLP7MSOhNNI5uo26GHwz9oGNdVLaqxH7HvApGOjgWtLRYsyyBG147traPd9rGPj3StGhyRBo9Khw7dYOH3bIPxfBVOm6piu48jtTmPWkwTtEXwt9/8dNyMvjT809MvsbUem5bZ594x7m3LjYwaxM8R9seGdyrJ+RUrfhCyxzsSRByyQVU4xxRGkpyT4uQJzGi1ZGf+TBEmRaYInEU+T53Gok+1EDtrS470Hh6SIDl8CWVcikz9htDTOidR7BxNk8Ci9ljJUx1nZt4vqbMmeOQgsncOxIbWGRPOnDN1pWFDg5eMs8/dz9Psv52BmX0ZfI5HFrrgvhFGSRg0h/4lYKzzQEL/BFVHej/TVlWBzHuoqtGSdk6Rwx6o0Wguf6M2AMTulDwc5HyOy94qw6HP54iAd/g9XJ4ayiqw6wiGNkHktYPef/n5Urn33rshOeDmlXMf23n9M0qdZIrm6tKRPeoPjH+u/32e0fNEo+F0zf3kd56zHk53KtbYc1J4/SjjLDmpyDE2kBWm5BXw1ZJZthQWRNKQ44EPaZBCrwgabkFVvcAPw0fyo6/kAbB0bXUng4wKH1AzIcSyheUNgWCfB46cIlgEJo+PkqEDjb9YhTg8Tpe81yTnMDdMncnD+D7BMr6zLMlLxwFJ4xcurCXgLTKnZ/pfigibB7dN4hmnGR8Cn6iyjNPrxeaQ99alFRGjwgExpDQrzv11rqgyDvMwEg/oZnl3Zh0PkfkjLRyl6NjmcWRXsiaPkeXYGeSJRtSyaZhGyhDZVgEq8YBoWfLngLUoxtzTnyvPFb7yTSUuY/b9rC4JQgeq/SLRBfIkSa1zPmEkZIjQVHp7AfMkc/19GwsVqyq1mwhwXg1UFQD9o5Txl1VXyXlMUSEJK8t7zbGNNnocGrgD4yRHLElrqsDSTBeOkyNXGfcp3xdBv42tSds2TnlXaViXcRWADFKxFXg/MVXwLz79Pn60/RZUBB+vH/DWbvibl5/mHJOMHGNPxPuBTk77aun50hW6b+g6rglrgpGSaniMVX0Zp076VTCBZsFIFfVxC9BFYg996E4mOcyBFcUP7t/iR/cf4kvPV+G0AbDIIwDtkGXBuq5Yryv+yzd/j19dfo3P62uuWIkdr2oyzpXU1neoXcbHuopFwamvIckKHj3JYkUDHxA9dOWkeKfvcvKptpKAMuPHB5kVxrElYeAko2SP/A9X7jW1bXBoxG/cSJvKHlfhcoVJREqKxCNjLQQQITuMHhpKChtnknTQj3ioEa8h1GtBTws5pCWc6SL+MQwbTSkpTgHWZnxnrLLDau/iXifH9EQhMejjHJ7NZ9KKMYSQ0ZMkEQ6/YzKjPOcP2Z+nPeqEfRbwB4MIlRbcpkoF4rxJjlgZ88SVwRPpnLQmFVaTDb1u0wxjpcJqtAuPrmX9MdVqqb+uX9MwzoZHR3E9iPML2xOhUKpDx6lfM04DGBr3WVTZ4eTytd05vQkFMQMPzAjcxnl/A6Yz5skZHmXIOCCarP34HNQ+fZ6LYapET+yc2Hg9FV5pjpEzS7JG4PvPPCIgcamwYlyFQVFnX5VqmbYn0DhGmjHQiZBGf34QhBtgmQZI2zNtPM6lwzFsswPmx75LrjhLoxQxZUeRdByT60H+07sTHimyUtJJevxwemauTMXbQpds9I6x5fbEutJqNcYMUXoioHkHGIGbNUimndxQfLonnLDkGY3HFfv8NtsHh48imW3N1rbzgrUvQB5gQyc7DuMTdm+bB1KqwwCMPYIO35kKDtnvMtJYtjXXn7w/SAD0JFJERRo3C39/JfH5EQ3mM2WkkGz01JAQF8ELuTLr6acOtwdWNGwYckTDRCDdDWAx4hi3L+XesQKO1c30Ugl8Dxw4Z0uuLpNDwfRSUkWZDqKcfZDJpmAhA5/LTK+en9leq2SZsjeaFv4hce1NdwWaKjSuwjJetL1dcGjHBnS0RXBtCy6XdexxU2DfO97uN7zdN2gnGoLL+EEvkRaqAumKv9f/hm9u30DQ8O39Wzy1Ddv1b3FZGq7LwPhy6dC9QVVx2/ZxmbalKqoC2Hd0KPquETTTbRyC2A2XfpChifqh+5sfSKaBHz+fotG8RXDK5bLplTIFzEcAPu4f8Sef/ghPeqUJPn++CqdNoejXjmVtWNcLdBX81Q/+ryGQFlf6djFq79Bdx+XXm6L3ncwUBeHz2I/mRdDBzM58ClQdRFFrE6QVzRm1dAEgfnoVT1Zt8viQkXL6PJo/NhAe1S3NSAj4eEzwWyPRWWHyScnPBtzc95zO6dHFs3GEyJP63YZX9MM0NSnLwEI+lSn3UfyXULixxhRlGJ9i8HudKVEogMy+Dr366GiMaURxmYozb8Gti6z3yAHPXkcFmeCdAwqVQSbTo/BFimr/Pqqnk8EOE7fBTwpfUircj2nBXDHwjnJkx6cK+lGK9xoB2z5FxNwoIjQEDKrw4/3dNim9TnibU54dVx6x5rp+t9FhBI7j8pL48MRZevQbg8jzV+xC8flVglBKG0kPGmm07zrfB0viOI6Qse88zB8ofWZUlB0IXjHjxbN0pGgsZrRNjBC0J7pM4Jus7DrSzE2ptNYgFgn2A3pc3jenccmeRxrTMBhC7kiu/AHpHkpb8jxj1XKgytjK1MOikkkODzklEBkHFqh16RKgyOscIjxp0X8ffDrzc66MhH1Jf8Z4HpyiWx6eWwSeyFfOMtQf6yxO1/R0qQRe6VTho/wJmpYW+HFcz0GVatQmP+eeIYl3ldvndMmpXUJFdVizCeXxcfksMEbiNB90kHJu2CrHVf5TiSUUpLX2wnKndn3lau+Kvu9YpjGq2Mqen9qgORo3jDP9/5GMG3Pt6X864bv0p34KYeImg3jWVvQ/vkcrR0UOdMV2u+PWRwBnkYZ2WQAZ+6hV6VTJYpuoq5VAMK9p+r8uf+ZMpXbgTY00bG6Dg9ZeuNhL8SPR6wFrVnaa7hkVQv3N2VmO1a479m0f25isr6aKiwLd9WhLB+0uN7zdRyqjdEAbsPdxHVdb2nF8NoplWcJOQ9vxj/IL/Kf2X/DHbz/BgoYXueIvXv8Y//cP/w7P1xVLG/2yHr693dEV+Px2x9vbDd1tCxlhvGaO57b3oFftHT0c0CGDxfA7YGlwTHFqa6zO0QTEQoZg+AgCqLbICLnuz/i33/0rNLXMjUcTZ89X4bR9vrzh//i9/4BlWcZpLzbIoTDt6SOlwnNjte+Hzc1ffvIQ36E3JoOFjBs+slgmyk4hmek3RTB8CetnkAVTlJjQiamTK02n6Y72zO8Ck5J9SKe89VnRsRImhfEoMusoKeanC2QjzvMoEA1S5hf0m9+BpyfwcqcskMJYlKmcFiELLkbwPsYNQgAnPaUTmGlAPXunPQJlfgMBLipdsVmrwfg4PLPAdYcqWiyCX6ncGb0co3ThlMW8Vsujpt5OdUrJVNwccY23pMDIfiFnKvmrTv8DGMAnjkoYe71ED2qAxcM5edjDGZ07HqtBVJyJAw7lgI80BedAgNHAAyfu7Lfa9DyHJ9bj3JLSzJLxBGRKabQuDh/LwGonpxHm8sfaC2OQfkOlBcdVrMzEPt0xlrLPsayUJD48LU6kFXhn/BQcUzucwjdWbgftjP2RgmVZAVGsBm/f1RzK8V7VTj2z4/4X358CxWUZx79vezfDQtE3RW8jWHlZG273ewRFHLFDho4AGMygKEawpFz2/UhH8s2V7PQSBO65evHDSZ1Rl50k2w9ZjO1HMsr15LHVpJ/c6zTKnmfEHPhIfQXDxmMOGczAHsZ2R7O5CRyJjcFgYWiYtk9h8DLQcuJlOA+ub201jFdTQta7zeCGfNl/njaJ/5aiTIe1G3w5cFuujmBTxqeY5BZCT7HDKfDzJLsqsA36VKO90EE+X7vivm/weR3yuaFd1hiTmoF7uax4fr5gaWveQcu6tTzjcDmSHoWogtokd4Ts+4777Ybb7Y5d9xi3Z9w0zESp1HeV53vv2O/72J8kghWKdV3h213mlekMkjKevQ8/5Zp0FWGcy9WAugX/eVXe+NahbWEjJkRp2rCCDHfHISVUHzU6Dr8QZ2iKXNVB3+qy0nrvCtztgD8RjKulYM486Ton4Vidsn9Z/SgQcqwFLgSLKH6+/hP+mfwAP779NgDgsj3h6VdPg76WBU2At2XDZ/k0aHEf8mo3Q2KkWvYIjGnv6G3BsqZsXS8r1stlZFBYwEwt/bymGrt2GnzOB+c0AdZLwyKLneKtuG87YBfeiwIf7t/gz7/7MzQVvMkNn5fXgwyen6/CaWsixhywgx5NuNjJjnsfx4F2VUp9fBzVev85J1NnH8DvbBtMIQPAEPopQ+rR0hz1483eX+j6AYSe5ne2CqegA3vHL4KSkvh+2ykw2ZGLpuOjJhwOgys0H2OxDaQ2EA3pYZ6iDhm0Va1MLZIBzsLjMDbrx20THxK3x8N0ccai1OfYV239AsucDxbMWr7RkKdfjqt0k6g15egK+zi2ahSZCCa8RtBgEsbumNS9bGkYVMwc+4xTJNWVMxkfxIP+LxvWByPODQrNtAT60ZQA8ZIbEcRr81NxNuRFp/Yz5cL5yp88hjt+EYEd7WZGAam54vAd8ZU4qCsgdTxnOLf5mkWFHPthZ+iIh+jBWneDJ+kk9z9JtB1zoEe64O8cDT9Ph6xwjRUNjXmRUn6GeZTJfWcaTos6HNyFZF1/n3Q4nQIZs+58kLLMLQUPFhQnnmD3WHIDsG0b1jbuA7pvI4VKMQz4bVf0/T5ORtOxWvZme7fa0tAvVygUl8sK0Y7bvUffr2+vuL/ZvYGBnwXL2nC/97hfaDglOvZ+iIxT1FqLUx5Vx6Z4uP5qLe5Lapbf1/ce+s7vkvMACcuqlClTqE6WYcjYzEoc/FHlEcuFo1OXNKbk0APZxvjccSYXz1aMS98BnSLvSXMAtQILwLNk3lOjwzkLq4z/GfRSFF06fcG1zL42ZhHYyXuGE1Je7IAJ/OCQNP1HkIgCQGoaKXDpey+nPdsKjPRW12mxJhVFutMtXe3G4nrXQUfjmgEFmmKRcT9uyAoZTtXbTfDyvOB6uWBpHuzMJ3S/0Ui1brxvDmgqFjee1xXP1ytu9xveXm+43e/Y930YCaeTGdgbzoXt+9PeoW1BW9TO9DFe6t1S/qTIhySATJNOF0pKT16eV0tj3DaHIY8wVsydPti2S7vtMJngWWScImA61gRmnrIyHOBweoxAhmQwqynamvfGCRCOkBC+wn4i2mY+FEGktwQNa1Kki+ujDhkY/Wb/Bn/x3b8avxi9/rp9h5+v/wQA2KTjH64/C804htOCntXmt+kO7S5Xh2y9rg1tWQHtGIuwHlimIBhPhY2ttQHL2lY7NbPjft8gXbFDAdkBafjYP+C/Pv8MqopfLr/GP62/KKuvZ89X4bQpkBFqu+R6h4bT5pkhc+T3fYctI8KPVqR0ErDqEUSMaIbnorrhXmi/CO0z42o2y94ZPBVWcMrC+bPIdHeZkoIgQ/GxifcABhCDGSxVsaXAs24RaHEFoCk4Zt1IdhKygeiYoqMElDJ42a9ALcU1U1697ZxWrVg0hIRBW+bTjLpJ7BEmjsjKIRLeXLj5Mne2I6VeiJAHzpoefstl+Kx7Pr8cHa12AmxOlcrE/DDe36E/xrH/27sbPogJznka7ek0p8XRQfLj+D2N+IPTLzQuNsLo8RUztUDPiHovgyaKHEh+GaB5Z/P4E6FiMMRKP801O0YM/0H20HgPToZwqfztPC2R2qT2PJ076ODEIVPGXbR/HPtxZVZKOX7PJzsWB9b+uJxNp85XqmiVIMiEglZk9YcxIGkIqdY9ULPUcDqAyde2LFGmd6Dvd6s67h4SiN3HJSMCb5fC9r5jl0Gf4wCDZo5iw+UqWORieygoyyBw485Vg6rgyR3MDui6kHNhPCHNLqftECj2fRjh3TbU54pQx753bNsOwXDEBGOVb7GTG/dtw9030KtA7QjuRQSyLpBlBDHu2wbZ+0wC09wD9RAWCSY9rqDYXChC5tSVNTe9UhgzbToPe3oeAzbakpSHk2c4nLdIOqWpkPqvjPGkWjpKVYnRJk9yYKekSyvSgZNJRofIoHFKfnfDtfZa077hUKTaCxxKoJtxkbgNGcsNhSqcDFG1ezqDz60PW82QJflbgVy5IJmnXXG/beh239bHjx+x+HH1Yid9s7eN3FMsGIG0OO6A0SiuUcaKxuVywdoEl3vD623Ddt+CXyjMX+cIOlKEBePAD2m40J5IpTpOepUC/Pc82EzLvllana5GVuA4g09K5aRWmQZ/2JISsCQvUEeV/qjNR7ZD8GfBlwepJWlGBIKGpjUA6lJZAcuYY5U69zoCV60tUW+sJI5rA/IQoYGj5/6EP3r9Q3zTX2hI1K8twX7sH/Dh/gJA0Ns45CPKi+Lfv/x18pACbQGA1cY+4Ni3DW9dcLksuCwL1iZQGSnkDJsSjYWJhXFIC/oNW7Nsi94NF7bSrop/uPxsQC6++v7enbHj+SqcNsAuuYYZWKgXbJtcs5Lfs8UwANgwSgUPFl7myosM4evHeZ5aRgAJORL69C5H9T2egz1UJcOZAjmmiZw3nYI5hWIchkSeFCucwgD+7YzhfOix7KUVrmKAKf2WaQCPcZVzE4LR33A1ndQof9FJSD+on+OhaBUbFe6ECovvntWFF8irwUCqFIxha3ZympxOTQWbIChjn0bEd5Y9IoKYOko58guefQUrjXXCuGohxUBr9FmNCFf4sRqkaUrkH08zU0DdqUo4VT3g1p0lCz7PnFrHS9ljNGoAImiyPHCOSKXZRHTldk/wKQBURtq2MRJHxc6uCYpIdQE+FXYxkk46lIevsz0WU807dCI7lK2GhNNeXUmrKZ3nKZ613Sqhj22EMiOYVPPI9SingF8exPaOH+2vOM7jKKvlNz8GPy+xFiyxH23Htg1DUkSGwXe9ADpSpLb7K1Qbet8BWaAAliZY1guuVzuSGkBTM/bU6RpAV7RlvIsoFDBFzAWLH1wiCt/n0LEc5JNi3IPURIDWbeO7YFfNvZdxnDlw3zuWtqD3Edn17QS7KF4uTwBsjPuO1/sbdN/jwtqn52dc1wuWq1j9ezjZkyl2bkCHjGR+Q3GsMpiV4zsGBSLxrMhloiRyDMb8V7piOWwQ2dHjICcOREZsePErl+2pY9LaTX0jqPrP1oWEyqGyY7HltUoll+cpTw2CojJb4A/ql3pjyKe4ypcGmMOKtgNyY85ZfhV9Kh64Hqd5lxQuDlCx1qLx7nvH50+v2HvHtx8/YFlWNBxzKHy2u7W0FwfW4OyaaZQ60t4UgCwrrtJwuVxx3zZ89/kV+323BUet4zbe6d33yjZLrbY9VDwnxU455tqMAM8YZz/UUwB9pJwuC3bALjtXaOyLQsxtWD5GZvW+de45ASvzxAAzjcUrVzoU8KJiEm+0VnTW8MBsTAvRpR5XqllaFPsgaHW8e1oWXK+A4AmQcV/b6+0O3REyv2HBv/3uz3HVCzy7ogcPAIhAr2Nn6OrWgd/qPyCYFP/L/S+Dd3zcY5FiIO2vPv57/Jvv/tSCgUNee+BITY8Nm0Xxs+vP8bdPPyWcpwzau10YH9ajy7QJSTY3ohPeT56vwmlTVdxu90F8c0S6ylEcv8nJ7/NvElZhh6aFyAyzyGTQ2KspQj1BPvVVKoYSD5Denwtr8p02o9faUF22n5tLAg6Qi7NCfRbhREpoksGAGX/vMPejH1LcjHlI3qecZ7hPPGQKAAAgAElEQVTwCACn8SLhZSMAqBdgH8BwIZUpXtl/TT5ghZl9akRy3NiYoSv72CTxnqos96voVIbpKQ61saezgxodmki0htIJ4Khy5RWPgE6IISfJjrwlw8zbGgdqaPltfjKtjBRKPENF955C0mk39jHpMCDj/iQBmrCS0oC17mcbR/G7wSO+hEFmgfKARGIO/Td/TSdlM+rAuez+dBprKUxjzwASTnAS0KHOYfn1UO8oj46rcTM8x7pHZ6e+d/ri71Ofs+LXXGVm55BF4ShnvzujFACINoCQpRzoKA4BKk2P/kccfV2GJFmWBfu+4fPnz9DesVwueHp5xrKu2LY79m3Hvu/Y/Rg9CJbLBc/Xp5HS1YREZOVRP77e7BBcRNCFcCJmfCnGpbja48Rh1RFIWxqAbiO2Q3vG4Q5jT4UCENuUDwgWQ4YAwDr01tPzM3rfxh6NXfHd6yv2+4bPtxsEwF1uWNaGZWlY1guenz/ivt1wf9ug24ZPv/4Oy7rg+fkZT09XPD1d8Xq/4+3T64A1JP4JzRCNstM0r57D8QUFXYRIFJRG3Rx0Y6PvjMydV0S4rL2RnLPZDyguYVV59NsUMgsyofa0wu7Gf+80VIw6ubfLevOmZ6fQ3rN2NG5CYMhoSYA4bc9l26zDGU/8+FUooa90Hu9w6kZsYvCHNERLBI0FE4o2Defj7fMN2+2OZVnw8eMHPF8vpEfDtcqahSwo80Ux7i7j4NIQ0lAILpcrvhHg7e2O29sd2x45qKGceatH2DiTOTPzvNO+lvnQbIfw2+34+HGAkaDvdnG0zeBYRc9V7uPjgsPHX0ZqH5nmxrsy5a57uId4MdpnSpgtAy86cWd9T98BYgNJfArTqI5hPe/PQ2/fgD/7xz/Dy3LFIoK/vfw9frb+HCuuaKJ4lTc86xMuesGlX8CB9XDaAIulM92Q4pWUUQCw4DKoWHhlX+Ar7v/rp3+XMAeKhZrMfv/w9vt4XV7x88s/GpIauiRIIYWCxwynocySrjsj+8HzVThtANKIOnl13GNRqnkpIta6AuP7XKC5giIWqjnu7/B2Ty2rnIBD/wegg1i94rlBdVb1nXLHJYdq4Dxq8x1icIJpyFN8DGSwQom9ICRAizAIx+J9WB7BJwXEM1GSLcvhg5eU1Hv6zphNTqfR6FbV1Lu9qsoDWZbmI3AsJwLNOvQ9LJMUjs9p2HNaj6WAurMR/HDOMfMepOzBo6GV3nNPEDMACz42hAyt9q5JvjuiOuFzoy32vFklBcIR9g3fUL43CHEseuKZgASA2PcyzAcBRTDhThjhKsbtX1gNGR7k+KqO7yAJpn+znMgRM46T2kZdJchymQr3qI+T1qn/NMSOlDnTYa6SeUQ75WOmnzjx6ISHWXSl0ZgOdT8o18rG3WglDe2k0WGUaNBioCWME1h0tOHpehlkJg377Y7Xz68QKJbLBZfLBU9PT7aX7I6mim27Q6VhaeMuIVmuSQcgkugaCrfDabMPOm0CNw81BqbQcVkR1MdnVnITl3u+dNDtOH+r130TvMlIMX4x+TXE88DJdr/D85GkKf6nbz/ift/x6fOr3UHW0TFSM3G/YxPBhw8veMUbboKx182Ye7uPgyZerlfst23sEyoUk3Ihf3c+Zt1L82eyDELpQEVOJX1GeiQ7Hk5Pqtke0Zqv3M/BkpMY1cQxUt7Nb6TJOHgBlA7o+mMYEYNHmzlUToQxrDEnM6sVOYOz92dBDUeu89/4G26dtRFBPg+gaNpXJdhoc5CZxanPIsWbevOMhmYpvj7XIbsLnIoyIQCgHfs25Mh3333Ctq14fnrGZV0DpnRQLeNEFTuGjB/xkT6sFZMnfm/Wbqh2EbUsK56fR5DifrvhZqtuRL2B+7KSO4vEmJvcuza9DXzFMAG6dkGAJthuHbf7NlDSBJdVsCxFxKRN4Xhg/IdtIdRfysLD1YchE1nmZ+jFPx/HC8OOB+AyyyjG7zRDvBbBTkJZpC4L8Nyf8IP9m1G2N/zL158UfdFten58/z38Dn4PAuDT8hk/ffoH/N7bj/Fxf0FHr/LA/g1aAAFhcxuk6dkQ8Sr5YFb3ogl3dtYDawgnD/jU3vAmN8Dk60FPe9FJljniFMS/c58nz9fjtNFTjcOjJOXoOEdf7G3UiTQwl2amLDwdsEZnkcg9gan0iZz0dwcAMriMUdm4OBVqX3xO8FG45RHcVek4bLXlojGsgVq2tbyHKgXckYlG32TUleaUGGUee7aQapzdwBQyB8PBiOZ8cdPnbV7RO+JekDoWPlYzjlxbR0TSJSUPXPOD0jvt40Slo4Kz94ow8GeDRhnaQOkZ9K7oeRUrxwXUE+LSSZDSdxo8+d4VRLRFDig7rEdDI8dXn4kPNTc1D3iMbwQlsuXjzPY4KScAYMgKm9WV6fOovcNVgh0zIpmZpe5rc4PDrwyZwEonjOTO+ZMvRVIhnBqkDNP8a7lUurYxt5MGc34Pp97p6cSgrDBVwDgtrjVOrXXl6PSVUegj6kk2TOOeqcPx35ZlrDz1HSIN69qw7WN/2P2+4bpeoF2x7TuajM/Yu/HIuPhVlwFLW2Tc5aQws1EA7BlNVbU7uMT6tzcKoCV95jQOJ328Pkn1hpizRfpEGiDdq5ts0qA5R4t2xae3Vzu8q49DIwRYlzEXy/UKWVfc7zv2fcOuwHq9YJWxujfM4I7bba9BIOv4UVDzMAskf8bltDyHcizzoMUStLE5yEPLmqOc5sDwV+RGSgkFJhp0zUD6hO2PkvkgJJM0AwpuZ2A49cK4cifTyg2nasIhBTNmfLp5GavVxE/jq+2tM/tGrGC3d3l/WKrsMIuQK8mh5z1o6JNjcHuAIKSSi9LJIGXHvc5B4v5223C/33B7u+Pl+RnXpyfbR9oiyJ62BiwNeeAgzj1QxWzHOF11c+audj/Ysox9ddv9bnd2aSnveA68cBQ55tbL5cxg+szfAKDvg4f2MCQsZXnvkNXmkuszXZKKSV3ge8tMTmeB0MfvPWeyMhqIefZRplD3ftjZjb/C48hmfafopa/4nz//IX6wfRv2xZHlmdfHLx/2F/zJpz8iDHSDJZQ54puMu/Zi1SwwNtm9Vj5kkfM5BzOE6zvWKOhNAfN/Wn+JX67f4ZDsG/IKlslFgoUMs6QaGtc7z1fntDnBsgGQTpyW3wCaGs1pZUZebDM5R22LYOaHbLnckOiIdSL5MlIfO3MGMIdEfgOH7WyviQtRRtgcg6xGqoFyIrAKnP7PwbFLBREGyWkD836mJH0pJVnMENPQv1JasHdUkGESLud0A1c2R3BneEqHJr2C3nwZW6dpU67jOK2EHApulmr8mQ0a+pQ8kFg6TXvRLD9oZdobRIVzWvvh3dmTbmPFoRvTIwpqGf7iZK52QIkQ/9LIbFy5AgQcZ9p/y/fsrFU1aXQXRqZQXRbaaifmtVIP0zdO0SQLJMoWftShDOr+OR+f0SWJkEzHOBtvPm5E1JUHkBN07LMOJ/F15uidbpSnd1w3V3aV2kunIp01PW2vjEq00LQ/TWCnefHey9EXp+fmHJy0bvNyv2/Ytg1La1iWC55exj4gacMZe/30Ca0tWNYFT5crpAm2+zDqhlF5g0iDtJHqtIhgvYwN6QDs+H8Erbne8VMa0QYNiWqmf7Ps7xhpU2orrDL2YPh8LIIwFFyAqJ9gpmp7wBHyv62CfduwbyMavW1bGuGLANKwrOMktLf7De3tFTsEbV3x8nS1A1iSGu63O/a+uxVDaCfn0OU6zVU/oTMvc6Zvzhw2Xh2eazi96UQDtR0WjChK5NxBrGmfpYymPvP00DQUTyLr0VdVOLVbK6T1+9jNNejpEGBlQUTzwNB5CpeI0R4jaAIk59B0J10XU5SnQyi5Ohq2gQ4cZPiObCaXwbaH2a8xTJk96P5227Dvn/HcFc/PT1gsC6qHbhA0GbrM9x2njcfCLrHgZQBz8lTQloZLG6eU4z74hMc/PoeyRbkG50AzVROmrIxwbpRptlJ7uV6xrmb8W86s2DiHz+yyrhv6s3+yIrJPHbJXFWNvLc0nz+6XdHshdh6n2IoqjXciiVNshHOjwE/e/gA/2L6FqODD/mE6TPARXNU+D8qScU3KwE0LPer0yDYTKtQhBxVE1p4THHj3BRalfr1Jz34YjQrGeu+n9hk/vf79XLrUTzFgf6W8BTvgWsnq9PnqnLb6VANtNhaGzGCjJKNNcUxr4JmVzvGpzPE/9hzwboIn89j1/Y6E4PUola+miYy77PwOl5DA6ayVSEo0o9nWF54ZPhZqnYnfWWWKwuawj6KmMvex5/KZOPHUuSTFTkDZb9lMCpoTAaY4XiEw6UeWaTUqbIVcgVq+gHqjVsTnJV2MjLI6bhOyVGkFb4fxT4YCwaYxD7XOHPzonVIfaFxnkW//WjaruzFj/YkJI+dLQMLQZoctjSyOdjY79U7ImapwA2qOlFD6pEcAc7JG382EuRtAiFlw5YoyD0camL86ntJxGj84uOnkzXPlof+GNCbS0HjvKcLeU+YMH3M/wzlkJuDmj9rgcQDhkZTw+Zv3uU3G5YNRJU2dtc9yzMfCfSbM3Q4Z8Rl81JanUYbh14YDtq7AelmgfdDTvt2xS0fvw6l5en6GwO5t2nfsveN6WYJHOuxghW3Dgg7d9/GiLePAkmUcw78sYz/argD6SPPVvmO1nCjF2JumZsn64ShNO7rkBbEAoGInrIngdrtD+47b7QZPWY87sHqHrCtkfUK7rHh6apBu91ndbxj3EwFP1+ehShRx+/tIid3JyJllDMl2p6fQKUr7qSRoRHDkNM52qM8ZjZ7LvSx1lH8ZQCD5arxa5RqPL+l4DF3jt8KD0ZZGNU9cyPuulWCh9v076ZuyHxKk989Qojxq4nTVMAQd50VngewE/yUCgBmIVDca7U3nzXiu0uK9ydKuaLIHEuZ5TVnRIHbxe1qxEsJ933d8+u7XeNs3fHx+wmX1wyYW4+OhH1hfeOCnNZerA4KuQN8VrTn/D9jG4vmC62WcEHu73bFv2ylNSP0apldgniplSp7PyIl8b5ZO2GwfFusmJK00GatT3Vux35kMGnZIH7hz/G73Pk6CtStAZrk8f3JqVigWAKKKXcoEz5gAUQsWbWhYYtw/uv8z/OT1D+yQFcRBMk3HWpuoQqXjwM6Ff1PIh+xTBYT2/NkGYYn5Tp0Tc8T6NXA35k1iYEn3yU2mMyBlo5Aa/N7OGKJbdR2bbPOgDk/hvjI1jzN9Hj1fj9MWWrrOKht4tbiGcA1ijhO5kgAeRffee06N5QeIPctTnYsGSYWOcEatRl4aPBOXAhEVcKJj0ZDEVVcHYXpH5Qj8ASMHhy4VWmVbMvKtXhFs3AEZXmcrWmWIk5KHz6/hIi845yXs/D2Z2htW5+Awdt9DgI+ljPaMbNggcIUb9CU53gnnZ/PtNTihIlNueKSngBx+KQEzH/6DmsOwitIpvE7rUKRK57S4Cl9xoMHpQ4I0oqlfqjf2AGjo8jrS3K/igtXhzhVIk+kOjybP+L6UgN0dRpKgnKRCmETvucdOpNUVOK97ovgD8skJPaHGyVFWmj+GxmnZ8fGINuw98dxxX1xt+1EaeqGR03K5oj5HR38T2euQlXm3NEo2kkoikQI0qVAde8S8/7IHWrud4jVqO38ty4JlWdD7jmZHM2vfY0KWpY07RDFSLQXDmUPrWLrJqMUMS1pKkDYMjdv9DsUyTqq0sW1v93G/lZ1IiSZ4ul7R72Nl7G3fcb+9YZHh+O22h25ZRkBDliuWi+BpGVcCjP1mgosdtuKCf9/vuH9WWxFseHp6wtKW1BdqKVu2l6064qnbyhQaYdZ0W5sRMvA9C4RNP9ZTZ7ImgykJX+GBCHoiaJnb9f1WKc8m/mBnAVSRLqEUTIc+gdOE2UBMJzT23Ma4GsqJm2wjGEjF8UPKM41aWZ51Eu/1RZmzBFKRYwm9Jo1LnUgBsx6829gnTMaG+vg4zdIOKHFel1lu8chqj0NeG25kyGe83fFp73h56bher+OSb5ubpZm5qjsUDao7/GTY1A3j4Kq2rlCM65EAp+8Viw1jxbg37nbfcLvdzHlTgC+RD7wwfmn+Ys5R8MHCXAjhYbPIuHKkXtuUGBO4Dyxx8akyP+1j9xR0rLSPwNOOvQmWy4q1tXF1VvhuNIbx30iftdW5pQG665B7dvQ+D0oAvPQnPOkToCNl9Ue3H+LHt3+eMyoImgcsGET2SwYVkgb8IKc8vXyWCRrHL7dFcG0Ldh1ZEug+p36x/Kjv6eYhdwLpdQ6VS81iArNkSXuKrTUF8M3+EX/6+Y/xn57/H9zaVurI1CZZMtVerYW++Hw1TtuEovgnkJuaJr8IjJkFPOEs5H5zh42X9ycAT56aHpXK7rRsjCWN09KG9T+O7xVgEgCRKkKEqS5YrYn5LjuHjQCerCsm3qpg5lEY+yEiS/lPNbhMoZzXzyIQIWds6m8yGB0irq80NOFyPetxexUPCAHK6aUsi7UA6x85ZRYhD2I+gjGn1bXZQUfFD68EC/zaCQJ5mtaHB+WQQRAbxe17igxyPMmWiK4YbTT+NIqqkK2OGIIX3AAJQjlCi7j7x50604iZbmLtTMd4OxghCtw5E6RzCLVTviUUf3U65hSk8srIeKJD23dS0woZNsfPLPYRjunhxdw3/SZljEf8HerQLHMb5/04BzFA1WCJ1L8+reA/eKrziWJ4z++4TplMaufYXkJe4DVa4S2mie8BufrKsqgdLNHzKFOMPTDrsgCX6zgKvKsdWKXQbUeXcbeZiKCpjHTEfVQep1PuADTSDPd9x7peIXYEPwCsy4LtfoPCnEAdBpnuO9Z1wb4LrsuKpW0DljZW1ha7G2u3i7HHeMZKyLIssQqxrBd4etWyXhFGvOFj27cDXh8FeDhQ40gWHCdR+AOxw0F2Sa0RQYfhmRc4GDZvIOSh87bYReLD9HO1E52GvgpZmilVKbETvirH/TeHNZCSe8gDYAogawapRnlzcKcAS0oIAsL4YJJQ53xHco9QGHQfKYzRrn8LiWwVDBIZ+yoVeSJfJI/TXAyZ6g5alZ0jw0RH8DwUrB764UEMJ8tGLQLtHfdbx77tuD7dcblcwnnzul3NkBcfj8J3meY9iIBfLi4Aukg4eMA4aEhF8bI+4fl5HEj09vkN2141V2A+4O5EC0ixpR1otj6jUxX6Mut8niOXUT6vIrBjZRllQ8btvUP3Ho7fuLqgBV2O4XdzetJaEsU4j6ONaxuaAOvaxmbXtzs2pDz+3dtv44ILoIofbj/At/u3ZS/gBBb87k2eX4SzOSNDop9SnuTLwGUGP/agQzY4GtcMmpQJjmPgXvIv60e3LZR4/0C3FeofbT+Evir++uVvsMtGci/lTMzBrGr5+5fVK4CvyGnTEH4UwVM9jhvIkx/J+JxXL6KJot4fCEDUCaLKZ3bRwydWyB6+tyaJUsSiHDEGG6/6MXtMqABZMw6jhvLwfXjZ2WMq8P1HB3xoOhrejuM5c8zZNZmqAyfbdDRAKnXCOXSD3cZuZVkhZX2NjegPx+e05F9dCEu2n2AdGTnq+WRFPUUFMOvE2ONz5cQ8RCJXQMZUnom00fiY1jml5+yhkU5a5ihgXchzhxJNzJHbgSKiz7m10rxGG6pqFw/nqoYAdvqTd+tIlPhe9ykotazg0zL9FM6CH6l14l1pk/lwMh79s+HjkZNUVlaZPl1hGF0MB8IUcpy0Nq3mHjF6gkspbRenmr7PgYEZfsZtCRRJnfMsP+AYcuVYhh3ULF/fldUbZh8Cbr6rzfuRMDYfOHzEP1pohSE1hW1jV7vzlFPVE5Q8dGOkCnaIHWagELQ+DiVZlwW33rFveQ/cvu8Yp4sJts2Tm8ZgRffAww4M4673WKnvXeMAEzdIFruBuO97pEUqhu4TdIiOu4NGHzIuCQbQ9y3mDSqV1sOBk9hfBMDgqLpr5nWXVaxNc54T8ceZpCCXB2WIXkQ8na8GJHmVNulwJoKUkxoJZdmn7xP0C36rtV2phAMzGchLfg27RJAnqHJvRzVSHM4SgWN9Ng2J9/A5/Re7Tt2lKEAbDn3VweZa2JnNq2jUKqTNMxygpdlF1t1tMYLJFJZh3Opp/PVGBQi6ZjuVbZ6Yz2ilOZHCbZveFa+vt5EKDMX1coHvY0pC9dVDBWScfe1oHqt/G9AugLThrJC8H/p4ODqtCT68vKCJ4PXTK7bIc6U5PaFt140h/5Wsm3dEvE7figQzh3+JQAPtTfSU8CboOvZU+aowbGVfMZy6FgsZEj0sS8NlXQDt2LpisXJNgZ/c/gDX+9MIColg78APtm/HxdnqNMirWs6/NBKi9wxckO4q46/f/Om9w1fs8qRtxb6P/wfPWPnS9gnO0zZgfvdW020GvQXAu1viMJUITFgLOe+K37r9EH/z9HfYlvvUyzRCPX72YIdnKnzpeu2vw2lTEyos5JgZLKpT03Vm44GbY9UiYPFw9si7bx89Q8AtfI/GWSkTnBr70HTMim0grz4qkbMef7cvCXX53f9xBenmzihbnVGNMVczNxvLuswgSH1HStC/sl6SByxa2naYg0FMRUrOSY6gtuJK5cDEjIOAm3ufRsqDe4cAwtjmiKkMwXK2l+kYOEhjvawEIzESK0j/Q49HwohXpjG6fix9BTkJtcOCOUt37Zamwx0MyyjIozWwc5NrwAegxrcpfDk7nwyoOz+qaaiMNlhReGmNMfjn3aLB2S/RmStLHzuDkdYSwglweGJTc2VLFJk1vSvjjuKHsQ9QNcbI8Na6RHOnmqKOc35/5hiF4eaUOhnTrMD5A881+cEJiWrFc4BjMCqrxzFuXiGRoBFS5DpokI3mwQpJayl93Ni01TkZOQ6+Z9IbGfssrb0ObNsOkeGg+cl2YSwPkwkh4En6eiRr753ocKQ1hkMWBKfjvji7KBkQ7LsiTklUmDIRG78i3eo0Q/KIjOGkIeZBgcCNS1q/KqPOT36vfJur7j7PSUP+vlzA7CUm7ybFKc8JTE7R6ZugebTuOjspEHA0vQQyQrYnrx/pdcgol3vuoCi0OmkHtnNjG2nccnGmRRe+/Pt0qGvquYon/4nd3qCXB3rLqTj0gUEbNommDt07LKXfAUu9pAZ/o/nO4JPRj+8zsv5ELf2N9iPNB0YE6IG07Nt/63vHr371CR8+POPpuqK1JYMYIZvcYRmj3LYNt23HZRFcljYO9BG6i0673aNV9xhfr1cAwP22Ydv3ceKqzrZTxW/oGjmuKPG0NLGDuZRXYh3imCk7tKgPbblLrHqO+xoHxHsfGQTr01hJ33a/SkDGiZTSAVksA22MeVlWPC1jpb/vDbfXz/jLX/w5BGNb0XW5YsUKEcGmKTtPg2GSadPBXm67Sj1LIgDgrzjqvWL70v2NUmguSYM4vcxGtjEzaupAi8fAr5XhVbmD/isaoz4+hUrleJQ1UMHjyz5DmwlnG73/fBVOmwJx90wcpdyap7MGg1anzZnQFeT3f3gfWjFe5hkLgXtSFmr50u+3X/eS2O87tavHOnMUuoBIsE5kiuqg0pDElXQaOJgEKD+uXNWJiwQkdT90SRAgGSgV0iKPk8hJV5MhForeaEFonKGwOilIi6QmgxBz0FgEEhupZ8VawI2KxqyaP3pUPld4PR//BIneHAnzOr9VGM5zWds4gbeWKJ/5SPWgCBHbI6QVNwHEkRqqIe399BMIR1TbFblHiJ1nfZ8ew1jSC6P5NIJjD4aM6FvsbbCVOsZJRjcrXsecj4Ic60iloQHLiQ8z5pr50vdYyTDyxAgp58bbc9ic57PRYiwRfsd+LIQRVZJndaaWagzW+TkqsSyfjupxv9n3WdEdhlhAQjLu0K8O2jtTdg6zGm8J48YK8OXTEoZVlgn5A4kUOUS7E4XHBdwOX4eqKxeEL6BIXg3lbjC2BiyXNfe1bTt0z9MZ08QdjlYYF06a8NUfg4vQ5TI+XilfCs8XUPs7mnf11YZup1wGlsf1AF7WCKuQi8NRjAuird7JOM6UO6YdPhTGMyMA2N7CpK+Y6zO61YGoznehSc5beST/jVTlSf6xRGVZyzB49zHbZ1e3CCB2f17dO8P6D0Fvbq/w9BbnkZ7ZsUvYkjDSaHba58DfqJjUBmBCl8s5z/JIZ931mOHR6CPWU0imHWzfAn/lGF+9Lo6q9pCjASDRm68KuuxmTREjVeDzp1fc3hqenp/w/PRkKZjmDAUxjD5aa+OwERH0vpmtk7wgMUEO0+ixNb9YXtH3HbfbHW+3O/Z9H3McZHXQZvRL7h90nnP8jFRtl3FZk+cr3ocWyNVyBXAP77lBZay2ydpwWVbDvaAtdJCHtfSyP2HdFP98+2387uffwdvbHbvRwaoLdBdsUkd2wg5pT5Hj5qt6OMhmkj02tpT7xhNhh9o7t/UdEp8v4lv1tkJ8JG2HHCpIrQMJ8WJj4TE6THX1nALOEcxJWhYo/uPLf8bb8hadVhpOHyD6jXlW0j/HLUVnz1fhtMUjwCJtIIYQrxC0drQohn1fHbbKQKP2/JxtkD93zKbqMwXz72xjZQgIgEUET4R3NdyO/XRqJwRh6b4CcRwpgphZYXJDZ3rR34cCpXENQ1iDOWg0p/0DxF9sq5ggn5VZHlNcWnCWdv0ev5USLv+pU2caLpOFUObuhL8D8UFXk5Fz5pSdjd8fLpKyTMLAe2Q4H8iyCKEqDGfl7yMaqwhE5zT2SHglA4J6KJ/juPYgTF8dTeFNZ6nVNszA5/12KUAThjBXLId+5OwXjARNRC8lmpWD8378l+NR/3rg2YGfjq4NByfb+bNnfyIscjWNEbbuAGQkrU6o2zSh6N55JJpLB5DHeeQflzXuiMwdnAiGAz0kPqsMO6axDbisuPpR3bOgSWDDFBXAV2tFU2mnysx5iLRiGcZW777KZWVGI3VIaT4VRHl6CqdMshBQo9f77RY4T3gIwS5kO6QAACAASURBVBbxP9O8vbwgSWODZMffHQV/X+iKGk/KH+a8r9q4g9HN6SoRi2ICAoKOEXAZ9O4BumEXtsDjWOlE1k1BHKfQNmITD06M7qtu5WDlMF405oPldTw+hGh7ltH8g9YfNHd5cxE2nsY/JgOMBgeciMAMwGhMWVYcK86pOqqKwIGWxryfmqjFkXn/va6FWv9lYIQrABonrKaN1EToAIxMkOzIK1t4iPVzzqNfYzFoZqzWhGSTlnIeOARRSO0Y31adjajp4nPg9t533PfPuPeOl6cnXJYFfmw+46n50fAYPOkrqCEvc7cePIAFILIvmghkXfG8LFjWhtfXV9zvVJZVmVklYR8439pcuDxRgOQLP16IsWJz0/IqhSa2JUCHLOnWrjvkKyRPkLU2RQTf7B/wYXvBv/z8E6w65nhXoK1ryRgsKoFAyTFaUQkJRUEc0klaptERANZ6OVeSf8N+IPyxbjegeJ7ThElHb85iymBEHV7SWf4V5mvuw050KXdMprAyGSBlTN66WcokdSnIAcbTNAfvPF+N0yat1e8+ohMF+N5TIgWmsA5C/kttTEomjf1j2W6RYLcRz4StARa/ZPTBKklNVTg77fEUgKDxLy+phlDMKl+sMMlqeiVmbOFECE1T5jg861BzbxxH2HzaXV8K1LKeNJjjbLUKyDkDYAdQaOjTUMBFafM8j5aG/BzOWLQ3of/R6muSrCt+SpMSXoXxz0e88OENjxz7+tvcxqQWyrynQQJgvkrIIH8U8wm1GI4Vwzy3Mge86nobRdxAwncWfWIbzrXOS3F+c/Z9wAgCLo4cw3L83NX52CcpDUoPYNTYqDci8AhcxZZM9IHTckkrU309DiX1ytHRnIMsXm526s/2JkYL0QevNDmUvRhhDIt/z0OWWDUZNmQchw+MFKaQMayrA+8mu4dAnIyfUbw7LzN9kHIvuKUZT7w55TEG0rAKI0sVuZ1Kqc3E73jVY34bQcDlAqQwZNiMERRkFBmj4fD7gdTuLMG51fWdcBtE68qYmCLG/rtqSX1OtZWrfyknpcw9cJSLSU9yoFdmhOIICxfTACLSnw1dvgroepN5OfGdvzIP+fzmXj8PdJluU+86A64+jnM1zIOZPmjWiTGFnklqzb9kG1CjlabdVUjYlAGPsUoEQnObCcFiePJDSCAYzpjrJnKmhfim9T5WahR2MbeYLq1oGDBYWmAc6iTBTzP38UfDEjxFUQBgV9w+v2Lfdnx8ecb1cg2nrU7DSBEcoqyF3G5uE4QOOdPjidPr5YLWFry93eyUyR4BqFlb+Yy5fSeSJXhMzqtKq4Pu+DMNl+HYN5fNzQGEAHYAyZhegUjD2lf8i9ffxcfbB3zcP5oNNXrpE+JPVDeO2TFellaqc1hjnu3KHgRPodg/UB0HwhB+jzL1GAQM+MhhRuhhtrmY9di+OGFYsh99znxVOPbCwnkGpGd41C7PU8/X+atQHTWRzx9vvZnn/Ph8FU6bE9t4SBSZQJP8Es+jVY3xLhX5aX9hJJ0RpZ5+PtAvC3I9li9ErSe/nbWDo6jOIimIbRBHbjtRhg8NtOSj+tNUnCNLPC9e+bGAQRB+kKIkq1WwT7UgvSeFVsboysvbPQBfGwyrFcfJMMPMn3ZyTDt/CphPSIQhmVcqZ8M5Ve9sACU/1BMMHwwxoHM6EWorDRwRjUpKs+ECibuubbNBz+/7KY1FuoK0mKXanv1KRmaucHCkqx340K6VKqIwle+ACfB6joA06l0xjDZSacdViNaQwxa0pYA0hWodb6wcBPJkkmlV4MeY1U0RjZPQHK9HPLticXk5/u8HhMXc2WEYp0/AeCZl8uFDKrKurVgIR6mZLtMQcIpWHzjU7tdV7Mj0PvINAj+zBPUAxywjFOMuJpGRUO9R7tg0DkBAaWHRp59Glu1m6mJiToR6dbyTcWWlrN103CJ7wE9FDWiSfzxjoUZrBX7MevbpKbg+aC6Pw1N41+g1Dl0BMBwQwiWlIPvKmI8nnFfdwxATb5dmYaZz52va4glOgJ0VaTj6hjde7eF9dR5Ac9yEvCLZwQHTDCpV+ZvZADYSZchojLzZbHKCk0imCQjxVYMnY0zH4MnBnmFbgmAbP3Q7gI10oFOv/RQyxME0I70ZQniFUw9/nQZGausIvlj6nVXT3fYy237OPvJZx0mqEMjShjNmObrz+UKuqQWw02jz+llmK1+7ao6CuFDZ5npX7HrHp96BD4rL5ZIOt8mLseq7Q9DouvIOYDE6yfn1YKqncw8YjE5kXLXx8vKMy7rg9XbHdr+hjxOFUAjC7SF1fk/dwqtIY0iJnOQvk0feJNskahkHdnCK84y482f6y32Mv3z9U3y4v2Dfu10D4un3vYzSdWI49+EwEXxtSSdRNU5P5el1edpVI626Ulaiieuy65XqqQaNvS7bTy46j7b1BFi8VfBeufhZAMAPNlTEHnlFsQd9G05MDdV3CcQrfRU3xvcnUBUsFHv58fNVOG0AGwmPjYnfpK3Z8OHHFfVZel4pR6+CBqc2PY3nUSuPmvf85krAx3b8tzDWprYLMziIJ0oB009RZOq0Cq0ccJmeInCQCoHbhcRx65HqJIAf/RtwzvgUE+iSwrRAJ9Vs4CXtigQaFuMtwqwJbRjuQ9NZkWOqiEduI000RA2KUjnABqA6ZPnUAz0I4BjIcXiP6HrUkDKf1VEgw0X4oIJ8/FCG4vCc9UMKqcI8G4G0ghrOjadYTnPmAKeURuSYE6GPZvgUylYMvWbz5wopHSItbaQxmQQT1KmeeuJ1UQg2Vk0j5dRTNMaR7CJLwcdwuHg+K+Z9Va4oS6JbN4DcQfM3nDauplCdRavz71qux+c5K4DiM0V+iik2lhmqtVDu07O5rRYpPECgtn8r+8m0RMnOIGCjT8NBZfUnflut9+YDcLmq7FS4IZXoQNAAq3wN2nXsSAONhmschXus7JPjRm8BS0VU+CqiBr6jiNVi9R/GlZ0al1Pr/JyOEcu6ysGNJRbSkfBuiBvUVzVbjslrNkFbF+C+j4NaiqE3oHdZExCSAhkZXZT0etD93kYGTny+tO92KiIH1dzhrrOUIyIssDNtMGop70SfsjLox3HgOoQ+jnH53DMMo8WOcUpfgkLZCgq6q0otfbEwCRDH2E92guaetvm8lKKltVBGHojh7SNx4fpXqZ0mY5Vq3/cxnt6x2anXDcBF9sFrkSYpdHBJzChUkTQjTr22CuQ6dABh+1qdUTmoKdCu2O4bfvXLX6O1hrY0rMuK63VBWxq0LUN+R1+jnd53mgTbQ68A0AN/JVgg6Rxdn55xuT7hfr/h86dXbPs++Nl505sSABRwccfTeVpsP56nOIaulXGeg69CkonowGAEFyXkXGg1ARoW/MnnP8QP7z9A04Z917jmRNVXCFkimLOqElePOM9pjD1PgHYYmMbKDCuGU6iKWOVkiW2AlkAZfM6Nh5uid4muWC6WD+Uk2/y9rtLxI/BAjOva0MsspyVzJNKWOkr7sB3izxj/+f5Sx/tRX0yDe1iCn6/GaZuf2eOP5cd3HC3OF2fDNgXy90HJWbsoAjPbTWPHy53V9ccjuaEYZtn8Tv/ls6Z9UgsilP4Ma3z3aMnhxUSUQi9yBAawMRmV4HkRLjsZSUAaIKwsGT6/bqRyLVyuUdkDwCHA6vCmzp2WlGimqLh0yNipYkMkUaLlva/gEEipjAjUbEbznxP6YYUQmKX23xMFMyUk/YHohJQGEIeYeOSXI/A5ljqeAYtHLusKpadHKEPjxo8PwswaAnV8bDNCHGIB0MwoUPieG2+gT3PUzZgM45ZSNuISWdXYe6riKzYzkwnRF68cSuBqNDqlbzLCTxjvGJyYR1xpaXbs/F+FhFxweilpeW5lItOxEwx2phIur1cwqu52JDyxr8lhtpMRI91lxofRXK5kOrzUn+NLXS1aHR2CoPCXy6XAo1dOxDpu1CY51ui705rvBct59wtgC03xXJd581Q6oxPDzdhrAnDoNh3JqtCDJ0FOC5VwI09p1e0R7RC4geEaJOopMD1FBy6c1P4T4nkMg74Duu0HfZpJbDL167RGczHNy/hXgx9dRjqvxSqAkJNuONQ4El0D92Nlahkw+XQaovywsxK0CDvDBICnYroa46Eqw5ID8CsJahrsGEsrPMsUn0K8GqjcjgQOefXXGb0h71aT2gQg7qDVmSoZBDF+dZCTN6y1fR/yUYFxP1hnXTImSkXHOEkXB3p4zISelNrOzKgIz30nLCUC34pxwiS2Hfe2YdsWXJ+uWFdBa3scMLMsSwYgCLfMG55yvohCtRXGGuAM2rxer1jXFff7js+fX+1ibqZXiUVxv1S6rqpTQMiAiFRdwwHP17p4AJBmVzXufhQB1t7wk7ffx49uP4SqYtu63d3orcwHybtGFkubZDpweHgbRM5Uzou11Ic+2O3Caz9MjsMo7hCLyxUKvqc+y6tIuuOzwEyyZebJoIlZtmL613S86xJrxzM1ahCPeA1EJ1JCmIaOsxyybCXWWjVJfCr0vZ+v1mn7TQYBpIFxnMzH7X/JiTs4S8cmHr47lI2ZKubH9+6/9mnpA2S0uJz7Iij6PmqZ1L/fb3JeABZ16BnZj8ck1Sw2M9WFRGlMqBRqjzG84zEztk/xYnVGsK0KtXbSnk4giQnnhCppcK4zdZnvQ2knNx8PEfHIVKXvR3R+LtCGwEuaTUOAy+SdWQkoG49zl2k4n98uEg6Liy2/l+kAJOOOnIqJdBxWTrkS8MqdgDnriKIqrGP11BW5zUWuvg6Y60XlNHbhefNxpFPjyjoNMg1nlOwbwtN78kS/OPdIEMJYG9FPdgxrP2xsMI7m/kLBOe2bMBEhZz+Am6SbweSGojpNyTRHaWEjzjOwEjVlOZNO5oAIbF47a1zqxWnHDbGoBKmnCIZCJ5QgYTpyin/RODRgwJScM+CNkAAPPD91IJ1S3jlD0emGwL1BHpDEHARgCeGBf02u6kkJlpuxDwiAoEO7HAiVZWjwliLmOQ0rgkdnLJph5hPE/B8OUaMxH6EezTiPZfssowNbIQcQdOP1fbW0BmdsDHFMp8kbOVKEAEDTmmkJymJwerI/sz1SAy4SOGS9U8YWdJsCR2wsTIHZftIPlaarBFJADdm4BDW2ZimwCqDZ5dUddpQ+jYPgIbYKmcp0HmxiMjJFZtIhy4vsygIZXbHvrjtGKuSyCmCrP6J7UHQuCnSj27HqdubkM57jkzRcLgD0ittdcHu7Q3WHaoPYipnXGGmLenIY00hXdjgQJ2JKwXtKZZJlMgKL7hB86C/43dvvoNuF23uvs+pyrNi0U64NOzK5EkxzUOQY/fErCjAOc2H4E1yDx3UlUoeRaMXQ/Yxt11WpM/lfHo1T8uHeT2Fd1DIApYkXn6NMIZ7mSgh8dTpH/Nihj6pYqXP76bTwF56vx2ljpQg/Kel4lP+jVbbDJufSNBHv9Nv/X0/SsMSG8GLMAUcZ8U5jJN+KUJspp44ZmBEk5V0+pwZJKHiPp9IqlSk8N7a5vTa1l4LblcRZvzXNR48FDkBz+VH2aKLMVc8UppeqSnPu5TH9xJyYVsn9ZXIAKXXj2eSn4PV0P45CP4aGFY+V4zqzcDHHJVuajDHqTCbKcAEZWSYFqqHcPN1wNDbPpUY00k+LOfLmPMoatc272qojcZSirpQGBfjfksbaFU3aSHIMB4tvvALph0loTfwcKXKWayS2FwEo9hCVn5UqdWNj5esczmjJ6U2t4lDUExcTe3ifQZtijgvy2oXAc+9l2Nwf02o4RVG3JT/YnHuf0JEO5hepKtxotGg3GZ8PZRJI/vGcgPsTk5ta8JnHc1ddHYp9QlqmGyVPpF8ggdBwNiWN9FwhoHUMtl5QEJvGh9OWCUo3jHxl4JRmCAsPNCahh9KhAMO9yz5BPSMs+cXvL/O76WJfERJHs8zjNO0KYZ238YsiT9LkEY4SbFzXEIFO/6aeEpHUN8Kw8rhDVED8DrBYfc05ZoLk1FDXJsVvprEDEot0Yu25M54HTDiuKXBygoXguSqGIgAV/hdyJdX5jWUtyzV1+0J8rkZbDnuzsQdZMP2JUJ+YD9QkfBm0MXcumyeZCoU0v1riOH4lJAuAbd/x+vkV0hqWRbCuF6zrgnVdTulE0QLmTO2T0oePi+s53VyfrrhcL7hc7nh9e8Vu96VxMKkJsIhgl1ZW8ceEt2iL0xFdIA1bKq8QKQ64AKKCBQ0/efsD9J7XNcS8+QzHSjph0Og8L/EZfVddPs0eiSiFy7LUqyJJP6UFox13qHNPnqOjSiuyIMYYSIic2lHSwNdylAAX3nkk2+/7uItL2jKV4TGctXHym044JJwm6ddCKT3ef74ep61YQw8A/9JovvCcVT9Hkjx0GqMtNya+h6d1MOS83qPxzBMOIpjgnWrCxN8JnC+hrBC1Zssles2lXfCpQifkzfvaQO1M4uLQnzXglQ7wZYorHyTg5poaPL4EPXGCdcopt96rG4v+5LG6LjykNhLjQqQnQNIRUJof37+TdfXQRjrcbBn5SW0uDL28w5+nTp1ZZg7D2ETOZpz3YyaRugLPqNoQ9H5gQT4BAxiHBLFLohmYOth8xxH2KfJcUxTO2psV+7Fo5U/fByRRj2eVo4hjhcYMt7ZA5z07bPSxtRBDyrGUOOZBTHxRnVgz5/QXrWjeD6Wc7Sa11rkSHqksvLrqePPjr2NlDMTLRI+xAqsWqSZ+PzgrXJmwAJzRmtEAAe9xZZYXTHFh64x8R1KKSU+qefGz+njZUPO+OUXSDYDIqk2+52nktDe3XGP+4iCXKtt8iEZ98/REgbLiAo5G5+/ZpgfVyHkIom0Ayb8xhDQwR33qy1fGNUN17CzlSPzuO9vDpbv1S/djTeM4e6o+Ffi9jHmwkKdGjj9+R9+YewWvjAkZ6czrIQOINlw8zcagFtlpE+P85bKmcxkt5RxXPHYeYgnIGMx5mbdO8Gj55Jx2DGTrgZbYjGYHL1oxIGmWC51FXXg5/u6ivZd+xX/zA29ozGkDaOjadBbcBjG9Yu1kMCQ7UCBPTjK67b2PVbdt7HtbloaXlxcs61pk1KAbxkvD2CudAYvEFI/Ydb2lhLcFT0+Cy/WCfdvw9nrDfdssyCV2RL+O8y5crkrqqLws3HnNj06h+VYE/fM9posCf/Hdn+Njf7G7jt1mcBhnfooWD7SVafqVTlXnulnHrzIRslOgPoNHfvI+Zif8UTaUy8XEV82oIUICGAYAvslBrE46dQ0eZBpuO0bmj+1DH/NKSxM09UwRAZ/Tsx7fnT3N5uT3P/8YP779Nva24X/75v90q+zUfOLnq3HahrEkgeSFT/eZBFBZFSEJ9N7qWSje1M9e7fB8yT8PPV9gOtgj53BMZcrXL8xXGoU4UIaf1nVK+JOW4KAhNxUNyvSdMUuR77kOnStX4Z5aO4My7XaNA0EetxKFq1RwI+5kIoSjimFYVmi0CASjGRIUsSkXwO4GPClrNeXYqZ+MMDnN6AE+bmU8ecqRTASiyoZTiZMenkzxFKL7KsgjyexwjHH2CaTgTt44E035mypybpgwac6GApMQphCmHafzGaKZ1k7w53Mj6WyUI9gJLom7vdKgy5QUduaS/+aYZZJgt/ltBqdkqhHhKMqTEMnoaO4JiBFLGmYH+4x+81O9cnbMiHG4NduKSGy0S8EBjL0FTexKk5i7Ub7skZsUPIJfyACT3AFQ4zKRrMRNxTUqiYAY0ERTDk+O1fEVFb2ur3B6Q5bC1Hvyse/fArTsp5zlQgVoeihwFXvvYEYBtcjtjGAAr+ZWx+OgJBgxRjPpGLvsaYfAymioF9pAyDU3bFg8jUkcHNIo7qLTCoorQYMhnJPzlGnGlfOnO9wBVgl4DVhSlrpRm++Sp3isiTuJ+cv4e8WkmM7p5JwjZZWRqCmY8V8zmeG/Icty3xwACGkVK+6kKwr8x+e4foET2MhOICexOnZSVrdzqJ7WLSggIx2qpJ2kc6jTaSP68ZRRN5yzD9ftTtoe/FRyaFIDk/xXCzRCsYyNfJMstVXTHVAZd8+NIE3Htn3C9fmKp+sFy7JiWRYAuS8s5Zg7PBNBpiCxsWWgs6GjS8MiwHJtWNcV27bhdt+w3Xe7nFvH3XZNSl+OxNgzK4RXJC6XwKmAtyL8m09/hm/0Zayy9dSj/iHuVD3YRJKHDZFW9/qkpmPozGMelHZnmh/XyQl//u5vl0hw8MZtp2mKJRpLthVZHEqvC65mSJilnP9Ni5tM0NDxEg35IUR6aI1kf0Ha8ZktpGu/YNUL/t2v/jV84QNQ9LeGf73/Mf73b/+D0fjjNoGvxmkbw2pxGaor2PG3mEmTvjxPYZtar6GlQHZJc5mgkbNVNrYj5ojp/EW47Nz61CxLXBBBMhdx+1Ib/dL4M43ljLDfBS1eeCSzjjXbbZbGkqk/FdwHkHnrIayO6TAMnJaaMs3HewfUfK8nxueap3QQDhyE1afQ/01xUDpkMSiQND3QOeo92HE3gWZRIYo2djOqQq0Ilx2dxb5H6oNTqtgA70p7WIqUdi3aQ2+1lmZi/FX+wKxgVKAp0GPPAiFnKJFUkmFsTDwl0aLaZbGJp4wYV9wN+sgIZdKlGctRJg06SkIGICU1Mdr2duLPNJfFwcnxquGgtKVOx25oWUn7PDt0ciLDkmyn1DRjmFmBk9t0eMLZ69aAK01e6QXKat1QqJn2IjbvvWda3EivkrTOgmZM7pszO8s/V7aA5oFEkvCn/Wb1ee9UYsiubagR23kfxBw8EMBz18LwzEbV5EMvMDtkcS9SGRPgFxO7PAkMcvPkzTh3nBthDHOmJrphAJ5nN0pDTjC1171audIkpZ9maYNxyA/xXMX6ZLw5Oxth+kl4vsLttOA1m6cqqaVVeTMxfxrtjpNTxYdGcu4xbCEb7GVmLE1CRYSOZ3SZzsGwEw5iEUq4CwmjdU7nJk6zeWxsM2ULxj4b0kT1fcsVvKraSgjc+Dcx4OLGcz8O6a4JLCBip9smp07oCP53dPpx9VAN9NJ1eYM3FGO/l44xNq1ZLEHm/y9z7/OrXZadBz3rnHvv96Oq+kfabtppt93EjhQkIiSQMmESwQwiYABKJIQYIGXKBIEyZ8IIGIEiMghMLIFA8AegzJgQAUIyEBzHxm5sd+xut7uqvu+773v2YrDXs9az9jm3qp0wqFOq777ve87Ze+31e6299t7xwwjcwiZ/bqGz3r/7gNvzHU+vHvHq6REPDw+TpxwShC36+jSKPnJ34ADgfmDKwUyWjDFncDYzDCs+4Cx/C2aGT7mL5M2UfQYNqeig0JkZPjre4smfktf1OSTtWCZooJyqWvXg0U22yK2mKhFN345Dz1JS1CybB1yrFUw+PmGPvGow2zNppHqy5MubjFy5dIYQUavv1Z/Oqo48ciLdNoXL622yBP/SH3GFD8Anx8f40eNPcNhxOvvWAbw9XuNX330fnxwf169mcWzG3EznuE8e+oICPwBfmaDNE1ZDrWfzMPg09jUbdxYkVREV4lVAl7N4yYjChD87iD/LYwBK8Xzp8yJwtjBbMaxcLVir5/i9K+zl3lmuLweQ71vBYkArP7yiALym+KsJArWysX4r19HXx6kMSOH0YM/tlEOuBhcpceQJVcgkkx7USwS5vNVKN7wcYgZSORYxxAyC1NFgcNCJMJqCXg2jzgy2ACQVUZSYZClkbVJTO4fVbFrOOJ+4pcasJqKm7Eu1jWDOHMVLsiS411p34i5tEt3DdiaPIwnUeLdmcopSa6ekcwUQp4yg9/U16gjVow7O6zHw0NIZ036ij3IoCbMFHDZnnSTRVI8Fl4u+41imXr/Gr5ZvEg9Z2mvaFrFVs758hkH+XAuvM5tljAl/9y6DDqM+lzNT77a1PBbte63jSD7wohfbWK/u/HOGiePy0E2NOYSyXla28TO6YR4Q+qh7wXGKExIBKB3/iYL5qa/t8PYniRPP52bUoX+azuDj0tY1O5TUFhwyftpYo52ty7PM8GRwULgtTqcunLCV3jmXPwYhKO9yjwHMBk0udEuuwT7yuc4n8C22jPeYveeMUfRFerh+9Tweg7rRWV8MYK39r/y80KHZurQkMj7BYcDNtYi1+bg+s9QxNB3EH5or3zAdqnG2Ib6BS4LBgTwjTNeD5cPWt+qf7Qq1nXTrHZHfMslGYVqw4xrcGwDu6GjLs9mGyBrIu0HvIbbUD/BQZOXLhiufs1Ef3j/juN+xbTse9nlcwL7vMfu2XrM9sYSJu16uF7+PA8cYc6btw21ZQrFgg7txhl6a6kuOQxB9mno1xmdm+OaHb+Dp+Sk3H4E8rxU/+X7cd8LihjhwLvyu8ggqgD3rmuk/zHHNYI84OtObdBijaKI0bTpB2zHkcvCiJ++qPBRwqc+oK3BxGQDn+lsmMQPa6POiabgZdiAO9FnuAfgnPnwbv/f0Q7zbjxN0r45X+HPvfhkfj48l9ojAMdbRvT5e4Zsfvo4/evjRFdTt+ooEbfMq5bC177xOAcHJsGo76z1RoWdf4HStxmFVku27vXxvbTMdg+WhaqM4hzX3mlFS5bvqXCSTR0ZnHaj0u+hUbWL5ztp2v7zPZk4GoAF19fv1s4WX8lJObkAG4rqFtSMRoM5aGq9O/7XNXNsmz+fC2gb/mdg6c3UeUTlNdFLcHbuVytIpfw3Ycoa51euw1X6pgrxymCx7l5DMGFiqi7MEj/DcKW3LcsbCEWFO5pKu1dCmQ6M6mhDmqx3ZczaqZhdzcxCTQ5MdQiPeu8ANjZQaAFd+Y1BLeZs3xgGYjXDwwhgsOiUzkcD5sKSJKKFv6a2CI3A9PDYrUVoicE99hvZuyp66f1azwnlQ9tKnGTe6kHJQWzlrSOAkSmixWjozlmV5TCKEMzCfIZwUnNUl897X6Ttf05Kp4O1UkiVv/MHVsUp5NaybHpyl6kxLvlG6nBpjJgAAIABJREFUYhI118YpiogbIdq2Wewid9a0LyjQEy4cDotZ49LKfDdoFgRN2Uh5lBLQbNWTR3PTGFD/IHmncX00WrjuAd9aAVN0TuZe6FSGiXCmVm+o8pN8GHks9QOqhdRVfD9KxqL1DLY9dvLj+dXeKF26Tdpp1QjkJyHFdDrLCfWBCo6xXtTPCF0XO9qJLFCuKK9i0YqOaZOQfgRhpP4/neeW8mxRzi19dhCl9H+rFq2StTN2cKm8Uf1MO1szlR2SM05Kh2zJj554Lvpv+45j1JEbKZvN0nvOaj0fBxw3bLbh8XHH06tHAJ4zu9vG0szCb6lzxYrMlrjjuA8c9xvuURJZZ4QSnIWv4HH4+U7rks+z2mugEo8uNtIjONTjP0otnrUZQDae+J/mPLWC2A0d79muGAzbtmUSJO9xZC4jifZnqT2afDpRYmc+oD3S1ZDF0vI8ZYGxQfyzzjw29KT8MHhFsQxhy9+qfYc8c2kvcPnjKzzia8cnAnbo2+PAGFPuH8YD/ty7X8L9zQ0/2X961XJeP3PQZvO02P8ZwA/c/a+Y2T8J4NcAfAvA3wXwb7n7s5m9AvBfAvjnAPwRgL/q7r/1Ze0rk+1xHkYFAoaBDRuORVn1L71UqGPvJMNfYCOHlBGsj4hvcH1dvLOCe9VmOnTxgwsj8VyrUKu9D6/PdBZyBuFL4ICjMarCopeeUUSns2WXCOsLHa5jXtXWom9SH6vRtvXBNNQCMwflgSeptGQpIXvs+OlGoHVFBeR0YjTD282vOguVja/ZsN0M3NnvpFSao4BUJsyIaeaUzkaOrAUb1hSjyRlmzCq9VC6aqjHA6I7o+o6feOclxq9+2Vw3YslKhlwHVDxuOAadw8KlzYgTts9GddOB0eg5zxhKnObuXCxlC+fDEwQCBndgf9iSVjnzDwBGHbUaOD/jwegMoTleLYiLUrk26xcPkDfWGbXUFVIq5CIwDAZXmc72UEF3yl7rh7OGQOe5MDrsrwlgLap3Ol25rX7HiYcTtW3UabSG51wqYXVdQxHsOf3HK21S1FSNk0kU1pM1zbNcdIJOgXG0GcHoxKEFXjRjTRgmjU7rC8dowXffqS8AWAQt4XfJ+m7Fs+GOpL2oIkevYD15P9qMtTbjGHFOpkeuyBa+a/OWJ2SVWrs61qCPo7+q835SqhZMtjqhE2d9/mvq3XFiBUOVisGiDDNZiLohgoLV+BGGVYhEYWTSbTispgfiducZ6uqtHSVQz65VN91OJDPGLK4mLxzFeQuimFSRZScqjqFRZWih76zgt5Nem7qJoRt1EcDtH2JEIl8ur7bSVlgeTE6YU43JrodVfdEMMDYz7HBg2+Jg8NJ5hR/ObQIsQYQDAwPPzwPHcNye79gfH/AYC65s2/Dw8BgByhzlLH0csdkJ4McNx3HH/QDGOHAMxx44rbWa5EuHQTdIItdSNsPGgXp18qTuKMr1/t+4fR3fef/tCQeQJadUSeo/IvnKk76bQ6qzZ0g87vfYMGWbY8Z6sWKmxqRLQCycqqmCvB3bkOMVHvLWsur66ytniJM3YmwJmzoSIqJrYBe8m78tHTaYreycA1UvTFlb/eCOrn6usF7bDtsBs4FxTBo+jgf8hc/+PAYc/y3+uxew8Kebaft3AfwfAL4W3/8jAP+xu/+amf3nAP4dAP9Z/P2xu/+qmf21eO6v/in6Odt3zECuhejyV2dURFpPykkZon12nJWkdv6nuWiUT6bNTuPSTnRofQt8T0NPZrT+aulyvpPjoQFgJn0tbOlNpLKoYUggiXLG5CG+pyU42rZr+2JEv/SiYUpFvd7vDWXpVjiDiqfMAiovtGU5K1JRONVb0WffWZLUtpy1mvBs5yY93jLMnaUs1gLmGCp7CSdwVEBUujNQKLpswrPEtKM2ltBZUuLxTIE0HT6NomX3G/piY+cGdKU9RQmeUOhAZQ9Di3ndpBFKSyNymIZAnBNNyqgfEwhsGTdvjmDOk0U7pNO8txkPqJ2Gdd5jGcj8vm2IzFg/M8ykB5nkqCGFLI4IPlsZieoyJmvyazVS/gyD/oHDa4ZM2D/f7cF7YWIcIR/Co9wsYTCI4KY7DDrcYyYw2ts22Zq/gJi8vZrePjNQn407XsfjvfglbySPAZvtyBkOszSq9W7NtpKdUvf4fCrxhThuoO3cGnKw7uzkotWNsloBAku8Sg/FO2ntZfwx1tygwgqulA11OloQSx1HoApG3qur7KDqj3S0YiFC0jfGyAq/XHOZ/HfWGzXbPducKBOGbCPvbeSOlm6hZ4DZ+dyJMkedDBMUDgc6dY4YsDVrn88mwDWPobDl5iYUINFrxPM5KKrsu9U/Mm50egROSg+fLy0f4zt0/Mey6YPk/uU3wQH12SJ8tBtGWMh6Xu9XOWwFZDnboLo+5Wqenlczl5UUSsiaHJBfLHG8zs7GEMAAoAbgortmEHXQJm8lzVNPs2zZoh3O3RjyhLZInhw2gPuk/74bdhhux4HdHfARm304jmPgdrtVkOMDmwPbw4YHmzDsm+G4T/0wz/TilvQODC4vKLty4ptigEkD0obY8w0+uAFd2G3b8uw2YthQsl92eMOBOUuH4dnmFgkN2zfg4RG62QqynaLLtAkj9V7NAhdNS3QrjUTqGIpXabev6K++sa94usQZ9Vwq5+w5RZvPKB8uLcC9zUoTp/XXWxX1J+MjvN/fv/yCijU8ph/7TN5uG66KdPX6ku2dogOzXwTwLwP4L+K7AfgXAPw38cjfBvCvxed/Nb4j7v+L9lJqvw3hTCyP353/acAwX6v/IYbnxFwcR3/16urR+YWR8t7m/FGYOEWGRvIa3C/DSDYcsGw5Q1D9JTx8cuHl9n/8eIZqeQdn3Jgaw8X+ps4FZOz9XVy8SkEvpU1Tav1wxiSIdog0NBsNiDj8OR50Os3n+WXBhND9fHFkYVhKZKch9eo+ecDr/zGOmRFL/p3GY5Md4yoKWnpuPK8alGqv0yDh9WkYuFFA40ofrd35vfaLt61oQwf+pCgHDYVk4q3/nzA1OV2EMJ9pmhmc0Tz5oF5tkKeXVrNhhYul97Uua7nyUZklWunhFyXHAtxwT8M+uK7cyBNSbmOEj+M7Z/ta7X8aRb1X+oAOF2GEz/KebduShvUe+2Twp+8GrWHtN2CW8GTAxjYZPCw6uDSSZ1/6UHKzif7ymWgYrljfksensa7ynSpvDLjZJs6zFSmtoiQrDrTFElfv6a87SrNRLoCciWIDG183Ga8bj+nr4zc9IqErSNvq2bM2ZiIhHKRN4MT5Ks1hoW9mf+7Sb8pLlEBb8Q7SCUwrHOs6mIbRmbjoySIYN1r2dLdmO9wtkDAY+WYU0CIzi6LAvu+1mYMhdauOFm6yMyDhH9WH6HMPplP9XHqZ32TtaPC+QXalXc2Jc1aVfOC1EQjxEH8Hg+JEY7VZsk0mZ1LPO1ZsTQdVU6pL16fqmwmGy64aSm8UdrsTwDdVdomqjTIVBjIm1UsXG+1PoXHlZAfSllXAW8HGnDnbUkGp3WdLm21za33Bvp5Htj9seHp6jVevX+P161d4enqa57tthnHc8O7dB3z22ed49+4dbrdb8afZLAzZLBOQavfm2qXJn9u2T/natpn0Cp1aEnJiI8E1ebjbcID6SZMv5G3SxIUfi0APDw94eHzA9rDDHnbgYcf2+IBtfwDl8mTUCV/QbxwjZ/t4c5XYhZLJb1d31W9afaL0RzY77bAMTMmuN87acCSu2EeuUBMMdxydzL0YzLWHX333fXzn+efbb+Ybvv38Z04+BzWBbTZ9wX3yBHnji66fdabtPwHw7wP4JL5/C8Afu/s9vv8ugO/G5+8C+J05Pr+b2U/i+T/8WToa2LDlLlGVoX3JVYp+xKFxYe/OHhq8qY9Y8cEFYq8sYeu7PS0wiwHh2L6kLSo2TsNz5G3NBttWwNHHuK71W0vx9BK3L//wUe6wo/lvx0uR/pWjZGV10tDp0+yrspgVLJdwaPaOkkV9QgO24sbB7En3ZqbP153kpLNZtG15kK0JLbrxRA/gvBwZRaRL9zSA/TlCbTnW7jEb2k/yfBn09bICIXA/cUuZkDU4IlyJ3y04eAgfOyKrxBmjVYY6DwWam0NQo5qftnVcjTkEa/JQBvpew+SkSBo2rtWSA2ybdBou6FTw0xWLObX87AJDp125PBtx58Ef+mykS9fflb6nEkiDtC6o0uckwRExDY6DjjHXZ3Q8n527akNho8FnW4nnxtee/87fhbu9jy+TFsbAoa5rUziVtXt3siaOC39AbBTDsQYuqsSr8NTwTZjj4YxrHO38rbl+luNzidXm2LdtC+csWw1c8pEz0hNfmfGZThwPdE7ZlFdLFJZZ0JDduSZS7UPpUA5cZ1cIrYRUmSAoHSl4Fp2cPOIDW6yvs4BnJnWYdYeUCUUQmImROt6kSsoXHGV/7ZdMiGTiiLSRcVxdqcdX3SN83nk7eChthKtyQ27AlaWRJiW7HvfLNmkZXOI1Hs+kUPACP1PHarJtXaagWDOgDslme43gJQA1NiScaYvVNnD4EB0mBxrT3miQl0eHQXhByOL5DmSr41SG8lzodgfMtpp5ChhnVX3paJf3Jror8VhsHTzjs/rg5jfc7wf2fcrzvu8wAB+en3G7Hbjf7zAA+8MOs1kGPnwGIWOMuXunV1ogkwmbwfYHlNFaeXmGXEM4X3k3yRY42Mcj/uz776QNd4syVfLYxVXJM2RPkyw8xshh274c7n7ZEqi/bdv02O9FnLy90e+TGQ3pW0bwS0viAcfJ7n3Zt0VH9dgAye9VLcZ6gwlDqdyyRiYoIQdVhW6Xo+9/+B6+fv86/uHTH+JHj3+MP//u+/jW8zfjUTU6c+3OTK7ucaafzky/fH1p0GZmfwXAD93975rZX/7yJn+2y8z+OoC/DgBvX300yWeGTVIklo7z9UXjlIczXkTf0ZQY4CKJ6GngBWbH6b4qkjaibO/lll66Y0vT2pcXY8ctmrorh5c8q8o86/kdbdwlxyJg6yAc0K0wqbSXbutzGjUtoTC0nR29C/VqrCubJspgQV06YzKmaKxgDedktPel7RgsX2nLEYwzI4KMhb2YwaQRY7tN4QZBtlgzMv2zznk6i6IobOO6uFrZIxR/qAxBaTJJXDmqrKz5Hul0uQDAXmxYa7KMMFuog3vb+kYPV2phltVp11kuy7Ivh2jzjjPUBuV07JloUCM15UWxc41Vk5lPYtQUOYLndBgF+i39gnqWDiJlow45Luy3d9QIiNOVjqbCxJZ5qK0MjU53c2x95nQvKv/ynQo2C1UV5IQjbux5Bl7l6HdDXUdIrPc0371y4ezMNsMxRpr1enNIGbLSiiicTown0iw3g6BDzNnnibr6fO2rFM8rHKpOKFuieiZ+2owZgryecjNJpoIPsAyvBfESjCufZAmntDGGZrIdCqjLKNTuqfYwfbvp3JDJhqii3WjOOmebD8DmDF/aII7p5JAtiSxlwP7Y3Fc69Af16WRxkyFbfymDjEWfh7LgrA8kYcyzo2BT/Dfb6uBrlTX+54BZlZymfcpt7XHuO38qXqZzqQGpoZIU2q/+5c2ipOog1SErVqdMV9m/tO3FGdvSL2mWXCB84WjoTXs2Ui49B8r1U/3twnNixq0fk0L7EBqFScW8RduUwlnjL16c37hODQBu0da2kX7Tfu/7JricCRofmDPHY+qlO3dytA1Pe82g7eYABmzbwbJRExwNgYU6sLCYWnQG9mPDm+fXE+bUsQ3jy1ibIMtzvDdnv4cbtod9eV/48vR2BBzeZ33XqwdOldyjHUmKxZmWamsJgfado0i+KtnOFRGGhOvqqsTUKP0auxC5O8oTYFu0mRE7MEHAf+LhzTd8y7+Brx+f4P7+wKvxWBo3/oxY+2osk/BZeaXp/C+6fpaZtn8ewL9iZv8SgNeYa9r+UwDfMLOHmG37RQA/iOd/AOB7AH7XzB4AfB1zQ5J2ufvfBPA3AeBbX/uWx2+CVH32/Fs9WGrKfX1mbY8lQYux1+as+uvwvmTUeRMN4QWzCtN12+VccRwuv8tGCEH3y9g0nAE9/mgo18l4m7h6ZZD5aKqKZmc8f0jDgo7DVEJ8rtnN1P4nHBWIMgMkhLDFWKnREr2d42GgNGjI+U4a7EXwCiKkhKoSMa6VCkSJMVWq6/a07cqsNM3hWckJ54AlYBwjnOGj1qu7yIs8q5bywunxOF5AwXSngRInQJInaT9tZJPJUa7lhBqor6goxVa2XYTKHSuZaTD7FfRr69XmInAadXatzoXOTFaXbdNz0HmZ9yKbaHO74vpeCn91atffzKpd/lv3KeMrfXT2tpBR+os7QlrqjTEsd2Vj0wWnzPoRmiD1usGQosLbb5SDEiNdu5dyS2dEdNAUe+2nZEAdknJU4pfIYJPPaOwNXH+oVKsxtLOoDLJ9f7m4Na/vyJ16ufB+MHNfssVt2isw1V05E/QzArPXUqTJE+QVM9SuqlFKKc5G6gKrpvn7ySaJLUynqLHXKpQFJxuqbrrdMsFawq90JUzxbeKrynNzRBpB2JTBok8Ba8lPA5xyKlmxJp/kGziDOS9eyoPuL7Ag6wFzbBFMzmdkM4YYL2e/POjVggTQXgv+wwHdtq1t/z4vmaVCzaK50ISbkFUSaln7Y4nKaacKXOEja7Savwgdx5hlWYmnPjuRVoGyTdhAW1FjSmy4x5p0b3gug2Lrn5JlsyhZFR1plcwwGTO12mk5i5ROT3Y4wkkuOHRjljYOi319nHp2S53GdzNJsBkOp+5wxL7wgA/cMflzsy2n6vN8sGVDftJ6tj0xUcevlO4eDhzPN4z70RMliStd0SdwNssSHJAiGTPDo47YuPLvVNeSzJloDTm99pG1yie+z47lt+Sy/mbarRjnRfs6qi3GmvtAZILIz+8ZwE2P3CGzlepnUc4oE37i2TmUFHjADcMGhh14tw+8vb+ulow7h8uoEwXnmcWr60uDNnf/GwD+xhyk/WUA/567/5tm9l8D+Ncxd5D8twH89/HK/xDf/6e4/z/69Rz+z3ytyZIUcDJWEIVOAuJvOg7trZf7OJeFAKqs1nstwBP+Ez+0X84+xNgJz9a4bIGBRorjQLfjXkqaTW/1mLxb7V2OwZa7NGBWD1L/luHr75bhRs2W0CF3NKbUoLD0YeGmoy+9nHpZhtOVSynxmrUjkLba8A6Q/G14WbVY4mKhhzqeIO63/EVdE7qusuS+OWwm/678q4YdzYHrSjCVoTBvvWqy86Cl05uzoVROphBDZiStYkPeYMAetGo86uJwCAHS4PAZ3faeuF3kpmS6Ltt64LJZwQl4bKOt7oE6omXWLNpKvCqDOsp5UFh8cTrZ72LpmqG8MkCpxMLQhlZnJYI3YzvHukVJXMLcRENwQpuStmzVAz2wA0FJpBefVom0ox0SjDkjEEVDEwI67lcKYx18IDbXA02hKtozuFjZPOAw88zGDylvnGOhk0xn2MAylXJ8AwxuxhF49jFyh8U0rnxp3dRowff6eSbXSi/pGgY6WRmA5jPUM+KIKW1MKa2yLtzNQCe/Cx0YlIpsEFrnNnMB39x8IEZCHWhoB1MbIEksCXrlPnljjmdL3k91osSwktf5njin2TdHO5F9LjVOLyF5NUnjBtc1ddJasdjqUgZdZKf5RH0NIgNLCzqxkzWrXrMQDiSdJv7LhBmUSkLBHFfxRiUZyuallJavwONEintKDxT28lPrO3lG7H4HajnyzgQHQLUZMhuBKwPwCiT5eG3oNHWhSzMFQVJYzt5zeG7qowGYfjI4dttK1uPZa7d/8u3+kMptOtQ+133mWjdTeWLfe7Spx/lMCDa3XJ/Fe+SBcR+4HSOfnYd1z/JO27esJqgqFk/5UpyfJwY22DYiuN3RA21itX+u80DJZyNsgSZTSt4K28ExjqLfCa8rvoPrvHhQqUI2J7tUzFCz5SddLEPcXuCHMPiXV9nG0GOhPz5sz/jNN/8PfvzwE+zY8Cuf/zLejNf4+PhowWD/1y9guLr+cc5p+w8A/JqZ/YcA/hcAfyt+/1sA/isz+w0APwLw1/5RGs9MSu7SVQbH9Rmby9XdeUSxbPkLIa4BY+DyUqdC68Xr/uq8ePKP/p6MmUqHRl44CmTyviDzikzp6FrBeAk/QizC6FXssTJ5593sR2Bff1ND85K75SgnjgEkh579BbFa3xng0Emvue2VDuW8Ln1rZGX1fHdqlEhqTfg8lYiULulDGXGuirdUUZpSxdUXyF45sNXfhUugUNQH60qtyQNh4B/h6XNGgrN+XLRfqnB23QNIDRgMqPUzVpRRxzydF4hDRCNPLyffv8AXA2O3Foiss2w923jFzfN6eRMRJB4muSfNyQ+GMg8cXkdjzOrGDY0Lyd/aU+kG5IMVKIjQ5F/vOKtuKzkjCQeTfjS4TH7XTWcENDpgpEXKBGWqaQB+K3g94SiuOQdr2ma4SY5lvZrBGoIpXTW74sPz3J9EY7g62Tt3Y02wba61Iq0h74Y8O53C6COVIFnVRB3kltbKdzJO8cc0QeVbczdawoXzidqciXBU7FpylCjnjLwj1lRZtju4S1wESaR91+mN6ZAaSeWLMqZO4bLNPUiFBCTaCoe8bAp1taN0qMLDYXGW3Be+oC6QTRhAnNWxAelL+No6qLXzm2FuA19yZ4m33jGVFmf9HVeObtpfcU4pY0y20GYmZBKgXjm1yYfifBC8ocmy1NVqRxjY8YHkwlM/s71zX/U8GUjTXk0CTjq9S4gMhl9jZ0WT5NMGmamxbnvLT9RWywZkgkR4pJ4o/i4dOTcXe7B9GXPXuxVy68ZpDh/AQbnMjaBUf2riQpMHojetnq3uN/jhOO4Hfun9LwEWqV6nXCBm81SWi67dHxLZTd0sMu8O2AxwX1oX2jES8GGWmNq2F9+v/mf6Chq4vdhFrtfLNvyqxLbUiSc2aZcsX6YtMmlrMakN62qhxUR8wbXhZjf8/Te/jT9++BMAwLCB//ujf4C39zf45P4xDIbvv/9FWa5Rffzk4U/wo4cff1EHAP6UQZu7/x0Afyc+/yaAv3TxzHsA/8afpt0vvobQxlrd8uywPvbyozNDnIIv9GdPiqllI+TG0s4Xt1skT8ODZp7ZpDgAyEyJOjNlsDvcemUmNW2vnZlPfmj1xm2IXZE1pVWjkfeqUZMHu4I+fYhvHmOdgjbL0agHJYPXFI8OvgRT+1q3fCdAqfTtTLuZjZO2xGFCe470lOw9DW0q36RcgCsUNsDafIUXgU47vSyKL8dLTUT8FG11fUmbbWm09MQ5lA+MFD4HhsVbVv4bSCvDvs3F2c1R9mitlRZVgwZtHPF8KVbQICW9LN9LufXYkh+xfi0I29wSRzNCjjq4mzgdPsJYAbUOs4wu50ZrDHVY7ohtw53GzskXlRRICopsZHAN5PJR22S2JcY8YoyqlxJHpIHit5O6nrFtzkIJIbbN8rDt0jfVUAVjDnJV9yvoRF1lxgrea5llQFYz0rWToIl/vzW5TtMf5T1M7LRS5uiT8NvOw78HINyh4y0nlTqYC+6jvQHkdvlJuMAcHQOzbEM/g+dOidfgEbVuVvZNZ2EyX928h1La+ZMJvry6mPSrMZZuN22wXUoqbps+/+qB61P/VAsrsxFUznjM8Y8xd+vrvSHLvVro5tRfI/GSyUgzrMpy0mBLFOnsUfkDhPisP4UsUS7lot9QD8rVSx/r9wqe6121AT1cvJh5A2oNXQ1o4opbree9mGWe9bVnCxs8yaNKSk5Vt0U7wFwHWqyd41K7r3NrK/T5VPBA6upAX2oSqqEokzWbNsQlw56JwWQvL/URDV7Dyo7LFiY+BnDkM1OxeuDbfGDYlqdQTH4fqZsZtLkz8BbdC8z1YWNgHMeEIxiLZXEezDTGMa3HwwP2bUPjK9/KfwieOe533I+Bbx8/h8ryMWFoMB/AMDzse54tt7nV7KXSO5BT/imv2HiLfK+0bNTF6Rf3DcCBcRxiP8tm0G5mgiqqBtSvLb6o/lttknd4chsRl/c9+BeLCbxWddGOfDD9Xi/R1ly/OX8/7MiATXXoZ/vn+Gz/HIDh0/0zwIBf+PBt/Nztz8T9d/iNt7+FD/Z8DaBc/zgzbf+/X+pcpvPJfyK9WZkBIlL+pQ4WDrv67Xy5/KXzocYc58xvy+yss2CWwj3HUhK9mLX8lhAIA/N3VZNNE8a9wUxLYy79fj3kNGQNdFPboCOqoEkVeBuQN+U1z0CCEPF86evlZJSyaG86q41NhIe4rlmyqzWLxrEByUOpuM6okT7VGMgdZgITX1dYlraDHuqQqJOdAd+SdUTUmgcBGl+o9tKxqOJbr4rzODCP9SNaNhWqsk1/eI2HiQezLO3yzbBHffjmU1nbFxw4ctwP+DFKIdNhVt5WJRAD9thVpmZqOHjH8CibMs6YlCNQjoXM4ooB4+YWOvNaDkrnRHdPYw1ZsjwNZeHrnFuy/r0lJLSLmu3JzORyKLp7nDGmmUa2yV0VUfRmyalT6BO/8/M4Jr25M6jitV8lQ30mst4pw+ryVgXHc3ZwOmUVflnDl8n343DYVruN9gRE/zjRZ3LAeuGrXWprQ/nQwZ6lppvc5sxbtWe6KUU8OfmLayTSOwFLtCz5YyJow4RT02rpSxMWVElX6caSAyFJwDAy2XAqLTGSNGa9mNgoI9vtjQQFFbys/AYJSkWnKPbYBxvbpDyLtDHSfJzgmd+2lrAlnGobeXYXtyDvZacX+jkWgHOmTx/ZFvp3nZFKNMY2/5+ipRZN9WeXJGEDTN3l+U5f99mv9GUkGUs+0XNCkXBrv/rF0vinrvPokwnIiIRyfRD1VREzWnIZqvByimkzUu2aAa/Xa5SvrfRqwpq2X5qjjGSSEqmTfOGh5B2liSMCtSNjpDEcN9zxwG3Yk+e8Zt85ttQJBGZgM2B/eAgWEfsWeKRsOGYNKveUAAAgAElEQVQyyA6dmEjMFC4A+HHHuD1j3/bcIKWOtXB4BH1jOA4beHjY09aVHVNbdiEP8Ttna/mOo9aqlf9dzwuUoRdHJE8XmxV/j7Rb3W8ePHoIwEy80Be4gDVtU9E9VE91ZiIvSJENHl4w0fQ1f/eVLRGLLK6Hv0hsg1qe++n+KQDg09efYR87Xvtr/O8f/Z8Y9kIp4HJ9pYK29WqOOEr405ejEV+E8Kqd5ReoA6bR/xfCYp3hqRjOa8ZoyGqxg65VagpXFOmESlglwZSSK5QhN0OrF+cQRqyF0HOVfOGm5CEr9Ua4ct2aWcO5Zyf1rkEUB38vFJVBUE3r6M8mXOxLnhc0NPeQgMp7cxxbwqrT8FOA5d0aRSStxHD4+gztm4lzEW06+VONOpvx9tlao5Uhm+2P7JrGkWsNOJejZtLi1w6qQx3WPoRYGyGGlBBTgTIoTadbgzmhm20b3rx5hddPj9j3PY14oTeYb3FYLMZ8v9/w+efvcBueGVWTfyuonoZ7klq0L1AbTnA9xhLQpIwK3emY4IJWWxi8LL9z0uGKJ2dg1PgmdZIE1mItOp8Hb0RZmeqz5PTF1vdEQ9FtBpD1btN0ZhHoiAyThkb4675zhptr5NIxRTpGlfmfu6kdBzP+3SlY9ctsh2PeUmcWihwSqcTZZqTxbLdE1PLso3TM2RAPS6vsRI49HWMvOCEJCiYzdDOJZBkRKJ43X+MGYC5HZLiigkINH0cGVC68RcXNM5XqaAHRWUV2QLLIKF8j5bVlz/NBK34mbOLEGvTgZpP21hlqZsiL0yhXOlHaxqnyB8/zKR26yW21n+WG6jKFTcrkiuCw7EIUYVv1f74If6wTq31OEmWz+oAKPniIMsvnpFxPtYlaQdpP6oMGhcoiu1da6itGGpGUlWDTPxr8w6x8BEkO5cyjsh76M9kZDFscbTDGxIW75xpsjoFuLOlzRrmdfiLVhg6aY8ggSZSg1QhzNroGlTqDNKjDtxmUGwad7QwMQgGKKsh1z+64H44dTOaxrXhY2Gun7nDAHqf/sds8LuDwgfvhcGfwJ2Pdqkiu1PrZ8XB3HEf4C5vhT/ZP8fXjaxMP3JWJaPSBcR8YpmctMpGnbesUcFNU7blJHr7fFu9evM9xIcrQDZXA6QWBnjRVvp9J19ShvLfatezR+vfUa+UX9HHVs77cmfIm4yMPmr7TcThBVkl07L7h7fEGn+/vFoBXugIHBn797d8TeT7LydX1lQnalIgAF5EjlTWg4+5O0LqDzs/Y44t37Avv1s2+zmZ5Px1eyTiBzCUlF8HY1aGMTYIMloCxITfts2ZHTnBah+1qnGS+pkBUkVovmcpAeojjASw0uWbBdBApqD2Fg8qwdxMIflMHOMcm5ipLp9qc1syc+rzf14N5IUiDFNFfaSji93xn0GiX9WVWNkmrCvBFrvL+jOvzduLvBnNgqgLz6vvc3VS8FDXiIQOQeGJbG2Bgb8C+73j79jXevH6Nh70sF7ce1kx850/HMRwfPjzj3fv3uN+OFzhHFfKESP1vrtW5wk1vxeXw4o7paq8CaQNk9oxYXg0d4au1KPwOsFyGKNuwZ2m/lwMHzDU6pQD6qIm3IJKu0Uy44+/8zPELdFeLu+mU8Z9goTKP84NlWyY7ndV7zay7y7bYdaO2Bled7AmDboFucFlzEjNAHmVe4vRSG+jINMZom+U058gbb1OPmmyak7PF7m02LfG67ACsnTuVkIhK/pbP5j/kaMiX+Ctyy7FIgCxNyCyb6BY1Mtp4I26VJHXd4LluTC87HbVROlodLm5U0pzoOpit9dPWPOZOn/P7nHERrXCRvJuvyS4xK8zxe7Y5sxLt95JdHVy0J7uGzvEF/0QQ1ARA+Sy3NC2YWwmiMGHZL09ZSzk6jbfL6pYKoB5qozDDLEO7ytpbJmJ0DQDtWyskyY+x2UXwpc7il80+X375TXXV2RpemiztI/6xgF9FrJ0X5o4jdovcIgkHmxt8wOesFGfCfdNFCvO8Lo7QfWAcPhOTC7+RDPu24eFhw+PD9C+2fYftM1jabPL0h/fPeL7d++Hjy99slGNWZJhN/tt32Ab8/be/hX/2p38RucdD6K9ZcTWDo+N+ALtUDCwqKWlvqqMXesS9CqrWREglOMsWhYxHGf845sz/psef6KDJymK/aFFpnbrOX6uXLtBXRgypmOgfiQin+Hr1K0MrW3kCul+isfDkj/jeh1/A33v7m1cgJlyeY7NZ1gog8XuR5NDrKxO08UpHaAHcQrNwyMMdl/t/Xrz7cjBXDo6u2SgYFCZ1OgqeWkza30lmlGzv/LlZagWl3MdwXEpRqoN4vlyYK9uI4XBXrWmwW3fSlrquAeGSFZr90DHw9CeACye/jc7ab9lj4lYypxdjW6+5W5Jk6dZ+WuZjVgjpbIMH/AmgFU+1d8UutnU1zeHxbE/lO0ejuBdMOArjvjgqORQnny1KCwxHjUzYHNa8vPN9DlfOxNHZO2/PlUkxUYD2sOGjj97gzetXc2bKfa4/8PMmHypy7sDtuOOzT9/h3YdbO0vqcqGzI+WGZ2y1UjR6GagxpqEFnwfWZLvuJNaJad3RTgcJDRueztWoyjOzNFhbOyJCe5Z1D+7Zfjn6MpbgNZ34rRdE93DECfaqt0yeZ7nofKAcxOq/Eg3npFHDcTybPM/3MWmSRl7OOCpoBCMZiCwJuOBraqIay6Ihwomo+2I6r+QhnjGYJJlL5nU8XZk3RNWGHqlcrT2XTXI2jg1a4ClmM9chlcTJv5F1Nqu2vMGDdq+UDJlCSnkMAjf77YbuvGkAS7TCwSCfKcoFlrY5ifuS7Ra9yjZNpUtgT7ojg4w2E1TaA/2y5W+tb80ZJh5iy7aBRo8sRQXSN8iYPIM/k25EMJfRalKoEjEhPzq+xYfo6KASG320ghNF/Zx53xqJe0JD2g8dPvuyhGkkH/SZ/Wl5rjZ6K3ii4TaeTBIsJd7VSPSXQXokocM+9568+ETlYMVe+FBjE7Hgs2Y1Gt8rwDXDphuWhDyPODyes7fJZTZxxLPZDMDTtmEbjtvtGdh32JiHctc5cPH21mtnFA/rT0wED59r1HIgi0Q4yN9R2gqPEsVtlu4Pj4QH2rv9uyV+NeE2P2/X9GvX4jtwcxI5/oPjok+1+ttJ8TY7WDqIQbiOIUxSbwAy8zsqmb/65HzFob2VPNjy0BkD5Uc82w0/ePp9cMfbNifuXN4zB2spm1+G0359NYK2xOuilkWpcmyGl3eBZGM90xq/Ujmd8KN9dOekGExK1xTmdkBxdz1wmdGs/l4i1Opo16Hg8x3XMeSYSkla8pqF2fAaixe/ZgafgWi018Rk2U53GWH2p6Zen1l/t2JZgd/SMb8yWxo0ZPuuRmq+tYUyrpkuS6cmhZ1wi/6vrKWlgWswikOzJGE7nNGgGjEAESSJ0yMotY2wXRgzq7Hm97TCaDdJu/Sm2otdGSn47QkPs1znPdb/cDzsOz756C1ev3qsdVT5b80k6TUzno7n5xs+/exz3J5vAGpjg3w/ZAkI/rWNGIsZFw0Qei0TUQLBzXSaNdvsGVhQPjiPlkYAcqiuIY235T/TIB6HZfnUxJeV7vACY9U3xKWo8OQ3Psezv3RdGYNVh+42J+U46bB4wq7XmqhxQIzopZ9Qch0MuxRjFRwwkf849BhIXshqA+onm6VViC2qYZMXuGZNEyNnl2IpL26w672QXzKYUfNQT8RYpMQvN8kgklIXAHPWwpNfGia7lZdn5r9bHsarMy46MoNtXg4H+x5SajgULpfNEMhYDUmt7VJC9bloqRtneH9f7Z5jWV/EwRKu0OFjNF6rdgP3GnRuSpEF/qQZTvfMEDOCJVR9LRM18JmxnTKpwWQqj8CMKe/ULBht3zQXrkPrcLMjFLZzzGpzoGbH9bX+kFyVxhBet6mLLODiRi6rTHtCI0mtuLeh428mwzmTWXQYdDil7c2AY9TAMllDmEVHMSGlgeDsRmyfTHNXwo2YJ02Vb0rf5Vo36+9N2d3meV9hW+qROcvmUcpflSfU3ZRNSxtTpfZBjeCrwbPZjnvMhgLALfTt7EvP3J0sce3IKo61HNjGgB8D/9T7v5g4T76UoY+wm8MduA/YHpMTFjzQ/OPCZV/m0/UUWy7no9O5X5Y0N7OYZSveTRR4vWsLeZvdsjnS8tsG4DWDmCCKjKWtT1Vggtsq/V99y5JetSf626JXasRwzI1IPt0/wwm/0S9hsVXPteYvjLJcX42gDWel1eRvuW9itDJji9rudml5+X5hEKDEpb3Rw5kbJC1IKnipWPhMtZtgpEPg/TfVQWd70yGvf7qwiNKp562B3szuhVFbn5l8xcy6gL8I1iIv59/yWW+sXKsRLPwZdVC0sYnX3HDFvd3iO2mcBDElnBDcqROmCKfRDkcEuA7ULgwsFVTijE68Z+is3RerRPe1YBhlixo/liJqXdMgLuOu6KRw3ktGC1/F91UeRojNDI8Pj/ja197i6fGpcJbN96x4OcIzq/f84RmfvvuA59sNJhA02yo8neuewLIWkoNBlp6lJOMkLI6s/QfohMz2tk2n3jr/9/WF874BVcooUDtE73gZboDJAwgeSlanGBWNnEeZHAYmVrqMNhBPMst+PPblbvIqtE3HacV9Bvqtl/ifUcPklLkzJs/SQvAjmRI59iIGWoDNx8qpmxHqoVvwS+mVmePIZVaOWbjkAZmnvkPrIeQ2+TmQTh7y2OFznQUrgFELeis4Vs+onGfpX3gyZ1GEB5KzrMoTy5ld9GvAobNnSSIqDCx6j7qHwTKzyrreLzwYb2NeUEDsSsLBc3yW7Vis30tiMXha1M+c7Q6Zz/0caqZx3pcgItd4Bo6d27RU2zo/wTWAFbhRb7vI49ZpxXuZdBD9wfPnZAMmC56mfvaFHrpxkV6arMlSaB/iJ1BmiyaaLCsb4tJe10+l0WMDqA4B4F4zae5wDGDbaybNi2RkrVmuXIA4tkiy9YANmOusps8yZ1H8qAfIOxM9JjPPTF4SQZyl7+NMGT6VeheNy0guinMx1uadR7qdhKxLr7fNbG5dD+AYA8dxx2aPeNDZ45TH7v8dqfNdjy4NWaj3NxgSZRo8iNPBdMm2b4A/AAa8ev/UxiqLBWRMxR0e5UZ7BFA+aoY1R0Db5LLMQfU5n2lwSgUJysbV/cTmHIWPqNDaTnReXXdtpz4T16WQJw9fr18t2Ejf6szDpqSdzDbz7Q5Q8BFEXntN8YTnf/vk16WZUHJO6yT+z1WV4MkWX19fmaCtX3ZigJeuLBG4wEFr0VaiXD1D5qWyuW5n9XWaM2zyaygVKtmN502pQleFL8qY99lW3VHjw1tq1MQ1W4QuM1/S3fJIe1av8FmwvYBChYul/Tqz1kQgANlO/QYtdfc7vswnFkdIFW03pgV3v+9pgCoe70rfWPPuQHp7thoX0qg7cFXuwrEXsyi+/UJpUr8lWjIjXLMWmo06DTAckqSxFZ74zoryMtYdm3RQtscHfPT2LV49Pi5O8g6zIXJaMI4xcDsOvH//Hp+/f8a4H9058BrCJsaUuO2zYCKLjtp4pLi8oYHf+kyXykDx1iQN2+l44gL5CYf0lXQnzNV8JhRc+eOE7cIxM69JO6tYO52A4i9Nfpx1Y/Co8EqqhuVAZs1jNIiSFlaJhCDAZnPm0p31RmHgrTb44AxqtTqy3wyIc7OTyvF7GMCqrovZZwDMcvvGwG6UfhHFn/JKXlH5jxfaFtMcw6iAo+lwF0fVe5VB6RniXGaoB2EnIQMjhmn0RcxYyjY/S+mUEqW815XgQceayeT7aoOSw5WH2UHAUuOO7LVXwGArTMGPaH3UAxy3x86trawxO3JMx212PriHKPlSaEIVnet1jDIR1S9xDgYTGOVrCneJPJZcdHwaEPpW+GnVMkLSdQ0t3/c4SoPHfpACJvpkjrnwobrvJRfl9HNkHoZjbhaSCPSmONMttSlL1qLtpV2fPMDlBNwqPrfGly4KIYWFfbOcO6IGkvQq8qw1AGt+tmiILm/UpxsXomjryN9sK12Z8q96B5BKFUu+Lx9gscMyRoPh8AG/32B4yA3CAPW2Fh3C+yb3l4sllWnkEv7ObxYw2+MD4HPHTWOibpsDWY+pS71Hnj0Gxr7Vbt7dFE0SBI4cReNNxlD2qBIMTDx90dUDNK9y09MzCf51OwpsfK5nLwYk45i/Eq9iILA1Hl0pVa9vi6w4eJg4mNSA4Ru3r+NHDz+S9gn1bLcOCPqC6yUExPWVDNquSq2KSc73gNU5Ov9ujVDtiXguHKZ06rw3cIIRLQBag7VyZOv30nHW70sgkEpIU3UoOtKR0r7PsNWdpvz6L/2d+KeNCUBzWNEKfZqdMVnPs+XNwl0zlM3gCTxmkc2odpWBWyaffS1j8OWRl9o6K4AyBKdrocX8WBk7ne1degSNVdL74llDOX1dEa3P9XEUWFPTHrGjHmDz3BcdZ9K/y4GoN1Fqs/Gnxx0fvX2D16+e9C4AYLORu8J5ZJANc93U8+2Oz9+9w/PzXc7bCegdcqZWlOrBAPNWCqKy02YRGJCsBycTbN1MxNSYrlit/GRhoFyZVn8vd0/Oi9X3WoOK0+XJmC4yzDINpY1AaFo94NmOJSqrzEKdKV1bUv65OksFA+V2Suvsq8oBZf1NwF94odM06TccOJx6FmhEQOG/5M4T7jnTSH6OtXfGXU05YCFSeEe54FyFwvX54BvBXRJQcSQ63zk2mRk4eznSxWqnxKFL/zBgTv71eo5DyMy2y496uXSausfLPlB3rjupNJwswX7yRkhvBD0OyOwQh+NkSMG36AsAbc1PrIczZ3Ix+kdxThqdgJGBjualEyUSnJvINaxm5vq4i2bG8nvraM03FnvKdW8AwuCN8h+ir+JqKxomS5VD6gHzfKh0ytW6Sy1b8wy8ZuNzMxCxWl4zDldl6YLZwoghZ5WiiYIh26vRZdAptrwWUBhJXE2kjNcYFLJavhDjl92Mq6zTq0H9k2WYJa81YOKLvHm27mzKtC2za67pXcM2w4659u24H/B97zuMIvSgyOfVzOTVxUSUfCv6BIydYI4fvP49fPfz76Re0QmJk9ogTodjYNrsuUHX9WY1rgBAj2SJdniod1oMO2PbOh4h980MG8akfcIutjBHXvrghDNBx/nul1/etp7hWJR2HENPZWsLlOd5FZZ+9fPv47ffbPiDxz8sg5NKddlDc7GtTf9/wfWVDNquAjb+7dOzfP78/pcvmMxW5L1yOrTJ5XzMRWesWL7Kgov98xKuUvxltI2f81FRhdbbm7zDVti7ONfe+8yVeRL4Xqk3jmgs48gspjyoTF3GPt8on8gre35Sutqx0gP1POFcUSuqPGCMWaJ2eG5/KmFI5bIENG1XM8epUxmDpREraFqgrsPyWK+0CK/YUXD2ps4Nq3Gln3OFAK9+N9borQ95uuXlwBgdDmbQ5rtPDw/4+KM3ePX0iH3bar2EjJaLsIbPnSF9HLjd73j//oYPz7cTA5WPkOaz3UveF2PvEOWZZZOFXz1oOR3hkDWdy1k5XB0KS7nfTnJhYeQ4gzl1i8NdHTOrXtyEz6mzqucsWUlHqM9OaSwBqDMzf9isj4a+XcHGgBYNT3Sq6AzqTplFl9I2G6zR6+HhoQfP48DhdexEvp8DUH1Bx2T+OOnD2Tx2UcFjlcVK4L5NGhFXFfBSEQrf5D3dxp44FASnwip93GQj8CE+EZqGFcJqrJiJRUPwZ2UptNwc4E6IRN6iR0rzA5g7t+77PAfpfj+kpLccKJjFTBWRKShInqvNSebvffbp7MjoIAWdSTybM6c25XGOnX1w5n++O/dHoKx4yYipJcuUATSYpG2dZK1g0JIqskmG2krouX1CzBHrf2Jmz4cBIPydFh0XkYgDeY70WvVu/Gpip5PPWo3NBMerMrNbdRmL8FbJFntSmpFWmmyz4ocYIs969KS6S9GYmuQXbDYUrRMfIxI5J7vIkZOWyRCLjObRM17AEpAy9CVHhm5TksTn3ahU71fx9jK2Kx43g8WunOO4A9s+SxblmaqOUHvGf7Cc6wh5p3B0iWerpwccP3z8I3wX3wmURGAzmDiNVr1WoDksN4IYAZ9tewuYrnitg+LLjSkrCFnXnFOOpPmx9T2PVFnltSUtIK11/rjyr1/iz9Z8B0bul5Fmv/NcyPWIA23UFj6Zfx5sxy+9/x6+/fxt/Obr38ZnXN9GPmjOQPgNJj6DyPNL11cjaDPAbYupexE+cIxnRcgXi7hipQBxYF5SNp0ZrgJAkw9pzhrHaOlH/Z6LxYsMwgz17zRlVnSqfy5Gmi2d1L3mO8ImngLfdZwqZGtnto5HGVSfubi60yuG0mQWLZSx5SN9zqOPjbCoF3LuL2H18n3UMZbBgPNzNB5NUEgDZnxFxpWe8iZ0E4rK4i39W/7csp2FJnHGU/PVb8nGasM8X05Dvu7wdMr4eeHadNx8ZzO8ev2Ej9++wdPjY4K5Wf8LzOzvMQaO4RjjwO12w7sPN9zv92agNMvt8X3aeBP0GJEmPB/f3es8wtR70n44DEppBkd1mRgRj7HQMahqcy1/VgPYdX3AJXhe2568s2r1iYcsCW3OcmUbWZrEyQ2dyXWhWRkigUv6Ut+zG9JSdgzU+ayW2ZT+26ajclo1QxyPDPbXiZ7EJ0U/+jPIuWnxPDeiyplYlklvNf4KoJVIdpZ1QywnYOndVmKYTFKwpW9IRgu9xZ7nIcDL5h0iC8h2ehCLOBQ69a2jHVpfM5psU7LtPHQsSr/GOOB+5FEMTIj5UKPPdifsusaR8MlD+Tu/c3MkyJ+merNMVslc9KB8l7BGeOKhO7bitZLjXiqFkEknEWM8WVPY1JboTeqTIkbpZQZ+ou/mbKrLcOdmRCx/Y1B4ulqEDuRZf83uoJJInDEwxA5+c2lAaazZXtuBN/nbOHqxhRcgxSBSr56uTnfai+zTyrppDxY2ZerhftRCT2aE8lh5DPqMChrfEh2aj3Zln7mZhElkPCBW/eYXLbrAUGWr1HdkZtHHXjjVJRAWJTFtVoiNiV2qVNxWM7Cya29DHdYvcmk32wbco3olN7xU/E0aMA+U2tpjm61Ysnl3YPMD27an3ahqIMG9Ik7xTxn0DTPwOqZ8b/tpXCJu0hz7Y6MaHPkyrkQs1G++4vDeI9pz/sL9Pl4XcR8v0+RycKUsH/0Rj8cj/unP/gIOO/C/fvzrcBs49CxMdSgoM968wBevr0bQBiy11mdsqVNCZb86b7zfHZirq7PVmnHQzECxr9VvS134qhjcBzhLsoZYTaEYyklKopXS13HR12pJEWPWvoyXBk1NOTizz9G1rRkLGta+lgOGOHhW4NPxpg6mgSoB4/hfpETqbpNWv+BhgXMOX6evLZ+yFwwbs16JX1cYgJb9PBnmej8NKqGWxfOE65S9Shusrs4FjGJQ+8t2/q0wAhiwI2ssm/CXQ6oK+GwsbTO8fvWETz7+GA/7dKT6uhTH5oBb7JY17rgfB+4H8Px8x+12w3FMp/IsxXHQM+GS4TDrRjnTkrYyHisi41n14PhY7koWv0ltPwBo4FLruAotzDwndl2fUAe5BKBtKJFnRE9jlGsghLU6Beom254GWLBoce8UnJavUBUGFYR6ISTfaDNYfF6ct7kuKxatI7YAyRktgjspNM8/nOsCRhwerXZpfqw1S5MesVPnSTHMPsYRhrnIlHJGod12LXGxPLeSpWkOj3VkFttrx5uykwQD4tyGP/ZeOQf8MfO9GRSdlYizpI/SEoKyhIBKM++pN2RC0HL0VVfHuvbCCwPdJEvpoJVJ1hJM6ni2MEe3NRDXS2e2q+25tqOSMEQmy8S8cJg1dSntHX5pljhJWmyo+nxSOTYzcXnRUkY588fH0/hlb5oMMz3rdFHB3v+pX2VDtErYXMjnRF7xZpoXLUOW+anUgZGJl9/TWq6gxO+n41fKOiccqTPAI3Qsfqc+EzQ1W4OCkej04gvVWaoHanyCoxOchaf8TJ5lEnBTjKqklkZO/pZGLbEQ4xR/xkh7BYc8KnAbMAOnTLoRxECCwjxaSN6atIV0Je/998Y70c++P2A/gk8M0BlnRaKh478057QhM0F2xAHc0r8oF6FkbxckR9kVPw4cY85sblucdrcOQGASLio+94Hc/An1txoJu8BvTMScNJWffks+aUG9+CkGVJg7hHn4vxij9VJ/Uz7vtmP3DX/pT/4Z/OHjj/EHr/4hfvrw2VzD24JtysTV/Pv5+moEbS9CaZ3x2oGKtvzt733x1U3ES7NSyiovPXPdPA871FZEaIFSbmFMKkg6m68MFuK7bE6ef92pyD0ZMxlaapfLflX7OrY2xQ4pMfPCVZMTAdmBtqHOhGluL15ICGU5/KS0f5bryqivQdrJ4VchXgxdGvn47yyA8R6z4xds4PlsN94Z4CU0S+ZHdQHPHaOdyPeRvoEFLdvZOvJ3grHiAumnpN8yCQtm+Kfh3vD6zSt88tEbPMRBodT8yZp+YMAxBteAzLVz92Pgfr/jfj/SMYH050AtxC/r0aHMMapiFufh9F7HbSJPPArnOYrCZjorLRgqgImj5fDW9VqdJhq8dBhtQ1/ZYuoDLI3VOM1YQrtYPEdvS5U7cSw6wuXZ6z4Jkgao08F1ZpLpILpnIsFc2y/6kh+qz/nO3ANkyyqlFtgoc2Lq9zZU1DvzkQgOAEl2IZMKa4KBOLfeWOHvbNur9+AlTeipzoQ6+BzCFyzId8WbL90aZ31Lj1eQJ3aIQY93ZyM/R2AJWCbfgCjnhaojfvD+bCqlZKjG57rxS43LJVCP8Vm1DUB4+aynihrxTc5fdMzDi5kEgmGeXk8alxGIsY0EPXWyXTh5khRrNsjQdnVrAbA+I3o5+Z23l6M/uC5TSy5Zwo/EAHlOZ+8l6QZE4FZ2RYP1NstGuCV5Y7DcsvG43gMAACAASURBVB+hY2u9GtIWp+VXAeQ9A7BotCSBYVnsDiV13RA9VcNclGjaYR2dCLHqDyrMpL/n/ZZQkbYpy6a/0fbk39nfBoPHLPd0DRx+BA9tWyu/R5E3rrkoNmVZd1x94Wq+7Yo/ZYZ9j0BTAlEtF95qp+1M9mg/mFUcI9Zrbts25SyaL7/VlpiZGmW9DLbvGOPIaoSZzFNZKvw0/gobNPX6zEgNGIsLqHSgEqPjYVzQEWSn5yav8wh2PnPWIwWXXQ30hcsppNKrIB8DP3f7On7u9g384NUf4Ldf/W6AKXrYC66Xrci8vhpBW14nc42u6H/2li4Z5LKPc1+rw1RtfAEA663eRJwHYvlo2g4T9bw6atBsQyiNpZ+0H+7JO+yDiotK4AoVV3E9TYCZL76JZDZMS+Xk3dwm+2zcayQG3co3lTQNoj6vQRBotyl04UyV19I5ZkHntNV+/r0ZPZPPHr/IGpAMyPinxlmlQwsc8i2D2mgj6WU6ZsGfxSZQY2CYAVnupdlXCC21ULZDqDaB391mwPb2zWt89PYNHh9yuqH4KoDaYrfDDfP4KMOO4+447scM2JrM9DKUqX+v5UfJoc9RoabuhsqL0qGUX+ZeuY2zWRywi1KMQhxTIkzAE6rutOnamkLiZmXQNs5Ip7BJRjscxdxcQ2S6Wpz0zXJIKnVhEl9/zq68gkXb2vEnkr+fOCIKJMiZcG/Zf83aMSsYFQaio2qWLlsWSp51Xd2yxPsM7Aa22J3LNuvbIedAt3ZmJWdwcm1e2sj5wXRXRm9dR5a5zy5OQZsPXLFpznY5HVxplANt2fqaoc2zBuXMvXIm4x9DOfwD4MYGdLCkVWhSjjJaenny4JaOdukMOrU6t0bvaIuz2IhjJ0KTeFbDc7UtE5CJ01lhklUG6/luYsvm/ZKBVc+Tb+gEFr9brgPk96RF4wPRD0xCeK0t5DgnnwhMwnoam01cda2eOoU5yVxLWrZYrR7xSB1F6fTsV21P6SzPd0k7mW3jO/G+IY4qov610orlH1qTCcBhQwNGuei1Q8YjOskHn1kQhws6YDrzLbEoqCFvFWCebbXzOV1eLASJTlEc1mxcwp/qMAKprIyYz9VkXvE3MT6YYBsO53mDqYAUb54Ds1hjrnTUwSdVpZKghhnwG0tUHTe74Xdf/T5+4d23F8KkONdOvi/Y3LQZoWtGyIht26ym8SnPRM7L/nThyWyfm4yMEbukT9lKSi3vrm2aWXTnyIThyXvp8tfrTjouLiAEvE5kPW1s1xpZ7wU+bEdjUt0O3oQXGhyl5/7s+2/j9fEkCDAcOPAbb//B5RCvrq9M0HZam/QlgF+0oG+fEzjoTLPeJ44vRBylJLWHpXSSSkAeYjXHFR+pA9jrd010lSjui4BNp7LbQBNGGYHJr6egAuUoJiSlMNvM0dKN8plhhftcn5sZQislucI6bRjLNDVbVso41V1o6BZ8XhiQNNaiBEqQyylZx6VttalrQWD9Vl5DJmoSdV7GJHEdpYCxBe7wo8GkZZzsLndNzDFYbctbj59KZEZYK9nVGgDw9LDj7cdv8OrpFR72PZV5VpmbSXBugA8cY/Y8jjs+f/+M2/Nz23Et5UgRAGuBacJHK6qbjAi7pYtC+YqX+tqFeK4xdKeTBjmBETgPe5VtNxR2zVQicJHw5wHTSRkZj8ANjtkBp8NpXR7BeV5DzqSQfwRPbaZH2nB4OjX7BoxFUais94yntydYtphynBuNeAZ3ura/cESZnkC39Yyq24QAbMvbLwbE9vnnxfFeKHb2Fbvq5SYYlBnS1cT5QX0mXKGjKkBFOrpj8MBtZcaSOhXuxucZ2QRdHeHE1+89ccRA39twE74o9ZUIjUpkyvlmgG3YN2B/esSbV6/w+PSEbdvnO/sD/LgDkQV//vCMDx/e43aLcqaW/VdnJThyhQkApCwqaSOsmX5Lk+1lrEpHsYPuDmzzcHsGyYDFDCJlb+7kl1duf77Bx3Hh/HCWo1tw2lrlrRxOC1hR9FLTEnppknW2l2stHVMnt3JOYnUBTz4XhGUvqmtTtoNYEQW9rTtmWXOpG75T/oTTflzAA8ud4xvOeQZf4kh9BdKfCSwTq+tLiWj4GZVA6QFp01WiZxyebFggkEBTSVnSQQIAR85Gr3RnO2JlQg92febu8HFgyAY81QDaszFCGNuibsjhcDY0fl5ma0gtiAoZNvCDt7+PzTd8+/nbqm4E8rjamZQCYuBzbBtsAAPHDNhskzXEW6iczhu9NV6laKduH3I8T7elVxVWOWcoCYBti2UYV8J3HhGK30ntZvmCz6iOkknRiKbjMtQ9tusHwGUoq27QdvKjrNeLd755+2ad5hQMvH1m+L/e/CbapgwvXF+ZoO3la1Vx/sLn64G2RcUn4iCNiLovcjd/9aWPdNZMabbOIC1QhhYuBwMVLJkIF20JpN59GfX1OOZTunZp0TnyRfKtwZxOhebV3nQM5HXZLlc+LlcxXiqIBLQ9VXqztPr1GE3eGef5QdNPwhZiolAWVuRNBY9/05hBnKT6qPdchJfOHHdanM2llpBAzlOAHR7ZMR7Q61LlV7M71UOZaFV+M7taCOWMpw7PULRyAI+PD/jkk7d43Le5hi1kYdgGGwObGlNMB9ndcRwH7seB5w/PePfhVjMgHcVQQhAWNUKJRyVY41WOmQZcYaHHLww1IDtMFiHHpTycCe68l8qaRN9zDCRfD+aK3ixt5KxUPSezcFd6CJadp+ESuU/VkHwl8ArGj6UER2cxNFA0010NC9550pJXQJv4jGIgOXeoVKqjdiQMvmsHUamiKFw5IGtJSg9ZGLgRQeSmGUwi34BtL91OHZKzjN7HrviIEYneMWw7JIhHBo4MSt0Lfo5LZ2k53r7AHovjULqplbdRfyz2Id8p6OPvBphj3ze8evWIV28/xts3b7DvO9w2bD4dFo/Dge/bPkubx8DDwwOeHne8e/8Bt9uB+/2O4xgYRyUTuh+zKOxATtm8ZbdIUBFZvZBDqaCaPDfP/V0PbkHxUQveLQ7ADjlSZ5q4ZvnkiISD1+O5s+uGTDAQrvQ5C7x5i0ensDvayLQvcVBxzlB6BS5qLQIQM559JVzBL77AoWTIz21+DesVEiZCscxVjOmcrxsZanrV2j9q26L6Jm7lbKXQT+0LW6y9uTzZwSPQzqCSSTjqKW7S5H3ExZxqaCg/bQQhS8h7yU+swgi5znv0t8RrYD8efW/5PY4m8epjMX6Fh/oH1Jydc4UKaXu0ukcfC/uwA7/z8f+Lj376Bl+7fQK6XIQz/aqgXZYb6kWbhblWHT5PTNw81qXFb2VjKIuqIES3MXEcSoSyO/FePEId65oUCzrPHM4GnsO4bcDQ2Sziu8Gks4qWNqrzNGECFgUX7aqNaiRZrpxWL3xc6Urob8JPS/tznbrjW+Ob+BX7Zfzg6fcv2ujXVyZoOzv+K2KVcxfNClGqyzXG2sZVf9rOitR105H+jvsFXQV2izYbFKn1vPMeqBwLltVopXKHOrGzAWauSukuY6IxP0HJvusf9+ks5XEHXs4Fec/k3kXyJInCtgr22bvBS9GscMgQzPqNnLERAc6s7TJ2wqCzHoL+eiw7F/xkdpsP8F2xTN5MSr3HodqqOiY+ho/g4C1nXzxTmhD25gBnt9OlXltEo/lqLHWQE/4NT08PePPmNfZ9h+17ZRiD5ogMYu6YFwO+RcD27v0znj885wGhlRUuOrdingvZPGHuQpfq00m4in7LfqsiPhk6RWg5CUDxdKO5IItsW7/50mYYjYTbU1YqmLALWSYMgTWDyBedkL4uQYNW4vVllIX+yTUBLI9ywPYwjMnRZfq8+DagDBkeuUHLJkGl5wHabMGbASYOmxlNhcGbE8npyMU62BmAjT4ki/IyygrhSH3EDGvxuuK0yi8Fx3q232LUBzf+CJhs60GgoPryaut542HOUpxcH/5jVUZWpVPZIrbd8OrpCa/evp0za49P4A6f9/szxnHHcRwYBzCOI4JYx/awT14wx7bt2HbHNraZjCF0bWwiC0FD3TjLnKf0lf3VhNWKHHWxJppljsgaJspOUf6Cp+YMi8xWZ5RpiauyjdQZXnyAAR9MENBuki8LwqY6lOZ0/AIeJhSq4qOQ0V0MKRW1jkfyBKCz5DmSZgdYOsw1S3xW56f4du1i3eEw6iOWnuL6Ur2OCBQAW0rVL94S32A+J3yE2ej5p4I885cctxuyTDsDktIonjSmToIkY0PHLokbdjDRX7v78OzHZh+Mlq2cAQM3akL9o/Y6+p4JrFGzgvQFm4h44zpdoiEoFZxEFxvwk8dP8cnzWwweQUP9aNU2A5/GIeK0uU/w9sDlTM4ObJvNsmkLP1ppFIA12wgtkBdb5Q6Am1TFjpPLGEse2dosuTZsMis1Q7meFKtxTq6YFRKtbkxwse87DI7jKAfBG0HEcbgKKDhA9+Wdmrnu+s9kgGe9sKUPAHzn9vP4zu3nAQB/+9xzXl+ZoK1fisx51blCdvnGvLrir9/shd/1b4hlKpSX3aHLPqVrvt/LlBQOlBMRn81qg5EyJr3hlVVz3ZBd8BcdJ7F6OmORAnx6bzIgcZEgWJUqrOWKZyhLMaTehUdGtcqt1uuLKAtQ1I0ygoYeGfg0NOFojFp8WgqiFEYpMs9flPwvcoEr3xQS6PNVa/qKGCt5wN1i9tDToWxKjbgvmw8Gw6TtLGuYswxOBWsr18wyo8fXr/HRmyc8xdlbyD7CLInBG9LfGAPHMfD8fMPt+VaB8qDjznVEZRRnOwS0uRSkVsEo7NhdENKsnksZjb9tFy0v2ah3+VedHVWw1wq6lR65l4zmTGaZWranMzwusOoYqowonA8vvGkAVzmjTkeWF12AHNAQmZwxM3EORpbLXgw4HA2XwEFMslMOa2wvy23dNExH82zsy3ng48TF3NVuK/2WLHSWozUbn3pnSTqUbij97CMmaAJnHntjV/Zfi9yDhswqJ91MYBLZy9dCM7qjByiqOcnflv3P9ifGt23D/rDj8fUTPnrzGg8PTxjD8elPP50yeXvG/X6Ekzhwu91m+eg+M+dz90vOps3ZUwbkjkokUf/XullPVBftFv2ymlPqT9LGqI8Z4GxJo1KchT8nHZegiDLUkhzRDmfsxnBOfEWbW1WIUA5Vn1K/0nevDNQETRzW+W4pYhc89LWFynXWZzpE1jNBc2HQck5G5MyTNiVTPXjKOfBsPu1etF4bcYjOWXgRZnW0RA2kbmubix5Kea2Ir9vRNZDiGR+nhEH5CUWSWdY+C4IWzZO7iRTpfXjOjHYwQyeaYZ3Vos4jOUxABlC8qDBaBbNUrXlky7ZhjKNVFVsg7rSOs5AXKCKM6zVH+Htvf4j78Yxf/Px72FY8Cy7NKiFgAHzrySQP+77lWuAuBnmWX9it7GdljqYT+tjaLsJ+HlY9Xoym+xVsrYS37Fkf8YoBa0IwjgFWxtC/XqsjILCerobcxSbQY7lKXF3Y6n/U6ysXtGmgss56nYOTbizP2ewXe2nt8P3UqQmDME9zqHprKtB9HApnwbtAIr9MwtMZnL+QGSS7bp0xdTZRbeZ5vCVM5NE6MqgrybYjj+C3YOo9lkKe/2hte7vUWC4wnzOUZVwLg/UlYXdvMJWhh8DgtSU1nSz0sRvQ17XRYU2reFZGa4aTA0qeiP55WHYpimjPUbtWxff5yEjFUqVonnXiibg0MCMOhy0noJtvALvh44/m+Wt7zKRxwbI6nJplnAZ+4D6A2/Mdn797j9vtlsGEKZmTHgsyVjgWju/P8pPesWteEtlv4upoa2DqxfNanDUxQmNu8l43AWcDOkaUXPEtZoPNslwzF3VXFNecgs3Q114g8B9rA06Zw8y4Dyi0Tu/zBLuVc4py2vgcwTzGnD2wbW7j35ym1XFxTIcrA8+STROlmk5M4GXLtrv0mCpXE71mdVzEqg9qgxCAnnf5wxVAA8ETsplJw/WItqiRU6eyz5o5zWAKesV4BMdFgKInTM7jqqxLBn7bvoVzEjUTdiB20pbga8PtduDTn/5xBGYjNhTopae3+1wj+7BZlSD67Hb4gGPu9jp5qAJ0qt19J8+Rv2TEiw5PZ80QON9KTQq+ikeJAi/mUh7jODLoFliyRE+kdEhChQmowGnBsfClnuHHhiRhNZ9ZqCyVN0pmAHIOl1Rr6Dij3QxcITRzbfWsM8uBFtwJvUtAy2ZVEqJgIcyDjBA3lAyB4lCppQ8zdeF6CDjnRDmDDNmcZD6zIUELmCRV19S8lNTRNuYtwQfFM4BZkzqrdWm+mwyWAe8M3mTxl9qU0IHzCBSDehpJ5UBqljzPAwmhu5232S8dckzX5RpK9OqKggM1OC0XxMAP3/4YNwN+5d0vFzwqexMJNfHhArtcczZtZrAyXWOIsQg+k6kC6aGvci7Z8ql4rHRSW0spSQ5Rk12xqj3I9ZmO2k6kI7U0ApEgtgndPrRyztTXZKIrYHovp3tmMcNbCWRrz/fLY3xXa/y+6PoKBW0xPG7YcDGQXucvghjPD2yA3y8TEyUILxNBTVQtyT+/k2r11BGNhLCTMHuVhZSzEGqxZcQgcK49z7GquiRjEn9so5x2sYHqJ/ShGZpgNmss75eBKci6jC019DQ2oZDnmp/CXcPVFXCL0Sn8ab+m2h10sFIe+Z7Xoup2KGsIqdfHaWy2MiIvCZ6Ov8PUb3Rnv0xzLcwuI8Z7M8E7oo5+y+wqgHDwAy53HI5UGAh8WwkH9n3HJ598hFevnrA3p2nuBLl76tbcM2qMAYwDtwE8357x4cMNz8/94OxhQpN0RAAG39WVGI0FJ9fSxc8iQuQP3XTF+c/sbM06178Ip5o8pcHpKsvX9J6b4RkO7gIoBmW+NanIktEyrTT8BzjqdUYu+TwNiMqhSlSHawvBHeOAI4+Nb/CkEQ1neoy58U1DMw1veG2ZMCARlxkrEp082Mu6TOi1gG5zLZO7ZQJiQ61fqzW+lo6Mkr6c17Os5Xg1AztFB/0tLzDpLVg9nzjJ/kvw2lq91TzYfL4qOuU54dOrxCNlaIvdXCk4Bzc7CFyNMfD5n3yK4xgl44G3nK2HNb2ZsXSKieVzM5CdwfpcLwbYCP2y8dkYmgSEfa0er/mOHy6DNMArgIin8lZIQ9EyN78JnGdZ4VkvcHBjjJJfCwIovE20mQ03IVuUay07UZVl8vNQ87FV27BDrZVY5IBwQo7UoeFBf/xaR6KsfzjjI/hLaQSgZqT87Ka3Z8Umzx+pYKcNmkcOWKOEp8yFHdPpxHhwQ8h7ufTI2d5oaepiSMxkKbOqYnXpB+eE1ShyucUJYb7yTQWYzVnU6K/RyYPPSh/2at4Yh5B6BifBB9ShpFGDJXAPrZwpsFTiTuMitnbgj9/+GL9jG773+Xdhvukb0V7YG/QVdes13IHjwEZ/2gyGIb6htX0i3Ies5w0A43tL2kDkPj2lvqwgLE/OcVWwLXQJpV3+bE1IdHe8Y+CMdVWQ+Y88Qd4MxjRAj7zoz8q3TJaUjbyGyS9oee13rNdXKGjjtSK/ZKl8sxocA7GBDRh3+U0Zf5lpQjHxvDz7dVysBQpGTQc+9YS85/35s6IolaVn0fAOA7nrCe4yzsUMFZhcGU/I+NL5gtWmIl5CZVJ6elXARLDXUrKXWEz8k3x2rqsQB6NuXTa0KhbFitqF2R7HXD/alO32HIybGlwALc9M+F9+KA2p1XOlhgTeYAP6jJOHvbKgQDOEjcTpgKEcWeVfkF8g+87XtH+1adgfHvDRR6/x9PTYDDPb3wHURhOGYwzc3CPIBp6fP+Dduw847geOY5ZTzcCbjr/KFYLFLZyILXE1JFV7NVsLR1bKcHTlhka9ur3Ec9XmdAC8EcNJNzd5tkrFWvIAVyxyVUJRijpxD+GPxMlU/Opkr8kAj+c4c0a4LDZBme8g4ifJztH523bkTEnCRiFgqaYDfsAQ8khcOnExZ7SOeFYPGefMWwUEdK6n4S4kU4BKHFP/KKOHLMC9J44DqSkhzrKe0rV8eDfRE/l7p1wcES/BvZ+fS55Vkpx5ogaRKjjp677wn7RDl4Hrd5M/nLMYVRVwHGMmBdwFhrn+6H4MHMcdsHk+IgEzQBIpsy2uBaQuq9VngRcrnOzbDrNJ0eO4T4d4OMZt4PHhIYLI4i0PmnF3bkVIyoOR/wTvsvtGyaPg2KY2MjJP/gYp1fPWfs1Q1LPJW8kvEKwXzWtX9gmbHiXDsWSw6bSTgmfubLcoDW5GlvC5p/yU8RLHU+DsBV9qUc5GMvVB4GBucMIZwMWCKilaD50nZBioIHC1PnEPZb8aQMITHnaCstzzOKXdXcbeeophUz+mk066K0qTJ3CiyQSPvLPBNtnVDy50tSbn5dsRCA1GAPNZTTHPk1fdfgWCo0qtKbej0WlFYU+OXFm+gN+AP3jzh9h9wy+8+w427O0pld0vupj4nf70wMO24NMAsx2t2ivkbU7UefqYpNUWwTF5ACBeq9LFjAeG1I7FZ76jTgTaJiZthLZ8jm8a/S+4q896U/XS3BilDpCviplripCHrvbDkJn65k9X/19Go69Q0HZWSkAR9uUpxBjgOACUYF88gZXIGgya+VysafSBy4lxIA/49BNhPZPQmWloI7pQtmEIOttZ3cux08eRNgJoHSLHYWIYW5aitbkoFKOgWipi6ukT74jB/Vku9jzKzp7xIPjAAutsY8H30rmheGN9eyZ8PA3uashagCzK5IvGeMWFbRdNdQRMevA5zpbMlDFNyGoHNjPLWRRVcKU7pbQsy8AIR4YkeHx6xEcfvcHT02Ot+QhLZ3AMC+cr5Gc4cD+O6fiNA88fbnh+nmtl6DwbuLEMDd4cCzdVSxmk9k7L54JucXJRMqvrKCpGorxsFSBYGbc53sIdbazF31pMzue3wp3Sli+wJa/giMZllYmkIY1J/ELaVbt6MC1lkzvTvaTbBLZ4To2vrlM7PZ+0IQwbamZ+vQh/v8vxmHxm2wzYWxxE/oudF9PXYUBjEnTpLrvBu7MJbpACcM9uMy5K57olr3VLaybTOcMcZTC1ih1JLXc5W4u8WU7ZFY9KI6i7wbtfoi00w6wnl7WAwrz0ejoYDFzn7o6zVHYehKs9UCZW/qBjsZaqqxOjNN33HTDgCFk3B+63Ox6eDJtA3pNkMvbshrPJMhTKLNfMjNJ7qcmG57lpupayYJYf2Ibg130ssjT5nzseOtDoyeNTKolQx5ZUqVfprsxNqO29sO+9lylzI531SEEZNSn1FB2N3pImmIpvOhCULXePA5c59nyg+pZXyfZ1W/AkusuSHkWrIizHIvptQUdCutiylMeTbxC2sNmMsjcapVWSGdImYdcZ3pVOSqGpL+bPPHLlWie3ZGDqsRIsUthDl7R1zAie80h8xvNDiFJrrQpnV9hcfWKLBNvvvvkh7nD80rvvovPhbGvb1s351kveGPN4n+nHWA5wHJ60rHWBAAb5qzYawWYh12g+aVY85WAmKjmBkDLi3Q53GElnFZyuo/lU7oeQv9vyzhXTCi8tfkFVQNn53ROcJSs5wy/+2np9EXWAr0jQRjvVZ9DOoL/s2zBXw+eUIC8ZXd4791NKLbIH8q61TzjzyKWM+YWyf6F7AbuxmDie87aXYIiymN/PO67ppSWOlQ3tQ7L1Nb+mSW3niwawZqhUrqs9UT4TqBZwE6SsO1/7SCNU73Gr796XzC62X6EYFFp0Z6QZIm9vpJEjuxE+jx95wC0DkSuj4T43DWD5Y6CvkaTQPn9Zy/KAOkxTcbQ/PODt21d49fQwD8YOB9ZcM1qhZGN9EQ8PHePA/XbDh+db7iA5x2NlR90zUOP3Sa8q7/LspWEz/i0lrjNQ+ZSXg1NYM3oSL6jczhf8XD5G4V0LUzVg4yyYoxwWOi9ArYVoY6IjEoxaitmaPlntcdE2HG+EAx8DowPlUKdW9CTxJFk7U5roxSTC4vBdlXjRSQPxzU0q0s+1nG1hxWC244gzs3xmoYUWgLVZIaWJarU5bk+9Q+M+wtpbHPROvGeQuui03CL+pID4QA9kdXa+ZrgbuIEfZD/ZH8rJADxLLxvVGYiCfKH9i2MQ9J7qYe6QsT/uc8Mh6asRBROWAa9xi/7PWQ05U3FdE7VtO+zBZuA25nb+99sdD48PpacD3BFliAW6FS6Mzk3x6rbv2HfL8QyschTOF3XM0Puq2CkYShNv9KlZ78Uv8PAVzBJHV25FBTTaQvWX0JK1XN6DZ6Jo7n7HwM1rNo/bkvKw6RQ10U+JitBE2WlBRL9plv6fOan0UIefdi7hVPRl7SAqWRM7LPq2Jx/w+YxjGh5W2Ra4zMCF3IEuAUuUosks9EJfDmYNYOdrk9P9KjhhW6uVpfPtsQX+VGLhB1G+z9UWHskN//+oe9cmS5LkOux43Krqqu7BAksQIAiQBCiJFE0ymun//wWZSTKJpgck0URJxGMJLIHdmemuR4brQ/hxPx6Z1TuC9KGRu9NVdW/Gy8P9+CM8Iob2FWkHrCne9Evw3owx5WXxHAt/aECprdr4icaU/jEG/vLjX+GwiX/+4z/rdCdNB2AS8NDV3dxbH9/NmPfC5Dj90R0eNg7xXQ8L9GYYBu3WwY4A1g1wiYRmsMCSpJ/IQ2Wl8AnezENprBeq0ZzHT3A6MdMZg/ffa1vSWtQp2WK779Vr8usV3mg5O8nM/nwTThuAxtRX3+lmUn02XwZ94jYD5aL68uarbFedYlA0Y/k66r4fDKZ/nsbYHIPe79U3GiLSnxNTS6pLjpeiWMbEbmQ661eliFS7AHqaqGmbrUQbbjphJ9oUDqeSUpEyUMlHeat6N6Jk4zSqMqosbbK9IZF2Gt/sZ0K36fysL06in8C1KQj0cbBw0kuevD4huMqn45gTtyF54hyz1VywmrbfCNKAyAbjSbfbwP39HYCBYwI2HCP3FvR+O+R0FKV55AAAIABJREFUM5/weeD15RXPzy+RDukpZ31InK9V2+Hs867YzjxTDpAo/PxmB3xspfmrJ8HWKubY3lUZTQ6FEAtAj5VX0KDSjKrGKXQfrT7f+ka+qn1r9XUaLkqgZhyGAjAs5T6XwzTi8uBKNyqlnX2PtseNBgZ5BKUwQsC6qhOk8qprGRBx3D2/t4jAwtsl7pW+5PDjyOAQDfnFB5Eq1vbI5VrJ+n+LXlgt1XvsXxoL3UZLu6JkJYWLtOCirxW+LGtJ+uAxdK5r5KDA4IxSa9XN3Z8d9D2CGSphrLefaoitLFDXf4RhNNclH+PuTpCbh3yEc5Dp0dLiVExejZaBJqOReeZc2RjAHeBvnicnzuNYK3FKhxQlUTJSffFf0GU6jgjscGqzD1qtl/NN3GHfHSZpjUDzslHyVhTVf+vFJVOc25IFog+rzhM1BZ/q3sBtJYUpqRxf61jpRVtLChxsYcpOz5wjSFvrd99GV3hTXR1meZqw3UybyAXoQw6wWWP2mhPymAwjnfvQcTMd616/pRFQQdWmK11+brYJ+T9pe5KVeKtOQ6k5jH9W87EXy6w7W97b0nl0OAYdJV0xKjAEHVZiJrMAOAc1z8Ff82COIHJ1d6yzHuc8MPaNeJzDNG7VGe80WK+ltATtDX/9+EsAhn/+4z89qdFlN3HcwOVGQEnbLNty6cBUs0cEXm7haIxabR23OtiI20QEkKruTENeYeQbdaF7+Kkz5g8ia7Ot1J2zyk6GQ9l2G952OqpkbSoaFWRjW4mt3PcRDnFBqkufok3VJRIcURvuOoxUzzfhtHVY7c6QEjAN/yBuV6RXte6f78S4KufdWZHjQdt+oN0r+crT4FXtKCPjCbwTdOKni0GSo2rIJ4cAuFLRwqEbkmOsCiV+5v660rl7XcRNdkMVLsfjOW9WONv1aQFaNMjVIbaf5ZJxvaVOnBz07HSZIiPpF8qHSsX3OnrqU097kCaKBCdxP4s/aYpQJGWcmNDFZ6R3TcdtjOWwUTEP5QgxHqQhXqKdbQGZ/glz3N3f49PHD7i/vwcB8PC4n+hmsNgv57HC53C8HQcmgNeXV3x5ecPb6yuOuKl5OuLwEm+KmQOigs8DTozTIhLqnJeiZn6bc9gl+moVeNk5PdWIVfDF3NxPAzjBdvHoyAt2qgxCIemMFt/WDFs2JqdQnbR1fZyGj2yhSP4HDYVS8OwjyT3MMFkfLfEMi0tUrqxbcP+SS0Wc73zNGNbpTnZdaRDyBCweCQOmDqTw7DvvHeMcrnnzOjGVJ5tayBmOpYgnVx66YWjxnbtj3JYTUSmA5AHHkRvkq7AJ8Z1GSbZbj66grIPjeuK7CnyZ4PWzvq5/04BwbxHrqiXNDDBSTd1gKJw4jlnOkjvu7+8jWj+i7CwjaE1asEDNiZBz0S54NJ3meOGYEyoOiaQGjLs7vL28rr6+rUN07u7EcVMwbsaJ6ihixOqH7gMsOu7U5C8ugUVDOW4QR77qo1ypiVs6rACEunx9VCuXy4iuQxf6ivsQvl/0sbxktNo8B5dVI9fYNACczmnSJUbLAnItSPG5VJ24vL6b8d6gbOeplnx9LXnMMDIpV6vOUXJMms7SS3zqBgXib+mHGrdLXYt3c5V2UVjmTafTCyfbs219SSHQ4KZgNbEvpgw6J6pgeSqkL7wYGOuArSxHHUFA8G4QgNkYsv9LGHlB3gpijRF3lYWuyIAbNntk+9nHHG2aNqUBq9W///C49rj9k89/gBsvt+Z8DQaQGmEu26Ray+81kYvO1eBx+rTBeDp1cL7r+5WmO1BXEcCYNumZvTGibOONpFRaWDCpR+UIUuZM2bPuAXrKLbbf9hp5l+Ci5QE/RvD1kIMou+yo45ZBktRI/O/955tw2tZTHW26AAXG/PzyBoVG15okdfb6d9ft4fTtXh4NOPay2kyXXddZRiqkeDcNAwEJddZar7c2dyfX5fNlkJMOQhcne3gaDAp+JRTR5w1EFSrPBoq8tHWXOMH0qvxQfqZC8l5mRa10Tn05IIYECK3IoO2hDaCgT7BY+77PufZnH5fLZy5txpd50qPUOYbhdquVoRLdqFkAiGkU6dxkGzRqKj3hw+M9nh4f8XB/DzOsDcU5Vsu2Fityf9Bq+TgOvLy+4Xh9xetbns8VBw6ok7UBeU6INQMjadDmxXJ405GrjBkQmGLMNpZSAicaLnCkEUtlv6+gsHhEGD3agZViZ3LisjNmgnFGry3mknNrljK1HJazQWHGJBDLk/hS6rzjCLtYsks8EJwQo+MUvMgy63few+YSHDGkTbbRR6Q+2l2rKp6KPVdphI5LHkWSDBhuefjAGIZ5HNVHKrBMRyiFmwEfcHVptbOcoEhjM/IhsT1wUuYE8K36DbiEZmu1zooETbEKbXP+Kw2JHyo65xHy7YoG0xIc1t5IlI8VtjnjgltfaYliMK/u7BoKSce9Zr6abY/YsxMdGbexAVbN580A3N1wxNUBx3HAxlpp0kCTKgeHzHO2X33d0/GSL63LjzprCQ4hrwxi1QqurMxJ8KMR2z2syYWoPdgj9DzNzcUT43bepwelhbxjiRi9Lxd11ffEdwlIUfYoL1arwZTPRff6Pu0Hk2aiCbMh+7Atsdj03QgqLOy66Lc8a4q3oAeAWk0MemkfcgS45D31tCr4MrKtnYhp9Hr1P+dm71a2ZcETHnp11XLwawfqLOVqiz889M+aNrlmhXNiaHenua9A7RgcT1oIfcHY67stuToxl5ig2VTVOHLsf/70lzAA/+TzP8ZwrdugjrYikRApquz03lNfc3/qWPRbvLVwf8TVQuymAUlz2gjsb+oxq7R7Sqo7llMNgBfgeVTF/uz2X1XcsZiyoRlLqQKg9nCVqVWzeJ96KPTW+uomeFI/y37g67ID30XS86Tcrz/fkNO2nnK6ScLzo8T7zRVtSpJS8RUcUmxN52C3+rf35NPWt97V6Eyb8P6u6puq76r9cFIE6NPxcq7wiFGRwVYCIccgwCnKY9kyooy9Gx7s2WRRocXujEogpX66YDX7ry+xjJdipxL0XG9fz8URDyU2rV9S9Vf4C9ImlZyHoHLc/d0eJeM8amw9X58Ehd6xpXB62gWVT4sYSsNlFznGuOHTpyc8fniIk+XqYuwaSxbAnGFkBi++HRNfvjzj5fllRcxIA1EsajDkOFEGoNrHTEUVHbcUkNc4C7jm5sT4NnE6d9F+RLn94sJNDlr1QRE0xpJsr3JaK6NUbGksnRglwLzRJwwFubvsepWO89mEAOlUsj0xXHIIYUNo4ILvEPjpdDKNK9cKxsgLVPdVGSqyxbcrHbIRzdhCV1zrC48py6TsU79r6FWHUaHDYmCrzhkHSvBagjSCkgdzwpJWdCJbqij0903mEKnT+d5iMs6Jbfynv2oAI536HGA468LL6Rc6MsiwyCZyHpXPWGVbq4wDt9stzT5RabJK16YkfhZWkX7TI+2L6XBRaO1TFad8WUdYTAbc7m6Yx4y74CbmGLDbiL2FgQfGPSwlJxoBV+eB/TvpX4v5UQunUydhYdc3OU6RYVbT9G8eTW5JF2dAABQ5Dab61sBJGrGfoqErfm2cQ7InRGdk5osoRR1fYupSWo0vU/6TF1qS81pBkiGoQZn7ZjetXoGHcQl7mfLXKOP5GVO3i4SLPrkKYpXyWuNiPaWfMsBIQ130qQwGgOfK4uVjTM1U3kTy7mqD/2xTvgSt+p39SCpKM2PrwWYTVIWYkeKeuGCSaicyLOTIZ1aXCo1Pig7ZyYGBP3/6BSYm/vjHPwo6VN889PZ+ZHoGP7RP7OP2JN5PdTE9xro+WZkCxdTrLtDqJ6b3FeHmfFaNiYNRzr3oWn0rHbvkY9dlRCfVfsJ/28iKAJLh02wMMoWta1cMac9NRGBw3S9xqt/C9it9tb9zfr4Jp01kZvv0SnH+5kF9rZq06zZAKn6yKreDtgLeqb8d/E4CFL90xtoEJZqoVLqKCKgyM0MHnOj3es3zHW3cWwOeP0q5EySkXhMlqRSgPKuIloyhUiuu6NR7VftVvQAku1F1WAJoDhgExgKxpRBGFHBUXj9Lqli0rgkdHJyDrrzVAKCM5rtswZQW1srwztECJukL63RRTTEna+hScdTOsY0x8PT0iIeHB4zbDR6nzcEGzA+4DdzibpNj1iWa7hNzAm/HG748v+Ll+WXd10RFCY3W1kA8J8jbWKd7Xboq/N/2zUQdVBp5fH0YmrV3SidI0k62mdP2L0SKX5K4NR6v+cprCaYnoPN6UR15/mUV2c9PJUBy5bhk1+ofGcu2ysA3rP4yxP01W2rk2vcE2KjADftyHEcFHTxSTk58RJpU5DUVOhk2hxmHJ9gtlQyN9masJvvO2neSQowGLoJOILMPXvQcTdO5ezveQtI41qJB2RgB7olESPnXyeQBAggZ3fy5jV0tsTC/27Bo8QzAC71TzxDDyJ/FdilH6ZTF/kWO5+4ujr+/0HnpZnTrgTMqc+wkTI4bG80KxSL9UDaamgG3+zvM5xdMXzzFDAFjGV1tjY7MOPrbj04jo35DNgE6Ks1R1ioNdT/erI8VfzgmUitPt1XQ961ufjk5X34mtYpK236SCrQFCPZH1VlzVqLPVhVmF7W2IkPpQk/9ppixnO/GBzpO7bPq+B1LhVX3jCZCgcV+Je7lgi/9NMa6/N2B3JPJOd5XC084rX21QCFiWZ505HI9iAMmezujrHBWFHEkJtNR0oOQzl5tEYONJa4ICVO3B36fhkPeKylv388pK7/F+7zy5Yo0hsI8fi5rjDUE7UzQ8BdPfw33A3/y+Z+e+wkUTnuNKFfxLuzdTOPVu/mUc4NGdNabYz0Wv5D/uUVnYT0Cs/v4VTYAi7TKtZ4XB/Ln+zymBM4MmpVqFkeooEZoK5hi2gZxUrNZLojKnliBi1nRc2W4OJynIbeghVc1RNE8AdPjEvH3n2/Caft6F/dHp3CvZRfAM7O1Vy5qSRDodI3vzsq/mnCZ5L3Wi/avIl2+5Y6nYt2/R1MU7HPfuKsOIvGookU6BL5Qwb5yXE7RShnjeZSWOOU7DbOZJeSiKrJsXTS6Is5jSBpNKhOCm/SH72g3vYTwSqf2AJIYgTEKG2vgvC+NZKXu4y/Mv24buMHUOAEbGkuoNM50eoWHai6lnxEJ7yACwAz393f47tPTctjGgGOlWdkw3MwwcR9HJThe3qYQbd3H9uXzM97e3vD69orjKGJm+ipZL+jSDdEi5oE4znyLBDt4/L10W4RHadqM8CbmQZ2ZTKBsWI8KqwU3NiYVZjGg3ZdoaJcwe7RnQ1VojDr3pylwE5BLsWSfbQUkhm90Q4+cVxvrvbG1vBxjuceGAR3qzYEySEbs3cO6wsHMcl+iRhRpgFrSwWrPZJCLKxMRkl3OWA7xgGPd2+PHWrUYJsa/0t6BOpadjFXztQxg3lPXDSiH4+52WycPkk94Ah/TUDNqqWUjcMNenPhB+1dYVEjU3yUuahrwooWuaoQMye/rxmr6B5Z0z0654zjecOShM7c8eEiRbX1kGcG2dsJizFukGKejhv4Y5/bqWxsda5zpkAPTj3Wq5P0d7sYtx+/xS+65Q9FmCI7MOfNagU20o6tc4S367vqo6Q1eXiwReguZOKUU9w1A8RVnSHiG16fwpF3ZY6wObtceq++lyqptOmqpjSiejP5nwKOCYT0bkfoyNUTQS1ZHkzocY8clhA5R3Vzpp8j6sj9oyLzFWjy9uRFpwJTZ6cj90gFPURP7ZYGpgUHNYeIEVmMeOLACUtscCNO3IED+wvo7f7tEThnLoF2X/Ywnj+1KWWJgQ+kG0Uf1TQbRUXbIbp9xQjTNru7GPK/7OGpOF+6wdu32prTZfQN+8fGX+MXDL/HHP/wT/N7L7wZWrzrOW44s50S5fddXujrYbNX2zpZieiyt0dImh8GmZWBg2MhsgrY1Q2hxQZwVLBhLGTr7F/N3YOGD03ESXgbCTuGVJEn/M3pC8SJ0zmqC/S/+3BMeSZ9kY0y4jdSxNa/vP9+E00aD7UpJXn92UcE7TxGn13ZmwgLDc9VXfXnvkyqokSYK5fslFDD8mlf4rRoH+bOMhqtWNJKpjFMY6dnHxXRDcbE7YHx3J4uAVxqDJfsxLC5veyqsbIMMH33NTf1ACMdZjFw6ot3RSLJu7i61d364aVZTM6ShKpf9tFo9qyFVf1zukmJUFbJHrVkQYqBdTGApi1AwA7j/cI+PT094fLjL8mbAuBVN77Bw6Qgv1+ARMX/Dcxw6Mo8j0iW9OemDDgGA4aRrjF95AyuKVSMQIM+xEQjPsqrvkJC6r+1CD2xlhe7GlgBdIUnjxqoMNnlQDKITxNrYhbV9je/oWEopNxpEOxUpFzBK1dCIiWbogNcwrEM7xuiXpu79ZuRwJv87btz/kPsuNP0RKWMpRaGAuLcsjQ4M2LiV8RYOU/ZjWB1lrRPUbYiCCwfcj+SprJaKvI8yDVXiyAkTUrnHWKlXMdb+rByJZ5pgCW+NFaZZArLyHg11/JXPdaC8aBojB5X3HNYlYCCbxeJ3kut2f5f81NKGYXVoijiZ2SOyeXPYYjXsJnSOeebuChrDeXBA1QiztffN4qoAn74MI7Nywi3CV4Z1pYjIF+sZDIDMOEEy9D5n0TDaMf856qajBEO2KyHSEaEDzaBGYq1dY6scbz954uD0FFWLi8xtynzLvBjpl/SsYFytwMuYSlHIdzKm/bMsUkEtmZ0cUuJvfKCrMOpsBBcVJgHll6D6LKos2yiniRUV6ht4B5joWN9XUV2GL/RDdvpC+BlQVn1cbiz7vA0wB0Vcm94DYWsYEqDY2uCfpvvaiLUuNg4bbHzGz8r5dOHHyi6hvcXqh3Sj05F4scRNRr/xc6GCpPoGb867iX/7s/8L4/sbfvfl50l9OLOSyoshxJO3W+V7Y0Wxk4j1U52BS7uq7TFf4xtmcUjMeqfS/Xv902ScgzIR+mF7mQ5yBs5ELxxw8NLlFYCOsTOAs1pD6W2I31eWjdqA3Sa/wGsYeJ3OMqu71rt6vg2nLR4FjXreG8RvHtwVQu+Oy1dLZxNNbV8Kyv6cPWpsoCNdlDZ6mlShSXMGAvA8gYP41FcudBwundZx6OdseTSDrg+VQNWxr9crw0n/ro97U1Wt4DJy9JSxlfohxTkmKch6CDJLCMoYzXRNKV9jMtzSQN/mzKQ+lk1pd5kh0pkGXwe/1lFvJGqP6LLs6K7exwAenj7gu6enOCGy6tqyt/PI6nV89eqx+7pq4PX1DcdxpGKj8aU9Iy248X87RGwD0E2xpCLbB9V5pjt5TDMA6vJUKsJy5JIH35FDC9qxtRYcANaYlfipXMcFNli+XwZIJpDUaJqRWH23jLeZrApo1F1oYpaGa5O7kPe1aiQpjOnQxelsQRMqJa4UlxkmWqQzWjhdZXDebjfMSLFcaX8TZjes7eGI1RwL8ggQBS3WQNe8FTbFwHjnjRoVVJC+9ctU4QG5L0z41CJJpvbVhbL3tZ2dnlKyLw18oQpr4j6nHEaxwMYbxGNrKZjLaLYTjWvlo6fe0sFQJ4Cn4HJOGSAgvhSm0UGn69MlcmHChHu/3w8oPkwp3McW1WUwB+v34zhwdxcpsiJEwypFcRWXUWbggp+Thy3+X0GFHSmQzWwTBsuTP7nCr6tnLF5VdYeh5rbjRMGLyLXI29a7rIPYlZ+nqO08vZVtTtjq+36VRvr5wmcwvHNRaqINdrKxL0xXE/EDCU1MIQhxXuGyqpkr+p6pkFzZByBZ3JmslmNJcuy3apvYORfTt3jexdgmb+yOsYfIW9LFzNaeTo0Q7c8WHOFnbmiHsVC8k2oy2UnHPJjKs0+7w00OIxwqdklLbVyJoZdvIL89h6YpZ2urxL/97t9hfv+G3/vyDxfPu5ziKL1ufEvwFIjRMZXNqzjTn6/a3d7rmAaeZ4JhwJGB6cKdJa9DtsGUIWeLeVNuTr1S0wIVxlhplLKtZtbLKUNR0dwCMBs7V7BBFYnoSJYpZ9nwHu34fBtO21fm8eqhYJdQXA3Szzhp9d258c7+guPxgRf4XQDKub6Ltq+AyH3rl06oy0f7GMm0nv11eb2AhIwO7ALIjywZySPaqAAkisCZuAUQCKlE+iwIGOf4THjVUJHodx7O8dfeOZMDNK4zFWEqyF8ILUSZQRS1vGM14hRwPkNL0GDxVjx/oxOzcVqWXW85ylGTloKkwwaenj7g46ePuN1uCVa9NQ/j7twHGl1fvjzj9eX1pBWTTRhYDJ6q+PE2a46ieeMYMdRd0zs7fWmkZKriWY9fxjoAplBuK6Oc03dOPKNR5rA6PIE1eqwgiELKVhkgGUsxqEJmH3a5y3RJcRCbuJ/Ua3CGldPGZm5xYXnU3Pq8c8vErBROYEU6Rbm0FWfTPlEuLUFu3G45vx0LSBnP+6zGuKUSL1T1NPCm1kDnY2gUOr4bhmM6bE7YGCtVJiOxRabOjsFJrrSPgEVOTDCXFQU9y5RJ1Mym6Ns6wEVAxHvzHVdWqiBXHstgCknyfiXD6sPE9LVGebuNNNq9/3NuS/7OtYcmYBE6kADfqnvWuwrXUu7Uii26zqMuA86FB+HXxRN0zbzJ0TJMR8d/RxzUUUd+FxqzdWt7thikZBCR9JQwXQ/M0R5wB1NAc88lENef1Dg55LyTTcwEnu4JiyPcURdb32QPU6YkNjoKzqs8oXI8FEc7QlU50nT5SRWkQOrzerv71qWrEPi0uIFYnedBJA+kYWqthgo2YOFtHupCJ8pnHqqY8GE1s40GyQNRf4+qgtLmKUt8DxxATVC0LTnAleqfCiUwjrZOV8PZJT0gpvB9SyaUOrV/iRBtKF3fVHAG5Sg3W7NjEvH2FFRic2CTQkvVOBbEGMD/+enP8Td3v8LvPf8ufv76O9h1cx9jYWEFVd97u1o+oxX7sUlFzHGteq/5I/2XvEXowqqOMQyI4/VT52sAzKpOvRor+WZ9AU97wcBwILDkmzoSkWmQVyUk02hGioVMhHwG03jSlnZgv2BoBUC5itdXJvfnm3DaqFTsYn5zSbl9xlJaQ9FRDZAmhA6YdUYr2u9OnjLe9j7f2AR9D0q8w6+lBMzqyNn+wrmiUGYQ5ajOayrkLH0hzbYDOHH0vAJwJY4U+NRjXisNuW9J6n1PpnX9JOlRpS7pFlNUjK5t2d6egpTlmLSJ/cnDA7SPqqs3q6bmfp7GmcAa7QlMb4ojPtPoY1PZfTTrwJEP+PjxCbfb3brglNFQAMCBw2utrd1f7AfmPPD2duDz8wveXt4abaibmNpWKa3VP9PlTpEtghX5scmFAenkeOpmIaYFtZGKMQMI0Y+dsZQ91Pwu+8rrpOasc0vRIAdaV6RDAHPtv9gmITvl7fOUd0cZUPmZQ3P6S5HOMnJBpbi+P3j5Lwecxo72H3kSZBqsvlYLIf3OI/RlLsUOSkeoHB7FWJlzhDJlvQ1ieMcVBUxcnzi/2TgNyVuWe/7WZ1YYg4pMc59XDA+a2mVjJB0jNyZkjkqb2rkLZK7CNwwPZys7iKxDMVbIUbNpVhcxA2vAPnJOOQAGyFomBmIVPKDvdncXfVLQKmFWjDqBz46dY8APzysEyhmkcbGDvTC6gJ838nGDvwtOBM9b8L+LXRR8152R7pDpODyMHjMxVd0zGm3raFS5GxCgE7hOFuZKKccqDhuQh0CY9GmG0VRBHeF9wSeOY6BW92CyyuhskcCvOrsk/zRnF4cP5OEXl3rU5YdJcc+LhxfWktrSsthAqmWUF7Hxe3aTnxvi+hDyYIIIWu16WvUEzCJYkMCDgplZV62kjJDmxiBbzKmSa+voIqcSzuXgv1RKbfTSyxyLBa0Wf87qc3mAyiLt4Uzb9pPf1NTuBSc89pFqXco/K6U8sFLeS9uXU+LLGSF71WJDCO3N8TdPv8av7r/Hf/79DZ9eP51oon+knoqhvOuzCUl4EjDrPe/h7q1VCn/JvfJW7f1aBDymw24OHyNX5VrnJ8AvSD8eMtb2vYbi5Z2oXN2evvZSr3bHOqhtzutAOXGamGiGI7+uttw9t5N4dHG4M38FG+VPzzfhtPHpDkWBxtlx68LFd1hHV4fy6oWOO7fbP2fR9rlW+TX6Ku63iiyNpX0lIWtnJC0kJKPXm46tsuuXSWky3n/l0Gh8laGxXkb2FKDeI+urn0vyl2ITcH6HplVRqGink6ARlSo8LgIMms66N5MsHnSmoJzmRZWnS6qJ1LMOExFB8gXi48R31nRNOvFmaRz3ussESNqqgWJx/G3oAk0PyFSdME4fPz7i49PTisSj5pR3lRxycsg6zGNFbqbHoSPPL/jy+bkMdkBWAkLx54A68y+QK94xJnxHv9UoqCiXVkFnwJMqajGv8e8O67aquxneBEDVnRh1+iAcrZyjVn30MRo9jvV9ndgPOmBMP6yxKf96KEWNblKJWrZe3GVZR8re1Phe5fGbvA9EtDCr8jowgYb1iS6WdF48Qd4SdeOeq1l0UmkgcTWiVo3CKCRtJRKdrIPiExq563wvB+aIu75qlaQcpgiUpGM4ejpujC8oDq70F9HTKtmwIvAm6JKrvkKvXKnhnqYN9XmNQ0kkdVJh+ZicCwdzEkSdATBM3jykwL/pJXXeLQtLZgl1QmKRCpoBtq51OJzBgEXPtzlxZxGYMHmfPNG4F1Wnezuym31iGv1+uAv5K/8OvkuAl1SVkVizaBJxlihp6yLw48AxDwxu2CfNOAdzOZEjjPs5rQ7DguAQZZYbJ1MX0ZAraq9fikejgvo55NiszGqgVuy8w4AK9W2PAC4X0Kz0m7vXxWkOsX9K/5xskxxvn0PSiEEqQ2ECdepQfU754ol+u052oA5dsRxP2tqeHFD4l+OOHgvfJ1mt+kTatzb5TgFAPU2Yo0hOlSprvpJCL5igj53+FZCpO9La3BCLuozwh1s4+vlBaDfvRM6VJamX/MFj7EX6AAAgAElEQVS6pyPnrnjQ4bwjk/qD/JPt9Ye0Pm4T/+N3fwqbA//V9/8F7o4HeUfJXPo6hKbgSPin9C0psdsFndrrs6DOyaC2VqalnNLwO9aptnn4VtqKMSdapU8cVk7bqS98N65NMvd1BdJtrc7fRtwdN0uuES5YYoAe4hDjF0sGQF+rXQG/vQPvP9+E06ZkK77XiH2B6/Y2VJgu6xY+2z+/+qzXLb/JJCREfK18fnfBoHCUc9Er0ajEii4S1LS9At+VlkAFFHWMkVGXVAQXtFo4uQR7zpmMfPk4SwsIu1Z0XYzjSJCMskP3z4DzIc5lYeqJRuzPNkAWS0PjEuyNEY3q8ulo4xwso+SL+GvIS0mLTbL4M08SaFudm7CmU8Tu66W58U870MgdGIb7uzs8Pj3i6fHDsnvmxJHyccCwIukTZQCrBT3psH35guPohKO6ZuRd6VLcriQOw5qrTUELy7HV/JV+9UavYIIYYgVkrLWDc2pNOqVOwtfnGeSwrDP5a3f4ojyVmQHtVGO216WF5tDO6J48Xas3HBvpFZQ84VdVkXenUUbyywD5uNun2qSRkxcwpnHmkVYIcCWl5tqGiTx6HGqxUt7Yv8Rgwzqy3ekscjfdFuWl7KWzISuHQAYzeKok2+hPjAXLUC+5v8B76gIXbAjncP3fy7lVk2Lmb4V9OiU55xaKv9on21IhqzPNo8+bYQ3lB+TvqegnecKqco5SAlQyhJOqK7YmXYBjrqiyjYFb6s2gwTFxuMOHY9xuWZ4n1vEUwKQrdRQEp7H2tVYin0MdANNuhpJU316PQO8UljEK6rD/Y9zOkjelZw7aTjUPlCOr+TQoH7IfTPesVVtt36OiUefNp7zDPfeYLv/R0xhUvXWSmRpFUo37NFmMwbhNzGKhv/he20iyS/UTVYdcAZ04JxxbmSxyWA4rSlzwiGpl29YyEvT0aA0aMWV5fypgoNjpwTtLPhhsWzqY76qU1Nw0lKZONvI0QKOe1+s4IGfMW1WjdZOleJ+YvqFOHzE/ZaT6qEe5e1IdougKPxq9LSUNTK0eJu21QMB6NDB9ZT7RRsjvhsGH43/67n/HH335R/ju9RMe5oPATdDcPQMWyW2ck6nj6kGI91fYonaeRDr7nKatqe8SfZuzbiujIE823sAyfx3ZhqNkm0Nkz8d0vEX2mdkBmzzNN6Q97QVef6J7eo3xlqx7yD1+J3uW9oo7DPt9f+fnm3Dazk8x7vV3X/v7pz6hniXq1aMKifXxtWex39jiV15Y9Y4GRKtaa/s7eApTCiU2Bo0umTC3Rno0VQNUGFiH45ycYlQz+5gJkjqk5HF5NxXdJptqqFKYysBHo3/1FqFsEKtF8Z4KYk1HgFkpIdv7a8BpHx1xWHWf9/YdctqU1YrJ7uQkvVokWIwwZIXLtrC+osRpIn2YMWsAHj484NPTB9w/PACwOJ0P2UYa2jmsmXPpAHxOvL2+4fXlFfPQyRFYFQOD860qsOmxkyEXSpWU474G6jqH0I2mgTfg0jkQ1QkhvTAa35EzmzbjuOlwh3ReBiQzU8tLXLkqXqQyd0OuNvSIIR0TNQgcXH6cPmO+tRMhm6SREYu2ecFSZrPtFakBpZFGhgUNyZmReot8/zU26cEufz7X/aa68UyVrTj0aWR5cYEjFLrMPedOHV1jXVmtroLF3jtI3/apUnxSSAyByeh04majelF2dRhcraOpkcaMGk1ZGn1VqfFw8A6PjLf9NQY3aj4D9XMwhoqidzAWc1wxW+pdAb6Qq1EulZnFBdkHpjNNcjn6XEFlLU1tmQlfVsYGLE6SjIGJpCjbFDrEHK4VMAYYutwmUAjvZXph7PPb2ADloF9Ohw5EyZZ/s7LNPYYeROTsP+VVVsPYftMZIeekjY2RnVJ29Jq89bfJMpXynNe8rG4UoDVDNos62iRa+5F0KJ0e7VEy1LnZiSuVZoqzu9ChAM0NdSmpFYdnmnbTC5wTDeAGT2dfevtK947vnkqkHMGQoebYWOpJDTXICLahR8COWJEpf2cSJUfTeCcPtH5StlcqJMdEMlq7S6/kaPVhrbq1G6Nq9MJWQl3hp/w0D2YKKoRD+eXuGf/bx/8Dv/3yMzy8PeCP5x9FzqAUVjtzC05Un0zOa7AcA0B+2ygs46QT3CFcbYayXSkX2bVcoS6HX3UNtq5qeu/Sr+tQnQMW2UTRzvTMvmTwRWXQlM/lX7JkswA0pUz1T9pWX3++Cadt7yQZd3eicBrSDuUXdV98teqSCOTFS03OHaeUc5W/nB+VGmHQeqlWQhoDGdJhY3+6UaW0UAdsGWce1lge0V5eV4K0jpORQDqGLUVy1mAS3KPc2CJMneyVS19mAFLxwH2lnRGM1PlAMba3asVQMgIthdpa+1tXVJNKhFBq9W6kiE8OndS1Z1eMi6jffer0ySXCaJGlNAB2BUriwPJ4WWohg60Vtod1B9vd7S75YMEK98p4KIeg3XyFx4Wj0yfe3g68vLzi7e3A27GiuOkYKTCm4q75UZqWAeyNx1W54mo+RFdlGs21XbE5Q13PTZeUtvaQ2zyUqUwd7Q65d6UmT8ZGOd2DB9GB2odiyd+sz0V+vIrWPNrA8CEyzLRgg6ZDJRY1hqqWVNW1kTPaveFkv8OQSqnays6yLJVQ0lywSFKh0rhwRjStygLCF9LJoK3HSn69ayJODI64HO/eZbZjYFTujjwZMtJ1K2XFZNzVlnAc6DzWXdJ1B15P07KU776/TeQckUaTvCBOuMyFWZzOmwyjy8ky5vjI0+En73AFg92jsxYGoOiGAcPTd4+4u7vhzYEvX77g9fk1y9jhsGnw26jVM5WhpFcZidxHmwZ/08u14sbBDJMA44h9j255bUYCUGaL9KDejp/7UzB/1feYo8BTymuexJncUI607jVBjBVCb304PyMmpOrLyWntLAzp8uj5Xk06dSEA6GXL+q+HTJmh9hpzruq1rcOWTpnKEnlnjBhoOhMu5WpeysQxqL3R2xWkFFwsh0/KWfSajE3h1xNYc35rFYcpdeurAC9nSFUESfR2mx7pZRr4O1aS3jwlNwZp0rfkb61xp41pnRySSYBG4N/zn8TVxM7FdOvgjE3p1OKnaIzEbpftBzpF3UIFABsDf/vhV/D7idfxiv/s+z+J8VlfZRTnjfVdBa1bkyf5RNlzMfimCxFBpupww55zM6Jn2TWu0p6bbuUSq/nJlHXpo68QL3lQ54v/FeYl77uDKeoA0ibJERkdxvj7YguHPt+E0/bTHwL5+ovOlz7XE7nV4tdl33sXWAybABsgo8ZJa1MVcKvHy6iq15DKTsFNCvfxLKVTRqUFo5NJm/h1udY+7zTcSZFKyPKdXUZ1DBxf3o0Fwlm8ZXkj0AJsQ7tPUyO9bQ69NmoWgCLAugMGHz39csh3dSy3psRsIGORKkTlh8xkyr4niCLlVAwGVeDl+K6p4acoQ6DNB/vtePr4hI9Pj+syWgA3ON4ccMjhBl40nnmB5erMdMPzyxuev7wWPYLmbEkOqao+0nYQfUn6FBtZ9l3poL/vMuGogID4t6mMfX9Z6G/5jvZrm3tvv0S5/QIEKWKizEmBptuFj63odZ2v3mpe/+qq1nS4efJ/IbwHXbkKQwdCQV8MgY1EKy13Yt2fpmhCnvQ2xLYKKUoypFy65eIo00QqxuFfM4zGMW7Jh+laem+/7y2M96bnRnWX1U6GSdZeu+CbOSNCWXRbgS7eGxete/WzU6uwJrFK3m8XNItUNOVrNXZYvZeKNwiYsyftLD6qVTg6Y2XE81QyHhojrVtW1h6urOml8w7A3w4YgDmAt9c33N/f4bc+PuFn333E85cv+P77H/H88gYcE29z4uYO3G7tIvlyHNbYjzjWfdEqTvQUc2/GXKVhL7ySVEi9JnJKXqxoEpJpgOS/XHHq3LjaMqH5RM6DMkHuPeVsmLZCR9oa3U1z/vI3HVH81ECEthn9WyeJIu/Xq3vUqlZD6aLNPBSKFFZcK5BtUBvLmOTUMVBixn3wRf5y2HqgjHyeByglMPIFWU8YlEMKVenurEz3frCihhmXbJ/9ajCGmrfEYME4Ryi/BAHVfNGmDdlvroRMwtRxUtbf4SLDurwZ/cqBMiIBlB40rNMJk59DwXEeyjk90yEd9UbXksfdZtSfTVNoWoR+jBtwu+FXt1/jv3n47/GHP/4Bfv/ld3HndwuHN2MwOV+mdG7yUP00+duzvyN1xJ4pZVt5Las8KnNnQAsmKA63usnvQE/dVbqcmXDZ60cbC3XckV2o+efprACQp5Ok3OyVn5przzfntO1OwfpMFP5vGFAGaS7e+ykO3V5X/q7lL/i8NQIdx/biRZ3VVuzpkIiIbrw8KzOkvlugEgrOxHjJNno/SvVZr14Ua3c63xswjRgBfopJSDHryRPSgqFzfwhpJnWmMFmAVzoePZLBjutcpR2AuhaTh6wozXXQCXdeAJyD0Ena5e0idNS+a1EjS4Mmo4tpEK5St9vA09Mjvvv0qa1sppwbeoTOJWVOuvn2+oq31zcAnumWba9M0J3dL8UxZWWtq0K2vz9kv+rg+tS2ax1qOGIctja8+qXaGJw3cSJUH76j2FMBpEKrjqyVSW80YzELZaYBm73qq8+UJxlM6Zu1VQlY+y1Xf5U/hN/2ckoch+eC0zo5svaOZJqqxco6o5A7bdxzHxygfDZldvhusTWPRFeDH4Ac9pA9bEqscK72r/F4ZqbvOdaq8hgDBzRIsyg2eRGze62ExffaZ/IngwVqGtQqVsjjlFSV4GMe515O2SxHMXWKVTCFvUwcdnlRV3q4KmIYGBhjwg+sCO+tvH4XR46d52oZgEzpzfuExsLIMQaO48APP3zG6+uBDx/u8fjhAz48fsTzyzM+//A9fvzxFfM4gOOA+cgj7Jf4Bw1j71heL2IisfNIUDj7y6Syfm7tJe4zSmfOyWKMmBtqVgHYiMNIPctzXnQ1Pec99bHlWNgeea1wQM1+WeGEzjN7IquxKJ7RqOj6Lfh5jmI84TklVTcylQdXsRm6KYVPVZP0uzCtaOgxQVZfh2zHOEeVyVHue7fqC7ADVgbIhk6i2zYsT5V5U91YLTAwuhkgkrq+JqNO8Ou4YPJ7VRuyN4OGRHAGBeKdVXpudRQfM7PZhPj8dwwJyJOfmu4PyNBAZei0ZRd46uLUJxk8I2FCHuQo+6zeHfN4i+wrIasceEV6GBzTxNYUPTgyTRbAzTGH48/u/gJ/Zn+Bf/Xrf4Hvvnx3mh/VwzXnpf9ddLtySm4xyEBPlMvIrslUBvE3W7T0wnbyc00E6r7A0m+k9Xt7LTfmLHtA5Auil2quOY81RtXr71T/k59vzmkDdPAKMO+8aBefb4/gaGPQv9NzZbXmx1ffvT8z5wiBlBKFsN4lc2t5ASaWMd1TsTO31q/tmESQ7PTuXhVXBXtOL8oee2fM3QnudeRIvKvOPoA+l80AC1owmJb4BmQ0u29olXisKhYU7Vsv0jArxXKa7Use1RZLcGvldn03DLi7u+Hp6RGPj0/vBC/675XuQyW0ovUvLy/48fOXZYzxvqQ8kc/aCht7JWRdfXSAqXGFnSZAV1QM9dz4pHFm1+aNKGmYbcq7IsqrprHf6p3fzVYKXinjmuKmunPwOwtAzQuoix7Fhbp/oPpZPLe1RaqIHDLyqtWkXIthpDe3lCwgHTgq96bQcoJWSpPOizIMU6HXieizjDfKmzsw5yYji3ZN1vg7Vw1AxS8zbppqicCkqI57XYJmNGKIBzqfZj0tcX8U/mjo7Y5dnxsxFNpnlUXQg8PkiBxpGEfiFPN/pLttZamwWb8IRaJMEGpB/DrpdczuCGfbswewOD5mFHDe6XQDayXu5fkVry+v+PLjZ9w93OP+/g6fPv0W7u6f8fnHzzhe3zDnWnkbvCfOyPIe91362s+WvG2ArGZ3+AuqiXHX9BJ5mTotDsTBnGFMFkJvdh6AOO3R1XDtAaLkx9SJ69MxgtcmAOPeQpf+IBlB96n25z2druBoSZVFmUgLFcWh2Jd4lHgsl/tyfEG7ndcrGBd18OTHNBYD3ajXPDDtdDSkjOMdO6cITAyS4JbI8cJVvnuhK/lF+71jaFfAWt/2XnvKoax+JgWlvzpGS513oayAOI3YQ3lkGKKxAbdtkPd6Sl/2IWWUdgqdFd/e1b6pfqxVUqhOD+ywMZoDUtMkmDGs7BdHpXyWWJYuj7vSbCX84E+/+7f4x/aP8OnlET87fnYhGzVsEwfrvMZ1pnPbVsJTnCHZEAjn8yqBxhA0UZy5klQXvbfqXvbCRZBMK39X5nvdV3/vJMoDtxRHpZmr7Vr6fJNOG593nZpmVNv2bilwOIpB9+//zn3h3/ygM2JtZL6eMAKYeuc979n7aWQpdbuhw8/6Xhckw444fQotItVS0wLI2Yzgur7R6s59a/LFSUA2MONPNVa1XAFHawpmXDUs1K/DhcIIDYJeKYWd+fMdq3S0fmCBZ/e6kajao5yUU464GH9psAAn3tFBLhZ1fHh8xIcP9/jw8IC73KLTeeg26IDVqiESYBeff3l5xvPnz5hHRfR3gBSVhjJ2vMlTOa7d4J2ku+seymqhq5soA8/UKG8tF526k+GymtqpX70Uw6RxdMlV/hLzTHrpRvvaA5WdyQEUXVVJc05HB1wxVs6ZAaUh1ztx4pTgW0uD5JyMAV62l6uM6gDMUtpXm6wBGsU14xmJJ38ZzZyeknKTtppuFHqo0uGqV65tm6YJkkFEUGm8qKHZZHzVu1Z3lpIbZkljTioVIPfMjU0ml/kkeyYgvGFLgSblOX8gn4lu2YS4VrsXAs/ofzuynvdYxZMrgyolHig2whlKuk8M3HLONH2+9odussSLokVf1JjXitLL4Xh5fcMYA7e7exgm7u9uGGPg9eXA8fa2TpmM+tZBCoF3AG5jrACKF71mGjlF2H0OkmY0naXvrafFnj0DenNQ9jRLn3tQrlEGVDK1gseVr5lGrQ1btrbq721/CXmhqZawdHPlxKm32LJd9q0SHT15FxCsYi9q4pMGpNveDZYpw9XB1Wwtq5g6RZ6bXdN0Y39kTZ7KGtlVT+ZIpzTnwYhuCiwVENHh1gA3XZyfqX5DzoO0FjrW6307G/SdVy/Gy4wRr7fKLtP3pGJi/Lk2COUEt4s+Tb6Dnm7YeKp0FtXWglKD3W6dNHbRj3fm1VEnUxpcth6HXTsc//d3f47Htw94evsl/Jj4T3/4kxrpdbXRZPHIZrVey+4Eur3gedhVzbVHuibK1+XcpI45t5N86aHHA5nqnjhvZdQRrM9375HlNr5Mm0Fd1woepI2g/PWV55t22rrNLYRJ2nQDqT0X405xXpe6/LQO5Ho4Da29XJ8gpiTg4mhYOlqW5RQsq0mZ1tV8HlurS+naujUghzBHY3rPnVwCjEw5I4CsL9j9VYc1IXOoMCxlmAJiSWXaY8RvoRLadLJYHaRU40l90DD+DLfeXtiArXWolEypTI4nQD0ja72dlr6wqNhoq0/qLqgxH9/NAoBhho9PH/Dpu0+45emEB6bfVAcBWBdJFs31aOpFrx8/f8HnHz8LiTxfb7ozXuiGwU6LUi0VIPAMGuiEcsZXdlbxk7ah9elfZeAWx5bRDylhSa88JU+VUdDYyY/SL10+6Xwr9SuBRDY6COvn1XCJjUT+fSvnaHtKgOVofBXDlF8pgQ0nRAFh7CVjKGFAhlFbONOlmHeQsTkGk/ICYxGFAYurAwAaq1V2tZWrnQAqhVfpy8lTmgTNYm4X/PYrRz0vU/TIlolTCcF9SaF8Uc5BOfKbwabwMJfjNMbAnEfdOxVvc/Ui8Z20dKbqOQZGHoBosfS1VjXbDU3FUoJxw1b/j0Bonw7cumxZzjVKDoFMayWd1t6ySP2L+a8ZWHw+p8NfX5sDHr/gcM8rWcwnIPM7jLLF1aAp9RIbdO0+2SYJP1MLWfG/eroyMdQfdLY4isFDWaT2nBfOWRi5tdrH4Ihj617J2NoUxwmqfggWnNTPhv2LFMXxI8eI6vNWlt8vx72+tqTJ2re820SpW8LA17Lru76TlnTP1XUjrchDDBz0IfbxKa6Vcum2xq7zY66d91FaBDXYCjGuSrTB7srwCi8TV1x04/aC1ZaJG+JS9U1HnNoK4jUHIL9ex6P1TCXVIVsBRwZ7veG7NlS4niuzHq2wrGB7bkuT7mlwThpufeldTMTMOvKuuGQei0Aa8HL/iuf7F7gD/8OH/xk/f/5t/NPPf1j7a12r4h/9ZNbkN/RHHSddBCm7AiU3q6OgLBDHS52oNohaC+o2RxgwFwewegRstOmf/7RnNwlQPbqo9/3nm3PadvyrL8B5x8la2540Mq0b/6Ex3qHzScqivSGflcXk2k7rQ/y+HQyQSv6sLVrdTea9TgEjJK4ozLms1u1kVkfLJPAUAi0v+z9yY/CqZKKiLjyKurdTSjoNsyBMi+6L4ijsotBZApDuwC4qbWBDJWU9f9yz3gvaXMyPeYxJGixl5zkW0luGU/3bhLB4oiswgmeezBmYNm6Gxw+P+O63PuGml2dGhD2LZ/usk9taVyvHnHh5fsXnH790g5sGTE6pt88z5UPmVfWxKvnVKi+ZlsEH3Tx4rXwWl3pCkaaRATFAdW5KfUAUxuLb9d50y/u2+G8aGKkQMiEo37sMtsj8tf0z3vtkOdlSju179USTBNNhjw+YQli2WxjU0JW86GumuCiDlYxZTYwWWw7McchR43SuttX5NBRXtesQCUvjK9YjUECE4iW2awaCaV6Q7KuP9WcFAeac6XDfxq3RPJ3eaIOb81nHanIpXz0cwqMvtRpU3/QUSJVNAzHBNvoFbGamAz/kmZLSavxua39kM/DWCnxOT/L4podc5CuCDXZ3gx0H4I7DJyyOyDdbqdPulYWRqzJWznJ22JEOW1gyy1C0wujFo7V30GAYNwPshjGP5RO77Btyx+02cjy5Mu4eF1Oj5iNBodilzuU8wWbJzPZtzqfZ2jsXRqOlDCqdl9MxxXHTmVJeMHoLVryw6OFFo+0hja4fByJ1S6ZXJbf22KCwl3I0oPNSzKhrRAiqD1m99TnjFEnBb8Em/mZC4+5NrW95STr1sDqlV1stTPTjoqesChEb8h3LdpKZAyAXDUJ2t2hK4xHF2+raxRyQcKbJbjnDnEHSYjZ6LA6tQ88unl1dRf2jfgUnnxra9hSi7OIF/aI/bYx68gnnfXOalxMaunjTcy0AG3IxPQ4um1MObQu5NitdAFTQiz+tpG45+I7X+wO/uPtr/OLjX8En8K+//5fwY2DOiQe/x81vCoGihy7I+S6he2ZBBq/in7ZVQY5PXuP1pDGnelJHGDBi//DIvi1SMxho5NXtIZZX095/ig5K3O81QDnZcxzv8F8835zT9u7TnJX+7AGZBjCK1wIq7wVuKvqDvO8GmyB0njozVxp5LryaRuFpYADIFEY9ktXSSK5l3VVG92lYSPfOWJlmRDGznmZTAFkNcvnZUyj2PvdUjwTmfvFK6PYl/NqrHEeRSPpyFleNTuzRv3Jmgiatt9Yq1AikdtKEGMwdV2Wb8yidaqZF/GI0VuIN03fivbzU1Qy3MfDw4R4fPz6ucdgIw7QDkMHlMkiAeezLiZ6Yx4Hnl1c8P3+JO/jEmJORVVpd5+lyAhSQaxIcRTs6HWsurM2dGt1CXp0CSDNIA0MsHQ0mpBEaBdWQQP/qgkPrt+L92oyddyCSwsID1vhVma/92Hik2tuP9M4qnK4kaUPjjYa5gncZOU2hk5BpXBbPG5BBF16nYfCKbOg+BmknP0tmRtF7hzbJ/cvUTBTOwC0Pz6EBPmzkCZHAwjMT4pUy8xXlBOo4eB3zGk3tWBGGmLmKaGn02Nb3om8hTLXNVTPH9CPS5Gp87dTbVVka3iY80pxv2cOovM/ZSpPDc6ZhAO5uN7y+vS3n8ZiwYesEWcVtK+VOXknHW+XYsYx6GXl1aiOQS73h9A/HWnUDoXxs2JSdwYBh4kBf7Sq6D9hawXRUUMEczahEBZXcAGupiRe6s+F30D/Kj9stjS5dj2vG3nZYXOFVueihEupUQMh8skw6erIygk73XZQ0GJiosEURGNAh/vJ0vXQ6x5A93Nz3K4C56zwvOnY7SZQYsAJkXgE9bNhEnZ++L1CZEoHpiuU7eHLLw6qnLnT/KY/JLx3LNo0rRM/0fHbC6l0Xemv9ah/uuLlpdiGjZ5tjfwedhkny7OYFf9NwgfIky2j9PL31vT2KDXHCMRtA2BzUv6a0AzKYoOPPFoNAGYg0IO5Hwr/57T9dsz4n/uD59/Hx9WM6Up9eP+JpPqKC+udx9zRCkdl3HKe2kkbnbKghX23ME17EZ3E4mfoZ6uxfMeg7vb989/2ndDx58dJNkOfvj9OGhh1NoM6PX3+uDsPFd++IzSUh3ydsGQRpTLU+f31CW7oKFWBDJzLpXi42NwIywFSFSO2zDSIVXbRJJST2Wym9+L6PnQJFp0TKCbCWUkYanK2eAFIeNU5Aa0q20WjXSGynnOPQPaBRVsBXzNMFr9Cp7hKyE5N1xXHFCLLCqzxnADBwdxt4fHzA4+MH3G4K/qNdV2CYOAJUfB4NmI458fb2hucvL3h9fU3DtdOixqj02sEmI5BNty7joFNfeWgBXuofq8Vlnbe9PxesU38KqTPwoc0ZypAz5fXqOFf1TE/VbCqH8un59x7oUa7VNLQ1/tpH1t+saHlVR6PSYMPhmaPfVNIZS5TdDC1FMRNraDzFvDZOtvKv8tNThgGVLpq8d51jqAE58sZCV7p6/uuI1LJomPuGBmqvVu6DvLyLpuRNU2Gyay4pO3y7vUQXSmbM9PMziZfRoQhQfdcUt4jZpqwopif5tnoWKWQFFzTmSDUTkAp+ug2MOdYqypyAG2Y4IeVKlHPgWNjvvhwsOq+Kg4t3vCLOgcN9fzNS+JK+kftCc3IAACAASURBVK3hAG63Wx5CUo/BrPiQEfkk0IY3ievx2qKNrnLFXKUxqNi4Ia2CMDxoUPpuitN9CnTyZ6SAep5K5zGX1mbZOYZdN7MqceIJVBaeboZqAr+KOy3nxeANT4q3NhnR4A1rGguTzKVe1jE9Vli1aIV5KvWOvCL8pYTehMcIMFfYBaz+ZJu7TjK5Q0dwmbgBoB+9L99XJSHynI+9A4LfhZjgQGp0tfqZhnleS9lxijqudYIkIwa1LtBpKLxXjC7HTRArowYiODKSzmfYpiaCV3qKb2Boj6eLrDJoYtrfalftvuRXpe/GM2vOfQWgHfCb4RdPf435+Fe5Ovvdy3f4+Pa4ZPQAfvvtt/Dz198+kc9PE17t7qtRa0SC1Ly+hbqX6bJGvldlGIGvg/ScaBN9paaI5Xb1guh3CbR9zRHjfP6UHVvA3zOnDSi+2j6FSvX1O7+5nivZy2/2pRo1Ji5Aoz7rqyfluOmqhZSMKBWNlr3ubfF863OtFv2mhwGF2jESIBXlGx5lS5ZgqZA7KRAJvAGCvhSiprlx3MMZ6Nw7G4pdgJoAp31yd7lipECvaGkXV3l5DWNVkv2m/DkKXpuiv3o2xZGxquiocGQasHcGPD19wIcPDxjjlip8d+gXTVea3Jwzv59z4u2Y8Am8vb3i9e0tVo4sFXVjLCu6JRg3JCmHlqCc73KFROi4H+oAEGxKAW86XtTlRr441cYB2SofdamicZ0fccqt2iuDqQqWzeBZNvmG80JOXsKAVNHCrxWwK2XflFco1MbK1JZWSoZKZIxO0zKeRA8m7k8RvdnwA9gvvCd/70ZQJ239vua8TtsMpZu8S0e0B4N0NZL7yFZ3R35+FdgpGdUVxPWfJi4Ve9pJLkomV4mDBn4cVV88AkhuqlxCvyGodeVuUIOBBp6BKeAmZT3GUzZED6cVT3Ja9hUInY+a09vdDW9HyAcdrkgvhdVpuDyef5GIl4wnBydOFy0ZFNMJUsncjBVi5BjLYWvvB11Nr2zYg3EVJHNgXUXAbwZXW5D80/Vm0VPN7tyft9MRWCtPOeYdt89YyMNrkt+D93Vv9eJq6sbrmHvumUueKzxPfA8D+Wp/HZ3EwjEkFgfZOqalvAlIWqFSwyVHo0hDb52nvFAbgFwEnDqVuiTockrf3pz56u0OakAdAnNBTJCMVNLIskWGDQ9k3PyeWRyZMm+2TijV1d3UFZ4nFU4r7G+pjcRzkpWwcDL+gmeJw5xj/h0DVAotmqiSVctIZNOkjMISRx7tZaA4bbGiK/WUbzTE1j9gscFe9mK6Wi9dPiBPDyBXYn94/BHfz+/Xuw78zduv8OfHX4bumfj56+/gj778gczqYjpxq6W9okmlOM/gz/VpZRY5ui0n/DhGXqStdmEF3H7zk/yw02VzMH/TI7cQvfv8vXPa9kc3l189zWlW4PvpLSxjzmoCz3b8iWW3v62YQD5VB0P7eLlK0WRMUt+IicmoNEBEGW39TjvcCzstQEpTQNoIpU9lHK0/aDjW6Wj1os+61Lrd+xINN+VmNV80FmXIzbxQPHcrJ1IN+UY/VfQOMeLW33q8cu3Vw+Wzq8YagcuYYvxiON8/3OG7pw+4u3uIQ0fQjJwelfGF3bbSo+aceH09cBwTb28HXl5ewgirMqShqjr203SuzTZ83tIRosIcXxAq9VZe/uXlbOX87GqVE42aoDRWNpqmvdII0anMgwoyiiX1JECrjq1WWpppdjo0335oFOm59aeidXQMyiiiEk3l6uSKkMlMHURnkobrIoANLDg+X8ZuGNNpxpAW7hixZ0y6tQyJpB21PT+jAUMHRCk0+kyZ1WZvbO/ycBJ1YNu532WI0UFMugLISbC1t+QmONUGhKWcuaHfYrXBU0l7GBgOOA8nWWVWW1yNqjlKwyqpJf1DM3WVFDWWLMV0Sgsfytq+sH3tjiDKFRczpsENHPMNgOF4O3C7M3hudQ3ngqjjAGzkPjfPtthPy5+UjxJhMknNzZzr8JEZPHa7u2XgLfnZHe6HnKCrSKLKBwocJ/rlGFBG1RjMONiRDKV3hN7J3zn2Pu72YZTg0S46x7ux4LkKIhiColOtdG+rgrHq13WmZZnkOQN4cFO2mQ4sy9VYZg6+aClw2gsA2I/0V1zPFfM0xIspOj5KnS0gUN9lECGVZuFK4nE7BCPoajEPDnArhX7fHwlBXAXIrp6GY/GR8QRthmNKTjI4bDVXbE7BmDCRMjhiZVBUncPzfnH2xaMyHstwRpWYk5r185CSuautkq+xldgUkgp/O3hFRueozI6hewMhdHb50ZRXYkztZ0akaHP1HLDbbbGeT8yHN/zob6vwdPzZw1/gz57+Eu6Oe7/Dv/71vyobN5q687vkhTUkz74seejZDYC1ftrN4Ae5fo3VbmO71T5mMWHhzL+N0pdOSKfN/l1l1b3zyjvPt+W0iYF7xbDbywVWXxl1Eb3ppZ/0pAOgm0HRYW0xvL8zNaHCwtCZ6WBWPd6Yob4DfNMhnOAu0DTwy2HT6tTI2cbUmwLTONSAUYUBK1Dr6i8EXMBO4l0JAKQDmy2DIj7ZQbgsGijFVUH3sVKB1u/6jmDqSVhanrN8kadnFqpnikuOP+2CHofNcYVj8/Bwj49Pj7i/v4tI46INL/7WhweWmB/Cs47bDbHC9rZOktR+x/Az0sReedFcI4+doBKdk+EpkOuAT86K0ogA7RTNTTZE8ffVWfRyjcq9M3U4hUhiZ6jTnTvF//W35srbCSToVKMuyN70Hx0PM2t3ua0Ajdx5piCkYwllmzzNSClZ2evd2gdU9TUR4Riznaq3pEGUUABAyrQB8ANqXLKrxRNeByrsQCrYWv2umbT+qhjEHdNIzxFjW2lBqEuRk8wDPGyp+KEkv9IvK/UN1eLaZ3cymha/ZqqxAFU/kKHwTkI/UV7nhILSwLfRmMaF3nZmxn1sa1+bu+M43gC7w20dDQm7VT25kptMifr8QuG14E4IHPGBexXd5zrR8jZqNZc6QEAiD22RVYiOu8Sy/mWTW0PKTOJHN8uCZwA6NukoBY/xNEnj3O6GffSF8QrWaaNWfRKZPDQh8aYTL2nLlbKWpaD0tvNgV/+WVI6oJ/nWkP3mKlrhr+ecGdvRIIjQ82tGYNs60A5L884qCvw8HTruyuSWiiorcuBZW9J8n+z81yCyH/pTgnINbHsV748PEgBwxEXzyN8NVnd+HhOzNbH4Y23NWvMyT10gCAk+uo5dDiZRS4W6V7DO8txZ8hrR9iyzZ2VcaMd2DHHqt7QOWPnu5Bd219l/FHCFjHOIDuqasuXO87BPEMC149VlSnT0avYxpLN/A3CL7CI3TLzhv/vwbzCnp030eDzgP/n8Jyv1N2q59zt8mk9gACtX41uPiteWw+baBfgR5UwXVwoY6HAikEn35NVqGlegsbUsn3j/bpfVn5Ii+W05bXzeEUwFFdKsGRAZUbzUVfJKKV4p9vUyIjDttXeZt75OcLftnYxK7OXLuHLvxNDVOjUKu6iXoFVTEZ1N3CjhWoLaYOmEl1k2CdIJtADDO+0LryKyIqAlEuXaF++wlZCUZOhtJxDw/bR4z/CWAwHh8ZzKZzI8RtKaiygGs9efaGtVaYSsn3f3d3h6ekiHbdAsidWBK77LSJWv1bS3SIP88vyC4ziSFBntAy9j7Wtd1is9M7sQoCl+LawOHfq7BOVFbzFeCHZqPEn7pbqQ+50AKsyYm6hX+VgjeFrP1PYA8NhnHSB/M/7TlKA8NIJDkZ6iaEL8kqVK9VL5W/2d3anju4xsuwO+p85Zu4g1ma2Nm0rRypYgU8T3Vl/keN1F7uUEMWidUoTBizz9NN5iPWkL+ESuzMlF34ssVFKS+GKl8EiDtaFeRhm4s06U9BxfrUjwX9axaN/S9XK8G3YIneoz4RORJa5Ou/d7L9F6gToYAoy0u6SwFia3wEMY8QHqKSbjdlt1HXH40LHoy8AJ5wCG5K+R1wt41xHRyXIK6sMxALOxZGgiU4XG3Yj0VzQQZb0Guc+PxNvmelfmysYphylPnO+ewpmBEYRBTpFIGkqFXod35SqOmcwU6VXOQz/hz0RhIfvDPnJvzgosjOS5SZqELs1h7fBixTUbPMk75JPtkl+vV9ku7+/an3Iq92dNvtZMXi96kwyFJao/idkoqIuxilykUbv+LiwVFaSp/KmENFy09TsnxKQImTkT5GRQu321nhnXcJSO9JQr1rfmuKfmZurr1kPqmT4NHSuBwr4K2gRNsr3zPJ4fBXMRSh1fXt6MnKMRacxTHMyKs3j+3ELdqxX3tjDX9SN1ONsSW0z+qTo2vdBGFf/ayD3ZaxodccAj3u7e8L/c/6+xCLJ6+HR8wO+//ENQlz74Pf7R6z+IPl7QVPR3tdFxOWADdeCa9lTQ04Lzkqlt2doo/f+1ufq7PN+M00YAf89xOr+fyL0+SPD7TcR5XzCKmUp4W5ELgL0WtI0VY/L373MVRICepZi+U5vFu/JNBXoi2AaC0d5uwMo3J3Jpyp4Oh+S9GnIz/E7GkQhlUxhqIFqNSdrs/VJFXSmN7Q0F8uiwF7GiewJoe0PRDQLp/p2dnNs0JaruqHYMx+PjIx6fHnF/d5dGqnntpYAfsHGDzyPvxmPXaCS/HhOvL294fV3/1arJGmTOuPK/Tod8zHcnIPx2kate+jrRnU7olXSxF3VRa4lncV0zVzrv0lDIP72mJ42nzsFu3qbQBA860DI1g8C8A68aKy5gbrDBRi2IRqOh5lssmhZISeOaTpWmK1HTZZ8d69hwSdsjAMTfpVrXM6xfDZDpx94NlbJFii9o0Krc7qtLq5smdUiqI6wipEsYu4EDF3hWAwZprC3arMM2KrBlqHvdipfYF+cHTIfU1nQ/ygVOr3TiKWmEceJa8pe0Z5DxhGPiG96nY7h6tyLE5eC1Ex2VI73wIk8b3XCVmHl3GziCZsQEM9TVN5wjQ+5xwyJP4gFb1/2P8zhwu7vD/Yd74Jg4psOPA0cUHKMfOkL+G4hVTK6U8kRJrpJJUIXtamisnHtreqaMVq6kDaWYCD0x35Nga2VNU8PEOE5x9PqsRiUYdw7gpbgY5331rwdDUcGy6IdGyznfdMSu0TMCgyErpVes6jCTK03KaV+8VKi5BjS6LJvJG6ILdyXPdxtwW/6uq83VPtvgu0IYdn6rc3LV3GrM9ZQcZ31XfdX3Q7F1nc35LEwqOF1XkNBnFCrncEmiDP7t/TR20QpzNmskNIj0uvgEQKV378X2cdL5zH8uCmUfgiSiOH0Cc0jgcNOOLKLonf3fdHLqcSvu7CYoHeXCtJQdcdxYF/leNYSf5sVyTMu5BtwmuFXg9faKf//hLyIACdzmDf/x9W+qxsDSf/j6c/z85XeQeyrNcl+rBjoXlkd7eh1GC0Sg1U/8qswykcmL5yf55+8834zT9p6zpkJ0+bl4Omq0XdVtZGZhErWx2jvaUIBCKsl2eeMJ6tvfuhGRvxUGKYPo+9HNSPMwItI2nlyKVTrIS2UA1pi6Y7o+91Zsi/h43zfFz/qI8uXmfF6BXPv8nTnnl7rKsI9jL6p4lODjivt1tPpl/+TRGTupCvlAo5l6ciawAPnp6QM+Pj3hdrvD3Vjfr+jQAORSWp/lgNGITgfJJ/yYeH058Pp2xFxHukAC53lMPBym2LbzkLXRhTGhCkuKJV1TfjqveXxOY6KAfX3fs4tLXnKO0Nn3fC89Vw2kCijOuuwXq1TckqumecQoiG/FvoA7DtmbaRpYQSmAxBsZkTq0y7cTmfMwLvPiQ6i9AT0NRKVK9+wueBOedGCMdX9XGllgJLn6XZVtFE3aM//Tsn19M42s3eCN/qm5rGj4XqBfA27B9YLzSzHup8hqxsEqb2mIqbFRcs/1Wt5FtjDAPY6xN71frnCGF+/SCNohzrHzFso8tD43mvo11eEVZVNGcPCvhK91j5ePShFiFY6Jh/t73N0G3g45AREGu0V/jM4kgEh1fLy/xzEnHu7vYGPg8+dnvL2+4nhbK/jrpMr9WZ8oPi1Zm53vaWDG7FRKvCUEeaxQaYDL4BLw0XfzF8C8pTc2Y174o1Yay4BMY1GK5Gw1u0AMtfh9TwH1AALlA49LyKfVHXrNQnCuENLhwXZCIhiLwAommGQgeONN48uIPWEyRySDBjetvSHXXCbp6ChDcF7S3FXvRjnFYWh9kkOe+lGVyeC4dw7TDslHX7MViulkfGfO5bgdHumDEpQTeyLT04X3agYDi6W9fqCVjkFWeHgWQsx9wzEdAsuHLHhgXDrM+6DzHh4TpaS04Zyu97iHCwBuY+D8BIYlkrI/FcxQHa08uCjr7SWjsow5ZHqkXsXiWllOMzExZNi9vbCCVwsrEipvA7cx4MNww4Bj4m8fvs8sJZ4w9uv7X+PfPf37iC+V/gIMD/MB/+UP/6KEMBVSI/7at633xIrBtDBtoILCgSXmeem4KQH+js8347S997znsP3Ud/8/Pck8YriVvo1G45/mDGifurhdpyzwXf2+M8UZnzbArxLSVhkO+164rENAukFDOn3BaAQ5w9pPFeX3dnfHOJNQvJhYacjtylzqXp8PwSFdbmbV0laXqQUfE+3oW6tBdtJdRATsVN9GLkddIE26Ci844tLsxw/4+PSI2+1urZ5ZAXk16UgKGC8cpjU/4/CRN3yJY/2pNGYrf1WnGA4yt6l8A2s9SSCGbdCrotRWZban3mVTBP4qtveBn9kAeIg5FTsvX+Z4fKszVWxd1kUmbw3uhyO0h2VFgHMlLOTvJkqW1eQ+muhc0rJptFKgboAfsq9N69l7poEaROoVjXhd3OI7ul9uM8kmmPpTT05DHHG+HMchSlXqRsm5GnOcgaBYnMRWRk+mA0ubloYKpB55yajENcWuRrWMRpMYQUV6294f0h1ldpB3pnulAflabWqrLnGIAPex3VB9TQMk5kij+GnsybiU5Sfq0mnyLg/XYB/yW5NVHit6WHwXpsy6NsLLoR23G7gCeP/hHr/16Qkf7u/xesy4JmQ5YLdheDkOPH14wMP9PQ53vLy84PXzD/jh8zO+fP6SuoKGpR40UysqXEWs1GUHYM4V0o6lmYolzNX0UYDpjPThNBnF8dMagJCLgUwZpZOaczEnfFiTgdV/zo4VjyndUb8kBtsAV+hrHts/BY824OaFu1f0cuQpkslT3nFZg08gC1JvzAMz5qj2Fyl1IPeuGCooUnRobSX/hWS5r8BGnsQasidKsa2jkqSha3u6I7KfM9Jta2/VSF26KYkOIO0RIz23vS154r11lHmPl2gvNBVWrAz4ke+uvcWla5bjVsH5TFUP2iY+sc4khzTIMY6OSyRdDVeQI05VXUMmETZiKNBQ9trHQYmTrlkdOuIgqeLDXrlJHRxRsU3wSY6h963ru8JoTcXs8947MOSzmRRefRlj4HaLDIa5sgMGEAFPjxR6Q6D4qs8d7mvV3odj2hF7SpdupY57wSv+64f/FtyusuTO8bvP/wB/9PKPAV9p+9OBe7vDnV+7Tn1PW/wdx9G+n7L8/+755p22/dl5Yvu2GPXEja6vYS+qTpjgZH74LsFbOyKsW93qkGUky6/yoE+DijKimKrhHFfl3WvXvDFgT3skIAnIyBicyCY6IDfw4mjjX9UzWpxoDNbO3080F1DIT1LBeRjfAaRF2k6jANc26uZUAXCDZI7lz6u7onaY5IjzzaYTvYApgOzudoePHz/EHWx3+e5k1CeMNU1p2fXUOubf8fZ24Pn5Fa+vb1lPdoNkltMq0rA2ncOaheKuriBbfK05Qaxa53H1P43mYJGUt+yjQTZybUT0/llTeBcSEMaJSxQXVKIif8lhrnVF39PA2akf9MkVtQ0IzJJPutnOmev0MlhGA3UsXU+JceNah8yhGHNZNh1xzjMAnyVucNgGipVWGb2z6nmNqHDJqWTDsKp5FbnOOlMTnwI/6bDVCJB2JudTDQ6LVWVXrDvXq0mYJatzYyc1OyxOtfTEkLbCXCAhJxb2VbMdcRtmbWVZ6lYWKhArica+cYw5gDo1s1YXNYWITbFfHne4xUqQO2w6zG6wuwd8uF/pcfd3dxh3y7F7e33B8faGt2Piy+fP+OHHz/jy+RnH8ZZ0zkDJJoBq6HsSQvA+R1n6ROfAZVbanlTyInVjykSPgie3eewPnHZ6N+dqjNJTTr4budKZuB3jOmVIEDMH4pJ1F9pom4X9HCv3E5LHHY6BSjMlXOeqhLBQpt8KI+e9es7sgVF6nhPBg4w2VaZ8UwEnk7kQRM9VgI0QnGeWG30fX7xYMpQdIZ2WAw2ruTTt2NbjZdwLH/SZQc7pRF4aT3kinyUGNFurdJ/e0BXXeuf+qfQ596GU6mjzlZ8J4crZtqzH0AfNzyrXhpVi012dPqcn4VfTtKUpu6iPDu5xrPvUhrXgkryYdfXes9Eul6vq4pXi+U7EFQRZvL5OqV0TcAvC6xxeXxYegZvbwLh1RhKYWm1mNlPInS3cuMU2Xb9ZrsYljQiCAHxO/PXH/4i/fvollOV//+3n+J2X314jiusCyj9YPz8dH/FxPrXe/f/grwH4e+i0qYIBzgpmexs7y52f7fuTcxYmwlcpzsnirWe74XTV172+pnrydzWmF89ZKY2r/hfLZl3Zfg0RZC7XDopAiU6MMmGcTO2PGD8nzWFnWmyTpcfsVxsCYpegI1TyRqH2fQpp0CDvWhWjVQ2HudNIxpInK5pBtY4aIQBwN274+PSQd7Ctdyamc+WQ+48cuc4k5T0UtXs4bC8veH17LSAzOx1jjzD2+JFFGiZ0hUbG1u6uE9oyeniahzAM1InoStWLmqkoLce1Xg0gFNq1Db+Jk6SrZfcdtB9SRbeh5+EF2S+PLspcbYbdMojmMu6SBpUWtd4xLVF6bOM5wFYKZe1rzysoijrNGorx978lwUzoqPJDGjb7Ie/oi6NYcgycg2IDk/r5Q8HUggd0fmaq0Lqs3JNXMnVLGIu9UZdnKeAaMzFnep2gl/MmlLIwiHQWyE/kxdXjMgoQ8rOmX64riD5W+qFl+R6UCJmedaWArjaaWUZqOQ/liNaHNN7VSF1/U1esetVgSh7VLrusCiptYiXsOCo98Vd/+z1uP/yI2+0ODx/ucXd3DwPw/OULjuPA29uBY64rQ9aplDywQPBV5q5rFktILszqs5wU3VVqCHnKssimGsb7ninSzB0R2Y8V0ZgHmGYdKP2IJn1c5P0KDKTk579kQg/DNrEEWI5y432pW+2GlN81RzwYQueRvMFTYT343wMMBw9jAHJ+N9O6Br2Nn/Klw8ZVWX6duegDLTBluu7BKhyIO93q6woQloL2dQfsZGlPx3TdO24lk3AMq0ASgH7wRfZnES1xY2j/LNvvoaIuOTzuH+5bNo4leSz6nrg0WL9nUKtdrwHRmdRls/SfC/1FAwq1fdEzgQKls4z/yPxtdKHsLAiXIKXYUAL7VCxrHudIxxraPt9rNodyh2TYWFH5FNbc7WnKN5jaH6f4EtcjPTh5WfKhDQzcBhanTO3c7akH8k/qzZinYUWzm4UOCV2oh6aIuQuba+3vl3d/i18+/q1Mgzhkc/3+s+M7fDw+Nlr83vM/wKfjkxL4YjJ/8/PNOm20JdRBu3paYIZiKmWY2of2Wbay/Yw69F1oA70jvX8EirZukUqoT5T2Idlb2jiLwD7Wtkn83LXW217/RbtplOTwy3CIr5lu0zbk6xhinB4Sot3JSKVE51QxZ5vJ/JUitv6Miz8TVEvRVhtsBAlQrI9GlU57CXk4oo5yeIALarFh1hwgEG3fbgOPjw94+PCA2xBTzCIlLa0Qmbeo6xDLw90xjwPPz894eVmHkzSyYavGamzOqdydlHivUcx9myPSblv/POEtDRhv1x9kvj+Vlnul+mx8m/scqrpoqlZEqSC3oDmyydZ5po16vZN81GlA68I4hniVF+i2d3dt0IRR3jGOW82EboTo3xmJbA57qqlTN7K0oe8HqckEYH0vTZs3K/nOg1RIjnJy0gez7U4omRMWJI8wGroONvH8MkXReJx9RyMP+abBupR4pRDCKgJcGQqRanUKFi36sL02SRHBJd9w9SKxwQCfR9Qf8xMOJQNlpGHtwyoGbH0LGlUqVBHVIAe39MlDrQbXihtpPaUPKtW20WYeE1+OF4yXdUz/8/MdPjw+wN3xw69/SLlWh/MCJRI3LTC/8KD3upzmjik1x/JbU3Yu/FMCRqONe47rsJpydYqugTcKUWkwoJw8J9UWTfV6iKI8264LdtdQZq1A5RnqhRertJiMc8dTahehVRPszgdkjZwbBf0NitdQuz4jfwKU6aXP1NZRrLFAvazg1BfRU3HwTOL2dplr2T8yCCDm2gJCiuMmfDuxk9BhqR/OqX2im1skBNmGx1sNAdJ56u31/d6JEKywvps1JwHAYFBxSDmlAcuqbNDFYImFFbEtwYC+10l4B6j046CgSm1zSRt/CzP1V4qGoj9O9QQtYSYHoHgr0wPy0RjxT5wrnSsPbEk514M+QGworKqAMfFgv4tOZSz6RZ3Gz23pltS57piSLObmdfDSJoi3Iix8lCZjH6b2ZjowlmP3w92P+MF+LPsTwK8evs+0yp+9fod/9vyHRUMZxNf8HeBbctq693XZ8ZNCfuddFSDfAGZ7E7vSun7jXPjUPxre46qpq3ZE8SP2IFHhNIN6S1uIopVuQNQp46HtRWEEKPu9L9N2gdKepXnQ2tcoKEFIIqZRgWbGZcld7mkIYX9HU2nEiAnHragm7XSVmQ25fnQeMsAl+o1OyOjm+w+PWx5j4MOHB3z4sFIiWyqrY0F8pI/WHtVDORjDJw4MHMeBz5+f8fL6Fndi6byWWpDD40TxrLpcZnLfo5dgKAokZ33tHq52LPUW2qSm9lelJPIbvMdfV50VzKATnVG8xsLrj2Frf1b2p9k3/wAAIABJREFU2mQunJ9Wus+u5Bm5prlHMOejqVwyDfUJDYGglQZVmgMJpNOTxpZZwypvZDv311GHr6iRUqch6rilXvYzi5RSytP9GuFEqXtSRWws9jBGG6dTVuy6y8N1dDWpFPy/Povz0kAjuRw2oZF1I0Tna73e78DRudUnZYV8KEbHCgQx3cySV82rmkqZu8J9UkH4KRzQGxD7MDwNj5IygAe+uLTDlbuiRRkcFegRbA78U9dLcXQCcRrkKw7ccDcGjjljvwd51ZIpLVYUAZlfh5zM6ul452m9xhWLkgsexFH6QdDIkXRX0CL/yczFvAXiuLSVzqbFcfPRehJEJNSQNac5mphWMlKBYeuyzzm9Wd6vyqKxYbr0qq2PSJsRF8z71FwBIPdxRWfMsS4uv411RUGkxB+8gqMgNOaBq1vVrtERTemkKuspauC8x/is8XfpPeepfpvSW3EPKl7KVCriqIl7d9hu8W6JaEpezEzOer67cUP9qzzLf5se2mW1+KL3tztrZxmXDKQ+AamDHJ7OHJkrV5iziCWeT/msp7vKPBRURje08T4htv/B/sGhu8LOTxFYr4ooe9lqrimtYtgVuSW4zr6GY6/ZDa1rrQsUNuGRNvQKKUz3sK0leMMoCvWFA4cf5aCz7VRLVsE2GqFjMp4W73vwCOXLUfYt1r45sXf53JxUcPhtldf5mRF1NwDPtxc8+wvMHF8+fMZ/+PRL/Msf/wTfHZ/iZcPNxxZYOj/fkNOGnTfzacLwm9xQPgyaWeL015vfDIRzH8b2TogbP9puxevyR2G9MkSiu2WRt3JsI3O98/4pMrzWx9SokKHoCSNzuYdri/KJphJBk+V5qSPLSVULD+UdFvQu3DQgebqOGrPaJcXabpPtyObtT62nFSMotnbOMF90LLL25f1e6zDDw4cHPD5+wP3thnG7xWoHTWHeyLYosObxwKwzwAB3jHBPeOjI2+tr0q3m8bKnOVcUIHXWczYJTjmHolTB9ICmA5NQPU0lakxP8ErFcrW1i7TF3JF11QnNdwRTEf0nH+RF58pLMiM0LDmr/QTKbaZDnmhbZLpVOi2ippocePYTIcvFo7GZPb03dtpzDpqe8kp5XWlyiLZiXOmVi3zLAEqXCh00rLfPVRrNUn7oSsPeSqdZOmHWKZ8KGMSr1TEa6ZSdEXOyVrbq3p0YtijEy+ZBDJqxAjK4Kk5MNcAQTmZGTAOXZGO/OpgJqVDarIeXNScvZx+VillTOd2L6CfaBZdFAY++eqTcbeRPDKRzYck4PZxXmO9AHcATvHy8/T/tvWvMbtt3F/Qbcz3vu885raEUsMEWBWOjISYIaQpGYhAMAhLrB4IYjRUxfMGIRqPVL0QTEkyMiNEQCReLUS6pII0xaIMY/QLhlihCCU3l0qZQoKU2Qs9+nzWHH8btN+Zaz7vPof+evf1njWTv93nWM9ecY4457vP2gu0meHq6pV4a7nzs846pAxjmWLj2oPHwNoLvfbkexLYB8BxbOjyS7k/SpNCJMQpZ2LFqtginlQSlbJjPgGK5Gy6KOm+JkdfsjIgfJhEzpFG+L1W0iurqjCgDBWQTDF4JwYZqau6TyYSHwg8JIW6mMUWMK2ABsyoEe94tJ268Vz9BZMuxV7XgcNtGBoimSykg57+FMbKC6KsQHfw3Gyu/rJx4D8nbbC1CDzitg9d971RXLn4dQuiRsK2rEYdLSwSzoa+zyKIr0ibYm+oCa34Xb3BfCcHABaJO6c4Av+u+WJLCDxrLJAxsSwbrcVWx/U+8LNP1z6Q+tX3VCdIeGXvq0pfFU2jmI14seteNMzTn3QIptn1VJ+dug2qZ+ImES9Cu8UrBel3TSHtv5XNe0pMmeTDM3DGHBYdht+2g4A0TO3YP8ti3BNRXBg2K3Uf1izuYrF66TNu4kKLxd0XQgvhgcfWDUmJFUuoFr2aOie/8yu9O1fkT3v54fM2nP+n0rAWGDydok/PHPdh6vTPlECE9trMA7NgGOTty9t6yLheNI87xSB3gg0+OjUi/qPZQb7iM4ZmlgdLijIZdf1ZZfHu3LqC37wI3LIlXn30LtNuCrjwB5zhTtwZsVuXRtSG3oP22ZnwyU+fjUq5BzTylYQjcW9BbucdV/XUKRz31m9Dv0vpRn8MpfH7zjE8+sTvYaulTuANk6Il/1mWdCmDqwP3up0Te7410lWEuvJrjwIalOezWDgd9yYP53XEKnidnh6Gx8/KLRG8lFHW1ULOBNaf1ujhWkBa1Gz8cS5qd7E54vBMu5autyfqhc4izYnP2yiEo2nF/Ezd2mvTIQuc6qQycyKAES3eqKsvZeaJXI9kHrWr8e9BT2iEL3I8MtMxSATCHbGwjf1eADgpiR6P6n6qKdF8NMIcfnuJwHuL9jqqasW+bbdKavRHGPdsvfptxdUrY3EIpJTbwqyVmvldsdh5TJeOd/QVEfA9PHshExG8OTPU59R/KD4ggWqvi5HVmnKgtZusUasuy811LGO27DW4cgjRnzPB74kgsiTzzBFltbbROBm1LMtOZMceP36isfV5I7e21WXGpumfof29P6N65IFCMaWKh1kaflbbldxLTp07+5C2SEStttfVDSTT/yKjDN3jsp/NxKVkaHx+I1CNrvVLPVBX3fU+K5ux+ONMKYGzI5IK3VSuFYzRwqDvtp/LIooKqwogNfykF4XeCNyX391kFnjATRRyWN9Cd8m72aoawDQXLS9oVsRMAk7qFc9Cq61Oag9Yq760eTMK5f6n5W/Bw1tuqCNlzy9AMdydfynXzdVbwmpKXcw4nyVLeRSTuumXuiZeiZw5tyFjKh8H0YLwCzaqRaZWcJro2nTY38aVOss0qHyiIRP6By5R4QkRF7YRfZFHkVhkF+NorGcMCmqGYc/pVSkh/rfz8ZLjEKDTSOv+/au14LxJLJXOllbh/lRR0fzVWwAjAa4kA4G88/yD++tMPLrHGET6goE3eXebV11lhlmE4BCP9rVfaD+Ei47oo5kdQ9pWySYTnnEe3oavdYqHXhw8piMHsHByWkHL54HxixqbNu8IzZ6kE/LS+dyEYeNIrddn4YmzJLPdwxSrpsxtMx74chFoGL13I0iJUzxFrumYFa7ExBB+9ecbHn3yEp20DxoY4qUhSpZa6ZiOc9YejMhX3/Y63P/IW95e73bEV9OIgsahlBljEFRs7UQu50mh1Gha9ACS+vYTy6+g/ikZmkJdLnfCBrK2T6WX2h+DwtlKAfvAfSrGaIemzRV1Mw4kmPjva7gwK2MhClO5oqhkmdvKbwPC0ZBqHkOXCqRzzUOxC9dm7GXjSlGHhRn3jelNWi2zctqEZGWFvfXJdgWuNU7yTDnJyOVoj3VGyJ7lsOlqgKtL5JJKZ0yzZJtCXM3JFEgZbkNn0OAgqjpoXRigcPzoeHNG38hYIyjBj+jUKYYBTLol28Vue5qcuKyDeWR3ncj7GYiegmg6JOUmCQYJQNRb99kkuwCK3h6CadGwOg8t2zVZrrlgRVBDFdlCo/kVLFY6CDGKCVsFF7JAaDYquIYM9GVQyw11kBz2d2RPdwLTJ/Y1lNDvnR4KSfo/6k28I4QxetXi96fyg1ah9OZl0SDbtmvgYrpRMAoq2Yhh+Ih/6ReoNgVNazECsa6xEstOHacGZENvbDShG+mCxxL/4r5InKYc8Btm0tPsmi1rcDZePCRo7TbxbYo3H0dvkfWJBi5ADOA9ViFRjIPmtZvWCxzMpkBhnZdF70gJNQxsZmW+pRM1gshUg/Rr6JvZuzYmZsguiW0/LSLyb1cQy3IFarWMY0FlbjgvRN2tj+xA6hsq47ibNhvD0Mih0ZEUU27YhPAHJdwonaNzZZjwWKwokrgEIusgwfGO1D/d5n0XfLQ6IA8GDVBaNV/CLPa8TnTMhnnqIjXMltvKZKFY/doUPJ2h7F6gT50wZWQGAB/MMyieyr4dZo26QUn2lQNqzysCQ+7JksgKdNWrmIJDbOMW4yXv1+2xMD/3w/6uPpCBcyWQD0mrPNfyHznDtCw5LkuwEwcJhNWO1rMO/Le2zgQNiEy87cifWKIwaPINaXW0qk7+vNioe1oEophSfP3qDjz/+CNu2paCmUo+ssu8H6ih1B92yQROfvtzx8rKbox6K35ELh6pTjKgRfBY90eJrcSfsQKP00KyzWml+cKKAFXx3Pr14KPWux9pn0XC8gFzio7qwCb0VdwNpBe1lAHr5vEKhvDxTE3E5dmTgpZuT01lz+ihu/ACBaNtqjNLQhJLWbHM47wAvO1tpq/X66ij6byOGU4KL7ffVMUhe9vvXRKXxXTmEVlk60hl4xBlmORfSaE2suFKrOzhRp5TRzedRPj90nWlLhracaQmIQ07CkMfR7XFoTM7spzE2ZEYmpmpA295ZIVzAeqB4KV4dAqifBMvOScxudWoQt0aw2ZQ1a1miNwuV2omQOnfnw410wMC2SdI47b3a1lwT/3XGq/fy4DDGGDS6e2k3cjOW383pOg+pS1d6hv1MWWu9ji+h65f+x/sS+J31pWabcqWXxnBL0YTkI3CbofKor8m+0ab6HXtu7zmoH24bmzz7bzXuVk8cINXsC9mRlBPmvhJmHxrXQWPVWfxefA159tcX2WN5yARvViPtjswwPE0WBDkz31BAdNSJ7vYn97ctWAePBo8ALIulZSJREWPD+53F9X4eTCn8ZvzeaR9uY9yLbDPXmqd3pq4lEsDbSfshCvFAaHJwxjqWia5dXwJaK+vCRgfOXI8nc2QJk0oeFt1iyjHpn5ZOXDeSHY1/0xgdt82WPU8RT/pYHbr76bljIFIMScv8zEJWcsWycJBghV8zoMWP/CMEiLt8aV92dbXzlabs8d5r08+y9eQe2/c628EHYdrhMlsUyPFffLhmwVGnjE8qodMPKKlEWyzvJCcBmCVjNb7vhg8iaEtEl4xWQRwP/XqXyimWHJhs4+TV84DN2lufHZXmUqGID0q9Tjn5Vufp+8tvpWNLOXMfKlu64lz9t6dr22HWSVSSl0LpumJoGZjKyBZW0po9BIcLaPtEOMRYLTqPDXo58F1oMjhbBjgc2N7uY8h+UXbOHPwqMIbgK77yY3z85g22sdW+Gi8QAZt9nvR8IqbHY9nVPif2XfEjf/st3r68bf2v+LXwZ31eSr6slea4UWdQCi7/z2xDBcfN3siylZmIJzzcUjwW2UOlcuv437YNYxvYd8W+73m6VLRRh2KXUfaRzQ3dglj6WD0Sv2tGdVaAOmo52OYWXd3op9JVoqG3Y8kMGydo0SeWR0UWO5Y52CQYG55aHnQ2S4pqiQazxqCcOq0tuS2zWv2oyAjJJ4FzmelyEPiQACVvItpYEsRe3WKg/P/maDRd03VAOBbS+lozYFmeTwTjQAtAuf1BzzCDpeO5zVyulHRb3SbvwepJZA8Dx3r/MNNNfB+4Rn94uNcT8gDa5phyRlZCBfd9x9x3jG1gu2217NqFL+QjKeLLMe3i7QlMYNdZS1spqTGGYGJg7nu3jfDMeshUnJLmjDRE8PJyt8viAWy3W15wnHRcyB3BpPCPwZCBk6B4d4HV2Ut7J+mWkQMcdOAaQkdoNpGkDLvlNGpOqPQuxfN24IfA7isLPDSsKpxvdWmvxnBAXZf03lYiRlDE/eyggJ/yaFX0U1ZJHnSpWVjGoibQdyBO8DSyWUJSdNapgiL1hlAwtsoZG5C0lIl94csDtmRQYyYt01gsb/4uJ2iE+5zBV+h7lPMDXu7nWNWa8pL7Yop853SkijHzUQzxhKaNjeAkVFjjeeajNkbn0JZGJm1qPIbzoEDt+mkV3PdpS99dDiZfXTPV9pCBZm6F7GmyTM348kE5SgqxlvszwkI0R+Mb8YFKmWN3wevlhYixVSbGOHjRCG42Y9BewhnJT0+4js30cZwiGXuNdcbqj45AjYk/EkvSlj/g84Ma1zhZ0mjIsDsgY+Yv6Mx24B3j/EEEbasSAWjQ/eHpdP9ZXYfgCosyP6qnszJc8rgp+HGbJPOkE45OwYrfCdoLtvV+zcSQE44urOtSSzaffBQ7KxaeCao9d6vTQ+UXDLkfLehUHIMqyZ/QNl41jJBKtbIojItjtB4DG4YZfVx4tq21577AYc1zjqPi+XbDJ598hOfnZ1cQE5Hd7wF0b5c0oBk0Vez7Hft9x4+8fcHLy26Kw5mFOeSkFsf3yDDS/0u8+xAbr8SwnBmBtd2oc00YcDDRVU3Huk6pUuz7zKXB3TgVlJivSQMgZuyyNdHSy/578IpA8+ALztKqqmeMJfshUd8mGZyJ85D4O+3gA7Y/ZJhAz1tShPuAKK8LHR3c+MWhD8cRIlmJfonf+RNJA0X2K3sRW1gi+TJqFutk1Bvt42Rb7nsEuNVjNmqOVmRBhVBNZyta7sTk7GwdNc3lo8nqZ9HU69Coy3VjOmaE6yIT0fYxiKgEGq8GaOMmRSfWjOsMcKBpTzlksyf3l90PlVCMbcM2xqKnKuBO1Sqa77BUTYXdMyYCxMmOCshtywSd4TK4gaBglg/8Zdgeqvt9x9i2CrqIpka+I8c2wch2gqi9CA/Pw3qIa4OCXaGsup9/jNkbSkJSMCFUzsWGcOZlwlQvif+5HYrfKfFTnI+Y58a0EytDn/GKidLZ9aFkNGQkymnrk5GaeJ7kM4o3pPmbIGc3rKK+ZJOLmyoUSOpKRUsBKpWjV9N+9E4afzefhlcc8JtnNovf83cQs1vUeiRbQP1y1h4YOVMl6RoY3xoLU8shLkTjdM1oHOKk2BlJz4XRi24dP3tds/3WV4XLwGovzmfda7WPH54tgjzLeka/CDf1a5Ei+aNMbymbAFTiIPibk4suO3VYiespajJHh8Yt7G8Xf+bCSFzF3jfC32Vhqq1EiT3At2FJl7CbcYqUwE+u3ve8My78s/Y5Epo03gPqh6DMbj/zHZd1D+5kG7mqYdcdtXXhXPsFfBBBW0Iw8uOfO7+m83P2HOkUHWbcUgGfttLaeTzDRizTyqP1QZxJjssiCx4FbCvuDQdPUdjPdb9MvYukS2Rc1j479RAap+0L9D52s1B4IRzE6NViyBreJg8pQxHoSPud+lrdS+NWWYu4jNEqzaCJFZbGVcOE70L7NUOWp3d6vXkBKBS3pxs+/vhjPD3dsq59Ku5qR2kXrXzG5xCg2vc5J/Z94uW+4+2nb3G/c8a7gtIjtqkHi765j8dKDioYSiUpRzyQreUY5oMzzu6+ENFM6b8e0BWBzfDZWO17G5GTHnYTE8uSsqT6r6Swgx8a71IAHc6pR3TQuFUllsTEK2TWC0LxV72ZHSUrReaV7Wz1kgVIG/VaDYLFsRIpvm2itMqXZpEH2gU5s658oTLj2l0FjX6zDBej2Behfqfwe/aTjmSOLmW3ohdyrC++8Xz6qwbs1OFBkxNDa8U0gkI9/G5ljs5OOFghR8eZZiDvWWvIRJngWdas9k/VZHTGaYJkv8oTdLyWYYnfI0i35eA+m+0OVNw5JmPgaZSj0JINFPQ2BvZHJnbcMI3o6sAA6He+LHzMsnBqYDrtVtvUmkcfa10Jf2LlWc8F+7OeaYWacjuvKLrDM3ZHjoIvFacpSlIO4aTmXkiBO3BVX/YtxivKRrsRUIzwOZiHgn9Kr7XfaC9NJQY0UW2rTlJRkMU6G592/1HpiAr8enVhS7rL05MRTd9yvanzT351PPuR+vF7BHM0++vQLRaljT15InE3X7wzakwa7l6txLU3kdzJzhx1bQZo/puqZgIyyR96brHdjNLhidaVP6Qh6Q05q4SJuSRmFOG3R/KaV3JENcay9jCWwTc1lnqMT5YMrnAdFmVQ4xzJ2iGCbQw7jMn3s8W+f0D90CCpmUCvQ1D3ZyrZXI3Dh9wfFJ3Yp/rhJqUjK2hzjT4rwFNo7W8N/T4ndl+jO31Vjvg45pa4RwGBw4cVtIF05omtPgvMzusIYwwcNW3WADOYvb2D7nnYDInFoQm2Xnry+4MaQ66SJ7Q9631ZHS9yKEC6gwMxV+TJcN3LKWdfTqjmhuKMHqUwKmvVaWAfNRwf1ZZhOS7r680ag2vbT0BUSPE/KnS666Njs/SPHQpJug0BttsTPvnkDZ49YDsL4hVKSoV+ofJz3zHnxMvbF3z69m4BG2h5xcO+M29K9reyhl521dqOG7RmkyJjJcKXJ6MH4RLzS71tXas+UJsNT/wmqcge9Q3hWKD4IOPndBjATEYOg5T/g+J58RfjcAdpDF2zOM3ZCycFoUSrzba5XAuvbJNtHhm8OZegI+jMS0W0z6aE8o+Ae/g9W7WfRFpdVXXM1lJdVL5SLFK0dbDlOpVpzuVS5GBm/b7UsrmlgRLxk9J7SbfmHJC/csb8CIdk6VPS7aw8OsPSD+kEB35zVh9St/k4a/DL0eHJ/G6Mk/g1BFEvZZH5vXRmFpgpNxEIhgxQsP0uYN50vrbseci8oTCkLmDPWjmhdaCrRKcxPekiQxa6gWjuwqH02+LAFT2OzxZqvw56/Fp9WjrDFbMeOPRXU9+cpyvX5mPs2P4I/c58UNYxaui2tOuiIGsl4Lho6DDJrpYd6fzPqk8QweEyft4o6x30ahYDwJVXr5odT9Jr0+/JLsrzZqmVWxITWWchKhC78m52mleTiw3SMhU566+2Ny2SsjbsFVjzftWsN2Y96zq6gykCf09Q8EDXSc3ay6DLaecUQGNpXx5OVNcGqdcXOoieAjibbSubwHxHt2QtxaPDpvsj+K8katfVWh9C9Vl78X2R3bIDRTyzq6UUavljyRiPwZwK1R37mKbn/CRdkQGMgS06lUJlX8cgvnW5m0MwxgaoXUsyRWx/tQJzo1m0ZcnnBPziNudll8siRwV0+33HvJtPmBZjyDuP+wc+wKCN4Zh1Cf5/NAPVoQd59l7VeR5MtYRHc4rs/fps8PrR/Su8Zo5O8FnsXWXeOq681CL5L7Os9TxObKwAsJR+oqdHmqcTHQqueamkJk/tHBkxNpghIfli1MkDYP8Fs5NWI8UfTZTJ4ZYnsF7adQ7edClKxdPtCW/ePOG2bY5mGR8LBugIdAXymHDSVHPu2Hc7IfL+suOtnxCZVAilp8elkWmQGx012wvjLeBTp4+8F45cKJJQ5HmCIGVsocgT8GqcKbmBarcd86+RmXTtq5XZXBKYTG60PGpZV6OdWv0jaEzRUuY9X03exEL7UphpjsN7IPkg032gX/BWBNpA3UWWKDgNJHBc5CoMbu67Sjz1SCAF3feUJEWcpifR9zXJIotM05jwshjWGSPNYP2l3udfY4cmJL1snSJOjoK3U1sOsFRwqhVTpAP9lUTOgCaCxfMRRGfNLUHln5cT99LByP7o+muWCf5MOWUdTQowZtJaAuRUCqovYwzM3Z2yfZqjtvB3QzG9HSX1aZ6C7R+NZZGGV9wFtjBIMmrwlPVLs8F97vb+NrDdbjU4pHe7sUWN3QphYwTNoamfOPG39LvJajyvASDzct72iX3tqJGtemjDqwmELoHQiJ/xTn+yJorPvnd7afUOtb04/NNarkuW4xZr+/hgHy6M5QsL0aga85aA5cSOPkOlNPY+q8/4uL6y1Q5rB040gcAsANOCdGM01zW3IPUO64b8xTASslGxHLXEnHYytXFAH7DKjqP5I22AWneom7XiKOSOgznm5xwF39OrqrnAOsSe6RdWNe+bPDBi1/FFKz/zn+U36g4+UvJb2vvSaYiyW4megsaJ+tn0tj/X6ImYXaNtPer6h22oQoEd2CEY2O3324ZnbJBtlJ4bdYKwwmf2cim64qaKiQ0QQZykMSHAphj7gIrpVaUgS0RyS0PgGLNsEAEGqUUZuN0U2Hfc73e83HffZ+xbEd4R23wwQZvwqNZTUtCa3x8FbK8GdM22dCauNojpD3WUw5M6LRymE2NyfK+U31nbSnP3WeeJA95+T3UVdZThi+8seRl0oISaBeicrLaf8Oz0KqNDKa7Q3Www1vHM5XwCIC8sVypaS0FCQarW7IRNYYOyXWUkxKWk3mN0Faxku1MgNQsogrENvPnoGW+ebhhj8+UmdXG5/U0vqTLkKhBM7Aqo2kEjc+62HPLtHbvPtqW/Q5k+RdGPnZPaoKp+HDfxm/9nil9SiaWS9A/2zixjF2MfSlF4v6D6Mh60AJSVcepwksc4LW3E2DTq1v/JO3AZ0zp4qd2TFAosbXMZ/+Rx5z/JPvqPXUh9o68VmE5Yiz2I+zMDWnnbNCJkwGLcrOplOVwo7hNrq9GGtz3npFMponjnSp0z+fxsZYHUQJSB6ETnxoOoWSCdZmea3PuXhCb6+Md1L5cuK7ONpdmiH5dBHxE89Cx5Pml/Vjx1Z/ao9FH+XjLWvq+qKaHrK+4TXW3V0WiMUvyeS2Re7StSdiGC7Taw36etDtinnYC2Dmzq21BaSCeED5xrkxRqQZeMpa4sUA52/qLTMsG77cfdtoFtlE1+SMKTHmbJNFbxV6nMqpdXUPrf32FZyzb05C37VLUv+w8btpIlWx85O9OwLsxXDPVQbv3yWUHs9Es558GCSP4twrF8z+0FeXgJ6YVkoBK83DNJNouJ46UquZp1gfSavRQmvxm7k/5Sl6L2+s3bkVB+yoknpQOraIbbdVoug/M6NOjhOrz2Ovd3ZZhqk7gazB334gqpvfHUxXaqbvSAIxRSuZkQRdFRIFlH6Ld4P2a9kL0tbNLGBt1R9XWRjPpiFcaiA5vujOrDQ4sDNSSTgSK+Vy55sdSj9FoWsV30sre5ylD4JT3JoU3vKdRs09s7fmTsuN023J5uuN1uVsCvogj/Y7j9021gAnaDGq33tr1v87gkdSD90wzQYMGyah0GFHRB0EMEIhvGbcP2Yiuv9vsd+1Q6ifIcPpigDaCg4lSplfKIMufK62xddLEteSkn9ZcwhMPcy0UgIO9QnCdYnbwQmPBk3aN+1Rp17tHxvTq2Vxvzr+/xUoHe3qIspT+48MZ1AAAgAElEQVTNWS+UQuLhUip5hJqViEAhS1JxPvQhh2C5q4p/yj7ayyUoFAWFMelzHFSXK4ixDXz80Ru8efO03FXigQt4LDtv2P/mNd33if1+x31O7C82y7ZmhYXHyB9m37Pd1alYHJLI9EBRQRaV1PrLCjOXSDovN7pK8JvTSspwhO62dzRPaSwaUl1BfsSSTsKJDdsSrAjgJ3NS/xdR1LU/De8qZAeL2D6PqG7tK5/SmU1m/2n5D5AHMlj7FUSv+PEglBhWy9sY1d5CtLSP2mV4BREpuyJnBVmxVIcTD3bKhHWPelK+6NJ1Mo3L6N8jpVgzqO0sUiq3OAZLR8VxLf2jSBvIY5M+Cck6yXjysRBlRj17YAbOvjzW+Ym6tDxbc/peeY1bG9sGFTvhETqx78C2DQDDV6sS3gdGJjxgQdo+d0oqhvZbmUlz3PPJ1FwlAFgwObYtxyVr4KTb2pnEcVVKXLy/+Aq7n7D2Uf8e+rW8GCityx+V/u9Cu2ByEhCuuqvqfLTw9/HQHXlswXP5XbgVXeixBpm6fiZEWqBBvXLlJjGO+Xo5FWHH8hl70wfZXvyL076e4Jn91yR6jmOzqdypKJcGC2m8ogJKuDT9AHomQCzPU6drzURrW+0RM0AQ9KsHTtXzOhZSAVMTmbCB57TT6niD4sL1NUUEuWUqYwWHLAg/qFyj7zviEJBS1oJts8M/1LO5j7UgOouc8oT3ZKr7BZoTCQd5cEPc/KCpeHm5A5A8IbLZNrVD0oYMyJx+NYj7277KYHpiOnjGfAGfvcsDn0oPBp9kB0kWFXWvraraKcHbhvl0w363659egw8maFuDGp4FOFfI7GTwO0c9+1o7pV8i2HtkCPpn1k3n7UT9q3PidZncQJdpCQvMjjjqI8kMMWz1KOmodUklz2aUAlzrY4TyQBcygS2fJ13qOm1q5qxJZ+hNchTZVq7SaEJCSj/KTiwzFuWsVY/KoWuGg+2SAk/Pgo/evMHz81MGEkModQ3PthBukeVJBelHDu/3O172HS8+w8aB0bpuH/T8NaflsPRGeybrcMJSjn3QxEYjxpKzdVTK+2nP+8xR7dHKq4CU30VrjzFv1UQJiQNfOm1qGXDMkJFt9XqiHaW68kqaBnXyrDn8XkjteTt6O1hzvcSLkF4D3CzEpzDER/aZhDu60FtB754rsUwiZYDcHZN+NGpIHcms65ozh71wiWY7z9dvLAcrDZgTmUYs90Kfe6lOrCOUDDdEG51LR3obWtgcdPXJrEn2IssSnnxy0aneJ51CxDnQm9nkYNqs9DaAgS0vjd2nAtghzrOR6a1+Klow7gIzZGCHOQDiy9GWxWpEDsmDUNT3D0MntjF8hi6WVkrSVdbxOEYURcZXbOXZK+fPeRFc6BRtv9Xns7qEPp05kmTZTsl0zpvHUsl1h1Ye0R84kq81+4AwZ25BZynnk8puPKg0+Fv6Xi/ROs6ddNdDZFhRAzgQMz9SoeSdx7QBje1S+eGp9wKKOuY+1KxqHM3ux68j9H3xT9pywFadWEWtO+zV9Kw7UrBbj6T3Tqm8latljpx/Kx7i3lshFfgEeavhQAksT1XVrmyAQDMZTo2eDcHKaGHndfo2BltWKQK/+mrYKYzZP8KC/5zZ06SVNDWtAJ1i2XqE1RyerYB/eXnBnDu2seF2syuIANN9I/py9+sNPPk7VaG7rTaYvqxk3Oz9vNJFfJREMkhF3JkaoyeaNFapOxEF4vykpmtvt1rG/gA+qKDt/AhaPHz2uK7P/vyQGAI7REdDzbNMj+rq7RxFlZMYx8DvcUfP99i5wEr9fhYTrH1vdZ22Rk6S5mJFsHif4XyWKdS1nALT10eHc5lGxTVrLpnz388C5KyXG118OSYFiY1ntGrJ49ObJ3zlR2+wudBY4OCC1fauxbPg1bm4CBP7vttG0323UxNPlSBOCZ9LBNMHPCritjn74CBWoFOv8ho2bTcsaCi8lT9gwXdc+D1VT7cFxvJEy3y5kpo030q+bKCl8Z7/UOao9hGsdt94gPu2uMMKUoT1X0+a2LOg7yExTTgmRgfEe2fKiBK2zcDRASKChVfZQL7isAhRaO039bfcmsWZSdvSe7jOzK7mdW1JnXDnyaoz3B/1KZ4fR/n4eZXt4JP+7HFSa9WVK2aSZdoMfzQtVHhFq5Hz3DC0hEiMd+vqiXxDgE2web2RjFFYADdkgPNXyX5kA7LqAQiGbcwf3FbX2RmwRTeGYMhmy8PRKN7e6/QgI/k57PUZlA3TE4fxqPPqczyP/x/bufq115dNy1pO0I7v4zpPlUbhtI7wGYEEWlcqpmzKEfH2Us3OKNMfQKxdDvaMJZHdZpDM9yjcdQqyz5awqs9FgEUwuI2jMWJmXfj/hGkWUslJ+RKDM144Uj5mOaZP3deNe9234e8aYwOYP+SsENu/cru1+y/RWAZ4QyxQaiTgoJ5CM1aPLNuo8eDdiZFI1LjyJsbJyxwSBymeEzKHB27OA4Rg0/9nM84CIH2joHUgP0FbypdR4TD0HaDtTz5cJzuqpdBVR15SBfb7hG7Wz7HbgSPrxJAdIEY7vbeBTQTYFXO/Y3+xvt82uxbCfJFh8ia6yAaAGWuavL6QV/viLpoJlQL//wnaAuF27LwAwZSfB/qJQxrVv9b08n092emkDEhZyHn9Z8lcPfv9FRbmGatytux7m03Ss3es7jWIfLRUcxUMQOjOlRVNzZceuWbI4iebglul9Sz3r0nxAieV8/AMppeiJgdo7FhQVtUd37dt4PnNMz756A22bbQ2+0luahcuAog9bHPWynnAjnCdE/j07R0vb1/6/jUQnUSa41Fo9YCtukXGeHXy8lSp8JuYGVft4TNkMUOntR+vTeezfRUpeViSKnXfpl9mncqp2mL3JTiJVVIlSogPCOtYrlGOo+bYcL8/D+SIsQGtH9v3Ej+naxjSsnNH2Q/EUIxbw0LEjURV+i99/f6Zo7w+OcX1BGpculvSHSAerZKD6t9i2A+4nMvaETteyrvqvrMe8qLrs4y7lxR55ffjLPbjJeLcCQmhxSmznZGC9H5zfM5JTe2EsoiEhmswkaaLAPiF8tTOetCLAhgbbhtwh13WXaekzYb2sKyLZ7HhdxkxjoLmboU8pmP5Cued2MB3QXMyz6a8aBj6WPenK6e3CpL3D+7ggg3ZoMBHjrzEPuRq9/n03qLdEWdb7qzHehg/PXkunQp2AT0xWfBHtsiDe5T5Kqf0nBd7ciKK+TbZ91AHt2Wt+8yEAHmgkFYrmiWrLSX5qNnl0skr8P2cCJPLS8Lhd2v5k0gUhxYpFXAc3BKz2k+eSyMbEj7uuy3RN7n1qz1St5SKUYkl1lpUz+9lQ7k8UPzX78grqjd+deEW1LYRUH8TN7qdQsSW9N82u5B7r6U2ZddUM3BsWykIi1f9cMYxxkHbA+Nl5XqZ1FH+sT5S2Em4M04PljvpRbNLccE2VO3zZss/N9gZB3kauSqm+tLIuPppu0F8/4QCsPNQnDYugwMDCvMNbb+9n4zuKxzGa/oUH1DQJkt0ucrJa4N9SDCFM/SuNqne8xmy+POaZ3gMgg5Bk3/ii4N7uWYhaTYH7Xn61BTF9GCtTsU5QnH/Mag9sawhkKdkJIUwYq+dKde8A+hY42Mgf0gBzw67ozA4f+ZhgNJnnv5xL6JlKB+xgQjGtuGjj97g44+eXFDHwnd1UMp6FGvw2HD6qeP09uXFl0SWY8QodIN0+kMlc90QtO3zafiPjgnzw+qSiJOH95KFMra/NHAenOQ2sEPqqOoruekG6yivpejYaGa3oy7wsBVRVlOefE7rSZrcNZxKuNP5zVqXcXjIsF02jhM70QbRIRyLoxd3rtBW/+bdKizp2XVFoyz4l1Xm297F0/oft13vrm7C+ttRhxXOrUbq0/F5jFe7oqLptJCLlZCPOqHFu3kSkX8X4DRgWHE+UZ35PV8vHi0Zo+asA80RsecjsMyn5lQIbrfN97rB7/7RdpJxyKYMwZhbNhH7OfLwAjHHwdYJE78cxoZdLyzONY3xWXbzDF4Zlv4TKYYzjdpkXvitBY3lgA5Q6CJlw49SEM+tdPCcDZdn/MUd6wxgJFmq6X7SPRIKFOu4H2fSG1XC3hH/lE4PvKx88Ha2l01qrug4S5zkJAon6VqARDho2JCutTO4SVulnT6wmadG+2Upx6qXZMUx6FyNZnn1H9isWcK3KCzLIffDX7D+xziTgPuJklNqRCpgs89GXm+HbS1iBqdsZ94TiVI/gXt0h2fw2i5vqb8sL9nXvAsv6E10TXUk5mt54IAcx8Ki+6i+PNGLzmhwQSC2XjSRTTxeMShUNPhtlcqu9Y+vWd/DzvrzM5WktWoKjUctoApev+87ZA5stw0bBmQbuIlAZRj/qtb1Mds4rqIXk8toEwrMMZEHqE3j83nfobpDINjfYfg/mKCNoQcnrFhK7hlO/Z9D4MPf+3vvju8eM9txyaI/pxvk8xnXuDpy/rlfIUAKy/vBjnc4HcEAzbwf6PSok+EETSr3ijUF6d1TD0aXJ9LwKifJv7NWzRq74Sq5l3KW5WQKecWJZi5WeH7zhI+en/D0fIPkFLm3TVntcjzZIeqfp2/af3m54+3bF+z7+UbSg7IJJaZgkkBB7hoZ3tM69XwxAB8BPKhsPI1PU2F3mARfSTf+dccdzbq2BqUbxvhJ2Bymvsoe1i7AhUD+7hoIHkfymLVL2lKQyfTpnMiYvKIAXrMzTVRPLIMT4KGZovHPpTjhMTERsdJ3YRZR0pELwrK8x/XwVM2hw+c0Mb1y0s5Z2fifgix17yT0Ve/ZRD9FN5VEme94z6+lYIX3aK8ocNT1Qa8IXvoyWOlVPCbHgQRZDZNH+pA2Gq/2KR15ooP/zjYgll+LDIzNT3b02bQ1xplQmwWPunXmfjm73yhWEBAJAiuuKHuoRcMSulVNvg7JwmfyJ9x4EjP7DxK3FYegWCd44p3/L+b38X6g6GutSmgdzdnQZdwEoB0tB5E01KQ9E380BssIvZNJRZfmVBWKmCUoW8ljlwbb9AwlWmzvIi1JV14ur9U4YZn2SUKPx/aMRtJ6Q9zfEYFgQzj1qSGcruKfCzTbU6qcRN7Hxm21oC689h9W61j+B1tZVrK1p68vj5TUzWP17XQmX43op7IvFrZOewdIPwyRvHTacPAfIwsuqCWZ0IOKWoHDnRpKbcvrw470SV9thGVa7grc3Q+IFI+PPiUTNN9bJ06Mh5sCJny7/W6qRLXxV9mO1IzNtylP1v0Y1yXNtabPdWy/wpZ1itNJLKilq1Ly9PNNIOope9XGD3barp+HMIDco++ITbXrO0IuBAPbtvmpwcBjr9XggwzaIhCpcV2F7nVoCkRtMOJZDbwpWn7G7xM2p202h2HBnd9l0To6Dg+4qOHgQtx+XsW1ynA/1wD10C4raIklHAsqmj+3IDromvSb05c7hCJeeuaKdfUra/rfexXCf3bs6SPl0sngBnNdnx4fBG+en/DJV7zB5sFaW4YJ9f0d2VBHQeLUIjMIc1e8vLzg07dv7cLsUHQh3Evg6C4AYgX9qaFrSrOU0zksM71p1OvrJMaTHGRvx8dkXdqhnWg9SbrgycFAks0Ls33iPpA7hHBvsgR7g2FsggnzvS5X0W3tiFN5Yhv+UdDaPkiWFq6vGcmDJ1EMXi+umRQlh2FpvKu+qKsvn6qOkUBloHM0ik3w2KyTA1BPadaW+KCh/0AZJ/9mKrFp8GrJx8r0SGWho1SNayznldQ72Rd2fIV5YsXtbASPI9pySE0xLe+sAaLwQukuj+uwnye8OhIsHzHLw1ScmQVRyH5Og44u6Rq6L7Dqr2Xl6aRoXeXRxy1on49W9B7CWZHHiZPCi+Wal7WGro/iZzzdkWRUxcYtGU+wLVci5AmtVjSDi9I1XjvZDHMi7chwo/GOuZ/1j/sEGquOc9pfaOpgEaHl6f0uCl2VNdmk2s/FsyGaQTx1CKp+nLvWWRu8r9sSeV31rWKnCuzhZ0ABxF2mMWu+yoNg0Mm1cY0P0z0DIwFE43S/LQdWwTh1+8inXbfnhEFbjZIyoMiLrTPAij77oRsanOw4o/uwYwzbYiGlKYKOgNSl4dIDxmJk7Tzu/2soS1qVVCsP4k0bRBX02VovtG6RYBlL8fZg7cDJTT94helTSKerZO0HXXCweQcnMurxVqQoeA6c2FiAfJ/4XPJbOAyxgOo2Nm/P+V+rb8n3s9ZFzanYxZJqtiILfvDgpJMjow1Ab+aLxtXpr8EHGbQBjx0C/7FruQP0YXpc1SNLQ6y+/MxjfYZWKwgSnhAAUn7Rxhl0B5mt4mpUlOqTnKnj5W7B2ErO3RrUYkHnzA6f+UEp92PUezQ2LYihcdMFD57pAgCME+3PPT+T50RYM0PFtcoQPL95xscffYRbZqWrRNxLVHsaOaCLYI2M81Ts9xd8+ulbvNzvhSYJdTMAgchEOt9r/8OIdfbwzBrjGn1S7RykqGPYPQIvJzqUcbmBGQhplcvam3J0r4Wd5Woi33M3y6qVuvS7WEKaLxyZJYXRpFixnIrXRP3In2SJ2l/+ZS0Tv68MLstTaX/sczhPNfOrqjkG64mgeXkxYbTuTWVjlEY5yp8JZkmTn2hVeiJosprJ9VNlQEHj6k5CbZg4dL+DZp9XR7sv8g0IHJ3OSnKgkW2VQ1/72DYlh8pCLS21YKb0Jj2hL53uXGORae2NNMyqe8FtJd/rAEaCMtgochY9z59SBHKj4AedJUxNqgE0MxPJmp02vMce3eDh7K9Oc05mtYawE36lg7iTGcxS+vxctjocxyfsxtHKSemteDJCp/gypdAVITspA9FP58tsei5WlMyfKyx3vayfbk6su3ZRby6y4+0BOQbwJVNW69wBvRXP5OqFufgXLt7alKqykcjPvLz1LFpiO7wu/Xzk06zvA0pr4Og5Zzaka9i885pkpz4Vj5gPpXm/pJKvJTtyJknWWhYBq6BvTbR2/ltQJtwtMJ1EAPFTJaMvm9gzYEsaxJhP1ZzFHhL+V40XJ7wAtIQI8ggUKhF7o+K5lm4W7fvEhdpZqJL1qVb2W8Yof4EHiH3U1B1d79o7LutDjmPzQC0DZyNybmmz7InqOGoMJM3PfuTDRVh3dx+d/rDdID6a+8TLp2+B5ydbyQBLGmwurLPRXj15o7W/f6vhEQFA28Bi5tSuMhiYm3PYWWcJPlPQJiJ/AcAPA9gB3FX1G0TkqwH8HgA/FcBfAPDLVfUHxaj1mwD8EgB/C8C/rKp/8t1teEdeRVjTSUzb9xjnKn/aVim/NUB8fY/aZwdeAqkn8nXWDjPWOhNXeD9GKN9XzWnv5vRFOyjeWBWsLn+j2dg8nAEMHryngMRGSwVtNTjmogcLPYB+DJP0ykkpHJ0mrTJLlklEMmD75KNnWkYkYFpmMNaWcJWCtt9CKQvmvuPTty+43/eHghbdqCjcJTV+i7HmfnrZuAiaj3tcZ+iAmM3j2SiiTWS62uDEKBTdQg0Xb0jWXXrRyuT+ZDdmoe+U6o8kBYhP2FhnUIAatrRBRT0Y1wV2PYBilnj0mWsKcjoDNVjszPJWtbcNJO/kAQPEb0Gn4XyYBmHJrinsQs9cJhq0CZoQn9V31gnFQ22mM267pgA7nZlVkcVzFWCEk0BMHwMvVK5apgCmaHgcid5c/qJnT1edd9RzcV8S13pM/FS95cQzPu+wit42G/4Q4Qgs40Ak7k/lRmpWoHsG1rbVFTMotRd4SAQhcNVnL8V9R5HlDcdw87uK9rn2J990h7SWxL28vEB3P1UwnPkxcHvaKHCr8tP5Mve8yfD7KwGZA2PE3lcP5sZIZ7I5wuwMYpAuKFoLlQXQZ5WBtDmiQX+pADPxtr+1xNCJi5IvVfjBiiGnNoA61S5ImBEEhr0U3HM4FXgJMxPy27VHBOAhXvXbuvy3ePa4/1PzTy7xo8DQUPP6JC5Gj36G3kxJRYdl0aDylxwE/nOQ15xTEqHLmPsyZuXu1Eh7UaIX0SN5QhktQq7hGTRa5n9cdtIeLXRIPeX6rbUR5+infxB1dQK1JAIRaTgtZtwF6Z0xfpIq73rM1PSgeumTKjKB5NifnSsopIsRPlML7jWD7zhevr8ftRRtYiY2khZzYRINXNL2W19jhi4LES6RsJQg84kNZoIetPRJtmFq5+7U8MrnWii/QrraKWGnqIFOs2vN7PvE/rc/xW2z609uTzcM2eCqxiQhtiiIWDVie4cnFOLLJXkFSq1uSGth+xBPzPQKn2em7Z9Q1b9O378FwB9S1d8gIt/i3/9dAL8YwNf7v58N4Df733fC6wEbUumO1LQPSx7q68HS+fN3QT/xbGkvBuwz4PIup+ERrqXdWBuesay9eJbbrkZO0JDHY9CEgXHU896EriyD6jj7kpFxkA9WmtQ/iih7FpeFsr8i/JrYhbUfvbnh+c1znQxELxpf1ZHXtiHaDEH5QxEsaWbY3r7c8faFlkRyP1arxREgOSih7NIgU7nEkpbsBGYMGYjQ6+UQVCDGQQSj106xzjIgfMjAHRwHJP68B1Dj9wzMjjTPDkUdqVGZ5iDDEOj4vgop9ol7h+MdZm92CqixRsPI+gZOYagTHZe5mZnnB4IiNB5a4yBMVKfjpMGKNmI57Rg25SJuFCppIE5rcoonkS+oHeLUevxI7yha1qCEfSEglWvyGMVWa93IsnxjGrqD8QDDs8RatdHOV2Vkq94w0GFlDzh2oz58nHhW2s7qUIjf8yfUao235hDHLPFImxFiMpMvEk81mbYAqe8vo2PhUk/ZnUEKHRvGJtS3eE/bEEab+5zY/eJWzsDnch34sj5oneDreE2foRub2vHXAtjl336cg0R9wWmKuU9y0nx2U2wPR9nFml3ns2ez/+zJeyd3Afb8OeTU33P+VX83l4BKyRCqZOpSJVmzroXwwgNWXybZ9NmZcX4kafV7cLuxyxlfP/5UT8rhY10a/WYxcJY4wfbI/6/Bik/otZbEpaok9aj9wJ8fQRML/YwYLstDEbgc/LHguWjgWHPKH0Byu1qSw/wYlXMOWs4myOWUWRsFvTw4rkukoZepPZi+q6sD+tkNLj95gVtUWEwgjbBSPQnZCJ8BaMF46jsyLMwPwcv9DYQCCoqCDCQN7pEr8jMrNg3KSw2QVEUHHvkMEZAI/MqDzXGlxMNSbp/TqJoHiYglrsQLDMHY/XJuiaSBjYUC/ZwLATaSG4lGPoMs/miWR34TgJ/nn78VwP8KC9q+CcDvVOOmPyIiXyUiP1lVv++1yk6C6JNnlf0IB7EvcTuv69GzqOezwucp6288/OWsf8GDYTxWZ6JXR8bnxKHRqDBenpqnMj7C5VCNv6OLUKQyCWNKa9BP++r/pyMcWHCfmCAk20rLM8qkxxdFzPSEDGdyy6u8bTc8v3nC8/MTNg/Y1lmL3JAvkhcmDhFMWKZkeF9VJ/Y5cd8n7i8vuN/tAJIKxGjhnSzmODvDARtRlTrX9zlJ13FiF0Ean0Sme6SRy7dVk9aBz0Eras18QWvphRZ5KzMXdGUHQZsqflXdtLFrnxcFntlNaic/Ljy24LKC9CL2Nwz267r8pAZrkHEJGWMDK+AlyjUmHQs9+VqzB/zT2u6JZUKnrvTyh7oIMXeqZMTsOdIwPs6gdUN5xClkihp34ayZ7fO6tX3ima51J4W07+k8utPBszYlU83f8KVpQYNxZBZSdplF5uBRigcyGHDlo65vFcBOFaWs8GyhhkknZHEkv5FwYr/b3Y+mb3bI2BoBy904swlK+FYbA67/pmE7BJAxUq/s8yXfmfvELvdMKkCBHeS8Axhqjst+v9fyaK/TxmZmV/lOonJv0BI+wXJdBsj+1UOzMO1ySDpenSrr9O30lxqpbDhYl3cSRD0DQrPts3yULCb9SoDm3h7B2Kfv88uZrdXus1on51eyzFI3Tl3Sg5I4C69WzbTO6J116djaa1YCYDPFieF3wprARac/GNNoZFkGDUirZrVapWmbpV8ROaBrbWjaZPhYThlJ+lxErfarLnZQgH7pOaIcfD1ukEDzGgUv0YkCIGZoFb6kU2kpr+aam9QVkZSSEOQGVb+R1H2KOLtDa3UVB0RhQw6S8GjMT50Nr/Ps+qSgVwtqcfjcvpMNNFq47xd9g0CnbaGZ2GDpJ0ueZTA8BoZvoREfCxE7fMcSrRNjn9BtYPc73gbCNumRnU7gswZtCuB/Fksz/peq+lsAfA0FYn8FwNf4568F8Jfp3e/xZy1oE5FfDeBXA8Anbz6hjIEP8alSzbcBCKYKtjZgjwTps0BXT+xePApmWKTGJnTyo3PWieH9TFi4QlmSR1YHOQ6VXeFCgozwVOkyrRJELLRVRrvVU13JAoricv6N0mKZtGEDLGF4GMgKxh893lNRyrL4I7IiEK29AUEbBTAET7cNT89PePP8jG0Lx7Q7gArxWGpABc5PEwo70jUzmaqYO/D2Zcfbt2/NcQIoVQtTHmEwhDZ6ExHCocw8dyQdxJciDtvUnHcloZzwTFSgaDUnMBHZ88p21tBVZi9pzozVxliq/sVAHCxpdbXVfoSj8Tk4CY/sAEB8fyyfDvSy5KhJ8tn7pzhqMFg7CLK/1y1K2MaWhDjtUIiNtmE4l8M+Wmf1nLUQY/S6n1NjIcOXvgzBTQDZtrKDYBvpM6jTN+STkT504RFHkF5hf5pLj8jwCtCu3jhZR3NcQkmukMuIuh4cKLmxMnEhVDgZJu12+ngtszu3OTOTtzlWFIhGbqxHrEyGsG2dTuEQrG2WqrOg6v6y28lkAFQn7rst3TF6KbbNj/bPdpB6H/D7hyDYw37otD02qtD7DhXBdtvsmgBIrtq6bTeM4SsRpjl8+66ATl+2acFXBnbhcMrAEDUc4auGnGY2X0BDTJiLI5/Lw4MylcVDLTXroQ0kF9yn3k5n04+YR+DB5ZjmgtT/0Xn+B3MAACAASURBVLaqbbOOcwLD/ADGP9L2fpWcVdW8PqLdVOn/+j4qHbS8z5GqEwMJ96aLSvk91Mfs8J6xOaL/hN5r8CC5s6YmXZNgtQdrE6e1neD5CHX7kei/KH6XVNTyBJBAn8m8Hp4cexDJ2LC40RN7384eCatv41lLXq3YBOgeeS0F7FDY8UoYxU0B3UgC1PZFzSVpnJ6XApa9p5UlWr+XKLoO9TXTCoXuix6WWhorsSQw9E2wbVBDC4u06SwG6dSURjyAGVEibQgElX/wavX9+Dv7GOFzxYRQHPgU23mhgv2+Y8DurZubB16x0dY7Jq6zLUVlkwvbEAwVTImTfH3PrAyo3839jvVxAD570PZzVfV7ReTvBvAdIvKdvdOqsu7sfgd44PdbAOCr/66foKGc1uANQL+eC0Xc2wY0N6X0H05HaGq/16sh5MZUKuOt8U4IdkCdAJrPZ2zqpmZLbO2HCCyYcR+g0hwdpgcb/OPyJBY66TivMz/Z6fXl8Eq4mC5lUEpFwogV/TlTr2RIS3FYNpSd2FruEfjSeGinNU0JmPOAUBSWMRp+YfabN0/Ythu20WdjFYpdBZtnnEK53FAKKhWsbyzdpzkfLy+0h431ILAsr4sh8GVuvowpgrHAZ3g/JmrviWVyPNzSPhREHh7FLjuEU/y2WmGOuwPfWB++GmxdWOkRrBKXrEKVtoMOH9W52MqzYskPjGPnsiy4fl8bKQ3S5/KOxvkMo5PfuQ1BjmOXn6Wsnryvx59OG2tyYc+Y9iaq3bDnMtepdu/QvZwq8WWaY4RBEmCT3CTNJ80pNI9MZgdpEOGHG8L4eYajn3znsy8wvWD4Vja4G36h4CqIVRTKpTP+jC/fiJP8yvWqevoonlFcSd9K9p0V+YO3QKEIiudKSo578QYab/rM3HbbMjl4v3uiZp/w8Ab3lz3rkjEwXO/lLJjaPviNbB0Au+MNO56en7BtUrNf4XiIzyZBzBnc90xIiUcZu1o4PGfNG27bhu3pBsiO/b7bXrrb5vrfeHN3nC3/Zjck8eFKw08BGeLHa4/h+nKiK7HFbklRcU5AZZrTBJRujaJEf5HhNtpkIbdjKPmVSTof/3DY8lRNfzeKCDB0ZJt8rk/pHEsU3sPW7TbrqRzrJY45POlkhizJGB40Gw5D1Zd/Gc/FDF7pNqV6XHvS9xVonUzpixqEJH77JkW/rEcXumf9OHwqTPsDwet+FNfL3/J/H8MK6h+3n++FDm+qwJVs1twLmQvgfIKZZSzJVHWoEz7oyTTJYpmQIp2orLsl0wPWJUm8445X40taghk+6UK0dM9SpwglrIAimx+nP0MmtQ45QuzVpb3wvi/cghQK9FLHLqPtj2K2KlonNW/vStmYlYF7nnrVt0crniecJl9oqZipePvWLuW+3TY8AZDbrdcrAp5giZcteBsY+54+84xk4Ctyx/CZgjZV/V7/+/0i8vsBfCOAvxrLHkXkJwP4fi/+vQB+Cr3+df7s9TYQQhhOJTkZwUSv9CjWi0pmBtwx4XcfBGzMiM2xAo6jSQ/VPBhjqNj/nwiRgMQHBT0Dcf/qdGF5jhToplnSssV+C0Hnm+M6/vabT6uXIC/LSJabtePyy3RCXWvyDI8Fr7Gp04xgqDLexlYKV7MrrbVZv5wt6TRN6EFP4AS7MPvNmyc8Pz9jG1se4cwOl0CxwYKkdJKm+jT7TIUSGU47UdKWJt336bMU3f0K3R20pVwaMqBSWxMdGVEOutn/SCrr8iPR6DiiFKxIlVoSdvn76++3ojip4RSXDpQD1vPC7CzET+kLneByYrqL5r3Fqo8chr4Q4xiiHY3ySXtL291wsNHuHfksyvhxMx37g4HJD7z4qfYrHGe3ep+Mz2pHkaot69v3fVGOKL/UDe0Ygu3mszWKPPY6AxoV3LE6ev6J6XZQwPb3OCtFQY47K7W3hxyw+mNtZ3LJ/oqv/U0dsxBVnHBK+PSDi17hC8L3OOzkETUnMsgwCucFH5tJG1AFbj4zuu+2ZNuIP0sX7zvmXpgKkAFPtBkBEtsfmRP3XRGn5E7VXPJkRTQDmXRsAEjY39B1InnK4pCBObTG3lc1mKNVSyX3qbZ8SPwgESn3N07FxK4lmo1SsWJBsM/dgky1WY5amiYZsM1YHrvA2IzOobfFHS3DKeykJB2yT/FdfTVHkHWELFaZmOEG8ee6V9jaxOIvpFRY/nnU7LyvmIXMHYo6gTAOVilG8n4CGXin7RRfKificWgFeYqQiWKg9C1Cx5bz02haNoj0WL6PNs6Hd5FFHlihDqscPwzqUq+RTAt85ojnO1z22dAE/oyrCI6Xp5FcCTK5FT0Tv8crvlcUVYkSQPKo+OqPVlPDfRU3Rup/JR0tzWepF0P3CpZeLkSM14IanvipZfwu5xDfQkJ1bVto63wWSWE70yiCutpDaGraWlzzMWHbAo+aNZfS05TsyXInEKutpHX6CLJ+XpxUnRP3u8n0kypu22ZZsVmzuNGEQmrSaAIiW840zlTUn81ZeGfQJiJfAWCo6g/7518I4D8E8O0AvhnAb/C/f8Bf+XYA/5qI/G7YASQ/9K79bN7OQ0KnQmseHnUwLQoaUdc7sk7fja+yZjzRyhze79xhwqHsnNj/lflFcG4KEActhz1H3k46YeEtcbY3BFE17y5B/ZrGqj3MqrU/i36wlmR8XKBEgP3eXb/8m+M0yiFXrQsdQ2loiHy5RNKktBRiZvRDEcHNNOEWBnYbA89vnvDm+cmP1nUa0yW9whmqMJ6+NMqC0uHLLXfoDKfIMsUv+4xQNBVIyb1moMnLJEF9JOJjBVaiRZPeR/6NIRSKHkrLu+S/1SJsSL3icDbYGV5Zp6zyAyXp/53+uirCk98r6NClssftpSnWHJ0Gp4mAeD/71yl62mJZuof1HcaAky+L39CeZbX6mH4HVIQcnJKTVFOMK3dKjxQx/6UyppltRDl7ugv4LvnSe9UZU5fFwTE70/Dyk4l0xkxcESL3qoUbI3EnEtKhzj64OYhDhexeJMW23RDL9dIhk+CDkmIeq34C8XFGTJexFx+kKP8IrEU+7vtEHzSHp80LOQ0tgrhtwLb5aYwzAgcLuiJgyT2WuldPhVZ8uK6e+463c8ee+/0k7VJLMPl9U+kgepAVjuUQwbj58eiexNuGYGw3L6c283a/W+DoM2lxYt3Uibnb2PKYCMLn8YSjU2VzJooTOfd9h26bBbm6AxGAPgjUGOZeyYtx28xW+ezhvhdNqnU022uBnNuQaasmIkEQ4zq24iXRGGlNvhVPPofNzDdJZkbe1mDPa2tgfGAM4y1JfRp6PZYRq2oumzW5DtmIIMsjVlUoZi4TBdCuCxmZKI5ZTWcu1nlk5wrX1Y8gv2mBsyF8V7C25J5eh6B52lS2vAflXH/TRgrNOiH7LlsgUXUpgmbSq0SEMx3pvGbDf4t9ja3jzWZGyV4kngn7VfleT3+29TeuM9eDrrKioJn47HzaC80Z/KBtXesSfCypu4L347AtXnrax7rLSR54FH5C4JY279DZogUWkIV6SqWCzlNxn3fMObE/3XAbNzuJedoMd+3ZVejIMDxTpJHUUo17jt9t5z/LTNvXAPj9rmRuAP5bVf2DIvLHAPxeEflVAP4igF/u5f9H2HH/3wU78v9XfoY2oG1YOqxLA6cOV9R6KONfDmL1eaEb7EeF0DgoPs0wxip9do85g7IusrKMy8jk/vE56wTqJ1tJHJ/nVamgli0hBE0JHy1eJKcgMBFd8EE5AJndlpiti/W7SMGBG588QRwh02UYEHh1DV59U98Mms4VE7LvEnjaNrz56AnPT0+4baMuA0UsBjH1MKeYIXfY39rG0n2WkxPBbhytHcvBWGaZdkfETz+eQjcHNbPQh7qyndWqLO9We23zLP3YcKHM7gF53jDMvByZrJBHrifGNjPt3r+I3lWdFxa8k64nfOD11Mlw1Y+mc8mZAT8K5+Ds95Mjp9cyIL4pA0almr3sIx3fUk1xp88ujs8XpCPMdmLFkX432jE2rBtP2uOGY4YAyLbXjfDRoM1SmPyMsYHPweDySgFUZZk124sFd/mOy9i+2z6rp63ufWy5J/Xlw15+8zPn41CeaNDeM9nd7xPQHeMplr4dHaSHm+38HqcjkEYiR/U8KKhBNJNx2H6/vKvLW+X4HJCke8roCNWkj/X9TpcB26BMLdkMPaGZta/9uDGrk9g279f1/hi+okGyf9u2YX+5w29P8XvOFJsMbE83vNw2vPwIgN0Cye02oPe6Jsb60AVFgFzql3edqdZJkkS9Oe+MNHCg90GanAdttnLbNnvLA7bYv3O6n5L2s2Ty2WfSxi7Y94kxwgqHb1H8prvxdOw5VAAb7+v0YR3BzzP2VvpM4CD/R4br//RCClcSSJOpmVwpiz9VnpjTTptG6fTT+jxzz/jEnoprdv6JVUHRt2mOduaJnSGZ1N0eHiFV5lIm48lTEZbDO41mUrrpwEPiIxWBb0Omb5WRQbIt7py5Loy9UCI+vp6cylncZhe8UkFLYIetC5wbMaIeCqyFyse7yZ3+vpmTroFAJ6qKWIINzocteIzmDiKnOf7cdm0VMfrzSootfA2hQFEVnEosDMsPDdpEwiBi3Uw+p9Irgjz09bM8ctIlZg0zpeK2C3LHhg1jG3XFwVZGcgNyFvseJ/QOgahvo0kkH8M7gzZV/W4AP+Pk+d8A8AtOniuAX/OuelcwXuGBr8+5tjQ+Y0+n9ZG0zumb/M6WRDrjTI0yIEURnAFAtJYd5oAqf6zdB8pMb3XZxXkzP+fFqdpNttARreGkRL/a6ZgC2qyYVuJ0jDWZciFNZAi8J8OZJE+v4aLhDLhiakY0PCll9967P2v5TPYRFYRW8JbEAgeOTIixMLG7fb6p3Wi+PW/4+KM3eLrdXHCnj+Ud866Yu+K+75j7bg5IBLdw4x/BwaylG6z7FqIcPi4mrMHr4odGu7XBHmwEPxTFmB6s3Jk/WhDYKl6dwI5VLonx31tZ5dnDk3Ej5JWN+sJjZci9nuiMMK5VMqvOrK2W7DWD70OqvQ3lvup53xt27I+00rrgvtSjJ31MfVVvs/Fkg9frLCaQ5XczrNzkiqzkexLfgUxMxP5JiB0ksQ3bG2OJmZDffnS0qtaBB2IO6dx3iAw7xCIcSTL4mWybE7rvrkdqF7pNvBmxxzay1yK0pNpnFKb6fi53YLfnQYon+mjca/gP3O979vfhEnvptM7HXDcNUf24vnKUpSI9S3L9ykuIWADCV6y7vbycZ6VNNc9e2VKXat2wZD4HyVI4S8lPAtkAnRvy6H+1WbQZRiPq9frEFSWvsjDda0vKY8JBRDDn3WbXXgTj+RlvPnrG/eWOeZ8+W7hhv9fpi5kQSue6bN0m5djG4pXA6Wkb2HXivu/YRPLs0ag3uI+uv0ya2D4jjeYxthtCN/HJ8tMPYQHEZuJyQ0osZyteGjHjBxvL+9t7NeqzjFBgbHQyAyE25wSm4sXXQA7er4hu/0sN0IEsXmHub/OAUDGg+048FEqmK74WYKU8MOXOef4UwhSETvBn4X/EdofZAgZCb41kJWZzFrT15Hs97j6FIlf/pJ3gLiQh17a9HjYSlR1Jpmz7tEhHhT7NV73e1T7ktz6giC0/I/wnJZoshMvrb1HvHrURbIbIdaFM5H52Rrv8p2mHAWISbbzelm8hvcpOTSimkLc0VKgGQzcpvU92IXYJhtYXGg9F1b0vvqqtwtsRs9rRnD13mYqtT+kzFN6Jviq2zWzfdtvcjm6QbeCNv3lHLUcGBHed2GAJRz5sqZn9V+BHc+T/lxSCzTJSJiNsY6XunFVGPu5NkXwQlUk7SvgUhq3DTZ5Rw6Ed5uBGsK03Z5ylMrr8DmfbYm3x2WWC1Pm0CGlsKVgL/aDKDnK0aRJlM1JdDA90abh3ZyECKj5AQF3hlBtFMuWarY4394yfxoEFemC+kMk8aCuWKsZXVNaKN6OzOjBM6LcheBob9rd3vP30LcWSms5EZZw6Lo0s2j8vuv5Ujlaz9Wh4X6vjs0BDTZfnh0pjycFxJq3M4PGXHI504LhPvWfloD3Ctr8dsBZP/cpG99jcyVgd5ylC7vpdSjxD2VunFbMH/NgvMBy7TKwo0tzNoYJ1+copL3gSKWTg0H+JVhZfCYJwSftqhFgyUgtbwjFRePAUOmsbeXIjYIeC5EpsRPBPy7mExlbtBN85p5+mavvb7DTD2P8ACzLEAsSXnLapvQy7xpIwe2+fdEAQJcwsm7nnIGzbRoZd3VaUA5PZT/X9I3Iy2MTzKzR6RxsxQ6i8a1XTo1l3i5a8rlxsvw8pae2z6RH44pC1buwR9DkRHAuoi87MC9Z21wlR9va0AXLzkyK9LGxVhS0v9UM12F6p7ReLGTW9z7z0WxQYww+0cZtx//QFz2+e8PR0w4475j7x9HSDjIn95SVt78AExpbJ1w3APvfcawep8D+GKvZhbe4rjEUG07ZQ8odBvY7Ijxsb0oykKuZ95p7PYFMRyS0ZoYbUEx/5PQNCb3faaXLbRpo5x9SWUd3vO+a05WXjNrxf3frkbLA3LlKneXoJYiSTj20MPH38EV5e3uLtp3te/WH7hbCAvZvJh5SHDnoyY81XXMS4Hmr22fPYSp5xO5XWQbYn+pR36HUni8yAF66Im7daOII2TsLvBPJUkfgRf68UMX5IhVV/Qj8IJ/09o+H2JX+JbRyLM6+BfHwnO8eRa8yxVjvaDwBL+1DJelsm2+UEbjNiuNkftXGJFW9WmJMgQrivfpaNN/GmoM+kNWUVhfzzENs/S1BzLu57yrJiCX6iLScBiaaWuLDve9Al7R3Tyetzvz7sw75PO4lXFeN286SQIlIzqoo5Rm4BAIB7WlZ0RlU9X4lD8MEEbQDcGWfB40xE5BNcKAZJmI8CyY0/T63RAqsmnOwAJt+XA6TBmNqXK0Zd5Zj4EMwwAp1dc8N2OkErM5MAOi6aAiPJOE3dkdHNY/KjWQkDc0LoLKOdboyx9gCuLZd0gkfANjzjk/i7cFW/SsmnzhYqH48yPNT0KKg7YFe9DKPi07cv+Szq6qQ9MS5n5U7ItP7WnnGKz/sayuOM7K/BGT6fpTzzPJmr/CHiDTm8fVJhgtCnPk7RFrdeZuq81wdcl9+ZhCm6bLD0GIAeQJbPGnLDvaAigzK0KPpVSUkBjwSHuzsN58p0L/KXtVAmXJa+a5WqE2ljUzUyQWVVxgB3nXImx4mlEh9ozA5MYEjeWRhOZ9Z8iEpLdsG08edDbCZh7i+473eM8ZQbrNPuqiXj4iTCqH/lljEE2za6wQy6+/4gQPwkVg4EkIdX5IZvWCA554TcNpvtCDp6++/iKfXWeSkyeT4oDi1FrD2qXpxrrrnezaA8FHbShojVDBfNGCoqGx6mx4Pb/V7LwIfbqNCj4bjEzGjtRSqWAuwqm9AAuA3cbpuh4SdYZlDo788ZB5iAbBqgfsBI9lsV+6cvGE83bE9P2OcOmRO3MYDbExTA3O+QORJ/SC3HT3rB93O5bGTbYPtHBxXQbxJ4+3vplALZl23w0kevK+xyJG39vTnV1wChlkZV642+zTirQqfpo7gWYcICiUkB2+YJloNd8n7l2CoyOLD6WFcXW6lO3F/e4unpGfv+KfY9DklZZ+lA9VMFXCB+Ydu32B5NGhakxR8AdqORyjA+aBq5ZKaSu4oIRKPPDE2fR3bQZTUW2OVBVaS3c/xaNxc93zDi4YzKyIYmAbTeVOpPinLZEAV8GSm9WkanD0wiJETT6Afq8KhV4xIOtNus/h9Hqz6B8r1ZT3lxorI34W/zyit/5uG28ZxW19Y2AVSiRXs9eYGT0JJF6WPDdSlq32Xx6TjwZfZ3KgSTJhrE755T10fWxn3afZb7fYfcNtw2m3VLXOeO4ZdyR9vSZJnu7nxH1PbBBG2B7qDs8MqcpmhrCDi7XIwiqcQUNvuk6/qJLr9JSFCRzKAhmLM7jl0++wWhVr22QKcdtCFVf/QNSid1DaslgzUAcTxlGNxg9HXOIZ3EtI9WF8/EJaIkIu1EtrAlWZ+UriADcRgH/48PZAFM4HZVX7O/uiMZxrY+2NJM/0ZtZ7foMINVwNfv7wIW8PX9M6GvL4umefB+lcXRaq3lHrT72kvlCpV5DscgWKEvR+2K1YpW9m0NcnnEzDiFpJEBEVP9mRzx73b/TDgyUbb4pbGkHMcif2C5P5qfVNZWsYDvSx6NmnIsz7/kf5yNLxiewQ7e5OPR4Yaes7W1qT6oGDM0UXUqhKRJHxxa+kI/6MJPB17R/lERyxjFlm+EUGXPOV2mTc5FkCcdBI90upXDNsbWBs9O2LqnM3/bbth9iWQUizu+dM7coxtH58XqB9s7JbaEzB2QWNoCmMO775ZjHn4o1FTbJ3S73RK/U2CHaCVgHMAgNUJGl0q8pRoQem+hkL0nTX6q9KqHfRSU3yfMFHYRttOMrwdVeHBOwdRZr1XrygVbumPtTFVMv/sNUOhuOD0/Dzw9v8HT08R93mymZr/jfp91aqUfOrLfyekQ298WB96XrvJ9dy93QBW3262WvkJw2wQ6njzwtHGeu/GHiPj+LqspAlK4nOX+SZVmm5PPG0HMsjed7f7Eft8hmy9b9GGJMR9+n6b5HrUaKA8SATDFdaQCqjROAV5H7tG8734oi+kvG8uQK7eD0a1cuoVkwtD7SqtfdCt+arMFCqjYRhPIjm274b6/NZ9pAjoo6FR3sJcETyWyUKs0qEzQpL4dYVNgDoHsVlsunHb7wV4B4Lcs0h198dvq2jQVGuPWdCjbBCVZIx0YNXDAF9/TeIUT6DU6H1YSnShGeJPIus+lqVNWO01N1NPTbPwRalaN7f/RHj7yNtZSKU3BjPGr2mxnu4HQeczIpO26CVv6HttvavwSw2JsrLzT/f2OqC6fj36CNjmUpYzxSdnC0CureVAgV8fkGE3FlB2473gRIFacmM7xhEskXkTatSxxEQkZmofwwQRtZ9BYq+ne1duSuuQPcOPFQxEqhspTiTUDAH6e9Uoi1Oo+cQSObPaOcaB2lJ/xe6dembRPvd1QEDi96wVr3x418xjpVpopGooIityEO16hwJlb0Z4FLUgiS0F+Xky/NBBC3JSaHIOJz1WnHFiwN6j0MZRB/swjXwqVf2+GYlHWgT//corgWkC4jQd0znqZX16HDOCyz++gLaOWCEXCg94PfHngHlS8OvlcF6RonrSTrg7yLsIzRPnjUoSTSB0XnikI2e+jmW3H0yBiztBYVlHk7C17xHsBc9aPCHZKMpf1Y5V2cMmc9rsMgexrGS9ZUzTIvVGOuwVpm/NFODg9+63eRwtyTRva/p9xpGd+eMSJJzpJjpvVj2SUQ5Ux21N+XHeFNJyy8FbkSOW1XdWZSxBL68ahIasVOEJqfgmnIfgr9LaV2FWxjQlgc8fj7rMg8FnVaRdzK3C/321PjNcWPLptA2P6PnTp2w1ELBgbm2Jsmzk++445xQM5r0uRe45L31h/b/vETpv9jYya/BhBdh1kFvg1YiS9cuZMFVN393ftYJLY1x33bWJsNgaxj9uDSds65vphV7wsNjh0htDA6px4UeA2hp12CgsY517LFSdirZGCD2hqpznCZCFnT318VTQmT7ycQhR42e2KhHA8I3Gnqnn5ehGr2/nyV5a+5RdWiAsNpDBWsD/m4+N9jUAuDjh73a81/OpGtEKIl/dlfSlpJ0aAx0aRyTpTM55gJ13NvtYOhYiCg9baexW2vny0rjS6nVxXRIgA2JBjZOcNaMM3TzTVHlhUpmmloDy0hSF1CrQzb6Mvxjj1LVVZ8ip1Rq3pOriuxqT3PMozYxG90kywjcdBzx/7koQ4tneCR3F74WFXY+CcD0ecPm4zdJGI4NmzsFk1gSEZvI0tllE+BnlXJ78IEJEfBvDn3jceF1zg8BMB/PX3jcQFF+DixQs+LLj48YIPBS5evOBDgi8lP/59qvqTzn74UGba/pyqfsP7RuKCCwBARP74xY8XfAhw8eIFHxJc/HjBhwIXL17wIcEXxY/vOGLxggsuuOCCCy644IILLrjggvcJV9B2wQUXXHDBBRdccMEFF1zwAcOHErT9lveNwAUXEFz8eMGHAhcvXvAhwcWPF3wocPHiBR8SfCH8+EEcRHLBBRdccMEFF1xwwQUXXHDBOXwoM20XXHDBBRdccMEFF1xwwQUXnMB7D9pE5BeJyJ8Tke8SkW953/hc8OUNIvJTROQPi8ifEZH/S0R+rT//ahH5DhH58/73x/tzEZH/zPnz/xCRn/V+e3DBlxuIyCYif0pE/gf//tNE5I86z/0eEXn252/8+3f57z/1feJ9wZcfiMhXici3ich3isifFZF/9NKNF7wvEJF/0+30nxaR3yUiH1368YIvAkTkt4vI94vIn6Znn1sXisg3e/k/LyLf/KPF670GbSKyAfgvAPxiAD8dwD8vIj/9feJ0wZc93AH8W6r60wH8HAC/xnnuWwD8IVX9egB/yL8Dxptf7/9+NYDf/MWjfMGXOfxaAH+Wvv9HAH6jqv4DAH4QwK/y578KwA/689/o5S644EsJvwnAH1TVfwjAz4Dx5aUbL/jCQUS+FsC/DuAbVPUfBrAB+BW49OMFXwz8VwB+0fLsc+lCEflqAL8OwM8G8I0Afl0Een+n8L5n2r4RwHep6ner6lsAvxvAN71nnC74MgZV/T5V/ZP++YdhTsnXwvjuW73YtwL4Z/3zNwH4nWrwRwB8lYj85C8Y7Qu+TEFEvg7APw3gt/p3AfDzAXybF1l5MXj02wD8Ai9/wQU/ahCRHwfgHwfw2wBAVd+q6t/EpRsveH9wA/CxiNwAfALg+3Dpxwu+AFDV/w3ADyyPP68u/KcAfIeq/oCq/iCA78AxEPxc8L6Dtq8F8Jfp+/f4swsu+DEHXz7xMwH8UQBfo6rf5z/9Tn1jIwAAA1lJREFUFQBf458vHr3gxxL+UwD/DoDp338CgL+pqnf/zvyWvOi//5CXv+CCLwX8NAB/DcDv8OW6v1VEvgKXbrzgPYCqfi+A/xjAX4IFaz8E4E/g0o8XvD/4vLrwS64j33fQdsEF7wVE5CsB/HcA/g1V/X/4N7UjVa9jVS/4MQUR+aUAvl9V/8T7xuWCC2CzGj8LwG9W1Z8J4P9FLf8BcOnGC7448GVk3wRLJvw9AL4CP8pZigsu+FLB+9KF7zto+14AP4W+f50/u+CCHzMQkSdYwPbfqOrv88d/NZb2+N/v9+cXj17wYwX/GIB/RkT+Amxp+M+H7Sn6Kl8OBHR+S170338cgL/xRSJ8wZc1fA+A71HVP+rfvw0WxF268YL3Af8kgP9bVf+aqr4A+H0wnXnpxwveF3xeXfgl15HvO2j7YwC+3k8DeoZtMv3294zTBV/G4GvcfxuAP6uq/wn99O0A4mSfbwbwB+j5v+SnA/0cAD9E0+MXXPB3DKr676nq16nqT4Xpvv9FVf8FAH8YwC/zYisvBo/+Mi9/zXpc8CUBVf0rAP6yiPyD/ugXAPgzuHTjBe8H/hKAnyMin7jdDn689OMF7ws+ry78nwD8QhH58T5z/Av92d8xvPfLtUXkl8D2dWwAfruq/vr3itAFX9YgIj8XwP8O4P9E7SP692H72n4vgL8XwF8E8MtV9QfcWPznsGUZfwvAr1TVP/6FI37BlzWIyM8D8G+r6i8Vkb8fNvP21QD+FIB/UVU/FZGPAPzXsH2YPwDgV6jqd78vnC/48gMR+Udgh+I8A/huAL8Slty9dOMFXziIyH8A4J+Dnfr8pwD8q7A9QZd+vODHFETkdwH4eQB+IoC/CjsF8r/H59SFIvKvwHxMAPj1qvo7flR4ve+g7YILLrjgggsuuOCCCy644ILH8L6XR15wwQUXXHDBBRdccMEFF1zwClxB2wUXXHDBBRdccMEFF1xwwQcMV9B2wQUXXHDBBRdccMEFF1zwAcMVtF1wwQUXXHDBBRdccMEFF3zAcAVtF1xwwQUXXHDBBRdccMEFHzBcQdsFF1xwwQUXXHDBBRdccMEHDFfQdsEFF1xwwQUXXHDBBRdc8AHDFbRdcMEFF1xwwQUXXHDBBRd8wPD/AUOn/iZV7TrRAAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "# show the results\n",
+ "show_result_pyplot(model, img, result, get_palette('cityscapes'))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "open-mmlab",
+ "language": "python",
+ "name": "open-mmlab"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ },
+ "pycharm": {
+ "stem_cell": {
+ "cell_type": "raw",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": []
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/demo/video_demo.py b/demo/video_demo.py
new file mode 100644
index 0000000..acdb531
--- /dev/null
+++ b/demo/video_demo.py
@@ -0,0 +1,111 @@
+from argparse import ArgumentParser
+
+import cv2
+
+from mmseg.apis import inference_segmentor, init_segmentor
+from mmseg.core.evaluation import get_palette
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument('video', help='Video file or webcam id')
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--palette',
+ default='cityscapes',
+ help='Color palette used for segmentation map')
+ parser.add_argument(
+ '--show', action='store_true', help='Whether to show draw result')
+ parser.add_argument(
+ '--show-wait-time', default=1, type=int, help='Wait time after imshow')
+ parser.add_argument(
+ '--output-file', default=None, type=str, help='Output video file path')
+ parser.add_argument(
+ '--output-fourcc',
+ default='MJPG',
+ type=str,
+ help='Fourcc of the output video')
+ parser.add_argument(
+ '--output-fps', default=-1, type=int, help='FPS of the output video')
+ parser.add_argument(
+ '--output-height',
+ default=-1,
+ type=int,
+ help='Frame height of the output video')
+ parser.add_argument(
+ '--output-width',
+ default=-1,
+ type=int,
+ help='Frame width of the output video')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ args = parser.parse_args()
+
+ assert args.show or args.output_file, \
+ 'At least one output should be enabled.'
+
+ # build the model from a config file and a checkpoint file
+ model = init_segmentor(args.config, args.checkpoint, device=args.device)
+
+ # build input video
+ cap = cv2.VideoCapture(args.video)
+ assert (cap.isOpened())
+ input_height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
+ input_width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
+ input_fps = cap.get(cv2.CAP_PROP_FPS)
+
+ # init output video
+ writer = None
+ output_height = None
+ output_width = None
+ if args.output_file is not None:
+ fourcc = cv2.VideoWriter_fourcc(*args.output_fourcc)
+ output_fps = args.output_fps if args.output_fps > 0 else input_fps
+ output_height = args.output_height if args.output_height > 0 else int(
+ input_height)
+ output_width = args.output_width if args.output_width > 0 else int(
+ input_width)
+ writer = cv2.VideoWriter(args.output_file, fourcc, output_fps,
+ (output_width, output_height), True)
+
+ # start looping
+ try:
+ while True:
+ flag, frame = cap.read()
+ if not flag:
+ break
+
+ # test a single image
+ result = inference_segmentor(model, frame)
+
+ # blend raw image and prediction
+ draw_img = model.show_result(
+ frame,
+ result,
+ palette=get_palette(args.palette),
+ show=False,
+ opacity=args.opacity)
+
+ if args.show:
+ cv2.imshow('video_demo', draw_img)
+ cv2.waitKey(args.show_wait_time)
+ if writer:
+ if draw_img.shape[0] != output_height or draw_img.shape[
+ 1] != output_width:
+ draw_img = cv2.resize(draw_img,
+ (output_width, output_height))
+ writer.write(draw_img)
+ finally:
+ if writer:
+ writer.release()
+ cap.release()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/docker/Dockerfile b/docker/Dockerfile
new file mode 100644
index 0000000..6f9acac
--- /dev/null
+++ b/docker/Dockerfile
@@ -0,0 +1,29 @@
+ARG PYTORCH="1.6.0"
+ARG CUDA="10.1"
+ARG CUDNN="7"
+ARG MMCV="1.3.13"
+
+FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
+
+ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX"
+ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
+ENV CMAKE_PREFIX_PATH="$(dirname $(which conda))/../"
+
+RUN apt-get update && apt-get install -y git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
+ && apt-get clean \
+ && rm -rf /var/lib/apt/lists/*
+
+RUN conda clean --all
+
+# Install MMCV
+ARG PYTORCH
+ARG CUDA
+ARG MMCV
+RUN ["/bin/bash", "-c", "pip install mmcv-full==${MMCV} -f https://download.openmmlab.com/mmcv/dist/cu${CUDA//./}/torch${PYTORCH}/index.html"]
+
+# Install MMSegmentation
+RUN git clone https://github.com/open-mmlab/mmsegmentation.git /mmsegmentation
+WORKDIR /mmsegmentation
+ENV FORCE_CUDA="1"
+RUN pip install -r requirements.txt
+RUN pip install --no-cache-dir -e .
diff --git a/docker/serve/Dockerfile b/docker/serve/Dockerfile
new file mode 100644
index 0000000..31a5d44
--- /dev/null
+++ b/docker/serve/Dockerfile
@@ -0,0 +1,49 @@
+ARG PYTORCH="1.6.0"
+ARG CUDA="10.1"
+ARG CUDNN="7"
+FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
+
+ARG MMCV="1.4.4"
+ARG MMSEG="0.21.0"
+
+ENV PYTHONUNBUFFERED TRUE
+
+RUN apt-get update && \
+ DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y \
+ ca-certificates \
+ g++ \
+ openjdk-11-jre-headless \
+ # MMDet Requirements
+ ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
+ && rm -rf /var/lib/apt/lists/*
+
+ENV PATH="/opt/conda/bin:$PATH"
+RUN export FORCE_CUDA=1
+
+# TORCHSEVER
+RUN pip install torchserve torch-model-archiver
+
+# MMLAB
+ARG PYTORCH
+ARG CUDA
+RUN ["/bin/bash", "-c", "pip install mmcv-full==${MMCV} -f https://download.openmmlab.com/mmcv/dist/cu${CUDA//./}/torch${PYTORCH}/index.html"]
+RUN pip install mmsegmentation==${MMSEG}
+
+RUN useradd -m model-server \
+ && mkdir -p /home/model-server/tmp
+
+COPY entrypoint.sh /usr/local/bin/entrypoint.sh
+
+RUN chmod +x /usr/local/bin/entrypoint.sh \
+ && chown -R model-server /home/model-server
+
+COPY config.properties /home/model-server/config.properties
+RUN mkdir /home/model-server/model-store && chown -R model-server /home/model-server/model-store
+
+EXPOSE 8080 8081 8082
+
+USER model-server
+WORKDIR /home/model-server
+ENV TEMP=/home/model-server/tmp
+ENTRYPOINT ["/usr/local/bin/entrypoint.sh"]
+CMD ["serve"]
diff --git a/docker/serve/config.properties b/docker/serve/config.properties
new file mode 100644
index 0000000..efb9c47
--- /dev/null
+++ b/docker/serve/config.properties
@@ -0,0 +1,5 @@
+inference_address=http://0.0.0.0:8080
+management_address=http://0.0.0.0:8081
+metrics_address=http://0.0.0.0:8082
+model_store=/home/model-server/model-store
+load_models=all
diff --git a/docker/serve/entrypoint.sh b/docker/serve/entrypoint.sh
new file mode 100644
index 0000000..41ba00b
--- /dev/null
+++ b/docker/serve/entrypoint.sh
@@ -0,0 +1,12 @@
+#!/bin/bash
+set -e
+
+if [[ "$1" = "serve" ]]; then
+ shift 1
+ torchserve --start --ts-config /home/model-server/config.properties
+else
+ eval "$@"
+fi
+
+# prevent docker exit
+tail -f /dev/null
diff --git a/docs/en/Makefile b/docs/en/Makefile
new file mode 100644
index 0000000..d4bb2cb
--- /dev/null
+++ b/docs/en/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/en/_static/css/readthedocs.css b/docs/en/_static/css/readthedocs.css
new file mode 100644
index 0000000..2e38d08
--- /dev/null
+++ b/docs/en/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../images/mmsegmentation.png");
+ background-size: 201px 40px;
+ height: 40px;
+ width: 201px;
+}
diff --git a/docs/en/_static/images/mmsegmentation.png b/docs/en/_static/images/mmsegmentation.png
new file mode 100644
index 0000000..009083a
Binary files /dev/null and b/docs/en/_static/images/mmsegmentation.png differ
diff --git a/docs/en/api.rst b/docs/en/api.rst
new file mode 100644
index 0000000..8285841
--- /dev/null
+++ b/docs/en/api.rst
@@ -0,0 +1,58 @@
+mmseg.apis
+--------------
+.. automodule:: mmseg.apis
+ :members:
+
+mmseg.core
+--------------
+
+seg
+^^^^^^^^^^
+.. automodule:: mmseg.core.seg
+ :members:
+
+evaluation
+^^^^^^^^^^
+.. automodule:: mmseg.core.evaluation
+ :members:
+
+utils
+^^^^^^^^^^
+.. automodule:: mmseg.core.utils
+ :members:
+
+mmseg.datasets
+--------------
+
+datasets
+^^^^^^^^^^
+.. automodule:: mmseg.datasets
+ :members:
+
+pipelines
+^^^^^^^^^^
+.. automodule:: mmseg.datasets.pipelines
+ :members:
+
+mmseg.models
+--------------
+
+segmentors
+^^^^^^^^^^
+.. automodule:: mmseg.models.segmentors
+ :members:
+
+backbones
+^^^^^^^^^^
+.. automodule:: mmseg.models.backbones
+ :members:
+
+decode_heads
+^^^^^^^^^^^^
+.. automodule:: mmseg.models.decode_heads
+ :members:
+
+losses
+^^^^^^^^^^
+.. automodule:: mmseg.models.losses
+ :members:
diff --git a/docs/en/changelog.md b/docs/en/changelog.md
new file mode 100644
index 0000000..3954430
--- /dev/null
+++ b/docs/en/changelog.md
@@ -0,0 +1,556 @@
+## Changelog
+
+
+### V0.21.1 (2/9/2022)
+
+**Bug Fixes**
+
+- Fix typos in docs. ([#1263](https://github.com/open-mmlab/mmsegmentation/pull/1263))
+- Fix repeating log by `setup_multi_processes`. ([#1267](https://github.com/open-mmlab/mmsegmentation/pull/1267))
+- Upgrade isort in pre-commit hook. ([#1270](https://github.com/open-mmlab/mmsegmentation/pull/1270))
+
+**Improvements**
+
+- Use MMCV load_state_dict func in ViT/Swin. ([#1272](https://github.com/open-mmlab/mmsegmentation/pull/1272))
+- Add exception for PointRend for support CPU-only. ([#1271](https://github.com/open-mmlab/mmsegmentation/pull/1270))
+
+### V0.21 (1/29/2022)
+
+**Highlights**
+
+- Officially Support CPUs training and inference, please use the latest MMCV (1.4.4) to try it out.
+- Support Segmenter: Transformer for Semantic Segmentation (ICCV'2021).
+- Support ISPRS Potsdam and Vaihingen Dataset.
+- Add Mosaic transform and `MultiImageMixDataset` class in `dataset_wrappers`.
+
+**New Features**
+
+- Support Segmenter: Transformer for Semantic Segmentation (ICCV'2021) ([#955](https://github.com/open-mmlab/mmsegmentation/pull/955))
+- Support ISPRS Potsdam and Vaihingen Dataset ([#1097](https://github.com/open-mmlab/mmsegmentation/pull/1097), [#1171](https://github.com/open-mmlab/mmsegmentation/pull/1171))
+- Add segformer‘s benchmark on cityscapes ([#1155](https://github.com/open-mmlab/mmsegmentation/pull/1155))
+- Add auto resume ([#1172](https://github.com/open-mmlab/mmsegmentation/pull/1172))
+- Add Mosaic transform and `MultiImageMixDataset` class in `dataset_wrappers` ([#1093](https://github.com/open-mmlab/mmsegmentation/pull/1093), [#1105](https://github.com/open-mmlab/mmsegmentation/pull/1105))
+- Add log collector ([#1175](https://github.com/open-mmlab/mmsegmentation/pull/1175))
+
+**Improvements**
+
+- New-style CPU training and inference ([#1251](https://github.com/open-mmlab/mmsegmentation/pull/1251))
+- Add UNet benchmark with multiple losses supervision ([#1143](https://github.com/open-mmlab/mmsegmentation/pull/1143))
+
+**Bug Fixes**
+
+- Fix the model statistics in doc for readthedoc ([#1153](https://github.com/open-mmlab/mmsegmentation/pull/1153))
+- Set random seed for `palette` if not given ([#1152](https://github.com/open-mmlab/mmsegmentation/pull/1152))
+- Add `COCOStuffDataset` in `class_names.py` ([#1222](https://github.com/open-mmlab/mmsegmentation/pull/1222))
+- Fix bug in non-distributed multi-gpu training/testing ([#1247](https://github.com/open-mmlab/mmsegmentation/pull/1247))
+- Delete unnecessary lines of STDCHead ([#1231](https://github.com/open-mmlab/mmsegmentation/pull/1231))
+
+**Contributors**
+
+- @jbwang1997 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1152
+- @BeaverCC made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1206
+- @Echo-minn made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1214
+- @rstrudel made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/955
+
+### V0.20.2 (12/15/2021)
+
+**Bug Fixes**
+
+- Revise --option to --options to avoid BC-breaking. ([#1140](https://github.com/open-mmlab/mmsegmentation/pull/1140))
+
+### V0.20.1 (12/14/2021)
+
+**Improvements**
+
+- Change options to cfg-options ([#1129](https://github.com/open-mmlab/mmsegmentation/pull/1129))
+
+
+**Bug Fixes**
+
+- Fix `` in metafile. ([#1127](https://github.com/open-mmlab/mmsegmentation/pull/1127))
+- Fix correct `num_classes` of HRNet in `LoveDA` dataset ([#1136](https://github.com/open-mmlab/mmsegmentation/pull/1136))
+
+
+
+### V0.20 (12/10/2021)
+
+**Highlights**
+
+- Support Twins ([#989](https://github.com/open-mmlab/mmsegmentation/pull/989))
+- Support a real-time segmentation model STDC ([#995](https://github.com/open-mmlab/mmsegmentation/pull/995))
+- Support a widely-used segmentation model in lane detection ERFNet ([#960](https://github.com/open-mmlab/mmsegmentation/pull/960))
+- Support A Remote Sensing Land-Cover Dataset LoveDA ([#1028](https://github.com/open-mmlab/mmsegmentation/pull/1028))
+- Support focal loss ([#1024](https://github.com/open-mmlab/mmsegmentation/pull/1024))
+
+**New Features**
+
+- Support Twins ([#989](https://github.com/open-mmlab/mmsegmentation/pull/989))
+- Support a real-time segmentation model STDC ([#995](https://github.com/open-mmlab/mmsegmentation/pull/995))
+- Support a widely-used segmentation model in lane detection ERFNet ([#960](https://github.com/open-mmlab/mmsegmentation/pull/960))
+- Add SETR cityscapes benchmark ([#1087](https://github.com/open-mmlab/mmsegmentation/pull/1087))
+- Add BiSeNetV1 COCO-Stuff 164k benchmark ([#1019](https://github.com/open-mmlab/mmsegmentation/pull/1019))
+- Support focal loss ([#1024](https://github.com/open-mmlab/mmsegmentation/pull/1024))
+- Add Cutout transform ([#1022](https://github.com/open-mmlab/mmsegmentation/pull/1022))
+
+**Improvements**
+
+- Set a random seed when the user does not set a seed ([#1039](https://github.com/open-mmlab/mmsegmentation/pull/1039))
+- Add CircleCI setup ([#1086](https://github.com/open-mmlab/mmsegmentation/pull/1086))
+- Skip CI on ignoring given paths ([#1078](https://github.com/open-mmlab/mmsegmentation/pull/1078))
+- Add abstract and image for every paper ([#1060](https://github.com/open-mmlab/mmsegmentation/pull/1060))
+- Create a symbolic link on windows ([#1090](https://github.com/open-mmlab/mmsegmentation/pull/1090))
+- Support video demo using trained model ([#1014](https://github.com/open-mmlab/mmsegmentation/pull/1014))
+
+**Bug Fixes**
+
+- Fix incorrectly loading init_cfg or pretrained models of several transformer models ([#999](https://github.com/open-mmlab/mmsegmentation/pull/999), [#1069](https://github.com/open-mmlab/mmsegmentation/pull/1069), [#1102](https://github.com/open-mmlab/mmsegmentation/pull/1102))
+- Fix EfficientMultiheadAttention in SegFormer ([#1037](https://github.com/open-mmlab/mmsegmentation/pull/1037))
+- Remove `fp16` folder in `configs` ([#1031](https://github.com/open-mmlab/mmsegmentation/pull/1031))
+- Fix several typos in .yml file (Dice Metric [#1041](https://github.com/open-mmlab/mmsegmentation/pull/1041), ADE20K dataset [#1120](https://github.com/open-mmlab/mmsegmentation/pull/1120), Training Memory (GB) [#1083](https://github.com/open-mmlab/mmsegmentation/pull/1083))
+- Fix test error when using `--show-dir` ([#1091](https://github.com/open-mmlab/mmsegmentation/pull/1091))
+- Fix dist training infinite waiting issue ([#1035](https://github.com/open-mmlab/mmsegmentation/pull/1035))
+- Change the upper version of mmcv to 1.5.0 ([#1096](https://github.com/open-mmlab/mmsegmentation/pull/1096))
+- Fix symlink failure on Windows ([#1038](https://github.com/open-mmlab/mmsegmentation/pull/1038))
+- Cancel previous runs that are not completed ([#1118](https://github.com/open-mmlab/mmsegmentation/pull/1118))
+- Unified links of readthedocs in docs ([#1119](https://github.com/open-mmlab/mmsegmentation/pull/1119))
+
+**Contributors**
+
+- @Junjue-Wang made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1028
+- @ddebby made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1066
+- @del-zhenwu made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1078
+- @KangBK0120 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1106
+- @zergzzlun made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1091
+- @fingertap made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1035
+- @irvingzhang0512 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1014
+- @littleSunlxy made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/989
+- @lkm2835
+- @RockeyCoss
+- @MengzhangLI
+- @Junjun2016
+- @xiexinch
+- @xvjiarui
+
+### V0.19 (11/02/2021)
+
+**Highlights**
+
+- Support TIMMBackbone wrapper ([#998](https://github.com/open-mmlab/mmsegmentation/pull/998))
+- Support custom hook ([#428](https://github.com/open-mmlab/mmsegmentation/pull/428))
+- Add codespell pre-commit hook ([#920](https://github.com/open-mmlab/mmsegmentation/pull/920))
+- Add FastFCN benchmark on ADE20K ([#972](https://github.com/open-mmlab/mmsegmentation/pull/972))
+
+**New Features**
+
+- Support TIMMBackbone wrapper ([#998](https://github.com/open-mmlab/mmsegmentation/pull/998))
+- Support custom hook ([#428](https://github.com/open-mmlab/mmsegmentation/pull/428))
+- Add FastFCN benchmark on ADE20K ([#972](https://github.com/open-mmlab/mmsegmentation/pull/972))
+- Add codespell pre-commit hook and fix typos ([#920](https://github.com/open-mmlab/mmsegmentation/pull/920))
+
+**Improvements**
+
+- Make inputs & channels smaller in unittests ([#1004](https://github.com/open-mmlab/mmsegmentation/pull/1004))
+- Change `self.loss_decode` back to `dict` in Single Loss situation ([#1002](https://github.com/open-mmlab/mmsegmentation/pull/1002))
+
+**Bug Fixes**
+
+- Fix typo in usage example ([#1003](https://github.com/open-mmlab/mmsegmentation/pull/1003))
+- Add contiguous after permutation in ViT ([#992](https://github.com/open-mmlab/mmsegmentation/pull/992))
+- Fix the invalid link ([#985](https://github.com/open-mmlab/mmsegmentation/pull/985))
+- Fix bug in CI with python 3.9 ([#994](https://github.com/open-mmlab/mmsegmentation/pull/994))
+- Fix bug when loading class name form file in custom dataset ([#923](https://github.com/open-mmlab/mmsegmentation/pull/923))
+
+**Contributors**
+
+- @ShoupingShan made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/923
+- @RockeyCoss made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/954
+- @HarborYuan made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/992
+- @lkm2835 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1003
+- @gszh made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/428
+- @VVsssssk
+- @MengzhangLI
+- @Junjun2016
+
+### V0.18 (10/07/2021)
+
+**Highlights**
+
+- Support three real-time segmentation models (ICNet [#884](https://github.com/open-mmlab/mmsegmentation/pull/884), BiSeNetV1 [#851](https://github.com/open-mmlab/mmsegmentation/pull/851), and BiSeNetV2 [#804](https://github.com/open-mmlab/mmsegmentation/pull/804))
+- Support one efficient segmentation model (FastFCN [#885](https://github.com/open-mmlab/mmsegmentation/pull/885))
+- Support one efficient non-local/self-attention based segmentation model (ISANet [#70](https://github.com/open-mmlab/mmsegmentation/pull/70))
+- Support COCO-Stuff 10k and 164k datasets ([#625](https://github.com/open-mmlab/mmsegmentation/pull/625))
+- Support evaluate concated dataset separately ([#833](https://github.com/open-mmlab/mmsegmentation/pull/833))
+- Support loading GT for evaluation from multi-file backend ([#867](https://github.com/open-mmlab/mmsegmentation/pull/867))
+
+**New Features**
+
+- Support three real-time segmentation models (ICNet [#884](https://github.com/open-mmlab/mmsegmentation/pull/884), BiSeNetV1 [#851](https://github.com/open-mmlab/mmsegmentation/pull/851), and BiSeNetV2 [#804](https://github.com/open-mmlab/mmsegmentation/pull/804))
+- Support one efficient segmentation model (FastFCN [#885](https://github.com/open-mmlab/mmsegmentation/pull/885))
+- Support one efficient non-local/self-attention based segmentation model (ISANet [#70](https://github.com/open-mmlab/mmsegmentation/pull/70))
+- Support COCO-Stuff 10k and 164k datasets ([#625](https://github.com/open-mmlab/mmsegmentation/pull/625))
+- Support evaluate concated dataset separately ([#833](https://github.com/open-mmlab/mmsegmentation/pull/833))
+
+**Improvements**
+
+- Support loading GT for evaluation from multi-file backend ([#867](https://github.com/open-mmlab/mmsegmentation/pull/867))
+- Auto-convert SyncBN to BN when training on DP automatly([#772](https://github.com/open-mmlab/mmsegmentation/pull/772))
+- Refactor Swin-Transformer ([#800](https://github.com/open-mmlab/mmsegmentation/pull/800))
+
+**Bug Fixes**
+
+- Update mmcv installation in dockerfile ([#860](https://github.com/open-mmlab/mmsegmentation/pull/860))
+- Fix number of iteration bug when resuming checkpoint in distributed train ([#866](https://github.com/open-mmlab/mmsegmentation/pull/866))
+- Fix parsing parse in val_step ([#906](https://github.com/open-mmlab/mmsegmentation/pull/906))
+
+### V0.17 (09/01/2021)
+
+**Highlights**
+
+- Support SegFormer
+- Support DPT
+- Support Dark Zurich and Nighttime Driving datasets
+- Support progressive evaluation
+
+**New Features**
+
+- Support SegFormer ([#599](https://github.com/open-mmlab/mmsegmentation/pull/599))
+- Support DPT ([#605](https://github.com/open-mmlab/mmsegmentation/pull/605))
+- Support Dark Zurich and Nighttime Driving datasets ([#815](https://github.com/open-mmlab/mmsegmentation/pull/815))
+- Support progressive evaluation ([#709](https://github.com/open-mmlab/mmsegmentation/pull/709))
+
+**Improvements**
+
+- Add multiscale_output interface and unittests for HRNet ([#830](https://github.com/open-mmlab/mmsegmentation/pull/830))
+- Support inherit cityscapes dataset ([#750](https://github.com/open-mmlab/mmsegmentation/pull/750))
+- Fix some typos in README.md ([#824](https://github.com/open-mmlab/mmsegmentation/pull/824))
+- Delete convert function and add instruction to ViT/Swin README.md ([#791](https://github.com/open-mmlab/mmsegmentation/pull/791))
+- Add vit/swin/mit convert weight scripts ([#783](https://github.com/open-mmlab/mmsegmentation/pull/783))
+- Add copyright files ([#796](https://github.com/open-mmlab/mmsegmentation/pull/796))
+
+**Bug Fixes**
+
+- Fix invalid checkpoint link in inference_demo.ipynb ([#814](https://github.com/open-mmlab/mmsegmentation/pull/814))
+- Ensure that items in dataset have the same order across multi machine ([#780](https://github.com/open-mmlab/mmsegmentation/pull/780))
+- Fix the log error ([#766](https://github.com/open-mmlab/mmsegmentation/pull/766))
+
+### V0.16 (08/04/2021)
+
+**Highlights**
+
+- Support PyTorch 1.9
+- Support SegFormer backbone MiT
+- Support md2yml pre-commit hook
+- Support frozen stage for HRNet
+
+**New Features**
+
+- Support SegFormer backbone MiT ([#594](https://github.com/open-mmlab/mmsegmentation/pull/594))
+- Support md2yml pre-commit hook ([#732](https://github.com/open-mmlab/mmsegmentation/pull/732))
+- Support mim ([#717](https://github.com/open-mmlab/mmsegmentation/pull/717))
+- Add mmseg2torchserve tool ([#552](https://github.com/open-mmlab/mmsegmentation/pull/552))
+
+**Improvements**
+
+- Support hrnet frozen stage ([#743](https://github.com/open-mmlab/mmsegmentation/pull/743))
+- Add template of reimplementation questions ([#741](https://github.com/open-mmlab/mmsegmentation/pull/741))
+- Output pdf and epub formats for readthedocs ([#742](https://github.com/open-mmlab/mmsegmentation/pull/742))
+- Refine the docstring of ResNet ([#723](https://github.com/open-mmlab/mmsegmentation/pull/723))
+- Replace interpolate with resize ([#731](https://github.com/open-mmlab/mmsegmentation/pull/731))
+- Update resource limit ([#700](https://github.com/open-mmlab/mmsegmentation/pull/700))
+- Update config.md ([#678](https://github.com/open-mmlab/mmsegmentation/pull/678))
+
+**Bug Fixes**
+
+- Fix ATTENTION registry ([#729](https://github.com/open-mmlab/mmsegmentation/pull/729))
+- Fix analyze log script ([#716](https://github.com/open-mmlab/mmsegmentation/pull/716))
+- Fix doc api display ([#725](https://github.com/open-mmlab/mmsegmentation/pull/725))
+- Fix patch_embed and pos_embed mismatch error ([#685](https://github.com/open-mmlab/mmsegmentation/pull/685))
+- Fix efficient test for multi-node ([#707](https://github.com/open-mmlab/mmsegmentation/pull/707))
+- Fix init_cfg in resnet backbone ([#697](https://github.com/open-mmlab/mmsegmentation/pull/697))
+- Fix efficient test bug ([#702](https://github.com/open-mmlab/mmsegmentation/pull/702))
+- Fix url error in config docs ([#680](https://github.com/open-mmlab/mmsegmentation/pull/680))
+- Fix mmcv installation ([#676](https://github.com/open-mmlab/mmsegmentation/pull/676))
+- Fix torch version ([#670](https://github.com/open-mmlab/mmsegmentation/pull/670))
+
+**Contributors**
+
+@sshuair @xiexinch @Junjun2016 @mmeendez8 @xvjiarui @sennnnn @puhsu @BIGWangYuDong @keke1u @daavoo
+
+### V0.15 (07/04/2021)
+
+**Highlights**
+
+- Support ViT, SETR, and Swin-Transformer
+- Add Chinese documentation
+- Unified parameter initialization
+
+**Bug Fixes**
+
+- Fix typo and links ([#608](https://github.com/open-mmlab/mmsegmentation/pull/608))
+- Fix Dockerfile ([#607](https://github.com/open-mmlab/mmsegmentation/pull/607))
+- Fix ViT init ([#609](https://github.com/open-mmlab/mmsegmentation/pull/609))
+- Fix mmcv version compatible table ([#658](https://github.com/open-mmlab/mmsegmentation/pull/658))
+- Fix model links of DMNEt ([#660](https://github.com/open-mmlab/mmsegmentation/pull/660))
+
+**New Features**
+
+- Support loading DeiT weights ([#538](https://github.com/open-mmlab/mmsegmentation/pull/538))
+- Support SETR ([#531](https://github.com/open-mmlab/mmsegmentation/pull/531), [#635](https://github.com/open-mmlab/mmsegmentation/pull/635))
+- Add config and models for ViT backbone with UperHead ([#520](https://github.com/open-mmlab/mmsegmentation/pull/531), [#635](https://github.com/open-mmlab/mmsegmentation/pull/520))
+- Support Swin-Transformer ([#511](https://github.com/open-mmlab/mmsegmentation/pull/511))
+- Add higher accuracy FastSCNN ([#606](https://github.com/open-mmlab/mmsegmentation/pull/606))
+- Add Chinese documentation ([#666](https://github.com/open-mmlab/mmsegmentation/pull/666))
+
+**Improvements**
+
+- Unified parameter initialization ([#567](https://github.com/open-mmlab/mmsegmentation/pull/567))
+- Separate CUDA and CPU in github action CI ([#602](https://github.com/open-mmlab/mmsegmentation/pull/602))
+- Support persistent dataloader worker ([#646](https://github.com/open-mmlab/mmsegmentation/pull/646))
+- Update meta file fields ([#661](https://github.com/open-mmlab/mmsegmentation/pull/661), [#664](https://github.com/open-mmlab/mmsegmentation/pull/664))
+
+### V0.14 (06/02/2021)
+
+**Highlights**
+
+- Support ONNX to TensorRT
+- Support MIM
+
+**Bug Fixes**
+
+- Fix ONNX to TensorRT verify ([#547](https://github.com/open-mmlab/mmsegmentation/pull/547))
+- Fix save best for EvalHook ([#575](https://github.com/open-mmlab/mmsegmentation/pull/575))
+
+**New Features**
+
+- Support loading DeiT weights ([#538](https://github.com/open-mmlab/mmsegmentation/pull/538))
+- Support ONNX to TensorRT ([#542](https://github.com/open-mmlab/mmsegmentation/pull/542))
+- Support output results for ADE20k ([#544](https://github.com/open-mmlab/mmsegmentation/pull/544))
+- Support MIM ([#549](https://github.com/open-mmlab/mmsegmentation/pull/549))
+
+**Improvements**
+
+- Add option for ViT output shape ([#530](https://github.com/open-mmlab/mmsegmentation/pull/530))
+- Infer batch size using len(result) ([#532](https://github.com/open-mmlab/mmsegmentation/pull/532))
+- Add compatible table between MMSeg and MMCV ([#558](https://github.com/open-mmlab/mmsegmentation/pull/558))
+
+### V0.13 (05/05/2021)
+
+**Highlights**
+
+- Support Pascal Context Class-59 dataset.
+- Support Visual Transformer Backbone.
+- Support mFscore metric.
+
+**Bug Fixes**
+
+- Fixed Colaboratory tutorial ([#451](https://github.com/open-mmlab/mmsegmentation/pull/451))
+- Fixed mIoU calculation range ([#471](https://github.com/open-mmlab/mmsegmentation/pull/471))
+- Fixed sem_fpn, unet README.md ([#492](https://github.com/open-mmlab/mmsegmentation/pull/492))
+- Fixed `num_classes` in FCN for Pascal Context 60-class dataset ([#488](https://github.com/open-mmlab/mmsegmentation/pull/488))
+- Fixed FP16 inference ([#497](https://github.com/open-mmlab/mmsegmentation/pull/497))
+
+**New Features**
+
+- Support dynamic export and visualize to pytorch2onnx ([#463](https://github.com/open-mmlab/mmsegmentation/pull/463))
+- Support export to torchscript ([#469](https://github.com/open-mmlab/mmsegmentation/pull/469), [#499](https://github.com/open-mmlab/mmsegmentation/pull/499))
+- Support Pascal Context Class-59 dataset ([#459](https://github.com/open-mmlab/mmsegmentation/pull/459))
+- Support Visual Transformer backbone ([#465](https://github.com/open-mmlab/mmsegmentation/pull/465))
+- Support UpSample Neck ([#512](https://github.com/open-mmlab/mmsegmentation/pull/512))
+- Support mFscore metric ([#509](https://github.com/open-mmlab/mmsegmentation/pull/509))
+
+**Improvements**
+
+- Add more CI for PyTorch ([#460](https://github.com/open-mmlab/mmsegmentation/pull/460))
+- Add print model graph args for tools/print_config.py ([#451](https://github.com/open-mmlab/mmsegmentation/pull/451))
+- Add cfg links in modelzoo README.md ([#468](https://github.com/open-mmlab/mmsegmentation/pull/469))
+- Add BaseSegmentor import to segmentors/__init__.py ([#495](https://github.com/open-mmlab/mmsegmentation/pull/495))
+- Add MMOCR, MMGeneration links ([#501](https://github.com/open-mmlab/mmsegmentation/pull/501), [#506](https://github.com/open-mmlab/mmsegmentation/pull/506))
+- Add Chinese QR code ([#506](https://github.com/open-mmlab/mmsegmentation/pull/506))
+- Use MMCV MODEL_REGISTRY ([#515](https://github.com/open-mmlab/mmsegmentation/pull/515))
+- Add ONNX testing tools ([#498](https://github.com/open-mmlab/mmsegmentation/pull/498))
+- Replace data_dict calling 'img' key to support MMDet3D ([#514](https://github.com/open-mmlab/mmsegmentation/pull/514))
+- Support reading class_weight from file in loss function ([#513](https://github.com/open-mmlab/mmsegmentation/pull/513))
+- Make tags as comment ([#505](https://github.com/open-mmlab/mmsegmentation/pull/505))
+- Use MMCV EvalHook ([#438](https://github.com/open-mmlab/mmsegmentation/pull/438))
+
+### V0.12 (04/03/2021)
+
+**Highlights**
+
+- Support FCN-Dilate 6 model.
+- Support Dice Loss.
+
+**Bug Fixes**
+
+- Fixed PhotoMetricDistortion Doc ([#388](https://github.com/open-mmlab/mmsegmentation/pull/388))
+- Fixed install scripts ([#399](https://github.com/open-mmlab/mmsegmentation/pull/399))
+- Fixed Dice Loss multi-class ([#417](https://github.com/open-mmlab/mmsegmentation/pull/417))
+
+**New Features**
+
+- Support Dice Loss ([#396](https://github.com/open-mmlab/mmsegmentation/pull/396))
+- Add plot logs tool ([#426](https://github.com/open-mmlab/mmsegmentation/pull/426))
+- Add opacity option to show_result ([#425](https://github.com/open-mmlab/mmsegmentation/pull/425))
+- Speed up mIoU metric ([#430](https://github.com/open-mmlab/mmsegmentation/pull/430))
+
+**Improvements**
+
+- Refactor unittest file structure ([#440](https://github.com/open-mmlab/mmsegmentation/pull/440))
+- Fix typos in the repo ([#449](https://github.com/open-mmlab/mmsegmentation/pull/449))
+- Include class-level metrics in the log ([#445](https://github.com/open-mmlab/mmsegmentation/pull/445))
+
+### V0.11 (02/02/2021)
+
+**Highlights**
+
+- Support memory efficient test, add more UNet models.
+
+**Bug Fixes**
+
+- Fixed TTA resize scale ([#334](https://github.com/open-mmlab/mmsegmentation/pull/334))
+- Fixed CI for pip 20.3 ([#307](https://github.com/open-mmlab/mmsegmentation/pull/307))
+- Fixed ADE20k test ([#359](https://github.com/open-mmlab/mmsegmentation/pull/359))
+
+**New Features**
+
+- Support memory efficient test ([#330](https://github.com/open-mmlab/mmsegmentation/pull/330))
+- Add more UNet benchmarks ([#324](https://github.com/open-mmlab/mmsegmentation/pull/324))
+- Support Lovasz Loss ([#351](https://github.com/open-mmlab/mmsegmentation/pull/351))
+
+**Improvements**
+
+- Move train_cfg/test_cfg inside model ([#341](https://github.com/open-mmlab/mmsegmentation/pull/341))
+
+### V0.10 (01/01/2021)
+
+**Highlights**
+
+- Support MobileNetV3, DMNet, APCNet. Add models of ResNet18V1b, ResNet18V1c, ResNet50V1b.
+
+**Bug Fixes**
+
+- Fixed CPU TTA ([#276](https://github.com/open-mmlab/mmsegmentation/pull/276))
+- Fixed CI for pip 20.3 ([#307](https://github.com/open-mmlab/mmsegmentation/pull/307))
+
+**New Features**
+
+- Add ResNet18V1b, ResNet18V1c, ResNet50V1b, ResNet101V1b models ([#316](https://github.com/open-mmlab/mmsegmentation/pull/316))
+- Support MobileNetV3 ([#268](https://github.com/open-mmlab/mmsegmentation/pull/268))
+- Add 4 retinal vessel segmentation benchmark ([#315](https://github.com/open-mmlab/mmsegmentation/pull/315))
+- Support DMNet ([#313](https://github.com/open-mmlab/mmsegmentation/pull/313))
+- Support APCNet ([#299](https://github.com/open-mmlab/mmsegmentation/pull/299))
+
+**Improvements**
+
+- Refactor Documentation page ([#311](https://github.com/open-mmlab/mmsegmentation/pull/311))
+- Support resize data augmentation according to original image size ([#291](https://github.com/open-mmlab/mmsegmentation/pull/291))
+
+### V0.9 (30/11/2020)
+
+**Highlights**
+
+- Support 4 medical dataset, UNet and CGNet.
+
+**New Features**
+
+- Support RandomRotate transform ([#215](https://github.com/open-mmlab/mmsegmentation/pull/215), [#260](https://github.com/open-mmlab/mmsegmentation/pull/260))
+- Support RGB2Gray transform ([#227](https://github.com/open-mmlab/mmsegmentation/pull/227))
+- Support Rerange transform ([#228](https://github.com/open-mmlab/mmsegmentation/pull/228))
+- Support ignore_index for BCE loss ([#210](https://github.com/open-mmlab/mmsegmentation/pull/210))
+- Add modelzoo statistics ([#263](https://github.com/open-mmlab/mmsegmentation/pull/263))
+- Support Dice evaluation metric ([#225](https://github.com/open-mmlab/mmsegmentation/pull/225))
+- Support Adjust Gamma transform ([#232](https://github.com/open-mmlab/mmsegmentation/pull/232))
+- Support CLAHE transform ([#229](https://github.com/open-mmlab/mmsegmentation/pull/229))
+
+**Bug Fixes**
+
+- Fixed detail API link ([#267](https://github.com/open-mmlab/mmsegmentation/pull/267))
+
+### V0.8 (03/11/2020)
+
+**Highlights**
+
+- Support 4 medical dataset, UNet and CGNet.
+
+**New Features**
+
+- Support customize runner ([#118](https://github.com/open-mmlab/mmsegmentation/pull/118))
+- Support UNet ([#161](https://github.com/open-mmlab/mmsegmentation/pull/162))
+- Support CHASE_DB1, DRIVE, STARE, HRD ([#203](https://github.com/open-mmlab/mmsegmentation/pull/203))
+- Support CGNet ([#223](https://github.com/open-mmlab/mmsegmentation/pull/223))
+
+### V0.7 (07/10/2020)
+
+**Highlights**
+
+- Support Pascal Context dataset and customizing class dataset.
+
+**Bug Fixes**
+
+- Fixed CPU inference ([#153](https://github.com/open-mmlab/mmsegmentation/pull/153))
+
+**New Features**
+
+- Add DeepLab OS16 models ([#154](https://github.com/open-mmlab/mmsegmentation/pull/154))
+- Support Pascal Context dataset ([#133](https://github.com/open-mmlab/mmsegmentation/pull/133))
+- Support customizing dataset classes ([#71](https://github.com/open-mmlab/mmsegmentation/pull/71))
+- Support customizing dataset palette ([#157](https://github.com/open-mmlab/mmsegmentation/pull/157))
+
+**Improvements**
+
+- Support 4D tensor output in ONNX ([#150](https://github.com/open-mmlab/mmsegmentation/pull/150))
+- Remove redundancies in ONNX export ([#160](https://github.com/open-mmlab/mmsegmentation/pull/160))
+- Migrate to MMCV DepthwiseSeparableConv ([#158](https://github.com/open-mmlab/mmsegmentation/pull/158))
+- Migrate to MMCV collect_env ([#137](https://github.com/open-mmlab/mmsegmentation/pull/137))
+- Use img_prefix and seg_prefix for loading ([#153](https://github.com/open-mmlab/mmsegmentation/pull/153))
+
+### V0.6 (10/09/2020)
+
+**Highlights**
+
+- Support new methods i.e. MobileNetV2, EMANet, DNL, PointRend, Semantic FPN, Fast-SCNN, ResNeSt.
+
+**Bug Fixes**
+
+- Fixed sliding inference ONNX export ([#90](https://github.com/open-mmlab/mmsegmentation/pull/90))
+
+**New Features**
+
+- Support MobileNet v2 ([#86](https://github.com/open-mmlab/mmsegmentation/pull/86))
+- Support EMANet ([#34](https://github.com/open-mmlab/mmsegmentation/pull/34))
+- Support DNL ([#37](https://github.com/open-mmlab/mmsegmentation/pull/37))
+- Support PointRend ([#109](https://github.com/open-mmlab/mmsegmentation/pull/109))
+- Support Semantic FPN ([#94](https://github.com/open-mmlab/mmsegmentation/pull/94))
+- Support Fast-SCNN ([#58](https://github.com/open-mmlab/mmsegmentation/pull/58))
+- Support ResNeSt backbone ([#47](https://github.com/open-mmlab/mmsegmentation/pull/47))
+- Support ONNX export (experimental) ([#12](https://github.com/open-mmlab/mmsegmentation/pull/12))
+
+**Improvements**
+
+- Support Upsample in ONNX ([#100](https://github.com/open-mmlab/mmsegmentation/pull/100))
+- Support Windows install (experimental) ([#75](https://github.com/open-mmlab/mmsegmentation/pull/75))
+- Add more OCRNet results ([#20](https://github.com/open-mmlab/mmsegmentation/pull/20))
+- Add PyTorch 1.6 CI ([#64](https://github.com/open-mmlab/mmsegmentation/pull/64))
+- Get version and githash automatically ([#55](https://github.com/open-mmlab/mmsegmentation/pull/55))
+
+### v0.5.1 (11/08/2020)
+
+**Highlights**
+
+- Support FP16 and more generalized OHEM
+
+**Bug Fixes**
+
+- Fixed Pascal VOC conversion script (#19)
+- Fixed OHEM weight assign bug (#54)
+- Fixed palette type when palette is not given (#27)
+
+**New Features**
+
+- Support FP16 (#21)
+- Generalized OHEM (#54)
+
+**Improvements**
+
+- Add load-from flag (#33)
+- Fixed training tricks doc about different learning rates of model (#26)
diff --git a/docs/en/conf.py b/docs/en/conf.py
new file mode 100644
index 0000000..87b16f2
--- /dev/null
+++ b/docs/en/conf.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+#
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../../'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMSegmentation'
+copyright = '2020-2021, OpenMMLab'
+author = 'MMSegmentation Authors'
+version_file = '../../mmseg/version.py'
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+# The full version, including alpha/beta/rc tags
+release = get_version()
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
+ 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser'
+]
+
+autodoc_mock_imports = [
+ 'matplotlib', 'pycocotools', 'mmseg.version', 'mmcv.ops'
+]
+
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The master toctree document.
+master_doc = 'index'
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+# html_theme = 'sphinx_rtd_theme'
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+html_theme_options = {
+ 'logo_url':
+ 'https://mmsegmentation.readthedocs.io/en/latest/',
+ 'menu': [
+ {
+ 'name':
+ 'Tutorial',
+ 'url':
+ 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
+ 'demo/MMSegmentation_Tutorial.ipynb'
+ },
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmsegmentation'
+ },
+ {
+ 'name':
+ 'Upstream',
+ 'children': [
+ {
+ 'name': 'MMCV',
+ 'url': 'https://github.com/open-mmlab/mmcv',
+ 'description': 'Foundational library for computer vision'
+ },
+ ]
+ },
+ ],
+ # Specify the language of shared menu
+ 'menu_lang':
+ 'en'
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# Enable ::: for my_st
+myst_enable_extensions = ['colon_fence']
+
+language = 'en'
+
+
+def builder_inited_handler(app):
+ subprocess.run(['./stat.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/docs/en/dataset_prepare.md b/docs/en/dataset_prepare.md
new file mode 100644
index 0000000..c115e86
--- /dev/null
+++ b/docs/en/dataset_prepare.md
@@ -0,0 +1,327 @@
+## Prepare datasets
+
+It is recommended to symlink the dataset root to `$MMSEGMENTATION/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+```none
+mmsegmentation
+├── mmseg
+├── tools
+├── configs
+├── data
+│ ├── cityscapes
+│ │ ├── leftImg8bit
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── gtFine
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── VOCdevkit
+│ │ ├── VOC2012
+│ │ │ ├── JPEGImages
+│ │ │ ├── SegmentationClass
+│ │ │ ├── ImageSets
+│ │ │ │ ├── Segmentation
+│ │ ├── VOC2010
+│ │ │ ├── JPEGImages
+│ │ │ ├── SegmentationClassContext
+│ │ │ ├── ImageSets
+│ │ │ │ ├── SegmentationContext
+│ │ │ │ │ ├── train.txt
+│ │ │ │ │ ├── val.txt
+│ │ │ ├── trainval_merged.json
+│ │ ├── VOCaug
+│ │ │ ├── dataset
+│ │ │ │ ├── cls
+│ ├── ade
+│ │ ├── ADEChallengeData2016
+│ │ │ ├── annotations
+│ │ │ │ ├── training
+│ │ │ │ ├── validation
+│ │ │ ├── images
+│ │ │ │ ├── training
+│ │ │ │ ├── validation
+│ ├── coco_stuff10k
+│ │ ├── images
+│ │ │ ├── train2014
+│ │ │ ├── test2014
+│ │ ├── annotations
+│ │ │ ├── train2014
+│ │ │ ├── test2014
+│ │ ├── imagesLists
+│ │ │ ├── train.txt
+│ │ │ ├── test.txt
+│ │ │ ├── all.txt
+│ ├── coco_stuff164k
+│ │ ├── images
+│ │ │ ├── train2017
+│ │ │ ├── val2017
+│ │ ├── annotations
+│ │ │ ├── train2017
+│ │ │ ├── val2017
+│ ├── CHASE_DB1
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── DRIVE
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── HRF
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── STARE
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+| ├── dark_zurich
+| │ ├── gps
+| │ │ ├── val
+| │ │ └── val_ref
+| │ ├── gt
+| │ │ └── val
+| │ ├── LICENSE.txt
+| │ ├── lists_file_names
+| │ │ ├── val_filenames.txt
+| │ │ └── val_ref_filenames.txt
+| │ ├── README.md
+| │ └── rgb_anon
+| │ | ├── val
+| │ | └── val_ref
+| ├── NighttimeDrivingTest
+| | ├── gtCoarse_daytime_trainvaltest
+| | │ └── test
+| | │ └── night
+| | └── leftImg8bit
+| | | └── test
+| | | └── night
+│ ├── loveDA
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ │ ├── test
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── potsdam
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ ├── val
+```
+
+### Cityscapes
+
+The data could be found [here](https://www.cityscapes-dataset.com/downloads/) after registration.
+
+By convention, `**labelTrainIds.png` are used for cityscapes training.
+We provided a [scripts](https://github.com/open-mmlab/mmsegmentation/blob/master/tools/convert_datasets/cityscapes.py) based on [cityscapesscripts](https://github.com/mcordts/cityscapesScripts)
+to generate `**labelTrainIds.png`.
+
+```shell
+# --nproc means 8 process for conversion, which could be omitted as well.
+python tools/convert_datasets/cityscapes.py data/cityscapes --nproc 8
+```
+
+### Pascal VOC
+
+Pascal VOC 2012 could be downloaded from [here](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar).
+Beside, most recent works on Pascal VOC dataset usually exploit extra augmentation data, which could be found [here](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/semantic_contours/benchmark.tgz).
+
+If you would like to use augmented VOC dataset, please run following command to convert augmentation annotations into proper format.
+
+```shell
+# --nproc means 8 process for conversion, which could be omitted as well.
+python tools/convert_datasets/voc_aug.py data/VOCdevkit data/VOCdevkit/VOCaug --nproc 8
+```
+
+Please refer to [concat dataset](https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/tutorials/customize_datasets.md#concatenate-dataset) for details about how to concatenate them and train them together.
+
+### ADE20K
+
+The training and validation set of ADE20K could be download from this [link](http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip).
+We may also download test set from [here](http://data.csail.mit.edu/places/ADEchallenge/release_test.zip).
+
+### Pascal Context
+
+The training and validation set of Pascal Context could be download from [here](http://host.robots.ox.ac.uk/pascal/VOC/voc2010/VOCtrainval_03-May-2010.tar). You may also download test set from [here](http://host.robots.ox.ac.uk:8080/eval/downloads/VOC2010test.tar) after registration.
+
+To split the training and validation set from original dataset, you may download trainval_merged.json from [here](https://codalabuser.blob.core.windows.net/public/trainval_merged.json).
+
+If you would like to use Pascal Context dataset, please install [Detail](https://github.com/zhanghang1989/detail-api) and then run the following command to convert annotations into proper format.
+
+```shell
+python tools/convert_datasets/pascal_context.py data/VOCdevkit data/VOCdevkit/VOC2010/trainval_merged.json
+```
+
+### COCO Stuff 10k
+
+The data could be downloaded [here](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip) by wget.
+
+For COCO Stuff 10k dataset, please run the following commands to download and convert the dataset.
+
+```shell
+# download
+mkdir coco_stuff10k && cd coco_stuff10k
+wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip
+
+# unzip
+unzip cocostuff-10k-v1.1.zip
+
+# --nproc means 8 process for conversion, which could be omitted as well.
+python tools/convert_datasets/coco_stuff10k.py /path/to/coco_stuff10k --nproc 8
+```
+
+By convention, mask labels in `/path/to/coco_stuff164k/annotations/*2014/*_labelTrainIds.png` are used for COCO Stuff 10k training and testing.
+
+### COCO Stuff 164k
+
+For COCO Stuff 164k dataset, please run the following commands to download and convert the augmented dataset.
+
+```shell
+# download
+mkdir coco_stuff164k && cd coco_stuff164k
+wget http://images.cocodataset.org/zips/train2017.zip
+wget http://images.cocodataset.org/zips/val2017.zip
+wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip
+
+# unzip
+unzip train2017.zip -d images/
+unzip val2017.zip -d images/
+unzip stuffthingmaps_trainval2017.zip -d annotations/
+
+# --nproc means 8 process for conversion, which could be omitted as well.
+python tools/convert_datasets/coco_stuff164k.py /path/to/coco_stuff164k --nproc 8
+```
+
+By convention, mask labels in `/path/to/coco_stuff164k/annotations/*2017/*_labelTrainIds.png` are used for COCO Stuff 164k training and testing.
+
+The details of this dataset could be found at [here](https://github.com/nightrome/cocostuff#downloads).
+
+### CHASE DB1
+
+The training and validation set of CHASE DB1 could be download from [here](https://staffnet.kingston.ac.uk/~ku15565/CHASE_DB1/assets/CHASEDB1.zip).
+
+To convert CHASE DB1 dataset to MMSegmentation format, you should run the following command:
+
+```shell
+python tools/convert_datasets/chase_db1.py /path/to/CHASEDB1.zip
+```
+
+The script will make directory structure automatically.
+
+### DRIVE
+
+The training and validation set of DRIVE could be download from [here](https://drive.grand-challenge.org/). Before that, you should register an account. Currently '1st_manual' is not provided officially.
+
+To convert DRIVE dataset to MMSegmentation format, you should run the following command:
+
+```shell
+python tools/convert_datasets/drive.py /path/to/training.zip /path/to/test.zip
+```
+
+The script will make directory structure automatically.
+
+### HRF
+
+First, download [healthy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy.zip), [glaucoma.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma.zip), [diabetic_retinopathy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy.zip), [healthy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy_manualsegm.zip), [glaucoma_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma_manualsegm.zip) and [diabetic_retinopathy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy_manualsegm.zip).
+
+To convert HRF dataset to MMSegmentation format, you should run the following command:
+
+```shell
+python tools/convert_datasets/hrf.py /path/to/healthy.zip /path/to/healthy_manualsegm.zip /path/to/glaucoma.zip /path/to/glaucoma_manualsegm.zip /path/to/diabetic_retinopathy.zip /path/to/diabetic_retinopathy_manualsegm.zip
+```
+
+The script will make directory structure automatically.
+
+### STARE
+
+First, download [stare-images.tar](http://cecas.clemson.edu/~ahoover/stare/probing/stare-images.tar), [labels-ah.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-ah.tar) and [labels-vk.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-vk.tar).
+
+To convert STARE dataset to MMSegmentation format, you should run the following command:
+
+```shell
+python tools/convert_datasets/stare.py /path/to/stare-images.tar /path/to/labels-ah.tar /path/to/labels-vk.tar
+```
+
+The script will make directory structure automatically.
+
+### Dark Zurich
+
+Since we only support test models on this dataset, you may only download [the validation set](https://data.vision.ee.ethz.ch/csakarid/shared/GCMA_UIoU/Dark_Zurich_val_anon.zip).
+
+### Nighttime Driving
+
+Since we only support test models on this dataset, you may only download [the test set](http://data.vision.ee.ethz.ch/daid/NighttimeDriving/NighttimeDrivingTest.zip).
+
+### LoveDA
+
+The data could be downloaded from Google Drive [here](https://drive.google.com/drive/folders/1ibYV0qwn4yuuh068Rnc-w4tPi0U0c-ti?usp=sharing).
+
+Or it can be downloaded from [zenodo](https://zenodo.org/record/5706578#.YZvN7SYRXdF), you should run the following command:
+
+```shell
+# Download Train.zip
+wget https://zenodo.org/record/5706578/files/Train.zip
+# Download Val.zip
+wget https://zenodo.org/record/5706578/files/Val.zip
+# Download Test.zip
+wget https://zenodo.org/record/5706578/files/Test.zip
+```
+
+For LoveDA dataset, please run the following command to download and re-organize the dataset.
+
+```shell
+python tools/convert_datasets/loveda.py /path/to/loveDA
+```
+
+Using trained model to predict test set of LoveDA and submit it to server can be found [here](https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/inference.md).
+
+More details about LoveDA can be found [here](https://github.com/Junjue-Wang/LoveDA).
+
+### ISPRS Potsdam
+
+The [Potsdam](https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-potsdam/)
+dataset is for urban semantic segmentation used in the 2D Semantic Labeling Contest - Potsdam.
+
+The dataset can be requested at the challenge [homepage](https://www2.isprs.org/commissions/comm2/wg4/benchmark/data-request-form/).
+The '2_Ortho_RGB.zip' and '5_Labels_all_noBoundary.zip' are required.
+
+For Potsdam dataset, please run the following command to download and re-organize the dataset.
+
+```shell
+python tools/convert_datasets/potsdam.py /path/to/potsdam
+```
+
+In our default setting, it will generate 3456 images for training and 2016 images for validation.
+
+### ISPRS Vaihingen
+
+The [Vaihingen](https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/)
+dataset is for urban semantic segmentation used in the 2D Semantic Labeling Contest - Vaihingen.
+
+The dataset can be requested at the challenge [homepage](https://www2.isprs.org/commissions/comm2/wg4/benchmark/data-request-form/).
+The 'ISPRS_semantic_labeling_Vaihingen.zip' and 'ISPRS_semantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE.zip' are required.
+
+For Vaihingen dataset, please run the following command to download and re-organize the dataset.
+
+```shell
+python tools/convert_datasets/vaihingen.py /path/to/vaihingen
+```
+
+In our default setting (`clip_size` =512, `stride_size`=256), it will generate 344 images for training and 398 images for validation.
diff --git a/docs/en/get_started.md b/docs/en/get_started.md
new file mode 100644
index 0000000..bd77456
--- /dev/null
+++ b/docs/en/get_started.md
@@ -0,0 +1,238 @@
+## Prerequisites
+
+- Linux or macOS (Windows is in experimental support)
+- Python 3.6+
+- PyTorch 1.3+
+- CUDA 9.2+ (If you build PyTorch from source, CUDA 9.0 is also compatible)
+- GCC 5+
+- [MMCV](https://mmcv.readthedocs.io/en/latest/#installation)
+
+The compatible MMSegmentation and MMCV versions are as below. Please install the correct version of MMCV to avoid installation issues.
+
+| MMSegmentation version | MMCV version |
+|:----------------------:|:--------------------------:|
+| master | mmcv-full>=1.4.4, <1.5.0 |
+| 0.21.0 | mmcv-full>=1.4.4, <1.5.0 |
+| 0.20.0 | mmcv-full>=1.3.13, <1.5.0 |
+| 0.19.0 | mmcv-full>=1.3.13, <1.3.17 |
+| 0.18.0 | mmcv-full>=1.3.13, <1.3.17 |
+| 0.17.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.16.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.15.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.14.1 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.14.0 | mmcv-full>=1.3.1, <1.3.2 |
+| 0.13.0 | mmcv-full>=1.3.1, <1.3.2 |
+| 0.12.0 | mmcv-full>=1.1.4, <1.3.2 |
+| 0.11.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.10.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.9.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.8.0 | mmcv-full>=1.1.4, <1.2.0 |
+| 0.7.0 | mmcv-full>=1.1.2, <1.2.0 |
+| 0.6.0 | mmcv-full>=1.1.2, <1.2.0 |
+
+:::{note}
+You need to run `pip uninstall mmcv` first if you have mmcv installed.
+If mmcv and mmcv-full are both installed, there will be `ModuleNotFoundError`.
+:::
+
+## Installation
+
+a. Create a conda virtual environment and activate it.
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+```
+
+b. Install PyTorch and torchvision following the [official instructions](https://pytorch.org/).
+Here we use PyTorch 1.6.0 and CUDA 10.1.
+You may also switch to other version by specifying the version number.
+
+```shell
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+```
+
+c. Install [MMCV](https://mmcv.readthedocs.io/en/latest/) following the [official instructions](https://mmcv.readthedocs.io/en/latest/#installation).
+Either `mmcv` or `mmcv-full` is compatible with MMSegmentation, but for methods like CCNet and PSANet, CUDA ops in `mmcv-full` is required.
+
+**Install mmcv for Linux:**
+
+The pre-build mmcv-full (with PyTorch 1.6 and CUDA 10.1) can be installed by running: (other available versions could be found [here](https://mmcv.readthedocs.io/en/latest/#install-with-pip))
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
+```
+
+**Install mmcv for Windows (Experimental):**
+
+For Windows, the installation of MMCV requires native C++ compilers, such as cl.exe. Please add the compiler to %PATH%.
+
+A typical path for cl.exe looks like the following if you have Windows SDK and Visual Studio installed on your computer:
+
+```shell
+C:\Program Files (x86)\Microsoft Visual Studio\2019\Professional\VC\Tools\MSVC\14.26.28801\bin\Hostx86\x64
+```
+
+Or you should download the cl compiler from web and then set up the path.
+
+Then, clone mmcv from github and install mmcv via pip:
+
+```shell
+git clone https://github.com/open-mmlab/mmcv.git
+cd mmcv
+pip install -e .
+```
+
+Or simply:
+
+```shell
+pip install mmcv
+```
+
+Currently, mmcv-full is not supported on Windows.
+
+d. Install MMSegmentation.
+
+```shell
+pip install mmsegmentation # install the latest release
+```
+
+or
+
+```shell
+pip install git+https://github.com/open-mmlab/mmsegmentation.git # install the master branch
+```
+
+Instead, if you would like to install MMSegmentation in `dev` mode, run following
+
+```shell
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # or "python setup.py develop"
+```
+
+:::{note}
+
+1. When training or testing models on Windows, please ensure that all the '\\' in paths are replaced with '/'. Add .replace('\\', '/') to your python code wherever path strings occur.
+2. The `version+git_hash` will also be saved in trained models meta, e.g. 0.5.0+c415a2e.
+3. When MMsegmentation is installed on `dev` mode, any local modifications made to the code will take effect without the need to reinstall it.
+4. If you would like to use `opencv-python-headless` instead of `opencv-python`,
+ you can install it before installing MMCV.
+5. Some dependencies are optional. Simply running `pip install -e .` will only install the minimum runtime requirements.
+ To use optional dependencies like `cityscapessripts` either install them manually with `pip install -r requirements/optional.txt` or specify desired extras when calling `pip` (e.g. `pip install -e .[optional]`). Valid keys for the extras field are: `all`, `tests`, `build`, and `optional`.
+:::
+
+### A from-scratch setup script
+
+#### Linux
+
+Here is a full script for setting up mmsegmentation with conda and link the dataset path (supposing that your dataset path is $DATA_ROOT).
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # or "python setup.py develop"
+
+mkdir data
+ln -s $DATA_ROOT data
+```
+
+#### Windows(Experimental)
+
+Here is a full script for setting up mmsegmentation with conda and link the dataset path (supposing that your dataset path is
+%DATA_ROOT%. Notice: It must be an absolute path).
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+set PATH=full\path\to\your\cpp\compiler;%PATH%
+pip install mmcv
+
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # or "python setup.py develop"
+
+mklink /D data %DATA_ROOT%
+```
+
+#### Developing with multiple MMSegmentation versions
+
+The train and test scripts already modify the `PYTHONPATH` to ensure the script use the MMSegmentation in the current directory.
+
+To use the default MMSegmentation installed in the environment rather than that you are working with, you can remove the following line in those scripts
+
+```shell
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
+```
+
+## Verification
+
+To verify whether MMSegmentation and the required environment are installed correctly, we can run sample python codes to initialize a segmentor and inference a demo image:
+
+```python
+from mmseg.apis import inference_segmentor, init_segmentor
+import mmcv
+
+config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'
+checkpoint_file = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
+
+# build the model from a config file and a checkpoint file
+model = init_segmentor(config_file, checkpoint_file, device='cuda:0')
+
+# test a single image and show the results
+img = 'test.jpg' # or img = mmcv.imread(img), which will only load it once
+result = inference_segmentor(model, img)
+# visualize the results in a new window
+model.show_result(img, result, show=True)
+# or save the visualization results to image files
+# you can change the opacity of the painted segmentation map in (0, 1].
+model.show_result(img, result, out_file='result.jpg', opacity=0.5)
+
+# test a video and show the results
+video = mmcv.VideoReader('video.mp4')
+for frame in video:
+ result = inference_segmentor(model, frame)
+ model.show_result(frame, result, wait_time=1)
+```
+
+The above code is supposed to run successfully upon you finish the installation.
+
+We also provide a demo script to test a single image.
+
+```shell
+python demo/image_demo.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${DEVICE_NAME}] [--palette-thr ${PALETTE}]
+```
+
+Examples:
+
+```shell
+python demo/image_demo.py demo/demo.jpg configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --palette cityscapes
+```
+
+A notebook demo can be found in [demo/inference_demo.ipynb](../demo/inference_demo.ipynb).
+
+Now we also provide a demo script to test a single video.
+
+```shell
+wget -O demo/demo.mp4 https://user-images.githubusercontent.com/22089207/144212749-44411ef4-b564-4b37-96d4-04bedec629ab.mp4
+python demo/video_demo.py ${VIDEO_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${DEVICE_NAME}] [--palette-thr ${PALETTE}] \
+ [--show] [--show-wait-time {SHOW_WAIT_TIME}] [--output-file {OUTPUT_FILE}] [--output-fps {OUTPUT_FPS}] \
+ [--output-height {OUTPUT_HEIGHT}] [--output-width {OUTPUT_WIDTH}] [--opacity {OPACITY}]
+```
+
+Examples:
+
+```shell
+wget -O demo/demo.mp4 https://user-images.githubusercontent.com/22089207/144212749-44411ef4-b564-4b37-96d4-04bedec629ab.mp4
+python demo/video_demo.py demo/demo.mp4 configs/cgnet/cgnet_680x680_60k_cityscapes.py \
+ checkpoints/cgnet_680x680_60k_cityscapes_20201101_110253-4c0b2f2d.pth \
+ --device cuda:0 --palette cityscapes --show
+```
diff --git a/docs/en/index.rst b/docs/en/index.rst
new file mode 100644
index 0000000..b778e18
--- /dev/null
+++ b/docs/en/index.rst
@@ -0,0 +1,62 @@
+Welcome to MMSegmenation's documentation!
+=======================================
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Get Started
+
+ get_started.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Dataset Preparation
+
+ dataset_prepare.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Model Zoo
+
+ model_zoo.md
+ modelzoo_statistics.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Quick Run
+
+ train.md
+ inference.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Tutorials
+
+ tutorials/index.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Useful Tools and Scripts
+
+ useful_tools.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Notes
+
+ changelog.md
+
+.. toctree::
+ :caption: Switch Language
+
+ switch_language.md
+
+.. toctree::
+ :caption: API Reference
+
+ api.rst
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/docs/en/inference.md b/docs/en/inference.md
new file mode 100644
index 0000000..cd6eaf0
--- /dev/null
+++ b/docs/en/inference.md
@@ -0,0 +1,130 @@
+## Inference with pretrained models
+
+We provide testing scripts to evaluate a whole dataset (Cityscapes, PASCAL VOC, ADE20k, etc.),
+and also some high-level apis for easier integration to other projects.
+
+### Test a dataset
+
+- single GPU
+- CPU
+- single node multiple GPU
+- multiple node
+
+You can use the following commands to test a dataset.
+
+```shell
+# single-gpu testing
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show]
+
+# CPU: disable GPUs and run single-gpu testing script
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show]
+
+# multi-gpu testing
+./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}]
+```
+
+Optional arguments:
+
+- `RESULT_FILE`: Filename of the output results in pickle format. If not specified, the results will not be saved to a file. (After mmseg v0.17, the output results become pre-evaluation results or format result paths)
+- `EVAL_METRICS`: Items to be evaluated on the results. Allowed values depend on the dataset, e.g., `mIoU` is available for all dataset. Cityscapes could be evaluated by `cityscapes` as well as standard `mIoU` metrics.
+- `--show`: If specified, segmentation results will be plotted on the images and shown in a new window. It is only applicable to single GPU testing and used for debugging and visualization. Please make sure that GUI is available in your environment, otherwise you may encounter the error like `cannot connect to X server`.
+- `--show-dir`: If specified, segmentation results will be plotted on the images and saved to the specified directory. It is only applicable to single GPU testing and used for debugging and visualization. You do NOT need a GUI available in your environment for using this option.
+- `--eval-options`: Optional parameters for `dataset.format_results` and `dataset.evaluate` during evaluation. When `efficient_test=True`, it will save intermediate results to local files to save CPU memory. Make sure that you have enough local storage space (more than 20GB). (`efficient_test` argument does not have effect after mmseg v0.17, we use a progressive mode to evaluation and format results which can largely save memory cost and evaluation time.)
+
+Examples:
+
+Assume that you have already downloaded the checkpoints to the directory `checkpoints/`.
+
+1. Test PSPNet and visualize the results. Press any key for the next image.
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --show
+ ```
+
+2. Test PSPNet and save the painted images for latter visualization.
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --show-dir psp_r50_512x1024_40ki_cityscapes_results
+ ```
+
+3. Test PSPNet on PASCAL VOC (without saving the test results) and evaluate the mIoU.
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_20k_voc12aug.py \
+ checkpoints/pspnet_r50-d8_512x1024_20k_voc12aug_20200605_003338-c57ef100.pth \
+ --eval mAP
+ ```
+
+4. Test PSPNet with 4 GPUs, and evaluate the standard mIoU and cityscapes metric.
+
+ ```shell
+ ./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ 4 --out results.pkl --eval mIoU cityscapes
+ ```
+
+ :::{note}
+ There is some gap (~0.1%) between cityscapes mIoU and our mIoU. The reason is that cityscapes average each class with class size by default.
+ We use the simple version without average for all datasets.
+:::
+
+5. Test PSPNet on cityscapes test split with 4 GPUs, and generate the png files to be submit to the official evaluation server.
+
+ First, add following to config file `configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py`,
+
+ ```python
+ data = dict(
+ test=dict(
+ img_dir='leftImg8bit/test',
+ ann_dir='gtFine/test'))
+ ```
+
+ Then run test.
+
+ ```shell
+ ./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ 4 --format-only --eval-options "imgfile_prefix=./pspnet_test_results"
+ ```
+
+ You will get png files under `./pspnet_test_results` directory.
+ You may run `zip -r results.zip pspnet_test_results/` and submit the zip file to [evaluation server](https://www.cityscapes-dataset.com/submit/).
+
+6. CPU memory efficient test DeeplabV3+ on Cityscapes (without saving the test results) and evaluate the mIoU.
+
+ ```shell
+ python tools/test.py \
+ configs/deeplabv3plus/deeplabv3plus_r18-d8_512x1024_80k_cityscapes.py \
+ deeplabv3plus_r18-d8_512x1024_80k_cityscapes_20201226_080942-cff257fe.pth \
+ --eval-options efficient_test=True \
+ --eval mIoU
+ ```
+
+ Using ```pmap``` to view CPU memory footprint, it used 2.25GB CPU memory with ```efficient_test=True``` and 11.06GB CPU memory with ```efficient_test=False``` . This optional parameter can save a lot of memory. (After mmseg v0.17, efficient_test has not effect and we use a progressive mode to evaluation and format results efficiently by default.)
+
+7. Test PSPNet on LoveDA test split with 1 GPU, and generate the png files to be submit to the official evaluation server.
+
+ First, add following to config file `configs/pspnet/pspnet_r50-d8_512x512_80k_loveda.py`,
+
+ ```python
+ data = dict(
+ test=dict(
+ img_dir='img_dir/test',
+ ann_dir='ann_dir/test'))
+ ```
+
+ Then run test.
+
+ ```shell
+ python ./tools/test.py configs/pspnet/pspnet_r50-d8_512x512_80k_loveda.py \
+ checkpoints/pspnet_r50-d8_512x512_80k_loveda_20211104_155728-88610f9f.pth \
+ --format-only --eval-options "imgfile_prefix=./pspnet_test_results"
+ ```
+
+ You will get png files under `./pspnet_test_results` directory.
+ You may run `zip -r -j Results.zip pspnet_test_results/` and submit the zip file to [evaluation server](https://codalab.lisn.upsaclay.fr/competitions/421).
diff --git a/docs/en/make.bat b/docs/en/make.bat
new file mode 100644
index 0000000..922152e
--- /dev/null
+++ b/docs/en/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/en/model_zoo.md b/docs/en/model_zoo.md
new file mode 100644
index 0000000..e6498ad
--- /dev/null
+++ b/docs/en/model_zoo.md
@@ -0,0 +1,181 @@
+# Benchmark and Model Zoo
+
+## Common settings
+
+* We use distributed training with 4 GPUs by default.
+* All pytorch-style pretrained backbones on ImageNet are train by ourselves, with the same procedure in the [paper](https://arxiv.org/pdf/1812.01187.pdf).
+ Our ResNet style backbone are based on ResNetV1c variant, where the 7x7 conv in the input stem is replaced with three 3x3 convs.
+* For the consistency across different hardwares, we report the GPU memory as the maximum value of `torch.cuda.max_memory_allocated()` for all 4 GPUs with `torch.backends.cudnn.benchmark=False`.
+ Note that this value is usually less than what `nvidia-smi` shows.
+* We report the inference time as the total time of network forwarding and post-processing, excluding the data loading time.
+ Results are obtained with the script `tools/benchmark.py` which computes the average time on 200 images with `torch.backends.cudnn.benchmark=False`.
+* There are two inference modes in this framework.
+
+ * `slide` mode: The `test_cfg` will be like `dict(mode='slide', crop_size=(769, 769), stride=(513, 513))`.
+
+ In this mode, multiple patches will be cropped from input image, passed into network individually.
+ The crop size and stride between patches are specified by `crop_size` and `stride`.
+ The overlapping area will be merged by average
+
+ * `whole` mode: The `test_cfg` will be like `dict(mode='whole')`.
+
+ In this mode, the whole imaged will be passed into network directly.
+
+ By default, we use `slide` inference for 769x769 trained model, `whole` inference for the rest.
+* For input size of 8x+1 (e.g. 769), `align_corner=True` is adopted as a traditional practice.
+ Otherwise, for input size of 8x (e.g. 512, 1024), `align_corner=False` is adopted.
+
+## Baselines
+
+### FCN
+
+Please refer to [FCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fcn) for details.
+
+### PSPNet
+
+Please refer to [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/pspnet) for details.
+
+### DeepLabV3
+
+Please refer to [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3) for details.
+
+### PSANet
+
+Please refer to [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/psanet) for details.
+
+### DeepLabV3+
+
+Please refer to [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3plus) for details.
+
+### UPerNet
+
+Please refer to [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/upernet) for details.
+
+### NonLocal Net
+
+Please refer to [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net) for details.
+
+### EncNet
+
+Please refer to [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/encnet) for details.
+
+### CCNet
+
+Please refer to [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ccnet) for details.
+
+### DANet
+
+Please refer to [DANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/danet) for details.
+
+### APCNet
+
+Please refer to [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/apcnet) for details.
+
+### HRNet
+
+Please refer to [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/hrnet) for details.
+
+### GCNet
+
+Please refer to [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/gcnet) for details.
+
+### DMNet
+
+Please refer to [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dmnet) for details.
+
+### ANN
+
+Please refer to [ANN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ann) for details.
+
+### OCRNet
+
+Please refer to [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ocrnet) for details.
+
+### Fast-SCNN
+
+Please refer to [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastscnn) for details.
+
+### ResNeSt
+
+Please refer to [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest) for details.
+
+### Semantic FPN
+
+Please refer to [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/sem_fpn) for details.
+
+### PointRend
+
+Please refer to [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/point_rend) for details.
+
+### MobileNetV2
+
+Please refer to [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v2) for details.
+
+### MobileNetV3
+
+Please refer to [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v3) for details.
+
+### EMANet
+
+Please refer to [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/emanet) for details.
+
+### DNLNet
+
+Please refer to [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dnlnet) for details.
+
+### CGNet
+
+Please refer to [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/cgnet) for details.
+
+### Mixed Precision (FP16) Training
+
+Please refer [Mixed Precision (FP16) Training on BiSeNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv2/bisenetv2_fcn_fp16_4x4_1024x1024_160k_cityscapes.py) for details.
+
+### U-Net
+
+Please refer to [U-Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/unet/README.md) for details.
+
+### ViT
+
+Please refer to [ViT](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/vit/README.md) for details.
+
+### Swin
+
+Please refer to [Swin](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/swin/README.md) for details.
+
+### SETR
+
+Please refer to [SETR](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/setr/README.md) for details.
+
+## Speed benchmark
+
+### Hardware
+
+* 8 NVIDIA Tesla V100 (32G) GPUs
+* Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
+
+### Software environment
+
+* Python 3.7
+* PyTorch 1.5
+* CUDA 10.1
+* CUDNN 7.6.03
+* NCCL 2.4.08
+
+### Training speed
+
+For fair comparison, we benchmark all implementations with ResNet-101V1c.
+The input size is fixed to 1024x512 with batch size 2.
+
+The training speed is reported as followed, in terms of second per iter (s/iter). The lower, the better.
+
+| Implementation | PSPNet (s/iter) | DeepLabV3+ (s/iter) |
+|----------------|-----------------|---------------------|
+| [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) | **0.83** | **0.85** |
+| [SegmenTron](https://github.com/LikeLy-Journey/SegmenTron) | 0.84 | 0.85 |
+| [CASILVision](https://github.com/CSAILVision/semantic-segmentation-pytorch) | 1.15 | N/A |
+| [vedaseg](https://github.com/Media-Smart/vedaseg) | 0.95 | 1.25 |
+
+:::{note}
+The output stride of DeepLabV3+ is 8.
+:::
diff --git a/docs/en/stat.py b/docs/en/stat.py
new file mode 100755
index 0000000..1398a70
--- /dev/null
+++ b/docs/en/stat.py
@@ -0,0 +1,65 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools as func
+import glob
+import os.path as osp
+import re
+
+import numpy as np
+
+url_prefix = 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
+
+files = sorted(glob.glob('../../configs/*/README.md'))
+
+stats = []
+titles = []
+num_ckpts = 0
+
+for f in files:
+ url = osp.dirname(f.replace('../../', url_prefix))
+
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ title = content.split('\n')[0].replace('#', '').strip()
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https?://download.*\.pth', content)
+ if 'mmsegmentation' in x)
+ if len(ckpts) == 0:
+ continue
+
+ _papertype = [
+ x for x in re.findall(r'', content)
+ ]
+ assert len(_papertype) > 0
+ papertype = _papertype[0]
+
+ paper = set([(papertype, title)])
+
+ titles.append(title)
+ num_ckpts += len(ckpts)
+ statsmsg = f"""
+\t* [{papertype}] [{title}]({url}) ({len(ckpts)} ckpts)
+"""
+ stats.append((paper, ckpts, statsmsg))
+
+allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _ in stats])
+msglist = '\n'.join(x for _, _, x in stats)
+
+papertypes, papercounts = np.unique([t for t, _ in allpapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# Model Zoo Statistics
+
+* Number of papers: {len(set(titles))}
+{countstr}
+
+* Number of checkpoints: {num_ckpts}
+{msglist}
+"""
+
+with open('modelzoo_statistics.md', 'w') as f:
+ f.write(modelzoo)
diff --git a/docs/en/switch_language.md b/docs/en/switch_language.md
new file mode 100644
index 0000000..f58efc4
--- /dev/null
+++ b/docs/en/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/docs/en/train.md b/docs/en/train.md
new file mode 100644
index 0000000..2c5dfb2
--- /dev/null
+++ b/docs/en/train.md
@@ -0,0 +1,105 @@
+## Train a model
+
+MMSegmentation implements distributed training and non-distributed training,
+which uses `MMDistributedDataParallel` and `MMDataParallel` respectively.
+
+All outputs (log files and checkpoints) will be saved to the working directory,
+which is specified by `work_dir` in the config file.
+
+By default we evaluate the model on the validation set after some iterations, you can change the evaluation interval by adding the interval argument in the training config.
+
+```python
+evaluation = dict(interval=4000) # This evaluate the model per 4000 iterations.
+```
+
+**\*Important\***: The default learning rate in config files is for 4 GPUs and 2 img/gpu (batch size = 4x2 = 8).
+Equivalently, you may also use 8 GPUs and 1 imgs/gpu since all models using cross-GPU SyncBN.
+
+To trade speed with GPU memory, you may pass in `--cfg-options model.backbone.with_cp=True` to enable checkpoint in backbone.
+
+### Train with a single GPU
+
+official support:
+
+```shell
+./tools/dist_train.sh ${CONFIG_FILE} 1 [optional arguments]
+```
+
+experimental support (Convert SyncBN to BN):
+
+```shell
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+If you want to specify the working directory in the command, you can add an argument `--work-dir ${YOUR_WORK_DIR}`.
+
+### Train with CPU
+
+The process of training on the CPU is consistent with single GPU training. We just need to disable GPUs before the training process.
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+```
+
+And then run the script [above](#train-with-a-single-gpu).
+
+```{warning}
+The process of training on the CPU is consistent with single GPU training. We just need to disable GPUs before the training process.
+```
+
+### Train with multiple GPUs
+
+```shell
+./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
+```
+
+Optional arguments are:
+
+- `--no-validate` (**not suggested**): By default, the codebase will perform evaluation at every k iterations during the training. To disable this behavior, use `--no-validate`.
+- `--work-dir ${WORK_DIR}`: Override the working directory specified in the config file.
+- `--resume-from ${CHECKPOINT_FILE}`: Resume from a previous checkpoint file (to continue the training process).
+- `--load-from ${CHECKPOINT_FILE}`: Load weights from a checkpoint file (to start finetuning for another task).
+
+Difference between `resume-from` and `load-from`:
+
+- `resume-from` loads both the model weights and optimizer state including the iteration number.
+- `load-from` loads only the model weights, starts the training from iteration 0.
+
+### Train with multiple machines
+
+If you run MMSegmentation on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `slurm_train.sh`. (This script also supports single machine training.)
+
+```shell
+[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} --work-dir ${WORK_DIR}
+```
+
+Here is an example of using 16 GPUs to train PSPNet on the dev partition.
+
+```shell
+GPUS=16 ./tools/slurm_train.sh dev pspr50 configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py /nfs/xxxx/psp_r50_512x1024_40ki_cityscapes
+```
+
+You can check [slurm_train.sh](../tools/slurm_train.sh) for full arguments and environment variables.
+
+If you have just multiple machines connected with ethernet, you can refer to
+PyTorch [launch utility](https://pytorch.org/docs/stable/distributed.html#launch-utility).
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+### Launch multiple jobs on a single machine
+
+If you launch multiple jobs on a single machine, e.g., 2 jobs of 4-GPU training on a machine with 8 GPUs,
+you need to specify different ports (29500 by default) for each job to avoid communication conflict. Otherwise, there will be error message saying `RuntimeError: Address already in use`.
+
+If you use `dist_train.sh` to launch training jobs, you can set the port in commands with environment variable `PORT`.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4
+```
+
+If you use `slurm_train.sh` to launch training jobs, you can set the port in commands with environment variable `MASTER_PORT`.
+
+```shell
+MASTER_PORT=29500 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE}
+MASTER_PORT=29501 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE}
+```
diff --git a/docs/en/tutorials/config.md b/docs/en/tutorials/config.md
new file mode 100644
index 0000000..f528e75
--- /dev/null
+++ b/docs/en/tutorials/config.md
@@ -0,0 +1,381 @@
+# Tutorial 1: Learn about Configs
+
+We incorporate modular and inheritance design into our config system, which is convenient to conduct various experiments.
+If you wish to inspect the config file, you may run `python tools/print_config.py /PATH/TO/CONFIG` to see the complete config.
+You may also pass `--cfg-options xxx.yyy=zzz` to see updated config.
+
+## Config File Structure
+
+There are 4 basic component types under `config/_base_`, dataset, model, schedule, default_runtime.
+Many methods could be easily constructed with one of each like DeepLabV3, PSPNet.
+The configs that are composed by components from `_base_` are called _primitive_.
+
+For all configs under the same folder, it is recommended to have only **one** _primitive_ config. All other configs should inherit from the _primitive_ config. In this way, the maximum of inheritance level is 3.
+
+For easy understanding, we recommend contributors to inherit from exiting methods.
+For example, if some modification is made base on DeepLabV3, user may first inherit the basic DeepLabV3 structure by specifying `_base_ = ../deeplabv3/deeplabv3_r50_512x1024_40ki_cityscapes.py`, then modify the necessary fields in the config files.
+
+If you are building an entirely new method that does not share the structure with any of the existing methods, you may create a folder `xxxnet` under `configs`,
+
+Please refer to [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html) for detailed documentation.
+
+## Config Name Style
+
+We follow the below style to name config files. Contributors are advised to follow the same style.
+
+```
+{model}_{backbone}_[misc]_[gpu x batch_per_gpu]_{resolution}_{schedule}_{dataset}
+```
+
+`{xxx}` is required field and `[yyy]` is optional.
+
+- `{model}`: model type like `psp`, `deeplabv3`, etc.
+- `{backbone}`: backbone type like `r50` (ResNet-50), `x101` (ResNeXt-101).
+- `[misc]`: miscellaneous setting/plugins of model, e.g. `dconv`, `gcb`, `attention`, `mstrain`.
+- `[gpu x batch_per_gpu]`: GPUs and samples per GPU, `8x2` is used by default.
+- `{schedule}`: training schedule, `20ki` means 20k iterations.
+- `{dataset}`: dataset like `cityscapes`, `voc12aug`, `ade`.
+
+## An Example of PSPNet
+
+To help the users have a basic idea of a complete config and the modules in a modern semantic segmentation system,
+we make brief comments on the config of PSPNet using ResNet50V1c as the following.
+For more detailed usage and the corresponding alternative for each modules, please refer to the API documentation.
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True) # Segmentation usually uses SyncBN
+model = dict(
+ type='EncoderDecoder', # Name of segmentor
+ pretrained='open-mmlab://resnet50_v1c', # The ImageNet pretrained backbone to be loaded
+ backbone=dict(
+ type='ResNetV1c', # The type of backbone. Please refer to mmseg/models/backbones/resnet.py for details.
+ depth=50, # Depth of backbone. Normally 50, 101 are used.
+ num_stages=4, # Number of stages of backbone.
+ out_indices=(0, 1, 2, 3), # The index of output feature maps produced in each stages.
+ dilations=(1, 1, 2, 4), # The dilation rate of each layer.
+ strides=(1, 2, 1, 1), # The stride of each layer.
+ norm_cfg=dict( # The configuration of norm layer.
+ type='SyncBN', # Type of norm layer. Usually it is SyncBN.
+ requires_grad=True), # Whether to train the gamma and beta in norm
+ norm_eval=False, # Whether to freeze the statistics in BN
+ style='pytorch', # The style of backbone, 'pytorch' means that stride 2 layers are in 3x3 conv, 'caffe' means stride 2 layers are in 1x1 convs.
+ contract_dilation=True), # When dilation > 1, whether contract first layer of dilation.
+ decode_head=dict(
+ type='PSPHead', # Type of decode head. Please refer to mmseg/models/decode_heads for available options.
+ in_channels=2048, # Input channel of decode head.
+ in_index=3, # The index of feature map to select.
+ channels=512, # The intermediate channels of decode head.
+ pool_scales=(1, 2, 3, 6), # The avg pooling scales of PSPHead. Please refer to paper for details.
+ dropout_ratio=0.1, # The dropout ratio before final classification layer.
+ num_classes=19, # Number of segmentation class. Usually 19 for cityscapes, 21 for VOC, 150 for ADE20k.
+ norm_cfg=dict(type='SyncBN', requires_grad=True), # The configuration of norm layer.
+ align_corners=False, # The align_corners argument for resize in decoding.
+ loss_decode=dict( # Config of loss function for the decode_head.
+ type='CrossEntropyLoss', # Type of loss used for segmentation.
+ use_sigmoid=False, # Whether use sigmoid activation for segmentation.
+ loss_weight=1.0)), # Loss weight of decode head.
+ auxiliary_head=dict(
+ type='FCNHead', # Type of auxiliary head. Please refer to mmseg/models/decode_heads for available options.
+ in_channels=1024, # Input channel of auxiliary head.
+ in_index=2, # The index of feature map to select.
+ channels=256, # The intermediate channels of decode head.
+ num_convs=1, # Number of convs in FCNHead. It is usually 1 in auxiliary head.
+ concat_input=False, # Whether concat output of convs with input before classification layer.
+ dropout_ratio=0.1, # The dropout ratio before final classification layer.
+ num_classes=19, # Number of segmentation class. Usually 19 for cityscapes, 21 for VOC, 150 for ADE20k.
+ norm_cfg=dict(type='SyncBN', requires_grad=True), # The configuration of norm layer.
+ align_corners=False, # The align_corners argument for resize in decoding.
+ loss_decode=dict( # Config of loss function for the decode_head.
+ type='CrossEntropyLoss', # Type of loss used for segmentation.
+ use_sigmoid=False, # Whether use sigmoid activation for segmentation.
+ loss_weight=0.4))) # Loss weight of auxiliary head, which is usually 0.4 of decode head.
+train_cfg = dict() # train_cfg is just a place holder for now.
+test_cfg = dict(mode='whole') # The test mode, options are 'whole' and 'sliding'. 'whole': whole image fully-convolutional test. 'sliding': sliding crop window on the image.
+dataset_type = 'CityscapesDataset' # Dataset type, this will be used to define the dataset.
+data_root = 'data/cityscapes/' # Root path of data.
+img_norm_cfg = dict( # Image normalization config to normalize the input images.
+ mean=[123.675, 116.28, 103.53], # Mean values used to pre-training the pre-trained backbone models.
+ std=[58.395, 57.12, 57.375], # Standard variance used to pre-training the pre-trained backbone models.
+ to_rgb=True) # The channel orders of image used to pre-training the pre-trained backbone models.
+crop_size = (512, 1024) # The crop size during training.
+train_pipeline = [ # Training pipeline.
+ dict(type='LoadImageFromFile'), # First pipeline to load images from file path.
+ dict(type='LoadAnnotations'), # Second pipeline to load annotations for current image.
+ dict(type='Resize', # Augmentation pipeline that resize the images and their annotations.
+ img_scale=(2048, 1024), # The largest scale of image.
+ ratio_range=(0.5, 2.0)), # The augmented scale range as ratio.
+ dict(type='RandomCrop', # Augmentation pipeline that randomly crop a patch from current image.
+ crop_size=(512, 1024), # The crop size of patch.
+ cat_max_ratio=0.75), # The max area ratio that could be occupied by single category.
+ dict(
+ type='RandomFlip', # Augmentation pipeline that flip the images and their annotations
+ flip_ratio=0.5), # The ratio or probability to flip
+ dict(type='PhotoMetricDistortion'), # Augmentation pipeline that distort current image with several photo metric methods.
+ dict(
+ type='Normalize', # Augmentation pipeline that normalize the input images
+ mean=[123.675, 116.28, 103.53], # These keys are the same of img_norm_cfg since the
+ std=[58.395, 57.12, 57.375], # keys of img_norm_cfg are used here as arguments
+ to_rgb=True),
+ dict(type='Pad', # Augmentation pipeline that pad the image to specified size.
+ size=(512, 1024), # The output size of padding.
+ pad_val=0, # The padding value for image.
+ seg_pad_val=255), # The padding value of 'gt_semantic_seg'.
+ dict(type='DefaultFormatBundle'), # Default format bundle to gather data in the pipeline
+ dict(type='Collect', # Pipeline that decides which keys in the data should be passed to the segmentor
+ keys=['img', 'gt_semantic_seg'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'), # First pipeline to load images from file path
+ dict(
+ type='MultiScaleFlipAug', # An encapsulation that encapsulates the test time augmentations
+ img_scale=(2048, 1024), # Decides the largest scale for testing, used for the Resize pipeline
+ flip=False, # Whether to flip images during testing
+ transforms=[
+ dict(type='Resize', # Use resize augmentation
+ keep_ratio=True), # Whether to keep the ratio between height and width, the img_scale set here will be suppressed by the img_scale set above.
+ dict(type='RandomFlip'), # Thought RandomFlip is added in pipeline, it is not used when flip=False
+ dict(
+ type='Normalize', # Normalization config, the values are from img_norm_cfg
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', # Convert image to tensor
+ keys=['img']),
+ dict(type='Collect', # Collect pipeline that collect necessary keys for testing.
+ keys=['img'])
+ ])
+]
+data = dict(
+ samples_per_gpu=2, # Batch size of a single GPU
+ workers_per_gpu=2, # Worker to pre-fetch data for each single GPU
+ train=dict( # Train dataset config
+ type='CityscapesDataset', # Type of dataset, refer to mmseg/datasets/ for details.
+ data_root='data/cityscapes/', # The root of dataset.
+ img_dir='leftImg8bit/train', # The image directory of dataset.
+ ann_dir='gtFine/train', # The annotation directory of dataset.
+ pipeline=[ # pipeline, this is passed by the train_pipeline created before.
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(
+ type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=(512, 1024), cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size=(512, 1024), pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg'])
+ ]),
+ val=dict( # Validation dataset config
+ type='CityscapesDataset',
+ data_root='data/cityscapes/',
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=[ # Pipeline is passed by test_pipeline created before
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]),
+ test=dict(
+ type='CityscapesDataset',
+ data_root='data/cityscapes/',
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]))
+log_config = dict( # config to register logger hook
+ interval=50, # Interval to print the log
+ hooks=[
+ # dict(type='TensorboardLoggerHook') # The Tensorboard logger is also supported
+ dict(type='TextLoggerHook', by_epoch=False)
+ ])
+dist_params = dict(backend='nccl') # Parameters to setup distributed training, the port can also be set.
+log_level = 'INFO' # The level of logging.
+load_from = None # load models as a pre-trained model from a given path. This will not resume training.
+resume_from = None # Resume checkpoints from a given path, the training will be resumed from the iteration when the checkpoint's is saved.
+workflow = [('train', 1)] # Workflow for runner. [('train', 1)] means there is only one workflow and the workflow named 'train' is executed once. The workflow trains the model by 40000 iterations according to the `runner.max_iters`.
+cudnn_benchmark = True # Whether use cudnn_benchmark to speed up, which is fast for fixed input size.
+optimizer = dict( # Config used to build optimizer, support all the optimizers in PyTorch whose arguments are also the same as those in PyTorch
+ type='SGD', # Type of optimizers, refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/optimizer/default_constructor.py#L13 for more details
+ lr=0.01, # Learning rate of optimizers, see detail usages of the parameters in the documentation of PyTorch
+ momentum=0.9, # Momentum
+ weight_decay=0.0005) # Weight decay of SGD
+optimizer_config = dict() # Config used to build the optimizer hook, refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py#L8 for implementation details.
+lr_config = dict(
+ policy='poly', # The policy of scheduler, also support Step, CosineAnnealing, Cyclic, etc. Refer to details of supported LrUpdater from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9.
+ power=0.9, # The power of polynomial decay.
+ min_lr=0.0001, # The minimum learning rate to stable the training.
+ by_epoch=False) # Whether count by epoch or not.
+runner = dict(
+ type='IterBasedRunner', # Type of runner to use (i.e. IterBasedRunner or EpochBasedRunner)
+ max_iters=40000) # Total number of iterations. For EpochBasedRunner use `max_epochs`
+checkpoint_config = dict( # Config to set the checkpoint hook, Refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py for implementation.
+ by_epoch=False, # Whether count by epoch or not.
+ interval=4000) # The save interval.
+evaluation = dict( # The config to build the evaluation hook. Please refer to mmseg/core/evaluation/eval_hook.py for details.
+ interval=4000, # The interval of evaluation.
+ metric='mIoU') # The evaluation metric.
+
+
+```
+
+## FAQ
+
+### Ignore some fields in the base configs
+
+Sometimes, you may set `_delete_=True` to ignore some of fields in base configs.
+You may refer to [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html#inherit-from-base-config-with-ignored-fields) for simple inllustration.
+
+In MMSegmentation, for example, to change the backbone of PSPNet with the following config.
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='MaskRCNN',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(...),
+ auxiliary_head=dict(...))
+```
+
+`ResNet` and `HRNet` use different keywords to construct.
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscpaes.py'
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ pretrained='open-mmlab://msra/hrnetv2_w32',
+ backbone=dict(
+ _delete_=True,
+ type='HRNet',
+ norm_cfg=norm_cfg,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256)))),
+ decode_head=dict(...),
+ auxiliary_head=dict(...))
+```
+
+The `_delete_=True` would replace all old keys in `backbone` field with new keys.
+
+### Use intermediate variables in configs
+
+Some intermediate variables are used in the configs files, like `train_pipeline`/`test_pipeline` in datasets.
+It's worth noting that when modifying intermediate variables in the children configs, user need to pass the intermediate variables into corresponding fields again.
+For example, we would like to change multi scale strategy to train/test a PSPNet. `train_pipeline`/`test_pipeline` are intermediate variable we would like modify.
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscapes.py'
+crop_size = (512, 1024)
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(1.0, 2.0)), # change to [1., 2.]
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75], # change to multi scale testing
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
+```
+
+We first define the new `train_pipeline`/`test_pipeline` and pass them into `data`.
+
+Similarly, if we would like to switch from `SyncBN` to `BN` or `MMSyncBN`, we need to substitute every `norm_cfg` in the config.
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscpaes.py'
+norm_cfg = dict(type='BN', requires_grad=True)
+model = dict(
+ backbone=dict(norm_cfg=norm_cfg),
+ decode_head=dict(norm_cfg=norm_cfg),
+ auxiliary_head=dict(norm_cfg=norm_cfg))
+```
diff --git a/docs/en/tutorials/customize_datasets.md b/docs/en/tutorials/customize_datasets.md
new file mode 100644
index 0000000..2fc1693
--- /dev/null
+++ b/docs/en/tutorials/customize_datasets.md
@@ -0,0 +1,211 @@
+# Tutorial 2: Customize Datasets
+
+## Customize datasets by reorganizing data
+
+The simplest way is to convert your dataset to organize your data into folders.
+
+An example of file structure is as followed.
+
+```none
+├── data
+│ ├── my_dataset
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ │ ├── xxx{img_suffix}
+│ │ │ │ ├── yyy{img_suffix}
+│ │ │ │ ├── zzz{img_suffix}
+│ │ │ ├── val
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ │ ├── xxx{seg_map_suffix}
+│ │ │ │ ├── yyy{seg_map_suffix}
+│ │ │ │ ├── zzz{seg_map_suffix}
+│ │ │ ├── val
+
+```
+
+A training pair will consist of the files with same suffix in img_dir/ann_dir.
+
+If `split` argument is given, only part of the files in img_dir/ann_dir will be loaded.
+We may specify the prefix of files we would like to be included in the split txt.
+
+More specifically, for a split txt like following,
+
+```none
+xxx
+zzz
+```
+
+Only
+`data/my_dataset/img_dir/train/xxx{img_suffix}`,
+`data/my_dataset/img_dir/train/zzz{img_suffix}`,
+`data/my_dataset/ann_dir/train/xxx{seg_map_suffix}`,
+`data/my_dataset/ann_dir/train/zzz{seg_map_suffix}` will be loaded.
+
+:::{note}
+The annotations are images of shape (H, W), the value pixel should fall in range `[0, num_classes - 1]`.
+You may use `'P'` mode of [pillow](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#palette) to create your annotation image with color.
+:::
+
+## Customize datasets by mixing dataset
+
+MMSegmentation also supports to mix dataset for training.
+Currently it supports to concat, repeat and multi-image mix datasets.
+
+### Repeat dataset
+
+We use `RepeatDataset` as wrapper to repeat the dataset.
+For example, suppose the original dataset is `Dataset_A`, to repeat it, the config looks like the following
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict( # This is the original config of Dataset_A
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+ )
+```
+
+### Concatenate dataset
+
+There 2 ways to concatenate the dataset.
+
+1. If the datasets you want to concatenate are in the same type with different annotation files,
+ you can concatenate the dataset configs like the following.
+
+ 1. You may concatenate two `ann_dir`.
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = ['anno_dir_1', 'anno_dir_2'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 2. You may concatenate two `split`.
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = 'anno_dir',
+ split = ['split_1.txt', 'split_2.txt'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 3. You may concatenate two `ann_dir` and `split` simultaneously.
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = ['anno_dir_1', 'anno_dir_2'],
+ split = ['split_1.txt', 'split_2.txt'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ In this case, `ann_dir_1` and `ann_dir_2` are corresponding to `split_1.txt` and `split_2.txt`.
+
+2. In case the dataset you want to concatenate is different, you can concatenate the dataset configs like the following.
+
+ ```python
+ dataset_A_train = dict()
+ dataset_B_train = dict()
+
+ data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+ )
+ ```
+
+A more complex example that repeats `Dataset_A` and `Dataset_B` by N and M times, respectively, and then concatenates the repeated datasets is as the following.
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict(
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+)
+dataset_A_val = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_A_test = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_B_train = dict(
+ type='RepeatDataset',
+ times=M,
+ dataset=dict(
+ type='Dataset_B',
+ ...
+ pipeline=train_pipeline
+ )
+)
+data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+)
+
+```
+
+### Multi-image Mix Dataset
+
+We use `MultiImageMixDataset` as a wrapper to mix images from multiple datasets.
+`MultiImageMixDataset` can be used by multiple images mixed data augmentation
+like mosaic and mixup.
+
+An example of using `MultiImageMixDataset` with `Mosaic` data augmentation:
+
+```python
+train_pipeline = [
+ dict(type='RandomMosaic', prob=1),
+ dict(type='Resize', img_scale=(1024, 512), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+
+train_dataset = dict(
+ type='MultiImageMixDataset',
+ dataset=dict(
+ classes=classes,
+ palette=palette,
+ type=dataset_type,
+ reduce_zero_label=False,
+ img_dir=data_root + "images/train",
+ ann_dir=data_root + "annotations/train",
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ ]
+ ),
+ pipeline=train_pipeline
+)
+
+```
diff --git a/docs/en/tutorials/customize_models.md b/docs/en/tutorials/customize_models.md
new file mode 100644
index 0000000..f637fd6
--- /dev/null
+++ b/docs/en/tutorials/customize_models.md
@@ -0,0 +1,234 @@
+# Tutorial 4: Customize Models
+
+## Customize optimizer
+
+Assume you want to add a optimizer named as `MyOptimizer`, which has arguments `a`, `b`, and `c`.
+You need to first implement the new optimizer in a file, e.g., in `mmseg/core/optimizer/my_optimizer.py`:
+
+```python
+from mmcv.runner import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+Then add this module in `mmseg/core/optimizer/__init__.py` thus the registry will
+find the new module and add it:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+Then you can use `MyOptimizer` in `optimizer` field of config files.
+In the configs, the optimizers are defined by the field `optimizer` like the following:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+To use your own optimizer, the field can be changed as
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+We already support to use all the optimizers implemented by PyTorch, and the only modification is to change the `optimizer` field of config files.
+For example, if you want to use `ADAM`, though the performance will drop a lot, the modification could be as the following.
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+The users can directly set arguments following the [API doc](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) of PyTorch.
+
+## Customize optimizer constructor
+
+Some models may have some parameter-specific settings for optimization, e.g. weight decay for BatchNoarm layers.
+The users can do those fine-grained parameter tuning through customizing optimizer constructor.
+
+```
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner import OPTIMIZER_BUILDERS
+from .cocktail_optimizer import CocktailOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module
+class CocktailOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+## Develop new components
+
+There are mainly 2 types of components in MMSegmentation.
+
+- backbone: usually stacks of convolutional network to extract feature maps, e.g., ResNet, HRNet.
+- head: the component for semantic segmentation map decoding.
+
+### Add new backbones
+
+Here we show how to develop new components with an example of MobileNet.
+
+1. Create a new file `mmseg/models/backbones/mobilenet.py`.
+
+```python
+import torch.nn as nn
+
+from ..registry import BACKBONES
+
+
+@BACKBONES.register_module
+class MobileNet(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # should return a tuple
+ pass
+
+ def init_weights(self, pretrained=None):
+ pass
+```
+
+2. Import the module in `mmseg/models/backbones/__init__.py`.
+
+```python
+from .mobilenet import MobileNet
+```
+
+3. Use it in your config file.
+
+```python
+model = dict(
+ ...
+ backbone=dict(
+ type='MobileNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+### Add new heads
+
+In MMSegmentation, we provide a base [BaseDecodeHead](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/decode_head.py) for all segmentation head.
+All newly implemented decode heads should be derived from it.
+Here we show how to develop a new head with the example of [PSPNet](https://arxiv.org/abs/1612.01105) as the following.
+
+First, add a new decode head in `mmseg/models/decode_heads/psp_head.py`.
+PSPNet implements a decode head for segmentation decode.
+To implement a decode head, basically we need to implement three functions of the new module as the following.
+
+```python
+@HEADS.register_module()
+class PSPHead(BaseDecodeHead):
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
+ super(PSPHead, self).__init__(**kwargs)
+
+ def init_weights(self):
+
+ def forward(self, inputs):
+
+```
+
+Next, the users need to add the module in the `mmseg/models/decode_heads/__init__.py` thus the corresponding registry could find and load them.
+
+To config file of PSPNet is as the following
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain_model/resnet50_v1c_trick-2cccc1ad.pth',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='PSPHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
+
+```
+
+### Add new loss
+
+Assume you want to add a new loss as `MyLoss` for segmentation decode.
+To add a new loss function, the users need implement it in `mmseg/models/losses/my_loss.py`.
+The decorator `weighted_loss` enable the loss to be weighted for each element.
+
+```python
+import torch
+import torch.nn as nn
+
+from ..builder import LOSSES
+from .utils import weighted_loss
+
+@weighted_loss
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+@LOSSES.register_module
+class MyLoss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(MyLoss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss = self.loss_weight * my_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss
+```
+
+Then the users need to add it in the `mmseg/models/losses/__init__.py`.
+
+```python
+from .my_loss import MyLoss, my_loss
+
+```
+
+To use it, modify the `loss_xxx` field.
+Then you need to modify the `loss_decode` field in the head.
+`loss_weight` could be used to balance multiple losses.
+
+```python
+loss_decode=dict(type='MyLoss', loss_weight=1.0))
+```
diff --git a/docs/en/tutorials/customize_runtime.md b/docs/en/tutorials/customize_runtime.md
new file mode 100644
index 0000000..dba0edc
--- /dev/null
+++ b/docs/en/tutorials/customize_runtime.md
@@ -0,0 +1,245 @@
+# Tutorial 6: Customize Runtime Settings
+
+## Customize optimization settings
+
+### Customize optimizer supported by Pytorch
+
+We already support to use all the optimizers implemented by PyTorch, and the only modification is to change the `optimizer` field of config files.
+For example, if you want to use `ADAM` (note that the performance could drop a lot), the modification could be as the following.
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+To modify the learning rate of the model, the users only need to modify the `lr` in the config of optimizer. The users can directly set arguments following the [API doc](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) of PyTorch.
+
+### Customize self-implemented optimizer
+
+#### 1. Define a new optimizer
+
+A customized optimizer could be defined as following.
+
+Assume you want to add a optimizer named `MyOptimizer`, which has arguments `a`, `b`, and `c`.
+You need to create a new directory named `mmseg/core/optimizer`.
+And then implement the new optimizer in a file, e.g., in `mmseg/core/optimizer/my_optimizer.py`:
+
+```python
+from .registry import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+#### 2. Add the optimizer to registry
+
+To find the above module defined above, this module should be imported into the main namespace at first. There are two options to achieve it.
+
+- Modify `mmseg/core/optimizer/__init__.py` to import it.
+
+ The newly defined module should be imported in `mmseg/core/optimizer/__init__.py` so that the registry will
+ find the new module and add it:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- Use `custom_imports` in the config to manually import it
+
+```python
+custom_imports = dict(imports=['mmseg.core.optimizer.my_optimizer'], allow_failed_imports=False)
+```
+
+The module `mmseg.core.optimizer.my_optimizer` will be imported at the beginning of the program and the class `MyOptimizer` is then automatically registered.
+Note that only the package containing the class `MyOptimizer` should be imported.
+`mmseg.core.optimizer.my_optimizer.MyOptimizer` **cannot** be imported directly.
+
+Actually users can use a totally different file directory structure using this importing method, as long as the module root can be located in `PYTHONPATH`.
+
+#### 3. Specify the optimizer in the config file
+
+Then you can use `MyOptimizer` in `optimizer` field of config files.
+In the configs, the optimizers are defined by the field `optimizer` like the following:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+To use your own optimizer, the field can be changed to
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+### Customize optimizer constructor
+
+Some models may have some parameter-specific settings for optimization, e.g. weight decay for BatchNorm layers.
+The users can do those fine-grained parameter tuning through customizing optimizer constructor.
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner.optimizer import OPTIMIZER_BUILDERS, OPTIMIZERS
+from mmseg.utils import get_root_logger
+from .my_optimizer import MyOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module()
+class MyOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+The default optimizer constructor is implemented [here](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/optimizer/default_constructor.py#L11), which could also serve as a template for new optimizer constructor.
+
+### Additional settings
+
+Tricks not implemented by the optimizer should be implemented through optimizer constructor (e.g., set parameter-wise learning rates) or hooks. We list some common settings that could stabilize the training or accelerate the training. Feel free to create PR, issue for more settings.
+
+- __Use gradient clip to stabilize training__:
+ Some models need gradient clip to clip the gradients to stabilize the training process. An example is as below:
+
+ ```python
+ optimizer_config = dict(
+ _delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
+ ```
+
+ If your config inherits the base config which already sets the `optimizer_config`, you might need `_delete_=True` to override the unnecessary settings. See the [config documentation](https://mmsegmentation.readthedocs.io/en/latest/config.html) for more details.
+
+- __Use momentum schedule to accelerate model convergence__:
+ We support momentum scheduler to modify model's momentum according to learning rate, which could make the model converge in a faster way.
+ Momentum scheduler is usually used with LR scheduler, for example, the following config is used in 3D detection to accelerate convergence.
+ For more details, please refer to the implementation of [CyclicLrUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L327) and [CyclicMomentumUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/momentum_updater.py#L130).
+
+ ```python
+ lr_config = dict(
+ policy='cyclic',
+ target_ratio=(10, 1e-4),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ momentum_config = dict(
+ policy='cyclic',
+ target_ratio=(0.85 / 0.95, 1),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ ```
+
+## Customize training schedules
+
+By default we use step learning rate with 40k/80k schedule, this calls [`PolyLrUpdaterHook`](https://github.com/open-mmlab/mmcv/blob/826d3a7b68596c824fa1e2cb89b6ac274f52179c/mmcv/runner/hooks/lr_updater.py#L196) in MMCV.
+We support many other learning rate schedule [here](https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py), such as `CosineAnnealing` and `Poly` schedule. Here are some examples
+
+- Step schedule:
+
+ ```python
+ lr_config = dict(policy='step', step=[9, 10])
+ ```
+
+- ConsineAnnealing schedule:
+
+ ```python
+ lr_config = dict(
+ policy='CosineAnnealing',
+ warmup='linear',
+ warmup_iters=1000,
+ warmup_ratio=1.0 / 10,
+ min_lr_ratio=1e-5)
+ ```
+
+## Customize workflow
+
+Workflow is a list of (phase, epochs) to specify the running order and epochs.
+By default it is set to be
+
+```python
+workflow = [('train', 1)]
+```
+
+which means running 1 epoch for training.
+Sometimes user may want to check some metrics (e.g. loss, accuracy) about the model on the validate set.
+In such case, we can set the workflow as
+
+```python
+[('train', 1), ('val', 1)]
+```
+
+so that 1 epoch for training and 1 epoch for validation will be run iteratively.
+
+:::{note}
+
+1. The parameters of model will not be updated during val epoch.
+2. Keyword `total_epochs` in the config only controls the number of training epochs and will not affect the validation workflow.
+3. Workflows `[('train', 1), ('val', 1)]` and `[('train', 1)]` will not change the behavior of `EvalHook` because `EvalHook` is called by `after_train_epoch` and validation workflow only affect hooks that are called through `after_val_epoch`. Therefore, the only difference between `[('train', 1), ('val', 1)]` and `[('train', 1)]` is that the runner will calculate losses on validation set after each training epoch.
+
+:::
+
+## Customize hooks
+
+### Use hooks implemented in MMCV
+
+If the hook is already implemented in MMCV, you can directly modify the config to use the hook as below
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+### Modify default runtime hooks
+
+There are some common hooks that are not registered through `custom_hooks`, they are
+
+- log_config
+- checkpoint_config
+- evaluation
+- lr_config
+- optimizer_config
+- momentum_config
+
+In those hooks, only the logger hook has the `VERY_LOW` priority, others' priority are `NORMAL`.
+The above-mentioned tutorials already covers how to modify `optimizer_config`, `momentum_config`, and `lr_config`.
+Here we reveals how what we can do with `log_config`, `checkpoint_config`, and `evaluation`.
+
+#### Checkpoint config
+
+The MMCV runner will use `checkpoint_config` to initialize [`CheckpointHook`](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/hooks/checkpoint.py#L9).
+
+```python
+checkpoint_config = dict(interval=1)
+```
+
+The users could set `max_keep_ckpts` to only save only small number of checkpoints or decide whether to store state dict of optimizer by `save_optimizer`. More details of the arguments are [here](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.CheckpointHook)
+
+#### Log config
+
+The `log_config` wraps multiple logger hooks and enables to set intervals. Now MMCV supports `WandbLoggerHook`, `MlflowLoggerHook`, and `TensorboardLoggerHook`.
+The detail usages can be found in the [doc](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.LoggerHook).
+
+```python
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')
+ ])
+```
+
+#### Evaluation config
+
+The config of `evaluation` will be used to initialize the [`EvalHook`](https://github.com/open-mmlab/mmsegmentation/blob/e3f6f655d69b777341aec2fe8829871cc0beadcb/mmseg/core/evaluation/eval_hooks.py#L7).
+Except the key `interval`, other arguments such as `metric` will be passed to the `dataset.evaluate()`
+
+```python
+evaluation = dict(interval=1, metric='mIoU')
+```
diff --git a/docs/en/tutorials/data_pipeline.md b/docs/en/tutorials/data_pipeline.md
new file mode 100644
index 0000000..1eecfe9
--- /dev/null
+++ b/docs/en/tutorials/data_pipeline.md
@@ -0,0 +1,171 @@
+# Tutorial 3: Customize Data Pipelines
+
+## Design of Data pipelines
+
+Following typical conventions, we use `Dataset` and `DataLoader` for data loading
+with multiple workers. `Dataset` returns a dict of data items corresponding
+the arguments of models' forward method.
+Since the data in semantic segmentation may not be the same size,
+we introduce a new `DataContainer` type in MMCV to help collect and distribute
+data of different size.
+See [here](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py) for more details.
+
+The data preparation pipeline and the dataset is decomposed. Usually a dataset
+defines how to process the annotations and a data pipeline defines all the steps to prepare a data dict.
+A pipeline consists of a sequence of operations. Each operation takes a dict as input and also output a dict for the next transform.
+
+The operations are categorized into data loading, pre-processing, formatting and test-time augmentation.
+
+Here is an pipeline example for PSPNet.
+
+```python
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 1024)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+```
+
+For each operation, we list the related dict fields that are added/updated/removed.
+
+### Data loading
+
+`LoadImageFromFile`
+
+- add: img, img_shape, ori_shape
+
+`LoadAnnotations`
+
+- add: gt_semantic_seg, seg_fields
+
+### Pre-processing
+
+`Resize`
+
+- add: scale, scale_idx, pad_shape, scale_factor, keep_ratio
+- update: img, img_shape, *seg_fields
+
+`RandomFlip`
+
+- add: flip
+- update: img, *seg_fields
+
+`Pad`
+
+- add: pad_fixed_size, pad_size_divisor
+- update: img, pad_shape, *seg_fields
+
+`RandomCrop`
+
+- update: img, pad_shape, *seg_fields
+
+`Normalize`
+
+- add: img_norm_cfg
+- update: img
+
+`SegRescale`
+
+- update: gt_semantic_seg
+
+`PhotoMetricDistortion`
+
+- update: img
+
+### Formatting
+
+`ToTensor`
+
+- update: specified by `keys`.
+
+`ImageToTensor`
+
+- update: specified by `keys`.
+
+`Transpose`
+
+- update: specified by `keys`.
+
+`ToDataContainer`
+
+- update: specified by `fields`.
+
+`DefaultFormatBundle`
+
+- update: img, gt_semantic_seg
+
+`Collect`
+
+- add: img_meta (the keys of img_meta is specified by `meta_keys`)
+- remove: all other keys except for those specified by `keys`
+
+### Test time augmentation
+
+`MultiScaleFlipAug`
+
+## Extend and use custom pipelines
+
+1. Write a new pipeline in any file, e.g., `my_pipeline.py`. It takes a dict as input and return a dict.
+
+ ```python
+ from mmseg.datasets import PIPELINES
+
+ @PIPELINES.register_module()
+ class MyTransform:
+
+ def __call__(self, results):
+ results['dummy'] = True
+ return results
+ ```
+
+2. Import the new class.
+
+ ```python
+ from .my_pipeline import MyTransform
+ ```
+
+3. Use it in config files.
+
+ ```python
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+ crop_size = (512, 1024)
+ train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='MyTransform'),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+ ]
+ ```
diff --git a/docs/en/tutorials/index.rst b/docs/en/tutorials/index.rst
new file mode 100644
index 0000000..e1a67a8
--- /dev/null
+++ b/docs/en/tutorials/index.rst
@@ -0,0 +1,9 @@
+.. toctree::
+ :maxdepth: 2
+
+ config.md
+ customize_datasets.md
+ data_pipeline.md
+ customize_models.md
+ training_tricks.md
+ customize_runtime.md
diff --git a/docs/en/tutorials/training_tricks.md b/docs/en/tutorials/training_tricks.md
new file mode 100644
index 0000000..1c8fe06
--- /dev/null
+++ b/docs/en/tutorials/training_tricks.md
@@ -0,0 +1,70 @@
+# Tutorial 5: Training Tricks
+
+MMSegmentation support following training tricks out of box.
+
+## Different Learning Rate(LR) for Backbone and Heads
+
+In semantic segmentation, some methods make the LR of heads larger than backbone to achieve better performance or faster convergence.
+
+In MMSegmentation, you may add following lines to config to make the LR of heads 10 times of backbone.
+
+```python
+optimizer=dict(
+ paramwise_cfg = dict(
+ custom_keys={
+ 'head': dict(lr_mult=10.)}))
+```
+
+With this modification, the LR of any parameter group with `'head'` in name will be multiplied by 10.
+You may refer to [MMCV doc](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.DefaultOptimizerConstructor) for further details.
+
+## Online Hard Example Mining (OHEM)
+
+We implement pixel sampler [here](https://github.com/open-mmlab/mmsegmentation/tree/master/mmseg/core/seg/sampler) for training sampling.
+Here is an example config of training PSPNet with OHEM enabled.
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
+```
+
+In this way, only pixels with confidence score under 0.7 are used to train. And we keep at least 100000 pixels during training. If `thresh` is not specified, pixels of top ``min_kept`` loss will be selected.
+
+## Class Balanced Loss
+
+For dataset that is not balanced in classes distribution, you may change the loss weight of each class.
+Here is an example for cityscapes dataset.
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
+ # DeepLab used this class weight for cityscapes
+ class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
+ 1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
+ 1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
+```
+
+`class_weight` will be passed into `CrossEntropyLoss` as `weight` argument. Please refer to [PyTorch Doc](https://pytorch.org/docs/stable/nn.html?highlight=crossentropy#torch.nn.CrossEntropyLoss) for details.
+
+## Multiple Losses
+
+For loss calculation, we support multiple losses training concurrently. Here is an example config of training `unet` on `DRIVE` dataset, whose loss function is `1:3` weighted sum of `CrossEntropyLoss` and `DiceLoss`:
+
+```python
+_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
+model = dict(
+ decode_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
+ auxiliary_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce',loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
+ )
+```
+
+In this way, `loss_weight` and `loss_name` will be weight and name in training log of corresponding loss, respectively.
+
+Note: If you want this loss item to be included into the backward graph, `loss_` must be the prefix of the name.
diff --git a/docs/en/useful_tools.md b/docs/en/useful_tools.md
new file mode 100644
index 0000000..d6dc576
--- /dev/null
+++ b/docs/en/useful_tools.md
@@ -0,0 +1,380 @@
+## Useful tools
+
+Apart from training/testing scripts, We provide lots of useful tools under the
+ `tools/` directory.
+
+### Get the FLOPs and params (experimental)
+
+We provide a script adapted from [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch) to compute the FLOPs and params of a given model.
+
+```shell
+python tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+You will get the result like this.
+
+```none
+==============================
+Input shape: (3, 2048, 1024)
+Flops: 1429.68 GMac
+Params: 48.98 M
+==============================
+```
+
+:::{note}
+This tool is still experimental and we do not guarantee that the number is correct. You may well use the result for simple comparisons, but double check it before you adopt it in technical reports or papers.
+:::
+
+(1) FLOPs are related to the input shape while parameters are not. The default input shape is (1, 3, 1280, 800).
+(2) Some operators are not counted into FLOPs like GN and custom operators.
+
+### Publish a model
+
+Before you upload a model to AWS, you may want to
+(1) convert model weights to CPU tensors, (2) delete the optimizer states and
+(3) compute the hash of the checkpoint file and append the hash id to the filename.
+
+```shell
+python tools/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+E.g.,
+
+```shell
+python tools/publish_model.py work_dirs/pspnet/latest.pth psp_r50_hszhao_200ep.pth
+```
+
+The final output filename will be `psp_r50_512x1024_40ki_cityscapes-{hash id}.pth`.
+
+### Convert to ONNX (experimental)
+
+We provide a script to convert model to [ONNX](https://github.com/onnx/onnx) format. The converted model could be visualized by tools like [Netron](https://github.com/lutzroeder/netron). Besides, we also support comparing the output results between PyTorch and ONNX model.
+
+```bash
+python tools/pytorch2onnx.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE} \
+ --input-img ${INPUT_IMG} \
+ --shape ${INPUT_SHAPE} \
+ --rescale-shape ${RESCALE_SHAPE} \
+ --show \
+ --verify \
+ --dynamic-export \
+ --cfg-options \
+ model.test_cfg.mode="whole"
+```
+
+Description of arguments:
+
+- `config` : The path of a model config file.
+- `--checkpoint` : The path of a model checkpoint file.
+- `--output-file`: The path of output ONNX model. If not specified, it will be set to `tmp.onnx`.
+- `--input-img` : The path of an input image for conversion and visualize.
+- `--shape`: The height and width of input tensor to the model. If not specified, it will be set to img_scale of test_pipeline.
+- `--rescale-shape`: rescale shape of output, set this value to avoid OOM, only work on `slide` mode.
+- `--show`: Determines whether to print the architecture of the exported model. If not specified, it will be set to `False`.
+- `--verify`: Determines whether to verify the correctness of an exported model. If not specified, it will be set to `False`.
+- `--dynamic-export`: Determines whether to export ONNX model with dynamic input and output shapes. If not specified, it will be set to `False`.
+- `--cfg-options`:Update config options.
+
+:::{note}
+This tool is still experimental. Some customized operators are not supported for now.
+:::
+
+### Evaluate ONNX model
+
+We provide `tools/deploy_test.py` to evaluate ONNX model with different backend.
+
+#### Prerequisite
+
+- Install onnx and onnxruntime-gpu
+
+ ```shell
+ pip install onnx onnxruntime-gpu
+ ```
+
+- Install TensorRT following [how-to-build-tensorrt-plugins-in-mmcv](https://mmcv.readthedocs.io/en/latest/tensorrt_plugin.html#how-to-build-tensorrt-plugins-in-mmcv)(optional)
+
+#### Usage
+
+```bash
+python tools/deploy_test.py \
+ ${CONFIG_FILE} \
+ ${MODEL_FILE} \
+ ${BACKEND} \
+ --out ${OUTPUT_FILE} \
+ --eval ${EVALUATION_METRICS} \
+ --show \
+ --show-dir ${SHOW_DIRECTORY} \
+ --cfg-options ${CFG_OPTIONS} \
+ --eval-options ${EVALUATION_OPTIONS} \
+ --opacity ${OPACITY} \
+```
+
+Description of all arguments
+
+- `config`: The path of a model config file.
+- `model`: The path of a converted model file.
+- `backend`: Backend of the inference, options: `onnxruntime`, `tensorrt`.
+- `--out`: The path of output result file in pickle format.
+- `--format-only` : Format the output results without perform evaluation. It is useful when you want to format the result to a specific format and submit it to the test server. If not specified, it will be set to `False`. Note that this argument is **mutually exclusive** with `--eval`.
+- `--eval`: Evaluation metrics, which depends on the dataset, e.g., "mIoU" for generic datasets, and "cityscapes" for Cityscapes. Note that this argument is **mutually exclusive** with `--format-only`.
+- `--show`: Show results flag.
+- `--show-dir`: Directory where painted images will be saved
+- `--cfg-options`: Override some settings in the used config file, the key-value pair in `xxx=yyy` format will be merged into config file.
+- `--eval-options`: Custom options for evaluation, the key-value pair in `xxx=yyy` format will be kwargs for `dataset.evaluate()` function
+- `--opacity`: Opacity of painted segmentation map. In (0, 1] range.
+
+#### Results and Models
+
+| Model | Config | Dataset | Metric | PyTorch | ONNXRuntime | TensorRT-fp32 | TensorRT-fp16 |
+| :--------: | :---------------------------------------------: | :--------: | :----: | :-----: | :---------: | :-----------: | :-----------: |
+| FCN | fcn_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 72.2 | 72.2 | 72.2 | 72.2 |
+| PSPNet | pspnet_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 77.8 | 77.8 | 77.8 | 77.8 |
+| deeplabv3 | deeplabv3_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.0 | 79.0 | 79.0 | 79.0 |
+| deeplabv3+ | deeplabv3plus_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.6 | 79.5 | 79.5 | 79.5 |
+| PSPNet | pspnet_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.2 | 78.1 | | |
+| deeplabv3 | deeplabv3_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.5 | 78.3 | | |
+| deeplabv3+ | deeplabv3plus_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.9 | 78.7 | | |
+
+:::{note}
+TensorRT is only available on configs with `whole mode`.
+:::
+
+### Convert to TorchScript (experimental)
+
+We also provide a script to convert model to [TorchScript](https://pytorch.org/docs/stable/jit.html) format. You can use the pytorch C++ API [LibTorch](https://pytorch.org/docs/stable/cpp_index.html) inference the trained model. The converted model could be visualized by tools like [Netron](https://github.com/lutzroeder/netron). Besides, we also support comparing the output results between PyTorch and TorchScript model.
+
+```shell
+python tools/pytorch2torchscript.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE}
+ --shape ${INPUT_SHAPE}
+ --verify \
+ --show
+```
+
+Description of arguments:
+
+- `config` : The path of a pytorch model config file.
+- `--checkpoint` : The path of a pytorch model checkpoint file.
+- `--output-file`: The path of output TorchScript model. If not specified, it will be set to `tmp.pt`.
+- `--input-img` : The path of an input image for conversion and visualize.
+- `--shape`: The height and width of input tensor to the model. If not specified, it will be set to `512 512`.
+- `--show`: Determines whether to print the traced graph of the exported model. If not specified, it will be set to `False`.
+- `--verify`: Determines whether to verify the correctness of an exported model. If not specified, it will be set to `False`.
+
+:::{note}
+It's only support PyTorch>=1.8.0 for now.
+:::
+
+:::{note}
+This tool is still experimental. Some customized operators are not supported for now.
+:::
+
+Examples:
+
+- Convert the cityscapes PSPNet pytorch model.
+
+ ```shell
+ python tools/pytorch2torchscript.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ --checkpoint checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --output-file checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pt \
+ --shape 512 1024
+ ```
+
+### Convert to TensorRT (experimental)
+
+A script to convert [ONNX](https://github.com/onnx/onnx) model to [TensorRT](https://developer.nvidia.com/tensorrt) format.
+
+Prerequisite
+
+- install `mmcv-full` with ONNXRuntime custom ops and TensorRT plugins follow [ONNXRuntime in mmcv](https://mmcv.readthedocs.io/en/latest/deployment/onnxruntime_op.html) and [TensorRT plugin in mmcv](https://github.com/open-mmlab/mmcv/blob/master/docs/en/deployment/tensorrt_plugin.md).
+- Use [pytorch2onnx](#convert-to-onnx-experimental) to convert the model from PyTorch to ONNX.
+
+Usage
+
+```bash
+python ${MMSEG_PATH}/tools/onnx2tensorrt.py \
+ ${CFG_PATH} \
+ ${ONNX_PATH} \
+ --trt-file ${OUTPUT_TRT_PATH} \
+ --min-shape ${MIN_SHAPE} \
+ --max-shape ${MAX_SHAPE} \
+ --input-img ${INPUT_IMG} \
+ --show \
+ --verify
+```
+
+Description of all arguments
+
+- `config` : Config file of the model.
+- `model` : Path to the input ONNX model.
+- `--trt-file` : Path to the output TensorRT engine.
+- `--max-shape` : Maximum shape of model input.
+- `--min-shape` : Minimum shape of model input.
+- `--fp16` : Enable fp16 model conversion.
+- `--workspace-size` : Max workspace size in GiB.
+- `--input-img` : Image for visualize.
+- `--show` : Enable result visualize.
+- `--dataset` : Palette provider, `CityscapesDataset` as default.
+- `--verify` : Verify the outputs of ONNXRuntime and TensorRT.
+- `--verbose` : Whether to verbose logging messages while creating TensorRT engine. Defaults to False.
+
+:::{note}
+Only tested on whole mode.
+:::
+
+## Miscellaneous
+
+### Print the entire config
+
+`tools/print_config.py` prints the whole config verbatim, expanding all its
+ imports.
+
+```shell
+python tools/print_config.py \
+ ${CONFIG} \
+ --graph \
+ --cfg-options ${OPTIONS [OPTIONS...]} \
+```
+
+Description of arguments:
+
+- `config` : The path of a pytorch model config file.
+- `--graph` : Determines whether to print the models graph.
+- `--cfg-options`: Custom options to replace the config file.
+
+### Plot training logs
+
+`tools/analyze_logs.py` plots loss/mIoU curves given a training log file. `pip install seaborn` first to install the dependency.
+
+```shell
+python tools/analyze_logs.py xxx.log.json [--keys ${KEYS}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
+```
+
+Examples:
+
+- Plot the mIoU, mAcc, aAcc metrics.
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
+ ```
+
+- Plot loss metric.
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys loss --legend loss
+ ```
+
+### Model conversion
+
+`tools/model_converters/` provide several scripts to convert pretrain models released by other repos to MMSegmentation style.
+
+#### ViT Swin MiT Transformer Models
+
+- ViT
+
+ `tools/model_converters/vit2mmseg.py` convert keys in timm pretrained vit models to MMSegmentation style.
+
+ ```shell
+ python tools/model_converters/vit2mmseg.py ${SRC} ${DST}
+ ```
+
+- Swin
+
+ `tools/model_converters/swin2mmseg.py` convert keys in official pretrained swin models to MMSegmentation style.
+
+ ```shell
+ python tools/model_converters/swin2mmseg.py ${SRC} ${DST}
+ ```
+
+- SegFormer
+
+ `tools/model_converters/mit2mmseg.py` convert keys in official pretrained mit models to MMSegmentation style.
+
+ ```shell
+ python tools/model_converters/mit2mmseg.py ${SRC} ${DST}
+ ```
+
+## Model Serving
+
+In order to serve an `MMSegmentation` model with [`TorchServe`](https://pytorch.org/serve/), you can follow the steps:
+
+### 1. Convert model from MMSegmentation to TorchServe
+
+```shell
+python tools/torchserve/mmseg2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+:::{note}
+${MODEL_STORE} needs to be an absolute path to a folder.
+:::
+
+### 2. Build `mmseg-serve` docker image
+
+```shell
+docker build -t mmseg-serve:latest docker/serve/
+```
+
+### 3. Run `mmseg-serve`
+
+Check the official docs for [running TorchServe with docker](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment).
+
+In order to run in GPU, you need to install [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). You can omit the `--gpus` argument in order to run in CPU.
+
+Example:
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
+mmseg-serve:latest
+```
+
+[Read the docs](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md) about the Inference (8080), Management (8081) and Metrics (8082) APIs
+
+### 4. Test deployment
+
+```shell
+curl -O https://raw.githubusercontent.com/open-mmlab/mmsegmentation/master/resources/3dogs.jpg
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg -o 3dogs_mask.png
+```
+
+The response will be a ".png" mask.
+
+You can visualize the output as follows:
+
+```python
+import matplotlib.pyplot as plt
+import mmcv
+plt.imshow(mmcv.imread("3dogs_mask.png", "grayscale"))
+plt.show()
+```
+
+You should see something similar to:
+
+
+
+And you can use `test_torchserve.py` to compare result of torchserve and pytorch, and visualize them.
+
+```shell
+python tools/torchserve/test_torchserve.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--result-image ${RESULT_IMAGE}] [--device ${DEVICE}]
+```
+
+Example:
+
+```shell
+python tools/torchserve/test_torchserve.py \
+demo/demo.png \
+configs/fcn/fcn_r50-d8_512x1024_40k_cityscapes.py \
+checkpoint/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608-efe53f0d.pth \
+fcn
+```
diff --git a/docs/zh_cn/Makefile b/docs/zh_cn/Makefile
new file mode 100644
index 0000000..d4bb2cb
--- /dev/null
+++ b/docs/zh_cn/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/zh_cn/_static/css/readthedocs.css b/docs/zh_cn/_static/css/readthedocs.css
new file mode 100644
index 0000000..2e38d08
--- /dev/null
+++ b/docs/zh_cn/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../images/mmsegmentation.png");
+ background-size: 201px 40px;
+ height: 40px;
+ width: 201px;
+}
diff --git a/docs/zh_cn/_static/images/mmsegmentation.png b/docs/zh_cn/_static/images/mmsegmentation.png
new file mode 100644
index 0000000..009083a
Binary files /dev/null and b/docs/zh_cn/_static/images/mmsegmentation.png differ
diff --git a/docs/zh_cn/api.rst b/docs/zh_cn/api.rst
new file mode 100644
index 0000000..8285841
--- /dev/null
+++ b/docs/zh_cn/api.rst
@@ -0,0 +1,58 @@
+mmseg.apis
+--------------
+.. automodule:: mmseg.apis
+ :members:
+
+mmseg.core
+--------------
+
+seg
+^^^^^^^^^^
+.. automodule:: mmseg.core.seg
+ :members:
+
+evaluation
+^^^^^^^^^^
+.. automodule:: mmseg.core.evaluation
+ :members:
+
+utils
+^^^^^^^^^^
+.. automodule:: mmseg.core.utils
+ :members:
+
+mmseg.datasets
+--------------
+
+datasets
+^^^^^^^^^^
+.. automodule:: mmseg.datasets
+ :members:
+
+pipelines
+^^^^^^^^^^
+.. automodule:: mmseg.datasets.pipelines
+ :members:
+
+mmseg.models
+--------------
+
+segmentors
+^^^^^^^^^^
+.. automodule:: mmseg.models.segmentors
+ :members:
+
+backbones
+^^^^^^^^^^
+.. automodule:: mmseg.models.backbones
+ :members:
+
+decode_heads
+^^^^^^^^^^^^
+.. automodule:: mmseg.models.decode_heads
+ :members:
+
+losses
+^^^^^^^^^^
+.. automodule:: mmseg.models.losses
+ :members:
diff --git a/docs/zh_cn/conf.py b/docs/zh_cn/conf.py
new file mode 100644
index 0000000..353b0bc
--- /dev/null
+++ b/docs/zh_cn/conf.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+#
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../../'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMSegmentation'
+copyright = '2020-2021, OpenMMLab'
+author = 'MMSegmentation Authors'
+version_file = '../../mmseg/version.py'
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+# The full version, including alpha/beta/rc tags
+release = get_version()
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
+ 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser'
+]
+
+autodoc_mock_imports = [
+ 'matplotlib', 'pycocotools', 'mmseg.version', 'mmcv.ops'
+]
+
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The master toctree document.
+master_doc = 'index'
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+# html_theme = 'sphinx_rtd_theme'
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+html_theme_options = {
+ 'logo_url':
+ 'https://mmsegmentation.readthedocs.io/zh-CN/latest/',
+ 'menu': [
+ {
+ 'name':
+ '教程',
+ 'url':
+ 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
+ 'demo/MMSegmentation_Tutorial.ipynb'
+ },
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmsegmentation'
+ },
+ {
+ 'name':
+ '上游库',
+ 'children': [
+ {
+ 'name': 'MMCV',
+ 'url': 'https://github.com/open-mmlab/mmcv',
+ 'description': '基础视觉库'
+ },
+ ]
+ },
+ ],
+ # Specify the language of shared menu
+ 'menu_lang':
+ 'cn',
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# Enable ::: for my_st
+myst_enable_extensions = ['colon_fence']
+
+language = 'zh-CN'
+
+
+def builder_inited_handler(app):
+ subprocess.run(['./stat.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/docs/zh_cn/dataset_prepare.md b/docs/zh_cn/dataset_prepare.md
new file mode 100644
index 0000000..9a8428a
--- /dev/null
+++ b/docs/zh_cn/dataset_prepare.md
@@ -0,0 +1,268 @@
+## 准备数据集
+
+推荐用软链接,将数据集根目录链接到 `$MMSEGMENTATION/data` 里。如果您的文件夹结构是不同的,您也许可以试着修改配置文件里对应的路径。
+
+```none
+mmsegmentation
+├── mmseg
+├── tools
+├── configs
+├── data
+│ ├── cityscapes
+│ │ ├── leftImg8bit
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── gtFine
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── VOCdevkit
+│ │ ├── VOC2012
+│ │ │ ├── JPEGImages
+│ │ │ ├── SegmentationClass
+│ │ │ ├── ImageSets
+│ │ │ │ ├── Segmentation
+│ │ ├── VOC2010
+│ │ │ ├── JPEGImages
+│ │ │ ├── SegmentationClassContext
+│ │ │ ├── ImageSets
+│ │ │ │ ├── SegmentationContext
+│ │ │ │ │ ├── train.txt
+│ │ │ │ │ ├── val.txt
+│ │ │ ├── trainval_merged.json
+│ │ ├── VOCaug
+│ │ │ ├── dataset
+│ │ │ │ ├── cls
+│ ├── ade
+│ │ ├── ADEChallengeData2016
+│ │ │ ├── annotations
+│ │ │ │ ├── training
+│ │ │ │ ├── validation
+│ │ │ ├── images
+│ │ │ │ ├── training
+│ │ │ │ ├── validation
+│ ├── CHASE_DB1
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── DRIVE
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── HRF
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── STARE
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+| ├── dark_zurich
+| │ ├── gps
+| │ │ ├── val
+| │ │ └── val_ref
+| │ ├── gt
+| │ │ └── val
+| │ ├── LICENSE.txt
+| │ ├── lists_file_names
+| │ │ ├── val_filenames.txt
+| │ │ └── val_ref_filenames.txt
+| │ ├── README.md
+| │ └── rgb_anon
+| │ | ├── val
+| │ | └── val_ref
+| ├── NighttimeDrivingTest
+| | ├── gtCoarse_daytime_trainvaltest
+| | │ └── test
+| | │ └── night
+| | └── leftImg8bit
+| | | └── test
+| | | └── night
+│ ├── loveDA
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ │ ├── test
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── potsdam
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ ├── val
+```
+
+### Cityscapes
+
+注册成功后,数据集可以在 [这里](https://www.cityscapes-dataset.com/downloads/) 下载。
+
+通常情况下,`**labelTrainIds.png` 被用来训练 cityscapes。
+基于 [cityscapesscripts](https://github.com/mcordts/cityscapesScripts),
+我们提供了一个 [脚本](https://github.com/open-mmlab/mmsegmentation/blob/master/tools/convert_datasets/cityscapes.py),
+去生成 `**labelTrainIds.png`。
+
+```shell
+# --nproc 8 意味着有 8 个进程用来转换,它也可以被忽略。
+python tools/convert_datasets/cityscapes.py data/cityscapes --nproc 8
+```
+
+### Pascal VOC
+
+Pascal VOC 2012 可以在 [这里](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar) 下载。
+此外,许多最近在 Pascal VOC 数据集上的工作都会利用增广的数据,它们可以在 [这里](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/semantic_contours/benchmark.tgz) 找到。
+
+如果您想使用增广后的 VOC 数据集,请运行下面的命令来将数据增广的标注转成正确的格式。
+
+```shell
+# --nproc 8 意味着有 8 个进程用来转换,它也可以被忽略。
+python tools/convert_datasets/voc_aug.py data/VOCdevkit data/VOCdevkit/VOCaug --nproc 8
+```
+
+关于如何拼接数据集 (concatenate) 并一起训练它们,更多细节请参考 [拼接连接数据集](https://github.com/open-mmlab/mmsegmentation/blob/master/docs/zh_cn/tutorials/customize_datasets.md#%E6%8B%BC%E6%8E%A5%E6%95%B0%E6%8D%AE%E9%9B%86) 。
+
+### ADE20K
+
+ADE20K 的训练集和验证集可以在 [这里](http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip) 下载。
+您还可以在 [这里](http://data.csail.mit.edu/places/ADEchallenge/release_test.zip) 下载验证集。
+
+### Pascal Context
+
+Pascal Context 的训练集和验证集可以在 [这里](http://host.robots.ox.ac.uk/pascal/VOC/voc2010/VOCtrainval_03-May-2010.tar) 下载。
+注册成功后,您还可以在 [这里](http://host.robots.ox.ac.uk:8080/eval/downloads/VOC2010test.tar) 下载验证集。
+
+为了从原始数据集里切分训练集和验证集, 您可以在 [这里](https://codalabuser.blob.core.windows.net/public/trainval_merged.json)
+下载 trainval_merged.json。
+
+如果您想使用 Pascal Context 数据集,
+请安装 [细节](https://github.com/zhanghang1989/detail-api) 然后再运行如下命令来把标注转换成正确的格式。
+
+```shell
+python tools/convert_datasets/pascal_context.py data/VOCdevkit data/VOCdevkit/VOC2010/trainval_merged.json
+```
+
+### CHASE DB1
+
+CHASE DB1 的训练集和验证集可以在 [这里](https://staffnet.kingston.ac.uk/~ku15565/CHASE_DB1/assets/CHASEDB1.zip) 下载。
+
+为了将 CHASE DB1 数据集转换成 MMSegmentation 的格式,您需要运行如下命令:
+
+```shell
+python tools/convert_datasets/chase_db1.py /path/to/CHASEDB1.zip
+```
+
+这个脚本将自动生成正确的文件夹结构。
+
+### DRIVE
+
+DRIVE 的训练集和验证集可以在 [这里](https://drive.grand-challenge.org/) 下载。
+在此之前,您需要注册一个账号,当前 '1st_manual' 并未被官方提供,因此需要您从其他地方获取。
+
+为了将 DRIVE 数据集转换成 MMSegmentation 格式,您需要运行如下命令:
+
+```shell
+python tools/convert_datasets/drive.py /path/to/training.zip /path/to/test.zip
+```
+
+这个脚本将自动生成正确的文件夹结构。
+
+### HRF
+
+首先,下载 [healthy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy.zip) [glaucoma.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma.zip), [diabetic_retinopathy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy.zip), [healthy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy_manualsegm.zip), [glaucoma_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma_manualsegm.zip) 以及 [diabetic_retinopathy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy_manualsegm.zip) 。
+
+为了将 HRF 数据集转换成 MMSegmentation 格式,您需要运行如下命令:
+
+```shell
+python tools/convert_datasets/hrf.py /path/to/healthy.zip /path/to/healthy_manualsegm.zip /path/to/glaucoma.zip /path/to/glaucoma_manualsegm.zip /path/to/diabetic_retinopathy.zip /path/to/diabetic_retinopathy_manualsegm.zip
+```
+
+这个脚本将自动生成正确的文件夹结构。
+
+### STARE
+
+首先,下载 [stare-images.tar](http://cecas.clemson.edu/~ahoover/stare/probing/stare-images.tar), [labels-ah.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-ah.tar) 和 [labels-vk.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-vk.tar) 。
+
+为了将 STARE 数据集转换成 MMSegmentation 格式,您需要运行如下命令:
+
+```shell
+python tools/convert_datasets/stare.py /path/to/stare-images.tar /path/to/labels-ah.tar /path/to/labels-vk.tar
+```
+
+这个脚本将自动生成正确的文件夹结构。
+
+### Dark Zurich
+
+因为我们只支持在此数据集上测试模型,所以您只需下载[验证集](https://data.vision.ee.ethz.ch/csakarid/shared/GCMA_UIoU/Dark_Zurich_val_anon.zip) 。
+
+### Nighttime Driving
+
+因为我们只支持在此数据集上测试模型,所以您只需下载[测试集](http://data.vision.ee.ethz.ch/daid/NighttimeDriving/NighttimeDrivingTest.zip) 。
+
+### LoveDA
+
+可以从 Google Drive 里下载 [LoveDA数据集](https://drive.google.com/drive/folders/1ibYV0qwn4yuuh068Rnc-w4tPi0U0c-ti?usp=sharing) 。
+
+或者它还可以从 [zenodo](https://zenodo.org/record/5706578#.YZvN7SYRXdF) 下载, 您需要运行如下命令:
+
+```shell
+# Download Train.zip
+wget https://zenodo.org/record/5706578/files/Train.zip
+# Download Val.zip
+wget https://zenodo.org/record/5706578/files/Val.zip
+# Download Test.zip
+wget https://zenodo.org/record/5706578/files/Test.zip
+```
+
+对于 LoveDA 数据集,请运行以下命令下载并重新组织数据集
+
+```shell
+python tools/convert_datasets/loveda.py /path/to/loveDA
+```
+
+请参照 [这里](https://github.com/open-mmlab/mmsegmentation/blob/master/docs/zh_cn/inference.md) 来使用训练好的模型去预测 LoveDA 测试集并且提交到官网。
+
+关于 LoveDA 的更多细节可以在[这里](https://github.com/Junjue-Wang/LoveDA) 找到。
+
+### ISPRS Potsdam
+
+[Potsdam](https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-potsdam/)
+数据集是一个有着2D 语义分割内容标注的城市遥感数据集。
+数据集可以从挑战[主页](https://www2.isprs.org/commissions/comm2/wg4/benchmark/data-request-form/) 获得。
+需要其中的 '2_Ortho_RGB.zip' 和 '5_Labels_all_noBoundary.zip'。
+
+对于 Potsdam 数据集,请运行以下命令下载并重新组织数据集
+
+```shell
+python tools/convert_datasets/potsdam.py /path/to/potsdam
+```
+
+使用我们默认的配置, 将生成 3456 张图片的训练集和 2016 张图片的验证集。
+
+### ISPRS Vaihingen
+
+[Vaihingen](https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/)
+数据集是一个有着2D 语义分割内容标注的城市遥感数据集。
+
+数据集可以从挑战 [主页](https://www2.isprs.org/commissions/comm2/wg4/benchmark/data-request-form/).
+需要其中的 'ISPRS_semantic_labeling_Vaihingen.zip' 和 'ISPRS_semantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE.zip'。
+
+对于 Vaihingen 数据集,请运行以下命令下载并重新组织数据集
+
+```shell
+python tools/convert_datasets/vaihingen.py /path/to/vaihingen
+```
+
+使用我们默认的配置 (`clip_size` =512, `stride_size`=256), 将生成 344 张图片的训练集和 398 张图片的验证集。
diff --git a/docs/zh_cn/get_started.md b/docs/zh_cn/get_started.md
new file mode 100644
index 0000000..372bab9
--- /dev/null
+++ b/docs/zh_cn/get_started.md
@@ -0,0 +1,223 @@
+## 依赖
+
+- Linux or macOS (Windows下支持需要 mmcv-full,但运行时可能会有一些问题。)
+- Python 3.6+
+- PyTorch 1.3+
+- CUDA 9.2+ (如果您基于源文件编译 PyTorch, CUDA 9.0也可以使用)
+- GCC 5+
+- [MMCV](https://mmcv.readthedocs.io/en/latest/#installation)
+
+可编译的 MMSegmentation 和 MMCV 版本如下所示,请对照对应版本安装以避免安装问题。
+
+| MMSegmentation 版本 | MMCV 版本 |
+|:-----------------:|:--------------------------:|
+| master | mmcv-full>=1.4.4, <1.5.0 |
+| 0.21.0 | mmcv-full>=1.4.4, <1.5.0 |
+| 0.20.0 | mmcv-full>=1.3.13, <1.5.0 |
+| 0.19.0 | mmcv-full>=1.3.13, <1.3.17 |
+| 0.18.0 | mmcv-full>=1.3.13, <1.3.17 |
+| 0.17.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.16.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.15.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.14.1 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.14.0 | mmcv-full>=1.3.1, <1.3.2 |
+| 0.13.0 | mmcv-full>=1.3.1, <1.3.2 |
+| 0.12.0 | mmcv-full>=1.1.4, <1.3.2 |
+| 0.11.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.10.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.9.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.8.0 | mmcv-full>=1.1.4, <1.2.0 |
+| 0.7.0 | mmcv-full>=1.1.2, <1.2.0 |
+| 0.6.0 | mmcv-full>=1.1.2, <1.2.0 |
+
+注意: 如果您已经安装好 mmcv, 您首先需要运行 `pip uninstall mmcv`。
+如果 mmcv 和 mmcv-full 同时被安装,会报错 `ModuleNotFoundError`。
+
+## 安装
+
+a. 创建一个 conda 虚拟环境并激活它
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+```
+
+b. 按照[官方教程](https://pytorch.org/) 安装 PyTorch 和 totchvision,
+这里我们使用 PyTorch1.6.0 和 CUDA10.1,
+您也可以切换至其他版本
+
+```shell
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+```
+
+c. 按照 [官方教程](https://mmcv.readthedocs.io/en/latest/#installation)
+安装 [MMCV](https://mmcv.readthedocs.io/en/latest/) ,
+`mmcv` 或 `mmcv-full` 和 MMSegmentation 均兼容,但对于 CCNet 和 PSANet,`mmcv-full` 里的 CUDA 运算是必须的
+
+**在 Linux 下安装 mmcv:**
+
+通过运行
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.5.0/index.html
+```
+
+可以安装好 mmcv-full (PyTorch 1.5 和 CUDA 10.1) 版本。
+其他 PyTorch 和 CUDA 版本的 MMCV 安装请参照[这里](https://mmcv.readthedocs.io/en/latest/#install-with-pip)
+
+**在 Windows 下安装 mmcv (有风险):**
+
+对于 Windows, MMCV 的安装需要本地 C++ 编译工具, 例如 cl.exe。 请添加编译工具至 %PATH%。
+
+如果您已经在电脑上安装好Windows SDK 和 Visual Studio,cl.exe 的一个典型路径看起来如下:
+
+```shell
+C:\Program Files (x86)\Microsoft Visual Studio\2019\Professional\VC\Tools\MSVC\14.26.28801\bin\Hostx86\x64
+```
+
+或者您需要从网上下载 cl 编译工具并安装至路径。
+
+随后,从 github 克隆 mmcv 并通过 pip 安装:
+
+```shell
+git clone https://github.com/open-mmlab/mmcv.git
+cd mmcv
+pip install -e .
+```
+
+或直接:
+
+```shell
+pip install mmcv
+```
+
+当前,mmcv-full 并不完全在 windows 上支持。
+
+d. 安装 MMSegmentation
+
+```shell
+pip install mmsegmentation # 安装最新版本
+```
+
+或者
+
+```shell
+pip install git+https://github.com/open-mmlab/mmsegmentation.git # 安装 master 分支
+```
+
+此外,如果您想安装 `dev` 模式的 MMSegmentation, 运行如下命令:
+
+```shell
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # 或者 "python setup.py develop"
+```
+
+注意:
+
+1. 当在 windows 下训练和测试模型时,请确保路径下所有的'\\' 被替换成 '/',
+ 在 python 代码里可以使用`.replace('\\', '/')`处理路径的字符串
+2. `version+git_hash` 也将被保存进 meta 训练模型里,即0.5.0+c415a2e
+3. 当 MMsegmentation 以 `dev` 模式被安装时,本地对代码的修改将不需要重新安装即可产生作用
+4. 如果您想使用 `opencv-python-headless` 替换 `opencv-python`,您可以在安装 MMCV 前安装它
+5. 一些依赖项是可选的。简单的运行 `pip install -e .` 将仅安装最必要的一些依赖。为了使用可选的依赖项如`cityscapessripts`,
+ 要么手动使用 `pip install -r requirements/optional.txt` 安装,要么专门从pip下安装(即 `pip install -e .[optional]`,
+ 其中选项可设置为 `all`, `tests`, `build`, 和 `optional`)
+
+### 完整的安装脚本
+
+#### Linux
+
+这里便是一个完整安装 MMSegmentation 的脚本,使用 conda 并链接了数据集的路径(以您的数据集路径为 $DATA_ROOT 来安装)。
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+pip install mmcv-full==latest+torch1.5.0+cu101 -f https://download.openmmlab.com/mmcv/dist/index.html
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # 或者 "python setup.py develop"
+
+mkdir data
+ln -s $DATA_ROOT data
+```
+
+#### Windows (有风险)
+
+这里便是一个完整安装 MMSegmentation 的脚本,使用 conda 并链接了数据集的路径(以您的数据集路径为 %DATA_ROOT% 来安装)。
+注意:它必须是一个绝对路径。
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+set PATH=full\path\to\your\cpp\compiler;%PATH%
+pip install mmcv
+
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # 或者 "python setup.py develop"
+
+mklink /D data %DATA_ROOT%
+```
+
+#### 使用多版本 MMSegmentation 进行开发
+
+训练和测试脚本已经修改了 `PYTHONPATH` 来确保使用当前路径的MMSegmentation。
+
+为了使用当前环境默认安装的 MMSegmentation 而不是正在工作的 MMSegmentation,您可以在那些脚本里移除下面的内容:
+
+```shell
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
+```
+
+## 验证
+
+为了验证 MMSegmentation 和它所需要的环境是否正确安装,我们可以使用样例 python 代码来初始化一个 segmentor 并推理一张 demo 图像。
+
+```python
+from mmseg.apis import inference_segmentor, init_segmentor
+import mmcv
+
+config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'
+checkpoint_file = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
+
+# 从一个 config 配置文件和 checkpoint 文件里创建分割模型
+model = init_segmentor(config_file, checkpoint_file, device='cuda:0')
+
+# 测试一张样例图片并得到结果
+img = 'test.jpg' # 或者 img = mmcv.imread(img), 这将只加载图像一次.
+result = inference_segmentor(model, img)
+# 在新的窗口里可视化结果
+model.show_result(img, result, show=True)
+# 或者保存图片文件的可视化结果
+# 您可以改变 segmentation map 的不透明度(opacity),在(0, 1]之间。
+model.show_result(img, result, out_file='result.jpg', opacity=0.5)
+
+# 测试一个视频并得到分割结果
+video = mmcv.VideoReader('video.mp4')
+for frame in video:
+ result = inference_segmentor(model, frame)
+ model.show_result(frame, result, wait_time=1)
+```
+
+当您完成 MMSegmentation 的安装时,上述代码应该可以成功运行。
+
+我们还提供一个 demo 脚本去可视化单张图片。
+
+```shell
+python demo/image_demo.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${DEVICE_NAME}] [--palette-thr ${PALETTE}]
+```
+
+样例:
+
+```shell
+python demo/image_demo.py demo/demo.jpg configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --palette cityscapes
+```
+
+推理的 demo 文档可在此查询:[demo/inference_demo.ipynb](../demo/inference_demo.ipynb) 。
diff --git a/docs/zh_cn/imgs/qq_group_qrcode.jpg b/docs/zh_cn/imgs/qq_group_qrcode.jpg
new file mode 100644
index 0000000..4173474
Binary files /dev/null and b/docs/zh_cn/imgs/qq_group_qrcode.jpg differ
diff --git a/docs/zh_cn/imgs/seggroup_qrcode.jpg b/docs/zh_cn/imgs/seggroup_qrcode.jpg
new file mode 100644
index 0000000..9684582
Binary files /dev/null and b/docs/zh_cn/imgs/seggroup_qrcode.jpg differ
diff --git a/docs/zh_cn/imgs/zhihu_qrcode.jpg b/docs/zh_cn/imgs/zhihu_qrcode.jpg
new file mode 100644
index 0000000..c745fb0
Binary files /dev/null and b/docs/zh_cn/imgs/zhihu_qrcode.jpg differ
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
new file mode 100644
index 0000000..8df7662
--- /dev/null
+++ b/docs/zh_cn/index.rst
@@ -0,0 +1,62 @@
+欢迎来到 MMSegmenation 的文档!
+=======================================
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 开始你的第一步
+
+ get_started.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 数据集准备
+
+ dataset_prepare.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 模型库
+
+ model_zoo.md
+ modelzoo_statistics.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 快速启动
+
+ train.md
+ inference.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 教程
+
+ tutorials/index.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 实用工具与脚本
+
+ useful_tools.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 说明
+
+ changelog.md
+
+.. toctree::
+ :caption: 语言切换
+
+ switch_language.md
+
+.. toctree::
+ :caption: 接口文档(英文)
+
+ api.rst
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/docs/zh_cn/inference.md b/docs/zh_cn/inference.md
new file mode 100644
index 0000000..b681dca
--- /dev/null
+++ b/docs/zh_cn/inference.md
@@ -0,0 +1,126 @@
+## 使用预训练模型推理
+
+我们提供测试脚本来评估完整数据集(Cityscapes, PASCAL VOC, ADE20k 等)上的结果,同时为了使其他项目的整合更容易,也提供一些高级 API。
+
+### 测试一个数据集
+
+- 单卡 GPU
+- CPU
+- 单节点多卡 GPU
+- 多节点
+
+您可以使用以下命令来测试一个数据集。
+
+```shell
+# 单卡 GPU 测试
+python tools/test.py ${配置文件} ${检查点文件} [--out ${结果文件}] [--eval ${评估指标}] [--show]
+
+# CPU: 禁用 GPU 并运行单 GPU 测试脚本
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py ${配置文件} ${检查点文件} [--out ${结果文件}] [--eval ${评估指标}] [--show]
+
+# 多卡GPU 测试
+./tools/dist_test.sh ${配置文件} ${检查点文件} ${GPU数目} [--out ${结果文件}] [--eval ${评估指标}]
+```
+
+可选参数:
+
+- `RESULT_FILE`: pickle 格式的输出结果的文件名,如果不专门指定,结果将不会被专门保存成文件。(MMseg v0.17 之后,args.out 将只会保存评估时的中间结果或者是分割图的保存路径。)
+- `EVAL_METRICS`: 在结果里将被评估的指标。这主要取决于数据集, `mIoU` 对于所有数据集都可获得,像 Cityscapes 数据集可以通过 `cityscapes` 命令来专门评估,就像标准的 `mIoU`一样。
+- `--show`: 如果被指定,分割结果将会在一张图像里画出来并且在另一个窗口展示。它仅仅是用来调试与可视化,并且仅针对单卡 GPU 测试。请确认 GUI 在您的环境里可用,否则您也许会遇到报错 `cannot connect to X server`
+- `--show-dir`: 如果被指定,分割结果将会在一张图像里画出来并且保存在指定文件夹里。它仅仅是用来调试与可视化,并且仅针对单卡GPU测试。使用该参数时,您的环境不需要 GUI。
+- `--eval-options`: 评估时的可选参数,当设置 `efficient_test=True` 时,它将会保存中间结果至本地文件里以节约 CPU 内存。请确认您本地硬盘有足够的存储空间(大于20GB)。(MMseg v0.17 之后,`efficient_test` 不再生效,我们重构了 test api,通过使用一种渐近式的方式来提升评估和保存结果的效率。)
+
+例子:
+
+假设您已经下载检查点文件至文件夹 `checkpoints/` 里。
+
+1. 测试 PSPNet 并可视化结果。按下任何键会进行到下一张图
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --show
+ ```
+
+2. 测试 PSPNet 并保存画出的图以便于之后的可视化
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --show-dir psp_r50_512x1024_40ki_cityscapes_results
+ ```
+
+3. 在数据集 PASCAL VOC (不保存测试结果) 上测试 PSPNet 并评估 mIoU
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_20k_voc12aug.py \
+ checkpoints/pspnet_r50-d8_512x1024_20k_voc12aug_20200605_003338-c57ef100.pth \
+ --eval mAP
+ ```
+
+4. 使用4卡 GPU 测试 PSPNet,并且在标准 mIoU 和 cityscapes 指标里评估模型
+
+ ```shell
+ ./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ 4 --out results.pkl --eval mIoU cityscapes
+ ```
+
+ 注意:在 cityscapes mIoU 和我们的 mIoU 指标会有一些差异 (~0.1%) 。因为 cityscapes 默认是根据类别样本数的多少进行加权平均,而我们对所有的数据集都是采取直接平均的方法来得到 mIoU。
+
+5. 在 cityscapes 数据集上4卡 GPU 测试 PSPNet, 并生成 png 文件以便提交给官方评估服务器
+
+ 首先,在配置文件里添加内容: `configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py`,
+
+ ```python
+ data = dict(
+ test=dict(
+ img_dir='leftImg8bit/test',
+ ann_dir='gtFine/test'))
+ ```
+
+ 随后,进行测试。
+
+ ```shell
+ ./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ 4 --format-only --eval-options "imgfile_prefix=./pspnet_test_results"
+ ```
+
+ 您会在文件夹 `./pspnet_test_results` 里得到生成的 png 文件。
+ 您也许可以运行 `zip -r results.zip pspnet_test_results/` 并提交 zip 文件给 [evaluation server](https://www.cityscapes-dataset.com/submit/) 。
+
+6. 在 Cityscapes 数据集上使用 CPU 高效内存选项来测试 DeeplabV3+ `mIoU` 指标 (没有保存测试结果)
+
+ ```shell
+ python tools/test.py \
+ configs/deeplabv3plus/deeplabv3plus_r18-d8_512x1024_80k_cityscapes.py \
+ deeplabv3plus_r18-d8_512x1024_80k_cityscapes_20201226_080942-cff257fe.pth \
+ --eval-options efficient_test=True \
+ --eval mIoU
+ ```
+
+ 使用 ```pmap``` 可查看 CPU 内存情况, ```efficient_test=True``` 会使用约 2.25GB 的 CPU 内存, ```efficient_test=False``` 会使用约 11.06GB 的 CPU 内存。 这个可选参数可以节约很多 CPU 内存。(MMseg v0.17 之后, `efficient_test` 参数将不再生效, 我们使用了一种渐近的方式来更加有效快速地评估和保存结果。)
+
+7. 在 LoveDA 数据集上1卡 GPU 测试 PSPNet, 并生成 png 文件以便提交给官方评估服务器
+
+ 首先,在配置文件里添加内容: `configs/pspnet/pspnet_r50-d8_512x512_80k_loveda.py`,
+
+ ```python
+ data = dict(
+ test=dict(
+ img_dir='img_dir/test',
+ ann_dir='ann_dir/test'))
+ ```
+
+ 随后,进行测试。
+
+ ```shell
+ python ./tools/test.py configs/pspnet/pspnet_r50-d8_512x512_80k_loveda.py \
+ checkpoints/pspnet_r50-d8_512x512_80k_loveda_20211104_155728-88610f9f.pth \
+ --format-only --eval-options "imgfile_prefix=./pspnet_test_results"
+ ```
+
+ 您会在文件夹 `./pspnet_test_results` 里得到生成的 png 文件。
+ 您也许可以运行 `zip -r -j Results.zip pspnet_test_results/` 并提交 zip 文件给 [evaluation server](https://codalab.lisn.upsaclay.fr/competitions/421) 。
diff --git a/docs/zh_cn/make.bat b/docs/zh_cn/make.bat
new file mode 100644
index 0000000..922152e
--- /dev/null
+++ b/docs/zh_cn/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/zh_cn/model_zoo.md b/docs/zh_cn/model_zoo.md
new file mode 100644
index 0000000..bfcc4c1
--- /dev/null
+++ b/docs/zh_cn/model_zoo.md
@@ -0,0 +1,152 @@
+# 标准与模型库
+
+## 共同设定
+
+* 我们默认使用 4 卡分布式训练
+* 所有 PyTorch 风格的 ImageNet 预训练网络由我们自己训练,和 [论文](https://arxiv.org/pdf/1812.01187.pdf) 保持一致。
+ 我们的 ResNet 网络是基于 ResNetV1c 的变种,在这里输入层的 7x7 卷积被 3个 3x3 取代
+* 为了在不同的硬件上保持一致,我们以 `torch.cuda.max_memory_allocated()` 的最大值作为 GPU 占用率,同时设置 `torch.backends.cudnn.benchmark=False`。
+ 注意,这通常比 `nvidia-smi` 显示的要少
+* 我们以网络 forward 和后处理的时间加和作为推理时间,除去数据加载时间。我们使用脚本 `tools/benchmark.py` 来获取推理时间,它在 `torch.backends.cudnn.benchmark=False` 的设定下,计算 200 张图片的平均推理时间
+* 在框架中,有两种推理模式
+ * `slide` 模式(滑动模式):测试的配置文件字段 `test_cfg` 会是 `dict(mode='slide', crop_size=(769, 769), stride=(513, 513))`.
+ 在这个模式下,从原图中裁剪多个小图分别输入网络中进行推理。小图的大小和小图之间的距离由 `crop_size` 和 `stride` 决定,重合区域会进行平均
+ * `whole` 模式 (全图模式):测试的配置文件字段 `test_cfg` 会是 `dict(mode='whole')`. 在这个模式下,全图会被直接输入到网络中进行推理。
+ 对于 769x769 下训练的模型,我们默认使用 `slide` 进行推理,其余模型用 `whole` 进行推理
+* 对于输入大小为 8x+1 (比如769),我们使用 `align_corners=True`。其余情况,对于输入大小为 8x (比如 512,1024),我们使用 `align_corners=False`
+
+## 基线
+
+### FCN
+
+请参考 [FCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fcn) 获得详细信息。
+
+### PSPNet
+
+请参考 [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/pspnet) 获得详细信息。
+
+### DeepLabV3
+
+请参考 [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3) 获得详细信息。
+
+### PSANet
+
+请参考 [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/psanet) 获得详细信息。
+
+### DeepLabV3+
+
+请参考 [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3plus) 获得详细信息。
+
+### UPerNet
+
+请参考 [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/upernet) 获得详细信息。
+
+### NonLocal Net
+
+请参考 [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nlnet) 获得详细信息。
+
+### EncNet
+
+请参考 [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/encnet) 获得详细信息。
+
+### CCNet
+
+请参考 [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ccnet) 获得详细信息。
+
+### DANet
+
+请参考 [DANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/danet) 获得详细信息。
+
+### APCNet
+
+请参考 [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/apcnet) 获得详细信息。
+
+### HRNet
+
+请参考 [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/hrnet) 获得详细信息。
+
+### GCNet
+
+请参考 [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/gcnet) 获得详细信息。
+
+### DMNet
+
+请参考 [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dmnet) 获得详细信息。
+
+### ANN
+
+请参考 [ANN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ann) 获得详细信息。
+
+### OCRNet
+
+请参考 [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ocrnet) 获得详细信息。
+
+### Fast-SCNN
+
+请参考 [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastscnn) 获得详细信息。
+
+### ResNeSt
+
+请参考 [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest) 获得详细信息。
+
+### Semantic FPN
+
+请参考 [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/semfpn) 获得详细信息。
+
+### PointRend
+
+请参考 [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/point_rend) 获得详细信息。
+
+### MobileNetV2
+
+请参考 [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v2) 获得详细信息。
+
+### MobileNetV3
+
+请参考 [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v3) 获得详细信息。
+
+### EMANet
+
+请参考 [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/emanet) 获得详细信息。
+
+### DNLNet
+
+请参考 [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dnlnet) 获得详细信息。
+
+### CGNet
+
+请参考 [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/cgnet) 获得详细信息。
+
+### Mixed Precision (FP16) Training
+
+请参考 [Mixed Precision (FP16) Training 在 BiSeNetV2 训练的样例](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv2/bisenetv2_fcn_fp16_4x4_1024x1024_160k_cityscapes.py) 获得详细信息。
+
+## 速度标定
+
+### 硬件
+
+* 8 NVIDIA Tesla V100 (32G) GPUs
+* Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
+
+### 软件环境
+
+* Python 3.7
+* PyTorch 1.5
+* CUDA 10.1
+* CUDNN 7.6.03
+* NCCL 2.4.08
+
+### 训练速度
+
+为了公平比较,我们全部使用 ResNet-101V1c 进行标定。输入大小为 1024x512,批量样本数为 2。
+
+训练速度如下表,指标为每次迭代的时间,以秒为单位,越低越快。
+
+| Implementation | PSPNet (s/iter) | DeepLabV3+ (s/iter) |
+|----------------|-----------------|---------------------|
+| [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) | **0.83** | **0.85** |
+| [SegmenTron](https://github.com/LikeLy-Journey/SegmenTron) | 0.84 | 0.85 |
+| [CASILVision](https://github.com/CSAILVision/semantic-segmentation-pytorch) | 1.15 | N/A |
+| [vedaseg](https://github.com/Media-Smart/vedaseg) | 0.95 | 1.25 |
+
+注意:DeepLabV3+ 的输出步长为 8。
diff --git a/docs/zh_cn/stat.py b/docs/zh_cn/stat.py
new file mode 100755
index 0000000..b3a1d73
--- /dev/null
+++ b/docs/zh_cn/stat.py
@@ -0,0 +1,65 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools as func
+import glob
+import os.path as osp
+import re
+
+import numpy as np
+
+url_prefix = 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
+
+files = sorted(glob.glob('../../configs/*/README.md'))
+
+stats = []
+titles = []
+num_ckpts = 0
+
+for f in files:
+ url = osp.dirname(f.replace('../../', url_prefix))
+
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ title = content.split('\n')[0].replace('#', '').strip()
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https?://download.*\.pth', content)
+ if 'mmsegmentation' in x)
+ if len(ckpts) == 0:
+ continue
+
+ _papertype = [
+ x for x in re.findall(r'', content)
+ ]
+ assert len(_papertype) > 0
+ papertype = _papertype[0]
+
+ paper = set([(papertype, title)])
+
+ titles.append(title)
+ num_ckpts += len(ckpts)
+ statsmsg = f"""
+\t* [{papertype}] [{title}]({url}) ({len(ckpts)} ckpts)
+"""
+ stats.append((paper, ckpts, statsmsg))
+
+allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _ in stats])
+msglist = '\n'.join(x for _, _, x in stats)
+
+papertypes, papercounts = np.unique([t for t, _ in allpapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# 模型库统计数据
+
+* 论文数量: {len(set(titles))}
+{countstr}
+
+* 模型数量: {num_ckpts}
+{msglist}
+"""
+
+with open('modelzoo_statistics.md', 'w') as f:
+ f.write(modelzoo)
diff --git a/docs/zh_cn/switch_language.md b/docs/zh_cn/switch_language.md
new file mode 100644
index 0000000..f58efc4
--- /dev/null
+++ b/docs/zh_cn/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/docs/zh_cn/train.md b/docs/zh_cn/train.md
new file mode 100644
index 0000000..6fd0ee1
--- /dev/null
+++ b/docs/zh_cn/train.md
@@ -0,0 +1,96 @@
+## 训练一个模型
+
+MMSegmentation 可以执行分布式训练和非分布式训练,分别使用 `MMDistributedDataParallel` 和 `MMDataParallel` 命令。
+
+所有的输出(日志 log 和检查点 checkpoints )将被保存到工作路径文件夹里,它可以通过配置文件里的 `work_dir` 指定。
+
+在一定迭代轮次后,我们默认在验证集上评估模型表现。您可以在训练配置文件中添加间隔参数来改变评估间隔。
+
+```python
+evaluation = dict(interval=4000) # 每4000 iterations 评估一次模型的性能
+```
+
+**\*重要提示\***: 在配置文件里的默认学习率是针对4卡 GPU 和2张图/GPU (此时 batchsize = 4x2 = 8)来设置的。
+同样,您也可以使用8卡 GPU 和 1张图/GPU 的设置,因为所有的模型均使用 cross-GPU 的 SyncBN 模式。
+
+我们可以在训练速度和 GPU 显存之间做平衡。当模型或者 Batch Size 比较大的时,可以传递`--cfg-options model.backbone.with_cp=True` ,使用 `with_cp` 来节省显存,但是速度会更慢,因为原先使用 `ith_cp` 时,是逐层反向传播(Back Propagation, BP),不会保存所有的梯度。
+
+### 使用单卡 GPU 训练
+
+```shell
+python tools/train.py ${配置文件} [可选参数]
+```
+
+如果您想在命令里定义工作文件夹路径,您可以添加一个参数`--work-dir ${工作路径}`。
+
+### 使用 CPU 训练
+
+使用 CPU 训练的流程和使用单 GPU 训练的流程一致,我们仅需要在训练流程开始前禁用 GPU。
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+```
+
+之后运行单 GPU 训练脚本即可。
+
+```{warning}
+我们不推荐用户使用 CPU 进行训练,这太过缓慢。我们支持这个功能是为了方便用户在没有 GPU 的机器上进行调试。
+```
+
+### 使用多卡 GPU 训练
+
+```shell
+./tools/dist_train.sh ${配置文件} ${GPU 个数} [可选参数]
+```
+
+可选参数可以为:
+
+- `--no-validate` (**不推荐**): 训练时代码库默认会在每 k 轮迭代后在验证集上进行评估,如果不需评估使用命令 `--no-validate`
+- `--work-dir ${工作路径}`: 在配置文件里重写工作路径文件夹
+- `--resume-from ${检查点文件}`: 继续使用先前的检查点 (checkpoint) 文件(可以继续训练过程)
+- `--load-from ${检查点文件}`: 从一个检查点 (checkpoint) 文件里加载权重(对另一个任务进行精调)
+
+`resume-from` 和 `load-from` 的区别:
+
+- `resume-from` 加载出模型权重和优化器状态包括迭代轮数等
+- `load-from` 仅加载模型权重,从第0轮开始训练
+
+### 使用多个机器训练
+
+如果您在一个集群上以[slurm](https://slurm.schedmd.com/) 运行 MMSegmentation,
+您可以使用脚本 `slurm_train.sh`(这个脚本同样支持单个机器的训练)。
+
+```shell
+[GPUS=${GPU 数量}] ./tools/slurm_train.sh ${分区} ${任务名称} ${配置文件} --work-dir ${工作路径}
+```
+
+这里是在 dev 分区里使用16块 GPU 训练 PSPNet 的例子。
+
+```shell
+GPUS=16 ./tools/slurm_train.sh dev pspr50 configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py /nfs/xxxx/psp_r50_512x1024_40ki_cityscapes
+```
+
+您可以查看 [slurm_train.sh](../tools/slurm_train.sh) 以熟悉全部的参数与环境变量。
+
+如果您多个机器已经有以太网连接, 您可以参考 PyTorch
+[launch utility](https://pytorch.org/docs/stable/distributed.html#launch-utility) 。
+若您没有像 InfiniBand 这样高速的网络连接,多机器训练通常会比较慢。
+
+### 在单个机器上启动多个任务
+
+如果您在单个机器上启动多个任务,例如在8卡 GPU 的一个机器上有2个4卡 GPU 的训练任务,您需要特别对每个任务指定不同的端口(默认为29500)来避免通讯冲突。
+否则,将会有报错信息 `RuntimeError: Address already in use`。
+
+如果您使用命令 `dist_train.sh` 来启动一个训练任务,您可以在命令行的用环境变量 `PORT` 设置端口。
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${配置文件} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${配置文件} 4
+```
+
+如果您使用命令 `slurm_train.sh` 来启动训练任务,您可以在命令行的用环境变量 `MASTER_PORT` 设置端口。
+
+```shell
+MASTER_PORT=29500 ./tools/slurm_train.sh ${分区} ${任务名称} ${配置文件}
+MASTER_PORT=29501 ./tools/slurm_train.sh ${分区} ${任务名称} ${配置文件}
+```
diff --git a/docs/zh_cn/tutorials/config.md b/docs/zh_cn/tutorials/config.md
new file mode 100644
index 0000000..cc9f8d3
--- /dev/null
+++ b/docs/zh_cn/tutorials/config.md
@@ -0,0 +1,377 @@
+# 教程 1: 学习配置文件
+
+我们整合了模块和继承设计到我们的配置里,这便于做很多实验。如果您想查看配置文件,您可以运行 `python tools/print_config.py /PATH/TO/CONFIG` 去查看完整的配置文件。您还可以传递参数
+`--cfg-options xxx.yyy=zzz` 去查看更新的配置。
+
+## 配置文件的结构
+
+在 `config/_base_` 文件夹下面有4种基本组件类型: 数据集(dataset),模型(model),训练策略(schedule)和运行时的默认设置(default runtime)。许多方法都可以方便地通过组合这些组件进行实现。
+这样,像 DeepLabV3, PSPNet 这样的模型可以容易地被构造。被来自 `_base_` 下的组件来构建的配置叫做 _原始配置 (primitive)_。
+
+对于所有在同一个文件夹下的配置文件,推荐**只有一个**对应的**原始配置**文件。所有其他的配置文件都应该继承自这个**原始配置**文件。这样就能保证配置文件的最大继承深度为 3。
+
+为了便于理解,我们推荐社区贡献者继承已有的方法配置文件。
+例如,如果一些修改是基于 DeepLabV3,使用者首先首先应该通过指定 `_base_ = ../deeplabv3/deeplabv3_r50_512x1024_40ki_cityscapes.py`来继承基础 DeepLabV3 结构,再去修改配置文件里其他内容以完成继承。
+
+如果您正在构建一个完整的新模型,它完全没有和已有的方法共享一些结构,您可能需要在 `configs` 下面创建一个文件夹 `xxxnet`。
+更详细的文档,请参照 [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html) 。
+
+## 配置文件命名风格
+
+我们按照下面的风格去命名配置文件,社区贡献者被建议使用同样的风格。
+
+```
+{model}_{backbone}_[misc]_[gpu x batch_per_gpu]_{resolution}_{schedule}_{dataset}
+```
+
+`{xxx}` 是被要求的文件 `[yyy]` 是可选的。
+
+- `{model}`: 模型种类,例如 `psp`, `deeplabv3` 等等
+- `{backbone}`: 主干网络种类,例如 `r50` (ResNet-50), `x101` (ResNeXt-101)
+- `[misc]`: 模型中各式各样的设置/插件,例如 `dconv`, `gcb`, `attention`, `mstrain`
+- `[gpu x batch_per_gpu]`: GPU数目 和每个 GPU 的样本数, 默认为 `8x2`
+- `{schedule}`: 训练方案, `20ki` 意思是 20k 迭代轮数
+- `{dataset}`: 数据集,如 `cityscapes`, `voc12aug`, `ade`
+
+## PSPNet 的一个例子
+
+为了帮助使用者熟悉这个流行的语义分割框架的完整配置文件和模块,我们在下面对使用 ResNet50V1c 的 PSPNet 的配置文件做了详细的注释说明。
+更多的详细使用和其他模块的替代项请参考 API 文档。
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True) # 分割框架通常使用 SyncBN
+model = dict(
+ type='EncoderDecoder', # 分割器(segmentor)的名字
+ pretrained='open-mmlab://resnet50_v1c', # 将被加载的 ImageNet 预训练主干网络
+ backbone=dict(
+ type='ResNetV1c', # 主干网络的类别。 可用选项请参考 mmseg/models/backbones/resnet.py
+ depth=50, # 主干网络的深度。通常为 50 和 101。
+ num_stages=4, # 主干网络状态(stages)的数目,这些状态产生的特征图作为后续的 head 的输入。
+ out_indices=(0, 1, 2, 3), # 每个状态产生的特征图输出的索引。
+ dilations=(1, 1, 2, 4), # 每一层(layer)的空心率(dilation rate)。
+ strides=(1, 2, 1, 1), # 每一层(layer)的步长(stride)。
+ norm_cfg=dict( # 归一化层(norm layer)的配置项。
+ type='SyncBN', # 归一化层的类别。通常是 SyncBN。
+ requires_grad=True), # 是否训练归一化里的 gamma 和 beta。
+ norm_eval=False, # 是否冻结 BN 里的统计项。
+ style='pytorch', # 主干网络的风格,'pytorch' 意思是步长为2的层为 3x3 卷积, 'caffe' 意思是步长为2的层为 1x1 卷积。
+ contract_dilation=True), # 当空洞 > 1, 是否压缩第一个空洞层。
+ decode_head=dict(
+ type='PSPHead', # 解码头(decode head)的类别。 可用选项请参考 mmseg/models/decode_heads。
+ in_channels=2048, # 解码头的输入通道数。
+ in_index=3, # 被选择的特征图(feature map)的索引。
+ channels=512, # 解码头中间态(intermediate)的通道数。
+ pool_scales=(1, 2, 3, 6), # PSPHead 平均池化(avg pooling)的规模(scales)。 细节请参考文章内容。
+ dropout_ratio=0.1, # 进入最后分类层(classification layer)之前的 dropout 比例。
+ num_classes=19, # 分割前景的种类数目。 通常情况下,cityscapes 为19,VOC为21,ADE20k 为150。
+ norm_cfg=dict(type='SyncBN', requires_grad=True), # 归一化层的配置项。
+ align_corners=False, # 解码里调整大小(resize)的 align_corners 参数。
+ loss_decode=dict( # 解码头(decode_head)里的损失函数的配置项。
+ type='CrossEntropyLoss', # 在分割里使用的损失函数的类别。
+ use_sigmoid=False, # 在分割里是否使用 sigmoid 激活。
+ loss_weight=1.0)), # 解码头里损失的权重。
+ auxiliary_head=dict(
+ type='FCNHead', # 辅助头(auxiliary head)的种类。可用选项请参考 mmseg/models/decode_heads。
+ in_channels=1024, # 辅助头的输入通道数。
+ in_index=2, # 被选择的特征图(feature map)的索引。
+ channels=256, # 辅助头中间态(intermediate)的通道数。
+ num_convs=1, # FCNHead 里卷积(convs)的数目. 辅助头里通常为1。
+ concat_input=False, # 在分类层(classification layer)之前是否连接(concat)输入和卷积的输出。
+ dropout_ratio=0.1, # 进入最后分类层(classification layer)之前的 dropout 比例。
+ num_classes=19, # 分割前景的种类数目。 通常情况下,cityscapes 为19,VOC为21,ADE20k 为150。
+ norm_cfg=dict(type='SyncBN', requires_grad=True), # 归一化层的配置项。
+ align_corners=False, # 解码里调整大小(resize)的 align_corners 参数。
+ loss_decode=dict( # 辅助头(auxiliary head)里的损失函数的配置项。
+ type='CrossEntropyLoss', # 在分割里使用的损失函数的类别。
+ use_sigmoid=False, # 在分割里是否使用 sigmoid 激活。
+ loss_weight=0.4))) # 辅助头里损失的权重。默认设置为0.4。
+train_cfg = dict() # train_cfg 当前仅是一个占位符。
+test_cfg = dict(mode='whole') # 测试模式, 选项是 'whole' 和 'sliding'. 'whole': 整张图像全卷积(fully-convolutional)测试。 'sliding': 图像上做滑动裁剪窗口(sliding crop window)。
+dataset_type = 'CityscapesDataset' # 数据集类型,这将被用来定义数据集。
+data_root = 'data/cityscapes/' # 数据的根路径。
+img_norm_cfg = dict( # 图像归一化配置,用来归一化输入的图像。
+ mean=[123.675, 116.28, 103.53], # 预训练里用于预训练主干网络模型的平均值。
+ std=[58.395, 57.12, 57.375], # 预训练里用于预训练主干网络模型的标准差。
+ to_rgb=True) # 预训练里用于预训练主干网络的图像的通道顺序。
+crop_size = (512, 1024) # 训练时的裁剪大小
+train_pipeline = [ #训练流程
+ dict(type='LoadImageFromFile'), # 第1个流程,从文件路径里加载图像。
+ dict(type='LoadAnnotations'), # 第2个流程,对于当前图像,加载它的注释信息。
+ dict(type='Resize', # 变化图像和其注释大小的数据增广的流程。
+ img_scale=(2048, 1024), # 图像的最大规模。
+ ratio_range=(0.5, 2.0)), # 数据增广的比例范围。
+ dict(type='RandomCrop', # 随机裁剪当前图像和其注释大小的数据增广的流程。
+ crop_size=(512, 1024), # 随机裁剪图像生成 patch 的大小。
+ cat_max_ratio=0.75), # 单个类别可以填充的最大区域的比例。
+ dict(
+ type='RandomFlip', # 翻转图像和其注释大小的数据增广的流程。
+ flip_ratio=0.5), # 翻转图像的概率
+ dict(type='PhotoMetricDistortion'), # 光学上使用一些方法扭曲当前图像和其注释的数据增广的流程。
+ dict(
+ type='Normalize', # 归一化当前图像的数据增广的流程。
+ mean=[123.675, 116.28, 103.53], # 这些键与 img_norm_cfg 一致,因为 img_norm_cfg 被
+ std=[58.395, 57.12, 57.375], # 用作参数。
+ to_rgb=True),
+ dict(type='Pad', # 填充当前图像到指定大小的数据增广的流程。
+ size=(512, 1024), # 填充的图像大小。
+ pad_val=0, # 图像的填充值。
+ seg_pad_val=255), # 'gt_semantic_seg'的填充值。
+ dict(type='DefaultFormatBundle'), # 流程里收集数据的默认格式捆。
+ dict(type='Collect', # 决定数据里哪些键被传递到分割器里的流程。
+ keys=['img', 'gt_semantic_seg'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'), # 第1个流程,从文件路径里加载图像。
+ dict(
+ type='MultiScaleFlipAug', # 封装测试时数据增广(test time augmentations)。
+ img_scale=(2048, 1024), # 决定测试时可改变图像的最大规模。用于改变图像大小的流程。
+ flip=False, # 测试时是否翻转图像。
+ transforms=[
+ dict(type='Resize', # 使用改变图像大小的数据增广。
+ keep_ratio=True), # 是否保持宽和高的比例,这里的图像比例设置将覆盖上面的图像规模大小的设置。
+ dict(type='RandomFlip'), # 考虑到 RandomFlip 已经被添加到流程里,当 flip=False 时它将不被使用。
+ dict(
+ type='Normalize', # 归一化配置项,值来自 img_norm_cfg。
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', # 将图像转为张量
+ keys=['img']),
+ dict(type='Collect', # 收集测试时必须的键的收集流程。
+ keys=['img'])
+ ])
+]
+data = dict(
+ samples_per_gpu=2, # 单个 GPU 的 Batch size
+ workers_per_gpu=2, # 单个 GPU 分配的数据加载线程数
+ train=dict( # 训练数据集配置
+ type='CityscapesDataset', # 数据集的类别, 细节参考自 mmseg/datasets/。
+ data_root='data/cityscapes/', # 数据集的根目录。
+ img_dir='leftImg8bit/train', # 数据集图像的文件夹。
+ ann_dir='gtFine/train', # 数据集注释的文件夹。
+ pipeline=[ # 流程, 由之前创建的 train_pipeline 传递进来。
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(
+ type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=(512, 1024), cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size=(512, 1024), pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg'])
+ ]),
+ val=dict( # 验证数据集的配置
+ type='CityscapesDataset',
+ data_root='data/cityscapes/',
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=[ # 由之前创建的 test_pipeline 传递的流程。
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]),
+ test=dict(
+ type='CityscapesDataset',
+ data_root='data/cityscapes/',
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]))
+log_config = dict( # 注册日志钩 (register logger hook) 的配置文件。
+ interval=50, # 打印日志的间隔
+ hooks=[
+ # dict(type='TensorboardLoggerHook') # 同样支持 Tensorboard 日志
+ dict(type='TextLoggerHook', by_epoch=False)
+ ])
+dist_params = dict(backend='nccl') # 用于设置分布式训练的参数,端口也同样可被设置。
+log_level = 'INFO' # 日志的级别。
+load_from = None # 从一个给定路径里加载模型作为预训练模型,它并不会消耗训练时间。
+resume_from = None # 从给定路径里恢复检查点(checkpoints),训练模式将从检查点保存的轮次开始恢复训练。
+workflow = [('train', 1)] # runner 的工作流程。 [('train', 1)] 意思是只有一个工作流程而且工作流程 'train' 仅执行一次。根据 `runner.max_iters` 工作流程训练模型的迭代轮数为40000次。
+cudnn_benchmark = True # 是否是使用 cudnn_benchmark 去加速,它对于固定输入大小的可以提高训练速度。
+optimizer = dict( # 用于构建优化器的配置文件。支持 PyTorch 中的所有优化器,同时它们的参数与PyTorch里的优化器参数一致。
+ type='SGD', # 优化器种类,更多细节可参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/optimizer/default_constructor.py#L13。
+ lr=0.01, # 优化器的学习率,参数的使用细节请参照对应的 PyTorch 文档。
+ momentum=0.9, # 动量 (Momentum)
+ weight_decay=0.0005) # SGD 的衰减权重 (weight decay)。
+optimizer_config = dict() # 用于构建优化器钩 (optimizer hook) 的配置文件,执行细节请参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py#L8。
+lr_config = dict(
+ policy='poly', # 调度流程的策略,同样支持 Step, CosineAnnealing, Cyclic 等. 请从 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9 参考 LrUpdater 的细节。
+ power=0.9, # 多项式衰减 (polynomial decay) 的幂。
+ min_lr=0.0001, # 用来稳定训练的最小学习率。
+ by_epoch=False) # 是否按照每个 epoch 去算学习率。
+runner = dict(
+ type='IterBasedRunner', # 将使用的 runner 的类别 (例如 IterBasedRunner 或 EpochBasedRunner)。
+ max_iters=40000) # 全部迭代轮数大小,对于 EpochBasedRunner 使用 `max_epochs` 。
+checkpoint_config = dict( # 设置检查点钩子 (checkpoint hook) 的配置文件。执行时请参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py。
+ by_epoch=False, # 是否按照每个 epoch 去算 runner。
+ interval=4000) # 保存的间隔
+evaluation = dict( # 构建评估钩 (evaluation hook) 的配置文件。细节请参考 mmseg/core/evaluation/eval_hook.py。
+ interval=4000, # 评估的间歇点
+ metric='mIoU') # 评估的指标
+
+
+```
+
+## FAQ
+
+### 忽略基础配置文件里的一些域内容。
+
+有时,您也许会设置 `_delete_=True` 去忽略基础配置文件里的一些域内容。
+您也许可以参照 [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html#inherit-from-base-config-with-ignored-fields) 来获得一些简单的指导。
+
+在 MMSegmentation 里,例如为了改变 PSPNet 的主干网络的某些内容:
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='MaskRCNN',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(...),
+ auxiliary_head=dict(...))
+```
+
+`ResNet` 和 `HRNet` 使用不同的关键词去构建。
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscpaes.py'
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ pretrained='open-mmlab://msra/hrnetv2_w32',
+ backbone=dict(
+ _delete_=True,
+ type='HRNet',
+ norm_cfg=norm_cfg,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256)))),
+ decode_head=dict(...),
+ auxiliary_head=dict(...))
+```
+
+`_delete_=True` 将用新的键去替换 `backbone` 域内所有老的键。
+
+### 使用配置文件里的中间变量
+
+配置文件里会使用一些中间变量,例如数据集里的 `train_pipeline`/`test_pipeline`。
+需要注意的是,在子配置文件里修改中间变量时,使用者需要再次传递这些变量给对应的域。
+例如,我们想改变在训练或测试时,PSPNet 的多尺度策略 (multi scale strategy),`train_pipeline`/`test_pipeline` 是我们想要修改的中间变量。
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscapes.py'
+crop_size = (512, 1024)
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(1.0, 2.0)), # 改成 [1., 2.]
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75], # 改成多尺度测试 (multi scale testing)。
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
+```
+
+我们首先定义新的 `train_pipeline`/`test_pipeline` 然后传递到 `data` 里。
+
+同样的,如果我们想从 `SyncBN` 切换到 `BN` 或者 `MMSyncBN`,我们需要配置文件里的每一个 `norm_cfg`。
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscpaes.py'
+norm_cfg = dict(type='BN', requires_grad=True)
+model = dict(
+ backbone=dict(norm_cfg=norm_cfg),
+ decode_head=dict(norm_cfg=norm_cfg),
+ auxiliary_head=dict(norm_cfg=norm_cfg))
+```
diff --git a/docs/zh_cn/tutorials/customize_datasets.md b/docs/zh_cn/tutorials/customize_datasets.md
new file mode 100644
index 0000000..c579a8f
--- /dev/null
+++ b/docs/zh_cn/tutorials/customize_datasets.md
@@ -0,0 +1,209 @@
+# 教程 2: 自定义数据集
+
+## 通过重新组织数据来定制数据集
+
+最简单的方法是将您的数据集进行转化,并组织成文件夹的形式。
+
+如下的文件结构就是一个例子。
+
+```none
+├── data
+│ ├── my_dataset
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ │ ├── xxx{img_suffix}
+│ │ │ │ ├── yyy{img_suffix}
+│ │ │ │ ├── zzz{img_suffix}
+│ │ │ ├── val
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ │ ├── xxx{seg_map_suffix}
+│ │ │ │ ├── yyy{seg_map_suffix}
+│ │ │ │ ├── zzz{seg_map_suffix}
+│ │ │ ├── val
+
+```
+
+一个训练对将由 img_dir/ann_dir 里同样首缀的文件组成。
+
+如果给定 `split` 参数,只有部分在 img_dir/ann_dir 里的文件会被加载。
+我们可以对被包括在 split 文本里的文件指定前缀。
+
+除此以外,一个 split 文本如下所示:
+
+```none
+xxx
+zzz
+```
+
+只有
+
+`data/my_dataset/img_dir/train/xxx{img_suffix}`,
+`data/my_dataset/img_dir/train/zzz{img_suffix}`,
+`data/my_dataset/ann_dir/train/xxx{seg_map_suffix}`,
+`data/my_dataset/ann_dir/train/zzz{seg_map_suffix}` 将被加载。
+
+注意:标注是跟图像同样的形状 (H, W),其中的像素值的范围是 `[0, num_classes - 1]`。
+您也可以使用 [pillow](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#palette) 的 `'P'` 模式去创建包含颜色的标注。
+
+## 通过混合数据去定制数据集
+
+MMSegmentation 同样支持混合数据集去训练。
+当前它支持拼接 (concat), 重复 (repeat) 和多图混合 (multi-image mix)数据集。
+
+### 重复数据集
+
+我们使用 `RepeatDataset` 作为包装 (wrapper) 去重复数据集。
+例如,假设原始数据集是 `Dataset_A`,为了重复它,配置文件如下:
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict( # 这是 Dataset_A 数据集的原始配置
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+ )
+```
+
+### 拼接数据集
+
+有2种方式去拼接数据集。
+
+1. 如果您想拼接的数据集是同样的类型,但有不同的标注文件,
+ 您可以按如下操作去拼接数据集的配置文件:
+
+ 1. 您也许可以拼接两个标注文件夹 `ann_dir`
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = ['anno_dir_1', 'anno_dir_2'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 2. 您也可以去拼接两个 `split` 文件列表
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = 'anno_dir',
+ split = ['split_1.txt', 'split_2.txt'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 3. 您也可以同时拼接 `ann_dir` 文件夹和 `split` 文件列表
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = ['anno_dir_1', 'anno_dir_2'],
+ split = ['split_1.txt', 'split_2.txt'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 在这样的情况下, `ann_dir_1` 和 `ann_dir_2` 分别对应于 `split_1.txt` 和 `split_2.txt`
+
+2. 如果您想拼接不同的数据集,您可以如下去拼接数据集的配置文件:
+
+ ```python
+ dataset_A_train = dict()
+ dataset_B_train = dict()
+
+ data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+ )
+ ```
+
+一个更复杂的例子如下:分别重复 `Dataset_A` 和 `Dataset_B` N 次和 M 次,然后再去拼接重复后的数据集
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict(
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+)
+dataset_A_val = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_A_test = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_B_train = dict(
+ type='RepeatDataset',
+ times=M,
+ dataset=dict(
+ type='Dataset_B',
+ ...
+ pipeline=train_pipeline
+ )
+)
+data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+)
+
+```
+
+### 多图混合集
+
+我们使用 `MultiImageMixDataset` 作为包装(wrapper)去混合多个数据集的图片。
+`MultiImageMixDataset`可以被类似mosaic和mixup的多图混合数据増广使用。
+
+`MultiImageMixDataset`与`Mosaic`数据増广一起使用的例子:
+
+```python
+train_pipeline = [
+ dict(type='RandomMosaic', prob=1),
+ dict(type='Resize', img_scale=(1024, 512), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+
+train_dataset = dict(
+ type='MultiImageMixDataset',
+ dataset=dict(
+ classes=classes,
+ palette=palette,
+ type=dataset_type,
+ reduce_zero_label=False,
+ img_dir=data_root + "images/train",
+ ann_dir=data_root + "annotations/train",
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ ]
+ ),
+ pipeline=train_pipeline
+)
+
+```
diff --git a/docs/zh_cn/tutorials/customize_models.md b/docs/zh_cn/tutorials/customize_models.md
new file mode 100644
index 0000000..c92d7db
--- /dev/null
+++ b/docs/zh_cn/tutorials/customize_models.md
@@ -0,0 +1,230 @@
+# 教程 4: 自定义模型
+
+## 自定义优化器 (optimizer)
+
+假设您想增加一个新的叫 `MyOptimizer` 的优化器,它的参数分别为 `a`, `b`, 和 `c`。
+您首先需要在一个文件里实现这个新的优化器,例如在 `mmseg/core/optimizer/my_optimizer.py` 里面:
+
+```python
+from mmcv.runner import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+然后增加这个模块到 `mmseg/core/optimizer/__init__.py` 里面,这样注册器 (registry) 将会发现这个新的模块并添加它:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+之后您可以在配置文件的 `optimizer` 域里使用 `MyOptimizer`,
+如下所示,在配置文件里,优化器被 `optimizer` 域所定义:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+为了使用您自己的优化器,域可以被修改为:
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+我们已经支持了 PyTorch 自带的全部优化器,唯一修改的地方是在配置文件里的 `optimizer` 域。例如,如果您想使用 `ADAM`,尽管数值表现会掉点,还是可以如下修改:
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+使用者可以直接按照 PyTorch [文档教程](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) 去设置参数。
+
+## 定制优化器的构造器 (optimizer constructor)
+
+对于优化,一些模型可能会有一些特别定义的参数,例如批归一化 (BatchNorm) 层里面的权重衰减 (weight decay)。
+使用者可以通过定制优化器的构造器来微调这些细粒度的优化器参数。
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner import OPTIMIZER_BUILDERS
+from .cocktail_optimizer import CocktailOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module
+class CocktailOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+## 开发和增加新的组件(Module)
+
+MMSegmentation 里主要有2种组件:
+
+- 主干网络 (backbone): 通常是卷积网络的堆叠,来做特征提取,例如 ResNet, HRNet
+- 解码头 (decoder head): 用于语义分割图的解码的组件(得到分割结果)
+
+### 添加新的主干网络
+
+这里我们以 MobileNet 为例,展示如何增加新的主干组件:
+
+1. 创建一个新的文件 `mmseg/models/backbones/mobilenet.py`
+
+```python
+import torch.nn as nn
+
+from ..registry import BACKBONES
+
+
+@BACKBONES.register_module
+class MobileNet(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # should return a tuple
+ pass
+
+ def init_weights(self, pretrained=None):
+ pass
+```
+
+2. 在 `mmseg/models/backbones/__init__.py` 里面导入模块
+
+```python
+from .mobilenet import MobileNet
+```
+
+3. 在您的配置文件里使用它
+
+```python
+model = dict(
+ ...
+ backbone=dict(
+ type='MobileNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+### 增加新的解码头 (decoder head)组件
+
+在 MMSegmentation 里面,对于所有的分割头,我们提供一个基类解码头 [BaseDecodeHead](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/decode_head.py) 。
+所有新建的解码头都应该继承它。这里我们以 [PSPNet](https://arxiv.org/abs/1612.01105) 为例,
+展示如何开发和增加一个新的解码头组件:
+
+首先,在 `mmseg/models/decode_heads/psp_head.py` 里添加一个新的解码头。
+PSPNet 中实现了一个语义分割的解码头。为了实现一个解码头,我们只需要在新构造的解码头中实现如下的3个函数:
+
+```python
+@HEADS.register_module()
+class PSPHead(BaseDecodeHead):
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
+ super(PSPHead, self).__init__(**kwargs)
+
+ def init_weights(self):
+
+ def forward(self, inputs):
+
+```
+
+接着,使用者需要在 `mmseg/models/decode_heads/__init__.py` 里面添加这个模块,这样对应的注册器 (registry) 可以查找并加载它们。
+
+PSPNet的配置文件如下所示:
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain_model/resnet50_v1c_trick-2cccc1ad.pth',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='PSPHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
+
+```
+
+### 增加新的损失函数
+
+假设您想添加一个新的损失函数 `MyLoss` 到语义分割解码器里。
+为了添加一个新的损失函数,使用者需要在 `mmseg/models/losses/my_loss.py` 里面去实现它。
+`weighted_loss` 可以对计算损失时的每个样本做加权。
+
+```python
+import torch
+import torch.nn as nn
+
+from ..builder import LOSSES
+from .utils import weighted_loss
+
+@weighted_loss
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+@LOSSES.register_module
+class MyLoss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(MyLoss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss = self.loss_weight * my_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss
+```
+
+然后使用者需要在 `mmseg/models/losses/__init__.py` 里面添加它:
+
+```python
+from .my_loss import MyLoss, my_loss
+
+```
+
+为了使用它,修改 `loss_xxx` 域。之后您需要在解码头组件里修改 `loss_decode` 域。
+`loss_weight` 可以被用来对不同的损失函数做加权。
+
+```python
+loss_decode=dict(type='MyLoss', loss_weight=1.0))
+```
diff --git a/docs/zh_cn/tutorials/customize_runtime.md b/docs/zh_cn/tutorials/customize_runtime.md
new file mode 100644
index 0000000..6331789
--- /dev/null
+++ b/docs/zh_cn/tutorials/customize_runtime.md
@@ -0,0 +1,248 @@
+# 教程 6: 自定义运行设定
+
+## 自定义优化设定
+
+### 自定义 PyTorch 支持的优化器
+
+我们已经支持 PyTorch 自带的所有优化器,唯一需要修改的地方是在配置文件里的 `optimizer` 域里面。
+例如,如果您想使用 `ADAM` (注意如下操作可能会让模型表现下降),可以使用如下修改:
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+为了修改模型的学习率,使用者仅需要修改配置文件里 optimizer 的 `lr` 即可。
+使用者可以参照 PyTorch 的 [API 文档](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim)
+直接设置参数。
+
+### 自定义自己实现的优化器
+
+#### 1. 定义一个新的优化器
+
+一个自定义的优化器可以按照如下去定义:
+
+假如您想增加一个叫做 `MyOptimizer` 的优化器,它的参数分别有 `a`, `b`, 和 `c`。
+您需要创建一个叫 `mmseg/core/optimizer` 的新文件夹。
+然后再在文件,即 `mmseg/core/optimizer/my_optimizer.py` 里面去实现这个新优化器:
+
+```python
+from .registry import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+#### 2. 增加优化器到注册表 (registry)
+
+为了让上述定义的模块被框架发现,首先这个模块应该被导入到主命名空间 (main namespace) 里。
+有两种方式可以实现它。
+
+- 修改 `mmseg/core/optimizer/__init__.py` 来导入它
+
+ 新的被定义的模块应该被导入到 `mmseg/core/optimizer/__init__.py` 这样注册表将会发现新的模块并添加它
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- 在配置文件里使用 `custom_imports` 去手动导入它
+
+```python
+custom_imports = dict(imports=['mmseg.core.optimizer.my_optimizer'], allow_failed_imports=False)
+```
+
+`mmseg.core.optimizer.my_optimizer` 模块将会在程序运行的开始被导入,并且 `MyOptimizer` 类将会自动注册。
+需要注意只有包含 `MyOptimizer` 类的包 (package) 应当被导入。
+而 `mmseg.core.optimizer.my_optimizer.MyOptimizer` **不能** 被直接导入。
+
+事实上,使用者完全可以用另一个按这样导入方法的文件夹结构,只要模块的根路径已经被添加到 `PYTHONPATH` 里面。
+
+#### 3. 在配置文件里定义优化器
+
+之后您可以在配置文件的 `optimizer` 域里面使用 `MyOptimizer`
+在配置文件里,优化器被定义在 `optimizer` 域里,如下所示:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+为了使用您自己的优化器,这个域可以被改成:
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+### 自定义优化器的构造器 (constructor)
+
+有些模型可能需要在优化器里有一些特别参数的设置,例如 批归一化层 (BatchNorm layers) 的 权重衰减 (weight decay)。
+使用者可以通过自定义优化器的构造器去微调这些细粒度参数。
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner.optimizer import OPTIMIZER_BUILDERS, OPTIMIZERS
+from mmseg.utils import get_root_logger
+from .my_optimizer import MyOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module()
+class MyOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+默认的优化器构造器的实现可以参照 [这里](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/optimizer/default_constructor.py#L11) ,它也可以被用作新的优化器构造器的模板。
+
+### 额外的设置
+
+优化器没有实现的一些技巧应该通过优化器构造器 (optimizer constructor) 或者钩子 (hook) 去实现,如设置基于参数的学习率 (parameter-wise learning rates)。我们列出一些常见的设置,它们可以稳定或加速模型的训练。
+如果您有更多的设置,欢迎在 PR 和 issue 里面提交。
+
+- __使用梯度截断 (gradient clip) 去稳定训练__:
+
+ 一些模型需要梯度截断去稳定训练过程,如下所示
+
+ ```python
+ optimizer_config = dict(
+ _delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
+ ```
+
+ 如果您的配置继承自已经设置了 `optimizer_config` 的基础配置 (base config),您可能需要 `_delete_=True` 来重写那些不需要的设置。更多细节请参照 [配置文件文档](https://mmsegmentation.readthedocs.io/en/latest/config.html) 。
+
+- __使用动量计划表 (momentum schedule) 去加速模型收敛__:
+
+ 我们支持动量计划表去让模型基于学习率修改动量,这样可能让模型收敛地更快。
+ 动量计划表经常和学习率计划表 (LR scheduler) 一起使用,例如如下配置文件就在 3D 检测里经常使用以加速收敛。
+ 更多细节请参考 [CyclicLrUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L327) 和 [CyclicMomentumUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/momentum_updater.py#L130) 的实现。
+
+ ```python
+ lr_config = dict(
+ policy='cyclic',
+ target_ratio=(10, 1e-4),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ momentum_config = dict(
+ policy='cyclic',
+ target_ratio=(0.85 / 0.95, 1),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ ```
+
+## 自定义训练计划表
+
+我们根据默认的训练迭代步数 40k/80k 来设置学习率,这在 MMCV 里叫做 [`PolyLrUpdaterHook`](https://github.com/open-mmlab/mmcv/blob/826d3a7b68596c824fa1e2cb89b6ac274f52179c/mmcv/runner/hooks/lr_updater.py#L196) 。
+我们也支持许多其他的学习率计划表:[这里](https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py) ,例如 `CosineAnnealing` 和 `Poly` 计划表。下面是一些例子:
+
+- 步计划表 Step schedule:
+
+ ```python
+ lr_config = dict(policy='step', step=[9, 10])
+ ```
+
+- 余弦退火计划表 ConsineAnnealing schedule:
+
+ ```python
+ lr_config = dict(
+ policy='CosineAnnealing',
+ warmup='linear',
+ warmup_iters=1000,
+ warmup_ratio=1.0 / 10,
+ min_lr_ratio=1e-5)
+ ```
+
+## 自定义工作流 (workflow)
+
+工作流是一个专门定义运行顺序和轮数 (running order and epochs) 的列表 (phase, epochs)。
+默认情况下它设置成:
+
+```python
+workflow = [('train', 1)]
+```
+
+意思是训练是跑 1 个 epoch。有时候使用者可能想检查模型在验证集上的一些指标(如 损失 loss,精确性 accuracy),我们可以这样设置工作流:
+
+```python
+[('train', 1), ('val', 1)]
+```
+
+于是 1 个 epoch 训练,1 个 epoch 验证将交替运行。
+
+**注意**:
+
+1. 模型的参数在验证的阶段不会被自动更新
+2. 配置文件里的关键词 `total_epochs` 仅控制训练的 epochs 数目,而不会影响验证时的工作流
+3. 工作流 `[('train', 1), ('val', 1)]` 和 `[('train', 1)]` 将不会改变 `EvalHook` 的行为,因为 `EvalHook` 被 `after_train_epoch`
+ 调用而且验证的工作流仅仅影响通过调用 `after_val_epoch` 的钩子 (hooks)。因此, `[('train', 1), ('val', 1)]` 和 `[('train', 1)]`
+ 的区别仅在于 runner 将在每次训练 epoch 结束后计算在验证集上的损失
+
+## 自定义钩 (hooks)
+
+### 使用 MMCV 实现的钩子 (hooks)
+
+如果钩子已经在 MMCV 里被实现,如下所示,您可以直接修改配置文件来使用钩子:
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+### 修改默认的运行时间钩子 (runtime hooks)
+
+以下的常用的钩子没有被 `custom_hooks` 注册:
+
+- log_config
+- checkpoint_config
+- evaluation
+- lr_config
+- optimizer_config
+- momentum_config
+
+在这些钩子里,只有 logger hook 有 `VERY_LOW` 优先级,其他的优先级都是 `NORMAL`。
+上述提及的教程已经包括了如何修改 `optimizer_config`,`momentum_config` 和 `lr_config`。
+这里我们展示我们如何处理 `log_config`, `checkpoint_config` 和 `evaluation`。
+
+#### 检查点配置文件 (Checkpoint config)
+
+MMCV runner 将使用 `checkpoint_config` 去初始化 [`CheckpointHook`](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/hooks/checkpoint.py#L9).
+
+```python
+checkpoint_config = dict(interval=1)
+```
+
+使用者可以设置 `max_keep_ckpts` 来仅保存一小部分检查点或者通过 `save_optimizer` 来决定是否保存优化器的状态字典 (state dict of optimizer)。 更多使用参数的细节请参考 [这里](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.CheckpointHook) 。
+
+#### 日志配置文件 (Log config)
+
+`log_config` 包裹了许多日志钩 (logger hooks) 而且能去设置间隔 (intervals)。现在 MMCV 支持 `WandbLoggerHook`, `MlflowLoggerHook` 和 `TensorboardLoggerHook`。
+详细的使用请参照 [文档](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.LoggerHook) 。
+
+```python
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')
+ ])
+```
+
+#### 评估配置文件 (Evaluation config)
+
+`evaluation` 的配置文件将被用来初始化 [`EvalHook`](https://github.com/open-mmlab/mmsegmentation/blob/e3f6f655d69b777341aec2fe8829871cc0beadcb/mmseg/core/evaluation/eval_hooks.py#L7) 。
+除了 `interval` 键,其他的像 `metric` 这样的参数将被传递给 `dataset.evaluate()` 。
+
+```python
+evaluation = dict(interval=1, metric='mIoU')
+```
diff --git a/docs/zh_cn/tutorials/data_pipeline.md b/docs/zh_cn/tutorials/data_pipeline.md
new file mode 100644
index 0000000..f3dfcd8
--- /dev/null
+++ b/docs/zh_cn/tutorials/data_pipeline.md
@@ -0,0 +1,166 @@
+# 教程 3: 自定义数据流程
+
+## 数据流程的设计
+
+按照通常的惯例,我们使用 `Dataset` 和 `DataLoader` 做多线程的数据加载。`Dataset` 返回一个数据内容的字典,里面对应于模型前传方法的各个参数。
+因为在语义分割中,输入的图像数据具有不同的大小,我们在 MMCV 里引入一个新的 `DataContainer` 类别去帮助收集和分发不同大小的输入数据。
+
+更多细节,请查看[这里](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py) 。
+
+数据的准备流程和数据集是解耦的。通常一个数据集定义了如何处理标注数据(annotations)信息,而一个数据流程定义了准备一个数据字典的所有步骤。一个流程包括了一系列操作,每个操作里都把一个字典作为输入,然后再输出一个新的字典给下一个变换操作。
+
+这些操作可分为数据加载 (data loading),预处理 (pre-processing),格式变化 (formatting) 和测试时数据增强 (test-time augmentation)。
+
+下面的例子就是 PSPNet 的一个流程:
+
+```python
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 1024)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+```
+
+对于每个操作,我们列出它添加、更新、移除的相关字典域 (dict fields):
+
+### 数据加载 Data loading
+
+`LoadImageFromFile`
+
+- 增加: img, img_shape, ori_shape
+
+`LoadAnnotations`
+
+- 增加: gt_semantic_seg, seg_fields
+
+### 预处理 Pre-processing
+
+`Resize`
+
+- 增加: scale, scale_idx, pad_shape, scale_factor, keep_ratio
+- 更新: img, img_shape, *seg_fields
+
+`RandomFlip`
+
+- 增加: flip
+- 更新: img, *seg_fields
+
+`Pad`
+
+- 增加: pad_fixed_size, pad_size_divisor
+- 更新: img, pad_shape, *seg_fields
+
+`RandomCrop`
+
+- 更新: img, pad_shape, *seg_fields
+
+`Normalize`
+
+- 增加: img_norm_cfg
+- 更新: img
+
+`SegRescale`
+
+- 更新: gt_semantic_seg
+
+`PhotoMetricDistortion`
+
+- 更新: img
+
+### 格式 Formatting
+
+`ToTensor`
+
+- 更新: 由 `keys` 指定
+
+`ImageToTensor`
+
+- 更新: 由 `keys` 指定
+
+`Transpose`
+
+- 更新: 由 `keys` 指定
+
+`ToDataContainer`
+
+- 更新: 由 `keys` 指定
+
+`DefaultFormatBundle`
+
+- 更新: img, gt_semantic_seg
+
+`Collect`
+
+- 增加: img_meta (the keys of img_meta is specified by `meta_keys`)
+- 移除: all other keys except for those specified by `keys`
+
+### 测试时数据增强 Test time augmentation
+
+`MultiScaleFlipAug`
+
+## 拓展和使用自定义的流程
+
+1. 在任何一个文件里写一个新的流程,例如 `my_pipeline.py`,它以一个字典作为输入并且输出一个字典
+
+ ```python
+ from mmseg.datasets import PIPELINES
+
+ @PIPELINES.register_module()
+ class MyTransform:
+
+ def __call__(self, results):
+ results['dummy'] = True
+ return results
+ ```
+
+2. 导入一个新类
+
+ ```python
+ from .my_pipeline import MyTransform
+ ```
+
+3. 在配置文件里使用它
+
+ ```python
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+ crop_size = (512, 1024)
+ train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='MyTransform'),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+ ]
+ ```
diff --git a/docs/zh_cn/tutorials/index.rst b/docs/zh_cn/tutorials/index.rst
new file mode 100644
index 0000000..e1a67a8
--- /dev/null
+++ b/docs/zh_cn/tutorials/index.rst
@@ -0,0 +1,9 @@
+.. toctree::
+ :maxdepth: 2
+
+ config.md
+ customize_datasets.md
+ data_pipeline.md
+ customize_models.md
+ training_tricks.md
+ customize_runtime.md
diff --git a/docs/zh_cn/tutorials/training_tricks.md b/docs/zh_cn/tutorials/training_tricks.md
new file mode 100644
index 0000000..be9112c
--- /dev/null
+++ b/docs/zh_cn/tutorials/training_tricks.md
@@ -0,0 +1,70 @@
+# 教程 5: 训练技巧
+
+MMSegmentation 支持如下训练技巧:
+
+## 主干网络和解码头组件使用不同的学习率 (Learning Rate, LR)
+
+在语义分割里,一些方法会让解码头组件的学习率大于主干网络的学习率,这样可以获得更好的表现或更快的收敛。
+
+在 MMSegmentation 里面,您也可以在配置文件里添加如下行来让解码头组件的学习率是主干组件的10倍。
+
+```python
+optimizer=dict(
+ paramwise_cfg = dict(
+ custom_keys={
+ 'head': dict(lr_mult=10.)}))
+```
+
+通过这种修改,任何被分组到 `'head'` 的参数的学习率都将乘以10。您也可以参照 [MMCV 文档](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.DefaultOptimizerConstructor) 获取更详细的信息。
+
+## 在线难样本挖掘 (Online Hard Example Mining, OHEM)
+
+对于训练时采样,我们在 [这里](https://github.com/open-mmlab/mmsegmentation/tree/master/mmseg/core/seg/sampler) 做了像素采样器。
+如下例子是使用 PSPNet 训练并采用 OHEM 策略的配置:
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
+```
+
+通过这种方式,只有置信分数在0.7以下的像素值点会被拿来训练。在训练时我们至少要保留100000个像素值点。如果 `thresh` 并未被指定,前 ``min_kept``
+个损失的像素值点才会被选择。
+
+## 类别平衡损失 (Class Balanced Loss)
+
+对于不平衡类别分布的数据集,您也许可以改变每个类别的损失权重。这里以 cityscapes 数据集为例:
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
+ # DeepLab 对 cityscapes 使用这种权重
+ class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
+ 1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
+ 1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
+```
+
+`class_weight` 将被作为 `weight` 参数,传递给 `CrossEntropyLoss`。详细信息请参照 [PyTorch 文档](https://pytorch.org/docs/stable/nn.html?highlight=crossentropy#torch.nn.CrossEntropyLoss) 。
+
+## 同时使用多种损失函数 (Multiple Losses)
+
+对于训练时损失函数的计算,我们目前支持多个损失函数同时使用。 以 `unet` 使用 `DRIVE` 数据集训练为例,
+使用 `CrossEntropyLoss` 和 `DiceLoss` 的 `1:3` 的加权和作为损失函数。配置文件写为:
+
+```python
+_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
+model = dict(
+ decode_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
+ auxiliary_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce',loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
+ )
+```
+
+通过这种方式,确定训练过程中损失函数的权重 `loss_weight` 和在训练日志里的名字 `loss_name`。
+
+注意: `loss_name` 的名字必须带有 `loss_` 前缀,这样它才能被包括在反传的图里。
diff --git a/docs/zh_cn/useful_tools.md b/docs/zh_cn/useful_tools.md
new file mode 100644
index 0000000..bdf2740
--- /dev/null
+++ b/docs/zh_cn/useful_tools.md
@@ -0,0 +1,368 @@
+## 常用工具
+
+除了训练和测试的脚本,我们在 `tools/` 文件夹路径下还提供许多有用的工具。
+
+### 计算参数量(params)和计算量( FLOPs) (试验性)
+
+我们基于 [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch)
+提供了一个用于计算给定模型参数量和计算量的脚本。
+
+```shell
+python tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+您将得到如下的结果:
+
+```none
+==============================
+Input shape: (3, 2048, 1024)
+Flops: 1429.68 GMac
+Params: 48.98 M
+==============================
+```
+
+**注意**: 这个工具仍然是试验性的,我们无法保证数字是正确的。您可以拿这些结果做简单的实验的对照,在写技术文档报告或者论文前您需要再次确认一下。
+
+(1) 计算量与输入的形状有关,而参数量与输入的形状无关,默认的输入形状是 (1, 3, 1280, 800);
+(2) 一些运算操作,如 GN 和其他定制的运算操作没有加入到计算量的计算中。
+
+### 发布模型
+
+在您上传一个模型到云服务器之前,您需要做以下几步:
+(1) 将模型权重转成 CPU 张量;
+(2) 删除记录优化器状态 (optimizer states)的相关信息;
+(3) 计算检查点文件 (checkpoint file) 的哈希编码(hash id)并且将哈希编码加到文件名中。
+
+```shell
+python tools/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+例如,
+
+```shell
+python tools/publish_model.py work_dirs/pspnet/latest.pth psp_r50_hszhao_200ep.pth
+```
+
+最终输出文件将是 `psp_r50_512x1024_40ki_cityscapes-{hash id}.pth`。
+
+### 导出 ONNX (试验性)
+
+我们提供了一个脚本来导出模型到 [ONNX](https://github.com/onnx/onnx) 格式。被转换的模型可以通过工具 [Netron](https://github.com/lutzroeder/netron)
+来可视化。除此以外,我们同样支持对 PyTorch 和 ONNX 模型的输出结果做对比。
+
+```bash
+python tools/pytorch2onnx.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE} \
+ --input-img ${INPUT_IMG} \
+ --shape ${INPUT_SHAPE} \
+ --rescale-shape ${RESCALE_SHAPE} \
+ --show \
+ --verify \
+ --dynamic-export \
+ --cfg-options \
+ model.test_cfg.mode="whole"
+```
+
+各个参数的描述:
+
+- `config` : 模型配置文件的路径
+- `--checkpoint` : 模型检查点文件的路径
+- `--output-file`: 输出的 ONNX 模型的路径。如果没有专门指定,它默认是 `tmp.onnx`
+- `--input-img` : 用来转换和可视化的一张输入图像的路径
+- `--shape`: 模型的输入张量的高和宽。如果没有专门指定,它将被设置成 `test_pipeline` 的 `img_scale`
+- `--rescale-shape`: 改变输出的形状。设置这个值来避免 OOM,它仅在 `slide` 模式下可以用
+- `--show`: 是否打印输出模型的结构。如果没有被专门指定,它将被设置成 `False`
+- `--verify`: 是否验证一个输出模型的正确性 (correctness)。如果没有被专门指定,它将被设置成 `False`
+- `--dynamic-export`: 是否导出形状变化的输入与输出的 ONNX 模型。如果没有被专门指定,它将被设置成 `False`
+- `--cfg-options`: 更新配置选项
+
+**注意**: 这个工具仍然是试验性的,目前一些自定义操作还没有被支持
+
+### 评估 ONNX 模型
+
+我们提供 `tools/deploy_test.py` 去评估不同后端的 ONNX 模型。
+
+#### 先决条件
+
+- 安装 onnx 和 onnxruntime-gpu
+
+ ```shell
+ pip install onnx onnxruntime-gpu
+ ```
+
+- 参考 [如何在 MMCV 里构建 tensorrt 插件](https://mmcv.readthedocs.io/en/latest/tensorrt_plugin.html#how-to-build-tensorrt-plugins-in-mmcv) 安装TensorRT (可选)
+
+#### 使用方法
+
+```bash
+python tools/deploy_test.py \
+ ${CONFIG_FILE} \
+ ${MODEL_FILE} \
+ ${BACKEND} \
+ --out ${OUTPUT_FILE} \
+ --eval ${EVALUATION_METRICS} \
+ --show \
+ --show-dir ${SHOW_DIRECTORY} \
+ --cfg-options ${CFG_OPTIONS} \
+ --eval-options ${EVALUATION_OPTIONS} \
+ --opacity ${OPACITY} \
+```
+
+各个参数的描述:
+
+- `config`: 模型配置文件的路径
+- `model`: 被转换的模型文件的路径
+- `backend`: 推理的后端,可选项:`onnxruntime`, `tensorrt`
+- `--out`: 输出结果成 pickle 格式文件的路径
+- `--format-only` : 不评估直接给输出结果的格式。通常用在当您想把结果输出成一些测试服务器需要的特定格式时。如果没有被专门指定,它将被设置成 `False`。 注意这个参数是用 `--eval` 来 **手动添加**
+- `--eval`: 评估指标,取决于每个数据集的要求,例如 "mIoU" 是大多数据集的指标而 "cityscapes" 仅针对 Cityscapes 数据集。注意这个参数是用 `--format-only` 来 **手动添加**
+- `--show`: 是否展示结果
+- `--show-dir`: 涂上结果的图像被保存的文件夹的路径
+- `--cfg-options`: 重写配置文件里的一些设置,`xxx=yyy` 格式的键值对将被覆盖到配置文件里
+- `--eval-options`: 自定义的评估的选项, `xxx=yyy` 格式的键值对将成为 `dataset.evaluate()` 函数的参数变量
+- `--opacity`: 涂上结果的分割图的透明度,范围在 (0, 1] 之间
+
+#### 结果和模型
+
+| 模型 | 配置文件 | 数据集 | 评价指标 | PyTorch | ONNXRuntime | TensorRT-fp32 | TensorRT-fp16 |
+| :--------: | :---------------------------------------------: | :--------: | :----: | :-----: | :---------: | :-----------: | :-----------: |
+| FCN | fcn_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 72.2 | 72.2 | 72.2 | 72.2 |
+| PSPNet | pspnet_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 77.8 | 77.8 | 77.8 | 77.8 |
+| deeplabv3 | deeplabv3_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.0 | 79.0 | 79.0 | 79.0 |
+| deeplabv3+ | deeplabv3plus_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.6 | 79.5 | 79.5 | 79.5 |
+| PSPNet | pspnet_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.2 | 78.1 | | |
+| deeplabv3 | deeplabv3_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.5 | 78.3 | | |
+| deeplabv3+ | deeplabv3plus_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.9 | 78.7 | | |
+
+**注意**: TensorRT 仅在使用 `whole mode` 测试模式时的配置文件里可用。
+
+### 导出 TorchScript (试验性)
+
+我们同样提供一个脚本去把模型导出成 [TorchScript](https://pytorch.org/docs/stable/jit.html) 格式。您可以使用 pytorch C++ API [LibTorch](https://pytorch.org/docs/stable/cpp_index.html) 去推理训练好的模型。
+被转换的模型能被像 [Netron](https://github.com/lutzroeder/netron) 的工具来可视化。此外,我们还支持 PyTorch 和 TorchScript 模型的输出结果的比较。
+
+```shell
+python tools/pytorch2torchscript.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE}
+ --shape ${INPUT_SHAPE}
+ --verify \
+ --show
+```
+
+各个参数的描述:
+
+- `config` : pytorch 模型的配置文件的路径
+- `--checkpoint` : pytorch 模型的检查点文件的路径
+- `--output-file`: TorchScript 模型输出的路径,如果没有被专门指定,它将被设置成 `tmp.pt`
+- `--input-img` : 用来转换和可视化的输入图像的路径
+- `--shape`: 模型的输入张量的宽和高。如果没有被专门指定,它将被设置成 `512 512`
+- `--show`: 是否打印输出模型的追踪图 (traced graph),如果没有被专门指定,它将被设置成 `False`
+- `--verify`: 是否验证一个输出模型的正确性 (correctness),如果没有被专门指定,它将被设置成 `False`
+
+**注意**: 目前仅支持 PyTorch>=1.8.0 版本
+
+**注意**: 这个工具仍然是试验性的,一些自定义操作符目前还不被支持
+
+例子:
+
+- 导出 PSPNet 在 cityscapes 数据集上的 pytorch 模型
+
+ ```shell
+ python tools/pytorch2torchscript.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ --checkpoint checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --output-file checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pt \
+ --shape 512 1024
+ ```
+
+### 导出 TensorRT (试验性)
+
+一个导出 [ONNX](https://github.com/onnx/onnx) 模型成 [TensorRT](https://developer.nvidia.com/tensorrt) 格式的脚本
+
+先决条件
+
+- 按照 [ONNXRuntime in mmcv](https://mmcv.readthedocs.io/en/latest/deployment/onnxruntime_op.html) 和 [TensorRT plugin in mmcv](https://github.com/open-mmlab/mmcv/blob/master/docs/en/deployment/tensorrt_plugin.md) ,用 ONNXRuntime 自定义运算 (custom ops) 和 TensorRT 插件安装 `mmcv-full`
+- 使用 [pytorch2onnx](#convert-to-onnx-experimental) 将模型从 PyTorch 转成 ONNX
+
+使用方法
+
+```bash
+python ${MMSEG_PATH}/tools/onnx2tensorrt.py \
+ ${CFG_PATH} \
+ ${ONNX_PATH} \
+ --trt-file ${OUTPUT_TRT_PATH} \
+ --min-shape ${MIN_SHAPE} \
+ --max-shape ${MAX_SHAPE} \
+ --input-img ${INPUT_IMG} \
+ --show \
+ --verify
+```
+
+各个参数的描述:
+
+- `config` : 模型的配置文件
+- `model` : 输入的 ONNX 模型的路径
+- `--trt-file` : 输出的 TensorRT 引擎的路径
+- `--max-shape` : 模型的输入的最大形状
+- `--min-shape` : 模型的输入的最小形状
+- `--fp16` : 做 fp16 模型转换
+- `--workspace-size` : 在 GiB 里的最大工作空间大小 (Max workspace size)
+- `--input-img` : 用来可视化的图像
+- `--show` : 做结果的可视化
+- `--dataset` : Palette provider, 默认为 `CityscapesDataset`
+- `--verify` : 验证 ONNXRuntime 和 TensorRT 的输出
+- `--verbose` : 当创建 TensorRT 引擎时,是否详细做信息日志。默认为 False
+
+**注意**: 仅在全图测试模式 (whole mode) 下测试过
+
+## 其他内容
+
+### 打印完整的配置文件
+
+`tools/print_config.py` 会逐字逐句的打印整个配置文件,展开所有的导入。
+
+```shell
+python tools/print_config.py \
+ ${CONFIG} \
+ --graph \
+ --cfg-options ${OPTIONS [OPTIONS...]} \
+```
+
+各个参数的描述:
+
+- `config` : pytorch 模型的配置文件的路径
+- `--graph` : 是否打印模型的图 (models graph)
+- `--cfg-options`: 自定义替换配置文件的选项
+
+### 对训练日志 (training logs) 画图
+
+`tools/analyze_logs.py` 会画出给定的训练日志文件的 loss/mIoU 曲线,首先需要 `pip install seaborn` 安装依赖包。
+
+```shell
+python tools/analyze_logs.py xxx.log.json [--keys ${KEYS}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
+```
+
+示例:
+
+- 对 mIoU, mAcc, aAcc 指标画图
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
+ ```
+
+- 对 loss 指标画图
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys loss --legend loss
+ ```
+
+### 转换其他仓库的权重
+
+`tools/model_converters/` 提供了若干个预训练权重转换脚本,支持将其他仓库的预训练权重的 key 转换为与 MMSegmentation 相匹配的 key。
+
+#### ViT Swin MiT Transformer 模型
+
+- ViT
+
+`tools/model_converters/vit2mmseg.py` 将 timm 预训练模型转换到 MMSegmentation。
+
+ ```shell
+ python tools/model_converters/vit2mmseg.py ${SRC} ${DST}
+ ```
+
+- Swin
+
+ `tools/model_converters/swin2mmseg.py` 将官方预训练模型转换到 MMSegmentation。
+
+ ```shell
+ python tools/model_converters/swin2mmseg.py ${SRC} ${DST}
+ ```
+
+- SegFormer
+
+ `tools/model_converters/mit2mmseg.py` 将官方预训练模型转换到 MMSegmentation。
+
+ ```shell
+ python tools/model_converters/mit2mmseg.py ${SRC} ${DST}
+ ```
+
+## 模型服务
+
+为了用 [`TorchServe`](https://pytorch.org/serve/) 服务 `MMSegmentation` 的模型 , 您可以遵循如下流程:
+
+### 1. 将 model 从 MMSegmentation 转换到 TorchServe
+
+```shell
+python tools/mmseg2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+**注意**: ${MODEL_STORE} 需要设置为某个文件夹的绝对路径
+
+### 2. 构建 `mmseg-serve` 容器镜像 (docker image)
+
+```shell
+docker build -t mmseg-serve:latest docker/serve/
+```
+
+### 3. 运行 `mmseg-serve`
+
+请查阅官方文档: [使用容器运行 TorchServe](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment)
+
+为了在 GPU 环境下使用, 您需要安装 [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). 若在 CPU 环境下使用,您可以忽略添加 `--gpus` 参数。
+
+示例:
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
+mmseg-serve:latest
+```
+
+阅读关于推理 (8080), 管理 (8081) 和指标 (8082) APIs 的 [文档](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md) 。
+
+### 4. 测试部署
+
+```shell
+curl -O https://raw.githubusercontent.com/open-mmlab/mmsegmentation/master/resources/3dogs.jpg
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg -o 3dogs_mask.png
+```
+
+得到的响应将是一个 ".png" 的分割掩码.
+
+您可以按照如下方法可视化输出:
+
+```python
+import matplotlib.pyplot as plt
+import mmcv
+plt.imshow(mmcv.imread("3dogs_mask.png", "grayscale"))
+plt.show()
+```
+
+看到的东西将会和下图类似:
+
+
+
+然后您可以使用 `test_torchserve.py` 比较 torchserve 和 pytorch 的结果,并将它们可视化。
+
+```shell
+python tools/torchserve/test_torchserve.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--result-image ${RESULT_IMAGE}] [--device ${DEVICE}]
+```
+
+示例:
+
+```shell
+python tools/torchserve/test_torchserve.py \
+demo/demo.png \
+configs/fcn/fcn_r50-d8_512x1024_40k_cityscapes.py \
+checkpoint/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608-efe53f0d.pth \
+fcn
+```
diff --git a/docs_kneron/stdc_step_by_step.md b/docs_kneron/stdc_step_by_step.md
new file mode 100644
index 0000000..ec35a68
--- /dev/null
+++ b/docs_kneron/stdc_step_by_step.md
@@ -0,0 +1,439 @@
+# Step 1: Environment
+
+## Step 1-1: Prerequisites
+
+- Python 3.6+
+- PyTorch 1.3+ (We recommend you installing PyTorch using Conda following the [Official PyTorch Installation Instruction](https://pytorch.org/))
+- (Optional) CUDA 9.2+ (If you installed PyTorch with cuda using Conda following the [Official PyTorch Installation Instruction](https://pytorch.org/), you can skip CUDA installation)
+- (Optional, used to build from source) GCC 5+
+- [mmcv-full](https://mmcv.readthedocs.io/en/latest/#installation) (Note: not `mmcv`!)
+
+**Note:** You need to run `pip uninstall mmcv` first if you have `mmcv` installed.
+If mmcv and mmcv-full are both installed, there will be `ModuleNotFoundError`.
+
+## Step 1-2: Install kneron-mmsegmentation
+
+### Step 1-2-1: Install PyTorch
+
+You can follow [Official PyTorch Installation Instruction](https://pytorch.org/) to install PyTorch using Conda:
+
+```shell
+conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -y
+```
+
+### Step 1-2-2: Install mmcv-full
+
+We recommend you installing mmcv-full using pip:
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html
+```
+
+Please replace `cu113` and `torch1.11.0` in the url to your desired one. For example, to install the `mmcv-full` with `CUDA 11.1` and `PyTorch 1.9.0`, use the following command:
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
+```
+
+If you see error messages while installing mmcv-full, please check if your installation instruction matches your installed version of PyTorch and Cuda, and see [MMCV pip Installation Instruction](https://github.com/open-mmlab/mmcv#install-with-pip) for different versions of MMCV compatible to different PyTorch and CUDA versions.
+
+### Step 1-2-3: Clone kneron-mmsegmentation Repository
+
+```shell
+git clone https://github.com/kneron/kneron-mmsegmentation.git
+cd kneron-mmsegmentation
+```
+
+### Step 1-2-4: Install Required Python Libraries for Building and Installing kneron-mmsegmentation
+
+```shell
+pip install -r requirements_kneron.txt
+pip install -v -e . # or "python setup.py develop"
+```
+
+# Step 2: Training Models on Standard Datasets
+
+kneron-mmsegmentation provides many existing and existing semantic segmentation models in [Model Zoo](https://mmsegmentation.readthedocs.io/en/latest/model_zoo.html), and supports several standard datasets like CityScapes, Pascal Context, Coco Stuff, ADE20K, etc. Here we demonstrate how to train *STDC-Seg*, a semantic segmentation algorithm, on *CityScapes*, a well-known semantic segmentation dataset.
+
+## Step 2-1: Download CityScapes Dataset
+
+1. Go to [CityScapes Official Website](https://www.cityscapes-dataset.com) and click *Download* link on the top of the page. If you're not logged in, it will navigate you to login page.
+2. If it is the first time you visiting CityScapes website, to download CityScapes dataset, you have to register an account.
+3. Click the *Register* link and it will navigate you to the registeration page.
+4. Fill in all the *required* fields, accept the terms and conditions, and click the *Register* button. If everything goes well, you will see *Registration Successful* on the page and recieve a registration confirmation mail in your email inbox.
+5. Click on the link provided in the confirmation mail, login with your newly registered account and password, and you should be able to download the CityScapes dataset.
+6. Download *leftImg8bit_trainvaltest.zip* (images) and *gtFine_trainvaltest.zip* (labels) and place them onto your server.
+
+## Step 2-2: Dataset Preparation
+
+We suggest that you extract the zipped files to somewhere outside the project directory and symlink (`ln`) the dataset root to `kneron-mmsegmentation/data` so you can use the dataset outside this project, as shown below:
+
+```shell
+# Replace all "path/to/your" below with where you want to put the dataset!
+
+# Extracting Cityscapes
+mkdir -p path/to/your/cityscapes
+unzip leftImg8bit_trainvaltest.zip -d path/to/your/cityscapes
+unzip gtFine_trainvaltest.zip -d path/to/your/cityscapes
+
+# symlink dataset to kneron-mmsegmentation/data # where "kneron-mmsegmentation" is the repository you cloned in step 0-4
+mkdir -p kneron-mmsegmentation/data
+ln -s $(realpath path/to/your/cityscapes) kneron-mmsegmentation/data
+
+# Replace all "path/to/your" above with where you want to put the dataset!
+```
+
+Then, we need *cityscapesScripts* to preprocess the CityScapes dataset. If you completely followed our [Step 1-2-4](#step-1-2-4-install-required-python-libraries-for-building-and-installing-kneron-mmsegmentation), you should have python library *cityscapesScripts* installed (if no, execute `pip install cityscapesScripts` command).
+
+```shell
+# Replace "path/to/your" with where you want to put the dataset!
+export CITYSCAPES_DATASET=$(realpath path/to/your/cityscapes)
+csCreateTrainIdLabelImgs
+```
+
+Wait several minutes and you'll see something like this:
+
+```plain
+Processing 5000 annotation files
+Progress: 100.0 %
+```
+
+The files inside the dataset folder should be something like:
+
+```plain
+kneron-mmsegmentation/data/cityscapes
+├── gtFine
+│ ├── test
+│ │ ├── ...
+│ ├── train
+│ │ ├── ...
+│ ├── val
+│ │ ├── frankfurt
+│ │ │ ├── frankfurt_000000_000294_gtFine_color.png
+│ │ │ ├── frankfurt_000000_000294_gtFine_instanceIds.png
+│ │ │ ├── frankfurt_000000_000294_gtFine_labelIds.png
+│ │ │ ├── frankfurt_000000_000294_gtFine_labelTrainIds.png
+│ │ │ ├── frankfurt_000000_000294_gtFine_polygons.png
+│ │ │ ├── ...
+│ │ ├── ...
+├── leftImg8bit
+│ ├── test
+│ │ ├── ...
+│ ├── train
+│ │ ├── ...
+│ ├── val
+│ │ ├── frankfurt
+│ │ │ ├── frankfurt_000000_000294_leftImg8bit.png
+│ │ ├── ...
+...
+```
+
+It's recommended that you *symlink* the dataset folder to mmdetection folder. However, if you place your dataset folder at different place and do not want to symlink, you have to change the corresponding paths in the config file.
+
+Now the dataset should be ready for training.
+
+
+## Step 2-3: Train STDC-Seg on CityScapes
+
+Short-Term Dense Concatenate Network (STDC network) is a light-weight network structure for convolutional neural network. If we apply this network structure to semantic segmentation task, it's called STDC-Seg. It's first introduced in [Rethinking BiSeNet For Real-time Semantic Segmentation
+](https://arxiv.org/abs/2104.13188). Please check the paper if you want to know the algorithm details.
+
+We only need a configuration file to train a deep learning model in either the original MMSegmentation or kneron-mmsegmentation. STDC-Seg is provided in the original MMSegmentation repository, but the original configuration file needs some modification due to our hardware limitation so that we can apply the trained model to our Kneron dongle.
+
+To make a configuration file compatible with our device, we have to:
+
+* Change the mean and std value in image normalization to `mean=[128., 128., 128.]` and `std=[256., 256., 256.]`.
+* Shrink the input size during inference phase. The original CityScapes image size is too large (2048(w)x1024(h)) for our device; 1024(w)x512(h) might be good for our device.
+
+To achieve this, you can modify the `img_scale` in `test_pipeline` and `img_norm_cfg` in the configuration file `configs/_base_/datasets/cityscapes.py`.
+
+Luckily, here in kneron-mmsegmentation, we provide a modified STDC-Seg configuration file (`configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py`) so we can easily apply the trained model to our device.
+
+To train STDC-Seg compatible with our device, just execute:
+
+```shell
+cd kneron-mmsegmentation
+python tools/train.py configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py
+```
+
+kneron-mmsegmentation will generate `work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes` folder and save the configuration file and all checkpoints there.
+
+# Step 3: Test Trained Model
+`tools/test.py` is a script that generates inference results from test set with our pytorch model and evaluates the results to see if our pytorch model is well trained (if `--eval` argument is given). Note that it's always good to evluate our pytorch model before deploying it.
+
+```shell
+python tools/test.py \
+ work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py \
+ work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth \
+ --eval mIoU
+```
+* `kn_stdc1_in1k-pre_512x1024_80k_cityscapes/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py` can be your training config.
+* `kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth` can be your model checkpoint.
+
+The expected result of the command above should be something similar to the following text (the numbers may slightly differ):
+```
+...
++---------------+-------+-------+
+| Class | IoU | Acc |
++---------------+-------+-------+
+| road | 97.49 | 98.59 |
+| sidewalk | 80.17 | 88.71 |
+| building | 89.52 | 95.25 |
+| wall | 57.92 | 66.99 |
+| fence | 55.5 | 70.15 |
+| pole | 38.93 | 47.51 |
+| traffic light | 49.95 | 59.97 |
+| traffic sign | 62.1 | 70.05 |
+| vegetation | 89.02 | 95.27 |
+| terrain | 60.18 | 72.26 |
+| sky | 91.84 | 96.34 |
+| person | 68.98 | 84.35 |
+| rider | 47.79 | 60.98 |
+| car | 91.63 | 96.48 |
+| truck | 74.31 | 83.52 |
+| bus | 80.24 | 86.83 |
+| train | 66.45 | 76.78 |
+| motorcycle | 48.69 | 58.18 |
+| bicycle | 65.81 | 81.68 |
++---------------+-------+-------+
+Summary:
+
++------+-------+-------+
+| aAcc | mIoU | mAcc |
++------+-------+-------+
+| 94.3 | 69.29 | 78.42 |
++------+-------+-------+
+```
+
+**NOTE: The training process might take some time, depending on your computation resource. If you just want to take a quick look at the deployment flow, you can download our pretrained model so you can skip Step 1, 2, and 3:**
+```
+# If you don't want to train your own model:
+mkdir -p work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes
+pushd work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes
+wget https://github.com/kneron/Model_Zoo/raw/main/mmsegmentation/stdc_1/latest.zip
+unzip latest.zip
+popd
+```
+
+# Step 4: Export ONNX and Verify
+
+## Step 4-1: Export ONNX
+
+`tools/pytorch2onnx_kneron.py` is a script provided by kneron-mmsegmentation to help users to convert our trained pytorch model to ONNX:
+```shell
+python tools/pytorch2onnx_kneron.py \
+ configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py \
+ --checkpoint work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth \
+ --output-file work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.onnx \
+ --verify
+```
+* `configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py` can be your training config.
+* `work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth` can be your model checkpoint.
+* `work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.onnx` can be any other path. Here for convenience, the ONNX file is placed in the same folder of our pytorch checkpoint.
+
+## Step 4-2: Verify ONNX
+
+`tools/deploy_test_kneron.py` is a script provided by kneron-mmsegmentation to help users to verify if our exported ONNX generates similar outputs with what our PyTorch model does:
+```shell
+python tools/deploy_test_kneron.py \
+ configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py \
+ work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.onnx \
+ --eval mIoU
+```
+* `configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py` can be your training config.
+* `work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth` can be your exported ONNX file.
+
+The expected result of the command above should be something similar to the following text (the numbers may slightly differ):
+
+```
+...
++---------------+-------+-------+
+| Class | IoU | Acc |
++---------------+-------+-------+
+| road | 97.52 | 98.62 |
+| sidewalk | 80.59 | 88.69 |
+| building | 89.59 | 95.38 |
+| wall | 58.02 | 66.85 |
+| fence | 55.37 | 69.76 |
+| pole | 44.4 | 52.28 |
+| traffic light | 50.23 | 60.07 |
+| traffic sign | 62.58 | 70.25 |
+| vegetation | 89.0 | 95.27 |
+| terrain | 60.47 | 72.27 |
+| sky | 90.56 | 97.07 |
+| person | 70.7 | 84.88 |
+| rider | 48.66 | 61.37 |
+| car | 91.58 | 95.98 |
+| truck | 73.92 | 82.66 |
+| bus | 79.92 | 85.95 |
+| train | 66.26 | 75.92 |
+| motorcycle | 48.88 | 57.91 |
+| bicycle | 66.9 | 82.0 |
++---------------+-------+-------+
+Summary:
+
++------+-------+-------+
+| aAcc | mIoU | mAcc |
++------+-------+-------+
+| 94.4 | 69.75 | 78.59 |
++------+-------+-------+
+```
+
+Note that the ONNX results may differ from the PyTorch results due to some implementation differences between PyTorch and ONNXRuntime.
+
+# Step 5: Convert ONNX File to [NEF](http://doc.kneron.com/docs/#toolchain/manual/#5-nef-workflow) Model for Kneron Platform
+
+## Step 5-1: Install Kneron toolchain docker:
+
+* Check [Kneron Toolchain Installation Document](http://doc.kneron.com/docs/#toolchain/manual/#1-installation)
+
+## Step 5-2: Mount Kneron toolchain docker
+
+* Mount a folder (e.g. '/mnt/hgfs/Competition') to toolchain docker container as `/data1`. The converted ONNX in Step 3 should be put here. All the toolchain operation should happen in this folder.
+```
+sudo docker run --rm -it -v /mnt/hgfs/Competition:/data1 kneron/toolchain:latest
+```
+
+## Step 5-3: Import KTC and the required libraries in python
+
+```python
+import ktc
+import numpy as np
+import os
+import onnx
+from PIL import Image
+```
+
+## Step 5-4: Optimize the onnx model
+
+```python
+onnx_path = '/data1/latest.onnx'
+m = onnx.load(onnx_path)
+m = ktc.onnx_optimizer.onnx2onnx_flow(m)
+onnx.save(m,'latest.opt.onnx')
+```
+
+## Step 5-5: Configure and load data needed for ktc, and check if onnx is ok for toolchain
+```python
+# npu (only) performance simulation
+km = ktc.ModelConfig((&)model_id_on_public_field, "0001", "720", onnx_model=m)
+eval_result = km.evaluate()
+print("\nNpu performance evaluation result:\n" + str(eval_result))
+```
+
+## Step 5-6: Quantize the onnx model
+We [sampled 3 images from Cityscapes dataset](https://www.kneron.com/tw/support/education-center/?folder=OpenMMLab%20Kneron%20Edition/misc/&download=41) (3 images) as quantization data. To test our quantized model:
+1. Download the [zip file](https://www.kneron.com/tw/support/education-center/?folder=OpenMMLab%20Kneron%20Edition/misc/&download=41)
+2. Extract the zip file as a folder named `cityscapes_minitest`
+3. Put the `cityscapes_minitest` into docker mounted folder (the path in docker container should be `/data1/cityscapes_minitest`)
+
+The following script will preprocess (should be the same as training code) our quantization data, and put it in a list:
+
+```python
+import os
+from os import walk
+
+img_list = []
+for (dirpath, dirnames, filenames) in walk("/data1/cityscapes_minitest"):
+ for f in filenames:
+ fullpath = os.path.join(dirpath, f)
+
+ image = Image.open(fullpath)
+ image = image.convert("RGB")
+ image = Image.fromarray(np.array(image)[...,::-1])
+ img_data = np.array(image.resize((1024, 512), Image.BILINEAR)) / 256 - 0.5
+ print(fullpath)
+ img_list.append(img_data)
+```
+
+Then perform quantization. The generated BIE model will put generated at `/data1/output.bie`.
+
+```python
+# fixed-point analysis
+bie_model_path = km.analysis({"input": img_list})
+print("\nFixed-point analysis done. Save bie model to '" + str(bie_model_path) + "'")
+```
+
+## Step 5-7: Compile
+
+The final step is compile the BIE model into an NEF model.
+```python
+# compile
+nef_model_path = ktc.compile([km])
+print("\nCompile done. Save Nef file to '" + str(nef_model_path) + "'")
+```
+
+You can find the NEF file at `/data1/batch_compile/models_720.nef`. `models_720.nef` is the final compiled model.
+
+# Step 6: Run [NEF](http://doc.kneron.com/docs/#toolchain/manual/#5-nef-workflow) model on [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1)
+
+* N/A
+
+# Step 7 (For Kneron AI Competition 2022): Run [NEF](http://doc.kneron.com/docs/#toolchain/manual/#5-nef-workflow) model on [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1)
+
+[WARNING] Don't do this step in toolchain docker enviroment mentioned in Step 5
+
+Recommend you read [Kneron PLUS official document](http://doc.kneron.com/docs/#plus_python/#_top) first.
+
+### Step 7-1: Download and Install PLUS python library(.whl)
+* Go to [Kneron education center](https://www.kneron.com/tw/support/education-center/)
+* Scroll down to OpenMMLab Kneron Edition table
+* Select Kneron Plus v1.13.0 (pre-built python library)
+* Your OS version(Ubuntu, Windows, MacOS, Raspberry pi)
+* Download KneronPLUS-1.3.0-py3-none-any_{your_os}.whl
+* unzip downloaded `KneronPLUS-1.3.0-py3-none-any.whl.zip`
+* pip install KneronPLUS-1.3.0-py3-none-any.whl
+
+### Step 7-2: Download STDC example code
+* Go to [Kneron education center](https://www.kneron.com/tw/support/education-center/)
+* Scroll down to **OpenMMLab Kneron Edition** table
+* Select **kneron-mmsegmentation**
+* Select **STDC**
+* Download **stdc_plus_demo.zip**
+* unzip downloaded **stdc_plus_demo**
+
+### Step 7-3: Test enviroment is ready (require [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1))
+In `stdc_plus_demo`, we provide a STDC-Seg example model and image for quick test.
+* Plug in [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1) into your computer USB port
+* Go to the stdc_plus_demo folder
+```bash
+cd /PATH/TO/stdc_plus_demo
+```
+
+* Install required python libraries
+```bash
+pip install -r requirements.txt
+```
+
+* Run example on [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1)
+```python
+python KL720DemoGenericInferenceSTDC_BypassHwPreProc.py -nef ./example_stdc_720.nef -img 000000000641.jpg
+```
+
+Then you can see the inference result is saved as output_000000000641.jpg in the same folder.
+The expected result of the command above will be something similar to the following text:
+```plain
+...
+[Connect Device]
+ - Success
+[Set Device Timeout]
+ - Success
+[Upload Model]
+ - Success
+[Read Image]
+ - Success
+[Starting Inference Work]
+ - Starting inference loop 1 times
+ - .
+[Retrieve Inference Node Output ]
+ - Success
+[Output Result Image]
+ - Output bounding boxes on 'output_000000000641.jpg'
+...
+```
+
+### Step 7-4: Run your NEF model and your image on [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1)
+Use the same script in previous step, but now we change the input NEF model path and image to yours
+```bash
+python KL720DemoGenericInferenceSTDC_BypassHwPreProc.py -img /PATH/TO/YOUR_IMAGE.bmp -nef /PATH/TO/YOUR/720_NEF_MODEL.nef
+```
\ No newline at end of file
diff --git a/mmseg/__init__.py b/mmseg/__init__.py
new file mode 100644
index 0000000..8da9bc6
--- /dev/null
+++ b/mmseg/__init__.py
@@ -0,0 +1,62 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+from packaging.version import parse
+
+from .version import __version__, version_info
+
+MMCV_MIN = '1.3.13'
+MMCV_MAX = '1.5.0'
+
+
+def digit_version(version_str: str, length: int = 4):
+ """Convert a version string into a tuple of integers.
+
+ This method is usually used for comparing two versions. For pre-release
+ versions: alpha < beta < rc.
+
+ Args:
+ version_str (str): The version string.
+ length (int): The maximum number of version levels. Default: 4.
+
+ Returns:
+ tuple[int]: The version info in digits (integers).
+ """
+ version = parse(version_str)
+ assert version.release, f'failed to parse version {version_str}'
+ release = list(version.release)
+ release = release[:length]
+ if len(release) < length:
+ release = release + [0] * (length - len(release))
+ if version.is_prerelease:
+ mapping = {'a': -3, 'b': -2, 'rc': -1}
+ val = -4
+ # version.pre can be None
+ if version.pre:
+ if version.pre[0] not in mapping:
+ warnings.warn(f'unknown prerelease version {version.pre[0]}, '
+ 'version checking may go wrong')
+ else:
+ val = mapping[version.pre[0]]
+ release.extend([val, version.pre[-1]])
+ else:
+ release.extend([val, 0])
+
+ elif version.is_postrelease:
+ release.extend([1, version.post])
+ else:
+ release.extend([0, 0])
+ return tuple(release)
+
+
+mmcv_min_version = digit_version(MMCV_MIN)
+mmcv_max_version = digit_version(MMCV_MAX)
+mmcv_version = digit_version(mmcv.__version__)
+
+
+assert (mmcv_min_version <= mmcv_version <= mmcv_max_version), \
+ f'MMCV=={mmcv.__version__} is used but incompatible. ' \
+ f'Please install mmcv>={mmcv_min_version}, <={mmcv_max_version}.'
+
+__all__ = ['__version__', 'version_info', 'digit_version']
diff --git a/mmseg/apis/__init__.py b/mmseg/apis/__init__.py
new file mode 100644
index 0000000..45be2fd
--- /dev/null
+++ b/mmseg/apis/__init__.py
@@ -0,0 +1,19 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+from .inference import (
+ inference_segmentor,
+ inference_segmentor_kn,
+ init_segmentor,
+ init_segmentor_kn,
+ show_result_pyplot,
+)
+from .test import multi_gpu_test, single_gpu_test
+from .train import (get_root_logger, init_random_seed, set_random_seed,
+ train_segmentor)
+
+__all__ = [
+ 'get_root_logger', 'set_random_seed', 'train_segmentor',
+ 'init_segmentor', 'init_segmentor_kn', 'inference_segmentor',
+ 'inference_segmentor_kn', 'multi_gpu_test', 'single_gpu_test',
+ 'show_result_pyplot', 'init_random_seed'
+]
diff --git a/mmseg/apis/inference.py b/mmseg/apis/inference.py
new file mode 100644
index 0000000..7faa83a
--- /dev/null
+++ b/mmseg/apis/inference.py
@@ -0,0 +1,178 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import matplotlib.pyplot as plt
+import mmcv
+import torch
+from mmcv.parallel import collate, scatter
+from mmcv.runner import load_checkpoint
+
+from mmseg.datasets.pipelines import Compose
+from mmseg.models import build_segmentor
+from mmseg.models.segmentors import ONNXRuntimeSegmentorKN
+
+
+def init_segmentor(config, checkpoint=None, device='cuda:0'):
+ """Initialize a segmentor from config file.
+
+ Args:
+ config (str or :obj:`mmcv.Config`): Config file path or the config
+ object.
+ checkpoint (str, optional): Checkpoint path. If left as None, the model
+ will not load any weights.
+ device (str, optional) CPU/CUDA device option. Default 'cuda:0'.
+ Use 'cpu' for loading model on CPU.
+ Returns:
+ nn.Module: The constructed segmentor.
+ """
+ if isinstance(config, str):
+ config = mmcv.Config.fromfile(config)
+ elif not isinstance(config, mmcv.Config):
+ raise TypeError('config must be a filename or Config object, '
+ 'but got {}'.format(type(config)))
+ config.model.pretrained = None
+ config.model.train_cfg = None
+ model = build_segmentor(config.model, test_cfg=config.get('test_cfg'))
+ if checkpoint is not None:
+ checkpoint = load_checkpoint(model, checkpoint, map_location='cpu')
+ model.CLASSES = checkpoint['meta']['CLASSES']
+ model.PALETTE = checkpoint['meta']['PALETTE']
+ model.cfg = config # save the config in the model for convenience
+ model.to(device)
+ model.eval()
+ return model
+
+
+def init_segmentor_kn(config, checkpoint=None, device='cuda:0'):
+ """Initialize a segmentor from config file.
+
+ Args:
+ config (str or :obj:`mmcv.Config`): Config file path or the config
+ object.
+ checkpoint (str, optional): Checkpoint path. If left as None, the model
+ will not load any weights.
+ device (str, optional) CPU/CUDA device option. Default 'cuda:0'.
+ Use 'cpu' for loading model on CPU.
+ Returns:
+ nn.Module: The constructed segmentor.
+ """
+ if checkpoint is None or not checkpoint.endswith(".onnx"):
+ return init_segmentor(config, checkpoint, device)
+ try:
+ _, device_id = device.split(":")
+ device_id = int(device_id)
+ except Exception:
+ device_id = None if device == 'cpu' else 0
+ model = ONNXRuntimeSegmentorKN(
+ checkpoint, cfg=config, device_id=device_id
+ ).eval()
+ return model
+
+
+class LoadImage:
+ """A simple pipeline to load image."""
+
+ def __call__(self, results):
+ """Call function to load images into results.
+
+ Args:
+ results (dict): A result dict contains the file name
+ of the image to be read.
+
+ Returns:
+ dict: ``results`` will be returned containing loaded image.
+ """
+
+ if isinstance(results['img'], str):
+ results['filename'] = results['img']
+ results['ori_filename'] = results['img']
+ else:
+ results['filename'] = None
+ results['ori_filename'] = None
+ img = mmcv.imread(results['img'])
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ return results
+
+
+def inference_segmentor(model, img):
+ """Inference image(s) with the segmentor.
+
+ Args:
+ model (nn.Module): The loaded segmentor.
+ imgs (str/ndarray or list[str/ndarray]): Either image files or loaded
+ images.
+
+ Returns:
+ (list[Tensor]): The segmentation result.
+ """
+ cfg = model.cfg
+ device = next(model.parameters()).device # model device
+ # build the data pipeline
+ test_pipeline = [LoadImage()] + cfg.data.test.pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ # prepare data
+ data = dict(img=img)
+ data = test_pipeline(data)
+ data = collate([data], samples_per_gpu=1)
+ if next(model.parameters()).is_cuda:
+ # scatter to specified GPU
+ data = scatter(data, [device])[0]
+ else:
+ data['img_metas'] = [i.data[0] for i in data['img_metas']]
+
+ # forward the model
+ with torch.no_grad():
+ result = model(return_loss=False, rescale=True, **data)
+ return result
+
+
+@torch.no_grad()
+def inference_segmentor_kn(model, img):
+ if isinstance(model, ONNXRuntimeSegmentorKN):
+ cfg = model.cfg
+ test_pipeline = [LoadImage()] + cfg.data.test.pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ data = dict(img=img)
+ data = test_pipeline(data)
+ data = collate([data], samples_per_gpu=1)
+ return model(return_loss=False, rescale=True, **data)
+ else:
+ return inference_segmentor(model, img)
+
+
+def show_result_pyplot(model,
+ img,
+ result,
+ palette=None,
+ fig_size=(15, 10),
+ opacity=0.5,
+ title='',
+ block=True):
+ """Visualize the segmentation results on the image.
+
+ Args:
+ model (nn.Module): The loaded segmentor.
+ img (str or np.ndarray): Image filename or loaded image.
+ result (list): The segmentation result.
+ palette (list[list[int]]] | None): The palette of segmentation
+ map. If None is given, random palette will be generated.
+ Default: None
+ fig_size (tuple): Figure size of the pyplot figure.
+ opacity(float): Opacity of painted segmentation map.
+ Default 0.5.
+ Must be in (0, 1] range.
+ title (str): The title of pyplot figure.
+ Default is ''.
+ block (bool): Whether to block the pyplot figure.
+ Default is True.
+ """
+ if hasattr(model, 'module'):
+ model = model.module
+ img = model.show_result(
+ img, result, palette=palette, show=False, opacity=opacity)
+ plt.figure(figsize=fig_size)
+ plt.imshow(mmcv.bgr2rgb(img))
+ plt.title(title)
+ plt.tight_layout()
+ plt.show(block=block)
diff --git a/mmseg/apis/test.py b/mmseg/apis/test.py
new file mode 100644
index 0000000..cc4fcc9
--- /dev/null
+++ b/mmseg/apis/test.py
@@ -0,0 +1,233 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.engine import collect_results_cpu, collect_results_gpu
+from mmcv.image import tensor2imgs
+from mmcv.runner import get_dist_info
+
+
+def np2tmp(array, temp_file_name=None, tmpdir=None):
+ """Save ndarray to local numpy file.
+
+ Args:
+ array (ndarray): Ndarray to save.
+ temp_file_name (str): Numpy file name. If 'temp_file_name=None', this
+ function will generate a file name with tempfile.NamedTemporaryFile
+ to save ndarray. Default: None.
+ tmpdir (str): Temporary directory to save Ndarray files. Default: None.
+ Returns:
+ str: The numpy file name.
+ """
+
+ if temp_file_name is None:
+ temp_file_name = tempfile.NamedTemporaryFile(
+ suffix='.npy', delete=False, dir=tmpdir).name
+ np.save(temp_file_name, array)
+ return temp_file_name
+
+
+def single_gpu_test(model,
+ data_loader,
+ show=False,
+ out_dir=None,
+ efficient_test=False,
+ opacity=0.5,
+ pre_eval=False,
+ format_only=False,
+ format_args={}):
+ """Test with single GPU by progressive mode.
+
+ Args:
+ model (nn.Module): Model to be tested.
+ data_loader (utils.data.Dataloader): Pytorch data loader.
+ show (bool): Whether show results during inference. Default: False.
+ out_dir (str, optional): If specified, the results will be dumped into
+ the directory to save output results.
+ efficient_test (bool): Whether save the results as local numpy files to
+ save CPU memory during evaluation. Mutually exclusive with
+ pre_eval and format_results. Default: False.
+ opacity(float): Opacity of painted segmentation map.
+ Default 0.5.
+ Must be in (0, 1] range.
+ pre_eval (bool): Use dataset.pre_eval() function to generate
+ pre_results for metric evaluation. Mutually exclusive with
+ efficient_test and format_results. Default: False.
+ format_only (bool): Only format result for results commit.
+ Mutually exclusive with pre_eval and efficient_test.
+ Default: False.
+ format_args (dict): The args for format_results. Default: {}.
+ Returns:
+ list: list of evaluation pre-results or list of save file names.
+ """
+ if efficient_test:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` will be deprecated, the '
+ 'evaluation is CPU memory friendly with pre_eval=True')
+ mmcv.mkdir_or_exist('.efficient_test')
+ # when none of them is set true, return segmentation results as
+ # a list of np.array.
+ assert [efficient_test, pre_eval, format_only].count(True) <= 1, \
+ '``efficient_test``, ``pre_eval`` and ``format_only`` are mutually ' \
+ 'exclusive, only one of them could be true .'
+
+ model.eval()
+ results = []
+ dataset = data_loader.dataset
+ prog_bar = mmcv.ProgressBar(len(dataset))
+ # The pipeline about how the data_loader retrieval samples from dataset:
+ # sampler -> batch_sampler -> indices
+ # The indices are passed to dataset_fetcher to get data from dataset.
+ # data_fetcher -> collate_fn(dataset[index]) -> data_sample
+ # we use batch_sampler to get correct data idx
+ loader_indices = data_loader.batch_sampler
+
+ for batch_indices, data in zip(loader_indices, data_loader):
+ with torch.no_grad():
+ result = model(return_loss=False, **data)
+
+ if show or out_dir:
+ img_tensor = data['img'][0]
+ img_metas = data['img_metas'][0].data[0]
+ imgs = tensor2imgs(img_tensor, **img_metas[0]['img_norm_cfg'])
+ assert len(imgs) == len(img_metas)
+
+ for img, img_meta in zip(imgs, img_metas):
+ h, w, _ = img_meta['img_shape']
+ img_show = img[:h, :w, :]
+
+ ori_h, ori_w = img_meta['ori_shape'][:-1]
+ img_show = mmcv.imresize(img_show, (ori_w, ori_h))
+
+ if out_dir:
+ out_file = osp.join(out_dir, img_meta['ori_filename'])
+ else:
+ out_file = None
+
+ model.module.show_result(
+ img_show,
+ result,
+ palette=dataset.PALETTE,
+ show=show,
+ out_file=out_file,
+ opacity=opacity)
+
+ if efficient_test:
+ result = [np2tmp(_, tmpdir='.efficient_test') for _ in result]
+
+ if format_only:
+ result = dataset.format_results(
+ result, indices=batch_indices, **format_args)
+ if pre_eval:
+ # TODO: adapt samples_per_gpu > 1.
+ # only samples_per_gpu=1 valid now
+ result = dataset.pre_eval(result, indices=batch_indices)
+ results.extend(result)
+ else:
+ results.extend(result)
+
+ batch_size = len(result)
+ for _ in range(batch_size):
+ prog_bar.update()
+
+ return results
+
+
+def multi_gpu_test(model,
+ data_loader,
+ tmpdir=None,
+ gpu_collect=False,
+ efficient_test=False,
+ pre_eval=False,
+ format_only=False,
+ format_args={}):
+ """Test model with multiple gpus by progressive mode.
+
+ This method tests model with multiple gpus and collects the results
+ under two different modes: gpu and cpu modes. By setting 'gpu_collect=True'
+ it encodes results to gpu tensors and use gpu communication for results
+ collection. On cpu mode it saves the results on different gpus to 'tmpdir'
+ and collects them by the rank 0 worker.
+
+ Args:
+ model (nn.Module): Model to be tested.
+ data_loader (utils.data.Dataloader): Pytorch data loader.
+ tmpdir (str): Path of directory to save the temporary results from
+ different gpus under cpu mode. The same path is used for efficient
+ test. Default: None.
+ gpu_collect (bool): Option to use either gpu or cpu to collect results.
+ Default: False.
+ efficient_test (bool): Whether save the results as local numpy files to
+ save CPU memory during evaluation. Mutually exclusive with
+ pre_eval and format_results. Default: False.
+ pre_eval (bool): Use dataset.pre_eval() function to generate
+ pre_results for metric evaluation. Mutually exclusive with
+ efficient_test and format_results. Default: False.
+ format_only (bool): Only format result for results commit.
+ Mutually exclusive with pre_eval and efficient_test.
+ Default: False.
+ format_args (dict): The args for format_results. Default: {}.
+
+ Returns:
+ list: list of evaluation pre-results or list of save file names.
+ """
+ if efficient_test:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` will be deprecated, the '
+ 'evaluation is CPU memory friendly with pre_eval=True')
+ mmcv.mkdir_or_exist('.efficient_test')
+ # when none of them is set true, return segmentation results as
+ # a list of np.array.
+ assert [efficient_test, pre_eval, format_only].count(True) <= 1, \
+ '``efficient_test``, ``pre_eval`` and ``format_only`` are mutually ' \
+ 'exclusive, only one of them could be true .'
+
+ model.eval()
+ results = []
+ dataset = data_loader.dataset
+ # The pipeline about how the data_loader retrieval samples from dataset:
+ # sampler -> batch_sampler -> indices
+ # The indices are passed to dataset_fetcher to get data from dataset.
+ # data_fetcher -> collate_fn(dataset[index]) -> data_sample
+ # we use batch_sampler to get correct data idx
+
+ # batch_sampler based on DistributedSampler, the indices only point to data
+ # samples of related machine.
+ loader_indices = data_loader.batch_sampler
+
+ rank, world_size = get_dist_info()
+ if rank == 0:
+ prog_bar = mmcv.ProgressBar(len(dataset))
+
+ for batch_indices, data in zip(loader_indices, data_loader):
+ with torch.no_grad():
+ result = model(return_loss=False, rescale=True, **data)
+
+ if efficient_test:
+ result = [np2tmp(_, tmpdir='.efficient_test') for _ in result]
+
+ if format_only:
+ result = dataset.format_results(
+ result, indices=batch_indices, **format_args)
+ if pre_eval:
+ # TODO: adapt samples_per_gpu > 1.
+ # only samples_per_gpu=1 valid now
+ result = dataset.pre_eval(result, indices=batch_indices)
+
+ results.extend(result)
+
+ if rank == 0:
+ batch_size = len(result) * world_size
+ for _ in range(batch_size):
+ prog_bar.update()
+
+ # collect results from all ranks
+ if gpu_collect:
+ results = collect_results_gpu(results, len(dataset))
+ else:
+ results = collect_results_cpu(results, len(dataset), tmpdir)
+ return results
diff --git a/mmseg/apis/train.py b/mmseg/apis/train.py
new file mode 100644
index 0000000..760701b
--- /dev/null
+++ b/mmseg/apis/train.py
@@ -0,0 +1,174 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+import torch.distributed as dist
+from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
+from mmcv.runner import HOOKS, build_optimizer, build_runner, get_dist_info
+from mmcv.utils import build_from_cfg
+
+from mmseg import digit_version
+from mmseg.core import DistEvalHook, EvalHook
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.utils import find_latest_checkpoint, get_root_logger
+
+
+def init_random_seed(seed=None, device='cuda'):
+ """Initialize random seed.
+
+ If the seed is not set, the seed will be automatically randomized,
+ and then broadcast to all processes to prevent some potential bugs.
+ Args:
+ seed (int, Optional): The seed. Default to None.
+ device (str): The device where the seed will be put on.
+ Default to 'cuda'.
+ Returns:
+ int: Seed to be used.
+ """
+ if seed is not None:
+ return seed
+
+ # Make sure all ranks share the same random seed to prevent
+ # some potential bugs. Please refer to
+ # https://github.com/open-mmlab/mmdetection/issues/6339
+ rank, world_size = get_dist_info()
+ seed = np.random.randint(2**31)
+ if world_size == 1:
+ return seed
+
+ if rank == 0:
+ random_num = torch.tensor(seed, dtype=torch.int32, device=device)
+ else:
+ random_num = torch.tensor(0, dtype=torch.int32, device=device)
+ dist.broadcast(random_num, src=0)
+ return random_num.item()
+
+
+def set_random_seed(seed, deterministic=False):
+ """Set random seed.
+
+ Args:
+ seed (int): Seed to be used.
+ deterministic (bool): Whether to set the deterministic option for
+ CUDNN backend, i.e., set `torch.backends.cudnn.deterministic`
+ to True and `torch.backends.cudnn.benchmark` to False.
+ Default: False.
+ """
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+ if deterministic:
+ torch.backends.cudnn.deterministic = True
+ torch.backends.cudnn.benchmark = False
+
+
+def train_segmentor(model,
+ dataset,
+ cfg,
+ distributed=False,
+ validate=False,
+ timestamp=None,
+ meta=None):
+ """Launch segmentor training."""
+ logger = get_root_logger(cfg.log_level)
+
+ # prepare data loaders
+ dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]
+ data_loaders = [
+ build_dataloader(
+ ds,
+ cfg.data.samples_per_gpu,
+ cfg.data.workers_per_gpu,
+ # cfg.gpus will be ignored if distributed
+ len(cfg.gpu_ids),
+ dist=distributed,
+ seed=cfg.seed,
+ drop_last=True) for ds in dataset
+ ]
+
+ # put model on gpus
+ if distributed:
+ find_unused_parameters = cfg.get('find_unused_parameters', False)
+ # Sets the `find_unused_parameters` parameter in
+ # torch.nn.parallel.DistributedDataParallel
+ model = MMDistributedDataParallel(
+ model.cuda(),
+ device_ids=[torch.cuda.current_device()],
+ broadcast_buffers=False,
+ find_unused_parameters=find_unused_parameters)
+ else:
+ if not torch.cuda.is_available():
+ assert digit_version(mmcv.__version__) >= digit_version('1.4.4'), \
+ 'Please use MMCV >= 1.4.4 for CPU training!'
+ model = MMDataParallel(model, device_ids=cfg.gpu_ids)
+ # build runner
+ optimizer = build_optimizer(model, cfg.optimizer)
+
+ if cfg.get('runner') is None:
+ cfg.runner = {'type': 'IterBasedRunner', 'max_iters': cfg.total_iters}
+ warnings.warn(
+ 'config is now expected to have a `runner` section, '
+ 'please set `runner` in your config.', UserWarning)
+
+ runner = build_runner(
+ cfg.runner,
+ default_args=dict(
+ model=model,
+ batch_processor=None,
+ optimizer=optimizer,
+ work_dir=cfg.work_dir,
+ logger=logger,
+ meta=meta))
+
+ # register hooks
+ runner.register_training_hooks(cfg.lr_config, cfg.optimizer_config,
+ cfg.checkpoint_config, cfg.log_config,
+ cfg.get('momentum_config', None))
+
+ # an ugly walkaround to make the .log and .log.json filenames the same
+ runner.timestamp = timestamp
+
+ # register eval hooks
+ if validate:
+ val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))
+ val_dataloader = build_dataloader(
+ val_dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=distributed,
+ shuffle=False)
+ eval_cfg = cfg.get('evaluation', {})
+ eval_cfg['by_epoch'] = cfg.runner['type'] != 'IterBasedRunner'
+ eval_hook = DistEvalHook if distributed else EvalHook
+ # In this PR (https://github.com/open-mmlab/mmcv/pull/1193), the
+ # priority of IterTimerHook has been modified from 'NORMAL' to 'LOW'.
+ runner.register_hook(
+ eval_hook(val_dataloader, **eval_cfg), priority='LOW')
+
+ # user-defined hooks
+ if cfg.get('custom_hooks', None):
+ custom_hooks = cfg.custom_hooks
+ assert isinstance(custom_hooks, list), \
+ f'custom_hooks expect list type, but got {type(custom_hooks)}'
+ for hook_cfg in cfg.custom_hooks:
+ assert isinstance(hook_cfg, dict), \
+ 'Each item in custom_hooks expects dict type, but got ' \
+ f'{type(hook_cfg)}'
+ hook_cfg = hook_cfg.copy()
+ priority = hook_cfg.pop('priority', 'NORMAL')
+ hook = build_from_cfg(hook_cfg, HOOKS)
+ runner.register_hook(hook, priority=priority)
+
+ if cfg.resume_from is None and cfg.get('auto_resume'):
+ resume_from = find_latest_checkpoint(cfg.work_dir)
+ if resume_from is not None:
+ cfg.resume_from = resume_from
+ if cfg.resume_from:
+ runner.resume(cfg.resume_from)
+ elif cfg.load_from:
+ runner.load_checkpoint(cfg.load_from)
+ runner.run(data_loaders, cfg.workflow)
diff --git a/mmseg/core/__init__.py b/mmseg/core/__init__.py
new file mode 100644
index 0000000..4022786
--- /dev/null
+++ b/mmseg/core/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .evaluation import * # noqa: F401, F403
+from .seg import * # noqa: F401, F403
+from .utils import * # noqa: F401, F403
diff --git a/mmseg/core/evaluation/__init__.py b/mmseg/core/evaluation/__init__.py
new file mode 100644
index 0000000..3d16d17
--- /dev/null
+++ b/mmseg/core/evaluation/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .class_names import get_classes, get_palette
+from .eval_hooks import DistEvalHook, EvalHook
+from .metrics import (eval_metrics, intersect_and_union, mean_dice,
+ mean_fscore, mean_iou, pre_eval_to_metrics)
+
+__all__ = [
+ 'EvalHook', 'DistEvalHook', 'mean_dice', 'mean_iou', 'mean_fscore',
+ 'eval_metrics', 'get_classes', 'get_palette', 'pre_eval_to_metrics',
+ 'intersect_and_union'
+]
diff --git a/mmseg/core/evaluation/class_names.py b/mmseg/core/evaluation/class_names.py
new file mode 100644
index 0000000..cc90517
--- /dev/null
+++ b/mmseg/core/evaluation/class_names.py
@@ -0,0 +1,285 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+
+
+def cityscapes_classes():
+ """Cityscapes class names for external use."""
+ return [
+ 'road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
+ 'traffic light', 'traffic sign', 'vegetation', 'terrain', 'sky',
+ 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle',
+ 'bicycle'
+ ]
+
+
+def ade_classes():
+ """ADE20K class names for external use."""
+ return [
+ 'wall', 'building', 'sky', 'floor', 'tree', 'ceiling', 'road', 'bed ',
+ 'windowpane', 'grass', 'cabinet', 'sidewalk', 'person', 'earth',
+ 'door', 'table', 'mountain', 'plant', 'curtain', 'chair', 'car',
+ 'water', 'painting', 'sofa', 'shelf', 'house', 'sea', 'mirror', 'rug',
+ 'field', 'armchair', 'seat', 'fence', 'desk', 'rock', 'wardrobe',
+ 'lamp', 'bathtub', 'railing', 'cushion', 'base', 'box', 'column',
+ 'signboard', 'chest of drawers', 'counter', 'sand', 'sink',
+ 'skyscraper', 'fireplace', 'refrigerator', 'grandstand', 'path',
+ 'stairs', 'runway', 'case', 'pool table', 'pillow', 'screen door',
+ 'stairway', 'river', 'bridge', 'bookcase', 'blind', 'coffee table',
+ 'toilet', 'flower', 'book', 'hill', 'bench', 'countertop', 'stove',
+ 'palm', 'kitchen island', 'computer', 'swivel chair', 'boat', 'bar',
+ 'arcade machine', 'hovel', 'bus', 'towel', 'light', 'truck', 'tower',
+ 'chandelier', 'awning', 'streetlight', 'booth', 'television receiver',
+ 'airplane', 'dirt track', 'apparel', 'pole', 'land', 'bannister',
+ 'escalator', 'ottoman', 'bottle', 'buffet', 'poster', 'stage', 'van',
+ 'ship', 'fountain', 'conveyer belt', 'canopy', 'washer', 'plaything',
+ 'swimming pool', 'stool', 'barrel', 'basket', 'waterfall', 'tent',
+ 'bag', 'minibike', 'cradle', 'oven', 'ball', 'food', 'step', 'tank',
+ 'trade name', 'microwave', 'pot', 'animal', 'bicycle', 'lake',
+ 'dishwasher', 'screen', 'blanket', 'sculpture', 'hood', 'sconce',
+ 'vase', 'traffic light', 'tray', 'ashcan', 'fan', 'pier', 'crt screen',
+ 'plate', 'monitor', 'bulletin board', 'shower', 'radiator', 'glass',
+ 'clock', 'flag'
+ ]
+
+
+def voc_classes():
+ """Pascal VOC class names for external use."""
+ return [
+ 'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
+ 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
+ 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
+ 'tvmonitor'
+ ]
+
+
+def cocostuff_classes():
+ """CocoStuff class names for external use."""
+ return [
+ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train',
+ 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign',
+ 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep',
+ 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella',
+ 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard',
+ 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard',
+ 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork',
+ 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
+ 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair',
+ 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv',
+ 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
+ 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
+ 'scissors', 'teddy bear', 'hair drier', 'toothbrush', 'banner',
+ 'blanket', 'branch', 'bridge', 'building-other', 'bush', 'cabinet',
+ 'cage', 'cardboard', 'carpet', 'ceiling-other', 'ceiling-tile',
+ 'cloth', 'clothes', 'clouds', 'counter', 'cupboard', 'curtain',
+ 'desk-stuff', 'dirt', 'door-stuff', 'fence', 'floor-marble',
+ 'floor-other', 'floor-stone', 'floor-tile', 'floor-wood', 'flower',
+ 'fog', 'food-other', 'fruit', 'furniture-other', 'grass', 'gravel',
+ 'ground-other', 'hill', 'house', 'leaves', 'light', 'mat', 'metal',
+ 'mirror-stuff', 'moss', 'mountain', 'mud', 'napkin', 'net', 'paper',
+ 'pavement', 'pillow', 'plant-other', 'plastic', 'platform',
+ 'playingfield', 'railing', 'railroad', 'river', 'road', 'rock', 'roof',
+ 'rug', 'salad', 'sand', 'sea', 'shelf', 'sky-other', 'skyscraper',
+ 'snow', 'solid-other', 'stairs', 'stone', 'straw', 'structural-other',
+ 'table', 'tent', 'textile-other', 'towel', 'tree', 'vegetable',
+ 'wall-brick', 'wall-concrete', 'wall-other', 'wall-panel',
+ 'wall-stone', 'wall-tile', 'wall-wood', 'water-other', 'waterdrops',
+ 'window-blind', 'window-other', 'wood'
+ ]
+
+
+def loveda_classes():
+ """LoveDA class names for external use."""
+ return [
+ 'background', 'building', 'road', 'water', 'barren', 'forest',
+ 'agricultural'
+ ]
+
+
+def potsdam_classes():
+ """Potsdam class names for external use."""
+ return [
+ 'impervious_surface', 'building', 'low_vegetation', 'tree', 'car',
+ 'clutter'
+ ]
+
+
+def vaihingen_classes():
+ """Vaihingen class names for external use."""
+ return [
+ 'impervious_surface', 'building', 'low_vegetation', 'tree', 'car',
+ 'clutter'
+ ]
+
+
+def cityscapes_palette():
+ """Cityscapes palette for external use."""
+ return [[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
+ [190, 153, 153], [153, 153, 153], [250, 170, 30], [220, 220, 0],
+ [107, 142, 35], [152, 251, 152], [70, 130, 180], [220, 20, 60],
+ [255, 0, 0], [0, 0, 142], [0, 0, 70], [0, 60, 100], [0, 80, 100],
+ [0, 0, 230], [119, 11, 32]]
+
+
+def ade_palette():
+ """ADE20K palette for external use."""
+ return [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
+ [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
+ [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
+ [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
+ [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
+ [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
+ [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
+ [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
+ [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
+ [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
+ [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
+ [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
+ [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
+ [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
+ [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255],
+ [11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255],
+ [0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0],
+ [255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0],
+ [0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255],
+ [173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255],
+ [255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20],
+ [255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255],
+ [255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255],
+ [0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255],
+ [0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0],
+ [143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0],
+ [8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255],
+ [255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112],
+ [92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160],
+ [163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163],
+ [255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0],
+ [255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0],
+ [10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255],
+ [255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204],
+ [41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255],
+ [71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255],
+ [184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194],
+ [102, 255, 0], [92, 0, 255]]
+
+
+def voc_palette():
+ """Pascal VOC palette for external use."""
+ return [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
+ [128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0],
+ [192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128],
+ [192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0],
+ [128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]]
+
+
+def cocostuff_palette():
+ """CocoStuff palette for external use."""
+ return [[0, 192, 64], [0, 192, 64], [0, 64, 96], [128, 192, 192],
+ [0, 64, 64], [0, 192, 224], [0, 192, 192], [128, 192, 64],
+ [0, 192, 96], [128, 192, 64], [128, 32, 192], [0, 0, 224],
+ [0, 0, 64], [0, 160, 192], [128, 0, 96], [128, 0, 192],
+ [0, 32, 192], [128, 128, 224], [0, 0, 192], [128, 160, 192],
+ [128, 128, 0], [128, 0, 32], [128, 32, 0], [128, 0, 128],
+ [64, 128, 32], [0, 160, 0], [0, 0, 0], [192, 128, 160], [0, 32, 0],
+ [0, 128, 128], [64, 128, 160], [128, 160, 0], [0, 128, 0],
+ [192, 128, 32], [128, 96, 128], [0, 0, 128], [64, 0, 32],
+ [0, 224, 128], [128, 0, 0], [192, 0, 160], [0, 96, 128],
+ [128, 128, 128], [64, 0, 160], [128, 224, 128], [128, 128, 64],
+ [192, 0, 32], [128, 96, 0], [128, 0, 192], [0, 128, 32],
+ [64, 224, 0], [0, 0, 64], [128, 128, 160], [64, 96, 0],
+ [0, 128, 192], [0, 128, 160], [192, 224, 0], [0, 128, 64],
+ [128, 128, 32], [192, 32, 128], [0, 64, 192], [0, 0, 32],
+ [64, 160, 128], [128, 64, 64], [128, 0, 160], [64, 32, 128],
+ [128, 192, 192], [0, 0, 160], [192, 160, 128], [128, 192, 0],
+ [128, 0, 96], [192, 32, 0], [128, 64, 128], [64, 128, 96],
+ [64, 160, 0], [0, 64, 0], [192, 128, 224], [64, 32, 0],
+ [0, 192, 128], [64, 128, 224], [192, 160, 0], [0, 192, 0],
+ [192, 128, 96], [192, 96, 128], [0, 64, 128], [64, 0, 96],
+ [64, 224, 128], [128, 64, 0], [192, 0, 224], [64, 96, 128],
+ [128, 192, 128], [64, 0, 224], [192, 224, 128], [128, 192, 64],
+ [192, 0, 96], [192, 96, 0], [128, 64, 192], [0, 128, 96],
+ [0, 224, 0], [64, 64, 64], [128, 128, 224], [0, 96, 0],
+ [64, 192, 192], [0, 128, 224], [128, 224, 0], [64, 192, 64],
+ [128, 128, 96], [128, 32, 128], [64, 0, 192], [0, 64, 96],
+ [0, 160, 128], [192, 0, 64], [128, 64, 224], [0, 32, 128],
+ [192, 128, 192], [0, 64, 224], [128, 160, 128], [192, 128, 0],
+ [128, 64, 32], [128, 32, 64], [192, 0, 128], [64, 192, 32],
+ [0, 160, 64], [64, 0, 0], [192, 192, 160], [0, 32, 64],
+ [64, 128, 128], [64, 192, 160], [128, 160, 64], [64, 128, 0],
+ [192, 192, 32], [128, 96, 192], [64, 0, 128], [64, 64, 32],
+ [0, 224, 192], [192, 0, 0], [192, 64, 160], [0, 96, 192],
+ [192, 128, 128], [64, 64, 160], [128, 224, 192], [192, 128, 64],
+ [192, 64, 32], [128, 96, 64], [192, 0, 192], [0, 192, 32],
+ [64, 224, 64], [64, 0, 64], [128, 192, 160], [64, 96, 64],
+ [64, 128, 192], [0, 192, 160], [192, 224, 64], [64, 128, 64],
+ [128, 192, 32], [192, 32, 192], [64, 64, 192], [0, 64, 32],
+ [64, 160, 192], [192, 64, 64], [128, 64, 160], [64, 32, 192],
+ [192, 192, 192], [0, 64, 160], [192, 160, 192], [192, 192, 0],
+ [128, 64, 96], [192, 32, 64], [192, 64, 128], [64, 192, 96],
+ [64, 160, 64], [64, 64, 0]]
+
+
+def loveda_palette():
+ """LoveDA palette for external use."""
+ return [[255, 255, 255], [255, 0, 0], [255, 255, 0], [0, 0, 255],
+ [159, 129, 183], [0, 255, 0], [255, 195, 128]]
+
+
+def potsdam_palette():
+ """Potsdam palette for external use."""
+ return [[255, 255, 255], [0, 0, 255], [0, 255, 255], [0, 255, 0],
+ [255, 255, 0], [255, 0, 0]]
+
+
+def vaihingen_palette():
+ """Vaihingen palette for external use."""
+ return [[255, 255, 255], [0, 0, 255], [0, 0, 255], [0, 255, 0],
+ [255, 255, 0], [255, 0, 0]]
+
+
+dataset_aliases = {
+ 'cityscapes': ['cityscapes'],
+ 'ade': ['ade', 'ade20k'],
+ 'voc': ['voc', 'pascal_voc', 'voc12', 'voc12aug'],
+ 'loveda': ['loveda'],
+ 'potsdam': ['potsdam'],
+ 'vaihingen': ['vaihingen'],
+ 'cocostuff': [
+ 'cocostuff', 'cocostuff10k', 'cocostuff164k', 'coco-stuff',
+ 'coco-stuff10k', 'coco-stuff164k', 'coco_stuff', 'coco_stuff10k',
+ 'coco_stuff164k'
+ ]
+}
+
+
+def get_classes(dataset):
+ """Get class names of a dataset."""
+ alias2name = {}
+ for name, aliases in dataset_aliases.items():
+ for alias in aliases:
+ alias2name[alias] = name
+
+ if mmcv.is_str(dataset):
+ if dataset in alias2name:
+ labels = eval(alias2name[dataset] + '_classes()')
+ else:
+ raise ValueError(f'Unrecognized dataset: {dataset}')
+ else:
+ raise TypeError(f'dataset must a str, but got {type(dataset)}')
+ return labels
+
+
+def get_palette(dataset):
+ """Get class palette (RGB) of a dataset."""
+ alias2name = {}
+ for name, aliases in dataset_aliases.items():
+ for alias in aliases:
+ alias2name[alias] = name
+
+ if mmcv.is_str(dataset):
+ if dataset in alias2name:
+ labels = eval(alias2name[dataset] + '_palette()')
+ else:
+ raise ValueError(f'Unrecognized dataset: {dataset}')
+ else:
+ raise TypeError(f'dataset must a str, but got {type(dataset)}')
+ return labels
diff --git a/mmseg/core/evaluation/eval_hooks.py b/mmseg/core/evaluation/eval_hooks.py
new file mode 100644
index 0000000..952db3b
--- /dev/null
+++ b/mmseg/core/evaluation/eval_hooks.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import warnings
+
+import torch.distributed as dist
+from mmcv.runner import DistEvalHook as _DistEvalHook
+from mmcv.runner import EvalHook as _EvalHook
+from torch.nn.modules.batchnorm import _BatchNorm
+
+
+class EvalHook(_EvalHook):
+ """Single GPU EvalHook, with efficient test support.
+
+ Args:
+ by_epoch (bool): Determine perform evaluation by epoch or by iteration.
+ If set to True, it will perform by epoch. Otherwise, by iteration.
+ Default: False.
+ efficient_test (bool): Whether save the results as local numpy files to
+ save CPU memory during evaluation. Default: False.
+ pre_eval (bool): Whether to use progressive mode to evaluate model.
+ Default: False.
+ Returns:
+ list: The prediction results.
+ """
+
+ greater_keys = ['mIoU', 'mAcc', 'aAcc']
+
+ def __init__(self,
+ *args,
+ by_epoch=False,
+ efficient_test=False,
+ pre_eval=False,
+ **kwargs):
+ super().__init__(*args, by_epoch=by_epoch, **kwargs)
+ self.pre_eval = pre_eval
+ if efficient_test:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` for evaluation hook '
+ 'is deprecated, the evaluation hook is CPU memory friendly '
+ 'with ``pre_eval=True`` as argument for ``single_gpu_test()`` '
+ 'function')
+
+ def _do_evaluate(self, runner):
+ """perform evaluation and save ckpt."""
+ if not self._should_evaluate(runner):
+ return
+
+ from mmseg.apis import single_gpu_test
+ results = single_gpu_test(
+ runner.model, self.dataloader, show=False, pre_eval=self.pre_eval)
+ runner.log_buffer.clear()
+ runner.log_buffer.output['eval_iter_num'] = len(self.dataloader)
+ key_score = self.evaluate(runner, results)
+ if self.save_best:
+ self._save_ckpt(runner, key_score)
+
+
+class DistEvalHook(_DistEvalHook):
+ """Distributed EvalHook, with efficient test support.
+
+ Args:
+ by_epoch (bool): Determine perform evaluation by epoch or by iteration.
+ If set to True, it will perform by epoch. Otherwise, by iteration.
+ Default: False.
+ efficient_test (bool): Whether save the results as local numpy files to
+ save CPU memory during evaluation. Default: False.
+ pre_eval (bool): Whether to use progressive mode to evaluate model.
+ Default: False.
+ Returns:
+ list: The prediction results.
+ """
+
+ greater_keys = ['mIoU', 'mAcc', 'aAcc']
+
+ def __init__(self,
+ *args,
+ by_epoch=False,
+ efficient_test=False,
+ pre_eval=False,
+ **kwargs):
+ super().__init__(*args, by_epoch=by_epoch, **kwargs)
+ self.pre_eval = pre_eval
+ if efficient_test:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` for evaluation hook '
+ 'is deprecated, the evaluation hook is CPU memory friendly '
+ 'with ``pre_eval=True`` as argument for ``multi_gpu_test()`` '
+ 'function')
+
+ def _do_evaluate(self, runner):
+ """perform evaluation and save ckpt."""
+ # Synchronization of BatchNorm's buffer (running_mean
+ # and running_var) is not supported in the DDP of pytorch,
+ # which may cause the inconsistent performance of models in
+ # different ranks, so we broadcast BatchNorm's buffers
+ # of rank 0 to other ranks to avoid this.
+ if self.broadcast_bn_buffer:
+ model = runner.model
+ for name, module in model.named_modules():
+ if isinstance(module,
+ _BatchNorm) and module.track_running_stats:
+ dist.broadcast(module.running_var, 0)
+ dist.broadcast(module.running_mean, 0)
+
+ if not self._should_evaluate(runner):
+ return
+
+ tmpdir = self.tmpdir
+ if tmpdir is None:
+ tmpdir = osp.join(runner.work_dir, '.eval_hook')
+
+ from mmseg.apis import multi_gpu_test
+ results = multi_gpu_test(
+ runner.model,
+ self.dataloader,
+ tmpdir=tmpdir,
+ gpu_collect=self.gpu_collect,
+ pre_eval=self.pre_eval)
+
+ runner.log_buffer.clear()
+
+ if runner.rank == 0:
+ print('\n')
+ runner.log_buffer.output['eval_iter_num'] = len(self.dataloader)
+ key_score = self.evaluate(runner, results)
+
+ if self.save_best:
+ self._save_ckpt(runner, key_score)
diff --git a/mmseg/core/evaluation/metrics.py b/mmseg/core/evaluation/metrics.py
new file mode 100644
index 0000000..a1c0908
--- /dev/null
+++ b/mmseg/core/evaluation/metrics.py
@@ -0,0 +1,395 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import OrderedDict
+
+import mmcv
+import numpy as np
+import torch
+
+
+def f_score(precision, recall, beta=1):
+ """calculate the f-score value.
+
+ Args:
+ precision (float | torch.Tensor): The precision value.
+ recall (float | torch.Tensor): The recall value.
+ beta (int): Determines the weight of recall in the combined score.
+ Default: False.
+
+ Returns:
+ [torch.tensor]: The f-score value.
+ """
+ score = (1 + beta**2) * (precision * recall) / (
+ (beta**2 * precision) + recall)
+ return score
+
+
+def intersect_and_union(pred_label,
+ label,
+ num_classes,
+ ignore_index,
+ label_map=dict(),
+ reduce_zero_label=False):
+ """Calculate intersection and Union.
+
+ Args:
+ pred_label (ndarray | str): Prediction segmentation map
+ or predict result filename.
+ label (ndarray | str): Ground truth segmentation map
+ or label filename.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ label_map (dict): Mapping old labels to new labels. The parameter will
+ work only when label is str. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. The parameter will
+ work only when label is str. Default: False.
+
+ Returns:
+ torch.Tensor: The intersection of prediction and ground truth
+ histogram on all classes.
+ torch.Tensor: The union of prediction and ground truth histogram on
+ all classes.
+ torch.Tensor: The prediction histogram on all classes.
+ torch.Tensor: The ground truth histogram on all classes.
+ """
+
+ if isinstance(pred_label, str):
+ pred_label = torch.from_numpy(np.load(pred_label))
+ else:
+ pred_label = torch.from_numpy((pred_label))
+
+ if isinstance(label, str):
+ label = torch.from_numpy(
+ mmcv.imread(label, flag='unchanged', backend='pillow'))
+ else:
+ label = torch.from_numpy(label)
+
+ if label_map is not None:
+ for old_id, new_id in label_map.items():
+ label[label == old_id] = new_id
+ if reduce_zero_label:
+ label[label == 0] = 255
+ label = label - 1
+ label[label == 254] = 255
+
+ mask = (label != ignore_index)
+ pred_label = pred_label[mask]
+ label = label[mask]
+
+ intersect = pred_label[pred_label == label]
+ area_intersect = torch.histc(
+ intersect.float(), bins=(num_classes), min=0, max=num_classes - 1)
+ area_pred_label = torch.histc(
+ pred_label.float(), bins=(num_classes), min=0, max=num_classes - 1)
+ area_label = torch.histc(
+ label.float(), bins=(num_classes), min=0, max=num_classes - 1)
+ area_union = area_pred_label + area_label - area_intersect
+ return area_intersect, area_union, area_pred_label, area_label
+
+
+def total_intersect_and_union(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ label_map=dict(),
+ reduce_zero_label=False):
+ """Calculate Total Intersection and Union.
+
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str] | Iterables): list of ground
+ truth segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+
+ Returns:
+ ndarray: The intersection of prediction and ground truth histogram
+ on all classes.
+ ndarray: The union of prediction and ground truth histogram on all
+ classes.
+ ndarray: The prediction histogram on all classes.
+ ndarray: The ground truth histogram on all classes.
+ """
+ total_area_intersect = torch.zeros((num_classes, ), dtype=torch.float64)
+ total_area_union = torch.zeros((num_classes, ), dtype=torch.float64)
+ total_area_pred_label = torch.zeros((num_classes, ), dtype=torch.float64)
+ total_area_label = torch.zeros((num_classes, ), dtype=torch.float64)
+ for result, gt_seg_map in zip(results, gt_seg_maps):
+ area_intersect, area_union, area_pred_label, area_label = \
+ intersect_and_union(
+ result, gt_seg_map, num_classes, ignore_index,
+ label_map, reduce_zero_label)
+ total_area_intersect += area_intersect
+ total_area_union += area_union
+ total_area_pred_label += area_pred_label
+ total_area_label += area_label
+ return total_area_intersect, total_area_union, total_area_pred_label, \
+ total_area_label
+
+
+def mean_iou(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ nan_to_num=None,
+ label_map=dict(),
+ reduce_zero_label=False):
+ """Calculate Mean Intersection and Union (mIoU)
+
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str]): list of ground truth
+ segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+
+ Returns:
+ dict[str, float | ndarray]:
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category IoU, shape (num_classes, ).
+ """
+ iou_result = eval_metrics(
+ results=results,
+ gt_seg_maps=gt_seg_maps,
+ num_classes=num_classes,
+ ignore_index=ignore_index,
+ metrics=['mIoU'],
+ nan_to_num=nan_to_num,
+ label_map=label_map,
+ reduce_zero_label=reduce_zero_label)
+ return iou_result
+
+
+def mean_dice(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ nan_to_num=None,
+ label_map=dict(),
+ reduce_zero_label=False):
+ """Calculate Mean Dice (mDice)
+
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str]): list of ground truth
+ segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+
+ Returns:
+ dict[str, float | ndarray]: Default metrics.
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category dice, shape (num_classes, ).
+ """
+
+ dice_result = eval_metrics(
+ results=results,
+ gt_seg_maps=gt_seg_maps,
+ num_classes=num_classes,
+ ignore_index=ignore_index,
+ metrics=['mDice'],
+ nan_to_num=nan_to_num,
+ label_map=label_map,
+ reduce_zero_label=reduce_zero_label)
+ return dice_result
+
+
+def mean_fscore(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ nan_to_num=None,
+ label_map=dict(),
+ reduce_zero_label=False,
+ beta=1):
+ """Calculate Mean Intersection and Union (mIoU)
+
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str]): list of ground truth
+ segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+ beta (int): Determines the weight of recall in the combined score.
+ Default: False.
+
+
+ Returns:
+ dict[str, float | ndarray]: Default metrics.
+ float: Overall accuracy on all images.
+ ndarray: Per category recall, shape (num_classes, ).
+ ndarray: Per category precision, shape (num_classes, ).
+ ndarray: Per category f-score, shape (num_classes, ).
+ """
+ fscore_result = eval_metrics(
+ results=results,
+ gt_seg_maps=gt_seg_maps,
+ num_classes=num_classes,
+ ignore_index=ignore_index,
+ metrics=['mFscore'],
+ nan_to_num=nan_to_num,
+ label_map=label_map,
+ reduce_zero_label=reduce_zero_label,
+ beta=beta)
+ return fscore_result
+
+
+def eval_metrics(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ metrics=['mIoU'],
+ nan_to_num=None,
+ label_map=dict(),
+ reduce_zero_label=False,
+ beta=1):
+ """Calculate evaluation metrics
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str] | Iterables): list of ground
+ truth segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ metrics (list[str] | str): Metrics to be evaluated, 'mIoU' and 'mDice'.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+ Returns:
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category evaluation metrics, shape (num_classes, ).
+ """
+
+ total_area_intersect, total_area_union, total_area_pred_label, \
+ total_area_label = total_intersect_and_union(
+ results, gt_seg_maps, num_classes, ignore_index, label_map,
+ reduce_zero_label)
+ ret_metrics = total_area_to_metrics(total_area_intersect, total_area_union,
+ total_area_pred_label,
+ total_area_label, metrics, nan_to_num,
+ beta)
+
+ return ret_metrics
+
+
+def pre_eval_to_metrics(pre_eval_results,
+ metrics=['mIoU'],
+ nan_to_num=None,
+ beta=1):
+ """Convert pre-eval results to metrics.
+
+ Args:
+ pre_eval_results (list[tuple[torch.Tensor]]): per image eval results
+ for computing evaluation metric
+ metrics (list[str] | str): Metrics to be evaluated, 'mIoU' and 'mDice'.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ Returns:
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category evaluation metrics, shape (num_classes, ).
+ """
+
+ # convert list of tuples to tuple of lists, e.g.
+ # [(A_1, B_1, C_1, D_1), ..., (A_n, B_n, C_n, D_n)] to
+ # ([A_1, ..., A_n], ..., [D_1, ..., D_n])
+ pre_eval_results = tuple(zip(*pre_eval_results))
+ assert len(pre_eval_results) == 4
+
+ total_area_intersect = sum(pre_eval_results[0])
+ total_area_union = sum(pre_eval_results[1])
+ total_area_pred_label = sum(pre_eval_results[2])
+ total_area_label = sum(pre_eval_results[3])
+
+ ret_metrics = total_area_to_metrics(total_area_intersect, total_area_union,
+ total_area_pred_label,
+ total_area_label, metrics, nan_to_num,
+ beta)
+
+ return ret_metrics
+
+
+def total_area_to_metrics(total_area_intersect,
+ total_area_union,
+ total_area_pred_label,
+ total_area_label,
+ metrics=['mIoU'],
+ nan_to_num=None,
+ beta=1):
+ """Calculate evaluation metrics
+ Args:
+ total_area_intersect (ndarray): The intersection of prediction and
+ ground truth histogram on all classes.
+ total_area_union (ndarray): The union of prediction and ground truth
+ histogram on all classes.
+ total_area_pred_label (ndarray): The prediction histogram on all
+ classes.
+ total_area_label (ndarray): The ground truth histogram on all classes.
+ metrics (list[str] | str): Metrics to be evaluated, 'mIoU' and 'mDice'.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ Returns:
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category evaluation metrics, shape (num_classes, ).
+ """
+ if isinstance(metrics, str):
+ metrics = [metrics]
+ allowed_metrics = ['mIoU', 'mDice', 'mFscore']
+ if not set(metrics).issubset(set(allowed_metrics)):
+ raise KeyError('metrics {} is not supported'.format(metrics))
+
+ all_acc = total_area_intersect.sum() / total_area_label.sum()
+ ret_metrics = OrderedDict({'aAcc': all_acc})
+ for metric in metrics:
+ if metric == 'mIoU':
+ iou = total_area_intersect / total_area_union
+ acc = total_area_intersect / total_area_label
+ ret_metrics['IoU'] = iou
+ ret_metrics['Acc'] = acc
+ elif metric == 'mDice':
+ dice = 2 * total_area_intersect / (
+ total_area_pred_label + total_area_label)
+ acc = total_area_intersect / total_area_label
+ ret_metrics['Dice'] = dice
+ ret_metrics['Acc'] = acc
+ elif metric == 'mFscore':
+ precision = total_area_intersect / total_area_pred_label
+ recall = total_area_intersect / total_area_label
+ f_value = torch.tensor(
+ [f_score(x[0], x[1], beta) for x in zip(precision, recall)])
+ ret_metrics['Fscore'] = f_value
+ ret_metrics['Precision'] = precision
+ ret_metrics['Recall'] = recall
+
+ ret_metrics = {
+ metric: value.numpy()
+ for metric, value in ret_metrics.items()
+ }
+ if nan_to_num is not None:
+ ret_metrics = OrderedDict({
+ metric: np.nan_to_num(metric_value, nan=nan_to_num)
+ for metric, metric_value in ret_metrics.items()
+ })
+ return ret_metrics
diff --git a/mmseg/core/seg/__init__.py b/mmseg/core/seg/__init__.py
new file mode 100644
index 0000000..5206b96
--- /dev/null
+++ b/mmseg/core/seg/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .builder import build_pixel_sampler
+from .sampler import BasePixelSampler, OHEMPixelSampler
+
+__all__ = ['build_pixel_sampler', 'BasePixelSampler', 'OHEMPixelSampler']
diff --git a/mmseg/core/seg/builder.py b/mmseg/core/seg/builder.py
new file mode 100644
index 0000000..1cecd34
--- /dev/null
+++ b/mmseg/core/seg/builder.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.utils import Registry, build_from_cfg
+
+PIXEL_SAMPLERS = Registry('pixel sampler')
+
+
+def build_pixel_sampler(cfg, **default_args):
+ """Build pixel sampler for segmentation map."""
+ return build_from_cfg(cfg, PIXEL_SAMPLERS, default_args)
diff --git a/mmseg/core/seg/sampler/__init__.py b/mmseg/core/seg/sampler/__init__.py
new file mode 100644
index 0000000..5a76485
--- /dev/null
+++ b/mmseg/core/seg/sampler/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_pixel_sampler import BasePixelSampler
+from .ohem_pixel_sampler import OHEMPixelSampler
+
+__all__ = ['BasePixelSampler', 'OHEMPixelSampler']
diff --git a/mmseg/core/seg/sampler/base_pixel_sampler.py b/mmseg/core/seg/sampler/base_pixel_sampler.py
new file mode 100644
index 0000000..03672cd
--- /dev/null
+++ b/mmseg/core/seg/sampler/base_pixel_sampler.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+
+class BasePixelSampler(metaclass=ABCMeta):
+ """Base class of pixel sampler."""
+
+ def __init__(self, **kwargs):
+ pass
+
+ @abstractmethod
+ def sample(self, seg_logit, seg_label):
+ """Placeholder for sample function."""
diff --git a/mmseg/core/seg/sampler/ohem_pixel_sampler.py b/mmseg/core/seg/sampler/ohem_pixel_sampler.py
new file mode 100644
index 0000000..833a287
--- /dev/null
+++ b/mmseg/core/seg/sampler/ohem_pixel_sampler.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..builder import PIXEL_SAMPLERS
+from .base_pixel_sampler import BasePixelSampler
+
+
+@PIXEL_SAMPLERS.register_module()
+class OHEMPixelSampler(BasePixelSampler):
+ """Online Hard Example Mining Sampler for segmentation.
+
+ Args:
+ context (nn.Module): The context of sampler, subclass of
+ :obj:`BaseDecodeHead`.
+ thresh (float, optional): The threshold for hard example selection.
+ Below which, are prediction with low confidence. If not
+ specified, the hard examples will be pixels of top ``min_kept``
+ loss. Default: None.
+ min_kept (int, optional): The minimum number of predictions to keep.
+ Default: 100000.
+ """
+
+ def __init__(self, context, thresh=None, min_kept=100000):
+ super(OHEMPixelSampler, self).__init__()
+ self.context = context
+ assert min_kept > 1
+ self.thresh = thresh
+ self.min_kept = min_kept
+
+ def sample(self, seg_logit, seg_label):
+ """Sample pixels that have high loss or with low prediction confidence.
+
+ Args:
+ seg_logit (torch.Tensor): segmentation logits, shape (N, C, H, W)
+ seg_label (torch.Tensor): segmentation label, shape (N, 1, H, W)
+
+ Returns:
+ torch.Tensor: segmentation weight, shape (N, H, W)
+ """
+ with torch.no_grad():
+ assert seg_logit.shape[2:] == seg_label.shape[2:]
+ assert seg_label.shape[1] == 1
+ seg_label = seg_label.squeeze(1).long()
+ batch_kept = self.min_kept * seg_label.size(0)
+ valid_mask = seg_label != self.context.ignore_index
+ seg_weight = seg_logit.new_zeros(size=seg_label.size())
+ valid_seg_weight = seg_weight[valid_mask]
+ if self.thresh is not None:
+ seg_prob = F.softmax(seg_logit, dim=1)
+
+ tmp_seg_label = seg_label.clone().unsqueeze(1)
+ tmp_seg_label[tmp_seg_label == self.context.ignore_index] = 0
+ seg_prob = seg_prob.gather(1, tmp_seg_label).squeeze(1)
+ sort_prob, sort_indices = seg_prob[valid_mask].sort()
+
+ if sort_prob.numel() > 0:
+ min_threshold = sort_prob[min(batch_kept,
+ sort_prob.numel() - 1)]
+ else:
+ min_threshold = 0.0
+ threshold = max(min_threshold, self.thresh)
+ valid_seg_weight[seg_prob[valid_mask] < threshold] = 1.
+ else:
+ if not isinstance(self.context.loss_decode, nn.ModuleList):
+ losses_decode = [self.context.loss_decode]
+ else:
+ losses_decode = self.context.loss_decode
+ losses = 0.0
+ for loss_module in losses_decode:
+ losses += loss_module(
+ seg_logit,
+ seg_label,
+ weight=None,
+ ignore_index=self.context.ignore_index,
+ reduction_override='none')
+
+ # faster than topk according to https://github.com/pytorch/pytorch/issues/22812 # noqa
+ _, sort_indices = losses[valid_mask].sort(descending=True)
+ valid_seg_weight[sort_indices[:batch_kept]] = 1.
+
+ seg_weight[valid_mask] = valid_seg_weight
+
+ return seg_weight
diff --git a/mmseg/core/utils/__init__.py b/mmseg/core/utils/__init__.py
new file mode 100644
index 0000000..be9de55
--- /dev/null
+++ b/mmseg/core/utils/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .misc import add_prefix
+
+__all__ = ['add_prefix']
diff --git a/mmseg/core/utils/misc.py b/mmseg/core/utils/misc.py
new file mode 100644
index 0000000..282bb8d
--- /dev/null
+++ b/mmseg/core/utils/misc.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def add_prefix(inputs, prefix):
+ """Add prefix for dict.
+
+ Args:
+ inputs (dict): The input dict with str keys.
+ prefix (str): The prefix to add.
+
+ Returns:
+
+ dict: The dict with keys updated with ``prefix``.
+ """
+
+ outputs = dict()
+ for name, value in inputs.items():
+ outputs[f'{prefix}.{name}'] = value
+
+ return outputs
diff --git a/mmseg/datasets/__init__.py b/mmseg/datasets/__init__.py
new file mode 100644
index 0000000..9f14325
--- /dev/null
+++ b/mmseg/datasets/__init__.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ade import ADE20KDataset
+from .builder import DATASETS, PIPELINES, build_dataloader, build_dataset
+from .chase_db1 import ChaseDB1Dataset
+from .cityscapes import CityscapesDataset
+from .coco_stuff import COCOStuffDataset
+from .custom import CustomDataset
+from .dark_zurich import DarkZurichDataset
+from .dataset_wrappers import (ConcatDataset, MultiImageMixDataset,
+ RepeatDataset)
+from .drive import DRIVEDataset
+from .hrf import HRFDataset
+from .isprs import ISPRSDataset
+from .loveda import LoveDADataset
+from .night_driving import NightDrivingDataset
+from .pascal_context import PascalContextDataset, PascalContextDataset59
+from .potsdam import PotsdamDataset
+from .stare import STAREDataset
+from .voc import PascalVOCDataset
+
+__all__ = [
+ 'CustomDataset', 'build_dataloader', 'ConcatDataset', 'RepeatDataset',
+ 'DATASETS', 'build_dataset', 'PIPELINES', 'CityscapesDataset',
+ 'PascalVOCDataset', 'ADE20KDataset', 'PascalContextDataset',
+ 'PascalContextDataset59', 'ChaseDB1Dataset', 'DRIVEDataset', 'HRFDataset',
+ 'STAREDataset', 'DarkZurichDataset', 'NightDrivingDataset',
+ 'COCOStuffDataset', 'LoveDADataset', 'MultiImageMixDataset',
+ 'ISPRSDataset', 'PotsdamDataset'
+]
diff --git a/mmseg/datasets/ade.py b/mmseg/datasets/ade.py
new file mode 100644
index 0000000..db94ceb
--- /dev/null
+++ b/mmseg/datasets/ade.py
@@ -0,0 +1,167 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import numpy as np
+from PIL import Image
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class ADE20KDataset(CustomDataset):
+ """ADE20K dataset.
+
+ In segmentation map annotation for ADE20K, 0 stands for background, which
+ is not included in 150 categories. ``reduce_zero_label`` is fixed to True.
+ The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is fixed to
+ '.png'.
+ """
+ CLASSES = (
+ 'wall', 'building', 'sky', 'floor', 'tree', 'ceiling', 'road', 'bed ',
+ 'windowpane', 'grass', 'cabinet', 'sidewalk', 'person', 'earth',
+ 'door', 'table', 'mountain', 'plant', 'curtain', 'chair', 'car',
+ 'water', 'painting', 'sofa', 'shelf', 'house', 'sea', 'mirror', 'rug',
+ 'field', 'armchair', 'seat', 'fence', 'desk', 'rock', 'wardrobe',
+ 'lamp', 'bathtub', 'railing', 'cushion', 'base', 'box', 'column',
+ 'signboard', 'chest of drawers', 'counter', 'sand', 'sink',
+ 'skyscraper', 'fireplace', 'refrigerator', 'grandstand', 'path',
+ 'stairs', 'runway', 'case', 'pool table', 'pillow', 'screen door',
+ 'stairway', 'river', 'bridge', 'bookcase', 'blind', 'coffee table',
+ 'toilet', 'flower', 'book', 'hill', 'bench', 'countertop', 'stove',
+ 'palm', 'kitchen island', 'computer', 'swivel chair', 'boat', 'bar',
+ 'arcade machine', 'hovel', 'bus', 'towel', 'light', 'truck', 'tower',
+ 'chandelier', 'awning', 'streetlight', 'booth', 'television receiver',
+ 'airplane', 'dirt track', 'apparel', 'pole', 'land', 'bannister',
+ 'escalator', 'ottoman', 'bottle', 'buffet', 'poster', 'stage', 'van',
+ 'ship', 'fountain', 'conveyer belt', 'canopy', 'washer', 'plaything',
+ 'swimming pool', 'stool', 'barrel', 'basket', 'waterfall', 'tent',
+ 'bag', 'minibike', 'cradle', 'oven', 'ball', 'food', 'step', 'tank',
+ 'trade name', 'microwave', 'pot', 'animal', 'bicycle', 'lake',
+ 'dishwasher', 'screen', 'blanket', 'sculpture', 'hood', 'sconce',
+ 'vase', 'traffic light', 'tray', 'ashcan', 'fan', 'pier', 'crt screen',
+ 'plate', 'monitor', 'bulletin board', 'shower', 'radiator', 'glass',
+ 'clock', 'flag')
+
+ PALETTE = [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
+ [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
+ [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
+ [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
+ [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
+ [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
+ [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
+ [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
+ [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
+ [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
+ [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
+ [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
+ [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
+ [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
+ [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255],
+ [11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255],
+ [0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0],
+ [255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0],
+ [0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255],
+ [173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255],
+ [255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20],
+ [255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255],
+ [255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255],
+ [0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255],
+ [0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0],
+ [143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0],
+ [8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255],
+ [255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112],
+ [92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160],
+ [163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163],
+ [255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0],
+ [255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0],
+ [10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255],
+ [255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204],
+ [41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255],
+ [71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255],
+ [184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194],
+ [102, 255, 0], [92, 0, 255]]
+
+ def __init__(self, **kwargs):
+ super(ADE20KDataset, self).__init__(
+ img_suffix='.jpg',
+ seg_map_suffix='.png',
+ reduce_zero_label=True,
+ **kwargs)
+
+ def results2img(self, results, imgfile_prefix, to_label_id, indices=None):
+ """Write the segmentation results to images.
+
+ Args:
+ results (list[ndarray]): Testing results of the
+ dataset.
+ imgfile_prefix (str): The filename prefix of the png files.
+ If the prefix is "somepath/xxx",
+ the png files will be named "somepath/xxx.png".
+ to_label_id (bool): whether convert output to label_id for
+ submission.
+ indices (list[int], optional): Indices of input results, if not
+ set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ list[str: str]: result txt files which contains corresponding
+ semantic segmentation images.
+ """
+ if indices is None:
+ indices = list(range(len(self)))
+
+ mmcv.mkdir_or_exist(imgfile_prefix)
+ result_files = []
+ for result, idx in zip(results, indices):
+
+ filename = self.img_infos[idx]['filename']
+ basename = osp.splitext(osp.basename(filename))[0]
+
+ png_filename = osp.join(imgfile_prefix, f'{basename}.png')
+
+ # The index range of official requirement is from 0 to 150.
+ # But the index range of output is from 0 to 149.
+ # That is because we set reduce_zero_label=True.
+ result = result + 1
+
+ output = Image.fromarray(result.astype(np.uint8))
+ output.save(png_filename)
+ result_files.append(png_filename)
+
+ return result_files
+
+ def format_results(self,
+ results,
+ imgfile_prefix,
+ to_label_id=True,
+ indices=None):
+ """Format the results into dir (standard format for ade20k evaluation).
+
+ Args:
+ results (list): Testing results of the dataset.
+ imgfile_prefix (str | None): The prefix of images files. It
+ includes the file path and the prefix of filename, e.g.,
+ "a/b/prefix".
+ to_label_id (bool): whether convert output to label_id for
+ submission. Default: False
+ indices (list[int], optional): Indices of input results, if not
+ set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ tuple: (result_files, tmp_dir), result_files is a list containing
+ the image paths, tmp_dir is the temporal directory created
+ for saving json/png files when img_prefix is not specified.
+ """
+
+ if indices is None:
+ indices = list(range(len(self)))
+
+ assert isinstance(results, list), 'results must be a list.'
+ assert isinstance(indices, list), 'indices must be a list.'
+
+ result_files = self.results2img(results, imgfile_prefix, to_label_id,
+ indices)
+ return result_files
diff --git a/mmseg/datasets/builder.py b/mmseg/datasets/builder.py
new file mode 100644
index 0000000..3529ab9
--- /dev/null
+++ b/mmseg/datasets/builder.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import platform
+import random
+from functools import partial
+
+import numpy as np
+import torch
+from mmcv.parallel import collate
+from mmcv.runner import get_dist_info
+from mmcv.utils import Registry, build_from_cfg, digit_version
+from torch.utils.data import DataLoader, DistributedSampler
+
+if platform.system() != 'Windows':
+ # https://github.com/pytorch/pytorch/issues/973
+ import resource
+ rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
+ base_soft_limit = rlimit[0]
+ hard_limit = rlimit[1]
+ soft_limit = min(max(4096, base_soft_limit), hard_limit)
+ resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))
+
+DATASETS = Registry('dataset')
+PIPELINES = Registry('pipeline')
+
+
+def _concat_dataset(cfg, default_args=None):
+ """Build :obj:`ConcatDataset by."""
+ from .dataset_wrappers import ConcatDataset
+ img_dir = cfg['img_dir']
+ ann_dir = cfg.get('ann_dir', None)
+ split = cfg.get('split', None)
+ # pop 'separate_eval' since it is not a valid key for common datasets.
+ separate_eval = cfg.pop('separate_eval', True)
+ num_img_dir = len(img_dir) if isinstance(img_dir, (list, tuple)) else 1
+ if ann_dir is not None:
+ num_ann_dir = len(ann_dir) if isinstance(ann_dir, (list, tuple)) else 1
+ else:
+ num_ann_dir = 0
+ if split is not None:
+ num_split = len(split) if isinstance(split, (list, tuple)) else 1
+ else:
+ num_split = 0
+ if num_img_dir > 1:
+ assert num_img_dir == num_ann_dir or num_ann_dir == 0
+ assert num_img_dir == num_split or num_split == 0
+ else:
+ assert num_split == num_ann_dir or num_ann_dir <= 1
+ num_dset = max(num_split, num_img_dir)
+
+ datasets = []
+ for i in range(num_dset):
+ data_cfg = copy.deepcopy(cfg)
+ if isinstance(img_dir, (list, tuple)):
+ data_cfg['img_dir'] = img_dir[i]
+ if isinstance(ann_dir, (list, tuple)):
+ data_cfg['ann_dir'] = ann_dir[i]
+ if isinstance(split, (list, tuple)):
+ data_cfg['split'] = split[i]
+ datasets.append(build_dataset(data_cfg, default_args))
+
+ return ConcatDataset(datasets, separate_eval)
+
+
+def build_dataset(cfg, default_args=None):
+ """Build datasets."""
+ from .dataset_wrappers import (ConcatDataset, MultiImageMixDataset,
+ RepeatDataset)
+ if isinstance(cfg, (list, tuple)):
+ dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
+ elif cfg['type'] == 'RepeatDataset':
+ dataset = RepeatDataset(
+ build_dataset(cfg['dataset'], default_args), cfg['times'])
+ elif cfg['type'] == 'MultiImageMixDataset':
+ cp_cfg = copy.deepcopy(cfg)
+ cp_cfg['dataset'] = build_dataset(cp_cfg['dataset'])
+ cp_cfg.pop('type')
+ dataset = MultiImageMixDataset(**cp_cfg)
+ elif isinstance(cfg.get('img_dir'), (list, tuple)) or isinstance(
+ cfg.get('split', None), (list, tuple)):
+ dataset = _concat_dataset(cfg, default_args)
+ else:
+ dataset = build_from_cfg(cfg, DATASETS, default_args)
+
+ return dataset
+
+
+def build_dataloader(dataset,
+ samples_per_gpu,
+ workers_per_gpu,
+ num_gpus=1,
+ dist=True,
+ shuffle=True,
+ seed=None,
+ drop_last=False,
+ pin_memory=True,
+ persistent_workers=True,
+ **kwargs):
+ """Build PyTorch DataLoader.
+
+ In distributed training, each GPU/process has a dataloader.
+ In non-distributed training, there is only one dataloader for all GPUs.
+
+ Args:
+ dataset (Dataset): A PyTorch dataset.
+ samples_per_gpu (int): Number of training samples on each GPU, i.e.,
+ batch size of each GPU.
+ workers_per_gpu (int): How many subprocesses to use for data loading
+ for each GPU.
+ num_gpus (int): Number of GPUs. Only used in non-distributed training.
+ dist (bool): Distributed training/test or not. Default: True.
+ shuffle (bool): Whether to shuffle the data at every epoch.
+ Default: True.
+ seed (int | None): Seed to be used. Default: None.
+ drop_last (bool): Whether to drop the last incomplete batch in epoch.
+ Default: False
+ pin_memory (bool): Whether to use pin_memory in DataLoader.
+ Default: True
+ persistent_workers (bool): If True, the data loader will not shutdown
+ the worker processes after a dataset has been consumed once.
+ This allows to maintain the workers Dataset instances alive.
+ The argument also has effect in PyTorch>=1.7.0.
+ Default: True
+ kwargs: any keyword argument to be used to initialize DataLoader
+
+ Returns:
+ DataLoader: A PyTorch dataloader.
+ """
+ rank, world_size = get_dist_info()
+ if dist:
+ sampler = DistributedSampler(
+ dataset, world_size, rank, shuffle=shuffle)
+ shuffle = False
+ batch_size = samples_per_gpu
+ num_workers = workers_per_gpu
+ else:
+ sampler = None
+ batch_size = num_gpus * samples_per_gpu
+ num_workers = num_gpus * workers_per_gpu
+
+ init_fn = partial(
+ worker_init_fn, num_workers=num_workers, rank=rank,
+ seed=seed) if seed is not None else None
+
+ if digit_version(torch.__version__) >= digit_version('1.8.0'):
+ data_loader = DataLoader(
+ dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ num_workers=num_workers,
+ collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
+ pin_memory=pin_memory,
+ shuffle=shuffle,
+ worker_init_fn=init_fn,
+ drop_last=drop_last,
+ persistent_workers=persistent_workers,
+ **kwargs)
+ else:
+ data_loader = DataLoader(
+ dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ num_workers=num_workers,
+ collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
+ pin_memory=pin_memory,
+ shuffle=shuffle,
+ worker_init_fn=init_fn,
+ drop_last=drop_last,
+ **kwargs)
+
+ return data_loader
+
+
+def worker_init_fn(worker_id, num_workers, rank, seed):
+ """Worker init func for dataloader.
+
+ The seed of each worker equals to num_worker * rank + worker_id + user_seed
+
+ Args:
+ worker_id (int): Worker id.
+ num_workers (int): Number of workers.
+ rank (int): The rank of current process.
+ seed (int): The random seed to use.
+ """
+
+ worker_seed = num_workers * rank + worker_id + seed
+ np.random.seed(worker_seed)
+ random.seed(worker_seed)
diff --git a/mmseg/datasets/chase_db1.py b/mmseg/datasets/chase_db1.py
new file mode 100644
index 0000000..7f14b2d
--- /dev/null
+++ b/mmseg/datasets/chase_db1.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class ChaseDB1Dataset(CustomDataset):
+ """Chase_db1 dataset.
+
+ In segmentation map annotation for Chase_db1, 0 stands for background,
+ which is included in 2 categories. ``reduce_zero_label`` is fixed to False.
+ The ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
+ '_1stHO.png'.
+ """
+
+ CLASSES = ('background', 'vessel')
+
+ PALETTE = [[120, 120, 120], [6, 230, 230]]
+
+ def __init__(self, **kwargs):
+ super(ChaseDB1Dataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='_1stHO.png',
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir)
diff --git a/mmseg/datasets/cityscapes.py b/mmseg/datasets/cityscapes.py
new file mode 100644
index 0000000..ed633d0
--- /dev/null
+++ b/mmseg/datasets/cityscapes.py
@@ -0,0 +1,214 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import numpy as np
+from mmcv.utils import print_log
+from PIL import Image
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class CityscapesDataset(CustomDataset):
+ """Cityscapes dataset.
+
+ The ``img_suffix`` is fixed to '_leftImg8bit.png' and ``seg_map_suffix`` is
+ fixed to '_gtFine_labelTrainIds.png' for Cityscapes dataset.
+ """
+
+ CLASSES = ('road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
+ 'traffic light', 'traffic sign', 'vegetation', 'terrain', 'sky',
+ 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle',
+ 'bicycle')
+
+ PALETTE = [[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
+ [190, 153, 153], [153, 153, 153], [250, 170, 30], [220, 220, 0],
+ [107, 142, 35], [152, 251, 152], [70, 130, 180], [220, 20, 60],
+ [255, 0, 0], [0, 0, 142], [0, 0, 70], [0, 60, 100],
+ [0, 80, 100], [0, 0, 230], [119, 11, 32]]
+
+ def __init__(self,
+ img_suffix='_leftImg8bit.png',
+ seg_map_suffix='_gtFine_labelTrainIds.png',
+ **kwargs):
+ super(CityscapesDataset, self).__init__(
+ img_suffix=img_suffix, seg_map_suffix=seg_map_suffix, **kwargs)
+
+ @staticmethod
+ def _convert_to_label_id(result):
+ """Convert trainId to id for cityscapes."""
+ if isinstance(result, str):
+ result = np.load(result)
+ import cityscapesscripts.helpers.labels as CSLabels
+ result_copy = result.copy()
+ for trainId, label in CSLabels.trainId2label.items():
+ result_copy[result == trainId] = label.id
+
+ return result_copy
+
+ def results2img(self, results, imgfile_prefix, to_label_id, indices=None):
+ """Write the segmentation results to images.
+
+ Args:
+ results (list[ndarray]): Testing results of the
+ dataset.
+ imgfile_prefix (str): The filename prefix of the png files.
+ If the prefix is "somepath/xxx",
+ the png files will be named "somepath/xxx.png".
+ to_label_id (bool): whether convert output to label_id for
+ submission.
+ indices (list[int], optional): Indices of input results,
+ if not set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ list[str: str]: result txt files which contains corresponding
+ semantic segmentation images.
+ """
+ if indices is None:
+ indices = list(range(len(self)))
+
+ mmcv.mkdir_or_exist(imgfile_prefix)
+ result_files = []
+ for result, idx in zip(results, indices):
+ if to_label_id:
+ result = self._convert_to_label_id(result)
+ filename = self.img_infos[idx]['filename']
+ basename = osp.splitext(osp.basename(filename))[0]
+
+ png_filename = osp.join(imgfile_prefix, f'{basename}.png')
+
+ output = Image.fromarray(result.astype(np.uint8)).convert('P')
+ import cityscapesscripts.helpers.labels as CSLabels
+ palette = np.zeros((len(CSLabels.id2label), 3), dtype=np.uint8)
+ for label_id, label in CSLabels.id2label.items():
+ palette[label_id] = label.color
+
+ output.putpalette(palette)
+ output.save(png_filename)
+ result_files.append(png_filename)
+
+ return result_files
+
+ def format_results(self,
+ results,
+ imgfile_prefix,
+ to_label_id=True,
+ indices=None):
+ """Format the results into dir (standard format for Cityscapes
+ evaluation).
+
+ Args:
+ results (list): Testing results of the dataset.
+ imgfile_prefix (str): The prefix of images files. It
+ includes the file path and the prefix of filename, e.g.,
+ "a/b/prefix".
+ to_label_id (bool): whether convert output to label_id for
+ submission. Default: False
+ indices (list[int], optional): Indices of input results,
+ if not set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ tuple: (result_files, tmp_dir), result_files is a list containing
+ the image paths, tmp_dir is the temporal directory created
+ for saving json/png files when img_prefix is not specified.
+ """
+ if indices is None:
+ indices = list(range(len(self)))
+
+ assert isinstance(results, list), 'results must be a list.'
+ assert isinstance(indices, list), 'indices must be a list.'
+
+ result_files = self.results2img(results, imgfile_prefix, to_label_id,
+ indices)
+
+ return result_files
+
+ def evaluate(self,
+ results,
+ metric='mIoU',
+ logger=None,
+ imgfile_prefix=None):
+ """Evaluation in Cityscapes/default protocol.
+
+ Args:
+ results (list): Testing results of the dataset.
+ metric (str | list[str]): Metrics to be evaluated.
+ logger (logging.Logger | None | str): Logger used for printing
+ related information during evaluation. Default: None.
+ imgfile_prefix (str | None): The prefix of output image file,
+ for cityscapes evaluation only. It includes the file path and
+ the prefix of filename, e.g., "a/b/prefix".
+ If results are evaluated with cityscapes protocol, it would be
+ the prefix of output png files. The output files would be
+ png images under folder "a/b/prefix/xxx.png", where "xxx" is
+ the image name of cityscapes. If not specified, a temp file
+ will be created for evaluation.
+ Default: None.
+
+ Returns:
+ dict[str, float]: Cityscapes/default metrics.
+ """
+
+ eval_results = dict()
+ metrics = metric.copy() if isinstance(metric, list) else [metric]
+ if 'cityscapes' in metrics:
+ eval_results.update(
+ self._evaluate_cityscapes(results, logger, imgfile_prefix))
+ metrics.remove('cityscapes')
+ if len(metrics) > 0:
+ eval_results.update(
+ super(CityscapesDataset,
+ self).evaluate(results, metrics, logger))
+
+ return eval_results
+
+ def _evaluate_cityscapes(self, results, logger, imgfile_prefix):
+ """Evaluation in Cityscapes protocol.
+
+ Args:
+ results (list): Testing results of the dataset.
+ logger (logging.Logger | str | None): Logger used for printing
+ related information during evaluation. Default: None.
+ imgfile_prefix (str | None): The prefix of output image file
+
+ Returns:
+ dict[str: float]: Cityscapes evaluation results.
+ """
+ try:
+ import cityscapesscripts.evaluation.evalPixelLevelSemanticLabeling as CSEval # noqa
+ except ImportError:
+ raise ImportError('Please run "pip install cityscapesscripts" to '
+ 'install cityscapesscripts first.')
+ msg = 'Evaluating in Cityscapes style'
+ if logger is None:
+ msg = '\n' + msg
+ print_log(msg, logger=logger)
+
+ result_dir = imgfile_prefix
+
+ eval_results = dict()
+ print_log(f'Evaluating results under {result_dir} ...', logger=logger)
+
+ CSEval.args.evalInstLevelScore = True
+ CSEval.args.predictionPath = osp.abspath(result_dir)
+ CSEval.args.evalPixelAccuracy = True
+ CSEval.args.JSONOutput = False
+
+ seg_map_list = []
+ pred_list = []
+
+ # when evaluating with official cityscapesscripts,
+ # **_gtFine_labelIds.png is used
+ for seg_map in mmcv.scandir(
+ self.ann_dir, 'gtFine_labelIds.png', recursive=True):
+ seg_map_list.append(osp.join(self.ann_dir, seg_map))
+ pred_list.append(CSEval.getPrediction(CSEval.args, seg_map))
+
+ eval_results.update(
+ CSEval.evaluateImgLists(pred_list, seg_map_list, CSEval.args))
+
+ return eval_results
diff --git a/mmseg/datasets/coco_stuff.py b/mmseg/datasets/coco_stuff.py
new file mode 100644
index 0000000..546a014
--- /dev/null
+++ b/mmseg/datasets/coco_stuff.py
@@ -0,0 +1,93 @@
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class COCOStuffDataset(CustomDataset):
+ """COCO-Stuff dataset.
+
+ In segmentation map annotation for COCO-Stuff, Train-IDs of the 10k version
+ are from 1 to 171, where 0 is the ignore index, and Train-ID of COCO Stuff
+ 164k is from 0 to 170, where 255 is the ignore index. So, they are all 171
+ semantic categories. ``reduce_zero_label`` is set to True and False for the
+ 10k and 164k versions, respectively. The ``img_suffix`` is fixed to '.jpg',
+ and ``seg_map_suffix`` is fixed to '.png'.
+ """
+ CLASSES = (
+ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train',
+ 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign',
+ 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep',
+ 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella',
+ 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard',
+ 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard',
+ 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork',
+ 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
+ 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair',
+ 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv',
+ 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
+ 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
+ 'scissors', 'teddy bear', 'hair drier', 'toothbrush', 'banner',
+ 'blanket', 'branch', 'bridge', 'building-other', 'bush', 'cabinet',
+ 'cage', 'cardboard', 'carpet', 'ceiling-other', 'ceiling-tile',
+ 'cloth', 'clothes', 'clouds', 'counter', 'cupboard', 'curtain',
+ 'desk-stuff', 'dirt', 'door-stuff', 'fence', 'floor-marble',
+ 'floor-other', 'floor-stone', 'floor-tile', 'floor-wood',
+ 'flower', 'fog', 'food-other', 'fruit', 'furniture-other', 'grass',
+ 'gravel', 'ground-other', 'hill', 'house', 'leaves', 'light', 'mat',
+ 'metal', 'mirror-stuff', 'moss', 'mountain', 'mud', 'napkin', 'net',
+ 'paper', 'pavement', 'pillow', 'plant-other', 'plastic', 'platform',
+ 'playingfield', 'railing', 'railroad', 'river', 'road', 'rock', 'roof',
+ 'rug', 'salad', 'sand', 'sea', 'shelf', 'sky-other', 'skyscraper',
+ 'snow', 'solid-other', 'stairs', 'stone', 'straw', 'structural-other',
+ 'table', 'tent', 'textile-other', 'towel', 'tree', 'vegetable',
+ 'wall-brick', 'wall-concrete', 'wall-other', 'wall-panel',
+ 'wall-stone', 'wall-tile', 'wall-wood', 'water-other', 'waterdrops',
+ 'window-blind', 'window-other', 'wood')
+
+ PALETTE = [[0, 192, 64], [0, 192, 64], [0, 64, 96], [128, 192, 192],
+ [0, 64, 64], [0, 192, 224], [0, 192, 192], [128, 192, 64],
+ [0, 192, 96], [128, 192, 64], [128, 32, 192], [0, 0, 224],
+ [0, 0, 64], [0, 160, 192], [128, 0, 96], [128, 0, 192],
+ [0, 32, 192], [128, 128, 224], [0, 0, 192], [128, 160, 192],
+ [128, 128, 0], [128, 0, 32], [128, 32, 0], [128, 0, 128],
+ [64, 128, 32], [0, 160, 0], [0, 0, 0], [192, 128, 160],
+ [0, 32, 0], [0, 128, 128], [64, 128, 160], [128, 160, 0],
+ [0, 128, 0], [192, 128, 32], [128, 96, 128], [0, 0, 128],
+ [64, 0, 32], [0, 224, 128], [128, 0, 0], [192, 0, 160],
+ [0, 96, 128], [128, 128, 128], [64, 0, 160], [128, 224, 128],
+ [128, 128, 64], [192, 0, 32], [128, 96, 0], [128, 0, 192],
+ [0, 128, 32], [64, 224, 0], [0, 0, 64], [128, 128, 160],
+ [64, 96, 0], [0, 128, 192], [0, 128, 160], [192, 224, 0],
+ [0, 128, 64], [128, 128, 32], [192, 32, 128], [0, 64, 192],
+ [0, 0, 32], [64, 160, 128], [128, 64, 64], [128, 0, 160],
+ [64, 32, 128], [128, 192, 192], [0, 0, 160], [192, 160, 128],
+ [128, 192, 0], [128, 0, 96], [192, 32, 0], [128, 64, 128],
+ [64, 128, 96], [64, 160, 0], [0, 64, 0], [192, 128, 224],
+ [64, 32, 0], [0, 192, 128], [64, 128, 224], [192, 160, 0],
+ [0, 192, 0], [192, 128, 96], [192, 96, 128], [0, 64, 128],
+ [64, 0, 96], [64, 224, 128], [128, 64, 0], [192, 0, 224],
+ [64, 96, 128], [128, 192, 128], [64, 0, 224], [192, 224, 128],
+ [128, 192, 64], [192, 0, 96], [192, 96, 0], [128, 64, 192],
+ [0, 128, 96], [0, 224, 0], [64, 64, 64], [128, 128, 224],
+ [0, 96, 0], [64, 192, 192], [0, 128, 224], [128, 224, 0],
+ [64, 192, 64], [128, 128, 96], [128, 32, 128], [64, 0, 192],
+ [0, 64, 96], [0, 160, 128], [192, 0, 64], [128, 64, 224],
+ [0, 32, 128], [192, 128, 192], [0, 64, 224], [128, 160, 128],
+ [192, 128, 0], [128, 64, 32], [128, 32, 64], [192, 0, 128],
+ [64, 192, 32], [0, 160, 64], [64, 0, 0], [192, 192, 160],
+ [0, 32, 64], [64, 128, 128], [64, 192, 160], [128, 160, 64],
+ [64, 128, 0], [192, 192, 32], [128, 96, 192], [64, 0, 128],
+ [64, 64, 32], [0, 224, 192], [192, 0, 0], [192, 64, 160],
+ [0, 96, 192], [192, 128, 128], [64, 64, 160], [128, 224, 192],
+ [192, 128, 64], [192, 64, 32], [128, 96, 64], [192, 0, 192],
+ [0, 192, 32], [64, 224, 64], [64, 0, 64], [128, 192, 160],
+ [64, 96, 64], [64, 128, 192], [0, 192, 160], [192, 224, 64],
+ [64, 128, 64], [128, 192, 32], [192, 32, 192], [64, 64, 192],
+ [0, 64, 32], [64, 160, 192], [192, 64, 64], [128, 64, 160],
+ [64, 32, 192], [192, 192, 192], [0, 64, 160], [192, 160, 192],
+ [192, 192, 0], [128, 64, 96], [192, 32, 64], [192, 64, 128],
+ [64, 192, 96], [64, 160, 64], [64, 64, 0]]
+
+ def __init__(self, **kwargs):
+ super(COCOStuffDataset, self).__init__(
+ img_suffix='.jpg', seg_map_suffix='_labelTrainIds.png', **kwargs)
diff --git a/mmseg/datasets/custom.py b/mmseg/datasets/custom.py
new file mode 100644
index 0000000..fe29dcf
--- /dev/null
+++ b/mmseg/datasets/custom.py
@@ -0,0 +1,466 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import warnings
+from collections import OrderedDict
+
+import mmcv
+import numpy as np
+from mmcv.utils import print_log
+from prettytable import PrettyTable
+from torch.utils.data import Dataset
+
+from mmseg.core import eval_metrics, intersect_and_union, pre_eval_to_metrics
+from mmseg.utils import get_root_logger
+from .builder import DATASETS
+from .pipelines import Compose, LoadAnnotations
+
+
+@DATASETS.register_module()
+class CustomDataset(Dataset):
+ """Custom dataset for semantic segmentation. An example of file structure
+ is as followed.
+
+ .. code-block:: none
+
+ ├── data
+ │ ├── my_dataset
+ │ │ ├── img_dir
+ │ │ │ ├── train
+ │ │ │ │ ├── xxx{img_suffix}
+ │ │ │ │ ├── yyy{img_suffix}
+ │ │ │ │ ├── zzz{img_suffix}
+ │ │ │ ├── val
+ │ │ ├── ann_dir
+ │ │ │ ├── train
+ │ │ │ │ ├── xxx{seg_map_suffix}
+ │ │ │ │ ├── yyy{seg_map_suffix}
+ │ │ │ │ ├── zzz{seg_map_suffix}
+ │ │ │ ├── val
+
+ The img/gt_semantic_seg pair of CustomDataset should be of the same
+ except suffix. A valid img/gt_semantic_seg filename pair should be like
+ ``xxx{img_suffix}`` and ``xxx{seg_map_suffix}`` (extension is also included
+ in the suffix). If split is given, then ``xxx`` is specified in txt file.
+ Otherwise, all files in ``img_dir/``and ``ann_dir`` will be loaded.
+ Please refer to ``docs/en/tutorials/new_dataset.md`` for more details.
+
+
+ Args:
+ pipeline (list[dict]): Processing pipeline
+ img_dir (str): Path to image directory
+ img_suffix (str): Suffix of images. Default: '.jpg'
+ ann_dir (str, optional): Path to annotation directory. Default: None
+ seg_map_suffix (str): Suffix of segmentation maps. Default: '.png'
+ split (str, optional): Split txt file. If split is specified, only
+ file with suffix in the splits will be loaded. Otherwise, all
+ images in img_dir/ann_dir will be loaded. Default: None
+ data_root (str, optional): Data root for img_dir/ann_dir. Default:
+ None.
+ test_mode (bool): If test_mode=True, gt wouldn't be loaded.
+ ignore_index (int): The label index to be ignored. Default: 255
+ reduce_zero_label (bool): Whether to mark label zero as ignored.
+ Default: False
+ classes (str | Sequence[str], optional): Specify classes to load.
+ If is None, ``cls.CLASSES`` will be used. Default: None.
+ palette (Sequence[Sequence[int]]] | np.ndarray | None):
+ The palette of segmentation map. If None is given, and
+ self.PALETTE is None, random palette will be generated.
+ Default: None
+ gt_seg_map_loader_cfg (dict, optional): build LoadAnnotations to
+ load gt for evaluation, load from disk by default. Default: None.
+ """
+
+ CLASSES = None
+
+ PALETTE = None
+
+ def __init__(self,
+ pipeline,
+ img_dir,
+ img_suffix='.jpg',
+ ann_dir=None,
+ seg_map_suffix='.png',
+ split=None,
+ data_root=None,
+ test_mode=False,
+ ignore_index=255,
+ reduce_zero_label=False,
+ classes=None,
+ palette=None,
+ gt_seg_map_loader_cfg=None):
+ self.pipeline = Compose(pipeline)
+ self.img_dir = img_dir
+ self.img_suffix = img_suffix
+ self.ann_dir = ann_dir
+ self.seg_map_suffix = seg_map_suffix
+ self.split = split
+ self.data_root = data_root
+ self.test_mode = test_mode
+ self.ignore_index = ignore_index
+ self.reduce_zero_label = reduce_zero_label
+ self.label_map = None
+ self.CLASSES, self.PALETTE = self.get_classes_and_palette(
+ classes, palette)
+ self.gt_seg_map_loader = LoadAnnotations(
+ ) if gt_seg_map_loader_cfg is None else LoadAnnotations(
+ **gt_seg_map_loader_cfg)
+
+ if test_mode:
+ assert self.CLASSES is not None, \
+ '`cls.CLASSES` or `classes` should be specified when testing'
+
+ # join paths if data_root is specified
+ if self.data_root is not None:
+ if not osp.isabs(self.img_dir):
+ self.img_dir = osp.join(self.data_root, self.img_dir)
+ if not (self.ann_dir is None or osp.isabs(self.ann_dir)):
+ self.ann_dir = osp.join(self.data_root, self.ann_dir)
+ if not (self.split is None or osp.isabs(self.split)):
+ self.split = osp.join(self.data_root, self.split)
+
+ # load annotations
+ self.img_infos = self.load_annotations(self.img_dir, self.img_suffix,
+ self.ann_dir,
+ self.seg_map_suffix, self.split)
+
+ def __len__(self):
+ """Total number of samples of data."""
+ return len(self.img_infos)
+
+ def load_annotations(self, img_dir, img_suffix, ann_dir, seg_map_suffix,
+ split):
+ """Load annotation from directory.
+
+ Args:
+ img_dir (str): Path to image directory
+ img_suffix (str): Suffix of images.
+ ann_dir (str|None): Path to annotation directory.
+ seg_map_suffix (str|None): Suffix of segmentation maps.
+ split (str|None): Split txt file. If split is specified, only file
+ with suffix in the splits will be loaded. Otherwise, all images
+ in img_dir/ann_dir will be loaded. Default: None
+
+ Returns:
+ list[dict]: All image info of dataset.
+ """
+
+ img_infos = []
+ if split is not None:
+ with open(split) as f:
+ for line in f:
+ img_name = line.strip()
+ img_info = dict(filename=img_name + img_suffix)
+ if ann_dir is not None:
+ seg_map = img_name + seg_map_suffix
+ img_info['ann'] = dict(seg_map=seg_map)
+ img_infos.append(img_info)
+ else:
+ for img in mmcv.scandir(img_dir, img_suffix, recursive=True):
+ img_info = dict(filename=img)
+ if ann_dir is not None:
+ seg_map = img.replace(img_suffix, seg_map_suffix)
+ img_info['ann'] = dict(seg_map=seg_map)
+ img_infos.append(img_info)
+ img_infos = sorted(img_infos, key=lambda x: x['filename'])
+
+ print_log(f'Loaded {len(img_infos)} images', logger=get_root_logger())
+ return img_infos
+
+ def get_ann_info(self, idx):
+ """Get annotation by index.
+
+ Args:
+ idx (int): Index of data.
+
+ Returns:
+ dict: Annotation info of specified index.
+ """
+
+ return self.img_infos[idx]['ann']
+
+ def pre_pipeline(self, results):
+ """Prepare results dict for pipeline."""
+ results['seg_fields'] = []
+ results['img_prefix'] = self.img_dir
+ results['seg_prefix'] = self.ann_dir
+ if self.custom_classes:
+ results['label_map'] = self.label_map
+
+ def __getitem__(self, idx):
+ """Get training/test data after pipeline.
+
+ Args:
+ idx (int): Index of data.
+
+ Returns:
+ dict: Training/test data (with annotation if `test_mode` is set
+ False).
+ """
+
+ if self.test_mode:
+ return self.prepare_test_img(idx)
+ else:
+ return self.prepare_train_img(idx)
+
+ def prepare_train_img(self, idx):
+ """Get training data and annotations after pipeline.
+
+ Args:
+ idx (int): Index of data.
+
+ Returns:
+ dict: Training data and annotation after pipeline with new keys
+ introduced by pipeline.
+ """
+
+ img_info = self.img_infos[idx]
+ ann_info = self.get_ann_info(idx)
+ results = dict(img_info=img_info, ann_info=ann_info)
+ self.pre_pipeline(results)
+ return self.pipeline(results)
+
+ def prepare_test_img(self, idx):
+ """Get testing data after pipeline.
+
+ Args:
+ idx (int): Index of data.
+
+ Returns:
+ dict: Testing data after pipeline with new keys introduced by
+ pipeline.
+ """
+
+ img_info = self.img_infos[idx]
+ results = dict(img_info=img_info)
+ self.pre_pipeline(results)
+ return self.pipeline(results)
+
+ def format_results(self, results, imgfile_prefix, indices=None, **kwargs):
+ """Place holder to format result to dataset specific output."""
+ raise NotImplementedError
+
+ def get_gt_seg_map_by_idx(self, index):
+ """Get one ground truth segmentation map for evaluation."""
+ ann_info = self.get_ann_info(index)
+ results = dict(ann_info=ann_info)
+ self.pre_pipeline(results)
+ self.gt_seg_map_loader(results)
+ return results['gt_semantic_seg']
+
+ def get_gt_seg_maps(self, efficient_test=None):
+ """Get ground truth segmentation maps for evaluation."""
+ if efficient_test is not None:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` has been deprecated '
+ 'since MMSeg v0.16, the ``get_gt_seg_maps()`` is CPU memory '
+ 'friendly by default. ')
+
+ for idx in range(len(self)):
+ ann_info = self.get_ann_info(idx)
+ results = dict(ann_info=ann_info)
+ self.pre_pipeline(results)
+ self.gt_seg_map_loader(results)
+ yield results['gt_semantic_seg']
+
+ def pre_eval(self, preds, indices):
+ """Collect eval result from each iteration.
+
+ Args:
+ preds (list[torch.Tensor] | torch.Tensor): the segmentation logit
+ after argmax, shape (N, H, W).
+ indices (list[int] | int): the prediction related ground truth
+ indices.
+
+ Returns:
+ list[torch.Tensor]: (area_intersect, area_union, area_prediction,
+ area_ground_truth).
+ """
+ # In order to compat with batch inference
+ if not isinstance(indices, list):
+ indices = [indices]
+ if not isinstance(preds, list):
+ preds = [preds]
+
+ pre_eval_results = []
+
+ for pred, index in zip(preds, indices):
+ seg_map = self.get_gt_seg_map_by_idx(index)
+ pre_eval_results.append(
+ intersect_and_union(pred, seg_map, len(self.CLASSES),
+ self.ignore_index, self.label_map,
+ self.reduce_zero_label))
+
+ return pre_eval_results
+
+ def get_classes_and_palette(self, classes=None, palette=None):
+ """Get class names of current dataset.
+
+ Args:
+ classes (Sequence[str] | str | None): If classes is None, use
+ default CLASSES defined by builtin dataset. If classes is a
+ string, take it as a file name. The file contains the name of
+ classes where each line contains one class name. If classes is
+ a tuple or list, override the CLASSES defined by the dataset.
+ palette (Sequence[Sequence[int]]] | np.ndarray | None):
+ The palette of segmentation map. If None is given, random
+ palette will be generated. Default: None
+ """
+ if classes is None:
+ self.custom_classes = False
+ return self.CLASSES, self.PALETTE
+
+ self.custom_classes = True
+ if isinstance(classes, str):
+ # take it as a file path
+ class_names = mmcv.list_from_file(classes)
+ elif isinstance(classes, (tuple, list)):
+ class_names = classes
+ else:
+ raise ValueError(f'Unsupported type {type(classes)} of classes.')
+
+ if self.CLASSES:
+ if not set(class_names).issubset(self.CLASSES):
+ raise ValueError('classes is not a subset of CLASSES.')
+
+ # dictionary, its keys are the old label ids and its values
+ # are the new label ids.
+ # used for changing pixel labels in load_annotations.
+ self.label_map = {}
+ for i, c in enumerate(self.CLASSES):
+ if c not in class_names:
+ self.label_map[i] = -1
+ else:
+ self.label_map[i] = class_names.index(c)
+
+ palette = self.get_palette_for_custom_classes(class_names, palette)
+
+ return class_names, palette
+
+ def get_palette_for_custom_classes(self, class_names, palette=None):
+
+ if self.label_map is not None:
+ # return subset of palette
+ palette = []
+ for old_id, new_id in sorted(
+ self.label_map.items(), key=lambda x: x[1]):
+ if new_id != -1:
+ palette.append(self.PALETTE[old_id])
+ palette = type(self.PALETTE)(palette)
+
+ elif palette is None:
+ if self.PALETTE is None:
+ # Get random state before set seed, and restore
+ # random state later.
+ # It will prevent loss of randomness, as the palette
+ # may be different in each iteration if not specified.
+ # See: https://github.com/open-mmlab/mmdetection/issues/5844
+ state = np.random.get_state()
+ np.random.seed(42)
+ # random palette
+ palette = np.random.randint(0, 255, size=(len(class_names), 3))
+ np.random.set_state(state)
+ else:
+ palette = self.PALETTE
+
+ return palette
+
+ def evaluate(self,
+ results,
+ metric='mIoU',
+ logger=None,
+ gt_seg_maps=None,
+ **kwargs):
+ """Evaluate the dataset.
+
+ Args:
+ results (list[tuple[torch.Tensor]] | list[str]): per image pre_eval
+ results or predict segmentation map for computing evaluation
+ metric.
+ metric (str | list[str]): Metrics to be evaluated. 'mIoU',
+ 'mDice' and 'mFscore' are supported.
+ logger (logging.Logger | None | str): Logger used for printing
+ related information during evaluation. Default: None.
+ gt_seg_maps (generator[ndarray]): Custom gt seg maps as input,
+ used in ConcatDataset
+
+ Returns:
+ dict[str, float]: Default metrics.
+ """
+ if isinstance(metric, str):
+ metric = [metric]
+ allowed_metrics = ['mIoU', 'mDice', 'mFscore']
+ if not set(metric).issubset(set(allowed_metrics)):
+ raise KeyError('metric {} is not supported'.format(metric))
+
+ eval_results = {}
+ # test a list of files
+ if mmcv.is_list_of(results, np.ndarray) or mmcv.is_list_of(
+ results, str):
+ if gt_seg_maps is None:
+ gt_seg_maps = self.get_gt_seg_maps()
+ num_classes = len(self.CLASSES)
+ ret_metrics = eval_metrics(
+ results,
+ gt_seg_maps,
+ num_classes,
+ self.ignore_index,
+ metric,
+ label_map=self.label_map,
+ reduce_zero_label=self.reduce_zero_label)
+ # test a list of pre_eval_results
+ else:
+ ret_metrics = pre_eval_to_metrics(results, metric)
+
+ # Because dataset.CLASSES is required for per-eval.
+ if self.CLASSES is None:
+ class_names = tuple(range(num_classes))
+ else:
+ class_names = self.CLASSES
+
+ # summary table
+ ret_metrics_summary = OrderedDict({
+ ret_metric: np.round(np.nanmean(ret_metric_value) * 100, 2)
+ for ret_metric, ret_metric_value in ret_metrics.items()
+ })
+
+ # each class table
+ ret_metrics.pop('aAcc', None)
+ ret_metrics_class = OrderedDict({
+ ret_metric: np.round(ret_metric_value * 100, 2)
+ for ret_metric, ret_metric_value in ret_metrics.items()
+ })
+ ret_metrics_class.update({'Class': class_names})
+ ret_metrics_class.move_to_end('Class', last=False)
+
+ # for logger
+ class_table_data = PrettyTable()
+ for key, val in ret_metrics_class.items():
+ class_table_data.add_column(key, val)
+
+ summary_table_data = PrettyTable()
+ for key, val in ret_metrics_summary.items():
+ if key == 'aAcc':
+ summary_table_data.add_column(key, [val])
+ else:
+ summary_table_data.add_column('m' + key, [val])
+
+ print_log('per class results:', logger)
+ print_log('\n' + class_table_data.get_string(), logger=logger)
+ print_log('Summary:', logger)
+ print_log('\n' + summary_table_data.get_string(), logger=logger)
+
+ # each metric dict
+ for key, value in ret_metrics_summary.items():
+ if key == 'aAcc':
+ eval_results[key] = value / 100.0
+ else:
+ eval_results['m' + key] = value / 100.0
+
+ ret_metrics_class.pop('Class', None)
+ for key, value in ret_metrics_class.items():
+ eval_results.update({
+ key + '.' + str(name): value[idx] / 100.0
+ for idx, name in enumerate(class_names)
+ })
+
+ return eval_results
diff --git a/mmseg/datasets/dark_zurich.py b/mmseg/datasets/dark_zurich.py
new file mode 100644
index 0000000..efc088f
--- /dev/null
+++ b/mmseg/datasets/dark_zurich.py
@@ -0,0 +1,13 @@
+from .builder import DATASETS
+from .cityscapes import CityscapesDataset
+
+
+@DATASETS.register_module()
+class DarkZurichDataset(CityscapesDataset):
+ """DarkZurichDataset dataset."""
+
+ def __init__(self, **kwargs):
+ super().__init__(
+ img_suffix='_rgb_anon.png',
+ seg_map_suffix='_gt_labelTrainIds.png',
+ **kwargs)
diff --git a/mmseg/datasets/dataset_wrappers.py b/mmseg/datasets/dataset_wrappers.py
new file mode 100644
index 0000000..1fb089f
--- /dev/null
+++ b/mmseg/datasets/dataset_wrappers.py
@@ -0,0 +1,277 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import bisect
+import collections
+import copy
+from itertools import chain
+
+import mmcv
+import numpy as np
+from mmcv.utils import build_from_cfg, print_log
+from torch.utils.data.dataset import ConcatDataset as _ConcatDataset
+
+from .builder import DATASETS, PIPELINES
+from .cityscapes import CityscapesDataset
+
+
+@DATASETS.register_module()
+class ConcatDataset(_ConcatDataset):
+ """A wrapper of concatenated dataset.
+
+ Same as :obj:`torch.utils.data.dataset.ConcatDataset`, but
+ support evaluation and formatting results
+
+ Args:
+ datasets (list[:obj:`Dataset`]): A list of datasets.
+ separate_eval (bool): Whether to evaluate the concatenated
+ dataset results separately, Defaults to True.
+ """
+
+ def __init__(self, datasets, separate_eval=True):
+ super(ConcatDataset, self).__init__(datasets)
+ self.CLASSES = datasets[0].CLASSES
+ self.PALETTE = datasets[0].PALETTE
+ self.separate_eval = separate_eval
+ assert separate_eval in [True, False], \
+ f'separate_eval can only be True or False,' \
+ f'but get {separate_eval}'
+ if any([isinstance(ds, CityscapesDataset) for ds in datasets]):
+ raise NotImplementedError(
+ 'Evaluating ConcatDataset containing CityscapesDataset'
+ 'is not supported!')
+
+ def evaluate(self, results, logger=None, **kwargs):
+ """Evaluate the results.
+
+ Args:
+ results (list[tuple[torch.Tensor]] | list[str]]): per image
+ pre_eval results or predict segmentation map for
+ computing evaluation metric.
+ logger (logging.Logger | str | None): Logger used for printing
+ related information during evaluation. Default: None.
+
+ Returns:
+ dict[str: float]: evaluate results of the total dataset
+ or each separate
+ dataset if `self.separate_eval=True`.
+ """
+ assert len(results) == self.cumulative_sizes[-1], \
+ ('Dataset and results have different sizes: '
+ f'{self.cumulative_sizes[-1]} v.s. {len(results)}')
+
+ # Check whether all the datasets support evaluation
+ for dataset in self.datasets:
+ assert hasattr(dataset, 'evaluate'), \
+ f'{type(dataset)} does not implement evaluate function'
+
+ if self.separate_eval:
+ dataset_idx = -1
+ total_eval_results = dict()
+ for size, dataset in zip(self.cumulative_sizes, self.datasets):
+ start_idx = 0 if dataset_idx == -1 else \
+ self.cumulative_sizes[dataset_idx]
+ end_idx = self.cumulative_sizes[dataset_idx + 1]
+
+ results_per_dataset = results[start_idx:end_idx]
+ print_log(
+ f'\nEvaluateing {dataset.img_dir} with '
+ f'{len(results_per_dataset)} images now',
+ logger=logger)
+
+ eval_results_per_dataset = dataset.evaluate(
+ results_per_dataset, logger=logger, **kwargs)
+ dataset_idx += 1
+ for k, v in eval_results_per_dataset.items():
+ total_eval_results.update({f'{dataset_idx}_{k}': v})
+
+ return total_eval_results
+
+ if len(set([type(ds) for ds in self.datasets])) != 1:
+ raise NotImplementedError(
+ 'All the datasets should have same types when '
+ 'self.separate_eval=False')
+ else:
+ if mmcv.is_list_of(results, np.ndarray) or mmcv.is_list_of(
+ results, str):
+ # merge the generators of gt_seg_maps
+ gt_seg_maps = chain(
+ *[dataset.get_gt_seg_maps() for dataset in self.datasets])
+ else:
+ # if the results are `pre_eval` results,
+ # we do not need gt_seg_maps to evaluate
+ gt_seg_maps = None
+ eval_results = self.datasets[0].evaluate(
+ results, gt_seg_maps=gt_seg_maps, logger=logger, **kwargs)
+ return eval_results
+
+ def get_dataset_idx_and_sample_idx(self, indice):
+ """Return dataset and sample index when given an indice of
+ ConcatDataset.
+
+ Args:
+ indice (int): indice of sample in ConcatDataset
+
+ Returns:
+ int: the index of sub dataset the sample belong to
+ int: the index of sample in its corresponding subset
+ """
+ if indice < 0:
+ if -indice > len(self):
+ raise ValueError(
+ 'absolute value of index should not exceed dataset length')
+ indice = len(self) + indice
+ dataset_idx = bisect.bisect_right(self.cumulative_sizes, indice)
+ if dataset_idx == 0:
+ sample_idx = indice
+ else:
+ sample_idx = indice - self.cumulative_sizes[dataset_idx - 1]
+ return dataset_idx, sample_idx
+
+ def format_results(self, results, imgfile_prefix, indices=None, **kwargs):
+ """format result for every sample of ConcatDataset."""
+ if indices is None:
+ indices = list(range(len(self)))
+
+ assert isinstance(results, list), 'results must be a list.'
+ assert isinstance(indices, list), 'indices must be a list.'
+
+ ret_res = []
+ for i, indice in enumerate(indices):
+ dataset_idx, sample_idx = self.get_dataset_idx_and_sample_idx(
+ indice)
+ res = self.datasets[dataset_idx].format_results(
+ [results[i]],
+ imgfile_prefix + f'/{dataset_idx}',
+ indices=[sample_idx],
+ **kwargs)
+ ret_res.append(res)
+ return sum(ret_res, [])
+
+ def pre_eval(self, preds, indices):
+ """do pre eval for every sample of ConcatDataset."""
+ # In order to compat with batch inference
+ if not isinstance(indices, list):
+ indices = [indices]
+ if not isinstance(preds, list):
+ preds = [preds]
+ ret_res = []
+ for i, indice in enumerate(indices):
+ dataset_idx, sample_idx = self.get_dataset_idx_and_sample_idx(
+ indice)
+ res = self.datasets[dataset_idx].pre_eval(preds[i], sample_idx)
+ ret_res.append(res)
+ return sum(ret_res, [])
+
+
+@DATASETS.register_module()
+class RepeatDataset(object):
+ """A wrapper of repeated dataset.
+
+ The length of repeated dataset will be `times` larger than the original
+ dataset. This is useful when the data loading time is long but the dataset
+ is small. Using RepeatDataset can reduce the data loading time between
+ epochs.
+
+ Args:
+ dataset (:obj:`Dataset`): The dataset to be repeated.
+ times (int): Repeat times.
+ """
+
+ def __init__(self, dataset, times):
+ self.dataset = dataset
+ self.times = times
+ self.CLASSES = dataset.CLASSES
+ self.PALETTE = dataset.PALETTE
+ self._ori_len = len(self.dataset)
+
+ def __getitem__(self, idx):
+ """Get item from original dataset."""
+ return self.dataset[idx % self._ori_len]
+
+ def __len__(self):
+ """The length is multiplied by ``times``"""
+ return self.times * self._ori_len
+
+
+@DATASETS.register_module()
+class MultiImageMixDataset:
+ """A wrapper of multiple images mixed dataset.
+
+ Suitable for training on multiple images mixed data augmentation like
+ mosaic and mixup. For the augmentation pipeline of mixed image data,
+ the `get_indexes` method needs to be provided to obtain the image
+ indexes, and you can set `skip_flags` to change the pipeline running
+ process.
+
+
+ Args:
+ dataset (:obj:`CustomDataset`): The dataset to be mixed.
+ pipeline (Sequence[dict]): Sequence of transform object or
+ config dict to be composed.
+ skip_type_keys (list[str], optional): Sequence of type string to
+ be skip pipeline. Default to None.
+ """
+
+ def __init__(self, dataset, pipeline, skip_type_keys=None):
+ assert isinstance(pipeline, collections.abc.Sequence)
+ if skip_type_keys is not None:
+ assert all([
+ isinstance(skip_type_key, str)
+ for skip_type_key in skip_type_keys
+ ])
+ self._skip_type_keys = skip_type_keys
+
+ self.pipeline = []
+ self.pipeline_types = []
+ for transform in pipeline:
+ if isinstance(transform, dict):
+ self.pipeline_types.append(transform['type'])
+ transform = build_from_cfg(transform, PIPELINES)
+ self.pipeline.append(transform)
+ else:
+ raise TypeError('pipeline must be a dict')
+
+ self.dataset = dataset
+ self.CLASSES = dataset.CLASSES
+ self.PALETTE = dataset.PALETTE
+ self.num_samples = len(dataset)
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, idx):
+ results = copy.deepcopy(self.dataset[idx])
+ for (transform, transform_type) in zip(self.pipeline,
+ self.pipeline_types):
+ if self._skip_type_keys is not None and \
+ transform_type in self._skip_type_keys:
+ continue
+
+ if hasattr(transform, 'get_indexes'):
+ indexes = transform.get_indexes(self.dataset)
+ if not isinstance(indexes, collections.abc.Sequence):
+ indexes = [indexes]
+ mix_results = [
+ copy.deepcopy(self.dataset[index]) for index in indexes
+ ]
+ results['mix_results'] = mix_results
+
+ results = transform(results)
+
+ if 'mix_results' in results:
+ results.pop('mix_results')
+
+ return results
+
+ def update_skip_type_keys(self, skip_type_keys):
+ """Update skip_type_keys.
+
+ It is called by an external hook.
+
+ Args:
+ skip_type_keys (list[str], optional): Sequence of type
+ string to be skip pipeline.
+ """
+ assert all([
+ isinstance(skip_type_key, str) for skip_type_key in skip_type_keys
+ ])
+ self._skip_type_keys = skip_type_keys
diff --git a/mmseg/datasets/drive.py b/mmseg/datasets/drive.py
new file mode 100644
index 0000000..6509911
--- /dev/null
+++ b/mmseg/datasets/drive.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class DRIVEDataset(CustomDataset):
+ """DRIVE dataset.
+
+ In segmentation map annotation for DRIVE, 0 stands for background, which is
+ included in 2 categories. ``reduce_zero_label`` is fixed to False. The
+ ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
+ '_manual1.png'.
+ """
+
+ CLASSES = ('background', 'vessel')
+
+ PALETTE = [[120, 120, 120], [6, 230, 230]]
+
+ def __init__(self, **kwargs):
+ super(DRIVEDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='_manual1.png',
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir)
diff --git a/mmseg/datasets/hrf.py b/mmseg/datasets/hrf.py
new file mode 100644
index 0000000..e4e10ae
--- /dev/null
+++ b/mmseg/datasets/hrf.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class HRFDataset(CustomDataset):
+ """HRF dataset.
+
+ In segmentation map annotation for HRF, 0 stands for background, which is
+ included in 2 categories. ``reduce_zero_label`` is fixed to False. The
+ ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
+ '.png'.
+ """
+
+ CLASSES = ('background', 'vessel')
+
+ PALETTE = [[120, 120, 120], [6, 230, 230]]
+
+ def __init__(self, **kwargs):
+ super(HRFDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir)
diff --git a/mmseg/datasets/isprs.py b/mmseg/datasets/isprs.py
new file mode 100644
index 0000000..504a022
--- /dev/null
+++ b/mmseg/datasets/isprs.py
@@ -0,0 +1,25 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class ISPRSDataset(CustomDataset):
+ """ISPRS dataset.
+
+ In segmentation map annotation for LoveDA, 0 is the ignore index.
+ ``reduce_zero_label`` should be set to True. The ``img_suffix`` and
+ ``seg_map_suffix`` are both fixed to '.png'.
+ """
+ CLASSES = ('impervious_surface', 'building', 'low_vegetation', 'tree',
+ 'car', 'clutter')
+
+ PALETTE = [[255, 255, 255], [0, 0, 255], [0, 0, 255], [0, 255, 0],
+ [255, 255, 0], [255, 0, 0]]
+
+ def __init__(self, **kwargs):
+ super(ISPRSDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=True,
+ **kwargs)
diff --git a/mmseg/datasets/loveda.py b/mmseg/datasets/loveda.py
new file mode 100644
index 0000000..90d654f
--- /dev/null
+++ b/mmseg/datasets/loveda.py
@@ -0,0 +1,92 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import numpy as np
+from PIL import Image
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class LoveDADataset(CustomDataset):
+ """LoveDA dataset.
+
+ In segmentation map annotation for LoveDA, 0 is the ignore index.
+ ``reduce_zero_label`` should be set to True. The ``img_suffix`` and
+ ``seg_map_suffix`` are both fixed to '.png'.
+ """
+ CLASSES = ('background', 'building', 'road', 'water', 'barren', 'forest',
+ 'agricultural')
+
+ PALETTE = [[255, 255, 255], [255, 0, 0], [255, 255, 0], [0, 0, 255],
+ [159, 129, 183], [0, 255, 0], [255, 195, 128]]
+
+ def __init__(self, **kwargs):
+ super(LoveDADataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=True,
+ **kwargs)
+
+ def results2img(self, results, imgfile_prefix, indices=None):
+ """Write the segmentation results to images.
+
+ Args:
+ results (list[ndarray]): Testing results of the
+ dataset.
+ imgfile_prefix (str): The filename prefix of the png files.
+ If the prefix is "somepath/xxx",
+ the png files will be named "somepath/xxx.png".
+ indices (list[int], optional): Indices of input results, if not
+ set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ list[str: str]: result txt files which contains corresponding
+ semantic segmentation images.
+ """
+
+ mmcv.mkdir_or_exist(imgfile_prefix)
+ result_files = []
+ for result, idx in zip(results, indices):
+
+ filename = self.img_infos[idx]['filename']
+ basename = osp.splitext(osp.basename(filename))[0]
+
+ png_filename = osp.join(imgfile_prefix, f'{basename}.png')
+
+ # The index range of official requirement is from 0 to 6.
+ output = Image.fromarray(result.astype(np.uint8))
+ output.save(png_filename)
+ result_files.append(png_filename)
+
+ return result_files
+
+ def format_results(self, results, imgfile_prefix, indices=None):
+ """Format the results into dir (standard format for LoveDA evaluation).
+
+ Args:
+ results (list): Testing results of the dataset.
+ imgfile_prefix (str): The prefix of images files. It
+ includes the file path and the prefix of filename, e.g.,
+ "a/b/prefix".
+ indices (list[int], optional): Indices of input results,
+ if not set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ tuple: (result_files, tmp_dir), result_files is a list containing
+ the image paths, tmp_dir is the temporal directory created
+ for saving json/png files when img_prefix is not specified.
+ """
+ if indices is None:
+ indices = list(range(len(self)))
+
+ assert isinstance(results, list), 'results must be a list.'
+ assert isinstance(indices, list), 'indices must be a list.'
+
+ result_files = self.results2img(results, imgfile_prefix, indices)
+
+ return result_files
diff --git a/mmseg/datasets/night_driving.py b/mmseg/datasets/night_driving.py
new file mode 100644
index 0000000..a9289a2
--- /dev/null
+++ b/mmseg/datasets/night_driving.py
@@ -0,0 +1,13 @@
+from .builder import DATASETS
+from .cityscapes import CityscapesDataset
+
+
+@DATASETS.register_module()
+class NightDrivingDataset(CityscapesDataset):
+ """NightDrivingDataset dataset."""
+
+ def __init__(self, **kwargs):
+ super().__init__(
+ img_suffix='_leftImg8bit.png',
+ seg_map_suffix='_gtCoarse_labelTrainIds.png',
+ **kwargs)
diff --git a/mmseg/datasets/pascal_context.py b/mmseg/datasets/pascal_context.py
new file mode 100644
index 0000000..1e7a09d
--- /dev/null
+++ b/mmseg/datasets/pascal_context.py
@@ -0,0 +1,104 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class PascalContextDataset(CustomDataset):
+ """PascalContext dataset.
+
+ In segmentation map annotation for PascalContext, 0 stands for background,
+ which is included in 60 categories. ``reduce_zero_label`` is fixed to
+ False. The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is
+ fixed to '.png'.
+
+ Args:
+ split (str): Split txt file for PascalContext.
+ """
+
+ CLASSES = ('background', 'aeroplane', 'bag', 'bed', 'bedclothes', 'bench',
+ 'bicycle', 'bird', 'boat', 'book', 'bottle', 'building', 'bus',
+ 'cabinet', 'car', 'cat', 'ceiling', 'chair', 'cloth',
+ 'computer', 'cow', 'cup', 'curtain', 'dog', 'door', 'fence',
+ 'floor', 'flower', 'food', 'grass', 'ground', 'horse',
+ 'keyboard', 'light', 'motorbike', 'mountain', 'mouse', 'person',
+ 'plate', 'platform', 'pottedplant', 'road', 'rock', 'sheep',
+ 'shelves', 'sidewalk', 'sign', 'sky', 'snow', 'sofa', 'table',
+ 'track', 'train', 'tree', 'truck', 'tvmonitor', 'wall', 'water',
+ 'window', 'wood')
+
+ PALETTE = [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
+ [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
+ [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
+ [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
+ [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
+ [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
+ [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
+ [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
+ [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
+ [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
+ [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
+ [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
+ [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
+ [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
+ [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255]]
+
+ def __init__(self, split, **kwargs):
+ super(PascalContextDataset, self).__init__(
+ img_suffix='.jpg',
+ seg_map_suffix='.png',
+ split=split,
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir) and self.split is not None
+
+
+@DATASETS.register_module()
+class PascalContextDataset59(CustomDataset):
+ """PascalContext dataset.
+
+ In segmentation map annotation for PascalContext, 0 stands for background,
+ which is included in 60 categories. ``reduce_zero_label`` is fixed to
+ False. The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is
+ fixed to '.png'.
+
+ Args:
+ split (str): Split txt file for PascalContext.
+ """
+
+ CLASSES = ('aeroplane', 'bag', 'bed', 'bedclothes', 'bench', 'bicycle',
+ 'bird', 'boat', 'book', 'bottle', 'building', 'bus', 'cabinet',
+ 'car', 'cat', 'ceiling', 'chair', 'cloth', 'computer', 'cow',
+ 'cup', 'curtain', 'dog', 'door', 'fence', 'floor', 'flower',
+ 'food', 'grass', 'ground', 'horse', 'keyboard', 'light',
+ 'motorbike', 'mountain', 'mouse', 'person', 'plate', 'platform',
+ 'pottedplant', 'road', 'rock', 'sheep', 'shelves', 'sidewalk',
+ 'sign', 'sky', 'snow', 'sofa', 'table', 'track', 'train',
+ 'tree', 'truck', 'tvmonitor', 'wall', 'water', 'window', 'wood')
+
+ PALETTE = [[180, 120, 120], [6, 230, 230], [80, 50, 50], [4, 200, 3],
+ [120, 120, 80], [140, 140, 140], [204, 5, 255], [230, 230, 230],
+ [4, 250, 7], [224, 5, 255], [235, 255, 7], [150, 5, 61],
+ [120, 120, 70], [8, 255, 51], [255, 6, 82], [143, 255, 140],
+ [204, 255, 4], [255, 51, 7], [204, 70, 3], [0, 102, 200],
+ [61, 230, 250], [255, 6, 51], [11, 102, 255], [255, 7, 71],
+ [255, 9, 224], [9, 7, 230], [220, 220, 220], [255, 9, 92],
+ [112, 9, 255], [8, 255, 214], [7, 255, 224], [255, 184, 6],
+ [10, 255, 71], [255, 41, 10], [7, 255, 255], [224, 255, 8],
+ [102, 8, 255], [255, 61, 6], [255, 194, 7], [255, 122, 8],
+ [0, 255, 20], [255, 8, 41], [255, 5, 153], [6, 51, 255],
+ [235, 12, 255], [160, 150, 20], [0, 163, 255], [140, 140, 140],
+ [250, 10, 15], [20, 255, 0], [31, 255, 0], [255, 31, 0],
+ [255, 224, 0], [153, 255, 0], [0, 0, 255], [255, 71, 0],
+ [0, 235, 255], [0, 173, 255], [31, 0, 255]]
+
+ def __init__(self, split, **kwargs):
+ super(PascalContextDataset59, self).__init__(
+ img_suffix='.jpg',
+ seg_map_suffix='.png',
+ split=split,
+ reduce_zero_label=True,
+ **kwargs)
+ assert osp.exists(self.img_dir) and self.split is not None
diff --git a/mmseg/datasets/pipelines/__init__.py b/mmseg/datasets/pipelines/__init__.py
new file mode 100644
index 0000000..8256a6f
--- /dev/null
+++ b/mmseg/datasets/pipelines/__init__.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .compose import Compose
+from .formatting import (Collect, ImageToTensor, ToDataContainer, ToTensor,
+ Transpose, to_tensor)
+from .loading import LoadAnnotations, LoadImageFromFile
+from .test_time_aug import MultiScaleFlipAug
+from .transforms import (CLAHE, AdjustGamma, Normalize, Pad,
+ PhotoMetricDistortion, RandomCrop, RandomCutOut,
+ RandomFlip, RandomMosaic, RandomRotate, Rerange,
+ Resize, RGB2Gray, SegRescale)
+
+__all__ = [
+ 'Compose', 'to_tensor', 'ToTensor', 'ImageToTensor', 'ToDataContainer',
+ 'Transpose', 'Collect', 'LoadAnnotations', 'LoadImageFromFile',
+ 'MultiScaleFlipAug', 'Resize', 'RandomFlip', 'Pad', 'RandomCrop',
+ 'Normalize', 'SegRescale', 'PhotoMetricDistortion', 'RandomRotate',
+ 'AdjustGamma', 'CLAHE', 'Rerange', 'RGB2Gray', 'RandomCutOut',
+ 'RandomMosaic'
+]
diff --git a/mmseg/datasets/pipelines/compose.py b/mmseg/datasets/pipelines/compose.py
new file mode 100644
index 0000000..30280c1
--- /dev/null
+++ b/mmseg/datasets/pipelines/compose.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import collections
+
+from mmcv.utils import build_from_cfg
+
+from ..builder import PIPELINES
+
+
+@PIPELINES.register_module()
+class Compose(object):
+ """Compose multiple transforms sequentially.
+
+ Args:
+ transforms (Sequence[dict | callable]): Sequence of transform object or
+ config dict to be composed.
+ """
+
+ def __init__(self, transforms):
+ assert isinstance(transforms, collections.abc.Sequence)
+ self.transforms = []
+ for transform in transforms:
+ if isinstance(transform, dict):
+ transform = build_from_cfg(transform, PIPELINES)
+ self.transforms.append(transform)
+ elif callable(transform):
+ self.transforms.append(transform)
+ else:
+ raise TypeError('transform must be callable or a dict')
+
+ def __call__(self, data):
+ """Call function to apply transforms sequentially.
+
+ Args:
+ data (dict): A result dict contains the data to transform.
+
+ Returns:
+ dict: Transformed data.
+ """
+
+ for t in self.transforms:
+ data = t(data)
+ if data is None:
+ return None
+ return data
+
+ def __repr__(self):
+ format_string = self.__class__.__name__ + '('
+ for t in self.transforms:
+ format_string += '\n'
+ format_string += f' {t}'
+ format_string += '\n)'
+ return format_string
diff --git a/mmseg/datasets/pipelines/formating.py b/mmseg/datasets/pipelines/formating.py
new file mode 100644
index 0000000..f6e53bf
--- /dev/null
+++ b/mmseg/datasets/pipelines/formating.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# flake8: noqa
+import warnings
+
+from .formatting import *
+
+warnings.warn('DeprecationWarning: mmseg.datasets.pipelines.formating will be '
+ 'deprecated in 2021, please replace it with '
+ 'mmseg.datasets.pipelines.formatting.')
diff --git a/mmseg/datasets/pipelines/formatting.py b/mmseg/datasets/pipelines/formatting.py
new file mode 100644
index 0000000..4e057c1
--- /dev/null
+++ b/mmseg/datasets/pipelines/formatting.py
@@ -0,0 +1,289 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections.abc import Sequence
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.parallel import DataContainer as DC
+
+from ..builder import PIPELINES
+
+
+def to_tensor(data):
+ """Convert objects of various python types to :obj:`torch.Tensor`.
+
+ Supported types are: :class:`numpy.ndarray`, :class:`torch.Tensor`,
+ :class:`Sequence`, :class:`int` and :class:`float`.
+
+ Args:
+ data (torch.Tensor | numpy.ndarray | Sequence | int | float): Data to
+ be converted.
+ """
+
+ if isinstance(data, torch.Tensor):
+ return data
+ elif isinstance(data, np.ndarray):
+ return torch.from_numpy(data)
+ elif isinstance(data, Sequence) and not mmcv.is_str(data):
+ return torch.tensor(data)
+ elif isinstance(data, int):
+ return torch.LongTensor([data])
+ elif isinstance(data, float):
+ return torch.FloatTensor([data])
+ else:
+ raise TypeError(f'type {type(data)} cannot be converted to tensor.')
+
+
+@PIPELINES.register_module()
+class ToTensor(object):
+ """Convert some results to :obj:`torch.Tensor` by given keys.
+
+ Args:
+ keys (Sequence[str]): Keys that need to be converted to Tensor.
+ """
+
+ def __init__(self, keys):
+ self.keys = keys
+
+ def __call__(self, results):
+ """Call function to convert data in results to :obj:`torch.Tensor`.
+
+ Args:
+ results (dict): Result dict contains the data to convert.
+
+ Returns:
+ dict: The result dict contains the data converted
+ to :obj:`torch.Tensor`.
+ """
+
+ for key in self.keys:
+ results[key] = to_tensor(results[key])
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(keys={self.keys})'
+
+
+@PIPELINES.register_module()
+class ImageToTensor(object):
+ """Convert image to :obj:`torch.Tensor` by given keys.
+
+ The dimension order of input image is (H, W, C). The pipeline will convert
+ it to (C, H, W). If only 2 dimension (H, W) is given, the output would be
+ (1, H, W).
+
+ Args:
+ keys (Sequence[str]): Key of images to be converted to Tensor.
+ """
+
+ def __init__(self, keys):
+ self.keys = keys
+
+ def __call__(self, results):
+ """Call function to convert image in results to :obj:`torch.Tensor` and
+ transpose the channel order.
+
+ Args:
+ results (dict): Result dict contains the image data to convert.
+
+ Returns:
+ dict: The result dict contains the image converted
+ to :obj:`torch.Tensor` and transposed to (C, H, W) order.
+ """
+
+ for key in self.keys:
+ img = results[key]
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ results[key] = to_tensor(img.transpose(2, 0, 1))
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(keys={self.keys})'
+
+
+@PIPELINES.register_module()
+class Transpose(object):
+ """Transpose some results by given keys.
+
+ Args:
+ keys (Sequence[str]): Keys of results to be transposed.
+ order (Sequence[int]): Order of transpose.
+ """
+
+ def __init__(self, keys, order):
+ self.keys = keys
+ self.order = order
+
+ def __call__(self, results):
+ """Call function to convert image in results to :obj:`torch.Tensor` and
+ transpose the channel order.
+
+ Args:
+ results (dict): Result dict contains the image data to convert.
+
+ Returns:
+ dict: The result dict contains the image converted
+ to :obj:`torch.Tensor` and transposed to (C, H, W) order.
+ """
+
+ for key in self.keys:
+ results[key] = results[key].transpose(self.order)
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + \
+ f'(keys={self.keys}, order={self.order})'
+
+
+@PIPELINES.register_module()
+class ToDataContainer(object):
+ """Convert results to :obj:`mmcv.DataContainer` by given fields.
+
+ Args:
+ fields (Sequence[dict]): Each field is a dict like
+ ``dict(key='xxx', **kwargs)``. The ``key`` in result will
+ be converted to :obj:`mmcv.DataContainer` with ``**kwargs``.
+ Default: ``(dict(key='img', stack=True),
+ dict(key='gt_semantic_seg'))``.
+ """
+
+ def __init__(self,
+ fields=(dict(key='img',
+ stack=True), dict(key='gt_semantic_seg'))):
+ self.fields = fields
+
+ def __call__(self, results):
+ """Call function to convert data in results to
+ :obj:`mmcv.DataContainer`.
+
+ Args:
+ results (dict): Result dict contains the data to convert.
+
+ Returns:
+ dict: The result dict contains the data converted to
+ :obj:`mmcv.DataContainer`.
+ """
+
+ for field in self.fields:
+ field = field.copy()
+ key = field.pop('key')
+ results[key] = DC(results[key], **field)
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(fields={self.fields})'
+
+
+@PIPELINES.register_module()
+class DefaultFormatBundle(object):
+ """Default formatting bundle.
+
+ It simplifies the pipeline of formatting common fields, including "img"
+ and "gt_semantic_seg". These fields are formatted as follows.
+
+ - img: (1)transpose, (2)to tensor, (3)to DataContainer (stack=True)
+ - gt_semantic_seg: (1)unsqueeze dim-0 (2)to tensor,
+ (3)to DataContainer (stack=True)
+ """
+
+ def __call__(self, results):
+ """Call function to transform and format common fields in results.
+
+ Args:
+ results (dict): Result dict contains the data to convert.
+
+ Returns:
+ dict: The result dict contains the data that is formatted with
+ default bundle.
+ """
+
+ if 'img' in results:
+ img = results['img']
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ results['img'] = DC(to_tensor(img), stack=True)
+ if 'gt_semantic_seg' in results:
+ # convert to long
+ results['gt_semantic_seg'] = DC(
+ to_tensor(results['gt_semantic_seg'][None,
+ ...].astype(np.int64)),
+ stack=True)
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__
+
+
+@PIPELINES.register_module()
+class Collect(object):
+ """Collect data from the loader relevant to the specific task.
+
+ This is usually the last stage of the data loader pipeline. Typically keys
+ is set to some subset of "img", "gt_semantic_seg".
+
+ The "img_meta" item is always populated. The contents of the "img_meta"
+ dictionary depends on "meta_keys". By default this includes:
+
+ - "img_shape": shape of the image input to the network as a tuple
+ (h, w, c). Note that images may be zero padded on the bottom/right
+ if the batch tensor is larger than this shape.
+
+ - "scale_factor": a float indicating the preprocessing scale
+
+ - "flip": a boolean indicating if image flip transform was used
+
+ - "filename": path to the image file
+
+ - "ori_shape": original shape of the image as a tuple (h, w, c)
+
+ - "pad_shape": image shape after padding
+
+ - "img_norm_cfg": a dict of normalization information:
+ - mean - per channel mean subtraction
+ - std - per channel std divisor
+ - to_rgb - bool indicating if bgr was converted to rgb
+
+ Args:
+ keys (Sequence[str]): Keys of results to be collected in ``data``.
+ meta_keys (Sequence[str], optional): Meta keys to be converted to
+ ``mmcv.DataContainer`` and collected in ``data[img_metas]``.
+ Default: (``filename``, ``ori_filename``, ``ori_shape``,
+ ``img_shape``, ``pad_shape``, ``scale_factor``, ``flip``,
+ ``flip_direction``, ``img_norm_cfg``)
+ """
+
+ def __init__(self,
+ keys,
+ meta_keys=('filename', 'ori_filename', 'ori_shape',
+ 'img_shape', 'pad_shape', 'scale_factor', 'flip',
+ 'flip_direction', 'img_norm_cfg')):
+ self.keys = keys
+ self.meta_keys = meta_keys
+
+ def __call__(self, results):
+ """Call function to collect keys in results. The keys in ``meta_keys``
+ will be converted to :obj:mmcv.DataContainer.
+
+ Args:
+ results (dict): Result dict contains the data to collect.
+
+ Returns:
+ dict: The result dict contains the following keys
+ - keys in``self.keys``
+ - ``img_metas``
+ """
+
+ data = {}
+ img_meta = {}
+ for key in self.meta_keys:
+ img_meta[key] = results[key]
+ data['img_metas'] = DC(img_meta, cpu_only=True)
+ for key in self.keys:
+ data[key] = results[key]
+ return data
+
+ def __repr__(self):
+ return self.__class__.__name__ + \
+ f'(keys={self.keys}, meta_keys={self.meta_keys})'
diff --git a/mmseg/datasets/pipelines/loading.py b/mmseg/datasets/pipelines/loading.py
new file mode 100644
index 0000000..e1c82bd
--- /dev/null
+++ b/mmseg/datasets/pipelines/loading.py
@@ -0,0 +1,154 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import numpy as np
+
+from ..builder import PIPELINES
+
+
+@PIPELINES.register_module()
+class LoadImageFromFile(object):
+ """Load an image from file.
+
+ Required keys are "img_prefix" and "img_info" (a dict that must contain the
+ key "filename"). Added or updated keys are "filename", "img", "img_shape",
+ "ori_shape" (same as `img_shape`), "pad_shape" (same as `img_shape`),
+ "scale_factor" (1.0) and "img_norm_cfg" (means=0 and stds=1).
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ color_type (str): The flag argument for :func:`mmcv.imfrombytes`.
+ Defaults to 'color'.
+ file_client_args (dict): Arguments to instantiate a FileClient.
+ See :class:`mmcv.fileio.FileClient` for details.
+ Defaults to ``dict(backend='disk')``.
+ imdecode_backend (str): Backend for :func:`mmcv.imdecode`. Default:
+ 'cv2'
+ """
+
+ def __init__(self,
+ to_float32=False,
+ color_type='color',
+ file_client_args=dict(backend='disk'),
+ imdecode_backend='cv2'):
+ self.to_float32 = to_float32
+ self.color_type = color_type
+ self.file_client_args = file_client_args.copy()
+ self.file_client = None
+ self.imdecode_backend = imdecode_backend
+
+ def __call__(self, results):
+ """Call functions to load image and get image meta information.
+
+ Args:
+ results (dict): Result dict from :obj:`mmseg.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded image and meta information.
+ """
+
+ if self.file_client is None:
+ self.file_client = mmcv.FileClient(**self.file_client_args)
+
+ if results.get('img_prefix') is not None:
+ filename = osp.join(results['img_prefix'],
+ results['img_info']['filename'])
+ else:
+ filename = results['img_info']['filename']
+ img_bytes = self.file_client.get(filename)
+ img = mmcv.imfrombytes(
+ img_bytes, flag=self.color_type, backend=self.imdecode_backend)
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ results['filename'] = filename
+ results['ori_filename'] = results['img_info']['filename']
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+ num_channels = 1 if len(img.shape) < 3 else img.shape[2]
+ results['img_norm_cfg'] = dict(
+ mean=np.zeros(num_channels, dtype=np.float32),
+ std=np.ones(num_channels, dtype=np.float32),
+ to_rgb=False)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(to_float32={self.to_float32},'
+ repr_str += f"color_type='{self.color_type}',"
+ repr_str += f"imdecode_backend='{self.imdecode_backend}')"
+ return repr_str
+
+
+@PIPELINES.register_module()
+class LoadAnnotations(object):
+ """Load annotations for semantic segmentation.
+
+ Args:
+ reduce_zero_label (bool): Whether reduce all label value by 1.
+ Usually used for datasets where 0 is background label.
+ Default: False.
+ file_client_args (dict): Arguments to instantiate a FileClient.
+ See :class:`mmcv.fileio.FileClient` for details.
+ Defaults to ``dict(backend='disk')``.
+ imdecode_backend (str): Backend for :func:`mmcv.imdecode`. Default:
+ 'pillow'
+ """
+
+ def __init__(self,
+ reduce_zero_label=False,
+ file_client_args=dict(backend='disk'),
+ imdecode_backend='pillow'):
+ self.reduce_zero_label = reduce_zero_label
+ self.file_client_args = file_client_args.copy()
+ self.file_client = None
+ self.imdecode_backend = imdecode_backend
+
+ def __call__(self, results):
+ """Call function to load multiple types annotations.
+
+ Args:
+ results (dict): Result dict from :obj:`mmseg.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded semantic segmentation annotations.
+ """
+
+ if self.file_client is None:
+ self.file_client = mmcv.FileClient(**self.file_client_args)
+
+ if results.get('seg_prefix', None) is not None:
+ filename = osp.join(results['seg_prefix'],
+ results['ann_info']['seg_map'])
+ else:
+ filename = results['ann_info']['seg_map']
+ img_bytes = self.file_client.get(filename)
+ gt_semantic_seg = mmcv.imfrombytes(
+ img_bytes, flag='unchanged',
+ backend=self.imdecode_backend).squeeze().astype(np.uint8)
+ # modify if custom classes
+ if results.get('label_map', None) is not None:
+ for old_id, new_id in results['label_map'].items():
+ gt_semantic_seg[gt_semantic_seg == old_id] = new_id
+ # reduce zero_label
+ if self.reduce_zero_label:
+ # avoid using underflow conversion
+ gt_semantic_seg[gt_semantic_seg == 0] = 255
+ gt_semantic_seg = gt_semantic_seg - 1
+ gt_semantic_seg[gt_semantic_seg == 254] = 255
+ results['gt_semantic_seg'] = gt_semantic_seg
+ results['seg_fields'].append('gt_semantic_seg')
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(reduce_zero_label={self.reduce_zero_label},'
+ repr_str += f"imdecode_backend='{self.imdecode_backend}')"
+ return repr_str
diff --git a/mmseg/datasets/pipelines/test_time_aug.py b/mmseg/datasets/pipelines/test_time_aug.py
new file mode 100644
index 0000000..5c17cbb
--- /dev/null
+++ b/mmseg/datasets/pipelines/test_time_aug.py
@@ -0,0 +1,134 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+
+from ..builder import PIPELINES
+from .compose import Compose
+
+
+@PIPELINES.register_module()
+class MultiScaleFlipAug(object):
+ """Test-time augmentation with multiple scales and flipping.
+
+ An example configuration is as followed:
+
+ .. code-block::
+
+ img_scale=(2048, 1024),
+ img_ratios=[0.5, 1.0],
+ flip=True,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ]
+
+ After MultiScaleFLipAug with above configuration, the results are wrapped
+ into lists of the same length as followed:
+
+ .. code-block::
+
+ dict(
+ img=[...],
+ img_shape=[...],
+ scale=[(1024, 512), (1024, 512), (2048, 1024), (2048, 1024)]
+ flip=[False, True, False, True]
+ ...
+ )
+
+ Args:
+ transforms (list[dict]): Transforms to apply in each augmentation.
+ img_scale (None | tuple | list[tuple]): Images scales for resizing.
+ img_ratios (float | list[float]): Image ratios for resizing
+ flip (bool): Whether apply flip augmentation. Default: False.
+ flip_direction (str | list[str]): Flip augmentation directions,
+ options are "horizontal" and "vertical". If flip_direction is list,
+ multiple flip augmentations will be applied.
+ It has no effect when flip == False. Default: "horizontal".
+ """
+
+ def __init__(self,
+ transforms,
+ img_scale,
+ img_ratios=None,
+ flip=False,
+ flip_direction='horizontal'):
+ self.transforms = Compose(transforms)
+ if img_ratios is not None:
+ img_ratios = img_ratios if isinstance(img_ratios,
+ list) else [img_ratios]
+ assert mmcv.is_list_of(img_ratios, float)
+ if img_scale is None:
+ # mode 1: given img_scale=None and a range of image ratio
+ self.img_scale = None
+ assert mmcv.is_list_of(img_ratios, float)
+ elif isinstance(img_scale, tuple) and mmcv.is_list_of(
+ img_ratios, float):
+ assert len(img_scale) == 2
+ # mode 2: given a scale and a range of image ratio
+ self.img_scale = [(int(img_scale[0] * ratio),
+ int(img_scale[1] * ratio))
+ for ratio in img_ratios]
+ else:
+ # mode 3: given multiple scales
+ self.img_scale = img_scale if isinstance(img_scale,
+ list) else [img_scale]
+ assert mmcv.is_list_of(self.img_scale, tuple) or self.img_scale is None
+ self.flip = flip
+ self.img_ratios = img_ratios
+ self.flip_direction = flip_direction if isinstance(
+ flip_direction, list) else [flip_direction]
+ assert mmcv.is_list_of(self.flip_direction, str)
+ if not self.flip and self.flip_direction != ['horizontal']:
+ warnings.warn(
+ 'flip_direction has no effect when flip is set to False')
+ if (self.flip
+ and not any([t['type'] == 'RandomFlip' for t in transforms])):
+ warnings.warn(
+ 'flip has no effect when RandomFlip is not in transforms')
+
+ def __call__(self, results):
+ """Call function to apply test time augment transforms on results.
+
+ Args:
+ results (dict): Result dict contains the data to transform.
+
+ Returns:
+ dict[str: list]: The augmented data, where each value is wrapped
+ into a list.
+ """
+
+ aug_data = []
+ if self.img_scale is None and mmcv.is_list_of(self.img_ratios, float):
+ h, w = results['img'].shape[:2]
+ img_scale = [(int(w * ratio), int(h * ratio))
+ for ratio in self.img_ratios]
+ else:
+ img_scale = self.img_scale
+ flip_aug = [False, True] if self.flip else [False]
+ for scale in img_scale:
+ for flip in flip_aug:
+ for direction in self.flip_direction:
+ _results = results.copy()
+ _results['scale'] = scale
+ _results['flip'] = flip
+ _results['flip_direction'] = direction
+ data = self.transforms(_results)
+ aug_data.append(data)
+ # list of dict to dict of list
+ aug_data_dict = {key: [] for key in aug_data[0]}
+ for data in aug_data:
+ for key, val in data.items():
+ aug_data_dict[key].append(val)
+ return aug_data_dict
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(transforms={self.transforms}, '
+ repr_str += f'img_scale={self.img_scale}, flip={self.flip})'
+ repr_str += f'flip_direction={self.flip_direction}'
+ return repr_str
diff --git a/mmseg/datasets/pipelines/transforms.py b/mmseg/datasets/pipelines/transforms.py
new file mode 100644
index 0000000..003a564
--- /dev/null
+++ b/mmseg/datasets/pipelines/transforms.py
@@ -0,0 +1,1311 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import mmcv
+import numpy as np
+from mmcv.utils import deprecated_api_warning, is_tuple_of
+from numpy import random
+
+from ..builder import PIPELINES
+
+
+@PIPELINES.register_module()
+class ResizeToMultiple(object):
+ """Resize images & seg to multiple of divisor.
+
+ Args:
+ size_divisor (int): images and gt seg maps need to resize to multiple
+ of size_divisor. Default: 32.
+ interpolation (str, optional): The interpolation mode of image resize.
+ Default: None
+ """
+
+ def __init__(self, size_divisor=32, interpolation=None):
+ self.size_divisor = size_divisor
+ self.interpolation = interpolation
+
+ def __call__(self, results):
+ """Call function to resize images, semantic segmentation map to
+ multiple of size divisor.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Resized results, 'img_shape', 'pad_shape' keys are updated.
+ """
+ # Align image to multiple of size divisor.
+ img = results['img']
+ img = mmcv.imresize_to_multiple(
+ img,
+ self.size_divisor,
+ scale_factor=1,
+ interpolation=self.interpolation
+ if self.interpolation else 'bilinear')
+
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['pad_shape'] = img.shape
+
+ # Align segmentation map to multiple of size divisor.
+ for key in results.get('seg_fields', []):
+ gt_seg = results[key]
+ gt_seg = mmcv.imresize_to_multiple(
+ gt_seg,
+ self.size_divisor,
+ scale_factor=1,
+ interpolation='nearest')
+ results[key] = gt_seg
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += (f'(size_divisor={self.size_divisor}, '
+ f'interpolation={self.interpolation})')
+ return repr_str
+
+
+@PIPELINES.register_module()
+class Resize(object):
+ """Resize images & seg.
+
+ This transform resizes the input image to some scale. If the input dict
+ contains the key "scale", then the scale in the input dict is used,
+ otherwise the specified scale in the init method is used.
+
+ ``img_scale`` can be None, a tuple (single-scale) or a list of tuple
+ (multi-scale). There are 4 multiscale modes:
+
+ - ``ratio_range is not None``:
+ 1. When img_scale is None, img_scale is the shape of image in results
+ (img_scale = results['img'].shape[:2]) and the image is resized based
+ on the original size. (mode 1)
+ 2. When img_scale is a tuple (single-scale), randomly sample a ratio from
+ the ratio range and multiply it with the image scale. (mode 2)
+
+ - ``ratio_range is None and multiscale_mode == "range"``: randomly sample a
+ scale from the a range. (mode 3)
+
+ - ``ratio_range is None and multiscale_mode == "value"``: randomly sample a
+ scale from multiple scales. (mode 4)
+
+ Args:
+ img_scale (tuple or list[tuple]): Images scales for resizing.
+ Default:None.
+ multiscale_mode (str): Either "range" or "value".
+ Default: 'range'
+ ratio_range (tuple[float]): (min_ratio, max_ratio).
+ Default: None
+ keep_ratio (bool): Whether to keep the aspect ratio when resizing the
+ image. Default: True
+ """
+
+ def __init__(self,
+ img_scale=None,
+ multiscale_mode='range',
+ ratio_range=None,
+ keep_ratio=True):
+ if img_scale is None:
+ self.img_scale = None
+ else:
+ if isinstance(img_scale, list):
+ self.img_scale = img_scale
+ else:
+ self.img_scale = [img_scale]
+ assert mmcv.is_list_of(self.img_scale, tuple)
+
+ if ratio_range is not None:
+ # mode 1: given img_scale=None and a range of image ratio
+ # mode 2: given a scale and a range of image ratio
+ assert self.img_scale is None or len(self.img_scale) == 1
+ else:
+ # mode 3 and 4: given multiple scales or a range of scales
+ assert multiscale_mode in ['value', 'range']
+
+ self.multiscale_mode = multiscale_mode
+ self.ratio_range = ratio_range
+ self.keep_ratio = keep_ratio
+
+ @staticmethod
+ def random_select(img_scales):
+ """Randomly select an img_scale from given candidates.
+
+ Args:
+ img_scales (list[tuple]): Images scales for selection.
+
+ Returns:
+ (tuple, int): Returns a tuple ``(img_scale, scale_dix)``,
+ where ``img_scale`` is the selected image scale and
+ ``scale_idx`` is the selected index in the given candidates.
+ """
+
+ assert mmcv.is_list_of(img_scales, tuple)
+ scale_idx = np.random.randint(len(img_scales))
+ img_scale = img_scales[scale_idx]
+ return img_scale, scale_idx
+
+ @staticmethod
+ def random_sample(img_scales):
+ """Randomly sample an img_scale when ``multiscale_mode=='range'``.
+
+ Args:
+ img_scales (list[tuple]): Images scale range for sampling.
+ There must be two tuples in img_scales, which specify the lower
+ and upper bound of image scales.
+
+ Returns:
+ (tuple, None): Returns a tuple ``(img_scale, None)``, where
+ ``img_scale`` is sampled scale and None is just a placeholder
+ to be consistent with :func:`random_select`.
+ """
+
+ assert mmcv.is_list_of(img_scales, tuple) and len(img_scales) == 2
+ img_scale_long = [max(s) for s in img_scales]
+ img_scale_short = [min(s) for s in img_scales]
+ long_edge = np.random.randint(
+ min(img_scale_long),
+ max(img_scale_long) + 1)
+ short_edge = np.random.randint(
+ min(img_scale_short),
+ max(img_scale_short) + 1)
+ img_scale = (long_edge, short_edge)
+ return img_scale, None
+
+ @staticmethod
+ def random_sample_ratio(img_scale, ratio_range):
+ """Randomly sample an img_scale when ``ratio_range`` is specified.
+
+ A ratio will be randomly sampled from the range specified by
+ ``ratio_range``. Then it would be multiplied with ``img_scale`` to
+ generate sampled scale.
+
+ Args:
+ img_scale (tuple): Images scale base to multiply with ratio.
+ ratio_range (tuple[float]): The minimum and maximum ratio to scale
+ the ``img_scale``.
+
+ Returns:
+ (tuple, None): Returns a tuple ``(scale, None)``, where
+ ``scale`` is sampled ratio multiplied with ``img_scale`` and
+ None is just a placeholder to be consistent with
+ :func:`random_select`.
+ """
+
+ assert isinstance(img_scale, tuple) and len(img_scale) == 2
+ min_ratio, max_ratio = ratio_range
+ assert min_ratio <= max_ratio
+ ratio = np.random.random_sample() * (max_ratio - min_ratio) + min_ratio
+ scale = int(img_scale[0] * ratio), int(img_scale[1] * ratio)
+ return scale, None
+
+ def _random_scale(self, results):
+ """Randomly sample an img_scale according to ``ratio_range`` and
+ ``multiscale_mode``.
+
+ If ``ratio_range`` is specified, a ratio will be sampled and be
+ multiplied with ``img_scale``.
+ If multiple scales are specified by ``img_scale``, a scale will be
+ sampled according to ``multiscale_mode``.
+ Otherwise, single scale will be used.
+
+ Args:
+ results (dict): Result dict from :obj:`dataset`.
+
+ Returns:
+ dict: Two new keys 'scale` and 'scale_idx` are added into
+ ``results``, which would be used by subsequent pipelines.
+ """
+
+ if self.ratio_range is not None:
+ if self.img_scale is None:
+ h, w = results['img'].shape[:2]
+ scale, scale_idx = self.random_sample_ratio((w, h),
+ self.ratio_range)
+ else:
+ scale, scale_idx = self.random_sample_ratio(
+ self.img_scale[0], self.ratio_range)
+ elif len(self.img_scale) == 1:
+ scale, scale_idx = self.img_scale[0], 0
+ elif self.multiscale_mode == 'range':
+ scale, scale_idx = self.random_sample(self.img_scale)
+ elif self.multiscale_mode == 'value':
+ scale, scale_idx = self.random_select(self.img_scale)
+ else:
+ raise NotImplementedError
+
+ results['scale'] = scale
+ results['scale_idx'] = scale_idx
+
+ def _resize_img(self, results):
+ """Resize images with ``results['scale']``."""
+ if self.keep_ratio:
+ img, scale_factor = mmcv.imrescale(
+ results['img'], results['scale'], return_scale=True)
+ # the w_scale and h_scale has minor difference
+ # a real fix should be done in the mmcv.imrescale in the future
+ new_h, new_w = img.shape[:2]
+ h, w = results['img'].shape[:2]
+ w_scale = new_w / w
+ h_scale = new_h / h
+ else:
+ img, w_scale, h_scale = mmcv.imresize(
+ results['img'], results['scale'], return_scale=True)
+ scale_factor = np.array([w_scale, h_scale, w_scale, h_scale],
+ dtype=np.float32)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['pad_shape'] = img.shape # in case that there is no padding
+ results['scale_factor'] = scale_factor
+ results['keep_ratio'] = self.keep_ratio
+
+ def _resize_seg(self, results):
+ """Resize semantic segmentation map with ``results['scale']``."""
+ for key in results.get('seg_fields', []):
+ if self.keep_ratio:
+ gt_seg = mmcv.imrescale(
+ results[key], results['scale'], interpolation='nearest')
+ else:
+ gt_seg = mmcv.imresize(
+ results[key], results['scale'], interpolation='nearest')
+ results[key] = gt_seg
+
+ def __call__(self, results):
+ """Call function to resize images, bounding boxes, masks, semantic
+ segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Resized results, 'img_shape', 'pad_shape', 'scale_factor',
+ 'keep_ratio' keys are added into result dict.
+ """
+
+ if 'scale' not in results:
+ self._random_scale(results)
+ self._resize_img(results)
+ self._resize_seg(results)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += (f'(img_scale={self.img_scale}, '
+ f'multiscale_mode={self.multiscale_mode}, '
+ f'ratio_range={self.ratio_range}, '
+ f'keep_ratio={self.keep_ratio})')
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomFlip(object):
+ """Flip the image & seg.
+
+ If the input dict contains the key "flip", then the flag will be used,
+ otherwise it will be randomly decided by a ratio specified in the init
+ method.
+
+ Args:
+ prob (float, optional): The flipping probability. Default: None.
+ direction(str, optional): The flipping direction. Options are
+ 'horizontal' and 'vertical'. Default: 'horizontal'.
+ """
+
+ @deprecated_api_warning({'flip_ratio': 'prob'}, cls_name='RandomFlip')
+ def __init__(self, prob=None, direction='horizontal'):
+ self.prob = prob
+ self.direction = direction
+ if prob is not None:
+ assert prob >= 0 and prob <= 1
+ assert direction in ['horizontal', 'vertical']
+
+ def __call__(self, results):
+ """Call function to flip bounding boxes, masks, semantic segmentation
+ maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Flipped results, 'flip', 'flip_direction' keys are added into
+ result dict.
+ """
+
+ if 'flip' not in results:
+ flip = True if np.random.rand() < self.prob else False
+ results['flip'] = flip
+ if 'flip_direction' not in results:
+ results['flip_direction'] = self.direction
+ if results['flip']:
+ # flip image
+ results['img'] = mmcv.imflip(
+ results['img'], direction=results['flip_direction'])
+
+ # flip segs
+ for key in results.get('seg_fields', []):
+ # use copy() to make numpy stride positive
+ results[key] = mmcv.imflip(
+ results[key], direction=results['flip_direction']).copy()
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(prob={self.prob})'
+
+
+@PIPELINES.register_module()
+class Pad(object):
+ """Pad the image & mask.
+
+ There are two padding modes: (1) pad to a fixed size and (2) pad to the
+ minimum size that is divisible by some number.
+ Added keys are "pad_shape", "pad_fixed_size", "pad_size_divisor",
+
+ Args:
+ size (tuple, optional): Fixed padding size.
+ size_divisor (int, optional): The divisor of padded size.
+ pad_val (float, optional): Padding value. Default: 0.
+ seg_pad_val (float, optional): Padding value of segmentation map.
+ Default: 255.
+ """
+
+ def __init__(self,
+ size=None,
+ size_divisor=None,
+ pad_val=0,
+ seg_pad_val=255):
+ self.size = size
+ self.size_divisor = size_divisor
+ self.pad_val = pad_val
+ self.seg_pad_val = seg_pad_val
+ # only one of size and size_divisor should be valid
+ assert size is not None or size_divisor is not None
+ assert size is None or size_divisor is None
+
+ def _pad_img(self, results):
+ """Pad images according to ``self.size``."""
+ if self.size is not None:
+ padded_img = mmcv.impad(
+ results['img'], shape=self.size, pad_val=self.pad_val)
+ elif self.size_divisor is not None:
+ padded_img = mmcv.impad_to_multiple(
+ results['img'], self.size_divisor, pad_val=self.pad_val)
+ results['img'] = padded_img
+ results['pad_shape'] = padded_img.shape
+ results['pad_fixed_size'] = self.size
+ results['pad_size_divisor'] = self.size_divisor
+
+ def _pad_seg(self, results):
+ """Pad masks according to ``results['pad_shape']``."""
+ for key in results.get('seg_fields', []):
+ results[key] = mmcv.impad(
+ results[key],
+ shape=results['pad_shape'][:2],
+ pad_val=self.seg_pad_val)
+
+ def __call__(self, results):
+ """Call function to pad images, masks, semantic segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Updated result dict.
+ """
+
+ self._pad_img(results)
+ self._pad_seg(results)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(size={self.size}, size_divisor={self.size_divisor}, ' \
+ f'pad_val={self.pad_val})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class Normalize(object):
+ """Normalize the image.
+
+ Added key is "img_norm_cfg".
+
+ Args:
+ mean (sequence): Mean values of 3 channels.
+ std (sequence): Std values of 3 channels.
+ to_rgb (bool): Whether to convert the image from BGR to RGB,
+ default is true.
+ """
+
+ def __init__(self, mean, std, to_rgb=True):
+ self.mean = np.array(mean, dtype=np.float32)
+ self.std = np.array(std, dtype=np.float32)
+ self.to_rgb = to_rgb
+
+ def __call__(self, results):
+ """Call function to normalize images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Normalized results, 'img_norm_cfg' key is added into
+ result dict.
+ """
+
+ results['img'] = mmcv.imnormalize(results['img'], self.mean, self.std,
+ self.to_rgb)
+ results['img_norm_cfg'] = dict(
+ mean=self.mean, std=self.std, to_rgb=self.to_rgb)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(mean={self.mean}, std={self.std}, to_rgb=' \
+ f'{self.to_rgb})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class Rerange(object):
+ """Rerange the image pixel value.
+
+ Args:
+ min_value (float or int): Minimum value of the reranged image.
+ Default: 0.
+ max_value (float or int): Maximum value of the reranged image.
+ Default: 255.
+ """
+
+ def __init__(self, min_value=0, max_value=255):
+ assert isinstance(min_value, float) or isinstance(min_value, int)
+ assert isinstance(max_value, float) or isinstance(max_value, int)
+ assert min_value < max_value
+ self.min_value = min_value
+ self.max_value = max_value
+
+ def __call__(self, results):
+ """Call function to rerange images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ Returns:
+ dict: Reranged results.
+ """
+
+ img = results['img']
+ img_min_value = np.min(img)
+ img_max_value = np.max(img)
+
+ assert img_min_value < img_max_value
+ # rerange to [0, 1]
+ img = (img - img_min_value) / (img_max_value - img_min_value)
+ # rerange to [min_value, max_value]
+ img = img * (self.max_value - self.min_value) + self.min_value
+ results['img'] = img
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(min_value={self.min_value}, max_value={self.max_value})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class CLAHE(object):
+ """Use CLAHE method to process the image.
+
+ See `ZUIDERVELD,K. Contrast Limited Adaptive Histogram Equalization[J].
+ Graphics Gems, 1994:474-485.` for more information.
+
+ Args:
+ clip_limit (float): Threshold for contrast limiting. Default: 40.0.
+ tile_grid_size (tuple[int]): Size of grid for histogram equalization.
+ Input image will be divided into equally sized rectangular tiles.
+ It defines the number of tiles in row and column. Default: (8, 8).
+ """
+
+ def __init__(self, clip_limit=40.0, tile_grid_size=(8, 8)):
+ assert isinstance(clip_limit, (float, int))
+ self.clip_limit = clip_limit
+ assert is_tuple_of(tile_grid_size, int)
+ assert len(tile_grid_size) == 2
+ self.tile_grid_size = tile_grid_size
+
+ def __call__(self, results):
+ """Call function to Use CLAHE method process images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Processed results.
+ """
+
+ for i in range(results['img'].shape[2]):
+ results['img'][:, :, i] = mmcv.clahe(
+ np.array(results['img'][:, :, i], dtype=np.uint8),
+ self.clip_limit, self.tile_grid_size)
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(clip_limit={self.clip_limit}, '\
+ f'tile_grid_size={self.tile_grid_size})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomCrop(object):
+ """Random crop the image & seg.
+
+ Args:
+ crop_size (tuple): Expected size after cropping, (h, w).
+ cat_max_ratio (float): The maximum ratio that single category could
+ occupy.
+ """
+
+ def __init__(self, crop_size, cat_max_ratio=1., ignore_index=255):
+ assert crop_size[0] > 0 and crop_size[1] > 0
+ self.crop_size = crop_size
+ self.cat_max_ratio = cat_max_ratio
+ self.ignore_index = ignore_index
+
+ def get_crop_bbox(self, img):
+ """Randomly get a crop bounding box."""
+ margin_h = max(img.shape[0] - self.crop_size[0], 0)
+ margin_w = max(img.shape[1] - self.crop_size[1], 0)
+ offset_h = np.random.randint(0, margin_h + 1)
+ offset_w = np.random.randint(0, margin_w + 1)
+ crop_y1, crop_y2 = offset_h, offset_h + self.crop_size[0]
+ crop_x1, crop_x2 = offset_w, offset_w + self.crop_size[1]
+
+ return crop_y1, crop_y2, crop_x1, crop_x2
+
+ def crop(self, img, crop_bbox):
+ """Crop from ``img``"""
+ crop_y1, crop_y2, crop_x1, crop_x2 = crop_bbox
+ img = img[crop_y1:crop_y2, crop_x1:crop_x2, ...]
+ return img
+
+ def __call__(self, results):
+ """Call function to randomly crop images, semantic segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Randomly cropped results, 'img_shape' key in result dict is
+ updated according to crop size.
+ """
+
+ img = results['img']
+ crop_bbox = self.get_crop_bbox(img)
+ if self.cat_max_ratio < 1.:
+ # Repeat 10 times
+ for _ in range(10):
+ seg_temp = self.crop(results['gt_semantic_seg'], crop_bbox)
+ labels, cnt = np.unique(seg_temp, return_counts=True)
+ cnt = cnt[labels != self.ignore_index]
+ if len(cnt) > 1 and np.max(cnt) / np.sum(
+ cnt) < self.cat_max_ratio:
+ break
+ crop_bbox = self.get_crop_bbox(img)
+
+ # crop the image
+ img = self.crop(img, crop_bbox)
+ img_shape = img.shape
+ results['img'] = img
+ results['img_shape'] = img_shape
+
+ # crop semantic seg
+ for key in results.get('seg_fields', []):
+ results[key] = self.crop(results[key], crop_bbox)
+
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(crop_size={self.crop_size})'
+
+
+@PIPELINES.register_module()
+class RandomRotate(object):
+ """Rotate the image & seg.
+
+ Args:
+ prob (float): The rotation probability.
+ degree (float, tuple[float]): Range of degrees to select from. If
+ degree is a number instead of tuple like (min, max),
+ the range of degree will be (``-degree``, ``+degree``)
+ pad_val (float, optional): Padding value of image. Default: 0.
+ seg_pad_val (float, optional): Padding value of segmentation map.
+ Default: 255.
+ center (tuple[float], optional): Center point (w, h) of the rotation in
+ the source image. If not specified, the center of the image will be
+ used. Default: None.
+ auto_bound (bool): Whether to adjust the image size to cover the whole
+ rotated image. Default: False
+ """
+
+ def __init__(self,
+ prob,
+ degree,
+ pad_val=0,
+ seg_pad_val=255,
+ center=None,
+ auto_bound=False):
+ self.prob = prob
+ assert prob >= 0 and prob <= 1
+ if isinstance(degree, (float, int)):
+ assert degree > 0, f'degree {degree} should be positive'
+ self.degree = (-degree, degree)
+ else:
+ self.degree = degree
+ assert len(self.degree) == 2, f'degree {self.degree} should be a ' \
+ f'tuple of (min, max)'
+ self.pal_val = pad_val
+ self.seg_pad_val = seg_pad_val
+ self.center = center
+ self.auto_bound = auto_bound
+
+ def __call__(self, results):
+ """Call function to rotate image, semantic segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Rotated results.
+ """
+
+ rotate = True if np.random.rand() < self.prob else False
+ degree = np.random.uniform(min(*self.degree), max(*self.degree))
+ if rotate:
+ # rotate image
+ results['img'] = mmcv.imrotate(
+ results['img'],
+ angle=degree,
+ border_value=self.pal_val,
+ center=self.center,
+ auto_bound=self.auto_bound)
+
+ # rotate segs
+ for key in results.get('seg_fields', []):
+ results[key] = mmcv.imrotate(
+ results[key],
+ angle=degree,
+ border_value=self.seg_pad_val,
+ center=self.center,
+ auto_bound=self.auto_bound,
+ interpolation='nearest')
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, ' \
+ f'degree={self.degree}, ' \
+ f'pad_val={self.pal_val}, ' \
+ f'seg_pad_val={self.seg_pad_val}, ' \
+ f'center={self.center}, ' \
+ f'auto_bound={self.auto_bound})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RGB2Gray(object):
+ """Convert RGB image to grayscale image.
+
+ This transform calculate the weighted mean of input image channels with
+ ``weights`` and then expand the channels to ``out_channels``. When
+ ``out_channels`` is None, the number of output channels is the same as
+ input channels.
+
+ Args:
+ out_channels (int): Expected number of output channels after
+ transforming. Default: None.
+ weights (tuple[float]): The weights to calculate the weighted mean.
+ Default: (0.299, 0.587, 0.114).
+ """
+
+ def __init__(self, out_channels=None, weights=(0.299, 0.587, 0.114)):
+ assert out_channels is None or out_channels > 0
+ self.out_channels = out_channels
+ assert isinstance(weights, tuple)
+ for item in weights:
+ assert isinstance(item, (float, int))
+ self.weights = weights
+
+ def __call__(self, results):
+ """Call function to convert RGB image to grayscale image.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with grayscale image.
+ """
+ img = results['img']
+ assert len(img.shape) == 3
+ assert img.shape[2] == len(self.weights)
+ weights = np.array(self.weights).reshape((1, 1, -1))
+ img = (img * weights).sum(2, keepdims=True)
+ if self.out_channels is None:
+ img = img.repeat(weights.shape[2], axis=2)
+ else:
+ img = img.repeat(self.out_channels, axis=2)
+
+ results['img'] = img
+ results['img_shape'] = img.shape
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(out_channels={self.out_channels}, ' \
+ f'weights={self.weights})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class AdjustGamma(object):
+ """Using gamma correction to process the image.
+
+ Args:
+ gamma (float or int): Gamma value used in gamma correction.
+ Default: 1.0.
+ """
+
+ def __init__(self, gamma=1.0):
+ assert isinstance(gamma, float) or isinstance(gamma, int)
+ assert gamma > 0
+ self.gamma = gamma
+ inv_gamma = 1.0 / gamma
+ self.table = np.array([(i / 255.0)**inv_gamma * 255
+ for i in np.arange(256)]).astype('uint8')
+
+ def __call__(self, results):
+ """Call function to process the image with gamma correction.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Processed results.
+ """
+
+ results['img'] = mmcv.lut_transform(
+ np.array(results['img'], dtype=np.uint8), self.table)
+
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(gamma={self.gamma})'
+
+
+@PIPELINES.register_module()
+class SegRescale(object):
+ """Rescale semantic segmentation maps.
+
+ Args:
+ scale_factor (float): The scale factor of the final output.
+ """
+
+ def __init__(self, scale_factor=1):
+ self.scale_factor = scale_factor
+
+ def __call__(self, results):
+ """Call function to scale the semantic segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with semantic segmentation map scaled.
+ """
+ for key in results.get('seg_fields', []):
+ if self.scale_factor != 1:
+ results[key] = mmcv.imrescale(
+ results[key], self.scale_factor, interpolation='nearest')
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(scale_factor={self.scale_factor})'
+
+
+@PIPELINES.register_module()
+class PhotoMetricDistortion(object):
+ """Apply photometric distortion to image sequentially, every transformation
+ is applied with a probability of 0.5. The position of random contrast is in
+ second or second to last.
+
+ 1. random brightness
+ 2. random contrast (mode 0)
+ 3. convert color from BGR to HSV
+ 4. random saturation
+ 5. random hue
+ 6. convert color from HSV to BGR
+ 7. random contrast (mode 1)
+
+ Args:
+ brightness_delta (int): delta of brightness.
+ contrast_range (tuple): range of contrast.
+ saturation_range (tuple): range of saturation.
+ hue_delta (int): delta of hue.
+ """
+
+ def __init__(self,
+ brightness_delta=32,
+ contrast_range=(0.5, 1.5),
+ saturation_range=(0.5, 1.5),
+ hue_delta=18):
+ self.brightness_delta = brightness_delta
+ self.contrast_lower, self.contrast_upper = contrast_range
+ self.saturation_lower, self.saturation_upper = saturation_range
+ self.hue_delta = hue_delta
+
+ def convert(self, img, alpha=1, beta=0):
+ """Multiple with alpha and add beat with clip."""
+ img = img.astype(np.float32) * alpha + beta
+ img = np.clip(img, 0, 255)
+ return img.astype(np.uint8)
+
+ def brightness(self, img):
+ """Brightness distortion."""
+ if random.randint(2):
+ return self.convert(
+ img,
+ beta=random.uniform(-self.brightness_delta,
+ self.brightness_delta))
+ return img
+
+ def contrast(self, img):
+ """Contrast distortion."""
+ if random.randint(2):
+ return self.convert(
+ img,
+ alpha=random.uniform(self.contrast_lower, self.contrast_upper))
+ return img
+
+ def saturation(self, img):
+ """Saturation distortion."""
+ if random.randint(2):
+ img = mmcv.bgr2hsv(img)
+ img[:, :, 1] = self.convert(
+ img[:, :, 1],
+ alpha=random.uniform(self.saturation_lower,
+ self.saturation_upper))
+ img = mmcv.hsv2bgr(img)
+ return img
+
+ def hue(self, img):
+ """Hue distortion."""
+ if random.randint(2):
+ img = mmcv.bgr2hsv(img)
+ img[:, :,
+ 0] = (img[:, :, 0].astype(int) +
+ random.randint(-self.hue_delta, self.hue_delta)) % 180
+ img = mmcv.hsv2bgr(img)
+ return img
+
+ def __call__(self, results):
+ """Call function to perform photometric distortion on images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with images distorted.
+ """
+
+ img = results['img']
+ # random brightness
+ img = self.brightness(img)
+
+ # mode == 0 --> do random contrast first
+ # mode == 1 --> do random contrast last
+ mode = random.randint(2)
+ if mode == 1:
+ img = self.contrast(img)
+
+ # random saturation
+ img = self.saturation(img)
+
+ # random hue
+ img = self.hue(img)
+
+ # random contrast
+ if mode == 0:
+ img = self.contrast(img)
+
+ results['img'] = img
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += (f'(brightness_delta={self.brightness_delta}, '
+ f'contrast_range=({self.contrast_lower}, '
+ f'{self.contrast_upper}), '
+ f'saturation_range=({self.saturation_lower}, '
+ f'{self.saturation_upper}), '
+ f'hue_delta={self.hue_delta})')
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomCutOut(object):
+ """CutOut operation.
+
+ Randomly drop some regions of image used in
+ `Cutout `_.
+ Args:
+ prob (float): cutout probability.
+ n_holes (int | tuple[int, int]): Number of regions to be dropped.
+ If it is given as a list, number of holes will be randomly
+ selected from the closed interval [`n_holes[0]`, `n_holes[1]`].
+ cutout_shape (tuple[int, int] | list[tuple[int, int]]): The candidate
+ shape of dropped regions. It can be `tuple[int, int]` to use a
+ fixed cutout shape, or `list[tuple[int, int]]` to randomly choose
+ shape from the list.
+ cutout_ratio (tuple[float, float] | list[tuple[float, float]]): The
+ candidate ratio of dropped regions. It can be `tuple[float, float]`
+ to use a fixed ratio or `list[tuple[float, float]]` to randomly
+ choose ratio from the list. Please note that `cutout_shape`
+ and `cutout_ratio` cannot be both given at the same time.
+ fill_in (tuple[float, float, float] | tuple[int, int, int]): The value
+ of pixel to fill in the dropped regions. Default: (0, 0, 0).
+ seg_fill_in (int): The labels of pixel to fill in the dropped regions.
+ If seg_fill_in is None, skip. Default: None.
+ """
+
+ def __init__(self,
+ prob,
+ n_holes,
+ cutout_shape=None,
+ cutout_ratio=None,
+ fill_in=(0, 0, 0),
+ seg_fill_in=None):
+
+ assert 0 <= prob and prob <= 1
+ assert (cutout_shape is None) ^ (cutout_ratio is None), \
+ 'Either cutout_shape or cutout_ratio should be specified.'
+ assert (isinstance(cutout_shape, (list, tuple))
+ or isinstance(cutout_ratio, (list, tuple)))
+ if isinstance(n_holes, tuple):
+ assert len(n_holes) == 2 and 0 <= n_holes[0] < n_holes[1]
+ else:
+ n_holes = (n_holes, n_holes)
+ if seg_fill_in is not None:
+ assert (isinstance(seg_fill_in, int) and 0 <= seg_fill_in
+ and seg_fill_in <= 255)
+ self.prob = prob
+ self.n_holes = n_holes
+ self.fill_in = fill_in
+ self.seg_fill_in = seg_fill_in
+ self.with_ratio = cutout_ratio is not None
+ self.candidates = cutout_ratio if self.with_ratio else cutout_shape
+ if not isinstance(self.candidates, list):
+ self.candidates = [self.candidates]
+
+ def __call__(self, results):
+ """Call function to drop some regions of image."""
+ cutout = True if np.random.rand() < self.prob else False
+ if cutout:
+ h, w, c = results['img'].shape
+ n_holes = np.random.randint(self.n_holes[0], self.n_holes[1] + 1)
+ for _ in range(n_holes):
+ x1 = np.random.randint(0, w)
+ y1 = np.random.randint(0, h)
+ index = np.random.randint(0, len(self.candidates))
+ if not self.with_ratio:
+ cutout_w, cutout_h = self.candidates[index]
+ else:
+ cutout_w = int(self.candidates[index][0] * w)
+ cutout_h = int(self.candidates[index][1] * h)
+
+ x2 = np.clip(x1 + cutout_w, 0, w)
+ y2 = np.clip(y1 + cutout_h, 0, h)
+ results['img'][y1:y2, x1:x2, :] = self.fill_in
+
+ if self.seg_fill_in is not None:
+ for key in results.get('seg_fields', []):
+ results[key][y1:y2, x1:x2] = self.seg_fill_in
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, '
+ repr_str += f'n_holes={self.n_holes}, '
+ repr_str += (f'cutout_ratio={self.candidates}, ' if self.with_ratio
+ else f'cutout_shape={self.candidates}, ')
+ repr_str += f'fill_in={self.fill_in}, '
+ repr_str += f'seg_fill_in={self.seg_fill_in})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomMosaic(object):
+ """Mosaic augmentation. Given 4 images, mosaic transform combines them into
+ one output image. The output image is composed of the parts from each sub-
+ image.
+
+ .. code:: text
+
+ mosaic transform
+ center_x
+ +------------------------------+
+ | pad | pad |
+ | +-----------+ |
+ | | | |
+ | | image1 |--------+ |
+ | | | | |
+ | | | image2 | |
+ center_y |----+-------------+-----------|
+ | | cropped | |
+ |pad | image3 | image4 |
+ | | | |
+ +----|-------------+-----------+
+ | |
+ +-------------+
+
+ The mosaic transform steps are as follows:
+ 1. Choose the mosaic center as the intersections of 4 images
+ 2. Get the left top image according to the index, and randomly
+ sample another 3 images from the custom dataset.
+ 3. Sub image will be cropped if image is larger than mosaic patch
+
+ Args:
+ prob (float): mosaic probability.
+ img_scale (Sequence[int]): Image size after mosaic pipeline of
+ a single image. The size of the output image is four times
+ that of a single image. The output image comprises 4 single images.
+ Default: (640, 640).
+ center_ratio_range (Sequence[float]): Center ratio range of mosaic
+ output. Default: (0.5, 1.5).
+ pad_val (int): Pad value. Default: 0.
+ seg_pad_val (int): Pad value of segmentation map. Default: 255.
+ """
+
+ def __init__(self,
+ prob,
+ img_scale=(640, 640),
+ center_ratio_range=(0.5, 1.5),
+ pad_val=0,
+ seg_pad_val=255):
+ assert 0 <= prob and prob <= 1
+ assert isinstance(img_scale, tuple)
+ self.prob = prob
+ self.img_scale = img_scale
+ self.center_ratio_range = center_ratio_range
+ self.pad_val = pad_val
+ self.seg_pad_val = seg_pad_val
+
+ def __call__(self, results):
+ """Call function to make a mosaic of image.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Result dict with mosaic transformed.
+ """
+ mosaic = True if np.random.rand() < self.prob else False
+ if mosaic:
+ results = self._mosaic_transform_img(results)
+ results = self._mosaic_transform_seg(results)
+ return results
+
+ def get_indexes(self, dataset):
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`MultiImageMixDataset`): The dataset.
+
+ Returns:
+ list: indexes.
+ """
+
+ indexes = [random.randint(0, len(dataset)) for _ in range(3)]
+ return indexes
+
+ def _mosaic_transform_img(self, results):
+ """Mosaic transform function.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+
+ assert 'mix_results' in results
+ if len(results['img'].shape) == 3:
+ mosaic_img = np.full(
+ (int(self.img_scale[0] * 2), int(self.img_scale[1] * 2), 3),
+ self.pad_val,
+ dtype=results['img'].dtype)
+ else:
+ mosaic_img = np.full(
+ (int(self.img_scale[0] * 2), int(self.img_scale[1] * 2)),
+ self.pad_val,
+ dtype=results['img'].dtype)
+
+ # mosaic center x, y
+ self.center_x = int(
+ random.uniform(*self.center_ratio_range) * self.img_scale[1])
+ self.center_y = int(
+ random.uniform(*self.center_ratio_range) * self.img_scale[0])
+ center_position = (self.center_x, self.center_y)
+
+ loc_strs = ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ for i, loc in enumerate(loc_strs):
+ if loc == 'top_left':
+ result_patch = copy.deepcopy(results)
+ else:
+ result_patch = copy.deepcopy(results['mix_results'][i - 1])
+
+ img_i = result_patch['img']
+ h_i, w_i = img_i.shape[:2]
+ # keep_ratio resize
+ scale_ratio_i = min(self.img_scale[0] / h_i,
+ self.img_scale[1] / w_i)
+ img_i = mmcv.imresize(
+ img_i, (int(w_i * scale_ratio_i), int(h_i * scale_ratio_i)))
+
+ # compute the combine parameters
+ paste_coord, crop_coord = self._mosaic_combine(
+ loc, center_position, img_i.shape[:2][::-1])
+ x1_p, y1_p, x2_p, y2_p = paste_coord
+ x1_c, y1_c, x2_c, y2_c = crop_coord
+
+ # crop and paste image
+ mosaic_img[y1_p:y2_p, x1_p:x2_p] = img_i[y1_c:y2_c, x1_c:x2_c]
+
+ results['img'] = mosaic_img
+ results['img_shape'] = mosaic_img.shape
+ results['ori_shape'] = mosaic_img.shape
+
+ return results
+
+ def _mosaic_transform_seg(self, results):
+ """Mosaic transform function for label annotations.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+
+ assert 'mix_results' in results
+ for key in results.get('seg_fields', []):
+ mosaic_seg = np.full(
+ (int(self.img_scale[0] * 2), int(self.img_scale[1] * 2)),
+ self.seg_pad_val,
+ dtype=results[key].dtype)
+
+ # mosaic center x, y
+ center_position = (self.center_x, self.center_y)
+
+ loc_strs = ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ for i, loc in enumerate(loc_strs):
+ if loc == 'top_left':
+ result_patch = copy.deepcopy(results)
+ else:
+ result_patch = copy.deepcopy(results['mix_results'][i - 1])
+
+ gt_seg_i = result_patch[key]
+ h_i, w_i = gt_seg_i.shape[:2]
+ # keep_ratio resize
+ scale_ratio_i = min(self.img_scale[0] / h_i,
+ self.img_scale[1] / w_i)
+ gt_seg_i = mmcv.imresize(
+ gt_seg_i,
+ (int(w_i * scale_ratio_i), int(h_i * scale_ratio_i)),
+ interpolation='nearest')
+
+ # compute the combine parameters
+ paste_coord, crop_coord = self._mosaic_combine(
+ loc, center_position, gt_seg_i.shape[:2][::-1])
+ x1_p, y1_p, x2_p, y2_p = paste_coord
+ x1_c, y1_c, x2_c, y2_c = crop_coord
+
+ # crop and paste image
+ mosaic_seg[y1_p:y2_p, x1_p:x2_p] = gt_seg_i[y1_c:y2_c,
+ x1_c:x2_c]
+
+ results[key] = mosaic_seg
+
+ return results
+
+ def _mosaic_combine(self, loc, center_position_xy, img_shape_wh):
+ """Calculate global coordinate of mosaic image and local coordinate of
+ cropped sub-image.
+
+ Args:
+ loc (str): Index for the sub-image, loc in ('top_left',
+ 'top_right', 'bottom_left', 'bottom_right').
+ center_position_xy (Sequence[float]): Mixing center for 4 images,
+ (x, y).
+ img_shape_wh (Sequence[int]): Width and height of sub-image
+
+ Returns:
+ tuple[tuple[float]]: Corresponding coordinate of pasting and
+ cropping
+ - paste_coord (tuple): paste corner coordinate in mosaic image.
+ - crop_coord (tuple): crop corner coordinate in mosaic image.
+ """
+
+ assert loc in ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ if loc == 'top_left':
+ # index0 to top left part of image
+ x1, y1, x2, y2 = max(center_position_xy[0] - img_shape_wh[0], 0), \
+ max(center_position_xy[1] - img_shape_wh[1], 0), \
+ center_position_xy[0], \
+ center_position_xy[1]
+ crop_coord = img_shape_wh[0] - (x2 - x1), img_shape_wh[1] - (
+ y2 - y1), img_shape_wh[0], img_shape_wh[1]
+
+ elif loc == 'top_right':
+ # index1 to top right part of image
+ x1, y1, x2, y2 = center_position_xy[0], \
+ max(center_position_xy[1] - img_shape_wh[1], 0), \
+ min(center_position_xy[0] + img_shape_wh[0],
+ self.img_scale[1] * 2), \
+ center_position_xy[1]
+ crop_coord = 0, img_shape_wh[1] - (y2 - y1), min(
+ img_shape_wh[0], x2 - x1), img_shape_wh[1]
+
+ elif loc == 'bottom_left':
+ # index2 to bottom left part of image
+ x1, y1, x2, y2 = max(center_position_xy[0] - img_shape_wh[0], 0), \
+ center_position_xy[1], \
+ center_position_xy[0], \
+ min(self.img_scale[0] * 2, center_position_xy[1] +
+ img_shape_wh[1])
+ crop_coord = img_shape_wh[0] - (x2 - x1), 0, img_shape_wh[0], min(
+ y2 - y1, img_shape_wh[1])
+
+ else:
+ # index3 to bottom right part of image
+ x1, y1, x2, y2 = center_position_xy[0], \
+ center_position_xy[1], \
+ min(center_position_xy[0] + img_shape_wh[0],
+ self.img_scale[1] * 2), \
+ min(self.img_scale[0] * 2, center_position_xy[1] +
+ img_shape_wh[1])
+ crop_coord = 0, 0, min(img_shape_wh[0],
+ x2 - x1), min(y2 - y1, img_shape_wh[1])
+
+ paste_coord = x1, y1, x2, y2
+ return paste_coord, crop_coord
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, '
+ repr_str += f'img_scale={self.img_scale}, '
+ repr_str += f'center_ratio_range={self.center_ratio_range}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'seg_pad_val={self.pad_val})'
+ return repr_str
diff --git a/mmseg/datasets/potsdam.py b/mmseg/datasets/potsdam.py
new file mode 100644
index 0000000..2986b8f
--- /dev/null
+++ b/mmseg/datasets/potsdam.py
@@ -0,0 +1,25 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class PotsdamDataset(CustomDataset):
+ """ISPRS Potsdam dataset.
+
+ In segmentation map annotation for Potsdam dataset, 0 is the ignore index.
+ ``reduce_zero_label`` should be set to True. The ``img_suffix`` and
+ ``seg_map_suffix`` are both fixed to '.png'.
+ """
+ CLASSES = ('impervious_surface', 'building', 'low_vegetation', 'tree',
+ 'car', 'clutter')
+
+ PALETTE = [[255, 255, 255], [0, 0, 255], [0, 255, 255], [0, 255, 0],
+ [255, 255, 0], [255, 0, 0]]
+
+ def __init__(self, **kwargs):
+ super(PotsdamDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=True,
+ **kwargs)
diff --git a/mmseg/datasets/stare.py b/mmseg/datasets/stare.py
new file mode 100644
index 0000000..a24d1d9
--- /dev/null
+++ b/mmseg/datasets/stare.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class STAREDataset(CustomDataset):
+ """STARE dataset.
+
+ In segmentation map annotation for STARE, 0 stands for background, which is
+ included in 2 categories. ``reduce_zero_label`` is fixed to False. The
+ ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
+ '.ah.png'.
+ """
+
+ CLASSES = ('background', 'vessel')
+
+ PALETTE = [[120, 120, 120], [6, 230, 230]]
+
+ def __init__(self, **kwargs):
+ super(STAREDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.ah.png',
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir)
diff --git a/mmseg/datasets/voc.py b/mmseg/datasets/voc.py
new file mode 100644
index 0000000..3cec9e3
--- /dev/null
+++ b/mmseg/datasets/voc.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class PascalVOCDataset(CustomDataset):
+ """Pascal VOC dataset.
+
+ Args:
+ split (str): Split txt file for Pascal VOC.
+ """
+
+ CLASSES = ('background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle',
+ 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
+ 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa',
+ 'train', 'tvmonitor')
+
+ PALETTE = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
+ [128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0],
+ [192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128],
+ [192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0],
+ [128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]]
+
+ def __init__(self, split, **kwargs):
+ super(PascalVOCDataset, self).__init__(
+ img_suffix='.jpg', seg_map_suffix='.png', split=split, **kwargs)
+ assert osp.exists(self.img_dir) and self.split is not None
diff --git a/mmseg/models/__init__.py b/mmseg/models/__init__.py
new file mode 100644
index 0000000..87d8108
--- /dev/null
+++ b/mmseg/models/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .backbones import * # noqa: F401,F403
+from .builder import (BACKBONES, HEADS, LOSSES, SEGMENTORS, build_backbone,
+ build_head, build_loss, build_segmentor)
+from .decode_heads import * # noqa: F401,F403
+from .losses import * # noqa: F401,F403
+from .necks import * # noqa: F401,F403
+from .segmentors import * # noqa: F401,F403
+
+__all__ = [
+ 'BACKBONES', 'HEADS', 'LOSSES', 'SEGMENTORS', 'build_backbone',
+ 'build_head', 'build_loss', 'build_segmentor'
+]
diff --git a/mmseg/models/backbones/__init__.py b/mmseg/models/backbones/__init__.py
new file mode 100644
index 0000000..434378e
--- /dev/null
+++ b/mmseg/models/backbones/__init__.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bisenetv1 import BiSeNetV1
+from .bisenetv2 import BiSeNetV2
+from .cgnet import CGNet
+from .erfnet import ERFNet
+from .fast_scnn import FastSCNN
+from .hrnet import HRNet
+from .icnet import ICNet
+from .mit import MixVisionTransformer
+from .mobilenet_v2 import MobileNetV2
+from .mobilenet_v3 import MobileNetV3
+from .resnest import ResNeSt
+from .resnet import ResNet, ResNetV1c, ResNetV1d
+from .resnext import ResNeXt
+from .stdc import STDCContextPathNet, STDCNet
+from .swin import SwinTransformer
+from .timm_backbone import TIMMBackbone
+from .twins import PCPVT, SVT
+from .unet import UNet
+from .vit import VisionTransformer
+
+__all__ = [
+ 'ResNet', 'ResNetV1c', 'ResNetV1d', 'ResNeXt', 'HRNet', 'FastSCNN',
+ 'ResNeSt', 'MobileNetV2', 'UNet', 'CGNet', 'MobileNetV3',
+ 'VisionTransformer', 'SwinTransformer', 'MixVisionTransformer',
+ 'BiSeNetV1', 'BiSeNetV2', 'ICNet', 'TIMMBackbone', 'ERFNet', 'PCPVT',
+ 'SVT', 'STDCNet', 'STDCContextPathNet'
+]
diff --git a/mmseg/models/backbones/bisenetv1.py b/mmseg/models/backbones/bisenetv1.py
new file mode 100644
index 0000000..4beb7b3
--- /dev/null
+++ b/mmseg/models/backbones/bisenetv1.py
@@ -0,0 +1,332 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import BACKBONES, build_backbone
+
+
+class SpatialPath(BaseModule):
+ """Spatial Path to preserve the spatial size of the original input image
+ and encode affluent spatial information.
+
+ Args:
+ in_channels(int): The number of channels of input
+ image. Default: 3.
+ num_channels (Tuple[int]): The number of channels of
+ each layers in Spatial Path.
+ Default: (64, 64, 64, 128).
+ Returns:
+ x (torch.Tensor): Feature map for Feature Fusion Module.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ num_channels=(64, 64, 64, 128),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(SpatialPath, self).__init__(init_cfg=init_cfg)
+ assert len(num_channels) == 4, 'Length of input channels \
+ of Spatial Path must be 4!'
+
+ self.layers = []
+ for i in range(len(num_channels)):
+ layer_name = f'layer{i + 1}'
+ self.layers.append(layer_name)
+ if i == 0:
+ self.add_module(
+ layer_name,
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=num_channels[i],
+ kernel_size=7,
+ stride=2,
+ padding=3,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ elif i == len(num_channels) - 1:
+ self.add_module(
+ layer_name,
+ ConvModule(
+ in_channels=num_channels[i - 1],
+ out_channels=num_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ else:
+ self.add_module(
+ layer_name,
+ ConvModule(
+ in_channels=num_channels[i - 1],
+ out_channels=num_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, x):
+ for i, layer_name in enumerate(self.layers):
+ layer_stage = getattr(self, layer_name)
+ x = layer_stage(x)
+ return x
+
+
+class AttentionRefinementModule(BaseModule):
+ """Attention Refinement Module (ARM) to refine the features of each stage.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ Returns:
+ x_out (torch.Tensor): Feature map of Attention Refinement Module.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channel,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(AttentionRefinementModule, self).__init__(init_cfg=init_cfg)
+ self.conv_layer = ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channel,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.atten_conv_layer = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ ConvModule(
+ in_channels=out_channel,
+ out_channels=out_channel,
+ kernel_size=1,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None), nn.Sigmoid())
+
+ def forward(self, x):
+ x = self.conv_layer(x)
+ x_atten = self.atten_conv_layer(x)
+ x_out = x * x_atten
+ return x_out
+
+
+class ContextPath(BaseModule):
+ """Context Path to provide sufficient receptive field.
+
+ Args:
+ backbone_cfg:(dict): Config of backbone of
+ Context Path.
+ context_channels (Tuple[int]): The number of channel numbers
+ of various modules in Context Path.
+ Default: (128, 256, 512).
+ align_corners (bool, optional): The align_corners argument of
+ resize operation. Default: False.
+ Returns:
+ x_16_up, x_32_up (torch.Tensor, torch.Tensor): Two feature maps
+ undergoing upsampling from 1/16 and 1/32 downsampling
+ feature maps. These two feature maps are used for Feature
+ Fusion Module and Auxiliary Head.
+ """
+
+ def __init__(self,
+ backbone_cfg,
+ context_channels=(128, 256, 512),
+ align_corners=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(ContextPath, self).__init__(init_cfg=init_cfg)
+ assert len(context_channels) == 3, 'Length of input channels \
+ of Context Path must be 3!'
+
+ self.backbone = build_backbone(backbone_cfg)
+
+ self.align_corners = align_corners
+ self.arm16 = AttentionRefinementModule(context_channels[1],
+ context_channels[0])
+ self.arm32 = AttentionRefinementModule(context_channels[2],
+ context_channels[0])
+ self.conv_head32 = ConvModule(
+ in_channels=context_channels[0],
+ out_channels=context_channels[0],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv_head16 = ConvModule(
+ in_channels=context_channels[0],
+ out_channels=context_channels[0],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.gap_conv = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ ConvModule(
+ in_channels=context_channels[2],
+ out_channels=context_channels[0],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, x):
+ x_4, x_8, x_16, x_32 = self.backbone(x)
+ x_gap = self.gap_conv(x_32)
+
+ x_32_arm = self.arm32(x_32)
+ x_32_sum = x_32_arm + x_gap
+ x_32_up = resize(input=x_32_sum, size=x_16.shape[2:], mode='nearest')
+ x_32_up = self.conv_head32(x_32_up)
+
+ x_16_arm = self.arm16(x_16)
+ x_16_sum = x_16_arm + x_32_up
+ x_16_up = resize(input=x_16_sum, size=x_8.shape[2:], mode='nearest')
+ x_16_up = self.conv_head16(x_16_up)
+
+ return x_16_up, x_32_up
+
+
+class FeatureFusionModule(BaseModule):
+ """Feature Fusion Module to fuse low level output feature of Spatial Path
+ and high level output feature of Context Path.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ Returns:
+ x_out (torch.Tensor): Feature map of Feature Fusion Module.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(FeatureFusionModule, self).__init__(init_cfg=init_cfg)
+ self.conv1 = ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.gap = nn.AdaptiveAvgPool2d((1, 1))
+ self.conv_atten = nn.Sequential(
+ ConvModule(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg), nn.Sigmoid())
+
+ def forward(self, x_sp, x_cp):
+ x_concat = torch.cat([x_sp, x_cp], dim=1)
+ x_fuse = self.conv1(x_concat)
+ x_atten = self.gap(x_fuse)
+ # Note: No BN and more 1x1 conv in paper.
+ x_atten = self.conv_atten(x_atten)
+ x_atten = x_fuse * x_atten
+ x_out = x_atten + x_fuse
+ return x_out
+
+
+@BACKBONES.register_module()
+class BiSeNetV1(BaseModule):
+ """BiSeNetV1 backbone.
+
+ This backbone is the implementation of `BiSeNet: Bilateral
+ Segmentation Network for Real-time Semantic
+ Segmentation `_.
+
+ Args:
+ backbone_cfg:(dict): Config of backbone of
+ Context Path.
+ in_channels (int): The number of channels of input
+ image. Default: 3.
+ spatial_channels (Tuple[int]): Size of channel numbers of
+ various layers in Spatial Path.
+ Default: (64, 64, 64, 128).
+ context_channels (Tuple[int]): Size of channel numbers of
+ various modules in Context Path.
+ Default: (128, 256, 512).
+ out_indices (Tuple[int] | int, optional): Output from which stages.
+ Default: (0, 1, 2).
+ align_corners (bool, optional): The align_corners argument of
+ resize operation in Bilateral Guided Aggregation Layer.
+ Default: False.
+ out_channels(int): The number of channels of output.
+ It must be the same with `in_channels` of decode_head.
+ Default: 256.
+ """
+
+ def __init__(self,
+ backbone_cfg,
+ in_channels=3,
+ spatial_channels=(64, 64, 64, 128),
+ context_channels=(128, 256, 512),
+ out_indices=(0, 1, 2),
+ align_corners=False,
+ out_channels=256,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+
+ super(BiSeNetV1, self).__init__(init_cfg=init_cfg)
+ assert len(spatial_channels) == 4, 'Length of input channels \
+ of Spatial Path must be 4!'
+
+ assert len(context_channels) == 3, 'Length of input channels \
+ of Context Path must be 3!'
+
+ self.out_indices = out_indices
+ self.align_corners = align_corners
+ self.context_path = ContextPath(backbone_cfg, context_channels,
+ self.align_corners)
+ self.spatial_path = SpatialPath(in_channels, spatial_channels)
+ self.ffm = FeatureFusionModule(context_channels[1], out_channels)
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ def forward(self, x):
+ # stole refactoring code from Coin Cheung, thanks
+ x_context8, x_context16 = self.context_path(x)
+ x_spatial = self.spatial_path(x)
+ x_fuse = self.ffm(x_spatial, x_context8)
+
+ outs = [x_fuse, x_context8, x_context16]
+ outs = [outs[i] for i in self.out_indices]
+ return tuple(outs)
diff --git a/mmseg/models/backbones/bisenetv2.py b/mmseg/models/backbones/bisenetv2.py
new file mode 100644
index 0000000..d908b32
--- /dev/null
+++ b/mmseg/models/backbones/bisenetv2.py
@@ -0,0 +1,622 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import (ConvModule, DepthwiseSeparableConvModule,
+ build_activation_layer, build_norm_layer)
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import BACKBONES
+
+
+class DetailBranch(BaseModule):
+ """Detail Branch with wide channels and shallow layers to capture low-level
+ details and generate high-resolution feature representation.
+
+ Args:
+ detail_channels (Tuple[int]): Size of channel numbers of each stage
+ in Detail Branch, in paper it has 3 stages.
+ Default: (64, 64, 128).
+ in_channels (int): Number of channels of input image. Default: 3.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ x (torch.Tensor): Feature map of Detail Branch.
+ """
+
+ def __init__(self,
+ detail_channels=(64, 64, 128),
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(DetailBranch, self).__init__(init_cfg=init_cfg)
+ detail_branch = []
+ for i in range(len(detail_channels)):
+ if i == 0:
+ detail_branch.append(
+ nn.Sequential(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ in_channels=detail_channels[i],
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)))
+ else:
+ detail_branch.append(
+ nn.Sequential(
+ ConvModule(
+ in_channels=detail_channels[i - 1],
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ in_channels=detail_channels[i],
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ in_channels=detail_channels[i],
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)))
+ self.detail_branch = nn.ModuleList(detail_branch)
+
+ def forward(self, x):
+ for stage in self.detail_branch:
+ x = stage(x)
+ return x
+
+
+class StemBlock(BaseModule):
+ """Stem Block at the beginning of Semantic Branch.
+
+ Args:
+ in_channels (int): Number of input channels.
+ Default: 3.
+ out_channels (int): Number of output channels.
+ Default: 16.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ x (torch.Tensor): First feature map in Semantic Branch.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ out_channels=16,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(StemBlock, self).__init__(init_cfg=init_cfg)
+
+ self.conv_first = ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.convs = nn.Sequential(
+ ConvModule(
+ in_channels=out_channels,
+ out_channels=out_channels // 2,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ in_channels=out_channels // 2,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.pool = nn.MaxPool2d(
+ kernel_size=3, stride=2, padding=1, ceil_mode=False)
+ self.fuse_last = ConvModule(
+ in_channels=out_channels * 2,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ x = self.conv_first(x)
+ x_left = self.convs(x)
+ x_right = self.pool(x)
+ x = self.fuse_last(torch.cat([x_left, x_right], dim=1))
+ return x
+
+
+class GELayer(BaseModule):
+ """Gather-and-Expansion Layer.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ exp_ratio (int): Expansion ratio for middle channels.
+ Default: 6.
+ stride (int): Stride of GELayer. Default: 1
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ x (torch.Tensor): Intermediate feature map in
+ Semantic Branch.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ exp_ratio=6,
+ stride=1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(GELayer, self).__init__(init_cfg=init_cfg)
+ mid_channel = in_channels * exp_ratio
+ self.conv1 = ConvModule(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ if stride == 1:
+ self.dwconv = nn.Sequential(
+ # ReLU in ConvModule not shown in paper
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=mid_channel,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=in_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.shortcut = None
+ else:
+ self.dwconv = nn.Sequential(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=mid_channel,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=in_channels,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ # ReLU in ConvModule not shown in paper
+ ConvModule(
+ in_channels=mid_channel,
+ out_channels=mid_channel,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ groups=mid_channel,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ )
+ self.shortcut = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ dw_norm_cfg=norm_cfg,
+ dw_act_cfg=None,
+ pw_norm_cfg=norm_cfg,
+ pw_act_cfg=None,
+ ))
+
+ self.conv2 = nn.Sequential(
+ ConvModule(
+ in_channels=mid_channel,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None,
+ ))
+
+ self.act = build_activation_layer(act_cfg)
+
+ def forward(self, x):
+ identity = x
+ x = self.conv1(x)
+ x = self.dwconv(x)
+ x = self.conv2(x)
+ if self.shortcut is not None:
+ shortcut = self.shortcut(identity)
+ x = x + shortcut
+ else:
+ x = x + identity
+ x = self.act(x)
+ return x
+
+
+class CEBlock(BaseModule):
+ """Context Embedding Block for large receptive filed in Semantic Branch.
+
+ Args:
+ in_channels (int): Number of input channels.
+ Default: 3.
+ out_channels (int): Number of output channels.
+ Default: 16.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ x (torch.Tensor): Last feature map in Semantic Branch.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ out_channels=16,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(CEBlock, self).__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.gap = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ build_norm_layer(norm_cfg, self.in_channels)[1])
+ self.conv_gap = ConvModule(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ # Note: in paper here is naive conv2d, no bn-relu
+ self.conv_last = ConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ identity = x
+ x = self.gap(x)
+ x = self.conv_gap(x)
+ x = identity + x
+ x = self.conv_last(x)
+ return x
+
+
+class SemanticBranch(BaseModule):
+ """Semantic Branch which is lightweight with narrow channels and deep
+ layers to obtain high-level semantic context.
+
+ Args:
+ semantic_channels(Tuple[int]): Size of channel numbers of
+ various stages in Semantic Branch.
+ Default: (16, 32, 64, 128).
+ in_channels (int): Number of channels of input image. Default: 3.
+ exp_ratio (int): Expansion ratio for middle channels.
+ Default: 6.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ semantic_outs (List[torch.Tensor]): List of several feature maps
+ for auxiliary heads (Booster) and Bilateral
+ Guided Aggregation Layer.
+ """
+
+ def __init__(self,
+ semantic_channels=(16, 32, 64, 128),
+ in_channels=3,
+ exp_ratio=6,
+ init_cfg=None):
+ super(SemanticBranch, self).__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.semantic_channels = semantic_channels
+ self.semantic_stages = []
+ for i in range(len(semantic_channels)):
+ stage_name = f'stage{i + 1}'
+ self.semantic_stages.append(stage_name)
+ if i == 0:
+ self.add_module(
+ stage_name,
+ StemBlock(self.in_channels, semantic_channels[i]))
+ elif i == (len(semantic_channels) - 1):
+ self.add_module(
+ stage_name,
+ nn.Sequential(
+ GELayer(semantic_channels[i - 1], semantic_channels[i],
+ exp_ratio, 2),
+ GELayer(semantic_channels[i], semantic_channels[i],
+ exp_ratio, 1),
+ GELayer(semantic_channels[i], semantic_channels[i],
+ exp_ratio, 1),
+ GELayer(semantic_channels[i], semantic_channels[i],
+ exp_ratio, 1)))
+ else:
+ self.add_module(
+ stage_name,
+ nn.Sequential(
+ GELayer(semantic_channels[i - 1], semantic_channels[i],
+ exp_ratio, 2),
+ GELayer(semantic_channels[i], semantic_channels[i],
+ exp_ratio, 1)))
+
+ self.add_module(f'stage{len(semantic_channels)}_CEBlock',
+ CEBlock(semantic_channels[-1], semantic_channels[-1]))
+ self.semantic_stages.append(f'stage{len(semantic_channels)}_CEBlock')
+
+ def forward(self, x):
+ semantic_outs = []
+ for stage_name in self.semantic_stages:
+ semantic_stage = getattr(self, stage_name)
+ x = semantic_stage(x)
+ semantic_outs.append(x)
+ return semantic_outs
+
+
+class BGALayer(BaseModule):
+ """Bilateral Guided Aggregation Layer to fuse the complementary information
+ from both Detail Branch and Semantic Branch.
+
+ Args:
+ out_channels (int): Number of output channels.
+ Default: 128.
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ output (torch.Tensor): Output feature map for Segment heads.
+ """
+
+ def __init__(self,
+ out_channels=128,
+ align_corners=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(BGALayer, self).__init__(init_cfg=init_cfg)
+ self.out_channels = out_channels
+ self.align_corners = align_corners
+ self.detail_dwconv = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ dw_norm_cfg=norm_cfg,
+ dw_act_cfg=None,
+ pw_norm_cfg=None,
+ pw_act_cfg=None,
+ ))
+ self.detail_down = nn.Sequential(
+ ConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ nn.AvgPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False))
+ self.semantic_conv = nn.Sequential(
+ ConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None))
+ self.semantic_dwconv = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ dw_norm_cfg=norm_cfg,
+ dw_act_cfg=None,
+ pw_norm_cfg=None,
+ pw_act_cfg=None,
+ ))
+ self.conv = ConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ inplace=True,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ )
+
+ def forward(self, x_d, x_s):
+ detail_dwconv = self.detail_dwconv(x_d)
+ detail_down = self.detail_down(x_d)
+ semantic_conv = self.semantic_conv(x_s)
+ semantic_dwconv = self.semantic_dwconv(x_s)
+ semantic_conv = resize(
+ input=semantic_conv,
+ size=detail_dwconv.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ fuse_1 = detail_dwconv * torch.sigmoid(semantic_conv)
+ fuse_2 = detail_down * torch.sigmoid(semantic_dwconv)
+ fuse_2 = resize(
+ input=fuse_2,
+ size=fuse_1.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ output = self.conv(fuse_1 + fuse_2)
+ return output
+
+
+@BACKBONES.register_module()
+class BiSeNetV2(BaseModule):
+ """BiSeNetV2: Bilateral Network with Guided Aggregation for
+ Real-time Semantic Segmentation.
+
+ This backbone is the implementation of
+ `BiSeNetV2 `_.
+
+ Args:
+ in_channels (int): Number of channel of input image. Default: 3.
+ detail_channels (Tuple[int], optional): Channels of each stage
+ in Detail Branch. Default: (64, 64, 128).
+ semantic_channels (Tuple[int], optional): Channels of each stage
+ in Semantic Branch. Default: (16, 32, 64, 128).
+ See Table 1 and Figure 3 of paper for more details.
+ semantic_expansion_ratio (int, optional): The expansion factor
+ expanding channel number of middle channels in Semantic Branch.
+ Default: 6.
+ bga_channels (int, optional): Number of middle channels in
+ Bilateral Guided Aggregation Layer. Default: 128.
+ out_indices (Tuple[int] | int, optional): Output from which stages.
+ Default: (0, 1, 2, 3, 4).
+ align_corners (bool, optional): The align_corners argument of
+ resize operation in Bilateral Guided Aggregation Layer.
+ Default: False.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ detail_channels=(64, 64, 128),
+ semantic_channels=(16, 32, 64, 128),
+ semantic_expansion_ratio=6,
+ bga_channels=128,
+ out_indices=(0, 1, 2, 3, 4),
+ align_corners=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ if init_cfg is None:
+ init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ super(BiSeNetV2, self).__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_indices = out_indices
+ self.detail_channels = detail_channels
+ self.semantic_channels = semantic_channels
+ self.semantic_expansion_ratio = semantic_expansion_ratio
+ self.bga_channels = bga_channels
+ self.align_corners = align_corners
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.detail = DetailBranch(self.detail_channels, self.in_channels)
+ self.semantic = SemanticBranch(self.semantic_channels,
+ self.in_channels,
+ self.semantic_expansion_ratio)
+ self.bga = BGALayer(self.bga_channels, self.align_corners)
+
+ def forward(self, x):
+ # stole refactoring code from Coin Cheung, thanks
+ x_detail = self.detail(x)
+ x_semantic_lst = self.semantic(x)
+ x_head = self.bga(x_detail, x_semantic_lst[-1])
+ outs = [x_head] + x_semantic_lst[:-1]
+ outs = [outs[i] for i in self.out_indices]
+ return tuple(outs)
diff --git a/mmseg/models/backbones/cgnet.py b/mmseg/models/backbones/cgnet.py
new file mode 100644
index 0000000..168194c
--- /dev/null
+++ b/mmseg/models/backbones/cgnet.py
@@ -0,0 +1,372 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule, build_conv_layer, build_norm_layer
+from mmcv.runner import BaseModule
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from ..builder import BACKBONES
+
+
+class GlobalContextExtractor(nn.Module):
+ """Global Context Extractor for CGNet.
+
+ This class is employed to refine the joint feature of both local feature
+ and surrounding context.
+
+ Args:
+ channel (int): Number of input feature channels.
+ reduction (int): Reductions for global context extractor. Default: 16.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ """
+
+ def __init__(self, channel, reduction=16, with_cp=False):
+ super(GlobalContextExtractor, self).__init__()
+ self.channel = channel
+ self.reduction = reduction
+ assert reduction >= 1 and channel >= reduction
+ self.with_cp = with_cp
+ self.avg_pool = nn.AdaptiveAvgPool2d(1)
+ self.fc = nn.Sequential(
+ nn.Linear(channel, channel // reduction), nn.ReLU(inplace=True),
+ nn.Linear(channel // reduction, channel), nn.Sigmoid())
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ num_batch, num_channel = x.size()[:2]
+ y = self.avg_pool(x).view(num_batch, num_channel)
+ y = self.fc(y).view(num_batch, num_channel, 1, 1)
+ return x * y
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class ContextGuidedBlock(nn.Module):
+ """Context Guided Block for CGNet.
+
+ This class consists of four components: local feature extractor,
+ surrounding feature extractor, joint feature extractor and global
+ context extractor.
+
+ Args:
+ in_channels (int): Number of input feature channels.
+ out_channels (int): Number of output feature channels.
+ dilation (int): Dilation rate for surrounding context extractor.
+ Default: 2.
+ reduction (int): Reduction for global context extractor. Default: 16.
+ skip_connect (bool): Add input to output or not. Default: True.
+ downsample (bool): Downsample the input to 1/2 or not. Default: False.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN', requires_grad=True).
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='PReLU').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ dilation=2,
+ reduction=16,
+ skip_connect=True,
+ downsample=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='PReLU'),
+ with_cp=False):
+ super(ContextGuidedBlock, self).__init__()
+ self.with_cp = with_cp
+ self.downsample = downsample
+
+ channels = out_channels if downsample else out_channels // 2
+ if 'type' in act_cfg and act_cfg['type'] == 'PReLU':
+ act_cfg['num_parameters'] = channels
+ kernel_size = 3 if downsample else 1
+ stride = 2 if downsample else 1
+ padding = (kernel_size - 1) // 2
+
+ self.conv1x1 = ConvModule(
+ in_channels,
+ channels,
+ kernel_size,
+ stride,
+ padding,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.f_loc = build_conv_layer(
+ conv_cfg,
+ channels,
+ channels,
+ kernel_size=3,
+ padding=1,
+ groups=channels,
+ bias=False)
+ self.f_sur = build_conv_layer(
+ conv_cfg,
+ channels,
+ channels,
+ kernel_size=3,
+ padding=dilation,
+ groups=channels,
+ dilation=dilation,
+ bias=False)
+
+ self.bn = build_norm_layer(norm_cfg, 2 * channels)[1]
+ self.activate = nn.PReLU(2 * channels)
+
+ if downsample:
+ self.bottleneck = build_conv_layer(
+ conv_cfg,
+ 2 * channels,
+ out_channels,
+ kernel_size=1,
+ bias=False)
+
+ self.skip_connect = skip_connect and not downsample
+ self.f_glo = GlobalContextExtractor(out_channels, reduction, with_cp)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ out = self.conv1x1(x)
+ loc = self.f_loc(out)
+ sur = self.f_sur(out)
+
+ joi_feat = torch.cat([loc, sur], 1) # the joint feature
+ joi_feat = self.bn(joi_feat)
+ joi_feat = self.activate(joi_feat)
+ if self.downsample:
+ joi_feat = self.bottleneck(joi_feat) # channel = out_channels
+ # f_glo is employed to refine the joint feature
+ out = self.f_glo(joi_feat)
+
+ if self.skip_connect:
+ return x + out
+ else:
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class InputInjection(nn.Module):
+ """Downsampling module for CGNet."""
+
+ def __init__(self, num_downsampling):
+ super(InputInjection, self).__init__()
+ self.pool = nn.ModuleList()
+ for i in range(num_downsampling):
+ self.pool.append(nn.AvgPool2d(3, stride=2, padding=1))
+
+ def forward(self, x):
+ for pool in self.pool:
+ x = pool(x)
+ return x
+
+
+@BACKBONES.register_module()
+class CGNet(BaseModule):
+ """CGNet backbone.
+
+ This backbone is the implementation of `A Light-weight Context Guided
+ Network for Semantic Segmentation `_.
+
+ Args:
+ in_channels (int): Number of input image channels. Normally 3.
+ num_channels (tuple[int]): Numbers of feature channels at each stages.
+ Default: (32, 64, 128).
+ num_blocks (tuple[int]): Numbers of CG blocks at stage 1 and stage 2.
+ Default: (3, 21).
+ dilations (tuple[int]): Dilation rate for surrounding context
+ extractors at stage 1 and stage 2. Default: (2, 4).
+ reductions (tuple[int]): Reductions for global context extractors at
+ stage 1 and stage 2. Default: (8, 16).
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN', requires_grad=True).
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='PReLU').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels=3,
+ num_channels=(32, 64, 128),
+ num_blocks=(3, 21),
+ dilations=(2, 4),
+ reductions=(8, 16),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='PReLU'),
+ norm_eval=False,
+ with_cp=False,
+ pretrained=None,
+ init_cfg=None):
+
+ super(CGNet, self).__init__(init_cfg)
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer=['Conv2d', 'Linear']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm']),
+ dict(type='Constant', val=0, layer='PReLU')
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.in_channels = in_channels
+ self.num_channels = num_channels
+ assert isinstance(self.num_channels, tuple) and len(
+ self.num_channels) == 3
+ self.num_blocks = num_blocks
+ assert isinstance(self.num_blocks, tuple) and len(self.num_blocks) == 2
+ self.dilations = dilations
+ assert isinstance(self.dilations, tuple) and len(self.dilations) == 2
+ self.reductions = reductions
+ assert isinstance(self.reductions, tuple) and len(self.reductions) == 2
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ if 'type' in self.act_cfg and self.act_cfg['type'] == 'PReLU':
+ self.act_cfg['num_parameters'] = num_channels[0]
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ cur_channels = in_channels
+ self.stem = nn.ModuleList()
+ for i in range(3):
+ self.stem.append(
+ ConvModule(
+ cur_channels,
+ num_channels[0],
+ 3,
+ 2 if i == 0 else 1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ cur_channels = num_channels[0]
+
+ self.inject_2x = InputInjection(1) # down-sample for Input, factor=2
+ self.inject_4x = InputInjection(2) # down-sample for Input, factor=4
+
+ cur_channels += in_channels
+ self.norm_prelu_0 = nn.Sequential(
+ build_norm_layer(norm_cfg, cur_channels)[1],
+ nn.PReLU(cur_channels))
+
+ # stage 1
+ self.level1 = nn.ModuleList()
+ for i in range(num_blocks[0]):
+ self.level1.append(
+ ContextGuidedBlock(
+ cur_channels if i == 0 else num_channels[1],
+ num_channels[1],
+ dilations[0],
+ reductions[0],
+ downsample=(i == 0),
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ with_cp=with_cp)) # CG block
+
+ cur_channels = 2 * num_channels[1] + in_channels
+ self.norm_prelu_1 = nn.Sequential(
+ build_norm_layer(norm_cfg, cur_channels)[1],
+ nn.PReLU(cur_channels))
+
+ # stage 2
+ self.level2 = nn.ModuleList()
+ for i in range(num_blocks[1]):
+ self.level2.append(
+ ContextGuidedBlock(
+ cur_channels if i == 0 else num_channels[2],
+ num_channels[2],
+ dilations[1],
+ reductions[1],
+ downsample=(i == 0),
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ with_cp=with_cp)) # CG block
+
+ cur_channels = 2 * num_channels[2]
+ self.norm_prelu_2 = nn.Sequential(
+ build_norm_layer(norm_cfg, cur_channels)[1],
+ nn.PReLU(cur_channels))
+
+ def forward(self, x):
+ output = []
+
+ # stage 0
+ inp_2x = self.inject_2x(x)
+ inp_4x = self.inject_4x(x)
+ for layer in self.stem:
+ x = layer(x)
+ x = self.norm_prelu_0(torch.cat([x, inp_2x], 1))
+ output.append(x)
+
+ # stage 1
+ for i, layer in enumerate(self.level1):
+ x = layer(x)
+ if i == 0:
+ down1 = x
+ x = self.norm_prelu_1(torch.cat([x, down1, inp_4x], 1))
+ output.append(x)
+
+ # stage 2
+ for i, layer in enumerate(self.level2):
+ x = layer(x)
+ if i == 0:
+ down2 = x
+ x = self.norm_prelu_2(torch.cat([down2, x], 1))
+ output.append(x)
+
+ return output
+
+ def train(self, mode=True):
+ """Convert the model into training mode will keeping the normalization
+ layer freezed."""
+ super(CGNet, self).train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmseg/models/backbones/erfnet.py b/mmseg/models/backbones/erfnet.py
new file mode 100644
index 0000000..8921c18
--- /dev/null
+++ b/mmseg/models/backbones/erfnet.py
@@ -0,0 +1,329 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_activation_layer, build_conv_layer, build_norm_layer
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import BACKBONES
+
+
+class DownsamplerBlock(BaseModule):
+ """Downsampler block of ERFNet.
+
+ This module is a little different from basical ConvModule.
+ The features from Conv and MaxPool layers are
+ concatenated before BatchNorm.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', eps=1e-3),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(DownsamplerBlock, self).__init__(init_cfg=init_cfg)
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.conv = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels - in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1)
+ self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
+ self.bn = build_norm_layer(self.norm_cfg, out_channels)[1]
+ self.act = build_activation_layer(self.act_cfg)
+
+ def forward(self, input):
+ conv_out = self.conv(input)
+ pool_out = self.pool(input)
+ pool_out = resize(
+ input=pool_out,
+ size=conv_out.size()[2:],
+ mode='bilinear',
+ align_corners=False)
+ output = torch.cat([conv_out, pool_out], 1)
+ output = self.bn(output)
+ output = self.act(output)
+ return output
+
+
+class NonBottleneck1d(BaseModule):
+ """Non-bottleneck block of ERFNet.
+
+ Args:
+ channels (int): Number of channels in Non-bottleneck block.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.
+ dilation (int): Dilation rate for last two conv layers.
+ Default 1.
+ num_conv_layer (int): Number of 3x1 and 1x3 convolution layers.
+ Default 2.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ channels,
+ drop_rate=0,
+ dilation=1,
+ num_conv_layer=2,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', eps=1e-3),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(NonBottleneck1d, self).__init__(init_cfg=init_cfg)
+
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.act = build_activation_layer(self.act_cfg)
+
+ self.convs_layers = nn.ModuleList()
+ for conv_layer in range(num_conv_layer):
+ first_conv_padding = (1, 0) if conv_layer == 0 else (dilation, 0)
+ first_conv_dilation = 1 if conv_layer == 0 else (dilation, 1)
+ second_conv_padding = (0, 1) if conv_layer == 0 else (0, dilation)
+ second_conv_dilation = 1 if conv_layer == 0 else (1, dilation)
+
+ self.convs_layers.append(
+ build_conv_layer(
+ self.conv_cfg,
+ channels,
+ channels,
+ kernel_size=(3, 1),
+ stride=1,
+ padding=first_conv_padding,
+ bias=True,
+ dilation=first_conv_dilation))
+ self.convs_layers.append(self.act)
+ self.convs_layers.append(
+ build_conv_layer(
+ self.conv_cfg,
+ channels,
+ channels,
+ kernel_size=(1, 3),
+ stride=1,
+ padding=second_conv_padding,
+ bias=True,
+ dilation=second_conv_dilation))
+ self.convs_layers.append(
+ build_norm_layer(self.norm_cfg, channels)[1])
+ if conv_layer == 0:
+ self.convs_layers.append(self.act)
+ else:
+ self.convs_layers.append(nn.Dropout(p=drop_rate))
+
+ def forward(self, input):
+ output = input
+ for conv in self.convs_layers:
+ output = conv(output)
+ output = self.act(output + input)
+ return output
+
+
+class UpsamplerBlock(BaseModule):
+ """Upsampler block of ERFNet.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', eps=1e-3),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(UpsamplerBlock, self).__init__(init_cfg=init_cfg)
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.conv = nn.ConvTranspose2d(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ output_padding=1,
+ bias=True)
+ self.bn = build_norm_layer(self.norm_cfg, out_channels)[1]
+ self.act = build_activation_layer(self.act_cfg)
+
+ def forward(self, input):
+ output = self.conv(input)
+ output = self.bn(output)
+ output = self.act(output)
+ return output
+
+
+@BACKBONES.register_module()
+class ERFNet(BaseModule):
+ """ERFNet backbone.
+
+ This backbone is the implementation of `ERFNet: Efficient Residual
+ Factorized ConvNet for Real-time SemanticSegmentation
+ `_.
+
+ Args:
+ in_channels (int): The number of channels of input
+ image. Default: 3.
+ enc_downsample_channels (Tuple[int]): Size of channel
+ numbers of various Downsampler block in encoder.
+ Default: (16, 64, 128).
+ enc_stage_non_bottlenecks (Tuple[int]): Number of stages of
+ Non-bottleneck block in encoder.
+ Default: (5, 8).
+ enc_non_bottleneck_dilations (Tuple[int]): Dilation rate of each
+ stage of Non-bottleneck block of encoder.
+ Default: (2, 4, 8, 16).
+ enc_non_bottleneck_channels (Tuple[int]): Size of channel
+ numbers of various Non-bottleneck block in encoder.
+ Default: (64, 128).
+ dec_upsample_channels (Tuple[int]): Size of channel numbers of
+ various Deconvolution block in decoder.
+ Default: (64, 16).
+ dec_stages_non_bottleneck (Tuple[int]): Number of stages of
+ Non-bottleneck block in decoder.
+ Default: (2, 2).
+ dec_non_bottleneck_channels (Tuple[int]): Size of channel
+ numbers of various Non-bottleneck block in decoder.
+ Default: (64, 16).
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.1.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+
+ super(ERFNet, self).__init__(init_cfg=init_cfg)
+ assert len(enc_downsample_channels) \
+ == len(dec_upsample_channels)+1, 'Number of downsample\
+ block of encoder does not \
+ match number of upsample block of decoder!'
+ assert len(enc_downsample_channels) \
+ == len(enc_stage_non_bottlenecks)+1, 'Number of \
+ downsample block of encoder does not match \
+ number of Non-bottleneck block of encoder!'
+ assert len(enc_downsample_channels) \
+ == len(enc_non_bottleneck_channels)+1, 'Number of \
+ downsample block of encoder does not match \
+ number of channels of Non-bottleneck block of encoder!'
+ assert enc_stage_non_bottlenecks[-1] \
+ % len(enc_non_bottleneck_dilations) == 0, 'Number of \
+ Non-bottleneck block of encoder does not match \
+ number of Non-bottleneck block of encoder!'
+ assert len(dec_upsample_channels) \
+ == len(dec_stages_non_bottleneck), 'Number of \
+ upsample block of decoder does not match \
+ number of Non-bottleneck block of decoder!'
+ assert len(dec_stages_non_bottleneck) \
+ == len(dec_non_bottleneck_channels), 'Number of \
+ Non-bottleneck block of decoder does not match \
+ number of channels of Non-bottleneck block of decoder!'
+
+ self.in_channels = in_channels
+ self.enc_downsample_channels = enc_downsample_channels
+ self.enc_stage_non_bottlenecks = enc_stage_non_bottlenecks
+ self.enc_non_bottleneck_dilations = enc_non_bottleneck_dilations
+ self.enc_non_bottleneck_channels = enc_non_bottleneck_channels
+ self.dec_upsample_channels = dec_upsample_channels
+ self.dec_stages_non_bottleneck = dec_stages_non_bottleneck
+ self.dec_non_bottleneck_channels = dec_non_bottleneck_channels
+ self.dropout_ratio = dropout_ratio
+
+ self.encoder = nn.ModuleList()
+ self.decoder = nn.ModuleList()
+
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.encoder.append(
+ DownsamplerBlock(self.in_channels, enc_downsample_channels[0]))
+
+ for i in range(len(enc_downsample_channels) - 1):
+ self.encoder.append(
+ DownsamplerBlock(enc_downsample_channels[i],
+ enc_downsample_channels[i + 1]))
+ # Last part of encoder is some dilated NonBottleneck1d blocks.
+ if i == len(enc_downsample_channels) - 2:
+ iteration_times = int(enc_stage_non_bottlenecks[-1] /
+ len(enc_non_bottleneck_dilations))
+ for j in range(iteration_times):
+ for k in range(len(enc_non_bottleneck_dilations)):
+ self.encoder.append(
+ NonBottleneck1d(enc_downsample_channels[-1],
+ self.dropout_ratio,
+ enc_non_bottleneck_dilations[k]))
+ else:
+ for j in range(enc_stage_non_bottlenecks[i]):
+ self.encoder.append(
+ NonBottleneck1d(enc_downsample_channels[i + 1],
+ self.dropout_ratio))
+
+ for i in range(len(dec_upsample_channels)):
+ if i == 0:
+ self.decoder.append(
+ UpsamplerBlock(enc_downsample_channels[-1],
+ dec_non_bottleneck_channels[i]))
+ else:
+ self.decoder.append(
+ UpsamplerBlock(dec_non_bottleneck_channels[i - 1],
+ dec_non_bottleneck_channels[i]))
+ for j in range(dec_stages_non_bottleneck[i]):
+ self.decoder.append(
+ NonBottleneck1d(dec_non_bottleneck_channels[i]))
+
+ def forward(self, x):
+ for enc in self.encoder:
+ x = enc(x)
+ for dec in self.decoder:
+ x = dec(x)
+ return [x]
diff --git a/mmseg/models/backbones/fast_scnn.py b/mmseg/models/backbones/fast_scnn.py
new file mode 100644
index 0000000..cbfbcaf
--- /dev/null
+++ b/mmseg/models/backbones/fast_scnn.py
@@ -0,0 +1,409 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.models.decode_heads.psp_head import PPM
+from mmseg.ops import resize
+from ..builder import BACKBONES
+from ..utils import InvertedResidual
+
+
+class LearningToDownsample(nn.Module):
+ """Learning to downsample module.
+
+ Args:
+ in_channels (int): Number of input channels.
+ dw_channels (tuple[int]): Number of output channels of the first and
+ the second depthwise conv (dwconv) layers.
+ out_channels (int): Number of output channels of the whole
+ 'learning to downsample' module.
+ conv_cfg (dict | None): Config of conv layers. Default: None
+ norm_cfg (dict | None): Config of norm layers. Default:
+ dict(type='BN')
+ act_cfg (dict): Config of activation layers. Default:
+ dict(type='ReLU')
+ dw_act_cfg (dict): In DepthwiseSeparableConvModule, activation config
+ of depthwise ConvModule. If it is 'default', it will be the same
+ as `act_cfg`. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ dw_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ dw_act_cfg=None):
+ super(LearningToDownsample, self).__init__()
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.dw_act_cfg = dw_act_cfg
+ dw_channels1 = dw_channels[0]
+ dw_channels2 = dw_channels[1]
+
+ self.conv = ConvModule(
+ in_channels,
+ dw_channels1,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.dsconv1 = DepthwiseSeparableConvModule(
+ dw_channels1,
+ dw_channels2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=self.dw_act_cfg)
+
+ self.dsconv2 = DepthwiseSeparableConvModule(
+ dw_channels2,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=self.dw_act_cfg)
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.dsconv1(x)
+ x = self.dsconv2(x)
+ return x
+
+
+class GlobalFeatureExtractor(nn.Module):
+ """Global feature extractor module.
+
+ Args:
+ in_channels (int): Number of input channels of the GFE module.
+ Default: 64
+ block_channels (tuple[int]): Tuple of ints. Each int specifies the
+ number of output channels of each Inverted Residual module.
+ Default: (64, 96, 128)
+ out_channels(int): Number of output channels of the GFE module.
+ Default: 128
+ expand_ratio (int): Adjusts number of channels of the hidden layer
+ in InvertedResidual by this amount.
+ Default: 6
+ num_blocks (tuple[int]): Tuple of ints. Each int specifies the
+ number of times each Inverted Residual module is repeated.
+ The repeated Inverted Residual modules are called a 'group'.
+ Default: (3, 3, 3)
+ strides (tuple[int]): Tuple of ints. Each int specifies
+ the downsampling factor of each 'group'.
+ Default: (2, 2, 1)
+ pool_scales (tuple[int]): Tuple of ints. Each int specifies
+ the parameter required in 'global average pooling' within PPM.
+ Default: (1, 2, 3, 6)
+ conv_cfg (dict | None): Config of conv layers. Default: None
+ norm_cfg (dict | None): Config of norm layers. Default:
+ dict(type='BN')
+ act_cfg (dict): Config of activation layers. Default:
+ dict(type='ReLU')
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False
+ """
+
+ def __init__(self,
+ in_channels=64,
+ block_channels=(64, 96, 128),
+ out_channels=128,
+ expand_ratio=6,
+ num_blocks=(3, 3, 3),
+ strides=(2, 2, 1),
+ pool_scales=(1, 2, 3, 6),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False):
+ super(GlobalFeatureExtractor, self).__init__()
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ assert len(block_channels) == len(num_blocks) == 3
+ self.bottleneck1 = self._make_layer(in_channels, block_channels[0],
+ num_blocks[0], strides[0],
+ expand_ratio)
+ self.bottleneck2 = self._make_layer(block_channels[0],
+ block_channels[1], num_blocks[1],
+ strides[1], expand_ratio)
+ self.bottleneck3 = self._make_layer(block_channels[1],
+ block_channels[2], num_blocks[2],
+ strides[2], expand_ratio)
+ self.ppm = PPM(
+ pool_scales,
+ block_channels[2],
+ block_channels[2] // 4,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=align_corners)
+
+ self.out = ConvModule(
+ block_channels[2] * 2,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def _make_layer(self,
+ in_channels,
+ out_channels,
+ blocks,
+ stride=1,
+ expand_ratio=6):
+ layers = [
+ InvertedResidual(
+ in_channels,
+ out_channels,
+ stride,
+ expand_ratio,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ ]
+ for i in range(1, blocks):
+ layers.append(
+ InvertedResidual(
+ out_channels,
+ out_channels,
+ 1,
+ expand_ratio,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ x = self.bottleneck1(x)
+ x = self.bottleneck2(x)
+ x = self.bottleneck3(x)
+ x = torch.cat([x, *self.ppm(x)], dim=1)
+ x = self.out(x)
+ return x
+
+
+class FeatureFusionModule(nn.Module):
+ """Feature fusion module.
+
+ Args:
+ higher_in_channels (int): Number of input channels of the
+ higher-resolution branch.
+ lower_in_channels (int): Number of input channels of the
+ lower-resolution branch.
+ out_channels (int): Number of output channels.
+ conv_cfg (dict | None): Config of conv layers. Default: None
+ norm_cfg (dict | None): Config of norm layers. Default:
+ dict(type='BN')
+ dwconv_act_cfg (dict): Config of activation layers in 3x3 conv.
+ Default: dict(type='ReLU').
+ conv_act_cfg (dict): Config of activation layers in the two 1x1 conv.
+ Default: None.
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ """
+
+ def __init__(self,
+ higher_in_channels,
+ lower_in_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dwconv_act_cfg=dict(type='ReLU'),
+ conv_act_cfg=None,
+ align_corners=False):
+ super(FeatureFusionModule, self).__init__()
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.dwconv_act_cfg = dwconv_act_cfg
+ self.conv_act_cfg = conv_act_cfg
+ self.align_corners = align_corners
+ self.dwconv = ConvModule(
+ lower_in_channels,
+ out_channels,
+ 3,
+ padding=1,
+ groups=out_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.dwconv_act_cfg)
+ self.conv_lower_res = ConvModule(
+ out_channels,
+ out_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.conv_act_cfg)
+
+ self.conv_higher_res = ConvModule(
+ higher_in_channels,
+ out_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.conv_act_cfg)
+
+ self.relu = nn.ReLU(True)
+
+ def forward(self, higher_res_feature, lower_res_feature):
+ lower_res_feature = resize(
+ lower_res_feature,
+ size=higher_res_feature.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ lower_res_feature = self.dwconv(lower_res_feature)
+ lower_res_feature = self.conv_lower_res(lower_res_feature)
+
+ higher_res_feature = self.conv_higher_res(higher_res_feature)
+ out = higher_res_feature + lower_res_feature
+ return self.relu(out)
+
+
+@BACKBONES.register_module()
+class FastSCNN(BaseModule):
+ """Fast-SCNN Backbone.
+
+ This backbone is the implementation of `Fast-SCNN: Fast Semantic
+ Segmentation Network `_.
+
+ Args:
+ in_channels (int): Number of input image channels. Default: 3.
+ downsample_dw_channels (tuple[int]): Number of output channels after
+ the first conv layer & the second conv layer in
+ Learning-To-Downsample (LTD) module.
+ Default: (32, 48).
+ global_in_channels (int): Number of input channels of
+ Global Feature Extractor(GFE).
+ Equal to number of output channels of LTD.
+ Default: 64.
+ global_block_channels (tuple[int]): Tuple of integers that describe
+ the output channels for each of the MobileNet-v2 bottleneck
+ residual blocks in GFE.
+ Default: (64, 96, 128).
+ global_block_strides (tuple[int]): Tuple of integers
+ that describe the strides (downsampling factors) for each of the
+ MobileNet-v2 bottleneck residual blocks in GFE.
+ Default: (2, 2, 1).
+ global_out_channels (int): Number of output channels of GFE.
+ Default: 128.
+ higher_in_channels (int): Number of input channels of the higher
+ resolution branch in FFM.
+ Equal to global_in_channels.
+ Default: 64.
+ lower_in_channels (int): Number of input channels of the lower
+ resolution branch in FFM.
+ Equal to global_out_channels.
+ Default: 128.
+ fusion_out_channels (int): Number of output channels of FFM.
+ Default: 128.
+ out_indices (tuple): Tuple of indices of list
+ [higher_res_features, lower_res_features, fusion_output].
+ Often set to (0,1,2) to enable aux. heads.
+ Default: (0, 1, 2).
+ conv_cfg (dict | None): Config of conv layers. Default: None
+ norm_cfg (dict | None): Config of norm layers. Default:
+ dict(type='BN')
+ act_cfg (dict): Config of activation layers. Default:
+ dict(type='ReLU')
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False
+ dw_act_cfg (dict): In DepthwiseSeparableConvModule, activation config
+ of depthwise ConvModule. If it is 'default', it will be the same
+ as `act_cfg`. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels=3,
+ downsample_dw_channels=(32, 48),
+ global_in_channels=64,
+ global_block_channels=(64, 96, 128),
+ global_block_strides=(2, 2, 1),
+ global_out_channels=128,
+ higher_in_channels=64,
+ lower_in_channels=128,
+ fusion_out_channels=128,
+ out_indices=(0, 1, 2),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ dw_act_cfg=None,
+ init_cfg=None):
+
+ super(FastSCNN, self).__init__(init_cfg)
+
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ]
+
+ if global_in_channels != higher_in_channels:
+ raise AssertionError('Global Input Channels must be the same \
+ with Higher Input Channels!')
+ elif global_out_channels != lower_in_channels:
+ raise AssertionError('Global Output Channels must be the same \
+ with Lower Input Channels!')
+
+ self.in_channels = in_channels
+ self.downsample_dw_channels1 = downsample_dw_channels[0]
+ self.downsample_dw_channels2 = downsample_dw_channels[1]
+ self.global_in_channels = global_in_channels
+ self.global_block_channels = global_block_channels
+ self.global_block_strides = global_block_strides
+ self.global_out_channels = global_out_channels
+ self.higher_in_channels = higher_in_channels
+ self.lower_in_channels = lower_in_channels
+ self.fusion_out_channels = fusion_out_channels
+ self.out_indices = out_indices
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.align_corners = align_corners
+ self.learning_to_downsample = LearningToDownsample(
+ in_channels,
+ downsample_dw_channels,
+ global_in_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ dw_act_cfg=dw_act_cfg)
+ self.global_feature_extractor = GlobalFeatureExtractor(
+ global_in_channels,
+ global_block_channels,
+ global_out_channels,
+ strides=self.global_block_strides,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+ self.feature_fusion = FeatureFusionModule(
+ higher_in_channels,
+ lower_in_channels,
+ fusion_out_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ dwconv_act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+
+ def forward(self, x):
+ higher_res_features = self.learning_to_downsample(x)
+ lower_res_features = self.global_feature_extractor(higher_res_features)
+ fusion_output = self.feature_fusion(higher_res_features,
+ lower_res_features)
+
+ outs = [higher_res_features, lower_res_features, fusion_output]
+ outs = [outs[i] for i in self.out_indices]
+ return tuple(outs)
diff --git a/mmseg/models/backbones/hrnet.py b/mmseg/models/backbones/hrnet.py
new file mode 100644
index 0000000..90feadc
--- /dev/null
+++ b/mmseg/models/backbones/hrnet.py
@@ -0,0 +1,642 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmcv.runner import BaseModule, ModuleList, Sequential
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from mmseg.ops import Upsample, resize
+from ..builder import BACKBONES
+from .resnet import BasicBlock, Bottleneck
+
+
+class HRModule(BaseModule):
+ """High-Resolution Module for HRNet.
+
+ In this module, every branch has 4 BasicBlocks/Bottlenecks. Fusion/Exchange
+ is in this module.
+ """
+
+ def __init__(self,
+ num_branches,
+ blocks,
+ num_blocks,
+ in_channels,
+ num_channels,
+ multiscale_output=True,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ block_init_cfg=None,
+ init_cfg=None):
+ super(HRModule, self).__init__(init_cfg)
+ self.block_init_cfg = block_init_cfg
+ self._check_branches(num_branches, num_blocks, in_channels,
+ num_channels)
+
+ self.in_channels = in_channels
+ self.num_branches = num_branches
+
+ self.multiscale_output = multiscale_output
+ self.norm_cfg = norm_cfg
+ self.conv_cfg = conv_cfg
+ self.with_cp = with_cp
+ self.branches = self._make_branches(num_branches, blocks, num_blocks,
+ num_channels)
+ self.fuse_layers = self._make_fuse_layers()
+ self.relu = nn.ReLU(inplace=False)
+
+ def _check_branches(self, num_branches, num_blocks, in_channels,
+ num_channels):
+ """Check branches configuration."""
+ if num_branches != len(num_blocks):
+ error_msg = f'NUM_BRANCHES({num_branches}) <> NUM_BLOCKS(' \
+ f'{len(num_blocks)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(num_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) <> NUM_CHANNELS(' \
+ f'{len(num_channels)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(in_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) <> NUM_INCHANNELS(' \
+ f'{len(in_channels)})'
+ raise ValueError(error_msg)
+
+ def _make_one_branch(self,
+ branch_index,
+ block,
+ num_blocks,
+ num_channels,
+ stride=1):
+ """Build one branch."""
+ downsample = None
+ if stride != 1 or \
+ self.in_channels[branch_index] != \
+ num_channels[branch_index] * block.expansion:
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ self.in_channels[branch_index],
+ num_channels[branch_index] * block.expansion,
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(self.norm_cfg, num_channels[branch_index] *
+ block.expansion)[1])
+
+ layers = []
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index],
+ stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=self.block_init_cfg))
+ self.in_channels[branch_index] = \
+ num_channels[branch_index] * block.expansion
+ for i in range(1, num_blocks[branch_index]):
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index],
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=self.block_init_cfg))
+
+ return Sequential(*layers)
+
+ def _make_branches(self, num_branches, block, num_blocks, num_channels):
+ """Build multiple branch."""
+ branches = []
+
+ for i in range(num_branches):
+ branches.append(
+ self._make_one_branch(i, block, num_blocks, num_channels))
+
+ return ModuleList(branches)
+
+ def _make_fuse_layers(self):
+ """Build fuse layer."""
+ if self.num_branches == 1:
+ return None
+
+ num_branches = self.num_branches
+ in_channels = self.in_channels
+ fuse_layers = []
+ num_out_branches = num_branches if self.multiscale_output else 1
+ for i in range(num_out_branches):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels[i])[1],
+ # we set align_corners=False for HRNet
+ Upsample(
+ scale_factor=2**(j - i),
+ mode='bilinear',
+ align_corners=False)))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv_downsamples = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[i])[1]))
+ else:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ nn.ReLU(inplace=False)))
+ fuse_layer.append(nn.Sequential(*conv_downsamples))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def forward(self, x):
+ """Forward function."""
+ if self.num_branches == 1:
+ return [self.branches[0](x[0])]
+
+ for i in range(self.num_branches):
+ x[i] = self.branches[i](x[i])
+
+ x_fuse = []
+ for i in range(len(self.fuse_layers)):
+ y = 0
+ for j in range(self.num_branches):
+ if i == j:
+ y += x[j]
+ elif j > i:
+ y = y + resize(
+ self.fuse_layers[i][j](x[j]),
+ size=x[i].shape[2:],
+ mode='bilinear',
+ align_corners=False)
+ else:
+ y += self.fuse_layers[i][j](x[j])
+ x_fuse.append(self.relu(y))
+ return x_fuse
+
+
+@BACKBONES.register_module()
+class HRNet(BaseModule):
+ """HRNet backbone.
+
+ This backbone is the implementation of `High-Resolution Representations
+ for Labeling Pixels and Regions `_.
+
+ Args:
+ extra (dict): Detailed configuration for each stage of HRNet.
+ There must be 4 stages, the configuration for each stage must have
+ 5 keys:
+
+ - num_modules (int): The number of HRModule in this stage.
+ - num_branches (int): The number of branches in the HRModule.
+ - block (str): The type of convolution block.
+ - num_blocks (tuple): The number of blocks in each branch.
+ The length must be equal to num_branches.
+ - num_channels (tuple): The number of channels in each branch.
+ The length must be equal to num_branches.
+ in_channels (int): Number of input image channels. Normally 3.
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Use `BN` by default.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: False.
+ multiscale_output (bool): Whether to output multi-level features
+ produced by multiple branches. If False, only the first level
+ feature will be output. Default: True.
+ pretrained (str, optional): Model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Example:
+ >>> from mmseg.models import HRNet
+ >>> import torch
+ >>> extra = dict(
+ >>> stage1=dict(
+ >>> num_modules=1,
+ >>> num_branches=1,
+ >>> block='BOTTLENECK',
+ >>> num_blocks=(4, ),
+ >>> num_channels=(64, )),
+ >>> stage2=dict(
+ >>> num_modules=1,
+ >>> num_branches=2,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4),
+ >>> num_channels=(32, 64)),
+ >>> stage3=dict(
+ >>> num_modules=4,
+ >>> num_branches=3,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4),
+ >>> num_channels=(32, 64, 128)),
+ >>> stage4=dict(
+ >>> num_modules=3,
+ >>> num_branches=4,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4, 4),
+ >>> num_channels=(32, 64, 128, 256)))
+ >>> self = HRNet(extra, in_channels=1)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 1, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 32, 8, 8)
+ (1, 64, 4, 4)
+ (1, 128, 2, 2)
+ (1, 256, 1, 1)
+ """
+
+ blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
+
+ def __init__(self,
+ extra,
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=False,
+ with_cp=False,
+ frozen_stages=-1,
+ zero_init_residual=False,
+ multiscale_output=True,
+ pretrained=None,
+ init_cfg=None):
+ super(HRNet, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ self.zero_init_residual = zero_init_residual
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ # Assert configurations of 4 stages are in extra
+ assert 'stage1' in extra and 'stage2' in extra \
+ and 'stage3' in extra and 'stage4' in extra
+ # Assert whether the length of `num_blocks` and `num_channels` are
+ # equal to `num_branches`
+ for i in range(4):
+ cfg = extra[f'stage{i + 1}']
+ assert len(cfg['num_blocks']) == cfg['num_branches'] and \
+ len(cfg['num_channels']) == cfg['num_branches']
+
+ self.extra = extra
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.frozen_stages = frozen_stages
+
+ # stem net
+ self.norm1_name, norm1 = build_norm_layer(self.norm_cfg, 64, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(self.norm_cfg, 64, postfix=2)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ 64,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.relu = nn.ReLU(inplace=True)
+
+ # stage 1
+ self.stage1_cfg = self.extra['stage1']
+ num_channels = self.stage1_cfg['num_channels'][0]
+ block_type = self.stage1_cfg['block']
+ num_blocks = self.stage1_cfg['num_blocks'][0]
+
+ block = self.blocks_dict[block_type]
+ stage1_out_channels = num_channels * block.expansion
+ self.layer1 = self._make_layer(block, 64, num_channels, num_blocks)
+
+ # stage 2
+ self.stage2_cfg = self.extra['stage2']
+ num_channels = self.stage2_cfg['num_channels']
+ block_type = self.stage2_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [channel * block.expansion for channel in num_channels]
+ self.transition1 = self._make_transition_layer([stage1_out_channels],
+ num_channels)
+ self.stage2, pre_stage_channels = self._make_stage(
+ self.stage2_cfg, num_channels)
+
+ # stage 3
+ self.stage3_cfg = self.extra['stage3']
+ num_channels = self.stage3_cfg['num_channels']
+ block_type = self.stage3_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [channel * block.expansion for channel in num_channels]
+ self.transition2 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+ self.stage3, pre_stage_channels = self._make_stage(
+ self.stage3_cfg, num_channels)
+
+ # stage 4
+ self.stage4_cfg = self.extra['stage4']
+ num_channels = self.stage4_cfg['num_channels']
+ block_type = self.stage4_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [channel * block.expansion for channel in num_channels]
+ self.transition3 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+ self.stage4, pre_stage_channels = self._make_stage(
+ self.stage4_cfg, num_channels, multiscale_output=multiscale_output)
+
+ self._freeze_stages()
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: the normalization layer named "norm2" """
+ return getattr(self, self.norm2_name)
+
+ def _make_transition_layer(self, num_channels_pre_layer,
+ num_channels_cur_layer):
+ """Make transition layer."""
+ num_branches_cur = len(num_channels_cur_layer)
+ num_branches_pre = len(num_channels_pre_layer)
+
+ transition_layers = []
+ for i in range(num_branches_cur):
+ if i < num_branches_pre:
+ if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
+ transition_layers.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_cur_layer[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_cur_layer[i])[1],
+ nn.ReLU(inplace=True)))
+ else:
+ transition_layers.append(None)
+ else:
+ conv_downsamples = []
+ for j in range(i + 1 - num_branches_pre):
+ in_channels = num_channels_pre_layer[-1]
+ out_channels = num_channels_cur_layer[i] \
+ if j == i - num_branches_pre else in_channels
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1],
+ nn.ReLU(inplace=True)))
+ transition_layers.append(nn.Sequential(*conv_downsamples))
+
+ return nn.ModuleList(transition_layers)
+
+ def _make_layer(self, block, inplanes, planes, blocks, stride=1):
+ """Make each layer."""
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(self.norm_cfg, planes * block.expansion)[1])
+
+ layers = []
+ block_init_cfg = None
+ if self.pretrained is None and not hasattr(
+ self, 'init_cfg') and self.zero_init_residual:
+ if block is BasicBlock:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm2'))
+ elif block is Bottleneck:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm3'))
+
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=block_init_cfg))
+ inplanes = planes * block.expansion
+ for i in range(1, blocks):
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=block_init_cfg))
+
+ return Sequential(*layers)
+
+ def _make_stage(self, layer_config, in_channels, multiscale_output=True):
+ """Make each stage."""
+ num_modules = layer_config['num_modules']
+ num_branches = layer_config['num_branches']
+ num_blocks = layer_config['num_blocks']
+ num_channels = layer_config['num_channels']
+ block = self.blocks_dict[layer_config['block']]
+
+ hr_modules = []
+ block_init_cfg = None
+ if self.pretrained is None and not hasattr(
+ self, 'init_cfg') and self.zero_init_residual:
+ if block is BasicBlock:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm2'))
+ elif block is Bottleneck:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm3'))
+
+ for i in range(num_modules):
+ # multi_scale_output is only used for the last module
+ if not multiscale_output and i == num_modules - 1:
+ reset_multiscale_output = False
+ else:
+ reset_multiscale_output = True
+
+ hr_modules.append(
+ HRModule(
+ num_branches,
+ block,
+ num_blocks,
+ in_channels,
+ num_channels,
+ reset_multiscale_output,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ block_init_cfg=block_init_cfg))
+
+ return Sequential(*hr_modules), in_channels
+
+ def _freeze_stages(self):
+ """Freeze stages param and norm stats."""
+ if self.frozen_stages >= 0:
+
+ self.norm1.eval()
+ self.norm2.eval()
+ for m in [self.conv1, self.norm1, self.conv2, self.norm2]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ if i == 1:
+ m = getattr(self, f'layer{i}')
+ t = getattr(self, f'transition{i}')
+ elif i == 4:
+ m = getattr(self, f'stage{i}')
+ else:
+ m = getattr(self, f'stage{i}')
+ t = getattr(self, f'transition{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+ t.eval()
+ for param in t.parameters():
+ param.requires_grad = False
+
+ def forward(self, x):
+ """Forward function."""
+
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.conv2(x)
+ x = self.norm2(x)
+ x = self.relu(x)
+ x = self.layer1(x)
+
+ x_list = []
+ for i in range(self.stage2_cfg['num_branches']):
+ if self.transition1[i] is not None:
+ x_list.append(self.transition1[i](x))
+ else:
+ x_list.append(x)
+ y_list = self.stage2(x_list)
+
+ x_list = []
+ for i in range(self.stage3_cfg['num_branches']):
+ if self.transition2[i] is not None:
+ x_list.append(self.transition2[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage3(x_list)
+
+ x_list = []
+ for i in range(self.stage4_cfg['num_branches']):
+ if self.transition3[i] is not None:
+ x_list.append(self.transition3[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage4(x_list)
+
+ return y_list
+
+ def train(self, mode=True):
+ """Convert the model into training mode will keeping the normalization
+ layer freezed."""
+ super(HRNet, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmseg/models/backbones/icnet.py b/mmseg/models/backbones/icnet.py
new file mode 100644
index 0000000..10e5427
--- /dev/null
+++ b/mmseg/models/backbones/icnet.py
@@ -0,0 +1,165 @@
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import BACKBONES, build_backbone
+from ..decode_heads.psp_head import PPM
+
+
+@BACKBONES.register_module()
+class ICNet(BaseModule):
+ """ICNet for Real-Time Semantic Segmentation on High-Resolution Images.
+
+ This backbone is the implementation of
+ `ICNet `_.
+
+ Args:
+ backbone_cfg (dict): Config dict to build backbone. Usually it is
+ ResNet but it can also be other backbones.
+ in_channels (int): The number of input image channels. Default: 3.
+ layer_channels (Sequence[int]): The numbers of feature channels at
+ layer 2 and layer 4 in ResNet. It can also be other backbones.
+ Default: (512, 2048).
+ light_branch_middle_channels (int): The number of channels of the
+ middle layer in light branch. Default: 32.
+ psp_out_channels (int): The number of channels of the output of PSP
+ module. Default: 512.
+ out_channels (Sequence[int]): The numbers of output feature channels
+ at each branches. Default: (64, 256, 256).
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module. Default: (1, 2, 3, 6).
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Dictionary to construct and config act layer.
+ Default: dict(type='ReLU').
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ backbone_cfg,
+ in_channels=3,
+ layer_channels=(512, 2048),
+ light_branch_middle_channels=32,
+ psp_out_channels=512,
+ out_channels=(64, 256, 256),
+ pool_scales=(1, 2, 3, 6),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ init_cfg=None):
+ if backbone_cfg is None:
+ raise TypeError('backbone_cfg must be passed from config file!')
+ if init_cfg is None:
+ init_cfg = [
+ dict(type='Kaiming', mode='fan_out', layer='Conv2d'),
+ dict(type='Constant', val=1, layer='_BatchNorm'),
+ dict(type='Normal', mean=0.01, layer='Linear')
+ ]
+ super(ICNet, self).__init__(init_cfg=init_cfg)
+ self.align_corners = align_corners
+ self.backbone = build_backbone(backbone_cfg)
+
+ # Note: Default `ceil_mode` is false in nn.MaxPool2d, set
+ # `ceil_mode=True` to keep information in the corner of feature map.
+ self.backbone.maxpool = nn.MaxPool2d(
+ kernel_size=3, stride=2, padding=1, ceil_mode=True)
+
+ self.psp_modules = PPM(
+ pool_scales=pool_scales,
+ in_channels=layer_channels[1],
+ channels=psp_out_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ align_corners=align_corners)
+
+ self.psp_bottleneck = ConvModule(
+ layer_channels[1] + len(pool_scales) * psp_out_channels,
+ psp_out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.conv_sub1 = nn.Sequential(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=light_branch_middle_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg),
+ ConvModule(
+ in_channels=light_branch_middle_channels,
+ out_channels=light_branch_middle_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg),
+ ConvModule(
+ in_channels=light_branch_middle_channels,
+ out_channels=out_channels[0],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg))
+
+ self.conv_sub2 = ConvModule(
+ layer_channels[0],
+ out_channels[1],
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+
+ self.conv_sub4 = ConvModule(
+ psp_out_channels,
+ out_channels[2],
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+
+ def forward(self, x):
+ output = []
+
+ # sub 1
+ output.append(self.conv_sub1(x))
+
+ # sub 2
+ x = resize(
+ x,
+ scale_factor=0.5,
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = self.backbone.stem(x)
+ x = self.backbone.maxpool(x)
+ x = self.backbone.layer1(x)
+ x = self.backbone.layer2(x)
+ output.append(self.conv_sub2(x))
+
+ # sub 4
+ x = resize(
+ x,
+ scale_factor=0.5,
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = self.backbone.layer3(x)
+ x = self.backbone.layer4(x)
+ psp_outs = self.psp_modules(x) + [x]
+ psp_outs = torch.cat(psp_outs, dim=1)
+ x = self.psp_bottleneck(psp_outs)
+
+ output.append(self.conv_sub4(x))
+
+ return output
diff --git a/mmseg/models/backbones/mit.py b/mmseg/models/backbones/mit.py
new file mode 100644
index 0000000..c97213a
--- /dev/null
+++ b/mmseg/models/backbones/mit.py
@@ -0,0 +1,431 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import warnings
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import Conv2d, build_activation_layer, build_norm_layer
+from mmcv.cnn.bricks.drop import build_dropout
+from mmcv.cnn.bricks.transformer import MultiheadAttention
+from mmcv.cnn.utils.weight_init import (constant_init, normal_init,
+ trunc_normal_init)
+from mmcv.runner import BaseModule, ModuleList, Sequential
+
+from ..builder import BACKBONES
+from ..utils import PatchEmbed, nchw_to_nlc, nlc_to_nchw
+
+
+class MixFFN(BaseModule):
+ """An implementation of MixFFN of Segformer.
+
+ The differences between MixFFN & FFN:
+ 1. Use 1X1 Conv to replace Linear layer.
+ 2. Introduce 3X3 Conv to encode positional information.
+ Args:
+ embed_dims (int): The feature dimension. Same as
+ `MultiheadAttention`. Defaults: 256.
+ feedforward_channels (int): The hidden dimension of FFNs.
+ Defaults: 1024.
+ act_cfg (dict, optional): The activation config for FFNs.
+ Default: dict(type='ReLU')
+ ffn_drop (float, optional): Probability of an element to be
+ zeroed in FFN. Default 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut.
+ init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ feedforward_channels,
+ act_cfg=dict(type='GELU'),
+ ffn_drop=0.,
+ dropout_layer=None,
+ init_cfg=None):
+ super(MixFFN, self).__init__(init_cfg)
+
+ self.embed_dims = embed_dims
+ self.feedforward_channels = feedforward_channels
+ self.act_cfg = act_cfg
+ self.activate = build_activation_layer(act_cfg)
+
+ in_channels = embed_dims
+ fc1 = Conv2d(
+ in_channels=in_channels,
+ out_channels=feedforward_channels,
+ kernel_size=1,
+ stride=1,
+ bias=True)
+ # 3x3 depth wise conv to provide positional encode information
+ pe_conv = Conv2d(
+ in_channels=feedforward_channels,
+ out_channels=feedforward_channels,
+ kernel_size=3,
+ stride=1,
+ padding=(3 - 1) // 2,
+ bias=True,
+ groups=feedforward_channels)
+ fc2 = Conv2d(
+ in_channels=feedforward_channels,
+ out_channels=in_channels,
+ kernel_size=1,
+ stride=1,
+ bias=True)
+ drop = nn.Dropout(ffn_drop)
+ layers = [fc1, pe_conv, self.activate, drop, fc2, drop]
+ self.layers = Sequential(*layers)
+ self.dropout_layer = build_dropout(
+ dropout_layer) if dropout_layer else torch.nn.Identity()
+
+ def forward(self, x, hw_shape, identity=None):
+ out = nlc_to_nchw(x, hw_shape)
+ out = self.layers(out)
+ out = nchw_to_nlc(out)
+ if identity is None:
+ identity = x
+ return identity + self.dropout_layer(out)
+
+
+class EfficientMultiheadAttention(MultiheadAttention):
+ """An implementation of Efficient Multi-head Attention of Segformer.
+
+ This module is modified from MultiheadAttention which is a module from
+ mmcv.cnn.bricks.transformer.
+ Args:
+ embed_dims (int): The embedding dimension.
+ num_heads (int): Parallel attention heads.
+ attn_drop (float): A Dropout layer on attn_output_weights.
+ Default: 0.0.
+ proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
+ Default: 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut. Default: None.
+ init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
+ Default: None.
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dim)
+ or (n, batch, embed_dim). Default: False.
+ qkv_bias (bool): enable bias for qkv if True. Default True.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (int): The ratio of spatial reduction of Efficient Multi-head
+ Attention of Segformer. Default: 1.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ attn_drop=0.,
+ proj_drop=0.,
+ dropout_layer=None,
+ init_cfg=None,
+ batch_first=True,
+ qkv_bias=False,
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1):
+ super().__init__(
+ embed_dims,
+ num_heads,
+ attn_drop,
+ proj_drop,
+ dropout_layer=dropout_layer,
+ init_cfg=init_cfg,
+ batch_first=batch_first,
+ bias=qkv_bias)
+
+ self.sr_ratio = sr_ratio
+ if sr_ratio > 1:
+ self.sr = Conv2d(
+ in_channels=embed_dims,
+ out_channels=embed_dims,
+ kernel_size=sr_ratio,
+ stride=sr_ratio)
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ # handle the BC-breaking from https://github.com/open-mmlab/mmcv/pull/1418 # noqa
+ from mmseg import digit_version, mmcv_version
+ if mmcv_version < digit_version('1.3.17'):
+ warnings.warn('The legacy version of forward function in'
+ 'EfficientMultiheadAttention is deprecated in'
+ 'mmcv>=1.3.17 and will no longer support in the'
+ 'future. Please upgrade your mmcv.')
+ self.forward = self.legacy_forward
+
+ def forward(self, x, hw_shape, identity=None):
+
+ x_q = x
+ if self.sr_ratio > 1:
+ x_kv = nlc_to_nchw(x, hw_shape)
+ x_kv = self.sr(x_kv)
+ x_kv = nchw_to_nlc(x_kv)
+ x_kv = self.norm(x_kv)
+ else:
+ x_kv = x
+
+ if identity is None:
+ identity = x_q
+
+ # Because the dataflow('key', 'query', 'value') of
+ # ``torch.nn.MultiheadAttention`` is (num_query, batch,
+ # embed_dims), We should adjust the shape of dataflow from
+ # batch_first (batch, num_query, embed_dims) to num_query_first
+ # (num_query ,batch, embed_dims), and recover ``attn_output``
+ # from num_query_first to batch_first.
+ if self.batch_first:
+ x_q = x_q.transpose(0, 1)
+ x_kv = x_kv.transpose(0, 1)
+
+ out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
+
+ if self.batch_first:
+ out = out.transpose(0, 1)
+
+ return identity + self.dropout_layer(self.proj_drop(out))
+
+ def legacy_forward(self, x, hw_shape, identity=None):
+ """multi head attention forward in mmcv version < 1.3.17."""
+
+ x_q = x
+ if self.sr_ratio > 1:
+ x_kv = nlc_to_nchw(x, hw_shape)
+ x_kv = self.sr(x_kv)
+ x_kv = nchw_to_nlc(x_kv)
+ x_kv = self.norm(x_kv)
+ else:
+ x_kv = x
+
+ if identity is None:
+ identity = x_q
+
+ # `need_weights=True` will let nn.MultiHeadAttention
+ # `return attn_output, attn_output_weights.sum(dim=1) / num_heads`
+ # The `attn_output_weights.sum(dim=1)` may cause cuda error. So, we set
+ # `need_weights=False` to ignore `attn_output_weights.sum(dim=1)`.
+ # This issue - `https://github.com/pytorch/pytorch/issues/37583` report
+ # the error that large scale tensor sum operation may cause cuda error.
+ out = self.attn(query=x_q, key=x_kv, value=x_kv, need_weights=False)[0]
+
+ return identity + self.dropout_layer(self.proj_drop(out))
+
+
+class TransformerEncoderLayer(BaseModule):
+ """Implements one encoder layer in Segformer.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed.
+ after the feed forward layer. Default 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0.
+ drop_path_rate (float): stochastic depth rate. Default 0.0.
+ qkv_bias (bool): enable bias for qkv if True.
+ Default: True.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dim)
+ or (n, batch, embed_dim). Default: False.
+ init_cfg (dict, optional): Initialization config dict.
+ Default:None.
+ sr_ratio (int): The ratio of spatial reduction of Efficient Multi-head
+ Attention of Segformer. Default: 1.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ batch_first=True,
+ sr_ratio=1):
+ super(TransformerEncoderLayer, self).__init__()
+
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ self.attn = EfficientMultiheadAttention(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ attn_drop=attn_drop_rate,
+ proj_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ batch_first=batch_first,
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio)
+
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ self.ffn = MixFFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg)
+
+ def forward(self, x, hw_shape):
+ x = self.attn(self.norm1(x), hw_shape, identity=x)
+ x = self.ffn(self.norm2(x), hw_shape, identity=x)
+ return x
+
+
+@BACKBONES.register_module()
+class MixVisionTransformer(BaseModule):
+ """The backbone of Segformer.
+
+ This backbone is the implementation of `SegFormer: Simple and
+ Efficient Design for Semantic Segmentation with
+ Transformers `_.
+ Args:
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (int): Embedding dimension. Default: 768.
+ num_stags (int): The num of stages. Default: 4.
+ num_layers (Sequence[int]): The layer number of each transformer encode
+ layer. Default: [3, 4, 6, 3].
+ num_heads (Sequence[int]): The attention heads of each transformer
+ encode layer. Default: [1, 2, 4, 8].
+ patch_sizes (Sequence[int]): The patch_size of each overlapped patch
+ embedding. Default: [7, 3, 3, 3].
+ strides (Sequence[int]): The stride of each overlapped patch embedding.
+ Default: [4, 2, 2, 2].
+ sr_ratios (Sequence[int]): The spatial reduction rate of each
+ transformer encode layer. Default: [8, 4, 2, 1].
+ out_indices (Sequence[int] | int): Output from which stages.
+ Default: (0, 1, 2, 3).
+ mlp_ratio (int): ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.0
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0
+ drop_path_rate (float): stochastic depth rate. Default 0.0
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ pretrained (str, optional): model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=64,
+ num_stages=4,
+ num_layers=[3, 4, 6, 3],
+ num_heads=[1, 2, 4, 8],
+ patch_sizes=[7, 3, 3, 3],
+ strides=[4, 2, 2, 2],
+ sr_ratios=[8, 4, 2, 1],
+ out_indices=(0, 1, 2, 3),
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN', eps=1e-6),
+ pretrained=None,
+ init_cfg=None):
+ super(MixVisionTransformer, self).__init__(init_cfg=init_cfg)
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be set at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is not None:
+ raise TypeError('pretrained must be a str or None')
+
+ self.embed_dims = embed_dims
+ self.num_stages = num_stages
+ self.num_layers = num_layers
+ self.num_heads = num_heads
+ self.patch_sizes = patch_sizes
+ self.strides = strides
+ self.sr_ratios = sr_ratios
+ assert num_stages == len(num_layers) == len(num_heads) \
+ == len(patch_sizes) == len(strides) == len(sr_ratios)
+
+ self.out_indices = out_indices
+ assert max(out_indices) < self.num_stages
+
+ # transformer encoder
+ dpr = [
+ x.item()
+ for x in torch.linspace(0, drop_path_rate, sum(num_layers))
+ ] # stochastic num_layer decay rule
+
+ cur = 0
+ self.layers = ModuleList()
+ for i, num_layer in enumerate(num_layers):
+ embed_dims_i = embed_dims * num_heads[i]
+ patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims_i,
+ kernel_size=patch_sizes[i],
+ stride=strides[i],
+ padding=patch_sizes[i] // 2,
+ norm_cfg=norm_cfg)
+ layer = ModuleList([
+ TransformerEncoderLayer(
+ embed_dims=embed_dims_i,
+ num_heads=num_heads[i],
+ feedforward_channels=mlp_ratio * embed_dims_i,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[cur + idx],
+ qkv_bias=qkv_bias,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratios[i]) for idx in range(num_layer)
+ ])
+ in_channels = embed_dims_i
+ # The ret[0] of build_norm_layer is norm name.
+ norm = build_norm_layer(norm_cfg, embed_dims_i)[1]
+ self.layers.append(ModuleList([patch_embed, layer, norm]))
+ cur += num_layer
+
+ def init_weights(self):
+ if self.init_cfg is None:
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=.02, bias=0.)
+ elif isinstance(m, nn.LayerNorm):
+ constant_init(m, val=1.0, bias=0.)
+ elif isinstance(m, nn.Conv2d):
+ fan_out = m.kernel_size[0] * m.kernel_size[
+ 1] * m.out_channels
+ fan_out //= m.groups
+ normal_init(
+ m, mean=0, std=math.sqrt(2.0 / fan_out), bias=0)
+ else:
+ super(MixVisionTransformer, self).init_weights()
+
+ def forward(self, x):
+ outs = []
+
+ for i, layer in enumerate(self.layers):
+ x, hw_shape = layer[0](x)
+ for block in layer[1]:
+ x = block(x, hw_shape)
+ x = layer[2](x)
+ x = nlc_to_nchw(x, hw_shape)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return outs
diff --git a/mmseg/models/backbones/mobilenet_v2.py b/mmseg/models/backbones/mobilenet_v2.py
new file mode 100644
index 0000000..cbb9c6c
--- /dev/null
+++ b/mmseg/models/backbones/mobilenet_v2.py
@@ -0,0 +1,197 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from ..builder import BACKBONES
+from ..utils import InvertedResidual, make_divisible
+
+
+@BACKBONES.register_module()
+class MobileNetV2(BaseModule):
+ """MobileNetV2 backbone.
+
+ This backbone is the implementation of
+ `MobileNetV2: Inverted Residuals and Linear Bottlenecks
+ `_.
+
+ Args:
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Default: 1.0.
+ strides (Sequence[int], optional): Strides of the first block of each
+ layer. If not specified, default config in ``arch_setting`` will
+ be used.
+ dilations (Sequence[int]): Dilation of each layer.
+ out_indices (None or Sequence[int]): Output from which stages.
+ Default: (7, ).
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU6').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ # Parameters to build layers. 3 parameters are needed to construct a
+ # layer, from left to right: expand_ratio, channel, num_blocks.
+ arch_settings = [[1, 16, 1], [6, 24, 2], [6, 32, 3], [6, 64, 4],
+ [6, 96, 3], [6, 160, 3], [6, 320, 1]]
+
+ def __init__(self,
+ widen_factor=1.,
+ strides=(1, 2, 2, 2, 1, 2, 1),
+ dilations=(1, 1, 1, 1, 1, 1, 1),
+ out_indices=(1, 2, 4, 6),
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU6'),
+ norm_eval=False,
+ with_cp=False,
+ pretrained=None,
+ init_cfg=None):
+ super(MobileNetV2, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.widen_factor = widen_factor
+ self.strides = strides
+ self.dilations = dilations
+ assert len(strides) == len(dilations) == len(self.arch_settings)
+ self.out_indices = out_indices
+ for index in out_indices:
+ if index not in range(0, 7):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, 7). But received {index}')
+
+ if frozen_stages not in range(-1, 7):
+ raise ValueError('frozen_stages must be in range(-1, 7). '
+ f'But received {frozen_stages}')
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ self.in_channels = make_divisible(32 * widen_factor, 8)
+
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.layers = []
+
+ for i, layer_cfg in enumerate(self.arch_settings):
+ expand_ratio, channel, num_blocks = layer_cfg
+ stride = self.strides[i]
+ dilation = self.dilations[i]
+ out_channels = make_divisible(channel * widen_factor, 8)
+ inverted_res_layer = self.make_layer(
+ out_channels=out_channels,
+ num_blocks=num_blocks,
+ stride=stride,
+ dilation=dilation,
+ expand_ratio=expand_ratio)
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, inverted_res_layer)
+ self.layers.append(layer_name)
+
+ def make_layer(self, out_channels, num_blocks, stride, dilation,
+ expand_ratio):
+ """Stack InvertedResidual blocks to build a layer for MobileNetV2.
+
+ Args:
+ out_channels (int): out_channels of block.
+ num_blocks (int): Number of blocks.
+ stride (int): Stride of the first block.
+ dilation (int): Dilation of the first block.
+ expand_ratio (int): Expand the number of channels of the
+ hidden layer in InvertedResidual by this ratio.
+ """
+ layers = []
+ for i in range(num_blocks):
+ layers.append(
+ InvertedResidual(
+ self.in_channels,
+ out_channels,
+ stride if i == 0 else 1,
+ expand_ratio=expand_ratio,
+ dilation=dilation if i == 0 else 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ with_cp=self.with_cp))
+ self.in_channels = out_channels
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ x = self.conv1(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+
+ if len(outs) == 1:
+ return outs[0]
+ else:
+ return tuple(outs)
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for param in self.conv1.parameters():
+ param.requires_grad = False
+ for i in range(1, self.frozen_stages + 1):
+ layer = getattr(self, f'layer{i}')
+ layer.eval()
+ for param in layer.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super(MobileNetV2, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmseg/models/backbones/mobilenet_v3.py b/mmseg/models/backbones/mobilenet_v3.py
new file mode 100644
index 0000000..dd3d6eb
--- /dev/null
+++ b/mmseg/models/backbones/mobilenet_v3.py
@@ -0,0 +1,267 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+from mmcv.cnn import ConvModule
+from mmcv.cnn.bricks import Conv2dAdaptivePadding
+from mmcv.runner import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from ..builder import BACKBONES
+from ..utils import InvertedResidualV3 as InvertedResidual
+
+
+@BACKBONES.register_module()
+class MobileNetV3(BaseModule):
+ """MobileNetV3 backbone.
+
+ This backbone is the improved implementation of `Searching for MobileNetV3
+ `_.
+
+ Args:
+ arch (str): Architecture of mobilnetv3, from {'small', 'large'}.
+ Default: 'small'.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ out_indices (tuple[int]): Output from which layer.
+ Default: (0, 1, 12).
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save
+ some memory while slowing down the training speed.
+ Default: False.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+ # Parameters to build each block:
+ # [kernel size, mid channels, out channels, with_se, act type, stride]
+ arch_settings = {
+ 'small': [[3, 16, 16, True, 'ReLU', 2], # block0 layer1 os=4
+ [3, 72, 24, False, 'ReLU', 2], # block1 layer2 os=8
+ [3, 88, 24, False, 'ReLU', 1],
+ [5, 96, 40, True, 'HSwish', 2], # block2 layer4 os=16
+ [5, 240, 40, True, 'HSwish', 1],
+ [5, 240, 40, True, 'HSwish', 1],
+ [5, 120, 48, True, 'HSwish', 1], # block3 layer7 os=16
+ [5, 144, 48, True, 'HSwish', 1],
+ [5, 288, 96, True, 'HSwish', 2], # block4 layer9 os=32
+ [5, 576, 96, True, 'HSwish', 1],
+ [5, 576, 96, True, 'HSwish', 1]],
+ 'large': [[3, 16, 16, False, 'ReLU', 1], # block0 layer1 os=2
+ [3, 64, 24, False, 'ReLU', 2], # block1 layer2 os=4
+ [3, 72, 24, False, 'ReLU', 1],
+ [5, 72, 40, True, 'ReLU', 2], # block2 layer4 os=8
+ [5, 120, 40, True, 'ReLU', 1],
+ [5, 120, 40, True, 'ReLU', 1],
+ [3, 240, 80, False, 'HSwish', 2], # block3 layer7 os=16
+ [3, 200, 80, False, 'HSwish', 1],
+ [3, 184, 80, False, 'HSwish', 1],
+ [3, 184, 80, False, 'HSwish', 1],
+ [3, 480, 112, True, 'HSwish', 1], # block4 layer11 os=16
+ [3, 672, 112, True, 'HSwish', 1],
+ [5, 672, 160, True, 'HSwish', 2], # block5 layer13 os=32
+ [5, 960, 160, True, 'HSwish', 1],
+ [5, 960, 160, True, 'HSwish', 1]]
+ } # yapf: disable
+
+ def __init__(self,
+ arch='small',
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ out_indices=(0, 1, 12),
+ frozen_stages=-1,
+ reduction_factor=1,
+ norm_eval=False,
+ with_cp=False,
+ pretrained=None,
+ init_cfg=None):
+ super(MobileNetV3, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ assert arch in self.arch_settings
+ assert isinstance(reduction_factor, int) and reduction_factor > 0
+ assert mmcv.is_tuple_of(out_indices, int)
+ for index in out_indices:
+ if index not in range(0, len(self.arch_settings[arch]) + 2):
+ raise ValueError(
+ 'the item in out_indices must in '
+ f'range(0, {len(self.arch_settings[arch])+2}). '
+ f'But received {index}')
+
+ if frozen_stages not in range(-1, len(self.arch_settings[arch]) + 2):
+ raise ValueError('frozen_stages must be in range(-1, '
+ f'{len(self.arch_settings[arch])+2}). '
+ f'But received {frozen_stages}')
+ self.arch = arch
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.reduction_factor = reduction_factor
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.layers = self._make_layer()
+
+ def _make_layer(self):
+ layers = []
+
+ # build the first layer (layer0)
+ in_channels = 16
+ layer = ConvModule(
+ in_channels=3,
+ out_channels=in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=dict(type='Conv2dAdaptivePadding'),
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='HSwish'))
+ self.add_module('layer0', layer)
+ layers.append('layer0')
+
+ layer_setting = self.arch_settings[self.arch]
+ for i, params in enumerate(layer_setting):
+ (kernel_size, mid_channels, out_channels, with_se, act,
+ stride) = params
+
+ if self.arch == 'large' and i >= 12 or self.arch == 'small' and \
+ i >= 8:
+ mid_channels = mid_channels // self.reduction_factor
+ out_channels = out_channels // self.reduction_factor
+
+ if with_se:
+ se_cfg = dict(
+ channels=mid_channels,
+ ratio=4,
+ act_cfg=(dict(type='ReLU'),
+ dict(type='HSigmoid', bias=3.0, divisor=6.0)))
+ else:
+ se_cfg = None
+
+ layer = InvertedResidual(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ mid_channels=mid_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ se_cfg=se_cfg,
+ with_expand_conv=(in_channels != mid_channels),
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type=act),
+ with_cp=self.with_cp)
+ in_channels = out_channels
+ layer_name = 'layer{}'.format(i + 1)
+ self.add_module(layer_name, layer)
+ layers.append(layer_name)
+
+ # build the last layer
+ # block5 layer12 os=32 for small model
+ # block6 layer16 os=32 for large model
+ layer = ConvModule(
+ in_channels=in_channels,
+ out_channels=576 if self.arch == 'small' else 960,
+ kernel_size=1,
+ stride=1,
+ dilation=4,
+ padding=0,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='HSwish'))
+ layer_name = 'layer{}'.format(len(layer_setting) + 1)
+ self.add_module(layer_name, layer)
+ layers.append(layer_name)
+
+ # next, convert backbone MobileNetV3 to a semantic segmentation version
+ if self.arch == 'small':
+ self.layer4.depthwise_conv.conv.stride = (1, 1)
+ self.layer9.depthwise_conv.conv.stride = (1, 1)
+ for i in range(4, len(layers)):
+ layer = getattr(self, layers[i])
+ if isinstance(layer, InvertedResidual):
+ modified_module = layer.depthwise_conv.conv
+ else:
+ modified_module = layer.conv
+
+ if i < 9:
+ modified_module.dilation = (2, 2)
+ pad = 2
+ else:
+ modified_module.dilation = (4, 4)
+ pad = 4
+
+ if not isinstance(modified_module, Conv2dAdaptivePadding):
+ # Adjust padding
+ pad *= (modified_module.kernel_size[0] - 1) // 2
+ modified_module.padding = (pad, pad)
+ else:
+ self.layer7.depthwise_conv.conv.stride = (1, 1)
+ self.layer13.depthwise_conv.conv.stride = (1, 1)
+ for i in range(7, len(layers)):
+ layer = getattr(self, layers[i])
+ if isinstance(layer, InvertedResidual):
+ modified_module = layer.depthwise_conv.conv
+ else:
+ modified_module = layer.conv
+
+ if i < 13:
+ modified_module.dilation = (2, 2)
+ pad = 2
+ else:
+ modified_module.dilation = (4, 4)
+ pad = 4
+
+ if not isinstance(modified_module, Conv2dAdaptivePadding):
+ # Adjust padding
+ pad *= (modified_module.kernel_size[0] - 1) // 2
+ modified_module.padding = (pad, pad)
+
+ return layers
+
+ def forward(self, x):
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return outs
+
+ def _freeze_stages(self):
+ for i in range(self.frozen_stages + 1):
+ layer = getattr(self, f'layer{i}')
+ layer.eval()
+ for param in layer.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super(MobileNetV3, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmseg/models/backbones/resnest.py b/mmseg/models/backbones/resnest.py
new file mode 100644
index 0000000..91952c2
--- /dev/null
+++ b/mmseg/models/backbones/resnest.py
@@ -0,0 +1,318 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from ..builder import BACKBONES
+from ..utils import ResLayer
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResNetV1d
+
+
+class RSoftmax(nn.Module):
+ """Radix Softmax module in ``SplitAttentionConv2d``.
+
+ Args:
+ radix (int): Radix of input.
+ groups (int): Groups of input.
+ """
+
+ def __init__(self, radix, groups):
+ super().__init__()
+ self.radix = radix
+ self.groups = groups
+
+ def forward(self, x):
+ batch = x.size(0)
+ if self.radix > 1:
+ x = x.view(batch, self.groups, self.radix, -1).transpose(1, 2)
+ x = F.softmax(x, dim=1)
+ x = x.reshape(batch, -1)
+ else:
+ x = torch.sigmoid(x)
+ return x
+
+
+class SplitAttentionConv2d(nn.Module):
+ """Split-Attention Conv2d in ResNeSt.
+
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int | tuple[int]): Same as nn.Conv2d.
+ stride (int | tuple[int]): Same as nn.Conv2d.
+ padding (int | tuple[int]): Same as nn.Conv2d.
+ dilation (int | tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of inter_channels. Default: 4.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ dcn (dict): Config dict for DCN. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ radix=2,
+ reduction_factor=4,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None):
+ super(SplitAttentionConv2d, self).__init__()
+ inter_channels = max(in_channels * radix // reduction_factor, 32)
+ self.radix = radix
+ self.groups = groups
+ self.channels = channels
+ self.with_dcn = dcn is not None
+ self.dcn = dcn
+ fallback_on_stride = False
+ if self.with_dcn:
+ fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
+ if self.with_dcn and not fallback_on_stride:
+ assert conv_cfg is None, 'conv_cfg must be None for DCN'
+ conv_cfg = dcn
+ self.conv = build_conv_layer(
+ conv_cfg,
+ in_channels,
+ channels * radix,
+ kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ groups=groups * radix,
+ bias=False)
+ self.norm0_name, norm0 = build_norm_layer(
+ norm_cfg, channels * radix, postfix=0)
+ self.add_module(self.norm0_name, norm0)
+ self.relu = nn.ReLU(inplace=True)
+ self.fc1 = build_conv_layer(
+ None, channels, inter_channels, 1, groups=self.groups)
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, inter_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.fc2 = build_conv_layer(
+ None, inter_channels, channels * radix, 1, groups=self.groups)
+ self.rsoftmax = RSoftmax(radix, groups)
+
+ @property
+ def norm0(self):
+ """nn.Module: the normalization layer named "norm0" """
+ return getattr(self, self.norm0_name)
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.norm0(x)
+ x = self.relu(x)
+
+ batch, rchannel = x.shape[:2]
+ batch = x.size(0)
+ if self.radix > 1:
+ splits = x.view(batch, self.radix, -1, *x.shape[2:])
+ gap = splits.sum(dim=1)
+ else:
+ gap = x
+ gap = F.adaptive_avg_pool2d(gap, 1)
+ gap = self.fc1(gap)
+
+ gap = self.norm1(gap)
+ gap = self.relu(gap)
+
+ atten = self.fc2(gap)
+ atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
+
+ if self.radix > 1:
+ attens = atten.view(batch, self.radix, -1, *atten.shape[2:])
+ out = torch.sum(attens * splits, dim=1)
+ else:
+ out = atten * x
+ return out.contiguous()
+
+
+class Bottleneck(_Bottleneck):
+ """Bottleneck block for ResNeSt.
+
+ Args:
+ inplane (int): Input planes of this block.
+ planes (int): Middle planes of this block.
+ groups (int): Groups of conv2.
+ width_per_group (int): Width per group of conv2. 64x4d indicates
+ ``groups=64, width_per_group=4`` and 32x8d indicates
+ ``groups=32, width_per_group=8``.
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of inter_channels in
+ SplitAttentionConv2d. Default: 4.
+ avg_down_stride (bool): Whether to use average pool for stride in
+ Bottleneck. Default: True.
+ kwargs (dict): Key word arguments for base class.
+ """
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ groups=1,
+ base_width=4,
+ base_channels=64,
+ radix=2,
+ reduction_factor=4,
+ avg_down_stride=True,
+ **kwargs):
+ """Bottleneck block for ResNeSt."""
+ super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
+
+ if groups == 1:
+ width = self.planes
+ else:
+ width = math.floor(self.planes *
+ (base_width / base_channels)) * groups
+
+ self.avg_down_stride = avg_down_stride and self.conv2_stride > 1
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, width, postfix=1)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.inplanes,
+ width,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.with_modulated_dcn = False
+ self.conv2 = SplitAttentionConv2d(
+ width,
+ width,
+ kernel_size=3,
+ stride=1 if self.avg_down_stride else self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ radix=radix,
+ reduction_factor=reduction_factor,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ dcn=self.dcn)
+ delattr(self, self.norm2_name)
+
+ if self.avg_down_stride:
+ self.avd_layer = nn.AvgPool2d(3, self.conv2_stride, padding=1)
+
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ self.planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+
+ if self.avg_down_stride:
+ out = self.avd_layer(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv3_plugin_names)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+@BACKBONES.register_module()
+class ResNeSt(ResNetV1d):
+ """ResNeSt backbone.
+
+ This backbone is the implementation of `ResNeSt:
+ Split-Attention Networks `_.
+
+ Args:
+ groups (int): Number of groups of Bottleneck. Default: 1
+ base_width (int): Base width of Bottleneck. Default: 4
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of inter_channels in
+ SplitAttentionConv2d. Default: 4.
+ avg_down_stride (bool): Whether to use average pool for stride in
+ Bottleneck. Default: True.
+ kwargs (dict): Keyword arguments for ResNet.
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3)),
+ 200: (Bottleneck, (3, 24, 36, 3))
+ }
+
+ def __init__(self,
+ groups=1,
+ base_width=4,
+ radix=2,
+ reduction_factor=4,
+ avg_down_stride=True,
+ **kwargs):
+ self.groups = groups
+ self.base_width = base_width
+ self.radix = radix
+ self.reduction_factor = reduction_factor
+ self.avg_down_stride = avg_down_stride
+ super(ResNeSt, self).__init__(**kwargs)
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer``."""
+ return ResLayer(
+ groups=self.groups,
+ base_width=self.base_width,
+ base_channels=self.base_channels,
+ radix=self.radix,
+ reduction_factor=self.reduction_factor,
+ avg_down_stride=self.avg_down_stride,
+ **kwargs)
diff --git a/mmseg/models/backbones/resnet.py b/mmseg/models/backbones/resnet.py
new file mode 100644
index 0000000..e8b961d
--- /dev/null
+++ b/mmseg/models/backbones/resnet.py
@@ -0,0 +1,714 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer, build_plugin_layer
+from mmcv.runner import BaseModule
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from ..builder import BACKBONES
+from ..utils import ResLayer
+
+
+class BasicBlock(BaseModule):
+ """Basic block for ResNet."""
+
+ expansion = 1
+
+ def __init__(self,
+ inplanes,
+ planes,
+ stride=1,
+ dilation=1,
+ downsample=None,
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None,
+ plugins=None,
+ init_cfg=None):
+ super(BasicBlock, self).__init__(init_cfg)
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
+
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes,
+ 3,
+ stride=stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ conv_cfg, planes, planes, 3, padding=1, bias=False)
+ self.add_module(self.norm2_name, norm2)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+ self.dilation = dilation
+ self.with_cp = with_cp
+
+ @property
+ def norm1(self):
+ """nn.Module: normalization layer after the first convolution layer"""
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: normalization layer after the second convolution layer"""
+ return getattr(self, self.norm2_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+class Bottleneck(BaseModule):
+ """Bottleneck block for ResNet.
+
+ If style is "pytorch", the stride-two layer is the 3x3 conv layer, if it is
+ "caffe", the stride-two layer is the first 1x1 conv layer.
+ """
+
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ stride=1,
+ dilation=1,
+ downsample=None,
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None,
+ plugins=None,
+ init_cfg=None):
+ super(Bottleneck, self).__init__(init_cfg)
+ assert style in ['pytorch', 'caffe']
+ assert dcn is None or isinstance(dcn, dict)
+ assert plugins is None or isinstance(plugins, list)
+ if plugins is not None:
+ allowed_position = ['after_conv1', 'after_conv2', 'after_conv3']
+ assert all(p['position'] in allowed_position for p in plugins)
+
+ self.inplanes = inplanes
+ self.planes = planes
+ self.stride = stride
+ self.dilation = dilation
+ self.style = style
+ self.with_cp = with_cp
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.dcn = dcn
+ self.with_dcn = dcn is not None
+ self.plugins = plugins
+ self.with_plugins = plugins is not None
+
+ if self.with_plugins:
+ # collect plugins for conv1/conv2/conv3
+ self.after_conv1_plugins = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv1'
+ ]
+ self.after_conv2_plugins = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv2'
+ ]
+ self.after_conv3_plugins = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv3'
+ ]
+
+ if self.style == 'pytorch':
+ self.conv1_stride = 1
+ self.conv2_stride = stride
+ else:
+ self.conv1_stride = stride
+ self.conv2_stride = 1
+
+ self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ norm_cfg, planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ fallback_on_stride = False
+ if self.with_dcn:
+ fallback_on_stride = dcn.pop('fallback_on_stride', False)
+ if not self.with_dcn or fallback_on_stride:
+ self.conv2 = build_conv_layer(
+ conv_cfg,
+ planes,
+ planes,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+ else:
+ assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
+ self.conv2 = build_conv_layer(
+ dcn,
+ planes,
+ planes,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ conv_cfg,
+ planes,
+ planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+
+ if self.with_plugins:
+ self.after_conv1_plugin_names = self.make_block_plugins(
+ planes, self.after_conv1_plugins)
+ self.after_conv2_plugin_names = self.make_block_plugins(
+ planes, self.after_conv2_plugins)
+ self.after_conv3_plugin_names = self.make_block_plugins(
+ planes * self.expansion, self.after_conv3_plugins)
+
+ def make_block_plugins(self, in_channels, plugins):
+ """make plugins for block.
+
+ Args:
+ in_channels (int): Input channels of plugin.
+ plugins (list[dict]): List of plugins cfg to build.
+
+ Returns:
+ list[str]: List of the names of plugin.
+ """
+ assert isinstance(plugins, list)
+ plugin_names = []
+ for plugin in plugins:
+ plugin = plugin.copy()
+ name, layer = build_plugin_layer(
+ plugin,
+ in_channels=in_channels,
+ postfix=plugin.pop('postfix', ''))
+ assert not hasattr(self, name), f'duplicate plugin {name}'
+ self.add_module(name, layer)
+ plugin_names.append(name)
+ return plugin_names
+
+ def forward_plugin(self, x, plugin_names):
+ """Forward function for plugins."""
+ out = x
+ for name in plugin_names:
+ out = getattr(self, name)(x)
+ return out
+
+ @property
+ def norm1(self):
+ """nn.Module: normalization layer after the first convolution layer"""
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: normalization layer after the second convolution layer"""
+ return getattr(self, self.norm2_name)
+
+ @property
+ def norm3(self):
+ """nn.Module: normalization layer after the third convolution layer"""
+ return getattr(self, self.norm3_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv3_plugin_names)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+@BACKBONES.register_module()
+class ResNet(BaseModule):
+ """ResNet backbone.
+
+ This backbone is the improved implementation of `Deep Residual Learning
+ for Image Recognition `_.
+
+ Args:
+ depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
+ in_channels (int): Number of input image channels. Default: 3.
+ stem_channels (int): Number of stem channels. Default: 64.
+ base_channels (int): Number of base channels of res layer. Default: 64.
+ num_stages (int): Resnet stages, normally 4. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ Default: (1, 2, 2, 2).
+ dilations (Sequence[int]): Dilation of each stage.
+ Default: (1, 1, 1, 1).
+ out_indices (Sequence[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer. Default: 'pytorch'.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
+ Default: False.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ conv_cfg (dict | None): Dictionary to construct and config conv layer.
+ When conv_cfg is None, cfg will be set to dict(type='Conv2d').
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN', requires_grad=True).
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ dcn (dict | None): Dictionary to construct and config DCN conv layer.
+ When dcn is not None, conv_cfg must be None. Default: None.
+ stage_with_dcn (Sequence[bool]): Whether to set DCN conv for each
+ stage. The length of stage_with_dcn is equal to num_stages.
+ Default: (False, False, False, False).
+ plugins (list[dict]): List of plugins for stages, each dict contains:
+
+ - cfg (dict, required): Cfg dict to build plugin.
+
+ - position (str, required): Position inside block to insert plugin,
+ options: 'after_conv1', 'after_conv2', 'after_conv3'.
+
+ - stages (tuple[bool], optional): Stages to apply plugin, length
+ should be same as 'num_stages'.
+ Default: None.
+ multi_grid (Sequence[int]|None): Multi grid dilation rates of last
+ stage. Default: None.
+ contract_dilation (bool): Whether contract first dilation of each layer
+ Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: True.
+ pretrained (str, optional): model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Example:
+ >>> from mmseg.models import ResNet
+ >>> import torch
+ >>> self = ResNet(depth=18)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 64, 8, 8)
+ (1, 128, 4, 4)
+ (1, 256, 2, 2)
+ (1, 512, 1, 1)
+ """
+
+ arch_settings = {
+ 18: (BasicBlock, (2, 2, 2, 2)),
+ 34: (BasicBlock, (3, 4, 6, 3)),
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self,
+ depth,
+ in_channels=3,
+ stem_channels=64,
+ base_channels=64,
+ num_stages=4,
+ strides=(1, 2, 2, 2),
+ dilations=(1, 1, 1, 1),
+ out_indices=(0, 1, 2, 3),
+ style='pytorch',
+ deep_stem=False,
+ avg_down=False,
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=False,
+ dcn=None,
+ stage_with_dcn=(False, False, False, False),
+ plugins=None,
+ multi_grid=None,
+ contract_dilation=False,
+ with_cp=False,
+ zero_init_residual=True,
+ pretrained=None,
+ init_cfg=None):
+ super(ResNet, self).__init__(init_cfg)
+ if depth not in self.arch_settings:
+ raise KeyError(f'invalid depth {depth} for resnet')
+
+ self.pretrained = pretrained
+ self.zero_init_residual = zero_init_residual
+ block_init_cfg = None
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ block = self.arch_settings[depth][0]
+ if self.zero_init_residual:
+ if block is BasicBlock:
+ block_init_cfg = dict(
+ type='Constant',
+ val=0,
+ override=dict(name='norm2'))
+ elif block is Bottleneck:
+ block_init_cfg = dict(
+ type='Constant',
+ val=0,
+ override=dict(name='norm3'))
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.depth = depth
+ self.stem_channels = stem_channels
+ self.base_channels = base_channels
+ self.num_stages = num_stages
+ assert num_stages >= 1 and num_stages <= 4
+ self.strides = strides
+ self.dilations = dilations
+ assert len(strides) == len(dilations) == num_stages
+ self.out_indices = out_indices
+ assert max(out_indices) < num_stages
+ self.style = style
+ self.deep_stem = deep_stem
+ self.avg_down = avg_down
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.with_cp = with_cp
+ self.norm_eval = norm_eval
+ self.dcn = dcn
+ self.stage_with_dcn = stage_with_dcn
+ if dcn is not None:
+ assert len(stage_with_dcn) == num_stages
+ self.plugins = plugins
+ self.multi_grid = multi_grid
+ self.contract_dilation = contract_dilation
+ self.block, stage_blocks = self.arch_settings[depth]
+ self.stage_blocks = stage_blocks[:num_stages]
+ self.inplanes = stem_channels
+
+ self._make_stem_layer(in_channels, stem_channels)
+
+ self.res_layers = []
+ for i, num_blocks in enumerate(self.stage_blocks):
+ stride = strides[i]
+ dilation = dilations[i]
+ dcn = self.dcn if self.stage_with_dcn[i] else None
+ if plugins is not None:
+ stage_plugins = self.make_stage_plugins(plugins, i)
+ else:
+ stage_plugins = None
+ # multi grid is applied to last layer only
+ stage_multi_grid = multi_grid if i == len(
+ self.stage_blocks) - 1 else None
+ planes = base_channels * 2**i
+ res_layer = self.make_res_layer(
+ block=self.block,
+ inplanes=self.inplanes,
+ planes=planes,
+ num_blocks=num_blocks,
+ stride=stride,
+ dilation=dilation,
+ style=self.style,
+ avg_down=self.avg_down,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ dcn=dcn,
+ plugins=stage_plugins,
+ multi_grid=stage_multi_grid,
+ contract_dilation=contract_dilation,
+ init_cfg=block_init_cfg)
+ self.inplanes = planes * self.block.expansion
+ layer_name = f'layer{i+1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ self._freeze_stages()
+
+ self.feat_dim = self.block.expansion * base_channels * 2**(
+ len(self.stage_blocks) - 1)
+
+ def make_stage_plugins(self, plugins, stage_idx):
+ """make plugins for ResNet 'stage_idx'th stage .
+
+ Currently we support to insert 'context_block',
+ 'empirical_attention_block', 'nonlocal_block' into the backbone like
+ ResNet/ResNeXt. They could be inserted after conv1/conv2/conv3 of
+ Bottleneck.
+
+ An example of plugins format could be :
+ >>> plugins=[
+ ... dict(cfg=dict(type='xxx', arg1='xxx'),
+ ... stages=(False, True, True, True),
+ ... position='after_conv2'),
+ ... dict(cfg=dict(type='yyy'),
+ ... stages=(True, True, True, True),
+ ... position='after_conv3'),
+ ... dict(cfg=dict(type='zzz', postfix='1'),
+ ... stages=(True, True, True, True),
+ ... position='after_conv3'),
+ ... dict(cfg=dict(type='zzz', postfix='2'),
+ ... stages=(True, True, True, True),
+ ... position='after_conv3')
+ ... ]
+ >>> self = ResNet(depth=18)
+ >>> stage_plugins = self.make_stage_plugins(plugins, 0)
+ >>> assert len(stage_plugins) == 3
+
+ Suppose 'stage_idx=0', the structure of blocks in the stage would be:
+ conv1-> conv2->conv3->yyy->zzz1->zzz2
+ Suppose 'stage_idx=1', the structure of blocks in the stage would be:
+ conv1-> conv2->xxx->conv3->yyy->zzz1->zzz2
+
+ If stages is missing, the plugin would be applied to all stages.
+
+ Args:
+ plugins (list[dict]): List of plugins cfg to build. The postfix is
+ required if multiple same type plugins are inserted.
+ stage_idx (int): Index of stage to build
+
+ Returns:
+ list[dict]: Plugins for current stage
+ """
+ stage_plugins = []
+ for plugin in plugins:
+ plugin = plugin.copy()
+ stages = plugin.pop('stages', None)
+ assert stages is None or len(stages) == self.num_stages
+ # whether to insert plugin into current stage
+ if stages is None or stages[stage_idx]:
+ stage_plugins.append(plugin)
+
+ return stage_plugins
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer``."""
+ return ResLayer(**kwargs)
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ def _make_stem_layer(self, in_channels, stem_channels):
+ """Make stem layer for ResNet."""
+ if self.deep_stem:
+ self.stem = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
+ nn.ReLU(inplace=True),
+ build_conv_layer(
+ self.conv_cfg,
+ stem_channels // 2,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
+ nn.ReLU(inplace=True),
+ build_conv_layer(
+ self.conv_cfg,
+ stem_channels // 2,
+ stem_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, stem_channels)[1],
+ nn.ReLU(inplace=True))
+ else:
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ stem_channels,
+ kernel_size=7,
+ stride=2,
+ padding=3,
+ bias=False)
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, stem_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.relu = nn.ReLU(inplace=True)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+
+ def _freeze_stages(self):
+ """Freeze stages param and norm stats."""
+ if self.frozen_stages >= 0:
+ if self.deep_stem:
+ self.stem.eval()
+ for param in self.stem.parameters():
+ param.requires_grad = False
+ else:
+ self.norm1.eval()
+ for m in [self.conv1, self.norm1]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ m = getattr(self, f'layer{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def forward(self, x):
+ """Forward function."""
+ if self.deep_stem:
+ x = self.stem(x)
+ else:
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep normalization layer
+ freezed."""
+ super(ResNet, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+
+@BACKBONES.register_module()
+class ResNetV1c(ResNet):
+ """ResNetV1c variant described in [1]_.
+
+ Compared with default ResNet(ResNetV1b), ResNetV1c replaces the 7x7 conv in
+ the input stem with three 3x3 convs. For more details please refer to `Bag
+ of Tricks for Image Classification with Convolutional Neural Networks
+ `_.
+ """
+
+ def __init__(self, **kwargs):
+ super(ResNetV1c, self).__init__(
+ deep_stem=True, avg_down=False, **kwargs)
+
+
+@BACKBONES.register_module()
+class ResNetV1d(ResNet):
+ """ResNetV1d variant described in [1]_.
+
+ Compared with default ResNet(ResNetV1b), ResNetV1d replaces the 7x7 conv in
+ the input stem with three 3x3 convs. And in the downsampling block, a 2x2
+ avg_pool with stride 2 is added before conv, whose stride is changed to 1.
+ """
+
+ def __init__(self, **kwargs):
+ super(ResNetV1d, self).__init__(
+ deep_stem=True, avg_down=True, **kwargs)
diff --git a/mmseg/models/backbones/resnext.py b/mmseg/models/backbones/resnext.py
new file mode 100644
index 0000000..805c27b
--- /dev/null
+++ b/mmseg/models/backbones/resnext.py
@@ -0,0 +1,150 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from ..builder import BACKBONES
+from ..utils import ResLayer
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResNet
+
+
+class Bottleneck(_Bottleneck):
+ """Bottleneck block for ResNeXt.
+
+ If style is "pytorch", the stride-two layer is the 3x3 conv layer, if it is
+ "caffe", the stride-two layer is the first 1x1 conv layer.
+ """
+
+ def __init__(self,
+ inplanes,
+ planes,
+ groups=1,
+ base_width=4,
+ base_channels=64,
+ **kwargs):
+ super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
+
+ if groups == 1:
+ width = self.planes
+ else:
+ width = math.floor(self.planes *
+ (base_width / base_channels)) * groups
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, width, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ self.norm_cfg, width, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.inplanes,
+ width,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ fallback_on_stride = False
+ self.with_modulated_dcn = False
+ if self.with_dcn:
+ fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
+ if not self.with_dcn or fallback_on_stride:
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+ else:
+ assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
+ self.conv2 = build_conv_layer(
+ self.dcn,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ self.planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+
+@BACKBONES.register_module()
+class ResNeXt(ResNet):
+ """ResNeXt backbone.
+
+ This backbone is the implementation of `Aggregated
+ Residual Transformations for Deep Neural
+ Networks `_.
+
+ Args:
+ depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
+ in_channels (int): Number of input image channels. Normally 3.
+ num_stages (int): Resnet stages, normally 4.
+ groups (int): Group of resnext.
+ base_width (int): Base width of resnext.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ dilations (Sequence[int]): Dilation of each stage.
+ out_indices (Sequence[int]): Output from which stages.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ frozen_stages (int): Stages to be frozen (all param fixed). -1 means
+ not freezing any parameters.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+
+ Example:
+ >>> from mmseg.models import ResNeXt
+ >>> import torch
+ >>> self = ResNeXt(depth=50)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 256, 8, 8)
+ (1, 512, 4, 4)
+ (1, 1024, 2, 2)
+ (1, 2048, 1, 1)
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self, groups=1, base_width=4, **kwargs):
+ self.groups = groups
+ self.base_width = base_width
+ super(ResNeXt, self).__init__(**kwargs)
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer``"""
+ return ResLayer(
+ groups=self.groups,
+ base_width=self.base_width,
+ base_channels=self.base_channels,
+ **kwargs)
diff --git a/mmseg/models/backbones/stdc.py b/mmseg/models/backbones/stdc.py
new file mode 100644
index 0000000..04f2f7a
--- /dev/null
+++ b/mmseg/models/backbones/stdc.py
@@ -0,0 +1,422 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Modified from https://github.com/MichaelFan01/STDC-Seg."""
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner.base_module import BaseModule, ModuleList, Sequential
+
+from mmseg.ops import resize
+from ..builder import BACKBONES, build_backbone
+from .bisenetv1 import AttentionRefinementModule
+
+
+class STDCModule(BaseModule):
+ """STDCModule.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels before scaling.
+ stride (int): The number of stride for the first conv layer.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (dict): The activation config for conv layers.
+ num_convs (int): Numbers of conv layers.
+ fusion_type (str): Type of fusion operation. Default: 'add'.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride,
+ norm_cfg=None,
+ act_cfg=None,
+ num_convs=4,
+ fusion_type='add',
+ init_cfg=None):
+ super(STDCModule, self).__init__(init_cfg=init_cfg)
+ assert num_convs > 1
+ assert fusion_type in ['add', 'cat']
+ self.stride = stride
+ self.with_downsample = True if self.stride == 2 else False
+ self.fusion_type = fusion_type
+
+ self.layers = ModuleList()
+ conv_0 = ConvModule(
+ in_channels, out_channels // 2, kernel_size=1, norm_cfg=norm_cfg)
+
+ if self.with_downsample:
+ self.downsample = ConvModule(
+ out_channels // 2,
+ out_channels // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=out_channels // 2,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ if self.fusion_type == 'add':
+ self.layers.append(nn.Sequential(conv_0, self.downsample))
+ self.skip = Sequential(
+ ConvModule(
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=in_channels,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ in_channels,
+ out_channels,
+ 1,
+ norm_cfg=norm_cfg,
+ act_cfg=None))
+ else:
+ self.layers.append(conv_0)
+ self.skip = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
+ else:
+ self.layers.append(conv_0)
+
+ for i in range(1, num_convs):
+ out_factor = 2**(i + 1) if i != num_convs - 1 else 2**i
+ self.layers.append(
+ ConvModule(
+ out_channels // 2**i,
+ out_channels // out_factor,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs):
+ if self.fusion_type == 'add':
+ out = self.forward_add(inputs)
+ else:
+ out = self.forward_cat(inputs)
+ return out
+
+ def forward_add(self, inputs):
+ layer_outputs = []
+ x = inputs.clone()
+ for layer in self.layers:
+ x = layer(x)
+ layer_outputs.append(x)
+ if self.with_downsample:
+ inputs = self.skip(inputs)
+
+ return torch.cat(layer_outputs, dim=1) + inputs
+
+ def forward_cat(self, inputs):
+ x0 = self.layers[0](inputs)
+ layer_outputs = [x0]
+ for i, layer in enumerate(self.layers[1:]):
+ if i == 0:
+ if self.with_downsample:
+ x = layer(self.downsample(x0))
+ else:
+ x = layer(x0)
+ else:
+ x = layer(x)
+ layer_outputs.append(x)
+ if self.with_downsample:
+ layer_outputs[0] = self.skip(x0)
+ return torch.cat(layer_outputs, dim=1)
+
+
+class FeatureFusionModule(BaseModule):
+ """Feature Fusion Module. This module is different from FeatureFusionModule
+ in BiSeNetV1. It uses two ConvModules in `self.attention` whose inter
+ channel number is calculated by given `scale_factor`, while
+ FeatureFusionModule in BiSeNetV1 only uses one ConvModule in
+ `self.conv_atten`.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ scale_factor (int): The number of channel scale factor.
+ Default: 4.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): The activation config for conv layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ scale_factor=4,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(FeatureFusionModule, self).__init__(init_cfg=init_cfg)
+ channels = out_channels // scale_factor
+ self.conv0 = ConvModule(
+ in_channels, out_channels, 1, norm_cfg=norm_cfg, act_cfg=act_cfg)
+ self.attention = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ ConvModule(
+ out_channels,
+ channels,
+ 1,
+ norm_cfg=None,
+ bias=False,
+ act_cfg=act_cfg),
+ ConvModule(
+ channels,
+ out_channels,
+ 1,
+ norm_cfg=None,
+ bias=False,
+ act_cfg=None), nn.Sigmoid())
+
+ def forward(self, spatial_inputs, context_inputs):
+ inputs = torch.cat([spatial_inputs, context_inputs], dim=1)
+ x = self.conv0(inputs)
+ attn = self.attention(x)
+ x_attn = x * attn
+ return x_attn + x
+
+
+@BACKBONES.register_module()
+class STDCNet(BaseModule):
+ """This backbone is the implementation of `Rethinking BiSeNet For Real-time
+ Semantic Segmentation `_.
+
+ Args:
+ stdc_type (int): The type of backbone structure,
+ `STDCNet1` and`STDCNet2` denotes two main backbones in paper,
+ whose FLOPs is 813M and 1446M, respectively.
+ in_channels (int): The num of input_channels.
+ channels (tuple[int]): The output channels for each stage.
+ bottleneck_type (str): The type of STDC Module type, the value must
+ be 'add' or 'cat'.
+ norm_cfg (dict): Config dict for normalization layer.
+ act_cfg (dict): The activation config for conv layers.
+ num_convs (int): Numbers of conv layer at each STDC Module.
+ Default: 4.
+ with_final_conv (bool): Whether add a conv layer at the Module output.
+ Default: True.
+ pretrained (str, optional): Model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Example:
+ >>> import torch
+ >>> stdc_type = 'STDCNet1'
+ >>> in_channels = 3
+ >>> channels = (32, 64, 256, 512, 1024)
+ >>> bottleneck_type = 'cat'
+ >>> inputs = torch.rand(1, 3, 1024, 2048)
+ >>> self = STDCNet(stdc_type, in_channels,
+ ... channels, bottleneck_type).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 256, 128, 256])
+ outputs[1].shape = torch.Size([1, 512, 64, 128])
+ outputs[2].shape = torch.Size([1, 1024, 32, 64])
+ """
+
+ arch_settings = {
+ 'STDCNet1': [(2, 1), (2, 1), (2, 1)],
+ 'STDCNet2': [(2, 1, 1, 1), (2, 1, 1, 1, 1), (2, 1, 1)]
+ }
+
+ def __init__(self,
+ stdc_type,
+ in_channels,
+ channels,
+ bottleneck_type,
+ norm_cfg,
+ act_cfg,
+ num_convs=4,
+ with_final_conv=False,
+ pretrained=None,
+ init_cfg=None):
+ super(STDCNet, self).__init__(init_cfg=init_cfg)
+ assert stdc_type in self.arch_settings, \
+ f'invalid structure {stdc_type} for STDCNet.'
+ assert bottleneck_type in ['add', 'cat'],\
+ f'bottleneck_type must be `add` or `cat`, got {bottleneck_type}'
+
+ assert len(channels) == 5,\
+ f'invalid channels length {len(channels)} for STDCNet.'
+
+ self.in_channels = in_channels
+ self.channels = channels
+ self.stage_strides = self.arch_settings[stdc_type]
+ self.prtrained = pretrained
+ self.num_convs = num_convs
+ self.with_final_conv = with_final_conv
+
+ self.stages = ModuleList([
+ ConvModule(
+ self.in_channels,
+ self.channels[0],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ self.channels[0],
+ self.channels[1],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ ])
+ # `self.num_shallow_features` is the number of shallow modules in
+ # `STDCNet`, which is noted as `Stage1` and `Stage2` in original paper.
+ # They are both not used for following modules like Attention
+ # Refinement Module and Feature Fusion Module.
+ # Thus they would be cut from `outs`. Please refer to Figure 4
+ # of original paper for more details.
+ self.num_shallow_features = len(self.stages)
+
+ for strides in self.stage_strides:
+ idx = len(self.stages) - 1
+ self.stages.append(
+ self._make_stage(self.channels[idx], self.channels[idx + 1],
+ strides, norm_cfg, act_cfg, bottleneck_type))
+ # After appending, `self.stages` is a ModuleList including several
+ # shallow modules and STDCModules.
+ # (len(self.stages) ==
+ # self.num_shallow_features + len(self.stage_strides))
+ if self.with_final_conv:
+ self.final_conv = ConvModule(
+ self.channels[-1],
+ max(1024, self.channels[-1]),
+ 1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def _make_stage(self, in_channels, out_channels, strides, norm_cfg,
+ act_cfg, bottleneck_type):
+ layers = []
+ for i, stride in enumerate(strides):
+ layers.append(
+ STDCModule(
+ in_channels if i == 0 else out_channels,
+ out_channels,
+ stride,
+ norm_cfg,
+ act_cfg,
+ num_convs=self.num_convs,
+ fusion_type=bottleneck_type))
+ return Sequential(*layers)
+
+ def forward(self, x):
+ outs = []
+ for stage in self.stages:
+ x = stage(x)
+ outs.append(x)
+ if self.with_final_conv:
+ outs[-1] = self.final_conv(outs[-1])
+ outs = outs[self.num_shallow_features:]
+ return tuple(outs)
+
+
+@BACKBONES.register_module()
+class STDCContextPathNet(BaseModule):
+ """STDCNet with Context Path. The `outs` below is a list of three feature
+ maps from deep to shallow, whose height and width is from small to big,
+ respectively. The biggest feature map of `outs` is outputted for
+ `STDCHead`, where Detail Loss would be calculated by Detail Ground-truth.
+ The other two feature maps are used for Attention Refinement Module,
+ respectively. Besides, the biggest feature map of `outs` and the last
+ output of Attention Refinement Module are concatenated for Feature Fusion
+ Module. Then, this fusion feature map `feat_fuse` would be outputted for
+ `decode_head`. More details please refer to Figure 4 of original paper.
+
+ Args:
+ backbone_cfg (dict): Config dict for stdc backbone.
+ last_in_channels (tuple(int)), The number of channels of last
+ two feature maps from stdc backbone. Default: (1024, 512).
+ out_channels (int): The channels of output feature maps.
+ Default: 128.
+ ffm_cfg (dict): Config dict for Feature Fusion Module. Default:
+ `dict(in_channels=512, out_channels=256, scale_factor=4)`.
+ upsample_mode (str): Algorithm used for upsampling:
+ ``'nearest'`` | ``'linear'`` | ``'bilinear'`` | ``'bicubic'`` |
+ ``'trilinear'``. Default: ``'nearest'``.
+ align_corners (str): align_corners argument of F.interpolate. It
+ must be `None` if upsample_mode is ``'nearest'``. Default: None.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Return:
+ outputs (tuple): The tuple of list of output feature map for
+ auxiliary heads and decoder head.
+ """
+
+ def __init__(self,
+ backbone_cfg,
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(
+ in_channels=512, out_channels=256, scale_factor=4),
+ upsample_mode='nearest',
+ align_corners=None,
+ norm_cfg=dict(type='BN'),
+ init_cfg=None):
+ super(STDCContextPathNet, self).__init__(init_cfg=init_cfg)
+ self.backbone = build_backbone(backbone_cfg)
+ self.arms = ModuleList()
+ self.convs = ModuleList()
+ for channels in last_in_channels:
+ self.arms.append(AttentionRefinementModule(channels, out_channels))
+ self.convs.append(
+ ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ norm_cfg=norm_cfg))
+ self.conv_avg = ConvModule(
+ last_in_channels[0], out_channels, 1, norm_cfg=norm_cfg)
+
+ self.ffm = FeatureFusionModule(**ffm_cfg)
+
+ self.upsample_mode = upsample_mode
+ self.align_corners = align_corners
+
+ def forward(self, x):
+ outs = list(self.backbone(x))
+ avg = F.adaptive_avg_pool2d(outs[-1], 1)
+ avg_feat = self.conv_avg(avg)
+
+ feature_up = resize(
+ avg_feat,
+ size=outs[-1].shape[2:],
+ mode=self.upsample_mode,
+ align_corners=self.align_corners)
+ arms_out = []
+ for i in range(len(self.arms)):
+ x_arm = self.arms[i](outs[len(outs) - 1 - i]) + feature_up
+ feature_up = resize(
+ x_arm,
+ size=outs[len(outs) - 1 - i - 1].shape[2:],
+ mode=self.upsample_mode,
+ align_corners=self.align_corners)
+ feature_up = self.convs[i](feature_up)
+ arms_out.append(feature_up)
+
+ feat_fuse = self.ffm(outs[0], arms_out[1])
+
+ # The `outputs` has four feature maps.
+ # `outs[0]` is outputted for `STDCHead` auxiliary head.
+ # Two feature maps of `arms_out` are outputted for auxiliary head.
+ # `feat_fuse` is outputted for decoder head.
+ outputs = [outs[0]] + list(arms_out) + [feat_fuse]
+ return tuple(outputs)
diff --git a/mmseg/models/backbones/swin.py b/mmseg/models/backbones/swin.py
new file mode 100644
index 0000000..d5d11ac
--- /dev/null
+++ b/mmseg/models/backbones/swin.py
@@ -0,0 +1,756 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from collections import OrderedDict
+from copy import deepcopy
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, build_dropout
+from mmcv.cnn.utils.weight_init import (constant_init, trunc_normal_,
+ trunc_normal_init)
+from mmcv.runner import (BaseModule, CheckpointLoader, ModuleList,
+ load_state_dict)
+from mmcv.utils import to_2tuple
+
+from ...utils import get_root_logger
+from ..builder import BACKBONES
+from ..utils.embed import PatchEmbed, PatchMerging
+
+
+class WindowMSA(BaseModule):
+ """Window based multi-head self-attention (W-MSA) module with relative
+ position bias.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (tuple[int]): The height and width of the window.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
+ init_cfg (dict | None, optional): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0.,
+ proj_drop_rate=0.,
+ init_cfg=None):
+
+ super().__init__(init_cfg=init_cfg)
+ self.embed_dims = embed_dims
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_embed_dims = embed_dims // num_heads
+ self.scale = qk_scale or head_embed_dims**-0.5
+
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1),
+ num_heads)) # 2*Wh-1 * 2*Ww-1, nH
+
+ # About 2x faster than original impl
+ Wh, Ww = self.window_size
+ rel_index_coords = self.double_step_seq(2 * Ww - 1, Wh, 1, Ww)
+ rel_position_index = rel_index_coords + rel_index_coords.T
+ rel_position_index = rel_position_index.flip(1).contiguous()
+ self.register_buffer('relative_position_index', rel_position_index)
+
+ self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop_rate)
+ self.proj = nn.Linear(embed_dims, embed_dims)
+ self.proj_drop = nn.Dropout(proj_drop_rate)
+
+ self.softmax = nn.Softmax(dim=-1)
+
+ def init_weights(self):
+ trunc_normal_(self.relative_position_bias_table, std=0.02)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+
+ x (tensor): input features with shape of (num_windows*B, N, C)
+ mask (tensor | None, Optional): mask with shape of (num_windows,
+ Wh*Ww, Wh*Ww), value should be between (-inf, 0].
+ """
+ B, N, C = x.shape
+ qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
+ C // self.num_heads).permute(2, 0, 3, 1, 4)
+ # make torchscript happy (cannot use tensor as tuple)
+ q, k, v = qkv[0], qkv[1], qkv[2]
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ relative_position_bias = self.relative_position_bias_table[
+ self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1],
+ self.window_size[0] * self.window_size[1],
+ -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(
+ 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B // nW, nW, self.num_heads, N,
+ N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ @staticmethod
+ def double_step_seq(step1, len1, step2, len2):
+ seq1 = torch.arange(0, step1 * len1, step1)
+ seq2 = torch.arange(0, step2 * len2, step2)
+ return (seq1[:, None] + seq2[None, :]).reshape(1, -1)
+
+
+class ShiftWindowMSA(BaseModule):
+ """Shifted Window Multihead Self-Attention Module.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (int): The height and width of the window.
+ shift_size (int, optional): The shift step of each window towards
+ right-bottom. If zero, act as regular window-msa. Defaults to 0.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Defaults: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Defaults: 0.
+ proj_drop_rate (float, optional): Dropout ratio of output.
+ Defaults: 0.
+ dropout_layer (dict, optional): The dropout_layer used before output.
+ Defaults: dict(type='DropPath', drop_prob=0.).
+ init_cfg (dict, optional): The extra config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ shift_size=0,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0,
+ proj_drop_rate=0,
+ dropout_layer=dict(type='DropPath', drop_prob=0.),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.window_size = window_size
+ self.shift_size = shift_size
+ assert 0 <= self.shift_size < self.window_size
+
+ self.w_msa = WindowMSA(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ window_size=to_2tuple(window_size),
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop_rate=attn_drop_rate,
+ proj_drop_rate=proj_drop_rate,
+ init_cfg=None)
+
+ self.drop = build_dropout(dropout_layer)
+
+ def forward(self, query, hw_shape):
+ B, L, C = query.shape
+ H, W = hw_shape
+ assert L == H * W, 'input feature has wrong size'
+ query = query.view(B, H, W, C)
+
+ # pad feature maps to multiples of window size
+ pad_r = (self.window_size - W % self.window_size) % self.window_size
+ pad_b = (self.window_size - H % self.window_size) % self.window_size
+ query = F.pad(query, (0, 0, 0, pad_r, 0, pad_b))
+ H_pad, W_pad = query.shape[1], query.shape[2]
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_query = torch.roll(
+ query,
+ shifts=(-self.shift_size, -self.shift_size),
+ dims=(1, 2))
+
+ # calculate attention mask for SW-MSA
+ img_mask = torch.zeros((1, H_pad, W_pad, 1), device=query.device)
+ h_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ # nW, window_size, window_size, 1
+ mask_windows = self.window_partition(img_mask)
+ mask_windows = mask_windows.view(
+ -1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-100.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+ else:
+ shifted_query = query
+ attn_mask = None
+
+ # nW*B, window_size, window_size, C
+ query_windows = self.window_partition(shifted_query)
+ # nW*B, window_size*window_size, C
+ query_windows = query_windows.view(-1, self.window_size**2, C)
+
+ # W-MSA/SW-MSA (nW*B, window_size*window_size, C)
+ attn_windows = self.w_msa(query_windows, mask=attn_mask)
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size,
+ self.window_size, C)
+
+ # B H' W' C
+ shifted_x = self.window_reverse(attn_windows, H_pad, W_pad)
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = torch.roll(
+ shifted_x,
+ shifts=(self.shift_size, self.shift_size),
+ dims=(1, 2))
+ else:
+ x = shifted_x
+
+ if pad_r > 0 or pad_b:
+ x = x[:, :H, :W, :].contiguous()
+
+ x = x.view(B, H * W, C)
+
+ x = self.drop(x)
+ return x
+
+ def window_reverse(self, windows, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ H (int): Height of image
+ W (int): Width of image
+ Returns:
+ x: (B, H, W, C)
+ """
+ window_size = self.window_size
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size,
+ window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+ def window_partition(self, x):
+ """
+ Args:
+ x: (B, H, W, C)
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ window_size = self.window_size
+ x = x.view(B, H // window_size, window_size, W // window_size,
+ window_size, C)
+ windows = x.permute(0, 1, 3, 2, 4, 5).contiguous()
+ windows = windows.view(-1, window_size, window_size, C)
+ return windows
+
+
+class SwinBlock(BaseModule):
+ """"
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ window_size (int, optional): The local window scale. Default: 7.
+ shift (bool, optional): whether to shift window or not. Default False.
+ qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ drop_rate (float, optional): Dropout rate. Default: 0.
+ attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
+ drop_path_rate (float, optional): Stochastic depth rate. Default: 0.
+ act_cfg (dict, optional): The config dict of activation function.
+ Default: dict(type='GELU').
+ norm_cfg (dict, optional): The config dict of normalization.
+ Default: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict | list | None, optional): The init config.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ window_size=7,
+ shift=False,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ init_cfg=None):
+
+ super(SwinBlock, self).__init__(init_cfg=init_cfg)
+
+ self.with_cp = with_cp
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
+ self.attn = ShiftWindowMSA(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=window_size // 2 if shift else 0,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop_rate=attn_drop_rate,
+ proj_drop_rate=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ init_cfg=None)
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=2,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=True,
+ init_cfg=None)
+
+ def forward(self, x, hw_shape):
+
+ def _inner_forward(x):
+ identity = x
+ x = self.norm1(x)
+ x = self.attn(x, hw_shape)
+
+ x = x + identity
+
+ identity = x
+ x = self.norm2(x)
+ x = self.ffn(x, identity=identity)
+
+ return x
+
+ if self.with_cp and x.requires_grad:
+ x = cp.checkpoint(_inner_forward, x)
+ else:
+ x = _inner_forward(x)
+
+ return x
+
+
+class SwinBlockSequence(BaseModule):
+ """Implements one stage in Swin Transformer.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ depth (int): The number of blocks in this stage.
+ window_size (int, optional): The local window scale. Default: 7.
+ qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ drop_rate (float, optional): Dropout rate. Default: 0.
+ attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
+ drop_path_rate (float | list[float], optional): Stochastic depth
+ rate. Default: 0.
+ downsample (BaseModule | None, optional): The downsample operation
+ module. Default: None.
+ act_cfg (dict, optional): The config dict of activation function.
+ Default: dict(type='GELU').
+ norm_cfg (dict, optional): The config dict of normalization.
+ Default: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict | list | None, optional): The init config.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ depth,
+ window_size=7,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ downsample=None,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ if isinstance(drop_path_rate, list):
+ drop_path_rates = drop_path_rate
+ assert len(drop_path_rates) == depth
+ else:
+ drop_path_rates = [deepcopy(drop_path_rate) for _ in range(depth)]
+
+ self.blocks = ModuleList()
+ for i in range(depth):
+ block = SwinBlock(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ feedforward_channels=feedforward_channels,
+ window_size=window_size,
+ shift=False if i % 2 == 0 else True,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=drop_path_rates[i],
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ with_cp=with_cp,
+ init_cfg=None)
+ self.blocks.append(block)
+
+ self.downsample = downsample
+
+ def forward(self, x, hw_shape):
+ for block in self.blocks:
+ x = block(x, hw_shape)
+
+ if self.downsample:
+ x_down, down_hw_shape = self.downsample(x, hw_shape)
+ return x_down, down_hw_shape, x, hw_shape
+ else:
+ return x, hw_shape, x, hw_shape
+
+
+@BACKBONES.register_module()
+class SwinTransformer(BaseModule):
+ """Swin Transformer backbone.
+
+ This backbone is the implementation of `Swin Transformer:
+ Hierarchical Vision Transformer using Shifted
+ Windows `_.
+ Inspiration from https://github.com/microsoft/Swin-Transformer.
+
+ Args:
+ pretrain_img_size (int | tuple[int]): The size of input image when
+ pretrain. Defaults: 224.
+ in_channels (int): The num of input channels.
+ Defaults: 3.
+ embed_dims (int): The feature dimension. Default: 96.
+ patch_size (int | tuple[int]): Patch size. Default: 4.
+ window_size (int): Window size. Default: 7.
+ mlp_ratio (int): Ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ depths (tuple[int]): Depths of each Swin Transformer stage.
+ Default: (2, 2, 6, 2).
+ num_heads (tuple[int]): Parallel attention heads of each Swin
+ Transformer stage. Default: (3, 6, 12, 24).
+ strides (tuple[int]): The patch merging or patch embedding stride of
+ each Swin Transformer stage. (In swin, we set kernel size equal to
+ stride.) Default: (4, 2, 2, 2).
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key,
+ value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ patch_norm (bool): If add a norm layer for patch embed and patch
+ merging. Default: True.
+ drop_rate (float): Dropout rate. Defaults: 0.
+ attn_drop_rate (float): Attention dropout rate. Default: 0.
+ drop_path_rate (float): Stochastic depth rate. Defaults: 0.1.
+ use_abs_pos_embed (bool): If True, add absolute position embedding to
+ the patch embedding. Defaults: False.
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='LN').
+ norm_cfg (dict): Config dict for normalization layer at
+ output of backone. Defaults: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ pretrained (str, optional): model pretrained path. Default: None.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ pretrain_img_size=224,
+ in_channels=3,
+ embed_dims=96,
+ patch_size=4,
+ window_size=7,
+ mlp_ratio=4,
+ depths=(2, 2, 6, 2),
+ num_heads=(3, 6, 12, 24),
+ strides=(4, 2, 2, 2),
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=True,
+ qk_scale=None,
+ patch_norm=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ use_abs_pos_embed=False,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ pretrained=None,
+ frozen_stages=-1,
+ init_cfg=None):
+ self.frozen_stages = frozen_stages
+
+ if isinstance(pretrain_img_size, int):
+ pretrain_img_size = to_2tuple(pretrain_img_size)
+ elif isinstance(pretrain_img_size, tuple):
+ if len(pretrain_img_size) == 1:
+ pretrain_img_size = to_2tuple(pretrain_img_size[0])
+ assert len(pretrain_img_size) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(pretrain_img_size)}'
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ init_cfg = init_cfg
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ super(SwinTransformer, self).__init__(init_cfg=init_cfg)
+
+ num_layers = len(depths)
+ self.out_indices = out_indices
+ self.use_abs_pos_embed = use_abs_pos_embed
+
+ assert strides[0] == patch_size, 'Use non-overlapping patch embed.'
+
+ self.patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims,
+ conv_type='Conv2d',
+ kernel_size=patch_size,
+ stride=strides[0],
+ padding='corner',
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None)
+
+ if self.use_abs_pos_embed:
+ patch_row = pretrain_img_size[0] // patch_size
+ patch_col = pretrain_img_size[1] // patch_size
+ num_patches = patch_row * patch_col
+ self.absolute_pos_embed = nn.Parameter(
+ torch.zeros((1, num_patches, embed_dims)))
+
+ self.drop_after_pos = nn.Dropout(p=drop_rate)
+
+ # set stochastic depth decay rule
+ total_depth = sum(depths)
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, total_depth)
+ ]
+
+ self.stages = ModuleList()
+ in_channels = embed_dims
+ for i in range(num_layers):
+ if i < num_layers - 1:
+ downsample = PatchMerging(
+ in_channels=in_channels,
+ out_channels=2 * in_channels,
+ stride=strides[i + 1],
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None)
+ else:
+ downsample = None
+
+ stage = SwinBlockSequence(
+ embed_dims=in_channels,
+ num_heads=num_heads[i],
+ feedforward_channels=mlp_ratio * in_channels,
+ depth=depths[i],
+ window_size=window_size,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[sum(depths[:i]):sum(depths[:i + 1])],
+ downsample=downsample,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ with_cp=with_cp,
+ init_cfg=None)
+ self.stages.append(stage)
+ if downsample:
+ in_channels = downsample.out_channels
+
+ self.num_features = [int(embed_dims * 2**i) for i in range(num_layers)]
+ # Add a norm layer for each output
+ for i in out_indices:
+ layer = build_norm_layer(norm_cfg, self.num_features[i])[1]
+ layer_name = f'norm{i}'
+ self.add_module(layer_name, layer)
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep layers freezed."""
+ super(SwinTransformer, self).train(mode)
+ self._freeze_stages()
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ self.patch_embed.eval()
+ for param in self.patch_embed.parameters():
+ param.requires_grad = False
+ if self.use_abs_pos_embed:
+ self.absolute_pos_embed.requires_grad = False
+ self.drop_after_pos.eval()
+
+ for i in range(1, self.frozen_stages + 1):
+
+ if (i - 1) in self.out_indices:
+ norm_layer = getattr(self, f'norm{i-1}')
+ norm_layer.eval()
+ for param in norm_layer.parameters():
+ param.requires_grad = False
+
+ m = self.stages[i - 1]
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def init_weights(self):
+ logger = get_root_logger()
+ if self.init_cfg is None:
+ logger.warn(f'No pre-trained weights for '
+ f'{self.__class__.__name__}, '
+ f'training start from scratch')
+ if self.use_abs_pos_embed:
+ trunc_normal_(self.absolute_pos_embed, std=0.02)
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=.02, bias=0.)
+ elif isinstance(m, nn.LayerNorm):
+ constant_init(m, val=1.0, bias=0.)
+ else:
+ assert 'checkpoint' in self.init_cfg, f'Only support ' \
+ f'specify `Pretrained` in ' \
+ f'`init_cfg` in ' \
+ f'{self.__class__.__name__} '
+ ckpt = CheckpointLoader.load_checkpoint(
+ self.init_cfg['checkpoint'], logger=logger, map_location='cpu')
+ if 'state_dict' in ckpt:
+ _state_dict = ckpt['state_dict']
+ elif 'model' in ckpt:
+ _state_dict = ckpt['model']
+ else:
+ _state_dict = ckpt
+
+ state_dict = OrderedDict()
+ for k, v in _state_dict.items():
+ if k.startswith('backbone.'):
+ state_dict[k[9:]] = v
+ else:
+ state_dict[k] = v
+
+ # strip prefix of state_dict
+ if list(state_dict.keys())[0].startswith('module.'):
+ state_dict = {k[7:]: v for k, v in state_dict.items()}
+
+ # reshape absolute position embedding
+ if state_dict.get('absolute_pos_embed') is not None:
+ absolute_pos_embed = state_dict['absolute_pos_embed']
+ N1, L, C1 = absolute_pos_embed.size()
+ N2, C2, H, W = self.absolute_pos_embed.size()
+ if N1 != N2 or C1 != C2 or L != H * W:
+ logger.warning('Error in loading absolute_pos_embed, pass')
+ else:
+ state_dict['absolute_pos_embed'] = absolute_pos_embed.view(
+ N2, H, W, C2).permute(0, 3, 1, 2).contiguous()
+
+ # interpolate position bias table if needed
+ relative_position_bias_table_keys = [
+ k for k in state_dict.keys()
+ if 'relative_position_bias_table' in k
+ ]
+ for table_key in relative_position_bias_table_keys:
+ table_pretrained = state_dict[table_key]
+ table_current = self.state_dict()[table_key]
+ L1, nH1 = table_pretrained.size()
+ L2, nH2 = table_current.size()
+ if nH1 != nH2:
+ logger.warning(f'Error in loading {table_key}, pass')
+ elif L1 != L2:
+ S1 = int(L1**0.5)
+ S2 = int(L2**0.5)
+ table_pretrained_resized = F.interpolate(
+ table_pretrained.permute(1, 0).reshape(1, nH1, S1, S1),
+ size=(S2, S2),
+ mode='bicubic')
+ state_dict[table_key] = table_pretrained_resized.view(
+ nH2, L2).permute(1, 0).contiguous()
+
+ # load state_dict
+ load_state_dict(self, state_dict, strict=False, logger=logger)
+
+ def forward(self, x):
+ x, hw_shape = self.patch_embed(x)
+
+ if self.use_abs_pos_embed:
+ x = x + self.absolute_pos_embed
+ x = self.drop_after_pos(x)
+
+ outs = []
+ for i, stage in enumerate(self.stages):
+ x, hw_shape, out, out_hw_shape = stage(x, hw_shape)
+ if i in self.out_indices:
+ norm_layer = getattr(self, f'norm{i}')
+ out = norm_layer(out)
+ out = out.view(-1, *out_hw_shape,
+ self.num_features[i]).permute(0, 3, 1,
+ 2).contiguous()
+ outs.append(out)
+
+ return outs
diff --git a/mmseg/models/backbones/timm_backbone.py b/mmseg/models/backbones/timm_backbone.py
new file mode 100644
index 0000000..01b29fc
--- /dev/null
+++ b/mmseg/models/backbones/timm_backbone.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+try:
+ import timm
+except ImportError:
+ timm = None
+
+from mmcv.cnn.bricks.registry import NORM_LAYERS
+from mmcv.runner import BaseModule
+
+from ..builder import BACKBONES
+
+
+@BACKBONES.register_module()
+class TIMMBackbone(BaseModule):
+ """Wrapper to use backbones from timm library. More details can be found in
+ `timm `_ .
+
+ Args:
+ model_name (str): Name of timm model to instantiate.
+ pretrained (bool): Load pretrained weights if True.
+ checkpoint_path (str): Path of checkpoint to load after
+ model is initialized.
+ in_channels (int): Number of input image channels. Default: 3.
+ init_cfg (dict, optional): Initialization config dict
+ **kwargs: Other timm & model specific arguments.
+ """
+
+ def __init__(
+ self,
+ model_name,
+ features_only=True,
+ pretrained=True,
+ checkpoint_path='',
+ in_channels=3,
+ init_cfg=None,
+ **kwargs,
+ ):
+ if timm is None:
+ raise RuntimeError('timm is not installed')
+ super(TIMMBackbone, self).__init__(init_cfg)
+ if 'norm_layer' in kwargs:
+ kwargs['norm_layer'] = NORM_LAYERS.get(kwargs['norm_layer'])
+ self.timm_model = timm.create_model(
+ model_name=model_name,
+ features_only=features_only,
+ pretrained=pretrained,
+ in_chans=in_channels,
+ checkpoint_path=checkpoint_path,
+ **kwargs,
+ )
+
+ # Make unused parameters None
+ self.timm_model.global_pool = None
+ self.timm_model.fc = None
+ self.timm_model.classifier = None
+
+ # Hack to use pretrained weights from timm
+ if pretrained or checkpoint_path:
+ self._is_init = True
+
+ def forward(self, x):
+ features = self.timm_model(x)
+ return features
diff --git a/mmseg/models/backbones/twins.py b/mmseg/models/backbones/twins.py
new file mode 100644
index 0000000..b41325b
--- /dev/null
+++ b/mmseg/models/backbones/twins.py
@@ -0,0 +1,587 @@
+import math
+import warnings
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.drop import build_dropout
+from mmcv.cnn.bricks.transformer import FFN
+from mmcv.cnn.utils.weight_init import (constant_init, normal_init,
+ trunc_normal_init)
+from mmcv.runner import BaseModule, ModuleList
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmseg.models.backbones.mit import EfficientMultiheadAttention
+from mmseg.models.builder import BACKBONES
+from ..utils.embed import PatchEmbed
+
+
+class GlobalSubsampledAttention(EfficientMultiheadAttention):
+ """Global Sub-sampled Attention (Spatial Reduction Attention)
+
+ This module is modified from EfficientMultiheadAttention,
+ which is a module from mmseg.models.backbones.mit.py.
+ Specifically, there is no difference between
+ `GlobalSubsampledAttention` and `EfficientMultiheadAttention`,
+ `GlobalSubsampledAttention` is built as a brand new class
+ because it is renamed as `Global sub-sampled attention (GSA)`
+ in paper.
+
+
+ Args:
+ embed_dims (int): The embedding dimension.
+ num_heads (int): Parallel attention heads.
+ attn_drop (float): A Dropout layer on attn_output_weights.
+ Default: 0.0.
+ proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
+ Default: 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut. Default: None.
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dims)
+ or (n, batch, embed_dims). Default: False.
+ qkv_bias (bool): enable bias for qkv if True. Default: True.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (int): The ratio of spatial reduction of GSA of PCPVT.
+ Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ attn_drop=0.,
+ proj_drop=0.,
+ dropout_layer=None,
+ batch_first=True,
+ qkv_bias=True,
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1,
+ init_cfg=None):
+ super(GlobalSubsampledAttention, self).__init__(
+ embed_dims,
+ num_heads,
+ attn_drop=attn_drop,
+ proj_drop=proj_drop,
+ dropout_layer=dropout_layer,
+ batch_first=batch_first,
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio,
+ init_cfg=init_cfg)
+
+
+class GSAEncoderLayer(BaseModule):
+ """Implements one encoder layer with GSA.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default: 0.0.
+ drop_path_rate (float): Stochastic depth rate. Default 0.0.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (float): Kernel_size of conv in Attention modules. Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ num_fcs=2,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1.,
+ init_cfg=None):
+ super(GSAEncoderLayer, self).__init__(init_cfg=init_cfg)
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims, postfix=1)[1]
+ self.attn = GlobalSubsampledAttention(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ attn_drop=attn_drop_rate,
+ proj_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio)
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims, postfix=2)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=num_fcs,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=False)
+
+ self.drop_path = build_dropout(
+ dict(type='DropPath', drop_prob=drop_path_rate)
+ ) if drop_path_rate > 0. else nn.Identity()
+
+ def forward(self, x, hw_shape):
+ x = x + self.drop_path(self.attn(self.norm1(x), hw_shape, identity=0.))
+ x = x + self.drop_path(self.ffn(self.norm2(x)))
+ return x
+
+
+class LocallyGroupedSelfAttention(BaseModule):
+ """Locally-grouped Self Attention (LSA) module.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads. Default: 8
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: False.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
+ window_size(int): Window size of LSA. Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads=8,
+ qkv_bias=False,
+ qk_scale=None,
+ attn_drop_rate=0.,
+ proj_drop_rate=0.,
+ window_size=1,
+ init_cfg=None):
+ super(LocallyGroupedSelfAttention, self).__init__(init_cfg=init_cfg)
+
+ assert embed_dims % num_heads == 0, f'dim {embed_dims} should be ' \
+ f'divided by num_heads ' \
+ f'{num_heads}.'
+ self.embed_dims = embed_dims
+ self.num_heads = num_heads
+ head_dim = embed_dims // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop_rate)
+ self.proj = nn.Linear(embed_dims, embed_dims)
+ self.proj_drop = nn.Dropout(proj_drop_rate)
+ self.window_size = window_size
+
+ def forward(self, x, hw_shape):
+ b, n, c = x.shape
+ h, w = hw_shape
+ x = x.view(b, h, w, c)
+
+ # pad feature maps to multiples of Local-groups
+ pad_l = pad_t = 0
+ pad_r = (self.window_size - w % self.window_size) % self.window_size
+ pad_b = (self.window_size - h % self.window_size) % self.window_size
+ x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
+
+ # calculate attention mask for LSA
+ Hp, Wp = x.shape[1:-1]
+ _h, _w = Hp // self.window_size, Wp // self.window_size
+ mask = torch.zeros((1, Hp, Wp), device=x.device)
+ mask[:, -pad_b:, :].fill_(1)
+ mask[:, :, -pad_r:].fill_(1)
+
+ # [B, _h, _w, window_size, window_size, C]
+ x = x.reshape(b, _h, self.window_size, _w, self.window_size,
+ c).transpose(2, 3)
+ mask = mask.reshape(1, _h, self.window_size, _w,
+ self.window_size).transpose(2, 3).reshape(
+ 1, _h * _w,
+ self.window_size * self.window_size)
+ # [1, _h*_w, window_size*window_size, window_size*window_size]
+ attn_mask = mask.unsqueeze(2) - mask.unsqueeze(3)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-1000.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+
+ # [3, B, _w*_h, nhead, window_size*window_size, dim]
+ qkv = self.qkv(x).reshape(b, _h * _w,
+ self.window_size * self.window_size, 3,
+ self.num_heads, c // self.num_heads).permute(
+ 3, 0, 1, 4, 2, 5)
+ q, k, v = qkv[0], qkv[1], qkv[2]
+ # [B, _h*_w, n_head, window_size*window_size, window_size*window_size]
+ attn = (q @ k.transpose(-2, -1)) * self.scale
+ attn = attn + attn_mask.unsqueeze(2)
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+ attn = (attn @ v).transpose(2, 3).reshape(b, _h, _w, self.window_size,
+ self.window_size, c)
+ x = attn.transpose(2, 3).reshape(b, _h * self.window_size,
+ _w * self.window_size, c)
+ if pad_r > 0 or pad_b > 0:
+ x = x[:, :h, :w, :].contiguous()
+
+ x = x.reshape(b, n, c)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class LSAEncoderLayer(BaseModule):
+ """Implements one encoder layer in Twins-SVT.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ drop_path_rate (float): Stochastic depth rate. Default 0.0.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ window_size (int): Window size of LSA. Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ num_fcs=2,
+ qkv_bias=True,
+ qk_scale=None,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ window_size=1,
+ init_cfg=None):
+
+ super(LSAEncoderLayer, self).__init__(init_cfg=init_cfg)
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims, postfix=1)[1]
+ self.attn = LocallyGroupedSelfAttention(embed_dims, num_heads,
+ qkv_bias, qk_scale,
+ attn_drop_rate, drop_rate,
+ window_size)
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims, postfix=2)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=num_fcs,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=False)
+
+ self.drop_path = build_dropout(
+ dict(type='DropPath', drop_prob=drop_path_rate)
+ ) if drop_path_rate > 0. else nn.Identity()
+
+ def forward(self, x, hw_shape):
+ x = x + self.drop_path(self.attn(self.norm1(x), hw_shape))
+ x = x + self.drop_path(self.ffn(self.norm2(x)))
+ return x
+
+
+class ConditionalPositionEncoding(BaseModule):
+ """The Conditional Position Encoding (CPE) module.
+
+ The CPE is the implementation of 'Conditional Positional Encodings
+ for Vision Transformers '_.
+
+ Args:
+ in_channels (int): Number of input channels.
+ embed_dims (int): The feature dimension. Default: 768.
+ stride (int): Stride of conv layer. Default: 1.
+ """
+
+ def __init__(self, in_channels, embed_dims=768, stride=1, init_cfg=None):
+ super(ConditionalPositionEncoding, self).__init__(init_cfg=init_cfg)
+ self.proj = nn.Conv2d(
+ in_channels,
+ embed_dims,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ bias=True,
+ groups=embed_dims)
+ self.stride = stride
+
+ def forward(self, x, hw_shape):
+ b, n, c = x.shape
+ h, w = hw_shape
+ feat_token = x
+ cnn_feat = feat_token.transpose(1, 2).view(b, c, h, w)
+ if self.stride == 1:
+ x = self.proj(cnn_feat) + cnn_feat
+ else:
+ x = self.proj(cnn_feat)
+ x = x.flatten(2).transpose(1, 2)
+ return x
+
+
+@BACKBONES.register_module()
+class PCPVT(BaseModule):
+ """The backbone of Twins-PCPVT.
+
+ This backbone is the implementation of `Twins: Revisiting the Design
+ of Spatial Attention in Vision Transformers
+ `_.
+
+ Args:
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (list): Embedding dimension. Default: [64, 128, 256, 512].
+ patch_sizes (list): The patch sizes. Default: [4, 2, 2, 2].
+ strides (list): The strides. Default: [4, 2, 2, 2].
+ num_heads (int): Number of attention heads. Default: [1, 2, 4, 8].
+ mlp_ratios (int): Ratio of mlp hidden dim to embedding dim.
+ Default: [4, 4, 4, 4].
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool): Enable bias for qkv if True. Default: False.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0
+ drop_path_rate (float): Stochastic depth rate. Default 0.0
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ depths (list): Depths of each stage. Default [3, 4, 6, 3]
+ sr_ratios (list): Kernel_size of conv in each Attn module in
+ Transformer encoder layer. Default: [8, 4, 2, 1].
+ norm_after_stage(bool): Add extra norm. Default False.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=[64, 128, 256, 512],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ num_heads=[1, 2, 4, 8],
+ mlp_ratios=[4, 4, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=False,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ norm_cfg=dict(type='LN'),
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False,
+ pretrained=None,
+ init_cfg=None):
+ super(PCPVT, self).__init__(init_cfg=init_cfg)
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be set at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is not None:
+ raise TypeError('pretrained must be a str or None')
+ self.depths = depths
+
+ # patch_embed
+ self.patch_embeds = ModuleList()
+ self.position_encoding_drops = ModuleList()
+ self.layers = ModuleList()
+
+ for i in range(len(depths)):
+ self.patch_embeds.append(
+ PatchEmbed(
+ in_channels=in_channels if i == 0 else embed_dims[i - 1],
+ embed_dims=embed_dims[i],
+ conv_type='Conv2d',
+ kernel_size=patch_sizes[i],
+ stride=strides[i],
+ padding='corner',
+ norm_cfg=norm_cfg))
+
+ self.position_encoding_drops.append(nn.Dropout(p=drop_rate))
+
+ self.position_encodings = ModuleList([
+ ConditionalPositionEncoding(embed_dim, embed_dim)
+ for embed_dim in embed_dims
+ ])
+
+ # transformer encoder
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+ cur = 0
+
+ for k in range(len(depths)):
+ _block = ModuleList([
+ GSAEncoderLayer(
+ embed_dims=embed_dims[k],
+ num_heads=num_heads[k],
+ feedforward_channels=mlp_ratios[k] * embed_dims[k],
+ attn_drop_rate=attn_drop_rate,
+ drop_rate=drop_rate,
+ drop_path_rate=dpr[cur + i],
+ num_fcs=2,
+ qkv_bias=qkv_bias,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ sr_ratio=sr_ratios[k]) for i in range(depths[k])
+ ])
+ self.layers.append(_block)
+ cur += depths[k]
+
+ self.norm_name, norm = build_norm_layer(
+ norm_cfg, embed_dims[-1], postfix=1)
+
+ self.out_indices = out_indices
+ self.norm_after_stage = norm_after_stage
+ if self.norm_after_stage:
+ self.norm_list = ModuleList()
+ for dim in embed_dims:
+ self.norm_list.append(build_norm_layer(norm_cfg, dim)[1])
+
+ def init_weights(self):
+ if self.init_cfg is not None:
+ super(PCPVT, self).init_weights()
+ else:
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=.02, bias=0.)
+ elif isinstance(m, (_BatchNorm, nn.GroupNorm, nn.LayerNorm)):
+ constant_init(m, val=1.0, bias=0.)
+ elif isinstance(m, nn.Conv2d):
+ fan_out = m.kernel_size[0] * m.kernel_size[
+ 1] * m.out_channels
+ fan_out //= m.groups
+ normal_init(
+ m, mean=0, std=math.sqrt(2.0 / fan_out), bias=0)
+
+ def forward(self, x):
+ outputs = list()
+
+ b = x.shape[0]
+
+ for i in range(len(self.depths)):
+ x, hw_shape = self.patch_embeds[i](x)
+ h, w = hw_shape
+ x = self.position_encoding_drops[i](x)
+ for j, blk in enumerate(self.layers[i]):
+ x = blk(x, hw_shape)
+ if j == 0:
+ x = self.position_encodings[i](x, hw_shape)
+ if self.norm_after_stage:
+ x = self.norm_list[i](x)
+ x = x.reshape(b, h, w, -1).permute(0, 3, 1, 2).contiguous()
+
+ if i in self.out_indices:
+ outputs.append(x)
+
+ return tuple(outputs)
+
+
+@BACKBONES.register_module()
+class SVT(PCPVT):
+ """The backbone of Twins-SVT.
+
+ This backbone is the implementation of `Twins: Revisiting the Design
+ of Spatial Attention in Vision Transformers
+ `_.
+
+ Args:
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (list): Embedding dimension. Default: [64, 128, 256, 512].
+ patch_sizes (list): The patch sizes. Default: [4, 2, 2, 2].
+ strides (list): The strides. Default: [4, 2, 2, 2].
+ num_heads (int): Number of attention heads. Default: [1, 2, 4].
+ mlp_ratios (int): Ratio of mlp hidden dim to embedding dim.
+ Default: [4, 4, 4].
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool): Enable bias for qkv if True. Default: False.
+ drop_rate (float): Dropout rate. Default 0.
+ attn_drop_rate (float): Dropout ratio of attention weight.
+ Default 0.0
+ drop_path_rate (float): Stochastic depth rate. Default 0.2.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ depths (list): Depths of each stage. Default [4, 4, 4].
+ sr_ratios (list): Kernel_size of conv in each Attn module in
+ Transformer encoder layer. Default: [4, 2, 1].
+ windiow_sizes (list): Window size of LSA. Default: [7, 7, 7],
+ input_features_slice(bool): Input features need slice. Default: False.
+ norm_after_stage(bool): Add extra norm. Default False.
+ strides (list): Strides in patch-Embedding modules. Default: (2, 2, 2)
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=[64, 128, 256],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ num_heads=[1, 2, 4],
+ mlp_ratios=[4, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=False,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2,
+ norm_cfg=dict(type='LN'),
+ depths=[4, 4, 4],
+ sr_ratios=[4, 2, 1],
+ windiow_sizes=[7, 7, 7],
+ norm_after_stage=True,
+ pretrained=None,
+ init_cfg=None):
+ super(SVT, self).__init__(in_channels, embed_dims, patch_sizes,
+ strides, num_heads, mlp_ratios, out_indices,
+ qkv_bias, drop_rate, attn_drop_rate,
+ drop_path_rate, norm_cfg, depths, sr_ratios,
+ norm_after_stage, pretrained, init_cfg)
+ # transformer encoder
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+
+ for k in range(len(depths)):
+ for i in range(depths[k]):
+ if i % 2 == 0:
+ self.layers[k][i] = \
+ LSAEncoderLayer(
+ embed_dims=embed_dims[k],
+ num_heads=num_heads[k],
+ feedforward_channels=mlp_ratios[k] * embed_dims[k],
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[sum(depths[:k])+i],
+ qkv_bias=qkv_bias,
+ window_size=windiow_sizes[k])
diff --git a/mmseg/models/backbones/unet.py b/mmseg/models/backbones/unet.py
new file mode 100644
index 0000000..c2d3366
--- /dev/null
+++ b/mmseg/models/backbones/unet.py
@@ -0,0 +1,438 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import (UPSAMPLE_LAYERS, ConvModule, build_activation_layer,
+ build_norm_layer)
+from mmcv.runner import BaseModule
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from mmseg.ops import Upsample
+from ..builder import BACKBONES
+from ..utils import UpConvBlock
+
+
+class BasicConvBlock(nn.Module):
+ """Basic convolutional block for UNet.
+
+ This module consists of several plain convolutional layers.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ num_convs (int): Number of convolutional layers. Default: 2.
+ stride (int): Whether use stride convolution to downsample
+ the input feature map. If stride=2, it only uses stride convolution
+ in the first convolutional layer to downsample the input feature
+ map. Options are 1 or 2. Default: 1.
+ dilation (int): Whether use dilated convolution to expand the
+ receptive field. Set dilation rate of each convolutional layer and
+ the dilation rate of the first convolutional layer is always 1.
+ Default: 1.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_convs=2,
+ stride=1,
+ dilation=1,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ dcn=None,
+ plugins=None):
+ super(BasicConvBlock, self).__init__()
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.with_cp = with_cp
+ convs = []
+ for i in range(num_convs):
+ convs.append(
+ ConvModule(
+ in_channels=in_channels if i == 0 else out_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=stride if i == 0 else 1,
+ dilation=1 if i == 0 else dilation,
+ padding=1 if i == 0 else dilation,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ self.convs = nn.Sequential(*convs)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.convs, x)
+ else:
+ out = self.convs(x)
+ return out
+
+
+@UPSAMPLE_LAYERS.register_module()
+class DeconvModule(nn.Module):
+ """Deconvolution upsample module in decoder for UNet (2X upsample).
+
+ This module uses deconvolution to upsample feature map in the decoder
+ of UNet.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ kernel_size (int): Kernel size of the convolutional layer. Default: 4.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ with_cp=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ *,
+ kernel_size=4,
+ scale_factor=2):
+ super(DeconvModule, self).__init__()
+
+ assert (kernel_size - scale_factor >= 0) and\
+ (kernel_size - scale_factor) % 2 == 0,\
+ f'kernel_size should be greater than or equal to scale_factor '\
+ f'and (kernel_size - scale_factor) should be even numbers, '\
+ f'while the kernel size is {kernel_size} and scale_factor is '\
+ f'{scale_factor}.'
+
+ stride = scale_factor
+ padding = (kernel_size - scale_factor) // 2
+ self.with_cp = with_cp
+ deconv = nn.ConvTranspose2d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding)
+
+ norm_name, norm = build_norm_layer(norm_cfg, out_channels)
+ activate = build_activation_layer(act_cfg)
+ self.deconv_upsamping = nn.Sequential(deconv, norm, activate)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.deconv_upsamping, x)
+ else:
+ out = self.deconv_upsamping(x)
+ return out
+
+
+@UPSAMPLE_LAYERS.register_module()
+class InterpConv(nn.Module):
+ """Interpolation upsample module in decoder for UNet.
+
+ This module uses interpolation to upsample feature map in the decoder
+ of UNet. It consists of one interpolation upsample layer and one
+ convolutional layer. It can be one interpolation upsample layer followed
+ by one convolutional layer (conv_first=False) or one convolutional layer
+ followed by one interpolation upsample layer (conv_first=True).
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ conv_first (bool): Whether convolutional layer or interpolation
+ upsample layer first. Default: False. It means interpolation
+ upsample layer followed by one convolutional layer.
+ kernel_size (int): Kernel size of the convolutional layer. Default: 1.
+ stride (int): Stride of the convolutional layer. Default: 1.
+ padding (int): Padding of the convolutional layer. Default: 1.
+ upsample_cfg (dict): Interpolation config of the upsample layer.
+ Default: dict(
+ scale_factor=2, mode='bilinear', align_corners=False).
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ with_cp=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ *,
+ conv_cfg=None,
+ conv_first=False,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False)):
+ super(InterpConv, self).__init__()
+
+ self.with_cp = with_cp
+ conv = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ upsample = Upsample(**upsample_cfg)
+ if conv_first:
+ self.interp_upsample = nn.Sequential(conv, upsample)
+ else:
+ self.interp_upsample = nn.Sequential(upsample, conv)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.interp_upsample, x)
+ else:
+ out = self.interp_upsample(x)
+ return out
+
+
+@BACKBONES.register_module()
+class UNet(BaseModule):
+ """UNet backbone.
+
+ This backbone is the implementation of `U-Net: Convolutional Networks
+ for Biomedical Image Segmentation `_.
+
+ Args:
+ in_channels (int): Number of input image channels. Default" 3.
+ base_channels (int): Number of base channels of each stage.
+ The output channels of the first stage. Default: 64.
+ num_stages (int): Number of stages in encoder, normally 5. Default: 5.
+ strides (Sequence[int 1 | 2]): Strides of each stage in encoder.
+ len(strides) is equal to num_stages. Normally the stride of the
+ first stage in encoder is 1. If strides[i]=2, it uses stride
+ convolution to downsample in the correspondence encoder stage.
+ Default: (1, 1, 1, 1, 1).
+ enc_num_convs (Sequence[int]): Number of convolutional layers in the
+ convolution block of the correspondence encoder stage.
+ Default: (2, 2, 2, 2, 2).
+ dec_num_convs (Sequence[int]): Number of convolutional layers in the
+ convolution block of the correspondence decoder stage.
+ Default: (2, 2, 2, 2).
+ downsamples (Sequence[int]): Whether use MaxPool to downsample the
+ feature map after the first stage of encoder
+ (stages: [1, num_stages)). If the correspondence encoder stage use
+ stride convolution (strides[i]=2), it will never use MaxPool to
+ downsample, even downsamples[i-1]=True.
+ Default: (True, True, True, True).
+ enc_dilations (Sequence[int]): Dilation rate of each stage in encoder.
+ Default: (1, 1, 1, 1, 1).
+ dec_dilations (Sequence[int]): Dilation rate of each stage in decoder.
+ Default: (1, 1, 1, 1).
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ upsample_cfg (dict): The upsample config of the upsample module in
+ decoder. Default: dict(type='InterpConv').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+
+ Notice:
+ The input image size should be divisible by the whole downsample rate
+ of the encoder. More detail of the whole downsample rate can be found
+ in UNet._check_input_divisible.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ base_channels=64,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ norm_eval=False,
+ dcn=None,
+ plugins=None,
+ pretrained=None,
+ init_cfg=None):
+ super(UNet, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+ assert len(strides) == num_stages, \
+ 'The length of strides should be equal to num_stages, '\
+ f'while the strides is {strides}, the length of '\
+ f'strides is {len(strides)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(enc_num_convs) == num_stages, \
+ 'The length of enc_num_convs should be equal to num_stages, '\
+ f'while the enc_num_convs is {enc_num_convs}, the length of '\
+ f'enc_num_convs is {len(enc_num_convs)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(dec_num_convs) == (num_stages-1), \
+ 'The length of dec_num_convs should be equal to (num_stages-1), '\
+ f'while the dec_num_convs is {dec_num_convs}, the length of '\
+ f'dec_num_convs is {len(dec_num_convs)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(downsamples) == (num_stages-1), \
+ 'The length of downsamples should be equal to (num_stages-1), '\
+ f'while the downsamples is {downsamples}, the length of '\
+ f'downsamples is {len(downsamples)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(enc_dilations) == num_stages, \
+ 'The length of enc_dilations should be equal to num_stages, '\
+ f'while the enc_dilations is {enc_dilations}, the length of '\
+ f'enc_dilations is {len(enc_dilations)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(dec_dilations) == (num_stages-1), \
+ 'The length of dec_dilations should be equal to (num_stages-1), '\
+ f'while the dec_dilations is {dec_dilations}, the length of '\
+ f'dec_dilations is {len(dec_dilations)}, and the num_stages is '\
+ f'{num_stages}.'
+ self.num_stages = num_stages
+ self.strides = strides
+ self.downsamples = downsamples
+ self.norm_eval = norm_eval
+ self.base_channels = base_channels
+
+ self.encoder = nn.ModuleList()
+ self.decoder = nn.ModuleList()
+
+ for i in range(num_stages):
+ enc_conv_block = []
+ if i != 0:
+ if strides[i] == 1 and downsamples[i - 1]:
+ enc_conv_block.append(nn.MaxPool2d(kernel_size=2))
+ upsample = (strides[i] != 1 or downsamples[i - 1])
+ self.decoder.append(
+ UpConvBlock(
+ conv_block=BasicConvBlock,
+ in_channels=base_channels * 2**i,
+ skip_channels=base_channels * 2**(i - 1),
+ out_channels=base_channels * 2**(i - 1),
+ num_convs=dec_num_convs[i - 1],
+ stride=1,
+ dilation=dec_dilations[i - 1],
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ upsample_cfg=upsample_cfg if upsample else None,
+ dcn=None,
+ plugins=None))
+
+ enc_conv_block.append(
+ BasicConvBlock(
+ in_channels=in_channels,
+ out_channels=base_channels * 2**i,
+ num_convs=enc_num_convs[i],
+ stride=strides[i],
+ dilation=enc_dilations[i],
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dcn=None,
+ plugins=None))
+ self.encoder.append((nn.Sequential(*enc_conv_block)))
+ in_channels = base_channels * 2**i
+
+ def forward(self, x):
+ self._check_input_divisible(x)
+ enc_outs = []
+ for enc in self.encoder:
+ x = enc(x)
+ enc_outs.append(x)
+ dec_outs = [x]
+ for i in reversed(range(len(self.decoder))):
+ x = self.decoder[i](enc_outs[i], x)
+ dec_outs.append(x)
+
+ return dec_outs
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep normalization layer
+ freezed."""
+ super(UNet, self).train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ def _check_input_divisible(self, x):
+ h, w = x.shape[-2:]
+ whole_downsample_rate = 1
+ for i in range(1, self.num_stages):
+ if self.strides[i] == 2 or self.downsamples[i - 1]:
+ whole_downsample_rate *= 2
+ assert (h % whole_downsample_rate == 0) \
+ and (w % whole_downsample_rate == 0),\
+ f'The input image size {(h, w)} should be divisible by the whole '\
+ f'downsample rate {whole_downsample_rate}, when num_stages is '\
+ f'{self.num_stages}, strides is {self.strides}, and downsamples '\
+ f'is {self.downsamples}.'
diff --git a/mmseg/models/backbones/vit.py b/mmseg/models/backbones/vit.py
new file mode 100644
index 0000000..9c920ba
--- /dev/null
+++ b/mmseg/models/backbones/vit.py
@@ -0,0 +1,413 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import warnings
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+from mmcv.cnn.utils.weight_init import (constant_init, kaiming_init,
+ trunc_normal_)
+from mmcv.runner import (BaseModule, CheckpointLoader, ModuleList,
+ load_state_dict)
+from torch.nn.modules.batchnorm import _BatchNorm
+from torch.nn.modules.utils import _pair as to_2tuple
+
+from mmseg.ops import resize
+from mmseg.utils import get_root_logger
+from ..builder import BACKBONES
+from ..utils import PatchEmbed
+
+
+class TransformerEncoderLayer(BaseModule):
+ """Implements one encoder layer in Vision Transformer.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default: 0.0.
+ drop_path_rate (float): stochastic depth rate. Default 0.0.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): enable bias for qkv if True. Default: True
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dim)
+ or (n, batch, embed_dim). Default: True.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ num_fcs=2,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ batch_first=True):
+ super(TransformerEncoderLayer, self).__init__()
+
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, embed_dims, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+
+ self.attn = MultiheadAttention(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ attn_drop=attn_drop_rate,
+ proj_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ batch_first=batch_first,
+ bias=qkv_bias)
+
+ self.norm2_name, norm2 = build_norm_layer(
+ norm_cfg, embed_dims, postfix=2)
+ self.add_module(self.norm2_name, norm2)
+
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=num_fcs,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg)
+
+ @property
+ def norm1(self):
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ return getattr(self, self.norm2_name)
+
+ def forward(self, x):
+ x = self.attn(self.norm1(x), identity=x)
+ x = self.ffn(self.norm2(x), identity=x)
+ return x
+
+
+@BACKBONES.register_module()
+class VisionTransformer(BaseModule):
+ """Vision Transformer.
+
+ This backbone is the implementation of `An Image is Worth 16x16 Words:
+ Transformers for Image Recognition at
+ Scale `_.
+
+ Args:
+ img_size (int | tuple): Input image size. Default: 224.
+ patch_size (int): The patch size. Default: 16.
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (int): embedding dimension. Default: 768.
+ num_layers (int): depth of transformer. Default: 12.
+ num_heads (int): number of attention heads. Default: 12.
+ mlp_ratio (int): ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ out_indices (list | tuple | int): Output from which stages.
+ Default: -1.
+ qkv_bias (bool): enable bias for qkv if True. Default: True.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.0
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0
+ drop_path_rate (float): stochastic depth rate. Default 0.0
+ with_cls_token (bool): Whether concatenating class token into image
+ tokens as transformer input. Default: True.
+ output_cls_token (bool): Whether output the cls_token. If set True,
+ `with_cls_token` must be True. Default: False.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ patch_norm (bool): Whether to add a norm in PatchEmbed Block.
+ Default: False.
+ final_norm (bool): Whether to add a additional layer to normalize
+ final feature map. Default: False.
+ interpolate_mode (str): Select the interpolate mode for position
+ embeding vector resize. Default: bicubic.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save
+ some memory while slowing down the training speed. Default: False.
+ pretrained (str, optional): model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=16,
+ in_channels=3,
+ embed_dims=768,
+ num_layers=12,
+ num_heads=12,
+ mlp_ratio=4,
+ out_indices=-1,
+ qkv_bias=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ with_cls_token=True,
+ output_cls_token=False,
+ norm_cfg=dict(type='LN'),
+ act_cfg=dict(type='GELU'),
+ patch_norm=False,
+ final_norm=False,
+ interpolate_mode='bicubic',
+ num_fcs=2,
+ norm_eval=False,
+ with_cp=False,
+ pretrained=None,
+ init_cfg=None):
+ super(VisionTransformer, self).__init__(init_cfg=init_cfg)
+
+ if isinstance(img_size, int):
+ img_size = to_2tuple(img_size)
+ elif isinstance(img_size, tuple):
+ if len(img_size) == 1:
+ img_size = to_2tuple(img_size[0])
+ assert len(img_size) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(img_size)}'
+
+ if output_cls_token:
+ assert with_cls_token is True, f'with_cls_token must be True if' \
+ f'set output_cls_token to True, but got {with_cls_token}'
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be set at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is not None:
+ raise TypeError('pretrained must be a str or None')
+
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.interpolate_mode = interpolate_mode
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.pretrained = pretrained
+
+ self.patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims,
+ conv_type='Conv2d',
+ kernel_size=patch_size,
+ stride=patch_size,
+ padding='corner',
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None,
+ )
+
+ num_patches = (img_size[0] // patch_size) * \
+ (img_size[1] // patch_size)
+
+ self.with_cls_token = with_cls_token
+ self.output_cls_token = output_cls_token
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims))
+ self.pos_embed = nn.Parameter(
+ torch.zeros(1, num_patches + 1, embed_dims))
+ self.drop_after_pos = nn.Dropout(p=drop_rate)
+
+ if isinstance(out_indices, int):
+ if out_indices == -1:
+ out_indices = num_layers - 1
+ self.out_indices = [out_indices]
+ elif isinstance(out_indices, list) or isinstance(out_indices, tuple):
+ self.out_indices = out_indices
+ else:
+ raise TypeError('out_indices must be type of int, list or tuple')
+
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, num_layers)
+ ] # stochastic depth decay rule
+
+ self.layers = ModuleList()
+ for i in range(num_layers):
+ self.layers.append(
+ TransformerEncoderLayer(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ feedforward_channels=mlp_ratio * embed_dims,
+ attn_drop_rate=attn_drop_rate,
+ drop_rate=drop_rate,
+ drop_path_rate=dpr[i],
+ num_fcs=num_fcs,
+ qkv_bias=qkv_bias,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ batch_first=True))
+
+ self.final_norm = final_norm
+ if final_norm:
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, embed_dims, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+
+ @property
+ def norm1(self):
+ return getattr(self, self.norm1_name)
+
+ def init_weights(self):
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg.get('type') == 'Pretrained'):
+ logger = get_root_logger()
+ checkpoint = CheckpointLoader.load_checkpoint(
+ self.init_cfg['checkpoint'], logger=logger, map_location='cpu')
+
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ else:
+ state_dict = checkpoint
+
+ if 'pos_embed' in state_dict.keys():
+ if self.pos_embed.shape != state_dict['pos_embed'].shape:
+ logger.info(msg=f'Resize the pos_embed shape from '
+ f'{state_dict["pos_embed"].shape} to '
+ f'{self.pos_embed.shape}')
+ h, w = self.img_size
+ pos_size = int(
+ math.sqrt(state_dict['pos_embed'].shape[1] - 1))
+ state_dict['pos_embed'] = self.resize_pos_embed(
+ state_dict['pos_embed'],
+ (h // self.patch_size, w // self.patch_size),
+ (pos_size, pos_size), self.interpolate_mode)
+
+ load_state_dict(self, state_dict, strict=False, logger=logger)
+ elif self.init_cfg is not None:
+ super(VisionTransformer, self).init_weights()
+ else:
+ # We only implement the 'jax_impl' initialization implemented at
+ # https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py#L353 # noqa: E501
+ trunc_normal_(self.pos_embed, std=.02)
+ trunc_normal_(self.cls_token, std=.02)
+ for n, m in self.named_modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=.02)
+ if m.bias is not None:
+ if 'ffn' in n:
+ nn.init.normal_(m.bias, mean=0., std=1e-6)
+ else:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.Conv2d):
+ kaiming_init(m, mode='fan_in', bias=0.)
+ elif isinstance(m, (_BatchNorm, nn.GroupNorm, nn.LayerNorm)):
+ constant_init(m, val=1.0, bias=0.)
+
+ def _pos_embeding(self, patched_img, hw_shape, pos_embed):
+ """Positiong embeding method.
+
+ Resize the pos_embed, if the input image size doesn't match
+ the training size.
+ Args:
+ patched_img (torch.Tensor): The patched image, it should be
+ shape of [B, L1, C].
+ hw_shape (tuple): The downsampled image resolution.
+ pos_embed (torch.Tensor): The pos_embed weighs, it should be
+ shape of [B, L2, c].
+ Return:
+ torch.Tensor: The pos encoded image feature.
+ """
+ assert patched_img.ndim == 3 and pos_embed.ndim == 3, \
+ 'the shapes of patched_img and pos_embed must be [B, L, C]'
+ x_len, pos_len = patched_img.shape[1], pos_embed.shape[1]
+ if x_len != pos_len:
+ if pos_len == (self.img_size[0] // self.patch_size) * (
+ self.img_size[1] // self.patch_size) + 1:
+ pos_h = self.img_size[0] // self.patch_size
+ pos_w = self.img_size[1] // self.patch_size
+ else:
+ raise ValueError(
+ 'Unexpected shape of pos_embed, got {}.'.format(
+ pos_embed.shape))
+ pos_embed = self.resize_pos_embed(pos_embed, hw_shape,
+ (pos_h, pos_w),
+ self.interpolate_mode)
+ return self.drop_after_pos(patched_img + pos_embed)
+
+ @staticmethod
+ def resize_pos_embed(pos_embed, input_shpae, pos_shape, mode):
+ """Resize pos_embed weights.
+
+ Resize pos_embed using bicubic interpolate method.
+ Args:
+ pos_embed (torch.Tensor): Position embedding weights.
+ input_shpae (tuple): Tuple for (downsampled input image height,
+ downsampled input image width).
+ pos_shape (tuple): The resolution of downsampled origin training
+ image.
+ mode (str): Algorithm used for upsampling:
+ ``'nearest'`` | ``'linear'`` | ``'bilinear'`` | ``'bicubic'`` |
+ ``'trilinear'``. Default: ``'nearest'``
+ Return:
+ torch.Tensor: The resized pos_embed of shape [B, L_new, C]
+ """
+ assert pos_embed.ndim == 3, 'shape of pos_embed must be [B, L, C]'
+ pos_h, pos_w = pos_shape
+ cls_token_weight = pos_embed[:, 0]
+ pos_embed_weight = pos_embed[:, (-1 * pos_h * pos_w):]
+ pos_embed_weight = pos_embed_weight.reshape(
+ 1, pos_h, pos_w, pos_embed.shape[2]).permute(0, 3, 1, 2)
+ pos_embed_weight = resize(
+ pos_embed_weight, size=input_shpae, align_corners=False, mode=mode)
+ cls_token_weight = cls_token_weight.unsqueeze(1)
+ pos_embed_weight = torch.flatten(pos_embed_weight, 2).transpose(1, 2)
+ pos_embed = torch.cat((cls_token_weight, pos_embed_weight), dim=1)
+ return pos_embed
+
+ def forward(self, inputs):
+ B = inputs.shape[0]
+
+ x, hw_shape = self.patch_embed(inputs)
+
+ # stole cls_tokens impl from Phil Wang, thanks
+ cls_tokens = self.cls_token.expand(B, -1, -1)
+ x = torch.cat((cls_tokens, x), dim=1)
+ x = self._pos_embeding(x, hw_shape, self.pos_embed)
+
+ if not self.with_cls_token:
+ # Remove class token for transformer encoder input
+ x = x[:, 1:]
+
+ outs = []
+ for i, layer in enumerate(self.layers):
+ x = layer(x)
+ if i == len(self.layers) - 1:
+ if self.final_norm:
+ x = self.norm1(x)
+ if i in self.out_indices:
+ if self.with_cls_token:
+ # Remove class token and reshape token for decoder head
+ out = x[:, 1:]
+ else:
+ out = x
+ B, _, C = out.shape
+ out = out.reshape(B, hw_shape[0], hw_shape[1],
+ C).permute(0, 3, 1, 2).contiguous()
+ if self.output_cls_token:
+ out = [out, x[:, 0]]
+ outs.append(out)
+
+ return tuple(outs)
+
+ def train(self, mode=True):
+ super(VisionTransformer, self).train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, nn.LayerNorm):
+ m.eval()
diff --git a/mmseg/models/builder.py b/mmseg/models/builder.py
new file mode 100644
index 0000000..5e18e4e
--- /dev/null
+++ b/mmseg/models/builder.py
@@ -0,0 +1,49 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from mmcv.cnn import MODELS as MMCV_MODELS
+from mmcv.cnn.bricks.registry import ATTENTION as MMCV_ATTENTION
+from mmcv.utils import Registry
+
+MODELS = Registry('models', parent=MMCV_MODELS)
+ATTENTION = Registry('attention', parent=MMCV_ATTENTION)
+
+BACKBONES = MODELS
+NECKS = MODELS
+HEADS = MODELS
+LOSSES = MODELS
+SEGMENTORS = MODELS
+
+
+def build_backbone(cfg):
+ """Build backbone."""
+ return BACKBONES.build(cfg)
+
+
+def build_neck(cfg):
+ """Build neck."""
+ return NECKS.build(cfg)
+
+
+def build_head(cfg):
+ """Build head."""
+ return HEADS.build(cfg)
+
+
+def build_loss(cfg):
+ """Build loss."""
+ return LOSSES.build(cfg)
+
+
+def build_segmentor(cfg, train_cfg=None, test_cfg=None):
+ """Build segmentor."""
+ if train_cfg is not None or test_cfg is not None:
+ warnings.warn(
+ 'train_cfg and test_cfg is deprecated, '
+ 'please specify them in model', UserWarning)
+ assert cfg.get('train_cfg') is None or train_cfg is None, \
+ 'train_cfg specified in both outer field and model field '
+ assert cfg.get('test_cfg') is None or test_cfg is None, \
+ 'test_cfg specified in both outer field and model field '
+ return SEGMENTORS.build(
+ cfg, default_args=dict(train_cfg=train_cfg, test_cfg=test_cfg))
diff --git a/mmseg/models/decode_heads/__init__.py b/mmseg/models/decode_heads/__init__.py
new file mode 100644
index 0000000..dcde813
--- /dev/null
+++ b/mmseg/models/decode_heads/__init__.py
@@ -0,0 +1,38 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ann_head import ANNHead
+from .apc_head import APCHead
+from .aspp_head import ASPPHead
+from .cc_head import CCHead
+from .da_head import DAHead
+from .dm_head import DMHead
+from .dnl_head import DNLHead
+from .dpt_head import DPTHead
+from .ema_head import EMAHead
+from .enc_head import EncHead
+from .fcn_head import FCNHead
+from .fpn_head import FPNHead
+from .gc_head import GCHead
+from .isa_head import ISAHead
+from .lraspp_head import LRASPPHead
+from .nl_head import NLHead
+from .ocr_head import OCRHead
+from .point_head import PointHead
+from .psa_head import PSAHead
+from .psp_head import PSPHead
+from .segformer_head import SegformerHead
+from .segmenter_mask_head import SegmenterMaskTransformerHead
+from .sep_aspp_head import DepthwiseSeparableASPPHead
+from .sep_fcn_head import DepthwiseSeparableFCNHead
+from .setr_mla_head import SETRMLAHead
+from .setr_up_head import SETRUPHead
+from .stdc_head import STDCHead
+from .uper_head import UPerHead
+
+__all__ = [
+ 'FCNHead', 'PSPHead', 'ASPPHead', 'PSAHead', 'NLHead', 'GCHead', 'CCHead',
+ 'UPerHead', 'DepthwiseSeparableASPPHead', 'ANNHead', 'DAHead', 'OCRHead',
+ 'EncHead', 'DepthwiseSeparableFCNHead', 'FPNHead', 'EMAHead', 'DNLHead',
+ 'PointHead', 'APCHead', 'DMHead', 'LRASPPHead', 'SETRUPHead',
+ 'SETRMLAHead', 'DPTHead', 'SETRMLAHead', 'SegmenterMaskTransformerHead',
+ 'SegformerHead', 'ISAHead', 'STDCHead'
+]
diff --git a/mmseg/models/decode_heads/ann_head.py b/mmseg/models/decode_heads/ann_head.py
new file mode 100644
index 0000000..c8d882e
--- /dev/null
+++ b/mmseg/models/decode_heads/ann_head.py
@@ -0,0 +1,246 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from ..builder import HEADS
+from ..utils import SelfAttentionBlock as _SelfAttentionBlock
+from .decode_head import BaseDecodeHead
+
+
+class PPMConcat(nn.ModuleList):
+ """Pyramid Pooling Module that only concat the features of each layer.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module.
+ """
+
+ def __init__(self, pool_scales=(1, 3, 6, 8)):
+ super(PPMConcat, self).__init__(
+ [nn.AdaptiveAvgPool2d(pool_scale) for pool_scale in pool_scales])
+
+ def forward(self, feats):
+ """Forward function."""
+ ppm_outs = []
+ for ppm in self:
+ ppm_out = ppm(feats)
+ ppm_outs.append(ppm_out.view(*feats.shape[:2], -1))
+ concat_outs = torch.cat(ppm_outs, dim=2)
+ return concat_outs
+
+
+class SelfAttentionBlock(_SelfAttentionBlock):
+ """Make a ANN used SelfAttentionBlock.
+
+ Args:
+ low_in_channels (int): Input channels of lower level feature,
+ which is the key feature for self-attention.
+ high_in_channels (int): Input channels of higher level feature,
+ which is the query feature for self-attention.
+ channels (int): Output channels of key/query transform.
+ out_channels (int): Output channels.
+ share_key_query (bool): Whether share projection weight between key
+ and query projection.
+ query_scale (int): The scale of query feature map.
+ key_pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module of key feature.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict|None): Config of activation layers.
+ """
+
+ def __init__(self, low_in_channels, high_in_channels, channels,
+ out_channels, share_key_query, query_scale, key_pool_scales,
+ conv_cfg, norm_cfg, act_cfg):
+ key_psp = PPMConcat(key_pool_scales)
+ if query_scale > 1:
+ query_downsample = nn.MaxPool2d(kernel_size=query_scale)
+ else:
+ query_downsample = None
+ super(SelfAttentionBlock, self).__init__(
+ key_in_channels=low_in_channels,
+ query_in_channels=high_in_channels,
+ channels=channels,
+ out_channels=out_channels,
+ share_key_query=share_key_query,
+ query_downsample=query_downsample,
+ key_downsample=key_psp,
+ key_query_num_convs=1,
+ key_query_norm=True,
+ value_out_num_convs=1,
+ value_out_norm=False,
+ matmul_norm=True,
+ with_out=True,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+
+class AFNB(nn.Module):
+ """Asymmetric Fusion Non-local Block(AFNB)
+
+ Args:
+ low_in_channels (int): Input channels of lower level feature,
+ which is the key feature for self-attention.
+ high_in_channels (int): Input channels of higher level feature,
+ which is the query feature for self-attention.
+ channels (int): Output channels of key/query transform.
+ out_channels (int): Output channels.
+ and query projection.
+ query_scales (tuple[int]): The scales of query feature map.
+ Default: (1,)
+ key_pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module of key feature.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict|None): Config of activation layers.
+ """
+
+ def __init__(self, low_in_channels, high_in_channels, channels,
+ out_channels, query_scales, key_pool_scales, conv_cfg,
+ norm_cfg, act_cfg):
+ super(AFNB, self).__init__()
+ self.stages = nn.ModuleList()
+ for query_scale in query_scales:
+ self.stages.append(
+ SelfAttentionBlock(
+ low_in_channels=low_in_channels,
+ high_in_channels=high_in_channels,
+ channels=channels,
+ out_channels=out_channels,
+ share_key_query=False,
+ query_scale=query_scale,
+ key_pool_scales=key_pool_scales,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.bottleneck = ConvModule(
+ out_channels + high_in_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ def forward(self, low_feats, high_feats):
+ """Forward function."""
+ priors = [stage(high_feats, low_feats) for stage in self.stages]
+ context = torch.stack(priors, dim=0).sum(dim=0)
+ output = self.bottleneck(torch.cat([context, high_feats], 1))
+ return output
+
+
+class APNB(nn.Module):
+ """Asymmetric Pyramid Non-local Block (APNB)
+
+ Args:
+ in_channels (int): Input channels of key/query feature,
+ which is the key feature for self-attention.
+ channels (int): Output channels of key/query transform.
+ out_channels (int): Output channels.
+ query_scales (tuple[int]): The scales of query feature map.
+ Default: (1,)
+ key_pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module of key feature.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict|None): Config of activation layers.
+ """
+
+ def __init__(self, in_channels, channels, out_channels, query_scales,
+ key_pool_scales, conv_cfg, norm_cfg, act_cfg):
+ super(APNB, self).__init__()
+ self.stages = nn.ModuleList()
+ for query_scale in query_scales:
+ self.stages.append(
+ SelfAttentionBlock(
+ low_in_channels=in_channels,
+ high_in_channels=in_channels,
+ channels=channels,
+ out_channels=out_channels,
+ share_key_query=True,
+ query_scale=query_scale,
+ key_pool_scales=key_pool_scales,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.bottleneck = ConvModule(
+ 2 * in_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, feats):
+ """Forward function."""
+ priors = [stage(feats, feats) for stage in self.stages]
+ context = torch.stack(priors, dim=0).sum(dim=0)
+ output = self.bottleneck(torch.cat([context, feats], 1))
+ return output
+
+
+@HEADS.register_module()
+class ANNHead(BaseDecodeHead):
+ """Asymmetric Non-local Neural Networks for Semantic Segmentation.
+
+ This head is the implementation of `ANNNet
+ `_.
+
+ Args:
+ project_channels (int): Projection channels for Nonlocal.
+ query_scales (tuple[int]): The scales of query feature map.
+ Default: (1,)
+ key_pool_scales (tuple[int]): The pooling scales of key feature map.
+ Default: (1, 3, 6, 8).
+ """
+
+ def __init__(self,
+ project_channels,
+ query_scales=(1, ),
+ key_pool_scales=(1, 3, 6, 8),
+ **kwargs):
+ super(ANNHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ assert len(self.in_channels) == 2
+ low_in_channels, high_in_channels = self.in_channels
+ self.project_channels = project_channels
+ self.fusion = AFNB(
+ low_in_channels=low_in_channels,
+ high_in_channels=high_in_channels,
+ out_channels=high_in_channels,
+ channels=project_channels,
+ query_scales=query_scales,
+ key_pool_scales=key_pool_scales,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.bottleneck = ConvModule(
+ high_in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.context = APNB(
+ in_channels=self.channels,
+ out_channels=self.channels,
+ channels=project_channels,
+ query_scales=query_scales,
+ key_pool_scales=key_pool_scales,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ low_feats, high_feats = self._transform_inputs(inputs)
+ output = self.fusion(low_feats, high_feats)
+ output = self.dropout(output)
+ output = self.bottleneck(output)
+ output = self.context(output)
+ output = self.cls_seg(output)
+
+ return output
diff --git a/mmseg/models/decode_heads/apc_head.py b/mmseg/models/decode_heads/apc_head.py
new file mode 100644
index 0000000..3198fd1
--- /dev/null
+++ b/mmseg/models/decode_heads/apc_head.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class ACM(nn.Module):
+ """Adaptive Context Module used in APCNet.
+
+ Args:
+ pool_scale (int): Pooling scale used in Adaptive Context
+ Module to extract region features.
+ fusion (bool): Add one conv to fuse residual feature.
+ in_channels (int): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ conv_cfg (dict | None): Config of conv layers.
+ norm_cfg (dict | None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ """
+
+ def __init__(self, pool_scale, fusion, in_channels, channels, conv_cfg,
+ norm_cfg, act_cfg):
+ super(ACM, self).__init__()
+ self.pool_scale = pool_scale
+ self.fusion = fusion
+ self.in_channels = in_channels
+ self.channels = channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.pooled_redu_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.input_redu_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.global_info = ConvModule(
+ self.channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.gla = nn.Conv2d(self.channels, self.pool_scale**2, 1, 1, 0)
+
+ self.residual_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ if self.fusion:
+ self.fusion_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, x):
+ """Forward function."""
+ pooled_x = F.adaptive_avg_pool2d(x, self.pool_scale)
+ # [batch_size, channels, h, w]
+ x = self.input_redu_conv(x)
+ # [batch_size, channels, pool_scale, pool_scale]
+ pooled_x = self.pooled_redu_conv(pooled_x)
+ batch_size = x.size(0)
+ # [batch_size, pool_scale * pool_scale, channels]
+ pooled_x = pooled_x.view(batch_size, self.channels,
+ -1).permute(0, 2, 1).contiguous()
+ # [batch_size, h * w, pool_scale * pool_scale]
+ affinity_matrix = self.gla(x + resize(
+ self.global_info(F.adaptive_avg_pool2d(x, 1)), size=x.shape[2:])
+ ).permute(0, 2, 3, 1).reshape(
+ batch_size, -1, self.pool_scale**2)
+ affinity_matrix = F.sigmoid(affinity_matrix)
+ # [batch_size, h * w, channels]
+ z_out = torch.matmul(affinity_matrix, pooled_x)
+ # [batch_size, channels, h * w]
+ z_out = z_out.permute(0, 2, 1).contiguous()
+ # [batch_size, channels, h, w]
+ z_out = z_out.view(batch_size, self.channels, x.size(2), x.size(3))
+ z_out = self.residual_conv(z_out)
+ z_out = F.relu(z_out + x)
+ if self.fusion:
+ z_out = self.fusion_conv(z_out)
+
+ return z_out
+
+
+@HEADS.register_module()
+class APCHead(BaseDecodeHead):
+ """Adaptive Pyramid Context Network for Semantic Segmentation.
+
+ This head is the implementation of
+ `APCNet `_.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Adaptive Context
+ Module. Default: (1, 2, 3, 6).
+ fusion (bool): Add one conv to fuse residual feature.
+ """
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), fusion=True, **kwargs):
+ super(APCHead, self).__init__(**kwargs)
+ assert isinstance(pool_scales, (list, tuple))
+ self.pool_scales = pool_scales
+ self.fusion = fusion
+ acm_modules = []
+ for pool_scale in self.pool_scales:
+ acm_modules.append(
+ ACM(pool_scale,
+ self.fusion,
+ self.in_channels,
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.acm_modules = nn.ModuleList(acm_modules)
+ self.bottleneck = ConvModule(
+ self.in_channels + len(pool_scales) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ acm_outs = [x]
+ for acm_module in self.acm_modules:
+ acm_outs.append(acm_module(x))
+ acm_outs = torch.cat(acm_outs, dim=1)
+ output = self.bottleneck(acm_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/aspp_head.py b/mmseg/models/decode_heads/aspp_head.py
new file mode 100644
index 0000000..1fbd1bc
--- /dev/null
+++ b/mmseg/models/decode_heads/aspp_head.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class ASPPModule(nn.ModuleList):
+ """Atrous Spatial Pyramid Pooling (ASPP) Module.
+
+ Args:
+ dilations (tuple[int]): Dilation rate of each layer.
+ in_channels (int): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ """
+
+ def __init__(self, dilations, in_channels, channels, conv_cfg, norm_cfg,
+ act_cfg):
+ super(ASPPModule, self).__init__()
+ self.dilations = dilations
+ self.in_channels = in_channels
+ self.channels = channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ for dilation in dilations:
+ self.append(
+ ConvModule(
+ self.in_channels,
+ self.channels,
+ 1 if dilation == 1 else 3,
+ dilation=dilation,
+ padding=0 if dilation == 1 else dilation,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+
+ def forward(self, x):
+ """Forward function."""
+ aspp_outs = []
+ for aspp_module in self:
+ aspp_outs.append(aspp_module(x))
+
+ return aspp_outs
+
+
+@HEADS.register_module()
+class ASPPHead(BaseDecodeHead):
+ """Rethinking Atrous Convolution for Semantic Image Segmentation.
+
+ This head is the implementation of `DeepLabV3
+ `_.
+
+ Args:
+ dilations (tuple[int]): Dilation rates for ASPP module.
+ Default: (1, 6, 12, 18).
+ """
+
+ def __init__(self, dilations=(1, 6, 12, 18), **kwargs):
+ super(ASPPHead, self).__init__(**kwargs)
+ assert isinstance(dilations, (list, tuple))
+ self.dilations = dilations
+ self.image_pool = nn.Sequential(
+ nn.AdaptiveAvgPool2d(1),
+ ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.aspp_modules = ASPPModule(
+ dilations,
+ self.in_channels,
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.bottleneck = ConvModule(
+ (len(dilations) + 1) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ aspp_outs = [
+ resize(
+ self.image_pool(x),
+ size=x.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ ]
+ aspp_outs.extend(self.aspp_modules(x))
+ aspp_outs = torch.cat(aspp_outs, dim=1)
+ output = self.bottleneck(aspp_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/cascade_decode_head.py b/mmseg/models/decode_heads/cascade_decode_head.py
new file mode 100644
index 0000000..f7c3da0
--- /dev/null
+++ b/mmseg/models/decode_heads/cascade_decode_head.py
@@ -0,0 +1,58 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+from .decode_head import BaseDecodeHead
+
+
+class BaseCascadeDecodeHead(BaseDecodeHead, metaclass=ABCMeta):
+ """Base class for cascade decode head used in
+ :class:`CascadeEncoderDecoder."""
+
+ def __init__(self, *args, **kwargs):
+ super(BaseCascadeDecodeHead, self).__init__(*args, **kwargs)
+
+ @abstractmethod
+ def forward(self, inputs, prev_output):
+ """Placeholder of forward function."""
+ pass
+
+ def forward_train(self, inputs, prev_output, img_metas, gt_semantic_seg,
+ train_cfg):
+ """Forward function for training.
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ prev_output (Tensor): The output of previous decode head.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ gt_semantic_seg (Tensor): Semantic segmentation masks
+ used if the architecture supports semantic segmentation task.
+ train_cfg (dict): The training config.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ seg_logits = self.forward(inputs, prev_output)
+ losses = self.losses(seg_logits, gt_semantic_seg)
+
+ return losses
+
+ def forward_test(self, inputs, prev_output, img_metas, test_cfg):
+ """Forward function for testing.
+
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ prev_output (Tensor): The output of previous decode head.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ test_cfg (dict): The testing config.
+
+ Returns:
+ Tensor: Output segmentation map.
+ """
+ return self.forward(inputs, prev_output)
diff --git a/mmseg/models/decode_heads/cc_head.py b/mmseg/models/decode_heads/cc_head.py
new file mode 100644
index 0000000..ed19eb4
--- /dev/null
+++ b/mmseg/models/decode_heads/cc_head.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+try:
+ from mmcv.ops import CrissCrossAttention
+except ModuleNotFoundError:
+ CrissCrossAttention = None
+
+
+@HEADS.register_module()
+class CCHead(FCNHead):
+ """CCNet: Criss-Cross Attention for Semantic Segmentation.
+
+ This head is the implementation of `CCNet
+ `_.
+
+ Args:
+ recurrence (int): Number of recurrence of Criss Cross Attention
+ module. Default: 2.
+ """
+
+ def __init__(self, recurrence=2, **kwargs):
+ if CrissCrossAttention is None:
+ raise RuntimeError('Please install mmcv-full for '
+ 'CrissCrossAttention ops')
+ super(CCHead, self).__init__(num_convs=2, **kwargs)
+ self.recurrence = recurrence
+ self.cca = CrissCrossAttention(self.channels)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs[0](x)
+ for _ in range(self.recurrence):
+ output = self.cca(output)
+ output = self.convs[1](output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/da_head.py b/mmseg/models/decode_heads/da_head.py
new file mode 100644
index 0000000..77fd663
--- /dev/null
+++ b/mmseg/models/decode_heads/da_head.py
@@ -0,0 +1,179 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, Scale
+from torch import nn
+
+from mmseg.core import add_prefix
+from ..builder import HEADS
+from ..utils import SelfAttentionBlock as _SelfAttentionBlock
+from .decode_head import BaseDecodeHead
+
+
+class PAM(_SelfAttentionBlock):
+ """Position Attention Module (PAM)
+
+ Args:
+ in_channels (int): Input channels of key/query feature.
+ channels (int): Output channels of key/query transform.
+ """
+
+ def __init__(self, in_channels, channels):
+ super(PAM, self).__init__(
+ key_in_channels=in_channels,
+ query_in_channels=in_channels,
+ channels=channels,
+ out_channels=in_channels,
+ share_key_query=False,
+ query_downsample=None,
+ key_downsample=None,
+ key_query_num_convs=1,
+ key_query_norm=False,
+ value_out_num_convs=1,
+ value_out_norm=False,
+ matmul_norm=False,
+ with_out=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=None)
+
+ self.gamma = Scale(0)
+
+ def forward(self, x):
+ """Forward function."""
+ out = super(PAM, self).forward(x, x)
+
+ out = self.gamma(out) + x
+ return out
+
+
+class CAM(nn.Module):
+ """Channel Attention Module (CAM)"""
+
+ def __init__(self):
+ super(CAM, self).__init__()
+ self.gamma = Scale(0)
+
+ def forward(self, x):
+ """Forward function."""
+ batch_size, channels, height, width = x.size()
+ proj_query = x.view(batch_size, channels, -1)
+ proj_key = x.view(batch_size, channels, -1).permute(0, 2, 1)
+ energy = torch.bmm(proj_query, proj_key)
+ energy_new = torch.max(
+ energy, -1, keepdim=True)[0].expand_as(energy) - energy
+ attention = F.softmax(energy_new, dim=-1)
+ proj_value = x.view(batch_size, channels, -1)
+
+ out = torch.bmm(attention, proj_value)
+ out = out.view(batch_size, channels, height, width)
+
+ out = self.gamma(out) + x
+ return out
+
+
+@HEADS.register_module()
+class DAHead(BaseDecodeHead):
+ """Dual Attention Network for Scene Segmentation.
+
+ This head is the implementation of `DANet
+ `_.
+
+ Args:
+ pam_channels (int): The channels of Position Attention Module(PAM).
+ """
+
+ def __init__(self, pam_channels, **kwargs):
+ super(DAHead, self).__init__(**kwargs)
+ self.pam_channels = pam_channels
+ self.pam_in_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.pam = PAM(self.channels, pam_channels)
+ self.pam_out_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.pam_conv_seg = nn.Conv2d(
+ self.channels, self.num_classes, kernel_size=1)
+
+ self.cam_in_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.cam = CAM()
+ self.cam_out_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.cam_conv_seg = nn.Conv2d(
+ self.channels, self.num_classes, kernel_size=1)
+
+ def pam_cls_seg(self, feat):
+ """PAM feature classification."""
+ if self.dropout is not None:
+ feat = self.dropout(feat)
+ output = self.pam_conv_seg(feat)
+ return output
+
+ def cam_cls_seg(self, feat):
+ """CAM feature classification."""
+ if self.dropout is not None:
+ feat = self.dropout(feat)
+ output = self.cam_conv_seg(feat)
+ return output
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ pam_feat = self.pam_in_conv(x)
+ pam_feat = self.pam(pam_feat)
+ pam_feat = self.pam_out_conv(pam_feat)
+ pam_out = self.pam_cls_seg(pam_feat)
+
+ cam_feat = self.cam_in_conv(x)
+ cam_feat = self.cam(cam_feat)
+ cam_feat = self.cam_out_conv(cam_feat)
+ cam_out = self.cam_cls_seg(cam_feat)
+
+ feat_sum = pam_feat + cam_feat
+ pam_cam_out = self.cls_seg(feat_sum)
+
+ return pam_cam_out, pam_out, cam_out
+
+ def forward_test(self, inputs, img_metas, test_cfg):
+ """Forward function for testing, only ``pam_cam`` is used."""
+ return self.forward(inputs)[0]
+
+ def losses(self, seg_logit, seg_label):
+ """Compute ``pam_cam``, ``pam``, ``cam`` loss."""
+ pam_cam_seg_logit, pam_seg_logit, cam_seg_logit = seg_logit
+ loss = dict()
+ loss.update(
+ add_prefix(
+ super(DAHead, self).losses(pam_cam_seg_logit, seg_label),
+ 'pam_cam'))
+ loss.update(
+ add_prefix(
+ super(DAHead, self).losses(pam_seg_logit, seg_label), 'pam'))
+ loss.update(
+ add_prefix(
+ super(DAHead, self).losses(cam_seg_logit, seg_label), 'cam'))
+ return loss
diff --git a/mmseg/models/decode_heads/decode_head.py b/mmseg/models/decode_heads/decode_head.py
new file mode 100644
index 0000000..1443a81
--- /dev/null
+++ b/mmseg/models/decode_heads/decode_head.py
@@ -0,0 +1,265 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+import torch
+import torch.nn as nn
+from mmcv.runner import BaseModule, auto_fp16, force_fp32
+
+from mmseg.core import build_pixel_sampler
+from mmseg.ops import resize
+from ..builder import build_loss
+from ..losses import accuracy
+
+
+class BaseDecodeHead(BaseModule, metaclass=ABCMeta):
+ """Base class for BaseDecodeHead.
+
+ Args:
+ in_channels (int|Sequence[int]): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ num_classes (int): Number of classes.
+ dropout_ratio (float): Ratio of dropout layer. Default: 0.1.
+ conv_cfg (dict|None): Config of conv layers. Default: None.
+ norm_cfg (dict|None): Config of norm layers. Default: None.
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU')
+ in_index (int|Sequence[int]): Input feature index. Default: -1
+ input_transform (str|None): Transformation type of input features.
+ Options: 'resize_concat', 'multiple_select', None.
+ 'resize_concat': Multiple feature maps will be resize to the
+ same size as first one and than concat together.
+ Usually used in FCN head of HRNet.
+ 'multiple_select': Multiple feature maps will be bundle into
+ a list and passed into decode head.
+ None: Only one select feature map is allowed.
+ Default: None.
+ loss_decode (dict | Sequence[dict]): Config of decode loss.
+ The `loss_name` is property of corresponding loss function which
+ could be shown in training log. If you want this loss
+ item to be included into the backward graph, `loss_` must be the
+ prefix of the name. Defaults to 'loss_ce'.
+ e.g. dict(type='CrossEntropyLoss'),
+ [dict(type='CrossEntropyLoss', loss_name='loss_ce'),
+ dict(type='DiceLoss', loss_name='loss_dice')]
+ Default: dict(type='CrossEntropyLoss').
+ ignore_index (int | None): The label index to be ignored. When using
+ masked BCE loss, ignore_index should be set to None. Default: 255.
+ sampler (dict|None): The config of segmentation map sampler.
+ Default: None.
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels,
+ channels,
+ *,
+ num_classes,
+ dropout_ratio=0.1,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='ReLU'),
+ in_index=-1,
+ input_transform=None,
+ loss_decode=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ ignore_index=255,
+ sampler=None,
+ align_corners=False,
+ init_cfg=dict(
+ type='Normal', std=0.01, override=dict(name='conv_seg'))):
+ super(BaseDecodeHead, self).__init__(init_cfg)
+ self._init_inputs(in_channels, in_index, input_transform)
+ self.channels = channels
+ self.num_classes = num_classes
+ self.dropout_ratio = dropout_ratio
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.in_index = in_index
+
+ self.ignore_index = ignore_index
+ self.align_corners = align_corners
+
+ if isinstance(loss_decode, dict):
+ self.loss_decode = build_loss(loss_decode)
+ elif isinstance(loss_decode, (list, tuple)):
+ self.loss_decode = nn.ModuleList()
+ for loss in loss_decode:
+ self.loss_decode.append(build_loss(loss))
+ else:
+ raise TypeError(f'loss_decode must be a dict or sequence of dict,\
+ but got {type(loss_decode)}')
+
+ if sampler is not None:
+ self.sampler = build_pixel_sampler(sampler, context=self)
+ else:
+ self.sampler = None
+
+ self.conv_seg = nn.Conv2d(channels, num_classes, kernel_size=1)
+ if dropout_ratio > 0:
+ self.dropout = nn.Dropout2d(dropout_ratio)
+ else:
+ self.dropout = None
+ self.fp16_enabled = False
+
+ def extra_repr(self):
+ """Extra repr."""
+ s = f'input_transform={self.input_transform}, ' \
+ f'ignore_index={self.ignore_index}, ' \
+ f'align_corners={self.align_corners}'
+ return s
+
+ def _init_inputs(self, in_channels, in_index, input_transform):
+ """Check and initialize input transforms.
+
+ The in_channels, in_index and input_transform must match.
+ Specifically, when input_transform is None, only single feature map
+ will be selected. So in_channels and in_index must be of type int.
+ When input_transform
+
+ Args:
+ in_channels (int|Sequence[int]): Input channels.
+ in_index (int|Sequence[int]): Input feature index.
+ input_transform (str|None): Transformation type of input features.
+ Options: 'resize_concat', 'multiple_select', None.
+ 'resize_concat': Multiple feature maps will be resize to the
+ same size as first one and than concat together.
+ Usually used in FCN head of HRNet.
+ 'multiple_select': Multiple feature maps will be bundle into
+ a list and passed into decode head.
+ None: Only one select feature map is allowed.
+ """
+
+ if input_transform is not None:
+ assert input_transform in ['resize_concat', 'multiple_select']
+ self.input_transform = input_transform
+ self.in_index = in_index
+ if input_transform is not None:
+ assert isinstance(in_channels, (list, tuple))
+ assert isinstance(in_index, (list, tuple))
+ assert len(in_channels) == len(in_index)
+ if input_transform == 'resize_concat':
+ self.in_channels = sum(in_channels)
+ else:
+ self.in_channels = in_channels
+ else:
+ assert isinstance(in_channels, int)
+ assert isinstance(in_index, int)
+ self.in_channels = in_channels
+
+ def _transform_inputs(self, inputs):
+ """Transform inputs for decoder.
+
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+
+ Returns:
+ Tensor: The transformed inputs
+ """
+
+ if self.input_transform == 'resize_concat':
+ inputs = [inputs[i] for i in self.in_index]
+ upsampled_inputs = [
+ resize(
+ input=x,
+ size=inputs[0].shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners) for x in inputs
+ ]
+ inputs = torch.cat(upsampled_inputs, dim=1)
+ elif self.input_transform == 'multiple_select':
+ inputs = [inputs[i] for i in self.in_index]
+ else:
+ inputs = inputs[self.in_index]
+
+ return inputs
+
+ @auto_fp16()
+ @abstractmethod
+ def forward(self, inputs):
+ """Placeholder of forward function."""
+ pass
+
+ def forward_train(self, inputs, img_metas, gt_semantic_seg, train_cfg):
+ """Forward function for training.
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ gt_semantic_seg (Tensor): Semantic segmentation masks
+ used if the architecture supports semantic segmentation task.
+ train_cfg (dict): The training config.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ seg_logits = self.forward(inputs)
+ losses = self.losses(seg_logits, gt_semantic_seg)
+ return losses
+
+ def forward_test(self, inputs, img_metas, test_cfg):
+ """Forward function for testing.
+
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ test_cfg (dict): The testing config.
+
+ Returns:
+ Tensor: Output segmentation map.
+ """
+ return self.forward(inputs)
+
+ def cls_seg(self, feat):
+ """Classify each pixel."""
+ if self.dropout is not None:
+ feat = self.dropout(feat)
+ output = self.conv_seg(feat)
+ return output
+
+ @force_fp32(apply_to=('seg_logit', ))
+ def losses(self, seg_logit, seg_label):
+ """Compute segmentation loss."""
+ loss = dict()
+ seg_logit = resize(
+ input=seg_logit,
+ size=seg_label.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ if self.sampler is not None:
+ seg_weight = self.sampler.sample(seg_logit, seg_label)
+ else:
+ seg_weight = None
+ seg_label = seg_label.squeeze(1)
+
+ if not isinstance(self.loss_decode, nn.ModuleList):
+ losses_decode = [self.loss_decode]
+ else:
+ losses_decode = self.loss_decode
+ for loss_decode in losses_decode:
+ if loss_decode.loss_name not in loss:
+ loss[loss_decode.loss_name] = loss_decode(
+ seg_logit,
+ seg_label,
+ weight=seg_weight,
+ ignore_index=self.ignore_index)
+ else:
+ loss[loss_decode.loss_name] += loss_decode(
+ seg_logit,
+ seg_label,
+ weight=seg_weight,
+ ignore_index=self.ignore_index)
+
+ loss['acc_seg'] = accuracy(seg_logit, seg_label)
+ return loss
diff --git a/mmseg/models/decode_heads/dm_head.py b/mmseg/models/decode_heads/dm_head.py
new file mode 100644
index 0000000..ffaa870
--- /dev/null
+++ b/mmseg/models/decode_heads/dm_head.py
@@ -0,0 +1,141 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, build_activation_layer, build_norm_layer
+
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class DCM(nn.Module):
+ """Dynamic Convolutional Module used in DMNet.
+
+ Args:
+ filter_size (int): The filter size of generated convolution kernel
+ used in Dynamic Convolutional Module.
+ fusion (bool): Add one conv to fuse DCM output feature.
+ in_channels (int): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ conv_cfg (dict | None): Config of conv layers.
+ norm_cfg (dict | None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ """
+
+ def __init__(self, filter_size, fusion, in_channels, channels, conv_cfg,
+ norm_cfg, act_cfg):
+ super(DCM, self).__init__()
+ self.filter_size = filter_size
+ self.fusion = fusion
+ self.in_channels = in_channels
+ self.channels = channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.filter_gen_conv = nn.Conv2d(self.in_channels, self.channels, 1, 1,
+ 0)
+
+ self.input_redu_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ if self.norm_cfg is not None:
+ self.norm = build_norm_layer(self.norm_cfg, self.channels)[1]
+ else:
+ self.norm = None
+ self.activate = build_activation_layer(self.act_cfg)
+
+ if self.fusion:
+ self.fusion_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, x):
+ """Forward function."""
+ generated_filter = self.filter_gen_conv(
+ F.adaptive_avg_pool2d(x, self.filter_size))
+ x = self.input_redu_conv(x)
+ b, c, h, w = x.shape
+ # [1, b * c, h, w], c = self.channels
+ x = x.view(1, b * c, h, w)
+ # [b * c, 1, filter_size, filter_size]
+ generated_filter = generated_filter.view(b * c, 1, self.filter_size,
+ self.filter_size)
+ pad = (self.filter_size - 1) // 2
+ if (self.filter_size - 1) % 2 == 0:
+ p2d = (pad, pad, pad, pad)
+ else:
+ p2d = (pad + 1, pad, pad + 1, pad)
+ x = F.pad(input=x, pad=p2d, mode='constant', value=0)
+ # [1, b * c, h, w]
+ output = F.conv2d(input=x, weight=generated_filter, groups=b * c)
+ # [b, c, h, w]
+ output = output.view(b, c, h, w)
+ if self.norm is not None:
+ output = self.norm(output)
+ output = self.activate(output)
+
+ if self.fusion:
+ output = self.fusion_conv(output)
+
+ return output
+
+
+@HEADS.register_module()
+class DMHead(BaseDecodeHead):
+ """Dynamic Multi-scale Filters for Semantic Segmentation.
+
+ This head is the implementation of
+ `DMNet `_.
+
+ Args:
+ filter_sizes (tuple[int]): The size of generated convolutional filters
+ used in Dynamic Convolutional Module. Default: (1, 3, 5, 7).
+ fusion (bool): Add one conv to fuse DCM output feature.
+ """
+
+ def __init__(self, filter_sizes=(1, 3, 5, 7), fusion=False, **kwargs):
+ super(DMHead, self).__init__(**kwargs)
+ assert isinstance(filter_sizes, (list, tuple))
+ self.filter_sizes = filter_sizes
+ self.fusion = fusion
+ dcm_modules = []
+ for filter_size in self.filter_sizes:
+ dcm_modules.append(
+ DCM(filter_size,
+ self.fusion,
+ self.in_channels,
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.dcm_modules = nn.ModuleList(dcm_modules)
+ self.bottleneck = ConvModule(
+ self.in_channels + len(filter_sizes) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ dcm_outs = [x]
+ for dcm_module in self.dcm_modules:
+ dcm_outs.append(dcm_module(x))
+ dcm_outs = torch.cat(dcm_outs, dim=1)
+ output = self.bottleneck(dcm_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/dnl_head.py b/mmseg/models/decode_heads/dnl_head.py
new file mode 100644
index 0000000..ab53d9a
--- /dev/null
+++ b/mmseg/models/decode_heads/dnl_head.py
@@ -0,0 +1,132 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import NonLocal2d
+from torch import nn
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+class DisentangledNonLocal2d(NonLocal2d):
+ """Disentangled Non-Local Blocks.
+
+ Args:
+ temperature (float): Temperature to adjust attention. Default: 0.05
+ """
+
+ def __init__(self, *arg, temperature, **kwargs):
+ super().__init__(*arg, **kwargs)
+ self.temperature = temperature
+ self.conv_mask = nn.Conv2d(self.in_channels, 1, kernel_size=1)
+
+ def embedded_gaussian(self, theta_x, phi_x):
+ """Embedded gaussian with temperature."""
+
+ # NonLocal2d pairwise_weight: [N, HxW, HxW]
+ pairwise_weight = torch.matmul(theta_x, phi_x)
+ if self.use_scale:
+ # theta_x.shape[-1] is `self.inter_channels`
+ pairwise_weight /= theta_x.shape[-1]**0.5
+ pairwise_weight /= self.temperature
+ pairwise_weight = pairwise_weight.softmax(dim=-1)
+ return pairwise_weight
+
+ def forward(self, x):
+ # x: [N, C, H, W]
+ n = x.size(0)
+
+ # g_x: [N, HxW, C]
+ g_x = self.g(x).view(n, self.inter_channels, -1)
+ g_x = g_x.permute(0, 2, 1)
+
+ # theta_x: [N, HxW, C], phi_x: [N, C, HxW]
+ if self.mode == 'gaussian':
+ theta_x = x.view(n, self.in_channels, -1)
+ theta_x = theta_x.permute(0, 2, 1)
+ if self.sub_sample:
+ phi_x = self.phi(x).view(n, self.in_channels, -1)
+ else:
+ phi_x = x.view(n, self.in_channels, -1)
+ elif self.mode == 'concatenation':
+ theta_x = self.theta(x).view(n, self.inter_channels, -1, 1)
+ phi_x = self.phi(x).view(n, self.inter_channels, 1, -1)
+ else:
+ theta_x = self.theta(x).view(n, self.inter_channels, -1)
+ theta_x = theta_x.permute(0, 2, 1)
+ phi_x = self.phi(x).view(n, self.inter_channels, -1)
+
+ # subtract mean
+ theta_x -= theta_x.mean(dim=-2, keepdim=True)
+ phi_x -= phi_x.mean(dim=-1, keepdim=True)
+
+ pairwise_func = getattr(self, self.mode)
+ # pairwise_weight: [N, HxW, HxW]
+ pairwise_weight = pairwise_func(theta_x, phi_x)
+
+ # y: [N, HxW, C]
+ y = torch.matmul(pairwise_weight, g_x)
+ # y: [N, C, H, W]
+ y = y.permute(0, 2, 1).contiguous().reshape(n, self.inter_channels,
+ *x.size()[2:])
+
+ # unary_mask: [N, 1, HxW]
+ unary_mask = self.conv_mask(x)
+ unary_mask = unary_mask.view(n, 1, -1)
+ unary_mask = unary_mask.softmax(dim=-1)
+ # unary_x: [N, 1, C]
+ unary_x = torch.matmul(unary_mask, g_x)
+ # unary_x: [N, C, 1, 1]
+ unary_x = unary_x.permute(0, 2, 1).contiguous().reshape(
+ n, self.inter_channels, 1, 1)
+
+ output = x + self.conv_out(y + unary_x)
+
+ return output
+
+
+@HEADS.register_module()
+class DNLHead(FCNHead):
+ """Disentangled Non-Local Neural Networks.
+
+ This head is the implementation of `DNLNet
+ `_.
+
+ Args:
+ reduction (int): Reduction factor of projection transform. Default: 2.
+ use_scale (bool): Whether to scale pairwise_weight by
+ sqrt(1/inter_channels). Default: False.
+ mode (str): The nonlocal mode. Options are 'embedded_gaussian',
+ 'dot_product'. Default: 'embedded_gaussian.'.
+ temperature (float): Temperature to adjust attention. Default: 0.05
+ """
+
+ def __init__(self,
+ reduction=2,
+ use_scale=True,
+ mode='embedded_gaussian',
+ temperature=0.05,
+ **kwargs):
+ super(DNLHead, self).__init__(num_convs=2, **kwargs)
+ self.reduction = reduction
+ self.use_scale = use_scale
+ self.mode = mode
+ self.temperature = temperature
+ self.dnl_block = DisentangledNonLocal2d(
+ in_channels=self.channels,
+ reduction=self.reduction,
+ use_scale=self.use_scale,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ mode=self.mode,
+ temperature=self.temperature)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs[0](x)
+ output = self.dnl_block(output)
+ output = self.convs[1](output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/dpt_head.py b/mmseg/models/decode_heads/dpt_head.py
new file mode 100644
index 0000000..a63f9d2
--- /dev/null
+++ b/mmseg/models/decode_heads/dpt_head.py
@@ -0,0 +1,293 @@
+import math
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, Linear, build_activation_layer
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class ReassembleBlocks(BaseModule):
+ """ViTPostProcessBlock, process cls_token in ViT backbone output and
+ rearrange the feature vector to feature map.
+
+ Args:
+ in_channels (int): ViT feature channels. Default: 768.
+ out_channels (List): output channels of each stage.
+ Default: [96, 192, 384, 768].
+ readout_type (str): Type of readout operation. Default: 'ignore'.
+ patch_size (int): The patch size. Default: 16.
+ init_cfg (dict, optional): Initialization config dict. Default: None.
+ """
+
+ def __init__(self,
+ in_channels=768,
+ out_channels=[96, 192, 384, 768],
+ readout_type='ignore',
+ patch_size=16,
+ init_cfg=None):
+ super(ReassembleBlocks, self).__init__(init_cfg)
+
+ assert readout_type in ['ignore', 'add', 'project']
+ self.readout_type = readout_type
+ self.patch_size = patch_size
+
+ self.projects = nn.ModuleList([
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channel,
+ kernel_size=1,
+ act_cfg=None,
+ ) for out_channel in out_channels
+ ])
+
+ self.resize_layers = nn.ModuleList([
+ nn.ConvTranspose2d(
+ in_channels=out_channels[0],
+ out_channels=out_channels[0],
+ kernel_size=4,
+ stride=4,
+ padding=0),
+ nn.ConvTranspose2d(
+ in_channels=out_channels[1],
+ out_channels=out_channels[1],
+ kernel_size=2,
+ stride=2,
+ padding=0),
+ nn.Identity(),
+ nn.Conv2d(
+ in_channels=out_channels[3],
+ out_channels=out_channels[3],
+ kernel_size=3,
+ stride=2,
+ padding=1)
+ ])
+ if self.readout_type == 'project':
+ self.readout_projects = nn.ModuleList()
+ for _ in range(len(self.projects)):
+ self.readout_projects.append(
+ nn.Sequential(
+ Linear(2 * in_channels, in_channels),
+ build_activation_layer(dict(type='GELU'))))
+
+ def forward(self, inputs):
+ assert isinstance(inputs, list)
+ out = []
+ for i, x in enumerate(inputs):
+ assert len(x) == 2
+ x, cls_token = x[0], x[1]
+ feature_shape = x.shape
+ if self.readout_type == 'project':
+ x = x.flatten(2).permute((0, 2, 1))
+ readout = cls_token.unsqueeze(1).expand_as(x)
+ x = self.readout_projects[i](torch.cat((x, readout), -1))
+ x = x.permute(0, 2, 1).reshape(feature_shape)
+ elif self.readout_type == 'add':
+ x = x.flatten(2) + cls_token.unsqueeze(-1)
+ x = x.reshape(feature_shape)
+ else:
+ pass
+ x = self.projects[i](x)
+ x = self.resize_layers[i](x)
+ out.append(x)
+ return out
+
+
+class PreActResidualConvUnit(BaseModule):
+ """ResidualConvUnit, pre-activate residual unit.
+
+ Args:
+ in_channels (int): number of channels in the input feature map.
+ act_cfg (dict): dictionary to construct and config activation layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ stride (int): stride of the first block. Default: 1
+ dilation (int): dilation rate for convs layers. Default: 1.
+ init_cfg (dict, optional): Initialization config dict. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ act_cfg,
+ norm_cfg,
+ stride=1,
+ dilation=1,
+ init_cfg=None):
+ super(PreActResidualConvUnit, self).__init__(init_cfg)
+
+ self.conv1 = ConvModule(
+ in_channels,
+ in_channels,
+ 3,
+ stride=stride,
+ padding=dilation,
+ dilation=dilation,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ bias=False,
+ order=('act', 'conv', 'norm'))
+
+ self.conv2 = ConvModule(
+ in_channels,
+ in_channels,
+ 3,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ bias=False,
+ order=('act', 'conv', 'norm'))
+
+ def forward(self, inputs):
+ inputs_ = inputs.clone()
+ x = self.conv1(inputs)
+ x = self.conv2(x)
+ return x + inputs_
+
+
+class FeatureFusionBlock(BaseModule):
+ """FeatureFusionBlock, merge feature map from different stages.
+
+ Args:
+ in_channels (int): Input channels.
+ act_cfg (dict): The activation config for ResidualConvUnit.
+ norm_cfg (dict): Config dict for normalization layer.
+ expand (bool): Whether expand the channels in post process block.
+ Default: False.
+ align_corners (bool): align_corner setting for bilinear upsample.
+ Default: True.
+ init_cfg (dict, optional): Initialization config dict. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ act_cfg,
+ norm_cfg,
+ expand=False,
+ align_corners=True,
+ init_cfg=None):
+ super(FeatureFusionBlock, self).__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.expand = expand
+ self.align_corners = align_corners
+
+ self.out_channels = in_channels
+ if self.expand:
+ self.out_channels = in_channels // 2
+
+ self.project = ConvModule(
+ self.in_channels,
+ self.out_channels,
+ kernel_size=1,
+ act_cfg=None,
+ bias=True)
+
+ self.res_conv_unit1 = PreActResidualConvUnit(
+ in_channels=self.in_channels, act_cfg=act_cfg, norm_cfg=norm_cfg)
+ self.res_conv_unit2 = PreActResidualConvUnit(
+ in_channels=self.in_channels, act_cfg=act_cfg, norm_cfg=norm_cfg)
+
+ def forward(self, *inputs):
+ x = inputs[0]
+ if len(inputs) == 2:
+ if x.shape != inputs[1].shape:
+ res = resize(
+ inputs[1],
+ size=(x.shape[2], x.shape[3]),
+ mode='bilinear',
+ align_corners=False)
+ else:
+ res = inputs[1]
+ x = x + self.res_conv_unit1(res)
+ x = self.res_conv_unit2(x)
+ x = resize(
+ x,
+ scale_factor=2,
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = self.project(x)
+ return x
+
+
+@HEADS.register_module()
+class DPTHead(BaseDecodeHead):
+ """Vision Transformers for Dense Prediction.
+
+ This head is implemented of `DPT `_.
+
+ Args:
+ embed_dims (int): The embed dimension of the ViT backbone.
+ Default: 768.
+ post_process_channels (List): Out channels of post process conv
+ layers. Default: [96, 192, 384, 768].
+ readout_type (str): Type of readout operation. Default: 'ignore'.
+ patch_size (int): The patch size. Default: 16.
+ expand_channels (bool): Whether expand the channels in post process
+ block. Default: False.
+ act_cfg (dict): The activation config for residual conv unit.
+ Default dict(type='ReLU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ """
+
+ def __init__(self,
+ embed_dims=768,
+ post_process_channels=[96, 192, 384, 768],
+ readout_type='ignore',
+ patch_size=16,
+ expand_channels=False,
+ act_cfg=dict(type='ReLU'),
+ norm_cfg=dict(type='BN'),
+ **kwargs):
+ super(DPTHead, self).__init__(**kwargs)
+
+ self.in_channels = self.in_channels
+ self.expand_channels = expand_channels
+ self.reassemble_blocks = ReassembleBlocks(embed_dims,
+ post_process_channels,
+ readout_type, patch_size)
+
+ self.post_process_channels = [
+ channel * math.pow(2, i) if expand_channels else channel
+ for i, channel in enumerate(post_process_channels)
+ ]
+ self.convs = nn.ModuleList()
+ for channel in self.post_process_channels:
+ self.convs.append(
+ ConvModule(
+ channel,
+ self.channels,
+ kernel_size=3,
+ padding=1,
+ act_cfg=None,
+ bias=False))
+ self.fusion_blocks = nn.ModuleList()
+ for _ in range(len(self.convs)):
+ self.fusion_blocks.append(
+ FeatureFusionBlock(self.channels, act_cfg, norm_cfg))
+ self.fusion_blocks[0].res_conv_unit1 = None
+ self.project = ConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=norm_cfg)
+ self.num_fusion_blocks = len(self.fusion_blocks)
+ self.num_reassemble_blocks = len(self.reassemble_blocks.resize_layers)
+ self.num_post_process_channels = len(self.post_process_channels)
+ assert self.num_fusion_blocks == self.num_reassemble_blocks
+ assert self.num_reassemble_blocks == self.num_post_process_channels
+
+ def forward(self, inputs):
+ assert len(inputs) == self.num_reassemble_blocks
+ x = self._transform_inputs(inputs)
+ x = self.reassemble_blocks(x)
+ x = [self.convs[i](feature) for i, feature in enumerate(x)]
+ out = self.fusion_blocks[0](x[-1])
+ for i in range(1, len(self.fusion_blocks)):
+ out = self.fusion_blocks[i](out, x[-(i + 1)])
+ out = self.project(out)
+ out = self.cls_seg(out)
+ return out
diff --git a/mmseg/models/decode_heads/ema_head.py b/mmseg/models/decode_heads/ema_head.py
new file mode 100644
index 0000000..f6de167
--- /dev/null
+++ b/mmseg/models/decode_heads/ema_head.py
@@ -0,0 +1,169 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+def reduce_mean(tensor):
+ """Reduce mean when distributed training."""
+ if not (dist.is_available() and dist.is_initialized()):
+ return tensor
+ tensor = tensor.clone()
+ dist.all_reduce(tensor.div_(dist.get_world_size()), op=dist.ReduceOp.SUM)
+ return tensor
+
+
+class EMAModule(nn.Module):
+ """Expectation Maximization Attention Module used in EMANet.
+
+ Args:
+ channels (int): Channels of the whole module.
+ num_bases (int): Number of bases.
+ num_stages (int): Number of the EM iterations.
+ """
+
+ def __init__(self, channels, num_bases, num_stages, momentum):
+ super(EMAModule, self).__init__()
+ assert num_stages >= 1, 'num_stages must be at least 1!'
+ self.num_bases = num_bases
+ self.num_stages = num_stages
+ self.momentum = momentum
+
+ bases = torch.zeros(1, channels, self.num_bases)
+ bases.normal_(0, math.sqrt(2. / self.num_bases))
+ # [1, channels, num_bases]
+ bases = F.normalize(bases, dim=1, p=2)
+ self.register_buffer('bases', bases)
+
+ def forward(self, feats):
+ """Forward function."""
+ batch_size, channels, height, width = feats.size()
+ # [batch_size, channels, height*width]
+ feats = feats.view(batch_size, channels, height * width)
+ # [batch_size, channels, num_bases]
+ bases = self.bases.repeat(batch_size, 1, 1)
+
+ with torch.no_grad():
+ for i in range(self.num_stages):
+ # [batch_size, height*width, num_bases]
+ attention = torch.einsum('bcn,bck->bnk', feats, bases)
+ attention = F.softmax(attention, dim=2)
+ # l1 norm
+ attention_normed = F.normalize(attention, dim=1, p=1)
+ # [batch_size, channels, num_bases]
+ bases = torch.einsum('bcn,bnk->bck', feats, attention_normed)
+ # l2 norm
+ bases = F.normalize(bases, dim=1, p=2)
+
+ feats_recon = torch.einsum('bck,bnk->bcn', bases, attention)
+ feats_recon = feats_recon.view(batch_size, channels, height, width)
+
+ if self.training:
+ bases = bases.mean(dim=0, keepdim=True)
+ bases = reduce_mean(bases)
+ # l2 norm
+ bases = F.normalize(bases, dim=1, p=2)
+ self.bases = (1 -
+ self.momentum) * self.bases + self.momentum * bases
+
+ return feats_recon
+
+
+@HEADS.register_module()
+class EMAHead(BaseDecodeHead):
+ """Expectation Maximization Attention Networks for Semantic Segmentation.
+
+ This head is the implementation of `EMANet
+ `_.
+
+ Args:
+ ema_channels (int): EMA module channels
+ num_bases (int): Number of bases.
+ num_stages (int): Number of the EM iterations.
+ concat_input (bool): Whether concat the input and output of convs
+ before classification layer. Default: True
+ momentum (float): Momentum to update the base. Default: 0.1.
+ """
+
+ def __init__(self,
+ ema_channels,
+ num_bases,
+ num_stages,
+ concat_input=True,
+ momentum=0.1,
+ **kwargs):
+ super(EMAHead, self).__init__(**kwargs)
+ self.ema_channels = ema_channels
+ self.num_bases = num_bases
+ self.num_stages = num_stages
+ self.concat_input = concat_input
+ self.momentum = momentum
+ self.ema_module = EMAModule(self.ema_channels, self.num_bases,
+ self.num_stages, self.momentum)
+
+ self.ema_in_conv = ConvModule(
+ self.in_channels,
+ self.ema_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ # project (0, inf) -> (-inf, inf)
+ self.ema_mid_conv = ConvModule(
+ self.ema_channels,
+ self.ema_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=None,
+ act_cfg=None)
+ for param in self.ema_mid_conv.parameters():
+ param.requires_grad = False
+
+ self.ema_out_conv = ConvModule(
+ self.ema_channels,
+ self.ema_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=None)
+ self.bottleneck = ConvModule(
+ self.ema_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ if self.concat_input:
+ self.conv_cat = ConvModule(
+ self.in_channels + self.channels,
+ self.channels,
+ kernel_size=3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ feats = self.ema_in_conv(x)
+ identity = feats
+ feats = self.ema_mid_conv(feats)
+ recon = self.ema_module(feats)
+ recon = F.relu(recon, inplace=True)
+ recon = self.ema_out_conv(recon)
+ output = F.relu(identity + recon, inplace=True)
+ output = self.bottleneck(output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/enc_head.py b/mmseg/models/decode_heads/enc_head.py
new file mode 100644
index 0000000..648c890
--- /dev/null
+++ b/mmseg/models/decode_heads/enc_head.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, build_norm_layer
+
+from mmseg.ops import Encoding, resize
+from ..builder import HEADS, build_loss
+from .decode_head import BaseDecodeHead
+
+
+class EncModule(nn.Module):
+ """Encoding Module used in EncNet.
+
+ Args:
+ in_channels (int): Input channels.
+ num_codes (int): Number of code words.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ """
+
+ def __init__(self, in_channels, num_codes, conv_cfg, norm_cfg, act_cfg):
+ super(EncModule, self).__init__()
+ self.encoding_project = ConvModule(
+ in_channels,
+ in_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ # TODO: resolve this hack
+ # change to 1d
+ if norm_cfg is not None:
+ encoding_norm_cfg = norm_cfg.copy()
+ if encoding_norm_cfg['type'] in ['BN', 'IN']:
+ encoding_norm_cfg['type'] += '1d'
+ else:
+ encoding_norm_cfg['type'] = encoding_norm_cfg['type'].replace(
+ '2d', '1d')
+ else:
+ # fallback to BN1d
+ encoding_norm_cfg = dict(type='BN1d')
+ self.encoding = nn.Sequential(
+ Encoding(channels=in_channels, num_codes=num_codes),
+ build_norm_layer(encoding_norm_cfg, num_codes)[1],
+ nn.ReLU(inplace=True))
+ self.fc = nn.Sequential(
+ nn.Linear(in_channels, in_channels), nn.Sigmoid())
+
+ def forward(self, x):
+ """Forward function."""
+ encoding_projection = self.encoding_project(x)
+ encoding_feat = self.encoding(encoding_projection).mean(dim=1)
+ batch_size, channels, _, _ = x.size()
+ gamma = self.fc(encoding_feat)
+ y = gamma.view(batch_size, channels, 1, 1)
+ output = F.relu_(x + x * y)
+ return encoding_feat, output
+
+
+@HEADS.register_module()
+class EncHead(BaseDecodeHead):
+ """Context Encoding for Semantic Segmentation.
+
+ This head is the implementation of `EncNet
+ `_.
+
+ Args:
+ num_codes (int): Number of code words. Default: 32.
+ use_se_loss (bool): Whether use Semantic Encoding Loss (SE-loss) to
+ regularize the training. Default: True.
+ add_lateral (bool): Whether use lateral connection to fuse features.
+ Default: False.
+ loss_se_decode (dict): Config of decode loss.
+ Default: dict(type='CrossEntropyLoss', use_sigmoid=True).
+ """
+
+ def __init__(self,
+ num_codes=32,
+ use_se_loss=True,
+ add_lateral=False,
+ loss_se_decode=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=0.2),
+ **kwargs):
+ super(EncHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ self.use_se_loss = use_se_loss
+ self.add_lateral = add_lateral
+ self.num_codes = num_codes
+ self.bottleneck = ConvModule(
+ self.in_channels[-1],
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ if add_lateral:
+ self.lateral_convs = nn.ModuleList()
+ for in_channels in self.in_channels[:-1]: # skip the last one
+ self.lateral_convs.append(
+ ConvModule(
+ in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.fusion = ConvModule(
+ len(self.in_channels) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.enc_module = EncModule(
+ self.channels,
+ num_codes=num_codes,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ if self.use_se_loss:
+ self.loss_se_decode = build_loss(loss_se_decode)
+ self.se_layer = nn.Linear(self.channels, self.num_classes)
+
+ def forward(self, inputs):
+ """Forward function."""
+ inputs = self._transform_inputs(inputs)
+ feat = self.bottleneck(inputs[-1])
+ if self.add_lateral:
+ laterals = [
+ resize(
+ lateral_conv(inputs[i]),
+ size=feat.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+ feat = self.fusion(torch.cat([feat, *laterals], 1))
+ encode_feat, output = self.enc_module(feat)
+ output = self.cls_seg(output)
+ if self.use_se_loss:
+ se_output = self.se_layer(encode_feat)
+ return output, se_output
+ else:
+ return output
+
+ def forward_test(self, inputs, img_metas, test_cfg):
+ """Forward function for testing, ignore se_loss."""
+ if self.use_se_loss:
+ return self.forward(inputs)[0]
+ else:
+ return self.forward(inputs)
+
+ @staticmethod
+ def _convert_to_onehot_labels(seg_label, num_classes):
+ """Convert segmentation label to onehot.
+
+ Args:
+ seg_label (Tensor): Segmentation label of shape (N, H, W).
+ num_classes (int): Number of classes.
+
+ Returns:
+ Tensor: Onehot labels of shape (N, num_classes).
+ """
+
+ batch_size = seg_label.size(0)
+ onehot_labels = seg_label.new_zeros((batch_size, num_classes))
+ for i in range(batch_size):
+ hist = seg_label[i].float().histc(
+ bins=num_classes, min=0, max=num_classes - 1)
+ onehot_labels[i] = hist > 0
+ return onehot_labels
+
+ def losses(self, seg_logit, seg_label):
+ """Compute segmentation and semantic encoding loss."""
+ seg_logit, se_seg_logit = seg_logit
+ loss = dict()
+ loss.update(super(EncHead, self).losses(seg_logit, seg_label))
+ se_loss = self.loss_se_decode(
+ se_seg_logit,
+ self._convert_to_onehot_labels(seg_label, self.num_classes))
+ loss['loss_se'] = se_loss
+ return loss
diff --git a/mmseg/models/decode_heads/fcn_head.py b/mmseg/models/decode_heads/fcn_head.py
new file mode 100644
index 0000000..3c8de51
--- /dev/null
+++ b/mmseg/models/decode_heads/fcn_head.py
@@ -0,0 +1,82 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class FCNHead(BaseDecodeHead):
+ """Fully Convolution Networks for Semantic Segmentation.
+
+ This head is implemented of `FCNNet `_.
+
+ Args:
+ num_convs (int): Number of convs in the head. Default: 2.
+ kernel_size (int): The kernel size for convs in the head. Default: 3.
+ concat_input (bool): Whether concat the input and output of convs
+ before classification layer.
+ dilation (int): The dilation rate for convs in the head. Default: 1.
+ """
+
+ def __init__(self,
+ num_convs=2,
+ kernel_size=3,
+ concat_input=True,
+ dilation=1,
+ **kwargs):
+ assert num_convs >= 0 and dilation > 0 and isinstance(dilation, int)
+ self.num_convs = num_convs
+ self.concat_input = concat_input
+ self.kernel_size = kernel_size
+ super(FCNHead, self).__init__(**kwargs)
+ if num_convs == 0:
+ assert self.in_channels == self.channels
+
+ conv_padding = (kernel_size // 2) * dilation
+ convs = []
+ convs.append(
+ ConvModule(
+ self.in_channels,
+ self.channels,
+ kernel_size=kernel_size,
+ padding=conv_padding,
+ dilation=dilation,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ for i in range(num_convs - 1):
+ convs.append(
+ ConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=kernel_size,
+ padding=conv_padding,
+ dilation=dilation,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ if num_convs == 0:
+ self.convs = nn.Identity()
+ else:
+ self.convs = nn.Sequential(*convs)
+ if self.concat_input:
+ self.conv_cat = ConvModule(
+ self.in_channels + self.channels,
+ self.channels,
+ kernel_size=kernel_size,
+ padding=kernel_size // 2,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs(x)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/fpn_head.py b/mmseg/models/decode_heads/fpn_head.py
new file mode 100644
index 0000000..e41f324
--- /dev/null
+++ b/mmseg/models/decode_heads/fpn_head.py
@@ -0,0 +1,69 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import Upsample, resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class FPNHead(BaseDecodeHead):
+ """Panoptic Feature Pyramid Networks.
+
+ This head is the implementation of `Semantic FPN
+ `_.
+
+ Args:
+ feature_strides (tuple[int]): The strides for input feature maps.
+ stack_lateral. All strides suppose to be power of 2. The first
+ one is of largest resolution.
+ """
+
+ def __init__(self, feature_strides, **kwargs):
+ super(FPNHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ assert len(feature_strides) == len(self.in_channels)
+ assert min(feature_strides) == feature_strides[0]
+ self.feature_strides = feature_strides
+
+ self.scale_heads = nn.ModuleList()
+ for i in range(len(feature_strides)):
+ head_length = max(
+ 1,
+ int(np.log2(feature_strides[i]) - np.log2(feature_strides[0])))
+ scale_head = []
+ for k in range(head_length):
+ scale_head.append(
+ ConvModule(
+ self.in_channels[i] if k == 0 else self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ if feature_strides[i] != feature_strides[0]:
+ scale_head.append(
+ Upsample(
+ scale_factor=2,
+ mode='bilinear',
+ align_corners=self.align_corners))
+ self.scale_heads.append(nn.Sequential(*scale_head))
+
+ def forward(self, inputs):
+
+ x = self._transform_inputs(inputs)
+
+ output = self.scale_heads[0](x[0])
+ for i in range(1, len(self.feature_strides)):
+ # non inplace
+ output = output + resize(
+ self.scale_heads[i](x[i]),
+ size=output.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/gc_head.py b/mmseg/models/decode_heads/gc_head.py
new file mode 100644
index 0000000..eed5074
--- /dev/null
+++ b/mmseg/models/decode_heads/gc_head.py
@@ -0,0 +1,48 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import ContextBlock
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+@HEADS.register_module()
+class GCHead(FCNHead):
+ """GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond.
+
+ This head is the implementation of `GCNet
+ `_.
+
+ Args:
+ ratio (float): Multiplier of channels ratio. Default: 1/4.
+ pooling_type (str): The pooling type of context aggregation.
+ Options are 'att', 'avg'. Default: 'avg'.
+ fusion_types (tuple[str]): The fusion type for feature fusion.
+ Options are 'channel_add', 'channel_mul'. Default: ('channel_add',)
+ """
+
+ def __init__(self,
+ ratio=1 / 4.,
+ pooling_type='att',
+ fusion_types=('channel_add', ),
+ **kwargs):
+ super(GCHead, self).__init__(num_convs=2, **kwargs)
+ self.ratio = ratio
+ self.pooling_type = pooling_type
+ self.fusion_types = fusion_types
+ self.gc_block = ContextBlock(
+ in_channels=self.channels,
+ ratio=self.ratio,
+ pooling_type=self.pooling_type,
+ fusion_types=self.fusion_types)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs[0](x)
+ output = self.gc_block(output)
+ output = self.convs[1](output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/isa_head.py b/mmseg/models/decode_heads/isa_head.py
new file mode 100644
index 0000000..c9224b6
--- /dev/null
+++ b/mmseg/models/decode_heads/isa_head.py
@@ -0,0 +1,142 @@
+import math
+
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from ..builder import HEADS
+from ..utils import SelfAttentionBlock as _SelfAttentionBlock
+from .decode_head import BaseDecodeHead
+
+
+class SelfAttentionBlock(_SelfAttentionBlock):
+ """Self-Attention Module.
+
+ Args:
+ in_channels (int): Input channels of key/query feature.
+ channels (int): Output channels of key/query transform.
+ conv_cfg (dict | None): Config of conv layers.
+ norm_cfg (dict | None): Config of norm layers.
+ act_cfg (dict | None): Config of activation layers.
+ """
+
+ def __init__(self, in_channels, channels, conv_cfg, norm_cfg, act_cfg):
+ super(SelfAttentionBlock, self).__init__(
+ key_in_channels=in_channels,
+ query_in_channels=in_channels,
+ channels=channels,
+ out_channels=in_channels,
+ share_key_query=False,
+ query_downsample=None,
+ key_downsample=None,
+ key_query_num_convs=2,
+ key_query_norm=True,
+ value_out_num_convs=1,
+ value_out_norm=False,
+ matmul_norm=True,
+ with_out=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.output_project = self.build_project(
+ in_channels,
+ in_channels,
+ num_convs=1,
+ use_conv_module=True,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ """Forward function."""
+ context = super(SelfAttentionBlock, self).forward(x, x)
+ return self.output_project(context)
+
+
+@HEADS.register_module()
+class ISAHead(BaseDecodeHead):
+ """Interlaced Sparse Self-Attention for Semantic Segmentation.
+
+ This head is the implementation of `ISA
+ `_.
+
+ Args:
+ isa_channels (int): The channels of ISA Module.
+ down_factor (tuple[int]): The local group size of ISA.
+ """
+
+ def __init__(self, isa_channels, down_factor=(8, 8), **kwargs):
+ super(ISAHead, self).__init__(**kwargs)
+ self.down_factor = down_factor
+
+ self.in_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.global_relation = SelfAttentionBlock(
+ self.channels,
+ isa_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.local_relation = SelfAttentionBlock(
+ self.channels,
+ isa_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.out_conv = ConvModule(
+ self.channels * 2,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x_ = self._transform_inputs(inputs)
+ x = self.in_conv(x_)
+ residual = x
+
+ n, c, h, w = x.size()
+ loc_h, loc_w = self.down_factor # size of local group in H- and W-axes
+ glb_h, glb_w = math.ceil(h / loc_h), math.ceil(w / loc_w)
+ pad_h, pad_w = glb_h * loc_h - h, glb_w * loc_w - w
+ if pad_h > 0 or pad_w > 0: # pad if the size is not divisible
+ padding = (pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
+ pad_h - pad_h // 2)
+ x = F.pad(x, padding)
+
+ # global relation
+ x = x.view(n, c, glb_h, loc_h, glb_w, loc_w)
+ # do permutation to gather global group
+ x = x.permute(0, 3, 5, 1, 2, 4) # (n, loc_h, loc_w, c, glb_h, glb_w)
+ x = x.reshape(-1, c, glb_h, glb_w)
+ # apply attention within each global group
+ x = self.global_relation(x) # (n * loc_h * loc_w, c, glb_h, glb_w)
+
+ # local relation
+ x = x.view(n, loc_h, loc_w, c, glb_h, glb_w)
+ # do permutation to gather local group
+ x = x.permute(0, 4, 5, 3, 1, 2) # (n, glb_h, glb_w, c, loc_h, loc_w)
+ x = x.reshape(-1, c, loc_h, loc_w)
+ # apply attention within each local group
+ x = self.local_relation(x) # (n * glb_h * glb_w, c, loc_h, loc_w)
+
+ # permute each pixel back to its original position
+ x = x.view(n, glb_h, glb_w, c, loc_h, loc_w)
+ x = x.permute(0, 3, 1, 4, 2, 5) # (n, c, glb_h, loc_h, glb_w, loc_w)
+ x = x.reshape(n, c, glb_h * loc_h, glb_w * loc_w)
+ if pad_h > 0 or pad_w > 0: # remove padding
+ x = x[:, :, pad_h // 2:pad_h // 2 + h, pad_w // 2:pad_w // 2 + w]
+
+ x = self.out_conv(torch.cat([x, residual], dim=1))
+ out = self.cls_seg(x)
+
+ return out
diff --git a/mmseg/models/decode_heads/lraspp_head.py b/mmseg/models/decode_heads/lraspp_head.py
new file mode 100644
index 0000000..c10ff0d
--- /dev/null
+++ b/mmseg/models/decode_heads/lraspp_head.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv import is_tuple_of
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class LRASPPHead(BaseDecodeHead):
+ """Lite R-ASPP (LRASPP) head is proposed in Searching for MobileNetV3.
+
+ This head is the improved implementation of `Searching for MobileNetV3
+ `_.
+
+ Args:
+ branch_channels (tuple[int]): The number of output channels in every
+ each branch. Default: (32, 64).
+ """
+
+ def __init__(self, branch_channels=(32, 64), **kwargs):
+ super(LRASPPHead, self).__init__(**kwargs)
+ if self.input_transform != 'multiple_select':
+ raise ValueError('in Lite R-ASPP (LRASPP) head, input_transform '
+ f'must be \'multiple_select\'. But received '
+ f'\'{self.input_transform}\'')
+ assert is_tuple_of(branch_channels, int)
+ assert len(branch_channels) == len(self.in_channels) - 1
+ self.branch_channels = branch_channels
+
+ self.convs = nn.Sequential()
+ self.conv_ups = nn.Sequential()
+ for i in range(len(branch_channels)):
+ self.convs.add_module(
+ f'conv{i}',
+ nn.Conv2d(
+ self.in_channels[i], branch_channels[i], 1, bias=False))
+ self.conv_ups.add_module(
+ f'conv_up{i}',
+ ConvModule(
+ self.channels + branch_channels[i],
+ self.channels,
+ 1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ bias=False))
+
+ self.conv_up_input = nn.Conv2d(self.channels, self.channels, 1)
+
+ self.aspp_conv = ConvModule(
+ self.in_channels[-1],
+ self.channels,
+ 1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ bias=False)
+ self.image_pool = nn.Sequential(
+ nn.AvgPool2d(kernel_size=49, stride=(16, 20)),
+ ConvModule(
+ self.in_channels[2],
+ self.channels,
+ 1,
+ act_cfg=dict(type='Sigmoid'),
+ bias=False))
+
+ def forward(self, inputs):
+ """Forward function."""
+ inputs = self._transform_inputs(inputs)
+
+ x = inputs[-1]
+
+ x = self.aspp_conv(x) * resize(
+ self.image_pool(x),
+ size=x.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = self.conv_up_input(x)
+
+ for i in range(len(self.branch_channels) - 1, -1, -1):
+ x = resize(
+ x,
+ size=inputs[i].size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = torch.cat([x, self.convs[i](inputs[i])], 1)
+ x = self.conv_ups[i](x)
+
+ return self.cls_seg(x)
diff --git a/mmseg/models/decode_heads/nl_head.py b/mmseg/models/decode_heads/nl_head.py
new file mode 100644
index 0000000..637517e
--- /dev/null
+++ b/mmseg/models/decode_heads/nl_head.py
@@ -0,0 +1,50 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import NonLocal2d
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+@HEADS.register_module()
+class NLHead(FCNHead):
+ """Non-local Neural Networks.
+
+ This head is the implementation of `NLNet
+ `_.
+
+ Args:
+ reduction (int): Reduction factor of projection transform. Default: 2.
+ use_scale (bool): Whether to scale pairwise_weight by
+ sqrt(1/inter_channels). Default: True.
+ mode (str): The nonlocal mode. Options are 'embedded_gaussian',
+ 'dot_product'. Default: 'embedded_gaussian.'.
+ """
+
+ def __init__(self,
+ reduction=2,
+ use_scale=True,
+ mode='embedded_gaussian',
+ **kwargs):
+ super(NLHead, self).__init__(num_convs=2, **kwargs)
+ self.reduction = reduction
+ self.use_scale = use_scale
+ self.mode = mode
+ self.nl_block = NonLocal2d(
+ in_channels=self.channels,
+ reduction=self.reduction,
+ use_scale=self.use_scale,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ mode=self.mode)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs[0](x)
+ output = self.nl_block(output)
+ output = self.convs[1](output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/ocr_head.py b/mmseg/models/decode_heads/ocr_head.py
new file mode 100644
index 0000000..09eadfb
--- /dev/null
+++ b/mmseg/models/decode_heads/ocr_head.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from ..utils import SelfAttentionBlock as _SelfAttentionBlock
+from .cascade_decode_head import BaseCascadeDecodeHead
+
+
+class SpatialGatherModule(nn.Module):
+ """Aggregate the context features according to the initial predicted
+ probability distribution.
+
+ Employ the soft-weighted method to aggregate the context.
+ """
+
+ def __init__(self, scale):
+ super(SpatialGatherModule, self).__init__()
+ self.scale = scale
+
+ def forward(self, feats, probs):
+ """Forward function."""
+ batch_size, num_classes, height, width = probs.size()
+ channels = feats.size(1)
+ probs = probs.view(batch_size, num_classes, -1)
+ feats = feats.view(batch_size, channels, -1)
+ # [batch_size, height*width, num_classes]
+ feats = feats.permute(0, 2, 1)
+ # [batch_size, channels, height*width]
+ probs = F.softmax(self.scale * probs, dim=2)
+ # [batch_size, channels, num_classes]
+ ocr_context = torch.matmul(probs, feats)
+ ocr_context = ocr_context.permute(0, 2, 1).contiguous().unsqueeze(3)
+ return ocr_context
+
+
+class ObjectAttentionBlock(_SelfAttentionBlock):
+ """Make a OCR used SelfAttentionBlock."""
+
+ def __init__(self, in_channels, channels, scale, conv_cfg, norm_cfg,
+ act_cfg):
+ if scale > 1:
+ query_downsample = nn.MaxPool2d(kernel_size=scale)
+ else:
+ query_downsample = None
+ super(ObjectAttentionBlock, self).__init__(
+ key_in_channels=in_channels,
+ query_in_channels=in_channels,
+ channels=channels,
+ out_channels=in_channels,
+ share_key_query=False,
+ query_downsample=query_downsample,
+ key_downsample=None,
+ key_query_num_convs=2,
+ key_query_norm=True,
+ value_out_num_convs=1,
+ value_out_norm=True,
+ matmul_norm=True,
+ with_out=True,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.bottleneck = ConvModule(
+ in_channels * 2,
+ in_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, query_feats, key_feats):
+ """Forward function."""
+ context = super(ObjectAttentionBlock,
+ self).forward(query_feats, key_feats)
+ output = self.bottleneck(torch.cat([context, query_feats], dim=1))
+ if self.query_downsample is not None:
+ output = resize(query_feats)
+
+ return output
+
+
+@HEADS.register_module()
+class OCRHead(BaseCascadeDecodeHead):
+ """Object-Contextual Representations for Semantic Segmentation.
+
+ This head is the implementation of `OCRNet
+ `_.
+
+ Args:
+ ocr_channels (int): The intermediate channels of OCR block.
+ scale (int): The scale of probability map in SpatialGatherModule in
+ Default: 1.
+ """
+
+ def __init__(self, ocr_channels, scale=1, **kwargs):
+ super(OCRHead, self).__init__(**kwargs)
+ self.ocr_channels = ocr_channels
+ self.scale = scale
+ self.object_context_block = ObjectAttentionBlock(
+ self.channels,
+ self.ocr_channels,
+ self.scale,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.spatial_gather_module = SpatialGatherModule(self.scale)
+
+ self.bottleneck = ConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs, prev_output):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ feats = self.bottleneck(x)
+ context = self.spatial_gather_module(feats, prev_output)
+ object_context = self.object_context_block(feats, context)
+ output = self.cls_seg(object_context)
+
+ return output
diff --git a/mmseg/models/decode_heads/point_head.py b/mmseg/models/decode_heads/point_head.py
new file mode 100644
index 0000000..eb54bbc
--- /dev/null
+++ b/mmseg/models/decode_heads/point_head.py
@@ -0,0 +1,363 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Modified from https://github.com/facebookresearch/detectron2/tree/master/projects/PointRend/point_head/point_head.py # noqa
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+try:
+ from mmcv.ops import point_sample
+except ModuleNotFoundError:
+ point_sample = None
+
+from mmseg.models.builder import HEADS
+from mmseg.ops import resize
+from ..losses import accuracy
+from .cascade_decode_head import BaseCascadeDecodeHead
+
+
+def calculate_uncertainty(seg_logits):
+ """Estimate uncertainty based on seg logits.
+
+ For each location of the prediction ``seg_logits`` we estimate
+ uncertainty as the difference between top first and top second
+ predicted logits.
+
+ Args:
+ seg_logits (Tensor): Semantic segmentation logits,
+ shape (batch_size, num_classes, height, width).
+
+ Returns:
+ scores (Tensor): T uncertainty scores with the most uncertain
+ locations having the highest uncertainty score, shape (
+ batch_size, 1, height, width)
+ """
+ top2_scores = torch.topk(seg_logits, k=2, dim=1)[0]
+ return (top2_scores[:, 1] - top2_scores[:, 0]).unsqueeze(1)
+
+
+@HEADS.register_module()
+class PointHead(BaseCascadeDecodeHead):
+ """A mask point head use in PointRend.
+
+ This head is implemented of `PointRend: Image Segmentation as
+ Rendering `_.
+ ``PointHead`` use shared multi-layer perceptron (equivalent to
+ nn.Conv1d) to predict the logit of input points. The fine-grained feature
+ and coarse feature will be concatenate together for predication.
+
+ Args:
+ num_fcs (int): Number of fc layers in the head. Default: 3.
+ in_channels (int): Number of input channels. Default: 256.
+ fc_channels (int): Number of fc channels. Default: 256.
+ num_classes (int): Number of classes for logits. Default: 80.
+ class_agnostic (bool): Whether use class agnostic classification.
+ If so, the output channels of logits will be 1. Default: False.
+ coarse_pred_each_layer (bool): Whether concatenate coarse feature with
+ the output of each fc layer. Default: True.
+ conv_cfg (dict|None): Dictionary to construct and config conv layer.
+ Default: dict(type='Conv1d'))
+ norm_cfg (dict|None): Dictionary to construct and config norm layer.
+ Default: None.
+ loss_point (dict): Dictionary to construct and config loss layer of
+ point head. Default: dict(type='CrossEntropyLoss', use_mask=True,
+ loss_weight=1.0).
+ """
+
+ def __init__(self,
+ num_fcs=3,
+ coarse_pred_each_layer=True,
+ conv_cfg=dict(type='Conv1d'),
+ norm_cfg=None,
+ act_cfg=dict(type='ReLU', inplace=False),
+ **kwargs):
+ super(PointHead, self).__init__(
+ input_transform='multiple_select',
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ init_cfg=dict(
+ type='Normal', std=0.01, override=dict(name='fc_seg')),
+ **kwargs)
+ if point_sample is None:
+ raise RuntimeError('Please install mmcv-full for '
+ 'point_sample ops')
+
+ self.num_fcs = num_fcs
+ self.coarse_pred_each_layer = coarse_pred_each_layer
+
+ fc_in_channels = sum(self.in_channels) + self.num_classes
+ fc_channels = self.channels
+ self.fcs = nn.ModuleList()
+ for k in range(num_fcs):
+ fc = ConvModule(
+ fc_in_channels,
+ fc_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.fcs.append(fc)
+ fc_in_channels = fc_channels
+ fc_in_channels += self.num_classes if self.coarse_pred_each_layer \
+ else 0
+ self.fc_seg = nn.Conv1d(
+ fc_in_channels,
+ self.num_classes,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+ if self.dropout_ratio > 0:
+ self.dropout = nn.Dropout(self.dropout_ratio)
+ delattr(self, 'conv_seg')
+
+ def cls_seg(self, feat):
+ """Classify each pixel with fc."""
+ if self.dropout is not None:
+ feat = self.dropout(feat)
+ output = self.fc_seg(feat)
+ return output
+
+ def forward(self, fine_grained_point_feats, coarse_point_feats):
+ x = torch.cat([fine_grained_point_feats, coarse_point_feats], dim=1)
+ for fc in self.fcs:
+ x = fc(x)
+ if self.coarse_pred_each_layer:
+ x = torch.cat((x, coarse_point_feats), dim=1)
+ return self.cls_seg(x)
+
+ def _get_fine_grained_point_feats(self, x, points):
+ """Sample from fine grained features.
+
+ Args:
+ x (list[Tensor]): Feature pyramid from by neck or backbone.
+ points (Tensor): Point coordinates, shape (batch_size,
+ num_points, 2).
+
+ Returns:
+ fine_grained_feats (Tensor): Sampled fine grained feature,
+ shape (batch_size, sum(channels of x), num_points).
+ """
+
+ fine_grained_feats_list = [
+ point_sample(_, points, align_corners=self.align_corners)
+ for _ in x
+ ]
+ if len(fine_grained_feats_list) > 1:
+ fine_grained_feats = torch.cat(fine_grained_feats_list, dim=1)
+ else:
+ fine_grained_feats = fine_grained_feats_list[0]
+
+ return fine_grained_feats
+
+ def _get_coarse_point_feats(self, prev_output, points):
+ """Sample from fine grained features.
+
+ Args:
+ prev_output (list[Tensor]): Prediction of previous decode head.
+ points (Tensor): Point coordinates, shape (batch_size,
+ num_points, 2).
+
+ Returns:
+ coarse_feats (Tensor): Sampled coarse feature, shape (batch_size,
+ num_classes, num_points).
+ """
+
+ coarse_feats = point_sample(
+ prev_output, points, align_corners=self.align_corners)
+
+ return coarse_feats
+
+ def forward_train(self, inputs, prev_output, img_metas, gt_semantic_seg,
+ train_cfg):
+ """Forward function for training.
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ prev_output (Tensor): The output of previous decode head.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ gt_semantic_seg (Tensor): Semantic segmentation masks
+ used if the architecture supports semantic segmentation task.
+ train_cfg (dict): The training config.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ x = self._transform_inputs(inputs)
+ with torch.no_grad():
+ points = self.get_points_train(
+ prev_output, calculate_uncertainty, cfg=train_cfg)
+ fine_grained_point_feats = self._get_fine_grained_point_feats(
+ x, points)
+ coarse_point_feats = self._get_coarse_point_feats(prev_output, points)
+ point_logits = self.forward(fine_grained_point_feats,
+ coarse_point_feats)
+ point_label = point_sample(
+ gt_semantic_seg.float(),
+ points,
+ mode='nearest',
+ align_corners=self.align_corners)
+ point_label = point_label.squeeze(1).long()
+
+ losses = self.losses(point_logits, point_label)
+
+ return losses
+
+ def forward_test(self, inputs, prev_output, img_metas, test_cfg):
+ """Forward function for testing.
+
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ prev_output (Tensor): The output of previous decode head.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ test_cfg (dict): The testing config.
+
+ Returns:
+ Tensor: Output segmentation map.
+ """
+
+ x = self._transform_inputs(inputs)
+ refined_seg_logits = prev_output.clone()
+ for _ in range(test_cfg.subdivision_steps):
+ refined_seg_logits = resize(
+ refined_seg_logits,
+ scale_factor=test_cfg.scale_factor,
+ mode='bilinear',
+ align_corners=self.align_corners)
+ batch_size, channels, height, width = refined_seg_logits.shape
+ point_indices, points = self.get_points_test(
+ refined_seg_logits, calculate_uncertainty, cfg=test_cfg)
+ fine_grained_point_feats = self._get_fine_grained_point_feats(
+ x, points)
+ coarse_point_feats = self._get_coarse_point_feats(
+ prev_output, points)
+ point_logits = self.forward(fine_grained_point_feats,
+ coarse_point_feats)
+
+ point_indices = point_indices.unsqueeze(1).expand(-1, channels, -1)
+ refined_seg_logits = refined_seg_logits.reshape(
+ batch_size, channels, height * width)
+ refined_seg_logits = refined_seg_logits.scatter_(
+ 2, point_indices, point_logits)
+ refined_seg_logits = refined_seg_logits.view(
+ batch_size, channels, height, width)
+
+ return refined_seg_logits
+
+ def losses(self, point_logits, point_label):
+ """Compute segmentation loss."""
+ loss = dict()
+ if not isinstance(self.loss_decode, nn.ModuleList):
+ losses_decode = [self.loss_decode]
+ else:
+ losses_decode = self.loss_decode
+ for loss_module in losses_decode:
+ loss['point' + loss_module.loss_name] = loss_module(
+ point_logits, point_label, ignore_index=self.ignore_index)
+
+ loss['acc_point'] = accuracy(point_logits, point_label)
+ return loss
+
+ def get_points_train(self, seg_logits, uncertainty_func, cfg):
+ """Sample points for training.
+
+ Sample points in [0, 1] x [0, 1] coordinate space based on their
+ uncertainty. The uncertainties are calculated for each point using
+ 'uncertainty_func' function that takes point's logit prediction as
+ input.
+
+ Args:
+ seg_logits (Tensor): Semantic segmentation logits, shape (
+ batch_size, num_classes, height, width).
+ uncertainty_func (func): uncertainty calculation function.
+ cfg (dict): Training config of point head.
+
+ Returns:
+ point_coords (Tensor): A tensor of shape (batch_size, num_points,
+ 2) that contains the coordinates of ``num_points`` sampled
+ points.
+ """
+ num_points = cfg.num_points
+ oversample_ratio = cfg.oversample_ratio
+ importance_sample_ratio = cfg.importance_sample_ratio
+ assert oversample_ratio >= 1
+ assert 0 <= importance_sample_ratio <= 1
+ batch_size = seg_logits.shape[0]
+ num_sampled = int(num_points * oversample_ratio)
+ point_coords = torch.rand(
+ batch_size, num_sampled, 2, device=seg_logits.device)
+ point_logits = point_sample(seg_logits, point_coords)
+ # It is crucial to calculate uncertainty based on the sampled
+ # prediction value for the points. Calculating uncertainties of the
+ # coarse predictions first and sampling them for points leads to
+ # incorrect results. To illustrate this: assume uncertainty func(
+ # logits)=-abs(logits), a sampled point between two coarse
+ # predictions with -1 and 1 logits has 0 logits, and therefore 0
+ # uncertainty value. However, if we calculate uncertainties for the
+ # coarse predictions first, both will have -1 uncertainty,
+ # and sampled point will get -1 uncertainty.
+ point_uncertainties = uncertainty_func(point_logits)
+ num_uncertain_points = int(importance_sample_ratio * num_points)
+ num_random_points = num_points - num_uncertain_points
+ idx = torch.topk(
+ point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1]
+ shift = num_sampled * torch.arange(
+ batch_size, dtype=torch.long, device=seg_logits.device)
+ idx += shift[:, None]
+ point_coords = point_coords.view(-1, 2)[idx.view(-1), :].view(
+ batch_size, num_uncertain_points, 2)
+ if num_random_points > 0:
+ rand_point_coords = torch.rand(
+ batch_size, num_random_points, 2, device=seg_logits.device)
+ point_coords = torch.cat((point_coords, rand_point_coords), dim=1)
+ return point_coords
+
+ def get_points_test(self, seg_logits, uncertainty_func, cfg):
+ """Sample points for testing.
+
+ Find ``num_points`` most uncertain points from ``uncertainty_map``.
+
+ Args:
+ seg_logits (Tensor): A tensor of shape (batch_size, num_classes,
+ height, width) for class-specific or class-agnostic prediction.
+ uncertainty_func (func): uncertainty calculation function.
+ cfg (dict): Testing config of point head.
+
+ Returns:
+ point_indices (Tensor): A tensor of shape (batch_size, num_points)
+ that contains indices from [0, height x width) of the most
+ uncertain points.
+ point_coords (Tensor): A tensor of shape (batch_size, num_points,
+ 2) that contains [0, 1] x [0, 1] normalized coordinates of the
+ most uncertain points from the ``height x width`` grid .
+ """
+
+ num_points = cfg.subdivision_num_points
+ uncertainty_map = uncertainty_func(seg_logits)
+ batch_size, _, height, width = uncertainty_map.shape
+ h_step = 1.0 / height
+ w_step = 1.0 / width
+
+ uncertainty_map = uncertainty_map.view(batch_size, height * width)
+ num_points = min(height * width, num_points)
+ point_indices = uncertainty_map.topk(num_points, dim=1)[1]
+ point_coords = torch.zeros(
+ batch_size,
+ num_points,
+ 2,
+ dtype=torch.float,
+ device=seg_logits.device)
+ point_coords[:, :, 0] = w_step / 2.0 + (point_indices %
+ width).float() * w_step
+ point_coords[:, :, 1] = h_step / 2.0 + (point_indices //
+ width).float() * h_step
+ return point_indices, point_coords
diff --git a/mmseg/models/decode_heads/psa_head.py b/mmseg/models/decode_heads/psa_head.py
new file mode 100644
index 0000000..df7593c
--- /dev/null
+++ b/mmseg/models/decode_heads/psa_head.py
@@ -0,0 +1,197 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+try:
+ from mmcv.ops import PSAMask
+except ModuleNotFoundError:
+ PSAMask = None
+
+
+@HEADS.register_module()
+class PSAHead(BaseDecodeHead):
+ """Point-wise Spatial Attention Network for Scene Parsing.
+
+ This head is the implementation of `PSANet
+ `_.
+
+ Args:
+ mask_size (tuple[int]): The PSA mask size. It usually equals input
+ size.
+ psa_type (str): The type of psa module. Options are 'collect',
+ 'distribute', 'bi-direction'. Default: 'bi-direction'
+ compact (bool): Whether use compact map for 'collect' mode.
+ Default: True.
+ shrink_factor (int): The downsample factors of psa mask. Default: 2.
+ normalization_factor (float): The normalize factor of attention.
+ psa_softmax (bool): Whether use softmax for attention.
+ """
+
+ def __init__(self,
+ mask_size,
+ psa_type='bi-direction',
+ compact=False,
+ shrink_factor=2,
+ normalization_factor=1.0,
+ psa_softmax=True,
+ **kwargs):
+ if PSAMask is None:
+ raise RuntimeError('Please install mmcv-full for PSAMask ops')
+ super(PSAHead, self).__init__(**kwargs)
+ assert psa_type in ['collect', 'distribute', 'bi-direction']
+ self.psa_type = psa_type
+ self.compact = compact
+ self.shrink_factor = shrink_factor
+ self.mask_size = mask_size
+ mask_h, mask_w = mask_size
+ self.psa_softmax = psa_softmax
+ if normalization_factor is None:
+ normalization_factor = mask_h * mask_w
+ self.normalization_factor = normalization_factor
+
+ self.reduce = ConvModule(
+ self.in_channels,
+ self.channels,
+ kernel_size=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.attention = nn.Sequential(
+ ConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ nn.Conv2d(
+ self.channels, mask_h * mask_w, kernel_size=1, bias=False))
+ if psa_type == 'bi-direction':
+ self.reduce_p = ConvModule(
+ self.in_channels,
+ self.channels,
+ kernel_size=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.attention_p = nn.Sequential(
+ ConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ nn.Conv2d(
+ self.channels, mask_h * mask_w, kernel_size=1, bias=False))
+ self.psamask_collect = PSAMask('collect', mask_size)
+ self.psamask_distribute = PSAMask('distribute', mask_size)
+ else:
+ self.psamask = PSAMask(psa_type, mask_size)
+ self.proj = ConvModule(
+ self.channels * (2 if psa_type == 'bi-direction' else 1),
+ self.in_channels,
+ kernel_size=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.bottleneck = ConvModule(
+ self.in_channels * 2,
+ self.channels,
+ kernel_size=3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ identity = x
+ align_corners = self.align_corners
+ if self.psa_type in ['collect', 'distribute']:
+ out = self.reduce(x)
+ n, c, h, w = out.size()
+ if self.shrink_factor != 1:
+ if h % self.shrink_factor and w % self.shrink_factor:
+ h = (h - 1) // self.shrink_factor + 1
+ w = (w - 1) // self.shrink_factor + 1
+ align_corners = True
+ else:
+ h = h // self.shrink_factor
+ w = w // self.shrink_factor
+ align_corners = False
+ out = resize(
+ out,
+ size=(h, w),
+ mode='bilinear',
+ align_corners=align_corners)
+ y = self.attention(out)
+ if self.compact:
+ if self.psa_type == 'collect':
+ y = y.view(n, h * w,
+ h * w).transpose(1, 2).view(n, h * w, h, w)
+ else:
+ y = self.psamask(y)
+ if self.psa_softmax:
+ y = F.softmax(y, dim=1)
+ out = torch.bmm(
+ out.view(n, c, h * w), y.view(n, h * w, h * w)).view(
+ n, c, h, w) * (1.0 / self.normalization_factor)
+ else:
+ x_col = self.reduce(x)
+ x_dis = self.reduce_p(x)
+ n, c, h, w = x_col.size()
+ if self.shrink_factor != 1:
+ if h % self.shrink_factor and w % self.shrink_factor:
+ h = (h - 1) // self.shrink_factor + 1
+ w = (w - 1) // self.shrink_factor + 1
+ align_corners = True
+ else:
+ h = h // self.shrink_factor
+ w = w // self.shrink_factor
+ align_corners = False
+ x_col = resize(
+ x_col,
+ size=(h, w),
+ mode='bilinear',
+ align_corners=align_corners)
+ x_dis = resize(
+ x_dis,
+ size=(h, w),
+ mode='bilinear',
+ align_corners=align_corners)
+ y_col = self.attention(x_col)
+ y_dis = self.attention_p(x_dis)
+ if self.compact:
+ y_dis = y_dis.view(n, h * w,
+ h * w).transpose(1, 2).view(n, h * w, h, w)
+ else:
+ y_col = self.psamask_collect(y_col)
+ y_dis = self.psamask_distribute(y_dis)
+ if self.psa_softmax:
+ y_col = F.softmax(y_col, dim=1)
+ y_dis = F.softmax(y_dis, dim=1)
+ x_col = torch.bmm(
+ x_col.view(n, c, h * w), y_col.view(n, h * w, h * w)).view(
+ n, c, h, w) * (1.0 / self.normalization_factor)
+ x_dis = torch.bmm(
+ x_dis.view(n, c, h * w), y_dis.view(n, h * w, h * w)).view(
+ n, c, h, w) * (1.0 / self.normalization_factor)
+ out = torch.cat([x_col, x_dis], 1)
+ out = self.proj(out)
+ out = resize(
+ out,
+ size=identity.shape[2:],
+ mode='bilinear',
+ align_corners=align_corners)
+ out = self.bottleneck(torch.cat((identity, out), dim=1))
+ out = self.cls_seg(out)
+ return out
diff --git a/mmseg/models/decode_heads/psp_head.py b/mmseg/models/decode_heads/psp_head.py
new file mode 100644
index 0000000..a27ae4b
--- /dev/null
+++ b/mmseg/models/decode_heads/psp_head.py
@@ -0,0 +1,103 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class PPM(nn.ModuleList):
+ """Pooling Pyramid Module used in PSPNet.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module.
+ in_channels (int): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ align_corners (bool): align_corners argument of F.interpolate.
+ """
+
+ def __init__(self, pool_scales, in_channels, channels, conv_cfg, norm_cfg,
+ act_cfg, align_corners, **kwargs):
+ super(PPM, self).__init__()
+ self.pool_scales = pool_scales
+ self.align_corners = align_corners
+ self.in_channels = in_channels
+ self.channels = channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ for pool_scale in pool_scales:
+ self.append(
+ nn.Sequential(
+ nn.AdaptiveAvgPool2d(pool_scale),
+ ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ **kwargs)))
+
+ def forward(self, x):
+ """Forward function."""
+ ppm_outs = []
+ for ppm in self:
+ ppm_out = ppm(x)
+ upsampled_ppm_out = resize(
+ ppm_out,
+ size=x.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ ppm_outs.append(upsampled_ppm_out)
+ return ppm_outs
+
+
+@HEADS.register_module()
+class PSPHead(BaseDecodeHead):
+ """Pyramid Scene Parsing Network.
+
+ This head is the implementation of
+ `PSPNet `_.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module. Default: (1, 2, 3, 6).
+ """
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
+ super(PSPHead, self).__init__(**kwargs)
+ assert isinstance(pool_scales, (list, tuple))
+ self.pool_scales = pool_scales
+ self.psp_modules = PPM(
+ self.pool_scales,
+ self.in_channels,
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+ self.bottleneck = ConvModule(
+ self.in_channels + len(pool_scales) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ psp_outs = [x]
+ psp_outs.extend(self.psp_modules(x))
+ psp_outs = torch.cat(psp_outs, dim=1)
+ output = self.bottleneck(psp_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/segformer_head.py b/mmseg/models/decode_heads/segformer_head.py
new file mode 100644
index 0000000..2e75d50
--- /dev/null
+++ b/mmseg/models/decode_heads/segformer_head.py
@@ -0,0 +1,66 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.models.builder import HEADS
+from mmseg.models.decode_heads.decode_head import BaseDecodeHead
+from mmseg.ops import resize
+
+
+@HEADS.register_module()
+class SegformerHead(BaseDecodeHead):
+ """The all mlp Head of segformer.
+
+ This head is the implementation of
+ `Segformer ` _.
+
+ Args:
+ interpolate_mode: The interpolate mode of MLP head upsample operation.
+ Default: 'bilinear'.
+ """
+
+ def __init__(self, interpolate_mode='bilinear', **kwargs):
+ super().__init__(input_transform='multiple_select', **kwargs)
+
+ self.interpolate_mode = interpolate_mode
+ num_inputs = len(self.in_channels)
+
+ assert num_inputs == len(self.in_index)
+
+ self.convs = nn.ModuleList()
+ for i in range(num_inputs):
+ self.convs.append(
+ ConvModule(
+ in_channels=self.in_channels[i],
+ out_channels=self.channels,
+ kernel_size=1,
+ stride=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+
+ self.fusion_conv = ConvModule(
+ in_channels=self.channels * num_inputs,
+ out_channels=self.channels,
+ kernel_size=1,
+ norm_cfg=self.norm_cfg)
+
+ def forward(self, inputs):
+ # Receive 4 stage backbone feature map: 1/4, 1/8, 1/16, 1/32
+ inputs = self._transform_inputs(inputs)
+ outs = []
+ for idx in range(len(inputs)):
+ x = inputs[idx]
+ conv = self.convs[idx]
+ outs.append(
+ resize(
+ input=conv(x),
+ size=inputs[0].shape[2:],
+ mode=self.interpolate_mode,
+ align_corners=self.align_corners))
+
+ out = self.fusion_conv(torch.cat(outs, dim=1))
+
+ out = self.cls_seg(out)
+
+ return out
diff --git a/mmseg/models/decode_heads/segmenter_mask_head.py b/mmseg/models/decode_heads/segmenter_mask_head.py
new file mode 100644
index 0000000..6a9b3d4
--- /dev/null
+++ b/mmseg/models/decode_heads/segmenter_mask_head.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.utils.weight_init import (constant_init, trunc_normal_,
+ trunc_normal_init)
+from mmcv.runner import ModuleList
+
+from mmseg.models.backbones.vit import TransformerEncoderLayer
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class SegmenterMaskTransformerHead(BaseDecodeHead):
+ """Segmenter: Transformer for Semantic Segmentation.
+
+ This head is the implementation of
+ `Segmenter: `_.
+
+ Args:
+ backbone_cfg:(dict): Config of backbone of
+ Context Path.
+ in_channels (int): The number of channels of input image.
+ num_layers (int): The depth of transformer.
+ num_heads (int): The number of attention heads.
+ embed_dims (int): The number of embedding dimension.
+ mlp_ratio (int): ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ drop_path_rate (float): stochastic depth rate. Default 0.1.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.0
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ init_std (float): The value of std in weight initialization.
+ Default: 0.02.
+ """
+
+ def __init__(
+ self,
+ in_channels,
+ num_layers,
+ num_heads,
+ embed_dims,
+ mlp_ratio=4,
+ drop_path_rate=0.1,
+ drop_rate=0.0,
+ attn_drop_rate=0.0,
+ num_fcs=2,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ init_std=0.02,
+ **kwargs,
+ ):
+ super(SegmenterMaskTransformerHead, self).__init__(
+ in_channels=in_channels, **kwargs)
+
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, num_layers)]
+ self.layers = ModuleList()
+ for i in range(num_layers):
+ self.layers.append(
+ TransformerEncoderLayer(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ feedforward_channels=mlp_ratio * embed_dims,
+ attn_drop_rate=attn_drop_rate,
+ drop_rate=drop_rate,
+ drop_path_rate=dpr[i],
+ num_fcs=num_fcs,
+ qkv_bias=qkv_bias,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ batch_first=True,
+ ))
+
+ self.dec_proj = nn.Linear(in_channels, embed_dims)
+
+ self.cls_emb = nn.Parameter(
+ torch.randn(1, self.num_classes, embed_dims))
+ self.patch_proj = nn.Linear(embed_dims, embed_dims, bias=False)
+ self.classes_proj = nn.Linear(embed_dims, embed_dims, bias=False)
+
+ self.decoder_norm = build_norm_layer(
+ norm_cfg, embed_dims, postfix=1)[1]
+ self.mask_norm = build_norm_layer(
+ norm_cfg, self.num_classes, postfix=2)[1]
+
+ self.init_std = init_std
+
+ delattr(self, 'conv_seg')
+
+ def init_weights(self):
+ trunc_normal_(self.cls_emb, std=self.init_std)
+ trunc_normal_init(self.patch_proj, std=self.init_std)
+ trunc_normal_init(self.classes_proj, std=self.init_std)
+ for n, m in self.named_modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=self.init_std, bias=0)
+ elif isinstance(m, nn.LayerNorm):
+ constant_init(m, val=1.0, bias=0.0)
+
+ def forward(self, inputs):
+ x = self._transform_inputs(inputs)
+ b, c, h, w = x.shape
+ x = x.permute(0, 2, 3, 1).contiguous().view(b, -1, c)
+
+ x = self.dec_proj(x)
+ cls_emb = self.cls_emb.expand(x.size(0), -1, -1)
+ x = torch.cat((x, cls_emb), 1)
+ for layer in self.layers:
+ x = layer(x)
+ x = self.decoder_norm(x)
+
+ patches = self.patch_proj(x[:, :-self.num_classes])
+ cls_seg_feat = self.classes_proj(x[:, -self.num_classes:])
+
+ patches = F.normalize(patches, dim=2, p=2)
+ cls_seg_feat = F.normalize(cls_seg_feat, dim=2, p=2)
+
+ masks = patches @ cls_seg_feat.transpose(1, 2)
+ masks = self.mask_norm(masks)
+ masks = masks.permute(0, 2, 1).contiguous().view(b, -1, h, w)
+
+ return masks
diff --git a/mmseg/models/decode_heads/sep_aspp_head.py b/mmseg/models/decode_heads/sep_aspp_head.py
new file mode 100644
index 0000000..4e894e2
--- /dev/null
+++ b/mmseg/models/decode_heads/sep_aspp_head.py
@@ -0,0 +1,102 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .aspp_head import ASPPHead, ASPPModule
+
+
+class DepthwiseSeparableASPPModule(ASPPModule):
+ """Atrous Spatial Pyramid Pooling (ASPP) Module with depthwise separable
+ conv."""
+
+ def __init__(self, **kwargs):
+ super(DepthwiseSeparableASPPModule, self).__init__(**kwargs)
+ for i, dilation in enumerate(self.dilations):
+ if dilation > 1:
+ self[i] = DepthwiseSeparableConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ dilation=dilation,
+ padding=dilation,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+
+@HEADS.register_module()
+class DepthwiseSeparableASPPHead(ASPPHead):
+ """Encoder-Decoder with Atrous Separable Convolution for Semantic Image
+ Segmentation.
+
+ This head is the implementation of `DeepLabV3+
+ `_.
+
+ Args:
+ c1_in_channels (int): The input channels of c1 decoder. If is 0,
+ the no decoder will be used.
+ c1_channels (int): The intermediate channels of c1 decoder.
+ """
+
+ def __init__(self, c1_in_channels, c1_channels, **kwargs):
+ super(DepthwiseSeparableASPPHead, self).__init__(**kwargs)
+ assert c1_in_channels >= 0
+ self.aspp_modules = DepthwiseSeparableASPPModule(
+ dilations=self.dilations,
+ in_channels=self.in_channels,
+ channels=self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ if c1_in_channels > 0:
+ self.c1_bottleneck = ConvModule(
+ c1_in_channels,
+ c1_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ else:
+ self.c1_bottleneck = None
+ self.sep_bottleneck = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ self.channels + c1_channels,
+ self.channels,
+ 3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ DepthwiseSeparableConvModule(
+ self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ aspp_outs = [
+ resize(
+ self.image_pool(x),
+ size=x.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ ]
+ aspp_outs.extend(self.aspp_modules(x))
+ aspp_outs = torch.cat(aspp_outs, dim=1)
+ output = self.bottleneck(aspp_outs)
+ if self.c1_bottleneck is not None:
+ c1_output = self.c1_bottleneck(inputs[0])
+ output = resize(
+ input=output,
+ size=c1_output.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ output = torch.cat([output, c1_output], dim=1)
+ output = self.sep_bottleneck(output)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/sep_fcn_head.py b/mmseg/models/decode_heads/sep_fcn_head.py
new file mode 100644
index 0000000..7f9658e
--- /dev/null
+++ b/mmseg/models/decode_heads/sep_fcn_head.py
@@ -0,0 +1,60 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import DepthwiseSeparableConvModule
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+@HEADS.register_module()
+class DepthwiseSeparableFCNHead(FCNHead):
+ """Depthwise-Separable Fully Convolutional Network for Semantic
+ Segmentation.
+
+ This head is implemented according to `Fast-SCNN: Fast Semantic
+ Segmentation Network `_.
+
+ Args:
+ in_channels(int): Number of output channels of FFM.
+ channels(int): Number of middle-stage channels in the decode head.
+ concat_input(bool): Whether to concatenate original decode input into
+ the result of several consecutive convolution layers.
+ Default: True.
+ num_classes(int): Used to determine the dimension of
+ final prediction tensor.
+ in_index(int): Correspond with 'out_indices' in FastSCNN backbone.
+ norm_cfg (dict | None): Config of norm layers.
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ loss_decode(dict): Config of loss type and some
+ relevant additional options.
+ dw_act_cfg (dict):Activation config of depthwise ConvModule. If it is
+ 'default', it will be the same as `act_cfg`. Default: None.
+ """
+
+ def __init__(self, dw_act_cfg=None, **kwargs):
+ super(DepthwiseSeparableFCNHead, self).__init__(**kwargs)
+ self.convs[0] = DepthwiseSeparableConvModule(
+ self.in_channels,
+ self.channels,
+ kernel_size=self.kernel_size,
+ padding=self.kernel_size // 2,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=dw_act_cfg)
+
+ for i in range(1, self.num_convs):
+ self.convs[i] = DepthwiseSeparableConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=self.kernel_size,
+ padding=self.kernel_size // 2,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=dw_act_cfg)
+
+ if self.concat_input:
+ self.conv_cat = DepthwiseSeparableConvModule(
+ self.in_channels + self.channels,
+ self.channels,
+ kernel_size=self.kernel_size,
+ padding=self.kernel_size // 2,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=dw_act_cfg)
diff --git a/mmseg/models/decode_heads/setr_mla_head.py b/mmseg/models/decode_heads/setr_mla_head.py
new file mode 100644
index 0000000..6bb94ae
--- /dev/null
+++ b/mmseg/models/decode_heads/setr_mla_head.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import Upsample
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class SETRMLAHead(BaseDecodeHead):
+ """Multi level feature aggretation head of SETR.
+
+ MLA head of `SETR `_.
+
+ Args:
+ mlahead_channels (int): Channels of conv-conv-4x of multi-level feature
+ aggregation. Default: 128.
+ up_scale (int): The scale factor of interpolate. Default:4.
+ """
+
+ def __init__(self, mla_channels=128, up_scale=4, **kwargs):
+ super(SETRMLAHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ self.mla_channels = mla_channels
+
+ num_inputs = len(self.in_channels)
+
+ # Refer to self.cls_seg settings of BaseDecodeHead
+ assert self.channels == num_inputs * mla_channels
+
+ self.up_convs = nn.ModuleList()
+ for i in range(num_inputs):
+ self.up_convs.append(
+ nn.Sequential(
+ ConvModule(
+ in_channels=self.in_channels[i],
+ out_channels=mla_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ ConvModule(
+ in_channels=mla_channels,
+ out_channels=mla_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ Upsample(
+ scale_factor=up_scale,
+ mode='bilinear',
+ align_corners=self.align_corners)))
+
+ def forward(self, inputs):
+ inputs = self._transform_inputs(inputs)
+ outs = []
+ for x, up_conv in zip(inputs, self.up_convs):
+ outs.append(up_conv(x))
+ out = torch.cat(outs, dim=1)
+ out = self.cls_seg(out)
+ return out
diff --git a/mmseg/models/decode_heads/setr_up_head.py b/mmseg/models/decode_heads/setr_up_head.py
new file mode 100644
index 0000000..87e7ea7
--- /dev/null
+++ b/mmseg/models/decode_heads/setr_up_head.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule, build_norm_layer
+
+from mmseg.ops import Upsample
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class SETRUPHead(BaseDecodeHead):
+ """Naive upsampling head and Progressive upsampling head of SETR.
+
+ Naive or PUP head of `SETR `_.
+
+ Args:
+ norm_layer (dict): Config dict for input normalization.
+ Default: norm_layer=dict(type='LN', eps=1e-6, requires_grad=True).
+ num_convs (int): Number of decoder convolutions. Default: 1.
+ up_scale (int): The scale factor of interpolate. Default:4.
+ kernel_size (int): The kernel size of convolution when decoding
+ feature information from backbone. Default: 3.
+ init_cfg (dict | list[dict] | None): Initialization config dict.
+ Default: dict(
+ type='Constant', val=1.0, bias=0, layer='LayerNorm').
+ """
+
+ def __init__(self,
+ norm_layer=dict(type='LN', eps=1e-6, requires_grad=True),
+ num_convs=1,
+ up_scale=4,
+ kernel_size=3,
+ init_cfg=[
+ dict(type='Constant', val=1.0, bias=0, layer='LayerNorm'),
+ dict(
+ type='Normal',
+ std=0.01,
+ override=dict(name='conv_seg'))
+ ],
+ **kwargs):
+
+ assert kernel_size in [1, 3], 'kernel_size must be 1 or 3.'
+
+ super(SETRUPHead, self).__init__(init_cfg=init_cfg, **kwargs)
+
+ assert isinstance(self.in_channels, int)
+
+ _, self.norm = build_norm_layer(norm_layer, self.in_channels)
+
+ self.up_convs = nn.ModuleList()
+ in_channels = self.in_channels
+ out_channels = self.channels
+ for _ in range(num_convs):
+ self.up_convs.append(
+ nn.Sequential(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=1,
+ padding=int(kernel_size - 1) // 2,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ Upsample(
+ scale_factor=up_scale,
+ mode='bilinear',
+ align_corners=self.align_corners)))
+ in_channels = out_channels
+
+ def forward(self, x):
+ x = self._transform_inputs(x)
+
+ n, c, h, w = x.shape
+ x = x.reshape(n, c, h * w).transpose(2, 1).contiguous()
+ x = self.norm(x)
+ x = x.transpose(1, 2).reshape(n, c, h, w).contiguous()
+
+ for up_conv in self.up_convs:
+ x = up_conv(x)
+ out = self.cls_seg(x)
+ return out
diff --git a/mmseg/models/decode_heads/stdc_head.py b/mmseg/models/decode_heads/stdc_head.py
new file mode 100644
index 0000000..1e678ac
--- /dev/null
+++ b/mmseg/models/decode_heads/stdc_head.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+@HEADS.register_module()
+class STDCHead(FCNHead):
+ """This head is the implementation of `Rethinking BiSeNet For Real-time
+ Semantic Segmentation `_.
+
+ Args:
+ boundary_threshold (float): The threshold of calculating boundary.
+ Default: 0.1.
+ """
+
+ def __init__(self, boundary_threshold=0.1, **kwargs):
+ super(STDCHead, self).__init__(**kwargs)
+ self.boundary_threshold = boundary_threshold
+ # Using register buffer to make laplacian kernel on the same
+ # device of `seg_label`.
+ self.register_buffer(
+ 'laplacian_kernel',
+ torch.tensor([-1, -1, -1, -1, 8, -1, -1, -1, -1],
+ dtype=torch.float32,
+ requires_grad=False).reshape((1, 1, 3, 3)))
+ self.fusion_kernel = torch.nn.Parameter(
+ torch.tensor([[6. / 10], [3. / 10], [1. / 10]],
+ dtype=torch.float32).reshape(1, 3, 1, 1),
+ requires_grad=False)
+
+ def losses(self, seg_logit, seg_label):
+ """Compute Detail Aggregation Loss."""
+ # Note: The paper claims `fusion_kernel` is a trainable 1x1 conv
+ # parameters. However, it is a constant in original repo and other
+ # codebase because it would not be added into computation graph
+ # after threshold operation.
+ seg_label = seg_label.float()
+ boundary_targets = F.conv2d(
+ seg_label, self.laplacian_kernel, padding=1)
+ boundary_targets = boundary_targets.clamp(min=0)
+ boundary_targets[boundary_targets > self.boundary_threshold] = 1
+ boundary_targets[boundary_targets <= self.boundary_threshold] = 0
+
+ boundary_targets_x2 = F.conv2d(
+ seg_label, self.laplacian_kernel, stride=2, padding=1)
+ boundary_targets_x2 = boundary_targets_x2.clamp(min=0)
+
+ boundary_targets_x4 = F.conv2d(
+ seg_label, self.laplacian_kernel, stride=4, padding=1)
+ boundary_targets_x4 = boundary_targets_x4.clamp(min=0)
+
+ boundary_targets_x4_up = F.interpolate(
+ boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')
+ boundary_targets_x2_up = F.interpolate(
+ boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')
+
+ boundary_targets_x2_up[
+ boundary_targets_x2_up > self.boundary_threshold] = 1
+ boundary_targets_x2_up[
+ boundary_targets_x2_up <= self.boundary_threshold] = 0
+
+ boundary_targets_x4_up[
+ boundary_targets_x4_up > self.boundary_threshold] = 1
+ boundary_targets_x4_up[
+ boundary_targets_x4_up <= self.boundary_threshold] = 0
+
+ boudary_targets_pyramids = torch.stack(
+ (boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up),
+ dim=1)
+
+ boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)
+ boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids,
+ self.fusion_kernel)
+
+ boudary_targets_pyramid[
+ boudary_targets_pyramid > self.boundary_threshold] = 1
+ boudary_targets_pyramid[
+ boudary_targets_pyramid <= self.boundary_threshold] = 0
+
+ loss = super(STDCHead, self).losses(seg_logit,
+ boudary_targets_pyramid.long())
+ return loss
diff --git a/mmseg/models/decode_heads/uper_head.py b/mmseg/models/decode_heads/uper_head.py
new file mode 100644
index 0000000..57d80be
--- /dev/null
+++ b/mmseg/models/decode_heads/uper_head.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+from .psp_head import PPM
+
+
+@HEADS.register_module()
+class UPerHead(BaseDecodeHead):
+ """Unified Perceptual Parsing for Scene Understanding.
+
+ This head is the implementation of `UPerNet
+ `_.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module applied on the last feature. Default: (1, 2, 3, 6).
+ """
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
+ super(UPerHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ # PSP Module
+ self.psp_modules = PPM(
+ pool_scales,
+ self.in_channels[-1],
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+ self.bottleneck = ConvModule(
+ self.in_channels[-1] + len(pool_scales) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ # FPN Module
+ self.lateral_convs = nn.ModuleList()
+ self.fpn_convs = nn.ModuleList()
+ for in_channels in self.in_channels[:-1]: # skip the top layer
+ l_conv = ConvModule(
+ in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ inplace=False)
+ fpn_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ inplace=False)
+ self.lateral_convs.append(l_conv)
+ self.fpn_convs.append(fpn_conv)
+
+ self.fpn_bottleneck = ConvModule(
+ len(self.in_channels) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def psp_forward(self, inputs):
+ """Forward function of PSP module."""
+ x = inputs[-1]
+ psp_outs = [x]
+ psp_outs.extend(self.psp_modules(x))
+ psp_outs = torch.cat(psp_outs, dim=1)
+ output = self.bottleneck(psp_outs)
+
+ return output
+
+ def forward(self, inputs):
+ """Forward function."""
+
+ inputs = self._transform_inputs(inputs)
+
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+
+ laterals.append(self.psp_forward(inputs))
+
+ # build top-down path
+ used_backbone_levels = len(laterals)
+ for i in range(used_backbone_levels - 1, 0, -1):
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] = laterals[i - 1] + resize(
+ laterals[i],
+ size=prev_shape,
+ mode='bilinear',
+ align_corners=self.align_corners)
+
+ # build outputs
+ fpn_outs = [
+ self.fpn_convs[i](laterals[i])
+ for i in range(used_backbone_levels - 1)
+ ]
+ # append psp feature
+ fpn_outs.append(laterals[-1])
+
+ for i in range(used_backbone_levels - 1, 0, -1):
+ fpn_outs[i] = resize(
+ fpn_outs[i],
+ size=fpn_outs[0].shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ fpn_outs = torch.cat(fpn_outs, dim=1)
+ output = self.fpn_bottleneck(fpn_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/losses/__init__.py b/mmseg/models/losses/__init__.py
new file mode 100644
index 0000000..fbc5b2d
--- /dev/null
+++ b/mmseg/models/losses/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .accuracy import Accuracy, accuracy
+from .cross_entropy_loss import (CrossEntropyLoss, binary_cross_entropy,
+ cross_entropy, mask_cross_entropy)
+from .dice_loss import DiceLoss
+from .focal_loss import FocalLoss
+from .lovasz_loss import LovaszLoss
+from .utils import reduce_loss, weight_reduce_loss, weighted_loss
+
+__all__ = [
+ 'accuracy', 'Accuracy', 'cross_entropy', 'binary_cross_entropy',
+ 'mask_cross_entropy', 'CrossEntropyLoss', 'reduce_loss',
+ 'weight_reduce_loss', 'weighted_loss', 'LovaszLoss', 'DiceLoss',
+ 'FocalLoss'
+]
diff --git a/mmseg/models/losses/accuracy.py b/mmseg/models/losses/accuracy.py
new file mode 100644
index 0000000..f2cd16b
--- /dev/null
+++ b/mmseg/models/losses/accuracy.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+
+def accuracy(pred, target, topk=1, thresh=None):
+ """Calculate accuracy according to the prediction and target.
+
+ Args:
+ pred (torch.Tensor): The model prediction, shape (N, num_class, ...)
+ target (torch.Tensor): The target of each prediction, shape (N, , ...)
+ topk (int | tuple[int], optional): If the predictions in ``topk``
+ matches the target, the predictions will be regarded as
+ correct ones. Defaults to 1.
+ thresh (float, optional): If not None, predictions with scores under
+ this threshold are considered incorrect. Default to None.
+
+ Returns:
+ float | tuple[float]: If the input ``topk`` is a single integer,
+ the function will return a single float as accuracy. If
+ ``topk`` is a tuple containing multiple integers, the
+ function will return a tuple containing accuracies of
+ each ``topk`` number.
+ """
+ assert isinstance(topk, (int, tuple))
+ if isinstance(topk, int):
+ topk = (topk, )
+ return_single = True
+ else:
+ return_single = False
+
+ maxk = max(topk)
+ if pred.size(0) == 0:
+ accu = [pred.new_tensor(0.) for i in range(len(topk))]
+ return accu[0] if return_single else accu
+ assert pred.ndim == target.ndim + 1
+ assert pred.size(0) == target.size(0)
+ assert maxk <= pred.size(1), \
+ f'maxk {maxk} exceeds pred dimension {pred.size(1)}'
+ pred_value, pred_label = pred.topk(maxk, dim=1)
+ # transpose to shape (maxk, N, ...)
+ pred_label = pred_label.transpose(0, 1)
+ correct = pred_label.eq(target.unsqueeze(0).expand_as(pred_label))
+ if thresh is not None:
+ # Only prediction values larger than thresh are counted as correct
+ correct = correct & (pred_value > thresh).t()
+ res = []
+ for k in topk:
+ correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
+ res.append(correct_k.mul_(100.0 / target.numel()))
+ return res[0] if return_single else res
+
+
+class Accuracy(nn.Module):
+ """Accuracy calculation module."""
+
+ def __init__(self, topk=(1, ), thresh=None):
+ """Module to calculate the accuracy.
+
+ Args:
+ topk (tuple, optional): The criterion used to calculate the
+ accuracy. Defaults to (1,).
+ thresh (float, optional): If not None, predictions with scores
+ under this threshold are considered incorrect. Default to None.
+ """
+ super().__init__()
+ self.topk = topk
+ self.thresh = thresh
+
+ def forward(self, pred, target):
+ """Forward function to calculate accuracy.
+
+ Args:
+ pred (torch.Tensor): Prediction of models.
+ target (torch.Tensor): Target for each prediction.
+
+ Returns:
+ tuple[float]: The accuracies under different topk criterions.
+ """
+ return accuracy(pred, target, self.topk, self.thresh)
diff --git a/mmseg/models/losses/cross_entropy_loss.py b/mmseg/models/losses/cross_entropy_loss.py
new file mode 100644
index 0000000..ee489a8
--- /dev/null
+++ b/mmseg/models/losses/cross_entropy_loss.py
@@ -0,0 +1,218 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..builder import LOSSES
+from .utils import get_class_weight, weight_reduce_loss
+
+
+def cross_entropy(pred,
+ label,
+ weight=None,
+ class_weight=None,
+ reduction='mean',
+ avg_factor=None,
+ ignore_index=-100):
+ """The wrapper function for :func:`F.cross_entropy`"""
+ # class_weight is a manual rescaling weight given to each class.
+ # If given, has to be a Tensor of size C element-wise losses
+ loss = F.cross_entropy(
+ pred,
+ label,
+ weight=class_weight,
+ reduction='none',
+ ignore_index=ignore_index)
+
+ # apply weights and do the reduction
+ if weight is not None:
+ weight = weight.float()
+ loss = weight_reduce_loss(
+ loss, weight=weight, reduction=reduction, avg_factor=avg_factor)
+
+ return loss
+
+
+def _expand_onehot_labels(labels, label_weights, target_shape, ignore_index):
+ """Expand onehot labels to match the size of prediction."""
+ bin_labels = labels.new_zeros(target_shape)
+ valid_mask = (labels >= 0) & (labels != ignore_index)
+ inds = torch.nonzero(valid_mask, as_tuple=True)
+
+ if inds[0].numel() > 0:
+ if labels.dim() == 3:
+ bin_labels[inds[0], labels[valid_mask], inds[1], inds[2]] = 1
+ else:
+ bin_labels[inds[0], labels[valid_mask]] = 1
+
+ valid_mask = valid_mask.unsqueeze(1).expand(target_shape).float()
+ if label_weights is None:
+ bin_label_weights = valid_mask
+ else:
+ bin_label_weights = label_weights.unsqueeze(1).expand(target_shape)
+ bin_label_weights *= valid_mask
+
+ return bin_labels, bin_label_weights
+
+
+def binary_cross_entropy(pred,
+ label,
+ weight=None,
+ reduction='mean',
+ avg_factor=None,
+ class_weight=None,
+ ignore_index=255):
+ """Calculate the binary CrossEntropy loss.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, 1).
+ label (torch.Tensor): The learning label of the prediction.
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ reduction (str, optional): The method used to reduce the loss.
+ Options are "none", "mean" and "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ class_weight (list[float], optional): The weight for each class.
+ ignore_index (int | None): The label index to be ignored. Default: 255
+
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ if pred.dim() != label.dim():
+ assert (pred.dim() == 2 and label.dim() == 1) or (
+ pred.dim() == 4 and label.dim() == 3), \
+ 'Only pred shape [N, C], label shape [N] or pred shape [N, C, ' \
+ 'H, W], label shape [N, H, W] are supported'
+ label, weight = _expand_onehot_labels(label, weight, pred.shape,
+ ignore_index)
+
+ # weighted element-wise losses
+ if weight is not None:
+ weight = weight.float()
+ loss = F.binary_cross_entropy_with_logits(
+ pred, label.float(), pos_weight=class_weight, reduction='none')
+ # do the reduction for the weighted loss
+ loss = weight_reduce_loss(
+ loss, weight, reduction=reduction, avg_factor=avg_factor)
+
+ return loss
+
+
+def mask_cross_entropy(pred,
+ target,
+ label,
+ reduction='mean',
+ avg_factor=None,
+ class_weight=None,
+ ignore_index=None):
+ """Calculate the CrossEntropy loss for masks.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the number
+ of classes.
+ target (torch.Tensor): The learning label of the prediction.
+ label (torch.Tensor): ``label`` indicates the class label of the mask'
+ corresponding object. This will be used to select the mask in the
+ of the class which the object belongs to when the mask prediction
+ if not class-agnostic.
+ reduction (str, optional): The method used to reduce the loss.
+ Options are "none", "mean" and "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ class_weight (list[float], optional): The weight for each class.
+ ignore_index (None): Placeholder, to be consistent with other loss.
+ Default: None.
+
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ assert ignore_index is None, 'BCE loss does not support ignore_index'
+ # TODO: handle these two reserved arguments
+ assert reduction == 'mean' and avg_factor is None
+ num_rois = pred.size()[0]
+ inds = torch.arange(0, num_rois, dtype=torch.long, device=pred.device)
+ pred_slice = pred[inds, label].squeeze(1)
+ return F.binary_cross_entropy_with_logits(
+ pred_slice, target, weight=class_weight, reduction='mean')[None]
+
+
+@LOSSES.register_module()
+class CrossEntropyLoss(nn.Module):
+ """CrossEntropyLoss.
+
+ Args:
+ use_sigmoid (bool, optional): Whether the prediction uses sigmoid
+ of softmax. Defaults to False.
+ use_mask (bool, optional): Whether to use mask cross entropy loss.
+ Defaults to False.
+ reduction (str, optional): . Defaults to 'mean'.
+ Options are "none", "mean" and "sum".
+ class_weight (list[float] | str, optional): Weight of each class. If in
+ str format, read them from a file. Defaults to None.
+ loss_weight (float, optional): Weight of the loss. Defaults to 1.0.
+ loss_name (str, optional): Name of the loss item. If you want this loss
+ item to be included into the backward graph, `loss_` must be the
+ prefix of the name. Defaults to 'loss_ce'.
+ """
+
+ def __init__(self,
+ use_sigmoid=False,
+ use_mask=False,
+ reduction='mean',
+ class_weight=None,
+ loss_weight=1.0,
+ loss_name='loss_ce'):
+ super(CrossEntropyLoss, self).__init__()
+ assert (use_sigmoid is False) or (use_mask is False)
+ self.use_sigmoid = use_sigmoid
+ self.use_mask = use_mask
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.class_weight = get_class_weight(class_weight)
+
+ if self.use_sigmoid:
+ self.cls_criterion = binary_cross_entropy
+ elif self.use_mask:
+ self.cls_criterion = mask_cross_entropy
+ else:
+ self.cls_criterion = cross_entropy
+ self._loss_name = loss_name
+
+ def forward(self,
+ cls_score,
+ label,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None,
+ **kwargs):
+ """Forward function."""
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.class_weight is not None:
+ class_weight = cls_score.new_tensor(self.class_weight)
+ else:
+ class_weight = None
+ loss_cls = self.loss_weight * self.cls_criterion(
+ cls_score,
+ label,
+ weight,
+ class_weight=class_weight,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss_cls
+
+ @property
+ def loss_name(self):
+ """Loss Name.
+
+ This function must be implemented and will return the name of this
+ loss function. This name will be used to combine different loss items
+ by simple sum operation. In addition, if you want this loss item to be
+ included into the backward graph, `loss_` must be the prefix of the
+ name.
+ Returns:
+ str: The name of this loss item.
+ """
+ return self._loss_name
diff --git a/mmseg/models/losses/dice_loss.py b/mmseg/models/losses/dice_loss.py
new file mode 100644
index 0000000..79a3abf
--- /dev/null
+++ b/mmseg/models/losses/dice_loss.py
@@ -0,0 +1,137 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Modified from https://github.com/LikeLy-Journey/SegmenTron/blob/master/
+segmentron/solver/loss.py (Apache-2.0 License)"""
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..builder import LOSSES
+from .utils import get_class_weight, weighted_loss
+
+
+@weighted_loss
+def dice_loss(pred,
+ target,
+ valid_mask,
+ smooth=1,
+ exponent=2,
+ class_weight=None,
+ ignore_index=255):
+ assert pred.shape[0] == target.shape[0]
+ total_loss = 0
+ num_classes = pred.shape[1]
+ for i in range(num_classes):
+ if i != ignore_index:
+ dice_loss = binary_dice_loss(
+ pred[:, i],
+ target[..., i],
+ valid_mask=valid_mask,
+ smooth=smooth,
+ exponent=exponent)
+ if class_weight is not None:
+ dice_loss *= class_weight[i]
+ total_loss += dice_loss
+ return total_loss / num_classes
+
+
+@weighted_loss
+def binary_dice_loss(pred, target, valid_mask, smooth=1, exponent=2, **kwards):
+ assert pred.shape[0] == target.shape[0]
+ pred = pred.reshape(pred.shape[0], -1)
+ target = target.reshape(target.shape[0], -1)
+ valid_mask = valid_mask.reshape(valid_mask.shape[0], -1)
+
+ num = torch.sum(torch.mul(pred, target) * valid_mask, dim=1) * 2 + smooth
+ den = torch.sum(pred.pow(exponent) + target.pow(exponent), dim=1) + smooth
+
+ return 1 - num / den
+
+
+@LOSSES.register_module()
+class DiceLoss(nn.Module):
+ """DiceLoss.
+
+ This loss is proposed in `V-Net: Fully Convolutional Neural Networks for
+ Volumetric Medical Image Segmentation `_.
+
+ Args:
+ smooth (float): A float number to smooth loss, and avoid NaN error.
+ Default: 1
+ exponent (float): An float number to calculate denominator
+ value: \\sum{x^exponent} + \\sum{y^exponent}. Default: 2.
+ reduction (str, optional): The method used to reduce the loss. Options
+ are "none", "mean" and "sum". This parameter only works when
+ per_image is True. Default: 'mean'.
+ class_weight (list[float] | str, optional): Weight of each class. If in
+ str format, read them from a file. Defaults to None.
+ loss_weight (float, optional): Weight of the loss. Default to 1.0.
+ ignore_index (int | None): The label index to be ignored. Default: 255.
+ loss_name (str, optional): Name of the loss item. If you want this loss
+ item to be included into the backward graph, `loss_` must be the
+ prefix of the name. Defaults to 'loss_dice'.
+ """
+
+ def __init__(self,
+ smooth=1,
+ exponent=2,
+ reduction='mean',
+ class_weight=None,
+ loss_weight=1.0,
+ ignore_index=255,
+ loss_name='loss_dice',
+ **kwards):
+ super(DiceLoss, self).__init__()
+ self.smooth = smooth
+ self.exponent = exponent
+ self.reduction = reduction
+ self.class_weight = get_class_weight(class_weight)
+ self.loss_weight = loss_weight
+ self.ignore_index = ignore_index
+ self._loss_name = loss_name
+
+ def forward(self,
+ pred,
+ target,
+ avg_factor=None,
+ reduction_override=None,
+ **kwards):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.class_weight is not None:
+ class_weight = pred.new_tensor(self.class_weight)
+ else:
+ class_weight = None
+
+ pred = F.softmax(pred, dim=1)
+ num_classes = pred.shape[1]
+ one_hot_target = F.one_hot(
+ torch.clamp(target.long(), 0, num_classes - 1),
+ num_classes=num_classes)
+ valid_mask = (target != self.ignore_index).long()
+
+ loss = self.loss_weight * dice_loss(
+ pred,
+ one_hot_target,
+ valid_mask=valid_mask,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ smooth=self.smooth,
+ exponent=self.exponent,
+ class_weight=class_weight,
+ ignore_index=self.ignore_index)
+ return loss
+
+ @property
+ def loss_name(self):
+ """Loss Name.
+
+ This function must be implemented and will return the name of this
+ loss function. This name will be used to combine different loss items
+ by simple sum operation. In addition, if you want this loss item to be
+ included into the backward graph, `loss_` must be the prefix of the
+ name.
+ Returns:
+ str: The name of this loss item.
+ """
+ return self._loss_name
diff --git a/mmseg/models/losses/focal_loss.py b/mmseg/models/losses/focal_loss.py
new file mode 100644
index 0000000..af1c711
--- /dev/null
+++ b/mmseg/models/losses/focal_loss.py
@@ -0,0 +1,327 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Modified from https://github.com/open-mmlab/mmdetection
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.ops import sigmoid_focal_loss as _sigmoid_focal_loss
+
+from ..builder import LOSSES
+from .utils import weight_reduce_loss
+
+
+# This method is used when cuda is not available
+def py_sigmoid_focal_loss(pred,
+ target,
+ one_hot_target=None,
+ weight=None,
+ gamma=2.0,
+ alpha=0.5,
+ class_weight=None,
+ valid_mask=None,
+ reduction='mean',
+ avg_factor=None):
+ """PyTorch version of `Focal Loss `_.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the
+ number of classes
+ target (torch.Tensor): The learning label of the prediction with
+ shape (N, C)
+ one_hot_target (None): Placeholder. It should be None.
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float | list[float], optional): A balanced form for Focal Loss.
+ Defaults to 0.5.
+ class_weight (list[float], optional): Weight of each class.
+ Defaults to None.
+ valid_mask (torch.Tensor, optional): A mask uses 1 to mark the valid
+ samples and uses 0 to mark the ignored samples. Default: None.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ """
+ if isinstance(alpha, list):
+ alpha = pred.new_tensor(alpha)
+ pred_sigmoid = pred.sigmoid()
+ target = target.type_as(pred)
+ one_minus_pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)
+ focal_weight = (alpha * target + (1 - alpha) *
+ (1 - target)) * one_minus_pt.pow(gamma)
+
+ loss = F.binary_cross_entropy_with_logits(
+ pred, target, reduction='none') * focal_weight
+ final_weight = torch.ones(1, pred.size(1)).type_as(loss)
+ if weight is not None:
+ if weight.shape != loss.shape and weight.size(0) == loss.size(0):
+ # For most cases, weight is of shape (N, ),
+ # which means it does not have the second axis num_class
+ weight = weight.view(-1, 1)
+ assert weight.dim() == loss.dim()
+ final_weight = final_weight * weight
+ if class_weight is not None:
+ final_weight = final_weight * pred.new_tensor(class_weight)
+ if valid_mask is not None:
+ final_weight = final_weight * valid_mask
+ loss = weight_reduce_loss(loss, final_weight, reduction, avg_factor)
+ return loss
+
+
+def sigmoid_focal_loss(pred,
+ target,
+ one_hot_target,
+ weight=None,
+ gamma=2.0,
+ alpha=0.5,
+ class_weight=None,
+ valid_mask=None,
+ reduction='mean',
+ avg_factor=None):
+ r"""A warpper of cuda version `Focal Loss
+ `_.
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the number
+ of classes.
+ target (torch.Tensor): The learning label of the prediction. It's shape
+ should be (N, )
+ one_hot_target (torch.Tensor): The learning label with shape (N, C)
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float | list[float], optional): A balanced form for Focal Loss.
+ Defaults to 0.5.
+ class_weight (list[float], optional): Weight of each class.
+ Defaults to None.
+ valid_mask (torch.Tensor, optional): A mask uses 1 to mark the valid
+ samples and uses 0 to mark the ignored samples. Default: None.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'. Options are "none", "mean" and "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ """
+ # Function.apply does not accept keyword arguments, so the decorator
+ # "weighted_loss" is not applicable
+ final_weight = torch.ones(1, pred.size(1)).type_as(pred)
+ if isinstance(alpha, list):
+ # _sigmoid_focal_loss doesn't accept alpha of list type. Therefore, if
+ # a list is given, we set the input alpha as 0.5. This means setting
+ # equal weight for foreground class and background class. By
+ # multiplying the loss by 2, the effect of setting alpha as 0.5 is
+ # undone. The alpha of type list is used to regulate the loss in the
+ # post-processing process.
+ loss = _sigmoid_focal_loss(pred.contiguous(), target.contiguous(),
+ gamma, 0.5, None, 'none') * 2
+ alpha = pred.new_tensor(alpha)
+ final_weight = final_weight * (
+ alpha * one_hot_target + (1 - alpha) * (1 - one_hot_target))
+ else:
+ loss = _sigmoid_focal_loss(pred.contiguous(), target.contiguous(),
+ gamma, alpha, None, 'none')
+ if weight is not None:
+ if weight.shape != loss.shape and weight.size(0) == loss.size(0):
+ # For most cases, weight is of shape (N, ),
+ # which means it does not have the second axis num_class
+ weight = weight.view(-1, 1)
+ assert weight.dim() == loss.dim()
+ final_weight = final_weight * weight
+ if class_weight is not None:
+ final_weight = final_weight * pred.new_tensor(class_weight)
+ if valid_mask is not None:
+ final_weight = final_weight * valid_mask
+ loss = weight_reduce_loss(loss, final_weight, reduction, avg_factor)
+ return loss
+
+
+@LOSSES.register_module()
+class FocalLoss(nn.Module):
+
+ def __init__(self,
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.5,
+ reduction='mean',
+ class_weight=None,
+ loss_weight=1.0,
+ loss_name='loss_focal'):
+ """`Focal Loss `_
+ Args:
+ use_sigmoid (bool, optional): Whether to the prediction is
+ used for sigmoid or softmax. Defaults to True.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float | list[float], optional): A balanced form for Focal
+ Loss. Defaults to 0.5. When a list is provided, the length
+ of the list should be equal to the number of classes.
+ Please be careful that this parameter is not the
+ class-wise weight but the weight of a binary classification
+ problem. This binary classification problem regards the
+ pixels which belong to one class as the foreground
+ and the other pixels as the background, each element in
+ the list is the weight of the corresponding foreground class.
+ The value of alpha or each element of alpha should be a float
+ in the interval [0, 1]. If you want to specify the class-wise
+ weight, please use `class_weight` parameter.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'. Options are "none", "mean" and
+ "sum".
+ class_weight (list[float], optional): Weight of each class.
+ Defaults to None.
+ loss_weight (float, optional): Weight of loss. Defaults to 1.0.
+ loss_name (str, optional): Name of the loss item. If you want this
+ loss item to be included into the backward graph, `loss_` must
+ be the prefix of the name. Defaults to 'loss_focal'.
+ """
+ super(FocalLoss, self).__init__()
+ assert use_sigmoid is True, \
+ 'AssertionError: Only sigmoid focal loss supported now.'
+ assert reduction in ('none', 'mean', 'sum'), \
+ "AssertionError: reduction should be 'none', 'mean' or " \
+ "'sum'"
+ assert isinstance(alpha, (float, list)), \
+ 'AssertionError: alpha should be of type float'
+ assert isinstance(gamma, float), \
+ 'AssertionError: gamma should be of type float'
+ assert isinstance(loss_weight, float), \
+ 'AssertionError: loss_weight should be of type float'
+ assert isinstance(loss_name, str), \
+ 'AssertionError: loss_name should be of type str'
+ assert isinstance(class_weight, list) or class_weight is None, \
+ 'AssertionError: class_weight must be None or of type list'
+ self.use_sigmoid = use_sigmoid
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = reduction
+ self.class_weight = class_weight
+ self.loss_weight = loss_weight
+ self._loss_name = loss_name
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None,
+ ignore_index=255,
+ **kwargs):
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape
+ (N, C) where C = number of classes, or
+ (N, C, d_1, d_2, ..., d_K) with K≥1 in the
+ case of K-dimensional loss.
+ target (torch.Tensor): The ground truth. If containing class
+ indices, shape (N) where each value is 0≤targets[i]≤C−1,
+ or (N, d_1, d_2, ..., d_K) with K≥1 in the case of
+ K-dimensional loss. If containing class probabilities,
+ same shape as the input.
+ weight (torch.Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to
+ average the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used
+ to override the original reduction method of the loss.
+ Options are "none", "mean" and "sum".
+ ignore_index (int, optional): The label index to be ignored.
+ Default: 255
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ assert isinstance(ignore_index, int), \
+ 'ignore_index must be of type int'
+ assert reduction_override in (None, 'none', 'mean', 'sum'), \
+ "AssertionError: reduction should be 'none', 'mean' or " \
+ "'sum'"
+ assert pred.shape == target.shape or \
+ (pred.size(0) == target.size(0) and
+ pred.shape[2:] == target.shape[1:]), \
+ "The shape of pred doesn't match the shape of target"
+
+ original_shape = pred.shape
+
+ # [B, C, d_1, d_2, ..., d_k] -> [C, B, d_1, d_2, ..., d_k]
+ pred = pred.transpose(0, 1)
+ # [C, B, d_1, d_2, ..., d_k] -> [C, N]
+ pred = pred.reshape(pred.size(0), -1)
+ # [C, N] -> [N, C]
+ pred = pred.transpose(0, 1).contiguous()
+
+ if original_shape == target.shape:
+ # target with shape [B, C, d_1, d_2, ...]
+ # transform it's shape into [N, C]
+ # [B, C, d_1, d_2, ...] -> [C, B, d_1, d_2, ..., d_k]
+ target = target.transpose(0, 1)
+ # [C, B, d_1, d_2, ..., d_k] -> [C, N]
+ target = target.reshape(target.size(0), -1)
+ # [C, N] -> [N, C]
+ target = target.transpose(0, 1).contiguous()
+ else:
+ # target with shape [B, d_1, d_2, ...]
+ # transform it's shape into [N, ]
+ target = target.view(-1).contiguous()
+ valid_mask = (target != ignore_index).view(-1, 1)
+ # avoid raising error when using F.one_hot()
+ target = torch.where(target == ignore_index, target.new_tensor(0),
+ target)
+
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.use_sigmoid:
+ num_classes = pred.size(1)
+ if torch.cuda.is_available() and pred.is_cuda:
+ if target.dim() == 1:
+ one_hot_target = F.one_hot(target, num_classes=num_classes)
+ else:
+ one_hot_target = target
+ target = target.argmax(dim=1)
+ valid_mask = (target != ignore_index).view(-1, 1)
+ calculate_loss_func = sigmoid_focal_loss
+ else:
+ one_hot_target = None
+ if target.dim() == 1:
+ target = F.one_hot(target, num_classes=num_classes)
+ else:
+ valid_mask = (target.argmax(dim=1) != ignore_index).view(
+ -1, 1)
+ calculate_loss_func = py_sigmoid_focal_loss
+
+ loss_cls = self.loss_weight * calculate_loss_func(
+ pred,
+ target,
+ one_hot_target,
+ weight,
+ gamma=self.gamma,
+ alpha=self.alpha,
+ class_weight=self.class_weight,
+ valid_mask=valid_mask,
+ reduction=reduction,
+ avg_factor=avg_factor)
+
+ if reduction == 'none':
+ # [N, C] -> [C, N]
+ loss_cls = loss_cls.transpose(0, 1)
+ # [C, N] -> [C, B, d1, d2, ...]
+ # original_shape: [B, C, d1, d2, ...]
+ loss_cls = loss_cls.reshape(original_shape[1],
+ original_shape[0],
+ *original_shape[2:])
+ # [C, B, d1, d2, ...] -> [B, C, d1, d2, ...]
+ loss_cls = loss_cls.transpose(0, 1).contiguous()
+ else:
+ raise NotImplementedError
+ return loss_cls
+
+ @property
+ def loss_name(self):
+ """Loss Name.
+
+ This function must be implemented and will return the name of this
+ loss function. This name will be used to combine different loss items
+ by simple sum operation. In addition, if you want this loss item to be
+ included into the backward graph, `loss_` must be the prefix of the
+ name.
+ Returns:
+ str: The name of this loss item.
+ """
+ return self._loss_name
diff --git a/mmseg/models/losses/lovasz_loss.py b/mmseg/models/losses/lovasz_loss.py
new file mode 100644
index 0000000..2bb0fad
--- /dev/null
+++ b/mmseg/models/losses/lovasz_loss.py
@@ -0,0 +1,323 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Modified from https://github.com/bermanmaxim/LovaszSoftmax/blob/master/pytor
+ch/lovasz_losses.py Lovasz-Softmax and Jaccard hinge loss in PyTorch Maxim
+Berman 2018 ESAT-PSI KU Leuven (MIT License)"""
+
+import mmcv
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..builder import LOSSES
+from .utils import get_class_weight, weight_reduce_loss
+
+
+def lovasz_grad(gt_sorted):
+ """Computes gradient of the Lovasz extension w.r.t sorted errors.
+
+ See Alg. 1 in paper.
+ """
+ p = len(gt_sorted)
+ gts = gt_sorted.sum()
+ intersection = gts - gt_sorted.float().cumsum(0)
+ union = gts + (1 - gt_sorted).float().cumsum(0)
+ jaccard = 1. - intersection / union
+ if p > 1: # cover 1-pixel case
+ jaccard[1:p] = jaccard[1:p] - jaccard[0:-1]
+ return jaccard
+
+
+def flatten_binary_logits(logits, labels, ignore_index=None):
+ """Flattens predictions in the batch (binary case) Remove labels equal to
+ 'ignore_index'."""
+ logits = logits.view(-1)
+ labels = labels.view(-1)
+ if ignore_index is None:
+ return logits, labels
+ valid = (labels != ignore_index)
+ vlogits = logits[valid]
+ vlabels = labels[valid]
+ return vlogits, vlabels
+
+
+def flatten_probs(probs, labels, ignore_index=None):
+ """Flattens predictions in the batch."""
+ if probs.dim() == 3:
+ # assumes output of a sigmoid layer
+ B, H, W = probs.size()
+ probs = probs.view(B, 1, H, W)
+ B, C, H, W = probs.size()
+ probs = probs.permute(0, 2, 3, 1).contiguous().view(-1, C) # B*H*W, C=P,C
+ labels = labels.view(-1)
+ if ignore_index is None:
+ return probs, labels
+ valid = (labels != ignore_index)
+ vprobs = probs[valid.nonzero().squeeze()]
+ vlabels = labels[valid]
+ return vprobs, vlabels
+
+
+def lovasz_hinge_flat(logits, labels):
+ """Binary Lovasz hinge loss.
+
+ Args:
+ logits (torch.Tensor): [P], logits at each prediction
+ (between -infty and +infty).
+ labels (torch.Tensor): [P], binary ground truth labels (0 or 1).
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+ if len(labels) == 0:
+ # only void pixels, the gradients should be 0
+ return logits.sum() * 0.
+ signs = 2. * labels.float() - 1.
+ errors = (1. - logits * signs)
+ errors_sorted, perm = torch.sort(errors, dim=0, descending=True)
+ perm = perm.data
+ gt_sorted = labels[perm]
+ grad = lovasz_grad(gt_sorted)
+ loss = torch.dot(F.relu(errors_sorted), grad)
+ return loss
+
+
+def lovasz_hinge(logits,
+ labels,
+ classes='present',
+ per_image=False,
+ class_weight=None,
+ reduction='mean',
+ avg_factor=None,
+ ignore_index=255):
+ """Binary Lovasz hinge loss.
+
+ Args:
+ logits (torch.Tensor): [B, H, W], logits at each pixel
+ (between -infty and +infty).
+ labels (torch.Tensor): [B, H, W], binary ground truth masks (0 or 1).
+ classes (str | list[int], optional): Placeholder, to be consistent with
+ other loss. Default: None.
+ per_image (bool, optional): If per_image is True, compute the loss per
+ image instead of per batch. Default: False.
+ class_weight (list[float], optional): Placeholder, to be consistent
+ with other loss. Default: None.
+ reduction (str, optional): The method used to reduce the loss. Options
+ are "none", "mean" and "sum". This parameter only works when
+ per_image is True. Default: 'mean'.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. This parameter only works when per_image is True.
+ Default: None.
+ ignore_index (int | None): The label index to be ignored. Default: 255.
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+ if per_image:
+ loss = [
+ lovasz_hinge_flat(*flatten_binary_logits(
+ logit.unsqueeze(0), label.unsqueeze(0), ignore_index))
+ for logit, label in zip(logits, labels)
+ ]
+ loss = weight_reduce_loss(
+ torch.stack(loss), None, reduction, avg_factor)
+ else:
+ loss = lovasz_hinge_flat(
+ *flatten_binary_logits(logits, labels, ignore_index))
+ return loss
+
+
+def lovasz_softmax_flat(probs, labels, classes='present', class_weight=None):
+ """Multi-class Lovasz-Softmax loss.
+
+ Args:
+ probs (torch.Tensor): [P, C], class probabilities at each prediction
+ (between 0 and 1).
+ labels (torch.Tensor): [P], ground truth labels (between 0 and C - 1).
+ classes (str | list[int], optional): Classes chosen to calculate loss.
+ 'all' for all classes, 'present' for classes present in labels, or
+ a list of classes to average. Default: 'present'.
+ class_weight (list[float], optional): The weight for each class.
+ Default: None.
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+ if probs.numel() == 0:
+ # only void pixels, the gradients should be 0
+ return probs * 0.
+ C = probs.size(1)
+ losses = []
+ class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
+ for c in class_to_sum:
+ fg = (labels == c).float() # foreground for class c
+ if (classes == 'present' and fg.sum() == 0):
+ continue
+ if C == 1:
+ if len(classes) > 1:
+ raise ValueError('Sigmoid output possible only with 1 class')
+ class_pred = probs[:, 0]
+ else:
+ class_pred = probs[:, c]
+ errors = (fg - class_pred).abs()
+ errors_sorted, perm = torch.sort(errors, 0, descending=True)
+ perm = perm.data
+ fg_sorted = fg[perm]
+ loss = torch.dot(errors_sorted, lovasz_grad(fg_sorted))
+ if class_weight is not None:
+ loss *= class_weight[c]
+ losses.append(loss)
+ return torch.stack(losses).mean()
+
+
+def lovasz_softmax(probs,
+ labels,
+ classes='present',
+ per_image=False,
+ class_weight=None,
+ reduction='mean',
+ avg_factor=None,
+ ignore_index=255):
+ """Multi-class Lovasz-Softmax loss.
+
+ Args:
+ probs (torch.Tensor): [B, C, H, W], class probabilities at each
+ prediction (between 0 and 1).
+ labels (torch.Tensor): [B, H, W], ground truth labels (between 0 and
+ C - 1).
+ classes (str | list[int], optional): Classes chosen to calculate loss.
+ 'all' for all classes, 'present' for classes present in labels, or
+ a list of classes to average. Default: 'present'.
+ per_image (bool, optional): If per_image is True, compute the loss per
+ image instead of per batch. Default: False.
+ class_weight (list[float], optional): The weight for each class.
+ Default: None.
+ reduction (str, optional): The method used to reduce the loss. Options
+ are "none", "mean" and "sum". This parameter only works when
+ per_image is True. Default: 'mean'.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. This parameter only works when per_image is True.
+ Default: None.
+ ignore_index (int | None): The label index to be ignored. Default: 255.
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+
+ if per_image:
+ loss = [
+ lovasz_softmax_flat(
+ *flatten_probs(
+ prob.unsqueeze(0), label.unsqueeze(0), ignore_index),
+ classes=classes,
+ class_weight=class_weight)
+ for prob, label in zip(probs, labels)
+ ]
+ loss = weight_reduce_loss(
+ torch.stack(loss), None, reduction, avg_factor)
+ else:
+ loss = lovasz_softmax_flat(
+ *flatten_probs(probs, labels, ignore_index),
+ classes=classes,
+ class_weight=class_weight)
+ return loss
+
+
+@LOSSES.register_module()
+class LovaszLoss(nn.Module):
+ """LovaszLoss.
+
+ This loss is proposed in `The Lovasz-Softmax loss: A tractable surrogate
+ for the optimization of the intersection-over-union measure in neural
+ networks `_.
+
+ Args:
+ loss_type (str, optional): Binary or multi-class loss.
+ Default: 'multi_class'. Options are "binary" and "multi_class".
+ classes (str | list[int], optional): Classes chosen to calculate loss.
+ 'all' for all classes, 'present' for classes present in labels, or
+ a list of classes to average. Default: 'present'.
+ per_image (bool, optional): If per_image is True, compute the loss per
+ image instead of per batch. Default: False.
+ reduction (str, optional): The method used to reduce the loss. Options
+ are "none", "mean" and "sum". This parameter only works when
+ per_image is True. Default: 'mean'.
+ class_weight (list[float] | str, optional): Weight of each class. If in
+ str format, read them from a file. Defaults to None.
+ loss_weight (float, optional): Weight of the loss. Defaults to 1.0.
+ loss_name (str, optional): Name of the loss item. If you want this loss
+ item to be included into the backward graph, `loss_` must be the
+ prefix of the name. Defaults to 'loss_lovasz'.
+ """
+
+ def __init__(self,
+ loss_type='multi_class',
+ classes='present',
+ per_image=False,
+ reduction='mean',
+ class_weight=None,
+ loss_weight=1.0,
+ loss_name='loss_lovasz'):
+ super(LovaszLoss, self).__init__()
+ assert loss_type in ('binary', 'multi_class'), "loss_type should be \
+ 'binary' or 'multi_class'."
+
+ if loss_type == 'binary':
+ self.cls_criterion = lovasz_hinge
+ else:
+ self.cls_criterion = lovasz_softmax
+ assert classes in ('all', 'present') or mmcv.is_list_of(classes, int)
+ if not per_image:
+ assert reduction == 'none', "reduction should be 'none' when \
+ per_image is False."
+
+ self.classes = classes
+ self.per_image = per_image
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.class_weight = get_class_weight(class_weight)
+ self._loss_name = loss_name
+
+ def forward(self,
+ cls_score,
+ label,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None,
+ **kwargs):
+ """Forward function."""
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.class_weight is not None:
+ class_weight = cls_score.new_tensor(self.class_weight)
+ else:
+ class_weight = None
+
+ # if multi-class loss, transform logits to probs
+ if self.cls_criterion == lovasz_softmax:
+ cls_score = F.softmax(cls_score, dim=1)
+
+ loss_cls = self.loss_weight * self.cls_criterion(
+ cls_score,
+ label,
+ self.classes,
+ self.per_image,
+ class_weight=class_weight,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss_cls
+
+ @property
+ def loss_name(self):
+ """Loss Name.
+
+ This function must be implemented and will return the name of this
+ loss function. This name will be used to combine different loss items
+ by simple sum operation. In addition, if you want this loss item to be
+ included into the backward graph, `loss_` must be the prefix of the
+ name.
+ Returns:
+ str: The name of this loss item.
+ """
+ return self._loss_name
diff --git a/mmseg/models/losses/utils.py b/mmseg/models/losses/utils.py
new file mode 100644
index 0000000..c37875f
--- /dev/null
+++ b/mmseg/models/losses/utils.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools
+
+import mmcv
+import numpy as np
+import torch.nn.functional as F
+
+
+def get_class_weight(class_weight):
+ """Get class weight for loss function.
+
+ Args:
+ class_weight (list[float] | str | None): If class_weight is a str,
+ take it as a file name and read from it.
+ """
+ if isinstance(class_weight, str):
+ # take it as a file path
+ if class_weight.endswith('.npy'):
+ class_weight = np.load(class_weight)
+ else:
+ # pkl, json or yaml
+ class_weight = mmcv.load(class_weight)
+
+ return class_weight
+
+
+def reduce_loss(loss, reduction):
+ """Reduce loss as specified.
+
+ Args:
+ loss (Tensor): Elementwise loss tensor.
+ reduction (str): Options are "none", "mean" and "sum".
+
+ Return:
+ Tensor: Reduced loss tensor.
+ """
+ reduction_enum = F._Reduction.get_enum(reduction)
+ # none: 0, elementwise_mean:1, sum: 2
+ if reduction_enum == 0:
+ return loss
+ elif reduction_enum == 1:
+ return loss.mean()
+ elif reduction_enum == 2:
+ return loss.sum()
+
+
+def weight_reduce_loss(loss, weight=None, reduction='mean', avg_factor=None):
+ """Apply element-wise weight and reduce loss.
+
+ Args:
+ loss (Tensor): Element-wise loss.
+ weight (Tensor): Element-wise weights.
+ reduction (str): Same as built-in losses of PyTorch.
+ avg_factor (float): Average factor when computing the mean of losses.
+
+ Returns:
+ Tensor: Processed loss values.
+ """
+ # if weight is specified, apply element-wise weight
+ if weight is not None:
+ assert weight.dim() == loss.dim()
+ if weight.dim() > 1:
+ assert weight.size(1) == 1 or weight.size(1) == loss.size(1)
+ loss = loss * weight
+
+ # if avg_factor is not specified, just reduce the loss
+ if avg_factor is None:
+ loss = reduce_loss(loss, reduction)
+ else:
+ # if reduction is mean, then average the loss by avg_factor
+ if reduction == 'mean':
+ loss = loss.sum() / avg_factor
+ # if reduction is 'none', then do nothing, otherwise raise an error
+ elif reduction != 'none':
+ raise ValueError('avg_factor can not be used with reduction="sum"')
+ return loss
+
+
+def weighted_loss(loss_func):
+ """Create a weighted version of a given loss function.
+
+ To use this decorator, the loss function must have the signature like
+ `loss_func(pred, target, **kwargs)`. The function only needs to compute
+ element-wise loss without any reduction. This decorator will add weight
+ and reduction arguments to the function. The decorated function will have
+ the signature like `loss_func(pred, target, weight=None, reduction='mean',
+ avg_factor=None, **kwargs)`.
+
+ :Example:
+
+ >>> import torch
+ >>> @weighted_loss
+ >>> def l1_loss(pred, target):
+ >>> return (pred - target).abs()
+
+ >>> pred = torch.Tensor([0, 2, 3])
+ >>> target = torch.Tensor([1, 1, 1])
+ >>> weight = torch.Tensor([1, 0, 1])
+
+ >>> l1_loss(pred, target)
+ tensor(1.3333)
+ >>> l1_loss(pred, target, weight)
+ tensor(1.)
+ >>> l1_loss(pred, target, reduction='none')
+ tensor([1., 1., 2.])
+ >>> l1_loss(pred, target, weight, avg_factor=2)
+ tensor(1.5000)
+ """
+
+ @functools.wraps(loss_func)
+ def wrapper(pred,
+ target,
+ weight=None,
+ reduction='mean',
+ avg_factor=None,
+ **kwargs):
+ # get element-wise loss
+ loss = loss_func(pred, target, **kwargs)
+ loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
+ return loss
+
+ return wrapper
diff --git a/mmseg/models/necks/__init__.py b/mmseg/models/necks/__init__.py
new file mode 100644
index 0000000..aba73f1
--- /dev/null
+++ b/mmseg/models/necks/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .fpn import FPN
+from .ic_neck import ICNeck
+from .jpu import JPU
+from .mla_neck import MLANeck
+from .multilevel_neck import MultiLevelNeck
+
+__all__ = ['FPN', 'MultiLevelNeck', 'MLANeck', 'ICNeck', 'JPU']
diff --git a/mmseg/models/necks/fpn.py b/mmseg/models/necks/fpn.py
new file mode 100644
index 0000000..975a48e
--- /dev/null
+++ b/mmseg/models/necks/fpn.py
@@ -0,0 +1,213 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule, auto_fp16
+
+from mmseg.ops import resize
+from ..builder import NECKS
+
+
+@NECKS.register_module()
+class FPN(BaseModule):
+ """Feature Pyramid Network.
+
+ This neck is the implementation of `Feature Pyramid Networks for Object
+ Detection `_.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ num_outs (int): Number of output scales.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Default: 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Default: -1, which means the last level.
+ add_extra_convs (bool | str): If bool, it decides whether to add conv
+ layers on top of the original feature maps. Default to False.
+ If True, its actual mode is specified by `extra_convs_on_inputs`.
+ If str, it specifies the source feature map of the extra convs.
+ Only the following options are allowed
+
+ - 'on_input': Last feat map of neck inputs (i.e. backbone feature).
+ - 'on_lateral': Last feature map after lateral convs.
+ - 'on_output': The last output feature map after fpn convs.
+ extra_convs_on_inputs (bool, deprecated): Whether to apply extra convs
+ on the original feature from the backbone. If True,
+ it is equivalent to `add_extra_convs='on_input'`. If False, it is
+ equivalent to set `add_extra_convs='on_output'`. Default to True.
+ relu_before_extra_convs (bool): Whether to apply relu before the extra
+ conv. Default: False.
+ no_norm_on_lateral (bool): Whether to apply norm on lateral.
+ Default: False.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (str): Config dict for activation layer in ConvModule.
+ Default: None.
+ upsample_cfg (dict): Config dict for interpolate layer.
+ Default: `dict(mode='nearest')`
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+
+ Example:
+ >>> import torch
+ >>> in_channels = [2, 3, 5, 7]
+ >>> scales = [340, 170, 84, 43]
+ >>> inputs = [torch.rand(1, c, s, s)
+ ... for c, s in zip(in_channels, scales)]
+ >>> self = FPN(in_channels, 11, len(in_channels)).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 11, 340, 340])
+ outputs[1].shape = torch.Size([1, 11, 170, 170])
+ outputs[2].shape = torch.Size([1, 11, 84, 84])
+ outputs[3].shape = torch.Size([1, 11, 43, 43])
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level=0,
+ end_level=-1,
+ add_extra_convs=False,
+ extra_convs_on_inputs=False,
+ relu_before_extra_convs=False,
+ no_norm_on_lateral=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=None,
+ upsample_cfg=dict(mode='nearest'),
+ init_cfg=dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')):
+ super(FPN, self).__init__(init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.num_outs = num_outs
+ self.relu_before_extra_convs = relu_before_extra_convs
+ self.no_norm_on_lateral = no_norm_on_lateral
+ self.fp16_enabled = False
+ self.upsample_cfg = upsample_cfg.copy()
+
+ if end_level == -1:
+ self.backbone_end_level = self.num_ins
+ assert num_outs >= self.num_ins - start_level
+ else:
+ # if end_level < inputs, no extra level is allowed
+ self.backbone_end_level = end_level
+ assert end_level <= len(in_channels)
+ assert num_outs == end_level - start_level
+ self.start_level = start_level
+ self.end_level = end_level
+ self.add_extra_convs = add_extra_convs
+ assert isinstance(add_extra_convs, (str, bool))
+ if isinstance(add_extra_convs, str):
+ # Extra_convs_source choices: 'on_input', 'on_lateral', 'on_output'
+ assert add_extra_convs in ('on_input', 'on_lateral', 'on_output')
+ elif add_extra_convs: # True
+ if extra_convs_on_inputs:
+ # For compatibility with previous release
+ # TODO: deprecate `extra_convs_on_inputs`
+ self.add_extra_convs = 'on_input'
+ else:
+ self.add_extra_convs = 'on_output'
+
+ self.lateral_convs = nn.ModuleList()
+ self.fpn_convs = nn.ModuleList()
+
+ for i in range(self.start_level, self.backbone_end_level):
+ l_conv = ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg if not self.no_norm_on_lateral else None,
+ act_cfg=act_cfg,
+ inplace=False)
+ fpn_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ self.lateral_convs.append(l_conv)
+ self.fpn_convs.append(fpn_conv)
+
+ # add extra conv layers (e.g., RetinaNet)
+ extra_levels = num_outs - self.backbone_end_level + self.start_level
+ if self.add_extra_convs and extra_levels >= 1:
+ for i in range(extra_levels):
+ if i == 0 and self.add_extra_convs == 'on_input':
+ in_channels = self.in_channels[self.backbone_end_level - 1]
+ else:
+ in_channels = out_channels
+ extra_fpn_conv = ConvModule(
+ in_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ self.fpn_convs.append(extra_fpn_conv)
+
+ @auto_fp16()
+ def forward(self, inputs):
+ assert len(inputs) == len(self.in_channels)
+
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i + self.start_level])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+
+ # build top-down path
+ used_backbone_levels = len(laterals)
+ for i in range(used_backbone_levels - 1, 0, -1):
+ # In some cases, fixing `scale factor` (e.g. 2) is preferred, but
+ # it cannot co-exist with `size` in `F.interpolate`.
+ if 'scale_factor' in self.upsample_cfg:
+ laterals[i - 1] = laterals[i - 1] + resize(
+ laterals[i], **self.upsample_cfg)
+ else:
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] = laterals[i - 1] + resize(
+ laterals[i], size=prev_shape, **self.upsample_cfg)
+
+ # build outputs
+ # part 1: from original levels
+ outs = [
+ self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
+ ]
+ # part 2: add extra levels
+ if self.num_outs > len(outs):
+ # use max pool to get more levels on top of outputs
+ # (e.g., Faster R-CNN, Mask R-CNN)
+ if not self.add_extra_convs:
+ for i in range(self.num_outs - used_backbone_levels):
+ outs.append(F.max_pool2d(outs[-1], 1, stride=2))
+ # add conv layers on top of original feature maps (RetinaNet)
+ else:
+ if self.add_extra_convs == 'on_input':
+ extra_source = inputs[self.backbone_end_level - 1]
+ elif self.add_extra_convs == 'on_lateral':
+ extra_source = laterals[-1]
+ elif self.add_extra_convs == 'on_output':
+ extra_source = outs[-1]
+ else:
+ raise NotImplementedError
+ outs.append(self.fpn_convs[used_backbone_levels](extra_source))
+ for i in range(used_backbone_levels + 1, self.num_outs):
+ if self.relu_before_extra_convs:
+ outs.append(self.fpn_convs[i](F.relu(outs[-1])))
+ else:
+ outs.append(self.fpn_convs[i](outs[-1]))
+ return tuple(outs)
diff --git a/mmseg/models/necks/ic_neck.py b/mmseg/models/necks/ic_neck.py
new file mode 100644
index 0000000..d836a6b
--- /dev/null
+++ b/mmseg/models/necks/ic_neck.py
@@ -0,0 +1,147 @@
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import NECKS
+
+
+class CascadeFeatureFusion(BaseModule):
+ """Cascade Feature Fusion Unit in ICNet.
+
+ Args:
+ low_channels (int): The number of input channels for
+ low resolution feature map.
+ high_channels (int): The number of input channels for
+ high resolution feature map.
+ out_channels (int): The number of output channels.
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Dictionary to construct and config act layer.
+ Default: dict(type='ReLU').
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Returns:
+ x (Tensor): The output tensor of shape (N, out_channels, H, W).
+ x_low (Tensor): The output tensor of shape (N, out_channels, H, W)
+ for Cascade Label Guidance in auxiliary heads.
+ """
+
+ def __init__(self,
+ low_channels,
+ high_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ init_cfg=None):
+ super(CascadeFeatureFusion, self).__init__(init_cfg=init_cfg)
+ self.align_corners = align_corners
+ self.conv_low = ConvModule(
+ low_channels,
+ out_channels,
+ 3,
+ padding=2,
+ dilation=2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv_high = ConvModule(
+ high_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x_low, x_high):
+ x_low = resize(
+ x_low,
+ size=x_high.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ # Note: Different from original paper, `x_low` is underwent
+ # `self.conv_low` rather than another 1x1 conv classifier
+ # before being used for auxiliary head.
+ x_low = self.conv_low(x_low)
+ x_high = self.conv_high(x_high)
+ x = x_low + x_high
+ x = F.relu(x, inplace=True)
+ return x, x_low
+
+
+@NECKS.register_module()
+class ICNeck(BaseModule):
+ """ICNet for Real-Time Semantic Segmentation on High-Resolution Images.
+
+ This head is the implementation of `ICHead
+ `_.
+
+ Args:
+ in_channels (int): The number of input image channels. Default: 3.
+ out_channels (int): The numbers of output feature channels.
+ Default: 128.
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Dictionary to construct and config act layer.
+ Default: dict(type='ReLU').
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=(64, 256, 256),
+ out_channels=128,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ init_cfg=None):
+ super(ICNeck, self).__init__(init_cfg=init_cfg)
+ assert len(in_channels) == 3, 'Length of input channels \
+ must be 3!'
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.align_corners = align_corners
+ self.cff_24 = CascadeFeatureFusion(
+ self.in_channels[2],
+ self.in_channels[1],
+ self.out_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+
+ self.cff_12 = CascadeFeatureFusion(
+ self.out_channels,
+ self.in_channels[0],
+ self.out_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+
+ def forward(self, inputs):
+ assert len(inputs) == 3, 'Length of input feature \
+ maps must be 3!'
+
+ x_sub1, x_sub2, x_sub4 = inputs
+ x_cff_24, x_24 = self.cff_24(x_sub4, x_sub2)
+ x_cff_12, x_12 = self.cff_12(x_cff_24, x_sub1)
+ # Note: `x_cff_12` is used for decode_head,
+ # `x_24` and `x_12` are used for auxiliary head.
+ return x_24, x_12, x_cff_12
diff --git a/mmseg/models/necks/jpu.py b/mmseg/models/necks/jpu.py
new file mode 100644
index 0000000..3cc6b9f
--- /dev/null
+++ b/mmseg/models/necks/jpu.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import NECKS
+
+
+@NECKS.register_module()
+class JPU(BaseModule):
+ """FastFCN: Rethinking Dilated Convolution in the Backbone
+ for Semantic Segmentation.
+
+ This Joint Pyramid Upsampling (JPU) neck is the implementation of
+ `FastFCN `_.
+
+ Args:
+ in_channels (Tuple[int], optional): The number of input channels
+ for each convolution operations before upsampling.
+ Default: (512, 1024, 2048).
+ mid_channels (int): The number of output channels of JPU.
+ Default: 512.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Default: 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Default: -1, which means the last level.
+ dilations (tuple[int]): Dilation rate of each Depthwise
+ Separable ConvModule. Default: (1, 2, 4, 8).
+ align_corners (bool, optional): The align_corners argument of
+ resize operation. Default: False.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=(512, 1024, 2048),
+ mid_channels=512,
+ start_level=0,
+ end_level=-1,
+ dilations=(1, 2, 4, 8),
+ align_corners=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(JPU, self).__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, tuple)
+ assert isinstance(dilations, tuple)
+ self.in_channels = in_channels
+ self.mid_channels = mid_channels
+ self.start_level = start_level
+ self.num_ins = len(in_channels)
+ if end_level == -1:
+ self.backbone_end_level = self.num_ins
+ else:
+ self.backbone_end_level = end_level
+ assert end_level <= len(in_channels)
+
+ self.dilations = dilations
+ self.align_corners = align_corners
+
+ self.conv_layers = nn.ModuleList()
+ self.dilation_layers = nn.ModuleList()
+ for i in range(self.start_level, self.backbone_end_level):
+ conv_layer = nn.Sequential(
+ ConvModule(
+ self.in_channels[i],
+ self.mid_channels,
+ kernel_size=3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.conv_layers.append(conv_layer)
+ for i in range(len(dilations)):
+ dilation_layer = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ in_channels=(self.backbone_end_level - self.start_level) *
+ self.mid_channels,
+ out_channels=self.mid_channels,
+ kernel_size=3,
+ stride=1,
+ padding=dilations[i],
+ dilation=dilations[i],
+ dw_norm_cfg=norm_cfg,
+ dw_act_cfg=None,
+ pw_norm_cfg=norm_cfg,
+ pw_act_cfg=act_cfg))
+ self.dilation_layers.append(dilation_layer)
+
+ def forward(self, inputs):
+ """Forward function."""
+ assert len(inputs) == len(self.in_channels), 'Length of inputs must \
+ be the same with self.in_channels!'
+
+ feats = [
+ self.conv_layers[i - self.start_level](inputs[i])
+ for i in range(self.start_level, self.backbone_end_level)
+ ]
+
+ h, w = feats[0].shape[2:]
+ for i in range(1, len(feats)):
+ feats[i] = resize(
+ feats[i],
+ size=(h, w),
+ mode='bilinear',
+ align_corners=self.align_corners)
+
+ feat = torch.cat(feats, dim=1)
+ concat_feat = torch.cat([
+ self.dilation_layers[i](feat) for i in range(len(self.dilations))
+ ],
+ dim=1)
+
+ outs = []
+
+ # Default: outs[2] is the output of JPU for decoder head, outs[1] is
+ # the feature map from backbone for auxiliary head. Additionally,
+ # outs[0] can also be used for auxiliary head.
+ for i in range(self.start_level, self.backbone_end_level - 1):
+ outs.append(inputs[i])
+ outs.append(concat_feat)
+ return tuple(outs)
diff --git a/mmseg/models/necks/mla_neck.py b/mmseg/models/necks/mla_neck.py
new file mode 100644
index 0000000..1513e29
--- /dev/null
+++ b/mmseg/models/necks/mla_neck.py
@@ -0,0 +1,118 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule, build_norm_layer
+
+from ..builder import NECKS
+
+
+class MLAModule(nn.Module):
+
+ def __init__(self,
+ in_channels=[1024, 1024, 1024, 1024],
+ out_channels=256,
+ norm_cfg=None,
+ act_cfg=None):
+ super(MLAModule, self).__init__()
+ self.channel_proj = nn.ModuleList()
+ for i in range(len(in_channels)):
+ self.channel_proj.append(
+ ConvModule(
+ in_channels=in_channels[i],
+ out_channels=out_channels,
+ kernel_size=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.feat_extract = nn.ModuleList()
+ for i in range(len(in_channels)):
+ self.feat_extract.append(
+ ConvModule(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs):
+
+ # feat_list -> [p2, p3, p4, p5]
+ feat_list = []
+ for x, conv in zip(inputs, self.channel_proj):
+ feat_list.append(conv(x))
+
+ # feat_list -> [p5, p4, p3, p2]
+ # mid_list -> [m5, m4, m3, m2]
+ feat_list = feat_list[::-1]
+ mid_list = []
+ for feat in feat_list:
+ if len(mid_list) == 0:
+ mid_list.append(feat)
+ else:
+ mid_list.append(mid_list[-1] + feat)
+
+ # mid_list -> [m5, m4, m3, m2]
+ # out_list -> [o2, o3, o4, o5]
+ out_list = []
+ for mid, conv in zip(mid_list, self.feat_extract):
+ out_list.append(conv(mid))
+
+ return tuple(out_list)
+
+
+@NECKS.register_module()
+class MLANeck(nn.Module):
+ """Multi-level Feature Aggregation.
+
+ This neck is `The Multi-level Feature Aggregation construction of
+ SETR `_.
+
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ norm_layer (dict): Config dict for input normalization.
+ Default: norm_layer=dict(type='LN', eps=1e-6, requires_grad=True).
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (dict): Config dict for activation layer in ConvModule.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ norm_layer=dict(type='LN', eps=1e-6, requires_grad=True),
+ norm_cfg=None,
+ act_cfg=None):
+ super(MLANeck, self).__init__()
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ # In order to build general vision transformer backbone, we have to
+ # move MLA to neck.
+ self.norm = nn.ModuleList([
+ build_norm_layer(norm_layer, in_channels[i])[1]
+ for i in range(len(in_channels))
+ ])
+
+ self.mla = MLAModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, inputs):
+ assert len(inputs) == len(self.in_channels)
+
+ # Convert from nchw to nlc
+ outs = []
+ for i in range(len(inputs)):
+ x = inputs[i]
+ n, c, h, w = x.shape
+ x = x.reshape(n, c, h * w).transpose(2, 1).contiguous()
+ x = self.norm[i](x)
+ x = x.transpose(1, 2).reshape(n, c, h, w).contiguous()
+ outs.append(x)
+
+ outs = self.mla(outs)
+ return tuple(outs)
diff --git a/mmseg/models/necks/multilevel_neck.py b/mmseg/models/necks/multilevel_neck.py
new file mode 100644
index 0000000..5151f87
--- /dev/null
+++ b/mmseg/models/necks/multilevel_neck.py
@@ -0,0 +1,78 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule, xavier_init
+
+from mmseg.ops import resize
+from ..builder import NECKS
+
+
+@NECKS.register_module()
+class MultiLevelNeck(nn.Module):
+ """MultiLevelNeck.
+
+ A neck structure connect vit backbone and decoder_heads.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ scales (List[float]): Scale factors for each input feature map.
+ Default: [0.5, 1, 2, 4]
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (dict): Config dict for activation layer in ConvModule.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ scales=[0.5, 1, 2, 4],
+ norm_cfg=None,
+ act_cfg=None):
+ super(MultiLevelNeck, self).__init__()
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.scales = scales
+ self.num_outs = len(scales)
+ self.lateral_convs = nn.ModuleList()
+ self.convs = nn.ModuleList()
+ for in_channel in in_channels:
+ self.lateral_convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ kernel_size=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ for _ in range(self.num_outs):
+ self.convs.append(
+ ConvModule(
+ out_channels,
+ out_channels,
+ kernel_size=3,
+ padding=1,
+ stride=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ # default init_weights for conv(msra) and norm in ConvModule
+ def init_weights(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ xavier_init(m, distribution='uniform')
+
+ def forward(self, inputs):
+ assert len(inputs) == len(self.in_channels)
+ inputs = [
+ lateral_conv(inputs[i])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+ # for len(inputs) not equal to self.num_outs
+ if len(inputs) == 1:
+ inputs = [inputs[0] for _ in range(self.num_outs)]
+ outs = []
+ for i in range(self.num_outs):
+ x_resize = resize(
+ inputs[i], scale_factor=self.scales[i], mode='bilinear')
+ outs.append(self.convs[i](x_resize))
+ return tuple(outs)
diff --git a/mmseg/models/segmentors/__init__.py b/mmseg/models/segmentors/__init__.py
new file mode 100644
index 0000000..c294a9e
--- /dev/null
+++ b/mmseg/models/segmentors/__init__.py
@@ -0,0 +1,12 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BaseSegmentor, ONNXRuntimeSegmentorKN
+from .cascade_encoder_decoder import CascadeEncoderDecoder
+from .encoder_decoder import EncoderDecoder
+
+__all__ = [
+ 'BaseSegmentor',
+ 'ONNXRuntimeSegmentorKN',
+ 'EncoderDecoder',
+ 'CascadeEncoderDecoder'
+]
diff --git a/mmseg/models/segmentors/base.py b/mmseg/models/segmentors/base.py
new file mode 100644
index 0000000..3778c4d
--- /dev/null
+++ b/mmseg/models/segmentors/base.py
@@ -0,0 +1,453 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from abc import ABCMeta, abstractmethod
+from collections import OrderedDict
+from typing import Any, Iterable, Union
+from os import path as osp
+
+import mmcv
+import numpy as np
+import torch
+import torch.distributed as dist
+from mmcv.runner import BaseModule, auto_fp16
+from mmseg.core import get_classes, get_palette
+from mmseg.ops import resize
+
+
+class BaseSegmentor(BaseModule, metaclass=ABCMeta):
+ """Base class for segmentors."""
+
+ def __init__(self, init_cfg=None):
+ super(BaseSegmentor, self).__init__(init_cfg)
+ self.fp16_enabled = False
+
+ @property
+ def with_neck(self):
+ """bool: whether the segmentor has neck"""
+ return hasattr(self, 'neck') and self.neck is not None
+
+ @property
+ def with_auxiliary_head(self):
+ """bool: whether the segmentor has auxiliary head"""
+ return hasattr(self,
+ 'auxiliary_head') and self.auxiliary_head is not None
+
+ @property
+ def with_decode_head(self):
+ """bool: whether the segmentor has decode head"""
+ return hasattr(self, 'decode_head') and self.decode_head is not None
+
+ @abstractmethod
+ def extract_feat(self, imgs):
+ """Placeholder for extract features from images."""
+ pass
+
+ @abstractmethod
+ def encode_decode(self, img, img_metas):
+ """Placeholder for encode images with backbone and decode into a
+ semantic segmentation map of the same size as input."""
+ pass
+
+ @abstractmethod
+ def forward_train(self, imgs, img_metas, **kwargs):
+ """Placeholder for Forward function for training."""
+ pass
+
+ @abstractmethod
+ def simple_test(self, img, img_meta, **kwargs):
+ """Placeholder for single image test."""
+ pass
+
+ @abstractmethod
+ def aug_test(self, imgs, img_metas, **kwargs):
+ """Placeholder for augmentation test."""
+ pass
+
+ def forward_test(self, imgs, img_metas, **kwargs):
+ """
+ Args:
+ imgs (List[Tensor]): the outer list indicates test-time
+ augmentations and inner Tensor should have a shape NxCxHxW,
+ which contains all images in the batch.
+ img_metas (List[List[dict]]): the outer list indicates test-time
+ augs (multiscale, flip, etc.) and the inner list indicates
+ images in a batch.
+ """
+ for var, name in [(imgs, 'imgs'), (img_metas, 'img_metas')]:
+ if not isinstance(var, list):
+ raise TypeError(f'{name} must be a list, but got '
+ f'{type(var)}')
+
+ num_augs = len(imgs)
+ if num_augs != len(img_metas):
+ raise ValueError(f'num of augmentations ({len(imgs)}) != '
+ f'num of image meta ({len(img_metas)})')
+ # all images in the same aug batch all of the same ori_shape and pad
+ # shape
+ for img_meta in img_metas:
+ ori_shapes = [_['ori_shape'] for _ in img_meta]
+ assert all(shape == ori_shapes[0] for shape in ori_shapes)
+ img_shapes = [_['img_shape'] for _ in img_meta]
+ assert all(shape == img_shapes[0] for shape in img_shapes)
+ pad_shapes = [_['pad_shape'] for _ in img_meta]
+ assert all(shape == pad_shapes[0] for shape in pad_shapes)
+
+ if num_augs == 1:
+ return self.simple_test(imgs[0], img_metas[0], **kwargs)
+ else:
+ return self.aug_test(imgs, img_metas, **kwargs)
+
+ @auto_fp16(apply_to=('img', ))
+ def forward(self, img, img_metas, return_loss=True, **kwargs):
+ """Calls either :func:`forward_train` or :func:`forward_test` depending
+ on whether ``return_loss`` is ``True``.
+
+ Note this setting will change the expected inputs. When
+ ``return_loss=True``, img and img_meta are single-nested (i.e. Tensor
+ and List[dict]), and when ``resturn_loss=False``, img and img_meta
+ should be double nested (i.e. List[Tensor], List[List[dict]]), with
+ the outer list indicating test time augmentations.
+ """
+ if return_loss:
+ return self.forward_train(img, img_metas, **kwargs)
+ else:
+ return self.forward_test(img, img_metas, **kwargs)
+
+ def train_step(self, data_batch, optimizer, **kwargs):
+ """The iteration step during training.
+
+ This method defines an iteration step during training, except for the
+ back propagation and optimizer updating, which are done in an optimizer
+ hook. Note that in some complicated cases or models, the whole process
+ including back propagation and optimizer updating is also defined in
+ this method, such as GAN.
+
+ Args:
+ data (dict): The output of dataloader.
+ optimizer (:obj:`torch.optim.Optimizer` | dict): The optimizer of
+ runner is passed to ``train_step()``. This argument is unused
+ and reserved.
+
+ Returns:
+ dict: It should contain at least 3 keys: ``loss``, ``log_vars``,
+ ``num_samples``.
+ ``loss`` is a tensor for back propagation, which can be a
+ weighted sum of multiple losses.
+ ``log_vars`` contains all the variables to be sent to the
+ logger.
+ ``num_samples`` indicates the batch size (when the model is
+ DDP, it means the batch size on each GPU), which is used for
+ averaging the logs.
+ """
+ losses = self(**data_batch)
+ loss, log_vars = self._parse_losses(losses)
+
+ outputs = dict(
+ loss=loss,
+ log_vars=log_vars,
+ num_samples=len(data_batch['img_metas']))
+
+ return outputs
+
+ def val_step(self, data_batch, optimizer=None, **kwargs):
+ """The iteration step during validation.
+
+ This method shares the same signature as :func:`train_step`, but used
+ during val epochs. Note that the evaluation after training epochs is
+ not implemented with this method, but an evaluation hook.
+ """
+ losses = self(**data_batch)
+ loss, log_vars = self._parse_losses(losses)
+
+ outputs = dict(
+ loss=loss,
+ log_vars=log_vars,
+ num_samples=len(data_batch['img_metas']))
+
+ return outputs
+
+ @staticmethod
+ def _parse_losses(losses):
+ """Parse the raw outputs (losses) of the network.
+
+ Args:
+ losses (dict): Raw output of the network, which usually contain
+ losses and other necessary information.
+
+ Returns:
+ tuple[Tensor, dict]: (loss, log_vars), loss is the loss tensor
+ which may be a weighted sum of all losses, log_vars contains
+ all the variables to be sent to the logger.
+ """
+ log_vars = OrderedDict()
+ for loss_name, loss_value in losses.items():
+ if isinstance(loss_value, torch.Tensor):
+ log_vars[loss_name] = loss_value.mean()
+ elif isinstance(loss_value, list):
+ log_vars[loss_name] = sum(_loss.mean() for _loss in loss_value)
+ else:
+ raise TypeError(
+ f'{loss_name} is not a tensor or list of tensors')
+
+ loss = sum(_value for _key, _value in log_vars.items()
+ if 'loss' in _key)
+
+ # If the loss_vars has different length, raise assertion error
+ # to prevent GPUs from infinite waiting.
+ if dist.is_available() and dist.is_initialized():
+ log_var_length = torch.tensor(len(log_vars), device=loss.device)
+ dist.all_reduce(log_var_length)
+ message = (f'rank {dist.get_rank()}' +
+ f' len(log_vars): {len(log_vars)}' + ' keys: ' +
+ ','.join(log_vars.keys()) + '\n')
+ assert log_var_length == len(log_vars) * dist.get_world_size(), \
+ 'loss log variables are different across GPUs!\n' + message
+
+ log_vars['loss'] = loss
+ for loss_name, loss_value in log_vars.items():
+ # reduce loss when distributed training
+ if dist.is_available() and dist.is_initialized():
+ loss_value = loss_value.data.clone()
+ dist.all_reduce(loss_value.div_(dist.get_world_size()))
+ log_vars[loss_name] = loss_value.item()
+
+ return loss, log_vars
+
+ def show_result(self,
+ img,
+ result,
+ palette=None,
+ win_name='',
+ show=False,
+ wait_time=0,
+ out_file=None,
+ opacity=0.5):
+ """Draw `result` over `img`.
+
+ Args:
+ img (str or Tensor): The image to be displayed.
+ result (Tensor): The semantic segmentation results to draw over
+ `img`.
+ palette (list[list[int]]] | np.ndarray | None): The palette of
+ segmentation map. If None is given, random palette will be
+ generated. Default: None
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ Default: 0.
+ show (bool): Whether to show the image.
+ Default: False.
+ out_file (str or None): The filename to write the image.
+ Default: None.
+ opacity(float): Opacity of painted segmentation map.
+ Default 0.5.
+ Must be in (0, 1] range.
+ Returns:
+ img (Tensor): Only if not `show` or `out_file`
+ """
+ img = mmcv.imread(img)
+ img = img.copy()
+ seg = result[0]
+ if palette is None:
+ if self.PALETTE is None:
+ # Get random state before set seed,
+ # and restore random state later.
+ # It will prevent loss of randomness, as the palette
+ # may be different in each iteration if not specified.
+ # See: https://github.com/open-mmlab/mmdetection/issues/5844
+ state = np.random.get_state()
+ np.random.seed(42)
+ # random palette
+ palette = np.random.randint(
+ 0, 255, size=(len(self.CLASSES), 3))
+ np.random.set_state(state)
+ else:
+ palette = self.PALETTE
+ palette = np.array(palette)
+ assert palette.shape[0] == len(self.CLASSES)
+ assert palette.shape[1] == 3
+ assert len(palette.shape) == 2
+ assert 0 < opacity <= 1.0
+ color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
+ for label, color in enumerate(palette):
+ color_seg[seg == label, :] = color
+ # convert to BGR
+ color_seg = color_seg[..., ::-1]
+
+ img = img * (1 - opacity) + color_seg * opacity
+ img = img.astype(np.uint8)
+ # if out_file specified, do not show image in window
+ if out_file is not None:
+ show = False
+
+ if show:
+ mmcv.imshow(img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(img, out_file)
+
+ if not (show or out_file):
+ warnings.warn('show==False and out_file is not specified, only '
+ 'result image will be returned')
+ return img
+
+
+class ONNXRuntimeSegmentorKN(BaseSegmentor):
+
+ def __init__(
+ self,
+ onnx_file: str,
+ cfg: Any,
+ device_id: Union[int, None] = 0):
+ super(ONNXRuntimeSegmentorKN, self).__init__()
+ import onnxruntime as ort
+
+ # get the custom op path
+ ort_custom_op_path = ''
+ try:
+ from mmcv.ops import get_onnxruntime_op_path
+ ort_custom_op_path = get_onnxruntime_op_path()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn(
+ 'If input model has custom op from mmcv, you may '
+ 'have to build mmcv with ONNXRuntime from source.')
+ session_options = ort.SessionOptions()
+ # register custom op for onnxruntime
+ if osp.exists(ort_custom_op_path):
+ session_options.register_custom_ops_library(ort_custom_op_path)
+ providers = ['CPUExecutionProvider']
+ provider_options = [{}]
+ is_cuda_available = (
+ ort.get_device() == 'GPU' and torch.cuda.is_available()
+ )
+ if is_cuda_available:
+ providers.insert(0, 'CUDAExecutionProvider')
+ device_id = device_id or 0
+ provider_options.insert(0, {'device_id': device_id})
+ sess = ort.InferenceSession(
+ onnx_file, session_options, providers, provider_options
+ )
+ self.sess = sess
+ sess_inputs = sess.get_inputs()
+ assert len(sess_inputs) == 1, "Only onnx with 1 input is supported"
+ self.input_name = sess_inputs[0].name
+ sess_outputs = sess.get_outputs()
+ self.num_classes = sess_outputs[0].shape[1]
+ assert len(sess_outputs) == 1, "Only onnx with 1 output is supported"
+ self.output_name_list = [sess_outputs[0].name]
+ self.cfg = cfg # TODO: necessary?
+ self.test_cfg = cfg.model.test_cfg
+ self.test_mode = self.test_cfg.mode # NOTE: either 'whole' or 'slide'
+ self.is_cuda_available = is_cuda_available
+ self.count_mat = None
+ try:
+ if 'test' in cfg.data:
+ dataset_name = cfg.data.test['type']
+ else:
+ dataset_name = cfg.data.train['type']
+ dataset_name = dataset_name.lower()[:-7]
+ self.CLASSES = get_classes(dataset_name)
+ self.PALETTE = get_palette(dataset_name)
+ except (AttributeError, KeyError):
+ warnings.warn(
+ "Failed to fetch dataset name from config; no CLASSES "
+ "and PALETTE for this ONNX model"
+ )
+ except ValueError:
+ warnings.warn(
+ "Failed to fetch CLASSES and PALETTE from dataset "
+ f"{dataset_name}; no CLASSES and PALETTE for this "
+ "ONNX MODEL."
+ )
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def encode_decode(self, img, img_metas):
+ raise NotImplementedError('This method is not implemented.')
+
+ def forward_train(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def forward_test(self, imgs, img_metas, **kwargs):
+ return super().forward_test(imgs, img_metas[0].data, **kwargs)
+
+ def simple_slide_inference(
+ self,
+ img: np.ndarray,
+ img_meta: Union[Iterable, None] = None):
+ h_stride, w_stride = self.test_cfg.stride
+ h_crop, w_crop = self.test_cfg.crop_size
+ _, _, h_img, w_img = img.shape
+ num_classes = self.num_classes
+ h_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1
+ w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1
+ preds = np.zeros((1, num_classes, h_img, w_img), dtype=np.float32)
+ # NOTE: count_mat should be invariant since
+ # input shape of kneron's onnx is fixed
+ if self.count_mat is None:
+ count_mat = np.zeros((1, 1, h_img, w_img), dtype=np.float32)
+ for h_idx in range(h_grids):
+ for w_idx in range(w_grids):
+ y1 = h_idx * h_stride
+ x1 = w_idx * w_stride
+ y2 = min(y1 + h_crop, h_img)
+ x2 = min(x1 + w_crop, w_img)
+ y1 = max(y2 - h_crop, 0)
+ x1 = max(x2 - w_crop, 0)
+ crop_img = img[:, :, y1:y2, x1:x2]
+ crop_seg_logit = self.sess.run(
+ self.output_name_list,
+ {self.input_name: crop_img}
+ )[0]
+ preds += np.pad(
+ crop_seg_logit,
+ ([0, 0],
+ [0, 0],
+ [int(y1), int(preds.shape[2] - y2)],
+ [int(x1), int(preds.shape[3] - x2)]),
+ )
+ if self.count_mat is None:
+ count_mat[:, :, y1:y2, x1:x2] += 1
+ if self.count_mat is None:
+ assert (count_mat == 0).sum() == 0
+ self.count_mat = count_mat
+ preds /= self.count_mat
+ return preds
+
+ @property
+ def module(self):
+ return self
+
+ @torch.no_grad()
+ def simple_test(
+ self,
+ img: torch.Tensor,
+ img_meta: Union[Iterable, None] = None,
+ **kwargs) -> list:
+ img = img.cpu().numpy()
+ # NOTE: not using run_with_iobinding since some ort versions
+ # generate wrong results when inferencing with CUDA
+ if self.test_mode == 'slide':
+ seg_pred = self.simple_slide_inference(img, img_meta)
+ else:
+ seg_pred = self.sess.run(
+ self.output_name_list, {self.input_name: img}
+ )[0]
+ if img_meta is not None:
+ ori_shape = img_meta[0]['ori_shape']
+ if not (ori_shape[0] == seg_pred.shape[-2]
+ and ori_shape[1] == seg_pred.shape[-1]):
+ seg_pred = torch.from_numpy(seg_pred).float()
+ seg_pred = resize(
+ seg_pred, size=tuple(ori_shape[:2]), mode='bilinear')
+ seg_pred = seg_pred.numpy()
+ elif img.shape[2:] != seg_pred.shape[2:]:
+ seg_pred = torch.from_numpy(seg_pred).float()
+ seg_pred = resize(
+ seg_pred, size=(img.shape[3], img.shape[2]), mode='bilinear')
+ seg_pred = seg_pred.numpy()
+ seg_pred = seg_pred.argmax(1)
+ return list(seg_pred)
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
diff --git a/mmseg/models/segmentors/cascade_encoder_decoder.py b/mmseg/models/segmentors/cascade_encoder_decoder.py
new file mode 100644
index 0000000..7f9f900
--- /dev/null
+++ b/mmseg/models/segmentors/cascade_encoder_decoder.py
@@ -0,0 +1,84 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from torch import nn
+
+from mmseg.core import add_prefix
+from mmseg.ops import resize
+from .. import builder
+from ..builder import SEGMENTORS
+from .encoder_decoder import EncoderDecoder
+
+
+@SEGMENTORS.register_module()
+class CascadeEncoderDecoder(EncoderDecoder):
+ """Cascade Encoder Decoder segmentors.
+
+ CascadeEncoderDecoder almost the same as EncoderDecoder, while decoders of
+ CascadeEncoderDecoder are cascaded. The output of previous decoder_head
+ will be the input of next decoder_head.
+ """
+
+ def __init__(self,
+ num_stages,
+ backbone,
+ decode_head,
+ neck=None,
+ auxiliary_head=None,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ init_cfg=None):
+ self.num_stages = num_stages
+ super(CascadeEncoderDecoder, self).__init__(
+ backbone=backbone,
+ decode_head=decode_head,
+ neck=neck,
+ auxiliary_head=auxiliary_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ pretrained=pretrained,
+ init_cfg=init_cfg)
+
+ def _init_decode_head(self, decode_head):
+ """Initialize ``decode_head``"""
+ assert isinstance(decode_head, list)
+ assert len(decode_head) == self.num_stages
+ self.decode_head = nn.ModuleList()
+ for i in range(self.num_stages):
+ self.decode_head.append(builder.build_head(decode_head[i]))
+ self.align_corners = self.decode_head[-1].align_corners
+ self.num_classes = self.decode_head[-1].num_classes
+
+ def encode_decode(self, img, img_metas):
+ """Encode images with backbone and decode into a semantic segmentation
+ map of the same size as input."""
+ x = self.extract_feat(img)
+ out = self.decode_head[0].forward_test(x, img_metas, self.test_cfg)
+ for i in range(1, self.num_stages):
+ out = self.decode_head[i].forward_test(x, out, img_metas,
+ self.test_cfg)
+ out = resize(
+ input=out,
+ size=img.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ return out
+
+ def _decode_head_forward_train(self, x, img_metas, gt_semantic_seg):
+ """Run forward function and calculate loss for decode head in
+ training."""
+ losses = dict()
+
+ loss_decode = self.decode_head[0].forward_train(
+ x, img_metas, gt_semantic_seg, self.train_cfg)
+
+ losses.update(add_prefix(loss_decode, 'decode_0'))
+
+ for i in range(1, self.num_stages):
+ # forward test again, maybe unnecessary for most methods.
+ prev_outputs = self.decode_head[i - 1].forward_test(
+ x, img_metas, self.test_cfg)
+ loss_decode = self.decode_head[i].forward_train(
+ x, prev_outputs, img_metas, gt_semantic_seg, self.train_cfg)
+ losses.update(add_prefix(loss_decode, f'decode_{i}'))
+
+ return losses
diff --git a/mmseg/models/segmentors/encoder_decoder.py b/mmseg/models/segmentors/encoder_decoder.py
new file mode 100644
index 0000000..a15c883
--- /dev/null
+++ b/mmseg/models/segmentors/encoder_decoder.py
@@ -0,0 +1,286 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmseg.core import add_prefix
+from mmseg.ops import resize
+from .. import builder
+from ..builder import SEGMENTORS
+from .base import BaseSegmentor
+
+
+@SEGMENTORS.register_module()
+class EncoderDecoder(BaseSegmentor):
+ """Encoder Decoder segmentors.
+
+ EncoderDecoder typically consists of backbone, decode_head, auxiliary_head.
+ Note that auxiliary_head is only used for deep supervision during training,
+ which could be dumped during inference.
+ """
+
+ def __init__(self,
+ backbone,
+ decode_head,
+ neck=None,
+ auxiliary_head=None,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ init_cfg=None):
+ super(EncoderDecoder, self).__init__(init_cfg)
+ if pretrained is not None:
+ assert backbone.get('pretrained') is None, \
+ 'both backbone and segmentor set pretrained weight'
+ backbone.pretrained = pretrained
+ self.backbone = builder.build_backbone(backbone)
+ if neck is not None:
+ self.neck = builder.build_neck(neck)
+ self._init_decode_head(decode_head)
+ self._init_auxiliary_head(auxiliary_head)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ assert self.with_decode_head
+
+ def _init_decode_head(self, decode_head):
+ """Initialize ``decode_head``"""
+ self.decode_head = builder.build_head(decode_head)
+ self.align_corners = self.decode_head.align_corners
+ self.num_classes = self.decode_head.num_classes
+
+ def _init_auxiliary_head(self, auxiliary_head):
+ """Initialize ``auxiliary_head``"""
+ if auxiliary_head is not None:
+ if isinstance(auxiliary_head, list):
+ self.auxiliary_head = nn.ModuleList()
+ for head_cfg in auxiliary_head:
+ self.auxiliary_head.append(builder.build_head(head_cfg))
+ else:
+ self.auxiliary_head = builder.build_head(auxiliary_head)
+
+ def extract_feat(self, img):
+ """Extract features from images."""
+ x = self.backbone(img)
+ if self.with_neck:
+ x = self.neck(x)
+ return x
+
+ def encode_decode(self, img, img_metas):
+ """Encode images with backbone and decode into a semantic segmentation
+ map of the same size as input."""
+ x = self.extract_feat(img)
+ out = self._decode_head_forward_test(x, img_metas)
+ out = resize(
+ input=out,
+ size=img.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ return out
+
+ def _decode_head_forward_train(self, x, img_metas, gt_semantic_seg):
+ """Run forward function and calculate loss for decode head in
+ training."""
+ losses = dict()
+ loss_decode = self.decode_head.forward_train(x, img_metas,
+ gt_semantic_seg,
+ self.train_cfg)
+
+ losses.update(add_prefix(loss_decode, 'decode'))
+ return losses
+
+ def _decode_head_forward_test(self, x, img_metas):
+ """Run forward function and calculate loss for decode head in
+ inference."""
+ seg_logits = self.decode_head.forward_test(x, img_metas, self.test_cfg)
+ return seg_logits
+
+ def _auxiliary_head_forward_train(self, x, img_metas, gt_semantic_seg):
+ """Run forward function and calculate loss for auxiliary head in
+ training."""
+ losses = dict()
+ if isinstance(self.auxiliary_head, nn.ModuleList):
+ for idx, aux_head in enumerate(self.auxiliary_head):
+ loss_aux = aux_head.forward_train(x, img_metas,
+ gt_semantic_seg,
+ self.train_cfg)
+ losses.update(add_prefix(loss_aux, f'aux_{idx}'))
+ else:
+ loss_aux = self.auxiliary_head.forward_train(
+ x, img_metas, gt_semantic_seg, self.train_cfg)
+ losses.update(add_prefix(loss_aux, 'aux'))
+
+ return losses
+
+ def forward_dummy(self, img):
+ """Dummy forward function."""
+ seg_logit = self.extract_feat(img)
+ seg_logit = self._decode_head_forward_test(seg_logit, None)
+
+ return seg_logit
+
+ def forward_train(self, img, img_metas, gt_semantic_seg):
+ """Forward function for training.
+
+ Args:
+ img (Tensor): Input images.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ gt_semantic_seg (Tensor): Semantic segmentation masks
+ used if the architecture supports semantic segmentation task.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+
+ x = self.extract_feat(img)
+
+ losses = dict()
+
+ loss_decode = self._decode_head_forward_train(x, img_metas,
+ gt_semantic_seg)
+ losses.update(loss_decode)
+
+ if self.with_auxiliary_head:
+ loss_aux = self._auxiliary_head_forward_train(
+ x, img_metas, gt_semantic_seg)
+ losses.update(loss_aux)
+
+ return losses
+
+ # TODO refactor
+ def slide_inference(self, img, img_meta, rescale):
+ """Inference by sliding-window with overlap.
+
+ If h_crop > h_img or w_crop > w_img, the small patch will be used to
+ decode without padding.
+ """
+
+ h_stride, w_stride = self.test_cfg.stride
+ h_crop, w_crop = self.test_cfg.crop_size
+ batch_size, _, h_img, w_img = img.size()
+ num_classes = self.num_classes
+ h_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1
+ w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1
+ preds = img.new_zeros((batch_size, num_classes, h_img, w_img))
+ count_mat = img.new_zeros((batch_size, 1, h_img, w_img))
+ for h_idx in range(h_grids):
+ for w_idx in range(w_grids):
+ y1 = h_idx * h_stride
+ x1 = w_idx * w_stride
+ y2 = min(y1 + h_crop, h_img)
+ x2 = min(x1 + w_crop, w_img)
+ y1 = max(y2 - h_crop, 0)
+ x1 = max(x2 - w_crop, 0)
+ crop_img = img[:, :, y1:y2, x1:x2]
+ crop_seg_logit = self.encode_decode(crop_img, img_meta)
+ preds += F.pad(crop_seg_logit,
+ (int(x1), int(preds.shape[3] - x2), int(y1),
+ int(preds.shape[2] - y2)))
+
+ count_mat[:, :, y1:y2, x1:x2] += 1
+ assert (count_mat == 0).sum() == 0
+ if torch.onnx.is_in_onnx_export():
+ # cast count_mat to constant while exporting to ONNX
+ count_mat = torch.from_numpy(
+ count_mat.cpu().detach().numpy()).to(device=img.device)
+ preds = preds / count_mat
+ if rescale:
+ preds = resize(
+ preds,
+ size=img_meta[0]['ori_shape'][:2],
+ mode='bilinear',
+ align_corners=self.align_corners,
+ warning=False)
+ return preds
+
+ def whole_inference(self, img, img_meta, rescale):
+ """Inference with full image."""
+
+ seg_logit = self.encode_decode(img, img_meta)
+ if rescale:
+ # support dynamic shape for onnx
+ if torch.onnx.is_in_onnx_export():
+ size = img.shape[2:]
+ else:
+ size = img_meta[0]['ori_shape'][:2]
+ seg_logit = resize(
+ seg_logit,
+ size=size,
+ mode='bilinear',
+ align_corners=self.align_corners,
+ warning=False)
+
+ return seg_logit
+
+ def inference(self, img, img_meta, rescale):
+ """Inference with slide/whole style.
+
+ Args:
+ img (Tensor): The input image of shape (N, 3, H, W).
+ img_meta (dict): Image info dict where each dict has: 'img_shape',
+ 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ rescale (bool): Whether rescale back to original shape.
+
+ Returns:
+ Tensor: The output segmentation map.
+ """
+
+ assert self.test_cfg.mode in ['slide', 'whole']
+ ori_shape = img_meta[0]['ori_shape']
+ assert all(_['ori_shape'] == ori_shape for _ in img_meta)
+ if self.test_cfg.mode == 'slide':
+ seg_logit = self.slide_inference(img, img_meta, rescale)
+ else:
+ seg_logit = self.whole_inference(img, img_meta, rescale)
+ output = F.softmax(seg_logit, dim=1)
+ flip = img_meta[0]['flip']
+ if flip:
+ flip_direction = img_meta[0]['flip_direction']
+ assert flip_direction in ['horizontal', 'vertical']
+ if flip_direction == 'horizontal':
+ output = output.flip(dims=(3, ))
+ elif flip_direction == 'vertical':
+ output = output.flip(dims=(2, ))
+
+ return output
+
+ def simple_test(self, img, img_meta, rescale=True):
+ """Simple test with single image."""
+ seg_logit = self.inference(img, img_meta, rescale)
+ seg_pred = seg_logit.argmax(dim=1)
+ if torch.onnx.is_in_onnx_export():
+ # our inference backend only support 4D output
+ seg_pred = seg_pred.unsqueeze(0)
+ return seg_pred
+ seg_pred = seg_pred.cpu().numpy()
+ # unravel batch dim
+ seg_pred = list(seg_pred)
+ return seg_pred
+
+ def aug_test(self, imgs, img_metas, rescale=True):
+ """Test with augmentations.
+
+ Only rescale=True is supported.
+ """
+ # aug_test rescale all imgs back to ori_shape for now
+ assert rescale
+ # to save memory, we get augmented seg logit inplace
+ seg_logit = self.inference(imgs[0], img_metas[0], rescale)
+ for i in range(1, len(imgs)):
+ cur_seg_logit = self.inference(imgs[i], img_metas[i], rescale)
+ seg_logit += cur_seg_logit
+ seg_logit /= len(imgs)
+ seg_pred = seg_logit.argmax(dim=1)
+ seg_pred = seg_pred.cpu().numpy()
+ # unravel batch dim
+ seg_pred = list(seg_pred)
+ return seg_pred
diff --git a/mmseg/models/utils/__init__.py b/mmseg/models/utils/__init__.py
new file mode 100644
index 0000000..2417c51
--- /dev/null
+++ b/mmseg/models/utils/__init__.py
@@ -0,0 +1,14 @@
+from .embed import PatchEmbed
+from .inverted_residual import InvertedResidual, InvertedResidualV3
+from .make_divisible import make_divisible
+from .res_layer import ResLayer
+from .se_layer import SELayer
+from .self_attention_block import SelfAttentionBlock
+from .shape_convert import nchw_to_nlc, nlc_to_nchw
+from .up_conv_block import UpConvBlock
+
+__all__ = [
+ 'ResLayer', 'SelfAttentionBlock', 'make_divisible', 'InvertedResidual',
+ 'UpConvBlock', 'InvertedResidualV3', 'SELayer', 'PatchEmbed',
+ 'nchw_to_nlc', 'nlc_to_nchw'
+]
diff --git a/mmseg/models/utils/embed.py b/mmseg/models/utils/embed.py
new file mode 100644
index 0000000..1515675
--- /dev/null
+++ b/mmseg/models/utils/embed.py
@@ -0,0 +1,330 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Sequence
+
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmcv.runner.base_module import BaseModule
+from mmcv.utils import to_2tuple
+
+
+class AdaptivePadding(nn.Module):
+ """Applies padding to input (if needed) so that input can get fully covered
+ by filter you specified. It support two modes "same" and "corner". The
+ "same" mode is same with "SAME" padding mode in TensorFlow, pad zero around
+ input. The "corner" mode would pad zero to bottom right.
+
+ Args:
+ kernel_size (int | tuple): Size of the kernel:
+ stride (int | tuple): Stride of the filter. Default: 1:
+ dilation (int | tuple): Spacing between kernel elements.
+ Default: 1.
+ padding (str): Support "same" and "corner", "corner" mode
+ would pad zero to bottom right, and "same" mode would
+ pad zero around input. Default: "corner".
+ Example:
+ >>> kernel_size = 16
+ >>> stride = 16
+ >>> dilation = 1
+ >>> input = torch.rand(1, 1, 15, 17)
+ >>> adap_pad = AdaptivePadding(
+ >>> kernel_size=kernel_size,
+ >>> stride=stride,
+ >>> dilation=dilation,
+ >>> padding="corner")
+ >>> out = adap_pad(input)
+ >>> assert (out.shape[2], out.shape[3]) == (16, 32)
+ >>> input = torch.rand(1, 1, 16, 17)
+ >>> out = adap_pad(input)
+ >>> assert (out.shape[2], out.shape[3]) == (16, 32)
+ """
+
+ def __init__(self, kernel_size=1, stride=1, dilation=1, padding='corner'):
+
+ super(AdaptivePadding, self).__init__()
+
+ assert padding in ('same', 'corner')
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ self.padding = padding
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.dilation = dilation
+
+ def get_pad_shape(self, input_shape):
+ input_h, input_w = input_shape
+ kernel_h, kernel_w = self.kernel_size
+ stride_h, stride_w = self.stride
+ output_h = math.ceil(input_h / stride_h)
+ output_w = math.ceil(input_w / stride_w)
+ pad_h = max((output_h - 1) * stride_h +
+ (kernel_h - 1) * self.dilation[0] + 1 - input_h, 0)
+ pad_w = max((output_w - 1) * stride_w +
+ (kernel_w - 1) * self.dilation[1] + 1 - input_w, 0)
+ return pad_h, pad_w
+
+ def forward(self, x):
+ pad_h, pad_w = self.get_pad_shape(x.size()[-2:])
+ if pad_h > 0 or pad_w > 0:
+ if self.padding == 'corner':
+ x = F.pad(x, [0, pad_w, 0, pad_h])
+ elif self.padding == 'same':
+ x = F.pad(x, [
+ pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
+ pad_h - pad_h // 2
+ ])
+ return x
+
+
+class PatchEmbed(BaseModule):
+ """Image to Patch Embedding.
+
+ We use a conv layer to implement PatchEmbed.
+
+ Args:
+ in_channels (int): The num of input channels. Default: 3
+ embed_dims (int): The dimensions of embedding. Default: 768
+ conv_type (str): The config dict for embedding
+ conv layer type selection. Default: "Conv2d".
+ kernel_size (int): The kernel_size of embedding conv. Default: 16.
+ stride (int, optional): The slide stride of embedding conv.
+ Default: None (Would be set as `kernel_size`).
+ padding (int | tuple | string ): The padding length of
+ embedding conv. When it is a string, it means the mode
+ of adaptive padding, support "same" and "corner" now.
+ Default: "corner".
+ dilation (int): The dilation rate of embedding conv. Default: 1.
+ bias (bool): Bias of embed conv. Default: True.
+ norm_cfg (dict, optional): Config dict for normalization layer.
+ Default: None.
+ input_size (int | tuple | None): The size of input, which will be
+ used to calculate the out size. Only work when `dynamic_size`
+ is False. Default: None.
+ init_cfg (`mmcv.ConfigDict`, optional): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=768,
+ conv_type='Conv2d',
+ kernel_size=16,
+ stride=None,
+ padding='corner',
+ dilation=1,
+ bias=True,
+ norm_cfg=None,
+ input_size=None,
+ init_cfg=None):
+ super(PatchEmbed, self).__init__(init_cfg=init_cfg)
+
+ self.embed_dims = embed_dims
+ if stride is None:
+ stride = kernel_size
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ if isinstance(padding, str):
+ self.adap_padding = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ # disable the padding of conv
+ padding = 0
+ else:
+ self.adap_padding = None
+ padding = to_2tuple(padding)
+
+ self.projection = build_conv_layer(
+ dict(type=conv_type),
+ in_channels=in_channels,
+ out_channels=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ if norm_cfg is not None:
+ self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
+ else:
+ self.norm = None
+
+ if input_size:
+ input_size = to_2tuple(input_size)
+ # `init_out_size` would be used outside to
+ # calculate the num_patches
+ # when `use_abs_pos_embed` outside
+ self.init_input_size = input_size
+ if self.adap_padding:
+ pad_h, pad_w = self.adap_padding.get_pad_shape(input_size)
+ input_h, input_w = input_size
+ input_h = input_h + pad_h
+ input_w = input_w + pad_w
+ input_size = (input_h, input_w)
+
+ # https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
+ h_out = (input_size[0] + 2 * padding[0] - dilation[0] *
+ (kernel_size[0] - 1) - 1) // stride[0] + 1
+ w_out = (input_size[1] + 2 * padding[1] - dilation[1] *
+ (kernel_size[1] - 1) - 1) // stride[1] + 1
+ self.init_out_size = (h_out, w_out)
+ else:
+ self.init_input_size = None
+ self.init_out_size = None
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Has shape (B, C, H, W). In most case, C is 3.
+
+ Returns:
+ tuple: Contains merged results and its spatial shape.
+
+ - x (Tensor): Has shape (B, out_h * out_w, embed_dims)
+ - out_size (tuple[int]): Spatial shape of x, arrange as
+ (out_h, out_w).
+ """
+
+ if self.adap_padding:
+ x = self.adap_padding(x)
+
+ x = self.projection(x)
+ out_size = (x.shape[2], x.shape[3])
+ x = x.flatten(2).transpose(1, 2)
+ if self.norm is not None:
+ x = self.norm(x)
+ return x, out_size
+
+
+class PatchMerging(BaseModule):
+ """Merge patch feature map.
+
+ This layer groups feature map by kernel_size, and applies norm and linear
+ layers to the grouped feature map. Our implementation uses `nn.Unfold` to
+ merge patch, which is about 25% faster than original implementation.
+ Instead, we need to modify pretrained models for compatibility.
+
+ Args:
+ in_channels (int): The num of input channels.
+ out_channels (int): The num of output channels.
+ kernel_size (int | tuple, optional): the kernel size in the unfold
+ layer. Defaults to 2.
+ stride (int | tuple, optional): the stride of the sliding blocks in the
+ unfold layer. Default: None. (Would be set as `kernel_size`)
+ padding (int | tuple | string ): The padding length of
+ embedding conv. When it is a string, it means the mode
+ of adaptive padding, support "same" and "corner" now.
+ Default: "corner".
+ dilation (int | tuple, optional): dilation parameter in the unfold
+ layer. Default: 1.
+ bias (bool, optional): Whether to add bias in linear layer or not.
+ Defaults: False.
+ norm_cfg (dict, optional): Config dict for normalization layer.
+ Default: dict(type='LN').
+ init_cfg (dict, optional): The extra config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=2,
+ stride=None,
+ padding='corner',
+ dilation=1,
+ bias=False,
+ norm_cfg=dict(type='LN'),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ if stride:
+ stride = stride
+ else:
+ stride = kernel_size
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ if isinstance(padding, str):
+ self.adap_padding = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ # disable the padding of unfold
+ padding = 0
+ else:
+ self.adap_padding = None
+
+ padding = to_2tuple(padding)
+ self.sampler = nn.Unfold(
+ kernel_size=kernel_size,
+ dilation=dilation,
+ padding=padding,
+ stride=stride)
+
+ sample_dim = kernel_size[0] * kernel_size[1] * in_channels
+
+ if norm_cfg is not None:
+ self.norm = build_norm_layer(norm_cfg, sample_dim)[1]
+ else:
+ self.norm = None
+
+ self.reduction = nn.Linear(sample_dim, out_channels, bias=bias)
+
+ def forward(self, x, input_size):
+ """
+ Args:
+ x (Tensor): Has shape (B, H*W, C_in).
+ input_size (tuple[int]): The spatial shape of x, arrange as (H, W).
+ Default: None.
+
+ Returns:
+ tuple: Contains merged results and its spatial shape.
+
+ - x (Tensor): Has shape (B, Merged_H * Merged_W, C_out)
+ - out_size (tuple[int]): Spatial shape of x, arrange as
+ (Merged_H, Merged_W).
+ """
+ B, L, C = x.shape
+ assert isinstance(input_size, Sequence), f'Expect ' \
+ f'input_size is ' \
+ f'`Sequence` ' \
+ f'but get {input_size}'
+
+ H, W = input_size
+ assert L == H * W, 'input feature has wrong size'
+
+ x = x.view(B, H, W, C).permute([0, 3, 1, 2]) # B, C, H, W
+ # Use nn.Unfold to merge patch. About 25% faster than original method,
+ # but need to modify pretrained model for compatibility
+
+ if self.adap_padding:
+ x = self.adap_padding(x)
+ H, W = x.shape[-2:]
+
+ x = self.sampler(x)
+ # if kernel_size=2 and stride=2, x should has shape (B, 4*C, H/2*W/2)
+
+ out_h = (H + 2 * self.sampler.padding[0] - self.sampler.dilation[0] *
+ (self.sampler.kernel_size[0] - 1) -
+ 1) // self.sampler.stride[0] + 1
+ out_w = (W + 2 * self.sampler.padding[1] - self.sampler.dilation[1] *
+ (self.sampler.kernel_size[1] - 1) -
+ 1) // self.sampler.stride[1] + 1
+
+ output_size = (out_h, out_w)
+ x = x.transpose(1, 2) # B, H/2*W/2, 4*C
+ x = self.norm(x) if self.norm else x
+ x = self.reduction(x)
+ return x, output_size
diff --git a/mmseg/models/utils/inverted_residual.py b/mmseg/models/utils/inverted_residual.py
new file mode 100644
index 0000000..c9cda76
--- /dev/null
+++ b/mmseg/models/utils/inverted_residual.py
@@ -0,0 +1,213 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import ConvModule
+from torch import nn
+from torch.utils import checkpoint as cp
+
+from .se_layer import SELayer
+
+
+class InvertedResidual(nn.Module):
+ """InvertedResidual block for MobileNetV2.
+
+ Args:
+ in_channels (int): The input channels of the InvertedResidual block.
+ out_channels (int): The output channels of the InvertedResidual block.
+ stride (int): Stride of the middle (first) 3x3 convolution.
+ expand_ratio (int): Adjusts number of channels of the hidden layer
+ in InvertedResidual by this amount.
+ dilation (int): Dilation rate of depthwise conv. Default: 1
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU6').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+
+ Returns:
+ Tensor: The output tensor.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride,
+ expand_ratio,
+ dilation=1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU6'),
+ with_cp=False,
+ **kwargs):
+ super(InvertedResidual, self).__init__()
+ self.stride = stride
+ assert stride in [1, 2], f'stride must in [1, 2]. ' \
+ f'But received {stride}.'
+ self.with_cp = with_cp
+ self.use_res_connect = self.stride == 1 and in_channels == out_channels
+ hidden_dim = int(round(in_channels * expand_ratio))
+
+ layers = []
+ if expand_ratio != 1:
+ layers.append(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=hidden_dim,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ **kwargs))
+ layers.extend([
+ ConvModule(
+ in_channels=hidden_dim,
+ out_channels=hidden_dim,
+ kernel_size=3,
+ stride=stride,
+ padding=dilation,
+ dilation=dilation,
+ groups=hidden_dim,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ **kwargs),
+ ConvModule(
+ in_channels=hidden_dim,
+ out_channels=out_channels,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None,
+ **kwargs)
+ ])
+ self.conv = nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ if self.use_res_connect:
+ return x + self.conv(x)
+ else:
+ return self.conv(x)
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class InvertedResidualV3(nn.Module):
+ """Inverted Residual Block for MobileNetV3.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ mid_channels (int): The input channels of the depthwise convolution.
+ kernel_size (int): The kernel size of the depthwise convolution.
+ Default: 3.
+ stride (int): The stride of the depthwise convolution. Default: 1.
+ se_cfg (dict): Config dict for se layer. Default: None, which means no
+ se layer.
+ with_expand_conv (bool): Use expand conv or not. If set False,
+ mid_channels must be the same with in_channels. Default: True.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+
+ Returns:
+ Tensor: The output tensor.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ mid_channels,
+ kernel_size=3,
+ stride=1,
+ se_cfg=None,
+ with_expand_conv=True,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ with_cp=False):
+ super(InvertedResidualV3, self).__init__()
+ self.with_res_shortcut = (stride == 1 and in_channels == out_channels)
+ assert stride in [1, 2]
+ self.with_cp = with_cp
+ self.with_se = se_cfg is not None
+ self.with_expand_conv = with_expand_conv
+
+ if self.with_se:
+ assert isinstance(se_cfg, dict)
+ if not self.with_expand_conv:
+ assert mid_channels == in_channels
+
+ if self.with_expand_conv:
+ self.expand_conv = ConvModule(
+ in_channels=in_channels,
+ out_channels=mid_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.depthwise_conv = ConvModule(
+ in_channels=mid_channels,
+ out_channels=mid_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=kernel_size // 2,
+ groups=mid_channels,
+ conv_cfg=dict(
+ type='Conv2dAdaptivePadding') if stride == 2 else conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ if self.with_se:
+ self.se = SELayer(**se_cfg)
+
+ self.linear_conv = ConvModule(
+ in_channels=mid_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ out = x
+
+ if self.with_expand_conv:
+ out = self.expand_conv(out)
+
+ out = self.depthwise_conv(out)
+
+ if self.with_se:
+ out = self.se(out)
+
+ out = self.linear_conv(out)
+
+ if self.with_res_shortcut:
+ return x + out
+ else:
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
diff --git a/mmseg/models/utils/make_divisible.py b/mmseg/models/utils/make_divisible.py
new file mode 100644
index 0000000..ed42c2e
--- /dev/null
+++ b/mmseg/models/utils/make_divisible.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def make_divisible(value, divisor, min_value=None, min_ratio=0.9):
+ """Make divisible function.
+
+ This function rounds the channel number to the nearest value that can be
+ divisible by the divisor. It is taken from the original tf repo. It ensures
+ that all layers have a channel number that is divisible by divisor. It can
+ be seen here: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py # noqa
+
+ Args:
+ value (int): The original channel number.
+ divisor (int): The divisor to fully divide the channel number.
+ min_value (int): The minimum value of the output channel.
+ Default: None, means that the minimum value equal to the divisor.
+ min_ratio (float): The minimum ratio of the rounded channel number to
+ the original channel number. Default: 0.9.
+
+ Returns:
+ int: The modified output channel number.
+ """
+
+ if min_value is None:
+ min_value = divisor
+ new_value = max(min_value, int(value + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than (1-min_ratio).
+ if new_value < min_ratio * value:
+ new_value += divisor
+ return new_value
diff --git a/mmseg/models/utils/res_layer.py b/mmseg/models/utils/res_layer.py
new file mode 100644
index 0000000..190a0c5
--- /dev/null
+++ b/mmseg/models/utils/res_layer.py
@@ -0,0 +1,96 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmcv.runner import Sequential
+from torch import nn as nn
+
+
+class ResLayer(Sequential):
+ """ResLayer to build ResNet style backbone.
+
+ Args:
+ block (nn.Module): block used to build ResLayer.
+ inplanes (int): inplanes of block.
+ planes (int): planes of block.
+ num_blocks (int): number of blocks.
+ stride (int): stride of the first block. Default: 1
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ multi_grid (int | None): Multi grid dilation rates of last
+ stage. Default: None
+ contract_dilation (bool): Whether contract first dilation of each layer
+ Default: False
+ """
+
+ def __init__(self,
+ block,
+ inplanes,
+ planes,
+ num_blocks,
+ stride=1,
+ dilation=1,
+ avg_down=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ multi_grid=None,
+ contract_dilation=False,
+ **kwargs):
+ self.block = block
+
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = []
+ conv_stride = stride
+ if avg_down:
+ conv_stride = 1
+ downsample.append(
+ nn.AvgPool2d(
+ kernel_size=stride,
+ stride=stride,
+ ceil_mode=True,
+ count_include_pad=False))
+ downsample.extend([
+ build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=conv_stride,
+ bias=False),
+ build_norm_layer(norm_cfg, planes * block.expansion)[1]
+ ])
+ downsample = nn.Sequential(*downsample)
+
+ layers = []
+ if multi_grid is None:
+ if dilation > 1 and contract_dilation:
+ first_dilation = dilation // 2
+ else:
+ first_dilation = dilation
+ else:
+ first_dilation = multi_grid[0]
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=stride,
+ dilation=first_dilation,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ inplanes = planes * block.expansion
+ for i in range(1, num_blocks):
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=1,
+ dilation=dilation if multi_grid is None else multi_grid[i],
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ super(ResLayer, self).__init__(*layers)
diff --git a/mmseg/models/utils/se_layer.py b/mmseg/models/utils/se_layer.py
new file mode 100644
index 0000000..16f52aa
--- /dev/null
+++ b/mmseg/models/utils/se_layer.py
@@ -0,0 +1,58 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from .make_divisible import make_divisible
+
+
+class SELayer(nn.Module):
+ """Squeeze-and-Excitation Module.
+
+ Args:
+ channels (int): The input (and output) channels of the SE layer.
+ ratio (int): Squeeze ratio in SELayer, the intermediate channel will be
+ ``int(channels/ratio)``. Default: 16.
+ conv_cfg (None or dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ act_cfg (dict or Sequence[dict]): Config dict for activation layer.
+ If act_cfg is a dict, two activation layers will be configured
+ by this dict. If act_cfg is a sequence of dicts, the first
+ activation layer will be configured by the first dict and the
+ second activation layer will be configured by the second dict.
+ Default: (dict(type='ReLU'), dict(type='HSigmoid', bias=3.0,
+ divisor=6.0)).
+ """
+
+ def __init__(self,
+ channels,
+ ratio=16,
+ conv_cfg=None,
+ act_cfg=(dict(type='ReLU'),
+ dict(type='HSigmoid', bias=3.0, divisor=6.0))):
+ super(SELayer, self).__init__()
+ if isinstance(act_cfg, dict):
+ act_cfg = (act_cfg, act_cfg)
+ assert len(act_cfg) == 2
+ assert mmcv.is_tuple_of(act_cfg, dict)
+ self.global_avgpool = nn.AdaptiveAvgPool2d(1)
+ self.conv1 = ConvModule(
+ in_channels=channels,
+ out_channels=make_divisible(channels // ratio, 8),
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[0])
+ self.conv2 = ConvModule(
+ in_channels=make_divisible(channels // ratio, 8),
+ out_channels=channels,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[1])
+
+ def forward(self, x):
+ out = self.global_avgpool(x)
+ out = self.conv1(out)
+ out = self.conv2(out)
+ return x * out
diff --git a/mmseg/models/utils/self_attention_block.py b/mmseg/models/utils/self_attention_block.py
new file mode 100644
index 0000000..c945fa7
--- /dev/null
+++ b/mmseg/models/utils/self_attention_block.py
@@ -0,0 +1,160 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import ConvModule, constant_init
+from torch import nn as nn
+from torch.nn import functional as F
+
+
+class SelfAttentionBlock(nn.Module):
+ """General self-attention block/non-local block.
+
+ Please refer to https://arxiv.org/abs/1706.03762 for details about key,
+ query and value.
+
+ Args:
+ key_in_channels (int): Input channels of key feature.
+ query_in_channels (int): Input channels of query feature.
+ channels (int): Output channels of key/query transform.
+ out_channels (int): Output channels.
+ share_key_query (bool): Whether share projection weight between key
+ and query projection.
+ query_downsample (nn.Module): Query downsample module.
+ key_downsample (nn.Module): Key downsample module.
+ key_query_num_convs (int): Number of convs for key/query projection.
+ value_num_convs (int): Number of convs for value projection.
+ matmul_norm (bool): Whether normalize attention map with sqrt of
+ channels
+ with_out (bool): Whether use out projection.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict|None): Config of activation layers.
+ """
+
+ def __init__(self, key_in_channels, query_in_channels, channels,
+ out_channels, share_key_query, query_downsample,
+ key_downsample, key_query_num_convs, value_out_num_convs,
+ key_query_norm, value_out_norm, matmul_norm, with_out,
+ conv_cfg, norm_cfg, act_cfg):
+ super(SelfAttentionBlock, self).__init__()
+ if share_key_query:
+ assert key_in_channels == query_in_channels
+ self.key_in_channels = key_in_channels
+ self.query_in_channels = query_in_channels
+ self.out_channels = out_channels
+ self.channels = channels
+ self.share_key_query = share_key_query
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.key_project = self.build_project(
+ key_in_channels,
+ channels,
+ num_convs=key_query_num_convs,
+ use_conv_module=key_query_norm,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ if share_key_query:
+ self.query_project = self.key_project
+ else:
+ self.query_project = self.build_project(
+ query_in_channels,
+ channels,
+ num_convs=key_query_num_convs,
+ use_conv_module=key_query_norm,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.value_project = self.build_project(
+ key_in_channels,
+ channels if with_out else out_channels,
+ num_convs=value_out_num_convs,
+ use_conv_module=value_out_norm,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ if with_out:
+ self.out_project = self.build_project(
+ channels,
+ out_channels,
+ num_convs=value_out_num_convs,
+ use_conv_module=value_out_norm,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ else:
+ self.out_project = None
+
+ self.query_downsample = query_downsample
+ self.key_downsample = key_downsample
+ self.matmul_norm = matmul_norm
+
+ self.init_weights()
+
+ def init_weights(self):
+ """Initialize weight of later layer."""
+ if self.out_project is not None:
+ if not isinstance(self.out_project, ConvModule):
+ constant_init(self.out_project, 0)
+
+ def build_project(self, in_channels, channels, num_convs, use_conv_module,
+ conv_cfg, norm_cfg, act_cfg):
+ """Build projection layer for key/query/value/out."""
+ if use_conv_module:
+ convs = [
+ ConvModule(
+ in_channels,
+ channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ ]
+ for _ in range(num_convs - 1):
+ convs.append(
+ ConvModule(
+ channels,
+ channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ else:
+ convs = [nn.Conv2d(in_channels, channels, 1)]
+ for _ in range(num_convs - 1):
+ convs.append(nn.Conv2d(channels, channels, 1))
+ if len(convs) > 1:
+ convs = nn.Sequential(*convs)
+ else:
+ convs = convs[0]
+ return convs
+
+ def forward(self, query_feats, key_feats):
+ """Forward function."""
+ batch_size = query_feats.size(0)
+ query = self.query_project(query_feats)
+ if self.query_downsample is not None:
+ query = self.query_downsample(query)
+ query = query.reshape(*query.shape[:2], -1)
+ query = query.permute(0, 2, 1).contiguous()
+
+ key = self.key_project(key_feats)
+ value = self.value_project(key_feats)
+ if self.key_downsample is not None:
+ key = self.key_downsample(key)
+ value = self.key_downsample(value)
+ key = key.reshape(*key.shape[:2], -1)
+ value = value.reshape(*value.shape[:2], -1)
+ value = value.permute(0, 2, 1).contiguous()
+
+ sim_map = torch.matmul(query, key)
+ if self.matmul_norm:
+ sim_map = (self.channels**-.5) * sim_map
+ sim_map = F.softmax(sim_map, dim=-1)
+
+ context = torch.matmul(sim_map, value)
+ context = context.permute(0, 2, 1).contiguous()
+ context = context.reshape(batch_size, -1, *query_feats.shape[2:])
+ if self.out_project is not None:
+ context = self.out_project(context)
+ return context
diff --git a/mmseg/models/utils/shape_convert.py b/mmseg/models/utils/shape_convert.py
new file mode 100644
index 0000000..0677348
--- /dev/null
+++ b/mmseg/models/utils/shape_convert.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def nlc_to_nchw(x, hw_shape):
+ """Convert [N, L, C] shape tensor to [N, C, H, W] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, L, C] before conversion.
+ hw_shape (Sequence[int]): The height and width of output feature map.
+
+ Returns:
+ Tensor: The output tensor of shape [N, C, H, W] after conversion.
+ """
+ H, W = hw_shape
+ assert len(x.shape) == 3
+ B, L, C = x.shape
+ assert L == H * W, 'The seq_len doesn\'t match H, W'
+ return x.transpose(1, 2).reshape(B, C, H, W)
+
+
+def nchw_to_nlc(x):
+ """Flatten [N, C, H, W] shape tensor to [N, L, C] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, C, H, W] before conversion.
+
+ Returns:
+ Tensor: The output tensor of shape [N, L, C] after conversion.
+ """
+ assert len(x.shape) == 4
+ return x.flatten(2).transpose(1, 2).contiguous()
diff --git a/mmseg/models/utils/up_conv_block.py b/mmseg/models/utils/up_conv_block.py
new file mode 100644
index 0000000..d8396d9
--- /dev/null
+++ b/mmseg/models/utils/up_conv_block.py
@@ -0,0 +1,102 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, build_upsample_layer
+
+
+class UpConvBlock(nn.Module):
+ """Upsample convolution block in decoder for UNet.
+
+ This upsample convolution block consists of one upsample module
+ followed by one convolution block. The upsample module expands the
+ high-level low-resolution feature map and the convolution block fuses
+ the upsampled high-level low-resolution feature map and the low-level
+ high-resolution feature map from encoder.
+
+ Args:
+ conv_block (nn.Sequential): Sequential of convolutional layers.
+ in_channels (int): Number of input channels of the high-level
+ skip_channels (int): Number of input channels of the low-level
+ high-resolution feature map from encoder.
+ out_channels (int): Number of output channels.
+ num_convs (int): Number of convolutional layers in the conv_block.
+ Default: 2.
+ stride (int): Stride of convolutional layer in conv_block. Default: 1.
+ dilation (int): Dilation rate of convolutional layer in conv_block.
+ Default: 1.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ upsample_cfg (dict): The upsample config of the upsample module in
+ decoder. Default: dict(type='InterpConv'). If the size of
+ high-level feature map is the same as that of skip feature map
+ (low-level feature map from encoder), it does not need upsample the
+ high-level feature map and the upsample_cfg is None.
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ """
+
+ def __init__(self,
+ conv_block,
+ in_channels,
+ skip_channels,
+ out_channels,
+ num_convs=2,
+ stride=1,
+ dilation=1,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ dcn=None,
+ plugins=None):
+ super(UpConvBlock, self).__init__()
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.conv_block = conv_block(
+ in_channels=2 * skip_channels,
+ out_channels=out_channels,
+ num_convs=num_convs,
+ stride=stride,
+ dilation=dilation,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dcn=None,
+ plugins=None)
+ if upsample_cfg is not None:
+ self.upsample = build_upsample_layer(
+ cfg=upsample_cfg,
+ in_channels=in_channels,
+ out_channels=skip_channels,
+ with_cp=with_cp,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ else:
+ self.upsample = ConvModule(
+ in_channels,
+ skip_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, skip, x):
+ """Forward function."""
+
+ x = self.upsample(x)
+ out = torch.cat([skip, x], dim=1)
+ out = self.conv_block(out)
+
+ return out
diff --git a/mmseg/ops/__init__.py b/mmseg/ops/__init__.py
new file mode 100644
index 0000000..bc075cd
--- /dev/null
+++ b/mmseg/ops/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .encoding import Encoding
+from .wrappers import Upsample, resize
+
+__all__ = ['Upsample', 'resize', 'Encoding']
diff --git a/mmseg/ops/encoding.py b/mmseg/ops/encoding.py
new file mode 100644
index 0000000..f397cc5
--- /dev/null
+++ b/mmseg/ops/encoding.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+
+class Encoding(nn.Module):
+ """Encoding Layer: a learnable residual encoder.
+
+ Input is of shape (batch_size, channels, height, width).
+ Output is of shape (batch_size, num_codes, channels).
+
+ Args:
+ channels: dimension of the features or feature channels
+ num_codes: number of code words
+ """
+
+ def __init__(self, channels, num_codes):
+ super(Encoding, self).__init__()
+ # init codewords and smoothing factor
+ self.channels, self.num_codes = channels, num_codes
+ std = 1. / ((num_codes * channels)**0.5)
+ # [num_codes, channels]
+ self.codewords = nn.Parameter(
+ torch.empty(num_codes, channels,
+ dtype=torch.float).uniform_(-std, std),
+ requires_grad=True)
+ # [num_codes]
+ self.scale = nn.Parameter(
+ torch.empty(num_codes, dtype=torch.float).uniform_(-1, 0),
+ requires_grad=True)
+
+ @staticmethod
+ def scaled_l2(x, codewords, scale):
+ num_codes, channels = codewords.size()
+ batch_size = x.size(0)
+ reshaped_scale = scale.view((1, 1, num_codes))
+ expanded_x = x.unsqueeze(2).expand(
+ (batch_size, x.size(1), num_codes, channels))
+ reshaped_codewords = codewords.view((1, 1, num_codes, channels))
+
+ scaled_l2_norm = reshaped_scale * (
+ expanded_x - reshaped_codewords).pow(2).sum(dim=3)
+ return scaled_l2_norm
+
+ @staticmethod
+ def aggregate(assignment_weights, x, codewords):
+ num_codes, channels = codewords.size()
+ reshaped_codewords = codewords.view((1, 1, num_codes, channels))
+ batch_size = x.size(0)
+
+ expanded_x = x.unsqueeze(2).expand(
+ (batch_size, x.size(1), num_codes, channels))
+ encoded_feat = (assignment_weights.unsqueeze(3) *
+ (expanded_x - reshaped_codewords)).sum(dim=1)
+ return encoded_feat
+
+ def forward(self, x):
+ assert x.dim() == 4 and x.size(1) == self.channels
+ # [batch_size, channels, height, width]
+ batch_size = x.size(0)
+ # [batch_size, height x width, channels]
+ x = x.view(batch_size, self.channels, -1).transpose(1, 2).contiguous()
+ # assignment_weights: [batch_size, channels, num_codes]
+ assignment_weights = F.softmax(
+ self.scaled_l2(x, self.codewords, self.scale), dim=2)
+ # aggregate
+ encoded_feat = self.aggregate(assignment_weights, x, self.codewords)
+ return encoded_feat
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(Nx{self.channels}xHxW =>Nx{self.num_codes}' \
+ f'x{self.channels})'
+ return repr_str
diff --git a/mmseg/ops/wrappers.py b/mmseg/ops/wrappers.py
new file mode 100644
index 0000000..ce67e4b
--- /dev/null
+++ b/mmseg/ops/wrappers.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+def resize(input,
+ size=None,
+ scale_factor=None,
+ mode='nearest',
+ align_corners=None,
+ warning=True):
+ if warning:
+ if size is not None and align_corners:
+ input_h, input_w = tuple(int(x) for x in input.shape[2:])
+ output_h, output_w = tuple(int(x) for x in size)
+ if output_h > input_h or output_w > output_h:
+ if ((output_h > 1 and output_w > 1 and input_h > 1
+ and input_w > 1) and (output_h - 1) % (input_h - 1)
+ and (output_w - 1) % (input_w - 1)):
+ warnings.warn(
+ f'When align_corners={align_corners}, '
+ 'the output would more aligned if '
+ f'input size {(input_h, input_w)} is `x+1` and '
+ f'out size {(output_h, output_w)} is `nx+1`')
+ return F.interpolate(input, size, scale_factor, mode, align_corners)
+
+
+class Upsample(nn.Module):
+
+ def __init__(self,
+ size=None,
+ scale_factor=None,
+ mode='nearest',
+ align_corners=None):
+ super(Upsample, self).__init__()
+ self.size = size
+ if isinstance(scale_factor, tuple):
+ self.scale_factor = tuple(float(factor) for factor in scale_factor)
+ else:
+ self.scale_factor = float(scale_factor) if scale_factor else None
+ self.mode = mode
+ self.align_corners = align_corners
+
+ def forward(self, x):
+ if not self.size:
+ size = [int(t * self.scale_factor) for t in x.shape[-2:]]
+ else:
+ size = self.size
+ return resize(x, size, None, self.mode, self.align_corners)
diff --git a/mmseg/utils/__init__.py b/mmseg/utils/__init__.py
new file mode 100644
index 0000000..ed002c7
--- /dev/null
+++ b/mmseg/utils/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .collect_env import collect_env
+from .logger import get_root_logger
+from .misc import find_latest_checkpoint
+from .set_env import setup_multi_processes
+
+__all__ = [
+ 'get_root_logger', 'collect_env', 'find_latest_checkpoint',
+ 'setup_multi_processes'
+]
diff --git a/mmseg/utils/collect_env.py b/mmseg/utils/collect_env.py
new file mode 100644
index 0000000..3379ecb
--- /dev/null
+++ b/mmseg/utils/collect_env.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.utils import collect_env as collect_base_env
+from mmcv.utils import get_git_hash
+
+import mmseg
+
+
+def collect_env():
+ """Collect the information of the running environments."""
+ env_info = collect_base_env()
+ env_info['MMSegmentation'] = f'{mmseg.__version__}+{get_git_hash()[:7]}'
+
+ return env_info
+
+
+if __name__ == '__main__':
+ for name, val in collect_env().items():
+ print('{}: {}'.format(name, val))
diff --git a/mmseg/utils/logger.py b/mmseg/utils/logger.py
new file mode 100644
index 0000000..0cb3c78
--- /dev/null
+++ b/mmseg/utils/logger.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+
+from mmcv.utils import get_logger
+
+
+def get_root_logger(log_file=None, log_level=logging.INFO):
+ """Get the root logger.
+
+ The logger will be initialized if it has not been initialized. By default a
+ StreamHandler will be added. If `log_file` is specified, a FileHandler will
+ also be added. The name of the root logger is the top-level package name,
+ e.g., "mmseg".
+
+ Args:
+ log_file (str | None): The log filename. If specified, a FileHandler
+ will be added to the root logger.
+ log_level (int): The root logger level. Note that only the process of
+ rank 0 is affected, while other processes will set the level to
+ "Error" and be silent most of the time.
+
+ Returns:
+ logging.Logger: The root logger.
+ """
+
+ logger = get_logger(name='mmseg', log_file=log_file, log_level=log_level)
+
+ return logger
diff --git a/mmseg/utils/misc.py b/mmseg/utils/misc.py
new file mode 100644
index 0000000..bd1b6b1
--- /dev/null
+++ b/mmseg/utils/misc.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import glob
+import os.path as osp
+import warnings
+
+
+def find_latest_checkpoint(path, suffix='pth'):
+ """This function is for finding the latest checkpoint.
+
+ It will be used when automatically resume, modified from
+ https://github.com/open-mmlab/mmdetection/blob/dev-v2.20.0/mmdet/utils/misc.py
+
+ Args:
+ path (str): The path to find checkpoints.
+ suffix (str): File extension for the checkpoint. Defaults to pth.
+
+ Returns:
+ latest_path(str | None): File path of the latest checkpoint.
+ """
+ if not osp.exists(path):
+ warnings.warn("The path of the checkpoints doesn't exist.")
+ return None
+ if osp.exists(osp.join(path, f'latest.{suffix}')):
+ return osp.join(path, f'latest.{suffix}')
+
+ checkpoints = glob.glob(osp.join(path, f'*.{suffix}'))
+ if len(checkpoints) == 0:
+ warnings.warn('The are no checkpoints in the path')
+ return None
+ latest = -1
+ latest_path = ''
+ for checkpoint in checkpoints:
+ if len(checkpoint) < len(latest_path):
+ continue
+ # `count` is iteration number, as checkpoints are saved as
+ # 'iter_xx.pth' or 'epoch_xx.pth' and xx is iteration number.
+ count = int(osp.basename(checkpoint).split('_')[-1].split('.')[0])
+ if count > latest:
+ latest = count
+ latest_path = checkpoint
+ return latest_path
diff --git a/mmseg/utils/set_env.py b/mmseg/utils/set_env.py
new file mode 100644
index 0000000..b2d3aaf
--- /dev/null
+++ b/mmseg/utils/set_env.py
@@ -0,0 +1,55 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import platform
+
+import cv2
+import torch.multiprocessing as mp
+
+from ..utils import get_root_logger
+
+
+def setup_multi_processes(cfg):
+ """Setup multi-processing environment variables."""
+ logger = get_root_logger()
+
+ # set multi-process start method
+ if platform.system() != 'Windows':
+ mp_start_method = cfg.get('mp_start_method', None)
+ current_method = mp.get_start_method(allow_none=True)
+ if mp_start_method in ('fork', 'spawn', 'forkserver'):
+ logger.info(
+ f'Multi-processing start method `{mp_start_method}` is '
+ f'different from the previous setting `{current_method}`.'
+ f'It will be force set to `{mp_start_method}`.')
+ mp.set_start_method(mp_start_method, force=True)
+ else:
+ logger.info(
+ f'Multi-processing start method is `{mp_start_method}`')
+
+ # disable opencv multithreading to avoid system being overloaded
+ opencv_num_threads = cfg.get('opencv_num_threads', None)
+ if isinstance(opencv_num_threads, int):
+ logger.info(f'OpenCV num_threads is `{opencv_num_threads}`')
+ cv2.setNumThreads(opencv_num_threads)
+ else:
+ logger.info(f'OpenCV num_threads is `{cv2.getNumThreads}')
+
+ if cfg.data.workers_per_gpu > 1:
+ # setup OMP threads
+ # This code is referred from https://github.com/pytorch/pytorch/blob/master/torch/distributed/run.py # noqa
+ omp_num_threads = cfg.get('omp_num_threads', None)
+ if 'OMP_NUM_THREADS' not in os.environ:
+ if isinstance(omp_num_threads, int):
+ logger.info(f'OMP num threads is {omp_num_threads}')
+ os.environ['OMP_NUM_THREADS'] = str(omp_num_threads)
+ else:
+ logger.info(f'OMP num threads is {os.environ["OMP_NUM_THREADS"] }')
+
+ # setup MKL threads
+ if 'MKL_NUM_THREADS' not in os.environ:
+ mkl_num_threads = cfg.get('mkl_num_threads', None)
+ if isinstance(mkl_num_threads, int):
+ logger.info(f'MKL num threads is {mkl_num_threads}')
+ os.environ['MKL_NUM_THREADS'] = str(mkl_num_threads)
+ else:
+ logger.info(f'MKL num threads is {os.environ["MKL_NUM_THREADS"]}')
diff --git a/mmseg/version.py b/mmseg/version.py
new file mode 100644
index 0000000..43cc13a
--- /dev/null
+++ b/mmseg/version.py
@@ -0,0 +1,18 @@
+# Copyright (c) Open-MMLab. All rights reserved.
+
+__version__ = '0.21.1'
+
+
+def parse_version_info(version_str):
+ version_info = []
+ for x in version_str.split('.'):
+ if x.isdigit():
+ version_info.append(int(x))
+ elif x.find('rc') != -1:
+ patch_version = x.split('rc')
+ version_info.append(int(patch_version[0]))
+ version_info.append(f'rc{patch_version[1]}')
+ return tuple(version_info)
+
+
+version_info = parse_version_info(__version__)
diff --git a/model-index.yml b/model-index.yml
new file mode 100644
index 0000000..1a491d9
--- /dev/null
+++ b/model-index.yml
@@ -0,0 +1,41 @@
+Import:
+- configs/ann/ann.yml
+- configs/apcnet/apcnet.yml
+- configs/bisenetv1/bisenetv1.yml
+- configs/bisenetv2/bisenetv2.yml
+- configs/ccnet/ccnet.yml
+- configs/cgnet/cgnet.yml
+- configs/danet/danet.yml
+- configs/deeplabv3/deeplabv3.yml
+- configs/deeplabv3plus/deeplabv3plus.yml
+- configs/dmnet/dmnet.yml
+- configs/dnlnet/dnlnet.yml
+- configs/dpt/dpt.yml
+- configs/emanet/emanet.yml
+- configs/encnet/encnet.yml
+- configs/erfnet/erfnet.yml
+- configs/fastfcn/fastfcn.yml
+- configs/fastscnn/fastscnn.yml
+- configs/fcn/fcn.yml
+- configs/gcnet/gcnet.yml
+- configs/hrnet/hrnet.yml
+- configs/icnet/icnet.yml
+- configs/isanet/isanet.yml
+- configs/mobilenet_v2/mobilenet_v2.yml
+- configs/mobilenet_v3/mobilenet_v3.yml
+- configs/nonlocal_net/nonlocal_net.yml
+- configs/ocrnet/ocrnet.yml
+- configs/point_rend/point_rend.yml
+- configs/psanet/psanet.yml
+- configs/pspnet/pspnet.yml
+- configs/resnest/resnest.yml
+- configs/segformer/segformer.yml
+- configs/segmenter/segmenter.yml
+- configs/sem_fpn/sem_fpn.yml
+- configs/setr/setr.yml
+- configs/stdc/stdc.yml
+- configs/swin/swin.yml
+- configs/twins/twins.yml
+- configs/unet/unet.yml
+- configs/upernet/upernet.yml
+- configs/vit/vit.yml
diff --git a/pytest.ini b/pytest.ini
new file mode 100644
index 0000000..9796e87
--- /dev/null
+++ b/pytest.ini
@@ -0,0 +1,7 @@
+[pytest]
+addopts = --xdoctest --xdoctest-style=auto
+norecursedirs = .git ignore build __pycache__ data docker docs .eggs
+
+filterwarnings= default
+ ignore:.*No cfgstr given in Cacher constructor or call.*:Warning
+ ignore:.*Define the __nice__ method for.*:Warning
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000..6da5ade
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,3 @@
+-r requirements/optional.txt
+-r requirements/runtime.txt
+-r requirements/tests.txt
diff --git a/requirements/docs.txt b/requirements/docs.txt
new file mode 100644
index 0000000..2017084
--- /dev/null
+++ b/requirements/docs.txt
@@ -0,0 +1,6 @@
+docutils==0.16.0
+myst-parser
+-e git+https://github.com/gaotongxiao/pytorch_sphinx_theme.git#egg=pytorch_sphinx_theme
+sphinx==4.0.2
+sphinx_copybutton
+sphinx_markdown_tables
diff --git a/requirements/mminstall.txt b/requirements/mminstall.txt
new file mode 100644
index 0000000..b1c42eb
--- /dev/null
+++ b/requirements/mminstall.txt
@@ -0,0 +1 @@
+mmcv-full>=1.3.1,<=1.4.0
diff --git a/requirements/onnx.txt b/requirements/onnx.txt
new file mode 100644
index 0000000..7944fcb
--- /dev/null
+++ b/requirements/onnx.txt
@@ -0,0 +1,3 @@
+onnx>=1.6.0
+onnxruntime
+onnxoptimizer
diff --git a/requirements/optional.txt b/requirements/optional.txt
new file mode 100644
index 0000000..47fa593
--- /dev/null
+++ b/requirements/optional.txt
@@ -0,0 +1 @@
+cityscapesscripts
diff --git a/requirements/readthedocs.txt b/requirements/readthedocs.txt
new file mode 100644
index 0000000..22a894b
--- /dev/null
+++ b/requirements/readthedocs.txt
@@ -0,0 +1,4 @@
+mmcv
+prettytable
+torch
+torchvision
diff --git a/requirements/runtime.txt b/requirements/runtime.txt
new file mode 100644
index 0000000..2712f50
--- /dev/null
+++ b/requirements/runtime.txt
@@ -0,0 +1,4 @@
+matplotlib
+numpy
+packaging
+prettytable
diff --git a/requirements/tests.txt b/requirements/tests.txt
new file mode 100644
index 0000000..991fd71
--- /dev/null
+++ b/requirements/tests.txt
@@ -0,0 +1,7 @@
+codecov
+flake8
+interrogate
+isort==4.3.21
+pytest
+xdoctest>=0.10.0
+yapf
diff --git a/requirements_kneron.txt b/requirements_kneron.txt
new file mode 100644
index 0000000..d188261
--- /dev/null
+++ b/requirements_kneron.txt
@@ -0,0 +1,2 @@
+-r requirements.txt
+-r requirements/onnx.txt
diff --git a/resources/3dogs.jpg b/resources/3dogs.jpg
new file mode 100644
index 0000000..02ef6fc
Binary files /dev/null and b/resources/3dogs.jpg differ
diff --git a/resources/3dogs_mask.png b/resources/3dogs_mask.png
new file mode 100644
index 0000000..339c2f5
Binary files /dev/null and b/resources/3dogs_mask.png differ
diff --git a/resources/mmseg-logo.png b/resources/mmseg-logo.png
new file mode 100644
index 0000000..009083a
Binary files /dev/null and b/resources/mmseg-logo.png differ
diff --git a/resources/seg_demo.gif b/resources/seg_demo.gif
new file mode 100644
index 0000000..2f0760f
Binary files /dev/null and b/resources/seg_demo.gif differ
diff --git a/setup.cfg b/setup.cfg
new file mode 100644
index 0000000..4839120
--- /dev/null
+++ b/setup.cfg
@@ -0,0 +1,19 @@
+[yapf]
+based_on_style = pep8
+blank_line_before_nested_class_or_def = true
+split_before_expression_after_opening_paren = true
+
+[isort]
+line_length = 79
+multi_line_output = 0
+extra_standard_library = setuptools
+known_first_party = mmseg
+known_third_party = PIL,cityscapesscripts,cv2,detail,matplotlib,mmcv,numpy,onnxruntime,packaging,prettytable,pytest,pytorch_sphinx_theme,requests,scipy,seaborn,torch,ts
+no_lines_before = STDLIB,LOCALFOLDER
+default_section = THIRDPARTY
+
+[codespell]
+skip = *.po,*.ts,*.ipynb
+count =
+quiet-level = 3
+ignore-words-list = formating,sur,hist
diff --git a/setup.py b/setup.py
new file mode 100755
index 0000000..dc758e2
--- /dev/null
+++ b/setup.py
@@ -0,0 +1,203 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import platform
+import shutil
+import sys
+import warnings
+from setuptools import find_packages, setup
+
+
+def readme():
+ with open('README.md', encoding='utf-8') as f:
+ content = f.read()
+ return content
+
+
+version_file = 'mmseg/version.py'
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+def parse_requirements(fname='requirements.txt', with_version=True):
+ """Parse the package dependencies listed in a requirements file but strips
+ specific versioning information.
+
+ Args:
+ fname (str): path to requirements file
+ with_version (bool, default=False): if True include version specs
+
+ Returns:
+ List[str]: list of requirements items
+
+ CommandLine:
+ python -c "import setup; print(setup.parse_requirements())"
+ """
+ import re
+ import sys
+ from os.path import exists
+ require_fpath = fname
+
+ def parse_line(line):
+ """Parse information from a line in a requirements text file."""
+ if line.startswith('-r '):
+ # Allow specifying requirements in other files
+ target = line.split(' ')[1]
+ for info in parse_require_file(target):
+ yield info
+ else:
+ info = {'line': line}
+ if line.startswith('-e '):
+ info['package'] = line.split('#egg=')[1]
+ else:
+ # Remove versioning from the package
+ pat = '(' + '|'.join(['>=', '==', '>']) + ')'
+ parts = re.split(pat, line, maxsplit=1)
+ parts = [p.strip() for p in parts]
+
+ info['package'] = parts[0]
+ if len(parts) > 1:
+ op, rest = parts[1:]
+ if ';' in rest:
+ # Handle platform specific dependencies
+ # http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
+ version, platform_deps = map(str.strip,
+ rest.split(';'))
+ info['platform_deps'] = platform_deps
+ else:
+ version = rest # NOQA
+ info['version'] = (op, version)
+ yield info
+
+ def parse_require_file(fpath):
+ with open(fpath, 'r') as f:
+ for line in f.readlines():
+ line = line.strip()
+ if line and not line.startswith('#'):
+ for info in parse_line(line):
+ yield info
+
+ def gen_packages_items():
+ if exists(require_fpath):
+ for info in parse_require_file(require_fpath):
+ parts = [info['package']]
+ if with_version and 'version' in info:
+ parts.extend(info['version'])
+ if not sys.version.startswith('3.4'):
+ # apparently package_deps are broken in 3.4
+ platform_deps = info.get('platform_deps')
+ if platform_deps is not None:
+ parts.append(';' + platform_deps)
+ item = ''.join(parts)
+ yield item
+
+ packages = list(gen_packages_items())
+ return packages
+
+
+def add_mim_extension():
+ """Add extra files that are required to support MIM into the package.
+
+ These files will be added by creating a symlink to the originals if the
+ package is installed in `editable` mode (e.g. pip install -e .), or by
+ copying from the originals otherwise.
+ """
+
+ # parse installment mode
+ if 'develop' in sys.argv:
+ # installed by `pip install -e .`
+ if platform.system() == 'Windows':
+ # set `copy` mode here since symlink fails on Windows.
+ mode = 'copy'
+ else:
+ mode = 'symlink'
+ elif 'sdist' in sys.argv or 'bdist_wheel' in sys.argv or \
+ platform.system() == 'Windows':
+ # installed by `pip install .`
+ # or create source distribution by `python setup.py sdist`
+ # set `copy` mode here since symlink fails with WinError on Windows.
+ mode = 'copy'
+ else:
+ return
+
+ filenames = ['tools', 'configs', 'model-index.yml']
+ repo_path = osp.dirname(__file__)
+ mim_path = osp.join(repo_path, 'mmseg', '.mim')
+ os.makedirs(mim_path, exist_ok=True)
+
+ for filename in filenames:
+ if osp.exists(filename):
+ src_path = osp.join(repo_path, filename)
+ tar_path = osp.join(mim_path, filename)
+
+ if osp.isfile(tar_path) or osp.islink(tar_path):
+ os.remove(tar_path)
+ elif osp.isdir(tar_path):
+ shutil.rmtree(tar_path)
+
+ if mode == 'symlink':
+ src_relpath = osp.relpath(src_path, osp.dirname(tar_path))
+ try:
+ os.symlink(src_relpath, tar_path)
+ except OSError:
+ # Creating a symbolic link on windows may raise an
+ # `OSError: [WinError 1314]` due to privilege. If
+ # the error happens, the src file will be copied
+ mode = 'copy'
+ warnings.warn(
+ f'Failed to create a symbolic link for {src_relpath}, '
+ f'and it will be copied to {tar_path}')
+ else:
+ continue
+
+ if mode == 'copy':
+ if osp.isfile(src_path):
+ shutil.copyfile(src_path, tar_path)
+ elif osp.isdir(src_path):
+ shutil.copytree(src_path, tar_path)
+ else:
+ warnings.warn(f'Cannot copy file {src_path}.')
+ else:
+ raise ValueError(f'Invalid mode {mode}')
+
+
+if __name__ == '__main__':
+ add_mim_extension()
+ setup(
+ name='mmsegmentation',
+ version=get_version(),
+ description='Open MMLab Semantic Segmentation Toolbox '
+ 'and Benchmark (Kneron Edition)',
+ long_description=readme(),
+ long_description_content_type='text/markdown',
+ author='MMSegmentation Contributors and Kneron',
+ author_email='',
+ keywords='computer vision, semantic segmentation',
+ url='http://github.com/kneron/MMSegmentationKN',
+ packages=find_packages(exclude=('configs', 'tools', 'demo')),
+ include_package_data=True,
+ classifiers=[
+ 'Development Status :: 4 - Beta',
+ 'License :: OSI Approved :: Apache Software License',
+ 'Operating System :: OS Independent',
+ 'Programming Language :: Python :: 3.6',
+ 'Programming Language :: Python :: 3.7',
+ 'Programming Language :: Python :: 3.8',
+ 'Programming Language :: Python :: 3.9',
+ ],
+ license='Apache License 2.0',
+ install_requires=parse_requirements('requirements/runtime.txt'),
+ extras_require={
+ 'all': parse_requirements('requirements_kneron.txt'),
+ 'tests': parse_requirements('requirements/tests.txt'),
+ 'build': parse_requirements('requirements/build.txt'),
+ 'optional': parse_requirements('requirements/optional.txt'),
+ 'onnx': parse_requirements('requirements/onnx.txt'),
+ },
+ ext_modules=[],
+ zip_safe=False)
diff --git a/tests/__init__.py b/tests/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/data/color.jpg b/tests/data/color.jpg
new file mode 100644
index 0000000..05d62b8
Binary files /dev/null and b/tests/data/color.jpg differ
diff --git a/tests/data/gray.jpg b/tests/data/gray.jpg
new file mode 100644
index 0000000..94edd73
Binary files /dev/null and b/tests/data/gray.jpg differ
diff --git a/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_instanceIds.png b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_instanceIds.png
new file mode 100644
index 0000000..dfe7aea
Binary files /dev/null and b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_instanceIds.png differ
diff --git a/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelIds.png b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelIds.png
new file mode 100644
index 0000000..faab6f5
Binary files /dev/null and b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelIds.png differ
diff --git a/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelTrainIds.png b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelTrainIds.png
new file mode 100644
index 0000000..659229b
Binary files /dev/null and b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelTrainIds.png differ
diff --git a/tests/data/pseudo_cityscapes_dataset/leftImg8bit/frankfurt_000000_000294_leftImg8bit.png b/tests/data/pseudo_cityscapes_dataset/leftImg8bit/frankfurt_000000_000294_leftImg8bit.png
new file mode 100644
index 0000000..2c83ee4
Binary files /dev/null and b/tests/data/pseudo_cityscapes_dataset/leftImg8bit/frankfurt_000000_000294_leftImg8bit.png differ
diff --git a/tests/data/pseudo_dataset/gts/00000_gt.png b/tests/data/pseudo_dataset/gts/00000_gt.png
new file mode 100644
index 0000000..48fc125
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00000_gt.png differ
diff --git a/tests/data/pseudo_dataset/gts/00001_gt.png b/tests/data/pseudo_dataset/gts/00001_gt.png
new file mode 100644
index 0000000..ccb49b0
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00001_gt.png differ
diff --git a/tests/data/pseudo_dataset/gts/00002_gt.png b/tests/data/pseudo_dataset/gts/00002_gt.png
new file mode 100644
index 0000000..db7250c
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00002_gt.png differ
diff --git a/tests/data/pseudo_dataset/gts/00003_gt.png b/tests/data/pseudo_dataset/gts/00003_gt.png
new file mode 100644
index 0000000..f96a1be
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00003_gt.png differ
diff --git a/tests/data/pseudo_dataset/gts/00004_gt.png b/tests/data/pseudo_dataset/gts/00004_gt.png
new file mode 100644
index 0000000..35b1cad
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00004_gt.png differ
diff --git a/tests/data/pseudo_dataset/imgs/00000_img.jpg b/tests/data/pseudo_dataset/imgs/00000_img.jpg
new file mode 100644
index 0000000..33ab8e2
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00000_img.jpg differ
diff --git a/tests/data/pseudo_dataset/imgs/00001_img.jpg b/tests/data/pseudo_dataset/imgs/00001_img.jpg
new file mode 100644
index 0000000..49c2229
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00001_img.jpg differ
diff --git a/tests/data/pseudo_dataset/imgs/00002_img.jpg b/tests/data/pseudo_dataset/imgs/00002_img.jpg
new file mode 100644
index 0000000..6baeb5f
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00002_img.jpg differ
diff --git a/tests/data/pseudo_dataset/imgs/00003_img.jpg b/tests/data/pseudo_dataset/imgs/00003_img.jpg
new file mode 100644
index 0000000..6e889d7
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00003_img.jpg differ
diff --git a/tests/data/pseudo_dataset/imgs/00004_img.jpg b/tests/data/pseudo_dataset/imgs/00004_img.jpg
new file mode 100644
index 0000000..474c915
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00004_img.jpg differ
diff --git a/tests/data/pseudo_dataset/splits/train.txt b/tests/data/pseudo_dataset/splits/train.txt
new file mode 100644
index 0000000..9e25ab0
--- /dev/null
+++ b/tests/data/pseudo_dataset/splits/train.txt
@@ -0,0 +1,4 @@
+00000
+00001
+00002
+00003
diff --git a/tests/data/pseudo_dataset/splits/val.txt b/tests/data/pseudo_dataset/splits/val.txt
new file mode 100644
index 0000000..59dd536
--- /dev/null
+++ b/tests/data/pseudo_dataset/splits/val.txt
@@ -0,0 +1 @@
+00004
diff --git a/tests/data/pseudo_loveda_dataset/ann_dir/0.png b/tests/data/pseudo_loveda_dataset/ann_dir/0.png
new file mode 100644
index 0000000..7823fd6
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/ann_dir/0.png differ
diff --git a/tests/data/pseudo_loveda_dataset/ann_dir/1.png b/tests/data/pseudo_loveda_dataset/ann_dir/1.png
new file mode 100644
index 0000000..bc50ac1
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/ann_dir/1.png differ
diff --git a/tests/data/pseudo_loveda_dataset/ann_dir/2.png b/tests/data/pseudo_loveda_dataset/ann_dir/2.png
new file mode 100644
index 0000000..c182838
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/ann_dir/2.png differ
diff --git a/tests/data/pseudo_loveda_dataset/img_dir/0.png b/tests/data/pseudo_loveda_dataset/img_dir/0.png
new file mode 100644
index 0000000..03a0652
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/img_dir/0.png differ
diff --git a/tests/data/pseudo_loveda_dataset/img_dir/1.png b/tests/data/pseudo_loveda_dataset/img_dir/1.png
new file mode 100644
index 0000000..2fe837f
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/img_dir/1.png differ
diff --git a/tests/data/pseudo_loveda_dataset/img_dir/2.png b/tests/data/pseudo_loveda_dataset/img_dir/2.png
new file mode 100644
index 0000000..b824499
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/img_dir/2.png differ
diff --git a/tests/data/pseudo_potsdam_dataset/ann_dir/2_10_0_0_512_512.png b/tests/data/pseudo_potsdam_dataset/ann_dir/2_10_0_0_512_512.png
new file mode 100644
index 0000000..6f22278
Binary files /dev/null and b/tests/data/pseudo_potsdam_dataset/ann_dir/2_10_0_0_512_512.png differ
diff --git a/tests/data/pseudo_potsdam_dataset/img_dir/2_10_0_0_512_512.png b/tests/data/pseudo_potsdam_dataset/img_dir/2_10_0_0_512_512.png
new file mode 100644
index 0000000..7821a18
Binary files /dev/null and b/tests/data/pseudo_potsdam_dataset/img_dir/2_10_0_0_512_512.png differ
diff --git a/tests/data/pseudo_vaihingen_dataset/ann_dir/area1_0_0_512_512.png b/tests/data/pseudo_vaihingen_dataset/ann_dir/area1_0_0_512_512.png
new file mode 100644
index 0000000..f58e187
Binary files /dev/null and b/tests/data/pseudo_vaihingen_dataset/ann_dir/area1_0_0_512_512.png differ
diff --git a/tests/data/pseudo_vaihingen_dataset/img_dir/area1_0_0_512_512.png b/tests/data/pseudo_vaihingen_dataset/img_dir/area1_0_0_512_512.png
new file mode 100644
index 0000000..648be0b
Binary files /dev/null and b/tests/data/pseudo_vaihingen_dataset/img_dir/area1_0_0_512_512.png differ
diff --git a/tests/data/seg.png b/tests/data/seg.png
new file mode 100644
index 0000000..f23a499
Binary files /dev/null and b/tests/data/seg.png differ
diff --git a/tests/test_apis/test_single_gpu.py b/tests/test_apis/test_single_gpu.py
new file mode 100644
index 0000000..b741896
--- /dev/null
+++ b/tests/test_apis/test_single_gpu.py
@@ -0,0 +1,72 @@
+import shutil
+from unittest.mock import MagicMock
+
+import numpy as np
+import pytest
+import torch
+import torch.nn as nn
+from torch.utils.data import DataLoader, Dataset, dataloader
+
+from mmseg.apis import single_gpu_test
+
+
+class ExampleDataset(Dataset):
+
+ def __getitem__(self, idx):
+ results = dict(img=torch.tensor([1]), img_metas=dict())
+ return results
+
+ def __len__(self):
+ return 1
+
+
+class ExampleModel(nn.Module):
+
+ def __init__(self):
+ super(ExampleModel, self).__init__()
+ self.test_cfg = None
+ self.conv = nn.Conv2d(3, 3, 3)
+
+ def forward(self, img, img_metas, return_loss=False, **kwargs):
+ return img
+
+
+def test_single_gpu():
+ test_dataset = ExampleDataset()
+ data_loader = DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_workers=0,
+ shuffle=False,
+ )
+ model = ExampleModel()
+
+ # Test efficient test compatibility (will be deprecated)
+ results = single_gpu_test(model, data_loader, efficient_test=True)
+ assert len(results) == 1
+ pred = np.load(results[0])
+ assert isinstance(pred, np.ndarray)
+ assert pred.shape == (1, )
+ assert pred[0] == 1
+
+ shutil.rmtree('.efficient_test')
+
+ # Test pre_eval
+ test_dataset.pre_eval = MagicMock(return_value=['success'])
+ results = single_gpu_test(model, data_loader, pre_eval=True)
+ assert results == ['success']
+
+ # Test format_only
+ test_dataset.format_results = MagicMock(return_value=['success'])
+ results = single_gpu_test(model, data_loader, format_only=True)
+ assert results == ['success']
+
+ # efficient_test, pre_eval and format_only are mutually exclusive
+ with pytest.raises(AssertionError):
+ single_gpu_test(
+ model,
+ dataloader,
+ efficient_test=True,
+ format_only=True,
+ pre_eval=True)
diff --git a/tests/test_config.py b/tests/test_config.py
new file mode 100644
index 0000000..2482144
--- /dev/null
+++ b/tests/test_config.py
@@ -0,0 +1,162 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import glob
+import os
+from os.path import dirname, exists, isdir, join, relpath
+
+from mmcv import Config
+from torch import nn
+
+from mmseg.models import build_segmentor
+
+
+def _get_config_directory():
+ """Find the predefined segmentor config directory."""
+ try:
+ # Assume we are running in the source mmsegmentation repo
+ repo_dpath = dirname(dirname(__file__))
+ except NameError:
+ # For IPython development when this __file__ is not defined
+ import mmseg
+ repo_dpath = dirname(dirname(mmseg.__file__))
+ config_dpath = join(repo_dpath, 'configs')
+ if not exists(config_dpath):
+ raise Exception('Cannot find config path')
+ return config_dpath
+
+
+def test_config_build_segmentor():
+ """Test that all segmentation models defined in the configs can be
+ initialized."""
+ config_dpath = _get_config_directory()
+ print('Found config_dpath = {!r}'.format(config_dpath))
+
+ config_fpaths = []
+ # one config each sub folder
+ for sub_folder in os.listdir(config_dpath):
+ if isdir(sub_folder):
+ config_fpaths.append(
+ list(glob.glob(join(config_dpath, sub_folder, '*.py')))[0])
+ config_fpaths = [p for p in config_fpaths if p.find('_base_') == -1]
+ config_names = [relpath(p, config_dpath) for p in config_fpaths]
+
+ print('Using {} config files'.format(len(config_names)))
+
+ for config_fname in config_names:
+ config_fpath = join(config_dpath, config_fname)
+ config_mod = Config.fromfile(config_fpath)
+
+ config_mod.model
+ print('Building segmentor, config_fpath = {!r}'.format(config_fpath))
+
+ # Remove pretrained keys to allow for testing in an offline environment
+ if 'pretrained' in config_mod.model:
+ config_mod.model['pretrained'] = None
+
+ print('building {}'.format(config_fname))
+ segmentor = build_segmentor(config_mod.model)
+ assert segmentor is not None
+
+ head_config = config_mod.model['decode_head']
+ _check_decode_head(head_config, segmentor.decode_head)
+
+
+def test_config_data_pipeline():
+ """Test whether the data pipeline is valid and can process corner cases.
+
+ CommandLine:
+ xdoctest -m tests/test_config.py test_config_build_data_pipeline
+ """
+ import numpy as np
+ from mmcv import Config
+
+ from mmseg.datasets.pipelines import Compose
+
+ config_dpath = _get_config_directory()
+ print('Found config_dpath = {!r}'.format(config_dpath))
+
+ import glob
+ config_fpaths = list(glob.glob(join(config_dpath, '**', '*.py')))
+ config_fpaths = [p for p in config_fpaths if p.find('_base_') == -1]
+ config_names = [relpath(p, config_dpath) for p in config_fpaths]
+
+ print('Using {} config files'.format(len(config_names)))
+
+ for config_fname in config_names:
+ config_fpath = join(config_dpath, config_fname)
+ print(
+ 'Building data pipeline, config_fpath = {!r}'.format(config_fpath))
+ config_mod = Config.fromfile(config_fpath)
+
+ # remove loading pipeline
+ load_img_pipeline = config_mod.train_pipeline.pop(0)
+ to_float32 = load_img_pipeline.get('to_float32', False)
+ config_mod.train_pipeline.pop(0)
+ config_mod.test_pipeline.pop(0)
+
+ train_pipeline = Compose(config_mod.train_pipeline)
+ test_pipeline = Compose(config_mod.test_pipeline)
+
+ img = np.random.randint(0, 255, size=(1024, 2048, 3), dtype=np.uint8)
+ if to_float32:
+ img = img.astype(np.float32)
+ seg = np.random.randint(0, 255, size=(1024, 2048, 1), dtype=np.uint8)
+
+ results = dict(
+ filename='test_img.png',
+ ori_filename='test_img.png',
+ img=img,
+ img_shape=img.shape,
+ ori_shape=img.shape,
+ gt_semantic_seg=seg)
+ results['seg_fields'] = ['gt_semantic_seg']
+
+ print('Test training data pipeline: \n{!r}'.format(train_pipeline))
+ output_results = train_pipeline(results)
+ assert output_results is not None
+
+ results = dict(
+ filename='test_img.png',
+ ori_filename='test_img.png',
+ img=img,
+ img_shape=img.shape,
+ ori_shape=img.shape,
+ )
+ print('Test testing data pipeline: \n{!r}'.format(test_pipeline))
+ output_results = test_pipeline(results)
+ assert output_results is not None
+
+
+def _check_decode_head(decode_head_cfg, decode_head):
+ if isinstance(decode_head_cfg, list):
+ assert isinstance(decode_head, nn.ModuleList)
+ assert len(decode_head_cfg) == len(decode_head)
+ num_heads = len(decode_head)
+ for i in range(num_heads):
+ _check_decode_head(decode_head_cfg[i], decode_head[i])
+ return
+ # check consistency between head_config and roi_head
+ assert decode_head_cfg['type'] == decode_head.__class__.__name__
+
+ assert decode_head_cfg['type'] == decode_head.__class__.__name__
+
+ in_channels = decode_head_cfg.in_channels
+ input_transform = decode_head.input_transform
+ assert input_transform in ['resize_concat', 'multiple_select', None]
+ if input_transform is not None:
+ assert isinstance(in_channels, (list, tuple))
+ assert isinstance(decode_head.in_index, (list, tuple))
+ assert len(in_channels) == len(decode_head.in_index)
+ elif input_transform == 'resize_concat':
+ assert sum(in_channels) == decode_head.in_channels
+ else:
+ assert isinstance(in_channels, int)
+ assert in_channels == decode_head.in_channels
+ assert isinstance(decode_head.in_index, int)
+
+ if decode_head_cfg['type'] == 'PointHead':
+ assert decode_head_cfg.channels+decode_head_cfg.num_classes == \
+ decode_head.fc_seg.in_channels
+ assert decode_head.fc_seg.out_channels == decode_head_cfg.num_classes
+ else:
+ assert decode_head_cfg.channels == decode_head.conv_seg.in_channels
+ assert decode_head.conv_seg.out_channels == decode_head_cfg.num_classes
diff --git a/tests/test_data/test_dataset.py b/tests/test_data/test_dataset.py
new file mode 100644
index 0000000..3d4c40a
--- /dev/null
+++ b/tests/test_data/test_dataset.py
@@ -0,0 +1,828 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import shutil
+import tempfile
+from typing import Generator
+from unittest.mock import MagicMock, patch
+
+import numpy as np
+import pytest
+import torch
+from PIL import Image
+
+from mmseg.core.evaluation import get_classes, get_palette
+from mmseg.datasets import (DATASETS, ADE20KDataset, CityscapesDataset,
+ COCOStuffDataset, ConcatDataset, CustomDataset,
+ ISPRSDataset, LoveDADataset, MultiImageMixDataset,
+ PascalVOCDataset, PotsdamDataset, RepeatDataset,
+ build_dataset)
+
+
+def test_classes():
+ assert list(CityscapesDataset.CLASSES) == get_classes('cityscapes')
+ assert list(PascalVOCDataset.CLASSES) == get_classes('voc') == get_classes(
+ 'pascal_voc')
+ assert list(
+ ADE20KDataset.CLASSES) == get_classes('ade') == get_classes('ade20k')
+ assert list(LoveDADataset.CLASSES) == get_classes('loveda')
+ assert list(PotsdamDataset.CLASSES) == get_classes('potsdam')
+ assert list(ISPRSDataset.CLASSES) == get_classes('vaihingen')
+ assert list(COCOStuffDataset.CLASSES) == get_classes('cocostuff')
+
+ with pytest.raises(ValueError):
+ get_classes('unsupported')
+
+
+def test_classes_file_path():
+ tmp_file = tempfile.NamedTemporaryFile()
+ classes_path = f'{tmp_file.name}.txt'
+ train_pipeline = [dict(type='LoadImageFromFile')]
+ kwargs = dict(pipeline=train_pipeline, img_dir='./', classes=classes_path)
+
+ # classes.txt with full categories
+ categories = get_classes('cityscapes')
+ with open(classes_path, 'w') as f:
+ f.write('\n'.join(categories))
+ assert list(CityscapesDataset(**kwargs).CLASSES) == categories
+
+ # classes.txt with sub categories
+ categories = ['road', 'sidewalk', 'building']
+ with open(classes_path, 'w') as f:
+ f.write('\n'.join(categories))
+ assert list(CityscapesDataset(**kwargs).CLASSES) == categories
+
+ # classes.txt with unknown categories
+ categories = ['road', 'sidewalk', 'unknown']
+ with open(classes_path, 'w') as f:
+ f.write('\n'.join(categories))
+
+ with pytest.raises(ValueError):
+ CityscapesDataset(**kwargs)
+
+ tmp_file.close()
+ os.remove(classes_path)
+ assert not osp.exists(classes_path)
+
+
+def test_palette():
+ assert CityscapesDataset.PALETTE == get_palette('cityscapes')
+ assert PascalVOCDataset.PALETTE == get_palette('voc') == get_palette(
+ 'pascal_voc')
+ assert ADE20KDataset.PALETTE == get_palette('ade') == get_palette('ade20k')
+ assert LoveDADataset.PALETTE == get_palette('loveda')
+ assert PotsdamDataset.PALETTE == get_palette('potsdam')
+ assert COCOStuffDataset.PALETTE == get_palette('cocostuff')
+
+ with pytest.raises(ValueError):
+ get_palette('unsupported')
+
+
+@patch('mmseg.datasets.CustomDataset.load_annotations', MagicMock)
+@patch('mmseg.datasets.CustomDataset.__getitem__',
+ MagicMock(side_effect=lambda idx: idx))
+def test_dataset_wrapper():
+ # CustomDataset.load_annotations = MagicMock()
+ # CustomDataset.__getitem__ = MagicMock(side_effect=lambda idx: idx)
+ dataset_a = CustomDataset(img_dir=MagicMock(), pipeline=[])
+ len_a = 10
+ dataset_a.img_infos = MagicMock()
+ dataset_a.img_infos.__len__.return_value = len_a
+ dataset_b = CustomDataset(img_dir=MagicMock(), pipeline=[])
+ len_b = 20
+ dataset_b.img_infos = MagicMock()
+ dataset_b.img_infos.__len__.return_value = len_b
+
+ concat_dataset = ConcatDataset([dataset_a, dataset_b])
+ assert concat_dataset[5] == 5
+ assert concat_dataset[25] == 15
+ assert len(concat_dataset) == len(dataset_a) + len(dataset_b)
+
+ repeat_dataset = RepeatDataset(dataset_a, 10)
+ assert repeat_dataset[5] == 5
+ assert repeat_dataset[15] == 5
+ assert repeat_dataset[27] == 7
+ assert len(repeat_dataset) == 10 * len(dataset_a)
+
+ img_scale = (60, 60)
+ pipeline = [
+ dict(type='RandomMosaic', prob=1, img_scale=img_scale),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Resize', img_scale=img_scale, keep_ratio=False),
+ ]
+
+ CustomDataset.load_annotations = MagicMock()
+ results = []
+ for _ in range(2):
+ height = np.random.randint(10, 30)
+ weight = np.random.randint(10, 30)
+ img = np.ones((height, weight, 3))
+ gt_semantic_seg = np.random.randint(5, size=(height, weight))
+ results.append(dict(gt_semantic_seg=gt_semantic_seg, img=img))
+
+ classes = ['0', '1', '2', '3', '4']
+ palette = [(0, 0, 0), (1, 1, 1), (2, 2, 2), (3, 3, 3), (4, 4, 4)]
+ CustomDataset.__getitem__ = MagicMock(side_effect=lambda idx: results[idx])
+ dataset_a = CustomDataset(
+ img_dir=MagicMock(),
+ pipeline=[],
+ test_mode=True,
+ classes=classes,
+ palette=palette)
+ len_a = 2
+ dataset_a.img_infos = MagicMock()
+ dataset_a.img_infos.__len__.return_value = len_a
+
+ multi_image_mix_dataset = MultiImageMixDataset(dataset_a, pipeline)
+ assert len(multi_image_mix_dataset) == len(dataset_a)
+
+ for idx in range(len_a):
+ results_ = multi_image_mix_dataset[idx]
+
+ # test skip_type_keys
+ multi_image_mix_dataset = MultiImageMixDataset(
+ dataset_a, pipeline, skip_type_keys=('RandomFlip'))
+ for idx in range(len_a):
+ results_ = multi_image_mix_dataset[idx]
+ assert results_['img'].shape == (img_scale[0], img_scale[1], 3)
+
+ skip_type_keys = ('RandomFlip', 'Resize')
+ multi_image_mix_dataset.update_skip_type_keys(skip_type_keys)
+ for idx in range(len_a):
+ results_ = multi_image_mix_dataset[idx]
+ assert results_['img'].shape[:2] != img_scale
+
+ # test pipeline
+ with pytest.raises(TypeError):
+ pipeline = [['Resize']]
+ multi_image_mix_dataset = MultiImageMixDataset(dataset_a, pipeline)
+
+
+def test_custom_dataset():
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True)
+ crop_size = (512, 1024)
+ train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(128, 256), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+ ]
+ test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(128, 256),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+ ]
+
+ # with img_dir and ann_dir
+ train_dataset = CustomDataset(
+ train_pipeline,
+ data_root=osp.join(osp.dirname(__file__), '../data/pseudo_dataset'),
+ img_dir='imgs/',
+ ann_dir='gts/',
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png')
+ assert len(train_dataset) == 5
+
+ # with img_dir, ann_dir, split
+ train_dataset = CustomDataset(
+ train_pipeline,
+ data_root=osp.join(osp.dirname(__file__), '../data/pseudo_dataset'),
+ img_dir='imgs/',
+ ann_dir='gts/',
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png',
+ split='splits/train.txt')
+ assert len(train_dataset) == 4
+
+ # no data_root
+ train_dataset = CustomDataset(
+ train_pipeline,
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'),
+ ann_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/gts'),
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png')
+ assert len(train_dataset) == 5
+
+ # with data_root but img_dir/ann_dir are abs path
+ train_dataset = CustomDataset(
+ train_pipeline,
+ data_root=osp.join(osp.dirname(__file__), '../data/pseudo_dataset'),
+ img_dir=osp.abspath(
+ osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs')),
+ ann_dir=osp.abspath(
+ osp.join(osp.dirname(__file__), '../data/pseudo_dataset/gts')),
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png')
+ assert len(train_dataset) == 5
+
+ # test_mode=True
+ test_dataset = CustomDataset(
+ test_pipeline,
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'),
+ img_suffix='img.jpg',
+ test_mode=True,
+ classes=('pseudo_class', ))
+ assert len(test_dataset) == 5
+
+ # training data get
+ train_data = train_dataset[0]
+ assert isinstance(train_data, dict)
+
+ # test data get
+ test_data = test_dataset[0]
+ assert isinstance(test_data, dict)
+
+ # get gt seg map
+ gt_seg_maps = train_dataset.get_gt_seg_maps(efficient_test=True)
+ assert isinstance(gt_seg_maps, Generator)
+ gt_seg_maps = list(gt_seg_maps)
+ assert len(gt_seg_maps) == 5
+
+ # format_results not implemented
+ with pytest.raises(NotImplementedError):
+ test_dataset.format_results([], '')
+
+ pseudo_results = []
+ for gt_seg_map in gt_seg_maps:
+ h, w = gt_seg_map.shape
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+
+ # test past evaluation without CLASSES
+ with pytest.raises(TypeError):
+ eval_results = train_dataset.evaluate(pseudo_results, metric=['mIoU'])
+
+ with pytest.raises(TypeError):
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mDice')
+
+ with pytest.raises(TypeError):
+ eval_results = train_dataset.evaluate(
+ pseudo_results, metric=['mDice', 'mIoU'])
+
+ # test past evaluation with CLASSES
+ train_dataset.CLASSES = tuple(['a'] * 7)
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mIoU')
+ assert isinstance(eval_results, dict)
+ assert 'mIoU' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mDice')
+ assert isinstance(eval_results, dict)
+ assert 'mDice' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mFscore')
+ assert isinstance(eval_results, dict)
+ assert 'mRecall' in eval_results
+ assert 'mPrecision' in eval_results
+ assert 'mFscore' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(
+ pseudo_results, metric=['mIoU', 'mDice', 'mFscore'])
+ assert isinstance(eval_results, dict)
+ assert 'mIoU' in eval_results
+ assert 'mDice' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+ assert 'mFscore' in eval_results
+ assert 'mPrecision' in eval_results
+ assert 'mRecall' in eval_results
+
+ assert not np.isnan(eval_results['mIoU'])
+ assert not np.isnan(eval_results['mDice'])
+ assert not np.isnan(eval_results['mAcc'])
+ assert not np.isnan(eval_results['aAcc'])
+ assert not np.isnan(eval_results['mFscore'])
+ assert not np.isnan(eval_results['mPrecision'])
+ assert not np.isnan(eval_results['mRecall'])
+
+ # test evaluation with pre-eval and the dataset.CLASSES is necessary
+ train_dataset.CLASSES = tuple(['a'] * 7)
+ pseudo_results = []
+ for idx in range(len(train_dataset)):
+ h, w = gt_seg_maps[idx].shape
+ pseudo_result = np.random.randint(low=0, high=7, size=(h, w))
+ pseudo_results.extend(train_dataset.pre_eval(pseudo_result, idx))
+ eval_results = train_dataset.evaluate(pseudo_results, metric=['mIoU'])
+ assert isinstance(eval_results, dict)
+ assert 'mIoU' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mDice')
+ assert isinstance(eval_results, dict)
+ assert 'mDice' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mFscore')
+ assert isinstance(eval_results, dict)
+ assert 'mRecall' in eval_results
+ assert 'mPrecision' in eval_results
+ assert 'mFscore' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(
+ pseudo_results, metric=['mIoU', 'mDice', 'mFscore'])
+ assert isinstance(eval_results, dict)
+ assert 'mIoU' in eval_results
+ assert 'mDice' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+ assert 'mFscore' in eval_results
+ assert 'mPrecision' in eval_results
+ assert 'mRecall' in eval_results
+
+ assert not np.isnan(eval_results['mIoU'])
+ assert not np.isnan(eval_results['mDice'])
+ assert not np.isnan(eval_results['mAcc'])
+ assert not np.isnan(eval_results['aAcc'])
+ assert not np.isnan(eval_results['mFscore'])
+ assert not np.isnan(eval_results['mPrecision'])
+ assert not np.isnan(eval_results['mRecall'])
+
+
+@pytest.mark.parametrize('separate_eval', [True, False])
+def test_eval_concat_custom_dataset(separate_eval):
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True)
+ test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(128, 256),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+ ]
+ data_root = osp.join(osp.dirname(__file__), '../data/pseudo_dataset')
+ img_dir = 'imgs/'
+ ann_dir = 'gts/'
+
+ cfg1 = dict(
+ type='CustomDataset',
+ pipeline=test_pipeline,
+ data_root=data_root,
+ img_dir=img_dir,
+ ann_dir=ann_dir,
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png',
+ classes=tuple(['a'] * 7))
+ dataset1 = build_dataset(cfg1)
+ assert len(dataset1) == 5
+ # get gt seg map
+ gt_seg_maps = dataset1.get_gt_seg_maps(efficient_test=True)
+ assert isinstance(gt_seg_maps, Generator)
+ gt_seg_maps = list(gt_seg_maps)
+ assert len(gt_seg_maps) == 5
+
+ # test past evaluation
+ pseudo_results = []
+ for gt_seg_map in gt_seg_maps:
+ h, w = gt_seg_map.shape
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+ eval_results1 = dataset1.evaluate(
+ pseudo_results, metric=['mIoU', 'mDice', 'mFscore'])
+
+ # We use same dir twice for simplicity
+ # with ann_dir
+ cfg2 = dict(
+ type='CustomDataset',
+ pipeline=test_pipeline,
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ ann_dir=[ann_dir, ann_dir],
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png',
+ classes=tuple(['a'] * 7),
+ separate_eval=separate_eval)
+ dataset2 = build_dataset(cfg2)
+ assert isinstance(dataset2, ConcatDataset)
+ assert len(dataset2) == 10
+
+ eval_results2 = dataset2.evaluate(
+ pseudo_results * 2, metric=['mIoU', 'mDice', 'mFscore'])
+
+ if separate_eval:
+ assert eval_results1['mIoU'] == eval_results2[
+ '0_mIoU'] == eval_results2['1_mIoU']
+ assert eval_results1['mDice'] == eval_results2[
+ '0_mDice'] == eval_results2['1_mDice']
+ assert eval_results1['mAcc'] == eval_results2[
+ '0_mAcc'] == eval_results2['1_mAcc']
+ assert eval_results1['aAcc'] == eval_results2[
+ '0_aAcc'] == eval_results2['1_aAcc']
+ assert eval_results1['mFscore'] == eval_results2[
+ '0_mFscore'] == eval_results2['1_mFscore']
+ assert eval_results1['mPrecision'] == eval_results2[
+ '0_mPrecision'] == eval_results2['1_mPrecision']
+ assert eval_results1['mRecall'] == eval_results2[
+ '0_mRecall'] == eval_results2['1_mRecall']
+ else:
+ assert eval_results1['mIoU'] == eval_results2['mIoU']
+ assert eval_results1['mDice'] == eval_results2['mDice']
+ assert eval_results1['mAcc'] == eval_results2['mAcc']
+ assert eval_results1['aAcc'] == eval_results2['aAcc']
+ assert eval_results1['mFscore'] == eval_results2['mFscore']
+ assert eval_results1['mPrecision'] == eval_results2['mPrecision']
+ assert eval_results1['mRecall'] == eval_results2['mRecall']
+
+ # test get dataset_idx and sample_idx from ConcateDataset
+ dataset_idx, sample_idx = dataset2.get_dataset_idx_and_sample_idx(3)
+ assert dataset_idx == 0
+ assert sample_idx == 3
+
+ dataset_idx, sample_idx = dataset2.get_dataset_idx_and_sample_idx(7)
+ assert dataset_idx == 1
+ assert sample_idx == 2
+
+ dataset_idx, sample_idx = dataset2.get_dataset_idx_and_sample_idx(-7)
+ assert dataset_idx == 0
+ assert sample_idx == 3
+
+ # test negative indice exceed length of dataset
+ with pytest.raises(ValueError):
+ dataset_idx, sample_idx = dataset2.get_dataset_idx_and_sample_idx(-11)
+
+ # test negative indice value
+ indice = -6
+ dataset_idx1, sample_idx1 = dataset2.get_dataset_idx_and_sample_idx(indice)
+ dataset_idx2, sample_idx2 = dataset2.get_dataset_idx_and_sample_idx(
+ len(dataset2) + indice)
+ assert dataset_idx1 == dataset_idx2
+ assert sample_idx1 == sample_idx2
+
+ # test evaluation with pre-eval and the dataset.CLASSES is necessary
+ pseudo_results = []
+ eval_results1 = []
+ for idx in range(len(dataset1)):
+ h, w = gt_seg_maps[idx].shape
+ pseudo_result = np.random.randint(low=0, high=7, size=(h, w))
+ pseudo_results.append(pseudo_result)
+ eval_results1.extend(dataset1.pre_eval(pseudo_result, idx))
+
+ assert len(eval_results1) == len(dataset1)
+ assert isinstance(eval_results1[0], tuple)
+ assert len(eval_results1[0]) == 4
+ assert isinstance(eval_results1[0][0], torch.Tensor)
+
+ eval_results1 = dataset1.evaluate(
+ eval_results1, metric=['mIoU', 'mDice', 'mFscore'])
+
+ pseudo_results = pseudo_results * 2
+ eval_results2 = []
+ for idx in range(len(dataset2)):
+ eval_results2.extend(dataset2.pre_eval(pseudo_results[idx], idx))
+
+ assert len(eval_results2) == len(dataset2)
+ assert isinstance(eval_results2[0], tuple)
+ assert len(eval_results2[0]) == 4
+ assert isinstance(eval_results2[0][0], torch.Tensor)
+
+ eval_results2 = dataset2.evaluate(
+ eval_results2, metric=['mIoU', 'mDice', 'mFscore'])
+
+ if separate_eval:
+ assert eval_results1['mIoU'] == eval_results2[
+ '0_mIoU'] == eval_results2['1_mIoU']
+ assert eval_results1['mDice'] == eval_results2[
+ '0_mDice'] == eval_results2['1_mDice']
+ assert eval_results1['mAcc'] == eval_results2[
+ '0_mAcc'] == eval_results2['1_mAcc']
+ assert eval_results1['aAcc'] == eval_results2[
+ '0_aAcc'] == eval_results2['1_aAcc']
+ assert eval_results1['mFscore'] == eval_results2[
+ '0_mFscore'] == eval_results2['1_mFscore']
+ assert eval_results1['mPrecision'] == eval_results2[
+ '0_mPrecision'] == eval_results2['1_mPrecision']
+ assert eval_results1['mRecall'] == eval_results2[
+ '0_mRecall'] == eval_results2['1_mRecall']
+ else:
+ assert eval_results1['mIoU'] == eval_results2['mIoU']
+ assert eval_results1['mDice'] == eval_results2['mDice']
+ assert eval_results1['mAcc'] == eval_results2['mAcc']
+ assert eval_results1['aAcc'] == eval_results2['aAcc']
+ assert eval_results1['mFscore'] == eval_results2['mFscore']
+ assert eval_results1['mPrecision'] == eval_results2['mPrecision']
+ assert eval_results1['mRecall'] == eval_results2['mRecall']
+
+ # test batch_indices for pre eval
+ eval_results2 = dataset2.pre_eval(pseudo_results,
+ list(range(len(pseudo_results))))
+
+ assert len(eval_results2) == len(dataset2)
+ assert isinstance(eval_results2[0], tuple)
+ assert len(eval_results2[0]) == 4
+ assert isinstance(eval_results2[0][0], torch.Tensor)
+
+ eval_results2 = dataset2.evaluate(
+ eval_results2, metric=['mIoU', 'mDice', 'mFscore'])
+
+ if separate_eval:
+ assert eval_results1['mIoU'] == eval_results2[
+ '0_mIoU'] == eval_results2['1_mIoU']
+ assert eval_results1['mDice'] == eval_results2[
+ '0_mDice'] == eval_results2['1_mDice']
+ assert eval_results1['mAcc'] == eval_results2[
+ '0_mAcc'] == eval_results2['1_mAcc']
+ assert eval_results1['aAcc'] == eval_results2[
+ '0_aAcc'] == eval_results2['1_aAcc']
+ assert eval_results1['mFscore'] == eval_results2[
+ '0_mFscore'] == eval_results2['1_mFscore']
+ assert eval_results1['mPrecision'] == eval_results2[
+ '0_mPrecision'] == eval_results2['1_mPrecision']
+ assert eval_results1['mRecall'] == eval_results2[
+ '0_mRecall'] == eval_results2['1_mRecall']
+ else:
+ assert eval_results1['mIoU'] == eval_results2['mIoU']
+ assert eval_results1['mDice'] == eval_results2['mDice']
+ assert eval_results1['mAcc'] == eval_results2['mAcc']
+ assert eval_results1['aAcc'] == eval_results2['aAcc']
+ assert eval_results1['mFscore'] == eval_results2['mFscore']
+ assert eval_results1['mPrecision'] == eval_results2['mPrecision']
+ assert eval_results1['mRecall'] == eval_results2['mRecall']
+
+
+def test_ade():
+ test_dataset = ADE20KDataset(
+ pipeline=[],
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'))
+ assert len(test_dataset) == 5
+
+ # Test format_results
+ pseudo_results = []
+ for _ in range(len(test_dataset)):
+ h, w = (2, 2)
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+
+ file_paths = test_dataset.format_results(pseudo_results, '.format_ade')
+ assert len(file_paths) == len(test_dataset)
+ temp = np.array(Image.open(file_paths[0]))
+ assert np.allclose(temp, pseudo_results[0] + 1)
+
+ shutil.rmtree('.format_ade')
+
+
+@pytest.mark.parametrize('separate_eval', [True, False])
+def test_concat_ade(separate_eval):
+ test_dataset = ADE20KDataset(
+ pipeline=[],
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'))
+ assert len(test_dataset) == 5
+
+ concat_dataset = ConcatDataset([test_dataset, test_dataset],
+ separate_eval=separate_eval)
+ assert len(concat_dataset) == 10
+ # Test format_results
+ pseudo_results = []
+ for _ in range(len(concat_dataset)):
+ h, w = (2, 2)
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+
+ # test format per image
+ file_paths = []
+ for i in range(len(pseudo_results)):
+ file_paths.extend(
+ concat_dataset.format_results([pseudo_results[i]],
+ '.format_ade',
+ indices=[i]))
+ assert len(file_paths) == len(concat_dataset)
+ temp = np.array(Image.open(file_paths[0]))
+ assert np.allclose(temp, pseudo_results[0] + 1)
+
+ shutil.rmtree('.format_ade')
+
+ # test default argument
+ file_paths = concat_dataset.format_results(pseudo_results, '.format_ade')
+ assert len(file_paths) == len(concat_dataset)
+ temp = np.array(Image.open(file_paths[0]))
+ assert np.allclose(temp, pseudo_results[0] + 1)
+
+ shutil.rmtree('.format_ade')
+
+
+def test_cityscapes():
+ test_dataset = CityscapesDataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__),
+ '../data/pseudo_cityscapes_dataset/leftImg8bit'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_cityscapes_dataset/gtFine'))
+ assert len(test_dataset) == 1
+
+ gt_seg_maps = list(test_dataset.get_gt_seg_maps())
+
+ # Test format_results
+ pseudo_results = []
+ for idx in range(len(test_dataset)):
+ h, w = gt_seg_maps[idx].shape
+ pseudo_results.append(np.random.randint(low=0, high=19, size=(h, w)))
+
+ file_paths = test_dataset.format_results(pseudo_results, '.format_city')
+ assert len(file_paths) == len(test_dataset)
+ temp = np.array(Image.open(file_paths[0]))
+ assert np.allclose(temp,
+ test_dataset._convert_to_label_id(pseudo_results[0]))
+
+ # Test cityscapes evaluate
+
+ test_dataset.evaluate(
+ pseudo_results, metric='cityscapes', imgfile_prefix='.format_city')
+
+ shutil.rmtree('.format_city')
+
+
+@pytest.mark.parametrize('separate_eval', [True, False])
+def test_concat_cityscapes(separate_eval):
+ cityscape_dataset = CityscapesDataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__),
+ '../data/pseudo_cityscapes_dataset/leftImg8bit'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_cityscapes_dataset/gtFine'))
+ assert len(cityscape_dataset) == 1
+ with pytest.raises(NotImplementedError):
+ _ = ConcatDataset([cityscape_dataset, cityscape_dataset],
+ separate_eval=separate_eval)
+ ade_dataset = ADE20KDataset(
+ pipeline=[],
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'))
+ assert len(ade_dataset) == 5
+ with pytest.raises(NotImplementedError):
+ _ = ConcatDataset([cityscape_dataset, ade_dataset],
+ separate_eval=separate_eval)
+
+
+def test_loveda():
+ test_dataset = LoveDADataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_loveda_dataset/img_dir'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_loveda_dataset/ann_dir'))
+ assert len(test_dataset) == 3
+
+ gt_seg_maps = list(test_dataset.get_gt_seg_maps())
+
+ # Test format_results
+ pseudo_results = []
+ for idx in range(len(test_dataset)):
+ h, w = gt_seg_maps[idx].shape
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+ file_paths = test_dataset.format_results(pseudo_results, '.format_loveda')
+ assert len(file_paths) == len(test_dataset)
+ # Test loveda evaluate
+
+ test_dataset.evaluate(
+ pseudo_results, metric='mIoU', imgfile_prefix='.format_loveda')
+
+ shutil.rmtree('.format_loveda')
+
+
+def test_potsdam():
+ test_dataset = PotsdamDataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_potsdam_dataset/img_dir'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_potsdam_dataset/ann_dir'))
+ assert len(test_dataset) == 1
+
+
+def test_vaihingen():
+ test_dataset = ISPRSDataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_vaihingen_dataset/img_dir'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_vaihingen_dataset/ann_dir'))
+ assert len(test_dataset) == 1
+
+
+@patch('mmseg.datasets.CustomDataset.load_annotations', MagicMock)
+@patch('mmseg.datasets.CustomDataset.__getitem__',
+ MagicMock(side_effect=lambda idx: idx))
+@pytest.mark.parametrize('dataset, classes', [
+ ('ADE20KDataset', ('wall', 'building')),
+ ('CityscapesDataset', ('road', 'sidewalk')),
+ ('CustomDataset', ('bus', 'car')),
+ ('PascalVOCDataset', ('aeroplane', 'bicycle')),
+])
+def test_custom_classes_override_default(dataset, classes):
+
+ dataset_class = DATASETS.get(dataset)
+
+ original_classes = dataset_class.CLASSES
+
+ # Test setting classes as a tuple
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=classes,
+ test_mode=True)
+
+ assert custom_dataset.CLASSES != original_classes
+ assert custom_dataset.CLASSES == classes
+
+ # Test setting classes as a list
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=list(classes),
+ test_mode=True)
+
+ assert custom_dataset.CLASSES != original_classes
+ assert custom_dataset.CLASSES == list(classes)
+
+ # Test overriding not a subset
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=[classes[0]],
+ test_mode=True)
+
+ assert custom_dataset.CLASSES != original_classes
+ assert custom_dataset.CLASSES == [classes[0]]
+
+ # Test default behavior
+ if dataset_class is CustomDataset:
+ with pytest.raises(AssertionError):
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=None,
+ test_mode=True)
+ else:
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=None,
+ test_mode=True)
+
+ assert custom_dataset.CLASSES == original_classes
+
+
+@patch('mmseg.datasets.CustomDataset.load_annotations', MagicMock)
+@patch('mmseg.datasets.CustomDataset.__getitem__',
+ MagicMock(side_effect=lambda idx: idx))
+def test_custom_dataset_random_palette_is_generated():
+ dataset = CustomDataset(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=('bus', 'car'),
+ test_mode=True)
+ assert len(dataset.PALETTE) == 2
+ for class_color in dataset.PALETTE:
+ assert len(class_color) == 3
+ assert all(x >= 0 and x <= 255 for x in class_color)
+
+
+@patch('mmseg.datasets.CustomDataset.load_annotations', MagicMock)
+@patch('mmseg.datasets.CustomDataset.__getitem__',
+ MagicMock(side_effect=lambda idx: idx))
+def test_custom_dataset_custom_palette():
+ dataset = CustomDataset(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=('bus', 'car'),
+ palette=[[100, 100, 100], [200, 200, 200]],
+ test_mode=True)
+ assert tuple(dataset.PALETTE) == tuple([[100, 100, 100], [200, 200, 200]])
diff --git a/tests/test_data/test_dataset_builder.py b/tests/test_data/test_dataset_builder.py
new file mode 100644
index 0000000..30910b0
--- /dev/null
+++ b/tests/test_data/test_dataset_builder.py
@@ -0,0 +1,200 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import os.path as osp
+
+import pytest
+from torch.utils.data import (DistributedSampler, RandomSampler,
+ SequentialSampler)
+
+from mmseg.datasets import (DATASETS, ConcatDataset, MultiImageMixDataset,
+ build_dataloader, build_dataset)
+
+
+@DATASETS.register_module()
+class ToyDataset(object):
+
+ def __init__(self, cnt=0):
+ self.cnt = cnt
+
+ def __item__(self, idx):
+ return idx
+
+ def __len__(self):
+ return 100
+
+
+def test_build_dataset():
+ cfg = dict(type='ToyDataset')
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ToyDataset)
+ assert dataset.cnt == 0
+ dataset = build_dataset(cfg, default_args=dict(cnt=1))
+ assert isinstance(dataset, ToyDataset)
+ assert dataset.cnt == 1
+
+ data_root = osp.join(osp.dirname(__file__), '../data/pseudo_dataset')
+ img_dir = 'imgs/'
+ ann_dir = 'gts/'
+
+ # We use same dir twice for simplicity
+ # with ann_dir
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ ann_dir=[ann_dir, ann_dir])
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 10
+
+ cfg = dict(type='MultiImageMixDataset', dataset=cfg, pipeline=[])
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, MultiImageMixDataset)
+ assert len(dataset) == 10
+
+ # with ann_dir, split
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=img_dir,
+ ann_dir=ann_dir,
+ split=['splits/train.txt', 'splits/val.txt'])
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 5
+
+ # with ann_dir, split
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=img_dir,
+ ann_dir=[ann_dir, ann_dir],
+ split=['splits/train.txt', 'splits/val.txt'])
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 5
+
+ # test mode
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ test_mode=True,
+ classes=('pseudo_class', ))
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 10
+
+ # test mode with splits
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ split=['splits/val.txt', 'splits/val.txt'],
+ test_mode=True,
+ classes=('pseudo_class', ))
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 2
+
+ # len(ann_dir) should be zero or len(img_dir) when len(img_dir) > 1
+ with pytest.raises(AssertionError):
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ ann_dir=[ann_dir, ann_dir, ann_dir])
+ build_dataset(cfg)
+
+ # len(splits) should be zero or len(img_dir) when len(img_dir) > 1
+ with pytest.raises(AssertionError):
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ split=['splits/val.txt', 'splits/val.txt', 'splits/val.txt'])
+ build_dataset(cfg)
+
+ # len(splits) == len(ann_dir) when only len(img_dir) == 1 and len(
+ # ann_dir) > 1
+ with pytest.raises(AssertionError):
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=img_dir,
+ ann_dir=[ann_dir, ann_dir],
+ split=['splits/val.txt', 'splits/val.txt', 'splits/val.txt'])
+ build_dataset(cfg)
+
+
+def test_build_dataloader():
+ dataset = ToyDataset()
+ samples_per_gpu = 3
+ # dist=True, shuffle=True, 1GPU
+ dataloader = build_dataloader(
+ dataset, samples_per_gpu=samples_per_gpu, workers_per_gpu=2)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert isinstance(dataloader.sampler, DistributedSampler)
+ assert dataloader.sampler.shuffle
+
+ # dist=True, shuffle=False, 1GPU
+ dataloader = build_dataloader(
+ dataset,
+ samples_per_gpu=samples_per_gpu,
+ workers_per_gpu=2,
+ shuffle=False)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert isinstance(dataloader.sampler, DistributedSampler)
+ assert not dataloader.sampler.shuffle
+
+ # dist=True, shuffle=True, 8GPU
+ dataloader = build_dataloader(
+ dataset,
+ samples_per_gpu=samples_per_gpu,
+ workers_per_gpu=2,
+ num_gpus=8)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert dataloader.num_workers == 2
+
+ # dist=False, shuffle=True, 1GPU
+ dataloader = build_dataloader(
+ dataset,
+ samples_per_gpu=samples_per_gpu,
+ workers_per_gpu=2,
+ dist=False)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert isinstance(dataloader.sampler, RandomSampler)
+ assert dataloader.num_workers == 2
+
+ # dist=False, shuffle=False, 1GPU
+ dataloader = build_dataloader(
+ dataset,
+ samples_per_gpu=3,
+ workers_per_gpu=2,
+ shuffle=False,
+ dist=False)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert isinstance(dataloader.sampler, SequentialSampler)
+ assert dataloader.num_workers == 2
+
+ # dist=False, shuffle=True, 8GPU
+ dataloader = build_dataloader(
+ dataset, samples_per_gpu=3, workers_per_gpu=2, num_gpus=8, dist=False)
+ assert dataloader.batch_size == samples_per_gpu * 8
+ assert len(dataloader) == int(
+ math.ceil(len(dataset) / samples_per_gpu / 8))
+ assert isinstance(dataloader.sampler, RandomSampler)
+ assert dataloader.num_workers == 16
diff --git a/tests/test_data/test_loading.py b/tests/test_data/test_loading.py
new file mode 100644
index 0000000..fdda93e
--- /dev/null
+++ b/tests/test_data/test_loading.py
@@ -0,0 +1,199 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+import tempfile
+
+import mmcv
+import numpy as np
+
+from mmseg.datasets.pipelines import LoadAnnotations, LoadImageFromFile
+
+
+class TestLoading(object):
+
+ @classmethod
+ def setup_class(cls):
+ cls.data_prefix = osp.join(osp.dirname(__file__), '../data')
+
+ def test_load_img(self):
+ results = dict(
+ img_prefix=self.data_prefix, img_info=dict(filename='color.jpg'))
+ transform = LoadImageFromFile()
+ results = transform(copy.deepcopy(results))
+ assert results['filename'] == osp.join(self.data_prefix, 'color.jpg')
+ assert results['ori_filename'] == 'color.jpg'
+ assert results['img'].shape == (288, 512, 3)
+ assert results['img'].dtype == np.uint8
+ assert results['img_shape'] == (288, 512, 3)
+ assert results['ori_shape'] == (288, 512, 3)
+ assert results['pad_shape'] == (288, 512, 3)
+ assert results['scale_factor'] == 1.0
+ np.testing.assert_equal(results['img_norm_cfg']['mean'],
+ np.zeros(3, dtype=np.float32))
+ assert repr(transform) == transform.__class__.__name__ + \
+ "(to_float32=False,color_type='color',imdecode_backend='cv2')"
+
+ # no img_prefix
+ results = dict(
+ img_prefix=None, img_info=dict(filename='tests/data/color.jpg'))
+ transform = LoadImageFromFile()
+ results = transform(copy.deepcopy(results))
+ assert results['filename'] == 'tests/data/color.jpg'
+ assert results['ori_filename'] == 'tests/data/color.jpg'
+ assert results['img'].shape == (288, 512, 3)
+
+ # to_float32
+ transform = LoadImageFromFile(to_float32=True)
+ results = transform(copy.deepcopy(results))
+ assert results['img'].dtype == np.float32
+
+ # gray image
+ results = dict(
+ img_prefix=self.data_prefix, img_info=dict(filename='gray.jpg'))
+ transform = LoadImageFromFile()
+ results = transform(copy.deepcopy(results))
+ assert results['img'].shape == (288, 512, 3)
+ assert results['img'].dtype == np.uint8
+
+ transform = LoadImageFromFile(color_type='unchanged')
+ results = transform(copy.deepcopy(results))
+ assert results['img'].shape == (288, 512)
+ assert results['img'].dtype == np.uint8
+ np.testing.assert_equal(results['img_norm_cfg']['mean'],
+ np.zeros(1, dtype=np.float32))
+
+ def test_load_seg(self):
+ results = dict(
+ seg_prefix=self.data_prefix,
+ ann_info=dict(seg_map='seg.png'),
+ seg_fields=[])
+ transform = LoadAnnotations()
+ results = transform(copy.deepcopy(results))
+ assert results['seg_fields'] == ['gt_semantic_seg']
+ assert results['gt_semantic_seg'].shape == (288, 512)
+ assert results['gt_semantic_seg'].dtype == np.uint8
+ assert repr(transform) == transform.__class__.__name__ + \
+ "(reduce_zero_label=False,imdecode_backend='pillow')"
+
+ # no img_prefix
+ results = dict(
+ seg_prefix=None,
+ ann_info=dict(seg_map='tests/data/seg.png'),
+ seg_fields=[])
+ transform = LoadAnnotations()
+ results = transform(copy.deepcopy(results))
+ assert results['gt_semantic_seg'].shape == (288, 512)
+ assert results['gt_semantic_seg'].dtype == np.uint8
+
+ # reduce_zero_label
+ transform = LoadAnnotations(reduce_zero_label=True)
+ results = transform(copy.deepcopy(results))
+ assert results['gt_semantic_seg'].shape == (288, 512)
+ assert results['gt_semantic_seg'].dtype == np.uint8
+
+ # mmcv backend
+ results = dict(
+ seg_prefix=self.data_prefix,
+ ann_info=dict(seg_map='seg.png'),
+ seg_fields=[])
+ transform = LoadAnnotations(imdecode_backend='pillow')
+ results = transform(copy.deepcopy(results))
+ # this image is saved by PIL
+ assert results['gt_semantic_seg'].shape == (288, 512)
+ assert results['gt_semantic_seg'].dtype == np.uint8
+
+ def test_load_seg_custom_classes(self):
+
+ test_img = np.random.rand(10, 10)
+ test_gt = np.zeros_like(test_img)
+ test_gt[2:4, 2:4] = 1
+ test_gt[2:4, 6:8] = 2
+ test_gt[6:8, 2:4] = 3
+ test_gt[6:8, 6:8] = 4
+
+ tmp_dir = tempfile.TemporaryDirectory()
+ img_path = osp.join(tmp_dir.name, 'img.jpg')
+ gt_path = osp.join(tmp_dir.name, 'gt.png')
+
+ mmcv.imwrite(test_img, img_path)
+ mmcv.imwrite(test_gt, gt_path)
+
+ # test only train with label with id 3
+ results = dict(
+ img_info=dict(filename=img_path),
+ ann_info=dict(seg_map=gt_path),
+ label_map={
+ 0: 0,
+ 1: 0,
+ 2: 0,
+ 3: 1,
+ 4: 0
+ },
+ seg_fields=[])
+
+ load_imgs = LoadImageFromFile()
+ results = load_imgs(copy.deepcopy(results))
+
+ load_anns = LoadAnnotations()
+ results = load_anns(copy.deepcopy(results))
+
+ gt_array = results['gt_semantic_seg']
+
+ true_mask = np.zeros_like(gt_array)
+ true_mask[6:8, 2:4] = 1
+
+ assert results['seg_fields'] == ['gt_semantic_seg']
+ assert gt_array.shape == (10, 10)
+ assert gt_array.dtype == np.uint8
+ np.testing.assert_array_equal(gt_array, true_mask)
+
+ # test only train with label with id 4 and 3
+ results = dict(
+ img_info=dict(filename=img_path),
+ ann_info=dict(seg_map=gt_path),
+ label_map={
+ 0: 0,
+ 1: 0,
+ 2: 0,
+ 3: 2,
+ 4: 1
+ },
+ seg_fields=[])
+
+ load_imgs = LoadImageFromFile()
+ results = load_imgs(copy.deepcopy(results))
+
+ load_anns = LoadAnnotations()
+ results = load_anns(copy.deepcopy(results))
+
+ gt_array = results['gt_semantic_seg']
+
+ true_mask = np.zeros_like(gt_array)
+ true_mask[6:8, 2:4] = 2
+ true_mask[6:8, 6:8] = 1
+
+ assert results['seg_fields'] == ['gt_semantic_seg']
+ assert gt_array.shape == (10, 10)
+ assert gt_array.dtype == np.uint8
+ np.testing.assert_array_equal(gt_array, true_mask)
+
+ # test no custom classes
+ results = dict(
+ img_info=dict(filename=img_path),
+ ann_info=dict(seg_map=gt_path),
+ seg_fields=[])
+
+ load_imgs = LoadImageFromFile()
+ results = load_imgs(copy.deepcopy(results))
+
+ load_anns = LoadAnnotations()
+ results = load_anns(copy.deepcopy(results))
+
+ gt_array = results['gt_semantic_seg']
+
+ assert results['seg_fields'] == ['gt_semantic_seg']
+ assert gt_array.shape == (10, 10)
+ assert gt_array.dtype == np.uint8
+ np.testing.assert_array_equal(gt_array, test_gt)
+
+ tmp_dir.cleanup()
diff --git a/tests/test_data/test_transform.py b/tests/test_data/test_transform.py
new file mode 100644
index 0000000..e9aa1d7
--- /dev/null
+++ b/tests/test_data/test_transform.py
@@ -0,0 +1,665 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+
+import mmcv
+import numpy as np
+import pytest
+from mmcv.utils import build_from_cfg
+from PIL import Image
+
+from mmseg.datasets.builder import PIPELINES
+
+
+def test_resize_to_multiple():
+ transform = dict(type='ResizeToMultiple', size_divisor=32)
+ transform = build_from_cfg(transform, PIPELINES)
+
+ img = np.random.randn(213, 232, 3)
+ seg = np.random.randint(0, 19, (213, 232))
+ results = dict()
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['pad_shape'] = img.shape
+
+ results = transform(results)
+ assert results['img'].shape == (224, 256, 3)
+ assert results['gt_semantic_seg'].shape == (224, 256)
+ assert results['img_shape'] == (224, 256, 3)
+ assert results['pad_shape'] == (224, 256, 3)
+
+
+def test_resize():
+ # test assertion if img_scale is a list
+ with pytest.raises(AssertionError):
+ transform = dict(type='Resize', img_scale=[1333, 800], keep_ratio=True)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if len(img_scale) while ratio_range is not None
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='Resize',
+ img_scale=[(1333, 800), (1333, 600)],
+ ratio_range=(0.9, 1.1),
+ keep_ratio=True)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion for invalid multiscale_mode
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='Resize',
+ img_scale=[(1333, 800), (1333, 600)],
+ keep_ratio=True,
+ multiscale_mode='2333')
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='Resize', img_scale=(1333, 800), keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ # (288, 512, 3)
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ resized_results = resize_module(results.copy())
+ assert resized_results['img_shape'] == (750, 1333, 3)
+
+ # test keep_ratio=False
+ transform = dict(
+ type='Resize',
+ img_scale=(1280, 800),
+ multiscale_mode='value',
+ keep_ratio=False)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert resized_results['img_shape'] == (800, 1280, 3)
+
+ # test multiscale_mode='range'
+ transform = dict(
+ type='Resize',
+ img_scale=[(1333, 400), (1333, 1200)],
+ multiscale_mode='range',
+ keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert max(resized_results['img_shape'][:2]) <= 1333
+ assert min(resized_results['img_shape'][:2]) >= 400
+ assert min(resized_results['img_shape'][:2]) <= 1200
+
+ # test multiscale_mode='value'
+ transform = dict(
+ type='Resize',
+ img_scale=[(1333, 800), (1333, 400)],
+ multiscale_mode='value',
+ keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert resized_results['img_shape'] in [(750, 1333, 3), (400, 711, 3)]
+
+ # test multiscale_mode='range'
+ transform = dict(
+ type='Resize',
+ img_scale=(1333, 800),
+ ratio_range=(0.9, 1.1),
+ keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert max(resized_results['img_shape'][:2]) <= 1333 * 1.1
+
+ # test img_scale=None and ratio_range is tuple.
+ # img shape: (288, 512, 3)
+ transform = dict(
+ type='Resize', img_scale=None, ratio_range=(0.5, 2.0), keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert int(288 * 0.5) <= resized_results['img_shape'][0] <= 288 * 2.0
+ assert int(512 * 0.5) <= resized_results['img_shape'][1] <= 512 * 2.0
+
+
+def test_flip():
+ # test assertion for invalid prob
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomFlip', prob=1.5)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion for invalid direction
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomFlip', prob=1, direction='horizonta')
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='RandomFlip', prob=1)
+ flip_module = build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ original_seg = copy.deepcopy(seg)
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = flip_module(results)
+
+ flip_module = build_from_cfg(transform, PIPELINES)
+ results = flip_module(results)
+ assert np.equal(original_img, results['img']).all()
+ assert np.equal(original_seg, results['gt_semantic_seg']).all()
+
+
+def test_random_crop():
+ # test assertion for invalid random crop
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomCrop', crop_size=(-1, 0))
+ build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ h, w, _ = img.shape
+ transform = dict(type='RandomCrop', crop_size=(h - 20, w - 20))
+ crop_module = build_from_cfg(transform, PIPELINES)
+ results = crop_module(results)
+ assert results['img'].shape[:2] == (h - 20, w - 20)
+ assert results['img_shape'][:2] == (h - 20, w - 20)
+ assert results['gt_semantic_seg'].shape[:2] == (h - 20, w - 20)
+
+
+def test_pad():
+ # test assertion if both size_divisor and size is None
+ with pytest.raises(AssertionError):
+ transform = dict(type='Pad')
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='Pad', size_divisor=32)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+ # original img already divisible by 32
+ assert np.equal(results['img'], original_img).all()
+ img_shape = results['img'].shape
+ assert img_shape[0] % 32 == 0
+ assert img_shape[1] % 32 == 0
+
+ resize_transform = dict(
+ type='Resize', img_scale=(1333, 800), keep_ratio=True)
+ resize_module = build_from_cfg(resize_transform, PIPELINES)
+ results = resize_module(results)
+ results = transform(results)
+ img_shape = results['img'].shape
+ assert img_shape[0] % 32 == 0
+ assert img_shape[1] % 32 == 0
+
+
+def test_rotate():
+ # test assertion degree should be tuple[float] or float
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomRotate', prob=0.5, degree=-10)
+ build_from_cfg(transform, PIPELINES)
+ # test assertion degree should be tuple[float] or float
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomRotate', prob=0.5, degree=(10., 20., 30.))
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='RandomRotate', degree=10., prob=1.)
+ transform = build_from_cfg(transform, PIPELINES)
+
+ assert str(transform) == f'RandomRotate(' \
+ f'prob={1.}, ' \
+ f'degree=({-10.}, {10.}), ' \
+ f'pad_val={0}, ' \
+ f'seg_pad_val={255}, ' \
+ f'center={None}, ' \
+ f'auto_bound={False})'
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ h, w, _ = img.shape
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+ assert results['img'].shape[:2] == (h, w)
+ assert results['gt_semantic_seg'].shape[:2] == (h, w)
+
+
+def test_normalize():
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True)
+ transform = dict(type='Normalize', **img_norm_cfg)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+
+ mean = np.array(img_norm_cfg['mean'])
+ std = np.array(img_norm_cfg['std'])
+ converted_img = (original_img[..., ::-1] - mean) / std
+ assert np.allclose(results['img'], converted_img)
+
+
+def test_rgb2gray():
+ # test assertion out_channels should be greater than 0
+ with pytest.raises(AssertionError):
+ transform = dict(type='RGB2Gray', out_channels=-1)
+ build_from_cfg(transform, PIPELINES)
+ # test assertion weights should be tuple[float]
+ with pytest.raises(AssertionError):
+ transform = dict(type='RGB2Gray', out_channels=1, weights=1.1)
+ build_from_cfg(transform, PIPELINES)
+
+ # test out_channels is None
+ transform = dict(type='RGB2Gray')
+ transform = build_from_cfg(transform, PIPELINES)
+
+ assert str(transform) == f'RGB2Gray(' \
+ f'out_channels={None}, ' \
+ f'weights={(0.299, 0.587, 0.114)})'
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ h, w, c = img.shape
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+ assert results['img'].shape == (h, w, c)
+ assert results['img_shape'] == (h, w, c)
+ assert results['ori_shape'] == (h, w, c)
+
+ # test out_channels = 2
+ transform = dict(type='RGB2Gray', out_channels=2)
+ transform = build_from_cfg(transform, PIPELINES)
+
+ assert str(transform) == f'RGB2Gray(' \
+ f'out_channels={2}, ' \
+ f'weights={(0.299, 0.587, 0.114)})'
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ h, w, c = img.shape
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+ assert results['img'].shape == (h, w, 2)
+ assert results['img_shape'] == (h, w, 2)
+ assert results['ori_shape'] == (h, w, c)
+
+
+def test_adjust_gamma():
+ # test assertion if gamma <= 0
+ with pytest.raises(AssertionError):
+ transform = dict(type='AdjustGamma', gamma=0)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if gamma is list
+ with pytest.raises(AssertionError):
+ transform = dict(type='AdjustGamma', gamma=[1.2])
+ build_from_cfg(transform, PIPELINES)
+
+ # test with gamma = 1.2
+ transform = dict(type='AdjustGamma', gamma=1.2)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+
+ inv_gamma = 1.0 / 1.2
+ table = np.array([((i / 255.0)**inv_gamma) * 255
+ for i in np.arange(0, 256)]).astype('uint8')
+ converted_img = mmcv.lut_transform(
+ np.array(original_img, dtype=np.uint8), table)
+ assert np.allclose(results['img'], converted_img)
+ assert str(transform) == f'AdjustGamma(gamma={1.2})'
+
+
+def test_rerange():
+ # test assertion if min_value or max_value is illegal
+ with pytest.raises(AssertionError):
+ transform = dict(type='Rerange', min_value=[0], max_value=[255])
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if min_value >= max_value
+ with pytest.raises(AssertionError):
+ transform = dict(type='Rerange', min_value=1, max_value=1)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if img_min_value == img_max_value
+ with pytest.raises(AssertionError):
+ transform = dict(type='Rerange', min_value=0, max_value=1)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ results['img'] = np.array([[1, 1], [1, 1]])
+ transform(results)
+
+ img_rerange_cfg = dict()
+ transform = dict(type='Rerange', **img_rerange_cfg)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+
+ min_value = np.min(original_img)
+ max_value = np.max(original_img)
+ converted_img = (original_img - min_value) / (max_value - min_value) * 255
+
+ assert np.allclose(results['img'], converted_img)
+ assert str(transform) == f'Rerange(min_value={0}, max_value={255})'
+
+
+def test_CLAHE():
+ # test assertion if clip_limit is None
+ with pytest.raises(AssertionError):
+ transform = dict(type='CLAHE', clip_limit=None)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if tile_grid_size is illegal
+ with pytest.raises(AssertionError):
+ transform = dict(type='CLAHE', tile_grid_size=(8.0, 8.0))
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if tile_grid_size is illegal
+ with pytest.raises(AssertionError):
+ transform = dict(type='CLAHE', tile_grid_size=(9, 9, 9))
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='CLAHE', clip_limit=2)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+
+ converted_img = np.empty(original_img.shape)
+ for i in range(original_img.shape[2]):
+ converted_img[:, :, i] = mmcv.clahe(
+ np.array(original_img[:, :, i], dtype=np.uint8), 2, (8, 8))
+
+ assert np.allclose(results['img'], converted_img)
+ assert str(transform) == f'CLAHE(clip_limit={2}, tile_grid_size={(8, 8)})'
+
+
+def test_seg_rescale():
+ results = dict()
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ h, w = seg.shape
+
+ transform = dict(type='SegRescale', scale_factor=1. / 2)
+ rescale_module = build_from_cfg(transform, PIPELINES)
+ rescale_results = rescale_module(results.copy())
+ assert rescale_results['gt_semantic_seg'].shape == (h // 2, w // 2)
+
+ transform = dict(type='SegRescale', scale_factor=1)
+ rescale_module = build_from_cfg(transform, PIPELINES)
+ rescale_results = rescale_module(results.copy())
+ assert rescale_results['gt_semantic_seg'].shape == (h, w)
+
+
+def test_cutout():
+ # test prob
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomCutOut', prob=1.5, n_holes=1)
+ build_from_cfg(transform, PIPELINES)
+ # test n_holes
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut', prob=0.5, n_holes=(5, 3), cutout_shape=(8, 8))
+ build_from_cfg(transform, PIPELINES)
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut',
+ prob=0.5,
+ n_holes=(3, 4, 5),
+ cutout_shape=(8, 8))
+ build_from_cfg(transform, PIPELINES)
+ # test cutout_shape and cutout_ratio
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut', prob=0.5, n_holes=1, cutout_shape=8)
+ build_from_cfg(transform, PIPELINES)
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut', prob=0.5, n_holes=1, cutout_ratio=0.2)
+ build_from_cfg(transform, PIPELINES)
+ # either of cutout_shape and cutout_ratio should be given
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomCutOut', prob=0.5, n_holes=1)
+ build_from_cfg(transform, PIPELINES)
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut',
+ prob=0.5,
+ n_holes=1,
+ cutout_shape=(2, 2),
+ cutout_ratio=(0.4, 0.4))
+ build_from_cfg(transform, PIPELINES)
+ # test seg_fill_in
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut',
+ prob=0.5,
+ n_holes=1,
+ cutout_shape=(8, 8),
+ seg_fill_in='a')
+ build_from_cfg(transform, PIPELINES)
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut',
+ prob=0.5,
+ n_holes=1,
+ cutout_shape=(8, 8),
+ seg_fill_in=256)
+ build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ results['pad_shape'] = img.shape
+ results['img_fields'] = ['img']
+
+ transform = dict(
+ type='RandomCutOut', prob=1, n_holes=1, cutout_shape=(10, 10))
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ assert 'cutout_shape' in repr(cutout_module)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() < img.sum()
+
+ transform = dict(
+ type='RandomCutOut', prob=1, n_holes=1, cutout_ratio=(0.8, 0.8))
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ assert 'cutout_ratio' in repr(cutout_module)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() < img.sum()
+
+ transform = dict(
+ type='RandomCutOut', prob=0, n_holes=1, cutout_ratio=(0.8, 0.8))
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() == img.sum()
+ assert cutout_result['gt_semantic_seg'].sum() == seg.sum()
+
+ transform = dict(
+ type='RandomCutOut',
+ prob=1,
+ n_holes=(2, 4),
+ cutout_shape=[(10, 10), (15, 15)],
+ fill_in=(255, 255, 255),
+ seg_fill_in=None)
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() > img.sum()
+ assert cutout_result['gt_semantic_seg'].sum() == seg.sum()
+
+ transform = dict(
+ type='RandomCutOut',
+ prob=1,
+ n_holes=1,
+ cutout_ratio=(0.8, 0.8),
+ fill_in=(255, 255, 255),
+ seg_fill_in=255)
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() > img.sum()
+ assert cutout_result['gt_semantic_seg'].sum() > seg.sum()
+
+
+def test_mosaic():
+ # test prob
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomMosaic', prob=1.5)
+ build_from_cfg(transform, PIPELINES)
+ # test assertion for invalid img_scale
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomMosaic', prob=1, img_scale=640)
+ build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+
+ transform = dict(type='RandomMosaic', prob=1, img_scale=(10, 12))
+ mosaic_module = build_from_cfg(transform, PIPELINES)
+ assert 'Mosaic' in repr(mosaic_module)
+
+ # test assertion for invalid mix_results
+ with pytest.raises(AssertionError):
+ mosaic_module(results)
+
+ results['mix_results'] = [copy.deepcopy(results)] * 3
+ results = mosaic_module(results)
+ assert results['img'].shape[:2] == (20, 24)
+
+ results = dict()
+ results['img'] = img[:, :, 0]
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+
+ transform = dict(type='RandomMosaic', prob=0, img_scale=(10, 12))
+ mosaic_module = build_from_cfg(transform, PIPELINES)
+ results['mix_results'] = [copy.deepcopy(results)] * 3
+ results = mosaic_module(results)
+ assert results['img'].shape[:2] == img.shape[:2]
+
+ transform = dict(type='RandomMosaic', prob=1, img_scale=(10, 12))
+ mosaic_module = build_from_cfg(transform, PIPELINES)
+ results = mosaic_module(results)
+ assert results['img'].shape[:2] == (20, 24)
diff --git a/tests/test_data/test_tta.py b/tests/test_data/test_tta.py
new file mode 100644
index 0000000..d61af27
--- /dev/null
+++ b/tests/test_data/test_tta.py
@@ -0,0 +1,151 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import pytest
+from mmcv.utils import build_from_cfg
+
+from mmseg.datasets.builder import PIPELINES
+
+
+def test_multi_scale_flip_aug():
+ # test assertion if img_scale=None, img_ratios=1 (not float).
+ with pytest.raises(AssertionError):
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=None,
+ img_ratios=1,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ build_from_cfg(tta_transform, PIPELINES)
+
+ # test assertion if img_scale=None, img_ratios=None.
+ with pytest.raises(AssertionError):
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=None,
+ img_ratios=None,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ build_from_cfg(tta_transform, PIPELINES)
+
+ # test assertion if img_scale=(512, 512), img_ratios=1 (not float).
+ with pytest.raises(AssertionError):
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=1,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ build_from_cfg(tta_transform, PIPELINES)
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=[0.5, 1.0, 2.0],
+ flip=False,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+
+ results = dict()
+ # (288, 512, 3)
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 256), (512, 512), (1024, 1024)]
+ assert tta_results['flip'] == [False, False, False]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=[0.5, 1.0, 2.0],
+ flip=True,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 256), (256, 256), (512, 512),
+ (512, 512), (1024, 1024), (1024, 1024)]
+ assert tta_results['flip'] == [False, True, False, True, False, True]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=1.0,
+ flip=False,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(512, 512)]
+ assert tta_results['flip'] == [False]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=1.0,
+ flip=True,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(512, 512), (512, 512)]
+ assert tta_results['flip'] == [False, True]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=None,
+ img_ratios=[0.5, 1.0, 2.0],
+ flip=False,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 144), (512, 288), (1024, 576)]
+ assert tta_results['flip'] == [False, False, False]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=None,
+ img_ratios=[0.5, 1.0, 2.0],
+ flip=True,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 144), (256, 144), (512, 288),
+ (512, 288), (1024, 576), (1024, 576)]
+ assert tta_results['flip'] == [False, True, False, True, False, True]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=[(256, 256), (512, 512), (1024, 1024)],
+ img_ratios=None,
+ flip=False,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 256), (512, 512), (1024, 1024)]
+ assert tta_results['flip'] == [False, False, False]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=[(256, 256), (512, 512), (1024, 1024)],
+ img_ratios=None,
+ flip=True,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 256), (256, 256), (512, 512),
+ (512, 512), (1024, 1024), (1024, 1024)]
+ assert tta_results['flip'] == [False, True, False, True, False, True]
diff --git a/tests/test_digit_version.py b/tests/test_digit_version.py
new file mode 100644
index 0000000..45daf09
--- /dev/null
+++ b/tests/test_digit_version.py
@@ -0,0 +1,21 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmseg import digit_version
+
+
+def test_digit_version():
+ assert digit_version('0.2.16') == (0, 2, 16, 0, 0, 0)
+ assert digit_version('1.2.3') == (1, 2, 3, 0, 0, 0)
+ assert digit_version('1.2.3rc0') == (1, 2, 3, 0, -1, 0)
+ assert digit_version('1.2.3rc1') == (1, 2, 3, 0, -1, 1)
+ assert digit_version('1.0rc0') == (1, 0, 0, 0, -1, 0)
+ assert digit_version('1.0') == digit_version('1.0.0')
+ assert digit_version('1.5.0+cuda90_cudnn7.6.3_lms') == digit_version('1.5')
+ assert digit_version('1.0.0dev') < digit_version('1.0.0a')
+ assert digit_version('1.0.0a') < digit_version('1.0.0a1')
+ assert digit_version('1.0.0a') < digit_version('1.0.0b')
+ assert digit_version('1.0.0b') < digit_version('1.0.0rc')
+ assert digit_version('1.0.0rc1') < digit_version('1.0.0')
+ assert digit_version('1.0.0') < digit_version('1.0.0post')
+ assert digit_version('1.0.0post') < digit_version('1.0.0post1')
+ assert digit_version('v1') == (1, 0, 0, 0, 0, 0)
+ assert digit_version('v1.1.5') == (1, 1, 5, 0, 0, 0)
diff --git a/tests/test_eval_hook.py b/tests/test_eval_hook.py
new file mode 100644
index 0000000..5267438
--- /dev/null
+++ b/tests/test_eval_hook.py
@@ -0,0 +1,204 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+import tempfile
+from unittest.mock import MagicMock, patch
+
+import mmcv.runner
+import pytest
+import torch
+import torch.nn as nn
+from mmcv.runner import obj_from_dict
+from torch.utils.data import DataLoader, Dataset
+
+from mmseg.apis import single_gpu_test
+from mmseg.core import DistEvalHook, EvalHook
+
+
+class ExampleDataset(Dataset):
+
+ def __getitem__(self, idx):
+ results = dict(img=torch.tensor([1]), img_metas=dict())
+ return results
+
+ def __len__(self):
+ return 1
+
+
+class ExampleModel(nn.Module):
+
+ def __init__(self):
+ super(ExampleModel, self).__init__()
+ self.test_cfg = None
+ self.conv = nn.Conv2d(3, 3, 3)
+
+ def forward(self, img, img_metas, test_mode=False, **kwargs):
+ return img
+
+ def train_step(self, data_batch, optimizer):
+ loss = self.forward(**data_batch)
+ return dict(loss=loss)
+
+
+def test_iter_eval_hook():
+ with pytest.raises(TypeError):
+ test_dataset = ExampleModel()
+ data_loader = [
+ DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_worker=0,
+ shuffle=False)
+ ]
+ EvalHook(data_loader)
+
+ test_dataset = ExampleDataset()
+ test_dataset.pre_eval = MagicMock(return_value=[torch.tensor([1])])
+ test_dataset.evaluate = MagicMock(return_value=dict(test='success'))
+ loader = DataLoader(test_dataset, batch_size=1)
+ model = ExampleModel()
+ data_loader = DataLoader(
+ test_dataset, batch_size=1, sampler=None, num_workers=0, shuffle=False)
+ optim_cfg = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+ optimizer = obj_from_dict(optim_cfg, torch.optim,
+ dict(params=model.parameters()))
+
+ # test EvalHook
+ with tempfile.TemporaryDirectory() as tmpdir:
+ eval_hook = EvalHook(data_loader, by_epoch=False, efficient_test=True)
+ runner = mmcv.runner.IterBasedRunner(
+ model=model,
+ optimizer=optimizer,
+ work_dir=tmpdir,
+ logger=logging.getLogger())
+ runner.register_hook(eval_hook)
+ runner.run([loader], [('train', 1)], 1)
+ test_dataset.evaluate.assert_called_with([torch.tensor([1])],
+ logger=runner.logger)
+
+
+def test_epoch_eval_hook():
+ with pytest.raises(TypeError):
+ test_dataset = ExampleModel()
+ data_loader = [
+ DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_worker=0,
+ shuffle=False)
+ ]
+ EvalHook(data_loader, by_epoch=True)
+
+ test_dataset = ExampleDataset()
+ test_dataset.pre_eval = MagicMock(return_value=[torch.tensor([1])])
+ test_dataset.evaluate = MagicMock(return_value=dict(test='success'))
+ loader = DataLoader(test_dataset, batch_size=1)
+ model = ExampleModel()
+ data_loader = DataLoader(
+ test_dataset, batch_size=1, sampler=None, num_workers=0, shuffle=False)
+ optim_cfg = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+ optimizer = obj_from_dict(optim_cfg, torch.optim,
+ dict(params=model.parameters()))
+
+ # test EvalHook with interval
+ with tempfile.TemporaryDirectory() as tmpdir:
+ eval_hook = EvalHook(data_loader, by_epoch=True, interval=2)
+ runner = mmcv.runner.EpochBasedRunner(
+ model=model,
+ optimizer=optimizer,
+ work_dir=tmpdir,
+ logger=logging.getLogger())
+ runner.register_hook(eval_hook)
+ runner.run([loader], [('train', 1)], 2)
+ test_dataset.evaluate.assert_called_once_with([torch.tensor([1])],
+ logger=runner.logger)
+
+
+def multi_gpu_test(model,
+ data_loader,
+ tmpdir=None,
+ gpu_collect=False,
+ pre_eval=False):
+ # Pre eval is set by default when training.
+ results = single_gpu_test(model, data_loader, pre_eval=True)
+ return results
+
+
+@patch('mmseg.apis.multi_gpu_test', multi_gpu_test)
+def test_dist_eval_hook():
+ with pytest.raises(TypeError):
+ test_dataset = ExampleModel()
+ data_loader = [
+ DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_worker=0,
+ shuffle=False)
+ ]
+ DistEvalHook(data_loader)
+
+ test_dataset = ExampleDataset()
+ test_dataset.pre_eval = MagicMock(return_value=[torch.tensor([1])])
+ test_dataset.evaluate = MagicMock(return_value=dict(test='success'))
+ loader = DataLoader(test_dataset, batch_size=1)
+ model = ExampleModel()
+ data_loader = DataLoader(
+ test_dataset, batch_size=1, sampler=None, num_workers=0, shuffle=False)
+ optim_cfg = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+ optimizer = obj_from_dict(optim_cfg, torch.optim,
+ dict(params=model.parameters()))
+
+ # test DistEvalHook
+ with tempfile.TemporaryDirectory() as tmpdir:
+ eval_hook = DistEvalHook(
+ data_loader, by_epoch=False, efficient_test=True)
+ runner = mmcv.runner.IterBasedRunner(
+ model=model,
+ optimizer=optimizer,
+ work_dir=tmpdir,
+ logger=logging.getLogger())
+ runner.register_hook(eval_hook)
+ runner.run([loader], [('train', 1)], 1)
+ test_dataset.evaluate.assert_called_with([torch.tensor([1])],
+ logger=runner.logger)
+
+
+@patch('mmseg.apis.multi_gpu_test', multi_gpu_test)
+def test_dist_eval_hook_epoch():
+ with pytest.raises(TypeError):
+ test_dataset = ExampleModel()
+ data_loader = [
+ DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_worker=0,
+ shuffle=False)
+ ]
+ DistEvalHook(data_loader)
+
+ test_dataset = ExampleDataset()
+ test_dataset.pre_eval = MagicMock(return_value=[torch.tensor([1])])
+ test_dataset.evaluate = MagicMock(return_value=dict(test='success'))
+ loader = DataLoader(test_dataset, batch_size=1)
+ model = ExampleModel()
+ data_loader = DataLoader(
+ test_dataset, batch_size=1, sampler=None, num_workers=0, shuffle=False)
+ optim_cfg = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+ optimizer = obj_from_dict(optim_cfg, torch.optim,
+ dict(params=model.parameters()))
+
+ # test DistEvalHook
+ with tempfile.TemporaryDirectory() as tmpdir:
+ eval_hook = DistEvalHook(data_loader, by_epoch=True, interval=2)
+ runner = mmcv.runner.EpochBasedRunner(
+ model=model,
+ optimizer=optimizer,
+ work_dir=tmpdir,
+ logger=logging.getLogger())
+ runner.register_hook(eval_hook)
+ runner.run([loader], [('train', 1)], 2)
+ test_dataset.evaluate.assert_called_with([torch.tensor([1])],
+ logger=runner.logger)
diff --git a/tests/test_inference.py b/tests/test_inference.py
new file mode 100644
index 0000000..f71a7ea
--- /dev/null
+++ b/tests/test_inference.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+
+from mmseg.apis import inference_segmentor, init_segmentor
+
+
+def test_test_time_augmentation_on_cpu():
+ config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'
+ config = mmcv.Config.fromfile(config_file)
+
+ # Remove pretrain model download for testing
+ config.model.pretrained = None
+ # Replace SyncBN with BN to inference on CPU
+ norm_cfg = dict(type='BN', requires_grad=True)
+ config.model.backbone.norm_cfg = norm_cfg
+ config.model.decode_head.norm_cfg = norm_cfg
+ config.model.auxiliary_head.norm_cfg = norm_cfg
+
+ # Enable test time augmentation
+ config.data.test.pipeline[1].flip = True
+
+ checkpoint_file = None
+ model = init_segmentor(config, checkpoint_file, device='cpu')
+
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), 'data/color.jpg'), 'color')
+ result = inference_segmentor(model, img)
+ assert result[0].shape == (288, 512)
diff --git a/tests/test_metrics.py b/tests/test_metrics.py
new file mode 100644
index 0000000..51ad1f3
--- /dev/null
+++ b/tests/test_metrics.py
@@ -0,0 +1,351 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+from mmseg.core.evaluation import (eval_metrics, mean_dice, mean_fscore,
+ mean_iou)
+from mmseg.core.evaluation.metrics import f_score
+
+
+def get_confusion_matrix(pred_label, label, num_classes, ignore_index):
+ """Intersection over Union
+ Args:
+ pred_label (np.ndarray): 2D predict map
+ label (np.ndarray): label 2D label map
+ num_classes (int): number of categories
+ ignore_index (int): index ignore in evaluation
+ """
+
+ mask = (label != ignore_index)
+ pred_label = pred_label[mask]
+ label = label[mask]
+
+ n = num_classes
+ inds = n * label + pred_label
+
+ mat = np.bincount(inds, minlength=n**2).reshape(n, n)
+
+ return mat
+
+
+# This func is deprecated since it's not memory efficient
+def legacy_mean_iou(results, gt_seg_maps, num_classes, ignore_index):
+ num_imgs = len(results)
+ assert len(gt_seg_maps) == num_imgs
+ total_mat = np.zeros((num_classes, num_classes), dtype=np.float)
+ for i in range(num_imgs):
+ mat = get_confusion_matrix(
+ results[i], gt_seg_maps[i], num_classes, ignore_index=ignore_index)
+ total_mat += mat
+ all_acc = np.diag(total_mat).sum() / total_mat.sum()
+ acc = np.diag(total_mat) / total_mat.sum(axis=1)
+ iou = np.diag(total_mat) / (
+ total_mat.sum(axis=1) + total_mat.sum(axis=0) - np.diag(total_mat))
+
+ return all_acc, acc, iou
+
+
+# This func is deprecated since it's not memory efficient
+def legacy_mean_dice(results, gt_seg_maps, num_classes, ignore_index):
+ num_imgs = len(results)
+ assert len(gt_seg_maps) == num_imgs
+ total_mat = np.zeros((num_classes, num_classes), dtype=np.float)
+ for i in range(num_imgs):
+ mat = get_confusion_matrix(
+ results[i], gt_seg_maps[i], num_classes, ignore_index=ignore_index)
+ total_mat += mat
+ all_acc = np.diag(total_mat).sum() / total_mat.sum()
+ acc = np.diag(total_mat) / total_mat.sum(axis=1)
+ dice = 2 * np.diag(total_mat) / (
+ total_mat.sum(axis=1) + total_mat.sum(axis=0))
+
+ return all_acc, acc, dice
+
+
+# This func is deprecated since it's not memory efficient
+def legacy_mean_fscore(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ beta=1):
+ num_imgs = len(results)
+ assert len(gt_seg_maps) == num_imgs
+ total_mat = np.zeros((num_classes, num_classes), dtype=np.float)
+ for i in range(num_imgs):
+ mat = get_confusion_matrix(
+ results[i], gt_seg_maps[i], num_classes, ignore_index=ignore_index)
+ total_mat += mat
+ all_acc = np.diag(total_mat).sum() / total_mat.sum()
+ recall = np.diag(total_mat) / total_mat.sum(axis=1)
+ precision = np.diag(total_mat) / total_mat.sum(axis=0)
+ fv = np.vectorize(f_score)
+ fscore = fv(precision, recall, beta=beta)
+
+ return all_acc, recall, precision, fscore
+
+
+def test_metrics():
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ label = np.random.randint(0, num_classes, size=pred_size)
+
+ # Test the availability of arg: ignore_index.
+ label[:, 2, 5:10] = ignore_index
+
+ # Test the correctness of the implementation of mIoU calculation.
+ ret_metrics = eval_metrics(
+ results, label, num_classes, ignore_index, metrics='mIoU')
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ all_acc_l, acc_l, iou_l = legacy_mean_iou(results, label, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, iou_l)
+ # Test the correctness of the implementation of mDice calculation.
+ ret_metrics = eval_metrics(
+ results, label, num_classes, ignore_index, metrics='mDice')
+ all_acc, acc, dice = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'Dice']
+ all_acc_l, acc_l, dice_l = legacy_mean_dice(results, label, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(dice, dice_l)
+ # Test the correctness of the implementation of mDice calculation.
+ ret_metrics = eval_metrics(
+ results, label, num_classes, ignore_index, metrics='mFscore')
+ all_acc, recall, precision, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Recall'], ret_metrics['Precision'], ret_metrics['Fscore']
+ all_acc_l, recall_l, precision_l, fscore_l = legacy_mean_fscore(
+ results, label, num_classes, ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(recall, recall_l)
+ assert np.allclose(precision, precision_l)
+ assert np.allclose(fscore, fscore_l)
+ # Test the correctness of the implementation of joint calculation.
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index,
+ metrics=['mIoU', 'mDice', 'mFscore'])
+ all_acc, acc, iou, dice, precision, recall, fscore = ret_metrics[
+ 'aAcc'], ret_metrics['Acc'], ret_metrics['IoU'], ret_metrics[
+ 'Dice'], ret_metrics['Precision'], ret_metrics[
+ 'Recall'], ret_metrics['Fscore']
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, iou_l)
+ assert np.allclose(dice, dice_l)
+ assert np.allclose(precision, precision_l)
+ assert np.allclose(recall, recall_l)
+ assert np.allclose(fscore, fscore_l)
+
+ # Test the correctness of calculation when arg: num_classes is larger
+ # than the maximum value of input maps.
+ results = np.random.randint(0, 5, size=pred_size)
+ label = np.random.randint(0, 4, size=pred_size)
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index=255,
+ metrics='mIoU',
+ nan_to_num=-1)
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ assert acc[-1] == -1
+ assert iou[-1] == -1
+
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index=255,
+ metrics='mDice',
+ nan_to_num=-1)
+ all_acc, acc, dice = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'Dice']
+ assert acc[-1] == -1
+ assert dice[-1] == -1
+
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index=255,
+ metrics='mFscore',
+ nan_to_num=-1)
+ all_acc, precision, recall, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Precision'], ret_metrics['Recall'], ret_metrics['Fscore']
+ assert precision[-1] == -1
+ assert recall[-1] == -1
+ assert fscore[-1] == -1
+
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index=255,
+ metrics=['mDice', 'mIoU', 'mFscore'],
+ nan_to_num=-1)
+ all_acc, acc, iou, dice, precision, recall, fscore = ret_metrics[
+ 'aAcc'], ret_metrics['Acc'], ret_metrics['IoU'], ret_metrics[
+ 'Dice'], ret_metrics['Precision'], ret_metrics[
+ 'Recall'], ret_metrics['Fscore']
+ assert acc[-1] == -1
+ assert dice[-1] == -1
+ assert iou[-1] == -1
+ assert precision[-1] == -1
+ assert recall[-1] == -1
+ assert fscore[-1] == -1
+
+ # Test the bug which is caused by torch.histc.
+ # torch.histc: https://pytorch.org/docs/stable/generated/torch.histc.html
+ # When the arg:bins is set to be same as arg:max,
+ # some channels of mIoU may be nan.
+ results = np.array([np.repeat(31, 59)])
+ label = np.array([np.arange(59)])
+ num_classes = 59
+ ret_metrics = eval_metrics(
+ results, label, num_classes, ignore_index=255, metrics='mIoU')
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ assert not np.any(np.isnan(iou))
+
+
+def test_mean_iou():
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ label = np.random.randint(0, num_classes, size=pred_size)
+ label[:, 2, 5:10] = ignore_index
+ ret_metrics = mean_iou(results, label, num_classes, ignore_index)
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ all_acc_l, acc_l, iou_l = legacy_mean_iou(results, label, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, iou_l)
+
+ results = np.random.randint(0, 5, size=pred_size)
+ label = np.random.randint(0, 4, size=pred_size)
+ ret_metrics = mean_iou(
+ results, label, num_classes, ignore_index=255, nan_to_num=-1)
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ assert acc[-1] == -1
+ assert acc[-1] == -1
+
+
+def test_mean_dice():
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ label = np.random.randint(0, num_classes, size=pred_size)
+ label[:, 2, 5:10] = ignore_index
+ ret_metrics = mean_dice(results, label, num_classes, ignore_index)
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'Dice']
+ all_acc_l, acc_l, dice_l = legacy_mean_dice(results, label, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, dice_l)
+
+ results = np.random.randint(0, 5, size=pred_size)
+ label = np.random.randint(0, 4, size=pred_size)
+ ret_metrics = mean_dice(
+ results, label, num_classes, ignore_index=255, nan_to_num=-1)
+ all_acc, acc, dice = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'Dice']
+ assert acc[-1] == -1
+ assert dice[-1] == -1
+
+
+def test_mean_fscore():
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ label = np.random.randint(0, num_classes, size=pred_size)
+ label[:, 2, 5:10] = ignore_index
+ ret_metrics = mean_fscore(results, label, num_classes, ignore_index)
+ all_acc, recall, precision, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Recall'], ret_metrics['Precision'], ret_metrics['Fscore']
+ all_acc_l, recall_l, precision_l, fscore_l = legacy_mean_fscore(
+ results, label, num_classes, ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(recall, recall_l)
+ assert np.allclose(precision, precision_l)
+ assert np.allclose(fscore, fscore_l)
+
+ ret_metrics = mean_fscore(
+ results, label, num_classes, ignore_index, beta=2)
+ all_acc, recall, precision, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Recall'], ret_metrics['Precision'], ret_metrics['Fscore']
+ all_acc_l, recall_l, precision_l, fscore_l = legacy_mean_fscore(
+ results, label, num_classes, ignore_index, beta=2)
+ assert all_acc == all_acc_l
+ assert np.allclose(recall, recall_l)
+ assert np.allclose(precision, precision_l)
+ assert np.allclose(fscore, fscore_l)
+
+ results = np.random.randint(0, 5, size=pred_size)
+ label = np.random.randint(0, 4, size=pred_size)
+ ret_metrics = mean_fscore(
+ results, label, num_classes, ignore_index=255, nan_to_num=-1)
+ all_acc, recall, precision, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Recall'], ret_metrics['Precision'], ret_metrics['Fscore']
+ assert recall[-1] == -1
+ assert precision[-1] == -1
+ assert fscore[-1] == -1
+
+
+def test_filename_inputs():
+ import tempfile
+
+ import cv2
+
+ def save_arr(input_arrays: list, title: str, is_image: bool, dir: str):
+ filenames = []
+ SUFFIX = '.png' if is_image else '.npy'
+ for idx, arr in enumerate(input_arrays):
+ filename = '{}/{}-{}{}'.format(dir, title, idx, SUFFIX)
+ if is_image:
+ cv2.imwrite(filename, arr)
+ else:
+ np.save(filename, arr)
+ filenames.append(filename)
+ return filenames
+
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ labels = np.random.randint(0, num_classes, size=pred_size)
+ labels[:, 2, 5:10] = ignore_index
+
+ with tempfile.TemporaryDirectory() as temp_dir:
+
+ result_files = save_arr(results, 'pred', False, temp_dir)
+ label_files = save_arr(labels, 'label', True, temp_dir)
+
+ ret_metrics = eval_metrics(
+ result_files,
+ label_files,
+ num_classes,
+ ignore_index,
+ metrics='mIoU')
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics[
+ 'Acc'], ret_metrics['IoU']
+ all_acc_l, acc_l, iou_l = legacy_mean_iou(results, labels, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, iou_l)
diff --git a/tests/test_models/__init__.py b/tests/test_models/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_backbones/__init__.py b/tests/test_models/test_backbones/__init__.py
new file mode 100644
index 0000000..8b673fa
--- /dev/null
+++ b/tests/test_models/test_backbones/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .utils import all_zeros, check_norm_state, is_block, is_norm
+
+__all__ = ['is_norm', 'is_block', 'all_zeros', 'check_norm_state']
diff --git a/tests/test_models/test_backbones/test_bisenetv1.py b/tests/test_models/test_backbones/test_bisenetv1.py
new file mode 100644
index 0000000..c067749
--- /dev/null
+++ b/tests/test_models/test_backbones/test_bisenetv1.py
@@ -0,0 +1,109 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import BiSeNetV1
+from mmseg.models.backbones.bisenetv1 import (AttentionRefinementModule,
+ ContextPath, FeatureFusionModule,
+ SpatialPath)
+
+
+def test_bisenetv1_backbone():
+ # Test BiSeNetV1 Standard Forward
+ backbone_cfg = dict(
+ type='ResNet',
+ in_channels=3,
+ depth=18,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 1, 1),
+ strides=(1, 2, 2, 2),
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True)
+ model = BiSeNetV1(in_channels=3, backbone_cfg=backbone_cfg)
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 64, 128)
+ feat = model(imgs)
+
+ assert len(feat) == 3
+ # output for segment Head
+ assert feat[0].shape == torch.Size([batch_size, 256, 8, 16])
+ # for auxiliary head 1
+ assert feat[1].shape == torch.Size([batch_size, 128, 8, 16])
+ # for auxiliary head 2
+ assert feat[2].shape == torch.Size([batch_size, 128, 4, 8])
+
+ # Test input with rare shape
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 95, 27)
+ feat = model(imgs)
+ assert len(feat) == 3
+
+ with pytest.raises(AssertionError):
+ # BiSeNetV1 spatial path channel constraints.
+ BiSeNetV1(
+ backbone_cfg=backbone_cfg,
+ in_channels=3,
+ spatial_channels=(16, 16, 16))
+
+ with pytest.raises(AssertionError):
+ # BiSeNetV1 context path constraints.
+ BiSeNetV1(
+ backbone_cfg=backbone_cfg,
+ in_channels=3,
+ context_channels=(16, 32, 64, 128))
+
+
+def test_bisenetv1_spatial_path():
+ with pytest.raises(AssertionError):
+ # BiSeNetV1 spatial path channel constraints.
+ SpatialPath(num_channels=(16, 16, 16), in_channels=3)
+
+
+def test_bisenetv1_context_path():
+ backbone_cfg = dict(
+ type='ResNet',
+ in_channels=3,
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 1, 1),
+ strides=(1, 2, 2, 2),
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True)
+
+ with pytest.raises(AssertionError):
+ # BiSeNetV1 context path constraints.
+ ContextPath(
+ backbone_cfg=backbone_cfg, context_channels=(16, 32, 64, 128))
+
+
+def test_bisenetv1_attention_refinement_module():
+ x_arm = AttentionRefinementModule(32, 8)
+ assert x_arm.conv_layer.in_channels == 32
+ assert x_arm.conv_layer.out_channels == 8
+ assert x_arm.conv_layer.kernel_size == (3, 3)
+ x = torch.randn(2, 32, 8, 16)
+ x_out = x_arm(x)
+ assert x_out.shape == torch.Size([2, 8, 8, 16])
+
+
+def test_bisenetv1_feature_fusion_module():
+ ffm = FeatureFusionModule(16, 32)
+ assert ffm.conv1.in_channels == 16
+ assert ffm.conv1.out_channels == 32
+ assert ffm.conv1.kernel_size == (1, 1)
+ assert ffm.gap.output_size == (1, 1)
+ assert ffm.conv_atten[0].in_channels == 32
+ assert ffm.conv_atten[0].out_channels == 32
+ assert ffm.conv_atten[0].kernel_size == (1, 1)
+
+ ffm = FeatureFusionModule(16, 16)
+ x1 = torch.randn(2, 8, 8, 16)
+ x2 = torch.randn(2, 8, 8, 16)
+ x_out = ffm(x1, x2)
+ assert x_out.shape == torch.Size([2, 16, 8, 16])
diff --git a/tests/test_models/test_backbones/test_bisenetv2.py b/tests/test_models/test_backbones/test_bisenetv2.py
new file mode 100644
index 0000000..cf2dfb3
--- /dev/null
+++ b/tests/test_models/test_backbones/test_bisenetv2.py
@@ -0,0 +1,57 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import ConvModule
+
+from mmseg.models.backbones import BiSeNetV2
+from mmseg.models.backbones.bisenetv2 import (BGALayer, DetailBranch,
+ SemanticBranch)
+
+
+def test_bisenetv2_backbone():
+ # Test BiSeNetV2 Standard Forward
+ model = BiSeNetV2()
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 128, 256)
+ feat = model(imgs)
+
+ assert len(feat) == 5
+ # output for segment Head
+ assert feat[0].shape == torch.Size([batch_size, 128, 16, 32])
+ # for auxiliary head 1
+ assert feat[1].shape == torch.Size([batch_size, 16, 32, 64])
+ # for auxiliary head 2
+ assert feat[2].shape == torch.Size([batch_size, 32, 16, 32])
+ # for auxiliary head 3
+ assert feat[3].shape == torch.Size([batch_size, 64, 8, 16])
+ # for auxiliary head 4
+ assert feat[4].shape == torch.Size([batch_size, 128, 4, 8])
+
+ # Test input with rare shape
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 95, 27)
+ feat = model(imgs)
+ assert len(feat) == 5
+
+
+def test_bisenetv2_DetailBranch():
+ x = torch.randn(1, 3, 32, 64)
+ detail_branch = DetailBranch(detail_channels=(64, 16, 32))
+ assert isinstance(detail_branch.detail_branch[0][0], ConvModule)
+ x_out = detail_branch(x)
+ assert x_out.shape == torch.Size([1, 32, 4, 8])
+
+
+def test_bisenetv2_SemanticBranch():
+ semantic_branch = SemanticBranch(semantic_channels=(16, 32, 64, 128))
+ assert semantic_branch.stage1.pool.stride == 2
+
+
+def test_bisenetv2_BGALayer():
+ x_a = torch.randn(1, 8, 8, 16)
+ x_b = torch.randn(1, 8, 2, 4)
+ bga = BGALayer(out_channels=8)
+ assert isinstance(bga.conv, ConvModule)
+ x_out = bga(x_a, x_b)
+ assert x_out.shape == torch.Size([1, 8, 8, 16])
diff --git a/tests/test_models/test_backbones/test_blocks.py b/tests/test_models/test_backbones/test_blocks.py
new file mode 100644
index 0000000..ad3ad2d
--- /dev/null
+++ b/tests/test_models/test_backbones/test_blocks.py
@@ -0,0 +1,170 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+import pytest
+import torch
+
+from mmseg.models.utils import (InvertedResidual, InvertedResidualV3, SELayer,
+ make_divisible)
+
+
+def test_make_divisible():
+ # test with min_value = None
+ assert make_divisible(10, 4) == 12
+ assert make_divisible(9, 4) == 12
+ assert make_divisible(1, 4) == 4
+
+ # test with min_value = 8
+ assert make_divisible(10, 4, 8) == 12
+ assert make_divisible(9, 4, 8) == 12
+ assert make_divisible(1, 4, 8) == 8
+
+
+def test_inv_residual():
+ with pytest.raises(AssertionError):
+ # test stride assertion.
+ InvertedResidual(32, 32, 3, 4)
+
+ # test default config with res connection.
+ # set expand_ratio = 4, stride = 1 and inp=oup.
+ inv_module = InvertedResidual(32, 32, 1, 4)
+ assert inv_module.use_res_connect
+ assert inv_module.conv[0].kernel_size == (1, 1)
+ assert inv_module.conv[0].padding == 0
+ assert inv_module.conv[1].kernel_size == (3, 3)
+ assert inv_module.conv[1].padding == 1
+ assert inv_module.conv[0].with_norm
+ assert inv_module.conv[1].with_norm
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 64, 64)
+
+ # test inv_residual module without res connection.
+ # set expand_ratio = 4, stride = 2.
+ inv_module = InvertedResidual(32, 32, 2, 4)
+ assert not inv_module.use_res_connect
+ assert inv_module.conv[0].kernel_size == (1, 1)
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 32, 32)
+
+ # test expand_ratio == 1
+ inv_module = InvertedResidual(32, 32, 1, 1)
+ assert inv_module.conv[0].kernel_size == (3, 3)
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 64, 64)
+
+ # test with checkpoint forward
+ inv_module = InvertedResidual(32, 32, 1, 1, with_cp=True)
+ assert inv_module.with_cp
+ x = torch.rand(1, 32, 64, 64, requires_grad=True)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 64, 64)
+
+
+def test_inv_residualv3():
+ with pytest.raises(AssertionError):
+ # test stride assertion.
+ InvertedResidualV3(32, 32, 16, stride=3)
+
+ with pytest.raises(AssertionError):
+ # test assertion.
+ InvertedResidualV3(32, 32, 16, with_expand_conv=False)
+
+ # test with se_cfg=None, with_expand_conv=False
+ inv_module = InvertedResidualV3(32, 32, 32, with_expand_conv=False)
+
+ assert inv_module.with_res_shortcut is True
+ assert inv_module.with_se is False
+ assert inv_module.with_expand_conv is False
+ assert not hasattr(inv_module, 'expand_conv')
+ assert isinstance(inv_module.depthwise_conv.conv, torch.nn.Conv2d)
+ assert inv_module.depthwise_conv.conv.kernel_size == (3, 3)
+ assert inv_module.depthwise_conv.conv.stride == (1, 1)
+ assert inv_module.depthwise_conv.conv.padding == (1, 1)
+ assert isinstance(inv_module.depthwise_conv.bn, torch.nn.BatchNorm2d)
+ assert isinstance(inv_module.depthwise_conv.activate, torch.nn.ReLU)
+ assert inv_module.linear_conv.conv.kernel_size == (1, 1)
+ assert inv_module.linear_conv.conv.stride == (1, 1)
+ assert inv_module.linear_conv.conv.padding == (0, 0)
+ assert isinstance(inv_module.linear_conv.bn, torch.nn.BatchNorm2d)
+
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 64, 64)
+
+ # test with se_cfg and with_expand_conv
+ se_cfg = dict(
+ channels=16,
+ ratio=4,
+ act_cfg=(dict(type='ReLU'),
+ dict(type='HSigmoid', bias=3.0, divisor=6.0)))
+ act_cfg = dict(type='HSwish')
+ inv_module = InvertedResidualV3(
+ 32, 40, 16, 3, 2, se_cfg=se_cfg, act_cfg=act_cfg)
+ assert inv_module.with_res_shortcut is False
+ assert inv_module.with_se is True
+ assert inv_module.with_expand_conv is True
+ assert inv_module.expand_conv.conv.kernel_size == (1, 1)
+ assert inv_module.expand_conv.conv.stride == (1, 1)
+ assert inv_module.expand_conv.conv.padding == (0, 0)
+ assert isinstance(inv_module.expand_conv.activate, mmcv.cnn.HSwish)
+
+ assert isinstance(inv_module.depthwise_conv.conv,
+ mmcv.cnn.bricks.Conv2dAdaptivePadding)
+ assert inv_module.depthwise_conv.conv.kernel_size == (3, 3)
+ assert inv_module.depthwise_conv.conv.stride == (2, 2)
+ assert inv_module.depthwise_conv.conv.padding == (0, 0)
+ assert isinstance(inv_module.depthwise_conv.bn, torch.nn.BatchNorm2d)
+ assert isinstance(inv_module.depthwise_conv.activate, mmcv.cnn.HSwish)
+ assert inv_module.linear_conv.conv.kernel_size == (1, 1)
+ assert inv_module.linear_conv.conv.stride == (1, 1)
+ assert inv_module.linear_conv.conv.padding == (0, 0)
+ assert isinstance(inv_module.linear_conv.bn, torch.nn.BatchNorm2d)
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 40, 32, 32)
+
+ # test with checkpoint forward
+ inv_module = InvertedResidualV3(
+ 32, 40, 16, 3, 2, se_cfg=se_cfg, act_cfg=act_cfg, with_cp=True)
+ assert inv_module.with_cp
+ x = torch.randn(2, 32, 64, 64, requires_grad=True)
+ output = inv_module(x)
+ assert output.shape == (2, 40, 32, 32)
+
+
+def test_se_layer():
+ with pytest.raises(AssertionError):
+ # test act_cfg assertion.
+ SELayer(32, act_cfg=(dict(type='ReLU'), ))
+
+ # test config with channels = 16.
+ se_layer = SELayer(16)
+ assert se_layer.conv1.conv.kernel_size == (1, 1)
+ assert se_layer.conv1.conv.stride == (1, 1)
+ assert se_layer.conv1.conv.padding == (0, 0)
+ assert isinstance(se_layer.conv1.activate, torch.nn.ReLU)
+ assert se_layer.conv2.conv.kernel_size == (1, 1)
+ assert se_layer.conv2.conv.stride == (1, 1)
+ assert se_layer.conv2.conv.padding == (0, 0)
+ assert isinstance(se_layer.conv2.activate, mmcv.cnn.HSigmoid)
+
+ x = torch.rand(1, 16, 64, 64)
+ output = se_layer(x)
+ assert output.shape == (1, 16, 64, 64)
+
+ # test config with channels = 16, act_cfg = dict(type='ReLU').
+ se_layer = SELayer(16, act_cfg=dict(type='ReLU'))
+ assert se_layer.conv1.conv.kernel_size == (1, 1)
+ assert se_layer.conv1.conv.stride == (1, 1)
+ assert se_layer.conv1.conv.padding == (0, 0)
+ assert isinstance(se_layer.conv1.activate, torch.nn.ReLU)
+ assert se_layer.conv2.conv.kernel_size == (1, 1)
+ assert se_layer.conv2.conv.stride == (1, 1)
+ assert se_layer.conv2.conv.padding == (0, 0)
+ assert isinstance(se_layer.conv2.activate, torch.nn.ReLU)
+
+ x = torch.rand(1, 16, 64, 64)
+ output = se_layer(x)
+ assert output.shape == (1, 16, 64, 64)
diff --git a/tests/test_models/test_backbones/test_cgnet.py b/tests/test_models/test_backbones/test_cgnet.py
new file mode 100644
index 0000000..f938525
--- /dev/null
+++ b/tests/test_models/test_backbones/test_cgnet.py
@@ -0,0 +1,151 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import CGNet
+from mmseg.models.backbones.cgnet import (ContextGuidedBlock,
+ GlobalContextExtractor)
+
+
+def test_cgnet_GlobalContextExtractor():
+ block = GlobalContextExtractor(16, 16, with_cp=True)
+ x = torch.randn(2, 16, 64, 64, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([2, 16, 64, 64])
+
+
+def test_cgnet_context_guided_block():
+ with pytest.raises(AssertionError):
+ # cgnet ContextGuidedBlock GlobalContextExtractor channel and reduction
+ # constraints.
+ ContextGuidedBlock(8, 8)
+
+ # test cgnet ContextGuidedBlock with checkpoint forward
+ block = ContextGuidedBlock(
+ 16, 16, act_cfg=dict(type='PReLU'), with_cp=True)
+ assert block.with_cp
+ x = torch.randn(2, 16, 64, 64, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([2, 16, 64, 64])
+
+ # test cgnet ContextGuidedBlock without checkpoint forward
+ block = ContextGuidedBlock(32, 32)
+ assert not block.with_cp
+ x = torch.randn(3, 32, 32, 32)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([3, 32, 32, 32])
+
+ # test cgnet ContextGuidedBlock with down sampling
+ block = ContextGuidedBlock(32, 32, downsample=True)
+ assert block.conv1x1.conv.in_channels == 32
+ assert block.conv1x1.conv.out_channels == 32
+ assert block.conv1x1.conv.kernel_size == (3, 3)
+ assert block.conv1x1.conv.stride == (2, 2)
+ assert block.conv1x1.conv.padding == (1, 1)
+
+ assert block.f_loc.in_channels == 32
+ assert block.f_loc.out_channels == 32
+ assert block.f_loc.kernel_size == (3, 3)
+ assert block.f_loc.stride == (1, 1)
+ assert block.f_loc.padding == (1, 1)
+ assert block.f_loc.groups == 32
+ assert block.f_loc.dilation == (1, 1)
+ assert block.f_loc.bias is None
+
+ assert block.f_sur.in_channels == 32
+ assert block.f_sur.out_channels == 32
+ assert block.f_sur.kernel_size == (3, 3)
+ assert block.f_sur.stride == (1, 1)
+ assert block.f_sur.padding == (2, 2)
+ assert block.f_sur.groups == 32
+ assert block.f_sur.dilation == (2, 2)
+ assert block.f_sur.bias is None
+
+ assert block.bottleneck.in_channels == 64
+ assert block.bottleneck.out_channels == 32
+ assert block.bottleneck.kernel_size == (1, 1)
+ assert block.bottleneck.stride == (1, 1)
+ assert block.bottleneck.bias is None
+
+ x = torch.randn(1, 32, 32, 32)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 16, 16])
+
+ # test cgnet ContextGuidedBlock without down sampling
+ block = ContextGuidedBlock(32, 32, downsample=False)
+ assert block.conv1x1.conv.in_channels == 32
+ assert block.conv1x1.conv.out_channels == 16
+ assert block.conv1x1.conv.kernel_size == (1, 1)
+ assert block.conv1x1.conv.stride == (1, 1)
+ assert block.conv1x1.conv.padding == (0, 0)
+
+ assert block.f_loc.in_channels == 16
+ assert block.f_loc.out_channels == 16
+ assert block.f_loc.kernel_size == (3, 3)
+ assert block.f_loc.stride == (1, 1)
+ assert block.f_loc.padding == (1, 1)
+ assert block.f_loc.groups == 16
+ assert block.f_loc.dilation == (1, 1)
+ assert block.f_loc.bias is None
+
+ assert block.f_sur.in_channels == 16
+ assert block.f_sur.out_channels == 16
+ assert block.f_sur.kernel_size == (3, 3)
+ assert block.f_sur.stride == (1, 1)
+ assert block.f_sur.padding == (2, 2)
+ assert block.f_sur.groups == 16
+ assert block.f_sur.dilation == (2, 2)
+ assert block.f_sur.bias is None
+
+ x = torch.randn(1, 32, 32, 32)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 32, 32])
+
+
+def test_cgnet_backbone():
+ with pytest.raises(AssertionError):
+ # check invalid num_channels
+ CGNet(num_channels=(32, 64, 128, 256))
+
+ with pytest.raises(AssertionError):
+ # check invalid num_blocks
+ CGNet(num_blocks=(3, 21, 3))
+
+ with pytest.raises(AssertionError):
+ # check invalid dilation
+ CGNet(num_blocks=2)
+
+ with pytest.raises(AssertionError):
+ # check invalid reduction
+ CGNet(reductions=16)
+
+ with pytest.raises(AssertionError):
+ # check invalid num_channels and reduction
+ CGNet(num_channels=(32, 64, 128), reductions=(64, 129))
+
+ # Test CGNet with default settings
+ model = CGNet()
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([2, 35, 112, 112])
+ assert feat[1].shape == torch.Size([2, 131, 56, 56])
+ assert feat[2].shape == torch.Size([2, 256, 28, 28])
+
+ # Test CGNet with norm_eval True and with_cp True
+ model = CGNet(norm_eval=True, with_cp=True)
+ with pytest.raises(TypeError):
+ # check invalid pretrained
+ model.init_weights(pretrained=8)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([2, 35, 112, 112])
+ assert feat[1].shape == torch.Size([2, 131, 56, 56])
+ assert feat[2].shape == torch.Size([2, 256, 28, 28])
diff --git a/tests/test_models/test_backbones/test_erfnet.py b/tests/test_models/test_backbones/test_erfnet.py
new file mode 100644
index 0000000..6ae7345
--- /dev/null
+++ b/tests/test_models/test_backbones/test_erfnet.py
@@ -0,0 +1,146 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import ERFNet
+from mmseg.models.backbones.erfnet import (DownsamplerBlock, NonBottleneck1d,
+ UpsamplerBlock)
+
+
+def test_erfnet_backbone():
+ # Test ERFNet Standard Forward.
+ model = ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 256, 512)
+ output = model(imgs)
+
+ # output for segment Head
+ assert output[0].shape == torch.Size([batch_size, 16, 128, 256])
+
+ # Test input with rare shape
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 527, 279)
+ output = model(imgs)
+ assert len(output[0]) == batch_size
+
+ with pytest.raises(AssertionError):
+ # Number of encoder downsample block and decoder upsample block.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(128, 64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ with pytest.raises(AssertionError):
+ # Number of encoder downsample block and encoder Non-bottleneck block.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8, 10),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ with pytest.raises(AssertionError):
+ # Number of encoder downsample block and
+ # channels of encoder Non-bottleneck block.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128, 256),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+
+ with pytest.raises(AssertionError):
+ # Number of encoder Non-bottleneck block and number of its channels.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8, 3),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ with pytest.raises(AssertionError):
+ # Number of decoder upsample block and decoder Non-bottleneck block.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2, 3),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ with pytest.raises(AssertionError):
+ # Number of decoder Non-bottleneck block and number of its channels.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16, 8),
+ dropout_ratio=0.1,
+ )
+
+
+def test_erfnet_downsampler_block():
+ x_db = DownsamplerBlock(16, 64)
+ assert x_db.conv.in_channels == 16
+ assert x_db.conv.out_channels == 48
+ assert len(x_db.bn.weight) == 64
+ assert x_db.pool.kernel_size == 2
+ assert x_db.pool.stride == 2
+
+
+def test_erfnet_non_bottleneck_1d():
+ x_nb1d = NonBottleneck1d(16, 0, 1)
+ assert x_nb1d.convs_layers[0].in_channels == 16
+ assert x_nb1d.convs_layers[0].out_channels == 16
+ assert x_nb1d.convs_layers[2].in_channels == 16
+ assert x_nb1d.convs_layers[2].out_channels == 16
+ assert x_nb1d.convs_layers[5].in_channels == 16
+ assert x_nb1d.convs_layers[5].out_channels == 16
+ assert x_nb1d.convs_layers[7].in_channels == 16
+ assert x_nb1d.convs_layers[7].out_channels == 16
+ assert x_nb1d.convs_layers[9].p == 0
+
+
+def test_erfnet_upsampler_block():
+ x_ub = UpsamplerBlock(64, 16)
+ assert x_ub.conv.in_channels == 64
+ assert x_ub.conv.out_channels == 16
+ assert len(x_ub.bn.weight) == 16
diff --git a/tests/test_models/test_backbones/test_fast_scnn.py b/tests/test_models/test_backbones/test_fast_scnn.py
new file mode 100644
index 0000000..7ee638b
--- /dev/null
+++ b/tests/test_models/test_backbones/test_fast_scnn.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import FastSCNN
+
+
+def test_fastscnn_backbone():
+ with pytest.raises(AssertionError):
+ # Fast-SCNN channel constraints.
+ FastSCNN(
+ 3, (32, 48),
+ 64, (64, 96, 128), (2, 2, 1),
+ global_out_channels=127,
+ higher_in_channels=64,
+ lower_in_channels=128)
+
+ # Test FastSCNN Standard Forward
+ model = FastSCNN(
+ in_channels=3,
+ downsample_dw_channels=(4, 6),
+ global_in_channels=8,
+ global_block_channels=(8, 12, 16),
+ global_block_strides=(2, 2, 1),
+ global_out_channels=16,
+ higher_in_channels=8,
+ lower_in_channels=16,
+ fusion_out_channels=16,
+ )
+ model.init_weights()
+ model.train()
+ batch_size = 4
+ imgs = torch.randn(batch_size, 3, 64, 128)
+ feat = model(imgs)
+
+ assert len(feat) == 3
+ # higher-res
+ assert feat[0].shape == torch.Size([batch_size, 8, 8, 16])
+ # lower-res
+ assert feat[1].shape == torch.Size([batch_size, 16, 2, 4])
+ # FFM output
+ assert feat[2].shape == torch.Size([batch_size, 16, 8, 16])
diff --git a/tests/test_models/test_backbones/test_hrnet.py b/tests/test_models/test_backbones/test_hrnet.py
new file mode 100644
index 0000000..8329c84
--- /dev/null
+++ b/tests/test_models/test_backbones/test_hrnet.py
@@ -0,0 +1,144 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from mmseg.models.backbones.hrnet import HRModule, HRNet
+from mmseg.models.backbones.resnet import BasicBlock, Bottleneck
+
+
+@pytest.mark.parametrize('block', [BasicBlock, Bottleneck])
+def test_hrmodule(block):
+ # Test multiscale forward
+ num_channles = (32, 64)
+ in_channels = [c * block.expansion for c in num_channles]
+ hrmodule = HRModule(
+ num_branches=2,
+ blocks=block,
+ in_channels=in_channels,
+ num_blocks=(4, 4),
+ num_channels=num_channles,
+ )
+
+ feats = [
+ torch.randn(1, in_channels[0], 64, 64),
+ torch.randn(1, in_channels[1], 32, 32)
+ ]
+ feats = hrmodule(feats)
+
+ assert len(feats) == 2
+ assert feats[0].shape == torch.Size([1, in_channels[0], 64, 64])
+ assert feats[1].shape == torch.Size([1, in_channels[1], 32, 32])
+
+ # Test single scale forward
+ num_channles = (32, 64)
+ in_channels = [c * block.expansion for c in num_channles]
+ hrmodule = HRModule(
+ num_branches=2,
+ blocks=block,
+ in_channels=in_channels,
+ num_blocks=(4, 4),
+ num_channels=num_channles,
+ multiscale_output=False,
+ )
+
+ feats = [
+ torch.randn(1, in_channels[0], 64, 64),
+ torch.randn(1, in_channels[1], 32, 32)
+ ]
+ feats = hrmodule(feats)
+
+ assert len(feats) == 1
+ assert feats[0].shape == torch.Size([1, in_channels[0], 64, 64])
+
+
+def test_hrnet_backbone():
+ # only have 3 stages
+ extra = dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)))
+
+ with pytest.raises(AssertionError):
+ # HRNet now only support 4 stages
+ HRNet(extra=extra)
+ extra['stage4'] = dict(
+ num_modules=3,
+ num_branches=3, # should be 4
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))
+
+ with pytest.raises(AssertionError):
+ # len(num_blocks) should equal num_branches
+ HRNet(extra=extra)
+
+ extra['stage4']['num_branches'] = 4
+
+ # Test hrnetv2p_w32
+ model = HRNet(extra=extra)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 64, 64)
+ feats = model(imgs)
+ assert len(feats) == 4
+ assert feats[0].shape == torch.Size([1, 32, 16, 16])
+ assert feats[3].shape == torch.Size([1, 256, 2, 2])
+
+ # Test single scale output
+ model = HRNet(extra=extra, multiscale_output=False)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 64, 64)
+ feats = model(imgs)
+ assert len(feats) == 1
+ assert feats[0].shape == torch.Size([1, 32, 16, 16])
+
+ # Test HRNET with two stage frozen
+ frozen_stages = 2
+ model = HRNet(extra, frozen_stages=frozen_stages)
+ model.init_weights()
+ model.train()
+ assert model.norm1.training is False
+
+ for layer in [model.conv1, model.norm1]:
+ for param in layer.parameters():
+ assert param.requires_grad is False
+ for i in range(1, frozen_stages + 1):
+ if i == 1:
+ layer = getattr(model, f'layer{i}')
+ transition = getattr(model, f'transition{i}')
+ elif i == 4:
+ layer = getattr(model, f'stage{i}')
+ else:
+ layer = getattr(model, f'stage{i}')
+ transition = getattr(model, f'transition{i}')
+
+ for mod in layer.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in layer.parameters():
+ assert param.requires_grad is False
+
+ for mod in transition.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in transition.parameters():
+ assert param.requires_grad is False
diff --git a/tests/test_models/test_backbones/test_icnet.py b/tests/test_models/test_backbones/test_icnet.py
new file mode 100644
index 0000000..a96d8d8
--- /dev/null
+++ b/tests/test_models/test_backbones/test_icnet.py
@@ -0,0 +1,50 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import ICNet
+
+
+def test_icnet_backbone():
+ with pytest.raises(TypeError):
+ # Must give backbone dict in config file.
+ ICNet(
+ in_channels=3,
+ layer_channels=(128, 512),
+ light_branch_middle_channels=8,
+ psp_out_channels=128,
+ out_channels=(16, 128, 128),
+ backbone_cfg=None)
+
+ # Test ICNet Standard Forward
+ model = ICNet(
+ layer_channels=(128, 512),
+ backbone_cfg=dict(
+ type='ResNetV1c',
+ in_channels=3,
+ depth=18,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ )
+ assert hasattr(model.backbone,
+ 'maxpool') and model.backbone.maxpool.ceil_mode is True
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 32, 64)
+ feat = model(imgs)
+
+ assert model.psp_modules[0][0].output_size == 1
+ assert model.psp_modules[1][0].output_size == 2
+ assert model.psp_modules[2][0].output_size == 3
+ assert model.psp_bottleneck.padding == 1
+ assert model.conv_sub1[0].padding == 1
+
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([batch_size, 64, 4, 8])
diff --git a/tests/test_models/test_backbones/test_mit.py b/tests/test_models/test_backbones/test_mit.py
new file mode 100644
index 0000000..9eec1fa
--- /dev/null
+++ b/tests/test_models/test_backbones/test_mit.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import MixVisionTransformer
+from mmseg.models.backbones.mit import EfficientMultiheadAttention, MixFFN
+
+
+def test_mit():
+ with pytest.raises(TypeError):
+ # Pretrained represents pretrain url and must be str or None.
+ MixVisionTransformer(pretrained=123)
+
+ # Test normal input
+ H, W = (224, 224)
+ temp = torch.randn((1, 3, H, W))
+ model = MixVisionTransformer(
+ embed_dims=32, num_heads=[1, 2, 5, 8], out_indices=(0, 1, 2, 3))
+ model.init_weights()
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 160, H // 16, W // 16)
+ assert outs[3].shape == (1, 256, H // 32, W // 32)
+
+ # Test non-squared input
+ H, W = (224, 256)
+ temp = torch.randn((1, 3, H, W))
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 160, H // 16, W // 16)
+ assert outs[3].shape == (1, 256, H // 32, W // 32)
+
+ # Test MixFFN
+ FFN = MixFFN(64, 128)
+ hw_shape = (32, 32)
+ token_len = 32 * 32
+ temp = torch.randn((1, token_len, 64))
+ # Self identity
+ out = FFN(temp, hw_shape)
+ assert out.shape == (1, token_len, 64)
+ # Out identity
+ outs = FFN(temp, hw_shape, temp)
+ assert out.shape == (1, token_len, 64)
+
+ # Test EfficientMHA
+ MHA = EfficientMultiheadAttention(64, 2)
+ hw_shape = (32, 32)
+ token_len = 32 * 32
+ temp = torch.randn((1, token_len, 64))
+ # Self identity
+ out = MHA(temp, hw_shape)
+ assert out.shape == (1, token_len, 64)
+ # Out identity
+ outs = MHA(temp, hw_shape, temp)
+ assert out.shape == (1, token_len, 64)
+
+
+def test_mit_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = MixVisionTransformer(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = MixVisionTransformer(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = MixVisionTransformer(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = MixVisionTransformer(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ MixVisionTransformer(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ MixVisionTransformer(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ MixVisionTransformer(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ MixVisionTransformer(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ MixVisionTransformer(pretrained=123, init_cfg=123)
diff --git a/tests/test_models/test_backbones/test_mobilenet_v3.py b/tests/test_models/test_backbones/test_mobilenet_v3.py
new file mode 100644
index 0000000..769ee14
--- /dev/null
+++ b/tests/test_models/test_backbones/test_mobilenet_v3.py
@@ -0,0 +1,67 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import MobileNetV3
+
+
+def test_mobilenet_v3():
+ with pytest.raises(AssertionError):
+ # check invalid arch
+ MobileNetV3('big')
+
+ with pytest.raises(AssertionError):
+ # check invalid reduction_factor
+ MobileNetV3(reduction_factor=0)
+
+ with pytest.raises(ValueError):
+ # check invalid out_indices
+ MobileNetV3(out_indices=(0, 1, 15))
+
+ with pytest.raises(ValueError):
+ # check invalid frozen_stages
+ MobileNetV3(frozen_stages=15)
+
+ with pytest.raises(TypeError):
+ # check invalid pretrained
+ model = MobileNetV3()
+ model.init_weights(pretrained=8)
+
+ # Test MobileNetV3 with default settings
+ model = MobileNetV3()
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 56, 56)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == (2, 16, 28, 28)
+ assert feat[1].shape == (2, 16, 14, 14)
+ assert feat[2].shape == (2, 576, 7, 7)
+
+ # Test MobileNetV3 with arch = 'large'
+ model = MobileNetV3(arch='large', out_indices=(1, 3, 16))
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 56, 56)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == (2, 16, 28, 28)
+ assert feat[1].shape == (2, 24, 14, 14)
+ assert feat[2].shape == (2, 960, 7, 7)
+
+ # Test MobileNetV3 with norm_eval True, with_cp True and frozen_stages=5
+ model = MobileNetV3(norm_eval=True, with_cp=True, frozen_stages=5)
+ with pytest.raises(TypeError):
+ # check invalid pretrained
+ model.init_weights(pretrained=8)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 56, 56)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == (2, 16, 28, 28)
+ assert feat[1].shape == (2, 16, 14, 14)
+ assert feat[2].shape == (2, 576, 7, 7)
diff --git a/tests/test_models/test_backbones/test_resnest.py b/tests/test_models/test_backbones/test_resnest.py
new file mode 100644
index 0000000..3013f34
--- /dev/null
+++ b/tests/test_models/test_backbones/test_resnest.py
@@ -0,0 +1,44 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import ResNeSt
+from mmseg.models.backbones.resnest import Bottleneck as BottleneckS
+
+
+def test_resnest_bottleneck():
+ with pytest.raises(AssertionError):
+ # Style must be in ['pytorch', 'caffe']
+ BottleneckS(64, 64, radix=2, reduction_factor=4, style='tensorflow')
+
+ # Test ResNeSt Bottleneck structure
+ block = BottleneckS(
+ 64, 256, radix=2, reduction_factor=4, stride=2, style='pytorch')
+ assert block.avd_layer.stride == 2
+ assert block.conv2.channels == 256
+
+ # Test ResNeSt Bottleneck forward
+ block = BottleneckS(64, 16, radix=2, reduction_factor=4)
+ x = torch.randn(2, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([2, 64, 56, 56])
+
+
+def test_resnest_backbone():
+ with pytest.raises(KeyError):
+ # ResNeSt depth should be in [50, 101, 152, 200]
+ ResNeSt(depth=18)
+
+ # Test ResNeSt with radix 2, reduction_factor 4
+ model = ResNeSt(
+ depth=50, radix=2, reduction_factor=4, out_indices=(0, 1, 2, 3))
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([2, 256, 56, 56])
+ assert feat[1].shape == torch.Size([2, 512, 28, 28])
+ assert feat[2].shape == torch.Size([2, 1024, 14, 14])
+ assert feat[3].shape == torch.Size([2, 2048, 7, 7])
diff --git a/tests/test_models/test_backbones/test_resnet.py b/tests/test_models/test_backbones/test_resnet.py
new file mode 100644
index 0000000..fa632f5
--- /dev/null
+++ b/tests/test_models/test_backbones/test_resnet.py
@@ -0,0 +1,575 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+from mmcv.ops import DeformConv2dPack
+from mmcv.utils.parrots_wrapper import _BatchNorm
+from torch.nn.modules import AvgPool2d, GroupNorm
+
+from mmseg.models.backbones import ResNet, ResNetV1d
+from mmseg.models.backbones.resnet import BasicBlock, Bottleneck
+from mmseg.models.utils import ResLayer
+from .utils import all_zeros, check_norm_state, is_block, is_norm
+
+
+def test_resnet_basic_block():
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ BasicBlock(64, 64, dcn=dcn)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ BasicBlock(64, 64, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ BasicBlock(64, 64, plugins=plugins)
+
+ # Test BasicBlock with checkpoint forward
+ block = BasicBlock(16, 16, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 16, 28, 28)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 16, 28, 28])
+
+ # test BasicBlock structure and forward
+ block = BasicBlock(32, 32)
+ assert block.conv1.in_channels == 32
+ assert block.conv1.out_channels == 32
+ assert block.conv1.kernel_size == (3, 3)
+ assert block.conv2.in_channels == 32
+ assert block.conv2.out_channels == 32
+ assert block.conv2.kernel_size == (3, 3)
+ x = torch.randn(1, 32, 28, 28)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 28, 28])
+
+
+def test_resnet_bottleneck():
+ with pytest.raises(AssertionError):
+ # Style must be in ['pytorch', 'caffe']
+ Bottleneck(64, 64, style='tensorflow')
+
+ with pytest.raises(AssertionError):
+ # Allowed positions are 'after_conv1', 'after_conv2', 'after_conv3'
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv4')
+ ]
+ Bottleneck(64, 16, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Need to specify different postfix to avoid duplicate plugin name
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ Bottleneck(64, 16, plugins=plugins)
+
+ with pytest.raises(KeyError):
+ # Plugin type is not supported
+ plugins = [dict(cfg=dict(type='WrongPlugin'), position='after_conv3')]
+ Bottleneck(64, 16, plugins=plugins)
+
+ # Test Bottleneck with checkpoint forward
+ block = Bottleneck(64, 16, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck style
+ block = Bottleneck(64, 64, stride=2, style='pytorch')
+ assert block.conv1.stride == (1, 1)
+ assert block.conv2.stride == (2, 2)
+ block = Bottleneck(64, 64, stride=2, style='caffe')
+ assert block.conv1.stride == (2, 2)
+ assert block.conv2.stride == (1, 1)
+
+ # Test Bottleneck DCN
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ with pytest.raises(AssertionError):
+ Bottleneck(64, 64, dcn=dcn, conv_cfg=dict(type='Conv'))
+ block = Bottleneck(64, 64, dcn=dcn)
+ assert isinstance(block.conv2, DeformConv2dPack)
+
+ # Test Bottleneck forward
+ block = Bottleneck(64, 16)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck with 1 ContextBlock after conv3
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ block = Bottleneck(64, 16, plugins=plugins)
+ assert block.context_block.in_channels == 64
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck with 1 GeneralizedAttention after conv2
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ block = Bottleneck(64, 16, plugins=plugins)
+ assert block.gen_attention_block.in_channels == 16
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck with 1 GeneralizedAttention after conv2, 1 NonLocal2d
+ # after conv2, 1 ContextBlock after conv3
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2'),
+ dict(cfg=dict(type='NonLocal2d'), position='after_conv2'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ block = Bottleneck(64, 16, plugins=plugins)
+ assert block.gen_attention_block.in_channels == 16
+ assert block.nonlocal_block.in_channels == 16
+ assert block.context_block.in_channels == 64
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck with 1 ContextBlock after conv2, 2 ContextBlock after
+ # conv3
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=1),
+ position='after_conv2'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=2),
+ position='after_conv3'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=3),
+ position='after_conv3')
+ ]
+ block = Bottleneck(64, 16, plugins=plugins)
+ assert block.context_block1.in_channels == 16
+ assert block.context_block2.in_channels == 64
+ assert block.context_block3.in_channels == 64
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+
+def test_resnet_res_layer():
+ # Test ResLayer of 3 Bottleneck w\o downsample
+ layer = ResLayer(Bottleneck, 64, 16, 3)
+ assert len(layer) == 3
+ assert layer[0].conv1.in_channels == 64
+ assert layer[0].conv1.out_channels == 16
+ for i in range(1, len(layer)):
+ assert layer[i].conv1.in_channels == 64
+ assert layer[i].conv1.out_channels == 16
+ for i in range(len(layer)):
+ assert layer[i].downsample is None
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test ResLayer of 3 Bottleneck with downsample
+ layer = ResLayer(Bottleneck, 64, 64, 3)
+ assert layer[0].downsample[0].out_channels == 256
+ for i in range(1, len(layer)):
+ assert layer[i].downsample is None
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 256, 56, 56])
+
+ # Test ResLayer of 3 Bottleneck with stride=2
+ layer = ResLayer(Bottleneck, 64, 64, 3, stride=2)
+ assert layer[0].downsample[0].out_channels == 256
+ assert layer[0].downsample[0].stride == (2, 2)
+ for i in range(1, len(layer)):
+ assert layer[i].downsample is None
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 256, 28, 28])
+
+ # Test ResLayer of 3 Bottleneck with stride=2 and average downsample
+ layer = ResLayer(Bottleneck, 64, 64, 3, stride=2, avg_down=True)
+ assert isinstance(layer[0].downsample[0], AvgPool2d)
+ assert layer[0].downsample[1].out_channels == 256
+ assert layer[0].downsample[1].stride == (1, 1)
+ for i in range(1, len(layer)):
+ assert layer[i].downsample is None
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 256, 28, 28])
+
+ # Test ResLayer of 3 Bottleneck with dilation=2
+ layer = ResLayer(Bottleneck, 64, 16, 3, dilation=2)
+ for i in range(len(layer)):
+ assert layer[i].conv2.dilation == (2, 2)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test ResLayer of 3 Bottleneck with dilation=2, contract_dilation=True
+ layer = ResLayer(Bottleneck, 64, 16, 3, dilation=2, contract_dilation=True)
+ assert layer[0].conv2.dilation == (1, 1)
+ for i in range(1, len(layer)):
+ assert layer[i].conv2.dilation == (2, 2)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test ResLayer of 3 Bottleneck with dilation=2, multi_grid
+ layer = ResLayer(Bottleneck, 64, 16, 3, dilation=2, multi_grid=(1, 2, 4))
+ assert layer[0].conv2.dilation == (1, 1)
+ assert layer[1].conv2.dilation == (2, 2)
+ assert layer[2].conv2.dilation == (4, 4)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+
+def test_resnet_backbone():
+ """Test resnet backbone."""
+ with pytest.raises(KeyError):
+ # ResNet depth should be in [18, 34, 50, 101, 152]
+ ResNet(20)
+
+ with pytest.raises(AssertionError):
+ # In ResNet: 1 <= num_stages <= 4
+ ResNet(50, num_stages=0)
+
+ with pytest.raises(AssertionError):
+ # len(stage_with_dcn) == num_stages
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ ResNet(50, dcn=dcn, stage_with_dcn=(True, ))
+
+ with pytest.raises(AssertionError):
+ # len(stage_with_plugin) == num_stages
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ stages=(False, True, True),
+ position='after_conv3')
+ ]
+ ResNet(50, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # In ResNet: 1 <= num_stages <= 4
+ ResNet(18, num_stages=5)
+
+ with pytest.raises(AssertionError):
+ # len(strides) == len(dilations) == num_stages
+ ResNet(18, strides=(1, ), dilations=(1, 1), num_stages=3)
+
+ with pytest.raises(TypeError):
+ # pretrained must be a string path
+ model = ResNet(18, pretrained=0)
+ model.init_weights()
+
+ with pytest.raises(AssertionError):
+ # Style must be in ['pytorch', 'caffe']
+ ResNet(50, style='tensorflow')
+
+ # Test ResNet18 norm_eval=True
+ model = ResNet(18, norm_eval=True)
+ model.init_weights()
+ model.train()
+ assert check_norm_state(model.modules(), False)
+
+ # Test ResNet18 with torchvision pretrained weight
+ model = ResNet(
+ depth=18, norm_eval=True, pretrained='torchvision://resnet18')
+ model.init_weights()
+ model.train()
+ assert check_norm_state(model.modules(), False)
+
+ # Test ResNet18 with first stage frozen
+ frozen_stages = 1
+ model = ResNet(18, frozen_stages=frozen_stages)
+ model.init_weights()
+ model.train()
+ assert model.norm1.training is False
+ for layer in [model.conv1, model.norm1]:
+ for param in layer.parameters():
+ assert param.requires_grad is False
+ for i in range(1, frozen_stages + 1):
+ layer = getattr(model, 'layer{}'.format(i))
+ for mod in layer.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in layer.parameters():
+ assert param.requires_grad is False
+
+ # Test ResNet18V1d with first stage frozen
+ model = ResNetV1d(depth=18, frozen_stages=frozen_stages)
+ assert len(model.stem) == 9
+ model.init_weights()
+ model.train()
+ check_norm_state(model.stem, False)
+ for param in model.stem.parameters():
+ assert param.requires_grad is False
+ for i in range(1, frozen_stages + 1):
+ layer = getattr(model, 'layer{}'.format(i))
+ for mod in layer.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in layer.parameters():
+ assert param.requires_grad is False
+
+ # Test ResNet18 forward
+ model = ResNet(18)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet18 with BatchNorm forward
+ model = ResNet(18)
+ for m in model.modules():
+ if is_norm(m):
+ assert isinstance(m, _BatchNorm)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet18 with layers 1, 2, 3 out forward
+ model = ResNet(18, out_indices=(0, 1, 2))
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 112, 112)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([1, 64, 28, 28])
+ assert feat[1].shape == torch.Size([1, 128, 14, 14])
+ assert feat[2].shape == torch.Size([1, 256, 7, 7])
+
+ # Test ResNet18 with checkpoint forward
+ model = ResNet(18, with_cp=True)
+ for m in model.modules():
+ if is_block(m):
+ assert m.with_cp
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet18 with checkpoint forward
+ model = ResNet(18, with_cp=True)
+ for m in model.modules():
+ if is_block(m):
+ assert m.with_cp
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet18 with GroupNorm forward
+ model = ResNet(
+ 18, norm_cfg=dict(type='GN', num_groups=32, requires_grad=True))
+ for m in model.modules():
+ if is_norm(m):
+ assert isinstance(m, GroupNorm)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet50 with 1 GeneralizedAttention after conv2, 1 NonLocal2d
+ # after conv2, 1 ContextBlock after conv3 in layers 2, 3, 4
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ stages=(False, True, True, True),
+ position='after_conv2'),
+ dict(cfg=dict(type='NonLocal2d'), position='after_conv2'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ stages=(False, True, True, False),
+ position='after_conv3')
+ ]
+ model = ResNet(50, plugins=plugins)
+ for m in model.layer1.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert not hasattr(m, 'gen_attention_block')
+ assert m.nonlocal_block.in_channels == 64
+ for m in model.layer2.modules():
+ if is_block(m):
+ assert m.nonlocal_block.in_channels == 128
+ assert m.gen_attention_block.in_channels == 128
+ assert m.context_block.in_channels == 512
+
+ for m in model.layer3.modules():
+ if is_block(m):
+ assert m.nonlocal_block.in_channels == 256
+ assert m.gen_attention_block.in_channels == 256
+ assert m.context_block.in_channels == 1024
+
+ for m in model.layer4.modules():
+ if is_block(m):
+ assert m.nonlocal_block.in_channels == 512
+ assert m.gen_attention_block.in_channels == 512
+ assert not hasattr(m, 'context_block')
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 256, 56, 56])
+ assert feat[1].shape == torch.Size([1, 512, 28, 28])
+ assert feat[2].shape == torch.Size([1, 1024, 14, 14])
+ assert feat[3].shape == torch.Size([1, 2048, 7, 7])
+
+ # Test ResNet50 with 1 ContextBlock after conv2, 1 ContextBlock after
+ # conv3 in layers 2, 3, 4
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=1),
+ stages=(False, True, True, False),
+ position='after_conv3'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=2),
+ stages=(False, True, True, False),
+ position='after_conv3')
+ ]
+
+ model = ResNet(50, plugins=plugins)
+ for m in model.layer1.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert not hasattr(m, 'context_block1')
+ assert not hasattr(m, 'context_block2')
+ for m in model.layer2.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert m.context_block1.in_channels == 512
+ assert m.context_block2.in_channels == 512
+
+ for m in model.layer3.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert m.context_block1.in_channels == 1024
+ assert m.context_block2.in_channels == 1024
+
+ for m in model.layer4.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert not hasattr(m, 'context_block1')
+ assert not hasattr(m, 'context_block2')
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 256, 56, 56])
+ assert feat[1].shape == torch.Size([1, 512, 28, 28])
+ assert feat[2].shape == torch.Size([1, 1024, 14, 14])
+ assert feat[3].shape == torch.Size([1, 2048, 7, 7])
+
+ # Test ResNet18 zero initialization of residual
+ model = ResNet(18, zero_init_residual=True)
+ model.init_weights()
+ for m in model.modules():
+ if isinstance(m, Bottleneck):
+ assert all_zeros(m.norm3)
+ elif isinstance(m, BasicBlock):
+ assert all_zeros(m.norm2)
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNetV1d forward
+ model = ResNetV1d(depth=18)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
diff --git a/tests/test_models/test_backbones/test_resnext.py b/tests/test_models/test_backbones/test_resnext.py
new file mode 100644
index 0000000..2aecaf0
--- /dev/null
+++ b/tests/test_models/test_backbones/test_resnext.py
@@ -0,0 +1,62 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import ResNeXt
+from mmseg.models.backbones.resnext import Bottleneck as BottleneckX
+from .utils import is_block
+
+
+def test_renext_bottleneck():
+ with pytest.raises(AssertionError):
+ # Style must be in ['pytorch', 'caffe']
+ BottleneckX(64, 64, groups=32, base_width=4, style='tensorflow')
+
+ # Test ResNeXt Bottleneck structure
+ block = BottleneckX(
+ 64, 64, groups=32, base_width=4, stride=2, style='pytorch')
+ assert block.conv2.stride == (2, 2)
+ assert block.conv2.groups == 32
+ assert block.conv2.out_channels == 128
+
+ # Test ResNeXt Bottleneck with DCN
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ with pytest.raises(AssertionError):
+ # conv_cfg must be None if dcn is not None
+ BottleneckX(
+ 64,
+ 64,
+ groups=32,
+ base_width=4,
+ dcn=dcn,
+ conv_cfg=dict(type='Conv'))
+ BottleneckX(64, 64, dcn=dcn)
+
+ # Test ResNeXt Bottleneck forward
+ block = BottleneckX(64, 16, groups=32, base_width=4)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+
+def test_resnext_backbone():
+ with pytest.raises(KeyError):
+ # ResNeXt depth should be in [50, 101, 152]
+ ResNeXt(depth=18)
+
+ # Test ResNeXt with group 32, base_width 4
+ model = ResNeXt(depth=50, groups=32, base_width=4)
+ print(model)
+ for m in model.modules():
+ if is_block(m):
+ assert m.conv2.groups == 32
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 256, 56, 56])
+ assert feat[1].shape == torch.Size([1, 512, 28, 28])
+ assert feat[2].shape == torch.Size([1, 1024, 14, 14])
+ assert feat[3].shape == torch.Size([1, 2048, 7, 7])
diff --git a/tests/test_models/test_backbones/test_stdc.py b/tests/test_models/test_backbones/test_stdc.py
new file mode 100644
index 0000000..1e3862b
--- /dev/null
+++ b/tests/test_models/test_backbones/test_stdc.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import STDCContextPathNet
+from mmseg.models.backbones.stdc import (AttentionRefinementModule,
+ FeatureFusionModule, STDCModule,
+ STDCNet)
+
+
+def test_stdc_context_path_net():
+ # Test STDCContextPathNet Standard Forward
+ model = STDCContextPathNet(
+ backbone_cfg=dict(
+ type='STDCNet',
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=True),
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(in_channels=384, out_channels=256, scale_factor=4))
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 256, 512)
+ feat = model(imgs)
+
+ assert len(feat) == 4
+ # output for segment Head
+ assert feat[0].shape == torch.Size([batch_size, 256, 32, 64])
+ # for auxiliary head 1
+ assert feat[1].shape == torch.Size([batch_size, 128, 16, 32])
+ # for auxiliary head 2
+ assert feat[2].shape == torch.Size([batch_size, 128, 32, 64])
+ # for auxiliary head 3
+ assert feat[3].shape == torch.Size([batch_size, 256, 32, 64])
+
+ # Test input with rare shape
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 527, 279)
+ model = STDCContextPathNet(
+ backbone_cfg=dict(
+ type='STDCNet',
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='add',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False),
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(in_channels=384, out_channels=256, scale_factor=4))
+ model.init_weights()
+ model.train()
+ feat = model(imgs)
+ assert len(feat) == 4
+
+
+def test_stdcnet():
+ with pytest.raises(AssertionError):
+ # STDC backbone constraints.
+ STDCNet(
+ stdc_type='STDCNet3',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False)
+
+ with pytest.raises(AssertionError):
+ # STDC bottleneck type constraints.
+ STDCNet(
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='dog',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False)
+
+ with pytest.raises(AssertionError):
+ # STDC channels length constraints.
+ STDCNet(
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(16, 32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False)
+
+
+def test_feature_fusion_module():
+ x_ffm = FeatureFusionModule(in_channels=64, out_channels=32)
+ assert x_ffm.conv0.in_channels == 64
+ assert x_ffm.attention[1].in_channels == 32
+ assert x_ffm.attention[2].in_channels == 8
+ assert x_ffm.attention[2].out_channels == 32
+ x1 = torch.randn(2, 32, 32, 64)
+ x2 = torch.randn(2, 32, 32, 64)
+ x_out = x_ffm(x1, x2)
+ assert x_out.shape == torch.Size([2, 32, 32, 64])
+
+
+def test_attention_refinement_module():
+ x_arm = AttentionRefinementModule(128, 32)
+ assert x_arm.conv_layer.in_channels == 128
+ assert x_arm.atten_conv_layer[1].conv.out_channels == 32
+ x = torch.randn(2, 128, 32, 64)
+ x_out = x_arm(x)
+ assert x_out.shape == torch.Size([2, 32, 32, 64])
+
+
+def test_stdc_module():
+ x_stdc = STDCModule(in_channels=32, out_channels=32, stride=4)
+ assert x_stdc.layers[0].conv.in_channels == 32
+ assert x_stdc.layers[3].conv.out_channels == 4
+ x = torch.randn(2, 32, 32, 64)
+ x_out = x_stdc(x)
+ assert x_out.shape == torch.Size([2, 32, 32, 64])
diff --git a/tests/test_models/test_backbones/test_swin.py b/tests/test_models/test_backbones/test_swin.py
new file mode 100644
index 0000000..4690001
--- /dev/null
+++ b/tests/test_models/test_backbones/test_swin.py
@@ -0,0 +1,99 @@
+import pytest
+import torch
+
+from mmseg.models.backbones.swin import SwinBlock, SwinTransformer
+
+
+def test_swin_block():
+ # test SwinBlock structure and forward
+ block = SwinBlock(embed_dims=32, num_heads=4, feedforward_channels=128)
+ assert block.ffn.embed_dims == 32
+ assert block.attn.w_msa.num_heads == 4
+ assert block.ffn.feedforward_channels == 128
+ x = torch.randn(1, 56 * 56, 32)
+ x_out = block(x, (56, 56))
+ assert x_out.shape == torch.Size([1, 56 * 56, 32])
+
+ # Test BasicBlock with checkpoint forward
+ block = SwinBlock(
+ embed_dims=64, num_heads=4, feedforward_channels=256, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 56 * 56, 64)
+ x_out = block(x, (56, 56))
+ assert x_out.shape == torch.Size([1, 56 * 56, 64])
+
+
+def test_swin_transformer():
+ """Test Swin Transformer backbone."""
+
+ with pytest.raises(TypeError):
+ # Pretrained arg must be str or None.
+ SwinTransformer(pretrained=123)
+
+ with pytest.raises(AssertionError):
+ # Because swin uses non-overlapping patch embed, so the stride of patch
+ # embed must be equal to patch size.
+ SwinTransformer(strides=(2, 2, 2, 2), patch_size=4)
+
+ # test pretrained image size
+ with pytest.raises(AssertionError):
+ SwinTransformer(pretrain_img_size=(112, 112, 112))
+
+ # Test absolute position embedding
+ temp = torch.randn((1, 3, 112, 112))
+ model = SwinTransformer(pretrain_img_size=112, use_abs_pos_embed=True)
+ model.init_weights()
+ model(temp)
+
+ # Test patch norm
+ model = SwinTransformer(patch_norm=False)
+ model(temp)
+
+ # Test normal inference
+ temp = torch.randn((1, 3, 256, 256))
+ model = SwinTransformer()
+ outs = model(temp)
+ assert outs[0].shape == (1, 96, 64, 64)
+ assert outs[1].shape == (1, 192, 32, 32)
+ assert outs[2].shape == (1, 384, 16, 16)
+ assert outs[3].shape == (1, 768, 8, 8)
+
+ # Test abnormal inference size
+ temp = torch.randn((1, 3, 255, 255))
+ model = SwinTransformer()
+ outs = model(temp)
+ assert outs[0].shape == (1, 96, 64, 64)
+ assert outs[1].shape == (1, 192, 32, 32)
+ assert outs[2].shape == (1, 384, 16, 16)
+ assert outs[3].shape == (1, 768, 8, 8)
+
+ # Test abnormal inference size
+ temp = torch.randn((1, 3, 112, 137))
+ model = SwinTransformer()
+ outs = model(temp)
+ assert outs[0].shape == (1, 96, 28, 35)
+ assert outs[1].shape == (1, 192, 14, 18)
+ assert outs[2].shape == (1, 384, 7, 9)
+ assert outs[3].shape == (1, 768, 4, 5)
+
+ # Test frozen
+ model = SwinTransformer(frozen_stages=4)
+ model.train()
+ for p in model.parameters():
+ assert not p.requires_grad
+
+ # Test absolute position embedding frozen
+ model = SwinTransformer(frozen_stages=4, use_abs_pos_embed=True)
+ model.train()
+ for p in model.parameters():
+ assert not p.requires_grad
+
+ # Test Swin with checkpoint forward
+ temp = torch.randn((1, 3, 56, 56))
+ model = SwinTransformer(with_cp=True)
+ for m in model.modules():
+ if isinstance(m, SwinBlock):
+ assert m.with_cp
+ model.init_weights()
+ model.train()
+ model(temp)
diff --git a/tests/test_models/test_backbones/test_timm_backbone.py b/tests/test_models/test_backbones/test_timm_backbone.py
new file mode 100644
index 0000000..85ef9aa
--- /dev/null
+++ b/tests/test_models/test_backbones/test_timm_backbone.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import TIMMBackbone
+from .utils import check_norm_state
+
+
+def test_timm_backbone():
+ with pytest.raises(TypeError):
+ # pretrained must be a string path
+ model = TIMMBackbone()
+ model.init_weights(pretrained=0)
+
+ # Test different norm_layer, can be: 'SyncBN', 'BN2d', 'GN', 'LN', 'IN'
+ # Test resnet18 from timm, norm_layer='BN2d'
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=32,
+ norm_layer='BN2d')
+
+ # Test resnet18 from timm, norm_layer='SyncBN'
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=32,
+ norm_layer='SyncBN')
+
+ # Test resnet18 from timm, features_only=True, output_stride=32
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=32)
+ model.init_weights()
+ model.train()
+ assert check_norm_state(model.modules(), True)
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 112, 112))
+ assert feats[1] == torch.Size((1, 64, 56, 56))
+ assert feats[2] == torch.Size((1, 128, 28, 28))
+ assert feats[3] == torch.Size((1, 256, 14, 14))
+ assert feats[4] == torch.Size((1, 512, 7, 7))
+
+ # Test resnet18 from timm, features_only=True, output_stride=16
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=16)
+ imgs = torch.randn(1, 3, 224, 224)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 112, 112))
+ assert feats[1] == torch.Size((1, 64, 56, 56))
+ assert feats[2] == torch.Size((1, 128, 28, 28))
+ assert feats[3] == torch.Size((1, 256, 14, 14))
+ assert feats[4] == torch.Size((1, 512, 14, 14))
+
+ # Test resnet18 from timm, features_only=True, output_stride=8
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=8)
+ imgs = torch.randn(1, 3, 224, 224)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 112, 112))
+ assert feats[1] == torch.Size((1, 64, 56, 56))
+ assert feats[2] == torch.Size((1, 128, 28, 28))
+ assert feats[3] == torch.Size((1, 256, 28, 28))
+ assert feats[4] == torch.Size((1, 512, 28, 28))
+
+ # Test efficientnet_b1 with pretrained weights
+ model = TIMMBackbone(model_name='efficientnet_b1', pretrained=True)
+
+ # Test resnetv2_50x1_bitm from timm, features_only=True, output_stride=8
+ model = TIMMBackbone(
+ model_name='resnetv2_50x1_bitm',
+ features_only=True,
+ pretrained=False,
+ output_stride=8)
+ imgs = torch.randn(1, 3, 8, 8)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 4, 4))
+ assert feats[1] == torch.Size((1, 256, 2, 2))
+ assert feats[2] == torch.Size((1, 512, 1, 1))
+ assert feats[3] == torch.Size((1, 1024, 1, 1))
+ assert feats[4] == torch.Size((1, 2048, 1, 1))
+
+ # Test resnetv2_50x3_bitm from timm, features_only=True, output_stride=8
+ model = TIMMBackbone(
+ model_name='resnetv2_50x3_bitm',
+ features_only=True,
+ pretrained=False,
+ output_stride=8)
+ imgs = torch.randn(1, 3, 8, 8)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 192, 4, 4))
+ assert feats[1] == torch.Size((1, 768, 2, 2))
+ assert feats[2] == torch.Size((1, 1536, 1, 1))
+ assert feats[3] == torch.Size((1, 3072, 1, 1))
+ assert feats[4] == torch.Size((1, 6144, 1, 1))
+
+ # Test resnetv2_101x1_bitm from timm, features_only=True, output_stride=8
+ model = TIMMBackbone(
+ model_name='resnetv2_101x1_bitm',
+ features_only=True,
+ pretrained=False,
+ output_stride=8)
+ imgs = torch.randn(1, 3, 8, 8)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 4, 4))
+ assert feats[1] == torch.Size((1, 256, 2, 2))
+ assert feats[2] == torch.Size((1, 512, 1, 1))
+ assert feats[3] == torch.Size((1, 1024, 1, 1))
+ assert feats[4] == torch.Size((1, 2048, 1, 1))
diff --git a/tests/test_models/test_backbones/test_twins.py b/tests/test_models/test_backbones/test_twins.py
new file mode 100644
index 0000000..c7d4a8e
--- /dev/null
+++ b/tests/test_models/test_backbones/test_twins.py
@@ -0,0 +1,170 @@
+import pytest
+import torch
+
+from mmseg.models.backbones.twins import (PCPVT, SVT,
+ ConditionalPositionEncoding,
+ LocallyGroupedSelfAttention)
+
+
+def test_pcpvt():
+ # Test normal input
+ H, W = (224, 224)
+ temp = torch.randn((1, 3, H, W))
+ model = PCPVT(
+ embed_dims=[32, 64, 160, 256],
+ num_heads=[1, 2, 5, 8],
+ mlp_ratios=[8, 8, 4, 4],
+ qkv_bias=True,
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False)
+ model.init_weights()
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 160, H // 16, W // 16)
+ assert outs[3].shape == (1, 256, H // 32, W // 32)
+
+
+def test_svt():
+ # Test normal input
+ H, W = (224, 224)
+ temp = torch.randn((1, 3, H, W))
+ model = SVT(
+ embed_dims=[32, 64, 128],
+ num_heads=[1, 2, 4],
+ mlp_ratios=[4, 4, 4],
+ qkv_bias=False,
+ depths=[4, 4, 4],
+ windiow_sizes=[7, 7, 7],
+ norm_after_stage=True)
+
+ model.init_weights()
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 128, H // 16, W // 16)
+
+
+def test_svt_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = SVT(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = SVT(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = SVT(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = SVT(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = SVT(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ model = SVT(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ model = SVT(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = SVT(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ model = SVT(pretrained=123, init_cfg=123)
+
+
+def test_pcpvt_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = PCPVT(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = PCPVT(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = PCPVT(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = PCPVT(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = PCPVT(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ model = PCPVT(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ model = PCPVT(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = PCPVT(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ model = PCPVT(pretrained=123, init_cfg=123)
+
+
+def test_locallygrouped_self_attention_module():
+ LSA = LocallyGroupedSelfAttention(embed_dims=32, window_size=3)
+ outs = LSA(torch.randn(1, 3136, 32), (56, 56))
+ assert outs.shape == torch.Size([1, 3136, 32])
+
+
+def test_conditional_position_encoding_module():
+ CPE = ConditionalPositionEncoding(in_channels=32, embed_dims=32, stride=2)
+ outs = CPE(torch.randn(1, 3136, 32), (56, 56))
+ assert outs.shape == torch.Size([1, 784, 32])
diff --git a/tests/test_models/test_backbones/test_unet.py b/tests/test_models/test_backbones/test_unet.py
new file mode 100644
index 0000000..9beb727
--- /dev/null
+++ b/tests/test_models/test_backbones/test_unet.py
@@ -0,0 +1,822 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+from mmcv.cnn import ConvModule
+
+from mmseg.models.backbones.unet import (BasicConvBlock, DeconvModule,
+ InterpConv, UNet, UpConvBlock)
+from mmseg.ops import Upsample
+from .utils import check_norm_state
+
+
+def test_unet_basic_conv_block():
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ BasicConvBlock(64, 64, dcn=dcn)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ BasicConvBlock(64, 64, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ BasicConvBlock(64, 64, plugins=plugins)
+
+ # test BasicConvBlock with checkpoint forward
+ block = BasicConvBlock(16, 16, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 16, 64, 64, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 16, 64, 64])
+
+ block = BasicConvBlock(16, 16, with_cp=False)
+ assert not block.with_cp
+ x = torch.randn(1, 16, 64, 64)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 16, 64, 64])
+
+ # test BasicConvBlock with stride convolution to downsample
+ block = BasicConvBlock(16, 16, stride=2)
+ x = torch.randn(1, 16, 64, 64)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 16, 32, 32])
+
+ # test BasicConvBlock structure and forward
+ block = BasicConvBlock(16, 64, num_convs=3, dilation=3)
+ assert block.convs[0].conv.in_channels == 16
+ assert block.convs[0].conv.out_channels == 64
+ assert block.convs[0].conv.kernel_size == (3, 3)
+ assert block.convs[0].conv.dilation == (1, 1)
+ assert block.convs[0].conv.padding == (1, 1)
+
+ assert block.convs[1].conv.in_channels == 64
+ assert block.convs[1].conv.out_channels == 64
+ assert block.convs[1].conv.kernel_size == (3, 3)
+ assert block.convs[1].conv.dilation == (3, 3)
+ assert block.convs[1].conv.padding == (3, 3)
+
+ assert block.convs[2].conv.in_channels == 64
+ assert block.convs[2].conv.out_channels == 64
+ assert block.convs[2].conv.kernel_size == (3, 3)
+ assert block.convs[2].conv.dilation == (3, 3)
+ assert block.convs[2].conv.padding == (3, 3)
+
+
+def test_deconv_module():
+ with pytest.raises(AssertionError):
+ # kernel_size should be greater than or equal to scale_factor and
+ # (kernel_size - scale_factor) should be even numbers
+ DeconvModule(64, 32, kernel_size=1, scale_factor=2)
+
+ with pytest.raises(AssertionError):
+ # kernel_size should be greater than or equal to scale_factor and
+ # (kernel_size - scale_factor) should be even numbers
+ DeconvModule(64, 32, kernel_size=3, scale_factor=2)
+
+ with pytest.raises(AssertionError):
+ # kernel_size should be greater than or equal to scale_factor and
+ # (kernel_size - scale_factor) should be even numbers
+ DeconvModule(64, 32, kernel_size=5, scale_factor=4)
+
+ # test DeconvModule with checkpoint forward and upsample 2X.
+ block = DeconvModule(64, 32, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 64, 128, 128, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ block = DeconvModule(64, 32, with_cp=False)
+ assert not block.with_cp
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test DeconvModule with different kernel size for upsample 2X.
+ x = torch.randn(1, 64, 64, 64)
+ block = DeconvModule(64, 32, kernel_size=2, scale_factor=2)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 128, 128])
+
+ block = DeconvModule(64, 32, kernel_size=6, scale_factor=2)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 128, 128])
+
+ # test DeconvModule with different kernel size for upsample 4X.
+ x = torch.randn(1, 64, 64, 64)
+ block = DeconvModule(64, 32, kernel_size=4, scale_factor=4)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ block = DeconvModule(64, 32, kernel_size=6, scale_factor=4)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+
+def test_interp_conv():
+ # test InterpConv with checkpoint forward and upsample 2X.
+ block = InterpConv(64, 32, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 64, 128, 128, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ block = InterpConv(64, 32, with_cp=False)
+ assert not block.with_cp
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test InterpConv with conv_first=False for upsample 2X.
+ block = InterpConv(64, 32, conv_first=False)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert isinstance(block.interp_upsample[0], Upsample)
+ assert isinstance(block.interp_upsample[1], ConvModule)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test InterpConv with conv_first=True for upsample 2X.
+ block = InterpConv(64, 32, conv_first=True)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert isinstance(block.interp_upsample[0], ConvModule)
+ assert isinstance(block.interp_upsample[1], Upsample)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test InterpConv with bilinear upsample for upsample 2X.
+ block = InterpConv(
+ 64,
+ 32,
+ conv_first=False,
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False))
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert isinstance(block.interp_upsample[0], Upsample)
+ assert isinstance(block.interp_upsample[1], ConvModule)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+ assert block.interp_upsample[0].mode == 'bilinear'
+
+ # test InterpConv with nearest upsample for upsample 2X.
+ block = InterpConv(
+ 64,
+ 32,
+ conv_first=False,
+ upsample_cfg=dict(scale_factor=2, mode='nearest'))
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert isinstance(block.interp_upsample[0], Upsample)
+ assert isinstance(block.interp_upsample[1], ConvModule)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+ assert block.interp_upsample[0].mode == 'nearest'
+
+
+def test_up_conv_block():
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ UpConvBlock(BasicConvBlock, 64, 32, 32, dcn=dcn)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ UpConvBlock(BasicConvBlock, 64, 32, 32, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ UpConvBlock(BasicConvBlock, 64, 32, 32, plugins=plugins)
+
+ # test UpConvBlock with checkpoint forward and upsample 2X.
+ block = UpConvBlock(BasicConvBlock, 64, 32, 32, with_cp=True)
+ skip_x = torch.randn(1, 32, 256, 256, requires_grad=True)
+ x = torch.randn(1, 64, 128, 128, requires_grad=True)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test UpConvBlock with upsample=True for upsample 2X. The spatial size of
+ # skip_x is 2X larger than x.
+ block = UpConvBlock(
+ BasicConvBlock, 64, 32, 32, upsample_cfg=dict(type='InterpConv'))
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test UpConvBlock with upsample=False for upsample 2X. The spatial size of
+ # skip_x is the same as that of x.
+ block = UpConvBlock(BasicConvBlock, 64, 32, 32, upsample_cfg=None)
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 256, 256)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test UpConvBlock with different upsample method for upsample 2X.
+ # The upsample method is interpolation upsample (bilinear or nearest).
+ block = UpConvBlock(
+ BasicConvBlock,
+ 64,
+ 32,
+ 32,
+ upsample_cfg=dict(
+ type='InterpConv',
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False)))
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test UpConvBlock with different upsample method for upsample 2X.
+ # The upsample method is deconvolution upsample.
+ block = UpConvBlock(
+ BasicConvBlock,
+ 64,
+ 32,
+ 32,
+ upsample_cfg=dict(type='DeconvModule', kernel_size=4, scale_factor=2))
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test BasicConvBlock structure and forward
+ block = UpConvBlock(
+ conv_block=BasicConvBlock,
+ in_channels=64,
+ skip_channels=32,
+ out_channels=32,
+ num_convs=3,
+ dilation=3,
+ upsample_cfg=dict(
+ type='InterpConv',
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False)))
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ assert block.conv_block.convs[0].conv.in_channels == 64
+ assert block.conv_block.convs[0].conv.out_channels == 32
+ assert block.conv_block.convs[0].conv.kernel_size == (3, 3)
+ assert block.conv_block.convs[0].conv.dilation == (1, 1)
+ assert block.conv_block.convs[0].conv.padding == (1, 1)
+
+ assert block.conv_block.convs[1].conv.in_channels == 32
+ assert block.conv_block.convs[1].conv.out_channels == 32
+ assert block.conv_block.convs[1].conv.kernel_size == (3, 3)
+ assert block.conv_block.convs[1].conv.dilation == (3, 3)
+ assert block.conv_block.convs[1].conv.padding == (3, 3)
+
+ assert block.conv_block.convs[2].conv.in_channels == 32
+ assert block.conv_block.convs[2].conv.out_channels == 32
+ assert block.conv_block.convs[2].conv.kernel_size == (3, 3)
+ assert block.conv_block.convs[2].conv.dilation == (3, 3)
+ assert block.conv_block.convs[2].conv.padding == (3, 3)
+
+ assert block.upsample.interp_upsample[1].conv.in_channels == 64
+ assert block.upsample.interp_upsample[1].conv.out_channels == 32
+ assert block.upsample.interp_upsample[1].conv.kernel_size == (1, 1)
+ assert block.upsample.interp_upsample[1].conv.dilation == (1, 1)
+ assert block.upsample.interp_upsample[1].conv.padding == (0, 0)
+
+
+def test_unet():
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ UNet(3, 64, 5, dcn=dcn)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ UNet(3, 64, 5, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ UNet(3, 64, 5, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=4,
+ strides=(1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2),
+ downsamples=(True, True, True),
+ enc_dilations=(1, 1, 1, 1),
+ dec_dilations=(1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 16.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 2, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 32.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=6,
+ strides=(1, 1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2, 2),
+ downsamples=(True, True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(strides)=num_stages
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(enc_num_convs)=num_stages
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(dec_num_convs)=num_stages-1
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(downsamples)=num_stages-1
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(enc_dilations)=num_stages
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(dec_dilations)=num_stages-1
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ # test UNet norm_eval=True
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ norm_eval=True)
+ unet.train()
+ assert check_norm_state(unet.modules(), False)
+
+ # test UNet norm_eval=False
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ norm_eval=False)
+ unet.train()
+ assert check_norm_state(unet.modules(), True)
+
+ # test UNet forward and outputs. The whole downsample rate is 16.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 8, 8])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 2, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 4.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 4.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 4.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 2.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, False, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 64, 64])
+ assert x_outs[1].shape == torch.Size([2, 32, 64, 64])
+ assert x_outs[2].shape == torch.Size([2, 16, 64, 64])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 1.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(False, False, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 128, 128])
+ assert x_outs[1].shape == torch.Size([2, 32, 128, 128])
+ assert x_outs[2].shape == torch.Size([2, 16, 128, 128])
+ assert x_outs[3].shape == torch.Size([2, 8, 128, 128])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 16.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 8, 8])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 2, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 4.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet init_weights method.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ pretrained=None)
+ unet.init_weights()
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
diff --git a/tests/test_models/test_backbones/test_vit.py b/tests/test_models/test_backbones/test_vit.py
new file mode 100644
index 0000000..4ce860c
--- /dev/null
+++ b/tests/test_models/test_backbones/test_vit.py
@@ -0,0 +1,176 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones.vit import VisionTransformer
+from .utils import check_norm_state
+
+
+def test_vit_backbone():
+ with pytest.raises(TypeError):
+ # pretrained must be a string path
+ model = VisionTransformer()
+ model.init_weights(pretrained=0)
+
+ with pytest.raises(TypeError):
+ # img_size must be int or tuple
+ model = VisionTransformer(img_size=512.0)
+
+ with pytest.raises(TypeError):
+ # out_indices must be int ,list or tuple
+ model = VisionTransformer(out_indices=1.)
+
+ with pytest.raises(TypeError):
+ # test upsample_pos_embed function
+ x = torch.randn(1, 196)
+ VisionTransformer.resize_pos_embed(x, 512, 512, 224, 224, 'bilinear')
+
+ with pytest.raises(AssertionError):
+ # The length of img_size tuple must be lower than 3.
+ VisionTransformer(img_size=(224, 224, 224))
+
+ with pytest.raises(TypeError):
+ # Pretrained must be None or Str.
+ VisionTransformer(pretrained=123)
+
+ with pytest.raises(AssertionError):
+ # with_cls_token must be True when output_cls_token == True
+ VisionTransformer(with_cls_token=False, output_cls_token=True)
+
+ # Test img_size isinstance tuple
+ imgs = torch.randn(1, 3, 224, 224)
+ model = VisionTransformer(img_size=(224, ))
+ model.init_weights()
+ model(imgs)
+
+ # Test img_size isinstance tuple
+ imgs = torch.randn(1, 3, 224, 224)
+ model = VisionTransformer(img_size=(224, 224))
+ model(imgs)
+
+ # Test norm_eval = True
+ model = VisionTransformer(norm_eval=True)
+ model.train()
+
+ # Test ViT backbone with input size of 224 and patch size of 16
+ model = VisionTransformer()
+ model.init_weights()
+ model.train()
+
+ assert check_norm_state(model.modules(), True)
+
+ # Test normal size input image
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test large size input image
+ imgs = torch.randn(1, 3, 256, 256)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 16, 16)
+
+ # Test small size input image
+ imgs = torch.randn(1, 3, 32, 32)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 2, 2)
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test unbalanced size input image
+ imgs = torch.randn(1, 3, 112, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 7, 14)
+
+ # Test irregular input image
+ imgs = torch.randn(1, 3, 234, 345)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 15, 22)
+
+ # Test with_cp=True
+ model = VisionTransformer(with_cp=True)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test with_cls_token=False
+ model = VisionTransformer(with_cls_token=False)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test final norm
+ model = VisionTransformer(final_norm=True)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test patch norm
+ model = VisionTransformer(patch_norm=True)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test output_cls_token
+ model = VisionTransformer(with_cls_token=True, output_cls_token=True)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[0][0].shape == (1, 768, 14, 14)
+ assert feat[0][1].shape == (1, 768)
+
+
+def test_vit_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = VisionTransformer(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = VisionTransformer(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = VisionTransformer(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = VisionTransformer(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = VisionTransformer(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ model = VisionTransformer(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ model = VisionTransformer(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = VisionTransformer(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ model = VisionTransformer(pretrained=123, init_cfg=123)
diff --git a/tests/test_models/test_backbones/utils.py b/tests/test_models/test_backbones/utils.py
new file mode 100644
index 0000000..54b6404
--- /dev/null
+++ b/tests/test_models/test_backbones/utils.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from torch.nn.modules import GroupNorm
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmseg.models.backbones.resnet import BasicBlock, Bottleneck
+from mmseg.models.backbones.resnext import Bottleneck as BottleneckX
+
+
+def is_block(modules):
+ """Check if is ResNet building block."""
+ if isinstance(modules, (BasicBlock, Bottleneck, BottleneckX)):
+ return True
+ return False
+
+
+def is_norm(modules):
+ """Check if is one of the norms."""
+ if isinstance(modules, (GroupNorm, _BatchNorm)):
+ return True
+ return False
+
+
+def all_zeros(modules):
+ """Check if the weight(and bias) is all zero."""
+ weight_zero = torch.allclose(modules.weight.data,
+ torch.zeros_like(modules.weight.data))
+ if hasattr(modules, 'bias'):
+ bias_zero = torch.allclose(modules.bias.data,
+ torch.zeros_like(modules.bias.data))
+ else:
+ bias_zero = True
+
+ return weight_zero and bias_zero
+
+
+def check_norm_state(modules, train_state):
+ """Check if norm layer is in correct train state."""
+ for mod in modules:
+ if isinstance(mod, _BatchNorm):
+ if mod.training != train_state:
+ return False
+ return True
diff --git a/tests/test_models/test_forward.py b/tests/test_models/test_forward.py
new file mode 100644
index 0000000..ee707b3
--- /dev/null
+++ b/tests/test_models/test_forward.py
@@ -0,0 +1,235 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""pytest tests/test_forward.py."""
+import copy
+from os.path import dirname, exists, join
+from unittest.mock import patch
+
+import numpy as np
+import pytest
+import torch
+import torch.nn as nn
+from mmcv.cnn.utils import revert_sync_batchnorm
+
+
+def _demo_mm_inputs(input_shape=(2, 3, 8, 16), num_classes=10):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+
+ rng = np.random.RandomState(0)
+
+ imgs = rng.rand(*input_shape)
+ segs = rng.randint(
+ low=0, high=num_classes - 1, size=(N, 1, H, W)).astype(np.uint8)
+
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': 1.0,
+ 'flip': False,
+ 'flip_direction': 'horizontal'
+ } for _ in range(N)]
+
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs),
+ 'img_metas': img_metas,
+ 'gt_semantic_seg': torch.LongTensor(segs)
+ }
+ return mm_inputs
+
+
+def _get_config_directory():
+ """Find the predefined segmentor config directory."""
+ try:
+ # Assume we are running in the source mmsegmentation repo
+ repo_dpath = dirname(dirname(dirname(__file__)))
+ except NameError:
+ # For IPython development when this __file__ is not defined
+ import mmseg
+ repo_dpath = dirname(dirname(dirname(mmseg.__file__)))
+ config_dpath = join(repo_dpath, 'configs')
+ if not exists(config_dpath):
+ raise Exception('Cannot find config path')
+ return config_dpath
+
+
+def _get_config_module(fname):
+ """Load a configuration as a python module."""
+ from mmcv import Config
+ config_dpath = _get_config_directory()
+ config_fpath = join(config_dpath, fname)
+ config_mod = Config.fromfile(config_fpath)
+ return config_mod
+
+
+def _get_segmentor_cfg(fname):
+ """Grab configs necessary to create a segmentor.
+
+ These are deep copied to allow for safe modification of parameters without
+ influencing other tests.
+ """
+ config = _get_config_module(fname)
+ model = copy.deepcopy(config.model)
+ return model
+
+
+def test_pspnet_forward():
+ _test_encoder_decoder_forward(
+ 'pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_fcn_forward():
+ _test_encoder_decoder_forward('fcn/fcn_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_deeplabv3_forward():
+ _test_encoder_decoder_forward(
+ 'deeplabv3/deeplabv3_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_deeplabv3plus_forward():
+ _test_encoder_decoder_forward(
+ 'deeplabv3plus/deeplabv3plus_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_gcnet_forward():
+ _test_encoder_decoder_forward(
+ 'gcnet/gcnet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_ann_forward():
+ _test_encoder_decoder_forward('ann/ann_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_ccnet_forward():
+ if not torch.cuda.is_available():
+ pytest.skip('CCNet requires CUDA')
+ _test_encoder_decoder_forward(
+ 'ccnet/ccnet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_danet_forward():
+ _test_encoder_decoder_forward(
+ 'danet/danet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_nonlocal_net_forward():
+ _test_encoder_decoder_forward(
+ 'nonlocal_net/nonlocal_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_upernet_forward():
+ _test_encoder_decoder_forward(
+ 'upernet/upernet_r50_512x1024_40k_cityscapes.py')
+
+
+def test_hrnet_forward():
+ _test_encoder_decoder_forward('hrnet/fcn_hr18s_512x1024_40k_cityscapes.py')
+
+
+def test_ocrnet_forward():
+ _test_encoder_decoder_forward(
+ 'ocrnet/ocrnet_hr18s_512x1024_40k_cityscapes.py')
+
+
+def test_psanet_forward():
+ _test_encoder_decoder_forward(
+ 'psanet/psanet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_encnet_forward():
+ _test_encoder_decoder_forward(
+ 'encnet/encnet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_sem_fpn_forward():
+ _test_encoder_decoder_forward('sem_fpn/fpn_r50_512x1024_80k_cityscapes.py')
+
+
+def test_point_rend_forward():
+ _test_encoder_decoder_forward(
+ 'point_rend/pointrend_r50_512x1024_80k_cityscapes.py')
+
+
+def test_mobilenet_v2_forward():
+ _test_encoder_decoder_forward(
+ 'mobilenet_v2/pspnet_m-v2-d8_512x1024_80k_cityscapes.py')
+
+
+def test_dnlnet_forward():
+ _test_encoder_decoder_forward(
+ 'dnlnet/dnl_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_emanet_forward():
+ _test_encoder_decoder_forward(
+ 'emanet/emanet_r50-d8_512x1024_80k_cityscapes.py')
+
+
+def test_isanet_forward():
+ _test_encoder_decoder_forward(
+ 'isanet/isanet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def get_world_size(process_group):
+
+ return 1
+
+
+def _check_input_dim(self, inputs):
+ pass
+
+
+@patch('torch.nn.modules.batchnorm._BatchNorm._check_input_dim',
+ _check_input_dim)
+@patch('torch.distributed.get_world_size', get_world_size)
+def _test_encoder_decoder_forward(cfg_file):
+ model = _get_segmentor_cfg(cfg_file)
+ model['pretrained'] = None
+ model['test_cfg']['mode'] = 'whole'
+
+ from mmseg.models import build_segmentor
+ segmentor = build_segmentor(model)
+ segmentor.init_weights()
+
+ if isinstance(segmentor.decode_head, nn.ModuleList):
+ num_classes = segmentor.decode_head[-1].num_classes
+ else:
+ num_classes = segmentor.decode_head.num_classes
+ # batch_size=2 for BatchNorm
+ input_shape = (2, 3, 32, 32)
+ mm_inputs = _demo_mm_inputs(input_shape, num_classes=num_classes)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ gt_semantic_seg = mm_inputs['gt_semantic_seg']
+
+ # convert to cuda Tensor if applicable
+ if torch.cuda.is_available():
+ segmentor = segmentor.cuda()
+ imgs = imgs.cuda()
+ gt_semantic_seg = gt_semantic_seg.cuda()
+ else:
+ segmentor = revert_sync_batchnorm(segmentor)
+
+ # Test forward train
+ losses = segmentor.forward(
+ imgs, img_metas, gt_semantic_seg=gt_semantic_seg, return_loss=True)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ with torch.no_grad():
+ segmentor.eval()
+ # pack into lists
+ img_list = [img[None, :] for img in imgs]
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ segmentor.forward(img_list, img_meta_list, return_loss=False)
diff --git a/tests/test_models/test_heads/__init__.py b/tests/test_models/test_heads/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/test_heads/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_heads/test_ann_head.py b/tests/test_models/test_heads/test_ann_head.py
new file mode 100644
index 0000000..c1e44bc
--- /dev/null
+++ b/tests/test_models/test_heads/test_ann_head.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import ANNHead
+from .utils import to_cuda
+
+
+def test_ann_head():
+
+ inputs = [torch.randn(1, 4, 45, 45), torch.randn(1, 8, 21, 21)]
+ head = ANNHead(
+ in_channels=[4, 8],
+ channels=2,
+ num_classes=19,
+ in_index=[-2, -1],
+ project_channels=8)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 21, 21)
diff --git a/tests/test_models/test_heads/test_apc_head.py b/tests/test_models/test_heads/test_apc_head.py
new file mode 100644
index 0000000..dc55ccc
--- /dev/null
+++ b/tests/test_models/test_heads/test_apc_head.py
@@ -0,0 +1,59 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import APCHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_apc_head():
+
+ with pytest.raises(AssertionError):
+ # pool_scales must be list|tuple
+ APCHead(in_channels=8, channels=2, num_classes=19, pool_scales=1)
+
+ # test no norm_cfg
+ head = APCHead(in_channels=8, channels=2, num_classes=19)
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = APCHead(
+ in_channels=8,
+ channels=2,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ # fusion=True
+ inputs = [torch.randn(1, 8, 45, 45)]
+ head = APCHead(
+ in_channels=8,
+ channels=2,
+ num_classes=19,
+ pool_scales=(1, 2, 3),
+ fusion=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.fusion is True
+ assert head.acm_modules[0].pool_scale == 1
+ assert head.acm_modules[1].pool_scale == 2
+ assert head.acm_modules[2].pool_scale == 3
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
+
+ # fusion=False
+ inputs = [torch.randn(1, 8, 45, 45)]
+ head = APCHead(
+ in_channels=8,
+ channels=2,
+ num_classes=19,
+ pool_scales=(1, 2, 3),
+ fusion=False)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.fusion is False
+ assert head.acm_modules[0].pool_scale == 1
+ assert head.acm_modules[1].pool_scale == 2
+ assert head.acm_modules[2].pool_scale == 3
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
diff --git a/tests/test_models/test_heads/test_aspp_head.py b/tests/test_models/test_heads/test_aspp_head.py
new file mode 100644
index 0000000..db9e893
--- /dev/null
+++ b/tests/test_models/test_heads/test_aspp_head.py
@@ -0,0 +1,76 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import ASPPHead, DepthwiseSeparableASPPHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_aspp_head():
+
+ with pytest.raises(AssertionError):
+ # pool_scales must be list|tuple
+ ASPPHead(in_channels=8, channels=4, num_classes=19, dilations=1)
+
+ # test no norm_cfg
+ head = ASPPHead(in_channels=8, channels=4, num_classes=19)
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = ASPPHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ inputs = [torch.randn(1, 8, 45, 45)]
+ head = ASPPHead(
+ in_channels=8, channels=4, num_classes=19, dilations=(1, 12, 24))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.aspp_modules[0].conv.dilation == (1, 1)
+ assert head.aspp_modules[1].conv.dilation == (12, 12)
+ assert head.aspp_modules[2].conv.dilation == (24, 24)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
+
+
+def test_dw_aspp_head():
+
+ # test w.o. c1
+ inputs = [torch.randn(1, 8, 45, 45)]
+ head = DepthwiseSeparableASPPHead(
+ c1_in_channels=0,
+ c1_channels=0,
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ dilations=(1, 12, 24))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.c1_bottleneck is None
+ assert head.aspp_modules[0].conv.dilation == (1, 1)
+ assert head.aspp_modules[1].depthwise_conv.dilation == (12, 12)
+ assert head.aspp_modules[2].depthwise_conv.dilation == (24, 24)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
+
+ # test with c1
+ inputs = [torch.randn(1, 4, 45, 45), torch.randn(1, 16, 21, 21)]
+ head = DepthwiseSeparableASPPHead(
+ c1_in_channels=4,
+ c1_channels=2,
+ in_channels=16,
+ channels=8,
+ num_classes=19,
+ dilations=(1, 12, 24))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.c1_bottleneck.in_channels == 4
+ assert head.c1_bottleneck.out_channels == 2
+ assert head.aspp_modules[0].conv.dilation == (1, 1)
+ assert head.aspp_modules[1].depthwise_conv.dilation == (12, 12)
+ assert head.aspp_modules[2].depthwise_conv.dilation == (24, 24)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
diff --git a/tests/test_models/test_heads/test_cc_head.py b/tests/test_models/test_heads/test_cc_head.py
new file mode 100644
index 0000000..0630417
--- /dev/null
+++ b/tests/test_models/test_heads/test_cc_head.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import CCHead
+from .utils import to_cuda
+
+
+def test_cc_head():
+ head = CCHead(in_channels=16, channels=8, num_classes=19)
+ assert len(head.convs) == 2
+ assert hasattr(head, 'cca')
+ if not torch.cuda.is_available():
+ pytest.skip('CCHead requires CUDA')
+ inputs = [torch.randn(1, 16, 23, 23)]
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_da_head.py b/tests/test_models/test_heads/test_da_head.py
new file mode 100644
index 0000000..7ab4a96
--- /dev/null
+++ b/tests/test_models/test_heads/test_da_head.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import DAHead
+from .utils import to_cuda
+
+
+def test_da_head():
+
+ inputs = [torch.randn(1, 16, 23, 23)]
+ head = DAHead(in_channels=16, channels=8, num_classes=19, pam_channels=8)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert isinstance(outputs, tuple) and len(outputs) == 3
+ for output in outputs:
+ assert output.shape == (1, head.num_classes, 23, 23)
+ test_output = head.forward_test(inputs, None, None)
+ assert test_output.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_decode_head.py b/tests/test_models/test_heads/test_decode_head.py
new file mode 100644
index 0000000..cb9ab97
--- /dev/null
+++ b/tests/test_models/test_heads/test_decode_head.py
@@ -0,0 +1,165 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest.mock import patch
+
+import pytest
+import torch
+
+from mmseg.models.decode_heads.decode_head import BaseDecodeHead
+from .utils import to_cuda
+
+
+@patch.multiple(BaseDecodeHead, __abstractmethods__=set())
+def test_decode_head():
+
+ with pytest.raises(AssertionError):
+ # default input_transform doesn't accept multiple inputs
+ BaseDecodeHead([32, 16], 16, num_classes=19)
+
+ with pytest.raises(AssertionError):
+ # default input_transform doesn't accept multiple inputs
+ BaseDecodeHead(32, 16, num_classes=19, in_index=[-1, -2])
+
+ with pytest.raises(AssertionError):
+ # supported mode is resize_concat only
+ BaseDecodeHead(32, 16, num_classes=19, input_transform='concat')
+
+ with pytest.raises(AssertionError):
+ # in_channels should be list|tuple
+ BaseDecodeHead(32, 16, num_classes=19, input_transform='resize_concat')
+
+ with pytest.raises(AssertionError):
+ # in_index should be list|tuple
+ BaseDecodeHead([32],
+ 16,
+ in_index=-1,
+ num_classes=19,
+ input_transform='resize_concat')
+
+ with pytest.raises(AssertionError):
+ # len(in_index) should equal len(in_channels)
+ BaseDecodeHead([32, 16],
+ 16,
+ num_classes=19,
+ in_index=[-1],
+ input_transform='resize_concat')
+
+ # test default dropout
+ head = BaseDecodeHead(32, 16, num_classes=19)
+ assert hasattr(head, 'dropout') and head.dropout.p == 0.1
+
+ # test set dropout
+ head = BaseDecodeHead(32, 16, num_classes=19, dropout_ratio=0.2)
+ assert hasattr(head, 'dropout') and head.dropout.p == 0.2
+
+ # test no input_transform
+ inputs = [torch.randn(1, 32, 45, 45)]
+ head = BaseDecodeHead(32, 16, num_classes=19)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.in_channels == 32
+ assert head.input_transform is None
+ transformed_inputs = head._transform_inputs(inputs)
+ assert transformed_inputs.shape == (1, 32, 45, 45)
+
+ # test input_transform = resize_concat
+ inputs = [torch.randn(1, 32, 45, 45), torch.randn(1, 16, 21, 21)]
+ head = BaseDecodeHead([32, 16],
+ 16,
+ num_classes=19,
+ in_index=[0, 1],
+ input_transform='resize_concat')
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.in_channels == 48
+ assert head.input_transform == 'resize_concat'
+ transformed_inputs = head._transform_inputs(inputs)
+ assert transformed_inputs.shape == (1, 48, 45, 45)
+
+ # test multi-loss, loss_decode is dict
+ with pytest.raises(TypeError):
+ # loss_decode must be a dict or sequence of dict.
+ BaseDecodeHead(3, 16, num_classes=19, loss_decode=['CrossEntropyLoss'])
+
+ inputs = torch.randn(2, 19, 8, 8).float()
+ target = torch.ones(2, 1, 64, 64).long()
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss = head.losses(seg_logit=inputs, seg_label=target)
+ assert 'loss_ce' in loss
+
+ # test multi-loss, loss_decode is list of dict
+ inputs = torch.randn(2, 19, 8, 8).float()
+ target = torch.ones(2, 1, 64, 64).long()
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2')
+ ])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss = head.losses(seg_logit=inputs, seg_label=target)
+ assert 'loss_1' in loss
+ assert 'loss_2' in loss
+
+ # 'loss_decode' must be a dict or sequence of dict
+ with pytest.raises(TypeError):
+ BaseDecodeHead(3, 16, num_classes=19, loss_decode=['CrossEntropyLoss'])
+ with pytest.raises(TypeError):
+ BaseDecodeHead(3, 16, num_classes=19, loss_decode=0)
+
+ # test multi-loss, loss_decode is list of dict
+ inputs = torch.randn(2, 19, 8, 8).float()
+ target = torch.ones(2, 1, 64, 64).long()
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=(dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2'),
+ dict(type='CrossEntropyLoss', loss_name='loss_3')))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss = head.losses(seg_logit=inputs, seg_label=target)
+ assert 'loss_1' in loss
+ assert 'loss_2' in loss
+ assert 'loss_3' in loss
+
+ # test multi-loss, loss_decode is list of dict, names of them are identical
+ inputs = torch.randn(2, 19, 8, 8).float()
+ target = torch.ones(2, 1, 64, 64).long()
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=(dict(type='CrossEntropyLoss', loss_name='loss_ce'),
+ dict(type='CrossEntropyLoss', loss_name='loss_ce'),
+ dict(type='CrossEntropyLoss', loss_name='loss_ce')))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss_3 = head.losses(seg_logit=inputs, seg_label=target)
+
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=(dict(type='CrossEntropyLoss', loss_name='loss_ce')))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss = head.losses(seg_logit=inputs, seg_label=target)
+ assert 'loss_ce' in loss
+ assert 'loss_ce' in loss_3
+ assert loss_3['loss_ce'] == 3 * loss['loss_ce']
diff --git a/tests/test_models/test_heads/test_dm_head.py b/tests/test_models/test_heads/test_dm_head.py
new file mode 100644
index 0000000..a922ff7
--- /dev/null
+++ b/tests/test_models/test_heads/test_dm_head.py
@@ -0,0 +1,59 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import DMHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_dm_head():
+
+ with pytest.raises(AssertionError):
+ # filter_sizes must be list|tuple
+ DMHead(in_channels=8, channels=4, num_classes=19, filter_sizes=1)
+
+ # test no norm_cfg
+ head = DMHead(in_channels=8, channels=4, num_classes=19)
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = DMHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ # fusion=True
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = DMHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ filter_sizes=(1, 3, 5),
+ fusion=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.fusion is True
+ assert head.dcm_modules[0].filter_size == 1
+ assert head.dcm_modules[1].filter_size == 3
+ assert head.dcm_modules[2].filter_size == 5
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # fusion=False
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = DMHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ filter_sizes=(1, 3, 5),
+ fusion=False)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.fusion is False
+ assert head.dcm_modules[0].filter_size == 1
+ assert head.dcm_modules[1].filter_size == 3
+ assert head.dcm_modules[2].filter_size == 5
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_dnl_head.py b/tests/test_models/test_heads/test_dnl_head.py
new file mode 100644
index 0000000..720cb07
--- /dev/null
+++ b/tests/test_models/test_heads/test_dnl_head.py
@@ -0,0 +1,44 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import DNLHead
+from .utils import to_cuda
+
+
+def test_dnl_head():
+ # DNL with 'embedded_gaussian' mode
+ head = DNLHead(in_channels=8, channels=4, num_classes=19)
+ assert len(head.convs) == 2
+ assert hasattr(head, 'dnl_block')
+ assert head.dnl_block.temperature == 0.05
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # NonLocal2d with 'dot_product' mode
+ head = DNLHead(
+ in_channels=8, channels=4, num_classes=19, mode='dot_product')
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # NonLocal2d with 'gaussian' mode
+ head = DNLHead(in_channels=8, channels=4, num_classes=19, mode='gaussian')
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # NonLocal2d with 'concatenation' mode
+ head = DNLHead(
+ in_channels=8, channels=4, num_classes=19, mode='concatenation')
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_dpt_head.py b/tests/test_models/test_heads/test_dpt_head.py
new file mode 100644
index 0000000..d8cd8b0
--- /dev/null
+++ b/tests/test_models/test_heads/test_dpt_head.py
@@ -0,0 +1,48 @@
+import pytest
+import torch
+
+from mmseg.models.decode_heads import DPTHead
+
+
+def test_dpt_head():
+
+ with pytest.raises(AssertionError):
+ # input_transform must be 'multiple_select'
+ head = DPTHead(
+ in_channels=[768, 768, 768, 768],
+ channels=4,
+ num_classes=19,
+ in_index=[0, 1, 2, 3])
+
+ head = DPTHead(
+ in_channels=[768, 768, 768, 768],
+ channels=4,
+ num_classes=19,
+ in_index=[0, 1, 2, 3],
+ input_transform='multiple_select')
+
+ inputs = [[torch.randn(4, 768, 2, 2),
+ torch.randn(4, 768)] for _ in range(4)]
+ output = head(inputs)
+ assert output.shape == torch.Size((4, 19, 16, 16))
+
+ # test readout operation
+ head = DPTHead(
+ in_channels=[768, 768, 768, 768],
+ channels=4,
+ num_classes=19,
+ in_index=[0, 1, 2, 3],
+ input_transform='multiple_select',
+ readout_type='add')
+ output = head(inputs)
+ assert output.shape == torch.Size((4, 19, 16, 16))
+
+ head = DPTHead(
+ in_channels=[768, 768, 768, 768],
+ channels=4,
+ num_classes=19,
+ in_index=[0, 1, 2, 3],
+ input_transform='multiple_select',
+ readout_type='project')
+ output = head(inputs)
+ assert output.shape == torch.Size((4, 19, 16, 16))
diff --git a/tests/test_models/test_heads/test_ema_head.py b/tests/test_models/test_heads/test_ema_head.py
new file mode 100644
index 0000000..1811cd2
--- /dev/null
+++ b/tests/test_models/test_heads/test_ema_head.py
@@ -0,0 +1,23 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import EMAHead
+from .utils import to_cuda
+
+
+def test_emanet_head():
+ head = EMAHead(
+ in_channels=4,
+ ema_channels=3,
+ channels=2,
+ num_stages=3,
+ num_bases=2,
+ num_classes=19)
+ for param in head.ema_mid_conv.parameters():
+ assert not param.requires_grad
+ assert hasattr(head, 'ema_module')
+ inputs = [torch.randn(1, 4, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_enc_head.py b/tests/test_models/test_heads/test_enc_head.py
new file mode 100644
index 0000000..9c84c75
--- /dev/null
+++ b/tests/test_models/test_heads/test_enc_head.py
@@ -0,0 +1,47 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import EncHead
+from .utils import to_cuda
+
+
+def test_enc_head():
+ # with se_loss, w.o. lateral
+ inputs = [torch.randn(1, 8, 21, 21)]
+ head = EncHead(in_channels=[8], channels=4, num_classes=19, in_index=[-1])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert isinstance(outputs, tuple) and len(outputs) == 2
+ assert outputs[0].shape == (1, head.num_classes, 21, 21)
+ assert outputs[1].shape == (1, head.num_classes)
+
+ # w.o se_loss, w.o. lateral
+ inputs = [torch.randn(1, 8, 21, 21)]
+ head = EncHead(
+ in_channels=[8],
+ channels=4,
+ use_se_loss=False,
+ num_classes=19,
+ in_index=[-1])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 21, 21)
+
+ # with se_loss, with lateral
+ inputs = [torch.randn(1, 4, 45, 45), torch.randn(1, 8, 21, 21)]
+ head = EncHead(
+ in_channels=[4, 8],
+ channels=4,
+ add_lateral=True,
+ num_classes=19,
+ in_index=[-2, -1])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert isinstance(outputs, tuple) and len(outputs) == 2
+ assert outputs[0].shape == (1, head.num_classes, 21, 21)
+ assert outputs[1].shape == (1, head.num_classes)
+ test_output = head.forward_test(inputs, None, None)
+ assert test_output.shape == (1, head.num_classes, 21, 21)
diff --git a/tests/test_models/test_heads/test_fcn_head.py b/tests/test_models/test_heads/test_fcn_head.py
new file mode 100644
index 0000000..4e633fb
--- /dev/null
+++ b/tests/test_models/test_heads/test_fcn_head.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmcv.utils.parrots_wrapper import SyncBatchNorm
+
+from mmseg.models.decode_heads import DepthwiseSeparableFCNHead, FCNHead
+from .utils import to_cuda
+
+
+def test_fcn_head():
+
+ with pytest.raises(AssertionError):
+ # num_convs must be not less than 0
+ FCNHead(num_classes=19, num_convs=-1)
+
+ # test no norm_cfg
+ head = FCNHead(in_channels=8, channels=4, num_classes=19)
+ for m in head.modules():
+ if isinstance(m, ConvModule):
+ assert not m.with_norm
+
+ # test with norm_cfg
+ head = FCNHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ for m in head.modules():
+ if isinstance(m, ConvModule):
+ assert m.with_norm and isinstance(m.bn, SyncBatchNorm)
+
+ # test concat_input=False
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(
+ in_channels=8, channels=4, num_classes=19, concat_input=False)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert len(head.convs) == 2
+ assert not head.concat_input and not hasattr(head, 'conv_cat')
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test concat_input=True
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(
+ in_channels=8, channels=4, num_classes=19, concat_input=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert len(head.convs) == 2
+ assert head.concat_input
+ assert head.conv_cat.in_channels == 12
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test kernel_size=3
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(in_channels=8, channels=4, num_classes=19)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ for i in range(len(head.convs)):
+ assert head.convs[i].kernel_size == (3, 3)
+ assert head.convs[i].padding == 1
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test kernel_size=1
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(in_channels=8, channels=4, num_classes=19, kernel_size=1)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ for i in range(len(head.convs)):
+ assert head.convs[i].kernel_size == (1, 1)
+ assert head.convs[i].padding == 0
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test num_conv
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(in_channels=8, channels=4, num_classes=19, num_convs=1)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert len(head.convs) == 1
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test num_conv = 0
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(
+ in_channels=8,
+ channels=8,
+ num_classes=19,
+ num_convs=0,
+ concat_input=False)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert isinstance(head.convs, torch.nn.Identity)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+
+def test_sep_fcn_head():
+ # test sep_fcn_head with concat_input=False
+ head = DepthwiseSeparableFCNHead(
+ in_channels=128,
+ channels=128,
+ concat_input=False,
+ num_classes=19,
+ in_index=-1,
+ norm_cfg=dict(type='BN', requires_grad=True, momentum=0.01))
+ x = [torch.rand(2, 128, 8, 8)]
+ output = head(x)
+ assert output.shape == (2, head.num_classes, 8, 8)
+ assert not head.concat_input
+ assert isinstance(head.convs[0], DepthwiseSeparableConvModule)
+ assert isinstance(head.convs[1], DepthwiseSeparableConvModule)
+ assert head.conv_seg.kernel_size == (1, 1)
+
+ head = DepthwiseSeparableFCNHead(
+ in_channels=64,
+ channels=64,
+ concat_input=True,
+ num_classes=19,
+ in_index=-1,
+ norm_cfg=dict(type='BN', requires_grad=True, momentum=0.01))
+ x = [torch.rand(3, 64, 8, 8)]
+ output = head(x)
+ assert output.shape == (3, head.num_classes, 8, 8)
+ assert head.concat_input
+ assert isinstance(head.convs[0], DepthwiseSeparableConvModule)
+ assert isinstance(head.convs[1], DepthwiseSeparableConvModule)
diff --git a/tests/test_models/test_heads/test_gc_head.py b/tests/test_models/test_heads/test_gc_head.py
new file mode 100644
index 0000000..c62ac9a
--- /dev/null
+++ b/tests/test_models/test_heads/test_gc_head.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import GCHead
+from .utils import to_cuda
+
+
+def test_gc_head():
+ head = GCHead(in_channels=4, channels=4, num_classes=19)
+ assert len(head.convs) == 2
+ assert hasattr(head, 'gc_block')
+ inputs = [torch.randn(1, 4, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_isa_head.py b/tests/test_models/test_heads/test_isa_head.py
new file mode 100644
index 0000000..b177f6d
--- /dev/null
+++ b/tests/test_models/test_heads/test_isa_head.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import ISAHead
+from .utils import to_cuda
+
+
+def test_isa_head():
+
+ inputs = [torch.randn(1, 8, 23, 23)]
+ isa_head = ISAHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ isa_channels=4,
+ down_factor=(8, 8))
+ if torch.cuda.is_available():
+ isa_head, inputs = to_cuda(isa_head, inputs)
+ output = isa_head(inputs)
+ assert output.shape == (1, isa_head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_lraspp_head.py b/tests/test_models/test_heads/test_lraspp_head.py
new file mode 100644
index 0000000..a46e6a1
--- /dev/null
+++ b/tests/test_models/test_heads/test_lraspp_head.py
@@ -0,0 +1,68 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import LRASPPHead
+
+
+def test_lraspp_head():
+ with pytest.raises(ValueError):
+ # check invalid input_transform
+ LRASPPHead(
+ in_channels=(4, 4, 123),
+ in_index=(0, 1, 2),
+ channels=32,
+ input_transform='resize_concat',
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+
+ with pytest.raises(AssertionError):
+ # check invalid branch_channels
+ LRASPPHead(
+ in_channels=(4, 4, 123),
+ in_index=(0, 1, 2),
+ channels=32,
+ branch_channels=64,
+ input_transform='multiple_select',
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+
+ # test with default settings
+ lraspp_head = LRASPPHead(
+ in_channels=(4, 4, 123),
+ in_index=(0, 1, 2),
+ channels=32,
+ input_transform='multiple_select',
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+ inputs = [
+ torch.randn(2, 4, 45, 45),
+ torch.randn(2, 4, 28, 28),
+ torch.randn(2, 123, 14, 14)
+ ]
+ with pytest.raises(RuntimeError):
+ # check invalid inputs
+ output = lraspp_head(inputs)
+
+ inputs = [
+ torch.randn(2, 4, 111, 111),
+ torch.randn(2, 4, 77, 77),
+ torch.randn(2, 123, 55, 55)
+ ]
+ output = lraspp_head(inputs)
+ assert output.shape == (2, 19, 111, 111)
diff --git a/tests/test_models/test_heads/test_nl_head.py b/tests/test_models/test_heads/test_nl_head.py
new file mode 100644
index 0000000..d4ef0b9
--- /dev/null
+++ b/tests/test_models/test_heads/test_nl_head.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import NLHead
+from .utils import to_cuda
+
+
+def test_nl_head():
+ head = NLHead(in_channels=8, channels=4, num_classes=19)
+ assert len(head.convs) == 2
+ assert hasattr(head, 'nl_block')
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_ocr_head.py b/tests/test_models/test_heads/test_ocr_head.py
new file mode 100644
index 0000000..5e5d669
--- /dev/null
+++ b/tests/test_models/test_heads/test_ocr_head.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import FCNHead, OCRHead
+from .utils import to_cuda
+
+
+def test_ocr_head():
+
+ inputs = [torch.randn(1, 8, 23, 23)]
+ ocr_head = OCRHead(
+ in_channels=8, channels=4, num_classes=19, ocr_channels=8)
+ fcn_head = FCNHead(in_channels=8, channels=4, num_classes=19)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(ocr_head, inputs)
+ head, inputs = to_cuda(fcn_head, inputs)
+ prev_output = fcn_head(inputs)
+ output = ocr_head(inputs, prev_output)
+ assert output.shape == (1, ocr_head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_point_head.py b/tests/test_models/test_heads/test_point_head.py
new file mode 100644
index 0000000..142ab16
--- /dev/null
+++ b/tests/test_models/test_heads/test_point_head.py
@@ -0,0 +1,61 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.utils import ConfigDict
+
+from mmseg.models.decode_heads import FCNHead, PointHead
+from .utils import to_cuda
+
+
+def test_point_head():
+
+ inputs = [torch.randn(1, 32, 45, 45)]
+ point_head = PointHead(
+ in_channels=[32], in_index=[0], channels=16, num_classes=19)
+ assert len(point_head.fcs) == 3
+ fcn_head = FCNHead(in_channels=32, channels=16, num_classes=19)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(point_head, inputs)
+ head, inputs = to_cuda(fcn_head, inputs)
+ prev_output = fcn_head(inputs)
+ test_cfg = ConfigDict(
+ subdivision_steps=2, subdivision_num_points=8196, scale_factor=2)
+ output = point_head.forward_test(inputs, prev_output, None, test_cfg)
+ assert output.shape == (1, point_head.num_classes, 180, 180)
+
+ # test multiple losses case
+ inputs = [torch.randn(1, 32, 45, 45)]
+ point_head_multiple_losses = PointHead(
+ in_channels=[32],
+ in_index=[0],
+ channels=16,
+ num_classes=19,
+ loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2')
+ ])
+ assert len(point_head_multiple_losses.fcs) == 3
+ fcn_head_multiple_losses = FCNHead(
+ in_channels=32,
+ channels=16,
+ num_classes=19,
+ loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2')
+ ])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(point_head_multiple_losses, inputs)
+ head, inputs = to_cuda(fcn_head_multiple_losses, inputs)
+ prev_output = fcn_head_multiple_losses(inputs)
+ test_cfg = ConfigDict(
+ subdivision_steps=2, subdivision_num_points=8196, scale_factor=2)
+ output = point_head_multiple_losses.forward_test(inputs, prev_output, None,
+ test_cfg)
+ assert output.shape == (1, point_head.num_classes, 180, 180)
+
+ fake_label = torch.ones([1, 180, 180], dtype=torch.long)
+
+ if torch.cuda.is_available():
+ fake_label = fake_label.cuda()
+ loss = point_head_multiple_losses.losses(output, fake_label)
+ assert 'pointloss_1' in loss
+ assert 'pointloss_2' in loss
diff --git a/tests/test_models/test_heads/test_psa_head.py b/tests/test_models/test_heads/test_psa_head.py
new file mode 100644
index 0000000..34f592b
--- /dev/null
+++ b/tests/test_models/test_heads/test_psa_head.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import PSAHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_psa_head():
+
+ with pytest.raises(AssertionError):
+ # psa_type must be in 'bi-direction', 'collect', 'distribute'
+ PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_type='gather')
+
+ # test no norm_cfg
+ head = PSAHead(
+ in_channels=4, channels=2, num_classes=19, mask_size=(13, 13))
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ # test 'bi-direction' psa_type
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4, channels=2, num_classes=19, mask_size=(13, 13))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'bi-direction' psa_type, shrink_factor=1
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ shrink_factor=1)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'bi-direction' psa_type with soft_max
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_softmax=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'collect' psa_type
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_type='collect')
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'collect' psa_type, shrink_factor=1
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ shrink_factor=1,
+ psa_type='collect')
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'collect' psa_type, shrink_factor=1, compact=True
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_type='collect',
+ shrink_factor=1,
+ compact=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'distribute' psa_type
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_type='distribute')
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
diff --git a/tests/test_models/test_heads/test_psp_head.py b/tests/test_models/test_heads/test_psp_head.py
new file mode 100644
index 0000000..fde4087
--- /dev/null
+++ b/tests/test_models/test_heads/test_psp_head.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import PSPHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_psp_head():
+
+ with pytest.raises(AssertionError):
+ # pool_scales must be list|tuple
+ PSPHead(in_channels=4, channels=2, num_classes=19, pool_scales=1)
+
+ # test no norm_cfg
+ head = PSPHead(in_channels=4, channels=2, num_classes=19)
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = PSPHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ inputs = [torch.randn(1, 4, 23, 23)]
+ head = PSPHead(
+ in_channels=4, channels=2, num_classes=19, pool_scales=(1, 2, 3))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.psp_modules[0][0].output_size == 1
+ assert head.psp_modules[1][0].output_size == 2
+ assert head.psp_modules[2][0].output_size == 3
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_segformer_head.py b/tests/test_models/test_heads/test_segformer_head.py
new file mode 100644
index 0000000..73afaba
--- /dev/null
+++ b/tests/test_models/test_heads/test_segformer_head.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import SegformerHead
+
+
+def test_segformer_head():
+ with pytest.raises(AssertionError):
+ # `in_channels` must have same length as `in_index`
+ SegformerHead(
+ in_channels=(1, 2, 3), in_index=(0, 1), channels=5, num_classes=2)
+
+ H, W = (64, 64)
+ in_channels = (32, 64, 160, 256)
+ shapes = [(H // 2**(i + 2), W // 2**(i + 2))
+ for i in range(len(in_channels))]
+ model = SegformerHead(
+ in_channels=in_channels,
+ in_index=[0, 1, 2, 3],
+ channels=256,
+ num_classes=19)
+
+ with pytest.raises(IndexError):
+ # in_index must match the input feature maps.
+ inputs = [
+ torch.randn((1, in_channel, *shape))
+ for in_channel, shape in zip(in_channels, shapes)
+ ][:3]
+ temp = model(inputs)
+
+ # Normal Input
+ # ((1, 32, 16, 16), (1, 64, 8, 8), (1, 160, 4, 4), (1, 256, 2, 2)
+ inputs = [
+ torch.randn((1, in_channel, *shape))
+ for in_channel, shape in zip(in_channels, shapes)
+ ]
+ temp = model(inputs)
+
+ assert temp.shape == (1, 19, H // 4, W // 4)
diff --git a/tests/test_models/test_heads/test_segmenter_mask_head.py b/tests/test_models/test_heads/test_segmenter_mask_head.py
new file mode 100644
index 0000000..7b681ac
--- /dev/null
+++ b/tests/test_models/test_heads/test_segmenter_mask_head.py
@@ -0,0 +1,24 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import SegmenterMaskTransformerHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_segmenter_mask_transformer_head():
+ head = SegmenterMaskTransformerHead(
+ in_channels=2,
+ channels=2,
+ num_classes=150,
+ num_layers=2,
+ num_heads=3,
+ embed_dims=192,
+ dropout_ratio=0.0)
+ assert _conv_has_norm(head, sync_bn=True)
+ head.init_weights()
+
+ inputs = [torch.randn(1, 2, 32, 32)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 32, 32)
diff --git a/tests/test_models/test_heads/test_setr_mla_head.py b/tests/test_models/test_heads/test_setr_mla_head.py
new file mode 100644
index 0000000..301bc0b
--- /dev/null
+++ b/tests/test_models/test_heads/test_setr_mla_head.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import SETRMLAHead
+from .utils import to_cuda
+
+
+def test_setr_mla_head(capsys):
+
+ with pytest.raises(AssertionError):
+ # MLA requires input multiple stage feature information.
+ SETRMLAHead(in_channels=8, channels=4, num_classes=19, in_index=1)
+
+ with pytest.raises(AssertionError):
+ # multiple in_indexs requires multiple in_channels.
+ SETRMLAHead(
+ in_channels=8, channels=4, num_classes=19, in_index=(0, 1, 2, 3))
+
+ with pytest.raises(AssertionError):
+ # channels should be len(in_channels) * mla_channels
+ SETRMLAHead(
+ in_channels=(8, 8, 8, 8),
+ channels=8,
+ mla_channels=4,
+ in_index=(0, 1, 2, 3),
+ num_classes=19)
+
+ # test inference of MLA head
+ img_size = (8, 8)
+ patch_size = 4
+ head = SETRMLAHead(
+ in_channels=(8, 8, 8, 8),
+ channels=16,
+ mla_channels=4,
+ in_index=(0, 1, 2, 3),
+ num_classes=19,
+ norm_cfg=dict(type='BN'))
+
+ h, w = img_size[0] // patch_size, img_size[1] // patch_size
+ # Input square NCHW format feature information
+ x = [
+ torch.randn(1, 8, h, w),
+ torch.randn(1, 8, h, w),
+ torch.randn(1, 8, h, w),
+ torch.randn(1, 8, h, w)
+ ]
+ if torch.cuda.is_available():
+ head, x = to_cuda(head, x)
+ out = head(x)
+ assert out.shape == (1, head.num_classes, h * 4, w * 4)
+
+ # Input non-square NCHW format feature information
+ x = [
+ torch.randn(1, 8, h, w * 2),
+ torch.randn(1, 8, h, w * 2),
+ torch.randn(1, 8, h, w * 2),
+ torch.randn(1, 8, h, w * 2)
+ ]
+ if torch.cuda.is_available():
+ head, x = to_cuda(head, x)
+ out = head(x)
+ assert out.shape == (1, head.num_classes, h * 4, w * 8)
diff --git a/tests/test_models/test_heads/test_setr_up_head.py b/tests/test_models/test_heads/test_setr_up_head.py
new file mode 100644
index 0000000..a051922
--- /dev/null
+++ b/tests/test_models/test_heads/test_setr_up_head.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import SETRUPHead
+from .utils import to_cuda
+
+
+def test_setr_up_head(capsys):
+
+ with pytest.raises(AssertionError):
+ # kernel_size must be [1/3]
+ SETRUPHead(num_classes=19, kernel_size=2)
+
+ with pytest.raises(AssertionError):
+ # in_channels must be int type and in_channels must be same
+ # as embed_dim.
+ SETRUPHead(in_channels=(4, 4), channels=2, num_classes=19)
+
+ # test init_cfg of head
+ head = SETRUPHead(
+ in_channels=4,
+ channels=2,
+ norm_cfg=dict(type='SyncBN'),
+ num_classes=19,
+ init_cfg=dict(type='Kaiming'))
+ super(SETRUPHead, head).init_weights()
+
+ # test inference of Naive head
+ # the auxiliary head of Naive head is same as Naive head
+ img_size = (4, 4)
+ patch_size = 2
+ head = SETRUPHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ num_convs=1,
+ up_scale=4,
+ kernel_size=1,
+ norm_cfg=dict(type='BN'))
+
+ h, w = img_size[0] // patch_size, img_size[1] // patch_size
+
+ # Input square NCHW format feature information
+ x = [torch.randn(1, 4, h, w)]
+ if torch.cuda.is_available():
+ head, x = to_cuda(head, x)
+ out = head(x)
+ assert out.shape == (1, head.num_classes, h * 4, w * 4)
+
+ # Input non-square NCHW format feature information
+ x = [torch.randn(1, 4, h, w * 2)]
+ if torch.cuda.is_available():
+ head, x = to_cuda(head, x)
+ out = head(x)
+ assert out.shape == (1, head.num_classes, h * 4, w * 8)
diff --git a/tests/test_models/test_heads/test_stdc_head.py b/tests/test_models/test_heads/test_stdc_head.py
new file mode 100644
index 0000000..1628209
--- /dev/null
+++ b/tests/test_models/test_heads/test_stdc_head.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import STDCHead
+from .utils import to_cuda
+
+
+def test_stdc_head():
+ inputs = [torch.randn(1, 32, 21, 21)]
+ head = STDCHead(
+ in_channels=32,
+ channels=8,
+ num_convs=1,
+ num_classes=2,
+ in_index=-1,
+ loss_decode=[
+ dict(
+ type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=1.0)
+ ])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert isinstance(outputs, torch.Tensor) and len(outputs) == 1
+ assert outputs.shape == torch.Size([1, head.num_classes, 21, 21])
+
+ fake_label = torch.ones_like(
+ outputs[:, 0:1, :, :], dtype=torch.int16).long()
+ loss = head.losses(seg_logit=outputs, seg_label=fake_label)
+ assert loss['loss_ce'] != torch.zeros_like(loss['loss_ce'])
+ assert loss['loss_dice'] != torch.zeros_like(loss['loss_dice'])
diff --git a/tests/test_models/test_heads/test_uper_head.py b/tests/test_models/test_heads/test_uper_head.py
new file mode 100644
index 0000000..09456a8
--- /dev/null
+++ b/tests/test_models/test_heads/test_uper_head.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import UPerHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_uper_head():
+
+ with pytest.raises(AssertionError):
+ # fpn_in_channels must be list|tuple
+ UPerHead(in_channels=4, channels=2, num_classes=19)
+
+ # test no norm_cfg
+ head = UPerHead(
+ in_channels=[4, 2], channels=2, num_classes=19, in_index=[-2, -1])
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = UPerHead(
+ in_channels=[4, 2],
+ channels=2,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'),
+ in_index=[-2, -1])
+ assert _conv_has_norm(head, sync_bn=True)
+
+ inputs = [torch.randn(1, 4, 45, 45), torch.randn(1, 2, 21, 21)]
+ head = UPerHead(
+ in_channels=[4, 2], channels=2, num_classes=19, in_index=[-2, -1])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
diff --git a/tests/test_models/test_heads/utils.py b/tests/test_models/test_heads/utils.py
new file mode 100644
index 0000000..675241c
--- /dev/null
+++ b/tests/test_models/test_heads/utils.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import ConvModule
+from mmcv.utils.parrots_wrapper import SyncBatchNorm
+
+
+def _conv_has_norm(module, sync_bn):
+ for m in module.modules():
+ if isinstance(m, ConvModule):
+ if not m.with_norm:
+ return False
+ if sync_bn:
+ if not isinstance(m.bn, SyncBatchNorm):
+ return False
+ return True
+
+
+def to_cuda(module, data):
+ module = module.cuda()
+ if isinstance(data, list):
+ for i in range(len(data)):
+ data[i] = data[i].cuda()
+ return module, data
diff --git a/tests/test_models/test_losses/__init__.py b/tests/test_models/test_losses/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/test_losses/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_losses/test_ce_loss.py b/tests/test_models/test_losses/test_ce_loss.py
new file mode 100644
index 0000000..2fe5c2e
--- /dev/null
+++ b/tests/test_models/test_losses/test_ce_loss.py
@@ -0,0 +1,89 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+
+def test_ce_loss():
+ from mmseg.models import build_loss
+
+ # use_mask and use_sigmoid cannot be true at the same time
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(
+ type='CrossEntropyLoss',
+ use_mask=True,
+ use_sigmoid=True,
+ loss_weight=1.0)
+ build_loss(loss_cfg)
+
+ # test loss with class weights
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ class_weight=[0.8, 0.2],
+ loss_weight=1.0,
+ loss_name='loss_ce')
+ loss_cls = build_loss(loss_cls_cfg)
+ fake_pred = torch.Tensor([[100, -100]])
+ fake_label = torch.Tensor([1]).long()
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(40.))
+
+ # test loss with class weights from file
+ import os
+ import tempfile
+
+ import mmcv
+ import numpy as np
+ tmp_file = tempfile.NamedTemporaryFile()
+
+ mmcv.dump([0.8, 0.2], f'{tmp_file.name}.pkl', 'pkl') # from pkl file
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ class_weight=f'{tmp_file.name}.pkl',
+ loss_weight=1.0,
+ loss_name='loss_ce')
+ loss_cls = build_loss(loss_cls_cfg)
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(40.))
+
+ np.save(f'{tmp_file.name}.npy', np.array([0.8, 0.2])) # from npy file
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ class_weight=f'{tmp_file.name}.npy',
+ loss_weight=1.0,
+ loss_name='loss_ce')
+ loss_cls = build_loss(loss_cls_cfg)
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(40.))
+ tmp_file.close()
+ os.remove(f'{tmp_file.name}.pkl')
+ os.remove(f'{tmp_file.name}.npy')
+
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)
+ loss_cls = build_loss(loss_cls_cfg)
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(200.))
+
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)
+ loss_cls = build_loss(loss_cls_cfg)
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(100.))
+
+ fake_pred = torch.full(size=(2, 21, 8, 8), fill_value=0.5)
+ fake_label = torch.ones(2, 8, 8).long()
+ assert torch.allclose(
+ loss_cls(fake_pred, fake_label), torch.tensor(0.9503), atol=1e-4)
+ fake_label[:, 0, 0] = 255
+ assert torch.allclose(
+ loss_cls(fake_pred, fake_label, ignore_index=255),
+ torch.tensor(0.9354),
+ atol=1e-4)
+
+ # test cross entropy loss has name `loss_ce`
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0,
+ loss_name='loss_ce')
+ loss_cls = build_loss(loss_cls_cfg)
+ assert loss_cls.loss_name == 'loss_ce'
+ # TODO test use_mask
diff --git a/tests/test_models/test_losses/test_dice_loss.py b/tests/test_models/test_losses/test_dice_loss.py
new file mode 100644
index 0000000..3936f5d
--- /dev/null
+++ b/tests/test_models/test_losses/test_dice_loss.py
@@ -0,0 +1,78 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+
+def test_dice_lose():
+ from mmseg.models import build_loss
+
+ # test dice loss with loss_type = 'multi_class'
+ loss_cfg = dict(
+ type='DiceLoss',
+ reduction='none',
+ class_weight=[1.0, 2.0, 3.0],
+ loss_weight=1.0,
+ ignore_index=1,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ logits = torch.rand(8, 3, 4, 4)
+ labels = (torch.rand(8, 4, 4) * 3).long()
+ dice_loss(logits, labels)
+
+ # test loss with class weights from file
+ import os
+ import tempfile
+
+ import mmcv
+ import numpy as np
+ tmp_file = tempfile.NamedTemporaryFile()
+
+ mmcv.dump([1.0, 2.0, 3.0], f'{tmp_file.name}.pkl', 'pkl') # from pkl file
+ loss_cfg = dict(
+ type='DiceLoss',
+ reduction='none',
+ class_weight=f'{tmp_file.name}.pkl',
+ loss_weight=1.0,
+ ignore_index=1,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ dice_loss(logits, labels, ignore_index=None)
+
+ np.save(f'{tmp_file.name}.npy', np.array([1.0, 2.0, 3.0])) # from npy file
+ loss_cfg = dict(
+ type='DiceLoss',
+ reduction='none',
+ class_weight=f'{tmp_file.name}.pkl',
+ loss_weight=1.0,
+ ignore_index=1,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ dice_loss(logits, labels, ignore_index=None)
+ tmp_file.close()
+ os.remove(f'{tmp_file.name}.pkl')
+ os.remove(f'{tmp_file.name}.npy')
+
+ # test dice loss with loss_type = 'binary'
+ loss_cfg = dict(
+ type='DiceLoss',
+ smooth=2,
+ exponent=3,
+ reduction='sum',
+ loss_weight=1.0,
+ ignore_index=0,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ logits = torch.rand(8, 2, 4, 4)
+ labels = (torch.rand(8, 4, 4) * 2).long()
+ dice_loss(logits, labels)
+
+ # test dice loss has name `loss_dice`
+ loss_cfg = dict(
+ type='DiceLoss',
+ smooth=2,
+ exponent=3,
+ reduction='sum',
+ loss_weight=1.0,
+ ignore_index=0,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ assert dice_loss.loss_name == 'loss_dice'
diff --git a/tests/test_models/test_losses/test_focal_loss.py b/tests/test_models/test_losses/test_focal_loss.py
new file mode 100644
index 0000000..687312b
--- /dev/null
+++ b/tests/test_models/test_losses/test_focal_loss.py
@@ -0,0 +1,216 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+import torch.nn.functional as F
+
+from mmseg.models import build_loss
+
+
+# test focal loss with use_sigmoid=False
+def test_use_sigmoid():
+ # can't init with use_sigmoid=True
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', use_sigmoid=False)
+ build_loss(loss_cfg)
+
+ # can't forward with use_sigmoid=True
+ with pytest.raises(NotImplementedError):
+ loss_cfg = dict(type='FocalLoss', use_sigmoid=True)
+ focal_loss = build_loss(loss_cfg)
+ focal_loss.use_sigmoid = False
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ focal_loss(fake_pred, fake_target)
+
+
+# reduction type must be 'none', 'mean' or 'sum'
+def test_wrong_reduction_type():
+ # can't init with wrong reduction
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', reduction='test')
+ build_loss(loss_cfg)
+
+ # can't forward with wrong reduction override
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ focal_loss(fake_pred, fake_target, reduction_override='test')
+
+
+# test focal loss can handle input parameters with
+# unacceptable types
+def test_unacceptable_parameters():
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', gamma='test')
+ build_loss(loss_cfg)
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', alpha='test')
+ build_loss(loss_cfg)
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', class_weight='test')
+ build_loss(loss_cfg)
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', loss_weight='test')
+ build_loss(loss_cfg)
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', loss_name=123)
+ build_loss(loss_cfg)
+
+
+# test if focal loss can be correctly initialize
+def test_init_focal_loss():
+ loss_cfg = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=3.0,
+ alpha=3.0,
+ class_weight=[1, 2, 3, 4],
+ reduction='sum')
+ focal_loss = build_loss(loss_cfg)
+ assert focal_loss.use_sigmoid is True
+ assert focal_loss.gamma == 3.0
+ assert focal_loss.alpha == 3.0
+ assert focal_loss.reduction == 'sum'
+ assert focal_loss.class_weight == [1, 2, 3, 4]
+ assert focal_loss.loss_weight == 1.0
+ assert focal_loss.loss_name == 'loss_focal'
+
+
+# test reduction override
+def test_reduction_override():
+ loss_cfg = dict(type='FocalLoss', reduction='mean')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss = focal_loss(fake_pred, fake_target, reduction_override='none')
+ assert loss.shape == fake_pred.shape
+
+
+# test wrong pred and target shape
+def test_wrong_pred_and_target_shape():
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 2, 2))
+ fake_target = F.one_hot(fake_target, num_classes=4)
+ fake_target = fake_target.permute(0, 3, 1, 2)
+ with pytest.raises(AssertionError):
+ focal_loss(fake_pred, fake_target)
+
+
+# test forward with different shape of target
+def test_forward_with_different_shape_of_target():
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss1 = focal_loss(fake_pred, fake_target)
+
+ fake_target = F.one_hot(fake_target, num_classes=4)
+ fake_target = fake_target.permute(0, 3, 1, 2)
+ loss2 = focal_loss(fake_pred, fake_target)
+ assert loss1 == loss2
+
+
+# test forward with weight
+def test_forward_with_weight():
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ weight = torch.rand(3 * 5 * 6, 1)
+ loss1 = focal_loss(fake_pred, fake_target, weight=weight)
+
+ weight2 = weight.view(-1)
+ loss2 = focal_loss(fake_pred, fake_target, weight=weight2)
+
+ weight3 = weight.expand(3 * 5 * 6, 4)
+ loss3 = focal_loss(fake_pred, fake_target, weight=weight3)
+ assert loss1 == loss2 == loss3
+
+
+# test none reduction type
+def test_none_reduction_type():
+ loss_cfg = dict(type='FocalLoss', reduction='none')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss = focal_loss(fake_pred, fake_target)
+ assert loss.shape == fake_pred.shape
+
+
+# test the usage of class weight
+def test_class_weight():
+ loss_cfg_cw = dict(
+ type='FocalLoss', reduction='none', class_weight=[1.0, 2.0, 3.0, 4.0])
+ loss_cfg = dict(type='FocalLoss', reduction='none')
+ focal_loss_cw = build_loss(loss_cfg_cw)
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss_cw = focal_loss_cw(fake_pred, fake_target)
+ loss = focal_loss(fake_pred, fake_target)
+ weight = torch.tensor([1, 2, 3, 4]).view(1, 4, 1, 1)
+ assert (loss * weight == loss_cw).all()
+
+
+# test ignore index
+def test_ignore_index():
+ loss_cfg = dict(type='FocalLoss', reduction='none')
+ # ignore_index within C classes
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 5, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ dim1 = torch.randint(0, 3, (4, ))
+ dim2 = torch.randint(0, 5, (4, ))
+ dim3 = torch.randint(0, 6, (4, ))
+ fake_target[dim1, dim2, dim3] = 4
+ loss1 = focal_loss(fake_pred, fake_target, ignore_index=4)
+ one_hot_target = F.one_hot(fake_target, num_classes=5)
+ one_hot_target = one_hot_target.permute(0, 3, 1, 2)
+ loss2 = focal_loss(fake_pred, one_hot_target, ignore_index=4)
+ assert (loss1 == loss2).all()
+ assert (loss1[dim1, :, dim2, dim3] == 0).all()
+ assert (loss2[dim1, :, dim2, dim3] == 0).all()
+
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss1 = focal_loss(fake_pred, fake_target, ignore_index=2)
+ one_hot_target = F.one_hot(fake_target, num_classes=4)
+ one_hot_target = one_hot_target.permute(0, 3, 1, 2)
+ loss2 = focal_loss(fake_pred, one_hot_target, ignore_index=2)
+ ignore_mask = one_hot_target == 2
+ assert (loss1 == loss2).all()
+ assert torch.sum(loss1 * ignore_mask) == 0
+ assert torch.sum(loss2 * ignore_mask) == 0
+
+ # ignore index is not in prediction's classes
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ dim1 = torch.randint(0, 3, (4, ))
+ dim2 = torch.randint(0, 5, (4, ))
+ dim3 = torch.randint(0, 6, (4, ))
+ fake_target[dim1, dim2, dim3] = 255
+ loss1 = focal_loss(fake_pred, fake_target, ignore_index=255)
+ assert (loss1[dim1, :, dim2, dim3] == 0).all()
+
+
+# test list alpha
+def test_alpha():
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+ alpha_float = 0.4
+ alpha = [0.4, 0.4, 0.4, 0.4]
+ alpha2 = [0.1, 0.3, 0.2, 0.1]
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ focal_loss.alpha = alpha_float
+ loss1 = focal_loss(fake_pred, fake_target)
+ focal_loss.alpha = alpha
+ loss2 = focal_loss(fake_pred, fake_target)
+ assert loss1 == loss2
+ focal_loss.alpha = alpha2
+ focal_loss(fake_pred, fake_target)
diff --git a/tests/test_models/test_losses/test_lovasz_loss.py b/tests/test_models/test_losses/test_lovasz_loss.py
new file mode 100644
index 0000000..bea3f4b
--- /dev/null
+++ b/tests/test_models/test_losses/test_lovasz_loss.py
@@ -0,0 +1,118 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+
+def test_lovasz_loss():
+ from mmseg.models import build_loss
+
+ # loss_type should be 'binary' or 'multi_class'
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='Binary',
+ reduction='none',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ build_loss(loss_cfg)
+
+ # reduction should be 'none' when per_image is False.
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='multi_class',
+ loss_name='loss_lovasz')
+ build_loss(loss_cfg)
+
+ # test lovasz loss with loss_type = 'multi_class' and per_image = False
+ loss_cfg = dict(
+ type='LovaszLoss',
+ reduction='none',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ logits = torch.rand(1, 3, 4, 4)
+ labels = (torch.rand(1, 4, 4) * 2).long()
+ lovasz_loss(logits, labels)
+
+ # test lovasz loss with loss_type = 'multi_class' and per_image = True
+ loss_cfg = dict(
+ type='LovaszLoss',
+ per_image=True,
+ reduction='mean',
+ class_weight=[1.0, 2.0, 3.0],
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ logits = torch.rand(1, 3, 4, 4)
+ labels = (torch.rand(1, 4, 4) * 2).long()
+ lovasz_loss(logits, labels, ignore_index=None)
+
+ # test loss with class weights from file
+ import os
+ import tempfile
+
+ import mmcv
+ import numpy as np
+ tmp_file = tempfile.NamedTemporaryFile()
+
+ mmcv.dump([1.0, 2.0, 3.0], f'{tmp_file.name}.pkl', 'pkl') # from pkl file
+ loss_cfg = dict(
+ type='LovaszLoss',
+ per_image=True,
+ reduction='mean',
+ class_weight=f'{tmp_file.name}.pkl',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ lovasz_loss(logits, labels, ignore_index=None)
+
+ np.save(f'{tmp_file.name}.npy', np.array([1.0, 2.0, 3.0])) # from npy file
+ loss_cfg = dict(
+ type='LovaszLoss',
+ per_image=True,
+ reduction='mean',
+ class_weight=f'{tmp_file.name}.npy',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ lovasz_loss(logits, labels, ignore_index=None)
+ tmp_file.close()
+ os.remove(f'{tmp_file.name}.pkl')
+ os.remove(f'{tmp_file.name}.npy')
+
+ # test lovasz loss with loss_type = 'binary' and per_image = False
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='binary',
+ reduction='none',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ logits = torch.rand(2, 4, 4)
+ labels = (torch.rand(2, 4, 4)).long()
+ lovasz_loss(logits, labels)
+
+ # test lovasz loss with loss_type = 'binary' and per_image = True
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='binary',
+ per_image=True,
+ reduction='mean',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ logits = torch.rand(2, 4, 4)
+ labels = (torch.rand(2, 4, 4)).long()
+ lovasz_loss(logits, labels, ignore_index=None)
+
+ # test lovasz loss has name `loss_lovasz`
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='binary',
+ per_image=True,
+ reduction='mean',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ assert lovasz_loss.loss_name == 'loss_lovasz'
diff --git a/tests/test_models/test_losses/test_utils.py b/tests/test_models/test_losses/test_utils.py
new file mode 100644
index 0000000..1d94387
--- /dev/null
+++ b/tests/test_models/test_losses/test_utils.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import pytest
+import torch
+
+from mmseg.models.losses import Accuracy, reduce_loss, weight_reduce_loss
+
+
+def test_weight_reduce_loss():
+ loss = torch.rand(1, 3, 4, 4)
+ weight = torch.zeros(1, 3, 4, 4)
+ weight[:, :, :2, :2] = 1
+
+ # test reduce_loss()
+ reduced = reduce_loss(loss, 'none')
+ assert reduced is loss
+
+ reduced = reduce_loss(loss, 'mean')
+ np.testing.assert_almost_equal(reduced.numpy(), loss.mean())
+
+ reduced = reduce_loss(loss, 'sum')
+ np.testing.assert_almost_equal(reduced.numpy(), loss.sum())
+
+ # test weight_reduce_loss()
+ reduced = weight_reduce_loss(loss, weight=None, reduction='none')
+ assert reduced is loss
+
+ reduced = weight_reduce_loss(loss, weight=weight, reduction='mean')
+ target = (loss * weight).mean()
+ np.testing.assert_almost_equal(reduced.numpy(), target)
+
+ reduced = weight_reduce_loss(loss, weight=weight, reduction='sum')
+ np.testing.assert_almost_equal(reduced.numpy(), (loss * weight).sum())
+
+ with pytest.raises(AssertionError):
+ weight_wrong = weight[0, 0, ...]
+ weight_reduce_loss(loss, weight=weight_wrong, reduction='mean')
+
+ with pytest.raises(AssertionError):
+ weight_wrong = weight[:, 0:2, ...]
+ weight_reduce_loss(loss, weight=weight_wrong, reduction='mean')
+
+
+def test_accuracy():
+ # test for empty pred
+ pred = torch.empty(0, 4)
+ label = torch.empty(0)
+ accuracy = Accuracy(topk=1)
+ acc = accuracy(pred, label)
+ assert acc.item() == 0
+
+ pred = torch.Tensor([[0.2, 0.3, 0.6, 0.5], [0.1, 0.1, 0.2, 0.6],
+ [0.9, 0.0, 0.0, 0.1], [0.4, 0.7, 0.1, 0.1],
+ [0.0, 0.0, 0.99, 0]])
+ # test for top1
+ true_label = torch.Tensor([2, 3, 0, 1, 2]).long()
+ accuracy = Accuracy(topk=1)
+ acc = accuracy(pred, true_label)
+ assert acc.item() == 100
+
+ # test for top1 with score thresh=0.8
+ true_label = torch.Tensor([2, 3, 0, 1, 2]).long()
+ accuracy = Accuracy(topk=1, thresh=0.8)
+ acc = accuracy(pred, true_label)
+ assert acc.item() == 40
+
+ # test for top2
+ accuracy = Accuracy(topk=2)
+ label = torch.Tensor([3, 2, 0, 0, 2]).long()
+ acc = accuracy(pred, label)
+ assert acc.item() == 100
+
+ # test for both top1 and top2
+ accuracy = Accuracy(topk=(1, 2))
+ true_label = torch.Tensor([2, 3, 0, 1, 2]).long()
+ acc = accuracy(pred, true_label)
+ for a in acc:
+ assert a.item() == 100
+
+ # topk is larger than pred class number
+ with pytest.raises(AssertionError):
+ accuracy = Accuracy(topk=5)
+ accuracy(pred, true_label)
+
+ # wrong topk type
+ with pytest.raises(AssertionError):
+ accuracy = Accuracy(topk='wrong type')
+ accuracy(pred, true_label)
+
+ # label size is larger than required
+ with pytest.raises(AssertionError):
+ label = torch.Tensor([2, 3, 0, 1, 2, 0]).long() # size mismatch
+ accuracy = Accuracy()
+ accuracy(pred, label)
+
+ # wrong pred dimension
+ with pytest.raises(AssertionError):
+ accuracy = Accuracy()
+ accuracy(pred[:, :, None], true_label)
diff --git a/tests/test_models/test_necks/__init__.py b/tests/test_models/test_necks/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/test_necks/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_necks/test_fpn.py b/tests/test_models/test_necks/test_fpn.py
new file mode 100644
index 0000000..c294006
--- /dev/null
+++ b/tests/test_models/test_necks/test_fpn.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models import FPN
+
+
+def test_fpn():
+ in_channels = [64, 128, 256, 512]
+ inputs = [
+ torch.randn(1, c, 56 // 2**i, 56 // 2**i)
+ for i, c in enumerate(in_channels)
+ ]
+
+ fpn = FPN(in_channels, 64, len(in_channels))
+ outputs = fpn(inputs)
+ assert outputs[0].shape == torch.Size([1, 64, 56, 56])
+ assert outputs[1].shape == torch.Size([1, 64, 28, 28])
+ assert outputs[2].shape == torch.Size([1, 64, 14, 14])
+ assert outputs[3].shape == torch.Size([1, 64, 7, 7])
+
+ fpn = FPN(
+ in_channels,
+ 64,
+ len(in_channels),
+ upsample_cfg=dict(mode='nearest', scale_factor=2.0))
+ outputs = fpn(inputs)
+ assert outputs[0].shape == torch.Size([1, 64, 56, 56])
+ assert outputs[1].shape == torch.Size([1, 64, 28, 28])
+ assert outputs[2].shape == torch.Size([1, 64, 14, 14])
+ assert outputs[3].shape == torch.Size([1, 64, 7, 7])
diff --git a/tests/test_models/test_necks/test_ic_neck.py b/tests/test_models/test_necks/test_ic_neck.py
new file mode 100644
index 0000000..3d13008
--- /dev/null
+++ b/tests/test_models/test_necks/test_ic_neck.py
@@ -0,0 +1,53 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.necks import ICNeck
+from mmseg.models.necks.ic_neck import CascadeFeatureFusion
+from ..test_heads.utils import _conv_has_norm, to_cuda
+
+
+def test_ic_neck():
+ # test with norm_cfg
+ neck = ICNeck(
+ in_channels=(4, 16, 16),
+ out_channels=8,
+ norm_cfg=dict(type='SyncBN'),
+ align_corners=False)
+ assert _conv_has_norm(neck, sync_bn=True)
+
+ inputs = [
+ torch.randn(1, 4, 32, 64),
+ torch.randn(1, 16, 16, 32),
+ torch.randn(1, 16, 8, 16)
+ ]
+ neck = ICNeck(
+ in_channels=(4, 16, 16),
+ out_channels=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ align_corners=False)
+ if torch.cuda.is_available():
+ neck, inputs = to_cuda(neck, inputs)
+
+ outputs = neck(inputs)
+ assert outputs[0].shape == (1, 4, 16, 32)
+ assert outputs[1].shape == (1, 4, 32, 64)
+ assert outputs[1].shape == (1, 4, 32, 64)
+
+
+def test_ic_neck_cascade_feature_fusion():
+ cff = CascadeFeatureFusion(64, 64, 32)
+ assert cff.conv_low.in_channels == 64
+ assert cff.conv_low.out_channels == 32
+ assert cff.conv_high.in_channels == 64
+ assert cff.conv_high.out_channels == 32
+
+
+def test_ic_neck_input_channels():
+ with pytest.raises(AssertionError):
+ # ICNet Neck input channel constraints.
+ ICNeck(
+ in_channels=(16, 64, 64, 64),
+ out_channels=32,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ align_corners=False)
diff --git a/tests/test_models/test_necks/test_jpu.py b/tests/test_models/test_necks/test_jpu.py
new file mode 100644
index 0000000..4c3fa9f
--- /dev/null
+++ b/tests/test_models/test_necks/test_jpu.py
@@ -0,0 +1,46 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.necks import JPU
+
+
+def test_fastfcn_neck():
+ # Test FastFCN Standard Forward
+ model = JPU(
+ in_channels=(64, 128, 256),
+ mid_channels=64,
+ start_level=0,
+ end_level=-1,
+ dilations=(1, 2, 4, 8),
+ )
+ model.init_weights()
+ model.train()
+ batch_size = 1
+ input = [
+ torch.randn(batch_size, 64, 64, 128),
+ torch.randn(batch_size, 128, 32, 64),
+ torch.randn(batch_size, 256, 16, 32)
+ ]
+ feat = model(input)
+
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([batch_size, 64, 64, 128])
+ assert feat[1].shape == torch.Size([batch_size, 128, 32, 64])
+ assert feat[2].shape == torch.Size([batch_size, 256, 64, 128])
+
+ with pytest.raises(AssertionError):
+ # FastFCN input and in_channels constraints.
+ JPU(in_channels=(256, 64, 128), start_level=0, end_level=5)
+
+ # Test not default start_level
+ model = JPU(in_channels=(64, 128, 256), start_level=1, end_level=-1)
+ input = [
+ torch.randn(batch_size, 64, 64, 128),
+ torch.randn(batch_size, 128, 32, 64),
+ torch.randn(batch_size, 256, 16, 32)
+ ]
+ feat = model(input)
+ assert len(feat) == 2
+ assert feat[0].shape == torch.Size([batch_size, 128, 32, 64])
+ assert feat[1].shape == torch.Size([batch_size, 2048, 32, 64])
diff --git a/tests/test_models/test_necks/test_mla_neck.py b/tests/test_models/test_necks/test_mla_neck.py
new file mode 100644
index 0000000..e385418
--- /dev/null
+++ b/tests/test_models/test_necks/test_mla_neck.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models import MLANeck
+
+
+def test_mla():
+ in_channels = [4, 4, 4, 4]
+ mla = MLANeck(in_channels, 32)
+
+ inputs = [torch.randn(1, c, 12, 12) for i, c in enumerate(in_channels)]
+ outputs = mla(inputs)
+ assert outputs[0].shape == torch.Size([1, 32, 12, 12])
+ assert outputs[1].shape == torch.Size([1, 32, 12, 12])
+ assert outputs[2].shape == torch.Size([1, 32, 12, 12])
+ assert outputs[3].shape == torch.Size([1, 32, 12, 12])
diff --git a/tests/test_models/test_necks/test_multilevel_neck.py b/tests/test_models/test_necks/test_multilevel_neck.py
new file mode 100644
index 0000000..9c71d51
--- /dev/null
+++ b/tests/test_models/test_necks/test_multilevel_neck.py
@@ -0,0 +1,32 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models import MultiLevelNeck
+
+
+def test_multilevel_neck():
+
+ # Test init_weights
+ MultiLevelNeck([266], 32).init_weights()
+
+ # Test multi feature maps
+ in_channels = [32, 64, 128, 256]
+ inputs = [torch.randn(1, c, 14, 14) for i, c in enumerate(in_channels)]
+
+ neck = MultiLevelNeck(in_channels, 32)
+ outputs = neck(inputs)
+ assert outputs[0].shape == torch.Size([1, 32, 7, 7])
+ assert outputs[1].shape == torch.Size([1, 32, 14, 14])
+ assert outputs[2].shape == torch.Size([1, 32, 28, 28])
+ assert outputs[3].shape == torch.Size([1, 32, 56, 56])
+
+ # Test one feature map
+ in_channels = [768]
+ inputs = [torch.randn(1, 768, 14, 14)]
+
+ neck = MultiLevelNeck(in_channels, 32)
+ outputs = neck(inputs)
+ assert outputs[0].shape == torch.Size([1, 32, 7, 7])
+ assert outputs[1].shape == torch.Size([1, 32, 14, 14])
+ assert outputs[2].shape == torch.Size([1, 32, 28, 28])
+ assert outputs[3].shape == torch.Size([1, 32, 56, 56])
diff --git a/tests/test_models/test_segmentors/__init__.py b/tests/test_models/test_segmentors/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/test_segmentors/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_segmentors/test_cascade_encoder_decoder.py b/tests/test_models/test_segmentors/test_cascade_encoder_decoder.py
new file mode 100644
index 0000000..07ad5c3
--- /dev/null
+++ b/tests/test_models/test_segmentors/test_cascade_encoder_decoder.py
@@ -0,0 +1,57 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv import ConfigDict
+
+from mmseg.models import build_segmentor
+from .utils import _segmentor_forward_train_test
+
+
+def test_cascade_encoder_decoder():
+
+ # test 1 decode head, w.o. aux head
+ cfg = ConfigDict(
+ type='CascadeEncoderDecoder',
+ num_stages=2,
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleCascadeDecodeHead')
+ ])
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test slide mode
+ cfg.test_cfg = ConfigDict(mode='slide', crop_size=(3, 3), stride=(2, 2))
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test 1 decode head, 1 aux head
+ cfg = ConfigDict(
+ type='CascadeEncoderDecoder',
+ num_stages=2,
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleCascadeDecodeHead')
+ ],
+ auxiliary_head=dict(type='ExampleDecodeHead'))
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test 1 decode head, 2 aux head
+ cfg = ConfigDict(
+ type='CascadeEncoderDecoder',
+ num_stages=2,
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleCascadeDecodeHead')
+ ],
+ auxiliary_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleDecodeHead')
+ ])
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
diff --git a/tests/test_models/test_segmentors/test_encoder_decoder.py b/tests/test_models/test_segmentors/test_encoder_decoder.py
new file mode 100644
index 0000000..4ed1437
--- /dev/null
+++ b/tests/test_models/test_segmentors/test_encoder_decoder.py
@@ -0,0 +1,47 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv import ConfigDict
+
+from mmseg.models import build_segmentor
+from .utils import _segmentor_forward_train_test
+
+
+def test_encoder_decoder():
+
+ # test 1 decode head, w.o. aux head
+
+ cfg = ConfigDict(
+ type='EncoderDecoder',
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=dict(type='ExampleDecodeHead'),
+ train_cfg=None,
+ test_cfg=dict(mode='whole'))
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test slide mode
+ cfg.test_cfg = ConfigDict(mode='slide', crop_size=(3, 3), stride=(2, 2))
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test 1 decode head, 1 aux head
+ cfg = ConfigDict(
+ type='EncoderDecoder',
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=dict(type='ExampleDecodeHead'),
+ auxiliary_head=dict(type='ExampleDecodeHead'))
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test 1 decode head, 2 aux head
+ cfg = ConfigDict(
+ type='EncoderDecoder',
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=dict(type='ExampleDecodeHead'),
+ auxiliary_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleDecodeHead')
+ ])
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
diff --git a/tests/test_models/test_segmentors/utils.py b/tests/test_models/test_segmentors/utils.py
new file mode 100644
index 0000000..1826dbf
--- /dev/null
+++ b/tests/test_models/test_segmentors/utils.py
@@ -0,0 +1,140 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+from torch import nn
+
+from mmseg.models import BACKBONES, HEADS
+from mmseg.models.decode_heads.cascade_decode_head import BaseCascadeDecodeHead
+from mmseg.models.decode_heads.decode_head import BaseDecodeHead
+
+
+def _demo_mm_inputs(input_shape=(1, 3, 8, 16), num_classes=10):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+
+ rng = np.random.RandomState(0)
+
+ imgs = rng.rand(*input_shape)
+ segs = rng.randint(
+ low=0, high=num_classes - 1, size=(N, 1, H, W)).astype(np.uint8)
+
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': 1.0,
+ 'flip': False,
+ 'flip_direction': 'horizontal'
+ } for _ in range(N)]
+
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs),
+ 'img_metas': img_metas,
+ 'gt_semantic_seg': torch.LongTensor(segs)
+ }
+ return mm_inputs
+
+
+@BACKBONES.register_module()
+class ExampleBackbone(nn.Module):
+
+ def __init__(self):
+ super(ExampleBackbone, self).__init__()
+ self.conv = nn.Conv2d(3, 3, 3)
+
+ def init_weights(self, pretrained=None):
+ pass
+
+ def forward(self, x):
+ return [self.conv(x)]
+
+
+@HEADS.register_module()
+class ExampleDecodeHead(BaseDecodeHead):
+
+ def __init__(self):
+ super(ExampleDecodeHead, self).__init__(3, 3, num_classes=19)
+
+ def forward(self, inputs):
+ return self.cls_seg(inputs[0])
+
+
+@HEADS.register_module()
+class ExampleCascadeDecodeHead(BaseCascadeDecodeHead):
+
+ def __init__(self):
+ super(ExampleCascadeDecodeHead, self).__init__(3, 3, num_classes=19)
+
+ def forward(self, inputs, prev_out):
+ return self.cls_seg(inputs[0])
+
+
+def _segmentor_forward_train_test(segmentor):
+ if isinstance(segmentor.decode_head, nn.ModuleList):
+ num_classes = segmentor.decode_head[-1].num_classes
+ else:
+ num_classes = segmentor.decode_head.num_classes
+ # batch_size=2 for BatchNorm
+ mm_inputs = _demo_mm_inputs(num_classes=num_classes)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ gt_semantic_seg = mm_inputs['gt_semantic_seg']
+
+ # convert to cuda Tensor if applicable
+ if torch.cuda.is_available():
+ segmentor = segmentor.cuda()
+ imgs = imgs.cuda()
+ gt_semantic_seg = gt_semantic_seg.cuda()
+
+ # Test forward train
+ losses = segmentor.forward(
+ imgs, img_metas, gt_semantic_seg=gt_semantic_seg, return_loss=True)
+ assert isinstance(losses, dict)
+
+ # Test train_step
+ data_batch = dict(
+ img=imgs, img_metas=img_metas, gt_semantic_seg=gt_semantic_seg)
+ outputs = segmentor.train_step(data_batch, None)
+ assert isinstance(outputs, dict)
+ assert 'loss' in outputs
+ assert 'log_vars' in outputs
+ assert 'num_samples' in outputs
+
+ # Test val_step
+ with torch.no_grad():
+ segmentor.eval()
+ data_batch = dict(
+ img=imgs, img_metas=img_metas, gt_semantic_seg=gt_semantic_seg)
+ outputs = segmentor.val_step(data_batch, None)
+ assert isinstance(outputs, dict)
+ assert 'loss' in outputs
+ assert 'log_vars' in outputs
+ assert 'num_samples' in outputs
+
+ # Test forward simple test
+ with torch.no_grad():
+ segmentor.eval()
+ # pack into lists
+ img_list = [img[None, :] for img in imgs]
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ segmentor.forward(img_list, img_meta_list, return_loss=False)
+
+ # Test forward aug test
+ with torch.no_grad():
+ segmentor.eval()
+ # pack into lists
+ img_list = [img[None, :] for img in imgs]
+ img_list = img_list + img_list
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ img_meta_list = img_meta_list + img_meta_list
+ segmentor.forward(img_list, img_meta_list, return_loss=False)
diff --git a/tests/test_models/test_utils/__init__.py b/tests/test_models/test_utils/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/tests/test_models/test_utils/test_embed.py b/tests/test_models/test_utils/test_embed.py
new file mode 100644
index 0000000..be20c97
--- /dev/null
+++ b/tests/test_models/test_utils/test_embed.py
@@ -0,0 +1,461 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.utils.embed import AdaptivePadding, PatchEmbed, PatchMerging
+
+
+def test_adaptive_padding():
+
+ for padding in ('same', 'corner'):
+ kernel_size = 16
+ stride = 16
+ dilation = 1
+ input = torch.rand(1, 1, 15, 17)
+ adap_pool = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ out = adap_pool(input)
+ # padding to divisible by 16
+ assert (out.shape[2], out.shape[3]) == (16, 32)
+ input = torch.rand(1, 1, 16, 17)
+ out = adap_pool(input)
+ # padding to divisible by 16
+ assert (out.shape[2], out.shape[3]) == (16, 32)
+
+ kernel_size = (2, 2)
+ stride = (2, 2)
+ dilation = (1, 1)
+
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ input = torch.rand(1, 1, 11, 13)
+ out = adap_pad(input)
+ # padding to divisible by 2
+ assert (out.shape[2], out.shape[3]) == (12, 14)
+
+ kernel_size = (2, 2)
+ stride = (10, 10)
+ dilation = (1, 1)
+
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ input = torch.rand(1, 1, 10, 13)
+ out = adap_pad(input)
+ # no padding
+ assert (out.shape[2], out.shape[3]) == (10, 13)
+
+ kernel_size = (11, 11)
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ input = torch.rand(1, 1, 11, 13)
+ out = adap_pad(input)
+ # all padding
+ assert (out.shape[2], out.shape[3]) == (21, 21)
+
+ # test padding as kernel is (7,9)
+ input = torch.rand(1, 1, 11, 13)
+ stride = (3, 4)
+ kernel_size = (4, 5)
+ dilation = (2, 2)
+ # actually (7, 9)
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ dilation_out = adap_pad(input)
+ assert (dilation_out.shape[2], dilation_out.shape[3]) == (16, 21)
+ kernel_size = (7, 9)
+ dilation = (1, 1)
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ kernel79_out = adap_pad(input)
+ assert (kernel79_out.shape[2], kernel79_out.shape[3]) == (16, 21)
+ assert kernel79_out.shape == dilation_out.shape
+
+ # assert only support "same" "corner"
+ with pytest.raises(AssertionError):
+ AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=1)
+
+
+def test_patch_embed():
+ B = 2
+ H = 3
+ W = 4
+ C = 3
+ embed_dims = 10
+ kernel_size = 3
+ stride = 1
+ dummy_input = torch.rand(B, C, H, W)
+ patch_merge_1 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=1,
+ norm_cfg=None)
+
+ x1, shape = patch_merge_1(dummy_input)
+ # test out shape
+ assert x1.shape == (2, 2, 10)
+ # test outsize is correct
+ assert shape == (1, 2)
+ # test L = out_h * out_w
+ assert shape[0] * shape[1] == x1.shape[1]
+
+ B = 2
+ H = 10
+ W = 10
+ C = 3
+ embed_dims = 10
+ kernel_size = 5
+ stride = 2
+ dummy_input = torch.rand(B, C, H, W)
+ # test dilation
+ patch_merge_2 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=2,
+ norm_cfg=None,
+ )
+
+ x2, shape = patch_merge_2(dummy_input)
+ # test out shape
+ assert x2.shape == (2, 1, 10)
+ # test outsize is correct
+ assert shape == (1, 1)
+ # test L = out_h * out_w
+ assert shape[0] * shape[1] == x2.shape[1]
+
+ stride = 2
+ input_size = (10, 10)
+
+ dummy_input = torch.rand(B, C, H, W)
+ # test stride and norm
+ patch_merge_3 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=2,
+ norm_cfg=dict(type='LN'),
+ input_size=input_size)
+
+ x3, shape = patch_merge_3(dummy_input)
+ # test out shape
+ assert x3.shape == (2, 1, 10)
+ # test outsize is correct
+ assert shape == (1, 1)
+ # test L = out_h * out_w
+ assert shape[0] * shape[1] == x3.shape[1]
+
+ # test the init_out_size with nn.Unfold
+ assert patch_merge_3.init_out_size[1] == (input_size[0] - 2 * 4 -
+ 1) // 2 + 1
+ assert patch_merge_3.init_out_size[0] == (input_size[0] - 2 * 4 -
+ 1) // 2 + 1
+ H = 11
+ W = 12
+ input_size = (H, W)
+ dummy_input = torch.rand(B, C, H, W)
+ # test stride and norm
+ patch_merge_3 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=2,
+ norm_cfg=dict(type='LN'),
+ input_size=input_size)
+
+ _, shape = patch_merge_3(dummy_input)
+ # when input_size equal to real input
+ # the out_size should be equal to `init_out_size`
+ assert shape == patch_merge_3.init_out_size
+
+ input_size = (H, W)
+ dummy_input = torch.rand(B, C, H, W)
+ # test stride and norm
+ patch_merge_3 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=2,
+ norm_cfg=dict(type='LN'),
+ input_size=input_size)
+
+ _, shape = patch_merge_3(dummy_input)
+ # when input_size equal to real input
+ # the out_size should be equal to `init_out_size`
+ assert shape == patch_merge_3.init_out_size
+
+ # test adap padding
+ for padding in ('same', 'corner'):
+ in_c = 2
+ embed_dims = 3
+ B = 2
+
+ # test stride is 1
+ input_size = (5, 5)
+ kernel_size = (5, 5)
+ stride = (1, 1)
+ dilation = 1
+ bias = False
+
+ x = torch.rand(B, in_c, *input_size)
+ patch_embed = PatchEmbed(
+ in_channels=in_c,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_embed(x)
+ assert x_out.size() == (B, 25, 3)
+ assert out_size == (5, 5)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test kernel_size == stride
+ input_size = (5, 5)
+ kernel_size = (5, 5)
+ stride = (5, 5)
+ dilation = 1
+ bias = False
+
+ x = torch.rand(B, in_c, *input_size)
+ patch_embed = PatchEmbed(
+ in_channels=in_c,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_embed(x)
+ assert x_out.size() == (B, 1, 3)
+ assert out_size == (1, 1)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test kernel_size == stride
+ input_size = (6, 5)
+ kernel_size = (5, 5)
+ stride = (5, 5)
+ dilation = 1
+ bias = False
+
+ x = torch.rand(B, in_c, *input_size)
+ patch_embed = PatchEmbed(
+ in_channels=in_c,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_embed(x)
+ assert x_out.size() == (B, 2, 3)
+ assert out_size == (2, 1)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test different kernel_size with different stride
+ input_size = (6, 5)
+ kernel_size = (6, 2)
+ stride = (6, 2)
+ dilation = 1
+ bias = False
+
+ x = torch.rand(B, in_c, *input_size)
+ patch_embed = PatchEmbed(
+ in_channels=in_c,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_embed(x)
+ assert x_out.size() == (B, 3, 3)
+ assert out_size == (1, 3)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+
+def test_patch_merging():
+
+ # Test the model with int padding
+ in_c = 3
+ out_c = 4
+ kernel_size = 3
+ stride = 3
+ padding = 1
+ dilation = 1
+ bias = False
+ # test the case `pad_to_stride` is False
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+ B, L, C = 1, 100, 3
+ input_size = (10, 10)
+ x = torch.rand(B, L, C)
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (1, 16, 4)
+ assert out_size == (4, 4)
+ # assert out size is consistent with real output
+ assert x_out.size(1) == out_size[0] * out_size[1]
+ in_c = 4
+ out_c = 5
+ kernel_size = 6
+ stride = 3
+ padding = 2
+ dilation = 2
+ bias = False
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+ B, L, C = 1, 100, 4
+ input_size = (10, 10)
+ x = torch.rand(B, L, C)
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (1, 4, 5)
+ assert out_size == (2, 2)
+ # assert out size is consistent with real output
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # Test with adaptive padding
+ for padding in ('same', 'corner'):
+ in_c = 2
+ out_c = 3
+ B = 2
+
+ # test stride is 1
+ input_size = (5, 5)
+ kernel_size = (5, 5)
+ stride = (1, 1)
+ dilation = 1
+ bias = False
+ L = input_size[0] * input_size[1]
+
+ x = torch.rand(B, L, in_c)
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (B, 25, 3)
+ assert out_size == (5, 5)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test kernel_size == stride
+ input_size = (5, 5)
+ kernel_size = (5, 5)
+ stride = (5, 5)
+ dilation = 1
+ bias = False
+ L = input_size[0] * input_size[1]
+
+ x = torch.rand(B, L, in_c)
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (B, 1, 3)
+ assert out_size == (1, 1)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test kernel_size == stride
+ input_size = (6, 5)
+ kernel_size = (5, 5)
+ stride = (5, 5)
+ dilation = 1
+ bias = False
+ L = input_size[0] * input_size[1]
+
+ x = torch.rand(B, L, in_c)
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (B, 2, 3)
+ assert out_size == (2, 1)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test different kernel_size with different stride
+ input_size = (6, 5)
+ kernel_size = (6, 2)
+ stride = (6, 2)
+ dilation = 1
+ bias = False
+ L = input_size[0] * input_size[1]
+
+ x = torch.rand(B, L, in_c)
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (B, 3, 3)
+ assert out_size == (1, 3)
+ assert x_out.size(1) == out_size[0] * out_size[1]
diff --git a/tests/test_sampler.py b/tests/test_sampler.py
new file mode 100644
index 0000000..1409224
--- /dev/null
+++ b/tests/test_sampler.py
@@ -0,0 +1,78 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.core import OHEMPixelSampler
+from mmseg.models.decode_heads import FCNHead
+
+
+def _context_for_ohem():
+ return FCNHead(in_channels=32, channels=16, num_classes=19)
+
+
+def _context_for_ohem_multiple_loss():
+ return FCNHead(
+ in_channels=32,
+ channels=16,
+ num_classes=19,
+ loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2')
+ ])
+
+
+def test_ohem_sampler():
+
+ with pytest.raises(AssertionError):
+ # seg_logit and seg_label must be of the same size
+ sampler = OHEMPixelSampler(context=_context_for_ohem())
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 89, 89))
+ sampler.sample(seg_logit, seg_label)
+
+ # test with thresh
+ sampler = OHEMPixelSampler(
+ context=_context_for_ohem(), thresh=0.7, min_kept=200)
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 45, 45))
+ seg_weight = sampler.sample(seg_logit, seg_label)
+ assert seg_weight.shape[0] == seg_logit.shape[0]
+ assert seg_weight.shape[1:] == seg_logit.shape[2:]
+ assert seg_weight.sum() > 200
+
+ # test w.o thresh
+ sampler = OHEMPixelSampler(context=_context_for_ohem(), min_kept=200)
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 45, 45))
+ seg_weight = sampler.sample(seg_logit, seg_label)
+ assert seg_weight.shape[0] == seg_logit.shape[0]
+ assert seg_weight.shape[1:] == seg_logit.shape[2:]
+ assert seg_weight.sum() == 200
+
+ # test multiple losses case
+ with pytest.raises(AssertionError):
+ # seg_logit and seg_label must be of the same size
+ sampler = OHEMPixelSampler(context=_context_for_ohem_multiple_loss())
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 89, 89))
+ sampler.sample(seg_logit, seg_label)
+
+ # test with thresh in multiple losses case
+ sampler = OHEMPixelSampler(
+ context=_context_for_ohem_multiple_loss(), thresh=0.7, min_kept=200)
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 45, 45))
+ seg_weight = sampler.sample(seg_logit, seg_label)
+ assert seg_weight.shape[0] == seg_logit.shape[0]
+ assert seg_weight.shape[1:] == seg_logit.shape[2:]
+ assert seg_weight.sum() > 200
+
+ # test w.o thresh in multiple losses case
+ sampler = OHEMPixelSampler(
+ context=_context_for_ohem_multiple_loss(), min_kept=200)
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 45, 45))
+ seg_weight = sampler.sample(seg_logit, seg_label)
+ assert seg_weight.shape[0] == seg_logit.shape[0]
+ assert seg_weight.shape[1:] == seg_logit.shape[2:]
+ assert seg_weight.sum() == 200
diff --git a/tests/test_utils/test_misc.py b/tests/test_utils/test_misc.py
new file mode 100644
index 0000000..7ce1fa6
--- /dev/null
+++ b/tests/test_utils/test_misc.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+
+from mmseg.utils import find_latest_checkpoint
+
+
+def test_find_latest_checkpoint():
+ with tempfile.TemporaryDirectory() as tempdir:
+ # no checkpoints in the path
+ path = tempdir
+ latest = find_latest_checkpoint(path)
+ assert latest is None
+
+ # The path doesn't exist
+ path = osp.join(tempdir, 'none')
+ latest = find_latest_checkpoint(path)
+ assert latest is None
+
+ # test when latest.pth exists
+ with tempfile.TemporaryDirectory() as tempdir:
+ with open(osp.join(tempdir, 'latest.pth'), 'w') as f:
+ f.write('latest')
+ path = tempdir
+ latest = find_latest_checkpoint(path)
+ assert latest == osp.join(tempdir, 'latest.pth')
+
+ with tempfile.TemporaryDirectory() as tempdir:
+ for iter in range(1600, 160001, 1600):
+ with open(osp.join(tempdir, f'iter_{iter}.pth'), 'w') as f:
+ f.write(f'iter_{iter}.pth')
+ latest = find_latest_checkpoint(tempdir)
+ assert latest == osp.join(tempdir, 'iter_160000.pth')
+
+ with tempfile.TemporaryDirectory() as tempdir:
+ for epoch in range(1, 21):
+ with open(osp.join(tempdir, f'epoch_{epoch}.pth'), 'w') as f:
+ f.write(f'epoch_{epoch}.pth')
+ latest = find_latest_checkpoint(tempdir)
+ assert latest == osp.join(tempdir, 'epoch_20.pth')
diff --git a/tests/test_utils/test_set_env.py b/tests/test_utils/test_set_env.py
new file mode 100644
index 0000000..0af4424
--- /dev/null
+++ b/tests/test_utils/test_set_env.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import multiprocessing as mp
+import os
+import platform
+
+import cv2
+import pytest
+from mmcv import Config
+
+from mmseg.utils import setup_multi_processes
+
+
+@pytest.mark.parametrize('workers_per_gpu', (0, 2))
+@pytest.mark.parametrize(('valid', 'env_cfg'), [(True,
+ dict(
+ mp_start_method='fork',
+ opencv_num_threads=0,
+ omp_num_threads=1,
+ mkl_num_threads=1)),
+ (False,
+ dict(
+ mp_start_method=1,
+ opencv_num_threads=0.1,
+ omp_num_threads='s',
+ mkl_num_threads='1'))])
+def test_setup_multi_processes(workers_per_gpu, valid, env_cfg):
+ # temp save system setting
+ sys_start_mehod = mp.get_start_method(allow_none=True)
+ sys_cv_threads = cv2.getNumThreads()
+ # pop and temp save system env vars
+ sys_omp_threads = os.environ.pop('OMP_NUM_THREADS', default=None)
+ sys_mkl_threads = os.environ.pop('MKL_NUM_THREADS', default=None)
+
+ config = dict(data=dict(workers_per_gpu=workers_per_gpu))
+ config.update(env_cfg)
+ cfg = Config(config)
+ setup_multi_processes(cfg)
+
+ # test when cfg is valid and workers_per_gpu > 0
+ # setup_multi_processes will work
+ if valid and workers_per_gpu > 0:
+ # test config without setting env
+
+ assert os.getenv('OMP_NUM_THREADS') == str(env_cfg['omp_num_threads'])
+ assert os.getenv('MKL_NUM_THREADS') == str(env_cfg['mkl_num_threads'])
+ # when set to 0, the num threads will be 1
+ assert cv2.getNumThreads() == env_cfg[
+ 'opencv_num_threads'] if env_cfg['opencv_num_threads'] > 0 else 1
+ if platform.system() != 'Windows':
+ assert mp.get_start_method() == env_cfg['mp_start_method']
+
+ # revert setting to avoid affecting other programs
+ if sys_start_mehod:
+ mp.set_start_method(sys_start_mehod, force=True)
+ cv2.setNumThreads(sys_cv_threads)
+ if sys_omp_threads:
+ os.environ['OMP_NUM_THREADS'] = sys_omp_threads
+ else:
+ os.environ.pop('OMP_NUM_THREADS')
+ if sys_mkl_threads:
+ os.environ['MKL_NUM_THREADS'] = sys_mkl_threads
+ else:
+ os.environ.pop('MKL_NUM_THREADS')
+
+ elif valid and workers_per_gpu == 0:
+
+ if platform.system() != 'Windows':
+ assert mp.get_start_method() == env_cfg['mp_start_method']
+ assert cv2.getNumThreads() == env_cfg[
+ 'opencv_num_threads'] if env_cfg['opencv_num_threads'] > 0 else 1
+ assert 'OMP_NUM_THREADS' not in os.environ
+ assert 'MKL_NUM_THREADS' not in os.environ
+ if sys_start_mehod:
+ mp.set_start_method(sys_start_mehod, force=True)
+ cv2.setNumThreads(sys_cv_threads)
+ if sys_omp_threads:
+ os.environ['OMP_NUM_THREADS'] = sys_omp_threads
+ if sys_mkl_threads:
+ os.environ['MKL_NUM_THREADS'] = sys_mkl_threads
+
+ else:
+ assert mp.get_start_method() == sys_start_mehod
+ assert cv2.getNumThreads() == sys_cv_threads
+ assert 'OMP_NUM_THREADS' not in os.environ
+ assert 'MKL_NUM_THREADS' not in os.environ
diff --git a/tools/analyze_logs.py b/tools/analyze_logs.py
new file mode 100644
index 0000000..8c62a34
--- /dev/null
+++ b/tools/analyze_logs.py
@@ -0,0 +1,130 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Modified from https://github.com/open-
+mmlab/mmdetection/blob/master/tools/analysis_tools/analyze_logs.py."""
+import argparse
+import json
+from collections import defaultdict
+
+import matplotlib.pyplot as plt
+import seaborn as sns
+
+
+def plot_curve(log_dicts, args):
+ if args.backend is not None:
+ plt.switch_backend(args.backend)
+ sns.set_style(args.style)
+ # if legend is None, use {filename}_{key} as legend
+ legend = args.legend
+ if legend is None:
+ legend = []
+ for json_log in args.json_logs:
+ for metric in args.keys:
+ legend.append(f'{json_log}_{metric}')
+ assert len(legend) == (len(args.json_logs) * len(args.keys))
+ metrics = args.keys
+
+ num_metrics = len(metrics)
+ for i, log_dict in enumerate(log_dicts):
+ epochs = list(log_dict.keys())
+ for j, metric in enumerate(metrics):
+ print(f'plot curve of {args.json_logs[i]}, metric is {metric}')
+ plot_epochs = []
+ plot_iters = []
+ plot_values = []
+ # In some log files, iters number is not correct, `pre_iter` is
+ # used to prevent generate wrong lines.
+ pre_iter = -1
+ for epoch in epochs:
+ epoch_logs = log_dict[epoch]
+ if metric not in epoch_logs.keys():
+ continue
+ if metric in ['mIoU', 'mAcc', 'aAcc']:
+ plot_epochs.append(epoch)
+ plot_values.append(epoch_logs[metric][0])
+ else:
+ for idx in range(len(epoch_logs[metric])):
+ if pre_iter > epoch_logs['iter'][idx]:
+ continue
+ pre_iter = epoch_logs['iter'][idx]
+ plot_iters.append(epoch_logs['iter'][idx])
+ plot_values.append(epoch_logs[metric][idx])
+ ax = plt.gca()
+ label = legend[i * num_metrics + j]
+ if metric in ['mIoU', 'mAcc', 'aAcc']:
+ ax.set_xticks(plot_epochs)
+ plt.xlabel('epoch')
+ plt.plot(plot_epochs, plot_values, label=label, marker='o')
+ else:
+ plt.xlabel('iter')
+ plt.plot(plot_iters, plot_values, label=label, linewidth=0.5)
+ plt.legend()
+ if args.title is not None:
+ plt.title(args.title)
+ if args.out is None:
+ plt.show()
+ else:
+ print(f'save curve to: {args.out}')
+ plt.savefig(args.out)
+ plt.cla()
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Analyze Json Log')
+ parser.add_argument(
+ 'json_logs',
+ type=str,
+ nargs='+',
+ help='path of train log in json format')
+ parser.add_argument(
+ '--keys',
+ type=str,
+ nargs='+',
+ default=['mIoU'],
+ help='the metric that you want to plot')
+ parser.add_argument('--title', type=str, help='title of figure')
+ parser.add_argument(
+ '--legend',
+ type=str,
+ nargs='+',
+ default=None,
+ help='legend of each plot')
+ parser.add_argument(
+ '--backend', type=str, default=None, help='backend of plt')
+ parser.add_argument(
+ '--style', type=str, default='dark', help='style of plt')
+ parser.add_argument('--out', type=str, default=None)
+ args = parser.parse_args()
+ return args
+
+
+def load_json_logs(json_logs):
+ # load and convert json_logs to log_dict, key is epoch, value is a sub dict
+ # keys of sub dict is different metrics
+ # value of sub dict is a list of corresponding values of all iterations
+ log_dicts = [dict() for _ in json_logs]
+ for json_log, log_dict in zip(json_logs, log_dicts):
+ with open(json_log, 'r') as log_file:
+ for line in log_file:
+ log = json.loads(line.strip())
+ # skip lines without `epoch` field
+ if 'epoch' not in log:
+ continue
+ epoch = log.pop('epoch')
+ if epoch not in log_dict:
+ log_dict[epoch] = defaultdict(list)
+ for k, v in log.items():
+ log_dict[epoch][k].append(v)
+ return log_dicts
+
+
+def main():
+ args = parse_args()
+ json_logs = args.json_logs
+ for json_log in json_logs:
+ assert json_log.endswith('.json')
+ log_dicts = load_json_logs(json_logs)
+ plot_curve(log_dicts, args)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/benchmark.py b/tools/benchmark.py
new file mode 100644
index 0000000..f6d6888
--- /dev/null
+++ b/tools/benchmark.py
@@ -0,0 +1,120 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+import time
+
+import mmcv
+import numpy as np
+import torch
+from mmcv import Config
+from mmcv.parallel import MMDataParallel
+from mmcv.runner import load_checkpoint, wrap_fp16_model
+
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.models import build_segmentor
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMSeg benchmark a model')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('checkpoint', help='checkpoint file')
+ parser.add_argument(
+ '--log-interval', type=int, default=50, help='interval of logging')
+ parser.add_argument(
+ '--work-dir',
+ help=('if specified, the results will be dumped '
+ 'into the directory as json'))
+ parser.add_argument('--repeat-times', type=int, default=1)
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ if args.work_dir is not None:
+ mmcv.mkdir_or_exist(osp.abspath(args.work_dir))
+ json_file = osp.join(args.work_dir, f'fps_{timestamp}.json')
+ else:
+ # use config filename as default work_dir if cfg.work_dir is None
+ work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ mmcv.mkdir_or_exist(osp.abspath(work_dir))
+ json_file = osp.join(work_dir, f'fps_{timestamp}.json')
+
+ repeat_times = args.repeat_times
+ # set cudnn_benchmark
+ torch.backends.cudnn.benchmark = False
+ cfg.model.pretrained = None
+ cfg.data.test.test_mode = True
+
+ benchmark_dict = dict(config=args.config, unit='img / s')
+ overall_fps_list = []
+ for time_index in range(repeat_times):
+ print(f'Run {time_index + 1}:')
+ # build the dataloader
+ # TODO: support multiple images per gpu (only minor changes are needed)
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=False,
+ shuffle=False)
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ model = build_segmentor(cfg.model, test_cfg=cfg.get('test_cfg'))
+ fp16_cfg = cfg.get('fp16', None)
+ if fp16_cfg is not None:
+ wrap_fp16_model(model)
+ if 'checkpoint' in args and osp.exists(args.checkpoint):
+ load_checkpoint(model, args.checkpoint, map_location='cpu')
+
+ model = MMDataParallel(model, device_ids=[0])
+
+ model.eval()
+
+ # the first several iterations may be very slow so skip them
+ num_warmup = 5
+ pure_inf_time = 0
+ total_iters = 200
+
+ # benchmark with 200 image and take the average
+ for i, data in enumerate(data_loader):
+
+ torch.cuda.synchronize()
+ start_time = time.perf_counter()
+
+ with torch.no_grad():
+ model(return_loss=False, rescale=True, **data)
+
+ torch.cuda.synchronize()
+ elapsed = time.perf_counter() - start_time
+
+ if i >= num_warmup:
+ pure_inf_time += elapsed
+ if (i + 1) % args.log_interval == 0:
+ fps = (i + 1 - num_warmup) / pure_inf_time
+ print(f'Done image [{i + 1:<3}/ {total_iters}], '
+ f'fps: {fps:.2f} img / s')
+
+ if (i + 1) == total_iters:
+ fps = (i + 1 - num_warmup) / pure_inf_time
+ print(f'Overall fps: {fps:.2f} img / s\n')
+ benchmark_dict[f'overall_fps_{time_index + 1}'] = round(fps, 2)
+ overall_fps_list.append(fps)
+ break
+ benchmark_dict['average_fps'] = round(np.mean(overall_fps_list), 2)
+ benchmark_dict['fps_variance'] = round(np.var(overall_fps_list), 4)
+ print(f'Average fps of {repeat_times} evaluations: '
+ f'{benchmark_dict["average_fps"]}')
+ print(f'The variance of {repeat_times} evaluations: '
+ f'{benchmark_dict["fps_variance"]}')
+ mmcv.dump(benchmark_dict, json_file, indent=4)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/browse_dataset.py b/tools/browse_dataset.py
new file mode 100644
index 0000000..d46487b
--- /dev/null
+++ b/tools/browse_dataset.py
@@ -0,0 +1,181 @@
+import argparse
+import os
+import warnings
+from pathlib import Path
+
+import mmcv
+import numpy as np
+from mmcv import Config, DictAction
+
+from mmseg.datasets.builder import build_dataset
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Browse a dataset')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument(
+ '--show-origin',
+ default=False,
+ action='store_true',
+ help='if True, omit all augmentation in pipeline,'
+ ' show origin image and seg map')
+ parser.add_argument(
+ '--skip-type',
+ type=str,
+ nargs='+',
+ default=['DefaultFormatBundle', 'Normalize', 'Collect'],
+ help='skip some useless pipeline,if `show-origin` is true, '
+ 'all pipeline except `Load` will be skipped')
+ parser.add_argument(
+ '--output-dir',
+ default='./output',
+ type=str,
+ help='If there is no display interface, you can save it')
+ parser.add_argument('--show', default=False, action='store_true')
+ parser.add_argument(
+ '--show-interval',
+ type=int,
+ default=999,
+ help='the interval of show (ms)')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='the opacity of semantic map')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def imshow_semantic(img,
+ seg,
+ class_names,
+ palette=None,
+ win_name='',
+ show=False,
+ wait_time=0,
+ out_file=None,
+ opacity=0.5):
+ """Draw `result` over `img`.
+
+ Args:
+ img (str or Tensor): The image to be displayed.
+ seg (Tensor): The semantic segmentation results to draw over
+ `img`.
+ class_names (list[str]): Names of each classes.
+ palette (list[list[int]]] | np.ndarray | None): The palette of
+ segmentation map. If None is given, random palette will be
+ generated. Default: None
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ Default: 0.
+ show (bool): Whether to show the image.
+ Default: False.
+ out_file (str or None): The filename to write the image.
+ Default: None.
+ opacity(float): Opacity of painted segmentation map.
+ Default 0.5.
+ Must be in (0, 1] range.
+ Returns:
+ img (Tensor): Only if not `show` or `out_file`
+ """
+ img = mmcv.imread(img)
+ img = img.copy()
+ if palette is None:
+ palette = np.random.randint(0, 255, size=(len(class_names), 3))
+ palette = np.array(palette)
+ assert palette.shape[0] == len(class_names)
+ assert palette.shape[1] == 3
+ assert len(palette.shape) == 2
+ assert 0 < opacity <= 1.0
+ color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
+ for label, color in enumerate(palette):
+ color_seg[seg == label, :] = color
+ # convert to BGR
+ color_seg = color_seg[..., ::-1]
+
+ img = img * (1 - opacity) + color_seg * opacity
+ img = img.astype(np.uint8)
+ # if out_file specified, do not show image in window
+ if out_file is not None:
+ show = False
+
+ if show:
+ mmcv.imshow(img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(img, out_file)
+
+ if not (show or out_file):
+ warnings.warn('show==False and out_file is not specified, only '
+ 'result image will be returned')
+ return img
+
+
+def _retrieve_data_cfg(_data_cfg, skip_type, show_origin):
+ if show_origin is True:
+ # only keep pipeline of Loading data and ann
+ _data_cfg['pipeline'] = [
+ x for x in _data_cfg.pipeline if 'Load' in x['type']
+ ]
+ else:
+ _data_cfg['pipeline'] = [
+ x for x in _data_cfg.pipeline if x['type'] not in skip_type
+ ]
+
+
+def retrieve_data_cfg(config_path, skip_type, cfg_options, show_origin=False):
+ cfg = Config.fromfile(config_path)
+ if cfg_options is not None:
+ cfg.merge_from_dict(cfg_options)
+ train_data_cfg = cfg.data.train
+ if isinstance(train_data_cfg, list):
+ for _data_cfg in train_data_cfg:
+ while 'dataset' in _data_cfg and _data_cfg[
+ 'type'] != 'MultiImageMixDataset':
+ _data_cfg = _data_cfg['dataset']
+ if 'pipeline' in _data_cfg:
+ _retrieve_data_cfg(_data_cfg, skip_type, show_origin)
+ else:
+ raise ValueError
+ else:
+ while 'dataset' in train_data_cfg and train_data_cfg[
+ 'type'] != 'MultiImageMixDataset':
+ train_data_cfg = train_data_cfg['dataset']
+ _retrieve_data_cfg(train_data_cfg, skip_type, show_origin)
+ return cfg
+
+
+def main():
+ args = parse_args()
+ cfg = retrieve_data_cfg(args.config, args.skip_type, args.cfg_options,
+ args.show_origin)
+ dataset = build_dataset(cfg.data.train)
+ progress_bar = mmcv.ProgressBar(len(dataset))
+ for item in dataset:
+ filename = os.path.join(args.output_dir,
+ Path(item['filename']).name
+ ) if args.output_dir is not None else None
+ imshow_semantic(
+ item['img'],
+ item['gt_semantic_seg'],
+ dataset.CLASSES,
+ dataset.PALETTE,
+ show=args.show,
+ wait_time=args.show_interval,
+ out_file=filename,
+ opacity=args.opacity,
+ )
+ progress_bar.update()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/chase_db1.py b/tools/convert_datasets/chase_db1.py
new file mode 100644
index 0000000..580e6e7
--- /dev/null
+++ b/tools/convert_datasets/chase_db1.py
@@ -0,0 +1,88 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import mmcv
+
+CHASE_DB1_LEN = 28 * 3
+TRAINING_LEN = 60
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert CHASE_DB1 dataset to mmsegmentation format')
+ parser.add_argument('dataset_path', help='path of CHASEDB1.zip')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ dataset_path = args.dataset_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'CHASE_DB1')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'validation'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'validation'))
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ print('Extracting CHASEDB1.zip...')
+ zip_file = zipfile.ZipFile(dataset_path)
+ zip_file.extractall(tmp_dir)
+
+ print('Generating training dataset...')
+
+ assert len(os.listdir(tmp_dir)) == CHASE_DB1_LEN, \
+ 'len(os.listdir(tmp_dir)) != {}'.format(CHASE_DB1_LEN)
+
+ for img_name in sorted(os.listdir(tmp_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(tmp_dir, img_name))
+ if osp.splitext(img_name)[1] == '.jpg':
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'training',
+ osp.splitext(img_name)[0] + '.png'))
+ else:
+ # The annotation img should be divided by 128, because some of
+ # the annotation imgs are not standard. We should set a
+ # threshold to convert the nonstandard annotation imgs. The
+ # value divided by 128 is equivalent to '1 if value >= 128
+ # else 0'
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(img_name)[0] + '.png'))
+
+ for img_name in sorted(os.listdir(tmp_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(tmp_dir, img_name))
+ if osp.splitext(img_name)[1] == '.jpg':
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'validation',
+ osp.splitext(img_name)[0] + '.png'))
+ else:
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(img_name)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/cityscapes.py b/tools/convert_datasets/cityscapes.py
new file mode 100644
index 0000000..17b6168
--- /dev/null
+++ b/tools/convert_datasets/cityscapes.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+import mmcv
+from cityscapesscripts.preparation.json2labelImg import json2labelImg
+
+
+def convert_json_to_label(json_file):
+ label_file = json_file.replace('_polygons.json', '_labelTrainIds.png')
+ json2labelImg(json_file, label_file, 'trainIds')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert Cityscapes annotations to TrainIds')
+ parser.add_argument('cityscapes_path', help='cityscapes data path')
+ parser.add_argument('--gt-dir', default='gtFine', type=str)
+ parser.add_argument('-o', '--out-dir', help='output path')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ cityscapes_path = args.cityscapes_path
+ out_dir = args.out_dir if args.out_dir else cityscapes_path
+ mmcv.mkdir_or_exist(out_dir)
+
+ gt_dir = osp.join(cityscapes_path, args.gt_dir)
+
+ poly_files = []
+ for poly in mmcv.scandir(gt_dir, '_polygons.json', recursive=True):
+ poly_file = osp.join(gt_dir, poly)
+ poly_files.append(poly_file)
+ if args.nproc > 1:
+ mmcv.track_parallel_progress(convert_json_to_label, poly_files,
+ args.nproc)
+ else:
+ mmcv.track_progress(convert_json_to_label, poly_files)
+
+ split_names = ['train', 'val', 'test']
+
+ for split in split_names:
+ filenames = []
+ for poly in mmcv.scandir(
+ osp.join(gt_dir, split), '_polygons.json', recursive=True):
+ filenames.append(poly.replace('_gtFine_polygons.json', ''))
+ with open(osp.join(out_dir, f'{split}.txt'), 'w') as f:
+ f.writelines(f + '\n' for f in filenames)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/coco_stuff10k.py b/tools/convert_datasets/coco_stuff10k.py
new file mode 100644
index 0000000..4f0fd53
--- /dev/null
+++ b/tools/convert_datasets/coco_stuff10k.py
@@ -0,0 +1,306 @@
+import argparse
+import os.path as osp
+import shutil
+from functools import partial
+
+import mmcv
+import numpy as np
+from PIL import Image
+from scipy.io import loadmat
+
+COCO_LEN = 10000
+
+clsID_to_trID = {
+ 0: 0,
+ 1: 1,
+ 2: 2,
+ 3: 3,
+ 4: 4,
+ 5: 5,
+ 6: 6,
+ 7: 7,
+ 8: 8,
+ 9: 9,
+ 10: 10,
+ 11: 11,
+ 13: 12,
+ 14: 13,
+ 15: 14,
+ 16: 15,
+ 17: 16,
+ 18: 17,
+ 19: 18,
+ 20: 19,
+ 21: 20,
+ 22: 21,
+ 23: 22,
+ 24: 23,
+ 25: 24,
+ 27: 25,
+ 28: 26,
+ 31: 27,
+ 32: 28,
+ 33: 29,
+ 34: 30,
+ 35: 31,
+ 36: 32,
+ 37: 33,
+ 38: 34,
+ 39: 35,
+ 40: 36,
+ 41: 37,
+ 42: 38,
+ 43: 39,
+ 44: 40,
+ 46: 41,
+ 47: 42,
+ 48: 43,
+ 49: 44,
+ 50: 45,
+ 51: 46,
+ 52: 47,
+ 53: 48,
+ 54: 49,
+ 55: 50,
+ 56: 51,
+ 57: 52,
+ 58: 53,
+ 59: 54,
+ 60: 55,
+ 61: 56,
+ 62: 57,
+ 63: 58,
+ 64: 59,
+ 65: 60,
+ 67: 61,
+ 70: 62,
+ 72: 63,
+ 73: 64,
+ 74: 65,
+ 75: 66,
+ 76: 67,
+ 77: 68,
+ 78: 69,
+ 79: 70,
+ 80: 71,
+ 81: 72,
+ 82: 73,
+ 84: 74,
+ 85: 75,
+ 86: 76,
+ 87: 77,
+ 88: 78,
+ 89: 79,
+ 90: 80,
+ 92: 81,
+ 93: 82,
+ 94: 83,
+ 95: 84,
+ 96: 85,
+ 97: 86,
+ 98: 87,
+ 99: 88,
+ 100: 89,
+ 101: 90,
+ 102: 91,
+ 103: 92,
+ 104: 93,
+ 105: 94,
+ 106: 95,
+ 107: 96,
+ 108: 97,
+ 109: 98,
+ 110: 99,
+ 111: 100,
+ 112: 101,
+ 113: 102,
+ 114: 103,
+ 115: 104,
+ 116: 105,
+ 117: 106,
+ 118: 107,
+ 119: 108,
+ 120: 109,
+ 121: 110,
+ 122: 111,
+ 123: 112,
+ 124: 113,
+ 125: 114,
+ 126: 115,
+ 127: 116,
+ 128: 117,
+ 129: 118,
+ 130: 119,
+ 131: 120,
+ 132: 121,
+ 133: 122,
+ 134: 123,
+ 135: 124,
+ 136: 125,
+ 137: 126,
+ 138: 127,
+ 139: 128,
+ 140: 129,
+ 141: 130,
+ 142: 131,
+ 143: 132,
+ 144: 133,
+ 145: 134,
+ 146: 135,
+ 147: 136,
+ 148: 137,
+ 149: 138,
+ 150: 139,
+ 151: 140,
+ 152: 141,
+ 153: 142,
+ 154: 143,
+ 155: 144,
+ 156: 145,
+ 157: 146,
+ 158: 147,
+ 159: 148,
+ 160: 149,
+ 161: 150,
+ 162: 151,
+ 163: 152,
+ 164: 153,
+ 165: 154,
+ 166: 155,
+ 167: 156,
+ 168: 157,
+ 169: 158,
+ 170: 159,
+ 171: 160,
+ 172: 161,
+ 173: 162,
+ 174: 163,
+ 175: 164,
+ 176: 165,
+ 177: 166,
+ 178: 167,
+ 179: 168,
+ 180: 169,
+ 181: 170,
+ 182: 171
+}
+
+
+def convert_to_trainID(tuple_path, in_img_dir, in_ann_dir, out_img_dir,
+ out_mask_dir, is_train):
+ imgpath, maskpath = tuple_path
+ shutil.copyfile(
+ osp.join(in_img_dir, imgpath),
+ osp.join(out_img_dir, 'train2014', imgpath) if is_train else osp.join(
+ out_img_dir, 'test2014', imgpath))
+ annotate = loadmat(osp.join(in_ann_dir, maskpath))
+ mask = annotate['S'].astype(np.uint8)
+ mask_copy = mask.copy()
+ for clsID, trID in clsID_to_trID.items():
+ mask_copy[mask == clsID] = trID
+ seg_filename = osp.join(out_mask_dir, 'train2014',
+ maskpath.split('.')[0] +
+ '_labelTrainIds.png') if is_train else osp.join(
+ out_mask_dir, 'test2014',
+ maskpath.split('.')[0] + '_labelTrainIds.png')
+ Image.fromarray(mask_copy).save(seg_filename, 'PNG')
+
+
+def generate_coco_list(folder):
+ train_list = osp.join(folder, 'imageLists', 'train.txt')
+ test_list = osp.join(folder, 'imageLists', 'test.txt')
+ train_paths = []
+ test_paths = []
+
+ with open(train_list) as f:
+ for filename in f:
+ basename = filename.strip()
+ imgpath = basename + '.jpg'
+ maskpath = basename + '.mat'
+ train_paths.append((imgpath, maskpath))
+
+ with open(test_list) as f:
+ for filename in f:
+ basename = filename.strip()
+ imgpath = basename + '.jpg'
+ maskpath = basename + '.mat'
+ test_paths.append((imgpath, maskpath))
+
+ return train_paths, test_paths
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description=\
+ 'Convert COCO Stuff 10k annotations to mmsegmentation format') # noqa
+ parser.add_argument('coco_path', help='coco stuff path')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--nproc', default=16, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ coco_path = args.coco_path
+ nproc = args.nproc
+
+ out_dir = args.out_dir or coco_path
+ out_img_dir = osp.join(out_dir, 'images')
+ out_mask_dir = osp.join(out_dir, 'annotations')
+
+ mmcv.mkdir_or_exist(osp.join(out_img_dir, 'train2014'))
+ mmcv.mkdir_or_exist(osp.join(out_img_dir, 'test2014'))
+ mmcv.mkdir_or_exist(osp.join(out_mask_dir, 'train2014'))
+ mmcv.mkdir_or_exist(osp.join(out_mask_dir, 'test2014'))
+
+ train_list, test_list = generate_coco_list(coco_path)
+ assert (len(train_list) +
+ len(test_list)) == COCO_LEN, 'Wrong length of list {} & {}'.format(
+ len(train_list), len(test_list))
+
+ if args.nproc > 1:
+ mmcv.track_parallel_progress(
+ partial(
+ convert_to_trainID,
+ in_img_dir=osp.join(coco_path, 'images'),
+ in_ann_dir=osp.join(coco_path, 'annotations'),
+ out_img_dir=out_img_dir,
+ out_mask_dir=out_mask_dir,
+ is_train=True),
+ train_list,
+ nproc=nproc)
+ mmcv.track_parallel_progress(
+ partial(
+ convert_to_trainID,
+ in_img_dir=osp.join(coco_path, 'images'),
+ in_ann_dir=osp.join(coco_path, 'annotations'),
+ out_img_dir=out_img_dir,
+ out_mask_dir=out_mask_dir,
+ is_train=False),
+ test_list,
+ nproc=nproc)
+ else:
+ mmcv.track_progress(
+ partial(
+ convert_to_trainID,
+ in_img_dir=osp.join(coco_path, 'images'),
+ in_ann_dir=osp.join(coco_path, 'annotations'),
+ out_img_dir=out_img_dir,
+ out_mask_dir=out_mask_dir,
+ is_train=True), train_list)
+ mmcv.track_progress(
+ partial(
+ convert_to_trainID,
+ in_img_dir=osp.join(coco_path, 'images'),
+ in_ann_dir=osp.join(coco_path, 'annotations'),
+ out_img_dir=out_img_dir,
+ out_mask_dir=out_mask_dir,
+ is_train=False), test_list)
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/coco_stuff164k.py b/tools/convert_datasets/coco_stuff164k.py
new file mode 100644
index 0000000..4533bf5
--- /dev/null
+++ b/tools/convert_datasets/coco_stuff164k.py
@@ -0,0 +1,263 @@
+import argparse
+import os.path as osp
+import shutil
+from functools import partial
+from glob import glob
+
+import mmcv
+import numpy as np
+from PIL import Image
+
+COCO_LEN = 123287
+
+clsID_to_trID = {
+ 0: 0,
+ 1: 1,
+ 2: 2,
+ 3: 3,
+ 4: 4,
+ 5: 5,
+ 6: 6,
+ 7: 7,
+ 8: 8,
+ 9: 9,
+ 10: 10,
+ 12: 11,
+ 13: 12,
+ 14: 13,
+ 15: 14,
+ 16: 15,
+ 17: 16,
+ 18: 17,
+ 19: 18,
+ 20: 19,
+ 21: 20,
+ 22: 21,
+ 23: 22,
+ 24: 23,
+ 26: 24,
+ 27: 25,
+ 30: 26,
+ 31: 27,
+ 32: 28,
+ 33: 29,
+ 34: 30,
+ 35: 31,
+ 36: 32,
+ 37: 33,
+ 38: 34,
+ 39: 35,
+ 40: 36,
+ 41: 37,
+ 42: 38,
+ 43: 39,
+ 45: 40,
+ 46: 41,
+ 47: 42,
+ 48: 43,
+ 49: 44,
+ 50: 45,
+ 51: 46,
+ 52: 47,
+ 53: 48,
+ 54: 49,
+ 55: 50,
+ 56: 51,
+ 57: 52,
+ 58: 53,
+ 59: 54,
+ 60: 55,
+ 61: 56,
+ 62: 57,
+ 63: 58,
+ 64: 59,
+ 66: 60,
+ 69: 61,
+ 71: 62,
+ 72: 63,
+ 73: 64,
+ 74: 65,
+ 75: 66,
+ 76: 67,
+ 77: 68,
+ 78: 69,
+ 79: 70,
+ 80: 71,
+ 81: 72,
+ 83: 73,
+ 84: 74,
+ 85: 75,
+ 86: 76,
+ 87: 77,
+ 88: 78,
+ 89: 79,
+ 91: 80,
+ 92: 81,
+ 93: 82,
+ 94: 83,
+ 95: 84,
+ 96: 85,
+ 97: 86,
+ 98: 87,
+ 99: 88,
+ 100: 89,
+ 101: 90,
+ 102: 91,
+ 103: 92,
+ 104: 93,
+ 105: 94,
+ 106: 95,
+ 107: 96,
+ 108: 97,
+ 109: 98,
+ 110: 99,
+ 111: 100,
+ 112: 101,
+ 113: 102,
+ 114: 103,
+ 115: 104,
+ 116: 105,
+ 117: 106,
+ 118: 107,
+ 119: 108,
+ 120: 109,
+ 121: 110,
+ 122: 111,
+ 123: 112,
+ 124: 113,
+ 125: 114,
+ 126: 115,
+ 127: 116,
+ 128: 117,
+ 129: 118,
+ 130: 119,
+ 131: 120,
+ 132: 121,
+ 133: 122,
+ 134: 123,
+ 135: 124,
+ 136: 125,
+ 137: 126,
+ 138: 127,
+ 139: 128,
+ 140: 129,
+ 141: 130,
+ 142: 131,
+ 143: 132,
+ 144: 133,
+ 145: 134,
+ 146: 135,
+ 147: 136,
+ 148: 137,
+ 149: 138,
+ 150: 139,
+ 151: 140,
+ 152: 141,
+ 153: 142,
+ 154: 143,
+ 155: 144,
+ 156: 145,
+ 157: 146,
+ 158: 147,
+ 159: 148,
+ 160: 149,
+ 161: 150,
+ 162: 151,
+ 163: 152,
+ 164: 153,
+ 165: 154,
+ 166: 155,
+ 167: 156,
+ 168: 157,
+ 169: 158,
+ 170: 159,
+ 171: 160,
+ 172: 161,
+ 173: 162,
+ 174: 163,
+ 175: 164,
+ 176: 165,
+ 177: 166,
+ 178: 167,
+ 179: 168,
+ 180: 169,
+ 181: 170,
+ 255: 255
+}
+
+
+def convert_to_trainID(maskpath, out_mask_dir, is_train):
+ mask = np.array(Image.open(maskpath))
+ mask_copy = mask.copy()
+ for clsID, trID in clsID_to_trID.items():
+ mask_copy[mask == clsID] = trID
+ seg_filename = osp.join(
+ out_mask_dir, 'train2017',
+ osp.basename(maskpath).split('.')[0] +
+ '_labelTrainIds.png') if is_train else osp.join(
+ out_mask_dir, 'val2017',
+ osp.basename(maskpath).split('.')[0] + '_labelTrainIds.png')
+ Image.fromarray(mask_copy).save(seg_filename, 'PNG')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description=\
+ 'Convert COCO Stuff 164k annotations to mmsegmentation format') # noqa
+ parser.add_argument('coco_path', help='coco stuff path')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--nproc', default=16, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ coco_path = args.coco_path
+ nproc = args.nproc
+
+ out_dir = args.out_dir or coco_path
+ out_img_dir = osp.join(out_dir, 'images')
+ out_mask_dir = osp.join(out_dir, 'annotations')
+
+ mmcv.mkdir_or_exist(osp.join(out_mask_dir, 'train2017'))
+ mmcv.mkdir_or_exist(osp.join(out_mask_dir, 'val2017'))
+
+ if out_dir != coco_path:
+ shutil.copytree(osp.join(coco_path, 'images'), out_img_dir)
+
+ train_list = glob(osp.join(coco_path, 'annotations', 'train2017', '*.png'))
+ train_list = [file for file in train_list if '_labelTrainIds' not in file]
+ test_list = glob(osp.join(coco_path, 'annotations', 'val2017', '*.png'))
+ test_list = [file for file in test_list if '_labelTrainIds' not in file]
+ assert (len(train_list) +
+ len(test_list)) == COCO_LEN, 'Wrong length of list {} & {}'.format(
+ len(train_list), len(test_list))
+
+ if args.nproc > 1:
+ mmcv.track_parallel_progress(
+ partial(
+ convert_to_trainID, out_mask_dir=out_mask_dir, is_train=True),
+ train_list,
+ nproc=nproc)
+ mmcv.track_parallel_progress(
+ partial(
+ convert_to_trainID, out_mask_dir=out_mask_dir, is_train=False),
+ test_list,
+ nproc=nproc)
+ else:
+ mmcv.track_progress(
+ partial(
+ convert_to_trainID, out_mask_dir=out_mask_dir, is_train=True),
+ train_list)
+ mmcv.track_progress(
+ partial(
+ convert_to_trainID, out_mask_dir=out_mask_dir, is_train=False),
+ test_list)
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/drive.py b/tools/convert_datasets/drive.py
new file mode 100644
index 0000000..f547579
--- /dev/null
+++ b/tools/convert_datasets/drive.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import cv2
+import mmcv
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert DRIVE dataset to mmsegmentation format')
+ parser.add_argument(
+ 'training_path', help='the training part of DRIVE dataset')
+ parser.add_argument(
+ 'testing_path', help='the testing part of DRIVE dataset')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ training_path = args.training_path
+ testing_path = args.testing_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'DRIVE')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'validation'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'validation'))
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ print('Extracting training.zip...')
+ zip_file = zipfile.ZipFile(training_path)
+ zip_file.extractall(tmp_dir)
+
+ print('Generating training dataset...')
+ now_dir = osp.join(tmp_dir, 'training', 'images')
+ for img_name in os.listdir(now_dir):
+ img = mmcv.imread(osp.join(now_dir, img_name))
+ mmcv.imwrite(
+ img,
+ osp.join(
+ out_dir, 'images', 'training',
+ osp.splitext(img_name)[0].replace('_training', '') +
+ '.png'))
+
+ now_dir = osp.join(tmp_dir, 'training', '1st_manual')
+ for img_name in os.listdir(now_dir):
+ cap = cv2.VideoCapture(osp.join(now_dir, img_name))
+ ret, img = cap.read()
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(img_name)[0] + '.png'))
+
+ print('Extracting test.zip...')
+ zip_file = zipfile.ZipFile(testing_path)
+ zip_file.extractall(tmp_dir)
+
+ print('Generating validation dataset...')
+ now_dir = osp.join(tmp_dir, 'test', 'images')
+ for img_name in os.listdir(now_dir):
+ img = mmcv.imread(osp.join(now_dir, img_name))
+ mmcv.imwrite(
+ img,
+ osp.join(
+ out_dir, 'images', 'validation',
+ osp.splitext(img_name)[0].replace('_test', '') + '.png'))
+
+ now_dir = osp.join(tmp_dir, 'test', '1st_manual')
+ if osp.exists(now_dir):
+ for img_name in os.listdir(now_dir):
+ cap = cv2.VideoCapture(osp.join(now_dir, img_name))
+ ret, img = cap.read()
+ # The annotation img should be divided by 128, because some of
+ # the annotation imgs are not standard. We should set a
+ # threshold to convert the nonstandard annotation imgs. The
+ # value divided by 128 is equivalent to '1 if value >= 128
+ # else 0'
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(img_name)[0] + '.png'))
+
+ now_dir = osp.join(tmp_dir, 'test', '2nd_manual')
+ if osp.exists(now_dir):
+ for img_name in os.listdir(now_dir):
+ cap = cv2.VideoCapture(osp.join(now_dir, img_name))
+ ret, img = cap.read()
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(img_name)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/hrf.py b/tools/convert_datasets/hrf.py
new file mode 100644
index 0000000..5e016e3
--- /dev/null
+++ b/tools/convert_datasets/hrf.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import mmcv
+
+HRF_LEN = 15
+TRAINING_LEN = 5
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert HRF dataset to mmsegmentation format')
+ parser.add_argument('healthy_path', help='the path of healthy.zip')
+ parser.add_argument(
+ 'healthy_manualsegm_path', help='the path of healthy_manualsegm.zip')
+ parser.add_argument('glaucoma_path', help='the path of glaucoma.zip')
+ parser.add_argument(
+ 'glaucoma_manualsegm_path', help='the path of glaucoma_manualsegm.zip')
+ parser.add_argument(
+ 'diabetic_retinopathy_path',
+ help='the path of diabetic_retinopathy.zip')
+ parser.add_argument(
+ 'diabetic_retinopathy_manualsegm_path',
+ help='the path of diabetic_retinopathy_manualsegm.zip')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ images_path = [
+ args.healthy_path, args.glaucoma_path, args.diabetic_retinopathy_path
+ ]
+ annotations_path = [
+ args.healthy_manualsegm_path, args.glaucoma_manualsegm_path,
+ args.diabetic_retinopathy_manualsegm_path
+ ]
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'HRF')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'validation'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'validation'))
+
+ print('Generating images...')
+ for now_path in images_path:
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ zip_file = zipfile.ZipFile(now_path)
+ zip_file.extractall(tmp_dir)
+
+ assert len(os.listdir(tmp_dir)) == HRF_LEN, \
+ 'len(os.listdir(tmp_dir)) != {}'.format(HRF_LEN)
+
+ for filename in sorted(os.listdir(tmp_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(tmp_dir, filename))
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'training',
+ osp.splitext(filename)[0] + '.png'))
+ for filename in sorted(os.listdir(tmp_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(tmp_dir, filename))
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Generating annotations...')
+ for now_path in annotations_path:
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ zip_file = zipfile.ZipFile(now_path)
+ zip_file.extractall(tmp_dir)
+
+ assert len(os.listdir(tmp_dir)) == HRF_LEN, \
+ 'len(os.listdir(tmp_dir)) != {}'.format(HRF_LEN)
+
+ for filename in sorted(os.listdir(tmp_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(tmp_dir, filename))
+ # The annotation img should be divided by 128, because some of
+ # the annotation imgs are not standard. We should set a
+ # threshold to convert the nonstandard annotation imgs. The
+ # value divided by 128 is equivalent to '1 if value >= 128
+ # else 0'
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(filename)[0] + '.png'))
+ for filename in sorted(os.listdir(tmp_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(tmp_dir, filename))
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/loveda.py b/tools/convert_datasets/loveda.py
new file mode 100644
index 0000000..3a06268
--- /dev/null
+++ b/tools/convert_datasets/loveda.py
@@ -0,0 +1,73 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import shutil
+import tempfile
+import zipfile
+
+import mmcv
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert LoveDA dataset to mmsegmentation format')
+ parser.add_argument('dataset_path', help='LoveDA folder path')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ dataset_path = args.dataset_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'loveDA')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'test'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
+
+ assert 'Train.zip' in os.listdir(dataset_path), \
+ 'Train.zip is not in {}'.format(dataset_path)
+ assert 'Val.zip' in os.listdir(dataset_path), \
+ 'Val.zip is not in {}'.format(dataset_path)
+ assert 'Test.zip' in os.listdir(dataset_path), \
+ 'Test.zip is not in {}'.format(dataset_path)
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ for dataset in ['Train', 'Val', 'Test']:
+ zip_file = zipfile.ZipFile(
+ os.path.join(dataset_path, dataset + '.zip'))
+ zip_file.extractall(tmp_dir)
+ data_type = dataset.lower()
+ for location in ['Rural', 'Urban']:
+ for image_type in ['images_png', 'masks_png']:
+ if image_type == 'images_png':
+ dst = osp.join(out_dir, 'img_dir', data_type)
+ else:
+ dst = osp.join(out_dir, 'ann_dir', data_type)
+ if dataset == 'Test' and image_type == 'masks_png':
+ continue
+ else:
+ src_dir = osp.join(tmp_dir, dataset, location,
+ image_type)
+ src_lst = os.listdir(src_dir)
+ for file in src_lst:
+ shutil.move(osp.join(src_dir, file), dst)
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/pascal_context.py b/tools/convert_datasets/pascal_context.py
new file mode 100644
index 0000000..03b79d5
--- /dev/null
+++ b/tools/convert_datasets/pascal_context.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from functools import partial
+
+import mmcv
+import numpy as np
+from detail import Detail
+from PIL import Image
+
+_mapping = np.sort(
+ np.array([
+ 0, 2, 259, 260, 415, 324, 9, 258, 144, 18, 19, 22, 23, 397, 25, 284,
+ 158, 159, 416, 33, 162, 420, 454, 295, 296, 427, 44, 45, 46, 308, 59,
+ 440, 445, 31, 232, 65, 354, 424, 68, 326, 72, 458, 34, 207, 80, 355,
+ 85, 347, 220, 349, 360, 98, 187, 104, 105, 366, 189, 368, 113, 115
+ ]))
+_key = np.array(range(len(_mapping))).astype('uint8')
+
+
+def generate_labels(img_id, detail, out_dir):
+
+ def _class_to_index(mask, _mapping, _key):
+ # assert the values
+ values = np.unique(mask)
+ for i in range(len(values)):
+ assert (values[i] in _mapping)
+ index = np.digitize(mask.ravel(), _mapping, right=True)
+ return _key[index].reshape(mask.shape)
+
+ mask = Image.fromarray(
+ _class_to_index(detail.getMask(img_id), _mapping=_mapping, _key=_key))
+ filename = img_id['file_name']
+ mask.save(osp.join(out_dir, filename.replace('jpg', 'png')))
+ return osp.splitext(osp.basename(filename))[0]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert PASCAL VOC annotations to mmsegmentation format')
+ parser.add_argument('devkit_path', help='pascal voc devkit path')
+ parser.add_argument('json_path', help='annoation json filepath')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ devkit_path = args.devkit_path
+ if args.out_dir is None:
+ out_dir = osp.join(devkit_path, 'VOC2010', 'SegmentationClassContext')
+ else:
+ out_dir = args.out_dir
+ json_path = args.json_path
+ mmcv.mkdir_or_exist(out_dir)
+ img_dir = osp.join(devkit_path, 'VOC2010', 'JPEGImages')
+
+ train_detail = Detail(json_path, img_dir, 'train')
+ train_ids = train_detail.getImgs()
+
+ val_detail = Detail(json_path, img_dir, 'val')
+ val_ids = val_detail.getImgs()
+
+ mmcv.mkdir_or_exist(
+ osp.join(devkit_path, 'VOC2010/ImageSets/SegmentationContext'))
+
+ train_list = mmcv.track_progress(
+ partial(generate_labels, detail=train_detail, out_dir=out_dir),
+ train_ids)
+ with open(
+ osp.join(devkit_path, 'VOC2010/ImageSets/SegmentationContext',
+ 'train.txt'), 'w') as f:
+ f.writelines(line + '\n' for line in sorted(train_list))
+
+ val_list = mmcv.track_progress(
+ partial(generate_labels, detail=val_detail, out_dir=out_dir), val_ids)
+ with open(
+ osp.join(devkit_path, 'VOC2010/ImageSets/SegmentationContext',
+ 'val.txt'), 'w') as f:
+ f.writelines(line + '\n' for line in sorted(val_list))
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/potsdam.py b/tools/convert_datasets/potsdam.py
new file mode 100644
index 0000000..95a97f6
--- /dev/null
+++ b/tools/convert_datasets/potsdam.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import math
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import mmcv
+import numpy as np
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert potsdam dataset to mmsegmentation format')
+ parser.add_argument('dataset_path', help='potsdam folder path')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--clip_size',
+ type=int,
+ help='clipped size of image after preparation',
+ default=512)
+ parser.add_argument(
+ '--stride_size',
+ type=int,
+ help='stride of clipping original images',
+ default=256)
+ args = parser.parse_args()
+ return args
+
+
+def clip_big_image(image_path, clip_save_dir, args, to_label=False):
+ # Original image of Potsdam dataset is very large, thus pre-processing
+ # of them is adopted. Given fixed clip size and stride size to generate
+ # clipped image, the intersection of width and height is determined.
+ # For example, given one 5120 x 5120 original image, the clip size is
+ # 512 and stride size is 256, thus it would generate 20x20 = 400 images
+ # whose size are all 512x512.
+ image = mmcv.imread(image_path)
+
+ h, w, c = image.shape
+ clip_size = args.clip_size
+ stride_size = args.stride_size
+
+ num_rows = math.ceil((h - clip_size) / stride_size) if math.ceil(
+ (h - clip_size) /
+ stride_size) * stride_size + clip_size >= h else math.ceil(
+ (h - clip_size) / stride_size) + 1
+ num_cols = math.ceil((w - clip_size) / stride_size) if math.ceil(
+ (w - clip_size) /
+ stride_size) * stride_size + clip_size >= w else math.ceil(
+ (w - clip_size) / stride_size) + 1
+
+ x, y = np.meshgrid(np.arange(num_cols + 1), np.arange(num_rows + 1))
+ xmin = x * clip_size
+ ymin = y * clip_size
+
+ xmin = xmin.ravel()
+ ymin = ymin.ravel()
+ xmin_offset = np.where(xmin + clip_size > w, w - xmin - clip_size,
+ np.zeros_like(xmin))
+ ymin_offset = np.where(ymin + clip_size > h, h - ymin - clip_size,
+ np.zeros_like(ymin))
+ boxes = np.stack([
+ xmin + xmin_offset, ymin + ymin_offset,
+ np.minimum(xmin + clip_size, w),
+ np.minimum(ymin + clip_size, h)
+ ],
+ axis=1)
+
+ if to_label:
+ color_map = np.array([[0, 0, 0], [255, 255, 255], [255, 0, 0],
+ [255, 255, 0], [0, 255, 0], [0, 255, 255],
+ [0, 0, 255]])
+ flatten_v = np.matmul(
+ image.reshape(-1, c),
+ np.array([2, 3, 4]).reshape(3, 1))
+ out = np.zeros_like(flatten_v)
+ for idx, class_color in enumerate(color_map):
+ value_idx = np.matmul(class_color,
+ np.array([2, 3, 4]).reshape(3, 1))
+ out[flatten_v == value_idx] = idx
+ image = out.reshape(h, w)
+
+ for box in boxes:
+ start_x, start_y, end_x, end_y = box
+ clipped_image = image[start_y:end_y,
+ start_x:end_x] if to_label else image[
+ start_y:end_y, start_x:end_x, :]
+ idx_i, idx_j = osp.basename(image_path).split('_')[2:4]
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(
+ clip_save_dir,
+ f'{idx_i}_{idx_j}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+
+
+def main():
+ args = parse_args()
+ splits = {
+ 'train': [
+ '2_10', '2_11', '2_12', '3_10', '3_11', '3_12', '4_10', '4_11',
+ '4_12', '5_10', '5_11', '5_12', '6_10', '6_11', '6_12', '6_7',
+ '6_8', '6_9', '7_10', '7_11', '7_12', '7_7', '7_8', '7_9'
+ ],
+ 'val': [
+ '5_15', '6_15', '6_13', '3_13', '4_14', '6_14', '5_14', '2_13',
+ '4_15', '2_14', '5_13', '4_13', '3_14', '7_13'
+ ]
+ }
+
+ dataset_path = args.dataset_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'potsdam')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
+
+ zipp_list = glob.glob(os.path.join(dataset_path, '*.zip'))
+ print('Find the data', zipp_list)
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ for zipp in zipp_list:
+ zip_file = zipfile.ZipFile(zipp)
+ zip_file.extractall(tmp_dir)
+ src_path_list = glob.glob(os.path.join(tmp_dir, '*.tif'))
+ if not len(src_path_list):
+ sub_tmp_dir = os.path.join(tmp_dir, os.listdir(tmp_dir)[0])
+ src_path_list = glob.glob(os.path.join(sub_tmp_dir, '*.tif'))
+
+ prog_bar = mmcv.ProgressBar(len(src_path_list))
+ for i, src_path in enumerate(src_path_list):
+ idx_i, idx_j = osp.basename(src_path).split('_')[2:4]
+ data_type = 'train' if f'{idx_i}_{idx_j}' in splits[
+ 'train'] else 'val'
+ if 'label' in src_path:
+ dst_dir = osp.join(out_dir, 'ann_dir', data_type)
+ clip_big_image(src_path, dst_dir, args, to_label=True)
+ else:
+ dst_dir = osp.join(out_dir, 'img_dir', data_type)
+ clip_big_image(src_path, dst_dir, args, to_label=False)
+ prog_bar.update()
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/stare.py b/tools/convert_datasets/stare.py
new file mode 100644
index 0000000..29b78c0
--- /dev/null
+++ b/tools/convert_datasets/stare.py
@@ -0,0 +1,166 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import gzip
+import os
+import os.path as osp
+import tarfile
+import tempfile
+
+import mmcv
+
+STARE_LEN = 20
+TRAINING_LEN = 10
+
+
+def un_gz(src, dst):
+ g_file = gzip.GzipFile(src)
+ with open(dst, 'wb+') as f:
+ f.write(g_file.read())
+ g_file.close()
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert STARE dataset to mmsegmentation format')
+ parser.add_argument('image_path', help='the path of stare-images.tar')
+ parser.add_argument('labels_ah', help='the path of labels-ah.tar')
+ parser.add_argument('labels_vk', help='the path of labels-vk.tar')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ image_path = args.image_path
+ labels_ah = args.labels_ah
+ labels_vk = args.labels_vk
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'STARE')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'validation'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'validation'))
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'gz'))
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'files'))
+
+ print('Extracting stare-images.tar...')
+ with tarfile.open(image_path) as f:
+ f.extractall(osp.join(tmp_dir, 'gz'))
+
+ for filename in os.listdir(osp.join(tmp_dir, 'gz')):
+ un_gz(
+ osp.join(tmp_dir, 'gz', filename),
+ osp.join(tmp_dir, 'files',
+ osp.splitext(filename)[0]))
+
+ now_dir = osp.join(tmp_dir, 'files')
+
+ assert len(os.listdir(now_dir)) == STARE_LEN, \
+ 'len(os.listdir(now_dir)) != {}'.format(STARE_LEN)
+
+ for filename in sorted(os.listdir(now_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'training',
+ osp.splitext(filename)[0] + '.png'))
+
+ for filename in sorted(os.listdir(now_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'gz'))
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'files'))
+
+ print('Extracting labels-ah.tar...')
+ with tarfile.open(labels_ah) as f:
+ f.extractall(osp.join(tmp_dir, 'gz'))
+
+ for filename in os.listdir(osp.join(tmp_dir, 'gz')):
+ un_gz(
+ osp.join(tmp_dir, 'gz', filename),
+ osp.join(tmp_dir, 'files',
+ osp.splitext(filename)[0]))
+
+ now_dir = osp.join(tmp_dir, 'files')
+
+ assert len(os.listdir(now_dir)) == STARE_LEN, \
+ 'len(os.listdir(now_dir)) != {}'.format(STARE_LEN)
+
+ for filename in sorted(os.listdir(now_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ # The annotation img should be divided by 128, because some of
+ # the annotation imgs are not standard. We should set a threshold
+ # to convert the nonstandard annotation imgs. The value divided by
+ # 128 equivalent to '1 if value >= 128 else 0'
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(filename)[0] + '.png'))
+
+ for filename in sorted(os.listdir(now_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'gz'))
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'files'))
+
+ print('Extracting labels-vk.tar...')
+ with tarfile.open(labels_vk) as f:
+ f.extractall(osp.join(tmp_dir, 'gz'))
+
+ for filename in os.listdir(osp.join(tmp_dir, 'gz')):
+ un_gz(
+ osp.join(tmp_dir, 'gz', filename),
+ osp.join(tmp_dir, 'files',
+ osp.splitext(filename)[0]))
+
+ now_dir = osp.join(tmp_dir, 'files')
+
+ assert len(os.listdir(now_dir)) == STARE_LEN, \
+ 'len(os.listdir(now_dir)) != {}'.format(STARE_LEN)
+
+ for filename in sorted(os.listdir(now_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(filename)[0] + '.png'))
+
+ for filename in sorted(os.listdir(now_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/vaihingen.py b/tools/convert_datasets/vaihingen.py
new file mode 100644
index 0000000..b025ae5
--- /dev/null
+++ b/tools/convert_datasets/vaihingen.py
@@ -0,0 +1,155 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import math
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import mmcv
+import numpy as np
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert vaihingen dataset to mmsegmentation format')
+ parser.add_argument('dataset_path', help='vaihingen folder path')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--clip_size',
+ type=int,
+ help='clipped size of image after preparation',
+ default=512)
+ parser.add_argument(
+ '--stride_size',
+ type=int,
+ help='stride of clipping original images',
+ default=256)
+ args = parser.parse_args()
+ return args
+
+
+def clip_big_image(image_path, clip_save_dir, to_label=False):
+ # Original image of Vaihingen dataset is very large, thus pre-processing
+ # of them is adopted. Given fixed clip size and stride size to generate
+ # clipped image, the intersection of width and height is determined.
+ # For example, given one 5120 x 5120 original image, the clip size is
+ # 512 and stride size is 256, thus it would generate 20x20 = 400 images
+ # whose size are all 512x512.
+ image = mmcv.imread(image_path)
+
+ h, w, c = image.shape
+ cs = args.clip_size
+ ss = args.stride_size
+
+ num_rows = math.ceil((h - cs) / ss) if math.ceil(
+ (h - cs) / ss) * ss + cs >= h else math.ceil((h - cs) / ss) + 1
+ num_cols = math.ceil((w - cs) / ss) if math.ceil(
+ (w - cs) / ss) * ss + cs >= w else math.ceil((w - cs) / ss) + 1
+
+ x, y = np.meshgrid(np.arange(num_cols + 1), np.arange(num_rows + 1))
+ xmin = x * cs
+ ymin = y * cs
+
+ xmin = xmin.ravel()
+ ymin = ymin.ravel()
+ xmin_offset = np.where(xmin + cs > w, w - xmin - cs, np.zeros_like(xmin))
+ ymin_offset = np.where(ymin + cs > h, h - ymin - cs, np.zeros_like(ymin))
+ boxes = np.stack([
+ xmin + xmin_offset, ymin + ymin_offset,
+ np.minimum(xmin + cs, w),
+ np.minimum(ymin + cs, h)
+ ],
+ axis=1)
+
+ if to_label:
+ color_map = np.array([[0, 0, 0], [255, 255, 255], [255, 0, 0],
+ [255, 255, 0], [0, 255, 0], [0, 255, 255],
+ [0, 0, 255]])
+ flatten_v = np.matmul(
+ image.reshape(-1, c),
+ np.array([2, 3, 4]).reshape(3, 1))
+ out = np.zeros_like(flatten_v)
+ for idx, class_color in enumerate(color_map):
+ value_idx = np.matmul(class_color,
+ np.array([2, 3, 4]).reshape(3, 1))
+ out[flatten_v == value_idx] = idx
+ image = out.reshape(h, w)
+
+ for box in boxes:
+ start_x, start_y, end_x, end_y = box
+ clipped_image = image[start_y:end_y,
+ start_x:end_x] if to_label else image[
+ start_y:end_y, start_x:end_x, :]
+ area_idx = osp.basename(image_path).split('_')[3].strip('.tif')
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(clip_save_dir,
+ f'{area_idx}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+
+
+def main():
+ splits = {
+ 'train': [
+ 'area1', 'area11', 'area13', 'area15', 'area17', 'area21',
+ 'area23', 'area26', 'area28', 'area3', 'area30', 'area32',
+ 'area34', 'area37', 'area5', 'area7'
+ ],
+ 'val': [
+ 'area6', 'area24', 'area35', 'area16', 'area14', 'area22',
+ 'area10', 'area4', 'area2', 'area20', 'area8', 'area31', 'area33',
+ 'area27', 'area38', 'area12', 'area29'
+ ],
+ }
+
+ dataset_path = args.dataset_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'vaihingen')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
+
+ zipp_list = glob.glob(os.path.join(dataset_path, '*.zip'))
+ print('Find the data', zipp_list)
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ for zipp in zipp_list:
+ zip_file = zipfile.ZipFile(zipp)
+ zip_file.extractall(tmp_dir)
+ src_path_list = glob.glob(os.path.join(tmp_dir, '*.tif'))
+ if 'ISPRS_semantic_labeling_Vaihingen' in zipp:
+ src_path_list = glob.glob(
+ os.path.join(os.path.join(tmp_dir, 'top'), '*.tif'))
+ if 'ISPRS_semantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE' in zipp: # noqa
+ src_path_list = glob.glob(os.path.join(tmp_dir, '*.tif'))
+ # delete unused area9 ground truth
+ for area_ann in src_path_list:
+ if 'area9' in area_ann:
+ src_path_list.remove(area_ann)
+ prog_bar = mmcv.ProgressBar(len(src_path_list))
+ for i, src_path in enumerate(src_path_list):
+ area_idx = osp.basename(src_path).split('_')[3].strip('.tif')
+ data_type = 'train' if area_idx in splits['train'] else 'val'
+ if 'noBoundary' in src_path:
+ dst_dir = osp.join(out_dir, 'ann_dir', data_type)
+ clip_big_image(src_path, dst_dir, to_label=True)
+ else:
+ dst_dir = osp.join(out_dir, 'img_dir', data_type)
+ clip_big_image(src_path, dst_dir, to_label=False)
+ prog_bar.update()
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ main()
diff --git a/tools/convert_datasets/voc_aug.py b/tools/convert_datasets/voc_aug.py
new file mode 100644
index 0000000..1d42c27
--- /dev/null
+++ b/tools/convert_datasets/voc_aug.py
@@ -0,0 +1,92 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from functools import partial
+
+import mmcv
+import numpy as np
+from PIL import Image
+from scipy.io import loadmat
+
+AUG_LEN = 10582
+
+
+def convert_mat(mat_file, in_dir, out_dir):
+ data = loadmat(osp.join(in_dir, mat_file))
+ mask = data['GTcls'][0]['Segmentation'][0].astype(np.uint8)
+ seg_filename = osp.join(out_dir, mat_file.replace('.mat', '.png'))
+ Image.fromarray(mask).save(seg_filename, 'PNG')
+
+
+def generate_aug_list(merged_list, excluded_list):
+ return list(set(merged_list) - set(excluded_list))
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert PASCAL VOC annotations to mmsegmentation format')
+ parser.add_argument('devkit_path', help='pascal voc devkit path')
+ parser.add_argument('aug_path', help='pascal voc aug path')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ devkit_path = args.devkit_path
+ aug_path = args.aug_path
+ nproc = args.nproc
+ if args.out_dir is None:
+ out_dir = osp.join(devkit_path, 'VOC2012', 'SegmentationClassAug')
+ else:
+ out_dir = args.out_dir
+ mmcv.mkdir_or_exist(out_dir)
+ in_dir = osp.join(aug_path, 'dataset', 'cls')
+
+ mmcv.track_parallel_progress(
+ partial(convert_mat, in_dir=in_dir, out_dir=out_dir),
+ list(mmcv.scandir(in_dir, suffix='.mat')),
+ nproc=nproc)
+
+ full_aug_list = []
+ with open(osp.join(aug_path, 'dataset', 'train.txt')) as f:
+ full_aug_list += [line.strip() for line in f]
+ with open(osp.join(aug_path, 'dataset', 'val.txt')) as f:
+ full_aug_list += [line.strip() for line in f]
+
+ with open(
+ osp.join(devkit_path, 'VOC2012/ImageSets/Segmentation',
+ 'train.txt')) as f:
+ ori_train_list = [line.strip() for line in f]
+ with open(
+ osp.join(devkit_path, 'VOC2012/ImageSets/Segmentation',
+ 'val.txt')) as f:
+ val_list = [line.strip() for line in f]
+
+ aug_train_list = generate_aug_list(ori_train_list + full_aug_list,
+ val_list)
+ assert len(aug_train_list) == AUG_LEN, 'len(aug_train_list) != {}'.format(
+ AUG_LEN)
+
+ with open(
+ osp.join(devkit_path, 'VOC2012/ImageSets/Segmentation',
+ 'trainaug.txt'), 'w') as f:
+ f.writelines(line + '\n' for line in aug_train_list)
+
+ aug_list = generate_aug_list(full_aug_list, ori_train_list + val_list)
+ assert len(aug_list) == AUG_LEN - len(
+ ori_train_list), 'len(aug_list) != {}'.format(AUG_LEN -
+ len(ori_train_list))
+ with open(
+ osp.join(devkit_path, 'VOC2012/ImageSets/Segmentation', 'aug.txt'),
+ 'w') as f:
+ f.writelines(line + '\n' for line in aug_list)
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/deploy_test.py b/tools/deploy_test.py
new file mode 100644
index 0000000..fedd645
--- /dev/null
+++ b/tools/deploy_test.py
@@ -0,0 +1,326 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import shutil
+import warnings
+from typing import Any, Iterable
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.parallel import MMDataParallel
+from mmcv.runner import get_dist_info
+from mmcv.utils import DictAction
+
+from mmseg.apis import single_gpu_test
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.models.segmentors.base import BaseSegmentor
+from mmseg.ops import resize
+
+
+class ONNXRuntimeSegmentor(BaseSegmentor):
+
+ def __init__(self, onnx_file: str, cfg: Any, device_id: int):
+ super(ONNXRuntimeSegmentor, self).__init__()
+ import onnxruntime as ort
+
+ # get the custom op path
+ ort_custom_op_path = ''
+ try:
+ from mmcv.ops import get_onnxruntime_op_path
+ ort_custom_op_path = get_onnxruntime_op_path()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn('If input model has custom op from mmcv, \
+ you may have to build mmcv with ONNXRuntime from source.')
+ session_options = ort.SessionOptions()
+ # register custom op for onnxruntime
+ if osp.exists(ort_custom_op_path):
+ session_options.register_custom_ops_library(ort_custom_op_path)
+ sess = ort.InferenceSession(onnx_file, session_options)
+ providers = ['CPUExecutionProvider']
+ options = [{}]
+ is_cuda_available = ort.get_device() == 'GPU'
+ if is_cuda_available:
+ providers.insert(0, 'CUDAExecutionProvider')
+ options.insert(0, {'device_id': device_id})
+
+ sess.set_providers(providers, options)
+
+ self.sess = sess
+ self.device_id = device_id
+ self.io_binding = sess.io_binding()
+ self.output_names = [_.name for _ in sess.get_outputs()]
+ for name in self.output_names:
+ self.io_binding.bind_output(name)
+ self.cfg = cfg
+ self.test_mode = cfg.model.test_cfg.mode
+ self.is_cuda_available = is_cuda_available
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def encode_decode(self, img, img_metas):
+ raise NotImplementedError('This method is not implemented.')
+
+ def forward_train(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def simple_test(self, img: torch.Tensor, img_meta: Iterable,
+ **kwargs) -> list:
+ if not self.is_cuda_available:
+ img = img.detach().cpu()
+ elif self.device_id >= 0:
+ img = img.cuda(self.device_id)
+ device_type = img.device.type
+ self.io_binding.bind_input(
+ name='input',
+ device_type=device_type,
+ device_id=self.device_id,
+ element_type=np.float32,
+ shape=img.shape,
+ buffer_ptr=img.data_ptr())
+ self.sess.run_with_iobinding(self.io_binding)
+ seg_pred = self.io_binding.copy_outputs_to_cpu()[0]
+ # whole might support dynamic reshape
+ ori_shape = img_meta[0]['ori_shape']
+ if not (ori_shape[0] == seg_pred.shape[-2]
+ and ori_shape[1] == seg_pred.shape[-1]):
+ seg_pred = torch.from_numpy(seg_pred).float()
+ seg_pred = resize(
+ seg_pred, size=tuple(ori_shape[:2]), mode='nearest')
+ seg_pred = seg_pred.long().detach().cpu().numpy()
+ seg_pred = seg_pred[0]
+ seg_pred = list(seg_pred)
+ return seg_pred
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+
+class TensorRTSegmentor(BaseSegmentor):
+
+ def __init__(self, trt_file: str, cfg: Any, device_id: int):
+ super(TensorRTSegmentor, self).__init__()
+ from mmcv.tensorrt import TRTWraper, load_tensorrt_plugin
+ try:
+ load_tensorrt_plugin()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn('If input model has custom op from mmcv, \
+ you may have to build mmcv with TensorRT from source.')
+ model = TRTWraper(
+ trt_file, input_names=['input'], output_names=['output'])
+
+ self.model = model
+ self.device_id = device_id
+ self.cfg = cfg
+ self.test_mode = cfg.model.test_cfg.mode
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def encode_decode(self, img, img_metas):
+ raise NotImplementedError('This method is not implemented.')
+
+ def forward_train(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def simple_test(self, img: torch.Tensor, img_meta: Iterable,
+ **kwargs) -> list:
+ with torch.cuda.device(self.device_id), torch.no_grad():
+ seg_pred = self.model({'input': img})['output']
+ seg_pred = seg_pred.detach().cpu().numpy()
+ # whole might support dynamic reshape
+ ori_shape = img_meta[0]['ori_shape']
+ if not (ori_shape[0] == seg_pred.shape[-2]
+ and ori_shape[1] == seg_pred.shape[-1]):
+ seg_pred = torch.from_numpy(seg_pred).float()
+ seg_pred = resize(
+ seg_pred, size=tuple(ori_shape[:2]), mode='nearest')
+ seg_pred = seg_pred.long().detach().cpu().numpy()
+ seg_pred = seg_pred[0]
+ seg_pred = list(seg_pred)
+ return seg_pred
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+
+def parse_args() -> argparse.Namespace:
+ parser = argparse.ArgumentParser(
+ description='mmseg backend test (and eval)')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('model', help='Input model file')
+ parser.add_argument(
+ '--backend',
+ help='Backend of the model.',
+ choices=['onnxruntime', 'tensorrt'])
+ parser.add_argument('--out', help='output result file in pickle format')
+ parser.add_argument(
+ '--format-only',
+ action='store_true',
+ help='Format the output results without perform evaluation. It is'
+ 'useful when you want to format the result to a specific format and '
+ 'submit it to the test server')
+ parser.add_argument(
+ '--eval',
+ type=str,
+ nargs='+',
+ help='evaluation metrics, which depends on the dataset, e.g., "mIoU"'
+ ' for generic datasets, and "cityscapes" for Cityscapes')
+ parser.add_argument('--show', action='store_true', help='show results')
+ parser.add_argument(
+ '--show-dir', help='directory where painted images will be saved')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--eval-options',
+ nargs='+',
+ action=DictAction,
+ help='custom options for evaluation')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ assert args.out or args.eval or args.format_only or args.show \
+ or args.show_dir, \
+ ('Please specify at least one operation (save/eval/format/show the '
+ 'results / save the results) with the argument "--out", "--eval"'
+ ', "--format-only", "--show" or "--show-dir"')
+
+ if args.eval and args.format_only:
+ raise ValueError('--eval and --format_only cannot be both specified')
+
+ if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):
+ raise ValueError('The output file must be a pkl file.')
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ cfg.model.pretrained = None
+ cfg.data.test.test_mode = True
+
+ # init distributed env first, since logger depends on the dist info.
+ distributed = False
+
+ # build the dataloader
+ # TODO: support multiple images per gpu (only minor changes are needed)
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=distributed,
+ shuffle=False)
+
+ # load onnx config and meta
+ cfg.model.train_cfg = None
+
+ if args.backend == 'onnxruntime':
+ model = ONNXRuntimeSegmentor(args.model, cfg=cfg, device_id=0)
+ elif args.backend == 'tensorrt':
+ model = TensorRTSegmentor(args.model, cfg=cfg, device_id=0)
+
+ model.CLASSES = dataset.CLASSES
+ model.PALETTE = dataset.PALETTE
+
+ # clean gpu memory when starting a new evaluation.
+ torch.cuda.empty_cache()
+ eval_kwargs = {} if args.eval_options is None else args.eval_options
+
+ # Deprecated
+ efficient_test = eval_kwargs.get('efficient_test', False)
+ if efficient_test:
+ warnings.warn(
+ '``efficient_test=True`` does not have effect in tools/test.py, '
+ 'the evaluation and format results are CPU memory efficient by '
+ 'default')
+
+ eval_on_format_results = (
+ args.eval is not None and 'cityscapes' in args.eval)
+ if eval_on_format_results:
+ assert len(args.eval) == 1, 'eval on format results is not ' \
+ 'applicable for metrics other than ' \
+ 'cityscapes'
+ if args.format_only or eval_on_format_results:
+ if 'imgfile_prefix' in eval_kwargs:
+ tmpdir = eval_kwargs['imgfile_prefix']
+ else:
+ tmpdir = '.format_cityscapes'
+ eval_kwargs.setdefault('imgfile_prefix', tmpdir)
+ mmcv.mkdir_or_exist(tmpdir)
+ else:
+ tmpdir = None
+
+ model = MMDataParallel(model, device_ids=[0])
+ results = single_gpu_test(
+ model,
+ data_loader,
+ args.show,
+ args.show_dir,
+ False,
+ args.opacity,
+ pre_eval=args.eval is not None and not eval_on_format_results,
+ format_only=args.format_only or eval_on_format_results,
+ format_args=eval_kwargs)
+
+ rank, _ = get_dist_info()
+ if rank == 0:
+ if args.out:
+ warnings.warn(
+ 'The behavior of ``args.out`` has been changed since MMSeg '
+ 'v0.16, the pickled outputs could be seg map as type of '
+ 'np.array, pre-eval results or file paths for '
+ '``dataset.format_results()``.')
+ print(f'\nwriting results to {args.out}')
+ mmcv.dump(results, args.out)
+ if args.eval:
+ dataset.evaluate(results, args.eval, **eval_kwargs)
+ if tmpdir is not None and eval_on_format_results:
+ # remove tmp dir when cityscapes evaluation
+ shutil.rmtree(tmpdir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/deploy_test_kneron.py b/tools/deploy_test_kneron.py
new file mode 100644
index 0000000..5be25a5
--- /dev/null
+++ b/tools/deploy_test_kneron.py
@@ -0,0 +1,215 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import shutil
+import warnings
+
+import mmcv
+import torch
+from mmcv.runner import get_dist_info
+from mmcv.utils import DictAction
+
+from mmseg.apis import single_gpu_test
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.models.segmentors.base import ONNXRuntimeSegmentorKN
+
+
+def parse_args() -> argparse.Namespace:
+ parser = argparse.ArgumentParser(
+ description='mmseg backend test (and eval)')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('model', help='Input model file (onnx only)')
+ parser.add_argument('--out', help='output result file in pickle format')
+ parser.add_argument(
+ '--format-only',
+ action='store_true',
+ help='Format the output results without perform evaluation. It is'
+ 'useful when you want to format the result to a specific format and '
+ 'submit it to the test server')
+ parser.add_argument(
+ '--eval',
+ type=str,
+ nargs='+',
+ help='evaluation metrics, which depends on the dataset, e.g., "mIoU"'
+ ' for generic datasets, and "cityscapes" for Cityscapes')
+ parser.add_argument('--show', action='store_true', help='show results')
+ parser.add_argument(
+ '--show-dir', help='directory where painted images will be saved')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--eval-options',
+ nargs='+',
+ action=DictAction,
+ help='custom options for evaluation')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=None,
+ help='input image height and width.')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ assert args.out or args.eval or args.format_only or args.show \
+ or args.show_dir, \
+ ('Please specify at least one operation (save/eval/format/show the '
+ 'results / save the results) with the argument "--out", "--eval"'
+ ', "--format-only", "--show" or "--show-dir"')
+
+ if args.eval and args.format_only:
+ raise ValueError('--eval and --format_only cannot be both specified')
+
+ if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):
+ raise ValueError('The output file must be a pkl file.')
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ cfg.model.pretrained = None
+ cfg.data.test.test_mode = True
+ if args.shape is not None:
+
+ if len(args.shape) == 1:
+ shape = (args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ shape = (args.shape[1], args.shape[0])
+ else:
+ raise ValueError('invalid input shape')
+
+ test_mode = cfg.model.test_cfg.mode
+ if test_mode == 'slide':
+ warnings.warn(
+ "We suggest you NOT assigning shape when exporting "
+ "slide-mode models. Assigning shape to slide-mode models "
+ "may result in unexpected results. To see which mode the "
+ "model is using, check cfg.model.test_cfg.mode, which "
+ "should be either 'whole' or 'slide'."
+ )
+ cfg.model.test_cfg['crop_size'] = shape
+ else:
+ cfg.test_pipeline[1]['img_scale'] = shape
+ cfg.data.test['pipeline'][1]['img_scale'] = shape
+
+ # init distributed env first, since logger depends on the dist info.
+ distributed = False
+
+ # build the dataloader
+ # TODO: support multiple images per gpu (only minor changes are needed)
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=distributed,
+ shuffle=False)
+
+ # load onnx config and meta
+ cfg.model.train_cfg = None
+
+ model = ONNXRuntimeSegmentorKN(args.model, cfg=cfg, device_id=0)
+
+ model.CLASSES = dataset.CLASSES
+ model.PALETTE = dataset.PALETTE
+
+ # clean gpu memory when starting a new evaluation.
+ torch.cuda.empty_cache()
+ eval_kwargs = {} if args.eval_options is None else args.eval_options
+
+ # Deprecated
+ efficient_test = eval_kwargs.get('efficient_test', False)
+ if efficient_test:
+ warnings.warn(
+ '"efficient_test=True" does not have effect in '
+ 'tools/test_kneron.py, the evaluation and format '
+ 'results are CPU memory efficient by default')
+
+ eval_on_format_results = (
+ args.eval is not None and 'cityscapes' in args.eval)
+ if eval_on_format_results:
+ assert len(args.eval) == 1, 'eval on format results is not ' \
+ 'applicable for metrics other than ' \
+ 'cityscapes'
+ if args.format_only or eval_on_format_results:
+ if 'imgfile_prefix' in eval_kwargs:
+ tmpdir = eval_kwargs['imgfile_prefix']
+ else:
+ tmpdir = '.format_cityscapes'
+ eval_kwargs.setdefault('imgfile_prefix', tmpdir)
+ mmcv.mkdir_or_exist(tmpdir)
+ else:
+ tmpdir = None
+
+ results = single_gpu_test(
+ model,
+ data_loader,
+ args.show,
+ args.show_dir,
+ False,
+ args.opacity,
+ pre_eval=args.eval is not None and not eval_on_format_results,
+ format_only=args.format_only or eval_on_format_results,
+ format_args=eval_kwargs)
+
+ rank, _ = get_dist_info()
+ if rank == 0:
+ if args.out:
+ warnings.warn(
+ 'The behavior of ``args.out`` has been changed since MMSeg '
+ 'v0.16, the pickled outputs could be seg map as type of '
+ 'np.array, pre-eval results or file paths for '
+ '``dataset.format_results()``.')
+ print(f'\nwriting results to {args.out}')
+ mmcv.dump(results, args.out)
+ if args.eval:
+ dataset.evaluate(results, args.eval, **eval_kwargs)
+ if tmpdir is not None and eval_on_format_results:
+ # remove tmp dir when cityscapes evaluation
+ shutil.rmtree(tmpdir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dist_test.sh b/tools/dist_test.sh
new file mode 100755
index 0000000..34fb465
--- /dev/null
+++ b/tools/dist_test.sh
@@ -0,0 +1,9 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+CHECKPOINT=$2
+GPUS=$3
+PORT=${PORT:-29500}
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
+ $(dirname "$0")/test.py $CONFIG $CHECKPOINT --launcher pytorch ${@:4}
diff --git a/tools/dist_train.sh b/tools/dist_train.sh
new file mode 100755
index 0000000..5b43fff
--- /dev/null
+++ b/tools/dist_train.sh
@@ -0,0 +1,9 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+GPUS=$2
+PORT=${PORT:-29500}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
+ $(dirname "$0")/train.py $CONFIG --launcher pytorch ${@:3}
diff --git a/tools/get_flops.py b/tools/get_flops.py
new file mode 100644
index 0000000..83dea0a
--- /dev/null
+++ b/tools/get_flops.py
@@ -0,0 +1,59 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+from mmcv import Config
+from mmcv.cnn import get_model_complexity_info
+
+from mmseg.models import build_segmentor
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a segmentor')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=[2048, 1024],
+ help='input image size')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+
+ args = parse_args()
+
+ if len(args.shape) == 1:
+ input_shape = (3, args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ input_shape = (3, ) + tuple(args.shape)
+ else:
+ raise ValueError('invalid input shape')
+
+ cfg = Config.fromfile(args.config)
+ cfg.model.pretrained = None
+ model = build_segmentor(
+ cfg.model,
+ train_cfg=cfg.get('train_cfg'),
+ test_cfg=cfg.get('test_cfg')).cuda()
+ model.eval()
+
+ if hasattr(model, 'forward_dummy'):
+ model.forward = model.forward_dummy
+ else:
+ raise NotImplementedError(
+ 'FLOPs counter is currently not currently supported with {}'.
+ format(model.__class__.__name__))
+
+ flops, params = get_model_complexity_info(model, input_shape)
+ split_line = '=' * 30
+ print('{0}\nInput shape: {1}\nFlops: {2}\nParams: {3}\n{0}'.format(
+ split_line, input_shape, flops, params))
+ print('!!!Please be cautious if you use the results in papers. '
+ 'You may need to check if all ops are supported and verify that the '
+ 'flops computation is correct.')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/mit2mmseg.py b/tools/model_converters/mit2mmseg.py
new file mode 100644
index 0000000..2eff1f7
--- /dev/null
+++ b/tools/model_converters/mit2mmseg.py
@@ -0,0 +1,82 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from collections import OrderedDict
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_mit(ckpt):
+ new_ckpt = OrderedDict()
+ # Process the concat between q linear weights and kv linear weights
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ # patch embedding conversion
+ elif k.startswith('patch_embed'):
+ stage_i = int(k.split('.')[0].replace('patch_embed', ''))
+ new_k = k.replace(f'patch_embed{stage_i}', f'layers.{stage_i-1}.0')
+ new_v = v
+ if 'proj.' in new_k:
+ new_k = new_k.replace('proj.', 'projection.')
+ # transformer encoder layer conversion
+ elif k.startswith('block'):
+ stage_i = int(k.split('.')[0].replace('block', ''))
+ new_k = k.replace(f'block{stage_i}', f'layers.{stage_i-1}.1')
+ new_v = v
+ if 'attn.q.' in new_k:
+ sub_item_k = k.replace('q.', 'kv.')
+ new_k = new_k.replace('q.', 'attn.in_proj_')
+ new_v = torch.cat([v, ckpt[sub_item_k]], dim=0)
+ elif 'attn.kv.' in new_k:
+ continue
+ elif 'attn.proj.' in new_k:
+ new_k = new_k.replace('proj.', 'attn.out_proj.')
+ elif 'attn.sr.' in new_k:
+ new_k = new_k.replace('sr.', 'sr.')
+ elif 'mlp.' in new_k:
+ string = f'{new_k}-'
+ new_k = new_k.replace('mlp.', 'ffn.layers.')
+ if 'fc1.weight' in new_k or 'fc2.weight' in new_k:
+ new_v = v.reshape((*v.shape, 1, 1))
+ new_k = new_k.replace('fc1.', '0.')
+ new_k = new_k.replace('dwconv.dwconv.', '1.')
+ new_k = new_k.replace('fc2.', '4.')
+ string += f'{new_k} {v.shape}-{new_v.shape}'
+ # norm layer conversion
+ elif k.startswith('norm'):
+ stage_i = int(k.split('.')[0].replace('norm', ''))
+ new_k = k.replace(f'norm{stage_i}', f'layers.{stage_i-1}.2')
+ new_v = v
+ else:
+ new_k = k
+ new_v = v
+ new_ckpt[new_k] = new_v
+ return new_ckpt
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in official pretrained segformer to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+ weight = convert_mit(state_dict)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/stdc2mmseg.py b/tools/model_converters/stdc2mmseg.py
new file mode 100644
index 0000000..9241f86
--- /dev/null
+++ b/tools/model_converters/stdc2mmseg.py
@@ -0,0 +1,71 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_stdc(ckpt, stdc_type):
+ new_state_dict = {}
+ if stdc_type == 'STDC1':
+ stage_lst = ['0', '1', '2.0', '2.1', '3.0', '3.1', '4.0', '4.1']
+ else:
+ stage_lst = [
+ '0', '1', '2.0', '2.1', '2.2', '2.3', '3.0', '3.1', '3.2', '3.3',
+ '3.4', '4.0', '4.1', '4.2'
+ ]
+ for k, v in ckpt.items():
+ ori_k = k
+ flag = False
+ if 'cp.' in k:
+ k = k.replace('cp.', '')
+ if 'features.' in k:
+ num_layer = int(k.split('.')[1])
+ feature_key_lst = 'features.' + str(num_layer) + '.'
+ stages_key_lst = 'stages.' + stage_lst[num_layer] + '.'
+ k = k.replace(feature_key_lst, stages_key_lst)
+ flag = True
+ if 'conv_list' in k:
+ k = k.replace('conv_list', 'layers')
+ flag = True
+ if 'avd_layer.' in k:
+ if 'avd_layer.0' in k:
+ k = k.replace('avd_layer.0', 'downsample.conv')
+ elif 'avd_layer.1' in k:
+ k = k.replace('avd_layer.1', 'downsample.bn')
+ flag = True
+ if flag:
+ new_state_dict[k] = ckpt[ori_k]
+
+ return new_state_dict
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in official pretrained STDC1/2 to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ parser.add_argument('type', help='model type: STDC1 or STDC2')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+
+ assert args.type in ['STDC1',
+ 'STDC2'], 'STD type should be STDC1 or STDC2!'
+ weight = convert_stdc(state_dict, args.type)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/swin2mmseg.py b/tools/model_converters/swin2mmseg.py
new file mode 100644
index 0000000..03b24ce
--- /dev/null
+++ b/tools/model_converters/swin2mmseg.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from collections import OrderedDict
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_swin(ckpt):
+ new_ckpt = OrderedDict()
+
+ def correct_unfold_reduction_order(x):
+ out_channel, in_channel = x.shape
+ x = x.reshape(out_channel, 4, in_channel // 4)
+ x = x[:, [0, 2, 1, 3], :].transpose(1,
+ 2).reshape(out_channel, in_channel)
+ return x
+
+ def correct_unfold_norm_order(x):
+ in_channel = x.shape[0]
+ x = x.reshape(4, in_channel // 4)
+ x = x[[0, 2, 1, 3], :].transpose(0, 1).reshape(in_channel)
+ return x
+
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ elif k.startswith('layers'):
+ new_v = v
+ if 'attn.' in k:
+ new_k = k.replace('attn.', 'attn.w_msa.')
+ elif 'mlp.' in k:
+ if 'mlp.fc1.' in k:
+ new_k = k.replace('mlp.fc1.', 'ffn.layers.0.0.')
+ elif 'mlp.fc2.' in k:
+ new_k = k.replace('mlp.fc2.', 'ffn.layers.1.')
+ else:
+ new_k = k.replace('mlp.', 'ffn.')
+ elif 'downsample' in k:
+ new_k = k
+ if 'reduction.' in k:
+ new_v = correct_unfold_reduction_order(v)
+ elif 'norm.' in k:
+ new_v = correct_unfold_norm_order(v)
+ else:
+ new_k = k
+ new_k = new_k.replace('layers', 'stages', 1)
+ elif k.startswith('patch_embed'):
+ new_v = v
+ if 'proj' in k:
+ new_k = k.replace('proj', 'projection')
+ else:
+ new_k = k
+ else:
+ new_v = v
+ new_k = k
+
+ new_ckpt[new_k] = new_v
+
+ return new_ckpt
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in official pretrained swin models to'
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+ weight = convert_swin(state_dict)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/twins2mmseg.py b/tools/model_converters/twins2mmseg.py
new file mode 100644
index 0000000..ab64aa5
--- /dev/null
+++ b/tools/model_converters/twins2mmseg.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from collections import OrderedDict
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_twins(args, ckpt):
+
+ new_ckpt = OrderedDict()
+
+ for k, v in list(ckpt.items()):
+ new_v = v
+ if k.startswith('head'):
+ continue
+ elif k.startswith('patch_embeds'):
+ if 'proj.' in k:
+ new_k = k.replace('proj.', 'projection.')
+ else:
+ new_k = k
+ elif k.startswith('blocks'):
+ # Union
+ if 'attn.q.' in k:
+ new_k = k.replace('q.', 'attn.in_proj_')
+ new_v = torch.cat([v, ckpt[k.replace('attn.q.', 'attn.kv.')]],
+ dim=0)
+ elif 'mlp.fc1' in k:
+ new_k = k.replace('mlp.fc1', 'ffn.layers.0.0')
+ elif 'mlp.fc2' in k:
+ new_k = k.replace('mlp.fc2', 'ffn.layers.1')
+ # Only pcpvt
+ elif args.model == 'pcpvt':
+ if 'attn.proj.' in k:
+ new_k = k.replace('proj.', 'attn.out_proj.')
+ else:
+ new_k = k
+
+ # Only svt
+ else:
+ if 'attn.proj.' in k:
+ k_lst = k.split('.')
+ if int(k_lst[2]) % 2 == 1:
+ new_k = k.replace('proj.', 'attn.out_proj.')
+ else:
+ new_k = k
+ else:
+ new_k = k
+ new_k = new_k.replace('blocks.', 'layers.')
+ elif k.startswith('pos_block'):
+ new_k = k.replace('pos_block', 'position_encodings')
+ if 'proj.0.' in new_k:
+ new_k = new_k.replace('proj.0.', 'proj.')
+ else:
+ new_k = k
+ if 'attn.kv.' not in k:
+ new_ckpt[new_k] = new_v
+ return new_ckpt
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in timm pretrained vit models to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ parser.add_argument('model', help='model: pcpvt or svt')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+
+ if 'state_dict' in checkpoint:
+ # timm checkpoint
+ state_dict = checkpoint['state_dict']
+ else:
+ state_dict = checkpoint
+
+ weight = convert_twins(args, state_dict)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/vit2mmseg.py b/tools/model_converters/vit2mmseg.py
new file mode 100644
index 0000000..bc18ebe
--- /dev/null
+++ b/tools/model_converters/vit2mmseg.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from collections import OrderedDict
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_vit(ckpt):
+
+ new_ckpt = OrderedDict()
+
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ if k.startswith('norm'):
+ new_k = k.replace('norm.', 'ln1.')
+ elif k.startswith('patch_embed'):
+ if 'proj' in k:
+ new_k = k.replace('proj', 'projection')
+ else:
+ new_k = k
+ elif k.startswith('blocks'):
+ if 'norm' in k:
+ new_k = k.replace('norm', 'ln')
+ elif 'mlp.fc1' in k:
+ new_k = k.replace('mlp.fc1', 'ffn.layers.0.0')
+ elif 'mlp.fc2' in k:
+ new_k = k.replace('mlp.fc2', 'ffn.layers.1')
+ elif 'attn.qkv' in k:
+ new_k = k.replace('attn.qkv.', 'attn.attn.in_proj_')
+ elif 'attn.proj' in k:
+ new_k = k.replace('attn.proj', 'attn.attn.out_proj')
+ else:
+ new_k = k
+ new_k = new_k.replace('blocks.', 'layers.')
+ else:
+ new_k = k
+ new_ckpt[new_k] = v
+
+ return new_ckpt
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in timm pretrained vit models to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+ if 'state_dict' in checkpoint:
+ # timm checkpoint
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ # deit checkpoint
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+ weight = convert_vit(state_dict)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/vitjax2mmseg.py b/tools/model_converters/vitjax2mmseg.py
new file mode 100644
index 0000000..e3a0986
--- /dev/null
+++ b/tools/model_converters/vitjax2mmseg.py
@@ -0,0 +1,122 @@
+import argparse
+import os.path as osp
+
+import mmcv
+import numpy as np
+import torch
+
+
+def vit_jax_to_torch(jax_weights, num_layer=12):
+ torch_weights = dict()
+
+ # patch embedding
+ conv_filters = jax_weights['embedding/kernel']
+ conv_filters = conv_filters.permute(3, 2, 0, 1)
+ torch_weights['patch_embed.projection.weight'] = conv_filters
+ torch_weights['patch_embed.projection.bias'] = jax_weights[
+ 'embedding/bias']
+
+ # pos embedding
+ torch_weights['pos_embed'] = jax_weights[
+ 'Transformer/posembed_input/pos_embedding']
+
+ # cls token
+ torch_weights['cls_token'] = jax_weights['cls']
+
+ # head
+ torch_weights['ln1.weight'] = jax_weights['Transformer/encoder_norm/scale']
+ torch_weights['ln1.bias'] = jax_weights['Transformer/encoder_norm/bias']
+
+ # transformer blocks
+ for i in range(num_layer):
+ jax_block = f'Transformer/encoderblock_{i}'
+ torch_block = f'layers.{i}'
+
+ # attention norm
+ torch_weights[f'{torch_block}.ln1.weight'] = jax_weights[
+ f'{jax_block}/LayerNorm_0/scale']
+ torch_weights[f'{torch_block}.ln1.bias'] = jax_weights[
+ f'{jax_block}/LayerNorm_0/bias']
+
+ # attention
+ query_weight = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/query/kernel']
+ query_bias = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/query/bias']
+ key_weight = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/key/kernel']
+ key_bias = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/key/bias']
+ value_weight = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/value/kernel']
+ value_bias = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/value/bias']
+
+ qkv_weight = torch.from_numpy(
+ np.stack((query_weight, key_weight, value_weight), 1))
+ qkv_weight = torch.flatten(qkv_weight, start_dim=1)
+ qkv_bias = torch.from_numpy(
+ np.stack((query_bias, key_bias, value_bias), 0))
+ qkv_bias = torch.flatten(qkv_bias, start_dim=0)
+
+ torch_weights[f'{torch_block}.attn.attn.in_proj_weight'] = qkv_weight
+ torch_weights[f'{torch_block}.attn.attn.in_proj_bias'] = qkv_bias
+ to_out_weight = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/out/kernel']
+ to_out_weight = torch.flatten(to_out_weight, start_dim=0, end_dim=1)
+ torch_weights[
+ f'{torch_block}.attn.attn.out_proj.weight'] = to_out_weight
+ torch_weights[f'{torch_block}.attn.attn.out_proj.bias'] = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/out/bias']
+
+ # mlp norm
+ torch_weights[f'{torch_block}.ln2.weight'] = jax_weights[
+ f'{jax_block}/LayerNorm_2/scale']
+ torch_weights[f'{torch_block}.ln2.bias'] = jax_weights[
+ f'{jax_block}/LayerNorm_2/bias']
+
+ # mlp
+ torch_weights[f'{torch_block}.ffn.layers.0.0.weight'] = jax_weights[
+ f'{jax_block}/MlpBlock_3/Dense_0/kernel']
+ torch_weights[f'{torch_block}.ffn.layers.0.0.bias'] = jax_weights[
+ f'{jax_block}/MlpBlock_3/Dense_0/bias']
+ torch_weights[f'{torch_block}.ffn.layers.1.weight'] = jax_weights[
+ f'{jax_block}/MlpBlock_3/Dense_1/kernel']
+ torch_weights[f'{torch_block}.ffn.layers.1.bias'] = jax_weights[
+ f'{jax_block}/MlpBlock_3/Dense_1/bias']
+
+ # transpose weights
+ for k, v in torch_weights.items():
+ if 'weight' in k and 'patch_embed' not in k and 'ln' not in k:
+ v = v.permute(1, 0)
+ torch_weights[k] = v
+
+ return torch_weights
+
+
+def main():
+ # stole refactoring code from Robin Strudel, thanks
+ parser = argparse.ArgumentParser(
+ description='Convert keys from jax official pretrained vit models to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ args = parser.parse_args()
+
+ jax_weights = np.load(args.src)
+ jax_weights_tensor = {}
+ for key in jax_weights.files:
+ value = torch.from_numpy(jax_weights[key])
+ jax_weights_tensor[key] = value
+ if 'L_16-i21k' in args.src:
+ num_layer = 24
+ else:
+ num_layer = 12
+ torch_weights = vit_jax_to_torch(jax_weights_tensor, num_layer)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(torch_weights, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/onnx2tensorrt.py b/tools/onnx2tensorrt.py
new file mode 100644
index 0000000..f8a258f
--- /dev/null
+++ b/tools/onnx2tensorrt.py
@@ -0,0 +1,276 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+from typing import Iterable, Optional, Union
+
+import matplotlib.pyplot as plt
+import mmcv
+import numpy as np
+import onnxruntime as ort
+import torch
+from mmcv.ops import get_onnxruntime_op_path
+from mmcv.tensorrt import (TRTWraper, is_tensorrt_plugin_loaded, onnx2trt,
+ save_trt_engine)
+
+from mmseg.apis.inference import LoadImage
+from mmseg.datasets import DATASETS
+from mmseg.datasets.pipelines import Compose
+
+
+def get_GiB(x: int):
+ """return x GiB."""
+ return x * (1 << 30)
+
+
+def _prepare_input_img(img_path: str,
+ test_pipeline: Iterable[dict],
+ shape: Optional[Iterable] = None,
+ rescale_shape: Optional[Iterable] = None) -> dict:
+ # build the data pipeline
+ if shape is not None:
+ test_pipeline[1]['img_scale'] = (shape[1], shape[0])
+ test_pipeline[1]['transforms'][0]['keep_ratio'] = False
+ test_pipeline = [LoadImage()] + test_pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ # prepare data
+ data = dict(img=img_path)
+ data = test_pipeline(data)
+ imgs = data['img']
+ img_metas = [i.data for i in data['img_metas']]
+
+ if rescale_shape is not None:
+ for img_meta in img_metas:
+ img_meta['ori_shape'] = tuple(rescale_shape) + (3, )
+
+ mm_inputs = {'imgs': imgs, 'img_metas': img_metas}
+
+ return mm_inputs
+
+
+def _update_input_img(img_list: Iterable, img_meta_list: Iterable):
+ # update img and its meta list
+ N = img_list[0].size(0)
+ img_meta = img_meta_list[0][0]
+ img_shape = img_meta['img_shape']
+ ori_shape = img_meta['ori_shape']
+ pad_shape = img_meta['pad_shape']
+ new_img_meta_list = [[{
+ 'img_shape':
+ img_shape,
+ 'ori_shape':
+ ori_shape,
+ 'pad_shape':
+ pad_shape,
+ 'filename':
+ img_meta['filename'],
+ 'scale_factor':
+ (img_shape[1] / ori_shape[1], img_shape[0] / ori_shape[0]) * 2,
+ 'flip':
+ False,
+ } for _ in range(N)]]
+
+ return img_list, new_img_meta_list
+
+
+def show_result_pyplot(img: Union[str, np.ndarray],
+ result: np.ndarray,
+ palette: Optional[Iterable] = None,
+ fig_size: Iterable[int] = (15, 10),
+ opacity: float = 0.5,
+ title: str = '',
+ block: bool = True):
+ img = mmcv.imread(img)
+ img = img.copy()
+ seg = result[0]
+ seg = mmcv.imresize(seg, img.shape[:2][::-1])
+ palette = np.array(palette)
+ assert palette.shape[1] == 3
+ assert len(palette.shape) == 2
+ assert 0 < opacity <= 1.0
+ color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
+ for label, color in enumerate(palette):
+ color_seg[seg == label, :] = color
+ # convert to BGR
+ color_seg = color_seg[..., ::-1]
+
+ img = img * (1 - opacity) + color_seg * opacity
+ img = img.astype(np.uint8)
+
+ plt.figure(figsize=fig_size)
+ plt.imshow(mmcv.bgr2rgb(img))
+ plt.title(title)
+ plt.tight_layout()
+ plt.show(block=block)
+
+
+def onnx2tensorrt(onnx_file: str,
+ trt_file: str,
+ config: dict,
+ input_config: dict,
+ fp16: bool = False,
+ verify: bool = False,
+ show: bool = False,
+ dataset: str = 'CityscapesDataset',
+ workspace_size: int = 1,
+ verbose: bool = False):
+ import tensorrt as trt
+ min_shape = input_config['min_shape']
+ max_shape = input_config['max_shape']
+ # create trt engine and wrapper
+ opt_shape_dict = {'input': [min_shape, min_shape, max_shape]}
+ max_workspace_size = get_GiB(workspace_size)
+ trt_engine = onnx2trt(
+ onnx_file,
+ opt_shape_dict,
+ log_level=trt.Logger.VERBOSE if verbose else trt.Logger.ERROR,
+ fp16_mode=fp16,
+ max_workspace_size=max_workspace_size)
+ save_dir, _ = osp.split(trt_file)
+ if save_dir:
+ os.makedirs(save_dir, exist_ok=True)
+ save_trt_engine(trt_engine, trt_file)
+ print(f'Successfully created TensorRT engine: {trt_file}')
+
+ if verify:
+ inputs = _prepare_input_img(
+ input_config['input_path'],
+ config.data.test.pipeline,
+ shape=min_shape[2:])
+
+ imgs = inputs['imgs']
+ img_metas = inputs['img_metas']
+ img_list = [img[None, :] for img in imgs]
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ # update img_meta
+ img_list, img_meta_list = _update_input_img(img_list, img_meta_list)
+
+ if max_shape[0] > 1:
+ # concate flip image for batch test
+ flip_img_list = [_.flip(-1) for _ in img_list]
+ img_list = [
+ torch.cat((ori_img, flip_img), 0)
+ for ori_img, flip_img in zip(img_list, flip_img_list)
+ ]
+
+ # Get results from ONNXRuntime
+ ort_custom_op_path = get_onnxruntime_op_path()
+ session_options = ort.SessionOptions()
+ if osp.exists(ort_custom_op_path):
+ session_options.register_custom_ops_library(ort_custom_op_path)
+ sess = ort.InferenceSession(onnx_file, session_options)
+ sess.set_providers(['CPUExecutionProvider'], [{}]) # use cpu mode
+ onnx_output = sess.run(['output'],
+ {'input': img_list[0].detach().numpy()})[0][0]
+
+ # Get results from TensorRT
+ trt_model = TRTWraper(trt_file, ['input'], ['output'])
+ with torch.no_grad():
+ trt_outputs = trt_model({'input': img_list[0].contiguous().cuda()})
+ trt_output = trt_outputs['output'][0].cpu().detach().numpy()
+
+ if show:
+ dataset = DATASETS.get(dataset)
+ assert dataset is not None
+ palette = dataset.PALETTE
+
+ show_result_pyplot(
+ input_config['input_path'],
+ (onnx_output[0].astype(np.uint8), ),
+ palette=palette,
+ title='ONNXRuntime',
+ block=False)
+ show_result_pyplot(
+ input_config['input_path'], (trt_output[0].astype(np.uint8), ),
+ palette=palette,
+ title='TensorRT')
+
+ np.testing.assert_allclose(
+ onnx_output, trt_output, rtol=1e-03, atol=1e-05)
+ print('TensorRT and ONNXRuntime output all close.')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert MMSegmentation models from ONNX to TensorRT')
+ parser.add_argument('config', help='Config file of the model')
+ parser.add_argument('model', help='Path to the input ONNX model')
+ parser.add_argument(
+ '--trt-file', type=str, help='Path to the output TensorRT engine')
+ parser.add_argument(
+ '--max-shape',
+ type=int,
+ nargs=4,
+ default=[1, 3, 400, 600],
+ help='Maximum shape of model input.')
+ parser.add_argument(
+ '--min-shape',
+ type=int,
+ nargs=4,
+ default=[1, 3, 400, 600],
+ help='Minimum shape of model input.')
+ parser.add_argument('--fp16', action='store_true', help='Enable fp16 mode')
+ parser.add_argument(
+ '--workspace-size',
+ type=int,
+ default=1,
+ help='Max workspace size in GiB')
+ parser.add_argument(
+ '--input-img', type=str, default='', help='Image for test')
+ parser.add_argument(
+ '--show', action='store_true', help='Whether to show output results')
+ parser.add_argument(
+ '--dataset',
+ type=str,
+ default='CityscapesDataset',
+ help='Dataset name')
+ parser.add_argument(
+ '--verify',
+ action='store_true',
+ help='Verify the outputs of ONNXRuntime and TensorRT')
+ parser.add_argument(
+ '--verbose',
+ action='store_true',
+ help='Whether to verbose logging messages while creating \
+ TensorRT engine.')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+
+ assert is_tensorrt_plugin_loaded(), 'TensorRT plugin should be compiled.'
+ args = parse_args()
+
+ if not args.input_img:
+ args.input_img = osp.join(osp.dirname(__file__), '../demo/demo.png')
+
+ # check arguments
+ assert osp.exists(args.config), 'Config {} not found.'.format(args.config)
+ assert osp.exists(args.model), \
+ 'ONNX model {} not found.'.format(args.model)
+ assert args.workspace_size >= 0, 'Workspace size less than 0.'
+ assert DATASETS.get(args.dataset) is not None, \
+ 'Dataset {} does not found.'.format(args.dataset)
+ for max_value, min_value in zip(args.max_shape, args.min_shape):
+ assert max_value >= min_value, \
+ 'max_shape should be larger than min shape'
+
+ input_config = {
+ 'min_shape': args.min_shape,
+ 'max_shape': args.max_shape,
+ 'input_path': args.input_img
+ }
+
+ cfg = mmcv.Config.fromfile(args.config)
+ onnx2tensorrt(
+ args.model,
+ args.trt_file,
+ cfg,
+ input_config,
+ fp16=args.fp16,
+ verify=args.verify,
+ show=args.show,
+ dataset=args.dataset,
+ workspace_size=args.workspace_size,
+ verbose=args.verbose)
diff --git a/tools/optimizer_scripts/.clang-format b/tools/optimizer_scripts/.clang-format
new file mode 100644
index 0000000..2593ef5
--- /dev/null
+++ b/tools/optimizer_scripts/.clang-format
@@ -0,0 +1 @@
+BasedOnStyle: Google
\ No newline at end of file
diff --git a/tools/optimizer_scripts/.gitignore b/tools/optimizer_scripts/.gitignore
new file mode 100644
index 0000000..991fd07
--- /dev/null
+++ b/tools/optimizer_scripts/.gitignore
@@ -0,0 +1,7 @@
+__pycache__
+.vscode
+*.pyc
+models.py
+temp.py
+.ssh/
+docker/test_models/
\ No newline at end of file
diff --git a/tools/optimizer_scripts/README.md b/tools/optimizer_scripts/README.md
new file mode 100644
index 0000000..cac99c5
--- /dev/null
+++ b/tools/optimizer_scripts/README.md
@@ -0,0 +1,189 @@
+# Converter Scripts
+
+[](http://192.168.200.1:8088/jiyuan/converter_scripts/commits/master)
+
+This project collects various optimization scripts and converter scritps for
+Kneron toolchain. This collection does not include the Keras to ONNX converter
+and the Caffe to ONNX converter. They are in seperate projects.
+
+**The scripts not listed below are used as libraries and cannot be used
+directly.**
+
+## onnx2onnx.py
+
+### 1.1. Description
+
+General optimizations on ONNX model for Kneron toolchain. Though Kneron
+toolchains are designed to take ONNX models as input, they have some
+restrictions on the models (e.g. inferenced shapes for all value_info). Thus, we
+have this tool to do some general optimization and conversion on ONNX models.
+**Notice that this script should take an valid ONNX model as input.** It cannot
+turn an invalid ONNX model into a valid one.
+
+### 1.2. Basic Usage
+
+```bash
+python onnx2onnx.py input.onnx -o output.onnx
+```
+
+### 1.3. Optimizations Included
+
+* Fusing BN into Conv.
+* Fusing BN into Gemm.
+* Fusing consecutive Gemm.
+* Eliminating Identify layers and Dropout layers.
+* Eliminating last shape changing nodes.
+* Replacing initializers into Constant nodes.
+* Replacing global AveragePool with GAP.
+* Replacing Squeeze and Unsqueeze with Reshape.
+* Replacing 1x1 depthwise with BN.
+* Inferencing Upsample shapes.
+* Transposing B in Gemm.
+
+## pytorch2onnx.py
+
+### 2.1. Description
+
+Convert Pytorch models or Pytorch generated ONNX models into Kneron toolchain
+compatible ONNX files. This script include most of the optimizations in
+`onnx2onnx.py`. It also includes some optimizations for Pytorch model only.
+
+### 2.2. Basic Usage
+
+```bash
+# Take Pytorch model name, input channel number, input height, input width
+python pytorch2onnx.py input.pth output.onnx --input-size 3 224 224
+# Or take Pytorch exported ONNX.
+python pytorch2onnx.py input.onnx output.onnx
+```
+
+### 2.3. Optimizations Included
+
+* Adding name to nodes.
+* Unsqueeze nodes constant folding.
+* Reshape nodes constant folding.
+* Optimizations in `onnx2onnx.py`.
+
+## editor.py
+
+### 3.1. Description
+
+This is an simple ONNX editor which achieves the following functions:
+
+* Add nop BN or Conv nodes.
+* Delete specific nodes or inputs.
+* Cut the graph from certain node (Delete all the nodes following the node).
+* Reshape inputs and outputs
+
+### 3.2 Usage
+
+```
+usage: editor.py [-h] [-c CUT_NODE [CUT_NODE ...]]
+ [--cut-type CUT_TYPE [CUT_TYPE ...]]
+ [-d DELETE_NODE [DELETE_NODE ...]]
+ [--delete-input DELETE_INPUT [DELETE_INPUT ...]]
+ [-i INPUT_CHANGE [INPUT_CHANGE ...]]
+ [-o OUTPUT_CHANGE [OUTPUT_CHANGE ...]]
+ [--add-conv ADD_CONV [ADD_CONV ...]]
+ [--add-bn ADD_BN [ADD_BN ...]]
+ in_file out_file
+
+Edit an ONNX model. The processing sequense is 'delete nodes/values' -> 'add
+nodes' -> 'change shapes'. Cutting cannot be done with other operations
+together
+
+positional arguments:
+ in_file input ONNX FILE
+ out_file ouput ONNX FILE
+
+optional arguments:
+ -h, --help show this help message and exit
+ -c CUT_NODE [CUT_NODE ...], --cut CUT_NODE [CUT_NODE ...]
+ remove nodes from the given nodes(inclusive)
+ --cut-type CUT_TYPE [CUT_TYPE ...]
+ remove nodes by type from the given nodes(inclusive)
+ -d DELETE_NODE [DELETE_NODE ...], --delete DELETE_NODE [DELETE_NODE ...]
+ delete nodes by names and only those nodes
+ --delete-input DELETE_INPUT [DELETE_INPUT ...]
+ delete inputs by names
+ -i INPUT_CHANGE [INPUT_CHANGE ...], --input INPUT_CHANGE [INPUT_CHANGE ...]
+ change input shape (e.g. -i 'input_0 1 3 224 224')
+ -o OUTPUT_CHANGE [OUTPUT_CHANGE ...], --output OUTPUT_CHANGE [OUTPUT_CHANGE ...]
+ change output shape (e.g. -o 'input_0 1 3 224 224')
+ --add-conv ADD_CONV [ADD_CONV ...]
+ add nop conv using specific input
+ --add-bn ADD_BN [ADD_BN ...]
+ add nop bn using specific input
+```
+
+### 3.3. Example
+
+Here is an example of when and how to use the editor.py.
+
+```bash
+# In the `res` folder, there is a vdsr model from tensorflow.
+# We need to convert this model firstly.
+./tf2onnx.sh res/vdsr_41_20layer_1.pb res/tmp.onnx images:0 output:0
+# This onnx file seems valid. But, it's channel last for the input and output.
+# It is using Traspose to convert to channel first, affacting the performance.
+# Thus, here we use the editor to delete these Transpose and reset the shapes.
+python editor.py debug.onnx new.onnx -d Conv2D__6 Conv2D_19__84 -i 'images:0 1 3 41 41' -o 'output:0 1 3 41 41'
+# Now, it has no Transpose and take channel first inputs directly.
+```
+
+## test_models_opt.py
+
+### 4.1. Description
+Compare all original and optimized onnx models under a specified directory.
+Using different endings to locate original and optimized model paths. Apply
+onnxruntime inference to the models, and compare the results from original
+and optimized models. Calculate basic statistics and store to a csv file.
+
+### 4.2. Usage
+
+```bash
+python DIR ending1 ending2 csv_out_file -p=Y/N
+
+# csv_out_file is file path for the stats data.
+# -p --plot is the plot option, if Y, stats plots will be generated.
+```
+
+### 4.3. Statistics
+* max_rel_diff
+* max_abs_diff
+* mean_rel_diff
+* mean_abs_diff
+* std_rel_diff
+* std_abs_diff
+* acc_with_diff_precision
+* percentile
+
+### 4.4. Plots
+* Max Relative Difference Histogram
+* Max Absolute Difference Histogram
+* Rel_diff Percentiles of Raw and Optimized Models
+* Abs_diff Percentiles of Raw and Optimized Models
+* Accuracies with Different Precisions
+
+## tensorflow2onnx.py
+
+### 5.1. Description
+Convert and optimize tensorflow models. If input file is frozen tensorflow .pb model,
+convert to onnx model and do the custmized optimization afterwards. If input model is already
+onnx model, apply optimization and save optimized model.
+
+### 5.2 Dependency
+
+This scripts depends on the tensorflow-onnx project. Please [check and install it](https://github.com/onnx/tensorflow-onnx/tree/r1.5) before using this script. We currently support up to version 1.5.5. For other versions, you may need to try it our yourself.
+
+### 5.3. Basic Usage
+```bash
+python tensorflow2onnx.py in_file out_file -t=True/False
+
+# -t --test, is the option for test mode, if True, shape change after input will not be eliminated.
+```
+
+### 5.4. Model Save Paths
+`in_file` is the input model path, `out_file` specifies output optimized model path.
+If input file is `.pb` model, an unoptimized onnx model will be saved to the output directory as well.
+
diff --git a/tools/optimizer_scripts/consecutive_conv_opt.py b/tools/optimizer_scripts/consecutive_conv_opt.py
new file mode 100644
index 0000000..0ed4a28
--- /dev/null
+++ b/tools/optimizer_scripts/consecutive_conv_opt.py
@@ -0,0 +1,85 @@
+import numpy as np
+import onnx
+import sys
+
+from tools.other import topological_sort
+from tools import helper
+
+
+def fuse_bias_in_consecutive_1x1_conv(g):
+ for second in g.node:
+ # Find two conv
+ if second.op_type != "Conv":
+ continue
+ first = helper.find_node_by_output_name(g, second.input[0])
+ if first is None or first.op_type != "Conv":
+ continue
+ # Check if the first one has only one folloing node
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, first.output[0]
+ )
+ )
+ != 1
+ ):
+ continue
+ # If first node has no bias, continue
+ if len(first.input) == 2:
+ continue
+ # Check their kernel size
+ first_kernel_shape = helper.get_list_attribute_by_name(
+ first, "kernel_shape", "int"
+ )
+ second_kernel_shape = helper.get_list_attribute_by_name(
+ second, "kernel_shape", "int"
+ )
+ prod = (
+ first_kernel_shape[0]
+ * first_kernel_shape[1]
+ * second_kernel_shape[0]
+ * second_kernel_shape[1]
+ )
+ if prod != 1:
+ continue
+ print("Found: ", first.name, " ", second.name)
+ # Get bias of the nodes
+ first_bias_node = helper.find_node_by_output_name(g, first.input[2])
+ second_weight_node = helper.find_node_by_output_name(
+ g, second.input[1]
+ )
+ second_bias_node = helper.find_node_by_output_name(g, second.input[2])
+ first_bias = helper.constant_to_numpy(first_bias_node)
+ second_weight = helper.constant_to_numpy(second_weight_node)
+ second_bias = helper.constant_to_numpy(second_bias_node)
+ # Calculate the weight for second node
+ first_bias = np.reshape(first_bias, (1, first_bias.size))
+ second_weight = np.reshape(
+ second_weight, (second_weight.shape[0], second_weight.shape[1])
+ )
+ second_weight = np.transpose(second_weight)
+ new_second_bias = second_bias + np.matmul(first_bias, second_weight)
+ new_second_bias = np.reshape(new_second_bias, (new_second_bias.size,))
+ # Generate new weight
+ new_first_bias = np.reshape(first_bias, (first_bias.size,))
+ for i in range(new_first_bias.shape[0]):
+ new_first_bias[i] = 0.0
+ new_first_bias_node = helper.numpy_to_constant(
+ first_bias_node.output[0], new_first_bias
+ )
+ new_second_bias_node = helper.numpy_to_constant(
+ second_bias_node.output[0], new_second_bias
+ )
+ # Delete old weight and add new weights
+ g.node.remove(first_bias_node)
+ g.node.remove(second_bias_node)
+ g.node.extend([new_first_bias_node, new_second_bias_node])
+ topological_sort(g)
+
+
+if __name__ == "__main__":
+ if len(sys.argv) != 3:
+ exit(1)
+ m = onnx.load(sys.argv[1])
+ fuse_bias_in_consecutive_1x1_conv(m.graph)
+ onnx.save(m, sys.argv[2])
diff --git a/tools/optimizer_scripts/docker/Dockerfile b/tools/optimizer_scripts/docker/Dockerfile
new file mode 100644
index 0000000..bb62f7f
--- /dev/null
+++ b/tools/optimizer_scripts/docker/Dockerfile
@@ -0,0 +1,24 @@
+FROM continuumio/miniconda3:latest
+LABEL maintainer="jiyuan@kneron.us"
+
+# Install python packages
+RUN conda update -y conda && \
+conda install -y python=3.6 && \
+conda install -y -c intel caffe && \
+conda install -y -c pytorch pytorch=1.3.1 torchvision=0.4.2 cpuonly && \
+conda install -y -c conda-forge tensorflow=1.5.1 keras=2.2.4 && \
+pip install onnx==1.4.1 onnxruntime==1.1.0 tf2onnx==1.5.4 && \
+ln -s /opt/conda/lib/libgflags.so.2.2.2 /opt/conda/lib/libgflags.so.2
+
+# Install git lfs packages
+RUN apt-get update && apt-get install -y curl apt-utils && \
+curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash && \
+apt-get install -y git-lfs
+
+RUN conda clean -a -y && rm -rf /var/lib/apt/lists/*
+
+# copy the test data
+COPY ./test_models /test_models
+
+# Clean the environment and finalize the process
+WORKDIR /root
\ No newline at end of file
diff --git a/tools/optimizer_scripts/editor.py b/tools/optimizer_scripts/editor.py
new file mode 100644
index 0000000..b04183c
--- /dev/null
+++ b/tools/optimizer_scripts/editor.py
@@ -0,0 +1,235 @@
+import onnx
+import onnx.utils
+
+try:
+ from onnx import optimizer
+except ImportError:
+ import onnxoptimizer as optimizer
+import argparse
+
+import tools.modhelper as helper
+import tools.other as other
+import tools.replacing as replacing
+
+# Main process
+# Argument parser
+parser = argparse.ArgumentParser(
+ description="Edit an ONNX model.\nThe processing sequense is 'delete "
+ "nodes/values' -> 'add nodes' -> 'change shapes'.\nCutting "
+ "cannot be done with other operations together"
+)
+parser.add_argument("in_file", type=str, help="input ONNX FILE")
+parser.add_argument("out_file", type=str, help="ouput ONNX FILE")
+parser.add_argument(
+ "-c",
+ "--cut",
+ dest="cut_node",
+ type=str,
+ nargs="+",
+ help="remove nodes from the given nodes(inclusive)",
+)
+parser.add_argument(
+ "--cut-type",
+ dest="cut_type",
+ type=str,
+ nargs="+",
+ help="remove nodes by type from the given nodes(inclusive)",
+)
+parser.add_argument(
+ "-d",
+ "--delete",
+ dest="delete_node",
+ type=str,
+ nargs="+",
+ help="delete nodes by names and only those nodes",
+)
+parser.add_argument(
+ "--delete-input",
+ dest="delete_input",
+ type=str,
+ nargs="+",
+ help="delete inputs by names",
+)
+parser.add_argument(
+ "--delete-output",
+ dest="delete_output",
+ type=str,
+ nargs="+",
+ help="delete outputs by names",
+)
+parser.add_argument(
+ "-i",
+ "--input",
+ dest="input_change",
+ type=str,
+ nargs="+",
+ help="change input shape (e.g. -i 'input_0 1 3 224 224')",
+)
+parser.add_argument(
+ "-o",
+ "--output",
+ dest="output_change",
+ type=str,
+ nargs="+",
+ help="change output shape (e.g. -o 'input_0 1 3 224 224')",
+)
+parser.add_argument(
+ "--add-conv",
+ dest="add_conv",
+ type=str,
+ nargs="+",
+ help="add nop conv using specific input",
+)
+parser.add_argument(
+ "--add-bn",
+ dest="add_bn",
+ type=str,
+ nargs="+",
+ help="add nop bn using specific input",
+)
+parser.add_argument(
+ "--rename-output",
+ dest="rename_output",
+ type=str,
+ nargs="+",
+ help="Rename the specific output(e.g. --rename-output old_name new_name)",
+)
+parser.add_argument(
+ "--pixel-bias-value",
+ dest="pixel_bias_value",
+ type=str,
+ nargs="+",
+ help='(per channel) set pixel value bias bn layer at model front for '
+ 'normalization( e.g. --pixel_bias_value "[104.0, 117.0, 123.0]" )',
+)
+parser.add_argument(
+ "--pixel-scale-value",
+ dest="pixel_scale_value",
+ type=str,
+ nargs="+",
+ help='(per channel) set pixel value scale bn layer at model front for '
+ 'normalization( e.g. --pixel_scale_value '
+ '"[0.0078125, 0.0078125, 0.0078125]" )',
+)
+
+args = parser.parse_args()
+
+# Load model and polish
+m = onnx.load(args.in_file)
+m = other.polish_model(m)
+g = m.graph
+replacing.replace_initializer_with_Constant(g)
+other.topological_sort(g)
+
+# Remove nodes according to the given arguments.
+if args.delete_node is not None:
+ helper.delete_nodes(g, args.delete_node)
+
+if args.delete_input is not None:
+ helper.delete_input(g, args.delete_input)
+
+if args.delete_output is not None:
+ helper.delete_output(g, args.delete_output)
+
+# Add do-nothing Conv node
+if args.add_conv is not None:
+ other.add_nop_conv_after(g, args.add_conv)
+ other.topological_sort(g)
+
+# Add do-nothing BN node
+if args.add_bn is not None:
+ other.add_nop_bn_after(g, args.add_bn)
+ other.topological_sort(g)
+
+# Add bias scale BN node
+if args.pixel_bias_value is not None or args.pixel_scale_value is not None:
+
+ if len(g.input) > 1:
+ raise ValueError(
+ " '--pixel-bias-value' and '--pixel-scale-value' "
+ "only support one input node model currently"
+ )
+
+ i_n = g.input[0]
+
+ pixel_bias_value = [0] * i_n.type.tensor_type.shape.dim[1].dim_value
+ pixel_scale_value = [1] * i_n.type.tensor_type.shape.dim[1].dim_value
+
+ if args.pixel_bias_value is not None and len(args.pixel_bias_value) == 1:
+ pixel_bias_value = [
+ float(n)
+ for n in args.pixel_bias_value[0]
+ .replace("[", "")
+ .replace("]", "")
+ .split(",")
+ ]
+
+ if args.pixel_scale_value is not None and len(args.pixel_scale_value) == 1:
+ pixel_scale_value = [
+ float(n)
+ for n in args.pixel_scale_value[0]
+ .replace("[", "")
+ .replace("]", "")
+ .split(",")
+ ]
+
+ if i_n.type.tensor_type.shape.dim[1].dim_value != len(
+ pixel_bias_value
+ ) or i_n.type.tensor_type.shape.dim[1].dim_value != len(pixel_scale_value):
+ raise ValueError(
+ "--pixel-bias-value ("
+ + str(pixel_bias_value)
+ + ") and --pixel-scale-value ("
+ + str(pixel_scale_value)
+ + ") should be same as input dimension:"
+ + str(i_n.type.tensor_type.shape.dim[1].dim_value)
+ )
+ other.add_bias_scale_bn_after(
+ g, i_n.name, pixel_bias_value, pixel_scale_value
+ )
+
+# Change input and output shapes as requested
+if args.input_change is not None:
+ other.change_input_shape(g, args.input_change)
+if args.output_change is not None:
+ other.change_output_shape(g, args.output_change)
+
+# Cutting nodes according to the given arguments.
+if args.cut_node is not None or args.cut_type is not None:
+ if args.cut_node is None:
+ other.remove_nodes(g, cut_types=args.cut_type)
+ elif args.cut_type is None:
+ other.remove_nodes(g, cut_nodes=args.cut_node)
+ else:
+ other.remove_nodes(g, cut_nodes=args.cut_node, cut_types=args.cut_type)
+ other.topological_sort(g)
+
+# Rename nodes
+if args.rename_output:
+ if len(args.rename_output) % 2 != 0:
+ print("Rename output should be paires of names.")
+ else:
+ for i in range(0, len(args.rename_output), 2):
+ other.rename_output_name(
+ g, args.rename_output[i], args.rename_output[i + 1]
+ )
+
+# Remove useless nodes
+if (
+ args.delete_node
+ or args.delete_input
+ or args.input_change
+ or args.output_change
+):
+ # If shape changed during the modification, redo shape inference.
+ while len(g.value_info) > 0:
+ g.value_info.pop()
+passes = ["extract_constant_to_initializer"]
+m = optimizer.optimize(m, passes)
+g = m.graph
+replacing.replace_initializer_with_Constant(g)
+other.topological_sort(g)
+# Polish and output
+m = other.polish_model(m)
+other.add_output_to_value_info(m.graph)
+onnx.save(m, args.out_file)
diff --git a/tools/optimizer_scripts/norm_on_scaled_onnx.py b/tools/optimizer_scripts/norm_on_scaled_onnx.py
new file mode 100644
index 0000000..7d462c2
--- /dev/null
+++ b/tools/optimizer_scripts/norm_on_scaled_onnx.py
@@ -0,0 +1,54 @@
+import onnx
+import sys
+import json
+
+from tools import special
+
+if len(sys.argv) != 3:
+ print("python norm_on_scaled_onnx.py input.onnx input.json")
+ exit(1)
+
+# Modify onnx
+m = onnx.load(sys.argv[1])
+special.add_0_5_to_normalized_input(m)
+onnx.save(m, sys.argv[1][:-4] + "norm.onnx")
+
+# Change input node
+origin_file = open(sys.argv[2], "r")
+origin_json = json.load(origin_file)
+origin_json["input_node"]["output_datapath_radix"] = [8]
+new_json_str = json.dumps(origin_json)
+
+# Modify json
+file = open(sys.argv[1][:-4] + "norm.onnx" + ".json", "w")
+s = """{{
+ \"{0}\" :
+ {{
+ \"bias_bitwidth\" : 16,
+ \"{0}_bias\" : [15],
+ \"{0}_weight\" : [3,3,3],
+ \"conv_coarse_shift\" : [-4,-4,-4],
+ \"conv_fine_shift\" : [0,0,0],
+ \"conv_total_shift\" : [-4,-4,-4],
+ \"cpu_mode\" : false,
+ \"delta_input_bitwidth\" : [0],
+ \"delta_output_bitwidth\" : 8,
+ \"flag_radix_bias_eq_output\" : true,
+ \"input_scale\" : [[1.0,1.0,1.0]],
+ \"output_scale\" : [1.0, 1.0, 1.0],
+ \"psum_bitwidth\" : 16,
+ \"weight_bitwidth\" : 8,
+ \"input_datapath_bitwidth\" : [8],
+ \"input_datapath_radix\" : [8],
+ \"working_input_bitwidth\" : 8,
+ \"working_input_radix\" : [8],
+ \"working_output_bitwidth\" : 16,
+ \"working_output_radix\" : 15,
+ \"output_datapath_bitwidth\" : 8,
+ \"output_datapath_radix\" : 7
+ }},\n""".format(
+ "input_norm"
+)
+file.write(s + new_json_str[1:])
+file.close()
+origin_file.close()
diff --git a/tools/optimizer_scripts/onnx1_3to1_4.py b/tools/optimizer_scripts/onnx1_3to1_4.py
new file mode 100644
index 0000000..6c6613f
--- /dev/null
+++ b/tools/optimizer_scripts/onnx1_3to1_4.py
@@ -0,0 +1,144 @@
+# ref http://192.168.200.1:8088/jiyuan/converter_scripts.git
+
+import sys
+import onnx
+from tools import other, helper
+
+"""
+Change onnx model from version 1.3 to version 1.4.
+- Modify the BN node by removing the spatial attribute
+- Modify the Upsample node by removing the 'scales' attribute,
+ and adding a constant node instead.
+- Model's ir_version and opset_import are updated.
+"""
+
+
+def remove_BN_spatial(g):
+ for node in g.node:
+ if node.op_type != "BatchNormalization":
+ continue
+ for att in node.attribute:
+ if att.name == "spatial":
+ node.attribute.remove(att)
+
+
+def upsample_attribute_to_const(g):
+ for node in g.node:
+ if node.op_type != "Upsample":
+ continue
+ scales_exist = False
+ for att in node.attribute:
+ if att.name == "scales":
+ scales_exist = True
+ break
+ if not scales_exist:
+ continue
+
+ shape = [len(att.floats)]
+ node.attribute.remove(att)
+ new_node = helper.list_to_constant(
+ node.name + "_input", shape, att.floats
+ )
+
+ g.node.extend([new_node])
+ value_info = onnx.helper.make_tensor_value_info(
+ node.name + "_input", onnx.TensorProto.FLOAT, shape
+ )
+ node.input.extend([node.name + "_input"])
+ g.value_info.extend([value_info])
+
+
+def relu6_to_clip(g):
+ for node in g.node:
+ if node.op_type != "Relu":
+ continue
+ max_val = helper.get_var_attribute_by_name(node, "max", "float")
+ if max_val is None:
+ continue
+ new_node = onnx.helper.make_node(
+ "Clip",
+ node.input,
+ node.output,
+ name=node.name,
+ max=max_val,
+ min=0.0,
+ )
+ g.node.remove(node)
+ g.node.extend([new_node])
+
+
+def PRelu_weight_reshape(g):
+ # For PRelu with single dimension weight. Expand it to 1, x, 1, 1
+ for node in g.node:
+ if node.op_type != "PRelu":
+ continue
+ slope = helper.find_node_by_output_name(g, node.input[1])
+ if slope is not None:
+ # Constant node
+ if len(slope.attribute[0].t.dims) != 1:
+ continue
+ slope.attribute[0].t.dims.append(slope.attribute[0].t.dims[0])
+ slope.attribute[0].t.dims[0] = 1
+ slope.attribute[0].t.dims.append(1)
+ slope.attribute[0].t.dims.append(1)
+ else:
+ # Initializer
+ for i in g.initializer:
+ if i.name == node.input[1]:
+ slope = i
+ break
+ if len(slope.dims) != 1:
+ continue
+ slope.dims.append(slope.dims[0])
+ slope.dims[0] = 1
+ slope.dims.append(1)
+ slope.dims.append(1)
+ input_value = helper.find_input_by_name(g, node.input[1])
+ new_input = onnx.helper.make_tensor_value_info(
+ node.input[1],
+ input_value.type.tensor_type.elem_type,
+ (1, slope.dims[1], 1, 1),
+ )
+ g.input.remove(input_value)
+ g.input.append(new_input)
+ value_info = helper.find_value_by_name(g, node.input[1])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+
+
+def do_convert(m):
+ graph = m.graph
+
+ # Modify the nodes.
+ remove_BN_spatial(graph)
+ upsample_attribute_to_const(graph)
+ relu6_to_clip(graph)
+ PRelu_weight_reshape(graph)
+ other.topological_sort(graph)
+
+ # Change model properties.
+ m.ir_version = 4
+ m.opset_import[0].version = 9
+ return m
+
+
+if __name__ == "__main__":
+ if len(sys.argv) != 3:
+ print("Usage:{} file_in file_out".format(sys.argv[0]))
+ exit(1)
+
+ model = onnx.load(sys.argv[1])
+ graph = model.graph
+
+ # Modify the nodes.
+ remove_BN_spatial(graph)
+ upsample_attribute_to_const(graph)
+ relu6_to_clip(graph)
+ PRelu_weight_reshape(graph)
+ other.topological_sort(graph)
+
+ # Change model properties.
+ model.ir_version = 4
+ model.opset_import[0].version = 9
+
+ onnx.save(model, sys.argv[2])
diff --git a/tools/optimizer_scripts/onnx1_4to1_6.py b/tools/optimizer_scripts/onnx1_4to1_6.py
new file mode 100644
index 0000000..caa5540
--- /dev/null
+++ b/tools/optimizer_scripts/onnx1_4to1_6.py
@@ -0,0 +1,211 @@
+# ref http://192.168.200.1:8088/jiyuan/converter_scripts.git
+
+import sys
+import onnx
+import onnx.utils
+from tools import other, helper, replacing
+
+"""
+Change onnx model from version 1.4 to version 1.6.
+"""
+
+
+def replace_all_attribute_to_const_node_in_pad_node(g):
+ node_to_remove = []
+ node_to_extend = []
+ for node in g.node:
+ if node.op_type != "Pad":
+ continue
+
+ pad_loc_node = None # must have
+ pad_mode = "constant"
+ pad_value_node = helper.list_to_constant(
+ node.name + "_pad_value", [], [0.0]
+ ) # need scalar
+ for att in node.attribute:
+ if att.name == "mode":
+ pad_mode = helper.get_var_attribute_by_name(
+ node, "mode", "string"
+ )
+ if att.name == "pads":
+ pad_loc_node = helper.list_to_constant(
+ node.name + "_pad_loc", [len(att.ints)], att.ints
+ )
+ if att.name == "value":
+ pad_value_node = helper.list_to_constant(
+ node.name + "_pad_value", [], [att.f]
+ )
+
+ new_node = onnx.helper.make_node(
+ "Pad",
+ [node.input[0], pad_loc_node.name, pad_value_node.name],
+ [node.output[0]],
+ name=node.output[0],
+ mode=pad_mode,
+ )
+ node_to_remove.append(node)
+ node_to_extend.append(new_node)
+ node_to_extend.append(pad_loc_node)
+ node_to_extend.append(pad_value_node)
+
+ for node in node_to_remove:
+ g.node.remove(node)
+ for node in node_to_extend:
+ g.node.extend([node])
+
+
+def upsampling_to_resize(g):
+ for node in g.node:
+ if node.op_type != "Upsample":
+ continue
+ upsampling_mode = helper.get_var_attribute_by_name(
+ node, "mode", "string"
+ )
+
+ scale_value_node = helper.find_node_by_output_name(g, node.input[1])
+ if scale_value_node.op_type != "Constant":
+ raise TypeError(
+ 'seems there is a dynamic "scales" param in Upsampling node: '
+ + node.name
+ + " , you might need to do constant folding first"
+ )
+
+ roi_node = helper.list_to_constant(node.name + "_roi_value", [0], [])
+
+ new_node = onnx.helper.make_node(
+ "Resize",
+ [node.input[0], roi_node.name, scale_value_node.name],
+ [node.output[0]],
+ name=node.output[0],
+ mode=upsampling_mode,
+ coordinate_transformation_mode="asymmetric",
+ )
+
+ g.node.remove(node)
+ g.node.extend([new_node])
+ g.node.extend([roi_node])
+
+
+def replace_all_attribute_to_const_node_in_slice_node(g):
+ for node in g.node:
+ if node.op_type != "Slice":
+ continue
+
+ axes_const_node = None
+ ends_const_node = None
+ starts_const_node = None
+ steps_const_node = None
+ for att in node.attribute:
+ if att.name == "axes":
+ axes_const_node = helper.list_to_constant(
+ node.name + "_axes_value", [len(att.ints)], att.ints
+ )
+
+ if att.name == "ends":
+ ends_const_node = helper.list_to_constant(
+ node.name + "_ends_value", [len(att.ints)], att.ints
+ )
+
+ if att.name == "starts":
+ starts_const_node = helper.list_to_constant(
+ node.name + "_starts_value", [len(att.ints)], att.ints
+ )
+
+ if att.name == "steps":
+ steps_const_node = helper.list_to_constant(
+ node.name + "_steps_value", [len(att.ints)], att.ints
+ )
+
+ # pop out from back
+ attr_len = len(node.attribute)
+ for i in range(attr_len):
+ node.attribute.remove(node.attribute[attr_len - 1 - i])
+
+ # according the spec, we need to add node in specific order
+ if starts_const_node is not None:
+ g.node.extend([starts_const_node])
+ node.input.extend([starts_const_node.name])
+ if ends_const_node is not None:
+ g.node.extend([ends_const_node])
+ node.input.extend([ends_const_node.name])
+ if axes_const_node is not None:
+ g.node.extend([axes_const_node])
+ node.input.extend([axes_const_node.name])
+ if steps_const_node is not None:
+ g.node.extend([steps_const_node])
+ node.input.extend([steps_const_node.name])
+
+
+def replace_min_max_attribute_to_const_node_in_clip_node(g):
+ for node in g.node:
+ if node.op_type != "Clip":
+ continue
+
+ max_const_node = None
+ min_const_node = None
+ for att in node.attribute:
+ if att.name == "max":
+ max_const_node = helper.list_to_constant(
+ node.name + "_max_value", [], [att.f]
+ )
+
+ if att.name == "min":
+ min_const_node = helper.list_to_constant(
+ node.name + "_min_value", [], [att.f]
+ )
+
+ # pop out from back
+ node.attribute.remove(node.attribute[1])
+ node.attribute.remove(node.attribute[0])
+
+ # according the spec, we need to add node in specific order
+ g.node.extend([min_const_node])
+ g.node.extend([max_const_node])
+ node.input.extend([min_const_node.name])
+ node.input.extend([max_const_node.name])
+
+
+def onnx1_4to1_6(model: onnx.ModelProto) -> onnx.ModelProto:
+ """Update ir_version from 4 to 6 and update opset from 9 to 11.
+
+ Args:
+ model (onnx.ModelProto): input onnx model.
+
+ Returns:
+ onnx.ModelProto: updated onnx model.
+ """
+ graph = model.graph
+
+ if model.opset_import[0].version == 11:
+ print("(Stop) the input model is already opset 11, no need to upgrade")
+ exit(1)
+
+ # deal with empty node name issue
+ other.add_name_to_node(graph)
+ # simplify the node param type from initializer to constant
+ replacing.replace_initializer_with_Constant(graph)
+
+ # Modify the nodes.
+ replace_min_max_attribute_to_const_node_in_clip_node(graph)
+ replace_all_attribute_to_const_node_in_slice_node(graph)
+ replace_all_attribute_to_const_node_in_pad_node(graph)
+ upsampling_to_resize(graph)
+ other.topological_sort(graph)
+
+ # Change model properties.
+ model.ir_version = 6
+ model.opset_import[0].version = 11
+
+ model = other.polish_model(model)
+ return model
+
+
+if __name__ == "__main__":
+ if len(sys.argv) != 3:
+ print("Usage:{} file_in file_out".format(sys.argv[0]))
+ exit(1)
+
+ model = onnx.load(sys.argv[1])
+ model = onnx1_4to1_6(model)
+
+ onnx.save(model, sys.argv[2])
diff --git a/tools/optimizer_scripts/onnx2onnx.py b/tools/optimizer_scripts/onnx2onnx.py
new file mode 100644
index 0000000..884dd2b
--- /dev/null
+++ b/tools/optimizer_scripts/onnx2onnx.py
@@ -0,0 +1,208 @@
+import onnx
+import onnx.utils
+
+import argparse
+import logging
+
+from tools import eliminating
+from tools import other
+from tools import special
+from tools import combo
+
+# from tools import temp
+
+
+def onnx2onnx_flow(
+ m: onnx.ModelProto,
+ disable_fuse_bn=False,
+ bn_on_skip=False,
+ bn_before_add=False,
+ bgr=False,
+ norm=False,
+ rgba2yynn=False,
+ eliminate_tail=False,
+ opt_matmul=False,
+ duplicate_shared_weights=True,
+) -> onnx.ModelProto:
+ """Optimize the onnx.
+
+ Args:
+ m (ModelProto): the input onnx ModelProto
+ disable_fuse_bn (bool, optional): do not fuse BN into Conv.
+ Defaults to False.
+ bn_on_skip (bool, optional): add BN operator on skip branches.
+ Defaults to False.
+ bn_before_add (bool, optional): add BN before Add node on every branch.
+ Defaults to False.
+ bgr (bool, optional): add an Conv layer to convert rgb input to bgr.
+ Defaults to False.
+ norm (bool, optional): add an Conv layer to add 0.5 tp the input.
+ Defaults to False.
+ rgba2yynn (bool, optional): add an Conv layer to convert rgb to yynn.
+ Defaults to False.
+ eliminate_tail (bool, optional): remove trailing NPU unsupported nodes.
+ Defaults to False.
+ opt_matmul(bool, optional): optimize MatMul layers due to NPU limit.
+ Defaults to False.
+ duplicate_shared_weights(bool, optional): duplicate shared weights.
+ Defaults to True.
+
+ Returns:
+ ModelProto: the optimized onnx model object.
+ """
+ # temp.weight_broadcast(m.graph)
+ m = combo.preprocess(m, disable_fuse_bn, duplicate_shared_weights)
+ # temp.fuse_bias_in_consecutive_1x1_conv(m.graph)
+
+ # Add BN on skip branch
+ if bn_on_skip:
+ other.add_bn_on_skip_branch(m.graph)
+ elif bn_before_add:
+ other.add_bn_before_add(m.graph)
+ other.add_bn_before_activation(m.graph)
+
+ # My optimization
+ m = combo.common_optimization(m)
+ # Special options
+ if bgr:
+ special.change_input_from_bgr_to_rgb(m)
+ if norm:
+ special.add_0_5_to_normalized_input(m)
+ if rgba2yynn:
+ special.add_rgb2yynn_node(m)
+
+ # Remove useless last node
+ if eliminate_tail:
+ eliminating.remove_useless_last_nodes(m.graph)
+
+ # Postprocessing
+ m = combo.postprocess(m)
+
+ # Put matmul after postprocess to avoid transpose moving downwards
+ if opt_matmul:
+ special.special_MatMul_process(m.graph)
+ m = other.polish_model(m)
+
+ return m
+
+
+# Main process
+if __name__ == "__main__":
+ # Argument parser
+ parser = argparse.ArgumentParser(
+ description="Optimize an ONNX model for Kneron compiler"
+ )
+ parser.add_argument("in_file", help="input ONNX FILE")
+ parser.add_argument(
+ "-o", "--output", dest="out_file", type=str, help="ouput ONNX FILE"
+ )
+ parser.add_argument("--log", default="i", type=str, help="set log level")
+ parser.add_argument(
+ "--bgr",
+ action="store_true",
+ default=False,
+ help="set if the model is trained in BGR mode",
+ )
+ parser.add_argument(
+ "--norm",
+ action="store_true",
+ default=False,
+ help="set if you have the input -0.5~0.5",
+ )
+ parser.add_argument(
+ "--rgba2yynn",
+ action="store_true",
+ default=False,
+ help="set if the model has yynn input but you want "
+ "to take rgba images",
+ )
+ parser.add_argument(
+ "--add-bn-on-skip",
+ dest="bn_on_skip",
+ action="store_true",
+ default=False,
+ help="set if you only want to add BN on skip branches",
+ )
+ parser.add_argument(
+ "--add-bn",
+ dest="bn_before_add",
+ action="store_true",
+ default=False,
+ help="set if you want to add BN before Add",
+ )
+ parser.add_argument(
+ "-t",
+ "--eliminate-tail-unsupported",
+ dest="eliminate_tail",
+ action="store_true",
+ default=False,
+ help="whether remove the last unsupported node for hardware",
+ )
+ parser.add_argument(
+ "--no-bn-fusion",
+ dest="disable_fuse_bn",
+ action="store_true",
+ default=False,
+ help="set if you have met errors which related to inferenced "
+ "shape mismatch. This option will prevent fusing "
+ "BatchNormalization into Conv.",
+ )
+ parser.add_argument(
+ "--opt-matmul",
+ dest="opt_matmul",
+ action="store_true",
+ default=False,
+ help="set if you want to optimize MatMul operations "
+ "for kneron hardware.",
+ )
+ parser.add_argument(
+ "--no-duplicate-shared-weights",
+ dest="no_duplicate_shared_weights",
+ action="store_true",
+ default=False,
+ help="do not duplicate shared weights. Defaults to False.",
+ )
+ args = parser.parse_args()
+
+ if args.out_file is None:
+ outfile = args.in_file[:-5] + "_polished.onnx"
+ else:
+ outfile = args.out_file
+
+ if args.log == "w":
+ logging.basicConfig(level=logging.WARN)
+ elif args.log == "d":
+ logging.basicConfig(level=logging.DEBUG)
+ elif args.log == "e":
+ logging.basicConfig(level=logging.ERROR)
+ else:
+ logging.basicConfig(level=logging.INFO)
+
+ # onnx Polish model includes:
+ # -- nop
+ # -- eliminate_identity
+ # -- eliminate_nop_transpose
+ # -- eliminate_nop_pad
+ # -- eliminate_unused_initializer
+ # -- fuse_consecutive_squeezes
+ # -- fuse_consecutive_transposes
+ # -- fuse_add_bias_into_conv
+ # -- fuse_transpose_into_gemm
+
+ # Basic model organize
+ m = onnx.load(args.in_file)
+
+ m = onnx2onnx_flow(
+ m,
+ args.disable_fuse_bn,
+ args.bn_on_skip,
+ args.bn_before_add,
+ args.bgr,
+ args.norm,
+ args.rgba2yynn,
+ args.eliminate_tail,
+ args.opt_matmul,
+ not args.no_duplicate_shared_weights,
+ )
+
+ onnx.save(m, outfile)
diff --git a/tools/optimizer_scripts/onnx_vs_onnx.py b/tools/optimizer_scripts/onnx_vs_onnx.py
new file mode 100644
index 0000000..d416045
--- /dev/null
+++ b/tools/optimizer_scripts/onnx_vs_onnx.py
@@ -0,0 +1,181 @@
+import onnxruntime
+import onnx
+import argparse
+import numpy as np
+from tools import helper
+
+
+onnx2np_dtype = {
+ 0: "float",
+ 1: "float32",
+ 2: "uint8",
+ 3: "int8",
+ 4: "uint16",
+ 5: "int16",
+ 6: "int32",
+ 7: "int64",
+ 8: "str",
+ 9: "bool",
+ 10: "float16",
+ 11: "double",
+ 12: "uint32",
+ 13: "uint64",
+ 14: "complex64",
+ 15: "complex128",
+ 16: "float",
+}
+
+
+def onnx_model_results(path_a, path_b, total_times=10):
+ """using onnxruntime to inference two onnx models' ouputs
+
+ :onnx model paths: two model paths
+ :total_times: inference times, default to be 10
+ :returns: inference results of two models
+ """
+ # load model a and model b to runtime
+ session_a = onnxruntime.InferenceSession(path_a, None)
+ session_b = onnxruntime.InferenceSession(path_b, None)
+ outputs_a = session_a.get_outputs()
+ outputs_b = session_b.get_outputs()
+
+ # check outputs
+ assert len(outputs_a) == len(
+ outputs_b
+ ), "Two models have different output numbers."
+ for i in range(len(outputs_a)):
+ out_shape_a, out_shape_b = outputs_a[i].shape, outputs_b[i].shape
+ out_shape_a = list(
+ map(lambda x: x if isinstance(x, int) else 1, out_shape_a)
+ )
+ out_shape_b = list(
+ map(lambda x: x if isinstance(x, int) else 1, out_shape_b)
+ )
+ assert (
+ out_shape_a == out_shape_b
+ ), "Output {} has unmatched shapes".format(i)
+
+ # load onnx graph_a and graph_b, to find the initializer and inputs
+ # then compare to remove the items in the inputs which will be initialized
+ model_a, model_b = onnx.load(path_a), onnx.load(path_b)
+ graph_a, graph_b = model_a.graph, model_b.graph
+ inputs_a, inputs_b = graph_a.input, graph_b.input
+ init_a, init_b = graph_a.initializer, graph_b.initializer
+
+ # remove initializer from raw inputs
+ input_names_a, input_names_b = set([ele.name for ele in inputs_a]), set(
+ [ele.name for ele in inputs_b]
+ )
+ init_names_a, init_names_b = set([ele.name for ele in init_a]), set(
+ [ele.name for ele in init_b]
+ )
+ real_inputs_names_a, real_inputs_names_b = (
+ input_names_a - init_names_a,
+ input_names_b - init_names_b,
+ )
+
+ # prepare and figure out matching of real inputs a and real inputs b
+ # try to keep original orders of each inputs
+ real_inputs_a, real_inputs_b = [], []
+ for item in inputs_a:
+ if item.name in real_inputs_names_a:
+ real_inputs_a.append(item)
+ for item in inputs_b:
+ if item.name in real_inputs_names_b:
+ real_inputs_b.append(item)
+
+ # suppose there's only one real single input tensor for each model
+ # find the real single inputs for model_a and model_b
+ real_single_input_a = None
+ real_single_input_b = None
+ size_a, size_b = 0, 0
+ shape_a, shape_b = [], []
+ for item_a in real_inputs_a:
+ size, shape = helper.find_size_shape_from_value(item_a)
+ if size:
+ assert (
+ real_single_input_a is None
+ ), "Multiple inputs of first model, single input expected."
+ real_single_input_a = item_a
+ size_a, shape_a = size, shape
+ for item_b in real_inputs_b:
+ size, shape = helper.find_size_shape_from_value(item_b)
+ if size:
+ assert (
+ real_single_input_b is None
+ ), "Multiple inputs of second model, single input expected."
+ real_single_input_b = item_b
+ size_b, shape_b = size, shape
+ assert size_a == size_b, "Sizes of two models do not match."
+
+ # construct inputs tensors
+ input_data_type_a = real_single_input_a.type.tensor_type.elem_type
+ input_data_type_b = real_single_input_b.type.tensor_type.elem_type
+ input_data_type_a = onnx2np_dtype[input_data_type_a]
+ input_data_type_b = onnx2np_dtype[input_data_type_b]
+
+ # run inference
+ times = 0
+ results_a = [[] for i in range(len(outputs_a))]
+ results_b = [[] for i in range(len(outputs_b))]
+ while times < total_times:
+ # initialize inputs by random data, default to be uniform
+ data = np.random.random(size_a)
+ input_a = np.reshape(data, shape_a).astype(input_data_type_a)
+ input_b = np.reshape(data, shape_b).astype(input_data_type_b)
+
+ input_dict_a = {}
+ input_dict_b = {}
+ for item_a in real_inputs_a:
+ item_type_a = onnx2np_dtype[item_a.type.tensor_type.elem_type]
+ input_dict_a[item_a.name] = (
+ np.array([]).astype(item_type_a)
+ if item_a.name != real_single_input_a.name
+ else input_a
+ )
+ for item_b in real_inputs_b:
+ item_type_b = onnx2np_dtype[item_b.type.tensor_type.elem_type]
+ input_dict_b[item_b.name] = (
+ np.array([]).astype(item_type_b)
+ if item_b.name != real_single_input_b.name
+ else input_b
+ )
+
+ ra = session_a.run([], input_dict_a)
+ rb = session_b.run([], input_dict_b)
+ for i in range(len(outputs_a)):
+ results_a[i].append(ra[i])
+ results_b[i].append(rb[i])
+ times += 1
+
+ return results_a, results_b
+
+
+if __name__ == "__main__":
+ # Argument parser.
+ parser = argparse.ArgumentParser(
+ description="Compare two ONNX models to check if "
+ "they have the same output."
+ )
+ parser.add_argument("in_file_a", help="input ONNX file a")
+ parser.add_argument("in_file_b", help="input ONNX file b")
+
+ args = parser.parse_args()
+
+ results_a, results_b = onnx_model_results(
+ args.in_file_a, args.in_file_b, total_times=10
+ )
+ ra_flat = helper.flatten_with_depth(results_a, 0)
+ rb_flat = helper.flatten_with_depth(results_b, 0)
+ shape_a = [item[1] for item in ra_flat]
+ shape_b = [item[1] for item in rb_flat]
+ assert shape_a == shape_b, "two results data shape doesn't match"
+ ra_raw = [item[0] for item in ra_flat]
+ rb_raw = [item[0] for item in rb_flat]
+
+ try:
+ np.testing.assert_almost_equal(ra_raw, rb_raw, 4)
+ print("Two models have the same behaviour.")
+ except Exception as mismatch:
+ print(mismatch)
+ exit(1)
diff --git a/tools/optimizer_scripts/onnx_vs_onnx_opt.py b/tools/optimizer_scripts/onnx_vs_onnx_opt.py
new file mode 100644
index 0000000..5ac4e6b
--- /dev/null
+++ b/tools/optimizer_scripts/onnx_vs_onnx_opt.py
@@ -0,0 +1,248 @@
+import argparse
+import glob
+import csv
+import numpy as np
+import matplotlib.pyplot as plt
+
+from tools import helper
+import onnx_vs_onnx as onnx_tester
+
+
+def compare_results(results_a, results_b):
+ """compare onnx model inference results
+ calculate basic statistical values
+ results: results from inference multiple times
+ returns: list of basic statistical values
+ """
+ # input results data can be of nonuniform shape
+ # get flatten data to compare
+ ra_flat = helper.flatten_with_depth(results_a, 0)
+ rb_flat = helper.flatten_with_depth(results_b, 0)
+ shape_a = [item[1] for item in ra_flat]
+ shape_b = [item[1] for item in rb_flat]
+ assert shape_a == shape_b, "two results data shape doesn't match"
+ ra_raw = [item[0] for item in ra_flat]
+ rb_raw = [item[0] for item in rb_flat]
+
+ # the statistical values
+ max_rel_diff = (
+ 0 # defined to be max( { abs(diff)/max(abs(ra), abs(rb) ) } )
+ )
+ max_abs_diff = 0 # defined to be max( { abs(ra-rb) } )
+ mean_rel_diff = 0
+ mean_abs_diff = 0
+ std_rel_diff = 0
+ std_abs_diff = 0
+ acc_with_diff_precision = []
+ rel_diff = []
+ abs_diff_percentiles = [] # rel_diff percentiles
+ rel_diff_percentiles = [] # abs_diff precentiles
+
+ raw_diff = [ra_raw[i] - rb_raw[i] for i in range(len(ra_raw))]
+ abs_diff = [abs(num) for num in raw_diff]
+ for i in range(len(ra_raw)):
+ divider = max([abs(ra_raw[i]), abs(rb_raw[i])])
+ val = abs_diff[i] / divider if divider != 0 else 0
+ rel_diff.append(val)
+
+ max_rel_diff = max(rel_diff)
+ max_abs_diff = max(abs_diff)
+ mean_rel_diff = np.average(rel_diff)
+ mean_abs_diff = np.average(abs_diff)
+ std_rel_diff = np.std(rel_diff)
+ std_abs_diff = np.std(abs_diff)
+
+ # calculate accuracy with different precison
+ for digit in range(8):
+ correct = 0
+ for i in range(len(ra_raw)):
+ if format(ra_raw[i], "." + str(digit) + "f") == format(
+ rb_raw[i], "." + str(digit) + "f"
+ ):
+ correct += 1
+ acc_with_diff_precision.append(
+ [digit, float(format(correct / len(ra_raw), ".3f"))]
+ )
+
+ # analyze rel_diff distribution
+ rel_diff.sort()
+ abs_diff.sort()
+ for i in range(20):
+ rel_diff_percentiles.append(
+ ["{}%".format(i * 5), rel_diff[int((i / 20) * len(rel_diff))]]
+ )
+ abs_diff_percentiles.append(
+ ["{}%".format(i * 5), abs_diff[int((i / 20) * len(abs_diff))]]
+ )
+
+ results = [
+ ["max_rel_diff", max_rel_diff],
+ ["max_abs_diff", max_abs_diff],
+ ["mean_rel_diff", mean_rel_diff],
+ ["mean_abs_diff", mean_abs_diff],
+ ["std_rel_diff", std_rel_diff],
+ ["std_abs_diff", std_abs_diff],
+ ["acc_with_diff_precision", acc_with_diff_precision],
+ ["rel_diff_percentiles", rel_diff_percentiles],
+ ["abs_diff_percentiles", abs_diff_percentiles],
+ ]
+
+ return results
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ description="test model optimization results"
+ )
+
+ parser.add_argument(
+ "dir", type=str, help="the directory that stores onnx models"
+ )
+ parser.add_argument(
+ "ending1", type=str, help="model file name ending(eg, .onnx)"
+ )
+ parser.add_argument(
+ "ending2", type=str, help="opt model file name ending(eg. _opt.onnx)"
+ )
+ parser.add_argument("out_file", type=str, help="output csv file name")
+ parser.add_argument("-p", "--plot", default="N", help="get plots (Y/N)")
+ parser.add_argument(
+ "-i", "--iter_times", default=10, type=int, help="inference times"
+ )
+
+ args = parser.parse_args()
+
+ old_models_paths = glob.glob(args.dir + "*" + args.ending1)
+ new_models_paths = glob.glob(args.dir + "*" + args.ending2)
+
+ stats_table = [
+ [
+ "Model",
+ "max_rel_diff",
+ "max_abs_diff",
+ "mean_rel_diff",
+ "mean_abs_diff",
+ "std_rel_diff",
+ "std_abs_diff",
+ "acc_with_diff_precision",
+ "rel_diff_percentiles",
+ "abs_diff_percentiles",
+ ]
+ ]
+
+ for new_model_path in new_models_paths:
+ old_model_path = new_model_path[: -len(args.ending2)] + args.ending1
+ if old_model_path not in old_models_paths:
+ continue
+
+ # run inference
+ results_a, results_b = onnx_tester.onnx_model_results(
+ old_model_path, new_model_path, total_times=args.iter_times
+ )
+
+ # compare inference results
+ comparision = compare_results(results_a, results_b)
+
+ new_line = [old_model_path.split("/")[-1]]
+ for item in comparision:
+ new_line.append(item[1])
+
+ stats_table.append(new_line)
+
+ # try to read existing file
+ old_stats_table = []
+ try:
+ old_file = open(args.out_file, "r")
+ reader = csv.reader(old_file)
+ old_header = reader.__next__()
+ for row in reader:
+ old_stats_table.append(row)
+ old_file.close()
+ except Exception:
+ pass
+
+ # compare and merge possible old stat data file with new stat data file
+ header = stats_table[0]
+ stats_table = stats_table[1:]
+ new_model_names = set([item[0] for item in stats_table])
+ for row in old_stats_table:
+ if row[0] not in new_model_names:
+ stats_table.append(row)
+ stats_table.insert(0, header)
+
+ # write a new stat data file, overwrite old file
+ new_file = open(args.out_file, "w", newline="")
+ writer = csv.writer(new_file)
+ for row in stats_table:
+ writer.writerow(row)
+ new_file.close()
+
+ # make some plots
+ if args.plot == "Y":
+ if len(stats_table) < 2:
+ exit(0)
+
+ sample_table = (
+ stats_table[1:] if len(stats_table) < 6 else stats_table[1:6]
+ )
+
+ max_rel_diffs = [round(float(item[1]), 2) for item in stats_table[1:]]
+ plt.hist(max_rel_diffs, bins=15)
+ plt.title("Max Relavtive Difference Histogram")
+ plt.xlabel("Max Relative Difference")
+ plt.ylabel("Counts")
+ plt.savefig("max_rel_diff_hist.png")
+ plt.close()
+
+ max_abs_diffs = [round(float(item[2]), 2) for item in stats_table[1:]]
+ plt.hist(max_abs_diffs, bins=15)
+ plt.title("Max Absolute Difference Histogram")
+ plt.xlabel("Max Absolute Difference")
+ plt.ylabel("Counts")
+ plt.savefig("max_abs_diff_hist.png")
+ plt.close()
+
+ for line in sample_table:
+ model_name = line[0]
+ percentiles = line[-2]
+ x = [
+ round(i * (1 / len(percentiles)), 2)
+ for i in range(len(percentiles))
+ ]
+ y = [ele[1] for ele in percentiles]
+ plt.plot(x, y, label=model_name)
+ plt.title("Rel_diff Percentiles of Raw and Optimized Models")
+ plt.xlabel("percentage")
+ plt.ylabel("relative difference")
+ plt.legend()
+ plt.savefig("rel_diff_percentiles.png")
+ plt.close()
+
+ for line in sample_table:
+ model_name = line[0]
+ percentiles = line[-1]
+ x = [
+ round(i * (1 / len(percentiles)), 2)
+ for i in range(len(percentiles))
+ ]
+ y = [ele[1] for ele in percentiles]
+ plt.plot(x, y, label=model_name)
+ plt.title("Abs_diff Percentiles of Raw and Optimized Models")
+ plt.xlabel("percentage")
+ plt.ylabel("absolute difference")
+ plt.legend()
+ plt.savefig("abs_diff_percentiles.png")
+ plt.close()
+
+ for line in sample_table:
+ model_name = line[0]
+ accuracies = line[-3]
+ x = [acc[0] for acc in accuracies]
+ y = [acc[1] for acc in accuracies]
+ plt.plot(x, y, label=model_name)
+ plt.title("Accuracies with Different Precisions")
+ plt.xlabel("Decimals")
+ plt.ylabel("Precision")
+ plt.legend()
+ plt.savefig("precisions.png")
+ plt.close()
diff --git a/tools/optimizer_scripts/pytorch2onnx.py b/tools/optimizer_scripts/pytorch2onnx.py
new file mode 100644
index 0000000..9dd79ec
--- /dev/null
+++ b/tools/optimizer_scripts/pytorch2onnx.py
@@ -0,0 +1,93 @@
+import onnx
+import onnx.utils
+
+import sys
+import logging
+import argparse
+
+from pytorch_exported_onnx_preprocess import torch_exported_onnx_flow
+
+# Debug use
+# logging.basicConfig(level=logging.DEBUG)
+
+######################################
+# Generate a prototype onnx #
+######################################
+
+parser = argparse.ArgumentParser(
+ description="Optimize a Pytorch generated model for Kneron compiler"
+)
+parser.add_argument("in_file", help="input ONNX or PTH FILE")
+parser.add_argument("out_file", help="ouput ONNX FILE")
+parser.add_argument(
+ "--input-size",
+ dest="input_size",
+ nargs=3,
+ help="if you using pth, please use this argument to set up the input "
+ "size of the model. It should be in 'CH H W' format, "
+ "e.g. '--input-size 3 256 512'.",
+)
+parser.add_argument(
+ "--no-bn-fusion",
+ dest="disable_fuse_bn",
+ action="store_true",
+ default=False,
+ help="set if you have met errors which related to inferenced shape "
+ "mismatch. This option will prevent fusing BatchNormalization "
+ "into Conv.",
+)
+
+args = parser.parse_args()
+
+if len(args.in_file) <= 4:
+ # When the filename is too short.
+ logging.error("Invalid input file: {}".format(args.in_file))
+ exit(1)
+elif args.in_file[-4:] == ".pth":
+ # Pytorch pth case
+ logging.warning("Converting from pth to onnx is not recommended.")
+ onnx_in = args.out_file
+ # Import pytorch libraries
+ from torch.autograd import Variable
+ import torch
+ import torch.onnx
+
+ # import torchvision
+ # Standard ImageNet input - 3 channels, 224x224.
+ # Values don't matter as we care about network structure.
+ # But they can also be real inputs.
+ if args.input_size is None:
+ logging.error("'--input-size' is required for the pth input file.")
+ exit(1)
+ dummy_input = Variable(
+ torch.randn(
+ 1,
+ int(args.input_size[0]),
+ int(args.input_size[1]),
+ int(args.input_size[2]),
+ )
+ )
+ # Obtain your model, it can be also constructed in your script explicitly.
+ model = torch.load(sys.argv[1], map_location="cpu")
+ # model = torchvision.models.resnet34(pretrained=True)
+ # Invoke export.
+ # torch.save(model, "resnet34.pth")
+ torch.onnx.export(model, dummy_input, args.out_file, opset_version=11)
+elif args.in_file[-4:] == "onnx":
+ onnx_in = args.in_file
+else:
+ # When the file is neither an onnx or a pytorch pth.
+ logging.error("Invalid input file: {}".format(args.in_file))
+ exit(1)
+
+onnx_out = args.out_file
+
+######################################
+# Optimize onnx #
+######################################
+
+m = onnx.load(onnx_in)
+
+m = torch_exported_onnx_flow(m, args.disable_fuse_bn)
+
+onnx.save(m, onnx_out)
diff --git a/tools/optimizer_scripts/pytorch_exported_onnx_preprocess.py b/tools/optimizer_scripts/pytorch_exported_onnx_preprocess.py
new file mode 100644
index 0000000..356f0e3
--- /dev/null
+++ b/tools/optimizer_scripts/pytorch_exported_onnx_preprocess.py
@@ -0,0 +1,82 @@
+import onnx
+import onnx.utils
+
+import logging
+import argparse
+
+from .tools import combo
+
+
+# Define general pytorch exported onnx optimize process
+def torch_exported_onnx_flow(
+ m: onnx.ModelProto, disable_fuse_bn=False
+) -> onnx.ModelProto:
+ """Optimize the Pytorch exported onnx.
+
+ Args:
+ m (ModelProto): the input onnx model
+ disable_fuse_bn (bool, optional): do not fuse BN into Conv.
+ Defaults to False.
+
+ Returns:
+ ModelProto: the optimized onnx model
+ """
+ m = combo.preprocess(m, disable_fuse_bn)
+ m = combo.pytorch_constant_folding(m)
+ m = combo.common_optimization(m)
+ m = combo.postprocess(m)
+
+ return m
+
+
+# Main Process
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ description="Optimize a Pytorch generated model for Kneron compiler"
+ )
+ parser.add_argument("in_file", help="input ONNX")
+ parser.add_argument("out_file", help="ouput ONNX FILE")
+ parser.add_argument("--log", default="i", type=str, help="set log level")
+ parser.add_argument(
+ "--no-bn-fusion",
+ dest="disable_fuse_bn",
+ action="store_true",
+ default=False,
+ help="set if you have met errors which related to inferenced shape "
+ "mismatch. This option will prevent fusing BatchNormalization "
+ "into Conv.",
+ )
+
+ args = parser.parse_args()
+
+ if args.log == "w":
+ logging.basicConfig(level=logging.WARN)
+ elif args.log == "d":
+ logging.basicConfig(level=logging.DEBUG)
+ elif args.log == "e":
+ logging.basicConfig(level=logging.ERROR)
+ else:
+ logging.basicConfig(level=logging.INFO)
+
+ if len(args.in_file) <= 4:
+ # When the filename is too short.
+ logging.error("Invalid input file: {}".format(args.in_file))
+ exit(1)
+ elif args.in_file[-4:] == "onnx":
+ onnx_in = args.in_file
+ else:
+ # When the file is not an onnx file.
+ logging.error("Invalid input file: {}".format(args.in_file))
+ exit(1)
+
+ onnx_out = args.out_file
+
+ ######################################
+ # Optimize onnx #
+ ######################################
+
+ m = onnx.load(onnx_in)
+
+ m = torch_exported_onnx_flow(m, args.disable_fuse_bn)
+
+ onnx.save(m, onnx_out)
diff --git a/tools/optimizer_scripts/res/first_insert_layer.json b/tools/optimizer_scripts/res/first_insert_layer.json
new file mode 100644
index 0000000..4fe3f59
--- /dev/null
+++ b/tools/optimizer_scripts/res/first_insert_layer.json
@@ -0,0 +1,27 @@
+{
+ "LAYERNAME" :
+ {
+ "bias_bitwidth" : 16,
+ "LAYERNAME_bias" : [15],
+ "LAYERNAME_weight" : [3,3,3],
+ "conv_coarse_shift" : [-4,-4,-4],
+ "conv_fine_shift" : [0,0,0],
+ "conv_total_shift" : [-4,-4,-4],
+ "cpu_mode" : false,
+ "delta_input_bitwidth" : [0],
+ "delta_output_bitwidth" : 8,
+ "flag_radix_bias_eq_output" : true,
+ "input_scale" : [[1.0,1.0,1.0]],
+ "output_scale" : [1.0, 1.0, 1.0],
+ "psum_bitwidth" : 16,
+ "weight_bitwidth" : 8,
+ "input_datapath_bitwidth" : [8],
+ "input_datapath_radix" : [7],
+ "working_input_bitwidth" : 8,
+ "working_input_radix" : [7],
+ "working_output_bitwidth" : 16,
+ "working_output_radix" : 15,
+ "output_datapath_bitwidth" : 8,
+ "output_datapath_radix" : 7
+ }
+}
diff --git a/tools/optimizer_scripts/res/test_onnx_tester_on_difference.sh b/tools/optimizer_scripts/res/test_onnx_tester_on_difference.sh
new file mode 100644
index 0000000..342b198
--- /dev/null
+++ b/tools/optimizer_scripts/res/test_onnx_tester_on_difference.sh
@@ -0,0 +1,9 @@
+#!/bin/bash
+
+python onnx_tester.py /test_models/mobilenet_v2_224.onnx /test_models/mobilenet_v2_224.cut.onnx
+if [ $? -eq 0 ]; then
+ echo "Those two model results should be different!"
+ exit 1
+fi
+
+exit 0
diff --git a/tools/optimizer_scripts/res/vdsr_41_20layer_1.pb b/tools/optimizer_scripts/res/vdsr_41_20layer_1.pb
new file mode 100644
index 0000000..81096de
Binary files /dev/null and b/tools/optimizer_scripts/res/vdsr_41_20layer_1.pb differ
diff --git a/tools/optimizer_scripts/tensorflow2onnx.py b/tools/optimizer_scripts/tensorflow2onnx.py
new file mode 100644
index 0000000..44b8667
--- /dev/null
+++ b/tools/optimizer_scripts/tensorflow2onnx.py
@@ -0,0 +1,180 @@
+import tensorflow as tf
+import tf2onnx
+import argparse
+import logging
+import sys
+import onnx
+import onnx.utils
+from tensorflow.python.platform import gfile
+from tools import combo, eliminating, replacing, other
+
+
+def tf2onnx_flow(pb_path: str, test_mode=False) -> onnx.ModelProto:
+ """Convert frozen graph pb file into onnx
+
+ Args:
+ pb_path (str): input pb file path
+ test_mode (bool, optional): test mode. Defaults to False.
+
+ Raises:
+ Exception: invalid input file
+
+ Returns:
+ onnx.ModelProto: converted onnx
+ """
+ TF2ONNX_VERSION = int(tf2onnx.version.version.replace(".", ""))
+
+ if 160 <= TF2ONNX_VERSION:
+ from tf2onnx import tf_loader
+ else:
+ from tf2onnx import loader as tf_loader
+
+ if pb_path[-3:] == ".pb":
+ model_name = pb_path.split("/")[-1][:-3]
+
+ # always reset tensorflow session at begin
+ tf.reset_default_graph()
+
+ with tf.Session() as sess:
+ with gfile.FastGFile(pb_path, "rb") as f:
+ graph_def = tf.GraphDef()
+ graph_def.ParseFromString(f.read())
+ sess.graph.as_default()
+ tf.import_graph_def(graph_def, name="")
+
+ if 160 <= int(tf2onnx.version.version.replace(".", "")):
+ (
+ onnx_nodes,
+ op_cnt,
+ attr_cnt,
+ output_shapes,
+ dtypes,
+ functions,
+ ) = tf2onnx.tf_utils.tflist_to_onnx(sess.graph, {})
+ else:
+ (
+ onnx_nodes,
+ op_cnt,
+ attr_cnt,
+ output_shapes,
+ dtypes,
+ ) = tf2onnx.tfonnx.tflist_to_onnx(
+ sess.graph.get_operations(), {}
+ )
+
+ for n in onnx_nodes:
+ if len(n.output) == 0:
+ onnx_nodes.remove(n)
+
+ # find inputs and outputs of graph
+ nodes_inputs = set()
+ nodes_outputs = set()
+
+ for n in onnx_nodes:
+ if n.op_type == "Placeholder":
+ continue
+ for input in n.input:
+ nodes_inputs.add(input)
+ for output in n.output:
+ nodes_outputs.add(output)
+
+ graph_input_names = set()
+ for input_name in nodes_inputs:
+ if input_name not in nodes_outputs:
+ graph_input_names.add(input_name)
+
+ graph_output_names = set()
+ for n in onnx_nodes:
+ if n.input and n.input[0] not in nodes_outputs:
+ continue
+ if len(n.output) == 0:
+ n.output.append(n.name + ":0")
+ graph_output_names.add(n.output[0])
+ else:
+ output_name = n.output[0]
+ if (output_name not in nodes_inputs) and (
+ 0 < len(n.input)
+ ):
+ graph_output_names.add(output_name)
+
+ logging.info("Model Inputs: %s", str(list(graph_input_names)))
+ logging.info("Model Outputs: %s", str(list(graph_output_names)))
+
+ graph_def, inputs, outputs = tf_loader.from_graphdef(
+ model_path=pb_path,
+ input_names=list(graph_input_names),
+ output_names=list(graph_output_names),
+ )
+
+ with tf.Graph().as_default() as tf_graph:
+ tf.import_graph_def(graph_def, name="")
+
+ if 160 <= TF2ONNX_VERSION:
+ with tf_loader.tf_session(graph=tf_graph):
+ onnx_graph = tf2onnx.tfonnx.process_tf_graph(
+ tf_graph=tf_graph,
+ input_names=inputs,
+ output_names=outputs,
+ opset=11,
+ )
+ else:
+ with tf.Session(graph=tf_graph):
+ onnx_graph = tf2onnx.tfonnx.process_tf_graph(
+ tf_graph=tf_graph,
+ input_names=inputs,
+ output_names=outputs,
+ opset=11,
+ )
+
+ # Optimize with tf2onnx.optimizer
+ onnx_graph = tf2onnx.optimizer.optimize_graph(onnx_graph)
+ model_proto = onnx_graph.make_model(model_name)
+
+ # Make tf2onnx output compatible with the spec. of other.polish_model
+ replacing.replace_initializer_with_Constant(model_proto.graph)
+ model_proto = other.polish_model(model_proto)
+
+ else:
+ raise Exception(
+ 'expect .pb file as input, but got "' + str(pb_path) + '"'
+ )
+
+ # rename
+ m = model_proto
+
+ m = combo.preprocess(m)
+ m = combo.common_optimization(m)
+ m = combo.tensorflow_optimization(m)
+ m = combo.postprocess(m)
+
+ if not test_mode:
+ g = m.graph
+ eliminating.eliminate_shape_changing_after_input(g)
+
+ m = other.polish_model(m)
+ return m
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ description="Convert tensorflow pb file to onnx file and optimized "
+ "onnx file. Or just optimize tensorflow onnx file."
+ )
+ parser.add_argument("in_file", help="input file")
+ parser.add_argument("out_file", help="output optimized model file")
+ parser.add_argument(
+ "-t",
+ "--test_mode",
+ default=False,
+ help="test mode will not eliminate shape changes after input",
+ )
+
+ args = parser.parse_args()
+ logging.basicConfig(
+ stream=sys.stdout,
+ format="[%(asctime)s] %(levelname)s: %(message)s",
+ level=logging.INFO,
+ )
+ m = tf2onnx_flow(args.in_file, args.test_mode)
+ onnx.save(m, args.out_file)
+ logging.info("Save Optimized ONNX: %s", args.out_file)
diff --git a/tools/optimizer_scripts/tflite_vs_onnx.py b/tools/optimizer_scripts/tflite_vs_onnx.py
new file mode 100644
index 0000000..e8405cf
--- /dev/null
+++ b/tools/optimizer_scripts/tflite_vs_onnx.py
@@ -0,0 +1,85 @@
+import argparse
+import numpy as np
+import tensorflow as tf
+import onnx
+import onnxruntime
+
+from tools import helper
+
+
+def compare_tflite_and_onnx(tflite_file, onnx_file, total_times=10):
+ # Setup onnx session and get meta data
+ onnx_session = onnxruntime.InferenceSession(onnx_file, None)
+ onnx_outputs = onnx_session.get_outputs()
+ assert len(onnx_outputs) == 1, "The onnx model has more than one output"
+ onnx_model = onnx.load(onnx_file)
+ onnx_graph = onnx_model.graph
+ onnx_inputs = onnx_graph.input
+ assert len(onnx_inputs) == 1, "The onnx model has more than one input"
+ _, onnx_input_shape = helper.find_size_shape_from_value(onnx_inputs[0])
+ # Setup TFLite sessio and get meta data
+ tflite_session = tf.lite.Interpreter(model_path=tflite_file)
+ tflite_session.allocate_tensors()
+ tflite_inputs = tflite_session.get_input_details()
+ tflite_outputs = tflite_session.get_output_details()
+ tflite_input_shape = tflite_inputs[0]["shape"]
+ # Compare input shape
+ assert len(onnx_input_shape) == len(
+ tflite_input_shape
+ ), "TFLite and ONNX shape unmatch."
+ assert onnx_input_shape == [
+ tflite_input_shape[0],
+ tflite_input_shape[3],
+ tflite_input_shape[1],
+ tflite_input_shape[2],
+ ], "TFLite and ONNX shape unmatch."
+ # Generate random number and run
+ tflite_results = []
+ onnx_results = []
+ for _ in range(total_times):
+ # Generate input
+ tflite_input_data = np.array(
+ np.random.random_sample(tflite_input_shape), dtype=np.float32
+ )
+ onnx_input_data = np.transpose(tflite_input_data, [0, 3, 1, 2])
+ # Run tflite
+ tflite_session.set_tensor(tflite_inputs[0]["index"], tflite_input_data)
+ tflite_session.invoke()
+ tflite_results.append(
+ tflite_session.get_tensor(tflite_outputs[0]["index"])
+ )
+ # Run onnx
+ onnx_input_dict = {onnx_inputs[0].name: onnx_input_data}
+ onnx_results.append(onnx_session.run([], onnx_input_dict)[0])
+
+ return tflite_results, onnx_results
+
+
+if __name__ == "__main__":
+ # Argument parser.
+ parser = argparse.ArgumentParser(
+ description="Compare a TFLite model and an ONNX model to check "
+ "if they have the same output."
+ )
+ parser.add_argument("tflite_file", help="input tflite file")
+ parser.add_argument("onnx_file", help="input ONNX file")
+
+ args = parser.parse_args()
+
+ results_a, results_b = compare_tflite_and_onnx(
+ args.tflite_file, args.onnx_file, total_times=10
+ )
+ ra_flat = helper.flatten_with_depth(results_a, 0)
+ rb_flat = helper.flatten_with_depth(results_b, 0)
+ shape_a = [item[1] for item in ra_flat]
+ shape_b = [item[1] for item in rb_flat]
+ assert shape_a == shape_b, "two results data shape doesn't match"
+ ra_raw = [item[0] for item in ra_flat]
+ rb_raw = [item[0] for item in rb_flat]
+
+ try:
+ np.testing.assert_almost_equal(ra_raw, rb_raw, 8)
+ print("Two models have the same behaviour.")
+ except Exception as mismatch:
+ print(mismatch)
+ exit(1)
diff --git a/tools/optimizer_scripts/tools/__init__.py b/tools/optimizer_scripts/tools/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/tools/optimizer_scripts/tools/combo.py b/tools/optimizer_scripts/tools/combo.py
new file mode 100644
index 0000000..1a20ebb
--- /dev/null
+++ b/tools/optimizer_scripts/tools/combo.py
@@ -0,0 +1,267 @@
+"""Combo functions that are usually called together.
+"""
+
+import logging
+
+try:
+ from onnx import optimizer
+except ImportError:
+ import onnxoptimizer as optimizer
+
+from . import helper
+from . import other
+from . import replacing
+from . import eliminating
+from . import fusing
+from . import constant_folding
+from . import removing_transpose
+from .common_pattern import torch_pattern_match, tf_pattern_match
+from .helper import logger
+
+
+def preprocess(
+ model_proto, disable_fuse_bn=False, duplicate_shared_weights=True
+):
+ """The most common used functions before other processing.
+
+ Args:
+ model_proto: the original model input
+ duplicate_shared_weights(bool, optional): duplicate shared weights.
+ Defaults to True.
+
+ Return:
+ the new model after preprocessing
+
+ It includes:
+
+ - inference shapes
+ - optimize model by ONNX library
+ - give names to the nodes
+ - replace initializer with Constant node
+ - replace -1 batch size with 1
+ - eliminate dropout and identity
+ - eliminate no children inputs
+ - topological sort
+
+ The optimizations provided by ONNX:
+
+ - eliminate_identity
+ - eliminate_nop_dropout
+ - eliminate_nop_transpose
+ - eliminate_nop_pad
+ - eliminate_unused_initializer
+ - eliminate_deadend
+ - fuse_consecutive_squeezes
+ - fuse_consecutive_transposes
+ - fuse_add_bias_into_conv
+ - fuse_transpose_into_gemm
+ - fuse_matmul_add_bias_into_gemm
+ - fuse_bn_into_conv
+ - fuse_pad_into_conv
+
+ """
+ logger.info("Preprocessing the model...")
+ helper.setup_current_opset_version(model_proto)
+ eliminating.eliminate_empty_value_infos(model_proto.graph)
+ other.add_name_to_node(model_proto.graph)
+ other.rename_all_node_name(model_proto.graph)
+ replacing.replace_initializer_with_Constant(model_proto.graph)
+ other.topological_sort(model_proto.graph)
+ m = other.polish_model(model_proto)
+ passes = [
+ "extract_constant_to_initializer",
+ "eliminate_nop_dropout",
+ "eliminate_deadend",
+ "fuse_matmul_add_bias_into_gemm",
+ "fuse_pad_into_conv",
+ ]
+ if not disable_fuse_bn:
+ passes.append("fuse_bn_into_conv")
+ m = optimizer.optimize(m, passes)
+ g = m.graph
+ # Add name again since onnx optimizer higher than 1.7 may remove node names
+ other.add_name_to_node(g)
+ if duplicate_shared_weights:
+ replacing.replace_initializer_with_Constant(
+ g, duplicate_shared_weights=True
+ )
+ other.duplicate_param_shared_constant(g)
+ else:
+ replacing.replace_initializer_with_Constant(
+ g, duplicate_shared_weights=False
+ )
+ other.topological_sort(g)
+ m = other.polish_model(m)
+ g = m.graph
+ eliminating.eliminate_consecutive_Cast(m.graph)
+ eliminating.eliminate_Cast_after_input(m.graph)
+ eliminating.eliminate_nop_pads(g)
+ eliminating.eliminate_nop_cast(g)
+ eliminating.eliminate_Identify_and_Dropout(g)
+ eliminating.eliminate_trivial_maxpool(g)
+ eliminating.eliminate_no_children_input(g)
+ other.format_value_info_shape(g)
+ other.topological_sort(g)
+ m = other.inference_shapes(m)
+ g = m.graph
+ replacing.replace_split_with_slices(g)
+ other.topological_sort(g)
+
+ return m
+
+
+def common_optimization(m):
+ """Common optimizations can be used in most cases.
+
+ :param m: the original model input\\
+ :return: the new model after preprocessing
+
+ It includes:
+
+ - transpose B in Gemm
+ - fuse BN into Gemm
+ - fuse consecutive Gemm
+ - replace AveragePool with GAP
+ - replace Squeeze/Unsqueeze with Reshape
+ - replace Reshape with Flatten
+ """
+ logger.info("Doing nodes fusion and replacement... ")
+ m = other.polish_model(m)
+ g = m.graph
+ other.transpose_B_in_Gemm(g)
+ fusing.fuse_BN_into_Gemm(g)
+ fusing.fuse_BN_with_Reshape_into_Gemm(g)
+ fusing.fuse_Gemm_into_Gemm(g)
+ fusing.fuse_consecutive_reducemean(g)
+ fusing.fuse_slice_nodes_into_conv(g)
+ fusing.fuse_relu_min_into_clip(g)
+ other.duplicate_shared_Flatten(g)
+ replacing.replace_average_pool_with_GAP(g)
+
+ m = other.polish_model(m)
+ g = m.graph
+
+ replacing.replace_Squeeze_with_Reshape(g)
+ replacing.replace_Unsqueeze_with_Reshape(g)
+ replacing.replace_Reshape_with_Flatten(g)
+ replacing.replace_ReduceMean_with_GlobalAveragePool(g)
+ replacing.replace_Sum_with_Adds(g)
+ replacing.replace_constant_input_concat_with_pad(g)
+ other.topological_sort(g)
+ return m
+
+
+def pytorch_constant_folding(m):
+ """Constant folding needed by Pytorch exported models. It should be done
+ before using onnx optimizers since the dynamic shape structure may affect
+ the optimizations.
+
+ :param m: the original model input\\
+ :return: the new model after preprocessing
+ """
+ logger.info("Working on constant folding.")
+ replacing.replace_shape_with_constant(m.graph)
+ replacing.replace_ConstantOfShape_with_constant(m.graph)
+
+ # constant_folding
+ m = other.inference_shapes(m)
+ while constant_folding.constant_folding(m.graph):
+ logging.debug("After constant folding jobs.")
+ other.topological_sort(m.graph)
+ while len(m.graph.value_info) != 0:
+ m.graph.value_info.pop()
+
+ m = other.inference_shapes(m)
+ replacing.replace_shape_with_constant(m.graph)
+ other.topological_sort(m.graph)
+ m = torch_pattern_match(m)
+ m = optimizer.optimize(m, ["eliminate_deadend"])
+ return m
+
+
+def tensorflow_optimization(m):
+ """Optimizations for tf models can be used in most cases.
+
+ :param m: the original model input\\
+ :return: the new model after preprocessing
+
+ It includes:
+
+ - eliminate shape change after input
+ - eliminate Reshape cast
+ - eliminate Squeeze before Reshape
+ - fuse Transpose into Constant
+ - replace Shape with Constant
+ """
+
+ fusing.fuse_Transpose_into_Constant(m.graph)
+ fusing.fuse_MatMul_and_Add_into_Gemm(m.graph)
+ other.topological_sort(m.graph)
+
+ m = other.polish_model(m)
+
+ # constant folding
+ replacing.replace_shape_with_constant(m.graph)
+
+ # constant_folding
+ m = other.inference_shapes(m)
+ while constant_folding.constant_folding(m.graph):
+ logging.debug("After constant folding jobs.")
+ other.topological_sort(m.graph)
+ while len(m.graph.value_info) != 0:
+ m.graph.value_info.pop()
+
+ m = other.inference_shapes(m)
+ replacing.replace_shape_with_constant(m.graph)
+ other.topological_sort(m.graph)
+ m = tf_pattern_match(m)
+ m = optimizer.optimize(m, ["eliminate_deadend"])
+
+ eliminating.eliminate_consecutive_reshape(m.graph)
+ eliminating.eliminate_Squeeze_before_Reshape(m.graph)
+ other.topological_sort(m.graph)
+ return m
+
+
+def postprocess(m):
+ """Inference the shape and prepare for export.
+
+ :param m: the original model input\\
+ :return: the new model after preprocessing
+ """
+ logger.info("Postprocessing the model...")
+ while len(m.graph.value_info) > 0:
+ m.graph.value_info.pop()
+ m = other.polish_model(m)
+ eliminating.eliminate_single_input_Concat(m.graph)
+ eliminating.eliminate_nop_Maxpool_and_AveragePool(m.graph)
+ eliminating.eliminate_trivial_elementwise_calculation(m.graph)
+ m = other.polish_model(m)
+
+ replacing.replace_depthwise_1x1_with_bn(m.graph)
+ m = other.polish_model(m)
+
+ # removing transpose
+ m = removing_transpose.eliminate_transposes(m)
+ m = other.polish_model(m)
+ removing_transpose.remove_trivial_transpose(m.graph)
+ removing_transpose.fuse_Transpose_into_Gemm_weight(m.graph)
+
+ # fuse some nodes
+ fusing.fuse_mul_and_add_into_bn(m.graph)
+ m = other.polish_model(m)
+ fusing.fuse_mul_and_add_into_gemm(m.graph)
+ m = other.polish_model(m)
+ fusing.fuse_conv_and_add_into_conv(m.graph)
+ m = other.polish_model(m)
+ replacing.replace_mul_to_bn(m.graph)
+ replacing.replace_div_to_bn(m.graph)
+ replacing.replace_add_to_bn(m.graph)
+ replacing.replace_sub_to_bn(m.graph)
+ replacing.replace_sub_with_bn_and_add(m.graph)
+ m = other.polish_model(m)
+
+ other.add_output_to_value_info(m.graph)
+ m = optimizer.optimize(m, ["eliminate_deadend"])
+ m.producer_name = "kneron_formatter"
+ return m
diff --git a/tools/optimizer_scripts/tools/common_pattern.py b/tools/optimizer_scripts/tools/common_pattern.py
new file mode 100644
index 0000000..19d4b35
--- /dev/null
+++ b/tools/optimizer_scripts/tools/common_pattern.py
@@ -0,0 +1,177 @@
+from collections import defaultdict
+import numpy as np
+import onnx.helper
+import onnx.utils
+
+from . import helper
+from . import other
+
+
+def torch_pattern_match(m):
+ # Create a map from optype to the nodes.
+ optype2node = defaultdict(list)
+ for node in m.graph.node:
+ optype2node[node.op_type].append(node)
+ for matmul_node in optype2node["MatMul"]:
+ pattern_matmul_mul_add(m.graph, matmul_node)
+ for resize_node in optype2node["Resize"]:
+ # torch nn.UpsamplingBilinear2d will be given us 4 input:
+ # "X, roi, scales, sizes"
+ if len(resize_node.input) != 4:
+ continue
+ make_UpsamplingBilinear2d_value_info(m.graph, resize_node.name)
+ m = onnx.shape_inference.infer_shapes(m)
+ polish_RESIZE_input_param_node(m.graph, resize_node.name)
+ m = other.polish_model(m)
+ return m
+
+
+def tf_pattern_match(m):
+ # Create a map from optype to the nodes.
+ optype2node = defaultdict(list)
+ for node in m.graph.node:
+ optype2node[node.op_type].append(node)
+ for matmul_node in optype2node["MatMul"]:
+ pattern_matmul_mul_add(m.graph, matmul_node)
+ for resize_node in optype2node["Resize"]:
+ # In tensorflow2onnx, ReizeXXX will be given us 4 input:
+ # "X, roi, scales, sizes"
+ # and node output name will be given the "node name + :0"
+ if len(resize_node.input) != 4:
+ continue
+ make_UpsamplingBilinear2d_value_info(m.graph, resize_node.name)
+ m = onnx.shape_inference.infer_shapes(m)
+ polish_RESIZE_input_param_node(m.graph, resize_node.name)
+ m = other.polish_model(m)
+ return m
+
+
+def pattern_matmul_mul_add(g, matmul_node):
+ # Check node match - Mul node
+ next_nodes = helper.find_nodes_by_input_name(g, matmul_node.output[0])
+ if len(next_nodes) != 1:
+ return
+ if next_nodes[0].op_type != "Mul":
+ return
+ mul_node = next_nodes[0]
+ # Check node match - Add node
+ next_nodes = helper.find_nodes_by_input_name(g, mul_node.output[0])
+ if len(next_nodes) != 1:
+ return
+ if next_nodes[0].op_type != "Add":
+ return
+ add_node = next_nodes[0]
+ # Check Mul weight
+ mul_weight_node = helper.find_node_by_output_name(g, mul_node.input[1])
+ if mul_weight_node.op_type != "Constant":
+ return
+ weight_size, mul_weight = helper.constant_to_list(mul_weight_node)
+ for i in mul_weight:
+ if i != 1:
+ return
+ channel = weight_size[0]
+ # Check Add weight
+ add_weight_node = helper.find_node_by_output_name(g, add_node.input[1])
+ if add_weight_node.op_type != "Constant":
+ return
+ # Check MatMul weight to see if it need weight broadcast
+ matmul_weight_node = helper.find_node_by_output_name(
+ g, matmul_node.input[1]
+ )
+ matmul_weight = helper.constant_to_numpy(matmul_weight_node)
+ if matmul_weight.shape[1] == 1:
+ # Weight broadcast
+ new_matmul_weight = np.tile(matmul_weight, channel)
+ new_matmul_weight_node = helper.numpy_to_constant(
+ matmul_weight_node.name, new_matmul_weight
+ )
+ g.node.remove(matmul_weight_node)
+ g.node.extend([new_matmul_weight_node])
+ value = helper.find_value_by_name(g, matmul_weight_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ # Remove Mul node
+ g.node.remove(mul_weight_node)
+ value = helper.find_value_by_name(g, mul_weight_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ g.node.remove(mul_node)
+ value = helper.find_value_by_name(g, mul_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ # Fuse Matmul and Add
+ gemm_node = onnx.helper.make_node(
+ "Gemm",
+ [matmul_node.input[0], matmul_node.input[1], add_node.input[1]],
+ [add_node.output[0]],
+ name=matmul_node.name,
+ alpha=1.0,
+ beta=1.0,
+ transA=0,
+ transB=0,
+ )
+ g.node.extend([gemm_node])
+ # Clean up
+ g.node.remove(matmul_node)
+ g.node.remove(add_node)
+ value = helper.find_value_by_name(g, matmul_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ other.topological_sort(g)
+
+
+def make_UpsamplingBilinear2d_value_info(g, resize_node_name):
+ resize_node = helper.find_node_by_node_name(g, resize_node_name)
+
+ shape_data_node = helper.find_node_by_output_name(g, resize_node.input[3])
+ shape_data = helper.constant_to_numpy(shape_data_node).astype(int)
+ l_shape_data = list(shape_data)
+ if l_shape_data[0] == 0:
+ l_shape_data[0] = 1 + l_shape_data[0]
+ shape_data = np.array(l_shape_data)
+
+ new_output_value_info = onnx.helper.make_tensor_value_info(
+ resize_node.output[0],
+ onnx.helper.TensorProto.FLOAT,
+ shape_data.tolist(),
+ )
+
+ g.value_info.extend([new_output_value_info])
+
+
+def polish_RESIZE_input_param_node(g, resize_node_name):
+ resize_node = helper.find_node_by_node_name(g, resize_node_name)
+
+ shape_data_node = helper.find_node_by_output_name(g, resize_node.input[3])
+ shape_data = helper.constant_to_numpy(shape_data_node).astype(int)
+
+ # handle 0 batch size which is invalid
+ if shape_data[0] == 0:
+ shape_data[0] = 1
+
+ pre_node_output_value_info = helper.find_value_by_name(
+ g, resize_node.input[0]
+ )
+ ori_shape = np.array(
+ [
+ pre_node_output_value_info.type.tensor_type.shape.dim[0].dim_value,
+ pre_node_output_value_info.type.tensor_type.shape.dim[1].dim_value,
+ pre_node_output_value_info.type.tensor_type.shape.dim[2].dim_value,
+ pre_node_output_value_info.type.tensor_type.shape.dim[3].dim_value,
+ ]
+ )
+
+ resize_node.input.remove(resize_node.input[3])
+
+ resize_scales = np.array(shape_data / ori_shape).astype(float)
+ resize_scale_node = helper.list_to_constant(
+ "resize_scales_node_" + resize_node.name,
+ resize_scales.shape,
+ resize_scales,
+ data_type=onnx.helper.TensorProto.FLOAT,
+ )
+
+ resize_node.input[2] = resize_scale_node.name
+ g.node.extend([resize_scale_node])
+
+ other.topological_sort(g)
diff --git a/tools/optimizer_scripts/tools/constant_folding.py b/tools/optimizer_scripts/tools/constant_folding.py
new file mode 100644
index 0000000..45ef674
--- /dev/null
+++ b/tools/optimizer_scripts/tools/constant_folding.py
@@ -0,0 +1,973 @@
+import onnx.utils
+import onnx
+import numpy as np
+import logging
+import traceback
+
+from . import helper
+from .other import topological_sort
+from .helper import logger
+
+
+def are_all_inputs_Constant_with_one_child(g, node):
+ for input_name in node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ if input_node is None or input_node.op_type != "Constant":
+ return False
+ relative_outputs = helper.find_nodes_by_input_name(g, input_name)
+ if len(relative_outputs) > 1:
+ return False
+ return True
+
+
+def constant_folding(g):
+ """ Do constant folding until nothing more can be done.
+
+ :param g: The onnx GraphProto\\
+ :return: If any node is folded, return True. Otherwise, return False.
+ """
+ keep_folding = True # Keep the while loop
+ folded = False # Return value
+ try:
+ # Before constant folding, duplicate the constant nodes.
+ duplicate_constant_node(g)
+ while keep_folding:
+ keep_folding = False
+ for node in g.node:
+ # Check if the node is foldable
+ if node.op_type not in constant_folding_nodes.keys():
+ continue
+ # Check if parents of the node are all
+ # single follower constant node.
+ if not are_all_inputs_Constant_with_one_child(g, node):
+ continue
+ # Constant folding for the specific node
+ if constant_folding_nodes[node.op_type](g, node):
+ logging.debug(
+ "Constant nodes and %s %s are folded.",
+ node.op_type,
+ node.name,
+ )
+ folded = True
+ keep_folding = True
+ else:
+ logging.debug(
+ "Constant nodes and %s %s are skipped.",
+ node.op_type,
+ node.name,
+ )
+ except Exception:
+ logger.error("An exception is raised while constant folding.")
+ logger.error(traceback.format_exc())
+ return folded
+
+
+def duplicate_constant_node(g):
+ """
+ Duplicate the constant node if its following nodes contain
+ constant folding nodes. Create and link the new constant nodes
+ to the constant folding nodes.
+ """
+ for node in g.node:
+ # Find a valid constant node
+ if node.op_type != "Constant":
+ continue
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+ if output_val_info is None:
+ print(
+ "Cannot inference the shape of Const node output: "
+ + node.output[0]
+ )
+ exit(1)
+ data_shape = helper.get_shape_from_value_info(output_val_info)
+ output_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+
+ # For constant that has only one following node, no need to duplicate
+ if len(output_nodes) < 2:
+ continue
+
+ # Check if its following nodes are foldable
+ foldable_output_nodes = list(
+ filter(
+ lambda n: n.op_type in constant_folding_nodes.keys(),
+ output_nodes,
+ )
+ )
+ if not foldable_output_nodes:
+ continue
+
+ # Duplicate the node needed by foldable nodes
+ for i in range(len(foldable_output_nodes)):
+ logging.debug(
+ f"Found constant {node.name} and "
+ f"{foldable_output_nodes[i].op_type} "
+ f"{foldable_output_nodes[i].name} are availble for folding. "
+ "Duplicate constant.",
+ )
+ output_name = node.output[0] + "_dup_" + str(i)
+ new_constant_node = onnx.helper.make_node(
+ "Constant",
+ [],
+ [output_name],
+ name=output_name,
+ value=node.attribute[0].t,
+ )
+ new_val_info = onnx.helper.make_tensor_value_info(
+ output_name, node.attribute[0].t.data_type, data_shape
+ )
+ input_ind = list(foldable_output_nodes[i].input).index(
+ node.output[0]
+ )
+ foldable_output_nodes[i].input[input_ind] = output_name
+
+ g.node.extend([new_constant_node])
+ g.value_info.extend([new_val_info])
+
+ # If all following nodes are foldable node, delete the original node.
+ if len(foldable_output_nodes) == len(output_nodes):
+ g.node.remove(node)
+ g.value_info.remove(output_val_info)
+
+ topological_sort(g)
+
+ return
+
+
+def slice_constant_folding(g, node):
+ op_version = helper.get_current_opset_version()
+ # only support opset 9 & 11
+ if op_version == 11:
+ return slice_constant_folding_Opset_11(g, node)
+ elif op_version == 9:
+ return slice_constant_folding_Opset_9(g, node)
+
+
+def slice_constant_folding_Opset_11(g, node):
+ """Fold constant and slice nodes to a single constant node."""
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_shape, data_list = helper.constant_to_list(pre_node)
+
+ starts_node = helper.find_node_by_output_name(g, node.input[1])
+ _, starts = helper.constant_to_list(starts_node)
+
+ ends_node = helper.find_node_by_output_name(g, node.input[2])
+ _, ends = helper.constant_to_list(ends_node)
+
+ axes_node = (
+ None
+ if len(node.input) <= 3
+ else helper.find_node_by_output_name(g, node.input[3])
+ )
+ if not axes_node:
+ axes = list(range(len(helper.get_shape(data_list))))
+ else:
+ _, axes = helper.constant_to_list(axes_node)
+
+ steps_node = (
+ None
+ if len(node.input) <= 4
+ else helper.find_node_by_output_name(g, node.input[4])
+ )
+ if not steps_node:
+ steps = [1] * len(helper.get_shape(data_list))
+ else:
+ _, steps = helper.constant_to_list(steps_node)
+
+ data_list = list(map(int, data_list))
+ starts = list(map(int, starts))
+ ends = list(map(int, ends))
+ axes = list(map(int, axes))
+ steps = list(map(int, steps))
+
+ data_list = np.reshape(data_list, pre_shape)
+
+ new_data = None
+ for idx, _ in enumerate(axes):
+ new_data = np.apply_along_axis(
+ lambda x: x[starts[idx]:ends[idx]:steps[idx]], idx, data_list
+ )
+
+ new_node = helper.list_to_constant(
+ node.output[0],
+ helper.get_shape(new_data),
+ helper.flatten_to_list(new_data),
+ )
+ g.node.extend([new_node])
+ value_info = helper.find_value_by_name(g, pre_node.output[0])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ g.node.remove(node)
+ g.node.remove(pre_node)
+
+ return True
+
+
+def slice_constant_folding_Opset_9(g, node):
+ """Fold constant and slice nodes to a single constant node."""
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_shape, data_list = helper.constant_to_list(pre_node)
+
+ data_list = np.reshape(data_list, pre_shape)
+ axes = helper.get_attribute_by_name(node, "axes")
+ ends = list(helper.get_attribute_by_name(node, "ends").ints)
+ starts = list(helper.get_attribute_by_name(node, "starts").ints)
+
+ if not axes:
+ axes = list(range(len(helper.get_shape(data_list))))
+ else:
+ axes = list(axes.ints)
+
+ new_data = helper.slice_data(data_list, starts, ends, axes)
+ new_node = helper.list_to_constant(
+ node.output[0],
+ helper.get_shape(new_data),
+ helper.flatten_to_list(new_data),
+ )
+ g.node.extend([new_node])
+ value_info = helper.find_value_by_name(g, pre_node.output[0])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ g.node.remove(node)
+ g.node.remove(pre_node)
+
+ return True
+
+
+def cast_constant_folding(g, node):
+ """Fold constant and cast node to a single constant node."""
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ data_type = node.attribute[0].i
+ if data_type in (6, 7):
+ data = list(map(int, data))
+ elif data_type == onnx.helper.TensorProto.FLOAT:
+ data = list(map(float, data))
+ else:
+ raise RuntimeError("data type not supported")
+
+ if shape == 1:
+ tensor = onnx.helper.make_tensor(
+ name=pre_node.attribute[0].name,
+ data_type=data_type,
+ dims=[],
+ vals=data,
+ )
+ else:
+ tensor = onnx.helper.make_tensor(
+ name=pre_node.attribute[0].name,
+ data_type=data_type,
+ dims=shape,
+ vals=helper.flatten_to_list(data),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=tensor
+ )
+ g.node.extend([new_node])
+
+ value_info = helper.find_value_by_name(g, pre_node.output[0])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ value_info = helper.find_value_by_name(g, node.output[0])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ g.node.remove(pre_node)
+ g.node.remove(node)
+
+ return True
+
+
+def reduceprod_constant_folding(g, node):
+ """Fold constant and reduceprod nodes to a single constant node."""
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data_set = helper.constant_to_list(pre_node)
+ tensor = pre_node.attribute[0].t
+
+ data_set = np.reshape(data_set, shape)
+ for att in node.attribute:
+ if att.name == "axes":
+ axes = list(att.ints)
+ else:
+ keepdims = int(att.i)
+
+ new_data = np.prod(data_set, axis=tuple(axes), keepdims=keepdims == 1)
+ new_shape = helper.get_shape(new_data)
+ new_flat_data = helper.flatten_to_list(new_data)
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0],
+ data_type=tensor.data_type,
+ dims=new_shape,
+ vals=new_flat_data,
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.node.extend([new_node])
+ value_info = None
+ for item in g.value_info:
+ if item.name == pre_node.output[0]:
+ value_info = item
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ g.node.remove(pre_node)
+ g.node.remove(node)
+
+ return True
+
+
+def reshape_constant_input_folding(g, node):
+ """Fold constant and reshape nodes to a single constant node."""
+ pre_data_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_shape_node = helper.find_node_by_output_name(g, node.input[1])
+
+ data = helper.constant_to_numpy(pre_data_node)
+ _, shape = helper.constant_to_list(pre_shape_node)
+ new_data = np.reshape(data, shape)
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0],
+ data_type=pre_data_node.attribute[0].t.data_type,
+ dims=new_data.shape,
+ vals=helper.flatten_to_list(new_data),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+ g.node.extend([new_node])
+
+ data_val_info = helper.find_value_by_name(g, pre_data_node.output[0])
+ shape_val_info = helper.find_value_by_name(g, pre_shape_node.output[0])
+
+ g.value_info.remove(data_val_info)
+ g.value_info.remove(shape_val_info)
+
+ g.node.remove(node)
+ g.node.remove(pre_data_node)
+ g.node.remove(pre_shape_node)
+
+ return True
+
+
+def concat_constant_folding(g, node):
+ """Fold constant and concat nodes to a single constant node."""
+ node_to_del = []
+ valid_inputs = True
+ for input_name in node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ input_node_output = helper.find_nodes_by_input_name(g, input_name)
+ if len(input_node_output) > 1:
+ valid_inputs = False
+ break
+ if input_node.op_type != "Constant":
+ valid_inputs = False
+ break
+
+ if not valid_inputs:
+ return False
+
+ input_data = []
+ input_shapes = []
+ for input_name in node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ s, d = helper.constant_to_list(input_node)
+ d = np.reshape(d, s)
+ input_data.append(d)
+ input_shapes.append(s)
+ node_to_del.append(input_node)
+
+ concat_data = np.concatenate(input_data, axis=node.attribute[0].i)
+ node_data_type = input_node.attribute[0].t.data_type
+ if concat_data.dtype in [np.int32, np.int64]:
+ node_data_type = onnx.helper.TensorProto.INT64
+ elif concat_data.dtype in [np.float32, np.float64]:
+ node_data_type = onnx.helper.TensorProto.FLOAT
+
+ new_node = helper.list_to_constant(
+ node.output[0],
+ helper.get_shape(concat_data),
+ helper.flatten_to_list(concat_data),
+ data_type=node_data_type,
+ )
+ g.node.extend([new_node])
+ node_to_del.append(node)
+
+ for input_name in node.input:
+ val_info = helper.find_value_by_name(g, input_name)
+ if val_info:
+ g.value_info.remove(val_info)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def transpose_constant_folding(g, node):
+ """Fold constant and transpose nodes to a single constant node."""
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ np_data = np.reshape(data, shape)
+ permutation = list(node.attribute[0].ints)
+
+ new_data = np.transpose(np_data, permutation)
+ new_shape = new_data.shape
+ new_node = helper.list_to_constant(
+ node.output[0],
+ new_shape,
+ new_data.flatten().tolist(),
+ data_type=pre_node.attribute[0].t.data_type,
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([node, pre_node])
+
+ pre_val_info = helper.find_value_by_name(g, node.input[0])
+ g.value_info.remove(pre_val_info)
+
+ next_val_info = helper.find_value_by_name(g, node.output[0])
+ g.value_info.remove(next_val_info)
+
+ new_val_info = onnx.helper.make_tensor_value_info(
+ node.output[0], pre_node.attribute[0].t.data_type, new_shape
+ )
+ g.value_info.extend([new_val_info])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+ folded = True
+
+ return folded
+
+
+def unsqueeze_constant_folding(g, node):
+ """Fold constant and unsqueeze nodes to a single constant node."""
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ if type(shape) == int:
+ np_data = data[0]
+ else:
+ np_data = np.reshape(data, shape)
+ axes = list(node.attribute[0].ints)
+ axes.sort()
+
+ for dim in axes:
+ np_data = np.expand_dims(np_data, axis=dim)
+ new_shape = np_data.shape
+ new_node = helper.list_to_constant(
+ node.output[0],
+ new_shape,
+ np_data.flatten().tolist(),
+ data_type=pre_node.attribute[0].t.data_type,
+ )
+ g.node.extend([new_node])
+ node_to_del.extend([node, pre_node])
+
+ pre_val_info = helper.find_value_by_name(g, node.input[0])
+ next_val_info = helper.find_value_by_name(g, node.output[0])
+ if pre_val_info is not None:
+ g.value_info.remove(pre_val_info)
+ else:
+ print(node.name)
+ if next_val_info is not None:
+ g.value_info.remove(next_val_info)
+
+ new_val_info = onnx.helper.make_tensor_value_info(
+ node.output[0], pre_node.attribute[0].t.data_type, new_shape
+ )
+ g.value_info.extend([new_val_info])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def gather_constant_folding(g, node):
+ """Fold constant and gather nodes to a single constant node."""
+ node_to_del = []
+
+ pre_data_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_indices_node = helper.find_node_by_output_name(g, node.input[1])
+
+ shape, data = helper.constant_to_list(pre_data_node)
+ indice_shape, indices = helper.constant_to_list(pre_indices_node)
+ if type(indice_shape) == int:
+ indices = indices[0]
+
+ np_data = np.reshape(data, shape)
+ if len(node.attribute) < 1:
+ axis = 0
+ else:
+ axis = node.attribute[0].i
+
+ new_data = np.take(np_data, indices, axis=axis)
+ new_shape = new_data.shape
+ new_node = helper.list_to_constant(
+ node.output[0],
+ new_shape,
+ new_data.flatten().tolist(),
+ data_type=pre_data_node.attribute[0].t.data_type,
+ )
+
+ node_to_del.extend([node, pre_data_node, pre_indices_node])
+ g.node.extend([new_node])
+
+ val_info_1 = helper.find_value_by_name(g, node.input[0])
+ val_info_2 = helper.find_value_by_name(g, node.input[1])
+ val_info_3 = helper.find_value_by_name(g, node.output[0])
+ new_val_info = onnx.helper.make_tensor_value_info(
+ new_node.output[0], pre_data_node.attribute[0].t.data_type, new_shape
+ )
+
+ if val_info_1 is not None:
+ g.value_info.remove(val_info_1)
+ if val_info_2 is not None:
+ g.value_info.remove(val_info_2)
+ if val_info_3 is not None:
+ g.value_info.remove(val_info_3)
+ g.value_info.extend([new_val_info])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def add_constant_folding(g, node):
+ """Fold constant and add nodes to a single constant node."""
+ node_to_del = []
+ pre_node_1 = helper.find_node_by_output_name(g, node.input[0])
+ pre_node_2 = helper.find_node_by_output_name(g, node.input[1])
+ if not pre_node_1 or not pre_node_2:
+ return False
+
+ shape1, data1 = helper.constant_to_list(pre_node_1)
+ shape2, data2 = helper.constant_to_list(pre_node_2)
+ np_data1 = np.reshape(data1, shape1)
+ np_data2 = np.reshape(data2, shape2)
+ try:
+ new_data = np.add(np_data1, np_data2)
+ except Exception:
+ raise RuntimeError("can't broadcast and add two data sets")
+
+ new_node = helper.list_to_constant(
+ node.output[0],
+ new_data.shape,
+ new_data.flatten().tolist(),
+ data_type=pre_node_1.attribute[0].t.data_type,
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([node, pre_node_1, pre_node_2])
+ g.value_info.remove(helper.find_value_by_name(g, pre_node_1.output[0]))
+ g.value_info.remove(helper.find_value_by_name(g, pre_node_2.output[0]))
+ folded = True
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return folded
+
+
+def sqrt_constant_folding(g, node):
+ """Fold constant and sqrt nodes to a single node."""
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ np_data = np.sqrt(np.reshape(data, shape))
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+ input_val_info = helper.find_value_by_name(g, node.input[0])
+ data_type = output_val_info.type.tensor_type.elem_type
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=data_type,
+ dims=shape,
+ vals=np_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.value_info.remove(input_val_info)
+ node_to_del.extend([pre_node, node])
+ g.node.extend([new_node])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def reciprocal_constant_folding(g, node):
+ """Fold constant and reciprocal nodes to a single constant node."""
+ node_to_del = []
+
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ data = list(map(lambda x: x if abs(x) > 1.0e-8 else 1.0e-8, data))
+ np_data = np.reshape(data, shape)
+ np_data = np.reciprocal(np_data)
+
+ input_val_info = helper.find_value_by_name(g, node.input[0])
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+ data_type = output_val_info.type.tensor_type.elem_type
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=data_type,
+ dims=shape,
+ vals=np_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ node_to_del.extend([node, pre_node])
+ g.node.extend([new_node])
+
+ g.value_info.remove(input_val_info)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def mul_constant_folding(g, node):
+ """Fold constant and mul nodes to a single constant node."""
+ node_to_del = []
+ pre_node_1 = helper.find_node_by_output_name(g, node.input[0])
+ pre_node_2 = helper.find_node_by_output_name(g, node.input[1])
+
+ pre_value_info1 = helper.find_value_by_name(g, node.input[0])
+ pre_value_info2 = helper.find_value_by_name(g, node.input[1])
+ if pre_value_info1 is None or pre_value_info2 is None:
+ return False
+
+ shape1, data1 = helper.constant_to_list(pre_node_1)
+ shape2, data2 = helper.constant_to_list(pre_node_2)
+ np_data1 = np.reshape(data1, shape1)
+ np_data2 = np.reshape(data2, shape2)
+
+ try:
+ new_data = np.multiply(np_data1, np_data2)
+ except Exception:
+ raise RuntimeError("can not broadcast and multiply two data sets")
+
+ # Special shape for single element.
+ if shape1 == 1 and shape2 == 1:
+ new_shape = []
+ else:
+ new_shape = new_data.shape
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=pre_node_1.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=new_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ node_to_del.extend([node, pre_node_1, pre_node_2])
+ g.node.extend([new_node])
+
+ g.value_info.remove(pre_value_info1)
+ g.value_info.remove(pre_value_info2)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def div_constant_folding(g, node):
+ """Fold constant and mul nodes to a single constant node."""
+ node_to_del = []
+ pre_node_1 = helper.find_node_by_output_name(g, node.input[0])
+ pre_node_2 = helper.find_node_by_output_name(g, node.input[1])
+
+ pre_value_info1 = helper.find_value_by_name(g, node.input[0])
+ pre_value_info2 = helper.find_value_by_name(g, node.input[1])
+ if pre_value_info1 is None or pre_value_info2 is None:
+ return False
+
+ shape1, data1 = helper.constant_to_list(pre_node_1)
+ shape2, data2 = helper.constant_to_list(pre_node_2)
+ np_data1 = np.reshape(data1, shape1)
+ np_data2 = np.reshape(data2, shape2)
+
+ try:
+ new_data = np.divide(np_data1, np_data2)
+ except Exception:
+ raise RuntimeError("can not broadcast and multiply two data sets")
+
+ # Special shape for single element.
+ if shape1 == 1 and shape2 == 1:
+ new_shape = []
+ else:
+ new_shape = new_data.shape
+
+ # Check data type if it is int
+ if pre_node_1.attribute[0].t.data_type == 7:
+ new_data = new_data.astype("int64")
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=pre_node_1.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=new_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ node_to_del.extend([node, pre_node_1, pre_node_2])
+ g.node.extend([new_node])
+
+ g.value_info.remove(pre_value_info1)
+ g.value_info.remove(pre_value_info2)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def sub_constant_folding(g, node):
+ """Fold constant and sub nodes to a single node."""
+ node_to_del = []
+ pre_node_1 = helper.find_node_by_output_name(g, node.input[0])
+ pre_node_2 = helper.find_node_by_output_name(g, node.input[1])
+ pre_val_info_1 = helper.find_value_by_name(g, node.input[0])
+ pre_val_info_2 = helper.find_value_by_name(g, node.input[1])
+
+ shape1, data1 = helper.constant_to_list(pre_node_1)
+ shape2, data2 = helper.constant_to_list(pre_node_2)
+
+ new_data = np.subtract(data1, data2)
+ # Special shape for single element.
+ if shape1 == 1 and shape2 == 1:
+ new_shape = []
+ else:
+ new_shape = new_data.shape
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=pre_node_1.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=helper.flatten_to_list(new_data),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([node, pre_node_1, pre_node_2])
+
+ g.value_info.remove(pre_val_info_1)
+ g.value_info.remove(pre_val_info_2)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def neg_constant_folding(g, node):
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+
+ shape, data_list = helper.constant_to_list(pre_node)
+ new_data_list = [-num for num in data_list]
+
+ new_tensor = onnx.helper.make_tensor(
+ name=pre_node.name + "_neg_tensor",
+ data_type=pre_node.attribute[0].t.data_type,
+ dims=shape,
+ vals=new_data_list,
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([pre_node, node])
+ g.value_info.remove(helper.find_value_by_name(g, node.input[0]))
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ return True
+
+
+def floor_constant_folding(g, node):
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+
+ shape, data = helper.constant_to_list(pre_node)
+ new_data = np.floor(data).flatten().tolist()
+
+ if shape == 1:
+ new_shape = []
+ else:
+ new_shape = shape
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=pre_node.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=helper.flatten_to_list(new_data),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([pre_node, node])
+ old_value = helper.find_value_by_name(g, node.input[0])
+ if old_value is not None:
+ g.value_info.remove(old_value)
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ return True
+
+
+def bn_constant_folding(g, node):
+ """Fold constant and mul nodes to a single constant node."""
+ # Prepare data
+ node_to_del = []
+ input_node = helper.find_node_by_output_name(g, node.input[0])
+ scale_node = helper.find_node_by_output_name(g, node.input[1])
+ bias_node = helper.find_node_by_output_name(g, node.input[2])
+ mean_node = helper.find_node_by_output_name(g, node.input[3])
+ var_node = helper.find_node_by_output_name(g, node.input[4])
+
+ input_value_info = []
+ for i in range(5):
+ input_value_info.append(helper.find_value_by_name(g, node.input[i]))
+
+ if input_value_info[0] is None:
+ return False
+
+ input_data = helper.constant_to_numpy(input_node)
+ scale_data = helper.constant_to_numpy(scale_node)
+ bias_data = helper.constant_to_numpy(bias_node)
+ mean_data = helper.constant_to_numpy(mean_node)
+ var_data = helper.constant_to_numpy(var_node)
+
+ epsilon = helper.get_var_attribute_by_name(node, "epsilon", "float")
+ if epsilon is None:
+ epsilon = 0.00001
+
+ # Calculate new node
+ new_data = (
+ scale_data * (input_data - mean_data) / np.sqrt(var_data + epsilon)
+ + bias_data
+ )
+
+ new_node = helper.numpy_to_constant(node.output[0], new_data)
+
+ # Reconnect the graph
+ node_to_del.extend(
+ [node, input_node, scale_node, bias_node, mean_node, var_node]
+ )
+ g.node.extend([new_node])
+
+ for value in input_value_info:
+ if value is not None:
+ g.value_info.remove(value)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def DequantizeLinear_constant_folding(g, node):
+ """Fold constant and mul nodes to a single constant node."""
+ # Prepare data
+ node_to_del = []
+ x_node = helper.find_node_by_output_name(g, node.input[0])
+ x_scale_node = helper.find_node_by_output_name(g, node.input[1])
+ if len(node.input) > 2:
+ x_zero_point_node = helper.find_node_by_output_name(g, node.input[2])
+ else:
+ x_zero_point_node = None
+
+ input_value_info = []
+ for i in range(len(node.input)):
+ input_value_info.append(helper.find_value_by_name(g, node.input[i]))
+
+ if input_value_info[0] is None:
+ return False
+
+ x_data = helper.constant_to_numpy(x_node)
+ x_scale_data = helper.constant_to_numpy(x_scale_node)
+ if x_zero_point_node is not None:
+ x_zero_point_data = helper.constant_to_numpy(x_zero_point_node)
+ else:
+ x_zero_point_data = np.array([0.0])
+
+ # Calculate new node
+ new_data = (
+ x_data.astype(np.float32) - x_zero_point_data.astype(np.float32)
+ ) * x_scale_data
+
+ new_node = helper.numpy_to_constant(node.output[0], new_data)
+
+ # Reconnect the graph
+ node_to_del.extend([node, x_node, x_scale_node])
+ if x_zero_point_node is not None:
+ node_to_del.append(x_zero_point_node)
+ g.node.extend([new_node])
+
+ for value in input_value_info:
+ if value is not None:
+ g.value_info.remove(value)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+# Available constant folding names to function map.
+constant_folding_nodes = {
+ "Add": add_constant_folding,
+ "BatchNormalization": bn_constant_folding,
+ "Cast": cast_constant_folding,
+ "Concat": concat_constant_folding,
+ "DequantizeLinear": DequantizeLinear_constant_folding,
+ "Div": div_constant_folding,
+ "Floor": floor_constant_folding,
+ "Gather": gather_constant_folding,
+ "Mul": mul_constant_folding,
+ "Reciprocal": reciprocal_constant_folding,
+ "ReduceProd": reduceprod_constant_folding,
+ "Reshape": reshape_constant_input_folding,
+ "Slice": slice_constant_folding,
+ "Sqrt": sqrt_constant_folding,
+ "Transpose": transpose_constant_folding,
+ "Unsqueeze": unsqueeze_constant_folding,
+ "Sub": sub_constant_folding,
+ "Neg": neg_constant_folding,
+}
diff --git a/tools/optimizer_scripts/tools/eliminating.py b/tools/optimizer_scripts/tools/eliminating.py
new file mode 100644
index 0000000..7871665
--- /dev/null
+++ b/tools/optimizer_scripts/tools/eliminating.py
@@ -0,0 +1,751 @@
+import collections
+import struct
+import onnx
+import numpy as np
+from . import other
+from . import helper
+from . import modhelper
+from .general_graph import Graph
+
+
+def eliminate_Identify_and_Dropout(g):
+ """
+ Eliminate Identify layers
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Identity" and node.op_type != "Dropout":
+ continue
+ # If this node is the last, leave it to `eliminate_useless_last node`
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ continue
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ try:
+ g.value_info.remove(value_between)
+ except Exception:
+ print("No value info to delete while eliminating identity layers.")
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+# Remove last useless nodes
+def remove_useless_last_nodes(g):
+ """Remove useless nodes from the tail of the graph"""
+ USELESS = [
+ "Reshape",
+ "Identity",
+ "Transpose",
+ "Flatten",
+ "Dropout",
+ "Mystery",
+ "Constant",
+ "Squeeze",
+ "Unsqueeze",
+ "Softmax",
+ ]
+ graph = Graph(g)
+ todo = collections.deque()
+ for node in graph.output_nodes:
+ if len(node.children) == 0:
+ todo.append(node)
+ node_to_remove = []
+ while todo:
+ # BFS find nodes to remove
+ cur_node = todo.popleft()
+ if cur_node.proto is None:
+ continue
+ if cur_node.proto.op_type not in USELESS:
+ continue
+ # Find the output
+ cur_node_output = helper.find_output_by_name(
+ g, cur_node.proto.output[0]
+ )
+ for cur_input in cur_node.parents:
+ cur_input.children.remove(cur_node)
+ if len(cur_input.children) == 0:
+ todo.append(cur_input)
+ if cur_node_output is not None:
+ cur_input_output = helper.find_value_by_name(
+ g, cur_input.proto.output[0]
+ )
+ cur_input_output_in_output = helper.find_output_by_name(
+ g, cur_input.proto.output[0]
+ )
+ if (
+ cur_input_output is not None
+ and cur_input_output_in_output is None
+ ):
+ g.output.extend([cur_input_output])
+ node_to_remove.append(cur_node.proto)
+ try:
+ g.value_info.remove(
+ helper.find_value_by_name(g, cur_node.proto.output[0])
+ )
+ except ValueError:
+ pass
+ if cur_node_output is not None:
+ g.output.remove(cur_node_output)
+ cur_node.proto = None
+ cur_node.parents.clear()
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+######################################
+# TF only optimization passes #
+######################################
+
+
+def eliminate_shape_changing_after_input(g):
+ """
+ Eliminate the Reshape node after input and reshape the input
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ REMOVE_LIST = [
+ "Reshape",
+ "Transpose",
+ "Flatten",
+ "Dropout",
+ "Squeeze",
+ "Unsqueeze",
+ ]
+ for node in g.node:
+ # Find an input and the shape node
+ if node.op_type not in REMOVE_LIST:
+ continue
+ old_input = helper.find_input_by_name(g, node.input[0])
+ if old_input is None:
+ continue
+ # If the input is used by multiple nodes, skip.
+ counter = 0
+ for tnode in g.node:
+ if old_input.name in tnode.input:
+ counter += 1
+ if counter > 1:
+ continue
+ # Remove Weight if any.
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+
+ if node.op_type == "Reshape":
+ shape_node = helper.find_node_by_output_name(g, node.input[1])
+ if shape_node.op_type != "Constant":
+ continue
+
+ # manuelly set the input shape
+ shape_info = helper.find_value_by_name(g, shape_node.output[0])
+ old_size, old_shape = helper.find_size_shape_from_value(shape_info)
+
+ _, new_shape = helper.constant_to_list(shape_node)
+ for i in range(len(new_shape)):
+ if new_shape[i] == -1:
+ dim = int(old_size // np.prod(new_shape) * (-1))
+ new_shape[i] = dim
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+
+ node_to_remove.append(node)
+
+ shape_outputs = helper.find_nodes_by_input_name(
+ g, shape_node.output[0]
+ )
+ if len(shape_outputs) == 1:
+ node_to_remove.append(shape_node)
+ g.value_info.remove(
+ helper.find_value_by_name(g, shape_node.output[0])
+ )
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ elif node.op_type == "Transpose":
+ permutation = list(node.attribute[0].ints)
+ pre_shape = helper.get_shape_from_value_info(old_input)
+ new_shape = [pre_shape[i] for i in permutation]
+
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+
+ node_to_remove.append(node)
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ elif node.op_type == "Flatten":
+ axis = node.attribute[0].int
+ pre_shape = helper.get_shape_from_value_info(old_input)
+ dim_1, dim_2 = 1, 1
+ if axis == 0:
+ dim_1 = 1
+ dim_2 = np.prod(pre_shape)
+ else:
+ dim_1 = np.prod(pre_shape[:axis]).astype(int)
+ dim_2 = np.prod(pre_shape[axis:]).astype(int)
+ new_shape = [dim_1, dim_2]
+
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+
+ node_to_remove.append(node)
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ elif node.op_type == "Dropout":
+ g.input.remove(old_input)
+ g.input.extend([output_val_info])
+ g.value_info.remove(output_val_info)
+
+ node_to_remove.append(node)
+ elif node.op_type == "Squeeze":
+ axis = list(node.attribute[0].ints)
+ pre_shape = helper.get_shape_from_value_info(old_input)
+ for pos in sorted(axis)[::-1]:
+ if pre_shape[pos] != 1:
+ raise RuntimeError("invalid axis for squeeze")
+ else:
+ pre_shape.pop(pos)
+ new_shape = pre_shape
+
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+
+ node_to_remove.append(node)
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ elif node.op_type == "Unsqueeze":
+ axis = list(node.attribute[0].ints)
+ pre_shape = helper.get_shape_from_value_info(old_input)
+ new_shape = pre_shape
+ for pos in axis:
+ new_shape.insert(pos, 1)
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+ node_to_remove.append(node)
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ else:
+ pass
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+ other.topological_sort(g)
+
+
+def eliminate_Reshape_Cast(g):
+ """Eliminate the cast layer for shape of Reshape layer
+
+ :param g: the onnx graph
+ """
+ # Find all reshape layers
+ for node in g.node:
+ if node.op_type != "Reshape":
+ continue
+ prev_node = helper.find_node_by_output_name(g, node.input[1])
+ if prev_node.op_type != "Cast":
+ continue
+ reshape_node = node
+ cast_node = prev_node
+ weight_node = helper.find_node_by_output_name(g, cast_node.input[0])
+ if weight_node is None:
+ raise RuntimeError("Unexpected None before Cast-Reshape.")
+ weight_node.attribute[0].t.data_type = 7
+ if weight_node.attribute[0].t.raw_data:
+ raw_data = weight_node.attribute[0].t.raw_data
+ int_data = [i[0] for i in struct.iter_unpack("i", raw_data)]
+ raw_data = struct.pack("q" * len(int_data), *int_data)
+ elif (
+ len(weight_node.attribute[0].t.int64_data) > 0
+ or len(weight_node.attribute[0].t.int32_data) > 0
+ ):
+ # It's already int. Do nothing
+ pass
+ else:
+ raise NotImplementedError()
+ # Change Value info
+ origin_weight_out = helper.find_value_by_name(g, weight_node.output[0])
+ weight_node.output.pop()
+ weight_node.output.extend([reshape_node.input[1]])
+ # Delete
+ g.value_info.remove(origin_weight_out)
+ g.node.remove(cast_node)
+
+
+def eliminate_Cast_after_input(g):
+ """Eliminate the cast layer right after the input
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Cast":
+ continue
+ old_input = helper.find_input_by_name(g, node.input[0])
+ if old_input is None:
+ continue
+ next_val_info = helper.find_value_by_name(g, node.output[0])
+ shape = helper.get_shape_from_value_info(next_val_info)
+ new_val_info = onnx.helper.make_tensor_value_info(
+ next_val_info.name, node.attribute[0].i, shape
+ )
+ # Delete old value_info
+ g.input.remove(old_input)
+ g.value_info.remove(next_val_info)
+ # Append nodes to node_to_remove
+ node_to_remove.append(node)
+ # Add new input
+ g.input.extend([new_val_info])
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_consecutive_Cast(g):
+ """If two cast is next to each other, remove the first cast
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Cast":
+ continue
+ first_node = helper.find_node_by_output_name(g, node.input[0])
+ if first_node is None or first_node.op_type != "Cast":
+ continue
+ # Here we have two consecutive Cast Node
+ # Reset the input of the later node
+ node.input[0] = first_node.input[0]
+ # Remove the first node and its output value info
+ node_to_remove.append(first_node)
+ first_output = helper.find_value_by_name(g, first_node.output[0])
+ g.value_info.remove(first_output)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_Squeeze_before_Reshape(g):
+ """If Squeeze and Reshape is next to each other, remove the first node
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Reshape":
+ continue
+ first_node = helper.find_node_by_output_name(g, node.input[0])
+ if not first_node:
+ continue
+ if first_node.op_type != "Squeeze":
+ continue
+ # Here we have two consecutive Cast Node
+ # Reset the input of the later node
+ node.input[0] = first_node.input[0]
+ # Remove the first node and its output value info
+ node_to_remove.append(first_node)
+ first_output = helper.find_value_by_name(g, first_node.output[0])
+ g.value_info.remove(first_output)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_no_children_input(g):
+ """Eliminate inputs with no children at all."""
+ # Create a set of input names
+ input_names = set([i.name for i in g.input])
+ # If a name is used in any node, remove this name from the set.
+ for n in g.node:
+ for i in n.input:
+ input_names.discard(i)
+ # Remove the inputs with the left names.
+ for i in input_names:
+ info = helper.find_input_by_name(g, i)
+ g.input.remove(info)
+
+
+def eliminate_consecutive_reshape(g):
+ """Replace consecutive reshape nodes by a single node."""
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Reshape":
+ continue
+ pre_data_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_shape_node = helper.find_node_by_output_name(g, node.input[1])
+ if not pre_data_node or not pre_shape_node:
+ continue
+ if pre_shape_node.op_type != "Constant":
+ continue
+ if pre_data_node.op_type != "Reshape":
+ continue
+
+ pre_pre_shape_node = helper.find_node_by_output_name(
+ g, pre_data_node.input[1]
+ )
+ if pre_pre_shape_node.op_type != "Constant":
+ continue
+
+ new_reshape_node = onnx.helper.make_node(
+ "Reshape",
+ [pre_data_node.input[0], node.input[1]],
+ [node.output[0]],
+ name=node.output[0],
+ )
+
+ g.node.extend([new_reshape_node])
+ node_to_del.append(node)
+ node_to_del.append(pre_data_node)
+ node_to_del.append(pre_pre_shape_node)
+
+ val_info_to_del1 = helper.find_value_by_name(g, node.input[0])
+ val_info_to_del2 = helper.find_value_by_name(g, pre_data_node.input[1])
+ g.value_info.remove(val_info_to_del1)
+ g.value_info.remove(val_info_to_del2)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+
+def eliminate_single_input_Concat(g):
+ """
+ Eliminate single input Concat layers
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Concat":
+ continue
+ # If this node has more than 1 input, continue.
+ if len(node.input) > 1:
+ continue
+ # If this node is output node, set its previous node as output nodes.
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ g.output.remove(todel_output)
+ g.output.extend([the_input_value])
+ node_to_remove.append(node)
+ continue
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ try:
+ g.value_info.remove(value_between)
+ except Exception:
+ print("No value info to delete while eliminating identity layers.")
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_nop_Maxpool_and_AveragePool(g):
+ """
+ Eliminate do nothing MaxPool and AveragePool layers.
+ Those layers have valid padding, 1x1 kernel and [1,1] strides.
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "MaxPool" and node.op_type != "AveragePool":
+ continue
+ # If this node is actually working, continue.
+ kernel = helper.get_list_attribute_by_name(node, "kernel_shape", "int")
+ pads = helper.get_list_attribute_by_name(node, "pads", "int")
+ strides = helper.get_list_attribute_by_name(node, "strides", "int")
+ if kernel != [1, 1] or pads != [0, 0, 0, 0] or strides != [1, 1]:
+ continue
+ # If this node is the output, set its previous node as output nodes.
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ g.output.remove(todel_output)
+ g.output.extend([the_input_value])
+ node_to_remove.append(node)
+ continue
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ try:
+ g.value_info.remove(value_between)
+ except Exception:
+ print("No value info to delete while eliminating identity layers.")
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_trivial_maxpool(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "MaxPool":
+ continue
+ pads = None
+ strides = None
+ dilation = None
+ kernel_shape = None
+ for att in node.attribute:
+ if att.name == "pads":
+ pads = list(att.ints)
+ elif att.name == "strides":
+ strides = list(att.ints)
+ elif att.name == "kernel_shape":
+ kernel_shape = list(att.ints)
+ elif att.name == "dilation":
+ dilation = list(att.ints)
+ else:
+ pass
+ if pads and any([pad != 0 for pad in pads]):
+ continue
+ if strides and any([stride != 1 for stride in strides]):
+ continue
+ if dilation and any([dila != 1 for dila in dilation]):
+ continue
+ if any([dim != 1 for dim in kernel_shape]):
+ continue
+
+ node_to_del.append(node)
+
+ next_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+
+ if next_nodes[0] is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if not output_value:
+ continue
+ else:
+ pre_val_info = helper.find_value_by_name(g, node.input[0])
+ g.output.extend([pre_val_info])
+ g.output.remove(output_value)
+
+ for next_node in next_nodes:
+ modhelper.replace_node_input(
+ next_node, node.output[0], node.input[0]
+ )
+
+ next_val_info = helper.find_value_by_name(g, node.output[0])
+ g.value_info.remove(next_val_info)
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ other.topological_sort(g)
+
+
+def eliminate_empty_value_infos(g):
+ to_remove = []
+ for value_info in g.value_info:
+ if len(value_info.type.tensor_type.shape.dim) == 0:
+ to_remove.append(value_info)
+ for value_info in to_remove:
+ g.value_info.remove(value_info)
+
+
+def eliminate_nop_pads(g):
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Pad":
+ continue
+ # Check if the Pad is empty or not
+ pads_node = helper.find_node_by_output_name(g, node.input[1])
+ pads_np = helper.constant_to_numpy(pads_node)
+ all_zero = True
+ for value in pads_np:
+ if value != 0:
+ all_zero = False
+ if not all_zero:
+ continue
+ # If this node is the output, set its previous node as output nodes.
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ g.output.remove(todel_output)
+ if helper.find_output_by_name(g, node.input[0]) is None:
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ if the_input_value is not None:
+ g.output.extend([the_input_value])
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ try:
+ g.value_info.remove(value_between)
+ except Exception:
+ helper.logger.info(
+ "No value info to delete while eliminating identity layers."
+ )
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_trivial_elementwise_calculation(g):
+ """Eliminate Add, Sub, Mul, Sub nodes which do nothing."""
+ node_to_remove = []
+ for node in g.node:
+ weight_node = None
+ if node.op_type == "Add" or node.op_type == "Sub":
+ # For add and sub, check if the weights are 0s.
+ weight_node = helper.find_node_by_output_name(g, node.input[1])
+ if weight_node is None or weight_node.op_type != "Constant":
+ continue
+ weight_np = helper.constant_to_numpy(weight_node)
+ if np.any(weight_np):
+ continue
+ elif node.op_type == "Mul" or node.op_type == "Div":
+ # For Mul and Div, check if the weights are 1s.
+ weight_node = helper.find_node_by_output_name(g, node.input[1])
+ if weight_node is None or weight_node.op_type != "Constant":
+ continue
+ weight_np = helper.constant_to_numpy(weight_node)
+ weight_np = weight_np - 1
+ if np.any(weight_np):
+ continue
+ else:
+ # For other nodes, just skip
+ continue
+ # Remove the node
+ node_to_remove.append(node)
+ output_value_info = helper.find_value_by_name(g, node.output[0])
+ if output_value_info is not None:
+ g.value_info.remove(output_value_info)
+ # Replace next node input if any.
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ if todel_output is not None:
+ g.output.remove(todel_output)
+ previous_output = helper.find_output_by_name(g, node.input[0])
+ if previous_output is None:
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ g.output.extend([the_input_value])
+ # Delete the constant node if it is not used by other nodes
+ constant_following_nodes = (
+ helper.find_following_nodes_by_input_value_name(
+ g, weight_node.output[0]
+ )
+ )
+ if len(constant_following_nodes) == 1:
+ node_to_remove.append(weight_node)
+ output_value_info = helper.find_value_by_name(
+ g, weight_node.output[0]
+ )
+ if output_value_info is not None:
+ g.value_info.remove(output_value_info)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_nop_cast(g):
+ """Eliminate do nothing Cast nodes."""
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Cast":
+ continue
+ # Get input value_info
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ helper.logger.debug(
+ f"Cannot find the input value_info for Cast node {node.name}. "
+ "Skip elimination check."
+ )
+ continue
+ # Get output value_info
+ output_value = helper.find_value_by_name(g, node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if output_value is None:
+ helper.logger.debug(
+ f"Cannot find the output value_info for Cast node {node.name}."
+ " Skip elimination check."
+ )
+ continue
+ # Compare the type.
+ if (
+ input_value.type.tensor_type.elem_type
+ != output_value.type.tensor_type.elem_type
+ ):
+ continue
+ # If this node is the output, set its previous node as output nodes.
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ g.output.remove(todel_output)
+ if helper.find_output_by_name(g, node.input[0]) is None:
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ if the_input_value is not None:
+ g.output.extend([the_input_value])
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ if value_between is not None:
+ g.value_info.remove(value_between)
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
diff --git a/tools/optimizer_scripts/tools/fusing.py b/tools/optimizer_scripts/tools/fusing.py
new file mode 100644
index 0000000..e19ca94
--- /dev/null
+++ b/tools/optimizer_scripts/tools/fusing.py
@@ -0,0 +1,1201 @@
+import onnx.helper
+import numpy as np
+from . import helper
+from .other import topological_sort
+from .modhelper import delete_value_with_name_if_exists, replace_node_input
+
+
+def fuse_Transpose_into_Constant(g):
+ """
+ Fuse Transpose layers into the Constant layers before
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ prev_node = helper.find_node_by_output_name(g, node.input[0])
+ if prev_node is None or prev_node.op_type != "Constant":
+ continue
+
+ pre_shape, data_list = helper.constant_to_list(prev_node)
+ w = np.reshape(data_list, pre_shape)
+ w = w.transpose(node.attribute[0].ints)
+ new_shape = w.shape
+ w = w.flatten()
+
+ new_tensor = onnx.helper.make_tensor(
+ name=prev_node.name + "_data",
+ data_type=prev_node.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=w.tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant",
+ [],
+ [node.output[0]],
+ name=node.output[0],
+ value=new_tensor,
+ )
+
+ value_between = helper.find_value_by_name(g, prev_node.output[0])
+ value_type = value_between.type.tensor_type.elem_type
+ g.value_info.remove(value_between)
+
+ g.node.extend([new_node])
+ node_to_remove.append(node)
+ node_to_remove.append(prev_node)
+
+ if new_node.output[0] not in [i.name for i in g.value_info]:
+ new_value = onnx.helper.make_tensor_value_info(
+ name=new_node.output[0], elem_type=value_type, shape=new_shape
+ )
+ g.value_info.extend([new_value])
+ if new_node.output[0]:
+ val_info_to_del = helper.find_value_by_name(
+ g, new_node.output[0]
+ )
+ g.value_info.remove(val_info_to_del)
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+ topological_sort(g)
+
+
+def fuse_Add_into_Conv(g):
+ """
+ Fuse Transpose layers into the Constant layers before
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Add":
+ continue
+ conv_node = helper.find_node_by_output_name(g, node.input[0])
+ cons_node = helper.find_node_by_output_name(g, node.input[1])
+ if conv_node is None or cons_node is None:
+ continue
+ if conv_node.op_type != "Conv" or cons_node.op_type != "Constant":
+ continue
+ if len(conv_node.input) > 2:
+ continue
+ # This layer should be fused. Connect constant node into convolution.
+ add_node = node
+ conv_node.input.extend([cons_node.output[0]])
+ old_value = helper.find_value_by_name(g, conv_node.output[0])
+ conv_node.output[0] = add_node.output[0]
+ # Remove origin conv_node_output
+ g.value_info.remove(old_value)
+ # Remove current node
+ node_to_remove.append(add_node)
+ # Apply changes to the model
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def fuse_BN_into_Gemm(g):
+ """Fuse the following BN into the previous Gemm.
+
+ :param g: the graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check for BN and Gemm
+ if node.op_type != "BatchNormalization":
+ continue
+ gemm_node = helper.find_node_by_output_name(g, node.input[0])
+ if gemm_node is None:
+ continue
+ if gemm_node.op_type != "Gemm":
+ continue
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, gemm_node.output[0]
+ )
+ )
+ > 1
+ ):
+ continue
+ bn_node = node
+ # Get original weights
+ gemm_b_node = helper.find_node_by_output_name(g, gemm_node.input[1])
+ gemm_b = helper.constant_to_numpy(gemm_b_node)
+ gemm_c_node = helper.find_node_by_output_name(g, gemm_node.input[2])
+ gemm_c = helper.constant_to_numpy(gemm_c_node)
+ bn_scale_node = helper.find_node_by_output_name(g, bn_node.input[1])
+ bn_scale = helper.constant_to_numpy(bn_scale_node)
+ bn_bias_node = helper.find_node_by_output_name(g, bn_node.input[2])
+ bn_bias = helper.constant_to_numpy(bn_bias_node)
+ bn_mean_node = helper.find_node_by_output_name(g, bn_node.input[3])
+ bn_mean = helper.constant_to_numpy(bn_mean_node)
+ bn_var_node = helper.find_node_by_output_name(g, bn_node.input[4])
+ bn_var = helper.constant_to_numpy(bn_var_node)
+ # Apply attributes
+ # epsilon
+ epsilon = helper.get_attribute_by_name(bn_node, "epsilon")
+ if epsilon is None:
+ epsilon = 0.00001
+ else:
+ epsilon = epsilon.f
+ bn_var = bn_var + epsilon
+ # alpha
+ alpha = helper.get_attribute_by_name(gemm_node, "alpha")
+ if alpha is None:
+ alpha = 1
+ else:
+ alpha = alpha.f
+ gemm_b = gemm_b * alpha
+ # beta
+ beta = helper.get_attribute_by_name(gemm_node, "beta")
+ if beta is None:
+ beta = 1
+ else:
+ beta = beta.f
+ gemm_c = gemm_c * beta
+ # transA
+ transA = helper.get_attribute_by_name(gemm_node, "transA")
+ if transA is not None and transA.i == 1:
+ raise RuntimeError("Do not support transA")
+ # transB
+ transB = helper.get_attribute_by_name(gemm_node, "transB")
+ if transB is not None and transB.i == 1:
+ gemm_b = gemm_b.transpose()
+ # Calculate new weights
+ new_gemm_b = gemm_b * bn_scale / np.sqrt(bn_var)
+ new_gemm_c = (gemm_c - bn_mean) * bn_scale / np.sqrt(bn_var) + bn_bias
+ # Replace original weights
+ new_gemm_b_node = helper.numpy_to_constant(
+ gemm_b_node.name + "_fused", new_gemm_b
+ )
+ new_gemm_c_node = helper.numpy_to_constant(
+ gemm_c_node.name + "_fused", new_gemm_c
+ )
+ g.node.extend([new_gemm_b_node, new_gemm_c_node])
+ node_to_remove.extend(
+ [
+ gemm_b_node,
+ gemm_c_node,
+ bn_node,
+ bn_scale_node,
+ bn_bias_node,
+ bn_mean_node,
+ bn_var_node,
+ ]
+ )
+ # Modify attributes
+ # alpha
+ alpha = helper.get_attribute_by_name(gemm_node, "alpha")
+ if alpha is not None:
+ alpha.f = 1.0
+ # beta
+ beta = helper.get_attribute_by_name(gemm_node, "beta")
+ if beta is not None:
+ beta.f = 1.0
+ # transB
+ transB = helper.get_attribute_by_name(gemm_node, "transB")
+ if transB is not None:
+ transB.i = 0
+ # Connect the new graph
+ gemm_node.input[1] = new_gemm_b_node.output[0]
+ gemm_node.input[2] = new_gemm_c_node.output[0]
+ gemm_b_value = helper.find_value_by_name(g, gemm_b_node.output[0])
+ gemm_c_value = helper.find_value_by_name(g, gemm_c_node.output[0])
+ gemm_b_value.name = new_gemm_b_node.output[0]
+ gemm_c_value.name = new_gemm_c_node.output[0]
+ gemm_value = helper.find_value_by_name(g, gemm_node.output[0])
+ g.value_info.remove(gemm_value)
+ gemm_node.output[0] = bn_node.output[0]
+ for i in range(1, 5):
+ value = helper.find_value_by_name(g, bn_node.input[i])
+ g.value_info.remove(value)
+ # Remove useless nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def fuse_BN_with_Reshape_into_Gemm(g):
+ """Fuse the following BN into the previous Gemm, even with Reshape or \\
+ Squeeze and Unsqueeze surrounding.
+
+ :param g: the graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check for BN and Gemm pattern: Gemm A BN B
+ # Find BatchNorm Node
+ if node.op_type != "BatchNormalization":
+ continue
+ bn_node = node
+ # Find A Node
+ a_node = helper.find_node_by_output_name(g, node.input[0])
+ if a_node is None or len(a_node.input) == 0:
+ continue
+ # Find Gemm Node
+ gemm_node = helper.find_node_by_output_name(g, a_node.input[0])
+ if gemm_node is None or gemm_node.op_type != "Gemm":
+ continue
+ # Find B Node
+ b_node_list = helper.find_following_nodes_by_input_value_name(
+ g, bn_node.output[0]
+ )
+ if len(b_node_list) == 0:
+ the_output = helper.find_output_by_name(g, bn_node.output[0])
+ if the_output is None:
+ continue
+ b_node = None
+ elif len(b_node_list) > 1:
+ continue
+ else:
+ b_node = b_node_list[0]
+ # Check for branches
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, gemm_node.output[0]
+ )
+ )
+ > 1
+ ):
+ continue
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, a_node.output[0]
+ )
+ )
+ > 1
+ ):
+ continue
+ # Check type of A
+ if a_node.op_type == "Unsqueeze":
+ axes = helper.get_attribute_by_name(a_node, "axes")
+ if axes.ints != [2]:
+ continue
+ elif a_node.op_type == "Reshape":
+ a = helper.constant_to_list(
+ helper.find_node_by_output_name(g, a_node.input[1])
+ )[1]
+ if len(a) != 3 or a[2] != 1:
+ continue
+ else:
+ continue
+ # Check type of B
+ if b_node is None:
+ pass
+ elif b_node.op_type == "Flatten":
+ pass
+ elif b_node.op_type == "Squeeze":
+ axes = helper.get_attribute_by_name(a_node, "axes")
+ if axes.ints != [2]:
+ continue
+ elif b_node.op_type == "Reshape":
+ a = helper.constant_to_list(
+ helper.find_node_by_output_name(g, b_node.input[1])
+ )[1]
+ if len(a) != 2:
+ continue
+ else:
+ continue
+ # Construct new Nodes
+ # Get original weights
+ gemm_b_node = helper.find_node_by_output_name(g, gemm_node.input[1])
+ gemm_b = helper.constant_to_numpy(gemm_b_node)
+ gemm_c_node = helper.find_node_by_output_name(g, gemm_node.input[2])
+ gemm_c = helper.constant_to_numpy(gemm_c_node)
+ bn_scale_node = helper.find_node_by_output_name(g, bn_node.input[1])
+ bn_scale = helper.constant_to_numpy(bn_scale_node)
+ bn_bias_node = helper.find_node_by_output_name(g, bn_node.input[2])
+ bn_bias = helper.constant_to_numpy(bn_bias_node)
+ bn_mean_node = helper.find_node_by_output_name(g, bn_node.input[3])
+ bn_mean = helper.constant_to_numpy(bn_mean_node)
+ bn_var_node = helper.find_node_by_output_name(g, bn_node.input[4])
+ bn_var = helper.constant_to_numpy(bn_var_node)
+ # Apply attributes
+ # epsilon
+ epsilon = helper.get_attribute_by_name(bn_node, "epsilon")
+ if epsilon is None:
+ epsilon = 0.00001
+ else:
+ epsilon = epsilon.f
+ bn_var = bn_var + epsilon
+ # alpha
+ alpha = helper.get_attribute_by_name(gemm_node, "alpha")
+ if alpha is None:
+ alpha = 1
+ else:
+ alpha = alpha.f
+ gemm_b = gemm_b * alpha
+ # beta
+ beta = helper.get_attribute_by_name(gemm_node, "beta")
+ if beta is None:
+ beta = 1
+ else:
+ beta = beta.f
+ gemm_c = gemm_c * beta
+ # transA
+ transA = helper.get_attribute_by_name(gemm_node, "transA")
+ if transA is not None and transA.i == 1:
+ raise RuntimeError("Do not support transA")
+ # transB
+ transB = helper.get_attribute_by_name(gemm_node, "transB")
+ if transB is not None and transB.i == 1:
+ gemm_b = gemm_b.transpose()
+ # Calculate new weights
+ new_gemm_b = gemm_b * bn_scale / np.sqrt(bn_var)
+ new_gemm_c = (gemm_c - bn_mean) * bn_scale / np.sqrt(bn_var) + bn_bias
+ # Replace original weights
+ new_gemm_b_node = helper.numpy_to_constant(
+ gemm_b_node.name + "_fused", new_gemm_b
+ )
+ new_gemm_c_node = helper.numpy_to_constant(
+ gemm_c_node.name + "_fused", new_gemm_c
+ )
+ g.node.extend([new_gemm_b_node, new_gemm_c_node])
+ # Modify attributes
+ # alpha
+ alpha = helper.get_attribute_by_name(gemm_node, "alpha")
+ if alpha is not None:
+ alpha.f = 1.0
+ # beta
+ beta = helper.get_attribute_by_name(gemm_node, "beta")
+ if beta is not None:
+ beta.f = 1.0
+ # transB
+ transB = helper.get_attribute_by_name(gemm_node, "transB")
+ if transB is not None:
+ transB.i = 0
+ # Remove useless nodes
+ node_to_remove.extend(
+ [
+ gemm_b_node,
+ gemm_c_node,
+ bn_node,
+ bn_scale_node,
+ bn_bias_node,
+ bn_mean_node,
+ bn_var_node,
+ a_node,
+ ]
+ )
+ if a_node.op_type == "Reshape":
+ node_to_remove.append(
+ helper.find_node_by_output_name(g, a_node.input[1])
+ )
+ if b_node is not None:
+ node_to_remove.append(b_node)
+ if b_node.op_type == "Reshape":
+ node_to_remove.append(
+ helper.find_node_by_output_name(g, b_node.input[1])
+ )
+ # Delete useless value infos
+ value = helper.find_value_by_name(g, a_node.output[0])
+ g.value_info.remove(value)
+ if a_node.op_type == "Reshape":
+ value = helper.find_value_by_name(g, a_node.input[1])
+ g.value_info.remove(value)
+ for i in range(1, 5):
+ value = helper.find_value_by_name(g, bn_node.input[i])
+ g.value_info.remove(value)
+ value = helper.find_value_by_name(g, bn_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ if b_node is not None:
+ value = helper.find_value_by_name(g, gemm_node.output[0])
+ g.value_info.remove(value)
+ if b_node.op_type == "Reshape":
+ value = helper.find_value_by_name(g, b_node.input[1])
+ g.value_info.remove(value)
+ # Connect the new graph
+ # Connect Gemm new weights
+ gemm_node.input[1] = new_gemm_b_node.output[0]
+ gemm_node.input[2] = new_gemm_c_node.output[0]
+ gemm_b_value = helper.find_value_by_name(g, gemm_b_node.output[0])
+ gemm_c_value = helper.find_value_by_name(g, gemm_c_node.output[0])
+ gemm_b_value.name = new_gemm_b_node.output[0]
+ gemm_b_value.type.tensor_type.shape.dim[
+ 0
+ ].dim_value = new_gemm_b.shape[0]
+ gemm_b_value.type.tensor_type.shape.dim[
+ 1
+ ].dim_value = new_gemm_b.shape[1]
+ gemm_c_value.name = new_gemm_c_node.output[0]
+ if b_node is None:
+ # If b node is None, set the Gemm output as the graph output
+ output_value = helper.find_output_by_name(g, bn_node.output[0])
+ g.output.remove(output_value)
+ g.output.extend(
+ [helper.find_value_by_name(g, gemm_node.output[0])]
+ )
+ else:
+ # Else, set node B output as gemm output
+ gemm_node.output[0] = b_node.output[0]
+ # Remove useless nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def fuse_Gemm_into_Gemm(g):
+ """Fuse the previous Gemm into the following Gemm.
+
+ :param g: the graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check for Gemm and Gemm
+ if node.op_type != "Gemm":
+ continue
+ prev_node = helper.find_node_by_output_name(g, node.input[0])
+ if prev_node is None:
+ continue
+ if prev_node.op_type != "Gemm":
+ continue
+ # Get original weights
+ prev_b_node = helper.find_node_by_output_name(g, prev_node.input[1])
+ prev_b = helper.constant_to_numpy(prev_b_node)
+ prev_c_node = helper.find_node_by_output_name(g, prev_node.input[2])
+ prev_c = helper.constant_to_numpy(prev_c_node)
+ b_node = helper.find_node_by_output_name(g, node.input[1])
+ b = helper.constant_to_numpy(b_node)
+ c_node = helper.find_node_by_output_name(g, node.input[2])
+ c = helper.constant_to_numpy(c_node)
+ # Apply attributes
+ # alpha
+ alpha = helper.get_attribute_by_name(node, "alpha")
+ if alpha is None:
+ alpha = 1
+ else:
+ alpha = alpha.f
+ b = b * alpha
+ alpha = helper.get_attribute_by_name(prev_node, "alpha")
+ if alpha is None:
+ alpha = 1
+ else:
+ alpha = alpha.f
+ prev_b = prev_b * alpha
+ # beta
+ beta = helper.get_attribute_by_name(node, "beta")
+ if beta is None:
+ beta = 1
+ else:
+ beta = beta.f
+ c = c * beta
+ beta = helper.get_attribute_by_name(prev_node, "beta")
+ if beta is None:
+ beta = 1
+ else:
+ beta = beta.f
+ prev_c = prev_c * beta
+ # transA
+ transA = helper.get_attribute_by_name(node, "transA")
+ if transA is not None and transA.i == 1:
+ raise RuntimeError("Do not support transA")
+ transA = helper.get_attribute_by_name(prev_node, "transA")
+ if transA is not None and transA.i == 1:
+ raise RuntimeError("Do not support transA")
+ # transB
+ transB = helper.get_attribute_by_name(node, "transB")
+ if transB is not None and transB.i == 1:
+ b = b.transpose()
+ transB = helper.get_attribute_by_name(prev_node, "transB")
+ if transB is not None and transB.i == 1:
+ prev_b = prev_b.transpose()
+ # Calculate new weights
+ new_b = prev_b.dot(b)
+ new_c = prev_c.dot(b) + c
+ # Replace original weights
+ new_b_node = helper.numpy_to_constant(b_node.name + "_fused", new_b)
+ new_c_node = helper.numpy_to_constant(c_node.name + "_fused", new_c)
+ g.node.extend([new_b_node, new_c_node])
+ node_to_remove.extend(
+ [b_node, c_node, prev_b_node, prev_c_node, prev_node]
+ )
+ # Modify attributes
+ # alpha
+ alpha = helper.get_attribute_by_name(node, "alpha")
+ if alpha is not None:
+ alpha.f = 1.0
+ # beta
+ beta = helper.get_attribute_by_name(node, "beta")
+ if beta is not None:
+ beta.f = 1.0
+ # transB
+ transB = helper.get_attribute_by_name(node, "transB")
+ if transB is not None:
+ transB.i = 0
+ # Connect the new graph
+ node.input[0] = prev_node.input[0]
+ delete_value_with_name_if_exists(g, prev_node.output[0])
+ for i in range(1, 3):
+ delete_value_with_name_if_exists(g, prev_node.input[i])
+ delete_value_with_name_if_exists(g, node.input[i])
+ node.input[1] = new_b_node.output[0]
+ node.input[2] = new_c_node.output[0]
+ # Remove useless nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def fuse_MatMul_and_Add_into_Gemm(g):
+ """
+ Fuse MatMul and Add layers into a new Gemm layers.
+
+ :param g: the onnx graph
+ :raises ValueError: MatMul must be followed by an Add node
+ """
+ node_to_remove = []
+ node_to_add = []
+ for node in g.node:
+ if node.op_type != "MatMul":
+ continue
+ add_node = None
+ for i in g.node:
+ if not i.input:
+ continue
+ if i.input[0] == node.output[0]:
+ add_node = i
+ break
+ value_to_remove = helper.find_value_by_name(g, node.output[0])
+ if (
+ add_node is None
+ or value_to_remove is None
+ or add_node.op_type != "Add"
+ ):
+ continue
+ input_list = node.input
+ input_list.append(add_node.input[1]),
+ new_node = onnx.helper.make_node(
+ "Gemm",
+ input_list,
+ add_node.output,
+ name=node.name,
+ alpha=1.0,
+ beta=1.0,
+ transA=0,
+ transB=0,
+ )
+ node_to_add.append(new_node)
+ node_to_remove.append(node)
+ node_to_remove.append(add_node)
+ g.value_info.remove(value_to_remove)
+ for node in node_to_remove:
+ g.node.remove(node)
+ g.node.extend(node_to_add)
+
+
+def fuse_consecutive_transposes(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ if pre_node.op_type != "Transpose":
+ continue
+
+ pre_permutation = list(pre_node.attribute[0].ints)
+ cur_permutation = list(node.attribute[0].ints)
+ if len(pre_permutation) != len(cur_permutation):
+ continue
+
+ new_permutation = []
+ for ind in cur_permutation:
+ new_permutation.append(pre_permutation[ind])
+
+ new_trans_node = onnx.helper.make_node(
+ "Transpose",
+ [pre_node.input[0]],
+ [node.output[0]],
+ name=node.name,
+ perm=new_permutation,
+ )
+
+ g.node.extend([new_trans_node])
+ node_to_del.extend([pre_node, node])
+
+ mid_val_info = helper.find_value_by_name(g, node.input[0])
+ if mid_val_info:
+ g.value_info.remove(mid_val_info)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ topological_sort(g)
+
+
+def fuse_mul_and_add_into_bn(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Add":
+ continue
+ add_node = node
+ input_nodes_add = [
+ helper.find_node_by_output_name(g, input_name)
+ for input_name in add_node.input
+ ]
+ if any([n is None for n in input_nodes_add]):
+ continue
+ mul_node, const_add = None, None
+ for input_node_add in input_nodes_add:
+ if input_node_add.op_type == "Mul":
+ mul_node = input_node_add
+ elif input_node_add.op_type == "Constant":
+ const_add = input_node_add
+ else:
+ pass
+ if not mul_node or not const_add:
+ continue
+ data_input_name, const_mul = None, None
+ for input_name in mul_node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ if not input_node:
+ data_input_name = input_name
+ elif input_node.op_type == "Constant":
+ if not const_mul:
+ const_mul = input_node
+ else:
+ data_input_name = input_name
+ else:
+ data_input_name = input_name
+
+ if not const_mul:
+ continue
+
+ scale_shape, scale_data = helper.constant_to_list(const_mul)
+ bias_shape, __ = helper.constant_to_list(const_add)
+ c_dim = len(scale_data)
+ if scale_shape != bias_shape:
+ continue
+
+ data_input_value = helper.find_value_by_name(g, data_input_name)
+ if data_input_value is None:
+ data_input_value = helper.find_input_by_name(g, data_input_name)
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ data_input_value
+ )
+ # only allow 4 dim data input due to the hardware limitation
+ if (
+ previous_node_output_shape is None
+ or len(previous_node_output_shape) != 4
+ ):
+ continue
+
+ # check if mul's dim and input channel dimension are matched
+ if previous_node_output_shape[1] != c_dim:
+ continue
+
+ if scale_shape == [1, c_dim, 1, 1]:
+ # remove all '1'
+ for _ in range(3):
+ const_add.attribute[0].t.dims.remove(1)
+ const_mul.attribute[0].t.dims.remove(1)
+ elif scale_shape == [1, c_dim]:
+ # remove all '1'
+ const_add.attribute[0].t.dims.remove(1)
+ const_mul.attribute[0].t.dims.remove(1)
+ elif scale_shape == 1 and c_dim == 1:
+ # Single value weight
+ const_add.attribute[0].t.dims.append(1)
+ const_mul.attribute[0].t.dims.append(1)
+ else:
+ continue
+
+ bn_name = add_node.output[0]
+ const_mean = helper.list_to_constant(
+ bn_name + "_mean", [c_dim], [0.0 for _ in range(c_dim)]
+ )
+ const_var = helper.list_to_constant(
+ bn_name + "_var", [c_dim], [1.0 for _ in range(c_dim)]
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ data_input_name,
+ const_mul.output[0],
+ const_add.output[0],
+ const_mean.output[0],
+ const_var.output[0],
+ ],
+ [add_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ mid_val_info = helper.find_value_by_name(g, mul_node.output[0])
+ scale_val_info = helper.find_value_by_name(g, const_mul.output[0])
+ bais_val_info = helper.find_value_by_name(g, const_add.output[0])
+ g.value_info.remove(mid_val_info)
+ g.value_info.remove(scale_val_info)
+ g.value_info.remove(bais_val_info)
+
+ new_scale_val_info = onnx.helper.make_tensor_value_info(
+ const_mul.output[0], const_mul.attribute[0].t.data_type, [c_dim]
+ )
+ new_bais_val_info = onnx.helper.make_tensor_value_info(
+ const_add.output[0], const_add.attribute[0].t.data_type, [c_dim]
+ )
+ mean_val_info = onnx.helper.make_tensor_value_info(
+ const_mean.output[0], const_mean.attribute[0].t.data_type, [c_dim]
+ )
+ var_val_info = onnx.helper.make_tensor_value_info(
+ const_var.output[0], const_var.attribute[0].t.data_type, [c_dim]
+ )
+
+ g.value_info.extend([new_scale_val_info])
+ g.value_info.extend([new_bais_val_info])
+ g.value_info.extend([mean_val_info])
+ g.value_info.extend([var_val_info])
+ g.node.extend([bn_node])
+ g.node.extend([const_mean])
+ g.node.extend([const_var])
+ node_to_del.extend([mul_node, add_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def fuse_mul_and_add_into_gemm(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Add":
+ continue
+ add_node = node
+ mul_node = helper.find_node_by_output_name(g, add_node.input[0])
+ if not mul_node or mul_node.op_type != "Mul":
+ continue
+ mul_const = helper.find_node_by_output_name(g, mul_node.input[1])
+ if not mul_const or mul_const.op_type != "Constant":
+ continue
+ add_const = helper.find_node_by_output_name(g, add_node.input[1])
+ if not add_const or add_const.op_type != "Constant":
+ continue
+
+ input_val = helper.find_value_by_name(g, mul_node.input[0])
+ if not input_val:
+ input_val = helper.find_input_by_name(g, mul_node.input[0])
+ if not input_val:
+ continue
+
+ _, input_shape = helper.find_size_shape_from_value(input_val)
+ if not input_shape:
+ continue
+
+ dim = int(np.prod(input_shape))
+ if input_shape != [1, dim]:
+ continue
+
+ mul_const_shape, mul_const_data = helper.constant_to_list(mul_const)
+ add_const_shape, __ = helper.constant_to_list(add_const)
+
+ if len(mul_const_shape) != 1 or mul_const_shape[0] != dim:
+ continue
+ if len(add_const_shape) != 1 or add_const_shape[0] != dim:
+ continue
+
+ b_data = np.zeros([dim, dim])
+ for i in range(dim):
+ b_data[i][i] = mul_const_data[i]
+ b_data = b_data.flatten().tolist()
+ b_tensor = onnx.helper.make_tensor(
+ name=mul_const.name + "_tensor",
+ data_type=mul_const.attribute[0].t.data_type,
+ dims=[dim, dim],
+ vals=b_data,
+ )
+ b_const_node = onnx.helper.make_node(
+ "Constant",
+ [],
+ [mul_const.output[0]],
+ value=b_tensor,
+ name=mul_const.output[0],
+ )
+
+ add_const.attribute[0].t.dims.insert(0, 1)
+
+ gemm_node = onnx.helper.make_node(
+ "Gemm",
+ [mul_node.input[0], b_const_node.output[0], add_const.output[0]],
+ [add_node.output[0]],
+ name=add_node.output[0],
+ )
+
+ g.node.extend([gemm_node, b_const_node])
+ node_to_del.extend([mul_const, mul_node, add_node])
+
+ val_info_mid = helper.find_value_by_name(g, mul_node.output[0])
+ val_info_mul_const = helper.find_value_by_name(g, mul_const.output[0])
+ val_info_add_const = helper.find_value_by_name(g, add_const.output[0])
+ if val_info_mid:
+ g.value_info.remove(val_info_mid)
+ if val_info_mul_const:
+ g.value_info.remove(val_info_mul_const)
+ if val_info_add_const:
+ g.value_info.remove(val_info_add_const)
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def fuse_conv_and_add_into_conv(g):
+ node_to_del = []
+ for node in g.node:
+ # Check if two nodes can be fused
+ if node.op_type != "Add":
+ continue
+ add_node = node
+ add_const = helper.find_node_by_output_name(g, add_node.input[1])
+ if not add_const or add_const.op_type != "Constant":
+ continue
+
+ conv_node = helper.find_node_by_output_name(g, add_node.input[0])
+ if not conv_node or conv_node.op_type != "Conv":
+ continue
+ weight_node = helper.find_node_by_output_name(g, conv_node.input[1])
+ if not weight_node or weight_node.op_type != "Constant":
+ continue
+
+ m_dim = weight_node.attribute[0].t.dims[0]
+ if add_const.attribute[0].t.dims != [1, m_dim, 1, 1]:
+ continue
+ for _ in range(3):
+ add_const.attribute[0].t.dims.remove(1)
+
+ # Link the add weight to constant.
+ conv_node.input.extend([add_const.output[0]])
+
+ # Remove the node
+ node_to_del.append(node)
+ output_value_info = helper.find_value_by_name(g, add_node.output[0])
+ if output_value_info is not None:
+ g.value_info.remove(output_value_info)
+ add_weight_value_info = helper.find_value_by_name(
+ g, add_const.output[0]
+ )
+ if add_weight_value_info is not None:
+ g.value_info.remove(add_weight_value_info)
+ # Replace next node input if any.
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, add_node.output[0]
+ )
+ for following_node in following_nodes:
+ replace_node_input(
+ following_node, add_node.output[0], add_node.input[0]
+ )
+ # Replace output if any
+ todel_output = helper.find_output_by_name(g, add_node.output[0])
+ if todel_output is not None:
+ g.output.remove(todel_output)
+ previous_output = helper.find_output_by_name(g, add_node.input[0])
+ if previous_output is None:
+ the_input_value = helper.find_value_by_name(
+ g, add_node.input[0]
+ )
+ g.output.extend([the_input_value])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def fuse_consecutive_reducemean(g):
+ node_to_del = []
+ for node in g.node:
+ # Find consecutive ReduceMean
+ if node.op_type != "ReduceMean":
+ continue
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ if pre_node is None or pre_node.op_type != "ReduceMean":
+ continue
+ # Check attributes
+ pre_keepdims = helper.get_var_attribute_by_name(
+ pre_node, "keepdims", "int"
+ )
+ pre_axes = helper.get_list_attribute_by_name(pre_node, "axes", "int")
+ cur_keepdims = helper.get_var_attribute_by_name(
+ node, "keepdims", "int"
+ )
+ cur_axes = helper.get_list_attribute_by_name(node, "axes", "int")
+ if pre_keepdims != 0 or cur_keepdims != 0:
+ continue
+ axes = sorted(pre_axes + cur_axes)
+ if axes != [2, 3]:
+ continue
+ # Merge two ReduceMean into GlobalAveragePool.
+ new_gap_node = onnx.helper.make_node(
+ "GlobalAveragePool",
+ [pre_node.input[0]],
+ [node.output[0] + "_intermedia"],
+ name=node.name + "_gap",
+ )
+ new_flatten_node = onnx.helper.make_node(
+ "Flatten",
+ [node.output[0] + "_intermedia"],
+ [node.output[0]],
+ name=node.name + "_flatten",
+ axis=1,
+ )
+
+ # Clean up
+ g.node.extend([new_gap_node, new_flatten_node])
+ node_to_del.extend([pre_node, node])
+ mid_val_info = helper.find_value_by_name(g, node.input[0])
+ if mid_val_info:
+ g.value_info.remove(mid_val_info)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ topological_sort(g)
+
+
+def fuse_slice_nodes_into_conv(g):
+ # define pattern checker
+ def check_is_slice(node):
+ if node.op_type == "Concat":
+ return True
+ if node.op_type != "Slice":
+ return False
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ if len(following_nodes) != 1:
+ return False
+ # also check attributes
+ if len(node.input) != 5:
+ return False
+ # starts should be 0 or 1
+ starts_node = helper.find_node_by_output_name(g, node.input[1])
+ if starts_node.op_type != "Constant":
+ return False
+ _, starts_list = helper.constant_to_list(starts_node)
+ for num in starts_list:
+ if num != 0 and num != 1:
+ return False
+ # ends
+ ends_node = helper.find_node_by_output_name(g, node.input[2])
+ if ends_node.op_type != "Constant":
+ return False
+ # axes should be 2 or 3
+ axes_node = helper.find_node_by_output_name(g, node.input[3])
+ if axes_node.op_type != "Constant":
+ return False
+ _, axes_list = helper.constant_to_list(axes_node)
+ for num in axes_list:
+ if num != 2 and num != 3:
+ return False
+ # Steps can only be 2
+ steps_node = helper.find_node_by_output_name(g, node.input[4])
+ if steps_node.op_type != "Constant":
+ return False
+ _, steps_list = helper.constant_to_list(steps_node)
+ for num in steps_list:
+ if num != 2:
+ return False
+ # Recursion
+ return check_is_slice(following_nodes[0])
+
+ # defind concat finder
+ def find_concat_node(node):
+ while node.op_type != "Concat":
+ node = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )[0]
+ return node
+
+ # define remove node function.
+ def remove_nodes(input_name):
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, input_name
+ )
+ # Remove concat directly
+ if (
+ len(following_nodes) == 1
+ and following_nodes[0].op_type == "Concat"
+ ):
+ g.node.remove(following_nodes[0])
+ return
+ for following_node in following_nodes:
+ # Recursion first
+ remove_nodes(following_node.output[0])
+ # Remove weights
+ for i in range(1, len(following_node.input)):
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, following_node.input[i]
+ )
+ )
+ > 1
+ ):
+ # More than one following nodes. Skip.
+ continue
+ input_weight = helper.find_node_by_output_name(
+ g, following_node.input[i]
+ )
+ g.node.remove(input_weight)
+ # Remove Slice nodes
+ g.node.remove(following_node)
+
+ # define remove value_info function
+ def remove_value_infos(input_name):
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, input_name
+ )
+ if following_nodes[0].op_type == "Concat":
+ return
+ for following_node in following_nodes:
+ output_value = helper.find_value_by_name(
+ g, following_node.output[0]
+ )
+ # Remove output values
+ if output_value is not None:
+ g.value_info.remove(output_value)
+ # Remove weight values
+ for i in range(1, len(following_node.input)):
+ input_value = helper.find_value_by_name(
+ g, following_node.input[i]
+ )
+ if input_value is not None:
+ g.value_info.remove(input_value)
+ # Recursion
+ remove_value_infos(following_node.output[0])
+
+ # define get slice position
+ def get_slice_position(final_slice_output):
+ slice_position = [0, 0]
+ prev_node = helper.find_node_by_output_name(g, final_slice_output)
+ while prev_node is not None:
+ starts_np = helper.constant_to_numpy(
+ helper.find_node_by_output_name(g, prev_node.input[1])
+ )
+ axes_np = helper.constant_to_numpy(
+ helper.find_node_by_output_name(g, prev_node.input[3])
+ )
+ for i in range(len(axes_np)):
+ if axes_np[i] == 2:
+ slice_position[0] = starts_np[i]
+ elif axes_np[i] == 3:
+ slice_position[1] = starts_np[i]
+ prev_node = helper.find_node_by_output_name(g, prev_node.input[0])
+ return slice_position
+
+ # Check pattern from each input
+ for input_value in g.input:
+ nodes_after_input = helper.find_following_nodes_by_input_value_name(
+ g, input_value.name
+ )
+ pattern_matched = True
+ for following_node in nodes_after_input:
+ if following_node.op_type != "Slice":
+ pattern_matched = False
+ break
+ else:
+ pattern_matched = check_is_slice(following_node)
+ if not pattern_matched:
+ continue
+ # Pattern found. Check limitation
+ # Currently only support 2D
+ if len(nodes_after_input) != 4:
+ continue
+ # Get the concat node
+ concat_node = find_concat_node(nodes_after_input[0])
+ # Get basic information
+ input_shape = helper.get_shape_from_value_info(input_value)
+ channel_num = input_shape[1]
+ # Construct weight
+ weight_np = np.zeros(
+ (input_shape[1] * 4, input_shape[1], 3, 3), dtype=np.float32
+ )
+ for i in range(4):
+ # Check each branch
+ slice_position = get_slice_position(concat_node.input[i])
+ for j in range(channel_num):
+ weight_np[
+ i * channel_num + j,
+ j,
+ slice_position[0],
+ slice_position[1],
+ ] = 1
+ weight_node = helper.numpy_to_constant(
+ concat_node.name + "_weight", weight_np
+ )
+ # Construct Conv node
+ new_conv = onnx.helper.make_node(
+ "Conv",
+ [input_value.name, concat_node.name + "_weight"],
+ [concat_node.output[0]],
+ name=concat_node.name + "_fused",
+ dilations=[1, 1],
+ group=1,
+ kernel_shape=[3, 3],
+ strides=[2, 2],
+ pads=[0, 0, 2, 2],
+ )
+ # Delete old nodes, weights and value_infos
+ remove_value_infos(input_value.name)
+ remove_nodes(input_value.name)
+ # Replace node
+ g.node.append(weight_node)
+ g.node.append(new_conv)
+
+
+def fuse_relu_min_into_clip(g):
+ node_to_del = []
+ for node in g.node:
+ # Check Min node
+ if node.op_type != "Min":
+ continue
+ min_node = node
+ # Check Constant node
+ min_const = helper.find_node_by_output_name(g, min_node.input[1])
+ if not min_const or min_const.op_type != "Constant":
+ continue
+ min_shape, min_value = helper.constant_to_list(min_const)
+ if min_shape != 1:
+ continue
+ # Check Relu node
+ relu_node = helper.find_node_by_output_name(g, min_node.input[0])
+ if not relu_node or relu_node.op_type != "Relu":
+ continue
+
+ # Create Clip node
+ relu_min_const_node = helper.list_to_constant(
+ relu_node.name + "_min_value", [], [0.0]
+ )
+ clip_node = onnx.helper.make_node(
+ "Clip",
+ [
+ relu_node.input[0],
+ relu_min_const_node.output[0],
+ min_const.output[0],
+ ],
+ [min_node.output[0]],
+ name=min_node.name,
+ )
+
+ node_to_del.extend([relu_node, min_node])
+
+ old_relu_const_val_info = helper.find_value_by_name(
+ g, min_node.input[0]
+ )
+ if old_relu_const_val_info:
+ g.value_info.remove(old_relu_const_val_info)
+ g.node.extend([relu_min_const_node, clip_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
diff --git a/tools/optimizer_scripts/tools/general_graph.py b/tools/optimizer_scripts/tools/general_graph.py
new file mode 100644
index 0000000..f9904f2
--- /dev/null
+++ b/tools/optimizer_scripts/tools/general_graph.py
@@ -0,0 +1,85 @@
+from collections import deque
+
+
+class Node:
+ """A Node which maps a node proto. It has pointers to its parents and
+ children.
+ """
+
+ def __init__(self, onnx_node):
+ """Initialize a node. This initialization only set up the mapping to
+ node proto. The pointers should be set up by outside.
+ """
+ self.name = None
+ self.parents = []
+ self.children = []
+ self.proto = None
+ self.output_value = None
+ if onnx_node is not None:
+ self.name = onnx_node.name
+ self.proto = onnx_node
+
+
+class Graph:
+ """A graph which is constructed from the onnx proto."""
+
+ def __init__(self, onnx_graph):
+ """Construct the graph from onnx."""
+ self.input_nodes = []
+ self.output_nodes = []
+ self.name2node = {}
+ self.output2node = {}
+ self.proto = onnx_graph
+ # Add input nodes
+ for value in onnx_graph.input:
+ input_node = Node(None)
+ input_node.name = "Input_" + value.name
+ input_node.output_value = value
+ self.name2node[input_node.name] = input_node
+ self.output2node[value.name] = input_node
+ self.input_nodes.append(input_node)
+ output_value_names = [value.name for value in onnx_graph.output]
+ # Add regular nodes
+ for onnx_node in onnx_graph.node:
+ node = Node(onnx_node)
+ self.name2node[node.name] = node
+ self.output2node[onnx_node.output[0]] = node
+ for value_name in onnx_node.input:
+ node.parents.append(self.output2node[value_name])
+ self.output2node[value_name].children.append(node)
+ if onnx_node.output[0] in output_value_names:
+ self.output_nodes.append(node)
+ # Add value infos
+ for value in onnx_graph.value_info:
+ node = self.output2node[value.name]
+ node.output_value = value
+
+ def get_sorted_node_list(self):
+ """Return a node list in topological order."""
+ visited = set()
+ todo = deque()
+ result = []
+ for node in self.input_nodes:
+ todo.append(node)
+ visited.add(node)
+ for onnx_node in self.proto.node:
+ if onnx_node.op_type == "Constant":
+ node = self.name2node[onnx_node.name]
+ todo.append(node)
+ visited.add(node)
+ while todo:
+ node = todo.popleft()
+ result.append(node)
+ for child in node.children:
+ if child in visited:
+ continue
+ ready = True
+ for child_parent in child.parents:
+ if child_parent in visited:
+ continue
+ ready = False
+ break
+ if ready:
+ todo.append(child)
+ visited.add(child)
+ return result
diff --git a/tools/optimizer_scripts/tools/helper.py b/tools/optimizer_scripts/tools/helper.py
new file mode 100644
index 0000000..02da09d
--- /dev/null
+++ b/tools/optimizer_scripts/tools/helper.py
@@ -0,0 +1,642 @@
+"""This module contains helper functions that do not modify the graph.
+"""
+import onnx
+import onnx.helper
+import struct
+import numpy as np
+import logging
+
+__ONNX_VERSION__ = -1
+
+logger = logging.getLogger("optimizer_scripts")
+
+
+def setup_current_opset_version(m):
+ global __ONNX_VERSION__
+ __ONNX_VERSION__ = m.opset_import[0].version
+ if __ONNX_VERSION__ not in [11]:
+ raise RuntimeError(
+ "Only support opset 11, but got " + str(__ONNX_VERSION__)
+ )
+
+
+def get_current_opset_version():
+ if __ONNX_VERSION__ == -1:
+ raise RuntimeError("do setup_current_opset_version first please")
+ return __ONNX_VERSION__
+
+
+def find_nodes_by_input_name(g, name):
+ nodes = []
+ for node in g.node:
+ if name in node.input:
+ nodes.append(node)
+ return nodes
+
+
+def find_node_by_output_name(g, name):
+ """
+ Find a node in the graph by its output name
+
+ :param g: the onnx graph\\
+ :param name: the target node output name\\
+ :returns: the node find by name
+ """
+ for i in g.node:
+ if name in i.output:
+ return i
+ return None
+
+
+def find_node_by_node_name(g, name):
+ """
+ Find a node in the graph by its output name
+
+ :param g: the onnx graph\\
+ :param name: the target node output name\\
+ :returns: the node find by name
+ """
+ for i in g.node:
+ if i.name == name:
+ return i
+ return None
+
+
+def find_following_nodes_by_input_value_name(g, name):
+ """ Find the following nodes of a specific value.
+
+ :param g: the onnx graph. \\
+ :param name: the value name. \\
+ :return: a list of following nodes.
+ """
+ return find_nodes_by_input_name(g, name)
+
+
+def find_value_by_name(g, name):
+ """
+ Find a value_info in the graph by name
+
+ :param g: the onnx graph\\
+ :param name: the target value_info name\\
+ :returns: the value_info find by name
+ """
+ for i in g.value_info:
+ if i.name == name:
+ return i
+ return None
+
+
+def find_output_by_name(g, name):
+ """
+ Find a value_info in the graph by name
+
+ :param g: the onnx graph\\
+ :param name: the target value_info name\\
+ :returns: the value_info find by name
+ """
+ for i in g.output:
+ if i.name == name:
+ return i
+ return None
+
+
+def find_input_by_name(g, name):
+ """
+ Find a input in the graph by name
+
+ :param g: the onnx graph\\
+ :param name: the target input name\\
+ :returns: the input find by name
+ """
+ for i in g.input:
+ if i.name == name:
+ return i
+ return None
+
+
+def list_to_constant(name, shape, data, data_type=None):
+ """Generate a constant node using the given infomation.
+
+ :name: the node name and the output value name\\
+ :shape: the data shape\\
+ :data: the data itself\\
+ :returns: the generated onnx constant node
+ """
+ if not data_type:
+ if isinstance(data, int):
+ data_type = onnx.helper.TensorProto.INT64
+ elif isinstance(data, float):
+ data_type = onnx.helper.TensorProto.FLOAT
+ elif len(data) > 0 and isinstance(data[0], int):
+ data_type = onnx.helper.TensorProto.INT64
+ else:
+ data_type = onnx.helper.TensorProto.FLOAT
+ tensor = onnx.helper.make_tensor(name, data_type, shape, data)
+ new_w_node = onnx.helper.make_node(
+ "Constant", [], [name], name=name, value=tensor
+ )
+ return new_w_node
+
+
+def scaler_to_constant(name, data, data_type=None):
+ """Generate a constant node using the given infomation.
+
+ :name: the node name and the output value name\\
+ :shape: the data shape\\
+ :data: the data itself\\
+ :returns: the generated onnx constant node
+ """
+ if not data_type:
+ if isinstance(data, int):
+ data_type = onnx.helper.TensorProto.INT64
+ elif isinstance(data, float):
+ data_type = onnx.helper.TensorProto.FLOAT
+ else:
+ logger.error("Cannot create scaler constant with a list.")
+ exit(1)
+ tensor = onnx.helper.make_tensor(name, data_type, None, [data])
+ new_w_node = onnx.helper.make_node(
+ "Constant", [], [name], name=name, value=tensor
+ )
+ return new_w_node
+
+
+def numpy_to_constant(name, np_array):
+ return list_to_constant(name, np_array.shape, np_array.flatten().tolist())
+
+
+def constant_to_list(node):
+ """Generate a list from the constant node
+
+ :node: the Constant node\\
+ :returns: the shape of the constant node, the data of the constant node
+ """
+ tensor = node.attribute[0].t
+ # 1. check data type
+ # 2. get data from raw or data
+ # 3. get shape from dim
+ if tensor.data_type == onnx.helper.TensorProto.INT32:
+ if len(tensor.int32_data) != 0:
+ data = list(tensor.int32_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("i", tensor.raw_data)]
+ elif tensor.data_type == onnx.helper.TensorProto.INT64:
+ if len(tensor.int64_data) != 0:
+ data = list(tensor.int64_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("q", tensor.raw_data)]
+ elif tensor.data_type == onnx.helper.TensorProto.INT8:
+ if len(tensor.int32_data) != 0:
+ data = list(tensor.int32_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("b", tensor.raw_data)]
+ elif tensor.data_type == onnx.helper.TensorProto.FLOAT:
+ if len(tensor.float_data) != 0:
+ data = list(tensor.float_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("f", tensor.raw_data)]
+ elif tensor.data_type == onnx.helper.TensorProto.DOUBLE:
+ if len(tensor.double_data) != 0:
+ data = list(tensor.double_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("d", tensor.raw_data)]
+ else:
+ print("Not supported data type {}".format(tensor.data_type))
+ raise RuntimeError
+ if len(tensor.dims) == 0:
+ shape = len(data)
+ else:
+ shape = list(tensor.dims)
+ return shape, data
+
+
+def constant_to_numpy(node):
+ """Generate a numpy array from the constant node
+
+ :node: the Constant node\\
+ :returns: the numpy array
+ """
+ shape, data = constant_to_list(node)
+ return np.array(data).reshape(shape)
+
+
+def all_constant_input(node):
+ """Find the inputs of the given node. If the inputs of this node are all\\
+ constant nodes, return True. Otherwise, return False.
+
+ :param node: the input node which has a Node structure\\
+ :return: whether the node of this node are all constant
+ """
+ if node.proto is None:
+ return False
+ isConstant = True
+ for parent in node.parents:
+ if parent.proto is None or parent.proto.op_type != "Constant":
+ isConstant = False
+ break
+ return isConstant
+
+
+def get_padding(size, kernel_size, strides):
+ """ Calculate the padding array for same padding in the Tensorflow fashion.\\
+ See https://www.tensorflow.org/api_guides/python/nn#Convolution for more.
+ """
+ if size[0] % strides[0] == 0:
+ pad_h = max(kernel_size[0] - strides[0], 0)
+ else:
+ pad_h = max(kernel_size[0] - (size[0] % strides[0]), 0)
+ if size[1] % strides[1] == 0:
+ pad_w = max(kernel_size[1] - strides[1], 0)
+ else:
+ pad_w = max(kernel_size[1] - (size[1] % strides[1]), 0)
+ return [pad_h // 2, pad_w // 2, pad_h - pad_h // 2, pad_w - pad_w // 2]
+
+
+def get_shape_from_value_info(value):
+ """Get shape from a value info.
+
+ :param value: the value_info proto\\
+ :return: list of the shape
+ """
+ return [d.dim_value for d in value.type.tensor_type.shape.dim]
+
+
+def find_size_shape_from_value(value):
+ """
+ Find the size of data within the value_info object.
+ :param value: value_info
+ :return: int size and list shape of the data in the value_info
+ """
+ if not value:
+ return None, None
+ if not value.type.tensor_type.shape.dim:
+ return 0, []
+ size = 1
+ shape = []
+ for i in range(len(value.type.tensor_type.shape.dim)):
+ size *= max(1, value.type.tensor_type.shape.dim[i].dim_value)
+ shape.append(max(1, value.type.tensor_type.shape.dim[i].dim_value))
+
+ return size, shape
+
+
+def get_attribute_by_name(node, attr_name):
+ """Get attribute proto with specific name in the given node proto.
+
+ :param node: the node proto.\\
+ :param attr_name: a str for the name of the target.\\
+ :return: if found, return the attribute_proto. Else, return None.
+ """
+ for attr in node.attribute:
+ if attr.name == attr_name:
+ return attr
+ return None
+
+
+def get_list_attribute_by_name(node, attr_name: str, attr_type: str):
+ """Get list attribute with specific name in the given node proto.
+
+ :param node: the node proto.\\
+ :param attr_name: a str for the name of the target.\\
+ :param attr_type: a str which should be "float" or "int".\\
+ :return: if found, return the list. Else, return None.
+ """
+ attr_proto = get_attribute_by_name(node, attr_name)
+ if attr_proto is None:
+ return None
+ if attr_type == "int":
+ if len(attr_proto.ints) == 0:
+ return None
+ else:
+ return list(attr_proto.ints)
+ elif attr_type == "float":
+ if len(attr_proto.ints) == 0:
+ return None
+ else:
+ return list(attr_proto.floats)
+ else:
+ print("Warning: undefined type for list attribute extraction")
+ return None
+
+
+def get_var_attribute_by_name(node, attr_name: str, attr_type: str):
+ """Get variable attribute with specific name in the given node proto.
+
+ :param node: the node proto.
+ :param attr_name: str for the name of the target.
+ :param attr_type: str which should be "float", "int", "string" or "tensor".
+ :return: if found, return the variable. Else, return None.
+ """
+ attr_proto = get_attribute_by_name(node, attr_name)
+ if attr_proto is None:
+ return None
+ if attr_type == "int":
+ return attr_proto.i
+ elif attr_type == "float":
+ return attr_proto.f
+ elif attr_type == "string":
+ if isinstance(attr_proto.s, bytes):
+ return attr_proto.s.decode("utf-8")
+ else:
+ return attr_proto.s
+ elif attr_type == "tensor":
+ return attr_proto.t
+ else:
+ print("Warning: undefined type for variable attribute extraction")
+ return None
+
+
+def flatten_with_depth(data, depth):
+ output = []
+ if type(data) not in [type(np.array([1])), type([1])]:
+ return [[data, 0]]
+ for item in data:
+ if type(item) not in [type(np.array([1])), type([1])]:
+ output.append([item, depth + 1])
+ else:
+ output += flatten_with_depth(item, depth + 1)
+ return output
+
+
+def flatten_to_list(data):
+ flatten_depth = flatten_with_depth(data, 0)
+ flat_data = [item[0] for item in flatten_depth]
+ return flat_data
+
+
+def get_shape(data):
+ shape = []
+ if type(data) not in [type(np.array([1])), type([1])]:
+ return []
+ sub_data = data[0]
+ shape.append(len(data))
+ while type(sub_data) in [type(np.array([1])), type([1])]:
+ shape.append(len(sub_data))
+ sub_data = sub_data[0]
+ return shape
+
+
+def slice_data(data, starts, ends, axes):
+ flat_data = [item[0] for item in flatten_with_depth(data, 0)]
+ shape = get_shape(data)
+
+ starts_updated = []
+ ends_updated = []
+ for i in range(len(starts)):
+ start_updated = min(starts[i], shape[i] - 1) % shape[i]
+ starts_updated.append(start_updated)
+ for j in range(len(starts)):
+ if ends[j] >= shape[j]:
+ end_updated = shape[j]
+ else:
+ end_updated = min(ends[j], shape[j]) % shape[j]
+ ends_updated.append(end_updated)
+
+ index_slices = []
+ for i in range(len(shape)):
+ if i not in axes:
+ index_slices.append(list(range(shape[i])))
+ else:
+ axe_ind = axes.index(i)
+ index_slices.append(
+ list(range(starts_updated[axe_ind], ends_updated[axe_ind]))
+ )
+
+ indices = [1]
+ for i in range(len(shape) - 1, -1, -1):
+ step = np.prod(shape[i + 1:])
+ temp_pos = indices
+ new_indices = []
+ for n in index_slices[i]:
+ for pos in temp_pos:
+ new_indices.append(int(n * step + pos))
+ indices = new_indices
+
+ sliced_data = [flat_data[k - 1] for k in indices]
+
+ # reshape to correct shape.
+ new_shape = []
+ for i in range(len(shape)):
+ if i not in axes:
+ new_shape.append(shape[i])
+ else:
+ axe_ind = axes.index(i)
+ new_shape.append(ends_updated[axe_ind] - starts_updated[axe_ind])
+ if any([dim < 1 for dim in new_shape]):
+ raise RuntimeError("Invalid starts ends.")
+
+ sliced_data = np.reshape(sliced_data, new_shape)
+
+ return sliced_data
+
+
+def concatenate(data_sets, axis):
+ # check shapes
+ shapes = []
+ shapes_ = []
+ for data_set in data_sets:
+ shape = get_shape(data_set)
+ shapes.append(list(shape))
+ shape.pop(axis)
+ shapes_.append(shape)
+ if not all([s == shapes_[0] for s in shapes_]):
+ raise RuntimeError("data sets shapes do not match")
+
+ new_dim = sum([s[axis] for s in shapes])
+ new_shape = list(shapes[0])
+ new_shape[axis] = new_dim
+
+ flat_data_sets = []
+ for data_set in data_sets:
+ flat_data_sets.append(flatten_to_list(data_set))
+
+ sub_block_size = 1
+ for i in range(axis + 1, len(shapes[0])):
+ sub_block_size *= shapes[0][i]
+
+ split_num = 1
+ for i in range(axis):
+ split_num *= shapes[0][i]
+
+ total_flat_data = []
+ for i in range(split_num):
+ for j in range(len(shapes)):
+ block_size = sub_block_size * shapes[j][axis]
+ total_flat_data.extend(
+ flat_data_sets[j][i * block_size:(i + 1) * block_size]
+ )
+
+ new_data = np.reshape(total_flat_data, new_shape)
+
+ return new_data
+
+
+def broadcast_data_sets(data_set_1, data_set_2):
+ shape1 = get_shape(data_set_1)
+ shape2 = get_shape(data_set_2)
+
+ # compare shapes and get broadcasted shape
+ list_a, list_b = (
+ (shape1, shape2) if len(shape1) > len(shape2) else (shape2, shape1)
+ )
+ while len(list_a) > len(list_b):
+ list_b.insert(0, 0)
+ broadcasted_shape = []
+ for i in range(len(list_a)):
+ if list_b[i] == 0:
+ broadcasted_shape.append(list_a[i])
+ elif list_b[i] == 1:
+ broadcasted_shape.append(list_a[i])
+ elif list_a[i] == 1:
+ broadcasted_shape.append(list_b[i])
+ elif list_a[i] == list_b[i]:
+ broadcasted_shape.append(list_a[i])
+ else:
+ raise RuntimeError("Can not broadcast two data sets")
+
+ # prepare data for broadcasting.
+ shape1 = list(map(lambda x: x if x != 0 else 1, shape1))
+ shape2 = list(map(lambda x: x if x != 0 else 1, shape2))
+ data_1 = np.reshape(data_set_1, shape1)
+ data_2 = np.reshape(data_set_2, shape2)
+
+ for i in range(len(shape1)):
+ if shape1[i] != broadcasted_shape[i]:
+ new_data_total = [
+ list(data_1) for _ in range(broadcasted_shape[i])
+ ]
+ data_1 = concatenate(new_data_total, axis=i)
+ for i in range(len(shape2)):
+ if shape2[i] != broadcasted_shape[i]:
+ new_data_total = [
+ list(data_2) for _ in range(broadcasted_shape[i])
+ ]
+ data_2 = concatenate(new_data_total, axis=i)
+
+ return data_1, data_2
+
+
+def add(data_set_1, data_set_2):
+ broadcasted_data_1, broadcasted_data_2 = broadcast_data_sets(
+ data_set_1, data_set_2
+ )
+
+ flat_data_1 = flatten_to_list(broadcasted_data_1)
+ flat_data_2 = flatten_to_list(broadcasted_data_2)
+ shape = get_shape(broadcasted_data_1)
+ res = []
+ for i in range(len(flat_data_1)):
+ res.append(flat_data_1[i] + flat_data_2[i])
+
+ res = np.reshape(res, shape)
+
+ return res
+
+
+def reduceprod(data_set, axis, keepdims=1):
+ flat_data = flatten_to_list(data_set)
+ old_shape = get_shape(data_set)
+
+ temp_shape = old_shape
+ temp_flat_data = flat_data
+ for ax in axis:
+ split_num = 1
+ step = 1
+ for i in range(ax):
+ split_num *= temp_shape[i]
+ for i in range(ax + 1, len(temp_shape)):
+ step *= temp_shape[i]
+
+ block_size = len(temp_flat_data) // split_num
+ new_flat_data = []
+ for j in range(split_num):
+ block_data = temp_flat_data[j * block_size:(j + 1) * block_size]
+ reduced_block_data = []
+ for k in range(step):
+ val = block_data[k]
+ for li in range(1, block_size // step):
+ val *= block_data[k + li * step]
+ reduced_block_data.append(val)
+ new_flat_data.extend(reduced_block_data)
+ temp_flat_data = new_flat_data
+ temp_shape[ax] = 1
+
+ new_flat_data = temp_flat_data
+ new_shape = temp_shape
+ if not keepdims:
+ axis = sorted(list(axis))
+ for pos in axis[::-1]:
+ new_shape.pop(pos)
+
+ return np.reshape(new_flat_data, new_shape)
+
+
+def transpose(data_set, permutation):
+ # find series of local swaps
+ data_set = list(data_set)
+ perm = list(permutation)
+ shape = get_shape(data_set)
+ flat_data = flatten_to_list(data_set)
+ assert set(perm) == set(range(len(shape))), "invalid permutation"
+
+ new_shape = [shape[i] for i in perm]
+ swaps = []
+ bubbled = True
+ while bubbled:
+ bubbled = False
+ for i in range(len(new_shape) - 1):
+ if perm[i] > perm[i + 1]:
+ swaps.append([i, i + 1])
+ p_1, p_2 = perm[i], perm[i + 1]
+ perm[i], perm[i + 1] = p_2, p_1
+ bubbled = True
+
+ # apply local swaps
+ current_shape = list(shape)
+ temp_flat_data = flat_data
+
+ for swap in swaps[::-1]:
+ ind_1, ind_2 = swap[0], swap[1]
+ dim_1 = current_shape[ind_1]
+ dim_2 = current_shape[ind_2]
+ split_num = 1
+ block_size = 1
+
+ for i in range(ind_1):
+ split_num *= current_shape[i]
+ for i in range(ind_2 + 1, len(current_shape)):
+ block_size *= current_shape[i]
+
+ data_blocks = np.reshape(temp_flat_data, [-1, block_size])
+ flat_data_1 = []
+ for k in range(split_num):
+ block = []
+ for m in range(dim_2):
+ for n in range(dim_1):
+ block_pos = k * dim_1 * dim_2 + n * dim_2 + m
+ block.extend(data_blocks[block_pos])
+ flat_data_1.extend(block)
+
+ temp_flat_data = flat_data_1
+ current_shape[ind_1] = dim_2
+ current_shape[ind_2] = dim_1
+
+ return np.reshape(temp_flat_data, current_shape)
+
+
+def subtract(data_set_1, data_set_2):
+ broadcasted_data_1, broadcasted_data_2 = broadcast_data_sets(
+ data_set_1, data_set_2
+ )
+
+ shape = get_shape(broadcasted_data_1)
+ flat_data_1 = flatten_to_list(broadcasted_data_1)
+ flat_data_2 = flatten_to_list(broadcasted_data_2)
+
+ substracted_data = [
+ flat_data_1[i] - flat_data_2[i] for i in range(len(flat_data_1))
+ ]
+
+ new_data = np.reshape(substracted_data, shape)
+
+ return new_data
diff --git a/tools/optimizer_scripts/tools/modhelper.py b/tools/optimizer_scripts/tools/modhelper.py
new file mode 100644
index 0000000..ca5e040
--- /dev/null
+++ b/tools/optimizer_scripts/tools/modhelper.py
@@ -0,0 +1,96 @@
+"""
+This module contains helper functions that do graph modifications.
+"""
+
+from . import helper
+
+
+def replace_node_input(node, old_input, new_input):
+ for i, input_name in enumerate(node.input):
+ if input_name == old_input:
+ node.input[i] = new_input
+
+
+def delete_nodes(g, node_list):
+ node_to_delete = []
+ # Find target nodes
+ for node in g.node:
+ if node.name not in node_list:
+ continue
+ else:
+ node_to_delete.append(node)
+ if len(node_list) != len(node_to_delete):
+ print("Some nodes do not exist in the graph. Skipping them.")
+ for node in node_to_delete:
+ # Check the node whether if it is valid to delete
+ if len(node.input) == 0:
+ print(
+ "Deleting an Constant node. "
+ "Please make sure you also delete all its following nodes"
+ )
+ elif len(node.input) > 1:
+ print(
+ f"Warning: Node {node.name} has more than one input. "
+ "This script cannot delete merge nodes."
+ )
+ # Connect the nodes around the target node.
+ # Set the following node input as the previous node output.
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ if len(node.input) == 0:
+ for following_node in following_nodes:
+ following_node.input.remove(node.output[0])
+ elif (
+ len(following_nodes) > 0
+ and len(node.input) == 1
+ and helper.find_input_by_name(g, node.input[0]) is not None
+ ):
+ # The node input is an input
+ new_input = helper.find_value_by_name(g, node.output[0])
+ g.input.append(new_input)
+ g.input.remove(helper.find_input_by_name(g, node.input[0]))
+ g.value_info.remove(new_input)
+ elif len(following_nodes) > 0:
+ for following_node in following_nodes:
+ replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ else:
+ # If the node is the output, replace it with previous input.
+ value = helper.find_value_by_name(g, node.input[0])
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name == node.output[0]:
+ g.output.extend([value])
+ else:
+ g.output.extend([output_value])
+ # Remove the node and value info.
+ g.node.remove(node)
+
+
+def delete_input(g, target_list):
+ for name in target_list:
+ input_value = helper.find_input_by_name(g, name)
+ if input_value is None:
+ print("Cannot find input {}".format(name))
+ continue
+ g.input.remove(input_value)
+
+
+def delete_output(g, target_list):
+ for name in target_list:
+ output_value = helper.find_output_by_name(g, name)
+ if output_value is None:
+ print("Cannot find output {}".format(name))
+ continue
+ g.output.remove(output_value)
+
+
+def delete_value_with_name_if_exists(g, name):
+ value = helper.find_value_by_name(g, name)
+ if value is not None:
+ g.value_info.remove(value)
diff --git a/tools/optimizer_scripts/tools/other.py b/tools/optimizer_scripts/tools/other.py
new file mode 100644
index 0000000..b003fbb
--- /dev/null
+++ b/tools/optimizer_scripts/tools/other.py
@@ -0,0 +1,1451 @@
+"""
+Optimization functions that are not fusing, eliminating or replacing.
+In most cases, these are the modifications on the original nodes.
+"""
+import struct
+import collections
+import numpy as np
+import onnx.helper
+import onnxoptimizer as optimizer
+import math
+import logging
+from . import helper
+from .modhelper import replace_node_input
+import copy
+from .helper import logger
+
+
+def polish_model(model):
+ """
+ This function combines several useful utility functions together.
+ """
+ onnx.checker.check_model(model)
+ onnx.helper.strip_doc_string(model)
+ model = onnx.shape_inference.infer_shapes(model)
+ model = optimizer.optimize(model)
+ onnx.checker.check_model(model)
+ return model
+
+
+def format_value_info_shape(g):
+ """
+ Replace -1 and 0 batch size in value info
+
+ :param g: the onnx graph
+ """
+ for value in g.input:
+ if len(value.type.tensor_type.shape.dim) > 0 and (
+ value.type.tensor_type.shape.dim[0].dim_value <= 0
+ or not isinstance(
+ value.type.tensor_type.shape.dim[0].dim_value, int
+ )
+ ):
+ value.type.tensor_type.shape.dim[0].dim_value = 1
+ for value in g.output:
+ if len(value.type.tensor_type.shape.dim) > 0 and (
+ value.type.tensor_type.shape.dim[0].dim_value <= 0
+ or not isinstance(
+ value.type.tensor_type.shape.dim[0].dim_value, int
+ )
+ ):
+ value.type.tensor_type.shape.dim[0].dim_value = 1
+ for value in g.value_info:
+ if len(value.type.tensor_type.shape.dim) > 0 and (
+ value.type.tensor_type.shape.dim[0].dim_value < 0
+ or not isinstance(
+ value.type.tensor_type.shape.dim[0].dim_value, int
+ )
+ ):
+ value.type.tensor_type.shape.dim[0].dim_value = 1
+
+
+def add_name_to_node(g):
+ """
+ If no name presents, give a name based on output name.
+
+ :param g: the onnx graph
+ """
+ for node in g.node:
+ if len(node.name) == 0:
+ node.name = node.output[0]
+
+
+def rename_all_node_name(g):
+ """
+ rename all nodes if the node name is a number:
+
+ new_name = old_name + "_kn"
+
+ :param g: the onnx graph
+ """
+
+ for node in g.node:
+ if not node.name.isdigit():
+ # Skip not number names
+ continue
+ new_node_name = node.name + "_kn"
+ new_node_output0_name = node.output[0] + "_kn"
+
+ # in order to keep same output node name, skip if it is output node.
+ output_value_info = helper.find_output_by_name(g, node.output[0])
+ if output_value_info is not None:
+ continue
+
+ # rename the input of all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ replace_node_input(
+ following_node, node.output[0], new_node_output0_name
+ )
+
+ # rename value info
+ value_info = helper.find_value_by_name(g, node.output[0])
+ if value_info is not None:
+ value_info.name = new_node_output0_name
+
+ # rename node
+ node.output[0] = new_node_output0_name
+ node.name = new_node_name
+
+
+def add_output_to_value_info(g):
+ """
+ If output does not present in value_info, copy one
+
+ :param g: the onnx graph
+ """
+ for output in g.output:
+ if helper.find_value_by_name(g, output.name) is None:
+ g.value_info.extend([output])
+
+
+def find_first_sequential_output(g, node):
+ for value_name in node.output:
+ value = helper.find_output_by_name(g, value_name)
+ if value is not None:
+ return value
+ next_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ if len(next_nodes) == 0:
+ # No following nodes
+ return None
+ return find_first_sequential_output(g, next_nodes[0])
+
+
+def remove_nodes(g, cut_nodes=[], cut_types=[]):
+ node_to_delete = []
+ # Find target nodes
+ for node in g.node:
+ if node.name not in cut_nodes and node.op_type not in cut_types:
+ continue
+ else:
+ node_to_delete.append(node)
+ # Mapping originnal outputs to new outputs.
+ # This mapping is to keep the output order.
+ output_mapping = {}
+ new_output = set()
+ for node in node_to_delete:
+ original_output = find_first_sequential_output(g, node)
+ if original_output.name not in output_mapping:
+ output_mapping[original_output.name] = []
+ for input_name in node.input:
+ value = helper.find_value_by_name(g, input_name)
+ if (
+ value is not None
+ and helper.find_output_by_name(g, input_name) is None
+ and value.name not in new_output
+ ):
+ output_mapping[original_output.name].append(value)
+ new_output.add(value.name)
+ # Remove them
+ while node_to_delete:
+ g.node.remove(node_to_delete.pop())
+ # Remove unreachable nodes
+ visited_values = set()
+ unused_constant_map = {}
+ for input_value in g.input:
+ visited_values.add(input_value.name)
+ for node in g.node:
+ if node.op_type == "Constant":
+ visited_values.add(node.output[0])
+ unused_constant_map[node.output[0]] = node
+ continue
+ can_reach = True
+ for input_name in node.input:
+ if input_name not in visited_values:
+ can_reach = False
+ break
+ if can_reach:
+ for output_name in node.output:
+ visited_values.add(output_name)
+ else:
+ node_to_delete.append(node)
+ # Mapping outputs again
+ for node in node_to_delete:
+ original_output = find_first_sequential_output(g, node)
+ if original_output is None:
+ continue
+ if original_output.name not in output_mapping:
+ output_mapping[original_output.name] = []
+ for input_name in node.input:
+ value = helper.find_value_by_name(g, input_name)
+ if (
+ value is not None
+ and helper.find_output_by_name(g, input_name) is None
+ and value.name not in new_output
+ ):
+ output_mapping[original_output.name].append(value)
+ new_output.add(value.name)
+ # Remove them
+ while node_to_delete:
+ g.node.remove(node_to_delete.pop())
+ # Remove unused constants
+ for node in g.node:
+ for input_name in node.input:
+ if input_name in unused_constant_map:
+ del unused_constant_map[input_name]
+ for node in unused_constant_map.values():
+ g.node.remove(node)
+ # Remove unreachable value infos
+ reachable_values = set()
+ for input_value in g.input:
+ reachable_values.add(input_value.name)
+ for node in g.node:
+ for input_name in node.input:
+ reachable_values.add(input_name)
+ for output_name in node.output:
+ reachable_values.add(output_name)
+ value_to_remove = []
+ for value_info in g.value_info:
+ if value_info.name not in reachable_values:
+ value_to_remove.append(value_info)
+ while value_to_remove:
+ value_info = value_to_remove.pop()
+ g.value_info.remove(value_info)
+ # Reorder output
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name in reachable_values:
+ logger.info("Keep output {}".format(output_value.name))
+ g.output.extend([output_value])
+ elif output_value.name in output_mapping:
+ real_outputs = [
+ i
+ for i in output_mapping[output_value.name]
+ if i.name in reachable_values
+ ]
+ logger.info(
+ "Replace output {} with {}".format(
+ output_value.name, [i.name for i in real_outputs]
+ )
+ )
+ g.output.extend(real_outputs)
+ else:
+ logger.info("Abandon output {}".format(output_value.name))
+ continue
+
+
+def transpose_B_in_Gemm(g):
+ """
+ If transB is set in Gemm, transpose it
+
+ :param g: the onnx graph
+ """
+ for node in g.node:
+ if node.op_type != "Gemm":
+ continue
+ do_it = False
+ for attr in node.attribute:
+ if attr.name == "transB":
+ if attr.i == 1:
+ attr.i = 0
+ do_it = True
+ break
+ if not do_it:
+ continue
+ # Transpose the weight and its output value
+ w_node = helper.find_node_by_output_name(g, node.input[1])
+ w_output = helper.find_value_by_name(g, node.input[1])
+ dim_0 = w_output.type.tensor_type.shape.dim[0].dim_value
+ dim_1 = w_output.type.tensor_type.shape.dim[1].dim_value
+ w_output.type.tensor_type.shape.dim[0].dim_value = dim_1
+ w_output.type.tensor_type.shape.dim[1].dim_value = dim_0
+ w_node.attribute[0].t.dims[0] = dim_1
+ w_node.attribute[0].t.dims[1] = dim_0
+ if w_node.attribute[0].t.raw_data:
+ raw_data = w_node.attribute[0].t.raw_data
+ fl_data = [i[0] for i in struct.iter_unpack("f", raw_data)]
+ else:
+ fl_data = w_node.attribute[0].t.float_data
+ w = np.reshape(fl_data, (dim_0, dim_1))
+ w = w.transpose((1, 0)).flatten()
+ if w_node.attribute[0].t.raw_data:
+ buf = struct.pack("%sf" % len(w), *w)
+ w_node.attribute[0].t.raw_data = buf
+ else:
+ for i in range(len(fl_data)):
+ w_node.attribute[0].t.float_data[i] = w[i]
+
+
+def topological_sort(g):
+ """
+ Topological sort all the layers.
+ Assume a node do not take the same value as more than one inputs.
+
+ :param g: the onnx graph
+ """
+ # TODO: Topological sort on the same branch
+ # Map from node name to its input degree
+ in_degree = {}
+ # Map from value info name to the nodes using it as input
+ output_nodes = collections.defaultdict(list)
+ # Map from node name to node object
+ node_map = {}
+ to_add = collections.deque()
+ # init
+ length = len(g.node)
+ for _ in range(length):
+ node = g.node.pop()
+ node_map[node.name] = node
+ if len([i for i in node.input if i != ""]) == 0:
+ to_add.append(node.name)
+ else:
+ in_degree[node.name] = len([i for i in node.input if i != ""])
+ for input_name in node.input:
+ if input_name == "":
+ continue
+ output_nodes[input_name].append(node.name)
+ # sort
+ # deal with input first
+ for value_info in g.input:
+ input_name = value_info.name
+ for node_name in output_nodes[input_name]:
+ in_degree[node_name] -= 1
+ if in_degree[node_name] == 0:
+ to_add.append(node_name)
+ del in_degree[node_name]
+ # main sort loop
+ sorted_nodes = []
+ while to_add:
+ node_name = to_add.pop()
+ node = node_map[node_name]
+ del node_map[node_name]
+ sorted_nodes.append(node)
+ # Expect only one output name for each node
+ next_node_names = []
+ for output_name in node.output:
+ next_node_names.extend(output_nodes[output_name])
+ for next_node_name in next_node_names:
+ in_degree[next_node_name] -= 1
+ if in_degree[next_node_name] == 0:
+ to_add.append(next_node_name)
+ del in_degree[next_node_name]
+ g.node.extend(sorted_nodes)
+ if in_degree:
+ raise RuntimeError(
+ "Unreachable nodes exist: {}".format(in_degree.keys())
+ )
+ if node_map:
+ raise RuntimeError("Unused nodes exist: {}".format(node_map.keys()))
+
+
+def remove_zero_value_info(g):
+ value_info_list = list(g.value_info)
+ for vi in value_info_list:
+ if not vi.type.tensor_type.shape.dim:
+ g.value_info.remove(vi)
+
+ for dim in vi.type.tensor_type.shape.dim:
+ if dim.dim_value == 0:
+ g.value_info.remove(vi)
+ break
+
+
+def inference_shapes(m):
+ while len(m.graph.value_info) > 0:
+ m.graph.value_info.pop()
+ g = m.graph
+ inferencing_shapes = True
+ while inferencing_shapes:
+ inferencing_shapes = False
+ if inference_cov_shape(g):
+ inferencing_shapes = True
+ if inference_upsample_shape(g):
+ inferencing_shapes = True
+ if inference_resize_shape(g):
+ inferencing_shapes = True
+ if inference_split_shape(g):
+ inferencing_shapes = True
+ if inferencing_shapes:
+ topological_sort(g)
+ m = polish_model(m)
+ g = m.graph
+ remove_zero_value_info(g)
+ m = polish_model(m)
+ return m
+
+
+def inference_resize_shape(g):
+ for node in g.node:
+ if node.op_type != "Resize":
+ continue
+
+ output_value = helper.find_value_by_name(g, node.output[0])
+ output_value = (
+ helper.find_output_by_name(g, node.output[0])
+ if output_value is None
+ else output_value
+ )
+ if output_value is not None:
+ continue
+
+ if len(node.input) == 4: # input: X, roi, scales, sizes
+ shape_node = helper.find_node_by_output_name(g, node.input[3])
+ if shape_node.op_type != "Constant":
+ continue
+
+ _, shape_value = helper.constant_to_list(shape_node)
+ output_value = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ onnx.TensorProto.FLOAT,
+ [int(v) for v in shape_value],
+ )
+ g.value_info.extend([output_value])
+ return True
+ else:
+ # If output shape is not given, inference from scales
+ # Get the input shape
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ continue
+ shape_value = helper.get_shape_from_value_info(input_value)
+ scales_node = helper.find_node_by_output_name(g, node.input[2])
+ if scales_node.op_type != "Constant":
+ continue
+ _, scales_value = helper.constant_to_list(scales_node)
+ for i in range(len(shape_value)):
+ shape_value[i] *= scales_value[i]
+ output_value = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ onnx.TensorProto.FLOAT,
+ [int(v) for v in shape_value],
+ )
+ g.value_info.extend([output_value])
+ return True
+ return False
+
+
+def inference_upsample_shape(g):
+ """For onnx v1.4.1+, onnx cannot inference upsample output shape. Let's\\
+ do it ourselves. This function only inference the next upsample without\\
+ output shape each time.
+
+ :param g: the graph\\
+ :return: True if any Upsample shape is generated. Otherwise, False.
+ """
+ for node in g.node:
+ if node.op_type != "Upsample":
+ continue
+ output_value = helper.find_value_by_name(g, node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if output_value and helper.get_shape_from_value_info(output_value):
+ continue
+ # Get input shape
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ continue
+ if not helper.get_shape_from_value_info(input_value):
+ continue
+ input_shape = helper.get_shape_from_value_info(input_value)
+ # Get upsample weight
+ weight_node = helper.find_node_by_output_name(g, node.input[1])
+ weight_shape, weight = helper.constant_to_list(weight_node)
+ if len(input_shape) != weight_shape[0]:
+ raise RuntimeError(
+ "Unmatch input shape and weight shape: {} vs {}".format(
+ input_shape, weight_shape
+ )
+ )
+ # Calculate shape
+ output_shape = list(input_shape)
+ for i in range(len(output_shape)):
+ output_shape[i] = int(input_shape[i] * weight[i])
+ output_value = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ input_value.type.tensor_type.elem_type,
+ output_shape,
+ )
+ g.value_info.extend([output_value])
+ return True
+ return False
+
+
+def inference_cov_shape(g):
+ processed = False
+ for node in g.node:
+ # Check for Conv output shape need to be inferrenced.
+ if node.op_type != "Conv":
+ continue
+ # Input shape is not ready yet. Skip.
+ input_value_info = helper.find_value_by_name(g, node.input[0])
+ if not input_value_info:
+ input_value_info = helper.find_input_by_name(g, node.input[0])
+ if not input_value_info:
+ continue
+ _, input_shape = helper.find_size_shape_from_value(input_value_info)
+ if not input_shape:
+ continue
+ # Output shape is already there. Skip.
+ output_value_info = helper.find_value_by_name(g, node.output[0])
+ if not output_value_info:
+ output_value_info = helper.find_output_by_name(g, node.output[0])
+ if output_value_info and helper.get_shape_from_value_info(
+ output_value_info
+ ):
+ continue
+
+ # Now start the inference.
+ # Check kernel shape
+ kernel_value_info = helper.find_value_by_name(g, node.input[1])
+ _, kernel_shape = helper.find_size_shape_from_value(kernel_value_info)
+ if not kernel_shape:
+ continue
+ # If auto_pad is set, use the auto_pad.
+ auto_pad = helper.get_var_attribute_by_name(node, "auto_pad", "string")
+ pads = None
+ if auto_pad is not None and auto_pad != "NOTSET":
+ if auto_pad == "SAME_LOWER" or auto_pad == "SAME_UPPER":
+ new_output_value_info = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ input_value_info.type.tensor_type.elem_type,
+ [
+ input_shape[0],
+ kernel_shape[0],
+ input_shape[2],
+ input_shape[3],
+ ],
+ )
+ if output_value_info:
+ g.value_info.remove(output_value_info)
+ g.value_info.extend([new_output_value_info])
+ processed = True
+ continue
+ elif auto_pad == "VALID":
+ pads = [0, 0, 0, 0]
+ else:
+ logger.error("Unrecognized auto_pad value: " + str(auto_pad))
+ exit(1)
+
+ strides = helper.get_attribute_by_name(node, "strides").ints
+ if not pads:
+ pads = helper.get_attribute_by_name(node, "pads").ints
+ dilation = helper.get_attribute_by_name(node, "dilations").ints
+
+ # Pytorch model has the case where strides only have one number
+ if len(strides) == 1:
+ strides.append(strides[0])
+ if len(dilation) == 1:
+ dilation.append(dilation[0])
+
+ H = math.floor(
+ (
+ input_shape[2]
+ + pads[0]
+ + pads[2]
+ - dilation[0] * (kernel_shape[2] - 1)
+ - 1
+ )
+ / strides[0]
+ + 1
+ )
+ W = math.floor(
+ (
+ input_shape[3]
+ + pads[1]
+ + pads[3]
+ - dilation[1] * (kernel_shape[3] - 1)
+ - 1
+ )
+ / strides[1]
+ + 1
+ )
+ output_shape = [input_shape[0], kernel_shape[0], H, W]
+
+ new_output_value_info = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ input_value_info.type.tensor_type.elem_type,
+ output_shape,
+ )
+
+ processed = True
+
+ if output_value_info:
+ g.value_info.remove(output_value_info)
+ g.value_info.extend([new_output_value_info])
+
+ return processed
+
+
+def inference_split_shape(g):
+ processed = False
+ for node in g.node:
+ if node.op_type != "Split":
+ continue
+
+ input_val_info = helper.find_value_by_name(g, node.input[0])
+ if not input_val_info:
+ input_val_info = helper.find_input_by_name(g, node.input[0])
+ if not input_val_info:
+ continue
+
+ _, input_shape = helper.find_size_shape_from_value(input_val_info)
+ if not input_shape:
+ continue
+
+ output_val_names = list(node.output)
+ output_vals = [
+ helper.find_value_by_name(g, val_name)
+ for val_name in output_val_names
+ ]
+
+ output_shapes = [
+ helper.find_size_shape_from_value(output_val)[1]
+ for output_val in output_vals
+ ]
+ if not any([len(s) == 0 for s in output_shapes]):
+ continue
+
+ for att in node.attribute:
+ if att.name == "axis":
+ axis = att.i
+ else:
+ split = list(att.ints)
+
+ new_output_vals = []
+ for i in range(len(output_val_names)):
+ new_shape = list(input_shape)
+ new_shape[axis] = split[i]
+ new_output_val = onnx.helper.make_tensor_value_info(
+ output_val_names[i],
+ input_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+ new_output_vals.append(new_output_val)
+
+ for val in output_vals:
+ if val is not None:
+ g.value_info.remove(val)
+ g.value_info.extend(new_output_vals)
+
+ processed = True
+
+ return processed
+
+
+def parse_shape_change_input(s: str):
+ """The input should be like 'input 1 1 224 224'."""
+ s_list = s.split(" ")
+ if len(s_list) < 2:
+ print("Cannot parse the shape change input: {}".format(s))
+ return None
+ shape = []
+ for i in range(1, len(s_list)):
+ shape.append(int(s_list[i]))
+ return s_list[0], shape
+
+
+def change_input_shape(g, target_list):
+ for target in target_list:
+ try:
+ name, shape = parse_shape_change_input(target)
+ input_value = helper.find_input_by_name(g, name)
+ if input_value is None:
+ print("Cannot find input {}".format(name))
+ continue
+ if len(shape) != len(input_value.type.tensor_type.shape.dim):
+ print("The dimension doesn't match for input {}".format(name))
+ continue
+ for i in range(len(shape)):
+ input_value.type.tensor_type.shape.dim[i].dim_value = shape[i]
+ except TypeError:
+ # This happens when the parser function returns None.
+ continue
+ except ValueError:
+ # This happens when the input cannot be converter into int
+ print("Cannot parse {} into name and int".format(target))
+ continue
+
+
+def change_output_shape(g, target_list):
+ for target in target_list:
+ try:
+ name, shape = parse_shape_change_input(target)
+ output_value = helper.find_output_by_name(g, name)
+ if output_value is None:
+ print("Cannot find output {}".format(name))
+ continue
+ if len(shape) != len(output_value.type.tensor_type.shape.dim):
+ print("The dimension doesn't match for output {}".format(name))
+ continue
+ for i in range(len(shape)):
+ output_value.type.tensor_type.shape.dim[i].dim_value = shape[i]
+ except TypeError:
+ # This happens when the parser function returns None.
+ continue
+ except ValueError:
+ # This happens when the input cannot be converter into int
+ print("Cannot parse {} into name and int".format(target))
+ continue
+
+
+def add_nop_conv_after(g, value_names):
+ """Add do-nothing depthwise Conv nodes after the given value info. It will\\
+ take the given names as the inputs of the new node and replace the inputs\\
+ of the following nodes.
+
+ :param g: the graph\\
+ :param value_names: a list of string which are the names of value_info.
+ """
+ for value_name in value_names:
+ # Find the value first
+ value = helper.find_value_by_name(g, value_name)
+ if value is None:
+ value = helper.find_input_by_name(g, value_name)
+ if value is None:
+ value = helper.find_output_by_name(g, value_name)
+ if value is None:
+ print("Cannot find an value_info named {}".format(value_name))
+ continue
+ # Get the channel number from value info
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_conv"
+ ones = [1.0] * channel
+ weight_node = helper.list_to_constant(
+ node_name + "_weight", [channel, 1, 1, 1], ones
+ )
+ # Construct BN node
+ conv_node = onnx.helper.make_node(
+ "Conv",
+ [value_name, weight_node.output[0]],
+ [node_name],
+ name=node_name,
+ dilations=[1, 1],
+ group=channel,
+ kernel_shape=[1, 1],
+ pads=[0, 0, 0, 0],
+ strides=[1, 1],
+ )
+ # Reconnect the graph
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, value_name
+ )
+ if len(following_nodes) > 0:
+ for following_node in following_nodes:
+ replace_node_input(following_node, value_name, node_name)
+ else:
+ new_value = onnx.helper.make_tensor_value_info(
+ node_name, value.type.tensor_type.elem_type, shape
+ )
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name == value_name:
+ g.output.extend([new_value])
+ else:
+ g.output.extend([output_value])
+ # Add node to the graph
+ g.node.extend([conv_node, weight_node])
+ topological_sort(g)
+
+
+def add_nop_bn_after(g, value_names):
+ """Add do-nothing BatchNormalization nodes after the given value info.
+ It will take the given names as the inputs of the new node and replace
+ the inputs of the following nodes.
+
+ :param g: the graph
+ :param value_names: a list of string which are the names of value_info.
+ """
+ for value_name in value_names:
+ # Find the value first
+ value = helper.find_value_by_name(g, value_name)
+ if value is None:
+ value = helper.find_input_by_name(g, value_name)
+ if value is None:
+ value = helper.find_output_by_name(g, value_name)
+ if value is None:
+ print("Cannot find an value_info named {}".format(value_name))
+ continue
+ # Get the channel number from value info
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [channel], ones
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [channel], zeros
+ )
+ mean_node = helper.list_to_constant(
+ node_name + "_mean", [channel], zeros
+ )
+ var_node = helper.list_to_constant(node_name + "_var", [channel], ones)
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ )
+ # Reconnect the graph
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, value_name
+ )
+ if len(following_nodes) > 0:
+ for following_node in following_nodes:
+ replace_node_input(following_node, value_name, node_name)
+ else:
+ new_value = onnx.helper.make_tensor_value_info(
+ node_name, value.type.tensor_type.elem_type, shape
+ )
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name == value_name:
+ g.output.extend([new_value])
+ else:
+ g.output.extend([output_value])
+ # Add node to the graph
+ g.node.extend([bn_node, scale_node, bias_node, mean_node, var_node])
+ topological_sort(g)
+
+
+def add_bias_scale_bn_after(g, value_name, channel_bias, channel_scale):
+ """
+ Add do-nothing BatchNormalization nodes after the given value info.
+ It will take the given names as the inputs of the new node and replace
+ the inputs of the following nodes.
+
+ :param g: the graph
+ :param value_name: a list of string which are the name of value_info.
+ """
+ # Find the value first
+ value = helper.find_value_by_name(g, value_name)
+ if value is None:
+ value = helper.find_input_by_name(g, value_name)
+ if value is None:
+ value = helper.find_output_by_name(g, value_name)
+ if value is None:
+ print("Cannot find an value_info named {}".format(value_name))
+ return
+ # Get the channel number from value info
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_scale_shift_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [len(channel_scale)], channel_scale
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [len(channel_bias)], channel_bias
+ )
+ mean_node = helper.list_to_constant(node_name + "_mean", [channel], zeros)
+ var_node = helper.list_to_constant(node_name + "_var", [channel], ones)
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ )
+ # Reconnect the graph
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, value_name
+ )
+ if len(following_nodes) > 0:
+ for following_node in following_nodes:
+ replace_node_input(following_node, value_name, node_name)
+ else:
+ new_value = onnx.helper.make_tensor_value_info(
+ node_name, value.type.tensor_type.elem_type, shape
+ )
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name == value_name:
+ g.output.extend([new_value])
+ else:
+ g.output.extend([output_value])
+ # Add node to the graph
+ g.node.extend([bn_node, scale_node, bias_node, mean_node, var_node])
+ topological_sort(g)
+
+
+def duplicate_shared_Flatten(g):
+ """To feed our compiler, bind Flatten with Gemm. If the output of one\\
+ Flatten goes to two Gemm nodes, duplicate the Flatten.
+
+ :param g: the graph
+ """
+ for node in g.node:
+ # Find a Flatten node
+ if node.op_type != "Flatten":
+ continue
+ # Check Flatten outputs. Get following Gemm
+ output_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ if len(output_nodes) < 2:
+ continue
+ gemm_nodes = []
+ for output_node in output_nodes:
+ if output_node.op_type == "Gemm":
+ gemm_nodes.append(output_node)
+ if len(gemm_nodes) < 2:
+ continue
+ # Process all the Gemm nodes except for the first one.
+ for i in range(1, len(gemm_nodes)):
+ # Duplicate
+ new_flatten_name = node.name + "_copy" + str(i)
+ new_flatten_node = onnx.helper.make_node(
+ "Flatten",
+ node.input,
+ [new_flatten_name],
+ name=new_flatten_name,
+ axis=1,
+ )
+ # Connect new graph
+ replace_node_input(gemm_nodes[i], node.output[0], new_flatten_name)
+ g.node.extend([new_flatten_node])
+ topological_sort(g)
+
+
+def deconv_to_conv_info_extraction(input_size, node_proto):
+ """Extract the information needed for deconv split.
+
+ :param input_size: input shape of the deconv node.\\
+ :param node_proto: the deconv node proto.\\
+ :return: a dictionary of extracted params.
+ """
+ attr = dict()
+ # Get attributes from Deconv node
+ attr["auto_pad"] = helper.get_var_attribute_by_name(
+ node_proto, "auto_pad", "string"
+ )
+ attr["dilations"] = helper.get_list_attribute_by_name(
+ node_proto, "dilations", "int"
+ )
+ attr["group"] = helper.get_var_attribute_by_name(
+ node_proto, "group", "int"
+ )
+ attr["kernel_shape"] = helper.get_list_attribute_by_name(
+ node_proto, "kernel_shape", "int"
+ )
+ attr["output_padding"] = helper.get_list_attribute_by_name(
+ node_proto, "output_padding", "int"
+ )
+ attr["pads"] = helper.get_list_attribute_by_name(node_proto, "pads", "int")
+ attr["strides"] = helper.get_list_attribute_by_name(
+ node_proto, "strides", "int"
+ )
+ # Get output_padding
+ if attr["output_padding"] is None:
+ if (
+ attr["auto_pad"] == "SAME_LOWER"
+ or attr["auto_pad"] == "SAME_UPPER"
+ ):
+ attr["output_padding"] = [
+ attr["strides"][0] - 1,
+ attr["strides"][1],
+ ]
+ else:
+ attr["output_padding"] = [
+ max(attr["strides"][0] - attr["kernel_shape"][0], 0),
+ max(attr["strides"][1] - attr["kernel_shape"][1], 0),
+ ]
+ # Calculate conv_padding
+ if attr["auto_pad"] == "SAME_LOWER" or attr["auto_pad"] == "SAME_UPPER":
+ pad1_h = (
+ attr["kernel_shape"][0] - (attr["kernel_shape"][0] - 1) // 2 - 1
+ )
+ pad1_w = (
+ attr["kernel_shape"][1] - (attr["kernel_shape"][1] - 1) // 2 - 1
+ )
+ head_h = min(
+ attr["kernel_shape"][0] // 2, (attr["output_padding"][0] + 1) // 2
+ )
+ head_w = min(
+ attr["kernel_shape"][1] // 2, (attr["output_padding"][1] + 1) // 2
+ )
+ tail_h = attr["output_padding"][0] - head_h
+ tail_w = attr["output_padding"][1] - head_w
+ attr["conv_pads"] = [
+ pad1_h + head_h,
+ pad1_w + head_w,
+ pad1_h + tail_h,
+ pad1_w + tail_w,
+ ]
+ elif attr["pads"] is not None:
+ sum_of_pads = sum(attr["pads"])
+ if sum_of_pads == 0:
+ # Valid padding
+ pad1_h = attr["kernel_shape"][0] - 0 - 1
+ pad1_w = attr["kernel_shape"][1] - 0 - 1
+ head_h = 0
+ head_w = 0
+ tail_h = attr["output_padding"][0] - head_h
+ tail_w = attr["output_padding"][1] - head_w
+ attr["conv_pads"] = [
+ pad1_h + head_h,
+ pad1_w + head_w,
+ pad1_h + tail_h,
+ pad1_w + tail_w,
+ ]
+ else:
+ # Calculate output shape
+ tmp_output_shape = [0, 0]
+ tmp_output_shape[0] = (
+ attr["strides"][0] * (input_size[2] - 1)
+ + attr["output_padding"][0]
+ + attr["kernel_shape"][0]
+ - attr["pads"][0]
+ - attr["pads"][2]
+ )
+ tmp_output_shape[1] = (
+ attr["strides"][1] * (input_size[3] - 1)
+ + attr["output_padding"][1]
+ + attr["kernel_shape"][1]
+ - attr["pads"][1]
+ - attr["pads"][3]
+ )
+ # Calculate real conv output shape
+ tmp_center_shape = [0, 0]
+ tmp_center_shape[0] = (input_size[2] - 1) * attr["strides"][0] + 1
+ tmp_center_shape[1] = (input_size[3] - 1) * attr["strides"][1] + 1
+ # Calculate padding
+ total_padding = [0, 0]
+ total_padding[0] = (
+ tmp_output_shape[0]
+ - tmp_center_shape[0]
+ + attr["kernel_shape"][0]
+ - 1
+ )
+ total_padding[1] = (
+ tmp_output_shape[1]
+ - tmp_center_shape[1]
+ + attr["kernel_shape"][1]
+ - 1
+ )
+ if total_padding[0] < 0 or total_padding[1] < 0:
+ raise RuntimeError(
+ node_proto.name + " cannot infer conv padding."
+ )
+ conv_pads_ = [0] * 4
+ conv_pads_[0] = total_padding[0] // 2
+ conv_pads_[1] = total_padding[1] // 2
+ conv_pads_[2] = total_padding[0] - total_padding[0] // 2
+ conv_pads_[3] = total_padding[1] - total_padding[1] // 2
+ attr["conv_pads"] = conv_pads_
+ else:
+ pad1_h = attr["kernel_shape"][0] - 0 - 1
+ pad1_w = attr["kernel_shape"][1] - 0 - 1
+ head_h = 0
+ head_w = 0
+ tail_h = attr["output_padding"][0] - head_h
+ tail_w = attr["output_padding"][1] - head_w
+ attr["conv_pads"] = [
+ pad1_h + head_h,
+ pad1_w + head_w,
+ pad1_h + tail_h,
+ pad1_w + tail_w,
+ ]
+ return attr
+
+
+def split_ConvTranspose(model):
+ """To feed our compiler, split ConvTranspose into Upsample and Conv.
+
+ :param model: the model
+ """
+ node_to_delete = []
+ # Change model properties for upsample.
+ if model.ir_version < 3:
+ print("Warning: Current model IR version is not fully supported.")
+ model.ir_version = 4
+ model.opset_import[0].version = 9
+ g = model.graph
+ # Get a Convtranspose layer
+ for node in g.node:
+ # Find a Flatten node
+ if node.op_type != "ConvTranspose":
+ continue
+ # Check auto_pad
+ auto_pad_proto = helper.get_attribute_by_name(node, "auto_pad")
+ if auto_pad_proto is not None:
+ print("Currently not split auto_pad ConvTranspose")
+ continue
+ # Check output_shape
+ output_shape_proto = helper.get_attribute_by_name(node, "output_shape")
+ if output_shape_proto is not None:
+ print("Currently not split output_shape ConvTranspose")
+ continue
+ # Get input shape
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ input_value = helper.find_input_by_name(g, node.input[0])
+ if input_value is None:
+ print("Cannot get value info named {}.".format(node.input[0]))
+ exit(1)
+ input_shape = helper.get_shape_from_value_info(input_value)
+ # Get attrbutes
+ attr = deconv_to_conv_info_extraction(input_shape, node)
+ # Generate Upsample scales
+ upsample_output_shape = list(input_shape)
+ upsample_output_shape[2] = (input_shape[2] - 1) * attr["strides"][
+ 0
+ ] + 1
+ upsample_output_shape[3] = (input_shape[3] - 1) * attr["strides"][
+ 1
+ ] + 1
+ upsample_node_name = node.name + "_inner_upsample"
+ upsample_scale_name = upsample_node_name + "_scales"
+ scales_np = np.ones([4]).astype("float32")
+ scales_np[2] = float(upsample_output_shape[2]) / input_shape[2]
+ scales_np[3] = float(upsample_output_shape[3]) / input_shape[3]
+ scales_node = helper.numpy_to_constant(upsample_scale_name, scales_np)
+ # Generate a Upsample layer and an internal value info
+ upsample_node = onnx.helper.make_node(
+ "Upsample",
+ [node.input[0], upsample_scale_name],
+ [upsample_node_name],
+ name=upsample_node_name,
+ mode="zeros",
+ )
+ upsample_value_info = onnx.helper.make_tensor_value_info(
+ upsample_node_name,
+ input_value.type.tensor_type.elem_type,
+ upsample_output_shape,
+ )
+ # Check the weight layer, it may need a transpose
+ if attr["group"] != input_shape[1]:
+ weight_node = helper.find_node_by_output_name(g, node.input[1])
+ weight_np = helper.constant_to_numpy(weight_node)
+ new_weight_np = np.transpose(weight_np, [1, 0, 2, 3])
+ new_weight_node = helper.numpy_to_constant(
+ node.input[1], new_weight_np
+ )
+ node_to_delete.append(weight_node)
+ g.node.extend([new_weight_node])
+ value = helper.find_value_by_name(g, node.input[1])
+ g.value_info.remove(value)
+ # Generate a Conv layer
+ conv_node_name = node.name + "_inner_conv"
+ conv_node_input = [upsample_node_name]
+ conv_node_input.extend(node.input[1:])
+ conv_node = onnx.helper.make_node(
+ "Conv",
+ conv_node_input,
+ [node.output[0]],
+ name=conv_node_name,
+ pads=[int(i) for i in attr["conv_pads"]],
+ dilations=[int(i) for i in attr["dilations"]],
+ group=int(attr["group"]),
+ kernel_shape=[int(i) for i in attr["kernel_shape"]],
+ strides=[int(1), int(1)],
+ )
+ # Reconnect the graph
+ g.node.extend([scales_node, upsample_node, conv_node])
+ g.value_info.extend([upsample_value_info])
+ node_to_delete.append(node)
+ # Delete useless nodes
+ for node in node_to_delete:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def add_bn_on_skip_branch(g):
+ for n in g.node:
+ # Find merge node (Add)
+ if n.op_type != "Add":
+ continue
+ if len(n.input) != 2:
+ continue
+ # TODO: Still need to consider more cases
+ # Check if skip branch exist
+ input_node_a = helper.find_node_by_output_name(g, n.input[0])
+ output_of_input_node_a = helper.find_nodes_by_input_name(
+ g, input_node_a.output[0]
+ )
+ input_node_b = helper.find_node_by_output_name(g, n.input[1])
+ output_of_input_node_b = helper.find_nodes_by_input_name(
+ g, input_node_b.output[0]
+ )
+ if (
+ len(output_of_input_node_a) == 1
+ and len(output_of_input_node_b) == 1
+ ):
+ continue
+ if len(output_of_input_node_a) == 2:
+ split_node = input_node_a
+ elif len(output_of_input_node_b) == 2:
+ split_node = input_node_b
+ else:
+ continue
+ # Get the channel number from value info
+ value_name = split_node.output[0]
+ value = helper.find_value_by_name(g, value_name)
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [channel], ones
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [channel], zeros
+ )
+ mean_node = helper.list_to_constant(
+ node_name + "_mean", [channel], zeros
+ )
+ var_node = helper.list_to_constant(node_name + "_var", [channel], ones)
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ )
+ # Reconnect the graph
+ replace_node_input(n, value_name, node_name)
+ # Add node to the graph
+ g.node.extend([bn_node, scale_node, bias_node, mean_node, var_node])
+ topological_sort(g)
+
+
+def add_bn_before_add(g):
+ for n in g.node:
+ # Find merge node (Add)
+ if n.op_type != "Add":
+ continue
+ if len(n.input) != 2:
+ continue
+ # Get two inputs
+ input_node_a = helper.find_node_by_output_name(g, n.input[0])
+ input_node_b = helper.find_node_by_output_name(g, n.input[1])
+ # Skip constant input add
+ if input_node_a is None or input_node_a.op_type == "Constant":
+ continue
+ if input_node_b is None or input_node_b.op_type == "Constant":
+ continue
+
+ def add_bn_after(prev_node):
+ # Get the channel number from value info
+ value_name = prev_node.output[0]
+ value = helper.find_value_by_name(g, value_name)
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [channel], ones
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [channel], zeros
+ )
+ mean_node = helper.list_to_constant(
+ node_name + "_mean", [channel], zeros
+ )
+ var_node = helper.list_to_constant(
+ node_name + "_var", [channel], ones
+ )
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ epsilon=0.00000001,
+ )
+ # Reconnect the graph
+ replace_node_input(n, value_name, node_name)
+ # Add node to the graph
+ g.node.extend(
+ [bn_node, scale_node, bias_node, mean_node, var_node]
+ )
+
+ if (
+ not input_node_a.op_type == "BatchNormalization"
+ or len(
+ helper.find_following_nodes_by_input_value_name(
+ g, input_node_a.output[0]
+ )
+ )
+ > 1
+ ):
+ add_bn_after(input_node_a)
+ if (
+ not input_node_b.op_type == "BatchNormalization"
+ or len(
+ helper.find_following_nodes_by_input_value_name(
+ g, input_node_b.output[0]
+ )
+ )
+ > 1
+ ):
+ add_bn_after(input_node_b)
+ topological_sort(g)
+
+
+def add_bn_before_activation(g):
+ activation_nodes = set(["Relu", "Clip", "PRelu", "LeakyRelu"])
+ previous_nodes = set(["Conv", "BatchNormalization"])
+ for n in g.node:
+ # Find activation node
+ if n.op_type not in activation_nodes:
+ continue
+ # Get input
+ input_node = helper.find_node_by_output_name(g, n.input[0])
+ if input_node is None or input_node.op_type in previous_nodes:
+ continue
+
+ def add_bn_after(prev_node):
+ # Get the channel number from value info
+ value_name = prev_node.output[0]
+ value = helper.find_value_by_name(g, value_name)
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [channel], ones
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [channel], zeros
+ )
+ mean_node = helper.list_to_constant(
+ node_name + "_mean", [channel], zeros
+ )
+ var_node = helper.list_to_constant(
+ node_name + "_var", [channel], ones
+ )
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ epsilon=0.00000001,
+ )
+ # Reconnect the graph
+ replace_node_input(n, value_name, node_name)
+ # Add node to the graph
+ g.node.extend(
+ [bn_node, scale_node, bias_node, mean_node, var_node]
+ )
+
+ add_bn_after(input_node)
+ topological_sort(g)
+
+
+def rename_output_name(g, original_name, new_name):
+ # Output
+ output_value = helper.find_output_by_name(g, original_name)
+ if output_value is None:
+ logging.error("Cannot find output value named " + original_name)
+ return
+ output_value.name = new_name
+ # Value Info
+ value_info = helper.find_value_by_name(g, original_name)
+ if value_info is not None:
+ value_info.name = new_name
+ # Node output
+ node = helper.find_node_by_output_name(g, original_name)
+ node.output[0] = new_name
+ # Node input
+ nodes = helper.find_nodes_by_input_name(g, original_name)
+ for node in nodes:
+ replace_node_input(node, original_name, new_name)
+
+
+def duplicate_param_shared_constant(g):
+ for node in g.node:
+ input_names = set()
+ for n, input_node_name in enumerate(node.input):
+ param_data_node = helper.find_node_by_output_name(
+ g, input_node_name
+ )
+ if (
+ param_data_node is None
+ or param_data_node.op_type != "Constant"
+ ):
+ continue
+ if param_data_node.name not in input_names:
+ input_names.add(input_node_name)
+ continue
+
+ new_node_name = param_data_node.name + "_" + str(n)
+ helper.logger.debug(
+ f"Duplicating weight: {param_data_node.name} -> "
+ f"{new_node_name}"
+ )
+ duplicated_node = copy.deepcopy(param_data_node)
+
+ duplicated_node.name = new_node_name
+ duplicated_node.output[0] = new_node_name
+
+ node.input[n] = new_node_name
+ g.node.extend([duplicated_node])
diff --git a/tools/optimizer_scripts/tools/removing_transpose.py b/tools/optimizer_scripts/tools/removing_transpose.py
new file mode 100644
index 0000000..89f772b
--- /dev/null
+++ b/tools/optimizer_scripts/tools/removing_transpose.py
@@ -0,0 +1,368 @@
+from . import helper
+from . import other
+from . import modhelper
+import numpy as np
+import onnx
+import onnx.utils
+
+
+def eliminate_transposes(m):
+ g = m.graph
+ keep_eliminating = True
+ while keep_eliminating:
+ while swap_transpose_with_single_next_node(g):
+ pass
+ splitted = split_transpose_for_multiple_next_nodes(g)
+ annihilated = annihilate_transposes(g)
+ multiple_trans_swapped = swap_multiple_transposes_with_node(g)
+ keep_eliminating = splitted or annihilated or multiple_trans_swapped
+
+ if keep_eliminating:
+ m = other.polish_model(m)
+ g = m.graph
+
+ return m
+
+
+def swap_transpose_with_single_next_node(g):
+ swapped = False
+ passable_nodes = set(
+ [
+ "Relu",
+ "Neg",
+ "LeakyRelu",
+ "Sqrt",
+ "Reciprocal",
+ "Add",
+ "Mul",
+ "Tanh",
+ ]
+ )
+ for node in g.node:
+ trans_node = node
+ # Check for transpose node
+ if trans_node.op_type != "Transpose":
+ continue
+ next_nodes = helper.find_nodes_by_input_name(g, trans_node.output[0])
+ if len(next_nodes) != 1:
+ continue
+ next_node = next_nodes[0]
+ # Check if the next node is the type can be swapped
+ if next_node.op_type not in passable_nodes:
+ continue
+
+ input_nodes = [
+ helper.find_node_by_output_name(g, input_name)
+ for input_name in next_node.input
+ ]
+
+ # Check if the node has nonconstant input
+ # other than the Transpose node itself
+ nonconstant_input = False
+ for input_node in input_nodes:
+ if input_node is None:
+ nonconstant_input = True
+ break
+ if input_node.name == trans_node.name:
+ continue
+ elif input_node.op_type == "Constant":
+ continue
+ else:
+ nonconstant_input = True
+ break
+ if nonconstant_input:
+ continue
+
+ for input_node in input_nodes:
+ if input_node.name == trans_node.name:
+ # if the input is just the transpose node
+ next_value_info = helper.find_value_by_name(
+ g, next_node.output[0]
+ )
+ mid_value_info = helper.find_value_by_name(
+ g, trans_node.output[0]
+ )
+
+ output_nodes = helper.find_nodes_by_input_name(
+ g, next_node.output[0]
+ )
+ for out_node in output_nodes:
+ modhelper.replace_node_input(
+ out_node, next_node.output[0], trans_node.name
+ )
+
+ next_node.input[0] = trans_node.input[0]
+ next_node.output[0] = next_node.name
+ trans_node.input[0] = next_node.name
+ trans_node.output[0] = trans_node.name
+
+ if next_value_info:
+ next_value_info.name = trans_node.name
+ if mid_value_info:
+ g.value_info.remove(mid_value_info)
+ else:
+ # if the input is a constant node
+ old_tensor = input_node.attribute[0].t
+ old_shape, data = helper.constant_to_list(input_node)
+ # If the constant node is a scaler, no action is needed
+ if type(old_shape) == int:
+ old_shape = [old_shape]
+ permutation = list(trans_node.attribute[0].ints)
+ while len(old_shape) < len(permutation):
+ old_shape.insert(0, 1)
+ np_data = np.reshape(data, old_shape)
+ reverse_perm = []
+ for i in range(len(permutation)):
+ reverse_perm.append(permutation.index(i))
+ np_data = np.transpose(np_data, reverse_perm)
+ new_shape = np_data.shape
+ new_tensor = onnx.helper.make_tensor(
+ name=old_tensor.name,
+ data_type=old_tensor.data_type,
+ dims=new_shape,
+ vals=np_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant",
+ [],
+ [input_node.output[0]],
+ name=input_node.name,
+ value=new_tensor,
+ )
+ g.node.extend([new_node])
+
+ g.value_info.remove(
+ helper.find_value_by_name(g, input_node.output[0])
+ )
+ g.node.remove(input_node)
+
+ swapped = True
+
+ other.topological_sort(g)
+ return swapped
+
+
+def swap_multiple_transposes_with_node(g):
+ # here only consider same input transposes
+ swapped = False
+ passable_nodes = set(["Add", "Mul"])
+ node_to_del = []
+ for node in g.node:
+ if node.op_type not in passable_nodes:
+ continue
+ input_nodes = [
+ helper.find_node_by_output_name(g, input_name)
+ for input_name in node.input
+ ]
+ if any([input_node is None for input_node in input_nodes]):
+ continue
+ if any(
+ [input_node.op_type != "Transpose" for input_node in input_nodes]
+ ):
+ continue
+
+ permutation = list(input_nodes[0].attribute[0].ints)
+ if any(
+ [
+ list(input_node.attribute[0].ints) != permutation
+ for input_node in input_nodes
+ ]
+ ):
+ continue
+
+ for input_name in node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ modhelper.replace_node_input(node, input_name, input_node.input[0])
+
+ node_to_del.extend(input_nodes)
+ for input_node in input_nodes:
+ input_val_info = helper.find_value_by_name(g, input_node.output[0])
+ if input_val_info is not None:
+ g.value_info.remove(input_val_info)
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+ if output_val_info is not None:
+ g.value_info.remove(output_val_info)
+
+ output_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ for i in range(len(output_nodes)):
+ new_trans_node_name = node.name + "_trans_" + str(i)
+ new_trans_node = onnx.helper.make_node(
+ "Transpose",
+ [node.output[0]],
+ [new_trans_node_name],
+ name=new_trans_node_name,
+ perm=permutation,
+ )
+ modhelper.replace_node_input(
+ output_nodes[i], node.output[0], new_trans_node_name
+ )
+
+ g.node.extend([new_trans_node])
+
+ swapped = True
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ other.topological_sort(g)
+ return swapped
+
+
+def annihilate_transposes(g):
+ node_to_del = []
+ annihilated = False
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ if not pre_node or pre_node.op_type != "Transpose":
+ continue
+ nodes_from_top_transpose = helper.find_nodes_by_input_name(
+ g, pre_node.output[0]
+ )
+ if len(nodes_from_top_transpose) > 1:
+ continue
+
+ perm_1 = list(pre_node.attribute[0].ints)
+ perm_2 = list(node.attribute[0].ints)
+ if perm_1 != perm_2:
+ continue
+
+ out_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ for out_node in out_nodes:
+ modhelper.replace_node_input(
+ out_node, node.output[0], pre_node.input[0]
+ )
+
+ node_to_del.extend([node, pre_node])
+ mid_value_info = helper.find_value_by_name(g, pre_node.output[0])
+ out_value_info = helper.find_value_by_name(g, node.output[0])
+ g.value_info.remove(mid_value_info)
+ g.value_info.remove(out_value_info)
+
+ annihilated = True
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return annihilated
+
+
+def split_transpose_for_multiple_next_nodes(g):
+ splitted = False
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ output_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ if len(output_nodes) < 2:
+ continue
+ for i in range(len(output_nodes)):
+ output_node = output_nodes[i]
+ new_trans_node_name = node.name + "_" + str(i)
+ new_trans_node = onnx.helper.make_node(
+ "Transpose",
+ [node.input[0]],
+ [new_trans_node_name],
+ name=new_trans_node_name,
+ perm=list(node.attribute[0].ints),
+ )
+ modhelper.replace_node_input(
+ output_node, node.output[0], new_trans_node.output[0]
+ )
+ g.node.extend([new_trans_node])
+
+ node_to_del.append(node)
+ val_info = helper.find_value_by_name(g, node.output[0])
+ g.value_info.remove(val_info)
+
+ splitted = True
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ other.topological_sort(g)
+ return splitted
+
+
+def remove_trivial_transpose(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ permutation = list(node.attribute[0].ints)
+ if permutation != list(range(len(permutation))):
+ continue
+
+ next_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ if not next_nodes:
+ input_val_info = helper.find_value_by_name(g, node.input[0])
+ out_val_info = helper.find_output_by_name(g, node.output[0])
+ if not input_val_info:
+ input_val_info = helper.find_input_by_name(g, node.input[0])
+ g.output.remove(out_val_info)
+ g.output.extend([input_val_info])
+ else:
+ out_val_info = helper.find_value_by_name(g, node.output[0])
+ for next_node in next_nodes:
+ modhelper.replace_node_input(
+ next_node, node.output[0], node.input[0]
+ )
+ g.value_info.remove(out_val_info)
+
+ node_to_del.append(node)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ other.topological_sort(g)
+
+
+def fuse_Transpose_into_Gemm_weight(g):
+ node_to_del = []
+ for node in g.node:
+ # Check pattern
+ if node.op_type != "Gemm":
+ continue
+ prev_node = helper.find_node_by_output_name(g, node.input[0])
+ if prev_node is None or prev_node.op_type != "Flatten":
+ continue
+ transpose_node = helper.find_node_by_output_name(g, prev_node.input[0])
+ if transpose_node.op_type != "Transpose":
+ continue
+ # Check attribute
+ perm = helper.get_list_attribute_by_name(transpose_node, "perm", "int")
+ if perm != [0, 2, 3, 1]:
+ continue
+ transB = helper.get_var_attribute_by_name(node, "transB", "int")
+ if transB is not None and transB == 1:
+ continue
+ # Get the original weight
+ origin_weight = helper.find_node_by_output_name(g, node.input[1])
+ origin_np = helper.constant_to_numpy(origin_weight)
+ # Calculate a new weight
+ shape = helper.get_shape_from_value_info(
+ helper.find_value_by_name(g, prev_node.input[0])
+ )
+ shape.append(-1)
+ new_np = np.reshape(origin_np, shape)
+ new_np = np.transpose(new_np, [0, 3, 1, 2, 4])
+ new_np = np.reshape(new_np, [-1, new_np.shape[-1]])
+ new_weight = helper.numpy_to_constant(origin_weight.output[0], new_np)
+ # Replace and eliminate
+ prev_node.input[0] = transpose_node.input[0]
+ node_to_del.append(transpose_node)
+ node_to_del.append(origin_weight)
+ g.value_info.remove(
+ helper.find_value_by_name(g, transpose_node.output[0])
+ )
+ g.node.extend([new_weight])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ other.topological_sort(g)
diff --git a/tools/optimizer_scripts/tools/replacing.py b/tools/optimizer_scripts/tools/replacing.py
new file mode 100644
index 0000000..fdbaa62
--- /dev/null
+++ b/tools/optimizer_scripts/tools/replacing.py
@@ -0,0 +1,1367 @@
+"""
+Optimizations that replace one node with another.
+"""
+import struct
+import copy
+import logging
+import onnx.helper
+import numpy as np
+from . import helper
+from . import modhelper
+from .other import topological_sort
+
+
+def replace_initializer_with_Constant(g, duplicate_shared_weights=True):
+ """
+ Replace initializers with Constant and a corresponding value_info
+ If the initializer has related input, remove it.
+
+ :param g: the onnx graph
+ """
+
+ input_map = {i.name: i for i in g.input}
+ for tensor in g.initializer:
+ # Check for the initializer related input and remove it
+ if tensor.name in input_map:
+ value_info = input_map[tensor.name]
+ g.input.remove(value_info)
+ following_nodes = helper.find_nodes_by_input_name(g, tensor.name)
+ if duplicate_shared_weights and len(following_nodes) >= 2:
+ for i, node in enumerate(following_nodes):
+ new_name = (
+ tensor.name + "_duplicated_No" + str(i)
+ if i > 0
+ else tensor.name
+ )
+ helper.logger.debug(
+ f"Duplicating weight: {tensor.name} -> {new_name}"
+ )
+ modhelper.replace_node_input(node, tensor.name, new_name)
+ new_node = onnx.helper.make_node(
+ "Constant", [], [new_name], name=new_name, value=tensor
+ )
+ # Add node to lists
+ g.node.extend([new_node])
+ else:
+ new_name = tensor.name
+ new_node = onnx.helper.make_node(
+ "Constant", [], [new_name], name=new_name, value=tensor
+ )
+ # Add node to lists
+ g.node.extend([new_node])
+
+ # if value info already exists, remove it as well.
+ value_info = helper.find_value_by_name(g, tensor.name)
+ if value_info is not None:
+ g.value_info.remove(value_info)
+
+ # Remove original initializer
+ while len(g.initializer) != 0:
+ g.initializer.pop()
+
+ topological_sort(g)
+
+
+def replace_Reshape_with_Flatten(g):
+ """
+ Replace Reshape node into Flatten node if applicable.
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Reshape":
+ continue
+ found_Gemm = False
+ # Flatten could be followed by Gemm
+ for i in g.node:
+ if len(i.input) == 0 or i.input[0] != node.output[0]:
+ continue
+ if i.op_type == "Gemm":
+ break
+ # Check weight
+ shape_node = helper.find_node_by_output_name(g, node.input[1])
+ if shape_node.op_type != "Constant":
+ continue
+ shape_value = helper.constant_to_numpy(shape_node)
+ if (shape_value.size != 2 or shape_value[0] != 1) and not found_Gemm:
+ continue
+ # Replace it
+ node.op_type = "Flatten"
+ for _ in range(len(node.attribute)):
+ node.attribute.pop()
+ shape_value = helper.find_value_by_name(g, shape_node.output[0])
+ node.input.pop()
+ node_to_remove.append(shape_node)
+ # If found shape value_info, remove it
+ if shape_value is not None:
+ g.value_info.remove(shape_value)
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def replace_Squeeze_with_Reshape(g):
+ """
+ Replace Squeeze nodes with Reshape node.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find Squeeze node
+ if node.op_type != "Squeeze":
+ continue
+ # Get the shape and Construct the shape
+ output_value = helper.find_value_by_name(g, node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if output_value is None:
+ raise RuntimeError("Cannot get shape for Squeeze")
+ shape = [
+ dim.dim_value for dim in output_value.type.tensor_type.shape.dim
+ ]
+ const_node = helper.list_to_constant(
+ node.name + "_shape", [len(shape)], shape
+ )
+ # Construct the Reshape layer with same input, output and name.
+ new_node = onnx.helper.make_node(
+ "Reshape",
+ [node.input[0], node.name + "_shape"],
+ node.output,
+ name=node.name,
+ )
+ # Append constructed nodes and append old node to remove_list
+ g.node.extend([const_node, new_node])
+ node_to_remove.append(node)
+ # Remove old nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ # Topological sort
+ topological_sort(g)
+
+
+def replace_Unsqueeze_with_Reshape(g):
+ """
+ Replace Unsqueeze nodes with Reshape node.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find Squeeze node
+ if node.op_type != "Unsqueeze":
+ continue
+ # Get the shape and Construct the shape
+ output_value = helper.find_value_by_name(g, node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if output_value is None:
+ raise RuntimeError("Cannot get shape for Unsqueeze")
+ shape = [
+ dim.dim_value for dim in output_value.type.tensor_type.shape.dim
+ ]
+
+ const_node = helper.list_to_constant(
+ node.name + "_shape", [len(shape)], shape
+ )
+ # Construct the Reshape layer with same input, output and name.
+ new_node = onnx.helper.make_node(
+ "Reshape",
+ [node.input[0], node.name + "_shape"],
+ node.output,
+ name=node.name,
+ )
+ # Append constructed nodes and append old node to remove_list
+ g.node.extend([const_node, new_node])
+ node_to_remove.append(node)
+ # Remove old nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ # Topological sort
+ topological_sort(g)
+
+
+def replace_average_pool_with_GAP(g):
+ """
+ Replace AveragePool nodes with GlobalAveragePool node when available.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a average pool layer
+ if node.op_type != "AveragePool":
+ continue
+ # Check attributes
+ not_replace = False
+ for attr in node.attribute:
+ if attr.name == "pads":
+ if list(attr.ints) != [0, 0, 0, 0]:
+ not_replace = True
+ break
+ if attr.name == "kernel_shape":
+ kernel_shape = list(attr.ints)
+ value_info = helper.find_value_by_name(g, node.input[0])
+ if value_info is None:
+ not_replace = True
+ break
+ input_shape = []
+ for dim in value_info.type.tensor_type.shape.dim:
+ input_shape.append(dim.dim_value)
+ if input_shape[-2:] != kernel_shape:
+ not_replace = True
+ break
+ if not_replace:
+ continue
+ # Replace it with GlobalAveragePool
+ new_node = onnx.helper.make_node(
+ "GlobalAveragePool", node.input, node.output, name=node.name
+ )
+ g.node.extend([new_node])
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def replace_dilated_conv(g):
+ """
+ If the dilation of a convolution is not (1, 1), replace it with a regular
+ convolution with an expanded kernel.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check if this is a conv layer
+ if node.op_type != "Conv":
+ continue
+ # Check if this has dilation
+ has_dilations = False
+ has_strides = False
+ for attr in node.attribute:
+ if attr.name == "dilations":
+ dilations = list(attr.ints)
+ if dilations != [1, 1]:
+ has_dilations = True
+ if attr.name == "strides":
+ strides = list(attr.ints)
+ if strides != [1, 1]:
+ has_strides = True
+ if has_dilations and has_strides:
+ print("Warning: Both strides and dilations are set in ", node.name)
+ continue
+ if not has_dilations:
+ continue
+ # Construct new kernel
+ w_node = helper.find_node_by_output_name(g, node.input[1])
+ w_output = helper.find_value_by_name(g, node.input[1])
+ shape = list(w_node.attribute[0].t.dims)
+ # get original weight from float_data or raw data
+ weight = list(w_node.attribute[0].t.float_data)
+ if len(weight) == 0:
+ # Unpack from raw data
+ raw_data = w_node.attribute[0].t.raw_data
+ weight = [i[0] for i in struct.iter_unpack("f", raw_data)]
+ weight = np.array(weight)
+ weight = np.reshape(weight, shape)
+ new_shape = copy.copy(shape)
+ new_shape[2] = 1 + (shape[2] - 1) * dilations[0]
+ new_shape[3] = 1 + (shape[3] - 1) * dilations[1]
+ new_weight = np.zeros(new_shape)
+ for batch in range(shape[0]):
+ for ch in range(shape[1]):
+ for h in range(shape[2]):
+ nh = h * dilations[0]
+ for w in range(shape[3]):
+ nw = w * dilations[1]
+ new_weight[batch, ch, nh, nw] = weight[batch, ch, h, w]
+ tensor = onnx.helper.make_tensor(
+ w_node.attribute[0].t.name,
+ w_node.attribute[0].t.data_type,
+ new_shape,
+ new_weight.ravel(),
+ )
+ new_w_node = onnx.helper.make_node(
+ "Constant", [], list(w_node.output), name=w_node.name, value=tensor
+ )
+ g.node.extend([new_w_node])
+ node_to_remove.append(w_node)
+ # Modify attributes and value info shapes
+ w_output.type.tensor_type.shape.dim[2].dim_value = new_shape[2]
+ w_output.type.tensor_type.shape.dim[3].dim_value = new_shape[3]
+ for attr in node.attribute:
+ if attr.name == "kernel_shape":
+ attr.ints[0] = new_shape[2]
+ attr.ints[1] = new_shape[3]
+ if attr.name == "dilations":
+ attr.ints[0] = 1
+ attr.ints[1] = 1
+ # Remove old weight nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def replace_depthwise_1x1_with_bn(g):
+ """Replace 1x1 DepthwiseConv node into BN node if applicable.
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check op_type
+ if node.op_type != "Conv":
+ continue
+ # Check attributes
+ attr_map = {attr.name: attr for attr in node.attribute}
+ if "group" not in attr_map or attr_map["group"].i == 1:
+ continue
+ if (
+ attr_map["kernel_shape"].ints[0] != 1
+ or attr_map["kernel_shape"].ints[1] != 1
+ ):
+ continue
+ if "pads" in attr_map and sum(attr_map["pads"].ints) != 0:
+ continue
+ # Check scale
+ scale_node = helper.find_node_by_output_name(g, node.input[1])
+ if scale_node is None or scale_node.attribute[0].t.dims[1] != 1:
+ continue
+ scale_node.attribute[0].t.dims.pop()
+ scale_node.attribute[0].t.dims.pop()
+ scale_node.attribute[0].t.dims.pop()
+ scale_info = helper.find_value_by_name(g, node.input[1])
+ if scale_info is not None:
+ scale_info.type.tensor_type.shape.dim.pop()
+ scale_info.type.tensor_type.shape.dim.pop()
+ scale_info.type.tensor_type.shape.dim.pop()
+ # Check bias
+ if len(node.input) == 3:
+ bias_name = node.input[2]
+ else:
+ bias_name = node.name + "_bias"
+ bias_node = helper.list_to_constant(
+ bias_name, [attr_map["group"].i], [0.0] * attr_map["group"].i
+ )
+ g.node.extend([bias_node])
+ # Construct mean and vars
+ mean_name = node.name + "_mean"
+ mean_node = helper.list_to_constant(
+ mean_name, [attr_map["group"].i], [0.0] * attr_map["group"].i
+ )
+ var_name = node.name + "_var"
+ var_node = helper.list_to_constant(
+ var_name, [attr_map["group"].i], [1.0] * attr_map["group"].i
+ )
+ g.node.extend([mean_node, var_node])
+ # Convert
+ bn_node = onnx.helper.make_node(
+ op_type="BatchNormalization",
+ inputs=[
+ node.input[0],
+ node.input[1],
+ bias_name,
+ mean_name,
+ var_name,
+ ],
+ outputs=node.output,
+ name=node.name,
+ epsilon=0.00001,
+ momentum=0.9,
+ )
+ g.node.extend([bn_node])
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def replace_shape_with_constant(g):
+ """Replace Shape with Constant.\\
+ This is the first step of reshape constant folding.
+
+ :param g: the input graph\\
+ :return: if anything modified, return true.
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a Shape
+ if node.op_type != "Shape":
+ continue
+ # Check its input
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ input_value = helper.find_input_by_name(g, node.input[0])
+ if (
+ input_value is None
+ or len(input_value.type.tensor_type.shape.dim) == 0
+ ):
+ continue
+ # Check for case where dimension could be 0 or -1
+ tmp = True
+ for d in input_value.type.tensor_type.shape.dim:
+ tmp = tmp and (d.dim_value > 0)
+ if not tmp:
+ continue
+ # Repalce it
+ input_shape = [
+ d.dim_value for d in input_value.type.tensor_type.shape.dim
+ ]
+ node_name = node.output[0]
+ new_node = helper.list_to_constant(
+ node_name, [len(input_shape)], input_shape
+ )
+ g.node.extend([new_node])
+ node_to_remove.append(node)
+
+ # if the input value_info is not used by other node
+ # delete this input value_info
+ val_info_used = sum(
+ [input_value.name in node.input for node in g.node]
+ )
+ if val_info_used == 1:
+ g.value_info.remove(input_value)
+
+ replaced = True if len(node_to_remove) > 0 else False
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+ topological_sort(g)
+
+ return replaced
+
+
+def replace_ConstantOfShape_with_constant(g):
+ """Replace Shape with Constant.\\
+ This is the first step of reshape constant folding.
+
+ :param g: the input graph\\
+ :return: if anything modified, return true.
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a Shape
+ if node.op_type != "ConstantOfShape":
+ continue
+ # Check input
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ input_value = helper.find_input_by_name(g, node.input[0])
+ if (
+ input_value is None
+ or len(input_value.type.tensor_type.shape.dim) == 0
+ ):
+ continue
+
+ # Replace to constant node
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ _, target_shape = helper.constant_to_list(pre_node)
+
+ value = helper.get_attribute_by_name(node, "value").i
+
+ node_name = node.output[0]
+ new_node = helper.list_to_constant(
+ node_name, [target_shape[0]], [value] * target_shape[0]
+ )
+
+ g.node.extend([new_node])
+
+ # remove old node
+ node_to_remove.append(node)
+
+ # delete value_info
+ val_info_used = sum(
+ [input_value.name in node.input for node in g.node]
+ )
+ if val_info_used == 1:
+ g.value_info.remove(input_value)
+
+ replaced = True if len(node_to_remove) > 0 else False
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+ topological_sort(g)
+
+ return replaced
+
+
+def replace_split_with_slices(g):
+ """Replace split node with slice nodes.
+ :param g: input graph.
+ :return:
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a Split
+ if node.op_type != "Split":
+ continue
+
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if not input_value:
+ input_value = helper.find_input_by_name(g, node.input[0])
+ _, shape = helper.find_size_shape_from_value(input_value)
+ if len(shape) == 0:
+ continue
+
+ output_val_names = list(node.output)
+
+ axis = 0
+ split = []
+ for item in node.attribute:
+ if item.name == "axis":
+ axis = item.i
+ if item.name == "split":
+ split = item.ints
+
+ # For opset 11, axis could be negative.
+ if axis < 0:
+ axis = len(shape) + axis
+
+ length = input_value.type.tensor_type.shape.dim[axis].dim_value
+ if len(split) > 0:
+ n_out = len(split)
+ pos = 0
+ for i in range(n_out):
+ pos += split[i]
+ new_node_name = output_val_names[i]
+ # Construct starts, ends, axes
+ starts_name = new_node_name + "_starts_" + str(i)
+ ends_name = new_node_name + "_ends_" + str(i)
+ axes_name = new_node_name + "_axes_" + str(i)
+ starts_node = helper.list_to_constant(
+ starts_name, (1,), [int(pos - split[i])]
+ )
+ ends_node = helper.list_to_constant(
+ ends_name, (1,), [int(pos)]
+ )
+ axes_node = helper.list_to_constant(
+ axes_name, (1,), [int(axis)]
+ )
+ # Construtc node
+ new_node = onnx.helper.make_node(
+ op_type="Slice",
+ inputs=[node.input[0], starts_name, ends_name, axes_name],
+ outputs=[node.output[i]],
+ name=new_node_name,
+ )
+ g.node.extend([starts_node, ends_node, axes_node, new_node])
+ node_to_remove.append(node)
+ else:
+ n_out = len(output_val_names)
+ width = length // n_out
+ for i in range(n_out):
+ new_node_name = output_val_names[i]
+ # Construct starts, ends, axes
+ starts_name = new_node_name + "_starts_" + str(i)
+ ends_name = new_node_name + "_ends_" + str(i)
+ axes_name = new_node_name + "_axes_" + str(i)
+ starts_node = helper.list_to_constant(
+ starts_name, (1,), [int(i * width)]
+ )
+ ends_node = helper.list_to_constant(
+ ends_name, (1,), [int((1 + i) * width)]
+ )
+ axes_node = helper.list_to_constant(
+ axes_name, (1,), [int(axis)]
+ )
+ # Construtc node
+ new_node = onnx.helper.make_node(
+ op_type="Slice",
+ inputs=[node.input[0], starts_name, ends_name, axes_name],
+ outputs=[node.output[i]],
+ name=new_node_name,
+ )
+ g.node.extend([starts_node, ends_node, axes_node, new_node])
+ node_to_remove.append(node)
+
+ for old_node in node_to_remove:
+ g.node.remove(old_node)
+ topological_sort(g)
+
+
+def replace_ReduceMean_with_GlobalAveragePool(g):
+ """
+ Replace ReduceMean with GlobalAveragePool node when available.
+
+ If there is preceeded Transpose, check the Transpose and the ReduceMean
+ together. If the keep_dims is set to 0, add a Flatten.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a ReduceMean layer
+ if node.op_type != "ReduceMean":
+ continue
+ # Find if it have previous Transpose and its attribute meet the need.
+ prev_node = helper.find_node_by_output_name(g, node.input[0])
+ if prev_node is not None and prev_node.op_type != "Transpose":
+ prev_node = None
+ if prev_node is not None:
+ perm = helper.get_list_attribute_by_name(prev_node, "perm", "int")
+ if perm != [0, 2, 3, 1]:
+ prev_node = None
+ # Check attributes
+ axes = helper.get_list_attribute_by_name(node, "axes", "int")
+ keepdims = helper.get_var_attribute_by_name(node, "keepdims", "int")
+ if axes is None:
+ continue
+ if prev_node is None and axes != [2, 3]:
+ continue
+ if prev_node is not None and axes != [1, 2]:
+ continue
+ if keepdims is None:
+ keepdims = 1
+ # Replace it with GlobalAveragePool
+ if prev_node:
+ input_list = prev_node.input
+ else:
+ input_list = node.input
+ if keepdims == 1:
+ output_list = node.output
+ else:
+ output_list = [node.output[0] + "_before_flatten"]
+ flatten_node = onnx.helper.make_node(
+ "Flatten",
+ output_list,
+ node.output,
+ name=node.name + "_flatten",
+ axis=1,
+ )
+ g.node.extend([flatten_node])
+ new_node = onnx.helper.make_node(
+ "GlobalAveragePool", input_list, output_list, name=node.name
+ )
+ g.node.extend([new_node])
+ node_to_remove.append(node)
+ if prev_node:
+ value = helper.find_value_by_name(g, prev_node.output[0])
+ if value:
+ g.value_info.remove(value)
+ node_to_remove.append(prev_node)
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def replace_mul_to_bn(g):
+ """Replace single Mul node with Batchnorm node.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Mul":
+ continue
+
+ mul_op_node = node
+
+ # only support one input node
+ if len(mul_op_node.input) != 2: # OP node and value node
+ continue
+
+ input_op_node_name = mul_op_node.input[0]
+ mul_value_node = helper.find_node_by_output_name(
+ g, mul_op_node.input[1]
+ )
+ if not mul_value_node or mul_value_node.op_type != "Constant":
+ continue
+
+ prev_shape_value_info = helper.find_value_by_name(
+ g, input_op_node_name
+ )
+ prev_shape_value_info = (
+ helper.find_input_by_name(g, input_op_node_name)
+ if prev_shape_value_info is None
+ else prev_shape_value_info
+ )
+ if prev_shape_value_info is None:
+ continue
+
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ prev_shape_value_info
+ )
+ scale_shape, scale_data = helper.constant_to_list(mul_value_node)
+
+ # channel dimension
+ c_dim = (
+ previous_node_output_shape[1]
+ if len(previous_node_output_shape) > 1
+ else 1
+ )
+
+ # only allow channelwise mul or const mul
+ if scale_shape == [1, c_dim, 1, 1]:
+ muls = scale_data
+ elif scale_shape == [c_dim, 1, 1]:
+ muls = scale_data
+ elif scale_shape == 1:
+ muls = scale_data * c_dim
+ else:
+ continue
+
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ bn_name = mul_op_node.output[0]
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ bias_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(zeros).shape, zeros
+ )
+ new_mul_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(muls).shape, muls
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ input_op_node_name,
+ new_mul_value_node.output[0],
+ bias_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [mul_op_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ scale_val_info = helper.find_value_by_name(g, mul_value_node.output[0])
+ g.value_info.remove(scale_val_info)
+
+ g.node.extend([bn_node])
+ g.node.extend([mean_value_node])
+ g.node.extend([variance_value_node])
+ g.node.extend([bias_value_node])
+ g.node.extend([new_mul_value_node])
+
+ node_to_del.extend([mul_op_node])
+ node_to_del.extend([mul_value_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_div_to_bn(g):
+ """Replace single Div node with Batchnorm node.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Div":
+ continue
+
+ div_op_node = node
+
+ # only support one input node
+ if len(div_op_node.input) != 2: # OP node and value node
+ continue
+
+ input_op_node_name = div_op_node.input[0]
+ div_value_node = helper.find_node_by_output_name(
+ g, div_op_node.input[1]
+ )
+ if not div_value_node or div_value_node.op_type != "Constant":
+ continue
+
+ prev_shape_value_info = helper.find_value_by_name(
+ g, input_op_node_name
+ )
+ prev_shape_value_info = (
+ helper.find_input_by_name(g, input_op_node_name)
+ if prev_shape_value_info is None
+ else prev_shape_value_info
+ )
+ if prev_shape_value_info is None:
+ continue
+
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ prev_shape_value_info
+ )
+ scale_shape, scale_data = helper.constant_to_list(div_value_node)
+
+ # channel dimension
+ c_dim = (
+ previous_node_output_shape[1]
+ if len(previous_node_output_shape) > 1
+ else 1
+ )
+
+ # only allow channelwise div or const div
+ if scale_shape == [1, c_dim, 1, 1]:
+ muls = scale_data
+ elif scale_shape == [c_dim, 1, 1]:
+ muls = scale_data
+ elif scale_shape == 1:
+ muls = scale_data * c_dim
+ else:
+ continue
+
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ muls = (1 / np.array(muls)).tolist()
+ bn_name = div_op_node.output[0]
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ bias_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(zeros).shape, zeros
+ )
+ new_mul_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(muls).shape, muls
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ input_op_node_name,
+ new_mul_value_node.output[0],
+ bias_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [div_op_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ scale_val_info = helper.find_value_by_name(g, div_value_node.output[0])
+ g.value_info.remove(scale_val_info)
+
+ g.node.extend([bn_node])
+ g.node.extend([mean_value_node])
+ g.node.extend([variance_value_node])
+ g.node.extend([bias_value_node])
+ g.node.extend([new_mul_value_node])
+
+ node_to_del.extend([div_op_node])
+ node_to_del.extend([div_value_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_add_to_bn(g):
+ """Replace single Add node with Batchnorm node.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Add":
+ continue
+
+ add_op_node = node
+
+ # only support one input node
+ if len(add_op_node.input) != 2: # OP node and value node
+ continue
+
+ input_op_node_name = add_op_node.input[0]
+ add_value_node = helper.find_node_by_output_name(
+ g, add_op_node.input[1]
+ )
+ if not add_value_node or add_value_node.op_type != "Constant":
+ continue
+
+ prev_shape_value_info = helper.find_value_by_name(
+ g, input_op_node_name
+ )
+ prev_shape_value_info = (
+ helper.find_input_by_name(g, input_op_node_name)
+ if prev_shape_value_info is None
+ else prev_shape_value_info
+ )
+ if prev_shape_value_info is None:
+ continue
+
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ prev_shape_value_info
+ )
+ bias_shape, bias_data = helper.constant_to_list(add_value_node)
+
+ # channel dimension
+ c_dim = (
+ previous_node_output_shape[1]
+ if len(previous_node_output_shape) > 1
+ else 1
+ )
+
+ # only allow channelwise add or const add
+ if bias_shape == [1, c_dim, 1, 1]:
+ bias = bias_data
+ elif bias_shape == [c_dim, 1, 1]:
+ bias = bias_data
+ elif bias_shape == 1:
+ bias = bias_data * c_dim
+ else:
+ continue
+
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ bn_name = add_op_node.output[0]
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ scale_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(ones).shape, ones
+ )
+ new_add_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(bias).shape, bias
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ input_op_node_name,
+ scale_value_node.output[0],
+ new_add_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [add_op_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ add_val_info = helper.find_value_by_name(g, add_value_node.output[0])
+ g.value_info.remove(add_val_info)
+
+ g.node.extend([bn_node])
+ g.node.extend([mean_value_node])
+ g.node.extend([variance_value_node])
+ g.node.extend([scale_value_node])
+ g.node.extend([new_add_value_node])
+
+ node_to_del.extend([add_op_node])
+ node_to_del.extend([add_value_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_sub_to_bn(g):
+ """Replace single Sub node with BatchNorm node.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Sub":
+ continue
+
+ sub_op_node = node
+
+ # only support one input node
+ if len(sub_op_node.input) != 2: # OP node and value node
+ continue
+
+ # Check the input type
+ input_1st_name = sub_op_node.input[0]
+ input_2nd_name = sub_op_node.input[1]
+ input_1st_node = helper.find_node_by_output_name(g, input_1st_name)
+ input_2nd_node = helper.find_node_by_output_name(g, input_2nd_name)
+ if input_1st_node is not None and input_1st_node.op_type == "Constant":
+ real_input_name = input_2nd_name
+ reverse = True
+ constant_node = input_1st_node
+ elif (
+ input_2nd_node is not None and input_2nd_node.op_type == "Constant"
+ ):
+ real_input_name = input_1st_name
+ reverse = False
+ constant_node = input_2nd_node
+ else:
+ continue
+
+ # Get shapes
+ prev_shape_value_info = helper.find_value_by_name(g, real_input_name)
+ prev_shape_value_info = (
+ helper.find_input_by_name(g, real_input_name)
+ if prev_shape_value_info is None
+ else prev_shape_value_info
+ )
+ if prev_shape_value_info is None:
+ continue
+
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ prev_shape_value_info
+ )
+ bias_shape, bias_data = helper.constant_to_list(constant_node)
+
+ # channel dimension
+ c_dim = (
+ previous_node_output_shape[1]
+ if len(previous_node_output_shape) > 1
+ else 1
+ )
+
+ # only allow channelwise sub or const sub
+ if bias_shape == [1, c_dim, 1, 1]:
+ bias = bias_data
+ elif bias_shape == [c_dim, 1, 1]:
+ bias = bias_data
+ elif bias_shape == 1:
+ bias = bias_data * c_dim
+ else:
+ continue
+
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ # If reversed provide special scaler
+ if reverse:
+ scale = [-1.0] * c_dim
+ else:
+ scale = ones
+ bias *= -1
+ bn_name = sub_op_node.output[0]
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ scale_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(scale).shape, scale
+ )
+ new_add_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(bias).shape, bias
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ real_input_name,
+ scale_value_node.output[0],
+ new_add_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [sub_op_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ add_val_info = helper.find_value_by_name(g, constant_node.output[0])
+ g.value_info.remove(add_val_info)
+
+ g.node.extend([bn_node])
+ g.node.extend([mean_value_node])
+ g.node.extend([variance_value_node])
+ g.node.extend([scale_value_node])
+ g.node.extend([new_add_value_node])
+
+ node_to_del.extend([sub_op_node])
+ node_to_del.extend([constant_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_sub_with_bn_and_add(g):
+ """Replace two input Sub node with BN and Add: A - B = A + (-1) * B
+ :param g: input graph.
+ :return:
+ """
+ for node in g.node:
+ if node.op_type != "Sub":
+ continue
+
+ sub_op_node = node
+
+ # only support one input node
+ if len(sub_op_node.input) != 2: # OP node and value node
+ continue
+
+ # Check the input type
+ input_1st_name = sub_op_node.input[0]
+ input_2nd_name = sub_op_node.input[1]
+ input_1st_node = helper.find_node_by_output_name(g, input_1st_name)
+ input_2nd_node = helper.find_node_by_output_name(g, input_2nd_name)
+ if input_1st_node is not None and input_1st_node.op_type == "Constant":
+ continue
+ elif (
+ input_2nd_node is not None and input_2nd_node.op_type == "Constant"
+ ):
+ continue
+
+ # Get shapes
+ input_2nd_value_info = helper.find_value_by_name(g, input_2nd_name)
+ if input_2nd_value_info is None:
+ input_2nd_value_info = helper.find_input_by_name(g, input_2nd_name)
+ if input_2nd_value_info is None:
+ continue
+
+ # Get channel dimension
+ _, input_2nd_shape = helper.find_size_shape_from_value(
+ input_2nd_value_info
+ )
+ if len(input_2nd_shape) < 2:
+ helper.logger.debug(
+ f"{sub_op_node.name} cannot be replaced "
+ "due to the input shape."
+ )
+ c_dim = input_2nd_shape[1]
+
+ # Create * -1 bn node.
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ scale = [-1.0] * c_dim
+ bn_name = input_2nd_name + "_neg_for_" + node.name
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ scale_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(scale).shape, scale
+ )
+ bias_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(zeros).shape, zeros
+ )
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ input_2nd_name,
+ scale_value_node.output[0],
+ bias_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [bn_name],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ # Change sub to add
+ sub_op_node.op_type = "Add"
+ # Replace add input
+ modhelper.replace_node_input(sub_op_node, input_2nd_name, bn_name)
+
+ g.node.extend(
+ [
+ scale_value_node,
+ bias_value_node,
+ mean_value_node,
+ variance_value_node,
+ bn_node,
+ ]
+ )
+
+ topological_sort(g)
+
+
+def replace_Sum_with_Adds(g):
+ node_to_del = []
+
+ for node in g.node:
+ # Check for sum
+ if node.op_type != "Sum":
+ continue
+ # Check for input number
+ if len(node.input) == 1:
+ # If input number is 1, delete the sum node.
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ node_to_del.append(node)
+ if helper.find_value_by_name(node.output[0]) is not None:
+ g.value_info.remove(helper.find_value_by_name(node.output[0]))
+ elif len(node.input) == 2:
+ # If input number is 2, replace it with add.
+ node.op_type = "Add"
+ continue
+ elif len(node.input) > 2:
+ # If input number is larger than 2, replace it with n-1 add.
+ input_count = len(node.input)
+ # First node has 2 inputs
+ first_node = onnx.helper.make_node(
+ "Add",
+ [node.input[0], node.input[1]],
+ [node.output[0] + "_replacement_1"],
+ name=node.name + "_replacement_1",
+ )
+ # Last node has the same output as the original sum node
+ last_node = onnx.helper.make_node(
+ "Add",
+ [
+ node.output[0] + "_replacement_" + str(input_count - 2),
+ node.input[input_count - 1],
+ ],
+ [node.output[0]],
+ name=node.name,
+ )
+ g.node.extend([first_node, last_node])
+ for i in range(2, input_count - 1):
+ new_node = onnx.helper.make_node(
+ "Add",
+ [
+ node.output[0] + "_replacement_" + str(i - 1),
+ node.input[i],
+ ],
+ [node.output[0] + "_replacement_" + str(i)],
+ name=node.name + "_replacement_" + str(i),
+ )
+ g.node.extend([new_node])
+ node_to_del.append(node)
+ else:
+ logging.error("Sum node must have at least 1 input.")
+ quit(1)
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_constant_input_concat_with_pad(g):
+ """
+ If single input is concating with constant node of same number.
+ Replace it with pad. Currently only support 2-3 inputs.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ # Check for Concat node
+ if node.op_type != "Concat":
+ continue
+
+ # Check concat node input
+ mode = None
+ value = 0
+ real_input_name = None
+ if len(node.input) == 2:
+ input_1st_node = helper.find_node_by_output_name(g, node.input[0])
+ input_2nd_node = helper.find_node_by_output_name(g, node.input[1])
+ if (
+ input_1st_node is not None
+ and input_1st_node.op_type == "Constant"
+ ):
+ mode = "left"
+ constant_value = helper.constant_to_numpy(input_1st_node)
+ real_input_name = node.input[1]
+ value = constant_value.flatten()[0]
+ # Check if the values are all the same.
+ if np.any(constant_value - value):
+ continue
+ elif (
+ input_2nd_node is not None
+ and input_2nd_node.op_type == "Constant"
+ ):
+ mode = "right"
+ constant_value = helper.constant_to_numpy(input_2nd_node)
+ real_input_name = node.input[0]
+ value = constant_value.flatten()[0]
+ # Check if the values are all the same.
+ if np.any(constant_value - value):
+ continue
+ else:
+ # No constant input case
+ continue
+ elif len(node.input) == 3:
+ # For 3 inputs concat node, the 1st and the 3rd input should be
+ # constant with the same value.
+ input_1st_node = helper.find_node_by_output_name(g, node.input[0])
+ input_2nd_node = helper.find_node_by_output_name(g, node.input[1])
+ input_3rd_node = helper.find_node_by_output_name(g, node.input[2])
+ if (
+ input_1st_node is None
+ or input_1st_node.op_type != "Constant"
+ or input_3rd_node is None
+ or input_3rd_node.op_type != "Constant"
+ ):
+ continue
+ mode = "both"
+ real_input_name = node.input[1]
+ input_1st_value = helper.constant_to_numpy(input_1st_node)
+ input_3rd_value = helper.constant_to_numpy(input_3rd_node)
+ value = input_1st_value.flatten()[0]
+ # Check if all the values are all the same
+ if np.any(input_1st_value - value):
+ continue
+ elif np.any(input_3rd_value - value):
+ continue
+ else:
+ # Too many inputs case.
+ continue
+ # Make weight nodes
+ input_value_info = helper.find_value_by_name(g, real_input_name)
+ input_shape = helper.get_shape_from_value_info(input_value_info)
+ pads = [0] * (len(input_shape) * 2)
+ axis = helper.get_var_attribute_by_name(node, "axis", "int")
+ if axis < 0:
+ axis = len(input_shape) - axis
+ if mode == "left":
+ left_value_info = helper.find_value_by_name(g, node.input[0])
+ left_input_shape = helper.get_shape_from_value_info(
+ left_value_info
+ )
+ pads[axis] = left_input_shape[axis]
+ elif mode == "right":
+ right_value_info = helper.find_value_by_name(g, node.input[1])
+ right_input_shape = helper.get_shape_from_value_info(
+ right_value_info
+ )
+ pads[axis + len(input_shape)] = right_input_shape[axis]
+ else:
+ # mode shoule be both
+ left_value_info = helper.find_value_by_name(g, node.input[0])
+ left_input_shape = helper.get_shape_from_value_info(
+ left_value_info
+ )
+ pads[axis] = left_input_shape[axis]
+ right_value_info = helper.find_value_by_name(g, node.input[2])
+ right_input_shape = helper.get_shape_from_value_info(
+ right_value_info
+ )
+ pads[axis + len(input_shape)] = right_input_shape[axis]
+ pads_node = helper.list_to_constant(
+ node.name + "_pads", (len(pads),), pads
+ )
+ constant_value_node = helper.scaler_to_constant(
+ node.name + "_constant_value", value
+ )
+ # Create new Pad node
+ new_pad_node = onnx.helper.make_node(
+ "Pad",
+ [real_input_name, pads_node.name, constant_value_node.name],
+ [node.output[0]],
+ name=node.name,
+ mode="constant",
+ )
+ # Replace
+ node_to_del.append(node)
+ g.node.extend([pads_node, constant_value_node, new_pad_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
diff --git a/tools/optimizer_scripts/tools/special.py b/tools/optimizer_scripts/tools/special.py
new file mode 100644
index 0000000..275f8c5
--- /dev/null
+++ b/tools/optimizer_scripts/tools/special.py
@@ -0,0 +1,489 @@
+"""Special operations on model.
+"""
+import onnx.helper
+import numpy as np
+from . import helper
+from . import other
+
+
+def change_first_conv_from_bgr_to_rgb(m):
+ """For input channel format BGR model, use this function to change the first
+ conv weight to adapt the input into RGB.
+
+ :param m: the model proto
+ """
+ # Check for first node.
+ g = m.graph
+ input_name = g.input[0].name
+ first_nodes = helper.find_following_nodes_by_input_value_name(
+ g, input_name
+ )
+ if len(first_nodes) > 1:
+ return False
+ first_node = first_nodes[0]
+ # Now we have the first node. Check this first node.
+ if first_node.op_type != "Conv":
+ return False
+ weight_value = helper.find_value_by_name(g, first_node.input[1])
+ weight_shape = helper.get_shape_from_value_info(weight_value)
+ if weight_shape[1] != 3:
+ return False
+ # Do weight shuffle
+ weight_node = helper.find_node_by_output_name(g, weight_value.name)
+ weight_np = helper.constant_to_numpy(weight_node)
+ b_channel = np.expand_dims(weight_np[:, 0, :, :], axis=1)
+ g_channel = np.expand_dims(weight_np[:, 1, :, :], axis=1)
+ r_channel = np.expand_dims(weight_np[:, 2, :, :], axis=1)
+ new_np = np.concatenate((r_channel, g_channel, b_channel), axis=1)
+ new_node = helper.numpy_to_constant(weight_value.name, new_np)
+ # Replace the weight and topological sort
+ g.node.remove(weight_node)
+ g.node.extend([new_node])
+ other.topological_sort(g)
+ return True
+
+
+def change_input_from_bgr_to_rgb(m):
+ """
+ For input channel format BGR model, use this function to modify the model
+ to accepct RGB image.If the first node is a non-group Conv.
+ Modify weight to adapt the input into RGB. Otherwise create a new node.
+
+ :param m: the model proto
+ """
+ g = m.graph
+ if len(g.input) > 1:
+ print("This model has multiple inputs. Cannot change to RGB input.")
+ return
+ input_shape = helper.get_shape_from_value_info(g.input[0])
+ if len(input_shape) != 4 or input_shape[1] != 3:
+ print("The input shape is invalid for bgr conversion.")
+ return
+ # Try change conv weight first
+ if change_first_conv_from_bgr_to_rgb(m):
+ return
+ # Otherwise, create a special conv node and replace the input
+ # Construct weight
+ weight_np = np.zeros((3, 3, 3, 3)).astype("float32")
+ weight_np[0, 2, 1, 1] = 1.0
+ weight_np[1, 1, 1, 1] = 1.0
+ weight_np[2, 0, 1, 1] = 1.0
+ new_weight = helper.numpy_to_constant("bgr_shuffle_weight", weight_np)
+ # Construct Conv
+ new_conv = onnx.helper.make_node(
+ "Conv",
+ ["rgb_input", "bgr_shuffle_weight"],
+ [g.input[0].name],
+ name="bgr_shuffle",
+ dilations=[1, 1],
+ kernel_shape=[3, 3],
+ pads=[1, 1, 1, 1],
+ strides=[1, 1],
+ )
+ # Connect the graph
+ old_input_value = g.input.pop()
+ new_input_value = onnx.helper.make_tensor_value_info(
+ "rgb_input", old_input_value.type.tensor_type.elem_type, input_shape
+ )
+ g.input.extend([new_input_value])
+ g.node.extend([new_weight, new_conv])
+ # topological sort
+ other.topological_sort(g)
+
+
+def add_0_5_to_normalized_input(m):
+ """For normalized input between -0.5 ~ 0.5, add 0.5 to the input to keep it
+ between 0 ~ 1.
+
+ :param m: the model proto
+ """
+ g = m.graph
+ if len(g.input) > 1:
+ print("This model has multiple inputs. Cannot normalize input.")
+ return
+ input_shape = helper.get_shape_from_value_info(g.input[0])
+ if len(input_shape) != 4:
+ print("The input shape is not BCHW. Cannot normalize input.")
+ return
+ # Construct weight
+ ch = input_shape[1]
+ weight_np = np.zeros((ch, ch, 3, 3)).astype("float32")
+ for i in range(ch):
+ weight_np[i, i, 1, 1] = 1.0
+ new_weight = helper.numpy_to_constant("input_norm_weight", weight_np)
+ # Construct bias
+ bias_np = np.array([0.5] * ch).astype("float32")
+ new_bias = helper.numpy_to_constant("input_norm_bias", bias_np)
+ # Construct Conv
+ new_conv = onnx.helper.make_node(
+ "Conv",
+ ["origin_input", "input_norm_weight", "input_norm_bias"],
+ [g.input[0].name],
+ name="input_norm",
+ dilations=[1, 1],
+ kernel_shape=[3, 3],
+ pads=[1, 1, 1, 1],
+ strides=[1, 1],
+ )
+ # Construct value_infos
+ old_input_value = g.input.pop()
+ weight_value = onnx.helper.make_tensor_value_info(
+ "input_norm_weight",
+ old_input_value.type.tensor_type.elem_type,
+ [3, 3, 3, 3],
+ )
+ bias_value = onnx.helper.make_tensor_value_info(
+ "input_norm_bias", old_input_value.type.tensor_type.elem_type, [3]
+ )
+ # Connect the graph
+ new_input_value = onnx.helper.make_tensor_value_info(
+ "origin_input", old_input_value.type.tensor_type.elem_type, input_shape
+ )
+ g.input.extend([new_input_value])
+ g.node.extend([new_weight, new_bias, new_conv])
+ g.value_info.extend([weight_value, bias_value, old_input_value])
+ # topological sort
+ other.topological_sort(g)
+
+
+def add_rgb2yynn_node(m):
+ """Add a conv layer which can convert rgb to yynn input."""
+ g = m.graph
+ if len(g.input) > 1:
+ print("This model has multiple inputs. Cannot change to rgb input.")
+ return
+ input_shape = helper.get_shape_from_value_info(g.input[0])
+ if len(input_shape) != 4:
+ print("The input shape is not BCHW. Cannot normalize input.")
+ return
+ # Construct weight
+ weight_np = np.zeros((3, 3, 4, 4)).astype("float32")
+ weight_np[1, 1, :3, :2] = np.array([[[[0.299], [0.587], [0.114]]]])
+ weight_np[1, 1, 3, 2:] = 1.0
+ weight_np = np.transpose(weight_np, (3, 2, 0, 1))
+ new_weight = helper.numpy_to_constant("input_rgb2yynn_weight", weight_np)
+ # Construct conv node
+ new_conv = onnx.helper.make_node(
+ "Conv",
+ ["new_input", "input_rgb2yynn_weight"],
+ [g.input[0].name],
+ name="input_rgba2yynn",
+ dilations=[1, 1],
+ kernel_shape=[3, 3],
+ pads=[1, 1, 1, 1],
+ strides=[1, 1],
+ )
+ # Construct value_infos
+ old_input_value = g.input.pop()
+ weight_value = onnx.helper.make_tensor_value_info(
+ "input_rgb2yynn_weight",
+ old_input_value.type.tensor_type.elem_type,
+ [4, 4, 3, 3],
+ )
+ # Connect the graph
+ new_input_value = onnx.helper.make_tensor_value_info(
+ "new_input", old_input_value.type.tensor_type.elem_type, input_shape
+ )
+ g.input.extend([new_input_value])
+ g.node.extend([new_weight, new_conv])
+ g.value_info.extend([weight_value, old_input_value])
+ # topological sort
+ other.topological_sort(g)
+
+
+def swap_MatMul_inputs(g, original_matmul_node):
+ # Create Transpose nodes
+ input_a_value = helper.find_value_by_name(g, original_matmul_node.input[0])
+ input_a_shape = helper.get_shape_from_value_info(input_a_value)
+ if len(input_a_shape) == 2:
+ perm = [1, 0]
+ else:
+ perm = [0, 2, 1]
+ new_input_b_node = onnx.helper.make_node(
+ "Transpose",
+ inputs=[input_a_value.name],
+ outputs=[input_a_value.name + "_transposed"],
+ name=f"{input_a_value.name}_transposed_for_"
+ f"{original_matmul_node.name}",
+ perm=perm,
+ )
+ input_b_value = helper.find_value_by_name(g, original_matmul_node.input[1])
+ input_b_shape = helper.get_shape_from_value_info(input_b_value)
+ if len(input_b_shape) == 3:
+ perm = [0, 2, 1]
+ else:
+ perm = [0, 1, 3, 2]
+ new_input_a_node = onnx.helper.make_node(
+ "Transpose",
+ inputs=[input_b_value.name],
+ outputs=[input_b_value.name + "_transposed"],
+ name=f"{input_b_value.name}_transposed_for_"
+ f"{original_matmul_node.name}",
+ perm=perm,
+ )
+ # Create new MatMul node
+ new_matmul_node = onnx.helper.make_node(
+ "MatMul",
+ inputs=[new_input_a_node.output[0], new_input_b_node.output[0]],
+ outputs=[original_matmul_node.output[0] + "_transposed"],
+ name=original_matmul_node.name + "_transposed",
+ )
+ # Create final Transpose node
+ output_value = helper.find_value_by_name(g, original_matmul_node.output[0])
+ output_shape = helper.get_shape_from_value_info(output_value)
+ if len(output_shape) == 3:
+ perm = [0, 2, 1]
+ else:
+ perm = [0, 1, 3, 2]
+ new_final_transpose_node = onnx.helper.make_node(
+ "Transpose",
+ inputs=[new_matmul_node.output[0]],
+ outputs=[original_matmul_node.output[0]],
+ name=original_matmul_node.name + "_final_transpose",
+ perm=perm,
+ )
+ # Add new nodes
+ g.node.extend(
+ [
+ new_input_a_node,
+ new_input_b_node,
+ new_matmul_node,
+ new_final_transpose_node,
+ ]
+ )
+ # Delete original nodes
+ g.node.remove(original_matmul_node)
+
+
+def split_MatMul_batch_then_concat(g, original_matmul_node):
+ new_nodes = []
+ final_concat_inputs = []
+ # Get the batch count
+ input_a_value = helper.find_value_by_name(g, original_matmul_node.input[0])
+ input_a_shape = helper.get_shape_from_value_info(input_a_value)
+ input_b_value = helper.find_value_by_name(g, original_matmul_node.input[1])
+ input_b_shape = helper.get_shape_from_value_info(input_b_value)
+ if len(input_a_shape) == 3:
+ batch_count = input_a_shape[0]
+ else:
+ batch_count = input_a_shape[1]
+ for i in range(batch_count):
+ # Create Split nodes for input A
+ starts_node = helper.list_to_constant(
+ f"{input_a_value.name}_sliced_{i}_starts", (1,), [i]
+ )
+ ends_node = helper.list_to_constant(
+ f"{input_a_value.name}_sliced_{i}_ends", (1,), [i + 1]
+ )
+ axes_node = helper.list_to_constant(
+ f"{input_a_value.name}_sliced_{i}_axes",
+ (1,),
+ [len(input_a_shape) - 3],
+ )
+ new_sliced_a_node = onnx.helper.make_node(
+ "Slice",
+ inputs=[
+ input_a_value.name,
+ starts_node.output[0],
+ ends_node.output[0],
+ axes_node.output[0],
+ ],
+ outputs=[f"{input_a_value.name}_sliced_{i}"],
+ name=f"{input_a_value.name}_sliced_{i}_for_"
+ f"{original_matmul_node.name}",
+ )
+ new_nodes.extend(
+ [starts_node, ends_node, axes_node, new_sliced_a_node]
+ )
+ # Create Split nodes for input B
+ starts_node = helper.list_to_constant(
+ f"{input_b_value.name}_sliced_{i}_starts", (1,), [i]
+ )
+ ends_node = helper.list_to_constant(
+ f"{input_b_value.name}_sliced_{i}_ends", (1,), [i + 1]
+ )
+ axes_node = helper.list_to_constant(
+ f"{input_b_value.name}_sliced_{i}_axes",
+ (1,),
+ [len(input_b_shape) - 3],
+ )
+ new_sliced_b_node = onnx.helper.make_node(
+ "Slice",
+ inputs=[
+ input_b_value.name,
+ starts_node.output[0],
+ ends_node.output[0],
+ axes_node.output[0],
+ ],
+ outputs=[f"{input_b_value.name}_sliced_{i}"],
+ name=f"{input_b_value.name}_sliced_{i}_for_"
+ f"{original_matmul_node.name}",
+ )
+ new_nodes.extend(
+ [starts_node, ends_node, axes_node, new_sliced_b_node]
+ )
+ # Create MatMul nodes
+ new_matmul_node = onnx.helper.make_node(
+ "MatMul",
+ inputs=[new_sliced_a_node.output[0], new_sliced_b_node.output[0]],
+ outputs=[f"{original_matmul_node.output[0]}_sliced_{i}"],
+ name=f"{original_matmul_node.name}_sliced_{i}",
+ )
+ new_nodes.append(new_matmul_node)
+ final_concat_inputs.append(new_matmul_node.output[0])
+ # Create Concat nodes
+ output_value = helper.find_value_by_name(g, original_matmul_node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(
+ g, original_matmul_node.output[0]
+ )
+ if output_value is None:
+ helper.logger.error(
+ f"Cannot find value_info for {original_matmul_node.output[0]}"
+ )
+ output_shape = helper.get_shape_from_value_info(output_value)
+ new_concat_node = onnx.helper.make_node(
+ "Concat",
+ inputs=final_concat_inputs,
+ outputs=[original_matmul_node.output[0]],
+ name=f"{original_matmul_node.name}_final_concat",
+ axis=len(output_shape) - 3,
+ )
+ new_nodes.append(new_concat_node)
+ # Add new nodes
+ g.node.extend(new_nodes)
+ # Delete original nodes
+ g.node.remove(original_matmul_node)
+
+
+def split_MatMul_Constant_input_then_concat(g, original_matmul_node):
+ new_nodes = []
+ final_concat_inputs = []
+ # Get the batch count
+ input_b_node = helper.find_node_by_output_name(
+ g, original_matmul_node.input[1]
+ )
+ input_b_np = helper.constant_to_numpy(input_b_node)
+ if len(input_b_np.shape) == 3:
+ batch_count = input_b_np.shape[0]
+ else:
+ batch_count = input_b_np.shape[1]
+ for i in range(batch_count):
+ # Create new constant node
+ if len(input_b_np.shape) == 3:
+ new_np = input_b_np[i:i + 1, ...]
+ else:
+ new_np = input_b_np[:, i:i + 1, ...]
+ new_weight = helper.numpy_to_constant(
+ f"{input_b_node.name}_sliced_{i}", new_np
+ )
+ new_nodes.append(new_weight)
+ # Create MatMul nodes
+ new_matmul_node = onnx.helper.make_node(
+ "MatMul",
+ inputs=[original_matmul_node.input[0], new_weight.output[0]],
+ outputs=[f"{original_matmul_node.output[0]}_sliced_{i}"],
+ name=f"{original_matmul_node.name}_sliced_{i}",
+ )
+ new_nodes.append(new_matmul_node)
+ final_concat_inputs.append(new_matmul_node.output[0])
+ # Create Concat nodes
+ output_value = helper.find_value_by_name(g, original_matmul_node.output[0])
+ output_shape = helper.get_shape_from_value_info(output_value)
+ new_concat_node = onnx.helper.make_node(
+ "Concat",
+ inputs=final_concat_inputs,
+ outputs=[original_matmul_node.output[0]],
+ name=f"{original_matmul_node.name}_final_concat",
+ axis=len(output_shape) - 3,
+ )
+ new_nodes.append(new_concat_node)
+ # Add new nodes
+ g.node.extend(new_nodes)
+ # Delete original value info
+ input_b_value = helper.find_value_by_name(g, original_matmul_node.input[1])
+ if input_b_value is not None:
+ g.value_info.remove(input_b_value)
+ # Delete original nodes
+ g.node.remove(original_matmul_node)
+ g.node.remove(input_b_node)
+
+
+def special_MatMul_process(g):
+ for node in g.node:
+ if node.op_type != "MatMul":
+ continue
+ input_a_name = node.input[0]
+ input_a_value = helper.find_value_by_name(g, input_a_name)
+ input_b_name = node.input[1]
+ input_b_value = helper.find_value_by_name(g, input_b_name)
+ if input_a_value is None or input_b_value is None:
+ continue
+ input_a_shape = helper.get_shape_from_value_info(input_a_value)
+ input_b_shape = helper.get_shape_from_value_info(input_b_value)
+ # Check shapes and choose the process
+ # Normal case, Skip
+ if len(input_b_shape) == 2:
+ continue
+ # Too many dimensions or too few dimensions. Not supported. Skip
+ if len(input_a_shape) > 4 or len(input_b_shape) > 4:
+ helper.logger.warning(
+ f"Cannot optimize MatMul {node.name}: "
+ "inputs have too many dimensions."
+ )
+ continue
+ if len(input_a_shape) < 2 or len(input_b_shape) < 2:
+ helper.logger.warning(
+ f"Cannot optimize MatMul {node.name}: "
+ "inputs have two few dimensions."
+ )
+ continue
+ # For 4 dimension, check the first dimension (should be 1)
+ # and treated as 3 dimensions.
+ extra_dim = None
+ if len(input_a_shape) == 4:
+ extra_dim = input_a_shape[0]
+ input_a_shape = input_a_shape[1:]
+ if len(input_b_shape) == 4:
+ if input_b_shape[0] != extra_dim:
+ helper.logger.warning(
+ f"Cannot optimize MatMul {node.name}: "
+ "input dimension batch sizes does not match "
+ f"({extra_dim} vs {input_b_shape[0]})."
+ )
+ continue
+ input_b_shape = input_b_shape[1:]
+ # Check input B dimension
+ # If B is 1 x W x V, it is the same as normal case.
+ if input_b_shape[0] == 1:
+ continue
+ # If B is B x W x V, but B is a constant.
+ input_b_node = helper.find_node_by_output_name(g, input_b_name)
+ if input_b_node is not None and input_b_node.op_type == "Constant":
+ # Constant input
+ helper.logger.debug(
+ f"Optimizing MatMul node {node.name}: split constant input."
+ )
+ split_MatMul_Constant_input_then_concat(g, node)
+ # If B is B x W x V and A is 1 x H x W, do the swap.
+ elif len(input_a_shape) == 2 or (
+ input_a_shape[0] == 1 and (extra_dim is None or extra_dim == 1)
+ ):
+ helper.logger.debug(
+ f"Optimizing MatMul node {node.name}: swap input."
+ )
+ swap_MatMul_inputs(g, node)
+ # If B is B x W x V and A is B x H x W, do the split.
+ elif input_b_shape[0] == input_a_shape[0]:
+ helper.logger.debug(
+ f"Optimizing MatMul node {node.name}: split input batch."
+ )
+ split_MatMul_batch_then_concat(g, node)
+ # Other cases are not supported: If B is B x W x V but A is X x H x W.
+ else:
+ helper.logger.warning(
+ f"Cannot optimize MatMul {node.name}: "
+ "unknown reason. Might be shape mismatch."
+ )
+ continue
+ other.topological_sort(g)
diff --git a/tools/print_config.py b/tools/print_config.py
new file mode 100644
index 0000000..3f9c08d
--- /dev/null
+++ b/tools/print_config.py
@@ -0,0 +1,69 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import warnings
+
+from mmcv import Config, DictAction
+
+from mmseg.apis import init_segmentor
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Print the whole config')
+ parser.add_argument('config', help='config file path')
+ parser.add_argument(
+ '--graph', action='store_true', help='print the models graph')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options, '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ print(f'Config:\n{cfg.pretty_text}')
+ # dump config
+ cfg.dump('example.py')
+ # dump models graph
+ if args.graph:
+ model = init_segmentor(args.config, device='cpu')
+ print(f'Model graph:\n{str(model)}')
+ with open('example-graph.txt', 'w') as f:
+ f.writelines(str(model))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/publish_model.py b/tools/publish_model.py
new file mode 100644
index 0000000..e266057
--- /dev/null
+++ b/tools/publish_model.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import subprocess
+
+import torch
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Process a checkpoint to be published')
+ parser.add_argument('in_file', help='input checkpoint filename')
+ parser.add_argument('out_file', help='output checkpoint filename')
+ args = parser.parse_args()
+ return args
+
+
+def process_checkpoint(in_file, out_file):
+ checkpoint = torch.load(in_file, map_location='cpu')
+ # remove optimizer for smaller file size
+ if 'optimizer' in checkpoint:
+ del checkpoint['optimizer']
+ # if it is necessary to remove some sensitive data in checkpoint['meta'],
+ # add the code here.
+ torch.save(checkpoint, out_file)
+ sha = subprocess.check_output(['sha256sum', out_file]).decode()
+ final_file = out_file.rstrip('.pth') + '-{}.pth'.format(sha[:8])
+ subprocess.Popen(['mv', out_file, final_file])
+
+
+def main():
+ args = parse_args()
+ process_checkpoint(args.in_file, args.out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/pytorch2onnx.py b/tools/pytorch2onnx.py
new file mode 100644
index 0000000..9de3404
--- /dev/null
+++ b/tools/pytorch2onnx.py
@@ -0,0 +1,392 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+from functools import partial
+
+import mmcv
+import numpy as np
+import onnxruntime as rt
+import torch
+import torch._C
+import torch.serialization
+from mmcv import DictAction
+from mmcv.onnx import register_extra_symbolics
+from mmcv.runner import load_checkpoint
+from torch import nn
+
+from mmseg.apis import show_result_pyplot
+from mmseg.apis.inference import LoadImage
+from mmseg.datasets.pipelines import Compose
+from mmseg.models import build_segmentor
+from mmseg.ops import resize
+
+torch.manual_seed(3)
+
+
+def _convert_batchnorm(module):
+ module_output = module
+ if isinstance(module, torch.nn.SyncBatchNorm):
+ module_output = torch.nn.BatchNorm2d(module.num_features, module.eps,
+ module.momentum, module.affine,
+ module.track_running_stats)
+ if module.affine:
+ module_output.weight.data = module.weight.data.clone().detach()
+ module_output.bias.data = module.bias.data.clone().detach()
+ # keep requires_grad unchanged
+ module_output.weight.requires_grad = module.weight.requires_grad
+ module_output.bias.requires_grad = module.bias.requires_grad
+ module_output.running_mean = module.running_mean
+ module_output.running_var = module.running_var
+ module_output.num_batches_tracked = module.num_batches_tracked
+ for name, child in module.named_children():
+ module_output.add_module(name, _convert_batchnorm(child))
+ del module
+ return module_output
+
+
+def _demo_mm_inputs(input_shape, num_classes):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+ rng = np.random.RandomState(0)
+ imgs = rng.rand(*input_shape)
+ segs = rng.randint(
+ low=0, high=num_classes - 1, size=(N, 1, H, W)).astype(np.uint8)
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': 1.0,
+ 'flip': False,
+ } for _ in range(N)]
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs).requires_grad_(True),
+ 'img_metas': img_metas,
+ 'gt_semantic_seg': torch.LongTensor(segs)
+ }
+ return mm_inputs
+
+
+def _prepare_input_img(img_path,
+ test_pipeline,
+ shape=None,
+ rescale_shape=None):
+ # build the data pipeline
+ if shape is not None:
+ test_pipeline[1]['img_scale'] = (shape[1], shape[0])
+ test_pipeline[1]['transforms'][0]['keep_ratio'] = False
+ test_pipeline = [LoadImage()] + test_pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ # prepare data
+ data = dict(img=img_path)
+ data = test_pipeline(data)
+ imgs = data['img']
+ img_metas = [i.data for i in data['img_metas']]
+
+ if rescale_shape is not None:
+ for img_meta in img_metas:
+ img_meta['ori_shape'] = tuple(rescale_shape) + (3, )
+
+ mm_inputs = {'imgs': imgs, 'img_metas': img_metas}
+
+ return mm_inputs
+
+
+def _update_input_img(img_list, img_meta_list, update_ori_shape=False):
+ # update img and its meta list
+ N, C, H, W = img_list[0].shape
+ img_meta = img_meta_list[0][0]
+ img_shape = (H, W, C)
+ if update_ori_shape:
+ ori_shape = img_shape
+ else:
+ ori_shape = img_meta['ori_shape']
+ pad_shape = img_shape
+ new_img_meta_list = [[{
+ 'img_shape':
+ img_shape,
+ 'ori_shape':
+ ori_shape,
+ 'pad_shape':
+ pad_shape,
+ 'filename':
+ img_meta['filename'],
+ 'scale_factor':
+ (img_shape[1] / ori_shape[1], img_shape[0] / ori_shape[0]) * 2,
+ 'flip':
+ False,
+ } for _ in range(N)]]
+
+ return img_list, new_img_meta_list
+
+
+def pytorch2onnx(model,
+ mm_inputs,
+ opset_version=11,
+ show=False,
+ output_file='tmp.onnx',
+ verify=False,
+ dynamic_export=False):
+ """Export Pytorch model to ONNX model and verify the outputs are same
+ between Pytorch and ONNX.
+
+ Args:
+ model (nn.Module): Pytorch model we want to export.
+ mm_inputs (dict): Contain the input tensors and img_metas information.
+ opset_version (int): The onnx op version. Default: 11.
+ show (bool): Whether print the computation graph. Default: False.
+ output_file (string): The path to where we store the output ONNX model.
+ Default: `tmp.onnx`.
+ verify (bool): Whether compare the outputs between Pytorch and ONNX.
+ Default: False.
+ dynamic_export (bool): Whether to export ONNX with dynamic axis.
+ Default: False.
+ """
+ model.cpu().eval()
+ test_mode = model.test_cfg.mode
+
+ if isinstance(model.decode_head, nn.ModuleList):
+ num_classes = model.decode_head[-1].num_classes
+ else:
+ num_classes = model.decode_head.num_classes
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+
+ img_list = [img[None, :] for img in imgs]
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ # update img_meta
+ img_list, img_meta_list = _update_input_img(img_list, img_meta_list)
+
+ # replace original forward function
+ origin_forward = model.forward
+ model.forward = partial(
+ model.forward,
+ img_metas=img_meta_list,
+ return_loss=False,
+ rescale=True)
+ dynamic_axes = None
+ if dynamic_export:
+ if test_mode == 'slide':
+ dynamic_axes = {'input': {0: 'batch'}, 'output': {1: 'batch'}}
+ else:
+ dynamic_axes = {
+ 'input': {
+ 0: 'batch',
+ 2: 'height',
+ 3: 'width'
+ },
+ 'output': {
+ 1: 'batch',
+ 2: 'height',
+ 3: 'width'
+ }
+ }
+
+ register_extra_symbolics(opset_version)
+ with torch.no_grad():
+ torch.onnx.export(
+ model, (img_list, ),
+ output_file,
+ input_names=['input'],
+ output_names=['output'],
+ export_params=True,
+ keep_initializers_as_inputs=False,
+ verbose=show,
+ opset_version=opset_version,
+ dynamic_axes=dynamic_axes)
+ print(f'Successfully exported ONNX model: {output_file}')
+ model.forward = origin_forward
+
+ if verify:
+ # check by onnx
+ import onnx
+ onnx_model = onnx.load(output_file)
+ onnx.checker.check_model(onnx_model)
+
+ if dynamic_export and test_mode == 'whole':
+ # scale image for dynamic shape test
+ img_list = [resize(_, scale_factor=1.5) for _ in img_list]
+ # concate flip image for batch test
+ flip_img_list = [_.flip(-1) for _ in img_list]
+ img_list = [
+ torch.cat((ori_img, flip_img), 0)
+ for ori_img, flip_img in zip(img_list, flip_img_list)
+ ]
+
+ # update img_meta
+ img_list, img_meta_list = _update_input_img(
+ img_list, img_meta_list, test_mode == 'whole')
+
+ # check the numerical value
+ # get pytorch output
+ with torch.no_grad():
+ pytorch_result = model(img_list, img_meta_list, return_loss=False)
+ pytorch_result = np.stack(pytorch_result, 0)
+
+ # get onnx output
+ input_all = [node.name for node in onnx_model.graph.input]
+ input_initializer = [
+ node.name for node in onnx_model.graph.initializer
+ ]
+ net_feed_input = list(set(input_all) - set(input_initializer))
+ assert (len(net_feed_input) == 1)
+ sess = rt.InferenceSession(output_file)
+ onnx_result = sess.run(
+ None, {net_feed_input[0]: img_list[0].detach().numpy()})[0][0]
+ # show segmentation results
+ if show:
+ import os.path as osp
+
+ import cv2
+ img = img_meta_list[0][0]['filename']
+ if not osp.exists(img):
+ img = imgs[0][:3, ...].permute(1, 2, 0) * 255
+ img = img.detach().numpy().astype(np.uint8)
+ ori_shape = img.shape[:2]
+ else:
+ ori_shape = LoadImage()({'img': img})['ori_shape']
+
+ # resize onnx_result to ori_shape
+ onnx_result_ = cv2.resize(onnx_result[0].astype(np.uint8),
+ (ori_shape[1], ori_shape[0]))
+ show_result_pyplot(
+ model,
+ img, (onnx_result_, ),
+ palette=model.PALETTE,
+ block=False,
+ title='ONNXRuntime',
+ opacity=0.5)
+
+ # resize pytorch_result to ori_shape
+ pytorch_result_ = cv2.resize(pytorch_result[0].astype(np.uint8),
+ (ori_shape[1], ori_shape[0]))
+ show_result_pyplot(
+ model,
+ img, (pytorch_result_, ),
+ title='PyTorch',
+ palette=model.PALETTE,
+ opacity=0.5)
+ # compare results
+ np.testing.assert_allclose(
+ pytorch_result.astype(np.float32) / num_classes,
+ onnx_result.astype(np.float32) / num_classes,
+ rtol=1e-5,
+ atol=1e-5,
+ err_msg='The outputs are different between Pytorch and ONNX')
+ print('The outputs are same between Pytorch and ONNX')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Convert MMSeg to ONNX')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('--checkpoint', help='checkpoint file', default=None)
+ parser.add_argument(
+ '--input-img', type=str, help='Images for input', default=None)
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ help='show onnx graph and segmentation results')
+ parser.add_argument(
+ '--verify', action='store_true', help='verify the onnx model')
+ parser.add_argument('--output-file', type=str, default='tmp.onnx')
+ parser.add_argument('--opset-version', type=int, default=11)
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=None,
+ help='input image height and width.')
+ parser.add_argument(
+ '--rescale_shape',
+ type=int,
+ nargs='+',
+ default=None,
+ help='output image rescale height and width, work for slide mode.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--dynamic-export',
+ action='store_true',
+ help='Whether to export onnx with dynamic axis.')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ cfg.model.pretrained = None
+
+ if args.shape is None:
+ img_scale = cfg.test_pipeline[1]['img_scale']
+ input_shape = (1, 3, img_scale[1], img_scale[0])
+ elif len(args.shape) == 1:
+ input_shape = (1, 3, args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ input_shape = (
+ 1,
+ 3,
+ ) + tuple(args.shape)
+ else:
+ raise ValueError('invalid input shape')
+
+ test_mode = cfg.model.test_cfg.mode
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ segmentor = build_segmentor(
+ cfg.model, train_cfg=None, test_cfg=cfg.get('test_cfg'))
+ # convert SyncBN to BN
+ segmentor = _convert_batchnorm(segmentor)
+
+ if args.checkpoint:
+ checkpoint = load_checkpoint(
+ segmentor, args.checkpoint, map_location='cpu')
+ segmentor.CLASSES = checkpoint['meta']['CLASSES']
+ segmentor.PALETTE = checkpoint['meta']['PALETTE']
+
+ # read input or create dummpy input
+ if args.input_img is not None:
+ preprocess_shape = (input_shape[2], input_shape[3])
+ rescale_shape = None
+ if args.rescale_shape is not None:
+ rescale_shape = [args.rescale_shape[0], args.rescale_shape[1]]
+ mm_inputs = _prepare_input_img(
+ args.input_img,
+ cfg.data.test.pipeline,
+ shape=preprocess_shape,
+ rescale_shape=rescale_shape)
+ else:
+ if isinstance(segmentor.decode_head, nn.ModuleList):
+ num_classes = segmentor.decode_head[-1].num_classes
+ else:
+ num_classes = segmentor.decode_head.num_classes
+ mm_inputs = _demo_mm_inputs(input_shape, num_classes)
+
+ # convert model to onnx file
+ pytorch2onnx(
+ segmentor,
+ mm_inputs,
+ opset_version=args.opset_version,
+ show=args.show,
+ output_file=args.output_file,
+ verify=args.verify,
+ dynamic_export=args.dynamic_export)
diff --git a/tools/pytorch2onnx_kneron.py b/tools/pytorch2onnx_kneron.py
new file mode 100644
index 0000000..f93b873
--- /dev/null
+++ b/tools/pytorch2onnx_kneron.py
@@ -0,0 +1,354 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import warnings
+import os
+import onnx
+import mmcv
+import numpy as np
+import onnxruntime as rt
+import torch
+import torch._C
+import torch.serialization
+from mmcv import DictAction
+from mmcv.onnx import register_extra_symbolics
+from mmcv.runner import load_checkpoint
+from torch import nn
+
+from mmseg.apis import show_result_pyplot
+from mmseg.apis.inference import LoadImage
+from mmseg.datasets.pipelines import Compose
+from mmseg.models import build_segmentor
+
+from optimizer_scripts.tools import other
+from optimizer_scripts.pytorch_exported_onnx_preprocess import (
+ torch_exported_onnx_flow,
+)
+
+torch.manual_seed(3)
+
+
+def _parse_normalize_cfg(test_pipeline):
+ transforms = None
+ for pipeline in test_pipeline:
+ if 'transforms' in pipeline:
+ transforms = pipeline['transforms']
+ break
+ assert transforms is not None, 'Failed to find `transforms`'
+ norm_config_li = [_ for _ in transforms if _['type'] == 'Normalize']
+ assert len(norm_config_li) == 1, '`norm_config` should only have one'
+ norm_config = norm_config_li[0]
+ return norm_config
+
+
+def _convert_batchnorm(module):
+ module_output = module
+ if isinstance(module, torch.nn.SyncBatchNorm):
+ module_output = torch.nn.BatchNorm2d(module.num_features, module.eps,
+ module.momentum, module.affine,
+ module.track_running_stats)
+ if module.affine:
+ module_output.weight.data = module.weight.data.clone().detach()
+ module_output.bias.data = module.bias.data.clone().detach()
+ # keep requires_grad unchanged
+ module_output.weight.requires_grad = module.weight.requires_grad
+ module_output.bias.requires_grad = module.bias.requires_grad
+ module_output.running_mean = module.running_mean
+ module_output.running_var = module.running_var
+ module_output.num_batches_tracked = module.num_batches_tracked
+ for name, child in module.named_children():
+ module_output.add_module(name, _convert_batchnorm(child))
+ del module
+ return module_output
+
+
+def _demo_mm_inputs(input_shape):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+ rng = np.random.RandomState(0)
+ img = torch.FloatTensor(rng.rand(*input_shape))
+ return img
+
+
+def _prepare_input_img(img_path,
+ test_pipeline,
+ shape=None):
+ # build the data pipeline
+ if shape is not None:
+ test_pipeline[1]['img_scale'] = (shape[1], shape[0])
+ test_pipeline[1]['transforms'][0]['keep_ratio'] = False
+ test_pipeline = [LoadImage()] + test_pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ # prepare data
+ data = dict(img=img_path)
+ data = test_pipeline(data)
+ img = torch.FloatTensor(data['img']).unsqueeze_(0)
+ return img
+
+
+def pytorch2onnx(model,
+ img,
+ norm_cfg=None,
+ opset_version=11,
+ show=False,
+ output_file='tmp.onnx',
+ verify=False):
+ """Export Pytorch model to ONNX model and verify the outputs are same
+ between Pytorch and ONNX.
+
+ Args:
+ model (nn.Module): Pytorch model we want to export.
+ img (dict): Input tensor (1xCxHxW)
+ opset_version (int): The onnx op version. Default: 11.
+ show (bool): Whether print the computation graph. Default: False.
+ output_file (string): The path to where we store the output ONNX model.
+ Default: `tmp.onnx`.
+ verify (bool): Whether compare the outputs between Pytorch and ONNX.
+ Default: False.
+ """
+ model.cpu().eval()
+
+ if isinstance(model.decode_head, nn.ModuleList):
+ num_classes = model.decode_head[-1].num_classes
+ else:
+ num_classes = model.decode_head.num_classes
+
+ # replace original forward function
+ model.forward = model.forward_dummy
+ origin_forward = model.forward
+
+ register_extra_symbolics(opset_version)
+ with torch.no_grad():
+ torch.onnx.export(
+ model, img,
+ output_file,
+ input_names=['input'],
+ output_names=['output'],
+ export_params=True,
+ keep_initializers_as_inputs=False,
+ verbose=show,
+ opset_version=opset_version,
+ dynamic_axes=None)
+ print(f'Successfully exported ONNX model: {output_file}')
+ model.forward = origin_forward
+ # NOTE: optimizing onnx for kneron inference
+ m = onnx.load(output_file)
+ # NOTE: PyTorch 1.10.x exports onnx ir_version == 7 for opset 11,
+ # but should be ir_version == 6
+ if opset_version == 11:
+ m.ir_version = 6
+ m = torch_exported_onnx_flow(m, disable_fuse_bn=False)
+ onnx.save(m, output_file)
+ print(f'{output_file} optimized by KNERON successfully.')
+
+ if verify:
+ onnx_model = onnx.load(output_file)
+ onnx.checker.check_model(onnx_model)
+
+ # check the numerical value
+ # get pytorch output
+ with torch.no_grad():
+ pytorch_result = model(img).numpy()
+
+ # get onnx output
+ input_all = [node.name for node in onnx_model.graph.input]
+ input_initializer = [
+ node.name for node in onnx_model.graph.initializer
+ ]
+ net_feed_input = list(set(input_all) - set(input_initializer))
+ assert (len(net_feed_input) == 1)
+ sess = rt.InferenceSession(
+ output_file, providers=['CPUExecutionProvider']
+ )
+ onnx_result = sess.run(
+ None, {net_feed_input[0]: img.detach().numpy()})[0]
+ # show segmentation results
+ if show:
+ import cv2
+ img = img[0][:3, ...].permute(1, 2, 0) * 255
+ img = img.detach().numpy().astype(np.uint8)
+ ori_shape = img.shape[:2]
+
+ # resize onnx_result to ori_shape
+ onnx_result_ = onnx_result[0].argmax(0)
+ onnx_result_ = cv2.resize(onnx_result_.astype(np.uint8),
+ (ori_shape[1], ori_shape[0]))
+ show_result_pyplot(
+ model,
+ img, (onnx_result_, ),
+ palette=model.PALETTE,
+ block=False,
+ title='ONNXRuntime',
+ opacity=0.5)
+
+ # resize pytorch_result to ori_shape
+ pytorch_result_ = pytorch_result.squeeze().argmax(0)
+ pytorch_result_ = cv2.resize(pytorch_result_.astype(np.uint8),
+ (ori_shape[1], ori_shape[0]))
+ show_result_pyplot(
+ model,
+ img, (pytorch_result_, ),
+ title='PyTorch',
+ palette=model.PALETTE,
+ opacity=0.5)
+ # compare results
+ np.testing.assert_allclose(
+ pytorch_result.astype(np.float32) / num_classes,
+ onnx_result.astype(np.float32) / num_classes,
+ rtol=1e-5,
+ atol=1e-5,
+ err_msg='The outputs are different between Pytorch and ONNX')
+ print('The outputs are same between Pytorch and ONNX')
+
+ if norm_cfg is not None:
+ print("Prepending BatchNorm layer to ONNX as data normalization...")
+ mean = norm_cfg['mean']
+ std = norm_cfg['std']
+ i_n = m.graph.input[0]
+ if (
+ i_n.type.tensor_type.shape.dim[1].dim_value != len(mean)
+ or i_n.type.tensor_type.shape.dim[1].dim_value != len(std)
+ ):
+ raise ValueError(
+ f"--pixel-bias-value ({mean}) and --pixel-scale-value "
+ f"({std}) should be same as input dimension: "
+ f"{i_n.type.tensor_type.shape.dim[1].dim_value}"
+ )
+ norm_bn_bias = [-1 * cm / cs + 128. / cs for cm, cs in zip(mean, std)]
+ norm_bn_scale = [1 / cs for cs in std]
+ other.add_bias_scale_bn_after(
+ m.graph, i_n.name, norm_bn_bias, norm_bn_scale
+ )
+ m = other.polish_model(m)
+ bn_outf = os.path.splitext(output_file)[0] + "_bn_prepended.onnx"
+ onnx.save(m, bn_outf)
+ print(f"BN-Prepended ONNX saved to {bn_outf}")
+
+ return
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Convert MMSeg to ONNX')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('--checkpoint', help='checkpoint file', default=None)
+ parser.add_argument(
+ '--input-img', type=str, help='Images for input', default=None)
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ help='show onnx graph and segmentation results')
+ parser.add_argument(
+ '--verify', action='store_true', help='verify the onnx model')
+ parser.add_argument('--output-file', type=str, default='tmp.onnx')
+ parser.add_argument('--opset-version', type=int, default=11)
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=None,
+ help='input image height and width.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--normalization-in-onnx',
+ action='store_true',
+ help='Prepend BatchNorm layer to onnx model as a role of data '
+ 'normalization according to the mean and std value in the given'
+ 'cfg file.'
+ )
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ assert args.opset_version == 11, (
+ "kneron_toolchain currently only supports opset 11"
+ )
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ cfg.model.pretrained = None
+
+ test_mode = cfg.model.test_cfg.mode
+
+ if args.shape is None:
+ if test_mode == 'slide':
+ crop_size = cfg.model.test_cfg['crop_size']
+ input_shape = (1, 3, crop_size[1], crop_size[0])
+ else:
+ img_scale = cfg.test_pipeline[1]['img_scale']
+ input_shape = (1, 3, img_scale[1], img_scale[0])
+ else:
+ if test_mode == 'slide':
+ warnings.warn(
+ "We suggest you NOT assigning shape when exporting "
+ "slide-mode models. Assigning shape to slide-mode models "
+ "may result in unexpected results. To see which mode the "
+ "model is using, check cfg.model.test_cfg.mode, which "
+ "should be either 'whole' or 'slide'."
+ )
+ if len(args.shape) == 1:
+ input_shape = (1, 3, args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ input_shape = (
+ 1,
+ 3,
+ ) + tuple(args.shape)
+ else:
+ raise ValueError('invalid input shape')
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ segmentor = build_segmentor(
+ cfg.model, train_cfg=None, test_cfg=cfg.get('test_cfg'))
+ # convert SyncBN to BN
+ segmentor = _convert_batchnorm(segmentor)
+
+ if args.checkpoint:
+ checkpoint = load_checkpoint(
+ segmentor, args.checkpoint, map_location='cpu')
+ segmentor.CLASSES = checkpoint['meta']['CLASSES']
+ segmentor.PALETTE = checkpoint['meta']['PALETTE']
+
+ # read input or create dummpy input
+ if args.input_img is not None:
+ preprocess_shape = (input_shape[2], input_shape[3])
+ img = _prepare_input_img(
+ args.input_img,
+ cfg.data.test.pipeline,
+ shape=preprocess_shape)
+ else:
+ img = _demo_mm_inputs(input_shape)
+
+ if args.normalization_in_onnx:
+ norm_cfg = _parse_normalize_cfg(cfg.test_pipeline)
+ else:
+ norm_cfg = None
+ # convert model to onnx file
+ pytorch2onnx(
+ segmentor,
+ img,
+ norm_cfg=norm_cfg,
+ opset_version=args.opset_version,
+ show=args.show,
+ output_file=args.output_file,
+ verify=args.verify,
+ )
diff --git a/tools/pytorch2torchscript.py b/tools/pytorch2torchscript.py
new file mode 100644
index 0000000..d76f5ec
--- /dev/null
+++ b/tools/pytorch2torchscript.py
@@ -0,0 +1,185 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import mmcv
+import numpy as np
+import torch
+import torch._C
+import torch.serialization
+from mmcv.runner import load_checkpoint
+from torch import nn
+
+from mmseg.models import build_segmentor
+
+torch.manual_seed(3)
+
+
+def digit_version(version_str):
+ digit_version = []
+ for x in version_str.split('.'):
+ if x.isdigit():
+ digit_version.append(int(x))
+ elif x.find('rc') != -1:
+ patch_version = x.split('rc')
+ digit_version.append(int(patch_version[0]) - 1)
+ digit_version.append(int(patch_version[1]))
+ return digit_version
+
+
+def check_torch_version():
+ torch_minimum_version = '1.8.0'
+ torch_version = digit_version(torch.__version__)
+
+ assert (torch_version >= digit_version(torch_minimum_version)), \
+ f'Torch=={torch.__version__} is not support for converting to ' \
+ f'torchscript. Please install pytorch>={torch_minimum_version}.'
+
+
+def _convert_batchnorm(module):
+ module_output = module
+ if isinstance(module, torch.nn.SyncBatchNorm):
+ module_output = torch.nn.BatchNorm2d(module.num_features, module.eps,
+ module.momentum, module.affine,
+ module.track_running_stats)
+ if module.affine:
+ module_output.weight.data = module.weight.data.clone().detach()
+ module_output.bias.data = module.bias.data.clone().detach()
+ # keep requires_grad unchanged
+ module_output.weight.requires_grad = module.weight.requires_grad
+ module_output.bias.requires_grad = module.bias.requires_grad
+ module_output.running_mean = module.running_mean
+ module_output.running_var = module.running_var
+ module_output.num_batches_tracked = module.num_batches_tracked
+ for name, child in module.named_children():
+ module_output.add_module(name, _convert_batchnorm(child))
+ del module
+ return module_output
+
+
+def _demo_mm_inputs(input_shape, num_classes):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+ rng = np.random.RandomState(0)
+ imgs = rng.rand(*input_shape)
+ segs = rng.randint(
+ low=0, high=num_classes - 1, size=(N, 1, H, W)).astype(np.uint8)
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': 1.0,
+ 'flip': False,
+ } for _ in range(N)]
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs).requires_grad_(True),
+ 'img_metas': img_metas,
+ 'gt_semantic_seg': torch.LongTensor(segs)
+ }
+ return mm_inputs
+
+
+def pytorch2libtorch(model,
+ input_shape,
+ show=False,
+ output_file='tmp.pt',
+ verify=False):
+ """Export Pytorch model to TorchScript model and verify the outputs are
+ same between Pytorch and TorchScript.
+
+ Args:
+ model (nn.Module): Pytorch model we want to export.
+ input_shape (tuple): Use this input shape to construct
+ the corresponding dummy input and execute the model.
+ show (bool): Whether print the computation graph. Default: False.
+ output_file (string): The path to where we store the
+ output TorchScript model. Default: `tmp.pt`.
+ verify (bool): Whether compare the outputs between
+ Pytorch and TorchScript. Default: False.
+ """
+ if isinstance(model.decode_head, nn.ModuleList):
+ num_classes = model.decode_head[-1].num_classes
+ else:
+ num_classes = model.decode_head.num_classes
+
+ mm_inputs = _demo_mm_inputs(input_shape, num_classes)
+
+ imgs = mm_inputs.pop('imgs')
+
+ # replace the original forword with forward_dummy
+ model.forward = model.forward_dummy
+ model.eval()
+ traced_model = torch.jit.trace(
+ model,
+ example_inputs=imgs,
+ check_trace=verify,
+ )
+
+ if show:
+ print(traced_model.graph)
+
+ traced_model.save(output_file)
+ print('Successfully exported TorchScript model: {}'.format(output_file))
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert MMSeg to TorchScript')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('--checkpoint', help='checkpoint file', default=None)
+ parser.add_argument(
+ '--show', action='store_true', help='show TorchScript graph')
+ parser.add_argument(
+ '--verify', action='store_true', help='verify the TorchScript model')
+ parser.add_argument('--output-file', type=str, default='tmp.pt')
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=[512, 512],
+ help='input image size (height, width)')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ check_torch_version()
+
+ if len(args.shape) == 1:
+ input_shape = (1, 3, args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ input_shape = (
+ 1,
+ 3,
+ ) + tuple(args.shape)
+ else:
+ raise ValueError('invalid input shape')
+
+ cfg = mmcv.Config.fromfile(args.config)
+ cfg.model.pretrained = None
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ segmentor = build_segmentor(
+ cfg.model, train_cfg=None, test_cfg=cfg.get('test_cfg'))
+ # convert SyncBN to BN
+ segmentor = _convert_batchnorm(segmentor)
+
+ if args.checkpoint:
+ load_checkpoint(segmentor, args.checkpoint, map_location='cpu')
+
+ # convert the PyTorch model to LibTorch model
+ pytorch2libtorch(
+ segmentor,
+ input_shape,
+ show=args.show,
+ output_file=args.output_file,
+ verify=args.verify)
diff --git a/tools/slurm_test.sh b/tools/slurm_test.sh
new file mode 100755
index 0000000..4e6f7bf
--- /dev/null
+++ b/tools/slurm_test.sh
@@ -0,0 +1,24 @@
+#!/usr/bin/env bash
+
+set -x
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+CHECKPOINT=$4
+GPUS=${GPUS:-4}
+GPUS_PER_NODE=${GPUS_PER_NODE:-4}
+CPUS_PER_TASK=${CPUS_PER_TASK:-5}
+PY_ARGS=${@:5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --cpus-per-task=${CPUS_PER_TASK} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/test.py ${CONFIG} ${CHECKPOINT} --launcher="slurm" ${PY_ARGS}
diff --git a/tools/slurm_train.sh b/tools/slurm_train.sh
new file mode 100755
index 0000000..ab23210
--- /dev/null
+++ b/tools/slurm_train.sh
@@ -0,0 +1,23 @@
+#!/usr/bin/env bash
+
+set -x
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+GPUS=${GPUS:-4}
+GPUS_PER_NODE=${GPUS_PER_NODE:-4}
+CPUS_PER_TASK=${CPUS_PER_TASK:-5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+PY_ARGS=${@:4}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --cpus-per-task=${CPUS_PER_TASK} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/train.py ${CONFIG} --launcher="slurm" ${PY_ARGS}
diff --git a/tools/test.py b/tools/test.py
new file mode 100644
index 0000000..d5dc0d5
--- /dev/null
+++ b/tools/test.py
@@ -0,0 +1,303 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import shutil
+import time
+import warnings
+
+import mmcv
+import torch
+from mmcv.cnn.utils import revert_sync_batchnorm
+from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
+from mmcv.runner import (get_dist_info, init_dist, load_checkpoint,
+ wrap_fp16_model)
+from mmcv.utils import DictAction
+
+from mmseg import digit_version
+from mmseg.apis import multi_gpu_test, single_gpu_test
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.models import build_segmentor
+from mmseg.utils import setup_multi_processes
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='mmseg test (and eval) a model')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('checkpoint', help='checkpoint file')
+ parser.add_argument(
+ '--work-dir',
+ help=('if specified, the evaluation metric results will be dumped'
+ 'into the directory as json'))
+ parser.add_argument(
+ '--aug-test', action='store_true', help='Use Flip and Multi scale aug')
+ parser.add_argument('--out', help='output result file in pickle format')
+ parser.add_argument(
+ '--format-only',
+ action='store_true',
+ help='Format the output results without perform evaluation. It is'
+ 'useful when you want to format the result to a specific format and '
+ 'submit it to the test server')
+ parser.add_argument(
+ '--eval',
+ type=str,
+ nargs='+',
+ help='evaluation metrics, which depends on the dataset, e.g., "mIoU"'
+ ' for generic datasets, and "cityscapes" for Cityscapes')
+ parser.add_argument('--show', action='store_true', help='show results')
+ parser.add_argument(
+ '--show-dir', help='directory where painted images will be saved')
+ parser.add_argument(
+ '--gpu-collect',
+ action='store_true',
+ help='whether to use gpu to collect results.')
+ parser.add_argument(
+ '--gpu-id',
+ type=int,
+ default=0,
+ help='id of gpu to use '
+ '(only applicable to non-distributed testing)')
+ parser.add_argument(
+ '--tmpdir',
+ help='tmp directory used for collecting results from multiple '
+ 'workers, available when gpu_collect is not specified')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--eval-options',
+ nargs='+',
+ action=DictAction,
+ help='custom options for evaluation')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+ assert args.out or args.eval or args.format_only or args.show \
+ or args.show_dir, \
+ ('Please specify at least one operation (save/eval/format/show the '
+ 'results / save the results) with the argument "--out", "--eval"'
+ ', "--format-only", "--show" or "--show-dir"')
+
+ if args.eval and args.format_only:
+ raise ValueError('--eval and --format_only cannot be both specified')
+
+ if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):
+ raise ValueError('The output file must be a pkl file.')
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # set multi-process settings
+ setup_multi_processes(cfg)
+
+ # set cudnn_benchmark
+ if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+ if args.aug_test:
+ # hard code index
+ cfg.data.test.pipeline[1].img_ratios = [
+ 0.5, 0.75, 1.0, 1.25, 1.5, 1.75
+ ]
+ cfg.data.test.pipeline[1].flip = True
+ cfg.model.pretrained = None
+ cfg.data.test.test_mode = True
+
+ if args.gpu_id is not None:
+ cfg.gpu_ids = [args.gpu_id]
+
+ # init distributed env first, since logger depends on the dist info.
+ if args.launcher == 'none':
+ cfg.gpu_ids = [args.gpu_id]
+ distributed = False
+ if len(cfg.gpu_ids) > 1:
+ warnings.warn(f'The gpu-ids is reset from {cfg.gpu_ids} to '
+ f'{cfg.gpu_ids[0:1]} to avoid potential error in '
+ 'non-distribute testing time.')
+ cfg.gpu_ids = cfg.gpu_ids[0:1]
+ else:
+ distributed = True
+ init_dist(args.launcher, **cfg.dist_params)
+
+ rank, _ = get_dist_info()
+ # allows not to create
+ if args.work_dir is not None and rank == 0:
+ mmcv.mkdir_or_exist(osp.abspath(args.work_dir))
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ if args.aug_test:
+ json_file = osp.join(args.work_dir,
+ f'eval_multi_scale_{timestamp}.json')
+ else:
+ json_file = osp.join(args.work_dir,
+ f'eval_single_scale_{timestamp}.json')
+ elif rank == 0:
+ work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ mmcv.mkdir_or_exist(osp.abspath(work_dir))
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ if args.aug_test:
+ json_file = osp.join(work_dir,
+ f'eval_multi_scale_{timestamp}.json')
+ else:
+ json_file = osp.join(work_dir,
+ f'eval_single_scale_{timestamp}.json')
+
+ # build the dataloader
+ # TODO: support multiple images per gpu (only minor changes are needed)
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=distributed,
+ shuffle=False)
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ model = build_segmentor(cfg.model, test_cfg=cfg.get('test_cfg'))
+ fp16_cfg = cfg.get('fp16', None)
+ if fp16_cfg is not None:
+ wrap_fp16_model(model)
+ checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu')
+ if 'CLASSES' in checkpoint.get('meta', {}):
+ model.CLASSES = checkpoint['meta']['CLASSES']
+ else:
+ print('"CLASSES" not found in meta, use dataset.CLASSES instead')
+ model.CLASSES = dataset.CLASSES
+ if 'PALETTE' in checkpoint.get('meta', {}):
+ model.PALETTE = checkpoint['meta']['PALETTE']
+ else:
+ print('"PALETTE" not found in meta, use dataset.PALETTE instead')
+ model.PALETTE = dataset.PALETTE
+
+ # clean gpu memory when starting a new evaluation.
+ torch.cuda.empty_cache()
+ eval_kwargs = {} if args.eval_options is None else args.eval_options
+
+ # Deprecated
+ efficient_test = eval_kwargs.get('efficient_test', False)
+ if efficient_test:
+ warnings.warn(
+ '``efficient_test=True`` does not have effect in tools/test.py, '
+ 'the evaluation and format results are CPU memory efficient by '
+ 'default')
+
+ eval_on_format_results = (
+ args.eval is not None and 'cityscapes' in args.eval)
+ if eval_on_format_results:
+ assert len(args.eval) == 1, 'eval on format results is not ' \
+ 'applicable for metrics other than ' \
+ 'cityscapes'
+ if args.format_only or eval_on_format_results:
+ if 'imgfile_prefix' in eval_kwargs:
+ tmpdir = eval_kwargs['imgfile_prefix']
+ else:
+ tmpdir = '.format_cityscapes'
+ eval_kwargs.setdefault('imgfile_prefix', tmpdir)
+ mmcv.mkdir_or_exist(tmpdir)
+ else:
+ tmpdir = None
+
+ if not distributed:
+ warnings.warn(
+ 'SyncBN is only supported with DDP. To be compatible with DP, '
+ 'we convert SyncBN to BN. Please use dist_train.sh which can '
+ 'avoid this error.')
+ if not torch.cuda.is_available():
+ assert digit_version(mmcv.__version__) >= digit_version('1.4.4'), \
+ 'Please use MMCV >= 1.4.4 for CPU training!'
+ model = revert_sync_batchnorm(model)
+ model = MMDataParallel(model, device_ids=cfg.gpu_ids)
+ results = single_gpu_test(
+ model,
+ data_loader,
+ args.show,
+ args.show_dir,
+ False,
+ args.opacity,
+ pre_eval=args.eval is not None and not eval_on_format_results,
+ format_only=args.format_only or eval_on_format_results,
+ format_args=eval_kwargs)
+ else:
+ model = MMDistributedDataParallel(
+ model.cuda(),
+ device_ids=[torch.cuda.current_device()],
+ broadcast_buffers=False)
+ results = multi_gpu_test(
+ model,
+ data_loader,
+ args.tmpdir,
+ args.gpu_collect,
+ False,
+ pre_eval=args.eval is not None and not eval_on_format_results,
+ format_only=args.format_only or eval_on_format_results,
+ format_args=eval_kwargs)
+
+ rank, _ = get_dist_info()
+ if rank == 0:
+ if args.out:
+ warnings.warn(
+ 'The behavior of ``args.out`` has been changed since MMSeg '
+ 'v0.16, the pickled outputs could be seg map as type of '
+ 'np.array, pre-eval results or file paths for '
+ '``dataset.format_results()``.')
+ print(f'\nwriting results to {args.out}')
+ mmcv.dump(results, args.out)
+ if args.eval:
+ eval_kwargs.update(metric=args.eval)
+ metric = dataset.evaluate(results, **eval_kwargs)
+ metric_dict = dict(config=args.config, metric=metric)
+ mmcv.dump(metric_dict, json_file, indent=4)
+ if tmpdir is not None and eval_on_format_results:
+ # remove tmp dir when cityscapes evaluation
+ shutil.rmtree(tmpdir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/torchserve/mmseg2torchserve.py b/tools/torchserve/mmseg2torchserve.py
new file mode 100644
index 0000000..9063634
--- /dev/null
+++ b/tools/torchserve/mmseg2torchserve.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser, Namespace
+from pathlib import Path
+from tempfile import TemporaryDirectory
+
+import mmcv
+
+try:
+ from model_archiver.model_packaging import package_model
+ from model_archiver.model_packaging_utils import ModelExportUtils
+except ImportError:
+ package_model = None
+
+
+def mmseg2torchserve(
+ config_file: str,
+ checkpoint_file: str,
+ output_folder: str,
+ model_name: str,
+ model_version: str = '1.0',
+ force: bool = False,
+):
+ """Converts mmsegmentation model (config + checkpoint) to TorchServe
+ `.mar`.
+
+ Args:
+ config_file:
+ In MMSegmentation config format.
+ The contents vary for each task repository.
+ checkpoint_file:
+ In MMSegmentation checkpoint format.
+ The contents vary for each task repository.
+ output_folder:
+ Folder where `{model_name}.mar` will be created.
+ The file created will be in TorchServe archive format.
+ model_name:
+ If not None, used for naming the `{model_name}.mar` file
+ that will be created under `output_folder`.
+ If None, `{Path(checkpoint_file).stem}` will be used.
+ model_version:
+ Model's version.
+ force:
+ If True, if there is an existing `{model_name}.mar`
+ file under `output_folder` it will be overwritten.
+ """
+ mmcv.mkdir_or_exist(output_folder)
+
+ config = mmcv.Config.fromfile(config_file)
+
+ with TemporaryDirectory() as tmpdir:
+ config.dump(f'{tmpdir}/config.py')
+
+ args = Namespace(
+ **{
+ 'model_file': f'{tmpdir}/config.py',
+ 'serialized_file': checkpoint_file,
+ 'handler': f'{Path(__file__).parent}/mmseg_handler.py',
+ 'model_name': model_name or Path(checkpoint_file).stem,
+ 'version': model_version,
+ 'export_path': output_folder,
+ 'force': force,
+ 'requirements_file': None,
+ 'extra_files': None,
+ 'runtime': 'python',
+ 'archive_format': 'default'
+ })
+ manifest = ModelExportUtils.generate_manifest_json(args)
+ package_model(args, manifest)
+
+
+def parse_args():
+ parser = ArgumentParser(
+ description='Convert mmseg models to TorchServe `.mar` format.')
+ parser.add_argument('config', type=str, help='config file path')
+ parser.add_argument('checkpoint', type=str, help='checkpoint file path')
+ parser.add_argument(
+ '--output-folder',
+ type=str,
+ required=True,
+ help='Folder where `{model_name}.mar` will be created.')
+ parser.add_argument(
+ '--model-name',
+ type=str,
+ default=None,
+ help='If not None, used for naming the `{model_name}.mar`'
+ 'file that will be created under `output_folder`.'
+ 'If None, `{Path(checkpoint_file).stem}` will be used.')
+ parser.add_argument(
+ '--model-version',
+ type=str,
+ default='1.0',
+ help='Number used for versioning.')
+ parser.add_argument(
+ '-f',
+ '--force',
+ action='store_true',
+ help='overwrite the existing `{model_name}.mar`')
+ args = parser.parse_args()
+
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ if package_model is None:
+ raise ImportError('`torch-model-archiver` is required.'
+ 'Try: pip install torch-model-archiver')
+
+ mmseg2torchserve(args.config, args.checkpoint, args.output_folder,
+ args.model_name, args.model_version, args.force)
diff --git a/tools/torchserve/mmseg_handler.py b/tools/torchserve/mmseg_handler.py
new file mode 100644
index 0000000..28fe501
--- /dev/null
+++ b/tools/torchserve/mmseg_handler.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import base64
+import os
+
+import cv2
+import mmcv
+import torch
+from mmcv.cnn.utils.sync_bn import revert_sync_batchnorm
+from ts.torch_handler.base_handler import BaseHandler
+
+from mmseg.apis import inference_segmentor, init_segmentor
+
+
+class MMsegHandler(BaseHandler):
+
+ def initialize(self, context):
+ properties = context.system_properties
+ self.map_location = 'cuda' if torch.cuda.is_available() else 'cpu'
+ self.device = torch.device(self.map_location + ':' +
+ str(properties.get('gpu_id')) if torch.cuda.
+ is_available() else self.map_location)
+ self.manifest = context.manifest
+
+ model_dir = properties.get('model_dir')
+ serialized_file = self.manifest['model']['serializedFile']
+ checkpoint = os.path.join(model_dir, serialized_file)
+ self.config_file = os.path.join(model_dir, 'config.py')
+
+ self.model = init_segmentor(self.config_file, checkpoint, self.device)
+ self.model = revert_sync_batchnorm(self.model)
+ self.initialized = True
+
+ def preprocess(self, data):
+ images = []
+
+ for row in data:
+ image = row.get('data') or row.get('body')
+ if isinstance(image, str):
+ image = base64.b64decode(image)
+ image = mmcv.imfrombytes(image)
+ images.append(image)
+
+ return images
+
+ def inference(self, data, *args, **kwargs):
+ results = [inference_segmentor(self.model, img) for img in data]
+ return results
+
+ def postprocess(self, data):
+ output = []
+
+ for image_result in data:
+ _, buffer = cv2.imencode('.png', image_result[0].astype('uint8'))
+ content = buffer.tobytes()
+ output.append(content)
+ return output
diff --git a/tools/torchserve/test_torchserve.py b/tools/torchserve/test_torchserve.py
new file mode 100644
index 0000000..5975285
--- /dev/null
+++ b/tools/torchserve/test_torchserve.py
@@ -0,0 +1,57 @@
+from argparse import ArgumentParser
+from io import BytesIO
+
+import matplotlib.pyplot as plt
+import mmcv
+import requests
+
+from mmseg.apis import inference_segmentor, init_segmentor
+
+
+def parse_args():
+ parser = ArgumentParser(
+ description='Compare result of torchserve and pytorch,'
+ 'and visualize them.')
+ parser.add_argument('img', help='Image file')
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument('model_name', help='The model name in the server')
+ parser.add_argument(
+ '--inference-addr',
+ default='127.0.0.1:8080',
+ help='Address and port of the inference server')
+ parser.add_argument(
+ '--result-image',
+ type=str,
+ default=None,
+ help='save server output in result-image')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+
+ args = parser.parse_args()
+ return args
+
+
+def main(args):
+ url = 'http://' + args.inference_addr + '/predictions/' + args.model_name
+ with open(args.img, 'rb') as image:
+ tmp_res = requests.post(url, image)
+ content = tmp_res.content
+ if args.result_image:
+ with open(args.result_image, 'wb') as out_image:
+ out_image.write(content)
+ plt.imshow(mmcv.imread(args.result_image, 'grayscale'))
+ plt.show()
+ else:
+ plt.imshow(plt.imread(BytesIO(content)))
+ plt.show()
+ model = init_segmentor(args.config, args.checkpoint, args.device)
+ image = mmcv.imread(args.img)
+ result = inference_segmentor(model, image)
+ plt.imshow(result[0])
+ plt.show()
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ main(args)
diff --git a/tools/train.py b/tools/train.py
new file mode 100644
index 0000000..1e1d01a
--- /dev/null
+++ b/tools/train.py
@@ -0,0 +1,234 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import copy
+import os
+import os.path as osp
+import time
+import warnings
+
+import mmcv
+import torch
+from mmcv.cnn.utils import revert_sync_batchnorm
+from mmcv.runner import get_dist_info, init_dist
+from mmcv.utils import Config, DictAction, get_git_hash
+
+from mmseg import __version__
+from mmseg.apis import init_random_seed, set_random_seed, train_segmentor
+from mmseg.datasets import build_dataset
+from mmseg.models import build_segmentor
+from mmseg.utils import collect_env, get_root_logger, setup_multi_processes
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a segmentor')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument('--work-dir', help='the dir to save logs and models')
+ parser.add_argument(
+ '--load-from', help='the checkpoint file to load weights from')
+ parser.add_argument(
+ '--resume-from', help='the checkpoint file to resume from')
+ parser.add_argument(
+ '--no-validate',
+ action='store_true',
+ help='whether not to evaluate the checkpoint during training')
+ group_gpus = parser.add_mutually_exclusive_group()
+ group_gpus.add_argument(
+ '--gpus',
+ type=int,
+ help='(Deprecated, please use --gpu-id) number of gpus to use '
+ '(only applicable to non-distributed training)')
+ group_gpus.add_argument(
+ '--gpu-ids',
+ type=int,
+ nargs='+',
+ help='(Deprecated, please use --gpu-id) ids of gpus to use '
+ '(only applicable to non-distributed training)')
+ group_gpus.add_argument(
+ '--gpu-id',
+ type=int,
+ default=0,
+ help='id of gpu to use '
+ '(only applicable to non-distributed training)')
+ parser.add_argument('--seed', type=int, default=None, help='random seed')
+ parser.add_argument(
+ '--deterministic',
+ action='store_true',
+ help='whether to set deterministic options for CUDNN backend.')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', type=int, default=0)
+ parser.add_argument(
+ '--auto-resume',
+ action='store_true',
+ help='resume from the latest checkpoint automatically.')
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # set cudnn_benchmark
+ if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ if args.load_from is not None:
+ cfg.load_from = args.load_from
+ if args.resume_from is not None:
+ cfg.resume_from = args.resume_from
+ if args.gpus is not None:
+ cfg.gpu_ids = range(1)
+ warnings.warn('`--gpus` is deprecated because we only support '
+ 'single GPU mode in non-distributed training. '
+ 'Use `gpus=1` now.')
+ if args.gpu_ids is not None:
+ cfg.gpu_ids = args.gpu_ids[0:1]
+ warnings.warn('`--gpu-ids` is deprecated, please use `--gpu-id`. '
+ 'Because we only support single GPU mode in '
+ 'non-distributed training. Use the first GPU '
+ 'in `gpu_ids` now.')
+ if args.gpus is None and args.gpu_ids is None:
+ cfg.gpu_ids = [args.gpu_id]
+
+ cfg.auto_resume = args.auto_resume
+
+ # init distributed env first, since logger depends on the dist info.
+ if args.launcher == 'none':
+ distributed = False
+ else:
+ distributed = True
+ init_dist(args.launcher, **cfg.dist_params)
+ # gpu_ids is used to calculate iter when resuming checkpoint
+ _, world_size = get_dist_info()
+ cfg.gpu_ids = range(world_size)
+
+ # create work_dir
+ mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
+ # dump config
+ cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
+ # init the logger before other steps
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ log_file = osp.join(cfg.work_dir, f'{timestamp}.log')
+ logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
+
+ # set multi-process settings
+ setup_multi_processes(cfg)
+
+ # init the meta dict to record some important information such as
+ # environment info and seed, which will be logged
+ meta = dict()
+ # log env info
+ env_info_dict = collect_env()
+ env_info = '\n'.join([f'{k}: {v}' for k, v in env_info_dict.items()])
+ dash_line = '-' * 60 + '\n'
+ logger.info('Environment info:\n' + dash_line + env_info + '\n' +
+ dash_line)
+ meta['env_info'] = env_info
+
+ # log some basic info
+ logger.info(f'Distributed training: {distributed}')
+ logger.info(f'Config:\n{cfg.pretty_text}')
+
+ # set random seeds
+ seed = init_random_seed(args.seed)
+ logger.info(f'Set random seed to {seed}, '
+ f'deterministic: {args.deterministic}')
+ set_random_seed(seed, deterministic=args.deterministic)
+ cfg.seed = seed
+ meta['seed'] = seed
+ meta['exp_name'] = osp.basename(args.config)
+
+ model = build_segmentor(
+ cfg.model,
+ train_cfg=cfg.get('train_cfg'),
+ test_cfg=cfg.get('test_cfg'))
+ model.init_weights()
+
+ # SyncBN is not support for DP
+ if not distributed:
+ warnings.warn(
+ 'SyncBN is only supported with DDP. To be compatible with DP, '
+ 'we convert SyncBN to BN. Please use dist_train.sh which can '
+ 'avoid this error.')
+ model = revert_sync_batchnorm(model)
+
+ logger.info(model)
+
+ datasets = [build_dataset(cfg.data.train)]
+ if len(cfg.workflow) == 2:
+ val_dataset = copy.deepcopy(cfg.data.val)
+ val_dataset.pipeline = cfg.data.train.pipeline
+ datasets.append(build_dataset(val_dataset))
+ if cfg.checkpoint_config is not None:
+ # save mmseg version, config file content and class names in
+ # checkpoints as meta data
+ cfg.checkpoint_config.meta = dict(
+ mmseg_version=f'{__version__}+{get_git_hash()[:7]}',
+ config=cfg.pretty_text,
+ CLASSES=datasets[0].CLASSES,
+ PALETTE=datasets[0].PALETTE)
+ # add an attribute for visualization convenience
+ model.CLASSES = datasets[0].CLASSES
+ # passing checkpoint meta for saving best checkpoint
+ meta.update(cfg.checkpoint_config.meta)
+ train_segmentor(
+ model,
+ datasets,
+ cfg,
+ distributed=distributed,
+ validate=(not args.no_validate),
+ timestamp=timestamp,
+ meta=meta)
+
+
+if __name__ == '__main__':
+ main()
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FVmnaxFJvsb8"
+ },
+ "source": [
+ "# MMSegmentation Tutorial\n",
+ "Welcome to MMSegmentation! \n",
+ "\n",
+ "In this tutorial, we demo\n",
+ "* How to do inference with MMSeg trained weight\n",
+ "* How to train on your own dataset and visualize the results. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QS8YHrEhbpas"
+ },
+ "source": [
+ "## Install MMSegmentation\n",
+ "This step may take several minutes. \n",
+ "\n",
+ "We use PyTorch 1.5.0 and CUDA 10.1 for this tutorial. You may install other versions by change the version number in pip install command. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "UWyLrLYaNEaL",
+ "outputId": "32a47fe3-f10d-47a1-f6b9-b7c235abdab1"
+ },
+ "outputs": [],
+ "source": [
+ "# Check nvcc version\r\n",
+ "!nvcc -V\r\n",
+ "# Check GCC version\r\n",
+ "!gcc --version"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "Ki3WUBjKbutg",
+ "outputId": "14bd14b0-4d8c-4fa9-e3f9-da35c0efc0d5"
+ },
+ "outputs": [],
+ "source": [
+ "# Install PyTorch\r\n",
+ "!pip install -U torch==1.5.0+cu101 torchvision==0.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html\r\n",
+ "# Install MMCV\r\n",
+ "!pip install mmcv-full==latest+torch1.5.0+cu101 -f https://download.openmmlab.com/mmcv/dist/index.html"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "nR-hHRvbNJJZ",
+ "outputId": "10c3b131-d4db-458c-fc10-b94b1c6ed546"
+ },
+ "outputs": [],
+ "source": [
+ "!rm -rf mmsegmentation\r\n",
+ "!git clone https://github.com/open-mmlab/mmsegmentation.git \r\n",
+ "%cd mmsegmentation\r\n",
+ "!pip install -e ."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "mAE_h7XhPT7d",
+ "outputId": "83bf0f8e-fc69-40b1-f9fe-0025724a217c"
+ },
+ "outputs": [],
+ "source": [
+ "# Check Pytorch installation\r\n",
+ "import torch, torchvision\r\n",
+ "print(torch.__version__, torch.cuda.is_available())\r\n",
+ "\r\n",
+ "# Check MMSegmentation installation\r\n",
+ "import mmseg\r\n",
+ "print(mmseg.__version__)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eUcuC3dUv32I"
+ },
+ "source": [
+ "## Run Inference with MMSeg trained weight"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "2hd41IGaiNet",
+ "outputId": "b7b2aafc-edf2-43e4-ea43-0b5dd0aa4b4a"
+ },
+ "outputs": [],
+ "source": [
+ "!mkdir checkpoints\r\n",
+ "!wget https://download.openmmlab.com/mmsegmentation/v0.5/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth -P checkpoints"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "H8Fxg8i-wHJE"
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.apis import inference_segmentor, init_segmentor, show_result_pyplot\r\n",
+ "from mmseg.core.evaluation import get_palette"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "umk8sJ0Xuace"
+ },
+ "outputs": [],
+ "source": [
+ "config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'\r\n",
+ "checkpoint_file = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "nWlQFuTgudxu",
+ "outputId": "5e45f4f6-5bcf-4d04-bb9c-0428ee84a576"
+ },
+ "outputs": [],
+ "source": [
+ "# build the model from a config file and a checkpoint file\r\n",
+ "model = init_segmentor(config_file, checkpoint_file, device='cuda:0')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "izFv6pSRujk9"
+ },
+ "outputs": [],
+ "source": [
+ "# test a single image\n",
+ "img = 'demo/demo.png'\n",
+ "result = inference_segmentor(model, img)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 504
+ },
+ "id": "bDcs9udgunQK",
+ "outputId": "7c55f713-4085-47fd-fa06-720a321d0795"
+ },
+ "outputs": [],
+ "source": [
+ "# show the results\r\n",
+ "show_result_pyplot(model, img, result, get_palette('cityscapes'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ta51clKX4cwM"
+ },
+ "source": [
+ "## Train a semantic segmentation model on a new dataset\n",
+ "\n",
+ "To train on a customized dataset, the following steps are neccessary. \n",
+ "1. Add a new dataset class. \n",
+ "2. Create a config file accordingly. \n",
+ "3. Perform training and evaluation. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "AcZg6x_K5Zs3"
+ },
+ "source": [
+ "### Add a new dataset\n",
+ "\n",
+ "Datasets in MMSegmentation require image and semantic segmentation maps to be placed in folders with the same perfix. To support a new dataset, we may need to modify the original file structure. \n",
+ "\n",
+ "In this tutorial, we give an example of converting the dataset. You may refer to [docs](https://github.com/open-mmlab/mmsegmentation/docs/en/tutorials/new_dataset.md) for details about dataset reorganization. \n",
+ "\n",
+ "We use [Standord Background Dataset](http://dags.stanford.edu/projects/scenedataset.html) as an example. The dataset contains 715 images chosen from existing public datasets [LabelMe](http://labelme.csail.mit.edu), [MSRC](http://research.microsoft.com/en-us/projects/objectclassrecognition), [PASCAL VOC](http://pascallin.ecs.soton.ac.uk/challenges/VOC) and [Geometric Context](http://www.cs.illinois.edu/homes/dhoiem/). Images from these datasets are mainly outdoor scenes, each containing approximately 320-by-240 pixels. \n",
+ "In this tutorial, we use the region annotations as labels. There are 8 classes in total, i.e. sky, tree, road, grass, water, building, mountain, and foreground object. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "TFIt7MHq5Wls",
+ "outputId": "74a126e4-c8a4-4d2f-a910-b58b71843a23"
+ },
+ "outputs": [],
+ "source": [
+ "# download and unzip\r\n",
+ "!wget http://dags.stanford.edu/data/iccv09Data.tar.gz -O standford_background.tar.gz\r\n",
+ "!tar xf standford_background.tar.gz"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 377
+ },
+ "id": "78LIci7F9WWI",
+ "outputId": "c432ddac-5a50-47b1-daac-5a26b07afea2"
+ },
+ "outputs": [],
+ "source": [
+ "# Let's take a look at the dataset\r\n",
+ "import mmcv\r\n",
+ "import matplotlib.pyplot as plt\r\n",
+ "\r\n",
+ "img = mmcv.imread('iccv09Data/images/6000124.jpg')\r\n",
+ "plt.figure(figsize=(8, 6))\r\n",
+ "plt.imshow(mmcv.bgr2rgb(img))\r\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "L5mNQuc2GsVE"
+ },
+ "source": [
+ "We need to convert the annotation into semantic map format as an image."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WnGZfribFHCx"
+ },
+ "outputs": [],
+ "source": [
+ "import os.path as osp\n",
+ "import numpy as np\n",
+ "from PIL import Image\n",
+ "# convert dataset annotation to semantic segmentation map\n",
+ "data_root = 'iccv09Data'\n",
+ "img_dir = 'images'\n",
+ "ann_dir = 'labels'\n",
+ "# define class and plaette for better visualization\n",
+ "classes = ('sky', 'tree', 'road', 'grass', 'water', 'bldg', 'mntn', 'fg obj')\n",
+ "palette = [[128, 128, 128], [129, 127, 38], [120, 69, 125], [53, 125, 34], \n",
+ " [0, 11, 123], [118, 20, 12], [122, 81, 25], [241, 134, 51]]\n",
+ "for file in mmcv.scandir(osp.join(data_root, ann_dir), suffix='.regions.txt'):\n",
+ " seg_map = np.loadtxt(osp.join(data_root, ann_dir, file)).astype(np.uint8)\n",
+ " seg_img = Image.fromarray(seg_map).convert('P')\n",
+ " seg_img.putpalette(np.array(palette, dtype=np.uint8))\n",
+ " seg_img.save(osp.join(data_root, ann_dir, file.replace('.regions.txt', \n",
+ " '.png')))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 377
+ },
+ "id": "5MCSS9ABfSks",
+ "outputId": "92b9bafc-589e-48fc-c9e9-476f125d6522"
+ },
+ "outputs": [],
+ "source": [
+ "# Let's take a look at the segmentation map we got\n",
+ "import matplotlib.patches as mpatches\n",
+ "img = Image.open('iccv09Data/labels/6000124.png')\n",
+ "plt.figure(figsize=(8, 6))\n",
+ "im = plt.imshow(np.array(img.convert('RGB')))\n",
+ "\n",
+ "# create a patch (proxy artist) for every color \n",
+ "patches = [mpatches.Patch(color=np.array(palette[i])/255., \n",
+ " label=classes[i]) for i in range(8)]\n",
+ "# put those patched as legend-handles into the legend\n",
+ "plt.legend(handles=patches, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0., \n",
+ " fontsize='large')\n",
+ "\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WbeLYCp2k5hl"
+ },
+ "outputs": [],
+ "source": [
+ "# split train/val set randomly\n",
+ "split_dir = 'splits'\n",
+ "mmcv.mkdir_or_exist(osp.join(data_root, split_dir))\n",
+ "filename_list = [osp.splitext(filename)[0] for filename in mmcv.scandir(\n",
+ " osp.join(data_root, ann_dir), suffix='.png')]\n",
+ "with open(osp.join(data_root, split_dir, 'train.txt'), 'w') as f:\n",
+ " # select first 4/5 as train set\n",
+ " train_length = int(len(filename_list)*4/5)\n",
+ " f.writelines(line + '\\n' for line in filename_list[:train_length])\n",
+ "with open(osp.join(data_root, split_dir, 'val.txt'), 'w') as f:\n",
+ " # select last 1/5 as train set\n",
+ " f.writelines(line + '\\n' for line in filename_list[train_length:])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HchvmGYB_rrO"
+ },
+ "source": [
+ "After downloading the data, we need to implement `load_annotations` function in the new dataset class `StandfordBackgroundDataset`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LbsWOw62_o-X"
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.datasets.builder import DATASETS\n",
+ "from mmseg.datasets.custom import CustomDataset\n",
+ "\n",
+ "@DATASETS.register_module()\n",
+ "class StandfordBackgroundDataset(CustomDataset):\n",
+ " CLASSES = classes\n",
+ " PALETTE = palette\n",
+ " def __init__(self, split, **kwargs):\n",
+ " super().__init__(img_suffix='.jpg', seg_map_suffix='.png', \n",
+ " split=split, **kwargs)\n",
+ " assert osp.exists(self.img_dir) and self.split is not None\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yUVtmn3Iq3WA"
+ },
+ "source": [
+ "### Create a config file\n",
+ "In the next step, we need to modify the config for the training. To accelerate the process, we finetune the model from trained weights."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Wwnj9tRzqX_A"
+ },
+ "outputs": [],
+ "source": [
+ "from mmcv import Config\n",
+ "cfg = Config.fromfile('configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1y2oV5w97jQo"
+ },
+ "source": [
+ "Since the given config is used to train PSPNet on cityscapes dataset, we need to modify it accordingly for our new dataset. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "eyKnYC1Z7iCV",
+ "outputId": "6195217b-187f-4675-994b-ba90d8bb3078"
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.apis import set_random_seed\n",
+ "\n",
+ "# Since we use ony one GPU, BN is used instead of SyncBN\n",
+ "cfg.norm_cfg = dict(type='BN', requires_grad=True)\n",
+ "cfg.model.backbone.norm_cfg = cfg.norm_cfg\n",
+ "cfg.model.decode_head.norm_cfg = cfg.norm_cfg\n",
+ "cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg\n",
+ "# modify num classes of the model in decode/auxiliary head\n",
+ "cfg.model.decode_head.num_classes = 8\n",
+ "cfg.model.auxiliary_head.num_classes = 8\n",
+ "\n",
+ "# Modify dataset type and path\n",
+ "cfg.dataset_type = 'StandfordBackgroundDataset'\n",
+ "cfg.data_root = data_root\n",
+ "\n",
+ "cfg.data.samples_per_gpu = 8\n",
+ "cfg.data.workers_per_gpu=8\n",
+ "\n",
+ "cfg.img_norm_cfg = dict(\n",
+ " mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)\n",
+ "cfg.crop_size = (256, 256)\n",
+ "cfg.train_pipeline = [\n",
+ " dict(type='LoadImageFromFile'),\n",
+ " dict(type='LoadAnnotations'),\n",
+ " dict(type='Resize', img_scale=(320, 240), ratio_range=(0.5, 2.0)),\n",
+ " dict(type='RandomCrop', crop_size=cfg.crop_size, cat_max_ratio=0.75),\n",
+ " dict(type='RandomFlip', flip_ratio=0.5),\n",
+ " dict(type='PhotoMetricDistortion'),\n",
+ " dict(type='Normalize', **cfg.img_norm_cfg),\n",
+ " dict(type='Pad', size=cfg.crop_size, pad_val=0, seg_pad_val=255),\n",
+ " dict(type='DefaultFormatBundle'),\n",
+ " dict(type='Collect', keys=['img', 'gt_semantic_seg']),\n",
+ "]\n",
+ "\n",
+ "cfg.test_pipeline = [\n",
+ " dict(type='LoadImageFromFile'),\n",
+ " dict(\n",
+ " type='MultiScaleFlipAug',\n",
+ " img_scale=(320, 240),\n",
+ " # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],\n",
+ " flip=False,\n",
+ " transforms=[\n",
+ " dict(type='Resize', keep_ratio=True),\n",
+ " dict(type='RandomFlip'),\n",
+ " dict(type='Normalize', **cfg.img_norm_cfg),\n",
+ " dict(type='ImageToTensor', keys=['img']),\n",
+ " dict(type='Collect', keys=['img']),\n",
+ " ])\n",
+ "]\n",
+ "\n",
+ "\n",
+ "cfg.data.train.type = cfg.dataset_type\n",
+ "cfg.data.train.data_root = cfg.data_root\n",
+ "cfg.data.train.img_dir = img_dir\n",
+ "cfg.data.train.ann_dir = ann_dir\n",
+ "cfg.data.train.pipeline = cfg.train_pipeline\n",
+ "cfg.data.train.split = 'splits/train.txt'\n",
+ "\n",
+ "cfg.data.val.type = cfg.dataset_type\n",
+ "cfg.data.val.data_root = cfg.data_root\n",
+ "cfg.data.val.img_dir = img_dir\n",
+ "cfg.data.val.ann_dir = ann_dir\n",
+ "cfg.data.val.pipeline = cfg.test_pipeline\n",
+ "cfg.data.val.split = 'splits/val.txt'\n",
+ "\n",
+ "cfg.data.test.type = cfg.dataset_type\n",
+ "cfg.data.test.data_root = cfg.data_root\n",
+ "cfg.data.test.img_dir = img_dir\n",
+ "cfg.data.test.ann_dir = ann_dir\n",
+ "cfg.data.test.pipeline = cfg.test_pipeline\n",
+ "cfg.data.test.split = 'splits/val.txt'\n",
+ "\n",
+ "# We can still use the pre-trained Mask RCNN model though we do not need to\n",
+ "# use the mask branch\n",
+ "cfg.load_from = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'\n",
+ "\n",
+ "# Set up working dir to save files and logs.\n",
+ "cfg.work_dir = './work_dirs/tutorial'\n",
+ "\n",
+ "cfg.runner.max_iters = 200\n",
+ "cfg.log_config.interval = 10\n",
+ "cfg.evaluation.interval = 200\n",
+ "cfg.checkpoint_config.interval = 200\n",
+ "\n",
+ "# Set seed to facitate reproducing the result\n",
+ "cfg.seed = 0\n",
+ "set_random_seed(0, deterministic=False)\n",
+ "cfg.gpu_ids = range(1)\n",
+ "\n",
+ "# Let's have a look at the final config used for training\n",
+ "print(f'Config:\\n{cfg.pretty_text}')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QWuH14LYF2gQ"
+ },
+ "source": [
+ "### Train and Evaluation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "jYKoSfdMF12B",
+ "outputId": "422219ca-d7a5-4890-f09f-88c959942e64"
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.datasets import build_dataset\n",
+ "from mmseg.models import build_segmentor\n",
+ "from mmseg.apis import train_segmentor\n",
+ "\n",
+ "\n",
+ "# Build the dataset\n",
+ "datasets = [build_dataset(cfg.data.train)]\n",
+ "\n",
+ "# Build the detector\n",
+ "model = build_segmentor(\n",
+ " cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))\n",
+ "# Add an attribute for visualization convenience\n",
+ "model.CLASSES = datasets[0].CLASSES\n",
+ "\n",
+ "# Create work_dir\n",
+ "mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))\n",
+ "train_segmentor(model, datasets, cfg, distributed=False, validate=True, \n",
+ " meta=dict())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DEkWOP-NMbc_"
+ },
+ "source": [
+ "Inference with trained model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 645
+ },
+ "id": "ekG__UfaH_OU",
+ "outputId": "1437419c-869a-4902-df86-d4f6f8b2597a"
+ },
+ "outputs": [],
+ "source": [
+ "img = mmcv.imread('iccv09Data/images/6000124.jpg')\n",
+ "\n",
+ "model.cfg = cfg\n",
+ "result = inference_segmentor(model, img)\n",
+ "plt.figure(figsize=(8, 6))\n",
+ "show_result_pyplot(model, img, result, palette)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "include_colab_link": true,
+ "name": "MMSegmentation Tutorial.ipynb",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "pycharm": {
+ "stem_cell": {
+ "cell_type": "raw",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": []
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/demo/demo.png b/demo/demo.png
new file mode 100644
index 0000000..1e82d7a
Binary files /dev/null and b/demo/demo.png differ
diff --git a/demo/image_demo.py b/demo/image_demo.py
new file mode 100644
index 0000000..05e1a79
--- /dev/null
+++ b/demo/image_demo.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser
+
+from mmseg.apis import inference_segmentor, init_segmentor, show_result_pyplot
+from mmseg.core.evaluation import get_palette
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument('img', help='Image file')
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--palette',
+ default='cityscapes',
+ help='Color palette used for segmentation map')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ args = parser.parse_args()
+
+ # build the model from a config file and a checkpoint file
+ model = init_segmentor(args.config, args.checkpoint, device=args.device)
+ # test a single image
+ result = inference_segmentor(model, args.img)
+ # show the results
+ show_result_pyplot(
+ model,
+ args.img,
+ result,
+ get_palette(args.palette),
+ opacity=args.opacity)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/demo/inference_demo.ipynb b/demo/inference_demo.ipynb
new file mode 100644
index 0000000..2f86f20
--- /dev/null
+++ b/demo/inference_demo.ipynb
@@ -0,0 +1,150 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "mkdir: cannot create directory ‘../checkpoints’: File exists\n",
+ "--2020-07-07 08:54:25-- https://open-mmlab.s3.ap-northeast-2.amazonaws.com/mmsegmentation/models/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth\n",
+ "Resolving open-mmlab.s3.ap-northeast-2.amazonaws.com (open-mmlab.s3.ap-northeast-2.amazonaws.com)... 52.219.58.55\n",
+ "Connecting to open-mmlab.s3.ap-northeast-2.amazonaws.com (open-mmlab.s3.ap-northeast-2.amazonaws.com)|52.219.58.55|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 196205945 (187M) [application/x-www-form-urlencoded]\n",
+ "Saving to: ‘../checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth.1’\n",
+ "\n",
+ "pspnet_r50-d8_512x1 100%[===================>] 187.12M 16.5MB/s in 13s \n",
+ "\n",
+ "2020-07-07 08:54:38 (14.8 MB/s) - ‘../checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth.1’ saved [196205945/196205945]\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "!mkdir ../checkpoints\n",
+ "!wget https://openmmlab.oss-accelerate.aliyuncs.com/mmsegmentation/v0.5/deeplabv3/deeplabv3_r50-d8_512x1024_40k_cityscapes/deeplabv3_r50-d8_512x1024_40k_cityscapes_20200605_022449-acadc2f8.pth -P ../checkpoints"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {
+ "pycharm": {
+ "is_executing": true
+ }
+ },
+ "outputs": [],
+ "source": [
+ "from mmseg.apis import init_segmentor, inference_segmentor, show_result_pyplot\n",
+ "from mmseg.core.evaluation import get_palette"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {
+ "pycharm": {
+ "is_executing": true
+ }
+ },
+ "outputs": [],
+ "source": [
+ "config_file = '../configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'\n",
+ "checkpoint_file = '../checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# build the model from a config file and a checkpoint file\n",
+ "model = init_segmentor(config_file, checkpoint_file, device='cuda:0')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# test a single image\n",
+ "img = 'demo.png'\n",
+ "result = inference_segmentor(model, img)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "/mnt/v-liubin/code/mmsegmentation/mmseg/models/segmentors/base.py:265: UserWarning: show==False and out_file is not specified, only result image will be returned\n",
+ " warnings.warn('show==False and out_file is not specified, only '\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAA20AAAHFCAYAAABhIhFgAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nOy9W49sS3Lf94vMtVZVdffe+1zmzI0URVKiLJkWDBiGZfhBMiDJ8ovhV9sfQE/+AH7yB5EBPRqG/SLAgAwZfrJhywRhQTKoi6nRcIYzHJ7bPvvS3VW1Lpnhh4jMlVXdvc8h54x4JFUAe3d31Vq5cuUlIv5xS1FVLnShC13oQhe60IUudKELXehC30wKf9IduNCFLnShC13oQhe60IUudKELPU0X0HahC13oQhe60IUudKELXehC32C6gLYLXehCF7rQhS50oQtd6EIX+gbTBbRd6EIXutCFLnShC13oQhe60DeYLqDtQhe60IUudKELXehCF7rQhb7BdAFtF7rQhS50oQtd6EIXutCFLvQNpl8IaBOR/1RE/j8R+YGI/De/iGdc6EIXutCFLnShC13oQhe60L8JJF/3OW0iEoHfBf468FPgt4H/UlX/ydf6oAtd6EIXutCFLnShC13oQhf6N4B+EZ62/wD4gar+UFUn4H8A/vNfwHMudKELXehCF7rQhS50oQtd6F976n4Bbf4S8JPm758Cf+ldN2y2G91dXdHFp7sTY0BEmOf55HNFQUFVyZrJOaNZ7V/rRRRAAREEkCDEGIkxIiKPP1QECQFVZZkXcs7elBJi8EZXCiKIiD3mqRcRARE0Z+Z58U5BCAHrxnpnEAEBQShvUn4rr6aqqGYQIYiQFVJKAKQle/vr3aULD7slSBA0QxAf2TMnrCpkyvfekCoSbG7E+5NzrsNd3qPMhXpDWvrjbdjzbORsPsrz/UoJhBBQzagqomsXCIKcjXh77/qZPVfVR0LWUQlhtV+UngrSrCFB0XWtqPdXhK7rfD3U0azPW+bF77SGFQgx2FoJAgrLsvg82t0xBltr3r74i3Z9t/bTr00pkVLycV+vF7H1jfh68Hka+g6R0Aye36dqbyxCCPh7ln9n45gzS0rklE9euczAOrunc5LVBiB2HcPQ0+2eIbFjeMe+//koE3UmS4++wz51ujv+9aSvN56itKloGtktL31ulWmefV0UBrWuh8dJTvaifRTYbAbnJzAvC5vNhkP/3YZ3Cee32d5WUjJe3XW21h/yuyoMzu4+//5Pnr6eQJinGvny93QW9M7PT8SsfF19/jrosZ39VTv3dXODVV64pCSQkTQxTyMg9MPAPE+klDkeDpWvg8vnZiJUV/1GkJX/NnJYfe+FEBrebN9JMBmUc0ZEGDYD8zQ/OnnqMkJEiF0EIC2JECMxBFJaTvQREaHveyQEqtArdD6s51P0Lmb85NQpKSVyzibLyniFImdX/QRMDom/U+ECdWx9nE/ZjFR5n13fyinZeIRgcvzRDp/pJGijI1lbpg4KXdc7vxJUM8uykJO6itRutNLjd63tP8rabdt7atAf4xPyJd+fX/sYv33quV/Wl6c+excPLzpZ9nlfcYN93cqhx/Rk10mz67e+psq6UCDGSAjxUX65dtf19frc9Xktvfri9eeq+tFjTfyitKUvJRH5m8DfBLi6vuKv/Cd/lfdu3gO0godCXSc8e3ZNP0R+9vHH9fPCuDRl37CJaZ65vz9w3O8Zx4W0ZDSn8kyQwDD0XN/suLm5Yrft6fotnCjdBtRUIt12gyq8/OQlh8M9OWciiefPbpCuByAliBH6rqeLEQmFgwUkONBTUAkQInGzYb+fePnJJ6ac58T1rqff7hBVcGY3xEDXd2XAbKJ9srOa8jzNM9M403WRYeiYcub1qzvmaeF4f0BIaE6oUpX4IAGJAdQArgBD37GoAawhCkGVLCtQQ2FWWJISo9CFQOgiOWWGoaff9IQQmKeF6f4ORJiTEkOgj7YhUs5kVdKSMCgjdDEYqFElJ2dWaveFrgNVA58ixAARtXfXjCA2RtsBkYA6CEEzQaIzx2QAHkgpMy+JOZlg6aIgOdP1kc1mKCuzMs4qGBUIgTkpXTDQmnNmnBL0Gz788AXPb65AOnu+j9u0LLz67HMD2imxAHMOPLu5ZrvrGYaelJRXn37GMi8cFyUI3DzbcdwfyctCFwOx61AJfPTdj7i+vrb3AjQrb9++5e71W5Z54niciTEQ+8g4JYYh8uy9DwghcDzcMY8jsd/y7W9/i6urLV0QpOvICuNxZFkSMUS2uw1dF9yQUIRZB7rY2kuJu9s9b97ecjgcieJrvI8EFVKGUIBbsHnWnE3Jp+Ojjz7iV379T/PBn//LvPfBR+ziOvY8+O2PR6rKPL/lO/KScfNL7PPm3dcDC5mIEH7up//LoafEpDY/v0xFfTegenitizsDRzmxvP4pv/nybzOmkWWa+fjjn3H39h7NxpPTkr5UkQ9BXNiZ5hm7yK/++p8hxsiyzHz++Uu+98u/zA9+9b+ta7IIzKJkwSqA53nm9vYNb29vGbZbXjx7wXYYvP0TdOh9e9i5VuRnbQxVrGszKUSx70/H6bSNcxXrMfWn/aztT6u0n/fzsc/aHqyGIG3uMcPXQ1p7Ye1Sr1sNOKdtnQCHJ/tilKoyfdpSozNVIPhUM2UO2vu+jB6OdwaElBZC6B4AIchu1JJqEC3vv177tHKcc3JDwcPvbDxXo+TzsCe+/jF/8JMfk4h89L3v8vs/+F1+8IMf8fmnnzGNE2hiGDr6YaAIlpwS87yQcyKEQOwiAdzgZtxrnBdyVq6f3bDbDhwPB0SVeV44zInrZ9fsdlvubu+RvuPXf+3X+OSnP2GZJ3DgpQAOLsbjCF3Hiw8/IGrm7ds7uu3A9e6K6f6OeVlIKsxzot8MfOd732W7M56bpslkfXhESdcMzXhpTid/Pxy3dl1nlICQePPmlvu7e+Z5JsaOfrNhs+kJoaPve4bNYAAO5XCYAWWcRhPtIsTYUQyKMUb6PhAEJEYQQVPieJw4Ho/M88Th7pYQIy+e3zD0PYgQKngr7xlO3nfOICSWlDgeRsZpIsTIdrvl/Q+/zfP332MIwv7+ltdv3pKmRBwGgpjOI3m28XK+VaFl2Rf5lOOLBAd9Dd47WetPrePHuJX9DATbQXUucnN/bt65pYcGh4dga32WljGMtgdD1Xsf46Tej8q7AjzG3ySgCuM0Mk0zOS+m0y6LjW0Mph9DBWRRFRUhp8Q0jhz2e8bjwpLh+vkVu+srQlKmeUKi8OzZc3bbG0IMrvdwCroBXUam/QHUMMkp3l+v+x//+7/z44cvYfSLAG1/APyp5u9f9s9OSFX/FvC3AD748AMNUtCt4o4jnxepSkKZjHWdBEJQsootFVX6fuDmJjD0kcM4MR9Hljk5GhZQGIaO6+stV9c7YtfzcNECZMZxZr+/J4RAWmZymjDYwAlajrHsmlS9GNb/dfFotZacCmURaaSRMbAnyZmVoAQRUjXAFM8iiHsUcspUq54EEAPD4szFfo+20bNbxiWQsqJdIBd+IAY4MxigBJAIwRRy8bko9sOq49dRtY2V0dqWBEGTWbyyZEIwJSGEQD90pKSkZUFSInYR7aL10YVoUNBW2VIgBkK/QViYp4mcMkGMhWS3KGrd2kqQYHNRx7AwN2dOwbxd1Vrpc7W+k02bCuRlYcmZGJINtYTKmEQCmhOCCwdZQfzqWgtIEoIUQK51SWZnWrkoEQ52SyNV0Q2CRAO6V1dbYjwyHifevvqC3c0zdtfXSBCm48TnH3/Ms2+9z3vPn9P7nG22G8I8Mx1HpiUQ48aYGY3n1ZezhMDuekfKsGRlGQ8GZJeMhg7I1aqc6xYIEMuWSGz7juvlNVG+y6xlrdr7dwi5WLvqOjIRbZ+d+/BOyUZe2eVbuj6whOCWh6dJgIiQ/N74rwhwg1NwJs3Prw7HGqF39t7noM5mqZkHafa9CDH2iBtWiif2yxTsnLUaugQxPqMZMCB30wckzdVTGyiWf4/vL4DB11zfdbx48T7DsOHzL77g4/0nvHj+jJubG4JEui460Drz2Jd3bvSJshVPAEVzbTp7t3b0VnVnnZ3HwJk2v1tfWgDUzIt/Xr5/CO6M35j35HE50gKxU5C1Ar28btp63en4PJzQP2pu/DnwWj01D68ta7nwowcqoX94+rkBMOfczec2LjH2j/dLFZGzSa7tlXFfPOIhPvV676BW0fTdpDBOC/v7e37vRz/i5WefMU8TaKbvonmtHEgnVTdsZkKI1da8rg8Y04LmzNXNNdc3O5aUiTGiOVuUR/WomfKfkyDSVWVZ6oZmZcAW0oIQkQDD0DP0A1EKwCv6m78iAjmjlUc8wk8fUa5VHprMQghI7MwQlNK6Vproia6LbLcbV7zNIygSCLLOUTg3CIggDeiQErETVjmvKSHdmZp8uolXOXxCZTwCipBVgOTP9NFyHlTkWp6OvDqOjId7lnm2NZ0TyTpnup08WOiNTtkCm1bfbLotuJWplRqPrfeHFNTaliYqqfAZbRhj4VEW+LN6fs/HSMT0wjIOKhYtFqSDYMZ88zanE11y7fM5+LMXfNKAFIwXmL5p4DJIRMXfSRUJDtKBeUkcj0emo+lSy5JM/sRIcJ0LIGbbE0EVlYwQHhifTqP+DIeIv3vxlLdev3fRLwK0/TbwGyLyaxhY+y+A/+pdNwybgW9/9BHH/eSLIDeWt3UhqCrJJ98WvVZhKp15kSRlQt8TBLq+Z+x7E2IK8zKxzJmb6w273ZbQ9TblAloWpEBROnNeePnZS/KyoGqIO3Qm9FNWg2+qvpnEUXNZnMXi0EoaA1dlr8QgLGkpcIdHN04Fs4KKNEzRv8ZBRTArG8kYZS7exeB98YEKIVQFX0IgpbxaSzFwWbeFrn2lgF5rFDBQlEVOLYth3V6rEJCqxIsohMCm6ziOs7mqcybEYj0XYufANyXI5vmQYLwmN2NUvDkKaFY6CQzb58R+5rC/tfnyFyuCI5hsW0MTADz0o4ZlipJyBm0+yxlVnwOKAIU8JZKWkFAlEAwIFsYszR708EUf0EbBfhi+UnmZg2yD1dFn28e10csKGI/Rwihjf42EwPEwsX/7BvSKrhs4piPjkkifvSSnxLc+/MgELzDEgG42HI8JyUd217tV2GpmjcwUui6aQpAX7nJimUeTB8uMR32ereuMJEGJTMcj98c915//iJdvXxE++nMEDNReba5AleX2c7j7mL7rid/7Tfq+Y5zMovW8230JY1Myma3u6bsbxndc2ZIgRPQEuP2rA92MWjF8qpL/0ZTqp9t3XuGbx34ERA3yFi8Fmh4IzuLoii7QU+OiyinX0Ktz4TVc3bAkU2BUwsoD1IF8yiuUrFZ4Ybu74qNvRd7e3fEHn37C7vaW73/0bUQ2zhfXXXgu4wtYk+ivs6yg4bHr1/F5x9i5DGtDsU/et4wrp6Aq50zr6jsf19UjROX7qzft8RX8ZaD+3Hv51b18Dyk3XrZ6b/tZwxbPvZZwqoo+9sSH3VAg8XTKfvnuoRIpYipRSjMhdITQAjNFSOuieIROrz+lVsHNeTHF1AdA8sQf/uQnfPbpF0zH0cJ7+45hs4YZ5pwtTSNZeFYXTfZmFIKZa1POLFNid7Xj6npHWhZ224H7eSIndVBiiqmEM4+gajUrlJCvAjLace66aCkBISCaT2BoI5FdCQ51j2V1mV0mfVkswqkVZI3huoQ4DkPHZrPjcLhnTKkRoQWUG7ALXUd0kBLO5MOJp1xcHonpE1KvCUwZtuuV9piUfA37+DzYfw5+s+GCEnJajSvFMJ/X0bEHrvvscNyzLJN77k1PSW48qLrtktawJ13TNVqvmYhWXfZJIGZhX9a2GjctRnpVyESCrGuhjIU6mCnvrw56RUrEwilXWcH6Y+CK2m91HRIRJHZ0AiqRnJZmFnhwv8MelLLTxdfPw1e29VzCUS0FxfE2khLBwVgWSPPMeH/geLTokZwSKa2hrNAA0KrrBbQB4Ke6nlFA8Vc6eZsyMlLH5N30tYM2VV1E5L8G/h5mivrbqvqP33VPkEDf9xyZmnZsEZgHxt2WQFC3NtidINmVaLOYhBhMge/MOhVDrNYzkWtUMzF2BA9tlOIueUQcaEpkDRzuj+uHU8dmm5nSwpA9vtsXbq890TgGq1uioE8FLcxyFcz2Vosp5I/tscL4iiXZEo7AgahIYCihPwAaWOYM3qcgggYbyxgDsYK2WC0mKUn7OArQMpXIvXi+/VKC2K/DVRayCgYE/bnF8lIWYcxKWvkWXd/RS2Q5HgwALUroLSQPsVjxebKnZm1Uzgb05KYPZqnIpKR0/ZabZ5F5umM8zrBkZ6blHSvUtXUmZf1YOEEU34CtJVCkUT5WYZfTwus3B2KM7HYDUSEE34bSQKzWwkZh/+KeOb9KGjVDTAgHDNxnYF4yKblMi0LUVTiAeV+XJbM/zuy2HdfXV8QIx8PC/vaerpuYjxNKZpkjOb0kp8xH3/oWw2DvvokW6nEc75kPmee7awPNcrpDRIS+Czy73kJO3L5dLBTO/f2hKsXRlqxiRoLsFq60cDwekOOBuz/8PUQCz54/Z+w3oMo4HUjzxNXumv74mtGV8c8+/4zv/Xt/nfeu3ieEJ9iXQs4z8zwxDIPpaF+BfFdW4JYcJn/ToJs+8ftT17y7LX3n3+UzXf9YVbNs6zyTyT7IoRuqBHpKsW/sVifPqECh8jLziB/mkUkVXQ4srDmywY1QtU1vNJT9pCYHPnjxnC4ov/vjHxLzzEff/iU2fVcNHVlN7Be9qvYDkFQ76DzmVGdzLtf8vSpMxeO4KlTe1/y4UbK2UT1bLv/E7inv2gKpFeSdhj2ee+rA5GgBdfnBdY9TO4ft7097Bp9uVyiGN63v/y4P29p++X4BngZMpxQp3qmmV2c/Cz0EcYW3pDQRa/g2ID+fD36N5OiApcr1aRx5+flLpv3BUjBiOAFsmpR5WshpIUiwaBkxA2H0tRskkNJssmOIzKrc7J4Ro6VgKB7donoCjhUY82xrLgQzUGZFHWu4pk5gIeuChC2aFtLQ0VV9xo0Rmlx2FeFM1YXsXcI6L/06rpoTEuIKbHMiDBu2uyu2Q09WZV4sHymEdc0LLtcFYghoEJZGbJsibQzJ+E4ElhNQFxx0iCElurCukOBAJcjZqssKse5sTqCFtN7pAisSQmnYDeoqhBgRFfIyETzMsoToBhTpohljwQ23RcU/1a/KZ1pCh5AT/uCL72yj5TNDiI1DfGAeKWBzhUfliet7N3yv8m8H9A7ICv+0rphUCRIsOqOsI0/dEXwpnRmfss+D+JoUWmBolFKqhu7izTJDS1mTzitFCJLJ0cyzyzyx3x8YDxPzNFXjeT63JElkhU7S8GAhakSjcE6miwdynGE++7IYGt9piF7pF5LTpqp/F/i7X/X643jkDz/+mJvdjSkIuorBat335EEJiuZg4TTSTOiJsFVC7EwJdk3dPCy2HEMItllcE7WFFBA5dddnhXm0+Oe0JM+nmJmnzP2bW6btaLHQbinIcebZ82uieOihFpuweabOY7ULMKJYp0+SJwSkFI2QuqgrkPANGYIQckZKGIAkt7ZYnp0ECy0U3PoUA5T394UdYzJMmdfNKQhRXZy5NqMi1mZVsIq1rhRNEUTdvxKkYuucc93TReEqOWl1s2JCJ3Shuqo1JcxFXhdWGThvy/LUooLkZHH3ofM5jmx27xG6I9PhnjzOJ/wqa7BYadSZW6jPyEoViiVUKAQhqvV98XEKDlLTNPL5pyPXL254dn3N0Ft8tGrjZVRFiwsKCmRbO9R4jX32SRgDVTNR1nUMGRIkcSYXVk/vlJTxcCDnnqvdls32ipyPHA8TyzSZB9HHMGfh7RevWJaFDz/8FrtNT4zKZugQrjmMB+7ynmfXV816XUlCYNhs2KXMtMDd3S1RDbjFoSOGzoVhrMJvmhKqmR///k/phs9QlHm2sIO+sxzSYqQYD/dcDQNXu4EQO2K0HIlP/sHfI/7Kb/D8l/5dpN9yTpuY+VBfsvQDIW5Zlq+uZvmqtjWCupqo3+g8ty+J/HwUiD32+XmI5FMArlDlSXFBsu35LtpoIRGRfApwGv3iHKQEN5xI6NyYovXfkkGmI3/h7n/ifzn8VfoY6YIJQctNDeteku60uJQq+2nP8ThyM9zw4598yn7OfPTBc3abKzPgucehBOGUHJI1h6pY8/F9qrbvWAGWrZDi7Vvfs/1lBVUm41ZQ1+pS2ljqC/9RD+nR2s76e5mL8GBMz8FUSsuTIPHBPH/Fzx77vHoInZ+Vvq/h1l/dS2ftld++qrpSJ+68Jf93DvweesfKOBlgO5/Qd3sxYR2D0/E2D5tqJoSOnH0+xDyPaUkVlAybnlg9bJaLtszJZE4M5ilw+340q6CpENlrAqiy6XtShEOaTUZkS0UQzRT/l6g9bxMNIOqs1bJa3k4Fus3gAGqg8/ZDtpEoYWMWCmmyOxNMAaHaO6p8q1685hlSDPP+Hn1vgC3GjrQsvHz9mvv7A1ebHtPV1MZQ1YF0IAQvEOEuryAdFl1jhpkgQsklym5ADeAFS2zs+pBRLSDYlXEfu9L3lDMJM8Jq84a236TxyHj+mXrchqzaeohC3PQ2XiWlIitL0Qucf5LV5rqksPjzypjS/LauzbBe99g281tE7V+Stq2zix5Z46sasCosp+GZa95d8WQWvugZ0WiIhBjoPEw5CGgwnTT4eOcHj1YP0aw9OXv/YhAxXli2heJG+dDX/lqobAYyaZ652x85Ho6kxSMVTu31/tOcHZ0DaanGflsjqfQtaU27aV286cssUzS5pO+gP7FCJCekLV4vnbbByDkQJQF9vVBCmyBcgrojeIhIiBHUQJg6akeaZ9SiI2XSiwJt4KrkiJWKlWuVPIMzeUkc95lpnCnxqDFG5s2GzXZgGyNSEEtxYyO2EuIqICR0QFd7UL1oTlkzeLiGKQqNcBapK6tUSCtovu9gcoZfkmOT3xMlmHUjCISI5Ozb3K7NyT1rQQ0U2MMpoYugRFk366rIN/3GvUSyKg/1klws5IJohGCueEQIXaDr+2IzYi5WP3Hhos7w3XOTRSz3yN9tGY9MxwO7Z88ZNhtUe0LY0O8COY7k/b0BQYFAtry2MrOeI6D+jNwAs+xFFQpjDoIpkmIewZyVvCRuv3jNeJh57z1L/i4Mq3qptGUwYoVpMItPyVbLeqpUmQfOx5qM+rrqAiwpF1ltAtw3vqoyHyfuU+bqemOJ6mX6vCXLS7sipZm7t/csS+ajjz7gercjdB1DFwg6eDXWbAnZNiK0MCGEwO5qx5IDeZkZj3tSzoQEQx/NQFKspyhdVwSUhfJmlN49nLok0uFI7DsrVnOcOSwW7tv1GJiUwDRN/P6P/jm/KpGb7/8m0u9o6aPNkdd3B+70ijxu2ac/OptzUwkJJRVh8CcM3M6ZufI0YHsqR+38+8eeUbzDj13R5lOpr7UVi5z35vFWnlb+qdzfDB3ZQKHnjP7uP/tn/Oj2e+Shhxi46j0fOXjBIt8Pfd9ZroK/fcoT+8MdLFYZ9fd/+JpPP9nx4Yv36fue0G/IYnErQ7AqbuVdSzRCFztidHd9iGaI0AXbldAFA38KaJvzARZ9Iadh56Vd21sr6FRWUFPCjqCm9FY+v+aQnAPvwivWMFFqy2asKukFpsiuRtKi3J6oRY08Ksq2NJ+fg5PyJGn+le9Ds+oey097as39celhW6e865RKbtNj++VcMX4q7NJC6nPVTaAd/5yTz2sk54VM5jjOLKXKc04EUWIfa1GEnK0CcUqJGGWNlCkai/9XinCZcVHZDgOqwqvPXjFszCMWMENfbNenG3BhVbytSFkB/db33XZLHAbPoTOjRUqZw+HIMk3EEH0nUGVo+aMYOUIxVjS6dlaTw1VPEAOsV7sdIfbc3t/x5ouX3N7tif2AbnoPv/cInIr+OkTMsB4CVecraPF0NgRp51BtnFWELqgV0gr2DiGsqSVVKkjhU22aTkFC5bviFYcasqiCklH1ypMCEqNF9iRlScmAc9EX3L2X5pklJSIlDDw02Zrtujxfp+uOCq4v1dVbDCuCm5vkbE8LNc+hWqLW9qWEpp5sl3YH27VF8ksB1yLuPexNby6FpUIJiVUWzYzTRJ5mNy600Nif5NFQq37djIJqXU+qjYEonVdHDaR54XB7z3GcSEuyeZL2Gqohoes6YtfRb7cMWzdyFEeHFobmoFkBL8BXwf1jnjQ5nS97p4eXtfTNAG0Cd4c9OcHzZ9d1Uz9QUpSqeUqzicydLNXCFGKw+O1w7jj1+1qXhi9WzbICLVYPy7AdyHPPPLmnRmvg8kkSeloSi1dKe/beM55dXzXevCKQM2RbnDEUpKqoJtRLNRbLwPrOuQrZdQwiHhuJOsOJ0RaWeRF7ukHRZcHqbVg1SPPMrVUBxa3V1W7onM6sCGshgfLw1shRXr1uOh/bFEsun/VH1S0f2UI21xE2QGRKvc1VKEcwYApFFFOai9k7BzHZ6qEbrXZgVTCVaZxZli8Ytls2VzdstjtEOrpth3QDevuGtD9g4airtc3GtrXUrMU0ggRyqSaJjVv0vmiwTd5FYV5mjvd3vJwnbl5cs7u+Iqf0QGmzsbT7AmtJcrMI+ZC7hSarWu5PwCpreahqoijta5Wi1v4rQF4WxvtM6Ae6GMiiBK8co9kS2q+f39CNI8f9kY8/ecn7336f969uiAIxdnSRdR17L2MQkkbMamlVPZ9dD0i64q0mDocD8zQhAbabLcn3Z0lkzjmZh3KB2HdI79bZJBBNGQgi1Qq3ZEXnBc0HY5wBOlU+++RHyIvvc/3ero7ti26mY+YwHXmz+T7yxwBsLQVXRZLt3m9UnltRDd7laXNodfL3V3mDp+RGC9hMGVJCgLSANgxCBB4TUqu1vTwnYjGIZ6FsDcNLKUEXefb9v8x/lL/DF8uG+9QTdeZbm8nAf85M88KsgZdjzzwZyokCvzTMTAH66MpZFsb5lvDmjq4zz56QyJpJIRBCR/JKsCWywditkJcZukAMnYcRuZFKhKGPnioiaCdEDUTNxNbAVQBZiIvcBVsAACAASURBVB5+5mF8At0wuNLWKBoi9KFjiEKW4FWO13GNPrt9tFLTwY9G+XgcGCXSZSWJ1XwzILDmC1Ul3XlIdG23VY5Owq3qxJg3okaJ1HzwFfTVXOCmLTnjgUU4F1b+VQBbu3be9VnT/NdAZczsr6/iJDwvBGNH1oBqQCSwLAtv396xfPY50zhSxq8fTDEEB2wpsyTzjIUuunfZlFspVaBR83T73Ids8zKNE8t0RNhgAUE2UCqn75NzYnavX+ul0AqKhLjZVq/BkhKx79gfjszTRH++zUUpHq2i+yMNO9BMSTHQM14Uuo5h2BJCx9vbt3zx8gvub++Y54VOI1yVVAJ5ZHJdmsua+S6exG5GzTJ3az67yVAlEiy3273pmRKavKAysBZrc8jX8jaROif+gqy7yHLhJVju+5IWUjLgFcMp6Cp1BkwPDGg2vWaeZ6Z5ZOgiXQyUgM9yq0iwnP+TNIC1L0HxFJM1xy5Qtu0KiQoMrakfTTSU8edVwzg/Qmfdg0X7WPuQshC6SAyxAjUP2aprvdDxeGR/2DOOE0PXs4ni41va1Qftf5k0a8HoSSs1mqrIxKITi0eHrYwldh3d0BO7aEbBGE6wXaCtcgm4J46GH1a5eTJN2ixlxyuPgbuGvhmgDXOxz6EUzzBQpNoACNRzkoqqYhuCBhSZt60kOa+gBmyZSYxo8QVnkBp76gAjF8Sf6Toh5cjVVY+mrZX+XOaKrO1MLN8l6iGEITDPE+PxSBcj/bBh6NdFLMUfDXY0QH366l9UCt4u9xT7fm6muzAiV8oUBxkO+CTQ98KikRiVJB7H4EqD/fPzRWRlHGV8s2ot4ME6lCfbtG5sogWXiBCcYa6Iu9ksUja6F/ionsOS1yU1Vh+x7/PJdiz99s6cJ/VWUtKijPsD03Fkud5x9eI5gYGu3/D8/Y+Im9fcv7m3q7OSY1FgSj5e6ZeQckb9vBQkOJOnWuFCwKpcihBDzzIvBt5u71jmpXpnsjPLtsNtiKTg4Z6uFGdntOV+y7GjMj3L4QnkvNr8LLTA4sTLyM1LphcXyIX5+TiO93sg8+y9F4QQ2N8fePPJJ/Bd5f3tTV3T7RyCWSItv8R75mOxu9paGfhlZpom8jwzS6AbLM8piwkWCZmYk1kLk7DZ9uSUmZaJ49FmfQiWlxYkkscFFVhcqRGUOW2YXr3h+M9/i1/9i3+N3eYGEWEIiWU68KP7Hd9+/u4y/19GZQzLTk11Jk6F7ddJj+mDjymfevbTfn+3NrkG8xRF/XQPydnPk7Yf1VS9Elfy3IWgxHja2mlOFLRyzSj51vJCTpUXZY9aMx4VCPz7f+6K35n+LNtpR8lLeN7NfH848ofjhvtk3rXva6xnVaoqy3xgs7zhV577mZtLYjweQMyDNi3JK9PNLCkzzs5r1fnrMXl4kikg0zKBTiiweP6PaIYFjvNCyokQO5MZebQ9m5WjK4/qY7FoIHbFWh9QMX4tsOavSb/KgAL+mOvkCOYti8VjInieXqTz0YzSIRIJ243xHM3EENh0wpLNMNJFIQyD83G4myOv8xVsBsK80HWRRQJZhJ0Dxzan0HIIy+8ZNLrCR630WUJO1X8+VnSkXSePflf+02YP6Prd6X54sgUsr6lzmQlPe8+a9r60v8FBylPFSIz/pjRxuN/zyQ9/j+39Szp34PZdR991ZqBUrADCZCF1IUZPu/B9olr3R1EeLSVLXE54DrWC6IRqT8Ll9ql2b4qrZkTT6RmrxeNSQITrGsuSuH97y5wywxCJ52OnoYL9gLAQIAtrjRbnO95+q1T3nelLX7z6mC9evuWwHzmOE8u8sIuDr7NS6r/oguU9OiRMJznMOWf6rq/K+lOFborWpRrp+1X30iysDTYGCV9GJSIAYi1E0ipOxRCeNaAsFXO4r9v1KvF0HvEiTbafFxHmeeTu/hbJif76ijbeo3ADVYWkls5Synk3IZIZq8g8l76zqswnhjUHFbUCes39L0CpzFNTLKZ53fN9m739buit4qIm8HD0FqylnElL5vb2Lct4ZJxni9a5Cmxikzu2Mj3r/4m18jQUNITWuOVvUAv14eNoBucQBZKF3BY5ZB43n/Ng9SCs3oLn3DVG7BWsKtXN24zvGojihmmXwCc5d+W9lAb8P07fGNAW26pLxbrpv6r44YmhhI2UfIfs3rTi3SkHHSqaLO/N2siUajkAImvYYYkBtmIQ3obY9uy7yLOrHZDpgjJNkWlarJok9kh1q1HOhrSHGHm229B1Hd0DORBtsTfueur0xZNPitXU/nZwimAhcsWKtS5MLQLT8+j6boME8/zlcaxjEdxLZB6uVYlX1XUPtMYM/1M9niV0PQmhwxZYF09t/dL8X6gk0atvhvPcKJ8Um8tQIKy6Q9Nz3rRYr0ByhX8WslTXeDOq5oLk7s0dh/2R5x+8oO+vkBC4vn6ffrjmcPua+Tg62LEcxIy58lX9sEQb8dXLKsV7q5V5BXHPmyrSd0QPAWVZmDPEPlKhVShu/eLCZ50HV6hQs9zgpdCrgqMFWJvQCpLZxMBRLPw1IuRgIaddNCC1jDOkkk8ZmsILSlI43Fl54Zv3X3B1c8X+9p6XP/mY/K0P+ODFewb6oZ6ZV2YhpURXPKhQPQTb7Zb0LPPmzRsP+5ms0lnfeZnqcvSC5e4cF0UOE5vtQAiRIS+ukKs/Z/FCRDa+5XBLXUYLU719w6f/+H/jl//i3yAOV2SU28M90g1snlSevjpJ85uY2P2XwjTfxbaL4eD0s3cz+vN2z69/l8K7hurq6RdCtc6TkkcrrCMWhNU73gjVItxFaK53Y8mDDti+6YLthU/SC0r9GQEOMvAv5mvLf+gcpKD1fEtVO85C9X1+5hX2tM/ollrAIDRFPApfD9IWDbL33srCd4YDKS+gtg7naWKp4dOwTKNXm7PS5JoVHVctUlVJmhiXIwUxpGQVARVlXLJXADRlPWta+W/TH8kzWTqCZI+icp7jnGYNZfS5k0jW9bzSQCBKRuNAqUpr8klAE0EnOsmE2JOwMzk3oaPrA3Pc8mn6gDgMDJ1wNViVxdgP9F4BNIfe+4HnHrmcqpzwdC18VSrDEJr7whNtnK/p9VOA7uxIEx9bLWN8Si3IPO2znniYnwajiqqdrXbc3/N7//Qfcv97/4Dvfvs7xK0Zl2IXTwDbPJthrBQQKznsgqkzIsXav4KIqtgWywDr5+WonBBKcKWthQIsiomw6pAhVGVcdEEzzHnh9vaOJWWGIRBbj6IbvNutmytAbHKtSlGIcuZYNPOCLgvznHj99gteffEF8zjZETSzhT0OvR3xpFVXWgfaQOW8gqrapeB6z2NzYhTRqneQLYe290cU3NqCtayZlKm5hBbhVdZFAaKncw+uI/i5b5Z+ES3UVToDBqpITgRV5iVx2O+5vbtlmWaur7Y+t+s5gutaNn1AwQtDFkTj10lmpnj4v9w48TiVXasnf9U/aGWKXdfF3r2HnXkx44a2YqnmzDJN7Pd77o5HlnG0iLV5IQO73VVjLM7NE9sN6FxOqdeuRoBMqe8Alo5SDOcGTk0fi1J4IWsFY8mVPyO2RiWY/jT0HV3oSDnVuRbBwubFKhE8quMGM1yEFNZ9Ia7tFmbZGDmfom8MaCuuy0e+ocSlLsWx5cJwfxzpHAH3/UA5X0UkErpkVv3C3NxDI51aiEJVP8uG02bTFWZmVS2fX18z9j3jOHLYHxgPYodbptXNXxZj30c7v8StllASFv15mszbV+G3C1ptF3x5z5J8GivjyFpghE12WRvFCiYidF1H0oWgVk0zh4C65dly8E6ZWhGlFiREFfq1O1rGSdCc6lko7RyVPjTyY91YYu9SLftna7JsBhCzUgprQZOS9xWEoMESucXCJuNZO+rztoZ12AVpXnj16Uu2Vweubm5gs6HrejbXL0j5DbpMgK7lmsWAZsmRkSqJpT4jeC6bHdxewhqyWc3qLi7Mxt4jdJ0VWlBrqYBTKQy1WtItdLQvB1zjAsHnyax/lttXMq6CiNUgjYEQpZZkzimD5/GJGHhKXjraFoAwTwt3r95wdX2NZmWaJj7/xA78fvH8GSknA8ohkAkcl0QvZuE3IBhJaSaXfbrMRBHmnNBFmQ578mLV+qZloSvxdBIIcWQ/wjRviu3LjBjuXZASmtnw63lZkK5D0sI4L3z2+i3Pf/z/8N73/20Syhf3C8P2g8cZ589B0YWRzfiaPbT+/8enczZ9HuraXnN+7VcBbGuO2xPPO9mURcF+uMFOwisVasBJNiEcmjWMh+XlypepeSghNBMq5SiO0D6qUuFQPx0/JGsmNmC8ZVPrfasy0/Jg/wQp/DSsWrgVjiq5fKbcrPvTPh/p+P1l58/1PJa+KHTGInSrPI8TL+J8krdmY+yjWsOMMs/ibAbJlEg52/gkOxg5eXj6nJR8XOqcTDobyEsLc/aiKckKZuWszCkzLzMpZVLyswqakH8L9U5Mal5SdCnDgBL84Fk/wkQWEGEUk5lZE4nAVfwECT05JLSzc7TC9pqr3YZhs+Fl/JCuHxhiIBK5UysgoZSc5VPw80DH/RJ6UNBNVk9eLe5Svmu+L3QOrgqAO7+ufCbuuWp0KzeQtiAC58WPATdTuOd55sf/5Lf42T/6+wxxYzKkGkVwLJPNw6YmBzovlFHSPXK20uJ9OSNNpIb1tWNZ2F9KAoPx1RKeWXdpVSDU1qmseVrFuFxC0+Zp5G6ayVNiO3TrwDWh/Harpxao5ceFlCzvro5pCe3siH3PdtNzOIwsSyIfDty/ect8HBkPI/O8IEHY7LbcvHiPLsbGYyvrGlLjPSd1KtrRL/p3CVsrvXElv/I1CSuI1+x82FI4rB03GrpR2OavrBEzBK1GqYbHYXzHxn6yitCq5kHtBmJngCJp5njYc393x/FwRDSxG/yg8FrIrj0HzPY2qOestXy1vMda8+B0Wdo4rJVnnfs9CRoaWNboK83XTdPB6hUEq1VQikOpmjFrniYOhyPH/R3jNLPMi/1bLH9TCaScUNaaDiYf1F/86aSAtUjTCt4q5Cw8WGJd+xoCEiMhZ6/m6dFruUSQrLl7MUSCF1hrrZBVA86Bp2zF4sb1amwyAboOW1Ub361NfGNA22l5dU+NLKWbAdRzrNwcO6dsSDebBavrmnKxxTwSHJzJurBL2uXastaN0C6E4gFWNdf1ZrCQxi4Gun7muD8wT77A8gqWNpuNeSVONpC/AELOC+O4ePnWBNXDx4NrRdRCGdrEYVE/X1GrZToEOWEQMUBO5jmKQUjBD3csVoPClULJSzjdzMXytlbHccUqOMMPTdldtNYfKODB5lPdO7cWokDzyTzXipPSCkdqzmBZvCswLd9Zb7OIV1gs0y1+/sZq2V6ZOhzv9yzjyOb6iqvrGwSxs/qWuYLqAp5KbH+xmNcdpVrXoYiFbanXGy+erJUBUnekqnop2kgXxatLekW1s0pEZS6aopGg5jBTpXpNy44XH28JAQl2lEPf2wGVYZrMW1ksqmK5g5sYmCY7Jy8GYR4X3s5vTSFIC5qUt1+8ZpkWpnmE5N5ShCV5MZqqshszCs06Uk+6zz6pR6wIhObM7AaOjK8pVYhW0OTq6hlK5+V5ZNWCzgSJGXEycV6IsWN/+4pnL3+Xw/yMP7zvuPnw5wuNfIoKl0j+7uthJD8/FcFSWjwHaXry+0PBWjyYwmpJf4y7PLjvfGwfa7sqhKfvasV4IoFmv/qitG0jtRoovkYKK24LFLVWfYB8IpSVRMc/vP8LDEN5bunXw/epoOCJ0jHlliDnSgysxpM2h6u0e84ni0W99SIKt3nDbT5ffy2EWGdyZCSKoJ23IWvoeO2PNgkBmvnlfiKKgb8SeohmknuhcaU5pWz5oMn/+bulnEh5Bs2MSzL+58+ak4WJ5pQY52S8YLbOLLowLgt5nplSAp0QlLc+WhL3vInZwqH6j9ntrthsOq6ePSf070G34VW6ck/P46X723ktdRAqBC/KcTOa7YSsyvL6s4COmq/cAKoTW1DTbhGP+kj75Yt13TWFxXh8PZb3GaeFP/jh7/Cz//e3ONze0z0rOsl6UU6ZZVns/aN4lVRqkZusypxS9bypi6VSVc+MyKVAlUfsaF4Bndo8F0/DCijMc7Qo1VRhhYCM54+jVSBGM33vc1e2r3jxlTqODiSxnO3FwYaNvc9ojAybDdvN1uXsHgXikmvlxhADIVk4Wt8P9OX81jo/4XT4vJx/620B6nEgti7MY28BLScraZ2oB2tiBTSmX1k1ZHu/bNX/2zV3Jq7K2bdZzRNTwNPQ94RusPxWEss4cnt3x3g4ojnRd5HtMNB3PX3XOR8Fq3J+tnZ8BJqVeIoGHvymZ588JnHa/bnyrYx4Pm/T2klXXH8NYmfnOWDLOTOPe8Zx5u5uzzLPzPPMMieWZWFZkldQzZRwilPnSj7ZyzZHcvLzpPBdKWZYVAk3spSiOIU3FA+2BtPLyMlDQ0t+YUktwXWs4HJMauSstpOuWMh868JvhuZE3kob9ilP8o+WvjGgLXi+kKpYiFgtg+/gCVcmVKml/jWgJCvUUAdqBV8B9YpYsC66bKHnTbhku/gLH1uPWSsKb0fXeSx/sLKfyzQxz+bSV4XNdmCzGXyBrDlABoBKWBwc7g/c39+T54Xiss6hna1msps2ihKhhtoMv1TFAQcMDm7xU9sBg/6nBU1wy1xoBFcQa0+97ahKllDPoev6jnm05NQCxEr1KmP6ptBTAKdILaQRPVcthlAP1T21yvvAi6la5bBwlbQuZk0e6od/VqyDJqz6zhTEMM/uCX24A+Z5YX7zluP9nn678zFZ47hNUK+hHDUkIuOHjJpHrlphEAvNksJUQhncat0r7aZ54TgmpiEjEXabDfg5gidMvlEX14hyC4kSEmhX0VwxAoUgVsAj9O65jMQYzEIuK6ouDC2IsNn0zOPsc2gFQHJz+qPmzHI82Nt4+ToBhmLxVeh88Qy+9hZ1ZtVUBCteiZAyoetrAE1E6bKFOEdZzSk5JWYHv0GEac5mVa6KvQG+lBbm0KHjxOG4Z8ozr29f84H0xOHXTooff11kwdgrrJlR/MTHd9af+6qkzT8e+Wm/fwWQ1fK0szZPrmsWXhtlUJLQW8/aY88pe7coK6HdR80bVSDn89eazVBqmfuiqNdwQD/Soj2I2wxWUt+rKOLnY1/uKLJT4KR41PnbPOWZfSx/sRbaKEooLeBYFQd1HluOMbDr1nDMV8vDIyvattAyTuvxCUcd6FwBLu8Q/SVVTD4IgoZyTtLpyJTUgiBUr0EQywXv/J2eh4nn0Q55JhfFNzMuE4f7e5Z55Hg/cjzuuR0X5mn0XNZEHBPKyH13z5sewqcvGa63vHj2Hu8//5C3+YZZdvQxUqsjN5NSgbuuc1cAWwvGfHJOi2cU3ikP5zP4Z+UMsRKW3hbeKIpcGXuador8XKNawsmaa3S2E1JV5nnk0x/+U372j/4v9vcHckoc9vfs7++4utqZZpJXD2kMka4anR06ZAufjV1ks9uYZ7sYQnzus2Ll9invSg2fLSt1tZWsOVfrgKqX0acq2lnNMxIxw3Rpq7SXl4wZxu04F6oxsvGcq4XjBzLdYDlNXdeR0sTr2z3j/p7NMJA7K0a22QxV47GCZWsJqKIfnunJJ9Tq7RoaY2zRl4LJzpQ8cqIYSnwMNUHXr8q9Acs13z1K4WpywgtqPpiUESohir5+KblRHSH2pjMtM/f3t+zv9yyTFRwZhp5+sEq2BSisRqLT4z3KbHIyK85nKx4QHw7nurV40GNtrWvhtK0WqK17JGZlaa3L/s4lFFr1yDwK9/f3HA8HK6wyzV68r3jYkjlA1O4seaFt+O46t65bVX6qdUzK9VVeaGOcq5EcRXPzPeygLZef2PFOyd+3HKkk4lFM5dis5JhNVwfKA9SlFria/UiHNgusCE1TK4vxrWGAT9A3BLTZmVHr79SSq6pYOGHvkEtBl2RDriuAUc10IbpCWBRnE4x2ynwpkporiIt10zebC0DFFV0BD0GwwQ700jug6Eh9b4BGYVwWttEry1S2hgFLBStaYjlAyzhxeHvPMo0GZLoetgP9dqCn48RjWDdDyXvLtXzrg0P/fMEoQBoZuo7NbsNCZsoLUrm2eYhMuc/V8qPQMB5nZnktXxxDoOsD6GIKWC6LemWGli8HmoUQ7biErIp4XltuGFs7/9U6JmbxkGJCdIWlXEczs0ENSKVkhWMk2Pk1eFWgZS7llE8GCRSW2azJXRfpYzlsMTB51dE+BiQt1ldXcEqeSNOV0pyXBm7X0/q8mhosIJoYD3uWac/8/MZCEh0MroreKaA1MBiNOWSIIZNzrCEx6uA6xKJciws1s1ZaZT8/aqH0JwSEjmEr5MlCTgtoN+VGG03f/MKqll+RPYwg2FapCkwqB/emYiAoSpGzySrlfQh9UIKABjjs9/TDjtjZelp8GCOJpJmYO3JK9t4pgWaWtEDf8epN4Ob6DR9/8gnzvPBrL/40w/YZ193VWr2Pr4eKn2DOiSiBoy50RLqyfut1f9R2jR4ofXw5MGv/PveuFXEOpyCt/F3XHWuo7nl7xXunFah42yJ0URilMhZvd+28CTRxYKX1vtNZOe1XSquyAEIg8dde/H3+j8N//ACEtmzwEbWi9uWcE6xvvf71FHBTihxpxsU7Ia0mfP4MWcesBXLnQO9JKvq0n3Oiqozac8wrTxQRJFFn68HKK6Ko5BBVoGKN1xGIq7f/FTteZ+c9NZc8kENGNg72vqX8Sn9Hn4/c399zuL1nf3/Pm7s7xvFImo5MUyDGzDLu2b++ZXP1is31jm9/+CHbeMXP0vtmBKOrRU3KbJysYVkBx/kcLSlX0FrkyFOKaFvd8imrfaECBh9MSVXaz0faQ3+lWZO6sMwTn/74d/nhb/893n7xhnkcTU7GYhRxj0CyggyhVBFEDYRbx5nnhRgiz5/fEGNkOh7sTChfhIIZ70LSakQBO56mr0zJC8j43NvZZTbY0ce3rOuS+xwQNt2aRyaynnsmAurrQxHEqzhHWTP1S85OCIL0A5utmbnmaeT17R37N2/oNzuGHpPdbhTX1DEva9GLImsrMKo9aubXdaQKpk8myMFk1vV7sFSMCtQzaECC6XXFyFO9vv7u6qDN7i8gcpXf52spxsCSlRCVhIcNBuVwvOfN2zvmw54Q4GrTs9lsiH0kiBlecTCxtt2Cs2aiT5aqrnpA5T+PrdezXLHmu0IV8InUsMjWkJVCu1uLgLe9k5bM/d1bjuNkx1vMC8sysczZQsKTpWrkE6OcRxWx5vKvcoMK2GpExMnZeBY+XIDaaohpdU6/zvd2EHOaSOwszFsN2pZ07GLcsccFRCJRxc/IXgHbiTqePdIsylpQrxrnK0P295LqqSvb8V30DQFtnMSBtYuyJhLmTDd0LKrs93t2wwDiBUHE47y7shWVIqIr2q+Ta9YTaujl+UZb7wV8w9hDyvllOLDKeWXqz7qdV/Dyw7ZVLZlxXWUGgzxmN6dMStazvIzklNAAV1dX9H1PDNEYdl4FVSkVkiv3OptggYiVf9VsgjVI4P333+e+v+ewP/pIrIplbn63g7rVgRVetAJfTDY2Xd+Tp8XaKHpaPGWi9Q9fpF20Dq2xxhnVeHLtyVlzrOEV6zqgKsRZTCpmByHF/Z40k5Zk4RSbgdhFunlmcq/bqixZP3JWy+moQiczLxZitP3gBtGJ5Ec9FAuMumX6RNirktLiIStUkOLLB6GJgxcrqkBK3L16wzxNa4XIBhS2v0v1QmeyLmh2a2e2AA0RQVOqMf0KJvxiXIWyhEa4GqOKXQcamTw2v85fAdYezirqawLPoFMLlZKm3+mszxnoRKzypq0uC9OdFqTkYvgC1iAwZy9xPZGlh5KvIJnC9jKZeYG0T4h6cRc3riR5y09/8ns+xj2f/Z3/jps/+x/yG3/mz/Ptb/0S0cOLvk7g1ktkxoTOp4dXfHB9w3W3e1Lxf4pOlY7z7x5n4S2geqwdaADaCVh4pK1isXwAY9a/z4EbDl6CBCQMwOwed7GQoUYRKHkg9n5ih9/ie70kpldFwM6KLPHpNRcY6J3ft+qBrWUfO304v+2150rekyDnEWqFchG0qxZ0Cj/b8W6tv+vXD5/3tLVb1h/NJTW/o34vheU+uf5E1vO4zkPI1n6tBa0UCCHW8CITCi4vPNf20/y+9f0Kbp4t/Klwz6+lI/e3b7m/u+X1m1tu7+44jhPoTFpec7x9xdvXn/HivQ/56P1bxu37LPGaMfcgfR2vk7LqDeht+22/r+vpnDefjjEePq8P2jgH1S2gewwESkU3p/cH9MyIoLz95Pf54f/5P3P36g3LtBDEPFZdF09WnqpaOGQQjy7y42AUxsXm49mzK/rBqu0GBMIqG4ryGHxNWq5bcNlj63YpYYFF128U+Sxr1UdE6hmuIrbPSzGyqshinjjTwUKV4/bezQjk4t8RutgxTplxHLl7+5bjYc88J6Tv/fri+QjmYSugJZZwuVNqg5hP9LmSG60tfzGesvgZvut+9r3g6R8GZm16Qxerm1dkadalrAp2LQzS6CotEBKPJPDzGLsuMk8Tr9685ri/J2hmO/QM/cCw6eoRO+ZdVAwA+Rs2xecKaGnBlK0jf67ieq7PQy252DKTNtSyWRAlvK2ZyeDyXRpv0IOd5oOimlmOR6Zxz70fWr1ME7OHQCavuquNXthSDGe9dCPBKtLWlZDVZE7tZyg9s75Yl05lYVkTppev+rRdWzZHqHyvcPggHZ2ns0Sk1tB+oPu6UCrg0YY0uHNqxSTNhK1j+SXi6BsC2hSGdfPYuLpFJwO23dhuN9xcX3N/f18tgqZEeIZYUkSyWyUc7RvXAS+vWhlwUeAFLEHU+wFYJcbCkKGUly7r2dovlpVVAIYYkVijZe27ZqErZrlRtbK5WrxY3Rvy8AAAIABJREFUIZCXxHh3YD5ODNsNu92O7vqKnLOdwUZj3VCtcdLWn1CFlWLWjcPdPX3fs+x6QoDdZmDTd+aWTslC21gXigKST8P0iqKlrqDNSyb0vu1No7YLixWoZVRVySubZS1ef55JUqLDy++mC4V1gxVF0ZuWXObJpZTPZQjC4TCRU6bf9Fb9se/pFWZdHCSvVI6TqO3V9zY+fXX1HstwZDnsScts5yQVQZlMEc2+SKxsstKG3BAEXeyNrTS6D5WYi31JdrBjiHbuU+1Eo+hVJcTXmikFqa5LS3gpZ4vomrkpgWKhrLkEDryCmDDsOjsiY6r7Tr1/oSLPVvGvvMQVt+CKYzkSIeKhorjfujEbVUUsrEIlhkBfAL9Ajh2iwnazsXBUFAkQfWzV96hOkJP3GQcPqpYbEJQ+wHKcef07/zv/4os/oP9Lf4P3P/xOVTS+LhIReg28nkau+g1TSmy6bIeFr6r9V6YHoOvsk6cB3Nnf7/CmnVO1TjbhkE89r55ZJu4hUIHgHtxg3p6TA+vRBrD5iXcSEcmuyPmZfa6gGH/1A5/zVIGbVXft11ZXneHEI92+YSvw302nXv/HRknPvreQoqo6PXpdGaeTcdfHZ1AaZdc33aMVCB8CrSfAxBP0OCg5jXxow6DqGIcWDBWlh7N74D4P3OeeD7qJ+P4Lrl9kXnx3Tz684c3rN7x69Zq727cs80LMiZfHP+T46iXXH36LD997n274kDDsuMtXD6rcnQO2FXiGRysDPjYuhZ+WMDltvntsjE/mhDb8/RSsnYQYs669nBP393t+8H//r9zdHTyNQum7QNcXHxReWdOV+m793AoVOMfSbGdU9j1IYHd1xX6eWZZlfXCZmGZvCBbCXlInoigTrj94EambzRXjeGRKix19IWLeBgcDtUEpsizWvVlBqjS6g+ha9RTznKlihTZS5jgeub2943B/z3QcSTmzub5iDZi2e0LsaiGcoHYYuYUZn871+b5fDdwlpFCds9ncWcp8PC1copzIhiKzLezL3rfWo2gVcbz9xtN2TkVHy2oRPvv9nv3+nmWe2PQ9Q7ehH3ovIhYfeHY0t2GXZe+FOuXhZEBcIhYgRwnbb3Uzf0fxiKazkdRmLQX3xLXQGDk3gJ6vf6lzMM8LeV6Y21SiRq98jOGWo6jKE9tLWt5Vxig66CqvUsr1F+9i9W7pqqGqel0G1wlKlFAQ8YIu6x6vVc1FiF2saRrtsK3BoOtwBDxlqGAAtDphtIzVYwamJw14Rt8Q0OaDg1DP4QJMoIDF84tVFyqVtZYy8eYFSMvCcbaQqd3QE7vOjQVm+y3t1XwIVwBzWlANxCgOEm0TuupLtVCohc1pWgECrAw7xOguzjbOmbriFAsVTNnymWInZA9bK+BtnhMhJdKcyLPF+Hb9huvrDdthUxMbxYtYNJpDtboUQTxPC+NxYZomdrsNu5tr+n4gxsiyZCQncwf7Csv+xu1mqXu3jHN2TxaFqVkfQi3l6wy6WFv85vbcvHWubVRKVabgVrDgG8TerVVk1rXyqJLqmpyEQJ4XxsNopZJ7WwtZIeepAgYRalWgUu7X7GC2eZd5IuUdMW6I1z1LOpLvj1ZMBCil+9cjbwpYM8tRwZIKzqTUN7cznCD00iFgVSqbnMYSalJUXRGrlmn5CoWNuftdjRlkLWErFMllP9qkxeyn2wQrIR1jQPFjMtI624IY0nOAlT1vUMs6E7PY5mCKfnnRBLXyUlkPVcOWtPbcw48FmDClP8ZA30diUJ7dXFULcbVCqed+qtJ3C2lZAM+5yLkaIoxnCJvthmmc+OTHP4Ag/Dt/5T/jevee53fIiar+88A4EeGjmxcc5pGuHxDBi+P80SDbadmNFTB9uaftq9FjQK70/7zNx67RspjLdboKUDugmmq8kRCQ3HiXcaEmUPIrxT01pZgG5FpuGUperj1NJLoSPNteCjaDWvnIOg5t8Yo2D6q95ssA3QPw9cjnj+lnrYJxXsGwvefUWvwojDuBz095eqri8aDN8uTTTrYetvU6edB+20Yxva39b5/XKlBr379YhtrWIFs2N+/RbSf+re+85tWrl7z89GNevb5jSTP7w8z42Rfcv33L9uZzvv+9X+GqH7mTZxz1/2fuTXdlOZI0sc/MPSIy8yz3kpesItlFVnct3QNpRgIGgiDphyQIEKA30APoHWcEQYCkwYymW5oButVbVVfXwmKTxe1uZ8vMCHe3+WFm7h558rLYoz+MKt5zTi4RvpibfbaPJwDtzcpVH2Lef156/tH97ZEErhy6/OyV2X5NmdmMwvrd0nmL+3OiofsCiBZd+OQv/xQvv/pSi0uItqIYxlhDTvWMtHsFU4A1uIdXBOxycxhG/T6kKZIO8sUAvtMakebG1eJezbBIHLC72GHOBc8//wKcVUGqhuaOFjzHlKqoN2xkdJG96BhruGo5pVcUoBDu7+41lPbhHsf9Acu8aOE2fQhgzeard8x+CgTzvCBMEwJ39I4WjwOcgGFiM2ifnoaOdk7OSK1ADgFKAcXYMIw0OY56MrR4TIiekoPuSb7OWuL9fr/H3e0t0nxEJOBis8HU5a0BsGrRjo4UT2o+m+LRHlcKqBUtOmE0NeyuU1ROL1p90aNwtJUQ6m0NaxhmEquoXS0lpDQGDzk1vuD7w1YZnAIj5IAFeX1m+l05U7hD0PHvanxsP70xNq3et+90sJHMmCFoMsKWCiAzDKMZOlCfg9WaE0WAredcd4/V5+AqNdWaC445Uem2+/LvUdJOr++M0hYLwYtjuAtRLRj2d1FvQTFBlUvWUp3QBdCmqAkjMw4Q5OOMKQZM0+SUVK+q4JSM43FRZkuj5UI5WNES5VIUcLbFZXgDaRFzpbPrGCtRC9tl1P5epKGCQ9BGxBDBfJhNIVQmWAoBknE4HDDPM4gjuFxhfCsauA2QtFQCfLTfhrcVwAvSnHBzOOL+9h7TdsL26hIUNLE/nwA/FSKwENBOgBmxlVKQSsLo1VKtxLu3uoSYNzNYeWgvk88MKtYigdULkUuLsSYiFFgzWFPee29cDQyVxkx8hfv9BGSVF5FzgWBBHAYtHJMY50zYJWtCd/HQ2bLg4SaDGZi2F4hhwDBcIFxvMB/ugXlWAczab2ZJqjhoXgXZPbPmWwKgECwH65G62YWHrYGgH/AqmME1P5CtemSRAogmszCohrUSqUXVvWouyYhsL1Rj1VwSEc/IboIfpgRnQLjli7iABghRG8LUfWq9ajoloFO8K98zYc/SrFfRQBFCwOGgxQ9ijBp2eqJclJyR5gVLTmpwgW1pyZViHuaCYSoYw4DMGZ/+8ufI5Yif/PiPMbz3n4LDoG1CpogxTAiw4jeN4DrqWl/nXiUibIcJCwpIlAccJWOiaIBj/d03sWg5+a3PH5PV5/5xTL5+z85yAwXyxsGsvAc96ukREmCggtb3Ii0QpQq/tKfJiXCTx8GdDvaydmG323lYn/NRVeIYLVymV9T0S30eSnuE1HYp7i1+fCzfpPa4/UPOfLZ6hszzEsyDnHLXrNhWnqh50tpe+L2oFhJpz9CFO1W03Yvg4yh2/ryoy1rJehxeeKoEPVbczr/fe7tWStAZYpolYM4BoAEpbLF79y389Nk7ePH8a/zus3/Aq9sH5GMCcsbxeMTxfsEH77+DZ0/fxefyDBnDo3v68/px+Eo1QOefwUop8tdA6jEqRUx+r+faE7vOMz963qkHuyqLIpjnA37zl3+GT/7m3+F4NJ42aIEJ5+0lZSTzvrXVJjB16QmMhoeYEeOAw36P7WZsSpXNh4gQCpA9XNSEigTto5c93NGgOCPjbr/H7etbBCFVJqF56bmcgH07t0qnJocd/BaLKLKzRCBEYlBW76HWETAP+rLH8eEOx/0e85whRTAE7xmrYNfbL7mXo55xy2P2nrT9Fdk9+lXQtPxarPeNbX7c3du/JgIM7GdOFV0BICXZyvUft7Bxi7xq7/SMkpBSwv39A+7uX0OKYIoDNpsB4zC0AiPei7QR4ck5PVUIXTE4LX8llaG5MUPtEzYfaeOCeKqM4z0YhuvuJ6sVrEpoxcMGQsmIoeHnZhjnOGAkRqYFKWckM/yvlKJOLhBpFA76WffgCMpDXZ4AzchQ37c1XBuU9LNu3IUZFbXKZYA7Zuoudh421REYMWrtAEmo+Nm3WrqIBTXmK2/R3H87dQGQxcf4Zvn7Tdd3RmkTq2/uzJODrBqKqk6gRSckZ2QHelUL1w0cB3VfpiXhMC845oxIjM00aVy0EyURgKzMpBJyL5SSKWJszyaIBIByDUdkfy6v7TVKJC0ZU0kggFg73W+nTa3Ux9Dqiupx05/ZQKg26ku4vQ0Yxwnbi63dv4W9MREWaXkd+roSWwxADAQSBQ/3N/d4uNtjmEaMIwHYNWAEdeUKe75Rdwik/RQIUmGMwPqU1D8tudUtfsjKiDlAqGDJWttqjAFZaK1Dnd7PQIc7njs7ps7TfqpAsNy6Wu3CvkFaKMGFSR/G0aLDzUsEuw8TpCTcvHiJYdpjd/0Eo5Xe3VxcoUxHzHd3KFm/xUEVDrFQLyINlS2WAyC2P16tyidHIIRAdf9PmbaWxhZjvoSlkIYWhaBMBg6C25SlwO4HVRax1lOpFCDEylADOlDZ3ciXMXSV2ajSgrTv+M/q1vDcom6RQVYJzi3DGkbJMFDP0N5ttg9ZtHl7zlkrbhbBcb8AMuua9x4g1UI0rMcs1+NQQFkV/WkcQTzj45/9DA9ffwrwvwLFEdvpApsf/5e4enoNgLCNAW9dP8W4vVZIT6yKHMH+9umQS4QTWtVQycWEaKSAY0mYWBU3zxw4IfH1GnbqmEBQrNl738up8SjneSdAHI89J32OmodQn7638uScAJlHr598vpDmg/rA1PAij77qY/TQtGJC3xWekguChUXnVJRXs1mIit+D6/KfCupTVuLevOYVAfpGTs4za8XKdjRrfpw/o+qZ3f3rnGwz3EPO1YqnYdAiyuNr5TpoIRv3jotY4Ybe+kztGUWcD7TiU6cgps5v9R5177Xfz+WQnOZ0re9Lj/kTmhxqfedaCKFU8NeuRQJeY4fXtMMH7z/Bk2ffw4svPsEXX7zA7f0tJAkgt/jlr2/wzrPXePb9B1xfPcM/zFcoWLf0WVm1zZNxWgmvt7q3c2IrbDQaang2wZs9g4wvrZS31WrZGLjRRVXkCpZlj09++Rf45G/+bxxutTlyiIxxGmtBq1R7ZTrg9bBN2zf3nqEPhCNkyRpWN8aOMKkaFBT/9muATvkRIBcUIaRlxvPnr3DYHxBCwDBaLj4EWSySyHi9pxHkJEDgZojxjxA0ioMJ2c5aFtEesTnDE63dFDGOo/U4PaIUsZ6ibozRuRO5QdOMAd35Wu+E/XQjPrWmxSgwAwig+dmWSnJ6F7Kw7hWNN1rT24XaroA6pVhMVuhITiKDXN5JQWDBJg6IISIOATGEqrDV1JGuUlwzuvgtlZ8ImnLAKFXG54IOx56c++4lcQ+zDZMhyNRCSUEEYm0XJCl15N/xHVGg4SjARozmHPHzZRgjKBWjaISPBDW++hxFrFqxe71BEC/5Xxehyb3HgknfF8cmj4wr7fvtu62fLgEt5LejjcYr7FuBMATtFywUrMKltovKMN7sxjuFqkjUvIAAEFkLmBQRy8MzmXgSMfFN13dHaQvOVMVowhMnLSxR37US9mpNhBVfAGDWMCBlqSXJjQUgzTNmCBAGCIDtSM1sCuhmVTrQg1ZKQUqlWsaIAArmXROrXtldawFlzN4r8ClX08MdBwwALrFFCIzD/T0O+yOWJddyrDlbKTArbLE/JMzHI3aXm0a0UqyruofiOSDyqpAqyNiYQhQFS7kUpOMR6SCYjxlhiBqeiXWIVk9oMLBTKwrWOevPBmT9dVOu+t57dg2BLUxUGYzfI9TeI/7I5nGjnnHU0EnSWO9+PDAFqg7HmSzAZiEpmdAOeBPIYvMt0EIILtSX4xG3z7/G9vIS0+7SQvgGLV2frRW5KK1x8N5umvjN2jCvE6ImPL18vluCINUCCqAzYKBj3IL5cMDdnXppmzXfgYV9lqn2U2NhBCareufPqx+v+WsOEg2FaoSyFEjwEyStvLgpZNozxi239EgQZhEFm1JW+W1ujVUUUCy8QwUPBw1BSvOMaRqQUsLrm1uknKBpv3mlwDiwECYIGJfbEdNmwjRtcH9/MKOiYIgRl7sdXr26wzRtIPkW93iNzYt/Cfr+2yCOeCDgbrMDvf8niBxB0xXG6VKL84SoxW1iwNXmEtGBS7eHHCyBHoRFcs3zOJQFA8dWzQpOd76rsjp3rkQVCJJkvL6/xf52DylFK52ODA/74RhAoqXBvcVDCOExxuzuvfKy+eu9u6ofntPKiaayUggDgeKAQMGK0+BRmEujDPfAK6fTQgvSmvqy5pgoD0yV+FVZmbU3WAsaXoEa5Vf+h+6JtsCgajRxJetUMPbTVD4PcG73Pb3I7tOEezvhbiHuB6fhdY/vE9DzWK/A2wGOaizpsn0MQDelsjv73fPqmtTxrtcHQPXInYYO9jnSNphHYGntpQur36XjNTWM7sSl8Q/HHSLv8MEPdnj69Ct89tkX+PrFF5jnGYGAF59/ivv9Hh/8IOG964IbXOCIDQqFVVVHN5KFEOt8Hl8OjPrcPQDgdThtPR1q6HOLfOkOqD83hNj9LVB5p704n//mb/HFv/9XWG4fVGELjGkarZCCoCQ1RgEtJ7PycTcIGx5i6eQymawVQhLqzpWYh//k6NueDQG1oIcaoQXHeYbkghgCxsB1HZVtuYLQnlAKTPErlZdr1L9XFPB/CAWuYAEcyeSA1PnFIWIsugYZlicEsnu1xV4ZIVyB7iFJ2xU9tKrRNCplVOM6KFhYpbiwtw/p94oUMAUUyViSGv8hXnRFxxDYsZaHdvervfZEBwGyyVURxT1htwFgRVaqQur71IqYUeUD7kkncxAICgF9H0cY7vXsit5j3IdGEhHAAipWyM1eq42LSBUXTaeISstmfKIaCtjPt/rnVsaRhqeaksXEVvhczy4LKn/hoPWsqXSmRaYz57gZjtx71htjAKx47DnDFGSNUU65uyuNvYyuPXQBEKz/Mun8smRQaTyZmFBI6c3173omzagtZ9pQifGY87zr8fUdUdqoI9T11eeTMRPGIWAaJ+yPR30fJ6QkGYIAdymHGNUlWwpKOmIcB3PRajJ8KaXbuqa6LJZTNgwaPKVUYmN0b41b/MQsi+z3QFX0ig+ykrhakIZBwy8jK9Pa72cga7hAkmCeOOvBUjIe7u9xcbXDuBkeMTOPN4a4T8qtS/paIECCNjFWL5JYo8MFaV4wWHLlqXWc0Y8favX280u+3k3pcQVJQLUdgH+mt1qSAZQ+yqFtvc6J7cUu4MEfWOdVANM8pDGBDjCy7wMr0H1kbXXrRn/wCc1CCJgRoeD+5gbLfNQQ091uVca1wGP6HaBZz7MiNl5bI3HAabRh4Z51at0cnQHWvDUilJJx8/oO85JwcbXDZhhQ4+xhSbT2s2EBRiEPIaw8x2SghuLUXCRygOiVOVFpvMqIDuyskCKad5YJoNLiw4mpKm61iA1IewyFgBAZwrUjDspxD7ncIcQIETXUbDYRyIwiBYclaRUqIVxsJlxeX2KzvcJuO4JQcJgz6LBYTz8CgTGNBC2/nbAZBzDUY353vzcFOODh4QB5/m+w213i6Qd/CNldIRfB58sWHEdspwHjByMyBewPBzwcj9jGEaVkbLZbLfBCDA7APC+Y5xlDHBFCwhCielWltORvBkhMcHqYm7R8lHme8eWnf4Or8m9QlgWIjBS15LBwAIYBMEVt3F3iQP85ZPPTWk313HWqrNWd7TWXtWxeffaRF0ZTzFC8jlYP/kwRQzV0ldryw2mtf6gUUcu4GzbsuSBWoZayLdpaA3IMFj2x3I16qEPS1x1UmeHnVHwGT5Yppyvl+PfEi3myxt9W6J6GGr7xe37ubOzOaftPO7vzIXkpemCtfLGDDbuPyFrBPKfn12E1FrZS8vS5577Znm/fQh9eCAAhqOfiy3yFy8sJH/34Gm+9/QSffvJbvL57wCER8sMRv/3V3+Pd9+7x3jvfBzZP8UVWzzif0YJ7r3OvdNYQ9P6zrsi5AkuCUNbhb3a3mv6g8uXNfa1KyXjx8iV++f/+H3jx/DnmeQGzetiC5aFLKWqgLaKhVmY081DonAs4Ui0iocUwWj9V7jfFZJqJfr0H9Yp8A84kauDMEFX4shqBYgjVOKwk4kaBdt5rOXZBzf8uXUUFhVrmwenkgsUa2bmpVGEGpogQg/au4tCFCnluWIZUI65050+q0QTibMt4RadcGypS4+Kj81VUOc7Oe/Q1NQhmlJwRwojIoY5bozhc6et5qI9BunPByIzu3lDF1ItnkXnnTsb1WGFrey0eLmhnlXOpPXX7a30ufXBNqSJT8AFBYQIh6H5Y3iMxAxxR0gJkaDuDx+YAX93V4DVE1k+Nry0BHMDFMCgTSMxbZUpbsR5fHp/hRi42z7kXQlrzHsdU673wypHfxJ9c4bMFrXzd8ZtNAG6EcNrT3EPqalvY3oidGxGw+R7E7w2cJFdLowFxj+S3kxt+fUeUNqkFF4DGbE6vGBjTOGKMAXPirupfI94QlCFQkdrsQUDIoi7ZyKM25V3UKpwsrCKnjBBdoOu9nP8oUzQ2bqCVHAGDIaV3kfs3/Tttjh2HAxGg+bdavGCMGv4hAg3rPByQUsZACmiJGQ/7PeI4VoElgHqbIG2sJNUqA0K1AmQjnOBKZ9D8Luqbq0or3U5nSr7GGJCImpm3DkK0bHtnXUGlUfOcorRik7UAyCO+hXrQxQWVWvdqf4ET0tBpMTyE0IVPz6xgnggHLlmakAwQi7tXhhYCY9oMKDlgmZcqsJgI6TiDcsbkSljR+OicBMnAJkq2UA+qUkR826sy60LHwUUDCACQS4EHcXhOWyv/XHC4v0dKC9LVhTYktXDIYqAgcNfIgWjV1qE9hqrwq3qwvykFXEM79dUeBANatyRwC+libsn54ptvaEdEwaSHBlWrrtEbhBVwlwzJGcv+oN7fOCjgAePq6VOQhbvMhyMOxyOIB1w/ucJms0EuwN39HstRywqfchBmxmazw/5wwGERXExaO/X4oMafBEYgwWazwdPrp5jSHrg9oJSM66SN2y/4KZjfAyHieDjg5avXuIU2bAcxFkkYAIhkTGNEzgIeRjx76x1cX12CETFQhJAgG+jJdv6KhfUQCMia15SXA/7k2f+KcvcLyCYjl2RAwgCnEFAYWBbEssU77/4WL/l/QZK32/k0On0kFyoOO2c1OH+demR8XYOhxmoMcdpiaP8wB+xUdVN49Tlgrew4OK6h8WZdLQYeqUZkdOqetN8JjWaZGSnlmpNZTbEGLqh7qACtkpcLcWlgsb9OPT3+k8wg5nOta3oqBmg9Z12Oc+Ci4wo+HvupBSvWiqnfsd/ues7skPdqcg9ZT+dJ1OYitJ6CRyHICljiZE3W89OwVmeEbXEWMF7miAee8OEHG+y2W3z66Wf48uuvsRz2QAj4/LNPcJiP+OD9gj+4IHwyX1ZPF2B8qHRAzf3/b1Cqa5ANNcDGEI/XbmtSh+mArt5pNV9XEI/HA37zp/8S+5cvcLS2ONM01DYD2fJxSyktL4ganpNSrGF2XCs6NXyuhZ09usj82KUp5QCsCMQI9Yaq4hYh4HHQqsX2nDVyaXlt7pmqBk4zotSrhgJLK2hVWiGSkmBRU3W54YZNZraQcYLkgCKkBeSQAYpgWjqeApUPIhXvOeQQsLrGe6VNrOqi57A0IQyQltJv4N9y68YNDocZhIwiA4RQe3yW0rdLaDRMpCkPYejpvs8zc8lqCgsERMHT5UwWnq5+zx/0PmIKRMVkogpxMRoqoFpFstj5ZANcdTRdqUwKDLYQxBgYYRgBUiMBM2EuGWwRZ+5dbfy/dIYQVXS9RU9PSWT/EgmEA8hCIFkMtzLVc6DfNc8es7U9sADCKgrWYdH9eTz15LtydM6+4twLzsPsOx7W3iWDNAUa0LBRinVLramEHWNqdLYeHODeOgEIvZ7Q5oVUgPjmCqT99R1R2mgd5ma5aqs4emeuISDEiMvNBssy16pxDhiZe02gT8hWQtkfFu3/AUFgtTgVgZYkzQGDWalLVQhRAbMSp4WFlQJhLchArKVRc2EQS7dfBYRg4Nf9VhrCJyQoJSBGdUtP40YBdskYpoxxGlFywXY7IsaxegO0elpUIARlfil7YqcRXyBveF8b/EV2hcCUN1bmUpMnpXnh9M+W+yK2/pGB3TBimY9gYiTjkxMqW63/NouFE38LjUoCDH1nePTAyy0bjCLN8lLPIhOCjTGblaS6y4G63zX8ykBuDQUkQoRgbik4Gg4IqCexaMheCAG81dzItORWjpetCI4pHLnof8s+4+lbVxg4YzkcIVALYuvkYTTM1prCtFYKAEq2cFE/DUBaEsj2lUgFKMSUo5yRjgvu8g2W7WalXHtvPZetRM1j2qXaWJlpWxNfRxtDcMsQa283RmeVP7lCx5CiWc8V8KnVtbamqAm+3rzb8tpYq5uBvZJlwcEAerAiKIEmBWnBh5wQglLdw/6Ih4cjJJdGrWcYn1tAN5sNDvt7LEkbxvKoLHAiQjoekHLCy9ev8Gz8PgIKUAp2lIG84HAz4+3bXyOGiPF4j226wS9uBtw/ZJ2nuTlCLPivf/R/4c9++99jt9vhbgNcXzP2B7W4D0OEELAsx5p38fBwh8+fv8b11QWe7C616BAdcbl5gZevMhgZeU6g2IrtuFcVAJYk2MbXeC1J99HTc/q1OCPAxMHLuffOSLyVZdMqY4WgZcjVuKKN1yvvNsHeMEivMtjfVc41QJq9cigxooVvuaCt3gayRsGn4zQazDmfPLdddV3MuHCqlDwGCOcd905lAAAgAElEQVS/f7q+6kEqtfWBoGlQeuZPhmocT1jOrndvMV7xVDesASfRIg0q9hcDFTwUU4q7nazj6zi+8oRHc3cQqjL7tErgm8bvYM9lw+n6zhLx68NTbC+v8NM/vsLF5SU+/d2neLg7gOaE5599hmXJ+OgjwYeXwO/SdV1jQuclBVCYUNLK1r9SSpynOqZoc5eaBwmgenuJWm6vG0NLR7MigsP+Ab/403+Bz3/79zjc7wERbTsT9SyUItXDxkGLL60UMyiPHMZo3jd7jvNsJlRXElm1O1bQ6CHqplKgVTlUYyaHoOfTPjNtRkg2r6FhzarpGZ/uczoBIJlO63tO8MJNihNq7zJAIyikyatcEqwlrb7PauTWnGq7MZuXrhoimoB2WlVM5ikBRoMOmCkAyFrROuv3vYDRCUXCdUsmwWxxbDEG3N3f4eH+Bk+un2qhrZIgHE3JpJWxpg819xDsNYtwHAU8MuifiicBgFYhsi6Ul9uvrFQ3SwQaJsktWoi6sDsPRXXe0wxtyjM4RlAcgFIQA2OcBo12AbAsgnlOOM6pnqdTD/ZjL5aG3PacQM+KecxKazvgXrRi42bj4VpqjTQXcuUZf8x3XbbocsjZ99ApcnXcUPJezElRnJbsfYPEPalUQwMCYYgBYwxAIFDug5OlzuV0rKuraMqID9kdBwBAUc30Cl8e45f++k4obQRgCAE5LeYuV+MWmzVCP9M2R/NHBtPGgXlJyIuWg57N6l3jee1QD4GBMeJwXDBEwhijlqoWYE4Zc84oKSEzY4gaQkliDQDZbRVqVUjLgsOcIVKwmUaM44i2w4AHBsDCNJuFokvcJjLlSoE8TElSog6IMZhFIyBa2fp2ebJ3RvK4chGNuVYKawChavh6yGPkqqh6Iqbz7JL7Q0r10NqgIWBsxggmQRwjsGhhkRZ+w7WXk3vrfN+KFScBlFlCxDyl6xhl8b4oACict5TkLgQydDlORFwZVsVk8DATVbyzH15WJpWJgJJRJCJI0ZC+OOh4c8YwaONghjY+LUUq6Mm5YF4EuZApVgW7y6cI0wGH+3vkJanybOFYZIcSaOGcFYdVClNFJw4ByXtZGSMTaEXMmkqdC9LhCCHGwKqIK8hSZUo06qB6EJoFvmeIHsLmYauwSkcwBmJMUDoGWZmcvl6kQs+6x75tDhQcFBB3Ia/GoNY6OSMVwTLPmKYRgXit+NbLwMWS67kjO/Dn4sZ12BqSMI0b3D/swWHG5cUECREDAbzRSnXbacRblzsgiCrsrGw5pYRf/vVf4vBwxPbiAm+/9QQ/2syYh47mhRAjMNCC//YP/3cgBIxccMUf4m9v/yfkvCg9hoCH+zvQMONw/B1uvvoSz1+8wothC9r8BM+e7PE//LP/B19+eYcAnWMGY3DB7evrYIk8Ib3Lz5UmUE5R/DqsZP3mynvSAXp/r/98doDQWRmlgmkDcSH0VplzG2M/188uUlYRGMeUQZFW1LtCS51Fnaglmj+e0/rZ54TkN73WAxf3Gqv3xIEIr97vv6MxGo/XvnmJHq+33//U0+l9IWvhE5sPd94iSBdO5n8bQJEzpOH8oSrzj1eh/STnAVIrV/ZzavPSSAn3zJ3O2YYNgHFEwMvwLj76wwlXV1v8+uNPcfvqFQSC25sX+OXPH/Djn/wE37smPC9XKFjnYwEAshoppV/ffjwdjZxViu0K4RzoR8UWqkgUzMsRv/7bP8Pnv/kF5v0eKAXD6PhC+XxaFpSUwQREK2vvchfQ9jnDNGLc7YBl0UINZkRV/YfbmJ1vF/fOA16hWsG8nT8O2Ow22Oy2ODzcqyGNVf5zIN/CSgPOh4t5QVypFCIEO1tCZPKneVqrwuhKBpsczxn5kXzzs2lh1eRg15UcXxX/xmrh23tStDiN39yKFimGSfYMW7NGYAbCdV0zMQYGlpzw8vkrSE7YTROGcQRRhLcn8UfwCfNSUjJ1/wR31J3tFCb4elF7X0QQSJWH0p+tOubmF6oyuBbkwXlZ1xXUceSsS6HeVbORgqYR0xDM8Cw4zlq1/OHwAAJjF7zQjp3hXgb0c1yhF1PY7Llq3HBc4WdVUwiKDUz8HPZV1q3OTuhIwHFp8/yZnWGVQ/04hN+Ahho4BGogLgVMBbk7hbCqx/VQkHlBCRDr5VyoIFKAR9EJKc7SSJDUyVv3LrexcWBIOpcf2Mnpb3F9J5Q2v168fIHtdsIu7joQQDAHiF51DRjEevA30wgZB0wpI6cZkGw5UYxGaIxxiJiXBSmppycw40gBBalakNyrkksG298lF0zBinvkgiUVUFE9fTnOWlwjDKqMoAG4Kvx86JVxRNTQFhJos1lSJbGL39XP6tjrnCsTUMHMgDZ97vpGAC0PqWd9evDdM9jGB1NEGsyysbKDMZuPHRYOAy53GywpY56PXS+Kbo8Eq9cq66lCQqwy3Ll8g34mrVBDvW3x8CapjMC/pRUXuftWXXwFNOQhfaKWgaIJt2oF0v1NktSr5rlBNGjiuLSYbUAgWfvWCamSvBweUK4uEOIG26uI5XBAur/Vio3dfvpeKNP3/DV/PbT1Mk5NcOauoQwlC5IxbwbMs6aMyanNb+kWZZRWlKHmCviYPAfUwWDwMQCSBJkaDfu5JGqhkbq2LaTNmaZWzPM1s/eKK6q6B+xKNKCVS0XHmucFmEabCzfAUbxPDDVzt9MuK/U+Do5sxKPK+4DLC8LDfo/yEhhGxiFriXliIB2P2G4iNtstCIyFYLxEtHgKvMl5Qc4JkmwPAEwckVLBZ5/+N9r7UQg3d3dAWhDDvwZB95FEK4eG8SUYv8IFz/jgyR4y3uDTu9/hg/gbvPpaUFLLlXAPZZtzR9vSwqRr7qQp1f38v831TXlKcvLcgA4UEQGkFcKqsYq51mNqgr5TtGxoDqb6IiYOuoagzwhdAaje61Q98atw9AZeT683WTJPFVIfXFUT6w+qv/v3qsX73D26Z0p3PzV8cP29f1avNBUrlNUHxhFRDd2qiolXemWu4e5vmi91Z7LB7naJUC3S0bHt7jv6r2Iyy42FVDDTK0RqiX+TJVrv15pdEx7KiJfhKb7/3ogwXuLj33yMVy+eIx8zjsdbfPKrv8cP/gh4+xp4Ider+xUL3QKJFQl4HIK7er69rLTmc5VH52Ylk4HaiiTnBV9+9lt88Yuf4eHVDXJKGIaAYRx0PYpgWRakpEXBOAbLAe1oqCqR3MJk67h1zR0897JOOp5Nzvv9XiDEEJAC4auvvgJDwZ7iZI+uMdYBrCmgLpWBVvE2GT5cDydW5UyjOCyzjPwfqlZ3kZo6BOVLpYXGFemMHD6SAu3X5p5ZH4/xQghgbT8EAIob7jwPHaiGe0X1pxuvCh4V7A/3eLi/wxACtldXiMOIEAe7X1OuEQIomOfelXZZj0lsvR576dn2cH1GVNmgDqk0xc4Bgv7aRaJRsKbYnScSOGnS3GEUECREBAaYIwLLKsUmF/WsPewPeNjvcdzvkXPBxXYD4bHRwGouOFHjunVwnlTngio7lZ0bryzUeD6o0iyx0+dj3q339/SK9ev9z8ffAxwT13kwNRxkf+teW8Bk7ddn2JAj4hBrLt4p3OU63+LLUXmJY3EGkLxQTh/a7tgYb5ZN/fWdUdqICp48fYJxnExz9Ulp77LIDhhtowNQ46Wg4kP7mOhrwcCVWHEAB68xDlZqFxWAZ1PAFOq0fLFcCo7HGYBg3AzAMEKgTbJj1NCD47JoqfcQUZnVGQ3GbXP+TuuhIdYLzvmdM2+vrOdlgH1Ubq104Sjd6/a8ThjBDonootbD1AOQ2sxaBL3hpncrCwTzcUbCA4Qirq8vtTFkYBwXZZaPlDc7yA2s9cKfDGR2jAq91aQ1Ae3Tkq0UgVaoIkLoSks7g6AzAIdd6YZlJJLz8nZYXfEBoNbIUUsRw5gkQcNp+7wVnwNBy9K/fvEc28unmMYR0+4KHCJKPiIdDvB+a5UqKhhojKUtkjF4mwOzgvwYWN3zKWsOhNagA2BhT25Z16XomIBUUHvK3B7lvPn3bVF7a1cVEjhhMETwElYOeqqS0dEinCkyq+EjBm0W76yPNIZ+WY4QXNh49Tycs4bX+1Jbz25B23VC1xwidtstDocD0uEILhrSlkSw8A0mZrzz7JmWoQ/aPFokA3NCLAJaZi0UFALScVaaGCJkCmAExEwoyCAGBg44Lg9YloIsGpZNWSt45PsN5vmPgXkGU8Jm+zmu5IjnX/4QH33wHCnd4ggB8qKh2N0euqJNBMtjNA+LJ0PL+rStl+w8LZx6QtR4sF73/n0mbZ7KaIKvlulX7NwkvO2Vi6g1EG1sy638pwVHanPjb1DGVnPuwr1/39V7xup8+yWTbs3QlK3Kt4h/r+D9JoHcr/Wpl6vfqzcqhG9USk722eam9Lya3kpPIcCqDVeJsfop3efa62YotDdOR1SHSFSBvEtEPlGu7koAUsAHzzSM+ePfRnz55XMsywPu7vf4+De/woc/LJCLLR7nfJFP4PF61D/Wr1dl2XvkETTqx/fV/u7XUkTw6vmX+NW//Re4+ey3WOYZMWovNl/rnDJy0jznKs+CRgMwaVuR1pePMMSIRTIkCzxkyw02deB1HTWNxKtruwFWiiCXjP3+Aa9fvgIRaZVoB//U1CNHBAJl3x7qqO93VYN9A8VvYB0PTfHIRfnaKZ91QUTIpuz0qRwaaSQMBArd+QqApHWrGma0fo1mDKyg29CbWBIt0IjSfi+lWPSW5l4/3N/j9uY1QISL3RbTMGAYRojlv9v2aSio8xHDpEUE1qa0wxqGkuqhMnr2Y9ftH9Ep/9LIqQK2KKQ27no7PyuCprABVrBmfTU6p+rF4hC0tULQYhq5FCwpYb/fawXzwwHzvCAtCbkIxhiBaXAbQBtQt3cNKTfDs/Mo5mBYsnEIcq+4eEiks3nnU2weWEKvtPVyoueBzfN2KsO6deu8juLKHsE8pHWVTOH2z3fyj0hTcqLms/Vywqevv0qdA4B1RSi7Y3ZnwRuuUxn9pus7obS5kLq62FrujGurAljrZgfOvcCo/wggxQ5JUAIaGHBvC220a/2cEwIK4sCQkmuFQFe3FPAVBCmIABazpE9jQIiDLXwxa551sV80PHOKA1q8tV3meWsFSYwBOuekYjzQNfvQvk0RoBZyA1BX+MEJRkMk/d5FXE41tujveSNlydlJtFnM6lJa2EApWjjCK/oYI1lSQZrvQET4CguunjzBNAwIkbAss1kWlMgLdBsrO6sFOHxIxUqmNwHIzCdJ9Kjv9VcXFFLnB1g4ZlWmTBD539R62WjRKGc8Hiqkh458F0hzDV1pQ9KwWw/prL2famSSfu5wd4/lOOPi6hq7yyvEaQOIWraW+wcce8uoAyhxoW3zsP8xkVnQ3FrTrFIxMIqHmfp73dzbAp4HuI9YxynjcyulZh2syoOvPuc5IEZLRXGD9n9jVgFnm+rZIh5GSQAkFQyTgY6i+RAFhDlr8QR9Wiv/DgdYbiDoj4MZHjZxg8NyAKAV3SBScxv7+XKI2EyjVmZMCmiC0UAUgIs1jXcDCgCOAfOyYH84YP/FF6BhtKgOrQYXl6PyGBOOAKGkGXQ8IMZBGa6oxF9SBuWihW1CABCQjz/Uyq5zwN/97AMcDkdM48d46+nPANKqpL6DAoskzgV5FqQ0o5S8KhxRyKpVii/feU/Q6XWqYDwOeeuUNxuP70+MsRZf0LLgBX16iVhJ6VVtWHJvjN4/chPShVRp1lDs8+NzOlgpaqcA8mQejyeNppzR+hl9+ErvRXIrqjF2BbLfsHbdY85eLdD4vHImBiKrfeeM0v3Gq0NgpQ+htKt3Xvu9O/zYjX6Fh+2nr0cH0di9Bmtl00Re99z1evoD7mXAPyxX+PBtwTiOGAfGJ//wBdLygPtbwae//nv80U83uNq8g8/yE3uqj487wfZ4fU6NeoAailevM60+X7h4IilKSrj51b/DX/3b/xP718+xP85aPn9orQBSykgpgYIaNwJrKwH1gjVeSOLyRj2FpWgkj/N1B7dNzOirTgsVwle6L3i4vbOUCcY0eA+2JucJliqgzF1lP1v4rhnHS9tMA8JS+bzv6ZzUGDyOA7IwcrHoE+fvQftfSWneEd9/j1gQaI9Tkf6cBfSFDogJ025j62ehZ9BcYs+nVUMgTDnwEE/3jKg8XZYFtzevcdw/YBgGXGwn8DAhsuUqUViRjC4Bt8V3cO9rU9ZAXKQZIHSu+r4WSGzymBi1GIenzTi+1cmZSkQMrlWm+ygVqntEZrhrw/BYk6BJOjFgGMc6nnlJeNjvcbi7weEwY5kXLMuCZU5Itnf5YqdyvMuDX596qXNpfTAJjlXUgN/WgakVHlfDusDb6lYjCQgs0Nxwe1RBa42y5nV9z0otuiJYp6T55/wuFROu5Fb7WDshPg9UBXvgiEBaIMeVxYx2HpoS1wnfE97DrJW8dZy0Cret+O1bXN8JpQ0CA2gCSF5tNiAWeoHqScgAgoVLFdK/I/sCO+NtCkGICth2JEAYFBRaSe5cAAqMaHvL6PpssTLbxQBWjEE9MGbBZFIPTipAzBkh9IA5oJGQWFaOeoYgWIUBFVhja8uLKCBNTAcjSLFQwGIxzy2pVV2x6uXR9mTmKyTBGIE5UVM6gK4/iPaCU0tiG0cu1ozbxgoYCLKkSzbXdCnA7as73L66xXY74OLpWyARpJI1NCqnelRg/U/IqwtWLbGFo2jYpSqVgTR3TEyg+Iy1+iChiHpj2mWeSRFIyRiGocvXaB6yYHMBaWioQJkKC0A5YzQPVi6iTF8KhqCHMWcPQdV8shAYGQwu2udGxKsAmnV6WXD78gWO84wnb10h8ASOEygewEvWUr1ozD2lBDPowH2BLijZ5iFSwCiVgTKzlo/3VbD1iZGbhbkYlPJ/yOiMSmVNTMAQ1PMoYmE7ELMiNguvgnD9WZurtuOr97PPq5BUBToQrFCgcqsAVKtjiBFDCCoUi0C82b3RZ066zzk7LXpYZ/fgeojaH66wAaq0zfMB47BBGAblEa6gEyEOE0pQJYMMAEAKXs0JT6ad5TQCKWnKv0hGmAqQCuZlRj7sVXiWor0ge8q0sLYxao6qn0OywY8UgPg4b2a0n8stIciA+fhP8LtXP0HcTVjAmDYv8c73/gLMM0gWFdrMePWScZgShl0HPKUBWeD3KC3d+zVcr6JFu98ZwRJCQIgByTxhu82IZTOhhoD49+1gFmghKCJSOvNwGDY+DKrhZaqoHIE0q6LNbxZuzfjRgfPOOtsrBMpdu9DE7qqKbf04dUJ9rcDVZ9tnHzdOcZDdKzhvvhr3bYpbVUKpkxt2w3+MEi421379XEmuR8qNEw2vv/ES+1wLOa9SA4DKa6fu1TOZUUx2BVnnfZ+W8j9ixGfLE7x3OeFHP/5jhDLhiy8/xcPxAXe3L/HxL/4KP/6Tf4p3rglf5evKd07nfk5JO734xANyGrbkdJBSweuXX+Ov/vzP8fLjj5GKeuO9p6saKwokJTUKckRkrkWbkuWBD8YTtGiYYD4ecX9zhyEwOLrBVFfajXVEZKX6GZkEsy70el8EQMmIMWJgMzQGa7NjZO19JrvJ6p7BFDnznhfWPHERVO8SSGX7/rhgWTK25lkkyViOsxmlzFhGBBI1FLd0lQB0ecoBXDEfd2e0csqgdKHFwGI1tq/zrLgawHWd9NwkmpFRcCEjgAiIIJJguLzEMI4YYgSR4iIwuf5q+6j3I4a2Y7Lztuqv5mHRDIgodiMBai44NUpCB8y1yA21KLl2ABVj6btVkauqhPcirC1iqljpLveBqQkoQMXMcc7YHw64vbvDcpyRDgcsKamyNi9IKVmF3rCKuJLKZ2yoLhdMto+GPF1VFPHWS44bHY8b/8ouW1TWgj0Uu+VJxiDGp/vnNyN3JVsiMwZbzVhq57V9zNQjYXhWMUz5JsOiJNRFcDgPdEODefB7/ouMWmZOgL6Sb+0f7EDUbptFo+pqSkwnU76twgZ8R5Q2ty6lrFb2WvrQTo43cUxZrQCRpMYpc1sTqJsZ8Pwa7xWm4QHaj8QBZyjawDWQKitJDCh6ZcJckHIGcwESIQXGELW89f1xwWC9pXLOmOcFS07YjCOmwRrpsqlXRtwKQbA6Yc3aBDv8Zm3Wd9uH0AvrzgtpHFhEkARahc+0/3kuWFI2pQmre3nyuAA1wR0m1IspckHD0a2sfQtzJDupgYGSCh7uDri/+xwhBkybEeM0YJk9FMLXMneHToFkFg/sozodIh1PzkkPNLfD6GFDmq0mOk0QsuVxBDIB6IDcGawpqa6wkCXtsykWSkCsFi0QhhCU8ZL1sAkRYPVwUGnhEgMRME2QoMpvEEFOqVqYiIBl/4AXy4zLi0sMmxEUAmIWHEXDUKMxjRgDcjb7i4XRKIxV2ohE2sdMpCrdADDAGZj3QRPktCCOkzFFFZaBK2kBfk/Wgj+q7LkSIyagmgUJphDAjA21V41ddZfF7me/O0Csg7WKlMkYFYuAi4CCh5c6QNL5SF5Q8nIWkK5ecvdANTWaoKzlqgUlZxzKA7a0A4cB7ikhIjx9+jbefvYEm6FjhXFCjhd45513QGHQ4jNzquC/WEnr43JAkqS0mDNyTsgpKx9LGVISNnLQNbezKSwgy4mVUqyKma8k1fUSaeeSoGHdyEAYB+Tle5j3f4jLq1+AeVCjCBF+/vk/x+a9K1xvpFrye+j9bQG+fhjGSpoQfNPHpmnCZrMFyhFFBNvdDpvN0BSmnGpKYDUXdCxeLbOszkZL8m5NpAuODw9AGCBlPquA9crUaWhhry01z2Cn+EmbW/NUt59nPTMnqoy84fc3fWb1+u9ZX6AZd0qvBPvwv+1+9s8TsdYv3RsmE1xHP40qPV1SwOJKDPm4TOmv4K/RY0U71FKwWClrzuP6+T7kAb/MEc/igD/8aQAo4/MvP8VhDri5u8fPf/F3+IOfRMSLHTKN9b4aRrcOuzy9Vt7UR8p7P1t7jQk3d7f4m3/9v+Gr3/wcEjTHaJoGqy5YzFOuOdAhNM8NEZBKwXFJ2I6N3/SPcXDIFqUgEGvrgxqO2E9FXKkoYgqVRmF4OfcQ2IqHoPJpIcv5dpkeWA2z3GsAZvA1zz5BYZkUQSoF+72Gh49TxLSd1BBKQBxirfJYclbepA9Wxd75NBkoNp6vZNnmxuRywegRLuXqxkCbYbd1c9omZOQkKDJrqXkQSlQ5GmPEdrfTs80BFKkuPkFTEFzBYtsHqTnpYpEbpdJKMcWuKiqVhtb895T8HodIrqhB9+sMb6jf640kzg+611pCjo759c0D7h/uMT/scVxmpFl7lqak3rW8pPY8aQkTrjDVu4pGNEmdPJC6aKPVGarj99W1eWlVkqqccsdzFf8yqtfLDAUErKp3uhIItPzS9shePvjeNvkAIq/rXvGsVOOE8ysYJrZqrwMQwwCIOjbE9txj/3oZxE7nhhXZcHoWLTjkuN8/fypPft/13VDaSkFZFkjwEENgJdWLlqaXAkh2V3H7yNnLBUVP+GwlygXgaYQUy1UpRWN8lwXLkrAkj+vTxYzM2I6xMrci6pqNPohckMqMuRRIGQBWspvGAWQNBQGYogWsz52XekXHuNvZl+7zfolj25NLCYBRs6yIq8VGgBpy0X+1WmD1BrXaj1vkekWz4nmo8hqifj6VgrwsuJ8XHAeNnQ6kAiWLOqa5gkCdZ+ielwoQRKzfWGOGRYzRiyBrKxDTGtoiSc4oSZUBQBUt9+ixgeuUM6JEJPu8iBl72DyVwpgpI6YEsURfAFhCQKBi80vWq0XAKVu1oGK0UKwVRdCebZbjF5iBnLA83KKkAZILUhEcZ0GKEdOoHgcUzXXKpWhxE2hVzFw0rJdzBiBYUkEMgDeb9PCAItAmzRkarhJmXKSEq6sdSslIVjAlBDbmJ0hZ5zIQUAoZXWtFTHU/K0MrArXUGijw8stkjJFMWCiY5qrcV6uY5Tp40rwansw7Dmk0KpqwH4Mq0CWp9a8vYtLovGNyOvkGDk/zmOz+aV6Qyz22m8va2D4MEeNuwvfefQ/X2x3o+gOAI2jYQrZP6y08DKJYNdlSCnLJGFMriyywPky54JgTaBGMnLELCcWMTSkvmPOMS+wRylG9/ZYTC2Qsx4Cv5wm5JByXAy7LCywpa96mr/d8BBGwm+6wGe4NlABxGCrNrSpunYTH/r4wwUcKj332PIAgzLTBV/GP8eTJHY7zc1BewIUgZGUPClAY8CbbpJ0gAdA6tJibdRmkhroigvu7W9ze3OPqyVvYbHbV0+YKVk8aj5UpecQn1yGyZ+bfAbhvA/T/oy6xsb3x7RYi7X/3z63f7XFhN7bzhg6lYfdkUAeAKtjtlK+a6ySPUsMqSG2K72oA69dOFLa6b93fK+W4+2xfpIVAeJE2KBH46EcfoXDCl59/jSURDjev8Pp3H+N7PxjxMH0PCcGa9mbNZ2d6tFQe7r1+Xmedpw5m+HxByDnh7vUNyjLjagq4iwN2g3r3ShEz3GgEBoWoBjdfMxKIFGy3A7bbLXLKiJGt6q/m4w9RW1yEQBbyRQAXDd32vmZW/o9DQMiioNOU3wxBCIMiAdX+zDhqBdIMCxNFFFZPDhGBo5b/pyIWzgnN5enAs/a6LVjmDBLB9ZMLXFxuISmjLAsWgbYzKUUxjRciASw8UJSflwQmxjAEFA6IQY3ETV8s5ozR9RFopE2pyboWzunubSlgElMACpIIGAUUtAJzShkyDQCs8rX1+Gu+9p7A23zV89bXdNQoEA6k0Vv2mlhuttPQ+csVAXQAzhWh/nPSKUrSDe0cv+h5mam2K51Rz3I6HHB/OGA+zFjmWSPMUlb8kkuN1HDFXtvsGIqsScmtAbuO0c9EU6J65bQz8cNV7lq9PBXFxaTKWzQDjt+JA2OIXYVG9DKo41n1sSenWwCv0O5roPi2KL1LVsWQyQTnX1kAACAASURBVPZUJ8a23kQMBDX4BNJq7sSK69ch0xZZYXxEc0A1tYhIlVOBwikOZoi0KfQ8VSDqNQLcEnZmr9v1nVDaOCbg+neg8n2IXGLd16JdJrqacgMFcGLVg4hCFTj+DTErvJgiVhk4s5bgtAICIRcMw4D5eMQ8zwr+Fq+qCNXOi+nUwfp2Sz8qC5GbZyt4ocRSiBEjYxxjHXszOHWWI1HrO5jM6uRjbRt4Vlmzv4tYPLCtSY0zhlYZ8zWpzZB75c2Ft5/KHqxBvW8Q0Zh3Zi01bEnQ2peaNO9EWjx7sDh6H7IzIgJqb5lwatkEoCEGLTdQBaYXOOlAmH03VDpY36lWcWK7F3l4i6417FmNI7cwS4+FZ269ZBaL1azJ5GJCAhpOoAnOQBgGMAeUpBUoAQ2t5JSx5IIlCYowypIxbbcYtyPm/R3y8QjnigXkhS2tSqF7bS3nz/eQvQWBh6KqYlVSwd3NHdKyYNpsFADD6iCRIINU2dTYNHh2kaaeUUvYbqSve2/MpFhoB9n+rEIXbD9WoWi0Vh38OyEESDBLKExJlYQ4DJBSkJYFYYjqiRcB5dwqevZXJzckG7NmAhUgRMZmmnC/LDjuDwZcLxBCRAhjnQee/AC4fh9uIenFQHBQSYwTHejRMATALAlj7c+oAkRg4RFSMFIGS8ZUsuaAlASRguUooKR8ZF72yPcv8Ku//ltc0AHPhhkegsEMHJYF22VWpVSAr159iBv+EE/HYcX03wTi3+SNWk3ccQM30Hr62VlG/C6/j//i2du4vbvBw11GzosCSbFCFiWjlKYsCtDyN6DAp1jijpihZskZ+4cZx/0Bwzji6Sbi7befgRKfWFzXc/qm3Ls3ztfnik5hOqExMkBy+tTHvOebX/dnnI7Rx+meFfWMn89tOx1X/5lvUsb7d7wHmY+1FWItLcfM+KfTXcOPndnELYy9pbF7fVU0xuRvP3b9/zeDlH6NXucNML6Hjz4CkAd8/uVnuD8e8PyLLxHHLd77g4Bp2uLX+w0Oy4InO0boDHFOI/v9HpvNpr7WlMZujeAQXvlyhhYmuz/scfX0HQzL+3iLJ8zlCCkZh/0DXry8tcJmGiLlcligLSviwNhd7JDM+JOKGcpIK1GWXJBYUDJMaVOekVK23q7Z/isWQq75vnU/K/4hlMBASubZMCohAIcZEmNV9GIp2reUVH5wsSiXlCtxJAH2hyOWeQExYbfb4ur6EiSCGRnJvIFUxAxk2hIJIYCyhvaTyQGVNWbkWgrAAzgvAAYF05ZDXwpp9AqprAvwKBNTVDt1ClAPh4SIzQQ8HGfcvXoFYsLl7kJzZK3IBFu+bRVRVVQJuswrQIK1L2l0LKKG1JK0uriFgdm587C7xkTbcxTHnJzCzhjWzlmj+yY7zp2FUw4jpnR03EBXphSU4wHLnDAfj1jmpJFDEGv/ZOsNN5Awlpqr1+bSQkdlNY82vzbfvoufOmsFMCO0mBwErOn8ykOh+5RyxuA1KaossrVi5+uEGnnWCy5XWF0iV7EltsNqvNbgJjXkA4pzJasSLmRGAmIQhaqUgxkIakgoWb3qxbzPsW5fNoWTECAonRW1wLGAQgm2eZ0UPv7G6zuhtIEEYVoQkrhJBmf5eCmgnFVTr5q41Ka2bnFa3Tpo3DCtzc/toNrrHFUJGbHBMKilKoYjDvOCpWTc7WfsNhsECIYxoqSMglhL93qYWrEy5xQC9sejNmmWgNt5QeCAzaS9MgCAeoIjVIVN31u/5fRXraLdZ0s3aYHqguRM1wpJ6D1dgWvWi/q94tZVdkmlAi7lVkSkuKKi1hiwNvsObCF8wkhcVr5SBwQny1/5Qa1cuXpD/2Xqk03PICZoz7ZApL1OeobmBUPsbiw9OKD2L7fvEXkPGqoWFbKwNgKBoV4wka6HDzMQtOF4iAHJrKcZESQFxWLtNUyhqNereBuLjBgHDE+uwQ8P2N89WL5P3TCQ5fkUW48ay25ro4CiEU0koAQNTTo8HLDfH7VHoS3qm4w4rq/7EpecLWzUvKseJuN0IaosouRH9wHalgoxSLJW/TSDSbEQ1WVesNmMUCaHZlARXfF5TtgEZZoAupy2teDy0Pg2hmJ/qyFnu92AIHj16gb3d/dIacb11VNAtjrQy++DOoVtNZ/zy3V+De3n1DJ5dE1t/G6KEgDJT5vAYLcg7LRRvZgn7+72Cvyr3+H18QG32YU+8O7uc/zonc81V5KBVw9v4+++/O/w/odPNaS3rgOtfq4UlE4ekxl13OtR/SzdZ4MVMlJQ0INz4NP5A7wT/xN89CHj/vVLfP75DV7e7JvxyR6HkjplYQ0I+vUCzCCBCELBZjfg6Yc/wp+m/3FlJDhd/LMKS6d0rh55urHOj9604342pM3fA6n6r1TvVf9V6kDzmet03GowKY/25NFn5WQvfs+1UmI7JUtg5/qEQXgoudiY2udFrWVlbbA5ZS4V6Po8urmc866dVcTb4O0zwE2egOl7+MEPC+blAct8wJKO+OJ3n2AaGN9/9x1cPiR8fbxCAOHyYgcE9dyJaM+0Fy+f4/r6KUJkbDdbBFbzH5/ylm5zGYSL3Q4/+cmPkD/6EPnzn6Ec7wAISjri/v4Of/3//SW++uprjQAppeZSO74PYcRSBFMccJiX2uNJ+35q49+haGakpyUAljYQtMKgCGlE0Jyr4dgrGidRoCgEIGuLjCyk1Wp9VtarjQiQwFgA8xbpHhMBeclV9hUQ0jxjfjhAiHCxu8Tm+gpLEQQBxHKGUtEKrwmo3hsQAcELhFRqA8S86RBIEkj0FdcIEiICBTUsimhES0bBIL4vlRIBEHIJCFH39tXNPY6He4zjhItpwDhNVuCuyc6VsaSntJXhQZWTUsSchmZYtHFnEeXXlQk85h1kfKnJxcd5Wfp6Z0QhAhfN3Fg6LPYffwmIA5gL4jCg5IKcSm3RIEW0v52PEYDWGNAPtPE6D+q9bo/ni0791RoUVM3wXqisFA0zrOkWPXsWoBR9hrY16fEhagGX+nrFj3Iy3nNXw78EaDSYG8sF3Zkz4K16m8LECmL1ZzbHQPGzWlcPAAqCWC0EoBr5pRtHmxedI503Xt8NpU20NG5KGeNKX6M1GkM/6RZ/DzvYVVO3uG+xqml131f82ImU2nsEhIGt0pG6wOOwoOQEh1YhBow54pj22rurlFoUQsvettLyOWcEYoQQNKxgmbEZY8MNBWoFs+IpcnIKOoPNGlS4vO0ADmz+DRQRYOWKq0fQhWT3gJrTVr8llsumi6Y9l1pxFhAsJp4sVyoiJ2tmyW3AnoROgLnaO8IUqfsag3mAWENBijTvWd1v0WIU0V2JPTHUUDgBlebq1nGShoT6s1d5PrYSRazSYVvUvucSAWAEA/QeUoNqAWOOoDhA5gNKKRgGA83WvKvuRj2YAqYFUhj7+z0CA+N2h2G8AF1HyM0eJR3hzAeiDcCdhNmAbfVAVjSp0/YEYmbCGANSzlqQhAitWt8JnVnvY2lLaTmjniunwt0LDmgp8KIVLB3IidJK6WjJP+d9owAtIKSeMLZE/FawR5swt3HNhz2GQfMO+zy0/pjQikUojUuhWtRH+UHEZrvDdl5wePEKh4cC5ltstmppF9KQzPNi9x93uSA4vXpd6fQLPTAkKKgCAeM44u233sWru1vkNKMsR1AAvnr4AX7+5T/HP3n/LzBlwc3xXWTeWRhHazbcK2WrB6ApavoSrcZRz0vHN92K++h+AIQC/vzwTxG2gh/9yQESAuLwHPd3RxQhRC5I5YyLklDjRBiAOudZ82PHAdvdJXgYEK9/gL9+8j8j09TGslowV6Aev+6Lv5pvD9ikvXZaiKL/rN9u5dWqoOHx1E6v36ewef5W3zpAn+veljc869vrbPV5zfDXeZXl8dr4a+556/OFPScFaMpZG1Kn7JDlqHQK2psU4155W4VUdlP1129kh/euvo8PPzrgcJjx+tULzIeMX338G7z8+ktstwHfu/wBXh6AzWZaNcqeU0Le3+CT/QG7iy2eXRU8ubq2HKumDpxCBpCWpr+eriCToFz9V/q5+R75q59hHL/G1cUlXr98bV51sVB257uCLAXjMGrfLPJIlX7dLfWiUyzqfQxwllIs34qsR2eDCAFS5ZdVOEM18hYBBbY8NcUFJWu5ebbKM+zthpg1h65oSCCKgELEOI2YthNKKRgjg+OAbJEXkbU9k3qNXDHUSAChtrJKUz5nm6cZVpQPRwAZan2mCvmbwr/eFAEBsuD+YY/bmztQKbi6uMA4bTAE5SegFgXyJvoiQq3Oqz1BBTywFgDLpYZmr47cSmgq/1pfa3nl+6k/dX16JcN/ZlLDnhqOQ82X7D3kp/d705UtoiZErXheUsayeLVOzYHMaB495r6YTzsFp4pn/3sbg+5p88qR4iuyYmfU4Rf4nhBAnYyvIfCej+kY1oQSrZVcx1U6jtOx+gc6XCLZ9olqJfJznnaCyQXE1XzFvIUksKiw3LCvuFuDTdlXw32ywdQzUPWPf/z1nVDaigjysnTa+3kizCAt126AspKJxo45V19/6RSnn14d4NVQSlQGx6yJq4i6TBzU2jxExrIEHOdZizoMAYek1iwPcYkEHEUs0XMAseZHrQCDKWz98NpZkTafRqsVZjF7Un83VeqS1hHA1MroNouPEqjninmoUa3saJ7O0xAe728CE0ba8BgAWXEMGxsFrtWdvMcPRD2PgFoEq5ApQIwjtlMECDgsfWArjGE7oCxtkqUlKCtINyDCQKvaVBHmGsydXFXxJ5h1mxAQTZkwwWLJo4U8dFX/bon4ln8hpSrtS9FeOWQatoiLHb8K8rLHzcsDpuOM3eU1hnHC1dMB8+FeizesCEJXxY+9Cm6yvD/Uda5V30xIxqACS1NBzWtoDNPJDFAh6vkO2a3qpGfTy+C7FSoVW4/SQpE9x86NBKpAtnWvyp0Sovp/a9UotSwHE1AlLQCAtCxIOauXx3LX+lw+fa7vsy4CeSNYB6RMoBjARXNMXXgf90fc3x/wjtMB/v8rbOeuHvgRUMODqAMhDeRK3TsGYxxHfPCD9/Du8R3ksuDh8ICUZrx69RqfvPwpfrj9Eu/kW9y++kgdvsEsoJ3RAcBZZQRoCgGtFH+q76GOaA2oe09JDxj+/f6f4T/bDrj68Q/xg/f/FstRK8QFAkJJSDy0ZxNrie3QxkaKRA0wBnyS/gjjMOJT/BRFri2k2weKFU9/0+ur+Z5RpntjgM/v3Ge/rW50Cgj7e/b3bh659Z1LD0ZEw2nq/c4M4putyuevyld6Y52HnHbK3GNZSvWz33h12Q2tcXLbmpUB79z4Tj7/pjnsZcSzd97H+3cHyLzg5d0NcGTclTsEusJ7zxJyyFWp9+uKF8ThDr+5EWD4PnLKZ5/BJ4OsZ5b6cREwXoCf/QThcMBmHDBME0padG9qbhc0ZNvD7kkBs0jjl+286p1VN6YmfwGt+pey5uUytBsKGl91/gZR/ip2P7HwY1/fqryThw3WIaqi5R/vcEMNSiHCFAKIg1YcTMmKjOjnSTSPVciqMTtdkQ9E567OErZiDejeNzjv7YC8OBepnMiOY3wLSsLd3R0OD/eYhhGb7QZDDNqTzOjPVhYVb1XvTMfpxIpddHsuWUM8H1XmwSmuoDMK2/nz2YdErsbSPmEyLGghG9Z55LQAKG/kUetntOPLnu5BAgSTE4Fh2jQAaf3kBI+L3XReNrxRCe0lnefOPl6z+h3qjPzU3qse+6DYxeW537c+Z7X0HTLu9AfPsyfux6br3s9IF0kNxl5YpuoiROBIiOTGeHNgQMv3n6jwtqdZ14lZywOwwZPOKFRxdJcjZ6v7jXgV+I4obQRoHCmr4sTRF7mLw4aBTheuuZj7vdemT+7r77Xb6evmPugMYA2MG+dxJc6JqAdCagmesCyzMhNmzOkAt4iWzBoyGAIg2sOMYkTw+qx1qK5gtDFrnxR9T3GoP9cBnX2znaHzwq0KTa2I5EwJQHXlimn+q3CBzuOlzL7rz8UMBqtrvRSwOkHq43yZowl1VdocDnfx21BwcjjMiOOEeDkgxIAwJPOOtjYPIFdAzntcuTvSnuTpZ5iLQMKJZdf2UxVH/g/UvVmTJcl1JvYdd4+4S2ZWb9ULCgQJgENiaBppRlzmTTLJZNJf0F/Tw/wGPci0mYkmyWSSaSRwSGGIoYYEiKW70d1odHVVLneJCHc/ejjnuHvEvZmV1Q3KegLoysx7Izx8Ped8Z5U4gUZQPWftJLZ5EKKfc7XyEiQIWjRzKEW8vfdAcmXOTdMYNDU61HLJzDjudkjThM3FBVbbC6y2G4y7vS5WLvuSYASyCpikHWRlek4JjYEumRPrhJYMAGPVETxVBmBAWoB7mglsc0ssUI9NfXbmYqd7MpU5W+5RBWiz4G3Zdy5IzR7ScQ/DiE23EgvfGS1jbXIudFfaqADbe4R+BXJyDruuA7sA76u7RPPY/a95xH3nvrPxP0SOyxrrPHZdh2fPnsmSsCQ5GKcJv/zol+CU8Yvrf4YPLn6IHLZYu5VkUIVajB6SeJurZNe7h1ksBYOlm/KS4fz18Y+wwvfx/pPvl2QPDoDnhOhCERZranezKHPZQ3KqPD4a328mfN43R24GcGaWNHOHPMEc87621wmIKkIkz87CUit+dn4W95V3KNi1ObB1Lver0nAuNZ4T6r7aZaCs6ewcuBVJ5fz1kJB4MrdUAVuhwC0Ztj4t/m4/O3effUYg3MYeE23x/gcf4Hg8YvfxiGnYIyWPuynicJxwud0jFg8J2btvdyM+zhlP8gHX0zTzDmithPdZBGfj1DXk9Rug1RNwF7BebzDu70rRbAMFABUrRrUmUPkO1IgH6lJpcoi4wmdMw1Gs6cbPuVoEiUiEwMzKx8h0WdID5ecmE5nAyGgTaKj1o6HpAEqiCuecpsln7PYHvHG1lXI/CtwEqLYt6bstu2UzTrsnc80QLTyMJZufut6bdwlyEm6v8RbSbyATEIhxdXmJvu8UrIkAXeqI2hoQney1c6dLFESqVCIAC/kj8zKu6/xeaUH5q+61GRGrWAdyAY4kuQsAxDjdQ9Ir0ZiFvDDq+dM9Z/HZjkjqvJK5xNpMcLW03dPN2VkvdO5Ubqq4mApwLncVer6YH5LPvHcIQSxnplSobXJRMBg1ADe020BBEd6KMDzruwMUeNGczpbxiJVXCmtLCA4rICWg5LicXZyhafZUjs9AlnOTyBTdzVCXjz+CaX8jQBtDBpORVYtVJ01XQ39tNGItsQPmKIaN4DUCXDMXrOj3pBOgxQZS4u2ae9SM2/eduneJ1WPLvcYrCWFJmSWWyHlMMcLFjNAt+rzgSFIlXolkVi2dshHOkup4RnAakGJCN0PiT7zLGKfqKkGgmnabudb7QCWWksRC7vZN8HJ1qZHjQmBJK4y5kOxQXWgASQKRtIxDex+BkFPCNB4wDCM4jbh88wn6rpMg6yT13tAwtaVy13RmrWxGBHERU0Zk9W9mB6EAR7bJKJM4A0QaI1c0Qnr+i3VNQajtMypaVCnI7TzV4qQ6/85J/TcXvICxaSqC1DQMSNOEcThifXk5A0RQupNZbWVsm0cFYCqsVkAVoyTMKMQ36VpmxrjbY5omwAGbVS/zq7ww20Q2VLQkINF90jmaCTrnGJIIHq4IE3OCTYBzGkfSAEb9LKsriHMkcW8ssQThJI1dWdTS16LksH2iE8KqXOl6D8dA6DsEYsSUAY7nGv3/7WpJ/0xoJLXuQ9hA7wNCCHhyeYX83lNM6Sn+cvgdjOst3r5Y46133kHf95Ux2Zls2Rk1gtzDMun9/X1IeAdhxBofTd85/TI140uVdtzX3kzQf4iX2XD1DFsMrlt4DFj/7F4DfS1gXYJXkRHuEZWaflthZmHqp4lSTPEycx1svpu/EGe/n3lpfFUgtwSiDwqQ9zVR+cbpl40igKqnRPP18nb9ORel52fCTvbp/O1zj/dXKzz79gfY727xm88npDRhOuxxc32NN0IHuNi0xfhk3GDYZ/xi12PtRiTzkKHHA7baf6WNqOrJmFmsM5xq8WBU63QFsnPxrUg8JY57TjNdCFitulJkPqfcnA8FakllKCZRvqlFhZzEh5GeDxE6UWLP7F2sPFEUH9YBKoYmAnAcB0zDhDhFvPPuO8hR3unYAj1I+BskDrxa1wBJFpdVzqYiV1d6rV5EusfkeUK/WmG16pFSlFlTF07WuVlvNqqsolmiota7qN1Pdf0w+9zuzwXIzPkJcgUQhbeTuOObkHKqyMEjL4euD4ALktyMJFlX3zvEKQmPbvp/nwXv7FXmwGvIi8krsleSBOqVPVompDZQlQhcE66YlW1pNdRPURuqm3mKERkeoZu7ILdumVJTWD1sVJnVOiFUmQSq4Jc+GKizfavQXr5vgLbszcVVBBGSZCMOcMHD+yDym86/2Ios5njRRAsWWOkAGkV36RrNN9FrXN8I0Aa0jAkibTfJFUxyZc3WUivJSzpxQLdFzshmxqQzmPXc4WlusgLAdjPRmXuSFvHTvJ7kxJWpU//yxFIkMyUpbmkujAkZzq3mB7p5l8ChRlhwQvhsYYmS3aaxcPKnZBC0OTQ3NCpJH8pGpGaegOLikrMBODs0KMGh3ommoQZnKgjUkgfOtxkF6zEtFhbtu/RJg5qzAQ2Co4wpZdzd7HB3c4v1xQbby62kfeegta64zeh+4qbAQAn4lqlsJYR5+nMww/wHHauvt6gP9TkqTEAcRHxp0lEtiupKgWaN1crQOm8Z5DoQmRW4KTZN9ZwSZ/g+oOs9xmFEnBK8E2Y1DQM4TujX6yKsMAyYmb3R3GWEoHEG2M+8kuo9ORVCZMUsmRjjMOLw2YS33n0DmKoyxJFYSGvqWQu+nhPYImDY8bznah2PnGUfVYImtVIagcUaNQ198MhTdYsl70ump7qk8nJPkhhorojQlp0kaJmI0AUPYilQa/14Hfn3dUXcliwvSbQNN88+q6DBNXNjv3Qu4Dvf/g6evf8MAHAYpJD4qu/Q972ksaF6zg3Kz45BIwwuSNBv7brXctf0pHXbtL1kiqKT51RAaJyZGpftKiiZkmLm3r1YtaULaHsVaxh41u7ZMTZ7rbVYnrTZKI7a/tt3+sErr/uEsse4SLaujwxIvUBe7oxmXGf2w/Id5+6bATai5uv7YdDJ+pz83f7bCt+yVn973eMHb1zgW+9/Gzc3e+z3L5GmiNvra/SbC4TSA7kmdvjZ4RJEA47HI4J3D67zYy4HQs5ibRqGQ/nMWAwBmtaeyqAsNrycUnKacbjuCVYwRsGXzLnEwOFwFIuazYideeVvrJmoLUsdJ5FEMokXEDNXeYfV5ZwURBmjKnxcrHwgUU6kwxHTmOCCxNC64OFJEjqQ7XURB1D0lhYzTtVCYvJJO/OZWcNQ5A6/WmGz6nH15InKVVEyQVZmAQIjdD3Mc0j4bm31VWvLQI0VowrbRVnOKgsApmwEGJYd8LSlV++jE1dsJ+WkvAtgIoSug/cOoA7eReyPI6ZhhzTV0i+PfYddZr00QYo0VwEU6Ft8pAqVZbjzNs+PcQ7YToHu/AkGOOl2oJnSva6Zh3cdGB7gWMENtY3JH8WZ9SwNbARjMkW+jDs0TJVMyZ507xJEQc+WDMWDgkPU9mOScbqsMuQZoCHlQyQWslqrgyrT5XxlTeL3utc3A7QxUGJTZNfgxPcYGVJ4tdkYbIoPB6IMLokMuC6uyNZy+3JyFxJVwYfnpCujow06bl2FssZiBNXUIEcwA+MU0XmHmLKkLtfA3qLxLgehmQuIYI+ikVMNLgOZuBTuNv1hNWI1WkiSei8gAoKJf3JjSlKXzrEeFO9K6lJq3MxSqqZgSzKR2d6kwn22OC6Zi6R1TZgzcpSsT+b+RmWOubpCOHV1Sozj3R7D7oB+1WG1WQveXBD1ZpqadVuw+eaPrPNGREIImYGUS00XmRDxUSZi1JlyWtPDlxSvICqZggqm0bs9TKMnKYUpkWw8yoXeAAJcUqJiIVutejiXkJOUCMgpIyXGMv2vjdni12bFlxsN8T2zBOOi8qysie8Yt89flPptQEO4Lb4TAua9awByyQp3vyBpk2OszTRbknTUoQ9+DqitvZzUxdOBvNRFsmKmKaUzo5QJSeyKRVwEVDGnMwDD396RuJyAZ1q9c+z3H+pqGVkrzN4HMk4sRST+9aEXhcKq7x98Tzsua2mZNsL+PQe07gNfD10PgaLTfi5AKhHSmb1fe1tpb055to6tReoxFpOlAq0Aqa+IXpfukicgR8dqXguvamvZ1/vO2utY3YrlgQlMy0RGFVDYz/LeJYA1Nqj0op3nE0sDaBYfds7auASzy+/uWxMG4zdfPse3N5d4+sFT3Oxe4OMP9xiGAdM0YTwe8QQTJhYaD6iL32WP6S5ifXEB33eFz953LfvQ/m2CXgg9CEGACAGAgzOX9EYDbMDIYofsu+12i3feeQdffPGbBrfp2dDHMzOmGDGMEevOlV6zyhPtDDLXkjwC/lD4lI0CnpCmiHGY4Fcd+lDSOKrFSmi3JZPqQsBmvYJzR4yqQJXxOVEsw0AfAM4iqGqtNiIHUpskgzThEp0QX4bEwU5E2FxcYdUH7Hc77Pc7rPtO1otMqb7wIgBmf8/aJbV+NvRiycPKd0CzI5fqUAnLSEzKk6vxYHnNFDuorqOs8wvyUvDWefguIATL2sgYxj2GwxEvbq9BU8TFdotV58++x97VhjsAc3pkSkxnxgYF6tn2IDV7rQHFKDMye9tsX5/SumZlmhAJB0Lwnbi/ljW026j8JL9CFcqpjoXq2EqjqOs1I+mVycJOrMmu1lCr7DNArEcXcKZolhZcCMgxwnuHRA7ZiSXYrGiOaokwS1BSeIILMrGx4b4Nlnid65sB2qBCaDbj7xw5MSvRlxNWH9JFXAYD1kaBssrLvVcWt25Wkmc63gAAIABJREFUAObiO7uHLUUTaXVzR4vnlHSymGC9ZsXjzFiHgJwYY4zgnCSwVdMLM7UvmqPEamzk8p5ckq3oD5uSlmFqOzkTfCexVSVRCDMAqQcn1qs2m6AyEMdSH4YF8CwJ2oyxNZveXDo8iUsh62dUiMg8/kRcGDNcJgQvg83skFLCeBwwHEe44BHu0SrZ0lriAsv9t4QKmvJCCbQSgcLg6lUKe+uZCk4kfQtaNfO4a1IHwyyQhkaBCshLqYDaV+cIaRJLMTRBCBEQ+oBpWMTsGbBt+pkzY0wSF+eDB08TxGKFhnhxYbQn8V02M4RStiGDkLKk9zdwWYLauckaCrPksWYLmx/FatlSgZrnrI6IZolcjGEzACapsSNgFgWkEVEpj2HDkFXxYB5PaIFl45o9wI0bBAOAB0hcWSyx0LmMXP+Q1zlq9RjL1P3t3Qfa6/cAGoXEqeVHpooLg4QBjNcFbDNa1PYBZz9vT61dbQ3Jc/THxuv82aiCr3S1Cjjp7+M02idt3PMZobpjtpfNsVtA6ZP7XsccfE/fTsQuPnXnooXwOQOYtBgj1X1bXf7mgti5cTmcZshc/s6Fq9HJ5+2VOCNmwufHgD98y+GDD76FLz7/EsMo9cyGwwFP4kt87t8oSW9WfY+LzQoxMTZX24am134sz8e56+TMsiVPSKKQKrxBlcuqPRaAU6SGM+2ihi8YLVbN/G5/xDgM6rKlPXZm4ZJRWB1NB1Tlm7Wj1jcT8OOUcDwMQGZ0q1MFEFONrc/CxOC7DjRFuClqfxuFmrabMgFUswk75XW1OlEtVFyShRSgIEp7sf5k3Nxc43C3k5JJ634mmbcKYHn9Ayv2gDKobdNicQFVYi9iaYocUZwV1fOoWOHaJq1frriMknMgJzVKg/cgR+i7gBAcYmIMhwGHwx63hz2mwx7TkOC8w3q1lhS7D1wVRJ35zv4hlLVCM+8Owvsd1cRypwKzfVrjc9uZsfsqSyVx022SG5FzIB9AuSZbkyRU2hdLk69nyOgLc+1VOVsmt7a9aJR3tXtc7sXs87r0ZSxO6Zh38J1YQYOTer3U95JUj/Ynsje3XmCKGGdRrYYjHrgsX8JD1zcDtBEgSFr+ZC0FbBa0JpAHb7/9Np5fv8QUR9gicGMVMNrUtmvFoc2lEWjObyMVFwyjveCksUqym0Xg1PgmS4s7ex+gCy5AU54lOMfwjpEhCTe09RmLKH8QCtApckRBcK0EXwV6Yx3WYgpqTUsTslcQCQFqpJYwMYxRYQaVQcqYnG7cEs/WLhYnSLV4c6eUeyTjFMHDLHhSWwW2V7mukwAZVxg/SFK7uuCRs9OivLn4BNfXNxPO0PTFBPRUvnZUU7mKA0oj1J7gZEEwjkh9/SVDZswOIRjzrgTL3EoINSOivZeUICtymxO15ry293olBnkSt8FSm05pEruaakViEQljBC6eXMGvBoy7A3xusoQCp4e+7BPTJhnNo2I1y0AhNMUFVZUTosUVhm9isikNSM9eAoowAsjntYgpab/kS6+MSt4hW1tc1xOISxJenSurR9ewc8t+Y2tTBgSwFX7X4u8tIWVy8M7iOcR11Ls2tum3f72OqH2/uLFknO03c8DWCpItwHl0H5Szm6ICWDLB09/tb+vhnFq0/ZFrKbRjcX8ZWXOLM5VB84ITa81Mq/xql8GTdzda47btzPlsBs5Xtf9oN6ZHdPO3Ec92FlSesRCcAKRCr+hkbqz/Atb0nBduQufbw0N7/eHvZxau0hfGMOyx2yU47/H0vXfw8vYOyBN2ux0+/OQT/O7vv4lf5ycAAEdeM/M5bLugPEJBTE7iWXAiqN8/5wbIRaE1SYmfHJVGVr5k9F0ER3dCp438UhZvGiFtTpN4ZIxjRJwiVsFrsWhU+UctaRKPVmO6cja5R8eo8gUzY5gihsOIzBmXl5sSow/V3aj4VDmggSpyErdZtXQAs2T2LpQ6q1uFA5LWZyQbZGlQ51Y/51raIDMhpoS73Q2m4wGrrsPFpkcfQnGjOwfY5vOpoRjmGcIW3jCnYwY0i7LI2jdVsIWq8HmvH1fFyvbtOtQMqzMayaHrBHR67+FCQN8JYHWOMIwRv3n+AuN+j2kYMI4TpmlCjIyuC1i6Hz50VTHJeKRYOYF57JiBNkdaWkgEKGuljMWWSB6p5+70snE3EZst7bLPijOd9aO24D1h1Xl4B4ysbsZFfuTmtbY5m/bb4MsyEdVrj0FSBUMbKXKLyWqKAJ0ToLZZrXGxkZIhRISUEvIwIcdRe9C8W7USUsdOUv93qiRRgbH0w7pWzgBzxaGvuL4ZoA1qwWAjxACK3kgu88nvug7eeUwQITvJlyKItcXvyKwcArrY4mE1CLbVyM80Zu2PAuG1vTLJrAJhDT6t90GAhP5NSv2o6woLk7pZDMoqjDvoZ4A4MDSWDGWY5Q/UTSjNNcBRXUB8lP7HCBAyQhfgfCejjAlWWw7Mpe6WCfG2ecSFToVmnf+UsvRNBWIEqoxCx82Qsgyka2rTYgGvZr2p2eOEyTiWcUs/GM5xEdZtKco8L2gFQ+rfOLVESoTbZBtLLDxlulRgNLBnQNJJliD9U4NbzSKomiADp1n2WqmZppog01A5sww3fTbrlaTalRpi3jkEBfGTm4rFp+5FASwpSaFT0aBK3RtyHn13BR9WOOxudV3TiQWx7k1hWsU5QBmoBaizFnhjoMT9ITMyZUmoQ1SYGqERHM3lFMYozE20+d3WyaxnALymlZbtpEwjZ6QY4UKo58f2pI6dgMZCrT3mOl/lsKtW25VzK2vqFUiy9q+UpfgHvlp2a/8tWTA3n8+3+72+BK945/mnatIEmt17auWw6x4rIFXWbY5PLbycC+3L9u93eavKjupS1PbpoWetX1/nOufet/z+VcDJEpOU/Xtff7m2/3Wtaa97lZimIr9V4dcAUQs67DwWPqaXCdHnLGZAXe/Hgre5qHim380pSSkhpYTPXuyQdgOueI93nr6DX3/2Ka5fHhB5xGcff4pn7z7Ft1Y3mGLC3eYDeO+wvrjAe0/fg/ciBr28vcZnL17gg6dP8eb2Umk/N++s42kZka1uCJJAoiiBmvmkpg6VqaQVrcxYmjchOtQU4wCkkPYUse37YqFiVaShsbI5yzrJWucLQi8p6wgU4A1xwnE/As7h6q038cblJcaj1p5VXp6dCrOk/WShRCUEHLWLRGbty5Un5qR8zxaOIDWtqlcHaOmOJ8rJ3X6P29tbODCeXGywXq/hGlfwskepOWMLhRIzw8UM9PP6oSL/c0nvb0PJbErPOSRhVWovyYqJh8Ua3Qjhc2Fcilp7ciAviS363iOxJKxLccCXL69x2B0QxxFxGhGjxJ3HGEHOo1v3MzB+H407pSHLTpu1V+dbx2Dg1QCkPNl6YrWyuMhoZ9s/w9nKGhlAdpJhPPL8Oa81/bwL8E5jJAmoggLOEgVu4jHbLswU7gruqsJ65gdUbnOOsF712F5eYbvZoOukTM0UZd+yC+g8YzgKzSBOhUIATRkDFSTLvktcFB1m9dbpqDPwSLb1jQFtRVMElJSuduXs4CkhwWJ6ZFMQAaRCbSKHkLK4zOiimXWgLOg5TaMSpNlm0MPH+q8kPtEvVItAFi/MQKkR1WgtGxokAm9mKS4IlGBEdjV2j5hLMLO5cXBZVMmgBJjfbAtpz7sGdJ0HJsngaIACAJJaNpi1QCcEUMyKbLP45BI3qZIBdMEh5oyYVaZPwgBkil19R5KNnLSwtYa+VcDgHFJxuzPii0arqNY/EyZke1giLAFGsGoYmNUNIpPbjfBaogKgAFVknWuZUJjgn1OqlLgspQka8lanafLZFnJBRDIF8X5NRRICpQQ4eV9mUv/mIMBvURdmfqm4TjXFsyMGxxF3tzfYXmzRdT0un7yJaThgOByAqWZKI6K5pakZkWjOUZmns6BrFEWI0DJSoFoLhbc8mFgKejNUOKBq4refLYMphedBsDLzOWU7ViLQFAurEWKazXNOXMD0zBxjB79dD1YFV87iZ04o698ynPtY0Ne9qnh5/rtWQKXFZ8v+tH2sv58Kwq+6lvWnattzK0orh7SWz2W/7P3zfp+fyVf1twjJVBVeleK3clGjLW/72+41pThLwfvc3w+CyAXfqHEj9wtQjwJsj71+25sS2med0NaF8+Se0oUmLo3qZ3MA1rZhgu987I+dC27+PTcBKoPh5vYO159+iP7m77H3Ad/57ncxMGOzXeHFlxmEERwZP/6bv8N3nr2LiYE3rkZ8/vmIfr0R7wEFEaPWhYzKv2w859yEWWWGrFQx54RhHMAxgqmDQxQlWdGokrpMZjjOACSN+Ez/RJDSQF0HVg8VU/4RgNV6pbUsqZQjyhqCkIlAmZE1sy+Da1ZGq+Di5J7DMOE4DHDe4/LNK1xebJEsnTyRxBUrnTYnHyaqJiWar7Rk6BV5InGtgZUzC8+GK8pQch4+l4wFIEfoeo/tZi3ZglPCy5cvMA4HrFZrbPuA0PdwPsg7dU+24KScx/pB3bsaA9bSzGqFrFktG2m+ubfGr0PPy2wntmLjUtEzQxAAkxQml6QXPWKKGKcBtzcvsbvdYZoiUhoRJ5FnnfK21WqFqzcu8fTdd0XOSRGzLOoPXg1wYo0rhCma1YPGLU5a48ZYp/gcEGy5Wsu9bCpPfMnK1rE+tLzbeydxbonVg03aC85J+MayG4UREMxNtS3hdZ7h6piaMwly8F7Ca/yTS6y3F1iHHiHIdymJott5D+8IzAljTJJ9O5qHjuIRJDBYkg6CmvAQk+dJRc1cx97I7oDIQue8H9rrmwHaWDaLO+msDYiVmACcIjglpElcIcDAcYg4Dkf0wSP0PUIICF4sLF5PVmUg5xgsTqSlIiuydrCezgIyynfZfG71jjYlDIkmICtBKJFOTYZMAkoykNY03erXiRjMVLRBNTK5dlz8qlEEZtOqZGZwSnC+Q+g7gCPSNAlIsaLazgmRN/DMGRm1sDJo6TIFOLXU5cxSlwzWlBJuBTcVaNdptiDnnFQgsLg9fR8ZoG00aIY/GDUrofALsa0RiWn9jasV7u4y4jiVHpv3uSMBy+aCCEBc/BR/MVvOSK/En0Hk1GW1sRwRodTkkA5DliWB4Ksmy15iWry6M1DqyJAk58hs2ULLDQqss4JiWSfvGOP+DkhHdJtL9KstVptLOCLsbm5LAfNcHctngN56xagaYCgRzToJZbVUqHOuWk6TWkpLeyXQvGqRTpiY/nQ+IHSdZkmzNXGIrXZaNbzU5qZvCHx1byHRPubKxCQGcREfCIiCRDNP8rxrv/VryVuWfOQsP3mgvZY1Lduv93y9QbXxbu1l/V6Kz/P3nfbonNvmfdc5wCRCRbPmTf+M7BLqvm1pU9OIktgqqGRwSbZUcQsVr5vXcat86N6vYu178N3tInyNq571eZtLF7Olq2nbDfvNRPdTaDVf+dn78dhh8MmZ4eZzuw5f/ALjL/4av7r5HBdvXOHq4gJvvfUWbq93JbFWoojj7hbPv/RYrXp8vrsFdg4vjm/iOIzoNgEMQtDkDH6xk85bCAWwMTMSRxzHATc3N7i+PWDTewwRJYlXLsqkFmigFPK1xfDe4+LyEtfX10hxaOLUuCYIwXwCpfizgjhP1WVSV8YZ2IK8izT+jZzHZitKv5wZoetEeUapCO6i3JWD4QywEImVQkM/bCwwCx81FnHLFIzc1IQjZZmSKO1ydYH1ZiOWvZxBzOhzxvrqCr1lUYTyoEaBbLzN6rAt6VSN5272cwvulnuarH/6LEmMtJUeMjaUG3kEUK+k0pxSkzNnn0ESCwXG4XCL/W6P29sdhuMROUZMk7i+5szwwWG93YJihzfffYp3336CfrXG8XBEihHnTxHXcZY5aL4uHigqf6ryvsgkpoAqYTHzuHWi+c/5RWffayYJhih2yx5iyeBc4uDVQEMspSNMluL8KoUXK4G3ztUx1L7MB9BmW69T49CveqxWa7jQqWiXQV4yoxIgxoopIsUJcRwxDuNMWdB6S2hgV+0XGAQJg0kqt5isuUxe5bzKpg9c3wzQphepexkW4M3SrzMzjuOEwzBK5jASwpQzYRpGjEdG8AN85+H7Hn3XYRM82HkhVASxkDUkmcXrSn5fbFD9S/1vxdqWzWxk8Wy5xjgxz5qu71Ctw0zD3arY9OPM4nbXCkZEUkZACEPVOIvLmJJ0c5csB4uqxcnuZdaskwQfeviwkkyFcUAcx5L233iI1zgvw6vV2kLti3TcbXKK6kNuTEv6qP7n9px+Jx46GczSZ/VCLOMoAoHOFzclA5IRGrYDAMSYsN1u0fU99vsjjodjBYxEoJxhBasZbmaJkj61a6THrQU8xQJl+0WBJflK+FD945kzMjkEkiQ2WSmZrZHVknJuWT58vg+zPuO9x2Yttf+mMWIcrzH2B3TrLTZrD8tVI/vFwVxOWxxVmDrJZLdCs5w/qaVjhblt7cW90hhXjQOzLFzOzoftVVtHcFlL59Q92dRQLX3iynTK3mOppZZiBGevcYB2/yk4rG0V6cVmowxemJJ8nPUcfT3I8+rrtyFzP7aNh6xGj73OgbVXtTsXbpfC+tIqc/r9ufaW4M/60vYT7flctkHzp1u3ZdMFG/g7uQ+2RR8Y81cAZ9bRAtJaVnCuvYVUes7a8MrXlcOv43V13O09RQsOVEB3Znbvh2WzR0++r9EwvLjf6M8SBC7VAyb0qCL05hMkiiDy2PYrvHjxEpfbNYKXJFzTNIHIgzBhGDOePXsXm/UaKX2Gf3NgHI8HXG22IACr1QYrf43NatXCq1kv2n5nZsQ84XAc8OHf/xgf/vB/w3B7gzQdSp/nNJ0q7ys1WLmABDDjeNhjGo4zEcjWiXXtbDswq7s9GvqlQqDjXN0o7XNUwdV7KSHgvUfXdQu+R3MNqcoFJ6ebdYAG5MzUYfsTVPgMFe+UqvQM6y26rsPtOCAfRlxdrBBCwPbJRUnWcS5OVZSI8yQ6xoOsW0vX/NkqWJv2TOnvbMjyj4XtaOGGtkUbvr3/QVrAGYfjHrvdHvu7O4zHI8YhIsaEOEkoR0oZm6sneOvNSwTvcLef4MMa6FaybkTIbu49U5o3JebiPM8H7rTUEpp7K4AANJeBWz5rBolX0xtza69K67YVky/kb9ObWziJWf8cieXNOwJyDc+ZxSdmUabbdjN+DjKw18yByWJtjxYgM0POpJRW1tpqGRKbmiJiShjHCYfjAWmawCyeaPO8BnIOMgG1mIf4LjGABAexkqo8lGdJNGbz9ND1jQFtOWewU4JghKKwVQDIyOxwOI64ub2DA+PyYltqiwnzy4hTRpxG0GHA0Tns+oC+X2Gz6hCcB5iK9sYWuPgKi6QLKYJW9doGzERTxU0cG8HKwmmVv9mYBFhBGK1VI9BbLAZEbpTlbQthl/iQwji1jwb2CoWpW3F2zIxg54yYxW3UKbjKVp+HgK7foFtdYBiOiOMB1mG2Q60corpPshwkzQwldE2TWZhFTO/1Tlwm5TDIhi6xccqolI2Uel9FtnBUlsBAg7M10PeY7E46DzklfHm9w3pKuLzcYv3WFVYXW0zHI0CqZfFOAapZ0mp7YNVWNkzHOV9eIltDDmslnFQ1VvqPjSoToQ16Xl5S3NIBnjTI39azXkmzHzrVbHoP+ODhvEMIhGlKGEep7ZbHDsiMKTKSA1xncWgmIBQRtcwrEWT8LSPQTGAyHumjpbN1ypwdiWXQ3Kw8KfjU97VWA0Kd09AFbcNmjyWIv/yNArSqABkxTQMyVihfN2PA7O/G9UAkXLEK671xYoSg+1XLMbRzfgo3MPsOzfePEZnb9kzYeqjNV/Xj6wI/eVcrePC93+Fkx9wPruznQxa2h6xtj+nzrG2qO7r2ts7bV3lXWadGWVQaXlwG6oyGu8Uzy3056z9VIaS8+L6FVUG9WB2be+d1Rc+/96QtqmtlbS9umc1x2//lfbin29Xp//57CvB4aOBnnk+qMMqI+Pc3/wb/5Hu/xL/46QTvnVqNIn76i1/iB3/wj3EcR0zjqLyDMU0DXOhxefkEl09ucOG3uNhsEHMU3qTZq4tL6+IQpkZplTgic8bPfvq3+OjDn2D82Q+xuz6I62Ohe5BYZKNlxYOAQJqZWFy2NawgZ3G7UnrIvuZEzpb4jIu4UKaJ1aWsuvFxKTCdCRjGCZ4ZXd8LHjNxMjh0XYB3ToRQArDck7pXY+LiwTFbM851vux5bSMxI4jPZOHRkmjEiRwVE55/+QLD8Q6X6y0crWX/hK4As3N0sI2Jb8ESq1BsYO1eClCU4KdUgjA/I/N6bCqnPUhaGmVlCyinA25eHnDYHzEctRzFMBZldb/q8ea338b7b76FruswDQP2wzVCYHSNtvUhWeL8d2f6bNZQzQZS+LRzCr4bF1trV5XVs42h+yDDq8tvMwsFRcnlafH4rO9VRnAuwIegYU5W1J0aWXH+DlNAV+S2HHMrL6vMWSCFuD4G7xD6Dt45xHHAmJLUfFa33nEccDjuEYcJnCPgHFb9BssdlrMmrVJfLZFxNUZUC4VX0YQLXFi62f+74R4JY2JmFahB0FwCu0SvkRKQxoj98YAuOHT9Cs4z+lWHNB6btOFJao+liOkwYOcdur7Hqu8FwHWdWLUsdm62kdoNSMWSBtSJlT4Dxc3x7ETTLFvszHICccNg/d3IPDOQ2ww5vgNSKoJ3S6zJE5DrJixaDhBCYEz7VD6PI4MPIzZXV/Dea8wXYYwSA9Wv1litN0jTgONBwFsEw6s2wFzkMpFs9oavZxVJHImmxEBWUrc55IzMAa7RklldOKMHUr+uuiEYUKyWG93QDbJr42vM7YdixN3LG9zd3OHyjSfoVh261UpA3TjNBSsIA2qz07Z0j5khR7dqd+y9zjvklCqYFfQD3whUAeLGKXtb+urYaro0oBgVREtxeIuUEDeUxECnhC0lCV52RPC+h/cZoAiXEihGTCkjZ0JMwOpig/U64Ljfw7FmpyliJjUi8JzAwnvZcwxQtmB2c+214O/7hf+WeSy1fWItFKBrRu5yd7a00R6JWQk9AyljnCJSYoTGmifnYbmiwOzQKROlFECU4J1aqB1kXZWBJ+1Ly5IWrc6u5Vvb+1v92UPy+EPf3wfalgLx173us55R8++5Zx5qDzgvjH8VC6A9Y4DnnLVuZiXGfO7OWeruG8dyP9M997Uva70nljKCg9RAemjIZt2alQOg+p293zIkL+Sl+TPcnLflBibMMmCei2OjxXP3zY+RrSYiaPbg+cIGrz4L9c7TtbTnYor44ovP8M7hX+Hi6Yc4DM/xn//+S/wPf/MWOGccDzuwD8j5iOMoGd5ySsiOsN/f4u/+5kdwnHGMGe+//S5efHGBLvRixRiPuLj9NW6vJMvkarVqyAsjcUJOGfvhgC+++ALPP/0Iv/w//mv4nDHFpIpbV3gRm3I3y7iYWWu1ZniVYmXPSOIkYnPNR41r12UnVTbOEp+pwswE0eL1o3w0Z8Z+d8Q0JWy36ypGQemwM0dQApGAQgMGzoRgMg8JiJWnebUtkBgzLHRDz2TKcDmhiJjlUMr3d9OIm5cv4WLGk60kGrFnfZMxeil3tfGkJ5YkA8xEmMtpza6bCff303mZVg2LKPKYyR42kbx44PSP+m5JQBanCXmK4DGqRUi9Zy4v8M6bb2O1WUvZpBjRed8Aj4YWzEc9U5DedxGp292CtjB8VVrr53Oww2WbLVosY3VN6YNTRHb60exrR1IHV0EaeUIfQqU9VGn+zLUbwuYzS4bwQpS0T+2+mblIKviTswg4PyFgQOd3+Gd/8hGmccIUBYfsd1v81V+9K6FFOYGzZC8NXQc4hynqviigS2LlXQLYMxIYgR0s1KatEQjIeSk2n8Rw/lReOnd9I0Bb0WqxiZL6eUHrrP8XAezZt57h73/6Ewz7I7xaQlJiwPUIjpE5gbO43LG5wqUMjhlpnJDiCpdXDr3r6iZ21JQBaN8PaGQc6g3ceDcSwHQSJ9Mq++W2JuZNP0qoH5iLX71kgyFPzUad2edm1h77KfIoK/1SRpES4pRABOxeRnR9j7BawYeu1KqKUUz03nlsr94AOCEOB0zjAMs4RUTwRIhmqWTWmmytgKMbz5v1DfWQNPdZ8HfK0GBfeQcX9YMREMbMHWBBdGUeZSM7IoSgqVkz4/bLF/Bdh/V2LUBVxyFrYdkjATh3hgmob7KCcvYkCSlZIFUuGYuoAkZds0JbyJJ06D3MpUC5ptmAFS0133zM9og4mHhLX88MzgkpOcCbEKYayZTEfTUm2ffsMY0T6PIK66sOx+MB0+Eo68jquNIwwKrFIxUitL8ETCwLRYTS9wwJp2RdJ0scY5rg6q7BlaGr5oxJmJFjI6+SIpfbtWVzxVXrbEzglECdbwqZnuEIDFRxUrOUMSNS1KZr4pcEhzSMyNMeHAdw6NGKqvfxmuXn7d8tS381+a3PLNt7qI1zn71KGD4HeB62slm7rweylm21/y7fsYwRqrv+1f1q+3+fFUjaun8dTkFabbMFY5lOLY6Sp3f+97Kt8p4lQFp0qlopME9mhQawlrik5hm7b/EdUHkDuWr5bvsCVOtgK4Ke32+n67IQWQHw2fvmdyz/nu/H+ee1LbsrM+P589+Af/bf4DL9CH/58wPWvcfl5QX+9Du3+Itfr8DTiLuXL/CznwSs1tsitHFmUMo47I+iJOSE/S//Fp/+8P/GZrtFcMCUGCNWeHdgfOf7f4SgGn/WJA43ty9wd73DJz//EX7+478CXnyOzFHzFGtssvWcja4qPWwCUo2vacQ5gFborlYRhnqTWKmFJuFWWwaFCMXTx7DFOE04HkfElND3HUIXYCvtyPaMvdOL27oCAgN9JWNyWSMo71iCIpqtUb15bv1hOAxTxG53h+PxiD4EbJ6sseqDeLRQ3YNL9zwDZGZBPLfDiGq2f6ToAAAgAElEQVQpkbKvue6m8vOM1cb4E+szZoUT4E0w+yRQedv85Y28uACYdq/zDqu+RyDC6AjpKEpkH7zmczBZgkChK+c6g+Bx/7W0atln98bWVWIj+1SV7VJImqpM3NCH07basZ3OR5GJ1JKYmxMuoRGVdhOjWIm9d+rVVpuXbKsmFzTtsyRmkzOFRoap3Zn/qTgADMaAyycv8f77n2N7cYdpTHjxRRY5o7xjhz/7k+cgxRg//uv30a06DMctDgeTIasfE5iQOMNzRGYH1gzZDlPNPdGc7YIJjE7YOF5xfSNAW7nMUgPbCg1hKYuSS/IB0/AgM/b7CWma0HUquDuPBluobC7FDIMWnC6CdvuOImRzJbwu19/R4IZmY9032WJib+5t8YdTS6Jqc4rgwhDpFw6gAHAsxFhu0tlRYd/SchhYkP55MdemjJzM7QNIMSGnI4bDEaHvELoeoQ+gfgUiyepoJQFct4ZLCTlPtetFGCet5aZxaWpdk35UAUEYit3TBBCrxoqxmDs+FYJNRSgAkOuBL8KQurRk+cs7VxJnMGfsb3c6V77MGVn2SoJYAvUAOXU5IhXLTiUs+ZutL23XrTI7eQEhbDF6QiYcCcByJZMuofxP9/5i82jwrroxkoDr4yGh6zv0nRBA075ZHRqhJQnjfof9KmC13qBfb9GHgGk4Ih4HBdEEr/7rEvSuLZkQgPrTq6tOcUklYSSmlZ35djdrU9aJJQNT1ybp0csyomYSJQtl0/qK9R3kkXNCTBMC+iaQ+CFAoYxeXUBkjgEXCCnq3OcRh+mIw4tPMRy+RHf5HhxciWFsxRrdxieAYPldQxJm95zsacx31jkS0f69bIfO3D8f/cNWrceCsfuA3EPWtmULr9P2Q+9cfvcYy925TJnn3vHQeM61YZ9ZH0oMXBMYL2T8DDimal0r4JbEBbL92xox4d8sZeaOZtZ5OYP6nb7LhNulgN32YT6O+69l/1uA+iqg9tg2l5+d+z7nhBfPP8c/93+D46RJtNAhpQRwxv7ugONxB86Mzz77Nd7/4BkuL7YYx1HaywpgnYMnjwkd4jhgx8BmvRJ5YbjGdPscOSckTogxYn884ri/w0/+r/8Jd8+/wN2vf4o0CjA2+ZJJRUvNfGuhCS1Nt3OcAXjKaC04LeAoykCbCZ4nsbJkB3ZvaV3B6ZCkYHZOGavNGttNJ9abhrd6QrPXGt5UeEGVm6y4tgjWNg55n7jI17VyVHta6thqnylHDPs7pGnC5WaFvl9J5j4rFE7n9+psAuuPAsgKrGpcI8/R2/Pwoml+Ns8mh3LJ+jeL55+1DAUO57gDYC6QRAQXglqIAB+zJOjQkjoASt1UayslQkS1wJ49NwraiE55a9sT614BpzWHtnxelAKkxpCZH8yZVlsuubxvLsjNlHg065VYASE0y7lOy2ZIEjyLOjqpMFBBAkBnopPOMVQGOGcchj2+//u/xNtvPcc4JOxva9x/ezlHiFOGuZD+4A8/Rug8bneX+Lf/7wdIsa+AC2Z80GeVRjOxWAMpWAeaPipPU5nzNBHj+esbA9rOE32d+QV6XnUeq/UaMSeknBFTBnIEpwmRZQXt8LrgETqv2e6kLpZ3cmrEYmCUQNnvbEPJBk8xITMjuEYL8ApITGVDcdmpBK5SL+Qw13HWMTvnNIufJrVn6d9cdDNukZv2rFuEYNn5Tqa1xlJMw4A4TnBHB+f2CKse/WarxUGbEgBEIE2gHTNKVh9z/yAlWGQ1Y5r/ElOxtpkWyQR8iT/Stg3EKGCwxCbQEgCnE9uOyG7l+h4W/3kHD+c0lm+akIoLi/lzNzFfbPF+7TSfYSTUgBtUoaol4myZIbXLAt5bWyNQ9Pdap6xtQlaYyhraWuTMwJTAKSNPHt06VF/0UlJcLGU5Zdy9eIFhtcfmyRX6fo3OAXGKQNQ80M0alwBMoKBsK6ydAXHLnM9EJd10bq+hWN8kO6YJIFqGQUFucR/NArKSUlCrJy9W8IQ4jsB2K+DLATm3/V9mNuEyJobXs1ZdOwGJIRmPI37293+Ljz/5EHHzBP/Bf/Rf4uryEh5U3Jfb2Ekbb158NnfIvJ+VLU9xs+QnggbjfBvt9dD3jwE1dt/rXI+9/3XbfZ02zQL1VZ9/6Pv72n0IZN5vXZqpHk+em9GWchTrZyX5wuLdM1fHZk5a0LekW1o4pBGgHp6LFig/Zq6XwPoc0H5onnJJZFE/b8+cJLySETiOorgFw7leP3cg36Prhd9fX7/ExcUWIQREDQPIDPRdh3Uf4INDv1qBQSosM4YhYv/8V5h+9SPEzT/H9YvP8dP/53/F7YvnuPvsIxz3GYQMT66x+FvMsZsXfp6tYx1WZuBmd8DxEPHWE64DJAVHS+ChirPcJjybTRCXDF7MwHQckVLGer1C3/eSCMuLNwaxNFfsRs7BeVnflA2AKe231aKavMJW07xKWAVRQuU+s3XNMiYpoemwWvXo+x7eB7XqtHxyuR8bKkg0KwNV4qyAajkzq5rNH9fEFfZM+x6TF9r9RUXZIe8XfbrIYeXT2ZltMlxT+90pVXfOw/sEkEf0kqXTQxJfzCyXIMmi7QI4Ezo85prPXesWaP127SZkIOdJgFHzDEH4bfDmovh63KfyWfte+TIDILE+OUD2jPFiJ+EmgMTGB6JyjszLq1gOTR5oD0GRew2QcvncKE6GQ0wJ3/ndj+D9S2xWL3HYm+xxfnQhSK1jM0YwM8YhYt1f4w//YABjg7/6y2/V+tBNxs2ShR0QZTtHUS6YvM716FqN3KR5G/6diWkzJqO0Sz4DMCfzmtzCE578/i2G24zxbiXBvOpXS1ps2lwKODOC9yAvQcA+hFIRPkMK+TEDGWdqXxCQYsYwRvTBIyUGxyTBtc6VpBVzp8X58+UHywa2IyJAJi/OmiRAIWZddJqDNXWpaGDaWe2OWHXUBTEQiB1SiqKRbDsGZYQxISEhpYhhf0DXd1hfXMKFAHYBoCgETjdiZsJxkkDjVecA5+AJUl9LZe/W+iIau8r6iyBSiCcQWs0yEXwfkKckqYIxx2pFC1U0G65aXbUNi0PMucbRUSBwSpg0tS6IJA2vARSo6wCLhoQhhcDFcudkhzSgymiWWEsXwkb7u6MKSjMDSwKrwpvRVMH6QqwyoaQ6LuPQHZBSRj5M6Lug4RQOwTMm0jT4LPekvRTt7C+ucLmVzGhJCVFx/8nirOscgZICajJAKevVaTraWnyzpv+3dRE3yVOiQ0TogtcSEgJgM9TtK7sCEKFrKudK4w2VsE5R3FKLa8+McJ+J9FLgHocRtOoA8gB1AE1l5nPOOB4m3Fxfo9/u8C//+/8K/+SP/2N88P0/AVOAJ6kptwRl9XcunxWL5+KeWZfO/H3u3leJyKe76PxFs9/PC8+PFcpf51q2+bAl6+E4vaUF5uuAwa/6/GPAnrSPSueASgga74ClG1Vp4x5F4BKA3WuN4PNtVuGt6c9rXI+Z/3a977Oi3bdnmRkxJwxpgCexGnoKIAIiK90jB/IO77/zBt7yT/Gl0o/1dgsXIHScGeMwYXTAkwuPFKXm2na9QoqpCvk5AW4tQrRaFIr7epqQDtf41c9/gp/93d9gd/MlhtvnuL5jIA5CqzmLi7z23xGBk4ytX/UCZooQr94XKtkwM25fPsfxMKHXkkUmvZX9QjWGkXV+SD0divIOqtmPrEJjFZYdEbogyjwGsNms4QkY9ofZyhCJs3icJry8vUOeMlYe4u0wS3LDleE1IguDkZPWjWVxP012f32yZAQkIoTQKTjyNSSA7jtdZ/ZRC7wMIDfzsmwnqycIUM+GZAzOda5NSegcyAVYHTQGS4INIgXT+fT4LGSS+dlWrtBY3x05kDMA57UmGxfqEVMSeUNlO98xJmaEMr7zMW3tu2vH5nKW3gSbqAYDq/KDyp6lLgi75GW7pWm0Baq53StNq/YK52TOpfavQ05KEVyVeySbqUOGlN8wryrRSTS8axYu0763ccdtiQ0zmEd88K1P8c5bH+N4jJjGhyPDvad7SSVnxmZ9gA8D/pP/9IjPP3+Cjz58Vt4r+5HgGYj6GZksk817aLYU0ns9xq+KT/xGgTYAzSKry1hmcOMDmzJjGDOm6YDsRmDNGK6fKLytWR3FWqViuPdwQQ3M3iHrdwzJAlU7AZTI8WbBcsp4fnsHHzw2fYccAhIyVp1sMkuzPsdP5TS3jYMzzTKB+SKCMxwxEgOJaha+QvCtjpk+R5DgxXnRCUJkiGBMsvEYjC4E9AhIKSPGWPx2uRF0jWn5IAk2psO+FBg0d4mYNaibrUo80G83WHWEKUYwEijFGQN3JAWpE4uWoWS1UmIgxBCz+XYErSBPyFoQm0iJbcqldpwvRFuzSypj8KiJJUCEyAZ2BdQ7z2CtZM+cgcRITjVaROg3a3hHiCpSmyVIgARKQK/wsayu4aa79GUdy/Ln6uICoBRNr1vD/OkXVKKgVX0OEAseUUnNyykjx1SZmPdwBITQISdSpiBzEQ877LKUd4hJrKYhOLjOA5MwqCacTd4YJYjfYhBn9B+YMYQlsWFGcaG1B10f9BmnezhCYs9yIV6y2Bm5qffnSPZYzgmdCygsmug8YDMhLDPyYQ/vL0GdLxvNkxNFDWcMU8ZhJAxhjwti/Ov//X9EZuD97/1T9H4NUF3d5VVkrrPf/sNe85Nf+zHvC50FRedA1UPAzb4/K3Q395y7/Nl+1T5/1avt8339/20A0nOulPdb45ZPLPlA06aS9RmYMV5izB98whvPiUXtffddBrjqnq1z99jrXuD1wBy3YG75LuHBGS9eXuOTj3+C760P6DcbXGy22K57fDS9gdSv0YUOwXX40999guHiv8DvvfW/SHyQd/jkV58ILVE6H+OEGD28C/jkk0/w/e/+XkPUVEmZElIu6i8kUxzlhOPtNV785nOMw4jMDkiT1jZzypddVeKQzOgJHST7zl4r7x6ORwCMdSf1oKCAy84HQ3icEs3iNVQmX1fQFFvZUfEOck54tfcezBneO2w2koBEXESlT44EmKWcsdsfcHtzh3gcsNmskZ1YwAw0EqMmwamdgPXEeQdOTsQQ5+AtxAIApwhyPQC17BlYs3lrwNqpN4s7T9cx34PFDZV5xlSNN5XP27XR90OXxeqlwgUQsdT2S0ktUzbb5k1RwaEoozU9V2sNp2Uv22FRifMCoVgbc2Zw5Jl7JBEhTtJq8AEpiqvefVdV0LRcicrps85J1moPHxymMeqzlnRfeLMrfiYN1bE/Z3uB2ukscyHzSnXM5aZKr9peyR8B7Loi15lXVAknaV/ZPFiXWPI3FCWXyjDvvHODP/zBz3F9s8fxEE/qtN1/PczZU8zIaY9n35oArPDpJ+/KvimKbpVVGSAEZNJ4OkY54+22TyAgZpwr6dBe3xDQRqUOlF1WP83MrWgIlwAPsZaE1Z1oRxCkOKavVgsgwFGG9x5ec/Of9fttiKEBKlZiZcuWkrjXxcNRXS47xBAQgpcikEGSlZS0/XZ2SjooLpuoVb5aqURAEpPY+3Ix9eszyy4X3Df/zpP6AAfJSsQqHEimHIeVX4F7qXuVEiNpAgsiktSn3iNa3SoWcEMKlnISYb+1Ko7DhL7faobGhBQjKI6IcSoCt41DLCzqSpCkeCFyTVYyow/MxZ2uEAGbXy5LVn4pyTTASKh7BRArHgNCAFjq+xVsXmKeFBxAND6XV1schwk5Rb1RNEBZtSQWpG0k0TlzPrJ10Z8z0D4Xt4CqgYRz+rt2/YwW0ZHEoHnv0AXxg488lSyM1QtdiIbrAkJwyCmLKw8DlDLGKSEleRmFgPXFFcbjLeLuCNasq9bd7MRdIecqds+Jsq4nSOWi+jcDko6aoBmxksT96bzEzOquY4yQK6PWmFObyX61kpIN04TkvCg/OOkanhEjFwByHCNWXY/iDOIAJC1j4Ai9B1zKOMQBfSb85Id/jo6Ap9//Y3h6mExy+XkqBC+F2XPffV03wqUwf0Ir7n3uDJA4eZZnPyssqW2/qvdLwGsnwZ593WyYr7LgPWZcbTuPvf+xfVq2tXSRnIEwMkognxltLa41TV8cLA6uNFToVttuESCtjSLMLft8bq88PLfL+L4lEHto7y/jAO0apxFffvkcF/EONzd3GL94CccRnQdy6PDL+B62mzUuLy/x9vuMdy6f4r2n/yHc8RP85vNPMUWHz3drEDmE1RqYRLkDAJQJWcv8pCSzm3NGHEekFBFjxBQnjMMg/GscsL+7K/VYyeiariDnJLyAaxwacVbLkVCXWmbFElygLL7QGrEiFlmh+d7WU1Kt6/pY1kbCLNOfgKBGmFCwJfTWYbVeA2C8fHGDoFn57H1EQBwnjOMO43EU5ap0uCihAd2HzqmXzqknQWZY0kzErECOJFZfZi+X/b/kie4c3S5jO00hXwDYAogtPXcKtjhjgeLZ32rlcUGsPEHCDOI4gRFF0awZhh0VX67SDozftWfC+Pn8xJd+ylcelmWUVXKXeRbPlaByG7OwqQCGowzwqT/X8uyXXAFsWb/RWMtsL0uPHFnxc8DiM4ikvA/nCeDOdA2za6ZEuG8J2UBtwzF04xG5EjLvYK6QBO9ZDA0ELQul4RpVi1z7YC6SPF/f1h0WkER3f/iDD3F7e8DxGBHjw4DodS9mYDhO+Pa3P4MPwEe/+h0QQumuJJHJIExwKutIt7kqprMYMRKz1u2LD77zGwLaVDDXTEXiDtYMrjkAolgXSd87Qt8H0NOMww6obmZGFHKxjrhFAgS2fxrGJgedy0a14sRyxSKs5omRpgmDCr196OA7h75fYRWkaCUIUu4NSmPKSVl0ghqxRQ/UWXdL7VP1lrQTMUc8JSBe547IamNBgZoI5L4LcIHhk8c0aWyA91pGQITnEnOXxW87s2gyciPE5iSuky5HAQuhQ+hXcGlCiiOG4yhWLa6WsaTMRtZafOmTkxgimwdC1aDlFqShOcDG6LjGWp1q7PRW5S6eWbN2zs3fhdnkhN3tHeDExYRTApuBRq1ldX8IETdBgFtfa9PSsd5DzVLN+kcAtQHbdUxL7bwjgg+SaMcHL+AzZZkn2Ha2uWXNSmlpnQGLWTP3EAZjvx+xuXRYb64A1yMedxgOx7L7nAFGrSNXsncVZlFBmPMeMaUiWJD22YBwyYZVBBRjg9JzU1TYWEG6bkTYrMX6mTWBDDm+TxE7X3u9KQ8HuIu1MD/IOSeIoohYXINjEkB/BIN2jB//yz/HH4Hx3vf+VDWg5spx6gqWmRFTROdCyWh77rrPdWze7ceDBrrnd2n3t3ctxZDHtH3fOF63ncdej3nfY+7/uu8+v8a1H6beOSfznOvr7B6a97qetCo6tsJr27/XHe1jXUlf1311fj8QnMfVkwvs3e9g/PgvsD8cMBykvlp6+n0M+QhOjDEmfDYcsPpHz3C7eR9Puy9wcXEFpj1+cX2Fro9wzmO96goxJe8R+hWC99jv9/JOBmLOIE2pvt/tMe52gNIq8xCAusVDNeYpCTgzFmRnwhJumBs5WxZHqFLKXPS9pFcXHZ0rHvUm3Mr90jATNM6gZhVmbc/2TtsHq2kGKHhywieGYUSKCd7VyCgiB6aMEDyQA3JvHkmubrbKisGoGYOJUMoFAWJtIHUnDBDeDkg2b5EqSF399QwUvn9uj8jbjL8sBXADZwbelvt9CdTa5Fhlvyl4kfn3cF74vPG143DA8TiJm6gLkpRNhTdTOOaciqLZkfUHi4PanvgK3sg8ZUj6kCzrMubntuA+BYEMoPOECVxCEKoL5hKI1s4QUXGDLCFI9p4yby3gA0K3wnq9AbFlXJ7PowFkK/VUZ3853y2FM3lB4kcntiRJTi1/ajRw6haqSuZxOp9cxcYqBl4FqYvX55zxe9/9TAqaH6bfOmCr7wHGIeLZs8+xuejw859+G+Sy1PTN0g9SgTGmLGWZooWkiNV/Sow4iXzO+UyoVnN9M0DbXAYHQzKuzG7QzcNFiwNQTmB0WF0muABwNjRfQZgh+4L0gcZ0WgVwhqY0TyrUmTuYI/jgsN5sMY0D0hjBOWqmQCAPA6ZhgHcBUz/BXWywulirG1szhHv5mIAop0cnqXRPaN3/VANbDp8AEAaQ2IClEjwIUQ7BoV/1iFNUxRTDhQ7OC/CaJtGchSDCeIpRCUVDDGyOimZFDx5PAjQ4YToMGDrCantRCIdoeh261Ra+W+N4HMBxkExJldLKe4xxadYtO/uWgpcUmKBYd4yhVVDDgNaoaaa60XbammdzS23Mz6SxEdm7InAM+wN2t3foVj1WmxXWm3XJemmWQ2b53XsC2LzS5++z+wHVHEFjLgGAI4B+sTUqkBTQBfjMM+dzYfgEr9pa5whJg73NTceAjg/iipigNWHUlEfQtUbGdNzj+a8/w8UbV+j6Dda9WIyHu72Ilgo+TUudcrFjqiayjtnpPQ4GaPU/IlDO6EJXxqtQUBmzMCImJ5ZdiIDgdMsbmOOcMcaMfjtncieXaea4zi6lCM4ZXuvScDYtp5z1EAK22w3ubl5is73EOA6g0OMv/uf/Fn/2nxGefvePYfGrxuYyxFId44ScE4ZxwsXFJVbUJCR4pODbXq+ydsyGisoaX8U2gVOdUStanG9//v5XxZ895mozbZqV+KE2X+UG+ZCF0O4w9+hzbT72al0RX/+5Fl6dArZ2nyxBGTfPVZm6EYaE4DX74IwrK52bp9NxLMd4n8vpQ9frzI8DoQsdnly+gcvbD4Gn72GcBuzu7nB9/SV6t8f3/70/w7rvkQFcvPy3uFhv8LPnB/yfH7+Nf/r2Nf67fx0KLfahr0k5YgYFh08/+wy/++wZiA5Kj0XRtd1c4q233sbN7S0oWGy70hUFF9l3oBwRc0Z2oc4OWYp/sX4yA5RZBCrV0ppnibmu+0ACojKwWgvH//L5c6w3W/SrtU4eS4mJZN4fDY5SnpNSxjBO6PsOjhiWEF6sgBZuoCncyZJU6Xw7KYcDBZG+I6z0e+edeBpx817rBOuuZRTgCQD73S28yiuRUXmwa5Ka6JwBVGUIA2SNom6mRDUrFBg0RnA3V4SVVhsLm/1tbyvdb+4nlQedD/CrLTqfIAkmJtztD7i7vQFACFeXMi6/sCMTYHkTRA/c8uaHzkWlcK45H8ZPSg+ZJWGMfuIDIxIhkC95FyyUpaUo7WhbAFfBm6ulAxqQaQXlybnimhnjgDge4TvNeLicRGuC2nOu874ozyRnoJ0/au5jje8jrC8usF6t0Qcv85oSKEe4tmYtVWBm77F6gsWzQPuZU0ZKERfbL3EcxtdwifxqV5wSjrsBbzy5QeIPQOzBMWFKY7H6S0mmiGmckJKUMIpRvNME3sgBIvcQUP2mgLZ6AnWPkCayaG8yYiJZpjgxEDxiTMg8wvFaMu5Yc7qARCjZaSpxOH+4ZCNSc8KBOEYM44S72yNWK8lamTkjjoPEUelBdrr56iFphreQimwTe6pHudb9UdGCSBJtEM0AW8FSjmrcl7aAlllzwKrvIZnzJCB7GkeAxV2062rVducZOatVKGYFfqIRkYxdWTRoZUwJKLXrGLubW0lgstmgX63RdR1ijMhRNuv24gLABVI8YtzvkUmJB8nceSIED3CSJCxZi2+bZs0RJMYszQkDmTtIM+GegVQYjSxHYOlxScPiPZAniAXMwSMDOatLrliqOpYEFuPhiF3YiXWrbIvqgmt1ywDShDhCyOciIzSwljQw2pwZbX9wPbT1DWXPWLkEiWXz+p8rcZ+O1P9bBTPREkvaXsFETmI3UwI5qQlDOZfzNA5HpC9GbK+22FxewHVrwB2LIEkQl0xABBMrBh8U8FjMWc55FvRtnzMA9h5+ZdpebdcRus5jtVrjeNhjfxiQpcogPCs4J6DvevzO7zzDp598iimOzTzdc/Fi9nXfTqlJH9DcElPC/nDE7f6IJ29e4fZwAHUe426Hb7//Hg6f/BS3XY/Ve38AOCBQwDhOcM7B+6B+7A5rLeK+FFu/jhvkq0DfUiyyn27xWcsG6J7fH5rVh9nIV7vafrbJpQ3MzcW9VnQ6/c3uPL3XxOxTMPMQWK2tv/6anW+rESwXgGoJ4E77cApcH7r3oXvaqwWDy2dad81zffgqV3m2WWijpRfbC+Tv/QmGX/wQE2dcPbnC9uICb7z7u3BvvwVH6qJ3WCPHjF8/3+FHP/0V/vyz34CnhPUmafkTGVVJ5MGMcRzUomGeEIQ4Rfzms1/j809/jZfPrwHOxbVcaHGeM3FeCKRQoZUq+AAYl9s1vJeaaFK1R5S7TCZg1lh1clSTYum0ZM1yTSpIixAOAZEMTDHhMIjs0a17eJYYeQGbYilz8hoRxH2rMpDLuQomuz6UtShhC8o/2eLJdV4SN0K/7os4jeI+afNbwIfxlwRzqiwxgWotIyLJhNyJj81M6UtU3gEDbI0id3mdZIlsrVY2Av3MdT36VQdHYuW4vTvg9uVLDMOAFBNc34n5xEPivEkzDzCX1PNLGnpCidjWuMnySgRYaQe1tkWyXpabJAxDrWVxIkzHEa4XPiOOI1z4btsL2d+lBzAAt2SXZR4yTLBo5pTBHDGOIzrVoZulz+awtMfmxsuqJzWhuwyltF+6BJGUfC8uqZeXW2y3F3BOAOI0DOj6HhS8ZIeOWhy3nfiWUbSgciZjM/7RH3yCrrvB3b6Wo/o6F5HkAEjptD1m/Yxv8YN//Ev81b96F+NxxDhOsgYFNer+T5ZrlSUW1DuV6dyJhXl5fTNAm110KuwWC0axyjBC8AjsEPrqh1w2xuynst3iytUwJWr2UwPSUSx0shAhSFaqaZKSAqJpIXFPC3KvI4kfC6FT4kqYKZnsnSaIqrAc9RBUBikvNo0WQKrJ4XlbbGPicmDKF8wAZwTKmGwnM1DSkWZGZCm4KTTeiUUjJhRxgqUvxUhLDkQaP+RIrRSVoIMljV0RxswAACAASURBVHycbjH4I8ZNh9Cv4TsBGDEmSGB0gAs9cj4ipVzSthdXN6Ji1XPOIKweCOlGEfbBAiBs3UgBTFSm3NJ18xD2RIhaiBowImMzJyZ2By8xcMGDUkJ2HiknTGOG7ztNypIBFormbH+R/BQ/bLEfENX1zGhgGjOII4BVIfieirhRsjMyxJWTbJ9yJaLeO8msqfvVu7JlAEgKYecF2PksVtX/j7p3a5IkOc7FPveIzKrqntnrAQEKMJA8PBfJ+KB3mclk+usyvRxJL9TlHFEAARDA4rY7uzvT3VWVmRHhenD3iMisqp6eJUitAoad6qq8xNXdP78mf4cFIQNqYS1Z1+fp4Yg0zRjGUfeLA+IYajru5qLS9rRJOQry2xArsWdmjMEztJUVk4i7PcbDAUKMKRXINFudI31IfY+9e57OKKn5fFc3TfYsbdtGoHGApAQp7pazFb4YHAPuDns8PZyxuxuRl4LAEX/445f44je/wUf/9AU++fcP+Onf/C0+/uhTK8khKMtiRFaJiCo4CoJnpOvaSy1oW+H4uft8/8jmb//M3efL9/jzL6/ZzmTprrngmzfuudX6ZwjWz3uuj/Wswy2d7XcGVvl/bwOb69DmJcD6pYDlOXBzDQheCHzd9wR3lW/gffts6a59aWtxRpeuvv1ztjFsH6p42Pa5iGBJC2KICH18OQEpC+Yf/B3K6Wvsl7d4HXcIP/yPnWBI5o4G7CJhlIRAI+Y843h6Uq8YU2pJKTWerEjBP/7iH/GXP/yL9jLJkJKVlpTS0vf3AtZG3ryUpbqda0JlFoDh9fdIFZEOVkqx5GBsQjeqpUNfYrvDC2UTVDlNGpuzzFowm5nw+uM7jCGqYpT09Wzu4/oQc8Fzy5sLlVwNkaowZUIJBqtSNk8WWg18nbERWNKsSlkRBA5VeXlNF84hmiu+Clyt+Lb+rRY0rlabbb1PZ2ps8hiKqBsnsAJ/vbjVF+B2LysHjgrKSbOMThMe3r3D6XTCMi+aK6EIRrDNwZouVUd+6mVJaXihA4tN+e+yp9U5rXPUrqsAM3u5JwGLIAZGISDGgOJhCB2fW8fL4+I7T0rillbuZsnpSlWAm6yiuDJqYWghBOp4cDfmOifSKHNTYjSw2I+vCEGYEULAp/evMYyj7j/RWK5xjLi7v4fkhPl8xtN5QqTSHI0aA0D1KNo2Uhk354JpmjDuM3J2UHl5+XOtDwMBgN2OMe4ipnPCNAmkdLFnUpARMR3PePz2HR6+2Zk1TemQv1xsA4XAlsneC4ozPPlOys+bBb8XoI2gPqx9NXb/pbHm7rADAGkaew7RCjQyJDcHEwVNpjuj9v0lM1WtlgaaehydHXJpQqEUQZaMYPXP5klTrQ+7wcztARzcFYGrpsWtSaBKkwFokesZBQPYUspTlWbYhi5i1grGRa9rOn1aFzb2Jujcynptiv0bQoC7LxSWWlRaQavPg828Ee0QAopk60+urH7Vr7zg/JRApwnDTot37/Z7cIiWbMZmnNWSqt8Z+OW1kNkDgN4K1b9S4VE7FETUshWJNGutCDg3S5ATKM0wKtUVVZ9hgmEIYIudLBbnV+fXJogs9iES1NUUUi12dSVE0JcEKCLNakdNfBLb7+6PH4haWmQbmzjDMMudKzqyAKPNqfNctqyPpSvcqmdNVHAgIIQBKXEraC2C8+nUiEwnYYsRYy/n4IzU+VPda/VfH3Cxs6AMXmx/gYBpmrE73CkgJpMorCg2U5ekxPZtSQvSso74FIgmDaCus92v7WOpinGwgLKtIQQoGWmaNRPqvNh+WMAgLBjx5re/xtPwI9x/8m8wjnuM4w4AgaM+fzpPiMMAArAsM3jcd3N+KewWE+ze79p3u71EfH7fNVXguHHf9rdeOHrJu7f3X3vurXf0/++BTA/2+u++iyXzuXYLyP1zLKfva9d2xK0C4S/9HXh+T32IBe27uIhWUCjAPJ1xmia8un+NsMZs+PbttzhPZ0yF8Pruxzh8+hkABSIFBTlnvPnd7/Fqv7MkIgWSF+RlQZnOSBbv6jtDxNy7QWB+whgjPv3kEzhDDqwugjGagsVqvta42Sp4oyb4AFx47S0YBPLC6KL/shjQNLlGQR9jiB67W1qQWJ0nVB4MYOXGX5aE8/EE4oBXr1/hsN9hWZZ2LhoaWAnuFUR0MkITwq2wdZZai9PZlBZ0Frgrr5BaGSKzlmQIEUAyTyP1ysldYi59u9Jl3wPOr5o8Zud7W5y7R38GNOvJ6K6tPMHfYc9VHmiFwslDLsQyFRdM5xOOT084H484TzOWJVnyB8G43+HTj+4QnL9K61/tlaxpFtd1wzOtWx+bBx+nzoEN1xKRlNLxKkjN4K3rt3YJfa5J3VQ3frf17usL5nnBEiIwhgqQ/LfViDYgroFEPzRyMScijBxNZmdds2jF1SVnnKcJkhOm8wmnKeFujDW5YJW3/F0XWAFV4fLq9RP2hyfkTTnaD239fRoTl7vYuO5HjiBSK1xaNAOkKoLYakgavfBEQYZZ2EBrmTNKmSE5X5Xn+/a9AG2AH8BeQAWUMF5GPORckJYEZjO9CzXB3mPJdBegUDBBk6/XUrOYMoGm38+VTKEeLGa1tokIEFwg1vfEEGvmqFrzC0X7hHYYqZROgyVIueB4OoIEiDFi3I1gYowDW9FqPwB6yOtCimpHmhbDyNnGAuIuEC0VrVuozEJGSth0fGU1Xk9Bz6IaC7XTaL81Q60e5hIC8gL0WT9dy4ICzOcJaVatyW6/w7AbAKirJUGBhoCQs9L2cT8gRiDnZK6nFfe6N6itmFS3xEZQOsCQpc4N4ESRkJi6jGCNwZIBuAjPEKWZlZSouMZWwUque0ypnTPgECLG/Q5Ukj3FE517B1a7HdIlc1EiznX6t8Sx/6sKEkyI1g/n7dvDXplpd6h69sNBNTvjEI1p1Z1Sa6b1Wrbe9bGUXM34TIQIYGmvbtfXs+JWPgL5dhHBPE34+s0bdTv20gjGiB0Q66V6HqQUzPOCYdSCuRpQ3rsQXjnjRKCBQcgocOCrew9VccDY7/cQZJTzgoACjvd4fYggRAzDj3D/1z+xovUK4nNeEArjeHzA6emIEAcQM4YY8IMf/Ah9AeS+9S5nHwIA1u5r299uty0wayBn/e+HgLcteLr1O7COWbvFjnpw1gt02354u9XX59jdc79/6Py/5NprwOY7yg7fuR+33t+SXW1oxjPP3rpPfrCrpFl7eg8Hb6UU5DQj5YzD4YDXd/cQCJYyQ4rg8XTC21//Z/zyH/5P7F/f4ZuvvsSbb7/FvMyQMCKXM86LWPZkQfaU5ZboIZeMh4cHBW0+hhAQY6iWmSUp9e9Tu6txpymqnG/08xncFbAOqwnjfYIQwIROKchF61DqpY2uekK2Gktlz1QlEmMcRwwWFtKepz3x1XRrUuMVjbfAwagrw6CgpJiikEQgrLJQywAmVXnIgVXeoaJhC6FlQWTJKM5jCoCcASu1REKVmV9LMrJqfbr/vphYF35S578DMwQAlgnS54yDyn95meFKx+U84enxiOl8xjTNmsxLgDhGfPLpZ/jsL36EPD11mFqVnKAmK6YiN+RJ75f+h6zPpTJ3l9m2xoR2Y8mWKq3W/ZCuKLNUmcjH71QzGBj0fq09y3Txe6ynif/IgJklQxP10NF4eIsErkpnf8Z1GnGRmd3iswSoSeWYCAMPGHa7Ku+nLJA0Iy0J52XG+XRCmiZQjMAYq/IDYhlVHbgbs9BzY/KcyQ6H/RP2+xOOp9LJMMAwDoCkVdHslzRmQhwHDeMpUFdt9z4K4+paEYBj0DqzlvXTQXdNxlaAPC9mbc/1nDGzevc90743oK01cyfr65N0bF9MyMrZTbBq0l6mGSRR3b6MWGlRR52AggKmgGwpk7fZiwSa+cgVEyJW6ytoys6qFaEGlpi0QGJhttpoBiAs61NAR/dW4EK/K1NCSgsWZhyPR4TAeH13wDAMADEkBMTNOZAiWOYFjkyVZrfNp19r3Y+cNE5rToJADVhpEUmuzKqPkepTsRIRYmQgZ+RipQE4QKsuEoYA7EYFoGleurINBgpccBcB5QWYijFnLW4gonRdxCwsHDHev0LKCWU+IacFRbJaHAHkwoicQcTKKH08ohmd0LkLVkuPEVkt0s1GqNyaxRaonYEiNVEK+SbQ7VhT0rYkJM58VNh4engExwEhEsbIVbtzXfz0dyQwjd2eapuDzR3I94xncIQzVbBVCqK6lz0pSKnvsELcrNbflQ7U6mnkLJp9FRYkW0SZrqSVllcJiwBSzNdeWzYzfoYKNnnDJMTAf4CAYjA3HdS50/cWPH79FnF31r1migQXeIjEhBsNqhdmnKcThvF11bT2wmRBF3fQnTlnOJra2l182/IQaVKRaXrCuLtHSgs4TzieGX/3d3+F/f4e43/1U8zDHUpJmBcg5wWDRIS4x+5QsN/fYRx2iDFiy9gqI73YDTbH/Rm+csUWsPVXCK4/s/+9F2y2wOh9rOva73Lls5Oqsvl96+xxDQjK5rfteK65Z14bcx8bdw1IXvtev1uD5/7va5+/r+05oLjdN+vP5iVgT7jlFtnPxeU+Xb/94vcOQChpbs90QPTR/R5x3CE8/grzH97g6eGIX37xG/z+i98gPh1BgXH86mucHp4QEHC3v8N5OuL87qRa7GGAq0SyELjWfxQUO4VOmlXbrcq1lJLxQnIk4+yj9tOBjCp8WqIxcoGBPEGaCZlMq/lwAIiiViwvEQDAlG/qCdInvyA0N7dgnhNLWjR2nAek6VS9PgQwV/qm5GUyodnlE1E5p/KJQAglIOeEDM00SEVQWC2BZLnuiWAeLKbYY+Cjjz/SZ82Lupp2e4xJNrvB3PSsX15DFwS1AqaisWvP1Gfbtm26e5BmVNb+qXyjmfkKJCUDPh4jDwxMWExOJFblOQW1PiYQtGK67wDfOaRCOAGSBaU0Fa0Ns52RPseBK9CpW9lOq9zTpt7t28fHzFikWWFMxKxAH0ANpdDnyOp+f1GveM3ksmn/MoFnuNQHmex9UVDS16Apxy9aQ5Z1dKzSApY5AzKj5AVzyjifzzidTpBlATEwhIj9EDQZjLlq8srKytVYoPGrUvsmIliWYhjB3YZF6w5LRil21pgwjAQOA+bzjJz7/aqyqbcYgdFC8odRgeEiY5MHASBPAAGlvIKUgiXnmgjQDSrNwJHME0o7PQwRcTcixvje+PHvDWhTILG1HDlYa0IrSLM58mKHLYQWp9Jp8FgYhQQsuQp2AlSNmfsNEwwRd1YF7ZAmtSipoCDUheEOnKmwzYjB65/495YRr3NZaBtYPyrDIFAmrQWWgZQYX08LKBB244j9/gAMQVP2h17/p64KmgQhIaV2cJW+FwT2g1egscaWVMSIpY+jEXgy31+qR4tNstYCyQHCglwEHPR9kRkihCESYowoRTPh5FQqAwyBkK2YM7O7WTJSKkhLQRZ3YQXyMmFZRoQYEQ6vEfKCvMxIy4yyLB7gpivZgwciBZNoDLn6PHdrWkQ0g2LxddJUrCLqihioXa5Ys9PowImnWQj9INpzl9OEN+cvsb/bYdzvEIcB7lYKmFaLsGZjHQODaZ0U7BAsWk5/L11G055x2jjdldfRn7tbsmcx3FBVPw/MtncJ4CXpeyrAWfczxtDOTGUUBoQscQx3zxexQqEEK26vwflNO2bH2c96KcYgUJlb3O1x9+oVjo9PgLNNYqRlUWHsitaWDEi378za2K7QfciNMenaq/9+GPeYl4TBYjFSXvAPv/hH/O1Pfor9J4+IH9+Z66pmqxuHAeMwIsRPdH9cgRK3AFN1Gaq/X+d+1wBbz+Rl8ze6v73dytC4IXkXf19rt2DLLXDm92wBWf++7TO38sH2Wdeuea5v1/r352rPgcF/ybYFaA0EPT93tLm+/217/a13XbcQuz9GU1BsQRyRxn3WeBFybwXBiAnTr/4e355ncCn43R//gK9//wUWIex3I2g3ala4pCVkKGgs6p4Z092E5elonRMwErgj/zllLNPSBGexJFJBEx6UrEKw8jRNTFW4xS1XHVZQwTiY50ypmakb74F5uRj6rYKy17/0Gauu3z4XQOURNcGWKyKF1WWPADaLfoiEslCVkKQ0S0MfgNfHFSntWAu/ZJQ7kAISEUHJLYkURfVSapYUwWBxztN5wjzNiGhlAUAuh1CrwQqj60Z3dW+YqoAI5Nrp9wC2614oquyLHhsEoOSMaZrw9PiA8zTj/u6A/TjArV8xRtCBkFLGAi3XE6p1U4XpnKn3ztR6fKKKazbFvdhGco8m39MX8V/SYgmrQuBqDSCbx44HCwgZhMhA8VANOBZqJ5qIEIQscKWBzH7OiohmPneR2e4jUwgM+wH3hzuEOIAlA55+/gZxa66tHVezve+K6HoFR4yHiJITjtMZS86Yp0ktTiUhDhHDfkQcBnAIFgfvStzWAR83cQNuPfEiStjtTk2+MkVLjAExAEkCgq0XMYHl+bpode7sOaUUk2FVEJQyAzRoJ3hEjBkhzJjOjQA1a5/2mQgIUWX7YTAlbymQxQ0yt9v3A7RdypVVGydeBbldqtYr2xSSE7JYYUha76zKxHqCuElJChTNUmPvIyO0rhUjIhSjJzXdNzuR1s3EvO18cyeone5e6RbtMA5aSDCxjsMGJhk4pwlpXvD69R3iMNg49BkFmi2QI4FDRCyLJpnoTOWecZItw6KOm2q/iDyGkKolxwm6By5nIUvvSyZvM4gFw26nRSBZNZcplxpTNIwD4iCYp7Rat1KkBViKxn0RihIGHlFSRiLTeHZTGcYDwrhHTBPCeUZJblYudRzKJDp9V6VXVIGTwLUdOkfUbSsBNK2uaAbPQoRoewPuBlGBmq+jLaoxVw4MRsH56YT5eELcjXCLkV9PhBpb0D/LrZHVslZT22qGzgpAXFuDTcCzSwLOLHoCxlyDn5tmkkGkNfmCJdoh9mBw+3/Xp17Qgpg1q+5pqa4Pa9/3piQJpPvINcmVyRhwHMYIgWc0E7N+evruqH3UK5SZLjOWnADECzcbB3GCxjhKUR/zbLJMYyLkiwNmwul4RNzvgQGaDABATmec3gFfff0t/urfRhwOe4QwYIyjxaKGOv39vr0Ghj5UqL/lDrn9fF3Ibr+79am/tv+94PZzgGZBuwawbgGWa0Chn6P+vdt+X+vHtX5fm9PtOry03QLMPVhxkH0JYJ6/7xIcNcDzXSx36z75O9q7nmP5z/32kti4a325PXfX3k8oWUtk5JowouDp29/hD//5f8a3X/4Jb958hWVJCAB2w4Bd3GG3HzEvC5bTGcLupmeeJjEgDBExxu7dJrAJICljOp9x2O3XhFeA1/f3OBwOalm3bLtJ1KLfj6p6IdphV27Tu8iRKW30pepNZlZ9o9u9+/oqcQe1f3IuSClj4E3qb1F6FccRQwiYpwWRd6gZ+8TDCdwSaM8k1jpkJmOJhQeY+0G1oImVLfAbIzGSAFwMVFkai1KKFiRfMqZ5wnw8qyVjHOEwrFl7/KU+bz1Psd0vdteNrXcrVMDPud5WlKeZ8nCaZ5yOR5yORyzThEKMw2Ff3ytZNBuyCfJFFCQRMaiWtLHEZKRJSQSqTG21zUyZveW7/vlyJKsEME0+3JweQa33qo/WuqeRNM7wMhnImuJl6ufM+HDHzrVuqlnTcl73gYBxf4dXn3yGyITp+IA0pfaai9a/e80VyOSvYrw/C7AsC5ZlxjTNSGnWfAGBsR8DYhgQLD9Fzb2gKdm7vAWocobv2S0zkiK4v5vw13/zDd6+kwqOmNXYk3LCMmtcGjMwjBE8MIYBICqmIF8Ptuq9rRi5yzcxZIAjRA5ISWVa5Bmff37CT37yiF/+4pM676XWOgYgJvcMWrYJOWv5jaBJWv7/kT1SoLW4SFbAi6CFDSvOMs2PlILX4a9xxC9U20aWiEQC+tNfugxuAtMc2SzWrS/AKtDUpAm3bJvixJUjKzGqj7m50GSLHZkbxKiIqFVqyQAJKEZEAUrKBgKCaoNqPJ0SBdeUaPZGnYseiHotjiyCaUoQKZqp0QRtZwRKcDwjkWmNVi6pNhlWhNkBCIegGXSmhDAMWJYFBC1UKla42835ECNU1LRr2Zgmkbu3as0ckgV5SXh6mxGGPQ6vdohhQM5JnxcGHO4GlDxiCmecjycvOqDZL6nFTfn8+4Fp26dpqTTCSS9yG2YpUrNylozq4kKAZvGCEcQKmCzZh9GOaIk0Si5YpgUUAgbzya/xEEQIxDUDlv9WOkarH2yeBJa5UfsvrtnVhaugVedUk8v0rrpOcLgyk0qB6pwhKIEUKpWIu8az+mJ3c+igsU824n+7y8sqS1YwImyizpbtxDiowsKZjPVxSTNCMp8EEVMgCJAz5mnBsFOQns2PwZME2ayigngC8rSA4w7ISX3Iu8ItRIQsBeCgCUXGARgC5uMJd3cjlpTw5Zdf4dPf/j/46Ac/xrjbgTvaspG92nM34+yXdy10+Pe3BeDtM/tRAtcT+Ny6b/u5v+fa/d7PrevhFsz1z9p+ls11/b+3vn+u3Rpj/75rv7/vGe3axjfW91wHbv2171/DFRf5TsCt3X/5zD9nqwLsM+O+vOdy7lbOckQokrEUYHr4Fn/65d/jj//0M7z7wxc4nycQAfvdiBj32O2iJs3iiGR1IM/TCcfjI86no6ZNl1xTzpeqebf445IxzwuSBfj3PSLrSy2dYq4WHksUuJEJr4bqswAor2Vyzwa/Dg2U9BY3MSAnAohTQl7V7IIIspUAoNCATMM8VHlO8RPWHS4hlaP8PiKATBDUWnLr2PMm8JhiC85HpfJul7lgYGCeZ0zThLRksGRE1qRm7sLuLxZ/Rwe6qh22qJu91+iklC2t//rkVmU7rrcV/ZCC8+mEk5WOmc5aPzcVQbC4NgdWbAloYH0IXMxFkmsBbZ9vsbUjBztwq1rXj42Q10CT81mTKbrx0RXhMCNXxS7BeHZJFSxLffY17tEA+2Vf9PpewctE6n1ihJwIECKEuDPXUqDWN17tUVT+72NsskB/ulQhMy1JSyksE1LSsIvIjHEcMIS4Kl0E8jj45kEjuDLXvi7tW2wNNu4FNezUuhqCDZUYzJq5PETW74URBj3HAYy05Co3afgOVHnMNp82p644KkVphvBY5yCEgGGMWse3oCay8xp0xZL2RG5gjVzBvTUCbdr3A7RZ6wk7oQGsKpp0GrI9fYqHrNoljkowSlLpmckLKa8JKooH2wKleK0wYFVfol97IlDoxUztYwChpt0xwka9L7Y9g6GeeLeWYElJC+uJAQYm7Mexpi4OIajVoVoEWiC05Kxp6alP1ABjKPo554RlNiIeFFS4UC1AS6EP01ia9gkG3ohIwYVrCou6XcYQsHABDxHpfEZekrnahQ5PEDxPP7EAxAgMiycSLOLMpR1+kYI0a0Dqcn5CHEaMd69qLRki0kDjYQ8O6jpZTFuzM2Ls24S6tbwQnsVjjPQAFlJXWM86WWPXqnXSQK1YMhLQinCr+wqs0LYReLfqCZoWzjoW9gcMgRDHqHFgFuR7DeALADBr2RsW22NifUHl2zoU05Ya/+szZa5n2pwvqSUJqXEZKAg5K0E3Qi5Emrq6bvtO6LT9j0pkAbfiEoCBgCEE28Pc4dFcQSNHRl40YNetfpqDVYl2tqB7MYBNgTHNM+K466ynqPXStOua+wzie64AKDhPGefzjDHu6hiYgDEwjtMCogHLUpDSCa9fH/Dw7Vvs719jSQt++Q//BR+9fo3P/5v/HjQ0d9wOx7d56dZvy2Jl9f0aqPV/++f+0VtWfY22XAMnPci6dk0P+giXroRbYLV99vb96523fkYfn+bjKbico/5Z197TP8PveY7dbcn7S9p1y9rzT7kF9F5y70v79Odst8CY7z3p3smVw6wBWd+viz1t9DSLpqdPX/0Sj79/xG9+/wXk+ITT8QHzdMbucI9hfw9GwW43ouSkZXSg0boimhRqOp5wfPeAh3cPcFVCKRrr60K189Q0zapYFEut3QYHsAlea1ZuQExQoAKeYZh6nUl/q9nzz7kIRmpK0H6pKhWuz1lbxQBgiAG7IVa3SPH4OKCmofcEEX4q3G0LgnWtWqAqMmu/sTlLpMrLMA54dTjg8d1brfaSpWW9BJBKQZ4XnJek6ehjxGgeQCpI29y7Yt0JPTNyKqgpFl2mc4XXonKMZyP2/bJKotHtwR7GNRAD5DTh7TdvcZoTprOueckZHAOG3QEhhma9orZbPbsnw+Pv+7cSvPZfKdnyE6zdDbtpvdFuU6XODwcAYVn06mJ8LjBjsUQ6FUAyN5fFK28W8Wvbe+uUc7un31OtAHsASMMlcg3ostn3x1X+38Dadj60FeQ54fR0wrIsCATsYwDvBsRAFr5jzzdZs/a4Z6ZdqIPGXLqc0nWvm+ppSUg0IwswDKSKHvOGSouCNWZNekcGkgVapzgtCV7sm6i5QxJpCJCIYJkWc3MO5gEEaDhShghD8gSiiDAE7Pe7arzIOaMULeRelpbILZiFzeWwluf7dvtegbZ+BRTNM2oApIMSEwhrnaRckESwLFkJs2XBYSEgFkjRNOOBWpUKqhkR/J81cb2UHMyNLJf1hrKLV/VmrDUh6FJUcAsTLFDSNWgOluKgFjaPS/NsUu7mKKVYhkmYhrE7qIbG3Nri9NFDhlzIZpvLOlRmyKLByBoTFGwcpCFg5Mkt1iKmEjaFtVpvQkEwc0YpCTXDDgSgANjGBdwyopa80geBSkHJwJxPmM8nUBhw/9FrZeRey8bipYZAqmEUTU6z6h/RhaDKTCAD985YvNC3uO+CyFrb4WAfaFi92yMVk0Fj3iyGu1t3qXOt2cEW0LBDHEYwFU1Ksom/c2KGItVHnUmQpGl/e4EW3qftVrb6H/2jBTBNLlVi4Sn2AUbmTsUMtWRmEa2z4oy1i6rYVwAAIABJREFUFESL7/P4coJYILy5CoSg36cEigzmqPuegmo0a5C7neksVZjxszowI4dGHHWAbEBuHezuY8mS1RIGT2qk6jKNVcmYz2cs+z3AQA5ksa3AXQw450WLjgbG27cP+IvPP8ebb95hGAdMpyf8+r/83/jkP/x3WuKDNdbDBdlbovQWjFwDJrfb81DkpeL7c9f1FrMtoNre3wt8twDkLeCF7vst2Or70P/+HANb7f3N8/r3bsHin7u9xAL15wBr/5LNx6COcG3ut3tAuuuB6+ANaN4Bxc6oFMHT+RFvv/gZfv6//0/49o/fYLdM2H/6OcIYMYw79RLJCcMwYtztMJ3OWIrgeD5iSTNiAQgZWQrOs1rQAgEpJ+V53JLUC8TioRMggjBoNrwinh3SLSc6qNEsPQSz5tfPbmnqIUOFXzXmyXmDXqAz6X+rt4LObTHezYSqNPbZOx6PePPN17X8TO9B0yvgWjzV+hopBYEISwEKdwrwKrSTeRFRdaUUIhwOd/jB53dYpjNODw+YSkIMWjC7kIALgYtgWRaMzObGFlZhIaKdhJ8yTQii/wukArdbUqSXO4bQzr/IVZdpvU+zgRZQrY8lpZPHhJALUFLSGnJJuWbggGEY1AvGhKGq4HYXReZaC7XYvNQyApYunAg1gyMzq6uidMCrJzYmj7WmX6o7bWvbZHjRjA8ZJg+aT67YehJktd7+Yuk8cYDmvtevvVs1AaCIrotb5mrylkgYBrPymXzVvaZ7x/Xxdculz2bgMFpCkWhz3XldbRPJ9ICtj1f3PRFc2KrMQbr3AUsu4CD4H/+HL/HwOKiHT9I4Vs9QHgIhJUEIGTxEcJCacCREjbfjVssdIkAcg3msqQJZ90ZGySPGnbo5gvS8GMAAhQFhHDSuv2juhMzQWnzB0ioQmUxOFQMIMa7AifU+ef7nf71WY34uTqysPlbTLLfkIICARG0nuQiQtbg0srIgd4lTFzUj2bpD0DQHsnqbgOBFn8n9XGtX6Mbmba34nncB1GmL2P0iVVtHRGZGVQ1W4FgDQzezBEcbOWfNmMnRgEPXD9GEI1LWYorYRvEr2cYfLNCHmMFihFHUsqaH2uYVnmDC+6a1bjQ+zQR/Cw7lwCi5okSArJgjqbuAd1djqSICk6X6v0xnIDnh6dtvcCTC7tVrBGYUO2nZx1sKWFizhUqHXDYSoogBAXM3UHCqSdh7Bl01q6Z17YPa/TATecygvqgPQvbabm5OF5trATCfzjifFtynghAJwzDo3Ph+dkkCOvfsDLdr1aLUrafOJzWNsH93Q2KvxIJZgZS/um5WHWwRwWKxFn2bL553+cU4DBjGAAGjSAbQgofJBIjC6tbJ5PDHBcYMkfbO5hIkkLQg5+Q9rusEcXteUxaIFAxpRpJXIHJfcgVcrg1flgQmYB8CUlaVZwwBX775WhMCQTODklmje6bi89YLsltAswYSLS1zHznzoRaUl4G+9/++vW4L3m69qwdjvUDv12/BGV5wLXV/97/f6uu1598CgM+1567ZWkK37V8LkL3PWrfdP7esZ8+1HrBt2/V1WPfJz2CBCr5zmvF4esLbP/waX/zTL/D1z/8XcMrY7+/A4yvMWXCQUul+IUYqQDqfMZ2OePv2HabjI6yKDna7vRZCPh9RckLKGfM0Y9zvwdGACATLnJBmA2yWrKzRVzJFnI05BOzuDphPU+WlNY5GB1lHWkqLYScisCVvKmiui1v3Ob2WUTwBQZUFjKfaS0KMGHf7mp6+vnsjqDObxwwarW/AEqsyAx4OIYKW0t/4lwDY7wYQRTwdjzg+PmApBY0jAsHKKREThlHjtHve0xK0WScc3JqCjSRXkLsCKZ3AToBpldFcStHJNDxoLb0QkeYFKSeVA+1w1xijccBoiVQmMQf5GCAlI6WMGByuW+08UZdYklBj8rV11E9KDUmQep+Bv22GzA8gA1X+6b6LpLJcILXyFtH3evK4Js1L+4ekhbXQ+oliWaKl5+e+25gsvtFyIwwD7u/vcbfbqSwtsgp32bZt3Nzl+BSgK6Dp+QjVu1YW1yvv8O/a3kLdYyZ0VkygeycgxgH7/YDj0ZQuTChJ93wI6sqYkhbzpjlj2EUwCpbF9nG47EeaF0jKGgcpBnKJQbGNRYExoUiEOpx1e4hUcc5QXACvDAY3MpFf2e55pn1vQBsATPI1dvI5mO/rYvZ7o8+QmJdU/bcLBeQiyMsCDgViAckhRgRuIMAzRzrwIwdsbs0DuvmSatlyACWWPt3jgKSz4xCpP6xr6Z5rDjr9shp3Z0Q/BLJYOYKLIA7yqACpZKS0QGIEh2SWPnOZsx3e0r3n1Xvr4aGOCNTI4bLytVZtnqW1bRK9EubgG62zbtbgaQJxqgylCVgKVtX8Lxbsrc8LHDGIgqmUitXB0Pu8CGrOGTKfsAjUPdT2BTMQzcQspMRbtWWpcSfrh2ozTAvqB56oxm41n2W9o98rxabKA8ttm9QRUi/5idEUA63eDbfYpZTx9PadprcdB8QYVrtGLMSzqpFgDPhKjaO6vqAuSc9W7NW9H42ptug1HVtgrXFUfdMrVyFjpB4PuD0o+uw+XrASW4amgra55ZryuRfR102HqsHyFcBLWd3BxMjQWo0xRP3N/N/VbTSYC0NLapIsSyZZ8hCCBwYzOACn8wIpC+7v7xGC1oCjoGszzZNqenkACODHP4E+/6n1V6pWeb0WLuatARzVeb+9hv9ft35lZfP99m9vWwvdJnrm4tPaqew2ULjVBC2OeHPsVn271uf3AZJbsWn/GuDsOavd1u3wFojrr3vpfvJntHV8edyebFa4SEEqCW/f/BG///n/gT99+RXOX/4cNGfswBg/eo1xHFFSwdPpjKesSYBQiiVh0GQlKJqdsBRTnpKm6M5LRspF64CmpKCpA2FpSVimyQBbK2D79PSktdo+/bjbIIQYAyRllQ8gqMyh/teUk1JD2C+EzLbfOuscoElJ/AIDhEIqvwiAOMTKS/a7PT797DN88+YNSpqrMOjPrt47xliZCV7n113A+tgiKQQOTpNRZZkiWis1Z8HT6YzjwxNOpxNYVIEbmCyWWp8dghUKj6FapFZjr+Cq/VDsfJfKV6kKtgRUvlwsC3CvaWQOuoONpw/jAAFwPs/IKemTS+ctQyrDhcCIMSLHjBwzEjTMRMQSxlB/XpzvBRDlVYIsn69iLvwOJr2uWOXz0kSnnkGtvZ6uA5Ltvmk7zaU+qWUTinmIiHuaoAO2QM2iWPmNuKxnCmd/OgGesEWKprw/7A+4u7/HfndAGMa6l1ye9LFWY8mmv5ef+8GZQrhTljTxWjSTN9zKtDlP9W+3Krsct3kX+eMEQLA0+ppJ1E1oceAa6tIKY2u30pwQAoGr/CVISdTqCU3zP44DYBnks+QqBzkt0DJWBTl7zJy7Xbc1IGa1cnNBEndx1XdURRl5fO316fT2vQJtc3mLzDOGcld9DnSdmp86uemnA3CaojZr7Yqg2noV7qhu2SytpK1ulWAH3gOSrROdTClmKfHJLLRmgR5x0m8493Kj7hB7P/Xwox0Ga+wgAnqouKYRVvCmY9fTQ0TYDVGrxs8zhhAQd1ovou+HAziuaoo1oyWgcYEMR2io8U3aM6h2SWqpaIZASqqudJZpBO7i5mmC3QXDD6ozFCbrRwjgrK4iImrVBBiRGRwEIlEPQkr6LAJSB5iYNH7A0/S7P7DGPEVwGNRVZJ6B5Qw4yEMTTEQ88Uj9oqXldWLj7+xW3ZN6KGHvfuvXXJpgmbqvI2kMQQlWYiBnTKcJC3eunN1zBEBhLSrpmSwJxdLOhj6zs4J0qz9SGb1lMuVunjzQ2c8SeayjZWNS14kujtTN/hdNO8rcGHIDbsZ8fN/rTnI4BnidFauj6NptnziBPYvqoamlPQgFBUBaMsRC03zERQpyn6Y4oGnElwQJ6spQGFrkuxvXNGXcHTJmAUYrYbHkjBgi5pSQTyeUeQGevgQMtPXLdattAdv28/ZvWVGq68+6/msjXzds9DebT0VPBq81Qnd+Nn14Hxjq773Vttdv393LSGVzfd8f6X67Bupe0m6Bt3+J9tzeuOWCeA2s3frt1ve3xlZspVwd8b55c5tDKgnT7/4Bb775A371s5/h4cvfQ1LG4W6HYXfA6XwGDyOGccRSjljmM86nM05Px+o9Id5PF8qrwAbs9jvkpFa0xWqDKt/T3bDMC9I8o+SsNY/c0lQKTscTTscjPv3kYzgv1QQkjCCWBdYFVBdSZeMq7/0T1EQdOk/6uS9l4LuRiJA1LRpEBOdpQZ4TdruhPay3PFVivZ7jjrXUVdK6oy4LudLKC4FvYsNIXQg9duv09Ijz40O1QnGM5jkjmtiNTcFncUVeAsgVdDWBhLWUS1PmGv13ul7Is1saqKnzdoXGmQsmm/J9mRc8HU+YzhOGGDBaivQmM9k6+VpyQPSsg97Hjs+v3kkMojUlIQoVWFYwJMp3gNKAIuhShyoOIC7XDzUWsV/Qxh0ycv3OZa3z8QyBuvcyM8ZeDnb6RNrnq4DGZTrVetjrBBwiPv3hDzFEBaXjuKuJvHJekJYFuWaX3D60G+yN1se5kVmormWY1v5fgra20cUjbC7fK+06ldOlAn5mPUdpWurSX4u9K5YkhIMpcU1+iZEwDITdftT4twKklJBCWiWVK0tWt0nztmKWGrOnCQPXRqIMrTdXoLK+D6NQUUsrcDkXm/a9AW0q6ANcq0krW2YiTdbQEQH0i6xoACDzexa1zMQ4dPWZNNjSgUnVXpBaLkTTOplWwRkEmXaFEGYT/Bhw1773CSgucFcFkvonNP6TUyUkxa73g6gWIxVPsxQM7rpmQx6GQecla3ZNkLoA6MblGsTa3DicULuQ3KF5A4ZkRG5F3OyAV3cAgQVyanxfjIwU2Nww3dXOfNYtZolYNR5eaLJ3oyHSA52zZtFxlxqHeWpm9jgonchiACCXNndkjK+miBWNdQTU2krjPSQVyHQGlhnIpQNrVO3vfQp4bA94xy2doft+bAKytIVHJUn1NzJwQ8bwfY1SNvegXilAqIZQtyCRNNcctvkswuuuClArb9Z1NMhERjixaVXAUKbChFrXzJ9SE5bYPgBQAbp+1nnz10Znlu56a2uloJjMbcaObke8+7GklPDweMK//5u/1aGJRpDp8SzIaYbgrsZfqra5sxCYggTE4I9foSzSnQtluAoj1VIcWTM7HY8zcBiw2+3AIMzzjHGIKAI8LSfkXBAsHfQ2LkFn8rYAfq09d00vqL0EOvTAq2/vE7pv3YfN99vnbPnprfeo6qxXCLVx3brnGijcbvVr77x+XTvvcqUP+pkuvtM7Xwb1eoBzCxx9V2vdd7n/ljXsqqD8zO5aqzvb81bPF8FpOuNPv/h7fPuz/wtPj18hLxn7IWASAQ8jCAWBBFwyMjGeThNKWlCs3I3G+8rqmd0L9Z9qBWixUwXK2nJSIKeJsZQmlKLJS2qcNrlKlyCWGIWYzGWRTIiXlVWrzxjs7+y9LcgUq9rnLgZOxIQ0aFIlERzPM1Ip2N8dsN/vkOe1k3mVcUwxTWapE/++/uv7AVawe2sJQe2zu4mhMLgk5cuSUeYCYsYYGYDSslJUKZmz1qJyzw0x/iowxV7tAtWSLxAT0CnDXccJhIDcpU1Bx1ubXAcKRt8JCBHjbsA8LTgejzgdn3A6Tygp49X9HcYYwCFUntmvD3PQmrYhaNkWzypdmY17zzjvgTJaKgADS5rx+PgOQZbKK7Wos7l7buZYyuZEXixB+6Iv+UDkYSnr/c6mJDUMgDRpFkyOjN1hD46sbnr1Zf3bTY4h1O/99e6FxAaWMgpSDtjtIgbLXrgsGo6QpxPO5zOIgCFGE714865bHKk7F76+/ZyR0ckqY0ndE6twA7HEIy48dK+rawlgSRnzkjAvGcO4R9hbrLk/Wy5FuWvN5UVvITCGXUQcRxQJIEqgIWCMmoayFM3+PheraSgLMgJiZHz51Sv86pcfKRA0Och9hcjlXrfIeTZ3eU8gW9e+N6ANdVB95zXzIBUlBA4MnNACqCAOAMIQMI4BIaorVCFCrwqhYJkTTGiusio6MAXVSmjhTO2NCtiE5KJNtwe3R0b7uN3g0D5GI8QCIESzqikwdZO1WgHaHERSYs/BzfSwYEYNooQIct1wZCmFjYjDiltn1UI4a+7Zt6a+1557CmNNx6+jU1pMteC8FyEnBJCENv8VTLNWsQ9NAA+VwEIPZ9EF4BiwGwc8nTKOpzNCjIijEVsIKKqbWk5igMCyZXZxTspAjBGLoCyzklfWWIV5UQYS44B4eAXaFWA4oZzPyLMGNBfRwqIlC8LQ1pJhJQrqzNkrjYkFaXGSG2XsSuCobtLi39taGEELBhrc7E6mkizOMWEgzSNkob8FzmBqFqjKClfMvduCm+9W8QjBnutMGh3Qsj9a4LklzKFL0l2FFD+nhAriRVzI97tsvB1hF7iRXZnXu2/e4vSjM17dH+wNxYAWzG0qg0OEx7L0x46h8WcMAoYBc04YuOLITuxBDUoXKCMuuSClBSEM2A1AwQIaP8bD4yN+98cv8OOf/LfYDeOLwdS2XXOn7CjIld++23te0q6N4dq7NrzzJmi61q5Z527fd+XM3biyp2cbPXZ37zWot/6Lrvzmp6pRzvXzLq2jvcvnGmT578+5P16OSbo5lot9sb5nTQO293yotfCy/+2/Aeot0D+/iCClBYcf/DUO6RHTwz1SSvjm6zf4+u0JJKqAHMcBUhLy4zukaQJANalFLlRBAWBAwfjt1j2rcjJS9yVmYD7PKGmp7knKEjT+O5B6JTgfa+tkCYvMusImIrgFbwvYvF91NvwarNfNG/scFa1BmnPG3at73L+6B3JqsXPdu6rlCFAXMhFIlo3Hh/WfFG9UrkIaO9x4AePu9SvsxgHvvv4WGZrNkYyXxBAgBAMCUhXVLkSrowO5tq0J3E7XobRTLI15n/Iql86CZcpl31Emviqo4oBAhJwXraeZM96+PeP4+IDT6Yx5mpHSAuIB9691Xd113pWvVIU55ScBgkxQJTsMaJsy05XCRBrDRFnlRAZDlow/fvFbfPbZx9iNLgyYx5bkain013nyLbciPWslqZYu44sVWPnqqTeRqxV8/xYpkCSQlEGDJ1Tx8a4lui119XAet5v7O4cw4G4fTO7JWKYJS0pIacEyTZhzxmHcIToYX2GKnvL7/m/8HB3Aq1ZjoO6b/u8eUPUyAIDVXjLxDiWra++8JJzOs9YMnNX69fqjAfeWhZotdn2/F8yzJhF5aav0Q0wmpAyw731ASNd8WTKWBZq8BAUxEJgHQDQesQ+PIxFLYseqBOgExmZvs1l9D8r8foA2Ut/udN5BBg3w9NUUP/i+0BDsxhFhvENYDJV7LJVoAWchQeACKowhSCOq2WuRdIxTur8FANQtAKQFDau7Y2iWN88gWLXskYFUKmG78Lvq/6rvVpSd7Qc1Aesf7l8tbpZBB9icaHQuojXhhb3JLRw9AykFq3RVbV90hMQARalpJpUIFzAg6qVObH7P0L71QZRE1MAauX+umY6doJEWoXbw5xY098tO54w4RnDwjJQBJXkEllTfZAeWTiaUoelYHh+PKEWLgMdhAMeInBNSMrAx7rVg9zwjLbPVxikokTU7pQgocNXkwTS1PlZN1ELIBHARJBjAqpoA1PVTq67ND2tNN69VJ0LVQuXjdw2u7xEQIZj//hADmK22iRF0B4ECJWhqUHZrZ9t7vuuqa+5qr9lVld5LX+VM94HTGT8P9Ze29oDqJUBaQkE8MyUsdgFiGST9LnNlZtV0duHzdb0///TTLjur7TViBNaznlIx1wa0NMawrFPZ1izoE7lkFBngNQ91LFx1DsZJFUCL4DQtYGTc3+/BYEzTCYfDDr/69S9x9+N/wg9/8u+eZ9I32ksscXTl32vg6p/bmrhwu63FgMvPzz//EuBce/6HPrsXEfzzddfLlzPr0oGQ5nSG+vflk9eW3a0160OsYtt5MvFz1f/+mmuukXT1rpc3X6GC59csX+kTM+PV/WvEOCJO/wb0+oDz+YSnpxOGcFbloYyIXn+MGXh4AgG1lEySrAlHOqFQgCYLiKzmmgOr10kIWKZZ02iHgCGoVSFnjY1m0oQTzTOgCfrOx5V3KfjQ39ZgrCrPRGOy++/rbFGjkeQ5Zb0GLGt8FgdVVLp3Cjq6058Ef7+6a27WoQeJXRxxcaDVPWfY73AfRxyPj5pluYi6xCGixsCbRY/YlLjOI4xvqQWIagkmMf6om0WqTGXhXyvrhodBlwIEat4kFLSkUYgBcdiDpOB0zCh5wXyc8PD2Hc7TCfNkSaHG0ZLNRKyoYFFhuMpFTssdfTv3s8QVLjN4qx4z/fSCVOaptMBOXI3Z930JrKCFy3LS1qT9QPBaf+2b9TiWecbD4yOYA/ZjhO/WJWn84243ABjqOy5jzEw+rVk1ba1YQEKAtJq+TATkBfOiWUHn6YxlmTTZmAjCOMJjst6XzVC7IdXaWrUIdY6u3ePyEXT/OWCT9W7PprxeckZOBdM0Y05ZaxxbuSxi1vwVofOow0X+nhe3UgTLnLEQAGjMWwxkhhIbVtHYNy01QgBHxDGiyIAvv7zf6nlM+YKaO8EHSYB5EmoI0kvEie8FaCsL4/Tla+R5RBkCMKIKjddqqHEA7sY9dvcHLNMMAZmpWbPDcClgCfU4uXFj7X/c3P1WTI4ApwICXZytFWXVbqDifvJ7gcuvDgZUHAhWIu2E3wR2uiKKVOFUnEB0faD2myb0EPcKWPVnvTuo3qqMrBszEdgSQQgFCHsBU65l6dzdzAlyfbbAAobJBCxqbokNbfmgavFCdgZnhCdfaDpLHXuLc5JK5ABBSQlTSpiZEYYBMUbE/aEGpQPAuNshjiOWecZyPNa51Trv5iNPqNnv++76tJXqUmnM1bEWUDVcxYLE/d8eIPXPY4sPbILAep1KyUgFONwdFASJA2TvwsUmh1PcGkNgi+yWpVqnxvecEV/ebBrymDtCtUATESI2dNkYpmJY2/FWf02g6fedyKtrUx+UZ8TWmCQT40c/+pG6lcIBlrk+EEyLniBFGUzg0NWX6QVLtSeXnBFgWcOgwH8pOobm5qpJB5yVn6cFu/0AkGDkgLwsyE9nTG++AH7y7y6Zb52G50AKbf5uvd2eyi2oElzGq72vbcHN9p3YfH7fM17+3sunXlqnrgilL3r2ZTM7zQrU9GLTc2N8H0C7fd/1az/0e29qLdyu1uUzbgE3bdfsbref0/7+sL5efaYIpGiSoMenR0zLAq1HRMhLPdkgaGa/nBYMgRHv9ureaAmYLldPR0XQORrGAeNuByLSIspJY3lD1Ni0UjSjsGMiwErSUPfcTqiutTg3E7H1TAimDF0J5g5ygPXuFnG/8fo9m8fBMI4oy1xT4V+edFqBs75VS88GVBA8PF0HomVwCt68/ROmadGSRdVzw85JZ90jA2xq9ZSqgCvQQsw1cMX4umemBIAszSXfwZNPsUYzU50F4ohht8MQdT1SmnA6nyBJ+0eecEPUuybEiN1uh2EcLzJqi/PfztKlXikMsmQb3gctRdTRQDKe6+h99eAOeULBQzOINXlJ+nV7hkC6Al7lWuqeYZ9FcHp4xJMIOAz47PNPDZ6pMtbXcv2OzX4B1FW1o6i+F/xcioi5vRa8e3jAsszIy2KhF4zdMGCIXuxZroznkkqs2rXxX/muKZy7+em+LwKknLGkgnnWuns5FZsLWMK+YAWuNaszsUa7i3B9JxMQgomhH0TOBGlJ1ULHDBBnCw/S87Ys5qLNASHqvpuniN9+8RGG0f0qFKpXCqBC10quJ6CG+NQYkmfa9wK0SWYsT3tUKxT1m9quMTZUBJjngmArEDwGjjSrlPowBwQm80uzzQCAgtVa659rwK0J26XVovLr3N3x1qKnAgkalOgp8IX6vrd/FWM117iegjSrlSZOIRMsi1TvtTovIPW11tJizspaB73fLVAbraYMWWyV+9OSZccMESTZCJtagpSfiA1f3TQYZFrDNpEN8HlclAnam0kQuGbTugwnjmS4T7UlQQMIQZkq+KnMVbiro+JuR9rPDKi21i1Q2YSIaQKfz4jjiN3dHUKMWofGizeaxrGIlktYkmokYwWiNg/GpHuZyh0u6vJ0kjHJep2LSAW9QGOECVgRsTpbNiYRda+Z04w8T9jfDTgc7lW7WgSxKQbrPLtfd9Vu2nM0EUkDZRrv1gM0D6bTaxwg+z5i0SyUAtR6I6G0QWucYQEhaLkC8T3Z3gcDc4Q+jkV/Dx5gz4wvfvc7/NVP/8p+zagxI3DrYq5bP1vspLsSEVvhUCeQuWiNPI/LYEIg62evoSNCNnlLoJk+52XCq7s9AkVQLshTwrZtXcqutfdZnFzY7mkGXXz+cJDTb8vrgOf2b00s8f9uQcFlf14q8PfP9SetLZG3wcT6rbSaq/XzfQx+3+35u9Xv0r3zQ1wNn7OOXWtrjvX+5z73nAbeLp9/zToIuO37/c09U/xZIoJcMuY//RxP3/wegURL0hjNLrlo7ayoJVmkwJIkAbvDXms0mmX+quxbvyTEcdSMgiKaAj4p33VQlosKXEqA1a0tsgtRqHS5B2/VxR6otbrW7ph6XakgrUs6gka7iwASYC7+aEwXzvOo1nhECM1drwrXbX7VOHLptePn0eOUfCEcIyYRoBQ8vn2Hp4d3gNVvg/GinNWy6bwv54JgBa4hgiwak6yp5HWuCqlMo1HFAFlpnQpemVBSAcLa3X1Fd0QQwoBxv8cwqHL0+PiE89MTpjlhv99jHLQ+7TBElFzAIWhduBgrsG5Z3nxx2onU2r4ag+SL7Ym2xAGatJg2v79vree2JlW+yPXSKhfZglTXP2C1b3wGXAZwDgFI5y2jV2Zzn40jmozRr7ugZp9Ch7OMAAAgAElEQVQm9Ay/Ubnt2S1FrDSB8rElZUzLhDIvyJIwcsQuRsSoCVw4Bng93mat66f6Gf7VGQxaWs1+LtcWQClFvZZIj4ha07LxW4tPzbnKeswMHqImqyO27JqElDLyPGMYF0jYa1I7UotjLoIhqFJ6mtdj+ZBWCiB5AUoChXH1W4ythMT/+r/9Zf1+7XkBwxUK4zI0JMdDcNh+F7pY9ov2vQBtICAOWsuJKMJoWz3wpaIdVOFcU/2KuhpgxLgbsbimJQRk6t27gD4FestACJDjONM0rcofGm1YrhQ01J/bYaGs9ct6FlmNSNtV6BZGnKhvpDMGLFkKgNA7jkHT5gu6NPw6Po3x8YyMze9bRPkD0EACQSxQ1wkhIKJ2j1q8nPRdZIRd7xdNLBLsaWwDpGAxRCbWkLpTSM4ABwvGRj1MILRSAkYUA2uSiqo9IUJmrnFlPhgSNSUnZ7LiyVw0zkrrcbT6fA7gchLktGA6PiHGiPHuDnHcVbO+B3RDgNO5oOwC9p++Qk4LsCSU0tK9woSwKrRst4egvj8Yc9OsVMr4ywaoaPdpIzJRZwFShiQlI+WEt9/MeHh3xhCDxpgUz2pp4quNify5vh494KSLHqzmuf83BEISL0RNKEEL2ZJtZvKMjaQZMikEyxqmxdlLKZrVE6VmHmtxAJ0wWXSz6jbS2n0pLxjF3EIg0AprRYu2pgTJ0qzP1f0j1OsFASOAE2vhepmKZnMjTeTSB/bbrrZDY1XUBJCsNEcDiLXgZilFXTc357vTKeMlTVafBa7bLmZRdndcolDLa2zZ9ZUVvABpAlxl9dd6Sbjubljqb+te94D1paBmCyi8T73Y3v++jVlb39ufQbF9Qpt+Xl55q22tWSTmPknvB19b8L4FYZeW1nZ9uvJsTwTyIWDRn7ehJu8d+YXQt3l3faKodSWXjKUsWM4zztMZ07dvkM4nrXeYFiRLNHJ8elJQlRm7oAL/YbcHiDFPS0v9DlRAVDtUh908UpZ5wjIvkFxa8gnnKVktbBrPXUBxwHjYIy+pjdAEZlQgsBLVlRZ1fCcIdG08G2UH6lZWNwJKMSWYCxmdC59daHRP4x1uKj88NgMKMjJgrvLKdcbQ3IS8/qnKSyrFLNOCwGqV9Ix3Hr+Wc6tN6oWUHQ8VQOusIgOkcT1sAC7UJGnrXU0FmszM2KMUARW1ilC1nunc5ZzxdDzj+PiI43nCfDpDiDGMo1pJoM+KwwDJCZGDKXNJE7Nck6s6wMRECK6oJBU8xORBgsWvUwNTJKtN1j2z8SYiufTUAlXZok6GXbPO8Oj7xE6gabhXYqXJCP5MQUsp729z6x+h1cNd7xu3cLaOKlhLOJ4mTNMZUhYECtiNI4Y4IjoYBtV92ca+3t86lJ5q9+Nr/+rW14Q+1VMOZWXt8+RAKRetAZsL0rxgXtTtETYXHCOGMVreh3ZmUs44zRPKotG1xKGGzkBC7XdKggTCfh8AFkzn/J2BG0AAD5A8AxRAHDAMnqEdOJ8jjk+DVvPavEOYqjVNw0aURuXu0T6/7wu5+H6ANmi6bWKtrSXeLVLiAVhQqxgahQqwrw47hHHEN7+7A0BgLtXlkF08kZbpibqUwkABKHYnvwcG9nISqx7fC2KAqdK6W8wET4QawNQ/qxeOjVk4oKnnoHIKfz11gYyCyjYJWkU9G2CoZ7mJZrmoJSXEgDwn5KIlK5jXTNwFGxfuGZaIwuYkEpk2w4AcrMi2tIgnBRVk4pEYXTYrGVBj69zk7VkTW2ICFcCZAVgdFPVucGe1fo6VsAiaiyPq/FmaYxAOhx12uwHzvGBZsjKonrgCWJYFy9u3atoeBmVIHrRsSlABkIUQxjtgUMCWlwlYFluoy/gRQTuwngJfTARs8oJnckQV0rbuAt2wu4cLYgiAFEQm5FLU5ShsM4J2STVERWoQVVBXze+r/cvY0gr/2eMeuEvnH4oVULcvyOqcuFAvZLX4bD5IVHNbvMSG2FHpa98AStAss6vOE+E3v/41/sN//K+RRdfYM2AFm4OVtls3MnLJVjpDH54jg2I0y7qvHSGwWu9qpk538xEFwcEKEzkhfTxOAD/g/DQh5YQhxLqml3PXucO+oKn1IuFe3mBYHjGdTyi54DEH/CndQeIdPn51j9eHV/Ci3FuW2a/bVhSUzXV05R5va3DUA47boOd97pCXvbruxteLgz1YWJd2v3zi9r3XANv72hZoydXvL+ftUpRZX39DLN+85XrjK3dtQdRLAN16Hbf7dTvi2+9WYKCFs5+ejng8HzEyA2nC6eFblOWMmYD54R3yMuN8Oqm7XSCMQTM4ZiFMSfPDESXzzLgxD7ZpPUujZIt9c6WYZ2izekmAlz2hym+CgZ7+Dc7T94cDjsej8XAAm7UDgMW/8yy/pnhrMm53HskBv/FYM9lXeGbue93QUGmFCauuZKurUzasoBQUCAIRZgAsajVLSa1BEerREqMmOHO3zlJEa+ExWaFtS+9vwBLMiKTyFrMWJvY4HC0po32ECaGVD4vBGGrySKH1OSkAKC94evgWD09nTOcJ86SJw/Z3d/XaDJhLbdH4es/46woyy/atjiBUAU9v3dM1YZv/oLW2rgFz3VgX66ifreeSUTYp9Ylue7G12K5OqOt6VlV6HQEWf3cX114V6r5uFa2iA2x+tz25V3jA1qQswDJhCIz9/g4hqmeJ1hJjvA8kNCDXv2t7jWdQ9bFJ/VdMOe81eCVnzCnjPM3IOev/k2UchWXVNGt0iFqHVbK6XGeLZ1M+rtb1ENWFNoYBlEVlc6K63jkXzLNgGBm7XcA85yo3f0jTeMEESAbHiGjFtT1Xwn/6T3+pIJVIZXTDEGQ5IYRUzqAs3fkWBPMq0vPzfjr+vQFtul+7NEid9opYa4RURwGx/ww77O8P2B8OePz6VJ8DoJnSnVQ2CVS1RjBtfq0Rptf2wAr2uaYJr9Tg0mUBxF3wkyiyQrd5twPuMyvBiUjTMqnGxbpcXDBHmx82gSc742BY7j7ACUrZiC1tSPAATv+6EhIL4tJuB9SoE2piQsoFCdlqF7rAvB6j16Bw3W4RWlkGm2uFBRbXUgpORKmuvb/bmdiK8RJMs9bcRTgOGCNj2I1Y5gWzudDk1FvKYNbIDJnVz5sG2xOlACWhZK0RI4PFGnLAsLvDMKqbXZ7OKGnjJifd3qm0dBsHsRnE5s/ic24/FGq2B48VGwIjglGyMlt1k4Tui8DqDsOtIHY9N6t3d/3ZtGyghnQ71Ayqer1ZC41hepyioFlTfYy+/kyWwEBMMDICX0oBe7rvvluk4eAXxeql1VKhwJpuC67FNWu5bUavZacdCaq5hcUsMtn6S01U4u+mrh9rhqXM8nQ+q0BkGmC9tK3g1r6hJ3ul9lm1XrAZZMby9ku8PT0ChRAYmFLAnAh5JLy6O1QS0PH81bJu347u+v7z9ruXtcvN2+yKdPFd37Yqo5e0l7pZ9td+qEUKaBYlfc61UdpvV9T81962vZe+Y7/0WZfjep9FsyVVuT6DHzKvV/skgjQn5Le/Q3z6Vr0d5ic8fvlbHE9ngAUDM+bpjLTMABgcB43pkVJd9jK51Z0vx9PLutIJqsSqmCRCiGzGLDHrkcc5m9xmwI1jAOZ0oQEHCJ9/9jmWtKy+VRfvpoPtaaSTr2aNRQNbIGgMt9SsJAoomisjiwURELp43cs9RwaMXI/UW8k5iAqf8P5RFfyjATRXDFZxilXRVVJGCEGtHkQWRtOEfbfUFfI46xqcAlfIqvWQ4DXhdNgaMOa8zkupeB8U5Arm84TpdMY0LyAi7Hc73B12dd3UeYdXgndnpgQ8w6gLa5v10a3TrGSBA4YQUSuBit3nfcba+rIWnNnAoSle62asL7JnbgRu6j8IthnFqXsaqPdUAMRyM/QEWkFs6PIZNPm4p0BiRc3EYg6JAA4Rhzu1agemmtnZQd5VJvGCtn339iHF3BNzKpizJhFZ5gU5Lche5qgbm+cyqLw5JcznGbkkS0anHjVjCAhDUMA2DBgCg2NAGAOYgkWQkWZIpaRKlJKRZy1jcTgE5Awsy+2skppkpBuVCCDJlPw7lRdRkLJa1mOkphAnwy0EPbie6RRqGMkU4JZHEGpcpp+f9+G27wdokxYQGqIKQi6GNSHbBD6dEcQYsKSMr/9QgGnE3SvG48MZZEUsa9Com+bQwIq+8jprrgYZgiYh4Qa82lMctGltETV5olNP6zX9gVg9wX17OQBY9Hqn4iKqQawHQplQFXSpEWgXKp2oAFTroQXLVAUsNgasJTzvFPlblLkEm3txVYTLrGSuCSh4WhLSeQGD6uFxxtZKm5vAbsK5CuAK5IqbyTU6rs0OmXaUmxuBEJm7SUYRUXc0aUHXpcgq5NADjymoVjAOQBgG5JSxLDOWOWFZ1Px+7XAonzDr7jLj+O4thv0Bu8MBIp5ZjBHCgGEPTE9Hi1FTBh8tfsE1kKUUY1bcaaOaMBBsPX37MKmVtGci1b3QmL7zqiiEHJTZugtpyRnn4wkSBgz7HZaU6qbu6bM3KWZdxdrS53vCtake3F09eZlq3IafIuniIOpk2m9JOoWIPcXfViAt81kt5L3drP6Sbq1gLrUlIcYAkY1blY/Bz8NuRMnF4jXcatwR2P49/Zvdomp7WTh23WkMt0jBeZqQUkKRBuaZB7y6u69ZMK8J276yzIzDbsTHr3+Iw+6ALBG/OR3wY1EXMA5DFRS3LPMaUOg/O9Wq64W1Re2SGvr3tPn72hsu23OWnZe03j3Rn3fLQrT97n3v21rC/HM/P32rwqlf2yk1pPsOMNdR2vZT//td5qFxqpePa/3ef15br4H9KwI6fgl+91vg6cFckTLmecY3X/2/1L1NrC1Zlh70rbV3RJx773svsyozK6uc1VS52o0lN9hqM2isBgvJIzBSDyxZYgTIkif23J556ikSEpIHyHjCzwwjwcAgIVp2Iyg3YMoN3dXVld31kz+VnS/fuz/nRMTeezFYa+29I865772qtqUiUi/vvedE7Ni/a61v/X4KCgFvPXuC+7s7dd0OZCnUCSmpMoaCAQJX0D3eAQAeC03mNlyMVmvyDEmpJo8SEavTat4X5lbFu0NewTC5haJ9W9O4A/U9/aVslpsFhGyehJUumnWtWoKqKAnjuU5T3C0fdfN5FkagAZ6+n7lkc/RRulkTrlXaS7XfOatC0kGcxuoyRKts17GRdkTxGDT5WBHSGDwHdOJj7Oh+D142NWydJqKCSbZOURwwTrlm/R6GETEEcGj8Qt02A6pDryk+DdWYHNQFwNiRa9jOk3T1cKjfUK0WX+ut/26U3flmXRjs2rjATzfgrUdBe9rRvdnmue+LACikQGaaRpN5I7Z5ELo+V9BtT1N7JzNhGIbat0vWHJVNGhh+zOLj+4CYTCbxz+19orFp65qwrKulxV+RU6rhOzBlfIzRYjsZgdgscQn5tKKUUmVx9pppkTCGATEGnQsLowkE9egKKkVRNRCYD1gBCjO4qDs3scZwxquAnFtJAPeMAoC8c+sIQQu+q6wmECmW6IjhLqDixbFly++4yxtqW1JXxs9eF/P6/x9LG6mzXUYz75IEyzTHZsp0sVZMEB7wpfBL+Pj0h5CjZqiKAWbCpxbQ12XA0X0lhuTVJUCt3lQPSo/liJUQOiXwjUlgBVylfqgp/3fX5shK94E5R28Pt00EEbxux4YsdDTHAadbJ2IAUrKCmCDEAZizCxlioMemgkwYMlCmwNJLJqg7YJOXt2KTGChLa8GaBIGhhNZdII24VcZEmikMxgBdqAlQ5kEoyDnVOmm+cUUIwowYuG5q8vT4gFkDnfEpU8lQi6TyS41zKFFTPedcwCIYeQKHCOCEdfH4BgeJ/VIQND1uQV61LMB8d4vxasLh5gmGGJGz7kkxaVgEWLNmFwtsGTfFYgCMAexBkR/ekBKyWVKre2G9TzQdsyEuM6AhOCgR3w1tT+WcscyafOXqasQwjShFLVQc9E53ewUETGIxAFT7ti+c7QzQrWXkX/R9dVToQktnpfIkAaVIswCb+8rp/gGCghiizueGE1Adp4ZwuIDUCOyyrBiGATArc0Uo7LF0jFQKxvGAeUkg1roqPdcTF6NU8wDJflhs8A4qSQXAIpp4oUis1kWAsKYF//yf/R/46P/8H1Ey4er6Bt/8ha/im3/h1xGvrzHxaMlR+nd3vSDCOE24PlzjMB5wKhGhXG/ic/fiR7+n+p8dKdtce8ca2n1+Joi4gLn7/Jy9SNee/l/p+mVwtW9jf8cl6+WbWoiaU3JLXHN+TwNavXub98utKZefdgFWZ8bfU+PoNme90dQ9AKILP/vvevts/723dQ6o6aeeK+Dc0rjpJNqLe1fkvMxI8wlFBPO84P7+Di9fPMf93RFX1wc8//wLzdg6ThjGSS1qAFJW2uuFo/3Y1VfKrt+EKuC7JW2Ig5b1KKjx7YMl0xBhdde288qg6nnjgpHrI93lvkBj4UtWZUtVrNb5aTuJ0OLFW59hKfG3Y6lrz6Sx4B2VdZFgs6qCWnrHZQ8iWMgDIKXgdDwBAkSLi3HeIh3J8j6FwecBHkBeLQIkVMvErKUlxgistVu1OHhGgHp7BLRt7YrjQpYN0evBStvLgtyEfJ8X0RqzwzDoTaxp/4W4JlxrMdy6ZsxdWZbuFGxkKl/L8wWwSdGENO0+O7XVhR6Vn1EITRasyyLoXRKl9kGqfFMsZABQuZG6HAebLU2bH3Wx6t4kgeQV81JQEBBCafurf76THzeADcCZZc9lpougwAFue8R53aWQjVK0DppYhlYRYC0F66oK8WVJWJcFJXeWYLemmeLG31FKQTqeUFKp86tAjMBDxDgFDGzlIYIZCLglSiEbq9h4yeottjnR2FYRgReOoqxhWDCacjiESvBdCePDDqy0I2dBSjrmZOFHgMrLLiJEXrFgrCIIsxYHL7537WznTaZDqOtzKcDQqxEev34uQFvVlklGtjgROROqUA+ja69GHvHs+hnmNOG0JgUQzkcvEU5vyyNAO+LmmV1aqjt7klEPth7cuuVqA2R+q4W6VejSjrqQWzM9XbBStM71QkLrNNn4xYg5B+1bTlYHDYKSszJGIxjTFLEcW29rPCAa0dFX+g7V2iC1BpndXIlwLmrdgpVWYFQtI9n89ASFzcyth8E2so3D67ysa0bJwBi6zGGVQJtrLFCBmYPN3DGgIh4F2bRIRITj7T3m06zZqqJZuUQzUhE1lwh/JotUzaBqXRqxLVIwP5ywnGZM04ir6ysIR00ZIWJmcgAkePLkSg9yWpBSNiKszKR3kfRtmp1J+N8IICR4YLIL7GzasAItHOoL05Nhgmb+Kqwa2NP9Ax4eTnV+ITsxVHQ/kQk2yO7K2AgNUgaNsRPGpbrHkDFFF5DqGdioPf195JNptxTrL9Tldl7UBdN8gbJQB4iAd997H/f3d3i4v4cDqXVNQBZcX1+rssM3OlCZFJFa2hrD0jEMUf3bm6bfT50xeVipnxqDouOaDhOOyxGneUEIATHEOtYoCXff+y3I/IDjKUOWB5zeeYK77/0mhg/+LPjtr2AapjOB+zIoIHx4vDqjEf7U3kqG3d+XPtvJ4J2A1b/3Ul9ef8nmpzG1R+7t+7LvU8E5GPlZrr4fbiVjI1b78bjlTJ/YCX6vfEcDSA7YLlkInbB1LOHsJ3U/qX/Wrks9+mndHF93v5Lr83vOLJwlIS8POB6P+PzFc9ze3mG5e4nj/T1AgnmeISiIHBEhGMepzZBobLCW/Li81p4cQcTKzzChlIzDdAAHRjB3pLRmAwJsxZ6VL8YYLIadLKGQ1THrxuPKNAoR67wgrcli+EiFwG6TEjS+nXcEVwTVZY32kr4tpNNXD7HQOWa0iMHumaJWCrGY9QZENCbXrQw5Z5SsdLhUeooK3ACn35Zmnkwh6EAZHvNpyjxpvShFE5KJAGzGF18DCweu8hiboOvKRB2gYJPQjXSOCul7iFTZG6JaKTa1Qnsg5ePvZNyaDKQHW/1PG3fLNEmQwBWgeSKMZu5AlV+05jGZfNOnzrekI3VSt1erQdoSYGy3dJMT61890SPzEEIADxGBI9KaEMuCgQsKWU29vkXaDtzVgI3e7s6wdHO5ZyYV/W7nsfdaceVwzgXLuuI4rxZjtpgrp7SyBNDxsFunQqjNSilWMzchrbkqRzgwYhgQI2OIEUMMiDFY6QGfP7W6EZwfQxUcJiOWbjMo0G8zlnIdLAAtQSJJwKweAgRBCNLJR3qV5OBSP00lVqVtP2FEhF/7tR/hf//2v4L7u5s6f8myXDqcEY6AaJZrtOkFTJl+5mZ74fq5AG3SC+G2uZg8SBLQYTUiEDng2dNr5DIh3T9otpas6L+IZoWrJm1Uu5Ra2DYpF7E7XE2gbn1rf1eNFhrx0wQbZuK0zd8UIMoYVJb0g1FPKYBggi9VwOLdIIL6uhYFUT2zca0J7CC7x6xmqHLCsLXsXJj11iJhSwSVOsFfUw8EUY0faM862yETiCxDlVmvNC+J1vwIQWvnFbO0iFhbQt08e/YniwLqGS052CRLJuGfN4AgkAoYybJoHu8fcIIWcB+GWLP9eJtMSqx7//w4aOCyFKmmeiLCEDUV8XKaEcKCkgVpzUjJiqUnIAnhMB6AcQKnhHWZkURjJtitt90KKKNwwRE1gYcziWJgr+ziICshriO3swNziYgMlFyzo7q1TEEMtaybu70i+1+6tRSiWmSVRMAF5t6gRSLZYiUYVkQcpC6WRSxLmahPI1CZJwfGxIRMrUKVykaX9i9151HnMqcF85Jwfa1pwlyIkH3Num7Rcwn1XIl08ZSdJaHeLh1vg+D+7han289x//wTCN7V/V2A65AhP/ldpNM97h9WlDTjlAMebj/H3Yu38HT8PsI7X0OzAPlZPRPdAAAv0vDGAOpVJ/0x0NdTpP3n2+fbPO77fA65LvXtklvj+bu2gKXv2WPvPm+v/8b3UR/Z607Z+znp2wfOgctFILNjrv6eVwGjyzvaaKHRrrPzR6+a3cfec7kPj7//p4N/5fgF7j76XXz88Uf4/PYLxJQ18dOSkNcVKWtijPHJoHEgwVyiRekbh4DjskJrOjrfNQHIUr4LNHW/8m3VoH3w9a8D0IzPOakK0euEBvY4LW3D3f0ArvUbRbaCERGh5AX3L1+C7FkxoAOhVlbH+r2Zyyp02Wkm489V66iCWa0ttjmEYspeVEAgAJYl4fjwoNYoo7saLSGa7jxGtUz5+5hAxQAoOtmFmhAYmC3konNL9/U23hMI1b2ySkwu41dRqjJc9ZawJFtkfNJB+GZj2fiKTyJRjWEqqaCQJRpx7wNRi9Yll1kHUE15369FZxXqvmCYglyAxu20Ha40RqxZqqWaHPCquZIrmOvXvfbL1nq/r7rewSkbWQIVVUwGDOOgsYbkvh9mXYzmxUPqIkp0Tm/6tj2u3T9rfXHvtdLfDreitaQp53RVRJBzRkpagHv2NPzLijVl5GqV0p6HISCaRUwtjha6kdQYU3Kp5xhEmGJAiANiYIRxwBA8BCBYaBhVl1nUuekXCFWe8f2xDWXq18jXrd0bWMCWITWXiLu7bwBScDh8DOYHk68tOQoBCcHowRlw0IsDfuVXPsVv/MafrLIYjDa05G/GCw1ASy5VyeD75o8N2ojoPwfw7wP4VET+NfvsywD+awDfBPAhgL8qIs9J3/afAPj3ADwA+I9E5Lde9w7A3KYMrfdXUwI0NltEE3PMy4qX9/dV8AoxgsytDVAaJcLV3CkC1bqJB2q2ySeCJnKo6qptHxxtC0sFlpVIBpP8k/azpkWwDSQETRjilkDrjMaaUYe6mzBPOinwjQ8DRc0drgM91o9oPrdEapY9W0sf1pkUR0ociNrGlwIRMxurn6jSanu+4p7u0Augrnyd25yUYrHLVFO9EzMoZ2VItoFrHSRrpxjw6pOP6Kt6J0wnv74Q7afWkWtuaAK1RFKMZmlrY5cNAdBfGRoLgKB7RZNm5o3fs3Y0V5ACqF92SStkiMrMecDhekAaV8g6Iy1r13Opa19jCCFAR2B1jjoA0f1CtqY7Rx3tCRkQjQERqjlcszLZUlS7hBAgQQWaXgvt7bvLILG5xkA1rcUzIZFZAY1os5WbABFCVocitdjqqnlwP7o921wOsYlx8bErAw8VWHEr+gZmKDA9zsjHB+QpYBhHkBXghDThNRfFit6Gj22TYAgdgCN7B5rArnSEQHnFi09/gPV/+0fI4YAkmlvuG3/iK3jvyQE5Z0hOJigVfPrJJ7i9u8dXfnHC019ccTW18qriexPV4ab25SfLWPfu/nqdJeoxKEXdT9l9/hiI2Vigdm3q/tz2+1Ibl4Db5bv7Wdi36UC3d8PE5ve9e/FFKCI4q0H/ptce2PVuyXtXy0vvPTvPHUg7B7bWnqDSqMe63a/V3gXzsavtv9dfG6WOKP24e/mAkjLeOlzjxRdf4PRwQlpWPe/MCNMIHgYMw6hKPOPvApi7FCP1iQBMkAlRXczXNVlqc30uGN2WXLTIfRFEA30q4LknwlYNQkSacRIdeyebNSlIJy0urEk6kgItnxVp/N7LlPTd1XvMukC0eacLwgTUmF2nfTWLLrQkTH1S0TssbLZ+ViUV0lACikGTPFSZRU9HHa/3oQMTBM3A6rKD81pVsFkqfMsJkKHlc7LY98WsdU4fBSgoWFed13GIrUyQ75edjNHTHrKQDKrWS5sBn7fuXykqO1HflmX4bbF22mbjWrCxA803U9PQwxKoCTd+LyaDMHHNxuwvZKdeRA04bCjU9lS+Suh2xV+2EJ5oLr2usCHWemlBJXl9P0NBKQEFlmSspxodUKwuhps+OTNtf/qZ8rWqmZbtuzVlzKcZp2XGshSktNZcC37WgGKJ0BR4hxA1o3QRrOtiVk2YfCQqi0yDATsNf9E4PV27ENUbplpeqUfde+EAACAASURBVIXE1BXdgZoaTtWBasB59ZayuezmSnsmQRwiYhzw4x/9Odze/wmEyDjMP0HgW7z91m91B6Xt+3171lWViy2ZCqw/YSOp2j2BasxclX0ugv3L15tY2v4+gP8UwD/oPvvbAP4nEfm7RPS37e+/BeDfBfBL9u9XAfxn9vM1Vydw1wXrhXibEav1IQCODzNuX97i9vkLRCZwZMRxwOHqGtM4QUA4WSV1PRAaEAhRgsmgFtPmhxtQQmCSSNvHJuR1nF7MDFUPc/a+ub5E3QuLD8cAm1FwlJRBZEHEIsZqLaU5qSk/y96y0mIABMbIq0bRtRDq30uylUwubgXef6q5WQua0MzWJ7GiahLYKaR3yeisFUpmMqIC08SRMiVqCScIqAczsMaCocv+BxdkSGOhmKEJO30cVBPyIDiDsnljP+jU+qg0jkAcQJFV+9YdDtdyO/MEqz81mZbIzfs5GSCyRCmlAhDTDhbdAfNdAqQgTlfK/sxUHw9PkMotZF18Adp+6061ZhFKKnxVhtOOhvN+ou267nQNbe3Jp6O5AJ5OCzIIa8o4XI2qOXU8BO+P7ktOQBli9Q1XsMOIuYHLbBoxFp2XlQmDWxQ75UjfpzbiTgtoP4g1y+P8cMRgtfR8itQ1VycgEFuQcQZLwXw8YTyMQKENM2Ly8ei7c8mN4PsZ9rMKMgVHgwhkkg4bkMvrCZ/94Ls4nrT8g3DA+vHvYPnGt7As9yiWjU7TDQPCCfn2U5QXPwK+8i00EUvbzyXXmm9SMrYpnc+vc/fKLTjqv5eLu6Jva3v5dtw/tdmmO1i1B0d78HCp/5fvfRz8nVkkxUGHoIop1PXpgnWsOqR136l7k7e97df+s/MYOBMOLCPpfggbOnNhRs766GewgrQt0+9jz3aP2H3SKbfO98el536ay+cq5wyOAYfDhHWZEeKAEAgIjEIagzUdJsSgdZZcK1qyYM0FgbfFmQGlndEE5j7xRckeX0bKg2zOma10Ckgz5oaAnLMZ86m5S5LHULfNUWOASPlCCKxh6VZyRPK2zLgrmOrf4uCbtrRsJ3TpsG3PsJVEFi1b4smj+vdo2n2y50qVicRkhFIEa844nRas84xxjEBRcdUBrnueaAFf5xfN+iKeBcveTEXqfSANQwi2j0AqmAYTvwQu1Gv8UikFIUZkCCJ54R9tLKUCTKhjNBLqb22osdJm+2MD9lDH3nhYk57ZkkpJ6b2OsKHnvrd8LRyU6rx0rpj2X04rioyAyT4wC6wHydSO+ZqZi9927f33Rkm1KU22kVKCJsow9zkIKATjAdQsTUQAicoQIXSKgUYVpFo2qL3b5nTDR3aPElCzTHo7YkaP+Tjj5e2DJjIjBSJxDNXQkVMyRYQKYyUnzEkLmruqXF1gI6YwmBVOgZ3KdGZRNMX6Boh1BeqEWp1aX9cGoHuLYn3g4vr7Z+MIjNdXGIeIcVDPoADC8uEHJm8GLOv7KPkdLAvhK+/+0zp5Yn0TNz5Y+8xkMqKtc84qJ1O0dbAyRtqJ6lUIKC5QYNuFG73mei1oE5H/hYi+ufv41wH8O/b7fwHgf4aCtl8H8A9E3/y/EtHbRPQ1EfnoVe8IQ8DN0xukZVHNORqiFXFh2TdfgZSAtK6AZFxfjTgcDhjGEfFwwP06Y11X3Nw8weHJE5RlQU7rGUMtEARQK9Le7fdziYU2G1t/Fni5RspZCSY6jRtRxUyV/YppggOBhTU70lk9MmNUUrpjSdZnbO6q/aFtC4yCQmbBs0POwUBeJ/jw2Thh2i9ts8CZPzBYnNEqgstZUl1oR+sPMygn25Tq8+3LUOo8djPUrQOLZopUkZiq4KwFKglEuVptPCaSs1XiiRFMQeOYmEDFg1TPXS4A0kNg37mrYrLA2Bg63+iSLfhdZ4aJkT1lMCJiZDAKci443t4Cd3c4XF8reLNsS1IEKauGNKFAxoCRlY1sxGBBS73VH/Kur4JWu4q4ATL4o84DKxozYccImuSM9Zhxun9Q/3Pu011shXRmjV9guJYNyB4nZ/dGGOGHIIogBbc/ksUYkLkwyzbLpL+jSIulg7omDVWa0M88saq0zQOXBqhkjEQ4PZwQmJGKZpEj00jHEJBtSoMJasuSUKAZPqcnN1jnI7gbeQ8lfOeUIshZkNeEsio4K5Tx/PmKu/vfw7KsVZPp9afieFArQMkqjHZuHO6GchgZXz8c8WLp3/444HrMAtcDOF/FLX3xSdsDsfa9u0Q7bD1//rwfLubKRXjy6uvcQrR9vl8ND10su/urUL4TsPtrX7vNQchF10hrx93u92Cs7ASiKhSjc3/dAag30aT2fdg8azPQi2zU3e97dLv+2zb9/XuguhecHrsIlr2QLCFADMAKjOOAI5nCjpqr/jAMtbakCoUrSlox5xnMhFQSotHXEBhDYcwpa3wQs1rICLU4c8oJY3QXd6ryqScnECZT8LlQpeCjJkWgLUjazE+RJlxJ2ymuCe8VR0Q4W9NNLJMRX1cGlk5B6opLYq4//bkwTJiub4B1Vndze2MBUFLBaX5AyVqvahxiVdj6lvWEId7HUhmBXkyElTyGTaxQUEEAV96Q7WEhtY6KZaISEaRSMC9rzWZ8dXONZ09vsCwLljWheklYxspC3MCUQD0x6oS3n1U86xK8bBQeHNBMHd3OJ9Xo9tavnsMTAKSMZT1hCF3MGQSQUJX2JB2N6xbZ+xUIVVNclXu1P6+6toIlEVlxc+OdHdCuViYThIgAjgHMg7rFBta6oZUKeGd7gNj/3I/H/nRlqoWplFIAS88/p1yTiYC14LmXDpCi7sppTepuLH1YkylROGCYBgyRMcRBLWoxmhxlrsIdmeGutMP+XAqa1a2nTLodG1DeyjdWGkCyyg8jI8QJ4zRgGrUfCK0PLEBaFoR4AperTj5kpHyDzAMgWYErFXDoXDZV1ITvuPs7wT/+jfdBnBEwINj5ckMEACBrTeLSD6gf8x6EXrh+1pi29zsg9jGA9+33DwD8oLvvh/bZGWgjor8O4K8DwPXNNb7ywddQ1oS3v/Y+jl88bA6vPVHBAEHrItwcJozThEUIp5e3+NI44Us3T5GWBXAtexxRWN0myCQ2Z/oA9NB1BLVqxXrkj+7o+SayeCltglRj40zC7nPBUs82o3CpbTihFssOIjXZjzNQ7xCAja5BPxMDLO5r7QwKkrUvVejvwZEKU+w5hTu3TKV9xeKVlBhVzRcECW4LU+vWWYIBak4JTGKBoGSMicCw9LDdIXMi1W9Rgse32Ua32Eam0oFF/cX/JhOONAGrAzzb/D3NBEyI1n6JaXCr777XDqlAWvsSIneN6Prqo0YgiBBI3fgciLvG6nR3DxyPOBxGTNOkdTpKQc5AseyTVzfXKEUBQJkXAGvddALa7E9fZzJrajFiWrXr5Gtg6+3rLgKNHWxZ0QIThhBRcqoaxXoy6isbw3ZRlHIryAqb58Kt0HbMBcnKQIhrKosG+ortVWGuZ7yIWRw7t1pIMU06WeFum3tRSyTZGvsOpZIhq1oLx0DKWNYMvmIghh0h9Fg2tRiq0EBYlhXjqO6NlNzNxLecCmSa+VRUqHP3XdOclyJY5lOnHBD7vkDSjDLcAE+/2k6VCAoKUta0yGVgBZCiSpufDvb0ozsX3HvQ2V/9O5wEKSA6vx7rT1+AefuG1wEx2fT1Td7n+/zSVWfsNRO3Z4yPulBWutKZ+V047kFcN+geuPVt17HuLHVvchXrR9NW2I9Kvi/Pcf8uV6bgFfO3v86sihVIFnjYfymCXGYAGp6wrAtoGCBLQhiiKYMYa8pYlxlrSlqna101bpkJcZoQYsDh+hp3L28BqBLD63XqpVrxP/zDH+BP/eK34Nr2GINaLayffu7IQAeTgjmNO2dQbEWWgVLdIpXVEAoCag0yb0ekgpS6Bc6UfzZnnjlXya0qan3+ilrXBACFCLKU6b0r4XvvfBmSV7x4viDUwsT6/XyatVB2YEzjoEWI7XLXzerlApjXDFpSESYrm2PZlo0/MNRN1ULoW3wbN2BSBDjNK+ZFvUSGw4T333sb11dXmtp9noFuf+eksUKeRVmEQKSZijMxmDKcPQuo3bMTdQgm6JvrvU8V2RrUUBgNOtKxV2W1XqlknOYVYYKFRujaEeUqQwixAn5rFyJWFkGTjVEnjza5r9HW2l/qpUVBnwyDLf5Q5QS3tDUAVmWmEFUJQYSrw2i8iuvZPScdj5/nnhah63cpWrM25YJlTUjLiixAssQiIpoDgEDVMqgxpDqmOAwKqDw/gRVjn65GTMNgSUgC2MoUBLqgGGK3baIC1U3f0azHPS3yf0UItfYeYJkfC0AZwxjx1rNrddskU+aI0lLJBdniJqVoMrz3v/qb+MEP/lLdN8KkCeeuJoCAz35yhZScQ+qclpTUImrj+O3fftfWVt1FhbwW9G5Q/cpJp4t4w+uPnYhERIQei/579XN/D8DfA4Avv/uOQhNLFDGHiFKUCHRPbJ5nIYRhwLxm3N3eYTmdcJwzvvrVdzFd3WBdV4wkWv29AOu6NK0qUYuteQPe6ZmI+gQWtTtiwiOhujrqZTUcHLxRT23QYrX64GCT1JURK8VX5mSktwNyNYOtaY36RVclH6sfuO2aUoAQtjoZD8oHNDHFAqrZnWBgkP3AkFsOO2ZFbOCITZpygtKIpj9bHIiBarzQxvmTHBKiEnPuhQ5Sgq5ZKKXex0AFfsHXyA41qqXN/Z6hTNoCixsTIIhkS0SCmgkR8PocqqHrtT4OgpSAqBWy5KatIxA4RISgVp51XtWFlkgDsIutvTFEjhMiR3AYMU4LTsfZgumzgTLbPPpy0yjZXiCLvSoNkFXBwrI5CjXg5S46qh0DAgWNxbPYPcCAIDVNL9l6lQ5Ekq2ba42qgBBY48oICO5+4XV/un3eNmzZ/O10ru7jDUVrTM73gACQEGq/ci4IAkTRc0Gs2SN7n3d37dB9ofE108DqmgggjoMFoC91/KhMx+demnKJqAIKhjI8zfBWUAphteQMHrxfRAX/LBlrSpiXFfdYccQD1nXFNKqjUaMMlwDXZbJ7WZy8/Gx/7x6obQHX48/L7t43hSOP9fOShehSH36Wy8GLA6hLoLEKOpXGnwM97Ldkx5w3Vj6ycdJuXJtfm0DzJqBuL4Rt+n2B+9c2nb7CacQr7t0JexV8FgEjqFtRDJiPD/jJJ8+thhG01IoIwhARKSBwQC6aiODh7ogiCTmL1X8sLZaGlM6OVweAqMbZBotZq7EjFoNKxrMCE7KfzW7OmVk/J0aIAeM0oph1oI9rcaDRW6sA1ARYTYuv9/MrJCxXNHoM3GZfSEf1WLPlzsuCvFFOi5VrmbVMjdF6iM5XJEIYhybcGyht23RrYxKgAk+VEZymu7XClL0iliC3Jb3yz31PqO5JvQQON1e4eXoNoYCX9w+Y5wV5TcaaCMliiiV3limfDjEQWunpbg6ZNdNyHcFWsNnMfK+syL3jMLWvSUFzNj7fgI+fhWIAbneka2hKQaixMh0YJJj7LXCGNC+eqyagm9NSjb8lWHIWKxQvbLGb8JwGgHqYieZUuEgb9ujA39voWC4FKRfklGsNtZTUalbMYssc1GOIuSpNURIygGEcMNRkOBougVwgOdd6tDEGxGFQudtEBQWglval6/ur+ITv796t18dT6dxesSkFy3rCsiwaGzio+ymRmCJUwWouBdlLdIkX+Q71vS4TTIcBbz8b8fFHT/Dh997DurisTljXjONpBceAadKakCEUDGOCwLNVX6DJO/rR/+mKlX9ZlrZP3O2RiL4G4FP7/EcAfqG77+v22SuvkhOWh3uEOGCdV5SUVCh1t4moliyCasuGEHA4HLBKQRwnAPcopeB0/4DbF3egMCCXjNNxtqLIqp0XKMIOuzxQ/cSdTZh97haUdth18bwdT4zXODftXKBQz7xIJyBJAhC2IMfFIH+34rdqWTGKoaCu8zMvm8QlnRbvfDhnl4imxS0m3BdRMKIEq70DTvy8NdK+iw+unz8/dCakss2Pg6LslAxk4EW1gCJqdanMSKBuIEzqv+/aFulcGoprvknvvSiomGWk9jNX4U1ELSgssLg4gdfxIKtDR5Y32TW4PlSVIwSCoIzNCK6YS56b06t/PBR0MREkF6R1RjDnf45RBZ7DiLKsOB3nbh7cbVYZSM1WJwbKHayKxw+IIyu4RqvUz51diNbhQb/3fe76pdTnN6mFLbNHH0vgwE21uYJioEsTBAU7AyYEkKYA9zFccjfRfeOf+Ub0vSFVEKKUPXAFHFmLegIYpQCFMC8rQhy85+rLb4qU6tJmypmStHAmDwE8DCgoTQizPuVSGteFy2cKBO0UGgHW85FSwXr/EsvzH6Nc/ynNqEeaNS2OEUyMgKQ+/rt049r+qyHLq9zi+usxEHj+uVz8fAvWGgDatnX+2+v63Pfj0lNOR/hMQHr8ciVdzzi9dXdtdJpGnUKuxfycA7BLwKzfG+cd7+aMaDNvj43xUTD7GnXs/vv9uPea7j2Y6+/r27oEojVTMCOlhPm04OpA4KBHMC0J08011IVSQdvD3QOWdcEwDCDOKEk2SlCnSTEGyKCWBvd80Fkr1g9VOxHrmoUQwDmrNavS9eZuFgatCTZNAx4eTshJ40VFLHbOeSvO5ClLqNKE9EtzvZcXGt01cNmRLr+1rCtePP8j5FQQTSFpjcEtPD1oYmtrHIfd+qL1ny0df/UUcYGjKTo9eVQWTx9ve43aONwaEdCy8FY+FxhB2SLSuuBuzRbfrTe5q5xaFJ0y157o2OFZms352s6zvsNkD5ib5saDyQft7yjVo8XHqSDK49/MetoOsp1RG3OL0+hxmH4cAAy10A4yuMblt3XW/a9tei1hP7tbGtrWy2rKSuNb0azR1S3P52H3XCkZp2XFNESMtP2uvWvLNJy2rUmfTSlhmResKVclCBOBOGAIZGn6A4YhYoyq2A5MWA9RE86wWti0zE2AiJWnSAm5eMkpL1vQXB/3Lo5nZ2YHyJoF8vz+vdW/rYfJYZbgp+SiSXq4oKSM1RKpCDRpDtnc5JoBtc6aNagxuVdXB9zdvYNhuMYwtFuOJ81YzYERhmgW7oRQvLyEbdVXZLPsryqSvcH1s4K2fwjgPwTwd+3nf9t9/jeJ6L+CJiB58bp4NkDNmvcvbiEiuJ4OIIoQK9a3vQhk1iUhQggRNzc3OEwj1pRwOi5Yy4IvPv8MgGavuskJcRgh0GB/1TY1SspEymlEWgyY4SZnacwBV09vIJFQTouddwcNBq7MZ1+JUr8IJhCaW5rvtdARE6kwyES/AnCACsW5SYaejlb680kaNLyKxkoVySaP67YPUQsD9oTJL3YLDp8LQu1MdMyJGVS62u7SzNbbqJfuXeQEyUQVsdguoj2JOesgMyMQKyOnYrVrtFyvAhibjyKq9bGJb2DKGblNnh1OZcTSrXF3GwpYTONIClzZanRtNPDkcXlmhbVtlEtz6xPJWFZgHELHMH2sbBa/jPn+DhSOmA5XoKjuEKBg1rHTZj1c7NtMsjHtnigW0VgK8WACVHmmpmauIXMd064CpmXnAoDMGvcnABJhUzuNclHXkdji4Yq1WbXjdZLd7bTLLGnMGVVZ0ZiNBI0RhOWu1NeKCnCNB1s3BZrslEBMGOB6WnO3TSec5qNqCwNhhjMJtcx1s6eaxkAQq3t4NR4wz4vOje2dtM5Y1lWtq+5/ZKSDRMyazFU4CJHVRXK51z1l+4lsLhnA1XSFaVzwwMcqwL9KiO+vN3F521rOmjDfqkU1MLFPi+/f+GeNZr3Zux/rT99Wfddjlgw0JZBTFAdxe3DSz1sfe1bb7oRpUNtzfs8euOyI1flYXgGo6tkqxnvEPuuWdb82b7TmcvmZS89XCixtfvpnuZ7NBnLP7nOgYgq1XAQlrUqfAXgdrJQzrmNUpQcD66LuVSp8Fi3o3I9dTJHHRm8D14LOKJqBLSPVFOPH0xGffvopqmVrIyTrgrp72TAO6hLHWvfJPRdqojMoa6hCbKfpFjZ+TS0ZQt1nzt9NFjG/GmwKMHcgQXZ7KwIYRs0wXMEZNDpaqD68E3Abb3N9JzfGVUUXn2ciU3oxQMWz95p7ZCktSx+rnJGKui9W90nWn5Goxj+BPMRas/8Ra0p6sXqkACGOA/LarGzKL7a8SGCK9JoZUtRbxWQKVQy4tcuFfrU4qmaw0WvdkwyuceGELr8I3FGpkGfIdE+rUsETS9HC3sOIZ1dPMZK6dgIFnozf1169X5vl0sfZrDT1zd1+8LOpb9QSGFyLRddFrIpZPXtrKjgtmqeBmDEGwlZs7wRBNHkspYx5zViXFad5tXpqRhmIDHi1mEqOAWMMGCNXt1uXNYdhwDAdNGFPpxwphTEUrSOHLNUVWUUxrufzfB93vaeO3lCvVLKo6gsgrbe21RPvShqfH0lY5lkNGeJeLdAYd18NQjfnUs+UK/FP81v4zv/9b+KTTz7b9t8MSq5oYGJNQcgt+2Xw7KgkABd0ZEHlL+9/KpbF9Hycj11vkvL/v4QmHXmXiH4I4O9Awdp/Q0R/DcAfAPirdvt/D033/3vQlP//8Wt7AAA5o7y8U0H8yzNopOoLD7hWWwmtQFAyY1kWfPTJJ4bsJ0zTFW6uPUZG44bm+YT725eWLjgq6IBgCgEFhIyi/rc82ITBRL1ugUiZ0U2IeHK4Ui1JWXE8req/D3SE1CwaGx5iAqgFHfdABwBSYUSLa6PQCx8Ambta8SyXRLUIZgVmBOTciEi0A1koAHKsMXq7+M/6Ds+KpJqBlpWFIKbNQs3+J0VN60kApYom2EmxI6Zk0wvYKj+yWC9jxLV9UfDn7qEOijYTDwDmq68mfADganIXn0/ynuioKiHWxzWhQqfxcEHZqRKTao1apiJtwTNRkhEjTUKS25uM8NdHHHiImKAQgZQtZbKgxKZBIgKGQQUJFX4K5vs7CAjjYcIwTtDMkz3hcyuPvjLYHLglVgG4u+nBCIu6CuY6NzrXunpS3SB9CJXXdXvUwX0gQuyEAwFQmDRIHNoHr3WEIhi8TesTo5i7cHuf/iybDJptf7fd4KK6CyU6z/ZdLsAQQIFVIFyKCUcCjfFMYAADZSwPK3S3ulsW2mAAS9NrcR0BCAVYLIOo5FwFHc0ky2DOXTtVMjOGpec3syDkiJQzllWzghZ4odlmQ0giWArXSTCyABf8/mVdl6LnLn22FfTb9bP2rQeC6H6CdpaeDpD1z/bAqsZs+X3WsGpRqf59NqxHPj9jnrJ9/yvvvfB9pW2d8K5Dbda3S/O4cVfs3rOxmGELsPbtnVlHu/7UOXvFfPdAt0hBEXWrKmlFThkxDhDJyqtywXCYEELAYTwghoAV5npXDLSZt4QCpVKFrzofbJYNcOOlCChrRsoqyJOIZtNzd3izumVSRS8zQDE0BWMIoBABKeoNEZoiiNHAmo/Vja2qB5TGL4onG0OH3LDx3akg1Ph1sdhbbzsMI549OSCJ4O7FS4D6cWJH9/o90NbdY9jq1iWl08W9UaRToxpvqLFtwem/gdUiSF7HrgJwtYaFjua6codZZTMOGsNdilo6OQPF5AzN9SAVuGrcfeM1qHKSgpSUCmKIEHMR1Ogp41KlgCP7ZGz2dlOI9EmBqCoKz+iLeB4A5Y9AAWLE1XTA1ZMbjIMJ9SVpAjtsr6Yw9fNcAFkBNKWlu9cp3W4J6mB5K+ti2hz4HEHcfTFhXVesy4wiGSjQLIxDRNiF6HiMeil6Jtekxa9PVk+tKiOCuj0SE2Jw90fGEBgxuvuiJovrx+jhFcTtmeoWCg0xYQBBsoY/WIbLfs57MLZ3M68W3p1yohFkXaONW+TufqEAX/A1Ab/5T97Hn/83fl9lXzt/wRLiMJv8EXTMV0Os/IYJWOYTSi5aP44DjmlAzjsDA5HKypWWq1yzySLJZPybVFbweURTEAFQ763uep1rJPBm2SP/g0e++ksX7hUAf+O1b90/B1TtClIGRv3QbQpMlsRDVJOVMzCfTjg+PCAMA4hH8GCF8MwywkPAGCLIiMKaNSNOSRmnlGvQaSDSQsreE2fw3UVQq14YAkJOIB5BVyMO04ScFog6EYJo5+oFb0sU5HjeevuMYG548HS17qgGAAHu5ogOSpxlnek2MZtbFVFAZNYaFENEKal+70KCP+qKuprdByqIM6nroGb6gxEnTUARASyrT44zf4sz7ARyN3VnoFkfbEMr+Oy81mtqdvuJBlZAyiiKCeIOywiqnfX6MIBUX+zaN/Ff7ZkiBmbaPHimTs+O2AsQIKr39+AJUHcRiJg7pmUzMu1ZGNQ2tVG0dVo4ZsI4BIxTQC6EkjNSzkgp43h/xPH+iGkaK4LxeRJRwiQiePL0Svu/zmqFFCBY56s2EIRkigOGEnfwzqXV9mytoVTnzgQY77tldyyuoaOWbZOy1j30Nc5BBbTo+7+bBsN0VVnqTi1OnH3MrsX2cStxVaLnzwpQa91lqxlE2DFxMISkPuduxArPVp0CbsJXLAreCoudC9NMG0Pn2ifphib13Q4W6tqJIKUVx7uX+KM//H08++ov4vrZl0yJBLgiZy2CT5YDnlRBEZurF77bG7efvcm1b+fxe5RVNRbdz+jjQOOnfWcvWOkHWwF4A0D2Glc+//yscezX6vyex9zd/oVdj7y7B1sbUFiFzgZO93PognUP0vYAbduFHQij8+8uWtc23SqYH074/KPv4+7FF7h7eYtkz6wnTWZwmCaACCEGBSSIADFEUpcby8qpDLF2xc+W8nuztHitUBA49+N36wzVzxqgUVa7rEkTfwyDgsWUNGGS9HOxFRF9zIGB4gWbyfmE1OQLOgJ7dwc62WiUywC5e17XDJCcMa8Jx+Os7mW9orZbX88MQkZj0QGxKmNkr40JrECNGSNT6HqNTp85CU7/9L5UCtaUkFLBOAREispHQMg1QuASmwAAIABJREFUNRFqsjMid9+27Nek8TsaW2g7RARepUHJOFXRqi8tU0rRguw5gUWLsV+Hq26+VH44i3l+5Ii20BVUz5ZOtNf/swFWanM7jiNurm80s2BVEqtywePZq9Du2Ql1Ni/TC9Fz0t5PKuGRe+c40GD1zllXpKzui+u6QqyGbQiMMU4ITIgxauhENWSgkxkKlnVBWrN5p+l8MTHioOcwhIAQVOaJISDG7twY/yQoz+3r7Oq6mezoJQc6Fg2fDdL4oKC+uqZUb3TKXR738/V6urtVMp0BPgFAXbkHZeYa98nG5TlaBmtoaRAOgAC3dwOef3bA175+D5Rv4DBGPDwkVdya5XG+1C0VftDccFVGhGQti+Rz77NIgBSq4ihRkzHdE8i7vge1l64/diKSf9EXVd9C6CYvHQ8nqodlnRc8/NFzUGAtmBwVoAzjCI4RPAxmttT03hQDxsOk7ZUCSaoxHGpmQL3EuUon1CvYyiCKGMcJOWdEFpRsoMZdxIz8e2wMqGeCnUXGrtC73tm4KgvZpLhEFWIZsIyBHWI3sOC1I3RzaPrlcRxBHHF9iFWDVSztPNAxcMcf5O4Pftisd/65adz2uWfqMRfUtL6V3xsggGWQqjopcQJONTXxRvduGkgmQTKiXyOGjFEW6XVcqC5/SkhCzzngXgia/0PtHUa2dlGOXfyHaVDAsOB2ZyLGxEXaoQUQAyEG1fqCgHXJDXQAFpxrLoHMCHFQAbgExCLIZcW6imZ0zLlqqfwcu7k/ZUbhgBgHxHHAkDOOx6MKccbc+Uwc3q6ZWxHrfhdzEXCpp20NCIBUkZJqkiMIhV0wQWsnq8k/iLpTxo5IAZ7Gw11HrPSGZU1sOi0xfUUnQMJospiF0EGPXeu84vY0Y4gB14cJfYpTt4CrEOZ2RmjmSvT3AZn9N0Fzl1LhJ0MwXV+ZJr65b/fwxd1vnKkBmk3t/mHGh7/zHSwQ/Om/8JdxdX1ThQJxpml/VPcbk3aaUN2sYFWAgwv3rY1LQngP9qi7p5+j/vI29+CsiSI/O8CRs7f33+m1cWu0+eg6r5+Xx1pptK1sAHy7LjHHN3FPufQMEW1qHj3WbnWL9C0u5SyezpNtPNYXV3D21rI9+PO4vI3bjc1d/77WqJ8NnL+bYPEguvNePP8cP/7tb+PlTz5BWldkIpSUsaSkSQqYMY2TWaPMMuYk3fqYTclTBa/ufap0Yzv+2mkhdUOOofNkQTsDLhAGZgzThNPDEdnm8nR/xO3tEZJWHN55p3LZ/vwAzk93Z2JDu2zhOoVWxWSymzfqXOM64BYCIc0n3K+zetCI0unS3eN0uZa2MHq+dyUDuljiInWdAFRBvO47EAqhWv5KFqxrwpqUP10/ucbVNFn9LU2UFZhqce0irdSPep5Y/dQa19VkD6091vieCKprsMaHCyAFKWU8PBxB0MRPUs9GN+OVJKrSV3bjb/d17nTUxZy7ezo1DxyfY4SAUDIye6iCJqybTzPyumCaBohwBeL2ZNsPliehCO12je+Hbdy5dkf5Zc4F83JCzitySsZTVXkexwnBZAgPe3CZckkZOWfMS8KyrEgpQzrrtXqoaYmAYQgY2K1kXk5ge7Z9n/Q0tX6HdjRrOItZ5JR/Z5PPbKE6q5FzjG3M3b51nMu53fctGczlq5eLAJdTNHwihIDpMNVYfQIsYYre8c+/8x6O9wNevDjgiy8e8N47fwbTOGNessXmKR1/990HzPMRz59f7d7eeMomzKFLeObSZfUkMHk3W7bvysOMVhRwja991fVzB9o++vGP8f43vglG0EXzStf10uQFBAApoawC0IKF1Mows1o5ZBgwHkaEQf9RCJp5CcVcIxiCgBANnHUB7oJsghMUcEBwPB4RhhNubm7g/qzMWiwQad0UyiyF1bdWBH2RcAjAlr/As0aFEAAWc6FoIIaEUBhAdvAoQCnmzu2Bvqj3wwmm1+JiNXUPMaCAa8p5txqcarYnc93IdiDF/cphrgxiIjXcfIOaTn+LKhVMmqBaSw1K0zipv7POiyeGqaMrbqnqhEPxpB6omQ0LGCxWh85AE4gMxGrfsnSEBI3HbnpLdVaNkME5TnNicIBawfAFIQ82ZrLsnMTqIlCtURYbUFDdBojQgsfNxUeEUVIBFyDEhGL17c5pnhIlKRllXSAckACEEHH99G1gPWE5PsA4ti9NXSPhBuVc491tJFM27BiibMceiyAHxmpCR3OfEni6bIgmzektf3UgfruJmhnSmGL/aj9C8DYMwDIgGjSHXjNIRJhPC+5yxv3DCW8/vcZYa+sIiDXGpllmAXGGS937qQtwByBwAUXHl8oKtR5s2yGIH0Wd637MAEqe8XAi/PC734FIwi//xb+CcZyqCyy5oEc+TcX6IrVr57Gg7VI+ILvPOu18B/b2fJouPNsvxdZdsgmCDr628HnbVi8g+3eyvbn2ney/PRA5Gyg6sLQDN28SH/AoIOrHdkELfFEz7LziNRrSvv+b+LAdQPL39Baxrc2gCYL9c70bY9/OfunqnNp9dQ7JvhNsNogD5lIK5uWI0x98Gw/HI+6PJ6yLxnpm9eLSmBEixGG0fpEBGNQMc727Xx3zBolRFXC9Vlju5t1Gr/FUHMG8AkFjSA7XB9zd3luMnApBZdV4dw7K+8SUPkrrBCjAB7/wC/j97/4ePImVO/z3U8pm+aqZdV1x2K2OVEFStoxHpLqjFSoIVjvUQbSPqwEC1KzBAnO92q+5v9NkFJeMvDC2C5JiEqJbSUiA9ThjTRk8RDx9+y08e/sZ5nlFSnfq78OoJXGSqDweSBOVabMMV4qSfe9KXe1Tc5u31bIO1dWDiGhsVYxanN3d7Cs9tym0CVE5QECRTQCmtm9EvXRkV08R1u8YY7OSsiahUZyr6ehTWnBaV9wfj1juH3A4jBjHQROylQxQ0P1bN6xUHldVWmeEuR1EIkIqgtNpxul0RM7quhhBGC02MAatPxg6Q0I2ASivBSknrOuMZc7VehpYcy6EqMlBhiFiHNjqkG7VamJ0Z6PYuyAc7ek1wRLE+ZyZ5xFbpmWxe9jkN5WtDNp503ZWuCq19ClCQPVA21yNM3kIz15ZdekSEdzdjfjud9/BN7/1GUpKSKsmNwQJvve9b+Dh/hlOD0qfYgA+/+wJ5ocf4p133oOG8xitoud47yvfwdtfWqtnmc/dvK5Y5hUSgrnUCr797a/i7i7gvfeO+OVf/vx8OCZXF2qyGQnwj3/zA6QlGH+/4E23u35uQJu7M51Olur/UYbbtFcxRg3QBBAs0KcUTUGKecHp/gGIAQJSK9xhAA8j2EDcEBg5aRCmFKtxQoBnfAOgG0oESRLub+9xd3ePcZxwNY2IwwQpCUtZ9Hk7BIUASoQwBLBo7JyDKzEt/kABMjLyk1ILFZYSQEV3B5EgFJh2Sl0kNeaqKGAj09o0fxMlhN3+1w2u/6bIGGNAKgpqpshYsgBFGSp15iqtFqXZgDSbvQuKRqjEYpR8ipwwOXOSjExUg8EJVN1R3c9XCT1htYw+IY4bYMQWlB7JXC+YlImVpEGcRaobSG+5U2FLLXchCPbnu8VTEczkpqZ0SwPtgbbVhYId1KOCWL88Rq8WuAZqOuYQ3L3V5pQ6FycHx7nbZqL7BYUR4ox19v4qWcxCGK3fBCBE4Hh3h5RWxPFKtYVs8XkckFOCCGG0dPuGSgETAIrNe8maxKXXiFHJzdzqYzMhxcfpmvwNYNOBGnhTC1uxdc+iAM7BIuUEMNUaRuhn1mVVOyuhJjlxYZUwEGH1zKYCLKVgzBmt/p5mA01EGFCwpqIuOEBVKBBMf1PXT89T6JhIKMDKShuYA0RWDNRlSgNZJirZaNaYpGZtq3JFKViOR0QCfv87/wwC4E//6l/G4ekT1bTVVLAK3oSwSYvuzK8KRva/bYzHmcxSPyjorDO+H6pwv1nuzbnZU+KeqTfgJmf3bPpQP2+29HKBxhevnyPbNvfCah/Ltr/exMXkMSAmJFoiZD+eXZs/i0Xu4nNNNqkTW61tm9s6ELeXqtDO4+a7vm27Zx9bV/vk4K10gpFs5/n+4QE//Kf/Az798YdqHeCAlPX+lJIqSGNEHAbEAOSsqf7X5egaNSu2XCCi5TBilM17NCmGKvXIrP2K6fTEqhXHLT1a6NbPckkZp3Xtkpo0XjJdReSkwu66rAiBIWQxsCSYLERCVMsGMqVZfz48qyMZL3DlVJ1OQQs4FgeY3d6qwrGmxefQlTPp39XTXgOeOZfqql0v74c03hvaVwBUHspFLD6NIWC1tomAYsTh6Q2mMeL+5S1KTgpY3SXTeTwBOYlZVZpFjY2FVj6pptXqfprXhFQU0DnrVPAuBgSgKeSHQYu01z1ncYM2MR7u4LMiBsj7jVzcO6IEECmgieOAm6trXN1cg0Aoy7G2qp4/BQmCZZ7x8uWt7lMIxjBoUWnoPvNcm27pDBWhmaLOQPLmfNU1NUhTEuaHI47HGQRgCgPCGCwhCapiWKCsNxVBXtV1dbUaaZ5cJgTGOETj2wFxCDgMwcI1Wj9V1CDbB3v6bHF3HW7TMWJ3kc21jludVLiuwUphC/7q3rvgh0F+UutK1t97flR5iykyNgCSCK+i7USEkgnf+92n+M7/FXFas/HtAjDpfhg1jq1Xfy6W6GWYRpDN9cP9Le6X58r7LYLKS2RdDYKra+0/IUEI+LV/60PFn6ZYdm6nMoE6HGOzPQSSCv7iv/1dcGQEr+tGwD/67x4d4s8PaPOLw9a9hFkqHQRQT3/ggA8++AAffvihfmxF+NiK9tbUt5aBMqeEMi+QcguKETToZg/DhGEaEWJACQFEUV0uES2rUYAQcH0VMU0jktW3eHl7BNFdFajU310tHr4XQmTtb7bzy4Cr3wsBh0PEdHVALoK8LljTimX1eBlL2W9CINnYCwLIspFU4k7udietzpZZEI6nBcsiuJsCbjiq2XgYICVjLUkTh5hQTzWgUrPeMLMJnxZPaAez1pjbL0v9o6VyB7wem4I9j/8SKAOIgZGKQPIKkcn67g21NtwoX4O2SSqjKkCNp1Ih2mMLt0WVq5manDLsBTPfc+7C5+DOmJIxMgesVTvqphsXJogtQ5C+y0kTwerF2IuK1QsJVk9Oiq9zbEJ4L4GJgoAQde9KycjzjDQvoDDi+uYAgQUzF0HKQKGA68MIyUr4VfjTDUo+2D3wsj3l0yM+d/Yv+/yJ1Nu4SC1qSjZB2X4vtCPgprEkNODfGRVqXIGIgqpvfOOb9qXGBhAR1gpeBJIyxsNoyV8IFNRdujF2dWNGLkAqkBAReavdI9FYjcC58hIhc5V0tbXFXUDMRblbywZipApTLqioddzBEnA8PuBwOODHv/f/gCjil/7cr4KuvoxhiMa0TbtO1MXVtL1wEahU5uf9MDpzBrl2z1z4Wo/G1gLZg6xOVNkxoe55nLNn/6z//LE+9dagjWUIbwaYHgN5jwIv1wTDrazeYRe299bBnbRjf78JYNz3q7oIAhvh/XI/cRmcXZps/3PvQtovxv73Kly3Z0pRxeL984/xxU8+w3x/wrxYUh2BKd4II2tWvCEOOB4fsJxOemaIEIeAOExqzcmE7DUrd2vq3lpMnbWI3cKu2eECB0yHA7KtUxi0RuOynECdhWfjHWC1I6MVV3bwIYABt7aWNe7I/ucz4fooqSfg/CImZKhSyXl2n52yiGA+LRiHAHfKry315FdQaXP1dAE2SaOMAGnffPk6y63Gq2UV+AEcQFo+qWjbbAqu07zovHCElHUzJ0WAyIQUCDk1QN//EyEtz5C18LeqmItagcxP3IEeAFMaAhoXJ+Cg/E55rUA127nOvypgWxy1Sx9kyk9IqZb+Yu8ahwFXN88wHa707OaMYtlNSy5YloTTfMI8Lyh5RQwBV+MBcYyIlqxDvZaKI5UzXiWQroZoO5B9PHIPDGIMuL4+KHS2OESNJfeQlYQ1C9Ka7cwl03WoonUYRrNMaiKYweLUmFsimx589fufO56qe5nrAw62Nzy49tqtQ2ZpNrmJSQGvu3vvY41BXar/DdC6fG6q18TubFH3vbe1p+V7Ws/sWTlja7P2hWurZX+OadtXEdI6qyb3cAz6vI/Fwjc2XtUObEWqNx0TI5cZDqKV1CjxSfOClBMCBlBU63HgLQbaXz93oO1yjMIrmKAzS4snKNUdqjFbJT7tgMm6gnLGMgPACXPUApwq7AUgDhiGwWpoRBRWRjRwwHgIkEOACMwfWeteIKtG5DQvYFar1jBEaLq9fgS24UxNRSEgkiDGaxxEsK4zckpNaDcQWmfCixR3TM6LFuvmdMFKgdbplLDMGZ/nBS/jLWIMGIZR0w1bnRNGQE7r9jCQZ5ii+re6jbh/t0m13RopAfU2bF1gWrEiNQuoZ0AqUiDEFTecr3LLtlR3BQVAMlyHWeWMjYTZCKU06gl36ewTkfhUahsKdsgb9UNcrW1b8LER1G3eNBtQ/4xrjAUgRmRVOmeoRtNr1bHH9KlKd1PDCGigiVgBodbsUe2xa7SPd3eYhoC8ZqRV38c5AeGAEEfEUeNOkBZINuDpA9kfu+5v9wv3eDqgMe6QC3JQt5/EBtjI96wgW2ybvkehN0XWfVwTgmArGEu/Xl1/TIARbOXl+jURhhiQjBg39yJ9/3L/AISozL5zh66WVAioAJnQ3IxscvoajKEAuaYnkw2oqu6WdUM7Q5Tqry4FOJ1OWDPw4//3txCOf4R3f+nPY/rWr0BIkwOEnFBIC8buXQX9TG4YJbo4THRAZ7+srwA8vg2ke57EmYyc3afzYpa2PTCvS6azL3BXxm3vzlwbu3HuwcPZ/XsgBZ/y7dw065LvncYbdo2fz8/ufY9+53/vhIqL7pTYP3auoX8MUAONR25m/Kwrj7+3t9j1gs9lq6Vmo7s/3uPh4+8hz7fIuUDyArGsrwRREDCooiSvM9ZlxnS4VkDl+1cyci5a1HdN5k6ppyxwgJTUTSlVrfN+fsZpxNtf+hI+/+K5JsOIURVXLhQ1ql+vAAIPqngdYqu5yqz7YE0rUs4aR2TPsDEWowAX12JPh6r12JV1VbkEBWEp2dduR6KOidVlsZ/dmnCr/1gJIKx/prAuaIo/tdBoogpixtXNtXoC5WKxYVaHKwQMQTPv5qwKchZUcMiEGte21xGoAcb4IlGVDVxe0Oc7yadbR11bB+OxtryP2RN0MX6uCKtz4O9Seax0ewbMAA+QrPxxXWaQleNJ5gZZcsIYCcN0XZN1EHvoi8UamwU7UFuVV0da2Tib9G77ARV4AspTUy4oadXU/GupLpMuPzAFjKMWsh8CYQiEEGPNw9Doabt8uh+jN+exgGc3+C9oQM5ouDSPK6K2ts7bWybtRpket4z53Jgc62UGuvlqNa7O3SfPQOJubL5XOLCW8CG1FEZPFAINMwGagr6OpZ+KXJRWScFIE9ai56mYIoAtsRFB5Vs2uZ+EKp3OVq6qSEFZ7PmqhVE3b8nFMksz4mG8MF/t+rkDbdv1dUFZIFU3j+3MdpeDm6ph9yxPDtY6gurF9QBBWQrKmgEs+j0TZtIDQoGBUc3l4zSpr35UwT+GQf2QxwwWwVoS0rxgnWcMTZEBwEFl5evWvYJpIEjg2r8ogxKgXKygthYJZLaUvT0w8c3az4E4cVRiZ/WPUXLGkhOWk0DkXomTxVTFGGor1aIlqBYslKYvEtEDNkTNeshGRF2I0y6VSsxFNJjcaWmIGlckIIiZocWCws40Jib0OgZT/+5kGkjT3gGVmTnjKjaXgbuilW1HKVN3xGKDcgczIQsk7dROJKr51WxELqTre4qvhbXlYJCIm/toHVYvKAqWZYbcZkzTqAUfTSsLUuUDh6aJ9XguBwfuLhQHRhwCchYsx1mtWDmhFAZz0uLdKWnCEwqYpogyRqTjCeucLgprwgywWPp+qhusnqusAYQi0NokzNVFNOfG0iKptU18rkl32DAOuLm5xlIEx5cvNQU36mNVW6z/toLpV9//SrWu52rds3fb+rmQSMVSnlDA+197D+vbb+Gjj3+oRJYBYit0TqWujVhAO5MYYGrxkS5IZwZEdO8z/Dt9N4k701iTZNpfcehi9wshrTOODxk//PD7eDiteOvqgPz1fxWSzAU4yNZd0IAgm5C21zT2Ql7zACjdfkH97FKR6kuCiNQzvfsMPcByd0bU+nO9e2Mnj14Ekxc/q/S5+3t/7SRmt5Z4fKw9uGUql8BJ106f9GHz3gCtddXRXKo0TvcO7frTjv2uDxeuqmmu7b8CbD3y+aX4vtdZJV/1vYgqPj67/QKffv93cfrwd7CsSd2yphGBgTVGLKcjRFT7n5YT8iy4fvIEV9dXyGkBQDVOerXaUWlZIaZkrSPtkkkINBtbR1gNQJmgaEqQeVlR1lVBhdGnakVzEGTnT8u20Nabx+YsubXNLpZm3bLbNgLxdq47C4b1bZu91kiUaPblYRwa7648wvbsDqv772QySw9mCMoTWxlosbCBgvk0I4lgHEe8996XwDHidHePObsnQQFIeQ4sBbxIUWuiZ9k1cOjyADMjwGMBfVzS7oHxUaINWFMWInVsDuya+6rR3mrlbuAmGK11yYdFIMJVmV15ElmKEJuwIRAkLXg4rXg4zUBKuLo6YGSNIb+eBgBjrVVWrbk2uPqT90f3Fee43x/cUz3/VeWhJWXMy4p1tXgrDRQDs4bxBOOpwxAxRU+13yVX6eawf8frFEMuG27uffQZ9/qByRz2CbXSD5B9HeVuKl5J71xqe9X32oe+vTODTPddDXupw2IcDhNG0XT/7fyqQNe3UVPLSP9uNNkwJSBoCFVaV32iZPXOE0FKGZCCtGaE6YAY1aWXhbU+JZsyP3kHyXIWWBxgMO9AERC3zNiPXT93oM3dCETM5RCu26hJPc8uP7zOrKsJv/tM14vq/cXqkrjGbcPMPbQkmTB5f8RKhGNgYBi0Avo4YjocMI6DAZEA4gEcNMOkxgWVpksQ6bz9CHnNWJcT7u7v8ezpE7AFcKsNiVHKCpgWjg04qL+9MXRBFSJ5F8jZCLsKVZr9MIDFg6hsrEU33HpSbV3gbfyQAyq3N7hPs04Dg8cRN9fXKHnF4sxgA0yoblJ7nbacM4hY0+8Sg1Nz62xjMIBoBy0LauwQIDVAvWpCHdxLhqwmBGFLYgnKq2r9F2MGKpgWizsrhjkbkPZngwUwE5lGkgkEyxwqdvQrldf7gsUEcpeIhA285AyU46yB8qyFYMdx0ExXHVGlIhB2P3xBKipkxOjpiANCKC5JVitdIC0l8PDyJcZpxNX1DdaiBC6LClJrBsauflw3U23fip2xGscFR5LqxGKFWkMuDfAzwatCNOWCa+Im8DDhaQwYCXj58iWY1c2xWhEcCDXJFwLgcDhUAu6CEFlg2rABmGSZYfR8H26e4t3330eJE370w4/AuTRa00EKrXWkezWQAFJaxjObGscTYmvBxqBJ8o4dkT7v9zt7MHIWSGNb7h8W3H7/D3CY/gn+dRwxPH0LgKDwCuERmZLKr8UmlwAOAYHDBnz1QK7stJMO3vq/91f/fQ+kqqDsbaNZ/tQR2plfAzq0a88/3//d1CWqxDo/sGfdPG/LQNFGUO7BkyefQAe2vA2vsvI6sLPLb9DORmu3ufh0QssFUFStfLSd10va44tjd373UwK0N76nCjH6cygFb18F3B4iyjpiNld+KgBKQWTVW6c1IVLE1dMnePLsmXLspLGljY4KSskN6HZ75lLX1AW3y1RIOl88RE2EtJwQuvi1Ns72e2fvwGc/+QzT9Q2ePH0Kt7CDGWEY1D3Z15Db7vWlqno8avNYLKGJf696FQ0FCMG07X0Yg6hcQuZZsVcqunJGZZ8mpHN9sY9FoGWxjD8Y7SsGZkUE4zThybMbpEJI9w//H3Vv1ivJkpyJfWbuEZlnqaq7994kZ9jCYKZFDShBEkZ60oue5ufph+hZAgYYSBBACSI4IkfsZu/NS/btrv0sGYu7mx7MzN0jMk91c56u4uLWOSczFg93c9vtMwVjsKFES2VXGWYIiaYDFKsJ92dHApKtcRFvsu1yTg2tAutrGriiTG4XoynGzqaJWiqYG6Wqh5W6p1zJ3lzrgtz3fJ0Xsv5uwDIvmN6/R14WMBGujiOiyYkQvGzCI2J0cQ/q0zueKGKlF90+7X5r2VHN6BBRB/ycMubTgtkaZTurCiFgGHTeOUQMgTEEgvcd7Puy9WMk6mnvibHv9sTOp3TZXqt8qTFfnytFn2RzFEgFzNBufk8bcBcegqbPX9Drq7XYdMk+8FLlHLUWWf4qpRRLi5SaCq3IrNzKZnA+VwAsdNzfzTghk/URLMhZ1NkrwBBC3cMAYxg8040MGE+do31qKJmOWd/BHNRsOka21hAfOr52RhsA7GsKAtOmrq1jAe2z0hbvLHogTQGtqX57IY+t0uO/ez2XKs8FlDLWR8FKhMcY1PsUA8arI8bjATweANEwbCoFeU063lw0BROonpNSCu4eHnB/d4fDMCIejziOA3JOyLlUaH1hRkFAZO9J5uNUxSmLIV1B+2hVbxUBHCK8F5Ul7KliyQpJH8W7wet8rVnvkkvBELXxYs6KdlkEViCujTWLIVyO8YCRWdP0kjVZNIIvyrV0jBZeDxwUxSsXq/1h5FSXuwq/XjgQdbUG0uriKgyxnRs5aD8tM3BdKEtWRaHYBCgZiAlZFTY1BYMDPMXB6UVBHPw6rWtyxCwxGnUb32wnOMt3JtE8hqQAViB4V2kpwHSasZzmDQvz6KGDwcD6FD7en8DBDL0h2JrEKvAiO70FFClYpgnLNGMYI47Xt1rTmEw0xgGH4wBeZ3BKwG5fqLFuaJ8uOIt5oi2hu0Yd7aCihebJBaptWoF6nx7u7xCPB7AIhuGAFx89x7KuePfmLbKBC/lenOcJ4+G63851iCSApIyVtS/MDKlxAAAgAElEQVSKGjG57g1vXH3KBR8PAzgOSEWAsmLIGVISUAad5wIIS90nzmc2CiBrI3aY4AwVTMBqV9xcMYPEC5eLEU8wOhaBgQgVFNIGxb/8xc9xvL7Gv/oX/wIpDfg8/iP+9lXELAGP718BadFnDQc8//RbePHiBaLV0Fbld8cZVWip8OjTKy8abdTu0fPPXNTJEqqDC1Ww+Dt6c/RtO4KW2tkffWSQ+nOeMNLOMiW6azdE8cTRO142nwOg3MBP+s/Pb3L+zaXzHBypKj9PKFR1zLR9h43Bd2kYXRTxUlrQxbTQ/4RDav834JOPP8W1nHC7fB/P7u/x+KMfKa9fk8lQUzwCA8OIq9tniOMISQnJDWZxXqnpXhSCGtNkmRLVIdcfxi9Ja+U8vUzT3RZQXjFE3hhT23ewX1jRjGtj72pcGy9mxkCaBZKsBt7lT6cy2/1lM+/9Um/mne16doOiWluIALIjJAJYlgXD8Wh/tVRD1WX0PHWUoBXWdU4EzwyRbDzXwBBAhHVJQPEaKgaxwv0XMfHIVCM7JAlFNG2/kLfSkQr/n9xqMiC0ftIDa0uYXLqMqM06Kl92cDIxxlrIlFDnJ1Web5lBjV6R36u0k0Xrx+fpEafTYtGrhCFEHK+uEIeAIcaWzunrL4Q94I83xW40pPgIDizm/L1+X7TuCeJOJzXUS1FwnmlZsS4J67pomwtSehvHqFlODIQhYrB60ODOGNrWQfPOeHPD7dKh9Lh/rxbM8GtVbFHTV2jzZvW6uiI7YmeBdSjOG15IbRCXB0hAS3l8gi9u1kB2Y/e940GRrmUTewfR7p2hzyNHF7Wf+9E56A6q48T2cBwwRrG2VFo4oejghFxUF2Am5FRqv+M2p7qupYg2j2ftURyjt6ew3UH6BgWCeCELpj++lkbbXpC13/UfEVTUuUspIR869mkovkB+r81Cw42By9IgpAwgoywrTo8THoMKpBCD5qUStQafRUBBa91ijIgGlHB9PGJdV6zLjHle8GgeRaImULTnxgAaByXPYgRmHjbPdj97n46YA5mHz9ooeL0OERA8x1ZEQVGKGQtC7VlBhaOUglQIWBMcc6UaC6WgQu6Spo8FeDqXDlGKFrAWZ8Kgs22rOdOWnOaKj2xFgQvU4Loede9fdOxnSgu50WjWnGuatslrDVSTHN2hsLyeRuJfBfLoqD+CWrEpKUMprtQ7nDs0JK85+OrlpMiQpO1MtfRPW60TUGsxnT7ZTZGivcnSmsxwU3ND0dWgBi8TIqwAW7QBdT49YF0TStZJzWkF8xF0vEEoCXldAAHysgDU7TUAQaz+jhkJUI+0eXezeY5gc5lFEAQKdFPMk25F3sMwoCwL1mVBQUDKwPHqGmld8O7Ne6h5p3T4D3//Jf74T3+g982lWfV1afyZ5gXtFYBOuHkfuCEyloWAUgzFTaOPj6cFgQXHo+J0qvOBu76F2DqUxASKew6rYl/g0dwaXFfJq6elYu5/qbJrlRU4Cf7+l7/CVTzgeMUYhhF/+5Of405ucf+7X4HmRxylID//HH/0w/8G1z/8c9DVrU1HQYixRt56A6yiUtqRkUFG+ympgRtjQKaMVtBp75YL5nXFOIxNoegO3z0aTdyLfLF5b0bR3lisBiK1v5803HrjjVEdK9JO2r77xsizddh9fgnB0mVMu+Jp/WNvOG1Uuv29q6b0gffrFRPpZ9FuYWtwNh/7+1+Qixdl2YV3gWwjYP7z5W9/h1evX4JDRAwBJa0G9qiK6nA84Pb2FkOMIBEsOWM6TQqoIIAgKKjEptDeUmlLsZVs89jS1DU65zDny7LgzavXHXx4P8XbcXsEpxo4xaM4rSqazVHHTPD0PjLeXRP/fH3NANWplvaZyVIyg4RtHlutp9V+2v1DZ5N8+Y+/wQ+ePatGIaNFUqoGaIq4y6hSClLRaALY2IkZiMU0cIZGcrT9ghoRrqjXXpJQh6UiD7YUwQAokiqMb2ZpNdBgF26V2KvLvCOvRmrGE6U5jWFivY8mOj2oMtvPvmeo+Hq7vtMZdSVjnR9QMnAYAoZ40J5lQVNAa0pst0cub4XtfhfTwZwOSTSW10eGRYA1FytFUGj+edb+a+5kYQ44HAZdD/aG14zI1BlkjYZ63eXSOJ9yyOx8RRePyqtqCqeuyrkm5nNQpwUEQ0m/MK596u6Th5z/cckBdXHM5C2LnDLONchie/o8hdKMuQsOSwDmsCjIklGy8iQFNSGjvYIDOYa3HiEqUCEJQIc2siKq7/t9jYA1wk6kdaSmI9byGQJe/fYGp4fhQ7P39THaXHhG6qbEXtaJQNA2nL/pmcK/N8ouHD24x1lEjjzast3kZwpAZ/17igNlTYnMy4J0mtRIIPVCCzMCItY1YSkn9QgQrEdJRBzHWrekBoRG21LOFmYllCGqIu88xJk5M2BtA7R/CcN1xMBAYPXT6f25Kr0ES6sQy+tVHRVMQMoKOxsCqoCRnBXpKCfMk0bvTqcJQwwYxgHDOCiUssCMvBbZhBnCFaDDhFA25udeMDFB4sKiKpD7lSb1nOplncFmZ1s1Ure97LXb5fWeRYBgBrBms0jLyXevkgn06pLaMASnWa8lZHgvP5B6pHpflKKSUhVYPFgRNEhTWOq5AhAbPHUlXoBKFbaVxxliJEdrsu4pLpZGQqwComT3fJeKNpqWgul0QhwVnSqMVxAxo03QQf0rLXuTbTLFQFN3FMCjzYtdY7Rb50nRAkCkArWEosW+ecHyuGqdmtFLIWWWn33jGxut273BhPY8ASp6pSsPxFxpDVBjPYZgESOPgamwIhKcloQBGSFGpckQDD5cB99EknS0VqnL2RXwhKfMo+s6L1q4XOmkCPKScLp/wP39HU4nxrKs+PIXv1RFsyiKVQIh3r9H+d1PkH/3DNPnP8Dbt2/x+PAen3/re7i9ftaKuo2fKOx3MboTzMuKIehefZwnTGnFJze3IA4oksEgXMcfQ+SE0/QAygWH4Qa5/DmIhouC9RI37iNqTxtiulwVgOpptq33cV5U/NczznBhbbbPdB7rc+SHo+bvTDz7n3dq4n5sevDmftv6uDPvs/HhM1nljgAC6sZ3g66mg7kxoeeRMHqe1FkWmzH2srE37N3ZdR5xFJR1wpsvf4x3b94gLwtIMmokThRQIQbC1TjgeDyCCVjXFW9evwHWFcTAuiZQEBwPBzAJ5nlRntjrjRtVT+fdXyOOBwxrsu19juTnyu7+8D3n593c3iIOA0ybaM2aIwOeAWMykXra6lKrdrYxap+1D+kcdrFQvYvNfE9VW0Xdo7YMAOyyCViWpC0XjD8G0zGU9jQlXyH4GSGoo5GgfDjBFO+q2FPVU9S4aGjPAFU+W6ARPAddcH3M6ZtFjUw2IC5vC1RE+p7L+hk6w4Sgwr+uke61noMyWxooaZSV4FF/Xwx9j+PxBodRatudAjJI/So8a6rq01Ho7RqSG5xQ51fKCqYjVS4w5mXFsswG5NJqwdjSbmNgxMBWRsOG9N0ba72xRWaU+zifGqt/9hTNXeBWnQw7v+f+PtvrK2lv+hl/YAQfshp/71EVW7jT1ZuH+7cfPKQ5Cs+cOHV4bb+KKHLn6XHGdJqQVm2XlFLCuiYFJYyEGAa8u7vCz37+HP/sT17jMD5WA2yZF6R9er7LYVtPsUUehoj376/w619qGYS3NiIAr18fcTr9/8Roc9EYei+DckRTPD3FETvefk4yv89gq/VslxitCdEzEnYPZ1/82j1vX8PQp3vo2dl6kWiqoSwrIIJVBGuMKEEVyWGICAdTnmPEYJt8GEIL3+oDzPkjVREUEVXKo0a8pIjm4MK4PQfnAttxErRpNXeF1OKlHlJ7UhVTGnIuyIUACsinGbNvEPMaxRgQD0eFmM9Fi4lhNWS2iIwW+bg6HnD/sKixEQg5m8dzq1ZXEVo9jtBEOIhVCzlog20QJqk6j+dl+8L2UVX1tJoRolYXXJ/QiSggr/Wrll9jIF5v4NHR5hUyQWrGoPaB03o0r7UKVnAcovYSydmBMNr7llJq3RYz9HcB4sAgazau06pGrBo9FpFyUI9SrCkZtXFBNGqXBdP9HSiMGMeI49UI72uyKTZkApXeiNPUXZ/XKKKZ7fbOQhZ9K4LoU1ekRl8ZwMoBLIwhHiAE3J8eddiidBgPEd/57rdx9/5R58Lml0W0B5xAo3gpAbk1a4eo04EtPQuAGUkwPcXuwwwHFXHnxLokzPOCm5ujotsRI1DVsQGoM8QZ7T7CtBEqhKqA5FJQkvMep5l2nhTdv6WoN/enP/kplnlBqyoFVggwPeDN65d4+euf4PGnf4Wf/fSXYCp49dnn+PZ//W/x+WffVmXNBOw0L5jXCcKE62HEsi6IV0pPx0PENf8lDvk9UICcMqZ5xnxIiIFwmh9BuWC8/gQP+CHYRcaZPrAVjvujulN6z0k3aZeu6yM/bba7e+3O700svfZMWACwiHdnnvWruFWfPYGuKdhnkbWdctJH7i4pFx4l426+Nin5PnbXW6RzIu0NMf+9Csazh23GK0CXV7wrD3CFseORxRBe59MDfvPzv8VpeoTryWxpekIMjsDx+oirm2udJym4f/sGyzTj+fPnEMl4d/caxBm3t7d1IzFZ8ahs14lIzChvPDAGxkrGbXcOs0vrAKgx5SUDKSVEZhwPR7Cl5xPU0MilgGRFzgVhHCzC1anFT6gTVeQTbShNyxk6gAMzTsjJbhMoEhCTGTy2Ls7TyI0GvXMqBfO8YF0zhiHg6uqqKrW+hkWUJwYo+2YDHCPpeo8WwNO8AIPlhzp0vU4qlYIgWl9jYgQMQSaY480faWngbHVONVonyGJ1w6yuPZEEJkNorDK0KdN9baI7dMeoCXilAPO6QErGtTkGVIS1+RmGUVMVSfdQrVCqpOHnXjBo0M7xKJpHXFNKmKcZp9MDpmmCFE01LUVQStJaToODH6KhPbL2EXb4+UtGmv+8ZN+0Ne2Vvi132l0BNcaeMvL8jMY71Tzu37z/TNDP00VwDCdvbGezN4yekguX0jfP7+96TW9kdqVBtvbKo1vbDtIb1vtu9PMnjof7E25uZ6xLNr4HzNOC6XHG3335BdL8mWak5YDTFPEf3lzjYTqhcMTNMWKeHzHPCaBQeaM6VVpatmfbDWNEWBnzHGrwph/fhQSCzfG1MdpciPXNdp3JNBn1hOFmxx4e/9LRf39JUXCDbO/RhI+lv8dOcD/1/H6oEZ1iYd+VnEFZU+PyPGOeJgWvCIw4RoRhwLpGhLBqmiQp6iOb0tpqBkQjc7Na9ot5EPMcFH1S9H+vqQncIoqOlkUm6LPV0HFgBDMQNVc7q9eIgSRAMLhdn8+cFEVHHmdwYByGoMaaMdKUHXYVQAggIQyHiLEQPv3kI0yp4HRSrxVQQFZ753MYmCuHCNQida70qnFiOfr7ZqSb1bjk4S4oKGDp0yebYh1C97cIhMkcsB1BiqP/mJHMjFKyGsQuvOHpkVzTX4lZwWxkRX1BMyYKMyBF2wO40cXAMAxgZuR1rU1dtYaCrUbXegfGUNOPNJLVDEYBIacVJQtYJiSJOOW1Gay2B3yuinkOmAiUMrIUCDOGXLR+zQ8H+WCgBLYItq2VzZmnPzEJKEREhhYRu2ApogZVHBS9CZruE0RbCTj9g4BxiMawBYELiAKCoaEBAKcF8QI3VK+sRaItYi1QZa7kgmnNGIYIHrWGUwCMQli1SWCn6rvytKM3Adg8+8uyWm++DGLtsQNChwztKHvK59Z1rnOhBrZGAVLOePXVV3j3/gFLSoh5QimCl9M93v32f8LrP/qX+OyH/wM++uQzAIK3795jmk54fhNA+e8Qp5/j2fU3MIYRc5nxPj/i7n4CScHNsxd4/+4f8Ks3r/Di+XMUYXzyyceY1wlD/l+Rxn9ba0V7pVp1/Q8ZXudTA5uuJw22zhO6scjapa2GzM7rlZLt4zx20Oaz3WV3YwAtOcvHsL3mLFol/X17A6RX1KR+61E4V0r8qOiUVpdUz9s9zwdFFyf1/KjP7pyLAgEYoEK6fiy1MLV0z1umB5R1BZUMDkH7aoqYwkGInuQh2htpWlYsxLi5vdaeqGKRD6utcuV1zQXHOsBS23CINHAbL+wHVDcIUCVav7s8x3XumZFzwem0oGSpjgqIApFVJboUSCHkVSNYGklBfcbeTvaf+8/8YM9uqBcbK+3OcXAiXwsyA03EHGECeH2VAlAR8rwizSuG4wE3N1cQSSjZVXFWQKyenqthhZqyHwlYSJucA1tl3JXdXARsa8DmfCOooc65OYv95WuPXLJdZnsyiPU7gyAZYUkpiNTqhQBgCBEcvIceqh9CRKO4p9OEtMwACW6OVxUR+9KhyMNGE51zRod62WhC56gQlOr8TkUwzQum04x1XczfQaAAzVLJBRwjDoM62GPU0pjBZFNfk7Yfb09H/c/9OH1UnSl04TP9+zxKjupw6h/stHh+dqMe2n0Ocmdox6uo+04a9/fr9+9x2Xjam3y750rLaNs7uPRnOdv/l/jBh0uoBOu81gCD4ytAVA+Y5ojHhyscIts+AJZlxP19QmZFIV0nxuk0Iw5R36iYY94MuJRzdSgM44ADZINMui/R+tDxtTDaBMAMINQNVKCZs7xTHKnjdrRtEwZsCOo/eSx7o+sSQZiX0oWpiGhh9RO5sgAM3YnAhwHj4YCcM2SakdekBb9OXEBVwJES8rwgAShR07pCDMAwgIeIIUTEIXYogp77rWkTJBmOoxLIGbQqp/us8Gp7wMEUrLYtJeSulsWBD3IWcDavgJCplKbIdp4qEUIqjjRENdVPsqIuUgwYY8AjZTAKhsA4vLg1JikIkk3Z0OvFR2uDZ9tF5HTitOJw73UZt+oNW31adiQTT0eAeiW1l42/j93D/tGaOc3zV/VOuWDgNqPehLHmVpN6g/TEYKexoXZqn5xLaXXF9kSwWq76HjwgBCuuzoxk0WOpiFIMsbSSGANK1pQmN+Q8MqppiuZ1t0iUo+25Ip6h8P0sUiPImbmmSUIaPPZepIinaJYCbXausNE6N7Z/rMAXYMTQ1omsqLikZDmsjNtnz3Hz6SfA+/dYFjVwiRlrsf5/piCCyNJdLb1C+ihIJ8hdPSdShp1dQdHvp0VTJK7pqN7kwFjrTmtCGZVGt4enXuRcFObcJWYpoBDNCWSKV9Fm6yULiI3fdSzNo8oigmlZwektQghYRRXF6QGYJ0L6yV/jzf09vvuDP8d4dQu6eoGr4dd4Rj9BmgXLuuDu7h1ub58jrTNCLnicZ0QGlmVCWjNIGBxGMEdVfB9OGI+EML5Clk/boDrjjUCbFgWVEOpkAAWa3oS6p6ilRl44Srf5nPWTzXkFZ6i3J1tRN7ZqSbo+s1Mr+jqwnZnVD3f3ClSf0qtFmxfcXG9j2MmlvXLz++/UXdelCZ3VbDxhSF66lz6PtuhBm84bmsExLzP+4f/5d3j36iuE4y3G7pn6fgFhCDgcjpX9DsOA4/EaLNrImAN3mRUwOtHsiGacs8n9ltpb64ZcsRV1Gv79l38PVxW2Nmzj1aZxIa0rJGccr64024p0D3sKHcHAMKJGrh4fHk12bVECL0UwNoo2UJGoNYblb9rdxXi3RgA7Rc2noBKGOVbdmCAyMCgCWQQ9ras6+aieAggQIJrdUHlUmz+PFNc68Mq3lRdnOMSHOR4NvMjKb9WRtRloM0zYjHKKtkNEIKRp2ZEZRazO2vYhszldecTxeIUYgJJXlLQiF3XcLvOMXBKYdW3GyIjmqGxz30scV3pVmQe5w9V+2rz0k+2OnpIzUspWj5awzBNSKSjZZWUAB81E8IRLDgFXxxFXx4MiMFcnPupY/Bn+d//7Hv3x8rE3ap7ilReMn42nwInANb8+3d/GjXO3W13pDQ/Te2jZB9C35SFCrf/c871LNahPv4/fr5UM9QZc/32f8n4OJHM5yraVUdt97mONY8Qw6B4jQxWvHvPuXPVTCEJkhMHKL8xeoUAoKevzWOvHB3PC92Ppf/6+42thtBURzFmVbGXuCnhQBW9vUfhBlnrVHWebo3eH/ROPzT3QjLnNZ2fezwsbxz7yJs5xGDBe3wAgpGXG47s7wEAESslIy4qQsmLyiNZaERroSVpWlGFVkFUi8GHEs49uQTxUBhCYEYeIEZZO5zNJ1FL5bHgRqFDy/k6B2Rr7Ato7pb2IojYq12eDEuQaUG9eLiJRwwGaJiHFPXKWNmJRkpILHu5PWKaCackYDrHWSa3FcBM75UMAdNkZBl7Y4MxFxNJVGgNiIvRpSzAByExIZrT1LQTq387kuUtjq+st1Qgmmw8HVuk3Idkmr30n0VISpDOemge60ZCmS+nvhRkjs3pIc0ZgRWtjZhRKWwMVaqyVJJpWG6Mqp2nVZxBrdIvUOA1W/Fih0bup8oiDiNQ5lG5f+T5xA86VsP2uq8IUgkSC0VCcmFnpo1cgmCBZaYsM3IfIlDwIDscjIIL51RsIlIa4J5CeXmwgKVtdF/OmT5MIoQgDUIREH2cVBh4VWBJyzri6Phg8r9Nfoxl9z45vGTP3foQAagNX4YDb51cbg0UEOB4OdQ3VGNa2DZV+ew1fBIEzhsNQlUBKCad7IP3q5/jJV79GOD7H9/7Vv8b3/vjvkTPh7uEBgYHTuuKQVkzThPd37/Gbl7/FMUZcPTzg4f4BEEFOJ4zHW5SckEDgtOCW/hIT/nOs+QvlJz6XAhSDtPtQqiOBL35+iU9vvKQZcC9xcxC4grY3JHwX7c0hQqWyXuKi0UqL7PQ/sfmsg+mAbLz525J4rfnS7xX5TiB5K5w/pI55umS7325edp/3111Svqj7bvv2m4srLRUB3n75Y/zyxz+FrILDkCE1TVx5QwEhhoCrmxuNIueC0+Mj3r97i8+/+ByOpQEiK1HpleumNrZ01p4eOsXaLJNcPHWfKiCC30/cQQOt+4psTszAKldKxvRwj2X5CFfXXd1IVfigtWO5HyecMPYzdXY0I6zAsRe7R7RXq+/XDBxXmwEo0nERrUE1Hi1ozjYvQWAOWoIgAKPA8T6LeGmDqeekNW06N3pOMOVaSGVo9PUQQQAhS4GnnEm3hnAjo7N/vN6WAyO5zHLl17KjFDgNRgP2ZWDcXh1BnHGa1GAbo5XD5BUxBhyHUUEbmNUR7eymKuO9k3i/Ij2Vu9Gie9bHvKaMaVqwLAuWJaGUBE+yIg4I0WvMDJxCBEGCAmoNEcfjiNHryPfOkp6GLhx9uuTlg3zisfFe2Pu0zK5u3/Rvvnlwt+901rpZke11uztpVFQAh+in0JyPekbFdOvXYSMHan3a0zr77zvUiYuz8/33fVbC/hn7zzaGG9xB2PoIN9my651mekFg0myzGPDs9gYCMR2iGY5EhJwXpFSAkkGw7LDUovn/lDkAviZGmxOnQGXzl19+iT/64z82RsWbULqfLjBAAgB7+/1DisDFp+8WD0DdEE4ET1rm3KXgXXqefaQQ6WR+K0bgCBwY4zONJByvrwEihYadJ6AITqcZyFlTObLWGDERkIpGZkRQphllPSIcVAgV0Tq2nLOhxgmYvN+aDsfR5vdDrszPdnMwIeYRGpPUzrsBWHSpeMG9ErvYu9bUtCECIC1kRjNcUilYUsE0LShC+Oo3v7W+JVrjRcyI41B7cgW0iA42hqZOdBZBhKaAojgy1TbCJrYWvi7sMPZW6B1M+aRuayjbFIO917t4MXGdN6cjQNN8TAg2SGH36Ms2QkxUvb5PUisZ/YgZwHDhzYp8SG1tdXT6XWAF1QiG5pazGmz7m4eo4y2rNuPOm7spNz4bn9gcWpV5LFrvwKVbI79Dv042b6H3Sop70NgM/a2qSmxRdyUwnOYFyzxXOuTAXe2d1LlnW5vSrffGKCUHmDFhVr3v9p85QByAZ10zxlTwkBaMMW4E3wc9pg4+Yo3sOTBSCRiG0Zp1tuNwPFQFTqDRtxohpyaeCWTtNQTLqgpqcGeFCJZZ05Tp9Aa/+g//J/Ljc3z+RxrxTKngzevX4JLweD8j5Ql5nvD2viCtBWldcDge8f7hEc8Q8XZd8Y1PP8P19TVIHiD5Nzgtz3F1PKrB/IEk/A+npfTLfJmHbh1xzWzS/yx1vlOO9kZOo4qmMbsh4fMJvw8MTMH7WmwMN591qeveK1EeeTX1ofvOoys4S6V+ynDysRDtd2H7ff9Zm6NLSarnz6nz0hlHfle/QykF+dWvEIcBU1ossqMRgiUVpCwgShiuDxBD1ZvmE968eqlRBA6gXKxmmGufRyKNdmXLDqjvKv2MFLfm6pyUIuYYkNbk2Y7S3fv0OEEgiPEASQnEQeG2ATxOE5Z1xRUMpCRvZfu+9UBVfi/s7Trf7vCrYynmzKAKbiP1Z0NyZSKLnqMaQUTak7SIIBrPC7Rd8xCCInhaOrejU+9r65wP1t+tECyXxntpRyxap1UQmJGpuUdEsKn7hRTkdcFSBMjq0DL3RCVMkqYXmBQx+0NlRAgBy7pY+mPCMI4Y4kFRtW+u6o7TF2JzqPQOt2a4EdXV6ia0M0tsXUWAJWnN8nyarMm18mCXw15OUFNldQYQY8DhcEAMA5a0ok3tljYuRdj23334aGv2tMNAqsFGlk77oUyvp7nNU+e6Max8VpGgrSZcttGsAm6I1jBdifjs/Z+Kev0hx1NX+Ri5M+gunoMtSJR/bgNU2yMrFoSC5QlKKjVY43jhxRwyIWhWkDopSHUsPgerEgGCRBROlfY5C/LZmX/4/HxNjLbOWi6Cx9NUlTsA2syuaOAegAreIliK4GTABsrMGNE0QyfgP2QSnjLY3OtoN2rE19W0XQy9BlZocjvHHlI9UE3FJoRhMGheTY8jOiKTEk0SwvFqREkJy2lCiIx1zlZ3o9DrSmyiefQ2N35/ghci25glAtDaKDKBobNKEAoI5NFEnc8sWkMQiUGGJJFUetbIkQhq/4WgXLsAACAASURBVJw2oQZXb4I4qNsKlnmvDFGsALwq2dF6h82YT1NdO2LdEAxtKC/uK+SAYsnHwZAdHQ9Qe+cxSiRgGMFp7fr8NWNDBMgS1EhLpSpxFdGvex8gVENJcmNoDvyhKGVNqexVts6cwF7VYkM4JLYCbQZYCIkY0Ws4s9ZwjUSIHJBBVgNnDgMmiwx2YopaSggHRiluDBltGMANAMQ4AKyNnrMAlHPtw+ag9TmX6hkciiAHrz/p3ooIxVMtpb2pkCNZ6ghU+bK0UFqQS0bOC2JhBempc9d+MvmcBozDEWU+uZ7TKdjY7MksZnqL4PHxHvfvjwp7XVRZ1PQUjR4TdQ/sHm7ia2OAz0tBIPWaWctZFOng8LsUbgAdGh3MUPSalfbAdVU0uBBaFC8ASAyQkDbDDQ31spSsvbJyAXJBYcYwBAVygmpjpQBSEu7fvMOP/+oRb14FfOc/O+L+/h4vXrzA+3dqjD5OC9ZpRhhGzI93yDkjkOBwdY2UE24OA9b5hHfv3uL29gbr+tcgjMj4UwTEDbLXB400VwKCgCVURarnkWI/+2WQs/vK7uf5N9vFNH5rBlvN6t2My67qLrv02aXDTbX2GhcuyO08P7x/3qXDU+P6aNRW7TKV1g0Oke67C/fb1ff4yNv3nRImGo24n0/46rcvcX+aEarSLEjrgmWZwBwh6wrCDUrJWOYVb9++w+k0q9ONutSm+lbm/Crb9RS7fykCqTu7GLojME0T1mXV/m+7BdGEW68V1TqSOBxwdYiYSqqOBXVGZnApCEF7ZQEAZa01Xde1yj4W0Zpl44DcKVQbunHnULcOvr8FGrIRJzrjCUTqaNJG2FINHL23QfAPUXs67taH2WRiCIrUODfgBWZAksn9qmd0s1xUT0hQ3kheAy6CdVVHWMoN5zjAAFWC1sspq1Gj7vFxwrrMCBzw0UfPAClY89ZoyGDlwZ1joBSt75nnGWmekQowjhFXh9jqgaD95DRSvafojVl64Tv/6SnQSsspZSxrwnw64bSsWJcGRhdjNE6ubRHysla2FJhxOA44Hq8wHgbEOGga5V0DuNor233ao+sJxeDj/zCjxd5DunclQp/aWGWeuEH6ofs1zvEhniZiYHPCSGlBLgXjMEIgWKYZMgriMGrtOdr7ewdQ592lWBYWehknm/nw393ht5f5eivTDTsjEiAFP2pPrOd+SPZ8aNbFnLq5mC4dGGN8xDe++RcocEAvnXcCIJINWI7BQjVN2d/DI9b21lUXK7b/maB69IXF6GXpU8fXxmjzg5z5FGXggZ4myAztkZXcgkhZDQRD0SMAo8lEAgy16MOeBiJqICR2TX/UJt68RbHanLPpBN4JwyLVmp+XCYEjIgckzhDirrbHxhoGjEPEQgERjKurI1BWUDxASsF8OuHh7gGyZ852jyJUOwHsoVo9iphNORfRKKfnzvsdfUv1kKUwhb8kG6srY90wOgefpZBliNWKxWEAS4YsiqYjAEpGbXBduPWWkiLIawIFBosy9Gb4tjlWkBr1AIkxpwMFfPHxLR6uR+0XNC/2bp6IBzVUVce1WkADZRHdcEKMsvPueZ1UnUtL/wRa8pdHbLR+0LztolE2S8aDsxIKpigA8DyD4Cb15jXN8LHebr4+LB1SVv1H1zzYWtWUFjvL08BIREFtiFDY6IWg8PnF0gOLbFI5sjeJNyTExISV0JDgdkpxhvVs696jJ5acVrx8+RrDeEBgqhD3zvz8VAFpPSAxhGNHZAACY8lZlSRShTFQ0XReSUjzjF//4meQeKzXuUcZRvN1PWyqWgoIbaI4kTzl1iI0FDaOmF6oqtcR1aBHsRo+o4lcVKHIKYGH46aNQzZ6UAVeFFGz7iv9JcZQ+8ssqyCyIpjp0z1TgCHzgq9+Rri7e4/rF4/I0wmffec7WNcFb16+RMkZ4zBgXjMCA+PhiDgOIGEEKrh7/xb3D494f3ePMQgS/y84FMF49c9xiMPvh7xyeiBS4ItKozsBJS162cRy/0lb8kpCZzKOumtg69AMtrZ324X6WUuz2rpa2rPd8bFV37fOu2bAls011cjqxrmXIL5/ewOvN9bq753i048E3fcfnhN/36bgahTNgXgKyv0bLI93kHUBotbhnqYFDw8nBIE5PwRDDFiWjHfv7jCfZo2CbQxCl7+mqEGjFhXNtY1Gx9cp+SLaS9CNi+072i8lY04ZKSXcPrvGn3zCGMeA7z6f8DAX/O7hiOFQ8PlNxg8/e8BPTvfA8QqBFpRC+CL+ElfyGr863GASxrtkymuBOnXgw+oVMZtJacBegMowgQJ98D7nwJQ3Jm29knNRo8gcfiFs11dLaPSTvKMvdSwGFK9dJzXClNc4Oil16dvq3S8AIkQbZYOQc8bDwwNOpxmSM4bAoBCQUcBFN0vOGYNHMkz2RUsNq3WkRVMsU6eHEsxxVHUAM/geHpBFcHUccBtil7LeHIGbkhNLpa/lCugMAkv9bAZUqXrWuq5YUsayrFofZ85WGDaAG4U5F+SkQCNkqafjEHE8RAzjAXEYEeKgafrMIFp0DW0tzyNtODueNti2fO3yd91c+FGjar5fnrh3ZZQ+d+6YNz7WOdtENz5KWZFXjRZnCxCUQmDOCLHpgeqL7CvhnrYIe37Vl49so129i9tfs1SgG71PzzO6fbi/n558zsV7h2DV8QlEBYfxHjkTQlzxrW/+HyCstdGLYhQ4Dw/opYfA0o5rhN3mwBifZ4m4gV27/Pq6UBv770+Z/RoabYC+iwg6A2vLsIS6BBRjYL4YnnDhP1MFmACoZAVUoEbCtc6rPts1xCY0ziJs9n1FmrQB7w28s4O64k8pyCUhxEGJMiusrOQVgRh8dQVwAHFECGKMGFgRMbDms49XwDzNBjLhjMyND/Xaa38TVgHbMxh7lRCoRUD6V1cNE7lYJIss1cMM2t6DAA61mSigCIXFvD8FCo+uhcqwqF/e9KARYpB5ooUJQQoiFJVSDcpiiqk+whklk9Y4ZNg727ZnMtRLJlCMuOaA43hAzivmZdX5SqUqVQQFJqkw+ag7DM6W2hrqx55xx3BUSKpgMzaL+h1r3QeshoyMifppLTqoHpsQA0oCStJ0UGKCeNi9Gi92rT+up7uOIbodQjauXiFQQ0XnmGtNnZuTur6eytOENVVAARGDfwbpORb13aZ+ohbZ96kJW2Vc/81rwnSaMI4HBKM7Oqhhdprn6qlclxklJ5CbgM7/UkaQAqGAaHMNCpW1lrzg8WFCCLOO17eBaPTX16TITuFlhtAuat+tsc+nt87wT7Wm0yaku58KR03qJku3GQdzBDAbmM1WTHt6SskFwWilRqGHCCTd/7pORRtnVwXHBZkK5YevIso6YownvH31GgjRUqJ0TWNUVVMs43QYIg6HK9y/f8S6nDBNJ6RlRhbC8fp/xu23/kd88cm/PkPUbeTYlIJuEqpXdjMvdcTYXaOzsBfA/rsn68jFM7u55L1q4woD4FKAqXsm+TlbRWILavL0QdVR1lfB9d+3td6pPfXzi6n7/jIffHbLNunuVr/zWmBPoS8WfU6WDiYlg99/CSozlHY0XWyeTvZeBeM4YFkT1pTxcP+AdZpwdRwAk8cKdZ01qjVEbdFBnmonOBxi44mboxlv/n1x/rI/UzT1fwwLfvBFwUefEP6r754AZOR1tfYqE0IkpLXgYU74Qn6EuPxMHY9FASjucsa/+fY93k4j/vLLF/hq2dLKdglks2a6HB2dOy+ogRFfe71iWTPWZUUWwWEcVFLUSJwphgZWIARFEt3IIAdTURoVtEfWtYe7kUrdFwytk2dRXcJdCvO0qGOUYJFD3VU+/GD8JwTSDIkYMI4D1pRRQJjXbKi2Rfllp78RWcsgaXNzczUCZGBpFdTB6VNMnPXywmnE6df1rgJIS7FNKWFZVyzzimlesSwrxJzF6sRTWSoimlpelK6ZGeM4IMaIwxgxjoNC9zMbAEkAOKqeQzAEZaeLFgHaO9T2v2+PrQzp17YRmxtHPe9wJWBPgWc7Y/dxz2v7x+jnnl4MwLKbVACQZOSskdmUC2JOyGL9+EQDA43nurTa6s1AAyF5sqYN+/0mm+va2Lgb9/ad987gtuOotkzpZUc/ISFM+OKL/wvLesD11e8QmJBFM39Un/W8NLuPaFZSKTZ2Uef3drCqW1eE405vcNvFny82N4qw/WHD7WtitDVP32bhsCE1VcgZtW/Y3pjr/tArzFtVGQaABNkAWTDpJDjRRNptun6Y1AQJgE3Ptqo0ffA1W95vCKF6Xd0AESlYp0Vhkq8Jw6ACkFgQO/CEmmZp8+V56GINKpkZ4zDqpuuV5SIobMaR79xuzisNdZLAa48YGi0pRZ2uqt5rzWGFBbYFo67xOTNVRCpVbgkQqn3WNtuOujSUbjMLPKzeMwdP7WwMX0Q9xPOakN+8xzivOBwPGMexesmEAuaT9fzy6CFE00U6dc+N0BZFNIHhBlfpfEz+HbCJyvmcCkoNjUcrxN4zKa3zMIU8MMKg54YQzPsllhrD8FID1wdcSNO+QAG61sQBRHnDpAHrGVeNNjIjyxmfnVeRBFD73/ldztVQ1D0SxKKV6kU414CqoLO1DAHBInXJ6DjEAXEYkFftoRQjQCgoaYFHSwu1mSRTp0MgDIza3sKPIUgFBQkcqmer1B5GXWmcHSzqFHAFGt3P/p2k2ydMWpfSHl3NYL8TjmNAjAOuj1dN+coKhhLiOVuu/V4IqrAbPTk/ikHrMEJs7nqnbfUL6joKBI+vD5DMeLx7xO0XCrU9rwX3j4+IISDlgpubGxwOR6AkTGvCadJoy930iEOIeHFzi2fPbnAz/Byl/Bk8Fa5qBOjGIOd0eclgA3rqPP+r7Zq2Aba7drsszkH6hLunz5Pd38Znu3v0xldVri8oZXsZ5imQPcx/f5e9IrFROy7NHTYnuBW3+3hf37Kdbx2P8sB5esCrV6/x7u4dUtJ70ukl8qufYZpXTYcnIOWs+zHNOBxGKOR/wP39A9I8YTxEEDGyACCF208lQ5gwXB1RRGuY07xoZok5G8VkTaOBPsHfvdxlQ1ffuJ3x/Y8ekYUwBEagBd9+vuL6JqNk7aHlKZi5FFBmLNOM+/tHlCIYQsDNYQBIgYzWVdONn4/AF89W/Pb98GF9+oNLUjZOHFVA9I9lmjEvCRwCxuNopQPb6z3jw9Fj+3qs/cGkZQOaxdEGKFXnaQ4eJuVPNTJIwOEwgqCoiCCVLxnaV9Mjo374upr6oSmeydLmhWrKp79QqfyyfqQGGcX2QU27vTy/54bQdqfkXLCmjGWetb/ktFrZBSl9sraCkVKwVlRkAXPAYYyI46CGWozaTiZw5WVkRiURWUYQdTIAtezysuPhDzn2C+oTdb7QzSl/qa3U5Wu2n1N1flc9jNDKXJwLmtwmA/FRkMCkkdQYrF5za5woynuuz7poGO3epdahbdb1ghEGNNnin0kbL7qryJ2T8AIVqsTXtM3z0YkAKY149+6fIxfBOMwI4529UzPUAKXpYP0rU1a90evcdKxbGt7QjAOsgeot9/Mk8vszVr4eRpuYQmjT7+AAukA1qxsCQ8O3PBc3Xp9ipM1D4QtlREVNHBe0qJwq6RVbwSBDBGPvWbHzAGzCtsRcowHAljAvvC5iPIC4ICcVKjwOuHr+HGEYkecZEEEMBKYAoVTDKo58dDpNkHmCLAtyjBARpOxQwQQaBpQlacQpMlIS68vVBHrJWjNAZli5J66UhhDpMiWJkW/0+rW2GUpO+kxuUTudD6kgHwCsv4oyw8wFSG70KNSzXmdznXUhKEsVbJlgKWlqOCUT9C6IMhROPqeEZU14eHgEQIjjgPEwYDweFCafXBkwA5MMsVBQDWGPRvlmd/S/ymRMODFXnAlTiqkp+Lvi2CItHbURaSNeZsI4RgzmWAjW2HmZA3LJatSFiJyBIRLYjLxxYOA4QOa19Uuxefb37BkYquAhkOQqnAC0aKFsFVIRMxyg6TVZAHHErC5iwKYQVE+ueZC3Ueqi+bBW10TQGg24M6G4kWxK1zIbaIHe+/39HdI8aWsG6edPU3ukZI3UEcAxoBRgiEAoOsosqoAKsbVa2Do3+nWunxLqePpzyN/PjKde9b/oSIIZAyXj9ctXnYKgStX19Q1evPgERMD3v/99/OKnP4Mn9KpRpPu2ja1xfiLjSc7f2JQ5ZqAfF4DpIWI5CR7eFtx+c8Zw0DGlJYGJ8OrVa7x+fYcQBPFwQADj84+fIcSA+/sJ7x8e8eLFCzy/JhT6G5zKv7RUU/q9KehV4BJUecC5yJb66WYVfCa6sxtvv6woPDWWdg/anNfHxKg7u+0ZAGfeUEI/ku3I3Vjrz90+8WxIT6phZ8/r9+iHz4Tun6acQYB1XfDq1z/Gl3/zF7h7uEfKmupL6RGQFYPVd1fAvxC0V2hoqehpWvDRpx8j54TH+xNyyhgOBzw+3OH+7g4hRIyDwmevD/dY5kWjuTAZ1BkRyg/M2WK05Gzrv/3+Hb7xMQEkGClhDBnDOKoDBkess2ZeUAFg6f+1Lh6k0a1cMDLh27dHzQIhwh3rfporr8QlO/jDBttO1nsLGgIMqMQUYpPRx+NBHbdSWpElGZ25M9bvAzOQcvc8oooMrSxAao1641VqnADKcpNNemCuPTVD0B5jrkB7fV5F8Db9igEEC1XzEPX/JdkopaIxEmlqtoIy61swMRLcQb2rF7/gTNjPuU5lZ1SUoq1YlgXzNGFeUjU6tS2LqrUpJeSal67rczxGHIYR42G0VNCIwFTTM13f2WRNEUPAm/UV01khrX7t/NjuYuIAj9JsdqvxdRMkZxMg/edmWMuGGLbz19eR+b/iqchGh1I1lXbkpFHZJRXMy6oZUSVjXjR1/ngY4DK6iNWVEc7u1BtZ/dj2+nApqn8ytbq1Om+2Dnua6P+WznhTDhsQWevlBZrWm1YF5DvEgFg3h+pmPey+SMDDw3exrMDDwxeIccY4vkfOP8HL393g5toyMVwjlMZDC1AxBSC9g7zNt79vP0fWBlj3pBDyXmd44vh6GG3YhmelW7sinudqcZVu0VxJgTF6nSAXuVtvRFVc8dQGczaHLTw8gMWKvhhADIxoG4xybuiRtIsSdlG4/h3VGaDKTeagBZ+WkjIwIxxHnCwFUaHFixluxRhFM7jWadaUqYEwDCMQBoTR6vpAiEFRGLmmizWFqgKUmHARi+bUwxqMrt4LppQaSdM5cqLtim1BNUJVshJ31CI5sIgZWQVJAAKDgmAwQ0AbvIrBJQMS9BpXFrJsGRFgCmouhgau7xwspUHvq/VwaZmxzjPu3t6Zos2domAeNRu3FO0RyMy4vhohHIBiEZgizchiroA1YtdeVFatiFVrm2zu0TkNiuDAC771fMZ/+Y2X2svLipcCEWIcMS8rrq6PGCKjQHuTlayGDwXgr39zjZ//7oAlB5zuHnHSAjN40T9ZbVu1N+1fJgazpT0Sb1gvs6dQQR0kvhZkwh+wlEhll1wKcgzVobISYRBgVeLZyCJVpoCaPkYtDaKkbE4UqYxxzZ4FbgMogKzZCuS30bRxiOCiSI+UNEYmB4fBVgGbSQBYLZgUEEVdFbamAmJMVVCdCIQLfMMFN0zuukLsX5uQ2hdJZ0Oj1JNabQITMLC2/uAQMI6j8UA7gwxwwWrCQrCqmdIEVy6aukImoYUVfXcDE2dKmWRCPgUsv4hgNi+qCWGBIA7As++8xzBMiGPAeHXE/fu3oFJQiPHq7WvcvngOpr/CKhPk6s/APFhj9+a8aLWBaOHxfqK6XzdGz2a+qRr4Tx87Jan7tzMVd3d46n477y6267/Pxtgbar0Bh/77gD6jq37nFxKwbbz8xLG//2WVUd9hHz1elhnzMkOkYLl7i9/+zf+Od69eKlqaedrhCkQgrDkjiCjSaThgGAes8wKBoKyroUMq/RAzwFoj9HCfja8IDldXNVukAOCiCMee2i0w77+9EZOPgxBJ8MNvvceffLHi+vYaLEApwdIvBcuyoIj2ZDuwAlJVYBCoQTPdP2CZV0CA58cRAuAmBkTWSB3njOS13BtB3pTlszXYzasqZS1K6FeoXDSZHgiUVWcYhoiSUj3fZWsjJLOYVHtFqQ4Oqnd3vS+LptOrgu6MW+uFc1oxLwtSygYKYvzdZKZHkrzelgkQQ9ZkptoWAAMhiANmaXomhwDF8kw2Jxla82OrWgIyVB+gy9PoLwtAEAshb4IbGo1dlwXLmjDNK+ZlRk4JVlJt/WtVlc05I6+TzjmrPjCOA64O0VIgtbREW6+0dF0tsUENBLR1s7HtDJFiJR5PW/J7buC62/58f1HCdkfvv/f53BtrJoGl1eOeGzpuNGmAQMeiuozWYBpCOxPKuuD9m/d4PM12rWIFxI/U4a1Grel8AAIKgLIdtTssaOtUvcQ/q95FTbcno/d2O6u3rQ4nf2+Gp2Jr0CJhygXLsiCntYJ1MUfw82cIA5k+JhuDjZhwdT3i5mqEyIKUAtZyi5Se4fH0ApEfDCiwdtpVhzkJhqhAfQyL7FPeLKEHBfydt/PRlrjYvP4hx9fGaPNjv6mZpVlTfoJtllwExXauWDi31S14XY5NXBWET2+yNomdsJaWHlWgKHqLfc9ALf4lRm08Sjrwdg8bn8CMU7uvFCBLg+bP0n0nWqytEQ8gxoiUk3rAYsD1zRUWEjzcP1YLfhwGjMMAAWm6BwkON9eIgbDMWZXnYullRYENSucNLCRapGsekGyeBBKFbW6xUNg4lZkHatE6MENSBnkfMAFyStVjVkgBRYCsQoJaLSAxG0w/qicW3Bv0O23GN0Bxg8IjEIJ4GDGMg6aO5oKUEtKaUHLGmlKtA6zRCyjjLtQav0Yi8DhqbnxJHXyJ/ptyQSDDs5TOm+6REzQnqtfbuUtBAKBkfHG14L/75mscBoIsAYchIhY1WnPJmO7vseaMZZoUFdMipzEENYiF8GdfPOKH3zhhTQVfvVzwv/3sFndpqAYIerpES+FrGd+9nkCVKTbLUlQRr5FlZUSeIisCZEdngwl4Eax2m+2Wo7rW7hn156o3uXRj1CtOp3scDzcb5blwUJCi3cFFMCBgHCMWma3gXp8bRFMMuQgkEBIiBpCGSoMJ7R3jLNTQHJ0/eBRR931Tn/T7qoKhbxRc375azp26bbJaxR+qkVMdEc7yCICw9T7S9YnEyIwKLBRjRIiE6hqwa9X94w4wVNoUq3+rhqq9AnNAWgre/uIFrl6seP7NBev0AOrQrab7R/zoR/8vnj/7GB+/eG+gSh9hyp9rZCUOCO7pd1rLbb33VLEnlb0K04TeJR7ezm41zu3cbYLk9vo/xLvpZtLeQJMLf29Nzd3T8lOjAHZ+xhol6p0SfXr4hhX6z6fO9eyKUvAwLfjtr/4O92++wvLVTxQ5lBRFtz8354KHxxlSMsabI8ZxwGEYME8TYMYRMxAPR0yPj1AQCO0xVoi0GXKMIEh1HBIHBM7wgq9Ohdm8i+8gAfDNZyv+2cf3mE6AlPv2nqaIOkhJKQWHQR0w9X5mwCynGVkEz48DUARHZhxjwPdePAMA/MeXb3CfChaTF/2xMY67xd1vZeebRbytjvIbBFb1n5Q2KUgFtnDIfjbDAOaY0IgXmq9FRPtClW6ehBxqyKJjXa2dKerrPGOaZk0JHaIas1ZKAY+ukdU/M9U0bDZQjlrzC9VzObhhwwjDiJuD0SgsHZ36ubconBnRrUUObfSD/kgsCAVYRBXuZVkxTQvWZcFaijmD1RjzipHs75MzEAKGw4hhCDiMB/3d69vNEe6OWsBrJp0n+X7RZ2gESHnoPmOKydI/nySIdi/9qkMXvsgB9pwD23Osz5nefjtpnnlUH21Dcb3Jo2qaDaXAaIVUx8yFFRdgTVjWBdPDCafHBXGMiCGCpGBaVttS3hLHx2MozPDEdZVlT73J2ZvJdvfXbBXpyxSM50vRVMTiUV1Fi01ZAYiKAfzlnGvAwOVFCLlWdhIuyR7Cs2c3uL291vpM20ccAsbDAVIWeHW8A5NI8VH3b3B+9J+K6ZUts6+dsK8B/NDxtTPaNvQoW8Kvh2lz4zDg6uoa9/d3GqkBTAfytC1TUFjzpjW/1AoZSWq9juItnD9rUzzYhSlcYdP0fxUeXPRvBaXQ2w+uMLGiSSlhKppdKVGVLg4oWJWR5ox5msBJc955DMiiodYQAqg4FGRAGAkHusE0zVjnBaf7e2UsIYJDwGApD4c4gG5HXN+qkic5I6UVKSeI5fGntKIkM0rEhavRkyl2ZHNQsinT1BRAN1JINNpUuveua9h7UYC6K7UeL1uqGzdBZXNP0LRKVQQMEl5kkxrHHUM2PVejKN5jJTBGHjCO2oTY+6/ktCp8bypW6C6oDSRKwWlOOJDODURLuqW04ngnOGcErpgWcxaIz43PnTQjzifjv/j2I1BWfP7sE3z39gqffPJxFRB3a8KPfvsSr16/wXKarZHnYFFS96IL0pogIpjWgo+uEv77P53xuxNjVYsaP3tz0FeycXt01Ui1zbXn76MT/vaLCKoC5MpFZT5OKGSomJ0BS7ILrBgpFPF9ahE+sgf5+NDqPe/uH3B7+6JOW2tELiY425QKQ1sylGZik5lDSawusPCeozTapDodcIARX192IdgpG0193gnSblB9lFU6mpF2cv1J3b2ozoJ9Lf6Z3qGAkAzdh0NQ+H+01FJnc+KCwl2x9q0uqRgrdKGh92XLChAQ5vcj7okAfoA36RUA87yAY0TOBfN6wqfp34P4iJf338SL2xt88ulnWOlPIRjAHAF4eswWZbX99Lod58ZbI8nZQpN0rpC0xetr6BoQiCsF+/V+un6gqVVtXnZLdXb0n7Htzb0wFivP2j7j8j2AnRHWGaKuIO2VBfdptmuKKWeaJibphMPDl/hE3uAob/EyRjzMb5HWdZO+U4rCfOeUcHt9DFiamAAAIABJREFUhZubKwQmxEB4WBPioPWm66w9ruZp1vcsAioFx5ub2q5Fa3VDe2dr/0KWxbB9920qaf1MBGWdMZdYU5IhnqrU0AOLlE5ZVcOnlAKOAWEHp70KcJ8Ft0FBFrwm/DLwi8/ndq73c6+nbpU5b0nUPmlgQqKTjVpo7zTNZJkMRneiaXVqRFiGg/UDdadMFnU01qcR4eo4ICV1WipYFyErMIDNkZZh3D67QYgB6+OMZV6QLW0ebgySrltVriWDx4hIWh+wmswr1UDXUYTQv4MPTerf5IYtLFunZDwsCdM0YZ5WJJO9YgaDljEUlFSQrX8ssaKFDtdHDGPEOAwIMSCEwUDLAO/xpr93XLTbL82IbCBeAFlzc51Pz6bRVMe832xbQqgCtF1/zjg+tPubZNk4hYEzXuZtBqqDpx8WFEAmi+pRmt2VsWbdVylnrPOKtNh8k8HYM0AUEXOBp7W685Dg0S8C1dwYVP3R9+bmXXa8TKN1pns4eBapYZbNwaoGmfYBlKI9RnPOcJRQ3y99bazPQXUS1JHQdox+qPe1OjACGUbDGXBVk8fSzfHedt8ffs0eq2G3THVOfp/x9rUz2ojQZqBuLsGZGxLAMIy4ur7G3d0dmsAHfCochcibM/visG1GJkVtMt608dq52rhPLZF+P6IpHQKtjctGOAzTccm8QsagvbGzpxZSsFxpY8p5XZCFwCIYSJlZLgUxOuPrGgD6/Kwr5vf32og3BhAHzIFBwwCKETEO4BgUrCAGDDFgFEIx2IxSFBmsiGCZZ0XomxakOVXm6+FwIihQBlBRlHrF1ueEDDZQTCms8ycKSy4uCdkEPWmdVJXHQFXsqqrSe7B8c/mGcKbWa1V1k0hnqFDN46fjAQKFlH58OGnKj2gPugTG9O4ed+/vQQSEqGmXuRQtzM8CihHO4IkZYTxYTr1lPitmdMc0duldxAAzvv3px/jhZy/wve99B+PHzThJIvjW5x/j//7Rz/B3X71B4FINNoXoj4AUsORKdwXAx88SPnuh9XxCCd/9SCOfKa14fEz4d/9xqEoxbBm0bxvVKE5vcsAiORxV/XDlTLw5rjFOMGOQVluRyOlYxyalGS8la82EON0QmXqTqmBwBUrA3d6GRWbPvbQ6WgYFVKNN+n9Z6z43dXCElnZE/X2pesbqOIy+q6pv/ETXtdG5pjpwSykFay+4jjzbjVo2gGItWN8+UEVJrftOJ7quG5MD+iiCHnNzJtT1I+MzEMu7bwqUp8HB18AEcV8B55+f3g1YVsHzb951OiGBU8bMgOSCQIzbFxFD/hvM7wvu+FPE+FMAAYfjFTD8AGv5LoYYzV/WpbC5wl/XoTu69SJWJxvBeLF41FHTfQW2z/eGMXrBSm3+OwNqrz4ZVcB7nF0Spn6ddH9r2lRBtwp6BIBKu/cF8t0cWlvcRtI/Ud+5rVn/fXXM+LuIYDo94u39A/Cbv0F5eINTWg0oJEFyqaBMDpaTc0IyYJvDza32abTa18M4IFiPMxBwmmZNlSNBGBTAg6vBxtVAuTRvun2kKlJax4Xm9ILgd3cRv4gjvnMzI1kvte3RZH+rpfJvdJrG4wFLLpjXjBc3BxBpXetv7+7xlqj2DfX7sBuBRE+uUx2HuJOri9rYPLpzqVfymFxGqkyhnHcKuTMSczoaCbiRA5OTTue9MZENIAtmoIVhQAgrsvfpJFiGTaUWXN3cIA4HMAFv0htgWUFgiGjbZCHVFfwdSy5IOSvgUp4xTROWJYEJlhWgO0LbJUjnCFSpXh1YRdPEl5SR1gXzvGBZEtY1VZ4HslTXYq0f7N5MhHGIOHi9egwavWQy4K2WxeF74tKua7XTF3akCEBcdb69UXae6GHaew8C1POyXn/5A7iAG2JVvhIu0H6jF033RzWEIIKUC9ZlxZq0rIKYEYLqggAwzzPWacbidYFGO2lNGMYjmBglhDOjUeusdW2UF7f3Jljk9dI7ubyDAIZenYug5IxSkjnRc82O0ihqNoNe6jy67KgGout39pnXlOr5sPIIshTiupk28wegRmKrh4EurBGRRR430sUyrno5o/Iql+0zbEhbpO1/wvG1Mdq0/oOqtXx+dBJ2o3Q1bwlt16J9VprBAeQaIaiZBpWBmgc4hEqgQaR54PSuegl6Zt5Etof9YytEAUJAIQvNC9TLFYFcVs1rDwOICEM8gp6x1g6YYA4MpDXD0WlcwVvnFcvjA2Rd1BAk0Sa7uQBY9R2t/8nqxDlEcIyIg6YOclA42xADohkgx+MVihTMy4y3L1+j5FyZtdc7VGRA25nEXQ57t4H8ILJUglSqMHClmKACfs2MgTQVrJQCyUV7hbWFBudSPdgE9Sz2wrD3YnifmoqkTJUAqpEA86wMI2NMGWlNlQ6U6SszySJIiQBZwUFTx6p3h7wWA5aCAVwdIlJu0Tu13zIEmpqgKF5UtZYxBvzR976D4RufA9efAMs95OpTyHqPT04zfnB9wJtPPsHj+1fwywABlWyGBNUI3rIkhGyeWmKAF9zyowr3ATiOC/7N9xh/8Y+fbBRNZTmWwtl5hJzwKSo6IRUBmddamJEBq3c0+rO1Sn5fURCb2N1LPbctpaOI9kvzJAtfYxcCUkqlK6cZMmOowQgJZF0hw9DqTLFXd6nWVvafNjp1A9yU/oIaGnUHjD9/c7l4LYxyBa7CWeoUblm/VdyWxkXqFX1xNPrIpdT7+LBcaJFPLVnNgkWDQVTnyp/SnFDnnlB9nzbu6nwh5cv/H3Vv1mPLkp2HfSsiMnPvXVX33LGb3W2yu0VaBmRTsGQLkDw8GDb84if9S/0GwQIIQbANkDQkkQbNqdlkz3c495xTw96ZMSw/rCEid9Xppt+uEjinqvaQGcOKNa9vrfcRb8oRH3z30Y1t6znFjfF4f8bh8IC6rcghYnv7Dh/fVsQYcX5g1PrXuDl9CKQT+PS/IdA0HN2XlZfrFBrYGmhj6tHAY8CRGkf1yDyvzwyHhv1nXUEajFbAFa9xD0djbdwHu8KQVuvpS607GnigjRdm/Rtee65IjPME2Ju0mrLz9PAOP/nf/xWeSgFQwLUipAmtZFwuZ1gWCtR4TjEiHFTqsNSuYUoojRCWGUTWw4nAtWJeFpD2e6ytIKSAKZE6WEZ6UsMhRkllauwAVdcTsjYiaw24XxPChzNoy96e4DlCpjzKwKG872kFpnnCkivuH5583wIErKLoV4tm3vz+d57w5X3E5w9J0hTV6csqTFxJHR9rxp06X5nSno9iOHFmcBG5gv3jH/0IP/jd33uuyXFXkMF2HvpngvK/ytwbdLPVpQHQCElUhNrmglsM3AogzgkBjPO2CfJybSIPQvC0R1DQ9ggNVArKKsAuJUu+7zwlcCREiqgk+kJjAX2yfnVSqi+8vOSMyyXjsq7Y8oZS2OWxya6aC6qWhIQgZ2paJiyz6C8pRalH1HY15GBinS+QMY2RsMa/BCkNcMfMXirKggb/y/bY7tpPHNxQ3+9fr1nebapRxAsMwEtqdiKYd9MYCy2YGaWR62SlZmSLnIeAKUYcjydMkwB/bTnjcnnC48Oq0TWLTtt4hKbilHBzcwTzhDhFVCJ03E+JBO9nM86S3cnAbCOVMdZaUHKWVMSyoVYxyO07TQMnJQvSs9UOMksNnjSWH6K+GPiH8eHhpy3i6D63AZuD2mUEnvN5sk0wvfHZfj5/ZX/0Oy1du24jE2opkI7l1Hnkr7m+MUabCBr9zTaZTeAFBBqK9+Xt7ugG9VZVpsy4d2Vv+e6eOCj7jApqlmnfBYwpJqBOrK6IK5nKuEUwJ3Rh40RjikSp4FRE2JCgLmIS5oMAxCkiTLcIqSBvZzFwKALYgGYHlYHWUGrD+fEsPZquFAa7qLU9Yk2pqO2MCmCLUsQZlhlxnpEmASOgKSGGiHma8dFnn+Lx4QHnt/dg3ntOJBVRc5pNSAzKkS9tM2W7udIrgtWALlhzx9GRL0ng7+1ejRmhivelez4Go5mgKSiqqCosseTpW9Nyfn7wuKcZWVNEyZeOYlQEQkREaCbkRDO2vjMpEKR+m1BqRdsKlkmiQq02gBtaVrq1QmelHXHWNCRipGkSRK/lBpSOqBQBzr7eEUC4/wqRodD/QG2EGJqP39in9Z8ZFaTOTqTG4Vt3CT9cL/jRm7nTBgk9WGuGiKvYNvc1rwYWQkBkoXnxBMr3bV8TBIjElIkoCyNrTT19wRma6oxVlQtmSzeWPd8JuNHDxgNNhiBeuyvnQa2Sux80OkgxwOpFgwQ8UUvFzWkWRTRLmq/1RZNmqsMp0z0uW+6AOTSyfPUu6/orvip2lyo3g9noRoAI4wZw7coB6Z6QqGpB5+fp9Sz7T8xI8zSsXV+ycfymVNJ4dp0+Lb0Pnbe2hrIC22NAWBqidFhGWTe0yjgcCl5/0TAvMy6PT4hpxeePj3j14QnvHt6i8oTf+rRhXs748PR/4bH9CwQHLeh89/qSNREjzfeagkIt9/V2h87gQe33G+jJ7rnfin6OeK+AXI/ofSJ1vJ+NY1TAmK2W9NpYu1bc6Op1G82oJA0GP+/fAbB7dmsZ5Rd/ipgKyuMT5lnQ//K2oZSyu3PXMQNSIkwpodaCFCEaoddfA/ePG7baMC8TKEQcDieRaQtwOp4EFZl078baVaXZQIriGqXeR0DFxEQB7+P9f/rLE5YJ+NbNhlcniQw0BeQxBMpxNRnQGj09xwRQlM///PGC2xjx8WlBZcbDmnHWfnNpEgS6QFBHeuelysYdfEjmI58z1yYbqBVkvYQHRZDhw1/tMEjTwaBK6zPa6NKu+V535bMhgLl0eogi76hJlCwSkOYJ07KAWsW6ZtSqZ5wb8prx5suvcT5fUHJV4DAB/oqtCcAMqyOqVuStutM0hqDJAkGd5wHF4Dvc4BCwp1IkgtZaxfl8Rs5bHwcF6fsFyYqqmu5vWTGHOeGwzJiXBSmS1tCrobbLYQt43iqr82TTK0l7srJtqG0kCJr7p5tgNXp9H0Y/sv1q7Xj69+zd63P9spG2A4BzKoDLtmd3YUhbnMbIiutQ6wZmBWFLEcfjEdM0qZ4liNpPjxc8Pjzgclm1pAI7/dBXUZ39REC1XoFEjgxdKxCiZMC4Vnp1/kZe3kDSjuEstYm1Vcl4GUoYHGG3KWgYS7mQg55RX6sYu8zc1YsDu7YXtoayE+aSHsc4rCwzammwxgXMANem6qIqCbt76yz9wBoHJY+k2377My2LbxhfRXOD7e97fSOMNr76baxLsKPBLqSkpF7rehFiRJoSPCSPYdG5p3v4ZQs/CHYbgIU2k3mp1XsVYLZXGIwx+Y8BsAKdSMG1Ao5wBxUg1XzM67mtF0xNcnQzCXgAOCrCH4GQUEsU71gIyBRdYNgqHQ4zwkcfYn18xNPjk6BxYT/NFCNy6a+ODXBZeieIJ+t8EdAIgqRUxghKEYEClhCA44K8ad2dOPJhnekDyZpXRs/3JmGsTQ8gQY0w7uN3pVoXS+4jBhGrx9MYpBeoJjGgLELao24afRgK0sW0tvQRdoPx+miwjjfAGjA2j9IRIKmBEG9RJEnTsObhxep+SNIQynnDJSbkddV+a9GhdnmYO6A1iohATKAidSGhFTBXhHJGymdQnHZFq601MXxYZtdad1ZU9UhZTrqxp+6BUgHaGl5fEv7qyyPC5NSixq4Z5iRe5dYVjdYYIan2o145UmO4kaQab3YviNFXr5hn1XEF+1tbZJCSRjAz1VOINeUjZzFEd8NVyOsUUTY1JpVvxJQQmJFz1tsxIjHSFKV+y4y6VgF0wJaUAsqaJV06Bim6DxGQ0+HCNAaNYKCnKZlTwNw1wqUkCktaBi06Q/N9MQNhpMWas0CmTxNaqWhZa02VJoWGKxBIAQwG45rlvAVIdHOakkbQ9yq/q/utnwujd0uvsTQThgjx1ppEdreI+5/cIH2QcfPZGTQTahPkvuMScLk84rKekVJCYsa6Vbx7W1EKcLw9Ik4zzucHNP4ZwunnSPN3d/16dumS+lOEsQI5cP9cj7J1Q0ze695tHu4Fxs6ow+7bwMuBG10v8bg8N7xtL68MRN2O/QZjLLC/HgFj3KWXFL7+6ZeUPFIFj/d3YUZ9eot3b94CYcY8Z8zHEwIxas6Y5hnMjJzL7p6m6CzHBdvlgmVZJDNDddtLzih58/kfDgcQJIIyHQ5IU/K0v9YsAtL3sw0ORZabKN8yKrUsih6R/+Of3WFZEv7p9+7lbNSK5eaIms/47vGtp9y2sfEwQ82d6G0zSqn4Ohc8akPpTY0+cc4EfPmQ8JiDIkATEEzOX++zPiJo+rHt985RIpklLAcJ5kfr9fLKN1rD/f09bm9vYQarUURrAGGvvRprHf1yBq5hgEZEDIoTPvzwiJgmPNy/k7YH5uhhxsObN7Aa7UABrdnvkoYsstloHCqXpYcogkWT9b1aQalnKZWccT6fUbYN57MY2tDyDngtM6RFi8LNG9pjSlH7p00Ik+hCUdMeR75klNpYylC6Mqd8Q7ObRAVow95YCQc8QtfPYD8EgfcZP/K5FxRsVwr7+d0baJ0n7A2coR5r90lIHX+T3sKSwtwzvlidJ0RS6nE4HDBN0WtHW2vIuWBdV5zPF1yeLija73TPY19IXVY6L+sGrlXk6dECGNq6iSXLCGTyp+t3urr+e0AD54yyruLwZa07s7Il4OVUU9sjwJG67dxc7VRvvzXoeLIlwzkzjfBK1tjvgiRt72vbK7n5fmh++Drwg5wNkxXjLirP08wik7T+7hXQwW+KsgHfEKMN6N6GfqY0JK0J3T33uPluMbMSdutnxr7ui6nC39QmZv/uNaEZI6tmNOgtpyC5qqE2IAbEgTBMEITQPZugDk/aa97YhVXdBAQEAKgxclSPUS2eYhJqRsuM6RDd8x4VuolZ0leWmxNCSjivGTFvO6NNPCIvaCH2pv8+KjkA11XnoP8pw56ZkYWLgYPUBYYo+fGsksU8TtwYVaxYgTg2pqQRSFYDjkLwvmKk30MwkApZseAROjtY0IO3U1evVJ1Bedoxzq487P7W55sH2DyJgKbfBqkHaFqXFIlQ2HYVAnxRRXC0ynh8PPd7AtrweKAPSN3bHCJSBO7fvsPXX73Gx7c3QiMGSzsQZz3cIN+/1WbPEhKmGLWGoUcQ5Bxd73tfD/NeXvOGziy0+mBwZuyuEYwEmqDIjBa7dxVEAgBgyvTombZzomsJllowY9rmiWcvbGkqKAYUR/seBr5hrxMpzK+0OdBewZLqymIkWhRRcuWTI0GFQEgpunOFIsDUsByPghJaa/egwQz2gLsP7yTVK2cZg0Kfj2q4fUslrpAmMbh2emQiLMuMaUoIMWA5zDgelx1NC7/Z76pdtSjcMQOoBVk9/SnFriS5MmwkYanj7M8h+5976onYpTLvQITybsZTI5x+sGlajnjxp8MMcEUp6pUtFU+PGfPdHW5Dw+XxNUqVuqTj9Edo6X8Ahc/GE6vDukp7sdev0YRfvEYlS4rog0aBr9ds3B+YoapgIa6QYlj0Z+McXtulQr00SNq9ZqMZRnv18+93dQkDN9zc4dEqHr/8Cd58/jPkbZM2KLUiLROWwwmlZtSSkDdzTAzqFvfaoePNLfK2omgj+hCkQfy2KZz/NEndayBpMxO1qTGbt3oYrDo5ekqWvkV91cQd0RVdm2NtwB//9M4dOaePPgBdHpE/YvzuJ4/e0NuMqCbFvt2Tb8MgQr7qmyTPYvzd1xMe1giKXV9jxq6li4x1iKTqa92wV+VSLC43eggdRdGWgwG0UvH111/j7vYWlqremECsDh+TSYMjzQeiaiBDeK2AdMnvIQTMy4KtZOTaJNuApZa9UvC6fxuMsDc5ESH21jhE4mhMPm5yh5HNXVKCyZnx4+Mjnp6eulNI1wxawyTRVUIKActhESfTFDVCFJB2ja5lcPu0916rZo7WPjoa/+y/8Hgu98qyBe7dMGCjxP0JbbzfPyMQpwHdL2bj+e9JRdfP1Wq1aHI1FsdiKRXZ6vhIHN/TlDDFyRuBG2iZGVrrtuHydMZ6WXFZN+Q1q7HX97F/x4zIZ+wNQmoNVAlylPfRbLs8JduW384qjWcjKI6A9Ey1Wvhm+t+VJ0v0maF/8jg4deIQeuZX1weoQ+crLZOCdEnk/GqiatiD5ZykpLp3JIkmEjly/PgdW5/rK6jextd0ZXxskAu+ljE8u89vur4RRhsBe6MHALThMhrtDN1R7BFpOF2jSWG0WBW5UA7jsJA7b2i3fv0lewjYPQimGAMAWsUUusJKMWgkTgjAUuksIGEKQWvSJNqYnL1ec0HihIaGrTwgTpP0biFCOQOXywW1NESawEEiCOZxIWv4GKIaEXLNKWIr1Q/UlPYRt7/X1TUAN2AmADmK8mOgAc1CPUSSfqL7IGmR6kk1hqSIWB7NsTepp9AFIoRE7tVkVXKdqfnrDCaSyJNtm42Few2Uz4V70eqOu9pOqEcVFT0iGbUZeVPFDxDwFeN0CFo7QEiBABJvWAymAChjbE0iBbB0P6CUhmkRT9pDCvjDn32J/+XuTjyKhwUA0O7f4vUvfom/ff0GWFep82NI+m0DWtAocOiRtZcURQrkiIu1RvzRT26V8Y2fZauQH7+6v52lmerk2DyU2i8sgYUOWT21LGmDkbpvKTSWpulmhPj+dWHq3mPdm8yMwoQ4fNLP9SiEWSKNMUaUnJFrBafO4qhACrKZEeZJ70UWcBr4kNQzitLXwE1yztMyS+1IE6O5tYZWCh4fzvjk4w/wqNDTMUZJXyQBS6IgChCpIDRENJuMe+CIcDhIH6wYAtLxiNPNSVaGJD3FC3aGvTJ5uW4FRIRL3tCKCMO8bmgtIqXJlZ4xtz/ogjutsqU6q8PFnzAuMwPEKI8J734x4+a3HsDMOG/F00iWZRKjuFXcffSJ1IFWRowLHjMBlbHk1zjcXNQEvjKKWDy5gYIDj4ihi64YYG807Q2lTrzMLEhzg4l2bQzuenM2Yxn7FEd5gkUqJdJnfPzl6/oAXV9XykokcQBdOfxqs9rt5/diwNPzvX6XLZOh4emrn+IXP/p/NB1tA1jBIlqTXkON9hMwBZMkp4Uo4HRzA6aAyoS8rZij8JP5IOmFOCbNeuiQ6ilG5FaEDke2oWe2tooYJMXV5IQY1qNy0xdX6NOUbqF4k9ClEr54nPB7n8nZCOrZkHR6Bipj3fZRBlvf0Vizf//o22d88Tjj9ePAO6422SNlg9MIuKpZUQWTyZoh28kbnotrGlajwPTLJul8xNDsmL7XlpLI+rnOSqs73R4fz3j79mtcztKjLpE590nr8hoiwaNvAT2DhZukrDZ1FFpGil8hSAsQnQPHXprQlRwCWIBtuBav6U4p4rAIovOkJRkhRu39Nta6dPqU7Tcjbjx5Jl8sKiuRPLChQMqeOEz7jt4bmOOwyZYBxA54ZSnBXWHvxn6zs9ZMfwnDe6b/9A0WJwKczpsiIhqEfW0FtbACmkXMyyStUwzUh3QOSkfSi4zxdDnj8nAWYJFcOxCXyTZ1vD2PqgFd7pL7VAjQfnyaXlktta+JMyFEB+vxB+nZvOaJBAbHKHgKeiZaq2hWjhS683UkHRvgWK/mzmJSHcLTrs1Yk5Y4vQestEmScxIGBwhpWVF/LoW+RhZhDyytc3ardn1gyYwz+YMGsB04XyEYlgO4n9VnxvLf4/pGGG12WWhX8oMVvj10gd7nd70gWnM02iVWdKOCx4EP+IqkghkMBJAs7niNer79nc2DwACaIj+R1h6hewAYmpo1eOMqFFUPYtEzKWaeGiCsHk8Ye3+SyFfeMjgGxNpQ3mWU5SLpdwyEWsBRwSEYyKVimRIaM7J6a2S8e4H1//cKMYgSGTQPvwr8Kmr1fm/E4tWMgVC1gJdDABoQWh3ajUh0yoRfIN6tMyDraXU1dnC8lx0A6d0htWUAPNxuIn00+nwjbf7Yv0S6b42l2DVREK8NkRsg1QSn8kxDwBShKUwuoonwgTDyyoDIa4nyNNWyai14umz45RePwOkRaA3/+k9X/NP/7Du4PR4BAA/nM/7k736Gv339FpfaBJWSG9jyQ5nd6IhuO4u3h4jAtODudkI63IFDwL/+jwFfvpVIckqy7iyV9l3BsOadNIB8uDYoi2YR6dAYRRUG6KddnDAjWcSJG5i7y5rUiGVo1A8AEbsdIrZzV76XacYUjX51j7UGz9AkWHQzaR7LkiI5tYYx6YtIUpEFPlhJxox5+4DRBQKiMv8QtH4NJKnYOrZiFfK14vXXb9WDqKi0qlDO84yb02ycCJe14PLwJMAOejaMZgEghoS8bginI5bDhPm4gCSs2gUWS61FGIrmGQFhyl5feqGMqgUBZZPeWdM8IVByQeGqrwpp659kuhZxE9qKGvVyh4UKHjCeXlfkdcLtd85CA8x4dXuHwsBlXXG7TLg5HUBxxmkOqK3go9sbLPMRH338Hay0IPOeN/nFouR4PZFttK6lqlhuRomyOXx58GyOCp7chnt9m0bj7PfdEMwKGr+r9xMI9r16sn/e+PP6Ls+NPa6DcegGI3Sf+xyujTp75s7BxYzzZcVP/u7HePv5z1EqI6UJCfB6FSjgUhzAW+x+knI1Y1lmMEWU9QK0iqhKXkDTtGPC9tVbfPBb30OGwP632qQXZuu9k5hF4ZTonypVGkUaQVz2TnebpxwzjW8jBOAwi1PyQCsOdw3/3Q8vKCsjThKB6C1cRKhEkvPa3NGj8whBamQouOJ4mBqmgL2iPqy3fTsAXvBp94xgRakbp9GG7aNuVOlLYqN1qHJqDetlA6UgezS8Z+NmlnrAljOgkRQznFkVw/XpjPXp7BGHaUrC81VmCbR5RIPIa2o2O0Ve5F7zRCRREfMZQRXeUeEmlnTCqmBjAnDREBigJCAih3nGYZkRU5CIbIjdQFCDqjtKVHn29R9pXg1WyeF0PcKNe6AkGUafAAAgAElEQVQ7+wcNmVTwC69m7CICYNkrdTw4lTQghHFXO/1U1YOsBr/yPjbDLK2Hqp9d4bPSammTVhsVQAyY5gmH+SQ1pyEq6upIX/Ks1qS+f90yzk8XrOeLGGqDXjr40n293nf5+TO1wn5llqhokfYPNMiqAEhf32E1dk+6oldSWc/M4FDARZCHofpiRxs32SOyMfgZ1KBIFPsgJEvVtoi8Au5YGr3LcnMkvTDvwT3kkVp3hJLv97MiK/Oy+mz3dOr8ntVyEcXqvevfb9tlxa+7vhlGG5F3WwfgxOFaPNmCBVh9iBxaGohyf+0iLajDgbf8Uj1Ela/uMT5QmcigGHRvC4+/Aix92nxnjU/UhsrZGUapBTklQeeqcjC3wI5YaIwrATvGT2CQ9h1rDNB5E09/ziANoRf1xM0pYs3al0UNLJ+dKtK2RrL8Ly/iLk9Yc4qljiZoWkPEPE9Ow5aqWmsTzj4g/zQ0BwaBrmWt8j418/x1hi38woqFR2HeCTtoDrukbaGnpBGMO7rS9dIM/ZZaWwWrKWSgqYJBKvANLIU1fY65oejnCJAayybzixb5sgairixA10LqkZgZ/+5Ht/iX/+gRj+cVP23Az9/+JT4IskIrBTwCyFpwHNRwcb9CqaAk3iCuMr4YCVNMeKg3eFcP+OrxgL/46aeoYDw+fY3KRWbOjNCaggUK06RAirx4xWA0FEWBwLUNkPfw9kKNyI1ekFSBJavjVG8Zhb6R5M6U0GvBRzQh3bHGDZenC3Iu3mdPlpvdeJIzDU8XobyhUOhMU+mgkDXOZYkKN6EhHtKIWfobAGTcxmR4lPOXMyo3pGXBFAtmSPoFIDV0tVRM8yznrlSkGJDiZESJVEUpqKy1uf5s7RGTpM8iEWGaZq1J0ygtGliIQIAVBmHSAERKWJO09VhikPqVok3sa0O+bGhTkzSQIHWyrF4UInYk0p0xpHKs6z3kirAodYynNwTQjJtvb1p7kRHijFe3d5gi4+n+HabjEaf5DjFOaApGs/LvYG2fdEMRA19WsTnyJiVV/8ujFma0oPOPneI0UNX4inEFATWxu+3TrvdC9Pr3UciSG1ndiJKfPaXrNwtkk1vGe7sIHNaG+zNfumOtBU9Pj3j45V/h3V/8IUptSHFCitQVHWbPQBE8CHLFP6SE480RU1S497IhxYDChCZeHgUIUKUyaO0Xi0K1rgXgsyAXny8OxNQ0VbC1im3b0GoGhcm1kL3BPCQTsZxLZuA7dxteHQr+8XfuJXLWtL/pky7UAtHsWt5tmYEhXDsHxLAkiW4TK3KdvwmKqWvAMPp3VQ2WtigyUNYjxCiOKuX9ZN97wQC0mnmGlBp0OmgI7uiSe4E0ZbE1PDw8uMNXrGFJ3w8EFI1GJeOrUdKDoVGTQFb/zogwBGB1g7ABG0mUW3g6BqRAEXj6SASLhKn8ro2RS8a2ZRBJq4Wb2yOWeUYMwBSjZoaoIRgs9Xqvz/Wz9LIyO9azmiEGwJXnrix3nc1Pi9847A1zLcXo0bOqDgfgEE7PQE6apqEKrDv7EA1J1FopVW0ILk4KdWDEiHk54Hg6CRqi1jv2/RcaqK14zV+tFVsu2NaM7XKRHmYNzifsspTXnX7qq6Wv7afiZVWke8wk84jK/+n6Dk63SktkUdZu0NqKuypNpCm0oizVGECqT1hz+MisYIDa15a5nxuxrjzqKIb6VZ2ojZKGlFoDrMHzz3VDt/Nsr1/W3hgd6K/vsSAXkzqj2XEYbP19T1TlEd1J5cHV2o/ZHBQauP36lMlvhNEWAuHm7igKFElBaZqi9qmxhR7zfjuFxZQENr8BlnfbvS0vWbeWrrEnW7fwX2QQxhhw5UG4uobd6HTGPXqhJmfZClblfFGNNUHsEYYWg8HY9rS2QHBAFE/nIoCjKHFUJcLDrSFrVEZC2vLkFANKbSDlPJJrPxCv/k0vvHa1GLYQkOhT9yYQST1DTFHtAoW9byYM+wGpVoeoe2UHm83qYqtAYfUckerSvXdR41G916myMHQ76F3Hu1bdOgNvdriHg27XrpKKOvAJAN8TZ0xsO27hcatuEIMoN2Nilqopn4+BsNWG/HRGJGCFAEmMCIj2+cos6VvcBNgji5EVAnnNFQXCn/3qDn/3cId5irg5kY+SyNKpoAXrZsAHsDa43O04+X+yLh5t0ZeY1dBlVGOeDHDoiIkMQZm01huBIWk/41a84DhglrrM7SLAFnb8xhPYFdm+pTVNAsZRFXlxENIJrAiXsh6RJMo90oXIepmP0IDcOsWIAkZoghYaVRkShZWAlBwg4bAcsIlEB1sBPViMJYb2IhpSWECY5gRKSXoIEoFo8EQDHUbc6a3Toihvaoyx5egnpBBQW0Uulo0gvGiaxJustfjqoRcFtLl6wwPLG/2S9rfsZ2Hg7VcJW2GE72+4LAuOtweEwNi2VfowtYrjHHE6fYB5XmR9a5Ua1iYNXluTNZ3S5IYcc0/Z6amwnf90OtAaDPe8+jtu1Nnf/VzCjTVfUyj/4JeSNq+vKyOOr1/rwnsnV8wBxPs5yFvk3+u6qNCX1YDZaNvueZayScjbBe/evsGbv/wjMGtzYq6IcRZHRAjIecN6PuNyEXAAB9ggq3klnJ/OIG6Yplmj4EEjK1XS4mIEus6uKxiBdkHNEZdVgEkOywGXpzNKrTieDjidTsjnFSU3pEmcKIxR8RwVKWU7U0QrFf/kW1/iMDPKNsw8BOEvw5qbtWeyfls35PxyiYDtkUToeq82TEna4RwOokTWKqizACzBe6QRSS80VVYzTpTQbEiGzltKQakFLWdxxFzVn7cQELlBellJtKrFhAhGjFGBmcQpa+UbTRFVg3iw4Iqz7lEAJOsFkqbOJPIkKBMw2RaH+nJJEfOF8npjZjHYjI8Ks9ZMoiLoj8sy44MP7nBzc9D69QHky9Mbyfe461+ysvszr0MgeP0zD0aeXbs/x7M1Kuf2OgNQZ0DTiHAtBduWsW4CS19yxuF0g3k+AmRoqPL9kCT6VDgoSFtFqQU9qgyAKyhEpBgQ44IYh3Q9NvpRJ7XqSZI6KLpTKRV527DlirJtIjdeQDPqa/eiKO2feeH1MLxhWsvY485oyOSN7wkFr1v3tXenxpUeAd9gkW3RonaqkBCQqpwQS9lv1NBM/pGsT6AO+W99TF1ncYvfdEoT4OSPd1oY9dzxF93bNCXc3B5xuTDWp5cXTsYlRr2lFgOdPgC40+bXmQ3Oe3/D5+z6RhhtzOKhYXRvvyOWMWAZwNdXCBHzsmA5HYXgtbjVa11YwAfYw/4YDLZhYXWlxEbhFxfOwEZU1EMYz2jkdCXc9fFrAwGuBskfrYOe2Mc84kaaN0z9NempFpCCemYQQFE9vMg7xs/MbqhNUeDO92vO+/Hrz2ZRp3FzgB08q03B1MfxMPTcZF0rkkLWwCZE5JrUu1CLeLPQrO7EjAuNAJj8BYEDI7r4gRqF3UsU2NJhroqHuXvhZcQW9eq7AohhKJWUFlkdlC3R8Jy+2rhnwxIyC3JgALlC2oi0ftxwzIApinBvTMiVEUlSPCzt3uUKA9D0rdIawlY1qgKkSZSmoB4s8c7LDf7x98748sd3OlfrmiaM1pwZRJZ2BJin7BlvUm/WLmt4ICUrJgaggCLigSt+HlRhUAW1BUKyNWxNcvxHD9nuMZLbfzgcsOWKw2Iu+XF4/RuVOyJd1GL2pnNgCNoku/NgVIr1yaR7x9ilVdrRaXq2pxhB3FBZeFWMkjIZYtCms1JYXxUIwKK08oywG/M4WyKJBrx7eIdPPvrYAVierQ11D2Y/x2J4hSSIkQ2ECqmvS8sk/a1YjGuy6Htgv6t4O7s8I1vnMEZzOj8TmpFYZAgRuRQ8fh1x+uwJTPeSckUBhzliXTckJmy5YcoXpJhEKcVPUfm3sOZb/OqL1zgcF7y6u4ODmvqzCOCr9iXKPzzqp0bx87qv9/ythtnzz3X+73v2gux56eL3fq5H/G3sAHBtsI2vuVQhEoXQ/t6N5hr4RK40LXj16hXmb38bJT/hcs563wAQo5SMbSviTEgRsQlgCQC0WlAykPMGag2n40FljaTdRjAqRcRkSpjR85CWxEDNG2JMiPOM080RXAvyY0EM0YF2LK1PhbLzaF8rYaggkhq5UiWLwzFT7atgGEJjbYzMvEOAZkD7QL3/qqVAeojyAK5BQIiY58X3gVQBLE0g7//Zf/NLUCyIFPAXf/kx3ryWeuRai6DXsjhBgqWCghyWfF2lx6rUz/QoRQO6IqiOH3eOhYA0JQdYUfMGZMBOJreCps0DuwbhwpvhvYGZFXE2CDtwKgpW/2P3sOf4LIYTA1nrKWImbbkCIMTkoDRBQ3M00OzoH7WoiaOBDGdlzAjaOVUtFZEGgfkeg2X8jEfCKmPbLljXDet68QbTNRdPrwUDaT5gyxtSlRqynIvoZi2LU2rLDgwyTTNCiO74kOEGc6kAMMOsiKOsSc0016KOwoiaC7Ztw7pmlFw0nf/9POjaWPOl2Kt2LjeCygDfg92H5LKyFHEYsAdQmuo2hocsdEqDc1u/DwsyyP5FUvRoAQGQIIMqbo3EoHejDkLnpTUBhNJBmi4cYkCKUctXLEK5T/EE4EadOSNeIg2rk2X7rur5aZpwezoAZR3qCAGjy3268j7YcX3x8L9ZD8AL+xR4R8rvu74RRhuYUbYMQDa1bEKs9p7VxZBO2VTyECM++OBW8oiZsVUh8FYLmoaTrbs62PpHNQfJaINx15Vkg2i/Nt664DUP6Qh8YteYSys/lXB1LsJk5D7yvwom/d0OJ1EDl+oHH3B2rLJSvJ4xJcRAupHszD3FgE09i7kOBbG6nmOKpDHD0eJ/6TIvo40Ghuw5GMSunppG7MrKTtN2g4hScsS+cUy1FBG0Bg3d2Mle7CiFZw1iKDSbnw7NjDe4P6erYM7o0fcBbAZN96C2BoTAPiY7+AKHLwZAQZDmoZreUC1dAdhHAnW5GEBh6XtDDEzRBwUA7mRwb94Ahw6SOkhwf50AJMs31yhDrhVLfML/+sOfIc3qLQ4R/+bPFnx1T9iaLxNqC57C6hxjUCDk0FQBYMFVfgjbWgMGMtNUyafGiK2hJIUgdgcBCYAJGrhlwGGYu/I99kMjIgEAGep9AGhNXEDTNCgiScdM04RaCi7ns0Tu0QuEeQdEsE9BEJWWUBDABh1YtBIhRfeUE6ymlVBbxbZubrSZEXX7wUlrEvapGwzsHSJ26kfDs1SUTY1sQs/r332nC9rusRaGH1Uwpii1ewGMkCYcIOvaak8vH2cv42RFRhv241oZcukmz22skRf9+Fd/fcJHP7wHt4ZlnkA4YJkSbm5vULYNX64bTseCj17d4Q5PuI1/hLKd8WH8GnfLHWL6Z6j8fQSYM2rgLUTIJePduzeIacLNSeDR3z7c4+Gy4buffQsz8TM+Zr9bw2nhdWNk4/08r+/6bzbcrtPN9x7U4T3lD53r7580KqrveZB/w2l7+DwRy5lPE+b5BjWfcSnSOqJsK87rBjGyAkJYUCMDJifRpDEvNxzmWdq/AFAVDA1B3AGGlKYZEabKW69EtIbDYZbMmTR5+4lpSqLQhggE/alcMpC1CRFislVndcj+j//gHhNllPUl+SyX1PsIJKsZbCBBZS2loJT2/EsQuS/4QDy+qGdM9y1IfWvNGb/7w1/i+z94wjQVoBYcb2/x8Ue/RKnAH/zB76BVjWLzy8Z5XCZBZF7FODb+wrrSSwpwlke2AyqjWFAEK1dwzkAQ+yWQAoq0KhqSGsDim2EIGII6bUi4eaIg/Eznar0dmZqjZ0u+gjpdSdr5AMrTIXI7ThOmKP1mQ4o4qTgxOeUozFeK6n4TDEDEKfnqnBrs+8DBXMtlN0rGc2QPrAxwI4kwXy44X87SNywXtGrgbs1P5OiqqqXg/v6dlLq0jEoRU4hY5gUpJTfYXDcZyEd+anugVjyw0BqDFUW3MaG0ipI3nJ827aHGXXXSq2l2yvt0NN59YTi1pBYPLJ3zSpbqvXmIMjclSFlC60U83lm+aXJD5iE0avvC6HoTqHd+DRQEQbyyI/UCARwbYCnBQenM8zZJgNdCkChdDOKYGRSrYMBo1usREogxZ6RioEnIhdn57MA5JY2YAjhMWtfJfSNHZW64iNidoe+7SB2Mxo+elS2Zl4bs1L3/+kYYbQxJo/D0jJBwuaw4HJYulrSmStZPEnhqEW/V5fwEAAgpYZ5nxHD0vOmmXsSq4A/crBmhhcPlsIrHQyNzmlZlhCxjhCtlve5Kfh/bFTxn0HsrPIQeNu44ipbCwP6s7sbqB2mnunEA54a8Sq+cFAIipE4oEaOszZ+7U0+vFIJRsRjHaVG63T7Voa8GRnXDFMlhHeTm/RPDvT3aSGYgyRqYUgWQFM0r8p+lDYgRLgZ5q5L/XNQYN2+LeLFCh3fVH7t6xL4UcIXHmDu0PkijbtYLK3iNyXDEQ8AcxZgpzGIUNBGcVVNbDIlLwAF0bETaxLHhf/7dN0ikXuL63BssawIt4pVBx0FNYoILYBOMBHF8EMRrXomQA+G//+2ASwb+zf97h7VJj7hlnhFTVJhsXK0RwYoaYtcT3UBz+gkBiRklaq0M911OVdI43Y1LQG4NMzMOWp+h+Lp6DlmL2W0E3L2MosENA5HXZwJWBlrVWhkGlmVRT3dTuq1AiIipF9ePhrvwTEaHKtSnB7K47t5pABEqZStYWRoUx0C4++BG0CtbQ0xJZIoyaWfY5nFsnfYBuJE3GrFX8lVGonJqjEp4uq2eKavvi4GQUsKWC2JMKGVDr7XSPVbZdJ3QYkah8bXWLL1prDdirfuQ75Yc8PYnN4g/eEIIAU9PGyhVZJxxmAPmANw/RByWIy6XJ4SY8fjuHktqAK9o5Stw/C5amLVuT1deH3jZCt49rgj8hIU3LKHitD6gHT9BGhSnl+p1X1Z29orhtWffOPIV53BF4dnevOD4crCbK/7h3xnHcvWsUd70+/UxyW175JxZok21CJLovBylmfFWkNcVRNKT7Xy+oG1FazaDIvaJIxM143A6YllmBx7ZTZYiIld1gvZIr9EU63aFECVrhsQ7LracJhEGkTESRdTIh/JINXN3hgxAuLQJr6IgMTbej8nXp7GgOzN2NWTTknCsCx4eLy/vAQ/rOL447JLMreJ3vv8F/sHvvsHhsKC1iK015C2DYkUIwD//5z/Fv/2D7/k3Yz8sXXuE8ATSqD3qvh8Y0iT9O90ekQhdq1WanatCWUuV1EnSljQsSiexZKVUiEIZ1XtkdXAM+U6EZL1AlcoQAihJg+aUBAFW0tJoqBcTPS1EM/x7lIMAHA7Wp1IzhPS4AF2+C72aDDHFfNyRgOegQAPIxw5SnDopqBIuNePiBJe6soKnywWP7+6xXrLLkdHQsRqqpsZmjKFHC0PAPM9I6fZZ/RkAtDY4MZRuJJOkoDbRN7k2EFethWsolZHLhvVSBGjuBX6yWxGfsqVcj4tmzzRjGXujB/2MCAnK4bII9Whg9vvJXomBo6fQvjfosXZeLc3W5JdxsoaIxupcxRCjDdHB6dCkBYWIPZbyHsv8GfRYKx9y3Zb6fEoRgWo9IFlTTBnA6Q5Y4tL1+OHnjo+40Qmczxd8/vnnO53Iv0vSHqjUujPY1J9r5ZG+BqNrLoDdITPSkYEt7dOanl/fCKNNFlp+IWK0uuEXP/85fvDDH+j7Ft1y7icL1xpOpxNef/Ua9w8PUh9mnh1liCEGRM2DndMsAuYAQBVDNpSpJiAFgsi0oVZVRqrAE7fG3YBiMQTNixaHfiZ2oMbJieCVv7peThAm1pUJ+V1SWPxQDt6iZ5xieK+oATN0t5BaOEg9EQEOAhggRkDga2WkX9cGGwCvh/Phq7bnxE/DQeDxc8NYyVVU/5BAZzNIEYD6GTJlltRwIU0NUQMuZ9Rc+6KSpMGxaQD63d7LS2++c4fpD1c0LJ7br6qMgJwOVf6CUTWNRBpuy62lTkaL0J2xstcnmjICQ0DEyCyfX2bQRVt/dW5UAGn8mhaPm3e4Gxg6gtYQW8Y/+S7h//yppBQzScSv5bKHxDaGz9zja7ZItrakHkxuyL7mSgRE8Ii4DqJxQ2Lxtj49PKI0mVMDQUM2LkRcwaWAVgrgtYzAqw9f4atf/QpmrCgOGIrWADxuGcsq/X/i0OyVitQs+HLFhI6SKTGENhAgRwMAgTNZl0lmVIWAlIIDutQqyG+sfet6yqnSAEF5lL3UN8jSOYTZj8LTR2ycr78yKEGg3hMQZP1pWKG0AxAt8kd7BWnYNtnmrhDvn9bHIkanKbnCd8GS4sxg5NLATyvagREwgc8PmOcPcffxJ2BmXJ7u8fXrhuX0AbhkXGpGY+Du8A41FDCWjqbnLgrg5nDA/K1PUUrBJ9MZSwiot9/CG74buiDQMA/sfn9uuD2PzI3X80/L/0R4MWXJnDv2LPc07zy6ux189kSL0Nvlj9F7DHg+u88an4uBwNb2Im96rjO4iZNzWy/qYOJdkb9BcB8PUncWtNjfoN/7CJXReWQCSJGkBb0p06wGwAC9zYLwIPRCpI4NkwOdpwh/VPmILgf/+Gd3+K++lfFffPwgIFZVnLEdEZK60Ud7XR4AYrK2J+/ntfYsY2d2X0AiLsfbDf/wH34FUEApGUXXMa/SJ7WWgvNatdxDznFjchS8BijyK4HShFjZyxpsH29ub/H0xRf+GoNRmRBaRd2ypIBuYgxwbZiSodwFV5w7ncpzmXp/OGY1wlT3oBilDyYB8zQhTAIWpKkmeqdRrxFiqR4h5J1YNS7FDCynIybIc4LJZv3bdAIDsbFv+zNs9u89u0p9Si/buqGCJVNlkCUMdcDXhlZEeBtvuUYLR4w4LhOmecbhdMTxuCDF5M4qm1evfTR9QFKQ2Y0FLdVRsDUBJWnIpaLUilwkFbO9QIvvm283MMd1HJZr/Fvv06qOuT1PvXu/yiHPeIknMsjTdnfv+lbw0A9N74OezWXtiaSfoNyPCKha+jKWnohM6TJG6KxJyuhIG9xRYcfMMSspCmp8j7Mb13k3bzs72nKMiYb59Iw5yWYjxKrZPDvnFZ6xdQNhY9aQ09WjRVYQJOz4fv4EfFOMNnSdvnsQhoGromGbbO8yATVXRdNZuwFEln4Xeo2cE41C/BrYhyk0ISgqTQRmhcZV5JPSqgMMWISu1Sb/moVhq6a1tWcb8ryGrs/Pfu/GWx0Oi6U/yQKRGX9u5NH+lNJVFA2i0BawGldqBBEUtUcFaKtqyImCGV84rAA06kiuhOB6n4a/rlN/bHz7T3ZN8Woa/ROkIX018giQ/lFBDnGsAmLQv2sCdzjAdlPjIy9xK32fxoc784TXbfEAdEBQecttl+MsSFL07OgRJComyyfjK7mAw8uNK8fLHAR2QIRxQuGim6aHth6tI/IdGMmkVRG2ovAwKlUETKIQar2X7a81vrQqgzE5kiERvN1a2t9q8Upri752RB2br2wbtnWVcVJAmicEEi/y9VKkecIy96d/67NP8dWvfuWG8bj2zA3buuFcG45LwjGd4JiTiYAWNErYKdWHDmXMw74zS3pQ0/EboE7ORXohNqBtEoGylgylFlCT5t5j9MrYvthUtiEsii6pwnw64YMP7nb77nWVQD9773G32KsCYiSiTgxFk6NjKriOSc9YG+et94peM2BOCaUrhp+Z4GmpGcwBLSdsDzPoLmNbC45zEmWdG7b1go8/+Qx5mXE+P4KZ8LSu2M5nvPrwIxz5O2A+dr7HQt/G20IgzPOCaZrxdV2QuOEYIqj17AentV0qqi73kCLpazby0+HnuAfueDMeexUUv87A2O3JwJfJ/7cVtlNqajZ2PwdVwVmS2EujQj3Or+JyWfHmx/8Rbz7/Fc7v3mErBTkXrJdVskhUkQRB07psoSuOhwMOxyPilFyG4mpOFg+kEIepaGKU1nyZ8SaNzeVnbdKqQvizuu12DjU4janmrfy2Gxh/8stXeCpHfPt0wQ8/OquHXRRkaXExrDAD1Iazw3DUw/eKAJMXz94n1FKR1xm/+NVn+J3ffgtmRmxAQwWlBC4N85Rw/2bFuq5Sj8rQLIIu6Eida9PNAgqE7bH0fSTChx99hNdffSl6hiE4Erru0Zrw1iCo243ZpaNkhqjzklS5HgSA8eI4RUzzBIqT1LOFiMqShlq3jK1k7VHZDR+nA7a6LDjKous4DHUGADFN+OSwOKn3NeD9EXBdwq5uNLhh1OB9YPtiWbSM0Ljisq4S3YPSD6wkRnnIcIZ7UEj47zwnHA4LlsOCeVkwORiUyJTiuh27o9+NP2ZvIWDyoTZx9tfSUHJFrhU1VxQ7e+81RF+6BqwAhnUkcJo1GaGVE+5wrsye1jjq135X7udlP5a/z5jsHuxbKN/sqdJdZrU9DdoeUR9XcKEj32lmALuu3BS3glHr2ZGWDbQvTaS8hnp0wgzq9xhBI0fz/6kvoK+Cj1vjcDbZXGUmhGENOmZA/84LlymPgRASAxwBktTfZ46Eq+ubYbSZsqyr1v2q/QOSzztG2+Sy9BxrsO06N/ccV4eYVVesNaW05wrQR3BEmmDQ4UYABKQ5gZBg7SWZGZUVirVIlKKUilaKejd6qNYUwdE7cm3IjdcYou6HbFQ0rnKb9ac1HFQw8Z0Cw8Pn+qEmdHHJQG09lQPiXZ1U0Y5kQCwDw+Erghz1d/DAWfqr+zkb51Tjo9EYzd/dy7Zds8rgy2dzc+YuB2ErFevDkyjOKtxC6qAQO2bJvHutMaS3XutRUoNcJlsbthRk0u4GXbFxQ3xHw+rxoqs1cE7xMi3sLhOaqqyJABalxvLka614yQD0ejJuviYGSfxUNlg8f9KG4kHThYFeVAwiGPLLxBDk0qDPtOcwvNB+lBChijg1XVdQDS3K3ZAvF5RSUVlTecYzTiS9cEL0CINtv9HmCkmPhEEBgwDt+2i3ilT2aFIAACAASURBVEFqLioX6b1DGQKtYEFCU9qvhJs9S2tjc6nYLis2BVEhIiAqaJD+nZsA8Iz3gEYexGgTNSsEmV9rQIWANBwOhx0PsP9Hhf86ZY6oRzAIQNAoPpQP2jgtqg3AbEVYauVorJEdMOpCVt4bacvGIs1yAwFoG0qLQJmxLIwtV2znDYdXMwI3rE9P+Dx/jqfLE/K24rjMyAx8+um38erVhwgxav3jnn/5PlxtzNoaqM2+Ol1RwHAeu/fVv2rKrN7fjdbdmo4KTVdQdpLJDPmr1+z+tbYRMR77epmBz9u6X71jY7XXGjfcXy5orWJmcWjEMIFZeilxK3jzN/8en//lf8B6fkQuGefzilYKqFakGHHecm9xEKKPb9LebCkJkAIrwi8pKBggdCXrawqR7FUpDcvhgBgJT4/3DpMt9CXnsORi9p07SYzf7yQ+X60G9fVoDPzNVwf87HXEn39+AgAcp4r/6ffeYds2bFXKH6B18B0JldzQtNi7bHcbjAPdz4GGnOcSkOYZl0vG5z8P+J3fBlKaME0R21qQizSSD8uE2w8z/vPf+wJ//aNvCzCTGiljGn5TgyIrvw52zlhpNwRwkT/GsoGYBEFS0hKFl3hqJKAtPLR2R4S+t9OJKWCKERwFMj2lhEYBedtQLytq1QwidYTt5q9AYczi+BvTAHcXS8ZSAzBNk9A2mwQRju36He2/1zmtrb4ajBq1bCDNdiHVXAmhyTsxCPqxOS0J8Mg7Q2REGQwHhuzn6faI4zwjWa2lnt1apTXOzino0RyAWI00tWilbk0cdjlLXXJTecaNHQjOnC6/7hr1PENFHxfLz6ID40m7Jy8puErfvJZnMo4rPQy/oY5WvyM8UHWjoUZRnwQ51XbPYdRafuGtQUhSBK3+FQywpWA2iJMvAmSTYgMikblN04Q0zdoCQ85V44asjcr3YoIQpwhOBHcmoVPauFCSoSefczlIV7RqVwwgbefAqnmD+j5fr12/SdsRQmvGKwkIL9fcjtc3w2jTq282edYQA+DK0oi68W6xx+yUlzwJ7p2oY9jUoh39aUL7phIFR4jqId2wM+S8R0QAiAKWRZQGG0PT+rlaKqxvWTPCaoO3hrsH5aXrum/NPt2nz8EWr+kYpG+GYPz0uoznK61cGWYQNmYU0Yy85qZAIx1LAGLqRchjHZ/ezFSLLnz97sOzfPAqDMmFlU+Jrw6Ua5PUmQY6c7NUD8eMlE1AzlWUOgPtCPJ+StZeIShgBFSZhR5AGXUIwYutGUCpEi0IujfWOwg6R/a1HBbg2brv02eftoAP59/AxYe7sf4naH/Bz0OgIfXyJcVT93StM7YmaktTDSoGSC2E7w0JQ1ZDniloHTr7IAoAthonjSixCUxmJCgCowqWFoM3niWW3i40eMQIhHlKYngWaRZgy2fpvAA8zaNprZqhXPn6NKvL6GA7zhxZ+hqCGaw1dq2yz3nYIiR9vFVROLtVJxETIaWA0hhJGvkJEEsDqFacDjNuTkdMicAhIgXSInrCaZmRAqGU0uGrmcDWT8nWWcfe3Flwtaeu6joRSlNgjJ+FnjH5vVatB7Kzo9+zcyqKXzfkzJgj55n97PHgxiWS9iV1ioiVEUJCSow0FYR5QQgJh5s7oGVc7r/EthZMy4ySM9YY8Hh5xKfhYwAZgnbaFShZn/1ZMn61l459H6XAvKfmvO8+u+uF90bjzrys/vfVOXtmZDIPvEAXFq1Hk2xxnS88vx+jyzlRRANmIjyeL/j6/ACkA+5ub3BcJuTtgjd/+yf44s//EOenFefzBdu2Sd1TiNpcvdN5StHrQ6Z5kvrHSWqJQ5jAQ2XpS0u15YzW1HiJYlBY+nEpkr5naUkxECIqghoXgUgcCyHpE1iVN6sqYadbeX8/hrVG5It8r3LAH//0Fr//7TcAF2SuCLk6P2jcgFzce1+tV6M7ska5avrHtdxkX6fpcEAIPVV9XibEFLE+nVFKwZQCjidxgnlEXc+01AQ1vP3qKzGuUlJ0TjgyI3TcchaFv3KrGrnvmR6gnlJt/DIBaCT11DGKs9L6RpIOA0EQCh8vT57Z4Ijb7qiT3xtLex5H+nzPJfwlSBSzaZ2ogYrobcUhrDzD+hBwRXc8Ahb58qIgRzoWhEFmQq4F+ZzBreHmdEQISY1viURa42XT6BStDABhmiPmw4zjQQy1oH0vW2soWVIcBdiMgFZ1LBVNHQ/E1QGtGgvol8DyF0V6NOeGlQ50Jd746Kiremsg5bnWexa1R/f6+Xt5/RMRGoUeaevs3Z+92yvj7yAfx/Bp39HRWdTf84HvXE9CW10/H2WmLEgEai9NYAoCiNL0WX43LZVJjMgT4iRlSCU3oSu9e87FEWHdsc7k8s7nrdgC7g9Q/n19tgFISmwDmDbQC5aRf8cMTYKjtsrzWz9jVxepYwWQcpOmzn4K5E4hgMA1Pv/y1fWNMdrM8+bbNygzMZoyoYYI9gZb93DDPSHPL3u9h9ztskaTcvWibh1ZL8B1b7UstnRaD55iYn1sBIJdBCA5UwXAzeuGzIPCgzHnofbdvz52dmWuvz9MT2nSjoxV+mid1lWqkClh3aAaAtp6AFRNQQyEaT547V6pFecnKeg271R0bz4g/aUsbGzjtHo1E8rDoPWZwsCsvs1fNnvNCAJX2+fzDiQ56yGGvl46pjAoVSVXtHXTehBStD1x/7YmCg5DkBoFAESN/sBgDuBaERAs5upjI1gUY1C+1CDGe2jz3/3oFv/yv7xgzPx43zXwIy8iN6SK/nX1BOq8U4xY24T7dUYIAf/H377Cmhum1MP6Kcr+MYtS7wa01a6BYemeImvVeFYkwjEhwHK3C0SYCNIiY6qCuiheX3JksmL6B3WDwRRZSUGpKCrXXUgMtQrMDE4R2KTQ2dDrHEIY6IqCXhXS5J7i5EIAEBqpRiNXgs++Z2MFpBA5oqfENRBqKZjThHlWZ4DCP8eYJGJxuWA+LJjmGR7qkm0DwJjnhFqbn1dzaPTnDvQwNJj1e5Csm6yPjDMMqWpSy3oNvAHZQXOKqFJhW9FrEQDzmI92JRhy5sCYYkJIhO0+oZyB4wdiFGx5w+PjI9a8oSpYDK8ZecuIhxtMrxK+eP0a3w7/Abx8Cg6f7hC+hkc5/QWlLxmrRSNeEMfDfV4y4GwNOiVg976BZ3TghIFD2We6Hv2MN3fDT+iWDOUMqqjrOWz+fRk599v7XAIBh+WIZT6g1A/RasblcsabX/0S7778Bb76q/8bT+/ucd42lE2At1hrV0MISDFhniek44Kb0wnr+YJcxCAIUdpXSJuKgBZEJlG02hLyyFWrDSlGxFCxHE+S3sxw73u5rMCrD1R2ivH2re99D/OyiGFHhMPtCa09U+/g7j8jxGGtiQhzavjWafX9/hfffwtiASJgsPdxQinQ0L+uMTvP6PuiQCzm8B/5BvY0brTSqqRgxxRRuSCw1bZGZEW9nuYEcJN0uCoyVJD8BG1YUtsV5Ijh6aqKMKQ5cEGQJYc2IfvSCavhU8MkiuNO5PWMoL0tTQaXKoAplk7qNMrQOixN7WOrEWova6DoxqLQlPAVEGOrjJU3tcXIz4OhV7q6TNzP3aBrQVtxSOplA7RPI7eG+4cnbOcLcisohTHNM47HAwIECCm6Hii1fX2lxIA8HBIOi6See6pd2UCtOl0zCJErmEQHsMyIwBINyrli3aR5eMmKTt46NoHppmUw1pyEeP/TdaZAPXCg6gPv9toI8Dl/s0+kqMBYjXv0+oW9u0Y8Hw3I/p29kSiALvv7NBg9U1fQVMcJ6K8Zvw3cMz9k3IOhFoKWcnWDl5TX1CL6Wi3iXKBoMm2f+SEqZsDhuCCGgLxlXC6r8Iy0bxfjmSa6nrbWFAJiSJhiQwvoodphH8YdYG5Ik+K2N3a+Pq5xT2u91tNs7a/28z+V5tpiGA0F+1e0ZqjWciC6te0K8+C+GI2362cAPRr2665nqYxXxaKdb465uaO3REKl1kONFIDC5hlCwKTROk/bsUnqg2uznN7mdUjW20oidYZ2KSeuKVPpB7CPuSnIgxhS+qzhoIG7Iurec6iiYd8ZJ0+CYpW3PCymzVWJP143CA8O1zr29PADpAaUc4erg7Kf0bMNE0WCAU49uuIM1z0v7Id3NIhbg6fXxkDAIjWNMSVMy6yf6ZFRTyHRouPa2MFQxuQnG700DJa0r/WyoefiD3vwG67dFtj4d8hQ8lOeJQpEA+HPfnWD+23GL95J/yDx3Ept0ATeRXCAnuZJIE1x0r/bcKZUwYistRbcp9BaF5ZjI3K3n0bmNSjQblj30JO/lyjIGYz2DCCvmwXxdoQh+g4hXLE2HsaYiLBuGTQRmBeMke9Sini0mT0lVnQOlrPAsp+NI0KMOBwWPF1W5MuKGKWYekoJzCxRDm16D2wASKITJUsKFwxqwQYoUN6+VrZQRM/2yeel/7wy6coxoLfdfdr5A9k67xdSWImkWCdIdMfoeox0A7pnU9LaGn0tRHArIAgS23FKaK3hzZuvQbCGwA2MimmKaDXj8d0bfHL4DNvlCSn8OWq6QwjLzpnhxhKxIrIymjbyJer05gruCxyjjfR3tWbm8ezzlE/VVgY6thTXbqyNct0MrVzyAGAwXH7cn9c69M9ej3HYGx4/D1y2Da9/8hd4/aN/j4d3b3B5OgsSndZbW7pYTBHL8YBlnnE4LpgOBxCCtoDI/nwiLR+IQKjKk5smDBIDtfT5KpDS7e1JlPYGBFZIcwoKXV5RKntARZpcb8jrhhaiyqWwm63LJOyOtu5Jw+9/+x1++PEFzGJQX1aJujPYZS8b31J6pUDIdaj5He5ZawWRRKZqVfAhc3Sy1S8R3KEbzKgCWA1FxIC4zAjTBBDhk1rx4aszfvYzAsWAwyw8QaDKk/aCM51FiGhbVzw8POJ0POpztf+V1S/uFBfRF+I0aV2+pn4m+b0ywKVga03QlkvxOm+Tly7PtNWD6RQvsxqjC6nVnZKi06akaWsRtTWUdRODn660/J0TQ/5jTRdn5bGtFdQsSIqbphmmlHB3muVzpXgrIDmzFv3rewNmN976MrHOjz0zw6LYwVNoqZfJgMAUXb8T/hgEdXXNeHp40jHoObTkiGu98UouyU8pv4mDjlRrlfRapWGrvRT1IAxzvDbc9rxl3zvsavd+jY6x15m7weDzcwTh8cmsqlp/5nU03GQNA1LLygofQgN/pUEe2bpdGWR2b0ZTtHe4YOsqECFOhDhPmKOA1cm99i2TQCbJjAv3ycoZUUe0Zh3c3t3h4eFBn7Bf0PlwREVwHXmUtc8d9NTPHbqePu6LRLr/E4q02cXN0gr0by1GFiXP6toAQDwKbMYAWAt+4cbbeF17LWzBxp/jZ39dKoC/ZQz96pJHiXQ2QbxL0QtChAKQgoHpWk1dlPorhYwPIXomOCAIdbVVcJHDbsLZjAj3rrKoXtyuCMgOHw9BactkGJRo8S5T/6ztDbMbn24EmWeuScG01wxCGE+IpDC6EafjjDhNIjQY4FYkXdGK1m2RR48nv0+YqGdDK9vN+0OQeiFL0WCd9PW+Mro3JGio2gW9PtcYLaB2A1uuvgi9UgoaJA2JTMAP/HVOAYd5wtoa1uENm2IIQMDzlgIjPdk+7BRyKFo+mzeJ1VtEWOaEf/s3H+CnX08aER6/tU99IGdsatg3dEh/kJcjODJeFToY6yaB57bnKLYLgBn9HJqzoZ9BMRJNCbaocmPCdr5IaqGmSJJGDchy1wdFTIZDyqyvFV2t42tN9io2MO/hw+8fV6A1zPOEwyxNgM3AlD3o9VFpmnDzwS0qS2QhMgNbRkqSqlLyhvX8hPkgLUhKZZRccToumE6S6uQoZnrfm5tb3NyccFm3/tz3s6K+7gRYzc7xKI4GRxk0byhMaQC40e4G3XeghrOuP8WAkALIItheXyOfDzHi7u4OKUVcHp8AbqAY0BAwzQtOR4nQ5CJF2zF0iPAA4DgnbA24XM746svXeHp8wu3NV1in7+DTz34bRJPzK+ENQ60oS1SjaQq0TfWlq0fHBrqHOhlsnSBNkR8fH4Fpxs286P0rvnz7DpGBjz78ADFOIEj0qbaCEKQg3ustmbGtK+IhonnGQafPqnRP7xnvdXrltTLmkX8iPD7c4+u/+ws8vLnH5fwkYByunApdU5DI0zQfcDgeYE7PLmuDn0UxSHodVGOAWnFQgGbyqFVN94HyRhYFTGfawDg/PiCkJP8AkAxN0WAB7OqixjRn449GtDCdB//tb32J3/4gI2fuNUZGw9aQyUdh9CzPvVzeD6veWtMm0EYcwo+gshSu1MoNkjpdp2nWPQuCEqlFabe3G25vz6BwwjxFSARJ21qnhLZl1VfknkwBuRQ8PT3idDyooQYFkmhAC5LSrSAmaZoQUwLHKA3LY0RrDXnbsNaMWhlcqrSeYUu13WfxiDPXeOTzWhrJEum6SyCAtOee1RdJpo18WoITndjttPnziDTKL/Ko1IaSN3Fu5Q25FI2qCG1xYxxujmiHCSkCcUqIZRLwF2YxaJQ4RH4EHVuX9Vyb8jPshGdvRxEcrEP9EyiQVH/Tqwx4pNWGmrM7Lex2BrPv60Z49hk70zEGHE4HLbFRa29lZC5d99LImyFLdn2U+kBV/ffzNvAe+86o317X5wLdPFO8PYyZCsw9YiS6eNtbbXpj1Zy0xg/OW4wMbNTkbUnkVQt2dIyKHntzw0eNZtO/WhEHy2gZS4ZH7wMomQLxGQjYeI1oA+NnBJG8oLaGxAlTmnB7e+tGG9CnL3OXMxd1kjsLg6+/YPvYda7WrnE4ntstL13fCKNtZLCW8tN1TB4gN/dKotPxIP16KhpgXpZOiuTCyT4rv/ecWP/kYDn/GvvtxcuMSkfeI3JYX2B/iIwpWm0QYOkaZsCR9HKhgJAIKUSAEuI0YT4cQCEORpUw6bpJX5JSWwdGUYRDQ7x8ZhwQXBFxZVGZhyUO+PpB+4ZNQIJ48hCFMdfa5D0bE3eBYOiElWckU4KZcbkUlHxxxDvx6FlaWYTVpcgtNf3ravAG6ihGmEXrOrqasTjb0HH6IXQjRgy1hsIBVNt1O+m+gSAQsdSDBUIuDcfjATc3C9at4OHtI0ounlpbWvVic1ZvjtPhwISfM/pBmWFtxaA1GSkGsNJM3OD59Lau//V3H/DLtx85HTd0AWOpHJL6qAKwqVIfgkdKyAxrQ5mztW2SRpMBh3QG0FNdxg0iwHqmBGJtiilX9jmaImpf75+R/mAdSv1vf/xjSdVt0j+uDN5hF5i1gGlCacLkdMt83gxgiuapCFK3p06IkjO2bcMjEdI84fZ0kF5GwZwYvUjfI+tEmOcJE2u0Fox8WYEt4/+j7s2fJEuS87DPPeK9zKyju2d6ZmdnscBosYAEA0EQpCSaLjPKTCaZ/leZJDP9JjNK1GGUSIEEIEIUAewusDM7uzvX9lWVme+ICNcP7h4RL6u6F/pFNnpjPVWVxzsiPDz8+PzzkgTx6S0IGbUVCaux06CPCjKNMYJiBOb1wThunBKXCeIK3dHAFWN3fQNJCYQZ05Sr0QmBsb6JTWGnG6lJIgGbHlfeuF3lQmWvv68QgzYvnieUpJ+XYkbolKqTz9GiyqvWAV5dHzCMEZQLXt1rPdDpGPDq1YDv//CPkctvAlCnyEQORM6it+B8OuGAGe8HwjeLwplCGBtcHVr35lHrTYDBnCERIKelCupxOeNHP/4xPvrgCQ4f/yYAfY4v/vrfYH/9FE+fHFQ6acC6TljXFYfDdTWqHLJW17idORtsaYtOokpQ0K97JmshUlLd2DmMm6ydXodwdX2D733vuyjPDrg/nvH6zWss04TT+QjJBSmvuL65hawJ46BNgH3+sxsNPse27wRS5yMDgCh9+bQkoCRdA6LvqQxv9xIpBUNk7IaIYRjBISBaTRWjaAYI6rgGWH25GPHFxmDZImb853u7M0qJ8F1AgEqY5JnSlJO2EiCyRiGkULjysA+mH94LVARWj55QEiGFgNPdfdNGRPjJjwlDHPD111d4c7fH02cT/t1/8CWI23r64ucH/M1fW687qF4kg93rOGVrqcAIUKZdd85/8fNfIK0rYgxG0CUorL0nh2EwGdL9OYmiDqaUakDKs2nK0SFwg7vAmzqXykQZLThcx5wbEoaCE3dVg0nv2QIUkTw71QW0LNBcBasKhgClYEoZ63rCPGlj62StG6Q0Aoka6DY7oF7enMSwy6CMGjSe11Rr8xTmP6NIgGTSwAAFg8w2+KLOc8FqTMowJ9bHz2apBgFhcuZyAhD4kSaa7sB2D17lCwBCbGgrf6ZhPygE2RzflLQ+bruJ+rne4og8YqRuArzS21D2GreAfH+v/hz+LO2K0n3GMlYC9OHZxz8t1QZ04pbOKNdvMGkgUaBtiPxc7nwSo29aKrBAd3VaPcPayqX8Gh7QUwgJV2dzq23UXl+XBfOq9t9AR3z11VdVFi7HPueEdS0IV9HGXxuI/y38rs2YAW1+NLP6bjKSb4XTpkdb6ASNiC/LisN+hCaww4UMu4Js3vjmXFLUU++iwpfXImpetwg6YgT7lLPZPDIJphf/VselB63f7b6ctx43dffdZ0lciQVqkEttW6ARdo66KfM4INCoVNhiMIIiSKKtCiTnFkEyp4oALClDZs2WKTmHCqrg4bMyEQID6yrVqCbS+kP/jrdIqIqM9D7dSPejiFLfOzRS6v9QDWI2titXeL6h+5gVoUZnzAwUzZZpn41Si9B9/P1Q5dQyhj7OkUMrIvf7qSIq9SVX6u4IrXYaDgysquhT0dYU0kenRH3K27HUh3WI6qW8PfybjGI+VC3FDEhiyLwiM6GAcTUW/Of/zkv8rz95huMaqjNeU/cigFCFKxS7Nyltziq8Wtqc9bczdhhFsk0nAw/CeAXWCoEEhVq2CnJprLXhVqdCcP3kpkImalsDU/6516Xmm5AHO0SdxG4rqr8Fr7fQbbwWFCuhS7Aa0wJZk5JlWGAgmr4RqAO9TBOQVzVa2Pq6eASVAzJnBGmwPSbr2YQmN+1grEV7RcKcWXhBP3S/qbJTv1E2G2BwuQhaa0JBI8/qMFgmlQklA9FRafJIcbZ18GYOlXiJmeE9CPv7VlEJChWJweZVs/6UEwDSDXFazVhhZBDe3B1Bw6ioAREcwmB1TEDkFQFvALy31Z+i4zhNMzDf4fn4EvvphPl8hTcp4vmTW4Swt80fNdvYVLtn0Ak5JxAx1nXG/ZvPNcO+/gmG45+j7N7DafcHwPh7gAiupv8O43iLofwXEP4Bcir41a8SptMLfPSdW1xdHZALIHhmzr/D7pqOcBgY+2v+SDWIpHfoBATrumKeFQZIY8LNTh1GZq+zLRh3I+arG1wPGkg7H+8Q9iOGw06zOZIQOOJcTJeLO3yCIhF5TdssdikozJA1o2R1BOZ5QlqTZswsc9jbq0SamdDgooBDxDAO2F9fWY2wG/UBkGxtQKAOIHsQQIVa/D0P5AB1bNw5W5elfucShhQCgRxKLejWkSCGgDW93XFziDxiMERFAWWvr9I5ZAbKLPizf3ljLuOMV78C8nyNP/i7LzEOGTkLXr68AoLWEaPuO1JtjqpPTSb6NewQTrYsd4gHxBjrxiUCy0rNyNmEyQLEArEMZJMthfNrM+dSWm8wNjhgsJ/wn9C9XTNVqmvDOGodE7WsbOBgNcQEyVtSNa9aDp1Wmc5nvHpzj2VeKiqoZDHiIwtYRyUK2Y0K+xzGAdGzeQTwELGP3oOSsK5LI1FxB5MOCCwQFpSitkDKCWWVavdsoKLue5gT4jaRy19JOgZkinccB6RV9bTPqWeO1Juget62RnzN275HDCJz/kLE3lo3lFzAJaPSZKO3Ff0CvueavKCtaQ/Q9oe/JiJtLQpwSYLnNm3vsKGJZbVP7NPQDBec/LE6u+RDWW9E7RF45SBTzV76vtPQJP2zVm8dzAIuVD+vUyXVfu/vzHujkn612oXdk8KtOP9OsfnTirxWolOKFzC0z/vPYRgwp1n1Evt8bu3SfuyciISwnae+XvXXOWzAt8pp64SRtPbn1auX2H30kerf0vUL6b7h89EMMDMsa41c9/lupKofYX/5gpRqkunG/jaHrQn2xfn7e/rbudyb87bz6B8P6aQTVrtxZ00ENQeu1aFxazbOBI5K88vECGPEzl4nexAmwrwsePPyFeZzizw/OgBkDJo86H4klr3L7nQRgjk9LM1BZnJnqz+ZKq4QAkq2Taf7gBK3AFgzFlqrsT8MEcNuaNFYU7C5bvQWVXQse3m4GHTstgpQ0KKuVB0S6r5z+QBiCh2YTmdM09xghAaDTSlvVFEIrW7pP/nhPYbQEH6P9flr9ZIwAhz9oxJ62Lm8NKTkjGnS7MaOCf/g+6/w2asDPn+9x5Idhulz1TYup5tuxcU6PYS+uLZlmurnGAC4Re6yWjnCVhfHDHCo8Mf6XB3bkmfTy8XY6suMOASjmu4nrzd47fOlwMGtTHbeuplR29zNCVGkfDtlDRKQbTSsGb2SC5Y11c8EDmAhzOcZKSksdbDvidEvl3VVcpNSKnyk5Eey3FXyCNPphNcvX+H6+vqB7KHWC5L7VO2r6D5qxAscIg4H1r+vBbMTgBSxdh20/W5nRNZovs0TxAqtfZsk17jUiB9yMuNdXVtdgwCReJtke/YMosFgzdoDMzBjLepISgEoHRHSn2KN/6itF2l2+M3NE3zy5ITj8QrDboendIV9OIB5aOPb7Rcud2q0JpQimOczkD/Dm9df4Otf/GNQEkhJKDnhxdcLXr9+hZurf47duMM5zcjniOnuz3E4/AjrnPDZjwMkf4UnccRBbjCfF5zl7yBDAApY19/F4XCFYRihtPe6QPs6Rt+xWo2OwnMAdUCur68gIljXbLTuYuQdmgE7H+/w1Re/QDi90sbuy6qBB1LmuxBHGwSCSDBD4z3bawAAIABJREFUzVgB84pkwSwKAV5xITmZjhNM04y8prreAwcUYhAtdWyr0Zy17QDZ9YLDJjdH21PI9o2KFjEkRrXVNrqWIUi6p0mxbMlDna6MbBEshELai1RMhx0OO8h5rqxzl8fGyBZtPSI2Xg4TlyyovaAoAFIQA+HrL5/i1fdnfPfjE87nAZ9+9jFi3LAn+WDp9+watcm16dTzecK6JlAMONzeKiOg9axLRZEz2cabheHpBTKHXKRD0ljmCKLsgjEIJJD2BYXCDSObswYtTdCMoCF/jDWSoCyXqZQawPHMFaw3VqbS6YRuHDsDmmPEMETteQsNuBVkQNS4dobT3X6PIdp1iIx5uzTCk+I1rbC+Xd7btvWP89Y3dT/dOGdmT1ogwFEgUoO7/sFm6D15eg0YLBVpxf3rOyTrzQsAwQjosu+n9fl728Hk3+Wh1gBBIfslW+Z9+50+oHN5ENB6n0r7ztuOOETEQTuXSkraLqurYydynX3xRWkwbbF713ltNh8Z62fNVPZ7iNvl3R6vMyZ+ehuPYlw8piMsAN8/f0XB2bl1r/a9gdyIacMMbJhZLx6rOXjuUPuxIS95eOTcbN63H22v9JP0NCPVft289m6/4dvhtPnkuqcpeEiA0ZYbHht8FwH/6ULTxoPqwkZ9rwlS3Ro2dXFoq6b7SW7g1FOTUZE3B+Xx4y0L4m2f3vov9lrn0NVXWzTT70VlpTlymqXzRqeWqQsWsQqOAYYuxir4/vzdte1zITACCOtqGzW3BU0w54K8kLud6sHQiWhfOaulsmF6MB/vqjHsa0BgDpdmdjSq6HWQDxSoL9JuettAWyrd3+zfataxnawpIzJYk4ixmFHDlotN6qVz78fb2j/0mQaH9/nY1XpPeL06d0a1Hs+vFjy/WvGdmzP+lx/fohTBuB/bI9QT+oZSTE/KxpAHYNityxs3oJIADGW11OgfQ0jUONjtGzwlZ3MejNWp5LbGQGaQSZ33vK5aIxRiG7t6y7T52+W1jpI9QykKx2LWZrWzG27kkbVW00NmvfSwXJcXJb8okADsdyNunt5inhfkV29aBo0AUMB4fdCsXVrNUL/0svzD7VCzXseyrXU3cvV3esxh87NZ1NsXsOq2gnG3x5K81lQAbwfiu1pd43pSP4Nm6ahBTvz+6iGAaC2niLZrKEKIVzNoWJCKILDAtyqVCUAJKhwKIoAQ1vMEGQaEqMZrGM4It75eqDpsviS/yQdc4Q4hjhhpjznp/bV1JJDaT0mfR2vWvsaLL/8n5PMZkn6OtE7I51N16BlAXmYgLbg7A8cQlcL+dMTPfvpTUFQZCvOvUAT48pdPcHodsTsccDz9Y8zLjDiOoPgXePb+J3j64X8MZkHOCt/Meamj1+pV2viv84pUcm3wKyLIxIglG0NZRsoJyzzh53/1Z/jl3/wFaJoxXF1hiCPGwRzv0EEMbW/NxQgfUsZ0vMdyPgFQ0iXJRWF7Bt1qulzJYugC8slbNVPvP+VVs5vcsfheHNVedadNTOrIqxa3EHiH9P3rb57hP/jkiJIT1kXbCpSOEEFUlMyRkdZzzWCfIYa3Om2dRFfHWiwAF4D6sAJtlxBjRAwFf/B3fwVm4MOPAq6ur3F1YPz+30n4m59cYVmV5ANF90lfbBwCAsEYOwMiB0zTjOP9vUK9dtqrMRclIoPoulJQWFHYp6WPmVlhk1abWIrR0K8rSH0iSECDWoZsTOjBIJrWSMDWiDsUxJo5Bwg8RAzQXn4ggFjZMatGsA3uYR2R1xyqzRFDRBrcXtHZKSIIkRGj1qQNQ6hNk4kYa1an1RklvY2SQzxT1sYs3MJvNRDietTRRu7MeduHZk51uhvNJoAAHAc8ffq03us6SS1l8aPA9uPOdnlUtsQCwqbzHI5acsY8r/DsU/v82yRU77Pu/ZAHa9EPf90zfI7eEgRdxEkhot5pARewz8s1rOrE9yIPOqDZevWF3mZum0y1q00eK/cYPdx3WzunaqQAjzwrYSt7FbLrMlD6Uet3OEC0dxc4DiDM7dxdeU2/e/tr6zzXut5mv2x+rb5CP4/Vbi/lcSX6a45vh9MGM5bsvw2skVghdRZlFHi0XhUY1QjP5YPTxWbxyMZRv/cIRKv/u5uBPlrfTi0VSud9pB47pK71v+0kvc2Ib7fV34obeZUBkAhhAPbjgEyEZUnK9OdfsPqx5qCyFeb3Etefu3kfHHTB0+xpY9tQWMxgUGeiOASAZHOfDj3wvnjMQHokGwbabgNuWKMzdmp7AiLHdepC8YwZuePD7RyXjlhntPaRpI0+v3Ts+vsyRViyGolir1UmJCZEtvYVnTI43IwIZUFKaXu+i2uVIg1Db+fUTFuDCNT7h+K7/XP2Dr73ZME/+sEr/JMfP2mZx6KOn4pO6c5vgsVQUhJv7VAE2TJq1DmZZA+kuU07rOn2KityKdqraYjgELXFAgIkJ2vqSjVCbL53ZTZLWLu6i20tlogAMQJrqvPNZHUZxP3SVYjeulqPvlaLEVi3+damAgardWPG4JwGWXHsOZmB6Sxg9WIZCIeAwTMrMSKLIGW5LGrCY1tCP5eV1p90jT0M4uj6qlnPjRPW12RI1V0CQUYAS+42WNTzENwY1Ih6MFhyoKI8g7YRuY5dlhU8JECAnAXIC+LNAo4CrUFViOUuMtacsCS97zgou2Ky3mVh0P5RgODl6yNubgXT+YRxHMF0QB88kFzwJgUMRlqwpgXLyhhiF/mxuTufTnh9f4/IjPfGf4kvP/sJjm8+A6V1S9IkAqVuU/nJ2eBRRZtC55Tx6uWLGpX1gMDp/g3WE3Dz7BnmecG6LFimM4bxL7EMLxGff4Dz+tuQIohDhpisMVE1PO/vXiGEAVc3NzieTvjs8y9w2A9ISWnjd/sdfut7HyEExpoy0jLh7quf4cWP/k/kJeFmP9SgkHotVk7AbpUKpCxYZsE8zThPE+bThJRWRA6Q3R5CZSsP1Z7oYYoKyS0Uqg5NItjZuhRbE/vDCI4DBKsRNHn9XIM0EgdQeGRfdkO/TQw8KPTpqyvcpSt88uSM333/NeLuGiyCaVkVrpZz5+65nhS4oUegWsP8mC5nc4R6A6/qQ/udmfD3/j3g935vBTNwe6s08lrfHJBzwfvfERAS/vIvnSDH7BnWa4xPbjDEAQWMP/x7X+H2dsE0TRUaWYTxz/7372MfqJI4FMsEAaob16zMxcMAjEZMAgCclRW0zItm+YuADW4oZC2TWKrTxkRNn1p9cBy0bpCszU9gNgiZ6wiFu2fJVoMJ31g39bBOOuJ7NQdGDAGFAApAoYghBByudgqJ7PR8SgU5r1pmUbLaNUWqznMbwGenlNaqQElWMmD9L0NUeyVbSwad5kZg5w4HXO7csfCXnCRNBMnYdLtiAA1WmL71XmuPyZeUjOk0qaPM2htsMHbdytzJD7/3riOjqqIHNuHmkdz+gkCSknFJdbylJpa0vEC5BLzmtu0R29q4/jLbx71wc8jzge3tIg5nbXtJc3z8Og5n96958M7et39VZW1sV3P4mDb3plsXdY/VyjXIyiksVmG2cfus79YFXDkaHnMi/V4ufQUNHtrfJsb+5/+viEgAj8qpoaVoK9bmkFEHsxTfKIG6IRtSltRfqH2zlC2p1TNsh7t9/+Hvevy6gXtg8AM2ubxZcNS9V6MNb7P6H9wRVb0h3TNfXp/o4VKpZyGFpY17pXh++eJNbX4qEFAWUNSi4iGQ1jJIbiPl9w3v/dHuX3uxaZQw+aZmDinZxsZMKCVYtqs92yZqA1TWH8HanV/fZ8sM1Gbexo7oz6l46lKVbi1N7Td86SJCF3PnrzWl0I5VBJQymK1vlphz1o+1yeQ4DtjtBnVd3alBewZb2vCwUjFYRowjKD1mjOPB4Q3amyGv12FFwKgyybq55e5Zm94gXA8ZHvjQmj/vi2ObeWk1VPW65PuaILkcXuLhuzHp3yEjHxlCgEgBFwHK2pJ1kRDCgBAIKSs0TGl3NSq6rAuuhmvEGGuUNGWFhvkg1fgqa+YYxYMoHmnTTzDT5jz+r591bpYqXOlrk3UGF0ExneO+FxFVmKcfa8ngXFDciVcLR1VT6eW/mkoXI6dnC5HxySef4NNPP9XvdpvN9hzt1xY53uqNFrmEQZ68/kCbxNfAhp2PUYyUQqrsVIhss25Qcsbr12+wzrPplnZx7Z2m0Lc1ZTO+xHoiakuK/WGPURJKEjz/6DmyDLpeSHB69Slw/ScI8R/CezZtnx3mNM746suX+MXdhCf7Hfb7AeMw1tv84pe/RFn+Erf7L/DTNy9xvLuHSK5y0ctycSYdY78tIhDTmST6dwEgpCQibg7MknF+8QpMQGRGoICcMu7vXuLnP/3vMTDj9fz3cS7XGHd77COBSbMv19dP8PmnP8Xt7sd49skO+/WI3flThAlKqJMKUniOf/PqP0TJK5bzivTZn4EZWJYF+/0BFAJKSqCovQcJhMDWF7QUSFrw4tUZkjKmedGMaFd/K2hQMu8+A6M9ZyZomaU3/yWQJJzmFcva+oGWkrEu2htpHEZrUK/uGoOQmzuGSpbRB6M6ad7u1A0eXgrw6hzx5niFP/t8xO5qj5uQ8J/+4CvsBsJizlgq0pobF61v14AOEGOspCP1el6rFxgiUbk70PZfhxIXAB995w6/9f17pHwACuHFC83olopxV/31O78NfPnlb+D1i51m1IaIOIx1b3z+/AV+69/61DLPjN3Ox0Z1/d//ox/h//7XP0SaskIJRWvAtLGwNnJmJsQnt3A4uJhsEhEigFAEKQZjENW2M4C2a+EYKuFZHe2gsu81dCIrPBsvBchFA7ClLLavKNzX9YcpmzqfIBijpGobDozdYQeQ1j+KtGDdsiR10qzGte75vdlkcqMtQ9QhVbIsrckuAgzjAMqC3dXB7Avtw5pT1iBRSsiZOhsHaiPYXtHXYtXHIEIMCtW8tA43j+tG+NvMPBENYjChFMIwND2tRruApKEK2rO/5aQEYy+kmlV+7NiYPUWq/HS3tXHsKtt5yWjexeXnBKn0Do1tPnVd0eakl+Yv+bpyRnj7QLWr/BykMqdlIRfD4Htc76yxs7Er6qxvMbW5n+4ky7Lg889/jtubpwCsXMVgcf3urDY51VISM2jf6TBv5MjvAQBir+XsCu92PfRrv/4j/18cLerdXiLsDwfcPLnBvCSsk1gSpZEleL3E9rtunBQ4SQnMnG9ztx0ZsVaBVejQhE7esRB8oD3tfHnmynr5YFVDNxL7+4Ejga0C3LoAfs+PvG7nYilagFtf1gwPB0bJ/mSkQTCLLgDWf6oSh3RGvylDB3fU61irAnXOLkbGMw9kxeZETeDJWd10OTExEL1hojtn5ngzQaCwD68t14XcrsUGzyRgwzylcrXNrhFfKIZuCJX7x0gzckJJwHSeQUwYHErCQRulRiOE8dYGNVKjTqZHIwUNaqN3zjZ7sI2W4RmhX+fP6yNRjciQZXV1mDtICBq00K8KWOYkcos0w5y9ENToywUUGaEIMES4/LNozRZyUkVr5710PR4YXKQyxkNEHAeNhBuUUki0PXkBAMfyFzAUxuuyt8wLgsHTiLR59XyezQnS87QapmI49DbGtfRX1IhTp1C/k4pgNJkr0iKBKkcK2fUxZfIIqh4bII7DwCzKKylhXVXfLMtaa0nFNqBaA4Rc5bOdremgUp3PptSFuCus1ter/riYkC3MRmtCdmOEiK4k7YHWdFeFTpPK7DgOGMf41iCWy1CeE44pW/a0yUMughDU2fJm5wzR/o4hYGSGlKy9nZhwur/DR9/9Pq6uDphSxu31eyjjb0DCYIE7hXeKaI+knDLW5YRlfYX51f+GYb7H3aszTjtgR4ycGO89f4ZxfY11mXA8J5yOZy0rktbHpx/fYG5GLgJiheNa+2KF/EJqppeg5B9uqMCghUUasdR0OmGeziqr5edY0gphQjEkQgoD0uGAcL7H/THjL94wUi6Yl4xzyfBm9KF8gbD8twgQTF9eYZ1inXsmwpIykAsGGCmRZKSi62eaZ/05LchrMsNTTPeo3heBEaUUeJbOMzwCwrjbYxgU8VIESkxisFi2oM80zVgXJTZxo8mdoSzcdBMsEFCcqKXJPDa/9RaajTi1e9KAHeOUR/zPf/0Mv//REc+vApZpNqZRG4uiDuW4G3E47FAIWGaFsCc6YJZrW9QJO9zjz375BF+fFWzHru9srTAUzJGL1gNxHA2OGVAkITIjUjG4GuPq5gqCm27RaOZ0nTOWJUGdGuD2yQ0gKwgBS8o4nc549izhh7/zJf70j58irasS9pQCr7VXh9fboNheC13OxAG0G8GDOafRaszRdBWRM1Tzxm5sCtxrneykKErsJFKnxZmufebSmhAgyIZe6PWb2zs5C3JejDXS69BcNrp9SyyzRrbuPGipbyGMETe3V9p3MDDO5xn3pxm7ccCyroiD9+vyOu52brc1BBflLpW8TR7Yfp75Cf3n0Qz1Pvj7tqNtVVLRSvUcTOpwAkjLWjNoFSHhDko9F1W7yhE37yoj6c1fJgJMB+Xc3L029O6clofe1luOB6BmGxi3drqK7K2YuS0rLWvabGM9b6ne8OaC7kXpnw+csXYb6uJ337k4QggYxwGbOtnufL3Dpq+Vdk1HTknbP/tr906j2/b6jwAShCgoSXUVh4KS392r7dvhtJHbz22QHL7kVLnjGHG4OoBDhEAjLdP5hDSvVXG0GjXdfuv8dEZmM6Vhe62ow+ZGzoVj51Ch6ky81ZGTzXe8+L7fdnz6dZ677Et9twN21DALjAWtGdr17gRmCKG1Fuivgyp38MapWx/PHKmOfpaYQFqQ1Izw+gDtSfx8fp8dSVZ1nihwY+R8xPCrz8KEYAaE4/71fFJr44rYHPHFmPmU+Up3wxNSC6vrs/a/1+u333xRe0S5iEDWgpwECam7prIThhAwjCN2+x1C8IhhroxaZIK9HXaxmTajcfM07z7UttmqOzHH12ygzUFEiFHpjmMM+JvXT3BMA26eHOBNwXOxzBs8o8aQLmEsIuCo46GflZrCvnTUNoqN1AhkcyyZBJFVJnzicymauRKryyuAWJRVqaMBFmU79eswE8bdiGW2Zpi2szFQqZyb4Dsdvz9LCxyIaBasd0DdQN6MoX2erFjfQ40Ec9JK1g1TBJkZ2eogg72X1wSSAB64boQFDvHsN0OXRjHqawFKxssXL8xJ1/VZa3Qe28TgBqb1qKsLw8aCNKPeIrfdJsRel6tDF6AZsR6u5J9vASWtSdMxuwhaielKM3iHoEYtWWsFRkFOK9JMGlnnHYQPKGBM0z2W6YQ7+ggUP8aeizE9EkqxBqilYJ/f4P71He7lF1jKPShPmM9HYAIWZsQ44u7NHY73R6RF+yhKKeao6dg7DFgogFGUzr44lFRraUikwWHsKNKyBN4cGaWgsJiTIJrRNN1aWchEWUdzykYGs+DF8aSZgiKYyVWl3l8WAQdnX9PvXz+/A+OA+dUeLr0sWh9BkrGuQMkrpmXF+TRhWRYjyGkNgZ2aXffOUGWvyYPunxxWxFEzRZIT1lnr8Rju8Bbc3d9Brm8xT7Puz1LQowGadrh0wAiERi702A7RTHnTlY8YjwLBN8cB//Sz9/E7HybEcsYQVvzuBxM+f7XHi3vCnDK+8yzit9+fjPRB8HX5bZxwgzf5Pc3GlAV0/jk+f72AyZpR+x3bMhrGjI+/d48YogY0jEBDM/SD7uEWoQ+DGoJ3RTPSJVvzaMu0JMt0OBTtzd0EZsbV9RWYGEkKUso4nydIl813O0aniutwNuQAQCFgvLpSWn9b16V4qxlCXQLo+Rb0BYYgpQySAs5KGgK5qKsOJh+RwaysolqfOFeIrO905olhXmZMp7nqXUd4eG9ZD6a5c8IxYIgR+92gmbIiNYsoonX1tzfXGKIGTuY1g3iFB5VdVxGjEkD5XlztuX4D2+jj3jLAQ6flLYGs7cuegXnLZ7nbP1kDz8y+P7Z1U0nDHnOcitSL9vLx6GHj6vsZGzatbIXAPtv2RSV+2Zyk+1yr6dreBep9iX/OgjOeqVJq/86+Jg3Q++9v2+P6edkmevxH9Twf+eZjZ9TzPH/2DG/uz+hiEpenbo/tj0e+j/Rn72SIUNdPHQvLYjrKp1gttkhLqrzr+FY4bbpeqD60iECyRu5Od0p5PAyKS+aoG0wQwbJGYE5wS6M+LpH1nzKBJGoTCcA/qREcu6o04W/GsZ/O2M8E5gx4XZ2ppX5h1t+baiA7h4OPRNo7lyaiJoJs4rnPEz7ESKunrkQK7A8EQmP08M/5rqjv1+imeEZINZluBFTHE76o6qBczBsRKHY1N9RFG4AuC0ft+nVs2hgRvP8LVS9Lo4ClMnVVeKY/Rv+7iBWEEtiUD7FlFh9TdNTq8PxcynqmmBg10mDP4AZwQfEmpSLISY2zyAnADgQglxX3b6buURkUCOOgrFkhRCBwzVjWQv+3q9nL267jXsSyXyJNju2aMRJ2+xGD1Tl88Trir355jRfLAWsChqFTICZgUgrSagZxytbAXaV0GAPCOLZNwTS4O3bO3CT2ezCtV1ymxPDrBAyD05UDVDyLqht+ZgFntk08w4EZcV2RU7KajYAf/OAH+Oxnn2JeE5Az0pJaX7PeFSflTKnoK9KIGotgFM2kAZZhqmNMtQ7xYvThG46vaZGMu/v7asxTKdq7KBesSCgp6XNMSaEdrHCzaVpwdzyDS9k4ic4mBwrYjQdAIl69eqVPJbB13pS934/fffFJKasazcRQMh09OCgRA2c0aAZZphuojKm1h1Bn+ABQ57l32lyjEWPYjbpGrMF8lRUBGBmFInKSaiyGELCLQZ1QCih5wTyfcTxP+PjD93B7+yG+Pv8+nhDpOLLCdnNOOE0zxvwv8OLVT5Hv7xHGjPPxiGmeEQJr36ZUUAohl3vkdTHyG4HA+tpZtId8wzXCErGMaGB1yCCCJOrASRELOniwy+ZBNJMDGIwQgKBoawvbJ8SUo2v0LT26NP2aS93UETSr6OyKYlEJZsL+2YLp5a7qsnG3Q8kZ5/MZaxEs84JlnpXGXgTjbqeywxa8YCelaoQlVc5Y+4B6PTAHXbMlq7yGrH3DGLov3b8+4upws9kjlnVVuLg5vr6nkjgBRN+bbbvaNqZV990HAY5qnLMLOD57NWBdIpgyXixP8fLIeHW3YllWfPaK8bMXOzx//gHiuMO9PLf+XgkcGJlHnORDgH5Rr6O95Bo8c38QfPydI66vPsCz95/peuAAKqUFMS1QMU0T1nnFMiuZEmDwWhFEtHrbkrPCkFkJYSr9vSFfqt4pYpBlHZ3cGesEQErGkhJQpLIuE1nwSNRxcfIDTzBrYLRlDZQxV1szEJGWqdgYxwAwRzg6RxE8XO834yHDt6snImWCDKzN2SEqI+u6asYwaNlDIIUxFgrY7fe4vt7jej+CiDF73aI7p5XYRf9xdRwsq2aEJUSkstvtDe68ZadEuLD5fF3Vo3OIO+l8cPTS7CL7uM/Wnf/X2umu6x85nwfF0Wq9Lw//TrObSIMy7hyzQphLDdq95Ya6Aan1V0RdtHT73ToWvobd1rD10T6nk+H6TW+T6vncRvXkRYFsB9nXJ7bnrGtx43C2/bJ/RU9VaumEuhnbcZCLV8I4gOZWTqS3XB793mPnaHPyjjF/5PhWOG2Aw9q2lN/JOpSHqI1/U1JjDtCUbkrYTG49esGpM3IpUI+50zaKD1xtskjEhbG7cSKwEbb+ngjd+/CV55FpdQYMtafvuyNh3/BiYe6EsyPMAiAV764R+u3C9rFFFzWv2SaBZbPEspsdoQLag8kmakTqSDnumdXQrgvelD2BLHOj97UlXNJYnLO66bkcoKh010m6+3E6WHI2TD+NZuWqw8qNYjgEtkWIR49+jES8PtIcIovMZYsCdn64ftecwho10ZPohmNRJRFVpJOTXjDjsBuwvzqAmJFLwv/wV3v8Z594VOmhY76ZL9/kPYpvLxQx/kNjYou7HfbXV/gff/I+TgsjZWAtbDTN1qvH4CgOkaKgzF0gDULknJVQYVlt3rlGKiFa7zfa9TMaoSTBm/LC1jJhKQnn9YTrXUCM+zr2zE2BFo5gYRQuiKLrW/sLiTGEJZUzKZB1xfHuDnEYMAwDhjhgSglY1zpObA55pba3e1rWFcEIYuIwIIsZ1gKwQWzdaZcikNCtGa+xsOckESznBcuSEK0RvF9n2A2QMWKaFpRl1f47YQCBkEtGWtaqajYWM4B50dq+rSI3OEX3N3DhQJFubMfjC+zGW3AYTGds6zBddVEmYGh6Jlp7A7Zei8xK367jo30zHxoGagqFIWpWlBhlXW0OtAWHy2wRAlKy5uKMVIqS0NgmXpYZ12PEfn8F5gNux98EQDif73A+n5GWbzDgn+KbN3f43vtPcTp+g9P9PYgE05qAlLXH0xAwTatS++ekKWhfP+S63G/fjQ9ohkwM2ie6xrwuSgSKsJdmPKnuEYNDmhBJMCPVMgceHrKIdEBo2VLDnAuoW99qvCozYAFzxGrjT1IapHVYcf3RCcdf3UKK9qGazhPOxzOWNdeGwSDr2ycG7y3ajkIj7bBMoAWjmBHiAGJG8sAMsTkVQOGgsP7dYP27iglTB7EwMZ7u73G4utIWLCXBy2eULEIHsBgsK4TQ7S2dY1b3QanbYqkYJ/+cZQ06gh8RbY77zbRHKQnAqgECGvD1iXH90YcgjLpm+kAhHDJ8sco6w4qJcLjZY3/YaebbMv0CgmQncskIQYMYOWcU9aPMSWaEQSGQiylNla0Bz55co0jAeZo6UiYHjwkU/JrBwwBCQYTSvPuK5BCxZ627UnIny9BwUFmM1hvNZLoPzugvDIJR7UczkEnHJQ6m38hJNqQGe3xec3ZYIape6oMTwzAA0CyeFCU38ZYKHIBAmr1bbD8PTpIB5R2hAAAgAElEQVTi+78b7xCLDvqZ9f6FFPqvWesCKdWoquUYzWbzYDsqoYRmMw0Sb6FyPXEPYXnLBo1mNgZY0PcRO7yq+i6w5aZorZN+y/n79dH0hcP7t6vibfcpxTOOvZ1qdarUvW7zWA2Szgb0l3sn0I3JYmNYs5z1HvsnMyfP/BsPuLt+bhDW/iksO9efxwfNjWKzaUOFZfv1StW/29FpOsSLo4gJkdjM81I/Vc/U7X/EUZmRq/dFmi1jqckDHd9urO0nM1fSoXpPvt5/jQP3rXHaYMayiOKYS86VgjgnWI8OQhh1pRYESJkxLWjYec9QmSAVdJkM6uO/QBUSAJBixbTqvKiABnurg8Qo9aLi5E3wKhwBjfYewIaK3T9R7f6OSAMwBkd08IPNXRYtAIbzFOmhEDw2djeFByRrBOzBD5VlV+juOJA5sGgrz2S+TzlcRi62U0W2MJ1FyYx6U+Zkgq3ZBYK1DOpGoduY7brs91EtIhixhCpsZe7ztgTdgvSNXVzVmrIxR4p63GY3qvr4rqi0IXcpBQ4UYjNSyGBugDqBxUyuYAXcfQPuIopRZ6/fKFKplJ3lalkzDrYw16Xg1XHC1+8JPrxquOh6f3WoLMIaTM5Za0RWh5UUh8ISrq9GYH+Df/H1byDtr7DfKVvcAOD26TUCB0gRHE9n3N1plkipvDulmbVvVjzssdvvsawrnDXRld1g419hLmLOzgOFI7p5loIyhkoMxGbYShMBm1dtbB0ogC1Dy8wIlqUSAf7yr34EWF3Eepo0MsZBswOisBpnQWVodF9sHCkycipYimCXM0KIKFAynvCIxPclZy5F7OeFwupyWUFUkChqVLp+oQBJs2wclY0NZviOu521Z/BRsisI1HmuDlm/ZTTd5k6C/5/tbcoF53kEyYo1K1ztar8zVjwPNOh5eOjxOXpe8gjjpS6qDKMP6xH8vjgwBg6gIYDkDM3Uw1KuLatfcsaUi0HzgBiH6sS/+PIXICR8+NEPQKLQ0F35E9zd/wWm+3ttZrqs+Hx+gzKro0bB5KsITqej3gvYYKaoWS41Flxuu2ebGNgbdEwEwQIUnp0Qq1P1b2RbbyEAIDes9XqqT6yGpgBisGov7C9kRpPJtq8nslpFgdZfsAACRsoJKRmzKaBw4qDjuHs6Q8A4/koDmvO8WGZGH1ANGAZbPROsOS2bPiERzXy06d5ImdrGbG6mzpUbP77HVCPORV6aRC7Tiul0j3lRJySvBTxE7HZ7gLR/pcPfKcKCf4/T8dNG7k3vEMHLGwioTih5rXSMSLmAhqjOpumqu/sjbm+Hbu/QLG6olHHdQHTw6qv3nuL994DbZxOGnRHdiFZBMxMKCSCMECMCAyUpjftxUue2ZLHsp5LAPL09t0sJcP/mDkUIKQvWeTWH59BGgEwXxoAYBs3Me6/LOlABQFJntXPQKskbszrcvr7JA6YqGyFov02GEpFoE2totlcEkKT2dhEsedV5tfYC66oENzmZbdTVx6vdFCCiCBoEHa9gWVzPtoAZAwBJuZ+JrSwQAQHVUXcUk9tZ27Ik08e24GvgxhwKhii7oAAiisIovZ4AkItluqU5o+86SovGPeq4+XxeLrraB81eDkTwvET1nWhrQfWnY1ANtrgfUR1T0XHKOSOnjBBV92+JsbrbEVT9qRcsF0HDduMb//mR89S67Ef6KraoiNtKbrW356o+4eVg9sPncg4gb+ooPUvH9XLofxNYQIQw7na4DRHrklB4e/7LW9bLi+r7Xvoom263JAOwcRjdvvXH7p1b4gIp765nA74lTpuIKjhdGGKKxqN3WkmcU8Hx/owQZgC64NOaUItifZ1JM6SrSWSfMR3dzZfDVRpxOvk1/XvsGYZmpAKEYRyRFo3m6rksmgszZGpPGzOGTPhE3NSC1eH5N8zJuDCWpKOjrP5BFw0pKdkmUCqWXmuy+kiDHiEI1u7rJil2bdsUqpJDsw/7ufJxqefkuujaAoQ9szFTsSsNe9bNZ2xuelZGd+Dc0WPA0+Pt8akpsDr3buxYNE7QOd12TnInExtDTPvFNedKp1nhasKEQNoUG8hNHvhyZes1i9VgMQdjwlLFFczRTgLEqgyBf/KjW/xHnwDff7YgBqpU6EKoLJMAIY4RwRxrD2qAtL+qEIHCiJf0Xdyv38U63ODJTg1JEEPyiuurawjpJslxwPF4wuk81SbswtazjMwhJ1X0gQjZjdPSCoVVl5uTbrvEk5sFRQjH4w6N/F+N0pwz8mrMWURVnn1D6aG5BKl1n2GIusn4dQOhJCW48PUvizYKDrsRwdYemwPtJC0MgIsHaaUaKs0c7JwYkKsexd5f2HJwg9GhkdDsIFgzG2QGf8kF+6u9rnWiajyCdMz12h53VT2kRpRe5/b2Fnd39xcrsN1MvXepIg4tG9To8fl0xhAZORfsBssKZzHIajHSF9dTqPqjZnG3W2jHNGd/A0bS4muLMYwDCgeFxFogq7ihSACJR0L1vVwW7OIOYRiQhXB3dwTHL3BO/xU+ePoMwxhxNY6YiUEcAazIpwkAgbEDckTOL0EQBES4jqkQ8Dp0giAFSSLW46gylgXTiz2G5xMEwO56VWZIj4ISVaPQNbcHAHRZ2pp3pjEx2nGTGx8vW4Y2ZrRVG65wSY2AkgWIrGyMq/alYo7QyEmTgiLA7tmElAvS1zs4dB+AepRSQMYQqIauNtAmg3BqG49tZNcNaEdUMFoUXMSMe6+57B3f7J8zuUkrjm9eQAS4uX2KnBJSLgqL3WmPyJyNwr5ujt6epT2jdHr7sYO6a+q+x1bb58gcM6ZyMec14Ksvv8L19S1AZEiKAsq6FlxOuBSErLyXYusxLSvO54LT/RFMjKvdHnGnRlZO2mNrHLhCT9dlxf3dEfdvwsZ6rkQEUNgeWVY1VSizYNgN9Zn8+QKpELl+KMWYCBW8oHJiOjfGaE4bVTZGt63cTokx1j0JHMHWDsCDYyAVuVwK8johp6yoh5R1PqvdIXWOqK4XD0ds4DWWme6yMP2ebjpSA6JaP/3QnegMOAAaNNlC0kpHNqU2VzH0C9dgjVyez/SEa/MqbnWjawH6arQ/IpKm4jb3vXG6/JTUnE7A3i9qd3hfzNJ9V0tyvGcmbdsjMdXO2v05VQ82x8CDbqVkIKEibqrDI/4dsozZ44fbPw/061uOIlI5J2ofZiLrTS8X1TydDhFczP+vd5gvj0pMJ5eyeDlL+pLv7VyN4Hbly2+UvGrLDWnv29fbN+rG3Bk7/RO5TAkA6UiF3nF8S5w27fXTjBeDApFG2FUJFMzzZNFLZ0MMhqmmDelEC6N2GoG2C6Y6VOZMhBbKAPUftvcd/ucHEzSib3UelUKYyepOzCk0D6FXULIqvjrEYEa+RQEJqPUSPtGEqqT9IRQ9oO8zTBFnv9d+ZC+MAzToYB9t8ntksW46vWPjwyD+W9Nm7hy3cW2pba+N8c2/d9Rk8xNoSpKq0iNwJZGoGcLSjNQqO3YWzfRAsxtmtG90e4XiPb7w+7osj3V4jZFwgNo8HT2+UyXLxSmZQcbcqRS1wdjUuGaE+/sGlDb3jz+/wedvVvzeRzM+jA2aIAX45fpbSDLg+/LXKIEQo0Zz/4/PbquBICAkDJiGj7A/HBBYc7Mpr8irNsZd14wwOPwlIhfB6V4zIt6+IY4DDp6ZISCUAjHDXsYBeVma0eePDCBCcHOT8Ud/9DWSEE6nEX/+rz5EyQKOWtNHKMoC6VkHLZ3QYn6D3TwWSdTsgEJAmTTrTlGzUWwGpCyrrQeVgSgAkjYoYIMtCghJBJQdLmfzRABRxwaFtllSdUb6KfbM7qV8bcdEYlQIZsrgEKv8SU6Y12Rrii6CMYKb6+v69/MPPrxw2h6MTvvb9B6Tk4pYBrtkrGvGEAI0+GFZtu55XRargqxrX/BogBUNKsLk5xGDKGkgpxp0KJuMt9chuTOU1wzIgnIWrCDkknB3f8RqTv7HH3+MdZ6wzGfAHGEBEEmz4yTJ5KNAkBFJswO5PouBqogRdyNoHTF99VRrgM4zuBQcv7oCAKSbDAoJhw+NiKI+uxkzhkuv2WV3uz14YPyzBj7UmhkmvbuiuiSSCkjjbKNWrE7aVkJy0qizn9dsneAbHRn8TRjD0wny9U6DBWYI6f1xJRup0Vxj82UOmrErWoMIsdMSgSTrePr6YCWbQGlQc2eGJSagMhKrESekLRuIo9bWjqPOf8oIgc0o1/YcUmnyvTa3P8yMFuDSNKywxn7tMCMBEGYs84zlbsUQo+rzQWvFCKgIjpSKlXjp/p468UcI1XgrpFHH+f6II2ecjifsDgewGWRLynjxq19hXQs++OA9XB320P6EHnBzyKw+h0gjqAEBec24Px4VQs0NWlYP1rY5DIW8pjUjw1gXReu22sQIxJwTdTgFMHIkDc2WWi7RO4RaQ2wlAVn1dDHnTJtZm+NXtGRAe3x5yQSMmVj1nWQjj/LAjOtPzz7ZXi6mO7K0IIEOlAezO2dH3P5yy63z7N1iMJy7+L4tUnW8twoShhF2uZ638zhBVnX0UDGtzOVBNkrIA0/4tcfmq253bWwiU1OW8u5r79o9OamTO2y0uYBDF6v8vsOVqvXq1h7ocu+CXfdv4yI5zPTSGXnnIWpbSc2UUs2SPXQBu/XQ2QZ08Tnmx5/YxaPPxW4+WZ06wXxeMK1KJOfIrwfn6g7vIwt0cvoOedAt8rFAhO4bgRVe+euOb4XTBlNu5nPWxaAKr/XIku6BScyIBmFdM86nczUGhkGVZMmKURfXmDWC3U+5OYr2Qst0mZCYlJRu8yeD/cQYa28WT+2W0hYNQaPp3OFuCWy9c/QumKkWyZNYyrq7txgCxv1oDF/b6S6i40ZFUNghbnQh0NRJEjdrVB8W4kYjoTmK2Aqf/+oKepOhMNiaswG5k+vfZ/L+PC2K589WM3yo07NRZhzYsjhe7Jy76/ePKFXJCCyCq1geNEjf5dNs/yrY7Hu1AJsjIYpG7yiwOQlUZWNr9Cq8JBuWPkTWSKVIdVR8bkTaOAKEOQd8+jLiq/sR+8FHCHj//ee4evIRhBhfH0d88/VXGOKA4WqPN/NQM52lCKZF8L3vRggKEhhBBOucMc1J2ThXRhiqoCtdddGanIIMHgQ5BJynGSyq2CGi3Agk6sDE0GWX3SBVE3W/S3j+YVKTlTKef/CFNthmxhAC/tk//w2cp2wQZAJbxoeIINzBg21cihfNqyDVjT4Qt6wBKa1zNgeFCaBSkIkRxeql/J8Zy15cqag3M2bhsLYLYX/00DkLrDWNYANLktXSAbVoWnWUrYVOp6R12ycH3bNrZBWAFHz+s59fXFs2/3d5cp0j4iaNZ4u331SK73at7buq7JTB0zKUb9vU/dREGOJgzqm2hGB4jrWDj3ukP4s1k9WxKOKR3oJlnpW11WozpQhevvgKx/WM9Poe03lCg4IKEgoECyDKOcZe78qa2TCUKbxTjwCgwNiNBHy04vUXCnvKIHOzCpZjhBTGtAhuPzpWfUxAJZ9yFapGoVTnvuR+Q5ZmqBZUtj0pGRIDlHxHDNNnxr3AnCm9WW3bogGGgW5wG36Is3yKlV5BiupUsf51xVpdsEG4USybfGFYus6KVgagxCr6XUAz4LVdiy5wFNJGCFKysfcxUFL9yOappb8Qax2nO0vkCxBV81f57USwmVae/dAIvWxkWf+IHFHSCgFwmmYMpI5tgNalMMzpYiWqcEdBTCczMSIXrIsSwMRxRNztgZCs7yBVuD+JgFhAISpaIM1AGBEZGAdWB3HcAayBOgKBLGAUos5/Ngp6giAwEAMhI6DkFbuh1XC5vIagjd4rWgVQYh5bYcyh1e+IqD4yP7hczI/qpAApGYUI67pgtbW3rkkzaaVlAitJj404B4XaOvy/EiJV+Lk6bgXafoI59LOre4gb+YTa62qzj1p9WYOUtf2q2mRiTpNLiVCFD4shU7yeXcnANLur458B6mrOq0Q2feYSJi7Q0su3/q5ZoAqSN91vxFd43DAHAGLGMMY6z96CCBbgSmtC6BasOzJ+3Vbr3Cl3UpKXJK3cwE/hwfbLrcwdNosT1drDd2572zPAV6j4BaXtR0VKq3kUbQuSxe3DNn+tBGR7ZgC257c3bYvTEfd95dIWfOQ+eyyN/7wYQXhpVEkJmRgMVvutG5B6q5sASUGWgvgWgKigZW/9bh51h0XlmDhDunZdjx3fEqfNDxXiEAKurq/w8cff1fEijU71KoQCKSPZmlGyMt8RMZgLBmsWyqvVE3RXEKgDVmqVo2LjQxw0UlkloHvf4GN1sy7WZDEqZC6tCygwJHXZuD5yaILllOL+GjMe7z/RxRLiOCiMwe/NhLaHcqScsb6+R+0ZxmRNhZpAb/qlUFPyJL743AD3lHKLovkG4kZYU9g6Tqnoxu/mafbKMHKDnHQHwXahVOH1++EBJOYQMLWMF3ULnbZKxeGcwTxPgtfSOWKnLVmvsRFzjnt3LjBVtkQqGinMMQClKTQlVVFKfJdLFZO+NovUKCtuFABSLBscuuia6AYWY4TIqpFnJpwTYUptc9ulA/ZWbXXOB7yZtOfZaL2rarsG357LCpHo5rf2EgoBQyCsUTNiEL3P/W6/kRWXhzcv79Djz/35d7sBh/2APhJc5Tkwbp7d4oMPn2vNJwc8/4gAb+bOwH/54Qv81//NBxYZ9snVqGgga+AeA2I15AUshJKl1pPq/NUJRX8U0ShwHAaMNsbsUUigZsD7uslVGDuXcY/mGSsnirQ6N9IgQrZaC72PAqZwARls7hREGd6GEKpjx8xq9KHJgf/U+KmRAdhba0oPtUMLP6NWc+sIwCa3tuloTh3V78paQKPVkvT6rjOXAWjtX0oYY9jU9l5GnT2rXlQMqiXGzNaLSWux3OrO2Vq0B81gSylISTMvOs8JJBkDR6TTGel0gog6IYuRPQSrk1hMvrI9Iwmwr82i1RFfc1ZDFQU5D4BMWI4TltMBIto4XUSdoyz63HI34J6vcfXBSWGyze2rYyQWiRdzepizBTi4wos4+DzlOropib2uU1aQwaT1nqlonVkqMBZVIPAB7w1/CAIwZW3arXNqc1U0AxICIxIhE+nVSEm9vY+mquGgjkdFSbhcQPs+Wh0yfF+qoqUszVQKwFLrwKpRy16L1ow/NRb1XD4fcAOd+u5FsjGefU30Uhaj9gRd5rm+wxDcvX4FjhEBhAFSHfbATeYJRQOi3ZFT0kwkF5QMxHFEIMJiBmE25EwxArJiuiTNCeeT4MnTYsy0ilJ479n7dbyKN2O3daFtV3xNt70CEOwGxnjt9WO2z1vaIOeMMfo4qbMXrLY/DiPioC0HAm+rcTmoAYgiyFK0Hli0vUsWZTktOeN8POu9EWE6z6pvTaaItA43Rr0mwFVmypqwrsnKMXpH3Uo+uJvnrVSY3NrrWoRY9+GqgULEeNAa5RCC1lUawQWzwpLJnMRa91v1W6nrPo5sbJvmCFtgxLwMEBWweGC+2WvFl7ntc82k6/Z5iJHxOGRa4FV4hfpBeeSwYF0JjCABQmI92QRiAQjerA9sxm0IjDW32lKVjs6pof47l9/v5sTtO3no1G2u++hrqgOKGNrFz3kRjPELSa2Js1kubbw3jhuh7l2VXM7+9aVDve6gaqtv9ztyR1/cTts+P9C7cUAMAUMAUkqAjPAMjL9fEEAds4SuC4UKNbvOaWja2GmQ8ZF6vssxJQEhvNXh9+Pb5bSRRcmiZst2+1GNWiLM01xre/xgJtAYcHVzg5cvvtG1CxWowAo5iSYYjgkGgARggBp5SylIYinwjr4WeEygTRhJazQ4NNpe3SPNgBYX3cucLdVnMPdC75f1s60fmkEDa/rYcex2sqCRRPEHdueENJpV9KRtUKECGwfG3L3aF3LXbKP9q4yJaM5hfVAfHPsR2VmpfDNNAEbDkMJY99qC88hcLSx9i5Sq8ew9f3o1YPVN3eZesrE/smY3duOAORSILLoZVXikH1KNSK/V4jq8zZBxQoJQjfnWyLtmIMwJCszY7Ufd0IzMAwIUy7Z6JsD2DBCgzKiiFhwHBpJuPF5TpvVCVA2dLvDUOU8OUSiQtALDCBR15qMSQoKYkOcJc1YDIsSIcReMxciHQ51IJkHKDyel5AzBzjEtWzOfFPolIWhQxHePONr7gjhmfOfDFb/6ZlRWtZxBRTc5d4RpKUg216Q9FcBlUIICDsY+Z4GDclH/CjNgRKw9AJAWzcRIKZDqNLvcNIhSf/ROiWfQCJrFSzyArDBOaza1NiCSGjYoRZuW6nRhHJUxkrg1F64XlNb/hnz5US1fRq71dy7lerNbRwubc9b3SBVDBZ148IIADKFu2J0wbe7La1NAjJSVdOByoTZTS7+Tk2ZsYxghwRxvmxop7RuttZA50VbbVxvOQirEUUxXBEKtfxIiLAJj+RQ4W6465owlKYxP67cUblgjwCWBhDDcTBiOjPnuCpqR1+uWlCv0fH6zw3DI2D9ZdF4669Sh79r7r7UH8EFlDiAqULdfNjLKRlihgSjRzAWKsSRbHVIuNmiC94c/NN0BlFWQUlGCCNubis+xR7o744aZDE4PgBgDezDOrT2/Z6mBBhSgsLEVFwEbk5SqGqo9Bqs8CQElAFjh5EupFMtU+Yhx3ZJq5secuMcOAtU6ZUCvmXLb/91MZNLgnhLtODKDbD5dtJ2YCDX4en11hTkVPHn/PQxBHZE3d9rPb50XpHVtJQ/k1wSOxwH/1796D0/fO8J73BXDrpai8kis8rCcJ4zxGuNuUNlm7c3GpAQh0zlimUfc3o4gaP1iloLBeuhBBMPI2O3VeRnMgdJstMIjUxIUThhFEKxGuxiSp46vOdfnOWE+T9iPsSI0OIaauXaII0GRAIAgxqi6y1lnqK3jx7IyyjjpYad+Pt1o9jlpATS9Ra77nNs7LmulFEMvutPX11+hsmB61odj0H2smnKKuul9AA0W9VkaN85F90K/Y9NTvVviD9+rWiYviXFdRG913DgGq01vdt04AqtoXz7p5HtzTTvWitBoa9hu0y7Z7w/9XLWauAxdM5u9bmPa9d97uEgdvaDtsAxG3elZ/W4XtOkdNiKDpgFtVm0PNCcYnoAgt322o/Eo+oMIPaMp7K7URpYaZNt4iHYHJIIyrUjnGYUI4zjW+ZV6Jgu8uY4nwhCNfwCtzKKZyqrDfEqkPC4PLaBK7/T1/fh2OW3V+NAtIeWClGaQQ2YAXXwCSC7gkpFLwfvvPcWXv4imaNoRaGMiIQkUPmF/K1EB1QhfLVrs5GFDdV5fs18qdIhq1AnonBG7uq8Boe0iccMdAnh/VvHwgzltJvMtcmCWPJmjJvX1AOLUxs/37moE+r03ZeIbg9Qx75QrudLaxEz0qcz2dKOgZnws6rrBaqMZVPV5u5NcKgWvq0D9nt5LZb3cuAq+j3gFCZQliAOubm5xYMb9m/tKgtDjlEvOWOa1krdIp2OLCAZmUAwKbUwOoVOlUFA6I7spfoHVG+Ss88kKUSxMG4hsf3gtmYgxWLKADO7hSq/i8ju5q8/fRYRzypjWFYcxIa8FKFL7R5EI0jIhr/ocYRyQ2aNdLYtMUjDsRqQ04fLIWZscK1VzqTLgSvF0POPNXWNEIxRk8VYVgrSs+N3fOeGrLz5GKWp8UhHNGucGn2WLSkMEWDJSSMhFo+cAFAZijZKbDOhcKMxY24WQfbauRtfZZuhdzp8LrL8uvXK36QtO3NDvNP2kkrKkDYM22h0Gr89QQommJqR9He0eNM7h/dserr13H1asblBS+JiUjgUDUIc7ErabsbtgHeEPczWWmJQAxF8HAH8YnStlTlwmNXbH2wtd1x/9mpcuE0pigTCVhdX6gnmUnIkR4A3hjVK/SK09AQFJsrEI67MUHwi3tSwyxgLsbzOwEJak+iuvWkdmhYyqy7rRIfH4mGjNl2hbCpcV1/vFvFVd82UbrS9AoWK2g8HMSJ+51jbDgjt2625ooXTtRHLGKmreudEKgjnApTZsZjNlAzXyh35PlEeMHw8eNnRLN35ek8stP0IMZU4kpXWfJ0Y6Z9Sm3caw2KzahmjR7M6WRfVhRL3fJxxY6brRa6ffvlrU2RcgRLAFcxACghDWNaFkoCQLSlhWoMHl9Z7dMAOAN29G/OkfryCs+N1/+2uwke0kC07GMSKlghcvnuA4DaqfxYw2gTFVAy9eXuPP//wa//4/vMNhr+PHApR1RSHCeWJ8880zPH16UJ0rwLIsWKYFc0pIawITYdzvoDWMSpjl6BYSox43nUc5IU8Tsgzgw95QKgSy3rdsdV/onG0dgn6/uXQh2ry4LlUZs8BanUFY2tltFB0rDgHwjFXRIgqqOscZwJsDLjaOjoqot2frhkNAjAYzhe5vQo7Ros156qbXP4td30x51FIIt1fqB7mTYR+H7twiD1+zsfKssY+Zjz2HABhai1Fj8XjY6qX9LmI2WJbKHAlo8qNvn9Xuo7WC6N/bdkGRzbBI93r3l+ko06cNEG+rs0El4TYkyXa83XiQ9lnXoT495MksvO0wfWDnzpIRH3NrRNDAnD3GqslnFg12ZHiJQKj2bP/k9ZtkdcHi5w0axHNmFeoRaf0Y1rerXfz/5viWOW2mrI1FKKdkxbmokUaIRrRSIcg06QbKTWHUjYRoS7/dHYEUTsMilf3s4Z248DRHst1iW4kcrI7gQeNZ/0g7gzoG0j4nLXor9X+9IanXVUiLNmq+3DxBvqG0pHQlu6j7LW3EFORpY3uXA0BSjR0vW26GFXw/86eC1EXQXiNslaMb4SBV9pshBCotuxv/IQaUlKqjWJe+G26PzKZnEtzIhTWOHcYRCAFxmJE7h9f9pkQMrAkbSkqCFcjqnF5dXyHljPNp0ns02Fnv/FXnorsjH1ryfh/JHCfycbIxqspAlQ4H0t5Z1JxVDjrvYhNQSiAoNAkAACAASURBVFFcuznIAnXclNVrxYsXb7CbC6JBQVfp14AuoGIsh2vOKKmx5BUAeV2x2+8xnaatfjXRK7lg3I21DxSTkviUQBjsX9shCLFTeojU1u+aMMSAw/UIEGFdElZjQs25k22OlW3Mj5wyypo2BkW030UEIQ7Invk1Y0c3IoXA+rqvReguhxTQK3SdZtcoui5D19ajEnEwofVA1Ixr4IB1XVACg4rmDotnBiEIkRDZiq7MwBLRTSpEkxMtNkDPUurQ5EuWMDeC1Ghi609luqW48yZaG4MCWgg0OEMoNQ3hhpw7LeSGTNtMma1uGEoiEGKwhA1hGALWlMA5IRgNv97+du363G2zj6LwaCIUcUilTzEbtGtbL1Kz7UURA8gZmjoBhD1ooZfwBiUSFK093q7YXZ/x+ufPkJKRK3TrdLheMFwvdfNtrSNs/ZdmnOqrrgGbzLgyyB1KhEAoKYP/H+repdeSJEkP+8zdI+Kcc+/NzMp6ZFV1V0/3aERJwACkFgSHBChwQQkQIYA7rbniH+BC/AnaciVAO3GnPyBIIggIkChxJE6PhB71TE/PsB+aqaqurqqsvI9zTkS4m2lhZu4e596qHu1KAVRl5r3nRHi4m5vb47PPgrMlisEXrc5GvPm22KNUFpyspNZp+qx1fyegRvG32QCy8ZNGnR0+6A6vKK0/YHquMpu2vUjQzJsE2Pc6NEck7McrpJRwetAGzPDAk7Q5ckPeQ4XwFbXzzgNHVWd0M3tZnVyNdtSpevIiGy6KQ1RFHXQA+XyGDEooFq0+bBy1Dm/hWUkyRBQyb3bJ7d2I27sRAYIvvtwhWvby7Xffw+GwBwP4xc9/geNxwvmszjhDoZggUYbgccA4Dvjy9YQ/+Dd7/O3f+8sGmSXC//mH7+HhOOD16wksGafjCXlWxkbxuiYRhfQ7I62ogU+SteZR2Oj7AZGCBME+AGS1eiA9A0JU45RLAQeFo4dilehFyUU0IMYNYuhrVwMSKpPKkkxVLsn2ip+dj9aGDXFBMFp2cwKslyOC94bjajfVHVbPBDtFXUahiClCaxvg8On2aVTPwAPmatd09fcuYmZ7eA0Yuqf6Z1qjeIMhuza4fGfzRKpK71oLVL2LCnTv5ro+rX4a0LPXHZ3oDI1oTh+69653cYe37snNPx+NWS7Wu/+ZwJED9qwskNTpDfuwQxWfEAF7K2utItvP1Lu4/da9R0OVOERV/xkevUCVEHTuYdXGJgaWAQ1giPWO22JcHl0hViBalXc7K/ogT+eY1JW7vG8NVP3/raaNbHPbDOjPrEmZkCpNANW4KKUgpYCU7DCWFhHbmDQilRmqhoKCHfC2RZP/XJ/anrMdnEUU9Al+VMYYIUU24+4vsx3V6K0Mat0hVqMy3ca0lxAWoyfXMQSxzUhtCzQ7omXLaoamg0kSpQoTZXQNSc1wU/uRgIvNgWYztnfye3YHd9NBYtAdag5l/271DtubElHXK6s3Fppj+tQl4g6gzlUpDHABnPyDLrMKbpBjE7FT5RIs8h2wP+whIlhWQVkXAGqgF3IxUkfH6x30A953T38vti7+jOjOpQ/HyTVCsGibOlWBgOubZ1orIc2ornNqWsojZ6LCheO9Ntj1Fenx1f28VqiJOQo+P4UZ+yFhDEEhaDUSCBAFI5VBpf5nCKyABPurK7z1thdKB4CKQmNtsk/zik8+eaMQNGbMixoBz9++wcuXzyAQrA8LZi6YzwvKmrEyI88zlmXVlgsR+Oi3fgv/9s//rCpdzz4Mtt6lo+F340/nbZsx17nLEIu+B+JGBCBbaRN4xF7lTYJCsQYRXB12mOesgSAizCIQgxfleUEpBbtJDcFIgkKEm2fPDcLjT1EqTYFgmnabyCygeoN6uerEtr+cftsPsY3cm6LwmhmtbXOdajqtDypBj7ZwsfO8DjakZIaaZVRCwJDI3tNbiUgzxGOo427seQ3S4oyloW9zYvLGwiie1eozzTbOQLFaY04OhWJqwHrPqdPDCCVAovZbA444nQYwq0EeghtCgjAwQuQqRyDP6Ktxl8UaFFvwztsEaPZHZ897XOvc82bR9HBPFeJboOeLZ88hXrtn0DtR+KaxHZhjag5NoJqA19rpAFlXIHl/QyXy0PYgnUiQBmIoJTtDNWPh3VBtYXXYbkWKZkDdWRj3Iw7TDkMMBtnLKMtSzygrZ1ZKehJIcaglKimI/9vFtDfHq9UFglv+inqwr1xsBmf2jEH1b0xJg0cdzDwQkLmgLBlyMn0RR8RhQBpHEK1YlwXR5qg8QaHKIHz+xR4pBrz97rsgehunk2AtBZ9//pmNsoBIMATCMI0YhogIMlKPARDGV19E/Mt/8R0UAKuxMs5zBHMGr+dKre9BaAFhzaUGPQVmz1TbMNTzlgTgdcZyewfOBTQMCPs94hARFj3vQrQMW4z67iMBUmomgHO2vd70qXS13m46iWgwDtwFAuu8EVpdT/seTKf2SIBK0nEx31Llr/9Z+0fo5BWAZkKMERPGeulD8W4/NQjT7oiayfWfkJ1zRB3J0uW10ZDoe5A+fgdAJJgMiwW0tzbKU4Z9+2k7BzwUZOahtufBtqfvdgB4MkshpoOAx7aSsNpUTyEnyDPo/llLLEi3T1twbjsH/g8SKLHYk/DBTik8ehWBk/r0OuNRcMd/R/Y7s0n6Lc0gxDEh7SfQvHy9o9aPTErTPe6UitV1eu9b+Hmpl9MJSgh1n1TiHyLgNzhswLfMaXtSygE1vnuHzf8U87s28LGWAvXPMfSw8i8zeUoTABr+um6J5i9o5IravfvifTd845AsStuUkQa+esfkYiP45q1FLe1jvgGbawQTCjdqLjDPFJCCbv5q7PXPE4VOuMPfGyEQODq5G8c3iezFJuo3uEWt+lv1H5PNqB4rh8v7yGb6yJmuuxurc0BkBzSgxooIzvOiDmC3XjWDSdCsYuegSvefX16vMIwBECNN8MLlNrn6/26wlXWP7JmRmuMZGlZbP4sKdfWIojvOMQYMY2tq7HPmRmxt4m1fD9FZvTqVLReHB7mR17WR6NYla0QAL997CeaitOmiNW4eba1YChuTFLZslb17YXiBrvoQUg/iUopCF0kN0iUXfPH5Hc6HBS+eX2N3s8f1kCr7Ws5a9/b82TWyPWOIAct51ueHiBQDOCWFQrLOCwFAKYgioOQRSHN2uDee2+HsvX36WkmQN0o2Y8FkqLBmXvKalXCAWBmnSNdmFSWRGMcRsi7IhTGNCasRmeTzSWGe/dLY+lztd8reaQfCBlJh1nPVHyFYnxs9cL0dgUZ+m0B7g9MKhnbCCZddETXO/d/d3vAARxMpje5ztqyYMeJy0QglBcI4JFBUYBOrN+tK0Q4nNmY9+46tR141UpuCuw26HiVbsMwGUopm8OrQo8FzQmfgm6FFtYAiQEghhsSEEhhUBM8++goPn70NXqMyYBIw3azYvXus7y9QuGPslOhaijqBkQAUhKhZCt8X3h6g1nVYXZDaqRa9p6JpP7DVR1KVN9/383qLQG+bMUQNQh7NCDEmypCaI4wONh09C9zJk5KeqEPKLBii6ZCQQChY1lLbDsDG6tBRgZK1MKtTysx4/dUbPLu+QsmM4/0JSy5IoWBdVggXzaQvKygE5MKY5xk5FzAX1Q2i2eNqt/ne8D3pxvSww82LBXlNOB8DohtOdTe35CECIQ5j1fvuCAh0/w5prPJeWGvUZbagpsCaqpvtYPfdPMl0tMKhk/YnFEYYIg6HSQmghgGRDOIaA9IwIKSIIVg/xxgNebDi9RevcX8/a0bL9opHfD0YXYoyPEbf8U15tQ0aghIwiSMcEsYXzyAAlnlBGlId/5gIg5GlcKwmper4FLWthmhtWymKfNJJcyNe9xXgel7q3y/tuWrEwiGi+m6ozp/J/oVZUI1we9xFrl0/EzpjVxigiFaJprqnZ0i0bXNxqXSEi58RYE3MzaJ7Cpp1cUnn0NZnbkat68tm0wlg8hq1BQqAi6907+tngP3dnqXohG++njK5yII6m6d0dsUjJ66zqapuMI3WHxQeBFLbLQKc61x45k1/pwP3IEFvN/r4qtnph5q0cXVWcr3CE+PejH3zO4F3ahYAmQhRqEMSPB5T/V4nC77GNTEDanW5dgN3si+d/xYo/Qa72K5vldMmolE/DYyqk8IUQBRbQR/MaCgGvRmon1u4VU4hIO5GCAjBDqfgBhkp/S+jebvb7/sktrUNQftjoY+K2ESnGLtIK5lt0QTNjbHqFVRj+XITuUdhAucGvkcIXchhEWjSuYhBM0NCxnYjBgTurkCC2NMxBtqOkboxuNdZF+aJxerWw50N/bFbiW0eqd6vOTaXN9WziYxNs93/Ub8M6v+sIIKmZMygFXj2iqqP4QpIqiXquQCDhMGdIX1IKVoYvi4ZUhg0ehatTVpl2rR3ilZAXUpnRMMcZmrmo+9j2IFONlday2aR2KCOWKCokWtX1CKb6E2Fk7oV263fozhItwQiXbTa3seVhxZzBxQBTucF5+NJacJDqPCsIqIZamg244P37nSsAFphTFtLV74C3edsZB5SCu7ujjidF9xc7XHz/Ar73Q4pJOziBBojrm8OuL07IYaAd14+w4cfvAvOBcu6orAWcJe1YM0FKUY1tFKyegmH69g8MaOELp/jGlkUhh1IWQR9Tf1s7LOd6pgT9ld7xCHh7s29rWHAAIWJFmhkdj8OdieVnZQSdgc1JvU5emc3Dq9uritVuGf8+mzxJhtW3AFtG2MYBhApmYBYrZEbQ4+2Ul0fNZx73QRRch7xViGdCDELIEVrg4wZU6P/Vq8FH6PZZW7EQHdtiC0LB9FMFaB7tmbpTF9zkeqkOYKKSB031xs+H5UPxOYppZY1FZRGluRlfoGQIvDhXyPkhz2++PiM3f6EwzsnzIsdoiCDJaPW+EkxU8VIktiZZ6H3ZVFCLYIYaQQUqttxCAgEwsFq86xEkLw5t2eFCa/LnwDl38cUXpo/2ltGuvZO2IAUTI/p/VmAaHPMLJBSlCTEtmgyx8PNn5JXuF5VB0gdhFI0Oy5FSTTAGghkEcx5xfLlLc6nGZGAdVk06CIZ8+mEsxGqqGIQzMcH5MI1wEaxZQxcvi8vCgElAx9++Bq/+7uf48svd/j0V8+QAvDJL6/qcaJipvN9c33CO+/fIQiQc8DHHz9DMgr9weCmIg1uGohQ1oz5eAazIPn5CyM1c3n1XSAAzGGbxkGDMqIkaC+e3yhMMCbElLSvbIhGUKNny7LMWE4zzqcFp+MDci6IQ1J69DW7EBsrru1jFiSvhyrsxxhyXlFKqS1GPHtZxAJq/p4sWOZFHe41Q8ahwVihaBWFew8aRBDNsgS737oWpYt/dJ4b7L00p2fj3FQHhSB9mLw3oi/tDvhZuc1Q+972cxTwIIeNqY9WQfUXS6lBk4CW0BBsPtrsLNc/aC6pv2uwd4tBWxTqkbudi6eN/Et7b3tFg4TOPGtGfTMX/RebzeMQ/ctn6VReBpjbOxK0DrXvO9nu3en6Ry9h9o6beXUlZeOI9JaVK2S3ktRM6ewXr78rm0c8GoCaDxeZznpmXc5O9wzqPvvkGpFBc7UGPhdGiLJ59lNrKVBUD4VtYLyasAaV5IsbNLn1z5G1JvkG4eiub5XTtimWR7fIxsbGzBeTp5Tm7JE406NCiokeplGdKY9EaDWwbTCtQ8u3D9soVT+cbg5TTBivBtUJ0ZLnVpXrkTyNNjtBQoMawYgoWKQpMi9WNONRrIYhGDuUU/xTcOEHtJOQc4W1DVNEgBA1g/CkeD1x2SFQU+UbQ6B3yAB3FB2z68q2fd6iWtLuU0eyvS2qMWcP6X3ZEEKF0rgxUueBmkLd7EH7d2V8hH5uGLRVQl8fyNIIS9xf7UlaQncP/9Odsto3pn68KQCxwZClzbiY0keDevh7t8nVv0vHd1uheTbIh+MJb27vcHP9DIuT7Ihn8LaKL1BHdvJ1DpuP1h3qztCvIzKZi86+xQKipRp9wfCcua4RzKAp+J0fvAbwDmIKWEvGeZ4RQ8I+7UBB2c1SVKcoi2etuR4iec24vb3HeV6wP0y4ubnG1W6PKwzVLyECxmnE1bU2Q3bWUnVg1InJXHC8P3YRU43gezAIUQlmUo289vNf1XibHRfSejfPnAaMY0JKEbdQ1ra1LIi7CVOHDvAvX13PGNIJv/pkBwqjsnhezL9AdY2uo5FO+BjqWN2h8YMB3ZqK0nhbtkub7xoExWjoxWvFsuqjMFxyvdlnQ8QGauIESHZ5go+XVQkDuI23sJpmXjflYR0BQEL6aq5LzOGKMdQecuzELcZiGqOn1brhODmReSnbfkMGK0eoRASQliR2sgHPSIYx4+p6xjkfkYYHX3g7T1pQxs8aZlTSG/Ji/FocowZMLp5ZMN0gqL0sq/agVpMUjJpdiRBN5xnpz5E/xi6+Xfe+vmMdZpOzOkVqbCuiQOHiEqyZNZmsi5YcOJGHGONjTM04BQTLumJZNUOeqv4G5sz43ve+wuHqjB/93x/gdDzjMEXEIWqN22GH/X5XnQ/XTcuasczOzuiQrOZo9NBk5ZkRvPrghOcv7vD++3cgAl69WvHuu79GKYLnVy/wkx+/ZQEtzdBPuzN+93c/w3uvBGsuOD1kXI87TCnhZz97C1Q+goQtYoC4oBxPWB+O6rD6GtmVBjtPTBRDJExTwnTY4+rmGtPhAFpX7A973Lx43sHklS6/lILjecb54Yg8rzjPswadrOZ5GCNevHiGdcm4u71DXlcUEWNVNa0TLKthZENBgHVZ1ZlirnZGII3nKLmN1YN5ptfOxCiCaRqrXUUi4CVDPNBptZEkQF5X5DVrywVn4nOZgwZnmBnrvKizC8+yXECdLw8lChDJlRTt4pfdZt1C21k6NE7nWqmdohEZss1RitYCEnkHNd2VZIRi/SI7y2E9waWJSD+6QIQUIlbkJy0uDfw9/g1d/GnUK9XJcXvma2vS6i01SLOKGItpyyL3l0gL/tTvOyN3d95txmif9715eb/tz7bB+gqJvxwJl2r3qK1O2BQ5Mjo28b7edTtfl7f1uerHUN+z+7vWI2oGttpHF06SnnfaAqbaUY+VbPsZC9ZlQYiX7XN0zbyucRNwsNd+DF992sF+6vp2OW3oJ5vgRA4UdFNSb2hHTatz13vDf982OwxaoAYnRVIWNDtESs6PBPPRxHVSo48RxNp4L8C315ACBjFHU1wetwvBYEjRw3RdlYkthVYE3BwTqkaGKkirm7LIxVoySlblGKM1+ObWz6nWBT4hBBvZAywl3TI3lZSgq0HzM7fzFgFRnR47auXNc3qHpi5Gu6cGSJ7YEN2wm7FKdVxPO6X6cz+M1HLZVPz5U1sk7YJBqW5S37B2V7I2EMUi6nADx5W5Pw5UqZP79Dh8TLJ9lBpkVKng9Tldxq8wcmbMxxn7cdl+GUDzQvzHVOf8N15m5JMzIdo+ab9XrII4AYhHNYPNdGFlpyoMDgr5LCXgD//wPfzd/0SNwmVdcfurX2O8ucGQRqs342ogavYFSIGQuyxFLgCfZqzLitNxxu4w4YP33sFbRVRJQvDm7oR5zTiMI2JIWMngls4aKEAcBzALHo4nCBHGSqRBVsOqDJOIBsEkMhY+gmc8SYBCQR12Nzr9QCI1jooAQzDImCnqtTDi8Qixniueab46POCwP4FlZ7TyFskXg2bY5wJpT7LL1i49dLNb+UfLS4A5jMFqS3WzcsmQsjYxSvr8mgUL2z2mEf4GNaFAraCfYEYQIKIQtzQOKrelgDs94XNHFrRSRJQYQYr1wDISCIfCcWHbUWwkI+ryMbznmBrPoPYYEm1WzEWqwS2kcE22FhVOVud1qNqnUPBw9wYhJCCtWAojrNqHK7OAVjYmYmV3DUQKTRQjZ0Dbe+RENRTtfJKaSQ9atujbT+e4m3uBtIbAYJQC08uMLHc4lr/cGDGqe+phU2UhF0YuOv5oY9AzSTqj3nQPqfPrJteldHER3M9HkBGCIWodZhEBl4y3337Ay5f3+NEfvQIBmHPBNE1gYYzTDsM4grnUfmcg6jIXLkNuREOdS6coJGCeC+ZV8IObGb/1/YeqhIZhQAwB87zgt77/FSIKfvzjdwAhxFjwt37vU7x4ASTrNUYs+N5375EC4S9+eQUaU6XOp6BTGFKwNjhbY1CgJRBTUhnFfsThcI3dOGAYB4SUcHV9jd2QUHLGznqr6j6MeLh7gy9vH1BOZ+RStJTCHCiCBRyJMO72ePWdDzHFhB/96MdY17XLBFKth1Y/SOePiUA5azaaUPVyDAHZapH6S7pUr8SAdVmA5Ps7VsEUa5BdbO3kBIPGl6oKxyFtAt4UA8bd0KDk1YjRP3X4AZeKzVEEPaGOvrIb/653++9sLQHZHMgqycWyisuqgf3dNIIogKmgkqS4leD2o5/t4iOx/U3bUTCr7tfzojkyT53AT9n97Zf+pfY2gbRuvq5FHVD7d0/sozrS5hb+Hts57edJCiz93r83dffs5rN77pOX23FuIzxhnzHFFjjoHaFucrTxOxq7sic6ykUdel34utBdRrGz2+p3GiqFLVjov6NutGI2eK699552BC6s2E68pVsvfy7MzqJHd7qUXQm9nHyzHfctc9q01iZAYWfTpEpxWZXeVsSwMU+nEFDDJh4WoWCFsKQRfUHtAyRcEFKqNKt1BNImrX+MJ6SkOnvR6KQTQKwGY9RDTgyuRQTDrTdDn5mx5rUaikMIoBiUNW8tGPcThmHQ4nyyaEdQ2EprIKsECFEYy3xCzqVlzkSjb42A4evdHHh0gEWZ/eoqwM/XjTBeOoLaJ6vNXfV7tk/ZaqtOMXf/AwCkEODEgTV6QvSk4PeXqxW2WqWSNVIZT422vjnE9o/QcPhCRiiiL4XAmiLnUixW0hy50I0pdE5Pryj9vm7YbubCNrNH08chQVLnMAWCwvlEeySFgHGI4EK4q2QU27kgo2rWoTTY7JOXj7NTP/Vu/l4hWNTfMifSviwgUAxa1O4/Ltrj8KuvYP0LI/bjDtMH74DSYOyqgpwjfv/3vwPgBNhBmDtGrho1JYClILNgWVbkuWDcPdfs6Tjg7uGIjz/5HC9fXOHZzTWCRVAzCZLVHk7TiCgBYYg4r8UcJ0Immx8QwjIDYUU+qYyfTFmPU7LxaLYJnCtZhtaGtgxKMhkW3ewWGCKtCfIopBlEv/psj08+nTAMVDPDDV7idoLVOuFiD3R/3xZ1Sx0Pnvg8YI6MfS7bRCsYyprLBg2iiBmw3c21/pB1LyQipN1kRDICEINCAK8ZHAOGQfU1rZqFhEV5RQv9lP0WzWnxWgp3lovp4RgDhjSgSEEkzcoWAWLHnuvdop0Om8UNEo0iBwjgtYxFAxAkioYQsoADC8ZR16yUrNmErPVuagORZc+U2CEwIEWJNarWE9exghSTOu+FoaQyOs7K9CsBgTSrwcKI1jeQC2p/JrcD2p7Q+fHv2PaotrIHG2Js9a3CbKgLbGXL9/sTutRVsbVIr98qRUDOpiLmWIpnUgU//IP3UMrbADJiStjvRsQYsc7zk88RW3wy3ejkMgBAXDBOI/K8YIwBJQS8fnMLFgbnGSWzNbQF1nVFMfjimgf85Cfv1DcJMeLFy4CRAJy1ZdD+MGIOhOWhgBGVHr0/E4qytnEvYtB6thgiYorYPbvCi5cvkcahkWW4wzUOiOOEoQievXiOw5cvscxnnE73uL+9x/GrO5VFw0p56aMIIzlBTyC8eXOHh9tbO8t8rozoqqIKqM6Dks5obWQ/2z3LYwtMb0xFZZ4EIKzw33yazWwK1TljY4DdyIqNKw6psQ+bXJXMGMYRu13EUvT8aM2SzTDvbheDINckDNl50yCrXIoxyjou2hEGdtbZfGxMDNZm1afTWXumijJTV3tKLhBbW5+ovaP9jIyB2K/iPR2tBUdDALUbPFVbJnIB6iKgFUx092fGWrgFOi7W7fLzvj5e/lLnopfv7r1U16OPT+Mp+fimq9rI1r8xfD31Sb2b66/6uO53wV7rchSeUe6/Uh1ruBzoXTYOo/0iQCoZjjy10P5xEaxLrnO5qTeD1HOmltZczEVDdPm+Rg2Buc6zv0DckexmgCKD2BqqP0F61F/fMqdNr8rUEyK86IaLwhrFTzRpVP+Xl9TwK4MQaxYrs2CEwSwZT3jT7Q5yMXHCAgFjzbk+X8Sa+JK2k+4XT+EuwQ5+UhgXa4bteHfUaFgMWE6qSFwRreuKmKJm0EQhN8M4Yp1nCAuGKSEmjV5O04gYB8RxQOYMWANc8aLZ7h208LcZit7rsNYweZbCp27jgHksVP/e76KIbaZtazxeKo12B988jnsWwMHi+ls/2E0Wvt5ps8wUVLkG0Z5Eu2kEjYMVwguc0tqhbp5ZFGNG0+ClGpqqiBjn4z0kJsRY82jWa09fRZQ/vc2Nv+/lUOu8myxJqxVgLpWSPQyXc2WGRVBmpY8/+dSc7a73k81Ndb82Gm07FP2xHTBfQ1JEpJT1u90O83xGLmu7H4uy4psD4HVIXhsyl4z72zuEmOrzwzoDtCCEgI8/PaDkBiN4KhLoQQYuAuICCYRlVTr2NCQ90FkV7O3rO+yGEdeHgxoz1ZkiDIhgEowpIUVtEJ2LIBo0MpDCdTYF7FDIEOx9RARrXgBSGmCiiCHF5iiUgtUgmdHaRMSodP8hAGQGd7T+UAztSTUN2jj6MvhUs90Xa9KKwjeraT/b0Ag9+qzPcXeOa7YnmCHXGyrhQv6EtfYnFJCwOjgUcb9mQJyJkIAYtK63OhCx3qvKXGj6ZfNuQEdZbqncvjEPWVa2eNRVjViBBgK8d58H6pyq3k/EnLs5jTq+YvqWC2OeBcPgfcOokXYENXajzZFYJoNgxE2iRB6+/4g00OBy0wAcBtGEGt1e/yAiKIXqzzeiIFy3v/ebmsIz3KTvYc5/ZDVvxxIhRQAAIABJREFUqJl6n8geJuRqiAi1VYHoa6m+t7VTRKcjO3ReG6TKbux7AtoyQ8oKATCOCXkFmAlXV9pLzKe+iGz2kut7tnOQCMqkmAUZUftrEWMMBCoF9+cZd5mwZsGHH57x2z94g4CAvGatsbJnjWPEl59fm2GmZwWTWA1cBrjVyIch4Y//7AYffz7gxfsaiPH96sESigkyJAwhYBwHjIc9Ds+ucX3Y2x5P0Mw1ILDa2TCC4oCcV8zzGZ/85Sf4i1/+TFuTMFtmV/dhEVgbDMtyF0ExBAKzOaPGag2QwfKp6XqbT22+jsqUKuYQSWmna6s76zbExTXuJlzdXOF8PGvdIjQYDFAlXnF5aKgX/VlecrWhiIAUdR4pBlBKkDx3Mv3Y2fi6q7BgLauuTUqAtW12m7sa9q5/ukuEtUl5ychrqfqw1o2jtQLQEo3mVPaOwGXMs4cRBluvcUjWu5TrueWj6VkF+vs5WyrX/cuajDBHUlhb2jhbY39mA1pnuZYnwHU1EEKbtXJ/AfW8qSeFIhZlq5OJvA1M60NX7+/fY65s0iJAkEbCp6NtOSyBIEhRyKFs7yV2ZjfaW0CYLg6JruzJf9IHLdECAVtbx0iWNkzEF5+5+EvwIJqgsZ5WG0W6iayT0sZT19ic98627nXo0xeB83a+v+n6ljhthtG+MFeYlehARVbaTiUDpPik2Y/dy6gCUxgU2MgcoA3zuBgznW6+yqombdP1guyTzlAFKVYg7IrXP6sMVMYgF0khEKUgr+q952WpB7o7nD1Uwe+hAVLbtCbM3jQ8iGA9MdaY1SEEsNsZAUAulUjA6cE1EqUvpO/bV/n45QLlktsJz6V8kteitSgBBUKIAsmEbhvUddluL4JHWeuS2Rxrvd/2eR5Jq/ZbB0NoGOKtxhWz8sZpxLDb414eUJZcN9JmND4Qqyd0peFY/DgMoJSQT6U+xg/PzbuaEUbQurxhHOphSmTRUO8zA1jtCCpBwcYBCwQq6lSTk5oIIZux46j8WjgeYjVg2rw+Xos2VjFDb7vfLhUeM2utxLJWuCfIawAv+oRZTcTta8Gf/vGCd957reyKUKKDzz/f4+H4Aukne/zOmxNkVYKEUhh/fEUmV4473+49sUikvnO/gIIlMx5OZ4z7CTtKFvHr30SdtxICBhIsoUCmhLMYq11IkJJrsKU+x+4PkDqg0orSSzFDQLTW9rxkzGtGCFQP8pAihpQQLWDDNXIqGHeDZTGNtKjuP+rkSuryeX2Kv08tPBfRe1BUp743kL2m48IhNYmBU8+FtIX6bk/wpnuc2piCtkYJnbOtSeKgtYpGdUwE8DKC14TmgJE5Bb632+t71sKSzPp0J14Q3yN6/HqvSicUYVYCF6eyL74XSacn2hyCCGKGUIhKHELiBjCQBv17ACpDo8PS3V7z2jUOLTou0nHBmEHje1nVe9PzWvfXwcAINbvYxNrJD/roLW1q9aq+YbGxBiuIb02Si9PrA81ElaZXYd8Tg096gEyZC/sxNqi+8hARQhwQLKN8gkIV3331CmVdcbx7g2VdzWF0J03lW/eP9pRkBIAShl2CLAuGIKBlwfHujPOScZ+B2cp4h4GwmyJIlK3yXDSqTsL42Z/f4M9++o6O3+C95/OKn/50h7/2O2ckg28vWfDrXwOf/XpCAWFeC8ZQMO4m7HY7kGg2+abs8N7772KaJhwOB0y7HShEMBesyxllmRECYcmC83xGPs/IhXF8+Tbee/8VhBmvv3iN11981RniUh0xzQpprzaAIBxqIGqZZ9y/eaPOJvR8cwp3h077ZvVazMxeG+x156j1TU6o5GevG/M9UUgaFAkR/f4ENMZsAiEAQfV9GgZ1iguDlxWAtw0ikztgmpRIZTmerObVWRe/2SDtbbn5dEYpjDQmTBNQJsZArh+pGseNnE7/X4lkrN2K3pHs3a3Ozv/d7zkfg+BRkoOs6YjXstbvmD1EhC2DoD3xqbyTT/E6LyavUZEJJCjrqnuDNeBBBGRjzG3Gv9oBvf0fvazC7AWqjep11rX3H1V96lB9Rxr4vGs9fKo9ADVxEGowIKVU5785F41Dobl023mqM92XIbmxbY6Qw+KridiOv/ad7d3qvkIIj2pPN9/8RrHr3Uu/r9og7I1uth4tOmnp9DMMpdJQOE6IVJ3ui0jAZo465++v4rh9K5w2gsEWnZvD3VZyoW0RvDYRaBGFarCg/ikiyMcTiM7VgWHhdoCFAO4hJag6y+7RQSbbqVyjqGLU1pCuwzyzwQWD9pgquRtTO6i9+aRuwnY42iehvVOiwor0xvocH1ApWmBcNJJHhs2P5CxmrXeVGva9ce6WfXOItL4mtpe3jdPseqpz2pwfM7C9RoWaMq2LCtSIYqWuk/bLTeAHm6/VOVGGwy38of2uWptWZ+GGh0WMQaieYGcA6T87ZUcAvBmpaEYFANIwIg0JR4tCJutlVN/HRuyGfg/r6F/I1Vr9vDupMCXBYlanO2/qYKchYJpGTLsRgNWD9fUAxnSoB7bUejGPkH7d9lc5r/nN+hbiY2MNQBRz5nulFkzRZhEkl31zYOZzwI/+r5c43DwDC/C9j76L+XzCL37+Bj/4csRHxyPKbDVVUGKYayH88AYVnurrUQ8T2s4vgNqstxStb0spID57tqmvJFDNAXt96ZAI0z5iSgPOyxm3p8XgnIMZ9JrRI3NMWhChKWOVHctUSxfphqBk4GRZ/eBF/FHh3iko/XioghyqzqmOZnXkYE5sd0SYvAe33QAIQtOV9XPAmrNCuqoz3+9/uycDktm9rnpVA74GNNzpAWQtlXXN21gUM0gDKbQsGiNgnhNCHoCk0fZ3vlzx2//2pHVVpI5PChF/8oMRr9/Sfm/KkNccaKJuPFGhV1S83smDK0Dn1SKIGp3uzAUBKCkZFbuBy7aePVJD08XWVkTrPsjgoh48U/ZXsZYWTrsu1dmthCJWmO6VddLRdlaEkBic2wJEvRMIas66rrVglXsc+dP6ngJ1UK1wTWWFUPdKIGW2iykgpdQV4pM6nyIoJSMEhYLHEDsIsGij6ZQQ84pB9hhSREpGCmUkMZ6ZoTg1fZsGaxq/gIgwW5/CabfTmlQzTk9LAcuKMRH2YwFRwXzKKEsxOKyeaSl5QIcRisJlD6MatqUwfvmLazCrI6TtRID1nPGnP0n47kcLDvsdKBC++vyI/+N/f4U3bwY47JnI2Dxt+8Qh4cXLdyBhxLJklHXG8f4WQhE5FyzLjHWeUbISf+RcUIrC5FIacH1zA+aCX/zs5zgdT5p1TpoRLsxV32sD3+Y8icFOxWtqQDgMCcciWLzxtDSjm8wWKLVmrdlILs+My0ybPwvgdoSrFrGzUJETLXA2poR1XVWKBarPSAOQ1a5hq5kFNPgRowYySjbD1+VxawBfZnGa8AOSs7aDMCgjH3bKBCxS7TLNUHu5QruPmFKtAV1rZzAMCTGqjVNr30WaDdJMiUcX+dCaMt58BWhtIaT/zuNbKeIKgIAQImn/QJvHdSnVyK/kWpu79qUKaHJh9pkiO1w90sYWaVm7fnD63YoyMBQKBapoCTLH3CH021mxUXmvtN7+u5xDCooyqLoUF/drCbeq16uthnr+9nbf1mauhtbmvnZU+KewBbH2n1N9O6aIUhiRrEDBN8OT3/FTHE1IiDbPJN9omzN6a339VZ01v74VTptuQDNkRbtrHE8nfP7rz/HhRx9CgqbIRQqEqa2nWJ1DUHgFBctIQTf3mgviBeEEQ6NTkcgKH/XwrVhnc9uZRVmdeu9YpMOKKwsWlSf8/Kw1CoCRdcRoiq9hqZNYBDdo9ASAMUfaZglO+Q14LZ8XfJaijTVZoL2oYM4KO1627UmNJOu4A7jlkl3Aq3nfftZnpZoJuVW0Zru3LWoOotTPmSJB3NyvMtdd4NAJqEZmvR8BHqMLG8d963BwN1ixnkWn01nHUrj73sYvtS938iFKWuNkAoXdQe/G2U2uR00deKGHlRaag1rNmzc030QbbWfvpklnpXA93Ji0ZmGaJuwPe+wPe1CwSE5xBRhqJg51BO2//up1I7mR64q7I+hwhyKbTMc0QGTutSkAApeCaNF8VVwKNQsp4nhKuD+PEBG89+4rPNy9watf3eLDNyfMQM1yuxL+4Aj8/Znwp3vCn++o6kh3sEPU3OKnv/oM3//eR+jlVKDMaZ999hqv39zj5nqPt54/xxSTsebVt0YmRmRCIcFhmDCMCfsD43w+4+E0Y2VGSslw7cWYCbmRNkBJkUKMZiDpKU7Uw8kMGieeGWHQIkgp4Oqt5x0dd/FZg1cRmYsKSGkHthso/soidV+7gZqS1oL2BxgA0x8CP+h1L3aWR2r3DI8OZHQODoNW1qyOCMQalHt7CQ12Rs1KC1SHuuMlAUMW/Ef/6xukAqSFNfJOJm8h4G++XvA//51nOB9athAQ5CwVMRA6veCHfjBjR6EsQEikxB3UHfI6nQrrJVL6c5PBISWM46iBtg5u1Eh9jZ1CBAxtb8HY0k0Hotp8WVxwRQDviWn1S2y942qU2xfUN2sfIESDOfZX4YIsx/odZ9sjEkSKeOu7b3D/8Uvt4UWE/Tjg778hTBKBlbCuBf/jTcACQQna68uNB2J1bIP1DEMaUEg19+H6GW7GHQKAN/MJp9sHsLXJWTMjrwyZ7/Hpp4zDfsR8WiCUwEwIGUBROOO4U2O/FMGyMNbzDEojCghxp3o0DgNKFqRScBUKJEXkzPjLXxL+6GbAf/DvrZbR1bM7CJDPM06nqAEED2KCcPtmwv/w332I/W5CEcF6XnB7LxBRopCbw4g1S4NVi+qwh9MZX37+GXIWY2VcNKDja3M6q14o5oTFWLNdQEGKAQ/394rKsbO6C/coUYjCdlB8n8FsAzFhJoWoS4D2cSsMloJEAQgEEnXcSmfYV+PQnhZDQAlAXh1q6YZ7+3wIAQ/HI3aHfbUbmqFMiMNgNa1aX7wez0hDssySIOfSWiHZ/fNaQB4oKFu57s+ljS1xYbD6q2gddGtSXJ0HQ6hQVfHNRWp7X1ESaUwYUzLHdPuoFnzbwsfbYG3emCq7d/9ClSwWGjuphjq28MjtyxEQtJ9nP5gQAoR1XzpBTn2UtGzeZX2hD8bPnerUijvWWhKgP7N3eOIWyollDLZO8GR6Wg0rwCut2/nns6/ts4ge37uGfB2tQdt6XPFxMarDuYlL955Y53zpnaX+a/PM4GP0NaJN4qJ5cb1hF5CGhCELhGJD6vd6vf9uP3f+f/vd5Vl6efWEL35LMrtT+BLE+fj6VjhtgBcpCjy8zSyqVFlrW2IkcAmQKG39TMdpDdNO677gRrxi2IMVdHoz4cKMEYwsgrWPZNth6sZJydqbKw0JFG0FmbHOipduE94krN9Q7oBx0YicMnW1Pl8esQ4ApmpAw5SRMr2VXCCk2Z2U3LgWq8soRoNtjkJR1RZiQEhGrmLpMt84Wq9BJslQw7ZG8MxheEo2qzC2Wodt/iUBVOA0rq4c9LW6+hRpDiFdeBdOlND8R2rwB1euHuG63BSi6+qOJIs2D/W0e1/LZ3+pP5OqFgTk7h8TpBQsS9bMwcXj3FjcOK02PwHKImgv+xsvb1mhDW5D/Q4XxrJmzEtGLhmFBdMwYF4WSAwWPOjhhF0E6XJypf6v13327z6jZDYhM7hk8LpsiGYEDUkqzNakHlrDYAcH3MgmhVgkIUxLqSxmzWiQ2qh4B+CvHwPuBuDXA20+x0Uw7ZISHdp7imVIxCKvMQasc8aXyz2WpeDZzQFDCIjjBKfbJmasBuJfiTCQRl6vrq6w3+9wOs2Yl4w5eE2SGKwpo0AdE20fAjCv8LqhSG1fK2uryvCQAoZk9W1xsCivEi+wReeJAO4ajurECg7zgpR2IDSW2Uu5y7kgL2fQ/oA0DvB6TGalYpfAGBC6w8ozqd3qZ1HyJBfiPiPvcx0TAEJeFjAII8QgKcacaMbB+XxSx5akOranz67xn/3ZJ9gvgrKsyNJtGlFjIgF4ds/qtNWJcFISqS0AHh2a0gxuCYScXSMRulgGYBk6lpYd8J0P60nFWecmDoM6eJYlFS7Ia0HubBECah0N234PIoo0QINCazpDHXMRVKKQOkry/dhZetKWQFxX2j+oa1vg89fDd9JOHeedAH/zHvheiKAEBNGekUkE/+CLjC+D4Ic7xm2KWO0cIWZMMSINA+acrf5aMO0OiGPAcv8GFALOX97ii9dv1GGJEcNuZ/Bh4OH+hBgThJSMhUKCIxd0PxWQFJRlwTwX5AxEWbBixO0D8OwKSAeClIT5mJEADMiQIMg54M1rwjwzaEfG6glMZsTnRUsWyAJPKSWEGDBOE0JMiCFiOd+D5QFjGvD2ey/x8Scf491XH5oDwFY+ITje3+PzX32pwYUYqzsgpEy3+5c3EMwombT+Zs0YJOL9999HjAOQDSpdWTE72QlaM5sgKDF2jrPaPRWsJcDdXBR2G6MGFliz027sEzTw6/EGtyuHadQ2CxDM58WcNkLvsLXtJBbooArH9S0ah1TPSaIEIENgsLriMmzZdoW4IATCaV4wyljrNKk7YfvLz+Wnofyk9emxg18aA6FDHAy42WWQCAXq1KYhIQzRmEMHv6NBNe35NRCp/9UYnw+lHxJZRn0zxBbk7K+a+ZMWlqvvbP8TC3ZpPZvqU0ffaPZ6a1i0x7Qymn6exhitVRJpjXxxeeImg1V5tPMghog4pOboESE0RvyWESKz97pg/HbyAKDV9V1evTVo07n9nNm+1barw2x2jMI+lazJZb3xB5DNjRtPenYwTFxsjLIZr95ouydabe8YIzZp3GZoPfl+/vvex+t9vUff6X8hqLwGZKzd33R9a5w2P6xBUFhK1Oji6f5UDzttlNwtuQkJM+M73/0u/uTHb/xmuoAhIh72Gi02oU05Q+YVIefq9Tv2GtkLxVsat3ghs2WoFJ5vG8I2Jjx6hs6INiWpGbenFGaTgRACvIm0Rq41pS8ikLKocVKCRs/F4RAqhDmXpgBDIwAgI9MQUsdAB6v1L4YjtME0AxiARtADodFobaNQfVap1bUIOlJ6eKbNN1JbMWkO02V0TajVWnW/8jtVGKAdBJvvktT5IxAiAdMwIA1JiWNqNk1QFZ/PP2nU0kksIAr0CaS9roZImGNSo6MNBlQjfZ2hC6q1B+TKwecVW2dJjTmyTIJDVanOts9bIL1XRMB7r17hlz//OWq9EnWKysZVn+9r2kURO5+1KRZtkGIEKzrWnAuOD0fknJW0pwqAva05TUWU1UycIc+gbBINrhMC3joXvLwvtWdNLzfF5Hgkr//SxwwxoJBCipgL5vMMPhy2is7miFkUnhHUkVzmBXk3QaQgZT+MALBS/DsMlMakxh0RKAjGMSkDXAg4ns44n2d1jNur65i9po2V5p4isNp7pxBAMWIaIw6HvVJiEyFa37Uigrv7E073D7X2iU0OXFxUTiKGYQ8i4Nefv0bdg9VYd6MHSGnAbprqnhMwHo4z7u4f8PzqgGm/Q/SoI8TaC9gLDbYvC4MKICloD8pumuMYkVcBrwrlXg3eikBa7yhSD5wUA9KYNLMPrbHVABRjMYq4/gxk0XYJf+OHt/jv/+MX9UjfZAQ94OLjrnLkUGK9fx9YKsUyJ5AGR0R3gpI1N54XxBghMWqArv0a4v02RfvNsenwdkCHqtfYxtcTeuhgHEFhRiisho18UL4htR2GB1QY5rwJVwIGN2aEL2BO3m8JAVNh/PVzwqtMOJUZw0jgVVvEKNQw4HkR/N2Hgv/tsOLnoaAIYb8fqh4JIsjram0eCjgMABOWZUHm4vE+RBg0SARrZiAohDCao1PX2JwihRzpz4eBUIo7HCtWIby50yb0gbXxtxRGFF+/gDe3e5zPZww7DeQMAYjCeP/9e3zx+gYQhb4FIhyur5TEIgaEFIztVNdiyQVfvr7DOE149z1ARGGe0fSHrrs6OpqJcSdBETqvX9832YSSRux3e5Q1g5M6FlwPFzdVldGyErXYmVO7ropmdcl6WIKV/VCDqL3h2uDi9axxUTDx5sKYFw0EeUYUwJPZ9BAI4zSqvREIaRgN7eSBFw0+EzOGkNQhsDNFSUIGjGZOiO2HGB0dQVoLW0fbLj+b3GZBye0liEApYowBwxgRjX24vmO9h+rxYvvFyblijIiD2k8UYoVrb17ebU27z4WP1P2D2j+l+6r9s3SBIP+0f9b38eYSdSXIWsE4OYre13o/siCEpx1sJd4LFqjUeriYNBBPpIiuklfwsmLJjEjR5gZgMr1YZUZtG4IGnBztoTpVTK9oHamT6G2dtSaX4msKuDLs1sktxu1sUDeXXmYEQc2MAQbx7mTfTcOtw0PN4e48brXNqatTdAuUutZQPhLAg2BKOGj7r4qJVNncLmd3mPmfRBcy0eUF5ethkAFqc/fHwtdd3wqnzTNEvSAQBIEEOWdoc8lQgcNSax9U0ZZLpkf7M0KMOSpY2YAonMFglFkuvmOCKY7/t80iRer3uTYJ1EtRUF4v0b+UOREujxcKE2g/K4VrKl376ABIevh5poO5VFRb3TTixcbNkNG5kToEN9fABWEYkFLAtvbd7lUKaIj90Pv/NdlGQwW7kdE9pTe37F6hTkKvoHqjq16t/OzxnJFtZnOw+siHoGHUfYzcFb7WQm1p9+5fqje0vMQhwrMlEUMioISNs9jYpPwQ1X/HQJAY9fnuHV1c/TGWM7csI1qknYjw/PkzvPXyLaRhwLIWM96k/ge0wy9QU5Bw1+TCiKzGqzl7ZPiOYEeJzxVDqfZbf6e6cPrdEGqvNnHyOlZ8w0BU577KkV2Ttb9Y1hVrpYpWeDBxwO88CL54FszA5crgVHLBsqxoWQqqzLG19pRgGaCAnDOQolbZsAAxeJxY15aNGGhZIaHB7yhoduzZ9QFDijifF8ync609atFZ0ahtCBWqHEIAi0bsSybc3R6rXDx7doWr62tt3rvMOB7PT+gD3TlEDjtVfbIuK0oxECWhyrHvH4cPBbVYARaIBJS14OHhWI2gXdJG2xwIkIiSc4U1KZJAny9Z1Ck3QQwWCHAYVy5GCEKxwvgKASFFhKTHidJgO8EC2/J4ncbFG/c9jvzdAKuVDZuAUn+5CuudOSJyjhUQxDIA9lyD/IYUWusAc5YpQIMOBCy3B3CO2L99b6XEgg6AXR1m/Xg1u+tYmjDC9plCjoagTb61UwGBixpg7N66f40sg8DuDPs+7+ZNzBE0pIStHA6r4MNZwGCEELEujLwsyjYnQAgjCIQUAvaJsBfGMRB2hx3G3VT1aLZm6TkzzssdeF1r5h8pIXCDwI5DwJQGMEVlEDXYdD9Y5oKSMzgQ1nXFWowkRYC8MpiDIk94wUCEGRqIda0VwHj13i32+xN2cQc2ZwIM/Du//QV+/CfPOuIaYJ7PVW4CKSmYknuojM3n2YIGDMqC9XhC3I1VB9cMZg2o+cu4+YV6QBERVs64vbvDu4c9yMnNzFokm6eYkuojUgbOkCLAwVoNuMR6zY3Y3lMGy5MoodnusMM0aTsgEeB4d4fzsm7GFs3ZEQFyafuKCBuYsYkn9rsJkUibrIPgdB1FtPYOQRETZEgnZ71GYcRpAElRmKqdaMOQEAmYa62v6Srfp/7vuq+7M9X+C4YgCgYD5VKQSftf5lJ0L4vWhuXCWM6z6l1mdTZjsCypnkVuuG9O4s5eaDMu3e/agNxuF5szZjszWaoudgesicrG0Kg/unBfq31Q3OYEmnPcXWIPJyLsxr0ShSRDJ5DCboWVXVLGAVLmqg9BwNLiWgDMwWNGIgYobsZOjtrwNG512EzTSINrAupYKRh/+3aXl+r2PgmgyrfiDy7svTaep+1nuyt6QHlDIDUbuN7SbcftSjW7BqxnQe5aWZkcNN2ATm66AX7N+5KgBowEGhS7fBUKVOv5H43ties3Om1E9BGAfw7gld3tvxaRf0ZELwH8twC+D+DnAP5zEXlN+nb/DMA/AHAE8I9E5Ie/6Tle9+OvXw9lw/pq7w1Pb9hhZU7LJX15JWtYM9bsHet1MrQR9bY2QUQ9a/K0KqNJCbNSCLP/kx/Nac8CeTF3CqnKT6Kbn7yYBTHqBu43bo1YBKrR46oQXQEa8xfxVjHEGIGobEDjbgAhG047W98pAJDaWNQe2O2UjasI1OPFjVivYWnjrdGtzpnwWXqaWCRo9Vu/yWBKzuRY7IdkI+i+3Ir6oZGh4/GE86oMVzFcCggqbhvQiHGxMfs7sgDn0xlCyva0rhmRBu1JKbACbGpKvc6LYvwVX96mpM2d22ZWlxGC1rhwi8oSdD73hx12u52Rf7R53cAQ/biRNs+9vPv8uNLtS3Hru1anzxWrH/TOZtqtq/8rBsT+N6QwLA6kBj0F/MUvfo4Xr094NwYciPD8+Q0YwOv7B+RyriQT/k4vz4zfy4w/+GhST6CDVNb1la5BsL+3GBmPGWIP5wXJ5D0GQuBoA2dIVoIVGZKxVhA4s/bggjkRIzANEWUJWIBKFONNeIkIbPAnd0SYGWFQGOSaGUC2eQAk503T3keX1c7tDjvrASkVak3C2uTWpzno2sYUq+HZ79JAGuEWFpyXgmFdcb4/gW72yFl7gwm0l2GMLcPi2VOXGkc3MBPuHmYsa0FKscLIfM8H27MpJQzjACnZ2jqgspntdiNIBHPXBwfQgz9Caz+qYWUy6AamG3xFNju+yqhZUQBQ6w8FSsdPphfEo1TBZQ3YTSPGYUJeVmRoNm3+asL5yx1AhP3bOicMGGmE6Uc2J8p3qjkwVR9D4Zlwxy4oM18khcSPkxIqcNDP8lp8BnRu0RxbXxo/FwlAGgYMg8LP1GnQoFjKwN+4A+IUwDkj54zjeQExW9ZBz6EYA8IQIEF7i/r66b3U4Wcj5Dmf77Dm1bJPYrWuUIeN2YwRW2tY+xJfH9Hm24ULlvOM04On7tIlAAAgAElEQVQiZoojQ4LCAbUPGmFIGgRYi+A8Zzj0ub9CiojTWJkERYC4uDMmlVF5Oc91AlNK6rSx61wl3nDUnYhgLRmDDEjGxKcQcEEypdjqmNn6fklF7iCoI3P/cMRbBmVm0+U9oiTZ+xERkDMQAogLhhQx7faKthkG5HmpNe61TtKDGjFi2E1IMYEIWOYZdJzhpjBRUB1c2Mia2lpcRvhrQC1EEOkeg82fGpqacdwRsEaru40RQ4wYk9oTaVTzcc2MzDY3RroiOUNibOf2hS3Tr+kIgkElIBK24yPC6XTG0XqiVSZSy+BWWbIAWkoRY5yq7STcIZHMwapzUkfRgfcIVg8tzR0gsz39hCaBhMeOXiCqevpxpVV9+3qfzVxwCwo+Xbem3x2GAdM0mDOdFEVFuvZk8B8aR2DNCCZH+eJ2ZDaZmkB+zktbK+iZtTmthqGr66NHMlWDDXY+XepqdrCouM0kNYtdr7B1zho6sVlG7qT2tmknWXCYqT6zmoTN5pL2DpsJgZLnLPOCNWtPUoxh84xvckj7+/SXy1R7i+bM+TrofBCIGIEJ5Tc86a+SacsA/omI/JCIbgD8ARH9CwD/CMC/FJH/koj+KYB/CuC/APCfAvh37b+/BeC/sj+/4WXVaNdGeP62aqARgBSD9RmzMzqQZr/so5X+WRxWov95IbA3quZSsDyxIVyp6IHJzSCHb6BivZjdOXr07Ro1UgdKN6Yyqulmqj3m/krX5TPau6BY1CyGuugCQlnWasTFpCLWR5A4F8RDwIvra8jVVXVQtB5OD2knCSEbu9S6C5O7Krnki4YhAOMugjmCIuqm6edGzx3vV/fYiwlEGBIgQSGJIlKpuz1jBFMycAfVHfeqDPRnfhAN44RxPyGvq0Houk0nqDTggMfRm2EkFLSfTik4nZQ5kq0fi0ADAR41DbHNBbPYfBaFflm21A+ganwZvDHGiGVZUUruFJJ9TrSe6eF00sh1FmXs+4aojk6mHn41GlQjmv7q1AxDXwM3mH2tQBgCIR0OWJYzloWBJSvlN+khUN1FUiZJgcIaxd6z5ILz6YxlWTBOA54d9khRmZl2MUCmAQ/nxbJUQIgJ4z7h/SHi+TjgOM9a91EKxnHAd7/7HbBo5n1DwWfrRaYfAtToqo1jiRBYI4sxJOT1AcfTDD4TKCYzRBymqsoUM4Eoo+RV220Q6RoUi6zCHAVjRg1E2F3t4QXPKbW5FRYUUoiRQ7a3h45urv1+RM7ZevS4rrBsUb/Oln3hXBDHAdRHrNTWsPeQCmv1rCWzsgQq+5saCRStjma1gMXghqvgeF51/kKw6Le9VDBD36BNMSUcpgQhwlqaHGmTdlJa86BtAYrVvIUUMe0npCHh/HDG3/nXd/hXf/tZFWaFPLYp8mhsq0+1WjLpIOkme+6YsTTSmwolK9bHcRwx7CYN4h0Jt5+8hSENYKxAIOyvXuJ8vsXqUDPA9qiNxGA5TFT3mI5DKtW/N0AGGUuwMMDaGiFFAsVoAT3viguD5rXDHABiYaSkhlkgQgqxBgwq1AzAM2P3W2atZVLo3ohxGrGuubI/AgDHCI6EsGbklXE8KRyYggY7NOgB8Lpi1fAznKVLYVUBKBmnh4IsEfsparsbK4qR5YjT+YyyrHaOq8KJMWi2xDJppIoRtQ9mPUdVT/q8/vSnL/HBd17jxVsJDosmAtY16b0vswUmR+rcsgV3g8lJje3XwJrXkRRzRkNKaD2r7DOFahP0QAp3pcKgZJmXons8l9LVuKojVEqBkGZ5RQS8aK+7uNvj8Ow5UoCyUp7O1QYKMUKYDYoYdS95X7fLc6AGeQW8rhcGpMBJs/ydHa2ga0OgISEyAGbkwihrwWI6aH+9x7Dfq20VmiFb9+eaEQujLAqnr80TO9XFcMRE1vPODFXVp9peBhZ00cbirjsIpaxasx/IHFbqyDJU5td1hZCe0cua9Zxasjpyg0LffTxWaeo3qEa9H4c+T81eaEiiqn/IZalJXY8ecpunZt/Jp4TVKbRZcbKlbLXtX3c5smQckuo+CkjDoP18zXlFtPKZEJCmEfDghSiTbu5sgiDKkuz/ARrs9mAI4QKiybZrpH9vG1uVNanPq3aayYnawl0QptpvbXoEMFh7J2bdLQEgVAb49sVgY5WarDAYqd/CIzQAmAJiZy/WP5mRVw1MlSIYeuISG0A9Q+pZwta+p9m5j5aQTAdQAHc1eT5UEUFMBZwTak3db7h+o9MmIp8A+MT+fkdEfwzgOwD+IYC/Zx/7bwD8T1Cn7R8C+OeiK/aviegFEX1g93nyCkSYhog1Z+QlgzkixUFT3OSF8s3YJI+uUJ9s7Yq4obCpNQYM06gYa1ZlFnMxRaGOUV+30hS43sXvBrSatd7Dx4Vg95dniBRCphLoZAxfd10EEC5+154XjA1IDV51RmtvNqNf7ZV2ILJ+HuqIiTWBrbAvYYALCqFJUz+E3tvxGSZFq4YYcXM44Hq/19oFFqylqGIWd1So7kqyCNVlNDlEpZTmqytwKcbcWOBpVHWmqNaOENCi7y2kaGuvTu04jgCRMpX1LyJkinirEWqUTNQVHMcB++sDTucTbt+cNJI4a23bMEXMs8MASTNwAAiMZPuY84rlJABp9lSDV5pZi8KQ4nBbhbhx8aywOj2n04L1vGo7A27GoIpCWwsxOFq/XG54f5189leteOpkL6aIaZoAAUqZK7xFBMa2KuAQQCIYTEEzSGG4ISBzwenENSqdhcGZAbZ6iagNqVWJhVqEHQT4e58Cnw7AvxkJ91X4WpajtgARoHF2G5zODrfqKdv3M+teRFSmWYggs/ZwzAhKJ88FUjLmOSM52YvOsDlBoYNheSZFaZJXgyn5FEZNo+qhakEcgjQ5z56V0MJ5jZCrfHjgpFkZmqnRwIVFfEMACbBmDRKkoNldCgGHw0HJWdZiwTCysVGVb7hR6bM7kEIjTTcWC2GoDaABBs4F5BmDShCgztp5WZV90FnEYGywar0gxoQUrLZnGLHfj5h2O4QQcZ8mnJc7HF6vuH2WjOreivV1FNXIc/9GAMuOd3IsDS3gLL9iskyA9Q4kjLsJCAllGbA8jLj9+ACKAQ7oCkg4f/YWZH+y+WvwoFAdQG8Xo8GxAELhYu1TLEuZVcaJnBk3aAJZBFE0y9TXIDNzvV+lPuh9+6Cvv4uEFdEcAXPaImEYUm3MG5MSSQwxIpmBR7ZH427E83eucZoCZqv5HcwYHKe9NbFXPfNw+xXmlZFLxrIs4PPZltTg+6VgQAbYW9kISFaUvGCMAbKfAOgZlUsBZzbmY91bg5HorLbWec3Yqiyq5+Lnnw1474OMIaiBe/tmxL/6X95HCLEzdtq+ISLbf+jOR7UNDvsrNUStRvX+9lZ1ge1j/2ytlbZUcARhFQHAKKLG9PVuh5dvvVRj02QiDBMOhwnTkJAL4+7NHTIKKDSSDjVmtO4rpIRlWbGsxYINlv0SC+cJawPs7E2LBGVZ9Oz2M8FnwGSUgs+dvjNzOyNEUMtMgsPaI4AQEczGCCEgHXYYrw9a/1uZYYHazByEyeqs1pP22CMLmDG7bgYgeg7f3z3UVhGuiygotDYGsT5lWpsb7IwuResmhRlnrPAszziNqktFsJ5nnOcVwtrfzUna1ChO1W4ELAPjdlK1lUTbg3RnRj07u7n1n4VWLAvPxPaBYf9qJSzbmGQGDc4C5hkBjW38m64YA+KQ9D3MnqPgGUe299S9EIcBZc2QUiqo6NKpiLA5YdWXVSaxzV6ZkdU5tA2d5VdtsC0CFFTCQIHbF54RRw3E9FetPbPAaU3AVCdZxyIUNlDb9jutoacuOKMcCV7Hrm/wyC0KoeM80GcoORVD3JC7nDgPfHXtpAD3JWhje/tfL1EDvUyVNYKCZiHlYi8/df1/qmkjou8D+A8B/D6AV50j9ikUPgmoQ/f/dF/7C/vZxmkjon8M4B8DwDiOOFsT32Y4djVPIiDrm9Aivm0h1RfK3c/0EIwRGKahPXRI2kTTa9BKwXI8d6OSR579NoOmAgvf7Nv3ga+EZr801S9QowHZhbWndN2IHtwZArw3WTNQyQxEYaOUd+EqXKOSISgUMg3al4e9h4tBLwDRQuFgPU/0t0jMWIYVsmoRq2e49DKiBDJjoq8fdDgFqRHppA5q+ETkYlFL0tqPWmvn02hT7kZwTBGHw5VCkpghJWMpuauLgY3Do9pbBqd2jOi/pK4HLi6tl/SF1q3tBmK3KjGBYoJR0Sgxx7pW0oplUdgQurUUK7ofdwnnU8a6ZOwOA26uBzw8ZCyrRrOYyepGCmIQpBgwnxUyqBAvxanHFLUfnzfrhlQyAFRonEDIs2tex9ZPsP/0Yk7sI0xdw1VXkiBtP+FyGAhSqDnOLbphxc7WcDtqJikFAocIWrU+Zl0yhkENqFUUpuwU+ACMIpu1CBuCV0j/L3Nv8nPLlp55/VYTEXvvrznt7fJm2pl22WVjZbkaXJSqVBQlBKhmTEBigBBiABIMGPMXMOIPsMQQCSGBVCCVagADoHBJYMumXG7TTabz3rzNab9mNxGx1noZvO9aEfs7NxsPkDKuzrnn29/esSNWrLXe7nmel78h8Ju9aDIBhzMFx1JqEFKDm3bxbU4sGcQ6N2y2V1hZKbjQdO/1fDbHXeuXZCvdYGQAVNK0Ve+7GN6RZ9bEnY20ZdbFK2z54mJHzoXD/mAOi423OLo+KsSv9kuCFoSqaIoZQVPE9NYW5DSOxifSaxs2WzabDSKZKZX2Pl8NbRGtvGVtvuoMOibRIVYtUHqcMM+pZXIFrVhWKK1yR1ROe0rqOHhnfB3UofUY5DsGnChcdbsd2Gw3GtjkxGYIfOh2/J0/nfjNX/DcXHvL9tYZbNBUM8hSlmp+TWbVeXx2OOWwSZsb6vjsdlecbnfMxw23r3qKiaZIUocTlzntJ8rYES6XPcFbOxrvgzWANYUyamWvVgr0udWY2Nt+ngVqn8PK2es6awrvHSnpsy6lIGUx3mJtL1K5o+QZ74RgyqRzMQhzEcQEN7oYW7KsiDburRQAEWE7dAx9T8ofInQ6T2ZdSykXnjx5aw6Q5/rJM62S5JnT8cTNq9ekaaL2vwol6K4SAs/HE986vaaUwnF/5K33/NF2R8r6nH3QfllCNI5qYLi4wjvHeDzofiY0CG9LxthA/MEfXDOnW7797QNv3vT89m9fcn+vc6qt9+aA6QanQ7Mk+upu+LWvfWzcdWmbofcRMTGvmuhcTaZm26SIeRs6N4vtHfoZx9WjS0ueOkuqWPIqhNXpbA/LpkZd1EEMwRNQiGuDh9mcSrMqe9ZZXtfAAlXTORH7DhEhzWt/ZTWfzCGuStb1HDlrhavmbYeh4+Lyks7WkCZEfEtg1MC++jMhdsisAafm19aVFF0p8zgyG0S2BUAx4ja9jpkLWpEX8+EM4TSXrD6EgAuOzWZgiJrMTKlAiFzf7Rk9pC7a85ZFiv9BlKDDuvTpVWe7RWE6Xiz+aJ0rNQheV8JXJ1R9gVJMwr8+n2XcHaZbYH5CSTSV6x93VMSDN+5eaHxLbevUdWqfUy7QBRg6mB2+CMzpbA68Mxirrz/jGpq9Z8WzW+zq8sEznYG43PSadtHOvQ6E6jow21WKFVF9tb2r59Ou76tuYO33cRakayxpvrCUM7/gQTSt1yALcmL5incibxWJs5ff8UV+6LW+e6iNN17rT/D+nzhoc85dAv8j8F+KyO0ZnlVE3KLM8BMdIvLrwK8D7HY7mab0YDDte2t/NgHnlHyKLcLaL+Q8flrDHAvF1M7EoEy5io2InAUDesofXpl49/UaZC0TuJKWW1ZA1lwr5X1UYy2g/JWycB8qrEzvwrXrqRDIgL5vblCIhTelm6deU7IGwYAqUaXE8XRintNivFYlY3WeMpK16lMbA9e1K2653zoK60mt/ASPixpA9w5mHxBmkmHRYVl2bRmuojfvPV4K750yP3eEf/GoY99pFj+lWTfm1Tnceo+1F+rCEb1tcirtebe54Tg7DyzOXg1IqBmjohndNCvMophoSEqFu9uJIg7v1YFcUJ+eac4ICeUOZU6nhBNn/XwMVx3sekohp4IfHJPBBWPXKQk9eDZdZJ9mfMkGA7DnVco5nMLgmzXRs2ywFgBUiyGa/HCOM/WxNkLtoaoT0P7pPJXYKe2Zr8ZQNHhbuSUG6VHOTjT+UhFhHCdm63Ok8D8NRIM5mXX8P8qBv1c8v3Gt17s4GitD52j3c5aZ46uCNrQ66LS5Q5vWVIc+NthW/VVtoOwsYMKtVsJKEKm+39veVIfszO/znhiEi4sdThJzWhrnSqzX6um60O7NOc+w6Y2fpwqytaWCuFp1d8xJ4W+hbcPqdA+D4IaBXDI+JUqawT0wXM7ucaYOsiqoAlKyJX/qxNJ9RqDtEziDWvkIORMdBrVz/D8ffcTf/95f6NQRVQzM+yP700wfoN8M1usp8uEsvH90vL12Wol0FRpt1UdfYS+VIC9LUAYmRS5Lb54zR12D3WHoCXSkmw3ZlIgdKrogokCDUgqH/T0OR+c7wmZi6YumY/AQdgyLM+ODU8XO+mwdmsxIheOLHZcfHnFOK3+x67UvkAjRZzoPp5TIxStkLgs5jTjviX5DwjGVE7sO5rrwgNsfbCiiVZgFRgxlTsxB21Jg/SP/aL7md19+zFEesybx6yEcj7u2Nzx//jk+ZILzbIaBQ99r7zGnfd3i0ONy4l//5BM248yj8UTJhTkljs4xPX+P7+wuybnQ9T1PnlxzPI3cvt2TCsRelU97yfRDx+HuwOl4XHiTK16ZZOHP/uwJz57/Cq9fHbm/e9ue7sPeVm3J2ZhUp7ImPqpTWL1K77wmIRwtSbWG4gJNsTf4FQ3DqX11QNd1BCf87Le+xWeff46k3KqnKlhWDNJr3y2FNM7cvr2lXF1DKU1FNztVnI1dt/SEKwUJviEFmt7/6tkJxRK4NP6gzk1MpY+WgCmrwEOKtgjAL02Z55RVNRU4HE+kOdH1GzaDtvQ4HQ/0m00L/rqhI1pgWYPhltuzrwrek4NCl1WdT/0hbU1Q2Gx7YtzANCEILnQMcUPhyOF40oErtYrvKaI82UdvDsT7kW1J7DvPFDUp5INvY/eQttH2NFh53qsIo71L9/oWHDtDDISAc3P7aF69J6XM2pSuk6GY7yRWPPDy44M25zSBGzzgg4nDePPZFkg4WGII8D6QglBkXeWyqSP6vrC63wo5fmdOPQxgWPu5dfiWZEK93uZj+9Dsb7uQOhoiZ35I8xFlQc69Oxi0eVzXIJZMaLbY6bXbLeh5f6II6isgigYb5ew6V3B9m9s1wfLjvmbtp9YXlir4j7/Gnyhoc851aMD234nI/2Qvf1Fhj865j4Av7fVPgW+sPv51e+1HHjVjsMC8zmF0+ls0oxwc06yVOf9gkOv7SxFIucEd1u8pqHwvrCBxZ+c457S9G2QvAgr1qBlS/bzDBwFrwlmdQnXizCB4T4yePBeThF6yrDmV1ULXzwezEqU5DEuQWVXWnLOmlmLQBKcBVwHGw4mDZYHaNa8EOtq9rQeiZZyW51H/mufEmzc37Tr9arU0jodtlEpQ9S371TKEmiKmFOF0PHFxe+Cvvspc9B3DdsNtdLq7WKXJ1SDZLbfhvN5HMLhCa6ArqFPrtVm1TgxvLRpqcL52XF0L3qsjqlXNWcUeSrHg02uVYrLviZodrc5AEd3AppGWnUtT4X4ewTu6GJfeU3bkIuTjXN1k3cydZlZzmnECsVOilP7n7PoM2mrfW43tVx6rlNB6P1tP7Jps0A3Rmeyza4ZGqxCNRdgqlILyTMP6fLm0DL/uZZ4uRnKekKSBdC7VuDhiH+iGHikwTxP5pJn5Z27gHxw6vvdwndu6dKHydHRcvK2D5dGun7Oj4Jmcx3Umu8zi3Hd9z2zy01XoZF29aT//iF1Zs6i0c9dGwK4s8zLGwKMnT/DRMx2Vd3AyhTvvVM0vxkgqmc1uw2a3Nd4jhBhbtjYL7DY75awZ9zZLMOddK9wmtaf94rrAjHI4JU8mrKHDo5L/dhOpgFHvgnea+c+12qbV/JQLcy4ENADMKeFjpwK/JTdu4auLS1tHpSU2Ys7gJm0Tsj8w9D27iwu8j/z1TxIvd5kXG8Ay4ZVP7EOHmIpmybKQykXFJZCCiwobxOYcaPNpsT07Z8cnfxxxMpqxFBN6cU3AJTvdNH0BP3n8AIj2T3LQoDzRB5Io1E+hvg7lTy0w3VwKOTvGm0fIqWeeMm++v+WN31IePeXZe+8pPyVBkpG7FzeICO99EPnWzx4AePvmhtu3r4llw2X4Fm/l9/DDQHmTuf2sYzyO/P1PJyaX6KLy5EoR5fGUog6kc02B+ZbIi7se5w44F82GZkLs6ILj9q6nlAQi3L39kH4z8tGHnxKiCiGMpxMhWlCaEv/osx8wvHlDGhN3tid1zjF4x9958YL9B4Hvx0hKibt7U1X1yquBmVIcaZ5bYiTECLOqxQYTGBIxfltxnI5PmeYbvL9BMlwGjwTHQWr1xxm3VxahLe9VqRFn3GAY+g6kEDqVlZ+OI9fX1zx7+pS7+zuzbYszJdnhQjAOriYZS8r0MdAPvforLtD5yDxOaKVToaWgfMaapC1SofxCmhKH+3t2u406/4q7NMSJNOVWFS3ZgAlHNDjtSsm4VJvwwPt2zhunONs+pQIkNAij/tEcs9qgKS09ROcpMZ2OVkXXoNEZP7ELCo90lnSuKr1YEq6eXRd/YOg65nHUQL62ZcjKaxSiVr6d0i8cmSJKdYiVFpImSsmKEkC/881u4NmXb5RyMCbyNmtgZzz7NE8KGw6Ly3suICfNYXf2vIGz4L3t8c3VWUctNkcEqn6BtKrOUrkRSeS8+JbacoIfezjv6Xrj8xHavFz7ACJFk23BM8+JdBotKA7gc3N2W8KoqrGLrNQrfZs60hxwha2K+QUP6Rh1rB54VIsveP5qO/ead73c5/L76uvWo6mfrpK11efyribnNQlgAOPV1Z1fbXG+tSBZVH/tZxzFx/O7eRClPvxEVcF84KRQUNrC6p3vfP4nqbKuj59EPdIB/y3wByLy36x+9T8D/xHwX9v///Hq9f/COfffowIkNz+Kz6Zf8iAbUeXS37kWddA2mw39bmB/c6DqQHoHwzAwmiCH8mNUdWzN5X84PFUiOp2943z61TGtgWV93/lYr5q3OkEbDsjZZ7SprhA7Z0RHrzhyC0K0J5fCMlrlxvWEIEZgrpj/81JqKUVJqV0wKWExWKKeq/PQbXpAVdVK65m0brWw3GyVyK6Taf23q069bZZnFdfV2KySHMuQrWMk1kGjMO1P/OqnR4rznLY9f+P7iX/8PHCqwhP2qbZBVfWoxstzLbOmZIWCdwEhr5xs81BrwHcWyeuLWU9OEI93nr4b6OLMMERm55ZqjtD6KbUcmm1SXaeCGwUo2dQkWbJPzUhgcBMUGlh/VUTwJVuftFol87QMnRnVRa2tns++Y3kgbX2ss3FK6l7Bj1fHko2zql3jLtEanCM1vFweqbf5mARCKbjg6UJAJGsfMAS8BnfdEKHANM6WzAg4F7RS4lQhb54m5nFmnmZk7OiOE2w3qwyeZtBzLkQHPoYzTkFlBjkzmG1v8ZZRlxVsyjmwtee9JkjSrL3nahxbx9W72oLdqhfrpeNqiqOeV4OedUW02kGVAHe40Cmsfs4t6HaS8UErRj44U03T59gDU1YDrLBHMQNVjANauaBa6dfnlZWk7ZRzmmxOVShkXdNtLsS6t6gx8pEGxcbU46TCr0P9nOAk2Z6iaoWI0A1RuW6ptGCzIQpEA6lpTOz3R7bbrVbsshnMB4kFrfA4qjKrC1E5Ds4cJAskQlAnMATH1dUlm+2G01E47meOnz/i6vLaklqO25s7cnH4nFQwhhoManB7eHXJRVeIMePi3OYCzuG7jt7mgHdOFRIJ9BttcFzmwJtXiddfXrHdXbDddLy4vGj75OXVY+6OBVKiHNWBznJJ9IUvXgY+f3mJC4B8wN//5hXz/l4rFBPIGJnePIJyoGTPxnl83xO6QHGFznV0wZOmxJRVWGO4uKD0PYfTlrvbO6Z5bmNccGy2lzx9csFhf+L29hYkt638u999zDe/CVeXEMIJ72E7z/zdTz9lezhxvx+RnFsL0GzPoXeOJ9PIn+cdGUfKnuggF+W6jW9rtfgSKR3eF4ZeKF6rRCF4Dqcdr189Q0rGOyHPG1Ka6OIjYu/pho5pnClFE7Tb7QYExvGeEAuhQMEzW/WXFux45aOeTpZ4VMRI7Dpi3zV4eE3B1Oy/whmdBvchEHdbto+vyVNiqn1ki5DFRKmyUHcGbA1EczhrMrDt/zgNhlJiHCetONvenYuKU4Ha/FpZXufqShFOJ5V7b6JfD13M1Z5VaQKCoZDMjkkR49kmXAxcXe1w1ypgpglKoe86Sk62b5vdyemd5KFZEEDRDDE4XAkcc8H1G7ogTEXTSSKF4DdsLnsO+xM5ezZDYNsPZ/eQSmKeJso46Z7dCT6ogrGnnFVcglMulMTQhH6aE14zBfUK3erfq+1HHoyhlKLVbB463UvD87XdWX/d8swWleB6rT/Mfw9B7ZL3QRE+zmk/Y6fwx8WO0vh9ataselYWf1VkLfRR/YLqU9pc9cvFtM+5QKUpnbkNsjTxfsCGsxGp7Xuk+QyCrN6wen0VRzdbXsesOW4Oivow9YOyMv7q+6ppyqsAtJhvG9q11ftrjrvarbzybB74R8vPjsqnV4XSpT9lfY+g8N6zFijtPs9fq8WnH4X2q8dPUmn7e8B/CPyuc+537LX/Cg3W/gfn3H8CfA/49+13/wSV+/8TVPL/P/7xX7Hgx2sVwX4ASivr45QnlqsSFxWWptH1xx9/zJ9/97vtrGIZqujqtospIp0fazf64QL8YQvp4WvvvOcrPiRiwYbLRmZ2Vi20SUJw2gcAACAASURBVMVyITWg8SQQp05XW1w0p7AGC8EyOs5pfzHvQtskcsnk/REwZ9HgTSEEtpcXTV0TyxpPaWY8HJtUdoNYoM5tDcSaQauOr9RnZk4+smrm++6Yr6RC+Wiv2P856mYUS+HrJ/jTzulmQX2eDoprRq5+Zanfleu4ZqTM5JQZx4mKR68PQuGT6ew5nUnYA3MujXu12Wzo+0WQoDm1LDBdbwGb945QilUnWHEubBQr0Bt9f/G0zbMezmkANM0q3z0MvbZucPW92Hf6lWKemIJlafK8602gnn6TEx8fCyFqdWAOji+24ey79fHUqp5uKtktjkddK8GqCb5u7H4R3qmwUW8VRvqMO2GVH0coSw5Oe9OUJvSxtp3dlHn+Z5/z5sl1e45r/PhioCunDRr01i2vY4IaXezI03SeKLLnUzOIvfHt9I9bpnb13Jpx8fjaL8AZj8tI/Ej95GL4U0qM04yfPV5gnmec96RpavLNk/VCC86R5tSgVQCHYgkpVFV3dCpA4b1nThrszdPMOM4E74ghUIoqqKWsmH5f1KnxQR1EQNVJ0cRHXed4DOZoga5XsajjaEGza0OgYiXOacItdFrZoTAMA8OwIRlMPedatbY9xcYtp8J+vyfGjmc/KLz6KwPFWZBt87itm5W9q0gDQTmDDml75xADfTcgp2vCacP8asSjynVVjc0Z767KTxdWkB2Doe8/v8IFYfvsqHPBUAxD3xP73nhphXTw+BhI0rGfIze3TzkWx+trFZrhJAzdpBBMccTTxM3bN6TjxHSraoKVqzJNierk+LhhyM/56x9t2Gy2zG+3pPEx/QDjqNyy7XbLtuvJORGjtp7wOVfMMCEENpuBl5vn/P74HiXft/00WDY+Z7U1WqXVoKaLgXHOUDKvXlxwe3PFbquO8bdefZfHb2+RqLDYbBkJo9jhvTrpf/f2ln/O3yRdPEZcR27rMCA+UpwqamoGP1jj6UQpmTwLffR88L4GLV2BP/p9IbOD8oHy57KQEeZSEBc47rWvY9ffcn19Yh5NWdlP7DZ3On1yJk2jiYksHFIs8Rcqn5easKl9A6u9sTy/CJcXF/i8SKvXPVdSVpRIDcbMifYhmEqeM7vl2r7tHGw2G8bjkVF0v6jrLMRAqYm8uqmsDhV9UhvoQq2IgKXUmqOoQZmJ2NR9tCIEmiOKCvsUaddee1K6rtOf00yek+7/Uas/zlsrmJUISavQx1UAXIxr7wTfdZrEzgnJM6AQ5hA0kRc7XafBa/9TQYguEqrNOo6Iiwq99EI/C/GYOF0MeK8NukUKMXimcUZSbkm9d700HY+YEt1pZtwOK+i6jfNXcdXMh3tob2vgtvj+ts+Uc3v/8HHWqlIphdpUW5UKdY3QEsA1AHIatNUKrChn25WiMNdV8NF82rNr0jMFa3tBmxuloZp0bsSl4vXghB5Z7PfqnivFoKy/sppnWX6sl6JV+HM023kSwsa5QIyuWqx2DotRzf9cmYvV+Grj9wdOqa1n/b2tcKmu2vLeJaFpwZlzXzGP9PgqyLbYmLVY0f7Iyh/5UcdPoh75z3j37urxb37F+wX4z3/sN3/F0WB2qxqpSCXcG9QsJ8rhoLjp1QSRB+dx3hN6R2eOfS4FqgiBva+IMGZdzD/8mjwP52j9jorZPSe0Vq7HQmYudVEXofbEEFlq4rk6ldAmlsPpRlhqtsYMuCllLYV8m2TeLd8RoauNsr0z4r5KmWYR5dY568dTCb7OHB6T0P2qR75c4xJstQVTg7hV+UqrHNUxWz77MDAG+MV9wUeTsY09eM+39wW3dfzJsJrdsgRKInXrte+WBjBkOp0QyZSCZizzuuKm17PI8X7V9BbGcUZu76hzb7Wmz0a/GGywGkXvFH9ejKfo7DsqhFSHQ+dMjAGiclrqb2tQ7INvTaVbw037/lwyMilkJsZANnEGhdcaL/KhYhEQi/DtG+GjYsIxDkoX+H0cn+40B+XEKr4mbuMecEcF3lVw8otICZbRjiEQY4Eg2qYjwVyy9mYKjpxdq64hynNABCsU2Uat6yt20RBP5assbZub3sHQR6Awr2AnxRoRV3htiN4CfKhOSUtBumVdgQaifrU+26ZrG/dut8WFoP24YqgPGOxa55TUaBVtWr6/u9fnmU1FT2pQp8e8UygPAmmckSrdTDW2ej0pBoL3Cs81GBm5ME8T+7t7Yuy42PZM40S82pFSYdOHljBAQJJoNSdWlP5yeKmkcIU6uhiVF2eKexp8jfis84+kFeLWpkAKv3Z7x3bTs7+lVcYrrKvNdrdAcFNO/NyfJ/7kWwNS4Tv23pyEENR5rAksX02YQKHQO+1fRCq8+SwwvnRI8Wx3nnmcVPHW1z5dgavLK3LJpHliOh41QGHZu6QUiIGc4PazjTrvAB7GGOk3G4btAEUY74PCWg3+/mLYQB+4jB3H48jpcIC+B4om2XJiPo4cT3pduj4Ks9Sx0okR8SQ3czwISKHsr+l618RufnkKbPtgXD5VCM5FA8/Qd1xtNgpdDVUu36Ctfcfjqwt2Fzvw+rvNENntItePr3AUuhjYH1SOPUZ1HFP6Ba6n13zj8C8ZTyOh04p/daoq97TzntgFdpc7fv6Dn0cun5DzbPZaWwrMc+F0PDKdTkzjkXnMkGZS0d5fLoshD0oTJComxhHdKpkCYImWKpSUypa79JgxFVwphJjYhs94/33fOOT1giWLwumdfl8qmd4qxs4WnvfKK41OxU/EOUIXef7smSac0D5wa7TbCiPS9qiiWTATlLLkQMnkkkzIJqkQUiln9IxgqryLq752Yu17vLahaQmp5qHToI4impxQ0adlLzBLqn9c3YsNgZJF1Wi9XwIR23NOhxOui2z6wYLQekHn+4nyEjMSoqIDREwp0iMEvK8boY5730VySWfnWNtAna8biniGL490XUcWx+WUCDdHDlOi73tCGNlfDcxDxzxPJsBkMPo2g5Y0YMiZqxe3DMkxJ8frx5u6xbSxXviB77oP9bUlmfhuQOYcq0rd+eedJeKKSKNhxM4UMes88m4RkDIfUXl+gdD3hCJtPeSULPhrLvD5NTefzDWBvErBqde3+CdLIFp/WZVZYUUncrTE6xm33PzmKsC1dD+Q6trp60aQb76oQT/tlM3nfzjWZ8+heslOzpL2ta5XAbmrDywJhqBUiNqjswmvNS2IunaWwLL5zFJtWl2pX30sASHaDOCHvfHB8ZdSj/z/6/AO+qFrzuoCZXL0fSRG7UuTrcn2POc2OfRPzcIufViqkzUbvyI61S+K7rzZYPcgIlsTzOvi6bq4Cjr0gp0zvLYpBenvDLJnD3V3sdPFV3+XC3NOzKepKbKpA6Sn947WcwqAsmyaVOfGtalRrxhQydjoHF3nKcUab5rCF6gz2QfNhPhSTIjEW98mM4x8xex/uKEoIL8O1pn4Sl1g68m6BCrr30lTWhOBXz04nl0OdEElmut4Bu/42widS/yhn1uz5aWypONcqysEb0BodWKHoWdMGTfS5LCbetE66KjnYzW2osqAw26rDXgnhW/4Kq2OnC3WmkCoO5XYWEXbsGvVV7+rOqvnY6zjVeFeqOHabBARptqSwcb5b305MmQNzj95/5JPN97UzR7uXucBSBB4b8wU38CixCI8Pnk+2apBDs5bw+118O7BZbPvBhXEnBJfq+SLrEG9fodKnN8cTg02U5vgSsvs2oZvcJ8WHLvK3czsXt8zfvKC09efMx2PegV1bmkUxfuT8O19YtfBP3seUBp9DYgLiOLOnUOrgQ0mtVxvndewuvMirUdecbSqV5VbLzkxnU7E6LnYbTGmnEGYNDiTbC2cvRrgedKKu8MhTgOkZVktVT7nXGViLo/TazCtkNAVgVkEJNseoRtKdhp0aoBTcLIyU84SKjYfK1RSclEoq2Vtu+Lpvef+cNBstvUtHKfZ9ja9VoVie/I4N3L51w93lDRbki23QKOwjCOoMXRo4FvA5rJOEhd0PL0rSPEq8mEYF+/EGlc7fOiRUgj9wN1Lx+lNoNtE/FZhasFrheF4mlvPMu+jSTwnpimRilhPP08uhYJjsEbm85wUrhaVWF9EVV9Pp5npdCSlbPB14c3miteHG3y/4/33tgwbrare3e9xCP0wUEqv7VpypngPHUjtIVQf0gSews088ccvD3z74/eQoIqluRRiCHyUCgFHltzsj8fmk6xgRSjEdJoTIUQ+/vgjnj99rBV8HPv9nuPhHpFCyAoRn/NEdBZoF08oQsTxQSx8I068ygUpE+tj6IJymCtEth+4un7E1G/Z72cO9wemcWR/f8/pOJPSrCqK0twsXDQlQWsxEYLy6UKIVLh4cAYTnCeStb6QogFryRmZBUTRFt57QhfI6X2+8bPa9mOxT+YwmqOb58Q8TvRdf74XSN1frSWG7ZXRWhOBJodqa5Y1ZMwbF1VzORkfIsX4s5ITs4E+hk2PzEmTNt7TBW9CSA6KoiO8+QXiPc5lltBQTF3SFDDFg2ilbvGtaLoKury0GteHwHbTI5Yg18SQJplzmhmT7mOx7bk1SanJk2gBRUnGfa3mrXF56z1YaxjbO1VBsWg/TAo+RELO2joE5f+mBJ0r1uerJiV0fm7uR65v9sz7mWQ3Kujz39wlhD056bjFvuP4waOV2ZV3ko9Pv3yLmzNhzogPxP3E4/HE7cfPDBVl4lw10Uf1eywwXtgIrULWEtosv3PWu2udvF8f2hPW/FATasJ8jsWTknoXjR/unLP1DGmcmkbC+qiXkkX94ZpkWXpeVoXQOl8qLNGfP8tVELWIgmGJoVpkcMZ7N2+h1EiXpQpWT9WCRGl1m9ZbELcEeizfox83X3DlouPcUgGTauOXNjIVbXbu3lbHA03k2Loptp/WW26P0vZptdGrc7SnU/eLlU/WgtMV8usvefxUBG0CZ6qJ4PBipFMpzGmZkBUhs/QYWnFzHlQWvLMG18GTgOwdYV4gcQIcU2LXRZNkXjZloBnqhdheCby+GcJSlgpLWS+cGDjc788mhbN+JmsIWGgZP2kwQNASeG18XYMDFTmQBu2p2QPvaxNSq/RYKrikwlwU7iGoulWMS4ZMihhJWt3M0ibag6ezxCY60fwCG2lGza0/ce701kBTYwA15B6Fam5D4Pks9CLa0oBFoALUmPztFPlb0vO/XWZej0dO0J6JglSUq1NrkBSTxO0HupC5f6Ok8m7oVK1xFRzUB+1YnHABI8lrYKm95Qw+9mCO6FcuvIKa5axGsjoGxdMC9XXVps2NagRsAxXncF1UhaiUETzPTsIvfz7TxdI2OZczf+3lif2HW15YE/f1Wc//LfyDlwXvI84JfYya0fWOIIWINoIGjNdjXIuCBfmrPY0V7GCdSlwlXELX0W89IRaOY5X0XwjUDfpW6vhVmKEF43bKUoR8GHF3J+TtPf2c2BShDJHBWnpcJOHX3maCwDBN/Fu548sIv/G0OlRmVHMhGX9smZ9LouGr4AnSiPawHXrG5JhLUaK8c9omIyXG2Rp5e79UJwFxnnHOeK9jGbwKoRxXEFrdEiqaIKNCoNJ4jXV8g3MQPX0ctHm7Bba1V0+Vy/DeM/Qd2+2WsB1MXl5alarOv4xZTlkCBm9BEt5RnCeJME+qoJiyNt+dk+7LtVG3A3L2TDbfa2/Mzz97yeU8U/ICiazJLkEWaLZOCkSqVL63vV57E3XxOb1LuLjB9Rd0Q2CeCve3Nwy7yPXFBXGY+PLzL5nuLhhvHP3W011tyXOmlExKmWl0lDHy8tU3lmRbmPn4g78g9le4+UhCuUPO9umcrd1Hzm0uuSKErspuC6cKW3MqEHMSTy6ZYLywaRqNkwey6oVJ5f9R2/2aoEpda1ul+KVSOJkj57KQnAbBv3Qz8WQqZA9pnttcaBlz27R3secogf9l+lli2DMM2rbkeNzz+WdfcJwyzCP39wdEFttifvaZkxqcg/CGm8NbRApplXDA6dqOHrrgQRzdsGXOwvF04HicePv6rbb4EYXGDcMAUedB9AvjBBRRELwnemfVBl3vXjVVAOXNJqtMLg6lJlpzmpmmkel0IM+qQvxbvwX/8B86fFQPzJmIjQE7WXY4NMNuytPVI09F8Dnhu86QLwbH9eoUHgGp2RCE3pvYlAjeKUy5pNEgxDb1redeToGCBjDOe/qLjb1BJfW982y3A944b2/mdCZk4VNhsw18OGwJP3jBzdt7wm7g7hvPudsfqFWEuuNl9JpL9Djr7edqix+3rFcvOja6T1coZCDLDD7w6LMbuD/QnUYOu4H76x3UjirU79PvTMYx1JMrHFJKpQFogmkcCx6t2ntxHEoBk1jHglGRQDiOXEwTswgSIsFPxkdW+xK8x/XaY44kfPDinlfPdsaxMsEgS2Q/erNnGDOPn1wTnOPzz14wTnu881wJlF/cIUETSjXJvrgCOl5ViKoFNO7cpug/tb2LD47xVAPf5RlqMJsU4uzVh43WM0yruWpvxZAL8zQxi/IzO4O0e6DMqek5VBPdaEgiTYijJkcfBhhrU+hdWRIq6wBUZ2qzn2D9MDUyWoK3lfK7ttbhzNd0nnMoI9VMLZ5GaWW5c5+zJnhrSLf+v1QhMK96yEtyRSzhqZW02Xqp1k+n5KzfrpxX41aDk8WCZbH+l6trWz7xbmi4vr/1GP8k0Ej4KQnaFul2W9jGGQAagb2Lhnt3ji6C8wpD0l5gKoe+4BjNubYHWQMy7z0lBFzRJsZTLmv/ZQml61napKgGLDAMvWW49dzzNDON4wO5VA2gSiUlG8wsehAXmKfU+qv5EAw7vgRn7eG5VRXAXvJ+ea0GbzF6MMWylEoL4nAGaypCQXl0YbvRZr7TAjtY6l9ClbbVzXkJbsE2bzyx4p7ttZoBqlmG9omWlavfo89a4UmOD8bCR4fE5TFzBOUR+KUPVAKiVd6cc/zbd5FXfss/7U8mJFDa10Rz9MTRJLSXDJFmmPNhpOs7HS+0aadetjROSzth64+33MMZL64dy4a7PDdMDWv1+UoErkPEMrZLwFYDPpu/uTBPiTRNOIGuQPS+EUa8Bc+SqwkM7Vw1u9eIxfbv6CBGfYZDHynSkXPhZyZ4exK+v1NOWipaSdGmn9KeW6gODBBsQ64ZrSCi4h323jIlrpNnlspB1HmSpc4xhVUUFkjnesIsmTXlKL736Sv8Jy9Jp5Enm8i/fN8jlxe6X9xrA/BcCkfJdKMj+8iZ0tUD46kJ++WZreOH9j60qFMTJlmUY0PRLHjnob+4xOHoNhuGPmggLIIna+bd7qIqqQbv8a5jfHu/NOVerfFpTBTV/GCa5lZtd86Rg8eL0PXOKkLLBZeixegKe8U5k6XWpBS+kFNiTkm5HqvPeuA0zUhOdH2vqpw1UIxeK43AIdUg23RDz3IXS3+mGDxP00wnWm0sq/1NM55VZRHqDqQo44LH8/6bxIuPVE1v6Af+/Ld/lTx6fOiY6RFXeYCFGKHrBn7+V/6I4C9INx2b+MKy9cZjuU3c3sH3vvgQ311wcSmEKDgXcKnj+9//Jof7A7/w5BPeH/aMRXgdl8FRxVfPPEXSaSA4R0/P3m9IqVDkgEMdrbtuyxgiLtWEmSBZq1UXVxdMJ4MIiuP6+pLLywvaomp7qa6ZlDM+KMcjRt8y4uM889g5LpLajjlpYFqSqkWqgKruaSFqoNOFwnscuAteoYWlMB4nZMoEH5FY2Ox2hnao/NC6djSB6oomFfzhFZJmLU6FoKR/W8PFKvVzKXRDx+5yp3yiUyadTpY00X06dp011a0Q2WVNlsZbL0xZnX3nstk87eclZBWccpHQq9ukIlqJoq2p2nwuOS/VXn/AUhbNAa4IGliqD76JgqkzXnBE8Ty+PZA2gvedJSW1pUtJykV0ttZ3pwk3zsxotSR0EObMuO2Ut+M9rgjdJpiAj84zijq6nfVYxHv606xKii4SPn1BuN0zPr8izVOr8Dx9fU//5S3z0DEVoQuejfeUL+9w28DBw+xcE+fwVvHBKRxfiwerUMt5c/SjwuBWe0ZOidNpZDY7cT1s2J8mhrsT2/3I4YPHygu3al5xei+d1wFOWPJOkrLuipBLxkmmFFW3lKJVNynKLffR44NQSqQ/zlzeHskinE6TCqk4DeJzFi42fbP9mKpoSJn3P3vL4WrHfLnBiRDnzKP7o/K5Li/ptzvefvkZDqHzDvEwbnokFzrRpIIPwVBRZx6j+YmLzV1TIvQxxuYz1X6iuref859CUEpATllbawQNgAqWNLE8Xi5CVVIWEy9L86TBSgxILs1mp5SpvTzX4nxg7o68GzgU81uKUWxAFnv6IInd/CCbRxQLeGo2+mwk6hmWsKbBI7WguvhB9b0PbLPymauPLxS8JqzQuR37Dh8jodPm7bHrEJwicASFH9u1dU6aorwDKJl5Ek3eRW/rxa2/XDUYCnQCrl70OpK0AsU6EK4jsA7SK+e++kc/Lnj7qQjacMqfEQSMAAhwOBy5ujgx9IMZeZM8dergBwXFM0+5OcTN+XHubEMWZ8IHIswGfRnOpNqlfW+TUxVa9UoHczVp7TryChJTDw0yTD0qpcXIbDcG71wgG9ttxHeR8TSS56QiFsGro+A1u+K98eTQxVOzJedNfZfxcd4TO98yQDhnPbO8VY00G+uEFfxSb1hp6MWCSFpGaYk1dDKK9yzKjStirSzE2zrJa2BUnchvHTKbSfjmvZLNj6XCOux6azbHKf8uxmhVQs9u6PgZN/AnPkOqgaeRUesCWWLeJrsuWatl8zSTg8Ju+yGqw5Wr8VjGoaa61xh6qX+Z0uCSiaRdebvf5a2WddVXVkOxOqRd/8LP1B5vJc+t0uK9I4ao/EwRitMm1nqKcsa9XOJ+15IGP3Nw7IbA1eVOoaImgpNtXjgfjLMQ+OLFI16+7cil001RnpgQiqOLHRUe3LZjKY3bh1O56mmEcByBk1Y3S0a8aDsMsKrn0gdsnbRYwy+wikHXRQ0Mx4nLWfilFyPf3QyMlxuKG60HmTnqwJ/FwjjODENn8JI2Xd5lJwtodcevnsH6ueq8SrkY9LZjtxkY5w+Y82NC7OjDBdvLPafjl+Q0Qu3JR02AFAgOZ1lRVjAUUEOds2W0SzaBhtCqcbrB6Yh77+3P4iRokspaiITQDIF3dQQ1CNwfTvRDz27omxEnOnrXo9wShaZNSVrQ6Y1jd7jLvHy502s1tEvfn7i6uNMssCU2vpZmfu3FCza5tLYQIrQKm2sZW9fWhS45haD+yu+f+N8/3hFC4MWnT7h9e8TTEToBb+IoFDovuDJTpsSf/s7Xcc6x254ITjgl2E2X3NwIX//ic74xj/zJPDF78AH6oSd4DQLKPPHe9IZvv7rheZfZD57/44lvMua4yP7+CeO+534/4ELk4mKj2eSU6TrILrHdZniisFdviZXCov6JcUscQp4nNputOsxnvGi1MdM8cnd/QnImBMcwdHRdT9f3DAK//OrI1e1Edl6z6ga1xHukQK49ykjklOkk86/5z/mu+xpjtnU6jsROBY5y2PD0+pLtZkMMERcCXWciUHitjpTEOE08erXHnwKbPrLZbhgPI0erJKqqrae/uOTJ06dc7C44nU7Mh1n/XxZKQDVR3iDtVfm4BvZ16a1IA80BzUmTr87lliBTPrmNpy2ZhaejsLN5nhnHiX4TjJfZls9q0a9dca34HQ5Hhtf3XM2Z4TDCMTHMS0UyRk+SgD+duHp9S0mZ7c0emTOnLM3JjDFyd70j9IGL7YY8ZWbnmcicrjZNUl6A0HXs5kI/ZnY3J+ZxwntPnmeKc1x/8ZZs/ketHGdXcHNq4iZzygy7Cy7nzGtfeHU1IDXp14KGoNUfZ022cSowZHDU+/sDKWkblsvLC4beq7y802TW6WrD01FpKjIrRPXyxQ2l74jiSddbpmkGZ7DLWtOwgNHVBGQRiosEp+0EiiiFRWPXguSECs+qamIRrZTklHUc0MRV1+l553k2IaZOESwp4WPg8jQTsxCsEbnfbDVBTObVFy84HjTxdrzaMneB/PSC66465V/Bh0IhvGqanf28wGbXRt85dJ1aQJxNxTfG2t9tcfSdo/luaZpQCSr1ZVTlW8Vu6DzzNFJmDdy6vqPbbZhm7ddY+8Y5zISgfMLomsdlSYvK86sXXjm+7x51vdXkd2v0YL7ceXCyGqtqxnDtDSs3qy2/6l/V9bX4WQsi7IwfJ4s9cQ6uiyOeEnJM+gnzV7Jou5Hqv4gIues4Pf9AE1OIQXY16XqcErteE5+lBqw5M40T05gIXQDpaKpaiLkL9TqXOytnY1Knxppqc+7Xf9XxUxG0qdCCwUOca5vW8XjgaNjybA5QzqVt2I18z8P4nbZIMjSeBEnlaNf43z6Exq8q1ZA8ONkyiNqf7McN6lJ1Wn6epkRKB1uwFU5ZGMcRRppyVCkKxYoRw5urA7a73BH7jv3NHXlOi/BIzW7bPVdBjtB1IJo9cybr7+xevChHp8yZ0/74zugpJnzhQSx/r4bWSvPZGnicNXpeZV/c6uE45/jmPvOL+wJz4TjNzKexcWcWsuuq8mTwAO+1yfDV9QXfTh33neeT5YK1+CTnk2GdtVhiAEdJhVMaiX2kGwZCiNo3plamalbFeQ2SfF7uZTVKS57o4Wt1wdbrsPetxqERfWtPHdvIzJ3FeRUp2W4GRp+YTlP9sFZSLbj3zhGBX7nJ/J9Pwipb7Oj6wHY7qOMtwi/uZ7oO5lwrZJX7F/leueSPjs8o9PRdjw9XhDDQ96E1hQ+hx5FNDdIqTzb5QoBc1OjpZQqnKfOb+YZf5p6PZG/zu5zBiWtVd03ZX4I2G1MRrSyGgE+J4BXq+74PPL4p/M4Wct8TO21M7pxjcvDicWQwZ8Z7T4gGpZqFYs22XPs+g7zYZNdm7yagEiOXVxfEzYbjYeaTv3gKOdFvOrr+OfitVScid7dPePrkJW290pHLTgAAIABJREFUNc9UidRFqogOzdhUzoI6nKX1x6sLL6wCzmDZ+Bi8rm0bK4dC0rLvQVITDDjsjyCZy6trPIXoHLsYm2Ji9pEYgnJlQqfj7HRedduZ4WLi9uaSN3cXOApzgmHbs9v1zNJB7Ilu5vISnj35nPsXf87f/M6f8Ajh4nQildyeuUKPF+7c+WFrrxSCD/RZ+Ct/uOe3nn2Lv/jjn8FLT3HC0A08efpI+1GWwv3tHYe7ERcypTimaeJwFLrwnOwHTuWKTCL2L/lFueX/mj80+GMhDsp1ds5xmhLvl1su84lJPFed55v7wp9uHXlOvL35WfJ4QSeCYyKnxP40EZxjFwNu/oDbw4n7uwzcwjPl0Tocp+OJUjJOhNNpVrXJUkjzSDcMWol0S2sI75RrNx2PzH8R6eSCKXi+CIH/+3OhTM/4R/57XN7O1qTeYLS59ourwltZnQRLFO4PRzYy8a0c+U78gDKrwE2eE4eUSeLpt9eErqPrO2okU5NIVfVzx8y/Id9BRBj6QRUEU2q8G92PHRdX12yvrpjSzP3Na6T0TKeJOWmFS4VEROF4ttSddwalpc2XWtQNtaGxJRbLnBGEXDyQ2jpvQaDREVRxUFekC4F8GplzIYo/42er4wnPnj0j5VoBt2DrB68YXt0wnDKbITI6hehPx4nDd77P43/lW8xTJk8j/N53eP52z2lKHMvSW7UlWbzn8WkmFs+ORMBxf79nnBO744S3gAXg8bOOrThidkwU5jTj+o7gtTdintPCpzbb0oWg9tlVmGtg6HV/uTocuHm8M7TDMjbeewKOEEygxGynonZUECkXbTPQKv9BxUL8xQYZetyX96Y+aBsXjqubE2F8xeZuyzxOHJ9c4732qE3BEweDbkeYfRX/SXgfkWzBTWeVbuPjeqdms4uZPgjTqEGrCnss+8pswWyMqizprTdn10c6U2OepTCdRtIMIwdtI5ALYx+5v7xk6iPiHRsRVYGuExULNCwp4P2SpAELvMyHOS+rCDEEai895wI+KGTeh0CIWl3LuTQ/M8YIYloO2gxVg9uUrLKrY6LIA6EfIn3UIMIFxzhlVTK1y3HiyNT9po6XUV5spdR5vw4m6r9KqWiuYrztJfHv6xsdLfFaRP0asbkmInhR+2PIfKOjrLwsEUrlV2JB/kOTITQ7osJLRmmZMrsvX5PuTjBO+r3V/ojyx2tfQVd9183A/Muz7V069vl+T/r0JenZJX0X6USxG+IccyqMY2JKM0Pul7TjqmdB8wGtqKFQSnubnFfVighpzswpG7rphx8/FUHbOtfqvEIrwur3qagEMSlrZgEhFWDO5mAtS6lmpOt09KAKjFZhyqsM/lnp1f5fq2vnzQOXtbdUA5b3v3t8ddSc87sP490HVCuNC0QxOG1UXGFGpYj1WMII9dX2GMzD1c0vU5LDR+uVVCfPPOP7zq6/Bl3n99nuZL2u4Ux+XCwArlmzd8IXqUtOF/BHx8LPvZoYZxX2GMfac+5HH/VZTJM2VL9+dMVVHxS6kjPOq+pXzdpZ+uQsu4VllOq6kiLMUybNR4ZNz8XljsPhSJ4VmqZyzgrTreV+11YcWj2rX4HCaLy3zVhKG4slo7wmpqrISsqLCMf5yFU+pgZGVWWqlEytU3gzFi54snc8nnUDCCGQfeTi+pJXL3+Oz75MFiQ5flBUZMElFTDZbgY2G4XLEno617eU1q5Xx0vFGwo5OXKY2vUdzy/XbiO3F/qgG1v2W9LFM+L4JTnNVFhki6/b5oU5XIuoyRK4LYtNQqD0PX7Y8ufDR/xe+Ih4ukJw/NMPbAu3z03Zgv8EY4Lb+0IXHYfjkd3mj/FhT/HRpMcDzne4oePySST4wBcvPmIeO3yaEf+Mi/iE1AnPvqHzQ0nc5tiKJh4Op8zps5/lww++A5RmjIoY7t0pKKsaeBVb6un6TmVTctEqhzl4mpiy/c/XSoKzRIwnF697oUFVs0wK7UggORmS1tMNWbOL2bMZdtDv+PLNXyX0A7vtFp9CXWzgI65kcjpwOk5MkyAeUh455pHYQfAdswyUAmNwcOgo09f4z6Y/4O14YkyZybLGa2jkWmSqPn9dIHUtKPyuc45HN4n7GNjfCU8eR0KANE+8ffUK3ES3eUrKyv/tNleE0HP3xQ8IXc+zxx+y3ezYPdqSUuLrl694ensgfhbo4wYfe7bbHSE4yEJJdwaRM57h6LgIAdnApz/4GsIGJ5mxZGarzpR5ZkyFMHRc7rYa5EsPL5/TX94j/cSYCofDDUMX2DiQaIqy3rO52BFiwGXlbWiCy+NcwbvC5s0lh9cK45+joi+mvfb9Gro9hynRhdrAW/ec4J06uiU3Z6mUwnS0nqbO8+9+7cQ/32z5o1cq116SCm9sLh5xsdlxOsyMhxFtbLzimLkC4vDTay7ffp/bVGCcmWdNpCx2w5Fy4tWLL8AlfIj8B+P/yq9v/h3mcSQlg0W7wjRlQtR1EbrVHNR256pwnAsUTWz2XcBFsQAyk7LHk8jo3punURO8YeHvkJUl5lEAeTHpelW8cc02mKYim80G7yOJTHeY2H7/S/Y3d/RFGLYDKReK6DPL08j85g1z+hlO00xAOL14TRJITiGTsSZJBFwM7HYDgmO/PzGOiT6CzIkggrs7qIhLAXxgOKndH3NmTGr/x4NCTNd890W9r6jQjHF5fAjELhisUOFjjz97w4sPHlNSMZ6m8WpzggLOKAliCZcQva1PUbSEfWeIHcPWQUp03vP6gyt2b27oYlYOX4a72zu6Y+QxDp9mnh5f8vbrzzHHDSQjpiDpQNEfKfHR5284bDo+j5By5sJQSgDOyFiDTEQf2E/TKvmnLRXC0LO96GDOzLPO0YgKqxxPJ6Z5Voffwemk1bi+74ndQNkFTh88InjH1vanruvRYKYmVqk5jbMjAMWxcMnA2odU2+/atToURZVnpRXU5EjsIs6nltzUPVFRKRroFCQVplm51BK8Jmu9Z4i1BYz2pAs+qACV91b5cxSpAdySkHec9xN7WJjQoCIxVvuDockMKaOIpEL0Dh86nH2nJkI0uJumRNV0UL/Q/l6Vn9YhYoiefrM1P9LhVtdXg0IRIU/ZFF8DKRXEz8S7A9NhPPe5pSKdZPnZ7BPHE3f/7x9y+dd+yV4v5NPE8MUbum2PXGz1XpzCeOeUyTnhSu2fmEghEr1jnCeDNVeOujCNs46V+eWanFSaipioV7w58Ojtvml4/LDjpyJoExy+KTU565GgTXa3uy2XV5ekrBkRFTOwlbIi+z84YYvgAXCOKEIaOvoiTL6QZ3WE93Ni28UlaPEOyqLg10754Gu+Olj7y7/n4fsV5qD96LyHlIpOxIOVgUXlakWcQY1qdqI2Z9ZMvG6aYhl4AZM9TeNIcrAzQrfdNY15szK8y99LYF2kIHmphtTP1aBR3+yXf1pWocwJ3pw4vtWFtPBbVlexGnPnlk2lBnY5CYf7vTrLjx4pr5Fkn9ENuOHuRYzv2MKntsPWbGwNbhWaOrO9uiAPhek4qohLFuZxVCeo3Z2009VamnOaKQvRI6Iy/TarDdZsuHPLvokUcqnVtoqFXu7fmbBJMaU3h9k3WLiTAvOUmchED30XeZw6snR8On3Mm0+fk6YJHzbEPpr8fqQfevChZVAPpSCzUOaM49Sed5GsWUDLF4l39KWz+63GpxgUSshS8GWpkE2AOHUi/0X/da42X/Ds+BLvC5Q6P1dNxakZyzqPl1rMAr8FJ4XXu/f5J+GX6fue3eWlZsq85/Z4VDhIwZI0TuFozmAfnUOk53gS3r79Jk8eP+b6egcENpsNzilPrR80I/9zjxcYslbiHOM48vn9S3IpJOebcl4VGZqS4/Hjx3zyg2/y4fvfo4vWq86BF1NtFcPhW9UAXb1q/LLCG6vAhfbcoRnlUgriOsax5/Xrn+H2LlhFPoBBwrwJGWl7EeMEfxnVWRS4evSYwUWGrZDSxGF/QCRTcmzr0nuPj4U0BQ7HIzZxceKYszCGoFBXmTkdJ+4Pb/j3Nr/D8fClhh/tmdUKek2sLeunChq1faDu53YNuxC5dh0udJxSYethPI70sdMWC12hiwNhp7CllGa2ux3X15c8enrJ5ePnfPMbX0Nm4fFf3PHEvebibkscHnH9aMujq0eEGDne33PxxWv+1fjS4ketTHXF4aaBnDvmLPRDR5mTOe26ZpDCy3HikAq7iy2XFwOXg0f2V7z95DVfPH2B6xMSHPFyp4iLXPlDRZOQzuNctL1A94acE9NBKCUgXvulddHjSuapnMjTTG9l4cqXC6aIeLanmkjTODskJJ48f4+td7hXP+BwuCC9vWfEU1zg8mrH8XBQTrEyOW3f1L0MoHjhP3W/wdt5UhimrcmUdEut1XPnHcf7Iy/mL+i7Dhc7prTXKltRaHcQ1BFLkIrHl5nQdzhURThLRtIyXTRZpkqLlCoF5shSUB5TwVC8hFTIBvmm7jNeIZ7zNGtmXqTZsQZJc+C8ENLM8fUNm++/5NaSw8NGURmU2Ro1O+URjRMUweXM4TSzLzpyGmxmprkQYtCAMc0c9hm8Vv3n08gpC5tNT+cdfRcRcRyP2lj7/v5Inidcmhm2W6akz7PrO2QsYOq4a0U/QfB9Tz8MdKUg88Th7W0LamIXTVUafFS1EH12We2581rdjxFTceDy8TUlJVwI9JbwLUWTyTInZu8p5oQq1FHI04gPgc1WHV7vHX5/4uKTN7x9ftmQRlVFmjnz5NWeR8OEbC+4HA98cDxx++EzuNrggxrBqoD95PNbDqcTh5NC/2IXta+lcRddCRQnFO9JvdJjRKCkmpA1SGZKbfz6GDjtBrwhNirb3zlhtNYrIoXT/nSmkKjjoXazmNiZJFkKCtWu+0LzJiwAKKWQx/GsULDWCHCnUWGhc6aLHTjPNJ2Y5oQv2hojCkt/0NV5nPcMXWQ+nnBOOeneBKvEDFNNWKzbS6wPZ3Z8HkfE6D51vIpRHFSFsyav9T3V3xILatb9ORuqqn7fV/jKPgdiZ9y/+pbVh1QxUmzcpQWDCjXtoRyZTycKqjxbkzNrzQhEZYS897gVukxS4f43f5cQOqaUmU4jJ+fxTHq9p4ltSjx7eWAaM4dr7b86HUcEYXuxYzCBw5IKMk1IzqqGOxWuPn9jhQ2FL1+GoInbGJE08aOOn4qgzTlwQZ2OIg4nCZw6P5cXF8bF8vikzT8RCK4ad4v8/z/m3uzHsiw77/vt4Qx3iIiMzKrMrKpmd3MwB0GiZZuUAPPFgmFYgATYguF/wK/+8wzLAgw/kDAsywJEk1aLk9jNHqqrsiqHiLjDGfbkh7X2OTeyhqb01AfozqyMG/fes88e1vrW932rVOMHHh1ctT9bKUU8mRTlWBxukIe4eNSU91Bg+MpE/rqJ/U339R97lcKCklf6oFVMxFArFKKpqzo3Q6F4SQJW+wOWBZG0Uaf1jegFrIGUv7JevvV7FyjmMVVwGYvleVQK1Prv7Wnm+68HFXuWrx2/rybJj0WZskEYpilwcwq0GwhIEJz1l+rnxhgx08Sadtb0o6571cHpJpBS4Xh/pN907K/2DOeRQmGepAmzU5SyojXrLiNUr5zFnapmVGZ5zfq3Uup3RB2oLrVbSpkz670W1R1SNziEOoQxQqfKckAnK5Wi33ud+aP5BSPP8Y3n5skTNn2HdV43PhEgxyjBtDxLSbxqWX+5q+pkWmTJVRGvq8J4lNakwaa1cvg7Jz3ScszEJJXR7W7HefNb/E7scWkijBPn88T9/UFgyeVTZQOuh2V5NElkDfxN85Q/9L8JiBgcLKkE2RjthTC8ZOkBVAquiBFPHBP+uuGDZ08ZzrL5Cr3DMI8jGMuYooIB8tkhgzGe/X7D4XSkWK8JdcBYT4qyLk3VOeZEComuu+XnPx/54NmneD9KoKGs/5Sh6Hev86UkSa5SraarzsEYs7ys5EzKlvP5BafTd2m6ln5boLBYo8cimHU1n8gqTqcImjePEwZD2G4Y5gjW4a1nPg2EPOiaExvzzXarVD1xi3POcZ4mfNtRTKGkifM4QCl8FL6gjF9wmh7kgF56qa2rxVqrdJS8LnJ1EBXDh7KAKSln+s+OfPDZW6L9kN3TK6ZxQnxxIr2zQJJ2C5OALiGJrmgcJuYx8NHtLXvXs28i339iGV8n2qblycsP+ei2w1rPMRiOpUhPMe+VqSDr5KPo2bx+jndXGJIYb2TRwC33JtA7KUVymnnRBn7lRn42bwp/9u4Wtxvom5YyGz6zhZJEY3Y6jWp+oxXyAiWJPms6F+a7hpIMWEuMkZIEyf9v2r8hxUjbi+ueon0ydIU1gDKC8soWkolz4Pj2Nee7t/yOd/yb+T9hwHEOiauba5yBKQTEjlx1TRpcGj1Yf4vPSXMgxUzTOC2QVmZI5RMUkW8qhdqkhE2ZX/c/5V+XD3R9Su/J5SxImSFamgKYFR3PKUvZwtiFmiemNUZaaaAJWSranLasRg1CCxETqlLUOCkKqLY40a1TUYAUy37f8f2YOZ5m3tVYIBemYSTPk8QSFUQyIquoeqCq84kha+Bv6ZyhayTUmqYg59M8U4pZ0Pa+9cK6KVoRsdIGYTgeySLiYlRphrUO13hMCJBlrKwmUzEECRST9Cp1RjVhRft4qnayOhSvmj7Zg4pBKvQGjLPYLIYWXdeSmurcucZHKQlol7MktqeXt7R//RneqzzDWqKyhJrWy3x6947NcGS83ZOc4RwjLmb2bw40EUrbE+O8gLA3r94yd56w61UuAd1pZAoz52kWBgKWEKMCp5BjYjxPlMbwcLtj2na8+PweMycFP1M9VhbtfQyRYddxuN5ADMvpXVhdbkspmJKZ5lmTHEMto4rb92NAOl04ftREWfblsn4H6hLOXxNbCm2utivyfSaOM+MwCQPDqw46JNoW9Vdw9F0rVTkF9je7zUIXdY3HlYh26GUVz3x9XGatwyulO8Ga7JayaOPlm0o1rGol1+pv1UlevL/Gd+VyHV4GQBpnZWQ9VyD3K6jUxe86K3tg7S8rJlCGqC1OjJXnYaxQrdf3McveJRMC1R3Lw2jPM+ddJ5KB0yR+GO9ONCkTjcG8fmD75QNunPCzmEy1bSNAjXe0OdJneb7VnCTEpBRoQ9s1oq92Fpx9rL//muuXIml7/3osyssLDcw1LaRI5dIuz9g8AhceBfq2FKIeaBLUXLwO6Nxq1HmpQ3r/Mu/Nrb/dffztXveNn5dXB8RS5FCw1pJSpDZU1E9aqgF1UFZ9lNxTRaCaxot4PiV83ypFTzYm2YQlwfWLFfW6VuoGVhMR5yw3p4k8hYVqcbzeYFqvfsxrAodR5PHRPT5Ojv82V86JaZ754N1A17Sc9Ns/OoKNIKx914G1gpDlS6fQCyMERcAwEiBMp0ESAKBtPdvdVjjO50GqGTU4ySu1sSDBkS1Gk2cdrwtQwBizUCplL9CnUx7PV9EZaLU5r8Ft0cZUKQsVNMGS60ica/mj8iv89OZXeN53NE2jPX7kSrmI9iRLYJiXCoi8QXWJK2XVJ9Z7qA2jJYBnqfBiHLa5GHlFr7M6ukZF4Ixx/FXzCf/V7cSNC9zfPRDil9osdkWIWT91GdtadaxAy/9nX3KaIjGclVvvaLseYwpjSKQs37FpHFYROIMETg/ziRhn2u6GgiWEwN27d2IjLhEbKUehBalWE+PZXj3h2dNrYuqJCT64veLtXSGEWcABnXONbzHWcDzP3N5syfman/74wPMPj1gz1SGStek7cd6zVaOhQnHVoi2jYFbROcby5s0LYnzCk1v73j4pQWvJhViymtWgPY2S9GfT5/P27Wua8w7fdXjf024lAVrBAw1AQgTVTc5xZiyZrmmErjWNxJQ4nU58Uu75b8Mfs5neEZR6Vg1H6vz3TbMEcNI/an3c9dyuFXKZQ0IFQvu1eeeIzoGRoHc8j/S7PU1tLO4c3ipYE2fOxwN/+dd/Trvd8fdvDObLf8fpdOIf2MSfTi946QZSnumzpTcP/L2Xid25ZThJP0HnG6bdDU9vNtycWx7uB4oF6y0hZjZ9K420U+J0mnHO859/r+fFfm002/eFf3CVMeYaY4QOvWfkB+aeeZ6Z5lnBNau6UxkWbzPpriW9ayglAAZTGoqVICaYQL9phUZVELv0VDP7stCxcrlAoIsEcEMRR8Gm9ULtCQHnG7ZboZHKdxAapOhA9DnqXvn75c9I4xlpGSIodIkGqr5F96zF8CpKUuW8578Mf8G/Ks8WIDHrHJE+hAlDJkxZzx090C2QJbjMOfPd9CO8hbtyzRf56WJ7vsTGxmGsDKTonFf9LEYSuJiS7KeqC7fOYp0hxyTTLUdSHrEp6feXYK4o4IWuR8Ec3LI/SqIsiUrbCh3RezGe6dtWaFGlsN3vyMYviWtBXCgZz0zngahni3WWvmvIzlC8MJHCPEMUvZ0YI8h3aPpupX0ayNqo27Ue33cY3adMzjS5sD9OHPYdKWWmEJmDJBwYI1XDkrFJqmfOu8XQBAON97T20qxtraRbK3QvtPH8dDoxpEzXOKwXnWTB0I6BZo6kTYOJmZs3D7ghgiaG5Eg0UjVyvqH9+Vummw3T9RZj4MnrA6Uk+sYJRRhHaDzzFHQaGLrWErYtPL2mK4Xxwxu2P38ne1uMy35Y9VZhmnn34R7GUZJcLc1YI03UK3BK1fKj4ECN9S/+93XX45zkFwPXsndKTFDHOYbIOZ6Yp1kMhIrIKEzOlBiJIZCSJPU2yzngvaPdbyghcj6PhBCwzgkTaf2kr//S+qMldlL5TU1g6xkkVOyCwyz9fut4mdq0/puUMF9XFfnKYJT3ozxgjcEk1qz06tXa/+vu61FlOq+tDGRPkn2mBk6VRVS9G7rP3jHPMyEX5nJh1qdyh7Zt9L+Fhh2D9iiVRpAr+yQXjHV0mw6vjdTRJO6reu/H1y9N0iZNqgveOumhXAPALL3EnPEIqq4buoW2qV3ldSBYNxFyBudIxqihgFCHjBOL25wyxIhvxRZ1fbgX09jUhfbY2e6bEIn194TKtHCwzbpg6++tAb0iX4pOpAVhr4iWXfjF8jMrqIFJODUvyEkW59q/7fGt5JR4+uqe0jqOz2+W15j8+N5syux/8iXDtiN++IQLddE6PrpDXc+J/cNEPgykmHC+JUwBczzjGoe52vJwu5ekCLi+P/NXdlpoqa7Ab7Z7KsT5TdP0fRqlzO3Mn9iZh1LpO+h7mIVOZozqtxrP4gaog762mFj/r+jkyUZpANrYdZmDMVMt6tfNSMeuJj9F6A6Veli1WsDKJ8+Xc40loa2XiNAjcQ70250EUFp5cu5y7kmwV3Ub/1v4Fe5vv8vNzX69TyCn1aSg6CYdMqKTLBZLJn1Dg08Q/ZVU19QASF8q3mGJgsxJgzT3XRC0pIBDkqDKec//On+H/+n2FfM2ELOCCkvirhvdI/0Til7Lhj3PgcN04DTPdFdbhnGmaSNtW7i5vqZxZyY/choHpiDfpVJbaRu6RpBoSmG/3/HZF2/pd3tC0qap1mCKY54ncnZgsqLUmXma2LQth/PEpu+5ucq8uzsQCIRYsCaRM/R9wzBMwIa2a7l7t+GnP3mB8YHnz38GmvjaHLm56jkRGYdZ0PmUF+pR1Xpdrs/PP39JCE/YbltA9sUCmCLVzcs1k1UnYK08Kwl6NXlPmfHhSNfN7PdgGukj9nCa6DpHv9nhnaeQiMkQi+F0PjPHia1vhfpjDU3bcGWvuL3/lNvwTqtNF5U0pALQdZ0mLWubkeo2ZRRtLYpwGsF5FEQSPQS2MiRkLrYaoArFyeObVqnMA433hJgZxyP3P74Tw4VN4ln4KWGe+F458i/ffkZ8IkdfXwzYE2dX2I3z4mLrvGHylv2V43e3Z/6fsWEaZ2m6bUS74duW1onhyO9+lPnOrVVgp67TmgyzuOB9nx27KfNn42s+LRMlF5wD6/QoLhBipsyQYydjZFG7fcOcEoFI0KSg8Q3WZjWAWOdK1oSg7oepQDaF1hj8pqdtW/rSM04zTdfhnWeaRX5AgVgyRE2IxElD9ZiRXLI8g1IocwWxyuXRuQBi9Tkqh+kR6JdLwZX1O4cMLatRkbWe33U/ADvJZ9nCLg5gYF88LxADgJGGH6Tf1N/JS2PmoiCXnKJVz1118doeQPd+by3WS/Ipz06qG5a199ZSCWalh7V9Qzmcefi//g3TIAGx13lPKZLwxMQwBTnTvWeeJsYwaNImumlr/eL8WSuFSQM73zlZtzFCEtdpSsZ3W77/mx8zjANvvviSMMZlXEHogo5CVPS/ArMGaKcA+x4QQ5NpGEnF4DpPTpmQMq0x4iOQNe6wQuWtNvbGGDa7jSSL9YDW7xBDZLPdLDb+JWem8CBnmAKb13cn9vdy5jWpiN+AAesNtun1LM0452kJNIczB29wYybO4h49hSCGM7YsGmHrRG7gvCPV9kTGMO069qaQYxJnwJw12FZgsMZOKWszCAUejMH5mnHpfNdmzku1HZbA4qvVsjX5QsHX+l6Pf85XrsukIGeRCIFKCVRI2iBrO6vhRhojR62EN9bi9lu6xpF1bI7HM+E8XoYd33pVfX0N1KojtSEvawMUZhEh9qPWEEb7UpZ6Q/Xe6jeoieDlzxXBuiB6yhO5cC1/ZFZ2cTOxcRxudpiHg8ZxdT8RydECLMEjG//w7p7508/wHz2nGMP27/024w/+itC3GC+mh28+ekLz5oHNacTYRjSDTs27XC1yXHwZpUDPSZ69y9IKLGpV1bnaQuviTs23P5lfmqRtdRS7iKjrIW5kwlovgv2UEo6Ma1vMNBCmoK81GmhrGRIwbbNQw8TAQaxOTV7t4nWbXl0Y9ZL5o9v/ewP5TZW31cZaERrnpDpRk0nqIbVmVpelZFd7XGB0Ia+v897hnCBV+6stbdtKIkDh/s29IqKCuJpc8Eq1unl1ZkOhS54nnx98XTgoAAAgAElEQVSAwusPr8llFgevIij/zc/vmIeZm5hpZvm82cLd8+sl+y8x8cGrdzQqVp6nQM6RFGZSzLhS8AX8w8CL04QI4YvQdq432CzJwzDM/HF4WHLCWjk0Bj62HbdWewstFZd1rGPOHGq1CaP9ni6SS7NSVZx1jx6W0Tf7umVh1H43F/BWbKujSIuXmbkE06yIDVnqYE+/uKPJhXHT8HCzldd4qyJg6VtUClhTsCEDSsVrG7X+TRhr6HzH1dU1H3/8iSS5Oi6JgulazKwiamuwbccfxo94tX3JrfZ7SqmIxW9MRJNQyB2AmJNW+AyUQEI3MSO0HlfXTZEDsDgjwVuRgCvnIu05qu6uZApxnc4XA5sSmCw92HzjeTAbDqlhu92zu7ricH+gZoFWtRPWmTXRqhu1sdKfDknC4hzYNq2sqSzIat82eLfnXgW+796+w7WN2DAXoR0aZ5nnxDDO+KZhv2mFYpJk0w9xJk7zEoSWUgjGYhi4O/TcXm/oXOHLd/c8udrReEu0hlAkfSVFxikzh8wYIsVYMp7z6ITWG17yySevKSXhMDTWsPENownLnMpKk6x9zPptTwyRMEPJvRgLtA3xQgsIMynWoVdHRIkEZY4YQ0mJVKL04NNmwrJapO3Dbtvjug1Pbp6w3+8w7UbWTU6M40DOgfRupuvEhh8g55n+/m/4x8d/RdAqjVgmy27rmo6uayRgKJmSzSOBvu5+y7qGi/1Ok//WRjxpCW4rTdkuAIbM9eE8EueZ3IoRwTwVpiniN3tsOUGYmM4jyVj+6fav+CL82hKIO+8YYsuYDSlK0+zbJ9fMm424dFr4/Y9G/uRVw3Ae6RwYEi6PlFL4nQ8LL66cNsT1ut0YrfjIEWsR2qWj8GJzxbO2J9TqBiz914omDZ/3kX+3sxjfUHCEFIkh8o/MT7guE9PoKDGRulYHT6neRahvOKmOrCeqBpTSI4Ku7+jMhl3p6NoWMaNYKbpGdXsL8FQrD8jaSBimcSaniCmq8SsVMFuTMsMKEj0rD/wT++f8L/yOJlIarKaMJ9KQ2ZUzv2X+gmwcpRjcOEvVNYg7ZdSA35hIUwaMMTQZ/gv+NZ+Vl/w8fULJjlXisE6udV2jzAvRfpacCSmSEzSNAbTa01iM8xiyMB+0KtN4MQCqmuQ4z7hDIQ6jVC63G0AMCpwV592s+26/ERfFfD5LgtI07Dc9Q0jELA6YsiqlOjEOAwWL9S1d2/DJ974rxiK24PsdeTjz+U++YDrPazCq4x9TwitaY4xZXP6KF3dJWwrTOEPSPbHr5Pi0Rns4miVqdk7cg+u1MIAuPlOSXLBOALZER7fpOQ8DvunwxmglPuMMWNV5u6aR5KiASZmSwPhCjqMm2JBpyDmxf3Mix0BCwLQwTAyT7D1N1y7P3VnHlDOvn2xBK4SUwqtne67PIwUF/AuUIkCa3E9hNRKrG6z+8Jsyq+VnhsVb4L2rgpLy2q++3bcVAer4VlDmUQGhQPEer+60LbKXkCImRWzfid5eK0G+8XTG8I/eZY7HkT98Uj/g2z9/yTPXOwJTWxy8d6/rj9cbpZotVQeGelpdJE51QDTGuoySNdzh64zr1M8GYSUUQk54a+jblv0OYm4evf5xUnUR28dEmYXJgbW47YZshN1Qk2d2HWH7IbPO3eevHpZ7fv38GmMtT794kDlUkP3fRmwWUyU0VvXeqKlcqds3p+ue081WPugH3/wofnmSNlA02FKy9j0zkIslhUzTWA3mkh6MXntLNWAipRi6ruP5ixe8+vxzpX850jyTm0YW/yXdUD/TpFTl1ljDVxK3b/3OC+L0+N+tffwPUvhbk5KaXFwmb7Wa9ljDVR69plIXm7Yl58I0z3SzbMxtSKTO0YaIm6Ephd3rg4iuYyK1LcFGvNr/3352J8Gjq1QlQ8iV8mFpWou3DkLkxWd3FfgQhMdU10sVVlpP2zWch8RwPIr2ZA6LY2VBbGv7TnRRxVi6rjCVvLpnKgpkDHyaZn4WJxyG77segJ1xeAyJwmdp5hwd/dSAMQytBW3MPQ2zzKUswVwys9xj0yiymS7MSeTq5kjfNtim5XQcxDp302AoNFYClIRZ+qjVxK8bRSzeniauRhHfppzxD5EPThMWuPvwinHbUTlg2xDxMbF/fRTXNe8ZPnnKsGlXR0EqgidjLvxoz4Th4fsvePrDzzHGEIzn/04v+ff+JU93ezEumaPOl6TVlkqvlQDZIQ3q0wU4VRu6OuMxS8NyB0Yr36kQSw0uV0RfAnCLkSNUPkfnfyoZYQ2J+2GMidHCP5+e88/832jList1Ypb1UfLqnlqbVgqlQNaH8w7vG23/oVS+nIhYjNop99sdx9NAKxG2VJ+QIHkcz2y3nu225e7uhG8s4yxBT1I616IhbZWumCJfvn3L8HBH0+0IfUfXbwhhpkkzMTrp+QWC0s+zuEs5R7e/YhrODKctX3z+jJvbV6TpxEdfZPbZ8sebVctWDSpkH7G8fP6SH/3oR3z5+iUh9RRjOJ5GOm9IxVJKWoJfa9WEyJhFB6xLa7FQr8mNAXLbsb9+wsuPX3KOhTxN3FxtaJpW9YKSJB/JnBrH1LYM0xnNlzgfHvif7/4PpcOu+5dzooHo+l4aIiP6R++dVH0X1m/N4IzSbuqGiQYJln9ofsZPzUteTbfELIfqXOee8TROrMiNRZo6F0MKiU1TeHFj8T5wePOOYxxlJpWMKxnrezatJgDWMG22vDkeeX73OSlnHrLl0+0TpcVk2qbwe58EnBEQLhdDLnHZz0NIpDLTt1LhMBcVCUl+K7VaAvPe92x7cxGnyHwXWmtmvy38xsfw128dP74znM8DPp65KhOUREmFaCCPI945xHDGKD1WxPWNt4RkFgpQNkLfE3DT4m3D85uOlCLjNFBSoe02ZBdVnyPrIGmA/bwcsNOJcZ6ZBzFCqDTiy4RtWddFtr1UpN5oc8aahDGFtm246j1X5Y7DeeRl+CFbN2NyJruGppWqwqAOeWCIISFN3a0aHqjNunM0tvA98ykmW35ePpY4AqGZF52XsmdlruwBa55gLnD86n9cCpjsMMXiEvjGkYExSCuO7W6Ht4XxPDCHQI5gcGK2srxZkfPMWq2cO4bToHujZbPbUoDxPOC6nqsPP6C8fkNtiCrGDkoYTQk04T8dTvz4/NcY6/nwo4+4yfDTH/5wsbyvlSNjhZ3grJX+sI1Ud0oWCUPKhXYM3Lw7MUyRuWRS12IvtLS5iObNGiNNi2PGINT9altvK5W7ggYVNC2yb4zHge1uhxmDmGY0Ts5U5+SMyEIzNVloYc7UdiiFnGbmkLRxuFTqwjxhSiYZi3ROL8uYlSIavlLkfHDO4hrRpNvGa6sIWauyJ1atrgJlphZ8FLxfHubjAF9A4q/PcGQPNo90bJfXJSBVY4g65/5DL2OsVMhbDzGRQzXEMmvTbgNd34r21BiK6s//08Hx8XbPW9/Q9cJ+Mt8S+Jbl/+BxdieZ3KVu2ZT3ftGsvyMJmjqRXiRmOjiPA2mNex9hwabaMNTYSKiXNba5/ODTpmG83rIJArvXr1JKAWdVG50vwPd6O0YBdChkzruWcdsqjHORdFuJbV59cqsg0nKHfPHxk/UTU2b/sy+xNc5VIAtnQffP7AupdRxuto+KPt90/dIkbbXZnliFmnWQ1WK2FA/FiJ1vq4FtBtdYzGyx9rG153LjuWCiiLXTxcS0wJwSjdVGt9YuG/d732x9qBdXrYL9olImXKBSWlZ/VNZ99Gf9fPkz5wtKnurZjJG+QW6O9MNMexhoMXhribdbdnPGjJKoWE3ukrrfpJRo2mbp5RNDYkqTDlc9IOSeYkhkdZz0Kjh3GJpGUMOchMfuVIBNMbSdJ4WGcUjStHqWKlHbSlUu6MQteph32w1dNVGxFoyIbnMSJ7RE5sfjTAyRW+PpjSVQeGcT28OIGwK29fhtK1x2Y9g4RaSOE/48s725wh0GcipLcCi9siRBjCHxZE682FxzGiIPx0AYBw4h4fHk26TPoqARKPtU6GJke3cmR6GmZmdonAc18LA6xk/eHLjPhWHX0Z0mrt8exUVQJ1Epme2rO47feSp29kkPQLVcds4uVJuC4W1n6RrDLln+z/lD/tw+5Wa/wVrPHJI2GIekzy4XizNZkuVKQ1MK4iMLmpKkkmekcpkpdI3HtY1oPXQzsbWK4wy+umfRsCBvyFry2YArRE1Wcyk8HA7czZE39i3j+SwaD9ZAz2iWKq0c1mRTuOCGT801R9vhvF+qPSFGhmHk7u0bmral9Q3jNNFvew7HIzFU11XRvzkjWi1hIon2M2eDMY4wjcSYqUrATMHmQjHiRta2nrfDzLv7M/M8sr99RiqZtusoaDuEkvE2Yawjx8A8jUCmbTumVLh72DOHyAc3P+dXvxj59KqBrZe+WCktbSAW37JiGIeWeWoxQNvUoMzQOgvGXTTjlTWEaouEDitr1HqLweGso9n0uq9lxuFIzonWOUYS05yYw4g1QpksSRqTxmxFfwc0zkoSPkzkVGicoVhJHNq+Y7MROqS1jjRJNbcojWYNjssSDSz6t4vpaJGgvOsafvVZw6afKEYgggz87OD5ZCdNtFNKlF5McJyTQPXFleV6YygxMRyOlOyoNYx6+bbTykahiSe6MNDvdozTzHAaSEko1jiLNw1Lv0VNQivBjhooOUfjvRpIZVAHYDAUq1RJ1Ray0KuMNDGuwWQROrxVauO2lQD5o53j990bnp1H1VH5BYkuun5yEc1vKQKAWmskYCuqeVZ9+DhMvKNwcA9Mdss8zxzOZxKWGw1uc5J+QSmLTiqnzN9Jf8F1PjCOs8xTrQyuz5KvxhsFAoWcCnYYOZqBUznxtH/Ds1z4qHzKHDM5R0JCXSNlXGJUTayTpKNpPDFI/60QpRdh2wpwVwG17/JjTJ75cfzO46AQ6NKBl/kVL5ov2TS/hzVqPVBjaW0bEwkUk0k54YDeO4Iv7K73WIquadXu1LxP45dSxPAL4+g2G0lunGccxKZ/GEa6rmF/tWM8j9pAuuBSEmdSpS9LX6eMyUKHnIcBZ6UHW4iJuzdvONwbzspmqfvoYvGP9Kf1zmJzITlLt99h5pnjMEEubIaZzWkkZjjfbOHGEFtpT1DNKRbaVsnicFsyphiKW5OQWpGFIo7FMWGdNoPe7mlaTwzSUzBnaWlSkjgsUgrWC5BYEXOxpHekGKX3XcxYAlOQ6lE2TvXeaoSxzLWMygbJKZBSYZ4DnVfAhDUvkGK0ppniYIMxme1h5HS7XSZyoTxORC6uR7Prb5F4Pdbur7HmtxXwllebFXgQjbCn2/ZK+Y9EZykxYW1ZYoDa+kCKppW6p1Q8a4U+6yI5Jo3jvvl7VBrxZdEBvrrcH//OOoqXA1Rqa6Z1YB4/mPJNm0n93KIJ1jcNmuzH531Hc2fxMVGJ2TXBF6aRJpulSAxgV9OUUsBuWroXz5jM4+pejd3W0+DR/13kngKUHa633Jwm3vshIHtF0Z6Ya8L27ZPhlyZpW7Viemg5WTB1oqdsRVSrDnHSy8ep6BoenxoXD4SvGmDUa07SkDbmQlM3cFAu9Tq431Tu1r99JXH7emONle74SHf2+Dc1qavmC2XdNFkttF3K7N4caYIIhwMyF9pXgWjE7Wk4nLH+wiFHEaUwzQTjkP4osmmuYvUiv4M0XJ1TlsaUXg5y13qaxjOMIzlGkY9nsCYxnGc5TGehqvrWkZIkLrnAPM9LQE7WviHe4hptKqnucSkHTIk0fUtjDKaI+8+7IlQGQfHVGa8U0hBojme18xV0UVyxYP/kihfXT7mfEg8PpyX5ds6y3W2gZMZxZpojb8wd4zjjnWGz6Wliprw7wfWJ4arnw/szZg7kkukyNCVTkAamzjl1d4uSYOlzLkCJkc2XD7QPHh+ilOCl9qD2yBZyYff2yPHpfhGTv/zoYyrNN6fV9vZtZ/j8iefu8xf8MD1l13e0XUcuanNcNzoNpDIWwYoTBTUuuKBYvD9vbW0rYbM0Rg5lobzVqqnVlg5VGmydI5u1gS26jow2iY1RAo/TcebN6Z639i2H+4cF4VyA+QXukv0g59VxyjvHF/4Jo9uwu+5VyyfV5hhn7g+Jvp3ZX1+TZkF1MeLW1rZutZU2hhhmvnz1OWbbsXE9YQ4YL/uItVad54XymBJ0jdxH73tc09Jbx7MPn2N8izOOKQV8M4rjVE4YcwXOc7qPDOcZm2fa3Z7Nfsvx/sDhYUccXlL4EcYYur4RpN4YUilcPblWi2LD1e01ff8BOW7BQte2OlYC6FCqagogrXuRQb+fx9hEykr/jFH0O84Qg5jCvH71in675Xw6cpfvxTXOWA7TATuJac0UDV3JhDBzmBNTjFSb+cYbjJN923uvDc7FxWucMxgxMJkKWBsXk5SLXW+dt+t2iXGe+bu/za/+6m/wHeeXyk8uhe8OsG91JZlOXeWUyWDWYDOkxNWVxUxyMkjhQqqpVs8SSsGPZ67jwO7JDf12w+eHgb5r2e22hBhXowuKhusG6Vu23oh3DuMcMUSqzhPWBuiigwnoboqzSkHMQqUUIwuHcUn6NoXAj15NPNw/8F+3P+ZZeiAZcY6t9tSukcbBOKTZbkpqZCROgdZmTSarW6kF7RNUcuQ+HAnTLE5mxnL39h2iBcuroYxWcc55ZLK199HKHLnESC8e6vrXXAgqR7iyr/kd/2fcphOboRCtobUW03iYAtZC1ztCqBVOLw5yRWl3eLS1HqIHZ3EqNTnj24ZfMz9jYyM/TN/jO+4zbuwDJSYaO7FtjvKsitCCVwMTpZWaGt7LfZ2nKIYgfYN1hfEkujVSpmk8m03HeV5pqDkXwhyxvrbzECOmbreF8yAGNOOEb7ysgxiFomgMrmmI57O0QrBaldtf09rC6TwxDhPBSjI5HA9SHYKlf2tdN/WsMFbOTmuMWMIXSRBLTHre6vllCleHMyZEHgzk/UYddPX9ZZGQoybqVs5XHEv/rlwSNkP72RtNouXrzNMgvbsUxKkgslDt5X2Tah1Tylqq0YQs1cbNaosfM5cUxDhLhTEl0e5iHMbkBSghZ67uToRdv2wqRvd2Y4xoB60l5yjMj1K4Ok2atF3uRebRnxKXvTfp6zn2DWYba7KD7k+PTci+zYxtCeGsWd4/pUIMmb41WOdprSHbsKwFqPHehGs9rojWs5TMv98Ubo6J82lkSkLxtvCtucJi8mguCgtl1Uiu22NZkrCvS+jWfCZL8lbHowjA+H7mWMetXP7212aX6/MwBmr7mMPtTuiKWgBJqrF/lDwZNUvRyrE4dIPre/oXH3B4/fq9j1pj6gVcXT99ea4VcH40TfRzqwynRNHOmm8b/PeuX5qkTazroYYgCxqJAesgR3K0yzf22uNonoI0hTR2HZsFeV4Tt/evOtkM0KvL3uXke6w7++arJlfLRxu4FBVevHL5YqsZxcUCeDTpzFcWs/wpVTdnDV0BvASmKaTqMiBfIEhl0aJiVQ2As46rRQ0MrAQSJiUBYozTw6Pj6smOGALjaWAeRkqBeZpxzuCduGXNMdB4R0boQTFK80Dfqtug2to7VyuFsijnOZCCImgGNYcxxCR26c4awmKqUlbxqY5DVJ2XTUZRtaSVM6sJhrjy9H1LSpH99TXjHDg9HImzBFRhChduZ4bRDtqb24MR969hnOFvPqNzDl9YyuwY0THlFCWZMcLnD1mamjqljlQahc8ZN8yChCMIkWFdwJRMMwZIsnk++/KBq7+7laQ0ZoqZpUeXug69c4afxB7vJcHE28V9MGJxqDsk0gA6q+akEB4BITIZJVhDxzqp/sEVu1CK61XvJxcJHOp4x7xWUGswJy0LqvFFohQ1AbGJbBMphEfrq1BU16gboVIU6xC5xmGbhlIc2TodR4MpaXEaPByOUDLn00jG0xiYwwS+xzSi/SlaGZlC4PjpnfRS8T05jIRs6Tce14oBhNN1YazB5BlvtvhuB/NISjOHhwfevrljOj3w3e99D2McOLHHFmrjM0wKjONMJ93KdbgdIeyw255d37O1zSLWNhZEwCbW/cPR8Nln14SUgUZoSznomOpzqU5uS/IjQU7bFnxbmIaZeZqYVXxfGodTcGwcRl69+pz91bVU4rueq90TAQucYY4PPLw7EebAMQfyHJhm2T8cmcY7XOv185V+Oow0jafZ9JgSCbMkdyHE1XWtRnVlTfQfaw2kN9Dge05ZwJsKEBgMz67q68SZqxiLXVqRSHJibSG5lvHFJ7DfsP3yM3zTMvU9X1hLThLQTvNIuD/wzHm8t7gCOxLl7SuOzXe+cgpIwKbBilnrd957ghpjGS7F9RJ21LVX9/KUDUWbNOcslDaMUAEpojcaj0f++/iX3KSZpLS3HBKzkX24qQ6/S/xjLyqXoiN01RbfSlW2aRu2zhFOE/MIxUkrBpsTcxInxqJ7bVEdbkH6olVDJqrhE7U9wOOramCrvlH2D8tVk/j+dsQWOa+9d6rBBNMURpBzwULXimOfNfL9hpTIcxQb+1ap9jkzxyT9qgqYGGlL4SU/5Rmf41PELgZMhQqwrw7ATqbLAkpVwLQ+bGj6jQDFwwQ5SbW3FPl+MYoOuJ7Xuh5zSJwejqxGU4YUZuY5LkGhAbrOcLi7w1pHv2lxphBilmS80equc2BFbrDZNMxDZgraEHs5wxToUrpVbQ/UNuJSSUrMD2eMs/Rtw4SYa1XdozEFhonrz94xfL8hWNF3liDV5tbJesLWtgYSr1gjPbBKcjz5/B2H84T1jpLEZdJZo/R1MXepc3vF1g0x10WiYxgzxUvvvdqNTwAESfiq5jkEBS7cum8IYIF+R8/GiBkdCmQ8/fKBucYVyIOuv2+902SjxoNr8v54/VcARieI7mVfI7e6WA9yj7mgFOWLdfILw8zylT1ILqeVM9H0CVtpndvPx8zf/WziT78L8wd7nEnkmHmbE/fTyP/ezQxBWDTO/uK0Yd2e61+++humvrBkFqHg8pPL8/4i8VoAVR4nbPUjlr989X1gHdv6c2ed7DyuIWwFZDAai8Rwsf5sZa/VPLAshiIiV1qyAS5T06Q/c3atGJqLV8p/67/kslBPq+t2pc9udhvaVk3F9Bbe4z997fVLkrQZzXLTYiTziEKYI67T5nhGeptYYxjGkTTNULJShi5+xQjFyFoR5tdr1sNmTpleq0rFrHTM9wGUb0NAVgDGXLyu5tuWou46cjBfvpYF6a2UG/lYs7ruXCzqellrub69pgP824HhdF5+vurlgFLwbcMHH31I37WCsqfI6TgSRqFrLUgPBed62r6Rzu3DROMMm36Lv2q47+45vX4nATUQxkBgAmNJOSuFISyVuksHTOesHK5azUuzCIKttSSEp+69NBUEtH/OKkwGcYDqNr04OtbJr6dqTOXRGFknTUF9I5/57u0db17fEWOQe1UEyCm3fh03o0kEFBuxSrPabUXvYV2DdeJCGUJUnr3q/yiUqA2MG3GIrBqjWjkh10NqRcpW1ok8+XaOPP/Jl7St5cmTPbdP9zwcR45REmaTZXONwfLzT18SUst+2+GblhxFS5VKxpik5u0eUxKJx7Th9/V8ZqEFy5WTVLnje46S3rrVbGB9MYtoW7gFMpfNqnUwJSlXy7BtC/8k/IXMAxl8/T5l0XQuTqrW4hBEylpDmCOn+cTRjlx7T+slEEilukoZhmFcGkGXIlVcELChKWZ5X+8952FiOAVO8biYr6QC89Dyne/9ilBEiyQlm77DuULbeuIceP36DYd3b5bK4wdPN1hrGc4DTd8SrWPX9jgX6LYbsnG0Do7nB9rWaqGj4V+6P+B/KN/j77yVtWsNfOnf8JdPf7QeFzkzjRIkbzd2SYpSlIp2LtC0Hu+90LJYKTTOeXKMhDAzngfdRGRscpKkO8TI4XBmOE9gDJvNlvNpoKjL2jicpU+Q6gadMarZEoqg0eReAnrpZZaiJUfp0xS1j+Th4Szat+WcrvTPqjF+DFplhALrvQGs9uCyy95ZFNCr7qJGXUzlPQTA8baQPHSbnpy3zJsddB1/8/QTXJG5lYxWtz74gLfblps4cMqZ4eqa11dP8UmorjX2Nkh1oWorloTTOYyzazPosu7HNXWBql0WGrHROWmNmDXlLMFwpTIba/jvup/Qp0hKEgjZXO3mCziPb8RBeJ5XpggGpYNLVbAkSEWovtlIovMQAg/DyJg8Rk01rBGjrhCCuE0q4IKR8/lfuN/m15t7XpY7xjlClrVJto/2hcvKqbFSl+y9Y2sNZ2tpjLgo5ihU+Lmuy8azK4UpCGOkUfbFOYrjY9Kec40zFOM0XpazIFWwImaK5lAtovOJueCM0AWdauGarpUYwUigplItSiiM58x0KJznIOfbcMa3QsFPChC3Xce263k4nSWKeoSDJcYQ5exHNe5FqFAL66eAb9XZOCW8s9L3yTqSOlfG88iTJ9dsOs/D20jOiTAnbNPQ+0ZA1yy6rRjiomlb+ofJE8A1jtIaSJkwToQCU87SM/Ui3vGNZ9M07L448OWLa2bnFvfHaBwhyv7e+mr0IsFvmCb6v/5cwLIs2j9yIWa5j6bxAqgYme8la5+9CkgjYF0tkIGAA1JZg2meZN0lSdgsUk32NixBmHR79Bpv1SQv4N9Ftg6m2ys+eHOUaqExkBLegM+RVAoTMgdTKtx+dsebj54sSZmhnmWPk6eaptfc7RfmXlwmPn/7awHwv0Z3VnvHJnWHlqRa22aUTBsS4f7AnYv0alyXYuZfbALzoO5Vvyhh08ppZYGtwcvFa0q5cIy8ZIiBLSsb5CsAWP23NXNaBsnohitzGmrwZC7GRNpe6PdjnfPWeQUTIq8/uuHpj19rm4cLOndJsg9fAJ1hnrHqcJ6zUQ12WcwE610scfflECyfLnPbx4wJke2rezlrqqlOKbRdw+Zqu3xHN0eu7s48PLq/3XsAACAASURBVNnyi6bIL0XStqCPpVS+nfJyhQ4YYwHjaDqHt4WcozSaDBFDZCnZ1pKsHvA4h99tLipXhjZFiFlsUvVzi34HkzJc6GxKEZSpivLrYGZFMmqi5Bt/MZFXml7bb5VysQYoOWemSWgsXeuX966X8455ClJNoppKrNd4OmP7noMxy8Mzprqqrd8rp8SbL17T9h0KKK0BT5ZqmHMGcqbrN+yur4gxckh3TPPMZz/7VIxBqAFFpqQoG3cpQFySJFh1ewCmZt7Oif5CbbGPx5lpONN4SeYE5bIUCiEIN923zTImq/Wz6BlCSIthQeMFTQlzWNCSuphSkH4lgmbqpps1YfNuoUU5qxvhRWJcFAJNKdEUT9s0bHdbNtstzkkD1Ddv3nI6DaohERpPKUIjMUii5pwBr3uDt4ybVl3ECpvDSC22LpQuBJxqsKQ0EvOg3H5FbfRFh+MTxrnQ9B2b3U4sd6nU2bJoLEoO68Fdd8YaMOvBKbuf2mPrRlYK2gJD5/oSbFYNyzoXK51Ifg5OUdhKp0wpYorox0rKkviltCT5IDzyWmFb0Mism76x1B6Y1lqurq74oH8KdnXas6YeptLzLYXAPM2Qy+Uts72+5eOXT8EIReR8HmlMwu/3WCcOciVFbj/4kI8//gTXNFKVcFYPAM/9/T3WWzZdx/X1Ts0QwPuW0xjwTcd+t2W76fFNyxwM282GXBL3d2dyCEInSom+6fhnT75P10viLcE77M0NT8Mz/jz8kImJzbbHOBHgh2kkTZPShpKitoY4B2nAewEeWWsZT2dmxQm8AiExSu8p03gBWlIm5ixBvnWUciI9PFAbt9fpIzodgzWRp7yRhDFFPs2Zj3IQTXAuOO+1KozoeKrzqG5AuQichZHnXvRzrLFrolMK1kTm9gnHza1G02tVXIKCokEaiI5Uom45NgrWFXzTMMyBmDKv2z3l41/X5NgsZ4IgvIa27Ti2H/LFfOKu3zMX8NU86iIJWZLpUqvlQmm3mHV/QgGxAhhJMDNmTVAVLJPG0IVcxKEWEmubAHF8q41lC7WJ+xoEFSPBWoqy59XepZeGB7UVji2QdC/OpfDjdKUaMifJsdp0l5yZQ1Tmi1AkXWPxXU/btXTNjisidhiJITJNswAERgyA8sUGUXs/+sZzu+1pDGxMy6ZpsQiDIoOwFkqR88yI/i+lRLKGOUSpBtT9BiipEIZBrNiN+YXuYb4Gpc6RG49rW5pNz1SkAbk1UIzDGNFkjePEcZjIKUuPwnFWYLfq4jOmt4ylULRHW50ZdX7FFElx/beK6juztqVxTio7vmkEdEmRMFXjFaHyuq6n61thn1AI04zve9q2YbvfYkrh7RevpQqra6zkLK6/JRONo7+6kp6YhyMjszI20P3XLFbl1ago9x3Xn91xutkyeUvedDyczgynAUqm6Vqur/ds+pb57YH8+o54GmiiVld0by65UFsyWmup7MfVKXwF6WSOFzWFM4wh6TPJQjdFYjPRoTnISbR1yO/JI4gU7dPpnJinhDnRvD5wO0StpLEySKyA+1nH2tZgPBWacSZstP1K3QHqsioXz9U8xmR/0fUfkbOtScZ7/5bTTAgyPug+VhBdo82ZsfP85MpwNnB+GJjbiK8995StVH8vw8UZfPF9dT+uIYiEWWW5+cv7X6tlsBQi4ZGtvn75NSRZKx+P/6Qu6/W/63jL31f65VrkWefxKrcStlKYZ5XuaB/c+sspsRgWlUIMAR/FLMp6aX8h+6pdPtMuX+T9pynPyaVMO85s7k6U88g4SzxvkGStUR31eDoT2wZvJSZxc8DFRPJfx9Rbr1+KpI1S+5UIVeTyMhgokRxnii2EbBVxEdRH32CpBOl/ylx0Dtc2zHNg07XYxutBVpZ+QiVlQQlDIk+zaI5qsm/sggDWjQU9YIxWCeRBtBjrBbnK0qvIKJq3WOcacdSTEqkhJ0fbSTuCAos9MsiGEyPae0fHwdQqnFjHx33Lk3FaEA5jDUXpT3JAODCWGMsy8byz+MaJO5W+cc6Zw8MDx4eDbnw1EBD7eeeqXawlFnCuIEi2TN62a+h2vThGTlrRsmYxr9huOrbbnrbvOE+vYRDzDzTA817Gt2kadrsNKWc1IxFudh0b9P5Lroe30bzQLcEKGVJJZFZaXaW7XCbuthRc18pz0blXdNzaxuMaT5wnod6WzOk80nZH0RMZw6CmLrL5iDkOIPo7NRCYppmmbej7jtA2HD64olpORwu7u7MivLK75Zwl2XVmGd9GEVyj5ipN2/Lsg44P7xtNbg0mF+lDWO9XqYIlCRXIKBfDLL2wJFCvldGYRe9kSxb6XEp4r3TJXHsfKmUIo20s7EIDdd4JpcCWZUM3SNVPKLm1B4mK4q0DJMg3ijzV7yiHvTyjookfVoAD5xusFxOdVKQCsKjojCXFIOY3uTBPURDxuo6tZ5PFObUA4zhDjtw+/4DNdsswiqMiuaXbSNLVKHhQgZkQE6/fviNOZ1zriSli1cxkHGbRDl5dEaaRh/EExjLFxNs3rxnPAykL7cYrvXijQTBGhPe2WB0CS/+q46M3HzA0E//i/KXoOVIFr8Ql0lqLs26hHtdxLFkO5JzSaq9/mbvnog5eMnbWWbq+wzkntOWYlr5+lSp7SVfd2CPfNX9J23qKN/zQ3tIS+L7TNWeE/jyNkyQxpdLQdG7oWq5JYU0MZd9aD0LnHOb2KW/3z0EpXNbWhM2sGjYc0stQzGpAA7dcKMXTNo4U52X/WE6V2lNJqwVZ1/AX7W4FFCoYWBNF1uCgVpZqsCa9qKR6aa3odUqpiVpZAB6922X8U45gai/ES8ZG5tXR8m+n5/xBOeG1llSPPBlGpedUe/56d+Yiga3vViQoRSsc/zbfMmaHLUka81KDpILPmVDyGsjlgnpq80f8Bv8j/y9t52i8siOs0BxzEpfY99kp0oJALdr9LT/yv8b3zM/YpZME9MaQdU76FHHGMOVM9pYmO+m5iASCVdtGAaPn7yV93jtDtzRClivo+IwpY+JEmQPxdKa0LUU1yMYoHZuCt5beWebGkzHENItZiOpO65yepllpgqvuvK436ywxiOaqacSIyzcNlIsG3xpLpCIeV41vYA4Sd+h3maOAPACu3bDddzSu0dYnkc2mw3vPHJU9o3FUyUVEEDkzHI5aeSkatBtIa5skzAXglhLTMOBiw3acyU+2hP2Gzln6u5NIMayhP03s93vsF2/Jd0dwDrdpKYn1PNYhqT38SsniQrkEvGaNoy4eWFYaa9s2xFl1SMbQbQWALxrg5RSZBunhVylnteq+ZBlaLZ7ngLNWTeflvAzGcf30mhwT091hgah8Nly/PXJ4tmfum2VPKhff8X1NWwViflFathaS/sPTt3oWC9usEMaBHNbKatO1+EbOSW9gNPCDm0AYR0ySympWcNw6J8BPiuqYvO4X1c8hX4IhCzChsY65vJc1+SrfeFuaSF0ydUyNm3Tv+rqsV2MYi9RTnBOmiCT7Vs8Ph1mlfOhkwzqD9R58ENAyFwWMH4NLAjTLf0v8Kj4LS1zy/kNY/qrjcQlU5czV6wP2OEgFfA7KFpKeur719H1D1xjmkIlxFjdUY/CnM9clk/23p2W/FElbQZpeusa/N0grEuRqSb5OLmPISXRTsvlBrWhlKkVNSt6C4EriUQOGGkDkAjar61r9VM2EJUYQCmBWytdXIA8M0xgwVnjFSwUDyzhOULK+tW42iogJ7WlcnncNZqp5AwtacIHQJknAQowYb/CdY3OaBHY1kuBaa2katzReTDHohFFURDfUpO5btbqSoh4kmtAtzcFLwu5a+k1HypnhcFaxqyRT0zDh+5Z+s8FsOs6nEYqgrAXZWNuu5cs3R84PZwm0qmObt1gvlvKSpFha3wg1LTtilI7yUDcsFjvjnCQp9N4yz6vejVIXUw2w5LLWiP6uiFZGKndRDmNtwi3PXuyIc2ERcRsrFLswB/l3LZnLc5P3zrkoPdEuz66a5pSLcacUTl3DthRSSUuwZEAqXGsrnHV9KAgRY+R4zhwezutGUysievDWDdzpJmGtGrxoeV5cI6XhKzkKImo8TZmZkxCbaj+XlAo5BrWLF9qr1cbCfd8t/UuwlqaRqmTdSEuBYmUMnBcakNUkPercjDE9AiWWZO2irQBFAiCZz5m59lEDff4e4z3j6cRwOpOj2LDvNi2u8fi2JcTMftczh4jzDafjiZyl39vD/I4YZlKQYOeJUq2Xam+Rjf48BamgmkLnLWGaaJpG3O5iELfIXDgcT+Q4Y53l7ZdvGaZZDoBSlGYLbduybT2brtGgyeouKGNnreNFeE6ZM38w7viR/Yul3YcxGqAYR9vrs9KqMyhyPMwUKg1EkzOl+BU542Sv1AR7miSpSVphWXblVMhotcUaTIn8Vv9jOt/RNp6uEyfPVxZu08DzMHI8nTkdB+nRVxJZaboCdtVE5xI9vUxU1ixzs99gdxsJypd1rG6MC8payEX2XWEDxeW95lmSnH67kaBsFiqV031AAAvRv1oFfsIcvrq7axNZRQF1TlxQAXX9r1yMKkSvAEQN6o3+mx70ekvWNGy3LdYKEDBNQRIkCndD5s/OW/6hg6ZS7EpZDQs1oU7m0mBBDGASRg1X9LUaiFV6sMkNyRriFLAG7dcpL46Fi/NTgDnnHTnO/Em+5h+XxJPeCs3ciCuat0ZcXfuG0zgzR9HVWiMAT7/Z8JYd/zz9fR7KhodyzX/m/xRXEm2KlK6hWGnRY4Gb/R7rDfPhxDjNarZlMGpAJACXULKdJpgJoUA2CrbUy7nCoMGac45t49h6z8kZrViucYHBYHPGURTkMWqk5Og6j+kk8ZpDIswz/abD+bUXaB1vZy0XreT1/JJkwjmvIIFIN0oMBAxF1xpoDGMK8+GeU2zY77ZEpIIX4khKWWUFrTJiVrZClkCEnKRJ+jAfcboXeytrp+saiWk0ABAjDtF1pZiI0wRtS39/5ioWdtse028ITs6QJhrsYQDjmLb9YipCjovRiGzpsld773DGSy/FvHT8YyWnmf+fuTf7tSU7zvx+sdbKYe99hjsUWRyKpChSA1uCpW61BQ9oNGC0bdgvDRgw0H73/+U3+9lPNmDYhmHADcPdUtsSW2qRlDiqyJruPefsIYc1+CFiZeY+VSSlt0oO995z9pC5poj44osvqPk3oeBDq+txhhCcnbWeOWk2O8219UNj9NJIsV3oxLqAOWdCI5nxPKhNtjktAKHl1TtfJE8XLsczs1GhyZkQE7cfPvHmi3ekNiznqNY9bTI1mxl+fnZ81lWroz7tR/76SzPC1hZItFaw3kYBLRVqG3a7G/pOtQaiTHp0bcAUbeIuCt6W6/NM11AFujc+1JVbrgtNC4A2P2brRut41XkGCziRBWDevtJeYP7S9QvEiarqOs/+5mAgoli8pL50KsruarvGBG/Uj/WhwzUqqJdzJiZVpH0uxlafc9sUfH0u4dkdreOx+YwXHz7BZSAeL1Z7qUBmV+18KUzDxK7XUq/D3nMZC10jzJMwlkhzHhEX+VXX5yJoA1FRBylLIGG7VzNWTdCJWpBKNjSUDaIo6+fVsVfVokoBw4I+Td+Ti/VDyWgnrqIoV13cdUFsiv63qfF1YV+nM50Tfus7v8M4Rn7wgx9c/dwHT3/Y4YLn/HhUBTbn2O96CIFxmInTRNN4o6cYDzZvF5j+OVPoDA2v/bMwQ+6D3xjsVaTFif7fwpNGMyeK7AmlaRX5tAykOEeaZx5N8arb9YuM9HgZmebIeJ6sP1qxXjrrvX7y8cTx6UTMBTEHSwzdb5qG0DVMU+aw76gtDZqivYYYB1LSInMQCBoELgCH1bhUasmKFNliqCieMwfVxnqKhQbNWKSkgiTaf8kxxxkIpDkzm1BK1xlNokDjA13bMg4jKUZVZgrCNEWiOf7iHZINRbS5q/eWS8YVFhXHKqih8yTM80xfKuVG7L+ZgiPGmcspczoaXmjZM9nUdMa5WH8dPcTEeVtLxZwWt6iLee9ALKCSfkO3lQVpEnbL+osp0oSwzFOll9Ws49oD0a3F3c5oXh5eeogPSYNlExlZ1VSvN/FaCKz/9iFwOOy5Dy+Wn4kUxEOKhY/PZwTh/p3X3N/udN+iConpeNIDO87M88Tp6QwpkeeZeZ7VERR15ufpwvF4ZJ96pRiOEx9+8oZUZl7dvWAfPO+//3OmlMko9W6aJxrfEscL86AKcRdrtJtzYZoyXedx5pQVMv/t3bcRa5ZXpJ4vRgdGLGh0fKk/0AXHYL9TpTSl5E7nmameRTYq6zC6ZTR1fCu6qGDXdDHRoOCJWUUSvGMJ9kUcyeqrugB/sP9rXjSDqmWOQZvtBnWOI/Bdt2e+PMLDqCBZSRQ8wrw4qyJrDzrdT1ugTBbxnv3tnubL7/FnX/7DJfvhfdCsRg2cKOS4vj/VWoXFQYBpGpSitwEvYsqb1i8FJ2EddydUZnBVEd3Wo1fgCFN1rT0VNTNe93j9U1grOeq810/ZugCZYRhxzvosrZATOSajutV3lo2Y0ebcEKMJhrA4I+IKJVsgsgGDBdRxnRNzCsxFRSuCrTsNYsC1DXc3e17cNrzz6pa+D8QhMl4Gvs/X+FLIfPmj9ym7lnJR5sGr+3uarsE9nHj7eFpsVmgCza6la15wfLqBGLnQ86/TH/IPm+8S3IgM6lTT74gx0nWtUngHFeAgpsW+ZaogjY5VdNoiJAPR+yt3WOpoL2MFst9BG2hKMfaLOq4q0mW2f06IUe9vbrShfC7auN0LeDfb/oauC8t3iuga8k5LAKoC7lZcrJ6TOWurGGJGmCjFE9B7yqidbHcd2TnGaWQcRgWlwD47kJ3QdB3uMuoqNhZFytc1ySkXJhRw67oG8YHGShNElAFQAYfSZKZxJKasYMFlYBwm5hgX4OUiNZtdtJWPUT8XyCdf+0jOC9lAwd3tjbUSEbqupW1bnFOf4nw6QckEyap027Z0uwPzPHEZRqWBL99REJLt02J9MjfBelDbNw0TKSUuxzNN45f9L/PM8c0bJCtYUxD6xjOMBhzOSelz+dM1XNv6KdnsbCygK9tFuL3Ksw/6e11CG/R71XRsKoGL+gg1oeHbhjYJQRJPLiCNW33JogJ1batnQ0pW0lPPZqnPZAkT7zZtZdCgR67Bt/Wp7MAs12Nk1mkN8rYDVBfJs5G5+nQnlCbQtg2NCSpls3HOVFCh9uLTOmpyofEwi4mNOEfwQQO8TY9GH5T1Jve3dN98z+ZwhRDq84g8u6lS8LnQPV3YfXJksv7EAE3X0HSNahqkzGiAf86Z82UGaczvUp0haQslOaZSno3qp6/PSdDG4nl471c00q44J22oW/nSa+i2oO5shtiRycWrUEaKiMtM8wyzDVylRWalANW/51Trk2oqd43Gn2/CNYi7Rir0cgvdJoTAOCoaWWOPeVQhi5QrTS0zjBPFCp+3MM5ibM1IrwehULoWGSI+FwtOteh6jokiukm1fYGp5Ng6zUULs5egwNLAobFFZps6eBX0iHZfcU6Ml1GbPTdhOX8qelQFC67HSUjTjARtwO29Z9cG2q7FNw3dfkfTdvjQkrxnmkfG8xEfhSaAPzilHqVMISBoAfxkaec6VMWyRyoNbMihWCbCCqNiVupELhDHCWm1IWpt1DrPs3KbvbPeR5U2AnPOSBYSiXEaKdQ6wkwaykIBWY4qEe35FfJ6qNe1xEqxtSHkUwCPgpbLwVidQ++hCea85myCoSsdqO2Fw95x/yLgQseHHylS6URT87tWabMlZ1VgdZWWV52aCpoIRQwHtXWbyVShuJoRqpScqhaXTVZ62b8mJQ6O/5K/4oPjZSkI1u+7OgWv1nz9jFKK0nztvmqNn/NO1f5kIiXY7Vpu9x3jNHF6PAGmXJkL8zRRdh2Pjycuw4h3qiBZCovzMQ4jw/nMz37yY/r9juADj6cT8zhy2O8ph2TS9trXLKZCmrU/W2Lm/Djx9PC09F6igj4E7u72NI1nHIwukSE7zfRshBTt/KqP7xQd9425BtetSNbx0b8WfYsig4rOLCIIuSSy7Yu6aXKMJBGatqEJLX3jePdFY3Vp3hzZzFe6N7ycCuRAiolxOOH61uZPjWHOmXmYaawNgdOufxgpzwK2ssk2rVMuTmjajsPtnnz3inJzz3e/8gekNDM9fkweJ5rO7qu/I+xvqNUs9cpUAZb1x6lonaMPDZPUInTrwWPZTc3UFRM9aSgLVciCu9rXyC5nQMgVcFDPoLLS+9c9tbVRlWKpdExF7JUJohQarvei98tzKfqzPm8pMFwuzJMqyy4Ndc2+Yd+5Cr4oWBCzICnpOU/Rvp1Ns5wzrRN8cNzeH3j33vOP9n/D/a4Qmp7YD6TbiWHe8fPHM3/T7XnrHd8siUPJNA9HGicM0QACWe+VVMg+Q0qquEhhCC1/Pn6L33PfY89MdJ5wORNCQ+h6pPFc2qAN52ejcdv+SwYSOQtQimgdfIyJuTpd3uEsM+mco3MZ6Tu63/8tVXHUA37xyzb603quzxG372n7luA9o9mc0DiatqXbFQWgsLnZOHYisNtpdj/HSNM2umZzBUOD1WlZBaNTdVUvgm8CgsO3DafzRW1VRuvvSiHUQM17ctTazQW5+SXXkmURT8xlobM3zlOsDKIOhDivjKBxot/1C3gRU9JowZxfF9R/KGNcQYSs/dy0e7Es+zHFTJwjTdfShAbftvjW04SGcY6UpLRsUKDB+0DftQq25WitmSKocL1m0AxcVHvTrvu0QIoz8xxxbdCehkXtxzwnXPC2XzKPH3+sgEexsgHWOvumCRyK49y2BmBydeoIm7rYzXUNQn7mbKxByt8hflNTYiJvG3CzJiGwe8iC1TWCT4XfPha+8lHk/22FH+xDNet4ExeSEGgQvEsWyFqm0sptauP6Oq/PbzUbiPTs6dUnlBpUXoU+y5/ACpCsA/epZ/fiNLFSRTyyV9q/6S0Up9TyskRUQo7qqyTQ84bqA5soT2lAVkpot9ux27XkvjfFVruXuqbXxzJbXWjGiIuJ+w/eMk2RyziZXZHldSkl5mgiXmm1e8NpYNdr32nTQmROWodN+vUh/eciaHNO6Pe9OdnOHNrVUJacibOpayGaSlEFg81hZepwgmaSgJyy0k3QWqdFdMSctGKF1mv2TZfVYvzr9/89gZH7+3ut9+mF169e8f7Pf05FYOfp0xziUgqTOZAi2mDUWcDhvaIn1VkTYcmUjHc96TLRjOp4ZMs7l6xCBXXRiZe1gXXJWge1qCxliknNixMwGWDnNNsW51nHxTnLDsEcMwUVk0hzMk/zesPVnhdgQYlR7prgcSFoc9YAXd/Sdh0ffPjWArEZrKFo1zZ0t/d6OMSEk4aUJ85PJ1yM+LZV7r6hG/WSzVgBpv6j+aoSk9IIU2bXqAz7PM0q2281Ei4XKFmDuaA1blJUpWueJ6AKmqg107owpWtoLZaOV2FtlLqIlaTC3XEwp6oG4VrXcDWEDlxTF6AsQVGKSWsCK6YpshTG5lK4PTj+6B/v+Na3X9B3Pd/988KPfmzrwMEij1pYs5BGV8lO9LBNBoyYY1f3jBbxYk6i0W9L1J+Zs1ipmZXsUiQgwZFy4c3bB6WxeUdOG4e2rKCEPfCydpY6jaKFvFpLYLWmQalt0zgvhvJ0PmtdnhNrVFtMfSpzOl0Yp0kfv+iamGNexGiKCMM4M8c3PD090TTtInhyPl94+3Dkxz/6CXke6Xed1S1l49lrz7gpRhpX6zSEZJn7pmloGqc94WBBMkVYWAOUNZNSpdRmU20stqcak9dX6rBSgvaHllokXQ2jWEDgg2ZFU0ocH08IcLg54L3j8eFIobDf93zrHcfd3vPVOzsTcgLJzHPG+xekjz4mDY/MkyrVXYCYioJpweO88Leh5Rsc9YwWCz/F4aXFSSHO4xqAUG9Uga2bmz3Nl97j+1/8Dqf+DqEwf/hjju//iJIzreg+Trt7ulfv0t6+pt/f4JwVfm5EPq7dqkRtpFodn2DZ5myGtZQqZZ/WEZTVsZI6T/Vfyz6tlPPnzoauh8y1syMVJLPMmH7OClRcgxU1A535f8ZXtA4g8y33xCsZ7FUOVd/PqFSHgY6skGcF1Ip9SS6JEkxK3zmyeGtWHxZb8c4+87tfOPK1mxO3TUtKEzGOzNPEcDnycB5h1nYvTRv4rt/T5MQ4D3wxTwZYrI+SC9D6pVn7WFu05MRT2vFT/5pvu7MKXYng2w7XtGoLZGNH7AyMVRzgymO0jGJMHI3ivzBbQlAKXc7svvouzasXpHEkO6PEb24X1onIOePrOFnwl+eJlB1i4i1zisRhVPqfK3SN9tW0fs2ayS5Z5zulRaQrCRScypGbrxNLgaCiSMMwko8n7alIIWAy/qUgXtkwKSUtwagAmAXKK+WQBVCr+7TbdQSvpQclF7JXerVzta+gXt5DNODzy93vsJNbYqONmIsAzlt5SaE0dc/AWE68P/2lqm5ai4+SEnNiKXOp+7BrGl23c2KKEXlxS3k8UsZJ/Y4si21wRcsncl5tpjO/L8eoNtKEfSoTpOIcImpcG+9JpgzoncNbg2opWds5zNrM2wcxFWXPy+PI9OpmDc6qvVpWzFquoyP/WYHM9tLZec7Y+rtfstnbZnNxywKu3/27p8I3zzA64TuPM3/tVZm0CX5Zb1W8bLn96i+KsmPEK50cUSElubpRfV4nZq82vyuy3mMN2p3YO1Zjr+dj2YTBtje2WbeUE3FWgZyUEr5tVJU8NFqv5oToHd7q3b3pYpScFJSMmZu3TwuoLgb21rpIVZINSKNnmXix+sjqJ5UlUBc7f9rLzOGDB8owcZpmbTlUVA22845xTlpysBnj7ZVS5nSyOmsR2qKKuKdBe9cJv3pBfC6CNrEsT13AYbuQ7WCQagS9WyTVl+iXKie7Kjgiq/GqtR3FR4b7lAAAIABJREFU/l4LEWuWq9YFlcJVgeLyUVvE8O9w3d/f4b2Qs+fFy3tO5xNPT088j6F1fRpHXyqVRTNmxcal8YoWX9VnoRslmOEvUizgWB3fKjZSC31x2HdsnifX4mtMsUvRsLV3y/XhogGC9gSLs35uFT4p8bpfjCZF1eDGXJBJ68DEORyi8vjB83Q8M33yoHWBaBPu2Zqsjt7hH0+4UJUxC1OciVPEB0frGibLYu72O0Oey4Kce79yv3N2hspBzJkQo9YqJm2GKqLyrl6UildsnFNKjFOm69rFsdLAWdXWgnPEZDVcJdOEKktuTkRKC2qfVfOA/vGyIu+1hsEWa/LuV2/ZZ/7h0qOrFJoG/tE/dNzfJU7HM9Mw8PKF8P0fdIS2RVJBFsEGE7/JrIfKKs63XDVoKaAOaIEgSlee06xiFU7wOFJJtE3Dru/p+h2q7OoRF/iD6a9xHyrJr6RPixXUMVv3xadBADEnCTKtdCZLnhEfuDnsOD0dGc6DFv3Lutedc6SYGMq4jNVWaa9iP1obpqiXdwWXEnkaKU7pqsfHN1o3lzNt22gtidVAqEpVIqWML8Lt3YFxnImXSZ2CWbOB05xpGuF/fPgh/+LmN9ZzJ8M4R6P/2GJwwjEP2vurqIjAze0BEMZx4ulpRNAmv6/3hfdu4xWfrxbtlwKnWfh3U4t4rXfdtY7f/7YW2TcdvN5ngtcA5Pnc5NPHlHjBOWGcIl3fstvt1IGeI8NZHfW32fE1EULJKpO/LKoamNdwdf185zxd3/H9V+/ib77IZfcCAeKHf83lg5+QhlH7N4agxfWPHzM8vaF/8Zr2239kQhBsFm1FXCFIsbKnqGAVBdmwILI5fdUu1DFbMrk18ERR+epKlOI+nRUT3f/1XrKBNLLZTwWtuXJOndfgnQF20bRJqkCKZX7HkRQT/yq+sncX7toLL7z+3fu1gL6KIdWWVQtVVKoLsDpCJWf+sf+QH+Uv8xgjaa51z47fv/kZX9vv+WoT6Qh6zpfEPEWOD4+M4xlK5nLJeKdCHQhM4vgLeiiZd8p1TUZJicv5Qmr26uznaUHXb+TIK/mQUYz2CLSHnpwTl0EVeg93t+Sns47T8hAYS0CATGeKitU5pChgE6dRHahSbavlrJuwiJ/8qvM2mVqyiJDHEZcTjsI86FnSlQLjCMnTiIBzpKS2bp4mPf9E7Ui7oTa2Xcc0zZSkrJFpUFaAbwIOVaBrBBopBoip45tDwLUKJs3jhAuRw90Lmr6nTAOPj09M00zNArku0IRGwZ6SwVVGip2N3uHEMvnmbOtj6NoX5/hS+9u8dF+Bzta/rKBUhQV0zBNTmflq/C1yKfzF6f/gND1o1ivqObXUWntv/kCh2++YHh4Jr+8VgB0no9zrZDpr9F1FfupeVcxUQeiqiFkoWsssQvZZSxWSIEXogiei4i65FPIc8X3HThSQ9WKKxy4s53kuCv57p+NTy1uXtV3KAgqvwM4vvzanM58ytr/kEsGEl9wCwgCL+m4uGjS4NQvAN85ZW4qIrqt5iiSfaHy3+MPzPC/sMrDMtLN6+OAWhlZhpfQuN/SZD1fASjlqn0DDEZYnvqpXu0aqNp+xBnclZaY4cTmdufnwgcNux83tAe8nW7Mwdw1P9ztKKbz44AmfVGq/sfrH5jIxVzaQ3ZDWuyn92DVqq0IIFKuHqxPVnmde/uKRtq37OJNPA9NlAhOeahtrBxUTg4H0Ipoomab1LNz6NPM4E7tA0wamWZ97NgHDX7ciPhdB2yY+W5B3qJN9vUBKwVDgWoxYeb2VerP50JyJaVYlveoZGRKSN9+zdbLXoP/693/fSw+xTAgNX/vae/zN3/yQYRiXwLSiRZoB0UPJbwrV63pe72ETPKEB3v7hQhiiCUVU3nxZEKEqM0zBmorq5zv7DJzDI/RdwxTjlcTq80LNFWEuSyAsbpUZ3m5kWeZmHU/NJgRSylzOFybvETea4EVFTlV9TKXiRVW14kgedI5dKRYg6cYbzgPzOCtNMWS6XU9K5yWo0gPIglhDpCsSFlPm6e0jiFtS7yVnSlAJ7JQzxKgGetQBDCGYMEp19ATvjE5gVJxsY1/QtH0uEC6RL/zkjaE1WtOWy7pBMyZmUpTzfb4UwlOynj7G167OoRnjLRq1zlLh7k4NUEqJxgvnS4AkSm0rqwONGbiMHWJli+HBsqsq3bFmg5wgOGJSulljzaTzPHC4f0nXd7RNR9v2DMMFiDjX8s5wVqpgLvZcq5O83FP97mLrzJx8EaFrG1KKjOOIbxpa3ygFYVLFOLFsl1iGs96uDx7falZUe5yNpFmdmsvpQujaRSXVeesVWRyvX7zk/v6GxzefMAwD45zIwwWSOl6aRMmLccpGN931Hbte6V3TlJb9Ps/RMn6JOMP30gMnN5Ite6lAkray2N/tleY1q+PSNgF3u9MaMnPE+76l6xqCgz9+T5u6N65dzgcAnJjCpCLr3/pydeJVdr/x3dWZtdRDAXOMxPFE/OQHNF4WSeRpnrk57Lm9PyxnWJ2vlAqvngrnjx+UAouQilIJvUSV8NbdaHOvdT//ur2jbTp612qG9KMfkIY3jJPWPoZSll5K6qxDuhyZPvwe8uV/gNgYYqhzsf3UGDVqOp8NDXdr9mG7f8oKiq11ajV0rrVIVZYf3ZNFyLXWhW3AxuKoiGwZjdWoCd1O9wjAeD4pCCfb897Oae8p0hjQou//38Yv8cX+wr2bV0VIQGUv9L42J/GzWNaC1Zx5J1zomXnInpxm3vM/4yvhkS92O16ERNfdE0LHPJ9JMfH4ySOPx5MKGhngMTMzj9PCXBnFcRFnSc/qmgouNHRtyxfLE/9J+rf8T+U36HY7/L5jXybunMM5bakyjIlmt+NyOvH49kjoeu0L6B1lUklu7z2h69j1gRAjs3jaXWd98iLFe0qc8a2KhpRRVZabL7yi/8ZXka6jd8JljOS4Ebpa5mBzqlrNeBVBW4YyZ5J3BO9VNRQoUenTwVqI4BwR7QPYhQZJxoiJCd+p3Rkvk4kmaPY3JK07Dk5W0RnRap3kHK5tcaFhmiatb3Mt0+UCGNDkA2KAddN4Drd7Gh8QgWEcOV8GFX1zjs7KFYr5AsIqckNJCJmvd3/IffiyZnPqjlD0wcZtk1Uh0BJ4x/8GQuFl+y7/1/G/53IZyIz0u15LFQxMFlF6+2LbxHHzh9/h6f/+NwqkF/1Zzot0CAavg8DcNgxNR/OLT0xNXGsxdc9aMJ6LqXGvNGifKx1Qa9xDo30uRSar5S/LPvHCOu8bRzVba4H1qsyZ6xrST12l2NKqmXR+9evrLhKvKtIFZKFgy1IzCaiqei788UcXZHezfF1OUf2MUgxQSMaSitfBWErat9JZXb6BHDV4W2yy1fTqGF3fadUHqqUVao7Ul9PHfhb1bsdl8/e6unJM7D56ov/oAYkZFyHN2gvQWe31vgnsHs/6uVFr12Wa8Uml/s/J2qUvYAQggf2+o5TM5eHC7n6nDeS9Ixq1Fxx+jnTDRJgd0zwRx7jsLXGe1jkyZSl7KKXYetI9DDBNq0BWvWJMjEPEB89h57g8qAJ1cNvz+7Ovz0fQlgvDZVijbNRRMTt8jViWQjXNa5C2dWC3wUYmz3GxnDFpIa5W2GidUg1GaiPMxXGp6e5fu6H02gZj+lmqSKlKSA3f+ta3+OEPf6j1UGb0coZmiiQnlMZv0F0WYY363FWYwTmHTJH9ZeLwcMa5q1IH3UTOLbvJ+dUZXzeoXCvpuBYXAmWKGkBu6tKWZpmo2+KMvlGKoli+8dpTLiuStogemOHWLJk5SjkynvWg0CbYfjGQtelsETU64mWp+dNDstYxmLiFCClGGlMcHS8jBeX7rzx39PlSXpqa1uyjeEecE+JsjrM6ScHaLCjVROfQO5jGmW6nKmopK1Lnismwl2KUS2u5YIjlnBJijUadrYXq0VU0WJxgK11rWMSRsgdpKWjLgW2txZpmvs6ymR0ww6FzMM1w2Avf+Q58969mdQ7KFquz4KysAZLlIjYuV1V0uq4XKGg2xYknRbh78Zrb21umOKH0hEjbNszR4c5vmIcHbcIc0+Lg/mre/7JU8SGws9rHRpQSMaeRmB2h1YN3HCaarkWDh6RUIzSDr/tRTEm2LN89jpMpWmoT2TEZIu8Cc5x588knzOMA4gkeLucL/a7jdFHj7oy6XL9zzgXX79i/uCXPM9EMqqvEdVQEIqdIxnFuB1UuFa+94ER4ao589/A9u0d9z3/+lYBIY8Oxybov0v2tNQm1vV6D+krFQunO/adQvGugRdZ/MAxnzj/+c9oA/e0NIo7z6WjNuhMplkWgZ302CHcv+VLX8faTN5yOF1yJZGnsPjWoziVoc2pX+P/cgdTvObQtwkyZz8TpTMqR/f0tp6PuxyCOedSspfhA2wZSHIiXI0UcyQyobSzAgwTmmIiVNv4M+KrPvf5Z6UJi+1XYVFywouNV0bdQSi3uN3W3zbypCqS7CgxTKpzOI4OocNM1OHa9L3ed4+XLnqfHwjxP5FQYreebvihbICoGZCodVVgduSvQUwKUSM7qwP2L3Y/4H/Irfjd8Hx8CTd/Rtp75fOEtsL/pEIHj2yPH8xPTrOd0SsWanqOB0sZm/ruw5zbP3OZVFOJyPvHwETQ549kzl8L4+ER7OXPPB5waC1y94/W771Jy5ng8M0wJ5gs3h4Z2v6fpOihFhT+8J8XIVFSNtbVzIDfCFAvBBUqKxBiJudB6rRGj7xCjhyJpGR/ZaOEtc1iKNsSOUW3KrLVb1Tq62mqhFDBZ72q0w35HaDvmGHHBIdO0qEmmmDg/PWmj51JovKfdiIPVGjKx7I6yUyA7T9P3+kwxKrV3mpmniV3XgHdqv3ad/i6ppyQWkLVNS0pwiRdjGmj23qFZKlfrXYtmmZz3tK7FS0BPFhsft1LlNris3ntFLBBav+OuecVw/gnOeRO3UlXqYg8q4ojjhfDFl7Rf+xIlw/1/9I84/8l3kaGexyw10OtaFmLryW3QGvRUJbTF/tBsUaEoNRVTfjRaZJ4UfI0pk4JmWXzjEQMVBfW5vIM2JRKByjhZ8A/z9arQFwI18/7LrtVfLc9+9tnXgoWXslQ2VDeivm+pjbcfNlOmtJmENkTXYELIMTMacL2I+ollnm291Qq0bQ/txblYQmfZBFZ2S7buaz9DKabIvjjGNl7I1TNtEbJFHqQOjwj+6czt2xPZWhTErCq/EWVmVQbZUpEq6hcFpy2qnPc0kqFYv+GUccFzc9NTSEq7nDPzSTi+faI7ncEk9+PDW05/+T0o2i6kAgOhVREfctFyijkukIL3KsLmRPt2LgmBJamyMlnGYaLtAmeBOWPKuL8+3vicBG2rJCsYh7zWJbnNvK8A8vLwFU1JpVxTG209BOfU0KMSvtur0qEyxidfoFFboJuP+6zgrd5P3UDOCbv9XhGloEVJtV6oUPjNb32T733ve7jTjBs10Ll9c2ZsPcO+Q0Q433Sf/pIY2Z3HxbzcvTktwV09y5Q+prSFUvu6OJVmjykb7cqEOdqgyF6MzOPEOKgcdinZxluWk6kJqmIppSBWa9fuew6HHd1uz5wyl8uF8XzR+sGszbpd45mq2pNXdTdFyd0ykCGoClDKUHs0dX6jYBkTOWpWJMaivWgsKOv6hhjXxqYRPWy7rllr8rJKHtdM1jpXKyXGiaqTDlPcOFyCC956yigal0vUFhN+bcgqdZEtgY2JRYhYKh3KnGi7GnZZwOS0V9xakyHmZ1vrAOuVpZmW1TcXBMnWzsJUnYpFgIKQ0sjHH8O7X/RQtFm05MQ8T4yjOgiLYEFd0HZwGiSgIIkrLJzBZ5cidibeQiGbQWz7HVOMDMOFUjJdf8PNfg9l5jfHn/I6PvFBvD7E6nx81lXnqcob4z1t23F/eIFzup5TUmrZnCbuXtziRTidzpxPFw32rPhYfSpDF5Ol4ESN8tJ2oOj8OafS928++gTxqDCFrZM4J+5vd+RsKmppHZOUVX21847j20fmeV56wtQmujXTu9vvCE3ge+/+iOtKtM0gw6c9omWlbQaprmM2BmFr0YvWfpRnH7XYStH1hBlsESjzif7yU/xdv8gjd63nHDWjMA0X3r71vHx5SwirvHqh8KfhwO+L8OI1SAgcHwYVepJg2SAhSMQd9vy13/FmKtzGiThNlPKGcnxDjLP2VfKOu9sbYpo5n0dSVuGM3WFP17ZISpx/+l1y2NO883Vyt8N7lJorMI7Doga5PHcNTktdB6uzXIfbmdO3XjXoXkexFE8hGlCiP6tA1TpHVneNft4SbJtwRj1v1iAyL+9zUvjtd1v6vuPh1PHJ2zM//XjmS/EtO1/W4LyGRrVeeetcLUFq3ev1nFen7ZHIP7z7Ca3fq2yMdwzDxCXNcHzi/nxDCMLxfOJyyVZLZopz0ULaOS3f0XatUuDePllBvf5njoW3jyf2jUfkkYYn9nKmTyNf9j8mzroO+5f3hMZzPh65PB1JU8Z3Pf1+x33bcjmdmIaR4TIu1PyYsta2TPozBFyxsHbj6Df7He3Le8J+t+z9OqMONmp4QtzYh1K0T5o3p6vd9ziEIZ8pJnyFzaVGw5ph8zct+33H5aLsEMSr8FUpyJzwJStFtmawxBG6FkqhdYJLCbwnTvOShZWuI+NUIMXObN8IpThjpWRC05CnibZrmKdIjGkBNn3w7HYdaZ60ps2e33u/HA51FcY50e56PUOFBWhjA+4s6/m5o7Rcju90/4xflP+Opa+i6LqYp1lZNTkSh5m2bfEG0hYv7L/zLcZ/85d2T2LgxHquXW57Hu73el/7jtbqCIEly9lY7XwRnV98wAVPsJp/bTKdmXxU0MuyTFpaoqsjFXj50ZGP3muX8UHkSjG0FLQ36Cbr9cvA/s8wqb/yqqCg/seZX1tWoSsLtmqNY86JOUeGy2WhB+cUiRNE8mL/y+Y+pSYYlrocPZRUdKlaKDsjNw+13SNXace6qTaXN3/FRkHHIZerMbT2i9ZqS3/Tny4kEQPK9buSgSfXd2FndsE0HML6azsnXRBC4+jalhS1hCQaiHx6milPJ5ph4vAPvoXvOsa//YA0K6Oo1kKLVx97nKyXac2MB2919NYOpMSrejbnHF3fEoJjHmZmA/jP55ED6qO3rVvP6l9xfS6CtnptaSpl63jUS1hUAa/eVxHLa+FCgCWpf/UxthgrFei6oHm9F/jVFMlqcNdxFu7v7tnt99brSZRDnguOjAsN7+xviT/5GD9Vgw/dGGkuWrjoh956Uq33Skx05/FqfD7rfhW5Y/HICihFCqfBU0UhmgYvKgxSsqrmlVJofNCGzYbuBSteTikzjxOUjBdH3wTu7u7Y3x7IGU7nnqe2IT88Mp5Gck44O2BqfzBQdNd78C6orLmo9P8wRi06L5liaobVOVh2p6jyT7aebjkmQtMwWKsBnANr7prySjmrnPPn8+9ETIksG7K21jRqfZinmGBBss2p4i6rk1pFRkrRhqwuOMbLpIGCAKlo7Uupgbsumupw1XyWcx6xjGids2zIzpobMQRLTEK7a8wR1GyothyAH/5N4b2vekgQZ23YHceROBldwYvWaImqka0RC1Bbj2Zb3FXYZ7PGKhUqGVInknj9+iUiwuVy4enpzDyPiDtxc9gvbQymYVDK3K8J1j7zEqHtdhwOe9rSAInoWkqMDE9vOJ+OhOAVDSsJyBsQIy9zPE+q5AayrHMVOalZbhbQJsdo9X66k7I4pjkzjfOqClcS4mDXdaTSMF4G8jxyOl3MgK9iP/MUmcaRpm2RAL/5atLvFkWbqzOwGe1qUW3218Di+djwWefCs3+v/yrmI1pW1Ryp/PAzKhXXxxM7n2l7fc5CoQme3e0N2anTeD6d8a5w//JeM/FFax8z8ENp+SM/8uL+Di+Ot588rucpHnGFE45Pmp7eZULb8vDwyG6/02XnldLpnDc1zILIqMIhWaklh72jbRukXEj5SDi+T760hNffwAukHEm10N6ioy2t+FOBso1ZdSs0cyZW6G/9F69C37R87ooRLy6I/bG4RgayrdnQug9y0Tq3aytlgR6Fr98Xyp0wvHPg619IvJsykr7Fi8cPENv3ixjFYjs3zY1ZBU0yAS/rWvlFGemLkOeZJCi1t+uYJs/D45Hx/BbnUTYB1TnTfVMVmCv1R0TY7XccDjt+Opz4rfTmysEbTBhrF97yTf99DjLQSFzO3BwCN3e3kDPD+UKMEXHCzauD0oyKZkzO54uCIcsQFx4/ebCelDa6YoSEUhbWiOx69r/xHiBM47Q4XJRC2UxdZSo4p73uStGaJoeAV8e4KkZVVgV2jhQgiRBKYRpHQt8R+o54ujAk2N/c6L67jASjrInV0zvvaZqwUtFT0ixfsV6yTaBpW6ZpVhXHnGm7wMt3XlEQnh6OnC8DhJbabFxZOKpWGQz9LiXTdi0pjxas2XlguXpxjjRGXAi87L/M6+brtjVWv6tsgAq1AesAlmpLFoUKWdAQwUTUvDanT3FeqPKSEsHsw5yFaRwZL4MuaZvXOuY5Fz7pbkhGez3ddDTDjKRaYlEQayOQp5lqzqpP6ZyzNkETw+nEfC4mlNYwTdalueIrMVJmz+7xwvl2Z+cE6KKxESiaDXyuQPLc//7sQEMH59fZw5LzCumYXd4mH9fwR7SOs2wCixj5rYfCn935RSysPoeavLWUJtfs7AIAbh5kMUfP/fIKChXTr7cBF7c+l/kqmwFcozTWk9gZeCIivHhzJDye1Z9LqpRdFmprpc9e3chSwwiRWp8sXv9s2sDhZkecIoOdIznl5SwGSH/7C9I047qG+f0PUbzY0wZ9rtnOjRLNFwue0Ho8QkyJebpWUPfemWq6ZsFDG/BOiMcBKMzjzCkr40qmGR/CM4XoT1+fo6BtY0QXNBS4MkC6FlKpdVnrz0CDr5ubW+5uTzwdnxajuc2sPP/KGrgFILJBlJb7+fXe5daArB9tKjSlLEElFG67nscpLRmA6iA7C1Zuh3iF/jopiDhy15BivqIJbKk1S+BpUJk4YZ5mTo9KgaiGJYkqI7Wdon6VYif12NZoh5zQGijLdrRGiUhZZY6HYWBOmTnOjPNMHEdtxpu1sLoWua5NgevGRmtSkhqJvmsZ50IcRpzUol6TpHeiAUwpSONpxTEO2ldtGjK+6HwlQ11z1HqhxXBsrtoDyokK3QRRQziMk9JETWBFHcTaN0uVLjNKc0zTjFjvo1KRKZGNw6ABmPfqbOZUTE544+5t1rarB6MUkyDXIVIU0gKcdUvoPXlncryaAa1N0edZVfK2alDeAkQpxZ7L3MaK0En9/GIHY9nGCc/BMgpKMRYsc4oagOEy8lH8kGm8kOwe5vHM6XTkt/eJb4cPOJ0uxhVf1+xiC34NuJRTZDifOLsTT+lomTdR1aYceXo8k4sqt21KTxa6KpgSqjVFV1q1uwIHVztWFnWpkmpZNRSrK0rikIzJor+g6wLn44npMpOK9fQ7DxunvJCmmcnUpELTkBG+sL/uKfSZEGyN26SeS5Wsun2N7ddSA2wzqzUgBKUAV7pKzdAIyHgkP/5MjWscLCso3L68Z7d/h8sYefvRz5mmibePjwzRcXNzgwaxj5xOZwpw//Le9rfe0iOeH/merzNwc3vD09ORZAXZuWgvpz+dHJd44ebuhqbvefroLaXA/vaANJ4cE5fLhWkamcYZcmGelV6bcySPI3f3e/aHA+JbxjhQ5oH49sec+dqKUC9OQx2f1Z6IZChu3ReAiLY6WPwOvWsWp7RsnAU701WhrgIza+3PMv6LMfvMUHFzr9fB96JYB/SN4+uvAF4xAR+8fsXNcOILbz/k4e0T59N5AbquHUVZgjjn9PND0HtMlm0oIty+fsX9qzvicOHtw4U4R+IcF8BL1+GKvNe+ZeK80sZ9MIEAz5vdATk/IGy8SlQt3jvHq3C2n1TbA7cvbun7jvPpzHy60AfP4fUrbl7c8sHPP4Jc2B92tMEhSenxHoiiNPqMBlcxJS07cNp7Ljg9Z10baF6/YJrjwjyp9eNSDBqTvOy5UqxXqO2lhDDnQmtBHGI0/JTIJo2eAEmJKEI8nThPiVev73HOE6cBdgel4LeFOAuNQzPMzms2+nwhWjmArysmZ1Wq7HrLsDgO93cc9h03hz3DZeCjj94wnM7McyK0La5oNiLGyDDonzeHndqbnGmbRs8jr6UNswVH/f2ttk2YRvrdgb2/4eBeL15QBqPX12BjCwWJni9L2eeyyUC0blJLCvTnwTnwGRFtL1BLMKiA8e2B7ptfJf/sF4vISLa6Wg2SVASsiJBCwD+N+JitZZId7BW0rY55ySBh+Q7nBFJkmCLOi9XX67rYdi5KKfOVp1u+mf/Js40LGLX0LAP/++7/1Hh1Q8P/rKsGQwoa1iBl84LNOa5/k6sMjNbTGQhkNeY6dIXfPWb8MDLtTBXbsv9fneC7Xij52ddsvkP9t6QME7QWuWTzQR3YIXIVLElZBb0Eo8cWrdF1eRMgKjRhj7bWQVcffD2fhcPjhf40wMV6A8Zo6r7rmhKxfqJVNNc2btM2zOO89I4FEK992PaHHfM4M54v5i+t9ZFbvG3+8BPrY6c0SLEzZprSch42XaPAr1Eu55jNZ9OPUVXKhr5vTOxHGC8z4rOKDZnwn/oypuwumGLnc8/r+vocBW161c1VUEpTep49exZe16OjOqqn4xNPT49X6MBnfk9FYe29kZrdqQ1gPztge24Ur/9eNxV4V4zvv7mPlBaFI3GeJoRlUdcaM03/rgsubRCUT31Pyle3WbOQ22Auzur8N01jCy4tDl3MtshKjfRYlKU0HjFZ99mQjgKuqKDC6XgmlTPjMJhwR1IDlDO4sNzWdfa0opZay3a5XBRty1obIJr+sYBgfWZ9FFXM0y7zhTmjUvtpdXbqYRmsBsCJugVTYTETfEjUAAAgAElEQVQ0db2McwJfaPsGZ9mzpvF0bUNBuAyDZqKKBg21xjAZrSQVaFt0U1eJ4ZKNR29BYm1kLbq2XNNw+8f/Hk9/8mfkcbI1AfOUcJ09dyn8efkD/niGpq0AltEnqQ3U4XS+6AhVNGyzWtM0IoZMAVzmonUQxdE2jsM+KFWhCMMwMk4qYiD1EN24lurQ1swcm+ylZrBC8JyOT7puo9ZqiW+0xibN4GfS+Q2X88UAmE+jir/MvlVnN6fEeD4R+4lSJu3TkkQdy5jQ6KowjiqDvxSWb84+VYtV2qzzDsFRzElTZwJ7dgHnydN0ZSSc6NqnQHYOT+Ty+MAJx3kYGU9n8C2d0ZF13y1PuNxHnCOvQqJrAy6UjcGtReWbd9SxstooluDts67KmV9/4uzeBWdvt8xsAaYj80ffZ5onhmEkjrNRveDDDz6mbVrariG4zDBmjk9H7l6/MEq5cP/injcfP3A8juTyqK072kATAkmEvw57OhHelYHDzZ7HN49aNyozJxpO6NkyTRMpdsQUOV8KBEc+FcbLoCqx3quSWevZtyrrHFNmiolffPhEeHvi/uU973zhC7Qh8HQ8Mn3yI+T+PWpGe+s41DneBkdXNZ6lZs2WCguqJ1rB5BUU0pC+Khiu76tntFKpa72FuRCLP6uYlADOMsRrGL8VMFnEVerclcLQ7Bh8R5My+ylyuQxKu6xnQVkzbOprrfdYAZqYCq5r6PuW4oSf/eR9hvOggLlTKfj1WfS7q9R+LhDahiaoSNBh3zOcjoS2o+v7enBsABq1S20TuO1bYi7sgwrTpBBoX7xUMO58om0bDi/u6G7v+Nv3f87TwxN918FBxUrI41Ie0Nj/xDtoOxJwHiZySvRdy94oWc67tf4M9d8XjuFmJRSK1dFvKPROe4INU1RwhMKuVcdryIF+1yoN3gnxMjI7debSOPDxB0qlbja1f9g6wIm27phGpWXDEtRkgSSO4rTtTBZhvKhw0le/8R6dD/zoRz/i4aM3dgaqY901iupfMmqkcmK6DJxKoeu7RVHZeVW9dUGQ3nqlApfxQrPfc/A3NNLrGWRjLbD0w1v2ygIs/DLkLROCY5qsWbZT4Secp6liFoALzbJGpLYGOOxJQdWHC5qRLqXw8cu9UknNGROBh6+9wxd/+ma5XzGK465rGKfENM/We1Lf5pyjC54xZbzH6o+usy7byxfHXdrjaTfLpVCt5YtU+G+O/5X6ONtFZYfGpz61tgAqZfFJypXNBW1jkJe1Xtfo/3z/v6qgCIIUR5sd/+nTPyOXpOunK1zG/4Wc3QL6vWz/M/7rN4FC5k93f8b7zc/tu9yVD+ldDzjIwuBHC2rs4MNZcmAFkwqCXIkwWVBd3yIs1Ps6DgvDbTmrgJJwWdhdJnafHJe+wDnNRiIQ66Xpl8DRaQmvBrXO07Za0141F3JSVVEnPTe3B0qKnE+aYVv1Ej491zVgC1azPpgglgg0jdMWKXacjlNUf4Tr5R+awP7QIakQx4jftQQHp6dhAYWarqFpW9qu5eb2oL5wzKsK/i+5PmdB2+osUjJv3rxhv9/TtR1rqsIOtWfRmAI/bnmZfMZkrN+imY0aQetyhOsa0rI4QL8sSPtln10f5eq1JavRzdq0M8dEdDPOBz3vLFtUnWJxz43eaviy1YctQ4YFJNvNXdZ7ySmTnQaEMcExnpRSg8naJutd4rVfi0ed2JQyc7I+R3WcLcMznC5EYBhngsPQqTVL6ZxXNUVZBUCwMa7c75IyQ9Q0drUxxQ7h0DZMWWcmm4R4znkxqvW5SsEcO0+/7xkMcY5FXxecIMETAAmawZuiPneJCUZomsD+sCOEwDDOjOO4ZC5Tmq0Hj6dIlZw2KqWJtDjRrE8NDOom9t4tGWEP9L/3Lcq+5/aP/4Djn/xb0tNpybCmohSZczkwxpZ/+S8T//SfhmXuMUQopcw4KpJRGzlWwyAUxiHzdGy4v29omszp7PnuX0Sm+UKcM+7+ntP5TNe1zNNMaBrmaVicvCXYrqakZGCmiCNsgyAr6D0cOoo4xlGRVKRQkjpVCQ3MT6ZAtzWIWnO4rm0fVDBknqbrwxwd63GKtOcHYu45Z1X3HIaBaRg3NFWl4oYmLL36bNWiymHOqBWCOGhDQ0xVIGbdW23jdf3YnKrzr2uz23XEeeL4OJKLKXVGPdCDBALVIG2cM9aaRUfh974ws+865gxePC44y2pUp+HZ4VGDgs8ocnd27tU9VgO3pebJ9p2+TiAO5OnC8W//QmloozZnbpqWpm2W7GOh8PR0IudEjpm2a7i9OeCdZ5omgvfcv7zl7cdvuRxPDKcT/a7l/uULM57wF2HPyxLZ9T0nfyTmxFscf+r25mTqehuGC9575mni8RN1rkQ83W7H/tDTeKWNFVFApipxxpRIMfHwyRseH0986ctfJMfCmI60hwkfan2wOZmLU3R9Vi6CYqZUV0hL891qrNXhVnVRDXw12FpZBDY99TymhgDW31I+PXfL1Jo1cyKrgNPG9pTnHs4CSApD03G765Val/Im8K/gyPX3lsKipuxDy+HVS0qceHjzYJRzb86ireMq4OQqAFXIybJ0c0Tahn7fk1LizdsjN7fCzaFXRd+8Fn1WtsmcMlO2nmdm7t2uw3cd59OJOCe6/QFpe37+/i+Yjid6U4HMaabb9aqcOEfmlKzfnfbgCqAtgQ49x8vEeYr4RsWl0jhzOg0qRpDzojYLm/HNmgsoThZKnQhKEbYm6MMU2fcB3wbiFBdwUyRpLblAI9YTtBSmQRWSb1/fKJBkdiOVjMtu3Z82/wgUr3QrQTOJoWuJ80zfH/it3/4NRDx/81ff4+HxCecc/a4hzgq65KIiX+KgawM5qdjGOE5aN9M0hKDKrpRC3/b4JjCNA5dYeNl8gZ2/5fd2/wwnfg0qqmu2mcvr1fXsvLL3OQNDnROmOWrtWn2NAa1Cxm2Niw18Dp54d+DpnVtyVQU2Z371h6yowHvmvsXNWlvmfc12OYSoAKpbFR9FoIQAacKHhjmOgMrA59pbdXM/D+V9fjb/Gd9o/2jd306ztLmA+IIr1U7UcTBAORdtCf78CHiupLg5P66uDebkBP758b+4SmQC0Lir13ftP9c9vKGuVuTnP87/ATKur5XN+ypwVIB/dfhTzlwoaf3dL5pfPLtljZ6WRkUi17ZXllN3fQglOCzgV8kZeTzz6u0FEVEl86jlKAqm1x7DKnSiJeKroqVz3lqGCfNotN8WUox437K/2VFy4ul4Yhwtw2a+5HKbIps1omfDNM5L4rgJToNGpzWvY8ykqOus75TyOI+RadL1F2dlP/VdQxlnzqdxOZ8LmtVVMb7A7vaAE8dlnJhMIOdXXZ+zoE2vYgeo/uPqF/qnoZNLLl5YKQ7PXv6Zj1801W5vXWh/n2VYf12Q9lmXVAepSqOWtbZiWbpFVbhynq/vx4yQ1lOoI18bXV/xb2UNhBaxBmTj+GG/c0tjzdnU+ygwj9o2oTYGVIddle7mqTDntCBymq41oRIL9LRySCBnslh3egu64rw2EK9j4e0+VFFQs3K51HozCy6rA4RmUfSqAUpemkjXk6Y2aPZBA6cUoxnQlZJZRGgbNfqh1Sayl5OqZ5E1sNrtOnxomGY1wsF7ppRQxobSXLuuxXnHPM+Q9Xlcq9mIUrQAmKKb0TnNDlSHohQtaO76Ftd5XH9D851vc/qzv6zLkVLgId/w/fQbzNLhSzJpciilFqhW570YwmnNLTfz/fAIP3tfePlOi1CQCeZ5YDhdKAjnp0dEhEvjtR+eV1W+ugb0ftbPK/XmRAje05hMtGalG3adouqtDzwez+p05qhrQmTNaJftAbkG5yJi6zNQKNpWIcarvVdKYRwGvpx/QJ4SH8WdBWgVwCiLMqTFr9TG4fV5xHn6feB8Ui65F+F23/N4Htc5MrpYE7Vua57nDXCictEp6doeh2mlsNq9atY4PTs0FOHuugZxgXdu4LBTakSOibFEGLcB3ub8WEfs6mzY1v3WPXH1Fikg3vaN/kJEKPOZ4YMf8PjmI4bTmeADh5sDbdcSmnY5d6oy4kM+Mk+6Bodh5IMPPuLly9d0bcM8z4QQuHt5x8PbJ6Zx5nS8gDhevX6p0t4UfuJafnPX0/Y9MZ74K9crjcyQ05QSp9O8ZjdyhlzodoHdrqPrVKCJOS5tWpxzuODZ9T0lRuZGBTTe/8lP2R8OeCfktz/BvfwGElpA1jYnn+EV5RoH5XoG271QqbR1DaxZtIoWV0DAvI/lO8SecRX0ubYtNU6owdES6NtZmhf0Wq72zvPrze6WF5dHQhNUCMrW3PpFqmScSzJF3EwSR9f3vL7rebwcVdijmBqqKeMKaB+4pU7M2RpXMajqJPVdC0V7DFJgmka43fHB/o53Hj6mMgO8cypBT6KdR87imWLENw23fU/KiePTkVTgdr/j4e1bLqez5ihzwjcN8xjp9x1jMatg53spKPXZOQXiRNi1gRF4nGeaWXD9hJvm1W7WOavzIlClmCVnYi5EIJTCZZisxlvXXb/rSKUgoaGpnxKCqjV6rzTNcaKAUVGhbXsocLlovzlnTcO9yasns4+UgqTMnPR5mr7TszQ4vvGN92jbnh9+/3scL2f6fU8QMfBC5yll2PtAahp1pIsyUrTRtVKOVWDCkQVOOYMXQtvysnmX3+n/CTfupVLlRMWVsmzc7o3fsV1j25+smTmhcR3vdt9mHP9CWR1hYtd3uq+oAasGS2HXLwIbucCwa3j7+obglAnjRYiuIO5ZyQwKJjy+2vP6PJCS0umcBc8xJWsgb2ei02BPWwkI2u7AgLymZRqGpY6uZpaFFbjYfnNtoq58QAtWpa4sC+IEawS+sauANii/FgVZn2tdmzUZlms7Dyn4hX2znQcb9avgqyz3svifcn0SLtV59oH1/f/h9O8vd1LPoH+b/4oslf6mD6qPvp57Ja93pUClfX7KZDv4SoGjP/Gj9kf4pwvd+28ZwRTF9Sx2JsFfNRbE7HztV1eKDlrOmThNJsRiZ7NztH3Hrtfs29PjWWn29iw18VEp3wrMmxCcBe3OaZsn75TOm3JhnJMx4tR37A8t5LV5veTCZdbPHy8zlEJMmTla32RTKEfWGQjOkaaJaZyZpvhrQrbPVdBWH6JcZXau0Amp2lju6j0VXb4ybfZxDUZ9fP5tcm0My+b/l5/VoIO/W/C2OFVAqZ2Kn9GZnifKrxzaGo9ZENb2QYvv57QGY6IbMDSeftfa71Xhphber0OwOnsxKXWsZM041PGqDkl1mELbUhrNVDmrn8Kcb+xwzNmaeVe0rLAgi1s6TC2YXWlbQknZ1A+90Xmug9XFIbVNU7NJpb5moz7pgseLHqZKUXSEtlGExjnaviVmQXIiTok0JwTHzd0Nj49PxFkPcxcCKSeapkGcmAoXNk5rA9uu62gbr+he8ErDc56cI17c4lQqiLCum1zAv/OScnOAop934At8rdHC+DrxfzqOHPPFUveZUvSAqj2C1MytbSEy5ar2uZiDF2Mm4eg8CFoYO88rz9iJYx4x1DmpwIqtmNVYXFOFRQSaQmgV0S9okfbxoqqmS/BEDeYLe4n8UfiANF4DCVvsJTSBptUmz6UUpG3+f+rerVeS7DoT+9a+RERmnlOnqrq6+sL7TSIpkSONRVAyBraswTzYMAYG/GLA/8zwi9/9Yhsw/OCxDcxIA3vG0hiCSFkSRUqUmuzqrsu5ZWZE7L2XH9Zae+/MU00ZfmoHwa5zTkbGZV/W9VvfOsGGi78ouPFlXjDPC5YcZIdZVpocHEq3djKYvSoqroLcmrSWwijeKKBRxywlrWnUegEz4lkVbikFd9e3QoBBsgeTYeNZYLQ3N3uMmxHPnm7x688KSpE1FoIwtE2hIEIKlsm5tj/Qou6w8ewO2xv9/qr7pds3RKhMrPV3ACUdMb/4CW4++RiHecE0RVxcXCIOY1W4vTwtDIVTORz2M8ZJIM0vP/kEF492GGIUIqFxwOXVBW5e32JZFhwPR9zd3uLRo0fw3uGjMOGbaY9hiPgLN2LvAsgrLC41aIk9rNOIekpc4Xn2WQ0MESHEAdvNBiVnHJ2DCxGH+wPub+8QhgjQK/hHH6rTZjdhGMzUTCUiD+qCf10MSfdc21tUu883Y6maXJqprVFmMpOJqhw+P4iaw2gHK1FAg0IWGKib7cYneku+7MNnqHIuZ9eX5sOP33mCX/A9DvevpW64MDYOoDFqo+5WHycsuR4M6VmZcwEcsN1tMI4R16+lznS7mzSYUfDy8jE+uHsDhhI/eImM34JwlwqOqsu2G4HmHfYHHPcHPHryGI6A5TgLGUeWIGOIA5aUMGICDQHrcRa4vkby06Jz6IWQimLAOAQccsIhF2wUVi91vy1rbRBqB9JSBJK2KzpeRdvnFABxs8E0DfDKMCiEYQVrlkAfISN6af3ilhWTk1qaeV5xf30DFyPmRcg3huhkNWn7GscsDqcTuJmwNXuQD0gFePe9d/H02Tv46G/+Bne3d8JA6wR267NkiCOU6IMZwzhU9FDIQt+f1lWcNa2lCdEhThHkPLbuMb6z+X1s/ZMaRIAZy2j6zJy2mmE+FR3d4pYsSKQJz4dv4pPNT1HAUnbgXJWhnLM8YxgRLy8kiDsfkeZV5GouKCSQMUlCn96MCJodF8dI7A6PZVmltYoGeQaFjVZ3igAOHrSIE+c9ae2TZDVRitSNZ9TsCHS+zPExNE4BoBUEVU83vmg52UN7onbjKDnGdm4v8d8mNWxuudpT3GRDDXjbekaVF3XE+jmETXKbt9N62naC/dUB+M30nRaIOn0duRS3mkc2B9JkiMlT1VlLnnFxTPjo1R9jVbhoWoQNNgyhOsrGGVCdOedqUEvek2sbJmjQ0WlAiblgnlfkdFZn1dna0TedU0rr0+dDQByk3vS4CqO3D1JCk0uBj5LQSMuKpTCmzYAQPUgTFusitXXOSZaOvHV1NXtWggUpZ/CakNdUmc9/1fG5cNrIES52I+ZFIiSAeO++aik5zIM2d4SIq5Ilb1quO985ZJQHDpuDwrNAraiYzrDI3fH/xmGz56vRYjV6+wwad969nW+foXvVGAM2FxsQGHe3BymuBWrUQYxNIQXwY8TLT15r35HuQXV1CHOdQPwiEdgTWLMSvWFozsmq+F2YwrboOwkjGxdIHZl+z5OQMuS1sYh5T9XxNuIHed8VXDRyAhIYB1FnfHc1OSSR2eiE7nWxHhlOIvRrkqwIeQ8fBPNu+GZmh2ka8fjpE8QYcH884PrlNUpKKDljWYCrq0vs9wcUJVYJmy02u0GcpZKRUkEMvvbimucVuSShfdXM55ql9w53i6QKLdYJ0FDcsNnAjaNkTwkY3A7vxA9hW5gBbNInIJrhKOP3/v2AE9oJjdqXIoYMw53UbHF3/6JZozkXpGytMGRvSHNwU7yof7eASf+ZOUQAYE02iboiay7Y7w8n0cfqJJWCggWP+QYHI6Eoll1ra2sYhqp4iSSD2ZzF/t0KcpZsai4J7aC6N0IMoDVVK5iL4Do4Z6nJ9G1N5lRwe5yRllRhdoAI6gLZgzFGHPaH2haglILDYcG0GbG92MCHgP3tHsejZO+YgXVZ8PvfvsR2IgQu4CpihYSl6cm+NgS1vq45W+3fE2VsRoOeavPTs+oKbKSryeKC9eM/x+2r11iWFZeXO1xc7NQAacaFZYzMGIkxIq1Js9Eb+EC4vzvg7uYO0zhid7GFDw677QRi4M3ra5RccH93hHMel5c7XTOS7T76hJUBKucSWe4dYsA4jaI4c8LxMOMiGHEACUyHWVqZjAGDBw5JICcxRGAr+/K4nxFDxPDyJ3Affk/H5bxOwBwjc/a59loDDOihv3T91upgnf1oxkirJVOlLIqqO4vq+iagtq+p89vtQ3tOrk6ls42jYyaS42eP3sOXr69VTrd6k3qdjq7dvnj96hVeLm9k55cMD6nP5Zxxd5jruzcDSTYuax3rMI4YxgFHjV6vy4zddkKJASVnbC/EwVlSQugMyj0cJH8msmV79QilsGTZCrC7uMT+7gbrKv3VnDas5pLgfMA6Lxi2Wxzu9mDt2MsAMkkPxKSQ+ZgLOEld2/1hPp22Xu6RjbHuRZsvIqTCIGQQeQQ1/GMIzQ5hnTGr7SKn13TwPmLUfmkoGfNKcLlVC6/riui99BhUuedKRpbwE+Ac4jgiMxDjgPffexeH/TU+/eQThHFEDF7avWvAcmRgTRnTFCQj46QpuyOpEYsxYE2DEG8ti5D6wCPEASF4XPhHuJre1fGU4OypndI5PACcb7XJ3I2luBE6liAQA+/Gr+DLm+/j5/hTlHKHw/09gC2GGKUVCxwCF1g/OQnqSKsfsUMssybzxJ190jZiq5d2JHbCfpZ1H4eIIXqd1lNqepluUui8GOzROZFTjuCgJRXHGT/Nf4LH8UO8E74o3/elc65Ud7LJdULpRQ6TQkwtmK/BFmrbktrWfnhU09actO57MDhz70Gro0Sup0Y6Oarl0byIGuSzmlw7sTpuBGEGB5SC//QBJbBeJNvW2bUnNcT67BtMeDxv8FHnUJljBu/hY9ASE7kWMZAoa2se6a1KJEFoAqF4uXDhIIRgBWqHJsQxgFZhAufc7ldKwdJHke3/CnE0dFvOBeN2xGYzVPhkmRNAkP5+SZFwqtusIXkcogxeKbXNi9m5RmKUEytJkPkPn7EG9PhcOG3OEYbtgDBGHPazRK/rSvGnRhwBIIsethRwwyD3GrVUR6xis0nx6gaf0tqIh37ZaRjCDM1/8F2YEUpRo73An30mTk5AzukkwuG1+HbaTvDOY54XHPdH7RliXelRizIBgYxdTQPCsAEnidznvFTjty4uRm2qXAgSvVIiCahw8l4WVE6NThkuCwkJkRamB8Efd0o4F679aiy7pjwnsqEqSw6E1ngQBysrnKb2sMpSR6J2tTQkhWRzQggo7CpRBxEhjgN4FohaLloDErwI6GFACBHLKn2JhjjCB99kiJPI5MWjS2Qu8JD2AxbpAEyIs8BUFCLhiCQL1K+OXATT7cQYc+QQ3Ihvjr+L5+GbGqkGXkwv8ffulzD5RCMBEyFor7m/Sff4o/QSIXgsc4ancrbeRCh752BEWxYRsueRhvMejgooL2AizMdUI6sPs13yuzPmIrLsqFdogKT8gza6F/iVRqE0cs6FkZQ4qGgBsPUKDOWAJRxRSgeVRXPYpnHA4AlrEfx6GKJSL3uB5XHv4MnzPqYFH2HTYfrJZKwEAL3XHngGLdVmqU7qHkkfgBwhOod7JeCo9ymMZS0IziPlpM5Qm4WSM/b3RwTKiJhxOQJTCFiLx3YgfPs5Y+tWUBKDqo+aiciy+rP6F5lbse7rO9XvUMvewxy46tC196+OgsxEPR/MKMs99nf3OBxmbLZbddiUZKJ3JJnRDzoXUUQxBoQhgiDZlfs7ae3ADFxeXcIRYXexBZeM6zd3SOuKu9t7hOCw22zqnDrvQNkMpSZPSynqlBUE57B9fAkw4/b6FoeDxzQpRJKhzo70gLQAk8muOAiDocDAZkybFXE9gsYtLOgBNbOqg0teIvkaTGnGD9AJQhg5Vj9r52uwjiFasOMcSibZnoLejHob/LGGUojAxcyyBo12xDLLDGTnEaLsU9uDD68mTy6Zloybg9D8k5emu7soe+P+sNR3KAUgH7rWI2JQx3HE5cUWh3nB8X4PQGD0+8OCOI04LivcxVYgsfd7JDBCzqAgRphneYZhM2K73WCeZ6zHGZvdBOcK7u73ggjRWmvkgrysmC5GLMcDxu0GYRzBR3HGMrM0u4UwRlYjqQjsL7i1Gwa16gugxYayC7oieNsTnoDMAt0bN4PUZgUHTgUFhKz63BFrr0NgLQUpLQiD6Ju0LNjstiAiyf4UNQRByCljGAJQGAUFvrAECJjhhwgmh7RmPH33CpvtDn/3058gFWCMrjJBkwY8nfOIAZoR40o0Ys42CAjRYes9jiT6YM0Z83HGsHuE39r8p7LufXM62pqtha6VdEKM8rb+TfKcODEK4fPw+Ob4e2Bk/L37MZZlRi5FA3AFXJI6b6dETFllN5cC9mIHVk+BDP3DVZcxASk4OHbt2dRwFpNJvsuVAEUzdGbLKDu39CCFslJztTnIF7U9Zc048hJSYXEcSlNU0OVQHR6CyYtmERoaq8qbB16VBt5Y12qVCmSAAbmO6lPRbZ2H1a5sVmxzp+tpVB3tNu2ETm1VDVEDUt1VrQ4Tal+KXKdO77W/E/pz7DOZD++dsK2TkuRASk2GYAkGAE7sw1KkBQdTezYiwJOwiW40i5s4IWWGj1Gh+DPKmmqT7Pp+GoQZv/whNr/2NYCAu3/7p0ivr0GsMGbvsN0OKLngcMyYNgO890jHJCUvzmM5LlhSVhh1QIgRefRK+iTwdKfIHO+kXnRZFsS8YNCSGteRSX3W8blw2rgog54zT72l5EnhD2cOPYBmyDFphRvhJOpfiCDbKiOVgtG3aCmzFlSz4FSJzBAFSnH1nOaEt8X2q2oM7Djff4DoiaTCyjkpeJZsQ5B6Jx+wrEkLstd2rS6yakIqZ8bhMMP5exAEZmaQRSJC1E2jZV9CJdwNpNRkkPSwICvolQ1o88B6T3IawVUrxSsTpWUU1zV1DhvXn0P0ADmUo9Cd5yQNjuMQ4GNAXsXA8MFJWpks/Q81GmWTO+8QiOGK/OyDx7oKnBHDoAWnAcMYEEKEj16iS6oQSgHGcRA6WxJigJwz1uOCzAwr/ezhnUIsAjH0dc4NntH34cipwAcSaCWJEnjiv4Dn4Zui5EhFFZEa7PLdm8e3eP3sGu/84gkajE8caSkqFyfQVxkv85GU1hpo5Dm9Yz5uCZeXwKL1auNAeP+DEZ9+EgQWmE8hqd5rNEvH1TJdp0QeKiidEGb44GsNmdWBGYmO9W/iUhCRkNCgkQUo1pcAACAASURBVCfRQRJI0LqKEyzCOnSMet1e6pTQPx1/ib/aX+ColMR22LPU+k71DErJtfF180dkvNKZIwldMzkxEq/Iy4L3LzLS6PDqKPBF5zw8ZXznfYcPHxUwPDICXuwDvnRl4+pAWrlvWfEWicTJc8vvLYN+nlkzZUwSUpSf7V9CJ8/sCwK6sT/mwxscX/wE97f3GGLAbrep7FS1ELw+iBoG5kzpvI7TKHubARcCtrstUkrY7w8YpxGbzQQiwqNHFygM3FzfYl1WXL++xYecwFG+9ywSfkm+lfDpvPngsbvYgcDYXGwRYgQKY9pscdwfQRCopmXbHAkhT01AUQMjheix2U64vd1jPs4YX/8M+OA3TxbSCQybuRqiLbvWBzdKtwCrOYomHN/ieFUjy+oD231PhloNvmY8vf0wiDhpGoFZ7XFl/IUTQyfEgGWe0bLhTVlWZ1+Nq7/HArcdMI5RnAmCBBKHAbGZcQIpG4IEYyB7dNqOWNaEw/1emlsrTPZwkGbmxEDKGZvNhON+LyRTJBmkaz/AwcNFj6fPn8E54Hg4oHDBdrfFuqxY50X6yXkPIgkaMgjrukjN67Iibib5e0oSKA0CY6ryhRsKJ47CjmkbRvZSq4mR0ac2WmwGpiJJvMMQB8kaqz4Mtb2KwPgtcJzXGX4Y4AqQFqn7HIZYSbOsj5PB/420B+uKhTU/HgPIB2QNWF5dXSKvC968vpFWPbLgdAk2p4VsX5cC5/X9qck4kyWbzRZEM8pxxvG4YAgJuLThsfXSHH3WzUGE6vDYQrfAsNkTbQPYOm+Igm9N/wQMwkf4M4G5L6uc6R3o6pEECWogUha5lDoos6aSmslnaBm4ItDDQsDN5YirTxcwE2IMyKXgsD+ilAGDUavr86V1lT52lvlnQaYE7zUXLHs3JcY4TXg8PMfGXdY6YVlerq4Vg/Dp9JwE+/ogTA0Qwp/atyp6m/y3zG2TEXacjjTaeWcMfL0mZaBCMSUL1xxtZvuu7pPqXPX1uXxyreoUUntGcyDbvZvMMzldETcQkpHdbsJyXHCYV9HfTslr9DnELtcgkhO971QHZi2F8ZqACUqml4xTAVJPW2HvFkXXl6h6dxyqw0ZEuPjt72L/r/4tps0gLXtWY1V3CK5U2/e4rCjHRYeMxFkLQoS27ga8eXqJzBlJ23/trve4vD0CRAhe+BLWpSDuImIMYi+/BYnSH58Lp41ICnZLYQSl5qW6EErnpMnCqTU9pcPIfqbKk6U/ah1FfxZB4h6jl7BFgUURTusAWtNOW8hn7EI4u+g/cFjkwGn/iGEckYzWfBEst9CSkxQDq8I1HdM7VXd3e6G4jxEpN0cvqXL23msvjW7DlYe0olbYKUpJnBU4Qkncfoc4A4QiG0Hpo51mFGoRqEWeVXk7L/UQNfsByWwNozDRcWH4EDBEISohVcz3d3s4jc4IsYdDYsZikKgYsdlMAttUIhqBDnIVIMsi9M9ZncwGSZXJsgarwQmmHRD6X2MxHKdBm54SCjt4KsqMpjVmnqqAiDHCh4Cb9AJ/fvyX+FL8PjZ0Vee8d15KMRihXCeXUp0fMZY7QpU2cQBbvVtz2NBde7fzeO89iUo6R7h4FPHVrzrc3Gg9FxeBFamSr3VVrOOlVPWkWqeSeTBjXVfktQnDUjJyEshmYak/qE/LRSB/VYGfZqyIJMOGIo2LSSOpKa3IuatTPQuQ9AGM3uFyJA3RpaG21ZhJAX7JBc4V5BTaHOQELipgSQ0p05x5xThFfO09h28+J5Af8eKepOE2EYYAvHdhiphRmPDVSWC51fERVddFLOns3/6d2rudQyHrO1PnsNkYfKbMs4ALI9++wP3tLbhkTBdbzVoDpM2hz+NPdQwArEoGZPV4Yvd6hNFh2kzS0PfuXohMvEd49AEeP3Io/Oe4vb7FPC94+uk19k8eIa0F76YFUxlw4P69gGEccfX4UXtPNV7GcUBOK477g8BdQCpPnMSrW0QNIHNuBLrn9zMOhyN2jxLc3Sdwu2ed8XPe+1PNrmowUpWHAMlarnVe6vh03vL5GjUjty14VoOlu+ZZEOGz1QabtVdntt6NpDj/2f0bcJaC93Ozqi2Jrr6ExBmL2w0uLjYoKWFJ0j7Dp6LGPVf0hMDtCJmBaRQEw/3tAYOXLEApGcRe2srkFTF63B6O+GjaYRtuQCnDO8LBBfwijMKm+PgSu8tL7O/vcfvmDsdlwaPCuLvbg3PBIUmtrdXwABm0JuwutyCIk0pB+ozlwgJlUhQIgzFp/ciyrELmUfuAKUsnAacFlW0+AUayj5w0Yhb9RwrJEgORihhjjoQZcVmTOAZKNV6YJUus18opSWPwCqES5mjyDpZUBIkeWpUF8dHTHcbNhP3+gJQLovNdhMlM7mYwF2atKzE5V1Bsv0FLQRxJEDMXLMuCu/s7/PTiT/CN7T+GIx1vFoiksXRbPSCcZnmLXrEGaU2vNTIfk1DFQgCF8Y34Q2z4CV6kn+Kj5f8W2T0NCB+8i3UVWyCnDBTRkSllzQgLRJUISpZTquMKACga7K1EFJJ591r+cLw/YA1O5b3MY0oZLgbNpHiQy8jrCj9IDy5mIFktOAHv+C9h5552oRDUz87371tZ28n2uzkxaFfiPvtlsqPpjHMnsN2XTlUObJ8/dN7a7eqKAdV/1WqyAEAX4KrXoJb0EFIQC+30z8gPvmdELoCsIRkDte8pSJaySOLEkTheMYaOeA5qz3ALUrDYLwLfZhQSJz2Q2GNik0htWz9s5BQuqnLCnrWfCkADNUNEiEJQktMR82HBZjchDEI6dDyqrR681LR6wuR2+Nr4A/w8/h1+dvka2exqiMN+/3gHOIfHNwcwqc08H1GmET5GML0N9Xd6fD6cNifeNKEAwWNyXvqHKGuQHZbGtNqDk5cjangVQD7UE0v3JzvmlBHUQx+8Uc4LY9SpcQmI8UUPbvEZb/MrP+nfxyj293f3tZ+aQSWHaYQfJ+Rlroo26+K3iE4z+kVYl5wRnEAHQZLZCkMUNirNduHMMLRebyFGjJsJTB5lOYpg32xAIOz3e6RlQYyyiPOaKw0/OamDaPTtvUOdUTJjHALiNICKLHCJJgCBCobdhPuDNLh2juBKweCdMGPFAQbwZb2mU0OcNCKSc1HEhGLaASCt6sygRrJzKUhLQikZ4zRovylozYFQQI9DQM5Q1qJQG26aoWZKj8iDWFh+vHdg75SqVZjLDv4WiX+C+/UFuDg8Cs/x1P9GNRZkHbRsrrM50WkRxWf9n5rhxxDjxJg1xehuDg6RwE4dokSqtAYyZWEqRcnayBGoxBcaIbXMYq3JLLkxqrLc3RhBmbUnm2IST5MMp2Zjcwy03sAJW2SMEeuy4rZ4/A/zl/Bb8TW+u94oicipIdzWq9UstP4zuqTred47zGvCui5nbQasZYRdR6Nw2ni+sMRMnRMY0TfedfjWM4cYxfn9UmRxpAF5Z6sUIKNFMqXbM0P1Cu9ULpwrxZNMm73UWxy1+uIsjsBpEELXT7XpJBhwPCxaVB01IAbdr/YlNc67AJ8YTKuwxyqE2Vd7kTBtJhz3B8zzgnVeELYb8PgIftjhyZcdyk//FHe391jmFW9eX2OYxtbsPEhGVSDHrmbqqI6bHM47bLZb3N/f4/b2HrvdDuZb2Zry3ohF1AhQyvMhBhyOC/K6IBxvgN0z+S49dFQ1XI8K/akwymaQtFP5M+KD1Zyp55EaUHx2Rv8ba+2rZeNFwTfn0Q4ZGa6BO3lOxrv3r/Hkzce4fnODtCzdUzcn0wIZBRGeREYF7xEGCVogeNDq4X2C90XlqzLqkUIOnccQAkpOONzciYHkCaXIPXMpGIaI+/sD3Dhgf5zxevcI711tsaaC4ANiHPDuo+eYpgHOSXOM25tbHOYZqTAO84r5/l4aZcMwCYKIAQAqwM3tARcXO+SUMASPWUdyTVozyoxAUkPJuWC/Fow736xoGxqNJ/WZUJNzgKLwSIw8CShpYlen35uRqn39lnmRDDGRkhqtmKZRSUukgXNW6KqhFkTOSRDQsBsM4Kg9w3YXogNzKji+eqWBXDuvM0bbH5ELIzjZ9zVYWxq81Q7HQAwehQPWOeEvXv8hHAFf2/zjU9nb3c/kWgvsqH7STBfZ4tTxo7ONVpiBzHjP/xoebz/AF+P3JFA4JPxteY3jYZbsWhEd+KXjF/CPXn8XRIS9u8cfPvo/xLmy2p+6hyB7lgmP6Qt46o74mP8a07QBsRBMzccZKSXMaVWZQfjO7g9wFZ/hJr/AXy1/BCLJvlkvT6Nt9N7LvLE4i+qPiqy3oIq9+meYf3W0ehnHpGWqBqfmzp2ya5leeKhD6hzJhU8shV4h9DVvp9rZoJmSVbRnI2VntOdpLlfTU9WOtNfvdF4DyMrdnOvufPYODCmByUWJVpSZ1kjgqv+pexFcQIWUMESQU2CBGwZFAond0eQvgRCCw2aKIKfB3CXhbUfVx0ZatmY4TSYc5gV3N3tldgfIOzy7/DJ+8+IPJLFDBAePLT3CM3wd31mOgHIP1DgLgHm4wY/j/1i5HErKahtJS5nyQEGdHp8Lp+1qKfhPPi7InIFVNtnNZsAfvxsAaPaBW5G4RFikdqfXoRVHy9DMclsggYCkRunoCC545D77gSaUa72Ds15SrPex650aF9BbbfcLLm4OwPPPftdKf8qMZZ4VziIZsTgNGgUqUsDoHOB9ZffzWvDlQCjENSLN5FCKU1YqbZwsODNROrrIXce8aIdt5pIz0poRIqsSLIg513vmVEBIcFF6SyRlrIxDQC4OnOVnwGE+HMU4ZILzAtW8cg48BKylYAUjxKiFmh7DZmMBTjE0F4GzZu4EBzcqVmOHLKVgnmeA5DNLp6d1RVqTQNkGwRazMpEFT4hKb55LhoOAIHJmpCVhGKOwUjqB/JAj6QsVfK0NkwkXKC2RwxA9pmlASrkWdjvnsJQ75JKxX1/j9eEOPn8BtQ2EwQZZ7QfWmhri0zqoTjMzuLZJOK1Paw5z0QhYCA6smVAiiTxCafiXJYGch4OwJ2IIABM8Oc04iSROte9Tb6hSXY8GTznXJfZohc6dL90DRAhDwLquuC0BL/KI/zk/xwUf8QV3f3IN8U/4RGH9l9Nf478+fOPkfsyMZU0IRXq9GaFRP0apdM9WGPOyYAgOm8nD7aSlw9XO4x+9l9p45lMmx2YQt4DOCWLIIp1nxBfmlPTv0jujgBYvE9XsJyrMEuhlTlOS1dzvHPi2HlAyluOMkhOGcVP3/2ldAQDyYM7mDQBAhWdP06AMXgRrzg1A69wGLHd7HJcFm/e+BjddyLNdvounX/4uyk//DIc3t5iOC1gZ2cgLFNqo2Z1zGCtJgCIQqphi+EAYpwk3b25BuIMLDj4L/be3gEq3DiTYIcEhLgXZYObdPqrMjDr2Mhaurns7r0ICCeIxwJ/M38MssBnT5gSf1iqeWNdqiTh36mSby2amzykhgEyaOXaP7l5j9+Lv8Pr2Hqux7T14JkNl6DoBgyD1E6Uw5nkRaKUP8M6BedW9n+WV64pnxEC4vdtju9vCU8GyiIGUC4MhjLsWAFmXjI8z8OzqOb6Wj/o0HillvLq+x9PHV1gP97i5vhWkAjlspoDlXomCstVJO/jQ1p1zhGVZpHVMLhg3EfNR5lgCl9InMxLhrjBSWtDMYR3KnkFBa9tqdrXX6ySsl1HJEBhtrhKAXICUGGk9aFBDdPWyrvAaiJ6XBakwhhiR5hUrCKo4AEiQzcdgqwKpCD14iAM2mw0oJ8zHGTf397KeIYatQfahawUgRYBoDXaSoKIFR4QPyxxXhX56j1gKSizYHw/4i9t/jYk3eC9+E8rxXBnvAILjXO0NMdpb4IEUJkm6b6hb7nX1E0AhwAEI/grbKCQ0h7jHL8I1llUye0K9H3EZd3gHT0BMeFae4MPX74Ocwx/t/g1e0ktYs/RSxDG9yDv84PYHcBH4Zvwn+JPlvwNRQWSGG0ZgYOzcY3xv+x/r2Ai9fKEVQx7AMSOlBWtKGNyA4AluGkAgPPdfx5fC9wHOqC14CNWpYHVajAKqyqVON5t4bTbE6R7tqdKpbffO0XuoQ3qZdeqmtdCPuJc1lybOon2/6hTXTRJqC61emrwt+3biHJ4HJk+p39vpTCDr34tSbQ5SZzkEW1/2fvo2OpZes6AlM5wXAqthiIICAmoCpLkDMkZh8NgEqT0rOSPntoeYGbwkYAiaFCk4HmapZ6VB17ckOdg7xDHi8fY5fnjxnyO40L2frMed/g9AhfHLfYA9PMa4w5L2cLxg1ZKX0Vlrp/8fOG3EQs1PDMzHBcuSMO0XfIFH3D8vgG8sW00AtAzM+WFqjiUsD3aEVf94VOIIJgu2Ce1qNYm6TSby9dSAJki6v8cvA8BmP+PxqzvQu+8KdMO+r1/35ISNyp8ac0HZ0aTXGGC1Tfv7A8jNku4vBc5BYYYagWRWKlGpP0rLjKgKhpiF4r4wlrLWWrLMjdSkN/ShY5XWBVyEu3YYB2w3A2bFnQ8bIfNIa8IQg/RzOy4Vpjhsg2ByAbgwAGWVptfeI0aH5AB2ArOKqnBkY5xmVsRPa78TGK7rWVSUHdAYpEgxwKUULLMorDBGhEEyObzKddZlBZFAsYT9MUtjYSJIT6uieH2PaQyYSWCgpOyPfZLdB2G29Jqet4xGCMpAtRhEpIDYwWPARJfIRMgsBoAjwTSPg6yVjfOIwaCssoqthYApwN78a6u87QIJqgoDqBjEVIWAMCapUoTACT1Y4SRB/TKBeGbvMB9mnEMv+3t1W+WtMqZ9x2oq6OQzgVkC/+3hS2AU5VZ8+/XOHUN/htuv9TulNGPDIoJAi4CywGCc7rcPn0S8cxXx1cdJGg6DQZRxwjBW79s5n1X9nRvjp4rtfI+dKjVp6UCdoyY90iDKy7lOHvXqmDtF3ozROlf6HWYg3fwS8/0bOCLEnj5fHbcaLQVg0JeUpAY0pVXlS9A1jpNoL5FXDL7WqqpONaNkePw+Hn9wgx+lhN+9+ViZcxnDFBSWZgpYxjrnVq9ScptvqdNlOA8JNqxCzBHicDpHDMl6ECRYozCo1BWdN0OoPqjMRBeQgDp+8qt4j6X+TV/yZP21NSDTXTTS267fhr2tR4O3F7ZZPDWy7CecsLXKv5vjHm4+4PGLn+P2bkZ+a9RYAmMxhioPjGGPvAS4LLsj0GIHZoc1M5AlM7dwxjKvCMEhRpL6tFywrLM4BrkFVDkXzMcZnLPIDgDXN3f45QBsjzfAuuIWAbcXT/DoybsAM968vlaIkQ59FmoI60sl3Ati0FTDlRx8Ye0pJ7JymQVyKKQRQHaEu2XFcV5l/XgSdmkd1Aor7+ZcHA6DX7V9653oMJsvFZRgSHDtuN9jTgXDEJD3BxBL0132Hnd3B6BkxGnEssxgYvggAc6gLJQpZYxDVGcXWFkyHRcXW1iLkjcvX+D1mxsMw4DYNaHOde3o5uRca8yMrY5MVugzW/yN7P2Cx0DSKnJeVqw6hsaQLPTp6tSSGZVZnTOG8Z3a3tIVBetv2C1HzVi168vfAI4TLpdLvPY3FQkwTiM204hplLZGXCQITCD8/v531Tlv+8Lkj4u6lxzh98b/QiF8VNeUzLg5JGLNPeMv4tv+P8RfHf4QqVxr4Ehk8jvxA2z8Jb49/UfWuu3UHiBSNnK7LqkG0lyo66noekmO+v26Ad5Wj0Ynv+nfOplvf+P6H1iG6cH3Ou/u1D2EboNWywoSlkjuril3MNn94E3Onr3dpL+GXbvKWEabR1LEna6zprfP7mYBkpIBctI3dEmY51kCQFpi0p5F30yZYSTo7JoPwQyeF+x/9JfYfOurKMuKcZDkRM4Fx/0i0+4chsFrv+EBP7j4z+ApqM0uSQFCAbnWE9De0eD3hYERO3wj/i7+bPkXVVekJSFuQi3F+lXH58JpK8xVAM9ZGlsyF2xvZix3C/jJdHJ+Lcx+cCVCo1mWQS7OA6M0A3ZcBOKBxiYJJjircSg2iYr97nc6mrIV+0+EzrhfENeEi5sDSBljwmYE+QAyp08X6QggvrqGCwFgKeAOQ5RFo1BHK5gkGRgAQlkbR2FFlAaABakUpGWVqGQRGtM4BjgvTbQzszArZmGIDNE/qMNr0DqqRp+wsTlcXl6AopcFPA5C3LEklJSxMmEYA9xmFCd7XpDWFTEEqTdxDnEYVbgwUmasqYBZHTR0BpTWdskmk/HPWeq7CFLjGLyyQk4T7m73lRXLoD+ukLCAKitYXhPiNCFuPY6HWXr+MDAOEpEBEdYsMKA4BMlKsbAlmiwJMSjTUEbKBTllNdO5wj5Sag1/zQlNqxj9MXqFvxKu3FN8OH4bP/cf1+bLwUt/EGdKBZI9KEoKgrq+O+Oim7cqzepnunD0ObhoB5hqa+pnhAazIVEteRbnO3iPzAXzslYoG+tYn2e73nZU50mf6Pvh5YNziASa1eryQjVX7XPgVOGf3zaA8d1wgx+lqxPniFnrRL3QAR8PxxODl0vGtJ3w/pXDs4uAb77rAGKsCWeNQU73yen4s8qG9vdzp/T0XU6dtUqy4jTAoVF3p0qOyPR4B9tCP8NOx+dhtrXJMF2TRdetM0YunMxj73ISiRGcVqm7WdcVw2ZXg0m9oUIQUy1onU/OBXn/BmH3VAI2+qzj1XNc7a8RD58qKYOvjmFzOkVpl2WtRqXchMEKkypa+ygJEgI5qVPMqryJZB57HMopTFuemtGPWctYWWTE6tZOxt0CRN1Ris3rgylHncTuHqhOgjnJ9Jadq5/rz3yyv+VaRMDl/gZPXvw95tt73B3FWbEcUffQGMcRu8udtCZZs86ZZpCdyJiiDqHA+RZhdtQenigFKwSxsNns4IiwJqVlVwiPPbe090CltE5pBTmP/f0BPzoQwpLwLM84RmC72eFiO+Dm+gZvXt9UUidiqWeblwSTfkHJb0q31p2TPSPwJsvIdftAR+5aWTCJZO3Hr3yhOwcA9xkhc95P147pF7j2WZ073WspZ6lvOUg/Jmh9L5TMyQE4zhL4DDHA+QAPOcdrjICJ4KcR67wCOWOj/e+IWAlI7jGvwjSZi1MQkTA6m9Nv+keyQDpehVC86JUm71H3CEgdKQAhiA7+ZPlrvBu+iIBt3QaF+/Us+0XsoIKCooHTzhg3R6QKM80+M4NrsJt0XxQMacD7v3iGN1+61e1HmNYRj26vEIJQppdcAHZdDy1gpFMHjGHOUq8Z217t/Jr6uQVFPwy/jhADbjevAJY1Ro7wYfw2Jrezx6rXrC687uf+M7t+Lx+qzdP9bsFZlejdHu5qausXuDrcOhPdPNLJefI90xNtrG0N9P/2IqxLiTz4Ww+67t/kRO701zgXXw/ObUiCWhcJHfcqQu1Zz+xW1Qu5FHh4rOuK+bhiTVpiBGgPReUK0PZQ5/ryXD/z4Yjjj3+CfHOHtBmlIXuQ4LnX2laof1F7+OaMxVpolALvCHFycM7DuQxp4KcWHikRDDMiBwTvsDoHUEFeF/Ck556RwJ0fnwunjRk4aFQsp9aT48ki2ZO9YmZ6wfO2Ok8ANbICiM/jzSju61DQKWMVKqYUmWRRQB3JXiGYQrt6eQdXhKzELwU+GfqeMX/0AukrH2J88liEdl2B3IzK6DGEiKxRKqkrK9pU2CIBskXiEPT/UQycLPRpw+BRknj3ac2IwWGIQYRILkipVBhdVMikNViWReGAnHWROIEuaWbGETAMAxYIvnyZFy2gFjhdzoRlZoRhwDAEHPZHrEmiNIEIKJLZM2NFnFEWpyRnrV+zpolCG79q4TkXrrVkKWUsSZ2PAgw+YBgjlsOM6asfYnz3Kfb/14/BEHiVD+2dCzPGUYreb29nOCStX5J5jIqbDkpDzVqbwCyEG8yoPTqsfwZpNNQ8a9aIo2gVOXeeF3gGBjcprMdo+kXJWkDh8uYCj68fSdbNEXzRf1kgG3/6pwW/9VttlTPbGmv/1RV/8vubNwU//3nG174eWhQnZRz2RzVSOjpkmO2R656ACtFzCKYd1nfr/HhIMw58P7w+O4frPioA/rflvaZE6hOdX/ctThsxvhuu8aN0dXJfi7YKTJeEOCWl+szeE96/8vj1ZxmbOON4PM/I0Zm2tb+3e5vR/TZH7e0ZNTl64h8zJKuiP4ucnh5NOXJhKUYpXTbHDgs46XUYrfk4ujE8yQSevYGtXy4Z02aDURsJt/UiF7L7Wt++kgvW/TWGvIBDy4DRdIU4TfjL8RLfyG/gY4D1zrP75ZRwe3sPYxYLMWDcThJcKwXruqrTGbDO0j/M+whnGQdqMC15f2oLgRpsS2+o9zaH2Pa1fVfNPvt+m7CzwdYh5w6y383Hg8qRk3NOgx/NPTM40Nna0Wce1wXP33yMdHOLw+2tMN9lMdTREWMRAdN2wsWjLYKP2N/vUbhzEk8g8g1aa8QjzlOtLRFVUnB7fSvQXZXLUxyxUUN6WRd1YgX2vS6rMOo6qXPzYcS7Tza4Ot7icDdjmY+4fnONTz+RnoHCRCuK9/7ugJyTOjcOJQsyJZJkaJyTfmMp5c6INESBA7zNtRm4VtPnMX7xfcxa94bO4YRe423zCzTocy4sLVV0tgqz1EzWPq/6d13bIUjtfckFcZTArCMNyJESejkhYNjvj3Be5HUcRmy2kwQ4mCVbBlJEhMxZ6xEnTb1lryv5SWFl2uMK658GBynjkjmt9azc3j+EgCXP+Hj5Gb4+/QAXtH0wGg+MXpizoeUbBGQbI9Vzzgh4SLL1nFYwBbCWd8iwsdRbQ4KE5DziccDjmwtYDwep+/a1hr/WeUH6uFJtIq9ytZNvVc7x2Tt0wbfCjA/9r4GnU/nda1cTH0ZkAaqgQmEC5+47nV4Bmr16srsVLcSuBQKMSMdx0ZYeJpxOSxFO1U8nydWpYNi1xGFuTi3Q2HbbOFSP0PSDrj1bI7ZSHh7U3u8k3NxycAAAIABJREFU4PoWr61+o9dppRKHyfpstWyfZedIqYyU7uS8Yl3ls6EmQFrtumMnvQyzkKaJfdNl2LjZdulWSjOICMf9AdZrLcQghCTe1zIjBwlO5X3CmpK8lTZot2A9kdcgiqoQUC1psvvYWi0lV+eV6DQ7e358Ppw2AuY5Y10lwt+K0oF3fvR3mK8ukDdjfcnKnsj9trSLQaMK6n3Z5qKOkEQtHrnGQ2OTuYAzndSyAAAXxtWrW0z75aSY2NK73jvk+3uUeUWBkjhVWEZjA1yTLFQ/UIVAQOEeORcgQzujC2HH8TjLazjt9ZKyLAzvqmP65OklQE4gKtoQ0vqwiZA2Eg3ptcQgHO727eVIU/uOhKCFCGkuig9uQso2dcoFaX+E95I5ycTot1oSwDCKZp+MsdIcYVfJDaTuLTBjLQWMAmTGODlMU8Td3YwlZTDPAjWJQTbHxQ7uncf12RiCUQ/enCltiDhGXD4VFikfAggKuXJi/LG+i8x7rguEiJBzQkkaMCCp1Yg6pQzLWPmaPTN4jtEIW688r3C3PoIyrAHTMpxIc9J16sjh1atm3AKo7I5NQDcB1iuH45Fxd8fSR0co9rTwdv0Mp+BkCbzddumO0xq1Xoi3Z+obQJ9DBAExBJ33+OHwKf4sXSEz8IP4Eh/6fbW3T+8p73HuDFl2qQV2M1JqTug4BPjNWFsa/PCLK8a4IDhI76u3RbQIqNTHFlek7sOT3x86aJ/luJH+jRR2YxaAKChdv1poXaoCeyiDxGFrjoUMjdUd0qmaM6UA1HYd/QM5cy/UwGEGpmkSOOUwKM2/7GtvhpD5P7q/gKK1IUUf7xSWAgDXThjCci5I3DlGEEU2DBHjNGEcPB49usAwbVGytBQ4HmUeRA4uYEjmPqWEIQ5nDpGtBYGrGMmDfSh1rHJ/AUBwfe9mmL1lA5w4AqSGJXWyFSpb5WEs6UDdmMnprO+ixBDkzuq0z9ejjGDIK778yd/ieHuL5e4grJ6m29ByC847XF5uMV1cCPzOgmAQHUXNcq0v3faW1qYpHNwHj+1uQiZGOkrv1LQw8rKCna/rGSTZr7DZYApR1sWy4v5wRD6uuHp0gatLhwkLpgTcvbmTmrQxYrN9KpBwVGmG169v4Mjh4slODVPr+aT3Yq7EnAw0GFQVXuo8Fcb+7l5JRKjNk851Qx5Q2z9vO0hqZMjWjAYxGEBWQ0uY77SXKgHkBTLFWVAXznvEIMgbq7122h6mlIJ1WeDcCmbC9mKUiD6A4CKSZTW5IBfG0Efc0PYbEbRvmGTbuCSsy4yIESU4OHi0Ju06ELC9IAZn8kEzEm8fCvmgoG8pbQEQmSNWeL8sCmICArQ9jM1RUMlK7TmIarsCAGJ0W0uGLqgijnnvNMl+lJ6mpPIT2vrJlnrbVVYuY4E3T+b8UXWgbM2dLIFaQ6gmUP/mKoOJ29+JLBDStLX9XOWekzH3zGBihfWrIwmA4eA1OymjFNT5Jdn6bXnKtewdAUDtG4K0PjoRcCjCBVFBnKj2ckuoml5RG5mgZSKo72XjKfGWrlSoCdLuAan+KKfoqHD31zr9nRS0Td6/LUPIygpAviCEQdiLg/Rmy2nFrEgOrzKhZEWjFUF7LUvC/v54wiZ+XifImSuHQU4Zy7JiHAVunrng6/QfYL5NYDiEcRBEWCA4H7vAdqd/2a4twYVn4av4cPgufnr8EwBGAmfS/C12SXd8Ppw2FlIOoxiuTgJQU4auX5Vi4QCczwxNrhtOomy+7hpWo1j6e5wanm9T1OfOnGPG5atbDHdzLTRtEVxIhDIEpYttGT0zlsjL4g6Dh/dOGQAZxQsEEETIRChpbfUdZpAza38syQyl0jDcaV1RUsL1zR7b3QYpy1jmnGU4nC0W1OcpuWCcJuTNKE6ZZu84Z6G990GiCMtRCT1aNs7gXEI9n4XcoTprDrSd4L3Hcn0jhaJO6gJSLjVzBUDgg8FDy/tFpThCyRIXWteMYYjYXm5wuDtKPyB9lgrhgThvfHuv6WsAHAXS5a0nCOA0OreuqUJtLBpjDobBsKTWzCuVbIBzCduLCcc1SwGrijtHJhKlTqo4h1RWDENAWqU3mDASOmQkzLxXZX0q9NR26wwo7Q3nkn5gGstKnG0T/Kr1K5JVuRNOzv9Vxz/ksJHtofoMnVNpilCDFOcNLOt5qhnJO1z4hKduwUveYPL6qCfRumaLWSTOjoiCC0q45dDWNjMAaab6dAf89vsJ5Eqt+yeEbm92kBZqcBcztO1p0f9qb0AGF/1spw1k1Q12fajz3xSEXafpuWI/VIPOHDdrwdAc987w7J61H2dmicrnE+fCvq6RV3M0tDXHpHApM0LtONGdehi0bdqOCEFqDFx1IZpDGMcBfA/8uAS8gRixbMXnBIQQsdmMuNhtME0jckk4HI6Y57VGHR3JvojTKKx8XjI0pSj7avPNYJFYAErxLc6lDKHD6as02I8ZKp+9DzRybRAv5l8JZRFjrukk6u5WczZiZaGadp2xE3ICLQu+/OJnuLu5FUMjKxlEsf5gcpFhHLB7fAl38Qh/f/kO7uMG3/n4Jwons+yMRpq5SHCDC1xRGQKppRJDTNgXaRwQQ8S9u8fNzV3tD5lXaRLdBwL8/QHLZoM1JVkDakB/4XCNkRxSLrgoGV9fFvzNNGCzHeDJYeueYCl7LDiAWPpdLvMMLlxrpOsCUP/K2z5gbT3D3GpAIe8TuGAdIsbNRlu+tLpo1iCbGElSy0wQ2Ge/J+Rsh2UR5mWnHiqZD0mkgdOi2WB6YLAxS7+2ZV4R4oAYxOFx3ldDLucCJoHuT9OAkS4x0ga/vfnn+DT9Lf7d/f8kwVhuRFi902NrYF0WMMQOEfkByRh4BzdUaaTDadlGDQ6BEAcZ+315gws8rcZj1TFEgDkC3VgDTp1frT0kmytx4JM60QzR9RYkImrs4DmLvCSFtTEV5DEhrlGetwA9etnGGKBWgmpOhTkKdBoGIV+9MtucVRD0df7nB6m8FPS11ArCSIbUYSK9H/fyQ5/THDrLnIIZyAz2BOP1lEfW8a6O5ml5TtG5Io8HzJz2nKJnmuxt82RDpxlPavBI6s9lQxRZ+ZCMUXUMq4jiqitP/27yBDVbR4S+cLh74E6/8glfR3eOXVzuCRJTKKeEPGekKH2PyQnHgI8BwQvTrdMSJYIEWHIRhy/Oi7TpmBVSacmStxymS6gUzKVgOa5gFJTJIWzFYfQhVHZ51Erh/gXMaZFxRGF4FxBcVL+GRbBpMTfT29ehHZ8Lpw0MhfLIL7XoGMDLb7yPNAS4zoorIIUnNoPVKLsrK40ZYmzwNtRV1dYydZEqWb7OERCCCnU9nxkXb/bY7pezjWCbSBsAei+bifkhfFM3tfce42bEStJzKJJi9rVPVCnddXUcnPMw7C9IGRtzkUhfFsd1nhchDVEHr72hMJSBgJIUwndcJKKj0EQxtn0tbGYw9oeDQi26KCXQosy6e6qQYvne7nu/DreZsPyLf42ckgg1a2rZ1ek0CBIhgwDvNEKk64GFCtXHgIvLDQ4HaWC4FsBtR/jtBuQIT3/4fdz8y3+j35HnKKVI9kyjfowCFNYxK7XWxzknBuDgJetW5DvOBBIAOHHipuCxzEkcLwjk0ZlEUGFpLRxC1KwiERIDb8pL8Ou/gnvnQxQvzGbVEWHGWoC/XG5hmeMYlVu9ZlDqsL3F/+KTwMWZD3ESGfv/cvSKsN+XNoeWQaxujq6Nb9IN3Nm5zPJ5dB4+RqQ14Z9vf4H/5vCN2vagyYH2/O291OBlxnM/498b3+BfrQqxJJmTdx4FXO0cfv1ZhnexRulbBgwAN1jCybtxe34bW/vZggRtXNo17feTzzqDx57PDHxXx7F6m2cWR3OyzLHnqrhQa6z6ZVHv3T25I8IYA444NjkHNTQI1Uhn1r6QJHu0dybPG53387kuovzGcYBBbuTNqD03M8ZR58GSxyyBKgrCersoDTeBsRwXHOe5yjK1UDBupEa2lILoSTMX7W25UB3DlFYsx0Vh4R6NNMbAbZ1s1/+f2xRvG1uxN7k5K50TLc+iWQbqIPydHLf7nY4ro9GPyprwYDw+3GF78xL88iVe3x9rzzx7ByO0cs5j2gzYXe7w6slzfLp7ap4r3gxbEG7qdWVeCN5pU/uUMQynwK3CQFoWHA6HGvmdD0eJOiuqAmsWO0rZm4mVpp2loB4sE80M7O9XpGGSwN26ghVunwtjQ1v89u6f4dP1b/BXyx/hWO6Rk8D9Zw08ppQrskYylKQkJNZXUcfaVBJkXRcAcAHjOOL+7g5eoeG2rln1ha9ypa0B8zss0JvWLL3DCEoY1NgTx2lAyBIcJu8wDoPWTUP1jLDjpWwsvg7W5sG5Tm6UIr2pvMe3pt/Fs/AVMAjPwlfwfPg6rumPkZNk3UJXKmL6gSHIj6y12ikJ+YxXJmOuTl6b51M7QxAh6wz8ePlf8Xz6GpwGTB5AyE+OHsrVuYXiXYN1zA1QZDqhBnX0mtaexmbjfrvHiw9e4sOfvafPy7WvHtszyScncgfUWrCYY9Jv7f6ebENoOtxZ1rpzZrh0GSiBexZ7VVsvpqKrSO+vApUTEhQRMVGaIDB7qNeVnX3aXUUdOxtHQ0dw0wuwdUtVBlTdA5MCVB2Zh6YEV+eR+vcj1PXTZujc0ND/2L6xz+uAd+/TJkECCs6BUtEMql39fJ2pLc/iYA9jxLJoy6ey6OVMzwr7qPdBanCdQahlEcYhwjmPcZOR1kWct2XBPLc+x9LmBsq50LgWgKIQ/hGb7Sj30HeTfwOsF50O6ckicxpI7Z/XQexAcabfNjGnx+fDaTs7Chgv8oz3/Sh/sAJb+UV+B4G5iQDbdI5c7b0EKOGIDoID4Xf2vwXURqfNMOrBKXd0wI82fw4ujIvrA/yaMM4JxSAnbEZo+34pBVgTohJ+2IYii/BxQUnAvJ8x74UgwUg4iCT75YUiU6LeJEYNs/SN6sWAFeOyNoYm32CHFZ5k4xFMhDUjsiiJyTBN1SkjUrKSbBhjoVJNi0cpVs9G8DECcBLd6LI//Tojko0BQGpSFOrpvIMPsqhrpNPkmjLzxCgKT5gnXTW6p2msdPf+yRXc40fioKaEZUn1egx5t5zlHXyQBuY5ZRyPsxgfqvScl/ooB03zewJxy7wxC6xzmRf4SeG5zBLBqUaTsmeVgqiCNKrMzJkBKqBUcP+LFxjeuQC/E2H2JSACcuGM//34aRV8zgOcq3kJg4LUwdW1ZfPZZ21MgMiaLiLcqQmRbpbqdyrLJJkxqYahrkdZ7xKNOiVlMC3VzoGSNPxgeFHV8nkErjDDSHI3WPFPh1/gOR361zv5nn23vy+Rw3ceMV5gxOZRwOAFNv14A1yMAMHXd3zw8k2XdgKX0OuJFsl9eJw6aO2CLQoOwPXkIk7/bepXnMRSDXywRcz1vBrUOFXK59Fg+649TDEDBIDbPEbcvAFd78WIs2ekFtCyvxm86WSuWPsv2Vqxvc7C5LiuSdsBBPjdU8CPlZCAGUi3L7AeD1iWjB/HHV4qbHWYBmw2I5z3OBwW5FWM2yUV5HXGugi8HETaBwvwzmGaBtzd3GE+SnbOB989rxAEFWbMxxUpZVxcXgDOg7bvVsIGeQExoJmpGeqWQ2fjEu7qo/q5P+nr1RladY82g6bODXNDenR6hu1UM5YgRsIXXv0c76wH7O+PeL0/IueOHbJbe+MUsdlucPP0PdwNG1xvLuuaKQB+uXuCD/gXFV0gDKEeQBYSJSVi6mMHaV1xd3+P42EGkavo/kF7W65rgtd6w2wBllzgh0H0EivEUo+UClCAeZ2xLAueMGF3PODVvOLL4+/gng/Y4Dm+kH4HPz7+L0gsBth8WOB2DrOSJBEZLNXVn0XGqayqbIVU9cfFo8dwjqQWklXPCtQGDTZn8tQIfOSaPgQUXcdxGAC3ahcdc9i0tYQPkrVSQjAjaPHkgeDgA9W9nZPVv6jNkE/hWeuyIOexylxzPJz2q5VSBam91hiTLgkh4olDhGcppyhcEKLAMr2NGQnpmtgQWg5BUs9NziEGjwMJFNksK5NZ1qT44Y7oNweq7IEPcEGaHRfVHdYqxk6tq6QPULYt0wxmPnUcUd+92zfV2jdZ3F2acMJ1II4JP3gR7n+qzkPbx718r06w/r2NC50qrs5Zrvu+u07p5HtzOHVNkpQw24uYM9OybMZiXq3gk6Pe72y8z4bqVI5Bxv1E8xGdzFUduqrOZP2dO1qdpJPPzEZB2xPkzMaDsLqbfXHucJ/obO2f6zwKF0UfmP6SjHdNKJQiz5sBhrTBWOZVSeSgfAMOJQQ4JROpffqgaATnql3tnPRQHieDMZsTrP4GUFvWnIxRN2dVQ5i9RVRh1s6FhxN5dnxunLZ+nRcA1yXhPTecnqCSqkYbqG0usDpozuE3lm/jy8sXH9hcxMDjfIVesXY7pp6XXcbFTcbP5j+BX4QyP2XWTMzZg5uBZd8tEDjF4QhyDwsKje3Keo2ZcWAEFzF45JQgxcWl4uFTzlhTFmIANZJrXd1biCPIEcYhgoKvlP9mnBkkkEtGGAes8yKBsSDF36WwMDZuJ6Q1acG9wzgFOB9FKZSC4KXI0yJg/Ti44DCNG9C91Nl5B2HOCgExRBQn28xXgxeqiFsETu0BcJHNVEA1G0alAM4jF9YIrm4uCLTSMmnjNIqiDbLhSu7rHJ0WlYoBbaxcogRMuQPLmoF8kOhuDIBzovRKAZVcX11S6QVG/+rJ1T5XK64Rwx5EV+qIdUsbDQrHDKDQqdxHM9bPjXbLhprjReQ0SmTwFxGKw1irIVpW4YFwsOeSuiokbvTYZ0EK6FgZs99brnTye+87pZwRNbKc1iO+61+Lk8sBwHLigNZtX5Vmy+69G1f88FnCfjuCHkAKmpR/6PC18e0/ehhF/uy/V2dNBXbvHFa2xWpANPXTHAHSjI383eAosvbQlNeZQkVtNv+WZ21egPwbt3BhwLQZMB+FTMhvFB4DPnl35taT0sB7pZsD06uyVhmH/REpZWy3G5VDIwo7IJdag3P38pc4vnkD7wgfIaKMAVfbCeM0wUcP7wM22x1effIpbu/2gJOaBHtlW3fFnDeW/pXWo5GV/IjBanzK/tsfjiI3hwCGA8cLYaOtorrbAB1stNa0woz4k9FscwB+8DcxivTsOkf6OZnzDjXy9AqnVqGcXAr4449xF1WuFj7ZXrk4xAhcXO4wbQa8uniKl5dPkdh1xlyPfugDEAxHRZrXpiOO84xpkog0M1BSwu31He73e4CFNCuDMY7aM8wRvA+1RjoXNYocYxo3ePXqBi54hOCrkbalGTkn7PdHMAOPPOGdKWING3xl9xtwmqnZ8rdwdfkY/+7w32ugTBzvy0db5C7LaPuNlSRLanRc3TeADNswTXj8eIfXr66RCxB8UCdTBAo51LrEXnKw1u7EISA7h8IO201ELqHqDNZ1w1zgvDBBF8cIlf6bkYpCFZ2wKZPuT9L5CN5rQ/AuQKI6pAXfxMSzHnprFmc7hFCdVRgNv/3ODJpGxCj12qHqBZNF0jTdLBNbH95Lv1GnWfga6LMlzacSvfkZcpKQXLUMPZWCkhNWiFNo42KyvD9E5+rN9LNiRT4MSG80AEbQ0K3t0wud/b2zDcFA6XQEgWqLJVYPhk7ezC4h8MZaEmnyu0tFFS0yI3cKOT8VGr0VT9VxpJMYqAraWpP2cKxsfFqmsf33xDGjLtvffW4/v5XITwUkUzu3H5F2bTv93IbufrKgSBf8fOBcqk73Vbk0Mh2qLDWn1+8wPZJEIEJxktF1BLWDxf4TUnHfrX2Zq3VdcTzMwnkwjfDBCZKBpNWVkCCVyqB9OkSEL0/fw1V4D+awnXyOJofUjURPdGhjkc0F9y0IJfWuGZ9lh9jxuXHagOZFewDfClu8KAtukCA5G4miOuZu4vovS6T9q+uX8KXjB+hjFjblhc+XuUbV7PqQ+x/TNT7a/5+gvGJeUjNKuw1ktTui3aygQvqapFwQCsNRE7793nNak2WtDgSVVFDAGKYRQxGIg9VdHQ9HNGx0ATtxxKBOak4FpzBPcVAM226DG2LAZhqwLhLxy+sKF7WAMxfwKoX7uWQc5gVhGBBDEIcvBkzbEey9EKNAlJYnh6QL0mnPOQ0hAMzYXE4Yp6HC3+rzQQz+zOdUrGL0GeGCd6IQcs6SvmYAi7Q0CGrU5VVgixRIjYAVRISo/YWILQLS3d9JHSJ5L9lIRkcFR3AuYPCyRkouWJZVp1igRSZ6nbOSXhlj8g73y4L5sGA3xcrI6fXypJRzxRUkV+CLw3/15i/qtRkAnBTC2sIReCdEmKNB58xPaDU8Ag/OiQAO7fsZWBeL0n720duORF0dFFps4jRGYY5I27sA8Af/D3Vv2qNbcpyJPZGZZ3mXqrpr39srm91UkxQXiZJIjSQSnNFiSoLgGQsayPYP8M/wXzH8wRjAhgEJMDwwxtBIMAWMpJE0kkiRFFex99t9t6p6t3NOZvhDRGTmeasuNR9bh+xbVe9yTi6RsccTzbu4TYf8un1GonqGdCYpecv1Aof9oMX+V/tN1d8/sr2QIqN1Cbss+ejoe3OmaoXT9X1hBtdVFeCasRQjLH/dUh242hM3F4mihHFeA1MsZil5hggJM46LoKsjPvV7V8an/KzWGRI59IsOu90Bh/0BLiNbVWvlHMBTMcar2rtcjF3NRYTeHmCg61qkZM6Vqvk8BMxknxKmJLzh9PQU/f034LoFQvAI4zn44j3sV0tcXu5ABHRtm1NUTcZZQbknSYHNCnpCdkXbOm0vN4jThNVqhaZbwD/3ybwulU1TGU8AEQusebajGMcUUf9+VZWwszM3hPNhMeXTATlLBMUdK98R+ggxIsWEi/0BXdsgeMIwaryTCIuFw/rsBNPyFN+6+TygBsuczmUOn3j0Ni6MftjSbwQFktjjsB9w6Eb0vYEkSWopJ0vjk0hwv+glEtN4rBctUpyksTQDh3HCol9gt9mBmbE+WaIJHi0twZywjo/B4x6Ik8poh8+HiM/c/F14X6DUHRGW/DJ+efX7+NvNv8c5zrHfDwjBY7lcZnQ1cVIWKG1R9AzYQ6OyXY/Tsxu4eHKB/WGP/qzX+QgAVmis9+CE/dZaTZQaLyRR9qQ1SUTbLtSRipyeyCT9mMRxJan9hhjJKWVFNCZBhRZ+FTMNxpREIERRXJtG+nQ659AE6RElPJiwXKzRLxYYLi5wOEzoOgach2UHWVRafjgBy3I04y/1ea8NC1lCAjmH0DSAOmv+av8H+OLi387Q7sBRcjeyU02NNHNSVK/pJHMrlZKhQfPPlFevKKukdauOXan9oiqr5DpWmOWF1hybzEKlN2ZnECqLhPOpJyHIbDi6GkFXmVLi8jCpdSsARTl9uhaoswEystNGjbT6MrCRDJREFl2T7yZCyeA6WrMrBtbR35gZZCVFtDb2qPrOFamY9TdcwyXnz6Xq39kAhUHp7axti/QHJScO7KJfV/PLxf9qDJE4qZ2uvzivAWb5XFRkypgkuuycpVMWQ90F4QfTGLF6+T7C2Sl23/0hUoW+Xst95z36cIJAbaaFPK38l7mV9PdratSctsYgBS+KED2WY8pRvmddHzGjzaYsk9hDmKzTtMR8JQYM9dboJmt3lA02oCIpkqiOEGU58Fmu6q0ICU+mdzBOg+bnX6/MlTMjFC/Ghc/FoMIwKqI1D5R6CCKTaDqkFbZEWC56nNxY4/x8C2z3Mk7nCqiFE2MiKnoaqUHBKYl302mUjrWua4qZWRGksLtbdNLIeBRPJk9JkZYY0lvGgRJj3A+4xCW81vdFZkzDhLDws55PZlsQOSw/9RqaszWICKc/+xns/+ZbAlrp6hS7YiwnLYRg7W0j3gaBAU9J0j77vtUImTwoaSSLbE0ZYEiIu3EOhynlvWyCR+MEWGFMku5p29k00koB3mkfGimEFiWAYRC7iQUqNqYk+qFL8OblqdIKkXUzniHTmVKWjBbUu/vk9gVOLp/i7rs3xetCIiwtBVQMGyX1WgagRD+ukiZXgk9XgcW7ZN7O68j5OsfClTtz+WnpDGZI1SjiJzTilIZiAFQGEVcLkgvTHSE0jbb6sFQD8zSqkEpzZTgllrQjFcbAPDXUjFmdXTFiKq/fNatQreFVpnmsUGQGbfVl5qVkSEFx9SlxvszFZ63s1Os7N4qfPU5RXBJmSpDWlWUAEQKa2x8HDRusVgvsdns07Yi2a1Xg1feq1+/IoLMxJnGe7Hd7TT9cIYQG7uw+/Pp28SxClPB2scaN+y+pokDwJ8/BLdbwbYOTxQIh3ERa9JimhO1uh8PuACKgaZorHlKL/7GBC1R7HJnBacJhe8B+f0DbdeiXPcLt10HQul1jyjMHEfTcQfmz8WtdiyM0znrvr9uVrKNpqhBzFHmkA7WehzOGkVdMzuprT97B1DY47A9I+4NOVIRdt1ji9GyBYXmKH954vjybGOb+Lgq2prgZTepZBY8APG4tVng8DdhsBKjCGqWTpqRbNsBi0UuxvXNI44TN5gAXI2LXo1kscNovJaXycoO2bdE2Lc78PXy2+xp8/ADx0R/gcvMIcVJIdpaSgcYHIDhF33Mqn4EbeA6fXf0qvuO+jsf+ITaXWzgPdH2P4BVtkx3Me51r2Z1ElUIr4ADb86d4en6Jvgu48ytfRApeoq3eo+86hOAwTQHDPmbQmnpjQ/AIyw6Hw4RIDq5pgBThVI47b7Vi6oxz4vB0rLAyjsTgQEDTSjbLfj+o7JQNMYhvEGF9uhawrpRwnj7AbbwEJA8C47Xui3iw/BF2l5cYhwnDOKHX/oRX40260UTaHaTmMYUnZ2U08/AK9ArICLxFfyKAQkYjzJGe/wqhURtzchRr2VDen8+CZ7W7IEuDrc4T5jZLmVO5n6QPzpGYK3trzheq8Vr5CutakI5ByhFgxnpOAAAgAElEQVQVBM94Y86YUMcQKWiNPYvLOK84TtPszZkBV/NlMkOFoVFezjXSti4Z6p6s4o0Ku8k10mUN5jlNZoTNDS/7u95lk8tUUR8ffTLfSVlvTg+vDB0A6N0Zlv0ZDocPMaQETlDwO4eQgWOqMbHSMaujiSA8PnNvZHTm4Ansjc0m7TUseq9ksUnJjiNgsWzhTtdoXrmPw2YLPDoHHj6egXEBwKo/wyqcVTRIhZ7rbbXVML2foPqNWQGMpbuBNiywc3s4illvj+kYzGR+fWSMtlqxIniE8AZOEbE6v49H9wccSMxwU/zk8M6dFKZs0xFhlIeU9ASQHU59SxXxt6dv4NvbP8V4GGdMToqGvXjI2IpKLbwpSkpisZat7qFuuWPIT1wxa28RHiZ1uCQs2gY4OxUGPgm0c9Jc/qYJ8MFjHA/5gNp9u64FvMdhpw11yQ6WrG2j9WQxAaHt4PaC0GVC3YpkvfxTwDq0f0yKEdMgPYBCG0AbVRpj1D2IszSelKbc74zNGFGmZDzSEDRnTNI+nyRd8bAXkAIBT3BiweSzL784L8IzQnoDEbP2zDA0KlEEqZHwt4TkrT+QCVCoss3VIRS4VwFFKKH2JvgMJc6Z4elwbH4g7bNSaKw0aJV6tykm/OftQ+zjhFFTjaZkjcWL8Di+7CXrnVS/tloS7t4VTsWJEV3C2Rnhxg2Hx4/jzLAxA8yMr/pR1xkPV2u5MBsfEeG1sMUrYVsZedUZ0++kmAT1NDFG9boRAcElOOcz+qelIg2HIRsM2YBj7XtEJYJLNB9j5gHlkNtOHc2jfq0oNMUjbGeEBJlLz68h82Uxdq0CU0Rf7WGWcbrq7+O1nys2tm9c0SYpuqilYxaDqxiuBIDO7mGFKKiM+x3IERaLXpRN0sbb1GS6B/mCaoXMRbDfH7C53GAcRpzdOMPp6Qm62y+BTu4JD6yWnUDA2UkZez4gWq9KhGmasA9niP1tLNYX2F5upJ/gIqFtFSGyWphyi0oZYcZ0GHDYH3A4DGj7Dqv1Es3qFuCbekHntGD3NEXHDDXda+Fl8z2opqfy4+ouq81WqRAVXeh4Ue3tzKDSq2lCTgF1JGd0seqxWi2xWZ3hndO7mZZEHF4j6wBwFB4+V7mAOEW8tD7BB3GP890eu+0ObrWQ2kQfwBCni/cOy+VC0q1VLWLvwG0rhf4hwFHC44ePkWLCYtHibvsxfKL9FXgEJL6Hyf0UpvEtdRqJERHagM45TS1U/mBpfACea16DCx7fCX+CR/QIm8s9xjFhuezR9B2CQeqniMQJPrRau+0wHiZ8+MEj7Pd7PLd+Gc8vXseuWeAC0i5C1lPT4p0icObU4LKT7Yv3wD8YsNtLts1q0YGdKtV27NUBh1SlNKkXq9ZBmIFhnLTVidBu13dYLsXbLuBjojxyYvzj/q/BiHit+ZIYKwR0TUDXt9jsBhz2A5qmQQimGluUSPV+dXCAWOp+ksq07Fg6omsG4JpKnzhW0u1jdpArfpnPYzkQWdHVlEkzTAv/qwyvbAAWo4JsjXVsbAAe9hLzEUWXM5YbpOvr5ixFPpO4MrkctUP+qJ5JXS8g16GJ/qLGZEyVQg6Q9ioEYV4zZwAnzELnNd9Qfcf0GWO7DORIzTxkWnSfkiKJwlNsenav4/nakMrtqntfI/Rnn1Mmn7jeHv1lLlM5j0lpsyYZ43sAnmtexwfj97Bpn2DcDeq0Fp2XvczBUt/zzVFkm/1h7ov8GF0IEY3yalK8i1w44qWGeRoiphCwfvE+hsOI5uMvwb+SsP/2DzC8/T4kQ8ih71b46bOv4n73OohURzDdoFqLHLM1IVxlRqEa4/PNJ/H+8B1cuieaRszwjb8WGbS+PkJGm8zIOcJ68RWE8BLuEMGdE55O39fVr3aeK6IGF0IqVAQptKXZITe5Wf6SzxIRfjT8Jd5P3xCCwbFiKlDilJKk4xnjt1CmWu6cvDaSTKDk58nDrN4mra8wT5mlFY1DxIcfPkG3khST3eGQidaMxBQj4jRW47LHlxQsW09TxgFC2waEfoEURzjv4bsl0mGnvXmEKH2QOToWhMmkGohzBHZOC0UZbdPAeZ9h3bNHzDwEamjGUVJKWKN+k9aTea15kAJ7DSWLxJiN3weP0HgQiwGcyJRVypvjSQpPU0zgKSKEIP25VPlnMlh+oRNSxSHGCIpGMFrjoAXewjRFkHjv0TbSwwhqVNpYZaplD4y2qjIZnb+E6P04iUAiMS7HKeI/bx9jO4yIMSJOEn1JnNCZvlmx1eqx8EFQNW2fzcC7c5dw/3mJYiYGiBlnp8DZGeHRI2TjBpgbB7VOSyRKa11HVu+L8fbagdI44Le7t7Dmw+x+eW2onPGUzLFgyE4OrlHnh3diHDuHD1c3cGO/waptkKaI7eUWKSnNEHLqaTFEqRovz8Z9vJZHo5spWfWnSqSQ8lo7zdIQOtTorNKPy4eu5i2VYK/e85qLL7RH2QC1mj1HvtzG0Erz3L1Cl88HnOdo0h8A3biLdPcuTh98Hw8/eIjLzRZAwtnJGk3j4JtOzx5B8nIcyCDyIWlw0zTh8nKDzWaH5WqN9ckC7e2XQavbgEZxY73vRh+VoAbUSNJ6oCmKIovlHSxuA4QfYbfdYrfdI04JfduAgjiq7B5Z+UmMcRoxTqPU600Jy0WH5XqNZnkD7uxFkBltuh6iVOnwNFIjyPRz550MvxBOMeJRnZ0KLIKNhioKO9K1CjPmoqQVIsu/vn36HF457BGaBmkcxDhiYL1eY7M+w7snd5G8L/R3zUUa2Z3iJOesMvYBsTUa73B6doLUeGwvN9hugdV6ibYNOASPaZzQtQ36JsB55dJeWmaQb9H1DcZhwoePH+EwDGjaBjfoRbze/go6twYnOd9N8IqUrBH/BExTxOryP4Bv/D4SN2ASPl63T7jTvIrGdfgv9H8jtFvsNls8fTJg1zbouh5t28ATMCVGSiPiPmG/P2A4HEBEuLO8h8+vfx1rfxP/gB+C1BA1j7yBpjiS1N85X2N0L97H8ON30bcBaRyAZQ8ki2AUBGVJ9y4MlYCcLi+Q58Lv9rsD4hQ1I8bh5DM/Bfzj2wIUxYzNdgekBApiIL81fBOvNl/K6sPr/S/hyfoB9odHOBwOEo1eSJ2yAGuVHU5GZwnZgSyRGC4Npamk8ZHz8OQwKGKrI4c3ui/LWoBnjZPFKe4qtlMMhxk96nNzrS4L4FdBnC7RN6dngu1cGfMwA1ONGDEGqnNJagAdGaFZL2KUptc24CODLf8o7Bq1DXrFYXONA8cicrISEZKep7dzBEqcx+10LnWcys5nbewQisF4fFkvt6NRFBj/Ssm1J5S5XHdH7WHMLE5nV+0pbLx6t+MaPFmUGdcsn1fLSktCjmaRh8IAmq5DGEaMkZEcY5wmkJPaT4OGyqMtIll001Qlv2a5R9V+S7RVSjI8fObZjGmISFEyu2qnsPMO3SsvYHzvQzTB4TMn/xKn3V3c6V/WfSLlwYVWynqXOdqY8tqzpfcXmg0hAKOURznv0RxF946vj5DRJukGq/4r6PqXoWxP/p9IO1VTJXR1wSpCATOe3D7HyeVT3HxwBlRKKXBVabNcU+aEf9z/Db57+ecgL9GYFKWBnxg0QtTjFCVVxDsgSUG3pflNGhly2nON2c0NtirlKhfYq7JjClrTBIwxYfvoqUbGPFJkGIrhNEZYf5w6GpCSFFeS9pyon2NM3YUW1HjEaURH0mB7m0bEw1Br4IjG5B0hpohxmCSypIicw2FAu+zRtAHDXhCfzHDN/Ew9QFNMUiiq47UccR6jlgLZHpPARnN1D1ViJfLnpSCfYjF2VYENjcdy0WfGURcWAyT93QCwooYN44jDbgAngSJfLju4IMqdJ8GQKwZMgncsqGlTqWuLIvUBIljmlXmRpzghjrIuKTGGUfsqMaFhhuMkvdtSwh89fRs/Ot/joE1wC+MHwqJIlMyjOOHjrzo8eEB4/ITQkB3fhAhC4ghE1hRUvZd6wByA/379Ku41i5mxBYjB//fDU/zJ7j2deNkDcEHIlCdJym7fNmBH8Jzw681beMFt0U4C0808p4U5wy19jkLr4Z1H07yAvv2iOCcUAfZB9wgPl+/hyekdfPrhj3BAEeomHBIDL20eYVyuMYZKQa8ug1Y3tMBcg1bRa25ZQC4LAYmslzPrNV3TadoTQYB1DEwI3uMnsVo7lVLWVKPGAdM0YooRnqM6cUTZngBEphz1KZEwy+1XZ4fmx8sNFZwoGxSsRljA5M4Q2ku4w4jzJxc4HEacnJygbYE4DcpDq4URVQKb3R6Hyy2GYcBitcBi2YKX97DnHths5Bwk5c8G924qHZFCMButCuIskUT+gxnM/YtYLnuMj97E4bDH44ePMQ0DvKJEejVkkwETKTDTNI1wPuD0bI31yQkWL3xOYGHN4K3FRvZGJzB57SlnfM/UU4m6j8NYlCqNsPdtgCcWRxBHJHZw2mzYlAanKkaCy6XOJWon0mo8jPMaZKNR75EWZ1jtlxjjhP15RNN4nC6XWK4XGNcrtKvFkQpjzyhyLsaIV97/kaAN1luqLR1caOCbBt3d13CWBqQf/h02F5eYhhHLkx437tzAOA5SdxHEYRgUzTdRAHHExfklnj69RPCEmzdOcNLcxWfDr8FxK8qUD3A+gbteHHyjOhoB7LcHTOM3cbH5Ayy6X0fXd1itFgjkUZKNgDN3Hz+3/G/x1/yHaEPAYThgvz1gtz3XuswKlxyS/h8ah1Vzgp8/+TdaV8d49e9ewn/57N/PFCuOCdM0AiRp+JRlKuDI45W/v4+1+x38hfs/sN8NSDGi71rs9wc9g4DTVgdzY4UA4io9irDVs5N7uHmP7sXn8cLJZ/Dij58DAFx2F/j6g3+H7XaPcb/HyIw/T3+IXzz91yAQzsJ9/MLJ7+JPdv8OF5eX2O32CMGhbUKWeZq4CUAif6SOGAZjSlBjQGqBGQp8AoZvO/TLBR59uEFk6Wm1pucwxSiIrKaUZmNBAVQq5EKL+pQSl3L+oWfPDAOuziGY6i6FeT+Z08w+0K+WS42BGjSjNtbyi+bMzymD1U3qzwGldEbfq7f1utZZc90SFQ/mrAOZYewQEdmJQZ3va8l1OmczotXYz/edj9qmVbO3WjXOb9SzLWsr/DfLB1R7pntcP2v23PqhtRFmtGeK0OyhBGs3VxuQ9fWpxVfxV/wE4yIibbYaDGAcUgT6HsE5WATTbsyuXpvrDNGyKJwipilhHKXVCBha50ZonKRpr375C+Dgs/7S9i26sxN8wv93eP7N59D5lQZPasP3qhFcVkV0r7JUhU/ZsohT1MM1Lfz+gEmR2xH+GRhtzjVYn/wM+ubzWbioDxoJwCv/8AK+9dPfB3BEmPZTtGIAAHtGcnUMzqohZk/MB+wyPsTj8R185/JPMQ0TiIBu0aHtWkwGPW2Fttpkr23bqkhVhAcnl71CgBgJksNaECQZAIUA1zVI+wGWBkgsiuJIJJ44ClifLhHagPOnexx2G2loCihRaXqllwPgtcYsHkEIk3rNGVEg+uOo4waa3iM9KYwwxYhRoXnF0yC4juMwIEWfa9swRbSLDqENGPaHLAhEu1cjgAlxYkxT0ggEtG4MeWzeBzCRAqqU/awjhJZK6hzDBYeGHaht0XRN7sUCVsQgZfFJ6wIYkCbZ1geENA3mMElapjEqcSPDgaS2rGbE5Eqag/bYccseFC2fnOE8gRUxLyrARoGtlfHfb97AzfAC3nUPc8pkHCN+0d9GpAs8oJ00DCIxMpx3+KV/4bGjbSHZJEqlbxzutB2WTYf/af2G6u4GqZxw6bZ4c/8OYif7GJJDs+nwO/09nC3W9Qkqaw7gy/0CXz69n40sS//LRo8aLX96eIBvD08xjhM2aY+vth/gDX8u6bx5/1gjUlKvtlj2aP0ppBowArgEa+F3jlxhRGJg0bboVz0uVmucdqcgACfjGunx+UwxTTEhHg44u3OG2zdPMDadKteu2sJsfaOk9pjhVSl8VXMUA3SZfR/C+M1fyhCHBMchRw0BS+1NGqW07xfVwzzylqok6V3VRsiDZIyaGpgdS7ZlDFDF3/J75gACIZry6QwSOmGcGFjchRsnnIQO2/YJdudbHPYPEUJA2zVo2zbzksM0YtztMQyDRGucw+17d7HoO7iT+8Dqrsw3St2vpLQUNcE8u945EANDLHWOQs5mEBEMIp5oBW5vguNjrE7WOBwGDPsROAwFFhoVXwgNlicn6NoWoV2Abr2B/cggTABJo1Ikg4lHdnbJdRX0BlVtWJ1mJS1YCLtdzPJJsiOQ53rlclZ/ZSopACQk+FIHWbxDogykiMMh4nxieLgMnrGfItKQcD4k7PYDamUhkxnUGGU5tz5GVa01skEelCLIB4AEut8dRnC3xMmLn0Z48F1cPj3H+ZMtnN9jueyxXPVoQitZCszY7/bYbHbYHaS5dr9YYrFai/F965OIuwZTGhEOQCAnaW2rXwZWH8KPf4Hkbori7z02i7tYLX4d3jfSc08dRFFTDc0ZucItfK7/TXz/8J+wc+do24P2PpuKcq1p4otwgpaW+PzitxDIoseAH3yW1ykx2o1HYIcmBXRpAaCkVpMj3H3nBm5tboHDhFVzC8P0IZ4+eYr+/nNSnzYOUi/DANS5K4IIqEI0ABjD4YDdTlr8NF2LsFpi+QufRbNt8NIPXs6672lo8dnF1/BXF/8XJmhvuPOEaRFzFmZPN/HFs3+NPzv8IS735wABy+USwVepcoqASuDs2NSMtqxUs4K6gAguNFj0DeI0Yr/dAAws6UyygVCML2jP01QrqtlgJW2oXsuWmqcpcIxSbKlvo5pFZz1tzvHmZkfR95D3/1h3rnVkyv+k+fevuejY4BCrqzhWnvE9G8Isw+aI1yU1eIuOqNLEdB2ivNa2FqCrRnH9zDLU+cB4SjMjzpyk8j3bwco5rfefW6ZWFVf4IB9bh1TGa5+xxZjr6XImKvZavQcE9PiF1e/h6+l/QYoRu90hl4Uf9gdwa03pkfUTs/TTNcxXRCoLXARLsOMwSFoxp4S277BoF/hY/3N4bfHz+G78Y4x3bmK7GwRkT/e8DT1O/A0sm5MyX4vu6ryZ5wQ1q3Ej5HIKIZArQ8XnFr+Fr4//K4LfYtIshKb5yWbZR8RoO8Oi+1mQETYpGpTO9R8/9c5c17QDRIVg6iJUu2qBVpSJsnrvjz/ENzb/L4bxkJkUK8PsuhZ+IU2tx3HUlEaHlCJa1yF0CqUfI6T5tRg4UGWJ6u6LeQiM5uYp+pdfwPa7P9K5W5SKiqEyDRj2AW3bYLVsMOxJw7dj/qzVIgHIqFXH8KR2pZiw2+zQaEPSEVI7Z7D2tmycBPnSaaNw8YooKIR3mA6jrPk4om0C9t5L75XszTelNGWhJW1lNDqRKibknEJDF6ZBjQlOp+mavnhUGQCsaXZeToxT1LQORQqaptwaoVkvpRGpQi4nJEX0lHFETVsMzhU44JmwMbKTNfKLDos3XsX4rR8Aea4yP0nxkEhAylFQB0oBr4dfAQCcxw5PcS4RWefQNA1+99ZrsKNeCmMdtj/e4e8/+93cN8/2vW0Dfuf2i7gRzvSsAGCHQAQEh1vDKcKPPd567T1MIeK5t+7g/lt3xJt8UsZs9Vnyt6aHKmeuvf/2vi3Ib+I1/EZKeLK9xF9d/B0+gQ8xTiiR1IqWiQhN26Dv72PRfgmOThDjBvvxP2GMH2TjbhjfwX7/ltCgO0Va3sC5fw5EHc52l4gxSl3bDLgjYZxGXG62OL/YYAwDDBI6qWC0FEnx8orn2QRKrq8gBtjyHY0/lGfIMhTUquQIrRo2c3ZtBpYq62QmnoMZ1o7K+oAUcVHp2owcu4JGt+XJdfRXUO9QvWavA0kVIUmVTtlFzjndlVfPgZZ30fs30bQ77C8eIY4jDts9Dgp8YfWl0Bl0fYe2bTG5FS65h0sL4GJTZp7Zbp16K7+MCuFv9yvcV73aWaNQ/tzcBNobAL+Frmc0iy3SYZPp0TzTzhH86o7WmQK8vosxAcRTVvqzkC9WdKbjq6oOnmF9yWXtD0RTMGCfck5yShf0/KSEUk5ee1ev59HMDKdRge+dvYCX0rvwhwGH4YDWR2xcwIP+FLPQ/pUx2tzkZ2iC1j0pL1aEu+EwYOwCXnn0Nt68cQ9P+zXaW6/ipHuK3eN3MBxGbDZ7bC73otjr4C2FKwSPxeoE7e1XQIubSARc8iX+evG3AIAX3fNoRg8aPW5Mp3A3/ht0oUdafCXzuZWnDOaRI/6xGLP2PwLhzN3HF/p/g7emb2LPT4AWlZ+lZAzcDq/iZngZlY4qZ48sNU/25qXv3cPp5VpkFhVFy2QxA0BgEDp8bvk1fBP/EQ8u38TDDz7E3bu3AddiOgyIueeaUWWCI2mFQADiNOLycodxnND1HbquxfJTr8G1klp6vr7EycUqK/nrZoUTdwsX0wNQJLzRflWycWCKIuNm8zxeP/sCvvHw/8OwP8A5h8Wik1ZAtXFRRQQsopbB15yD10yXpuuxWi7w5OFjDIcRvgn4VP9rOE7AQ5bBNc3a+ivtaQSPiHL/KeG14n4nNRlKna6mR87FjYB1QbiuU2PCyB6o9/7ouu71IrqAojaWK6fuiUVxJTPLsi2ueV6OLpbFKB9lhnA6w1nU1gdHkci8kFyiszLHYog7hji/aTZyHcM1Q9NafYuOHr9vbOLY3Jj/du2Es46cP8mZM8jvbv48o+2s4xFQG6L5c0y407yKB/33EWPC/iDOKWZgGCQzoWmk9QUfG5hcRkvquLSSlBiF3w2HATFKY+yXVj+Ns/YmXmm/AOc8frr9Nfz48bvYLd6bGaKLbYe7b9/J6wwg81+T2/VMGYVcBJqU5COmhqCmPdEXCIDXrDo3RXBkbeL97OsjYbSJV7gwiVK7YYbbnIHM0IaOCIDp6DDIuzPiZTDe3X0H3778OvbjttzPhL2e1dC24kV3Dkk9ys47xBjRBg/fBAyqrBqUaNMENaq42sF6sph5jfPLTmq4yBEwRkzjBO8cpqqBrM2zLuS09XA+ANoGoP6saVQJLEoZA2kcxfszTWJwqFfT0oO8l0bXRB5TarHoW/i2xeV0jpQidvuD1JsFjyF7nMn045lSYd4kRwR4SbfxPqDtgnj427Y6xPkfRRWD5uEnZULi0R8fPES4dxvd7RtInDAMg6CLkqZiJkZoFdrZW2+XORMyTy5Y01+PlaBKAWIdfzSur6fQjAMThI6twTmjaTy6RY/e91gsFwAS+kWHc0U2attGvdkLgXxN9YOllk4akY/5wDtHuHV5AzfiqXhjzM5U682W/s62Q/92h6EdcevBDVAnghOg7LUVQVmUFAKycZszxCsnCANVo+OAu6en+NXlz2Cz32MY3kRS1M4pJgWYUeVseQ/r/ksgOlHyXCC4L2Ca/gLT9ACzBqrOYbPZYpwmLJ9cgF1Atz3Hg90Wh/3VyIgYfJMwZDiQKynDNnzKKQ0Vu9Qznor7We5Hcs7jFDNNXmHOmpIDokp5cGKkcanBECVZ+FdpOsy6l5WAPKIz+/1wGADLxKp4mnNVUTYq4zNL4SPvrL53bIjRyYsIywMWixtq10XEp29X42KQC3Cnz8MUY7e8lc9n/XwR42VWFp0tKdH500Vw5X+OTF+tFWpuviLkN+7B4272MSkCd3DL21ma2rrYbc1gKze2UVepm8BsLbMqdawcVXKk/HpcVUJXv3d8cV3zVo0hP0ONF+fxZHWG53ebjBJ8xPCrB8/loL3z/uoWnh8OCMFjynJBIxmK0ouUcPvpB3jSLuAWNxC6UyzbJRbaF3O6+AA87GyCICKEs/ug0IF8C3SnaqCwlgLI3r3ZvQN0QBMDHh/WuLe7jX79VXhCNrIBi7YU9McypQoYhDR7ghkvtZ/NtJXnWimfzCnD6gv+lFgTEyfAObRtwM1HpwjbIDXNZOBg8iCrv8pj4IQeJ/hU/xVM0x/h4eYtPPzwA6zPTtA0AQ6SMl9nkSQ9a9M0Yrs9CGhIG3Dn5Hm83H4e/P4K754+wdhOeHzvKU4uVjDAjtP+Hp5f/hQuNo/QeIe2bzMoQXWEcH/xOt5f/wAPLt7GfrMDmMVw877QecXaWJ045dzK2odAWC9bbLcbXJyfgwG82H8avVsqPZfvX3dl1Z2rh+nfUbxQufGSOFFscKWnm8jRq/e2fq2ad4Caa5a6t5oQys9iJCCHGM3RPzuh5hzQUtd8lIAMJnSdoVTTSaVhzteGLN26pg15pslY26ycaVBPxPDvISUbSPoukSBTEj2T3YgYuP79wr6O+E9++tXNyPpBfpdn716ZO65uTX0fAFdCGp4c3ui/DI+At/nbSJw0jXx+h+ikRUBxCuhqGnouSzlRSiw4CuMoiJExoe1avH72C/jU+pcQ6h7QAJ7/8R28+6n38yo458AzEMfZrunP8uwC619F4uxfRzmKyzBWaWeF8PHuF/Ct4Y/hxwkxcnZePev6SBhtwNFG66G7zpuovEAOnCkESglGiNaAGeSywiQfoPzjaXoPA++lT5c+E0QKNSow8WmK0pMlMUKrufokNTcE2dhu2WN7scM4DPAaIXqm6FYiY0bp58GmRApsvfce0UfNJ5f6FIMknnkmSDyVXS/NAPe7w9Gjao+WVF6YlBvGiOlyB0unIi9RMo4R3hXPqvcecJIi17YBoQ3gScafpggfAmgYNYKhDAjqIXOEpg3qTWV47WljY8vk76C9amTcyfpoQASvnVkBfiFBXbzYYLrcor11AwTJ0U+xALEQkQhVrbWzQup8sMFotRfOOIxoulbaQUCEbq10G7uylW/u3IR/6XnEBx+qC7PKC2fkHm5t26IJHp9f/haCF2SzoI0UiYDTpye49fgmQghKSyYkhBZX0eHFd+7jzXtvwxpvOwDrwwprrIBGPHPWD8gYrynR3a4FtgCywWaKJQIpvWkAACAASURBVCoFFnm9Zq9B0kWLeNFidJRUX8AjNDfR9V9FihvsDn8CxoApRhwOA8bDCOeWWHRfRkqrnNabEoPjEi79PNL4R2Bs8oCclyavzhHCuEd/scE+CiO7olyrZ8XQpqYpAlQcCNmRoJ93Oc2wKOYlumXGDP0EJUVpITFGjkXgZEVh3m+wKNG18Kzonwu4xbFTphb0c3ALujK28vfRd6pnyHqI44bqe/glXLPI306rs2rsJII/9GWSs+fW4y182OqMrG7Xe3/FyKyvIgDzDWyqOsY10K9Ax0ZSxUuuvHbN5xg0n/vx+7Vy/Awltb53+YTN/SrXP34lc5PM/2p6rJRBYly2S1ye3MCSE+Ad/vH07hXHElVjPR7xk26FF/QEE7RnETXwNMF5YNF5LLqAFsALm0d4a3ETAMGvbsNG165vKrhU2RNqetQRRptP/kA179gkPG3PsVvs4SePT52/hhQneAU0cVR4TIrW19QjpgmHYZDXnAdrA20wY6qfcbT39d5GTVnkxCBmvPGN1wBitENAmJqcpsVlByRtEJTR6kgj1z3O8NnVb+Cv4x/g6fZDHMaItu+xWrRYLBcYI4OjKIjDJLDiw/6AYZzQNAFn65v4/Opr6HCK8XxE/3dr/MPP/EgcpWyueMlG+dj6c7gZXkHwHl3bFMJBGe/a38YXbvwW/iz9n3h88QH22z1SSugXvcoaWw/7kkbrbLWZQX2LxXqFcRzx9OFT7A8D+mWPm83zaLiZox+iPu81AdYpdFw+lzVbbQlkMOcZvVuly7OsDgUqqvVB+6Ouo6uYhw1IdEBLYWCLdM15+uwrlWwvtXa20nT0vWKgpNk3r+OQFmFTJHG2TnPmKC21c+Wq1oNc9ZbKJUjJC4ME7M6+UUP/Z7ODZA+Pruu479wcuf79+Sv1C+V51+QulIshdOhKBLFedwbQUI/Xu3+ByBPex/ew9zscdgOmcQQnSVMPjUecWPQFa7lkd9K9iiliHCPiOGYHbL/s8fGTL+CTKzHYjmUq52WWd1zyePl7z2s5gupJ16+AyHCbP6npQUfzM/Gmnt6alT8XXsO33dcFdCVOmOI1qfvV9ZEx2mzhGJh502aCSldOlKuKqZjiFDkbRYkBSilbwHUEjhno/AKLvkdME8ZBFomIEIKgJKYEKcYmQtd3iNOEtm2QWIoYY0pwCvl62O3hScKcMUbExPBmXJaZ6MEjlMQPSzmxrvDVvFPCdrPBQA5Je6+RGpUZEpUZ+52EfKejKBugxZZE4t1UxiGGqR1SaKNvUR6dpqy0iw4hBIzDIAajpkw2XcAhpgzMQo7hgkccOSPfyUJK6t9yudBtklSivMdqhDJH8Y4mBWWJglJHnNB3LfrgEZzD4KVOKTIwjRHNC/fQvSgF3MQWHS0M1nuHrmsQtEebfBAAXC5EtXqrcRBvTtBaBSMoZmSUT2itFDmH8eETTO+8j6Cpm8waFWTGYZwwTQneaoT8EutwWxROZq2vE2O9iQFtbEzrAVLd+FmMvCY1pQUMGEkh7g1d0CtncHnURZAIE5olYRh3UbqsaMU59QQZ6zYjj3PUG5CzaIXtSIJyCbRgbtA2vwOkhMYltD4hthM4AeMhABCwm2h0mxjRtQiLX8Mw/j/wjUStnXP4/q0XMZDDcBixb3Z49dHbWKa91A6ypNNav0JqA3584z521MBp2kKZW2GuRJTz8aXWo0zfDOKyguWy92oDK6Oh4fgrR/egsobHwrCuOy1bc9X4OP69vmoDpQRp9UwT5RTd8hzKEf7je+Zz063/yXFmKqscJHJvmXNJky38wFXC8Hg6zDVYzD897+M1mH3nGZ873oF6/54VRbj6sKKe2l1nZ+0Zzy3vVp81JUFfqb9v0fvIwI9Xt/HKNKGdDthL19lMi9elGOU7sih3MZb+noA2hIY4MM7PL3G58SBO2K8YY3OqWSKuGPtugXL6jXHMlbOsN+dx0IzuiAhDM4GaiL/pvoWbuxM8f3kfPAHLIPJBfKxivMQkKIvDMIKI0DZBlBmXMOnYrS5YlD8FtfFWkjA3xCRdi7HeL4qBkRXNqtI1GwksCLXZ2JdXW17hi+t/iz/H/46L3Qab80vst4L0xjrXpOUFk+SLY7VYY708wZdOfg8N9ZI1khjdtsHq6QIv/eg+LMwj2SRA5xa4s1jgcJB+UtL2QkfOxbm5cKf48q3/AV93/xuenD/GYT9gmiIWixZNI3WIRLauMm9Wudcului6HoftDudPpIn5sl/i1cXP4F54HXWpg83fnInIFCGCyeSGpT2SRjVnBGJ3YtPdYr6PI+VXhkJGBEYEsyCkmmO5pu0rB65ixin3aZ1jDtZn/tjW46PXzFSx10oGpXJzmq/CdT/LiDR7hRQ50nidGWGZKmtjRjR/+V7hG06fyqoPyLpDgPrys0kjO8eYiyj3n3kJ6zWpeAoz+MqKXc/rZqusVnuJYFfff4bcKYvHCNTh04t/hUQjLpuH2LRPsdvuMQ4Txomlvtr7bLDZWOU+kpo8jRHWYiQ0DU6Xt3B/+Qo+tfgKHPlSezlbBtONZI0njnjrtffwyW+9ivrDZk9UnfCqBXCgWZCMZz8yT+FiADKAQB1+dvXb+MvpDzGOMfckftb1kTHagML4az3IqbJkxGD53XZ4rrsEil+iAhONGClimTq5ty7Ya/0v4nF6F08O76mCq8qgD1kopikhskDch7ZRhU0eGqN492OUxouhVSRJAwo5HpR5J7lEroZhyvURU2T4KA1ODXr38RNpJF0LaHKk1rpcKaZc5F8L9MzcsqIGgeyHeDMJADyXBoUEdF2HpmsAlp5Mg4KlCJoeSbohSX8lC1E3Icg6KVyqrTGzNvcmCw2LwjHFCeMotYCSFVfVEmiqnFcABbFYkqBiajPRDI6hSrHzDv2iwTi63Fuv6wQdbcaVk4SdU4wAQdM7HabJ43Kzx5kPENAYtZIIii4ntGH1IiacJeqkyiuk99F+twcAdF2Dpmnw2eVvIFCbU75mChZVijeR9MYzNsCMsd/jndfeAzaiwDmIJ5qdKasu38eUpqI2yb8lxaVivqK/5SbwUucyG9aMPYu3Ub2F+XWjR03VIwDJKQgLAYlAaABK0jQ7pZyHft6eg5zHe8sHuGguQfS65OyrUuCipsN6h261wDvLT+DVp++jSyP6aYRzhMtuieQ8LhdrbFc3UFKby+zzul7zs76uRH6uUYiPvfhsysQ1kZu5elCP5+prc6OKcRxN+knXLEVcytnyrdOsOuKZd4DJ/hnPuOaq16h43NWTTNBoCGdUTHcsFOm67AO24erezRV9e27+3jXTqQ1XU1h+sq0nz6mzL2Z7mG8k58Q7U16LwSLKEwDiqqzCvPJX51eUIsogSXmrrqM9WQQAkmL2gxNzTtnTOcuXHAmonlHT2a5fYZWkJrtWMMzxAyJ4AsbVEstljxKRv7JsZf2AfM6MH+Tt5iJL7EvMCu7DDPKEx+tLPF59B1Oc8PrT1xBigzVOZGaWeaI8XvoHEqaUFLJX064JQlMKMEOksoddlpEyLprTEEpqbDHK5HnFaNDPJUKpNZVPUgr40vJ/xOP2Lfxg85d4uHsXl2kv7ysIFQCEJuC0P8OnVl/Fc82rQAISaePcmJAmxsf+9iXwMiFZTTsn5GQYPVfDMKJtFTjJGrZXaaMOHb50+nv4G/r3+HDzLsZhwmaa4JsRXd+izTXhcl5dCGhCgzhFfHj+IYb9DtOU0LUdXuk/g9faL0LqslNZt4oYsrFQmSjGe606na/hYVxERmUIGI0LFuUYo9TycI5ZzMoPys2u/lq/XZT4AjZHNlpmM49mJ8XaQtWcuuYtuZpFf5rjrjYY6o9kHlONzMHk9lweMPzMWLR7zCJpCh5in7IIWn7NZDkg70Wpr7S7ZTfL8URyo+f58804P3Y4Xifp5PU53zkGHLkuk6e+Z+mXC2W1Dp9b/BZGPuDb/j9i0zzG+eGhRLDHSUsYMNNrJArJgofhHIJvcHNxD6fdDXxu9TV4l3soZZrK2W4AKBGWmx77cAARENMEwW+29MfjyastwPV8rJyrnJUZrZl+DFROEBlU61ZYN7cx+PeQpn8uzbWvSyvUvXSelAoKo9W3j4NLapzoQQSwbfZ4s30Hr+9exSJ15swBWJhhhl4G5aa+RBCEqpSykbLsGkSIIScIj4TDMGEaJrReDJ6Y5ilSM2biSjykvXsL8YOHcOMGEVJbI1DgEZzU45ISxrFEAEUYqaHiSAwMIkSNwj3Ta68eGZ00wIzEUefrpLATANRzPg4R4zRJlMmJ8JL84EkVNMI4JEjLg5CbTAtgRon2xWmSSJ2mpwTIgToMkyCXaY+7oE2uJdqmeGchAE76c0hTbokajkhXCJqI4JsG06QKI0HTSqjkyqvXKEbxYtheh+DR9YTd7oDdZov16TpHMSXl0xWGozfzJ0vg5hmw2eXDOMWI3XaPaZzQNg0Wix532pexcGuBsIdFqUxRrP+rpSI04jhhiiNimiSaxSUKHaeIaRwkNTV7RAt7tZo1ud2xr1EvYx5GE3ORU/1uHKlmymLEG0qmRXwNvZLBs6ajQzfgYfNIaNcR3unfy0a6RwDAICaEo2r0el3eW7yKPh5w47ABgfBgdTPn7BvX+Inpcj9Bk6+NBDtHV5wfNu+jtShKTH0/e/Z1BtBcuNl9Z6BrR7t2PMb6e/bp3H6MKkWqehLNHlvzCRUrqqBFc4xdM3Qicdo0oQU0YmNKrim9uZVBpRcTJM1S+JoJZn2O3jsxFIHzmHdpI+5QvzbTBgAADhIRT1zT0LUqnZ6hCdNUpwXp53V/iaQe02u/QLqmjYGaTGU3jOBBQJXyZtzKoQBtZAWrUv6kX6E0Hc9gJWyCvd6QSonK79m4ymAYHu/ceRE3L5+I0aaf7VLEzd1FXr/oPTarMzRNm1fIVUyEbT5qwNZ0zXm9AGTPflFwiCA1GilplEXH6gIa5/GjW2+hnVrcHm/jbHOKxRQAdhijOggzSIlG+PW8JVZZmWnGxqFNrjMcuNKH6RZkq2VeevuynvlUr3Sho8TQ6IQgHp7R8/jZ1W/jneY72PMldvEC7w3fEdgJcvh4/3M48bdxAy9inKZ8LwP+AokqN41TpdDqeebChT2R1tKr3K+dJzruntb4zOpX8W33J3i4F8MtjhN204SDytiyjsIvUlT57j3arsNry5/Da+0Xsy6U97VaW1uOQnJmOMh8LJmvUGRmhEWG6DzndCMTNvZvdGJIr7LlarT81zq1jow1uyxr5PjcXL1+wntceF8e3zWfNkMQKDx9dtcMcDI3eY4lhPxu6boybsq/FRlfHL5Gz3Y/kcXOeUDT+pNmJznntdxH7mVlKfnJVOnXx7KOZtyvjJtQoon1+4QcbCm3qAwa3ZtSxgC01OFzi9/Ek+ZdPGnfwZuHv8FhEkeD1Lla9pr850j07FVzgpcWn8Hd5uM48bfzSMRwqsbLnB2wYfC49+ZtPPr4U4Ak+DJEacUTFFei7E11no2pQAZQEt+NlvNy5cvN3pO7rvxNvNh/Ghf7B5jiPxejDZjPTF+9Lk+2kk35IJjMtPOYU/ES4yJcYu8PWPLCvimfTaXozzlC8C4TcFZA1BqP0wTfNkhOFFT7DBHA3gOc4EMDjEnh2VkO5DVz6u7exLBawl1sMY1m6OkhZ2mwZ7/PomxEVX8zVzHZ+Wfq15jFYPBO0ItS3RYAovhDIdCnKBEwjiJkncH1x4g4CJEmBuI4YrL7Bi9w/BRyk0+owTSME1j7pIXGz1oSAIJC1jQNyAH73VApvAQXgrRvUP2HU8K4GzQlrygyzIzhMOJwkKhgaAKmmBD3A5rGq0dZ1mGcJkwRCI7Qtp00MtRG6MNuj80lYbFaSl1hjIoCKo8y9Ca/WoLOThA3OzAxppiwV2h0R4ST9QL3Fy/jk4uvoMEJMlslZE+XbG0RIMwAUkTihKg9RXgi3H7zBt6996HQhHNYbHucvXeCKUrNo6/SBBwJgigbmh5JulBJxE0Vy4cdEqVIE7NGq3XnHBWemg7JqRig0hA86t8JlCRdNrQNfrh6E4MfEH3EBW3yvnryoKxVVcr40TGZCy/C0PR40PRFQQOunK0r6XK1klMZY/XFprDh+NxcH3l6dlqaKc41KzYvt75CAMF4DFXGGmlRo91bDZmYrh0zPCH4gCZUiq0qgs7g7ZUHOo2IxRgBjdqLd1ccQuIskb5kRBUAxDUXJ8YUxxLBIFIFukL945LCVRRuVZUJsFqhrGOgRKhM0ckjIFMyUTH3+e4BEqUV3fBI6RAmfeW7FhFhlLHWqKFgRpoiavzHaqfmdFW9/pOuBMzoKZO/yaoEpDRdnWZej+pM5vEDxSFXT1MWd2Lg3cUZsCg0HTjhYnmqnyck57Btl4D2oLxODh87Nq6sSd7nanJc1omoZBHUkQbnPGIX8X73Pi66czTJI8WEcRjx3P4uzsZT2UIWimUqq4BkqIjIQt9o3pxS1k7DUawHJccNgETryp5mpVIbSOf9IdMvGBnQgwgvdJ8GEWHkPe73r6ti53C7ebHQA0vElFjqpckTvPNwoiWLQ0PHw9XzAJHJbFvMnAHp8uYrGuGSbuGT3Vex7y7wjcv/gDFOmKYJ0yh9DG0PiGzdHXwT4EPAJ/pfwCvh83KGZ0YRl2crKm71YG0SbdEgjesQZQAx0vnY2hpwhMnvrN9APljbUVa/KG10kir8jFLDVMhs9gfPX+ej1+dC5Rmyghl41mm2Q8vXvHx8H/19xs+OhnL8+fL8Sqed/SzGEF0ZS45Pwsy7FCfEBHhP6IOHM33A+ezI4CR1xylFDArm5kwWGS/Je1WPdc7LjI7nke35xxlXli6vT+Yh1SbZ2T9z93HW3scp3UPChIfTm3h7/OZsGMyMj7U/j1N/Bw4tbjb38+tCb4VH2jJn3QvA6Ee8//JD3WLBl8CUME7CC4hQmtIfPTfvoXh3ROc2Tasi7LxnOnCbsRHqnfBx3Ox/gHH6x+tWMF8fGaMNwFwYQQ2GIyK295X3zqggq5waCSBVZEhz5pmjKLLMiJwwTlNlCROk+NPgsas0EkeyeU5qu6TQcRJDLkja3hgZLg1I0byaKMK0nhMhb+a1EP1EaLsGIwGTpkmW9MGEmCQlUGrB0jNh/mU55akOCcxOBVEFf60KVpykDi8Ej7bxoDaIN2PS8DAkmgRmbY0gQngcIlJM0jzVPEZk3hKboxhS0TmM4zRTSFISIwURGWzF1qwNAS4oCIsiAcU4lT3RZ00xYhwGMQ4dwTdBjIhphHOSBqnHFnFKAEc0bcBZdw+fW34NPzj8GR647yMlYLuV5tDL9UK+J2cQoubOmXNKCSNHHDa7bHCenqzQdR06f4Len2o9mik0VDiGUnGpvWBYHUEIXpoRc8Ir770I1zd4+tw5mhTwUz98FQ0C0AlVEYDkSTGqaAYTQoDihpBECS1N1sBYSHPsMzOulVb15HHMNZpWHJ44qaEGWESAPOAbj2+efSs3mx5oNFEOp8kzMPOwMlbqpEtjbFnp53LW6y9aGlk2tYgzOJD9Ewnw+RiW75nj10QLuRwfkAhDvon8PcWI3W5C7TxyjtD3LdquE+Urz4EyQpgpiFafSCSpUVzVyclHiyMjsSs9/rJ3+aqyTFHbVUwTPEmua0q6lmR+XY2Ac8rACjDj2vnKKDVlN83OZlEVkJ8/TRNcVIAilPEDpAaiVpKQwPowi5I6jxDM98n2LwSv9zOpGgGqKRo5qj+/GA4JcB4MlwWswP+GDEpAGo2L0ZqPlzTOet4GuQPKVABy4rRwJDwH7HTe9fiiAh+pYaCOOyKHGuY/d6vS9Td4gtkgKuFu9HJV3ZPRms3G8KjreEw+WiN4o3GY488FGFjXcg6TBkPu8648jdkkQfmMsRXb3mNQ5Dw2/a4oOOacEJ6XYsIUR+y2e2yS1OKhJ7xz9h7eTYYuK87EcUpIkfAzF58G+bIijovDg1n4WmRTbo2OU65zB6QnquOo/bOUI1g/ViLAmqMrvc5YdxUNCEho0OKWf1mNthItsyi2J4AowbPPiqhAk3PmGbXiavtv9JM3NMOJ67kz7w4xVu4MPZ/hi6vfBwC8Ofwd3tp/Q3iQko3VzXduhZ9d/g5AjBYLOIRCMLpcOZJeUV023Yyf6BvlV9MrbA0lakwoCJEZWyDTeznTbHODSQapdXfsxHBOU+blTvcoj/X4eHAlN2YPKPKgeqmcqivOuOPvl0gyUzlbMqUqOlg9Z2bs6L6XmHu5rui49diOdMkc0am+ZNoe9H3nlE/HpGA1QltN26BvOySOiClhu9+X6BsByVpW0bwG7qpjzAZDpccdVZn6JW96Nh9OmslStwdg04b0CcZczCEI4IZ/HgBw5p/Hx9qfqeYs56GhBaC8gBUNXbUvzAnBFo3t/5h8xHa1E8TmlIAgsiROE6KCJpGTsc/2k1DxHgVbY5GBTuW/0UFK4vSx7ycSViLTlKj551dfwyHs8Adv/s941vWRMdrmNSOcN1pfmHkgZwdldhdllaZ7MeN0OsHH9x8ThsmAdcP43v5PcTF+kL/lFC7X5Il4ICR9kLQWbBhHtE4g6of9AE4xW98pJUy50a6OhsoBzweLURl9pVG2aasE8YxE9SqVqI+lRtr62LpQVkCsxiinfJqnR/vIEEmqBOexWdqlHA5OLPVkjVNDTcfgAHJOG13LTx+sUBhwOh5LI2G40l8NkmYaJ1NiaGaEDodRD5msd99L4/Jhilh2LWICxvGg7QoYTdtmVEhSTwknoG0bLFatgIWMMcPi2qZOg6RrEhht1+HE30TnVvjU4leRDgkf4ocAWBr6PjrHYrlAqzV8IMm7t6M/xgn7/Rbb7YA4RnhPWJ8usOg63Ayv4PXmK9JPLtOv8rNYFeiyyn6nKX6qfDMILjAAjyY1eP3tV8BvKztjBuUTK4TlTV5xiaXlx05Wm8AgK25VUBdi5GbIWZFQxSpq81WjpZQsxUnWex/2cIEQQsAHi4d40D7MzJE5wnxIjhysFxKpkmbiOGvFmU51zMQZYSmBS2FvDVmtNOsqIdy1ASFIjztRDBOiCp5sQKgQk3qV4jlmJE3HIQDiWEgpYRylF9xxtJ8TY787aCNOHF2V5mPqh57DbIxSeTblfytiUcvyOk+wnG3KHx0RMa/QsJ8RUHCFUkVlb1kzcPN0z1Mi53UXxQhwzsM7QtN1WK1Wggyr25hYFG5SoCRyXmuUoghPqpSYJM26hX/UzWuVfo68omVcBpJR7x2QO7E6M4nKehj6oTSqxk+8crrMNe95JzRqNbVEEGdG+YT8SIr85YXGIgNBHRmcUlFkNEzUmKGnyk9ul6DzuDbTRA1BMb4FKTnBegeqGUDaZxMyJ5dNA5NxUosdo/Ffa9lxTEeQqpsKzY5B8M5Svoyfs6b1mONFeppyvpWcWSlTM9njQEGiXWMY4aYJ7IIa/Ql2Mjy8/MuMcZzwjfW3ME1TBpX63OYNeAoAM8IQ4NiDNNWrNHwnpVXKMisBOTJUoxVKSYHUXIOSRvlkRI7JOBMAYDLDNtOs0LJFxZyDpAYDIMTMoZ2HaG0wQ8hIwBwfgDOjhGUcMkCVE6xRv6RpzVqT19ISLjF+qvkSPtF8yRA04CEyDApmVbsbGJwRoBPVr6lOUhkMZprNHTHFkEB+b64UQx0lKad+2X2tXquiu8RILuKD+4+wvuhx48MTpFzOArVVGeBJWu2oc17vimdex0bcP/V69fKMQx8xEj76vTa2akkwf6A41Mr5LjV4dmUk69ow09+56gFX68kmP7INToREwvsSItKUMEwHXG4P8HoG7Ax7bcfkmOGcykQg9wgk1XWhETug6Jh2nvNY1JhhG39Vz5V/cjU5dXJleQS2ElZ1gpixSyAmNOhVV4GugQRiGKlaxoT5yhfLQfbQdBpCokn0Hp0rW8/IFDEOB4lGKqaC1Jc6QV1n03sInCS4IbKSAHWoW99G6Z3q8phMF4wozrdAHbyhxj7j+sgYbeaeSlylCujrtW1fvTz/O/9ruffGXIB7wx2AitKUvT4mFJwr6I1kJKBs2ZUHJmbs9wcFtJhEmdWc19A0mEZJPwQV5lF71ctcATtVZsRIHZsaXE6UXYmoMRyTeodTPti1YSaNmsUojTHN3jOF2JRGp+7TJoiR6h2B4eBIIlWiTDkRWgrcQSGgb7VxMUiMVe/zesaYEC3N0/RxkpRIIundRTEheH+lcSCn4uH3Xnu/jQnj4YDmbAVGwMX5pbRdaALIO42YFYJo2qANgAU+v2uLcg9IEfjhMCBOEU3wWPRrfLL/l/keP939Gr7Nf4z3Ft+F8w6H/YDtZoctE0IjoXICgL4FkvTm2VzswQx0XcBytUTbtbjbvI5P9/8qK91CBSZ1WRlQtUbZTV0LL2hxrAjnLIpo3q7dFFsDVUhsTJazMmxXUs+uI8oeULURZ15w4fl6L07g7K52SCHhafcUznm81b+Pwe1hCpptOJE6OYCMcCn6XlXzQNZ82tKPLG1OTySbcs+YJo2Gq6EyM2Ls/KujY4qiNJq3CxVi6Vz0lnS961K9dHV1jZ/xtm5vWWKu1uKq0lueQ7O/swGfXyvZASUyUYSifcc+T0pn5gw5vjfI5RTuZ02kMm+O5l/eMYOLiNG0Hdq2QZwGHAZJp/Qk621rloweqhrX2Qoor680etR7YyfB/wT9q16zogTpWVMhL/K8Ui7z3tv+m2bDmRatzqw000YWqAC0b6Qqpmyfm6l0Qs81m7MzYnszAwQo45/LMr1XVuvmn+Mj+rJ02xmtVUJS5IsaGzrfen5XRBQX58DVFK6Uowy1Kn/lvOTpKW3CUrXnAIMgiWq5IEiRPhvYpgxqHTcDQzNhnCKa2GTe98OT7wNoEWPEnYtb6CZR6DglnIwr9LGDpYX1TcCggAZyiE1WKK/NNUtlByTiAzuVArZhixb1NplnVOcvz4+qfmu2piyyxOJ+gwAAIABJREFUlqg0vTYnr8kP1rpy05yVVi2qYUAdxAUExWVSVmedrq+duxIJkNfB0Fo8JQSq6Z5AWk8nPJpyFreZrUmtCIIon86cLyLSitLPE2bsESJnjAeGbUB32WAIBzBHIBKacw+3cRijcISULGposkCzSExR1wh/psvKwWNy12SSvqinq9SXzfjUEd3PAgv2L1cJfcfppXz0WRmxymjLEzH6Q5bdc/7LkJrGIpMsQltJD/2o7F1SHZiJ4TwLJgQ8wCF/3zZ15qwDl0ionTvda/ELJCARYhqgeG7woRHEdRuv0jMZDaDihfaRrKMAIHMMR2QjVPUX6aVY6jHNwZI06yGqo8n4XopsOYxljsxHzAazweSMlxFYPV5hWJ3PdOxpjKCYwC2pnFNnDyFH5u1plprNJCnRnKD9Y2s9KWXbgJFA2dkOCZzU6sozro+O0UammM4VHGFmigrFRxE3KgIwxUp4Ui0r7OCWg0D5gPDxuSyHxm6QGHApvxwnxjQOwhpIhHjUhp7JDk59O74qzA7vPMDw5DyHiZ0q7wkATxG+UsgsuuUcgUkAUGrDJ0fCdC0szF0rfICME66kWraNR980GMBIWs9ijJuZK0Zvh4zzkpA1rNbFmxSEIis/ukfmqam91IlLnY6loQLIDa6HUby1UwQuL3cIbcjzBKT2JpgHl6Sv13LZIwRB3iSQHpJy8MZhwmE/gAD0ix6vLb90hZH+VPcrOKP7+MD9EA/8j5GmCeMwYhwnHA5ymG5++nWAgO7+XcT/n7p3+7ktSe6EfpG51t7f951Tpy5d3dXV1d12t5tu3/C0B2MxmvE8WFykMRIvg2Y0EuJhpPkD+AfggReeeAGBRpqHgRcLDUIgEBJGjASMACEb1L7IHrsv7q6+uauqq87t+/ZeKzN4iIiMyFxrf+e0x0g1S1Xn23uvtfISGRn3jHjvfaRTwWs3b+Knr/4yAOCT0xdBIRlsz8xHPDNFiZ0fQzayPBpPxZt/uJFxIVKV5UB+E7qsmLESQrbC1RzaMuFAY9AVj42mgDVrXiLkOeHPrt/D7XTGmgven37c8IAra/0SVyZJ8UcUe1ZPS2AsOu5GUq3/F1x7Z9esLQDt7AM6yEufvWLGw984rr2eB1q0GZc+xXv3aXju/nk2xjTKx8ybvykwoT7Ucpxv38YuXQi0dHw1qeeKkmS7PUwT7s4rbj/6COb59ffJ8XlQMHs4tG9N4ebu1xEmOv5xgOSs7xJsx/Mk4c6979gdDv272iGvlzDaLnSV/FwgeUPdLFsGwF189EvFioCF+/MxRbQg4kN4Ugdt7dlvTajcxZmI37y9B6NDxossFDTAIjxr7UR6aDhvnm5MhGkyw6EKRQQ5TwsxrM7ThGmaxQK+ytnedfX+33vlQ1h4VWXGo+UhjlWiN6aUcDzM+MTj1zBhUv5T9XmFWyuPo3uNAGYLkSSfV1BWbT4AXGkZANZWWr3CTAQUKy0QI3K4KWqNJ2ufVVUjW0UaFsoUoBWQ8+XZMxAWpbuUWD14esdkLjuLa5ERrMqc4U0oXiwKKJmZBpHOmqO2FRNuOOSKkCVkISZwEv53/OiABx9c4/GnnmirFdfvH3D4cEah2mznJgBLmDJpSQddG63TKUZ/4cMZEgLcpL+2N7f7P0C1ebloeHa7U4yXDQqeLDacuYb9u7/dVezkhlOCZxKt5FjXmW5hqp+Ngdvv1gL0PVIZu0FCWgulTALH8rnJa1LHtnmTJ5cVwZptNMgVPhlvkfx9wGmzGFdE4ZJSD278M5kGhm/sCY1MpCmlYlX6nMZ1MvmDAk3vyKITQSqEz37906ifr/jo9WeYKOPN77zR3qmltkQjpMeo2tajwJ+tTZZT48RFs9yS5nwIsRNqIKnF5sRb2rFzfWyUNlvA9n1QfgDfF3F/cOUWVy/WKxcG+ohj+8x4f/1TvLd8s91LOSFNqRFqy1xEGtYjfQqBWBYNy6i1nT+pldRSAPcuXBBHmRnLR09R786dYgHdjqVUSWeqYUayiE6YIuGJ40oargizXrFY8tjaMIEKAqNyXoGccUyEfJxxnjMIGXMWd3op3PqpDCxa88cKiOdJQs1KYZSlYMvYuaXwNdjoje6ZlOQcFzSssZ4XTZ4APH78FIk0QyYY6yIb5fT997C8/T7yZ96ChXyiERGBD0GUwHUtePb4GarW2ZsPE96kn0Yp7tkSJpXwqfRlvHZ4B5+fb/G7t/8DpnzCfMWtttjNZ98Cg3D1idfwlbd+A9ePrzGnCVf0SHCpACtWx5kgZrGOZV0qEsnn5bw29LSUIfIeB7+bEUM0XKlVQndMOLS6XGad4lCM2ohxR9gtxkS0LAmJnbIU+ibg9x/+kaTgB3CX7sAZW4JiwobO0cItaxNALig6cD92hE9rcnhv9FT34RgDo2zj6xWH+xQZ7/flryjQbt9/kQLXC/oSNtqtUP9mGP/4bj+m7f671M7WkBQ9nD5iZrHSThPhvFYkWvHg+oDzPOHu9oQSioBe9lrGMQ0CUMCnUYGz/i+2v6OM94JHEG12x3Z5vO3O5j0b4SXchgtqcDx5EWy2OIGGVC5ihZ7J1k/5F1HztGz78vFeGsV9eOVt7ICjayPt4KB90OQI4b6d/TRPSIUoMXe3UofpMM+4OhwAFFR9XuQmDXPU7L+1Fqyl4nQWemo0jkiefXq8xWN+1kSlRAkfvPoR+JUs/Qf6/AuPvwLR90rLHm1HC5glAzJNSWp0IuHu9g5rISBxq5VFqGDyM5+kckxtylxQ0BqNQhuDgIsbbzThtFb27NS+aTwKROe8VomiSLUCVZSVBFLlVDxlicTwIx5jFTItpZ0K6rbuNm4bn5uLY7hcVEwCyijiMtmeMI+Mh0aCPe/km99/A09efYa7V+5wfHyFT/3gTTmPC1dDDKao1EIum9Jh41Otk21fsCjHmRh2TlbgWJuh0UYfemnTaFEQ4OGZPeUvKOjWCvdvWaIZmYvyxM3xBu6+7cqScV8PtDv0YLOAQnyQTF3miBKL/WUmgAk16a8sETXT5DQ3jsg/6ujNMBPkeUvSYRIEJyClqTVhRpzKLvvYyGo1I4J+NuVd5f8WyQO4cYC0Xi8rwE0iYgtRlSvXCV989/NY/mxFAuHq2ZUkcdItZ+UzYskpm5HZximRRCjBulBcV4XZ97rKb7UiTUmU1n+elDbbGE7UGWAjHowv/c7n8Ud/+RtYD2vHMkkFSzAwEZDThE/88A28+aPX9fhMgJBtG05Y+A5nPmkbAtQcCMAa6r3QNCGTeMOKejYQigQDEDe0ecOMyELiyCMfI2gSg+sZeOVGwjRuT425l1XORwFALUWLO+vGrJK5T/YCN0TwnWBCvzKnlubXYKXhlyTM4EyEelpwkwjz8YA8H8RKlkgSf5SimZ6EfKyagGQpBSlZ0WnCcj6Jl4NjgW05mzEfJmE0CzqPUBSop8OMwzwJUy4SblpYSx1IAp9mZCcS5k7LGbwsbW2LJslo4QUKhrVI7bT1vCDnhIfXD/FLN7+Bia7D2lEgqowDXeNA1/hXHvwdWLwzVM34WvojrFXOEF2nV/GAHkpyGOs7CucNswGQMP93/vBTOP3iHYgJn//mZ4RgaIhWUYLSxMIYllvXZhUWO4EyYQXoUnSj7ySloYbjaEyboIrugZAmCa997/BjfPv4XQBA4T5hDBjNiNEiu/QghgkMvq5bodbWj9tZFbeKRc9Me43vV7Yu3XM2dkl43b+2+gA3PLbxx3vy9wXKaZzTTtdtX3csdIRb//2SUB2Vusuwkd6Y41+EeQb6y+IRP1xf4dHDB1KLUffY6bzg7nS+mJbYh2xet73QlN1JeGgOepBtRYwo2uzNMjb7IhY4vrm/nqMwd/mZcc1erud+54RPvlAA0BI+jf02C3f7x/bJ5fFuxjDsScelEer9O/fD2A0p3a/s9+3S5HWgWvB8WfH89hbNs8AsusGF4TB70jJjA/KO9S5iYmXGU7obYm/lhd/+xO8FocIUNol4qGD8/Ec/g5s0YZoqllXooSTrkjNyTGLcBEut0ZkzwEnyGoDBmpCIiaT4tQwajATm0hnqwIw5SaKW03nd7Dfjh+uifDSUK7LASNJwWC9lXcFF1OAl7MsEKXEhEes1ZKD1sjls5XhSbjzFBmImuKSlezzzpt1LrQ1C8vN1CIZyMA7nGV/+/S9CzmgCqYazsBtLGUxwlLFR1rA1QiEGyI0n8rhwHkqlncO18FBXLmzYirM7tLv7StBWU1NEennPcM8VMBFp+wDHqJ6ZoyDuZTNnOa9Ispbuf2wtxfNm9teCRsWkqkdxOELH1T9R7KQd6FtN8YqwN3jF/AkbS2boganJk67nG8wDrySAkIGEVvtPlDKZv5ylbYJkkzuo65d9odrX+Bu1x2IJcmbgyEepc8cAjjbNni/E8HijTYqKqowtkrUziUxr8CH4uWoike0LgGAJkczxZSvHxetjobSZUGhfWswryXZPmPGV3/si3v3SD9orLvRY1qqE43LAO996CyZLNX2Ggs+NJAvZmOkqFvNkFOAs79SyYjlLxsFlrViLH1iW/kVZyVncnxNRS5QBvRd4CXJKmKcZa85YybMhmQ6WkhAf1NIYp22yKJxJhJRkumxHtlN/mNUtDYSbB9cSfqiJP1JKKABuVdsnlrodoKQFsOUU6GFOmI9z8zRb/bvKjLpIenpYhjMFMBFwdZyBVx5gWST98HlZcb49w4SJNGWgSoX729Vc4tw2VM7ChMoq5wdbbH+VkJmEJPHWulMs7hqAutslJPJ0d9YC3Ef89INfwWv5bTmnp4RHPJEm5nj4QufGVmJcSoGFA6xLwbp4OmVjUvo4zPUtYxbsIwZ+5ms/1SkEiqH6VZhdrQyUVft0YdrSRouVqWpIgStmjdonUiHC8SclwpzlnOSzq+dIifCd4/fwJEs6fks84tzCvWAJpEk8/BoVlqajNMGvf44ag+uv3VC6HSUpXp1xZxjDvvzI3Xg6xkq4cM8figqO7cVxDvcJrtE7GH+LnCXej5+t0O3L9BfPIcV5S8he6dqP/cZnAaFBx+MRr776ihizqtCZZal49vy5MNEOQnE+tp4pYFCEHYfnfSwmZO+FLTn8muzeZhnHYcLWxlhlfbbx7Cky3MHjksLc/x7xr8fFS9dorY+JR7xth28fkmdj2Y4PZpgkauFrl4wKo+HjPvzt90fkLfvrGNuP+Odt9f14KGefRdAEdUsRT0AXVhrb7Q0fwzrqv6wKnAwr7jN/a9XkLA2c1jpJH7//2p+08Vro8GY+WlYj54y310/htbtXnLYq/q0FuDpkPTbAOC0Lrp9dIRuPT0BiuZ+yhmIt0CQeAd4EPS8kkRtYC+bjAVOmluUUTbRPBjmFttFklbhqRS1Co1ey5FhC9xuUlRYgrGPl0mBYqsom1qcabQzkpKn9a/J+TR1gzZ5MOtZkPBSsJXr93JkrcIrHNAFUW2IXNzT065tIDNetdmLWogUkvJXIhOqqb7scF1ZYoahGgB3NjmH4b2e0Im+L4cuNCtgq6N+YwbbfpwSjc+6xldsDjwC1PaQrJS23PWyJTACnR6zn4cwIbbhv+9PoSjjvqr+OxcTj2Iz3m8zlV8hYTCT4AZOFZexZo8Xa2eFQc1EUdtvnJOGLCl85eqSNVa2DTKosq1GBWZIsOb3pRtaKdYu33AScCGvxRJMldNPnKhImlvHpqZ3horaHPGtzabCou2fw/Pp4KG3ollsXQGGom3U+z/jpP/hcB4CouAF6IBFirhMhVqwKlq7dZOWJzSol71vI3yhALuuKepbzWutaFPkU4EBLpzzPU8tqOOWM+TCJZaFWCV+IihuLF+t8PqMs6yBAAbVKmv12li2MkxvBUjgRWpryFkppoZ2mkAA4TAnzlLCsRdtWgp3EklaIME9SP2tdK86nM+pakAAcr46YDjMqV9RVEGxVeBT1Btaqaf9NJCFNjnKYcF7FIuTjkpSzAiPWgsy+FyTc0dOKr1PF+aQMi4V5Hw52+BUwN7lckulwWQsWTTwiGSmPePXqk3g1v+VhRDVgTmCoRoZ6QQBomS/0oKkpWt1TcV+zC2YmkG6eab2Zl7c2j4Y5zYzhc1hbsI+0tWO427KOknp/BdcfHx/j2XSHQhXfP/5ARqWZIZudjW20FmK8DUHshbQ9QdYFNH8ngHnzvN0TnG05se5RgpyJyXgvKWpxPP7u2FY/RhN0LwnvLgw7nLq7e0rozvd+Dtvfbc1HgTp+3wrKvSC636aREO46t99zJlzfXOGVVx4gG/OgirLe4fb2znEwjCcqG/2k0/jL5qk9oX/vIsSTHReeIT3TOzzRGHnXc6/ImzDkty+FqbBpFds7F3EGbdTBlw4geIfG8e723bft4opTmqQTsiiBPXjtj2/oP+zv1t+uoaBXpMKdQF7H9+Le3OI7gObtMQOXeWOM6pG5S9h5e2o/ROFRPSwMWGZS2SeWoMf6I4w4YWP0PaV9YyuktitNrdbr9+b38L35PQOCwoRg4a1J6Uhl4O3DpyUzpR5vIDKeJ7A5r0VC+hUezZjDEuKVsoZ7JsKURdEy3nHAjLfOb/oQIF6Aw5T1LDmwrqWVwFhLBUrF8eoAEGFZF6yVJawSGqYGBqrWkqzc1iOlBE4Fq0jyoCTJVDIlVEvI1XiEtFZVAPcaLwCQ1PitiRsMnZKG6Nn+JKPHCaTeU2Lo2X7Htb09VbVOnqRdJ2Pc0tZmacO4G93fEcfJVU8PyVUcDmOxjIw9TYo0Id4h751r/zv7oQprsY2XI7zdXyePmxJsHjgSWEJhGYDVTtFRAjXPtbTLKSrTQO8KD3CjLSUysY30/aprmiiWQvGotjTNApfmIbV10L457N9QbkCycrvS2cbe1RTyJSAipHZUlxts7H4TwaHrmEjEQSVEiQVOMiTZ6KmNJfJcHRcDgJXhAXJvH99cHw+lrRHn8BNRsAP0f+W+/a9pxJNtJruv1osgUMjy2nmeHJQFQXA7vCrJGwl11U2nodiyxaJFmjAfDpjnCdM8t9THgkzGjICoxBOCxUcZlSgpGrutcfSA35MwAmEyFh4HIklJnzNub0+t4HcUAowxHADg7gTSdxhotbcoJ02jO2FZV0l5fzqDa8V8nJH1nBOYsNaCWrTwLDM4ZKq0uZES4NN5Qb0743jIWM4LVlVQU06t6HVKCXQQIlm1fo6XChCmk5N43aqVR9CJBVlBzniVKmmglbkxS1mCq+sjHhwe4eevfx0P85u+Dhvhx7IQ2UwYzW/Nlp5cNyEDLZU9xedjg9QYbhMwAjFnlCYYMkOLVgNErLWL5MdoiWpEWK0/NmDWcEc5HzhJqYqc8a1H38aaCoiBJ/QMzyFlE1hrejkMbRzumTMDxb7w6L/2Xo3+qe2e9t9HQa7zKFwQ4LdW+svj8jXZayvuRm+rVzTHeY0MmroxXVLW9q5eUbnfSzd66MZ29uo0WrujN89oyvZZEfCnQ8aD6ytc3zzENKlRZV3w7PYOd7d3WkvRhd4Ig5eZd+sT0W5rfPPCHGHMDVrQ9/7LFNcXXz1sRuVpbGFjeAj/tk87eH2579h2/16E5wgVq68o93pBcLwscsH2d/R4jcLKnnEARm8D/l/2zlGDfYPV3sybEuYJB/q25K8pJa64OU8HCJQTrm6OOOYJbqA0K7oo74nkexN/uaKsC57fnVCWsPpN8DMi0M81JTtxHATSNjmDISOAO+BhlF6oyTomExh/+P7Nj7r5u3WFXPjr+vNv5nVTKRf+RfAj14Rn5Ta0L21OSQx7ldkVL/3MBFxfH/F2fQuvPn9FShkpr11rkVTrqYocxZASBiw1Dc26wllr42E0TpBmGTYVIaN5m1iUOKLUKo4JflCbj0QNeP08OUvNsLNNVWHCDElrT+o18d0CU/FRqwbCSLmYpLjusqFFKwF+EktkQW4KFEOzcrUQQX/Kcc94Lqu8Co5eI50dpfa2DLb6mrJH0plh00YkqldP6yPe6a4K9Muf8ZMYITLCZkoU3qmtvd63bcd14Dho7xC17JGsbVDD6ZHnOuztsrIeslRaYxNWK9hn6PAaYGAiAPnK+6E3XSt7T+XyXvG08h2s5YeolbhItSITUJHEmGBLFTGNqJULIR9GTxv1SNLL8tCPhdImm6+hv/7VuHpEYU83VbK0/kM7lBrRNNGAiAciqinJQ0aZWiPmaNYhrc92vDqicsVaCspSNFOkjO1wmHC4OoJIiBDIMkgGJg9FeiWsImBnTIcZp7OERyadp1lJ17DgU0qtHhAlc7dX5CRp+/NhQmHG6e6kGZt65p+JMCVhammeMR8PqGCczyuW0wqgYqlnVI2RXs7iUZymhOlwEAWveO03LlLLolg5ABXypynhcJw185cUsn7y9BaHqwllXdr5vGkWRTApwzDrWqKM/pizXKVIGGITTnPGUhlrLZjBKFxwe3unXkt5JCXC8eogXsJ8wJyu8DC/qbimVlvqFXBXBDnsrJCljwlf/P2fwh///Dfwye+8gZuPrmQ9K5pVxdqHWiSJoNmtLLxSGIAp6w1/GcKsih5+r7ULXrD8UYbjIAtvISATKBPmeUbOGc/mZ/j6g2+DACy0YGWvr2aTjWQxhm6YpdXXoCeLL/IqxTC2rbgZ2t0RbJug2mBD3d84qr22e4FTR9918zLCdHy/++UFz7+Y2Mb5XHrvPkUWMCGvwpI+jAL0OF//bs+6Iif4UNtvec547dVXcTwehJZxwboWPH78BHencweBKIyOa/WycDDbU1yWOM/x+/Dotl27z0HI2b1UaB3o5O5zjIYM9sie19MiKWy/bNcxyhO+ZjLufU9xa2OAaZcpf5BLpD3lfAM/7daG74elPeSkocfZ+xRT72f/mah8GO/olNTQvuG4ed1McLVyJKe7E6brjAfXB61ZJ16iUhYJ2U8SYeLnKjNwPGK+OuLpkye4Oy0asmf9yT8ie/Rjbut/EXI78sgFKPTg24ZbG4XWHQuThxVAQ2MIJSQCfPWsNEE8Ch/mJ8Cws7p2d0b8uD7BB/gI+VpreyZLyBd4ZZhURsZfevYLneC+uxNDWnYRi+wpC19z2iK/UfCcyLhbZBRXiSoJqdNTOIuYKGuNQm+fubbazRlRSapa90vPXqWEKQHTNHfJ1CpXVNazYyGaoAveGWUZreFbagFlqSkK1uQWyA5JFkW4jXVYEw9WHVbLwlC17A0lC91EyxBJLfQxKCRcu2pvbelI18VoBTOoFhRIZJrI4ErLOGQNJTTcs+ggGIRVmGc1qFRI2H0ynBi0OIrftQyI1b+VhDoabeVWqPau8TZOABXrX/d6q90IRGmIoUYDpeVtfkp3lAG7csluIID+9XJbgG8a5wFWIsOe59YXmtI8xHhtro+F0gYYwCxDi3hb2mebRMdEOBCsHhC2QUUGjACQzxNd4ZhvcDedwOLHR6kshxyZARKCzyQei+PhiHU9Y52rZDhcFmUIWRGbsei5rFIZU1k1RjrMj/VAcyLcnU84nc7tLFiaJhA0S6ESspahMWckjSGe5oxSC853K+Z5xnSYAUqYZ8a6rFiXtTsDM+WE49UBdJhUscySdpQZ00xYzlprDkA5Lc2SmbLUJgMqlrOMSbJaasV3PeDWFLZ5wvXNUUMadb4kCtezp15EfJoyrq5m5CkHIcgtOtQijKHFjRec7yTMkQiqiF1h+sxbOH7+Hc28JEw5TxNyIuR5wjRNOOZrXOeH+Nnjv4oreqW35DJCbD4giUKSxrcTwNtNwwBueMbxcMAxHUX1V1TrjYhC8VgVv3VV975TV4C5ncUzj2t3kZxJs/oiosB5OOwpL1imink+4MnVE7x7/T0oh9aENRwIQBSk3Gpr9ND2iAnzo8JlazMMsFPw9hQRGuDyMmFwMSRrL0zQCS2Hd/baudhFu/+SRi1cEv79fbo4tz0ld6vcxLn06fwbDLrv94Vu9u3Zd5mvKhZBaE5Ems5/xsNXHuJwOAIQI826nPH4yRMsa90wkTF8bm+dbbz3KnK8/3UfOr2QMgrEGyHmwmXFULdjiVKHt+qwi96vft73GSF6b0t/38Z9adSd93kcZnwO2/l3LRJdvjf01ylV7WkVJS4oWPtrLGdfIv9t49zZL5c81bL/axP0JMJBQonKueDJ8hR3z5/jeHWFq6sDQOK3WcuKZSWs66rFzQHKCSlNmNKER49ex4N1xfl0i9N5AdWKUq0I8dYjfR/cLkDzBc9fwmy5tzV87WE3oYtj4xBSR7o+QOMnDHox4WNZ+VpXCVFLUg6olabrxa0ef3nB//Xod4bxRnrlKTR8bqZcov1D6PllDCK0ZG8EK26vD1qoo9I5w3lTwqX/MHcSo/FXb38OmSalhbnjlQCwcMXCC9bzGbUybnDEhEnqnkLqnlnmZhllMJJan+qRq4kgKWkIEvkqCQmm5MxYxqxZyQMMiNRbSZrQo1oooXsxmSWkVo7BAHme5XiNwc6ba+OsHIs72+LWlgRXitA73ERVVeOzKt4NOXQMBM38aLTP1leXq7KFxFpvABdJUuNxhsr34Sjr8op5V6uMp8kupPhmqRwJvFrH/VEGkwGYWaOW7DyjFdg22mvvBJqgClmsPxfb25IO1vqG28gYazNnavO6JHPY9bFR2uYpN2VtjwlQAEybVHusF+IkNNHOCRlBceC/Of0UPjl9AY/xYVOSaq1ILMWgE2XkXLEujOV8xvE4g+YjUiqYJgYfD2iIAGjxYAjyrHKmjtlDJMMsZKOskoADQAsXJEDOYi1y7oyIcHU8IM8T1rVIVsUiSmMfemmfa9s4TWmbM+bjjJQnGZO0LOGYLN60WmorM0BJ3e0E1FV+N+JgikCtXmct5YT5MOPq6iBKniKzrReIUNaiBcclU+Q8zwInI7i2udqmlxTOy3nBcnIl9Hh1wOce/hymfMRyOOIuJ/BakecJjz73aazvf4g3ps/hmB4AAF7Pn8Ynpy81QbUthRJFOiKZAAAgAElEQVQM8UJC1zCFDR9wSf+1MJu0ZrzxZ6/h+rmlFaJOWmK4UFjaGT4O59LQCqFK6lpnRxYyAxY8irXmUs6gTHj/+AGmnPHDq/fwfLoNY2ANq+3bg9mLxJwj5NbKBITwFFjfoH5/Xbguedjibw0H4IrX+OzeNd6KynavHMRnLxM6fy4wniEu/+UVuK1QGcfZPAdG4Ll/x63gfbhaVA5ie3t/Lyu/OwJdG3P864I25YTj9RGv3Nwg5RlJz1Te3d3h6bNnkmSIHZf6NuPnhM5zfGE9OiG9G7nOLagJWzH2/tn2v11e0Et5uRyVoiKRuu8mRCCs20gzur5qvRffL91zXqce1PA8EGBjeBR/uwT7vf6xhfU4Jm8t0PXQwrj3+/mkHicuKLB7eB/vEVTQA0Aq1IkAJ3h3XgqW9Tlub+9wdXXA4TDjcDzqEQAN5WeAyxnreivnnRKJ14IIx6Oc3TqfFizLAjBZxFIYX6/IRTjsL+9lGmew6/fMzhPRUNUE6svtYdyn5G9s+MKwFqJQMZCyZigVQ7JHQFGPX61hb4e6SI0trWhKvmGU4Xbkoa1gcd+U0ct5zqKUV4CLll0i8/xEGdEaFroSeZD1yVzwO1d/gKyer5ySlkPIgXkVSB5w4Rtvnz6Jq/UGUsYCjZeXVaKxWjkdwM/dtT3MTRliEOz4Q+P9MNgYzadBITBYcTefCHEGGo+/4iNeWx81ZbbRvsYPCad8hw/z40DnfT0+sbwO4uwrzzLCVQ3eHpKpEVe2rmYkCky690KOn7nHLaiizc4ZkpquPXGHPFcgyQJbJAmCEmuzJIYf/eCQZDs+5/tLvmvSH52XZSdv9J+DTKdgkzyGblQw3YKZUVb3m1aIxzSmNLQxyfv/HGSPlPA6OWQYyYzebb+bpu2/ownLPVOh9pr8sdj/QAqINFNjVc9R2KfQ7IUpYdU09GmeUFZN0JjcUwS4hg+wnidKSHbwoLnmEQbvlqTr6yOOVwep4VVkA0D7z6rI2kastYArY8oZhRnLsiBNCae7M6p6dKL1szJwOq9IicXDpmnacyKpQ6NFsWvR8wCcAkOkViDZCETVkJOUM/KUcJgnTPMEIjkX19LoM1odsVqcCHNlnM8L8pTQDsmzWG64iLezllWKdet8QIT5OOOnHnwVX7r6VSRMeD9/iD/l74LBSFPG6z/1C3jlMfCJ/Fkc6UFbF8mAKQqXZR8iQGPmgWLmnkEw6/gtQePlGViBt/7wTRBpPTYN0eDq+MlEEk7KZiF2AZ4BAUwKSpJ2kpSZVpLPeSLcHk740dUHmo6Z8KPD+zbI1pYRwJH5mxKvAXCtv2ShKc7Xw5a4X3u5ZA0fr/s8QTF8YM8i5aO6X+jZf9fWUz8ixOO3/iK12La3HfK+oDlee8pU720Zxd/Q7zCYkSHH9zvlkN0D2Xk0aCv86h0ArAmTEo5X17i5vkJOaqEtjOd3t+2M7FbI3oNF753pYbJ9x0M5A47s4e/QyyXFoFMed97bu0bv0CVP2fh8814rHvHOs5cUsVHgN2Zu4/YPdq6Cwl7plSMDlmKEC+TD/MeVG5+pl5E+tBHfMG66D+dLymmD3wueTWT8YFgbcmUDQIOP8V6DTSkVz549x+ku43B1xGGaAQDruggfr6VZsokYq/YzTROur68kq/Nywu3dWbIxSm+BNox7DI1XmhCHtk602Yd9tIDBc/y8t5fivXGPjeGVEXa459oqVQw7qkFaWw0dbm3HNc7JZbW9/jbjpL0nQ3udZgwwKk4LkJXnGv4S92NtLwzjJK6o5ModM8u5/HLGujhDzClbkEsbc85Sn+/d+c+AqW6BG/arnUujWprsVoombqseWioqGg/jvnBx/8XFz7AXbF4Kw2s+4vX1kcg+WZLOoGr9XO33Lt3ho+lxgL1fH56fYOoDsttApiwOjloZq2bgtkcSeZTbyLucP9PwuwHbkSIq2YniLgj7gVJLuAcAP333WXG+RGgxOodEykLXUkpqHE8uopueYXhMyUM3GaL0QXiW7Hn1zKkBhqsrleLJVNmPa8NXM5eT0baOr7scfel6odJGRFcA/lcAR33+HzHzv09EXwDwmwA+AeC3Afw7zHwmoiOA/wLAvwTgfQB/i5m/dX8fYQ3tNE8jRpeFpm3oCcebDXH23k8ETFOWtO1kKdQrKNuZN1Hq1mXB7e0JN3PGNE9yGL+1HQm5LE7SkMpi4Rw7fQvu1vAFWnh5BVgUv+vrgxQPZWiWx6p9QyrA14K6rkgpaZijI66kCSasi3joLIumIIh4x0qpWM8xeyXABOREuLm5wjxPWNczTqfVCWTVRCEpt9DVUhigovAwxKwAF7DCKiXZaMv5jFJKqAPj6+iKIbdNmDLheHXE529+CV84/Ap4TSgoePiDazx8cIPHbzwFV2Dma7yVPgMwvMabMiDWDdMsI8bk26oZg1U8sYxCDD3tS2pyrc2CYrBiiMdqnjLmaQIoSYmI9axZtTRxA1iS3BDUlR/Oaqo1nxJJyG2e8MePvoUyLSi54o5O3qcSg4A2JucFmlmNvoAotTBdI+sbZW2XcTq/7HF8fMhguL32LIH9/f7N/tE9oXf4fXfrm+0qKgLbcAUXlffGN851fMY73gvlcm8IBWHThYRRWRhhtPVKesa46HUzYdW+x7FHPOnHLXQrTRmvPXqlhRSLUaHi9nTG8+d3zdDSz2uA0kZYjPcio+89ynvztc32IsUsztcMMPFc3t61URC7fi/h9h7+xfCYsMYQohBp2XZ+27a0IfQCmOGkCQhbBdAVAadZ4zbYSxgdWu6+j2PaKIj2dHuBNg28yHser63n2NtkWDKmfq80uRRWB2yLH/4sYVkLyvM7nNJZU4YXlHB2TUKqLAoBYF7B9RnIzlW3efKAy1q7zXBPx5mSinidUue4mrQGLPmE29yj8u6A3YVc126ja2ENbJ/te29daN7QwyAc17K/jtsmd6l+116/tfboaFzbbrQ9gpoIx6KsrUNb+0qP7U0BsvE/yxvQQjTHATBUwfL1AYBSJWO2hRsSCFOWoyEpSXkGuyx3RkKWAD7mJkOJ4qbRTcuKYnjBMWg77mIdp2Xe5Mi/ENCFGqW165ROeO/qPaSckfRIingEV5iXSBqIaaH8ev/wwQamRslTSs3I4lFFKmPgEmftw+qhawF2RbanL2FtLtKXHlGezs8bRWyz2U4NRBSOYsUjWZq9PAHQ75KkRhUq0cDU+KNRetZ9kGPlfCRjKQCXBXaOso2n/9BfLyClL+NpOwH4dWZ+SkQzgP+diP5HAP8egP+YmX+TiP5zAH8XwH+mf3/MzF8ior8N4D8C8Lfu60AIlw3WBGeDcmT2OzH0UZiLChSAGBIpBJhgFukvHf8KPlx/iNPd98C1YC0FqWSJfyfxqM2HjKI1xg6nBdPVEXaC3lPYO0EWuiKfEjkiCbEW166mDYJ5X87LivNS2mYGAcfjjPkwN4S+mmfkRDjdnlxBq5AaEVRhHh0iOZ9yuJrBkHCPsq6iPIWrltIOUMrZOTk/ty6SCON0d8Lx6oBXH76O2/MZp+d3LZzT4NkpqyDJfliBaE+tEAXyeHUAQUsFLGtrq1vGwLwsm+b18RHeyO/gC+lfBhUpQAoQckmYFklxLKVovE+L4G4b0TJ/hc4SSZFTQtJCiRoCOpxl02OI4pkrFZzTZvOnRksZpZyxLqxMgjVxjOBhM+ZoDT8i8XyuqYpX7XiHrz/4U8HR5JnVUCU+vPGxEEhtyhmgIZfsBNUEC9NFe0/MJbJq99snV/KCELIRTInE+hmJ1sUrWq7vocXYEawjEzfu1azE7ca98+l/vwwTv7cviJlCaMJzT5cqiML5zmEeo/IRn9t6M/ef7du+LOhVJJApfgTMc8Zrrz6SSAJFjlorfvzREwkN20hKlxSb7e/7z+3j2hZH+J57/e9NAB0F2AvXZpzQMxfUK8J7/Y1r1StvLni6ZNAh6WaOe8YJ3wccDCwewranQNkzUfA0r9Q4kt257Ywuzrv1tjEM9Cw3PrfnnQSgWQn79iL/MFHQwrpG48RIU/yzeJhjxmE7l12KRNAUKkFAlX5LwCNrr6wtjQW2+9r6pTaXtsqjwsrVnwnjd7gNa7nXRgdp91r4nPtnmtBvRp6OC/fv3Gvo7i7CPg7H+y+QLq2HDa7s39+SDwsvpMbH9p+/RAN1jGZgorBucTCDccBhFUZSGQXcGcfPCyGdpYZsYgApnkMT75zwYFVMrF+yYuYTZkjmWgvHrcxAqR7SOwj6GjHZz3HAR/udwVjlwBhoLeBOOfOQTOa4FyJMAwzDxZCImRq+u7GyG1n3JoNNSA4/cqNn48w8EyftpRmID7ZXn+fb9nPXf0AaspvWvpaJ4QqgmAKnjw95NcygxIymuFFyr509I4IYoc4EhBqpm6tI7eeqwqbIoffvqxcqbSwtPNWvs/7PAH4dwN/R3/8hgP8AorT9W/oZAP4RgP+EiIhfMJLO+jhq43aHPEaUwi72NwOzUeWPW4ixe+7ECzMhU8Z8yDjdrahVzl9Nk8YzM2Ga5EzY+XTG3d0ZN1myPnKtLVvhWqQgp9U0sjGYMmfjG+NUEyXkWeLHa1FvVq2YDrNaRWTHumAOTLNkZyx6xi1aS6T8gCh7RITX0zvga+BZ+QDPl8coEr9o0EZCAs2aoCSLZ3OaE7CIRemjD59gXVYcr6+luHatmKeMlVlSBdmG12BlGW6VVMsA0jzj+OgBcHdSa4WkGM45oRYNBW2uZFnPaRLvJuWEV/Nb+Es3vwHCBIaGfrJQRvEmqaK6Jtw8u9Z0vaSw9UQZVYmEbT5mlmKITJJZiC2UMQFcxYPGtjEDZiVX1AGPZ16YkdaEqzrLJmVRvLvsbST4QCRE4MPpsZwHnCZ8+8F3cZtPugcgY1hrwCTnNhz2h1l80NoHMuWtIkSGb/33ywrO9vc9wc0nZ4eTsfPM3pYfz5BFATH8yuNYDOdo+3Dbc6MSEYWdPaEgEFk3uyDC5hI8LiksrDjqNKqtWiPI0VM2fr+vz0vep0sKkPDDqnIJIR8OuHlwlIL3RQoATznhdD4HYaSNFHGttorpy197lvCfpJ091mHei8YDdsa2J+iLl93X5bLyuIfzUYDfCqMR7iPuj/vSbeK9x9KmRPASIPZ7WwOQZr+1luCNswhHUZAarx5X2eSmC/AY57e3lltY+PrgnnAf+b3uwmtU1nx+cSMza01TTVLS+s9aCJp9tfcUy3hVFptaWz+T5zeKjsCYOgE0eC5eOn13xBefd5TCa1Mae6HafuoMjW0dfby97+USbd4K5pfWuh8nwh7cp+Ndi+zRT05X9vZRaGjcG32DQ4eXcbff1ZbobWo4UcqKUqJCzAEEEd/8PoFRCoCVm6Ruj6cpi1I2JaQ8YVKZgJJGkbl1xs6S6G8k8qUmFFnWBbxWlRNV7sGw7oEWdGNvtMHwv1+jaMjoeWj0wvXzH7muz3ofn7Zcuh8m7H1SXAoENkC9e8VFGJWL4ryGCW4wW40bBAp0SY8XkECsMnsOhCC2x76N5gq3FyN5gsivKSVkjUgjoiZ72T4ukFBdofEVddWkPyDUsg4Oku31UmfaSMzGvw3gSwD+UwBfB/Ahs8aiAe8CeEc/vwPgOzInXonoI0gI5Xsv05cjj37r9mWME/dDgDtsxO8PaGMIRgDenr+Cx+t7Wt9LNN5UCmbNUEUQy/S6JixLwd3zOzyaJ+AgSkzS+vHeIzoMaZ6WOCHohrPNUauf+yJZzPPdGSWrdq6vFXWpg7nFRdv87fzb68dP4xPT50CU8Nn5qwCAH6/v4vH8A3xn+RoqShgDmss+kvg8TaL9rxVPHz/Fs2e3Wv9rljAASdSqSib8DFqpyKcVxyrer/zqI7z1hV/G8etnWOAGmIEEfB9/BKLnqihJ/5+dfxFzOrSt/vb8s1CtKlBcPdhOktmTGcjnhLe+/abya3mw6NyM7hAAVEnmwaznvAgq/Dg+VKVuEk1pOKYbWt3bUREnXTOuLMXXp6QGgQROrGmFxar2/Pgcj+enoET43vUPYBYfCZ3Qvx0OBxLBFpRgkqKzIIEHNTjab+0gPQ+8jztUfMlrywxfJADZ+Mb7pkCMz+/v93sY+tDP3px6YWh/XPacWR23bXAngMbfX0a5irYoiZdXxR4RJrRpI97f9tFaH0crHe28drw64HA44HR7h9NpwYOHD5DzhOfPn0tIZC3ocC6M32jufYLopbn8RVwRd/aVqcv9jt65Pa9nNKht5ECXeJSfcLeXhocv46vRjfAONfXK52WXyRNRjolzSmpYHKnG+NyLfje+1Z+scdj018ut7UsJ5F17+/tubEM5ZrdGJmTK2RENq1ceYePvPXj78LbQ8abwtnFp2Jnif1RAe+W8F1pHL63RbX9FFpZiwWL93WEW5JgLsLQ9wR3iUreWNAjhY6SSd2c8yZuKgn30Ovbz7WHa0+54lGQ7/s14Nsr7/jsvd420wuWpyox6XgY06OmffNsOgKsc8RBZTJStFPCHWMSWcj5hPQtu5URiJJsknBJJ/aEiuesxFsUHVcwSEY7zjJprC88sK2DF7xpcYank/1mufu4uZ4+8KUSKyS/hb6Qr9v3yHjee2O7Gxd4gvCpVQf4SIdYe971i/Y0QiSNme5d7OdHG0WF3UP649RXaqoyFV6yrzjxJqa6Us0R1ZcncnrOElFKYN0GyxycmCe+bMkpetrAK10spbSxxaV8lotcA/DcAfvZl3rvvIqK/B+DvAcAbh9d3NqcK0+Sf46JEhU1UMXOp+YFxIMS6NwJs/QPvHH8OmWb8v+tvoa5nMFcsy4oEySYkGyfhcDzgVE84nRc8efocDx89wHyYsSwreF1ASC6IDQTbCVYyWCJlcfcuS2mISYmQpyzFq5dVMrftMCg/2GjeqQTKE27ya/jy8dfwIL/e+mEAr+V38Hp+B6+kt1CD2cBSubIlF4F8f1Y/wDdP/7fIflqbDsxYkxTe9kLzfv7MmWJFS7xChNfSp/GpwyddINa5vD69g1JPLfabEuG19BlMSVLoWqy0ual9DdEUYYtH/tw334ZqTzArutX3SCkK86TCTlIrtQg8VYuZSxpdfVTP5nGtbYwNvcJa2MVEWAtjSnImkLJ69tKErz/4JjgzTvmMu3wnWUBb7RITQ7aXk0BS2uKlA7K64kPpGsR6Me23ob2Riu0pI+35XYVkEPh2+MSeQjZ+TynpXLbCsuP8DrNsQsCLGVQvcHR3dp+Pwvx9StPlUKb+mb3P1mYUBEavW+zXwnq38AQsK+kYXtkETQ21lsxoGQmMu2dPcV7kjOvp9g7n01nLhJQggDqjJT2Tex8cYomCl1LYTMp4SQXg/na3AvgIwwaP3TW7L6zyEg7v7NcLbXR97kyB1RgTqYDjbcAhhpzBUiGKiH6ivdAPdE9ZMRoTlJXAr8SnkDSD2948fI69kGs8vN9PMWywC5MMfXrb4fOFOfkjmiodCVSrKLbKB1o7vF0/2zdEJCH+ymeTTQH7OCj8xMRD6mhOm2cHc6XqDf8p/rq715PyNm8/Cq0Og8jn2qcG9+7h9ltnzKMgRnYeGZe9torjHl3wufe/j/CLQv4OT7Ext4LqezT9Po7X9727/8PrjS6H/Xff1opRTh5Ox82gQpqgImnf55UBLLDs6J1co2NLUw4Fvq1tvUcJ85w0YZ8n5jC51jxztVQvZ4QxULZXrLwPYFsaq5//lq5K29TlbYj41t709kYYDkqeS+16vyGTPwOTDeNM2gu7DD/0gB5lbC822kDtu426YSj3Izaa2ZpkS+zEICacSwUWTXVEpN63hDRpRF4jR6z9OeK/QLz4ybJHMvOHRPSPAfwVAK8R0aTets8C+K4+9l0AnwPwLhFNAF6FJCQZ2/r7AP4+APzUg8+zM6T41GVmbcSswbsJ6yLmMosyYAs8Wg6MaL2WP4PjdEA9FKznVYo5a9d2NmjKCXw84Hx3wt3tHUqtuLm5xvH6CjgesawL6p2FuHHrc1yMlmQFZFUqAYinbJrFlVpRJWkFMxjiTWItGGup42ut4l3LCVOaMdERv3T4GzjyNepqjMs2tiiIr+fPKkS5bWoQyaGslJC4ooLwRnobwIpvr7+LOqnyWERhKOdgAYgYTZD6aMdZOxUlsB1WHTbj6/nT4GkkH+RMkjSbohK2nCWCQBQWgAvjc995G+989y3M5wlIdk5NN2YrxmqEMW4I+b+sax8nrZtSEr7InA2vmuBh7RM1uCYQUiYgE9KUMU0ZPz48xreuvwMAONEiQnFhUKWWOSimZ+hIqwrkopv7ehdNApOzEf3x3IIzAWNoRB1ZCQaEy0rFVgnw37feFto8x5bTeEdAtAmWsu7+vne1vUSRFgfGsREkENa++3V4ph/7GJo4KlL3wewnuUb4mtJjmV91VF7E9oLy4DKoh1cyQz3MkrVsThL+U4qE29SitYSY9fzayMTjHP17VGQvzaXBDU7zdr1vQ7v3GQ3uU45b2xeMHvbMvQrfjjA7Pt5D6DJOS38RbsE6q6ReLOvyflS4eaff2LYPkwDaMnXBm95X1k0gvn/hin4/whCKa/x2/J3G5/r2LylfMRyrw109e2lH4LbL3yTVC4aV+JucXfPabmwzafJBnJ+JBhR4jymxZIlGbH4t+kMiQQxeUmWqb7utSdsfmzsBruMZShGmKSyiw47CMxH30N13ePDQ1wayu8rdHn3t3+qvfhxd6zvvdMjZteHwYf+RXLRvIZZtzKGPTvPred/+XJpWsLnf1kUfoCZ3KkYEWcMaKSwyCkNygbtCZzjez9/WsYKR5xlznpGSlmYiOZfcz0+8cUnpciWPIqilYl0XLEuVCDJNBscDnPdoyGhwsN/j3w5eg6IXjYZxfnG2MbJgz4tpre9TWQ5oRM2Y5XR0oD/D+50SGsdHO9OxrgYWaZQgRm004qHPx/1lWctrrVgB0EKhrZ0xgpBUMb90vUz2yE8CWFRhuwbwr0GSi/xjAH8TkkHy3wXw3+or/51+/z/0/v/CLzJNQ0fftPaREEeCLxvWiaggCgcebBYkrkrUwm4cEzkc6Bpfvfkb+F38Fp6UD6VGGDMqLzjMGWmaADByllph52XVei4rru7OuHlwg2maQFeQw89nEUglc6DEu9oBYRhZrwWdlwGy2YgATqkdF5WYfD2gyBYmIbVKUs445Af4F6//DbySPyku9lpFUcoET4MQSKMyITPTkKoMlQFOplDM+EL+FXzh+Cv4vbv/Cbf5KVY+4W59IkojEbh4Ae+H0+vIeUL6zKuYPv8ZmSNrH5FIWFYq0gO3NgxVPnIK1qdOGARqdcJRmZEmYK4JXDJSjkLDFp+ihVxKEAgQGGgxSDV4Cw1OVvfFRVE0AZvIXOCE83FBmjK+ff1dfDg9bkSpqpdOpuIKpeBCYLzaYQ0HyLkyUpVgVhHoUqhjiOHqzwdEgXiP9PXK7PaKVvD4mzHj+4VsPzO5JwDoVHXUvXDvQ+/n2JTFYc5RUL587c9xVDY2wucAm/uF/3FEP9llxL9jAnIHvRA6js3wrBfMjEnM09QphEIYfZBR2dvMZcCjSzPf9T4gnB3dVbxe7Klsvb9AcQtPXrziHDsPj/zQN8EmVDgOduLuIHj764rNTaew0HwNrW7Nm9TY53d0Y8o4J1cm7DttMxHYnUsQGNp88cWbb+PuYyCc2d7ayPW5Ae722VoxD5jvf7LWd5Ux+9zTBx3lrrJgIeJV94J5pBqHVblBVu36+ojDYUZufImxLlqvyTzKJHwShFbyRYp5F9ydzljWBWV1GYN0LowoGDt9JIr14Hq6KLKMe1gTWZp7KzROXpS3jF7QYd0j/W4oFHhHWMWulZfYq9t3Qr/t2sc/SyJjBmkExbUXA/cVAX9IZaWUEWmMKUw7DepPrUBWh5syD8n2aB7TbOFuYJSWVI46umFvc4ODr5/DJ8q5GidWIefayhnP6AxKhHmaMc8TskbuJKXFlvnSDXtexJ5oUo9cBfMB67ridFo80d1wXWJr97G7RveGhwg9HdrIEdjymxeiV5QjmtzU9zkQyd022ptxiTf0NvZ56dqJfNF/DdVGijvKUs1juDNOJkZdTvcN4KU8bW8D+Ick59oSgP+Kmf97IvoDAL9JRP8hgP8HwD/Q5/8BgP+SiP4EwAcA/vZL9BHPEA+LP260eBh8tDraZvMNsVfkmhsxFOR8NL2Fr1z9Gv6w/m94fPtjzSYpi5MraziaEJh5FpCty4rnz29xd3eLeZqQ50nSC2tqYasGz2B4NszamFPL8EdCcKUGGrWCjATbFJLEgzSjSqKET8//AgiET85fxCv0iVavS8L5GMypMRSDExG3bHEd01OAiG5YkXNqBOcXrv51AMDj8kN8P/2RIJrSKoPdF4+/isxXeF6e493nP8Dp5iy2TKvbZgyb5HlLEMJEDUakgb5Jx2ohoOIpNSGBYJbY2io1cqudh1YMsU8AY0QRRBrKKeEDJZjdGjiUsbfjcYnaBkskdVpO04Inh6ciBGRWj5qfM7Ri5HGuDe8M+dofYQaVoe+LlyolQk0keGeCDA/KhnFh+x40t3vFs47u3af4jBbjMPYIMxhx7hnC/RZaF5SasQpNxNkM1DwJrWG9v7UWXu5v7D3C86VsSoPlse9Y/xmJ+aBsdZbCnWfGRi95t/aUOAmfFdo4WX1HdkFInunbT6F2dFTUxrb3xnDpSjQE5ITMgTKGlxMCC/t54UtjMGF4r+0NoxzW2qGCwPS3vAaByfrv6J8NrzbjYVNjRg/YiOO+Br4WQQAkDIvk7+4pRT42Y5IvsSmUmG9FIh9jvMMDru8pjK7Q9U3EMdu4SYmFJd3YKmxxv8Z11SeUt4zCsuFIDAO3/gVPg+CcCKfTgloZh+MBc86yX5NYyUmPERAscZeeWYFmO55nHI5XWJc7Ud6W0s6gy76/3zBkVzV+BxVyA6+Lxb7nLEK7JIFirUyzs5pIyo4AACAASURBVHoKG24wj2tgcJP2XZWNsN+2Z/D9i7jM6EThX2X6O92rHNHtvSjMZG9pl//YEQk0cs2hZ+vW+iXSowjke0xPTer4NJw3zmDAUYR7l76bvCDjYamYVBmncsLpdNYacVMzPAiIuK2nJCdxammeY+M3+9EiofeeHPVfuPvT5NfdK/Jpfcv5lY/bdqrJv3v4xP0/O+OKNA4AbRa7f2MkweO1BwMKf3ea38gPutE6VrGzJz0ofqf/l7heJnvk1wD88s7v3wDwqzu/3wH4t19+CHb1549aoJAuXFzYaF3TT+29biyICIzNPR0vAMYnps/jZ6//On6v/s+4PT/VkCLx7FQtJJjkHxWKgLIU1LXgVBakpTRlM5/OmCs3RdSUBus354TDnIGUdA6rhkdJ3CvpuESXSSiV8Xr+LN6avwgG4TOHrzhymBJUGClnhY/UmjBoiFerj+n1+fcyZ7/lBH6P0ifx6vFTpncCeUA4Ah48ucHDxzc43ZxRwUiqOKashSZzkDnYiz6bVVp+EwWueQkTQNXlDks20hJ3KMEvVWkoQYqCkgn6AndWBY01gWZncRoIkCUOsVj6SYusv3v9fdQD45wX8agZ0azc1ks4YBoIl0LSiKjCXOYsHpCibYiinYKy1zOC3sJM4b4/23bCDgFugi5xECVtUWjzXmR845wCydwVxC/K5kHQjsLV+F5vaDEhhjYbecs/XiykjpZPb+uSELx9vwudxGZYLdzxZYa0F6p5XxiaN9oLtym5Mcjb4wvP786sPdutiTTWwWXPGwm0E63bJsNc7u/flDFuZxosfMjoa2zrRUrgHizuM1J0nsym4InQLbcutUH2pLdoNIH9mW4VRikx/tyFQfp5I2OD9xsowhyG/b13+VP7z3km3D2P2Utc96DuVpHZ7nu5d7lPpxnbCIHYTgtpI4l4GWkeM3A+r1jXgjxlHA4z5vmAo/IdQgJlyVIsBZT9/JEUbiYcr24wH66wLCuWkyhwtejKGd0JHTL6PRGVdCLPy9sgo3xk0Zxia8Nr6lbdPsnesRA+CvyfrTHh/ZWHZaJxqBHiG/hv+c3L4QcZHLq1t3GNuHiZz+zxgbhf7Znm7Qw4QwQc5gnzlMFQD1YtUlfWjKeKL0WN2yBqMB3ptv1OO6HMPpaRdhmNC3tNEw2VdW3F3g1MhjdJE5zk5JFA+7wNaBZ3fUbOMksStbVWKWu0A9sO3vvTeYnLsTOasZpyuXtdokixPYIpbE7pou/foiCoG8HYUpeMk8zUFmh6oNPjeDqeNorGTYgiH+DefF8strTrJzrT9v/31QuIsa7E5WeHX9EJr8YYmtAXnhsPXhLwiflz+Oor/yZ+5+l/jfNSsJxXUGGr36qKW/+aFNa0s2fiqi6lSl0E49nm+dNBHz/3NtYf/RjrR0+0HdlIpTLARQtYJ3z5+FfxaP4UmCWM8yo/aHPv5MHKwOTCmonzzcOF7ELwQOSYuSlGHhDIPbGOCkKXEDNQdZhnia2xFnNNms2jksEojJ2lE1LlDkRtkyT2jI6JhOZUX+K2GKnq+yShhwQ5k1agRTS5SuQEqVePxctntbMBamckKWUcDhNyznieb/FHD74JAHhOz1FQxJO59EQgKmscsl3GcAsTGrnK2cFaGQnCUOWcWmqCqcO0F1Bf9Hl4o31qa9iUDOreFe9lrxRGgWYUfvoF3BOcGwAGIdvuRWGJvI+N9Sy2+DJU7QJ596kPym5/Tu8+JeA+YTUqn7vvs6T2vRR2GUMjXxSG2Qul2sbmvW14ar+G41z8jIaMwVvaUyiBcAZvR4nzNOUABlwzg8kWb4MZoVN04qx8LpeUxt4AcGktfc7R67ARRneUqf4HK80R96vD1PDO50Yui5rArv9EG3VrzaWQ8Ovl+e7M1CayuzVGD6TRgA1su/n3tECCSPaExLh5t+sQ9+Q4pxdevBXzElHwNO170o3G1BDxQqQGupZESzOwnyuWZcE8nXE8zDgej433VY1sqcon5yRKHGkYMhFhnmfMkyQxW84n3N4tWNdi7M7hAGNjasDssMDW2CNA7KhFrKJAmoTKlvkSXCkAvQuHbEip7TF76St28dfpSr8WPt72I8Yr7ozoZcUgQ+hAd8dvfNpu+5EGi0QZ+x/abQrCtv11XVuIpoGp6vxqLb0AD4dNU97Y+L5Fd23XwcKKe5iEdbY2h1mY9NpYZJuzyBSUEnKS5Hk5Z4WrG4/7qDUZWNIxF5Z2a5UzcMtasa5ncHem3+HUlP92mfFjK7OocDd8bxwhwGE/NLfjp0T7z3F/z0SMPjoiNqr9DcYii3iy9yjOh0O0xQ7t2Vy7hDz+RpefvUCr4/WxUtrsknm4JWxLhPzzxpPGkh3NkndwfFIppqxzJF7e6KP0Bn7tlb+LH5z/BH/y/P/E89NTTYetzZNtXkt9CjB7FkjZx6FfZrSzepYJ6OqIX3z0G/jjZ7+Fpd4BxKiZceY7UGV8+vhlfOnqryLR1Kycca3tc9vwWWujjavdCgP6yw1HrC3VFJplQZvkboPpBgoZFBHeF2YiCkhlgLjilQ9v8PZ33xRvotKppOtkiUWM2di4XGnxKWQoE9U0uO0B3WiZCJwZtUDjtgUqcl6i4nQ6Yz2vAFkGpgn5kEFs1e6BNRdgysg54/tXP8QPjz8SQRuEigKupRXjTUlCVBsQgnwZK967V43tBzBbQhHoGTWv59XzrnHNTZg1/BIiWRGLuL9I6PFwYLu2Me6RMffU5D5lxe47ozLM3BN644obYZbfR/I+Evfx2jKQ/d/8961A+uLvYzu0+dwJhRfuxWv0BlwK67PvlxQUgMOeoZ379r19Cj9WIAh7e+MeFSDz4u2FG25hsQ+DPcW2MczI2+4xTHibdg6U2nPNOMLxOe/J4GAKp48/3rfPSq+lxa3wEy1Y2xG6yMIAun3aTbS1OLzey0JGn/XW6O21+W+acUC07pqy381/Pxy3a6O75Fkxil3yTIddHITYPm1+hP/9Eotx3igY9+8aX+n7784rh34ZQEoFxHbmmNtALbRsWVYsS8HpfMaD6yOm6aA6XmnG3BOzJPMCUEkMgqT8JueMfPMA01xwOp9wOp/1nBxEeOYqpXSyGBzPq9Nkx0Cn3X0Y+ojb8bnYgu9Jb9FbGFe3ebhHisz9u+KR2F5mSGq4zc7fN/QiLNhIx3ZaVvninkc2IwoUzkSwgIs2lsqQtPvDu3ZEI3petmOkhrZkcubuVMYfHE7217NzqxF/dz5+1QrwsmBdVpySZBOfpoOGU1IIqYwrjnYezmWPhGk64shArQeUsuLuvGA5ycl6k2u3+7mngT09in8Zfu4uzMaOKY2ygmJfossZriM4Ysghtyy3frxlb3zSf5R5DD5bmWDb8g7NHsb057rubViuj6XS1jIs7l6BAtjTqiRZhkFL2d7eaBYCva+AYbZ3LT5YBSgGPkU/g08++CL+afoneLZ+gA+W72kCEUNgt5oRCK9Nn5VwwETA9FCUhIgAqvGQTm9KE3714d/s1uiPT/8ElVd85eqvKwoOthJjrDoJ6pi6X91cL9yTz43SNAG5CWVRG1GBhrKNhdq5NhO2uVYcn82Y35hR54rpcEBKEzosZGpW+BwzpTC1c94dY6m2Niq/hHARW6tFk4hYzTmDEyvDLY1BysYutWKmGXnKWA8Fp+mEb9y8iyV79k+pQ16V8Uq4ZO5XM4hkjWr4dDp8UpgRIeWMPPmiCbGU72Nx2M0abdaPuyjVS14eF9oUiwJ8Lz67IWL71yWBfZ/udMjU/jYG11b20lmuvRHs/bhPN+7zpr2Ut0JGu2H2UWF7UejY+OyLPAvbMEwrBO/9R3zovGXd0F1oc6PLaOKJQrBbiq1vOxf0orBRHwt2n99T4Bi0Wd/7YNkJDPqlX1+f884ouzHG5zrFIsJcP8X7Eb7WzmaoJq0CMNeFr4EJC/2+oIHsmgAsMIpC0/2SwQsV5d099hISw948YVzAdvFO2wEUezjhSsZOjzu0aFTMbCntvFIc79iWwFjXszJABUxSELdbXxUSagVOpWA5LzgcDzgcr3DUBBHMrII9ScOlCAwIqElkg8oSwXFzdY2rwxHLcofnpxXrsmKpDKwV2XQXNn/faDY1o2CcnAucUzbjgtwvzJoA2TlWpAM9DAdQRb4SIUjUrX1csxEn+OKPaPiMqACJhL4/njCgDZ3Y6aZvQBDCxSbtfeyqo+t7bZH+N/AtwgZ395TT/X1lgij06IlW0r0g2PVRAdKmzF/XvDBqWbGciyQuyRmTZhk3OaPh2FBux8dMMAyccwYdtDSVLFA3lZFe7K+DRRH0fD3CLcIrQmbTUgt5i88FHowmKIbeX0TPwriZu/B+gqBkIqn9W6uZ7mSv95JBf70Mf7943U/aP0ZKW0fULzPcSFQtHBEGIO7E6PZce77rS76V2iOvIa3gI+HL138NKy949/w1Z7qOtfoi4fOHX1avGOMb87v4EE/0+FejFoFj69kTy0ao/3/l+q+1R1uoIsWuRoGsF2xccOmJs32ObYyQIk2WIpEYg/JAe1+4CRFEBKSEtz94C4fDFcqx4Hh3ACU9YxeUNmqCSm1p+jX1h3jTtB5ZFJBstMLcq/zVGHyXeUiUGPteJZFBnjJS1gPkU8Y0T/jRg/fBmfFseo4Ppo8cQPCNiiyH8HoFeLM1e6VIvYGdwJSksGJHsBzo4fd+p9paRcH9PgH4vuea0v0CZWKE+fDU5XtBsGz9RSYYvnaKQ9d6wO3wa2uBg3Bmvxr+dU/rcztC68sqWbseC2Ou+ndsa2xnX9mgzd/LhL2fR8N7o3Ej06jcDFXdQXvFWwu/9ZTT1CiAK2vBqjkoE0A8M7Ez9ghvmIXa9pT1NAoyl69LBoio8MSxgEPo0s4+Gcfb7ecggSlGOC7D+tujoZfH7nu8Fwqatd76H9qL+4NZHqlAUzT25hW/v3DeO+OlruMd3L9H+Gh7qG+t+0yELpxv9/2LffjZIObWYnd/86qeD68K45RIswY7PW9lBeA8vaq7163zFDtFZeDu7ozzsmI5HnB9PGI6TJIhWo0P0CzMXFdwQcuizLYLCDgcrpBywXlZPLMfM1BDoO2gILU9anMOCgnAWAtLHb22HsZbRoX4HkFyWHoxWBLKWjv7Q/dKxx+9maYAtG4ZXApqAub5CEJFKZGn9CHaNkuDxXagf06B2IfTzSHOIyw5VD4PtLR/b0snub/fjXm4NtNw2hD89C4/BlmwH0sYg2xmyZRd5Tyc3WtKVmvPjovY1qehNQIhYZ7D2Lk2OsRsmbct5N2Ga7zL6Fa/rm1KG5mC/R7F36Khsgdh73l+MV/x0PueJnJIBGd5ZhgabdXh9ugT9AkZX459udHtL+76+ChtZAL95Ud62hMFur3mKH5p8cmG14ZYVtCTAM8oqmnVTAzIOOJnpl+FhQPYptldDGbNKsW64NyUOWi/mSQ0L+cUkDESKwTs9FCQ2F97hlnj3NGeMQLoxKhNbGzB/xIcHQesjHhuw6p6dixaLQmEN//sjSiC6L8kyUsYoAo4MyEpjUAVtWqsvloHTTgWmJk3rbZmLYTDaI14B8QbVmsBmHC4yjjSAXUGvnHzpy1L5UfTEznXEBVqm32Ds7RfgwWUFQC7wnqwZHmoUb9ubY1N2NqBszMvvy4JNGMo255CIjgbGMDFdnrBeosnI75vCbGP19vltueoyaq7itsIk0YE2yB9DIPwHEcyKtcW9rR3Ju4+z9FFIZL7Z7YWVXTf9xRru297dGRckUFZuJ+ft/BQWlHkqMEKzIrjod8Gc25txrNLcV/3wv0+vMYrWpIj7dmVONF71O5TBvYU6T780WvcdUpS18YmLUq8uzM+ezww5oZPRgQMvv7A3jSaoExKzUJ4N7XMSgPO2E6NYUSdcu6YHnFnT3EjIoePCYIqeW9DIXUOF3B579o+09OD+72yih96vtjbi3ul663dMzoaZYXG+wJv6t7V/ZEMR5VftnqlOt4S2iH4PrOEEDaSWipOtycs5xVXVzOujlfizeACi/KR82uScdL4A7GF7RfUKkaQ43FGKQmn04rKpRvzHu5y+NdlCoGJzNv3WtzzDlPbgxHAvofjVZnBa+/B7ylD+BT3hOFXUDYYwFoZvCxg89ykjDxNO8wgzpQ02VfgR8P2ufx6XN9wa9ivW37kfd0nj+51yhrSSBRKNw1t2iV7VOUMZvekskVUuEfQ4nyEZtsaUmix5zO2Z2rLHhdxw8PqiZKUkEp5k+3az76jtQeOvFTKTC3LilLM4M5NiRujCPrxDTKO/WN8395TGpgaF7fZunxIehzKDUgvWDQCYHs60DxzMkRS1klFHS1ugPH9LcMHg3S9/DmXT4axXUb9i9fHQmkjsrTtGi7DNCysLWFkrrZowfpuhLsJr+4OboF1BkDKneJjDLLF2w+qPbW4i8DgmENEm5+ZSynJUWfJyYuqCGLFrgnAu1/+AX72a19AOtvBUQ8V8m6F1dgmcxhsEaIjxMaYm2VcasSZIjFAv1uHMBv/klLgE2JpyUEpsbm7581+47AJVYDJpPXSEpYiTM4uI1qWz6RWV9Ys9NHm2hEUUqafJZRxognvH3+M7159r03qRCtM2PMQh448tN/cNuIW3qQ8qFbz9IkQlluGzOT4ZyvVmIptaCUQITtkr1TrGJwvXRR8XjYUL35nZCSqXV82DnnIlGLnYjHkrY1ZBtCeNUEzKQ7GUIguPCTMa2dCHVH2LqiDaezaxkdko9u+G0e+G5q3I6iOv3eZINszdRAETEi93/DUvx/p2/a91ocK20kzywbkiNtHU5K3b0FJcAOUw7A/07W3MpdC6Aw+/X3afa6NZYC9z7GHv3nhgfvPMozrYl7G0ZvWiioPsI7jHj3NA8rqR24cfE+haBTDFEgyFmHpbxWzGSLMG+Fi2y+2RtYShdZ9PsILqH03ZXu738LvO2B0eFj90O09N3b4M/vrv9MB9YLVeJO162Y8YFsn8ZKFWftbvWYga8u2SA6TpH07DTD4UuMhjLDOAZ62Zk2gNsNGa1/ofmGgVAlxfPbsLmRrplayhmFK2njGt/cYC1/hNgavzQa9ryOmDfcPbXDjmU6HzJiHBifDB6MHUUK4z6DSc0WEdvv3wiR8/bSp6TADPLnxNazbCJ/Ys0JsoObRM+f7BW0eTg9YeXZKfo59Q/e0CUGx/bN63YMwVIxQcRpigXTcxuHTdcOT5qRschm3CaSG66J4iUzQ40QP9wCHDkkiLYm0Uer/lkWyu6VUwVoWilKW0MjkfGIvKoS5ApRxlVPD31Kq1ios+pvL8xGvJwrrqkNeTLfk/SMSyXDuAv1u9KYB2xckivObJv5c14YRtPYp8Apgu5f+Wa+PhdLGLPG4bs0y7oiNLGEEqdYLwhg7LAnq5SJC0TpaZqmObbuCw+ptq6DELRuiZCQkUFICSgCnJAWjQ7FuIxbU9o10ojkMtU/ZhJ/7p29hKpNk2rBNpXVguJ1/M5IaGST5H0XOiKNGGQgaU8+EhNz2sh0eM6JgJeTM6m7on4xI5pBTUidRFeZk/SbqY4HjBme0RB6lVqzL6spYh9s6FpbClZWBuCnauulE5JDthLv5DtOUwInxrZvv4KP0VNfMMruZkq1MNIph7PgUXf694sVoVlh4mF2e57bmTiM9dt4Vtvi3R+Ze6AkMHf2z+wTz/u/OtEJ/KBcUiiEhiVE2iryXxuE702JWHH+JQ8ltZEN3PMCjCaH21vhOvO/P7Cu5e79tn72kWESvWM+w+6sXtHxu8floPfU2to0JU2U9MK696hrYyMQL3DCvtcTVBaWmKegujuOICpML/2Ph5588Nt/hZYaofVyNHh/3IhKYXUHYwuUy3vdz8r3dNr+uX9yf0ThowrHQREkL36V96PhREIaUOJJ9aXMWvtGSBwfBzsZk9KlTJzqYKxx13C1Dr7S0gfcejCIst/d6ZSzMtoUXOm/bvy7hsVHWscsoBMY1s75cqJXxSrkajxdoVML4eUT3wP98vqqA6cJbG+qkVoNumKP2K96wEFYGAigD3d6sICasq44F/Vj6XE+BU1CPhxGCHS3UNWD4+AH3ljfcdg7UYBcXxx6RyBYTOAkltFG7dbb3Ot9Gg5OtTVPehjkQu7rfTbHJWgoPijAJPKV7hdveo6Z6jLS2p6uu9osSQsZXN+20VtBlQwr0Ynv1/Lqj9UEBq2Fd4FJt+96o0w7f4bbW1B31sznZPL01G0R8bjvq+IblOWFenXaBQSlhnTLmLGUQcjYaEdpim4PRB2k9TwlEE9Y0af1gKVC+rmIsTspnKjQZihkZWuNpsyf6PsM8ovjUzdIxth0JifReYbt9nbo/MmfqAO2kzouyb7q+j112OBH6fdF74fpYKG12eSy5EcAkNaWM8AUiP1q6gcaetS2Fg4ZApERd3R8DtrmEJdzCiJARL3GXWvy7pAfWlNZVLQdKTJtMS4RXHz/E04dPUbDqPPSmCkcpZUyHA/JpcuEzQEEYg4wxURoNoU4ojSBX1kLQoYlIdMhr7exBvaXBCnXlItNj+OHodn/Ab3NfAwBqRa0FpQClFollr86cozdVFCJuSmCPuQzLeNLCSWfGR8cnmKcJKSd84+bbqLDi4tJGrawHbS38lds6xqaFcKkHjxgtT5ymbuamvAg8kp5PM2LKAdkife+6YWdGnWB0jxTU3xnDU7oJ7Pzu9+6Xtfc8Oz60nvHFZrnBpLdWuqU5tm0Khz1pZSBGT7rR7bH0wJ5gI7+78HP/1S8S1/2wrUuC7qV+7ldmfMa9skab3/oxtMjsNl4/1+HMzAQm60lmOXCMxge2uGMKTTsZQ/0+ifMdlbuth217RQXMxjbCqwnCHMQv5nvbN5zpzt7tzM8A0MMoeCxgMGZEsGmlSFQIf/H3tmtnilrrWuFHphi0ealgY1nSYh1H4w1xl+makzOdADO0Z/e8lSOs9p5JMdlGWJMIe1+/LVRfRoGPyk8bK/eYGPu9rw8zJo5tR+OH0efRIOL3dYl3zmxGJa8TBlW241pDdhMrzCxyQGLWMjQBj5yNboTk0PQF2rwjuQUlYjQk+Q1v38hqU6y0CTc4ashs4FX+TIj0adgf5MzQpXuQ9uim/LUEPtFL51FF9nQwdgzfI55GuMi222EMyidFXnE6iGEuXWsdHdH1DkdmIoHy7WgwcoXR5IFOwden+giMS2ecwjv38hVto9vbCOu2//x+G/H9cKdUcKkotOKcpJh8Sl7rj1kzTzN35V1cCQw8Y5gpGx+G4pyVegohnC4bqAOjDX0QDIYZO58KuNJa1e9mLCoFcalaaGRo1ekBXV6Tkf1shzXcM57ncl2XQZP2X43Xx0JpI0I7b8SACO/MYIhbu5rlmEKYQZOEtY2gaHiYkCE3oeWJbUCW91PKaDYklkUlZHm+WlijEoIkaevJiIb1bMisjPyd997CR194gvVgpQAUBRTpXvvxIzwsD5CnHJCKmnBDPikndiYMBJg1ZpOpD6kDwCkhD5s7BsI4EwegdeYioa9t0w1bXhWZSOpEiKyodUUpBWW1kEYnEA1fuc/2aMSsEwj/P+bevMmS3LgT/Dki3sus6m5SpDSSRqZzZDOzspk17ff/AGu2a7Y2u2MzuiVSw1MkRfZVVZn5AvD9w28EXnbrvwqyK19EIACHw+EXHA4Sz+jl0tDahs8vX+GLx69w2Tf0feA3189dcR1joI+hG0mzIZL2u7j3CxWe9NT6gLTKKaurUwjjSYlKAnTm19MVBtv85t4Mn7nBeZ+CC5tv1qVKXbm84D8JE303ZnDVoXGvwQqbMaRzr3ByuFSPbVa4qsA2f6kZ2me8vbbKsIaV/G9WdFcrE7OS+22ubLCv3lm//J6NqYdq0FrgUaJaAh+xZ9Y7VsaLeOYZqSgi9CUgmZWhM57WHQVQaCrfwHnb8v3i2fw+VmfmcgFj5VTpt/P70pgrDtWIQdA4+QtXSErDRMnRZPxZKsxKqc6EKIdJrSODLSuwIcA5l6udOj2f6Xo23iyMaTaiV7RPsDP3JlXwzjhmJTBDyIkmLYTJnIEm+eK7mF8u40y++h60IpEKbDNfcxgnxT+XocnK8t6TrLZBYSFquhqVcNL0fDaSYDjf8+j11bbDkMorP/ZBCsMugAVwxv0sNDSeKuxWqaHKKS3zBSS+UPn0a2zNDD+hS6td1+IWvHE2T1arrl6H6UmU9B2HJ9Fbgib0EJ7epV4noSIOgIkvJZnf2uY03wiaQEz2yB/dTE/FZWYnTM4rMq8PfWSS2TavJ76TOhQgJuPkzHrjXZS/V8Z+OmG8Wpa1QO+M3j1uMbiY6m62kEHU4niqRmjTtp490UK4b8KB2y2hiTbFKaok7OqgkbNudO8OzuSFrgJ+00OJCG1PsjDp2XflfCaAhQF5VjCN91XexWBfjScFrk3RLvP1URhtpphADZ9W+kagTYNHlMERxcGHIVfzYAbxcwOareq0xVlmAGAeuMG+8sYAuDE2yckkhxAQgM5olmud7GEwCIuH/vO/+RMQOoalpTahzozLy46H2+WU4jbCGMWgsVOUhG+dQ4mSbYfwE0j6/IHN92GJEqEHglIwREDOAiEYPlO39H1hvKRhl3o/CBhHR+839EP3oGXNW6/BGleOoSGlNWCK8mRvDdfrBT/87o9xe7gBIBzbDcd2OLx8DIxu4QejnMOzuixEa7Ugno8JkDBZw6QpMPKbjJFkuKNYqdZ4+F0HDSMx4LMCEgY0J6U/GKWUWdDxqiH7lYalMn8u7w0MF9BaxsNzEqSG0Tn8bVakylOO0LECxVT3qg92n5VBICuR53pPVVHAO4fxZVhW4WZ15S3jNMFOOL2vY1hBCsjT6mSab82JzMKJjQaa06QJWGGPupJjK2fkOklyPlj1wVPG6Mm5Ma8wVtzE84zbwP03rUreN3jXBkI+T3AVSgRUZTCMjhF4QOB/ZRBa2Ew2WE4h065BYRjewAAAIABJREFUmAKoJGVKQarD9zXUlnJXE7XGeDMAnuRQ6rwT2GolbV6JmWmbmf3ohvquzps5GmA26O7RQEarBJemDpAQolHTyoZy40wznM6rCSj9w+kqsHn1Nhasv/V5bt+7H2F4sAgfUydYgmUlLN8mdAMRY9skOyVbZWlOQuWtyMUG3VIFU9iS5l/+nEefXZE1gFazyHGY6jP5ZoeCp7Xeonx61Y6SpF6TydHE1xCrUmDOrWoZS9Ge11sYyUz3wnEf2oe1F6WdepZ9h89tk5t1/nsxnmWG8kJAnfYaXaTz2SPhkGiIkxwC3BgIOQ1jNk6HEsHFiuPoS+FfRUbM45/n6WtJls56zoyn5eN7bPlEEYYHmQvbvuOyX9C2ppE09WvnZan+Wb72IWGU3A8cfeA4uvM7dpwkjkkZg+TjMXfBxir3hIhA2ybHcxCjj45xG5JAcNuK/ltwHIpHrt3rDYmh71bDMPEwd34kPfSbro/EaIMfTgkGsNWBL3an0kxjBm/kyrELmMGSnYvSJKIU957pPskmIgJvIbAJEiwDIuwMsIYfZiM4ppzvDMBQL9z+9OZ+V4lAW6x8sRLdgHgazNvtQscYgSY0yawtE8lQQhEl53AClU9FaM6bbGcSSbvoHA9WpjPjppOr29400TLAaKqwGK+yTEJmsGndLvwhBtIOtIsYa0/7M/72u/+Itm1iuYN1LyKDb+x1+t4TAFl0rSZsvLSQSZ3kJH3bbC9j2vy6mjc59OasrGQlZvYc37tqGaJ4Zs9zM1EuGODasLCeTyGKXlesbGaBtWozrpWGhDQBcl25i+cKQ6XK/V4zqjnUxARrVH9/xOcQvShh6lAOtT7j0X7n+2o8RG/WMPBUdtnD6bf6ctWBZXwtQpsUX648pfmWxpxaHX/z78hwqJg7KeQUCuuEg5XCPl/3aKeWX3vaHQMevja3D1TGffoSlf4yjc9tGEzTCqPTIXkdgbNagc3w8s6UvqySJ4U42h5J9bN+adssdJlXnYmSinrqT3ybx2hlzNk4RHrumfbO172VuPxsbdyThKyXzJB5fA3mGN9E/RM8ud5AwT06MgO66Eyc6/EBC1wjmnDlXa0dM9YJ8H3WvZvOMHTrhO6bsuRCrvhXfuWgZV5fUBqd88WbKsSsaz5XV3KCMrypTgNgsEbYJLz4qKhRWQ8pj+1e0rZ9EzRbFdZFp3MfkPitP7W62cfPasx7w/wrrXfWZSpZa/I1K5tp1XnABibL3sjFj+5hr4aY3L4RhfFUxeXsBDHQM1+KHs/PYs6dnQ/35uw9npj1I6pFC97ufW8wZiJMvAq6J60PjHFDvx1oe8O+XbBfGvZt9/2gVcfJJCGIYQZaY1z2DcwXALoPrjOO46YGXPCbURHmZDzzhGbn+uYXJLy3kURPNGqgbXLcv4YOmh+ssSirx+mptnvXOf0tjDW7Pg6jjXTDLxPYs1ssi+ngsIetTQ4TzCtQSZ9E8/AKFc5pP6xPLJuPmg3P6jsNCod4diap36089OVb/W9MHqbmsFNpgyAE5se8Kg5McUAW7ElZkXmhBYa1lUMwAhZDxIB5Q22zqIY6HkNW1AY0FFGYlTBu8Y6aZ2oMTXjhsxXYQKDW8GF/Rr907JcN+w785vFz/Orh1wApvhlg7uK5HAPdU8jGQNqED2amEigzIzaspkO3EUpNM2mcxlBlkI9rvVYMMyvGhnNN97pgIvm6b5RFB+bVtOppm+nKcCN4ygYmUU3zbjQyw+chO6GJwhFZS07CJJUt31R4GdbuWQE8tVBgiP7PqwnzN3nOfVM43qqOua7V+6x4Stl7fVg/r+90vPQhkezdvGwN+9bQ9otuBFclF4ynp2c8Pz3jOJIhByD24q5XQ6jcz32oeJ1XF7/tatk9A3h2EswKlNHGvLIWBuU4fZsaXd7OBqOJ49ZaWZ2vcAYfBarSFDVB60mwsCkgylEpOQq1j4L/pnx78sp6+zj9VvVS/7Uwrdzt84ra2ShH+httGs7n1eKV0TvX42No++8S52Q0EFnmzHMdGTY2Jd34emk7eMprBpvBLIpdCmJxnKQ6TTao3EzSwf+Q9yXWFkLK6upLY01YoyOk2zLc7qBojCgSSlQZ5aPpCkhRk7l8AXBdY0k2ScJr6c2Ev9BXWOE7nVlHMQ/MQZHUqsL3zYgM3KZkV46b6KWbxGzSeZK0Sa8pNKBwGVQo8wfwkVJgDZPMAOWkEZxw5fQUyKtRO5IpO8vSgF3H2eekVZj1Cj6P+XTZVGRPzR9YArpEW7Xmapx9E2CeMDi1Nq806oDNugSACPGcZS+nepKGlGTPYMa4dfRbx8uzZvHeN2zb5lk75T/91o/VMh40fMwJjG3bsA/GuGwanhnHC7wcXSK2vD8xASj9Dt4X4yVfpLK0CkdUqqe0wOEf2/gaJwhMTWSF7JzAVI4A8YzwkH12Hl76itKg18dhtDH0sGQOmiL5j0ZCgmWeZ5aDKFuimhXdJtqjphvS/L0qQZQ+UMFDYPAcnlIUltSkEa01mZhbttqF3KsKsGUBBptLmQFoVycNwspKLHnsucuX18WQZC7peW7TOKTws9gbNgBw77j1Ae7dBVGeAO75GEMzBaXxIRVUW8O2N/z87a+w7Rs+f/gSHy4fRBE1XLEwyz5SwhLOmMpMJEQocnsIDww5468eFNlM+/qkqPgJwfVaeS735wQ5s1D1+r/ls/Vlyo1BMcNILnjzKmHAk7+Py/buFKPCO1nxXr+1MRtJ0OfDmOPz+4bSN3TZ+5KEzaSsrsp/20vz+VSYcKK2E6zrJvKXszBMPCQrUkS4Plzw9vENrhfZTyHhulJX7wNPL094er6hHyLgR9JHIrMgp7pXV3CD141Sq5tO7++v5ry2mpaiBhZtzYZi0PiZvmkiaNKyvormimJwyzwOxeBSnEQ764BfZZWLuRRlmp49VkR6KjA7ebIC5Hx/0sPMadc0rCQU3zPeZpyenQ+8fF/L5FWwaZwNo6fnVZbJ1RDqOkr5dIP5OtMk3yuajLXgMZq7CnmVxfsDFCPTZ+jMs/XvyPXm3ui8DWeY9Ndgkm+kfKbEPO+5tBQ0vwrjt1unK6LTapgXy/x+5meFrqq+4fCZA6JUofMxGzEQx/e+73h8uGLfdtxenvD0fKD7WV1RQ+hLLcbCawoaXvfejDLReRbYKXjKypmP2fwBn5Xq+CbzJZv/Y6pCIzXAmLPuppF69WLAczik5tG2hquG6m17k7T/zO7E5m7ZsWt7te5ZO5EGgkdm2X7voul3joKrvN5pmgeOQ84qdCf53rC3zXWwlVMpH1dhlxyxFP3btg0XBg4+ZGuPJujKtJojHBjGM/0OptFJeG/IF3YmEiA4LVqdiTi9TeMxqHAsJ6fBwgPAwOgdHYRtY3BrCzo6Xx+H0YaMAP0LuFHibgXzJKtlRNmNkSq4a7AWV51a+dx0dS8I+CRmCqflKJf5N3KGxvC9uCFB5Ik3/BsXmNqGZ7I09qg40JltQqgc3JdYqkPCjI5gig0pLnhSCKzQ6Br22Lsk9mDo+SbR78Gs8fnDE4k489W+NwJo27FtDV+8+RK/fvO5/H74CqDmfRrMQJdVuT5sxW5MTED30OmkXRk/InhGCB8r25p4UCgU4jA8J2UrMfhgdYHR8LTlcqEovGbUWbl/y1VDHfPcDxhDQa1XrLiyT5sZbzKkZ2Yu/TZmCr2ralfg5rxSJ1s9CLFrIX6NEbDNqz1rBnemcX/DQQtLHCSB8G1W9WorVUE0gZy9q/lvhmlu27qVfbFzv1zBIsK+73jz8Ih939UT6WlzwaPjw4dnvP/6a/TOPo/r2J5Xfs90Pqlik0G/wnXAfY4isLZyOE+uooT5cGDhNWNxfnXfyIsV+LMxZDt3gid7N/x75TGFN1o/Ueo1w3ACrNTjbRBXhSgpHUW5ANzAyGGVppQWp8dkYOa+znPhdXrPc68arjl0clas5nqr4WXzZL2Pjjn20uWr0AzOBr2UOdNDXtmIxCpwWbUKMbMeM2JaRabWeU6Y/FUhn9on5XEnGh0MtFF4mTkGxoRn71euM+Fhxo8pehE1pFL0xMOlLy6n/D0vadA5Mos8KJEdanBujbDRwMbAbYjZIpiRUXh8uOK3vvsWj28fcHvqOG7PHmoYOKVoO8NRdJFgVAY/efk0BjovzxLE9s9x9MsK0PJG0JIHIl0RiZLHOgzrMWTP1RgDaBv2LU/2rHjn5/E78+SRo2NY+rzpfBldEnTYKlVrDR3Qw9ttTqbQz4yrbFmg/Ey4xNT/Fe+4x08Wz5nTmXJK/4PBPNBZDlUfLEbnAGIFrig77Lh3+aTnA4d8EX5s/Nv7bqXS3PCItuQQMIPdTp/wlcs7CiIpnQT5TjzAePEdTMG/M+2JMNBkO5W230ymv1YHPiKjzc4Lw9C9AJa/AwTsCSHzRIcSLkM2JybZXOaqDYCvzhkDyyws/eMCHD4gNvAe3UwSDNfBaMiMqk4Pmj2vDpIZPNFG7Vm+p+ktl2yQZhDSMJKQtoZ53205mQDuCgMzeIhHpGsSEfa8rYodVm+HHlCJMUq7BIjx3IB923B5uOB//tbfYdDAaAOd7FwYaB1aFyS1NnGESsxXVvKkj6b8wWEc+pcaYZsOF651JezdmRVZ8GeBakBkBSJS0ychGzsb1w1843VWaohif0FVvgOmWXTld37GTfQSWWhkwTTvHVCKKv1mlwO8kIFJ8TKhl3kx4O9PqxonGjiHeNWVmDsoxNzfsyLomChKqHmGV4ZJVjgWLS6MioA5f5+VkgRHa7her3j79g0um6VWFhwendFvz/jw9ISnp0PChnU8JjZYDfNk2JoieX8OBE2s54byFHcynUPu5t+1v2bCR131fQjpeJ6VvTVvmDs9O1/yu6wyrfu2ehkPLVxGFLbKs5vGQXpITQkvkgEwGdUcC6JcmJJlOM3GX55zYr/Fu5OMSfzhNUdF0Ookb2hlWJxX2k5yqtzH6orTByLqIbefjeWY/2vYoh1O/CdwZAbr7KXPyjYc3yIr7JzQ1ILDWmSICRwdF4G78gObYxV/hJ7w15odBi8gekJsYoxBeHzcse97GLcKyGsGeAl5N52gdxy943br1QhLuA1YQxFmZBqKjvUObDthu+y4Pb8AgzHUwCMCnp9f8PkXjO3Lr8GaQKKPwLhJEeCsAzlk3qYRPBUSELO3GkJWo0d1YKbfNOONt5yVqjTm5E2Hvki1OvuIgUYbmIboHBQRPKdkZZSfpTGYeF7gQa7jOHAo7XEXFZ8SPTgXKTwfQAlJlgGVsc1wUZT32vLcC53sxFMR8y3mYCw+kCry7GXlr54Q4M+YdesLMzaWVSZAnDu0NezNdClJ9mN9F3DkrETW8lJ/nAFHrYGZ0HvHrR+grrorZyec/OPrQQ1AT866hK2z4J/41KSYEQF7a+K8SHzGIgkN2wzSSBoT6FRqv3d9PEab/1AmMuArYMWh5Mqf/LDVHp9kmYitPCNW5YAwBhiAC1wlPAqW4BKCIg48gQlmApPuARt14ILp2mCxKy/OFJTZssePJ7ihhlETtmR+Y2G1UdKXjxvFkQWMSJyiFQ4jxCEZH4/exWPvTC3jJY5aOCm8rWEj4Ng6ju2GbdtwXAf+8Ts/FAbWdGWFk+94iDARdLIaX5mRJ2JdoFGB8/vZY78Ke6T1fCoKfzUkBIyW3nvmPkNiRQMqRSCMNQrS8nuOXhblOVWzMgqywRaKT1VO7LIn9w2aKBUiVJl0PlgUSW7drdPK6zgm+IrTLF1EpNm5ytMJ+igLfPP+N4Ofpqe1brkGmuaCDUGzDFPzudpAeuyI4OCsGFbBR17Oy9u7Ux+Up2wbHh+v+PTxDbDtCOYHEWwdePf+hqcPz4iVJackmLIZI5qFI7BtBD+bidfOhDAYlq8LHu+tkBXjDRFhsFakUs2ucI5kOJz3WOXypU6axz+NPeX2qxBxw4JTjBmd6yjsXPvZaI5Lo+Dz6Zyn6F+aG9P+L5N3oTDHnLLfM41W2BZ7/BbXfccFXJnJXZoN89fnobnxms8fr+ekKZfWMTuVXPGbFELnW97nXEu0U3RMnG6mvqVx1jpyad/rxfD9JhE5s27GEnNV/gUUZ5BxLdUviICjD1wuhMtlV8cNoUfavDjWJje3ww19VV0xcAEx8HK74flFkjiEsR0OuNJTfWjGE9HmxszoA08vB56PG9og1UfI9SlmxvPTi+Jd9t56cs3MJ5Wmy/EkNpaBkdCb9Cv53ewuj2Lid9XY5mKE2JdUz5KFtU2phJWOiB8zFErbWrChoYaLYkVuSbc12os9ytKGwmIKmn/FkOgkiv5yVJajJHIkSMyfiqNX5agnl7Fkbfa8NGpP01/C4JFmEFTxSdEpgK5uJ57eNux2LrDrV7IKt0ESmWybGDWyztLwlt94zogsYwDk9Ol4195BomMGHsYFzOJMOG4dt9FF12G4eg8gjhpQUBxzr/HWiUYMca01UGvYADD3wr/y1VQfuqev3Ls+GqPNhVeDr7hRRt7EJSO1PJA4UZS1dxBDzPbM2bEBvmzj50Iog2CKush9oQjyQxlUHwoXxnYFYfgTd8lJG64gMsp+bT/vItXPYGdOsLTeqd/GMELv0MyLo6MfQ407gh1KzlrG4JQkIqMYauSbR4Ox/OvDb9D2hq8ev8bnj1/KOTUg7LSLoadGtC2JY0SYHud/zHM60wFy2TMxW4joRub5t+czxowjTgrYLGy9XkfbHXgsz6d/cQdyqKzR/iXOYKQa7SlzZfYQiVxzhCoGQ/Y3ZAqhvbP24HQVcAYTj5hepXObI6CarYzjJhTKCe50ZVjiN53eW5hXVrQCzvP12oqBMMu0edtpoCqy5o+l6fv8t8JhYb/nMq8ZASe1gm2/A0XaaOdREp//+HjFm8dHtE33/4xos/cD79494en5WbAZ8VwFN+b1zvwy4y3C3qx/33zlfQZ2X1c6z33NjrS5HnJagyqIK7zHN/eUjGoEzfSzrtPpkcMzr1ALTkGpvpnn5D02OpfdCE6rwVZyIaPsQOtiAGYHCef5XHGR4ThfNNFjrdP6vhqv0v6prbhKHxdjEkpo1HYeNsVOguO84mb3C6gok71xjio7XLSikFnIOP32zLnm1qI+czBF+1zUjAIBK1SMCV/AnArSVuvUNyPqSB94//4Jzy83vLle8PD4kMqKscOtY3ADcxd8JghE7jZxKIDwcL3icrngdrvh+XagH8f9o3HSgLUW9EbM2DZJjMTMHl4T/ddy9pBrXYVX+RfKn7Pib+gB3TmZPL4zbm615rkcK3vWfKYpOTdWZMZa73AH4HxMSIFjbm/CiRtSymmIEly0zD8QdGEZV6v8nPlMgXkx/zKuKl+oMuv+HJv7W3l/boUhORUaSY6GTQ/j7izO+lsfOIYlpqBareGYRbv6nZff1nMhJVxS8iFs2PYd+7bhz17+GA+4Fh3FVu2IxMAbGPi7t/+EX++fi05FG7Ym5/1eLgPXLrkTeh+4HV0OEudEjbMHacJg6bsJdRYn/mXbsO0NtF/BYBwvR+0nkLdklrHI06Y4NhbXx2G0ZRqzWxN0gMpbToemT5Ml7W0TA22EcWbKVJosJK4zsxt0dS1CVawuU4LcSeBCAAAnRXA1odKcGSkT04l2FcSWuIMZP3XoKCTT6GGhW9sjjKXRJQSxa+xwnXAR4iQp9IcbtE0FxH7ZdZl6w48+/Yl71YgIv3z4Vx8DghxM7m3pYYWMWGmL+XlfyQtkxCTBJGBkRY30HL+s4GWEn69gfxaQNL0oQE23PDPtDE8ihYmhybMRsPHE4P2slsKaF2DcEbLlfXiiM4qrgm7Mv/YNDnfCkwJk8DYb66RYmQIWINR2Kh7WymgRHycmtR6YNS+j8ttwUWmLtS8ZX+vL5sZr70+tU7wTOmvTN6m80tNl3/DmzVs8XmX/p6X5h5731PsN799/wIcPz/6trLrSst5QhLIHdw4jfU0Y8KnMiq6jH+dnNcQvNpYXQX/HIFsp9Kv61leezEaDOYRZn5sBmbusRB81LHgLTwr6nSt/H2IqFPlwBGQveRbYdfxWRvIpXLHgIN0RfQMtB+epRt1ZUQtP8VmJPN/XlTGpv6V6znAwV2X3PP8jbEnqyf3PPKXSgNQLFZPKH9OgWnMzWLZCHis4IWuZJ53TBEFBPwMa1sVKO618InM9bIPAc78deNc7nm8db9484Hq5Supyza7dGG582LcMOY6n2X5ijZQhanh8fMTDA+N2e8GHpxe8vByxBcLnRJI4/ir4OxkxqxwzY9i/zPSrDwg5JVWmx9RfH606jkAuY3WkkeC0mu16UvpecePZrRf1mq7nKh0FTs/Uh3JWGDOrYh11ObTL5mJulZgAW6FKQuTMs9e8Np6/PoctI7SfLZjalu9yqC58vG1O5jo49SCys5KH9JNvMWBwZ3STxRNU0mWB93u37+B7t++C0PB7t98pKCNTTBpho4an7YZxGdi3TfMVmEzQZHy6b/5PvvpDfOf6GX55/Vd8tX/tfRkshiC1hn0b2PcLxugaUixJQYb3e75mXqN1dllJu4HR9x0X3rATYdOsz5Jo5NtfTQ3f166Pw2hTHAUNCokY4wzGgdAwYVMYwTSVsiRJZPIOaYx0Y6ixJlQpIVDmsZ/ggNF4xLCXl3miYdJd7anet8wI1HgkD3tTYaD7vNx74MUnkre6jLB6R2dgHAdGH3qu2XTwonrox1iEPWpbjQjbvuFyveI3bz7Hvzz+CtQa3m3vy77aMQZIFUsx1rjOxpVykz1uCbezd3ueLK3VMII04ovrnnJiqZZtlYdeL57ANUVByKsKmvV39e2YQwImpUN6XhOGzO2/Yj9UAZjqnBlMoC8cITO98lS4tbwmEcKmKqJRSYHVX85z4l4/Ys9aFkSvXfeMhm9qZ3qyaKsqj6sqy/joA59OU722n8HCaVsjXK47Pn3ziG2/Yttjcg0GBkta4w/v38v5NDjjMKG3vKu8ghJO787M6bvcBpd3YaSfD3W9p8Bng2tVfjZK7q0GZePtvkDNv+vK1qo/ANC2Db1300ZQ4pmxmntr4ynTicOY5EOhI808Eopq5YGV5iqe5j5Xh0iC8tW5Ye2FI2Y2ulwZzXNyMqhzW2Hc5dCuOq+jbWm/mbI4KUnzilvmcVGHfZfxl4q5Jp4fZxoFYl9a4pOUHCMm1yi+J+akZKfmilMi4TCBnaWH0WYZZ06O2sEY/QXHccPD4wPePL7BZsmJBoFIlH1qsrrGRNhGd/k2hpk5jK6keL1c0dqG1p7w4fnmTlGaeJygTsOznUYMn+EYKrLY9BWu/TTc2L4j0ReKCuc6luPSDEPDeUDpg1RDLONsR3a4uDjiHWJK2UCttxTwlJA4tnBtieUIw0X+HT5nolWX4zakCT+ZJLQGxZQ8pARP7nlWcb/pCmNLMep0qmNsS7uqUEdEl+ggZgvzyNwpKysUc4KBP3n6Q3z3+CzJBim7EaMP4F+u/4qfX38BJDzZtY8df/H+P+Oh77iMDSDLkmzw6V8mcGcc6KA+0G83EGQ1zwywRg1tsxVUxk4bfvf5+/ju7RO8oON/fPI3kvuAdEFDt0kQJA+CfN8xjg1HP9A1+UuikmlAba4Ttm1LRiHwfDCO/gJqB0xeeFcU7673e0U2x4DRkI4zWF8fh9FmV2aGdnp8ImTYRNTz3CTcUWZd9oSKV0pnyIBzyeKZmNf6gdhb5iFkatDotGRUTy8jLWVyique09ISgao8k/qMMNxIE+9Es2ILbc3m3BhDkoccHZ059tSdIAT4GBjcPT14a8DWNtAG3OhAA7DtF/zVb/0teIfHB+f++HEAQzMnwTw0OeSowuAT32XrHLYm/1pfG6UkDHnQz13Sn1JuUiGRUVcEY1HiUMqVGqZyiyKFiYYQzgp/hcegLd/pX3Os3ItemVrWNpNAnd4aRrLi6hgN0nboahVVYS2jxSa7s/LxDQhEUlB8/xCdxmflJfSWvR1Gxe18n968qtxX2splrZ1l+N/UvXkv2dxWxo0pLw+PF3zy5lHnnyKGGgYPNDCenp/x7v0HHMeAcysT9lkhrMAVnJ8N3xpGlPuf+1JXg8+4Aep+rRk/udy8Id/KfFNoZa4rPxeecw6xqwqD9bMaln7mlI2tYrb3jntGwmwAz3ivhob852cQEUIeJAFtWUgDt9ZuzCdYLyi1lxSt4jCY6Pb+Kly+cpl0NlIynOcxyiska7rIZWb+KQaqKMxBl3MIbf4+48IQkI3i6G9KQKAoEnkdQMiqiNZC1QE4Y8jLkugUY1jiGKEZzvJOBHvMm9RnyvBbRuTW0vsI1XO+Qupf5lh5HEzo755wvNzwyaef4nrZk7Tjoliy49qR6oTJAIbynzdv3uB6veLD0xNuN8mASIZjh5tc18o8szhZkw6b8Rg8Uf4Ohp9LErJ0nlvsv7n0sIZClk8w0+DZoctcP7PiflwvJGmHON8m+UJZp3GqAjDi0Gbk+rh+n7DDanwUnmSUYynrU1deFakrEQgusDqdcszpwxGSqiHRk8dIRxkoPI0IAzl5DmMbGx75gv/67i9AtGGLlHy1Xm3zj55/H3+A3wUT4//57L+DNxt9wl9+/V9wYVmJOhhoW+hBmSJ8Uiv8fQz0EWtX27Zhv+zi1AB87tjoNRD+41d/hv/+6V+j06FPp+0MoaD493mMUsnKM5wXWVn5O5jj7KTJOEsKT1pEUfZAEr32TdfHYbRlniej7uciSFy5TqlhU4CDWJ0TyFAPMiMrIZNyO2qPL9Ll5hW3YFVBiMaoSMuCq3IXLI4rP7K2OTHphapHALYUT23iwpl4H+iHZmDkLowfDOYQQOKpMoIQZtlI4n2vlw23/Ybnyw3bNtAvHf/w5p+jP0mBGwOR2n+wrgQalBnmSfgl4W4rhvIohVPMwkXryYo5AxoKeUJTyCNtUOLEQ4oUR1xSxuZVy/ru3M7qxUoxKYrAvbom2PM17nxjjKWs1c2cAAAgAElEQVTWabHyXgrzmMyVmFIhRqFk4uL8aZZuk+BygZ7LKr3NMM99CwUwCoSBa49mIfct+4V745ZnboJ9Ae981fezslLLCV8Ox5KQLoWyzaFYikeu4c3jFQ8Pj9i3Bnc0KU8YfeDl5QXv333Q5AFIOFZK56hvBfiZtjh9P3de5oxl3GKcDaJSU1LY5HDqdUIXKdfKFl+iODB7vapyP/wvr76evuVTQJwSxdmwLOG8YBBlb3ngaEZtEe7pWR6H0I/Z+bvVI/1W6GxvhzovCLZHMdp2pRkxYqzyTYS78ketd2VkrZW+s7FrcHLC9Wp8at/rmMnfmrjBV3f1tyi192hU8LteRQ26zaI091H2W8H5XN72SYj9hEUp9n/gOKzGSm4jyVZCwRkonZOYYGan1dBC3aHHUgLJYPPxMuBTwhFm4Pml4/b5l3h8vOLx4Ypt21ThHjiSXDPNYUD9rmSrROS8nIZkPNz3HcfthqfnHDIZ8JPSpc9rx4tpAaGkApzGpo6XcLnmZShhNCvFcPnNGW1Afu+4hc8hJDiz+9h64tWluZWNfHse0VQyNnbWq+BNoLZs4QBh89DXuBZmozwnct6diYkA7A24XHYMiIxwI5cZt0MMlMINVN7IuMZjqDPdEn6EYRp9NV2ZtH1xMjU1Qm31Vlafttbwye0zgAfaJt/8ycsf4814A7qSD3Cs4gkybP2wMUDYsEGOifgMn+EL/hq2KvoVfYXv9e+CaHOj0KoJPq7wK54bgH4cOPpwQ9v2aY5uuM5qjdR5pQv+81d/jr978094omdwoddAkOM56VZlRLPOZ/TozCDz3cwN1vqN3YWeDRBtaDQWdFSvj8Nos8t7ooJM5kkw2RyXyygZIeWSBBVZR+EJo9NwBc0D5SycUDSN8RDANuE5Mjkp8RYl3p+T/RECKmGW537LfJMl7DEkKYj8HSFU7QOHT7w+lpbf2CBDJt++bfj12y9wXA40anh3fY/PL186M2oarjOY5ewMa2vUs1Zy/zJuzg9CMWB9FwJIfvmyPFn4QmKYWscspOtFLkClXgqJhVCqjNfC+HsC2RyfS8WfTCaEwcHEaQPpPeNMj2G4k91x1V5RJhYKjQn/bHgwUJP0ZNDndNTIxjAQScfPsEd/5z1hXjvyr7Vn/6xcm5AI+ojQrvVKR+2L10MBTJQLmim9mepNtZ6+q22bMmzjMfGLZX3scibYuVRIjbDvG96+fYOHy8XrNKEyxsBxHHh+fsKHl45+697GLATOYYW5P4GPVXbRc13K1+5PsvRtbTcbCmeDLeCwtoynrOjl24S53st6mdsZbMrpokSZc9aHeWVK3lXjJuqwuRk4Y5g30LhVjhwdEy1522Ygg1xRUmJwYS0HaWudpvxTHJ5OgLimp/GofQncWBm7l76MUFPo/nisowcyLYw731n/y1PkhEkZr2t+SfG3DG3m5AqDzr1ioNnULPiX5zFXuTSd4bJumzIXLiwYA4ZtRY0XE+i+GmHcOgFl+h4DblRBZBmx4Utej9Hx4f0TXl5ueHy44vrwgH1rqGs+0bStkFjW6SyHrcz1csG+73i+3PDy/Cz7eiwfwKJOhsn1OCvWNZLyjZUxR2+k5mN7SyJkE0Wnr+dW8x2HPp9loFqVuS4Lwc0DpOaO1zUfLxAQkNchTk8d6EQgRGmcEoxAtOtrjk7K2qbi4ugHGgEPD1cAjOOQ5BV7E8NwJAxE3YLFy/WKy2VXWQwctxe8PN9wO2KlyR0xOv5bk8Qc277hoT3g399+F7RV3YMHwH3gD55/DxfewV11tQuljngnEYsoIfeExGOB5X87/hz/7ZP/6XrhP+8/wu98+X2wHjU1Bov25HpBzaJJpFnTW8PWJLSTIHvB7TzEIBdSffaQM+72Dd/lt/iPT3+Cf3j8AZ7aS50zBPAgAEP0wrZpfgfnEHUEjMerjo6imycqKhOOTryU2oatMTa22XR2Gq6uj8toA0wbdH371Auic5Y7msqVn/cYAjzMEhxTnVM9bkR7uTSd01z3JAKmvKmCPy+tlgnvnhxlRIMllrbbeWlmqEVbQQSkxB5hilCCYOip8Zcd7x8+4EdvfoZ31w842g2EpnyHNasjq+IYXtZ1WE0I2Sx67lKpAhvZ05obaKvLWOjgWCKX8YlxWF9prPgMDlgYEBrMIi5042uek8AJcqL8uN57NUYRhqBqpNpqi+OvKLm5Hm9ElUxTsEzJcbGJUAGq8lLrmmG8d6lCiIq/akCmcMbU19yX2qcU/8+c5GJ4G1djOhty1YDMH5wIDzEGdHpfjeTEgk/aCZdx8PO44i081jcp2a5EUPWmEgGXywWfvn3E/nBV9pDcFEw4+oEPH57w/Pzi9J+FvK0UrK4Ma+31mi7qtxkPtHw2GwP52zmkbr5s9fheyN29Nkyw1aJGY/HeH5Q+rBEVRvm8ag0YrnJf5nlrij0VHEUImNBNnCWVOGQqafW1kqHP/pJH69tqanRHIUy1oSBoNkhVC4HN7fVYxzdlVejfeJWV9PNbmMIVsOU59m9ps66jzLRfZH6es7Z3S2V00KRg0lXDmc4VvGJcmnwvbRpn0/K+eho0K69y/YnenToUW6ooFnYWSeoweseHD0+43Q5crzsu1yuYB47OLgPZHb0Sd9UseochGfma6AG2Yvd43bHvm2SafH6RfT8ceLLWTTE1XSTzG+ZwxppTYuAAj5YWvknnSdCkzp4J/5QqT4qWD0gta/QlctskmZTJOZ/rPm0Z8+H1zRxUEO+a4UTkY6hhtHCWhIQmVB3D6kir79jwfDBu/RmA6IAgwFbCjTJcF3X5QehHR4Os1tHlgsu242gHmDvMoWS4Duev/P4P7/8En7ZP8FvjO0XfcacHh7noodf2MkcyMMsZhIY1F14Mag0/vv4MX21fo1PHvm8+fxoI//RbP8Bvv3wPv/38fYwh2Rx77xiKA1l40DFlCY0kQiTM81V2OEFagr5xHBi3G26943hp2PcNn94e8WfPf4S//c4/YjRJaCJjKSuanYG2XXB5uOKiRw6g0LmuRpJGgqnO3vsRiUzSKvl8FRp3o58ylQWeX7k+DqMtM8Kkd8nWsIQEYwrGCF1bQsosqe+iai0rhpcxHCQm7NUjTXglBElSowbHnJCEAcZwz0dGtiusxmgUNtZ6bTWrj4He7dBpdgNsxs/QCTM4rHvDxXZpaO0CIsb/evsTfP3ma7S2YRDjaAfMS8RmDOp+OE5454zLE/bs2UItZKCQqRnAJB4RF1ZEKdzxjrAuwjzFtrvgpLmww8bz0Cg/pS0zUcD32ixXByjVZdwgCeVpOmaBZvdZOHODZvKqeYwtZGq9ciJ/RYHPAiW3GYbMHJ562pxfsaRQWGgUn0bUmKLPm5NCGLfUclumpKiBabLW4MzKYg4pdEES45sNZr5DL2tDPmg0133vmo31XK/hORRaFfxpn60LOP3QuUcj7I3w+HjF2zdvsV8uUxdI0yF3fP3uCcftllTaBZDehvxz4uvMGkZu+KtzdUVr/mZC5L1VtWgqDjQ9raguvl0ZfvfCIXOX77W9vs7PaxgfYNlcMz3zkJXQRG6F3uS5Mcm8ggqffx490OJsq5iTpPgyQ0vCj2x4XL9xvKSkCiH0FtR/5n2Z52WOTOWburJd+urOodrOeXwqbzkbYNbz86isDPH8rBjk82VyJjlwXC4UHj1hJ41r6J3aVy+zxnB2GtaVfgo6cJ5asTDzkVI3137U/kzzExTJ1BJs/ej40A88P99wvUqSkj6APg494sfGuaO1DdsmdR1HRydZ/QdklcIy1tH1Aft+we3lGS+3A8cYINOrHNdyldDinMecyFefLExaeKPqPJOOESt1Sda6TmEroaokO5az3CLXj4gAwgSwQOu6ylDGTYlYXCr6xExOR2cMDljBw6RCLsZPx6G1dOQCTX9jj6cctmyYqfw1AQIw1MBhPBODng+IYSMJlsxZwSwhxFGPfPeP7YfYaAPtYlQ3Ilzpgr/88F/cMKH0EQOywrXJ5qMGxnFIYpl8fCgT8P+9/R/oJKbIjW5gzZ9ofJYgJwr+5vIFvti+wtYJnz59B6YXdw23bmAMbn70FJHIzbYDl10Or+4jR31A9ReWObPvkomRgYMZR+94y5/gL7/633E8PuOvH/8et9sNx3HIQd+toV0vfnRBI6Nrkr13Ly+gXVan960BG7BfAB4XMTpvB176gX7IWXDlDMqJGVbnbvBej0x65fo4jDYg06IQt+KLiOLsTi86q6qEuafCN6Yyrm+R7kE1JmDfDBA3MLGmSKVQMmlSGkwxydkjwjUb9drAWcZGhhpqckZEtz0PJH2ysZS9AAwehzo9gil+2D9IpsfLjh9++hN8uH6QzFLmHQZAsDMiSA+3ToahYzFNOITykpd6DZ6CXmXKUcZ9yWk3aVJyDIWhVZRhkTplKpeBng+wS8ZRRjnA9SRU67dVyQFP6QYj9ZlSfbmNs0IyE1sVtvHOA2NUEROlkTCva7mhEyIxDvaGeCctk+Z9FJ5DWM8Kb8aBteciy+9WCVF8P5WOe7Oze7xO9jqrbR1zxz12rqQITlpr4BN3M6XDcDSHXZ7xEDCEJ315ZfqmGOuV0hceIoUBJqXgfXc2q7yFiPDpZ5/izeO1CGH7M3rH0+3A09MHHLfDj+twYkzX0CWr1UoSAR4WmFeGViFtUn8+f+j+ylfFZeV7K4PNvj0bhjn0dG3U3TMmZ4Mw97leXKZopbN8f/4EgO4zM5okSJa4wFVWIHP7hfZdB6Oom2PcbIZlmVTmoZb1MCblF3IepwI89z71eQ6NnMd+9VGIk/urpbUOnn7PsyXmP8AnHuIOjRN/Ta3RVKfiUkXx1E6W2/VdoSur15W6s9PjNQeCGQ0eFsscso5krxIbnTOqYzj/TX0vdYNc3znFJVJEHPkef0VKV64zjgNH77hcLrg+XHG5PGJcJOTaQs6a8SXdq7Tve50TRCDNlijJkt7g+jBwu93wcjt85c35HjM2aprtUh1G7qgLfo8U2TNg8sN6bngV7JijT+98VOPooOBpjl8vLw8iMQu5LuQhx9aybx+YVxGTrHEpRz7eSMNTZ3DAivTLIypCwVA6RNTnvfWBQK6ISxv5RTZpdQycH4kWKWIn8dkkDUVu6DFNzOAufWxE+D/f/F/4d8fv4Peffs9T+O/Y8YgHCUUkMRlufeDlONBHx4f2jM+vX+N/Pf4kxibRv4SpqgMv8YYGoA/G/7v/Df4T/wfsY8cA48ePP8XvHN/D7/TfFtQNxnBFjtEPju0riReYU04SDu3YiLGpiaOcAU3l8fbygD/FH+Mfrz8AYcf36C2oNfCuK7LE6EfXlWdZ0ZTnDQcP9EN4e9s2tCYredu+46qLIrfjwHHrOPoBZtsiEPhfsttveX08RpsiG9DVGJmJoRBHtIczhqSuykRYyRgjHk3fWDJWm6KUqNmYbnBLE7YIWBzhVP74cw2xl+QdtqLGeg6E9SnF4QOAxvZ6iI4yoMF6eOG24evrO9yuHf/82Y/QNg17IBLFkHK3GLEnLuoKXE+x/7n/6dbeCT7OrEqqMq8M5U8SfhKl+uhVJheJY+ohka4GuDK6UtRNALCspiIYdTp3+XTVSTMpPVP2uShzVpyh8JWx9C/I5MdCmaIEaQNSGBxzSwYeAI15NuUljMQwtNx4TdIsH6Zq5WLc4DQTisVK0Yu2rEw2pOIrcv2z4Kb0K5hrFpgNwKB4XyGev12vns2GQoQZmOAqhb1XprOHcp2L0EQG0tfO1s6ZRohkf8LD9YJBDWBJgcxdVnWOMfD0rAlHek0AMLsVWOd+0q5KO2ALCSKHeWnckc0vIFJkn5XUeWXstfDIVR1zuOw87qurthF0luvN9JIpUfCQwgV1fr1mAMaKOxLfShpgfBVwUDYEgv4TtIn2g7aQ+jaGeKpHor3S69kIbi1N5bam+zVDDLinvpwF5Fxnxr81Mc/JeQ5megtnyRyGaaw4PMmVbnKbM9QRWmpPQwbPo2dKPlm9zKn3jKwMrzDkPfX+h45hBoo1H20HDqLmxE3TXPAv2SRcrPDkvahhdLoU1DwlFP1PY3O7Hei943rZ8fDwgMubR4BldcGMmW2bHEgI2c3JQSBRYYTWHrDvO263G24vhx+YXELk7XfWP/JzWGgdOT2b8SIObasnjelkvM8BZzlMMw+YZN5LZTmpADnjsVMISvliyLu0jK0INsIRdcW1isyzTBfgWePRh5x11ntOk/NlbO7k4Dj3BmV2GK9zh5CNfZWRA8Avr7/Gv+y/0j4PfKd/B//+9u/APPD9999Ds3zqRPjNw+f4q/3v0ZnQP4w6h7WNTfec9XRmsPFR0uQ7f/PpPwQtMPA5f4nvf/l9bLpvjYgkUf9m+vmkayVHnQ0tg9xoJOWjRlG3ARxdsmq2bcP/8f4vcdku+HH7KX52+RcMlv3lYwwM6NYdBqjfgC4JA9vlisYMScREkIO8CWhiwI0rox83HEfHrR8YPfTye9c9DSxfH4/RxpiSPUxc2a6zfL+bCdL0rjIbKf+0iRMch3Sp35Nw8MShZ6ABz9jDkBWtMeLQPZEbHEwpef2ASPvJmjFIYBa2sm0NP377U2AH9n3D19f3eN6fsdMG8cKmzgw5LmCY8ecTZFY8Kz6S6KzeUedHPOFfJxtFulcPQYJFs1ccL0RiGReL6S3rQIoDOxpkdWXPWOafWZex3/dyGSxUZVUSqtKR4To/53oYfH5j5LVQ8KU+oxHzxASBZxIUsrExMhjigExTLmw195ykZ4ZrFnu1fDWsIitbO9Vb6Wv2YhtznlfJ8tWTQrxW4CqsGS/5aikrgCRaiHJZ4cuidbVnjJ2IUNqNKUxWlXY/4Ltcdrx98yjHV8BOHJG6+tHx4fkZ799/kBCK0u6djIdmMBRQjPCnFaQ7lxkcrxu7p9ZL3XVFJo/len/ba0b2bFBUA+DbXone/ZZcOTMQ6xmIOk6sSpxJdNTwIQCxwpYMZut54S/RjRhPDh5idCceZoM55rg5cioGGGU+z5crunbW0moM85z5t+A1mshz+ZvCVCufm/u3qCfLoCLTbSWFa3m9ROGhCf9cZrUodJyU4qlJ25+uoU/yfEDi2QNO4xt2xmI2vLKBXt/VcFXvT8YV5hGvCg4bsEl+2zA7n1QY7KBsIsLRZXXgOA5crldcLzs2XQlg/zbkjYT0Gj7YlWyBUZKutX3H1houlwu6Zrg9bsdZV6BsmqRVf6h8VvhNHzJzKlgaA2iFrwZGEAiwMc3zrRasjzg/D2opZRKdC682HhZf+AOKcmR1ca6ERTei+M5LJl7kq7WYokKSUyDgS3yEGvwoLJ57kvkyTfdnxHo9CoeJNd86w0Cjhi+3d/hy+xoEwu+2d+Ahuum+EX65/yta3zA4Mp+fwt/VONwvTWWE6T6h58H0T44R+vlnv8CfPv2h0+4gxg8ffwQw43dvv41P+2fBadJ0sfUQItvOAEyhenhpz/jl9dcQJybw95cfgED4ur/H09OLnPtGhO16xYVkYaE1gh2JYPPQI44Uv50lAY+NxrZtEhU3dt3/xuhdz1TuPdFY4OOb7PePx2gDioR1DyU12ddGhJY4BQPybCWwXI6nZW7YvCddTQuDjZCW4RWLhSfbZF0wCWbLIjP8cGtw9SgYUAwC964KOnuGRiNaUMOx3/B3n/4Ql13On/iwP+mB4KKIt9RjS1ZiiUvyfrgayqlgZG0D5af3M+q2kC3L1KPj0iQUwp1lkFWS0JXUcKsuFxEyWi742TlkMX+Wx2ClnAp4SYiTblIdWYlACD3/LjMvY6ZKI6jDvtpnEcrprGhzmXBVucnn9AAWNttzJ6PXLlizkWjDm2Ol7XM3YLMDwgR0NDqRMVejhcN8XjGOUHyT/JqQE0LZGJBmhLIQyHRWm5VfXbZhXSpKB1BPq8b3Vu8yHPV9mFjrsDLro08aZFqxflloRlbeHh6u+OTtIy77rmewQUJMGOjHC94/v+Dp+cVXvrMxn22PFUoYrmumsU7f3e1L4MmEaf67uuJdhJTVi9x4lyx1xl9r/VZXHBHA03hn3kxefn4HNcak7ro/FAjW5mli7SHI9yDmlbJQrCzkLc79ga6OwsLcRp6D+q0imRF70CRslF1+5KCBRgS2uaDfkoY7m/LpvEq+KLg2gRTCXfvBEXI0r5JXWnaETM/OtC3g2Rjm9nAa1/ma6W411jG82nYxOms/5+/MCWr876yjx1zK+3LljQDnuqvD59ygyBtLIW7f+Fl/8qjmxcxZsBLuQm0IZn3CWuJLjolcXR7ZyuQElkZxSLm2f7sduB0dT23Dp5++0UO1AzfbRsDoyuXYFVIbEh6yJ2fQ5vt7iDZct4aHywW349CzJLvCSDWzso+bdyJwkDgc5fGm9BoMpLDT/IWNV7X9K07sSchC7emMfA6aWDkVI5wxysoQsIEoLU5TSODOhlZCRNZFDWaiVAUp76m9njwb8paCaq67rKJ2Flj7yHpN7rj8bgTfckEE9C75EjiXY89/C0B05J/tv3K9hEDgw/BuY0I6rSmaSwOc6TDrMARCax1jKH6Y8LPrL8Bg/OnTHwEA/ubtP+Dz/QsQgC8uX2EfG/7r+79A4zM9bLpPj5S2iQi3QxY0/vqTf8Bze8G79sGB+JfLr/R7Bt0AHOKolj2hEv7Y0EA0JPKNhMlLfgio8+QG9mOA5PLQZ30kyXB2DJK5E2eFmrxdMYl6fRxGG0HDn5OQhljWFjZCdYSFMJxzo8imMNa0zlTGY84x1CAcnr7fp0NDGJDGyJyjKQFb5pjRhcn59FGiREQR57T98lIptjXwpQPU8KNPfoYvH7/Ctm9AAw7qONpA47RXjVkP1DYFaMGIDBWz9ZOFpTGjjDudsPJTcUfQOOY0Lk6UcfZKxrvIxrUyeFL9ksDmAnI8H9SwZaas4xf2fVbSAPSocYykcAATvqoxVj32NbRwJHxw7nBK6e2ZMpMQtn4hMRXva2qTnGYBcxO5UpAMIOt/nHuUItW5rhB621RVQBcbickRQc+AitXbKsSqd2y+Zhpc7pPx36E4xz3SPXvIojlUzqs38V2hIWXY65UdEaS9Swaomuk5YKnG8EAJ2TVPhQmmBM/18Yq3n7zBvl/k+84Asca3d7x79wEvt1tRMqqgmbDi/Up06kPNixXPPEdSz5JxtlK0763AGUQB49noszJ9ALbX/V44Ze5nrn8uM/elhFwCCMdC1BErKrHKYfVkfEe4XIZfObXI4Gg9NDcDJOiRIuzGrK2i6BWFLHpjWc96F4dd21K/0q+ygd2fsv4/UlzHqkjGWcZNxaPDd5pz9l3Q28qwz+Gz4rTgUk126lQYDAn5cPa0Ps2odZGidUGWbU5zm+ZshmHouBuGPaKi8HB5kM07Ln9jfxrrBmmeRstlQprEzBkmGzeTcVxhZusDK5rq2Bh+LPEHxXkArtvYyElZc0RIsoevv36Pbd+wtX3i3Qzws/zioLuu++eHnudmefO9ftT9SYVfTlic+Wt1UIVxF9EuUZnRA7tikCGI30UWWA0FuVneEPyYDQ55cSLbxPPkR+yzCGdBneeVp3fvo3/TuxAvxfiAMM1hcnhsJTXOu8zzW015rWMDcByHZA3f5Pw90nnsSfJyx3QsxKgZ6ExyxlvuChl8EzoRsmmcxkTfp33gQJrboNgVVGS2jVubnjF+evkFfm4GFcUK1lOT89b+78/+G5iBP7j9Hn7/6XcBAt7R1/jrx7/Dnz79Ib5/fA/7Tnj38B7//J0fyTYlPUqBekDN4LTwILJ9dCnUxxAHRRpypwEk3gqAeaRQ48WV5Ikt3NTx/ebr4zDaUImXIWkwxYMzysS0GSZ/KmosQ2RkEjKkhl/MLXyWVuwZpbrRS7US8gjWxCEa+ujAGBWqMgAbDFnuyfvUJLa24eXhkHPTrhv+4dN/EmWAGjbaVVgpQ/O0/LKUGkqIdQYhD4uyklCFMp3SA554G6kSSmh7K8L6/KvFLcu5ZBaOcl47s6KEPIweepQsR7FjyRkeQTMIIa+okoELRoSxMrMzi8xomBk47k+JWZHkCY85HCzeGV0F7JS+9/5Zv2etW7915Ve4hKJTGHsEn/Lp27i3/hIStZ/76GVyJ4Lh2OKV7++avg5lbH6TVS/rxzQnZ8F2lrvF8AIsFDNCx0w5yHicDbgYcx942F4Y6xugKyKTEeh+jIK6GuhbvIjazNBzGx8eLvjk7Rtctl32vOhB9DwGXm4v+PD0jJebhkLccbRokylFDSeUBu/LdKb2Qq3g7iVz1Bwwtjl8tUpm9xlHq1WW+CZa4bRpeDbwVnXm+/gm+iLjMqUGPvU4FMAgpVijyM6gLAvcG072Tuc613Bn5qwkZbhkEKJK8u9X3o2hiRfa5prYBB/XTxmy8DfgWS6JqDiRMhZc9XP8VUI7491wNpd9PZTWx2hBx9nWtTkVoWQ0QRoIEEV6xG5iDrlmMBYd4Q5bdFmu/UCm29TnTE8hy72WNM+kbOFzqfrg9ymMOdOA9UM1m9gj56/BrOYgn0etyG6VEw6tG/f5UHEKRX2IEdaPDqLbfbrI/U/47l2dw4ZYxYKfIQgKueUym1Odlab8vc83KE+r/H/uuQ2qfJbm6dQXW7HqinOZl7FSDoyUgC6a8RxgEy35o9lxd7oYG0Tna1uTc1obAZcdG2nmQQxw7+jeaXXgIJw5NUWcQpxkmjtMYA4TobODrezA7XiexjOHULKjrY9I3GIqSEF7iNETbk6r+onfGw/eN3GUHINPeK2NJF7o+oDcGAcfSFE3rJRHguOuURI/vv4UP7r+VL5ngfEHn/wEP2w/BSwb5S302hCp0TkHk0LniMg7Y2z6j9sY03xlBmhMPBburInIVq2XVhrzgrGm66Mx2gB4Dw0ZsYoAwD1UYZmS8cVMcco8wEAvg53qQipP5EcvWWg3q6E01BKWpeZRkgbYX5tTEqY4PGTR+9IatomTqg0AACAASURBVK3hl4+/Bl8Gtm3DV4/v8PX1vQhw2hxeMzgtKcnwUMsCcVxU/iQmiOmD8JSxEX0mN9JDtiloErBVo0mJ0/+1YnDJR5TK+WqLLvVn0qzm3SRAkiKtoFVxOgtpiLE2k/5MF7PBNdeVpy5PzoDXLp7gLy2kyR42U9COK0saqhVaCqdayO/tdUv3ohylFSLOdVcGJb+Tgpven1bocnk2FjrjNeHB2uUEfciNE+4zUKuVsbzSdO/Kym5R1SaNyJh8wdMkMARGXtS96Kv+3TbC9eGKT95ISCQAkJ6PxMy4HTd8eHrBy8sRq/mTLlLaMnpJyumrcMzfl3fSZ8v2WIQjdPRNO/Y+0+n7fL96Z3WEUU3L7wP/7Pf3Vv7udrY4P4If5W6k3pRfbHWoymP7Ttgz+3AqG6vnjar7hFnCY1gVg3vajpB7pcvSnQpsrYOzggqRAYMixBj3aJ/qPJsamZ1H2aiKMvmb9fiT/8vLslI+ShPlB3OnOT1KK7uYi3HiXZkPZR1B6uAYcVeOoiRP86187AZpPMl1RRsVbnnJcx+5SodoV56bcVXD47gkS3O5OxjQI1okw7U4eBwnzgyUwjnOPWXrl8v+6SJCPtcPub7aRVWvXpF5URo226IfecWOY/5l/N7l9yFMSGV04khI2mKC/Q5NGhAz0K/wWjeUFlOaGThYxoi4Q+0J0AuDNfSmHwPH7SbJOCBRLZd9BzbZAUUF5MqLHGi2GbfYoG/zuPCFqb+cy5Zpd6/Tr4nfxadiCBKAQw2bgRYyyNtXgMic/XFcTvA+73L0mGtbM5wrjUFQIvvQhnfaIgaaz8mmimZemSRFFDWjt9CFVNk9gbTtW41Oaw2k6f8lZJsQ67aARySZl+uE0/P1kRhtCUyGhJ+AZQ9bkTMLAZRGaRCDRjAHZ5rGhHN1/kyYmRlcXbMtRpZH+yALATHQAGWmqR2BDcBO+MF3foRta2jbhq8e3okBQ6HAEKDG2SgrcxiJ2XPAb00s51FFYSrLbqgZKRruxGCEcX9gZEU+K2WGM8WVCsyzfjWZThRPqkde25lxfPcK0WrL2E7nC2NN2pvgmgRNDRvTsBdVLvIqmU1wqTuJ1pRVzL4LSIPx5DCyiZgBWIyzYqTJamdONhJ9KeK//D4pXmmMjQc5FEUpq3XE+4ynRAv+74yPDJcx5PRFwkMYERXm1GIRujyVq3R5FvgBL89EkFtw2ILhJxUjGRiZzn1MseFyaXh4uODxesW+7ciMaIyOp5cXPD+94KYJRxKJRH00gZgm95n3GCDfxNLPva2GfKX91yTzvbDJvOoxl5+Nu3v1VQX3tT6punSnCN/5fNJRDPCgG1WyrMSsIEkYYssUJquTQw8msQE1ZZTT10m25HngKZCdfwXgQgtm4Cg1MUTEm0A/8TT43K+eXQvb5mk+p3mlPy2cu+hTqfw8zrMhPmP7HjXN9ds45NCi/H2MU+KrPFIdHKVNgS8yaQVJDpdVw33itfecVyYV8hYODbICZerh2Cece2YKWkCWZJo/13pamh9KY+z6BkDUXWHM4bgiixoIsr+dTU6Zw9t7kvpr9Jjg9JJZaGg9lMbsfEWfaMZ/mqjscnbm3zon6TwOlnCl4i+Fr2psVnYWCC4nGiPjUyG789iYMn+Pp9jkZMUL6RgwANKkL02zxPbeQdwAlkOjb7dDj3hSnOoRDEXH4sCHPLeELRY6mBO43GOK6Y8zpUq9CUWnaeL6jzFdjufktVAqm8adSHToY7gRyVCjiCc2phPd5aHxPXDdDqU/Mo/2eXyqMGGHavdsj2IfktWRIQd0U9P/ADQ9B1nsAbELaGuStMeMNEqY5+BX1k7bxCCX4wVk7jZ93ojB6nbnIUdzyHaHTbK7Jnzcuz4So40TNwdoqIfCMQIdfD09fAR3LklykmQYlPYXcSKxRAudB/iw1PixomWZ/EyBM2PKwx4BeEyZldkY+77jF5/8Gr98/BWwNfRLxFkSElFqff3WT+n4T+zwJHtin81YMM9QFqpXkugccEcJh5r3Z6mMUcIjIOGQgicxlNsiLNEZbHpmfHtA0qcuhfvMQPK9yp8qz2oBC2c5G1r2XcRFh9EYYVzBmCNcYQ2b1Z9CReMxjHBbCyVN2smFFWavPzMd9jrqN1FGBIYhwhGygDW1dkf5y99UxWp+eH5XxyhWPc/hdpye3RP8NcAmVVvLcMZlwgklwVfuXwndzfjVfo2kK+dWCEDbGG8fr3h4eFCPWl0N//B0w/sPT2Vf5NzbeaUqVJEYn1iJTfB9y2sOz5DffPrtDqSFQXdfOVu/e20V7X5dGbPlCyXrNcy2B9eFg+IxlLi4ZL8mdDHBJiOl78NNEyud8tz3ziLxW2Y9pBeoikLtB2tzBp7hZSD4xskpIB0ElL6Zs4oUr7MsK1grxrDVb0p/Xm2299VbnPl1dlI1PeDWDPMcZjrDMs/uOZQ5X5n3nPCQ6gfbmYRWX+KLNk2yJlW/dsiKc4bDVAmOAf+V4X4t+oK1kPNj6LxyHCclxuGxca1hvAFPlT+zEdMo6DliVhhgMegaWW8yHwiKt5qSNEy0Ee3YCp2zbMrhkvMGwxj5cDtneRwRPpUGY8Lauosbb1MLKprjNjXjM5EynnPZLFli5axKBuHndsxONMtIxOGN295oUnyPIRkCQ5c4pMxGuDw8oGkklrEYArA3xCJB5l0sTt3LvuPoA0cPfbLoE5TGlBvcOYSYzB79pUQm9J9533wFX3OeYtU5DURpqZYk3M/S8id+OZcvirj+ydwz+DBLzgiGrFoRFYhDRpy4ZIwN7Jw++a61BuySDfX2ciASq0D2cWpmTGKNtDs6eAO2ndCQHTKcuyjtHJLjYtwObJq9lSCHexM3SeoDViOwYd8a+mDdE65J2xaZpPP1kRhtqCNGZpjpKxtRcLAJlaYaNTBVBA8FkLLyZhBjHB1gSSJiGc1WDBU8JP5Y97MZIE6cO+HlckPbNuwb8Fff/XtA04TKXOgBDovwH6NrnPgdVneaPVkhsCdUJRyzbow3ZQRC3Gkm+8oLCU7aJICazcmJB8eeFL1XfuaO38xd7iiVs4fSVsrO38yezBkOAcAUpzAMzq3RAm9AKA2sY8LG9NBcdNbwxfTcG4sELFK7GNGy+Tx7tmdh6WuY3ifn0JPHPb67Z7Bl3Nj7oImTbLH+QPetTaipin0Bx8ffVRBOQnHSGldK2Wykrb+pSsXMgM+OhAzwmEbbcJphl0evHI9ygntukhWOh8uOx0/e4Hq5wNZhmEXovhwHnj4843a7pVWc9bVeBZEV4bMCfF9hrGrfeh7eC3PM99XJwejD4vojtHT+/l4o4yrc9Z7RFvsgZrpJfwmYP8+KbhaeLkIKAFBBy34oKyEdFD7SuoCWs8xjgERdxL4WlTuD3XscbWRuJ0yyBqLHyvHMK9wQYYgjyti8tjmcvwRfWaGfkqe20NHE3AtNjDz2QYMGI+nZfr13/872hgaZWx0Z/0q9Wu9rToDcKRNljbLRrHTYCBvPK/DZOx3zv2i/wRQStC7tA18UOM/7r1y99Smme4s415aVOMOHdEZIKNEsn6W7OxwVXkIT45g4vnVkEajZ3DWQkoFPgQLBpynyXNtNylOEhtqXIY0tT0BOp24reg6PKgfVeRMtlhBDBbywfZfBI+kLr1ypI2GOT3gtLJF9jDGV9RXJNGfX7U081rqTDPOzHGSgScbBRvvEzAiHxf7ZAeUJZ2MAL7cj6cDeTPA8R6kY+qH76flhGedgn1/FKZvgAQBqsiokB7QbURtjSbRVcBN1+J4trdGySINW+Kl6gFMfM7h33I6OwcC+E7YtmWxUx8mqDRVOabgRGsfCi1XQGoH2ht7hUXZ9DFAnDCJcLzvaptuXKDLMG08j7484SazxwZpJvr+AgTh8ewPGod9ujH3bQLThsgMgW32r0Sqr6+Mw2owL6A2nML0Q2qzheVQHxumIHYnW6Qg9tEPtIi1+YvfwZdyUQt8oW6q0tKEN7x7fo186bpcDP3nz81BoVMFnsKacF+SPwf67KKZ3FJ56vaIUuYYRMEaMLi0/dQXNXruAgeO02vgRbuYYi3lb5mn2MBaP/tSdORzejD9j7vO+CyQ6MGNxyTz1myzUos+hOBjkbqwxAzx0v8hIZRSeXBslRUafBvzzRKvwxZkogafzJeEs1SDGdO9iOX2TYSWHc26nQhgKxHl1JRREV0JSXTmEw+rIddoXxZxIjZ/DuRK81tqSDioObSO17dvIK8+TyFzgMGDP/VgpxkTKeC873r55wH59kHmiHx5j4Pn5Rc4wOnpdYVvwX+MDBPjZXU7bQJkDZ9irgLP9APk6zcHUp9cMKCsr7PBMP6uy956vwuqyQ8T4St4Hl8fX++iKP/wbrxOZfhRPp5rSrDey0vli6fyjbMbZUOUt7TdSXsJsKZ/TfOBozVZZOMmqYUdfLLwBmfKzkSBTnVzhMRjXqz7sbceVs97NToLAXRxXUMd0FQbrziZEuvD6br7OylktZitU0S9pN7ASa1bzPHAzoM6JExhUKGyGzTmMAhdsIhm6bsSz/t+8l8Gzgx4NL0pZ+Xe5OBRs11k8vZ4o4M72ooPmHHBZz6zHHyXZ7jAr/kgS2LgjpuWd0TG33ADMmKkg6qu8Ehh4nKhFWw9DtKK/EgP53qckdKL6aKAwbPh8xlRs7gZDzjgzWFy6c+1HrWNyOq/mUfrlZrOd9ebfyhgsrwVajGRY2yy6ltVr4xKUCR/RzGuK7LVHdaJwfkkE6pKPz2fOnT6fOXd6QeQLAgAlx4MZzxNv8H9Uz4fQ9bY1CS+0sGHXuZF0/tyHcJAzQQ/1Vueuhg8TSEIit4ZtG46z0NEZQ+lxllFm4AEkZ7A9bLjuF+ybjnM/8Hw78KIhorZARHRgaw3bvqER0AnYWvxW8CIs9c71cRhtOAsLZg6Zo4xEskP6fJhpXQ2k7kk8OBlMaeb6JPDQxGSFZ3SJoraBd+Ann/wMrTV88fAVXrYbAELDVqjWDrbWw7fC+Cvux/OA5AnDWAiPKFQUc1cQkkKW+5jL1tryFDO86CSxTwiuDjKShyIJDxuT+coC1AWYM9cQwTP/JZgQ1Pq9XwluR6ezLjdaArthZLoxwBqrnjBBijPGhJ9kSdbsPoZLu4tjBSwEydPVJzzXew6S4FRXUtSjjjm+Od+EsM1vcj3ZEPB9H9OVld545iqS17ySNyY0IlrZxoO1fTrBVRU7W3GwrE7nFZOiqKdxzl52nstNfTPFhlKljFCsSDsj+CIfFzPWAODhesGbN2/EO5ZgP/qBl5cXPD29oB8HjB7X8nkKvzrBGjDO3mp7Nu+DWo9qvLfx+MZVjgRjhum1UMmYZZPw9fkwjxXS/TTeKhidn7Eco1KdCLVvlUYM9jpHJDJhqMKW+DBHeeO3VTNSAXyCe+6tyRbC7PKSKuRdQ4oS8I4oBnX5W3AmfCREhdLuxMeNLuw8eaOfKkcnfFGmzVDzosw81nXVt77L++aCR8zOhRxiWPmgl1L4qSC2tjvx8tSxCIHO9VVZRYnR5i/t+/w8jyY4rTKkdm21SIyf6CezSTdh4DUUsPJ3xw9imKWEpfRn5AjUoH9OglM7Tg6V6CFc+YbJOc3er3Uz8vExzKzHLiUea30+zV/AskZanXVE4DzZ8Lxkh4YEG58sx7M8qCKj/M6reIYFQqKRE9vKBo71N9NAjVuwDseMCAWAqFbveCwdDh6U9UAZwknHA8OOB/K6dZhJXmHzFbB8LNDUTdclrb3ocQYvB9YuwPA3GTsx9RIWMz4yzenDYYYWbLxC9uZxsEoIDdTEHUn75ostQVOJPrx9lRNQd5KdbQzBE5dw13TWMQOwFP0E3VrUXB8t+obCMMZAP9RhvMsq2vW647JJH59fBvglvsm4P0bH0TuIGtpG2Lcd+6VhaxpKmQXbneujMdpWukc20HI5wYMw1N4Zo8uekjHs4OrqTXYmklJx50N6GwCz3rdG2PYdXzx+iZ+//QW2bQM34P3+wRmBnBzGsJCR0Ydmekyraa6wJs688pjYpEwokKQk8tuPOzYhQFVoeV0LxTYQOylVtictTVuBh+pniSGaEpZLry9jGLKv0HHgma+sp3asAzxmfphygvOKm2RyU0UqKR5usKXZX/ZbpO77YdVaQV49DIXMPsj4rIrOjINwChCIanpyhq1cJDIAYIeHmjFRjCaI08GW4Kunp15nmRp7V+yrLPey4kSL58wV0lC+YzxOypmVn4RuMFh7X889M5+G1XluE15XDmWugqfCv9AxEKJCy/g+Q3naWinqSo8IzobH6463bx+wNcJxSHKR3mUF/xgDvR84jkVGr4JvgdjJz/FkPXllRq2UpmX9tXxWmr7tNRucr63SFV42v3vFSIzwnVhRyXXU8MHKv7jMl6yyhVrlOQs0zLDM+cSfS7+NG5IqWJm6/Kf+IIDahlhhS3MDNoeUVwfViROAQnH2QKx05h4tYCOiEtprCouwhcqNynxw5wSX3UeCA0toUCTPhOs0dxdyJJSR9VhXelgWga9IvnqdJ3WBWvnr3YhkJ2oOsAnIm6P8U6JIguBwc8jokWkz7QHzYWMr7rXOCmDpvekMrHxpKsMmfKycgtzUWs9qr8nnofiqSftEBjs1SvY1lQ3k04ULLbQ0wzJkE43kd85zzjDbHDCclApmGfiqk6nqBlVG6/tJjMuYhGwWmDMP1h+1I+n5LPtjJd1hoLRix7kWbSfVfQ55Dw7Wmeue/wTKGDydMToXKsw74Leeuy4x6zGKsMKzqtPG2JT3iaN3rMdTWXyC8dAGSfxBRICulHFrurWYJQQSejSyTqLLZcdl22RFS+VsH9A8Fwqt6oOSt4KdV8m7jp02XB8esBGh9wNt28G94+l2Q9czIQz6fSfs+wMASRZj6mMYbGWYJEHVbtQkDpCXW8cxCG0wnp5f8Pxy+OHrMT+0ogEwdYwBHLcD9CIJafZ9x+WyFR1pdX00Rpt7r4wgdbYH4bIPDkPS+Y9b9zPT2BQtZY9E0CXMWAGbk340AMc+QJsYav/82Y/x9fVrtLZhEMt5Hvzi7kzWhjoOjEOWXK2Nu1JpYizLogxAswgOOxslSV8/SHeloXmdquzOzAZngTH/Loab8ptB8Ill6UtXxuIgRj5K8KRQKhOfmTdUOYcKCuHd5EpPIXIb1cSDqtFgfUpC1NuoYnAwuyHkxpYLGiQcZ2UFMC96YWiOu9y5UI8m1csFeTLnlXWe8do8NKey1gCRfPNyKP5WI/kHJ1KbBEcWnnEfiqa0l5QLaCy4MUvAz7QKkiUtZ8I3vm+m3aTECAZXGI5VPcjzlsDaXuAQiDYCrxV+/z7RTl7xmNiq4GfIfpLbbeDzL24Aa5bZCamzgrGapisYKBXmeLAsX+jAvi9lZkM3cD/DUVfxZtjnduvzutpHJxi8L+lZdpBlT6LAGPNpHVaa8cGlX5zGPJiNriiIFgzhPax8rKUZy4XmbBWeCJH1a9g5VQJz5XNB8EShBIQjSHlb8rBXXmSKWyg/Tfc12D+xMmh8McYz/+u/XHZi+g7opqSFYHH+kFhAwkfMWSIbR14+j2pX86CGxRZ6ZNaQserYyv3xuknD/xRdOcFf5j25bxMgcCOtzKfzHMkyQLhqKqvOHBBpindA9pwBsgcNaL7XzNqzMZYexoHJaS4br1zpEcx+Xh8gOgKrwpqlEYE9BI9ZjiralKZsrATdshVAdC2Gr+wW/BnOAj15fHDCOTtFK8gZ/GrQqj4jBnCtY0mMiSrkV+x5MzgsFL/0I9M6bDR1lnJSps2YzWQ6tRt4sY4HcUr7VIvy+evaU/b5aTpQdvCcDfz0nUWcgZeOCqOBusJMp3Gs3STftnvSB5V/dmbQGLpyVaM+mvfBKwQz48bs3pTepUIaQyNYLEqG9Whk8rwPL42wGXhNj2dJWaFszrfWNKQ48abBOI6O9x9ecL02XC9XPG4H2pUA7Hg/DvgAEaOhYcPAfr3iYdvwoqGNo9gLpP9nyRnRgE31pefnZxBuiOiDAU44nFmj8WQwO90e/cBxdDw/p+MC7lwfh9FWhFn6rRkdB0EOtu7d94iBOYVlQe8z0cihhlVhEOF82264XW/YLjv+/rN/kk2iyTDqpCtdNul7HAHAmhLUQyy/YVKY98uX4BO82cE4eplGAg/lKQDPCllQt1C85uu0CM8WupaWf62MeZSm89kyDov3hSuMLoDNO4hQaJDAZw4Du4ieLAz8I1kqByQNKyfFD0jMaUptXHGQWiEguVOUF2cFiFQE8RIHAueEN5jRHEwvIDh/73hczE9b2axiMvs847kJ42qIZFpzqVYMtvwtVBBUL2jUEQ4Ro/kU+ugKqXmgw0uUDwG28nZ2UFbmVs4AUwJtpcD7TbVvzFZXwGww1rrsdxoVSkbHNJ9lrhPAHTeN/2k2vlTrjTlufUVRQjNPkvLjZHRZfWt+Pc/FMF5mI8zgWTk4anuzwvT6ZasLBWeprjyer9RS+i1GQB2fMMrW33o5V3ryfM+hclnRSiOgEpMA3ceqb6Y5IorsmoYsDMr5uq9OSyGjE/uOeXjijswfZvjyvBN70Qy+ebVbD+q2qat0E6paZqKpHQA121RSLNK4LJ1zC+3QcUe2ZhgcyuaSraS60yYnz0h98zmVFit8BGd4fHw5jVe8rIZkkkUun9mrIC9oNFKV50KgOqczo0wYjH+NJ6VXVPoZEiZrdJTp1Mbcno2ISrEjBYrs5Ay5EgUThh30m+ZVI8GRrUgLLO00FwG4gWXV2iHe4SDLMgpwx196TPZMvxkW67bkdYjpyNPDwlFtDDKtFymPqnl5j/TfNAfYJVt6E99JEhYz7KqMMT40YE6dUMSl+qDFxL1LPxeTNfA4D4h3scz21DfWKXnmKzO668hN1Wu/t9awbYxD7RxsDbsSylC+13uXA75zZapTE4B2iXDDtjVHRiPZY1giCUx2uf64kreRp6JtBOIN1sMxeqyAMf5/5t51SZIlOQ/7PDKrunvmHC0XC2IBGLgAIQAkQJA/pPd/CRkkmUiClABiAS5tAe7lzHRXZYbrR/jl88isnrOimWxyz/ZUVcbFw8Pv4RGBbVfsukH7gr139H2PUygBO+hl2/B223DdbljbYnvQPGg7aC3NqsxgcnxprMIa7ajxEs6fmIci2+GMhe1BPX++DqfNJLx7ybCDPHxv2t73encZbHwYRhUAoI9IwBziaW3ct7MsC3728t+gq+Dz5RX//ekXGJNBR7Y7HH0+QETr8fomaJP5TCF49EYOYHglg9k+uyC2/gViubgn0uyEeVN3ZPnijBnhpyhnQYv4PP8u0uIeurl8guOKJsF7GCAg6cDGh7pTN4+PGdYa8GgK6DevV+mCnC3/jccg9JuWAhXkCG1KDM4jkmfMGCsBRWQzBPVJZ7/OS8pjN8hPOvM+2TAo7VYxHv/GUOZVPLFIb601K/FUMDVVtipwho8V7fibdz1PpqscaWqC/tRRqfUZEWYwPghqJN0mj5dVv4DcLp2fDMHoJhwkMrCsTAkqEU6GInIBbw7wicF0/tRCFW7WnK4QzsfLv1XH7xyOOV15xtcMlwjixMOzMbw/Vinwnr0fgbs8qnnuu/Q2N8EF2JoC4wTD/nH5QtaDDgVltnlSSh4iRLQAHOiVAz3+Tzp6bnRpyG61E9zc+Mr0VzLKSA7WVVEEfIy/M/yw8zSjiVNXCyqjgffMv6PhxQ4qt9beyQyqOlVPPk/ZDOJ2UOIZqMHSYvALMkWQDMcsZmPSikvFUBXuDEFtW0PYCdQmAFpcRgEtxqDwE0R53GzsTex4sBmElvN4VZj7igCMGeBOY4/oaNguQB7Yxbii1hXFaYCjkpSvsw3r6oJVgm3gWHBmiQgFG6OfmcYCf1zQy3nPlSgmaWf/eQCR8GOkn+nu1c4YtOAtWYo0xGQIaPTc+6Cji93rBYWdPt6xB22NjJOw9kjWzjof1H8OnwCU/F7qdIVIx/P1ivYy0vZaGxkIr5/f8PZ2x2YOePGdm4zTEltDW0bqX06Iw2s4NnwF21uAIc6tMAcN5Nj5/cIHzaCK3hc4VYUN3/uAUwTaFjuAinE0Zu/trePmZ8W7XmC0KeltOVKNY/HU/iRe7tO73/T5Opw2wI7I7OPywV4dJR9gc8UB2N0Nmsa8E41hZ1kWrEvD2/Mdf/fxp5Cl4ZeXX6HHhZjHI5zVTppUHcxxml4EkIJUmg2kfFAUwZ4qRVOAijlo/k6Iac6eo/V3QjT5+A3vGkCNUYsIuh9D7PA7g7RcOQv1Nxk1RxvK54TmwOuNPKVTwlSkAZAHyxwNcgXGCiMbJY5fN6zI+FEakuOnMA8eMAohUynCnRVSc2ashdnPcaMhBMJAn7oZzXCM0v96NJWMvwLxMZ0w6QdRJlZFylhTaQh4ThVaVlXZMDszumm8OegZCITDS1pA2EuOap6HnuXSiGSMebRfsCxzfDe7P4mtxON3F7Hx243fTx1kx1UcyFOFbwQRBMNg1xOYclgBTN7RVUuznXPmq8xGdR3pjBFebWMuIMOi9C2F3ub0lwrrY1WTq7H+52z1K42cUISq05grXx1xkxFakbq69aied3ieRkoq1+6/YmfGIYpUXZb7QDjeUESKf3eDw+W8FzD5ERflhgNvTcbBJC0MhKH7jnPs8AkQhyIVrnd5qDMeHBe1Dqcda4ydaaGuliYczuP+U+VlII3rs8BAdTBnMFmaJ+2UvR+qKHeW+XiD15GBKaXWhHE0S8u8TiRpYHLi/ZTLUBdDtrbYkJ+nEoejMjl9VUHYPX7WfuAzSOehBqNymmUj6EBZECxrzdH0i+NjLAqyVZLn5pXQkBnsKQUNMD6TeZMXGI+G20lhJq6n8Z/QD1xW+8SeEVpFFFyfR/AOvMVUDHKJcgSVDdfpzbOEqLwi9niNcWU4V/2Yfy9IOBQA11VwvbRxumATdN1wvwOvbxoBZvlU/QAAIABJREFUdb++pyYlJuSMOrYhuNCZzgqZ1hr63vF6u+N6BS6LQnfgvu24bXtkPI20XBRbT5qg2WXjfGpk7wMjmkxn+9qcDsehTX6S6Hbv2Lc9Li4vgYB5pGKn+sLmdNG472/MkZ04rZk551laft5FvULM52rQlsKDzhZEEMBtvXGf3gJRNefa6EELxkerJHiYm2X699HzVThtvXe8vd2DaN1ZC0FpEzgO/dgPl0r7ClVbFqyXBcvS8B+/+c/4fH0DmuLe9iCKQVg2UXZvW6RcIlTXCa/rmaxwAEi65G9JMMk2gkHQQ/6cTA85b2d9CZVLohgtn6aRkCApjpKrHzZgFCWKdiw3KWawsHQU5ErCexdjcfQvZDHI8CJKnuc7N7seh5vtpYMfETE3GrzsGcekuVIcyGw7c467suslNUpJeIvfpDob8yqjr5IeravZYJrGTfoSULvQ24wH+DRUYZ31OFI5nWymGils53OfRgpcEIcKqWlaxXGg8TL8PLaib4nvxqWyll4Y43Re8P7ZEDqqstFu0vn7G38pTYUUNLceQXFWKGSTIKr6CYK+unY0Ah7aGGfvvyDded4Kn2p957/P6Zc5xprwOzszXFIPY0gjP1eIDOd+DHOhX4crZVNrdaApK/J3P6lXaKnm3MH1CH4P+TCMiLGKLmGE+hgHLM14q+xvdr6ntuOob99n0egaFpdH8JSrlnSiiac4veyAM8cNMktDfEwuPV13OV/XOXvk9M9yJViv8OqkdwN2bvSMpjMNtgRH3Gk1meqJZQywOwU5VkNztEsCAwPvIkwbru8cJzZHbmBWlV2ll+PR2necN95MBtJf5nA1GSsyHjCNvYosm9QdFBduSTsJzGM7pPZu6GoS2+cSV2JBT6NJEajQzmsDXmxccZdVHV2xI+K7kAwPPKHwBsNb9OPUh2uHXXvQ/7xC6M7Nqf4OytG4Fgp+x1j0JfBR+Deud3gkupxKcP25bgZgUuPldgL1eeC6U3qmQMeZCV2xXxRoDU06mgDNlh2GLrE+zjwvzUUPD1SGDjBnawQWbN5CNtWES8i4x+zz5zs+21yqOSViGWyqY/Vtlz7mtbdxIbUC69LGPZik7/q+oeuO1ta4bgT7qOupgYqxB3nfd9y3DdIWrNdLOG7nurMGBMQMoCgpvl95KfvkVRWtK7Ztw7Ztdvj72FOnAwUxlxoKbs/eZawoPq0rlnbBvm+43TZsupszK/Bdox7T0AM1zaN5/HwVThuQdy4JgL03NGyhVPdtMwYm5pORStFXoF8Vyyq4XW74qw9/jbGaZIJJTbroiAaMU2563Fmyx2lQHGlngkiuLUGeE+03iEZIcHl1Vy5JbLHZsPJ7tvUATyx+4iykEJzsnM31JmEs/I9M77UyrzJGDJ+VtaMt9eiepqmXsnsS5Cx0p6NCayCOETp1GHUxjCTCIadOlZQUrivcGfWhKGk0AimnNg2HpQwgy+k4FzP3EtBYomuei2yHdMT0sFBHpTGG6UzZEZyeSuHC3uV4jfkgjFV26ADaSyG5gjIlOuKI9GlkJHCHsSpn7BTtu1EkyBSJVEInytMQ5ClmLi/8FV8ILIWps27gWoBymiCLhImUz+CvTyqVagz/f3vUEm0m4E/g4FU0hEMgMg4JUcIH1aJPxz14aTCfG5ZF1Ej2GypLZ6ydE0CsftlUeqRzvJvSbCgwMAeW0nHqlraJJCwA5Y7LUangxPdvjCKsL0zqapbl8XPqrf+v926Ltx7ttUNQ3LjqNR3fYeudLh1WXxXwFZyGxS+jVjV5Pq/YJ8/4SMMQSWwR3vzQIceJHAJocCPmLKARSOhxH2GOSQBK0+7+m+HR9+w57Qp4HhGGaOCQfp/HOlbYUxa4/E/aSploE4KyBGF6RJYqIwGul2/8GP2U6enAqfYx7Bi7K1cNPRaBAw8AeCDNT2JhCBjMjlg5G/VSxpQAGlw0a+BpzvSJXnxOxNL6Zr0Sw/QsEXpr/FQM1FmXS+LMB+kiOeFMnYNpHD7dou1036XDONN56GD11j3wQeOPfnicBWz4i6OJ4s5hpQNug7R5abz3jk3tcI77PWUGACwCaIOGIxEICtxXveyygMZicPTxJ9Wyz1U2WcYYK/2tDYfGGr2sDX0f5bqd3r53xb7fsWEEp1oTuy5HsW8b9l2hckdbVixrw6U13KG4bxv6Xq/gEsFYVtx3tH0f/Nhc90mBtC3NUw7yDdH2kPv9oHeXRSBygTRzOHsfAQQFREd2D6RhWcROnx9z0owm7287fr19xrIuWG134yqDJnc+eYhnmkE4I90Hz1fjtPmz9w7tGzY/9p4G1myyfvH8a+hFsSwNv3z6Ff7x+gu4ERkKAKkw3eHb1ZZLdbw7KCB6whgAUA64EKWjcdOgCHlSpOhgBDlEiun7OzbbnCo4f4/4nYjlH/t+KoFKpjJkMHKCI0SXK1f7I1XQxqsifH1jvTtnD6KC0yC93cRt6NIy36Wt4NwHDwmd6adjW6Ts6ZdRjoGKjxOOor3Z6LRSBySkQ5Ij16mEl6sCyA2uNErqBtdDsInBkfqKGw17ZFYyp9Ik1BKVnAX6+08oDDn+zvu53IkczsTciNk0VlaVjiAOo0PSDmpGo3SpY0lzm2EnHnEejgW4E6Tz5b+818GVRE5NGkbnxH3AFmYaSABnutFD+ZkqD/tdPdrZe0Zei+FQNUmJY5Dzwzx0nFc3uI+8Nz9cJj8fRlEMdF95U9U4+vy9J+Wmz4XvMunM9GTY+Oidzgxn6mnH7khkhLwEymaCVyfLnuPYTc4qxp1EQgUJW4pKt0xCTpZjOJ7Sfc6pGZeiwEHgowZNQhSbY0yIzBuOonxqwuN8e72GekNmwpbzDdMnox0PwKvDqkc6czxUxQHEaYAG0GBnFzJZfjjClY81Tib0wxN8fm3ewbJKpjHPXM96UVMuBMysgwbcvEKYHG9/SxaEf659PNLF6seuuz3UWtEbfJeWNBl34kaB/Lfu+zW8y2PdW+v4vORUzCosWnB5rEo4Txxk0Sh4sG8CFslV0giMDMIKeIico1k35R5JF16zY2enjD04SOdBRncCwp8Asow9W3HPb+/YrWzTPODD56uK2JwTYx7qxWi5nLycDVT+5NVt5vkcsQfFh5NlRSRtFB2DAGQsjvTexyK3dui2j9U62bBeVuhlhUjDsqzmIBlM6uvvQ3e9yAU/3H4LUOAf1/+OO24Fl0qLP7MSOhNNI5uo26GHwz9oGNdVLaqxH7HvApGOjgWtLRYsyyBG147traPd9rGPj3StGhyRBo9Khw7dYOH3bIPxfBVOm6piu48jtTmPWkwTtEXwt9/8dNyMvjT809MvsbUem5bZ594x7m3LjYwaxM8R9seGdyrJ+RUrfhCyxzsSRByyQVU4xxRGkpyT4uQJzGi1ZGf+TBEmRaYInEU+T53Gok+1EDtrS470Hh6SIDl8CWVcikz9htDTOidR7BxNk8Ci9ljJUx1nZt4vqbMmeOQgsncOxIbWGRPOnDN1pWFDg5eMs8/dz9Psv52BmX0ZfI5HFrrgvhFGSRg0h/4lYKzzQEL/BFVHej/TVlWBzHuoqtGSdk6Rwx6o0Wguf6M2AMTulDwc5HyOy94qw6HP54iAd/g9XJ4ayiqw6wiGNkHktYPef/n5Urn33rshOeDmlXMf23n9M0qdZIrm6tKRPeoPjH+u/32e0fNEo+F0zf3kd56zHk53KtbYc1J4/SjjLDmpyDE2kBWm5BXw1ZJZthQWRNKQ44EPaZBCrwgabkFVvcAPw0fyo6/kAbB0bXUng4wKH1AzIcSyheUNgWCfB46cIlgEJo+PkqEDjb9YhTg8Tpe81yTnMDdMncnD+D7BMr6zLMlLxwFJ4xcurCXgLTKnZ/pfigibB7dN4hmnGR8Cn6iyjNPrxeaQ99alFRGjwgExpDQrzv11rqgyDvMwEg/oZnl3Zh0PkfkjLRyl6NjmcWRXsiaPkeXYGeSJRtSyaZhGyhDZVgEq8YBoWfLngLUoxtzTnyvPFb7yTSUuY/b9rC4JQgeq/SLRBfIkSa1zPmEkZIjQVHp7AfMkc/19GwsVqyq1mwhwXg1UFQD9o5Txl1VXyXlMUSEJK8t7zbGNNnocGrgD4yRHLElrqsDSTBeOkyNXGfcp3xdBv42tSds2TnlXaViXcRWADFKxFXg/MVXwLz79Pn60/RZUBB+vH/DWbvibl5/mHJOMHGNPxPuBTk77aun50hW6b+g6rglrgpGSaniMVX0Zp076VTCBZsFIFfVxC9BFYg996E4mOcyBFcUP7t/iR/cf4kvPV+G0AbDIIwDtkGXBuq5Yryv+yzd/j19dfo3P62uuWIkdr2oyzpXU1neoXcbHuopFwamvIckKHj3JYkUDHxA9dOWkeKfvcvKptpKAMuPHB5kVxrElYeAko2SP/A9X7jW1bXBoxG/cSJvKHlfhcoVJREqKxCNjLQQQITuMHhpKChtnknTQj3ioEa8h1GtBTws5pCWc6SL+MQwbTSkpTgHWZnxnrLLDau/iXifH9EQhMejjHJ7NZ9KKMYSQ0ZMkEQ6/YzKjPOcP2Z+nPeqEfRbwB4MIlRbcpkoF4rxJjlgZ88SVwRPpnLQmFVaTDb1u0wxjpcJqtAuPrmX9MdVqqb+uX9MwzoZHR3E9iPML2xOhUKpDx6lfM04DGBr3WVTZ4eTytd05vQkFMQMPzAjcxnl/A6Yz5skZHmXIOCCarP34HNQ+fZ6LYapET+yc2Hg9FV5pjpEzS7JG4PvPPCIgcamwYlyFQVFnX5VqmbYn0DhGmjHQiZBGf34QhBtgmQZI2zNtPM6lwzFsswPmx75LrjhLoxQxZUeRdByT60H+07sTHimyUtJJevxwemauTMXbQpds9I6x5fbEutJqNcYMUXoioHkHGIGbNUimndxQfLonnLDkGY3HFfv8NtsHh48imW3N1rbzgrUvQB5gQyc7DuMTdm+bB1KqwwCMPYIO35kKDtnvMtJYtjXXn7w/SAD0JFJERRo3C39/JfH5EQ3mM2WkkGz01JAQF8ELuTLr6acOtwdWNGwYckTDRCDdDWAx4hi3L+XesQKO1c30Ugl8Dxw4Z0uuLpNDwfRSUkWZDqKcfZDJpmAhA5/LTK+en9leq2SZsjeaFv4hce1NdwWaKjSuwjJetL1dcGjHBnS0RXBtCy6XdexxU2DfO97uN7zdN2gnGoLL+EEvkRaqAumKv9f/hm9u30DQ8O39Wzy1Ddv1b3FZGq7LwPhy6dC9QVVx2/ZxmbalKqoC2Hd0KPquETTTbRyC2A2XfpChifqh+5sfSKaBHz+fotG8RXDK5bLplTIFzEcAPu4f8Sef/ghPeqUJPn++CqdNoejXjmVtWNcLdBX81Q/+ryGQFlf6djFq79Bdx+XXm6L3ncwUBeHz2I/mRdDBzM58ClQdRFFrE6QVzRm1dAEgfnoVT1Zt8viQkXL6PJo/NhAe1S3NSAj4eEzwWyPRWWHyScnPBtzc95zO6dHFs3GEyJP63YZX9MM0NSnLwEI+lSn3UfyXULixxhRlGJ9i8HudKVEogMy+Dr366GiMaURxmYozb8Gti6z3yAHPXkcFmeCdAwqVQSbTo/BFimr/Pqqnk8EOE7fBTwpfUircj2nBXDHwjnJkx6cK+lGK9xoB2z5FxNwoIjQEDKrw4/3dNim9TnibU54dVx6x5rp+t9FhBI7j8pL48MRZevQbg8jzV+xC8flVglBKG0kPGmm07zrfB0viOI6Qse88zB8ofWZUlB0IXjHjxbN0pGgsZrRNjBC0J7pM4Jus7DrSzE2ptNYgFgn2A3pc3jenccmeRxrTMBhC7kiu/AHpHkpb8jxj1XKgytjK1MOikkkODzklEBkHFqh16RKgyOscIjxp0X8ffDrzc66MhH1Jf8Z4HpyiWx6eWwSeyFfOMtQf6yxO1/R0qQRe6VTho/wJmpYW+HFcz0GVatQmP+eeIYl3ldvndMmpXUJFdVizCeXxcfksMEbiNB90kHJu2CrHVf5TiSUUpLX2wnKndn3lau+Kvu9YpjGq2Mqen9qgORo3jDP9/5GMG3Pt6X864bv0p34KYeImg3jWVvQ/vkcrR0UOdMV2u+PWRwBnkYZ2WQAZ+6hV6VTJYpuoq5VAMK9p+r8uf+ZMpXbgTY00bG6Dg9ZeuNhL8SPR6wFrVnaa7hkVQv3N2VmO1a479m0f25isr6aKiwLd9WhLB+0uN7zdRyqjdEAbsPdxHVdb2nF8NoplWcJOQ9vxj/IL/Kf2X/DHbz/BgoYXueIvXv8Y//cP/w7P1xVLG/2yHr693dEV+Px2x9vbDd1tCxlhvGaO57b3oFftHT0c0CGDxfA7YGlwTHFqa6zO0QTEQoZg+AgCqLbICLnuz/i33/0rNLXMjUcTZ89X4bR9vrzh//i9/4BlWcZpLzbIoTDt6SOlwnNjte+Hzc1ffvIQ36E3JoOFjBs+slgmyk4hmek3RTB8CetnkAVTlJjQiamTK02n6Y72zO8Ck5J9SKe89VnRsRImhfEoMusoKeanC2QjzvMoEA1S5hf0m9+BpyfwcqcskMJYlKmcFiELLkbwPsYNQgAnPaUTmGlAPXunPQJlfgMBLipdsVmrwfg4PLPAdYcqWiyCX6ncGb0co3ThlMW8Vsujpt5OdUrJVNwccY23pMDIfiFnKvmrTv8DGMAnjkoYe71ED2qAxcM5edjDGZ07HqtBVJyJAw7lgI80BedAgNHAAyfu7Lfa9DyHJ9bj3JLSzJLxBGRKabQuDh/LwGonpxHm8sfaC2OQfkOlBcdVrMzEPt0xlrLPsayUJD48LU6kFXhn/BQcUzucwjdWbgftjP2RgmVZAVGsBm/f1RzK8V7VTj2z4/4X358CxWUZx79vezfDQtE3RW8jWHlZG273ewRFHLFDho4AGMygKEawpFz2/UhH8s2V7PQSBO65evHDSZ1Rl50k2w9ZjO1HMsr15LHVpJ/c6zTKnmfEHPhIfQXDxmMOGczAHsZ2R7O5CRyJjcFgYWiYtk9h8DLQcuJlOA+ub201jFdTQta7zeCGfNl/njaJ/5aiTIe1G3w5cFuujmBTxqeY5BZCT7HDKfDzJLsqsA36VKO90EE+X7vivm/weR3yuaFd1hiTmoF7uax4fr5gaWveQcu6tTzjcDmSHoWogtokd4Ts+4777Ybb7Y5d9xi3Z9w0zESp1HeV53vv2O/72J8kghWKdV3h213mlekMkjKevQ8/5Zp0FWGcy9WAugX/eVXe+NahbWEjJkRp2rCCDHfHISVUHzU6Dr8QZ2iKXNVB3+qy0nrvCtztgD8RjKulYM486Ton4Vidsn9Z/SgQcqwFLgSLKH6+/hP+mfwAP779NgDgsj3h6VdPg76WBU2At2XDZ/k0aHEf8mo3Q2KkWvYIjGnv6G3BsqZsXS8r1stlZFBYwEwt/bymGrt2GnzOB+c0AdZLwyKLneKtuG87YBfeiwIf7t/gz7/7MzQVvMkNn5fXgwyen6/CaWsixhywgx5NuNjJjnsfx4F2VUp9fBzVev85J1NnH8DvbBtMIQPAEPopQ+rR0hz1483eX+j6AYSe5ne2CqegA3vHL4KSkvh+2ykw2ZGLpuOjJhwOgys0H2OxDaQ2EA3pYZ6iDhm0Va1MLZIBzsLjMDbrx20THxK3x8N0ccai1OfYV239AsucDxbMWr7RkKdfjqt0k6g15egK+zi2ahSZCCa8RtBgEsbumNS9bGkYVMwc+4xTJNWVMxkfxIP+LxvWByPODQrNtAT60ZQA8ZIbEcRr81NxNuRFp/Yz5cL5yp88hjt+EYEd7WZGAam54vAd8ZU4qCsgdTxnOLf5mkWFHPthZ+iIh+jBWneDJ+kk9z9JtB1zoEe64O8cDT9Ph6xwjRUNjXmRUn6GeZTJfWcaTos6HNyFZF1/n3Q4nQIZs+58kLLMLQUPFhQnnmD3WHIDsG0b1jbuA7pvI4VKMQz4bVf0/T5ORtOxWvZme7fa0tAvVygUl8sK0Y7bvUffr2+vuL/ZvYGBnwXL2nC/97hfaDglOvZ+iIxT1FqLUx5Vx6Z4uP5qLe5Lapbf1/ce+s7vkvMACcuqlClTqE6WYcjYzEoc/FHlEcuFo1OXNKbk0APZxvjccSYXz1aMS98BnSLvSXMAtQILwLNk3lOjwzkLq4z/GfRSFF06fcG1zL42ZhHYyXuGE1Je7IAJ/OCQNP1HkIgCQGoaKXDpey+nPdsKjPRW12mxJhVFutMtXe3G4nrXQUfjmgEFmmKRcT9uyAoZTtXbTfDyvOB6uWBpHuzMJ3S/0Ui1brxvDmgqFjee1xXP1ytu9xveXm+43e/Y930YCaeTGdgbzoXt+9PeoW1BW9TO9DFe6t1S/qTIhySATJNOF0pKT16eV0tj3DaHIY8wVsydPti2S7vtMJngWWScImA61gRmnrIyHOBweoxAhmQwqynamvfGCRCOkBC+wn4i2mY+FEGktwQNa1Kki+ujDhkY/Wb/Bn/x3b8avxi9/rp9h5+v/wQA2KTjH64/C804htOCntXmt+kO7S5Xh2y9rg1tWQHtGIuwHlimIBhPhY2ttQHL2lY7NbPjft8gXbFDAdkBafjYP+C/Pv8MqopfLr/GP62/KKuvZ89X4bQpkBFqu+R6h4bT5pkhc+T3fYctI8KPVqR0ErDqEUSMaIbnorrhXmi/CO0z42o2y94ZPBVWcMrC+bPIdHeZkoIgQ/GxifcABhCDGSxVsaXAs24RaHEFoCk4Zt1IdhKygeiYoqMElDJ42a9ALcU1U1697ZxWrVg0hIRBW+bTjLpJ7BEmjsjKIRLeXLj5Mne2I6VeiJAHzpoefstl+Kx7Pr8cHa12AmxOlcrE/DDe36E/xrH/27sbPogJznka7ek0p8XRQfLj+D2N+IPTLzQuNsLo8RUztUDPiHovgyaKHEh+GaB5Z/P4E6FiMMRKP801O0YM/0H20HgPToZwqfztPC2R2qT2PJ076ODEIVPGXbR/HPtxZVZKOX7PJzsWB9b+uJxNp85XqmiVIMiEglZk9YcxIGkIqdY9ULPUcDqAyde2LFGmd6Dvd6s67h4SiN3HJSMCb5fC9r5jl0Gf4wCDZo5iw+UqWORieygoyyBw485Vg6rgyR3MDui6kHNhPCHNLqftECj2fRjh3TbU54pQx753bNsOwXDEBGOVb7GTG/dtw9030KtA7QjuRQSyLpBlBDHu2wbZ+0wC09wD9RAWCSY9rqDYXChC5tSVNTe9UhgzbToPe3oeAzbakpSHk2c4nLdIOqWpkPqvjPGkWjpKVYnRJk9yYKekSyvSgZNJRofIoHFKfnfDtfZa077hUKTaCxxKoJtxkbgNGcsNhSqcDFG1ezqDz60PW82QJflbgVy5IJmnXXG/beh239bHjx+x+HH1Yid9s7eN3FMsGIG0OO6A0SiuUcaKxuVywdoEl3vD623Ddt+CXyjMX+cIOlKEBePAD2m40J5IpTpOepUC/Pc82EzLvllana5GVuA4g09K5aRWmQZ/2JISsCQvUEeV/qjNR7ZD8GfBlwepJWlGBIKGpjUA6lJZAcuYY5U69zoCV60tUW+sJI5rA/IQoYGj5/6EP3r9Q3zTX2hI1K8twX7sH/Dh/gJA0Ns45CPKi+Lfv/x18pACbQGA1cY+4Ni3DW9dcLksuCwL1iZQGSnkDJsSjYWJhXFIC/oNW7Nsi94NF7bSrop/uPxsQC6++v7enbHj+SqcNsAuuYYZWKgXbJtcs5Lfs8UwANgwSgUPFl7myosM4evHeZ5aRgAJORL69C5H9T2egz1UJcOZAjmmiZw3nYI5hWIchkSeFCucwgD+7YzhfOix7KUVrmKAKf2WaQCPcZVzE4LR33A1ndQof9FJSD+on+OhaBUbFe6ECovvntWFF8irwUCqFIxha3ZympxOTQWbIChjn0bEd5Y9IoKYOko58guefQUrjXXCuGohxUBr9FmNCFf4sRqkaUrkH08zU0DdqUo4VT3g1p0lCz7PnFrHS9ljNGoAImiyPHCOSKXZRHTldk/wKQBURtq2MRJHxc6uCYpIdQE+FXYxkk46lIevsz0WU807dCI7lK2GhNNeXUmrKZ3nKZ613Sqhj22EMiOYVPPI9SingF8exPaOH+2vOM7jKKvlNz8GPy+xFiyxH23Htg1DUkSGwXe9ADpSpLb7K1Qbet8BWaAAliZY1guuVzuSGkBTM/bU6RpAV7RlvIsoFDBFzAWLH1wiCt/n0LEc5JNi3IPURIDWbeO7YFfNvZdxnDlw3zuWtqD3Edn17QS7KF4uTwBsjPuO1/sbdN/jwtqn52dc1wuWq1j9ezjZkyl2bkCHjGR+Q3GsMpiV4zsGBSLxrMhloiRyDMb8V7piOWwQ2dHjICcOREZsePErl+2pY9LaTX0jqPrP1oWEyqGyY7HltUoll+cpTw2CojJb4A/ql3pjyKe4ypcGmMOKtgNyY85ZfhV9Kh64Hqd5lxQuDlCx1qLx7nvH50+v2HvHtx8/YFlWNBxzKHy2u7W0FwfW4OyaaZQ60t4UgCwrrtJwuVxx3zZ89/kV+323BUet4zbe6d33yjZLrbY9VDwnxU455tqMAM8YZz/UUwB9pJwuC3bALjtXaOyLQsxtWD5GZvW+de45ASvzxAAzjcUrVzoU8KJiEm+0VnTW8MBsTAvRpR5XqllaFPsgaHW8e1oWXK+A4AmQcV/b6+0O3REyv2HBv/3uz3HVCzy7ogcPAIhAr2Nn6OrWgd/qPyCYFP/L/S+Dd3zcY5FiIO2vPv57/Jvv/tSCgUNee+BITY8Nm0Xxs+vP8bdPPyWcpwzau10YH9ajy7QJSTY3ohPeT56vwmlTVdxu90F8c0S6ylEcv8nJ7/NvElZhh6aFyAyzyGTQ2KspQj1BPvVVKoYSD5Denwtr8p02o9faUF22n5tLAg6Qi7NCfRbhREpoksGAGX/vMPejH1LcjHlI3qecZ7hPPGQKAAAgAElEQVTwCACn8SLhZSMAqBdgH8BwIZUpXtl/TT5ghZl9akRy3NiYoSv72CTxnqos96voVIbpKQ61saezgxodmki0htIJ4Khy5RWPgE6IISfJjrwlw8zbGgdqaPltfjKtjBRKPENF955C0mk39jHpMCDj/iQBmrCS0oC17mcbR/G7wSO+hEFmgfKARGIO/Td/TSdlM+rAuez+dBprKUxjzwASTnAS0KHOYfn1UO8oj46rcTM8x7pHZ6e+d/ri71Ofs+LXXGVm55BF4ShnvzujFACINoCQpRzoKA4BKk2P/kccfV2GJFmWBfu+4fPnz9DesVwueHp5xrKu2LY79m3Hvu/Y/Rg9CJbLBc/Xp5HS1YREZOVRP77e7BBcRNCFcCJmfCnGpbja48Rh1RFIWxqAbiO2Q3vG4Q5jT4UCENuUDwgWQ4YAwDr01tPzM3rfxh6NXfHd6yv2+4bPtxsEwF1uWNaGZWlY1guenz/ivt1wf9ug24ZPv/4Oy7rg+fkZT09XPD1d8Xq/4+3T64A1JP4JzRCNstM0r57D8QUFXYRIFJRG3Rx0Y6PvjMydV0S4rL2RnLPZDyguYVV59NsUMgsyofa0wu7Gf+80VIw6ubfLevOmZ6fQ3rN2NG5CYMhoSYA4bc9l26zDGU/8+FUooa90Hu9w6kZsYvCHNERLBI0FE4o2Defj7fMN2+2OZVnw8eMHPF8vpEfDtcqahSwo80Ux7i7j4NIQ0lAILpcrvhHg7e2O29sd2x45qKGceatH2DiTOTPzvNO+lvnQbIfw2+34+HGAkaDvdnG0zeBYRc9V7uPjgsPHX0ZqH5nmxrsy5a57uId4MdpnSpgtAy86cWd9T98BYgNJfArTqI5hPe/PQ2/fgD/7xz/Dy3LFIoK/vfw9frb+HCuuaKJ4lTc86xMuesGlX8CB9XDaAIulM92Q4pWUUQCw4DKoWHhlX+Ar7v/rp3+XMAeKhZrMfv/w9vt4XV7x88s/GpIauiRIIYWCxwynocySrjsj+8HzVThtANKIOnl13GNRqnkpIta6AuP7XKC5giIWqjnu7/B2Ty2rnIBD/wegg1i94rlBdVb1nXLHJYdq4Dxq8x1icIJpyFN8DGSwQom9ICRAizAIx+J9WB7BJwXEM1GSLcvhg5eU1Hv6zphNTqfR6FbV1Lu9qsoDWZbmI3AsJwLNOvQ9LJMUjs9p2HNaj6WAurMR/HDOMfMepOzBo6GV3nNPEDMACz42hAyt9q5JvjuiOuFzoy32vFklBcIR9g3fUL43CHEseuKZgASA2PcyzAcBRTDhThjhKsbtX1gNGR7k+KqO7yAJpn+znMgRM46T2kZdJchymQr3qI+T1qn/NMSOlDnTYa6SeUQ75WOmnzjx6ISHWXSl0ZgOdT8o18rG3WglDe2k0WGUaNBioCWME1h0tOHpehlkJg377Y7Xz68QKJbLBZfLBU9PT7aX7I6mim27Q6VhaeMuIVmuSQcgkugaCrfDabMPOm0CNw81BqbQcVkR1MdnVnITl3u+dNDtOH+r130TvMlIMX4x+TXE88DJdr/D85GkKf6nbz/ift/x6fOr3UHW0TFSM3G/YxPBhw8veMUbboKx182Ye7uPgyZerlfst23sEyoUk3Ihf3c+Zt1L82eyDELpQEVOJX1GeiQ7Hk5Pqtke0Zqv3M/BkpMY1cQxUt7Nb6TJOHgBlA7o+mMYEYNHmzlUToQxrDEnM6sVOYOz92dBDUeu89/4G26dtRFBPg+gaNpXJdhoc5CZxanPIsWbevOMhmYpvj7XIbsLnIoyIQCgHfs25Mh3333Ctq14fnrGZV0DpnRQLeNEFTuGjB/xkT6sFZMnfm/Wbqh2EbUsK56fR5DifrvhZqtuRL2B+7KSO4vEmJvcuza9DXzFMAG6dkGAJthuHbf7NlDSBJdVsCxFxKRN4Xhg/IdtIdRfysLD1YchE1nmZ+jFPx/HC8OOB+AyyyjG7zRDvBbBTkJZpC4L8Nyf8IP9m1G2N/zL158UfdFten58/z38Dn4PAuDT8hk/ffoH/N7bj/Fxf0FHr/LA/g1aAAFhcxuk6dkQ8Sr5YFb3ogl3dtYDawgnD/jU3vAmN8Dk60FPe9FJljniFMS/c58nz9fjtNFTjcOjJOXoOEdf7G3UiTQwl2amLDwdsEZnkcg9gan0iZz0dwcAMriMUdm4OBVqX3xO8FG45RHcVek4bLXlojGsgVq2tbyHKgXckYlG32TUleaUGGUee7aQapzdwBQyB8PBiOZ8cdPnbV7RO+JekDoWPlYzjlxbR0TSJSUPXPOD0jvt40Slo4Kz94ow8GeDRhnaQOkZ9K7oeRUrxwXUE+LSSZDSdxo8+d4VRLRFDig7rEdDI8dXn4kPNTc1D3iMbwQlsuXjzPY4KScAYMgKm9WV6fOovcNVgh0zIpmZpe5rc4PDrwyZwEonjOTO+ZMvRVIhnBqkDNP8a7lUurYxt5MGc34Pp97p6cSgrDBVwDgtrjVOrXXl6PSVUegj6kk2TOOeqcPx35ZlrDz1HSIN69qw7WN/2P2+4bpeoF2x7TuajM/Yu/HIuPhVlwFLW2Tc5aQws1EA7BlNVbU7uMT6tzcKoCV95jQOJ328Pkn1hpizRfpEGiDdq5ts0qA5R4t2xae3Vzu8q49DIwRYlzEXy/UKWVfc7zv2fcOuwHq9YJWxujfM4I7bba9BIOv4UVDzMAskf8bltDyHcizzoMUStLE5yEPLmqOc5sDwV+RGSgkFJhp0zUD6hO2PkvkgJJM0AwpuZ2A49cK4cifTyg2nasIhBTNmfLp5GavVxE/jq+2tM/tGrGC3d3l/WKrsMIuQK8mh5z1o6JNjcHuAIKSSi9LJIGXHvc5B4v5223C/33B7u+Pl+RnXpyfbR9oiyJ62BiwNeeAgzj1QxWzHOF11c+audj/Ysox9ddv9bnd2aSnveA68cBQ55tbL5cxg+szfAKDvg4f2MCQsZXnvkNXmkuszXZKKSV3ge8tMTmeB0MfvPWeyMhqIefZRplD3ftjZjb/C48hmfafopa/4nz//IX6wfRv2xZHlmdfHLx/2F/zJpz8iDHSDJZQ54puMu/Zi1SwwNtm9Vj5kkfM5BzOE6zvWKOhNAfN/Wn+JX67f4ZDsG/IKlslFgoUMs6QaGtc7z1fntDnBsgGQTpyW3wCaGs1pZUZebDM5R22LYOaHbLnckOiIdSL5MlIfO3MGMIdEfgOH7WyviQtRRtgcg6xGqoFyIrAKnP7PwbFLBREGyWkD836mJH0pJVnMENPQv1JasHdUkGESLud0A1c2R3BneEqHJr2C3nwZW6dpU67jOK2EHApulmr8mQ0a+pQ8kFg6TXvRLD9oZdobRIVzWvvh3dmTbmPFoRvTIwpqGf7iZK52QIkQ/9LIbFy5AgQcZ9p/y/fsrFU1aXQXRqZQXRbaaifmtVIP0zdO0SQLJMoWftShDOr+OR+f0SWJkEzHOBtvPm5E1JUHkBN07LMOJ/F15uidbpSnd1w3V3aV2kunIp01PW2vjEq00LQ/TWCnefHey9EXp+fmHJy0bvNyv2/Ytg1La1iWC55exj4gacMZe/30Ca0tWNYFT5crpAm2+zDqhlF5g0iDtJHqtIhgvYwN6QDs+H8Erbne8VMa0QYNiWqmf7Ps7xhpU2orrDL2YPh8LIIwFFyAqJ9gpmp7wBHyv62CfduwbyMavW1bGuGLANKwrOMktLf7De3tFTsEbV3x8nS1A1iSGu63O/a+uxVDaCfn0OU6zVU/oTMvc6Zvzhw2Xh2eazi96UQDtR0WjChK5NxBrGmfpYymPvP00DQUTyLr0VdVOLVbK6T1+9jNNejpEGBlQUTzwNB5CpeI0R4jaAIk59B0J10XU5SnQyi5Ohq2gQ4cZPiObCaXwbaH2a8xTJk96P5227Dvn/HcFc/PT1gsC6qHbhA0GbrM9x2njcfCLrHgZQBz8lTQloZLG6eU4z74hMc/PoeyRbkG50AzVROmrIxwbpRptlJ7uV6xrmb8W86s2DiHz+yyrhv6s3+yIrJPHbJXFWNvLc0nz+6XdHshdh6n2IoqjXciiVNshHOjwE/e/gA/2L6FqODD/mE6TPARXNU+D8qScU3KwE0LPer0yDYTKtQhBxVE1p4THHj3BRalfr1Jz34YjQrGeu+n9hk/vf79XLrUTzFgf6W8BTvgWsnq9PnqnLb6VANtNhaGzGCjJKNNcUxr4JmVzvGpzPE/9hzwboIn89j1/Y6E4PUola+miYy77PwOl5DA6ayVSEo0o9nWF54ZPhZqnYnfWWWKwuawj6KmMvex5/KZOPHUuSTFTkDZb9lMCpoTAaY4XiEw6UeWaTUqbIVcgVq+gHqjVsTnJV2MjLI6bhOyVGkFb4fxT4YCwaYxD7XOHPzonVIfaFxnkW//WjaruzFj/YkJI+dLQMLQZoctjSyOdjY79U7ImapwA2qOlFD6pEcAc7JG382EuRtAiFlw5YoyD0camL86ntJxGj84uOnkzXPlof+GNCbS0HjvKcLeU+YMH3M/wzlkJuDmj9rgcQDhkZTw+Zv3uU3G5YNRJU2dtc9yzMfCfSbM3Q4Z8Rl81JanUYbh14YDtq7AelmgfdDTvt2xS0fvw6l5en6GwO5t2nfsveN6WYJHOuxghW3Dgg7d9/GiLePAkmUcw78sYz/argD6SPPVvmO1nCjF2JumZsn64ShNO7rkBbEAoGInrIngdrtD+47b7QZPWY87sHqHrCtkfUK7rHh6apBu91ndbxj3EwFP1+ehShRx+/tIid3JyJllDMl2p6fQKUr7qSRoRHDkNM52qM8ZjZ7LvSx1lH8ZQCD5arxa5RqPL+l4DF3jt8KD0ZZGNU9cyPuulWCh9v076ZuyHxKk989Qojxq4nTVMAQd50VngewE/yUCgBmIVDca7U3nzXiu0uK9ydKuaLIHEuZ5TVnRIHbxe1qxEsJ933d8+u7XeNs3fHx+wmX1wyYW4+OhH1hfeOCnNZerA4KuQN8VrTn/D9jG4vmC62WcEHu73bFv2ylNSP0apldgniplSp7PyIl8b5ZO2GwfFusmJK00GatT3Vux35kMGnZIH7hz/G73Pk6CtStAZrk8f3JqVigWAKKKXcoEz5gAUQsWbWhYYtw/uv8z/OT1D+yQFcRBMk3HWpuoQqXjwM6Ff1PIh+xTBYT2/NkGYYn5Tp0Tc8T6NXA35k1iYEn3yU2mMyBlo5Aa/N7OGKJbdR2bbPOgDk/hvjI1jzN9Hj1fj9MWWrrOKht4tbiGcA1ijhO5kgAeRffee06N5QeIPctTnYsGSYWOcEatRl4aPBOXAhEVcKJj0ZDEVVcHYXpH5Qj8ASMHhy4VWmVbMvKtXhFs3AEZXmcrWmWIk5KHz6/hIi845yXs/D2Z2htW5+Awdt9DgI+ljPaMbNggcIUb9CU53gnnZ/PtNTihIlNueKSngBx+KQEzH/6DmsOwitIpvE7rUKRK57S4Cl9xoMHpQ4I0oqlfqjf2AGjo8jrS3K/igtXhzhVIk+kOjybP+L6UgN0dRpKgnKRCmETvucdOpNUVOK97ovgD8skJPaHGyVFWmj+GxmnZ8fGINuw98dxxX1xt+1EaeqGR03K5oj5HR38T2euQlXm3NEo2kkoikQI0qVAde8S8/7IHWrud4jVqO38ty4JlWdD7jmZHM2vfY0KWpY07RDFSLQXDmUPrWLrJqMUMS1pKkDYMjdv9DsUyTqq0sW1v93G/lZ1IiSZ4ul7R72Nl7G3fcb+9YZHh+O22h25ZRkBDliuWi+BpGVcCjP1mgosdtuKCf9/vuH9WWxFseHp6wtKW1BdqKVu2l6064qnbyhQaYdZ0W5sRMvA9C4RNP9ZTZ7ImgykJX+GBCHoiaJnb9f1WKc8m/mBnAVSRLqEUTIc+gdOE2UBMJzT23Ma4GsqJm2wjGEjF8UPKM41aWZ51Eu/1RZmzBFKRYwm9Jo1LnUgBsx6829gnTMaG+vg4zdIOKHFel1lu8chqj0NeG25kyGe83fFp73h56bher+OSb5ubpZm5qjsUDao7/GTY1A3j4Kq2rlCM65EAp+8Viw1jxbg37nbfcLvdzHlTgC+RD7wwfmn+Ys5R8MHCXAjhYbPIuHKkXtuUGBO4Dyxx8akyP+1j9xR0rLSPwNOOvQmWy4q1tXF1VvhuNIbx30iftdW5pQG665B7dvQ+D0oAvPQnPOkToCNl9Ue3H+LHt3+eMyoImgcsGET2SwYVkgb8IKc8vXyWCRrHL7dFcG0Ldh1ZEug+p36x/Kjv6eYhdwLpdQ6VS81iArNkSXuKrTUF8M3+EX/6+Y/xn57/H9zaVurI1CZZMtVerYW++Hw1TtuEovgnkJuaJr8IjJkFPOEs5H5zh42X9ycAT56aHpXK7rRsjCWN09KG9T+O7xVgEgCRKkKEqS5YrYn5LjuHjQCerCsm3qpg5lEY+yEiS/lPNbhMoZzXzyIQIWds6m8yGB0irq80NOFyPetxexUPCAHK6aUsi7UA6x85ZRYhD2I+gjGn1bXZQUfFD68EC/zaCQJ5mtaHB+WQQRAbxe17igxyPMmWiK4YbTT+NIqqkK2OGIIX3AAJQjlCi7j7x50604iZbmLtTMd4OxghCtw5E6RzCLVTviUUf3U65hSk8srIeKJD23dS0woZNsfPLPYRjunhxdw3/SZljEf8HerQLHMb5/04BzFA1WCJ1L8+reA/eKrziWJ4z++4TplMaufYXkJe4DVa4S2mie8BufrKsqgdLNHzKFOMPTDrsgCX6zgKvKsdWKXQbUeXcbeZiKCpjHTEfVQep1PuADTSDPd9x7peIXYEPwCsy4LtfoPCnEAdBpnuO9Z1wb4LrsuKpW0DljZW1ha7G2u3i7HHeMZKyLIssQqxrBd4etWyXhFGvOFj27cDXh8FeDhQ40gWHCdR+AOxw0F2Sa0RQYfhmRc4GDZvIOSh87bYReLD9HO1E52GvgpZmilVKbETvirH/TeHNZCSe8gDYAogawapRnlzcKcAS0oIAsL4YJJQ53xHco9QGHQfKYzRrn8LiWwVDBIZ+yoVeSJfJI/TXAyZ6g5alZ0jw0RH8DwUrB764UEMJ8tGLQLtHfdbx77tuD7dcblcwnnzul3NkBcfj8J3meY9iIBfLi4Aukg4eMA4aEhF8bI+4fl5HEj09vkN2141V2A+4O5EC0ixpR1otj6jUxX6Mut8niOXUT6vIrBjZRllQ8btvUP3Ho7fuLqgBV2O4XdzetJaEsU4j6ONaxuaAOvaxmbXtzs2pDz+3dtv44ILoIofbj/At/u3ZS/gBBb87k2eX4SzOSNDop9SnuTLwGUGP/agQzY4GtcMmpQJjmPgXvIv60e3LZR4/0C3FeofbT+Evir++uVvsMtGci/lTMzBrGr5+5fVK4CvyGnTEH4UwVM9jhvIkx/J+JxXL6KJot4fCEDUCaLKZ3bRwydWyB6+tyaJUsSiHDEGG6/6MXtMqABZMw6jhvLwfXjZ2WMq8P1HB3xoOhrejuM5c8zZNZmqAyfbdDRAKnXCOXSD3cZuZVkhZX2NjegPx+e05F9dCEu2n2AdGTnq+WRFPUUFMOvE2ONz5cQ8RCJXQMZUnom00fiY1jml5+yhkU5a5ihgXchzhxJNzJHbgSKiz7m10rxGG6pqFw/nqoYAdvqTd+tIlPhe9ykotazg0zL9FM6CH6l14l1pk/lwMh79s+HjkZNUVlaZPl1hGF0MB8IUcpy0Nq3mHjF6gkspbRenmr7PgYEZfsZtCRRJnfMsP+AYcuVYhh3ULF/fldUbZh8Cbr6rzfuRMDYfOHzEP1pohSE1hW1jV7vzlFPVE5Q8dGOkCnaIHWagELQ+DiVZlwW33rFveQ/cvu8Yp4sJts2Tm8ZgRffAww4M4673WKnvXeMAEzdIFruBuO97pEUqhu4TdIiOu4NGHzIuCQbQ9y3mDSqV1sOBk9hfBMDgqLpr5nWXVaxNc54T8ceZpCCXB2WIXkQ8na8GJHmVNulwJoKUkxoJZdmn7xP0C36rtV2phAMzGchLfg27RJAnqHJvRzVSHM4SgWN9Ng2J9/A5/Re7Tt2lKEAbDn3VweZa2JnNq2jUKqTNMxygpdlF1t1tMYLJFJZh3Opp/PVGBQi6ZjuVbZ6Yz2ilOZHCbZveFa+vt5EKDMX1coHvY0pC9dVDBWScfe1oHqt/G9AugLThrJC8H/p4ODqtCT68vKCJ4PXTK7bIc6U5PaFt140h/5Wsm3dEvE7figQzh3+JQAPtTfSU8CboOvZU+aowbGVfMZy6FgsZEj0sS8NlXQDt2LpisXJNgZ/c/gDX+9MIColg78APtm/HxdnqNMirWs6/NBKi9wxckO4q46/f/Om9w1fs8qRtxb6P/wfPWPnS9gnO0zZgfvdW020GvQXAu1viMJUITFgLOe+K37r9EH/z9HfYlvvUyzRCPX72YIdnKnzpeu2vw2lTEyos5JgZLKpT03Vm44GbY9UiYPFw9si7bx89Q8AtfI/GWSkTnBr70HTMim0grz4qkbMef7cvCXX53f9xBenmzihbnVGNMVczNxvLuswgSH1HStC/sl6SByxa2naYg0FMRUrOSY6gtuJK5cDEjIOAm3ufRsqDe4cAwtjmiKkMwXK2l+kYOEhjvawEIzESK0j/Q49HwohXpjG6fix9BTkJtcOCOUt37Zamwx0MyyjIozWwc5NrwAegxrcpfDk7nwyoOz+qaaiMNlhReGmNMfjn3aLB2S/RmStLHzuDkdYSwglweGJTc2VLFJk1vSvjjuKHsQ9QNcbI8Na6RHOnmqKOc35/5hiF4eaUOhnTrMD5A881+cEJiWrFc4BjMCqrxzFuXiGRoBFS5DpokI3mwQpJayl93Ni01TkZOQ6+Z9IbGfssrb0ObNsOkeGg+cl2YSwPkwkh4En6eiRr753ocKQ1hkMWBKfjvji7KBkQ7LsiTklUmDIRG78i3eo0Q/KIjOGkIeZBgcCNS1q/KqPOT36vfJur7j7PSUP+vlzA7CUm7ybFKc8JTE7R6ZugebTuOjspEHA0vQQyQrYnrx/pdcgol3vuoCi0OmkHtnNjG2nccnGmRRe+/Pt0qGvquYon/4nd3qCXB3rLqTj0gUEbNommDt07LKXfAUu9pAZ/o/nO4JPRj+8zsv5ELf2N9iPNB0YE6IG07Nt/63vHr371CR8+POPpuqK1JYMYIZvcYRmj3LYNt23HZRFcljYO9BG6i0673aNV9xhfr1cAwP22Ydv3ceKqzrZTxW/oGjmuKPG0NLGDuZRXYh3imCk7tKgPbblLrHqO+xoHxHsfGQTr01hJ33a/SkDGiZTSAVksA22MeVlWPC1jpb/vDbfXz/jLX/w5BGNb0XW5YsUKEcGmKTtPg2GSadPBXm67Sj1LIgDgrzjqvWL70v2NUmguSYM4vcxGtjEzaupAi8fAr5XhVbmD/isaoz4+hUrleJQ1UMHjyz5DmwlnG73/fBVOmwJx90wcpdyap7MGg1anzZnQFeT3f3gfWjFe5hkLgXtSFmr50u+3X/eS2O87tavHOnMUuoBIsE5kiuqg0pDElXQaOJgEKD+uXNWJiwQkdT90SRAgGSgV0iKPk8hJV5MhForeaEFonKGwOilIi6QmgxBz0FgEEhupZ8VawI2KxqyaP3pUPld4PR//BIneHAnzOr9VGM5zWds4gbeWKJ/5SPWgCBHbI6QVNwHEkRqqIe399BMIR1TbFblHiJ1nfZ8ew1jSC6P5NIJjD4aM6FvsbbCVOsZJRjcrXsecj4Ic60iloQHLiQ8z5pr50vdYyTDyxAgp58bbc9ic57PRYiwRfsd+LIQRVZJndaaWagzW+TkqsSyfjupxv9n3WdEdhlhAQjLu0K8O2jtTdg6zGm8J48YK8OXTEoZVlgn5A4kUOUS7E4XHBdwOX4eqKxeEL6BIXg3lbjC2BiyXNfe1bTt0z9MZ08QdjlYYF06a8NUfg4vQ5TI+XilfCs8XUPs7mnf11YZup1wGlsf1AF7WCKuQi8NRjAuird7JOM6UO6YdPhTGMyMA2N7CpK+Y6zO61YGoznehSc5beST/jVTlSf6xRGVZyzB49zHbZ1e3CCB2f17dO8P6D0Fvbq/w9BbnkZ7ZsUvYkjDSaHba58DfqJjUBmBCl8s5z/JIZ931mOHR6CPWU0imHWzfAn/lGF+9Lo6q9pCjASDRm68KuuxmTREjVeDzp1fc3hqenp/w/PRkKZjmDAUxjD5aa+OwERH0vpmtk7wgMUEO0+ixNb9YXtH3HbfbHW+3O/Z9H3McZHXQZvRL7h90nnP8jFRtl3FZk+cr3ocWyNVyBXAP77lBZay2ydpwWVbDvaAtdJCHtfSyP2HdFP98+2387uffwdvbHbvRwaoLdBdsUkd2wg5pT5Hj5qt6OMhmkj02tpT7xhNhh9o7t/UdEp8v4lv1tkJ8JG2HHCpIrQMJ8WJj4TE6THX1nALOEcxJWhYo/uPLf8bb8hadVhpOHyD6jXlW0j/HLUVnz1fhtMUjwCJtIIYQrxC0drQohn1fHbbKQKP2/JxtkD93zKbqMwXz72xjZQgIgEUET4R3NdyO/XRqJwRh6b4CcRwpgphZYXJDZ3rR34cCpXENQ1iDOWg0p/0DxF9sq5ggn5VZHlNcWnCWdv0ev5USLv+pU2caLpOFUObuhL8D8UFXk5Fz5pSdjd8fLpKyTMLAe2Q4H8iyCKEqDGfl7yMaqwhE5zT2SHglA4J6KJ/juPYgTF8dTeFNZ6nVNszA5/12KUAThjBXLId+5OwXjARNRC8lmpWD8378l+NR/3rg2YGfjq4NByfb+bNnfyIscjWNEbbuAGQkrU6o2zSh6N55JJpLB5DHeeQflzXuiMwdnAiGAz0kPqsMO6axDbisuPpR3bOgSWDDFBXAV2tFU2mnysx5iLRiGcZW777KZWVGI3VIaT4VRHl6CqdMshBQo9f77RY4T3gIwS5kO6QAACAASURBVBbxP9O8vbwgSWODZMffHQV/X+iKGk/KH+a8r9q4g9HN6SoRi2ICAoKOEXAZ9O4BumEXtsDjWOlE1k1BHKfQNmITD06M7qtu5WDlMF405oPldTw+hGh7ltH8g9YfNHd5cxE2nsY/JgOMBgeciMAMwGhMWVYcK86pOqqKwIGWxryfmqjFkXn/va6FWv9lYIQrABonrKaN1EToAIxMkOzIK1t4iPVzzqNfYzFoZqzWhGSTlnIeOARRSO0Y31adjajp4nPg9t533PfPuPeOl6cnXJYFfmw+46n50fAYPOkrqCEvc7cePIAFILIvmghkXfG8LFjWhtfXV9zvVJZVmVklYR8439pcuDxRgOQLP16IsWJz0/IqhSa2JUCHLOnWrjvkKyRPkLU2RQTf7B/wYXvBv/z8E6w65nhXoK1ryRgsKoFAyTFaUQkJRUEc0klaptERANZ6OVeSf8N+IPyxbjegeJ7ThElHb85iymBEHV7SWf4V5mvuw050KXdMprAyGSBlTN66WcokdSnIAcbTNAfvPF+N0yat1e8+ohMF+N5TIgWmsA5C/kttTEomjf1j2W6RYLcRz4StARa/ZPTBKklNVTg77fEUgKDxLy+phlDMKl+sMMlqeiVmbOFECE1T5jg861BzbxxH2HzaXV8K1LKeNJjjbLUKyDkDYAdQaOjTUMBFafM8j5aG/BzOWLQ3of/R6muSrCt+SpMSXoXxz0e88OENjxz7+tvcxqQWyrynQQJgvkrIIH8U8wm1GI4Vwzy3Mge86nobRdxAwncWfWIbzrXOS3F+c/Z9wAgCLo4cw3L83NX52CcpDUoPYNTYqDci8AhcxZZM9IHTckkrU309DiX1ytHRnIMsXm526s/2JkYL0QevNDmUvRhhDIt/z0OWWDUZNmQchw+MFKaQMayrA+8mu4dAnIyfUbw7LzN9kHIvuKUZT7w55TEG0rAKI0sVuZ1Kqc3E73jVY34bQcDlAqQwZNiMERRkFBmj4fD7gdTuLMG51fWdcBtE68qYmCLG/rtqSX1OtZWrfyknpcw9cJSLSU9yoFdmhOIICxfTACLSnw1dvgroepN5OfGdvzIP+fzmXj8PdJluU+86A64+jnM1zIOZPmjWiTGFnklqzb9kG1CjlabdVUjYlAGPsUoEQnObCcFiePJDSCAYzpjrJnKmhfim9T5WahR2MbeYLq1oGDBYWmAc6iTBTzP38UfDEjxFUQBgV9w+v2Lfdnx8ecb1cg2nrU7DSBEcoqyF3G5uE4QOOdPjidPr5YLWFry93eyUyR4BqFlb+Yy5fSeSJXhMzqtKq4Pu+DMNl+HYN5fNzQGEAHYAyZhegUjD2lf8i9ffxcfbB3zcP5oNNXrpE+JPVDeO2TFellaqc1hjnu3KHgRPodg/UB0HwhB+jzL1GAQM+MhhRuhhtrmY9di+OGFYsh99znxVOPbCwnkGpGd41C7PU8/X+atQHTWRzx9vvZnn/Ph8FU6bE9t4SBSZQJP8Es+jVY3xLhX5aX9hJJ0RpZ5+PtAvC3I9li9ErSe/nbWDo6jOIimIbRBHbjtRhg8NtOSj+tNUnCNLPC9e+bGAQRB+kKIkq1WwT7UgvSeFVsboysvbPQBfGwyrFcfJMMPMn3ZyTDt/CphPSIQhmVcqZ8M5Ve9sACU/1BMMHwwxoHM6EWorDRwRjUpKs+ECibuubbNBz+/7KY1FuoK0mKXanv1KRmaucHCkqx340K6VKqIwle+ACfB6joA06l0xjDZSacdViNaQwxa0pYA0hWodb6wcBPJkkmlV4MeY1U0RjZPQHK9HPLticXk5/u8HhMXc2WEYp0/AeCZl8uFDKrKurVgIR6mZLtMQcIpWHzjU7tdV7Mj0PvINAj+zBPUAxywjFOMuJpGRUO9R7tg0DkBAaWHRp59Glu1m6mJiToR6dbyTcWWlrN103CJ7wE9FDWiSfzxjoUZrBX7MevbpKbg+aC6Pw1N41+g1Dl0BMBwQwiWlIPvKmI8nnFfdwxATb5dmYaZz52va4glOgJ0VaTj6hjde7eF9dR5Ac9yEvCLZwQHTDCpV+ZvZADYSZchojLzZbHKCk0imCQjxVYMnY0zH4MnBnmFbgmAbP3Q7gI10oFOv/RQyxME0I70ZQniFUw9/nQZGausIvlj6nVXT3fYy237OPvJZx0mqEMjShjNmObrz+UKuqQWw02jz+llmK1+7ao6CuFDZ5npX7HrHp96BD4rL5ZIOt8mLseq7Q9DouvIOYDE6yfn1YKqncw8YjE5kXLXx8vKMy7rg9XbHdr+hjxOFUAjC7SF1fk/dwqtIY0iJnOQvk0feJNskahkHdnCK84y482f6y32Mv3z9U3y4v2Dfu10D4un3vYzSdWI49+EwEXxtSSdRNU5P5el1edpVI626Ulaiieuy65XqqQaNvS7bTy46j7b1BFi8VfBeufhZAMAPNlTEHnlFsQd9G05MDdV3CcQrfRU3xvcnUBUsFHv58fNVOG0AGwmPjYnfpK3Z8OHHFfVZel4pR6+CBqc2PY3nUSuPmvf85krAx3b8tzDWprYLMziIJ0oB009RZOq0Cq0ccJmeInCQCoHbhcRx65HqJIAf/RtwzvgUE+iSwrRAJ9Vs4CXtigQaFuMtwqwJbRjuQ9NZkWOqiEduI000RA2KUjnABqA6ZPnUAz0I4BjIcXiP6HrUkDKf1VEgw0X4oIJ8/FCG4vCc9UMKqcI8G4G0ghrOjadYTnPmAKeURuSYE6GPZvgUylYMvWbz5wopHSItbaQxmQQT1KmeeuJ1UQg2Vk0j5dRTNMaR7CJLwcdwuHg+K+Z9Va4oS6JbN4DcQfM3nDauplCdRavz71qux+c5K4DiM0V+iik2lhmqtVDu07O5rRYpPECgtn8r+8m0RMnOIGCjT8NBZfUnflut9+YDcLmq7FS4IZXoQNAAq3wN2nXsSAONhmschXus7JPjRm8BS0VU+CqiBr6jiNVi9R/GlZ0al1Pr/JyOEcu6ysGNJRbSkfBuiBvUVzVbjslrNkFbF+C+j4NaiqE3oHdZExCSAhkZXZT0etD93kYGTny+tO92KiIH1dzhrrOUIyIssDNtMGop70SfsjLox3HgOoQ+jnH53DMMo8WOcUpfgkLZCgq6q0otfbEwCRDH2E92guaetvm8lKKltVBGHojh7SNx4fpXqZ0mY5Vq3/cxnt6x2anXDcBF9sFrkSYpdHBJzChUkTQjTr22CuQ6dABh+1qdUTmoKdCu2O4bfvXLX6O1hrY0rMuK63VBWxq0LUN+R1+jnd53mgTbQ68A0AN/JVgg6Rxdn55xuT7hfr/h86dXbPs++Nl505sSABRwccfTeVpsP56nOIaulXGeg69CkonowGAEFyXkXGg1ARoW/MnnP8QP7z9A04Z917jmRNVXCFkimLOqElePOM9pjD1PgHYYmMbKDCuGU6iKWOVkiW2AlkAZfM6Nh5uid4muWC6WD+Uk2/y9rtLxI/BAjOva0MsspyVzJNKWOkr7sB3izxj/+f5Sx/tRX0yDe1iCn6/GaZuf2eOP5cd3HC3OF2fDNgXy90HJWbsoAjPbTWPHy53V9ccjuaEYZtn8Tv/ls6Z9UgsilP4Ma3z3aMnhxUSUQi9yBAawMRmV4HkRLjsZSUAaIKwsGT6/bqRyLVyuUdkDwCHA6vCmzp2WlGimqLh0yNipYkMkUaLlva/gEEipjAjUbEbznxP6YYUQmKX23xMFMyUk/YHohJQGEIeYeOSXI/A5ljqeAYtHLusKpadHKEPjxo8PwswaAnV8bDNCHGIB0MwoUPieG2+gT3PUzZgM45ZSNuISWdXYe6riKzYzkwnRF68cSuBqNDqlbzLCTxjvGJyYR1xpaXbs/F+FhFxweilpeW5lItOxEwx2phIur1cwqu52JDyxr8lhtpMRI91lxofRXK5kOrzUn+NLXS1aHR2CoPCXy6XAo1dOxDpu1CY51ui705rvBct59wtgC03xXJd581Q6oxPDzdhrAnDoNh3JqtCDJ0FOC5VwI09p1e0R7RC4geEaJOopMD1FBy6c1P4T4nkMg74Duu0HfZpJbDL167RGczHNy/hXgx9dRjqvxSqAkJNuONQ4El0D92Nlahkw+XQaovywsxK0CDvDBICnYroa46Eqw5ID8CsJahrsGEsrPMsUn0K8GqjcjgQOefXXGb0h71aT2gQg7qDVmSoZBDF+dZCTN6y1fR/yUYFxP1hnXTImSkXHOEkXB3p4zISelNrOzKgIz30nLCUC34pxwiS2Hfe2YdsWXJ+uWFdBa3scMLMsSwYgCLfMG55yvohCtRXGGuAM2rxer1jXFff7js+fX+1ibqZXiUVxv1S6rqpTQMiAiFRdwwHP17p4AJBmVzXufhQB1t7wk7ffx49uP4SqYtu63d3orcwHybtGFkubZDpweHgbRM5Uzou11Ic+2O3Caz9MjsMo7hCLyxUKvqc+y6tIuuOzwEyyZebJoIlZtmL613S86xJrxzM1ahCPeA1EJ1JCmIaOsxyybCXWWjVJfCr0vZ+v1mn7TQYBpIFxnMzH7X/JiTs4S8cmHr47lI2ZKubH9+6/9mnpA2S0uJz7Iij6PmqZ1L/fb3JeABZ16BnZj8ck1Sw2M9WFRGlMqBRqjzG84zEztk/xYnVGsK0KtXbSnk4giQnnhCppcK4zdZnvQ2knNx8PEfHIVKXvR3R+LtCGwEuaTUOAy+SdWQkoG49zl2k4n98uEg6Liy2/l+kAJOOOnIqJdBxWTrkS8MqdgDnriKIqrGP11BW5zUWuvg6Y60XlNHbhefNxpFPjyjoNMg1nlOwbwtN78kS/OPdIEMJYG9FPdgxrP2xsMI7m/kLBOe2bMBEhZz+Am6SbweSGojpNyTRHaWEjzjOwEjVlOZNO5oAIbF47a1zqxWnHDbGoBKmnCIZCJ5QgYTpyin/RODRgwJScM+CNkAAPPD91IJ1S3jlD0emGwL1BHpDEHARgCeGBf02u6kkJlpuxDwiAoEO7HAiVZWjwliLmOQ0rgkdnLJph5hPE/B8OUaMxH6EezTiPZfssowNbIQcQdOP1fbW0BmdsDHFMp8kbOVKEAEDTmmkJymJwerI/sz1SAy4SOGS9U8YWdJsCR2wsTIHZftIPlaarBFJADdm4BDW2ZimwCqDZ5dUddpQ+jYPgIbYKmcp0HmxiMjJFZtIhy4vsygIZXbHvrjtGKuSyCmCrP6J7UHQuCnSj27HqdubkM57jkzRcLgD0ittdcHu7Q3WHaoPYipnXGGmLenIY00hXdjgQJ2JKwXtKZZJlMgKL7hB86C/43dvvoNuF23uvs+pyrNi0U64NOzK5EkxzUOQY/fErCjAOc2H4E1yDx3UlUoeRaMXQ/Yxt11WpM/lfHo1T8uHeT2Fd1DIApYkXn6NMIZ7mSgh8dTpH/Nihj6pYqXP76bTwF56vx2ljpQg/Kel4lP+jVbbDJufSNBHv9Nv/X0/SsMSG8GLMAUcZ8U5jJN+KUJspp44ZmBEk5V0+pwZJKHiPp9IqlSk8N7a5vTa1l4LblcRZvzXNR48FDkBz+VH2aKLMVc8UppeqSnPu5TH9xJyYVsn9ZXIAKXXj2eSn4PV0P45CP4aGFY+V4zqzcDHHJVuajDHqTCbKcAEZWSYFqqHcPN1wNDbPpUY00k+LOfLmPMoatc272qojcZSirpQGBfjfksbaFU3aSHIMB4tvvALph0loTfwcKXKWayS2FwEo9hCVn5UqdWNj5esczmjJ6U2t4lDUExcTe3ifQZtijgvy2oXAc+9l2Nwf02o4RVG3JT/YnHuf0JEO5hepKtxotGg3GZ8PZRJI/vGcgPsTk5ta8JnHc1ddHYp9QlqmGyVPpF8ggdBwNiWN9FwhoHUMtl5QEJvGh9OWCUo3jHxl4JRmCAsPNCahh9KhAMO9yz5BPSMs+cXvL/O76WJfERJHs8zjNO0KYZ238YsiT9LkEY4SbFzXEIFO/6aeEpHUN8Kw8rhDVED8DrBYfc05ZoLk1FDXJsVvprEDEot0Yu25M54HTDiuKXBygoXguSqGIgAV/hdyJdX5jWUtyzV1+0J8rkZbDnuzsQdZMP2JUJ+YD9QkfBm0MXcumyeZCoU0v1riOH4lJAuAbd/x+vkV0hqWRbCuF6zrgnVdTulE0QLmTO2T0oePi+s53VyfrrhcL7hc7nh9e8Vu96VxMKkJsIhgl1ZW8ceEt2iL0xFdIA1bKq8QKQ64AKKCBQ0/efsD9J7XNcS8+QzHSjph0Og8L/EZfVddPs0eiSiFy7LUqyJJP6UFox13qHNPnqOjSiuyIMYYSIic2lHSwNdylAAX3nkk2+/7uItL2jKV4TGctXHym044JJwm6ddCKT3ef74ep61YQw8A/9JovvCcVT9Hkjx0GqMtNya+h6d1MOS83qPxzBMOIpjgnWrCxN8JnC+hrBC1Zssles2lXfCpQifkzfvaQO1M4uLQnzXglQ7wZYorHyTg5poaPL4EPXGCdcopt96rG4v+5LG6LjykNhLjQqQnQNIRUJof37+TdfXQRjrcbBn5SW0uDL28w5+nTp1ZZg7D2ETOZpz3YyaRugLPqNoQ9H5gQT4BAxiHBLFLohmYOth8xxH2KfJcUxTO2psV+7Fo5U/fByRRj2eVo4hjhcYMt7ZA5z07bPSxtRBDyrGUOOZBTHxRnVgz5/QXrWjeD6Wc7Sa11rkSHqksvLrqePPjr2NlDMTLRI+xAqsWqSZ+PzgrXJmwAJzRmtEAAe9xZZYXTHFh64x8R1KKSU+qefGz+njZUPO+OUXSDYDIqk2+52nktDe3XGP+4iCXKtt8iEZ98/REgbLiAo5G5+/ZpgfVyHkIom0Ayb8xhDQwR33qy1fGNUN17CzlSPzuO9vDpbv1S/djTeM4e6o+Ffi9jHmwkKdGjj9+R9+YewWvjAkZ6czrIQOINlw8zcagFtlpE+P85bKmcxkt5RxXPHYeYgnIGMx5mbdO8Gj55Jx2DGTrgZbYjGYHL1oxIGmWC51FXXg5/u6ivZd+xX/zA29ozGkDaOjadBbcBjG9Yu1kMCQ7UCBPTjK67b2PVbdt7HtbloaXlxcs61pk1KAbxkvD2CudAYvEFI/Ydb2lhLcFT0+Cy/WCfdvw9nrDfdssyCV2RL+O8y5crkrqqLws3HnNj06h+VYE/fM9posCf/Hdn+Njf7G7jt1mcBhnfooWD7SVafqVTlXnulnHrzIRslOgPoNHfvI+Zif8UTaUy8XEV82oIUICGAYAvslBrE46dQ0eZBpuO0bmj+1DH/NKSxM09UwRAZ/Tsx7fnT3N5uT3P/8YP779Nva24X/75v90q+zUfOLnq3HahrEkgeSFT/eZBFBZFSEJ9N7qWSje1M9e7fB8yT8PPV9gOtgj53BMZcrXL8xXGoU4UIaf1nVK+JOW4KAhNxUNyvSdMUuR77kOnStX4Z5aO4My7XaNA0EetxKFq1RwI+5kIoSjimFYVmi0CASjGRIUsSkXwO4GPClrNeXYqZ+MMDnN6AE+bmU8ecqRTASiyoZTiZMenkzxFKL7KsgjyexwjHH2CaTgTt44E035mypybpgwac6GApMQphCmHafzGaKZ1k7w53Mj6WyUI9gJLom7vdKgy5QUduaS/+aYZZJgt/ltBqdkqhHhKMqTEMnoaO4JiBFLGmYH+4x+81O9cnbMiHG4NduKSGy0S8EBjL0FTexKk5i7Ub7skZsUPIJfyACT3AFQ4zKRrMRNxTUqiYAY0ERTDk+O1fEVFb2ur3B6Q5bC1Hvyse/fArTsp5zlQgVoeihwFXvvYEYBtcjtjGAAr+ZWx+OgJBgxRjPpGLvsaYfAymioF9pAyDU3bFg8jUkcHNIo7qLTCoorQYMhnJPzlGnGlfOnO9wBVgl4DVhSlrpRm++Sp3isiTuJ+cv4e8WkmM7p5JwjZZWRqCmY8V8zmeG/Icty3xwACGkVK+6kKwr8x+e4foET2MhOICexOnZSVrdzqJ7WLSggIx2qpJ2kc6jTaSP68ZRRN5yzD9ftTtoe/FRyaFIDk/xXCzRCsYyNfJMstVXTHVAZd8+NIE3Htn3C9fmKp+sFy7JiWRYAuS8s5Zg7PBNBpiCxsWWgs6GjS8MiwHJtWNcV27bhdt+w3Xe7nFvH3XZNSl+OxNgzK4RXJC6XwKmAtyL8m09/hm/0Zayy9dSj/iHuVD3YRJKHDZFW9/qkpmPozGMelHZnmh/XyQl//u5vl0hw8MZtp2mKJRpLthVZHEqvC65mSJilnP9Ni5tM0NDxEg35IUR6aI1kf0Ha8ZktpGu/YNUL/t2v/jV84QNQ9LeGf73/Mf73b/+D0fjjNoGvxmkbw2pxGaor2PG3mEmTvjxPYZtar6GlQHZJc5mgkbNVNrYj5ojp/EW47Nz61CxLXBBBMhdx+1Ib/dL4M43ljLDfBS1eeCSzjjXbbZbGkqk/FdwHkHnrIayO6TAMnJaaMs3HewfUfK8nxueap3QQDhyE1afQ/01xUDpkMSiQND3QOeo92HE3gWZRIYo2djOqQq0Ilx2dxb5H6oNTqtgA70p7WIqUdi3aQ2+1lmZi/FX+wKxgVKAp0GPPAiFnKJFUkmFsTDwl0aLaZbGJp4wYV9wN+sgIZdKlGctRJg06SkIGICU1Mdr2duLPNJfFwcnxquGgtKVOx25oWUn7PDt0ciLDkmyn1DRjmFmBk9t0eMLZ69aAK01e6QXKat1QqJn2IjbvvWda3EivkrTOgmZM7pszO8s/V7aA5oFEkvCn/Wb1ee9UYsiubagR23kfxBw8EMBz18LwzEbV5EMvMDtkcS9SGRPgFxO7PAkMcvPkzTh3nBthDHOmJrphAJ5nN0pDTjC1171audIkpZ9maYNxyA/xXMX6ZLw5Oxth+kl4vsLttOA1m6cqqaVVeTMxfxrtjpNTxYdGcu4xbCEb7GVmLE1CRYSOZ3SZzsGwEw5iEUq4CwmjdU7nJk6zeWxsM2ULxj4b0kT1fcsVvKraSgjc+Dcx4OLGcz8O6a4JLCBip9smp07oCP53dPpx9VAN9NJ1eYM3FGO/l44xNq1ZLEHm/y9z7/OrXZadBz3rnHvv96Oq+kfabtppt93EjhQkIiSQMmESwQwiYABKJIQYIGXKBIEyZ8IIGIEiMghMLIFA8AegzJgQAUIyEBzHxm5sd+xut7uqvu+773v2YrDXs9az9jm3qp0wqFOq777ve87Ze+31e6299t7xwwjcwiZ/bqGz3r/7gNvzHU+vHvHq6REPDw+TpxwShC36+jSKPnJ34ADgfmDKwUyWjDFncDYzDCs+4Cx/C2aGT7mL5M2UfQYNqeig0JkZPjre4smfktf1OSTtWCZooJyqWvXg0U22yK2mKhFN345Dz1JS1CybB1yrFUw+PmGPvGow2zNppHqy5MubjFy5dIYQUavv1Z/Oqo48ciLdNoXL622yBP/SH3GFD8Anx8f40eNPcNhxOvvWAbw9XuNX330fnxwf169mcWzG3EznuE8e+oICPwBfmaDNE1ZDrWfzMPg09jUbdxYkVREV4lVAl7N4yYjChD87iD/LYwBK8Xzp8yJwtjBbMaxcLVir5/i9K+zl3lmuLweQ71vBYkArP7yiALym+KsJArWysX4r19HXx6kMSOH0YM/tlEOuBhcpceQJVcgkkx7USwS5vNVKN7wcYgZSORYxxAyC1NFgcNCJMJqCXg2jzgy2ACQVUZSYZClkbVJTO4fVbFrOOJ+4pcasJqKm7Eu1jWDOHMVLsiS411p34i5tEt3DdiaPIwnUeLdmcopSa6ekcwUQp4yg9/U16gjVow7O6zHw0NIZ036ij3IoCbMFHDZnnSTRVI8Fl4u+41imXr/Gr5ZvEg9Z2mvaFrFVs758hkH+XAuvM5tljAl/9y6DDqM+lzNT77a1PBbte63jSD7wohfbWK/u/HOGiePy0E2NOYSyXla28TO6YR4Q+qh7wXGKExIBKB3/iYL5qa/t8PYniRPP52bUoX+azuDj0tY1O5TUFhwyftpYo52ty7PM8GRwULgtTqcunLCV3jmXPwYhKO9yjwHMBk0udEuuwT7yuc4n8C22jPeYveeMUfRFerh+9Tweg7rRWV8MYK39r/y80KHZurQkMj7BYcDNtYi1+bg+s9QxNB3EH5or3zAdqnG2Ib6BS4LBgTwjTNeD5cPWt+qf7Qq1nXTrHZHfMslGYVqw4xrcGwDu6GjLs9mGyBrIu0HvIbbUD/BQZOXLhiufs1Ef3j/juN+xbTse9nlcwL7vMfu2XrM9sYSJu16uF7+PA8cYc6btw21ZQrFgg7txhl6a6kuOQxB9mno1xmdm+OaHb+Dp+Sk3H4E8rxU/+X7cd8LihjhwLvyu8ggqgD3rmuk/zHHNYI84OtObdBijaKI0bTpB2zHkcvCiJ++qPBRwqc+oK3BxGQDn+lsmMQPa6POiabgZdiAO9FnuAfgnPnwbv/f0Q7zbjxN0r45X+HPvfhkfj48l9ojAMdbRvT5e4Zsfvo4/evjRFdTt+ooEbfMq5bC177xOAcHJsGo76z1RoWdf4HStxmFVku27vXxvbTMdg+WhaqM4hzX3mlFS5bvqXCSTR0ZnHaj0u+hUbWL5ztp2v7zPZk4GoAF19fv1s4WX8lJObkAG4rqFtSMRoM5aGq9O/7XNXNsmz+fC2gb/mdg6c3UeUTlNdFLcHbuVytIpfw3Ycoa51euw1X6pgrxymCx7l5DMGFiqi7MEj/DcKW3LcsbCEWFO5pKu1dCmQ6M6mhDmqx3ZczaqZhdzcxCTQ5MdQiPeu8ANjZQaAFd+Y1BLeZs3xgGYjXDwwhgsOiUzkcD5sKSJKKFv6a2CI3A9PDYrUVoicE99hvZuyp66f1azwnlQ9tKnGTe6kHJQWzlrSOAkSmixWjozlmV5TCKEMzCfIZwUnNUl897X6Ttf05Kp4O1UkiVv/MHVsUp5NaybHpyl6kxLvlG6nBpjJgAAIABJREFUYhI118YpiogbIdq2Wewid9a0LyjQEy4cDotZ49LKfDdoFgRN2Uh5lBLQbNWTR3PTGFD/IHmncX00WrjuAd9aAVN0TuZe6FSGiXCmVm+o8pN8GHks9QOqhdRVfD9KxqL1DLY9dvLj+dXeKF26Tdpp1QjkJyHFdDrLCfWBCo6xXtTPCF0XO9qJLFCuKK9i0YqOaZOQfgRhpP4/neeW8mxRzi19dhCl9H+rFq2StTN2cKm8Uf1MO1szlR2SM05Kh2zJj554Lvpv+45j1JEbKZvN0nvOaj0fBxw3bLbh8XHH06tHAJ4zu9vG0szCb6lzxYrMlrjjuA8c9xvuURJZZ4QSnIWv4HH4+U7rks+z2mugEo8uNtIjONTjP0otnrUZQDae+J/mPLWC2A0d79muGAzbtmUSJO9xZC4jifZnqT2afDpRYmc+oD3S1ZDF0vI8ZYGxQfyzzjw29KT8MHhFsQxhy9+qfYc8c2kvcPnjKzzia8cnAnbo2+PAGFPuH8YD/ty7X8L9zQ0/2X961XJeP3PQZvO02P8ZwA/c/a+Y2T8J4NcAfAvA3wXwb7n7s5m9AvBfAvjnAPwRgL/q7r/1Ze0rk+1xHkYFAoaBDRuORVn1L71UqGPvJMNfYCOHlBGsj4hvcH1dvLOCe9VmOnTxgwsj8VyrUKu9D6/PdBZyBuFL4ICjMarCopeeUUSns2WXCOsLHa5jXtXWom9SH6vRtvXBNNQCMwflgSeptGQpIXvs+OlGoHVFBeR0YjTD282vOguVja/ZsN0M3NnvpFSao4BUJsyIaeaUzkaOrAUb1hSjyRlmzCq9VC6aqjHA6I7o+o6feOclxq9+2Vw3YslKhlwHVDxuOAadw8KlzYgTts9GddOB0eg5zxhKnObuXCxlC+fDEwQCBndgf9iSVjnzDwBGHbUaOD/jwegMoTleLYiLUrk26xcPkDfWGbXUFVIq5CIwDAZXmc72UEF3yl7rh7OGQOe5MDrsrwlgLap3Ol25rX7HiYcTtW3UabSG51wqYXVdQxHsOf3HK21S1FSNk0kU1pM1zbNcdIJOgXG0GcHoxKEFXjRjTRgmjU7rC8dowXffqS8AWAQt4XfJ+m7Fs+GOpL2oIkevYD15P9qMtTbjGHFOpkeuyBa+a/OWJ2SVWrs61qCPo7+q835SqhZMtjqhE2d9/mvq3XFiBUOVisGiDDNZiLohgoLV+BGGVYhEYWTSbTispgfiducZ6uqtHSVQz65VN91OJDPGLK4mLxzFeQuimFSRZScqjqFRZWih76zgt5Nem7qJoRt1EcDtH2JEIl8ur7bSVlgeTE6YU43JrodVfdEMMDYz7HBg2+Jg8NJ5hR/ObQIsQYQDAwPPzwPHcNye79gfH/AYC65s2/Dw8BgByhzlLH0csdkJ4McNx3HH/QDGOHAMxx44rbWa5EuHQTdIItdSNsPGgXp18qTuKMr1/t+4fR3fef/tCQeQJadUSeo/IvnKk76bQ6qzZ0g87vfYMGWbY8Z6sWKmxqRLQCycqqmCvB3bkOMVHvLWsur66ytniJM3YmwJmzoSIqJrYBe8m78tHTaYreycA1UvTFlb/eCOrn6usF7bDtsBs4FxTBo+jgf8hc/+PAYc/y3+uxew8Kebaft3AfwfAL4W3/8jAP+xu/+amf3nAP4dAP9Z/P2xu/+qmf21eO6v/in6Odt3zECuhejyV2dURFpPykkZon12nJWkdv6nuWiUT6bNTuPSTnRofQt8T0NPZrT+aulyvpPjoQFgJn0tbOlNpLKoYUggiXLG5CG+pyU42rZr+2JEv/SiYUpFvd7vDWXpVjiDiqfMAiovtGU5K1JRONVb0WffWZLUtpy1mvBs5yY93jLMnaUs1gLmGCp7CSdwVEBUujNQKLpswrPEtKM2ltBZUuLxTIE0HT6NomX3G/piY+cGdKU9RQmeUOhAZQ9Di3ndpBFKSyNymIZAnBNNyqgfEwhsGTdvjmDOk0U7pNO8txkPqJ2Gdd5jGcj8vm2IzFg/M8ykB5nkqCGFLI4IPlsZieoyJmvyazVS/gyD/oHDa4ZM2D/f7cF7YWIcIR/Co9wsYTCI4KY7DDrcYyYw2ts22Zq/gJi8vZrePjNQn407XsfjvfglbySPAZvtyBkOszSq9W7NtpKdUvf4fCrxhThuoO3cGnKw7uzkotWNsloBAku8Sg/FO2ntZfwx1tygwgqulA11OloQSx1HoApG3qur7KDqj3S0YiFC0jfGyAq/XHOZ/HfWGzXbPducKBOGbCPvbeSOlm6hZ4DZ+dyJMkedDBMUDgc6dY4YsDVrn88mwDWPobDl5iYUINFrxPM5KKrsu9U/Mm50egROSg+fLy0f4zt0/Mey6YPk/uU3wQH12SJ8tBtGWMh6Xu9XOWwFZDnboLo+5Wqenlczl5UUSsiaHJBfLHG8zs7GEMAAoAbgortmEHXQJm8lzVNPs2zZoh3O3RjyhLZInhw2gPuk/74bdhhux4HdHfARm304jmPgdrtVkOMDmwPbw4YHmzDsm+G4T/0wz/TilvQODC4vKLty4ptigEkD0obY8w0+uAFd2G3b8uw2YthQsl92eMOBOUuH4dnmFgkN2zfg4RG62QqynaLLtAkj9V7NAhdNS3QrjUTqGIpXabev6K++sa94usQZ9Vwq5+w5RZvPKB8uLcC9zUoTp/XXWxX1J+MjvN/fv/yCijU8ph/7TN5uG66KdPX6ku2dogOzXwTwLwP4L+K7AfgXAPw38cjfBvCvxed/Nb4j7v+L9lJqvw3hTCyP353/acAwX6v/IYbnxFwcR3/16urR+YWR8t7m/FGYOEWGRvIa3C/DSDYcsGw5Q1D9JTx8cuHl9n/8eIZqeQdn3Jgaw8X+ps4FZOz9XVy8SkEvpU1Tav1wxiSIdog0NBsNiDj8OR50Os3n+WXBhND9fHFkYVhKZKch9eo+ecDr/zGOmRFL/p3GY5Md4yoKWnpuPK8alGqv0yDh9WkYuFFA40ofrd35vfaLt61oQwf+pCgHDYVk4q3/nzA1OV2EMJ9pmhmc0Tz5oF5tkKeXVrNhhYul97Uua7nyUZklWunhFyXHAtxwT8M+uK7cyBNSbmOEj+M7Z/ta7X8aRb1X+oAOF2GEz/KebduShvUe+2Twp+8GrWHtN2CW8GTAxjYZPCw6uDSSZ1/6UHKzif7ymWgYrljfksensa7ynSpvDLjZJs6zFSmtoiQrDrTFElfv6a87SrNRLoCciWIDG183Ga8bj+nr4zc9IqErSNvq2bM2ZiIhHKRN4MT5Ks1hoW9mf+7Sb8pLlEBb8Q7SCUwrHOs6mIbRmbjoySIYN1r2dLdmO9wtkDAY+WYU0CIzi6LAvu+1mYMhdauOFm6yMyDhH9WH6HMPplP9XHqZ32TtaPC+QXalXc2Jc1aVfOC1EQjxEH8Hg+JEY7VZsk0mZ1LPO1ZsTQdVU6pL16fqmwmGy64aSm8UdrsTwDdVdomqjTIVBjIm1UsXG+1PoXHlZAfSllXAW8HGnDnbUkGp3WdLm21za33Bvp5Htj9seHp6jVevX+P161d4enqa57tthnHc8O7dB3z22ed49+4dbrdb8afZLAzZLBOQavfm2qXJn9u2T/natpn0Cp1aEnJiI8E1ebjbcID6SZMv5G3SxIUfi0APDw94eHzA9rDDHnbgYcf2+IBtfwDl8mTUCV/QbxwjZ/t4c5XYhZLJb1d31W9afaL0RzY77bAMTMmuN87acCSu2EeuUBMMdxydzL0YzLWHX333fXzn+efbb+Ybvv38Z04+BzWBbTZ9wX3yBHnji66fdabtPwHw7wP4JL5/C8Afu/s9vv8ugO/G5+8C+J05Pr+b2U/i+T/8WToa2LDlLlGVoX3JVYp+xKFxYe/OHhq8qY9Y8cEFYq8sYeu7PS0wiwHh2L6kLSo2TsNz5G3NBttWwNHHuK71W0vx9BK3L//wUe6wo/lvx0uR/pWjZGV10tDp0+yrspgVLJdwaPaOkkV9QgO24sbB7En3ZqbP153kpLNZtG15kK0JLbrxRA/gvBwZRaRL9zSA/TlCbTnW7jEb2k/yfBn09bICIXA/cUuZkDU4IlyJ3y04eAgfOyKrxBmjVYY6DwWam0NQo5qftnVcjTkEa/JQBvpew+SkSBo2rtWSA2ybdBou6FTw0xWLObX87AJDp125PBtx58Ef+mykS9fflb6nEkiDtC6o0uckwRExDY6DjjHXZ3Q8n527akNho8FnW4nnxtee/87fhbu9jy+TFsbAoa5rUziVtXt3siaOC39AbBTDsQYuqsSr8NTwTZjj4YxrHO38rbl+luNzidXm2LdtC+csWw1c8pEz0hNfmfGZThwPdE7ZlFdLFJZZ0JDduSZS7UPpUA5cZ1cIrYRUmSAoHSl4Fp2cPOIDW6yvs4BnJnWYdYeUCUUQmImROt6kSsoXHGV/7ZdMiGTiiLSRcVxdqcdX3SN83nk7eChthKtyQ27AlaWRJiW7HvfLNmkZXOI1Hs+kUPACP1PHarJtXaagWDOgDslme43gJQA1NiScaYvVNnD4EB0mBxrT3miQl0eHQXhByOL5DmSr41SG8lzodgfMtpp5ChhnVX3paJf3Jror8VhsHTzjs/rg5jfc7wf2fcrzvu8wAB+en3G7Hbjf7zAA+8MOs1kGPnwGIWOMuXunV1ogkwmbwfYHlNFaeXmGXEM4X3k3yRY42Mcj/uz776QNd4syVfLYxVXJM2RPkyw8xshh274c7n7ZEqi/bdv02O9FnLy90e+TGQ3pW0bwS0viAcfJ7n3Zt0VH9dgAye9VLcZ6gwlDqdyyRiYoIQdVhW6Xo+9/+B6+fv86/uHTH+JHj3+MP//u+/jW8zfjUTU6c+3OTK7ucaafzky/fH1p0GZmfwXAD93975rZX/7yJn+2y8z+OoC/DgBvX300yWeGTVIklo7z9UXjlIczXkTf0ZQY4CKJ6GngBWbH6b4qkjaibO/lll66Y0vT2pcXY8ctmrorh5c8q8o86/kdbdwlxyJg6yAc0K0wqbSXbutzGjUtoTC0nR29C/VqrCubJspgQV06YzKmaKxgDedktPel7RgsX2nLEYwzI4KMhb2YwaQRY7tN4QZBtlgzMv2zznk6i6IobOO6uFrZIxR/qAxBaTJJXDmqrKz5Hul0uQDAXmxYa7KMMFuog3vb+kYPV2phltVp11kuy7Ivh2jzjjPUBuV07JloUCM15UWxc41Vk5lPYtQUOYLndBgF+i39gnqWDiJlow45Luy3d9QIiNOVjqbCxJZ5qK0MjU53c2x95nQvKv/ynQo2C1UV5IQjbux5Bl7l6HdDXUdIrPc0371y4ezMNsMxRpr1enNIGbLSiiicTown0iw3g6BDzNnnibr6fO2rFM8rHKpOKFuieiZ+2owZgryecjNJpoIPsAyvBfESjCufZAmntDGGZrIdCqjLKNTuqfYwfbvp3JDJhqii3WjOOmebD8DmDF/aII7p5JAtiSxlwP7Y3Fc69Af16WRxkyFbfymDjEWfh7LgrA8kYcyzo2BT/Dfb6uBrlTX+54BZlZymfcpt7XHuO38qXqZzqQGpoZIU2q/+5c2ipOog1SErVqdMV9m/tO3FGdvSL2mWXCB84WjoTXs2Ui49B8r1U/3twnNixq0fk0L7EBqFScW8RduUwlnjL16c37hODQBu0da2kX7Tfu/7JricCRofmDPHY+qlO3dytA1Pe82g7eYABmzbwbJRExwNgYU6sLCYWnQG9mPDm+fXE+bUsQ3jy1ibIMtzvDdnv4cbtod9eV/48vR2BBzeZ33XqwdOldyjHUmKxZmWamsJgfado0i+KtnOFRGGhOvqqsTUKP0auxC5O8oTYFu0mRE7MEHAf+LhzTd8y7+Brx+f4P7+wKvxWBo3/oxY+2osk/BZeaXp/C+6fpaZtn8ewL9iZv8SgNeYa9r+UwDfMLOHmG37RQA/iOd/AOB7AH7XzB4AfB1zQ5J2ufvfBPA3AeBbX/uWx2+CVH32/Fs9WGrKfX1mbY8lQYux1+as+uvwvmTUeRMN4QWzCtN12+VccRwuv8tGCEH3y9g0nAE9/mgo18l4m7h6ZZD5aKqKZmc8f0jDgo7DVEJ8rtnN1P4nHBWIMgMkhLDFWKnREr2d42GgNGjI+U4a7EXwCiKkhKoSMa6VCkSJMVWq6/a07cqsNM3hWckJ54AlYBwjnOGj1qu7yIs8q5bywunxOF5AwXSngRInQJInaT9tZJPJUa7lhBqor6goxVa2XYTKHSuZaTD7FfRr69XmInAadXatzoXOTFaXbdNz0HmZ9yKbaHO74vpeCn91atffzKpd/lv3KeMrfXT2tpBR+os7QlrqjTEsd2Vj0wWnzPoRmiD1usGQosLbb5SDEiNdu5dyS2dEdNAUe+2nZEAdknJU4pfIYJPPaOwNXH+oVKsxtLOoDLJ9f7m4Na/vyJ16ufB+MHNfssVt2isw1V05E/QzArPXUqTJE+QVM9SuqlFKKc5G6gKrpvn7ySaJLUynqLHXKpQFJxuqbrrdMsFawq90JUzxbeKrynNzRBpB2JTBok8Ba8lPA5xyKlmxJp/kGziDOS9eyoPuL7Ag6wFzbBFMzmdkM4YYL2e/POjVggTQXgv+wwHdtq1t/z4vmaVCzaK50ISbkFUSaln7Y4nKaacKXOEja7Savwgdx5hlWYmnPjuRVoGyTdhAW1FjSmy4x5p0b3gug2Lrn5JlsyhZFR1plcwwGTO12mk5i5ROT3Y4wkkuOHRjljYOi319nHp2S53GdzNJsBkOp+5wxL7wgA/cMflzsy2n6vN8sGVDftJ6tj0xUcevlO4eDhzPN4z70RMliStd0SdwNssSHJAiGTPDo47YuPLvVNeSzJloDTm99pG1yie+z47lt+Sy/mbarRjnRfs6qi3GmvtAZILIz+8ZwE2P3CGzlepnUc4oE37i2TmUFHjADcMGhh14tw+8vb+ulow7h8uoEwXnmcWr60uDNnf/GwD+xhyk/WUA/567/5tm9l8D+Ncxd5D8twH89/HK/xDf/6e4/z/69Rz+z3ytyZIUcDJWEIVOAuJvOg7trZf7OJeFAKqs1nstwBP+Ez+0X84+xNgJz9a4bIGBRorjQLfjXkqaTW/1mLxb7V2OwZa7NGBWD1L/luHr75bhRs2W0CF3NKbUoLD0YeGmoy+9nHpZhtOVSynxmrUjkLba8A6Q/G14WbVY4mKhhzqeIO63/EVdE7qusuS+OWwm/678q4YdzYHrSjCVoTBvvWqy86Cl05uzoVROphBDZiStYkPeYMAetGo86uJwCAHS4PAZ3faeuF3kpmS6Ltt64LJZwQl4bKOt7oE6omXWLNpKvCqDOsp5UFh8cTrZ72LpmqG8MkCpxMLQhlZnJYI3YzvHukVJXMLcRENwQpuStmzVAz2wA0FJpBefVom0ox0SjDkjEEVDEwI67lcKYx18IDbXA02hKtozuFjZPOAw88zGDylvnGOhk0xn2MAylXJ8AwxuxhF49jFyh8U0rnxp3dRowff6eSbXSi/pGgY6WRmA5jPUM+KIKW1MKa2yLtzNQCe/Cx0YlIpsEFrnNnMB39x8IEZCHWhoB1MbIEksCXrlPnljjmdL3k91osSwktf5njin2TdHO5F9LjVOLyF5NUnjBtc1ddJasdjqUgZdZKf5RH0NIgNLCzqxkzWrXrMQDiSdJv7LhBmUSkLBHFfxRiUZyuallJavwONEintKDxT28lPrO3lG7H4HajnyzgQHQLUZMhuBKwPwCiT5eG3oNHWhSzMFQVJYzt5zeG7qowGYfjI4dttK1uPZa7d/8u3+kMptOtQ+133mWjdTeWLfe7Spx/lMCDa3XJ/Fe+SBcR+4HSOfnYd1z/JO27esJqgqFk/5UpyfJwY22DYiuN3RA21itX+u80DJZyNsgSZTSt4K28ExjqLfCa8rvoPrvHhQqUI2J7tUzFCz5SddLEPcXuCHMPiXV9nG0GOhPz5sz/jNN/8PfvzwE+zY8Cuf/zLejNf4+PhowWD/1y9guLr+cc5p+w8A/JqZ/YcA/hcAfyt+/1sA/isz+w0APwLw1/5RGs9MSu7SVQbH9Rmby9XdeUSxbPkLIa4BY+DyUqdC68Xr/uq8ePKP/p6MmUqHRl44CmTyviDzikzp6FrBeAk/QizC6FXssTJ5593sR2Bff1ND85K75SgnjgEkh579BbFa3xng0Emvue2VDuW8Ln1rZGX1fHdqlEhqTfg8lYiULulDGXGuirdUUZpSxdUXyF45sNXfhUugUNQH60qtyQNh4B/h6XNGgrN+XLRfqnB23QNIDRgMqPUzVpRRxzydF4hDRCNPLyffv8AXA2O3Foiss2w923jFzfN6eRMRJB4muSfNyQ+GMg8cXkdjzOrGDY0Lyd/aU+kG5IMVKIjQ5F/vOKtuKzkjCQeTfjS4TH7XTWcENDpgpEXKBGWqaQB+K3g94SiuOQdr2ma4SY5lvZrBGoIpXTW74sPz3J9EY7g62Tt3Y02wba61Iq0h74Y8O53C6COVIFnVRB3kltbKdzJO8cc0QeVbczdawoXzidqciXBU7FpylCjnjLwj1lRZtju4S1wESaR91+mN6ZAaSeWLMqZO4bLNPUiFBCTaCoe8bAp1taN0qMLDYXGW3Be+oC6QTRhAnNWxAelL+No6qLXzm2FuA19yZ4m33jGVFmf9HVeObtpfcU4pY0y20GYmZBKgXjm1yYfifBC8ocmy1NVqRxjY8YHkwlM/s71zX/U8GUjTXk0CTjq9S4gMhl9jZ0WT5NMGmamxbnvLT9RWywZkgkR4pJ4o/i4dOTcXe7B9GXPXuxVy68ZpDh/AQbnMjaBUf2riQpMHojetnq3uN/jhOO4Hfun9LwEWqV6nXCBm81SWi67dHxLZTd0sMu8O2AxwX1oX2jES8GGWmNq2F9+v/mf6Chq4vdhFrtfLNvyqxLbUiSc2aZcsX6YtMmlrMakN62qhxUR8wbXhZjf8/Te/jT9++BMAwLCB//ujf4C39zf45P4xDIbvv/9FWa5Rffzk4U/wo4cff1EHAP6UQZu7/x0Afyc+/yaAv3TxzHsA/8afpt0vvobQxlrd8uywPvbyozNDnIIv9GdPiqllI+TG0s4Xt1skT8ODZp7ZpDgAyEyJOjNlsDvcemUmNW2vnZlPfmj1xm2IXZE1pVWjkfeqUZMHu4I+fYhvHmOdgjbL0agHJYPXFI8OvgRT+1q3fCdAqfTtTLuZjZO2xGFCe470lOw9DW0q36RcgCsUNsDafIUXgU47vSyKL8dLTUT8FG11fUmbbWm09MQ5lA+MFD4HhsVbVv4bSCvDvs3F2c1R9mitlRZVgwZtHPF8KVbQICW9LN9LufXYkh+xfi0I29wSRzNCjjq4mzgdPsJYAbUOs4wu50ZrDHVY7ohtw53GzskXlRRICopsZHAN5PJR22S2JcY8YoyqlxJHpIHit5O6nrFtzkIJIbbN8rDt0jfVUAVjDnJV9yvoRF1lxgrea5llQFYz0rWToIl/vzW5TtMf5T1M7LRS5uiT8NvOw78HINyh4y0nlTqYC+6jvQHkdvlJuMAcHQOzbEM/g+dOidfgEbVuVvZNZ2EyX928h1La+ZMJvry6mPSrMZZuN22wXUoqbps+/+qB61P/VAsrsxFUznjM8Y8xd+vrvSHLvVro5tRfI/GSyUgzrMpy0mBLFOnsUfkDhPisP4UsUS7lot9QD8rVSx/r9wqe6121AT1cvJh5A2oNXQ1o4opbree9mGWe9bVnCxs8yaNKSk5Vt0U7wFwHWqyd41K7r3NrK/T5VPBA6upAX2oSqqEokzWbNsQlw56JwWQvL/URDV7Dyo7LFiY+BnDkM1OxeuDbfGDYlqdQTH4fqZsZtLkz8BbdC8z1YWNgHMeEIxiLZXEezDTGMa3HwwP2bUPjK9/KfwieOe533I+Bbx8/h8ryMWFoMB/AMDzse54tt7nV7KXSO5BT/imv2HiLfK+0bNTF6Rf3DcCBcRxiP8tm0G5mgiqqBtSvLb6o/lttknd4chsRl/c9+BeLCbxWddGOfDD9Xi/R1ly/OX8/7MiATXXoZ/vn+Gz/HIDh0/0zwIBf+PBt/Nztz8T9d/iNt7+FD/Z8DaBc/zgzbf+/X+pcpvPJfyK9WZkBIlL+pQ4WDrv67Xy5/KXzocYc58xvy+yss2CWwj3HUhK9mLX8lhAIA/N3VZNNE8a9wUxLYy79fj3kNGQNdFPboCOqoEkVeBuQN+U1z0CCEPF86evlZJSyaG86q41NhIe4rlmyqzWLxrEByUOpuM6okT7VGMgdZgITX1dYlraDHuqQqJOdAd+SdUTUmgcBGl+o9tKxqOJbr4rzODCP9SNaNhWqsk1/eI2HiQezLO3yzbBHffjmU1nbFxw4ctwP+DFKIdNhVt5WJRAD9thVpmZqOHjH8CibMs6YlCNQjoXM4ooB4+YWOvNaDkrnRHdPYw1ZsjwNZeHrnFuy/r0lJLSLmu3JzORyKLp7nDGmmUa2yV0VUfRmyalT6BO/8/M4Jr25M6jitV8lQ30mst4pw+ryVgXHc3ZwOmUVflnDl8n343DYVruN9gRE/zjRZ3LAeuGrXWprQ/nQwZ6lppvc5sxbtWe6KUU8OfmLayTSOwFLtCz5YyJow4RT02rpSxMWVElX6caSAyFJwDAy2XAqLTGSNGa9mNgoI9vtjQQFFbys/AYJSkWnKPbYBxvbpDyLtDHSfJzgmd+2lrAlnGobeXYXtyDvZacX+jkWgHOmTx/ZFvp3nZFKNMY2/5+ipRZN9WeXJGEDTN3l+U5f99mv9GUkGUs+0XNCkXBrv/rF0vinrvPokwnIiIRyfRD1VREzWnIZqvByimkzUu2aAa/Xa5SvrfRqwpq2X5qjjGSSEqmTfOGh5B2liSMCtSNjpDEcN9zxwG3Yk+e8Zt85ttQJBGZgM2B/eAgWEfsWeKRsOGYNKveUAAAgAElEQVQyyA6dmEjMFC4A+HHHuD1j3/bcIKWOtXB4BH1jOA4beHjY09aVHVNbdiEP8Ttna/mOo9aqlf9dzwuUoRdHJE8XmxV/j7Rb3W8ePHoIwEy80Be4gDVtU9E9VE91ZiIvSJENHl4w0fQ1f/eVLRGLLK6Hv0hsg1qe++n+KQDg09efYR87Xvtr/O8f/Z8Y9kIp4HJ9pYK29WqOOEr405ejEV+E8Kqd5ReoA6bR/xfCYp3hqRjOa8ZoyGqxg65VagpXFOmESlglwZSSK5QhN0OrF+cQRqyF0HOVfOGm5CEr9Ua4ct2aWcO5Zyf1rkEUB38vFJVBUE3r6M8mXOxLnhc0NPeQgMp7cxxbwqrT8FOA5d0aRSStxHD4+gztm4lzEW06+VONOpvx9tlao5Uhm+2P7JrGkWsNOJejZtLi1w6qQx3WPoRYGyGGlBBTgTIoTadbgzmhm20b3rx5hddPj9j3PY14oTeYb3FYLMZ8v9/w+efvcBueGVWTfyuonoZ7klq0L1AbTnA9xhLQpIwK3emY4IJWWxi8LL9z0uGKJ2dg1PgmdZIE1mItOp8Hb0RZmeqz5PTF1vdEQ9FtBpD1btN0ZhHoiAyThkb4675zhptr5NIxRTpGlfmfu6kdBzP+3SlY9ctsh2PeUmcWihwSqcTZZqTxbLdE1PLso3TM2RAPS6vsRI49HWMvOCEJCiYzdDOJZBkRKJ43X+MGYC5HZLiigkINH0cGVC68RcXNM5XqaAHRWUV2QLLIKF8j5bVlz/NBK34mbOLEGvTgZpP21hlqZsiL0yhXOlHaxqnyB8/zKR26yW21n+WG6jKFTcrkiuCw7EIUYVv1f74If6wTq31OEmWz+oAKPniIMsvnpFxPtYlaQdpP6oMGhcoiu1da6itGGpGUlWDTPxr8w6x8BEkO5cyjsh76M9kZDFscbTDGxIW75xpsjoFuLOlzRrmdfiLVhg6aY8ggSZSg1QhzNroGlTqDNKjDtxmUGwad7QwMQgGKKsh1z+64H44dTOaxrXhY2Gun7nDAHqf/sds8LuDwgfvhcGfwJ2Pdqkiu1PrZ8XB3HEf4C5vhT/ZP8fXjaxMP3JWJaPSBcR8YpmctMpGnbesUcFNU7blJHr7fFu9evM9xIcrQDZXA6QWBnjRVvp9J19ShvLfatezR+vfUa+UX9HHVs77cmfIm4yMPmr7TcThBVkl07L7h7fEGn+/vFoBXugIHBn797d8TeT7LydX1lQnalIgAF5EjlTWg4+5O0LqDzs/Y44t37Avv1s2+zmZ5Px1eyTiBzCUlF8HY1aGMTYIMloCxITfts2ZHTnBah+1qnGS+pkBUkVovmcpAeojjASw0uWbBdBApqD2Fg8qwdxMIflMHOMcm5ipLp9qc1syc+rzf14N5IUiDFNFfaSji93xn0GiX9WVWNkmrCvBFrvL+jOvzduLvBnNgqgLz6vvc3VS8FDXiIQOQeGJbG2Bgb8C+73j79jXevH6Nh70sF7ce1kx850/HMRwfPjzj3fv3uN+OFzhHFfKESP1vrtW5wk1vxeXw4o7paq8CaQNk9oxYXg0d4au1KPwOsFyGKNuwZ2m/lwMHzDU6pQD6qIm3IJKu0Uy44+/8zPELdFeLu+mU8Z9goTKP84NlWyY7ndV7zay7y7bYdaO2Bled7AmDboFucFlzEjNAHmVe4vRSG+jINMZom+U058gbb1OPmmyak7PF7m02LfG67ACsnTuVkIhK/pbP5j/kaMiX+Ctyy7FIgCxNyCyb6BY1Mtp4I26VJHXd4LluTC87HbVROlodLm5U0pzoOpit9dPWPOZOn/P7nHERrXCRvJuvyS4xK8zxe7Y5sxLt95JdHVy0J7uGzvEF/0QQ1ARA+Sy3NC2YWwmiMGHZL09ZSzk6jbfL6pYKoB5qozDDLEO7ytpbJmJ0DQDtWyskyY+x2UXwpc7il80+X375TXXV2RpemiztI/6xgF9FrJ0X5o4jdovcIgkHmxt8wOesFGfCfdNFCvO8Lo7QfWAcPhOTC7+RDPu24eFhw+PD9C+2fYftM1jabPL0h/fPeL7d++Hjy99slGNWZJhN/tt32Ab8/be/hX/2p38RucdD6K9ZcTWDo+N+ALtUDCwqKWlvqqMXesS9CqrWREglOMsWhYxHGf845sz/psef6KDJymK/aFFpnbrOX6uXLtBXRgypmOgfiQin+Hr1K0MrW3kCul+isfDkj/jeh1/A33v7m1cgJlyeY7NZ1gog8XuR5NDrKxO08UpHaAHcQrNwyMMdl/t/Xrz7cjBXDo6u2SgYFCZ1OgqeWkza30lmlGzv/LlZagWl3MdwXEpRqoN4vlyYK9uI4XBXrWmwW3fSlrquAeGSFZr90DHw9CeACye/jc7ab9lj4lYypxdjW6+5W5Jk6dZ+WuZjVgjpbIMH/AmgFU+1d8UutnU1zeHxbE/lO0ejuBdMOArjvjgqORQnny1KCwxHjUzYHNa8vPN9DlfOxNHZO2/PlUkxUYD2sOGjj97gzetXc2bKfa4/8PMmHypy7sDtuOOzT9/h3YdbO0vqcqGzI+WGZ2y1UjR6GagxpqEFnwfWZLvuJNaJad3RTgcJDRueztWoyjOzNFhbOyJCe5Z1D+7Zfjn6MpbgNZ34rRdE93DECfaqt0yeZ7nofKAcxOq/Eg3npFHDcTybPM/3MWmSRl7OOCpoBCMZiCwJuOBraqIay6Ihwomo+2I6r+QhnjGYJJlL5nU8XZk3RNWGHqlcrT2XTXI2jg1a4ClmM9chlcTJv5F1Nqu2vMGDdq+UDJlCSnkMAjf77YbuvGkAS7TCwSCfKcoFlrY5ifuS7Ra9yjZNpUtgT7ojg4w2E1TaA/2y5W+tb80ZJh5iy7aBRo8sRQXSN8iYPIM/k25EMJfRalKoEjEhPzq+xYfo6KASG320ghNF/Zx53xqJe0JD2g8dPvuyhGkkH/SZ/Wl5rjZ6K3ii4TaeTBIsJd7VSPSXQXokocM+9568+ETlYMVe+FBjE7Hgs2Y1Gt8rwDXDphuWhDyPODyes7fJZTZxxLPZDMDTtmEbjtvtGdh32JiHctc5cPH21mtnFA/rT0wED59r1HIgi0Q4yN9R2gqPEsVtlu4Pj4QH2rv9uyV+NeE2P2/X9GvX4jtwcxI5/oPjok+1+ttJ8TY7WDqIQbiOIUxSbwAy8zsqmb/65HzFob2VPNjy0BkD5Uc82w0/ePp9cMfbNifuXN4zB2spm1+G0359NYK2xOuilkWpcmyGl3eBZGM90xq/Ujmd8KN9dOekGExK1xTmdkBxdz1wmdGs/l4i1Opo16Hg8x3XMeSYSkla8pqF2fAaixe/ZgafgWi018Rk2U53GWH2p6Zen1l/t2JZgd/SMb8yWxo0ZPuuRmq+tYUyrpkuS6cmhZ1wi/6vrKWlgWswikOzJGE7nNGgGjEAESSJ0yMotY2wXRgzq7Hm97TCaDdJu/Sm2otdGSn47QkPs1znPdb/cDzsOz756C1ev3qsdVT5b80k6TUzno7n5xs+/exz3J5vAGpjg3w/ZAkI/rWNGIsZFw0Qei0TUQLBzXSaNdvsGVhQPjiPlkYAcqiuIY235T/TIB6HZfnUxJeV7vACY9U3xKWo8OQ3Psezv3RdGYNVh+42J+U46bB4wq7XmqhxQIzopZ9Qch0MuxRjFRwwkf849BhIXshqA+onm6VViC2qYZMXuGZNEyNnl2IpL26w672QXzKYUfNQT8RYpMQvN8kgklIXAHPWwpNfGia7lZdn5r9bHsarMy46MoNtXg4H+x5SajgULpfNEMhYDUmt7VJC9bloqRtneH9f7Z5jWV/EwRKu0OFjNF6rdgP3GnRuSpEF/qQZTvfMEDOCJVR9LRM18JmxnTKpwWQqj8CMKe/ULBht3zQXrkPrcLMjFLZzzGpzoGbH9bX+kFyVxhBet6mLLODiRi6rTHtCI0mtuLeh428mwzmTWXQYdDil7c2AY9TAMllDmEVHMSGlgeDsRmyfTHNXwo2YJ02Vb0rf5Vo36+9N2d3meV9hW+qROcvmUcpflSfU3ZRNSxtTpfZBjeCrwbPZjnvMhgLALfTt7EvP3J0sce3IKo61HNjGgB8D/9T7v5g4T76UoY+wm8MduA/YHpMTFjzQ/OPCZV/m0/UUWy7no9O5X5Y0N7OYZSveTRR4vWsLeZvdsjnS8tsG4DWDmCCKjKWtT1Vggtsq/V99y5JetSf626JXasRwzI1IPt0/wwm/0S9hsVXPteYvjLJcX42gDWel1eRvuW9itDJji9rudml5+X5hEKDEpb3Rw5kbJC1IKnipWPhMtZtgpEPg/TfVQWd70yGvf7qwiNKp562B3szuhVFbn5l8xcy6gL8I1iIv59/yWW+sXKsRLPwZdVC0sYnX3HDFvd3iO2mcBDElnBDcqROmCKfRDkcEuA7ULgwsFVTijE68Z+is3RerRPe1YBhlixo/liJqXdMgLuOu6KRw3ktGC1/F91UeRojNDI8Pj/ja197i6fGpcJbN96x4OcIzq/f84RmfvvuA59sNJhA02yo8neuewLIWkoNBlp6lJOMkLI6s/QfohMz2tk2n3jr/9/WF874BVcooUDtE73gZboDJAwgeSlanGBWNnEeZHAYmVrqMNhBPMst+PPblbvIqtE3HacV9Bvqtl/ifUcPklLkzJs/SQvAjmRI59iIGWoDNx8qpmxHqoVvwS+mVmePIZVaOWbjkAZmnvkPrIeQ2+TmQTh7y2OFznQUrgFELeis4Vs+onGfpX3gyZ1GEB5KzrMoTy5ld9GvAobNnSSIqDCx6j7qHwTKzyrreLzwYb2NeUEDsSsLBc3yW7Vis30tiMXha1M+c7Q6Zz/0caqZx3pcgItd4Bo6d27RU2zo/wTWAFbhRb7vI49ZpxXuZdBD9wfPnZAMmC56mfvaFHrpxkV6arMlSaB/iJ1BmiyaaLCsb4tJe10+l0WMDqA4B4F4zae5wDGDbaybNi2RkrVmuXIA4tkiy9YANmOusps8yZ1H8qAfIOxM9JjPPTF4SQZyl7+NMGT6VeheNy0guinMx1uadR7qdhKxLr7fNbG5dD+AYA8dxx2aPeNDZ45TH7v8dqfNdjy4NWaj3NxgSZRo8iNPBdMm2b4A/AAa8ev/UxiqLBWRMxR0e5UZ7BFA+aoY1R0Db5LLMQfU5n2lwSgUJysbV/cTmHIWPqNDaTnReXXdtpz4T16WQJw9fr18t2Ejf6szDpqSdzDbz7Q5Q8BFEXntN8YTnf/vk16WZUHJO6yT+z1WV4MkWX19fmaCtX3ZigJeuLBG4wEFr0VaiXD1D5qWyuW5n9XWaM2zyaygVKtmN502pQleFL8qY99lW3VHjw1tq1MQ1W4QuM1/S3fJIe1av8FmwvYBChYul/Tqz1kQgANlO/QYtdfc7vswnFkdIFW03pgV3v+9pgCoe70rfWPPuQHp7thoX0qg7cFXuwrEXsyi+/UJpUr8lWjIjXLMWmo06DTAckqSxFZ74zoryMtYdm3RQtscHfPT2LV49Pi5O8g6zIXJaMI4xcDsOvH//Hp+/f8a4H9058BrCJsaUuO2zYCKLjtp4pLi8oYHf+kyXykDx1iQN2+l44gL5CYf0lXQnzNV8JhRc+eOE7cIxM69JO6tYO52A4i9Nfpx1Y/Co8EqqhuVAZs1jNIiSFlaJhCDAZnPm0p31RmHgrTb44AxqtTqy3wyIc7OTyvF7GMCqrovZZwDMcvvGwG6UfhHFn/JKXlH5jxfaFtMcw6iAo+lwF0fVe5VB6RniXGaoB2EnIQMjhmn0RcxYyjY/S+mUEqW815XgQceayeT7aoOSw5WH2UHAUuOO7LVXwGArTMGPaH3UAxy3x86trawxO3JMx212PriHKPlSaEIVnet1jDIR1S9xDgYTGOVrCneJPJZcdHwaEPpW+GnVMkLSdQ0t3/c4SoPHfpACJvpkjrnwobrvJRfl9HNkHoZjbhaSCPSmONMttSlL1qLtpV2fPMDlBNwqPrfGly4KIYWFfbOcO6IGkvQq8qw1AGt+tmiILm/UpxsXomjryN9sK12Z8q96B5BKFUu+Lx9gscMyRoPh8AG/32B4yA3CAPW2Fh3C+yb3l4sllWnkEv7ObxYw2+MD4HPHTWOibpsDWY+pS71Hnj0Gxr7Vbt7dFE0SBI4cReNNxlD2qBIMTDx90dUDNK9y09MzCf51OwpsfK5nLwYk45i/Eq9iILA1Hl0pVa9vi6w4eJg4mNSA4Ru3r+NHDz+S9gn1bLcOCPqC6yUExPWVDNquSq2KSc73gNU5Ov9ujVDtiXguHKZ06rw3cIIRLQBag7VyZOv30nHW70sgkEpIU3UoOtKR0r7PsNWdpvz6L/2d+KeNCUBzWNEKfZqdMVnPs+XNwl0zlM3gCTxmkc2odpWBWyaffS1j8OWRl9o6K4AyBKdrocX8WBk7ne1degSNVdL74llDOX1dEa3P9XEUWFPTHrGjHmDz3BcdZ9K/y4GoN1Fqs/Gnxx0fvX2D16+e9C4AYLORu8J5ZJANc93U8+2Oz9+9w/PzXc7bCegdcqZWlOrBAPNWCqKy02YRGJCsBycTbN1MxNSYrlit/GRhoFyZVn8vd0/Oi9X3WoOK0+XJmC4yzDINpY1AaFo94NmOJSqrzEKdKV1bUv65OksFA+V2Suvsq8oBZf1NwF94odM06TccOJx6FmhEQOG/5M4T7jnTSH6OtXfGXU05YCFSeEe54FyFwvX54BvBXRJQcSQ63zk2mRk4eznSxWqnxKFL/zBgTv71eo5DyMy2y496uXSausfLPlB3rjupNJwswX7yRkhvBD0OyOwQh+NkSMG36AsAbc1PrIczZ3Ix+kdxThqdgJGBjualEyUSnJvINaxm5vq4i2bG8nvraM03FnvKdW8AwuCN8h+ir+JqKxomS5VD6gHzfKh0ytW6Sy1b8wy8ZuNzMxCxWl4zDldl6YLZwoghZ5WiiYIh26vRZdAptrwWUBhJXE2kjNcYFLJavhDjl92Mq6zTq0H9k2WYJa81YOKLvHm27mzKtC2za67pXcM2w4659u24H/B97zuMIvSgyOfVzOTVxUSUfCv6BIydYI4fvP49fPfz76Re0QmJk9ogTodjYNrsuUHX9WY1rgBAj2SJdniod1oMO2PbOh4h980MG8akfcIutjBHXvrghDNBx/nul1/etp7hWJR2HENPZWsLlOd5FZZ+9fPv47ffbPiDxz8sg5NKddlDc7GtTf9/wfWVDNquAjb+7dOzfP78/pcvmMxW5L1yOrTJ5XzMRWesWL7Kgov98xKuUvxltI2f81FRhdbbm7zDVti7ONfe+8yVeRL4Xqk3jmgs48gspjyoTF3GPt8on8gre35Sutqx0gP1POFcUSuqPGCMWaJ2eG5/KmFI5bIENG1XM8epUxmDpREraFqgrsPyWK+0CK/YUXD2ps4Nq3Gln3OFAK9+N9borQ95uuXlwBgdDmbQ5rtPDw/4+KM3ePX0iH3bar2EjJaLsIbPnSF9HLjd73j//oYPz7cTA5WPkOaz3UveF2PvEOWZZZOFXz1oOR3hkDWdy1k5XB0KS7nfTnJhYeQ4gzl1i8NdHTOrXtyEz6mzqucsWUlHqM9OaSwBqDMzf9isj4a+XcHGgBYNT3Sq6AzqTplFl9I2G6zR6+HhoQfP48DhdexEvp8DUH1Bx2T+OOnD2Tx2UcFjlcVK4L5NGhFXFfBSEQrf5D3dxp44FASnwip93GQj8CE+EZqGFcJqrJiJRUPwZ2UptNwc4E6IRN6iR0rzA5g7t+77PAfpfj+kpLccKJjFTBWRKShInqvNSebvffbp7MjoIAWdSTybM6c25XGOnX1w5n++O/dHoKx4yYipJcuUATSYpG2dZK1g0JIqskmG2krouX1CzBHrf2Jmz4cBIPydFh0XkYgDeY70WvVu/Gpip5PPWo3NBMerMrNbdRmL8FbJFntSmpFWmmyz4ocYIs969KS6S9GYmuQXbDYUrRMfIxI5J7vIkZOWyRCLjObRM17AEpAy9CVHhm5TksTn3ahU71fx9jK2Kx43g8WunOO4A9s+SxblmaqOUHvGf7Cc6wh5p3B0iWerpwccP3z8I3wX3wmURGAzmDiNVr1WoDksN4IYAZ9tewuYrnitg+LLjSkrCFnXnFOOpPmx9T2PVFnltSUtIK11/rjyr1/iz9Z8B0bul5Fmv/NcyPWIA23UFj6Zfx5sxy+9/x6+/fxt/Obr38ZnXN9GPmjOQPgNJj6DyPNL11cjaDPAbYupexE+cIxnRcgXi7hipQBxYF5SNp0ZrgJAkw9pzhrHaOlH/Z6LxYsMwgz17zRlVnSqfy5Gmi2d1L3mO8ImngLfdZwqZGtnto5HGVSfubi60yuG0mQWLZSx5SN9zqOPjbCoF3LuL2H18n3UMZbBgPNzNB5NUEgDZnxFxpWe8iZ0E4rK4i39W/7csp2FJnHGU/PVb8nGasM8X05Dvu7wdMr4eeHadNx8ZzO8ev2Ej9++wdPjY4K5Wf8LzOzvMQaO4RjjwO12w7sPN9zv92agNMvt8X3aeBP0GJEmPB/f3es8wtR70n44DEppBkd1mRgRj7HQMahqcy1/VgPYdX3AJXhe2568s2r1iYcsCW3OcmUbWZrEyQ2dyXWhWRkigUv6Ut+zG9JSdgzU+ayW2ZT+26ajclo1QxyPDPbXiZ7EJ0U/+jPIuWnxPDeiyplYlklvNf4KoJVIdpZ1QywnYOndVmKYTFKwpW9IRgu9xZ7nIcDL5h0iC8h2ehCLOBQ69a2jHVpfM5psU7LtPHQsSr/GOOB+5FEMTIj5UKPPdifsusaR8MlD+Tu/c3MkyJ+merNMVslc9KB8l7BGeOKhO7bitZLjXiqFkEknEWM8WVPY1JboTeqTIkbpZQZ+ou/mbKrLcOdmRCx/Y1B4ulqEDuRZf83uoJJInDEwxA5+c2lAaazZXtuBN/nbOHqxhRcgxSBSr56uTnfai+zTyrppDxY2ZerhftRCT2aE8lh5DPqMChrfEh2aj3Zln7mZhElkPCBW/eYXLbrAUGWr1HdkZtHHXjjVJRAWJTFtVoiNiV2qVNxWM7Cya29DHdYvcmk32wbco3olN7xU/E0aMA+U2tpjm61Ysnl3YPMD27an3ahqIMG9Ik7xTxn0DTPwOqZ8b/tpXCJu0hz7Y6MaHPkyrkQs1G++4vDeI9pz/sL9Pl4XcR8v0+RycKUsH/0Rj8cj/unP/gIOO/C/fvzrcBs49CxMdSgoM968wBevr0bQBiy11mdsqVNCZb86b7zfHZirq7PVmnHQzECxr9VvS134qhjcBzhLsoZYTaEYyklKopXS13HR12pJEWPWvoyXBk1NOTizz9G1rRkLGta+lgOGOHhW4NPxpg6mgSoB4/hfpETqbpNWv+BhgXMOX6evLZ+yFwwbs16JX1cYgJb9PBnmej8NKqGWxfOE65S9Shusrs4FjGJQ+8t2/q0wAhiwI2ssm/CXQ6oK+GwsbTO8fvWETz7+GA/7dKT6uhTH5oBb7JY17rgfB+4H8Px8x+12w3FMp/IsxXHQM+GS4TDrRjnTkrYyHisi41n14PhY7koWv0ltPwBo4FLruAotzDwndl2fUAe5BKBtKJFnRE9jlGsghLU6Beom254GWLBoce8UnJavUBUGFYR6ISTfaDNYfF6ct7kuKxatI7YAyRktgjspNM8/nOsCRhwerXZpfqw1S5MesVPnSTHMPsYRhrnIlHJGod12LXGxPLeSpWkOj3VkFttrx5uykwQD4tyGP/ZeOQf8MfO9GRSdlYizpI/SEoKyhIBKM++pN2RC0HL0VVfHuvbCCwPdJEvpoJVJ1hJM6ni2MEe3NRDXS2e2q+25tqOSMEQmy8S8cJg1dSntHX5pljhJWmyo+nxSOTYzcXnRUkY588fH0/hlb5oMMz3rdFHB3v+pX2VDtErYXMjnRF7xZpoXLUOW+anUgZGJl9/TWq6gxO+n41fKOiccqTPAI3Qsfqc+EzQ1W4OCkej04gvVWaoHanyCoxOchaf8TJ5lEnBTjKqklkZO/pZGLbEQ4xR/xkh7BYc8KnAbMAOnTLoRxECCwjxaSN6atIV0Je/998Y70c++P2A/gk8M0BlnRaKh478057QhM0F2xAHc0r8oF6FkbxckR9kVPw4cY85sblucdrcOQGASLio+94Hc/An1txoJu8BvTMScNJWffks+aUG9+CkGVJg7hHn4vxij9VJ/Uz7vtmP3DX/pT/4Z/OHjj/EHr/4hfvrw2VzD24JtysTV/Pv5+moEbS9CaZ3x2oGKtvzt733x1U3ES7NSyiovPXPdPA871FZEaIFSbmFMKkg6m68MFuK7bE6ef92pyD0ZMxlaapfLflX7OrY2xQ4pMfPCVZMTAdmBtqHOhGluL15ICGU5/KS0f5bryqivQdrJ4VchXgxdGvn47yyA8R6z4xds4PlsN94Z4CU0S+ZHdQHPHaOdyPeRvoEFLdvZOvJ3grHiAumnpN8yCQtm+Kfh3vD6zSt88tEbPMRBodT8yZp+YMAxBteAzLVz92Pgfr/jfj/SMYH050AtxC/r0aHMMapiFufh9F7HbSJPPArnOYrCZjorLRgqgImj5fDW9VqdJhq8dBhtQ1/ZYuoDLI3VOM1YQrtYPEdvS5U7cSw6wuXZ6z4Jkgao08F1ZpLpILpnIsFc2y/6kh+qz/nO3ANkyyqlFtgoc2Lq9zZU1DvzkQgOAEl2IZMKa4KBOLfeWOHvbNur9+AlTeipzoQ6+BzCFyzId8WbL90aZ31Lj1eQJ3aIQY93ZyM/R2AJWCbfgCjnhaojfvD+bCqlZKjG57rxS43LJVCP8Vm1DUB4+aynihrxTc5fdMzDi5kEgmGeXk8alxGIsY0EPXWyXTh5khRrNsjQdnVrAbA+I3o5+Z23l6M/uC5TSy5Zwo/EAHlOZ+8l6QZE4FZ2RYP1NstGuCV5Y7DcsvG43gMAACAASURBVB+hY2u9GtIWp+VXAeQ9A7BotCSBYVnsDiV13RA9VcNclGjaYR2dCLHqDyrMpL/n/ZZQkbYpy6a/0fbk39nfBoPHLPd0DRx+BA9tWyu/R5E3rrkoNmVZd1x94Wq+7Yo/ZYZ9j0BTAlEtF95qp+1M9mg/mFUcI9Zrbts25SyaL7/VlpiZGmW9DLbvGOPIaoSZzFNZKvw0/gobNPX6zEgNGIsLqHSgEqPjYVzQEWSn5yav8wh2PnPWIwWXXQ30hcsppNKrIB8DP3f7On7u9g384NUf4Ldf/W6AKXrYC66Xrci8vhpBW14nc42u6H/2li4Z5LKPc1+rw1RtfAEA663eRJwHYvlo2g4T9bw6atBsQyiNpZ+0H+7JO+yDiotK4AoVV3E9TYCZL76JZDZMS+Xk3dwm+2zcayQG3co3lTQNoj6vQRBotyl04UyV19I5ZkHntNV+/r0ZPZPPHr/IGpAMyPinxlmlQwsc8i2D2mgj6WU6ZsGfxSZQY2CYAVnupdlXCC21ULZDqDaB391mwPb2zWt89PYNHh9yuqH4KoDaYrfDDfP4KMOO4+447scM2JrM9DKUqX+v5UfJoc9RoabuhsqL0qGUX+ZeuY2zWRywi1KMQhxTIkzAE6rutOnamkLiZmXQNs5Ip7BJRjscxdxcQ2S6Wpz0zXJIKnVhEl9/zq68gkXb2vEnkr+fOCIKJMiZcG/Zf83aMSsYFQaio2qWLlsWSp51Xd2yxPsM7Aa22J3LNuvbIedAt3ZmJWdwcm1e2sj5wXRXRm9dR5a5zy5OQZsPXLFpznY5HVxplANt2fqaoc2zBuXMvXIm4x9DOfwD4MYGdLCkVWhSjjJaenny4JaOdukMOrU6t0bvaIuz2IhjJ0KTeFbDc7UtE5CJ01lhklUG6/luYsvm/ZKBVc+Tb+gEFr9brgPk96RF4wPRD0xCeK0t5DgnnwhMwnoam01cda2eOoU5yVxLWrZYrR7xSB1F6fTsV21P6SzPd0k7mW3jO/G+IY4qov610orlH1qTCcBhQwNGuei1Q8YjOskHn1kQhws6YDrzLbEoqCFvFWCebbXzOV1eLASJTlEc1mxcwp/qMAKprIyYz9VkXvE3MT6YYBsO53mDqYAUb54Ds1hjrnTUwSdVpZKghhnwG0tUHTe74Xdf/T5+4d23F8KkONdOvi/Y3LQZoWtGyIht26ym8SnPRM7L/nThyWyfm4yMEbukT9lKSi3vrm2aWXTnyIThyXvp8tfrTjouLiAEvE5kPW1s1xpZ7wU+bEdjUt0O3oQXGhyl5/7s+2/j9fEkCDAcOPAbb//B5RCvrq9M0HZam/QlgF+0oG+fEzjoTLPeJ44vRBylJLWHpXSSSkAeYjXHFR+pA9jrd010lSjui4BNp7LbQBNGGYHJr6egAuUoJiSlMNvM0dKN8plhhftcn5sZQislucI6bRjLNDVbVso41V1o6BZ8XhiQNNaiBEqQyylZx6VttalrQWD9Vl5DJmoSdV7GJHEdpYCxBe7wo8GkZZzsLndNzDFYbctbj59KZEZYK9nVGgDw9LDj7cdv8OrpFR72PZV5VpmbSXBugA8cY/Y8jjs+f/+M2/Nz23Et5UgRAGuBacJHK6qbjAi7pYtC+YqX+tqFeK4xdKeTBjmBETgPe5VtNxR2zVQicJHw5wHTSRkZj8ANjtkBp8NpXR7BeV5DzqSQfwRPbaZH2nB4OjX7BoxFUais94yntydYtphynBuNeAZ3ura/cESZnkC39Yyq24QAbMvbLwbE9vnnxfFeKHb2Fbvq5SYYlBnS1cT5QX0mXKGjKkBFOrpj8MBtZcaSOhXuxucZ2QRdHeHE1+89ccRA39twE74o9ZUIjUpkyvlmgG3YN2B/esSbV6/w+PSEbdvnO/sD/LgDkQV//vCMDx/e43aLcqaW/VdnJThyhQkApCwqaSOsmX5Lk+1lrEpHsYPuDmzzcHsGyYDFDCJlb+7kl1duf77Bx3Hh/HCWo1tw2lrlrRxOC1hR9FLTEnppknW2l2stHVMnt3JOYnUBTz4XhGUvqmtTtoNYEQW9rTtmWXOpG75T/oTTflzAA8ud4xvOeQZf4kh9BdKfCSwTq+tLiWj4GZVA6QFp01WiZxyebFggkEBTSVnSQQIAR85Gr3RnO2JlQg92febu8HFgyAY81QDaszFCGNuibsjhcDY0fl5ma0gtiAoZNvCDt7+PzTd8+/nbqm4E8rjamZQCYuBzbBtsAAPHDNhskzXEW6iczhu9NV6laKduH3I8T7elVxVWOWcoCYBti2UYV8J3HhGK30ntZvmCz6iOkknRiKbjMtQ9tusHwGUoq27QdvKjrNeLd755+2ad5hQMvH1m+L/e/CbapgwvXF+ZoO3la1Vx/sLn64G2RcUn4iCNiLovcjd/9aWPdNZMabbOIC1QhhYuBwMVLJkIF20JpN59GfX1OOZTunZp0TnyRfKtwZxOhebV3nQM5HXZLlc+LlcxXiqIBLQ9VXqztPr1GE3eGef5QdNPwhZiolAWVuRNBY9/05hBnKT6qPdchJfOHHdanM2llpBAzlOAHR7ZMR7Q61LlV7M71UOZaFV+M7taCOWMpw7PULRyAI+PD/jkk7d43Le5hi1kYdgGGwObGlNMB9ndcRwH7seB5w/PePfhVjMgHcVQQhAWNUKJRyVY41WOmQZcYaHHLww1IDtMFiHHpTycCe68l8qaRN9zDCRfD+aK3ixt5KxUPSezcFd6CJadp+ESuU/VkHwl8ArGj6UER2cxNFA0010NC9550pJXQJv4jGIgOXeoVKqjdiQMvmsHUamiKFw5IGtJSg9ZGLgRQeSmGUwi34BtL91OHZKzjN7HrviIEYneMWw7JIhHBo4MSt0Lfo5LZ2k53r7AHovjULqplbdRfyz2Id8p6OPvBphj3ze8evWIV28/xts3b7DvO9w2bD4dFo/Dge/bPkubx8DDwwOeHne8e/8Bt9uB+/2O4xgYRyUTuh+zKOxATtm8ZbdIUBFZvZBDqaCaPDfP/V0PbkHxUQveLQ7ADjlSZ5q4ZvnkiISD1+O5s+uGTDAQrvQ5C7x5i0ensDvayLQvcVBxzlB6BS5qLQIQM559JVzBL77AoWTIz21+DesVEiZCscxVjOmcrxsZanrV2j9q26L6Jm7lbKXQT+0LW6y9uTzZwSPQzqCSSTjqKW7S5H3ExZxqaCg/bQQhS8h7yU+swgi5znv0t8RrYD8efW/5PY4m8epjMX6Fh/oH1Jydc4UKaXu0ukcfC/uwA7/z8f+Lj376Bl+7fQK6XIQz/aqgXZYb6kWbhblWHT5PTNw81qXFb2VjKIuqIES3MXEcSoSyO/FePEId65oUCzrPHM4GnsO4bcDQ2Sziu8Gks4qWNqrzNGECFgUX7aqNaiRZrpxWL3xc6Urob8JPS/tznbrjW+Ob+BX7Zfzg6fcv2ujXVyZoOzv+K2KVcxfNClGqyzXG2sZVf9rOitR105H+jvsFXQV2izYbFKn1vPMeqBwLltVopXKHOrGzAWauSukuY6IxP0HJvusf9+ks5XEHXs4Fec/k3kXyJInCtgr22bvBS9GscMgQzPqNnLERAc6s7TJ2wqCzHoL+eiw7F/xkdpsP8F2xTN5MSr3HodqqOiY+ho/g4C1nXzxTmhD25gBnt9OlXltEo/lqLHWQE/4NT08PePPmNfZ9h+17ZRiD5ogMYu6YFwO+RcD27v0znj885wGhlRUuOrdingvZPGHuQpfq00m4in7LfqsiPhk6RWg5CUDxdKO5IItsW7/50mYYjYTbU1YqmLALWSYMgTWDyBedkL4uQYNW4vVllIX+yTUBLI9ywPYwjMnRZfq8+DagDBkeuUHLJkGl5wHabMGbASYOmxlNhcGbE8npyMU62BmAjT4ki/IyygrhSH3EDGvxuuK0yi8Fx3q232LUBzf+CJhs60GgoPryaut542HOUpxcH/5jVUZWpVPZIrbd8OrpCa/evp0za49P4A6f9/szxnHHcRwYBzCOI4JYx/awT14wx7bt2HbHNraZjCF0bWwiC0FD3TjLnKf0lf3VhNWKHHWxJppljsgaJspOUf6Cp+YMi8xWZ5RpiauyjdQZXnyAAR9MENBuki8LwqY6lOZ0/AIeJhSq4qOQ0V0MKRW1jkfyBKCz5DmSZgdYOsw1S3xW56f4du1i3eEw6iOWnuL6Ur2OCBQAW0rVL94S32A+J3yE2ej5p4I885cctxuyTDsDktIonjSmToIkY0PHLokbdjDRX7v78OzHZh+Mlq2cAQM3akL9o/Y6+p4JrFGzgvQFm4h44zpdoiEoFZxEFxvwk8dP8cnzWwweQUP9aNU2A5/GIeK0uU/w9sDlTM4ObJvNsmkLP1ppFIA12wgtkBdb5Q6Am1TFjpPLGEse2dosuTZsMis1Q7meFKtxTq6YFRKtbkxwse87DI7jKAfBG0HEcbgKKDhA9+Wdmrnu+s9kgGe9sKUPAHzn9vP4zu3nAQB/+9xzXl+ZoK1fisx51blCdvnGvLrir9/shd/1b4hlKpSX3aHLPqVrvt/LlBQOlBMRn81qg5EyJr3hlVVz3ZBd8BcdJ7F6OmORAnx6bzIgcZEgWJUqrOWKZyhLMaTehUdGtcqt1uuLKAtQ1I0ygoYeGfg0NOFojFp8WgqiFEYpMs9flPwvcoEr3xQS6PNVa/qKGCt5wN1i9tDToWxKjbgvmw8Gw6TtLGuYswxOBWsr18wyo8fXr/HRmyc8xdlbyD7CLInBG9LfGAPHMfD8fMPt+VaB8qDjznVEZRRnOwS0uRSkVsEo7NhdENKsnksZjb9tFy0v2ah3+VedHVWw1wq6lR65l4zmTGaZWranMzwusOoYqowonA8vvGkAVzmjTkeWF12AHNAQmZwxM3EORpbLXgw4HA2XwEFMslMOa2wvy23dNExH82zsy3ng48TF3NVuK/2WLHSWozUbn3pnSTqUbij97CMmaAJnHntjV/Zfi9yDhswqJ91MYBLZy9dCM7qjByiqOcnflv3P9ifGt23D/rDj8fUTPnrzGg8PTxjD8elPP50yeXvG/X6Ekzhwu91m+eg+M+dz90vOps3ZUwbkjkokUf/XullPVBftFv2ymlPqT9LGqI8Z4GxJo1KchT8nHZegiDLUkhzRDmfsxnBOfEWbW1WIUA5Vn1K/0nevDNQETRzW+W4pYhc89LWFynXWZzpE1jNBc2HQck5G5MyTNiVTPXjKOfBsPu1etF4bcYjOWXgRZnW0RA2kbmubix5Kea2Ir9vRNZDiGR+nhEH5CUWSWdY+C4IWzZO7iRTpfXjOjHYwQyeaYZ3Vos4jOUxABlC8qDBaBbNUrXlky7ZhjKNVFVsg7rSOs5AXKCKM6zVH+Htvf4j78Yxf/Px72FY8Cy7NKiFgAHzrySQP+77lWuAuBnmWX9it7GdljqYT+tjaLsJ+HlY9Xoym+xVsrYS37Fkf8YoBa0IwjgFWxtC/XqsjILCerobcxSbQY7lKXF3Y6n/U6ysXtGmgss56nYOTbizP2ewXe2nt8P3UqQmDME9zqHprKtB9HApnwbtAIr9MwtMZnL+QGSS7bp0xdTZRbeZ5vCVM5NE6MqgrybYjj+C3YOo9lkKe/2hte7vUWC4wnzOUZVwLg/UlYXdvMJWhh8DgtSU1nSz0sRvQ17XRYU2reFZGa4aTA0qeiP55WHYpimjPUbtWxff5yEjFUqVonnXiibg0MCMOhy0noJtvALvh44/m+Wt7zKRxwbI6nJplnAZ+4D6A2/Mdn797j9vtlsGEKZmTHgsyVjgWju/P8pPesWteEtlv4upoa2DqxfNanDUxQmNu8l43AWcDOkaUXPEtZoPNslwzF3VXFNecgs3Q114g8B9rA06Zw8y4Dyi0Tu/zBLuVc4py2vgcwTzGnD2wbW7j35ym1XFxTIcrA8+STROlmk5M4GXLtrv0mCpXE71mdVzEqg9qgxCAnnf5wxVAA8ETsplJw/WItqiRU6eyz5o5zWAKesV4BMdFgKInTM7jqqxLBn7bvoVzEjUTdiB20pbga8PtduDTn/5xBGYjNhTopae3+1wj+7BZlSD67Hb4gGPu9jp5qAJ0qt19J8+Rv2TEiw5PZ80QON9KTQq+ikeJAi/mUh7jODLoFliyRE+kdEhChQmowGnBsfClnuHHhiRhNZ9ZqCyVN0pmAHIOl1Rr6Dij3QxcITRzbfWsM8uBFtwJvUtAy2ZVEqJgIcyDjBA3lAyB4lCppQ8zdeF6CDjnRDmDDNmcZD6zIUELmCRV19S8lNTRNuYtwQfFM4BZkzqrdWm+mwyWAe8M3mTxl9qU0IHzCBSDehpJ5UBqljzPAwmhu5232S8dckzX5RpK9OqKggM1OC0XxMAP3/4YNwN+5d0vFzwqexMJNfHhArtcczZtZrAyXWOIsQg+k6kC6aGvci7Z8ql4rHRSW0spSQ5Rk12xqj3I9ZmO2k6kI7U0ApEgtgndPrRyztTXZKIrYHovp3tmMcNbCWRrz/fLY3xXa/y+6PoKBW0xPG7YcDGQXucvghjPD2yA3y8TEyUILxNBTVQtyT+/k2r11BGNhLCTMHuVhZSzEGqxZcQgcK49z7GquiRjEn9so5x2sYHqJ/ShGZpgNmss75eBKci6jC019DQ2oZDnmp/CXcPVFXCL0Sn8ab+m2h10sFIe+Z7Xoup2KGsIqdfHaWy2MiIvCZ6Ov8PUb3Rnv0xzLcwuI8Z7M8E7oo5+y+wqgHDwAy53HI5UGAh8WwkH9n3HJ598hFevnrA3p2nuBLl76tbcM2qMAYwDtwE8357x4cMNz8/94OxhQpN0RAAG39WVGI0FJ9fSxc8iQuQP3XTF+c/sbM06178Ip5o8pcHpKsvX9J6b4RkO7gIoBmW+NanIktEyrTT8BzjqdUYu+TwNiMqhSlSHawvBHeOAI4+Nb/CkEQ1neoy58U1DMw1veG2ZMCARlxkrEp082Mu6TOi1gG5zLZO7ZQJiQ61fqzW+lo6Mkr6c17Os5Xg1AztFB/0tLzDpLVg9nzjJ/kvw2lq91TzYfL4qOuU54dOrxCNlaIvdXCk4Bzc7CFyNMfD5n3yK4xgl44G3nK2HNb2ZsXSKieVzM5CdwfpcLwbYCP2y8dkYmgSEfa0er/mOHy6DNMArgIin8lZIQ9EyN78JnGdZ4VkvcHBjjJJfCwIovE20mQ03IVuUay07UZVl8vNQ87FV27BDrZVY5IBwQo7UoeFBf/xaR6KsfzjjI/hLaQSgZqT87Ka3Z8Umzx+pYKcNmkcOWKOEp8yFHdPpxHhwQ8h7ufTI2d5oaepiSMxkKbOqYnXpB+eE1ShyucUJYb7yTQWYzVnU6K/RyYPPSh/2at4Yh5B6BifBB9ShpFGDJXAPrZwpsFTiTuMitnbgj9/+GL9jG773+Xdhvukb0V7YG/QVdes13IHjwEZ/2gyGIb6htX0i3Ies5w0A43tL2kDkPj2lvqwgLE/OcVWwLXQJpV3+bE1IdHe8Y+CMdVWQ+Y88Qd4MxjRAj7zoz8q3TJaUjbyGyS9oee13rNdXKGjjtSK/ZKl8sxocA7GBDRh3+U0Zf5lpQjHxvDz7dVysBQpGTQc+9YS85/35s6IolaVn0fAOA7nrCe4yzsUMFZhcGU/I+NL5gtWmIl5CZVJ6elXARLDXUrKXWEz8k3x2rqsQB6NuXTa0KhbFitqF2R7HXD/alO32HIybGlwALc9M+F9+KA2p1XOlhgTeYAP6jJOHvbKgQDOEjcTpgKEcWeVfkF8g+87XtH+1adgfHvDRR6/x9PTYDDPb3wHURhOGYwzc3CPIBp6fP+Dduw847geOY5ZTzcCbjr/KFYLFLZyILXE1JFV7NVsLR1bKcHTlhka9ur3Ec9XmdAC8EcNJNzd5tkrFWvIAVyxyVUJRijpxD+GPxMlU/Opkr8kAj+c4c0a4LDZBme8g4ifJztH523bkTEnCRiFgqaYDfsAQ8khcOnExZ7SOeFYPGefMWwUEdK6n4S4kU4BKHFP/KKOHLMC9J44DqSkhzrKe0rV8eDfRE/l7p1wcES/BvZ+fS55Vkpx5ogaRKjjp677wn7RDl4Hrd5M/nLMYVRVwHGMmBdwFhrn+6H4MHMcdsHk+IgEzQBIpsy2uBaQuq9VngRcrnOzbDrNJ0eO4T4d4OMZt4PHhIYLI4i0PmnF3bkVIyoOR/wTvsvtGyaPg2KY2MjJP/gYp1fPWfs1Q1LPJW8kvEKwXzWtX9gmbHiXDsWSw6bSTgmfubLcoDW5GlvC5p/yU8RLHU+DsBV9qUc5GMvVB4GBucMIZwMWCKilaD50nZBioIHC1PnEPZb8aQMITHnaCstzzOKXdXcbeeophUz+mk066K0qTJ3CiyQSPvLPBNtnVDy50tSbn5dsRCA1GAPNZTTHPk1fdfgWCo0qtKbej0WlFYU+OXFm+gN+AP3jzh9h9wy+8+w427O0pld0vupj4nf70wMO24NMAsx2t2ivkbU7UefqYpNUWwTF5ACBeq9LFjAeG1I7FZ76jTgTaJiZthLZ8jm8a/S+4q896U/XS3BilDpCviplripCHrvbDkJn65k9X/19Go69Q0HZWSkAR9uUpxBjgOACUYF88gZXIGgya+VysafSBy4lxIA/49BNhPZPQmWloI7pQtmEIOttZ3cux08eRNgJoHSLHYWIYW5aitbkoFKOgWipi6ukT74jB/Vku9jzKzp7xIPjAAutsY8H30rmheGN9eyZ8PA3uashagCzK5IvGeMWFbRdNdQRMevA5zpbMlDFNyGoHNjPLWRRVcKU7pbQsy8AIR4YkeHx6xEcfvcHT02Ot+QhLZ3AMC+cr5Gc4cD+O6fiNA88fbnh+nmtl6DwbuLEMDd4cCzdVSxmk9k7L54JucXJRMqvrKCpGorxsFSBYGbc53sIdbazF31pMzue3wp3Sli+wJa/giMZllYmkIY1J/ELaVbt6MC1lkzvTvaTbBLZ4To2vrlM7PZ+0IQwbamZ+vQh/v8vxmHxm2wzYWxxE/oudF9PXYUBjEnTpLrvBu7MJbpACcM9uMy5K57olr3VLaybTOcMcZTC1ih1JLXc5W4u8WU7ZFY9KI6i7wbtfoi00w6wnl7WAwrz0ejoYDFzn7o6zVHYehKs9UCZW/qBjsZaqqxOjNN33HTDgCFk3B+63Ox6eDJtA3pNkMvbshrPJMhTKLNfMjNJ7qcmG57lpupayYJYf2Ibg130ssjT5nzseOtDoyeNTKolQx5ZUqVfprsxNqO29sO+9lylzI531SEEZNSn1FB2N3pImmIpvOhCULXePA5c59nyg+pZXyfZ1W/AkusuSHkWrIizHIvptQUdCutiylMeTbxC2sNmMsjcapVWSGdImYdcZ3pVOSqGpL+bPPHLlWie3ZGDqsRIsUthDl7R1zAie80h8xvNDiFJrrQpnV9hcfWKLBNvvvvkh7nD80rvvovPhbGvb1s351kveGPN4n+nHWA5wHJ60rHWBAAb5qzYawWYh12g+aVY85WAmKjmBkDLi3Q53GElnFZyuo/lU7oeQv9vyzhXTCi8tfkFVQNn53ROcJSs5wy/+2np9EXWAr0jQRjvVZ9DOoL/s2zBXw+eUIC8ZXd4791NKLbIH8q61TzjzyKWM+YWyf6F7AbuxmDie87aXYIiymN/PO67ppSWOlQ3tQ7L1Nb+mSW3niwawZqhUrqs9UT4TqBZwE6SsO1/7SCNU73Gr796XzC62X6EYFFp0Z6QZIm9vpJEjuxE+jx95wC0DkSuj4T43DWD5Y6CvkaTQPn9Zy/KAOkxTcbQ/PODt21d49fQwD8YOB9ZcM1qhZGN9EQ8PHePA/XbDh+db7iA5x2NlR90zUOP3Sa8q7/LspWEz/i0lrjNQ+ZSXg1NYM3oSL6jczhf8XD5G4V0LUzVg4yyYoxwWOi9ArYVoY6IjEoxaitmaPlntcdE2HG+EAx8DowPlUKdW9CTxJFk7U5roxSTC4vBdlXjRSQPxzU0q0s+1nG1hxWC244gzs3xmoYUWgLVZIaWJarU5bk+9Q+M+wtpbHPROvGeQuui03CL+pID4QA9kdXa+ZrgbuIEfZD/ZH8rJADxLLxvVGYiCfKH9i2MQ9J7qYe6QsT/uc8Mh6asRBROWAa9xi/7PWQ05U3FdE7VtO+zBZuA25nb+99sdD48PpacD3BFliAW6FS6Mzk3x6rbv2HfL8QyschTOF3XM0Puq2CkYShNv9KlZ78Uv8PAVzBJHV25FBTTaQvWX0JK1XN6DZ6Jo7n7HwM1rNo/bkvKw6RQ10U+JitBE2WlBRL9plv6fOan0UIefdi7hVPRl7SAqWRM7LPq2Jx/w+YxjGh5W2Ra4zMCF3IEuAUuUosks9EJfDmYNYOdrk9P9KjhhW6uVpfPtsQX+VGLhB1G+z9UWHskN//+oe9cmS5LkOux43Krqqu7BAksQIAiQBCiJFE0ymun//wWZSTKJpgck0URJxGMJLIHdmemuR4brQ/hxPx6Z1TuC9KGRu9NVdW/Gy8P9+CM8Iob2FWkHrCne9Evw3owx5WXxHAt/aECprdr4icaU/jEG/vLjX+GwiX/+4z/rdCdNB2AS8NDV3dxbH9/NmPfC5Dj90R0eNg7xXQ8L9GYYBu3WwY4A1g1wiYRmsMCSpJ/IQ2Wl8AnezENprBeq0ZzHT3A6MdMZg/ffa1vSWtQp2WK779Vr8usV3mg5O8nM/nwTThuAxtRX3+lmUn02XwZ94jYD5aL68uarbFedYlA0Y/k66r4fDKZ/nsbYHIPe79U3GiLSnxNTS6pLjpeiWMbEbmQ661eliFS7AHqaqGmbrUQbbjphJ9oUDqeSUpEyUMlHeat6N6Jk4zSqMqosbbK9IZF2Gt/sZ0K36fysL06in8C1KQj0cbBw0kuevD4huMqn45gTtyF54hyz1VywmrbfCNKAyAbjSbfbwP39HYCBYwI2HCP3FvR+O+R0FKV55AAAIABJREFUM5/weeD15RXPzy+RDukpZ31InK9V2+Hs867YzjxTDpAo/PxmB3xspfmrJ8HWKubY3lUZTQ6FEAtAj5VX0KDSjKrGKXQfrT7f+ka+qn1r9XUaLkqgZhyGAjAs5T6XwzTi8uBKNyqlnX2PtseNBgZ5BKUwQsC6qhOk8qprGRBx3D2/t4jAwtsl7pW+5PDjyOAQDfnFB5Eq1vbI5VrJ+n+LXlgt1XvsXxoL3UZLu6JkJYWLtOCirxW+LGtJ+uAxdK5r5KDA4IxSa9XN3Z8d9D2CGSphrLefaoitLFDXf4RhNNclH+PuTpCbh3yEc5Dp0dLiVExejZaBJqOReeZc2RjAHeBvnicnzuNYK3FKhxQlUTJSffFf0GU6jgjscGqzD1qtl/NN3GHfHSZpjUDzslHyVhTVf+vFJVOc25IFog+rzhM1BZ/q3sBtJYUpqRxf61jpRVtLChxsYcpOz5wjSFvrd99GV3hTXR1meZqw3UybyAXoQw6wWWP2mhPymAwjnfvQcTMd616/pRFQQdWmK11+brYJ+T9pe5KVeKtOQ6k5jH9W87EXy6w7W97b0nl0OAYdJV0xKjAEHVZiJrMAOAc1z8Ff82COIHJ1d6yzHuc8MPaNeJzDNG7VGe80WK+ltATtDX/9+EsAhn/+4z89qdFlN3HcwOVGQEnbLNty6cBUs0cEXm7haIxabR23OtiI20QEkKruTENeYeQbdaF7+Kkz5g8ia7Ot1J2zyk6GQ9l2G952OqpkbSoaFWRjW4mt3PcRDnFBqkufok3VJRIcURvuOoxUzzfhtHVY7c6QEjAN/yBuV6RXte6f78S4KufdWZHjQdt+oN0r+crT4FXtKCPjCbwTdOKni0GSo2rIJ4cAuFLRwqEbkmOsCiV+5v660rl7XcRNdkMVLsfjOW9WONv1aQFaNMjVIbaf5ZJxvaVOnBz07HSZIiPpF8qHSsX3OnrqU097kCaKBCdxP4s/aYpQJGWcmNDFZ6R3TcdtjOWwUTEP5QgxHqQhXqKdbQGZ/glz3N3f49PHD7i/vwcB8PC4n+hmsNgv57HC53C8HQcmgNeXV3x5ecPb6yuOuKl5OuLwEm+KmQOigs8DTozTIhLqnJeiZn6bc9gl+moVeNk5PdWIVfDF3NxPAzjBdvHoyAt2qgxCIemMFt/WDFs2JqdQnbR1fZyGj2yhSP4HDYVS8OwjyT3MMFkfLfEMi0tUrqxbcP+SS0Wc73zNGNbpTnZdaRDyBCweCQOmDqTw7DvvHeMcrnnzOjGVJ5tayBmOpYgnVx66YWjxnbtj3JYTUSmA5AHHkRvkq7AJ8Z1GSbZbj66grIPjeuK7CnyZ4PWzvq5/04BwbxHrqiXNDDBSTd1gKJw4jlnOkjvu7+8jWj+i7CwjaE1asEDNiZBz0S54NJ3meOGYEyoOiaQGjLs7vL28rr6+rUN07u7EcVMwbsaJ6ihixOqH7gMsOu7U5C8ugUVDOW4QR77qo1ypiVs6rACEunx9VCuXy4iuQxf6ivsQvl/0sbxktNo8B5dVI9fYNACczmnSJUbLAnItSPG5VJ24vL6b8d6gbOeplnx9LXnMMDIpV6vOUXJMms7SS3zqBgXib+mHGrdLXYt3c5V2UVjmTafTCyfbs219SSHQ4KZgNbEvpgw6J6pgeSqkL7wYGOuArSxHHUFA8G4QgNkYsv9LGHlB3gpijRF3lYWuyIAbNntk+9nHHG2aNqUBq9W///C49rj9k89/gBsvt+Z8DQaQGmEu26Ray+81kYvO1eBx+rTBeDp1cL7r+5WmO1BXEcCYNumZvTGibOONpFRaWDCpR+UIUuZM2bPuAXrKLbbf9hp5l+Ci5QE/RvD1kIMou+yo45ZBktRI/O/955tw2tZTHW26AAXG/PzyBoVG15okdfb6d9ft4fTtXh4NOPay2kyXXddZRiqkeDcNAwEJddZar7c2dyfX5fNlkJMOQhcne3gaDAp+JRTR5w1EFSrPBoq8tHWXOMH0qvxQfqZC8l5mRa10Tn05IIYECK3IoO2hDaCgT7BY+77PufZnH5fLZy5txpd50qPUOYbhdquVoRLdqFkAiGkU6dxkGzRqKj3hw+M9nh4f8XB/DzOsDcU5Vsu2Fityf9Bq+TgOvLy+4Xh9xetbns8VBw6ok7UBeU6INQMjadDmxXJ405GrjBkQmGLMNpZSAicaLnCkEUtlv6+gsHhEGD3agZViZ3LisjNmgnFGry3mknNrljK1HJazQWHGJBDLk/hS6rzjCLtYsks8EJwQo+MUvMgy63few+YSHDGkTbbRR6Q+2l2rKp6KPVdphI5LHkWSDBhuefjAGIZ5HNVHKrBMRyiFmwEfcHVptbOcoEhjM/IhsT1wUuYE8K36DbiEZmu1zooETbEKbXP+Kw2JHyo65xHy7YoG0xIc1t5IlI8VtjnjgltfaYliMK/u7BoKSce9Zr6abY/YsxMdGbexAVbN580A3N1wxNUBx3HAxlpp0kCTKgeHzHO2X33d0/GSL63LjzprCQ4hrwxi1QqurMxJ8KMR2z2syYWoPdgj9DzNzcUT43bepwelhbxjiRi9Lxd11ffEdwlIUfYoL1arwZTPRff6Pu0Hk2aiCbMh+7Atsdj03QgqLOy66Lc8a4q3oAeAWk0MemkfcgS45D31tCr4MrKtnYhp9Hr1P+dm71a2ZcETHnp11XLwawfqLOVqiz889M+aNrlmhXNiaHenua9A7RgcT1oIfcHY67stuToxl5ig2VTVOHLsf/70lzAA/+TzP8ZwrdugjrYikRApquz03lNfc3/qWPRbvLVwf8TVQuymAUlz2gjsb+oxq7R7Sqo7llMNgBfgeVTF/uz2X1XcsZiyoRlLqQKg9nCVqVWzeJ96KPTW+uomeFI/y37g67ID30XS86Tcrz/fkNO2nnK6ScLzo8T7zRVtSpJS8RUcUmxN52C3+rf35NPWt97V6Eyb8P6u6puq76r9cFIE6NPxcq7wiFGRwVYCIccgwCnKY9kyooy9Gx7s2WRRocXujEogpX66YDX7ry+xjJdipxL0XG9fz8URDyU2rV9S9Vf4C9ImlZyHoHLc/d0eJeM8amw9X58Ehd6xpXB62gWVT4sYSsNlFznGuOHTpyc8fniIk+XqYuwaSxbAnGFkBi++HRNfvjzj5fllRcxIA1EsajDkOFEGoNrHTEUVHbcUkNc4C7jm5sT4NnE6d9F+RLn94sJNDlr1QRE0xpJsr3JaK6NUbGksnRglwLzRJwwFubvsepWO89mEAOlUsj0xXHIIYUNo4ILvEPjpdDKNK9cKxsgLVPdVGSqyxbcrHbIRzdhCV1zrC48py6TsU79r6FWHUaHDYmCrzhkHSvBagjSCkgdzwpJWdCJbqij0903mEKnT+d5iMs6Jbfynv2oAI536HGA468LL6Rc6MsiwyCZyHpXPWGVbq4wDt9stzT5RabJK16YkfhZWkX7TI+2L6XBRaO1TFad8WUdYTAbc7m6Yx4y74CbmGLDbiL2FgQfGPSwlJxoBV+eB/TvpX4v5UQunUydhYdc3OU6RYVbT9G8eTW5JF2dAABQ5Dab61sBJGrGfoqErfm2cQ7InRGdk5osoRR1fYupSWo0vU/6TF1qS81pBkiGoQZn7ZjetXoGHcQl7mfLXKOP5GVO3i4SLPrkKYpXyWuNiPaWfMsBIQ130qQwGgOfK4uVjTM1U3kTy7mqD/2xTvgSt+p39SCpKM2PrwWYTVIWYkeKeuGCSaicyLOTIZ1aXCo1Pig7ZyYGBP3/6BSYm/vjHPwo6VN889PZ+ZHoGP7RP7OP2JN5PdTE9xro+WZkCxdTrLtDqJ6b3FeHmfFaNiYNRzr3oWn0rHbvkY9dlRCfVfsJ/28iKAJLh02wMMoWta1cMac9NRGBw3S9xqt/C9it9tb9zfr4Jp01kZvv0SnH+5kF9rZq06zZAKn6yKreDtgLeqb8d/E4CFL90xtoEJZqoVLqKCKgyM0MHnOj3es3zHW3cWwOeP0q5EySkXhMlqRSgPKuIloyhUiuu6NR7VftVvQAku1F1WAJoDhgExgKxpRBGFHBUXj9Lqli0rgkdHJyDrrzVAKCM5rtswZQW1srwztECJukL63RRTTEna+hScdTOsY0x8PT0iIeHB4zbDR6nzcEGzA+4DdzibpNj1iWa7hNzAm/HG748v+Ll+WXd10RFCY3W1kA8J8jbWKd7Xboq/N/2zUQdVBp5fH0YmrV3SidI0k62mdP2L0SKX5K4NR6v+cprCaYnoPN6UR15/mUV2c9PJUBy5bhk1+ofGcu2ysA3rP4yxP01W2rk2vcE2KjADftyHEcFHTxSTk58RJpU5DUVOhk2hxmHJ9gtlQyN9masJvvO2neSQowGLoJOILMPXvQcTdO5ezveQtI41qJB2RgB7olESPnXyeQBAggZ3fy5jV0tsTC/27Bo8QzAC71TzxDDyJ/FdilH6ZTF/kWO5+4ujr+/0HnpZnTrgTMqc+wkTI4bG80KxSL9UDaamgG3+zvM5xdMXzzFDAFjGV1tjY7MOPrbj04jo35DNgE6Ks1R1ioNdT/erI8VfzgmUitPt1XQ961ufjk5X34mtYpK236SCrQFCPZH1VlzVqLPVhVmF7W2IkPpQk/9ppixnO/GBzpO7bPq+B1LhVX3jCZCgcV+Je7lgi/9NMa6/N2B3JPJOd5XC084rX21QCFiWZ505HI9iAMmezujrHBWFHEkJtNR0oOQzl5tEYONJa4ICVO3B36fhkPeKylv388pK7/F+7zy5Yo0hsI8fi5rjDUE7UzQ8BdPfw33A3/y+Z+e+wkUTnuNKFfxLuzdTOPVu/mUc4NGdNabYz0Wv5D/uUVnYT0Cs/v4VTYAi7TKtZ4XB/Ln+zymBM4MmpVqFkeooEZoK5hi2gZxUrNZLojKnliBi1nRc2W4OJynIbeghVc1RNE8AdPjEvH3n2/Caft6F/dHp3CvZRfAM7O1Vy5qSRDodI3vzsq/mnCZ5L3Wi/avIl2+5Y6nYt2/R1MU7HPfuKsOIvGookU6BL5Qwb5yXE7RShnjeZSWOOU7DbOZJeSiKrJsXTS6Is5jSBpNKhOCm/SH72g3vYTwSqf2AJIYgTEKG2vgvC+NZKXu4y/Mv24buMHUOAEbGkuoNM50eoWHai6lnxEJ7yACwAz393f47tPTctjGgGOlWdkw3MwwcR9HJThe3qYQbd3H9uXzM97e3vD69orjKGJm+ipZL+jSDdEi5oE4znyLBDt4/L10W4RHadqM8CbmQZ2ZTKBsWI8KqwU3NiYVZjGg3ZdoaJcwe7RnQ1VojDr3pylwE5BLsWSfbQUkhm90Q4+cVxvrvbG1vBxjuceGAR3qzYEySEbs3cO6wsHMcl+iRhRpgFrSwWrPZJCLKxMRkl3OWA7xgGPd2+PHWrUYJsa/0t6BOpadjFXztQxg3lPXDSiH4+52WycPkk94Ah/TUDNqqWUjcMNenPhB+1dYVEjU3yUuahrwooWuaoQMye/rxmr6B5Z0z0654zjecOShM7c8eEiRbX1kGcG2dsJizFukGKejhv4Y5/bqWxsda5zpkAPTj3Wq5P0d7sYtx+/xS+65Q9FmCI7MOfNagU20o6tc4S367vqo6Q1eXiwReguZOKUU9w1A8RVnSHiG16fwpF3ZY6wObtceq++lyqptOmqpjSiejP5nwKOCYT0bkfoyNUTQS1ZHkzocY8clhA5R3Vzpp8j6sj9oyLzFWjy9uRFpwJTZ6cj90gFPURP7ZYGpgUHNYeIEVmMeOLACUtscCNO3IED+wvo7f7tEThnLoF2X/Ywnj+1KWWJgQ+kG0Uf1TQbRUXbIbp9xQjTNru7GPK/7OGpOF+6wdu32prTZfQN+8fGX+MXDL/HHP/wT/N7L7wZWrzrOW44s50S5fddXujrYbNX2zpZieiyt0dImh8GmZWBg2MhsgrY1Q2hxQZwVLBhLGTr7F/N3YOGD03ESXgbCTuGVJEn/M3pC8SJ0zmqC/S/+3BMeSZ9kY0y4jdSxNa/vP9+E00aD7UpJXn92UcE7TxGn13ZmwgLDc9VXfXnvkyqokSYK5fslFDD8mlf4rRoH+bOMhqtWNJKpjFMY6dnHxXRDcbE7YHx3J4uAVxqDJfsxLC5veyqsbIMMH33NTf1ACMdZjFw6ot3RSLJu7i61d364aVZTM6ShKpf9tFo9qyFVf1zukmJUFbJHrVkQYqBdTGApi1AwA7j/cI+PT094fLjL8mbAuBVN77Bw6Qgv1+ARMX/Dcxw6Mo8j0iW9OemDDgGA4aRrjF95AyuKVSMQIM+xEQjPsqrvkJC6r+1CD2xlhe7GlgBdIUnjxqoMNnlQDKITxNrYhbV9je/oWEopNxpEOxUpFzBK1dCIiWbogNcwrEM7xuiXpu79ZuRwJv87btz/kPsuNP0RKWMpRaGAuLcsjQ4M2LiV8RYOU/ZjWB1lrRPUbYiCCwfcj+SprJaKvI8yDVXiyAkTUrnHWKlXMdb+rByJZ5pgCW+NFaZZArLyHg11/JXPdaC8aBojB5X3HNYlYCCbxeJ3kut2f5f81NKGYXVoijiZ2SOyeXPYYjXsJnSOeebuChrDeXBA1QiztffN4qoAn74MI7Nywi3CV4Z1pYjIF+sZDIDMOEEy9D5n0TDaMf856qajBEO2KyHSEaEDzaBGYq1dY6scbz954uD0FFWLi8xtynzLvBjpl/SsYFytwMuYSlHIdzKm/bMsUkEtmZ0cUuJvfKCrMOpsBBcVJgHll6D6LKos2yiniRUV6ht4B5joWN9XUV2GL/RDdvpC+BlQVn1cbiz7vA0wB0Vcm94DYWsYEqDY2uCfpvvaiLUuNg4bbHzGz8r5dOHHyi6hvcXqh3Sj05F4scRNRr/xc6GCpPoGb867iX/7s/8L4/sbfvfl50l9OLOSyoshxJO3W+V7Y0Wxk4j1U52BS7uq7TFf4xtmcUjMeqfS/Xv902ScgzIR+mF7mQ5yBs5ELxxw8NLlFYCOsTOAs1pD6W2I31eWjdqA3Sa/wGsYeJ3OMqu71rt6vg2nLR4FjXreG8RvHtwVQu+Oy1dLZxNNbV8Kyv6cPWpsoCNdlDZ6mlShSXMGAvA8gYP41FcudBwundZx6OdseTSDrg+VQNWxr9crw0n/ro97U1Wt4DJy9JSxlfohxTkmKch6CDJLCMoYzXRNKV9jMtzSQN/mzKQ+lk1pd5kh0pkGXwe/1lFvJGqP6LLs6K7exwAenj7gu6enOCGy6tqyt/PI6nV89eqx+7pq4PX1DcdxpGKj8aU9Iy248X87RGwD0E2xpCLbB9V5pjt5TDMA6vJUKsJy5JIH35FDC9qxtRYcANaYlfipXMcFNli+XwZIJpDUaJqRWH23jLeZrApo1F1oYpaGa5O7kPe1aiQpjOnQxelsQRMqJa4UlxkmWqQzWjhdZXDebjfMSLFcaX8TZjes7eGI1RwL8ggQBS3WQNe8FTbFwHjnjRoVVJC+9ctU4QG5L0z41CJJpvbVhbL3tZ2dnlKyLw18oQpr4j6nHEaxwMYbxGNrKZjLaLYTjWvlo6fe0sFQJ4Cn4HJOGSAgvhSm0UGn69MlcmHChHu/3w8oPkwp3McW1WUwB+v34zhwdxcpsiJEwypFcRWXUWbggp+Thy3+X0GFHSmQzWwTBsuTP7nCr6tnLF5VdYeh5rbjRMGLyLXI29a7rIPYlZ+nqO08vZVtTtjq+36VRvr5wmcwvHNRaqINdrKxL0xXE/EDCU1MIQhxXuGyqpkr+p6pkFzZByBZ3JmslmNJcuy3apvYORfTt3jexdgmb+yOsYfIW9LFzNaeTo0Q7c8WHOFnbmiHsVC8k2oy2UnHPJjKs0+7w00OIxwqdklLbVyJoZdvIL89h6YpZ2urxL/97t9hfv+G3/vyDxfPu5ziKL1ufEvwFIjRMZXNqzjTn6/a3d7rmAaeZ4JhwJGB6cKdJa9DtsGUIWeLeVNuTr1S0wIVxlhplLKtZtbLKUNR0dwCMBs7V7BBFYnoSJYpZ9nwHu34fBtO21fm8eqhYJdQXA3Szzhp9d258c7+guPxgRf4XQDKub6Ltq+AyH3rl06oy0f7GMm0nv11eb2AhIwO7ALIjywZySPaqAAkisCZuAUQCKlE+iwIGOf4THjVUJHodx7O8dfeOZMDNK4zFWEqyF8ILUSZQRS1vGM14hRwPkNL0GDxVjx/oxOzcVqWXW85ylGTloKkwwaenj7g46ePuN1uCVa9NQ/j7twHGl1fvjzj9eX1pBWTTRhYDJ6q+PE2a46ieeMYMdRd0zs7fWmkZKriWY9fxjoAplBuK6Oc03dOPKNR5rA6PIE1eqwgiELKVhkgGUsxqEJmH3a5y3RJcRCbuJ/Ua3CGldPGZm5xYXnU3Pq8c8vErBROYEU6Rbm0FWfTPlEuLUFu3G45vx0LSBnP+6zGuKUSL1T1NPCm1kDnY2gUOr4bhmM6bE7YGCtVJiOxRabOjsFJrrSPgEVOTDCXFQU9y5RJ1Mym6Ns6wEVAxHvzHVdWqiBXHstgCknyfiXD6sPE9LVGebuNNNq9/3NuS/7OtYcmYBE6kADfqnvWuwrXUu7Uii26zqMuA86FB+HXxRN0zbzJ0TJMR8d/RxzUUUd+FxqzdWt7thikZBCR9JQwXQ/M0R5wB1NAc88lENef1Dg55LyTTcwEnu4JiyPcURdb32QPU6YkNjoKzqs8oXI8FEc7QlU50nT5SRWkQOrzerv71qWrEPi0uIFYnedBJA+kYWqthgo2YOFtHupCJ8pnHqqY8GE1s40GyQNRf4+qgtLmKUt8DxxATVC0LTnAleqfCiUwjrZOV8PZJT0gpvB9SyaUOrV/iRBtKF3fVHAG5Sg3W7NjEvH2FFRic2CTQkvVOBbEGMD/+enP8Td3v8LvPf8ufv76O9h1cx9jYWEFVd97u1o+oxX7sUlFzHGteq/5I/2XvEXowqqOMQyI4/VT52sAzKpOvRor+WZ9AU97wcBwILDkmzoSkWmQVyUk02hGioVMhHwG03jSlnZgv2BoBUC5itdXJvfnm3DaqFTsYn5zSbl9xlJaQ9FRDZAmhA6YdUYr2u9OnjLe9j7f2AR9D0q8w6+lBMzqyNn+wrmiUGYQ5ajOayrkLH0hzbYDOHH0vAJwJY4U+NRjXisNuW9J6n1PpnX9JOlRpS7pFlNUjK5t2d6egpTlmLSJ/cnDA7SPqqs3q6bmfp7GmcAa7QlMb4ojPtPoY1PZfTTrwJEP+PjxCbfb3brglNFQAMCBw2utrd1f7AfmPPD2duDz8wveXt4abaibmNpWKa3VP9PlTpEtghX5scmFAenkeOpmIaYFtZGKMQMI0Y+dsZQ91Pwu+8rrpOasc0vRIAdaV6RDAHPtv9gmITvl7fOUd0cZUPmZQ3P6S5HOMnJBpbi+P3j5Lwecxo72H3kSZBqsvlYLIf3OI/RlLsUOSkeoHB7FWJlzhDJlvQ1ieMcVBUxcnzi/2TgNyVuWe/7WZ1YYg4pMc59XDA+a2mVjJB0jNyZkjkqb2rkLZK7CNwwPZys7iKxDMVbIUbNpVhcxA2vAPnJOOQAGyFomBmIVPKDvdncXfVLQKmFWjDqBz46dY8APzysEyhmkcbGDvTC6gJ838nGDvwtOBM9b8L+LXRR8152R7pDpODyMHjMxVd0zGm3raFS5GxCgE7hOFuZKKccqDhuQh0CY9GmG0VRBHeF9wSeOY6BW92CyyuhskcCvOrsk/zRnF4cP5OEXl3rU5YdJcc+LhxfWktrSsthAqmWUF7Hxe3aTnxvi+hDyYIIIWu16WvUEzCJYkMCDgplZV62kjJDmxiBbzKmSa+voIqcSzuXgv1RKbfTSyxyLBa0Wf87qc3mAyiLt4Uzb9pPf1NTuBSc89pFqXco/K6U8sFLeS9uXU+LLGSF71WJDCO3N8TdPv8av7r/Hf/79DZ9eP51oon+knoqhvOuzCUl4EjDrPe/h7q1VCn/JvfJW7f1aBDymw24OHyNX5VrnJ8AvSD8eMtb2vYbi5Z2oXN2evvZSr3bHOqhtzutAOXGamGiGI7+uttw9t5N4dHG4M38FG+VPzzfhtPHpDkWBxtlx68LFd1hHV4fy6oWOO7fbP2fR9rlW+TX6Ku63iiyNpX0lIWtnJC0kJKPXm46tsuuXSWky3n/l0Gh8laGxXkb2FKDeI+urn0vyl2ITcH6HplVRqGink6ARlSo8LgIMms66N5MsHnSmoJzmRZWnS6qJ1LMOExFB8gXi48R31nRNOvFmaRz3ussESNqqgWJx/G3oAk0PyFSdME4fPz7i49PTisSj5pR3lRxycsg6zGNFbqbHoSPPL/jy+bkMdkBWAkLx54A68y+QK94xJnxHv9UoqCiXVkFnwJMqajGv8e8O67aquxneBEDVnRh1+iAcrZyjVn30MRo9jvV9ndgPOmBMP6yxKf96KEWNblKJWrZe3GVZR8re1Phe5fGbvA9EtDCr8jowgYb1iS6WdF48Qd4SdeOeq1l0UmkgcTWiVo3CKCRtJRKdrIPiExq563wvB+aIu75qlaQcpgiUpGM4ejpujC8oDq70F9HTKtmwIvAm6JKrvkKvXKnhnqYN9XmNQ0kkdVJh+ZicCwdzEkSdATBM3jykwL/pJXXeLQtLZgl1QmKRCpoBtq51OJzBgEXPtzlxZxGYMHmfPNG4F1Wnezuym31iGv1+uAv5K/8OvkuAl1SVkVizaBJxlihp6yLw48AxDwxu2CfNOAdzOZEjjPs5rQ7DguAQZZYbJ1MX0ZAraq9fikejgvo55NiszGqgVuy8w4AK9W2PAC4X0Kz0m7vXxWkOsX9K/5xskxxvn0PSiEEqQ2ECdepQfU754ol+u052oA5dsRxP2tqeHFD4l+OOHgvfJ1mt+kTatzb5TgFAPU2Yo0hOlSprvpJCL5igj53+FZCpO9La3BCLuozwh1s4+vlBaDfvRM6VJamX/MFj7EX6AAAgAElEQVS6pyPnrnjQ4bwjk/qD/JPt9Ye0Pm4T/+N3fwqbA//V9/8F7o4HeUfJXPo6hKbgSPin9C0psdsFndrrs6DOyaC2VqalnNLwO9aptnn4VtqKMSdapU8cVk7bqS98N65NMvd1BdJtrc7fRtwdN0uuES5YYoAe4hDjF0sGQF+rXQG/vQPvP9+E06ZkK77XiH2B6/Y2VJgu6xY+2z+/+qzXLb/JJCREfK18fnfBoHCUc9Er0ajEii4S1LS9At+VlkAFFHWMkVGXVAQXtFo4uQR7zpmMfPk4SwsIu1Z0XYzjSJCMskP3z4DzIc5lYeqJRuzPNkAWS0PjEuyNEY3q8ulo4xwso+SL+GvIS0mLTbL4M08SaFudm7CmU8Tu66W58U870MgdGIb7uzs8Pj3i6fHDsnvmxJHyccCwIukTZQCrBT3psH35guPohKO6ZuRd6VLcriQOw5qrTUELy7HV/JV+9UavYIIYYgVkrLWDc2pNOqVOwtfnGeSwrDP5a3f4ojyVmQHtVGO216WF5tDO6J48Xas3HBvpFZQ84VdVkXenUUbyywD5uNun2qSRkxcwpnHmkVYIcCWl5tqGiTx6HGqxUt7Yv8Rgwzqy3ekscjfdFuWl7KWzISuHQAYzeKok2+hPjAXLUC+5v8B76gIXbAjncP3fy7lVk2Lmb4V9OiU55xaKv9on21IhqzPNo8+bYQ3lB+TvqegnecKqco5SAlQyhJOqK7YmXYBjrqiyjYFb6s2gwTFxuMOHY9xuWZ4n1vEUwKQrdRQEp7H2tVYin0MdANNuhpJU316PQO8UljEK6rD/Y9zOkjelZw7aTjUPlCOr+TQoH7IfTPesVVtt36OiUefNp7zDPfeYLv/R0xhUvXWSmRpFUo37NFmMwbhNzGKhv/he20iyS/UTVYdcAZ04JxxbmSxyWA4rSlzwiGpl29YyEvT0aA0aMWV5fypgoNjpwTtLPhhsWzqY76qU1Nw0lKZONvI0QKOe1+s4IGfMW1WjdZOleJ+YvqFOHzE/ZaT6qEe5e1IdougKPxq9LSUNTK0eJu21QMB6NDB9ZT7RRsjvhsGH43/67n/HH335R/ju9RMe5oPATdDcPQMWyW2ck6nj6kGI91fYonaeRDr7nKatqe8SfZuzbiujIE823sAyfx3ZhqNkm0Nkz8d0vEX2mdkBmzzNN6Q97QVef6J7eo3xlqx7yD1+J3uW9oo7DPt9f+fnm3Dazk8x7vV3X/v7pz6hniXq1aMKifXxtWex39jiV15Y9Y4GRKtaa/s7eApTCiU2Bo0umTC3Rno0VQNUGFiH45ycYlQz+5gJkjqk5HF5NxXdJptqqFKYysBHo3/1FqFsEKtF8Z4KYk1HgFkpIdv7a8BpHx1xWHWf9/YdctqU1YrJ7uQkvVokWIwwZIXLtrC+osRpIn2YMWsAHj484NPTB9w/PACwOJ0P2UYa2jmsmXPpAHxOvL2+4fXlFfPQyRFYFQOD860qsOmxkyEXSpWU474G6jqH0I2mgTfg0jkQ1QkhvTAa35EzmzbjuOlwh3ReBiQzU8tLXLkqXqQyd0OuNvSIIR0TNQgcXH6cPmO+tRMhm6SREYu2ecFSZrPtFakBpZFGhgUNyZmReot8/zU26cEufz7X/aa68UyVrTj0aWR5cYEjFLrMPedOHV1jXVmtroLF3jtI3/apUnxSSAyByeh04majelF2dRhcraOpkcaMGk1ZGn1VqfFw8A6PjLf9NQY3aj4D9XMwhoqidzAWc1wxW+pdAb6Qq1EulZnFBdkHpjNNcjn6XEFlLU1tmQlfVsYGLE6SjIGJpCjbFDrEHK4VMAYYutwmUAjvZXph7PPb2ADloF9Ohw5EyZZ/s7LNPYYeROTsP+VVVsPYftMZIeekjY2RnVJ29Jq89bfJMpXynNe8rG4UoDVDNos62iRa+5F0KJ0e7VEy1LnZiSuVZoqzu9ChAM0NdSmpFYdnmnbTC5wTDeAGT2dfevtK947vnkqkHMGQoebYWOpJDTXICLahR8COWJEpf2cSJUfTeCcPtH5StlcqJMdEMlq7S6/kaPVhrbq1G6Nq9MJWQl3hp/w0D2YKKoRD+eXuGf/bx/8Dv/3yMzy8PeCP5x9FzqAUVjtzC05Un0zOa7AcA0B+2ygs46QT3CFcbYayXSkX2bVcoS6HX3UNtq5qeu/Sr+tQnQMW2UTRzvTMvmTwRWXQlM/lX7JkswA0pUz1T9pWX3++Cadt7yQZd3eicBrSDuUXdV98teqSCOTFS03OHaeUc5W/nB+VGmHQeqlWQhoDGdJhY3+6UaW0UAdsGWce1lge0V5eV4K0jpORQDqGLUVy1mAS3KPc2CJMneyVS19mAFLxwH2lnRGM1PlAMba3asVQMgIthdpa+1tXVJNKhFBq9W6kiE8OndS1Z1eMi6jffer0ySXCaJGlNAB2BUriwPJ4WWohg60Vtod1B9vd7S75YMEK98p4KIeg3XyFx4Wj0yfe3g68vLzi7e3A27GiuOkYKTCm4q75UZqWAeyNx1W54mo+RFdlGs21XbE5Q13PTZeUtvaQ2zyUqUwd7Q65d6UmT8ZGOd2DB9GB2odiyd+sz0V+vIrWPNrA8CEyzLRgg6ZDJRY1hqqWVNW1kTPaveFkv8OQSqnays6yLJVQ0lywSFKh0rhwRjStygLCF9LJoK3HSn69ayJODI64HO/eZbZjYFTujjwZMtJ1K2XFZNzVlnAc6DzWXdJ1B15P07KU776/TeQckUaTvCBOuMyFWZzOmwyjy8ky5vjI0+En73AFg92jsxYGoOiGAcPTd4+4u7vhzYEvX77g9fk1y9jhsGnw26jVM5WhpFcZidxHmwZ/08u14sbBDJMA44h9j255bUYCUGaL9KDejp/7UzB/1feYo8BTymuexJncUI607jVBjBVCb304PyMmpOrLyWntLAzp8uj5Xk06dSEA6GXL+q+HTJmh9hpzruq1rcOWTpnKEnlnjBhoOhMu5WpeysQxqL3R2xWkFFwsh0/KWfSajE3h1xNYc35rFYcpdeurAC9nSFUESfR2mx7pZRr4O1aS3jwlNwZp0rfkb61xp41pnRySSYBG4N/zn8TVxM7FdOvgjE3p1OKnaIzEbpftBzpF3UIFABsDf/vhV/D7idfxiv/s+z+J8VlfZRTnjfVdBa1bkyf5RNlzMfimCxFBpupww55zM6Jn2TWu0p6bbuUSq/nJlHXpo68QL3lQ54v/FeYl77uDKeoA0ibJERkdxvj7YguHPt+E0/bTHwL5+ovOlz7XE7nV4tdl33sXWAybABsgo8ZJa1MVcKvHy6iq15DKTsFNCvfxLKVTRqUFo5NJm/h1udY+7zTcSZFKyPKdXUZ1DBxf3o0Fwlm8ZXkj0AJsQ7tPUyO9bQ69NmoWgCLAugMGHz39csh3dSy3psRsIGORKkTlh8xkyr4niCLlVAwGVeDl+K6p4acoQ6DNB/vtePr4hI9Pj+syWgA3ON4ccMjhBl40nnmB5erMdMPzyxuev7wWPYLmbEkOqao+0nYQfUn6FBtZ9l3poL/vMuGogID4t6mMfX9Z6G/5jvZrm3tvv0S5/QIEKWKizEmBptuFj63odZ2v3mpe/+qq1nS4efJ/IbwHXbkKQwdCQV8MgY1EKy13Yt2fpmhCnvQ2xLYKKUoypFy65eIo00QqxuFfM4zGMW7Jh+laem+/7y2M96bnRnWX1U6GSdZeu+CbOSNCWXRbgS7eGxete/WzU6uwJrFK3m8XNItUNOVrNXZYvZeKNwiYsyftLD6qVTg6Y2XE81QyHhojrVtW1h6urOml8w7A3w4YgDmAt9c33N/f4bc+PuFn333E85cv+P77H/H88gYcE29z4uYO3G7tIvlyHNbYjzjWfdEqTvQUc2/GXKVhL7ySVEi9JnJKXqxoEpJpgOS/XHHq3LjaMqH5RM6DMkHuPeVsmLZCR9oa3U1z/vI3HVH81ECEthn9WyeJIu/Xq3vUqlZD6aLNPBSKFFZcK5BtUBvLmOTUMVBixn3wRf5y2HqgjHyeByglMPIFWU8YlEMKVenurEz3frCihhmXbJ/9ajCGmrfEYME4Ryi/BAHVfNGmDdlvroRMwtRxUtbf4SLDurwZ/cqBMiIBlB40rNMJk59DwXEeyjk90yEd9UbXksfdZtSfTVNoWoR+jBtwu+FXt1/jv3n47/GHP/4Bfv/ld3HndwuHN2MwOV+mdG7yUP00+duzvyN1xJ4pZVt5Las8KnNnQAsmKA63usnvQE/dVbqcmXDZ60cbC3XckV2o+efprACQp5Ok3OyVn5przzfntO1OwfpMFP5vGFAGaS7e+ykO3V5X/q7lL/i8NQIdx/biRZ3VVuzpkIiIbrw8KzOkvlugEgrOxHjJNno/SvVZr14Ua3c63xswjRgBfopJSDHryRPSgqFzfwhpJnWmMFmAVzoePZLBjutcpR2AuhaTh6wozXXQCXdeAJyD0Ena5e0idNS+a1EjS4Mmo4tpEK5St9vA09Mjvvv0qa1sppwbeoTOJWVOuvn2+oq31zcAnumWba9M0J3dL8UxZWWtq0K2vz9kv+rg+tS2ax1qOGIctja8+qXaGJw3cSJUH76j2FMBpEKrjqyVSW80YzELZaYBm73qq8+UJxlM6Zu1VQlY+y1Xf5U/hN/2ckoch+eC0zo5svaOZJqqxco6o5A7bdxzHxygfDZldvhusTWPRFeDH4Ac9pA9bEqscK72r/F4ZqbvOdaq8hgDBzRIsyg2eRGze62ExffaZ/IngwVqGtQqVsjjlFSV4GMe515O2SxHMXWKVTCFvUwcdnlRV3q4KmIYGBhjwg+sCO+tvH4XR46d52oZgEzpzfuExsLIMQaO48APP3zG6+uBDx/u8fjhAz48fsTzyzM+//A9fvzxFfM4gOOA+cgj7Jf4Bw1j71heL2IisfNIUDj7y6Syfm7tJe4zSmfOyWKMmBtqVgHYiMNIPctzXnQ1Pec99bHlWNgeea1wQM1+WeGEzjN7IquxKJ7RqOj6Lfh5jmI84TklVTcylQdXsRm6KYVPVZP0uzCtaOgxQVZfh2zHOEeVyVHue7fqC7ADVgbIhk6i2zYsT5V5U91YLTAwuhkgkrq+JqNO8Ou4YPJ7VRuyN4OGRHAGBeKdVXpudRQfM7PZhPj8dwwJyJOfmu4PyNBAZei0ZRd46uLUJxk8I2FCHuQo+6zeHfN4i+wrIasceEV6GBzTxNYUPTgyTRbAzTGH48/u/gJ/Zn+Bf/Xrf4Hvvnx3mh/VwzXnpf9ddLtySm4xyEBPlMvIrslUBvE3W7T0wnbyc00E6r7A0m+k9Xt7LTfmLHtA5Auil2quOY81RtXr71T/k59vzmkDdPAKMO+8aBefb4/gaGPQv9NzZbXmx1ffvT8z5wiBlBKFsN4lc2t5ASaWMd1TsTO31q/tmESQ7PTuXhVXBXtOL8oee2fM3QnudeRIvKvOPoA+l80AC1owmJb4BmQ0u29olXisKhYU7Vsv0jArxXKa7Use1RZLcGvldn03DLi7u+Hp6RGPj0/vBC/675XuQyW0ovUvLy/48fOXZYzxvqQ8kc/aCht7JWRdfXSAqXGFnSZAV1QM9dz4pHFm1+aNKGmYbcq7IsqrprHf6p3fzVYKXinjmuKmunPwOwtAzQuoix7Fhbp/oPpZPLe1RaqIHDLyqtWkXIthpDe3lCwgHTgq96bQcoJWSpPOizIMU6HXieizjDfKmzsw5yYji3ZN1vg7Vw1AxS8zbppqicCkqI57XYJmNGKIBzqfZj0tcX8U/mjo7Y5dnxsxFNpnlUXQg8PkiBxpGEfiFPN/pLttZamwWb8IRaJMEGpB/DrpdczuCGfbswewOD5mFHDe6XQDayXu5fkVry+v+PLjZ9w93OP+/g6fPv0W7u6f8fnHzzhe3zDnWnkbvCfOyPIe91362s+WvG2ArGZ3+AuqiXHX9BJ5mTotDsTBnGFMFkJvdh6AOO3R1XDtAaLkx9SJ69MxgtcmAOPeQpf+IBlB96n25z2druBoSZVFmUgLFcWh2Jd4lHgsl/tyfEG7ndcrGBd18OTHNBYD3ajXPDDtdDSkjOMdO6cITAyS4JbI8cJVvnuhK/lF+71jaFfAWt/2XnvKoax+JgWlvzpGS513oayAOI3YQ3lkGKKxAbdtkPd6Sl/2IWWUdgqdFd/e1b6pfqxVUqhOD+ywMZoDUtMkmDGs7BdHpXyWWJYuj7vSbCX84E+/+7f4x/aP8OnlET87fnYhGzVsEwfrvMZ1pnPbVsJTnCHZEAjn8yqBxhA0UZy5klQXvbfqXvbCRZBMK39X5nvdV3/vJMoDtxRHpZmr7Vr6fJNOG593nZpmVNv2bilwOIpB9+//zn3h3/ygM2JtZL6eMAKYeuc979n7aWQpdbuhw8/6Xhckw444fQotItVS0wLI2Yzgur7R6s59a/LFSUA2MONPNVa1XAFHawpmXDUs1K/DhcIIDYJeKYWd+fMdq3S0fmCBZ/e6kajao5yUU464GH9psAAn3tFBLhZ1fHh8xIcP9/jw8IC73KLTeeg26IDVqiESYBeff3l5xvPnz5hHRfR3gBSVhjJ2vMlTOa7d4J2ku+seymqhq5soA8/UKG8tF526k+GymtqpX70Uw6RxdMlV/hLzTHrpRvvaA5WdyQEUXVVJc05HB1wxVs6ZAaUh1ztx4pTgW0uD5JyMAV62l6uM6gDMUtpXm6wBGsU14xmJJ38ZzZyeknKTtppuFHqo0uGqV65tm6YJkkFEUGm8qKHZZHzVu1Z3lpIbZkljTioVIPfMjU0ml/kkeyYgvGFLgSblOX8gn4lu2YS4VrsXAs/ofzuynvdYxZMrgyolHig2whlKuk8M3HLONH2+9odussSLokVf1JjXitLL4Xh5fcMYA7e7exgm7u9uGGPg9eXA8fa2TpmM+tZBCoF3AG5jrACKF71mGjlF2H0OkmY0naXvrafFnj0DenNQ9jRLn3tQrlEGVDK1gseVr5lGrQ1btrbq721/CXmhqZawdHPlxKm32LJd9q0SHT15FxCsYi9q4pMGpNveDZYpw9XB1Wwtq5g6RZ6bXdN0Y39kTZ7KGtlVT+ZIpzTnwYhuCiwVENHh1gA3XZyfqX5DzoO0FjrW6307G/SdVy/Gy4wRr7fKLtP3pGJi/Lk2COUEt4s+Tb6Dnm7YeKp0FtXWglKD3W6dNHbRj3fm1VEnUxpcth6HXTsc//d3f47Htw94evsl/Jj4T3/4kxrpdbXRZPHIZrVey+4Eur3gedhVzbVHuibK1+XcpI45t5N86aHHA5nqnjhvZdQRrM9375HlNr5Mm0Fd1woepI2g/PWV55t22rrNLYRJ2nQDqT0X405xXpe6/LQO5Ho4Da29XJ8gpiTg4mhYOlqW5RQsq0mZ1tV8HlurS+naujUghzBHY3rPnVwCjEw5I4CsL9j9VYc1IXOoMCxlmAJiSWXaY8RvoRLadLJYHaRU40l90DD+DLfeXtiArXWolEypTI4nQD0ja72dlr6wqNhoq0/qLqgxH9/NAoBhho9PH/Dpu0+45emEB6bfVAcBWBdJFs31aOpFrx8/f8HnHz8LiTxfb7ozXuiGwU6LUi0VIPAMGuiEcsZXdlbxk7ah9elfZeAWx5bRDylhSa88JU+VUdDYyY/SL10+6Xwr9SuBRDY6COvn1XCJjUT+fSvnaHtKgOVofBXDlF8pgQ0nRAFh7CVjKGFAhlFbONOlmHeQsTkGk/ICYxGFAYurAwAaq1V2tZWrnQAqhVfpy8lTmgTNYm4X/PYrRz0vU/TIlolTCcF9SaF8Uc5BOfKbwabwMJfjNMbAnEfdOxVvc/Ui8Z20dKbqOQZGHoBosfS1VjXbDU3FUoJxw1b/j0Bonw7cumxZzjVKDoFMayWd1t6ySP2L+a8ZWHw+p8NfX5sDHr/gcM8rWcwnIPM7jLLF1aAp9RIbdO0+2SYJP1MLWfG/eroyMdQfdLY4isFDWaT2nBfOWRi5tdrH4Ihj617J2NoUxwmqfggWnNTPhv2LFMXxI8eI6vNWlt8vx72+tqTJ2re820SpW8LA17Lru76TlnTP1XUjrchDDBz0IfbxKa6Vcum2xq7zY66d91FaBDXYCjGuSrTB7srwCi8TV1x04/aC1ZaJG+JS9U1HnNoK4jUHIL9ex6P1TCXVIVsBRwZ7veG7NlS4niuzHq2wrGB7bkuT7mlwThpufeldTMTMOvKuuGQei0Aa8HL/iuf7F7gD/8OH/xk/f/5t/NPPf1j7a12r4h/9ZNbkN/RHHSddBCm7AiU3q6OgLBDHS52oNohaC+o2RxgwFwewegRstOmf/7RnNwlQPbqo9/3nm3PadvyrL8B5x8la2540Mq0b/6Ex3qHzScqivSGflcXk2k7rQ/y+HQyQSv6sLVrdTea9TgEjJK4ozLms1u1kVkfLJPAUAi0v+z9yY/CqZKKiLjyKurdTSjoNsyBMi+6L4ijsotBZApDuwC4qbWBDJWU9f9yz3gvaXMyPeYxJGixl5zkW0luGU/3bhLB4oiswgmeezBmYNm6Gxw+P+O63PuGml2dGhD2LZ/usk9taVyvHnHh5fsXnH790g5sGTE6pt88z5UPmVfWxKvnVKi+ZlsEH3Tx4rXwWl3pCkaaRATFAdW5KfUAUxuLb9d50y/u2+G8aGKkQMiEo37sMtsj8tf0z3vtkOdlSju179USTBNNhjw+YQli2WxjU0JW86GumuCiDlYxZTYwWWw7McchR43SuttX5NBRXtesQCUvjK9YjUECE4iW2awaCaV6Q7KuP9WcFAeac6XDfxq3RPJ3eaIOb81nHanIpXz0cwqMvtRpU3/QUSJVNAzHBNvoFbGamAz/kmZLSavxua39kM/DWCnxOT/L4podc5CuCDXZ3gx0H4I7DJyyOyDdbqdPulYWRqzJWznJ22JEOW1gyy1C0wujFo7V30GAYNwPshjGP5RO77Btyx+02cjy5Mu4eF1Oj5iNBodilzuU8wWbJzPZtzqfZ2jsXRqOlDCqdl9MxxXHTmVJeMHoLVryw6OFFo+0hja4fByJ1S6ZXJbf22KCwl3I0oPNSzKhrRAiqD1m99TnjFEnBb8Em/mZC4+5NrW95STr1sDqlV1stTPTjoqesChEb8h3LdpKZAyAXDUJ2t2hK4xHF2+raxRyQcKbJbjnDnEHSYjZ6LA6tQ88unl1dRf2jfgUnnxra9hSi7OIF/aI/bYx68gnnfXOalxMaunjTcy0AG3IxPQ4um1MObQu5NitdAFTQiz+tpG45+I7X+wO/uPtr/OLjX8En8K+//5fwY2DOiQe/x81vCoGihy7I+S6he2ZBBq/in7ZVQY5PXuP1pDGnelJHGDBi//DIvi1SMxho5NXtIZZX095/ig5K3O81QDnZcxzv8F8835zT9u7TnJX+7AGZBjCK1wIq7wVuKvqDvO8GmyB0njozVxp5LryaRuFpYADIFEY9ktXSSK5l3VVG92lYSPfOWJlmRDGznmZTAFkNcvnZUyj2PvdUjwTmfvFK6PYl/NqrHEeRSPpyFleNTuzRv3Jmgiatt9Yq1AikdtKEGMwdV2Wb8yidaqZF/GI0VuIN03fivbzU1Qy3MfDw4R4fPz6ucdgIw7QDkMHlMkiAeezLiZ6Yx4Hnl1c8P3+JO/jEmJORVVpd5+lyAhSQaxIcRTs6HWsurM2dGt1CXp0CSDNIA0MsHQ0mpBEaBdWQQP/qgkPrt+L92oyddyCSwsID1vhVma/92Hik2tuP9M4qnK4kaUPjjYa5gncZOU2hk5BpXBbPG5BBF16nYfCKbOg+BmknP0tmRtF7hzbJ/cvUTBTOwC0Pz6EBPmzkCZHAwjMT4pUy8xXlBOo4eB3zGk3tWBGGmLmKaGn02Nb3om8hTLXNVTPH9CPS5Gp87dTbVVka3iY80pxv2cOovM/ZSpPDc6ZhAO5uN7y+vS3n8ZiwYesEWcVtK+VOXknHW+XYsYx6GXl1aiOQS73h9A/HWnUDoXxs2JSdwYBh4kBf7Sq6D9hawXRUUMEczahEBZXcAGupiRe6s+F30D/Kj9stjS5dj2vG3nZYXOFVueihEupUQMh8skw6erIygk73XZQ0GJiosEURGNAh/vJ0vXQ6x5A93Nz3K4C56zwvOnY7SZQYsAJkXgE9bNhEnZ++L1CZEoHpiuU7eHLLw6qnLnT/KY/JLx3LNo0rRM/0fHbC6l0Xemv9ah/uuLlpdiGjZ5tjfwedhkny7OYFf9NwgfIky2j9PL31vT2KDXHCMRtA2BzUv6a0AzKYoOPPFoNAGYg0IO5Hwr/57T9dsz4n/uD59/Hx9WM6Up9eP+JpPqKC+udx9zRCkdl3HKe2kkbnbKghX23ME17EZ3E4mfoZ6uxfMeg7vb989/2ndDx58dJNkOfvj9OGhh1NoM6PX3+uDsPFd++IzSUh3ydsGQRpTLU+f31CW7oKFWBDJzLpXi42NwIywFSFSO2zDSIVXbRJJST2Wym9+L6PnQJFp0TKCbCWUkYanK2eAFIeNU5Aa0q20WjXSGynnOPQPaBRVsBXzNMFr9Cp7hKyE5N1xXHFCLLCqzxnADBwdxt4fHzA4+MH3G4K/qNdV2CYOAJUfB4NmI458fb2hucvL3h9fU3DtdOixqj02sEmI5BNty7joFNfeWgBXuofq8Vlnbe9PxesU38KqTPwoc0ZypAz5fXqOFf1TE/VbCqH8un59x7oUa7VNLQ1/tpH1t+saHlVR6PSYMPhmaPfVNIZS5TdDC1FMRNraDzFvDZOtvKv8tNThgGVLpq8d51jqAE58sZCV7p6/uuI1LJomPuGBmqvVu6DvLyLpuRNU2Gyay4pO3y7vUQXSmbM9PMziZfRoQhQfdcUt4jZpqwopif5tnoWKWQFFzTmSDUTkAp+ug2MOdYqypyAG2Y4IeVKlHPgWNjvvhwsOq+Kg4t3vCLOgcN9fzNS+JK+kftCc3IAACAASURBVK3hAG63Wx5CUo/BrPiQEfkk0IY3ievx2qKNrnLFXKUxqNi4Ia2CMDxoUPpuitN9CnTyZ6SAep5K5zGX1mbZOYZdN7MqceIJVBaeboZqAr+KOy3nxeANT4q3NhnR4A1rGguTzKVe1jE9Vli1aIV5KvWOvCL8pYTehMcIMFfYBaz+ZJu7TjK5Q0dwmbgBoB+9L99XJSHynI+9A4LfhZjgQGp0tfqZhnleS9lxijqudYIkIwa1LtBpKLxXjC7HTRArowYiODKSzmfYpiaCV3qKb2Boj6eLrDJoYtrfalftvuRXpe/GM2vOfQWgHfCb4RdPf435+Fe5Ovvdy3f4+Pa4ZPQAfvvtt/Dz198+kc9PE17t7qtRa0SC1Ly+hbqX6bJGvldlGIGvg/ScaBN9paaI5Xb1guh3CbR9zRHjfP6UHVvA3zOnDSi+2j6FSvX1O7+5nivZy2/2pRo1Ji5Aoz7rqyfluOmqhZSMKBWNlr3ubfF863OtFv2mhwGF2jESIBXlGx5lS5ZgqZA7KRAJvAGCvhSiprlx3MMZ6Nw7G4pdgJoAp31yd7lipECvaGkXV3l5DWNVkv2m/DkKXpuiv3o2xZGxquiocGQasHcGPD19wIcPDxjjlip8d+gXTVea3Jwzv59z4u2Y8Am8vb3i9e0tVo4sFXVjLCu6JRg3JCmHlqCc73KFROi4H+oAEGxKAW86XtTlRr441cYB2SofdamicZ0fccqt2iuDqQqWzeBZNvmG80JOXsKAVNHCrxWwK2XflFco1MbK1JZWSoZKZIxO0zKeRA8m7k8RvdnwA9gvvCd/70ZQJ239vua8TtsMpZu8S0e0B4N0NZL7yFZ3R35+FdgpGdUVxPWfJi4Ve9pJLkomV4mDBn4cVV88AkhuqlxCvyGodeVuUIOBBp6BKeAmZT3GUzZED6cVT3Ja9hUInY+a09vdDW9HyAcdrkgvhdVpuDyef5GIl4wnBydOFy0ZFNMJUsncjBVi5BjLYWvvB11Nr2zYg3EVJHNgXUXAbwZXW5D80/Vm0VPN7tyft9MRWCtPOeYdt89YyMNrkt+D93Vv9eJq6sbrmHvumUueKzxPfA8D+Wp/HZ3EwjEkFgfZOqalvAlIWqFSwyVHo0hDb52nvFAbgFwEnDqVuiTockrf3pz56u0OakAdAnNBTJCMVNLIskWGDQ9k3PyeWRyZMm+2TijV1d3UFZ4nFU4r7G+pjcRzkpWwcDL+gmeJw5xj/h0DVAotmqiSVctIZNOkjMISRx7tZaA4bbGiK/WUbzTE1j9gscFe9mK6Wi9dPiBPDyBXYn94/BHfz+/Xuw78zduv8OfHX4bumfj56+/gj778gczqYjpxq6W9okmlOM/gz/VpZRY5ui0n/DhGXqStdmEF3H7zk/yw02VzMH/TI7cQvfv8vXPa9kc3l189zWlW4PvpLSxjzmoCz3b8iWW3v62YQD5VB0P7eLlK0WRMUt+IicmoNEBEGW39TjvcCzstQEpTQNoIpU9lHK0/aDjW6Wj1os+61Lrd+xINN+VmNV80FmXIzbxQPHcrJ1IN+UY/VfQOMeLW33q8cu3Vw+Wzq8YagcuYYvxiON8/3OG7pw+4u3uIQ0fQjJwelfGF3bbSo+aceH09cBwTb28HXl5ewgirMqShqjr203SuzTZ83tIRosIcXxAq9VZe/uXlbOX87GqVE42aoDRWNpqmvdII0anMgwoyiiX1JECrjq1WWpppdjo0335oFOm59aeidXQMyiiiEk3l6uSKkMlMHURnkobrIoANLDg+X8ZuGNNpxpAW7hixZ0y6tQyJpB21PT+jAUMHRCk0+kyZ1WZvbO/ycBJ1YNu532WI0UFMugLISbC1t+QmONUGhKWcuaHfYrXBU0l7GBgOOA8nWWVWW1yNqjlKwyqpJf1DM3WVFDWWLMV0Sgsfytq+sH3tjiDKFRczpsENHPMNgOF4O3C7M3hudQ3ngqjjAGzkPjfPtthPy5+UjxJhMknNzZzr8JEZPHa7u2XgLfnZHe6HnKCrSKLKBwocJ/rlGFBG1RjMONiRDKV3hN7J3zn2Pu72YZTg0S46x7ux4LkKIhiColOtdG+rgrHq13WmZZnkOQN4cFO2mQ4sy9VYZg6+aClw2gsA2I/0V1zPFfM0xIspOj5KnS0gUN9lECGVZuFK4nE7BCPoajEPDnArhX7fHwlBXAXIrp6GY/GR8QRthmNKTjI4bDVXbE7BmDCRMjhiZVBUncPzfnH2xaMyHstwRpWYk5r185CSuautkq+xldgUkgp/O3hFRueozI6hewMhdHb50ZRXYkztZ0akaHP1HLDbbbGeT8yHN/zob6vwdPzZw1/gz57+Eu6Oe7/Dv/71vyobN5q687vkhTUkz74seejZDYC1ftrN4Ae5fo3VbmO71T5mMWHhzL+N0pdOSKfN/l1l1b3zyjvPt+W0iYF7xbDbywVWXxl1Eb3ppZ/0pAOgm0HRYW0xvL8zNaHCwtCZ6WBWPd6Yob4DfNMhnOAu0DTwy2HT6tTI2cbUmwLTONSAUYUBK1Dr6i8EXMBO4l0JAKQDmy2DIj7ZQbgsGijFVUH3sVKB1u/6jmDqSVhanrN8kadnFqpnikuOP+2CHofNcYVj8/Bwj49Pj7i/v4tI46INL/7WhweWmB/Cs47bDbHC9rZOktR+x/Az0sReedFcI4+doBKdk+EpkOuAT86K0ogA7RTNTTZE8ffVWfRyjcq9M3U4hUhiZ6jTnTvF//W35srbCSToVKMuyN70Hx0PM2t3ua0Ajdx5piCkYwllmzzNSClZ2evd2gdU9TUR4Riznaq3pEGUUABAyrQB8ANqXLKrxRNeByrsQCrYWv2umbT+qhjEHdNIzxFjW2lBqEuRk8wDPGyp+KEkv9IvK/UN1eLaZ3cymha/ZqqxAFU/kKHwTkI/UV7nhILSwLfRmMaF3nZmxn1sa1+bu+M43gC7w20dDQm7VT25kptMifr8QuG14E4IHPGBexXd5zrR8jZqNZc6QEAiD22RVYiOu8Sy/mWTW0PKTOJHN8uCZwA6NukoBY/xNEnj3O6GffSF8QrWaaNWfRKZPDQh8aYTL2nLlbKWpaD0tvNgV/+WVI6oJ/nWkP3mKlrhr+ecGdvRIIjQ82tGYNs60A5L884qCvw8HTruyuSWiiorcuBZW9J8n+z81yCyH/pTgnINbHsV748PEgBwxEXzyN8NVnd+HhOzNbH4Y23NWvMyT10gCAk+uo5dDiZRS4W6V7DO8txZ8hrR9iyzZ2VcaMd2DHHqt7QOWPnu5Bd219l/FHCFjHOIDuqasuXO87BPEMC149VlSnT0avYxpLN/A3CL7CI3TLzhv/vwbzCnp030eDzgP/n8Jyv1N2q59zt8mk9gACtX41uPiteWw+baBfgR5UwXVwoY6HAikEn35NVqGlegsbUsn3j/bpfVn5Ii+W05bXzeEUwFFdKsGRAZUbzUVfJKKV4p9vUyIjDttXeZt75OcLftnYxK7OXLuHLvxNDVOjUKu6iXoFVTEZ1N3CjhWoLaYOmEl1k2CdIJtADDO+0LryKyIqAlEuXaF++wlZCUZOhtJxDw/bR4z/CWAwHh8ZzKZzI8RtKaiygGs9efaGtVaYSsn3f3d3h6ekiHbdAsidWBK77LSJWv1bS3SIP88vyC4ziSFBntAy9j7Wtd1is9M7sQoCl+LawOHfq7BOVFbzFeCHZqPEn7pbqQ+50AKsyYm6hX+VgjeFrP1PYA8NhnHSB/M/7TlKA8NIJDkZ6iaEL8kqVK9VL5W/2d3anju4xsuwO+p85Zu4g1ma2Nm0rRypYgU8T3Vl/keN1F7uUEMWidUoTBizz9NN5iPWkL+ESuzMlF34ssVFKS+GKl8EiDtaFeRhm4s06U9BxfrUjwX9axaN/S9XK8G3YIneoz4RORJa5Ou/d7L9F6gToYAoy0u6SwFia3wEMY8QHqKSbjdlt1HXH40LHoy8AJ5wCG5K+R1wt41xHRyXIK6sMxALOxZGgiU4XG3Yj0VzQQZb0Guc+PxNvmelfmysYphylPnO+ewpmBEYRBTpFIGkqFXod35SqOmcwU6VXOQz/hz0RhIfvDPnJvzgosjOS5SZqELs1h7fBixTUbPMk75JPtkl+vV9ku7+/an3Iq92dNvtZMXi96kwyFJao/idkoqIuxilykUbv+LiwVFaSp/KmENFy09TsnxKQImTkT5GRQu321nhnXcJSO9JQr1rfmuKfmZurr1kPqmT4NHSuBwr4K2gRNsr3zPJ4fBXMRSh1fXt6MnKMRacxTHMyKs3j+3ELdqxX3tjDX9SN1ONsSW0z+qTo2vdBGFf/ayD3ZaxodccAj3u7e8L/c/6+xCLJ6+HR8wO+//ENQlz74Pf7R6z+IPl7QVPR3tdFxOWADdeCa9lTQ04Lzkqlt2doo/f+1ufq7PN+M00YAf89xOr+fyL0+SPD7TcR5XzCKmUp4W5ELgL0WtI0VY/L373MVRICepZi+U5vFu/JNBXoi2AaC0d5uwMo3J3Jpyp4Oh+S9GnIz/E7GkQhlUxhqIFqNSdrs/VJFXSmN7Q0F8uiwF7GiewJoe0PRDQLp/p2dnNs0JaruqHYMx+PjIx6fHnF/d5dGqnntpYAfsHGDzyPvxmPXaCS/HhOvL294fV3/1arJGmTOuPK/Tod8zHcnIPx2kate+jrRnU7olXSxF3VRa4lncV0zVzrv0lDIP72mJ42nzsFu3qbQBA860DI1g8C8A68aKy5gbrDBRi2IRqOh5lssmhZISeOaTpWmK1HTZZ8d69hwSdsjAMTfpVrXM6xfDZDpx94NlbJFii9o0Krc7qtLq5smdUiqI6wipEsYu4EDF3hWAwZprC3arMM2KrBlqHvdipfYF+cHTIfU1nQ/ygVOr3TiKWmEceJa8pe0Z5DxhGPiG96nY7h6tyLE5eC1Ex2VI73wIk8b3XCVmHl3GziCZsQEM9TVN5wjQ+5xwyJP4gFb1/2P8zhwu7vD/Yd74Jg4psOPA0cUHKMfOkL+G4hVTK6U8kRJrpJJUIXtamisnHtreqaMVq6kDaWYCD0x35Nga2VNU8PEOE5x9PqsRiUYdw7gpbgY5331rwdDUcGy6IdGyznfdMSu0TMCgyErpVes6jCTK03KaV+8VKi5BjS6LJvJG6ILdyXPdxtwW/6uq83VPtvgu0IYdn6rc3LV3GrM9ZQcZ31XfdX3Q7F1nc35LEwqOF1XkNBnFCrncEmiDP7t/TR20QpzNmskNIj0uvgEQKV378X2cdL5zH8uCmUfgiSiOH0Cc0jgcNOOLKLonf3fdHLqcSvu7CYoHeXCtJQdcdxYF/leNYSf5sVyTMu5BtwmuFXg9faKf//hLyIACdzmDf/x9W+qxsDSf/j6c/z85XeQeyrNcl+rBjoXlkd7eh1GC0Sg1U/8qswykcmL5yf55+8834zT9p6zpkJ0+bl4Omq0XdVtZGZhErWx2jvaUIBCKsl2eeMJ6tvfuhGRvxUGKYPo+9HNSPMwItI2nlyKVTrIS2UA1pi6Y7o+91Zsi/h43zfFz/qI8uXmfF6BXPv8nTnnl7rKsI9jL6p4lODjivt1tPpl/+TRGTupCvlAo5l6ciawAPnp6QM+Pj3hdrvD3Vjfr+jQAORSWp/lgNGITgfJJ/yYeH058Pp2xFxHukAC53lMPBym2LbzkLXRhTGhCkuKJV1TfjqveXxOY6KAfX3fs4tLXnKO0Nn3fC89Vw2kCijOuuwXq1TckqumecQoiG/FvoA7DtmbaRpYQSmAxBsZkTq0y7cTmfMwLvPiQ6i9AT0NRKVK9+wueBOedGCMdX9XGllgJLn6XZVtFE3aM//Tsn19M42s3eCN/qm5rGj4XqBfA27B9YLzSzHup8hqxsEqb2mIqbFRcs/1Wt5FtjDAPY6xN71frnCGF+/SCNohzrHzFso8tD43mvo11eEVZVNGcPCvhK91j5ePShFiFY6Jh/t73N0G3g45AREGu0V/jM4kgEh1fLy/xzEnHu7vYGPg8+dnvL2+4nhbK/jrpMr9WZ8oPi1Zm53vaWDG7FRKvCUEeaxQaYDL4BLw0XfzF8C8pTc2Y174o1Yay4BMY1GK5Gw1u0AMtfh9TwH1AALlA49LyKfVHXrNQnCuENLhwXZCIhiLwAommGQgeONN48uIPWEyRySDBjetvSHXXCbp6ChDcF7S3FXvRjnFYWh9kkOe+lGVyeC4dw7TDslHX7MViulkfGfO5bgdHumDEpQTeyLT04X3agYDi6W9fqCVjkFWeHgWQsx9wzEdAsuHLHhgXDrM+6DzHh4TpaS04Zyu97iHCwBuY+D8BIYlkrI/FcxQHa08uCjr7SWjsow5ZHqkXsXiWllOMzExZNi9vbCCVwsrEipvA7cx4MNww4Bj4m8fvs8sJZ4w9uv7X+PfPf37iC+V/gIMD/MB/+UP/6KEMBVSI/7at633xIrBtDBtoILCgSXmeem4KQH+js8347S997znsP3Ud/8/Pck8YriVvo1G45/mDGifurhdpyzwXf2+M8UZnzbArxLSVhkO+164rENAukFDOn3BaAQ5w9pPFeX3dnfHOJNQvJhYacjtylzqXp8PwSFdbmbV0laXqQUfE+3oW6tBdtJdRATsVN9GLkddIE26Ci844tLsxw/4+PSI2+1urZ5ZAXk16UgKGC8cpjU/4/CRN3yJY/2pNGYrf1WnGA4yt6l8A2s9SSCGbdCrotRWZban3mVTBP4qtveBn9kAeIg5FTsvX+Z4fKszVWxd1kUmbw3uhyO0h2VFgHMlLOTvJkqW1eQ+muhc0rJptFKgboAfsq9N69l7poEaROoVjXhd3OI7ul9uM8kmmPpTT05DHHG+HMchSlXqRsm5GnOcgaBYnMRWRk+mA0ubloYKpB55yajENcWuRrWMRpMYQUV6294f0h1ldpB3pnulAflabWqrLnGIAPex3VB9TQMk5kij+GnsybiU5Sfq0mnyLg/XYB/yW5NVHit6WHwXpsy6NsLLoR23G7gCeP/hHr/16Qkf7u/xesy4JmQ5YLdheDkOPH14wMP9PQ53vLy84PXzD/jh8zO+fP6SuoKGpR40UysqXEWs1GUHYM4V0o6lmYolzNX0UYDpjPThNBnF8dMagJCLgUwZpZOaczEnfFiTgdV/zo4VjyndUb8kBtsAV+hrHts/BY824OaFu1f0cuQpkslT3nFZg08gC1JvzAMz5qj2Fyl1IPeuGCooUnRobSX/hWS5r8BGnsQasidKsa2jkqSha3u6I7KfM9Jta2/VSF26KYkOIO0RIz23vS154r11lHmPl2gvNBVWrAz4ke+uvcWla5bjVsH5TFUP2iY+sc4khzTIMY6OSyRdDVeQI05VXUMmETZiKNBQ9trHQYmTrlkdOuIgqeLDXrlJHRxRsU3wSY6h963ru8JoTcXs8947MOSzmRRefRlj4HaLDIa5sgMGEAFPjxR6Q6D4qs8d7mvV3odj2hF7SpdupY57wSv+64f/FtyusuTO8bvP/wB/9PKPAV9p+9OBe7vDnV+7Tn1PW/wdx9G+n7L8/+755p22/dl5Yvu2GPXEja6vYS+qTpjgZH74LsFbOyKsW93qkGUky6/yoE+DijKimKrhHFfl3WvXvDFgT3skIAnIyBicyCY6IDfw4mjjX9UzWpxoDNbO3080F1DIT1LBeRjfAaRF2k6jANc26uZUAXCDZI7lz6u7onaY5IjzzaYTvYApgOzudoePHz/EHWx3+e5k1CeMNU1p2fXUOubf8fZ24Pn5Fa+vb1lPdoNkltMq0rA2ncOaheKuriBbfK05Qaxa53H1P43mYJGUt+yjQTZybUT0/llTeBcSEMaJSxQXVKIif8lhrnVF39PA2akf9MkVtQ0IzJJPutnOmev0MlhGA3UsXU+JceNah8yhGHNZNh1xzjMAnyVucNgGipVWGb2z6nmNqHDJqWTDsKp5FbnOOlMTnwI/6bDVCJB2JudTDQ6LVWVXrDvXq0mYJatzYyc1OyxOtfTEkLbCXCAhJxb2VbMdcRtmbWVZ6lYWKhArica+cYw5gDo1s1YXNYWITbFfHne4xUqQO2w6zG6wuwd8uF/pcfd3dxh3y7F7e33B8faGt2Piy+fP+OHHz/jy+RnH8ZZ0zkDJJoBq6HsSQvA+R1n6ROfAZVbanlTyInVjykSPgie3eewPnHZ6N+dqjNJTTr4budKZuB3jOmVIEDMH4pJ1F9pom4X9HCv3E5LHHY6BSjMlXOeqhLBQpt8KI+e9es7sgVF6nhPBg4w2VaZ8UwEnk7kQRM9VgI0QnGeWG30fX7xYMpQdIZ2WAw2ruTTt2NbjZdwLH/SZQc7pRF4aT3kinyUGNFurdJ/e0BXXeuf+qfQ596GU6mjzlZ8J4crZtqzH0AfNzyrXhpVi012dPqcn4VfTtKUpu6iPDu5xrPvUhrXgkryYdfXes9Eul6vq4pXi+U7EFQRZvL5OqV0TcAvC6xxeXxYegZvbwLh1RhKYWm1mNlPInS3cuMU2Xb9ZrsYljQiCAHxO/PXH/4i/fvollOV//+3n+J2X314jiusCyj9YPz8dH/FxPrXe/f/grwH4e+i0qYIBzgpmexs7y52f7fuTcxYmwlcpzsnirWe74XTV172+pnrydzWmF89ZKY2r/hfLZl3Zfg0RZC7XDopAiU6MMmGcTO2PGD8nzWFnWmyTpcfsVxsCYpegI1TyRqH2fQpp0CDvWhWjVQ2HudNIxpInK5pBtY4aIQBwN274+PSQd7Ctdyamc+WQ+48cuc4k5T0UtXs4bC8veH17LSAzOx1jjzD2+JFFGiZ0hUbG1u6uE9oyeniahzAM1InoStWLmqkoLce1Xg0gFNq1Db+Jk6SrZfcdtB9SRbeh5+EF2S+PLspcbYbdMojmMu6SBpUWtd4xLVF6bOM5wFYKZe1rzysoijrNGorx978lwUzoqPJDGjb7Ie/oi6NYcgycg2IDk/r5Q8HUggd0fmaq0Lqs3JNXMnVLGIu9UZdnKeAaMzFnep2gl/MmlLIwiHQWyE/kxdXjMgoQ8rOmX64riD5W+qFl+R6UCJmedaWArjaaWUZqOQ/liNaHNN7VSF1/U1esetVgSh7VLrusCiptYiXsOCo98Vd/+z1uP/yI2+0ODx/ucXd3DwPw/OULjuPA29uBY64rQ9aplDywQPBV5q5rFktILszqs5wU3VVqCHnKssimGsb7ninSzB0R2Y8V0ZgHmGYdKP2IJn1c5P0KDKTk579kQg/DNrEEWI5y432pW+2GlN81RzwYQueRvMFTYT343wMMBw9jAHJ+N9O6Br2Nn/Klw8ZVWX6duegDLTBluu7BKhyIO93q6woQloL2dQfsZGlPx3TdO24lk3AMq0ASgH7wRfZnES1xY2j/LNvvoaIuOTzuH+5bNo4leSz6nrg0WL9nUKtdrwHRmdRls/SfC/1FAwq1fdEzgQKls4z/yPxtdKHsLAiXIKXYUAL7VCxrHudIxxraPt9rNodyh2TYWFH5FNbc7WnKN5jaH6f4EtcjPTh5WfKhDQzcBhanTO3c7akH8k/qzZinYUWzm4UOCV2oh6aIuQuba+3vl3d/i18+/q1Mgzhkc/3+s+M7fDw+Nlr83vM/wKfjkxL4YjJ/8/PNOm20JdRBu3paYIZiKmWY2of2Wbay/Yw69F1oA70jvX8EirZukUqoT5T2Idlb2jiLwD7Wtkn83LXW217/RbtplOTwy3CIr5lu0zbk6xhinB4Sot3JSKVE51QxZ5vJ/JUitv6Miz8TVEvRVhtsBAlQrI9GlU57CXk4oo5yeIALarFh1hwgEG3fbgOPjw94+PCA2xBTzCIlLa0Qmbeo6xDLw90xjwPPz894eVmHkzSyYavGamzOqdydlHivUcx9myPSblv/POEtDRhv1x9kvj+Vlnul+mx8m/scqrpoqlZEqSC3oDmyydZ5po16vZN81GlA68I4hniVF+i2d3dt0IRR3jGOW82EboTo3xmJbA57qqlTN7K0oe8HqckEYH0vTZs3K/nOg1RIjnJy0gez7U4omRMWJI8wGroONvH8MkXReJx9RyMP+abBupR4pRDCKgJcGQqRanUKFi36sL02SRHBJd9w9SKxwQCfR9Qf8xMOJQNlpGHtwyoGbH0LGlUqVBHVIAe39MlDrQbXihtpPaUPKtW20WYeE1+OF4yXdUz/8/MdPjw+wN3xw69/SLlWh/MCJRI3LTC/8KD3upzmjik1x/JbU3Yu/FMCRqONe47rsJpydYqugTcKUWkwoJw8J9UWTfV6iKI8264LdtdQZq1A5RnqhRertJiMc8dTahehVRPszgdkjZwbBf0NitdQuz4jfwKU6aXP1NZRrLFAvazg1BfRU3HwTOL2dplr2T8yCCDm2gJCiuMmfDuxk9BhqR/OqX2im1skBNmGx1sNAdJ56u31/d6JEKywvps1JwHAYFBxSDmlAcuqbNDFYImFFbEtwYC+10l4B6j046CgSm1zSRt/CzP1V4qGoj9O9QQtYSYHoHgr0wPy0RjxT5wrnSsPbEk514M+QGworKqAMfFgv4tOZSz6RZ3Gz23pltS57piSLObmdfDSJoi3Iix8lCZjH6b2ZjowlmP3w92P+MF+LPsTwK8evs+0yp+9fod/9vyHRUMZxNf8HeBbctq693XZ8ZNCfuddFSDfAGZ7E7vSun7jXPjUPxre46qpq3ZE8SP2IFHhNIN6S1uIopVuQNQp46HtRWEEKPu9L9N2gdKepXnQ2tcoKEFIIqZRgWbGZcld7mkIYX9HU2nEiAnHragm7XSVmQ25fnQeMsAl+o1OyOjm+w+PWx5j4MOHB3z4sFIiWyqrY0F8pI/WHtVDORjDJw4MHMeBz5+f8fL6Fndi6byWWpDD40TxrLpcZnLfo5dgKAokZ33tHq52LPUW2qSm9lelJPIbvMdfV50VzKATnVG8xsLrj2Frf1b2p9k3/wAAIABJREFU2mQunJ9Wus+u5Bm5prlHMOejqVwyDfUJDYGglQZVmgMJpNOTxpZZwypvZDv311GHr6iRUqch6rilXvYzi5RSytP9GuFEqXtSRWws9jBGG6dTVuy6y8N1dDWpFPy/Povz0kAjuRw2oZF1I0Tna73e78DRudUnZYV8KEbHCgQx3cySV82rmkqZu8J9UkH4KRzQGxD7MDwNj5IygAe+uLTDlbuiRRkcFegRbA78U9dLcXQCcRrkKw7ccDcGjjljvwd51ZIpLVYUAZlfh5zM6ul452m9xhWLkgsexFH6QdDIkXRX0CL/yczFvAXiuLSVzqbFcfPRehJEJNSQNac5mphWMlKBYeuyzzm9Wd6vyqKxYbr0qq2PSJsRF8z71FwBIPdxRWfMsS4uv411RUGkxB+8gqMgNOaBq1vVrtERTemkKuspauC8x/is8XfpPeepfpvSW3EPKl7KVCriqIl7d9hu8W6JaEpezEzOer67cUP9qzzLf5se2mW1+KL3tztrZxmXDKQ+AamDHJ7OHJkrV5iziCWeT/msp7vKPBRURje08T4htv/B/sGhu8LOTxFYr4ooe9lqrimtYtgVuSW4zr6GY6/ZDa1rrQsUNuGRNvQKKUz3sK0leMMoCvWFA4cf5aCz7VRLVsE2GqFjMp4W73vwCOXLUfYt1r45sXf53JxUcPhtldf5mRF1NwDPtxc8+wvMHF8+fMZ/+PRL/Msf/wTfHZ/iZcPNxxZYOj/fkNOGnTfzacLwm9xQPgyaWeL015vfDIRzH8b2TogbP9puxevyR2G9MkSiu2WRt3JsI3O98/4pMrzWx9SokKHoCSNzuYdri/KJphJBk+V5qSPLSVULD+UdFvQu3DQgebqOGrPaJcXabpPtyObtT62nFSMotnbOMF90LLL25f1e6zDDw4cHPD5+wP3thnG7xWoHTWHeyLYosObxwKwzwAB3jHBPeOjI2+tr0q3m8bKnOVcUIHXWczYJTjmHolTB9ICmA5NQPU0lakxP8ErFcrW1i7TF3JF11QnNdwRTEf0nH+RF58pLMiM0LDmr/QTKbaZDnmhbZLpVOi2ippocePYTIcvFo7GZPb03dtpzDpqe8kp5XWlyiLZiXOmVi3zLAEqXCh00rLfPVRrNUn7oSsPeSqdZOmHWKZ8KGMSr1TEa6ZSdEXOyVrbq3p0YtijEy+ZBDJqxAjK4Kk5MNcAQTmZGTAOXZGO/OpgJqVDarIeXNScvZx+VillTOd2L6CfaBZdFAY++eqTcbeRPDKRzYck4PZxXmO9AHcATvHy8/T/tvWvMbtt3F/Qbcz3vu885raEUsMEWBWOjISYIaQpGYhAMAhLrB4IYjRUxfMGIRqPVL0QTEkyMiNEQCReLUS6pII0xaIMY/QLhlihCCU3l0qZQoKU2Qs9+nzWHH8btN+Zaz7vPof+evf1njWTv93nWM9ecY4457vP2gu0meHq6pV4a7nzs846pAxjmWLj2oPHwNoLvfbkexLYB8BxbOjyS7k/SpNCJMQpZ2LFqtginlQSlbJjPgGK5Gy6KOm+JkdfsjIgfJhEzpFG+L1W0iurqjCgDBWQTDF4JwYZqau6TyYSHwg8JIW6mMUWMK2ABsyoEe94tJ268Vz9BZMuxV7XgcNtGBoimSykg57+FMbKC6KsQHfw3Gyu/rJx4D8nbbC1CDzitg9d971RXLn4dQuiRsK2rEYdLSwSzoa+zyKIr0ibYm+oCa34Xb3BfCcHABaJO6c4Av+u+WJLCDxrLJAxsSwbrcVWx/U+8LNP1z6Q+tX3VCdIeGXvq0pfFU2jmI14seteNMzTn3QIptn1VJ+dug2qZ+ImES9Cu8UrBel3TSHtv5XNe0pMmeTDM3DGHBYdht+2g4A0TO3YP8ti3BNRXBg2K3Uf1izuYrF66TNu4kKLxd0XQgvhgcfWDUmJFUuoFr2aOie/8yu9O1fkT3v54fM2nP+n0rAWGDydok/PHPdh6vTPlECE9trMA7NgGOTty9t6yLheNI87xSB3gg0+OjUi/qPZQb7iM4ZmlgdLijIZdf1ZZfHu3LqC37wI3LIlXn30LtNuCrjwB5zhTtwZsVuXRtSG3oP22ZnwyU+fjUq5BzTylYQjcW9BbucdV/XUKRz31m9Dv0vpRn8MpfH7zjE8+sTvYaulTuANk6Il/1mWdCmDqwP3up0Te7410lWEuvJrjwIalOezWDgd9yYP53XEKnidnh6Gx8/KLRG8lFHW1ULOBNaf1ujhWkBa1Gz8cS5qd7E54vBMu5autyfqhc4izYnP2yiEo2nF/Ezd2mvTIQuc6qQycyKAES3eqKsvZeaJXI9kHrWr8e9BT2iEL3I8MtMxSATCHbGwjf1eADgpiR6P6n6qKdF8NMIcfnuJwHuL9jqqasW+bbdKavRHGPdsvfptxdUrY3EIpJTbwqyVmvldsdh5TJeOd/QVEfA9PHshExG8OTPU59R/KD4ggWqvi5HVmnKgtZusUasuy811LGO27DW4cgjRnzPB74kgsiTzzBFltbbROBm1LMtOZMceP36isfV5I7e21WXGpumfof29P6N65IFCMaWKh1kaflbbldxLTp07+5C2SEStttfVDSTT/yKjDN3jsp/NxKVkaHx+I1CNrvVLPVBX3fU+K5ux+ONMKYGzI5IK3VSuFYzRwqDvtp/LIooKqwogNfykF4XeCNyX391kFnjATRRyWN9Cd8m72aoawDQXLS9oVsRMAk7qFc9Cq61Oag9Yq760eTMK5f6n5W/Bw1tuqCNlzy9AMdydfynXzdVbwmpKXcw4nyVLeRSTuumXuiZeiZw5tyFjKh8H0YLwCzaqRaZWcJro2nTY38aVOss0qHyiIRP6By5R4QkRF7YRfZFHkVhkF+NorGcMCmqGYc/pVSkh/rfz8ZLjEKDTSOv+/au14LxJLJXOllbh/lRR0fzVWwAjAa4kA4G88/yD++tMPLrHGET6goE3eXebV11lhlmE4BCP9rVfaD+Ei47oo5kdQ9pWySYTnnEe3oavdYqHXhw8piMHsHByWkHL54HxixqbNu8IzZ6kE/LS+dyEYeNIrddn4YmzJLPdwxSrpsxtMx74chFoGL13I0iJUzxFrumYFa7ExBB+9ecbHn3yEp20DxoY4qUhSpZa6ZiOc9YejMhX3/Y63P/IW95e73bEV9OIgsahlBljEFRs7UQu50mh1Gha9ACS+vYTy6+g/ikZmkJdLnfCBrK2T6WX2h+DwtlKAfvAfSrGaIemzRV1Mw4kmPjva7gwK2MhClO5oqhkmdvKbwPC0ZBqHkOXCqRzzUOxC9dm7GXjSlGHhRn3jelNWi2zctqEZGWFvfXJdgWuNU7yTDnJyOVoj3VGyJ7lsOlqgKtL5JJKZ0yzZJtCXM3JFEgZbkNn0OAgqjpoXRigcPzoeHNG38hYIyjBj+jUKYYBTLol28Vue5qcuKyDeWR3ncj7GYiegmg6JOUmCQYJQNRb99kkuwCK3h6CadGwOg8t2zVZrrlgRVBDFdlCo/kVLFY6CDGKCVsFF7JAaDYquIYM9GVQyw11kBz2d2RPdwLTJ/Y1lNDvnR4KSfo/6k28I4QxetXi96fyg1ah9OZl0SDbtmvgYrpRMAoq2Yhh+Ih/6ReoNgVNazECsa6xEstOHacGZENvbDShG+mCxxL/4r5InKYc8Btm0tPsmi1rcDZePCRo7TbxbYo3H0dvkfWJBi5ADOA9ViFRjIPmtZvWCxzMpkBhnZdF70gJNQxsZmW+pRM1gshUg/Rr6JvZuzYmZsguiW0/LSLyb1cQy3IFarWMY0FlbjgvRN2tj+xA6hsq47ibNhvD0Mih0ZEUU27YhPAHJdwonaNzZZjwWKwokrgEIusgwfGO1D/d5n0XfLQ6IA8GDVBaNV/CLPa8TnTMhnnqIjXMltvKZKFY/doUPJ2h7F6gT50wZWQGAB/MMyieyr4dZo26QUn2lQNqzysCQ+7JksgKdNWrmIJDbOMW4yXv1+2xMD/3w/6uPpCBcyWQD0mrPNfyHznDtCw5LkuwEwcJhNWO1rMO/Le2zgQNiEy87cifWKIwaPINaXW0qk7+vNioe1oEophSfP3qDjz/+CNu2paCmUo+ssu8H6ih1B92yQROfvtzx8rKbox6K35ELh6pTjKgRfBY90eJrcSfsQKP00KyzWml+cKKAFXx3Pr14KPWux9pn0XC8gFzio7qwCb0VdwNpBe1lAHr5vEKhvDxTE3E5dmTgpZuT01lz+ihu/ACBaNtqjNLQhJLWbHM47wAvO1tpq/X66ij6byOGU4KL7ffVMUhe9vvXRKXxXTmEVlk60hl4xBlmORfSaE2suFKrOzhRp5TRzedRPj90nWlLhracaQmIQ07CkMfR7XFoTM7spzE2ZEYmpmpA295ZIVzAeqB4KV4dAqifBMvOScxudWoQt0aw2ZQ1a1miNwuV2omQOnfnw410wMC2SdI47b3a1lwT/3XGq/fy4DDGGDS6e2k3cjOW383pOg+pS1d6hv1MWWu9ji+h65f+x/sS+J31pWabcqWXxnBL0YTkI3CbofKor8m+0ab6HXtu7zmoH24bmzz7bzXuVk8cINXsC9mRlBPmvhJmHxrXQWPVWfxefA159tcX2WN5yARvViPtjswwPE0WBDkz31BAdNSJ7vYn97ctWAePBo8ALIulZSJREWPD+53F9X4eTCn8ZvzeaR9uY9yLbDPXmqd3pq4lEsDbSfshCvFAaHJwxjqWia5dXwJaK+vCRgfOXI8nc2QJk0oeFt1iyjHpn5ZOXDeSHY1/0xgdt82WPU8RT/pYHbr76bljIFIMScv8zEJWcsWycJBghV8zoMWP/CMEiLt8aV92dbXzlabs8d5r08+y9eQe2/c628EHYdrhMlsUyPFffLhmwVGnjE8qodMPKKlEWyzvJCcBmCVjNb7vhg8iaEtEl4xWQRwP/XqXyimWHJhs4+TV84DN2lufHZXmUqGID0q9Tjn5Vufp+8tvpWNLOXMfKlu64lz9t6dr22HWSVSSl0LpumJoGZjKyBZW0po9BIcLaPtEOMRYLTqPDXo58F1oMjhbBjgc2N7uY8h+UXbOHPwqMIbgK77yY3z85g22sdW+Gi8QAZt9nvR8IqbHY9nVPif2XfEjf/st3r68bf2v+LXwZ31eSr6slea4UWdQCi7/z2xDBcfN3siylZmIJzzcUjwW2UOlcuv437YNYxvYd8W+73m6VLRRh2KXUfaRzQ3dglj6WD0Sv2tGdVaAOmo52OYWXd3op9JVoqG3Y8kMGydo0SeWR0UWO5Y52CQYG55aHnQ2S4pqiQazxqCcOq0tuS2zWv2oyAjJJ4FzmelyEPiQACVvItpYEsRe3WKg/P/maDRd03VAOBbS+lozYFmeTwTjQAtAuf1BzzCDpeO5zVyulHRb3SbvwepJZA8Dx3r/MNNNfB+4Rn94uNcT8gDa5phyRlZCBfd9x9x3jG1gu2217NqFL+QjKeLLMe3i7QlMYNdZS1spqTGGYGJg7nu3jfDMeshUnJLmjDRE8PJyt8viAWy3W15wnHRcyB3BpPCPwZCBk6B4d4HV2Ut7J+mWkQMcdOAaQkdoNpGkDLvlNGpOqPQuxfN24IfA7isLPDSsKpxvdWmvxnBAXZf03lYiRlDE/eyggJ/yaFX0U1ZJHnSpWVjGoibQdyBO8DSyWUJSdNapgiL1hlAwtsoZG5C0lIl94csDtmRQYyYt01gsb/4uJ2iE+5zBV+h7lPMDXu7nWNWa8pL7Yop853SkijHzUQzxhKaNjeAkVFjjeeajNkbn0JZGJm1qPIbzoEDt+mkV3PdpS99dDiZfXTPV9pCBZm6F7GmyTM348kE5SgqxlvszwkI0R+Mb8YFKmWN3wevlhYixVSbGOHjRCG42Y9BewhnJT0+4js30cZwiGXuNdcbqj45AjYk/EkvSlj/g84Ma1zhZ0mjIsDsgY+Yv6Mx24B3j/EEEbasSAWjQ/eHpdP9ZXYfgCosyP6qnszJc8rgp+HGbJPOkE45OwYrfCdoLtvV+zcSQE44urOtSSzaffBQ7KxaeCao9d6vTQ+UXDLkfLehUHIMqyZ/QNl41jJBKtbIojItjtB4DG4YZfVx4tq21577AYc1zjqPi+XbDJ598hOfnZ1cQE5Hd7wF0b5c0oBk0Vez7Hft9x4+8fcHLy26Kw5mFOeSkFsf3yDDS/0u8+xAbr8SwnBmBtd2oc00YcDDRVU3Huk6pUuz7zKXB3TgVlJivSQMgZuyyNdHSy/578IpA8+ALztKqqmeMJfshUd8mGZyJ85D4O+3gA7Y/ZJhAz1tShPuAKK8LHR3c+MWhD8cRIlmJfonf+RNJA0X2K3sRW1gi+TJqFutk1Bvt42Rb7nsEuNVjNmqOVmRBhVBNZyta7sTk7GwdNc3lo8nqZ9HU69Coy3VjOmaE6yIT0fYxiKgEGq8GaOMmRSfWjOsMcKBpTzlksyf3l90PlVCMbcM2xqKnKuBO1Sqa77BUTYXdMyYCxMmOCshtywSd4TK4gaBglg/8Zdgeqvt9x9i2CrqIpka+I8c2wch2gqi9CA/Pw3qIa4OCXaGsup9/jNkbSkJSMCFUzsWGcOZlwlQvif+5HYrfKfFTnI+Y58a0EytDn/GKidLZ9aFkNGQkymnrk5GaeJ7kM4o3pPmbIGc3rKK+ZJOLmyoUSOpKRUsBKpWjV9N+9E4afzefhlcc8JtnNovf83cQs1vUeiRbQP1y1h4YOVMl6RoY3xoLU8shLkTjdM1oHOKk2BlJz4XRi24dP3tds/3WV4XLwGovzmfda7WPH54tgjzLeka/CDf1a5Ei+aNMbymbAFTiIPibk4suO3VYiespajJHh8Yt7G8Xf+bCSFzF3jfC32Vhqq1EiT3At2FJl7CbcYqUwE+u3ve8My78s/Y5Epo03gPqh6DMbj/zHZd1D+5kG7mqYdcdtXXhXPsFfBBBW0Iw8uOfO7+m83P2HOkUHWbcUgGfttLaeTzDRizTyqP1QZxJjssiCx4FbCvuDQdPUdjPdb9MvYukS2Rc1j479RAap+0L9D52s1B4IRzE6NViyBreJg8pQxHoSPud+lrdS+NWWYu4jNEqzaCJFZbGVcOE70L7NUOWp3d6vXkBKBS3pxs+/vhjPD3dsq59Ku5qR2kXrXzG5xCg2vc5J/Z94uW+4+2nb3G/c8a7gtIjtqkHi765j8dKDioYSiUpRzyQreUY5oMzzu6+ENFM6b8e0BWBzfDZWO17G5GTHnYTE8uSsqT6r6Swgx8a71IAHc6pR3TQuFUllsTEK2TWC0LxV72ZHSUrReaV7Wz1kgVIG/VaDYLFsRIpvm2itMqXZpEH2gU5s658oTLj2l0FjX6zDBej2Behfqfwe/aTjmSOLmW3ohdyrC++8Xz6qwbs1OFBkxNDa8U0gkI9/G5ljs5OOFghR8eZZiDvWWvIRJngWdas9k/VZHTGaYJkv8oTdLyWYYnfI0i35eA+m+0OVNw5JmPgaZSj0JINFPQ2BvZHJnbcMI3o6sAA6He+LHzMsnBqYDrtVtvUmkcfa10Jf2LlWc8F+7OeaYWacjuvKLrDM3ZHjoIvFacpSlIO4aTmXkiBO3BVX/YtxivKRrsRUIzwOZiHgn9Kr7XfaC9NJQY0UW2rTlJRkMU6G592/1HpiAr8enVhS7rL05MRTd9yvanzT351PPuR+vF7BHM0++vQLRaljT15InE3X7wzakwa7l6txLU3kdzJzhx1bQZo/puqZgIyyR96brHdjNLhidaVP6Qh6Q05q4SJuSRmFOG3R/KaV3JENcay9jCWwTc1lnqMT5YMrnAdFmVQ4xzJ2iGCbQw7jMn3s8W+f0D90CCpmUCvQ1D3ZyrZXI3Dh9wfFJ3Yp/rhJqUjK2hzjT4rwFNo7W8N/T4ndl+jO31Vjvg45pa4RwGBw4cVtIF05omtPgvMzusIYwwcNW3WADOYvb2D7nnYDInFoQm2Xnry+4MaQ66SJ7Q9631ZHS9yKEC6gwMxV+TJcN3LKWdfTqjmhuKMHqUwKmvVaWAfNRwf1ZZhOS7r680ag2vbT0BUSPE/KnS666Njs/SPHQpJug0BttsTPvnkDZ49YDsL4hVKSoV+ofJz3zHnxMvbF3z69m4BG2h5xcO+M29K9reyhl521dqOG7RmkyJjJcKXJ6MH4RLzS71tXas+UJsNT/wmqcge9Q3hWKD4IOPndBjATEYOg5T/g+J58RfjcAdpDF2zOM3ZCycFoUSrzba5XAuvbJNtHhm8OZegI+jMS0W0z6aE8o+Ae/g9W7WfRFpdVXXM1lJdVL5SLFK0dbDlOpVpzuVS5GBm/b7UsrmlgRLxk9J7SbfmHJC/csb8CIdk6VPS7aw8OsPSD+kEB35zVh9St/k4a/DL0eHJ/G6Mk/g1BFEvZZH5vXRmFpgpNxEIhgxQsP0uYN50vrbseci8oTCkLmDPWjmhdaCrRKcxPekiQxa6gWjuwqH02+LAFT2OzxZqvw56/Fp9WjrDFbMeOPRXU9+cpyvX5mPs2P4I/c58UNYxaui2tOuiIGsl4Lho6DDJrpYd6fzPqk8QweEyft4o6x30ahYDwJVXr5odT9Jr0+/JLsrzZqmVWxITWWchKhC78m52mleTiw3SMhU566+2Ny2SsjbsFVjzftWsN2Y96zq6gykCf09Q8EDXSc3ay6DLaecUQGNpXx5OVNcGqdcXOoieAjibbSubwHxHt2QtxaPDpvsj+K8katfVWh9C9Vl78X2R3bIDRTyzq6UUavljyRiPwZwK1R37mKbn/CRdkQGMgS06lUJlX8cgvnW5m0MwxgaoXUsyRWx/tQJzo1m0ZcnnBPziNudll8siRwV0+33HvJtPmBZjyDuP+wc+wKCN4Zh1Cf5/NAPVoQd59l7VeR5MtYRHc4rs/fps8PrR/Su8Zo5O8FnsXWXeOq681CL5L7Os9TxObKwAsJR+oqdHmqcTHQqueamkJk/tHBkxNpghIfli1MkDYP8Fs5NWI8UfTZTJ4ZYnsF7adQ7edClKxdPtCW/ePOG2bY5mGR8LBugIdAXymHDSVHPu2Hc7IfL+suOtnxCZVAilp8elkWmQGx012wvjLeBTp4+8F45cKJJQ5HmCIGVsocgT8GqcKbmBarcd86+RmXTtq5XZXBKYTG60PGpZV6OdWv0jaEzRUuY9X03exEL7UphpjsN7IPkg032gX/BWBNpA3UWWKDgNJHBc5CoMbu67Sjz1SCAF3feUJEWcpifR9zXJIotM05jwshjWGSPNYP2l3udfY4cmJL1snSJOjoK3U1sOsFRwqhVTpAP9lUTOgCaCxfMRRGfNLUHln5cT99LByP7o+muWCf5MOWUdTQowZtJaAuRUCqovYwzM3Z2yfZqjtvB3QzG9HSX1aZ6C7R+NZZGGV9wFtjBIMmrwlPVLs8F97vb+NrDdbjU4pHe7sUWN3QphYwTNoamfOPG39LvJajyvASDzct72iX3tqJGtemjDqwmELoHQiJ/xTn+yJorPvnd7afUOtb04/NNarkuW4xZr+/hgHy6M5QsL0aga85aA5cSOPkOlNPY+q8/4uL6y1Q5rB040gcAsANOCdGM01zW3IPUO64b8xTASslGxHLXEnHYytXFAH7DKjqP5I22AWneom7XiKOSOgznm5xwF39OrqrnAOsSe6RdWNe+bPDBi1/FFKz/zn+U36g4+UvJb2vvSaYiyW4megsaJ+tn0tj/X6ImYXaNtPer6h22oQoEd2CEY2O3324ZnbJBtlJ4bdYKwwmf2cim64qaKiQ0QQZykMSHAphj7gIrpVaUgS0RyS0PgGLNsEAEGqUUZuN0U2Hfc73e83HffZ+xbEd4R23wwQZvwqNZTUtCa3x8FbK8GdM22dCauNojpD3WUw5M6LRymE2NyfK+U31nbSnP3WeeJA95+T3UVdZThi+8seRl0oISaBeicrLaf8Oz0KqNDKa7Q3Www1vHM5XwCIC8sVypaS0FCQarW7IRNYYOyXWUkxKWk3mN0Faxku1MgNQsogrENvPnoGW+ebhhj8+UmdXG5/U0vqTLkKhBM7Aqo2kEjc+62HPLtHbvPtqW/Q5k+RdGPnZPaoKp+HDfxm/9nil9SiaWS9A/2zixjF2MfSlF4v6D6Mh60AJSVcepwksc4LW3E2DTq1v/JO3AZ0zp4qd2TFAosbXMZ/+Rx5z/JPvqPXUh9o68VmE5Yiz2I+zMDWnnbNCJkwGLcrOplOVwo7hNrq9GGtz3npFMponjnSp0z+fxsZYHUQJSB6ETnxoOoWSCdZmea3PuXhCb6+Md1L5cuK7ONpdmiH5dBHxE89Cx5Pml/Vjx1Z/ao9FH+XjLWvq+qKaHrK+4TXW3V0WiMUvyeS2Re7StSdiGC7Taw36etDtinnYC2Dmzq21BaSCeED5xrkxRqQZeMpa4sUA52/qLTMsG77cfdtoFtlE1+SMKTHmbJNFbxV6nMqpdXUPrf32FZyzb05C37VLUv+w8btpIlWx85O9OwLsxXDPVQbv3yWUHs9Es558GCSP4twrF8z+0FeXgJ6YVkoBK83DNJNouJ46UquZp1gfSavRQmvxm7k/5Sl6L2+s3bkVB+yoknpQOraIbbdVoug/M6NOjhOrz2Ovd3ZZhqk7gazB334gqpvfHUxXaqbvSAIxRSuZkQRdFRIFlH6Ld4P2a9kL0tbNLGBt1R9XWRjPpiFcaiA5vujOrDQ4sDNSSTgSK+Vy55sdSj9FoWsV30sre5ylD4JT3JoU3vKdRs09s7fmTsuN023J5uuN1uVsCvogj/Y7j9021gAnaDGq33tr1v87gkdSD90wzQYMGyah0GFHRB0EMEIhvGbcP2Yiuv9vsd+1Q6ifIcPpigDaCg4lSplfKIMufK62xddLEteSkn9ZcwhMPcy0UgIO9QnCdYnbwQmPBk3aN+1Rp17tHxvTq2Vxvzr+/xUoHe3qIspT+48MZ1AAAgAElEQVTNWS+UQuLhUip5hJqViEAhS1JxPvQhh2C5q4p/yj7ayyUoFAWFMelzHFSXK4ixDXz80Ru8efO03FXigQt4LDtv2P/mNd33if1+x31O7C82y7ZmhYXHyB9m37Pd1alYHJLI9EBRQRaV1PrLCjOXSDovN7pK8JvTSspwhO62dzRPaSwaUl1BfsSSTsKJDdsSrAjgJ3NS/xdR1LU/De8qZAeL2D6PqG7tK5/SmU1m/2n5D5AHMlj7FUSv+PEglBhWy9sY1d5CtLSP2mV4BREpuyJnBVmxVIcTD3bKhHWPelK+6NJ1Mo3L6N8jpVgzqO0sUiq3OAZLR8VxLf2jSBvIY5M+Cck6yXjysRBlRj17YAbOvjzW+Ym6tDxbc/peeY1bG9sGFTvhETqx78C2DQDDV6sS3gdGJjxgQdo+d0oqhvZbmUlz3PPJ1FwlAFgwObYtxyVr4KTb2pnEcVVKXLy/+Aq7n7D2Uf8e+rW8GCityx+V/u9Cu2ByEhCuuqvqfLTw9/HQHXlswXP5XbgVXeixBpm6fiZEWqBBvXLlJjGO+Xo5FWHH8hl70wfZXvyL076e4Jn91yR6jmOzqdypKJcGC2m8ogJKuDT9AHomQCzPU6drzURrW+0RM0AQ9KsHTtXzOhZSAVMTmbCB57TT6niD4sL1NUUEuWUqYwWHLAg/qFyj7zviEJBS1oJts8M/1LO5j7UgOouc8oT3ZKr7BZoTCQd5cEPc/KCpeHm5A5A8IbLZNrVD0oYMyJx+NYj7277KYHpiOnjGfAGfvcsDn0oPBp9kB0kWFXWvraraKcHbhvl0w363659egw8maFuDGp4FOFfI7GTwO0c9+1o7pV8i2HtkCPpn1k3n7UT9q3PidZncQJdpCQvMjjjqI8kMMWz1KOmodUklz2aUAlzrY4TyQBcygS2fJ13qOm1q5qxJZ+hNchTZVq7SaEJCSj/KTiwzFuWsVY/KoWuGg+2SAk/Pgo/evMHz81MGEkModQ3PthBukeVJBelHDu/3O172HS8+w8aB0bpuH/T8NaflsPRGeybrcMJSjn3QxEYjxpKzdVTK+2nP+8xR7dHKq4CU30VrjzFv1UQJiQNfOm1qGXDMkJFt9XqiHaW68kqaBnXyrDn8XkjteTt6O1hzvcSLkF4D3CzEpzDER/aZhDu60FtB754rsUwiZYDcHZN+NGpIHcms65ozh71wiWY7z9dvLAcrDZgTmUYs90Kfe6lOrCOUDDdEG51LR3obWtgcdPXJrEn2IssSnnxy0aneJ51CxDnQm9nkYNqs9DaAgS0vjd2nAtghzrOR6a1+Klow7gIzZGCHOQDiy9GWxWpEDsmDUNT3D0MntjF8hi6WVkrSVdbxOEYURcZXbOXZK+fPeRFc6BRtv9Xns7qEPp05kmTZTsl0zpvHUsl1h1Ye0R84kq81+4AwZ25BZynnk8puPKg0+Fv6Xi/ROs6ddNdDZFhRAzgQMz9SoeSdx7QBje1S+eGp9wKKOuY+1KxqHM3ux68j9H3xT9pywFadWEWtO+zV9Kw7UrBbj6T3Tqm8latljpx/Kx7i3lshFfgEeavhQAksT1XVrmyAQDMZTo2eDcHKaGHndfo2BltWKQK/+mrYKYzZP8KC/5zZ06SVNDWtAJ1i2XqE1RyerYB/eXnBnDu2seF2syuIANN9I/py9+sNPPk7VaG7rTaYvqxk3Oz9vNJFfJREMkhF3JkaoyeaNFapOxEF4vykpmtvt1rG/gA+qKDt/AhaPHz2uK7P/vyQGAI7REdDzbNMj+rq7RxFlZMYx8DvcUfP99i5wEr9fhYTrH1vdZ22Rk6S5mJFsHif4XyWKdS1nALT10eHc5lGxTVrLpnz388C5KyXG118OSYFiY1ntGrJ49ObJ3zlR2+wudBY4OCC1fauxbPg1bm4CBP7vttG0323UxNPlSBOCZ9LBNMHPCritjn74CBWoFOv8ho2bTcsaCi8lT9gwXdc+D1VT7cFxvJEy3y5kpo030q+bKCl8Z7/UOao9hGsdt94gPu2uMMKUoT1X0+a2LOg7yExTTgmRgfEe2fKiBK2zcDRASKChVfZQL7isAhRaO039bfcmsWZSdvSe7jOzK7mdW1JnXDnyaoz3B/1KZ4fR/n4eZXt4JP+7HFSa9WVK2aSZdoMfzQtVHhFq5Hz3DC0hEiMd+vqiXxDgE2web2RjFFYADdkgPNXyX5kA7LqAQiGbcwf3FbX2RmwRTeGYMhmy8PRKN7e6/QgI/k57PUZlA3TE4fxqPPqczyP/x/bufq115dNy1pO0I7v4zpPlUbhtI7wGYEEWlcqpmzKEfH2Us3OKNMfQKxdDvaMJZHdZpDM9yjcdQqyz5awqs9FgEUwuI2jMWJmXfj/hGkWUslJ+RKDM144Uj5mOaZP3deNe9234e8aYwOYP+SsENu/cru1+y/RWAZ4QyxQaiTgoJ5CM1aPLNuo8eDdiZFI1LjyJsbJyxwSBymeEzKHB27OA4Rg0/9nM84CIH2joHUgP0FbypdR4TD0HaDtTz5cJzuqpdBVR15SBfb7hG7Wz7HbgSPrxJAdIEY7vbeBTQTYFXO/Y3+xvt82uxbCfJFh8ia6yAaAGWuavL6QV/viLpoJlQL//wnaAuF27LwAwZSfB/qJQxrVv9b08n092emkDEhZyHn9Z8lcPfv9FRbmGatytux7m03Ss3es7jWIfLRUcxUMQOjOlRVNzZceuWbI4iebglul9Sz3r0nxAieV8/AMppeiJgdo7FhQVtUd37dt4PnNMz756A22bbQ2+0luahcuAog9bHPWynnAjnCdE/j07R0vb1/6/jUQnUSa41Fo9YCtukXGeHXy8lSp8JuYGVft4TNkMUOntR+vTeezfRUpeViSKnXfpl9mncqp2mL3JTiJVVIlSogPCOtYrlGOo+bYcL8/D+SIsQGtH9v3Ej+naxjSsnNH2Q/EUIxbw0LEjURV+i99/f6Zo7w+OcX1BGpculvSHSAerZKD6t9i2A+4nMvaETteyrvqvrMe8qLrs4y7lxR55ffjLPbjJeLcCQmhxSmznZGC9H5zfM5JTe2EsoiEhmswkaaLAPiF8tTOetCLAhgbbhtwh13WXaekzYb2sKyLZ7HhdxkxjoLmboU8pmP5Cued2MB3QXMyz6a8aBj6WPenK6e3CpL3D+7ggg3ZoMBHjrzEPuRq9/n03qLdEWdb7qzHehg/PXkunQp2AT0xWfBHtsiDe5T5Kqf0nBd7ciKK+TbZ91AHt2Wt+8yEAHmgkFYrmiWrLSX5qNnl0skr8P2cCJPLS8Lhd2v5k0gUhxYpFXAc3BKz2k+eSyMbEj7uuy3RN7n1qz1St5SKUYkl1lpUz+9lQ7k8UPzX78grqjd+deEW1LYRUH8TN7qdQsSW9N82u5B7r6U2ZddUM3BsWykIi1f9cMYxxkHbA+Nl5XqZ1FH+sT5S2Em4M04PljvpRbNLccE2VO3zZss/N9gZB3kauSqm+tLIuPppu0F8/4QCsPNQnDYugwMDCvMNbb+9n4zuKxzGa/oUH1DQJkt0ucrJa4N9SDCFM/SuNqne8xmy+POaZ3gMgg5Bk3/ii4N7uWYhaTYH7Xn61BTF9GCtTsU5QnH/Mag9sawhkKdkJIUwYq+dKde8A+hY42Mgf0gBzw67ozA4f+ZhgNJnnv5xL6JlKB+xgQjGtuGjj97g44+eXFDHwnd1UMp6FGvw2HD6qeP09uXFl0SWY8QodIN0+kMlc90QtO3zafiPjgnzw+qSiJOH95KFMra/NHAenOQ2sEPqqOoruekG6yivpejYaGa3oy7wsBVRVlOefE7rSZrcNZxKuNP5zVqXcXjIsF02jhM70QbRIRyLoxd3rtBW/+bdKizp2XVFoyz4l1Xm297F0/oft13vrm7C+ttRhxXOrUbq0/F5jFe7oqLptJCLlZCPOqHFu3kSkX8X4DRgWHE+UZ35PV8vHi0Zo+asA80RsecjsMyn5lQIbrfN97rB7/7RdpJxyKYMwZhbNhH7OfLwAjHHwdYJE78cxoZdLyzONY3xWXbzDF4Zlv4TKYYzjdpkXvitBY3lgA5Q6CJlw49SEM+tdPCcDZdn/MUd6wxgJFmq6X7SPRIKFOu4H2fSG1XC3hH/lE4PvKx88Ha2l01qrug4S5zkJAon6VqARDho2JCutTO4SVulnT6wmadG+2Upx6qXZMUx6FyNZnn1H9isWcK3KCzLIffDX7D+xziTgPuJklNqRCpgs89GXm+HbS1iBqdsZ94TiVI/gXt0h2fw2i5vqb8sL9nXvAsv6E10TXUk5mt54IAcx8Ki+6i+PNGLzmhwQSC2XjSRTTxeMShUNPhtlcqu9Y+vWd/DzvrzM5WktWoKjUctoApev+87ZA5stw0bBmQbuIlAZRj/qtb1Mds4rqIXk8toEwrMMZEHqE3j83nfobpDINjfYfg/mKCNoQcnrFhK7hlO/Z9D4MPf+3vvju8eM9txyaI/pxvk8xnXuDpy/rlfIUAKy/vBjnc4HcEAzbwf6PSok+EETSr3ijUF6d1TD0aXJ9LwKifJv7NWzRq74Sq5l3KW5WQKecWJZi5WeH7zhI+en/D0fIPkFLm3TVntcjzZIeqfp2/af3m54+3bF+z7+UbSg7IJJaZgkkBB7hoZ3tM69XwxAB8BPKhsPI1PU2F3mARfSTf+dccdzbq2BqUbxvhJ2Bymvsoe1i7AhUD+7hoIHkfymLVL2lKQyfTpnMiYvKIAXrMzTVRPLIMT4KGZovHPpTjhMTERsdJ3YRZR0pELwrK8x/XwVM2hw+c0Mb1y0s5Z2fifgix17yT0Ve/ZRD9FN5VEme94z6+lYIX3aK8ocNT1Qa8IXvoyWOlVPCbHgQRZDZNH+pA2Gq/2KR15ooP/zjYgll+LDIzNT3b02bQ1xplQmwWPunXmfjm73yhWEBAJAiuuKHuoRcMSulVNvg7JwmfyJ9x4EjP7DxK3FYegWCd44p3/L+b38X6g6GutSmgdzdnQZdwEoB0tB5E01KQ9E380BssIvZNJRZfmVBWKmCUoW8ljlwbb9AwlWmzvIi1JV14ur9U4YZn2SUKPx/aMRtJ6Q9zfEYFgQzj1qSGcruKfCzTbU6qcRN7Hxm21oC689h9W61j+B1tZVrK1p68vj5TUzWP17XQmX43op7IvFrZOewdIPwyRvHTacPAfIwsuqCWZ0IOKWoHDnRpKbcvrw470SV9thGVa7grc3Q+IFI+PPiUTNN9bJ06Mh5sCJny7/W6qRLXxV9mO1IzNtylP1v0Y1yXNtabPdWy/wpZ1itNJLKilq1Ly9PNNIOope9XGD3barp+HMIDco++ITbXrO0IuBAPbtvmpwcBjr9XggwzaIhCpcV2F7nVoCkRtMOJZDbwpWn7G7xM2p202h2HBnd9l0To6Dg+4qOHgQtx+XsW1ynA/1wD10C4raIklHAsqmj+3IDromvSb05c7hCJeeuaKdfUra/rfexXCf3bs6SPl0sngBnNdnx4fBG+en/DJV7zB5sFaW4YJ9f0d2VBHQeLUIjMIc1e8vLzg07dv7cLsUHQh3Evg6C4AYgX9qaFrSrOU0zksM71p1OvrJMaTHGRvx8dkXdqhnWg9SbrgycFAks0Ls33iPpA7hHBvsgR7g2FsggnzvS5X0W3tiFN5Yhv+UdDaPkiWFq6vGcmDJ1EMXi+umRQlh2FpvKu+qKsvn6qOkUBloHM0ik3w2KyTA1BPadaW+KCh/0AZJ/9mKrFp8GrJx8r0SGWho1SNayznldQ72Rd2fIV5YsXtbASPI9pySE0xLe+sAaLwQukuj+uwnye8OhIsHzHLw1ScmQVRyH5Og44u6Rq6L7Dqr2Xl6aRoXeXRxy1on49W9B7CWZHHiZPCi+Wal7WGro/iZzzdkWRUxcYtGU+wLVci5AmtVjSDi9I1XjvZDHMi7chwo/GOuZ/1j/sEGquOc9pfaOpgEaHl6f0uCl2VNdmk2s/FsyGaQTx1CKp+nLvWWRu8r9sSeV31rWKnCuzhZ0ABxF2mMWu+yoNg0Mm1cY0P0z0DIwFE43S/LQdWwTh1+8inXbfnhEFbjZIyoMiLrTPAij77oRsanOw4o/uwYwzbYiGlKYKOgNSl4dIDxmJk7Tzu/2soS1qVVCsP4k0bRBX02VovtG6RYBlL8fZg7cDJTT94helTSKerZO0HXXCweQcnMurxVqQoeA6c2FiAfJ/4XPJbOAyxgOo2Nm/P+V+rb8n3s9ZFzanYxZJqtiILfvDgpJMjow1Ab+aLxtXpr8EHGbQBjx0C/7FruQP0YXpc1SNLQ6y+/MxjfYZWKwgSnhAAUn7Rxhl0B5mt4mpUlOqTnKnj5W7B2ErO3RrUYkHnzA6f+UEp92PUezQ2LYihcdMFD57pAgCME+3PPT+T50RYM0PFtcoQPL95xscffYRbZqWrRNxLVHsaOaCLYI2M81Ts9xd8+ulbvNzvhSYJdTMAgchEOt9r/8OIdfbwzBrjGn1S7RykqGPYPQIvJzqUcbmBGQhplcvam3J0r4Wd5Woi33M3y6qVuvS7WEKaLxyZJYXRpFixnIrXRP3In2SJ2l/+ZS0Tv68MLstTaX/sczhPNfOrqjkG64mgeXkxYbTuTWVjlEY5yp8JZkmTn2hVeiJosprJ9VNlQEHj6k5CbZg4dL+DZp9XR7sv8g0IHJ3OSnKgkW2VQ1/72DYlh8pCLS21YKb0Jj2hL53uXGORae2NNMyqe8FtJd/rAEaCMtgochY9z59SBHKj4AedJUxNqgE0MxPJmp02vMce3eDh7K9Oc05mtYawE36lg7iTGcxS+vxctjocxyfsxtHKSemteDJCp/gypdAVITspA9FP58tsei5WlMyfKyx3vayfbk6su3ZRby6y4+0BOQbwJVNW69wBvRXP5OqFufgXLt7alKqykcjPvLz1LFpiO7wu/Xzk06zvA0pr4Og5Zzaka9i885pkpz4Vj5gPpXm/pJKvJTtyJknWWhYBq6BvTbR2/ltQJtwtMJ1EAPFTJaMvm9gzYEsaxJhP1ZzFHhL+V40XJ7wAtIQI8ggUKhF7o+K5lm4W7fvEhdpZqJL1qVb2W8Yof4EHiH3U1B1d79o7LutDjmPzQC0DZyNybmmz7InqOGoMJM3PfuTDRVh3dx+d/rDdID6a+8TLp2+B5ydbyQBLGmwurLPRXj15o7W/f6vhEQFA28Bi5tSuMhiYm3PYWWcJPlPQJiJ/AcAPA9gB3FX1G0TkqwH8HgA/FcBfAPDLVfUHxaj1mwD8EgB/C8C/rKp/8t1teEdeRVjTSUzb9xjnKn/aVim/NUB8fY/aZwdeAqkn8nXWDjPWOhNXeD9GKN9XzWnv5vRFOyjeWBWsLn+j2dg8nAEMHryngMRGSwVtNTjmogcLPYB+DJP0ykkpHJ0mrTJLlklEMmD75KNnWkYkYFpmMNaWcJWCtt9CKQvmvuPTty+43/eHghbdqCjcJTV+i7HmfnrZuAiaj3tcZ+iAmM3j2SiiTWS62uDEKBTdQg0Xb0jWXXrRyuT+ZDdmoe+U6o8kBYhP2FhnUIAatrRBRT0Y1wV2PYBilnj0mWsKcjoDNVjszPJWtbcNJO/kAQPEb0Gn4XyYBmHJrinsQs9cJhq0CZoQn9V31gnFQ22mM267pgA7nZlVkcVzFWCEk0BMHwMvVK5apgCmaHgcid5c/qJnT1edd9RzcV8S13pM/FS95cQzPu+wit42G/4Q4Qgs40Ak7k/lRmpWoHsG1rbVFTMotRd4SAQhcNVnL8V9R5HlDcdw87uK9rn2J990h7SWxL28vEB3P1UwnPkxcHvaKHCr8tP5Mve8yfD7KwGZA2PE3lcP5sZIZ7I5wuwMYpAuKFoLlQXQZ5WBtDmiQX+pADPxtr+1xNCJi5IvVfjBiiGnNoA61S5ImBEEhr0U3HM4FXgJMxPy27VHBOAhXvXbuvy3ePa4/1PzTy7xo8DQUPP6JC5Gj36G3kxJRYdl0aDylxwE/nOQ15xTEqHLmPsyZuXu1Eh7UaIX0SN5QhktQq7hGTRa5n9cdtIeLXRIPeX6rbUR5+infxB1dQK1JAIRaTgtZtwF6Z0xfpIq73rM1PSgeumTKjKB5NifnSsopIsRPlML7jWD7zhevr8ftRRtYiY2khZzYRINXNL2W19jhi4LES6RsJQg84kNZoIetPRJtmFq5+7U8MrnWii/QrraKWGnqIFOs2vN7PvE/rc/xW2z609uTzcM2eCqxiQhtiiIWDVie4cnFOLLJXkFSq1uSGth+xBPzPQKn2em7Z9Q1b9O378FwB9S1d8gIt/i3/9dAL8YwNf7v58N4Df733fC6wEbUumO1LQPSx7q68HS+fN3QT/xbGkvBuwz4PIup+ERrqXdWBuesay9eJbbrkZO0JDHY9CEgXHU896EriyD6jj7kpFxkA9WmtQ/iih7FpeFsr8i/JrYhbUfvbnh+c1znQxELxpf1ZHXtiHaDEH5QxEsaWbY3r7c8faFlkRyP1arxREgOSih7NIgU7nEkpbsBGYMGYjQ6+UQVCDGQQSj106xzjIgfMjAHRwHJP68B1Dj9wzMjjTPDkUdqVGZ5iDDEOj4vgop9ol7h+MdZm92CqixRsPI+gZOYagTHZe5mZnnB4IiNB5a4yBMVKfjpMGKNmI57Rg25SJuFCppIE5rcoonkS+oHeLUevxI7yha1qCEfSEglWvyGMVWa93IsnxjGrqD8QDDs8RatdHOV2Vkq94w0GFlDzh2oz58nHhW2s7qUIjf8yfUao235hDHLPFImxFiMpMvEk81mbYAqe8vo2PhUk/ZnUEKHRvGJtS3eE/bEEab+5zY/eJWzsDnch34sj5oneDreE2foRub2vHXAtjl336cg0R9wWmKuU9y0nx2U2wPR9nFml3ns2ez/+zJeyd3Afb8OeTU33P+VX83l4BKyRCqZOpSJVmzroXwwgNWXybZ9NmZcX4kafV7cLuxyxlfP/5UT8rhY10a/WYxcJY4wfbI/6/Bik/otZbEpaok9aj9wJ8fQRML/YwYLstDEbgc/LHguWjgWHPKH0Byu1qSw/wYlXMOWs4myOWUWRsFvTw4rkukoZepPZi+q6sD+tkNLj95gVtUWEwgjbBSPQnZCJ8BaMF46jsyLMwPwcv9DYQCCoqCDCQN7pEr8jMrNg3KSw2QVEUHHvkMEZAI/MqDzXGlxMNSbp/TqJoHiYglrsQLDMHY/XJuiaSBjYUC/ZwLATaSG4lGPoMs/miWR34TgJ/nn78VwP8KC9q+CcDvVOOmPyIiXyUiP1lVv++1yk6C6JNnlf0IB7EvcTuv69GzqOezwucp6288/OWsf8GDYTxWZ6JXR8bnxKHRqDBenpqnMj7C5VCNv6OLUKQyCWNKa9BP++r/pyMcWHCfmCAk20rLM8qkxxdFzPSEDGdyy6u8bTc8v3nC8/MTNg/Y1lmL3JAvkhcmDhFMWKZkeF9VJ/Y5cd8n7i8vuN/tAJIKxGjhnSzmODvDARtRlTrX9zlJ13FiF0Ean0Sme6SRy7dVk9aBz0Eras18QWvphRZ5KzMXdGUHQZsqflXdtLFrnxcFntlNaic/Ljy24LKC9CL2Nwz267r8pAZrkHEJGWMDK+AlyjUmHQs9+VqzB/zT2u6JZUKnrvTyh7oIMXeqZMTsOdIwPs6gdUN5xClkihp34ayZ7fO6tX3ima51J4W07+k8utPBszYlU83f8KVpQYNxZBZSdplF5uBRigcyGHDlo65vFcBOFaWs8GyhhkknZHEkv5FwYr/b3Y+mb3bI2BoBy904swlK+FYbA67/pmE7BJAxUq/s8yXfmfvELvdMKkCBHeS8Axhqjst+v9fyaK/TxmZmV/lOonJv0BI+wXJdBsj+1UOzMO1ySDpenSrr9O30lxqpbDhYl3cSRD0DQrPts3yULCb9SoDm3h7B2Kfv88uZrdXus1on51eyzFI3Tl3Sg5I4C69WzbTO6J116djaa1YCYDPFieF3wprARac/GNNoZFkGDUirZrVapWmbpV8ROaBrbWjaZPhYThlJ+lxErfarLnZQgH7pOaIcfD1ukEDzGgUv0YkCIGZoFb6kU2kpr+aam9QVkZSSEOQGVb+R1H2KOLtDa3UVB0RhQw6S8GjMT50Nr/Ps+qSgVwtqcfjcvpMNNFq47xd9g0CnbaGZ2GDpJ0ueZTA8BoZvoREfCxE7fMcSrRNjn9BtYPc73gbCNumRnU7gswZtCuB/Fksz/peq+lsAfA0FYn8FwNf4568F8Jfp3e/xZy1oE5FfDeBXA8Anbz6hjIEP8alSzbcBCKYKtjZgjwTps0BXT+xePApmWKTGJnTyo3PWieH9TFi4QlmSR1YHOQ6VXeFCgozwVOkyrRJELLRVRrvVU13JAoricv6N0mKZtGEDLGF4GMgKxh893lNRyrL4I7IiEK29AUEbBTAET7cNT89PePP8jG0Lx7Q7gArxWGpABc5PEwo70jUzmaqYO/D2Zcfbt2/NcQIoVQtTHmEwhDZ6ExHCocw8dyQdxJciDtvUnHcloZzwTFSgaDUnMBHZ88p21tBVZi9pzozVxliq/sVAHCxpdbXVfoSj8Tk4CY/sAEB8fyyfDvSy5KhJ8tn7pzhqMFg7CLK/1y1K2MaWhDjtUIiNtmE4l8M+Wmf1nLUQY/S6n1NjIcOXvgzBTQDZtrKDYBvpM6jTN+STkT504RFHkF5hf5pLj8jwCtCu3jhZR3NcQkmukMuIuh4cKLmxMnEhVDgZJu12+ngtszu3OTOTtzlWFIhGbqxHrEyGsG2dTuEQrG2WqrOg6v6y28lkAFQn7rst3TF6KbbNj/bPdpB6H/D7hyDYw37otD02qtD7DhXBdtvsmgBIrtq6bTeM4SsRpjl8+66ATl+2acFXBnbhcMrAEDUc4auGnGY2X0BDTJiLI5/Lw4MylcVDLTXroQ0kF9yn3k5n04+YR+DB5ZjmgtT/0Xn+B3MAACAASURBVLaqbbOOcwLD/ADGP9L2fpWcVdW8PqLdVOn/+j4qHbS8z5GqEwMJ96aLSvk91Mfs8J6xOaL/hN5r8CC5s6YmXZNgtQdrE6e1neD5CHX7kei/KH6XVNTyBJBAn8m8Hp4cexDJ2LC40RN7384eCatv41lLXq3YBOgeeS0F7FDY8UoYxU0B3UgC1PZFzSVpnJ6XApa9p5UlWr+XKLoO9TXTCoXuix6WWhorsSQw9E2wbVBDC4u06SwG6dSURjyAGVEibQgElX/wavX9+Dv7GOFzxYRQHPgU23mhgv2+Y8DurZubB16x0dY7Jq6zLUVlkwvbEAwVTImTfH3PrAyo3839jvVxAD570PZzVfV7ReTvBvAdIvKdvdOqsu7sfgd44PdbAOCr/66foKGc1uANQL+eC0Xc2wY0N6X0H05HaGq/16sh5MZUKuOt8U4IdkCdAJrPZ2zqpmZLbO2HCCyYcR+g0hwdpgcb/OPyJBY66TivMz/Z6fXl8Eq4mC5lUEpFwogV/TlTr2RIS3FYNpSd2FruEfjSeGinNU0JmPOAUBSWMRp+YfabN0/Ythu20WdjFYpdBZtnnEK53FAKKhWsbyzdpzkfLy+0h431ILAsr4sh8GVuvowpgrHAZ3g/JmrviWVyPNzSPhREHh7FLjuEU/y2WmGOuwPfWB++GmxdWOkRrBKXrEKVtoMOH9W52MqzYskPjGPnsiy4fl8bKQ3S5/KOxvkMo5PfuQ1BjmOXn6Wsnryvx59OG2tyYc+Y9iaq3bDnMtepdu/QvZwq8WWaY4RBEmCT3CTNJ80pNI9MZgdpEOGHG8L4eYajn3znsy8wvWD4Vja4G36h4CqIVRTKpTP+jC/fiJP8yvWqevoonlFcSd9K9p0V+YO3QKEIiudKSo578QYab/rM3HbbMjl4v3uiZp/w8Ab3lz3rkjEwXO/lLJjaPviNbB0Au+MNO56en7BtUrNf4XiIzyZBzBnc90xIiUcZu1o4PGfNG27bhu3pBsiO/b7bXrrb5vrfeHN3nC3/Zjck8eFKw08BGeLHa4/h+nKiK7HFbklRcU5AZZrTBJRujaJEf5HhNtpkIbdjKPmVSTof/3DY8lRNfzeKCDB0ZJt8rk/pHEsU3sPW7TbrqRzrJY45POlkhizJGB40Gw5D1Zd/Gc/FDF7pNqV6XHvS9xVonUzpixqEJH77JkW/rEcXumf9OHwqTPsDwet+FNfL3/J/H8MK6h+3n++FDm+qwJVs1twLmQvgfIKZZSzJVHWoEz7oyTTJYpmQIp2orLsl0wPWJUm8445X40taghk+6UK0dM9SpwglrIAimx+nP0MmtQ45QuzVpb3wvi/cghQK9FLHLqPtj2K2KlonNW/vStmYlYF7nnrVt0crniecJl9oqZipePvWLuW+3TY8AZDbrdcrAp5giZcteBsY+54+84xk4Ctyx/CZgjZV/V7/+/0i8vsBfCOAvxrLHkXkJwP4fi/+vQB+Cr3+df7s9TYQQhhOJTkZwUSv9CjWi0pmBtwx4XcfBGzMiM2xAo6jSQ/VPBhjqNj/nwiRgMQHBT0Dcf/qdGF5jhToplnSssV+C0Hnm+M6/vabT6uXIC/LSJabtePyy3RCXWvyDI8Fr7Gp04xgqDLexlYKV7MrrbVZv5wt6TRN6EFP4AS7MPvNmyc8Pz9jG1se4cwOl0CxwYKkdJKm+jT7TIUSGU47UdKWJt336bMU3f0K3R20pVwaMqBSWxMdGVEOutn/SCrr8iPR6DiiFKxIlVoSdvn76++3ojip4RSXDpQD1vPC7CzET+kLneByYrqL5r3Fqo8chr4Q4xiiHY3ySXtL291wsNHuHfksyvhxMx37g4HJD7z4qfYrHGe3ep+Mz2pHkaot69v3fVGOKL/UDe0Ygu3mszWKPPY6AxoV3LE6ev6J6XZQwPb3OCtFQY47K7W3hxyw+mNtZ3LJ/oqv/U0dsxBVnHBK+PSDi17hC8L3OOzkETUnMsgwCucFH5tJG1AFbj4zuu+2ZNuIP0sX7zvmXpgKkAFPtBkBEtsfmRP3XRGn5E7VXPJkRTQDmXRsAEjY39B1InnK4pCBObTG3lc1mKNVSyX3qbZ8SPwgESn3N07FxK4lmo1SsWJBsM/dgky1WY5amiYZsM1YHrvA2IzOobfFHS3DKeykJB2yT/FdfTVHkHWELFaZmOEG8ee6V9jaxOIvpFRY/nnU7LyvmIXMHYo6gTAOVilG8n4CGXin7RRfKificWgFeYqQiWKg9C1Cx5bz02haNoj0WL6PNs6Hd5FFHlihDqscPwzqUq+RTAt85ojnO1z22dAE/oyrCI6Xp5FcCTK5FT0Tv8crvlcUVYkSQPKo+OqPVlPDfRU3Rup/JR0tzWepF0P3CpZeLkSM14IanvipZfwu5xDfQkJ1bVto63wWSWE70yiCutpDaGraWlzzMWHbAo+aNZfS05TsyXInEKutpHX6CLJ+XpxUnRP3u8n0kypu22ZZsVmzuNGEQmrSaAIiW840zlTUn81ZeGfQJiJfAWCo6g/7518I4D8E8O0AvhnAb/C/f8Bf+XYA/5qI/G7YASQ/9K79bN7OQ0KnQmseHnUwLQoaUdc7sk7fja+yZjzRyhze79xhwqHsnNj/lflFcG4KEActhz1H3k46YeEtcbY3BFE17y5B/ZrGqj3MqrU/i36wlmR8XKBEgP3eXb/8m+M0yiFXrQsdQ2loiHy5RNKktBRiZvRDEcHNNOEWBnYbA89vnvDm+cmP1nUa0yW9whmqMJ6+NMqC0uHLLXfoDKfIMsUv+4xQNBVIyb1moMnLJEF9JOJjBVaiRZPeR/6NIRSKHkrLu+S/1SJsSL3icDbYGV5Zp6zyAyXp/53+uirCk98r6NClssftpSnWHJ0Gp4mAeD/71yl62mJZuof1HcaAky+L39CeZbX6mH4HVIQcnJKTVFOMK3dKjxQx/6UyppltRDl7ugv4LvnSe9UZU5fFwTE70/Dyk4l0xkxcESL3qoUbI3EnEtKhzj64OYhDhexeJMW23RDL9dIhk+CDkmIeq34C8XFGTJexFx+kKP8IrEU+7vtEHzSHp80LOQ0tgrhtwLb5aYwzAgcLuiJgyT2WuldPhVZ8uK6e+463c8ee+/0k7VJLMPl9U+kgepAVjuUQwbj58eiexNuGYGw3L6c283a/W+DoM2lxYt3Uibnb2PKYCMLn8YSjU2VzJooTOfd9h26bBbm6AxGAPgjUGOZeyYtx28xW+ezhvhdNqnU022uBnNuQaasmIkEQ4zq24iXRGGlNvhVPPofNzDdJZkbe1mDPa2tgfGAM4y1JfRp6PZYRq2oumzW5DtmIIMsjVlUoZi4TBdCuCxmZKI5ZTWcu1nlk5wrX1Y8gv2mBsyF8V7C25J5eh6B52lS2vAflXH/TRgrNOiH7LlsgUXUpgmbSq0SEMx3pvGbDf4t9ja3jzWZGyV4kngn7VfleT3+29TeuM9eDrrKioJn47HzaC80Z/KBtXesSfCypu4L347AtXnrax7rLSR54FH5C4JY279DZogUWkIV6SqWCzlNxn3fMObE/3XAbNzuJedoMd+3ZVejIMDxTpJHUUo17jt9t5z/LTNvXAPj9rmRuAP5bVf2DIvLHAPxeEflVAP4igF/u5f9H2HH/3wU78v9XfoY2oG1YOqxLA6cOV9R6KONfDmL1eaEb7EeF0DgoPs0wxip9do85g7IusrKMy8jk/vE56wTqJ1tJHJ/nVamgli0hBE0JHy1eJKcgMBFd8EE5AJndlpiti/W7SMGBG588QRwh02UYEHh1DV59U98Mms4VE7LvEnjaNrz56AnPT0+4baMuA0UsBjH1MKeYIXfY39rG0n2WkxPBbhytHcvBWGaZdkfETz+eQjcHNbPQh7qyndWqLO9We23zLP3YcKHM7gF53jDMvByZrJBHrifGNjPt3r+I3lWdFxa8k64nfOD11Mlw1Y+mc8mZAT8K5+Ds95Mjp9cyIL4pA0almr3sIx3fUk1xp88ujs8XpCPMdmLFkX432jE2rBtP2uOGY4YAyLbXjfDRoM1SmPyMsYHPweDySgFUZZk124sFd/mOy9i+2z6rp63ufWy5J/Xlw15+8zPn41CeaNDeM9nd7xPQHeMplr4dHaSHm+38HqcjkEYiR/U8KKhBNJNx2H6/vKvLW+X4HJCke8roCNWkj/X9TpcB26BMLdkMPaGZta/9uDGrk9g279f1/hi+okGyf9u2YX+5w29P8XvOFJsMbE83vNw2vPwIgN0Cye02oPe6Jsb60AVFgFzql3edqdZJkkS9Oe+MNHCg90GanAdttnLbNnvLA7bYv3O6n5L2s2Ty2WfSxi7Y94kxwgqHb1H8prvxdOw5VAAb7+v0YR3BzzP2VvpM4CD/R4br//RCClcSSJOpmVwpiz9VnpjTTptG6fTT+jxzz/jEnoprdv6JVUHRt2mOduaJnSGZ1N0eHiFV5lIm48lTEZbDO41mUrrpwEPiIxWBb0Omb5WRQbIt7py5Loy9UCI+vp6cylncZhe8UkFLYIetC5wbMaIeCqyFyse7yZ3+vpmTroFAJ6qKWIINzocteIzmDiKnOf7cdm0VMfrzSootfA2hQFEVnEosDMsPDdpEwiBi3Uw+p9Irgjz09bM8ctIlZg0zpeK2C3LHhg1jG3XFwVZGcgNyFvseJ/QOgahvo0kkH8M7gzZV/W4AP+Pk+d8A8AtOniuAX/OuelcwXuGBr8+5tjQ+Y0+n9ZG0zumb/M6WRDrjTI0yIEURnAFAtJYd5oAqf6zdB8pMb3XZxXkzP+fFqdpNttARreGkRL/a6ZgC2qyYVuJ0jDWZciFNZAi8J8OZJE+v4aLhDLhiakY0PCll9967P2v5TPYRFYRW8JbEAgeOTIixMLG7fb6p3Wi+PW/4+KM3eLrdXHCnj+Ud866Yu+K+75j7bg5IBLdw4x/BwaylG6z7FqIcPi4mrMHr4odGu7XBHmwEPxTFmB6s3Jk/WhDYKl6dwI5VLonx31tZ5dnDk3Ej5JWN+sJjZci9nuiMMK5VMqvOrK2W7DWD70OqvQ3lvup53xt27I+00rrgvtSjJ31MfVVvs/Fkg9frLCaQ5XczrNzkiqzkexLfgUxMxP5JiB0ksQ3bG2OJmZDffnS0qtaBB2IO6dx3iAw7xCIcSTL4mWybE7rvrkdqF7pNvBmxxzay1yK0pNpnFKb6fi53YLfnQYon+mjca/gP3O979vfhEnvptM7HXDcNUf24vnKUpSI9S3L9ykuIWADCV6y7vbycZ6VNNc9e2VKXat2wZD4HyVI4S8lPAtkAnRvy6H+1WbQZRiPq9frEFSWvsjDda0vKY8JBRDDn3WbXXgTj+RlvPnrG/eWOeZ8+W7hhv9fpi5kQSue6bN0m5djG4pXA6Wkb2HXivu/YRPLs0ag3uI+uv0ya2D4jjeYxthtCN/HJ8tMPYQHEZuJyQ0osZyteGjHjBxvL+9t7NeqzjFBgbHQyAyE25wSm4sXXQA7er4hu/0sN0IEsXmHub/OAUDGg+048FEqmK74WYKU8MOXOef4UwhSETvBn4X/EdofZAgZCb41kJWZzFrT15Hs97j6FIlf/pJ3gLiQh17a9HjYSlR1Jpmz7tEhHhT7NV73e1T7ktz6giC0/I/wnJZoshMvrb1HvHrURbIbIdaFM5H52Rrv8p2mHAWISbbzelm8hvcpOTSimkLc0VKgGQzcpvU92IXYJhtYXGg9F1b0vvqqtwtsRs9rRnD13mYqtT+kzFN6Jviq2zWzfdtvcjm6QbeCNv3lHLUcGBHed2GAJRz5sqZn9V+BHc+T/lxSCzTJSJiNsY6XunFVGPu5NkXwQlUk7SvgUhq3DTZ5Rw6Ed5uBGsK03Z5ylMrr8DmfbYm3x2WWC1Pm0CGlsKVgL/aDKDnK0aRJlM1JdDA90abh3ZyECKj5AQF3hlBtFMuWarY4394yfxoEFemC+kMk8aCuWKsZXVNaKN6OzOjBM6LcheBob9rd3vP30LcWSms5EZZw6Lo0s2j8vuv5Ujlaz9Wh4X6vjs0BDTZfnh0pjycFxJq3M4PGXHI504LhPvWfloD3Ctr8dsBZP/cpG99jcyVgd5ylC7vpdSjxD2VunFbMH/NgvMBy7TKwo0tzNoYJ1+copL3gSKWTg0H+JVhZfCYJwSftqhFgyUgtbwjFRePAUOmsbeXIjYIeC5EpsRPBPy7mExlbtBN85p5+mavvb7DTD2P8ACzLEAsSXnLapvQy7xpIwe2+fdEAQJcwsm7nnIGzbRoZd3VaUA5PZT/X9I3Iy2MTzKzR6RxsxQ6i8a1XTo1l3i5a8rlxsvw8pae2z6RH44pC1buwR9DkRHAuoi87MC9Z21wlR9va0AXLzkyK9LGxVhS0v9UM12F6p7ReLGTW9z7z0WxQYww+0cZtx//QFz2+e8PR0w4475j7x9HSDjIn95SVt78AExpbJ1w3APvfcawep8D+GKvZhbe4rjEUG07ZQ8odBvY7Ijxsb0oykKuZ95p7PYFMRyS0ZoYbUEx/5PQNCb3faaXLbRpo5x9SWUd3vO+a05WXjNrxf3frkbLA3LlKneXoJYiSTj20MPH38EV5e3uLtp3te/WH7hbCAvZvJh5SHDnoyY81XXMS4Hmr22fPYSp5xO5XWQbYn+pR36HUni8yAF66Im7daOII2TsLvBPJUkfgRf68UMX5IhVV/Qj8IJ/09o+H2JX+JbRyLM6+BfHwnO8eRa8yxVjvaDwBL+1DJelsm2+UEbjNiuNkftXGJFW9WmJMgQrivfpaNN/GmoM+kNWUVhfzzENs/S1BzLu57yrJiCX6iLScBiaaWuLDve9Al7R3Tyetzvz7sw75PO4lXFeN286SQIlIzqoo5Rm4BAIB7WlZ0RlU9X4lD8MEEbQDcGWfB40xE5BNcKAZJmI8CyY0/T63RAqsmnOwAJt+XA6TBmNqXK0Zd5Zj4EMwwAp1dc8N2OkErM5MAOi6aAiPJOE3dkdHNY/KjWQkDc0LoLKOdboyx9gCuLZd0gkfANjzjk/i7cFW/SsmnzhYqH48yPNT0KKg7YFe9DKPi07cv+Szq6qQ9MS5n5U7ItP7WnnGKz/sayuOM7K/BGT6fpTzzPJmr/CHiDTm8fVJhgtCnPk7RFrdeZuq81wdcl9+ZhCm6bLD0GIAeQJbPGnLDvaAigzK0KPpVSUkBjwSHuzsN58p0L/KXtVAmXJa+a5WqE2ljUzUyQWVVxgB3nXImx4mlEh9ozA5MYEjeWRhOZ9Z8iEpLdsG08edDbCZh7i+473eM8ZQbrNPuqiXj4iTCqH/lljEE2za6wQy6+/4gQPwkVg4EkIdX5IZvWCA554TcNpvtCDp6++/iKfXWeSkyeT4oDi1FrD2qXpxrrrnezaA8FHbShojVDBfNGCoqGx6mx4Pb/V7LwIfbqNCj4bjEzGjtRSqWAuwqm9AAuA3cbpuh4SdYZlDo788ZB5iAbBqgfsBI9lsV+6cvGE83bE9P2OcOmRO3MYDbExTA3O+QORJ/SC3HT3rB93O5bGTbYPtHBxXQbxJ4+3vplALZl23w0kevK+xyJG39vTnV1wChlkZV642+zTirQqfpo7gWYcICiUkB2+YJloNd8n7l2CoyOLD6WFcXW6lO3F/e4unpGfv+KfY9DklZZ+lA9VMFXCB+Ydu32B5NGhakxR8AdqORyjA+aBq5ZKaSu4oIRKPPDE2fR3bQZTUW2OVBVaS3c/xaNxc93zDi4YzKyIYmAbTeVOpPinLZEAV8GSm9WkanD0wiJETT6Afq8KhV4xIOtNus/h9Hqz6B8r1ZT3lxorI34W/zyit/5uG28ZxW19Y2AVSiRXs9eYGT0JJF6WPDdSlq32Xx6TjwZfZ3KgSTJhrE755T10fWxn3afZb7fYfcNtw2m3VLXOeO4ZdyR9vSZJnu7nxH1PbBBG2B7qDs8MqcpmhrCDi7XIwiqcQUNvuk6/qJLr9JSFCRzKAhmLM7jl0++wWhVr22QKcdtCFVf/QNSid1DaslgzUAcTxlGNxg9HXOIZ3EtI9WF8/EJaIkIu1EtrAlWZ+UriADcRgH/48PZAFM4HZVX7O/uiMZxrY+2NJM/0ZtZ7foMINVwNfv7wIW8PX9M6GvL4umefB+lcXRaq3lHrT72kvlCpV5DscgWKEvR+2K1YpW9m0NcnnEzDiFpJEBEVP9mRzx73b/TDgyUbb4pbGkHMcif2C5P5qfVNZWsYDvSx6NmnIsz7/kf5yNLxiewQ7e5OPR4Yaes7W1qT6oGDM0UXUqhKRJHxxa+kI/6MJPB17R/lERyxjFlm+EUGXPOV2mTc5FkCcdBI90upXDNsbWBs9O2LqnM3/bbth9iWQUizu+dM7coxtH58XqB9s7JbaEzB2QWNoCmMO775ZjHn4o1FTbJ3S73RK/U2CHaCVgHMAgNUJGl0q8pRoQem+hkL0nTX6q9KqHfRSU3yfMFHYRttOMrwdVeHBOwdRZr1XrygVbumPtTFVMv/sNUOhuOD0/Dzw9v8HT08R93mymZr/jfp91aqUfOrLfyekQ298WB96XrvJ9dy93QBW3262WvkJw2wQ6njzwtHGeu/GHiPj+LqspAlK4nOX+SZVmm5PPG0HMsjed7f7Eft8hmy9b9GGJMR9+n6b5HrUaKA8SATDFdaQCqjROAV5H7tG8734oi+kvG8uQK7eD0a1cuoVkwtD7SqtfdCt+arMFCqjYRhPIjm274b6/NZ9pAjoo6FR3sJcETyWyUKs0qEzQpL4dYVNgDoHsVlsunHb7wV4B4Lcs0h198dvq2jQVGuPWdCjbBCVZIx0YNXDAF9/TeIUT6DU6H1YSnShGeJPIus+lqVNWO01N1NPTbPwRalaN7f/RHj7yNtZSKU3BjPGr2mxnu4HQeczIpO26CVv6HttvavwSw2JsrLzT/f2OqC6fj36CNjmUpYzxSdnC0CureVAgV8fkGE3FlB2473gRIFacmM7xhEskXkTatSxxEQkZmofwwQRtZ9BYq+ne1duSuuQPcOPFQxEqhspTiTUDAH6e9Uoi1Oo+cQSObPaOcaB2lJ/xe6dembRPvd1QEDi96wVr3x418xjpVpopGooIityEO16hwJlb0Z4FLUgiS0F+Xky/NBBC3JSaHIOJz1WnHFiwN6j0MZRB/swjXwqVf2+GYlHWgT//corgWkC4jQd0znqZX16HDOCyz++gLaOWCEXCg94PfHngHlS8OvlcF6RonrSTrg7yLsIzRPnjUoSTSB0XnikI2e+jmW3H0yBiztBYVlHk7C17xHsBc9aPCHZKMpf1Y5V2cMmc9rsMgexrGS9ZUzTIvVGOuwVpm/NFODg9+63eRwtyTRva/p9xpGd+eMSJJzpJjpvVj2SUQ5Ux21N+XHeFNJyy8FbkSOW1XdWZSxBL68ahIasVOEJqfgmnIfgr9LaV2FWxjQlgc8fj7rMg8FnVaRdzK3C/321PjNcWPLptA2P6PnTp2w1ELBgbm2Jsmzk++445xQM5r0uRe45L31h/b/vETpv9jYya/BhBdh1kFvg1YiS9cuZMFVN393ftYJLY1x33bWJsNgaxj9uDSds65vphV7wsNjh0htDA6px4UeA2hp12CgsY517LFSdirZGCD2hqpznCZCFnT318VTQmT7ycQhR42e2KhHA8I3Gnqnn5ehGr2/nyV5a+5RdWiAsNpDBWsD/m4+N9jUAuDjh73a81/OpGtEKIl/dlfSlpJ0aAx0aRyTpTM55gJ13NvtYOhYiCg9baexW2vny0rjS6nVxXRIgA2JBjZOcNaMM3TzTVHlhUpmmloDy0hSF1CrQzb6Mvxjj1LVVZ8ip1Rq3pOriuxqT3PMozYxG90kywjcdBzx/7koQ4tneCR3F74WFXY+CcD0ecPm4zdJGI4NmzsFk1gSEZvI0tllE+BnlXJ78IEJEfBvDn3jceF1zg8BMB/PX3jcQFF+DixQs+LLj48YIPBS5evOBDgi8lP/59qvqTzn74UGba/pyqfsP7RuKCCwBARP74xY8XfAhw8eIFHxJc/HjBhwIXL17wIcEXxY/vOGLxggsuuOCCCy644IILLrjggvcJV9B2wQUXXHDBBRdccMEFF1zwAcOHErT9lveNwAUXEFz8eMGHAhcvXvAhwcWPF3wocPHiBR8SfCH8+EEcRHLBBRdccMEFF1xwwQUXXHDBOXwoM20XXHDBBRdccMEFF1xwwQUXnMB7D9pE5BeJyJ8Tke8SkW953/hc8OUNIvJTROQPi8ifEZH/S0R+rT//ahH5DhH58/73x/tzEZH/zPnz/xCRn/V+e3DBlxuIyCYif0pE/gf//tNE5I86z/0eEXn252/8+3f57z/1feJ9wZcfiMhXici3ich3isifFZF/9NKNF7wvEJF/0+30nxaR3yUiH1368YIvAkTkt4vI94vIn6Znn1sXisg3e/k/LyLf/KPF670GbSKyAfgvAPxiAD8dwD8vIj/9feJ0wZc93AH8W6r60wH8HAC/xnnuWwD8IVX9egB/yL8Dxptf7/9+NYDf/MWjfMGXOfxaAH+Wvv9HAH6jqv4DAH4QwK/y578KwA/689/o5S644EsJvwnAH1TVfwjAz4Dx5aUbL/jCQUS+FsC/DuAbVPUfBrAB+BW49OMFXwz8VwB+0fLsc+lCEflqAL8OwM8G8I0Afl0Een+n8L5n2r4RwHep6ner6lsAvxvAN71nnC74MgZV/T5V/ZP++YdhTsnXwvjuW73YtwL4Z/3zNwH4nWrwRwB8lYj85C8Y7Qu+TEFEvg7APw3gt/p3AfDzAXybF1l5MXj02wD8Ai9/wQU/ahCRHwfgHwfw2wBAVd+q6t/EpRsveH9wA/CxiNwAfALg+3Dpxwu+AFDV/w3ADyyPP68u/KcAfIeq/oCq/iCA78AxEPxc8L6Dtq8F8Jfp+/f4swsu+DEHXz7xMwH8UQBfo6rf5z/9Tn1jIwAAA1lJREFUFQBf458vHr3gxxL+UwD/DoDp338CgL+pqnf/zvyWvOi//5CXv+CCLwX8NAB/DcDv8OW6v1VEvgKXbrzgPYCqfi+A/xjAX4IFaz8E4E/g0o8XvD/4vLrwS64j33fQdsEF7wVE5CsB/HcA/g1V/X/4N7UjVa9jVS/4MQUR+aUAvl9V/8T7xuWCC2CzGj8LwG9W1Z8J4P9FLf8BcOnGC7448GVk3wRLJvw9AL4CP8pZigsu+FLB+9KF7zto+14AP4W+f50/u+CCHzMQkSdYwPbfqOrv88d/NZb2+N/v9+cXj17wYwX/GIB/RkT+Amxp+M+H7Sn6Kl8OBHR+S170338cgL/xRSJ8wZc1fA+A71HVP+rfvw0WxF268YL3Af8kgP9bVf+aqr4A+H0wnXnpxwveF3xeXfgl15HvO2j7YwC+3k8DeoZtMv3294zTBV/G4GvcfxuAP6uq/wn99O0A4mSfbwbwB+j5v+SnA/0cAD9E0+MXXPB3DKr676nq16nqT4Xpvv9FVf8FAH8YwC/zYisvBo/+Mi9/zXpc8CUBVf0rAP6yiPyD/ugXAPgzuHTjBe8H/hKAnyMin7jdDn689OMF7ws+ry78nwD8QhH58T5z/Av92d8xvPfLtUXkl8D2dWwAfruq/vr3itAFX9YgIj8XwP8O4P9E7SP692H72n4vgL8XwF8E8MtV9QfcWPznsGUZfwvAr1TVP/6FI37BlzWIyM8D8G+r6i8Vkb8fNvP21QD+FIB/UVU/FZGPAPzXsH2YPwDgV6jqd78vnC/48gMR+Udgh+I8A/huAL8Slty9dOMFXziIyH8A4J+Dnfr8pwD8q7A9QZd+vODHFETkdwH4eQB+IoC/CjsF8r/H59SFIvKvwHxMAPj1qvo7flR4ve+g7YILLrjgggsuuOCCCy644ILH8L6XR15wwQUXXHDBBRdccMEFF1zwClxB2wUXXHDBBRdccMEFF1xwwQcMV9B2wQUXXHDBBRdccMEFF1zwAcMVtF1wwQUXXHDBBRdccMEFF3zAcAVtF1xwwQUXXHDBBRdccMEFHzBcQdsFF1xwwQUXXHDBBRdccMEHDFfQdsEFF1xwwQUXXHDBBRdc8AHDFbRdcMEFF1xwwQUXXHDBBRd8wPD/AUOn/iZV7TrRAAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "# show the results\n",
+ "show_result_pyplot(model, img, result, get_palette('cityscapes'))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "open-mmlab",
+ "language": "python",
+ "name": "open-mmlab"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.7"
+ },
+ "pycharm": {
+ "stem_cell": {
+ "cell_type": "raw",
+ "metadata": {
+ "collapsed": false
+ },
+ "source": []
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/demo/video_demo.py b/demo/video_demo.py
new file mode 100644
index 0000000..acdb531
--- /dev/null
+++ b/demo/video_demo.py
@@ -0,0 +1,111 @@
+from argparse import ArgumentParser
+
+import cv2
+
+from mmseg.apis import inference_segmentor, init_segmentor
+from mmseg.core.evaluation import get_palette
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument('video', help='Video file or webcam id')
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--palette',
+ default='cityscapes',
+ help='Color palette used for segmentation map')
+ parser.add_argument(
+ '--show', action='store_true', help='Whether to show draw result')
+ parser.add_argument(
+ '--show-wait-time', default=1, type=int, help='Wait time after imshow')
+ parser.add_argument(
+ '--output-file', default=None, type=str, help='Output video file path')
+ parser.add_argument(
+ '--output-fourcc',
+ default='MJPG',
+ type=str,
+ help='Fourcc of the output video')
+ parser.add_argument(
+ '--output-fps', default=-1, type=int, help='FPS of the output video')
+ parser.add_argument(
+ '--output-height',
+ default=-1,
+ type=int,
+ help='Frame height of the output video')
+ parser.add_argument(
+ '--output-width',
+ default=-1,
+ type=int,
+ help='Frame width of the output video')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ args = parser.parse_args()
+
+ assert args.show or args.output_file, \
+ 'At least one output should be enabled.'
+
+ # build the model from a config file and a checkpoint file
+ model = init_segmentor(args.config, args.checkpoint, device=args.device)
+
+ # build input video
+ cap = cv2.VideoCapture(args.video)
+ assert (cap.isOpened())
+ input_height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
+ input_width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
+ input_fps = cap.get(cv2.CAP_PROP_FPS)
+
+ # init output video
+ writer = None
+ output_height = None
+ output_width = None
+ if args.output_file is not None:
+ fourcc = cv2.VideoWriter_fourcc(*args.output_fourcc)
+ output_fps = args.output_fps if args.output_fps > 0 else input_fps
+ output_height = args.output_height if args.output_height > 0 else int(
+ input_height)
+ output_width = args.output_width if args.output_width > 0 else int(
+ input_width)
+ writer = cv2.VideoWriter(args.output_file, fourcc, output_fps,
+ (output_width, output_height), True)
+
+ # start looping
+ try:
+ while True:
+ flag, frame = cap.read()
+ if not flag:
+ break
+
+ # test a single image
+ result = inference_segmentor(model, frame)
+
+ # blend raw image and prediction
+ draw_img = model.show_result(
+ frame,
+ result,
+ palette=get_palette(args.palette),
+ show=False,
+ opacity=args.opacity)
+
+ if args.show:
+ cv2.imshow('video_demo', draw_img)
+ cv2.waitKey(args.show_wait_time)
+ if writer:
+ if draw_img.shape[0] != output_height or draw_img.shape[
+ 1] != output_width:
+ draw_img = cv2.resize(draw_img,
+ (output_width, output_height))
+ writer.write(draw_img)
+ finally:
+ if writer:
+ writer.release()
+ cap.release()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/docker/Dockerfile b/docker/Dockerfile
new file mode 100644
index 0000000..6f9acac
--- /dev/null
+++ b/docker/Dockerfile
@@ -0,0 +1,29 @@
+ARG PYTORCH="1.6.0"
+ARG CUDA="10.1"
+ARG CUDNN="7"
+ARG MMCV="1.3.13"
+
+FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
+
+ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX"
+ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
+ENV CMAKE_PREFIX_PATH="$(dirname $(which conda))/../"
+
+RUN apt-get update && apt-get install -y git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
+ && apt-get clean \
+ && rm -rf /var/lib/apt/lists/*
+
+RUN conda clean --all
+
+# Install MMCV
+ARG PYTORCH
+ARG CUDA
+ARG MMCV
+RUN ["/bin/bash", "-c", "pip install mmcv-full==${MMCV} -f https://download.openmmlab.com/mmcv/dist/cu${CUDA//./}/torch${PYTORCH}/index.html"]
+
+# Install MMSegmentation
+RUN git clone https://github.com/open-mmlab/mmsegmentation.git /mmsegmentation
+WORKDIR /mmsegmentation
+ENV FORCE_CUDA="1"
+RUN pip install -r requirements.txt
+RUN pip install --no-cache-dir -e .
diff --git a/docker/serve/Dockerfile b/docker/serve/Dockerfile
new file mode 100644
index 0000000..31a5d44
--- /dev/null
+++ b/docker/serve/Dockerfile
@@ -0,0 +1,49 @@
+ARG PYTORCH="1.6.0"
+ARG CUDA="10.1"
+ARG CUDNN="7"
+FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
+
+ARG MMCV="1.4.4"
+ARG MMSEG="0.21.0"
+
+ENV PYTHONUNBUFFERED TRUE
+
+RUN apt-get update && \
+ DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y \
+ ca-certificates \
+ g++ \
+ openjdk-11-jre-headless \
+ # MMDet Requirements
+ ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
+ && rm -rf /var/lib/apt/lists/*
+
+ENV PATH="/opt/conda/bin:$PATH"
+RUN export FORCE_CUDA=1
+
+# TORCHSEVER
+RUN pip install torchserve torch-model-archiver
+
+# MMLAB
+ARG PYTORCH
+ARG CUDA
+RUN ["/bin/bash", "-c", "pip install mmcv-full==${MMCV} -f https://download.openmmlab.com/mmcv/dist/cu${CUDA//./}/torch${PYTORCH}/index.html"]
+RUN pip install mmsegmentation==${MMSEG}
+
+RUN useradd -m model-server \
+ && mkdir -p /home/model-server/tmp
+
+COPY entrypoint.sh /usr/local/bin/entrypoint.sh
+
+RUN chmod +x /usr/local/bin/entrypoint.sh \
+ && chown -R model-server /home/model-server
+
+COPY config.properties /home/model-server/config.properties
+RUN mkdir /home/model-server/model-store && chown -R model-server /home/model-server/model-store
+
+EXPOSE 8080 8081 8082
+
+USER model-server
+WORKDIR /home/model-server
+ENV TEMP=/home/model-server/tmp
+ENTRYPOINT ["/usr/local/bin/entrypoint.sh"]
+CMD ["serve"]
diff --git a/docker/serve/config.properties b/docker/serve/config.properties
new file mode 100644
index 0000000..efb9c47
--- /dev/null
+++ b/docker/serve/config.properties
@@ -0,0 +1,5 @@
+inference_address=http://0.0.0.0:8080
+management_address=http://0.0.0.0:8081
+metrics_address=http://0.0.0.0:8082
+model_store=/home/model-server/model-store
+load_models=all
diff --git a/docker/serve/entrypoint.sh b/docker/serve/entrypoint.sh
new file mode 100644
index 0000000..41ba00b
--- /dev/null
+++ b/docker/serve/entrypoint.sh
@@ -0,0 +1,12 @@
+#!/bin/bash
+set -e
+
+if [[ "$1" = "serve" ]]; then
+ shift 1
+ torchserve --start --ts-config /home/model-server/config.properties
+else
+ eval "$@"
+fi
+
+# prevent docker exit
+tail -f /dev/null
diff --git a/docs/en/Makefile b/docs/en/Makefile
new file mode 100644
index 0000000..d4bb2cb
--- /dev/null
+++ b/docs/en/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/en/_static/css/readthedocs.css b/docs/en/_static/css/readthedocs.css
new file mode 100644
index 0000000..2e38d08
--- /dev/null
+++ b/docs/en/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../images/mmsegmentation.png");
+ background-size: 201px 40px;
+ height: 40px;
+ width: 201px;
+}
diff --git a/docs/en/_static/images/mmsegmentation.png b/docs/en/_static/images/mmsegmentation.png
new file mode 100644
index 0000000..009083a
Binary files /dev/null and b/docs/en/_static/images/mmsegmentation.png differ
diff --git a/docs/en/api.rst b/docs/en/api.rst
new file mode 100644
index 0000000..8285841
--- /dev/null
+++ b/docs/en/api.rst
@@ -0,0 +1,58 @@
+mmseg.apis
+--------------
+.. automodule:: mmseg.apis
+ :members:
+
+mmseg.core
+--------------
+
+seg
+^^^^^^^^^^
+.. automodule:: mmseg.core.seg
+ :members:
+
+evaluation
+^^^^^^^^^^
+.. automodule:: mmseg.core.evaluation
+ :members:
+
+utils
+^^^^^^^^^^
+.. automodule:: mmseg.core.utils
+ :members:
+
+mmseg.datasets
+--------------
+
+datasets
+^^^^^^^^^^
+.. automodule:: mmseg.datasets
+ :members:
+
+pipelines
+^^^^^^^^^^
+.. automodule:: mmseg.datasets.pipelines
+ :members:
+
+mmseg.models
+--------------
+
+segmentors
+^^^^^^^^^^
+.. automodule:: mmseg.models.segmentors
+ :members:
+
+backbones
+^^^^^^^^^^
+.. automodule:: mmseg.models.backbones
+ :members:
+
+decode_heads
+^^^^^^^^^^^^
+.. automodule:: mmseg.models.decode_heads
+ :members:
+
+losses
+^^^^^^^^^^
+.. automodule:: mmseg.models.losses
+ :members:
diff --git a/docs/en/changelog.md b/docs/en/changelog.md
new file mode 100644
index 0000000..3954430
--- /dev/null
+++ b/docs/en/changelog.md
@@ -0,0 +1,556 @@
+## Changelog
+
+
+### V0.21.1 (2/9/2022)
+
+**Bug Fixes**
+
+- Fix typos in docs. ([#1263](https://github.com/open-mmlab/mmsegmentation/pull/1263))
+- Fix repeating log by `setup_multi_processes`. ([#1267](https://github.com/open-mmlab/mmsegmentation/pull/1267))
+- Upgrade isort in pre-commit hook. ([#1270](https://github.com/open-mmlab/mmsegmentation/pull/1270))
+
+**Improvements**
+
+- Use MMCV load_state_dict func in ViT/Swin. ([#1272](https://github.com/open-mmlab/mmsegmentation/pull/1272))
+- Add exception for PointRend for support CPU-only. ([#1271](https://github.com/open-mmlab/mmsegmentation/pull/1270))
+
+### V0.21 (1/29/2022)
+
+**Highlights**
+
+- Officially Support CPUs training and inference, please use the latest MMCV (1.4.4) to try it out.
+- Support Segmenter: Transformer for Semantic Segmentation (ICCV'2021).
+- Support ISPRS Potsdam and Vaihingen Dataset.
+- Add Mosaic transform and `MultiImageMixDataset` class in `dataset_wrappers`.
+
+**New Features**
+
+- Support Segmenter: Transformer for Semantic Segmentation (ICCV'2021) ([#955](https://github.com/open-mmlab/mmsegmentation/pull/955))
+- Support ISPRS Potsdam and Vaihingen Dataset ([#1097](https://github.com/open-mmlab/mmsegmentation/pull/1097), [#1171](https://github.com/open-mmlab/mmsegmentation/pull/1171))
+- Add segformer‘s benchmark on cityscapes ([#1155](https://github.com/open-mmlab/mmsegmentation/pull/1155))
+- Add auto resume ([#1172](https://github.com/open-mmlab/mmsegmentation/pull/1172))
+- Add Mosaic transform and `MultiImageMixDataset` class in `dataset_wrappers` ([#1093](https://github.com/open-mmlab/mmsegmentation/pull/1093), [#1105](https://github.com/open-mmlab/mmsegmentation/pull/1105))
+- Add log collector ([#1175](https://github.com/open-mmlab/mmsegmentation/pull/1175))
+
+**Improvements**
+
+- New-style CPU training and inference ([#1251](https://github.com/open-mmlab/mmsegmentation/pull/1251))
+- Add UNet benchmark with multiple losses supervision ([#1143](https://github.com/open-mmlab/mmsegmentation/pull/1143))
+
+**Bug Fixes**
+
+- Fix the model statistics in doc for readthedoc ([#1153](https://github.com/open-mmlab/mmsegmentation/pull/1153))
+- Set random seed for `palette` if not given ([#1152](https://github.com/open-mmlab/mmsegmentation/pull/1152))
+- Add `COCOStuffDataset` in `class_names.py` ([#1222](https://github.com/open-mmlab/mmsegmentation/pull/1222))
+- Fix bug in non-distributed multi-gpu training/testing ([#1247](https://github.com/open-mmlab/mmsegmentation/pull/1247))
+- Delete unnecessary lines of STDCHead ([#1231](https://github.com/open-mmlab/mmsegmentation/pull/1231))
+
+**Contributors**
+
+- @jbwang1997 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1152
+- @BeaverCC made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1206
+- @Echo-minn made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1214
+- @rstrudel made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/955
+
+### V0.20.2 (12/15/2021)
+
+**Bug Fixes**
+
+- Revise --option to --options to avoid BC-breaking. ([#1140](https://github.com/open-mmlab/mmsegmentation/pull/1140))
+
+### V0.20.1 (12/14/2021)
+
+**Improvements**
+
+- Change options to cfg-options ([#1129](https://github.com/open-mmlab/mmsegmentation/pull/1129))
+
+
+**Bug Fixes**
+
+- Fix `` in metafile. ([#1127](https://github.com/open-mmlab/mmsegmentation/pull/1127))
+- Fix correct `num_classes` of HRNet in `LoveDA` dataset ([#1136](https://github.com/open-mmlab/mmsegmentation/pull/1136))
+
+
+
+### V0.20 (12/10/2021)
+
+**Highlights**
+
+- Support Twins ([#989](https://github.com/open-mmlab/mmsegmentation/pull/989))
+- Support a real-time segmentation model STDC ([#995](https://github.com/open-mmlab/mmsegmentation/pull/995))
+- Support a widely-used segmentation model in lane detection ERFNet ([#960](https://github.com/open-mmlab/mmsegmentation/pull/960))
+- Support A Remote Sensing Land-Cover Dataset LoveDA ([#1028](https://github.com/open-mmlab/mmsegmentation/pull/1028))
+- Support focal loss ([#1024](https://github.com/open-mmlab/mmsegmentation/pull/1024))
+
+**New Features**
+
+- Support Twins ([#989](https://github.com/open-mmlab/mmsegmentation/pull/989))
+- Support a real-time segmentation model STDC ([#995](https://github.com/open-mmlab/mmsegmentation/pull/995))
+- Support a widely-used segmentation model in lane detection ERFNet ([#960](https://github.com/open-mmlab/mmsegmentation/pull/960))
+- Add SETR cityscapes benchmark ([#1087](https://github.com/open-mmlab/mmsegmentation/pull/1087))
+- Add BiSeNetV1 COCO-Stuff 164k benchmark ([#1019](https://github.com/open-mmlab/mmsegmentation/pull/1019))
+- Support focal loss ([#1024](https://github.com/open-mmlab/mmsegmentation/pull/1024))
+- Add Cutout transform ([#1022](https://github.com/open-mmlab/mmsegmentation/pull/1022))
+
+**Improvements**
+
+- Set a random seed when the user does not set a seed ([#1039](https://github.com/open-mmlab/mmsegmentation/pull/1039))
+- Add CircleCI setup ([#1086](https://github.com/open-mmlab/mmsegmentation/pull/1086))
+- Skip CI on ignoring given paths ([#1078](https://github.com/open-mmlab/mmsegmentation/pull/1078))
+- Add abstract and image for every paper ([#1060](https://github.com/open-mmlab/mmsegmentation/pull/1060))
+- Create a symbolic link on windows ([#1090](https://github.com/open-mmlab/mmsegmentation/pull/1090))
+- Support video demo using trained model ([#1014](https://github.com/open-mmlab/mmsegmentation/pull/1014))
+
+**Bug Fixes**
+
+- Fix incorrectly loading init_cfg or pretrained models of several transformer models ([#999](https://github.com/open-mmlab/mmsegmentation/pull/999), [#1069](https://github.com/open-mmlab/mmsegmentation/pull/1069), [#1102](https://github.com/open-mmlab/mmsegmentation/pull/1102))
+- Fix EfficientMultiheadAttention in SegFormer ([#1037](https://github.com/open-mmlab/mmsegmentation/pull/1037))
+- Remove `fp16` folder in `configs` ([#1031](https://github.com/open-mmlab/mmsegmentation/pull/1031))
+- Fix several typos in .yml file (Dice Metric [#1041](https://github.com/open-mmlab/mmsegmentation/pull/1041), ADE20K dataset [#1120](https://github.com/open-mmlab/mmsegmentation/pull/1120), Training Memory (GB) [#1083](https://github.com/open-mmlab/mmsegmentation/pull/1083))
+- Fix test error when using `--show-dir` ([#1091](https://github.com/open-mmlab/mmsegmentation/pull/1091))
+- Fix dist training infinite waiting issue ([#1035](https://github.com/open-mmlab/mmsegmentation/pull/1035))
+- Change the upper version of mmcv to 1.5.0 ([#1096](https://github.com/open-mmlab/mmsegmentation/pull/1096))
+- Fix symlink failure on Windows ([#1038](https://github.com/open-mmlab/mmsegmentation/pull/1038))
+- Cancel previous runs that are not completed ([#1118](https://github.com/open-mmlab/mmsegmentation/pull/1118))
+- Unified links of readthedocs in docs ([#1119](https://github.com/open-mmlab/mmsegmentation/pull/1119))
+
+**Contributors**
+
+- @Junjue-Wang made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1028
+- @ddebby made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1066
+- @del-zhenwu made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1078
+- @KangBK0120 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1106
+- @zergzzlun made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1091
+- @fingertap made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1035
+- @irvingzhang0512 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1014
+- @littleSunlxy made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/989
+- @lkm2835
+- @RockeyCoss
+- @MengzhangLI
+- @Junjun2016
+- @xiexinch
+- @xvjiarui
+
+### V0.19 (11/02/2021)
+
+**Highlights**
+
+- Support TIMMBackbone wrapper ([#998](https://github.com/open-mmlab/mmsegmentation/pull/998))
+- Support custom hook ([#428](https://github.com/open-mmlab/mmsegmentation/pull/428))
+- Add codespell pre-commit hook ([#920](https://github.com/open-mmlab/mmsegmentation/pull/920))
+- Add FastFCN benchmark on ADE20K ([#972](https://github.com/open-mmlab/mmsegmentation/pull/972))
+
+**New Features**
+
+- Support TIMMBackbone wrapper ([#998](https://github.com/open-mmlab/mmsegmentation/pull/998))
+- Support custom hook ([#428](https://github.com/open-mmlab/mmsegmentation/pull/428))
+- Add FastFCN benchmark on ADE20K ([#972](https://github.com/open-mmlab/mmsegmentation/pull/972))
+- Add codespell pre-commit hook and fix typos ([#920](https://github.com/open-mmlab/mmsegmentation/pull/920))
+
+**Improvements**
+
+- Make inputs & channels smaller in unittests ([#1004](https://github.com/open-mmlab/mmsegmentation/pull/1004))
+- Change `self.loss_decode` back to `dict` in Single Loss situation ([#1002](https://github.com/open-mmlab/mmsegmentation/pull/1002))
+
+**Bug Fixes**
+
+- Fix typo in usage example ([#1003](https://github.com/open-mmlab/mmsegmentation/pull/1003))
+- Add contiguous after permutation in ViT ([#992](https://github.com/open-mmlab/mmsegmentation/pull/992))
+- Fix the invalid link ([#985](https://github.com/open-mmlab/mmsegmentation/pull/985))
+- Fix bug in CI with python 3.9 ([#994](https://github.com/open-mmlab/mmsegmentation/pull/994))
+- Fix bug when loading class name form file in custom dataset ([#923](https://github.com/open-mmlab/mmsegmentation/pull/923))
+
+**Contributors**
+
+- @ShoupingShan made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/923
+- @RockeyCoss made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/954
+- @HarborYuan made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/992
+- @lkm2835 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1003
+- @gszh made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/428
+- @VVsssssk
+- @MengzhangLI
+- @Junjun2016
+
+### V0.18 (10/07/2021)
+
+**Highlights**
+
+- Support three real-time segmentation models (ICNet [#884](https://github.com/open-mmlab/mmsegmentation/pull/884), BiSeNetV1 [#851](https://github.com/open-mmlab/mmsegmentation/pull/851), and BiSeNetV2 [#804](https://github.com/open-mmlab/mmsegmentation/pull/804))
+- Support one efficient segmentation model (FastFCN [#885](https://github.com/open-mmlab/mmsegmentation/pull/885))
+- Support one efficient non-local/self-attention based segmentation model (ISANet [#70](https://github.com/open-mmlab/mmsegmentation/pull/70))
+- Support COCO-Stuff 10k and 164k datasets ([#625](https://github.com/open-mmlab/mmsegmentation/pull/625))
+- Support evaluate concated dataset separately ([#833](https://github.com/open-mmlab/mmsegmentation/pull/833))
+- Support loading GT for evaluation from multi-file backend ([#867](https://github.com/open-mmlab/mmsegmentation/pull/867))
+
+**New Features**
+
+- Support three real-time segmentation models (ICNet [#884](https://github.com/open-mmlab/mmsegmentation/pull/884), BiSeNetV1 [#851](https://github.com/open-mmlab/mmsegmentation/pull/851), and BiSeNetV2 [#804](https://github.com/open-mmlab/mmsegmentation/pull/804))
+- Support one efficient segmentation model (FastFCN [#885](https://github.com/open-mmlab/mmsegmentation/pull/885))
+- Support one efficient non-local/self-attention based segmentation model (ISANet [#70](https://github.com/open-mmlab/mmsegmentation/pull/70))
+- Support COCO-Stuff 10k and 164k datasets ([#625](https://github.com/open-mmlab/mmsegmentation/pull/625))
+- Support evaluate concated dataset separately ([#833](https://github.com/open-mmlab/mmsegmentation/pull/833))
+
+**Improvements**
+
+- Support loading GT for evaluation from multi-file backend ([#867](https://github.com/open-mmlab/mmsegmentation/pull/867))
+- Auto-convert SyncBN to BN when training on DP automatly([#772](https://github.com/open-mmlab/mmsegmentation/pull/772))
+- Refactor Swin-Transformer ([#800](https://github.com/open-mmlab/mmsegmentation/pull/800))
+
+**Bug Fixes**
+
+- Update mmcv installation in dockerfile ([#860](https://github.com/open-mmlab/mmsegmentation/pull/860))
+- Fix number of iteration bug when resuming checkpoint in distributed train ([#866](https://github.com/open-mmlab/mmsegmentation/pull/866))
+- Fix parsing parse in val_step ([#906](https://github.com/open-mmlab/mmsegmentation/pull/906))
+
+### V0.17 (09/01/2021)
+
+**Highlights**
+
+- Support SegFormer
+- Support DPT
+- Support Dark Zurich and Nighttime Driving datasets
+- Support progressive evaluation
+
+**New Features**
+
+- Support SegFormer ([#599](https://github.com/open-mmlab/mmsegmentation/pull/599))
+- Support DPT ([#605](https://github.com/open-mmlab/mmsegmentation/pull/605))
+- Support Dark Zurich and Nighttime Driving datasets ([#815](https://github.com/open-mmlab/mmsegmentation/pull/815))
+- Support progressive evaluation ([#709](https://github.com/open-mmlab/mmsegmentation/pull/709))
+
+**Improvements**
+
+- Add multiscale_output interface and unittests for HRNet ([#830](https://github.com/open-mmlab/mmsegmentation/pull/830))
+- Support inherit cityscapes dataset ([#750](https://github.com/open-mmlab/mmsegmentation/pull/750))
+- Fix some typos in README.md ([#824](https://github.com/open-mmlab/mmsegmentation/pull/824))
+- Delete convert function and add instruction to ViT/Swin README.md ([#791](https://github.com/open-mmlab/mmsegmentation/pull/791))
+- Add vit/swin/mit convert weight scripts ([#783](https://github.com/open-mmlab/mmsegmentation/pull/783))
+- Add copyright files ([#796](https://github.com/open-mmlab/mmsegmentation/pull/796))
+
+**Bug Fixes**
+
+- Fix invalid checkpoint link in inference_demo.ipynb ([#814](https://github.com/open-mmlab/mmsegmentation/pull/814))
+- Ensure that items in dataset have the same order across multi machine ([#780](https://github.com/open-mmlab/mmsegmentation/pull/780))
+- Fix the log error ([#766](https://github.com/open-mmlab/mmsegmentation/pull/766))
+
+### V0.16 (08/04/2021)
+
+**Highlights**
+
+- Support PyTorch 1.9
+- Support SegFormer backbone MiT
+- Support md2yml pre-commit hook
+- Support frozen stage for HRNet
+
+**New Features**
+
+- Support SegFormer backbone MiT ([#594](https://github.com/open-mmlab/mmsegmentation/pull/594))
+- Support md2yml pre-commit hook ([#732](https://github.com/open-mmlab/mmsegmentation/pull/732))
+- Support mim ([#717](https://github.com/open-mmlab/mmsegmentation/pull/717))
+- Add mmseg2torchserve tool ([#552](https://github.com/open-mmlab/mmsegmentation/pull/552))
+
+**Improvements**
+
+- Support hrnet frozen stage ([#743](https://github.com/open-mmlab/mmsegmentation/pull/743))
+- Add template of reimplementation questions ([#741](https://github.com/open-mmlab/mmsegmentation/pull/741))
+- Output pdf and epub formats for readthedocs ([#742](https://github.com/open-mmlab/mmsegmentation/pull/742))
+- Refine the docstring of ResNet ([#723](https://github.com/open-mmlab/mmsegmentation/pull/723))
+- Replace interpolate with resize ([#731](https://github.com/open-mmlab/mmsegmentation/pull/731))
+- Update resource limit ([#700](https://github.com/open-mmlab/mmsegmentation/pull/700))
+- Update config.md ([#678](https://github.com/open-mmlab/mmsegmentation/pull/678))
+
+**Bug Fixes**
+
+- Fix ATTENTION registry ([#729](https://github.com/open-mmlab/mmsegmentation/pull/729))
+- Fix analyze log script ([#716](https://github.com/open-mmlab/mmsegmentation/pull/716))
+- Fix doc api display ([#725](https://github.com/open-mmlab/mmsegmentation/pull/725))
+- Fix patch_embed and pos_embed mismatch error ([#685](https://github.com/open-mmlab/mmsegmentation/pull/685))
+- Fix efficient test for multi-node ([#707](https://github.com/open-mmlab/mmsegmentation/pull/707))
+- Fix init_cfg in resnet backbone ([#697](https://github.com/open-mmlab/mmsegmentation/pull/697))
+- Fix efficient test bug ([#702](https://github.com/open-mmlab/mmsegmentation/pull/702))
+- Fix url error in config docs ([#680](https://github.com/open-mmlab/mmsegmentation/pull/680))
+- Fix mmcv installation ([#676](https://github.com/open-mmlab/mmsegmentation/pull/676))
+- Fix torch version ([#670](https://github.com/open-mmlab/mmsegmentation/pull/670))
+
+**Contributors**
+
+@sshuair @xiexinch @Junjun2016 @mmeendez8 @xvjiarui @sennnnn @puhsu @BIGWangYuDong @keke1u @daavoo
+
+### V0.15 (07/04/2021)
+
+**Highlights**
+
+- Support ViT, SETR, and Swin-Transformer
+- Add Chinese documentation
+- Unified parameter initialization
+
+**Bug Fixes**
+
+- Fix typo and links ([#608](https://github.com/open-mmlab/mmsegmentation/pull/608))
+- Fix Dockerfile ([#607](https://github.com/open-mmlab/mmsegmentation/pull/607))
+- Fix ViT init ([#609](https://github.com/open-mmlab/mmsegmentation/pull/609))
+- Fix mmcv version compatible table ([#658](https://github.com/open-mmlab/mmsegmentation/pull/658))
+- Fix model links of DMNEt ([#660](https://github.com/open-mmlab/mmsegmentation/pull/660))
+
+**New Features**
+
+- Support loading DeiT weights ([#538](https://github.com/open-mmlab/mmsegmentation/pull/538))
+- Support SETR ([#531](https://github.com/open-mmlab/mmsegmentation/pull/531), [#635](https://github.com/open-mmlab/mmsegmentation/pull/635))
+- Add config and models for ViT backbone with UperHead ([#520](https://github.com/open-mmlab/mmsegmentation/pull/531), [#635](https://github.com/open-mmlab/mmsegmentation/pull/520))
+- Support Swin-Transformer ([#511](https://github.com/open-mmlab/mmsegmentation/pull/511))
+- Add higher accuracy FastSCNN ([#606](https://github.com/open-mmlab/mmsegmentation/pull/606))
+- Add Chinese documentation ([#666](https://github.com/open-mmlab/mmsegmentation/pull/666))
+
+**Improvements**
+
+- Unified parameter initialization ([#567](https://github.com/open-mmlab/mmsegmentation/pull/567))
+- Separate CUDA and CPU in github action CI ([#602](https://github.com/open-mmlab/mmsegmentation/pull/602))
+- Support persistent dataloader worker ([#646](https://github.com/open-mmlab/mmsegmentation/pull/646))
+- Update meta file fields ([#661](https://github.com/open-mmlab/mmsegmentation/pull/661), [#664](https://github.com/open-mmlab/mmsegmentation/pull/664))
+
+### V0.14 (06/02/2021)
+
+**Highlights**
+
+- Support ONNX to TensorRT
+- Support MIM
+
+**Bug Fixes**
+
+- Fix ONNX to TensorRT verify ([#547](https://github.com/open-mmlab/mmsegmentation/pull/547))
+- Fix save best for EvalHook ([#575](https://github.com/open-mmlab/mmsegmentation/pull/575))
+
+**New Features**
+
+- Support loading DeiT weights ([#538](https://github.com/open-mmlab/mmsegmentation/pull/538))
+- Support ONNX to TensorRT ([#542](https://github.com/open-mmlab/mmsegmentation/pull/542))
+- Support output results for ADE20k ([#544](https://github.com/open-mmlab/mmsegmentation/pull/544))
+- Support MIM ([#549](https://github.com/open-mmlab/mmsegmentation/pull/549))
+
+**Improvements**
+
+- Add option for ViT output shape ([#530](https://github.com/open-mmlab/mmsegmentation/pull/530))
+- Infer batch size using len(result) ([#532](https://github.com/open-mmlab/mmsegmentation/pull/532))
+- Add compatible table between MMSeg and MMCV ([#558](https://github.com/open-mmlab/mmsegmentation/pull/558))
+
+### V0.13 (05/05/2021)
+
+**Highlights**
+
+- Support Pascal Context Class-59 dataset.
+- Support Visual Transformer Backbone.
+- Support mFscore metric.
+
+**Bug Fixes**
+
+- Fixed Colaboratory tutorial ([#451](https://github.com/open-mmlab/mmsegmentation/pull/451))
+- Fixed mIoU calculation range ([#471](https://github.com/open-mmlab/mmsegmentation/pull/471))
+- Fixed sem_fpn, unet README.md ([#492](https://github.com/open-mmlab/mmsegmentation/pull/492))
+- Fixed `num_classes` in FCN for Pascal Context 60-class dataset ([#488](https://github.com/open-mmlab/mmsegmentation/pull/488))
+- Fixed FP16 inference ([#497](https://github.com/open-mmlab/mmsegmentation/pull/497))
+
+**New Features**
+
+- Support dynamic export and visualize to pytorch2onnx ([#463](https://github.com/open-mmlab/mmsegmentation/pull/463))
+- Support export to torchscript ([#469](https://github.com/open-mmlab/mmsegmentation/pull/469), [#499](https://github.com/open-mmlab/mmsegmentation/pull/499))
+- Support Pascal Context Class-59 dataset ([#459](https://github.com/open-mmlab/mmsegmentation/pull/459))
+- Support Visual Transformer backbone ([#465](https://github.com/open-mmlab/mmsegmentation/pull/465))
+- Support UpSample Neck ([#512](https://github.com/open-mmlab/mmsegmentation/pull/512))
+- Support mFscore metric ([#509](https://github.com/open-mmlab/mmsegmentation/pull/509))
+
+**Improvements**
+
+- Add more CI for PyTorch ([#460](https://github.com/open-mmlab/mmsegmentation/pull/460))
+- Add print model graph args for tools/print_config.py ([#451](https://github.com/open-mmlab/mmsegmentation/pull/451))
+- Add cfg links in modelzoo README.md ([#468](https://github.com/open-mmlab/mmsegmentation/pull/469))
+- Add BaseSegmentor import to segmentors/__init__.py ([#495](https://github.com/open-mmlab/mmsegmentation/pull/495))
+- Add MMOCR, MMGeneration links ([#501](https://github.com/open-mmlab/mmsegmentation/pull/501), [#506](https://github.com/open-mmlab/mmsegmentation/pull/506))
+- Add Chinese QR code ([#506](https://github.com/open-mmlab/mmsegmentation/pull/506))
+- Use MMCV MODEL_REGISTRY ([#515](https://github.com/open-mmlab/mmsegmentation/pull/515))
+- Add ONNX testing tools ([#498](https://github.com/open-mmlab/mmsegmentation/pull/498))
+- Replace data_dict calling 'img' key to support MMDet3D ([#514](https://github.com/open-mmlab/mmsegmentation/pull/514))
+- Support reading class_weight from file in loss function ([#513](https://github.com/open-mmlab/mmsegmentation/pull/513))
+- Make tags as comment ([#505](https://github.com/open-mmlab/mmsegmentation/pull/505))
+- Use MMCV EvalHook ([#438](https://github.com/open-mmlab/mmsegmentation/pull/438))
+
+### V0.12 (04/03/2021)
+
+**Highlights**
+
+- Support FCN-Dilate 6 model.
+- Support Dice Loss.
+
+**Bug Fixes**
+
+- Fixed PhotoMetricDistortion Doc ([#388](https://github.com/open-mmlab/mmsegmentation/pull/388))
+- Fixed install scripts ([#399](https://github.com/open-mmlab/mmsegmentation/pull/399))
+- Fixed Dice Loss multi-class ([#417](https://github.com/open-mmlab/mmsegmentation/pull/417))
+
+**New Features**
+
+- Support Dice Loss ([#396](https://github.com/open-mmlab/mmsegmentation/pull/396))
+- Add plot logs tool ([#426](https://github.com/open-mmlab/mmsegmentation/pull/426))
+- Add opacity option to show_result ([#425](https://github.com/open-mmlab/mmsegmentation/pull/425))
+- Speed up mIoU metric ([#430](https://github.com/open-mmlab/mmsegmentation/pull/430))
+
+**Improvements**
+
+- Refactor unittest file structure ([#440](https://github.com/open-mmlab/mmsegmentation/pull/440))
+- Fix typos in the repo ([#449](https://github.com/open-mmlab/mmsegmentation/pull/449))
+- Include class-level metrics in the log ([#445](https://github.com/open-mmlab/mmsegmentation/pull/445))
+
+### V0.11 (02/02/2021)
+
+**Highlights**
+
+- Support memory efficient test, add more UNet models.
+
+**Bug Fixes**
+
+- Fixed TTA resize scale ([#334](https://github.com/open-mmlab/mmsegmentation/pull/334))
+- Fixed CI for pip 20.3 ([#307](https://github.com/open-mmlab/mmsegmentation/pull/307))
+- Fixed ADE20k test ([#359](https://github.com/open-mmlab/mmsegmentation/pull/359))
+
+**New Features**
+
+- Support memory efficient test ([#330](https://github.com/open-mmlab/mmsegmentation/pull/330))
+- Add more UNet benchmarks ([#324](https://github.com/open-mmlab/mmsegmentation/pull/324))
+- Support Lovasz Loss ([#351](https://github.com/open-mmlab/mmsegmentation/pull/351))
+
+**Improvements**
+
+- Move train_cfg/test_cfg inside model ([#341](https://github.com/open-mmlab/mmsegmentation/pull/341))
+
+### V0.10 (01/01/2021)
+
+**Highlights**
+
+- Support MobileNetV3, DMNet, APCNet. Add models of ResNet18V1b, ResNet18V1c, ResNet50V1b.
+
+**Bug Fixes**
+
+- Fixed CPU TTA ([#276](https://github.com/open-mmlab/mmsegmentation/pull/276))
+- Fixed CI for pip 20.3 ([#307](https://github.com/open-mmlab/mmsegmentation/pull/307))
+
+**New Features**
+
+- Add ResNet18V1b, ResNet18V1c, ResNet50V1b, ResNet101V1b models ([#316](https://github.com/open-mmlab/mmsegmentation/pull/316))
+- Support MobileNetV3 ([#268](https://github.com/open-mmlab/mmsegmentation/pull/268))
+- Add 4 retinal vessel segmentation benchmark ([#315](https://github.com/open-mmlab/mmsegmentation/pull/315))
+- Support DMNet ([#313](https://github.com/open-mmlab/mmsegmentation/pull/313))
+- Support APCNet ([#299](https://github.com/open-mmlab/mmsegmentation/pull/299))
+
+**Improvements**
+
+- Refactor Documentation page ([#311](https://github.com/open-mmlab/mmsegmentation/pull/311))
+- Support resize data augmentation according to original image size ([#291](https://github.com/open-mmlab/mmsegmentation/pull/291))
+
+### V0.9 (30/11/2020)
+
+**Highlights**
+
+- Support 4 medical dataset, UNet and CGNet.
+
+**New Features**
+
+- Support RandomRotate transform ([#215](https://github.com/open-mmlab/mmsegmentation/pull/215), [#260](https://github.com/open-mmlab/mmsegmentation/pull/260))
+- Support RGB2Gray transform ([#227](https://github.com/open-mmlab/mmsegmentation/pull/227))
+- Support Rerange transform ([#228](https://github.com/open-mmlab/mmsegmentation/pull/228))
+- Support ignore_index for BCE loss ([#210](https://github.com/open-mmlab/mmsegmentation/pull/210))
+- Add modelzoo statistics ([#263](https://github.com/open-mmlab/mmsegmentation/pull/263))
+- Support Dice evaluation metric ([#225](https://github.com/open-mmlab/mmsegmentation/pull/225))
+- Support Adjust Gamma transform ([#232](https://github.com/open-mmlab/mmsegmentation/pull/232))
+- Support CLAHE transform ([#229](https://github.com/open-mmlab/mmsegmentation/pull/229))
+
+**Bug Fixes**
+
+- Fixed detail API link ([#267](https://github.com/open-mmlab/mmsegmentation/pull/267))
+
+### V0.8 (03/11/2020)
+
+**Highlights**
+
+- Support 4 medical dataset, UNet and CGNet.
+
+**New Features**
+
+- Support customize runner ([#118](https://github.com/open-mmlab/mmsegmentation/pull/118))
+- Support UNet ([#161](https://github.com/open-mmlab/mmsegmentation/pull/162))
+- Support CHASE_DB1, DRIVE, STARE, HRD ([#203](https://github.com/open-mmlab/mmsegmentation/pull/203))
+- Support CGNet ([#223](https://github.com/open-mmlab/mmsegmentation/pull/223))
+
+### V0.7 (07/10/2020)
+
+**Highlights**
+
+- Support Pascal Context dataset and customizing class dataset.
+
+**Bug Fixes**
+
+- Fixed CPU inference ([#153](https://github.com/open-mmlab/mmsegmentation/pull/153))
+
+**New Features**
+
+- Add DeepLab OS16 models ([#154](https://github.com/open-mmlab/mmsegmentation/pull/154))
+- Support Pascal Context dataset ([#133](https://github.com/open-mmlab/mmsegmentation/pull/133))
+- Support customizing dataset classes ([#71](https://github.com/open-mmlab/mmsegmentation/pull/71))
+- Support customizing dataset palette ([#157](https://github.com/open-mmlab/mmsegmentation/pull/157))
+
+**Improvements**
+
+- Support 4D tensor output in ONNX ([#150](https://github.com/open-mmlab/mmsegmentation/pull/150))
+- Remove redundancies in ONNX export ([#160](https://github.com/open-mmlab/mmsegmentation/pull/160))
+- Migrate to MMCV DepthwiseSeparableConv ([#158](https://github.com/open-mmlab/mmsegmentation/pull/158))
+- Migrate to MMCV collect_env ([#137](https://github.com/open-mmlab/mmsegmentation/pull/137))
+- Use img_prefix and seg_prefix for loading ([#153](https://github.com/open-mmlab/mmsegmentation/pull/153))
+
+### V0.6 (10/09/2020)
+
+**Highlights**
+
+- Support new methods i.e. MobileNetV2, EMANet, DNL, PointRend, Semantic FPN, Fast-SCNN, ResNeSt.
+
+**Bug Fixes**
+
+- Fixed sliding inference ONNX export ([#90](https://github.com/open-mmlab/mmsegmentation/pull/90))
+
+**New Features**
+
+- Support MobileNet v2 ([#86](https://github.com/open-mmlab/mmsegmentation/pull/86))
+- Support EMANet ([#34](https://github.com/open-mmlab/mmsegmentation/pull/34))
+- Support DNL ([#37](https://github.com/open-mmlab/mmsegmentation/pull/37))
+- Support PointRend ([#109](https://github.com/open-mmlab/mmsegmentation/pull/109))
+- Support Semantic FPN ([#94](https://github.com/open-mmlab/mmsegmentation/pull/94))
+- Support Fast-SCNN ([#58](https://github.com/open-mmlab/mmsegmentation/pull/58))
+- Support ResNeSt backbone ([#47](https://github.com/open-mmlab/mmsegmentation/pull/47))
+- Support ONNX export (experimental) ([#12](https://github.com/open-mmlab/mmsegmentation/pull/12))
+
+**Improvements**
+
+- Support Upsample in ONNX ([#100](https://github.com/open-mmlab/mmsegmentation/pull/100))
+- Support Windows install (experimental) ([#75](https://github.com/open-mmlab/mmsegmentation/pull/75))
+- Add more OCRNet results ([#20](https://github.com/open-mmlab/mmsegmentation/pull/20))
+- Add PyTorch 1.6 CI ([#64](https://github.com/open-mmlab/mmsegmentation/pull/64))
+- Get version and githash automatically ([#55](https://github.com/open-mmlab/mmsegmentation/pull/55))
+
+### v0.5.1 (11/08/2020)
+
+**Highlights**
+
+- Support FP16 and more generalized OHEM
+
+**Bug Fixes**
+
+- Fixed Pascal VOC conversion script (#19)
+- Fixed OHEM weight assign bug (#54)
+- Fixed palette type when palette is not given (#27)
+
+**New Features**
+
+- Support FP16 (#21)
+- Generalized OHEM (#54)
+
+**Improvements**
+
+- Add load-from flag (#33)
+- Fixed training tricks doc about different learning rates of model (#26)
diff --git a/docs/en/conf.py b/docs/en/conf.py
new file mode 100644
index 0000000..87b16f2
--- /dev/null
+++ b/docs/en/conf.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+#
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../../'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMSegmentation'
+copyright = '2020-2021, OpenMMLab'
+author = 'MMSegmentation Authors'
+version_file = '../../mmseg/version.py'
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+# The full version, including alpha/beta/rc tags
+release = get_version()
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
+ 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser'
+]
+
+autodoc_mock_imports = [
+ 'matplotlib', 'pycocotools', 'mmseg.version', 'mmcv.ops'
+]
+
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The master toctree document.
+master_doc = 'index'
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+# html_theme = 'sphinx_rtd_theme'
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+html_theme_options = {
+ 'logo_url':
+ 'https://mmsegmentation.readthedocs.io/en/latest/',
+ 'menu': [
+ {
+ 'name':
+ 'Tutorial',
+ 'url':
+ 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
+ 'demo/MMSegmentation_Tutorial.ipynb'
+ },
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmsegmentation'
+ },
+ {
+ 'name':
+ 'Upstream',
+ 'children': [
+ {
+ 'name': 'MMCV',
+ 'url': 'https://github.com/open-mmlab/mmcv',
+ 'description': 'Foundational library for computer vision'
+ },
+ ]
+ },
+ ],
+ # Specify the language of shared menu
+ 'menu_lang':
+ 'en'
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# Enable ::: for my_st
+myst_enable_extensions = ['colon_fence']
+
+language = 'en'
+
+
+def builder_inited_handler(app):
+ subprocess.run(['./stat.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/docs/en/dataset_prepare.md b/docs/en/dataset_prepare.md
new file mode 100644
index 0000000..c115e86
--- /dev/null
+++ b/docs/en/dataset_prepare.md
@@ -0,0 +1,327 @@
+## Prepare datasets
+
+It is recommended to symlink the dataset root to `$MMSEGMENTATION/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+```none
+mmsegmentation
+├── mmseg
+├── tools
+├── configs
+├── data
+│ ├── cityscapes
+│ │ ├── leftImg8bit
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── gtFine
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── VOCdevkit
+│ │ ├── VOC2012
+│ │ │ ├── JPEGImages
+│ │ │ ├── SegmentationClass
+│ │ │ ├── ImageSets
+│ │ │ │ ├── Segmentation
+│ │ ├── VOC2010
+│ │ │ ├── JPEGImages
+│ │ │ ├── SegmentationClassContext
+│ │ │ ├── ImageSets
+│ │ │ │ ├── SegmentationContext
+│ │ │ │ │ ├── train.txt
+│ │ │ │ │ ├── val.txt
+│ │ │ ├── trainval_merged.json
+│ │ ├── VOCaug
+│ │ │ ├── dataset
+│ │ │ │ ├── cls
+│ ├── ade
+│ │ ├── ADEChallengeData2016
+│ │ │ ├── annotations
+│ │ │ │ ├── training
+│ │ │ │ ├── validation
+│ │ │ ├── images
+│ │ │ │ ├── training
+│ │ │ │ ├── validation
+│ ├── coco_stuff10k
+│ │ ├── images
+│ │ │ ├── train2014
+│ │ │ ├── test2014
+│ │ ├── annotations
+│ │ │ ├── train2014
+│ │ │ ├── test2014
+│ │ ├── imagesLists
+│ │ │ ├── train.txt
+│ │ │ ├── test.txt
+│ │ │ ├── all.txt
+│ ├── coco_stuff164k
+│ │ ├── images
+│ │ │ ├── train2017
+│ │ │ ├── val2017
+│ │ ├── annotations
+│ │ │ ├── train2017
+│ │ │ ├── val2017
+│ ├── CHASE_DB1
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── DRIVE
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── HRF
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── STARE
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+| ├── dark_zurich
+| │ ├── gps
+| │ │ ├── val
+| │ │ └── val_ref
+| │ ├── gt
+| │ │ └── val
+| │ ├── LICENSE.txt
+| │ ├── lists_file_names
+| │ │ ├── val_filenames.txt
+| │ │ └── val_ref_filenames.txt
+| │ ├── README.md
+| │ └── rgb_anon
+| │ | ├── val
+| │ | └── val_ref
+| ├── NighttimeDrivingTest
+| | ├── gtCoarse_daytime_trainvaltest
+| | │ └── test
+| | │ └── night
+| | └── leftImg8bit
+| | | └── test
+| | | └── night
+│ ├── loveDA
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ │ ├── test
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── potsdam
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ ├── val
+```
+
+### Cityscapes
+
+The data could be found [here](https://www.cityscapes-dataset.com/downloads/) after registration.
+
+By convention, `**labelTrainIds.png` are used for cityscapes training.
+We provided a [scripts](https://github.com/open-mmlab/mmsegmentation/blob/master/tools/convert_datasets/cityscapes.py) based on [cityscapesscripts](https://github.com/mcordts/cityscapesScripts)
+to generate `**labelTrainIds.png`.
+
+```shell
+# --nproc means 8 process for conversion, which could be omitted as well.
+python tools/convert_datasets/cityscapes.py data/cityscapes --nproc 8
+```
+
+### Pascal VOC
+
+Pascal VOC 2012 could be downloaded from [here](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar).
+Beside, most recent works on Pascal VOC dataset usually exploit extra augmentation data, which could be found [here](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/semantic_contours/benchmark.tgz).
+
+If you would like to use augmented VOC dataset, please run following command to convert augmentation annotations into proper format.
+
+```shell
+# --nproc means 8 process for conversion, which could be omitted as well.
+python tools/convert_datasets/voc_aug.py data/VOCdevkit data/VOCdevkit/VOCaug --nproc 8
+```
+
+Please refer to [concat dataset](https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/tutorials/customize_datasets.md#concatenate-dataset) for details about how to concatenate them and train them together.
+
+### ADE20K
+
+The training and validation set of ADE20K could be download from this [link](http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip).
+We may also download test set from [here](http://data.csail.mit.edu/places/ADEchallenge/release_test.zip).
+
+### Pascal Context
+
+The training and validation set of Pascal Context could be download from [here](http://host.robots.ox.ac.uk/pascal/VOC/voc2010/VOCtrainval_03-May-2010.tar). You may also download test set from [here](http://host.robots.ox.ac.uk:8080/eval/downloads/VOC2010test.tar) after registration.
+
+To split the training and validation set from original dataset, you may download trainval_merged.json from [here](https://codalabuser.blob.core.windows.net/public/trainval_merged.json).
+
+If you would like to use Pascal Context dataset, please install [Detail](https://github.com/zhanghang1989/detail-api) and then run the following command to convert annotations into proper format.
+
+```shell
+python tools/convert_datasets/pascal_context.py data/VOCdevkit data/VOCdevkit/VOC2010/trainval_merged.json
+```
+
+### COCO Stuff 10k
+
+The data could be downloaded [here](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip) by wget.
+
+For COCO Stuff 10k dataset, please run the following commands to download and convert the dataset.
+
+```shell
+# download
+mkdir coco_stuff10k && cd coco_stuff10k
+wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip
+
+# unzip
+unzip cocostuff-10k-v1.1.zip
+
+# --nproc means 8 process for conversion, which could be omitted as well.
+python tools/convert_datasets/coco_stuff10k.py /path/to/coco_stuff10k --nproc 8
+```
+
+By convention, mask labels in `/path/to/coco_stuff164k/annotations/*2014/*_labelTrainIds.png` are used for COCO Stuff 10k training and testing.
+
+### COCO Stuff 164k
+
+For COCO Stuff 164k dataset, please run the following commands to download and convert the augmented dataset.
+
+```shell
+# download
+mkdir coco_stuff164k && cd coco_stuff164k
+wget http://images.cocodataset.org/zips/train2017.zip
+wget http://images.cocodataset.org/zips/val2017.zip
+wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip
+
+# unzip
+unzip train2017.zip -d images/
+unzip val2017.zip -d images/
+unzip stuffthingmaps_trainval2017.zip -d annotations/
+
+# --nproc means 8 process for conversion, which could be omitted as well.
+python tools/convert_datasets/coco_stuff164k.py /path/to/coco_stuff164k --nproc 8
+```
+
+By convention, mask labels in `/path/to/coco_stuff164k/annotations/*2017/*_labelTrainIds.png` are used for COCO Stuff 164k training and testing.
+
+The details of this dataset could be found at [here](https://github.com/nightrome/cocostuff#downloads).
+
+### CHASE DB1
+
+The training and validation set of CHASE DB1 could be download from [here](https://staffnet.kingston.ac.uk/~ku15565/CHASE_DB1/assets/CHASEDB1.zip).
+
+To convert CHASE DB1 dataset to MMSegmentation format, you should run the following command:
+
+```shell
+python tools/convert_datasets/chase_db1.py /path/to/CHASEDB1.zip
+```
+
+The script will make directory structure automatically.
+
+### DRIVE
+
+The training and validation set of DRIVE could be download from [here](https://drive.grand-challenge.org/). Before that, you should register an account. Currently '1st_manual' is not provided officially.
+
+To convert DRIVE dataset to MMSegmentation format, you should run the following command:
+
+```shell
+python tools/convert_datasets/drive.py /path/to/training.zip /path/to/test.zip
+```
+
+The script will make directory structure automatically.
+
+### HRF
+
+First, download [healthy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy.zip), [glaucoma.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma.zip), [diabetic_retinopathy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy.zip), [healthy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy_manualsegm.zip), [glaucoma_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma_manualsegm.zip) and [diabetic_retinopathy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy_manualsegm.zip).
+
+To convert HRF dataset to MMSegmentation format, you should run the following command:
+
+```shell
+python tools/convert_datasets/hrf.py /path/to/healthy.zip /path/to/healthy_manualsegm.zip /path/to/glaucoma.zip /path/to/glaucoma_manualsegm.zip /path/to/diabetic_retinopathy.zip /path/to/diabetic_retinopathy_manualsegm.zip
+```
+
+The script will make directory structure automatically.
+
+### STARE
+
+First, download [stare-images.tar](http://cecas.clemson.edu/~ahoover/stare/probing/stare-images.tar), [labels-ah.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-ah.tar) and [labels-vk.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-vk.tar).
+
+To convert STARE dataset to MMSegmentation format, you should run the following command:
+
+```shell
+python tools/convert_datasets/stare.py /path/to/stare-images.tar /path/to/labels-ah.tar /path/to/labels-vk.tar
+```
+
+The script will make directory structure automatically.
+
+### Dark Zurich
+
+Since we only support test models on this dataset, you may only download [the validation set](https://data.vision.ee.ethz.ch/csakarid/shared/GCMA_UIoU/Dark_Zurich_val_anon.zip).
+
+### Nighttime Driving
+
+Since we only support test models on this dataset, you may only download [the test set](http://data.vision.ee.ethz.ch/daid/NighttimeDriving/NighttimeDrivingTest.zip).
+
+### LoveDA
+
+The data could be downloaded from Google Drive [here](https://drive.google.com/drive/folders/1ibYV0qwn4yuuh068Rnc-w4tPi0U0c-ti?usp=sharing).
+
+Or it can be downloaded from [zenodo](https://zenodo.org/record/5706578#.YZvN7SYRXdF), you should run the following command:
+
+```shell
+# Download Train.zip
+wget https://zenodo.org/record/5706578/files/Train.zip
+# Download Val.zip
+wget https://zenodo.org/record/5706578/files/Val.zip
+# Download Test.zip
+wget https://zenodo.org/record/5706578/files/Test.zip
+```
+
+For LoveDA dataset, please run the following command to download and re-organize the dataset.
+
+```shell
+python tools/convert_datasets/loveda.py /path/to/loveDA
+```
+
+Using trained model to predict test set of LoveDA and submit it to server can be found [here](https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/inference.md).
+
+More details about LoveDA can be found [here](https://github.com/Junjue-Wang/LoveDA).
+
+### ISPRS Potsdam
+
+The [Potsdam](https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-potsdam/)
+dataset is for urban semantic segmentation used in the 2D Semantic Labeling Contest - Potsdam.
+
+The dataset can be requested at the challenge [homepage](https://www2.isprs.org/commissions/comm2/wg4/benchmark/data-request-form/).
+The '2_Ortho_RGB.zip' and '5_Labels_all_noBoundary.zip' are required.
+
+For Potsdam dataset, please run the following command to download and re-organize the dataset.
+
+```shell
+python tools/convert_datasets/potsdam.py /path/to/potsdam
+```
+
+In our default setting, it will generate 3456 images for training and 2016 images for validation.
+
+### ISPRS Vaihingen
+
+The [Vaihingen](https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/)
+dataset is for urban semantic segmentation used in the 2D Semantic Labeling Contest - Vaihingen.
+
+The dataset can be requested at the challenge [homepage](https://www2.isprs.org/commissions/comm2/wg4/benchmark/data-request-form/).
+The 'ISPRS_semantic_labeling_Vaihingen.zip' and 'ISPRS_semantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE.zip' are required.
+
+For Vaihingen dataset, please run the following command to download and re-organize the dataset.
+
+```shell
+python tools/convert_datasets/vaihingen.py /path/to/vaihingen
+```
+
+In our default setting (`clip_size` =512, `stride_size`=256), it will generate 344 images for training and 398 images for validation.
diff --git a/docs/en/get_started.md b/docs/en/get_started.md
new file mode 100644
index 0000000..bd77456
--- /dev/null
+++ b/docs/en/get_started.md
@@ -0,0 +1,238 @@
+## Prerequisites
+
+- Linux or macOS (Windows is in experimental support)
+- Python 3.6+
+- PyTorch 1.3+
+- CUDA 9.2+ (If you build PyTorch from source, CUDA 9.0 is also compatible)
+- GCC 5+
+- [MMCV](https://mmcv.readthedocs.io/en/latest/#installation)
+
+The compatible MMSegmentation and MMCV versions are as below. Please install the correct version of MMCV to avoid installation issues.
+
+| MMSegmentation version | MMCV version |
+|:----------------------:|:--------------------------:|
+| master | mmcv-full>=1.4.4, <1.5.0 |
+| 0.21.0 | mmcv-full>=1.4.4, <1.5.0 |
+| 0.20.0 | mmcv-full>=1.3.13, <1.5.0 |
+| 0.19.0 | mmcv-full>=1.3.13, <1.3.17 |
+| 0.18.0 | mmcv-full>=1.3.13, <1.3.17 |
+| 0.17.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.16.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.15.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.14.1 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.14.0 | mmcv-full>=1.3.1, <1.3.2 |
+| 0.13.0 | mmcv-full>=1.3.1, <1.3.2 |
+| 0.12.0 | mmcv-full>=1.1.4, <1.3.2 |
+| 0.11.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.10.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.9.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.8.0 | mmcv-full>=1.1.4, <1.2.0 |
+| 0.7.0 | mmcv-full>=1.1.2, <1.2.0 |
+| 0.6.0 | mmcv-full>=1.1.2, <1.2.0 |
+
+:::{note}
+You need to run `pip uninstall mmcv` first if you have mmcv installed.
+If mmcv and mmcv-full are both installed, there will be `ModuleNotFoundError`.
+:::
+
+## Installation
+
+a. Create a conda virtual environment and activate it.
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+```
+
+b. Install PyTorch and torchvision following the [official instructions](https://pytorch.org/).
+Here we use PyTorch 1.6.0 and CUDA 10.1.
+You may also switch to other version by specifying the version number.
+
+```shell
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+```
+
+c. Install [MMCV](https://mmcv.readthedocs.io/en/latest/) following the [official instructions](https://mmcv.readthedocs.io/en/latest/#installation).
+Either `mmcv` or `mmcv-full` is compatible with MMSegmentation, but for methods like CCNet and PSANet, CUDA ops in `mmcv-full` is required.
+
+**Install mmcv for Linux:**
+
+The pre-build mmcv-full (with PyTorch 1.6 and CUDA 10.1) can be installed by running: (other available versions could be found [here](https://mmcv.readthedocs.io/en/latest/#install-with-pip))
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
+```
+
+**Install mmcv for Windows (Experimental):**
+
+For Windows, the installation of MMCV requires native C++ compilers, such as cl.exe. Please add the compiler to %PATH%.
+
+A typical path for cl.exe looks like the following if you have Windows SDK and Visual Studio installed on your computer:
+
+```shell
+C:\Program Files (x86)\Microsoft Visual Studio\2019\Professional\VC\Tools\MSVC\14.26.28801\bin\Hostx86\x64
+```
+
+Or you should download the cl compiler from web and then set up the path.
+
+Then, clone mmcv from github and install mmcv via pip:
+
+```shell
+git clone https://github.com/open-mmlab/mmcv.git
+cd mmcv
+pip install -e .
+```
+
+Or simply:
+
+```shell
+pip install mmcv
+```
+
+Currently, mmcv-full is not supported on Windows.
+
+d. Install MMSegmentation.
+
+```shell
+pip install mmsegmentation # install the latest release
+```
+
+or
+
+```shell
+pip install git+https://github.com/open-mmlab/mmsegmentation.git # install the master branch
+```
+
+Instead, if you would like to install MMSegmentation in `dev` mode, run following
+
+```shell
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # or "python setup.py develop"
+```
+
+:::{note}
+
+1. When training or testing models on Windows, please ensure that all the '\\' in paths are replaced with '/'. Add .replace('\\', '/') to your python code wherever path strings occur.
+2. The `version+git_hash` will also be saved in trained models meta, e.g. 0.5.0+c415a2e.
+3. When MMsegmentation is installed on `dev` mode, any local modifications made to the code will take effect without the need to reinstall it.
+4. If you would like to use `opencv-python-headless` instead of `opencv-python`,
+ you can install it before installing MMCV.
+5. Some dependencies are optional. Simply running `pip install -e .` will only install the minimum runtime requirements.
+ To use optional dependencies like `cityscapessripts` either install them manually with `pip install -r requirements/optional.txt` or specify desired extras when calling `pip` (e.g. `pip install -e .[optional]`). Valid keys for the extras field are: `all`, `tests`, `build`, and `optional`.
+:::
+
+### A from-scratch setup script
+
+#### Linux
+
+Here is a full script for setting up mmsegmentation with conda and link the dataset path (supposing that your dataset path is $DATA_ROOT).
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # or "python setup.py develop"
+
+mkdir data
+ln -s $DATA_ROOT data
+```
+
+#### Windows(Experimental)
+
+Here is a full script for setting up mmsegmentation with conda and link the dataset path (supposing that your dataset path is
+%DATA_ROOT%. Notice: It must be an absolute path).
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+set PATH=full\path\to\your\cpp\compiler;%PATH%
+pip install mmcv
+
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # or "python setup.py develop"
+
+mklink /D data %DATA_ROOT%
+```
+
+#### Developing with multiple MMSegmentation versions
+
+The train and test scripts already modify the `PYTHONPATH` to ensure the script use the MMSegmentation in the current directory.
+
+To use the default MMSegmentation installed in the environment rather than that you are working with, you can remove the following line in those scripts
+
+```shell
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
+```
+
+## Verification
+
+To verify whether MMSegmentation and the required environment are installed correctly, we can run sample python codes to initialize a segmentor and inference a demo image:
+
+```python
+from mmseg.apis import inference_segmentor, init_segmentor
+import mmcv
+
+config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'
+checkpoint_file = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
+
+# build the model from a config file and a checkpoint file
+model = init_segmentor(config_file, checkpoint_file, device='cuda:0')
+
+# test a single image and show the results
+img = 'test.jpg' # or img = mmcv.imread(img), which will only load it once
+result = inference_segmentor(model, img)
+# visualize the results in a new window
+model.show_result(img, result, show=True)
+# or save the visualization results to image files
+# you can change the opacity of the painted segmentation map in (0, 1].
+model.show_result(img, result, out_file='result.jpg', opacity=0.5)
+
+# test a video and show the results
+video = mmcv.VideoReader('video.mp4')
+for frame in video:
+ result = inference_segmentor(model, frame)
+ model.show_result(frame, result, wait_time=1)
+```
+
+The above code is supposed to run successfully upon you finish the installation.
+
+We also provide a demo script to test a single image.
+
+```shell
+python demo/image_demo.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${DEVICE_NAME}] [--palette-thr ${PALETTE}]
+```
+
+Examples:
+
+```shell
+python demo/image_demo.py demo/demo.jpg configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --palette cityscapes
+```
+
+A notebook demo can be found in [demo/inference_demo.ipynb](../demo/inference_demo.ipynb).
+
+Now we also provide a demo script to test a single video.
+
+```shell
+wget -O demo/demo.mp4 https://user-images.githubusercontent.com/22089207/144212749-44411ef4-b564-4b37-96d4-04bedec629ab.mp4
+python demo/video_demo.py ${VIDEO_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${DEVICE_NAME}] [--palette-thr ${PALETTE}] \
+ [--show] [--show-wait-time {SHOW_WAIT_TIME}] [--output-file {OUTPUT_FILE}] [--output-fps {OUTPUT_FPS}] \
+ [--output-height {OUTPUT_HEIGHT}] [--output-width {OUTPUT_WIDTH}] [--opacity {OPACITY}]
+```
+
+Examples:
+
+```shell
+wget -O demo/demo.mp4 https://user-images.githubusercontent.com/22089207/144212749-44411ef4-b564-4b37-96d4-04bedec629ab.mp4
+python demo/video_demo.py demo/demo.mp4 configs/cgnet/cgnet_680x680_60k_cityscapes.py \
+ checkpoints/cgnet_680x680_60k_cityscapes_20201101_110253-4c0b2f2d.pth \
+ --device cuda:0 --palette cityscapes --show
+```
diff --git a/docs/en/index.rst b/docs/en/index.rst
new file mode 100644
index 0000000..b778e18
--- /dev/null
+++ b/docs/en/index.rst
@@ -0,0 +1,62 @@
+Welcome to MMSegmenation's documentation!
+=======================================
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Get Started
+
+ get_started.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Dataset Preparation
+
+ dataset_prepare.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Model Zoo
+
+ model_zoo.md
+ modelzoo_statistics.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Quick Run
+
+ train.md
+ inference.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Tutorials
+
+ tutorials/index.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Useful Tools and Scripts
+
+ useful_tools.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Notes
+
+ changelog.md
+
+.. toctree::
+ :caption: Switch Language
+
+ switch_language.md
+
+.. toctree::
+ :caption: API Reference
+
+ api.rst
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/docs/en/inference.md b/docs/en/inference.md
new file mode 100644
index 0000000..cd6eaf0
--- /dev/null
+++ b/docs/en/inference.md
@@ -0,0 +1,130 @@
+## Inference with pretrained models
+
+We provide testing scripts to evaluate a whole dataset (Cityscapes, PASCAL VOC, ADE20k, etc.),
+and also some high-level apis for easier integration to other projects.
+
+### Test a dataset
+
+- single GPU
+- CPU
+- single node multiple GPU
+- multiple node
+
+You can use the following commands to test a dataset.
+
+```shell
+# single-gpu testing
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show]
+
+# CPU: disable GPUs and run single-gpu testing script
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show]
+
+# multi-gpu testing
+./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}]
+```
+
+Optional arguments:
+
+- `RESULT_FILE`: Filename of the output results in pickle format. If not specified, the results will not be saved to a file. (After mmseg v0.17, the output results become pre-evaluation results or format result paths)
+- `EVAL_METRICS`: Items to be evaluated on the results. Allowed values depend on the dataset, e.g., `mIoU` is available for all dataset. Cityscapes could be evaluated by `cityscapes` as well as standard `mIoU` metrics.
+- `--show`: If specified, segmentation results will be plotted on the images and shown in a new window. It is only applicable to single GPU testing and used for debugging and visualization. Please make sure that GUI is available in your environment, otherwise you may encounter the error like `cannot connect to X server`.
+- `--show-dir`: If specified, segmentation results will be plotted on the images and saved to the specified directory. It is only applicable to single GPU testing and used for debugging and visualization. You do NOT need a GUI available in your environment for using this option.
+- `--eval-options`: Optional parameters for `dataset.format_results` and `dataset.evaluate` during evaluation. When `efficient_test=True`, it will save intermediate results to local files to save CPU memory. Make sure that you have enough local storage space (more than 20GB). (`efficient_test` argument does not have effect after mmseg v0.17, we use a progressive mode to evaluation and format results which can largely save memory cost and evaluation time.)
+
+Examples:
+
+Assume that you have already downloaded the checkpoints to the directory `checkpoints/`.
+
+1. Test PSPNet and visualize the results. Press any key for the next image.
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --show
+ ```
+
+2. Test PSPNet and save the painted images for latter visualization.
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --show-dir psp_r50_512x1024_40ki_cityscapes_results
+ ```
+
+3. Test PSPNet on PASCAL VOC (without saving the test results) and evaluate the mIoU.
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_20k_voc12aug.py \
+ checkpoints/pspnet_r50-d8_512x1024_20k_voc12aug_20200605_003338-c57ef100.pth \
+ --eval mAP
+ ```
+
+4. Test PSPNet with 4 GPUs, and evaluate the standard mIoU and cityscapes metric.
+
+ ```shell
+ ./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ 4 --out results.pkl --eval mIoU cityscapes
+ ```
+
+ :::{note}
+ There is some gap (~0.1%) between cityscapes mIoU and our mIoU. The reason is that cityscapes average each class with class size by default.
+ We use the simple version without average for all datasets.
+:::
+
+5. Test PSPNet on cityscapes test split with 4 GPUs, and generate the png files to be submit to the official evaluation server.
+
+ First, add following to config file `configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py`,
+
+ ```python
+ data = dict(
+ test=dict(
+ img_dir='leftImg8bit/test',
+ ann_dir='gtFine/test'))
+ ```
+
+ Then run test.
+
+ ```shell
+ ./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ 4 --format-only --eval-options "imgfile_prefix=./pspnet_test_results"
+ ```
+
+ You will get png files under `./pspnet_test_results` directory.
+ You may run `zip -r results.zip pspnet_test_results/` and submit the zip file to [evaluation server](https://www.cityscapes-dataset.com/submit/).
+
+6. CPU memory efficient test DeeplabV3+ on Cityscapes (without saving the test results) and evaluate the mIoU.
+
+ ```shell
+ python tools/test.py \
+ configs/deeplabv3plus/deeplabv3plus_r18-d8_512x1024_80k_cityscapes.py \
+ deeplabv3plus_r18-d8_512x1024_80k_cityscapes_20201226_080942-cff257fe.pth \
+ --eval-options efficient_test=True \
+ --eval mIoU
+ ```
+
+ Using ```pmap``` to view CPU memory footprint, it used 2.25GB CPU memory with ```efficient_test=True``` and 11.06GB CPU memory with ```efficient_test=False``` . This optional parameter can save a lot of memory. (After mmseg v0.17, efficient_test has not effect and we use a progressive mode to evaluation and format results efficiently by default.)
+
+7. Test PSPNet on LoveDA test split with 1 GPU, and generate the png files to be submit to the official evaluation server.
+
+ First, add following to config file `configs/pspnet/pspnet_r50-d8_512x512_80k_loveda.py`,
+
+ ```python
+ data = dict(
+ test=dict(
+ img_dir='img_dir/test',
+ ann_dir='ann_dir/test'))
+ ```
+
+ Then run test.
+
+ ```shell
+ python ./tools/test.py configs/pspnet/pspnet_r50-d8_512x512_80k_loveda.py \
+ checkpoints/pspnet_r50-d8_512x512_80k_loveda_20211104_155728-88610f9f.pth \
+ --format-only --eval-options "imgfile_prefix=./pspnet_test_results"
+ ```
+
+ You will get png files under `./pspnet_test_results` directory.
+ You may run `zip -r -j Results.zip pspnet_test_results/` and submit the zip file to [evaluation server](https://codalab.lisn.upsaclay.fr/competitions/421).
diff --git a/docs/en/make.bat b/docs/en/make.bat
new file mode 100644
index 0000000..922152e
--- /dev/null
+++ b/docs/en/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/en/model_zoo.md b/docs/en/model_zoo.md
new file mode 100644
index 0000000..e6498ad
--- /dev/null
+++ b/docs/en/model_zoo.md
@@ -0,0 +1,181 @@
+# Benchmark and Model Zoo
+
+## Common settings
+
+* We use distributed training with 4 GPUs by default.
+* All pytorch-style pretrained backbones on ImageNet are train by ourselves, with the same procedure in the [paper](https://arxiv.org/pdf/1812.01187.pdf).
+ Our ResNet style backbone are based on ResNetV1c variant, where the 7x7 conv in the input stem is replaced with three 3x3 convs.
+* For the consistency across different hardwares, we report the GPU memory as the maximum value of `torch.cuda.max_memory_allocated()` for all 4 GPUs with `torch.backends.cudnn.benchmark=False`.
+ Note that this value is usually less than what `nvidia-smi` shows.
+* We report the inference time as the total time of network forwarding and post-processing, excluding the data loading time.
+ Results are obtained with the script `tools/benchmark.py` which computes the average time on 200 images with `torch.backends.cudnn.benchmark=False`.
+* There are two inference modes in this framework.
+
+ * `slide` mode: The `test_cfg` will be like `dict(mode='slide', crop_size=(769, 769), stride=(513, 513))`.
+
+ In this mode, multiple patches will be cropped from input image, passed into network individually.
+ The crop size and stride between patches are specified by `crop_size` and `stride`.
+ The overlapping area will be merged by average
+
+ * `whole` mode: The `test_cfg` will be like `dict(mode='whole')`.
+
+ In this mode, the whole imaged will be passed into network directly.
+
+ By default, we use `slide` inference for 769x769 trained model, `whole` inference for the rest.
+* For input size of 8x+1 (e.g. 769), `align_corner=True` is adopted as a traditional practice.
+ Otherwise, for input size of 8x (e.g. 512, 1024), `align_corner=False` is adopted.
+
+## Baselines
+
+### FCN
+
+Please refer to [FCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fcn) for details.
+
+### PSPNet
+
+Please refer to [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/pspnet) for details.
+
+### DeepLabV3
+
+Please refer to [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3) for details.
+
+### PSANet
+
+Please refer to [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/psanet) for details.
+
+### DeepLabV3+
+
+Please refer to [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3plus) for details.
+
+### UPerNet
+
+Please refer to [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/upernet) for details.
+
+### NonLocal Net
+
+Please refer to [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net) for details.
+
+### EncNet
+
+Please refer to [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/encnet) for details.
+
+### CCNet
+
+Please refer to [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ccnet) for details.
+
+### DANet
+
+Please refer to [DANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/danet) for details.
+
+### APCNet
+
+Please refer to [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/apcnet) for details.
+
+### HRNet
+
+Please refer to [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/hrnet) for details.
+
+### GCNet
+
+Please refer to [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/gcnet) for details.
+
+### DMNet
+
+Please refer to [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dmnet) for details.
+
+### ANN
+
+Please refer to [ANN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ann) for details.
+
+### OCRNet
+
+Please refer to [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ocrnet) for details.
+
+### Fast-SCNN
+
+Please refer to [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastscnn) for details.
+
+### ResNeSt
+
+Please refer to [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest) for details.
+
+### Semantic FPN
+
+Please refer to [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/sem_fpn) for details.
+
+### PointRend
+
+Please refer to [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/point_rend) for details.
+
+### MobileNetV2
+
+Please refer to [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v2) for details.
+
+### MobileNetV3
+
+Please refer to [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v3) for details.
+
+### EMANet
+
+Please refer to [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/emanet) for details.
+
+### DNLNet
+
+Please refer to [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dnlnet) for details.
+
+### CGNet
+
+Please refer to [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/cgnet) for details.
+
+### Mixed Precision (FP16) Training
+
+Please refer [Mixed Precision (FP16) Training on BiSeNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv2/bisenetv2_fcn_fp16_4x4_1024x1024_160k_cityscapes.py) for details.
+
+### U-Net
+
+Please refer to [U-Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/unet/README.md) for details.
+
+### ViT
+
+Please refer to [ViT](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/vit/README.md) for details.
+
+### Swin
+
+Please refer to [Swin](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/swin/README.md) for details.
+
+### SETR
+
+Please refer to [SETR](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/setr/README.md) for details.
+
+## Speed benchmark
+
+### Hardware
+
+* 8 NVIDIA Tesla V100 (32G) GPUs
+* Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
+
+### Software environment
+
+* Python 3.7
+* PyTorch 1.5
+* CUDA 10.1
+* CUDNN 7.6.03
+* NCCL 2.4.08
+
+### Training speed
+
+For fair comparison, we benchmark all implementations with ResNet-101V1c.
+The input size is fixed to 1024x512 with batch size 2.
+
+The training speed is reported as followed, in terms of second per iter (s/iter). The lower, the better.
+
+| Implementation | PSPNet (s/iter) | DeepLabV3+ (s/iter) |
+|----------------|-----------------|---------------------|
+| [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) | **0.83** | **0.85** |
+| [SegmenTron](https://github.com/LikeLy-Journey/SegmenTron) | 0.84 | 0.85 |
+| [CASILVision](https://github.com/CSAILVision/semantic-segmentation-pytorch) | 1.15 | N/A |
+| [vedaseg](https://github.com/Media-Smart/vedaseg) | 0.95 | 1.25 |
+
+:::{note}
+The output stride of DeepLabV3+ is 8.
+:::
diff --git a/docs/en/stat.py b/docs/en/stat.py
new file mode 100755
index 0000000..1398a70
--- /dev/null
+++ b/docs/en/stat.py
@@ -0,0 +1,65 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools as func
+import glob
+import os.path as osp
+import re
+
+import numpy as np
+
+url_prefix = 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
+
+files = sorted(glob.glob('../../configs/*/README.md'))
+
+stats = []
+titles = []
+num_ckpts = 0
+
+for f in files:
+ url = osp.dirname(f.replace('../../', url_prefix))
+
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ title = content.split('\n')[0].replace('#', '').strip()
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https?://download.*\.pth', content)
+ if 'mmsegmentation' in x)
+ if len(ckpts) == 0:
+ continue
+
+ _papertype = [
+ x for x in re.findall(r'', content)
+ ]
+ assert len(_papertype) > 0
+ papertype = _papertype[0]
+
+ paper = set([(papertype, title)])
+
+ titles.append(title)
+ num_ckpts += len(ckpts)
+ statsmsg = f"""
+\t* [{papertype}] [{title}]({url}) ({len(ckpts)} ckpts)
+"""
+ stats.append((paper, ckpts, statsmsg))
+
+allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _ in stats])
+msglist = '\n'.join(x for _, _, x in stats)
+
+papertypes, papercounts = np.unique([t for t, _ in allpapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# Model Zoo Statistics
+
+* Number of papers: {len(set(titles))}
+{countstr}
+
+* Number of checkpoints: {num_ckpts}
+{msglist}
+"""
+
+with open('modelzoo_statistics.md', 'w') as f:
+ f.write(modelzoo)
diff --git a/docs/en/switch_language.md b/docs/en/switch_language.md
new file mode 100644
index 0000000..f58efc4
--- /dev/null
+++ b/docs/en/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/docs/en/train.md b/docs/en/train.md
new file mode 100644
index 0000000..2c5dfb2
--- /dev/null
+++ b/docs/en/train.md
@@ -0,0 +1,105 @@
+## Train a model
+
+MMSegmentation implements distributed training and non-distributed training,
+which uses `MMDistributedDataParallel` and `MMDataParallel` respectively.
+
+All outputs (log files and checkpoints) will be saved to the working directory,
+which is specified by `work_dir` in the config file.
+
+By default we evaluate the model on the validation set after some iterations, you can change the evaluation interval by adding the interval argument in the training config.
+
+```python
+evaluation = dict(interval=4000) # This evaluate the model per 4000 iterations.
+```
+
+**\*Important\***: The default learning rate in config files is for 4 GPUs and 2 img/gpu (batch size = 4x2 = 8).
+Equivalently, you may also use 8 GPUs and 1 imgs/gpu since all models using cross-GPU SyncBN.
+
+To trade speed with GPU memory, you may pass in `--cfg-options model.backbone.with_cp=True` to enable checkpoint in backbone.
+
+### Train with a single GPU
+
+official support:
+
+```shell
+./tools/dist_train.sh ${CONFIG_FILE} 1 [optional arguments]
+```
+
+experimental support (Convert SyncBN to BN):
+
+```shell
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+If you want to specify the working directory in the command, you can add an argument `--work-dir ${YOUR_WORK_DIR}`.
+
+### Train with CPU
+
+The process of training on the CPU is consistent with single GPU training. We just need to disable GPUs before the training process.
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+```
+
+And then run the script [above](#train-with-a-single-gpu).
+
+```{warning}
+The process of training on the CPU is consistent with single GPU training. We just need to disable GPUs before the training process.
+```
+
+### Train with multiple GPUs
+
+```shell
+./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
+```
+
+Optional arguments are:
+
+- `--no-validate` (**not suggested**): By default, the codebase will perform evaluation at every k iterations during the training. To disable this behavior, use `--no-validate`.
+- `--work-dir ${WORK_DIR}`: Override the working directory specified in the config file.
+- `--resume-from ${CHECKPOINT_FILE}`: Resume from a previous checkpoint file (to continue the training process).
+- `--load-from ${CHECKPOINT_FILE}`: Load weights from a checkpoint file (to start finetuning for another task).
+
+Difference between `resume-from` and `load-from`:
+
+- `resume-from` loads both the model weights and optimizer state including the iteration number.
+- `load-from` loads only the model weights, starts the training from iteration 0.
+
+### Train with multiple machines
+
+If you run MMSegmentation on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `slurm_train.sh`. (This script also supports single machine training.)
+
+```shell
+[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} --work-dir ${WORK_DIR}
+```
+
+Here is an example of using 16 GPUs to train PSPNet on the dev partition.
+
+```shell
+GPUS=16 ./tools/slurm_train.sh dev pspr50 configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py /nfs/xxxx/psp_r50_512x1024_40ki_cityscapes
+```
+
+You can check [slurm_train.sh](../tools/slurm_train.sh) for full arguments and environment variables.
+
+If you have just multiple machines connected with ethernet, you can refer to
+PyTorch [launch utility](https://pytorch.org/docs/stable/distributed.html#launch-utility).
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+### Launch multiple jobs on a single machine
+
+If you launch multiple jobs on a single machine, e.g., 2 jobs of 4-GPU training on a machine with 8 GPUs,
+you need to specify different ports (29500 by default) for each job to avoid communication conflict. Otherwise, there will be error message saying `RuntimeError: Address already in use`.
+
+If you use `dist_train.sh` to launch training jobs, you can set the port in commands with environment variable `PORT`.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4
+```
+
+If you use `slurm_train.sh` to launch training jobs, you can set the port in commands with environment variable `MASTER_PORT`.
+
+```shell
+MASTER_PORT=29500 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE}
+MASTER_PORT=29501 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE}
+```
diff --git a/docs/en/tutorials/config.md b/docs/en/tutorials/config.md
new file mode 100644
index 0000000..f528e75
--- /dev/null
+++ b/docs/en/tutorials/config.md
@@ -0,0 +1,381 @@
+# Tutorial 1: Learn about Configs
+
+We incorporate modular and inheritance design into our config system, which is convenient to conduct various experiments.
+If you wish to inspect the config file, you may run `python tools/print_config.py /PATH/TO/CONFIG` to see the complete config.
+You may also pass `--cfg-options xxx.yyy=zzz` to see updated config.
+
+## Config File Structure
+
+There are 4 basic component types under `config/_base_`, dataset, model, schedule, default_runtime.
+Many methods could be easily constructed with one of each like DeepLabV3, PSPNet.
+The configs that are composed by components from `_base_` are called _primitive_.
+
+For all configs under the same folder, it is recommended to have only **one** _primitive_ config. All other configs should inherit from the _primitive_ config. In this way, the maximum of inheritance level is 3.
+
+For easy understanding, we recommend contributors to inherit from exiting methods.
+For example, if some modification is made base on DeepLabV3, user may first inherit the basic DeepLabV3 structure by specifying `_base_ = ../deeplabv3/deeplabv3_r50_512x1024_40ki_cityscapes.py`, then modify the necessary fields in the config files.
+
+If you are building an entirely new method that does not share the structure with any of the existing methods, you may create a folder `xxxnet` under `configs`,
+
+Please refer to [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html) for detailed documentation.
+
+## Config Name Style
+
+We follow the below style to name config files. Contributors are advised to follow the same style.
+
+```
+{model}_{backbone}_[misc]_[gpu x batch_per_gpu]_{resolution}_{schedule}_{dataset}
+```
+
+`{xxx}` is required field and `[yyy]` is optional.
+
+- `{model}`: model type like `psp`, `deeplabv3`, etc.
+- `{backbone}`: backbone type like `r50` (ResNet-50), `x101` (ResNeXt-101).
+- `[misc]`: miscellaneous setting/plugins of model, e.g. `dconv`, `gcb`, `attention`, `mstrain`.
+- `[gpu x batch_per_gpu]`: GPUs and samples per GPU, `8x2` is used by default.
+- `{schedule}`: training schedule, `20ki` means 20k iterations.
+- `{dataset}`: dataset like `cityscapes`, `voc12aug`, `ade`.
+
+## An Example of PSPNet
+
+To help the users have a basic idea of a complete config and the modules in a modern semantic segmentation system,
+we make brief comments on the config of PSPNet using ResNet50V1c as the following.
+For more detailed usage and the corresponding alternative for each modules, please refer to the API documentation.
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True) # Segmentation usually uses SyncBN
+model = dict(
+ type='EncoderDecoder', # Name of segmentor
+ pretrained='open-mmlab://resnet50_v1c', # The ImageNet pretrained backbone to be loaded
+ backbone=dict(
+ type='ResNetV1c', # The type of backbone. Please refer to mmseg/models/backbones/resnet.py for details.
+ depth=50, # Depth of backbone. Normally 50, 101 are used.
+ num_stages=4, # Number of stages of backbone.
+ out_indices=(0, 1, 2, 3), # The index of output feature maps produced in each stages.
+ dilations=(1, 1, 2, 4), # The dilation rate of each layer.
+ strides=(1, 2, 1, 1), # The stride of each layer.
+ norm_cfg=dict( # The configuration of norm layer.
+ type='SyncBN', # Type of norm layer. Usually it is SyncBN.
+ requires_grad=True), # Whether to train the gamma and beta in norm
+ norm_eval=False, # Whether to freeze the statistics in BN
+ style='pytorch', # The style of backbone, 'pytorch' means that stride 2 layers are in 3x3 conv, 'caffe' means stride 2 layers are in 1x1 convs.
+ contract_dilation=True), # When dilation > 1, whether contract first layer of dilation.
+ decode_head=dict(
+ type='PSPHead', # Type of decode head. Please refer to mmseg/models/decode_heads for available options.
+ in_channels=2048, # Input channel of decode head.
+ in_index=3, # The index of feature map to select.
+ channels=512, # The intermediate channels of decode head.
+ pool_scales=(1, 2, 3, 6), # The avg pooling scales of PSPHead. Please refer to paper for details.
+ dropout_ratio=0.1, # The dropout ratio before final classification layer.
+ num_classes=19, # Number of segmentation class. Usually 19 for cityscapes, 21 for VOC, 150 for ADE20k.
+ norm_cfg=dict(type='SyncBN', requires_grad=True), # The configuration of norm layer.
+ align_corners=False, # The align_corners argument for resize in decoding.
+ loss_decode=dict( # Config of loss function for the decode_head.
+ type='CrossEntropyLoss', # Type of loss used for segmentation.
+ use_sigmoid=False, # Whether use sigmoid activation for segmentation.
+ loss_weight=1.0)), # Loss weight of decode head.
+ auxiliary_head=dict(
+ type='FCNHead', # Type of auxiliary head. Please refer to mmseg/models/decode_heads for available options.
+ in_channels=1024, # Input channel of auxiliary head.
+ in_index=2, # The index of feature map to select.
+ channels=256, # The intermediate channels of decode head.
+ num_convs=1, # Number of convs in FCNHead. It is usually 1 in auxiliary head.
+ concat_input=False, # Whether concat output of convs with input before classification layer.
+ dropout_ratio=0.1, # The dropout ratio before final classification layer.
+ num_classes=19, # Number of segmentation class. Usually 19 for cityscapes, 21 for VOC, 150 for ADE20k.
+ norm_cfg=dict(type='SyncBN', requires_grad=True), # The configuration of norm layer.
+ align_corners=False, # The align_corners argument for resize in decoding.
+ loss_decode=dict( # Config of loss function for the decode_head.
+ type='CrossEntropyLoss', # Type of loss used for segmentation.
+ use_sigmoid=False, # Whether use sigmoid activation for segmentation.
+ loss_weight=0.4))) # Loss weight of auxiliary head, which is usually 0.4 of decode head.
+train_cfg = dict() # train_cfg is just a place holder for now.
+test_cfg = dict(mode='whole') # The test mode, options are 'whole' and 'sliding'. 'whole': whole image fully-convolutional test. 'sliding': sliding crop window on the image.
+dataset_type = 'CityscapesDataset' # Dataset type, this will be used to define the dataset.
+data_root = 'data/cityscapes/' # Root path of data.
+img_norm_cfg = dict( # Image normalization config to normalize the input images.
+ mean=[123.675, 116.28, 103.53], # Mean values used to pre-training the pre-trained backbone models.
+ std=[58.395, 57.12, 57.375], # Standard variance used to pre-training the pre-trained backbone models.
+ to_rgb=True) # The channel orders of image used to pre-training the pre-trained backbone models.
+crop_size = (512, 1024) # The crop size during training.
+train_pipeline = [ # Training pipeline.
+ dict(type='LoadImageFromFile'), # First pipeline to load images from file path.
+ dict(type='LoadAnnotations'), # Second pipeline to load annotations for current image.
+ dict(type='Resize', # Augmentation pipeline that resize the images and their annotations.
+ img_scale=(2048, 1024), # The largest scale of image.
+ ratio_range=(0.5, 2.0)), # The augmented scale range as ratio.
+ dict(type='RandomCrop', # Augmentation pipeline that randomly crop a patch from current image.
+ crop_size=(512, 1024), # The crop size of patch.
+ cat_max_ratio=0.75), # The max area ratio that could be occupied by single category.
+ dict(
+ type='RandomFlip', # Augmentation pipeline that flip the images and their annotations
+ flip_ratio=0.5), # The ratio or probability to flip
+ dict(type='PhotoMetricDistortion'), # Augmentation pipeline that distort current image with several photo metric methods.
+ dict(
+ type='Normalize', # Augmentation pipeline that normalize the input images
+ mean=[123.675, 116.28, 103.53], # These keys are the same of img_norm_cfg since the
+ std=[58.395, 57.12, 57.375], # keys of img_norm_cfg are used here as arguments
+ to_rgb=True),
+ dict(type='Pad', # Augmentation pipeline that pad the image to specified size.
+ size=(512, 1024), # The output size of padding.
+ pad_val=0, # The padding value for image.
+ seg_pad_val=255), # The padding value of 'gt_semantic_seg'.
+ dict(type='DefaultFormatBundle'), # Default format bundle to gather data in the pipeline
+ dict(type='Collect', # Pipeline that decides which keys in the data should be passed to the segmentor
+ keys=['img', 'gt_semantic_seg'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'), # First pipeline to load images from file path
+ dict(
+ type='MultiScaleFlipAug', # An encapsulation that encapsulates the test time augmentations
+ img_scale=(2048, 1024), # Decides the largest scale for testing, used for the Resize pipeline
+ flip=False, # Whether to flip images during testing
+ transforms=[
+ dict(type='Resize', # Use resize augmentation
+ keep_ratio=True), # Whether to keep the ratio between height and width, the img_scale set here will be suppressed by the img_scale set above.
+ dict(type='RandomFlip'), # Thought RandomFlip is added in pipeline, it is not used when flip=False
+ dict(
+ type='Normalize', # Normalization config, the values are from img_norm_cfg
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', # Convert image to tensor
+ keys=['img']),
+ dict(type='Collect', # Collect pipeline that collect necessary keys for testing.
+ keys=['img'])
+ ])
+]
+data = dict(
+ samples_per_gpu=2, # Batch size of a single GPU
+ workers_per_gpu=2, # Worker to pre-fetch data for each single GPU
+ train=dict( # Train dataset config
+ type='CityscapesDataset', # Type of dataset, refer to mmseg/datasets/ for details.
+ data_root='data/cityscapes/', # The root of dataset.
+ img_dir='leftImg8bit/train', # The image directory of dataset.
+ ann_dir='gtFine/train', # The annotation directory of dataset.
+ pipeline=[ # pipeline, this is passed by the train_pipeline created before.
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(
+ type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=(512, 1024), cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size=(512, 1024), pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg'])
+ ]),
+ val=dict( # Validation dataset config
+ type='CityscapesDataset',
+ data_root='data/cityscapes/',
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=[ # Pipeline is passed by test_pipeline created before
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]),
+ test=dict(
+ type='CityscapesDataset',
+ data_root='data/cityscapes/',
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]))
+log_config = dict( # config to register logger hook
+ interval=50, # Interval to print the log
+ hooks=[
+ # dict(type='TensorboardLoggerHook') # The Tensorboard logger is also supported
+ dict(type='TextLoggerHook', by_epoch=False)
+ ])
+dist_params = dict(backend='nccl') # Parameters to setup distributed training, the port can also be set.
+log_level = 'INFO' # The level of logging.
+load_from = None # load models as a pre-trained model from a given path. This will not resume training.
+resume_from = None # Resume checkpoints from a given path, the training will be resumed from the iteration when the checkpoint's is saved.
+workflow = [('train', 1)] # Workflow for runner. [('train', 1)] means there is only one workflow and the workflow named 'train' is executed once. The workflow trains the model by 40000 iterations according to the `runner.max_iters`.
+cudnn_benchmark = True # Whether use cudnn_benchmark to speed up, which is fast for fixed input size.
+optimizer = dict( # Config used to build optimizer, support all the optimizers in PyTorch whose arguments are also the same as those in PyTorch
+ type='SGD', # Type of optimizers, refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/optimizer/default_constructor.py#L13 for more details
+ lr=0.01, # Learning rate of optimizers, see detail usages of the parameters in the documentation of PyTorch
+ momentum=0.9, # Momentum
+ weight_decay=0.0005) # Weight decay of SGD
+optimizer_config = dict() # Config used to build the optimizer hook, refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py#L8 for implementation details.
+lr_config = dict(
+ policy='poly', # The policy of scheduler, also support Step, CosineAnnealing, Cyclic, etc. Refer to details of supported LrUpdater from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9.
+ power=0.9, # The power of polynomial decay.
+ min_lr=0.0001, # The minimum learning rate to stable the training.
+ by_epoch=False) # Whether count by epoch or not.
+runner = dict(
+ type='IterBasedRunner', # Type of runner to use (i.e. IterBasedRunner or EpochBasedRunner)
+ max_iters=40000) # Total number of iterations. For EpochBasedRunner use `max_epochs`
+checkpoint_config = dict( # Config to set the checkpoint hook, Refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py for implementation.
+ by_epoch=False, # Whether count by epoch or not.
+ interval=4000) # The save interval.
+evaluation = dict( # The config to build the evaluation hook. Please refer to mmseg/core/evaluation/eval_hook.py for details.
+ interval=4000, # The interval of evaluation.
+ metric='mIoU') # The evaluation metric.
+
+
+```
+
+## FAQ
+
+### Ignore some fields in the base configs
+
+Sometimes, you may set `_delete_=True` to ignore some of fields in base configs.
+You may refer to [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html#inherit-from-base-config-with-ignored-fields) for simple inllustration.
+
+In MMSegmentation, for example, to change the backbone of PSPNet with the following config.
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='MaskRCNN',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(...),
+ auxiliary_head=dict(...))
+```
+
+`ResNet` and `HRNet` use different keywords to construct.
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscpaes.py'
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ pretrained='open-mmlab://msra/hrnetv2_w32',
+ backbone=dict(
+ _delete_=True,
+ type='HRNet',
+ norm_cfg=norm_cfg,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256)))),
+ decode_head=dict(...),
+ auxiliary_head=dict(...))
+```
+
+The `_delete_=True` would replace all old keys in `backbone` field with new keys.
+
+### Use intermediate variables in configs
+
+Some intermediate variables are used in the configs files, like `train_pipeline`/`test_pipeline` in datasets.
+It's worth noting that when modifying intermediate variables in the children configs, user need to pass the intermediate variables into corresponding fields again.
+For example, we would like to change multi scale strategy to train/test a PSPNet. `train_pipeline`/`test_pipeline` are intermediate variable we would like modify.
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscapes.py'
+crop_size = (512, 1024)
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(1.0, 2.0)), # change to [1., 2.]
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75], # change to multi scale testing
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
+```
+
+We first define the new `train_pipeline`/`test_pipeline` and pass them into `data`.
+
+Similarly, if we would like to switch from `SyncBN` to `BN` or `MMSyncBN`, we need to substitute every `norm_cfg` in the config.
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscpaes.py'
+norm_cfg = dict(type='BN', requires_grad=True)
+model = dict(
+ backbone=dict(norm_cfg=norm_cfg),
+ decode_head=dict(norm_cfg=norm_cfg),
+ auxiliary_head=dict(norm_cfg=norm_cfg))
+```
diff --git a/docs/en/tutorials/customize_datasets.md b/docs/en/tutorials/customize_datasets.md
new file mode 100644
index 0000000..2fc1693
--- /dev/null
+++ b/docs/en/tutorials/customize_datasets.md
@@ -0,0 +1,211 @@
+# Tutorial 2: Customize Datasets
+
+## Customize datasets by reorganizing data
+
+The simplest way is to convert your dataset to organize your data into folders.
+
+An example of file structure is as followed.
+
+```none
+├── data
+│ ├── my_dataset
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ │ ├── xxx{img_suffix}
+│ │ │ │ ├── yyy{img_suffix}
+│ │ │ │ ├── zzz{img_suffix}
+│ │ │ ├── val
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ │ ├── xxx{seg_map_suffix}
+│ │ │ │ ├── yyy{seg_map_suffix}
+│ │ │ │ ├── zzz{seg_map_suffix}
+│ │ │ ├── val
+
+```
+
+A training pair will consist of the files with same suffix in img_dir/ann_dir.
+
+If `split` argument is given, only part of the files in img_dir/ann_dir will be loaded.
+We may specify the prefix of files we would like to be included in the split txt.
+
+More specifically, for a split txt like following,
+
+```none
+xxx
+zzz
+```
+
+Only
+`data/my_dataset/img_dir/train/xxx{img_suffix}`,
+`data/my_dataset/img_dir/train/zzz{img_suffix}`,
+`data/my_dataset/ann_dir/train/xxx{seg_map_suffix}`,
+`data/my_dataset/ann_dir/train/zzz{seg_map_suffix}` will be loaded.
+
+:::{note}
+The annotations are images of shape (H, W), the value pixel should fall in range `[0, num_classes - 1]`.
+You may use `'P'` mode of [pillow](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#palette) to create your annotation image with color.
+:::
+
+## Customize datasets by mixing dataset
+
+MMSegmentation also supports to mix dataset for training.
+Currently it supports to concat, repeat and multi-image mix datasets.
+
+### Repeat dataset
+
+We use `RepeatDataset` as wrapper to repeat the dataset.
+For example, suppose the original dataset is `Dataset_A`, to repeat it, the config looks like the following
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict( # This is the original config of Dataset_A
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+ )
+```
+
+### Concatenate dataset
+
+There 2 ways to concatenate the dataset.
+
+1. If the datasets you want to concatenate are in the same type with different annotation files,
+ you can concatenate the dataset configs like the following.
+
+ 1. You may concatenate two `ann_dir`.
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = ['anno_dir_1', 'anno_dir_2'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 2. You may concatenate two `split`.
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = 'anno_dir',
+ split = ['split_1.txt', 'split_2.txt'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 3. You may concatenate two `ann_dir` and `split` simultaneously.
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = ['anno_dir_1', 'anno_dir_2'],
+ split = ['split_1.txt', 'split_2.txt'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ In this case, `ann_dir_1` and `ann_dir_2` are corresponding to `split_1.txt` and `split_2.txt`.
+
+2. In case the dataset you want to concatenate is different, you can concatenate the dataset configs like the following.
+
+ ```python
+ dataset_A_train = dict()
+ dataset_B_train = dict()
+
+ data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+ )
+ ```
+
+A more complex example that repeats `Dataset_A` and `Dataset_B` by N and M times, respectively, and then concatenates the repeated datasets is as the following.
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict(
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+)
+dataset_A_val = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_A_test = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_B_train = dict(
+ type='RepeatDataset',
+ times=M,
+ dataset=dict(
+ type='Dataset_B',
+ ...
+ pipeline=train_pipeline
+ )
+)
+data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+)
+
+```
+
+### Multi-image Mix Dataset
+
+We use `MultiImageMixDataset` as a wrapper to mix images from multiple datasets.
+`MultiImageMixDataset` can be used by multiple images mixed data augmentation
+like mosaic and mixup.
+
+An example of using `MultiImageMixDataset` with `Mosaic` data augmentation:
+
+```python
+train_pipeline = [
+ dict(type='RandomMosaic', prob=1),
+ dict(type='Resize', img_scale=(1024, 512), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+
+train_dataset = dict(
+ type='MultiImageMixDataset',
+ dataset=dict(
+ classes=classes,
+ palette=palette,
+ type=dataset_type,
+ reduce_zero_label=False,
+ img_dir=data_root + "images/train",
+ ann_dir=data_root + "annotations/train",
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ ]
+ ),
+ pipeline=train_pipeline
+)
+
+```
diff --git a/docs/en/tutorials/customize_models.md b/docs/en/tutorials/customize_models.md
new file mode 100644
index 0000000..f637fd6
--- /dev/null
+++ b/docs/en/tutorials/customize_models.md
@@ -0,0 +1,234 @@
+# Tutorial 4: Customize Models
+
+## Customize optimizer
+
+Assume you want to add a optimizer named as `MyOptimizer`, which has arguments `a`, `b`, and `c`.
+You need to first implement the new optimizer in a file, e.g., in `mmseg/core/optimizer/my_optimizer.py`:
+
+```python
+from mmcv.runner import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+Then add this module in `mmseg/core/optimizer/__init__.py` thus the registry will
+find the new module and add it:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+Then you can use `MyOptimizer` in `optimizer` field of config files.
+In the configs, the optimizers are defined by the field `optimizer` like the following:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+To use your own optimizer, the field can be changed as
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+We already support to use all the optimizers implemented by PyTorch, and the only modification is to change the `optimizer` field of config files.
+For example, if you want to use `ADAM`, though the performance will drop a lot, the modification could be as the following.
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+The users can directly set arguments following the [API doc](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) of PyTorch.
+
+## Customize optimizer constructor
+
+Some models may have some parameter-specific settings for optimization, e.g. weight decay for BatchNoarm layers.
+The users can do those fine-grained parameter tuning through customizing optimizer constructor.
+
+```
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner import OPTIMIZER_BUILDERS
+from .cocktail_optimizer import CocktailOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module
+class CocktailOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+## Develop new components
+
+There are mainly 2 types of components in MMSegmentation.
+
+- backbone: usually stacks of convolutional network to extract feature maps, e.g., ResNet, HRNet.
+- head: the component for semantic segmentation map decoding.
+
+### Add new backbones
+
+Here we show how to develop new components with an example of MobileNet.
+
+1. Create a new file `mmseg/models/backbones/mobilenet.py`.
+
+```python
+import torch.nn as nn
+
+from ..registry import BACKBONES
+
+
+@BACKBONES.register_module
+class MobileNet(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # should return a tuple
+ pass
+
+ def init_weights(self, pretrained=None):
+ pass
+```
+
+2. Import the module in `mmseg/models/backbones/__init__.py`.
+
+```python
+from .mobilenet import MobileNet
+```
+
+3. Use it in your config file.
+
+```python
+model = dict(
+ ...
+ backbone=dict(
+ type='MobileNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+### Add new heads
+
+In MMSegmentation, we provide a base [BaseDecodeHead](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/decode_head.py) for all segmentation head.
+All newly implemented decode heads should be derived from it.
+Here we show how to develop a new head with the example of [PSPNet](https://arxiv.org/abs/1612.01105) as the following.
+
+First, add a new decode head in `mmseg/models/decode_heads/psp_head.py`.
+PSPNet implements a decode head for segmentation decode.
+To implement a decode head, basically we need to implement three functions of the new module as the following.
+
+```python
+@HEADS.register_module()
+class PSPHead(BaseDecodeHead):
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
+ super(PSPHead, self).__init__(**kwargs)
+
+ def init_weights(self):
+
+ def forward(self, inputs):
+
+```
+
+Next, the users need to add the module in the `mmseg/models/decode_heads/__init__.py` thus the corresponding registry could find and load them.
+
+To config file of PSPNet is as the following
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain_model/resnet50_v1c_trick-2cccc1ad.pth',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='PSPHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
+
+```
+
+### Add new loss
+
+Assume you want to add a new loss as `MyLoss` for segmentation decode.
+To add a new loss function, the users need implement it in `mmseg/models/losses/my_loss.py`.
+The decorator `weighted_loss` enable the loss to be weighted for each element.
+
+```python
+import torch
+import torch.nn as nn
+
+from ..builder import LOSSES
+from .utils import weighted_loss
+
+@weighted_loss
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+@LOSSES.register_module
+class MyLoss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(MyLoss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss = self.loss_weight * my_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss
+```
+
+Then the users need to add it in the `mmseg/models/losses/__init__.py`.
+
+```python
+from .my_loss import MyLoss, my_loss
+
+```
+
+To use it, modify the `loss_xxx` field.
+Then you need to modify the `loss_decode` field in the head.
+`loss_weight` could be used to balance multiple losses.
+
+```python
+loss_decode=dict(type='MyLoss', loss_weight=1.0))
+```
diff --git a/docs/en/tutorials/customize_runtime.md b/docs/en/tutorials/customize_runtime.md
new file mode 100644
index 0000000..dba0edc
--- /dev/null
+++ b/docs/en/tutorials/customize_runtime.md
@@ -0,0 +1,245 @@
+# Tutorial 6: Customize Runtime Settings
+
+## Customize optimization settings
+
+### Customize optimizer supported by Pytorch
+
+We already support to use all the optimizers implemented by PyTorch, and the only modification is to change the `optimizer` field of config files.
+For example, if you want to use `ADAM` (note that the performance could drop a lot), the modification could be as the following.
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+To modify the learning rate of the model, the users only need to modify the `lr` in the config of optimizer. The users can directly set arguments following the [API doc](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) of PyTorch.
+
+### Customize self-implemented optimizer
+
+#### 1. Define a new optimizer
+
+A customized optimizer could be defined as following.
+
+Assume you want to add a optimizer named `MyOptimizer`, which has arguments `a`, `b`, and `c`.
+You need to create a new directory named `mmseg/core/optimizer`.
+And then implement the new optimizer in a file, e.g., in `mmseg/core/optimizer/my_optimizer.py`:
+
+```python
+from .registry import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+#### 2. Add the optimizer to registry
+
+To find the above module defined above, this module should be imported into the main namespace at first. There are two options to achieve it.
+
+- Modify `mmseg/core/optimizer/__init__.py` to import it.
+
+ The newly defined module should be imported in `mmseg/core/optimizer/__init__.py` so that the registry will
+ find the new module and add it:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- Use `custom_imports` in the config to manually import it
+
+```python
+custom_imports = dict(imports=['mmseg.core.optimizer.my_optimizer'], allow_failed_imports=False)
+```
+
+The module `mmseg.core.optimizer.my_optimizer` will be imported at the beginning of the program and the class `MyOptimizer` is then automatically registered.
+Note that only the package containing the class `MyOptimizer` should be imported.
+`mmseg.core.optimizer.my_optimizer.MyOptimizer` **cannot** be imported directly.
+
+Actually users can use a totally different file directory structure using this importing method, as long as the module root can be located in `PYTHONPATH`.
+
+#### 3. Specify the optimizer in the config file
+
+Then you can use `MyOptimizer` in `optimizer` field of config files.
+In the configs, the optimizers are defined by the field `optimizer` like the following:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+To use your own optimizer, the field can be changed to
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+### Customize optimizer constructor
+
+Some models may have some parameter-specific settings for optimization, e.g. weight decay for BatchNorm layers.
+The users can do those fine-grained parameter tuning through customizing optimizer constructor.
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner.optimizer import OPTIMIZER_BUILDERS, OPTIMIZERS
+from mmseg.utils import get_root_logger
+from .my_optimizer import MyOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module()
+class MyOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+The default optimizer constructor is implemented [here](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/optimizer/default_constructor.py#L11), which could also serve as a template for new optimizer constructor.
+
+### Additional settings
+
+Tricks not implemented by the optimizer should be implemented through optimizer constructor (e.g., set parameter-wise learning rates) or hooks. We list some common settings that could stabilize the training or accelerate the training. Feel free to create PR, issue for more settings.
+
+- __Use gradient clip to stabilize training__:
+ Some models need gradient clip to clip the gradients to stabilize the training process. An example is as below:
+
+ ```python
+ optimizer_config = dict(
+ _delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
+ ```
+
+ If your config inherits the base config which already sets the `optimizer_config`, you might need `_delete_=True` to override the unnecessary settings. See the [config documentation](https://mmsegmentation.readthedocs.io/en/latest/config.html) for more details.
+
+- __Use momentum schedule to accelerate model convergence__:
+ We support momentum scheduler to modify model's momentum according to learning rate, which could make the model converge in a faster way.
+ Momentum scheduler is usually used with LR scheduler, for example, the following config is used in 3D detection to accelerate convergence.
+ For more details, please refer to the implementation of [CyclicLrUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L327) and [CyclicMomentumUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/momentum_updater.py#L130).
+
+ ```python
+ lr_config = dict(
+ policy='cyclic',
+ target_ratio=(10, 1e-4),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ momentum_config = dict(
+ policy='cyclic',
+ target_ratio=(0.85 / 0.95, 1),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ ```
+
+## Customize training schedules
+
+By default we use step learning rate with 40k/80k schedule, this calls [`PolyLrUpdaterHook`](https://github.com/open-mmlab/mmcv/blob/826d3a7b68596c824fa1e2cb89b6ac274f52179c/mmcv/runner/hooks/lr_updater.py#L196) in MMCV.
+We support many other learning rate schedule [here](https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py), such as `CosineAnnealing` and `Poly` schedule. Here are some examples
+
+- Step schedule:
+
+ ```python
+ lr_config = dict(policy='step', step=[9, 10])
+ ```
+
+- ConsineAnnealing schedule:
+
+ ```python
+ lr_config = dict(
+ policy='CosineAnnealing',
+ warmup='linear',
+ warmup_iters=1000,
+ warmup_ratio=1.0 / 10,
+ min_lr_ratio=1e-5)
+ ```
+
+## Customize workflow
+
+Workflow is a list of (phase, epochs) to specify the running order and epochs.
+By default it is set to be
+
+```python
+workflow = [('train', 1)]
+```
+
+which means running 1 epoch for training.
+Sometimes user may want to check some metrics (e.g. loss, accuracy) about the model on the validate set.
+In such case, we can set the workflow as
+
+```python
+[('train', 1), ('val', 1)]
+```
+
+so that 1 epoch for training and 1 epoch for validation will be run iteratively.
+
+:::{note}
+
+1. The parameters of model will not be updated during val epoch.
+2. Keyword `total_epochs` in the config only controls the number of training epochs and will not affect the validation workflow.
+3. Workflows `[('train', 1), ('val', 1)]` and `[('train', 1)]` will not change the behavior of `EvalHook` because `EvalHook` is called by `after_train_epoch` and validation workflow only affect hooks that are called through `after_val_epoch`. Therefore, the only difference between `[('train', 1), ('val', 1)]` and `[('train', 1)]` is that the runner will calculate losses on validation set after each training epoch.
+
+:::
+
+## Customize hooks
+
+### Use hooks implemented in MMCV
+
+If the hook is already implemented in MMCV, you can directly modify the config to use the hook as below
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+### Modify default runtime hooks
+
+There are some common hooks that are not registered through `custom_hooks`, they are
+
+- log_config
+- checkpoint_config
+- evaluation
+- lr_config
+- optimizer_config
+- momentum_config
+
+In those hooks, only the logger hook has the `VERY_LOW` priority, others' priority are `NORMAL`.
+The above-mentioned tutorials already covers how to modify `optimizer_config`, `momentum_config`, and `lr_config`.
+Here we reveals how what we can do with `log_config`, `checkpoint_config`, and `evaluation`.
+
+#### Checkpoint config
+
+The MMCV runner will use `checkpoint_config` to initialize [`CheckpointHook`](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/hooks/checkpoint.py#L9).
+
+```python
+checkpoint_config = dict(interval=1)
+```
+
+The users could set `max_keep_ckpts` to only save only small number of checkpoints or decide whether to store state dict of optimizer by `save_optimizer`. More details of the arguments are [here](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.CheckpointHook)
+
+#### Log config
+
+The `log_config` wraps multiple logger hooks and enables to set intervals. Now MMCV supports `WandbLoggerHook`, `MlflowLoggerHook`, and `TensorboardLoggerHook`.
+The detail usages can be found in the [doc](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.LoggerHook).
+
+```python
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')
+ ])
+```
+
+#### Evaluation config
+
+The config of `evaluation` will be used to initialize the [`EvalHook`](https://github.com/open-mmlab/mmsegmentation/blob/e3f6f655d69b777341aec2fe8829871cc0beadcb/mmseg/core/evaluation/eval_hooks.py#L7).
+Except the key `interval`, other arguments such as `metric` will be passed to the `dataset.evaluate()`
+
+```python
+evaluation = dict(interval=1, metric='mIoU')
+```
diff --git a/docs/en/tutorials/data_pipeline.md b/docs/en/tutorials/data_pipeline.md
new file mode 100644
index 0000000..1eecfe9
--- /dev/null
+++ b/docs/en/tutorials/data_pipeline.md
@@ -0,0 +1,171 @@
+# Tutorial 3: Customize Data Pipelines
+
+## Design of Data pipelines
+
+Following typical conventions, we use `Dataset` and `DataLoader` for data loading
+with multiple workers. `Dataset` returns a dict of data items corresponding
+the arguments of models' forward method.
+Since the data in semantic segmentation may not be the same size,
+we introduce a new `DataContainer` type in MMCV to help collect and distribute
+data of different size.
+See [here](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py) for more details.
+
+The data preparation pipeline and the dataset is decomposed. Usually a dataset
+defines how to process the annotations and a data pipeline defines all the steps to prepare a data dict.
+A pipeline consists of a sequence of operations. Each operation takes a dict as input and also output a dict for the next transform.
+
+The operations are categorized into data loading, pre-processing, formatting and test-time augmentation.
+
+Here is an pipeline example for PSPNet.
+
+```python
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 1024)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+```
+
+For each operation, we list the related dict fields that are added/updated/removed.
+
+### Data loading
+
+`LoadImageFromFile`
+
+- add: img, img_shape, ori_shape
+
+`LoadAnnotations`
+
+- add: gt_semantic_seg, seg_fields
+
+### Pre-processing
+
+`Resize`
+
+- add: scale, scale_idx, pad_shape, scale_factor, keep_ratio
+- update: img, img_shape, *seg_fields
+
+`RandomFlip`
+
+- add: flip
+- update: img, *seg_fields
+
+`Pad`
+
+- add: pad_fixed_size, pad_size_divisor
+- update: img, pad_shape, *seg_fields
+
+`RandomCrop`
+
+- update: img, pad_shape, *seg_fields
+
+`Normalize`
+
+- add: img_norm_cfg
+- update: img
+
+`SegRescale`
+
+- update: gt_semantic_seg
+
+`PhotoMetricDistortion`
+
+- update: img
+
+### Formatting
+
+`ToTensor`
+
+- update: specified by `keys`.
+
+`ImageToTensor`
+
+- update: specified by `keys`.
+
+`Transpose`
+
+- update: specified by `keys`.
+
+`ToDataContainer`
+
+- update: specified by `fields`.
+
+`DefaultFormatBundle`
+
+- update: img, gt_semantic_seg
+
+`Collect`
+
+- add: img_meta (the keys of img_meta is specified by `meta_keys`)
+- remove: all other keys except for those specified by `keys`
+
+### Test time augmentation
+
+`MultiScaleFlipAug`
+
+## Extend and use custom pipelines
+
+1. Write a new pipeline in any file, e.g., `my_pipeline.py`. It takes a dict as input and return a dict.
+
+ ```python
+ from mmseg.datasets import PIPELINES
+
+ @PIPELINES.register_module()
+ class MyTransform:
+
+ def __call__(self, results):
+ results['dummy'] = True
+ return results
+ ```
+
+2. Import the new class.
+
+ ```python
+ from .my_pipeline import MyTransform
+ ```
+
+3. Use it in config files.
+
+ ```python
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+ crop_size = (512, 1024)
+ train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='MyTransform'),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+ ]
+ ```
diff --git a/docs/en/tutorials/index.rst b/docs/en/tutorials/index.rst
new file mode 100644
index 0000000..e1a67a8
--- /dev/null
+++ b/docs/en/tutorials/index.rst
@@ -0,0 +1,9 @@
+.. toctree::
+ :maxdepth: 2
+
+ config.md
+ customize_datasets.md
+ data_pipeline.md
+ customize_models.md
+ training_tricks.md
+ customize_runtime.md
diff --git a/docs/en/tutorials/training_tricks.md b/docs/en/tutorials/training_tricks.md
new file mode 100644
index 0000000..1c8fe06
--- /dev/null
+++ b/docs/en/tutorials/training_tricks.md
@@ -0,0 +1,70 @@
+# Tutorial 5: Training Tricks
+
+MMSegmentation support following training tricks out of box.
+
+## Different Learning Rate(LR) for Backbone and Heads
+
+In semantic segmentation, some methods make the LR of heads larger than backbone to achieve better performance or faster convergence.
+
+In MMSegmentation, you may add following lines to config to make the LR of heads 10 times of backbone.
+
+```python
+optimizer=dict(
+ paramwise_cfg = dict(
+ custom_keys={
+ 'head': dict(lr_mult=10.)}))
+```
+
+With this modification, the LR of any parameter group with `'head'` in name will be multiplied by 10.
+You may refer to [MMCV doc](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.DefaultOptimizerConstructor) for further details.
+
+## Online Hard Example Mining (OHEM)
+
+We implement pixel sampler [here](https://github.com/open-mmlab/mmsegmentation/tree/master/mmseg/core/seg/sampler) for training sampling.
+Here is an example config of training PSPNet with OHEM enabled.
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
+```
+
+In this way, only pixels with confidence score under 0.7 are used to train. And we keep at least 100000 pixels during training. If `thresh` is not specified, pixels of top ``min_kept`` loss will be selected.
+
+## Class Balanced Loss
+
+For dataset that is not balanced in classes distribution, you may change the loss weight of each class.
+Here is an example for cityscapes dataset.
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
+ # DeepLab used this class weight for cityscapes
+ class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
+ 1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
+ 1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
+```
+
+`class_weight` will be passed into `CrossEntropyLoss` as `weight` argument. Please refer to [PyTorch Doc](https://pytorch.org/docs/stable/nn.html?highlight=crossentropy#torch.nn.CrossEntropyLoss) for details.
+
+## Multiple Losses
+
+For loss calculation, we support multiple losses training concurrently. Here is an example config of training `unet` on `DRIVE` dataset, whose loss function is `1:3` weighted sum of `CrossEntropyLoss` and `DiceLoss`:
+
+```python
+_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
+model = dict(
+ decode_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
+ auxiliary_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce',loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
+ )
+```
+
+In this way, `loss_weight` and `loss_name` will be weight and name in training log of corresponding loss, respectively.
+
+Note: If you want this loss item to be included into the backward graph, `loss_` must be the prefix of the name.
diff --git a/docs/en/useful_tools.md b/docs/en/useful_tools.md
new file mode 100644
index 0000000..d6dc576
--- /dev/null
+++ b/docs/en/useful_tools.md
@@ -0,0 +1,380 @@
+## Useful tools
+
+Apart from training/testing scripts, We provide lots of useful tools under the
+ `tools/` directory.
+
+### Get the FLOPs and params (experimental)
+
+We provide a script adapted from [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch) to compute the FLOPs and params of a given model.
+
+```shell
+python tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+You will get the result like this.
+
+```none
+==============================
+Input shape: (3, 2048, 1024)
+Flops: 1429.68 GMac
+Params: 48.98 M
+==============================
+```
+
+:::{note}
+This tool is still experimental and we do not guarantee that the number is correct. You may well use the result for simple comparisons, but double check it before you adopt it in technical reports or papers.
+:::
+
+(1) FLOPs are related to the input shape while parameters are not. The default input shape is (1, 3, 1280, 800).
+(2) Some operators are not counted into FLOPs like GN and custom operators.
+
+### Publish a model
+
+Before you upload a model to AWS, you may want to
+(1) convert model weights to CPU tensors, (2) delete the optimizer states and
+(3) compute the hash of the checkpoint file and append the hash id to the filename.
+
+```shell
+python tools/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+E.g.,
+
+```shell
+python tools/publish_model.py work_dirs/pspnet/latest.pth psp_r50_hszhao_200ep.pth
+```
+
+The final output filename will be `psp_r50_512x1024_40ki_cityscapes-{hash id}.pth`.
+
+### Convert to ONNX (experimental)
+
+We provide a script to convert model to [ONNX](https://github.com/onnx/onnx) format. The converted model could be visualized by tools like [Netron](https://github.com/lutzroeder/netron). Besides, we also support comparing the output results between PyTorch and ONNX model.
+
+```bash
+python tools/pytorch2onnx.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE} \
+ --input-img ${INPUT_IMG} \
+ --shape ${INPUT_SHAPE} \
+ --rescale-shape ${RESCALE_SHAPE} \
+ --show \
+ --verify \
+ --dynamic-export \
+ --cfg-options \
+ model.test_cfg.mode="whole"
+```
+
+Description of arguments:
+
+- `config` : The path of a model config file.
+- `--checkpoint` : The path of a model checkpoint file.
+- `--output-file`: The path of output ONNX model. If not specified, it will be set to `tmp.onnx`.
+- `--input-img` : The path of an input image for conversion and visualize.
+- `--shape`: The height and width of input tensor to the model. If not specified, it will be set to img_scale of test_pipeline.
+- `--rescale-shape`: rescale shape of output, set this value to avoid OOM, only work on `slide` mode.
+- `--show`: Determines whether to print the architecture of the exported model. If not specified, it will be set to `False`.
+- `--verify`: Determines whether to verify the correctness of an exported model. If not specified, it will be set to `False`.
+- `--dynamic-export`: Determines whether to export ONNX model with dynamic input and output shapes. If not specified, it will be set to `False`.
+- `--cfg-options`:Update config options.
+
+:::{note}
+This tool is still experimental. Some customized operators are not supported for now.
+:::
+
+### Evaluate ONNX model
+
+We provide `tools/deploy_test.py` to evaluate ONNX model with different backend.
+
+#### Prerequisite
+
+- Install onnx and onnxruntime-gpu
+
+ ```shell
+ pip install onnx onnxruntime-gpu
+ ```
+
+- Install TensorRT following [how-to-build-tensorrt-plugins-in-mmcv](https://mmcv.readthedocs.io/en/latest/tensorrt_plugin.html#how-to-build-tensorrt-plugins-in-mmcv)(optional)
+
+#### Usage
+
+```bash
+python tools/deploy_test.py \
+ ${CONFIG_FILE} \
+ ${MODEL_FILE} \
+ ${BACKEND} \
+ --out ${OUTPUT_FILE} \
+ --eval ${EVALUATION_METRICS} \
+ --show \
+ --show-dir ${SHOW_DIRECTORY} \
+ --cfg-options ${CFG_OPTIONS} \
+ --eval-options ${EVALUATION_OPTIONS} \
+ --opacity ${OPACITY} \
+```
+
+Description of all arguments
+
+- `config`: The path of a model config file.
+- `model`: The path of a converted model file.
+- `backend`: Backend of the inference, options: `onnxruntime`, `tensorrt`.
+- `--out`: The path of output result file in pickle format.
+- `--format-only` : Format the output results without perform evaluation. It is useful when you want to format the result to a specific format and submit it to the test server. If not specified, it will be set to `False`. Note that this argument is **mutually exclusive** with `--eval`.
+- `--eval`: Evaluation metrics, which depends on the dataset, e.g., "mIoU" for generic datasets, and "cityscapes" for Cityscapes. Note that this argument is **mutually exclusive** with `--format-only`.
+- `--show`: Show results flag.
+- `--show-dir`: Directory where painted images will be saved
+- `--cfg-options`: Override some settings in the used config file, the key-value pair in `xxx=yyy` format will be merged into config file.
+- `--eval-options`: Custom options for evaluation, the key-value pair in `xxx=yyy` format will be kwargs for `dataset.evaluate()` function
+- `--opacity`: Opacity of painted segmentation map. In (0, 1] range.
+
+#### Results and Models
+
+| Model | Config | Dataset | Metric | PyTorch | ONNXRuntime | TensorRT-fp32 | TensorRT-fp16 |
+| :--------: | :---------------------------------------------: | :--------: | :----: | :-----: | :---------: | :-----------: | :-----------: |
+| FCN | fcn_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 72.2 | 72.2 | 72.2 | 72.2 |
+| PSPNet | pspnet_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 77.8 | 77.8 | 77.8 | 77.8 |
+| deeplabv3 | deeplabv3_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.0 | 79.0 | 79.0 | 79.0 |
+| deeplabv3+ | deeplabv3plus_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.6 | 79.5 | 79.5 | 79.5 |
+| PSPNet | pspnet_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.2 | 78.1 | | |
+| deeplabv3 | deeplabv3_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.5 | 78.3 | | |
+| deeplabv3+ | deeplabv3plus_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.9 | 78.7 | | |
+
+:::{note}
+TensorRT is only available on configs with `whole mode`.
+:::
+
+### Convert to TorchScript (experimental)
+
+We also provide a script to convert model to [TorchScript](https://pytorch.org/docs/stable/jit.html) format. You can use the pytorch C++ API [LibTorch](https://pytorch.org/docs/stable/cpp_index.html) inference the trained model. The converted model could be visualized by tools like [Netron](https://github.com/lutzroeder/netron). Besides, we also support comparing the output results between PyTorch and TorchScript model.
+
+```shell
+python tools/pytorch2torchscript.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE}
+ --shape ${INPUT_SHAPE}
+ --verify \
+ --show
+```
+
+Description of arguments:
+
+- `config` : The path of a pytorch model config file.
+- `--checkpoint` : The path of a pytorch model checkpoint file.
+- `--output-file`: The path of output TorchScript model. If not specified, it will be set to `tmp.pt`.
+- `--input-img` : The path of an input image for conversion and visualize.
+- `--shape`: The height and width of input tensor to the model. If not specified, it will be set to `512 512`.
+- `--show`: Determines whether to print the traced graph of the exported model. If not specified, it will be set to `False`.
+- `--verify`: Determines whether to verify the correctness of an exported model. If not specified, it will be set to `False`.
+
+:::{note}
+It's only support PyTorch>=1.8.0 for now.
+:::
+
+:::{note}
+This tool is still experimental. Some customized operators are not supported for now.
+:::
+
+Examples:
+
+- Convert the cityscapes PSPNet pytorch model.
+
+ ```shell
+ python tools/pytorch2torchscript.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ --checkpoint checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --output-file checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pt \
+ --shape 512 1024
+ ```
+
+### Convert to TensorRT (experimental)
+
+A script to convert [ONNX](https://github.com/onnx/onnx) model to [TensorRT](https://developer.nvidia.com/tensorrt) format.
+
+Prerequisite
+
+- install `mmcv-full` with ONNXRuntime custom ops and TensorRT plugins follow [ONNXRuntime in mmcv](https://mmcv.readthedocs.io/en/latest/deployment/onnxruntime_op.html) and [TensorRT plugin in mmcv](https://github.com/open-mmlab/mmcv/blob/master/docs/en/deployment/tensorrt_plugin.md).
+- Use [pytorch2onnx](#convert-to-onnx-experimental) to convert the model from PyTorch to ONNX.
+
+Usage
+
+```bash
+python ${MMSEG_PATH}/tools/onnx2tensorrt.py \
+ ${CFG_PATH} \
+ ${ONNX_PATH} \
+ --trt-file ${OUTPUT_TRT_PATH} \
+ --min-shape ${MIN_SHAPE} \
+ --max-shape ${MAX_SHAPE} \
+ --input-img ${INPUT_IMG} \
+ --show \
+ --verify
+```
+
+Description of all arguments
+
+- `config` : Config file of the model.
+- `model` : Path to the input ONNX model.
+- `--trt-file` : Path to the output TensorRT engine.
+- `--max-shape` : Maximum shape of model input.
+- `--min-shape` : Minimum shape of model input.
+- `--fp16` : Enable fp16 model conversion.
+- `--workspace-size` : Max workspace size in GiB.
+- `--input-img` : Image for visualize.
+- `--show` : Enable result visualize.
+- `--dataset` : Palette provider, `CityscapesDataset` as default.
+- `--verify` : Verify the outputs of ONNXRuntime and TensorRT.
+- `--verbose` : Whether to verbose logging messages while creating TensorRT engine. Defaults to False.
+
+:::{note}
+Only tested on whole mode.
+:::
+
+## Miscellaneous
+
+### Print the entire config
+
+`tools/print_config.py` prints the whole config verbatim, expanding all its
+ imports.
+
+```shell
+python tools/print_config.py \
+ ${CONFIG} \
+ --graph \
+ --cfg-options ${OPTIONS [OPTIONS...]} \
+```
+
+Description of arguments:
+
+- `config` : The path of a pytorch model config file.
+- `--graph` : Determines whether to print the models graph.
+- `--cfg-options`: Custom options to replace the config file.
+
+### Plot training logs
+
+`tools/analyze_logs.py` plots loss/mIoU curves given a training log file. `pip install seaborn` first to install the dependency.
+
+```shell
+python tools/analyze_logs.py xxx.log.json [--keys ${KEYS}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
+```
+
+Examples:
+
+- Plot the mIoU, mAcc, aAcc metrics.
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
+ ```
+
+- Plot loss metric.
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys loss --legend loss
+ ```
+
+### Model conversion
+
+`tools/model_converters/` provide several scripts to convert pretrain models released by other repos to MMSegmentation style.
+
+#### ViT Swin MiT Transformer Models
+
+- ViT
+
+ `tools/model_converters/vit2mmseg.py` convert keys in timm pretrained vit models to MMSegmentation style.
+
+ ```shell
+ python tools/model_converters/vit2mmseg.py ${SRC} ${DST}
+ ```
+
+- Swin
+
+ `tools/model_converters/swin2mmseg.py` convert keys in official pretrained swin models to MMSegmentation style.
+
+ ```shell
+ python tools/model_converters/swin2mmseg.py ${SRC} ${DST}
+ ```
+
+- SegFormer
+
+ `tools/model_converters/mit2mmseg.py` convert keys in official pretrained mit models to MMSegmentation style.
+
+ ```shell
+ python tools/model_converters/mit2mmseg.py ${SRC} ${DST}
+ ```
+
+## Model Serving
+
+In order to serve an `MMSegmentation` model with [`TorchServe`](https://pytorch.org/serve/), you can follow the steps:
+
+### 1. Convert model from MMSegmentation to TorchServe
+
+```shell
+python tools/torchserve/mmseg2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+:::{note}
+${MODEL_STORE} needs to be an absolute path to a folder.
+:::
+
+### 2. Build `mmseg-serve` docker image
+
+```shell
+docker build -t mmseg-serve:latest docker/serve/
+```
+
+### 3. Run `mmseg-serve`
+
+Check the official docs for [running TorchServe with docker](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment).
+
+In order to run in GPU, you need to install [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). You can omit the `--gpus` argument in order to run in CPU.
+
+Example:
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
+mmseg-serve:latest
+```
+
+[Read the docs](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md) about the Inference (8080), Management (8081) and Metrics (8082) APIs
+
+### 4. Test deployment
+
+```shell
+curl -O https://raw.githubusercontent.com/open-mmlab/mmsegmentation/master/resources/3dogs.jpg
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg -o 3dogs_mask.png
+```
+
+The response will be a ".png" mask.
+
+You can visualize the output as follows:
+
+```python
+import matplotlib.pyplot as plt
+import mmcv
+plt.imshow(mmcv.imread("3dogs_mask.png", "grayscale"))
+plt.show()
+```
+
+You should see something similar to:
+
+
+
+And you can use `test_torchserve.py` to compare result of torchserve and pytorch, and visualize them.
+
+```shell
+python tools/torchserve/test_torchserve.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--result-image ${RESULT_IMAGE}] [--device ${DEVICE}]
+```
+
+Example:
+
+```shell
+python tools/torchserve/test_torchserve.py \
+demo/demo.png \
+configs/fcn/fcn_r50-d8_512x1024_40k_cityscapes.py \
+checkpoint/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608-efe53f0d.pth \
+fcn
+```
diff --git a/docs/zh_cn/Makefile b/docs/zh_cn/Makefile
new file mode 100644
index 0000000..d4bb2cb
--- /dev/null
+++ b/docs/zh_cn/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/zh_cn/_static/css/readthedocs.css b/docs/zh_cn/_static/css/readthedocs.css
new file mode 100644
index 0000000..2e38d08
--- /dev/null
+++ b/docs/zh_cn/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../images/mmsegmentation.png");
+ background-size: 201px 40px;
+ height: 40px;
+ width: 201px;
+}
diff --git a/docs/zh_cn/_static/images/mmsegmentation.png b/docs/zh_cn/_static/images/mmsegmentation.png
new file mode 100644
index 0000000..009083a
Binary files /dev/null and b/docs/zh_cn/_static/images/mmsegmentation.png differ
diff --git a/docs/zh_cn/api.rst b/docs/zh_cn/api.rst
new file mode 100644
index 0000000..8285841
--- /dev/null
+++ b/docs/zh_cn/api.rst
@@ -0,0 +1,58 @@
+mmseg.apis
+--------------
+.. automodule:: mmseg.apis
+ :members:
+
+mmseg.core
+--------------
+
+seg
+^^^^^^^^^^
+.. automodule:: mmseg.core.seg
+ :members:
+
+evaluation
+^^^^^^^^^^
+.. automodule:: mmseg.core.evaluation
+ :members:
+
+utils
+^^^^^^^^^^
+.. automodule:: mmseg.core.utils
+ :members:
+
+mmseg.datasets
+--------------
+
+datasets
+^^^^^^^^^^
+.. automodule:: mmseg.datasets
+ :members:
+
+pipelines
+^^^^^^^^^^
+.. automodule:: mmseg.datasets.pipelines
+ :members:
+
+mmseg.models
+--------------
+
+segmentors
+^^^^^^^^^^
+.. automodule:: mmseg.models.segmentors
+ :members:
+
+backbones
+^^^^^^^^^^
+.. automodule:: mmseg.models.backbones
+ :members:
+
+decode_heads
+^^^^^^^^^^^^
+.. automodule:: mmseg.models.decode_heads
+ :members:
+
+losses
+^^^^^^^^^^
+.. automodule:: mmseg.models.losses
+ :members:
diff --git a/docs/zh_cn/conf.py b/docs/zh_cn/conf.py
new file mode 100644
index 0000000..353b0bc
--- /dev/null
+++ b/docs/zh_cn/conf.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+#
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../../'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMSegmentation'
+copyright = '2020-2021, OpenMMLab'
+author = 'MMSegmentation Authors'
+version_file = '../../mmseg/version.py'
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+# The full version, including alpha/beta/rc tags
+release = get_version()
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
+ 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser'
+]
+
+autodoc_mock_imports = [
+ 'matplotlib', 'pycocotools', 'mmseg.version', 'mmcv.ops'
+]
+
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The master toctree document.
+master_doc = 'index'
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+# html_theme = 'sphinx_rtd_theme'
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+html_theme_options = {
+ 'logo_url':
+ 'https://mmsegmentation.readthedocs.io/zh-CN/latest/',
+ 'menu': [
+ {
+ 'name':
+ '教程',
+ 'url':
+ 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
+ 'demo/MMSegmentation_Tutorial.ipynb'
+ },
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmsegmentation'
+ },
+ {
+ 'name':
+ '上游库',
+ 'children': [
+ {
+ 'name': 'MMCV',
+ 'url': 'https://github.com/open-mmlab/mmcv',
+ 'description': '基础视觉库'
+ },
+ ]
+ },
+ ],
+ # Specify the language of shared menu
+ 'menu_lang':
+ 'cn',
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# Enable ::: for my_st
+myst_enable_extensions = ['colon_fence']
+
+language = 'zh-CN'
+
+
+def builder_inited_handler(app):
+ subprocess.run(['./stat.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/docs/zh_cn/dataset_prepare.md b/docs/zh_cn/dataset_prepare.md
new file mode 100644
index 0000000..9a8428a
--- /dev/null
+++ b/docs/zh_cn/dataset_prepare.md
@@ -0,0 +1,268 @@
+## 准备数据集
+
+推荐用软链接,将数据集根目录链接到 `$MMSEGMENTATION/data` 里。如果您的文件夹结构是不同的,您也许可以试着修改配置文件里对应的路径。
+
+```none
+mmsegmentation
+├── mmseg
+├── tools
+├── configs
+├── data
+│ ├── cityscapes
+│ │ ├── leftImg8bit
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── gtFine
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── VOCdevkit
+│ │ ├── VOC2012
+│ │ │ ├── JPEGImages
+│ │ │ ├── SegmentationClass
+│ │ │ ├── ImageSets
+│ │ │ │ ├── Segmentation
+│ │ ├── VOC2010
+│ │ │ ├── JPEGImages
+│ │ │ ├── SegmentationClassContext
+│ │ │ ├── ImageSets
+│ │ │ │ ├── SegmentationContext
+│ │ │ │ │ ├── train.txt
+│ │ │ │ │ ├── val.txt
+│ │ │ ├── trainval_merged.json
+│ │ ├── VOCaug
+│ │ │ ├── dataset
+│ │ │ │ ├── cls
+│ ├── ade
+│ │ ├── ADEChallengeData2016
+│ │ │ ├── annotations
+│ │ │ │ ├── training
+│ │ │ │ ├── validation
+│ │ │ ├── images
+│ │ │ │ ├── training
+│ │ │ │ ├── validation
+│ ├── CHASE_DB1
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── DRIVE
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── HRF
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+│ ├── STARE
+│ │ ├── images
+│ │ │ ├── training
+│ │ │ ├── validation
+│ │ ├── annotations
+│ │ │ ├── training
+│ │ │ ├── validation
+| ├── dark_zurich
+| │ ├── gps
+| │ │ ├── val
+| │ │ └── val_ref
+| │ ├── gt
+| │ │ └── val
+| │ ├── LICENSE.txt
+| │ ├── lists_file_names
+| │ │ ├── val_filenames.txt
+| │ │ └── val_ref_filenames.txt
+| │ ├── README.md
+| │ └── rgb_anon
+| │ | ├── val
+| │ | └── val_ref
+| ├── NighttimeDrivingTest
+| | ├── gtCoarse_daytime_trainvaltest
+| | │ └── test
+| | │ └── night
+| | └── leftImg8bit
+| | | └── test
+| | | └── night
+│ ├── loveDA
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ │ ├── test
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ ├── potsdam
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ ├── val
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ ├── val
+```
+
+### Cityscapes
+
+注册成功后,数据集可以在 [这里](https://www.cityscapes-dataset.com/downloads/) 下载。
+
+通常情况下,`**labelTrainIds.png` 被用来训练 cityscapes。
+基于 [cityscapesscripts](https://github.com/mcordts/cityscapesScripts),
+我们提供了一个 [脚本](https://github.com/open-mmlab/mmsegmentation/blob/master/tools/convert_datasets/cityscapes.py),
+去生成 `**labelTrainIds.png`。
+
+```shell
+# --nproc 8 意味着有 8 个进程用来转换,它也可以被忽略。
+python tools/convert_datasets/cityscapes.py data/cityscapes --nproc 8
+```
+
+### Pascal VOC
+
+Pascal VOC 2012 可以在 [这里](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar) 下载。
+此外,许多最近在 Pascal VOC 数据集上的工作都会利用增广的数据,它们可以在 [这里](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/semantic_contours/benchmark.tgz) 找到。
+
+如果您想使用增广后的 VOC 数据集,请运行下面的命令来将数据增广的标注转成正确的格式。
+
+```shell
+# --nproc 8 意味着有 8 个进程用来转换,它也可以被忽略。
+python tools/convert_datasets/voc_aug.py data/VOCdevkit data/VOCdevkit/VOCaug --nproc 8
+```
+
+关于如何拼接数据集 (concatenate) 并一起训练它们,更多细节请参考 [拼接连接数据集](https://github.com/open-mmlab/mmsegmentation/blob/master/docs/zh_cn/tutorials/customize_datasets.md#%E6%8B%BC%E6%8E%A5%E6%95%B0%E6%8D%AE%E9%9B%86) 。
+
+### ADE20K
+
+ADE20K 的训练集和验证集可以在 [这里](http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip) 下载。
+您还可以在 [这里](http://data.csail.mit.edu/places/ADEchallenge/release_test.zip) 下载验证集。
+
+### Pascal Context
+
+Pascal Context 的训练集和验证集可以在 [这里](http://host.robots.ox.ac.uk/pascal/VOC/voc2010/VOCtrainval_03-May-2010.tar) 下载。
+注册成功后,您还可以在 [这里](http://host.robots.ox.ac.uk:8080/eval/downloads/VOC2010test.tar) 下载验证集。
+
+为了从原始数据集里切分训练集和验证集, 您可以在 [这里](https://codalabuser.blob.core.windows.net/public/trainval_merged.json)
+下载 trainval_merged.json。
+
+如果您想使用 Pascal Context 数据集,
+请安装 [细节](https://github.com/zhanghang1989/detail-api) 然后再运行如下命令来把标注转换成正确的格式。
+
+```shell
+python tools/convert_datasets/pascal_context.py data/VOCdevkit data/VOCdevkit/VOC2010/trainval_merged.json
+```
+
+### CHASE DB1
+
+CHASE DB1 的训练集和验证集可以在 [这里](https://staffnet.kingston.ac.uk/~ku15565/CHASE_DB1/assets/CHASEDB1.zip) 下载。
+
+为了将 CHASE DB1 数据集转换成 MMSegmentation 的格式,您需要运行如下命令:
+
+```shell
+python tools/convert_datasets/chase_db1.py /path/to/CHASEDB1.zip
+```
+
+这个脚本将自动生成正确的文件夹结构。
+
+### DRIVE
+
+DRIVE 的训练集和验证集可以在 [这里](https://drive.grand-challenge.org/) 下载。
+在此之前,您需要注册一个账号,当前 '1st_manual' 并未被官方提供,因此需要您从其他地方获取。
+
+为了将 DRIVE 数据集转换成 MMSegmentation 格式,您需要运行如下命令:
+
+```shell
+python tools/convert_datasets/drive.py /path/to/training.zip /path/to/test.zip
+```
+
+这个脚本将自动生成正确的文件夹结构。
+
+### HRF
+
+首先,下载 [healthy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy.zip) [glaucoma.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma.zip), [diabetic_retinopathy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy.zip), [healthy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy_manualsegm.zip), [glaucoma_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma_manualsegm.zip) 以及 [diabetic_retinopathy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy_manualsegm.zip) 。
+
+为了将 HRF 数据集转换成 MMSegmentation 格式,您需要运行如下命令:
+
+```shell
+python tools/convert_datasets/hrf.py /path/to/healthy.zip /path/to/healthy_manualsegm.zip /path/to/glaucoma.zip /path/to/glaucoma_manualsegm.zip /path/to/diabetic_retinopathy.zip /path/to/diabetic_retinopathy_manualsegm.zip
+```
+
+这个脚本将自动生成正确的文件夹结构。
+
+### STARE
+
+首先,下载 [stare-images.tar](http://cecas.clemson.edu/~ahoover/stare/probing/stare-images.tar), [labels-ah.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-ah.tar) 和 [labels-vk.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-vk.tar) 。
+
+为了将 STARE 数据集转换成 MMSegmentation 格式,您需要运行如下命令:
+
+```shell
+python tools/convert_datasets/stare.py /path/to/stare-images.tar /path/to/labels-ah.tar /path/to/labels-vk.tar
+```
+
+这个脚本将自动生成正确的文件夹结构。
+
+### Dark Zurich
+
+因为我们只支持在此数据集上测试模型,所以您只需下载[验证集](https://data.vision.ee.ethz.ch/csakarid/shared/GCMA_UIoU/Dark_Zurich_val_anon.zip) 。
+
+### Nighttime Driving
+
+因为我们只支持在此数据集上测试模型,所以您只需下载[测试集](http://data.vision.ee.ethz.ch/daid/NighttimeDriving/NighttimeDrivingTest.zip) 。
+
+### LoveDA
+
+可以从 Google Drive 里下载 [LoveDA数据集](https://drive.google.com/drive/folders/1ibYV0qwn4yuuh068Rnc-w4tPi0U0c-ti?usp=sharing) 。
+
+或者它还可以从 [zenodo](https://zenodo.org/record/5706578#.YZvN7SYRXdF) 下载, 您需要运行如下命令:
+
+```shell
+# Download Train.zip
+wget https://zenodo.org/record/5706578/files/Train.zip
+# Download Val.zip
+wget https://zenodo.org/record/5706578/files/Val.zip
+# Download Test.zip
+wget https://zenodo.org/record/5706578/files/Test.zip
+```
+
+对于 LoveDA 数据集,请运行以下命令下载并重新组织数据集
+
+```shell
+python tools/convert_datasets/loveda.py /path/to/loveDA
+```
+
+请参照 [这里](https://github.com/open-mmlab/mmsegmentation/blob/master/docs/zh_cn/inference.md) 来使用训练好的模型去预测 LoveDA 测试集并且提交到官网。
+
+关于 LoveDA 的更多细节可以在[这里](https://github.com/Junjue-Wang/LoveDA) 找到。
+
+### ISPRS Potsdam
+
+[Potsdam](https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-potsdam/)
+数据集是一个有着2D 语义分割内容标注的城市遥感数据集。
+数据集可以从挑战[主页](https://www2.isprs.org/commissions/comm2/wg4/benchmark/data-request-form/) 获得。
+需要其中的 '2_Ortho_RGB.zip' 和 '5_Labels_all_noBoundary.zip'。
+
+对于 Potsdam 数据集,请运行以下命令下载并重新组织数据集
+
+```shell
+python tools/convert_datasets/potsdam.py /path/to/potsdam
+```
+
+使用我们默认的配置, 将生成 3456 张图片的训练集和 2016 张图片的验证集。
+
+### ISPRS Vaihingen
+
+[Vaihingen](https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/)
+数据集是一个有着2D 语义分割内容标注的城市遥感数据集。
+
+数据集可以从挑战 [主页](https://www2.isprs.org/commissions/comm2/wg4/benchmark/data-request-form/).
+需要其中的 'ISPRS_semantic_labeling_Vaihingen.zip' 和 'ISPRS_semantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE.zip'。
+
+对于 Vaihingen 数据集,请运行以下命令下载并重新组织数据集
+
+```shell
+python tools/convert_datasets/vaihingen.py /path/to/vaihingen
+```
+
+使用我们默认的配置 (`clip_size` =512, `stride_size`=256), 将生成 344 张图片的训练集和 398 张图片的验证集。
diff --git a/docs/zh_cn/get_started.md b/docs/zh_cn/get_started.md
new file mode 100644
index 0000000..372bab9
--- /dev/null
+++ b/docs/zh_cn/get_started.md
@@ -0,0 +1,223 @@
+## 依赖
+
+- Linux or macOS (Windows下支持需要 mmcv-full,但运行时可能会有一些问题。)
+- Python 3.6+
+- PyTorch 1.3+
+- CUDA 9.2+ (如果您基于源文件编译 PyTorch, CUDA 9.0也可以使用)
+- GCC 5+
+- [MMCV](https://mmcv.readthedocs.io/en/latest/#installation)
+
+可编译的 MMSegmentation 和 MMCV 版本如下所示,请对照对应版本安装以避免安装问题。
+
+| MMSegmentation 版本 | MMCV 版本 |
+|:-----------------:|:--------------------------:|
+| master | mmcv-full>=1.4.4, <1.5.0 |
+| 0.21.0 | mmcv-full>=1.4.4, <1.5.0 |
+| 0.20.0 | mmcv-full>=1.3.13, <1.5.0 |
+| 0.19.0 | mmcv-full>=1.3.13, <1.3.17 |
+| 0.18.0 | mmcv-full>=1.3.13, <1.3.17 |
+| 0.17.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.16.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.15.0 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.14.1 | mmcv-full>=1.3.7, <1.3.17 |
+| 0.14.0 | mmcv-full>=1.3.1, <1.3.2 |
+| 0.13.0 | mmcv-full>=1.3.1, <1.3.2 |
+| 0.12.0 | mmcv-full>=1.1.4, <1.3.2 |
+| 0.11.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.10.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.9.0 | mmcv-full>=1.1.4, <1.3.0 |
+| 0.8.0 | mmcv-full>=1.1.4, <1.2.0 |
+| 0.7.0 | mmcv-full>=1.1.2, <1.2.0 |
+| 0.6.0 | mmcv-full>=1.1.2, <1.2.0 |
+
+注意: 如果您已经安装好 mmcv, 您首先需要运行 `pip uninstall mmcv`。
+如果 mmcv 和 mmcv-full 同时被安装,会报错 `ModuleNotFoundError`。
+
+## 安装
+
+a. 创建一个 conda 虚拟环境并激活它
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+```
+
+b. 按照[官方教程](https://pytorch.org/) 安装 PyTorch 和 totchvision,
+这里我们使用 PyTorch1.6.0 和 CUDA10.1,
+您也可以切换至其他版本
+
+```shell
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+```
+
+c. 按照 [官方教程](https://mmcv.readthedocs.io/en/latest/#installation)
+安装 [MMCV](https://mmcv.readthedocs.io/en/latest/) ,
+`mmcv` 或 `mmcv-full` 和 MMSegmentation 均兼容,但对于 CCNet 和 PSANet,`mmcv-full` 里的 CUDA 运算是必须的
+
+**在 Linux 下安装 mmcv:**
+
+通过运行
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.5.0/index.html
+```
+
+可以安装好 mmcv-full (PyTorch 1.5 和 CUDA 10.1) 版本。
+其他 PyTorch 和 CUDA 版本的 MMCV 安装请参照[这里](https://mmcv.readthedocs.io/en/latest/#install-with-pip)
+
+**在 Windows 下安装 mmcv (有风险):**
+
+对于 Windows, MMCV 的安装需要本地 C++ 编译工具, 例如 cl.exe。 请添加编译工具至 %PATH%。
+
+如果您已经在电脑上安装好Windows SDK 和 Visual Studio,cl.exe 的一个典型路径看起来如下:
+
+```shell
+C:\Program Files (x86)\Microsoft Visual Studio\2019\Professional\VC\Tools\MSVC\14.26.28801\bin\Hostx86\x64
+```
+
+或者您需要从网上下载 cl 编译工具并安装至路径。
+
+随后,从 github 克隆 mmcv 并通过 pip 安装:
+
+```shell
+git clone https://github.com/open-mmlab/mmcv.git
+cd mmcv
+pip install -e .
+```
+
+或直接:
+
+```shell
+pip install mmcv
+```
+
+当前,mmcv-full 并不完全在 windows 上支持。
+
+d. 安装 MMSegmentation
+
+```shell
+pip install mmsegmentation # 安装最新版本
+```
+
+或者
+
+```shell
+pip install git+https://github.com/open-mmlab/mmsegmentation.git # 安装 master 分支
+```
+
+此外,如果您想安装 `dev` 模式的 MMSegmentation, 运行如下命令:
+
+```shell
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # 或者 "python setup.py develop"
+```
+
+注意:
+
+1. 当在 windows 下训练和测试模型时,请确保路径下所有的'\\' 被替换成 '/',
+ 在 python 代码里可以使用`.replace('\\', '/')`处理路径的字符串
+2. `version+git_hash` 也将被保存进 meta 训练模型里,即0.5.0+c415a2e
+3. 当 MMsegmentation 以 `dev` 模式被安装时,本地对代码的修改将不需要重新安装即可产生作用
+4. 如果您想使用 `opencv-python-headless` 替换 `opencv-python`,您可以在安装 MMCV 前安装它
+5. 一些依赖项是可选的。简单的运行 `pip install -e .` 将仅安装最必要的一些依赖。为了使用可选的依赖项如`cityscapessripts`,
+ 要么手动使用 `pip install -r requirements/optional.txt` 安装,要么专门从pip下安装(即 `pip install -e .[optional]`,
+ 其中选项可设置为 `all`, `tests`, `build`, 和 `optional`)
+
+### 完整的安装脚本
+
+#### Linux
+
+这里便是一个完整安装 MMSegmentation 的脚本,使用 conda 并链接了数据集的路径(以您的数据集路径为 $DATA_ROOT 来安装)。
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+pip install mmcv-full==latest+torch1.5.0+cu101 -f https://download.openmmlab.com/mmcv/dist/index.html
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # 或者 "python setup.py develop"
+
+mkdir data
+ln -s $DATA_ROOT data
+```
+
+#### Windows (有风险)
+
+这里便是一个完整安装 MMSegmentation 的脚本,使用 conda 并链接了数据集的路径(以您的数据集路径为 %DATA_ROOT% 来安装)。
+注意:它必须是一个绝对路径。
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch
+set PATH=full\path\to\your\cpp\compiler;%PATH%
+pip install mmcv
+
+git clone https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -e . # 或者 "python setup.py develop"
+
+mklink /D data %DATA_ROOT%
+```
+
+#### 使用多版本 MMSegmentation 进行开发
+
+训练和测试脚本已经修改了 `PYTHONPATH` 来确保使用当前路径的MMSegmentation。
+
+为了使用当前环境默认安装的 MMSegmentation 而不是正在工作的 MMSegmentation,您可以在那些脚本里移除下面的内容:
+
+```shell
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
+```
+
+## 验证
+
+为了验证 MMSegmentation 和它所需要的环境是否正确安装,我们可以使用样例 python 代码来初始化一个 segmentor 并推理一张 demo 图像。
+
+```python
+from mmseg.apis import inference_segmentor, init_segmentor
+import mmcv
+
+config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'
+checkpoint_file = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
+
+# 从一个 config 配置文件和 checkpoint 文件里创建分割模型
+model = init_segmentor(config_file, checkpoint_file, device='cuda:0')
+
+# 测试一张样例图片并得到结果
+img = 'test.jpg' # 或者 img = mmcv.imread(img), 这将只加载图像一次.
+result = inference_segmentor(model, img)
+# 在新的窗口里可视化结果
+model.show_result(img, result, show=True)
+# 或者保存图片文件的可视化结果
+# 您可以改变 segmentation map 的不透明度(opacity),在(0, 1]之间。
+model.show_result(img, result, out_file='result.jpg', opacity=0.5)
+
+# 测试一个视频并得到分割结果
+video = mmcv.VideoReader('video.mp4')
+for frame in video:
+ result = inference_segmentor(model, frame)
+ model.show_result(frame, result, wait_time=1)
+```
+
+当您完成 MMSegmentation 的安装时,上述代码应该可以成功运行。
+
+我们还提供一个 demo 脚本去可视化单张图片。
+
+```shell
+python demo/image_demo.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${DEVICE_NAME}] [--palette-thr ${PALETTE}]
+```
+
+样例:
+
+```shell
+python demo/image_demo.py demo/demo.jpg configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --palette cityscapes
+```
+
+推理的 demo 文档可在此查询:[demo/inference_demo.ipynb](../demo/inference_demo.ipynb) 。
diff --git a/docs/zh_cn/imgs/qq_group_qrcode.jpg b/docs/zh_cn/imgs/qq_group_qrcode.jpg
new file mode 100644
index 0000000..4173474
Binary files /dev/null and b/docs/zh_cn/imgs/qq_group_qrcode.jpg differ
diff --git a/docs/zh_cn/imgs/seggroup_qrcode.jpg b/docs/zh_cn/imgs/seggroup_qrcode.jpg
new file mode 100644
index 0000000..9684582
Binary files /dev/null and b/docs/zh_cn/imgs/seggroup_qrcode.jpg differ
diff --git a/docs/zh_cn/imgs/zhihu_qrcode.jpg b/docs/zh_cn/imgs/zhihu_qrcode.jpg
new file mode 100644
index 0000000..c745fb0
Binary files /dev/null and b/docs/zh_cn/imgs/zhihu_qrcode.jpg differ
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
new file mode 100644
index 0000000..8df7662
--- /dev/null
+++ b/docs/zh_cn/index.rst
@@ -0,0 +1,62 @@
+欢迎来到 MMSegmenation 的文档!
+=======================================
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 开始你的第一步
+
+ get_started.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 数据集准备
+
+ dataset_prepare.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 模型库
+
+ model_zoo.md
+ modelzoo_statistics.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 快速启动
+
+ train.md
+ inference.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 教程
+
+ tutorials/index.rst
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 实用工具与脚本
+
+ useful_tools.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 说明
+
+ changelog.md
+
+.. toctree::
+ :caption: 语言切换
+
+ switch_language.md
+
+.. toctree::
+ :caption: 接口文档(英文)
+
+ api.rst
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/docs/zh_cn/inference.md b/docs/zh_cn/inference.md
new file mode 100644
index 0000000..b681dca
--- /dev/null
+++ b/docs/zh_cn/inference.md
@@ -0,0 +1,126 @@
+## 使用预训练模型推理
+
+我们提供测试脚本来评估完整数据集(Cityscapes, PASCAL VOC, ADE20k 等)上的结果,同时为了使其他项目的整合更容易,也提供一些高级 API。
+
+### 测试一个数据集
+
+- 单卡 GPU
+- CPU
+- 单节点多卡 GPU
+- 多节点
+
+您可以使用以下命令来测试一个数据集。
+
+```shell
+# 单卡 GPU 测试
+python tools/test.py ${配置文件} ${检查点文件} [--out ${结果文件}] [--eval ${评估指标}] [--show]
+
+# CPU: 禁用 GPU 并运行单 GPU 测试脚本
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py ${配置文件} ${检查点文件} [--out ${结果文件}] [--eval ${评估指标}] [--show]
+
+# 多卡GPU 测试
+./tools/dist_test.sh ${配置文件} ${检查点文件} ${GPU数目} [--out ${结果文件}] [--eval ${评估指标}]
+```
+
+可选参数:
+
+- `RESULT_FILE`: pickle 格式的输出结果的文件名,如果不专门指定,结果将不会被专门保存成文件。(MMseg v0.17 之后,args.out 将只会保存评估时的中间结果或者是分割图的保存路径。)
+- `EVAL_METRICS`: 在结果里将被评估的指标。这主要取决于数据集, `mIoU` 对于所有数据集都可获得,像 Cityscapes 数据集可以通过 `cityscapes` 命令来专门评估,就像标准的 `mIoU`一样。
+- `--show`: 如果被指定,分割结果将会在一张图像里画出来并且在另一个窗口展示。它仅仅是用来调试与可视化,并且仅针对单卡 GPU 测试。请确认 GUI 在您的环境里可用,否则您也许会遇到报错 `cannot connect to X server`
+- `--show-dir`: 如果被指定,分割结果将会在一张图像里画出来并且保存在指定文件夹里。它仅仅是用来调试与可视化,并且仅针对单卡GPU测试。使用该参数时,您的环境不需要 GUI。
+- `--eval-options`: 评估时的可选参数,当设置 `efficient_test=True` 时,它将会保存中间结果至本地文件里以节约 CPU 内存。请确认您本地硬盘有足够的存储空间(大于20GB)。(MMseg v0.17 之后,`efficient_test` 不再生效,我们重构了 test api,通过使用一种渐近式的方式来提升评估和保存结果的效率。)
+
+例子:
+
+假设您已经下载检查点文件至文件夹 `checkpoints/` 里。
+
+1. 测试 PSPNet 并可视化结果。按下任何键会进行到下一张图
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --show
+ ```
+
+2. 测试 PSPNet 并保存画出的图以便于之后的可视化
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --show-dir psp_r50_512x1024_40ki_cityscapes_results
+ ```
+
+3. 在数据集 PASCAL VOC (不保存测试结果) 上测试 PSPNet 并评估 mIoU
+
+ ```shell
+ python tools/test.py configs/pspnet/pspnet_r50-d8_512x1024_20k_voc12aug.py \
+ checkpoints/pspnet_r50-d8_512x1024_20k_voc12aug_20200605_003338-c57ef100.pth \
+ --eval mAP
+ ```
+
+4. 使用4卡 GPU 测试 PSPNet,并且在标准 mIoU 和 cityscapes 指标里评估模型
+
+ ```shell
+ ./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ 4 --out results.pkl --eval mIoU cityscapes
+ ```
+
+ 注意:在 cityscapes mIoU 和我们的 mIoU 指标会有一些差异 (~0.1%) 。因为 cityscapes 默认是根据类别样本数的多少进行加权平均,而我们对所有的数据集都是采取直接平均的方法来得到 mIoU。
+
+5. 在 cityscapes 数据集上4卡 GPU 测试 PSPNet, 并生成 png 文件以便提交给官方评估服务器
+
+ 首先,在配置文件里添加内容: `configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py`,
+
+ ```python
+ data = dict(
+ test=dict(
+ img_dir='leftImg8bit/test',
+ ann_dir='gtFine/test'))
+ ```
+
+ 随后,进行测试。
+
+ ```shell
+ ./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ 4 --format-only --eval-options "imgfile_prefix=./pspnet_test_results"
+ ```
+
+ 您会在文件夹 `./pspnet_test_results` 里得到生成的 png 文件。
+ 您也许可以运行 `zip -r results.zip pspnet_test_results/` 并提交 zip 文件给 [evaluation server](https://www.cityscapes-dataset.com/submit/) 。
+
+6. 在 Cityscapes 数据集上使用 CPU 高效内存选项来测试 DeeplabV3+ `mIoU` 指标 (没有保存测试结果)
+
+ ```shell
+ python tools/test.py \
+ configs/deeplabv3plus/deeplabv3plus_r18-d8_512x1024_80k_cityscapes.py \
+ deeplabv3plus_r18-d8_512x1024_80k_cityscapes_20201226_080942-cff257fe.pth \
+ --eval-options efficient_test=True \
+ --eval mIoU
+ ```
+
+ 使用 ```pmap``` 可查看 CPU 内存情况, ```efficient_test=True``` 会使用约 2.25GB 的 CPU 内存, ```efficient_test=False``` 会使用约 11.06GB 的 CPU 内存。 这个可选参数可以节约很多 CPU 内存。(MMseg v0.17 之后, `efficient_test` 参数将不再生效, 我们使用了一种渐近的方式来更加有效快速地评估和保存结果。)
+
+7. 在 LoveDA 数据集上1卡 GPU 测试 PSPNet, 并生成 png 文件以便提交给官方评估服务器
+
+ 首先,在配置文件里添加内容: `configs/pspnet/pspnet_r50-d8_512x512_80k_loveda.py`,
+
+ ```python
+ data = dict(
+ test=dict(
+ img_dir='img_dir/test',
+ ann_dir='ann_dir/test'))
+ ```
+
+ 随后,进行测试。
+
+ ```shell
+ python ./tools/test.py configs/pspnet/pspnet_r50-d8_512x512_80k_loveda.py \
+ checkpoints/pspnet_r50-d8_512x512_80k_loveda_20211104_155728-88610f9f.pth \
+ --format-only --eval-options "imgfile_prefix=./pspnet_test_results"
+ ```
+
+ 您会在文件夹 `./pspnet_test_results` 里得到生成的 png 文件。
+ 您也许可以运行 `zip -r -j Results.zip pspnet_test_results/` 并提交 zip 文件给 [evaluation server](https://codalab.lisn.upsaclay.fr/competitions/421) 。
diff --git a/docs/zh_cn/make.bat b/docs/zh_cn/make.bat
new file mode 100644
index 0000000..922152e
--- /dev/null
+++ b/docs/zh_cn/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/zh_cn/model_zoo.md b/docs/zh_cn/model_zoo.md
new file mode 100644
index 0000000..bfcc4c1
--- /dev/null
+++ b/docs/zh_cn/model_zoo.md
@@ -0,0 +1,152 @@
+# 标准与模型库
+
+## 共同设定
+
+* 我们默认使用 4 卡分布式训练
+* 所有 PyTorch 风格的 ImageNet 预训练网络由我们自己训练,和 [论文](https://arxiv.org/pdf/1812.01187.pdf) 保持一致。
+ 我们的 ResNet 网络是基于 ResNetV1c 的变种,在这里输入层的 7x7 卷积被 3个 3x3 取代
+* 为了在不同的硬件上保持一致,我们以 `torch.cuda.max_memory_allocated()` 的最大值作为 GPU 占用率,同时设置 `torch.backends.cudnn.benchmark=False`。
+ 注意,这通常比 `nvidia-smi` 显示的要少
+* 我们以网络 forward 和后处理的时间加和作为推理时间,除去数据加载时间。我们使用脚本 `tools/benchmark.py` 来获取推理时间,它在 `torch.backends.cudnn.benchmark=False` 的设定下,计算 200 张图片的平均推理时间
+* 在框架中,有两种推理模式
+ * `slide` 模式(滑动模式):测试的配置文件字段 `test_cfg` 会是 `dict(mode='slide', crop_size=(769, 769), stride=(513, 513))`.
+ 在这个模式下,从原图中裁剪多个小图分别输入网络中进行推理。小图的大小和小图之间的距离由 `crop_size` 和 `stride` 决定,重合区域会进行平均
+ * `whole` 模式 (全图模式):测试的配置文件字段 `test_cfg` 会是 `dict(mode='whole')`. 在这个模式下,全图会被直接输入到网络中进行推理。
+ 对于 769x769 下训练的模型,我们默认使用 `slide` 进行推理,其余模型用 `whole` 进行推理
+* 对于输入大小为 8x+1 (比如769),我们使用 `align_corners=True`。其余情况,对于输入大小为 8x (比如 512,1024),我们使用 `align_corners=False`
+
+## 基线
+
+### FCN
+
+请参考 [FCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fcn) 获得详细信息。
+
+### PSPNet
+
+请参考 [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/pspnet) 获得详细信息。
+
+### DeepLabV3
+
+请参考 [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3) 获得详细信息。
+
+### PSANet
+
+请参考 [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/psanet) 获得详细信息。
+
+### DeepLabV3+
+
+请参考 [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3plus) 获得详细信息。
+
+### UPerNet
+
+请参考 [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/upernet) 获得详细信息。
+
+### NonLocal Net
+
+请参考 [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nlnet) 获得详细信息。
+
+### EncNet
+
+请参考 [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/encnet) 获得详细信息。
+
+### CCNet
+
+请参考 [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ccnet) 获得详细信息。
+
+### DANet
+
+请参考 [DANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/danet) 获得详细信息。
+
+### APCNet
+
+请参考 [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/apcnet) 获得详细信息。
+
+### HRNet
+
+请参考 [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/hrnet) 获得详细信息。
+
+### GCNet
+
+请参考 [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/gcnet) 获得详细信息。
+
+### DMNet
+
+请参考 [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dmnet) 获得详细信息。
+
+### ANN
+
+请参考 [ANN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ann) 获得详细信息。
+
+### OCRNet
+
+请参考 [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ocrnet) 获得详细信息。
+
+### Fast-SCNN
+
+请参考 [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastscnn) 获得详细信息。
+
+### ResNeSt
+
+请参考 [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest) 获得详细信息。
+
+### Semantic FPN
+
+请参考 [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/semfpn) 获得详细信息。
+
+### PointRend
+
+请参考 [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/point_rend) 获得详细信息。
+
+### MobileNetV2
+
+请参考 [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v2) 获得详细信息。
+
+### MobileNetV3
+
+请参考 [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v3) 获得详细信息。
+
+### EMANet
+
+请参考 [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/emanet) 获得详细信息。
+
+### DNLNet
+
+请参考 [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dnlnet) 获得详细信息。
+
+### CGNet
+
+请参考 [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/cgnet) 获得详细信息。
+
+### Mixed Precision (FP16) Training
+
+请参考 [Mixed Precision (FP16) Training 在 BiSeNetV2 训练的样例](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv2/bisenetv2_fcn_fp16_4x4_1024x1024_160k_cityscapes.py) 获得详细信息。
+
+## 速度标定
+
+### 硬件
+
+* 8 NVIDIA Tesla V100 (32G) GPUs
+* Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
+
+### 软件环境
+
+* Python 3.7
+* PyTorch 1.5
+* CUDA 10.1
+* CUDNN 7.6.03
+* NCCL 2.4.08
+
+### 训练速度
+
+为了公平比较,我们全部使用 ResNet-101V1c 进行标定。输入大小为 1024x512,批量样本数为 2。
+
+训练速度如下表,指标为每次迭代的时间,以秒为单位,越低越快。
+
+| Implementation | PSPNet (s/iter) | DeepLabV3+ (s/iter) |
+|----------------|-----------------|---------------------|
+| [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) | **0.83** | **0.85** |
+| [SegmenTron](https://github.com/LikeLy-Journey/SegmenTron) | 0.84 | 0.85 |
+| [CASILVision](https://github.com/CSAILVision/semantic-segmentation-pytorch) | 1.15 | N/A |
+| [vedaseg](https://github.com/Media-Smart/vedaseg) | 0.95 | 1.25 |
+
+注意:DeepLabV3+ 的输出步长为 8。
diff --git a/docs/zh_cn/stat.py b/docs/zh_cn/stat.py
new file mode 100755
index 0000000..b3a1d73
--- /dev/null
+++ b/docs/zh_cn/stat.py
@@ -0,0 +1,65 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools as func
+import glob
+import os.path as osp
+import re
+
+import numpy as np
+
+url_prefix = 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
+
+files = sorted(glob.glob('../../configs/*/README.md'))
+
+stats = []
+titles = []
+num_ckpts = 0
+
+for f in files:
+ url = osp.dirname(f.replace('../../', url_prefix))
+
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ title = content.split('\n')[0].replace('#', '').strip()
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https?://download.*\.pth', content)
+ if 'mmsegmentation' in x)
+ if len(ckpts) == 0:
+ continue
+
+ _papertype = [
+ x for x in re.findall(r'', content)
+ ]
+ assert len(_papertype) > 0
+ papertype = _papertype[0]
+
+ paper = set([(papertype, title)])
+
+ titles.append(title)
+ num_ckpts += len(ckpts)
+ statsmsg = f"""
+\t* [{papertype}] [{title}]({url}) ({len(ckpts)} ckpts)
+"""
+ stats.append((paper, ckpts, statsmsg))
+
+allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _ in stats])
+msglist = '\n'.join(x for _, _, x in stats)
+
+papertypes, papercounts = np.unique([t for t, _ in allpapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# 模型库统计数据
+
+* 论文数量: {len(set(titles))}
+{countstr}
+
+* 模型数量: {num_ckpts}
+{msglist}
+"""
+
+with open('modelzoo_statistics.md', 'w') as f:
+ f.write(modelzoo)
diff --git a/docs/zh_cn/switch_language.md b/docs/zh_cn/switch_language.md
new file mode 100644
index 0000000..f58efc4
--- /dev/null
+++ b/docs/zh_cn/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/docs/zh_cn/train.md b/docs/zh_cn/train.md
new file mode 100644
index 0000000..6fd0ee1
--- /dev/null
+++ b/docs/zh_cn/train.md
@@ -0,0 +1,96 @@
+## 训练一个模型
+
+MMSegmentation 可以执行分布式训练和非分布式训练,分别使用 `MMDistributedDataParallel` 和 `MMDataParallel` 命令。
+
+所有的输出(日志 log 和检查点 checkpoints )将被保存到工作路径文件夹里,它可以通过配置文件里的 `work_dir` 指定。
+
+在一定迭代轮次后,我们默认在验证集上评估模型表现。您可以在训练配置文件中添加间隔参数来改变评估间隔。
+
+```python
+evaluation = dict(interval=4000) # 每4000 iterations 评估一次模型的性能
+```
+
+**\*重要提示\***: 在配置文件里的默认学习率是针对4卡 GPU 和2张图/GPU (此时 batchsize = 4x2 = 8)来设置的。
+同样,您也可以使用8卡 GPU 和 1张图/GPU 的设置,因为所有的模型均使用 cross-GPU 的 SyncBN 模式。
+
+我们可以在训练速度和 GPU 显存之间做平衡。当模型或者 Batch Size 比较大的时,可以传递`--cfg-options model.backbone.with_cp=True` ,使用 `with_cp` 来节省显存,但是速度会更慢,因为原先使用 `ith_cp` 时,是逐层反向传播(Back Propagation, BP),不会保存所有的梯度。
+
+### 使用单卡 GPU 训练
+
+```shell
+python tools/train.py ${配置文件} [可选参数]
+```
+
+如果您想在命令里定义工作文件夹路径,您可以添加一个参数`--work-dir ${工作路径}`。
+
+### 使用 CPU 训练
+
+使用 CPU 训练的流程和使用单 GPU 训练的流程一致,我们仅需要在训练流程开始前禁用 GPU。
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+```
+
+之后运行单 GPU 训练脚本即可。
+
+```{warning}
+我们不推荐用户使用 CPU 进行训练,这太过缓慢。我们支持这个功能是为了方便用户在没有 GPU 的机器上进行调试。
+```
+
+### 使用多卡 GPU 训练
+
+```shell
+./tools/dist_train.sh ${配置文件} ${GPU 个数} [可选参数]
+```
+
+可选参数可以为:
+
+- `--no-validate` (**不推荐**): 训练时代码库默认会在每 k 轮迭代后在验证集上进行评估,如果不需评估使用命令 `--no-validate`
+- `--work-dir ${工作路径}`: 在配置文件里重写工作路径文件夹
+- `--resume-from ${检查点文件}`: 继续使用先前的检查点 (checkpoint) 文件(可以继续训练过程)
+- `--load-from ${检查点文件}`: 从一个检查点 (checkpoint) 文件里加载权重(对另一个任务进行精调)
+
+`resume-from` 和 `load-from` 的区别:
+
+- `resume-from` 加载出模型权重和优化器状态包括迭代轮数等
+- `load-from` 仅加载模型权重,从第0轮开始训练
+
+### 使用多个机器训练
+
+如果您在一个集群上以[slurm](https://slurm.schedmd.com/) 运行 MMSegmentation,
+您可以使用脚本 `slurm_train.sh`(这个脚本同样支持单个机器的训练)。
+
+```shell
+[GPUS=${GPU 数量}] ./tools/slurm_train.sh ${分区} ${任务名称} ${配置文件} --work-dir ${工作路径}
+```
+
+这里是在 dev 分区里使用16块 GPU 训练 PSPNet 的例子。
+
+```shell
+GPUS=16 ./tools/slurm_train.sh dev pspr50 configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py /nfs/xxxx/psp_r50_512x1024_40ki_cityscapes
+```
+
+您可以查看 [slurm_train.sh](../tools/slurm_train.sh) 以熟悉全部的参数与环境变量。
+
+如果您多个机器已经有以太网连接, 您可以参考 PyTorch
+[launch utility](https://pytorch.org/docs/stable/distributed.html#launch-utility) 。
+若您没有像 InfiniBand 这样高速的网络连接,多机器训练通常会比较慢。
+
+### 在单个机器上启动多个任务
+
+如果您在单个机器上启动多个任务,例如在8卡 GPU 的一个机器上有2个4卡 GPU 的训练任务,您需要特别对每个任务指定不同的端口(默认为29500)来避免通讯冲突。
+否则,将会有报错信息 `RuntimeError: Address already in use`。
+
+如果您使用命令 `dist_train.sh` 来启动一个训练任务,您可以在命令行的用环境变量 `PORT` 设置端口。
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${配置文件} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${配置文件} 4
+```
+
+如果您使用命令 `slurm_train.sh` 来启动训练任务,您可以在命令行的用环境变量 `MASTER_PORT` 设置端口。
+
+```shell
+MASTER_PORT=29500 ./tools/slurm_train.sh ${分区} ${任务名称} ${配置文件}
+MASTER_PORT=29501 ./tools/slurm_train.sh ${分区} ${任务名称} ${配置文件}
+```
diff --git a/docs/zh_cn/tutorials/config.md b/docs/zh_cn/tutorials/config.md
new file mode 100644
index 0000000..cc9f8d3
--- /dev/null
+++ b/docs/zh_cn/tutorials/config.md
@@ -0,0 +1,377 @@
+# 教程 1: 学习配置文件
+
+我们整合了模块和继承设计到我们的配置里,这便于做很多实验。如果您想查看配置文件,您可以运行 `python tools/print_config.py /PATH/TO/CONFIG` 去查看完整的配置文件。您还可以传递参数
+`--cfg-options xxx.yyy=zzz` 去查看更新的配置。
+
+## 配置文件的结构
+
+在 `config/_base_` 文件夹下面有4种基本组件类型: 数据集(dataset),模型(model),训练策略(schedule)和运行时的默认设置(default runtime)。许多方法都可以方便地通过组合这些组件进行实现。
+这样,像 DeepLabV3, PSPNet 这样的模型可以容易地被构造。被来自 `_base_` 下的组件来构建的配置叫做 _原始配置 (primitive)_。
+
+对于所有在同一个文件夹下的配置文件,推荐**只有一个**对应的**原始配置**文件。所有其他的配置文件都应该继承自这个**原始配置**文件。这样就能保证配置文件的最大继承深度为 3。
+
+为了便于理解,我们推荐社区贡献者继承已有的方法配置文件。
+例如,如果一些修改是基于 DeepLabV3,使用者首先首先应该通过指定 `_base_ = ../deeplabv3/deeplabv3_r50_512x1024_40ki_cityscapes.py`来继承基础 DeepLabV3 结构,再去修改配置文件里其他内容以完成继承。
+
+如果您正在构建一个完整的新模型,它完全没有和已有的方法共享一些结构,您可能需要在 `configs` 下面创建一个文件夹 `xxxnet`。
+更详细的文档,请参照 [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html) 。
+
+## 配置文件命名风格
+
+我们按照下面的风格去命名配置文件,社区贡献者被建议使用同样的风格。
+
+```
+{model}_{backbone}_[misc]_[gpu x batch_per_gpu]_{resolution}_{schedule}_{dataset}
+```
+
+`{xxx}` 是被要求的文件 `[yyy]` 是可选的。
+
+- `{model}`: 模型种类,例如 `psp`, `deeplabv3` 等等
+- `{backbone}`: 主干网络种类,例如 `r50` (ResNet-50), `x101` (ResNeXt-101)
+- `[misc]`: 模型中各式各样的设置/插件,例如 `dconv`, `gcb`, `attention`, `mstrain`
+- `[gpu x batch_per_gpu]`: GPU数目 和每个 GPU 的样本数, 默认为 `8x2`
+- `{schedule}`: 训练方案, `20ki` 意思是 20k 迭代轮数
+- `{dataset}`: 数据集,如 `cityscapes`, `voc12aug`, `ade`
+
+## PSPNet 的一个例子
+
+为了帮助使用者熟悉这个流行的语义分割框架的完整配置文件和模块,我们在下面对使用 ResNet50V1c 的 PSPNet 的配置文件做了详细的注释说明。
+更多的详细使用和其他模块的替代项请参考 API 文档。
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True) # 分割框架通常使用 SyncBN
+model = dict(
+ type='EncoderDecoder', # 分割器(segmentor)的名字
+ pretrained='open-mmlab://resnet50_v1c', # 将被加载的 ImageNet 预训练主干网络
+ backbone=dict(
+ type='ResNetV1c', # 主干网络的类别。 可用选项请参考 mmseg/models/backbones/resnet.py
+ depth=50, # 主干网络的深度。通常为 50 和 101。
+ num_stages=4, # 主干网络状态(stages)的数目,这些状态产生的特征图作为后续的 head 的输入。
+ out_indices=(0, 1, 2, 3), # 每个状态产生的特征图输出的索引。
+ dilations=(1, 1, 2, 4), # 每一层(layer)的空心率(dilation rate)。
+ strides=(1, 2, 1, 1), # 每一层(layer)的步长(stride)。
+ norm_cfg=dict( # 归一化层(norm layer)的配置项。
+ type='SyncBN', # 归一化层的类别。通常是 SyncBN。
+ requires_grad=True), # 是否训练归一化里的 gamma 和 beta。
+ norm_eval=False, # 是否冻结 BN 里的统计项。
+ style='pytorch', # 主干网络的风格,'pytorch' 意思是步长为2的层为 3x3 卷积, 'caffe' 意思是步长为2的层为 1x1 卷积。
+ contract_dilation=True), # 当空洞 > 1, 是否压缩第一个空洞层。
+ decode_head=dict(
+ type='PSPHead', # 解码头(decode head)的类别。 可用选项请参考 mmseg/models/decode_heads。
+ in_channels=2048, # 解码头的输入通道数。
+ in_index=3, # 被选择的特征图(feature map)的索引。
+ channels=512, # 解码头中间态(intermediate)的通道数。
+ pool_scales=(1, 2, 3, 6), # PSPHead 平均池化(avg pooling)的规模(scales)。 细节请参考文章内容。
+ dropout_ratio=0.1, # 进入最后分类层(classification layer)之前的 dropout 比例。
+ num_classes=19, # 分割前景的种类数目。 通常情况下,cityscapes 为19,VOC为21,ADE20k 为150。
+ norm_cfg=dict(type='SyncBN', requires_grad=True), # 归一化层的配置项。
+ align_corners=False, # 解码里调整大小(resize)的 align_corners 参数。
+ loss_decode=dict( # 解码头(decode_head)里的损失函数的配置项。
+ type='CrossEntropyLoss', # 在分割里使用的损失函数的类别。
+ use_sigmoid=False, # 在分割里是否使用 sigmoid 激活。
+ loss_weight=1.0)), # 解码头里损失的权重。
+ auxiliary_head=dict(
+ type='FCNHead', # 辅助头(auxiliary head)的种类。可用选项请参考 mmseg/models/decode_heads。
+ in_channels=1024, # 辅助头的输入通道数。
+ in_index=2, # 被选择的特征图(feature map)的索引。
+ channels=256, # 辅助头中间态(intermediate)的通道数。
+ num_convs=1, # FCNHead 里卷积(convs)的数目. 辅助头里通常为1。
+ concat_input=False, # 在分类层(classification layer)之前是否连接(concat)输入和卷积的输出。
+ dropout_ratio=0.1, # 进入最后分类层(classification layer)之前的 dropout 比例。
+ num_classes=19, # 分割前景的种类数目。 通常情况下,cityscapes 为19,VOC为21,ADE20k 为150。
+ norm_cfg=dict(type='SyncBN', requires_grad=True), # 归一化层的配置项。
+ align_corners=False, # 解码里调整大小(resize)的 align_corners 参数。
+ loss_decode=dict( # 辅助头(auxiliary head)里的损失函数的配置项。
+ type='CrossEntropyLoss', # 在分割里使用的损失函数的类别。
+ use_sigmoid=False, # 在分割里是否使用 sigmoid 激活。
+ loss_weight=0.4))) # 辅助头里损失的权重。默认设置为0.4。
+train_cfg = dict() # train_cfg 当前仅是一个占位符。
+test_cfg = dict(mode='whole') # 测试模式, 选项是 'whole' 和 'sliding'. 'whole': 整张图像全卷积(fully-convolutional)测试。 'sliding': 图像上做滑动裁剪窗口(sliding crop window)。
+dataset_type = 'CityscapesDataset' # 数据集类型,这将被用来定义数据集。
+data_root = 'data/cityscapes/' # 数据的根路径。
+img_norm_cfg = dict( # 图像归一化配置,用来归一化输入的图像。
+ mean=[123.675, 116.28, 103.53], # 预训练里用于预训练主干网络模型的平均值。
+ std=[58.395, 57.12, 57.375], # 预训练里用于预训练主干网络模型的标准差。
+ to_rgb=True) # 预训练里用于预训练主干网络的图像的通道顺序。
+crop_size = (512, 1024) # 训练时的裁剪大小
+train_pipeline = [ #训练流程
+ dict(type='LoadImageFromFile'), # 第1个流程,从文件路径里加载图像。
+ dict(type='LoadAnnotations'), # 第2个流程,对于当前图像,加载它的注释信息。
+ dict(type='Resize', # 变化图像和其注释大小的数据增广的流程。
+ img_scale=(2048, 1024), # 图像的最大规模。
+ ratio_range=(0.5, 2.0)), # 数据增广的比例范围。
+ dict(type='RandomCrop', # 随机裁剪当前图像和其注释大小的数据增广的流程。
+ crop_size=(512, 1024), # 随机裁剪图像生成 patch 的大小。
+ cat_max_ratio=0.75), # 单个类别可以填充的最大区域的比例。
+ dict(
+ type='RandomFlip', # 翻转图像和其注释大小的数据增广的流程。
+ flip_ratio=0.5), # 翻转图像的概率
+ dict(type='PhotoMetricDistortion'), # 光学上使用一些方法扭曲当前图像和其注释的数据增广的流程。
+ dict(
+ type='Normalize', # 归一化当前图像的数据增广的流程。
+ mean=[123.675, 116.28, 103.53], # 这些键与 img_norm_cfg 一致,因为 img_norm_cfg 被
+ std=[58.395, 57.12, 57.375], # 用作参数。
+ to_rgb=True),
+ dict(type='Pad', # 填充当前图像到指定大小的数据增广的流程。
+ size=(512, 1024), # 填充的图像大小。
+ pad_val=0, # 图像的填充值。
+ seg_pad_val=255), # 'gt_semantic_seg'的填充值。
+ dict(type='DefaultFormatBundle'), # 流程里收集数据的默认格式捆。
+ dict(type='Collect', # 决定数据里哪些键被传递到分割器里的流程。
+ keys=['img', 'gt_semantic_seg'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'), # 第1个流程,从文件路径里加载图像。
+ dict(
+ type='MultiScaleFlipAug', # 封装测试时数据增广(test time augmentations)。
+ img_scale=(2048, 1024), # 决定测试时可改变图像的最大规模。用于改变图像大小的流程。
+ flip=False, # 测试时是否翻转图像。
+ transforms=[
+ dict(type='Resize', # 使用改变图像大小的数据增广。
+ keep_ratio=True), # 是否保持宽和高的比例,这里的图像比例设置将覆盖上面的图像规模大小的设置。
+ dict(type='RandomFlip'), # 考虑到 RandomFlip 已经被添加到流程里,当 flip=False 时它将不被使用。
+ dict(
+ type='Normalize', # 归一化配置项,值来自 img_norm_cfg。
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', # 将图像转为张量
+ keys=['img']),
+ dict(type='Collect', # 收集测试时必须的键的收集流程。
+ keys=['img'])
+ ])
+]
+data = dict(
+ samples_per_gpu=2, # 单个 GPU 的 Batch size
+ workers_per_gpu=2, # 单个 GPU 分配的数据加载线程数
+ train=dict( # 训练数据集配置
+ type='CityscapesDataset', # 数据集的类别, 细节参考自 mmseg/datasets/。
+ data_root='data/cityscapes/', # 数据集的根目录。
+ img_dir='leftImg8bit/train', # 数据集图像的文件夹。
+ ann_dir='gtFine/train', # 数据集注释的文件夹。
+ pipeline=[ # 流程, 由之前创建的 train_pipeline 传递进来。
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(
+ type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=(512, 1024), cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size=(512, 1024), pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg'])
+ ]),
+ val=dict( # 验证数据集的配置
+ type='CityscapesDataset',
+ data_root='data/cityscapes/',
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=[ # 由之前创建的 test_pipeline 传递的流程。
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]),
+ test=dict(
+ type='CityscapesDataset',
+ data_root='data/cityscapes/',
+ img_dir='leftImg8bit/val',
+ ann_dir='gtFine/val',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]))
+log_config = dict( # 注册日志钩 (register logger hook) 的配置文件。
+ interval=50, # 打印日志的间隔
+ hooks=[
+ # dict(type='TensorboardLoggerHook') # 同样支持 Tensorboard 日志
+ dict(type='TextLoggerHook', by_epoch=False)
+ ])
+dist_params = dict(backend='nccl') # 用于设置分布式训练的参数,端口也同样可被设置。
+log_level = 'INFO' # 日志的级别。
+load_from = None # 从一个给定路径里加载模型作为预训练模型,它并不会消耗训练时间。
+resume_from = None # 从给定路径里恢复检查点(checkpoints),训练模式将从检查点保存的轮次开始恢复训练。
+workflow = [('train', 1)] # runner 的工作流程。 [('train', 1)] 意思是只有一个工作流程而且工作流程 'train' 仅执行一次。根据 `runner.max_iters` 工作流程训练模型的迭代轮数为40000次。
+cudnn_benchmark = True # 是否是使用 cudnn_benchmark 去加速,它对于固定输入大小的可以提高训练速度。
+optimizer = dict( # 用于构建优化器的配置文件。支持 PyTorch 中的所有优化器,同时它们的参数与PyTorch里的优化器参数一致。
+ type='SGD', # 优化器种类,更多细节可参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/optimizer/default_constructor.py#L13。
+ lr=0.01, # 优化器的学习率,参数的使用细节请参照对应的 PyTorch 文档。
+ momentum=0.9, # 动量 (Momentum)
+ weight_decay=0.0005) # SGD 的衰减权重 (weight decay)。
+optimizer_config = dict() # 用于构建优化器钩 (optimizer hook) 的配置文件,执行细节请参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py#L8。
+lr_config = dict(
+ policy='poly', # 调度流程的策略,同样支持 Step, CosineAnnealing, Cyclic 等. 请从 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9 参考 LrUpdater 的细节。
+ power=0.9, # 多项式衰减 (polynomial decay) 的幂。
+ min_lr=0.0001, # 用来稳定训练的最小学习率。
+ by_epoch=False) # 是否按照每个 epoch 去算学习率。
+runner = dict(
+ type='IterBasedRunner', # 将使用的 runner 的类别 (例如 IterBasedRunner 或 EpochBasedRunner)。
+ max_iters=40000) # 全部迭代轮数大小,对于 EpochBasedRunner 使用 `max_epochs` 。
+checkpoint_config = dict( # 设置检查点钩子 (checkpoint hook) 的配置文件。执行时请参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py。
+ by_epoch=False, # 是否按照每个 epoch 去算 runner。
+ interval=4000) # 保存的间隔
+evaluation = dict( # 构建评估钩 (evaluation hook) 的配置文件。细节请参考 mmseg/core/evaluation/eval_hook.py。
+ interval=4000, # 评估的间歇点
+ metric='mIoU') # 评估的指标
+
+
+```
+
+## FAQ
+
+### 忽略基础配置文件里的一些域内容。
+
+有时,您也许会设置 `_delete_=True` 去忽略基础配置文件里的一些域内容。
+您也许可以参照 [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html#inherit-from-base-config-with-ignored-fields) 来获得一些简单的指导。
+
+在 MMSegmentation 里,例如为了改变 PSPNet 的主干网络的某些内容:
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='MaskRCNN',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(...),
+ auxiliary_head=dict(...))
+```
+
+`ResNet` 和 `HRNet` 使用不同的关键词去构建。
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscpaes.py'
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ pretrained='open-mmlab://msra/hrnetv2_w32',
+ backbone=dict(
+ _delete_=True,
+ type='HRNet',
+ norm_cfg=norm_cfg,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256)))),
+ decode_head=dict(...),
+ auxiliary_head=dict(...))
+```
+
+`_delete_=True` 将用新的键去替换 `backbone` 域内所有老的键。
+
+### 使用配置文件里的中间变量
+
+配置文件里会使用一些中间变量,例如数据集里的 `train_pipeline`/`test_pipeline`。
+需要注意的是,在子配置文件里修改中间变量时,使用者需要再次传递这些变量给对应的域。
+例如,我们想改变在训练或测试时,PSPNet 的多尺度策略 (multi scale strategy),`train_pipeline`/`test_pipeline` 是我们想要修改的中间变量。
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscapes.py'
+crop_size = (512, 1024)
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(1.0, 2.0)), # 改成 [1., 2.]
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75], # 改成多尺度测试 (multi scale testing)。
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
+```
+
+我们首先定义新的 `train_pipeline`/`test_pipeline` 然后传递到 `data` 里。
+
+同样的,如果我们想从 `SyncBN` 切换到 `BN` 或者 `MMSyncBN`,我们需要配置文件里的每一个 `norm_cfg`。
+
+```python
+_base_ = '../pspnet/psp_r50_512x1024_40ki_cityscpaes.py'
+norm_cfg = dict(type='BN', requires_grad=True)
+model = dict(
+ backbone=dict(norm_cfg=norm_cfg),
+ decode_head=dict(norm_cfg=norm_cfg),
+ auxiliary_head=dict(norm_cfg=norm_cfg))
+```
diff --git a/docs/zh_cn/tutorials/customize_datasets.md b/docs/zh_cn/tutorials/customize_datasets.md
new file mode 100644
index 0000000..c579a8f
--- /dev/null
+++ b/docs/zh_cn/tutorials/customize_datasets.md
@@ -0,0 +1,209 @@
+# 教程 2: 自定义数据集
+
+## 通过重新组织数据来定制数据集
+
+最简单的方法是将您的数据集进行转化,并组织成文件夹的形式。
+
+如下的文件结构就是一个例子。
+
+```none
+├── data
+│ ├── my_dataset
+│ │ ├── img_dir
+│ │ │ ├── train
+│ │ │ │ ├── xxx{img_suffix}
+│ │ │ │ ├── yyy{img_suffix}
+│ │ │ │ ├── zzz{img_suffix}
+│ │ │ ├── val
+│ │ ├── ann_dir
+│ │ │ ├── train
+│ │ │ │ ├── xxx{seg_map_suffix}
+│ │ │ │ ├── yyy{seg_map_suffix}
+│ │ │ │ ├── zzz{seg_map_suffix}
+│ │ │ ├── val
+
+```
+
+一个训练对将由 img_dir/ann_dir 里同样首缀的文件组成。
+
+如果给定 `split` 参数,只有部分在 img_dir/ann_dir 里的文件会被加载。
+我们可以对被包括在 split 文本里的文件指定前缀。
+
+除此以外,一个 split 文本如下所示:
+
+```none
+xxx
+zzz
+```
+
+只有
+
+`data/my_dataset/img_dir/train/xxx{img_suffix}`,
+`data/my_dataset/img_dir/train/zzz{img_suffix}`,
+`data/my_dataset/ann_dir/train/xxx{seg_map_suffix}`,
+`data/my_dataset/ann_dir/train/zzz{seg_map_suffix}` 将被加载。
+
+注意:标注是跟图像同样的形状 (H, W),其中的像素值的范围是 `[0, num_classes - 1]`。
+您也可以使用 [pillow](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#palette) 的 `'P'` 模式去创建包含颜色的标注。
+
+## 通过混合数据去定制数据集
+
+MMSegmentation 同样支持混合数据集去训练。
+当前它支持拼接 (concat), 重复 (repeat) 和多图混合 (multi-image mix)数据集。
+
+### 重复数据集
+
+我们使用 `RepeatDataset` 作为包装 (wrapper) 去重复数据集。
+例如,假设原始数据集是 `Dataset_A`,为了重复它,配置文件如下:
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict( # 这是 Dataset_A 数据集的原始配置
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+ )
+```
+
+### 拼接数据集
+
+有2种方式去拼接数据集。
+
+1. 如果您想拼接的数据集是同样的类型,但有不同的标注文件,
+ 您可以按如下操作去拼接数据集的配置文件:
+
+ 1. 您也许可以拼接两个标注文件夹 `ann_dir`
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = ['anno_dir_1', 'anno_dir_2'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 2. 您也可以去拼接两个 `split` 文件列表
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = 'anno_dir',
+ split = ['split_1.txt', 'split_2.txt'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 3. 您也可以同时拼接 `ann_dir` 文件夹和 `split` 文件列表
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ img_dir = 'img_dir',
+ ann_dir = ['anno_dir_1', 'anno_dir_2'],
+ split = ['split_1.txt', 'split_2.txt'],
+ pipeline=train_pipeline
+ )
+ ```
+
+ 在这样的情况下, `ann_dir_1` 和 `ann_dir_2` 分别对应于 `split_1.txt` 和 `split_2.txt`
+
+2. 如果您想拼接不同的数据集,您可以如下去拼接数据集的配置文件:
+
+ ```python
+ dataset_A_train = dict()
+ dataset_B_train = dict()
+
+ data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+ )
+ ```
+
+一个更复杂的例子如下:分别重复 `Dataset_A` 和 `Dataset_B` N 次和 M 次,然后再去拼接重复后的数据集
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict(
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+)
+dataset_A_val = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_A_test = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_B_train = dict(
+ type='RepeatDataset',
+ times=M,
+ dataset=dict(
+ type='Dataset_B',
+ ...
+ pipeline=train_pipeline
+ )
+)
+data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+)
+
+```
+
+### 多图混合集
+
+我们使用 `MultiImageMixDataset` 作为包装(wrapper)去混合多个数据集的图片。
+`MultiImageMixDataset`可以被类似mosaic和mixup的多图混合数据増广使用。
+
+`MultiImageMixDataset`与`Mosaic`数据増广一起使用的例子:
+
+```python
+train_pipeline = [
+ dict(type='RandomMosaic', prob=1),
+ dict(type='Resize', img_scale=(1024, 512), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+
+train_dataset = dict(
+ type='MultiImageMixDataset',
+ dataset=dict(
+ classes=classes,
+ palette=palette,
+ type=dataset_type,
+ reduce_zero_label=False,
+ img_dir=data_root + "images/train",
+ ann_dir=data_root + "annotations/train",
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ ]
+ ),
+ pipeline=train_pipeline
+)
+
+```
diff --git a/docs/zh_cn/tutorials/customize_models.md b/docs/zh_cn/tutorials/customize_models.md
new file mode 100644
index 0000000..c92d7db
--- /dev/null
+++ b/docs/zh_cn/tutorials/customize_models.md
@@ -0,0 +1,230 @@
+# 教程 4: 自定义模型
+
+## 自定义优化器 (optimizer)
+
+假设您想增加一个新的叫 `MyOptimizer` 的优化器,它的参数分别为 `a`, `b`, 和 `c`。
+您首先需要在一个文件里实现这个新的优化器,例如在 `mmseg/core/optimizer/my_optimizer.py` 里面:
+
+```python
+from mmcv.runner import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+然后增加这个模块到 `mmseg/core/optimizer/__init__.py` 里面,这样注册器 (registry) 将会发现这个新的模块并添加它:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+之后您可以在配置文件的 `optimizer` 域里使用 `MyOptimizer`,
+如下所示,在配置文件里,优化器被 `optimizer` 域所定义:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+为了使用您自己的优化器,域可以被修改为:
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+我们已经支持了 PyTorch 自带的全部优化器,唯一修改的地方是在配置文件里的 `optimizer` 域。例如,如果您想使用 `ADAM`,尽管数值表现会掉点,还是可以如下修改:
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+使用者可以直接按照 PyTorch [文档教程](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) 去设置参数。
+
+## 定制优化器的构造器 (optimizer constructor)
+
+对于优化,一些模型可能会有一些特别定义的参数,例如批归一化 (BatchNorm) 层里面的权重衰减 (weight decay)。
+使用者可以通过定制优化器的构造器来微调这些细粒度的优化器参数。
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner import OPTIMIZER_BUILDERS
+from .cocktail_optimizer import CocktailOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module
+class CocktailOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+## 开发和增加新的组件(Module)
+
+MMSegmentation 里主要有2种组件:
+
+- 主干网络 (backbone): 通常是卷积网络的堆叠,来做特征提取,例如 ResNet, HRNet
+- 解码头 (decoder head): 用于语义分割图的解码的组件(得到分割结果)
+
+### 添加新的主干网络
+
+这里我们以 MobileNet 为例,展示如何增加新的主干组件:
+
+1. 创建一个新的文件 `mmseg/models/backbones/mobilenet.py`
+
+```python
+import torch.nn as nn
+
+from ..registry import BACKBONES
+
+
+@BACKBONES.register_module
+class MobileNet(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # should return a tuple
+ pass
+
+ def init_weights(self, pretrained=None):
+ pass
+```
+
+2. 在 `mmseg/models/backbones/__init__.py` 里面导入模块
+
+```python
+from .mobilenet import MobileNet
+```
+
+3. 在您的配置文件里使用它
+
+```python
+model = dict(
+ ...
+ backbone=dict(
+ type='MobileNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+### 增加新的解码头 (decoder head)组件
+
+在 MMSegmentation 里面,对于所有的分割头,我们提供一个基类解码头 [BaseDecodeHead](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/decode_head.py) 。
+所有新建的解码头都应该继承它。这里我们以 [PSPNet](https://arxiv.org/abs/1612.01105) 为例,
+展示如何开发和增加一个新的解码头组件:
+
+首先,在 `mmseg/models/decode_heads/psp_head.py` 里添加一个新的解码头。
+PSPNet 中实现了一个语义分割的解码头。为了实现一个解码头,我们只需要在新构造的解码头中实现如下的3个函数:
+
+```python
+@HEADS.register_module()
+class PSPHead(BaseDecodeHead):
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
+ super(PSPHead, self).__init__(**kwargs)
+
+ def init_weights(self):
+
+ def forward(self, inputs):
+
+```
+
+接着,使用者需要在 `mmseg/models/decode_heads/__init__.py` 里面添加这个模块,这样对应的注册器 (registry) 可以查找并加载它们。
+
+PSPNet的配置文件如下所示:
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain_model/resnet50_v1c_trick-2cccc1ad.pth',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='PSPHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
+
+```
+
+### 增加新的损失函数
+
+假设您想添加一个新的损失函数 `MyLoss` 到语义分割解码器里。
+为了添加一个新的损失函数,使用者需要在 `mmseg/models/losses/my_loss.py` 里面去实现它。
+`weighted_loss` 可以对计算损失时的每个样本做加权。
+
+```python
+import torch
+import torch.nn as nn
+
+from ..builder import LOSSES
+from .utils import weighted_loss
+
+@weighted_loss
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+@LOSSES.register_module
+class MyLoss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(MyLoss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss = self.loss_weight * my_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss
+```
+
+然后使用者需要在 `mmseg/models/losses/__init__.py` 里面添加它:
+
+```python
+from .my_loss import MyLoss, my_loss
+
+```
+
+为了使用它,修改 `loss_xxx` 域。之后您需要在解码头组件里修改 `loss_decode` 域。
+`loss_weight` 可以被用来对不同的损失函数做加权。
+
+```python
+loss_decode=dict(type='MyLoss', loss_weight=1.0))
+```
diff --git a/docs/zh_cn/tutorials/customize_runtime.md b/docs/zh_cn/tutorials/customize_runtime.md
new file mode 100644
index 0000000..6331789
--- /dev/null
+++ b/docs/zh_cn/tutorials/customize_runtime.md
@@ -0,0 +1,248 @@
+# 教程 6: 自定义运行设定
+
+## 自定义优化设定
+
+### 自定义 PyTorch 支持的优化器
+
+我们已经支持 PyTorch 自带的所有优化器,唯一需要修改的地方是在配置文件里的 `optimizer` 域里面。
+例如,如果您想使用 `ADAM` (注意如下操作可能会让模型表现下降),可以使用如下修改:
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+为了修改模型的学习率,使用者仅需要修改配置文件里 optimizer 的 `lr` 即可。
+使用者可以参照 PyTorch 的 [API 文档](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim)
+直接设置参数。
+
+### 自定义自己实现的优化器
+
+#### 1. 定义一个新的优化器
+
+一个自定义的优化器可以按照如下去定义:
+
+假如您想增加一个叫做 `MyOptimizer` 的优化器,它的参数分别有 `a`, `b`, 和 `c`。
+您需要创建一个叫 `mmseg/core/optimizer` 的新文件夹。
+然后再在文件,即 `mmseg/core/optimizer/my_optimizer.py` 里面去实现这个新优化器:
+
+```python
+from .registry import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+#### 2. 增加优化器到注册表 (registry)
+
+为了让上述定义的模块被框架发现,首先这个模块应该被导入到主命名空间 (main namespace) 里。
+有两种方式可以实现它。
+
+- 修改 `mmseg/core/optimizer/__init__.py` 来导入它
+
+ 新的被定义的模块应该被导入到 `mmseg/core/optimizer/__init__.py` 这样注册表将会发现新的模块并添加它
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- 在配置文件里使用 `custom_imports` 去手动导入它
+
+```python
+custom_imports = dict(imports=['mmseg.core.optimizer.my_optimizer'], allow_failed_imports=False)
+```
+
+`mmseg.core.optimizer.my_optimizer` 模块将会在程序运行的开始被导入,并且 `MyOptimizer` 类将会自动注册。
+需要注意只有包含 `MyOptimizer` 类的包 (package) 应当被导入。
+而 `mmseg.core.optimizer.my_optimizer.MyOptimizer` **不能** 被直接导入。
+
+事实上,使用者完全可以用另一个按这样导入方法的文件夹结构,只要模块的根路径已经被添加到 `PYTHONPATH` 里面。
+
+#### 3. 在配置文件里定义优化器
+
+之后您可以在配置文件的 `optimizer` 域里面使用 `MyOptimizer`
+在配置文件里,优化器被定义在 `optimizer` 域里,如下所示:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+为了使用您自己的优化器,这个域可以被改成:
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+### 自定义优化器的构造器 (constructor)
+
+有些模型可能需要在优化器里有一些特别参数的设置,例如 批归一化层 (BatchNorm layers) 的 权重衰减 (weight decay)。
+使用者可以通过自定义优化器的构造器去微调这些细粒度参数。
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner.optimizer import OPTIMIZER_BUILDERS, OPTIMIZERS
+from mmseg.utils import get_root_logger
+from .my_optimizer import MyOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module()
+class MyOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+默认的优化器构造器的实现可以参照 [这里](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/optimizer/default_constructor.py#L11) ,它也可以被用作新的优化器构造器的模板。
+
+### 额外的设置
+
+优化器没有实现的一些技巧应该通过优化器构造器 (optimizer constructor) 或者钩子 (hook) 去实现,如设置基于参数的学习率 (parameter-wise learning rates)。我们列出一些常见的设置,它们可以稳定或加速模型的训练。
+如果您有更多的设置,欢迎在 PR 和 issue 里面提交。
+
+- __使用梯度截断 (gradient clip) 去稳定训练__:
+
+ 一些模型需要梯度截断去稳定训练过程,如下所示
+
+ ```python
+ optimizer_config = dict(
+ _delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
+ ```
+
+ 如果您的配置继承自已经设置了 `optimizer_config` 的基础配置 (base config),您可能需要 `_delete_=True` 来重写那些不需要的设置。更多细节请参照 [配置文件文档](https://mmsegmentation.readthedocs.io/en/latest/config.html) 。
+
+- __使用动量计划表 (momentum schedule) 去加速模型收敛__:
+
+ 我们支持动量计划表去让模型基于学习率修改动量,这样可能让模型收敛地更快。
+ 动量计划表经常和学习率计划表 (LR scheduler) 一起使用,例如如下配置文件就在 3D 检测里经常使用以加速收敛。
+ 更多细节请参考 [CyclicLrUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L327) 和 [CyclicMomentumUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/momentum_updater.py#L130) 的实现。
+
+ ```python
+ lr_config = dict(
+ policy='cyclic',
+ target_ratio=(10, 1e-4),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ momentum_config = dict(
+ policy='cyclic',
+ target_ratio=(0.85 / 0.95, 1),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ ```
+
+## 自定义训练计划表
+
+我们根据默认的训练迭代步数 40k/80k 来设置学习率,这在 MMCV 里叫做 [`PolyLrUpdaterHook`](https://github.com/open-mmlab/mmcv/blob/826d3a7b68596c824fa1e2cb89b6ac274f52179c/mmcv/runner/hooks/lr_updater.py#L196) 。
+我们也支持许多其他的学习率计划表:[这里](https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py) ,例如 `CosineAnnealing` 和 `Poly` 计划表。下面是一些例子:
+
+- 步计划表 Step schedule:
+
+ ```python
+ lr_config = dict(policy='step', step=[9, 10])
+ ```
+
+- 余弦退火计划表 ConsineAnnealing schedule:
+
+ ```python
+ lr_config = dict(
+ policy='CosineAnnealing',
+ warmup='linear',
+ warmup_iters=1000,
+ warmup_ratio=1.0 / 10,
+ min_lr_ratio=1e-5)
+ ```
+
+## 自定义工作流 (workflow)
+
+工作流是一个专门定义运行顺序和轮数 (running order and epochs) 的列表 (phase, epochs)。
+默认情况下它设置成:
+
+```python
+workflow = [('train', 1)]
+```
+
+意思是训练是跑 1 个 epoch。有时候使用者可能想检查模型在验证集上的一些指标(如 损失 loss,精确性 accuracy),我们可以这样设置工作流:
+
+```python
+[('train', 1), ('val', 1)]
+```
+
+于是 1 个 epoch 训练,1 个 epoch 验证将交替运行。
+
+**注意**:
+
+1. 模型的参数在验证的阶段不会被自动更新
+2. 配置文件里的关键词 `total_epochs` 仅控制训练的 epochs 数目,而不会影响验证时的工作流
+3. 工作流 `[('train', 1), ('val', 1)]` 和 `[('train', 1)]` 将不会改变 `EvalHook` 的行为,因为 `EvalHook` 被 `after_train_epoch`
+ 调用而且验证的工作流仅仅影响通过调用 `after_val_epoch` 的钩子 (hooks)。因此, `[('train', 1), ('val', 1)]` 和 `[('train', 1)]`
+ 的区别仅在于 runner 将在每次训练 epoch 结束后计算在验证集上的损失
+
+## 自定义钩 (hooks)
+
+### 使用 MMCV 实现的钩子 (hooks)
+
+如果钩子已经在 MMCV 里被实现,如下所示,您可以直接修改配置文件来使用钩子:
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+### 修改默认的运行时间钩子 (runtime hooks)
+
+以下的常用的钩子没有被 `custom_hooks` 注册:
+
+- log_config
+- checkpoint_config
+- evaluation
+- lr_config
+- optimizer_config
+- momentum_config
+
+在这些钩子里,只有 logger hook 有 `VERY_LOW` 优先级,其他的优先级都是 `NORMAL`。
+上述提及的教程已经包括了如何修改 `optimizer_config`,`momentum_config` 和 `lr_config`。
+这里我们展示我们如何处理 `log_config`, `checkpoint_config` 和 `evaluation`。
+
+#### 检查点配置文件 (Checkpoint config)
+
+MMCV runner 将使用 `checkpoint_config` 去初始化 [`CheckpointHook`](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/hooks/checkpoint.py#L9).
+
+```python
+checkpoint_config = dict(interval=1)
+```
+
+使用者可以设置 `max_keep_ckpts` 来仅保存一小部分检查点或者通过 `save_optimizer` 来决定是否保存优化器的状态字典 (state dict of optimizer)。 更多使用参数的细节请参考 [这里](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.CheckpointHook) 。
+
+#### 日志配置文件 (Log config)
+
+`log_config` 包裹了许多日志钩 (logger hooks) 而且能去设置间隔 (intervals)。现在 MMCV 支持 `WandbLoggerHook`, `MlflowLoggerHook` 和 `TensorboardLoggerHook`。
+详细的使用请参照 [文档](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.LoggerHook) 。
+
+```python
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')
+ ])
+```
+
+#### 评估配置文件 (Evaluation config)
+
+`evaluation` 的配置文件将被用来初始化 [`EvalHook`](https://github.com/open-mmlab/mmsegmentation/blob/e3f6f655d69b777341aec2fe8829871cc0beadcb/mmseg/core/evaluation/eval_hooks.py#L7) 。
+除了 `interval` 键,其他的像 `metric` 这样的参数将被传递给 `dataset.evaluate()` 。
+
+```python
+evaluation = dict(interval=1, metric='mIoU')
+```
diff --git a/docs/zh_cn/tutorials/data_pipeline.md b/docs/zh_cn/tutorials/data_pipeline.md
new file mode 100644
index 0000000..f3dfcd8
--- /dev/null
+++ b/docs/zh_cn/tutorials/data_pipeline.md
@@ -0,0 +1,166 @@
+# 教程 3: 自定义数据流程
+
+## 数据流程的设计
+
+按照通常的惯例,我们使用 `Dataset` 和 `DataLoader` 做多线程的数据加载。`Dataset` 返回一个数据内容的字典,里面对应于模型前传方法的各个参数。
+因为在语义分割中,输入的图像数据具有不同的大小,我们在 MMCV 里引入一个新的 `DataContainer` 类别去帮助收集和分发不同大小的输入数据。
+
+更多细节,请查看[这里](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py) 。
+
+数据的准备流程和数据集是解耦的。通常一个数据集定义了如何处理标注数据(annotations)信息,而一个数据流程定义了准备一个数据字典的所有步骤。一个流程包括了一系列操作,每个操作里都把一个字典作为输入,然后再输出一个新的字典给下一个变换操作。
+
+这些操作可分为数据加载 (data loading),预处理 (pre-processing),格式变化 (formatting) 和测试时数据增强 (test-time augmentation)。
+
+下面的例子就是 PSPNet 的一个流程:
+
+```python
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 1024)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+```
+
+对于每个操作,我们列出它添加、更新、移除的相关字典域 (dict fields):
+
+### 数据加载 Data loading
+
+`LoadImageFromFile`
+
+- 增加: img, img_shape, ori_shape
+
+`LoadAnnotations`
+
+- 增加: gt_semantic_seg, seg_fields
+
+### 预处理 Pre-processing
+
+`Resize`
+
+- 增加: scale, scale_idx, pad_shape, scale_factor, keep_ratio
+- 更新: img, img_shape, *seg_fields
+
+`RandomFlip`
+
+- 增加: flip
+- 更新: img, *seg_fields
+
+`Pad`
+
+- 增加: pad_fixed_size, pad_size_divisor
+- 更新: img, pad_shape, *seg_fields
+
+`RandomCrop`
+
+- 更新: img, pad_shape, *seg_fields
+
+`Normalize`
+
+- 增加: img_norm_cfg
+- 更新: img
+
+`SegRescale`
+
+- 更新: gt_semantic_seg
+
+`PhotoMetricDistortion`
+
+- 更新: img
+
+### 格式 Formatting
+
+`ToTensor`
+
+- 更新: 由 `keys` 指定
+
+`ImageToTensor`
+
+- 更新: 由 `keys` 指定
+
+`Transpose`
+
+- 更新: 由 `keys` 指定
+
+`ToDataContainer`
+
+- 更新: 由 `keys` 指定
+
+`DefaultFormatBundle`
+
+- 更新: img, gt_semantic_seg
+
+`Collect`
+
+- 增加: img_meta (the keys of img_meta is specified by `meta_keys`)
+- 移除: all other keys except for those specified by `keys`
+
+### 测试时数据增强 Test time augmentation
+
+`MultiScaleFlipAug`
+
+## 拓展和使用自定义的流程
+
+1. 在任何一个文件里写一个新的流程,例如 `my_pipeline.py`,它以一个字典作为输入并且输出一个字典
+
+ ```python
+ from mmseg.datasets import PIPELINES
+
+ @PIPELINES.register_module()
+ class MyTransform:
+
+ def __call__(self, results):
+ results['dummy'] = True
+ return results
+ ```
+
+2. 导入一个新类
+
+ ```python
+ from .my_pipeline import MyTransform
+ ```
+
+3. 在配置文件里使用它
+
+ ```python
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+ crop_size = (512, 1024)
+ train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='MyTransform'),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+ ]
+ ```
diff --git a/docs/zh_cn/tutorials/index.rst b/docs/zh_cn/tutorials/index.rst
new file mode 100644
index 0000000..e1a67a8
--- /dev/null
+++ b/docs/zh_cn/tutorials/index.rst
@@ -0,0 +1,9 @@
+.. toctree::
+ :maxdepth: 2
+
+ config.md
+ customize_datasets.md
+ data_pipeline.md
+ customize_models.md
+ training_tricks.md
+ customize_runtime.md
diff --git a/docs/zh_cn/tutorials/training_tricks.md b/docs/zh_cn/tutorials/training_tricks.md
new file mode 100644
index 0000000..be9112c
--- /dev/null
+++ b/docs/zh_cn/tutorials/training_tricks.md
@@ -0,0 +1,70 @@
+# 教程 5: 训练技巧
+
+MMSegmentation 支持如下训练技巧:
+
+## 主干网络和解码头组件使用不同的学习率 (Learning Rate, LR)
+
+在语义分割里,一些方法会让解码头组件的学习率大于主干网络的学习率,这样可以获得更好的表现或更快的收敛。
+
+在 MMSegmentation 里面,您也可以在配置文件里添加如下行来让解码头组件的学习率是主干组件的10倍。
+
+```python
+optimizer=dict(
+ paramwise_cfg = dict(
+ custom_keys={
+ 'head': dict(lr_mult=10.)}))
+```
+
+通过这种修改,任何被分组到 `'head'` 的参数的学习率都将乘以10。您也可以参照 [MMCV 文档](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.DefaultOptimizerConstructor) 获取更详细的信息。
+
+## 在线难样本挖掘 (Online Hard Example Mining, OHEM)
+
+对于训练时采样,我们在 [这里](https://github.com/open-mmlab/mmsegmentation/tree/master/mmseg/core/seg/sampler) 做了像素采样器。
+如下例子是使用 PSPNet 训练并采用 OHEM 策略的配置:
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
+```
+
+通过这种方式,只有置信分数在0.7以下的像素值点会被拿来训练。在训练时我们至少要保留100000个像素值点。如果 `thresh` 并未被指定,前 ``min_kept``
+个损失的像素值点才会被选择。
+
+## 类别平衡损失 (Class Balanced Loss)
+
+对于不平衡类别分布的数据集,您也许可以改变每个类别的损失权重。这里以 cityscapes 数据集为例:
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
+ # DeepLab 对 cityscapes 使用这种权重
+ class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
+ 1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
+ 1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
+```
+
+`class_weight` 将被作为 `weight` 参数,传递给 `CrossEntropyLoss`。详细信息请参照 [PyTorch 文档](https://pytorch.org/docs/stable/nn.html?highlight=crossentropy#torch.nn.CrossEntropyLoss) 。
+
+## 同时使用多种损失函数 (Multiple Losses)
+
+对于训练时损失函数的计算,我们目前支持多个损失函数同时使用。 以 `unet` 使用 `DRIVE` 数据集训练为例,
+使用 `CrossEntropyLoss` 和 `DiceLoss` 的 `1:3` 的加权和作为损失函数。配置文件写为:
+
+```python
+_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
+model = dict(
+ decode_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
+ auxiliary_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce',loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
+ )
+```
+
+通过这种方式,确定训练过程中损失函数的权重 `loss_weight` 和在训练日志里的名字 `loss_name`。
+
+注意: `loss_name` 的名字必须带有 `loss_` 前缀,这样它才能被包括在反传的图里。
diff --git a/docs/zh_cn/useful_tools.md b/docs/zh_cn/useful_tools.md
new file mode 100644
index 0000000..bdf2740
--- /dev/null
+++ b/docs/zh_cn/useful_tools.md
@@ -0,0 +1,368 @@
+## 常用工具
+
+除了训练和测试的脚本,我们在 `tools/` 文件夹路径下还提供许多有用的工具。
+
+### 计算参数量(params)和计算量( FLOPs) (试验性)
+
+我们基于 [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch)
+提供了一个用于计算给定模型参数量和计算量的脚本。
+
+```shell
+python tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+您将得到如下的结果:
+
+```none
+==============================
+Input shape: (3, 2048, 1024)
+Flops: 1429.68 GMac
+Params: 48.98 M
+==============================
+```
+
+**注意**: 这个工具仍然是试验性的,我们无法保证数字是正确的。您可以拿这些结果做简单的实验的对照,在写技术文档报告或者论文前您需要再次确认一下。
+
+(1) 计算量与输入的形状有关,而参数量与输入的形状无关,默认的输入形状是 (1, 3, 1280, 800);
+(2) 一些运算操作,如 GN 和其他定制的运算操作没有加入到计算量的计算中。
+
+### 发布模型
+
+在您上传一个模型到云服务器之前,您需要做以下几步:
+(1) 将模型权重转成 CPU 张量;
+(2) 删除记录优化器状态 (optimizer states)的相关信息;
+(3) 计算检查点文件 (checkpoint file) 的哈希编码(hash id)并且将哈希编码加到文件名中。
+
+```shell
+python tools/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+例如,
+
+```shell
+python tools/publish_model.py work_dirs/pspnet/latest.pth psp_r50_hszhao_200ep.pth
+```
+
+最终输出文件将是 `psp_r50_512x1024_40ki_cityscapes-{hash id}.pth`。
+
+### 导出 ONNX (试验性)
+
+我们提供了一个脚本来导出模型到 [ONNX](https://github.com/onnx/onnx) 格式。被转换的模型可以通过工具 [Netron](https://github.com/lutzroeder/netron)
+来可视化。除此以外,我们同样支持对 PyTorch 和 ONNX 模型的输出结果做对比。
+
+```bash
+python tools/pytorch2onnx.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE} \
+ --input-img ${INPUT_IMG} \
+ --shape ${INPUT_SHAPE} \
+ --rescale-shape ${RESCALE_SHAPE} \
+ --show \
+ --verify \
+ --dynamic-export \
+ --cfg-options \
+ model.test_cfg.mode="whole"
+```
+
+各个参数的描述:
+
+- `config` : 模型配置文件的路径
+- `--checkpoint` : 模型检查点文件的路径
+- `--output-file`: 输出的 ONNX 模型的路径。如果没有专门指定,它默认是 `tmp.onnx`
+- `--input-img` : 用来转换和可视化的一张输入图像的路径
+- `--shape`: 模型的输入张量的高和宽。如果没有专门指定,它将被设置成 `test_pipeline` 的 `img_scale`
+- `--rescale-shape`: 改变输出的形状。设置这个值来避免 OOM,它仅在 `slide` 模式下可以用
+- `--show`: 是否打印输出模型的结构。如果没有被专门指定,它将被设置成 `False`
+- `--verify`: 是否验证一个输出模型的正确性 (correctness)。如果没有被专门指定,它将被设置成 `False`
+- `--dynamic-export`: 是否导出形状变化的输入与输出的 ONNX 模型。如果没有被专门指定,它将被设置成 `False`
+- `--cfg-options`: 更新配置选项
+
+**注意**: 这个工具仍然是试验性的,目前一些自定义操作还没有被支持
+
+### 评估 ONNX 模型
+
+我们提供 `tools/deploy_test.py` 去评估不同后端的 ONNX 模型。
+
+#### 先决条件
+
+- 安装 onnx 和 onnxruntime-gpu
+
+ ```shell
+ pip install onnx onnxruntime-gpu
+ ```
+
+- 参考 [如何在 MMCV 里构建 tensorrt 插件](https://mmcv.readthedocs.io/en/latest/tensorrt_plugin.html#how-to-build-tensorrt-plugins-in-mmcv) 安装TensorRT (可选)
+
+#### 使用方法
+
+```bash
+python tools/deploy_test.py \
+ ${CONFIG_FILE} \
+ ${MODEL_FILE} \
+ ${BACKEND} \
+ --out ${OUTPUT_FILE} \
+ --eval ${EVALUATION_METRICS} \
+ --show \
+ --show-dir ${SHOW_DIRECTORY} \
+ --cfg-options ${CFG_OPTIONS} \
+ --eval-options ${EVALUATION_OPTIONS} \
+ --opacity ${OPACITY} \
+```
+
+各个参数的描述:
+
+- `config`: 模型配置文件的路径
+- `model`: 被转换的模型文件的路径
+- `backend`: 推理的后端,可选项:`onnxruntime`, `tensorrt`
+- `--out`: 输出结果成 pickle 格式文件的路径
+- `--format-only` : 不评估直接给输出结果的格式。通常用在当您想把结果输出成一些测试服务器需要的特定格式时。如果没有被专门指定,它将被设置成 `False`。 注意这个参数是用 `--eval` 来 **手动添加**
+- `--eval`: 评估指标,取决于每个数据集的要求,例如 "mIoU" 是大多数据集的指标而 "cityscapes" 仅针对 Cityscapes 数据集。注意这个参数是用 `--format-only` 来 **手动添加**
+- `--show`: 是否展示结果
+- `--show-dir`: 涂上结果的图像被保存的文件夹的路径
+- `--cfg-options`: 重写配置文件里的一些设置,`xxx=yyy` 格式的键值对将被覆盖到配置文件里
+- `--eval-options`: 自定义的评估的选项, `xxx=yyy` 格式的键值对将成为 `dataset.evaluate()` 函数的参数变量
+- `--opacity`: 涂上结果的分割图的透明度,范围在 (0, 1] 之间
+
+#### 结果和模型
+
+| 模型 | 配置文件 | 数据集 | 评价指标 | PyTorch | ONNXRuntime | TensorRT-fp32 | TensorRT-fp16 |
+| :--------: | :---------------------------------------------: | :--------: | :----: | :-----: | :---------: | :-----------: | :-----------: |
+| FCN | fcn_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 72.2 | 72.2 | 72.2 | 72.2 |
+| PSPNet | pspnet_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 77.8 | 77.8 | 77.8 | 77.8 |
+| deeplabv3 | deeplabv3_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.0 | 79.0 | 79.0 | 79.0 |
+| deeplabv3+ | deeplabv3plus_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.6 | 79.5 | 79.5 | 79.5 |
+| PSPNet | pspnet_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.2 | 78.1 | | |
+| deeplabv3 | deeplabv3_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.5 | 78.3 | | |
+| deeplabv3+ | deeplabv3plus_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.9 | 78.7 | | |
+
+**注意**: TensorRT 仅在使用 `whole mode` 测试模式时的配置文件里可用。
+
+### 导出 TorchScript (试验性)
+
+我们同样提供一个脚本去把模型导出成 [TorchScript](https://pytorch.org/docs/stable/jit.html) 格式。您可以使用 pytorch C++ API [LibTorch](https://pytorch.org/docs/stable/cpp_index.html) 去推理训练好的模型。
+被转换的模型能被像 [Netron](https://github.com/lutzroeder/netron) 的工具来可视化。此外,我们还支持 PyTorch 和 TorchScript 模型的输出结果的比较。
+
+```shell
+python tools/pytorch2torchscript.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE}
+ --shape ${INPUT_SHAPE}
+ --verify \
+ --show
+```
+
+各个参数的描述:
+
+- `config` : pytorch 模型的配置文件的路径
+- `--checkpoint` : pytorch 模型的检查点文件的路径
+- `--output-file`: TorchScript 模型输出的路径,如果没有被专门指定,它将被设置成 `tmp.pt`
+- `--input-img` : 用来转换和可视化的输入图像的路径
+- `--shape`: 模型的输入张量的宽和高。如果没有被专门指定,它将被设置成 `512 512`
+- `--show`: 是否打印输出模型的追踪图 (traced graph),如果没有被专门指定,它将被设置成 `False`
+- `--verify`: 是否验证一个输出模型的正确性 (correctness),如果没有被专门指定,它将被设置成 `False`
+
+**注意**: 目前仅支持 PyTorch>=1.8.0 版本
+
+**注意**: 这个工具仍然是试验性的,一些自定义操作符目前还不被支持
+
+例子:
+
+- 导出 PSPNet 在 cityscapes 数据集上的 pytorch 模型
+
+ ```shell
+ python tools/pytorch2torchscript.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ --checkpoint checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --output-file checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pt \
+ --shape 512 1024
+ ```
+
+### 导出 TensorRT (试验性)
+
+一个导出 [ONNX](https://github.com/onnx/onnx) 模型成 [TensorRT](https://developer.nvidia.com/tensorrt) 格式的脚本
+
+先决条件
+
+- 按照 [ONNXRuntime in mmcv](https://mmcv.readthedocs.io/en/latest/deployment/onnxruntime_op.html) 和 [TensorRT plugin in mmcv](https://github.com/open-mmlab/mmcv/blob/master/docs/en/deployment/tensorrt_plugin.md) ,用 ONNXRuntime 自定义运算 (custom ops) 和 TensorRT 插件安装 `mmcv-full`
+- 使用 [pytorch2onnx](#convert-to-onnx-experimental) 将模型从 PyTorch 转成 ONNX
+
+使用方法
+
+```bash
+python ${MMSEG_PATH}/tools/onnx2tensorrt.py \
+ ${CFG_PATH} \
+ ${ONNX_PATH} \
+ --trt-file ${OUTPUT_TRT_PATH} \
+ --min-shape ${MIN_SHAPE} \
+ --max-shape ${MAX_SHAPE} \
+ --input-img ${INPUT_IMG} \
+ --show \
+ --verify
+```
+
+各个参数的描述:
+
+- `config` : 模型的配置文件
+- `model` : 输入的 ONNX 模型的路径
+- `--trt-file` : 输出的 TensorRT 引擎的路径
+- `--max-shape` : 模型的输入的最大形状
+- `--min-shape` : 模型的输入的最小形状
+- `--fp16` : 做 fp16 模型转换
+- `--workspace-size` : 在 GiB 里的最大工作空间大小 (Max workspace size)
+- `--input-img` : 用来可视化的图像
+- `--show` : 做结果的可视化
+- `--dataset` : Palette provider, 默认为 `CityscapesDataset`
+- `--verify` : 验证 ONNXRuntime 和 TensorRT 的输出
+- `--verbose` : 当创建 TensorRT 引擎时,是否详细做信息日志。默认为 False
+
+**注意**: 仅在全图测试模式 (whole mode) 下测试过
+
+## 其他内容
+
+### 打印完整的配置文件
+
+`tools/print_config.py` 会逐字逐句的打印整个配置文件,展开所有的导入。
+
+```shell
+python tools/print_config.py \
+ ${CONFIG} \
+ --graph \
+ --cfg-options ${OPTIONS [OPTIONS...]} \
+```
+
+各个参数的描述:
+
+- `config` : pytorch 模型的配置文件的路径
+- `--graph` : 是否打印模型的图 (models graph)
+- `--cfg-options`: 自定义替换配置文件的选项
+
+### 对训练日志 (training logs) 画图
+
+`tools/analyze_logs.py` 会画出给定的训练日志文件的 loss/mIoU 曲线,首先需要 `pip install seaborn` 安装依赖包。
+
+```shell
+python tools/analyze_logs.py xxx.log.json [--keys ${KEYS}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
+```
+
+示例:
+
+- 对 mIoU, mAcc, aAcc 指标画图
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
+ ```
+
+- 对 loss 指标画图
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys loss --legend loss
+ ```
+
+### 转换其他仓库的权重
+
+`tools/model_converters/` 提供了若干个预训练权重转换脚本,支持将其他仓库的预训练权重的 key 转换为与 MMSegmentation 相匹配的 key。
+
+#### ViT Swin MiT Transformer 模型
+
+- ViT
+
+`tools/model_converters/vit2mmseg.py` 将 timm 预训练模型转换到 MMSegmentation。
+
+ ```shell
+ python tools/model_converters/vit2mmseg.py ${SRC} ${DST}
+ ```
+
+- Swin
+
+ `tools/model_converters/swin2mmseg.py` 将官方预训练模型转换到 MMSegmentation。
+
+ ```shell
+ python tools/model_converters/swin2mmseg.py ${SRC} ${DST}
+ ```
+
+- SegFormer
+
+ `tools/model_converters/mit2mmseg.py` 将官方预训练模型转换到 MMSegmentation。
+
+ ```shell
+ python tools/model_converters/mit2mmseg.py ${SRC} ${DST}
+ ```
+
+## 模型服务
+
+为了用 [`TorchServe`](https://pytorch.org/serve/) 服务 `MMSegmentation` 的模型 , 您可以遵循如下流程:
+
+### 1. 将 model 从 MMSegmentation 转换到 TorchServe
+
+```shell
+python tools/mmseg2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+**注意**: ${MODEL_STORE} 需要设置为某个文件夹的绝对路径
+
+### 2. 构建 `mmseg-serve` 容器镜像 (docker image)
+
+```shell
+docker build -t mmseg-serve:latest docker/serve/
+```
+
+### 3. 运行 `mmseg-serve`
+
+请查阅官方文档: [使用容器运行 TorchServe](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment)
+
+为了在 GPU 环境下使用, 您需要安装 [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). 若在 CPU 环境下使用,您可以忽略添加 `--gpus` 参数。
+
+示例:
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
+mmseg-serve:latest
+```
+
+阅读关于推理 (8080), 管理 (8081) 和指标 (8082) APIs 的 [文档](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md) 。
+
+### 4. 测试部署
+
+```shell
+curl -O https://raw.githubusercontent.com/open-mmlab/mmsegmentation/master/resources/3dogs.jpg
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg -o 3dogs_mask.png
+```
+
+得到的响应将是一个 ".png" 的分割掩码.
+
+您可以按照如下方法可视化输出:
+
+```python
+import matplotlib.pyplot as plt
+import mmcv
+plt.imshow(mmcv.imread("3dogs_mask.png", "grayscale"))
+plt.show()
+```
+
+看到的东西将会和下图类似:
+
+
+
+然后您可以使用 `test_torchserve.py` 比较 torchserve 和 pytorch 的结果,并将它们可视化。
+
+```shell
+python tools/torchserve/test_torchserve.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--result-image ${RESULT_IMAGE}] [--device ${DEVICE}]
+```
+
+示例:
+
+```shell
+python tools/torchserve/test_torchserve.py \
+demo/demo.png \
+configs/fcn/fcn_r50-d8_512x1024_40k_cityscapes.py \
+checkpoint/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608-efe53f0d.pth \
+fcn
+```
diff --git a/docs_kneron/stdc_step_by_step.md b/docs_kneron/stdc_step_by_step.md
new file mode 100644
index 0000000..ec35a68
--- /dev/null
+++ b/docs_kneron/stdc_step_by_step.md
@@ -0,0 +1,439 @@
+# Step 1: Environment
+
+## Step 1-1: Prerequisites
+
+- Python 3.6+
+- PyTorch 1.3+ (We recommend you installing PyTorch using Conda following the [Official PyTorch Installation Instruction](https://pytorch.org/))
+- (Optional) CUDA 9.2+ (If you installed PyTorch with cuda using Conda following the [Official PyTorch Installation Instruction](https://pytorch.org/), you can skip CUDA installation)
+- (Optional, used to build from source) GCC 5+
+- [mmcv-full](https://mmcv.readthedocs.io/en/latest/#installation) (Note: not `mmcv`!)
+
+**Note:** You need to run `pip uninstall mmcv` first if you have `mmcv` installed.
+If mmcv and mmcv-full are both installed, there will be `ModuleNotFoundError`.
+
+## Step 1-2: Install kneron-mmsegmentation
+
+### Step 1-2-1: Install PyTorch
+
+You can follow [Official PyTorch Installation Instruction](https://pytorch.org/) to install PyTorch using Conda:
+
+```shell
+conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -y
+```
+
+### Step 1-2-2: Install mmcv-full
+
+We recommend you installing mmcv-full using pip:
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html
+```
+
+Please replace `cu113` and `torch1.11.0` in the url to your desired one. For example, to install the `mmcv-full` with `CUDA 11.1` and `PyTorch 1.9.0`, use the following command:
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
+```
+
+If you see error messages while installing mmcv-full, please check if your installation instruction matches your installed version of PyTorch and Cuda, and see [MMCV pip Installation Instruction](https://github.com/open-mmlab/mmcv#install-with-pip) for different versions of MMCV compatible to different PyTorch and CUDA versions.
+
+### Step 1-2-3: Clone kneron-mmsegmentation Repository
+
+```shell
+git clone https://github.com/kneron/kneron-mmsegmentation.git
+cd kneron-mmsegmentation
+```
+
+### Step 1-2-4: Install Required Python Libraries for Building and Installing kneron-mmsegmentation
+
+```shell
+pip install -r requirements_kneron.txt
+pip install -v -e . # or "python setup.py develop"
+```
+
+# Step 2: Training Models on Standard Datasets
+
+kneron-mmsegmentation provides many existing and existing semantic segmentation models in [Model Zoo](https://mmsegmentation.readthedocs.io/en/latest/model_zoo.html), and supports several standard datasets like CityScapes, Pascal Context, Coco Stuff, ADE20K, etc. Here we demonstrate how to train *STDC-Seg*, a semantic segmentation algorithm, on *CityScapes*, a well-known semantic segmentation dataset.
+
+## Step 2-1: Download CityScapes Dataset
+
+1. Go to [CityScapes Official Website](https://www.cityscapes-dataset.com) and click *Download* link on the top of the page. If you're not logged in, it will navigate you to login page.
+2. If it is the first time you visiting CityScapes website, to download CityScapes dataset, you have to register an account.
+3. Click the *Register* link and it will navigate you to the registeration page.
+4. Fill in all the *required* fields, accept the terms and conditions, and click the *Register* button. If everything goes well, you will see *Registration Successful* on the page and recieve a registration confirmation mail in your email inbox.
+5. Click on the link provided in the confirmation mail, login with your newly registered account and password, and you should be able to download the CityScapes dataset.
+6. Download *leftImg8bit_trainvaltest.zip* (images) and *gtFine_trainvaltest.zip* (labels) and place them onto your server.
+
+## Step 2-2: Dataset Preparation
+
+We suggest that you extract the zipped files to somewhere outside the project directory and symlink (`ln`) the dataset root to `kneron-mmsegmentation/data` so you can use the dataset outside this project, as shown below:
+
+```shell
+# Replace all "path/to/your" below with where you want to put the dataset!
+
+# Extracting Cityscapes
+mkdir -p path/to/your/cityscapes
+unzip leftImg8bit_trainvaltest.zip -d path/to/your/cityscapes
+unzip gtFine_trainvaltest.zip -d path/to/your/cityscapes
+
+# symlink dataset to kneron-mmsegmentation/data # where "kneron-mmsegmentation" is the repository you cloned in step 0-4
+mkdir -p kneron-mmsegmentation/data
+ln -s $(realpath path/to/your/cityscapes) kneron-mmsegmentation/data
+
+# Replace all "path/to/your" above with where you want to put the dataset!
+```
+
+Then, we need *cityscapesScripts* to preprocess the CityScapes dataset. If you completely followed our [Step 1-2-4](#step-1-2-4-install-required-python-libraries-for-building-and-installing-kneron-mmsegmentation), you should have python library *cityscapesScripts* installed (if no, execute `pip install cityscapesScripts` command).
+
+```shell
+# Replace "path/to/your" with where you want to put the dataset!
+export CITYSCAPES_DATASET=$(realpath path/to/your/cityscapes)
+csCreateTrainIdLabelImgs
+```
+
+Wait several minutes and you'll see something like this:
+
+```plain
+Processing 5000 annotation files
+Progress: 100.0 %
+```
+
+The files inside the dataset folder should be something like:
+
+```plain
+kneron-mmsegmentation/data/cityscapes
+├── gtFine
+│ ├── test
+│ │ ├── ...
+│ ├── train
+│ │ ├── ...
+│ ├── val
+│ │ ├── frankfurt
+│ │ │ ├── frankfurt_000000_000294_gtFine_color.png
+│ │ │ ├── frankfurt_000000_000294_gtFine_instanceIds.png
+│ │ │ ├── frankfurt_000000_000294_gtFine_labelIds.png
+│ │ │ ├── frankfurt_000000_000294_gtFine_labelTrainIds.png
+│ │ │ ├── frankfurt_000000_000294_gtFine_polygons.png
+│ │ │ ├── ...
+│ │ ├── ...
+├── leftImg8bit
+│ ├── test
+│ │ ├── ...
+│ ├── train
+│ │ ├── ...
+│ ├── val
+│ │ ├── frankfurt
+│ │ │ ├── frankfurt_000000_000294_leftImg8bit.png
+│ │ ├── ...
+...
+```
+
+It's recommended that you *symlink* the dataset folder to mmdetection folder. However, if you place your dataset folder at different place and do not want to symlink, you have to change the corresponding paths in the config file.
+
+Now the dataset should be ready for training.
+
+
+## Step 2-3: Train STDC-Seg on CityScapes
+
+Short-Term Dense Concatenate Network (STDC network) is a light-weight network structure for convolutional neural network. If we apply this network structure to semantic segmentation task, it's called STDC-Seg. It's first introduced in [Rethinking BiSeNet For Real-time Semantic Segmentation
+](https://arxiv.org/abs/2104.13188). Please check the paper if you want to know the algorithm details.
+
+We only need a configuration file to train a deep learning model in either the original MMSegmentation or kneron-mmsegmentation. STDC-Seg is provided in the original MMSegmentation repository, but the original configuration file needs some modification due to our hardware limitation so that we can apply the trained model to our Kneron dongle.
+
+To make a configuration file compatible with our device, we have to:
+
+* Change the mean and std value in image normalization to `mean=[128., 128., 128.]` and `std=[256., 256., 256.]`.
+* Shrink the input size during inference phase. The original CityScapes image size is too large (2048(w)x1024(h)) for our device; 1024(w)x512(h) might be good for our device.
+
+To achieve this, you can modify the `img_scale` in `test_pipeline` and `img_norm_cfg` in the configuration file `configs/_base_/datasets/cityscapes.py`.
+
+Luckily, here in kneron-mmsegmentation, we provide a modified STDC-Seg configuration file (`configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py`) so we can easily apply the trained model to our device.
+
+To train STDC-Seg compatible with our device, just execute:
+
+```shell
+cd kneron-mmsegmentation
+python tools/train.py configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py
+```
+
+kneron-mmsegmentation will generate `work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes` folder and save the configuration file and all checkpoints there.
+
+# Step 3: Test Trained Model
+`tools/test.py` is a script that generates inference results from test set with our pytorch model and evaluates the results to see if our pytorch model is well trained (if `--eval` argument is given). Note that it's always good to evluate our pytorch model before deploying it.
+
+```shell
+python tools/test.py \
+ work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py \
+ work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth \
+ --eval mIoU
+```
+* `kn_stdc1_in1k-pre_512x1024_80k_cityscapes/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py` can be your training config.
+* `kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth` can be your model checkpoint.
+
+The expected result of the command above should be something similar to the following text (the numbers may slightly differ):
+```
+...
++---------------+-------+-------+
+| Class | IoU | Acc |
++---------------+-------+-------+
+| road | 97.49 | 98.59 |
+| sidewalk | 80.17 | 88.71 |
+| building | 89.52 | 95.25 |
+| wall | 57.92 | 66.99 |
+| fence | 55.5 | 70.15 |
+| pole | 38.93 | 47.51 |
+| traffic light | 49.95 | 59.97 |
+| traffic sign | 62.1 | 70.05 |
+| vegetation | 89.02 | 95.27 |
+| terrain | 60.18 | 72.26 |
+| sky | 91.84 | 96.34 |
+| person | 68.98 | 84.35 |
+| rider | 47.79 | 60.98 |
+| car | 91.63 | 96.48 |
+| truck | 74.31 | 83.52 |
+| bus | 80.24 | 86.83 |
+| train | 66.45 | 76.78 |
+| motorcycle | 48.69 | 58.18 |
+| bicycle | 65.81 | 81.68 |
++---------------+-------+-------+
+Summary:
+
++------+-------+-------+
+| aAcc | mIoU | mAcc |
++------+-------+-------+
+| 94.3 | 69.29 | 78.42 |
++------+-------+-------+
+```
+
+**NOTE: The training process might take some time, depending on your computation resource. If you just want to take a quick look at the deployment flow, you can download our pretrained model so you can skip Step 1, 2, and 3:**
+```
+# If you don't want to train your own model:
+mkdir -p work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes
+pushd work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes
+wget https://github.com/kneron/Model_Zoo/raw/main/mmsegmentation/stdc_1/latest.zip
+unzip latest.zip
+popd
+```
+
+# Step 4: Export ONNX and Verify
+
+## Step 4-1: Export ONNX
+
+`tools/pytorch2onnx_kneron.py` is a script provided by kneron-mmsegmentation to help users to convert our trained pytorch model to ONNX:
+```shell
+python tools/pytorch2onnx_kneron.py \
+ configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py \
+ --checkpoint work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth \
+ --output-file work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.onnx \
+ --verify
+```
+* `configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py` can be your training config.
+* `work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth` can be your model checkpoint.
+* `work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.onnx` can be any other path. Here for convenience, the ONNX file is placed in the same folder of our pytorch checkpoint.
+
+## Step 4-2: Verify ONNX
+
+`tools/deploy_test_kneron.py` is a script provided by kneron-mmsegmentation to help users to verify if our exported ONNX generates similar outputs with what our PyTorch model does:
+```shell
+python tools/deploy_test_kneron.py \
+ configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py \
+ work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.onnx \
+ --eval mIoU
+```
+* `configs/stdc/kn_stdc1_in1k-pre_512x1024_80k_cityscapes.py` can be your training config.
+* `work_dirs/kn_stdc1_in1k-pre_512x1024_80k_cityscapes/latest.pth` can be your exported ONNX file.
+
+The expected result of the command above should be something similar to the following text (the numbers may slightly differ):
+
+```
+...
++---------------+-------+-------+
+| Class | IoU | Acc |
++---------------+-------+-------+
+| road | 97.52 | 98.62 |
+| sidewalk | 80.59 | 88.69 |
+| building | 89.59 | 95.38 |
+| wall | 58.02 | 66.85 |
+| fence | 55.37 | 69.76 |
+| pole | 44.4 | 52.28 |
+| traffic light | 50.23 | 60.07 |
+| traffic sign | 62.58 | 70.25 |
+| vegetation | 89.0 | 95.27 |
+| terrain | 60.47 | 72.27 |
+| sky | 90.56 | 97.07 |
+| person | 70.7 | 84.88 |
+| rider | 48.66 | 61.37 |
+| car | 91.58 | 95.98 |
+| truck | 73.92 | 82.66 |
+| bus | 79.92 | 85.95 |
+| train | 66.26 | 75.92 |
+| motorcycle | 48.88 | 57.91 |
+| bicycle | 66.9 | 82.0 |
++---------------+-------+-------+
+Summary:
+
++------+-------+-------+
+| aAcc | mIoU | mAcc |
++------+-------+-------+
+| 94.4 | 69.75 | 78.59 |
++------+-------+-------+
+```
+
+Note that the ONNX results may differ from the PyTorch results due to some implementation differences between PyTorch and ONNXRuntime.
+
+# Step 5: Convert ONNX File to [NEF](http://doc.kneron.com/docs/#toolchain/manual/#5-nef-workflow) Model for Kneron Platform
+
+## Step 5-1: Install Kneron toolchain docker:
+
+* Check [Kneron Toolchain Installation Document](http://doc.kneron.com/docs/#toolchain/manual/#1-installation)
+
+## Step 5-2: Mount Kneron toolchain docker
+
+* Mount a folder (e.g. '/mnt/hgfs/Competition') to toolchain docker container as `/data1`. The converted ONNX in Step 3 should be put here. All the toolchain operation should happen in this folder.
+```
+sudo docker run --rm -it -v /mnt/hgfs/Competition:/data1 kneron/toolchain:latest
+```
+
+## Step 5-3: Import KTC and the required libraries in python
+
+```python
+import ktc
+import numpy as np
+import os
+import onnx
+from PIL import Image
+```
+
+## Step 5-4: Optimize the onnx model
+
+```python
+onnx_path = '/data1/latest.onnx'
+m = onnx.load(onnx_path)
+m = ktc.onnx_optimizer.onnx2onnx_flow(m)
+onnx.save(m,'latest.opt.onnx')
+```
+
+## Step 5-5: Configure and load data needed for ktc, and check if onnx is ok for toolchain
+```python
+# npu (only) performance simulation
+km = ktc.ModelConfig((&)model_id_on_public_field, "0001", "720", onnx_model=m)
+eval_result = km.evaluate()
+print("\nNpu performance evaluation result:\n" + str(eval_result))
+```
+
+## Step 5-6: Quantize the onnx model
+We [sampled 3 images from Cityscapes dataset](https://www.kneron.com/tw/support/education-center/?folder=OpenMMLab%20Kneron%20Edition/misc/&download=41) (3 images) as quantization data. To test our quantized model:
+1. Download the [zip file](https://www.kneron.com/tw/support/education-center/?folder=OpenMMLab%20Kneron%20Edition/misc/&download=41)
+2. Extract the zip file as a folder named `cityscapes_minitest`
+3. Put the `cityscapes_minitest` into docker mounted folder (the path in docker container should be `/data1/cityscapes_minitest`)
+
+The following script will preprocess (should be the same as training code) our quantization data, and put it in a list:
+
+```python
+import os
+from os import walk
+
+img_list = []
+for (dirpath, dirnames, filenames) in walk("/data1/cityscapes_minitest"):
+ for f in filenames:
+ fullpath = os.path.join(dirpath, f)
+
+ image = Image.open(fullpath)
+ image = image.convert("RGB")
+ image = Image.fromarray(np.array(image)[...,::-1])
+ img_data = np.array(image.resize((1024, 512), Image.BILINEAR)) / 256 - 0.5
+ print(fullpath)
+ img_list.append(img_data)
+```
+
+Then perform quantization. The generated BIE model will put generated at `/data1/output.bie`.
+
+```python
+# fixed-point analysis
+bie_model_path = km.analysis({"input": img_list})
+print("\nFixed-point analysis done. Save bie model to '" + str(bie_model_path) + "'")
+```
+
+## Step 5-7: Compile
+
+The final step is compile the BIE model into an NEF model.
+```python
+# compile
+nef_model_path = ktc.compile([km])
+print("\nCompile done. Save Nef file to '" + str(nef_model_path) + "'")
+```
+
+You can find the NEF file at `/data1/batch_compile/models_720.nef`. `models_720.nef` is the final compiled model.
+
+# Step 6: Run [NEF](http://doc.kneron.com/docs/#toolchain/manual/#5-nef-workflow) model on [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1)
+
+* N/A
+
+# Step 7 (For Kneron AI Competition 2022): Run [NEF](http://doc.kneron.com/docs/#toolchain/manual/#5-nef-workflow) model on [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1)
+
+[WARNING] Don't do this step in toolchain docker enviroment mentioned in Step 5
+
+Recommend you read [Kneron PLUS official document](http://doc.kneron.com/docs/#plus_python/#_top) first.
+
+### Step 7-1: Download and Install PLUS python library(.whl)
+* Go to [Kneron education center](https://www.kneron.com/tw/support/education-center/)
+* Scroll down to OpenMMLab Kneron Edition table
+* Select Kneron Plus v1.13.0 (pre-built python library)
+* Your OS version(Ubuntu, Windows, MacOS, Raspberry pi)
+* Download KneronPLUS-1.3.0-py3-none-any_{your_os}.whl
+* unzip downloaded `KneronPLUS-1.3.0-py3-none-any.whl.zip`
+* pip install KneronPLUS-1.3.0-py3-none-any.whl
+
+### Step 7-2: Download STDC example code
+* Go to [Kneron education center](https://www.kneron.com/tw/support/education-center/)
+* Scroll down to **OpenMMLab Kneron Edition** table
+* Select **kneron-mmsegmentation**
+* Select **STDC**
+* Download **stdc_plus_demo.zip**
+* unzip downloaded **stdc_plus_demo**
+
+### Step 7-3: Test enviroment is ready (require [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1))
+In `stdc_plus_demo`, we provide a STDC-Seg example model and image for quick test.
+* Plug in [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1) into your computer USB port
+* Go to the stdc_plus_demo folder
+```bash
+cd /PATH/TO/stdc_plus_demo
+```
+
+* Install required python libraries
+```bash
+pip install -r requirements.txt
+```
+
+* Run example on [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1)
+```python
+python KL720DemoGenericInferenceSTDC_BypassHwPreProc.py -nef ./example_stdc_720.nef -img 000000000641.jpg
+```
+
+Then you can see the inference result is saved as output_000000000641.jpg in the same folder.
+The expected result of the command above will be something similar to the following text:
+```plain
+...
+[Connect Device]
+ - Success
+[Set Device Timeout]
+ - Success
+[Upload Model]
+ - Success
+[Read Image]
+ - Success
+[Starting Inference Work]
+ - Starting inference loop 1 times
+ - .
+[Retrieve Inference Node Output ]
+ - Success
+[Output Result Image]
+ - Output bounding boxes on 'output_000000000641.jpg'
+...
+```
+
+### Step 7-4: Run your NEF model and your image on [KL720 USB accelerator](https://www.kneo.ai/products/hardwares/HW2020122500000007/1)
+Use the same script in previous step, but now we change the input NEF model path and image to yours
+```bash
+python KL720DemoGenericInferenceSTDC_BypassHwPreProc.py -img /PATH/TO/YOUR_IMAGE.bmp -nef /PATH/TO/YOUR/720_NEF_MODEL.nef
+```
\ No newline at end of file
diff --git a/mmseg/__init__.py b/mmseg/__init__.py
new file mode 100644
index 0000000..8da9bc6
--- /dev/null
+++ b/mmseg/__init__.py
@@ -0,0 +1,62 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+from packaging.version import parse
+
+from .version import __version__, version_info
+
+MMCV_MIN = '1.3.13'
+MMCV_MAX = '1.5.0'
+
+
+def digit_version(version_str: str, length: int = 4):
+ """Convert a version string into a tuple of integers.
+
+ This method is usually used for comparing two versions. For pre-release
+ versions: alpha < beta < rc.
+
+ Args:
+ version_str (str): The version string.
+ length (int): The maximum number of version levels. Default: 4.
+
+ Returns:
+ tuple[int]: The version info in digits (integers).
+ """
+ version = parse(version_str)
+ assert version.release, f'failed to parse version {version_str}'
+ release = list(version.release)
+ release = release[:length]
+ if len(release) < length:
+ release = release + [0] * (length - len(release))
+ if version.is_prerelease:
+ mapping = {'a': -3, 'b': -2, 'rc': -1}
+ val = -4
+ # version.pre can be None
+ if version.pre:
+ if version.pre[0] not in mapping:
+ warnings.warn(f'unknown prerelease version {version.pre[0]}, '
+ 'version checking may go wrong')
+ else:
+ val = mapping[version.pre[0]]
+ release.extend([val, version.pre[-1]])
+ else:
+ release.extend([val, 0])
+
+ elif version.is_postrelease:
+ release.extend([1, version.post])
+ else:
+ release.extend([0, 0])
+ return tuple(release)
+
+
+mmcv_min_version = digit_version(MMCV_MIN)
+mmcv_max_version = digit_version(MMCV_MAX)
+mmcv_version = digit_version(mmcv.__version__)
+
+
+assert (mmcv_min_version <= mmcv_version <= mmcv_max_version), \
+ f'MMCV=={mmcv.__version__} is used but incompatible. ' \
+ f'Please install mmcv>={mmcv_min_version}, <={mmcv_max_version}.'
+
+__all__ = ['__version__', 'version_info', 'digit_version']
diff --git a/mmseg/apis/__init__.py b/mmseg/apis/__init__.py
new file mode 100644
index 0000000..45be2fd
--- /dev/null
+++ b/mmseg/apis/__init__.py
@@ -0,0 +1,19 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+from .inference import (
+ inference_segmentor,
+ inference_segmentor_kn,
+ init_segmentor,
+ init_segmentor_kn,
+ show_result_pyplot,
+)
+from .test import multi_gpu_test, single_gpu_test
+from .train import (get_root_logger, init_random_seed, set_random_seed,
+ train_segmentor)
+
+__all__ = [
+ 'get_root_logger', 'set_random_seed', 'train_segmentor',
+ 'init_segmentor', 'init_segmentor_kn', 'inference_segmentor',
+ 'inference_segmentor_kn', 'multi_gpu_test', 'single_gpu_test',
+ 'show_result_pyplot', 'init_random_seed'
+]
diff --git a/mmseg/apis/inference.py b/mmseg/apis/inference.py
new file mode 100644
index 0000000..7faa83a
--- /dev/null
+++ b/mmseg/apis/inference.py
@@ -0,0 +1,178 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import matplotlib.pyplot as plt
+import mmcv
+import torch
+from mmcv.parallel import collate, scatter
+from mmcv.runner import load_checkpoint
+
+from mmseg.datasets.pipelines import Compose
+from mmseg.models import build_segmentor
+from mmseg.models.segmentors import ONNXRuntimeSegmentorKN
+
+
+def init_segmentor(config, checkpoint=None, device='cuda:0'):
+ """Initialize a segmentor from config file.
+
+ Args:
+ config (str or :obj:`mmcv.Config`): Config file path or the config
+ object.
+ checkpoint (str, optional): Checkpoint path. If left as None, the model
+ will not load any weights.
+ device (str, optional) CPU/CUDA device option. Default 'cuda:0'.
+ Use 'cpu' for loading model on CPU.
+ Returns:
+ nn.Module: The constructed segmentor.
+ """
+ if isinstance(config, str):
+ config = mmcv.Config.fromfile(config)
+ elif not isinstance(config, mmcv.Config):
+ raise TypeError('config must be a filename or Config object, '
+ 'but got {}'.format(type(config)))
+ config.model.pretrained = None
+ config.model.train_cfg = None
+ model = build_segmentor(config.model, test_cfg=config.get('test_cfg'))
+ if checkpoint is not None:
+ checkpoint = load_checkpoint(model, checkpoint, map_location='cpu')
+ model.CLASSES = checkpoint['meta']['CLASSES']
+ model.PALETTE = checkpoint['meta']['PALETTE']
+ model.cfg = config # save the config in the model for convenience
+ model.to(device)
+ model.eval()
+ return model
+
+
+def init_segmentor_kn(config, checkpoint=None, device='cuda:0'):
+ """Initialize a segmentor from config file.
+
+ Args:
+ config (str or :obj:`mmcv.Config`): Config file path or the config
+ object.
+ checkpoint (str, optional): Checkpoint path. If left as None, the model
+ will not load any weights.
+ device (str, optional) CPU/CUDA device option. Default 'cuda:0'.
+ Use 'cpu' for loading model on CPU.
+ Returns:
+ nn.Module: The constructed segmentor.
+ """
+ if checkpoint is None or not checkpoint.endswith(".onnx"):
+ return init_segmentor(config, checkpoint, device)
+ try:
+ _, device_id = device.split(":")
+ device_id = int(device_id)
+ except Exception:
+ device_id = None if device == 'cpu' else 0
+ model = ONNXRuntimeSegmentorKN(
+ checkpoint, cfg=config, device_id=device_id
+ ).eval()
+ return model
+
+
+class LoadImage:
+ """A simple pipeline to load image."""
+
+ def __call__(self, results):
+ """Call function to load images into results.
+
+ Args:
+ results (dict): A result dict contains the file name
+ of the image to be read.
+
+ Returns:
+ dict: ``results`` will be returned containing loaded image.
+ """
+
+ if isinstance(results['img'], str):
+ results['filename'] = results['img']
+ results['ori_filename'] = results['img']
+ else:
+ results['filename'] = None
+ results['ori_filename'] = None
+ img = mmcv.imread(results['img'])
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ return results
+
+
+def inference_segmentor(model, img):
+ """Inference image(s) with the segmentor.
+
+ Args:
+ model (nn.Module): The loaded segmentor.
+ imgs (str/ndarray or list[str/ndarray]): Either image files or loaded
+ images.
+
+ Returns:
+ (list[Tensor]): The segmentation result.
+ """
+ cfg = model.cfg
+ device = next(model.parameters()).device # model device
+ # build the data pipeline
+ test_pipeline = [LoadImage()] + cfg.data.test.pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ # prepare data
+ data = dict(img=img)
+ data = test_pipeline(data)
+ data = collate([data], samples_per_gpu=1)
+ if next(model.parameters()).is_cuda:
+ # scatter to specified GPU
+ data = scatter(data, [device])[0]
+ else:
+ data['img_metas'] = [i.data[0] for i in data['img_metas']]
+
+ # forward the model
+ with torch.no_grad():
+ result = model(return_loss=False, rescale=True, **data)
+ return result
+
+
+@torch.no_grad()
+def inference_segmentor_kn(model, img):
+ if isinstance(model, ONNXRuntimeSegmentorKN):
+ cfg = model.cfg
+ test_pipeline = [LoadImage()] + cfg.data.test.pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ data = dict(img=img)
+ data = test_pipeline(data)
+ data = collate([data], samples_per_gpu=1)
+ return model(return_loss=False, rescale=True, **data)
+ else:
+ return inference_segmentor(model, img)
+
+
+def show_result_pyplot(model,
+ img,
+ result,
+ palette=None,
+ fig_size=(15, 10),
+ opacity=0.5,
+ title='',
+ block=True):
+ """Visualize the segmentation results on the image.
+
+ Args:
+ model (nn.Module): The loaded segmentor.
+ img (str or np.ndarray): Image filename or loaded image.
+ result (list): The segmentation result.
+ palette (list[list[int]]] | None): The palette of segmentation
+ map. If None is given, random palette will be generated.
+ Default: None
+ fig_size (tuple): Figure size of the pyplot figure.
+ opacity(float): Opacity of painted segmentation map.
+ Default 0.5.
+ Must be in (0, 1] range.
+ title (str): The title of pyplot figure.
+ Default is ''.
+ block (bool): Whether to block the pyplot figure.
+ Default is True.
+ """
+ if hasattr(model, 'module'):
+ model = model.module
+ img = model.show_result(
+ img, result, palette=palette, show=False, opacity=opacity)
+ plt.figure(figsize=fig_size)
+ plt.imshow(mmcv.bgr2rgb(img))
+ plt.title(title)
+ plt.tight_layout()
+ plt.show(block=block)
diff --git a/mmseg/apis/test.py b/mmseg/apis/test.py
new file mode 100644
index 0000000..cc4fcc9
--- /dev/null
+++ b/mmseg/apis/test.py
@@ -0,0 +1,233 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.engine import collect_results_cpu, collect_results_gpu
+from mmcv.image import tensor2imgs
+from mmcv.runner import get_dist_info
+
+
+def np2tmp(array, temp_file_name=None, tmpdir=None):
+ """Save ndarray to local numpy file.
+
+ Args:
+ array (ndarray): Ndarray to save.
+ temp_file_name (str): Numpy file name. If 'temp_file_name=None', this
+ function will generate a file name with tempfile.NamedTemporaryFile
+ to save ndarray. Default: None.
+ tmpdir (str): Temporary directory to save Ndarray files. Default: None.
+ Returns:
+ str: The numpy file name.
+ """
+
+ if temp_file_name is None:
+ temp_file_name = tempfile.NamedTemporaryFile(
+ suffix='.npy', delete=False, dir=tmpdir).name
+ np.save(temp_file_name, array)
+ return temp_file_name
+
+
+def single_gpu_test(model,
+ data_loader,
+ show=False,
+ out_dir=None,
+ efficient_test=False,
+ opacity=0.5,
+ pre_eval=False,
+ format_only=False,
+ format_args={}):
+ """Test with single GPU by progressive mode.
+
+ Args:
+ model (nn.Module): Model to be tested.
+ data_loader (utils.data.Dataloader): Pytorch data loader.
+ show (bool): Whether show results during inference. Default: False.
+ out_dir (str, optional): If specified, the results will be dumped into
+ the directory to save output results.
+ efficient_test (bool): Whether save the results as local numpy files to
+ save CPU memory during evaluation. Mutually exclusive with
+ pre_eval and format_results. Default: False.
+ opacity(float): Opacity of painted segmentation map.
+ Default 0.5.
+ Must be in (0, 1] range.
+ pre_eval (bool): Use dataset.pre_eval() function to generate
+ pre_results for metric evaluation. Mutually exclusive with
+ efficient_test and format_results. Default: False.
+ format_only (bool): Only format result for results commit.
+ Mutually exclusive with pre_eval and efficient_test.
+ Default: False.
+ format_args (dict): The args for format_results. Default: {}.
+ Returns:
+ list: list of evaluation pre-results or list of save file names.
+ """
+ if efficient_test:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` will be deprecated, the '
+ 'evaluation is CPU memory friendly with pre_eval=True')
+ mmcv.mkdir_or_exist('.efficient_test')
+ # when none of them is set true, return segmentation results as
+ # a list of np.array.
+ assert [efficient_test, pre_eval, format_only].count(True) <= 1, \
+ '``efficient_test``, ``pre_eval`` and ``format_only`` are mutually ' \
+ 'exclusive, only one of them could be true .'
+
+ model.eval()
+ results = []
+ dataset = data_loader.dataset
+ prog_bar = mmcv.ProgressBar(len(dataset))
+ # The pipeline about how the data_loader retrieval samples from dataset:
+ # sampler -> batch_sampler -> indices
+ # The indices are passed to dataset_fetcher to get data from dataset.
+ # data_fetcher -> collate_fn(dataset[index]) -> data_sample
+ # we use batch_sampler to get correct data idx
+ loader_indices = data_loader.batch_sampler
+
+ for batch_indices, data in zip(loader_indices, data_loader):
+ with torch.no_grad():
+ result = model(return_loss=False, **data)
+
+ if show or out_dir:
+ img_tensor = data['img'][0]
+ img_metas = data['img_metas'][0].data[0]
+ imgs = tensor2imgs(img_tensor, **img_metas[0]['img_norm_cfg'])
+ assert len(imgs) == len(img_metas)
+
+ for img, img_meta in zip(imgs, img_metas):
+ h, w, _ = img_meta['img_shape']
+ img_show = img[:h, :w, :]
+
+ ori_h, ori_w = img_meta['ori_shape'][:-1]
+ img_show = mmcv.imresize(img_show, (ori_w, ori_h))
+
+ if out_dir:
+ out_file = osp.join(out_dir, img_meta['ori_filename'])
+ else:
+ out_file = None
+
+ model.module.show_result(
+ img_show,
+ result,
+ palette=dataset.PALETTE,
+ show=show,
+ out_file=out_file,
+ opacity=opacity)
+
+ if efficient_test:
+ result = [np2tmp(_, tmpdir='.efficient_test') for _ in result]
+
+ if format_only:
+ result = dataset.format_results(
+ result, indices=batch_indices, **format_args)
+ if pre_eval:
+ # TODO: adapt samples_per_gpu > 1.
+ # only samples_per_gpu=1 valid now
+ result = dataset.pre_eval(result, indices=batch_indices)
+ results.extend(result)
+ else:
+ results.extend(result)
+
+ batch_size = len(result)
+ for _ in range(batch_size):
+ prog_bar.update()
+
+ return results
+
+
+def multi_gpu_test(model,
+ data_loader,
+ tmpdir=None,
+ gpu_collect=False,
+ efficient_test=False,
+ pre_eval=False,
+ format_only=False,
+ format_args={}):
+ """Test model with multiple gpus by progressive mode.
+
+ This method tests model with multiple gpus and collects the results
+ under two different modes: gpu and cpu modes. By setting 'gpu_collect=True'
+ it encodes results to gpu tensors and use gpu communication for results
+ collection. On cpu mode it saves the results on different gpus to 'tmpdir'
+ and collects them by the rank 0 worker.
+
+ Args:
+ model (nn.Module): Model to be tested.
+ data_loader (utils.data.Dataloader): Pytorch data loader.
+ tmpdir (str): Path of directory to save the temporary results from
+ different gpus under cpu mode. The same path is used for efficient
+ test. Default: None.
+ gpu_collect (bool): Option to use either gpu or cpu to collect results.
+ Default: False.
+ efficient_test (bool): Whether save the results as local numpy files to
+ save CPU memory during evaluation. Mutually exclusive with
+ pre_eval and format_results. Default: False.
+ pre_eval (bool): Use dataset.pre_eval() function to generate
+ pre_results for metric evaluation. Mutually exclusive with
+ efficient_test and format_results. Default: False.
+ format_only (bool): Only format result for results commit.
+ Mutually exclusive with pre_eval and efficient_test.
+ Default: False.
+ format_args (dict): The args for format_results. Default: {}.
+
+ Returns:
+ list: list of evaluation pre-results or list of save file names.
+ """
+ if efficient_test:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` will be deprecated, the '
+ 'evaluation is CPU memory friendly with pre_eval=True')
+ mmcv.mkdir_or_exist('.efficient_test')
+ # when none of them is set true, return segmentation results as
+ # a list of np.array.
+ assert [efficient_test, pre_eval, format_only].count(True) <= 1, \
+ '``efficient_test``, ``pre_eval`` and ``format_only`` are mutually ' \
+ 'exclusive, only one of them could be true .'
+
+ model.eval()
+ results = []
+ dataset = data_loader.dataset
+ # The pipeline about how the data_loader retrieval samples from dataset:
+ # sampler -> batch_sampler -> indices
+ # The indices are passed to dataset_fetcher to get data from dataset.
+ # data_fetcher -> collate_fn(dataset[index]) -> data_sample
+ # we use batch_sampler to get correct data idx
+
+ # batch_sampler based on DistributedSampler, the indices only point to data
+ # samples of related machine.
+ loader_indices = data_loader.batch_sampler
+
+ rank, world_size = get_dist_info()
+ if rank == 0:
+ prog_bar = mmcv.ProgressBar(len(dataset))
+
+ for batch_indices, data in zip(loader_indices, data_loader):
+ with torch.no_grad():
+ result = model(return_loss=False, rescale=True, **data)
+
+ if efficient_test:
+ result = [np2tmp(_, tmpdir='.efficient_test') for _ in result]
+
+ if format_only:
+ result = dataset.format_results(
+ result, indices=batch_indices, **format_args)
+ if pre_eval:
+ # TODO: adapt samples_per_gpu > 1.
+ # only samples_per_gpu=1 valid now
+ result = dataset.pre_eval(result, indices=batch_indices)
+
+ results.extend(result)
+
+ if rank == 0:
+ batch_size = len(result) * world_size
+ for _ in range(batch_size):
+ prog_bar.update()
+
+ # collect results from all ranks
+ if gpu_collect:
+ results = collect_results_gpu(results, len(dataset))
+ else:
+ results = collect_results_cpu(results, len(dataset), tmpdir)
+ return results
diff --git a/mmseg/apis/train.py b/mmseg/apis/train.py
new file mode 100644
index 0000000..760701b
--- /dev/null
+++ b/mmseg/apis/train.py
@@ -0,0 +1,174 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+import torch.distributed as dist
+from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
+from mmcv.runner import HOOKS, build_optimizer, build_runner, get_dist_info
+from mmcv.utils import build_from_cfg
+
+from mmseg import digit_version
+from mmseg.core import DistEvalHook, EvalHook
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.utils import find_latest_checkpoint, get_root_logger
+
+
+def init_random_seed(seed=None, device='cuda'):
+ """Initialize random seed.
+
+ If the seed is not set, the seed will be automatically randomized,
+ and then broadcast to all processes to prevent some potential bugs.
+ Args:
+ seed (int, Optional): The seed. Default to None.
+ device (str): The device where the seed will be put on.
+ Default to 'cuda'.
+ Returns:
+ int: Seed to be used.
+ """
+ if seed is not None:
+ return seed
+
+ # Make sure all ranks share the same random seed to prevent
+ # some potential bugs. Please refer to
+ # https://github.com/open-mmlab/mmdetection/issues/6339
+ rank, world_size = get_dist_info()
+ seed = np.random.randint(2**31)
+ if world_size == 1:
+ return seed
+
+ if rank == 0:
+ random_num = torch.tensor(seed, dtype=torch.int32, device=device)
+ else:
+ random_num = torch.tensor(0, dtype=torch.int32, device=device)
+ dist.broadcast(random_num, src=0)
+ return random_num.item()
+
+
+def set_random_seed(seed, deterministic=False):
+ """Set random seed.
+
+ Args:
+ seed (int): Seed to be used.
+ deterministic (bool): Whether to set the deterministic option for
+ CUDNN backend, i.e., set `torch.backends.cudnn.deterministic`
+ to True and `torch.backends.cudnn.benchmark` to False.
+ Default: False.
+ """
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+ if deterministic:
+ torch.backends.cudnn.deterministic = True
+ torch.backends.cudnn.benchmark = False
+
+
+def train_segmentor(model,
+ dataset,
+ cfg,
+ distributed=False,
+ validate=False,
+ timestamp=None,
+ meta=None):
+ """Launch segmentor training."""
+ logger = get_root_logger(cfg.log_level)
+
+ # prepare data loaders
+ dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]
+ data_loaders = [
+ build_dataloader(
+ ds,
+ cfg.data.samples_per_gpu,
+ cfg.data.workers_per_gpu,
+ # cfg.gpus will be ignored if distributed
+ len(cfg.gpu_ids),
+ dist=distributed,
+ seed=cfg.seed,
+ drop_last=True) for ds in dataset
+ ]
+
+ # put model on gpus
+ if distributed:
+ find_unused_parameters = cfg.get('find_unused_parameters', False)
+ # Sets the `find_unused_parameters` parameter in
+ # torch.nn.parallel.DistributedDataParallel
+ model = MMDistributedDataParallel(
+ model.cuda(),
+ device_ids=[torch.cuda.current_device()],
+ broadcast_buffers=False,
+ find_unused_parameters=find_unused_parameters)
+ else:
+ if not torch.cuda.is_available():
+ assert digit_version(mmcv.__version__) >= digit_version('1.4.4'), \
+ 'Please use MMCV >= 1.4.4 for CPU training!'
+ model = MMDataParallel(model, device_ids=cfg.gpu_ids)
+ # build runner
+ optimizer = build_optimizer(model, cfg.optimizer)
+
+ if cfg.get('runner') is None:
+ cfg.runner = {'type': 'IterBasedRunner', 'max_iters': cfg.total_iters}
+ warnings.warn(
+ 'config is now expected to have a `runner` section, '
+ 'please set `runner` in your config.', UserWarning)
+
+ runner = build_runner(
+ cfg.runner,
+ default_args=dict(
+ model=model,
+ batch_processor=None,
+ optimizer=optimizer,
+ work_dir=cfg.work_dir,
+ logger=logger,
+ meta=meta))
+
+ # register hooks
+ runner.register_training_hooks(cfg.lr_config, cfg.optimizer_config,
+ cfg.checkpoint_config, cfg.log_config,
+ cfg.get('momentum_config', None))
+
+ # an ugly walkaround to make the .log and .log.json filenames the same
+ runner.timestamp = timestamp
+
+ # register eval hooks
+ if validate:
+ val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))
+ val_dataloader = build_dataloader(
+ val_dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=distributed,
+ shuffle=False)
+ eval_cfg = cfg.get('evaluation', {})
+ eval_cfg['by_epoch'] = cfg.runner['type'] != 'IterBasedRunner'
+ eval_hook = DistEvalHook if distributed else EvalHook
+ # In this PR (https://github.com/open-mmlab/mmcv/pull/1193), the
+ # priority of IterTimerHook has been modified from 'NORMAL' to 'LOW'.
+ runner.register_hook(
+ eval_hook(val_dataloader, **eval_cfg), priority='LOW')
+
+ # user-defined hooks
+ if cfg.get('custom_hooks', None):
+ custom_hooks = cfg.custom_hooks
+ assert isinstance(custom_hooks, list), \
+ f'custom_hooks expect list type, but got {type(custom_hooks)}'
+ for hook_cfg in cfg.custom_hooks:
+ assert isinstance(hook_cfg, dict), \
+ 'Each item in custom_hooks expects dict type, but got ' \
+ f'{type(hook_cfg)}'
+ hook_cfg = hook_cfg.copy()
+ priority = hook_cfg.pop('priority', 'NORMAL')
+ hook = build_from_cfg(hook_cfg, HOOKS)
+ runner.register_hook(hook, priority=priority)
+
+ if cfg.resume_from is None and cfg.get('auto_resume'):
+ resume_from = find_latest_checkpoint(cfg.work_dir)
+ if resume_from is not None:
+ cfg.resume_from = resume_from
+ if cfg.resume_from:
+ runner.resume(cfg.resume_from)
+ elif cfg.load_from:
+ runner.load_checkpoint(cfg.load_from)
+ runner.run(data_loaders, cfg.workflow)
diff --git a/mmseg/core/__init__.py b/mmseg/core/__init__.py
new file mode 100644
index 0000000..4022786
--- /dev/null
+++ b/mmseg/core/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .evaluation import * # noqa: F401, F403
+from .seg import * # noqa: F401, F403
+from .utils import * # noqa: F401, F403
diff --git a/mmseg/core/evaluation/__init__.py b/mmseg/core/evaluation/__init__.py
new file mode 100644
index 0000000..3d16d17
--- /dev/null
+++ b/mmseg/core/evaluation/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .class_names import get_classes, get_palette
+from .eval_hooks import DistEvalHook, EvalHook
+from .metrics import (eval_metrics, intersect_and_union, mean_dice,
+ mean_fscore, mean_iou, pre_eval_to_metrics)
+
+__all__ = [
+ 'EvalHook', 'DistEvalHook', 'mean_dice', 'mean_iou', 'mean_fscore',
+ 'eval_metrics', 'get_classes', 'get_palette', 'pre_eval_to_metrics',
+ 'intersect_and_union'
+]
diff --git a/mmseg/core/evaluation/class_names.py b/mmseg/core/evaluation/class_names.py
new file mode 100644
index 0000000..cc90517
--- /dev/null
+++ b/mmseg/core/evaluation/class_names.py
@@ -0,0 +1,285 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+
+
+def cityscapes_classes():
+ """Cityscapes class names for external use."""
+ return [
+ 'road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
+ 'traffic light', 'traffic sign', 'vegetation', 'terrain', 'sky',
+ 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle',
+ 'bicycle'
+ ]
+
+
+def ade_classes():
+ """ADE20K class names for external use."""
+ return [
+ 'wall', 'building', 'sky', 'floor', 'tree', 'ceiling', 'road', 'bed ',
+ 'windowpane', 'grass', 'cabinet', 'sidewalk', 'person', 'earth',
+ 'door', 'table', 'mountain', 'plant', 'curtain', 'chair', 'car',
+ 'water', 'painting', 'sofa', 'shelf', 'house', 'sea', 'mirror', 'rug',
+ 'field', 'armchair', 'seat', 'fence', 'desk', 'rock', 'wardrobe',
+ 'lamp', 'bathtub', 'railing', 'cushion', 'base', 'box', 'column',
+ 'signboard', 'chest of drawers', 'counter', 'sand', 'sink',
+ 'skyscraper', 'fireplace', 'refrigerator', 'grandstand', 'path',
+ 'stairs', 'runway', 'case', 'pool table', 'pillow', 'screen door',
+ 'stairway', 'river', 'bridge', 'bookcase', 'blind', 'coffee table',
+ 'toilet', 'flower', 'book', 'hill', 'bench', 'countertop', 'stove',
+ 'palm', 'kitchen island', 'computer', 'swivel chair', 'boat', 'bar',
+ 'arcade machine', 'hovel', 'bus', 'towel', 'light', 'truck', 'tower',
+ 'chandelier', 'awning', 'streetlight', 'booth', 'television receiver',
+ 'airplane', 'dirt track', 'apparel', 'pole', 'land', 'bannister',
+ 'escalator', 'ottoman', 'bottle', 'buffet', 'poster', 'stage', 'van',
+ 'ship', 'fountain', 'conveyer belt', 'canopy', 'washer', 'plaything',
+ 'swimming pool', 'stool', 'barrel', 'basket', 'waterfall', 'tent',
+ 'bag', 'minibike', 'cradle', 'oven', 'ball', 'food', 'step', 'tank',
+ 'trade name', 'microwave', 'pot', 'animal', 'bicycle', 'lake',
+ 'dishwasher', 'screen', 'blanket', 'sculpture', 'hood', 'sconce',
+ 'vase', 'traffic light', 'tray', 'ashcan', 'fan', 'pier', 'crt screen',
+ 'plate', 'monitor', 'bulletin board', 'shower', 'radiator', 'glass',
+ 'clock', 'flag'
+ ]
+
+
+def voc_classes():
+ """Pascal VOC class names for external use."""
+ return [
+ 'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
+ 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
+ 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
+ 'tvmonitor'
+ ]
+
+
+def cocostuff_classes():
+ """CocoStuff class names for external use."""
+ return [
+ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train',
+ 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign',
+ 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep',
+ 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella',
+ 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard',
+ 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard',
+ 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork',
+ 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
+ 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair',
+ 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv',
+ 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
+ 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
+ 'scissors', 'teddy bear', 'hair drier', 'toothbrush', 'banner',
+ 'blanket', 'branch', 'bridge', 'building-other', 'bush', 'cabinet',
+ 'cage', 'cardboard', 'carpet', 'ceiling-other', 'ceiling-tile',
+ 'cloth', 'clothes', 'clouds', 'counter', 'cupboard', 'curtain',
+ 'desk-stuff', 'dirt', 'door-stuff', 'fence', 'floor-marble',
+ 'floor-other', 'floor-stone', 'floor-tile', 'floor-wood', 'flower',
+ 'fog', 'food-other', 'fruit', 'furniture-other', 'grass', 'gravel',
+ 'ground-other', 'hill', 'house', 'leaves', 'light', 'mat', 'metal',
+ 'mirror-stuff', 'moss', 'mountain', 'mud', 'napkin', 'net', 'paper',
+ 'pavement', 'pillow', 'plant-other', 'plastic', 'platform',
+ 'playingfield', 'railing', 'railroad', 'river', 'road', 'rock', 'roof',
+ 'rug', 'salad', 'sand', 'sea', 'shelf', 'sky-other', 'skyscraper',
+ 'snow', 'solid-other', 'stairs', 'stone', 'straw', 'structural-other',
+ 'table', 'tent', 'textile-other', 'towel', 'tree', 'vegetable',
+ 'wall-brick', 'wall-concrete', 'wall-other', 'wall-panel',
+ 'wall-stone', 'wall-tile', 'wall-wood', 'water-other', 'waterdrops',
+ 'window-blind', 'window-other', 'wood'
+ ]
+
+
+def loveda_classes():
+ """LoveDA class names for external use."""
+ return [
+ 'background', 'building', 'road', 'water', 'barren', 'forest',
+ 'agricultural'
+ ]
+
+
+def potsdam_classes():
+ """Potsdam class names for external use."""
+ return [
+ 'impervious_surface', 'building', 'low_vegetation', 'tree', 'car',
+ 'clutter'
+ ]
+
+
+def vaihingen_classes():
+ """Vaihingen class names for external use."""
+ return [
+ 'impervious_surface', 'building', 'low_vegetation', 'tree', 'car',
+ 'clutter'
+ ]
+
+
+def cityscapes_palette():
+ """Cityscapes palette for external use."""
+ return [[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
+ [190, 153, 153], [153, 153, 153], [250, 170, 30], [220, 220, 0],
+ [107, 142, 35], [152, 251, 152], [70, 130, 180], [220, 20, 60],
+ [255, 0, 0], [0, 0, 142], [0, 0, 70], [0, 60, 100], [0, 80, 100],
+ [0, 0, 230], [119, 11, 32]]
+
+
+def ade_palette():
+ """ADE20K palette for external use."""
+ return [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
+ [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
+ [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
+ [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
+ [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
+ [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
+ [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
+ [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
+ [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
+ [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
+ [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
+ [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
+ [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
+ [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
+ [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255],
+ [11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255],
+ [0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0],
+ [255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0],
+ [0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255],
+ [173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255],
+ [255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20],
+ [255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255],
+ [255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255],
+ [0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255],
+ [0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0],
+ [143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0],
+ [8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255],
+ [255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112],
+ [92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160],
+ [163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163],
+ [255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0],
+ [255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0],
+ [10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255],
+ [255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204],
+ [41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255],
+ [71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255],
+ [184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194],
+ [102, 255, 0], [92, 0, 255]]
+
+
+def voc_palette():
+ """Pascal VOC palette for external use."""
+ return [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
+ [128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0],
+ [192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128],
+ [192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0],
+ [128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]]
+
+
+def cocostuff_palette():
+ """CocoStuff palette for external use."""
+ return [[0, 192, 64], [0, 192, 64], [0, 64, 96], [128, 192, 192],
+ [0, 64, 64], [0, 192, 224], [0, 192, 192], [128, 192, 64],
+ [0, 192, 96], [128, 192, 64], [128, 32, 192], [0, 0, 224],
+ [0, 0, 64], [0, 160, 192], [128, 0, 96], [128, 0, 192],
+ [0, 32, 192], [128, 128, 224], [0, 0, 192], [128, 160, 192],
+ [128, 128, 0], [128, 0, 32], [128, 32, 0], [128, 0, 128],
+ [64, 128, 32], [0, 160, 0], [0, 0, 0], [192, 128, 160], [0, 32, 0],
+ [0, 128, 128], [64, 128, 160], [128, 160, 0], [0, 128, 0],
+ [192, 128, 32], [128, 96, 128], [0, 0, 128], [64, 0, 32],
+ [0, 224, 128], [128, 0, 0], [192, 0, 160], [0, 96, 128],
+ [128, 128, 128], [64, 0, 160], [128, 224, 128], [128, 128, 64],
+ [192, 0, 32], [128, 96, 0], [128, 0, 192], [0, 128, 32],
+ [64, 224, 0], [0, 0, 64], [128, 128, 160], [64, 96, 0],
+ [0, 128, 192], [0, 128, 160], [192, 224, 0], [0, 128, 64],
+ [128, 128, 32], [192, 32, 128], [0, 64, 192], [0, 0, 32],
+ [64, 160, 128], [128, 64, 64], [128, 0, 160], [64, 32, 128],
+ [128, 192, 192], [0, 0, 160], [192, 160, 128], [128, 192, 0],
+ [128, 0, 96], [192, 32, 0], [128, 64, 128], [64, 128, 96],
+ [64, 160, 0], [0, 64, 0], [192, 128, 224], [64, 32, 0],
+ [0, 192, 128], [64, 128, 224], [192, 160, 0], [0, 192, 0],
+ [192, 128, 96], [192, 96, 128], [0, 64, 128], [64, 0, 96],
+ [64, 224, 128], [128, 64, 0], [192, 0, 224], [64, 96, 128],
+ [128, 192, 128], [64, 0, 224], [192, 224, 128], [128, 192, 64],
+ [192, 0, 96], [192, 96, 0], [128, 64, 192], [0, 128, 96],
+ [0, 224, 0], [64, 64, 64], [128, 128, 224], [0, 96, 0],
+ [64, 192, 192], [0, 128, 224], [128, 224, 0], [64, 192, 64],
+ [128, 128, 96], [128, 32, 128], [64, 0, 192], [0, 64, 96],
+ [0, 160, 128], [192, 0, 64], [128, 64, 224], [0, 32, 128],
+ [192, 128, 192], [0, 64, 224], [128, 160, 128], [192, 128, 0],
+ [128, 64, 32], [128, 32, 64], [192, 0, 128], [64, 192, 32],
+ [0, 160, 64], [64, 0, 0], [192, 192, 160], [0, 32, 64],
+ [64, 128, 128], [64, 192, 160], [128, 160, 64], [64, 128, 0],
+ [192, 192, 32], [128, 96, 192], [64, 0, 128], [64, 64, 32],
+ [0, 224, 192], [192, 0, 0], [192, 64, 160], [0, 96, 192],
+ [192, 128, 128], [64, 64, 160], [128, 224, 192], [192, 128, 64],
+ [192, 64, 32], [128, 96, 64], [192, 0, 192], [0, 192, 32],
+ [64, 224, 64], [64, 0, 64], [128, 192, 160], [64, 96, 64],
+ [64, 128, 192], [0, 192, 160], [192, 224, 64], [64, 128, 64],
+ [128, 192, 32], [192, 32, 192], [64, 64, 192], [0, 64, 32],
+ [64, 160, 192], [192, 64, 64], [128, 64, 160], [64, 32, 192],
+ [192, 192, 192], [0, 64, 160], [192, 160, 192], [192, 192, 0],
+ [128, 64, 96], [192, 32, 64], [192, 64, 128], [64, 192, 96],
+ [64, 160, 64], [64, 64, 0]]
+
+
+def loveda_palette():
+ """LoveDA palette for external use."""
+ return [[255, 255, 255], [255, 0, 0], [255, 255, 0], [0, 0, 255],
+ [159, 129, 183], [0, 255, 0], [255, 195, 128]]
+
+
+def potsdam_palette():
+ """Potsdam palette for external use."""
+ return [[255, 255, 255], [0, 0, 255], [0, 255, 255], [0, 255, 0],
+ [255, 255, 0], [255, 0, 0]]
+
+
+def vaihingen_palette():
+ """Vaihingen palette for external use."""
+ return [[255, 255, 255], [0, 0, 255], [0, 0, 255], [0, 255, 0],
+ [255, 255, 0], [255, 0, 0]]
+
+
+dataset_aliases = {
+ 'cityscapes': ['cityscapes'],
+ 'ade': ['ade', 'ade20k'],
+ 'voc': ['voc', 'pascal_voc', 'voc12', 'voc12aug'],
+ 'loveda': ['loveda'],
+ 'potsdam': ['potsdam'],
+ 'vaihingen': ['vaihingen'],
+ 'cocostuff': [
+ 'cocostuff', 'cocostuff10k', 'cocostuff164k', 'coco-stuff',
+ 'coco-stuff10k', 'coco-stuff164k', 'coco_stuff', 'coco_stuff10k',
+ 'coco_stuff164k'
+ ]
+}
+
+
+def get_classes(dataset):
+ """Get class names of a dataset."""
+ alias2name = {}
+ for name, aliases in dataset_aliases.items():
+ for alias in aliases:
+ alias2name[alias] = name
+
+ if mmcv.is_str(dataset):
+ if dataset in alias2name:
+ labels = eval(alias2name[dataset] + '_classes()')
+ else:
+ raise ValueError(f'Unrecognized dataset: {dataset}')
+ else:
+ raise TypeError(f'dataset must a str, but got {type(dataset)}')
+ return labels
+
+
+def get_palette(dataset):
+ """Get class palette (RGB) of a dataset."""
+ alias2name = {}
+ for name, aliases in dataset_aliases.items():
+ for alias in aliases:
+ alias2name[alias] = name
+
+ if mmcv.is_str(dataset):
+ if dataset in alias2name:
+ labels = eval(alias2name[dataset] + '_palette()')
+ else:
+ raise ValueError(f'Unrecognized dataset: {dataset}')
+ else:
+ raise TypeError(f'dataset must a str, but got {type(dataset)}')
+ return labels
diff --git a/mmseg/core/evaluation/eval_hooks.py b/mmseg/core/evaluation/eval_hooks.py
new file mode 100644
index 0000000..952db3b
--- /dev/null
+++ b/mmseg/core/evaluation/eval_hooks.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import warnings
+
+import torch.distributed as dist
+from mmcv.runner import DistEvalHook as _DistEvalHook
+from mmcv.runner import EvalHook as _EvalHook
+from torch.nn.modules.batchnorm import _BatchNorm
+
+
+class EvalHook(_EvalHook):
+ """Single GPU EvalHook, with efficient test support.
+
+ Args:
+ by_epoch (bool): Determine perform evaluation by epoch or by iteration.
+ If set to True, it will perform by epoch. Otherwise, by iteration.
+ Default: False.
+ efficient_test (bool): Whether save the results as local numpy files to
+ save CPU memory during evaluation. Default: False.
+ pre_eval (bool): Whether to use progressive mode to evaluate model.
+ Default: False.
+ Returns:
+ list: The prediction results.
+ """
+
+ greater_keys = ['mIoU', 'mAcc', 'aAcc']
+
+ def __init__(self,
+ *args,
+ by_epoch=False,
+ efficient_test=False,
+ pre_eval=False,
+ **kwargs):
+ super().__init__(*args, by_epoch=by_epoch, **kwargs)
+ self.pre_eval = pre_eval
+ if efficient_test:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` for evaluation hook '
+ 'is deprecated, the evaluation hook is CPU memory friendly '
+ 'with ``pre_eval=True`` as argument for ``single_gpu_test()`` '
+ 'function')
+
+ def _do_evaluate(self, runner):
+ """perform evaluation and save ckpt."""
+ if not self._should_evaluate(runner):
+ return
+
+ from mmseg.apis import single_gpu_test
+ results = single_gpu_test(
+ runner.model, self.dataloader, show=False, pre_eval=self.pre_eval)
+ runner.log_buffer.clear()
+ runner.log_buffer.output['eval_iter_num'] = len(self.dataloader)
+ key_score = self.evaluate(runner, results)
+ if self.save_best:
+ self._save_ckpt(runner, key_score)
+
+
+class DistEvalHook(_DistEvalHook):
+ """Distributed EvalHook, with efficient test support.
+
+ Args:
+ by_epoch (bool): Determine perform evaluation by epoch or by iteration.
+ If set to True, it will perform by epoch. Otherwise, by iteration.
+ Default: False.
+ efficient_test (bool): Whether save the results as local numpy files to
+ save CPU memory during evaluation. Default: False.
+ pre_eval (bool): Whether to use progressive mode to evaluate model.
+ Default: False.
+ Returns:
+ list: The prediction results.
+ """
+
+ greater_keys = ['mIoU', 'mAcc', 'aAcc']
+
+ def __init__(self,
+ *args,
+ by_epoch=False,
+ efficient_test=False,
+ pre_eval=False,
+ **kwargs):
+ super().__init__(*args, by_epoch=by_epoch, **kwargs)
+ self.pre_eval = pre_eval
+ if efficient_test:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` for evaluation hook '
+ 'is deprecated, the evaluation hook is CPU memory friendly '
+ 'with ``pre_eval=True`` as argument for ``multi_gpu_test()`` '
+ 'function')
+
+ def _do_evaluate(self, runner):
+ """perform evaluation and save ckpt."""
+ # Synchronization of BatchNorm's buffer (running_mean
+ # and running_var) is not supported in the DDP of pytorch,
+ # which may cause the inconsistent performance of models in
+ # different ranks, so we broadcast BatchNorm's buffers
+ # of rank 0 to other ranks to avoid this.
+ if self.broadcast_bn_buffer:
+ model = runner.model
+ for name, module in model.named_modules():
+ if isinstance(module,
+ _BatchNorm) and module.track_running_stats:
+ dist.broadcast(module.running_var, 0)
+ dist.broadcast(module.running_mean, 0)
+
+ if not self._should_evaluate(runner):
+ return
+
+ tmpdir = self.tmpdir
+ if tmpdir is None:
+ tmpdir = osp.join(runner.work_dir, '.eval_hook')
+
+ from mmseg.apis import multi_gpu_test
+ results = multi_gpu_test(
+ runner.model,
+ self.dataloader,
+ tmpdir=tmpdir,
+ gpu_collect=self.gpu_collect,
+ pre_eval=self.pre_eval)
+
+ runner.log_buffer.clear()
+
+ if runner.rank == 0:
+ print('\n')
+ runner.log_buffer.output['eval_iter_num'] = len(self.dataloader)
+ key_score = self.evaluate(runner, results)
+
+ if self.save_best:
+ self._save_ckpt(runner, key_score)
diff --git a/mmseg/core/evaluation/metrics.py b/mmseg/core/evaluation/metrics.py
new file mode 100644
index 0000000..a1c0908
--- /dev/null
+++ b/mmseg/core/evaluation/metrics.py
@@ -0,0 +1,395 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import OrderedDict
+
+import mmcv
+import numpy as np
+import torch
+
+
+def f_score(precision, recall, beta=1):
+ """calculate the f-score value.
+
+ Args:
+ precision (float | torch.Tensor): The precision value.
+ recall (float | torch.Tensor): The recall value.
+ beta (int): Determines the weight of recall in the combined score.
+ Default: False.
+
+ Returns:
+ [torch.tensor]: The f-score value.
+ """
+ score = (1 + beta**2) * (precision * recall) / (
+ (beta**2 * precision) + recall)
+ return score
+
+
+def intersect_and_union(pred_label,
+ label,
+ num_classes,
+ ignore_index,
+ label_map=dict(),
+ reduce_zero_label=False):
+ """Calculate intersection and Union.
+
+ Args:
+ pred_label (ndarray | str): Prediction segmentation map
+ or predict result filename.
+ label (ndarray | str): Ground truth segmentation map
+ or label filename.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ label_map (dict): Mapping old labels to new labels. The parameter will
+ work only when label is str. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. The parameter will
+ work only when label is str. Default: False.
+
+ Returns:
+ torch.Tensor: The intersection of prediction and ground truth
+ histogram on all classes.
+ torch.Tensor: The union of prediction and ground truth histogram on
+ all classes.
+ torch.Tensor: The prediction histogram on all classes.
+ torch.Tensor: The ground truth histogram on all classes.
+ """
+
+ if isinstance(pred_label, str):
+ pred_label = torch.from_numpy(np.load(pred_label))
+ else:
+ pred_label = torch.from_numpy((pred_label))
+
+ if isinstance(label, str):
+ label = torch.from_numpy(
+ mmcv.imread(label, flag='unchanged', backend='pillow'))
+ else:
+ label = torch.from_numpy(label)
+
+ if label_map is not None:
+ for old_id, new_id in label_map.items():
+ label[label == old_id] = new_id
+ if reduce_zero_label:
+ label[label == 0] = 255
+ label = label - 1
+ label[label == 254] = 255
+
+ mask = (label != ignore_index)
+ pred_label = pred_label[mask]
+ label = label[mask]
+
+ intersect = pred_label[pred_label == label]
+ area_intersect = torch.histc(
+ intersect.float(), bins=(num_classes), min=0, max=num_classes - 1)
+ area_pred_label = torch.histc(
+ pred_label.float(), bins=(num_classes), min=0, max=num_classes - 1)
+ area_label = torch.histc(
+ label.float(), bins=(num_classes), min=0, max=num_classes - 1)
+ area_union = area_pred_label + area_label - area_intersect
+ return area_intersect, area_union, area_pred_label, area_label
+
+
+def total_intersect_and_union(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ label_map=dict(),
+ reduce_zero_label=False):
+ """Calculate Total Intersection and Union.
+
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str] | Iterables): list of ground
+ truth segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+
+ Returns:
+ ndarray: The intersection of prediction and ground truth histogram
+ on all classes.
+ ndarray: The union of prediction and ground truth histogram on all
+ classes.
+ ndarray: The prediction histogram on all classes.
+ ndarray: The ground truth histogram on all classes.
+ """
+ total_area_intersect = torch.zeros((num_classes, ), dtype=torch.float64)
+ total_area_union = torch.zeros((num_classes, ), dtype=torch.float64)
+ total_area_pred_label = torch.zeros((num_classes, ), dtype=torch.float64)
+ total_area_label = torch.zeros((num_classes, ), dtype=torch.float64)
+ for result, gt_seg_map in zip(results, gt_seg_maps):
+ area_intersect, area_union, area_pred_label, area_label = \
+ intersect_and_union(
+ result, gt_seg_map, num_classes, ignore_index,
+ label_map, reduce_zero_label)
+ total_area_intersect += area_intersect
+ total_area_union += area_union
+ total_area_pred_label += area_pred_label
+ total_area_label += area_label
+ return total_area_intersect, total_area_union, total_area_pred_label, \
+ total_area_label
+
+
+def mean_iou(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ nan_to_num=None,
+ label_map=dict(),
+ reduce_zero_label=False):
+ """Calculate Mean Intersection and Union (mIoU)
+
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str]): list of ground truth
+ segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+
+ Returns:
+ dict[str, float | ndarray]:
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category IoU, shape (num_classes, ).
+ """
+ iou_result = eval_metrics(
+ results=results,
+ gt_seg_maps=gt_seg_maps,
+ num_classes=num_classes,
+ ignore_index=ignore_index,
+ metrics=['mIoU'],
+ nan_to_num=nan_to_num,
+ label_map=label_map,
+ reduce_zero_label=reduce_zero_label)
+ return iou_result
+
+
+def mean_dice(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ nan_to_num=None,
+ label_map=dict(),
+ reduce_zero_label=False):
+ """Calculate Mean Dice (mDice)
+
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str]): list of ground truth
+ segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+
+ Returns:
+ dict[str, float | ndarray]: Default metrics.
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category dice, shape (num_classes, ).
+ """
+
+ dice_result = eval_metrics(
+ results=results,
+ gt_seg_maps=gt_seg_maps,
+ num_classes=num_classes,
+ ignore_index=ignore_index,
+ metrics=['mDice'],
+ nan_to_num=nan_to_num,
+ label_map=label_map,
+ reduce_zero_label=reduce_zero_label)
+ return dice_result
+
+
+def mean_fscore(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ nan_to_num=None,
+ label_map=dict(),
+ reduce_zero_label=False,
+ beta=1):
+ """Calculate Mean Intersection and Union (mIoU)
+
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str]): list of ground truth
+ segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+ beta (int): Determines the weight of recall in the combined score.
+ Default: False.
+
+
+ Returns:
+ dict[str, float | ndarray]: Default metrics.
+ float: Overall accuracy on all images.
+ ndarray: Per category recall, shape (num_classes, ).
+ ndarray: Per category precision, shape (num_classes, ).
+ ndarray: Per category f-score, shape (num_classes, ).
+ """
+ fscore_result = eval_metrics(
+ results=results,
+ gt_seg_maps=gt_seg_maps,
+ num_classes=num_classes,
+ ignore_index=ignore_index,
+ metrics=['mFscore'],
+ nan_to_num=nan_to_num,
+ label_map=label_map,
+ reduce_zero_label=reduce_zero_label,
+ beta=beta)
+ return fscore_result
+
+
+def eval_metrics(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ metrics=['mIoU'],
+ nan_to_num=None,
+ label_map=dict(),
+ reduce_zero_label=False,
+ beta=1):
+ """Calculate evaluation metrics
+ Args:
+ results (list[ndarray] | list[str]): List of prediction segmentation
+ maps or list of prediction result filenames.
+ gt_seg_maps (list[ndarray] | list[str] | Iterables): list of ground
+ truth segmentation maps or list of label filenames.
+ num_classes (int): Number of categories.
+ ignore_index (int): Index that will be ignored in evaluation.
+ metrics (list[str] | str): Metrics to be evaluated, 'mIoU' and 'mDice'.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ label_map (dict): Mapping old labels to new labels. Default: dict().
+ reduce_zero_label (bool): Whether ignore zero label. Default: False.
+ Returns:
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category evaluation metrics, shape (num_classes, ).
+ """
+
+ total_area_intersect, total_area_union, total_area_pred_label, \
+ total_area_label = total_intersect_and_union(
+ results, gt_seg_maps, num_classes, ignore_index, label_map,
+ reduce_zero_label)
+ ret_metrics = total_area_to_metrics(total_area_intersect, total_area_union,
+ total_area_pred_label,
+ total_area_label, metrics, nan_to_num,
+ beta)
+
+ return ret_metrics
+
+
+def pre_eval_to_metrics(pre_eval_results,
+ metrics=['mIoU'],
+ nan_to_num=None,
+ beta=1):
+ """Convert pre-eval results to metrics.
+
+ Args:
+ pre_eval_results (list[tuple[torch.Tensor]]): per image eval results
+ for computing evaluation metric
+ metrics (list[str] | str): Metrics to be evaluated, 'mIoU' and 'mDice'.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ Returns:
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category evaluation metrics, shape (num_classes, ).
+ """
+
+ # convert list of tuples to tuple of lists, e.g.
+ # [(A_1, B_1, C_1, D_1), ..., (A_n, B_n, C_n, D_n)] to
+ # ([A_1, ..., A_n], ..., [D_1, ..., D_n])
+ pre_eval_results = tuple(zip(*pre_eval_results))
+ assert len(pre_eval_results) == 4
+
+ total_area_intersect = sum(pre_eval_results[0])
+ total_area_union = sum(pre_eval_results[1])
+ total_area_pred_label = sum(pre_eval_results[2])
+ total_area_label = sum(pre_eval_results[3])
+
+ ret_metrics = total_area_to_metrics(total_area_intersect, total_area_union,
+ total_area_pred_label,
+ total_area_label, metrics, nan_to_num,
+ beta)
+
+ return ret_metrics
+
+
+def total_area_to_metrics(total_area_intersect,
+ total_area_union,
+ total_area_pred_label,
+ total_area_label,
+ metrics=['mIoU'],
+ nan_to_num=None,
+ beta=1):
+ """Calculate evaluation metrics
+ Args:
+ total_area_intersect (ndarray): The intersection of prediction and
+ ground truth histogram on all classes.
+ total_area_union (ndarray): The union of prediction and ground truth
+ histogram on all classes.
+ total_area_pred_label (ndarray): The prediction histogram on all
+ classes.
+ total_area_label (ndarray): The ground truth histogram on all classes.
+ metrics (list[str] | str): Metrics to be evaluated, 'mIoU' and 'mDice'.
+ nan_to_num (int, optional): If specified, NaN values will be replaced
+ by the numbers defined by the user. Default: None.
+ Returns:
+ float: Overall accuracy on all images.
+ ndarray: Per category accuracy, shape (num_classes, ).
+ ndarray: Per category evaluation metrics, shape (num_classes, ).
+ """
+ if isinstance(metrics, str):
+ metrics = [metrics]
+ allowed_metrics = ['mIoU', 'mDice', 'mFscore']
+ if not set(metrics).issubset(set(allowed_metrics)):
+ raise KeyError('metrics {} is not supported'.format(metrics))
+
+ all_acc = total_area_intersect.sum() / total_area_label.sum()
+ ret_metrics = OrderedDict({'aAcc': all_acc})
+ for metric in metrics:
+ if metric == 'mIoU':
+ iou = total_area_intersect / total_area_union
+ acc = total_area_intersect / total_area_label
+ ret_metrics['IoU'] = iou
+ ret_metrics['Acc'] = acc
+ elif metric == 'mDice':
+ dice = 2 * total_area_intersect / (
+ total_area_pred_label + total_area_label)
+ acc = total_area_intersect / total_area_label
+ ret_metrics['Dice'] = dice
+ ret_metrics['Acc'] = acc
+ elif metric == 'mFscore':
+ precision = total_area_intersect / total_area_pred_label
+ recall = total_area_intersect / total_area_label
+ f_value = torch.tensor(
+ [f_score(x[0], x[1], beta) for x in zip(precision, recall)])
+ ret_metrics['Fscore'] = f_value
+ ret_metrics['Precision'] = precision
+ ret_metrics['Recall'] = recall
+
+ ret_metrics = {
+ metric: value.numpy()
+ for metric, value in ret_metrics.items()
+ }
+ if nan_to_num is not None:
+ ret_metrics = OrderedDict({
+ metric: np.nan_to_num(metric_value, nan=nan_to_num)
+ for metric, metric_value in ret_metrics.items()
+ })
+ return ret_metrics
diff --git a/mmseg/core/seg/__init__.py b/mmseg/core/seg/__init__.py
new file mode 100644
index 0000000..5206b96
--- /dev/null
+++ b/mmseg/core/seg/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .builder import build_pixel_sampler
+from .sampler import BasePixelSampler, OHEMPixelSampler
+
+__all__ = ['build_pixel_sampler', 'BasePixelSampler', 'OHEMPixelSampler']
diff --git a/mmseg/core/seg/builder.py b/mmseg/core/seg/builder.py
new file mode 100644
index 0000000..1cecd34
--- /dev/null
+++ b/mmseg/core/seg/builder.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.utils import Registry, build_from_cfg
+
+PIXEL_SAMPLERS = Registry('pixel sampler')
+
+
+def build_pixel_sampler(cfg, **default_args):
+ """Build pixel sampler for segmentation map."""
+ return build_from_cfg(cfg, PIXEL_SAMPLERS, default_args)
diff --git a/mmseg/core/seg/sampler/__init__.py b/mmseg/core/seg/sampler/__init__.py
new file mode 100644
index 0000000..5a76485
--- /dev/null
+++ b/mmseg/core/seg/sampler/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_pixel_sampler import BasePixelSampler
+from .ohem_pixel_sampler import OHEMPixelSampler
+
+__all__ = ['BasePixelSampler', 'OHEMPixelSampler']
diff --git a/mmseg/core/seg/sampler/base_pixel_sampler.py b/mmseg/core/seg/sampler/base_pixel_sampler.py
new file mode 100644
index 0000000..03672cd
--- /dev/null
+++ b/mmseg/core/seg/sampler/base_pixel_sampler.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+
+class BasePixelSampler(metaclass=ABCMeta):
+ """Base class of pixel sampler."""
+
+ def __init__(self, **kwargs):
+ pass
+
+ @abstractmethod
+ def sample(self, seg_logit, seg_label):
+ """Placeholder for sample function."""
diff --git a/mmseg/core/seg/sampler/ohem_pixel_sampler.py b/mmseg/core/seg/sampler/ohem_pixel_sampler.py
new file mode 100644
index 0000000..833a287
--- /dev/null
+++ b/mmseg/core/seg/sampler/ohem_pixel_sampler.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..builder import PIXEL_SAMPLERS
+from .base_pixel_sampler import BasePixelSampler
+
+
+@PIXEL_SAMPLERS.register_module()
+class OHEMPixelSampler(BasePixelSampler):
+ """Online Hard Example Mining Sampler for segmentation.
+
+ Args:
+ context (nn.Module): The context of sampler, subclass of
+ :obj:`BaseDecodeHead`.
+ thresh (float, optional): The threshold for hard example selection.
+ Below which, are prediction with low confidence. If not
+ specified, the hard examples will be pixels of top ``min_kept``
+ loss. Default: None.
+ min_kept (int, optional): The minimum number of predictions to keep.
+ Default: 100000.
+ """
+
+ def __init__(self, context, thresh=None, min_kept=100000):
+ super(OHEMPixelSampler, self).__init__()
+ self.context = context
+ assert min_kept > 1
+ self.thresh = thresh
+ self.min_kept = min_kept
+
+ def sample(self, seg_logit, seg_label):
+ """Sample pixels that have high loss or with low prediction confidence.
+
+ Args:
+ seg_logit (torch.Tensor): segmentation logits, shape (N, C, H, W)
+ seg_label (torch.Tensor): segmentation label, shape (N, 1, H, W)
+
+ Returns:
+ torch.Tensor: segmentation weight, shape (N, H, W)
+ """
+ with torch.no_grad():
+ assert seg_logit.shape[2:] == seg_label.shape[2:]
+ assert seg_label.shape[1] == 1
+ seg_label = seg_label.squeeze(1).long()
+ batch_kept = self.min_kept * seg_label.size(0)
+ valid_mask = seg_label != self.context.ignore_index
+ seg_weight = seg_logit.new_zeros(size=seg_label.size())
+ valid_seg_weight = seg_weight[valid_mask]
+ if self.thresh is not None:
+ seg_prob = F.softmax(seg_logit, dim=1)
+
+ tmp_seg_label = seg_label.clone().unsqueeze(1)
+ tmp_seg_label[tmp_seg_label == self.context.ignore_index] = 0
+ seg_prob = seg_prob.gather(1, tmp_seg_label).squeeze(1)
+ sort_prob, sort_indices = seg_prob[valid_mask].sort()
+
+ if sort_prob.numel() > 0:
+ min_threshold = sort_prob[min(batch_kept,
+ sort_prob.numel() - 1)]
+ else:
+ min_threshold = 0.0
+ threshold = max(min_threshold, self.thresh)
+ valid_seg_weight[seg_prob[valid_mask] < threshold] = 1.
+ else:
+ if not isinstance(self.context.loss_decode, nn.ModuleList):
+ losses_decode = [self.context.loss_decode]
+ else:
+ losses_decode = self.context.loss_decode
+ losses = 0.0
+ for loss_module in losses_decode:
+ losses += loss_module(
+ seg_logit,
+ seg_label,
+ weight=None,
+ ignore_index=self.context.ignore_index,
+ reduction_override='none')
+
+ # faster than topk according to https://github.com/pytorch/pytorch/issues/22812 # noqa
+ _, sort_indices = losses[valid_mask].sort(descending=True)
+ valid_seg_weight[sort_indices[:batch_kept]] = 1.
+
+ seg_weight[valid_mask] = valid_seg_weight
+
+ return seg_weight
diff --git a/mmseg/core/utils/__init__.py b/mmseg/core/utils/__init__.py
new file mode 100644
index 0000000..be9de55
--- /dev/null
+++ b/mmseg/core/utils/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .misc import add_prefix
+
+__all__ = ['add_prefix']
diff --git a/mmseg/core/utils/misc.py b/mmseg/core/utils/misc.py
new file mode 100644
index 0000000..282bb8d
--- /dev/null
+++ b/mmseg/core/utils/misc.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def add_prefix(inputs, prefix):
+ """Add prefix for dict.
+
+ Args:
+ inputs (dict): The input dict with str keys.
+ prefix (str): The prefix to add.
+
+ Returns:
+
+ dict: The dict with keys updated with ``prefix``.
+ """
+
+ outputs = dict()
+ for name, value in inputs.items():
+ outputs[f'{prefix}.{name}'] = value
+
+ return outputs
diff --git a/mmseg/datasets/__init__.py b/mmseg/datasets/__init__.py
new file mode 100644
index 0000000..9f14325
--- /dev/null
+++ b/mmseg/datasets/__init__.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ade import ADE20KDataset
+from .builder import DATASETS, PIPELINES, build_dataloader, build_dataset
+from .chase_db1 import ChaseDB1Dataset
+from .cityscapes import CityscapesDataset
+from .coco_stuff import COCOStuffDataset
+from .custom import CustomDataset
+from .dark_zurich import DarkZurichDataset
+from .dataset_wrappers import (ConcatDataset, MultiImageMixDataset,
+ RepeatDataset)
+from .drive import DRIVEDataset
+from .hrf import HRFDataset
+from .isprs import ISPRSDataset
+from .loveda import LoveDADataset
+from .night_driving import NightDrivingDataset
+from .pascal_context import PascalContextDataset, PascalContextDataset59
+from .potsdam import PotsdamDataset
+from .stare import STAREDataset
+from .voc import PascalVOCDataset
+
+__all__ = [
+ 'CustomDataset', 'build_dataloader', 'ConcatDataset', 'RepeatDataset',
+ 'DATASETS', 'build_dataset', 'PIPELINES', 'CityscapesDataset',
+ 'PascalVOCDataset', 'ADE20KDataset', 'PascalContextDataset',
+ 'PascalContextDataset59', 'ChaseDB1Dataset', 'DRIVEDataset', 'HRFDataset',
+ 'STAREDataset', 'DarkZurichDataset', 'NightDrivingDataset',
+ 'COCOStuffDataset', 'LoveDADataset', 'MultiImageMixDataset',
+ 'ISPRSDataset', 'PotsdamDataset'
+]
diff --git a/mmseg/datasets/ade.py b/mmseg/datasets/ade.py
new file mode 100644
index 0000000..db94ceb
--- /dev/null
+++ b/mmseg/datasets/ade.py
@@ -0,0 +1,167 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import numpy as np
+from PIL import Image
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class ADE20KDataset(CustomDataset):
+ """ADE20K dataset.
+
+ In segmentation map annotation for ADE20K, 0 stands for background, which
+ is not included in 150 categories. ``reduce_zero_label`` is fixed to True.
+ The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is fixed to
+ '.png'.
+ """
+ CLASSES = (
+ 'wall', 'building', 'sky', 'floor', 'tree', 'ceiling', 'road', 'bed ',
+ 'windowpane', 'grass', 'cabinet', 'sidewalk', 'person', 'earth',
+ 'door', 'table', 'mountain', 'plant', 'curtain', 'chair', 'car',
+ 'water', 'painting', 'sofa', 'shelf', 'house', 'sea', 'mirror', 'rug',
+ 'field', 'armchair', 'seat', 'fence', 'desk', 'rock', 'wardrobe',
+ 'lamp', 'bathtub', 'railing', 'cushion', 'base', 'box', 'column',
+ 'signboard', 'chest of drawers', 'counter', 'sand', 'sink',
+ 'skyscraper', 'fireplace', 'refrigerator', 'grandstand', 'path',
+ 'stairs', 'runway', 'case', 'pool table', 'pillow', 'screen door',
+ 'stairway', 'river', 'bridge', 'bookcase', 'blind', 'coffee table',
+ 'toilet', 'flower', 'book', 'hill', 'bench', 'countertop', 'stove',
+ 'palm', 'kitchen island', 'computer', 'swivel chair', 'boat', 'bar',
+ 'arcade machine', 'hovel', 'bus', 'towel', 'light', 'truck', 'tower',
+ 'chandelier', 'awning', 'streetlight', 'booth', 'television receiver',
+ 'airplane', 'dirt track', 'apparel', 'pole', 'land', 'bannister',
+ 'escalator', 'ottoman', 'bottle', 'buffet', 'poster', 'stage', 'van',
+ 'ship', 'fountain', 'conveyer belt', 'canopy', 'washer', 'plaything',
+ 'swimming pool', 'stool', 'barrel', 'basket', 'waterfall', 'tent',
+ 'bag', 'minibike', 'cradle', 'oven', 'ball', 'food', 'step', 'tank',
+ 'trade name', 'microwave', 'pot', 'animal', 'bicycle', 'lake',
+ 'dishwasher', 'screen', 'blanket', 'sculpture', 'hood', 'sconce',
+ 'vase', 'traffic light', 'tray', 'ashcan', 'fan', 'pier', 'crt screen',
+ 'plate', 'monitor', 'bulletin board', 'shower', 'radiator', 'glass',
+ 'clock', 'flag')
+
+ PALETTE = [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
+ [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
+ [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
+ [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
+ [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
+ [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
+ [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
+ [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
+ [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
+ [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
+ [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
+ [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
+ [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
+ [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
+ [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255],
+ [11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255],
+ [0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0],
+ [255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0],
+ [0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255],
+ [173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255],
+ [255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20],
+ [255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255],
+ [255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255],
+ [0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255],
+ [0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0],
+ [143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0],
+ [8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255],
+ [255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112],
+ [92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160],
+ [163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163],
+ [255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0],
+ [255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0],
+ [10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255],
+ [255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204],
+ [41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255],
+ [71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255],
+ [184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194],
+ [102, 255, 0], [92, 0, 255]]
+
+ def __init__(self, **kwargs):
+ super(ADE20KDataset, self).__init__(
+ img_suffix='.jpg',
+ seg_map_suffix='.png',
+ reduce_zero_label=True,
+ **kwargs)
+
+ def results2img(self, results, imgfile_prefix, to_label_id, indices=None):
+ """Write the segmentation results to images.
+
+ Args:
+ results (list[ndarray]): Testing results of the
+ dataset.
+ imgfile_prefix (str): The filename prefix of the png files.
+ If the prefix is "somepath/xxx",
+ the png files will be named "somepath/xxx.png".
+ to_label_id (bool): whether convert output to label_id for
+ submission.
+ indices (list[int], optional): Indices of input results, if not
+ set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ list[str: str]: result txt files which contains corresponding
+ semantic segmentation images.
+ """
+ if indices is None:
+ indices = list(range(len(self)))
+
+ mmcv.mkdir_or_exist(imgfile_prefix)
+ result_files = []
+ for result, idx in zip(results, indices):
+
+ filename = self.img_infos[idx]['filename']
+ basename = osp.splitext(osp.basename(filename))[0]
+
+ png_filename = osp.join(imgfile_prefix, f'{basename}.png')
+
+ # The index range of official requirement is from 0 to 150.
+ # But the index range of output is from 0 to 149.
+ # That is because we set reduce_zero_label=True.
+ result = result + 1
+
+ output = Image.fromarray(result.astype(np.uint8))
+ output.save(png_filename)
+ result_files.append(png_filename)
+
+ return result_files
+
+ def format_results(self,
+ results,
+ imgfile_prefix,
+ to_label_id=True,
+ indices=None):
+ """Format the results into dir (standard format for ade20k evaluation).
+
+ Args:
+ results (list): Testing results of the dataset.
+ imgfile_prefix (str | None): The prefix of images files. It
+ includes the file path and the prefix of filename, e.g.,
+ "a/b/prefix".
+ to_label_id (bool): whether convert output to label_id for
+ submission. Default: False
+ indices (list[int], optional): Indices of input results, if not
+ set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ tuple: (result_files, tmp_dir), result_files is a list containing
+ the image paths, tmp_dir is the temporal directory created
+ for saving json/png files when img_prefix is not specified.
+ """
+
+ if indices is None:
+ indices = list(range(len(self)))
+
+ assert isinstance(results, list), 'results must be a list.'
+ assert isinstance(indices, list), 'indices must be a list.'
+
+ result_files = self.results2img(results, imgfile_prefix, to_label_id,
+ indices)
+ return result_files
diff --git a/mmseg/datasets/builder.py b/mmseg/datasets/builder.py
new file mode 100644
index 0000000..3529ab9
--- /dev/null
+++ b/mmseg/datasets/builder.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import platform
+import random
+from functools import partial
+
+import numpy as np
+import torch
+from mmcv.parallel import collate
+from mmcv.runner import get_dist_info
+from mmcv.utils import Registry, build_from_cfg, digit_version
+from torch.utils.data import DataLoader, DistributedSampler
+
+if platform.system() != 'Windows':
+ # https://github.com/pytorch/pytorch/issues/973
+ import resource
+ rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
+ base_soft_limit = rlimit[0]
+ hard_limit = rlimit[1]
+ soft_limit = min(max(4096, base_soft_limit), hard_limit)
+ resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))
+
+DATASETS = Registry('dataset')
+PIPELINES = Registry('pipeline')
+
+
+def _concat_dataset(cfg, default_args=None):
+ """Build :obj:`ConcatDataset by."""
+ from .dataset_wrappers import ConcatDataset
+ img_dir = cfg['img_dir']
+ ann_dir = cfg.get('ann_dir', None)
+ split = cfg.get('split', None)
+ # pop 'separate_eval' since it is not a valid key for common datasets.
+ separate_eval = cfg.pop('separate_eval', True)
+ num_img_dir = len(img_dir) if isinstance(img_dir, (list, tuple)) else 1
+ if ann_dir is not None:
+ num_ann_dir = len(ann_dir) if isinstance(ann_dir, (list, tuple)) else 1
+ else:
+ num_ann_dir = 0
+ if split is not None:
+ num_split = len(split) if isinstance(split, (list, tuple)) else 1
+ else:
+ num_split = 0
+ if num_img_dir > 1:
+ assert num_img_dir == num_ann_dir or num_ann_dir == 0
+ assert num_img_dir == num_split or num_split == 0
+ else:
+ assert num_split == num_ann_dir or num_ann_dir <= 1
+ num_dset = max(num_split, num_img_dir)
+
+ datasets = []
+ for i in range(num_dset):
+ data_cfg = copy.deepcopy(cfg)
+ if isinstance(img_dir, (list, tuple)):
+ data_cfg['img_dir'] = img_dir[i]
+ if isinstance(ann_dir, (list, tuple)):
+ data_cfg['ann_dir'] = ann_dir[i]
+ if isinstance(split, (list, tuple)):
+ data_cfg['split'] = split[i]
+ datasets.append(build_dataset(data_cfg, default_args))
+
+ return ConcatDataset(datasets, separate_eval)
+
+
+def build_dataset(cfg, default_args=None):
+ """Build datasets."""
+ from .dataset_wrappers import (ConcatDataset, MultiImageMixDataset,
+ RepeatDataset)
+ if isinstance(cfg, (list, tuple)):
+ dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
+ elif cfg['type'] == 'RepeatDataset':
+ dataset = RepeatDataset(
+ build_dataset(cfg['dataset'], default_args), cfg['times'])
+ elif cfg['type'] == 'MultiImageMixDataset':
+ cp_cfg = copy.deepcopy(cfg)
+ cp_cfg['dataset'] = build_dataset(cp_cfg['dataset'])
+ cp_cfg.pop('type')
+ dataset = MultiImageMixDataset(**cp_cfg)
+ elif isinstance(cfg.get('img_dir'), (list, tuple)) or isinstance(
+ cfg.get('split', None), (list, tuple)):
+ dataset = _concat_dataset(cfg, default_args)
+ else:
+ dataset = build_from_cfg(cfg, DATASETS, default_args)
+
+ return dataset
+
+
+def build_dataloader(dataset,
+ samples_per_gpu,
+ workers_per_gpu,
+ num_gpus=1,
+ dist=True,
+ shuffle=True,
+ seed=None,
+ drop_last=False,
+ pin_memory=True,
+ persistent_workers=True,
+ **kwargs):
+ """Build PyTorch DataLoader.
+
+ In distributed training, each GPU/process has a dataloader.
+ In non-distributed training, there is only one dataloader for all GPUs.
+
+ Args:
+ dataset (Dataset): A PyTorch dataset.
+ samples_per_gpu (int): Number of training samples on each GPU, i.e.,
+ batch size of each GPU.
+ workers_per_gpu (int): How many subprocesses to use for data loading
+ for each GPU.
+ num_gpus (int): Number of GPUs. Only used in non-distributed training.
+ dist (bool): Distributed training/test or not. Default: True.
+ shuffle (bool): Whether to shuffle the data at every epoch.
+ Default: True.
+ seed (int | None): Seed to be used. Default: None.
+ drop_last (bool): Whether to drop the last incomplete batch in epoch.
+ Default: False
+ pin_memory (bool): Whether to use pin_memory in DataLoader.
+ Default: True
+ persistent_workers (bool): If True, the data loader will not shutdown
+ the worker processes after a dataset has been consumed once.
+ This allows to maintain the workers Dataset instances alive.
+ The argument also has effect in PyTorch>=1.7.0.
+ Default: True
+ kwargs: any keyword argument to be used to initialize DataLoader
+
+ Returns:
+ DataLoader: A PyTorch dataloader.
+ """
+ rank, world_size = get_dist_info()
+ if dist:
+ sampler = DistributedSampler(
+ dataset, world_size, rank, shuffle=shuffle)
+ shuffle = False
+ batch_size = samples_per_gpu
+ num_workers = workers_per_gpu
+ else:
+ sampler = None
+ batch_size = num_gpus * samples_per_gpu
+ num_workers = num_gpus * workers_per_gpu
+
+ init_fn = partial(
+ worker_init_fn, num_workers=num_workers, rank=rank,
+ seed=seed) if seed is not None else None
+
+ if digit_version(torch.__version__) >= digit_version('1.8.0'):
+ data_loader = DataLoader(
+ dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ num_workers=num_workers,
+ collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
+ pin_memory=pin_memory,
+ shuffle=shuffle,
+ worker_init_fn=init_fn,
+ drop_last=drop_last,
+ persistent_workers=persistent_workers,
+ **kwargs)
+ else:
+ data_loader = DataLoader(
+ dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ num_workers=num_workers,
+ collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
+ pin_memory=pin_memory,
+ shuffle=shuffle,
+ worker_init_fn=init_fn,
+ drop_last=drop_last,
+ **kwargs)
+
+ return data_loader
+
+
+def worker_init_fn(worker_id, num_workers, rank, seed):
+ """Worker init func for dataloader.
+
+ The seed of each worker equals to num_worker * rank + worker_id + user_seed
+
+ Args:
+ worker_id (int): Worker id.
+ num_workers (int): Number of workers.
+ rank (int): The rank of current process.
+ seed (int): The random seed to use.
+ """
+
+ worker_seed = num_workers * rank + worker_id + seed
+ np.random.seed(worker_seed)
+ random.seed(worker_seed)
diff --git a/mmseg/datasets/chase_db1.py b/mmseg/datasets/chase_db1.py
new file mode 100644
index 0000000..7f14b2d
--- /dev/null
+++ b/mmseg/datasets/chase_db1.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class ChaseDB1Dataset(CustomDataset):
+ """Chase_db1 dataset.
+
+ In segmentation map annotation for Chase_db1, 0 stands for background,
+ which is included in 2 categories. ``reduce_zero_label`` is fixed to False.
+ The ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
+ '_1stHO.png'.
+ """
+
+ CLASSES = ('background', 'vessel')
+
+ PALETTE = [[120, 120, 120], [6, 230, 230]]
+
+ def __init__(self, **kwargs):
+ super(ChaseDB1Dataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='_1stHO.png',
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir)
diff --git a/mmseg/datasets/cityscapes.py b/mmseg/datasets/cityscapes.py
new file mode 100644
index 0000000..ed633d0
--- /dev/null
+++ b/mmseg/datasets/cityscapes.py
@@ -0,0 +1,214 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import numpy as np
+from mmcv.utils import print_log
+from PIL import Image
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class CityscapesDataset(CustomDataset):
+ """Cityscapes dataset.
+
+ The ``img_suffix`` is fixed to '_leftImg8bit.png' and ``seg_map_suffix`` is
+ fixed to '_gtFine_labelTrainIds.png' for Cityscapes dataset.
+ """
+
+ CLASSES = ('road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
+ 'traffic light', 'traffic sign', 'vegetation', 'terrain', 'sky',
+ 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle',
+ 'bicycle')
+
+ PALETTE = [[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
+ [190, 153, 153], [153, 153, 153], [250, 170, 30], [220, 220, 0],
+ [107, 142, 35], [152, 251, 152], [70, 130, 180], [220, 20, 60],
+ [255, 0, 0], [0, 0, 142], [0, 0, 70], [0, 60, 100],
+ [0, 80, 100], [0, 0, 230], [119, 11, 32]]
+
+ def __init__(self,
+ img_suffix='_leftImg8bit.png',
+ seg_map_suffix='_gtFine_labelTrainIds.png',
+ **kwargs):
+ super(CityscapesDataset, self).__init__(
+ img_suffix=img_suffix, seg_map_suffix=seg_map_suffix, **kwargs)
+
+ @staticmethod
+ def _convert_to_label_id(result):
+ """Convert trainId to id for cityscapes."""
+ if isinstance(result, str):
+ result = np.load(result)
+ import cityscapesscripts.helpers.labels as CSLabels
+ result_copy = result.copy()
+ for trainId, label in CSLabels.trainId2label.items():
+ result_copy[result == trainId] = label.id
+
+ return result_copy
+
+ def results2img(self, results, imgfile_prefix, to_label_id, indices=None):
+ """Write the segmentation results to images.
+
+ Args:
+ results (list[ndarray]): Testing results of the
+ dataset.
+ imgfile_prefix (str): The filename prefix of the png files.
+ If the prefix is "somepath/xxx",
+ the png files will be named "somepath/xxx.png".
+ to_label_id (bool): whether convert output to label_id for
+ submission.
+ indices (list[int], optional): Indices of input results,
+ if not set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ list[str: str]: result txt files which contains corresponding
+ semantic segmentation images.
+ """
+ if indices is None:
+ indices = list(range(len(self)))
+
+ mmcv.mkdir_or_exist(imgfile_prefix)
+ result_files = []
+ for result, idx in zip(results, indices):
+ if to_label_id:
+ result = self._convert_to_label_id(result)
+ filename = self.img_infos[idx]['filename']
+ basename = osp.splitext(osp.basename(filename))[0]
+
+ png_filename = osp.join(imgfile_prefix, f'{basename}.png')
+
+ output = Image.fromarray(result.astype(np.uint8)).convert('P')
+ import cityscapesscripts.helpers.labels as CSLabels
+ palette = np.zeros((len(CSLabels.id2label), 3), dtype=np.uint8)
+ for label_id, label in CSLabels.id2label.items():
+ palette[label_id] = label.color
+
+ output.putpalette(palette)
+ output.save(png_filename)
+ result_files.append(png_filename)
+
+ return result_files
+
+ def format_results(self,
+ results,
+ imgfile_prefix,
+ to_label_id=True,
+ indices=None):
+ """Format the results into dir (standard format for Cityscapes
+ evaluation).
+
+ Args:
+ results (list): Testing results of the dataset.
+ imgfile_prefix (str): The prefix of images files. It
+ includes the file path and the prefix of filename, e.g.,
+ "a/b/prefix".
+ to_label_id (bool): whether convert output to label_id for
+ submission. Default: False
+ indices (list[int], optional): Indices of input results,
+ if not set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ tuple: (result_files, tmp_dir), result_files is a list containing
+ the image paths, tmp_dir is the temporal directory created
+ for saving json/png files when img_prefix is not specified.
+ """
+ if indices is None:
+ indices = list(range(len(self)))
+
+ assert isinstance(results, list), 'results must be a list.'
+ assert isinstance(indices, list), 'indices must be a list.'
+
+ result_files = self.results2img(results, imgfile_prefix, to_label_id,
+ indices)
+
+ return result_files
+
+ def evaluate(self,
+ results,
+ metric='mIoU',
+ logger=None,
+ imgfile_prefix=None):
+ """Evaluation in Cityscapes/default protocol.
+
+ Args:
+ results (list): Testing results of the dataset.
+ metric (str | list[str]): Metrics to be evaluated.
+ logger (logging.Logger | None | str): Logger used for printing
+ related information during evaluation. Default: None.
+ imgfile_prefix (str | None): The prefix of output image file,
+ for cityscapes evaluation only. It includes the file path and
+ the prefix of filename, e.g., "a/b/prefix".
+ If results are evaluated with cityscapes protocol, it would be
+ the prefix of output png files. The output files would be
+ png images under folder "a/b/prefix/xxx.png", where "xxx" is
+ the image name of cityscapes. If not specified, a temp file
+ will be created for evaluation.
+ Default: None.
+
+ Returns:
+ dict[str, float]: Cityscapes/default metrics.
+ """
+
+ eval_results = dict()
+ metrics = metric.copy() if isinstance(metric, list) else [metric]
+ if 'cityscapes' in metrics:
+ eval_results.update(
+ self._evaluate_cityscapes(results, logger, imgfile_prefix))
+ metrics.remove('cityscapes')
+ if len(metrics) > 0:
+ eval_results.update(
+ super(CityscapesDataset,
+ self).evaluate(results, metrics, logger))
+
+ return eval_results
+
+ def _evaluate_cityscapes(self, results, logger, imgfile_prefix):
+ """Evaluation in Cityscapes protocol.
+
+ Args:
+ results (list): Testing results of the dataset.
+ logger (logging.Logger | str | None): Logger used for printing
+ related information during evaluation. Default: None.
+ imgfile_prefix (str | None): The prefix of output image file
+
+ Returns:
+ dict[str: float]: Cityscapes evaluation results.
+ """
+ try:
+ import cityscapesscripts.evaluation.evalPixelLevelSemanticLabeling as CSEval # noqa
+ except ImportError:
+ raise ImportError('Please run "pip install cityscapesscripts" to '
+ 'install cityscapesscripts first.')
+ msg = 'Evaluating in Cityscapes style'
+ if logger is None:
+ msg = '\n' + msg
+ print_log(msg, logger=logger)
+
+ result_dir = imgfile_prefix
+
+ eval_results = dict()
+ print_log(f'Evaluating results under {result_dir} ...', logger=logger)
+
+ CSEval.args.evalInstLevelScore = True
+ CSEval.args.predictionPath = osp.abspath(result_dir)
+ CSEval.args.evalPixelAccuracy = True
+ CSEval.args.JSONOutput = False
+
+ seg_map_list = []
+ pred_list = []
+
+ # when evaluating with official cityscapesscripts,
+ # **_gtFine_labelIds.png is used
+ for seg_map in mmcv.scandir(
+ self.ann_dir, 'gtFine_labelIds.png', recursive=True):
+ seg_map_list.append(osp.join(self.ann_dir, seg_map))
+ pred_list.append(CSEval.getPrediction(CSEval.args, seg_map))
+
+ eval_results.update(
+ CSEval.evaluateImgLists(pred_list, seg_map_list, CSEval.args))
+
+ return eval_results
diff --git a/mmseg/datasets/coco_stuff.py b/mmseg/datasets/coco_stuff.py
new file mode 100644
index 0000000..546a014
--- /dev/null
+++ b/mmseg/datasets/coco_stuff.py
@@ -0,0 +1,93 @@
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class COCOStuffDataset(CustomDataset):
+ """COCO-Stuff dataset.
+
+ In segmentation map annotation for COCO-Stuff, Train-IDs of the 10k version
+ are from 1 to 171, where 0 is the ignore index, and Train-ID of COCO Stuff
+ 164k is from 0 to 170, where 255 is the ignore index. So, they are all 171
+ semantic categories. ``reduce_zero_label`` is set to True and False for the
+ 10k and 164k versions, respectively. The ``img_suffix`` is fixed to '.jpg',
+ and ``seg_map_suffix`` is fixed to '.png'.
+ """
+ CLASSES = (
+ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train',
+ 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign',
+ 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep',
+ 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella',
+ 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard',
+ 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard',
+ 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork',
+ 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
+ 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair',
+ 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv',
+ 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
+ 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
+ 'scissors', 'teddy bear', 'hair drier', 'toothbrush', 'banner',
+ 'blanket', 'branch', 'bridge', 'building-other', 'bush', 'cabinet',
+ 'cage', 'cardboard', 'carpet', 'ceiling-other', 'ceiling-tile',
+ 'cloth', 'clothes', 'clouds', 'counter', 'cupboard', 'curtain',
+ 'desk-stuff', 'dirt', 'door-stuff', 'fence', 'floor-marble',
+ 'floor-other', 'floor-stone', 'floor-tile', 'floor-wood',
+ 'flower', 'fog', 'food-other', 'fruit', 'furniture-other', 'grass',
+ 'gravel', 'ground-other', 'hill', 'house', 'leaves', 'light', 'mat',
+ 'metal', 'mirror-stuff', 'moss', 'mountain', 'mud', 'napkin', 'net',
+ 'paper', 'pavement', 'pillow', 'plant-other', 'plastic', 'platform',
+ 'playingfield', 'railing', 'railroad', 'river', 'road', 'rock', 'roof',
+ 'rug', 'salad', 'sand', 'sea', 'shelf', 'sky-other', 'skyscraper',
+ 'snow', 'solid-other', 'stairs', 'stone', 'straw', 'structural-other',
+ 'table', 'tent', 'textile-other', 'towel', 'tree', 'vegetable',
+ 'wall-brick', 'wall-concrete', 'wall-other', 'wall-panel',
+ 'wall-stone', 'wall-tile', 'wall-wood', 'water-other', 'waterdrops',
+ 'window-blind', 'window-other', 'wood')
+
+ PALETTE = [[0, 192, 64], [0, 192, 64], [0, 64, 96], [128, 192, 192],
+ [0, 64, 64], [0, 192, 224], [0, 192, 192], [128, 192, 64],
+ [0, 192, 96], [128, 192, 64], [128, 32, 192], [0, 0, 224],
+ [0, 0, 64], [0, 160, 192], [128, 0, 96], [128, 0, 192],
+ [0, 32, 192], [128, 128, 224], [0, 0, 192], [128, 160, 192],
+ [128, 128, 0], [128, 0, 32], [128, 32, 0], [128, 0, 128],
+ [64, 128, 32], [0, 160, 0], [0, 0, 0], [192, 128, 160],
+ [0, 32, 0], [0, 128, 128], [64, 128, 160], [128, 160, 0],
+ [0, 128, 0], [192, 128, 32], [128, 96, 128], [0, 0, 128],
+ [64, 0, 32], [0, 224, 128], [128, 0, 0], [192, 0, 160],
+ [0, 96, 128], [128, 128, 128], [64, 0, 160], [128, 224, 128],
+ [128, 128, 64], [192, 0, 32], [128, 96, 0], [128, 0, 192],
+ [0, 128, 32], [64, 224, 0], [0, 0, 64], [128, 128, 160],
+ [64, 96, 0], [0, 128, 192], [0, 128, 160], [192, 224, 0],
+ [0, 128, 64], [128, 128, 32], [192, 32, 128], [0, 64, 192],
+ [0, 0, 32], [64, 160, 128], [128, 64, 64], [128, 0, 160],
+ [64, 32, 128], [128, 192, 192], [0, 0, 160], [192, 160, 128],
+ [128, 192, 0], [128, 0, 96], [192, 32, 0], [128, 64, 128],
+ [64, 128, 96], [64, 160, 0], [0, 64, 0], [192, 128, 224],
+ [64, 32, 0], [0, 192, 128], [64, 128, 224], [192, 160, 0],
+ [0, 192, 0], [192, 128, 96], [192, 96, 128], [0, 64, 128],
+ [64, 0, 96], [64, 224, 128], [128, 64, 0], [192, 0, 224],
+ [64, 96, 128], [128, 192, 128], [64, 0, 224], [192, 224, 128],
+ [128, 192, 64], [192, 0, 96], [192, 96, 0], [128, 64, 192],
+ [0, 128, 96], [0, 224, 0], [64, 64, 64], [128, 128, 224],
+ [0, 96, 0], [64, 192, 192], [0, 128, 224], [128, 224, 0],
+ [64, 192, 64], [128, 128, 96], [128, 32, 128], [64, 0, 192],
+ [0, 64, 96], [0, 160, 128], [192, 0, 64], [128, 64, 224],
+ [0, 32, 128], [192, 128, 192], [0, 64, 224], [128, 160, 128],
+ [192, 128, 0], [128, 64, 32], [128, 32, 64], [192, 0, 128],
+ [64, 192, 32], [0, 160, 64], [64, 0, 0], [192, 192, 160],
+ [0, 32, 64], [64, 128, 128], [64, 192, 160], [128, 160, 64],
+ [64, 128, 0], [192, 192, 32], [128, 96, 192], [64, 0, 128],
+ [64, 64, 32], [0, 224, 192], [192, 0, 0], [192, 64, 160],
+ [0, 96, 192], [192, 128, 128], [64, 64, 160], [128, 224, 192],
+ [192, 128, 64], [192, 64, 32], [128, 96, 64], [192, 0, 192],
+ [0, 192, 32], [64, 224, 64], [64, 0, 64], [128, 192, 160],
+ [64, 96, 64], [64, 128, 192], [0, 192, 160], [192, 224, 64],
+ [64, 128, 64], [128, 192, 32], [192, 32, 192], [64, 64, 192],
+ [0, 64, 32], [64, 160, 192], [192, 64, 64], [128, 64, 160],
+ [64, 32, 192], [192, 192, 192], [0, 64, 160], [192, 160, 192],
+ [192, 192, 0], [128, 64, 96], [192, 32, 64], [192, 64, 128],
+ [64, 192, 96], [64, 160, 64], [64, 64, 0]]
+
+ def __init__(self, **kwargs):
+ super(COCOStuffDataset, self).__init__(
+ img_suffix='.jpg', seg_map_suffix='_labelTrainIds.png', **kwargs)
diff --git a/mmseg/datasets/custom.py b/mmseg/datasets/custom.py
new file mode 100644
index 0000000..fe29dcf
--- /dev/null
+++ b/mmseg/datasets/custom.py
@@ -0,0 +1,466 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import warnings
+from collections import OrderedDict
+
+import mmcv
+import numpy as np
+from mmcv.utils import print_log
+from prettytable import PrettyTable
+from torch.utils.data import Dataset
+
+from mmseg.core import eval_metrics, intersect_and_union, pre_eval_to_metrics
+from mmseg.utils import get_root_logger
+from .builder import DATASETS
+from .pipelines import Compose, LoadAnnotations
+
+
+@DATASETS.register_module()
+class CustomDataset(Dataset):
+ """Custom dataset for semantic segmentation. An example of file structure
+ is as followed.
+
+ .. code-block:: none
+
+ ├── data
+ │ ├── my_dataset
+ │ │ ├── img_dir
+ │ │ │ ├── train
+ │ │ │ │ ├── xxx{img_suffix}
+ │ │ │ │ ├── yyy{img_suffix}
+ │ │ │ │ ├── zzz{img_suffix}
+ │ │ │ ├── val
+ │ │ ├── ann_dir
+ │ │ │ ├── train
+ │ │ │ │ ├── xxx{seg_map_suffix}
+ │ │ │ │ ├── yyy{seg_map_suffix}
+ │ │ │ │ ├── zzz{seg_map_suffix}
+ │ │ │ ├── val
+
+ The img/gt_semantic_seg pair of CustomDataset should be of the same
+ except suffix. A valid img/gt_semantic_seg filename pair should be like
+ ``xxx{img_suffix}`` and ``xxx{seg_map_suffix}`` (extension is also included
+ in the suffix). If split is given, then ``xxx`` is specified in txt file.
+ Otherwise, all files in ``img_dir/``and ``ann_dir`` will be loaded.
+ Please refer to ``docs/en/tutorials/new_dataset.md`` for more details.
+
+
+ Args:
+ pipeline (list[dict]): Processing pipeline
+ img_dir (str): Path to image directory
+ img_suffix (str): Suffix of images. Default: '.jpg'
+ ann_dir (str, optional): Path to annotation directory. Default: None
+ seg_map_suffix (str): Suffix of segmentation maps. Default: '.png'
+ split (str, optional): Split txt file. If split is specified, only
+ file with suffix in the splits will be loaded. Otherwise, all
+ images in img_dir/ann_dir will be loaded. Default: None
+ data_root (str, optional): Data root for img_dir/ann_dir. Default:
+ None.
+ test_mode (bool): If test_mode=True, gt wouldn't be loaded.
+ ignore_index (int): The label index to be ignored. Default: 255
+ reduce_zero_label (bool): Whether to mark label zero as ignored.
+ Default: False
+ classes (str | Sequence[str], optional): Specify classes to load.
+ If is None, ``cls.CLASSES`` will be used. Default: None.
+ palette (Sequence[Sequence[int]]] | np.ndarray | None):
+ The palette of segmentation map. If None is given, and
+ self.PALETTE is None, random palette will be generated.
+ Default: None
+ gt_seg_map_loader_cfg (dict, optional): build LoadAnnotations to
+ load gt for evaluation, load from disk by default. Default: None.
+ """
+
+ CLASSES = None
+
+ PALETTE = None
+
+ def __init__(self,
+ pipeline,
+ img_dir,
+ img_suffix='.jpg',
+ ann_dir=None,
+ seg_map_suffix='.png',
+ split=None,
+ data_root=None,
+ test_mode=False,
+ ignore_index=255,
+ reduce_zero_label=False,
+ classes=None,
+ palette=None,
+ gt_seg_map_loader_cfg=None):
+ self.pipeline = Compose(pipeline)
+ self.img_dir = img_dir
+ self.img_suffix = img_suffix
+ self.ann_dir = ann_dir
+ self.seg_map_suffix = seg_map_suffix
+ self.split = split
+ self.data_root = data_root
+ self.test_mode = test_mode
+ self.ignore_index = ignore_index
+ self.reduce_zero_label = reduce_zero_label
+ self.label_map = None
+ self.CLASSES, self.PALETTE = self.get_classes_and_palette(
+ classes, palette)
+ self.gt_seg_map_loader = LoadAnnotations(
+ ) if gt_seg_map_loader_cfg is None else LoadAnnotations(
+ **gt_seg_map_loader_cfg)
+
+ if test_mode:
+ assert self.CLASSES is not None, \
+ '`cls.CLASSES` or `classes` should be specified when testing'
+
+ # join paths if data_root is specified
+ if self.data_root is not None:
+ if not osp.isabs(self.img_dir):
+ self.img_dir = osp.join(self.data_root, self.img_dir)
+ if not (self.ann_dir is None or osp.isabs(self.ann_dir)):
+ self.ann_dir = osp.join(self.data_root, self.ann_dir)
+ if not (self.split is None or osp.isabs(self.split)):
+ self.split = osp.join(self.data_root, self.split)
+
+ # load annotations
+ self.img_infos = self.load_annotations(self.img_dir, self.img_suffix,
+ self.ann_dir,
+ self.seg_map_suffix, self.split)
+
+ def __len__(self):
+ """Total number of samples of data."""
+ return len(self.img_infos)
+
+ def load_annotations(self, img_dir, img_suffix, ann_dir, seg_map_suffix,
+ split):
+ """Load annotation from directory.
+
+ Args:
+ img_dir (str): Path to image directory
+ img_suffix (str): Suffix of images.
+ ann_dir (str|None): Path to annotation directory.
+ seg_map_suffix (str|None): Suffix of segmentation maps.
+ split (str|None): Split txt file. If split is specified, only file
+ with suffix in the splits will be loaded. Otherwise, all images
+ in img_dir/ann_dir will be loaded. Default: None
+
+ Returns:
+ list[dict]: All image info of dataset.
+ """
+
+ img_infos = []
+ if split is not None:
+ with open(split) as f:
+ for line in f:
+ img_name = line.strip()
+ img_info = dict(filename=img_name + img_suffix)
+ if ann_dir is not None:
+ seg_map = img_name + seg_map_suffix
+ img_info['ann'] = dict(seg_map=seg_map)
+ img_infos.append(img_info)
+ else:
+ for img in mmcv.scandir(img_dir, img_suffix, recursive=True):
+ img_info = dict(filename=img)
+ if ann_dir is not None:
+ seg_map = img.replace(img_suffix, seg_map_suffix)
+ img_info['ann'] = dict(seg_map=seg_map)
+ img_infos.append(img_info)
+ img_infos = sorted(img_infos, key=lambda x: x['filename'])
+
+ print_log(f'Loaded {len(img_infos)} images', logger=get_root_logger())
+ return img_infos
+
+ def get_ann_info(self, idx):
+ """Get annotation by index.
+
+ Args:
+ idx (int): Index of data.
+
+ Returns:
+ dict: Annotation info of specified index.
+ """
+
+ return self.img_infos[idx]['ann']
+
+ def pre_pipeline(self, results):
+ """Prepare results dict for pipeline."""
+ results['seg_fields'] = []
+ results['img_prefix'] = self.img_dir
+ results['seg_prefix'] = self.ann_dir
+ if self.custom_classes:
+ results['label_map'] = self.label_map
+
+ def __getitem__(self, idx):
+ """Get training/test data after pipeline.
+
+ Args:
+ idx (int): Index of data.
+
+ Returns:
+ dict: Training/test data (with annotation if `test_mode` is set
+ False).
+ """
+
+ if self.test_mode:
+ return self.prepare_test_img(idx)
+ else:
+ return self.prepare_train_img(idx)
+
+ def prepare_train_img(self, idx):
+ """Get training data and annotations after pipeline.
+
+ Args:
+ idx (int): Index of data.
+
+ Returns:
+ dict: Training data and annotation after pipeline with new keys
+ introduced by pipeline.
+ """
+
+ img_info = self.img_infos[idx]
+ ann_info = self.get_ann_info(idx)
+ results = dict(img_info=img_info, ann_info=ann_info)
+ self.pre_pipeline(results)
+ return self.pipeline(results)
+
+ def prepare_test_img(self, idx):
+ """Get testing data after pipeline.
+
+ Args:
+ idx (int): Index of data.
+
+ Returns:
+ dict: Testing data after pipeline with new keys introduced by
+ pipeline.
+ """
+
+ img_info = self.img_infos[idx]
+ results = dict(img_info=img_info)
+ self.pre_pipeline(results)
+ return self.pipeline(results)
+
+ def format_results(self, results, imgfile_prefix, indices=None, **kwargs):
+ """Place holder to format result to dataset specific output."""
+ raise NotImplementedError
+
+ def get_gt_seg_map_by_idx(self, index):
+ """Get one ground truth segmentation map for evaluation."""
+ ann_info = self.get_ann_info(index)
+ results = dict(ann_info=ann_info)
+ self.pre_pipeline(results)
+ self.gt_seg_map_loader(results)
+ return results['gt_semantic_seg']
+
+ def get_gt_seg_maps(self, efficient_test=None):
+ """Get ground truth segmentation maps for evaluation."""
+ if efficient_test is not None:
+ warnings.warn(
+ 'DeprecationWarning: ``efficient_test`` has been deprecated '
+ 'since MMSeg v0.16, the ``get_gt_seg_maps()`` is CPU memory '
+ 'friendly by default. ')
+
+ for idx in range(len(self)):
+ ann_info = self.get_ann_info(idx)
+ results = dict(ann_info=ann_info)
+ self.pre_pipeline(results)
+ self.gt_seg_map_loader(results)
+ yield results['gt_semantic_seg']
+
+ def pre_eval(self, preds, indices):
+ """Collect eval result from each iteration.
+
+ Args:
+ preds (list[torch.Tensor] | torch.Tensor): the segmentation logit
+ after argmax, shape (N, H, W).
+ indices (list[int] | int): the prediction related ground truth
+ indices.
+
+ Returns:
+ list[torch.Tensor]: (area_intersect, area_union, area_prediction,
+ area_ground_truth).
+ """
+ # In order to compat with batch inference
+ if not isinstance(indices, list):
+ indices = [indices]
+ if not isinstance(preds, list):
+ preds = [preds]
+
+ pre_eval_results = []
+
+ for pred, index in zip(preds, indices):
+ seg_map = self.get_gt_seg_map_by_idx(index)
+ pre_eval_results.append(
+ intersect_and_union(pred, seg_map, len(self.CLASSES),
+ self.ignore_index, self.label_map,
+ self.reduce_zero_label))
+
+ return pre_eval_results
+
+ def get_classes_and_palette(self, classes=None, palette=None):
+ """Get class names of current dataset.
+
+ Args:
+ classes (Sequence[str] | str | None): If classes is None, use
+ default CLASSES defined by builtin dataset. If classes is a
+ string, take it as a file name. The file contains the name of
+ classes where each line contains one class name. If classes is
+ a tuple or list, override the CLASSES defined by the dataset.
+ palette (Sequence[Sequence[int]]] | np.ndarray | None):
+ The palette of segmentation map. If None is given, random
+ palette will be generated. Default: None
+ """
+ if classes is None:
+ self.custom_classes = False
+ return self.CLASSES, self.PALETTE
+
+ self.custom_classes = True
+ if isinstance(classes, str):
+ # take it as a file path
+ class_names = mmcv.list_from_file(classes)
+ elif isinstance(classes, (tuple, list)):
+ class_names = classes
+ else:
+ raise ValueError(f'Unsupported type {type(classes)} of classes.')
+
+ if self.CLASSES:
+ if not set(class_names).issubset(self.CLASSES):
+ raise ValueError('classes is not a subset of CLASSES.')
+
+ # dictionary, its keys are the old label ids and its values
+ # are the new label ids.
+ # used for changing pixel labels in load_annotations.
+ self.label_map = {}
+ for i, c in enumerate(self.CLASSES):
+ if c not in class_names:
+ self.label_map[i] = -1
+ else:
+ self.label_map[i] = class_names.index(c)
+
+ palette = self.get_palette_for_custom_classes(class_names, palette)
+
+ return class_names, palette
+
+ def get_palette_for_custom_classes(self, class_names, palette=None):
+
+ if self.label_map is not None:
+ # return subset of palette
+ palette = []
+ for old_id, new_id in sorted(
+ self.label_map.items(), key=lambda x: x[1]):
+ if new_id != -1:
+ palette.append(self.PALETTE[old_id])
+ palette = type(self.PALETTE)(palette)
+
+ elif palette is None:
+ if self.PALETTE is None:
+ # Get random state before set seed, and restore
+ # random state later.
+ # It will prevent loss of randomness, as the palette
+ # may be different in each iteration if not specified.
+ # See: https://github.com/open-mmlab/mmdetection/issues/5844
+ state = np.random.get_state()
+ np.random.seed(42)
+ # random palette
+ palette = np.random.randint(0, 255, size=(len(class_names), 3))
+ np.random.set_state(state)
+ else:
+ palette = self.PALETTE
+
+ return palette
+
+ def evaluate(self,
+ results,
+ metric='mIoU',
+ logger=None,
+ gt_seg_maps=None,
+ **kwargs):
+ """Evaluate the dataset.
+
+ Args:
+ results (list[tuple[torch.Tensor]] | list[str]): per image pre_eval
+ results or predict segmentation map for computing evaluation
+ metric.
+ metric (str | list[str]): Metrics to be evaluated. 'mIoU',
+ 'mDice' and 'mFscore' are supported.
+ logger (logging.Logger | None | str): Logger used for printing
+ related information during evaluation. Default: None.
+ gt_seg_maps (generator[ndarray]): Custom gt seg maps as input,
+ used in ConcatDataset
+
+ Returns:
+ dict[str, float]: Default metrics.
+ """
+ if isinstance(metric, str):
+ metric = [metric]
+ allowed_metrics = ['mIoU', 'mDice', 'mFscore']
+ if not set(metric).issubset(set(allowed_metrics)):
+ raise KeyError('metric {} is not supported'.format(metric))
+
+ eval_results = {}
+ # test a list of files
+ if mmcv.is_list_of(results, np.ndarray) or mmcv.is_list_of(
+ results, str):
+ if gt_seg_maps is None:
+ gt_seg_maps = self.get_gt_seg_maps()
+ num_classes = len(self.CLASSES)
+ ret_metrics = eval_metrics(
+ results,
+ gt_seg_maps,
+ num_classes,
+ self.ignore_index,
+ metric,
+ label_map=self.label_map,
+ reduce_zero_label=self.reduce_zero_label)
+ # test a list of pre_eval_results
+ else:
+ ret_metrics = pre_eval_to_metrics(results, metric)
+
+ # Because dataset.CLASSES is required for per-eval.
+ if self.CLASSES is None:
+ class_names = tuple(range(num_classes))
+ else:
+ class_names = self.CLASSES
+
+ # summary table
+ ret_metrics_summary = OrderedDict({
+ ret_metric: np.round(np.nanmean(ret_metric_value) * 100, 2)
+ for ret_metric, ret_metric_value in ret_metrics.items()
+ })
+
+ # each class table
+ ret_metrics.pop('aAcc', None)
+ ret_metrics_class = OrderedDict({
+ ret_metric: np.round(ret_metric_value * 100, 2)
+ for ret_metric, ret_metric_value in ret_metrics.items()
+ })
+ ret_metrics_class.update({'Class': class_names})
+ ret_metrics_class.move_to_end('Class', last=False)
+
+ # for logger
+ class_table_data = PrettyTable()
+ for key, val in ret_metrics_class.items():
+ class_table_data.add_column(key, val)
+
+ summary_table_data = PrettyTable()
+ for key, val in ret_metrics_summary.items():
+ if key == 'aAcc':
+ summary_table_data.add_column(key, [val])
+ else:
+ summary_table_data.add_column('m' + key, [val])
+
+ print_log('per class results:', logger)
+ print_log('\n' + class_table_data.get_string(), logger=logger)
+ print_log('Summary:', logger)
+ print_log('\n' + summary_table_data.get_string(), logger=logger)
+
+ # each metric dict
+ for key, value in ret_metrics_summary.items():
+ if key == 'aAcc':
+ eval_results[key] = value / 100.0
+ else:
+ eval_results['m' + key] = value / 100.0
+
+ ret_metrics_class.pop('Class', None)
+ for key, value in ret_metrics_class.items():
+ eval_results.update({
+ key + '.' + str(name): value[idx] / 100.0
+ for idx, name in enumerate(class_names)
+ })
+
+ return eval_results
diff --git a/mmseg/datasets/dark_zurich.py b/mmseg/datasets/dark_zurich.py
new file mode 100644
index 0000000..efc088f
--- /dev/null
+++ b/mmseg/datasets/dark_zurich.py
@@ -0,0 +1,13 @@
+from .builder import DATASETS
+from .cityscapes import CityscapesDataset
+
+
+@DATASETS.register_module()
+class DarkZurichDataset(CityscapesDataset):
+ """DarkZurichDataset dataset."""
+
+ def __init__(self, **kwargs):
+ super().__init__(
+ img_suffix='_rgb_anon.png',
+ seg_map_suffix='_gt_labelTrainIds.png',
+ **kwargs)
diff --git a/mmseg/datasets/dataset_wrappers.py b/mmseg/datasets/dataset_wrappers.py
new file mode 100644
index 0000000..1fb089f
--- /dev/null
+++ b/mmseg/datasets/dataset_wrappers.py
@@ -0,0 +1,277 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import bisect
+import collections
+import copy
+from itertools import chain
+
+import mmcv
+import numpy as np
+from mmcv.utils import build_from_cfg, print_log
+from torch.utils.data.dataset import ConcatDataset as _ConcatDataset
+
+from .builder import DATASETS, PIPELINES
+from .cityscapes import CityscapesDataset
+
+
+@DATASETS.register_module()
+class ConcatDataset(_ConcatDataset):
+ """A wrapper of concatenated dataset.
+
+ Same as :obj:`torch.utils.data.dataset.ConcatDataset`, but
+ support evaluation and formatting results
+
+ Args:
+ datasets (list[:obj:`Dataset`]): A list of datasets.
+ separate_eval (bool): Whether to evaluate the concatenated
+ dataset results separately, Defaults to True.
+ """
+
+ def __init__(self, datasets, separate_eval=True):
+ super(ConcatDataset, self).__init__(datasets)
+ self.CLASSES = datasets[0].CLASSES
+ self.PALETTE = datasets[0].PALETTE
+ self.separate_eval = separate_eval
+ assert separate_eval in [True, False], \
+ f'separate_eval can only be True or False,' \
+ f'but get {separate_eval}'
+ if any([isinstance(ds, CityscapesDataset) for ds in datasets]):
+ raise NotImplementedError(
+ 'Evaluating ConcatDataset containing CityscapesDataset'
+ 'is not supported!')
+
+ def evaluate(self, results, logger=None, **kwargs):
+ """Evaluate the results.
+
+ Args:
+ results (list[tuple[torch.Tensor]] | list[str]]): per image
+ pre_eval results or predict segmentation map for
+ computing evaluation metric.
+ logger (logging.Logger | str | None): Logger used for printing
+ related information during evaluation. Default: None.
+
+ Returns:
+ dict[str: float]: evaluate results of the total dataset
+ or each separate
+ dataset if `self.separate_eval=True`.
+ """
+ assert len(results) == self.cumulative_sizes[-1], \
+ ('Dataset and results have different sizes: '
+ f'{self.cumulative_sizes[-1]} v.s. {len(results)}')
+
+ # Check whether all the datasets support evaluation
+ for dataset in self.datasets:
+ assert hasattr(dataset, 'evaluate'), \
+ f'{type(dataset)} does not implement evaluate function'
+
+ if self.separate_eval:
+ dataset_idx = -1
+ total_eval_results = dict()
+ for size, dataset in zip(self.cumulative_sizes, self.datasets):
+ start_idx = 0 if dataset_idx == -1 else \
+ self.cumulative_sizes[dataset_idx]
+ end_idx = self.cumulative_sizes[dataset_idx + 1]
+
+ results_per_dataset = results[start_idx:end_idx]
+ print_log(
+ f'\nEvaluateing {dataset.img_dir} with '
+ f'{len(results_per_dataset)} images now',
+ logger=logger)
+
+ eval_results_per_dataset = dataset.evaluate(
+ results_per_dataset, logger=logger, **kwargs)
+ dataset_idx += 1
+ for k, v in eval_results_per_dataset.items():
+ total_eval_results.update({f'{dataset_idx}_{k}': v})
+
+ return total_eval_results
+
+ if len(set([type(ds) for ds in self.datasets])) != 1:
+ raise NotImplementedError(
+ 'All the datasets should have same types when '
+ 'self.separate_eval=False')
+ else:
+ if mmcv.is_list_of(results, np.ndarray) or mmcv.is_list_of(
+ results, str):
+ # merge the generators of gt_seg_maps
+ gt_seg_maps = chain(
+ *[dataset.get_gt_seg_maps() for dataset in self.datasets])
+ else:
+ # if the results are `pre_eval` results,
+ # we do not need gt_seg_maps to evaluate
+ gt_seg_maps = None
+ eval_results = self.datasets[0].evaluate(
+ results, gt_seg_maps=gt_seg_maps, logger=logger, **kwargs)
+ return eval_results
+
+ def get_dataset_idx_and_sample_idx(self, indice):
+ """Return dataset and sample index when given an indice of
+ ConcatDataset.
+
+ Args:
+ indice (int): indice of sample in ConcatDataset
+
+ Returns:
+ int: the index of sub dataset the sample belong to
+ int: the index of sample in its corresponding subset
+ """
+ if indice < 0:
+ if -indice > len(self):
+ raise ValueError(
+ 'absolute value of index should not exceed dataset length')
+ indice = len(self) + indice
+ dataset_idx = bisect.bisect_right(self.cumulative_sizes, indice)
+ if dataset_idx == 0:
+ sample_idx = indice
+ else:
+ sample_idx = indice - self.cumulative_sizes[dataset_idx - 1]
+ return dataset_idx, sample_idx
+
+ def format_results(self, results, imgfile_prefix, indices=None, **kwargs):
+ """format result for every sample of ConcatDataset."""
+ if indices is None:
+ indices = list(range(len(self)))
+
+ assert isinstance(results, list), 'results must be a list.'
+ assert isinstance(indices, list), 'indices must be a list.'
+
+ ret_res = []
+ for i, indice in enumerate(indices):
+ dataset_idx, sample_idx = self.get_dataset_idx_and_sample_idx(
+ indice)
+ res = self.datasets[dataset_idx].format_results(
+ [results[i]],
+ imgfile_prefix + f'/{dataset_idx}',
+ indices=[sample_idx],
+ **kwargs)
+ ret_res.append(res)
+ return sum(ret_res, [])
+
+ def pre_eval(self, preds, indices):
+ """do pre eval for every sample of ConcatDataset."""
+ # In order to compat with batch inference
+ if not isinstance(indices, list):
+ indices = [indices]
+ if not isinstance(preds, list):
+ preds = [preds]
+ ret_res = []
+ for i, indice in enumerate(indices):
+ dataset_idx, sample_idx = self.get_dataset_idx_and_sample_idx(
+ indice)
+ res = self.datasets[dataset_idx].pre_eval(preds[i], sample_idx)
+ ret_res.append(res)
+ return sum(ret_res, [])
+
+
+@DATASETS.register_module()
+class RepeatDataset(object):
+ """A wrapper of repeated dataset.
+
+ The length of repeated dataset will be `times` larger than the original
+ dataset. This is useful when the data loading time is long but the dataset
+ is small. Using RepeatDataset can reduce the data loading time between
+ epochs.
+
+ Args:
+ dataset (:obj:`Dataset`): The dataset to be repeated.
+ times (int): Repeat times.
+ """
+
+ def __init__(self, dataset, times):
+ self.dataset = dataset
+ self.times = times
+ self.CLASSES = dataset.CLASSES
+ self.PALETTE = dataset.PALETTE
+ self._ori_len = len(self.dataset)
+
+ def __getitem__(self, idx):
+ """Get item from original dataset."""
+ return self.dataset[idx % self._ori_len]
+
+ def __len__(self):
+ """The length is multiplied by ``times``"""
+ return self.times * self._ori_len
+
+
+@DATASETS.register_module()
+class MultiImageMixDataset:
+ """A wrapper of multiple images mixed dataset.
+
+ Suitable for training on multiple images mixed data augmentation like
+ mosaic and mixup. For the augmentation pipeline of mixed image data,
+ the `get_indexes` method needs to be provided to obtain the image
+ indexes, and you can set `skip_flags` to change the pipeline running
+ process.
+
+
+ Args:
+ dataset (:obj:`CustomDataset`): The dataset to be mixed.
+ pipeline (Sequence[dict]): Sequence of transform object or
+ config dict to be composed.
+ skip_type_keys (list[str], optional): Sequence of type string to
+ be skip pipeline. Default to None.
+ """
+
+ def __init__(self, dataset, pipeline, skip_type_keys=None):
+ assert isinstance(pipeline, collections.abc.Sequence)
+ if skip_type_keys is not None:
+ assert all([
+ isinstance(skip_type_key, str)
+ for skip_type_key in skip_type_keys
+ ])
+ self._skip_type_keys = skip_type_keys
+
+ self.pipeline = []
+ self.pipeline_types = []
+ for transform in pipeline:
+ if isinstance(transform, dict):
+ self.pipeline_types.append(transform['type'])
+ transform = build_from_cfg(transform, PIPELINES)
+ self.pipeline.append(transform)
+ else:
+ raise TypeError('pipeline must be a dict')
+
+ self.dataset = dataset
+ self.CLASSES = dataset.CLASSES
+ self.PALETTE = dataset.PALETTE
+ self.num_samples = len(dataset)
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, idx):
+ results = copy.deepcopy(self.dataset[idx])
+ for (transform, transform_type) in zip(self.pipeline,
+ self.pipeline_types):
+ if self._skip_type_keys is not None and \
+ transform_type in self._skip_type_keys:
+ continue
+
+ if hasattr(transform, 'get_indexes'):
+ indexes = transform.get_indexes(self.dataset)
+ if not isinstance(indexes, collections.abc.Sequence):
+ indexes = [indexes]
+ mix_results = [
+ copy.deepcopy(self.dataset[index]) for index in indexes
+ ]
+ results['mix_results'] = mix_results
+
+ results = transform(results)
+
+ if 'mix_results' in results:
+ results.pop('mix_results')
+
+ return results
+
+ def update_skip_type_keys(self, skip_type_keys):
+ """Update skip_type_keys.
+
+ It is called by an external hook.
+
+ Args:
+ skip_type_keys (list[str], optional): Sequence of type
+ string to be skip pipeline.
+ """
+ assert all([
+ isinstance(skip_type_key, str) for skip_type_key in skip_type_keys
+ ])
+ self._skip_type_keys = skip_type_keys
diff --git a/mmseg/datasets/drive.py b/mmseg/datasets/drive.py
new file mode 100644
index 0000000..6509911
--- /dev/null
+++ b/mmseg/datasets/drive.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class DRIVEDataset(CustomDataset):
+ """DRIVE dataset.
+
+ In segmentation map annotation for DRIVE, 0 stands for background, which is
+ included in 2 categories. ``reduce_zero_label`` is fixed to False. The
+ ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
+ '_manual1.png'.
+ """
+
+ CLASSES = ('background', 'vessel')
+
+ PALETTE = [[120, 120, 120], [6, 230, 230]]
+
+ def __init__(self, **kwargs):
+ super(DRIVEDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='_manual1.png',
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir)
diff --git a/mmseg/datasets/hrf.py b/mmseg/datasets/hrf.py
new file mode 100644
index 0000000..e4e10ae
--- /dev/null
+++ b/mmseg/datasets/hrf.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class HRFDataset(CustomDataset):
+ """HRF dataset.
+
+ In segmentation map annotation for HRF, 0 stands for background, which is
+ included in 2 categories. ``reduce_zero_label`` is fixed to False. The
+ ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
+ '.png'.
+ """
+
+ CLASSES = ('background', 'vessel')
+
+ PALETTE = [[120, 120, 120], [6, 230, 230]]
+
+ def __init__(self, **kwargs):
+ super(HRFDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir)
diff --git a/mmseg/datasets/isprs.py b/mmseg/datasets/isprs.py
new file mode 100644
index 0000000..504a022
--- /dev/null
+++ b/mmseg/datasets/isprs.py
@@ -0,0 +1,25 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class ISPRSDataset(CustomDataset):
+ """ISPRS dataset.
+
+ In segmentation map annotation for LoveDA, 0 is the ignore index.
+ ``reduce_zero_label`` should be set to True. The ``img_suffix`` and
+ ``seg_map_suffix`` are both fixed to '.png'.
+ """
+ CLASSES = ('impervious_surface', 'building', 'low_vegetation', 'tree',
+ 'car', 'clutter')
+
+ PALETTE = [[255, 255, 255], [0, 0, 255], [0, 0, 255], [0, 255, 0],
+ [255, 255, 0], [255, 0, 0]]
+
+ def __init__(self, **kwargs):
+ super(ISPRSDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=True,
+ **kwargs)
diff --git a/mmseg/datasets/loveda.py b/mmseg/datasets/loveda.py
new file mode 100644
index 0000000..90d654f
--- /dev/null
+++ b/mmseg/datasets/loveda.py
@@ -0,0 +1,92 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import numpy as np
+from PIL import Image
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class LoveDADataset(CustomDataset):
+ """LoveDA dataset.
+
+ In segmentation map annotation for LoveDA, 0 is the ignore index.
+ ``reduce_zero_label`` should be set to True. The ``img_suffix`` and
+ ``seg_map_suffix`` are both fixed to '.png'.
+ """
+ CLASSES = ('background', 'building', 'road', 'water', 'barren', 'forest',
+ 'agricultural')
+
+ PALETTE = [[255, 255, 255], [255, 0, 0], [255, 255, 0], [0, 0, 255],
+ [159, 129, 183], [0, 255, 0], [255, 195, 128]]
+
+ def __init__(self, **kwargs):
+ super(LoveDADataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=True,
+ **kwargs)
+
+ def results2img(self, results, imgfile_prefix, indices=None):
+ """Write the segmentation results to images.
+
+ Args:
+ results (list[ndarray]): Testing results of the
+ dataset.
+ imgfile_prefix (str): The filename prefix of the png files.
+ If the prefix is "somepath/xxx",
+ the png files will be named "somepath/xxx.png".
+ indices (list[int], optional): Indices of input results, if not
+ set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ list[str: str]: result txt files which contains corresponding
+ semantic segmentation images.
+ """
+
+ mmcv.mkdir_or_exist(imgfile_prefix)
+ result_files = []
+ for result, idx in zip(results, indices):
+
+ filename = self.img_infos[idx]['filename']
+ basename = osp.splitext(osp.basename(filename))[0]
+
+ png_filename = osp.join(imgfile_prefix, f'{basename}.png')
+
+ # The index range of official requirement is from 0 to 6.
+ output = Image.fromarray(result.astype(np.uint8))
+ output.save(png_filename)
+ result_files.append(png_filename)
+
+ return result_files
+
+ def format_results(self, results, imgfile_prefix, indices=None):
+ """Format the results into dir (standard format for LoveDA evaluation).
+
+ Args:
+ results (list): Testing results of the dataset.
+ imgfile_prefix (str): The prefix of images files. It
+ includes the file path and the prefix of filename, e.g.,
+ "a/b/prefix".
+ indices (list[int], optional): Indices of input results,
+ if not set, all the indices of the dataset will be used.
+ Default: None.
+
+ Returns:
+ tuple: (result_files, tmp_dir), result_files is a list containing
+ the image paths, tmp_dir is the temporal directory created
+ for saving json/png files when img_prefix is not specified.
+ """
+ if indices is None:
+ indices = list(range(len(self)))
+
+ assert isinstance(results, list), 'results must be a list.'
+ assert isinstance(indices, list), 'indices must be a list.'
+
+ result_files = self.results2img(results, imgfile_prefix, indices)
+
+ return result_files
diff --git a/mmseg/datasets/night_driving.py b/mmseg/datasets/night_driving.py
new file mode 100644
index 0000000..a9289a2
--- /dev/null
+++ b/mmseg/datasets/night_driving.py
@@ -0,0 +1,13 @@
+from .builder import DATASETS
+from .cityscapes import CityscapesDataset
+
+
+@DATASETS.register_module()
+class NightDrivingDataset(CityscapesDataset):
+ """NightDrivingDataset dataset."""
+
+ def __init__(self, **kwargs):
+ super().__init__(
+ img_suffix='_leftImg8bit.png',
+ seg_map_suffix='_gtCoarse_labelTrainIds.png',
+ **kwargs)
diff --git a/mmseg/datasets/pascal_context.py b/mmseg/datasets/pascal_context.py
new file mode 100644
index 0000000..1e7a09d
--- /dev/null
+++ b/mmseg/datasets/pascal_context.py
@@ -0,0 +1,104 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class PascalContextDataset(CustomDataset):
+ """PascalContext dataset.
+
+ In segmentation map annotation for PascalContext, 0 stands for background,
+ which is included in 60 categories. ``reduce_zero_label`` is fixed to
+ False. The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is
+ fixed to '.png'.
+
+ Args:
+ split (str): Split txt file for PascalContext.
+ """
+
+ CLASSES = ('background', 'aeroplane', 'bag', 'bed', 'bedclothes', 'bench',
+ 'bicycle', 'bird', 'boat', 'book', 'bottle', 'building', 'bus',
+ 'cabinet', 'car', 'cat', 'ceiling', 'chair', 'cloth',
+ 'computer', 'cow', 'cup', 'curtain', 'dog', 'door', 'fence',
+ 'floor', 'flower', 'food', 'grass', 'ground', 'horse',
+ 'keyboard', 'light', 'motorbike', 'mountain', 'mouse', 'person',
+ 'plate', 'platform', 'pottedplant', 'road', 'rock', 'sheep',
+ 'shelves', 'sidewalk', 'sign', 'sky', 'snow', 'sofa', 'table',
+ 'track', 'train', 'tree', 'truck', 'tvmonitor', 'wall', 'water',
+ 'window', 'wood')
+
+ PALETTE = [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
+ [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
+ [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
+ [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
+ [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
+ [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
+ [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
+ [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
+ [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
+ [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
+ [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
+ [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
+ [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
+ [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
+ [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255]]
+
+ def __init__(self, split, **kwargs):
+ super(PascalContextDataset, self).__init__(
+ img_suffix='.jpg',
+ seg_map_suffix='.png',
+ split=split,
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir) and self.split is not None
+
+
+@DATASETS.register_module()
+class PascalContextDataset59(CustomDataset):
+ """PascalContext dataset.
+
+ In segmentation map annotation for PascalContext, 0 stands for background,
+ which is included in 60 categories. ``reduce_zero_label`` is fixed to
+ False. The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is
+ fixed to '.png'.
+
+ Args:
+ split (str): Split txt file for PascalContext.
+ """
+
+ CLASSES = ('aeroplane', 'bag', 'bed', 'bedclothes', 'bench', 'bicycle',
+ 'bird', 'boat', 'book', 'bottle', 'building', 'bus', 'cabinet',
+ 'car', 'cat', 'ceiling', 'chair', 'cloth', 'computer', 'cow',
+ 'cup', 'curtain', 'dog', 'door', 'fence', 'floor', 'flower',
+ 'food', 'grass', 'ground', 'horse', 'keyboard', 'light',
+ 'motorbike', 'mountain', 'mouse', 'person', 'plate', 'platform',
+ 'pottedplant', 'road', 'rock', 'sheep', 'shelves', 'sidewalk',
+ 'sign', 'sky', 'snow', 'sofa', 'table', 'track', 'train',
+ 'tree', 'truck', 'tvmonitor', 'wall', 'water', 'window', 'wood')
+
+ PALETTE = [[180, 120, 120], [6, 230, 230], [80, 50, 50], [4, 200, 3],
+ [120, 120, 80], [140, 140, 140], [204, 5, 255], [230, 230, 230],
+ [4, 250, 7], [224, 5, 255], [235, 255, 7], [150, 5, 61],
+ [120, 120, 70], [8, 255, 51], [255, 6, 82], [143, 255, 140],
+ [204, 255, 4], [255, 51, 7], [204, 70, 3], [0, 102, 200],
+ [61, 230, 250], [255, 6, 51], [11, 102, 255], [255, 7, 71],
+ [255, 9, 224], [9, 7, 230], [220, 220, 220], [255, 9, 92],
+ [112, 9, 255], [8, 255, 214], [7, 255, 224], [255, 184, 6],
+ [10, 255, 71], [255, 41, 10], [7, 255, 255], [224, 255, 8],
+ [102, 8, 255], [255, 61, 6], [255, 194, 7], [255, 122, 8],
+ [0, 255, 20], [255, 8, 41], [255, 5, 153], [6, 51, 255],
+ [235, 12, 255], [160, 150, 20], [0, 163, 255], [140, 140, 140],
+ [250, 10, 15], [20, 255, 0], [31, 255, 0], [255, 31, 0],
+ [255, 224, 0], [153, 255, 0], [0, 0, 255], [255, 71, 0],
+ [0, 235, 255], [0, 173, 255], [31, 0, 255]]
+
+ def __init__(self, split, **kwargs):
+ super(PascalContextDataset59, self).__init__(
+ img_suffix='.jpg',
+ seg_map_suffix='.png',
+ split=split,
+ reduce_zero_label=True,
+ **kwargs)
+ assert osp.exists(self.img_dir) and self.split is not None
diff --git a/mmseg/datasets/pipelines/__init__.py b/mmseg/datasets/pipelines/__init__.py
new file mode 100644
index 0000000..8256a6f
--- /dev/null
+++ b/mmseg/datasets/pipelines/__init__.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .compose import Compose
+from .formatting import (Collect, ImageToTensor, ToDataContainer, ToTensor,
+ Transpose, to_tensor)
+from .loading import LoadAnnotations, LoadImageFromFile
+from .test_time_aug import MultiScaleFlipAug
+from .transforms import (CLAHE, AdjustGamma, Normalize, Pad,
+ PhotoMetricDistortion, RandomCrop, RandomCutOut,
+ RandomFlip, RandomMosaic, RandomRotate, Rerange,
+ Resize, RGB2Gray, SegRescale)
+
+__all__ = [
+ 'Compose', 'to_tensor', 'ToTensor', 'ImageToTensor', 'ToDataContainer',
+ 'Transpose', 'Collect', 'LoadAnnotations', 'LoadImageFromFile',
+ 'MultiScaleFlipAug', 'Resize', 'RandomFlip', 'Pad', 'RandomCrop',
+ 'Normalize', 'SegRescale', 'PhotoMetricDistortion', 'RandomRotate',
+ 'AdjustGamma', 'CLAHE', 'Rerange', 'RGB2Gray', 'RandomCutOut',
+ 'RandomMosaic'
+]
diff --git a/mmseg/datasets/pipelines/compose.py b/mmseg/datasets/pipelines/compose.py
new file mode 100644
index 0000000..30280c1
--- /dev/null
+++ b/mmseg/datasets/pipelines/compose.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import collections
+
+from mmcv.utils import build_from_cfg
+
+from ..builder import PIPELINES
+
+
+@PIPELINES.register_module()
+class Compose(object):
+ """Compose multiple transforms sequentially.
+
+ Args:
+ transforms (Sequence[dict | callable]): Sequence of transform object or
+ config dict to be composed.
+ """
+
+ def __init__(self, transforms):
+ assert isinstance(transforms, collections.abc.Sequence)
+ self.transforms = []
+ for transform in transforms:
+ if isinstance(transform, dict):
+ transform = build_from_cfg(transform, PIPELINES)
+ self.transforms.append(transform)
+ elif callable(transform):
+ self.transforms.append(transform)
+ else:
+ raise TypeError('transform must be callable or a dict')
+
+ def __call__(self, data):
+ """Call function to apply transforms sequentially.
+
+ Args:
+ data (dict): A result dict contains the data to transform.
+
+ Returns:
+ dict: Transformed data.
+ """
+
+ for t in self.transforms:
+ data = t(data)
+ if data is None:
+ return None
+ return data
+
+ def __repr__(self):
+ format_string = self.__class__.__name__ + '('
+ for t in self.transforms:
+ format_string += '\n'
+ format_string += f' {t}'
+ format_string += '\n)'
+ return format_string
diff --git a/mmseg/datasets/pipelines/formating.py b/mmseg/datasets/pipelines/formating.py
new file mode 100644
index 0000000..f6e53bf
--- /dev/null
+++ b/mmseg/datasets/pipelines/formating.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# flake8: noqa
+import warnings
+
+from .formatting import *
+
+warnings.warn('DeprecationWarning: mmseg.datasets.pipelines.formating will be '
+ 'deprecated in 2021, please replace it with '
+ 'mmseg.datasets.pipelines.formatting.')
diff --git a/mmseg/datasets/pipelines/formatting.py b/mmseg/datasets/pipelines/formatting.py
new file mode 100644
index 0000000..4e057c1
--- /dev/null
+++ b/mmseg/datasets/pipelines/formatting.py
@@ -0,0 +1,289 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections.abc import Sequence
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.parallel import DataContainer as DC
+
+from ..builder import PIPELINES
+
+
+def to_tensor(data):
+ """Convert objects of various python types to :obj:`torch.Tensor`.
+
+ Supported types are: :class:`numpy.ndarray`, :class:`torch.Tensor`,
+ :class:`Sequence`, :class:`int` and :class:`float`.
+
+ Args:
+ data (torch.Tensor | numpy.ndarray | Sequence | int | float): Data to
+ be converted.
+ """
+
+ if isinstance(data, torch.Tensor):
+ return data
+ elif isinstance(data, np.ndarray):
+ return torch.from_numpy(data)
+ elif isinstance(data, Sequence) and not mmcv.is_str(data):
+ return torch.tensor(data)
+ elif isinstance(data, int):
+ return torch.LongTensor([data])
+ elif isinstance(data, float):
+ return torch.FloatTensor([data])
+ else:
+ raise TypeError(f'type {type(data)} cannot be converted to tensor.')
+
+
+@PIPELINES.register_module()
+class ToTensor(object):
+ """Convert some results to :obj:`torch.Tensor` by given keys.
+
+ Args:
+ keys (Sequence[str]): Keys that need to be converted to Tensor.
+ """
+
+ def __init__(self, keys):
+ self.keys = keys
+
+ def __call__(self, results):
+ """Call function to convert data in results to :obj:`torch.Tensor`.
+
+ Args:
+ results (dict): Result dict contains the data to convert.
+
+ Returns:
+ dict: The result dict contains the data converted
+ to :obj:`torch.Tensor`.
+ """
+
+ for key in self.keys:
+ results[key] = to_tensor(results[key])
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(keys={self.keys})'
+
+
+@PIPELINES.register_module()
+class ImageToTensor(object):
+ """Convert image to :obj:`torch.Tensor` by given keys.
+
+ The dimension order of input image is (H, W, C). The pipeline will convert
+ it to (C, H, W). If only 2 dimension (H, W) is given, the output would be
+ (1, H, W).
+
+ Args:
+ keys (Sequence[str]): Key of images to be converted to Tensor.
+ """
+
+ def __init__(self, keys):
+ self.keys = keys
+
+ def __call__(self, results):
+ """Call function to convert image in results to :obj:`torch.Tensor` and
+ transpose the channel order.
+
+ Args:
+ results (dict): Result dict contains the image data to convert.
+
+ Returns:
+ dict: The result dict contains the image converted
+ to :obj:`torch.Tensor` and transposed to (C, H, W) order.
+ """
+
+ for key in self.keys:
+ img = results[key]
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ results[key] = to_tensor(img.transpose(2, 0, 1))
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(keys={self.keys})'
+
+
+@PIPELINES.register_module()
+class Transpose(object):
+ """Transpose some results by given keys.
+
+ Args:
+ keys (Sequence[str]): Keys of results to be transposed.
+ order (Sequence[int]): Order of transpose.
+ """
+
+ def __init__(self, keys, order):
+ self.keys = keys
+ self.order = order
+
+ def __call__(self, results):
+ """Call function to convert image in results to :obj:`torch.Tensor` and
+ transpose the channel order.
+
+ Args:
+ results (dict): Result dict contains the image data to convert.
+
+ Returns:
+ dict: The result dict contains the image converted
+ to :obj:`torch.Tensor` and transposed to (C, H, W) order.
+ """
+
+ for key in self.keys:
+ results[key] = results[key].transpose(self.order)
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + \
+ f'(keys={self.keys}, order={self.order})'
+
+
+@PIPELINES.register_module()
+class ToDataContainer(object):
+ """Convert results to :obj:`mmcv.DataContainer` by given fields.
+
+ Args:
+ fields (Sequence[dict]): Each field is a dict like
+ ``dict(key='xxx', **kwargs)``. The ``key`` in result will
+ be converted to :obj:`mmcv.DataContainer` with ``**kwargs``.
+ Default: ``(dict(key='img', stack=True),
+ dict(key='gt_semantic_seg'))``.
+ """
+
+ def __init__(self,
+ fields=(dict(key='img',
+ stack=True), dict(key='gt_semantic_seg'))):
+ self.fields = fields
+
+ def __call__(self, results):
+ """Call function to convert data in results to
+ :obj:`mmcv.DataContainer`.
+
+ Args:
+ results (dict): Result dict contains the data to convert.
+
+ Returns:
+ dict: The result dict contains the data converted to
+ :obj:`mmcv.DataContainer`.
+ """
+
+ for field in self.fields:
+ field = field.copy()
+ key = field.pop('key')
+ results[key] = DC(results[key], **field)
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(fields={self.fields})'
+
+
+@PIPELINES.register_module()
+class DefaultFormatBundle(object):
+ """Default formatting bundle.
+
+ It simplifies the pipeline of formatting common fields, including "img"
+ and "gt_semantic_seg". These fields are formatted as follows.
+
+ - img: (1)transpose, (2)to tensor, (3)to DataContainer (stack=True)
+ - gt_semantic_seg: (1)unsqueeze dim-0 (2)to tensor,
+ (3)to DataContainer (stack=True)
+ """
+
+ def __call__(self, results):
+ """Call function to transform and format common fields in results.
+
+ Args:
+ results (dict): Result dict contains the data to convert.
+
+ Returns:
+ dict: The result dict contains the data that is formatted with
+ default bundle.
+ """
+
+ if 'img' in results:
+ img = results['img']
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ results['img'] = DC(to_tensor(img), stack=True)
+ if 'gt_semantic_seg' in results:
+ # convert to long
+ results['gt_semantic_seg'] = DC(
+ to_tensor(results['gt_semantic_seg'][None,
+ ...].astype(np.int64)),
+ stack=True)
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__
+
+
+@PIPELINES.register_module()
+class Collect(object):
+ """Collect data from the loader relevant to the specific task.
+
+ This is usually the last stage of the data loader pipeline. Typically keys
+ is set to some subset of "img", "gt_semantic_seg".
+
+ The "img_meta" item is always populated. The contents of the "img_meta"
+ dictionary depends on "meta_keys". By default this includes:
+
+ - "img_shape": shape of the image input to the network as a tuple
+ (h, w, c). Note that images may be zero padded on the bottom/right
+ if the batch tensor is larger than this shape.
+
+ - "scale_factor": a float indicating the preprocessing scale
+
+ - "flip": a boolean indicating if image flip transform was used
+
+ - "filename": path to the image file
+
+ - "ori_shape": original shape of the image as a tuple (h, w, c)
+
+ - "pad_shape": image shape after padding
+
+ - "img_norm_cfg": a dict of normalization information:
+ - mean - per channel mean subtraction
+ - std - per channel std divisor
+ - to_rgb - bool indicating if bgr was converted to rgb
+
+ Args:
+ keys (Sequence[str]): Keys of results to be collected in ``data``.
+ meta_keys (Sequence[str], optional): Meta keys to be converted to
+ ``mmcv.DataContainer`` and collected in ``data[img_metas]``.
+ Default: (``filename``, ``ori_filename``, ``ori_shape``,
+ ``img_shape``, ``pad_shape``, ``scale_factor``, ``flip``,
+ ``flip_direction``, ``img_norm_cfg``)
+ """
+
+ def __init__(self,
+ keys,
+ meta_keys=('filename', 'ori_filename', 'ori_shape',
+ 'img_shape', 'pad_shape', 'scale_factor', 'flip',
+ 'flip_direction', 'img_norm_cfg')):
+ self.keys = keys
+ self.meta_keys = meta_keys
+
+ def __call__(self, results):
+ """Call function to collect keys in results. The keys in ``meta_keys``
+ will be converted to :obj:mmcv.DataContainer.
+
+ Args:
+ results (dict): Result dict contains the data to collect.
+
+ Returns:
+ dict: The result dict contains the following keys
+ - keys in``self.keys``
+ - ``img_metas``
+ """
+
+ data = {}
+ img_meta = {}
+ for key in self.meta_keys:
+ img_meta[key] = results[key]
+ data['img_metas'] = DC(img_meta, cpu_only=True)
+ for key in self.keys:
+ data[key] = results[key]
+ return data
+
+ def __repr__(self):
+ return self.__class__.__name__ + \
+ f'(keys={self.keys}, meta_keys={self.meta_keys})'
diff --git a/mmseg/datasets/pipelines/loading.py b/mmseg/datasets/pipelines/loading.py
new file mode 100644
index 0000000..e1c82bd
--- /dev/null
+++ b/mmseg/datasets/pipelines/loading.py
@@ -0,0 +1,154 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import numpy as np
+
+from ..builder import PIPELINES
+
+
+@PIPELINES.register_module()
+class LoadImageFromFile(object):
+ """Load an image from file.
+
+ Required keys are "img_prefix" and "img_info" (a dict that must contain the
+ key "filename"). Added or updated keys are "filename", "img", "img_shape",
+ "ori_shape" (same as `img_shape`), "pad_shape" (same as `img_shape`),
+ "scale_factor" (1.0) and "img_norm_cfg" (means=0 and stds=1).
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ color_type (str): The flag argument for :func:`mmcv.imfrombytes`.
+ Defaults to 'color'.
+ file_client_args (dict): Arguments to instantiate a FileClient.
+ See :class:`mmcv.fileio.FileClient` for details.
+ Defaults to ``dict(backend='disk')``.
+ imdecode_backend (str): Backend for :func:`mmcv.imdecode`. Default:
+ 'cv2'
+ """
+
+ def __init__(self,
+ to_float32=False,
+ color_type='color',
+ file_client_args=dict(backend='disk'),
+ imdecode_backend='cv2'):
+ self.to_float32 = to_float32
+ self.color_type = color_type
+ self.file_client_args = file_client_args.copy()
+ self.file_client = None
+ self.imdecode_backend = imdecode_backend
+
+ def __call__(self, results):
+ """Call functions to load image and get image meta information.
+
+ Args:
+ results (dict): Result dict from :obj:`mmseg.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded image and meta information.
+ """
+
+ if self.file_client is None:
+ self.file_client = mmcv.FileClient(**self.file_client_args)
+
+ if results.get('img_prefix') is not None:
+ filename = osp.join(results['img_prefix'],
+ results['img_info']['filename'])
+ else:
+ filename = results['img_info']['filename']
+ img_bytes = self.file_client.get(filename)
+ img = mmcv.imfrombytes(
+ img_bytes, flag=self.color_type, backend=self.imdecode_backend)
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ results['filename'] = filename
+ results['ori_filename'] = results['img_info']['filename']
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+ num_channels = 1 if len(img.shape) < 3 else img.shape[2]
+ results['img_norm_cfg'] = dict(
+ mean=np.zeros(num_channels, dtype=np.float32),
+ std=np.ones(num_channels, dtype=np.float32),
+ to_rgb=False)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(to_float32={self.to_float32},'
+ repr_str += f"color_type='{self.color_type}',"
+ repr_str += f"imdecode_backend='{self.imdecode_backend}')"
+ return repr_str
+
+
+@PIPELINES.register_module()
+class LoadAnnotations(object):
+ """Load annotations for semantic segmentation.
+
+ Args:
+ reduce_zero_label (bool): Whether reduce all label value by 1.
+ Usually used for datasets where 0 is background label.
+ Default: False.
+ file_client_args (dict): Arguments to instantiate a FileClient.
+ See :class:`mmcv.fileio.FileClient` for details.
+ Defaults to ``dict(backend='disk')``.
+ imdecode_backend (str): Backend for :func:`mmcv.imdecode`. Default:
+ 'pillow'
+ """
+
+ def __init__(self,
+ reduce_zero_label=False,
+ file_client_args=dict(backend='disk'),
+ imdecode_backend='pillow'):
+ self.reduce_zero_label = reduce_zero_label
+ self.file_client_args = file_client_args.copy()
+ self.file_client = None
+ self.imdecode_backend = imdecode_backend
+
+ def __call__(self, results):
+ """Call function to load multiple types annotations.
+
+ Args:
+ results (dict): Result dict from :obj:`mmseg.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded semantic segmentation annotations.
+ """
+
+ if self.file_client is None:
+ self.file_client = mmcv.FileClient(**self.file_client_args)
+
+ if results.get('seg_prefix', None) is not None:
+ filename = osp.join(results['seg_prefix'],
+ results['ann_info']['seg_map'])
+ else:
+ filename = results['ann_info']['seg_map']
+ img_bytes = self.file_client.get(filename)
+ gt_semantic_seg = mmcv.imfrombytes(
+ img_bytes, flag='unchanged',
+ backend=self.imdecode_backend).squeeze().astype(np.uint8)
+ # modify if custom classes
+ if results.get('label_map', None) is not None:
+ for old_id, new_id in results['label_map'].items():
+ gt_semantic_seg[gt_semantic_seg == old_id] = new_id
+ # reduce zero_label
+ if self.reduce_zero_label:
+ # avoid using underflow conversion
+ gt_semantic_seg[gt_semantic_seg == 0] = 255
+ gt_semantic_seg = gt_semantic_seg - 1
+ gt_semantic_seg[gt_semantic_seg == 254] = 255
+ results['gt_semantic_seg'] = gt_semantic_seg
+ results['seg_fields'].append('gt_semantic_seg')
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(reduce_zero_label={self.reduce_zero_label},'
+ repr_str += f"imdecode_backend='{self.imdecode_backend}')"
+ return repr_str
diff --git a/mmseg/datasets/pipelines/test_time_aug.py b/mmseg/datasets/pipelines/test_time_aug.py
new file mode 100644
index 0000000..5c17cbb
--- /dev/null
+++ b/mmseg/datasets/pipelines/test_time_aug.py
@@ -0,0 +1,134 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+
+from ..builder import PIPELINES
+from .compose import Compose
+
+
+@PIPELINES.register_module()
+class MultiScaleFlipAug(object):
+ """Test-time augmentation with multiple scales and flipping.
+
+ An example configuration is as followed:
+
+ .. code-block::
+
+ img_scale=(2048, 1024),
+ img_ratios=[0.5, 1.0],
+ flip=True,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ]
+
+ After MultiScaleFLipAug with above configuration, the results are wrapped
+ into lists of the same length as followed:
+
+ .. code-block::
+
+ dict(
+ img=[...],
+ img_shape=[...],
+ scale=[(1024, 512), (1024, 512), (2048, 1024), (2048, 1024)]
+ flip=[False, True, False, True]
+ ...
+ )
+
+ Args:
+ transforms (list[dict]): Transforms to apply in each augmentation.
+ img_scale (None | tuple | list[tuple]): Images scales for resizing.
+ img_ratios (float | list[float]): Image ratios for resizing
+ flip (bool): Whether apply flip augmentation. Default: False.
+ flip_direction (str | list[str]): Flip augmentation directions,
+ options are "horizontal" and "vertical". If flip_direction is list,
+ multiple flip augmentations will be applied.
+ It has no effect when flip == False. Default: "horizontal".
+ """
+
+ def __init__(self,
+ transforms,
+ img_scale,
+ img_ratios=None,
+ flip=False,
+ flip_direction='horizontal'):
+ self.transforms = Compose(transforms)
+ if img_ratios is not None:
+ img_ratios = img_ratios if isinstance(img_ratios,
+ list) else [img_ratios]
+ assert mmcv.is_list_of(img_ratios, float)
+ if img_scale is None:
+ # mode 1: given img_scale=None and a range of image ratio
+ self.img_scale = None
+ assert mmcv.is_list_of(img_ratios, float)
+ elif isinstance(img_scale, tuple) and mmcv.is_list_of(
+ img_ratios, float):
+ assert len(img_scale) == 2
+ # mode 2: given a scale and a range of image ratio
+ self.img_scale = [(int(img_scale[0] * ratio),
+ int(img_scale[1] * ratio))
+ for ratio in img_ratios]
+ else:
+ # mode 3: given multiple scales
+ self.img_scale = img_scale if isinstance(img_scale,
+ list) else [img_scale]
+ assert mmcv.is_list_of(self.img_scale, tuple) or self.img_scale is None
+ self.flip = flip
+ self.img_ratios = img_ratios
+ self.flip_direction = flip_direction if isinstance(
+ flip_direction, list) else [flip_direction]
+ assert mmcv.is_list_of(self.flip_direction, str)
+ if not self.flip and self.flip_direction != ['horizontal']:
+ warnings.warn(
+ 'flip_direction has no effect when flip is set to False')
+ if (self.flip
+ and not any([t['type'] == 'RandomFlip' for t in transforms])):
+ warnings.warn(
+ 'flip has no effect when RandomFlip is not in transforms')
+
+ def __call__(self, results):
+ """Call function to apply test time augment transforms on results.
+
+ Args:
+ results (dict): Result dict contains the data to transform.
+
+ Returns:
+ dict[str: list]: The augmented data, where each value is wrapped
+ into a list.
+ """
+
+ aug_data = []
+ if self.img_scale is None and mmcv.is_list_of(self.img_ratios, float):
+ h, w = results['img'].shape[:2]
+ img_scale = [(int(w * ratio), int(h * ratio))
+ for ratio in self.img_ratios]
+ else:
+ img_scale = self.img_scale
+ flip_aug = [False, True] if self.flip else [False]
+ for scale in img_scale:
+ for flip in flip_aug:
+ for direction in self.flip_direction:
+ _results = results.copy()
+ _results['scale'] = scale
+ _results['flip'] = flip
+ _results['flip_direction'] = direction
+ data = self.transforms(_results)
+ aug_data.append(data)
+ # list of dict to dict of list
+ aug_data_dict = {key: [] for key in aug_data[0]}
+ for data in aug_data:
+ for key, val in data.items():
+ aug_data_dict[key].append(val)
+ return aug_data_dict
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(transforms={self.transforms}, '
+ repr_str += f'img_scale={self.img_scale}, flip={self.flip})'
+ repr_str += f'flip_direction={self.flip_direction}'
+ return repr_str
diff --git a/mmseg/datasets/pipelines/transforms.py b/mmseg/datasets/pipelines/transforms.py
new file mode 100644
index 0000000..003a564
--- /dev/null
+++ b/mmseg/datasets/pipelines/transforms.py
@@ -0,0 +1,1311 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import mmcv
+import numpy as np
+from mmcv.utils import deprecated_api_warning, is_tuple_of
+from numpy import random
+
+from ..builder import PIPELINES
+
+
+@PIPELINES.register_module()
+class ResizeToMultiple(object):
+ """Resize images & seg to multiple of divisor.
+
+ Args:
+ size_divisor (int): images and gt seg maps need to resize to multiple
+ of size_divisor. Default: 32.
+ interpolation (str, optional): The interpolation mode of image resize.
+ Default: None
+ """
+
+ def __init__(self, size_divisor=32, interpolation=None):
+ self.size_divisor = size_divisor
+ self.interpolation = interpolation
+
+ def __call__(self, results):
+ """Call function to resize images, semantic segmentation map to
+ multiple of size divisor.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Resized results, 'img_shape', 'pad_shape' keys are updated.
+ """
+ # Align image to multiple of size divisor.
+ img = results['img']
+ img = mmcv.imresize_to_multiple(
+ img,
+ self.size_divisor,
+ scale_factor=1,
+ interpolation=self.interpolation
+ if self.interpolation else 'bilinear')
+
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['pad_shape'] = img.shape
+
+ # Align segmentation map to multiple of size divisor.
+ for key in results.get('seg_fields', []):
+ gt_seg = results[key]
+ gt_seg = mmcv.imresize_to_multiple(
+ gt_seg,
+ self.size_divisor,
+ scale_factor=1,
+ interpolation='nearest')
+ results[key] = gt_seg
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += (f'(size_divisor={self.size_divisor}, '
+ f'interpolation={self.interpolation})')
+ return repr_str
+
+
+@PIPELINES.register_module()
+class Resize(object):
+ """Resize images & seg.
+
+ This transform resizes the input image to some scale. If the input dict
+ contains the key "scale", then the scale in the input dict is used,
+ otherwise the specified scale in the init method is used.
+
+ ``img_scale`` can be None, a tuple (single-scale) or a list of tuple
+ (multi-scale). There are 4 multiscale modes:
+
+ - ``ratio_range is not None``:
+ 1. When img_scale is None, img_scale is the shape of image in results
+ (img_scale = results['img'].shape[:2]) and the image is resized based
+ on the original size. (mode 1)
+ 2. When img_scale is a tuple (single-scale), randomly sample a ratio from
+ the ratio range and multiply it with the image scale. (mode 2)
+
+ - ``ratio_range is None and multiscale_mode == "range"``: randomly sample a
+ scale from the a range. (mode 3)
+
+ - ``ratio_range is None and multiscale_mode == "value"``: randomly sample a
+ scale from multiple scales. (mode 4)
+
+ Args:
+ img_scale (tuple or list[tuple]): Images scales for resizing.
+ Default:None.
+ multiscale_mode (str): Either "range" or "value".
+ Default: 'range'
+ ratio_range (tuple[float]): (min_ratio, max_ratio).
+ Default: None
+ keep_ratio (bool): Whether to keep the aspect ratio when resizing the
+ image. Default: True
+ """
+
+ def __init__(self,
+ img_scale=None,
+ multiscale_mode='range',
+ ratio_range=None,
+ keep_ratio=True):
+ if img_scale is None:
+ self.img_scale = None
+ else:
+ if isinstance(img_scale, list):
+ self.img_scale = img_scale
+ else:
+ self.img_scale = [img_scale]
+ assert mmcv.is_list_of(self.img_scale, tuple)
+
+ if ratio_range is not None:
+ # mode 1: given img_scale=None and a range of image ratio
+ # mode 2: given a scale and a range of image ratio
+ assert self.img_scale is None or len(self.img_scale) == 1
+ else:
+ # mode 3 and 4: given multiple scales or a range of scales
+ assert multiscale_mode in ['value', 'range']
+
+ self.multiscale_mode = multiscale_mode
+ self.ratio_range = ratio_range
+ self.keep_ratio = keep_ratio
+
+ @staticmethod
+ def random_select(img_scales):
+ """Randomly select an img_scale from given candidates.
+
+ Args:
+ img_scales (list[tuple]): Images scales for selection.
+
+ Returns:
+ (tuple, int): Returns a tuple ``(img_scale, scale_dix)``,
+ where ``img_scale`` is the selected image scale and
+ ``scale_idx`` is the selected index in the given candidates.
+ """
+
+ assert mmcv.is_list_of(img_scales, tuple)
+ scale_idx = np.random.randint(len(img_scales))
+ img_scale = img_scales[scale_idx]
+ return img_scale, scale_idx
+
+ @staticmethod
+ def random_sample(img_scales):
+ """Randomly sample an img_scale when ``multiscale_mode=='range'``.
+
+ Args:
+ img_scales (list[tuple]): Images scale range for sampling.
+ There must be two tuples in img_scales, which specify the lower
+ and upper bound of image scales.
+
+ Returns:
+ (tuple, None): Returns a tuple ``(img_scale, None)``, where
+ ``img_scale`` is sampled scale and None is just a placeholder
+ to be consistent with :func:`random_select`.
+ """
+
+ assert mmcv.is_list_of(img_scales, tuple) and len(img_scales) == 2
+ img_scale_long = [max(s) for s in img_scales]
+ img_scale_short = [min(s) for s in img_scales]
+ long_edge = np.random.randint(
+ min(img_scale_long),
+ max(img_scale_long) + 1)
+ short_edge = np.random.randint(
+ min(img_scale_short),
+ max(img_scale_short) + 1)
+ img_scale = (long_edge, short_edge)
+ return img_scale, None
+
+ @staticmethod
+ def random_sample_ratio(img_scale, ratio_range):
+ """Randomly sample an img_scale when ``ratio_range`` is specified.
+
+ A ratio will be randomly sampled from the range specified by
+ ``ratio_range``. Then it would be multiplied with ``img_scale`` to
+ generate sampled scale.
+
+ Args:
+ img_scale (tuple): Images scale base to multiply with ratio.
+ ratio_range (tuple[float]): The minimum and maximum ratio to scale
+ the ``img_scale``.
+
+ Returns:
+ (tuple, None): Returns a tuple ``(scale, None)``, where
+ ``scale`` is sampled ratio multiplied with ``img_scale`` and
+ None is just a placeholder to be consistent with
+ :func:`random_select`.
+ """
+
+ assert isinstance(img_scale, tuple) and len(img_scale) == 2
+ min_ratio, max_ratio = ratio_range
+ assert min_ratio <= max_ratio
+ ratio = np.random.random_sample() * (max_ratio - min_ratio) + min_ratio
+ scale = int(img_scale[0] * ratio), int(img_scale[1] * ratio)
+ return scale, None
+
+ def _random_scale(self, results):
+ """Randomly sample an img_scale according to ``ratio_range`` and
+ ``multiscale_mode``.
+
+ If ``ratio_range`` is specified, a ratio will be sampled and be
+ multiplied with ``img_scale``.
+ If multiple scales are specified by ``img_scale``, a scale will be
+ sampled according to ``multiscale_mode``.
+ Otherwise, single scale will be used.
+
+ Args:
+ results (dict): Result dict from :obj:`dataset`.
+
+ Returns:
+ dict: Two new keys 'scale` and 'scale_idx` are added into
+ ``results``, which would be used by subsequent pipelines.
+ """
+
+ if self.ratio_range is not None:
+ if self.img_scale is None:
+ h, w = results['img'].shape[:2]
+ scale, scale_idx = self.random_sample_ratio((w, h),
+ self.ratio_range)
+ else:
+ scale, scale_idx = self.random_sample_ratio(
+ self.img_scale[0], self.ratio_range)
+ elif len(self.img_scale) == 1:
+ scale, scale_idx = self.img_scale[0], 0
+ elif self.multiscale_mode == 'range':
+ scale, scale_idx = self.random_sample(self.img_scale)
+ elif self.multiscale_mode == 'value':
+ scale, scale_idx = self.random_select(self.img_scale)
+ else:
+ raise NotImplementedError
+
+ results['scale'] = scale
+ results['scale_idx'] = scale_idx
+
+ def _resize_img(self, results):
+ """Resize images with ``results['scale']``."""
+ if self.keep_ratio:
+ img, scale_factor = mmcv.imrescale(
+ results['img'], results['scale'], return_scale=True)
+ # the w_scale and h_scale has minor difference
+ # a real fix should be done in the mmcv.imrescale in the future
+ new_h, new_w = img.shape[:2]
+ h, w = results['img'].shape[:2]
+ w_scale = new_w / w
+ h_scale = new_h / h
+ else:
+ img, w_scale, h_scale = mmcv.imresize(
+ results['img'], results['scale'], return_scale=True)
+ scale_factor = np.array([w_scale, h_scale, w_scale, h_scale],
+ dtype=np.float32)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['pad_shape'] = img.shape # in case that there is no padding
+ results['scale_factor'] = scale_factor
+ results['keep_ratio'] = self.keep_ratio
+
+ def _resize_seg(self, results):
+ """Resize semantic segmentation map with ``results['scale']``."""
+ for key in results.get('seg_fields', []):
+ if self.keep_ratio:
+ gt_seg = mmcv.imrescale(
+ results[key], results['scale'], interpolation='nearest')
+ else:
+ gt_seg = mmcv.imresize(
+ results[key], results['scale'], interpolation='nearest')
+ results[key] = gt_seg
+
+ def __call__(self, results):
+ """Call function to resize images, bounding boxes, masks, semantic
+ segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Resized results, 'img_shape', 'pad_shape', 'scale_factor',
+ 'keep_ratio' keys are added into result dict.
+ """
+
+ if 'scale' not in results:
+ self._random_scale(results)
+ self._resize_img(results)
+ self._resize_seg(results)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += (f'(img_scale={self.img_scale}, '
+ f'multiscale_mode={self.multiscale_mode}, '
+ f'ratio_range={self.ratio_range}, '
+ f'keep_ratio={self.keep_ratio})')
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomFlip(object):
+ """Flip the image & seg.
+
+ If the input dict contains the key "flip", then the flag will be used,
+ otherwise it will be randomly decided by a ratio specified in the init
+ method.
+
+ Args:
+ prob (float, optional): The flipping probability. Default: None.
+ direction(str, optional): The flipping direction. Options are
+ 'horizontal' and 'vertical'. Default: 'horizontal'.
+ """
+
+ @deprecated_api_warning({'flip_ratio': 'prob'}, cls_name='RandomFlip')
+ def __init__(self, prob=None, direction='horizontal'):
+ self.prob = prob
+ self.direction = direction
+ if prob is not None:
+ assert prob >= 0 and prob <= 1
+ assert direction in ['horizontal', 'vertical']
+
+ def __call__(self, results):
+ """Call function to flip bounding boxes, masks, semantic segmentation
+ maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Flipped results, 'flip', 'flip_direction' keys are added into
+ result dict.
+ """
+
+ if 'flip' not in results:
+ flip = True if np.random.rand() < self.prob else False
+ results['flip'] = flip
+ if 'flip_direction' not in results:
+ results['flip_direction'] = self.direction
+ if results['flip']:
+ # flip image
+ results['img'] = mmcv.imflip(
+ results['img'], direction=results['flip_direction'])
+
+ # flip segs
+ for key in results.get('seg_fields', []):
+ # use copy() to make numpy stride positive
+ results[key] = mmcv.imflip(
+ results[key], direction=results['flip_direction']).copy()
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(prob={self.prob})'
+
+
+@PIPELINES.register_module()
+class Pad(object):
+ """Pad the image & mask.
+
+ There are two padding modes: (1) pad to a fixed size and (2) pad to the
+ minimum size that is divisible by some number.
+ Added keys are "pad_shape", "pad_fixed_size", "pad_size_divisor",
+
+ Args:
+ size (tuple, optional): Fixed padding size.
+ size_divisor (int, optional): The divisor of padded size.
+ pad_val (float, optional): Padding value. Default: 0.
+ seg_pad_val (float, optional): Padding value of segmentation map.
+ Default: 255.
+ """
+
+ def __init__(self,
+ size=None,
+ size_divisor=None,
+ pad_val=0,
+ seg_pad_val=255):
+ self.size = size
+ self.size_divisor = size_divisor
+ self.pad_val = pad_val
+ self.seg_pad_val = seg_pad_val
+ # only one of size and size_divisor should be valid
+ assert size is not None or size_divisor is not None
+ assert size is None or size_divisor is None
+
+ def _pad_img(self, results):
+ """Pad images according to ``self.size``."""
+ if self.size is not None:
+ padded_img = mmcv.impad(
+ results['img'], shape=self.size, pad_val=self.pad_val)
+ elif self.size_divisor is not None:
+ padded_img = mmcv.impad_to_multiple(
+ results['img'], self.size_divisor, pad_val=self.pad_val)
+ results['img'] = padded_img
+ results['pad_shape'] = padded_img.shape
+ results['pad_fixed_size'] = self.size
+ results['pad_size_divisor'] = self.size_divisor
+
+ def _pad_seg(self, results):
+ """Pad masks according to ``results['pad_shape']``."""
+ for key in results.get('seg_fields', []):
+ results[key] = mmcv.impad(
+ results[key],
+ shape=results['pad_shape'][:2],
+ pad_val=self.seg_pad_val)
+
+ def __call__(self, results):
+ """Call function to pad images, masks, semantic segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Updated result dict.
+ """
+
+ self._pad_img(results)
+ self._pad_seg(results)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(size={self.size}, size_divisor={self.size_divisor}, ' \
+ f'pad_val={self.pad_val})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class Normalize(object):
+ """Normalize the image.
+
+ Added key is "img_norm_cfg".
+
+ Args:
+ mean (sequence): Mean values of 3 channels.
+ std (sequence): Std values of 3 channels.
+ to_rgb (bool): Whether to convert the image from BGR to RGB,
+ default is true.
+ """
+
+ def __init__(self, mean, std, to_rgb=True):
+ self.mean = np.array(mean, dtype=np.float32)
+ self.std = np.array(std, dtype=np.float32)
+ self.to_rgb = to_rgb
+
+ def __call__(self, results):
+ """Call function to normalize images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Normalized results, 'img_norm_cfg' key is added into
+ result dict.
+ """
+
+ results['img'] = mmcv.imnormalize(results['img'], self.mean, self.std,
+ self.to_rgb)
+ results['img_norm_cfg'] = dict(
+ mean=self.mean, std=self.std, to_rgb=self.to_rgb)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(mean={self.mean}, std={self.std}, to_rgb=' \
+ f'{self.to_rgb})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class Rerange(object):
+ """Rerange the image pixel value.
+
+ Args:
+ min_value (float or int): Minimum value of the reranged image.
+ Default: 0.
+ max_value (float or int): Maximum value of the reranged image.
+ Default: 255.
+ """
+
+ def __init__(self, min_value=0, max_value=255):
+ assert isinstance(min_value, float) or isinstance(min_value, int)
+ assert isinstance(max_value, float) or isinstance(max_value, int)
+ assert min_value < max_value
+ self.min_value = min_value
+ self.max_value = max_value
+
+ def __call__(self, results):
+ """Call function to rerange images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ Returns:
+ dict: Reranged results.
+ """
+
+ img = results['img']
+ img_min_value = np.min(img)
+ img_max_value = np.max(img)
+
+ assert img_min_value < img_max_value
+ # rerange to [0, 1]
+ img = (img - img_min_value) / (img_max_value - img_min_value)
+ # rerange to [min_value, max_value]
+ img = img * (self.max_value - self.min_value) + self.min_value
+ results['img'] = img
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(min_value={self.min_value}, max_value={self.max_value})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class CLAHE(object):
+ """Use CLAHE method to process the image.
+
+ See `ZUIDERVELD,K. Contrast Limited Adaptive Histogram Equalization[J].
+ Graphics Gems, 1994:474-485.` for more information.
+
+ Args:
+ clip_limit (float): Threshold for contrast limiting. Default: 40.0.
+ tile_grid_size (tuple[int]): Size of grid for histogram equalization.
+ Input image will be divided into equally sized rectangular tiles.
+ It defines the number of tiles in row and column. Default: (8, 8).
+ """
+
+ def __init__(self, clip_limit=40.0, tile_grid_size=(8, 8)):
+ assert isinstance(clip_limit, (float, int))
+ self.clip_limit = clip_limit
+ assert is_tuple_of(tile_grid_size, int)
+ assert len(tile_grid_size) == 2
+ self.tile_grid_size = tile_grid_size
+
+ def __call__(self, results):
+ """Call function to Use CLAHE method process images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Processed results.
+ """
+
+ for i in range(results['img'].shape[2]):
+ results['img'][:, :, i] = mmcv.clahe(
+ np.array(results['img'][:, :, i], dtype=np.uint8),
+ self.clip_limit, self.tile_grid_size)
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(clip_limit={self.clip_limit}, '\
+ f'tile_grid_size={self.tile_grid_size})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomCrop(object):
+ """Random crop the image & seg.
+
+ Args:
+ crop_size (tuple): Expected size after cropping, (h, w).
+ cat_max_ratio (float): The maximum ratio that single category could
+ occupy.
+ """
+
+ def __init__(self, crop_size, cat_max_ratio=1., ignore_index=255):
+ assert crop_size[0] > 0 and crop_size[1] > 0
+ self.crop_size = crop_size
+ self.cat_max_ratio = cat_max_ratio
+ self.ignore_index = ignore_index
+
+ def get_crop_bbox(self, img):
+ """Randomly get a crop bounding box."""
+ margin_h = max(img.shape[0] - self.crop_size[0], 0)
+ margin_w = max(img.shape[1] - self.crop_size[1], 0)
+ offset_h = np.random.randint(0, margin_h + 1)
+ offset_w = np.random.randint(0, margin_w + 1)
+ crop_y1, crop_y2 = offset_h, offset_h + self.crop_size[0]
+ crop_x1, crop_x2 = offset_w, offset_w + self.crop_size[1]
+
+ return crop_y1, crop_y2, crop_x1, crop_x2
+
+ def crop(self, img, crop_bbox):
+ """Crop from ``img``"""
+ crop_y1, crop_y2, crop_x1, crop_x2 = crop_bbox
+ img = img[crop_y1:crop_y2, crop_x1:crop_x2, ...]
+ return img
+
+ def __call__(self, results):
+ """Call function to randomly crop images, semantic segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Randomly cropped results, 'img_shape' key in result dict is
+ updated according to crop size.
+ """
+
+ img = results['img']
+ crop_bbox = self.get_crop_bbox(img)
+ if self.cat_max_ratio < 1.:
+ # Repeat 10 times
+ for _ in range(10):
+ seg_temp = self.crop(results['gt_semantic_seg'], crop_bbox)
+ labels, cnt = np.unique(seg_temp, return_counts=True)
+ cnt = cnt[labels != self.ignore_index]
+ if len(cnt) > 1 and np.max(cnt) / np.sum(
+ cnt) < self.cat_max_ratio:
+ break
+ crop_bbox = self.get_crop_bbox(img)
+
+ # crop the image
+ img = self.crop(img, crop_bbox)
+ img_shape = img.shape
+ results['img'] = img
+ results['img_shape'] = img_shape
+
+ # crop semantic seg
+ for key in results.get('seg_fields', []):
+ results[key] = self.crop(results[key], crop_bbox)
+
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(crop_size={self.crop_size})'
+
+
+@PIPELINES.register_module()
+class RandomRotate(object):
+ """Rotate the image & seg.
+
+ Args:
+ prob (float): The rotation probability.
+ degree (float, tuple[float]): Range of degrees to select from. If
+ degree is a number instead of tuple like (min, max),
+ the range of degree will be (``-degree``, ``+degree``)
+ pad_val (float, optional): Padding value of image. Default: 0.
+ seg_pad_val (float, optional): Padding value of segmentation map.
+ Default: 255.
+ center (tuple[float], optional): Center point (w, h) of the rotation in
+ the source image. If not specified, the center of the image will be
+ used. Default: None.
+ auto_bound (bool): Whether to adjust the image size to cover the whole
+ rotated image. Default: False
+ """
+
+ def __init__(self,
+ prob,
+ degree,
+ pad_val=0,
+ seg_pad_val=255,
+ center=None,
+ auto_bound=False):
+ self.prob = prob
+ assert prob >= 0 and prob <= 1
+ if isinstance(degree, (float, int)):
+ assert degree > 0, f'degree {degree} should be positive'
+ self.degree = (-degree, degree)
+ else:
+ self.degree = degree
+ assert len(self.degree) == 2, f'degree {self.degree} should be a ' \
+ f'tuple of (min, max)'
+ self.pal_val = pad_val
+ self.seg_pad_val = seg_pad_val
+ self.center = center
+ self.auto_bound = auto_bound
+
+ def __call__(self, results):
+ """Call function to rotate image, semantic segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Rotated results.
+ """
+
+ rotate = True if np.random.rand() < self.prob else False
+ degree = np.random.uniform(min(*self.degree), max(*self.degree))
+ if rotate:
+ # rotate image
+ results['img'] = mmcv.imrotate(
+ results['img'],
+ angle=degree,
+ border_value=self.pal_val,
+ center=self.center,
+ auto_bound=self.auto_bound)
+
+ # rotate segs
+ for key in results.get('seg_fields', []):
+ results[key] = mmcv.imrotate(
+ results[key],
+ angle=degree,
+ border_value=self.seg_pad_val,
+ center=self.center,
+ auto_bound=self.auto_bound,
+ interpolation='nearest')
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, ' \
+ f'degree={self.degree}, ' \
+ f'pad_val={self.pal_val}, ' \
+ f'seg_pad_val={self.seg_pad_val}, ' \
+ f'center={self.center}, ' \
+ f'auto_bound={self.auto_bound})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RGB2Gray(object):
+ """Convert RGB image to grayscale image.
+
+ This transform calculate the weighted mean of input image channels with
+ ``weights`` and then expand the channels to ``out_channels``. When
+ ``out_channels`` is None, the number of output channels is the same as
+ input channels.
+
+ Args:
+ out_channels (int): Expected number of output channels after
+ transforming. Default: None.
+ weights (tuple[float]): The weights to calculate the weighted mean.
+ Default: (0.299, 0.587, 0.114).
+ """
+
+ def __init__(self, out_channels=None, weights=(0.299, 0.587, 0.114)):
+ assert out_channels is None or out_channels > 0
+ self.out_channels = out_channels
+ assert isinstance(weights, tuple)
+ for item in weights:
+ assert isinstance(item, (float, int))
+ self.weights = weights
+
+ def __call__(self, results):
+ """Call function to convert RGB image to grayscale image.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with grayscale image.
+ """
+ img = results['img']
+ assert len(img.shape) == 3
+ assert img.shape[2] == len(self.weights)
+ weights = np.array(self.weights).reshape((1, 1, -1))
+ img = (img * weights).sum(2, keepdims=True)
+ if self.out_channels is None:
+ img = img.repeat(weights.shape[2], axis=2)
+ else:
+ img = img.repeat(self.out_channels, axis=2)
+
+ results['img'] = img
+ results['img_shape'] = img.shape
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(out_channels={self.out_channels}, ' \
+ f'weights={self.weights})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class AdjustGamma(object):
+ """Using gamma correction to process the image.
+
+ Args:
+ gamma (float or int): Gamma value used in gamma correction.
+ Default: 1.0.
+ """
+
+ def __init__(self, gamma=1.0):
+ assert isinstance(gamma, float) or isinstance(gamma, int)
+ assert gamma > 0
+ self.gamma = gamma
+ inv_gamma = 1.0 / gamma
+ self.table = np.array([(i / 255.0)**inv_gamma * 255
+ for i in np.arange(256)]).astype('uint8')
+
+ def __call__(self, results):
+ """Call function to process the image with gamma correction.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Processed results.
+ """
+
+ results['img'] = mmcv.lut_transform(
+ np.array(results['img'], dtype=np.uint8), self.table)
+
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(gamma={self.gamma})'
+
+
+@PIPELINES.register_module()
+class SegRescale(object):
+ """Rescale semantic segmentation maps.
+
+ Args:
+ scale_factor (float): The scale factor of the final output.
+ """
+
+ def __init__(self, scale_factor=1):
+ self.scale_factor = scale_factor
+
+ def __call__(self, results):
+ """Call function to scale the semantic segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with semantic segmentation map scaled.
+ """
+ for key in results.get('seg_fields', []):
+ if self.scale_factor != 1:
+ results[key] = mmcv.imrescale(
+ results[key], self.scale_factor, interpolation='nearest')
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(scale_factor={self.scale_factor})'
+
+
+@PIPELINES.register_module()
+class PhotoMetricDistortion(object):
+ """Apply photometric distortion to image sequentially, every transformation
+ is applied with a probability of 0.5. The position of random contrast is in
+ second or second to last.
+
+ 1. random brightness
+ 2. random contrast (mode 0)
+ 3. convert color from BGR to HSV
+ 4. random saturation
+ 5. random hue
+ 6. convert color from HSV to BGR
+ 7. random contrast (mode 1)
+
+ Args:
+ brightness_delta (int): delta of brightness.
+ contrast_range (tuple): range of contrast.
+ saturation_range (tuple): range of saturation.
+ hue_delta (int): delta of hue.
+ """
+
+ def __init__(self,
+ brightness_delta=32,
+ contrast_range=(0.5, 1.5),
+ saturation_range=(0.5, 1.5),
+ hue_delta=18):
+ self.brightness_delta = brightness_delta
+ self.contrast_lower, self.contrast_upper = contrast_range
+ self.saturation_lower, self.saturation_upper = saturation_range
+ self.hue_delta = hue_delta
+
+ def convert(self, img, alpha=1, beta=0):
+ """Multiple with alpha and add beat with clip."""
+ img = img.astype(np.float32) * alpha + beta
+ img = np.clip(img, 0, 255)
+ return img.astype(np.uint8)
+
+ def brightness(self, img):
+ """Brightness distortion."""
+ if random.randint(2):
+ return self.convert(
+ img,
+ beta=random.uniform(-self.brightness_delta,
+ self.brightness_delta))
+ return img
+
+ def contrast(self, img):
+ """Contrast distortion."""
+ if random.randint(2):
+ return self.convert(
+ img,
+ alpha=random.uniform(self.contrast_lower, self.contrast_upper))
+ return img
+
+ def saturation(self, img):
+ """Saturation distortion."""
+ if random.randint(2):
+ img = mmcv.bgr2hsv(img)
+ img[:, :, 1] = self.convert(
+ img[:, :, 1],
+ alpha=random.uniform(self.saturation_lower,
+ self.saturation_upper))
+ img = mmcv.hsv2bgr(img)
+ return img
+
+ def hue(self, img):
+ """Hue distortion."""
+ if random.randint(2):
+ img = mmcv.bgr2hsv(img)
+ img[:, :,
+ 0] = (img[:, :, 0].astype(int) +
+ random.randint(-self.hue_delta, self.hue_delta)) % 180
+ img = mmcv.hsv2bgr(img)
+ return img
+
+ def __call__(self, results):
+ """Call function to perform photometric distortion on images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with images distorted.
+ """
+
+ img = results['img']
+ # random brightness
+ img = self.brightness(img)
+
+ # mode == 0 --> do random contrast first
+ # mode == 1 --> do random contrast last
+ mode = random.randint(2)
+ if mode == 1:
+ img = self.contrast(img)
+
+ # random saturation
+ img = self.saturation(img)
+
+ # random hue
+ img = self.hue(img)
+
+ # random contrast
+ if mode == 0:
+ img = self.contrast(img)
+
+ results['img'] = img
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += (f'(brightness_delta={self.brightness_delta}, '
+ f'contrast_range=({self.contrast_lower}, '
+ f'{self.contrast_upper}), '
+ f'saturation_range=({self.saturation_lower}, '
+ f'{self.saturation_upper}), '
+ f'hue_delta={self.hue_delta})')
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomCutOut(object):
+ """CutOut operation.
+
+ Randomly drop some regions of image used in
+ `Cutout `_.
+ Args:
+ prob (float): cutout probability.
+ n_holes (int | tuple[int, int]): Number of regions to be dropped.
+ If it is given as a list, number of holes will be randomly
+ selected from the closed interval [`n_holes[0]`, `n_holes[1]`].
+ cutout_shape (tuple[int, int] | list[tuple[int, int]]): The candidate
+ shape of dropped regions. It can be `tuple[int, int]` to use a
+ fixed cutout shape, or `list[tuple[int, int]]` to randomly choose
+ shape from the list.
+ cutout_ratio (tuple[float, float] | list[tuple[float, float]]): The
+ candidate ratio of dropped regions. It can be `tuple[float, float]`
+ to use a fixed ratio or `list[tuple[float, float]]` to randomly
+ choose ratio from the list. Please note that `cutout_shape`
+ and `cutout_ratio` cannot be both given at the same time.
+ fill_in (tuple[float, float, float] | tuple[int, int, int]): The value
+ of pixel to fill in the dropped regions. Default: (0, 0, 0).
+ seg_fill_in (int): The labels of pixel to fill in the dropped regions.
+ If seg_fill_in is None, skip. Default: None.
+ """
+
+ def __init__(self,
+ prob,
+ n_holes,
+ cutout_shape=None,
+ cutout_ratio=None,
+ fill_in=(0, 0, 0),
+ seg_fill_in=None):
+
+ assert 0 <= prob and prob <= 1
+ assert (cutout_shape is None) ^ (cutout_ratio is None), \
+ 'Either cutout_shape or cutout_ratio should be specified.'
+ assert (isinstance(cutout_shape, (list, tuple))
+ or isinstance(cutout_ratio, (list, tuple)))
+ if isinstance(n_holes, tuple):
+ assert len(n_holes) == 2 and 0 <= n_holes[0] < n_holes[1]
+ else:
+ n_holes = (n_holes, n_holes)
+ if seg_fill_in is not None:
+ assert (isinstance(seg_fill_in, int) and 0 <= seg_fill_in
+ and seg_fill_in <= 255)
+ self.prob = prob
+ self.n_holes = n_holes
+ self.fill_in = fill_in
+ self.seg_fill_in = seg_fill_in
+ self.with_ratio = cutout_ratio is not None
+ self.candidates = cutout_ratio if self.with_ratio else cutout_shape
+ if not isinstance(self.candidates, list):
+ self.candidates = [self.candidates]
+
+ def __call__(self, results):
+ """Call function to drop some regions of image."""
+ cutout = True if np.random.rand() < self.prob else False
+ if cutout:
+ h, w, c = results['img'].shape
+ n_holes = np.random.randint(self.n_holes[0], self.n_holes[1] + 1)
+ for _ in range(n_holes):
+ x1 = np.random.randint(0, w)
+ y1 = np.random.randint(0, h)
+ index = np.random.randint(0, len(self.candidates))
+ if not self.with_ratio:
+ cutout_w, cutout_h = self.candidates[index]
+ else:
+ cutout_w = int(self.candidates[index][0] * w)
+ cutout_h = int(self.candidates[index][1] * h)
+
+ x2 = np.clip(x1 + cutout_w, 0, w)
+ y2 = np.clip(y1 + cutout_h, 0, h)
+ results['img'][y1:y2, x1:x2, :] = self.fill_in
+
+ if self.seg_fill_in is not None:
+ for key in results.get('seg_fields', []):
+ results[key][y1:y2, x1:x2] = self.seg_fill_in
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, '
+ repr_str += f'n_holes={self.n_holes}, '
+ repr_str += (f'cutout_ratio={self.candidates}, ' if self.with_ratio
+ else f'cutout_shape={self.candidates}, ')
+ repr_str += f'fill_in={self.fill_in}, '
+ repr_str += f'seg_fill_in={self.seg_fill_in})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomMosaic(object):
+ """Mosaic augmentation. Given 4 images, mosaic transform combines them into
+ one output image. The output image is composed of the parts from each sub-
+ image.
+
+ .. code:: text
+
+ mosaic transform
+ center_x
+ +------------------------------+
+ | pad | pad |
+ | +-----------+ |
+ | | | |
+ | | image1 |--------+ |
+ | | | | |
+ | | | image2 | |
+ center_y |----+-------------+-----------|
+ | | cropped | |
+ |pad | image3 | image4 |
+ | | | |
+ +----|-------------+-----------+
+ | |
+ +-------------+
+
+ The mosaic transform steps are as follows:
+ 1. Choose the mosaic center as the intersections of 4 images
+ 2. Get the left top image according to the index, and randomly
+ sample another 3 images from the custom dataset.
+ 3. Sub image will be cropped if image is larger than mosaic patch
+
+ Args:
+ prob (float): mosaic probability.
+ img_scale (Sequence[int]): Image size after mosaic pipeline of
+ a single image. The size of the output image is four times
+ that of a single image. The output image comprises 4 single images.
+ Default: (640, 640).
+ center_ratio_range (Sequence[float]): Center ratio range of mosaic
+ output. Default: (0.5, 1.5).
+ pad_val (int): Pad value. Default: 0.
+ seg_pad_val (int): Pad value of segmentation map. Default: 255.
+ """
+
+ def __init__(self,
+ prob,
+ img_scale=(640, 640),
+ center_ratio_range=(0.5, 1.5),
+ pad_val=0,
+ seg_pad_val=255):
+ assert 0 <= prob and prob <= 1
+ assert isinstance(img_scale, tuple)
+ self.prob = prob
+ self.img_scale = img_scale
+ self.center_ratio_range = center_ratio_range
+ self.pad_val = pad_val
+ self.seg_pad_val = seg_pad_val
+
+ def __call__(self, results):
+ """Call function to make a mosaic of image.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Result dict with mosaic transformed.
+ """
+ mosaic = True if np.random.rand() < self.prob else False
+ if mosaic:
+ results = self._mosaic_transform_img(results)
+ results = self._mosaic_transform_seg(results)
+ return results
+
+ def get_indexes(self, dataset):
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`MultiImageMixDataset`): The dataset.
+
+ Returns:
+ list: indexes.
+ """
+
+ indexes = [random.randint(0, len(dataset)) for _ in range(3)]
+ return indexes
+
+ def _mosaic_transform_img(self, results):
+ """Mosaic transform function.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+
+ assert 'mix_results' in results
+ if len(results['img'].shape) == 3:
+ mosaic_img = np.full(
+ (int(self.img_scale[0] * 2), int(self.img_scale[1] * 2), 3),
+ self.pad_val,
+ dtype=results['img'].dtype)
+ else:
+ mosaic_img = np.full(
+ (int(self.img_scale[0] * 2), int(self.img_scale[1] * 2)),
+ self.pad_val,
+ dtype=results['img'].dtype)
+
+ # mosaic center x, y
+ self.center_x = int(
+ random.uniform(*self.center_ratio_range) * self.img_scale[1])
+ self.center_y = int(
+ random.uniform(*self.center_ratio_range) * self.img_scale[0])
+ center_position = (self.center_x, self.center_y)
+
+ loc_strs = ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ for i, loc in enumerate(loc_strs):
+ if loc == 'top_left':
+ result_patch = copy.deepcopy(results)
+ else:
+ result_patch = copy.deepcopy(results['mix_results'][i - 1])
+
+ img_i = result_patch['img']
+ h_i, w_i = img_i.shape[:2]
+ # keep_ratio resize
+ scale_ratio_i = min(self.img_scale[0] / h_i,
+ self.img_scale[1] / w_i)
+ img_i = mmcv.imresize(
+ img_i, (int(w_i * scale_ratio_i), int(h_i * scale_ratio_i)))
+
+ # compute the combine parameters
+ paste_coord, crop_coord = self._mosaic_combine(
+ loc, center_position, img_i.shape[:2][::-1])
+ x1_p, y1_p, x2_p, y2_p = paste_coord
+ x1_c, y1_c, x2_c, y2_c = crop_coord
+
+ # crop and paste image
+ mosaic_img[y1_p:y2_p, x1_p:x2_p] = img_i[y1_c:y2_c, x1_c:x2_c]
+
+ results['img'] = mosaic_img
+ results['img_shape'] = mosaic_img.shape
+ results['ori_shape'] = mosaic_img.shape
+
+ return results
+
+ def _mosaic_transform_seg(self, results):
+ """Mosaic transform function for label annotations.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+
+ assert 'mix_results' in results
+ for key in results.get('seg_fields', []):
+ mosaic_seg = np.full(
+ (int(self.img_scale[0] * 2), int(self.img_scale[1] * 2)),
+ self.seg_pad_val,
+ dtype=results[key].dtype)
+
+ # mosaic center x, y
+ center_position = (self.center_x, self.center_y)
+
+ loc_strs = ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ for i, loc in enumerate(loc_strs):
+ if loc == 'top_left':
+ result_patch = copy.deepcopy(results)
+ else:
+ result_patch = copy.deepcopy(results['mix_results'][i - 1])
+
+ gt_seg_i = result_patch[key]
+ h_i, w_i = gt_seg_i.shape[:2]
+ # keep_ratio resize
+ scale_ratio_i = min(self.img_scale[0] / h_i,
+ self.img_scale[1] / w_i)
+ gt_seg_i = mmcv.imresize(
+ gt_seg_i,
+ (int(w_i * scale_ratio_i), int(h_i * scale_ratio_i)),
+ interpolation='nearest')
+
+ # compute the combine parameters
+ paste_coord, crop_coord = self._mosaic_combine(
+ loc, center_position, gt_seg_i.shape[:2][::-1])
+ x1_p, y1_p, x2_p, y2_p = paste_coord
+ x1_c, y1_c, x2_c, y2_c = crop_coord
+
+ # crop and paste image
+ mosaic_seg[y1_p:y2_p, x1_p:x2_p] = gt_seg_i[y1_c:y2_c,
+ x1_c:x2_c]
+
+ results[key] = mosaic_seg
+
+ return results
+
+ def _mosaic_combine(self, loc, center_position_xy, img_shape_wh):
+ """Calculate global coordinate of mosaic image and local coordinate of
+ cropped sub-image.
+
+ Args:
+ loc (str): Index for the sub-image, loc in ('top_left',
+ 'top_right', 'bottom_left', 'bottom_right').
+ center_position_xy (Sequence[float]): Mixing center for 4 images,
+ (x, y).
+ img_shape_wh (Sequence[int]): Width and height of sub-image
+
+ Returns:
+ tuple[tuple[float]]: Corresponding coordinate of pasting and
+ cropping
+ - paste_coord (tuple): paste corner coordinate in mosaic image.
+ - crop_coord (tuple): crop corner coordinate in mosaic image.
+ """
+
+ assert loc in ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ if loc == 'top_left':
+ # index0 to top left part of image
+ x1, y1, x2, y2 = max(center_position_xy[0] - img_shape_wh[0], 0), \
+ max(center_position_xy[1] - img_shape_wh[1], 0), \
+ center_position_xy[0], \
+ center_position_xy[1]
+ crop_coord = img_shape_wh[0] - (x2 - x1), img_shape_wh[1] - (
+ y2 - y1), img_shape_wh[0], img_shape_wh[1]
+
+ elif loc == 'top_right':
+ # index1 to top right part of image
+ x1, y1, x2, y2 = center_position_xy[0], \
+ max(center_position_xy[1] - img_shape_wh[1], 0), \
+ min(center_position_xy[0] + img_shape_wh[0],
+ self.img_scale[1] * 2), \
+ center_position_xy[1]
+ crop_coord = 0, img_shape_wh[1] - (y2 - y1), min(
+ img_shape_wh[0], x2 - x1), img_shape_wh[1]
+
+ elif loc == 'bottom_left':
+ # index2 to bottom left part of image
+ x1, y1, x2, y2 = max(center_position_xy[0] - img_shape_wh[0], 0), \
+ center_position_xy[1], \
+ center_position_xy[0], \
+ min(self.img_scale[0] * 2, center_position_xy[1] +
+ img_shape_wh[1])
+ crop_coord = img_shape_wh[0] - (x2 - x1), 0, img_shape_wh[0], min(
+ y2 - y1, img_shape_wh[1])
+
+ else:
+ # index3 to bottom right part of image
+ x1, y1, x2, y2 = center_position_xy[0], \
+ center_position_xy[1], \
+ min(center_position_xy[0] + img_shape_wh[0],
+ self.img_scale[1] * 2), \
+ min(self.img_scale[0] * 2, center_position_xy[1] +
+ img_shape_wh[1])
+ crop_coord = 0, 0, min(img_shape_wh[0],
+ x2 - x1), min(y2 - y1, img_shape_wh[1])
+
+ paste_coord = x1, y1, x2, y2
+ return paste_coord, crop_coord
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, '
+ repr_str += f'img_scale={self.img_scale}, '
+ repr_str += f'center_ratio_range={self.center_ratio_range}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'seg_pad_val={self.pad_val})'
+ return repr_str
diff --git a/mmseg/datasets/potsdam.py b/mmseg/datasets/potsdam.py
new file mode 100644
index 0000000..2986b8f
--- /dev/null
+++ b/mmseg/datasets/potsdam.py
@@ -0,0 +1,25 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class PotsdamDataset(CustomDataset):
+ """ISPRS Potsdam dataset.
+
+ In segmentation map annotation for Potsdam dataset, 0 is the ignore index.
+ ``reduce_zero_label`` should be set to True. The ``img_suffix`` and
+ ``seg_map_suffix`` are both fixed to '.png'.
+ """
+ CLASSES = ('impervious_surface', 'building', 'low_vegetation', 'tree',
+ 'car', 'clutter')
+
+ PALETTE = [[255, 255, 255], [0, 0, 255], [0, 255, 255], [0, 255, 0],
+ [255, 255, 0], [255, 0, 0]]
+
+ def __init__(self, **kwargs):
+ super(PotsdamDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=True,
+ **kwargs)
diff --git a/mmseg/datasets/stare.py b/mmseg/datasets/stare.py
new file mode 100644
index 0000000..a24d1d9
--- /dev/null
+++ b/mmseg/datasets/stare.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class STAREDataset(CustomDataset):
+ """STARE dataset.
+
+ In segmentation map annotation for STARE, 0 stands for background, which is
+ included in 2 categories. ``reduce_zero_label`` is fixed to False. The
+ ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
+ '.ah.png'.
+ """
+
+ CLASSES = ('background', 'vessel')
+
+ PALETTE = [[120, 120, 120], [6, 230, 230]]
+
+ def __init__(self, **kwargs):
+ super(STAREDataset, self).__init__(
+ img_suffix='.png',
+ seg_map_suffix='.ah.png',
+ reduce_zero_label=False,
+ **kwargs)
+ assert osp.exists(self.img_dir)
diff --git a/mmseg/datasets/voc.py b/mmseg/datasets/voc.py
new file mode 100644
index 0000000..3cec9e3
--- /dev/null
+++ b/mmseg/datasets/voc.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+from .builder import DATASETS
+from .custom import CustomDataset
+
+
+@DATASETS.register_module()
+class PascalVOCDataset(CustomDataset):
+ """Pascal VOC dataset.
+
+ Args:
+ split (str): Split txt file for Pascal VOC.
+ """
+
+ CLASSES = ('background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle',
+ 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
+ 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa',
+ 'train', 'tvmonitor')
+
+ PALETTE = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
+ [128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0],
+ [192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128],
+ [192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0],
+ [128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]]
+
+ def __init__(self, split, **kwargs):
+ super(PascalVOCDataset, self).__init__(
+ img_suffix='.jpg', seg_map_suffix='.png', split=split, **kwargs)
+ assert osp.exists(self.img_dir) and self.split is not None
diff --git a/mmseg/models/__init__.py b/mmseg/models/__init__.py
new file mode 100644
index 0000000..87d8108
--- /dev/null
+++ b/mmseg/models/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .backbones import * # noqa: F401,F403
+from .builder import (BACKBONES, HEADS, LOSSES, SEGMENTORS, build_backbone,
+ build_head, build_loss, build_segmentor)
+from .decode_heads import * # noqa: F401,F403
+from .losses import * # noqa: F401,F403
+from .necks import * # noqa: F401,F403
+from .segmentors import * # noqa: F401,F403
+
+__all__ = [
+ 'BACKBONES', 'HEADS', 'LOSSES', 'SEGMENTORS', 'build_backbone',
+ 'build_head', 'build_loss', 'build_segmentor'
+]
diff --git a/mmseg/models/backbones/__init__.py b/mmseg/models/backbones/__init__.py
new file mode 100644
index 0000000..434378e
--- /dev/null
+++ b/mmseg/models/backbones/__init__.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bisenetv1 import BiSeNetV1
+from .bisenetv2 import BiSeNetV2
+from .cgnet import CGNet
+from .erfnet import ERFNet
+from .fast_scnn import FastSCNN
+from .hrnet import HRNet
+from .icnet import ICNet
+from .mit import MixVisionTransformer
+from .mobilenet_v2 import MobileNetV2
+from .mobilenet_v3 import MobileNetV3
+from .resnest import ResNeSt
+from .resnet import ResNet, ResNetV1c, ResNetV1d
+from .resnext import ResNeXt
+from .stdc import STDCContextPathNet, STDCNet
+from .swin import SwinTransformer
+from .timm_backbone import TIMMBackbone
+from .twins import PCPVT, SVT
+from .unet import UNet
+from .vit import VisionTransformer
+
+__all__ = [
+ 'ResNet', 'ResNetV1c', 'ResNetV1d', 'ResNeXt', 'HRNet', 'FastSCNN',
+ 'ResNeSt', 'MobileNetV2', 'UNet', 'CGNet', 'MobileNetV3',
+ 'VisionTransformer', 'SwinTransformer', 'MixVisionTransformer',
+ 'BiSeNetV1', 'BiSeNetV2', 'ICNet', 'TIMMBackbone', 'ERFNet', 'PCPVT',
+ 'SVT', 'STDCNet', 'STDCContextPathNet'
+]
diff --git a/mmseg/models/backbones/bisenetv1.py b/mmseg/models/backbones/bisenetv1.py
new file mode 100644
index 0000000..4beb7b3
--- /dev/null
+++ b/mmseg/models/backbones/bisenetv1.py
@@ -0,0 +1,332 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import BACKBONES, build_backbone
+
+
+class SpatialPath(BaseModule):
+ """Spatial Path to preserve the spatial size of the original input image
+ and encode affluent spatial information.
+
+ Args:
+ in_channels(int): The number of channels of input
+ image. Default: 3.
+ num_channels (Tuple[int]): The number of channels of
+ each layers in Spatial Path.
+ Default: (64, 64, 64, 128).
+ Returns:
+ x (torch.Tensor): Feature map for Feature Fusion Module.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ num_channels=(64, 64, 64, 128),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(SpatialPath, self).__init__(init_cfg=init_cfg)
+ assert len(num_channels) == 4, 'Length of input channels \
+ of Spatial Path must be 4!'
+
+ self.layers = []
+ for i in range(len(num_channels)):
+ layer_name = f'layer{i + 1}'
+ self.layers.append(layer_name)
+ if i == 0:
+ self.add_module(
+ layer_name,
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=num_channels[i],
+ kernel_size=7,
+ stride=2,
+ padding=3,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ elif i == len(num_channels) - 1:
+ self.add_module(
+ layer_name,
+ ConvModule(
+ in_channels=num_channels[i - 1],
+ out_channels=num_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ else:
+ self.add_module(
+ layer_name,
+ ConvModule(
+ in_channels=num_channels[i - 1],
+ out_channels=num_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, x):
+ for i, layer_name in enumerate(self.layers):
+ layer_stage = getattr(self, layer_name)
+ x = layer_stage(x)
+ return x
+
+
+class AttentionRefinementModule(BaseModule):
+ """Attention Refinement Module (ARM) to refine the features of each stage.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ Returns:
+ x_out (torch.Tensor): Feature map of Attention Refinement Module.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channel,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(AttentionRefinementModule, self).__init__(init_cfg=init_cfg)
+ self.conv_layer = ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channel,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.atten_conv_layer = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ ConvModule(
+ in_channels=out_channel,
+ out_channels=out_channel,
+ kernel_size=1,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None), nn.Sigmoid())
+
+ def forward(self, x):
+ x = self.conv_layer(x)
+ x_atten = self.atten_conv_layer(x)
+ x_out = x * x_atten
+ return x_out
+
+
+class ContextPath(BaseModule):
+ """Context Path to provide sufficient receptive field.
+
+ Args:
+ backbone_cfg:(dict): Config of backbone of
+ Context Path.
+ context_channels (Tuple[int]): The number of channel numbers
+ of various modules in Context Path.
+ Default: (128, 256, 512).
+ align_corners (bool, optional): The align_corners argument of
+ resize operation. Default: False.
+ Returns:
+ x_16_up, x_32_up (torch.Tensor, torch.Tensor): Two feature maps
+ undergoing upsampling from 1/16 and 1/32 downsampling
+ feature maps. These two feature maps are used for Feature
+ Fusion Module and Auxiliary Head.
+ """
+
+ def __init__(self,
+ backbone_cfg,
+ context_channels=(128, 256, 512),
+ align_corners=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(ContextPath, self).__init__(init_cfg=init_cfg)
+ assert len(context_channels) == 3, 'Length of input channels \
+ of Context Path must be 3!'
+
+ self.backbone = build_backbone(backbone_cfg)
+
+ self.align_corners = align_corners
+ self.arm16 = AttentionRefinementModule(context_channels[1],
+ context_channels[0])
+ self.arm32 = AttentionRefinementModule(context_channels[2],
+ context_channels[0])
+ self.conv_head32 = ConvModule(
+ in_channels=context_channels[0],
+ out_channels=context_channels[0],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv_head16 = ConvModule(
+ in_channels=context_channels[0],
+ out_channels=context_channels[0],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.gap_conv = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ ConvModule(
+ in_channels=context_channels[2],
+ out_channels=context_channels[0],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, x):
+ x_4, x_8, x_16, x_32 = self.backbone(x)
+ x_gap = self.gap_conv(x_32)
+
+ x_32_arm = self.arm32(x_32)
+ x_32_sum = x_32_arm + x_gap
+ x_32_up = resize(input=x_32_sum, size=x_16.shape[2:], mode='nearest')
+ x_32_up = self.conv_head32(x_32_up)
+
+ x_16_arm = self.arm16(x_16)
+ x_16_sum = x_16_arm + x_32_up
+ x_16_up = resize(input=x_16_sum, size=x_8.shape[2:], mode='nearest')
+ x_16_up = self.conv_head16(x_16_up)
+
+ return x_16_up, x_32_up
+
+
+class FeatureFusionModule(BaseModule):
+ """Feature Fusion Module to fuse low level output feature of Spatial Path
+ and high level output feature of Context Path.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ Returns:
+ x_out (torch.Tensor): Feature map of Feature Fusion Module.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(FeatureFusionModule, self).__init__(init_cfg=init_cfg)
+ self.conv1 = ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.gap = nn.AdaptiveAvgPool2d((1, 1))
+ self.conv_atten = nn.Sequential(
+ ConvModule(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg), nn.Sigmoid())
+
+ def forward(self, x_sp, x_cp):
+ x_concat = torch.cat([x_sp, x_cp], dim=1)
+ x_fuse = self.conv1(x_concat)
+ x_atten = self.gap(x_fuse)
+ # Note: No BN and more 1x1 conv in paper.
+ x_atten = self.conv_atten(x_atten)
+ x_atten = x_fuse * x_atten
+ x_out = x_atten + x_fuse
+ return x_out
+
+
+@BACKBONES.register_module()
+class BiSeNetV1(BaseModule):
+ """BiSeNetV1 backbone.
+
+ This backbone is the implementation of `BiSeNet: Bilateral
+ Segmentation Network for Real-time Semantic
+ Segmentation `_.
+
+ Args:
+ backbone_cfg:(dict): Config of backbone of
+ Context Path.
+ in_channels (int): The number of channels of input
+ image. Default: 3.
+ spatial_channels (Tuple[int]): Size of channel numbers of
+ various layers in Spatial Path.
+ Default: (64, 64, 64, 128).
+ context_channels (Tuple[int]): Size of channel numbers of
+ various modules in Context Path.
+ Default: (128, 256, 512).
+ out_indices (Tuple[int] | int, optional): Output from which stages.
+ Default: (0, 1, 2).
+ align_corners (bool, optional): The align_corners argument of
+ resize operation in Bilateral Guided Aggregation Layer.
+ Default: False.
+ out_channels(int): The number of channels of output.
+ It must be the same with `in_channels` of decode_head.
+ Default: 256.
+ """
+
+ def __init__(self,
+ backbone_cfg,
+ in_channels=3,
+ spatial_channels=(64, 64, 64, 128),
+ context_channels=(128, 256, 512),
+ out_indices=(0, 1, 2),
+ align_corners=False,
+ out_channels=256,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+
+ super(BiSeNetV1, self).__init__(init_cfg=init_cfg)
+ assert len(spatial_channels) == 4, 'Length of input channels \
+ of Spatial Path must be 4!'
+
+ assert len(context_channels) == 3, 'Length of input channels \
+ of Context Path must be 3!'
+
+ self.out_indices = out_indices
+ self.align_corners = align_corners
+ self.context_path = ContextPath(backbone_cfg, context_channels,
+ self.align_corners)
+ self.spatial_path = SpatialPath(in_channels, spatial_channels)
+ self.ffm = FeatureFusionModule(context_channels[1], out_channels)
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ def forward(self, x):
+ # stole refactoring code from Coin Cheung, thanks
+ x_context8, x_context16 = self.context_path(x)
+ x_spatial = self.spatial_path(x)
+ x_fuse = self.ffm(x_spatial, x_context8)
+
+ outs = [x_fuse, x_context8, x_context16]
+ outs = [outs[i] for i in self.out_indices]
+ return tuple(outs)
diff --git a/mmseg/models/backbones/bisenetv2.py b/mmseg/models/backbones/bisenetv2.py
new file mode 100644
index 0000000..d908b32
--- /dev/null
+++ b/mmseg/models/backbones/bisenetv2.py
@@ -0,0 +1,622 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import (ConvModule, DepthwiseSeparableConvModule,
+ build_activation_layer, build_norm_layer)
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import BACKBONES
+
+
+class DetailBranch(BaseModule):
+ """Detail Branch with wide channels and shallow layers to capture low-level
+ details and generate high-resolution feature representation.
+
+ Args:
+ detail_channels (Tuple[int]): Size of channel numbers of each stage
+ in Detail Branch, in paper it has 3 stages.
+ Default: (64, 64, 128).
+ in_channels (int): Number of channels of input image. Default: 3.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ x (torch.Tensor): Feature map of Detail Branch.
+ """
+
+ def __init__(self,
+ detail_channels=(64, 64, 128),
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(DetailBranch, self).__init__(init_cfg=init_cfg)
+ detail_branch = []
+ for i in range(len(detail_channels)):
+ if i == 0:
+ detail_branch.append(
+ nn.Sequential(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ in_channels=detail_channels[i],
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)))
+ else:
+ detail_branch.append(
+ nn.Sequential(
+ ConvModule(
+ in_channels=detail_channels[i - 1],
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ in_channels=detail_channels[i],
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ in_channels=detail_channels[i],
+ out_channels=detail_channels[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)))
+ self.detail_branch = nn.ModuleList(detail_branch)
+
+ def forward(self, x):
+ for stage in self.detail_branch:
+ x = stage(x)
+ return x
+
+
+class StemBlock(BaseModule):
+ """Stem Block at the beginning of Semantic Branch.
+
+ Args:
+ in_channels (int): Number of input channels.
+ Default: 3.
+ out_channels (int): Number of output channels.
+ Default: 16.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ x (torch.Tensor): First feature map in Semantic Branch.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ out_channels=16,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(StemBlock, self).__init__(init_cfg=init_cfg)
+
+ self.conv_first = ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.convs = nn.Sequential(
+ ConvModule(
+ in_channels=out_channels,
+ out_channels=out_channels // 2,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ in_channels=out_channels // 2,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.pool = nn.MaxPool2d(
+ kernel_size=3, stride=2, padding=1, ceil_mode=False)
+ self.fuse_last = ConvModule(
+ in_channels=out_channels * 2,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ x = self.conv_first(x)
+ x_left = self.convs(x)
+ x_right = self.pool(x)
+ x = self.fuse_last(torch.cat([x_left, x_right], dim=1))
+ return x
+
+
+class GELayer(BaseModule):
+ """Gather-and-Expansion Layer.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ exp_ratio (int): Expansion ratio for middle channels.
+ Default: 6.
+ stride (int): Stride of GELayer. Default: 1
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ x (torch.Tensor): Intermediate feature map in
+ Semantic Branch.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ exp_ratio=6,
+ stride=1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(GELayer, self).__init__(init_cfg=init_cfg)
+ mid_channel = in_channels * exp_ratio
+ self.conv1 = ConvModule(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ if stride == 1:
+ self.dwconv = nn.Sequential(
+ # ReLU in ConvModule not shown in paper
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=mid_channel,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=in_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.shortcut = None
+ else:
+ self.dwconv = nn.Sequential(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=mid_channel,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=in_channels,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ # ReLU in ConvModule not shown in paper
+ ConvModule(
+ in_channels=mid_channel,
+ out_channels=mid_channel,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ groups=mid_channel,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ )
+ self.shortcut = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ dw_norm_cfg=norm_cfg,
+ dw_act_cfg=None,
+ pw_norm_cfg=norm_cfg,
+ pw_act_cfg=None,
+ ))
+
+ self.conv2 = nn.Sequential(
+ ConvModule(
+ in_channels=mid_channel,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None,
+ ))
+
+ self.act = build_activation_layer(act_cfg)
+
+ def forward(self, x):
+ identity = x
+ x = self.conv1(x)
+ x = self.dwconv(x)
+ x = self.conv2(x)
+ if self.shortcut is not None:
+ shortcut = self.shortcut(identity)
+ x = x + shortcut
+ else:
+ x = x + identity
+ x = self.act(x)
+ return x
+
+
+class CEBlock(BaseModule):
+ """Context Embedding Block for large receptive filed in Semantic Branch.
+
+ Args:
+ in_channels (int): Number of input channels.
+ Default: 3.
+ out_channels (int): Number of output channels.
+ Default: 16.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ x (torch.Tensor): Last feature map in Semantic Branch.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ out_channels=16,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(CEBlock, self).__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.gap = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ build_norm_layer(norm_cfg, self.in_channels)[1])
+ self.conv_gap = ConvModule(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ # Note: in paper here is naive conv2d, no bn-relu
+ self.conv_last = ConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ identity = x
+ x = self.gap(x)
+ x = self.conv_gap(x)
+ x = identity + x
+ x = self.conv_last(x)
+ return x
+
+
+class SemanticBranch(BaseModule):
+ """Semantic Branch which is lightweight with narrow channels and deep
+ layers to obtain high-level semantic context.
+
+ Args:
+ semantic_channels(Tuple[int]): Size of channel numbers of
+ various stages in Semantic Branch.
+ Default: (16, 32, 64, 128).
+ in_channels (int): Number of channels of input image. Default: 3.
+ exp_ratio (int): Expansion ratio for middle channels.
+ Default: 6.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ semantic_outs (List[torch.Tensor]): List of several feature maps
+ for auxiliary heads (Booster) and Bilateral
+ Guided Aggregation Layer.
+ """
+
+ def __init__(self,
+ semantic_channels=(16, 32, 64, 128),
+ in_channels=3,
+ exp_ratio=6,
+ init_cfg=None):
+ super(SemanticBranch, self).__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.semantic_channels = semantic_channels
+ self.semantic_stages = []
+ for i in range(len(semantic_channels)):
+ stage_name = f'stage{i + 1}'
+ self.semantic_stages.append(stage_name)
+ if i == 0:
+ self.add_module(
+ stage_name,
+ StemBlock(self.in_channels, semantic_channels[i]))
+ elif i == (len(semantic_channels) - 1):
+ self.add_module(
+ stage_name,
+ nn.Sequential(
+ GELayer(semantic_channels[i - 1], semantic_channels[i],
+ exp_ratio, 2),
+ GELayer(semantic_channels[i], semantic_channels[i],
+ exp_ratio, 1),
+ GELayer(semantic_channels[i], semantic_channels[i],
+ exp_ratio, 1),
+ GELayer(semantic_channels[i], semantic_channels[i],
+ exp_ratio, 1)))
+ else:
+ self.add_module(
+ stage_name,
+ nn.Sequential(
+ GELayer(semantic_channels[i - 1], semantic_channels[i],
+ exp_ratio, 2),
+ GELayer(semantic_channels[i], semantic_channels[i],
+ exp_ratio, 1)))
+
+ self.add_module(f'stage{len(semantic_channels)}_CEBlock',
+ CEBlock(semantic_channels[-1], semantic_channels[-1]))
+ self.semantic_stages.append(f'stage{len(semantic_channels)}_CEBlock')
+
+ def forward(self, x):
+ semantic_outs = []
+ for stage_name in self.semantic_stages:
+ semantic_stage = getattr(self, stage_name)
+ x = semantic_stage(x)
+ semantic_outs.append(x)
+ return semantic_outs
+
+
+class BGALayer(BaseModule):
+ """Bilateral Guided Aggregation Layer to fuse the complementary information
+ from both Detail Branch and Semantic Branch.
+
+ Args:
+ out_channels (int): Number of output channels.
+ Default: 128.
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Returns:
+ output (torch.Tensor): Output feature map for Segment heads.
+ """
+
+ def __init__(self,
+ out_channels=128,
+ align_corners=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(BGALayer, self).__init__(init_cfg=init_cfg)
+ self.out_channels = out_channels
+ self.align_corners = align_corners
+ self.detail_dwconv = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ dw_norm_cfg=norm_cfg,
+ dw_act_cfg=None,
+ pw_norm_cfg=None,
+ pw_act_cfg=None,
+ ))
+ self.detail_down = nn.Sequential(
+ ConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ nn.AvgPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False))
+ self.semantic_conv = nn.Sequential(
+ ConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None))
+ self.semantic_dwconv = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ dw_norm_cfg=norm_cfg,
+ dw_act_cfg=None,
+ pw_norm_cfg=None,
+ pw_act_cfg=None,
+ ))
+ self.conv = ConvModule(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ inplace=True,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ )
+
+ def forward(self, x_d, x_s):
+ detail_dwconv = self.detail_dwconv(x_d)
+ detail_down = self.detail_down(x_d)
+ semantic_conv = self.semantic_conv(x_s)
+ semantic_dwconv = self.semantic_dwconv(x_s)
+ semantic_conv = resize(
+ input=semantic_conv,
+ size=detail_dwconv.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ fuse_1 = detail_dwconv * torch.sigmoid(semantic_conv)
+ fuse_2 = detail_down * torch.sigmoid(semantic_dwconv)
+ fuse_2 = resize(
+ input=fuse_2,
+ size=fuse_1.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ output = self.conv(fuse_1 + fuse_2)
+ return output
+
+
+@BACKBONES.register_module()
+class BiSeNetV2(BaseModule):
+ """BiSeNetV2: Bilateral Network with Guided Aggregation for
+ Real-time Semantic Segmentation.
+
+ This backbone is the implementation of
+ `BiSeNetV2 `_.
+
+ Args:
+ in_channels (int): Number of channel of input image. Default: 3.
+ detail_channels (Tuple[int], optional): Channels of each stage
+ in Detail Branch. Default: (64, 64, 128).
+ semantic_channels (Tuple[int], optional): Channels of each stage
+ in Semantic Branch. Default: (16, 32, 64, 128).
+ See Table 1 and Figure 3 of paper for more details.
+ semantic_expansion_ratio (int, optional): The expansion factor
+ expanding channel number of middle channels in Semantic Branch.
+ Default: 6.
+ bga_channels (int, optional): Number of middle channels in
+ Bilateral Guided Aggregation Layer. Default: 128.
+ out_indices (Tuple[int] | int, optional): Output from which stages.
+ Default: (0, 1, 2, 3, 4).
+ align_corners (bool, optional): The align_corners argument of
+ resize operation in Bilateral Guided Aggregation Layer.
+ Default: False.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ detail_channels=(64, 64, 128),
+ semantic_channels=(16, 32, 64, 128),
+ semantic_expansion_ratio=6,
+ bga_channels=128,
+ out_indices=(0, 1, 2, 3, 4),
+ align_corners=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ if init_cfg is None:
+ init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ super(BiSeNetV2, self).__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_indices = out_indices
+ self.detail_channels = detail_channels
+ self.semantic_channels = semantic_channels
+ self.semantic_expansion_ratio = semantic_expansion_ratio
+ self.bga_channels = bga_channels
+ self.align_corners = align_corners
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.detail = DetailBranch(self.detail_channels, self.in_channels)
+ self.semantic = SemanticBranch(self.semantic_channels,
+ self.in_channels,
+ self.semantic_expansion_ratio)
+ self.bga = BGALayer(self.bga_channels, self.align_corners)
+
+ def forward(self, x):
+ # stole refactoring code from Coin Cheung, thanks
+ x_detail = self.detail(x)
+ x_semantic_lst = self.semantic(x)
+ x_head = self.bga(x_detail, x_semantic_lst[-1])
+ outs = [x_head] + x_semantic_lst[:-1]
+ outs = [outs[i] for i in self.out_indices]
+ return tuple(outs)
diff --git a/mmseg/models/backbones/cgnet.py b/mmseg/models/backbones/cgnet.py
new file mode 100644
index 0000000..168194c
--- /dev/null
+++ b/mmseg/models/backbones/cgnet.py
@@ -0,0 +1,372 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule, build_conv_layer, build_norm_layer
+from mmcv.runner import BaseModule
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from ..builder import BACKBONES
+
+
+class GlobalContextExtractor(nn.Module):
+ """Global Context Extractor for CGNet.
+
+ This class is employed to refine the joint feature of both local feature
+ and surrounding context.
+
+ Args:
+ channel (int): Number of input feature channels.
+ reduction (int): Reductions for global context extractor. Default: 16.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ """
+
+ def __init__(self, channel, reduction=16, with_cp=False):
+ super(GlobalContextExtractor, self).__init__()
+ self.channel = channel
+ self.reduction = reduction
+ assert reduction >= 1 and channel >= reduction
+ self.with_cp = with_cp
+ self.avg_pool = nn.AdaptiveAvgPool2d(1)
+ self.fc = nn.Sequential(
+ nn.Linear(channel, channel // reduction), nn.ReLU(inplace=True),
+ nn.Linear(channel // reduction, channel), nn.Sigmoid())
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ num_batch, num_channel = x.size()[:2]
+ y = self.avg_pool(x).view(num_batch, num_channel)
+ y = self.fc(y).view(num_batch, num_channel, 1, 1)
+ return x * y
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class ContextGuidedBlock(nn.Module):
+ """Context Guided Block for CGNet.
+
+ This class consists of four components: local feature extractor,
+ surrounding feature extractor, joint feature extractor and global
+ context extractor.
+
+ Args:
+ in_channels (int): Number of input feature channels.
+ out_channels (int): Number of output feature channels.
+ dilation (int): Dilation rate for surrounding context extractor.
+ Default: 2.
+ reduction (int): Reduction for global context extractor. Default: 16.
+ skip_connect (bool): Add input to output or not. Default: True.
+ downsample (bool): Downsample the input to 1/2 or not. Default: False.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN', requires_grad=True).
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='PReLU').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ dilation=2,
+ reduction=16,
+ skip_connect=True,
+ downsample=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='PReLU'),
+ with_cp=False):
+ super(ContextGuidedBlock, self).__init__()
+ self.with_cp = with_cp
+ self.downsample = downsample
+
+ channels = out_channels if downsample else out_channels // 2
+ if 'type' in act_cfg and act_cfg['type'] == 'PReLU':
+ act_cfg['num_parameters'] = channels
+ kernel_size = 3 if downsample else 1
+ stride = 2 if downsample else 1
+ padding = (kernel_size - 1) // 2
+
+ self.conv1x1 = ConvModule(
+ in_channels,
+ channels,
+ kernel_size,
+ stride,
+ padding,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.f_loc = build_conv_layer(
+ conv_cfg,
+ channels,
+ channels,
+ kernel_size=3,
+ padding=1,
+ groups=channels,
+ bias=False)
+ self.f_sur = build_conv_layer(
+ conv_cfg,
+ channels,
+ channels,
+ kernel_size=3,
+ padding=dilation,
+ groups=channels,
+ dilation=dilation,
+ bias=False)
+
+ self.bn = build_norm_layer(norm_cfg, 2 * channels)[1]
+ self.activate = nn.PReLU(2 * channels)
+
+ if downsample:
+ self.bottleneck = build_conv_layer(
+ conv_cfg,
+ 2 * channels,
+ out_channels,
+ kernel_size=1,
+ bias=False)
+
+ self.skip_connect = skip_connect and not downsample
+ self.f_glo = GlobalContextExtractor(out_channels, reduction, with_cp)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ out = self.conv1x1(x)
+ loc = self.f_loc(out)
+ sur = self.f_sur(out)
+
+ joi_feat = torch.cat([loc, sur], 1) # the joint feature
+ joi_feat = self.bn(joi_feat)
+ joi_feat = self.activate(joi_feat)
+ if self.downsample:
+ joi_feat = self.bottleneck(joi_feat) # channel = out_channels
+ # f_glo is employed to refine the joint feature
+ out = self.f_glo(joi_feat)
+
+ if self.skip_connect:
+ return x + out
+ else:
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class InputInjection(nn.Module):
+ """Downsampling module for CGNet."""
+
+ def __init__(self, num_downsampling):
+ super(InputInjection, self).__init__()
+ self.pool = nn.ModuleList()
+ for i in range(num_downsampling):
+ self.pool.append(nn.AvgPool2d(3, stride=2, padding=1))
+
+ def forward(self, x):
+ for pool in self.pool:
+ x = pool(x)
+ return x
+
+
+@BACKBONES.register_module()
+class CGNet(BaseModule):
+ """CGNet backbone.
+
+ This backbone is the implementation of `A Light-weight Context Guided
+ Network for Semantic Segmentation `_.
+
+ Args:
+ in_channels (int): Number of input image channels. Normally 3.
+ num_channels (tuple[int]): Numbers of feature channels at each stages.
+ Default: (32, 64, 128).
+ num_blocks (tuple[int]): Numbers of CG blocks at stage 1 and stage 2.
+ Default: (3, 21).
+ dilations (tuple[int]): Dilation rate for surrounding context
+ extractors at stage 1 and stage 2. Default: (2, 4).
+ reductions (tuple[int]): Reductions for global context extractors at
+ stage 1 and stage 2. Default: (8, 16).
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN', requires_grad=True).
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='PReLU').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels=3,
+ num_channels=(32, 64, 128),
+ num_blocks=(3, 21),
+ dilations=(2, 4),
+ reductions=(8, 16),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='PReLU'),
+ norm_eval=False,
+ with_cp=False,
+ pretrained=None,
+ init_cfg=None):
+
+ super(CGNet, self).__init__(init_cfg)
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer=['Conv2d', 'Linear']),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm']),
+ dict(type='Constant', val=0, layer='PReLU')
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.in_channels = in_channels
+ self.num_channels = num_channels
+ assert isinstance(self.num_channels, tuple) and len(
+ self.num_channels) == 3
+ self.num_blocks = num_blocks
+ assert isinstance(self.num_blocks, tuple) and len(self.num_blocks) == 2
+ self.dilations = dilations
+ assert isinstance(self.dilations, tuple) and len(self.dilations) == 2
+ self.reductions = reductions
+ assert isinstance(self.reductions, tuple) and len(self.reductions) == 2
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ if 'type' in self.act_cfg and self.act_cfg['type'] == 'PReLU':
+ self.act_cfg['num_parameters'] = num_channels[0]
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ cur_channels = in_channels
+ self.stem = nn.ModuleList()
+ for i in range(3):
+ self.stem.append(
+ ConvModule(
+ cur_channels,
+ num_channels[0],
+ 3,
+ 2 if i == 0 else 1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ cur_channels = num_channels[0]
+
+ self.inject_2x = InputInjection(1) # down-sample for Input, factor=2
+ self.inject_4x = InputInjection(2) # down-sample for Input, factor=4
+
+ cur_channels += in_channels
+ self.norm_prelu_0 = nn.Sequential(
+ build_norm_layer(norm_cfg, cur_channels)[1],
+ nn.PReLU(cur_channels))
+
+ # stage 1
+ self.level1 = nn.ModuleList()
+ for i in range(num_blocks[0]):
+ self.level1.append(
+ ContextGuidedBlock(
+ cur_channels if i == 0 else num_channels[1],
+ num_channels[1],
+ dilations[0],
+ reductions[0],
+ downsample=(i == 0),
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ with_cp=with_cp)) # CG block
+
+ cur_channels = 2 * num_channels[1] + in_channels
+ self.norm_prelu_1 = nn.Sequential(
+ build_norm_layer(norm_cfg, cur_channels)[1],
+ nn.PReLU(cur_channels))
+
+ # stage 2
+ self.level2 = nn.ModuleList()
+ for i in range(num_blocks[1]):
+ self.level2.append(
+ ContextGuidedBlock(
+ cur_channels if i == 0 else num_channels[2],
+ num_channels[2],
+ dilations[1],
+ reductions[1],
+ downsample=(i == 0),
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ with_cp=with_cp)) # CG block
+
+ cur_channels = 2 * num_channels[2]
+ self.norm_prelu_2 = nn.Sequential(
+ build_norm_layer(norm_cfg, cur_channels)[1],
+ nn.PReLU(cur_channels))
+
+ def forward(self, x):
+ output = []
+
+ # stage 0
+ inp_2x = self.inject_2x(x)
+ inp_4x = self.inject_4x(x)
+ for layer in self.stem:
+ x = layer(x)
+ x = self.norm_prelu_0(torch.cat([x, inp_2x], 1))
+ output.append(x)
+
+ # stage 1
+ for i, layer in enumerate(self.level1):
+ x = layer(x)
+ if i == 0:
+ down1 = x
+ x = self.norm_prelu_1(torch.cat([x, down1, inp_4x], 1))
+ output.append(x)
+
+ # stage 2
+ for i, layer in enumerate(self.level2):
+ x = layer(x)
+ if i == 0:
+ down2 = x
+ x = self.norm_prelu_2(torch.cat([down2, x], 1))
+ output.append(x)
+
+ return output
+
+ def train(self, mode=True):
+ """Convert the model into training mode will keeping the normalization
+ layer freezed."""
+ super(CGNet, self).train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmseg/models/backbones/erfnet.py b/mmseg/models/backbones/erfnet.py
new file mode 100644
index 0000000..8921c18
--- /dev/null
+++ b/mmseg/models/backbones/erfnet.py
@@ -0,0 +1,329 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_activation_layer, build_conv_layer, build_norm_layer
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import BACKBONES
+
+
+class DownsamplerBlock(BaseModule):
+ """Downsampler block of ERFNet.
+
+ This module is a little different from basical ConvModule.
+ The features from Conv and MaxPool layers are
+ concatenated before BatchNorm.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', eps=1e-3),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(DownsamplerBlock, self).__init__(init_cfg=init_cfg)
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.conv = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels - in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1)
+ self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
+ self.bn = build_norm_layer(self.norm_cfg, out_channels)[1]
+ self.act = build_activation_layer(self.act_cfg)
+
+ def forward(self, input):
+ conv_out = self.conv(input)
+ pool_out = self.pool(input)
+ pool_out = resize(
+ input=pool_out,
+ size=conv_out.size()[2:],
+ mode='bilinear',
+ align_corners=False)
+ output = torch.cat([conv_out, pool_out], 1)
+ output = self.bn(output)
+ output = self.act(output)
+ return output
+
+
+class NonBottleneck1d(BaseModule):
+ """Non-bottleneck block of ERFNet.
+
+ Args:
+ channels (int): Number of channels in Non-bottleneck block.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.
+ dilation (int): Dilation rate for last two conv layers.
+ Default 1.
+ num_conv_layer (int): Number of 3x1 and 1x3 convolution layers.
+ Default 2.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ channels,
+ drop_rate=0,
+ dilation=1,
+ num_conv_layer=2,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', eps=1e-3),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(NonBottleneck1d, self).__init__(init_cfg=init_cfg)
+
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.act = build_activation_layer(self.act_cfg)
+
+ self.convs_layers = nn.ModuleList()
+ for conv_layer in range(num_conv_layer):
+ first_conv_padding = (1, 0) if conv_layer == 0 else (dilation, 0)
+ first_conv_dilation = 1 if conv_layer == 0 else (dilation, 1)
+ second_conv_padding = (0, 1) if conv_layer == 0 else (0, dilation)
+ second_conv_dilation = 1 if conv_layer == 0 else (1, dilation)
+
+ self.convs_layers.append(
+ build_conv_layer(
+ self.conv_cfg,
+ channels,
+ channels,
+ kernel_size=(3, 1),
+ stride=1,
+ padding=first_conv_padding,
+ bias=True,
+ dilation=first_conv_dilation))
+ self.convs_layers.append(self.act)
+ self.convs_layers.append(
+ build_conv_layer(
+ self.conv_cfg,
+ channels,
+ channels,
+ kernel_size=(1, 3),
+ stride=1,
+ padding=second_conv_padding,
+ bias=True,
+ dilation=second_conv_dilation))
+ self.convs_layers.append(
+ build_norm_layer(self.norm_cfg, channels)[1])
+ if conv_layer == 0:
+ self.convs_layers.append(self.act)
+ else:
+ self.convs_layers.append(nn.Dropout(p=drop_rate))
+
+ def forward(self, input):
+ output = input
+ for conv in self.convs_layers:
+ output = conv(output)
+ output = self.act(output + input)
+ return output
+
+
+class UpsamplerBlock(BaseModule):
+ """Upsampler block of ERFNet.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', eps=1e-3),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(UpsamplerBlock, self).__init__(init_cfg=init_cfg)
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.conv = nn.ConvTranspose2d(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ output_padding=1,
+ bias=True)
+ self.bn = build_norm_layer(self.norm_cfg, out_channels)[1]
+ self.act = build_activation_layer(self.act_cfg)
+
+ def forward(self, input):
+ output = self.conv(input)
+ output = self.bn(output)
+ output = self.act(output)
+ return output
+
+
+@BACKBONES.register_module()
+class ERFNet(BaseModule):
+ """ERFNet backbone.
+
+ This backbone is the implementation of `ERFNet: Efficient Residual
+ Factorized ConvNet for Real-time SemanticSegmentation
+ `_.
+
+ Args:
+ in_channels (int): The number of channels of input
+ image. Default: 3.
+ enc_downsample_channels (Tuple[int]): Size of channel
+ numbers of various Downsampler block in encoder.
+ Default: (16, 64, 128).
+ enc_stage_non_bottlenecks (Tuple[int]): Number of stages of
+ Non-bottleneck block in encoder.
+ Default: (5, 8).
+ enc_non_bottleneck_dilations (Tuple[int]): Dilation rate of each
+ stage of Non-bottleneck block of encoder.
+ Default: (2, 4, 8, 16).
+ enc_non_bottleneck_channels (Tuple[int]): Size of channel
+ numbers of various Non-bottleneck block in encoder.
+ Default: (64, 128).
+ dec_upsample_channels (Tuple[int]): Size of channel numbers of
+ various Deconvolution block in decoder.
+ Default: (64, 16).
+ dec_stages_non_bottleneck (Tuple[int]): Number of stages of
+ Non-bottleneck block in decoder.
+ Default: (2, 2).
+ dec_non_bottleneck_channels (Tuple[int]): Size of channel
+ numbers of various Non-bottleneck block in decoder.
+ Default: (64, 16).
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.1.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+
+ super(ERFNet, self).__init__(init_cfg=init_cfg)
+ assert len(enc_downsample_channels) \
+ == len(dec_upsample_channels)+1, 'Number of downsample\
+ block of encoder does not \
+ match number of upsample block of decoder!'
+ assert len(enc_downsample_channels) \
+ == len(enc_stage_non_bottlenecks)+1, 'Number of \
+ downsample block of encoder does not match \
+ number of Non-bottleneck block of encoder!'
+ assert len(enc_downsample_channels) \
+ == len(enc_non_bottleneck_channels)+1, 'Number of \
+ downsample block of encoder does not match \
+ number of channels of Non-bottleneck block of encoder!'
+ assert enc_stage_non_bottlenecks[-1] \
+ % len(enc_non_bottleneck_dilations) == 0, 'Number of \
+ Non-bottleneck block of encoder does not match \
+ number of Non-bottleneck block of encoder!'
+ assert len(dec_upsample_channels) \
+ == len(dec_stages_non_bottleneck), 'Number of \
+ upsample block of decoder does not match \
+ number of Non-bottleneck block of decoder!'
+ assert len(dec_stages_non_bottleneck) \
+ == len(dec_non_bottleneck_channels), 'Number of \
+ Non-bottleneck block of decoder does not match \
+ number of channels of Non-bottleneck block of decoder!'
+
+ self.in_channels = in_channels
+ self.enc_downsample_channels = enc_downsample_channels
+ self.enc_stage_non_bottlenecks = enc_stage_non_bottlenecks
+ self.enc_non_bottleneck_dilations = enc_non_bottleneck_dilations
+ self.enc_non_bottleneck_channels = enc_non_bottleneck_channels
+ self.dec_upsample_channels = dec_upsample_channels
+ self.dec_stages_non_bottleneck = dec_stages_non_bottleneck
+ self.dec_non_bottleneck_channels = dec_non_bottleneck_channels
+ self.dropout_ratio = dropout_ratio
+
+ self.encoder = nn.ModuleList()
+ self.decoder = nn.ModuleList()
+
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.encoder.append(
+ DownsamplerBlock(self.in_channels, enc_downsample_channels[0]))
+
+ for i in range(len(enc_downsample_channels) - 1):
+ self.encoder.append(
+ DownsamplerBlock(enc_downsample_channels[i],
+ enc_downsample_channels[i + 1]))
+ # Last part of encoder is some dilated NonBottleneck1d blocks.
+ if i == len(enc_downsample_channels) - 2:
+ iteration_times = int(enc_stage_non_bottlenecks[-1] /
+ len(enc_non_bottleneck_dilations))
+ for j in range(iteration_times):
+ for k in range(len(enc_non_bottleneck_dilations)):
+ self.encoder.append(
+ NonBottleneck1d(enc_downsample_channels[-1],
+ self.dropout_ratio,
+ enc_non_bottleneck_dilations[k]))
+ else:
+ for j in range(enc_stage_non_bottlenecks[i]):
+ self.encoder.append(
+ NonBottleneck1d(enc_downsample_channels[i + 1],
+ self.dropout_ratio))
+
+ for i in range(len(dec_upsample_channels)):
+ if i == 0:
+ self.decoder.append(
+ UpsamplerBlock(enc_downsample_channels[-1],
+ dec_non_bottleneck_channels[i]))
+ else:
+ self.decoder.append(
+ UpsamplerBlock(dec_non_bottleneck_channels[i - 1],
+ dec_non_bottleneck_channels[i]))
+ for j in range(dec_stages_non_bottleneck[i]):
+ self.decoder.append(
+ NonBottleneck1d(dec_non_bottleneck_channels[i]))
+
+ def forward(self, x):
+ for enc in self.encoder:
+ x = enc(x)
+ for dec in self.decoder:
+ x = dec(x)
+ return [x]
diff --git a/mmseg/models/backbones/fast_scnn.py b/mmseg/models/backbones/fast_scnn.py
new file mode 100644
index 0000000..cbfbcaf
--- /dev/null
+++ b/mmseg/models/backbones/fast_scnn.py
@@ -0,0 +1,409 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.models.decode_heads.psp_head import PPM
+from mmseg.ops import resize
+from ..builder import BACKBONES
+from ..utils import InvertedResidual
+
+
+class LearningToDownsample(nn.Module):
+ """Learning to downsample module.
+
+ Args:
+ in_channels (int): Number of input channels.
+ dw_channels (tuple[int]): Number of output channels of the first and
+ the second depthwise conv (dwconv) layers.
+ out_channels (int): Number of output channels of the whole
+ 'learning to downsample' module.
+ conv_cfg (dict | None): Config of conv layers. Default: None
+ norm_cfg (dict | None): Config of norm layers. Default:
+ dict(type='BN')
+ act_cfg (dict): Config of activation layers. Default:
+ dict(type='ReLU')
+ dw_act_cfg (dict): In DepthwiseSeparableConvModule, activation config
+ of depthwise ConvModule. If it is 'default', it will be the same
+ as `act_cfg`. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ dw_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ dw_act_cfg=None):
+ super(LearningToDownsample, self).__init__()
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.dw_act_cfg = dw_act_cfg
+ dw_channels1 = dw_channels[0]
+ dw_channels2 = dw_channels[1]
+
+ self.conv = ConvModule(
+ in_channels,
+ dw_channels1,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.dsconv1 = DepthwiseSeparableConvModule(
+ dw_channels1,
+ dw_channels2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=self.dw_act_cfg)
+
+ self.dsconv2 = DepthwiseSeparableConvModule(
+ dw_channels2,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=self.dw_act_cfg)
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.dsconv1(x)
+ x = self.dsconv2(x)
+ return x
+
+
+class GlobalFeatureExtractor(nn.Module):
+ """Global feature extractor module.
+
+ Args:
+ in_channels (int): Number of input channels of the GFE module.
+ Default: 64
+ block_channels (tuple[int]): Tuple of ints. Each int specifies the
+ number of output channels of each Inverted Residual module.
+ Default: (64, 96, 128)
+ out_channels(int): Number of output channels of the GFE module.
+ Default: 128
+ expand_ratio (int): Adjusts number of channels of the hidden layer
+ in InvertedResidual by this amount.
+ Default: 6
+ num_blocks (tuple[int]): Tuple of ints. Each int specifies the
+ number of times each Inverted Residual module is repeated.
+ The repeated Inverted Residual modules are called a 'group'.
+ Default: (3, 3, 3)
+ strides (tuple[int]): Tuple of ints. Each int specifies
+ the downsampling factor of each 'group'.
+ Default: (2, 2, 1)
+ pool_scales (tuple[int]): Tuple of ints. Each int specifies
+ the parameter required in 'global average pooling' within PPM.
+ Default: (1, 2, 3, 6)
+ conv_cfg (dict | None): Config of conv layers. Default: None
+ norm_cfg (dict | None): Config of norm layers. Default:
+ dict(type='BN')
+ act_cfg (dict): Config of activation layers. Default:
+ dict(type='ReLU')
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False
+ """
+
+ def __init__(self,
+ in_channels=64,
+ block_channels=(64, 96, 128),
+ out_channels=128,
+ expand_ratio=6,
+ num_blocks=(3, 3, 3),
+ strides=(2, 2, 1),
+ pool_scales=(1, 2, 3, 6),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False):
+ super(GlobalFeatureExtractor, self).__init__()
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ assert len(block_channels) == len(num_blocks) == 3
+ self.bottleneck1 = self._make_layer(in_channels, block_channels[0],
+ num_blocks[0], strides[0],
+ expand_ratio)
+ self.bottleneck2 = self._make_layer(block_channels[0],
+ block_channels[1], num_blocks[1],
+ strides[1], expand_ratio)
+ self.bottleneck3 = self._make_layer(block_channels[1],
+ block_channels[2], num_blocks[2],
+ strides[2], expand_ratio)
+ self.ppm = PPM(
+ pool_scales,
+ block_channels[2],
+ block_channels[2] // 4,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=align_corners)
+
+ self.out = ConvModule(
+ block_channels[2] * 2,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def _make_layer(self,
+ in_channels,
+ out_channels,
+ blocks,
+ stride=1,
+ expand_ratio=6):
+ layers = [
+ InvertedResidual(
+ in_channels,
+ out_channels,
+ stride,
+ expand_ratio,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ ]
+ for i in range(1, blocks):
+ layers.append(
+ InvertedResidual(
+ out_channels,
+ out_channels,
+ 1,
+ expand_ratio,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ x = self.bottleneck1(x)
+ x = self.bottleneck2(x)
+ x = self.bottleneck3(x)
+ x = torch.cat([x, *self.ppm(x)], dim=1)
+ x = self.out(x)
+ return x
+
+
+class FeatureFusionModule(nn.Module):
+ """Feature fusion module.
+
+ Args:
+ higher_in_channels (int): Number of input channels of the
+ higher-resolution branch.
+ lower_in_channels (int): Number of input channels of the
+ lower-resolution branch.
+ out_channels (int): Number of output channels.
+ conv_cfg (dict | None): Config of conv layers. Default: None
+ norm_cfg (dict | None): Config of norm layers. Default:
+ dict(type='BN')
+ dwconv_act_cfg (dict): Config of activation layers in 3x3 conv.
+ Default: dict(type='ReLU').
+ conv_act_cfg (dict): Config of activation layers in the two 1x1 conv.
+ Default: None.
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ """
+
+ def __init__(self,
+ higher_in_channels,
+ lower_in_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dwconv_act_cfg=dict(type='ReLU'),
+ conv_act_cfg=None,
+ align_corners=False):
+ super(FeatureFusionModule, self).__init__()
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.dwconv_act_cfg = dwconv_act_cfg
+ self.conv_act_cfg = conv_act_cfg
+ self.align_corners = align_corners
+ self.dwconv = ConvModule(
+ lower_in_channels,
+ out_channels,
+ 3,
+ padding=1,
+ groups=out_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.dwconv_act_cfg)
+ self.conv_lower_res = ConvModule(
+ out_channels,
+ out_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.conv_act_cfg)
+
+ self.conv_higher_res = ConvModule(
+ higher_in_channels,
+ out_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.conv_act_cfg)
+
+ self.relu = nn.ReLU(True)
+
+ def forward(self, higher_res_feature, lower_res_feature):
+ lower_res_feature = resize(
+ lower_res_feature,
+ size=higher_res_feature.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ lower_res_feature = self.dwconv(lower_res_feature)
+ lower_res_feature = self.conv_lower_res(lower_res_feature)
+
+ higher_res_feature = self.conv_higher_res(higher_res_feature)
+ out = higher_res_feature + lower_res_feature
+ return self.relu(out)
+
+
+@BACKBONES.register_module()
+class FastSCNN(BaseModule):
+ """Fast-SCNN Backbone.
+
+ This backbone is the implementation of `Fast-SCNN: Fast Semantic
+ Segmentation Network `_.
+
+ Args:
+ in_channels (int): Number of input image channels. Default: 3.
+ downsample_dw_channels (tuple[int]): Number of output channels after
+ the first conv layer & the second conv layer in
+ Learning-To-Downsample (LTD) module.
+ Default: (32, 48).
+ global_in_channels (int): Number of input channels of
+ Global Feature Extractor(GFE).
+ Equal to number of output channels of LTD.
+ Default: 64.
+ global_block_channels (tuple[int]): Tuple of integers that describe
+ the output channels for each of the MobileNet-v2 bottleneck
+ residual blocks in GFE.
+ Default: (64, 96, 128).
+ global_block_strides (tuple[int]): Tuple of integers
+ that describe the strides (downsampling factors) for each of the
+ MobileNet-v2 bottleneck residual blocks in GFE.
+ Default: (2, 2, 1).
+ global_out_channels (int): Number of output channels of GFE.
+ Default: 128.
+ higher_in_channels (int): Number of input channels of the higher
+ resolution branch in FFM.
+ Equal to global_in_channels.
+ Default: 64.
+ lower_in_channels (int): Number of input channels of the lower
+ resolution branch in FFM.
+ Equal to global_out_channels.
+ Default: 128.
+ fusion_out_channels (int): Number of output channels of FFM.
+ Default: 128.
+ out_indices (tuple): Tuple of indices of list
+ [higher_res_features, lower_res_features, fusion_output].
+ Often set to (0,1,2) to enable aux. heads.
+ Default: (0, 1, 2).
+ conv_cfg (dict | None): Config of conv layers. Default: None
+ norm_cfg (dict | None): Config of norm layers. Default:
+ dict(type='BN')
+ act_cfg (dict): Config of activation layers. Default:
+ dict(type='ReLU')
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False
+ dw_act_cfg (dict): In DepthwiseSeparableConvModule, activation config
+ of depthwise ConvModule. If it is 'default', it will be the same
+ as `act_cfg`. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels=3,
+ downsample_dw_channels=(32, 48),
+ global_in_channels=64,
+ global_block_channels=(64, 96, 128),
+ global_block_strides=(2, 2, 1),
+ global_out_channels=128,
+ higher_in_channels=64,
+ lower_in_channels=128,
+ fusion_out_channels=128,
+ out_indices=(0, 1, 2),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ dw_act_cfg=None,
+ init_cfg=None):
+
+ super(FastSCNN, self).__init__(init_cfg)
+
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
+ ]
+
+ if global_in_channels != higher_in_channels:
+ raise AssertionError('Global Input Channels must be the same \
+ with Higher Input Channels!')
+ elif global_out_channels != lower_in_channels:
+ raise AssertionError('Global Output Channels must be the same \
+ with Lower Input Channels!')
+
+ self.in_channels = in_channels
+ self.downsample_dw_channels1 = downsample_dw_channels[0]
+ self.downsample_dw_channels2 = downsample_dw_channels[1]
+ self.global_in_channels = global_in_channels
+ self.global_block_channels = global_block_channels
+ self.global_block_strides = global_block_strides
+ self.global_out_channels = global_out_channels
+ self.higher_in_channels = higher_in_channels
+ self.lower_in_channels = lower_in_channels
+ self.fusion_out_channels = fusion_out_channels
+ self.out_indices = out_indices
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.align_corners = align_corners
+ self.learning_to_downsample = LearningToDownsample(
+ in_channels,
+ downsample_dw_channels,
+ global_in_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ dw_act_cfg=dw_act_cfg)
+ self.global_feature_extractor = GlobalFeatureExtractor(
+ global_in_channels,
+ global_block_channels,
+ global_out_channels,
+ strides=self.global_block_strides,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+ self.feature_fusion = FeatureFusionModule(
+ higher_in_channels,
+ lower_in_channels,
+ fusion_out_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ dwconv_act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+
+ def forward(self, x):
+ higher_res_features = self.learning_to_downsample(x)
+ lower_res_features = self.global_feature_extractor(higher_res_features)
+ fusion_output = self.feature_fusion(higher_res_features,
+ lower_res_features)
+
+ outs = [higher_res_features, lower_res_features, fusion_output]
+ outs = [outs[i] for i in self.out_indices]
+ return tuple(outs)
diff --git a/mmseg/models/backbones/hrnet.py b/mmseg/models/backbones/hrnet.py
new file mode 100644
index 0000000..90feadc
--- /dev/null
+++ b/mmseg/models/backbones/hrnet.py
@@ -0,0 +1,642 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmcv.runner import BaseModule, ModuleList, Sequential
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from mmseg.ops import Upsample, resize
+from ..builder import BACKBONES
+from .resnet import BasicBlock, Bottleneck
+
+
+class HRModule(BaseModule):
+ """High-Resolution Module for HRNet.
+
+ In this module, every branch has 4 BasicBlocks/Bottlenecks. Fusion/Exchange
+ is in this module.
+ """
+
+ def __init__(self,
+ num_branches,
+ blocks,
+ num_blocks,
+ in_channels,
+ num_channels,
+ multiscale_output=True,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ block_init_cfg=None,
+ init_cfg=None):
+ super(HRModule, self).__init__(init_cfg)
+ self.block_init_cfg = block_init_cfg
+ self._check_branches(num_branches, num_blocks, in_channels,
+ num_channels)
+
+ self.in_channels = in_channels
+ self.num_branches = num_branches
+
+ self.multiscale_output = multiscale_output
+ self.norm_cfg = norm_cfg
+ self.conv_cfg = conv_cfg
+ self.with_cp = with_cp
+ self.branches = self._make_branches(num_branches, blocks, num_blocks,
+ num_channels)
+ self.fuse_layers = self._make_fuse_layers()
+ self.relu = nn.ReLU(inplace=False)
+
+ def _check_branches(self, num_branches, num_blocks, in_channels,
+ num_channels):
+ """Check branches configuration."""
+ if num_branches != len(num_blocks):
+ error_msg = f'NUM_BRANCHES({num_branches}) <> NUM_BLOCKS(' \
+ f'{len(num_blocks)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(num_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) <> NUM_CHANNELS(' \
+ f'{len(num_channels)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(in_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) <> NUM_INCHANNELS(' \
+ f'{len(in_channels)})'
+ raise ValueError(error_msg)
+
+ def _make_one_branch(self,
+ branch_index,
+ block,
+ num_blocks,
+ num_channels,
+ stride=1):
+ """Build one branch."""
+ downsample = None
+ if stride != 1 or \
+ self.in_channels[branch_index] != \
+ num_channels[branch_index] * block.expansion:
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ self.in_channels[branch_index],
+ num_channels[branch_index] * block.expansion,
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(self.norm_cfg, num_channels[branch_index] *
+ block.expansion)[1])
+
+ layers = []
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index],
+ stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=self.block_init_cfg))
+ self.in_channels[branch_index] = \
+ num_channels[branch_index] * block.expansion
+ for i in range(1, num_blocks[branch_index]):
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index],
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=self.block_init_cfg))
+
+ return Sequential(*layers)
+
+ def _make_branches(self, num_branches, block, num_blocks, num_channels):
+ """Build multiple branch."""
+ branches = []
+
+ for i in range(num_branches):
+ branches.append(
+ self._make_one_branch(i, block, num_blocks, num_channels))
+
+ return ModuleList(branches)
+
+ def _make_fuse_layers(self):
+ """Build fuse layer."""
+ if self.num_branches == 1:
+ return None
+
+ num_branches = self.num_branches
+ in_channels = self.in_channels
+ fuse_layers = []
+ num_out_branches = num_branches if self.multiscale_output else 1
+ for i in range(num_out_branches):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels[i])[1],
+ # we set align_corners=False for HRNet
+ Upsample(
+ scale_factor=2**(j - i),
+ mode='bilinear',
+ align_corners=False)))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv_downsamples = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[i])[1]))
+ else:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ nn.ReLU(inplace=False)))
+ fuse_layer.append(nn.Sequential(*conv_downsamples))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def forward(self, x):
+ """Forward function."""
+ if self.num_branches == 1:
+ return [self.branches[0](x[0])]
+
+ for i in range(self.num_branches):
+ x[i] = self.branches[i](x[i])
+
+ x_fuse = []
+ for i in range(len(self.fuse_layers)):
+ y = 0
+ for j in range(self.num_branches):
+ if i == j:
+ y += x[j]
+ elif j > i:
+ y = y + resize(
+ self.fuse_layers[i][j](x[j]),
+ size=x[i].shape[2:],
+ mode='bilinear',
+ align_corners=False)
+ else:
+ y += self.fuse_layers[i][j](x[j])
+ x_fuse.append(self.relu(y))
+ return x_fuse
+
+
+@BACKBONES.register_module()
+class HRNet(BaseModule):
+ """HRNet backbone.
+
+ This backbone is the implementation of `High-Resolution Representations
+ for Labeling Pixels and Regions `_.
+
+ Args:
+ extra (dict): Detailed configuration for each stage of HRNet.
+ There must be 4 stages, the configuration for each stage must have
+ 5 keys:
+
+ - num_modules (int): The number of HRModule in this stage.
+ - num_branches (int): The number of branches in the HRModule.
+ - block (str): The type of convolution block.
+ - num_blocks (tuple): The number of blocks in each branch.
+ The length must be equal to num_branches.
+ - num_channels (tuple): The number of channels in each branch.
+ The length must be equal to num_branches.
+ in_channels (int): Number of input image channels. Normally 3.
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Use `BN` by default.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: False.
+ multiscale_output (bool): Whether to output multi-level features
+ produced by multiple branches. If False, only the first level
+ feature will be output. Default: True.
+ pretrained (str, optional): Model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Example:
+ >>> from mmseg.models import HRNet
+ >>> import torch
+ >>> extra = dict(
+ >>> stage1=dict(
+ >>> num_modules=1,
+ >>> num_branches=1,
+ >>> block='BOTTLENECK',
+ >>> num_blocks=(4, ),
+ >>> num_channels=(64, )),
+ >>> stage2=dict(
+ >>> num_modules=1,
+ >>> num_branches=2,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4),
+ >>> num_channels=(32, 64)),
+ >>> stage3=dict(
+ >>> num_modules=4,
+ >>> num_branches=3,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4),
+ >>> num_channels=(32, 64, 128)),
+ >>> stage4=dict(
+ >>> num_modules=3,
+ >>> num_branches=4,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4, 4),
+ >>> num_channels=(32, 64, 128, 256)))
+ >>> self = HRNet(extra, in_channels=1)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 1, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 32, 8, 8)
+ (1, 64, 4, 4)
+ (1, 128, 2, 2)
+ (1, 256, 1, 1)
+ """
+
+ blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
+
+ def __init__(self,
+ extra,
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=False,
+ with_cp=False,
+ frozen_stages=-1,
+ zero_init_residual=False,
+ multiscale_output=True,
+ pretrained=None,
+ init_cfg=None):
+ super(HRNet, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ self.zero_init_residual = zero_init_residual
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ # Assert configurations of 4 stages are in extra
+ assert 'stage1' in extra and 'stage2' in extra \
+ and 'stage3' in extra and 'stage4' in extra
+ # Assert whether the length of `num_blocks` and `num_channels` are
+ # equal to `num_branches`
+ for i in range(4):
+ cfg = extra[f'stage{i + 1}']
+ assert len(cfg['num_blocks']) == cfg['num_branches'] and \
+ len(cfg['num_channels']) == cfg['num_branches']
+
+ self.extra = extra
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.frozen_stages = frozen_stages
+
+ # stem net
+ self.norm1_name, norm1 = build_norm_layer(self.norm_cfg, 64, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(self.norm_cfg, 64, postfix=2)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ 64,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.relu = nn.ReLU(inplace=True)
+
+ # stage 1
+ self.stage1_cfg = self.extra['stage1']
+ num_channels = self.stage1_cfg['num_channels'][0]
+ block_type = self.stage1_cfg['block']
+ num_blocks = self.stage1_cfg['num_blocks'][0]
+
+ block = self.blocks_dict[block_type]
+ stage1_out_channels = num_channels * block.expansion
+ self.layer1 = self._make_layer(block, 64, num_channels, num_blocks)
+
+ # stage 2
+ self.stage2_cfg = self.extra['stage2']
+ num_channels = self.stage2_cfg['num_channels']
+ block_type = self.stage2_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [channel * block.expansion for channel in num_channels]
+ self.transition1 = self._make_transition_layer([stage1_out_channels],
+ num_channels)
+ self.stage2, pre_stage_channels = self._make_stage(
+ self.stage2_cfg, num_channels)
+
+ # stage 3
+ self.stage3_cfg = self.extra['stage3']
+ num_channels = self.stage3_cfg['num_channels']
+ block_type = self.stage3_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [channel * block.expansion for channel in num_channels]
+ self.transition2 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+ self.stage3, pre_stage_channels = self._make_stage(
+ self.stage3_cfg, num_channels)
+
+ # stage 4
+ self.stage4_cfg = self.extra['stage4']
+ num_channels = self.stage4_cfg['num_channels']
+ block_type = self.stage4_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [channel * block.expansion for channel in num_channels]
+ self.transition3 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+ self.stage4, pre_stage_channels = self._make_stage(
+ self.stage4_cfg, num_channels, multiscale_output=multiscale_output)
+
+ self._freeze_stages()
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: the normalization layer named "norm2" """
+ return getattr(self, self.norm2_name)
+
+ def _make_transition_layer(self, num_channels_pre_layer,
+ num_channels_cur_layer):
+ """Make transition layer."""
+ num_branches_cur = len(num_channels_cur_layer)
+ num_branches_pre = len(num_channels_pre_layer)
+
+ transition_layers = []
+ for i in range(num_branches_cur):
+ if i < num_branches_pre:
+ if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
+ transition_layers.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_cur_layer[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_cur_layer[i])[1],
+ nn.ReLU(inplace=True)))
+ else:
+ transition_layers.append(None)
+ else:
+ conv_downsamples = []
+ for j in range(i + 1 - num_branches_pre):
+ in_channels = num_channels_pre_layer[-1]
+ out_channels = num_channels_cur_layer[i] \
+ if j == i - num_branches_pre else in_channels
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1],
+ nn.ReLU(inplace=True)))
+ transition_layers.append(nn.Sequential(*conv_downsamples))
+
+ return nn.ModuleList(transition_layers)
+
+ def _make_layer(self, block, inplanes, planes, blocks, stride=1):
+ """Make each layer."""
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(self.norm_cfg, planes * block.expansion)[1])
+
+ layers = []
+ block_init_cfg = None
+ if self.pretrained is None and not hasattr(
+ self, 'init_cfg') and self.zero_init_residual:
+ if block is BasicBlock:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm2'))
+ elif block is Bottleneck:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm3'))
+
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=block_init_cfg))
+ inplanes = planes * block.expansion
+ for i in range(1, blocks):
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=block_init_cfg))
+
+ return Sequential(*layers)
+
+ def _make_stage(self, layer_config, in_channels, multiscale_output=True):
+ """Make each stage."""
+ num_modules = layer_config['num_modules']
+ num_branches = layer_config['num_branches']
+ num_blocks = layer_config['num_blocks']
+ num_channels = layer_config['num_channels']
+ block = self.blocks_dict[layer_config['block']]
+
+ hr_modules = []
+ block_init_cfg = None
+ if self.pretrained is None and not hasattr(
+ self, 'init_cfg') and self.zero_init_residual:
+ if block is BasicBlock:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm2'))
+ elif block is Bottleneck:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm3'))
+
+ for i in range(num_modules):
+ # multi_scale_output is only used for the last module
+ if not multiscale_output and i == num_modules - 1:
+ reset_multiscale_output = False
+ else:
+ reset_multiscale_output = True
+
+ hr_modules.append(
+ HRModule(
+ num_branches,
+ block,
+ num_blocks,
+ in_channels,
+ num_channels,
+ reset_multiscale_output,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ block_init_cfg=block_init_cfg))
+
+ return Sequential(*hr_modules), in_channels
+
+ def _freeze_stages(self):
+ """Freeze stages param and norm stats."""
+ if self.frozen_stages >= 0:
+
+ self.norm1.eval()
+ self.norm2.eval()
+ for m in [self.conv1, self.norm1, self.conv2, self.norm2]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ if i == 1:
+ m = getattr(self, f'layer{i}')
+ t = getattr(self, f'transition{i}')
+ elif i == 4:
+ m = getattr(self, f'stage{i}')
+ else:
+ m = getattr(self, f'stage{i}')
+ t = getattr(self, f'transition{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+ t.eval()
+ for param in t.parameters():
+ param.requires_grad = False
+
+ def forward(self, x):
+ """Forward function."""
+
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.conv2(x)
+ x = self.norm2(x)
+ x = self.relu(x)
+ x = self.layer1(x)
+
+ x_list = []
+ for i in range(self.stage2_cfg['num_branches']):
+ if self.transition1[i] is not None:
+ x_list.append(self.transition1[i](x))
+ else:
+ x_list.append(x)
+ y_list = self.stage2(x_list)
+
+ x_list = []
+ for i in range(self.stage3_cfg['num_branches']):
+ if self.transition2[i] is not None:
+ x_list.append(self.transition2[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage3(x_list)
+
+ x_list = []
+ for i in range(self.stage4_cfg['num_branches']):
+ if self.transition3[i] is not None:
+ x_list.append(self.transition3[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage4(x_list)
+
+ return y_list
+
+ def train(self, mode=True):
+ """Convert the model into training mode will keeping the normalization
+ layer freezed."""
+ super(HRNet, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmseg/models/backbones/icnet.py b/mmseg/models/backbones/icnet.py
new file mode 100644
index 0000000..10e5427
--- /dev/null
+++ b/mmseg/models/backbones/icnet.py
@@ -0,0 +1,165 @@
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import BACKBONES, build_backbone
+from ..decode_heads.psp_head import PPM
+
+
+@BACKBONES.register_module()
+class ICNet(BaseModule):
+ """ICNet for Real-Time Semantic Segmentation on High-Resolution Images.
+
+ This backbone is the implementation of
+ `ICNet `_.
+
+ Args:
+ backbone_cfg (dict): Config dict to build backbone. Usually it is
+ ResNet but it can also be other backbones.
+ in_channels (int): The number of input image channels. Default: 3.
+ layer_channels (Sequence[int]): The numbers of feature channels at
+ layer 2 and layer 4 in ResNet. It can also be other backbones.
+ Default: (512, 2048).
+ light_branch_middle_channels (int): The number of channels of the
+ middle layer in light branch. Default: 32.
+ psp_out_channels (int): The number of channels of the output of PSP
+ module. Default: 512.
+ out_channels (Sequence[int]): The numbers of output feature channels
+ at each branches. Default: (64, 256, 256).
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module. Default: (1, 2, 3, 6).
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Dictionary to construct and config act layer.
+ Default: dict(type='ReLU').
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ backbone_cfg,
+ in_channels=3,
+ layer_channels=(512, 2048),
+ light_branch_middle_channels=32,
+ psp_out_channels=512,
+ out_channels=(64, 256, 256),
+ pool_scales=(1, 2, 3, 6),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ init_cfg=None):
+ if backbone_cfg is None:
+ raise TypeError('backbone_cfg must be passed from config file!')
+ if init_cfg is None:
+ init_cfg = [
+ dict(type='Kaiming', mode='fan_out', layer='Conv2d'),
+ dict(type='Constant', val=1, layer='_BatchNorm'),
+ dict(type='Normal', mean=0.01, layer='Linear')
+ ]
+ super(ICNet, self).__init__(init_cfg=init_cfg)
+ self.align_corners = align_corners
+ self.backbone = build_backbone(backbone_cfg)
+
+ # Note: Default `ceil_mode` is false in nn.MaxPool2d, set
+ # `ceil_mode=True` to keep information in the corner of feature map.
+ self.backbone.maxpool = nn.MaxPool2d(
+ kernel_size=3, stride=2, padding=1, ceil_mode=True)
+
+ self.psp_modules = PPM(
+ pool_scales=pool_scales,
+ in_channels=layer_channels[1],
+ channels=psp_out_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ align_corners=align_corners)
+
+ self.psp_bottleneck = ConvModule(
+ layer_channels[1] + len(pool_scales) * psp_out_channels,
+ psp_out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.conv_sub1 = nn.Sequential(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=light_branch_middle_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg),
+ ConvModule(
+ in_channels=light_branch_middle_channels,
+ out_channels=light_branch_middle_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg),
+ ConvModule(
+ in_channels=light_branch_middle_channels,
+ out_channels=out_channels[0],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg))
+
+ self.conv_sub2 = ConvModule(
+ layer_channels[0],
+ out_channels[1],
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+
+ self.conv_sub4 = ConvModule(
+ psp_out_channels,
+ out_channels[2],
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+
+ def forward(self, x):
+ output = []
+
+ # sub 1
+ output.append(self.conv_sub1(x))
+
+ # sub 2
+ x = resize(
+ x,
+ scale_factor=0.5,
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = self.backbone.stem(x)
+ x = self.backbone.maxpool(x)
+ x = self.backbone.layer1(x)
+ x = self.backbone.layer2(x)
+ output.append(self.conv_sub2(x))
+
+ # sub 4
+ x = resize(
+ x,
+ scale_factor=0.5,
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = self.backbone.layer3(x)
+ x = self.backbone.layer4(x)
+ psp_outs = self.psp_modules(x) + [x]
+ psp_outs = torch.cat(psp_outs, dim=1)
+ x = self.psp_bottleneck(psp_outs)
+
+ output.append(self.conv_sub4(x))
+
+ return output
diff --git a/mmseg/models/backbones/mit.py b/mmseg/models/backbones/mit.py
new file mode 100644
index 0000000..c97213a
--- /dev/null
+++ b/mmseg/models/backbones/mit.py
@@ -0,0 +1,431 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import warnings
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import Conv2d, build_activation_layer, build_norm_layer
+from mmcv.cnn.bricks.drop import build_dropout
+from mmcv.cnn.bricks.transformer import MultiheadAttention
+from mmcv.cnn.utils.weight_init import (constant_init, normal_init,
+ trunc_normal_init)
+from mmcv.runner import BaseModule, ModuleList, Sequential
+
+from ..builder import BACKBONES
+from ..utils import PatchEmbed, nchw_to_nlc, nlc_to_nchw
+
+
+class MixFFN(BaseModule):
+ """An implementation of MixFFN of Segformer.
+
+ The differences between MixFFN & FFN:
+ 1. Use 1X1 Conv to replace Linear layer.
+ 2. Introduce 3X3 Conv to encode positional information.
+ Args:
+ embed_dims (int): The feature dimension. Same as
+ `MultiheadAttention`. Defaults: 256.
+ feedforward_channels (int): The hidden dimension of FFNs.
+ Defaults: 1024.
+ act_cfg (dict, optional): The activation config for FFNs.
+ Default: dict(type='ReLU')
+ ffn_drop (float, optional): Probability of an element to be
+ zeroed in FFN. Default 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut.
+ init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ feedforward_channels,
+ act_cfg=dict(type='GELU'),
+ ffn_drop=0.,
+ dropout_layer=None,
+ init_cfg=None):
+ super(MixFFN, self).__init__(init_cfg)
+
+ self.embed_dims = embed_dims
+ self.feedforward_channels = feedforward_channels
+ self.act_cfg = act_cfg
+ self.activate = build_activation_layer(act_cfg)
+
+ in_channels = embed_dims
+ fc1 = Conv2d(
+ in_channels=in_channels,
+ out_channels=feedforward_channels,
+ kernel_size=1,
+ stride=1,
+ bias=True)
+ # 3x3 depth wise conv to provide positional encode information
+ pe_conv = Conv2d(
+ in_channels=feedforward_channels,
+ out_channels=feedforward_channels,
+ kernel_size=3,
+ stride=1,
+ padding=(3 - 1) // 2,
+ bias=True,
+ groups=feedforward_channels)
+ fc2 = Conv2d(
+ in_channels=feedforward_channels,
+ out_channels=in_channels,
+ kernel_size=1,
+ stride=1,
+ bias=True)
+ drop = nn.Dropout(ffn_drop)
+ layers = [fc1, pe_conv, self.activate, drop, fc2, drop]
+ self.layers = Sequential(*layers)
+ self.dropout_layer = build_dropout(
+ dropout_layer) if dropout_layer else torch.nn.Identity()
+
+ def forward(self, x, hw_shape, identity=None):
+ out = nlc_to_nchw(x, hw_shape)
+ out = self.layers(out)
+ out = nchw_to_nlc(out)
+ if identity is None:
+ identity = x
+ return identity + self.dropout_layer(out)
+
+
+class EfficientMultiheadAttention(MultiheadAttention):
+ """An implementation of Efficient Multi-head Attention of Segformer.
+
+ This module is modified from MultiheadAttention which is a module from
+ mmcv.cnn.bricks.transformer.
+ Args:
+ embed_dims (int): The embedding dimension.
+ num_heads (int): Parallel attention heads.
+ attn_drop (float): A Dropout layer on attn_output_weights.
+ Default: 0.0.
+ proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
+ Default: 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut. Default: None.
+ init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
+ Default: None.
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dim)
+ or (n, batch, embed_dim). Default: False.
+ qkv_bias (bool): enable bias for qkv if True. Default True.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (int): The ratio of spatial reduction of Efficient Multi-head
+ Attention of Segformer. Default: 1.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ attn_drop=0.,
+ proj_drop=0.,
+ dropout_layer=None,
+ init_cfg=None,
+ batch_first=True,
+ qkv_bias=False,
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1):
+ super().__init__(
+ embed_dims,
+ num_heads,
+ attn_drop,
+ proj_drop,
+ dropout_layer=dropout_layer,
+ init_cfg=init_cfg,
+ batch_first=batch_first,
+ bias=qkv_bias)
+
+ self.sr_ratio = sr_ratio
+ if sr_ratio > 1:
+ self.sr = Conv2d(
+ in_channels=embed_dims,
+ out_channels=embed_dims,
+ kernel_size=sr_ratio,
+ stride=sr_ratio)
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ # handle the BC-breaking from https://github.com/open-mmlab/mmcv/pull/1418 # noqa
+ from mmseg import digit_version, mmcv_version
+ if mmcv_version < digit_version('1.3.17'):
+ warnings.warn('The legacy version of forward function in'
+ 'EfficientMultiheadAttention is deprecated in'
+ 'mmcv>=1.3.17 and will no longer support in the'
+ 'future. Please upgrade your mmcv.')
+ self.forward = self.legacy_forward
+
+ def forward(self, x, hw_shape, identity=None):
+
+ x_q = x
+ if self.sr_ratio > 1:
+ x_kv = nlc_to_nchw(x, hw_shape)
+ x_kv = self.sr(x_kv)
+ x_kv = nchw_to_nlc(x_kv)
+ x_kv = self.norm(x_kv)
+ else:
+ x_kv = x
+
+ if identity is None:
+ identity = x_q
+
+ # Because the dataflow('key', 'query', 'value') of
+ # ``torch.nn.MultiheadAttention`` is (num_query, batch,
+ # embed_dims), We should adjust the shape of dataflow from
+ # batch_first (batch, num_query, embed_dims) to num_query_first
+ # (num_query ,batch, embed_dims), and recover ``attn_output``
+ # from num_query_first to batch_first.
+ if self.batch_first:
+ x_q = x_q.transpose(0, 1)
+ x_kv = x_kv.transpose(0, 1)
+
+ out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
+
+ if self.batch_first:
+ out = out.transpose(0, 1)
+
+ return identity + self.dropout_layer(self.proj_drop(out))
+
+ def legacy_forward(self, x, hw_shape, identity=None):
+ """multi head attention forward in mmcv version < 1.3.17."""
+
+ x_q = x
+ if self.sr_ratio > 1:
+ x_kv = nlc_to_nchw(x, hw_shape)
+ x_kv = self.sr(x_kv)
+ x_kv = nchw_to_nlc(x_kv)
+ x_kv = self.norm(x_kv)
+ else:
+ x_kv = x
+
+ if identity is None:
+ identity = x_q
+
+ # `need_weights=True` will let nn.MultiHeadAttention
+ # `return attn_output, attn_output_weights.sum(dim=1) / num_heads`
+ # The `attn_output_weights.sum(dim=1)` may cause cuda error. So, we set
+ # `need_weights=False` to ignore `attn_output_weights.sum(dim=1)`.
+ # This issue - `https://github.com/pytorch/pytorch/issues/37583` report
+ # the error that large scale tensor sum operation may cause cuda error.
+ out = self.attn(query=x_q, key=x_kv, value=x_kv, need_weights=False)[0]
+
+ return identity + self.dropout_layer(self.proj_drop(out))
+
+
+class TransformerEncoderLayer(BaseModule):
+ """Implements one encoder layer in Segformer.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed.
+ after the feed forward layer. Default 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0.
+ drop_path_rate (float): stochastic depth rate. Default 0.0.
+ qkv_bias (bool): enable bias for qkv if True.
+ Default: True.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dim)
+ or (n, batch, embed_dim). Default: False.
+ init_cfg (dict, optional): Initialization config dict.
+ Default:None.
+ sr_ratio (int): The ratio of spatial reduction of Efficient Multi-head
+ Attention of Segformer. Default: 1.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ batch_first=True,
+ sr_ratio=1):
+ super(TransformerEncoderLayer, self).__init__()
+
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ self.attn = EfficientMultiheadAttention(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ attn_drop=attn_drop_rate,
+ proj_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ batch_first=batch_first,
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio)
+
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ self.ffn = MixFFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg)
+
+ def forward(self, x, hw_shape):
+ x = self.attn(self.norm1(x), hw_shape, identity=x)
+ x = self.ffn(self.norm2(x), hw_shape, identity=x)
+ return x
+
+
+@BACKBONES.register_module()
+class MixVisionTransformer(BaseModule):
+ """The backbone of Segformer.
+
+ This backbone is the implementation of `SegFormer: Simple and
+ Efficient Design for Semantic Segmentation with
+ Transformers `_.
+ Args:
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (int): Embedding dimension. Default: 768.
+ num_stags (int): The num of stages. Default: 4.
+ num_layers (Sequence[int]): The layer number of each transformer encode
+ layer. Default: [3, 4, 6, 3].
+ num_heads (Sequence[int]): The attention heads of each transformer
+ encode layer. Default: [1, 2, 4, 8].
+ patch_sizes (Sequence[int]): The patch_size of each overlapped patch
+ embedding. Default: [7, 3, 3, 3].
+ strides (Sequence[int]): The stride of each overlapped patch embedding.
+ Default: [4, 2, 2, 2].
+ sr_ratios (Sequence[int]): The spatial reduction rate of each
+ transformer encode layer. Default: [8, 4, 2, 1].
+ out_indices (Sequence[int] | int): Output from which stages.
+ Default: (0, 1, 2, 3).
+ mlp_ratio (int): ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.0
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0
+ drop_path_rate (float): stochastic depth rate. Default 0.0
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ pretrained (str, optional): model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=64,
+ num_stages=4,
+ num_layers=[3, 4, 6, 3],
+ num_heads=[1, 2, 4, 8],
+ patch_sizes=[7, 3, 3, 3],
+ strides=[4, 2, 2, 2],
+ sr_ratios=[8, 4, 2, 1],
+ out_indices=(0, 1, 2, 3),
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN', eps=1e-6),
+ pretrained=None,
+ init_cfg=None):
+ super(MixVisionTransformer, self).__init__(init_cfg=init_cfg)
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be set at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is not None:
+ raise TypeError('pretrained must be a str or None')
+
+ self.embed_dims = embed_dims
+ self.num_stages = num_stages
+ self.num_layers = num_layers
+ self.num_heads = num_heads
+ self.patch_sizes = patch_sizes
+ self.strides = strides
+ self.sr_ratios = sr_ratios
+ assert num_stages == len(num_layers) == len(num_heads) \
+ == len(patch_sizes) == len(strides) == len(sr_ratios)
+
+ self.out_indices = out_indices
+ assert max(out_indices) < self.num_stages
+
+ # transformer encoder
+ dpr = [
+ x.item()
+ for x in torch.linspace(0, drop_path_rate, sum(num_layers))
+ ] # stochastic num_layer decay rule
+
+ cur = 0
+ self.layers = ModuleList()
+ for i, num_layer in enumerate(num_layers):
+ embed_dims_i = embed_dims * num_heads[i]
+ patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims_i,
+ kernel_size=patch_sizes[i],
+ stride=strides[i],
+ padding=patch_sizes[i] // 2,
+ norm_cfg=norm_cfg)
+ layer = ModuleList([
+ TransformerEncoderLayer(
+ embed_dims=embed_dims_i,
+ num_heads=num_heads[i],
+ feedforward_channels=mlp_ratio * embed_dims_i,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[cur + idx],
+ qkv_bias=qkv_bias,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratios[i]) for idx in range(num_layer)
+ ])
+ in_channels = embed_dims_i
+ # The ret[0] of build_norm_layer is norm name.
+ norm = build_norm_layer(norm_cfg, embed_dims_i)[1]
+ self.layers.append(ModuleList([patch_embed, layer, norm]))
+ cur += num_layer
+
+ def init_weights(self):
+ if self.init_cfg is None:
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=.02, bias=0.)
+ elif isinstance(m, nn.LayerNorm):
+ constant_init(m, val=1.0, bias=0.)
+ elif isinstance(m, nn.Conv2d):
+ fan_out = m.kernel_size[0] * m.kernel_size[
+ 1] * m.out_channels
+ fan_out //= m.groups
+ normal_init(
+ m, mean=0, std=math.sqrt(2.0 / fan_out), bias=0)
+ else:
+ super(MixVisionTransformer, self).init_weights()
+
+ def forward(self, x):
+ outs = []
+
+ for i, layer in enumerate(self.layers):
+ x, hw_shape = layer[0](x)
+ for block in layer[1]:
+ x = block(x, hw_shape)
+ x = layer[2](x)
+ x = nlc_to_nchw(x, hw_shape)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return outs
diff --git a/mmseg/models/backbones/mobilenet_v2.py b/mmseg/models/backbones/mobilenet_v2.py
new file mode 100644
index 0000000..cbb9c6c
--- /dev/null
+++ b/mmseg/models/backbones/mobilenet_v2.py
@@ -0,0 +1,197 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from ..builder import BACKBONES
+from ..utils import InvertedResidual, make_divisible
+
+
+@BACKBONES.register_module()
+class MobileNetV2(BaseModule):
+ """MobileNetV2 backbone.
+
+ This backbone is the implementation of
+ `MobileNetV2: Inverted Residuals and Linear Bottlenecks
+ `_.
+
+ Args:
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Default: 1.0.
+ strides (Sequence[int], optional): Strides of the first block of each
+ layer. If not specified, default config in ``arch_setting`` will
+ be used.
+ dilations (Sequence[int]): Dilation of each layer.
+ out_indices (None or Sequence[int]): Output from which stages.
+ Default: (7, ).
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU6').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ # Parameters to build layers. 3 parameters are needed to construct a
+ # layer, from left to right: expand_ratio, channel, num_blocks.
+ arch_settings = [[1, 16, 1], [6, 24, 2], [6, 32, 3], [6, 64, 4],
+ [6, 96, 3], [6, 160, 3], [6, 320, 1]]
+
+ def __init__(self,
+ widen_factor=1.,
+ strides=(1, 2, 2, 2, 1, 2, 1),
+ dilations=(1, 1, 1, 1, 1, 1, 1),
+ out_indices=(1, 2, 4, 6),
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU6'),
+ norm_eval=False,
+ with_cp=False,
+ pretrained=None,
+ init_cfg=None):
+ super(MobileNetV2, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.widen_factor = widen_factor
+ self.strides = strides
+ self.dilations = dilations
+ assert len(strides) == len(dilations) == len(self.arch_settings)
+ self.out_indices = out_indices
+ for index in out_indices:
+ if index not in range(0, 7):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, 7). But received {index}')
+
+ if frozen_stages not in range(-1, 7):
+ raise ValueError('frozen_stages must be in range(-1, 7). '
+ f'But received {frozen_stages}')
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ self.in_channels = make_divisible(32 * widen_factor, 8)
+
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.layers = []
+
+ for i, layer_cfg in enumerate(self.arch_settings):
+ expand_ratio, channel, num_blocks = layer_cfg
+ stride = self.strides[i]
+ dilation = self.dilations[i]
+ out_channels = make_divisible(channel * widen_factor, 8)
+ inverted_res_layer = self.make_layer(
+ out_channels=out_channels,
+ num_blocks=num_blocks,
+ stride=stride,
+ dilation=dilation,
+ expand_ratio=expand_ratio)
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, inverted_res_layer)
+ self.layers.append(layer_name)
+
+ def make_layer(self, out_channels, num_blocks, stride, dilation,
+ expand_ratio):
+ """Stack InvertedResidual blocks to build a layer for MobileNetV2.
+
+ Args:
+ out_channels (int): out_channels of block.
+ num_blocks (int): Number of blocks.
+ stride (int): Stride of the first block.
+ dilation (int): Dilation of the first block.
+ expand_ratio (int): Expand the number of channels of the
+ hidden layer in InvertedResidual by this ratio.
+ """
+ layers = []
+ for i in range(num_blocks):
+ layers.append(
+ InvertedResidual(
+ self.in_channels,
+ out_channels,
+ stride if i == 0 else 1,
+ expand_ratio=expand_ratio,
+ dilation=dilation if i == 0 else 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ with_cp=self.with_cp))
+ self.in_channels = out_channels
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ x = self.conv1(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+
+ if len(outs) == 1:
+ return outs[0]
+ else:
+ return tuple(outs)
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for param in self.conv1.parameters():
+ param.requires_grad = False
+ for i in range(1, self.frozen_stages + 1):
+ layer = getattr(self, f'layer{i}')
+ layer.eval()
+ for param in layer.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super(MobileNetV2, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmseg/models/backbones/mobilenet_v3.py b/mmseg/models/backbones/mobilenet_v3.py
new file mode 100644
index 0000000..dd3d6eb
--- /dev/null
+++ b/mmseg/models/backbones/mobilenet_v3.py
@@ -0,0 +1,267 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+from mmcv.cnn import ConvModule
+from mmcv.cnn.bricks import Conv2dAdaptivePadding
+from mmcv.runner import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from ..builder import BACKBONES
+from ..utils import InvertedResidualV3 as InvertedResidual
+
+
+@BACKBONES.register_module()
+class MobileNetV3(BaseModule):
+ """MobileNetV3 backbone.
+
+ This backbone is the improved implementation of `Searching for MobileNetV3
+ `_.
+
+ Args:
+ arch (str): Architecture of mobilnetv3, from {'small', 'large'}.
+ Default: 'small'.
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ out_indices (tuple[int]): Output from which layer.
+ Default: (0, 1, 12).
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save
+ some memory while slowing down the training speed.
+ Default: False.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+ # Parameters to build each block:
+ # [kernel size, mid channels, out channels, with_se, act type, stride]
+ arch_settings = {
+ 'small': [[3, 16, 16, True, 'ReLU', 2], # block0 layer1 os=4
+ [3, 72, 24, False, 'ReLU', 2], # block1 layer2 os=8
+ [3, 88, 24, False, 'ReLU', 1],
+ [5, 96, 40, True, 'HSwish', 2], # block2 layer4 os=16
+ [5, 240, 40, True, 'HSwish', 1],
+ [5, 240, 40, True, 'HSwish', 1],
+ [5, 120, 48, True, 'HSwish', 1], # block3 layer7 os=16
+ [5, 144, 48, True, 'HSwish', 1],
+ [5, 288, 96, True, 'HSwish', 2], # block4 layer9 os=32
+ [5, 576, 96, True, 'HSwish', 1],
+ [5, 576, 96, True, 'HSwish', 1]],
+ 'large': [[3, 16, 16, False, 'ReLU', 1], # block0 layer1 os=2
+ [3, 64, 24, False, 'ReLU', 2], # block1 layer2 os=4
+ [3, 72, 24, False, 'ReLU', 1],
+ [5, 72, 40, True, 'ReLU', 2], # block2 layer4 os=8
+ [5, 120, 40, True, 'ReLU', 1],
+ [5, 120, 40, True, 'ReLU', 1],
+ [3, 240, 80, False, 'HSwish', 2], # block3 layer7 os=16
+ [3, 200, 80, False, 'HSwish', 1],
+ [3, 184, 80, False, 'HSwish', 1],
+ [3, 184, 80, False, 'HSwish', 1],
+ [3, 480, 112, True, 'HSwish', 1], # block4 layer11 os=16
+ [3, 672, 112, True, 'HSwish', 1],
+ [5, 672, 160, True, 'HSwish', 2], # block5 layer13 os=32
+ [5, 960, 160, True, 'HSwish', 1],
+ [5, 960, 160, True, 'HSwish', 1]]
+ } # yapf: disable
+
+ def __init__(self,
+ arch='small',
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ out_indices=(0, 1, 12),
+ frozen_stages=-1,
+ reduction_factor=1,
+ norm_eval=False,
+ with_cp=False,
+ pretrained=None,
+ init_cfg=None):
+ super(MobileNetV3, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ assert arch in self.arch_settings
+ assert isinstance(reduction_factor, int) and reduction_factor > 0
+ assert mmcv.is_tuple_of(out_indices, int)
+ for index in out_indices:
+ if index not in range(0, len(self.arch_settings[arch]) + 2):
+ raise ValueError(
+ 'the item in out_indices must in '
+ f'range(0, {len(self.arch_settings[arch])+2}). '
+ f'But received {index}')
+
+ if frozen_stages not in range(-1, len(self.arch_settings[arch]) + 2):
+ raise ValueError('frozen_stages must be in range(-1, '
+ f'{len(self.arch_settings[arch])+2}). '
+ f'But received {frozen_stages}')
+ self.arch = arch
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.reduction_factor = reduction_factor
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.layers = self._make_layer()
+
+ def _make_layer(self):
+ layers = []
+
+ # build the first layer (layer0)
+ in_channels = 16
+ layer = ConvModule(
+ in_channels=3,
+ out_channels=in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=dict(type='Conv2dAdaptivePadding'),
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='HSwish'))
+ self.add_module('layer0', layer)
+ layers.append('layer0')
+
+ layer_setting = self.arch_settings[self.arch]
+ for i, params in enumerate(layer_setting):
+ (kernel_size, mid_channels, out_channels, with_se, act,
+ stride) = params
+
+ if self.arch == 'large' and i >= 12 or self.arch == 'small' and \
+ i >= 8:
+ mid_channels = mid_channels // self.reduction_factor
+ out_channels = out_channels // self.reduction_factor
+
+ if with_se:
+ se_cfg = dict(
+ channels=mid_channels,
+ ratio=4,
+ act_cfg=(dict(type='ReLU'),
+ dict(type='HSigmoid', bias=3.0, divisor=6.0)))
+ else:
+ se_cfg = None
+
+ layer = InvertedResidual(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ mid_channels=mid_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ se_cfg=se_cfg,
+ with_expand_conv=(in_channels != mid_channels),
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type=act),
+ with_cp=self.with_cp)
+ in_channels = out_channels
+ layer_name = 'layer{}'.format(i + 1)
+ self.add_module(layer_name, layer)
+ layers.append(layer_name)
+
+ # build the last layer
+ # block5 layer12 os=32 for small model
+ # block6 layer16 os=32 for large model
+ layer = ConvModule(
+ in_channels=in_channels,
+ out_channels=576 if self.arch == 'small' else 960,
+ kernel_size=1,
+ stride=1,
+ dilation=4,
+ padding=0,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='HSwish'))
+ layer_name = 'layer{}'.format(len(layer_setting) + 1)
+ self.add_module(layer_name, layer)
+ layers.append(layer_name)
+
+ # next, convert backbone MobileNetV3 to a semantic segmentation version
+ if self.arch == 'small':
+ self.layer4.depthwise_conv.conv.stride = (1, 1)
+ self.layer9.depthwise_conv.conv.stride = (1, 1)
+ for i in range(4, len(layers)):
+ layer = getattr(self, layers[i])
+ if isinstance(layer, InvertedResidual):
+ modified_module = layer.depthwise_conv.conv
+ else:
+ modified_module = layer.conv
+
+ if i < 9:
+ modified_module.dilation = (2, 2)
+ pad = 2
+ else:
+ modified_module.dilation = (4, 4)
+ pad = 4
+
+ if not isinstance(modified_module, Conv2dAdaptivePadding):
+ # Adjust padding
+ pad *= (modified_module.kernel_size[0] - 1) // 2
+ modified_module.padding = (pad, pad)
+ else:
+ self.layer7.depthwise_conv.conv.stride = (1, 1)
+ self.layer13.depthwise_conv.conv.stride = (1, 1)
+ for i in range(7, len(layers)):
+ layer = getattr(self, layers[i])
+ if isinstance(layer, InvertedResidual):
+ modified_module = layer.depthwise_conv.conv
+ else:
+ modified_module = layer.conv
+
+ if i < 13:
+ modified_module.dilation = (2, 2)
+ pad = 2
+ else:
+ modified_module.dilation = (4, 4)
+ pad = 4
+
+ if not isinstance(modified_module, Conv2dAdaptivePadding):
+ # Adjust padding
+ pad *= (modified_module.kernel_size[0] - 1) // 2
+ modified_module.padding = (pad, pad)
+
+ return layers
+
+ def forward(self, x):
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return outs
+
+ def _freeze_stages(self):
+ for i in range(self.frozen_stages + 1):
+ layer = getattr(self, f'layer{i}')
+ layer.eval()
+ for param in layer.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super(MobileNetV3, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmseg/models/backbones/resnest.py b/mmseg/models/backbones/resnest.py
new file mode 100644
index 0000000..91952c2
--- /dev/null
+++ b/mmseg/models/backbones/resnest.py
@@ -0,0 +1,318 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from ..builder import BACKBONES
+from ..utils import ResLayer
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResNetV1d
+
+
+class RSoftmax(nn.Module):
+ """Radix Softmax module in ``SplitAttentionConv2d``.
+
+ Args:
+ radix (int): Radix of input.
+ groups (int): Groups of input.
+ """
+
+ def __init__(self, radix, groups):
+ super().__init__()
+ self.radix = radix
+ self.groups = groups
+
+ def forward(self, x):
+ batch = x.size(0)
+ if self.radix > 1:
+ x = x.view(batch, self.groups, self.radix, -1).transpose(1, 2)
+ x = F.softmax(x, dim=1)
+ x = x.reshape(batch, -1)
+ else:
+ x = torch.sigmoid(x)
+ return x
+
+
+class SplitAttentionConv2d(nn.Module):
+ """Split-Attention Conv2d in ResNeSt.
+
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int | tuple[int]): Same as nn.Conv2d.
+ stride (int | tuple[int]): Same as nn.Conv2d.
+ padding (int | tuple[int]): Same as nn.Conv2d.
+ dilation (int | tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of inter_channels. Default: 4.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ dcn (dict): Config dict for DCN. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ radix=2,
+ reduction_factor=4,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None):
+ super(SplitAttentionConv2d, self).__init__()
+ inter_channels = max(in_channels * radix // reduction_factor, 32)
+ self.radix = radix
+ self.groups = groups
+ self.channels = channels
+ self.with_dcn = dcn is not None
+ self.dcn = dcn
+ fallback_on_stride = False
+ if self.with_dcn:
+ fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
+ if self.with_dcn and not fallback_on_stride:
+ assert conv_cfg is None, 'conv_cfg must be None for DCN'
+ conv_cfg = dcn
+ self.conv = build_conv_layer(
+ conv_cfg,
+ in_channels,
+ channels * radix,
+ kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ groups=groups * radix,
+ bias=False)
+ self.norm0_name, norm0 = build_norm_layer(
+ norm_cfg, channels * radix, postfix=0)
+ self.add_module(self.norm0_name, norm0)
+ self.relu = nn.ReLU(inplace=True)
+ self.fc1 = build_conv_layer(
+ None, channels, inter_channels, 1, groups=self.groups)
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, inter_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.fc2 = build_conv_layer(
+ None, inter_channels, channels * radix, 1, groups=self.groups)
+ self.rsoftmax = RSoftmax(radix, groups)
+
+ @property
+ def norm0(self):
+ """nn.Module: the normalization layer named "norm0" """
+ return getattr(self, self.norm0_name)
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.norm0(x)
+ x = self.relu(x)
+
+ batch, rchannel = x.shape[:2]
+ batch = x.size(0)
+ if self.radix > 1:
+ splits = x.view(batch, self.radix, -1, *x.shape[2:])
+ gap = splits.sum(dim=1)
+ else:
+ gap = x
+ gap = F.adaptive_avg_pool2d(gap, 1)
+ gap = self.fc1(gap)
+
+ gap = self.norm1(gap)
+ gap = self.relu(gap)
+
+ atten = self.fc2(gap)
+ atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
+
+ if self.radix > 1:
+ attens = atten.view(batch, self.radix, -1, *atten.shape[2:])
+ out = torch.sum(attens * splits, dim=1)
+ else:
+ out = atten * x
+ return out.contiguous()
+
+
+class Bottleneck(_Bottleneck):
+ """Bottleneck block for ResNeSt.
+
+ Args:
+ inplane (int): Input planes of this block.
+ planes (int): Middle planes of this block.
+ groups (int): Groups of conv2.
+ width_per_group (int): Width per group of conv2. 64x4d indicates
+ ``groups=64, width_per_group=4`` and 32x8d indicates
+ ``groups=32, width_per_group=8``.
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of inter_channels in
+ SplitAttentionConv2d. Default: 4.
+ avg_down_stride (bool): Whether to use average pool for stride in
+ Bottleneck. Default: True.
+ kwargs (dict): Key word arguments for base class.
+ """
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ groups=1,
+ base_width=4,
+ base_channels=64,
+ radix=2,
+ reduction_factor=4,
+ avg_down_stride=True,
+ **kwargs):
+ """Bottleneck block for ResNeSt."""
+ super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
+
+ if groups == 1:
+ width = self.planes
+ else:
+ width = math.floor(self.planes *
+ (base_width / base_channels)) * groups
+
+ self.avg_down_stride = avg_down_stride and self.conv2_stride > 1
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, width, postfix=1)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.inplanes,
+ width,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.with_modulated_dcn = False
+ self.conv2 = SplitAttentionConv2d(
+ width,
+ width,
+ kernel_size=3,
+ stride=1 if self.avg_down_stride else self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ radix=radix,
+ reduction_factor=reduction_factor,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ dcn=self.dcn)
+ delattr(self, self.norm2_name)
+
+ if self.avg_down_stride:
+ self.avd_layer = nn.AvgPool2d(3, self.conv2_stride, padding=1)
+
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ self.planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+
+ if self.avg_down_stride:
+ out = self.avd_layer(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv3_plugin_names)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+@BACKBONES.register_module()
+class ResNeSt(ResNetV1d):
+ """ResNeSt backbone.
+
+ This backbone is the implementation of `ResNeSt:
+ Split-Attention Networks `_.
+
+ Args:
+ groups (int): Number of groups of Bottleneck. Default: 1
+ base_width (int): Base width of Bottleneck. Default: 4
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of inter_channels in
+ SplitAttentionConv2d. Default: 4.
+ avg_down_stride (bool): Whether to use average pool for stride in
+ Bottleneck. Default: True.
+ kwargs (dict): Keyword arguments for ResNet.
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3)),
+ 200: (Bottleneck, (3, 24, 36, 3))
+ }
+
+ def __init__(self,
+ groups=1,
+ base_width=4,
+ radix=2,
+ reduction_factor=4,
+ avg_down_stride=True,
+ **kwargs):
+ self.groups = groups
+ self.base_width = base_width
+ self.radix = radix
+ self.reduction_factor = reduction_factor
+ self.avg_down_stride = avg_down_stride
+ super(ResNeSt, self).__init__(**kwargs)
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer``."""
+ return ResLayer(
+ groups=self.groups,
+ base_width=self.base_width,
+ base_channels=self.base_channels,
+ radix=self.radix,
+ reduction_factor=self.reduction_factor,
+ avg_down_stride=self.avg_down_stride,
+ **kwargs)
diff --git a/mmseg/models/backbones/resnet.py b/mmseg/models/backbones/resnet.py
new file mode 100644
index 0000000..e8b961d
--- /dev/null
+++ b/mmseg/models/backbones/resnet.py
@@ -0,0 +1,714 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer, build_plugin_layer
+from mmcv.runner import BaseModule
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from ..builder import BACKBONES
+from ..utils import ResLayer
+
+
+class BasicBlock(BaseModule):
+ """Basic block for ResNet."""
+
+ expansion = 1
+
+ def __init__(self,
+ inplanes,
+ planes,
+ stride=1,
+ dilation=1,
+ downsample=None,
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None,
+ plugins=None,
+ init_cfg=None):
+ super(BasicBlock, self).__init__(init_cfg)
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
+
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes,
+ 3,
+ stride=stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ conv_cfg, planes, planes, 3, padding=1, bias=False)
+ self.add_module(self.norm2_name, norm2)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+ self.dilation = dilation
+ self.with_cp = with_cp
+
+ @property
+ def norm1(self):
+ """nn.Module: normalization layer after the first convolution layer"""
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: normalization layer after the second convolution layer"""
+ return getattr(self, self.norm2_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+class Bottleneck(BaseModule):
+ """Bottleneck block for ResNet.
+
+ If style is "pytorch", the stride-two layer is the 3x3 conv layer, if it is
+ "caffe", the stride-two layer is the first 1x1 conv layer.
+ """
+
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ stride=1,
+ dilation=1,
+ downsample=None,
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None,
+ plugins=None,
+ init_cfg=None):
+ super(Bottleneck, self).__init__(init_cfg)
+ assert style in ['pytorch', 'caffe']
+ assert dcn is None or isinstance(dcn, dict)
+ assert plugins is None or isinstance(plugins, list)
+ if plugins is not None:
+ allowed_position = ['after_conv1', 'after_conv2', 'after_conv3']
+ assert all(p['position'] in allowed_position for p in plugins)
+
+ self.inplanes = inplanes
+ self.planes = planes
+ self.stride = stride
+ self.dilation = dilation
+ self.style = style
+ self.with_cp = with_cp
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.dcn = dcn
+ self.with_dcn = dcn is not None
+ self.plugins = plugins
+ self.with_plugins = plugins is not None
+
+ if self.with_plugins:
+ # collect plugins for conv1/conv2/conv3
+ self.after_conv1_plugins = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv1'
+ ]
+ self.after_conv2_plugins = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv2'
+ ]
+ self.after_conv3_plugins = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv3'
+ ]
+
+ if self.style == 'pytorch':
+ self.conv1_stride = 1
+ self.conv2_stride = stride
+ else:
+ self.conv1_stride = stride
+ self.conv2_stride = 1
+
+ self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ norm_cfg, planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ fallback_on_stride = False
+ if self.with_dcn:
+ fallback_on_stride = dcn.pop('fallback_on_stride', False)
+ if not self.with_dcn or fallback_on_stride:
+ self.conv2 = build_conv_layer(
+ conv_cfg,
+ planes,
+ planes,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+ else:
+ assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
+ self.conv2 = build_conv_layer(
+ dcn,
+ planes,
+ planes,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ conv_cfg,
+ planes,
+ planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+
+ if self.with_plugins:
+ self.after_conv1_plugin_names = self.make_block_plugins(
+ planes, self.after_conv1_plugins)
+ self.after_conv2_plugin_names = self.make_block_plugins(
+ planes, self.after_conv2_plugins)
+ self.after_conv3_plugin_names = self.make_block_plugins(
+ planes * self.expansion, self.after_conv3_plugins)
+
+ def make_block_plugins(self, in_channels, plugins):
+ """make plugins for block.
+
+ Args:
+ in_channels (int): Input channels of plugin.
+ plugins (list[dict]): List of plugins cfg to build.
+
+ Returns:
+ list[str]: List of the names of plugin.
+ """
+ assert isinstance(plugins, list)
+ plugin_names = []
+ for plugin in plugins:
+ plugin = plugin.copy()
+ name, layer = build_plugin_layer(
+ plugin,
+ in_channels=in_channels,
+ postfix=plugin.pop('postfix', ''))
+ assert not hasattr(self, name), f'duplicate plugin {name}'
+ self.add_module(name, layer)
+ plugin_names.append(name)
+ return plugin_names
+
+ def forward_plugin(self, x, plugin_names):
+ """Forward function for plugins."""
+ out = x
+ for name in plugin_names:
+ out = getattr(self, name)(x)
+ return out
+
+ @property
+ def norm1(self):
+ """nn.Module: normalization layer after the first convolution layer"""
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: normalization layer after the second convolution layer"""
+ return getattr(self, self.norm2_name)
+
+ @property
+ def norm3(self):
+ """nn.Module: normalization layer after the third convolution layer"""
+ return getattr(self, self.norm3_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv3_plugin_names)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+@BACKBONES.register_module()
+class ResNet(BaseModule):
+ """ResNet backbone.
+
+ This backbone is the improved implementation of `Deep Residual Learning
+ for Image Recognition `_.
+
+ Args:
+ depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
+ in_channels (int): Number of input image channels. Default: 3.
+ stem_channels (int): Number of stem channels. Default: 64.
+ base_channels (int): Number of base channels of res layer. Default: 64.
+ num_stages (int): Resnet stages, normally 4. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ Default: (1, 2, 2, 2).
+ dilations (Sequence[int]): Dilation of each stage.
+ Default: (1, 1, 1, 1).
+ out_indices (Sequence[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer. Default: 'pytorch'.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
+ Default: False.
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ conv_cfg (dict | None): Dictionary to construct and config conv layer.
+ When conv_cfg is None, cfg will be set to dict(type='Conv2d').
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN', requires_grad=True).
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ dcn (dict | None): Dictionary to construct and config DCN conv layer.
+ When dcn is not None, conv_cfg must be None. Default: None.
+ stage_with_dcn (Sequence[bool]): Whether to set DCN conv for each
+ stage. The length of stage_with_dcn is equal to num_stages.
+ Default: (False, False, False, False).
+ plugins (list[dict]): List of plugins for stages, each dict contains:
+
+ - cfg (dict, required): Cfg dict to build plugin.
+
+ - position (str, required): Position inside block to insert plugin,
+ options: 'after_conv1', 'after_conv2', 'after_conv3'.
+
+ - stages (tuple[bool], optional): Stages to apply plugin, length
+ should be same as 'num_stages'.
+ Default: None.
+ multi_grid (Sequence[int]|None): Multi grid dilation rates of last
+ stage. Default: None.
+ contract_dilation (bool): Whether contract first dilation of each layer
+ Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: True.
+ pretrained (str, optional): model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Example:
+ >>> from mmseg.models import ResNet
+ >>> import torch
+ >>> self = ResNet(depth=18)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 64, 8, 8)
+ (1, 128, 4, 4)
+ (1, 256, 2, 2)
+ (1, 512, 1, 1)
+ """
+
+ arch_settings = {
+ 18: (BasicBlock, (2, 2, 2, 2)),
+ 34: (BasicBlock, (3, 4, 6, 3)),
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self,
+ depth,
+ in_channels=3,
+ stem_channels=64,
+ base_channels=64,
+ num_stages=4,
+ strides=(1, 2, 2, 2),
+ dilations=(1, 1, 1, 1),
+ out_indices=(0, 1, 2, 3),
+ style='pytorch',
+ deep_stem=False,
+ avg_down=False,
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=False,
+ dcn=None,
+ stage_with_dcn=(False, False, False, False),
+ plugins=None,
+ multi_grid=None,
+ contract_dilation=False,
+ with_cp=False,
+ zero_init_residual=True,
+ pretrained=None,
+ init_cfg=None):
+ super(ResNet, self).__init__(init_cfg)
+ if depth not in self.arch_settings:
+ raise KeyError(f'invalid depth {depth} for resnet')
+
+ self.pretrained = pretrained
+ self.zero_init_residual = zero_init_residual
+ block_init_cfg = None
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ block = self.arch_settings[depth][0]
+ if self.zero_init_residual:
+ if block is BasicBlock:
+ block_init_cfg = dict(
+ type='Constant',
+ val=0,
+ override=dict(name='norm2'))
+ elif block is Bottleneck:
+ block_init_cfg = dict(
+ type='Constant',
+ val=0,
+ override=dict(name='norm3'))
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.depth = depth
+ self.stem_channels = stem_channels
+ self.base_channels = base_channels
+ self.num_stages = num_stages
+ assert num_stages >= 1 and num_stages <= 4
+ self.strides = strides
+ self.dilations = dilations
+ assert len(strides) == len(dilations) == num_stages
+ self.out_indices = out_indices
+ assert max(out_indices) < num_stages
+ self.style = style
+ self.deep_stem = deep_stem
+ self.avg_down = avg_down
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.with_cp = with_cp
+ self.norm_eval = norm_eval
+ self.dcn = dcn
+ self.stage_with_dcn = stage_with_dcn
+ if dcn is not None:
+ assert len(stage_with_dcn) == num_stages
+ self.plugins = plugins
+ self.multi_grid = multi_grid
+ self.contract_dilation = contract_dilation
+ self.block, stage_blocks = self.arch_settings[depth]
+ self.stage_blocks = stage_blocks[:num_stages]
+ self.inplanes = stem_channels
+
+ self._make_stem_layer(in_channels, stem_channels)
+
+ self.res_layers = []
+ for i, num_blocks in enumerate(self.stage_blocks):
+ stride = strides[i]
+ dilation = dilations[i]
+ dcn = self.dcn if self.stage_with_dcn[i] else None
+ if plugins is not None:
+ stage_plugins = self.make_stage_plugins(plugins, i)
+ else:
+ stage_plugins = None
+ # multi grid is applied to last layer only
+ stage_multi_grid = multi_grid if i == len(
+ self.stage_blocks) - 1 else None
+ planes = base_channels * 2**i
+ res_layer = self.make_res_layer(
+ block=self.block,
+ inplanes=self.inplanes,
+ planes=planes,
+ num_blocks=num_blocks,
+ stride=stride,
+ dilation=dilation,
+ style=self.style,
+ avg_down=self.avg_down,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ dcn=dcn,
+ plugins=stage_plugins,
+ multi_grid=stage_multi_grid,
+ contract_dilation=contract_dilation,
+ init_cfg=block_init_cfg)
+ self.inplanes = planes * self.block.expansion
+ layer_name = f'layer{i+1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ self._freeze_stages()
+
+ self.feat_dim = self.block.expansion * base_channels * 2**(
+ len(self.stage_blocks) - 1)
+
+ def make_stage_plugins(self, plugins, stage_idx):
+ """make plugins for ResNet 'stage_idx'th stage .
+
+ Currently we support to insert 'context_block',
+ 'empirical_attention_block', 'nonlocal_block' into the backbone like
+ ResNet/ResNeXt. They could be inserted after conv1/conv2/conv3 of
+ Bottleneck.
+
+ An example of plugins format could be :
+ >>> plugins=[
+ ... dict(cfg=dict(type='xxx', arg1='xxx'),
+ ... stages=(False, True, True, True),
+ ... position='after_conv2'),
+ ... dict(cfg=dict(type='yyy'),
+ ... stages=(True, True, True, True),
+ ... position='after_conv3'),
+ ... dict(cfg=dict(type='zzz', postfix='1'),
+ ... stages=(True, True, True, True),
+ ... position='after_conv3'),
+ ... dict(cfg=dict(type='zzz', postfix='2'),
+ ... stages=(True, True, True, True),
+ ... position='after_conv3')
+ ... ]
+ >>> self = ResNet(depth=18)
+ >>> stage_plugins = self.make_stage_plugins(plugins, 0)
+ >>> assert len(stage_plugins) == 3
+
+ Suppose 'stage_idx=0', the structure of blocks in the stage would be:
+ conv1-> conv2->conv3->yyy->zzz1->zzz2
+ Suppose 'stage_idx=1', the structure of blocks in the stage would be:
+ conv1-> conv2->xxx->conv3->yyy->zzz1->zzz2
+
+ If stages is missing, the plugin would be applied to all stages.
+
+ Args:
+ plugins (list[dict]): List of plugins cfg to build. The postfix is
+ required if multiple same type plugins are inserted.
+ stage_idx (int): Index of stage to build
+
+ Returns:
+ list[dict]: Plugins for current stage
+ """
+ stage_plugins = []
+ for plugin in plugins:
+ plugin = plugin.copy()
+ stages = plugin.pop('stages', None)
+ assert stages is None or len(stages) == self.num_stages
+ # whether to insert plugin into current stage
+ if stages is None or stages[stage_idx]:
+ stage_plugins.append(plugin)
+
+ return stage_plugins
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer``."""
+ return ResLayer(**kwargs)
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ def _make_stem_layer(self, in_channels, stem_channels):
+ """Make stem layer for ResNet."""
+ if self.deep_stem:
+ self.stem = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
+ nn.ReLU(inplace=True),
+ build_conv_layer(
+ self.conv_cfg,
+ stem_channels // 2,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
+ nn.ReLU(inplace=True),
+ build_conv_layer(
+ self.conv_cfg,
+ stem_channels // 2,
+ stem_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, stem_channels)[1],
+ nn.ReLU(inplace=True))
+ else:
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ stem_channels,
+ kernel_size=7,
+ stride=2,
+ padding=3,
+ bias=False)
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, stem_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.relu = nn.ReLU(inplace=True)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+
+ def _freeze_stages(self):
+ """Freeze stages param and norm stats."""
+ if self.frozen_stages >= 0:
+ if self.deep_stem:
+ self.stem.eval()
+ for param in self.stem.parameters():
+ param.requires_grad = False
+ else:
+ self.norm1.eval()
+ for m in [self.conv1, self.norm1]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ m = getattr(self, f'layer{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def forward(self, x):
+ """Forward function."""
+ if self.deep_stem:
+ x = self.stem(x)
+ else:
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep normalization layer
+ freezed."""
+ super(ResNet, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+
+@BACKBONES.register_module()
+class ResNetV1c(ResNet):
+ """ResNetV1c variant described in [1]_.
+
+ Compared with default ResNet(ResNetV1b), ResNetV1c replaces the 7x7 conv in
+ the input stem with three 3x3 convs. For more details please refer to `Bag
+ of Tricks for Image Classification with Convolutional Neural Networks
+ `_.
+ """
+
+ def __init__(self, **kwargs):
+ super(ResNetV1c, self).__init__(
+ deep_stem=True, avg_down=False, **kwargs)
+
+
+@BACKBONES.register_module()
+class ResNetV1d(ResNet):
+ """ResNetV1d variant described in [1]_.
+
+ Compared with default ResNet(ResNetV1b), ResNetV1d replaces the 7x7 conv in
+ the input stem with three 3x3 convs. And in the downsampling block, a 2x2
+ avg_pool with stride 2 is added before conv, whose stride is changed to 1.
+ """
+
+ def __init__(self, **kwargs):
+ super(ResNetV1d, self).__init__(
+ deep_stem=True, avg_down=True, **kwargs)
diff --git a/mmseg/models/backbones/resnext.py b/mmseg/models/backbones/resnext.py
new file mode 100644
index 0000000..805c27b
--- /dev/null
+++ b/mmseg/models/backbones/resnext.py
@@ -0,0 +1,150 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from ..builder import BACKBONES
+from ..utils import ResLayer
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResNet
+
+
+class Bottleneck(_Bottleneck):
+ """Bottleneck block for ResNeXt.
+
+ If style is "pytorch", the stride-two layer is the 3x3 conv layer, if it is
+ "caffe", the stride-two layer is the first 1x1 conv layer.
+ """
+
+ def __init__(self,
+ inplanes,
+ planes,
+ groups=1,
+ base_width=4,
+ base_channels=64,
+ **kwargs):
+ super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
+
+ if groups == 1:
+ width = self.planes
+ else:
+ width = math.floor(self.planes *
+ (base_width / base_channels)) * groups
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, width, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ self.norm_cfg, width, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.inplanes,
+ width,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ fallback_on_stride = False
+ self.with_modulated_dcn = False
+ if self.with_dcn:
+ fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
+ if not self.with_dcn or fallback_on_stride:
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+ else:
+ assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
+ self.conv2 = build_conv_layer(
+ self.dcn,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ self.planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+
+@BACKBONES.register_module()
+class ResNeXt(ResNet):
+ """ResNeXt backbone.
+
+ This backbone is the implementation of `Aggregated
+ Residual Transformations for Deep Neural
+ Networks `_.
+
+ Args:
+ depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
+ in_channels (int): Number of input image channels. Normally 3.
+ num_stages (int): Resnet stages, normally 4.
+ groups (int): Group of resnext.
+ base_width (int): Base width of resnext.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ dilations (Sequence[int]): Dilation of each stage.
+ out_indices (Sequence[int]): Output from which stages.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ frozen_stages (int): Stages to be frozen (all param fixed). -1 means
+ not freezing any parameters.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+
+ Example:
+ >>> from mmseg.models import ResNeXt
+ >>> import torch
+ >>> self = ResNeXt(depth=50)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 256, 8, 8)
+ (1, 512, 4, 4)
+ (1, 1024, 2, 2)
+ (1, 2048, 1, 1)
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self, groups=1, base_width=4, **kwargs):
+ self.groups = groups
+ self.base_width = base_width
+ super(ResNeXt, self).__init__(**kwargs)
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer``"""
+ return ResLayer(
+ groups=self.groups,
+ base_width=self.base_width,
+ base_channels=self.base_channels,
+ **kwargs)
diff --git a/mmseg/models/backbones/stdc.py b/mmseg/models/backbones/stdc.py
new file mode 100644
index 0000000..04f2f7a
--- /dev/null
+++ b/mmseg/models/backbones/stdc.py
@@ -0,0 +1,422 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Modified from https://github.com/MichaelFan01/STDC-Seg."""
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner.base_module import BaseModule, ModuleList, Sequential
+
+from mmseg.ops import resize
+from ..builder import BACKBONES, build_backbone
+from .bisenetv1 import AttentionRefinementModule
+
+
+class STDCModule(BaseModule):
+ """STDCModule.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels before scaling.
+ stride (int): The number of stride for the first conv layer.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (dict): The activation config for conv layers.
+ num_convs (int): Numbers of conv layers.
+ fusion_type (str): Type of fusion operation. Default: 'add'.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride,
+ norm_cfg=None,
+ act_cfg=None,
+ num_convs=4,
+ fusion_type='add',
+ init_cfg=None):
+ super(STDCModule, self).__init__(init_cfg=init_cfg)
+ assert num_convs > 1
+ assert fusion_type in ['add', 'cat']
+ self.stride = stride
+ self.with_downsample = True if self.stride == 2 else False
+ self.fusion_type = fusion_type
+
+ self.layers = ModuleList()
+ conv_0 = ConvModule(
+ in_channels, out_channels // 2, kernel_size=1, norm_cfg=norm_cfg)
+
+ if self.with_downsample:
+ self.downsample = ConvModule(
+ out_channels // 2,
+ out_channels // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=out_channels // 2,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ if self.fusion_type == 'add':
+ self.layers.append(nn.Sequential(conv_0, self.downsample))
+ self.skip = Sequential(
+ ConvModule(
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=in_channels,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ in_channels,
+ out_channels,
+ 1,
+ norm_cfg=norm_cfg,
+ act_cfg=None))
+ else:
+ self.layers.append(conv_0)
+ self.skip = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
+ else:
+ self.layers.append(conv_0)
+
+ for i in range(1, num_convs):
+ out_factor = 2**(i + 1) if i != num_convs - 1 else 2**i
+ self.layers.append(
+ ConvModule(
+ out_channels // 2**i,
+ out_channels // out_factor,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs):
+ if self.fusion_type == 'add':
+ out = self.forward_add(inputs)
+ else:
+ out = self.forward_cat(inputs)
+ return out
+
+ def forward_add(self, inputs):
+ layer_outputs = []
+ x = inputs.clone()
+ for layer in self.layers:
+ x = layer(x)
+ layer_outputs.append(x)
+ if self.with_downsample:
+ inputs = self.skip(inputs)
+
+ return torch.cat(layer_outputs, dim=1) + inputs
+
+ def forward_cat(self, inputs):
+ x0 = self.layers[0](inputs)
+ layer_outputs = [x0]
+ for i, layer in enumerate(self.layers[1:]):
+ if i == 0:
+ if self.with_downsample:
+ x = layer(self.downsample(x0))
+ else:
+ x = layer(x0)
+ else:
+ x = layer(x)
+ layer_outputs.append(x)
+ if self.with_downsample:
+ layer_outputs[0] = self.skip(x0)
+ return torch.cat(layer_outputs, dim=1)
+
+
+class FeatureFusionModule(BaseModule):
+ """Feature Fusion Module. This module is different from FeatureFusionModule
+ in BiSeNetV1. It uses two ConvModules in `self.attention` whose inter
+ channel number is calculated by given `scale_factor`, while
+ FeatureFusionModule in BiSeNetV1 only uses one ConvModule in
+ `self.conv_atten`.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ scale_factor (int): The number of channel scale factor.
+ Default: 4.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): The activation config for conv layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ scale_factor=4,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(FeatureFusionModule, self).__init__(init_cfg=init_cfg)
+ channels = out_channels // scale_factor
+ self.conv0 = ConvModule(
+ in_channels, out_channels, 1, norm_cfg=norm_cfg, act_cfg=act_cfg)
+ self.attention = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ ConvModule(
+ out_channels,
+ channels,
+ 1,
+ norm_cfg=None,
+ bias=False,
+ act_cfg=act_cfg),
+ ConvModule(
+ channels,
+ out_channels,
+ 1,
+ norm_cfg=None,
+ bias=False,
+ act_cfg=None), nn.Sigmoid())
+
+ def forward(self, spatial_inputs, context_inputs):
+ inputs = torch.cat([spatial_inputs, context_inputs], dim=1)
+ x = self.conv0(inputs)
+ attn = self.attention(x)
+ x_attn = x * attn
+ return x_attn + x
+
+
+@BACKBONES.register_module()
+class STDCNet(BaseModule):
+ """This backbone is the implementation of `Rethinking BiSeNet For Real-time
+ Semantic Segmentation `_.
+
+ Args:
+ stdc_type (int): The type of backbone structure,
+ `STDCNet1` and`STDCNet2` denotes two main backbones in paper,
+ whose FLOPs is 813M and 1446M, respectively.
+ in_channels (int): The num of input_channels.
+ channels (tuple[int]): The output channels for each stage.
+ bottleneck_type (str): The type of STDC Module type, the value must
+ be 'add' or 'cat'.
+ norm_cfg (dict): Config dict for normalization layer.
+ act_cfg (dict): The activation config for conv layers.
+ num_convs (int): Numbers of conv layer at each STDC Module.
+ Default: 4.
+ with_final_conv (bool): Whether add a conv layer at the Module output.
+ Default: True.
+ pretrained (str, optional): Model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Example:
+ >>> import torch
+ >>> stdc_type = 'STDCNet1'
+ >>> in_channels = 3
+ >>> channels = (32, 64, 256, 512, 1024)
+ >>> bottleneck_type = 'cat'
+ >>> inputs = torch.rand(1, 3, 1024, 2048)
+ >>> self = STDCNet(stdc_type, in_channels,
+ ... channels, bottleneck_type).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 256, 128, 256])
+ outputs[1].shape = torch.Size([1, 512, 64, 128])
+ outputs[2].shape = torch.Size([1, 1024, 32, 64])
+ """
+
+ arch_settings = {
+ 'STDCNet1': [(2, 1), (2, 1), (2, 1)],
+ 'STDCNet2': [(2, 1, 1, 1), (2, 1, 1, 1, 1), (2, 1, 1)]
+ }
+
+ def __init__(self,
+ stdc_type,
+ in_channels,
+ channels,
+ bottleneck_type,
+ norm_cfg,
+ act_cfg,
+ num_convs=4,
+ with_final_conv=False,
+ pretrained=None,
+ init_cfg=None):
+ super(STDCNet, self).__init__(init_cfg=init_cfg)
+ assert stdc_type in self.arch_settings, \
+ f'invalid structure {stdc_type} for STDCNet.'
+ assert bottleneck_type in ['add', 'cat'],\
+ f'bottleneck_type must be `add` or `cat`, got {bottleneck_type}'
+
+ assert len(channels) == 5,\
+ f'invalid channels length {len(channels)} for STDCNet.'
+
+ self.in_channels = in_channels
+ self.channels = channels
+ self.stage_strides = self.arch_settings[stdc_type]
+ self.prtrained = pretrained
+ self.num_convs = num_convs
+ self.with_final_conv = with_final_conv
+
+ self.stages = ModuleList([
+ ConvModule(
+ self.in_channels,
+ self.channels[0],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ self.channels[0],
+ self.channels[1],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ ])
+ # `self.num_shallow_features` is the number of shallow modules in
+ # `STDCNet`, which is noted as `Stage1` and `Stage2` in original paper.
+ # They are both not used for following modules like Attention
+ # Refinement Module and Feature Fusion Module.
+ # Thus they would be cut from `outs`. Please refer to Figure 4
+ # of original paper for more details.
+ self.num_shallow_features = len(self.stages)
+
+ for strides in self.stage_strides:
+ idx = len(self.stages) - 1
+ self.stages.append(
+ self._make_stage(self.channels[idx], self.channels[idx + 1],
+ strides, norm_cfg, act_cfg, bottleneck_type))
+ # After appending, `self.stages` is a ModuleList including several
+ # shallow modules and STDCModules.
+ # (len(self.stages) ==
+ # self.num_shallow_features + len(self.stage_strides))
+ if self.with_final_conv:
+ self.final_conv = ConvModule(
+ self.channels[-1],
+ max(1024, self.channels[-1]),
+ 1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def _make_stage(self, in_channels, out_channels, strides, norm_cfg,
+ act_cfg, bottleneck_type):
+ layers = []
+ for i, stride in enumerate(strides):
+ layers.append(
+ STDCModule(
+ in_channels if i == 0 else out_channels,
+ out_channels,
+ stride,
+ norm_cfg,
+ act_cfg,
+ num_convs=self.num_convs,
+ fusion_type=bottleneck_type))
+ return Sequential(*layers)
+
+ def forward(self, x):
+ outs = []
+ for stage in self.stages:
+ x = stage(x)
+ outs.append(x)
+ if self.with_final_conv:
+ outs[-1] = self.final_conv(outs[-1])
+ outs = outs[self.num_shallow_features:]
+ return tuple(outs)
+
+
+@BACKBONES.register_module()
+class STDCContextPathNet(BaseModule):
+ """STDCNet with Context Path. The `outs` below is a list of three feature
+ maps from deep to shallow, whose height and width is from small to big,
+ respectively. The biggest feature map of `outs` is outputted for
+ `STDCHead`, where Detail Loss would be calculated by Detail Ground-truth.
+ The other two feature maps are used for Attention Refinement Module,
+ respectively. Besides, the biggest feature map of `outs` and the last
+ output of Attention Refinement Module are concatenated for Feature Fusion
+ Module. Then, this fusion feature map `feat_fuse` would be outputted for
+ `decode_head`. More details please refer to Figure 4 of original paper.
+
+ Args:
+ backbone_cfg (dict): Config dict for stdc backbone.
+ last_in_channels (tuple(int)), The number of channels of last
+ two feature maps from stdc backbone. Default: (1024, 512).
+ out_channels (int): The channels of output feature maps.
+ Default: 128.
+ ffm_cfg (dict): Config dict for Feature Fusion Module. Default:
+ `dict(in_channels=512, out_channels=256, scale_factor=4)`.
+ upsample_mode (str): Algorithm used for upsampling:
+ ``'nearest'`` | ``'linear'`` | ``'bilinear'`` | ``'bicubic'`` |
+ ``'trilinear'``. Default: ``'nearest'``.
+ align_corners (str): align_corners argument of F.interpolate. It
+ must be `None` if upsample_mode is ``'nearest'``. Default: None.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Return:
+ outputs (tuple): The tuple of list of output feature map for
+ auxiliary heads and decoder head.
+ """
+
+ def __init__(self,
+ backbone_cfg,
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(
+ in_channels=512, out_channels=256, scale_factor=4),
+ upsample_mode='nearest',
+ align_corners=None,
+ norm_cfg=dict(type='BN'),
+ init_cfg=None):
+ super(STDCContextPathNet, self).__init__(init_cfg=init_cfg)
+ self.backbone = build_backbone(backbone_cfg)
+ self.arms = ModuleList()
+ self.convs = ModuleList()
+ for channels in last_in_channels:
+ self.arms.append(AttentionRefinementModule(channels, out_channels))
+ self.convs.append(
+ ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ norm_cfg=norm_cfg))
+ self.conv_avg = ConvModule(
+ last_in_channels[0], out_channels, 1, norm_cfg=norm_cfg)
+
+ self.ffm = FeatureFusionModule(**ffm_cfg)
+
+ self.upsample_mode = upsample_mode
+ self.align_corners = align_corners
+
+ def forward(self, x):
+ outs = list(self.backbone(x))
+ avg = F.adaptive_avg_pool2d(outs[-1], 1)
+ avg_feat = self.conv_avg(avg)
+
+ feature_up = resize(
+ avg_feat,
+ size=outs[-1].shape[2:],
+ mode=self.upsample_mode,
+ align_corners=self.align_corners)
+ arms_out = []
+ for i in range(len(self.arms)):
+ x_arm = self.arms[i](outs[len(outs) - 1 - i]) + feature_up
+ feature_up = resize(
+ x_arm,
+ size=outs[len(outs) - 1 - i - 1].shape[2:],
+ mode=self.upsample_mode,
+ align_corners=self.align_corners)
+ feature_up = self.convs[i](feature_up)
+ arms_out.append(feature_up)
+
+ feat_fuse = self.ffm(outs[0], arms_out[1])
+
+ # The `outputs` has four feature maps.
+ # `outs[0]` is outputted for `STDCHead` auxiliary head.
+ # Two feature maps of `arms_out` are outputted for auxiliary head.
+ # `feat_fuse` is outputted for decoder head.
+ outputs = [outs[0]] + list(arms_out) + [feat_fuse]
+ return tuple(outputs)
diff --git a/mmseg/models/backbones/swin.py b/mmseg/models/backbones/swin.py
new file mode 100644
index 0000000..d5d11ac
--- /dev/null
+++ b/mmseg/models/backbones/swin.py
@@ -0,0 +1,756 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from collections import OrderedDict
+from copy import deepcopy
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, build_dropout
+from mmcv.cnn.utils.weight_init import (constant_init, trunc_normal_,
+ trunc_normal_init)
+from mmcv.runner import (BaseModule, CheckpointLoader, ModuleList,
+ load_state_dict)
+from mmcv.utils import to_2tuple
+
+from ...utils import get_root_logger
+from ..builder import BACKBONES
+from ..utils.embed import PatchEmbed, PatchMerging
+
+
+class WindowMSA(BaseModule):
+ """Window based multi-head self-attention (W-MSA) module with relative
+ position bias.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (tuple[int]): The height and width of the window.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
+ init_cfg (dict | None, optional): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0.,
+ proj_drop_rate=0.,
+ init_cfg=None):
+
+ super().__init__(init_cfg=init_cfg)
+ self.embed_dims = embed_dims
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_embed_dims = embed_dims // num_heads
+ self.scale = qk_scale or head_embed_dims**-0.5
+
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1),
+ num_heads)) # 2*Wh-1 * 2*Ww-1, nH
+
+ # About 2x faster than original impl
+ Wh, Ww = self.window_size
+ rel_index_coords = self.double_step_seq(2 * Ww - 1, Wh, 1, Ww)
+ rel_position_index = rel_index_coords + rel_index_coords.T
+ rel_position_index = rel_position_index.flip(1).contiguous()
+ self.register_buffer('relative_position_index', rel_position_index)
+
+ self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop_rate)
+ self.proj = nn.Linear(embed_dims, embed_dims)
+ self.proj_drop = nn.Dropout(proj_drop_rate)
+
+ self.softmax = nn.Softmax(dim=-1)
+
+ def init_weights(self):
+ trunc_normal_(self.relative_position_bias_table, std=0.02)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+
+ x (tensor): input features with shape of (num_windows*B, N, C)
+ mask (tensor | None, Optional): mask with shape of (num_windows,
+ Wh*Ww, Wh*Ww), value should be between (-inf, 0].
+ """
+ B, N, C = x.shape
+ qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
+ C // self.num_heads).permute(2, 0, 3, 1, 4)
+ # make torchscript happy (cannot use tensor as tuple)
+ q, k, v = qkv[0], qkv[1], qkv[2]
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ relative_position_bias = self.relative_position_bias_table[
+ self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1],
+ self.window_size[0] * self.window_size[1],
+ -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(
+ 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B // nW, nW, self.num_heads, N,
+ N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ @staticmethod
+ def double_step_seq(step1, len1, step2, len2):
+ seq1 = torch.arange(0, step1 * len1, step1)
+ seq2 = torch.arange(0, step2 * len2, step2)
+ return (seq1[:, None] + seq2[None, :]).reshape(1, -1)
+
+
+class ShiftWindowMSA(BaseModule):
+ """Shifted Window Multihead Self-Attention Module.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (int): The height and width of the window.
+ shift_size (int, optional): The shift step of each window towards
+ right-bottom. If zero, act as regular window-msa. Defaults to 0.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Defaults: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Defaults: 0.
+ proj_drop_rate (float, optional): Dropout ratio of output.
+ Defaults: 0.
+ dropout_layer (dict, optional): The dropout_layer used before output.
+ Defaults: dict(type='DropPath', drop_prob=0.).
+ init_cfg (dict, optional): The extra config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ shift_size=0,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0,
+ proj_drop_rate=0,
+ dropout_layer=dict(type='DropPath', drop_prob=0.),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.window_size = window_size
+ self.shift_size = shift_size
+ assert 0 <= self.shift_size < self.window_size
+
+ self.w_msa = WindowMSA(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ window_size=to_2tuple(window_size),
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop_rate=attn_drop_rate,
+ proj_drop_rate=proj_drop_rate,
+ init_cfg=None)
+
+ self.drop = build_dropout(dropout_layer)
+
+ def forward(self, query, hw_shape):
+ B, L, C = query.shape
+ H, W = hw_shape
+ assert L == H * W, 'input feature has wrong size'
+ query = query.view(B, H, W, C)
+
+ # pad feature maps to multiples of window size
+ pad_r = (self.window_size - W % self.window_size) % self.window_size
+ pad_b = (self.window_size - H % self.window_size) % self.window_size
+ query = F.pad(query, (0, 0, 0, pad_r, 0, pad_b))
+ H_pad, W_pad = query.shape[1], query.shape[2]
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_query = torch.roll(
+ query,
+ shifts=(-self.shift_size, -self.shift_size),
+ dims=(1, 2))
+
+ # calculate attention mask for SW-MSA
+ img_mask = torch.zeros((1, H_pad, W_pad, 1), device=query.device)
+ h_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ # nW, window_size, window_size, 1
+ mask_windows = self.window_partition(img_mask)
+ mask_windows = mask_windows.view(
+ -1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-100.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+ else:
+ shifted_query = query
+ attn_mask = None
+
+ # nW*B, window_size, window_size, C
+ query_windows = self.window_partition(shifted_query)
+ # nW*B, window_size*window_size, C
+ query_windows = query_windows.view(-1, self.window_size**2, C)
+
+ # W-MSA/SW-MSA (nW*B, window_size*window_size, C)
+ attn_windows = self.w_msa(query_windows, mask=attn_mask)
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size,
+ self.window_size, C)
+
+ # B H' W' C
+ shifted_x = self.window_reverse(attn_windows, H_pad, W_pad)
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = torch.roll(
+ shifted_x,
+ shifts=(self.shift_size, self.shift_size),
+ dims=(1, 2))
+ else:
+ x = shifted_x
+
+ if pad_r > 0 or pad_b:
+ x = x[:, :H, :W, :].contiguous()
+
+ x = x.view(B, H * W, C)
+
+ x = self.drop(x)
+ return x
+
+ def window_reverse(self, windows, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ H (int): Height of image
+ W (int): Width of image
+ Returns:
+ x: (B, H, W, C)
+ """
+ window_size = self.window_size
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size,
+ window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+ def window_partition(self, x):
+ """
+ Args:
+ x: (B, H, W, C)
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ window_size = self.window_size
+ x = x.view(B, H // window_size, window_size, W // window_size,
+ window_size, C)
+ windows = x.permute(0, 1, 3, 2, 4, 5).contiguous()
+ windows = windows.view(-1, window_size, window_size, C)
+ return windows
+
+
+class SwinBlock(BaseModule):
+ """"
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ window_size (int, optional): The local window scale. Default: 7.
+ shift (bool, optional): whether to shift window or not. Default False.
+ qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ drop_rate (float, optional): Dropout rate. Default: 0.
+ attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
+ drop_path_rate (float, optional): Stochastic depth rate. Default: 0.
+ act_cfg (dict, optional): The config dict of activation function.
+ Default: dict(type='GELU').
+ norm_cfg (dict, optional): The config dict of normalization.
+ Default: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict | list | None, optional): The init config.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ window_size=7,
+ shift=False,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ init_cfg=None):
+
+ super(SwinBlock, self).__init__(init_cfg=init_cfg)
+
+ self.with_cp = with_cp
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
+ self.attn = ShiftWindowMSA(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=window_size // 2 if shift else 0,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop_rate=attn_drop_rate,
+ proj_drop_rate=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ init_cfg=None)
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=2,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=True,
+ init_cfg=None)
+
+ def forward(self, x, hw_shape):
+
+ def _inner_forward(x):
+ identity = x
+ x = self.norm1(x)
+ x = self.attn(x, hw_shape)
+
+ x = x + identity
+
+ identity = x
+ x = self.norm2(x)
+ x = self.ffn(x, identity=identity)
+
+ return x
+
+ if self.with_cp and x.requires_grad:
+ x = cp.checkpoint(_inner_forward, x)
+ else:
+ x = _inner_forward(x)
+
+ return x
+
+
+class SwinBlockSequence(BaseModule):
+ """Implements one stage in Swin Transformer.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ depth (int): The number of blocks in this stage.
+ window_size (int, optional): The local window scale. Default: 7.
+ qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ drop_rate (float, optional): Dropout rate. Default: 0.
+ attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
+ drop_path_rate (float | list[float], optional): Stochastic depth
+ rate. Default: 0.
+ downsample (BaseModule | None, optional): The downsample operation
+ module. Default: None.
+ act_cfg (dict, optional): The config dict of activation function.
+ Default: dict(type='GELU').
+ norm_cfg (dict, optional): The config dict of normalization.
+ Default: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict | list | None, optional): The init config.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ depth,
+ window_size=7,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ downsample=None,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ if isinstance(drop_path_rate, list):
+ drop_path_rates = drop_path_rate
+ assert len(drop_path_rates) == depth
+ else:
+ drop_path_rates = [deepcopy(drop_path_rate) for _ in range(depth)]
+
+ self.blocks = ModuleList()
+ for i in range(depth):
+ block = SwinBlock(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ feedforward_channels=feedforward_channels,
+ window_size=window_size,
+ shift=False if i % 2 == 0 else True,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=drop_path_rates[i],
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ with_cp=with_cp,
+ init_cfg=None)
+ self.blocks.append(block)
+
+ self.downsample = downsample
+
+ def forward(self, x, hw_shape):
+ for block in self.blocks:
+ x = block(x, hw_shape)
+
+ if self.downsample:
+ x_down, down_hw_shape = self.downsample(x, hw_shape)
+ return x_down, down_hw_shape, x, hw_shape
+ else:
+ return x, hw_shape, x, hw_shape
+
+
+@BACKBONES.register_module()
+class SwinTransformer(BaseModule):
+ """Swin Transformer backbone.
+
+ This backbone is the implementation of `Swin Transformer:
+ Hierarchical Vision Transformer using Shifted
+ Windows `_.
+ Inspiration from https://github.com/microsoft/Swin-Transformer.
+
+ Args:
+ pretrain_img_size (int | tuple[int]): The size of input image when
+ pretrain. Defaults: 224.
+ in_channels (int): The num of input channels.
+ Defaults: 3.
+ embed_dims (int): The feature dimension. Default: 96.
+ patch_size (int | tuple[int]): Patch size. Default: 4.
+ window_size (int): Window size. Default: 7.
+ mlp_ratio (int): Ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ depths (tuple[int]): Depths of each Swin Transformer stage.
+ Default: (2, 2, 6, 2).
+ num_heads (tuple[int]): Parallel attention heads of each Swin
+ Transformer stage. Default: (3, 6, 12, 24).
+ strides (tuple[int]): The patch merging or patch embedding stride of
+ each Swin Transformer stage. (In swin, we set kernel size equal to
+ stride.) Default: (4, 2, 2, 2).
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key,
+ value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ patch_norm (bool): If add a norm layer for patch embed and patch
+ merging. Default: True.
+ drop_rate (float): Dropout rate. Defaults: 0.
+ attn_drop_rate (float): Attention dropout rate. Default: 0.
+ drop_path_rate (float): Stochastic depth rate. Defaults: 0.1.
+ use_abs_pos_embed (bool): If True, add absolute position embedding to
+ the patch embedding. Defaults: False.
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='LN').
+ norm_cfg (dict): Config dict for normalization layer at
+ output of backone. Defaults: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ pretrained (str, optional): model pretrained path. Default: None.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ pretrain_img_size=224,
+ in_channels=3,
+ embed_dims=96,
+ patch_size=4,
+ window_size=7,
+ mlp_ratio=4,
+ depths=(2, 2, 6, 2),
+ num_heads=(3, 6, 12, 24),
+ strides=(4, 2, 2, 2),
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=True,
+ qk_scale=None,
+ patch_norm=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ use_abs_pos_embed=False,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ pretrained=None,
+ frozen_stages=-1,
+ init_cfg=None):
+ self.frozen_stages = frozen_stages
+
+ if isinstance(pretrain_img_size, int):
+ pretrain_img_size = to_2tuple(pretrain_img_size)
+ elif isinstance(pretrain_img_size, tuple):
+ if len(pretrain_img_size) == 1:
+ pretrain_img_size = to_2tuple(pretrain_img_size[0])
+ assert len(pretrain_img_size) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(pretrain_img_size)}'
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ init_cfg = init_cfg
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ super(SwinTransformer, self).__init__(init_cfg=init_cfg)
+
+ num_layers = len(depths)
+ self.out_indices = out_indices
+ self.use_abs_pos_embed = use_abs_pos_embed
+
+ assert strides[0] == patch_size, 'Use non-overlapping patch embed.'
+
+ self.patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims,
+ conv_type='Conv2d',
+ kernel_size=patch_size,
+ stride=strides[0],
+ padding='corner',
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None)
+
+ if self.use_abs_pos_embed:
+ patch_row = pretrain_img_size[0] // patch_size
+ patch_col = pretrain_img_size[1] // patch_size
+ num_patches = patch_row * patch_col
+ self.absolute_pos_embed = nn.Parameter(
+ torch.zeros((1, num_patches, embed_dims)))
+
+ self.drop_after_pos = nn.Dropout(p=drop_rate)
+
+ # set stochastic depth decay rule
+ total_depth = sum(depths)
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, total_depth)
+ ]
+
+ self.stages = ModuleList()
+ in_channels = embed_dims
+ for i in range(num_layers):
+ if i < num_layers - 1:
+ downsample = PatchMerging(
+ in_channels=in_channels,
+ out_channels=2 * in_channels,
+ stride=strides[i + 1],
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None)
+ else:
+ downsample = None
+
+ stage = SwinBlockSequence(
+ embed_dims=in_channels,
+ num_heads=num_heads[i],
+ feedforward_channels=mlp_ratio * in_channels,
+ depth=depths[i],
+ window_size=window_size,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[sum(depths[:i]):sum(depths[:i + 1])],
+ downsample=downsample,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ with_cp=with_cp,
+ init_cfg=None)
+ self.stages.append(stage)
+ if downsample:
+ in_channels = downsample.out_channels
+
+ self.num_features = [int(embed_dims * 2**i) for i in range(num_layers)]
+ # Add a norm layer for each output
+ for i in out_indices:
+ layer = build_norm_layer(norm_cfg, self.num_features[i])[1]
+ layer_name = f'norm{i}'
+ self.add_module(layer_name, layer)
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep layers freezed."""
+ super(SwinTransformer, self).train(mode)
+ self._freeze_stages()
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ self.patch_embed.eval()
+ for param in self.patch_embed.parameters():
+ param.requires_grad = False
+ if self.use_abs_pos_embed:
+ self.absolute_pos_embed.requires_grad = False
+ self.drop_after_pos.eval()
+
+ for i in range(1, self.frozen_stages + 1):
+
+ if (i - 1) in self.out_indices:
+ norm_layer = getattr(self, f'norm{i-1}')
+ norm_layer.eval()
+ for param in norm_layer.parameters():
+ param.requires_grad = False
+
+ m = self.stages[i - 1]
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def init_weights(self):
+ logger = get_root_logger()
+ if self.init_cfg is None:
+ logger.warn(f'No pre-trained weights for '
+ f'{self.__class__.__name__}, '
+ f'training start from scratch')
+ if self.use_abs_pos_embed:
+ trunc_normal_(self.absolute_pos_embed, std=0.02)
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=.02, bias=0.)
+ elif isinstance(m, nn.LayerNorm):
+ constant_init(m, val=1.0, bias=0.)
+ else:
+ assert 'checkpoint' in self.init_cfg, f'Only support ' \
+ f'specify `Pretrained` in ' \
+ f'`init_cfg` in ' \
+ f'{self.__class__.__name__} '
+ ckpt = CheckpointLoader.load_checkpoint(
+ self.init_cfg['checkpoint'], logger=logger, map_location='cpu')
+ if 'state_dict' in ckpt:
+ _state_dict = ckpt['state_dict']
+ elif 'model' in ckpt:
+ _state_dict = ckpt['model']
+ else:
+ _state_dict = ckpt
+
+ state_dict = OrderedDict()
+ for k, v in _state_dict.items():
+ if k.startswith('backbone.'):
+ state_dict[k[9:]] = v
+ else:
+ state_dict[k] = v
+
+ # strip prefix of state_dict
+ if list(state_dict.keys())[0].startswith('module.'):
+ state_dict = {k[7:]: v for k, v in state_dict.items()}
+
+ # reshape absolute position embedding
+ if state_dict.get('absolute_pos_embed') is not None:
+ absolute_pos_embed = state_dict['absolute_pos_embed']
+ N1, L, C1 = absolute_pos_embed.size()
+ N2, C2, H, W = self.absolute_pos_embed.size()
+ if N1 != N2 or C1 != C2 or L != H * W:
+ logger.warning('Error in loading absolute_pos_embed, pass')
+ else:
+ state_dict['absolute_pos_embed'] = absolute_pos_embed.view(
+ N2, H, W, C2).permute(0, 3, 1, 2).contiguous()
+
+ # interpolate position bias table if needed
+ relative_position_bias_table_keys = [
+ k for k in state_dict.keys()
+ if 'relative_position_bias_table' in k
+ ]
+ for table_key in relative_position_bias_table_keys:
+ table_pretrained = state_dict[table_key]
+ table_current = self.state_dict()[table_key]
+ L1, nH1 = table_pretrained.size()
+ L2, nH2 = table_current.size()
+ if nH1 != nH2:
+ logger.warning(f'Error in loading {table_key}, pass')
+ elif L1 != L2:
+ S1 = int(L1**0.5)
+ S2 = int(L2**0.5)
+ table_pretrained_resized = F.interpolate(
+ table_pretrained.permute(1, 0).reshape(1, nH1, S1, S1),
+ size=(S2, S2),
+ mode='bicubic')
+ state_dict[table_key] = table_pretrained_resized.view(
+ nH2, L2).permute(1, 0).contiguous()
+
+ # load state_dict
+ load_state_dict(self, state_dict, strict=False, logger=logger)
+
+ def forward(self, x):
+ x, hw_shape = self.patch_embed(x)
+
+ if self.use_abs_pos_embed:
+ x = x + self.absolute_pos_embed
+ x = self.drop_after_pos(x)
+
+ outs = []
+ for i, stage in enumerate(self.stages):
+ x, hw_shape, out, out_hw_shape = stage(x, hw_shape)
+ if i in self.out_indices:
+ norm_layer = getattr(self, f'norm{i}')
+ out = norm_layer(out)
+ out = out.view(-1, *out_hw_shape,
+ self.num_features[i]).permute(0, 3, 1,
+ 2).contiguous()
+ outs.append(out)
+
+ return outs
diff --git a/mmseg/models/backbones/timm_backbone.py b/mmseg/models/backbones/timm_backbone.py
new file mode 100644
index 0000000..01b29fc
--- /dev/null
+++ b/mmseg/models/backbones/timm_backbone.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+try:
+ import timm
+except ImportError:
+ timm = None
+
+from mmcv.cnn.bricks.registry import NORM_LAYERS
+from mmcv.runner import BaseModule
+
+from ..builder import BACKBONES
+
+
+@BACKBONES.register_module()
+class TIMMBackbone(BaseModule):
+ """Wrapper to use backbones from timm library. More details can be found in
+ `timm `_ .
+
+ Args:
+ model_name (str): Name of timm model to instantiate.
+ pretrained (bool): Load pretrained weights if True.
+ checkpoint_path (str): Path of checkpoint to load after
+ model is initialized.
+ in_channels (int): Number of input image channels. Default: 3.
+ init_cfg (dict, optional): Initialization config dict
+ **kwargs: Other timm & model specific arguments.
+ """
+
+ def __init__(
+ self,
+ model_name,
+ features_only=True,
+ pretrained=True,
+ checkpoint_path='',
+ in_channels=3,
+ init_cfg=None,
+ **kwargs,
+ ):
+ if timm is None:
+ raise RuntimeError('timm is not installed')
+ super(TIMMBackbone, self).__init__(init_cfg)
+ if 'norm_layer' in kwargs:
+ kwargs['norm_layer'] = NORM_LAYERS.get(kwargs['norm_layer'])
+ self.timm_model = timm.create_model(
+ model_name=model_name,
+ features_only=features_only,
+ pretrained=pretrained,
+ in_chans=in_channels,
+ checkpoint_path=checkpoint_path,
+ **kwargs,
+ )
+
+ # Make unused parameters None
+ self.timm_model.global_pool = None
+ self.timm_model.fc = None
+ self.timm_model.classifier = None
+
+ # Hack to use pretrained weights from timm
+ if pretrained or checkpoint_path:
+ self._is_init = True
+
+ def forward(self, x):
+ features = self.timm_model(x)
+ return features
diff --git a/mmseg/models/backbones/twins.py b/mmseg/models/backbones/twins.py
new file mode 100644
index 0000000..b41325b
--- /dev/null
+++ b/mmseg/models/backbones/twins.py
@@ -0,0 +1,587 @@
+import math
+import warnings
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.drop import build_dropout
+from mmcv.cnn.bricks.transformer import FFN
+from mmcv.cnn.utils.weight_init import (constant_init, normal_init,
+ trunc_normal_init)
+from mmcv.runner import BaseModule, ModuleList
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmseg.models.backbones.mit import EfficientMultiheadAttention
+from mmseg.models.builder import BACKBONES
+from ..utils.embed import PatchEmbed
+
+
+class GlobalSubsampledAttention(EfficientMultiheadAttention):
+ """Global Sub-sampled Attention (Spatial Reduction Attention)
+
+ This module is modified from EfficientMultiheadAttention,
+ which is a module from mmseg.models.backbones.mit.py.
+ Specifically, there is no difference between
+ `GlobalSubsampledAttention` and `EfficientMultiheadAttention`,
+ `GlobalSubsampledAttention` is built as a brand new class
+ because it is renamed as `Global sub-sampled attention (GSA)`
+ in paper.
+
+
+ Args:
+ embed_dims (int): The embedding dimension.
+ num_heads (int): Parallel attention heads.
+ attn_drop (float): A Dropout layer on attn_output_weights.
+ Default: 0.0.
+ proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
+ Default: 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut. Default: None.
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dims)
+ or (n, batch, embed_dims). Default: False.
+ qkv_bias (bool): enable bias for qkv if True. Default: True.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (int): The ratio of spatial reduction of GSA of PCPVT.
+ Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ attn_drop=0.,
+ proj_drop=0.,
+ dropout_layer=None,
+ batch_first=True,
+ qkv_bias=True,
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1,
+ init_cfg=None):
+ super(GlobalSubsampledAttention, self).__init__(
+ embed_dims,
+ num_heads,
+ attn_drop=attn_drop,
+ proj_drop=proj_drop,
+ dropout_layer=dropout_layer,
+ batch_first=batch_first,
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio,
+ init_cfg=init_cfg)
+
+
+class GSAEncoderLayer(BaseModule):
+ """Implements one encoder layer with GSA.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default: 0.0.
+ drop_path_rate (float): Stochastic depth rate. Default 0.0.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (float): Kernel_size of conv in Attention modules. Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ num_fcs=2,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1.,
+ init_cfg=None):
+ super(GSAEncoderLayer, self).__init__(init_cfg=init_cfg)
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims, postfix=1)[1]
+ self.attn = GlobalSubsampledAttention(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ attn_drop=attn_drop_rate,
+ proj_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio)
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims, postfix=2)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=num_fcs,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=False)
+
+ self.drop_path = build_dropout(
+ dict(type='DropPath', drop_prob=drop_path_rate)
+ ) if drop_path_rate > 0. else nn.Identity()
+
+ def forward(self, x, hw_shape):
+ x = x + self.drop_path(self.attn(self.norm1(x), hw_shape, identity=0.))
+ x = x + self.drop_path(self.ffn(self.norm2(x)))
+ return x
+
+
+class LocallyGroupedSelfAttention(BaseModule):
+ """Locally-grouped Self Attention (LSA) module.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads. Default: 8
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: False.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
+ window_size(int): Window size of LSA. Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads=8,
+ qkv_bias=False,
+ qk_scale=None,
+ attn_drop_rate=0.,
+ proj_drop_rate=0.,
+ window_size=1,
+ init_cfg=None):
+ super(LocallyGroupedSelfAttention, self).__init__(init_cfg=init_cfg)
+
+ assert embed_dims % num_heads == 0, f'dim {embed_dims} should be ' \
+ f'divided by num_heads ' \
+ f'{num_heads}.'
+ self.embed_dims = embed_dims
+ self.num_heads = num_heads
+ head_dim = embed_dims // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop_rate)
+ self.proj = nn.Linear(embed_dims, embed_dims)
+ self.proj_drop = nn.Dropout(proj_drop_rate)
+ self.window_size = window_size
+
+ def forward(self, x, hw_shape):
+ b, n, c = x.shape
+ h, w = hw_shape
+ x = x.view(b, h, w, c)
+
+ # pad feature maps to multiples of Local-groups
+ pad_l = pad_t = 0
+ pad_r = (self.window_size - w % self.window_size) % self.window_size
+ pad_b = (self.window_size - h % self.window_size) % self.window_size
+ x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
+
+ # calculate attention mask for LSA
+ Hp, Wp = x.shape[1:-1]
+ _h, _w = Hp // self.window_size, Wp // self.window_size
+ mask = torch.zeros((1, Hp, Wp), device=x.device)
+ mask[:, -pad_b:, :].fill_(1)
+ mask[:, :, -pad_r:].fill_(1)
+
+ # [B, _h, _w, window_size, window_size, C]
+ x = x.reshape(b, _h, self.window_size, _w, self.window_size,
+ c).transpose(2, 3)
+ mask = mask.reshape(1, _h, self.window_size, _w,
+ self.window_size).transpose(2, 3).reshape(
+ 1, _h * _w,
+ self.window_size * self.window_size)
+ # [1, _h*_w, window_size*window_size, window_size*window_size]
+ attn_mask = mask.unsqueeze(2) - mask.unsqueeze(3)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-1000.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+
+ # [3, B, _w*_h, nhead, window_size*window_size, dim]
+ qkv = self.qkv(x).reshape(b, _h * _w,
+ self.window_size * self.window_size, 3,
+ self.num_heads, c // self.num_heads).permute(
+ 3, 0, 1, 4, 2, 5)
+ q, k, v = qkv[0], qkv[1], qkv[2]
+ # [B, _h*_w, n_head, window_size*window_size, window_size*window_size]
+ attn = (q @ k.transpose(-2, -1)) * self.scale
+ attn = attn + attn_mask.unsqueeze(2)
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+ attn = (attn @ v).transpose(2, 3).reshape(b, _h, _w, self.window_size,
+ self.window_size, c)
+ x = attn.transpose(2, 3).reshape(b, _h * self.window_size,
+ _w * self.window_size, c)
+ if pad_r > 0 or pad_b > 0:
+ x = x[:, :h, :w, :].contiguous()
+
+ x = x.reshape(b, n, c)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class LSAEncoderLayer(BaseModule):
+ """Implements one encoder layer in Twins-SVT.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ drop_path_rate (float): Stochastic depth rate. Default 0.0.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ window_size (int): Window size of LSA. Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ num_fcs=2,
+ qkv_bias=True,
+ qk_scale=None,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ window_size=1,
+ init_cfg=None):
+
+ super(LSAEncoderLayer, self).__init__(init_cfg=init_cfg)
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims, postfix=1)[1]
+ self.attn = LocallyGroupedSelfAttention(embed_dims, num_heads,
+ qkv_bias, qk_scale,
+ attn_drop_rate, drop_rate,
+ window_size)
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims, postfix=2)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=num_fcs,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=False)
+
+ self.drop_path = build_dropout(
+ dict(type='DropPath', drop_prob=drop_path_rate)
+ ) if drop_path_rate > 0. else nn.Identity()
+
+ def forward(self, x, hw_shape):
+ x = x + self.drop_path(self.attn(self.norm1(x), hw_shape))
+ x = x + self.drop_path(self.ffn(self.norm2(x)))
+ return x
+
+
+class ConditionalPositionEncoding(BaseModule):
+ """The Conditional Position Encoding (CPE) module.
+
+ The CPE is the implementation of 'Conditional Positional Encodings
+ for Vision Transformers '_.
+
+ Args:
+ in_channels (int): Number of input channels.
+ embed_dims (int): The feature dimension. Default: 768.
+ stride (int): Stride of conv layer. Default: 1.
+ """
+
+ def __init__(self, in_channels, embed_dims=768, stride=1, init_cfg=None):
+ super(ConditionalPositionEncoding, self).__init__(init_cfg=init_cfg)
+ self.proj = nn.Conv2d(
+ in_channels,
+ embed_dims,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ bias=True,
+ groups=embed_dims)
+ self.stride = stride
+
+ def forward(self, x, hw_shape):
+ b, n, c = x.shape
+ h, w = hw_shape
+ feat_token = x
+ cnn_feat = feat_token.transpose(1, 2).view(b, c, h, w)
+ if self.stride == 1:
+ x = self.proj(cnn_feat) + cnn_feat
+ else:
+ x = self.proj(cnn_feat)
+ x = x.flatten(2).transpose(1, 2)
+ return x
+
+
+@BACKBONES.register_module()
+class PCPVT(BaseModule):
+ """The backbone of Twins-PCPVT.
+
+ This backbone is the implementation of `Twins: Revisiting the Design
+ of Spatial Attention in Vision Transformers
+ `_.
+
+ Args:
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (list): Embedding dimension. Default: [64, 128, 256, 512].
+ patch_sizes (list): The patch sizes. Default: [4, 2, 2, 2].
+ strides (list): The strides. Default: [4, 2, 2, 2].
+ num_heads (int): Number of attention heads. Default: [1, 2, 4, 8].
+ mlp_ratios (int): Ratio of mlp hidden dim to embedding dim.
+ Default: [4, 4, 4, 4].
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool): Enable bias for qkv if True. Default: False.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0
+ drop_path_rate (float): Stochastic depth rate. Default 0.0
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ depths (list): Depths of each stage. Default [3, 4, 6, 3]
+ sr_ratios (list): Kernel_size of conv in each Attn module in
+ Transformer encoder layer. Default: [8, 4, 2, 1].
+ norm_after_stage(bool): Add extra norm. Default False.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=[64, 128, 256, 512],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ num_heads=[1, 2, 4, 8],
+ mlp_ratios=[4, 4, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=False,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ norm_cfg=dict(type='LN'),
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False,
+ pretrained=None,
+ init_cfg=None):
+ super(PCPVT, self).__init__(init_cfg=init_cfg)
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be set at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is not None:
+ raise TypeError('pretrained must be a str or None')
+ self.depths = depths
+
+ # patch_embed
+ self.patch_embeds = ModuleList()
+ self.position_encoding_drops = ModuleList()
+ self.layers = ModuleList()
+
+ for i in range(len(depths)):
+ self.patch_embeds.append(
+ PatchEmbed(
+ in_channels=in_channels if i == 0 else embed_dims[i - 1],
+ embed_dims=embed_dims[i],
+ conv_type='Conv2d',
+ kernel_size=patch_sizes[i],
+ stride=strides[i],
+ padding='corner',
+ norm_cfg=norm_cfg))
+
+ self.position_encoding_drops.append(nn.Dropout(p=drop_rate))
+
+ self.position_encodings = ModuleList([
+ ConditionalPositionEncoding(embed_dim, embed_dim)
+ for embed_dim in embed_dims
+ ])
+
+ # transformer encoder
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+ cur = 0
+
+ for k in range(len(depths)):
+ _block = ModuleList([
+ GSAEncoderLayer(
+ embed_dims=embed_dims[k],
+ num_heads=num_heads[k],
+ feedforward_channels=mlp_ratios[k] * embed_dims[k],
+ attn_drop_rate=attn_drop_rate,
+ drop_rate=drop_rate,
+ drop_path_rate=dpr[cur + i],
+ num_fcs=2,
+ qkv_bias=qkv_bias,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ sr_ratio=sr_ratios[k]) for i in range(depths[k])
+ ])
+ self.layers.append(_block)
+ cur += depths[k]
+
+ self.norm_name, norm = build_norm_layer(
+ norm_cfg, embed_dims[-1], postfix=1)
+
+ self.out_indices = out_indices
+ self.norm_after_stage = norm_after_stage
+ if self.norm_after_stage:
+ self.norm_list = ModuleList()
+ for dim in embed_dims:
+ self.norm_list.append(build_norm_layer(norm_cfg, dim)[1])
+
+ def init_weights(self):
+ if self.init_cfg is not None:
+ super(PCPVT, self).init_weights()
+ else:
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=.02, bias=0.)
+ elif isinstance(m, (_BatchNorm, nn.GroupNorm, nn.LayerNorm)):
+ constant_init(m, val=1.0, bias=0.)
+ elif isinstance(m, nn.Conv2d):
+ fan_out = m.kernel_size[0] * m.kernel_size[
+ 1] * m.out_channels
+ fan_out //= m.groups
+ normal_init(
+ m, mean=0, std=math.sqrt(2.0 / fan_out), bias=0)
+
+ def forward(self, x):
+ outputs = list()
+
+ b = x.shape[0]
+
+ for i in range(len(self.depths)):
+ x, hw_shape = self.patch_embeds[i](x)
+ h, w = hw_shape
+ x = self.position_encoding_drops[i](x)
+ for j, blk in enumerate(self.layers[i]):
+ x = blk(x, hw_shape)
+ if j == 0:
+ x = self.position_encodings[i](x, hw_shape)
+ if self.norm_after_stage:
+ x = self.norm_list[i](x)
+ x = x.reshape(b, h, w, -1).permute(0, 3, 1, 2).contiguous()
+
+ if i in self.out_indices:
+ outputs.append(x)
+
+ return tuple(outputs)
+
+
+@BACKBONES.register_module()
+class SVT(PCPVT):
+ """The backbone of Twins-SVT.
+
+ This backbone is the implementation of `Twins: Revisiting the Design
+ of Spatial Attention in Vision Transformers
+ `_.
+
+ Args:
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (list): Embedding dimension. Default: [64, 128, 256, 512].
+ patch_sizes (list): The patch sizes. Default: [4, 2, 2, 2].
+ strides (list): The strides. Default: [4, 2, 2, 2].
+ num_heads (int): Number of attention heads. Default: [1, 2, 4].
+ mlp_ratios (int): Ratio of mlp hidden dim to embedding dim.
+ Default: [4, 4, 4].
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool): Enable bias for qkv if True. Default: False.
+ drop_rate (float): Dropout rate. Default 0.
+ attn_drop_rate (float): Dropout ratio of attention weight.
+ Default 0.0
+ drop_path_rate (float): Stochastic depth rate. Default 0.2.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ depths (list): Depths of each stage. Default [4, 4, 4].
+ sr_ratios (list): Kernel_size of conv in each Attn module in
+ Transformer encoder layer. Default: [4, 2, 1].
+ windiow_sizes (list): Window size of LSA. Default: [7, 7, 7],
+ input_features_slice(bool): Input features need slice. Default: False.
+ norm_after_stage(bool): Add extra norm. Default False.
+ strides (list): Strides in patch-Embedding modules. Default: (2, 2, 2)
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=[64, 128, 256],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ num_heads=[1, 2, 4],
+ mlp_ratios=[4, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=False,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2,
+ norm_cfg=dict(type='LN'),
+ depths=[4, 4, 4],
+ sr_ratios=[4, 2, 1],
+ windiow_sizes=[7, 7, 7],
+ norm_after_stage=True,
+ pretrained=None,
+ init_cfg=None):
+ super(SVT, self).__init__(in_channels, embed_dims, patch_sizes,
+ strides, num_heads, mlp_ratios, out_indices,
+ qkv_bias, drop_rate, attn_drop_rate,
+ drop_path_rate, norm_cfg, depths, sr_ratios,
+ norm_after_stage, pretrained, init_cfg)
+ # transformer encoder
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+
+ for k in range(len(depths)):
+ for i in range(depths[k]):
+ if i % 2 == 0:
+ self.layers[k][i] = \
+ LSAEncoderLayer(
+ embed_dims=embed_dims[k],
+ num_heads=num_heads[k],
+ feedforward_channels=mlp_ratios[k] * embed_dims[k],
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[sum(depths[:k])+i],
+ qkv_bias=qkv_bias,
+ window_size=windiow_sizes[k])
diff --git a/mmseg/models/backbones/unet.py b/mmseg/models/backbones/unet.py
new file mode 100644
index 0000000..c2d3366
--- /dev/null
+++ b/mmseg/models/backbones/unet.py
@@ -0,0 +1,438 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import (UPSAMPLE_LAYERS, ConvModule, build_activation_layer,
+ build_norm_layer)
+from mmcv.runner import BaseModule
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from mmseg.ops import Upsample
+from ..builder import BACKBONES
+from ..utils import UpConvBlock
+
+
+class BasicConvBlock(nn.Module):
+ """Basic convolutional block for UNet.
+
+ This module consists of several plain convolutional layers.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ num_convs (int): Number of convolutional layers. Default: 2.
+ stride (int): Whether use stride convolution to downsample
+ the input feature map. If stride=2, it only uses stride convolution
+ in the first convolutional layer to downsample the input feature
+ map. Options are 1 or 2. Default: 1.
+ dilation (int): Whether use dilated convolution to expand the
+ receptive field. Set dilation rate of each convolutional layer and
+ the dilation rate of the first convolutional layer is always 1.
+ Default: 1.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_convs=2,
+ stride=1,
+ dilation=1,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ dcn=None,
+ plugins=None):
+ super(BasicConvBlock, self).__init__()
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.with_cp = with_cp
+ convs = []
+ for i in range(num_convs):
+ convs.append(
+ ConvModule(
+ in_channels=in_channels if i == 0 else out_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=stride if i == 0 else 1,
+ dilation=1 if i == 0 else dilation,
+ padding=1 if i == 0 else dilation,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ self.convs = nn.Sequential(*convs)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.convs, x)
+ else:
+ out = self.convs(x)
+ return out
+
+
+@UPSAMPLE_LAYERS.register_module()
+class DeconvModule(nn.Module):
+ """Deconvolution upsample module in decoder for UNet (2X upsample).
+
+ This module uses deconvolution to upsample feature map in the decoder
+ of UNet.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ kernel_size (int): Kernel size of the convolutional layer. Default: 4.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ with_cp=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ *,
+ kernel_size=4,
+ scale_factor=2):
+ super(DeconvModule, self).__init__()
+
+ assert (kernel_size - scale_factor >= 0) and\
+ (kernel_size - scale_factor) % 2 == 0,\
+ f'kernel_size should be greater than or equal to scale_factor '\
+ f'and (kernel_size - scale_factor) should be even numbers, '\
+ f'while the kernel size is {kernel_size} and scale_factor is '\
+ f'{scale_factor}.'
+
+ stride = scale_factor
+ padding = (kernel_size - scale_factor) // 2
+ self.with_cp = with_cp
+ deconv = nn.ConvTranspose2d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding)
+
+ norm_name, norm = build_norm_layer(norm_cfg, out_channels)
+ activate = build_activation_layer(act_cfg)
+ self.deconv_upsamping = nn.Sequential(deconv, norm, activate)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.deconv_upsamping, x)
+ else:
+ out = self.deconv_upsamping(x)
+ return out
+
+
+@UPSAMPLE_LAYERS.register_module()
+class InterpConv(nn.Module):
+ """Interpolation upsample module in decoder for UNet.
+
+ This module uses interpolation to upsample feature map in the decoder
+ of UNet. It consists of one interpolation upsample layer and one
+ convolutional layer. It can be one interpolation upsample layer followed
+ by one convolutional layer (conv_first=False) or one convolutional layer
+ followed by one interpolation upsample layer (conv_first=True).
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ conv_first (bool): Whether convolutional layer or interpolation
+ upsample layer first. Default: False. It means interpolation
+ upsample layer followed by one convolutional layer.
+ kernel_size (int): Kernel size of the convolutional layer. Default: 1.
+ stride (int): Stride of the convolutional layer. Default: 1.
+ padding (int): Padding of the convolutional layer. Default: 1.
+ upsample_cfg (dict): Interpolation config of the upsample layer.
+ Default: dict(
+ scale_factor=2, mode='bilinear', align_corners=False).
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ with_cp=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ *,
+ conv_cfg=None,
+ conv_first=False,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False)):
+ super(InterpConv, self).__init__()
+
+ self.with_cp = with_cp
+ conv = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ upsample = Upsample(**upsample_cfg)
+ if conv_first:
+ self.interp_upsample = nn.Sequential(conv, upsample)
+ else:
+ self.interp_upsample = nn.Sequential(upsample, conv)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.interp_upsample, x)
+ else:
+ out = self.interp_upsample(x)
+ return out
+
+
+@BACKBONES.register_module()
+class UNet(BaseModule):
+ """UNet backbone.
+
+ This backbone is the implementation of `U-Net: Convolutional Networks
+ for Biomedical Image Segmentation `_.
+
+ Args:
+ in_channels (int): Number of input image channels. Default" 3.
+ base_channels (int): Number of base channels of each stage.
+ The output channels of the first stage. Default: 64.
+ num_stages (int): Number of stages in encoder, normally 5. Default: 5.
+ strides (Sequence[int 1 | 2]): Strides of each stage in encoder.
+ len(strides) is equal to num_stages. Normally the stride of the
+ first stage in encoder is 1. If strides[i]=2, it uses stride
+ convolution to downsample in the correspondence encoder stage.
+ Default: (1, 1, 1, 1, 1).
+ enc_num_convs (Sequence[int]): Number of convolutional layers in the
+ convolution block of the correspondence encoder stage.
+ Default: (2, 2, 2, 2, 2).
+ dec_num_convs (Sequence[int]): Number of convolutional layers in the
+ convolution block of the correspondence decoder stage.
+ Default: (2, 2, 2, 2).
+ downsamples (Sequence[int]): Whether use MaxPool to downsample the
+ feature map after the first stage of encoder
+ (stages: [1, num_stages)). If the correspondence encoder stage use
+ stride convolution (strides[i]=2), it will never use MaxPool to
+ downsample, even downsamples[i-1]=True.
+ Default: (True, True, True, True).
+ enc_dilations (Sequence[int]): Dilation rate of each stage in encoder.
+ Default: (1, 1, 1, 1, 1).
+ dec_dilations (Sequence[int]): Dilation rate of each stage in decoder.
+ Default: (1, 1, 1, 1).
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ upsample_cfg (dict): The upsample config of the upsample module in
+ decoder. Default: dict(type='InterpConv').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+
+ Notice:
+ The input image size should be divisible by the whole downsample rate
+ of the encoder. More detail of the whole downsample rate can be found
+ in UNet._check_input_divisible.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ base_channels=64,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ norm_eval=False,
+ dcn=None,
+ plugins=None,
+ pretrained=None,
+ init_cfg=None):
+ super(UNet, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+ assert len(strides) == num_stages, \
+ 'The length of strides should be equal to num_stages, '\
+ f'while the strides is {strides}, the length of '\
+ f'strides is {len(strides)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(enc_num_convs) == num_stages, \
+ 'The length of enc_num_convs should be equal to num_stages, '\
+ f'while the enc_num_convs is {enc_num_convs}, the length of '\
+ f'enc_num_convs is {len(enc_num_convs)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(dec_num_convs) == (num_stages-1), \
+ 'The length of dec_num_convs should be equal to (num_stages-1), '\
+ f'while the dec_num_convs is {dec_num_convs}, the length of '\
+ f'dec_num_convs is {len(dec_num_convs)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(downsamples) == (num_stages-1), \
+ 'The length of downsamples should be equal to (num_stages-1), '\
+ f'while the downsamples is {downsamples}, the length of '\
+ f'downsamples is {len(downsamples)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(enc_dilations) == num_stages, \
+ 'The length of enc_dilations should be equal to num_stages, '\
+ f'while the enc_dilations is {enc_dilations}, the length of '\
+ f'enc_dilations is {len(enc_dilations)}, and the num_stages is '\
+ f'{num_stages}.'
+ assert len(dec_dilations) == (num_stages-1), \
+ 'The length of dec_dilations should be equal to (num_stages-1), '\
+ f'while the dec_dilations is {dec_dilations}, the length of '\
+ f'dec_dilations is {len(dec_dilations)}, and the num_stages is '\
+ f'{num_stages}.'
+ self.num_stages = num_stages
+ self.strides = strides
+ self.downsamples = downsamples
+ self.norm_eval = norm_eval
+ self.base_channels = base_channels
+
+ self.encoder = nn.ModuleList()
+ self.decoder = nn.ModuleList()
+
+ for i in range(num_stages):
+ enc_conv_block = []
+ if i != 0:
+ if strides[i] == 1 and downsamples[i - 1]:
+ enc_conv_block.append(nn.MaxPool2d(kernel_size=2))
+ upsample = (strides[i] != 1 or downsamples[i - 1])
+ self.decoder.append(
+ UpConvBlock(
+ conv_block=BasicConvBlock,
+ in_channels=base_channels * 2**i,
+ skip_channels=base_channels * 2**(i - 1),
+ out_channels=base_channels * 2**(i - 1),
+ num_convs=dec_num_convs[i - 1],
+ stride=1,
+ dilation=dec_dilations[i - 1],
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ upsample_cfg=upsample_cfg if upsample else None,
+ dcn=None,
+ plugins=None))
+
+ enc_conv_block.append(
+ BasicConvBlock(
+ in_channels=in_channels,
+ out_channels=base_channels * 2**i,
+ num_convs=enc_num_convs[i],
+ stride=strides[i],
+ dilation=enc_dilations[i],
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dcn=None,
+ plugins=None))
+ self.encoder.append((nn.Sequential(*enc_conv_block)))
+ in_channels = base_channels * 2**i
+
+ def forward(self, x):
+ self._check_input_divisible(x)
+ enc_outs = []
+ for enc in self.encoder:
+ x = enc(x)
+ enc_outs.append(x)
+ dec_outs = [x]
+ for i in reversed(range(len(self.decoder))):
+ x = self.decoder[i](enc_outs[i], x)
+ dec_outs.append(x)
+
+ return dec_outs
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep normalization layer
+ freezed."""
+ super(UNet, self).train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ def _check_input_divisible(self, x):
+ h, w = x.shape[-2:]
+ whole_downsample_rate = 1
+ for i in range(1, self.num_stages):
+ if self.strides[i] == 2 or self.downsamples[i - 1]:
+ whole_downsample_rate *= 2
+ assert (h % whole_downsample_rate == 0) \
+ and (w % whole_downsample_rate == 0),\
+ f'The input image size {(h, w)} should be divisible by the whole '\
+ f'downsample rate {whole_downsample_rate}, when num_stages is '\
+ f'{self.num_stages}, strides is {self.strides}, and downsamples '\
+ f'is {self.downsamples}.'
diff --git a/mmseg/models/backbones/vit.py b/mmseg/models/backbones/vit.py
new file mode 100644
index 0000000..9c920ba
--- /dev/null
+++ b/mmseg/models/backbones/vit.py
@@ -0,0 +1,413 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import warnings
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+from mmcv.cnn.utils.weight_init import (constant_init, kaiming_init,
+ trunc_normal_)
+from mmcv.runner import (BaseModule, CheckpointLoader, ModuleList,
+ load_state_dict)
+from torch.nn.modules.batchnorm import _BatchNorm
+from torch.nn.modules.utils import _pair as to_2tuple
+
+from mmseg.ops import resize
+from mmseg.utils import get_root_logger
+from ..builder import BACKBONES
+from ..utils import PatchEmbed
+
+
+class TransformerEncoderLayer(BaseModule):
+ """Implements one encoder layer in Vision Transformer.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default: 0.0.
+ drop_path_rate (float): stochastic depth rate. Default 0.0.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): enable bias for qkv if True. Default: True
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dim)
+ or (n, batch, embed_dim). Default: True.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ num_fcs=2,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ batch_first=True):
+ super(TransformerEncoderLayer, self).__init__()
+
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, embed_dims, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+
+ self.attn = MultiheadAttention(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ attn_drop=attn_drop_rate,
+ proj_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ batch_first=batch_first,
+ bias=qkv_bias)
+
+ self.norm2_name, norm2 = build_norm_layer(
+ norm_cfg, embed_dims, postfix=2)
+ self.add_module(self.norm2_name, norm2)
+
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=num_fcs,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg)
+
+ @property
+ def norm1(self):
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ return getattr(self, self.norm2_name)
+
+ def forward(self, x):
+ x = self.attn(self.norm1(x), identity=x)
+ x = self.ffn(self.norm2(x), identity=x)
+ return x
+
+
+@BACKBONES.register_module()
+class VisionTransformer(BaseModule):
+ """Vision Transformer.
+
+ This backbone is the implementation of `An Image is Worth 16x16 Words:
+ Transformers for Image Recognition at
+ Scale `_.
+
+ Args:
+ img_size (int | tuple): Input image size. Default: 224.
+ patch_size (int): The patch size. Default: 16.
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (int): embedding dimension. Default: 768.
+ num_layers (int): depth of transformer. Default: 12.
+ num_heads (int): number of attention heads. Default: 12.
+ mlp_ratio (int): ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ out_indices (list | tuple | int): Output from which stages.
+ Default: -1.
+ qkv_bias (bool): enable bias for qkv if True. Default: True.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.0
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0
+ drop_path_rate (float): stochastic depth rate. Default 0.0
+ with_cls_token (bool): Whether concatenating class token into image
+ tokens as transformer input. Default: True.
+ output_cls_token (bool): Whether output the cls_token. If set True,
+ `with_cls_token` must be True. Default: False.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ patch_norm (bool): Whether to add a norm in PatchEmbed Block.
+ Default: False.
+ final_norm (bool): Whether to add a additional layer to normalize
+ final feature map. Default: False.
+ interpolate_mode (str): Select the interpolate mode for position
+ embeding vector resize. Default: bicubic.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save
+ some memory while slowing down the training speed. Default: False.
+ pretrained (str, optional): model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ img_size=224,
+ patch_size=16,
+ in_channels=3,
+ embed_dims=768,
+ num_layers=12,
+ num_heads=12,
+ mlp_ratio=4,
+ out_indices=-1,
+ qkv_bias=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ with_cls_token=True,
+ output_cls_token=False,
+ norm_cfg=dict(type='LN'),
+ act_cfg=dict(type='GELU'),
+ patch_norm=False,
+ final_norm=False,
+ interpolate_mode='bicubic',
+ num_fcs=2,
+ norm_eval=False,
+ with_cp=False,
+ pretrained=None,
+ init_cfg=None):
+ super(VisionTransformer, self).__init__(init_cfg=init_cfg)
+
+ if isinstance(img_size, int):
+ img_size = to_2tuple(img_size)
+ elif isinstance(img_size, tuple):
+ if len(img_size) == 1:
+ img_size = to_2tuple(img_size[0])
+ assert len(img_size) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(img_size)}'
+
+ if output_cls_token:
+ assert with_cls_token is True, f'with_cls_token must be True if' \
+ f'set output_cls_token to True, but got {with_cls_token}'
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be set at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is not None:
+ raise TypeError('pretrained must be a str or None')
+
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.interpolate_mode = interpolate_mode
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.pretrained = pretrained
+
+ self.patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims,
+ conv_type='Conv2d',
+ kernel_size=patch_size,
+ stride=patch_size,
+ padding='corner',
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None,
+ )
+
+ num_patches = (img_size[0] // patch_size) * \
+ (img_size[1] // patch_size)
+
+ self.with_cls_token = with_cls_token
+ self.output_cls_token = output_cls_token
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims))
+ self.pos_embed = nn.Parameter(
+ torch.zeros(1, num_patches + 1, embed_dims))
+ self.drop_after_pos = nn.Dropout(p=drop_rate)
+
+ if isinstance(out_indices, int):
+ if out_indices == -1:
+ out_indices = num_layers - 1
+ self.out_indices = [out_indices]
+ elif isinstance(out_indices, list) or isinstance(out_indices, tuple):
+ self.out_indices = out_indices
+ else:
+ raise TypeError('out_indices must be type of int, list or tuple')
+
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, num_layers)
+ ] # stochastic depth decay rule
+
+ self.layers = ModuleList()
+ for i in range(num_layers):
+ self.layers.append(
+ TransformerEncoderLayer(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ feedforward_channels=mlp_ratio * embed_dims,
+ attn_drop_rate=attn_drop_rate,
+ drop_rate=drop_rate,
+ drop_path_rate=dpr[i],
+ num_fcs=num_fcs,
+ qkv_bias=qkv_bias,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ batch_first=True))
+
+ self.final_norm = final_norm
+ if final_norm:
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, embed_dims, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+
+ @property
+ def norm1(self):
+ return getattr(self, self.norm1_name)
+
+ def init_weights(self):
+ if (isinstance(self.init_cfg, dict)
+ and self.init_cfg.get('type') == 'Pretrained'):
+ logger = get_root_logger()
+ checkpoint = CheckpointLoader.load_checkpoint(
+ self.init_cfg['checkpoint'], logger=logger, map_location='cpu')
+
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ else:
+ state_dict = checkpoint
+
+ if 'pos_embed' in state_dict.keys():
+ if self.pos_embed.shape != state_dict['pos_embed'].shape:
+ logger.info(msg=f'Resize the pos_embed shape from '
+ f'{state_dict["pos_embed"].shape} to '
+ f'{self.pos_embed.shape}')
+ h, w = self.img_size
+ pos_size = int(
+ math.sqrt(state_dict['pos_embed'].shape[1] - 1))
+ state_dict['pos_embed'] = self.resize_pos_embed(
+ state_dict['pos_embed'],
+ (h // self.patch_size, w // self.patch_size),
+ (pos_size, pos_size), self.interpolate_mode)
+
+ load_state_dict(self, state_dict, strict=False, logger=logger)
+ elif self.init_cfg is not None:
+ super(VisionTransformer, self).init_weights()
+ else:
+ # We only implement the 'jax_impl' initialization implemented at
+ # https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py#L353 # noqa: E501
+ trunc_normal_(self.pos_embed, std=.02)
+ trunc_normal_(self.cls_token, std=.02)
+ for n, m in self.named_modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=.02)
+ if m.bias is not None:
+ if 'ffn' in n:
+ nn.init.normal_(m.bias, mean=0., std=1e-6)
+ else:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.Conv2d):
+ kaiming_init(m, mode='fan_in', bias=0.)
+ elif isinstance(m, (_BatchNorm, nn.GroupNorm, nn.LayerNorm)):
+ constant_init(m, val=1.0, bias=0.)
+
+ def _pos_embeding(self, patched_img, hw_shape, pos_embed):
+ """Positiong embeding method.
+
+ Resize the pos_embed, if the input image size doesn't match
+ the training size.
+ Args:
+ patched_img (torch.Tensor): The patched image, it should be
+ shape of [B, L1, C].
+ hw_shape (tuple): The downsampled image resolution.
+ pos_embed (torch.Tensor): The pos_embed weighs, it should be
+ shape of [B, L2, c].
+ Return:
+ torch.Tensor: The pos encoded image feature.
+ """
+ assert patched_img.ndim == 3 and pos_embed.ndim == 3, \
+ 'the shapes of patched_img and pos_embed must be [B, L, C]'
+ x_len, pos_len = patched_img.shape[1], pos_embed.shape[1]
+ if x_len != pos_len:
+ if pos_len == (self.img_size[0] // self.patch_size) * (
+ self.img_size[1] // self.patch_size) + 1:
+ pos_h = self.img_size[0] // self.patch_size
+ pos_w = self.img_size[1] // self.patch_size
+ else:
+ raise ValueError(
+ 'Unexpected shape of pos_embed, got {}.'.format(
+ pos_embed.shape))
+ pos_embed = self.resize_pos_embed(pos_embed, hw_shape,
+ (pos_h, pos_w),
+ self.interpolate_mode)
+ return self.drop_after_pos(patched_img + pos_embed)
+
+ @staticmethod
+ def resize_pos_embed(pos_embed, input_shpae, pos_shape, mode):
+ """Resize pos_embed weights.
+
+ Resize pos_embed using bicubic interpolate method.
+ Args:
+ pos_embed (torch.Tensor): Position embedding weights.
+ input_shpae (tuple): Tuple for (downsampled input image height,
+ downsampled input image width).
+ pos_shape (tuple): The resolution of downsampled origin training
+ image.
+ mode (str): Algorithm used for upsampling:
+ ``'nearest'`` | ``'linear'`` | ``'bilinear'`` | ``'bicubic'`` |
+ ``'trilinear'``. Default: ``'nearest'``
+ Return:
+ torch.Tensor: The resized pos_embed of shape [B, L_new, C]
+ """
+ assert pos_embed.ndim == 3, 'shape of pos_embed must be [B, L, C]'
+ pos_h, pos_w = pos_shape
+ cls_token_weight = pos_embed[:, 0]
+ pos_embed_weight = pos_embed[:, (-1 * pos_h * pos_w):]
+ pos_embed_weight = pos_embed_weight.reshape(
+ 1, pos_h, pos_w, pos_embed.shape[2]).permute(0, 3, 1, 2)
+ pos_embed_weight = resize(
+ pos_embed_weight, size=input_shpae, align_corners=False, mode=mode)
+ cls_token_weight = cls_token_weight.unsqueeze(1)
+ pos_embed_weight = torch.flatten(pos_embed_weight, 2).transpose(1, 2)
+ pos_embed = torch.cat((cls_token_weight, pos_embed_weight), dim=1)
+ return pos_embed
+
+ def forward(self, inputs):
+ B = inputs.shape[0]
+
+ x, hw_shape = self.patch_embed(inputs)
+
+ # stole cls_tokens impl from Phil Wang, thanks
+ cls_tokens = self.cls_token.expand(B, -1, -1)
+ x = torch.cat((cls_tokens, x), dim=1)
+ x = self._pos_embeding(x, hw_shape, self.pos_embed)
+
+ if not self.with_cls_token:
+ # Remove class token for transformer encoder input
+ x = x[:, 1:]
+
+ outs = []
+ for i, layer in enumerate(self.layers):
+ x = layer(x)
+ if i == len(self.layers) - 1:
+ if self.final_norm:
+ x = self.norm1(x)
+ if i in self.out_indices:
+ if self.with_cls_token:
+ # Remove class token and reshape token for decoder head
+ out = x[:, 1:]
+ else:
+ out = x
+ B, _, C = out.shape
+ out = out.reshape(B, hw_shape[0], hw_shape[1],
+ C).permute(0, 3, 1, 2).contiguous()
+ if self.output_cls_token:
+ out = [out, x[:, 0]]
+ outs.append(out)
+
+ return tuple(outs)
+
+ def train(self, mode=True):
+ super(VisionTransformer, self).train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, nn.LayerNorm):
+ m.eval()
diff --git a/mmseg/models/builder.py b/mmseg/models/builder.py
new file mode 100644
index 0000000..5e18e4e
--- /dev/null
+++ b/mmseg/models/builder.py
@@ -0,0 +1,49 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from mmcv.cnn import MODELS as MMCV_MODELS
+from mmcv.cnn.bricks.registry import ATTENTION as MMCV_ATTENTION
+from mmcv.utils import Registry
+
+MODELS = Registry('models', parent=MMCV_MODELS)
+ATTENTION = Registry('attention', parent=MMCV_ATTENTION)
+
+BACKBONES = MODELS
+NECKS = MODELS
+HEADS = MODELS
+LOSSES = MODELS
+SEGMENTORS = MODELS
+
+
+def build_backbone(cfg):
+ """Build backbone."""
+ return BACKBONES.build(cfg)
+
+
+def build_neck(cfg):
+ """Build neck."""
+ return NECKS.build(cfg)
+
+
+def build_head(cfg):
+ """Build head."""
+ return HEADS.build(cfg)
+
+
+def build_loss(cfg):
+ """Build loss."""
+ return LOSSES.build(cfg)
+
+
+def build_segmentor(cfg, train_cfg=None, test_cfg=None):
+ """Build segmentor."""
+ if train_cfg is not None or test_cfg is not None:
+ warnings.warn(
+ 'train_cfg and test_cfg is deprecated, '
+ 'please specify them in model', UserWarning)
+ assert cfg.get('train_cfg') is None or train_cfg is None, \
+ 'train_cfg specified in both outer field and model field '
+ assert cfg.get('test_cfg') is None or test_cfg is None, \
+ 'test_cfg specified in both outer field and model field '
+ return SEGMENTORS.build(
+ cfg, default_args=dict(train_cfg=train_cfg, test_cfg=test_cfg))
diff --git a/mmseg/models/decode_heads/__init__.py b/mmseg/models/decode_heads/__init__.py
new file mode 100644
index 0000000..dcde813
--- /dev/null
+++ b/mmseg/models/decode_heads/__init__.py
@@ -0,0 +1,38 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ann_head import ANNHead
+from .apc_head import APCHead
+from .aspp_head import ASPPHead
+from .cc_head import CCHead
+from .da_head import DAHead
+from .dm_head import DMHead
+from .dnl_head import DNLHead
+from .dpt_head import DPTHead
+from .ema_head import EMAHead
+from .enc_head import EncHead
+from .fcn_head import FCNHead
+from .fpn_head import FPNHead
+from .gc_head import GCHead
+from .isa_head import ISAHead
+from .lraspp_head import LRASPPHead
+from .nl_head import NLHead
+from .ocr_head import OCRHead
+from .point_head import PointHead
+from .psa_head import PSAHead
+from .psp_head import PSPHead
+from .segformer_head import SegformerHead
+from .segmenter_mask_head import SegmenterMaskTransformerHead
+from .sep_aspp_head import DepthwiseSeparableASPPHead
+from .sep_fcn_head import DepthwiseSeparableFCNHead
+from .setr_mla_head import SETRMLAHead
+from .setr_up_head import SETRUPHead
+from .stdc_head import STDCHead
+from .uper_head import UPerHead
+
+__all__ = [
+ 'FCNHead', 'PSPHead', 'ASPPHead', 'PSAHead', 'NLHead', 'GCHead', 'CCHead',
+ 'UPerHead', 'DepthwiseSeparableASPPHead', 'ANNHead', 'DAHead', 'OCRHead',
+ 'EncHead', 'DepthwiseSeparableFCNHead', 'FPNHead', 'EMAHead', 'DNLHead',
+ 'PointHead', 'APCHead', 'DMHead', 'LRASPPHead', 'SETRUPHead',
+ 'SETRMLAHead', 'DPTHead', 'SETRMLAHead', 'SegmenterMaskTransformerHead',
+ 'SegformerHead', 'ISAHead', 'STDCHead'
+]
diff --git a/mmseg/models/decode_heads/ann_head.py b/mmseg/models/decode_heads/ann_head.py
new file mode 100644
index 0000000..c8d882e
--- /dev/null
+++ b/mmseg/models/decode_heads/ann_head.py
@@ -0,0 +1,246 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from ..builder import HEADS
+from ..utils import SelfAttentionBlock as _SelfAttentionBlock
+from .decode_head import BaseDecodeHead
+
+
+class PPMConcat(nn.ModuleList):
+ """Pyramid Pooling Module that only concat the features of each layer.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module.
+ """
+
+ def __init__(self, pool_scales=(1, 3, 6, 8)):
+ super(PPMConcat, self).__init__(
+ [nn.AdaptiveAvgPool2d(pool_scale) for pool_scale in pool_scales])
+
+ def forward(self, feats):
+ """Forward function."""
+ ppm_outs = []
+ for ppm in self:
+ ppm_out = ppm(feats)
+ ppm_outs.append(ppm_out.view(*feats.shape[:2], -1))
+ concat_outs = torch.cat(ppm_outs, dim=2)
+ return concat_outs
+
+
+class SelfAttentionBlock(_SelfAttentionBlock):
+ """Make a ANN used SelfAttentionBlock.
+
+ Args:
+ low_in_channels (int): Input channels of lower level feature,
+ which is the key feature for self-attention.
+ high_in_channels (int): Input channels of higher level feature,
+ which is the query feature for self-attention.
+ channels (int): Output channels of key/query transform.
+ out_channels (int): Output channels.
+ share_key_query (bool): Whether share projection weight between key
+ and query projection.
+ query_scale (int): The scale of query feature map.
+ key_pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module of key feature.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict|None): Config of activation layers.
+ """
+
+ def __init__(self, low_in_channels, high_in_channels, channels,
+ out_channels, share_key_query, query_scale, key_pool_scales,
+ conv_cfg, norm_cfg, act_cfg):
+ key_psp = PPMConcat(key_pool_scales)
+ if query_scale > 1:
+ query_downsample = nn.MaxPool2d(kernel_size=query_scale)
+ else:
+ query_downsample = None
+ super(SelfAttentionBlock, self).__init__(
+ key_in_channels=low_in_channels,
+ query_in_channels=high_in_channels,
+ channels=channels,
+ out_channels=out_channels,
+ share_key_query=share_key_query,
+ query_downsample=query_downsample,
+ key_downsample=key_psp,
+ key_query_num_convs=1,
+ key_query_norm=True,
+ value_out_num_convs=1,
+ value_out_norm=False,
+ matmul_norm=True,
+ with_out=True,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+
+class AFNB(nn.Module):
+ """Asymmetric Fusion Non-local Block(AFNB)
+
+ Args:
+ low_in_channels (int): Input channels of lower level feature,
+ which is the key feature for self-attention.
+ high_in_channels (int): Input channels of higher level feature,
+ which is the query feature for self-attention.
+ channels (int): Output channels of key/query transform.
+ out_channels (int): Output channels.
+ and query projection.
+ query_scales (tuple[int]): The scales of query feature map.
+ Default: (1,)
+ key_pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module of key feature.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict|None): Config of activation layers.
+ """
+
+ def __init__(self, low_in_channels, high_in_channels, channels,
+ out_channels, query_scales, key_pool_scales, conv_cfg,
+ norm_cfg, act_cfg):
+ super(AFNB, self).__init__()
+ self.stages = nn.ModuleList()
+ for query_scale in query_scales:
+ self.stages.append(
+ SelfAttentionBlock(
+ low_in_channels=low_in_channels,
+ high_in_channels=high_in_channels,
+ channels=channels,
+ out_channels=out_channels,
+ share_key_query=False,
+ query_scale=query_scale,
+ key_pool_scales=key_pool_scales,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.bottleneck = ConvModule(
+ out_channels + high_in_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ def forward(self, low_feats, high_feats):
+ """Forward function."""
+ priors = [stage(high_feats, low_feats) for stage in self.stages]
+ context = torch.stack(priors, dim=0).sum(dim=0)
+ output = self.bottleneck(torch.cat([context, high_feats], 1))
+ return output
+
+
+class APNB(nn.Module):
+ """Asymmetric Pyramid Non-local Block (APNB)
+
+ Args:
+ in_channels (int): Input channels of key/query feature,
+ which is the key feature for self-attention.
+ channels (int): Output channels of key/query transform.
+ out_channels (int): Output channels.
+ query_scales (tuple[int]): The scales of query feature map.
+ Default: (1,)
+ key_pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module of key feature.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict|None): Config of activation layers.
+ """
+
+ def __init__(self, in_channels, channels, out_channels, query_scales,
+ key_pool_scales, conv_cfg, norm_cfg, act_cfg):
+ super(APNB, self).__init__()
+ self.stages = nn.ModuleList()
+ for query_scale in query_scales:
+ self.stages.append(
+ SelfAttentionBlock(
+ low_in_channels=in_channels,
+ high_in_channels=in_channels,
+ channels=channels,
+ out_channels=out_channels,
+ share_key_query=True,
+ query_scale=query_scale,
+ key_pool_scales=key_pool_scales,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.bottleneck = ConvModule(
+ 2 * in_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, feats):
+ """Forward function."""
+ priors = [stage(feats, feats) for stage in self.stages]
+ context = torch.stack(priors, dim=0).sum(dim=0)
+ output = self.bottleneck(torch.cat([context, feats], 1))
+ return output
+
+
+@HEADS.register_module()
+class ANNHead(BaseDecodeHead):
+ """Asymmetric Non-local Neural Networks for Semantic Segmentation.
+
+ This head is the implementation of `ANNNet
+ `_.
+
+ Args:
+ project_channels (int): Projection channels for Nonlocal.
+ query_scales (tuple[int]): The scales of query feature map.
+ Default: (1,)
+ key_pool_scales (tuple[int]): The pooling scales of key feature map.
+ Default: (1, 3, 6, 8).
+ """
+
+ def __init__(self,
+ project_channels,
+ query_scales=(1, ),
+ key_pool_scales=(1, 3, 6, 8),
+ **kwargs):
+ super(ANNHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ assert len(self.in_channels) == 2
+ low_in_channels, high_in_channels = self.in_channels
+ self.project_channels = project_channels
+ self.fusion = AFNB(
+ low_in_channels=low_in_channels,
+ high_in_channels=high_in_channels,
+ out_channels=high_in_channels,
+ channels=project_channels,
+ query_scales=query_scales,
+ key_pool_scales=key_pool_scales,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.bottleneck = ConvModule(
+ high_in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.context = APNB(
+ in_channels=self.channels,
+ out_channels=self.channels,
+ channels=project_channels,
+ query_scales=query_scales,
+ key_pool_scales=key_pool_scales,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ low_feats, high_feats = self._transform_inputs(inputs)
+ output = self.fusion(low_feats, high_feats)
+ output = self.dropout(output)
+ output = self.bottleneck(output)
+ output = self.context(output)
+ output = self.cls_seg(output)
+
+ return output
diff --git a/mmseg/models/decode_heads/apc_head.py b/mmseg/models/decode_heads/apc_head.py
new file mode 100644
index 0000000..3198fd1
--- /dev/null
+++ b/mmseg/models/decode_heads/apc_head.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class ACM(nn.Module):
+ """Adaptive Context Module used in APCNet.
+
+ Args:
+ pool_scale (int): Pooling scale used in Adaptive Context
+ Module to extract region features.
+ fusion (bool): Add one conv to fuse residual feature.
+ in_channels (int): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ conv_cfg (dict | None): Config of conv layers.
+ norm_cfg (dict | None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ """
+
+ def __init__(self, pool_scale, fusion, in_channels, channels, conv_cfg,
+ norm_cfg, act_cfg):
+ super(ACM, self).__init__()
+ self.pool_scale = pool_scale
+ self.fusion = fusion
+ self.in_channels = in_channels
+ self.channels = channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.pooled_redu_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.input_redu_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.global_info = ConvModule(
+ self.channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.gla = nn.Conv2d(self.channels, self.pool_scale**2, 1, 1, 0)
+
+ self.residual_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ if self.fusion:
+ self.fusion_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, x):
+ """Forward function."""
+ pooled_x = F.adaptive_avg_pool2d(x, self.pool_scale)
+ # [batch_size, channels, h, w]
+ x = self.input_redu_conv(x)
+ # [batch_size, channels, pool_scale, pool_scale]
+ pooled_x = self.pooled_redu_conv(pooled_x)
+ batch_size = x.size(0)
+ # [batch_size, pool_scale * pool_scale, channels]
+ pooled_x = pooled_x.view(batch_size, self.channels,
+ -1).permute(0, 2, 1).contiguous()
+ # [batch_size, h * w, pool_scale * pool_scale]
+ affinity_matrix = self.gla(x + resize(
+ self.global_info(F.adaptive_avg_pool2d(x, 1)), size=x.shape[2:])
+ ).permute(0, 2, 3, 1).reshape(
+ batch_size, -1, self.pool_scale**2)
+ affinity_matrix = F.sigmoid(affinity_matrix)
+ # [batch_size, h * w, channels]
+ z_out = torch.matmul(affinity_matrix, pooled_x)
+ # [batch_size, channels, h * w]
+ z_out = z_out.permute(0, 2, 1).contiguous()
+ # [batch_size, channels, h, w]
+ z_out = z_out.view(batch_size, self.channels, x.size(2), x.size(3))
+ z_out = self.residual_conv(z_out)
+ z_out = F.relu(z_out + x)
+ if self.fusion:
+ z_out = self.fusion_conv(z_out)
+
+ return z_out
+
+
+@HEADS.register_module()
+class APCHead(BaseDecodeHead):
+ """Adaptive Pyramid Context Network for Semantic Segmentation.
+
+ This head is the implementation of
+ `APCNet `_.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Adaptive Context
+ Module. Default: (1, 2, 3, 6).
+ fusion (bool): Add one conv to fuse residual feature.
+ """
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), fusion=True, **kwargs):
+ super(APCHead, self).__init__(**kwargs)
+ assert isinstance(pool_scales, (list, tuple))
+ self.pool_scales = pool_scales
+ self.fusion = fusion
+ acm_modules = []
+ for pool_scale in self.pool_scales:
+ acm_modules.append(
+ ACM(pool_scale,
+ self.fusion,
+ self.in_channels,
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.acm_modules = nn.ModuleList(acm_modules)
+ self.bottleneck = ConvModule(
+ self.in_channels + len(pool_scales) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ acm_outs = [x]
+ for acm_module in self.acm_modules:
+ acm_outs.append(acm_module(x))
+ acm_outs = torch.cat(acm_outs, dim=1)
+ output = self.bottleneck(acm_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/aspp_head.py b/mmseg/models/decode_heads/aspp_head.py
new file mode 100644
index 0000000..1fbd1bc
--- /dev/null
+++ b/mmseg/models/decode_heads/aspp_head.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class ASPPModule(nn.ModuleList):
+ """Atrous Spatial Pyramid Pooling (ASPP) Module.
+
+ Args:
+ dilations (tuple[int]): Dilation rate of each layer.
+ in_channels (int): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ """
+
+ def __init__(self, dilations, in_channels, channels, conv_cfg, norm_cfg,
+ act_cfg):
+ super(ASPPModule, self).__init__()
+ self.dilations = dilations
+ self.in_channels = in_channels
+ self.channels = channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ for dilation in dilations:
+ self.append(
+ ConvModule(
+ self.in_channels,
+ self.channels,
+ 1 if dilation == 1 else 3,
+ dilation=dilation,
+ padding=0 if dilation == 1 else dilation,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+
+ def forward(self, x):
+ """Forward function."""
+ aspp_outs = []
+ for aspp_module in self:
+ aspp_outs.append(aspp_module(x))
+
+ return aspp_outs
+
+
+@HEADS.register_module()
+class ASPPHead(BaseDecodeHead):
+ """Rethinking Atrous Convolution for Semantic Image Segmentation.
+
+ This head is the implementation of `DeepLabV3
+ `_.
+
+ Args:
+ dilations (tuple[int]): Dilation rates for ASPP module.
+ Default: (1, 6, 12, 18).
+ """
+
+ def __init__(self, dilations=(1, 6, 12, 18), **kwargs):
+ super(ASPPHead, self).__init__(**kwargs)
+ assert isinstance(dilations, (list, tuple))
+ self.dilations = dilations
+ self.image_pool = nn.Sequential(
+ nn.AdaptiveAvgPool2d(1),
+ ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.aspp_modules = ASPPModule(
+ dilations,
+ self.in_channels,
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.bottleneck = ConvModule(
+ (len(dilations) + 1) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ aspp_outs = [
+ resize(
+ self.image_pool(x),
+ size=x.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ ]
+ aspp_outs.extend(self.aspp_modules(x))
+ aspp_outs = torch.cat(aspp_outs, dim=1)
+ output = self.bottleneck(aspp_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/cascade_decode_head.py b/mmseg/models/decode_heads/cascade_decode_head.py
new file mode 100644
index 0000000..f7c3da0
--- /dev/null
+++ b/mmseg/models/decode_heads/cascade_decode_head.py
@@ -0,0 +1,58 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+from .decode_head import BaseDecodeHead
+
+
+class BaseCascadeDecodeHead(BaseDecodeHead, metaclass=ABCMeta):
+ """Base class for cascade decode head used in
+ :class:`CascadeEncoderDecoder."""
+
+ def __init__(self, *args, **kwargs):
+ super(BaseCascadeDecodeHead, self).__init__(*args, **kwargs)
+
+ @abstractmethod
+ def forward(self, inputs, prev_output):
+ """Placeholder of forward function."""
+ pass
+
+ def forward_train(self, inputs, prev_output, img_metas, gt_semantic_seg,
+ train_cfg):
+ """Forward function for training.
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ prev_output (Tensor): The output of previous decode head.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ gt_semantic_seg (Tensor): Semantic segmentation masks
+ used if the architecture supports semantic segmentation task.
+ train_cfg (dict): The training config.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ seg_logits = self.forward(inputs, prev_output)
+ losses = self.losses(seg_logits, gt_semantic_seg)
+
+ return losses
+
+ def forward_test(self, inputs, prev_output, img_metas, test_cfg):
+ """Forward function for testing.
+
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ prev_output (Tensor): The output of previous decode head.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ test_cfg (dict): The testing config.
+
+ Returns:
+ Tensor: Output segmentation map.
+ """
+ return self.forward(inputs, prev_output)
diff --git a/mmseg/models/decode_heads/cc_head.py b/mmseg/models/decode_heads/cc_head.py
new file mode 100644
index 0000000..ed19eb4
--- /dev/null
+++ b/mmseg/models/decode_heads/cc_head.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+try:
+ from mmcv.ops import CrissCrossAttention
+except ModuleNotFoundError:
+ CrissCrossAttention = None
+
+
+@HEADS.register_module()
+class CCHead(FCNHead):
+ """CCNet: Criss-Cross Attention for Semantic Segmentation.
+
+ This head is the implementation of `CCNet
+ `_.
+
+ Args:
+ recurrence (int): Number of recurrence of Criss Cross Attention
+ module. Default: 2.
+ """
+
+ def __init__(self, recurrence=2, **kwargs):
+ if CrissCrossAttention is None:
+ raise RuntimeError('Please install mmcv-full for '
+ 'CrissCrossAttention ops')
+ super(CCHead, self).__init__(num_convs=2, **kwargs)
+ self.recurrence = recurrence
+ self.cca = CrissCrossAttention(self.channels)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs[0](x)
+ for _ in range(self.recurrence):
+ output = self.cca(output)
+ output = self.convs[1](output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/da_head.py b/mmseg/models/decode_heads/da_head.py
new file mode 100644
index 0000000..77fd663
--- /dev/null
+++ b/mmseg/models/decode_heads/da_head.py
@@ -0,0 +1,179 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, Scale
+from torch import nn
+
+from mmseg.core import add_prefix
+from ..builder import HEADS
+from ..utils import SelfAttentionBlock as _SelfAttentionBlock
+from .decode_head import BaseDecodeHead
+
+
+class PAM(_SelfAttentionBlock):
+ """Position Attention Module (PAM)
+
+ Args:
+ in_channels (int): Input channels of key/query feature.
+ channels (int): Output channels of key/query transform.
+ """
+
+ def __init__(self, in_channels, channels):
+ super(PAM, self).__init__(
+ key_in_channels=in_channels,
+ query_in_channels=in_channels,
+ channels=channels,
+ out_channels=in_channels,
+ share_key_query=False,
+ query_downsample=None,
+ key_downsample=None,
+ key_query_num_convs=1,
+ key_query_norm=False,
+ value_out_num_convs=1,
+ value_out_norm=False,
+ matmul_norm=False,
+ with_out=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=None)
+
+ self.gamma = Scale(0)
+
+ def forward(self, x):
+ """Forward function."""
+ out = super(PAM, self).forward(x, x)
+
+ out = self.gamma(out) + x
+ return out
+
+
+class CAM(nn.Module):
+ """Channel Attention Module (CAM)"""
+
+ def __init__(self):
+ super(CAM, self).__init__()
+ self.gamma = Scale(0)
+
+ def forward(self, x):
+ """Forward function."""
+ batch_size, channels, height, width = x.size()
+ proj_query = x.view(batch_size, channels, -1)
+ proj_key = x.view(batch_size, channels, -1).permute(0, 2, 1)
+ energy = torch.bmm(proj_query, proj_key)
+ energy_new = torch.max(
+ energy, -1, keepdim=True)[0].expand_as(energy) - energy
+ attention = F.softmax(energy_new, dim=-1)
+ proj_value = x.view(batch_size, channels, -1)
+
+ out = torch.bmm(attention, proj_value)
+ out = out.view(batch_size, channels, height, width)
+
+ out = self.gamma(out) + x
+ return out
+
+
+@HEADS.register_module()
+class DAHead(BaseDecodeHead):
+ """Dual Attention Network for Scene Segmentation.
+
+ This head is the implementation of `DANet
+ `_.
+
+ Args:
+ pam_channels (int): The channels of Position Attention Module(PAM).
+ """
+
+ def __init__(self, pam_channels, **kwargs):
+ super(DAHead, self).__init__(**kwargs)
+ self.pam_channels = pam_channels
+ self.pam_in_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.pam = PAM(self.channels, pam_channels)
+ self.pam_out_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.pam_conv_seg = nn.Conv2d(
+ self.channels, self.num_classes, kernel_size=1)
+
+ self.cam_in_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.cam = CAM()
+ self.cam_out_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.cam_conv_seg = nn.Conv2d(
+ self.channels, self.num_classes, kernel_size=1)
+
+ def pam_cls_seg(self, feat):
+ """PAM feature classification."""
+ if self.dropout is not None:
+ feat = self.dropout(feat)
+ output = self.pam_conv_seg(feat)
+ return output
+
+ def cam_cls_seg(self, feat):
+ """CAM feature classification."""
+ if self.dropout is not None:
+ feat = self.dropout(feat)
+ output = self.cam_conv_seg(feat)
+ return output
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ pam_feat = self.pam_in_conv(x)
+ pam_feat = self.pam(pam_feat)
+ pam_feat = self.pam_out_conv(pam_feat)
+ pam_out = self.pam_cls_seg(pam_feat)
+
+ cam_feat = self.cam_in_conv(x)
+ cam_feat = self.cam(cam_feat)
+ cam_feat = self.cam_out_conv(cam_feat)
+ cam_out = self.cam_cls_seg(cam_feat)
+
+ feat_sum = pam_feat + cam_feat
+ pam_cam_out = self.cls_seg(feat_sum)
+
+ return pam_cam_out, pam_out, cam_out
+
+ def forward_test(self, inputs, img_metas, test_cfg):
+ """Forward function for testing, only ``pam_cam`` is used."""
+ return self.forward(inputs)[0]
+
+ def losses(self, seg_logit, seg_label):
+ """Compute ``pam_cam``, ``pam``, ``cam`` loss."""
+ pam_cam_seg_logit, pam_seg_logit, cam_seg_logit = seg_logit
+ loss = dict()
+ loss.update(
+ add_prefix(
+ super(DAHead, self).losses(pam_cam_seg_logit, seg_label),
+ 'pam_cam'))
+ loss.update(
+ add_prefix(
+ super(DAHead, self).losses(pam_seg_logit, seg_label), 'pam'))
+ loss.update(
+ add_prefix(
+ super(DAHead, self).losses(cam_seg_logit, seg_label), 'cam'))
+ return loss
diff --git a/mmseg/models/decode_heads/decode_head.py b/mmseg/models/decode_heads/decode_head.py
new file mode 100644
index 0000000..1443a81
--- /dev/null
+++ b/mmseg/models/decode_heads/decode_head.py
@@ -0,0 +1,265 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+import torch
+import torch.nn as nn
+from mmcv.runner import BaseModule, auto_fp16, force_fp32
+
+from mmseg.core import build_pixel_sampler
+from mmseg.ops import resize
+from ..builder import build_loss
+from ..losses import accuracy
+
+
+class BaseDecodeHead(BaseModule, metaclass=ABCMeta):
+ """Base class for BaseDecodeHead.
+
+ Args:
+ in_channels (int|Sequence[int]): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ num_classes (int): Number of classes.
+ dropout_ratio (float): Ratio of dropout layer. Default: 0.1.
+ conv_cfg (dict|None): Config of conv layers. Default: None.
+ norm_cfg (dict|None): Config of norm layers. Default: None.
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU')
+ in_index (int|Sequence[int]): Input feature index. Default: -1
+ input_transform (str|None): Transformation type of input features.
+ Options: 'resize_concat', 'multiple_select', None.
+ 'resize_concat': Multiple feature maps will be resize to the
+ same size as first one and than concat together.
+ Usually used in FCN head of HRNet.
+ 'multiple_select': Multiple feature maps will be bundle into
+ a list and passed into decode head.
+ None: Only one select feature map is allowed.
+ Default: None.
+ loss_decode (dict | Sequence[dict]): Config of decode loss.
+ The `loss_name` is property of corresponding loss function which
+ could be shown in training log. If you want this loss
+ item to be included into the backward graph, `loss_` must be the
+ prefix of the name. Defaults to 'loss_ce'.
+ e.g. dict(type='CrossEntropyLoss'),
+ [dict(type='CrossEntropyLoss', loss_name='loss_ce'),
+ dict(type='DiceLoss', loss_name='loss_dice')]
+ Default: dict(type='CrossEntropyLoss').
+ ignore_index (int | None): The label index to be ignored. When using
+ masked BCE loss, ignore_index should be set to None. Default: 255.
+ sampler (dict|None): The config of segmentation map sampler.
+ Default: None.
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels,
+ channels,
+ *,
+ num_classes,
+ dropout_ratio=0.1,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='ReLU'),
+ in_index=-1,
+ input_transform=None,
+ loss_decode=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ ignore_index=255,
+ sampler=None,
+ align_corners=False,
+ init_cfg=dict(
+ type='Normal', std=0.01, override=dict(name='conv_seg'))):
+ super(BaseDecodeHead, self).__init__(init_cfg)
+ self._init_inputs(in_channels, in_index, input_transform)
+ self.channels = channels
+ self.num_classes = num_classes
+ self.dropout_ratio = dropout_ratio
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.in_index = in_index
+
+ self.ignore_index = ignore_index
+ self.align_corners = align_corners
+
+ if isinstance(loss_decode, dict):
+ self.loss_decode = build_loss(loss_decode)
+ elif isinstance(loss_decode, (list, tuple)):
+ self.loss_decode = nn.ModuleList()
+ for loss in loss_decode:
+ self.loss_decode.append(build_loss(loss))
+ else:
+ raise TypeError(f'loss_decode must be a dict or sequence of dict,\
+ but got {type(loss_decode)}')
+
+ if sampler is not None:
+ self.sampler = build_pixel_sampler(sampler, context=self)
+ else:
+ self.sampler = None
+
+ self.conv_seg = nn.Conv2d(channels, num_classes, kernel_size=1)
+ if dropout_ratio > 0:
+ self.dropout = nn.Dropout2d(dropout_ratio)
+ else:
+ self.dropout = None
+ self.fp16_enabled = False
+
+ def extra_repr(self):
+ """Extra repr."""
+ s = f'input_transform={self.input_transform}, ' \
+ f'ignore_index={self.ignore_index}, ' \
+ f'align_corners={self.align_corners}'
+ return s
+
+ def _init_inputs(self, in_channels, in_index, input_transform):
+ """Check and initialize input transforms.
+
+ The in_channels, in_index and input_transform must match.
+ Specifically, when input_transform is None, only single feature map
+ will be selected. So in_channels and in_index must be of type int.
+ When input_transform
+
+ Args:
+ in_channels (int|Sequence[int]): Input channels.
+ in_index (int|Sequence[int]): Input feature index.
+ input_transform (str|None): Transformation type of input features.
+ Options: 'resize_concat', 'multiple_select', None.
+ 'resize_concat': Multiple feature maps will be resize to the
+ same size as first one and than concat together.
+ Usually used in FCN head of HRNet.
+ 'multiple_select': Multiple feature maps will be bundle into
+ a list and passed into decode head.
+ None: Only one select feature map is allowed.
+ """
+
+ if input_transform is not None:
+ assert input_transform in ['resize_concat', 'multiple_select']
+ self.input_transform = input_transform
+ self.in_index = in_index
+ if input_transform is not None:
+ assert isinstance(in_channels, (list, tuple))
+ assert isinstance(in_index, (list, tuple))
+ assert len(in_channels) == len(in_index)
+ if input_transform == 'resize_concat':
+ self.in_channels = sum(in_channels)
+ else:
+ self.in_channels = in_channels
+ else:
+ assert isinstance(in_channels, int)
+ assert isinstance(in_index, int)
+ self.in_channels = in_channels
+
+ def _transform_inputs(self, inputs):
+ """Transform inputs for decoder.
+
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+
+ Returns:
+ Tensor: The transformed inputs
+ """
+
+ if self.input_transform == 'resize_concat':
+ inputs = [inputs[i] for i in self.in_index]
+ upsampled_inputs = [
+ resize(
+ input=x,
+ size=inputs[0].shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners) for x in inputs
+ ]
+ inputs = torch.cat(upsampled_inputs, dim=1)
+ elif self.input_transform == 'multiple_select':
+ inputs = [inputs[i] for i in self.in_index]
+ else:
+ inputs = inputs[self.in_index]
+
+ return inputs
+
+ @auto_fp16()
+ @abstractmethod
+ def forward(self, inputs):
+ """Placeholder of forward function."""
+ pass
+
+ def forward_train(self, inputs, img_metas, gt_semantic_seg, train_cfg):
+ """Forward function for training.
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ gt_semantic_seg (Tensor): Semantic segmentation masks
+ used if the architecture supports semantic segmentation task.
+ train_cfg (dict): The training config.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ seg_logits = self.forward(inputs)
+ losses = self.losses(seg_logits, gt_semantic_seg)
+ return losses
+
+ def forward_test(self, inputs, img_metas, test_cfg):
+ """Forward function for testing.
+
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ test_cfg (dict): The testing config.
+
+ Returns:
+ Tensor: Output segmentation map.
+ """
+ return self.forward(inputs)
+
+ def cls_seg(self, feat):
+ """Classify each pixel."""
+ if self.dropout is not None:
+ feat = self.dropout(feat)
+ output = self.conv_seg(feat)
+ return output
+
+ @force_fp32(apply_to=('seg_logit', ))
+ def losses(self, seg_logit, seg_label):
+ """Compute segmentation loss."""
+ loss = dict()
+ seg_logit = resize(
+ input=seg_logit,
+ size=seg_label.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ if self.sampler is not None:
+ seg_weight = self.sampler.sample(seg_logit, seg_label)
+ else:
+ seg_weight = None
+ seg_label = seg_label.squeeze(1)
+
+ if not isinstance(self.loss_decode, nn.ModuleList):
+ losses_decode = [self.loss_decode]
+ else:
+ losses_decode = self.loss_decode
+ for loss_decode in losses_decode:
+ if loss_decode.loss_name not in loss:
+ loss[loss_decode.loss_name] = loss_decode(
+ seg_logit,
+ seg_label,
+ weight=seg_weight,
+ ignore_index=self.ignore_index)
+ else:
+ loss[loss_decode.loss_name] += loss_decode(
+ seg_logit,
+ seg_label,
+ weight=seg_weight,
+ ignore_index=self.ignore_index)
+
+ loss['acc_seg'] = accuracy(seg_logit, seg_label)
+ return loss
diff --git a/mmseg/models/decode_heads/dm_head.py b/mmseg/models/decode_heads/dm_head.py
new file mode 100644
index 0000000..ffaa870
--- /dev/null
+++ b/mmseg/models/decode_heads/dm_head.py
@@ -0,0 +1,141 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, build_activation_layer, build_norm_layer
+
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class DCM(nn.Module):
+ """Dynamic Convolutional Module used in DMNet.
+
+ Args:
+ filter_size (int): The filter size of generated convolution kernel
+ used in Dynamic Convolutional Module.
+ fusion (bool): Add one conv to fuse DCM output feature.
+ in_channels (int): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ conv_cfg (dict | None): Config of conv layers.
+ norm_cfg (dict | None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ """
+
+ def __init__(self, filter_size, fusion, in_channels, channels, conv_cfg,
+ norm_cfg, act_cfg):
+ super(DCM, self).__init__()
+ self.filter_size = filter_size
+ self.fusion = fusion
+ self.in_channels = in_channels
+ self.channels = channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.filter_gen_conv = nn.Conv2d(self.in_channels, self.channels, 1, 1,
+ 0)
+
+ self.input_redu_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ if self.norm_cfg is not None:
+ self.norm = build_norm_layer(self.norm_cfg, self.channels)[1]
+ else:
+ self.norm = None
+ self.activate = build_activation_layer(self.act_cfg)
+
+ if self.fusion:
+ self.fusion_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, x):
+ """Forward function."""
+ generated_filter = self.filter_gen_conv(
+ F.adaptive_avg_pool2d(x, self.filter_size))
+ x = self.input_redu_conv(x)
+ b, c, h, w = x.shape
+ # [1, b * c, h, w], c = self.channels
+ x = x.view(1, b * c, h, w)
+ # [b * c, 1, filter_size, filter_size]
+ generated_filter = generated_filter.view(b * c, 1, self.filter_size,
+ self.filter_size)
+ pad = (self.filter_size - 1) // 2
+ if (self.filter_size - 1) % 2 == 0:
+ p2d = (pad, pad, pad, pad)
+ else:
+ p2d = (pad + 1, pad, pad + 1, pad)
+ x = F.pad(input=x, pad=p2d, mode='constant', value=0)
+ # [1, b * c, h, w]
+ output = F.conv2d(input=x, weight=generated_filter, groups=b * c)
+ # [b, c, h, w]
+ output = output.view(b, c, h, w)
+ if self.norm is not None:
+ output = self.norm(output)
+ output = self.activate(output)
+
+ if self.fusion:
+ output = self.fusion_conv(output)
+
+ return output
+
+
+@HEADS.register_module()
+class DMHead(BaseDecodeHead):
+ """Dynamic Multi-scale Filters for Semantic Segmentation.
+
+ This head is the implementation of
+ `DMNet `_.
+
+ Args:
+ filter_sizes (tuple[int]): The size of generated convolutional filters
+ used in Dynamic Convolutional Module. Default: (1, 3, 5, 7).
+ fusion (bool): Add one conv to fuse DCM output feature.
+ """
+
+ def __init__(self, filter_sizes=(1, 3, 5, 7), fusion=False, **kwargs):
+ super(DMHead, self).__init__(**kwargs)
+ assert isinstance(filter_sizes, (list, tuple))
+ self.filter_sizes = filter_sizes
+ self.fusion = fusion
+ dcm_modules = []
+ for filter_size in self.filter_sizes:
+ dcm_modules.append(
+ DCM(filter_size,
+ self.fusion,
+ self.in_channels,
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.dcm_modules = nn.ModuleList(dcm_modules)
+ self.bottleneck = ConvModule(
+ self.in_channels + len(filter_sizes) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ dcm_outs = [x]
+ for dcm_module in self.dcm_modules:
+ dcm_outs.append(dcm_module(x))
+ dcm_outs = torch.cat(dcm_outs, dim=1)
+ output = self.bottleneck(dcm_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/dnl_head.py b/mmseg/models/decode_heads/dnl_head.py
new file mode 100644
index 0000000..ab53d9a
--- /dev/null
+++ b/mmseg/models/decode_heads/dnl_head.py
@@ -0,0 +1,132 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import NonLocal2d
+from torch import nn
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+class DisentangledNonLocal2d(NonLocal2d):
+ """Disentangled Non-Local Blocks.
+
+ Args:
+ temperature (float): Temperature to adjust attention. Default: 0.05
+ """
+
+ def __init__(self, *arg, temperature, **kwargs):
+ super().__init__(*arg, **kwargs)
+ self.temperature = temperature
+ self.conv_mask = nn.Conv2d(self.in_channels, 1, kernel_size=1)
+
+ def embedded_gaussian(self, theta_x, phi_x):
+ """Embedded gaussian with temperature."""
+
+ # NonLocal2d pairwise_weight: [N, HxW, HxW]
+ pairwise_weight = torch.matmul(theta_x, phi_x)
+ if self.use_scale:
+ # theta_x.shape[-1] is `self.inter_channels`
+ pairwise_weight /= theta_x.shape[-1]**0.5
+ pairwise_weight /= self.temperature
+ pairwise_weight = pairwise_weight.softmax(dim=-1)
+ return pairwise_weight
+
+ def forward(self, x):
+ # x: [N, C, H, W]
+ n = x.size(0)
+
+ # g_x: [N, HxW, C]
+ g_x = self.g(x).view(n, self.inter_channels, -1)
+ g_x = g_x.permute(0, 2, 1)
+
+ # theta_x: [N, HxW, C], phi_x: [N, C, HxW]
+ if self.mode == 'gaussian':
+ theta_x = x.view(n, self.in_channels, -1)
+ theta_x = theta_x.permute(0, 2, 1)
+ if self.sub_sample:
+ phi_x = self.phi(x).view(n, self.in_channels, -1)
+ else:
+ phi_x = x.view(n, self.in_channels, -1)
+ elif self.mode == 'concatenation':
+ theta_x = self.theta(x).view(n, self.inter_channels, -1, 1)
+ phi_x = self.phi(x).view(n, self.inter_channels, 1, -1)
+ else:
+ theta_x = self.theta(x).view(n, self.inter_channels, -1)
+ theta_x = theta_x.permute(0, 2, 1)
+ phi_x = self.phi(x).view(n, self.inter_channels, -1)
+
+ # subtract mean
+ theta_x -= theta_x.mean(dim=-2, keepdim=True)
+ phi_x -= phi_x.mean(dim=-1, keepdim=True)
+
+ pairwise_func = getattr(self, self.mode)
+ # pairwise_weight: [N, HxW, HxW]
+ pairwise_weight = pairwise_func(theta_x, phi_x)
+
+ # y: [N, HxW, C]
+ y = torch.matmul(pairwise_weight, g_x)
+ # y: [N, C, H, W]
+ y = y.permute(0, 2, 1).contiguous().reshape(n, self.inter_channels,
+ *x.size()[2:])
+
+ # unary_mask: [N, 1, HxW]
+ unary_mask = self.conv_mask(x)
+ unary_mask = unary_mask.view(n, 1, -1)
+ unary_mask = unary_mask.softmax(dim=-1)
+ # unary_x: [N, 1, C]
+ unary_x = torch.matmul(unary_mask, g_x)
+ # unary_x: [N, C, 1, 1]
+ unary_x = unary_x.permute(0, 2, 1).contiguous().reshape(
+ n, self.inter_channels, 1, 1)
+
+ output = x + self.conv_out(y + unary_x)
+
+ return output
+
+
+@HEADS.register_module()
+class DNLHead(FCNHead):
+ """Disentangled Non-Local Neural Networks.
+
+ This head is the implementation of `DNLNet
+ `_.
+
+ Args:
+ reduction (int): Reduction factor of projection transform. Default: 2.
+ use_scale (bool): Whether to scale pairwise_weight by
+ sqrt(1/inter_channels). Default: False.
+ mode (str): The nonlocal mode. Options are 'embedded_gaussian',
+ 'dot_product'. Default: 'embedded_gaussian.'.
+ temperature (float): Temperature to adjust attention. Default: 0.05
+ """
+
+ def __init__(self,
+ reduction=2,
+ use_scale=True,
+ mode='embedded_gaussian',
+ temperature=0.05,
+ **kwargs):
+ super(DNLHead, self).__init__(num_convs=2, **kwargs)
+ self.reduction = reduction
+ self.use_scale = use_scale
+ self.mode = mode
+ self.temperature = temperature
+ self.dnl_block = DisentangledNonLocal2d(
+ in_channels=self.channels,
+ reduction=self.reduction,
+ use_scale=self.use_scale,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ mode=self.mode,
+ temperature=self.temperature)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs[0](x)
+ output = self.dnl_block(output)
+ output = self.convs[1](output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/dpt_head.py b/mmseg/models/decode_heads/dpt_head.py
new file mode 100644
index 0000000..a63f9d2
--- /dev/null
+++ b/mmseg/models/decode_heads/dpt_head.py
@@ -0,0 +1,293 @@
+import math
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, Linear, build_activation_layer
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class ReassembleBlocks(BaseModule):
+ """ViTPostProcessBlock, process cls_token in ViT backbone output and
+ rearrange the feature vector to feature map.
+
+ Args:
+ in_channels (int): ViT feature channels. Default: 768.
+ out_channels (List): output channels of each stage.
+ Default: [96, 192, 384, 768].
+ readout_type (str): Type of readout operation. Default: 'ignore'.
+ patch_size (int): The patch size. Default: 16.
+ init_cfg (dict, optional): Initialization config dict. Default: None.
+ """
+
+ def __init__(self,
+ in_channels=768,
+ out_channels=[96, 192, 384, 768],
+ readout_type='ignore',
+ patch_size=16,
+ init_cfg=None):
+ super(ReassembleBlocks, self).__init__(init_cfg)
+
+ assert readout_type in ['ignore', 'add', 'project']
+ self.readout_type = readout_type
+ self.patch_size = patch_size
+
+ self.projects = nn.ModuleList([
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channel,
+ kernel_size=1,
+ act_cfg=None,
+ ) for out_channel in out_channels
+ ])
+
+ self.resize_layers = nn.ModuleList([
+ nn.ConvTranspose2d(
+ in_channels=out_channels[0],
+ out_channels=out_channels[0],
+ kernel_size=4,
+ stride=4,
+ padding=0),
+ nn.ConvTranspose2d(
+ in_channels=out_channels[1],
+ out_channels=out_channels[1],
+ kernel_size=2,
+ stride=2,
+ padding=0),
+ nn.Identity(),
+ nn.Conv2d(
+ in_channels=out_channels[3],
+ out_channels=out_channels[3],
+ kernel_size=3,
+ stride=2,
+ padding=1)
+ ])
+ if self.readout_type == 'project':
+ self.readout_projects = nn.ModuleList()
+ for _ in range(len(self.projects)):
+ self.readout_projects.append(
+ nn.Sequential(
+ Linear(2 * in_channels, in_channels),
+ build_activation_layer(dict(type='GELU'))))
+
+ def forward(self, inputs):
+ assert isinstance(inputs, list)
+ out = []
+ for i, x in enumerate(inputs):
+ assert len(x) == 2
+ x, cls_token = x[0], x[1]
+ feature_shape = x.shape
+ if self.readout_type == 'project':
+ x = x.flatten(2).permute((0, 2, 1))
+ readout = cls_token.unsqueeze(1).expand_as(x)
+ x = self.readout_projects[i](torch.cat((x, readout), -1))
+ x = x.permute(0, 2, 1).reshape(feature_shape)
+ elif self.readout_type == 'add':
+ x = x.flatten(2) + cls_token.unsqueeze(-1)
+ x = x.reshape(feature_shape)
+ else:
+ pass
+ x = self.projects[i](x)
+ x = self.resize_layers[i](x)
+ out.append(x)
+ return out
+
+
+class PreActResidualConvUnit(BaseModule):
+ """ResidualConvUnit, pre-activate residual unit.
+
+ Args:
+ in_channels (int): number of channels in the input feature map.
+ act_cfg (dict): dictionary to construct and config activation layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ stride (int): stride of the first block. Default: 1
+ dilation (int): dilation rate for convs layers. Default: 1.
+ init_cfg (dict, optional): Initialization config dict. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ act_cfg,
+ norm_cfg,
+ stride=1,
+ dilation=1,
+ init_cfg=None):
+ super(PreActResidualConvUnit, self).__init__(init_cfg)
+
+ self.conv1 = ConvModule(
+ in_channels,
+ in_channels,
+ 3,
+ stride=stride,
+ padding=dilation,
+ dilation=dilation,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ bias=False,
+ order=('act', 'conv', 'norm'))
+
+ self.conv2 = ConvModule(
+ in_channels,
+ in_channels,
+ 3,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ bias=False,
+ order=('act', 'conv', 'norm'))
+
+ def forward(self, inputs):
+ inputs_ = inputs.clone()
+ x = self.conv1(inputs)
+ x = self.conv2(x)
+ return x + inputs_
+
+
+class FeatureFusionBlock(BaseModule):
+ """FeatureFusionBlock, merge feature map from different stages.
+
+ Args:
+ in_channels (int): Input channels.
+ act_cfg (dict): The activation config for ResidualConvUnit.
+ norm_cfg (dict): Config dict for normalization layer.
+ expand (bool): Whether expand the channels in post process block.
+ Default: False.
+ align_corners (bool): align_corner setting for bilinear upsample.
+ Default: True.
+ init_cfg (dict, optional): Initialization config dict. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ act_cfg,
+ norm_cfg,
+ expand=False,
+ align_corners=True,
+ init_cfg=None):
+ super(FeatureFusionBlock, self).__init__(init_cfg)
+
+ self.in_channels = in_channels
+ self.expand = expand
+ self.align_corners = align_corners
+
+ self.out_channels = in_channels
+ if self.expand:
+ self.out_channels = in_channels // 2
+
+ self.project = ConvModule(
+ self.in_channels,
+ self.out_channels,
+ kernel_size=1,
+ act_cfg=None,
+ bias=True)
+
+ self.res_conv_unit1 = PreActResidualConvUnit(
+ in_channels=self.in_channels, act_cfg=act_cfg, norm_cfg=norm_cfg)
+ self.res_conv_unit2 = PreActResidualConvUnit(
+ in_channels=self.in_channels, act_cfg=act_cfg, norm_cfg=norm_cfg)
+
+ def forward(self, *inputs):
+ x = inputs[0]
+ if len(inputs) == 2:
+ if x.shape != inputs[1].shape:
+ res = resize(
+ inputs[1],
+ size=(x.shape[2], x.shape[3]),
+ mode='bilinear',
+ align_corners=False)
+ else:
+ res = inputs[1]
+ x = x + self.res_conv_unit1(res)
+ x = self.res_conv_unit2(x)
+ x = resize(
+ x,
+ scale_factor=2,
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = self.project(x)
+ return x
+
+
+@HEADS.register_module()
+class DPTHead(BaseDecodeHead):
+ """Vision Transformers for Dense Prediction.
+
+ This head is implemented of `DPT `_.
+
+ Args:
+ embed_dims (int): The embed dimension of the ViT backbone.
+ Default: 768.
+ post_process_channels (List): Out channels of post process conv
+ layers. Default: [96, 192, 384, 768].
+ readout_type (str): Type of readout operation. Default: 'ignore'.
+ patch_size (int): The patch size. Default: 16.
+ expand_channels (bool): Whether expand the channels in post process
+ block. Default: False.
+ act_cfg (dict): The activation config for residual conv unit.
+ Default dict(type='ReLU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ """
+
+ def __init__(self,
+ embed_dims=768,
+ post_process_channels=[96, 192, 384, 768],
+ readout_type='ignore',
+ patch_size=16,
+ expand_channels=False,
+ act_cfg=dict(type='ReLU'),
+ norm_cfg=dict(type='BN'),
+ **kwargs):
+ super(DPTHead, self).__init__(**kwargs)
+
+ self.in_channels = self.in_channels
+ self.expand_channels = expand_channels
+ self.reassemble_blocks = ReassembleBlocks(embed_dims,
+ post_process_channels,
+ readout_type, patch_size)
+
+ self.post_process_channels = [
+ channel * math.pow(2, i) if expand_channels else channel
+ for i, channel in enumerate(post_process_channels)
+ ]
+ self.convs = nn.ModuleList()
+ for channel in self.post_process_channels:
+ self.convs.append(
+ ConvModule(
+ channel,
+ self.channels,
+ kernel_size=3,
+ padding=1,
+ act_cfg=None,
+ bias=False))
+ self.fusion_blocks = nn.ModuleList()
+ for _ in range(len(self.convs)):
+ self.fusion_blocks.append(
+ FeatureFusionBlock(self.channels, act_cfg, norm_cfg))
+ self.fusion_blocks[0].res_conv_unit1 = None
+ self.project = ConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=norm_cfg)
+ self.num_fusion_blocks = len(self.fusion_blocks)
+ self.num_reassemble_blocks = len(self.reassemble_blocks.resize_layers)
+ self.num_post_process_channels = len(self.post_process_channels)
+ assert self.num_fusion_blocks == self.num_reassemble_blocks
+ assert self.num_reassemble_blocks == self.num_post_process_channels
+
+ def forward(self, inputs):
+ assert len(inputs) == self.num_reassemble_blocks
+ x = self._transform_inputs(inputs)
+ x = self.reassemble_blocks(x)
+ x = [self.convs[i](feature) for i, feature in enumerate(x)]
+ out = self.fusion_blocks[0](x[-1])
+ for i in range(1, len(self.fusion_blocks)):
+ out = self.fusion_blocks[i](out, x[-(i + 1)])
+ out = self.project(out)
+ out = self.cls_seg(out)
+ return out
diff --git a/mmseg/models/decode_heads/ema_head.py b/mmseg/models/decode_heads/ema_head.py
new file mode 100644
index 0000000..f6de167
--- /dev/null
+++ b/mmseg/models/decode_heads/ema_head.py
@@ -0,0 +1,169 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+def reduce_mean(tensor):
+ """Reduce mean when distributed training."""
+ if not (dist.is_available() and dist.is_initialized()):
+ return tensor
+ tensor = tensor.clone()
+ dist.all_reduce(tensor.div_(dist.get_world_size()), op=dist.ReduceOp.SUM)
+ return tensor
+
+
+class EMAModule(nn.Module):
+ """Expectation Maximization Attention Module used in EMANet.
+
+ Args:
+ channels (int): Channels of the whole module.
+ num_bases (int): Number of bases.
+ num_stages (int): Number of the EM iterations.
+ """
+
+ def __init__(self, channels, num_bases, num_stages, momentum):
+ super(EMAModule, self).__init__()
+ assert num_stages >= 1, 'num_stages must be at least 1!'
+ self.num_bases = num_bases
+ self.num_stages = num_stages
+ self.momentum = momentum
+
+ bases = torch.zeros(1, channels, self.num_bases)
+ bases.normal_(0, math.sqrt(2. / self.num_bases))
+ # [1, channels, num_bases]
+ bases = F.normalize(bases, dim=1, p=2)
+ self.register_buffer('bases', bases)
+
+ def forward(self, feats):
+ """Forward function."""
+ batch_size, channels, height, width = feats.size()
+ # [batch_size, channels, height*width]
+ feats = feats.view(batch_size, channels, height * width)
+ # [batch_size, channels, num_bases]
+ bases = self.bases.repeat(batch_size, 1, 1)
+
+ with torch.no_grad():
+ for i in range(self.num_stages):
+ # [batch_size, height*width, num_bases]
+ attention = torch.einsum('bcn,bck->bnk', feats, bases)
+ attention = F.softmax(attention, dim=2)
+ # l1 norm
+ attention_normed = F.normalize(attention, dim=1, p=1)
+ # [batch_size, channels, num_bases]
+ bases = torch.einsum('bcn,bnk->bck', feats, attention_normed)
+ # l2 norm
+ bases = F.normalize(bases, dim=1, p=2)
+
+ feats_recon = torch.einsum('bck,bnk->bcn', bases, attention)
+ feats_recon = feats_recon.view(batch_size, channels, height, width)
+
+ if self.training:
+ bases = bases.mean(dim=0, keepdim=True)
+ bases = reduce_mean(bases)
+ # l2 norm
+ bases = F.normalize(bases, dim=1, p=2)
+ self.bases = (1 -
+ self.momentum) * self.bases + self.momentum * bases
+
+ return feats_recon
+
+
+@HEADS.register_module()
+class EMAHead(BaseDecodeHead):
+ """Expectation Maximization Attention Networks for Semantic Segmentation.
+
+ This head is the implementation of `EMANet
+ `_.
+
+ Args:
+ ema_channels (int): EMA module channels
+ num_bases (int): Number of bases.
+ num_stages (int): Number of the EM iterations.
+ concat_input (bool): Whether concat the input and output of convs
+ before classification layer. Default: True
+ momentum (float): Momentum to update the base. Default: 0.1.
+ """
+
+ def __init__(self,
+ ema_channels,
+ num_bases,
+ num_stages,
+ concat_input=True,
+ momentum=0.1,
+ **kwargs):
+ super(EMAHead, self).__init__(**kwargs)
+ self.ema_channels = ema_channels
+ self.num_bases = num_bases
+ self.num_stages = num_stages
+ self.concat_input = concat_input
+ self.momentum = momentum
+ self.ema_module = EMAModule(self.ema_channels, self.num_bases,
+ self.num_stages, self.momentum)
+
+ self.ema_in_conv = ConvModule(
+ self.in_channels,
+ self.ema_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ # project (0, inf) -> (-inf, inf)
+ self.ema_mid_conv = ConvModule(
+ self.ema_channels,
+ self.ema_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=None,
+ act_cfg=None)
+ for param in self.ema_mid_conv.parameters():
+ param.requires_grad = False
+
+ self.ema_out_conv = ConvModule(
+ self.ema_channels,
+ self.ema_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=None)
+ self.bottleneck = ConvModule(
+ self.ema_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ if self.concat_input:
+ self.conv_cat = ConvModule(
+ self.in_channels + self.channels,
+ self.channels,
+ kernel_size=3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ feats = self.ema_in_conv(x)
+ identity = feats
+ feats = self.ema_mid_conv(feats)
+ recon = self.ema_module(feats)
+ recon = F.relu(recon, inplace=True)
+ recon = self.ema_out_conv(recon)
+ output = F.relu(identity + recon, inplace=True)
+ output = self.bottleneck(output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/enc_head.py b/mmseg/models/decode_heads/enc_head.py
new file mode 100644
index 0000000..648c890
--- /dev/null
+++ b/mmseg/models/decode_heads/enc_head.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, build_norm_layer
+
+from mmseg.ops import Encoding, resize
+from ..builder import HEADS, build_loss
+from .decode_head import BaseDecodeHead
+
+
+class EncModule(nn.Module):
+ """Encoding Module used in EncNet.
+
+ Args:
+ in_channels (int): Input channels.
+ num_codes (int): Number of code words.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ """
+
+ def __init__(self, in_channels, num_codes, conv_cfg, norm_cfg, act_cfg):
+ super(EncModule, self).__init__()
+ self.encoding_project = ConvModule(
+ in_channels,
+ in_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ # TODO: resolve this hack
+ # change to 1d
+ if norm_cfg is not None:
+ encoding_norm_cfg = norm_cfg.copy()
+ if encoding_norm_cfg['type'] in ['BN', 'IN']:
+ encoding_norm_cfg['type'] += '1d'
+ else:
+ encoding_norm_cfg['type'] = encoding_norm_cfg['type'].replace(
+ '2d', '1d')
+ else:
+ # fallback to BN1d
+ encoding_norm_cfg = dict(type='BN1d')
+ self.encoding = nn.Sequential(
+ Encoding(channels=in_channels, num_codes=num_codes),
+ build_norm_layer(encoding_norm_cfg, num_codes)[1],
+ nn.ReLU(inplace=True))
+ self.fc = nn.Sequential(
+ nn.Linear(in_channels, in_channels), nn.Sigmoid())
+
+ def forward(self, x):
+ """Forward function."""
+ encoding_projection = self.encoding_project(x)
+ encoding_feat = self.encoding(encoding_projection).mean(dim=1)
+ batch_size, channels, _, _ = x.size()
+ gamma = self.fc(encoding_feat)
+ y = gamma.view(batch_size, channels, 1, 1)
+ output = F.relu_(x + x * y)
+ return encoding_feat, output
+
+
+@HEADS.register_module()
+class EncHead(BaseDecodeHead):
+ """Context Encoding for Semantic Segmentation.
+
+ This head is the implementation of `EncNet
+ `_.
+
+ Args:
+ num_codes (int): Number of code words. Default: 32.
+ use_se_loss (bool): Whether use Semantic Encoding Loss (SE-loss) to
+ regularize the training. Default: True.
+ add_lateral (bool): Whether use lateral connection to fuse features.
+ Default: False.
+ loss_se_decode (dict): Config of decode loss.
+ Default: dict(type='CrossEntropyLoss', use_sigmoid=True).
+ """
+
+ def __init__(self,
+ num_codes=32,
+ use_se_loss=True,
+ add_lateral=False,
+ loss_se_decode=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=0.2),
+ **kwargs):
+ super(EncHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ self.use_se_loss = use_se_loss
+ self.add_lateral = add_lateral
+ self.num_codes = num_codes
+ self.bottleneck = ConvModule(
+ self.in_channels[-1],
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ if add_lateral:
+ self.lateral_convs = nn.ModuleList()
+ for in_channels in self.in_channels[:-1]: # skip the last one
+ self.lateral_convs.append(
+ ConvModule(
+ in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.fusion = ConvModule(
+ len(self.in_channels) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.enc_module = EncModule(
+ self.channels,
+ num_codes=num_codes,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ if self.use_se_loss:
+ self.loss_se_decode = build_loss(loss_se_decode)
+ self.se_layer = nn.Linear(self.channels, self.num_classes)
+
+ def forward(self, inputs):
+ """Forward function."""
+ inputs = self._transform_inputs(inputs)
+ feat = self.bottleneck(inputs[-1])
+ if self.add_lateral:
+ laterals = [
+ resize(
+ lateral_conv(inputs[i]),
+ size=feat.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+ feat = self.fusion(torch.cat([feat, *laterals], 1))
+ encode_feat, output = self.enc_module(feat)
+ output = self.cls_seg(output)
+ if self.use_se_loss:
+ se_output = self.se_layer(encode_feat)
+ return output, se_output
+ else:
+ return output
+
+ def forward_test(self, inputs, img_metas, test_cfg):
+ """Forward function for testing, ignore se_loss."""
+ if self.use_se_loss:
+ return self.forward(inputs)[0]
+ else:
+ return self.forward(inputs)
+
+ @staticmethod
+ def _convert_to_onehot_labels(seg_label, num_classes):
+ """Convert segmentation label to onehot.
+
+ Args:
+ seg_label (Tensor): Segmentation label of shape (N, H, W).
+ num_classes (int): Number of classes.
+
+ Returns:
+ Tensor: Onehot labels of shape (N, num_classes).
+ """
+
+ batch_size = seg_label.size(0)
+ onehot_labels = seg_label.new_zeros((batch_size, num_classes))
+ for i in range(batch_size):
+ hist = seg_label[i].float().histc(
+ bins=num_classes, min=0, max=num_classes - 1)
+ onehot_labels[i] = hist > 0
+ return onehot_labels
+
+ def losses(self, seg_logit, seg_label):
+ """Compute segmentation and semantic encoding loss."""
+ seg_logit, se_seg_logit = seg_logit
+ loss = dict()
+ loss.update(super(EncHead, self).losses(seg_logit, seg_label))
+ se_loss = self.loss_se_decode(
+ se_seg_logit,
+ self._convert_to_onehot_labels(seg_label, self.num_classes))
+ loss['loss_se'] = se_loss
+ return loss
diff --git a/mmseg/models/decode_heads/fcn_head.py b/mmseg/models/decode_heads/fcn_head.py
new file mode 100644
index 0000000..3c8de51
--- /dev/null
+++ b/mmseg/models/decode_heads/fcn_head.py
@@ -0,0 +1,82 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class FCNHead(BaseDecodeHead):
+ """Fully Convolution Networks for Semantic Segmentation.
+
+ This head is implemented of `FCNNet `_.
+
+ Args:
+ num_convs (int): Number of convs in the head. Default: 2.
+ kernel_size (int): The kernel size for convs in the head. Default: 3.
+ concat_input (bool): Whether concat the input and output of convs
+ before classification layer.
+ dilation (int): The dilation rate for convs in the head. Default: 1.
+ """
+
+ def __init__(self,
+ num_convs=2,
+ kernel_size=3,
+ concat_input=True,
+ dilation=1,
+ **kwargs):
+ assert num_convs >= 0 and dilation > 0 and isinstance(dilation, int)
+ self.num_convs = num_convs
+ self.concat_input = concat_input
+ self.kernel_size = kernel_size
+ super(FCNHead, self).__init__(**kwargs)
+ if num_convs == 0:
+ assert self.in_channels == self.channels
+
+ conv_padding = (kernel_size // 2) * dilation
+ convs = []
+ convs.append(
+ ConvModule(
+ self.in_channels,
+ self.channels,
+ kernel_size=kernel_size,
+ padding=conv_padding,
+ dilation=dilation,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ for i in range(num_convs - 1):
+ convs.append(
+ ConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=kernel_size,
+ padding=conv_padding,
+ dilation=dilation,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ if num_convs == 0:
+ self.convs = nn.Identity()
+ else:
+ self.convs = nn.Sequential(*convs)
+ if self.concat_input:
+ self.conv_cat = ConvModule(
+ self.in_channels + self.channels,
+ self.channels,
+ kernel_size=kernel_size,
+ padding=kernel_size // 2,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs(x)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/fpn_head.py b/mmseg/models/decode_heads/fpn_head.py
new file mode 100644
index 0000000..e41f324
--- /dev/null
+++ b/mmseg/models/decode_heads/fpn_head.py
@@ -0,0 +1,69 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import Upsample, resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class FPNHead(BaseDecodeHead):
+ """Panoptic Feature Pyramid Networks.
+
+ This head is the implementation of `Semantic FPN
+ `_.
+
+ Args:
+ feature_strides (tuple[int]): The strides for input feature maps.
+ stack_lateral. All strides suppose to be power of 2. The first
+ one is of largest resolution.
+ """
+
+ def __init__(self, feature_strides, **kwargs):
+ super(FPNHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ assert len(feature_strides) == len(self.in_channels)
+ assert min(feature_strides) == feature_strides[0]
+ self.feature_strides = feature_strides
+
+ self.scale_heads = nn.ModuleList()
+ for i in range(len(feature_strides)):
+ head_length = max(
+ 1,
+ int(np.log2(feature_strides[i]) - np.log2(feature_strides[0])))
+ scale_head = []
+ for k in range(head_length):
+ scale_head.append(
+ ConvModule(
+ self.in_channels[i] if k == 0 else self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ if feature_strides[i] != feature_strides[0]:
+ scale_head.append(
+ Upsample(
+ scale_factor=2,
+ mode='bilinear',
+ align_corners=self.align_corners))
+ self.scale_heads.append(nn.Sequential(*scale_head))
+
+ def forward(self, inputs):
+
+ x = self._transform_inputs(inputs)
+
+ output = self.scale_heads[0](x[0])
+ for i in range(1, len(self.feature_strides)):
+ # non inplace
+ output = output + resize(
+ self.scale_heads[i](x[i]),
+ size=output.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/gc_head.py b/mmseg/models/decode_heads/gc_head.py
new file mode 100644
index 0000000..eed5074
--- /dev/null
+++ b/mmseg/models/decode_heads/gc_head.py
@@ -0,0 +1,48 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import ContextBlock
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+@HEADS.register_module()
+class GCHead(FCNHead):
+ """GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond.
+
+ This head is the implementation of `GCNet
+ `_.
+
+ Args:
+ ratio (float): Multiplier of channels ratio. Default: 1/4.
+ pooling_type (str): The pooling type of context aggregation.
+ Options are 'att', 'avg'. Default: 'avg'.
+ fusion_types (tuple[str]): The fusion type for feature fusion.
+ Options are 'channel_add', 'channel_mul'. Default: ('channel_add',)
+ """
+
+ def __init__(self,
+ ratio=1 / 4.,
+ pooling_type='att',
+ fusion_types=('channel_add', ),
+ **kwargs):
+ super(GCHead, self).__init__(num_convs=2, **kwargs)
+ self.ratio = ratio
+ self.pooling_type = pooling_type
+ self.fusion_types = fusion_types
+ self.gc_block = ContextBlock(
+ in_channels=self.channels,
+ ratio=self.ratio,
+ pooling_type=self.pooling_type,
+ fusion_types=self.fusion_types)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs[0](x)
+ output = self.gc_block(output)
+ output = self.convs[1](output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/isa_head.py b/mmseg/models/decode_heads/isa_head.py
new file mode 100644
index 0000000..c9224b6
--- /dev/null
+++ b/mmseg/models/decode_heads/isa_head.py
@@ -0,0 +1,142 @@
+import math
+
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from ..builder import HEADS
+from ..utils import SelfAttentionBlock as _SelfAttentionBlock
+from .decode_head import BaseDecodeHead
+
+
+class SelfAttentionBlock(_SelfAttentionBlock):
+ """Self-Attention Module.
+
+ Args:
+ in_channels (int): Input channels of key/query feature.
+ channels (int): Output channels of key/query transform.
+ conv_cfg (dict | None): Config of conv layers.
+ norm_cfg (dict | None): Config of norm layers.
+ act_cfg (dict | None): Config of activation layers.
+ """
+
+ def __init__(self, in_channels, channels, conv_cfg, norm_cfg, act_cfg):
+ super(SelfAttentionBlock, self).__init__(
+ key_in_channels=in_channels,
+ query_in_channels=in_channels,
+ channels=channels,
+ out_channels=in_channels,
+ share_key_query=False,
+ query_downsample=None,
+ key_downsample=None,
+ key_query_num_convs=2,
+ key_query_norm=True,
+ value_out_num_convs=1,
+ value_out_norm=False,
+ matmul_norm=True,
+ with_out=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.output_project = self.build_project(
+ in_channels,
+ in_channels,
+ num_convs=1,
+ use_conv_module=True,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ """Forward function."""
+ context = super(SelfAttentionBlock, self).forward(x, x)
+ return self.output_project(context)
+
+
+@HEADS.register_module()
+class ISAHead(BaseDecodeHead):
+ """Interlaced Sparse Self-Attention for Semantic Segmentation.
+
+ This head is the implementation of `ISA
+ `_.
+
+ Args:
+ isa_channels (int): The channels of ISA Module.
+ down_factor (tuple[int]): The local group size of ISA.
+ """
+
+ def __init__(self, isa_channels, down_factor=(8, 8), **kwargs):
+ super(ISAHead, self).__init__(**kwargs)
+ self.down_factor = down_factor
+
+ self.in_conv = ConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.global_relation = SelfAttentionBlock(
+ self.channels,
+ isa_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.local_relation = SelfAttentionBlock(
+ self.channels,
+ isa_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.out_conv = ConvModule(
+ self.channels * 2,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x_ = self._transform_inputs(inputs)
+ x = self.in_conv(x_)
+ residual = x
+
+ n, c, h, w = x.size()
+ loc_h, loc_w = self.down_factor # size of local group in H- and W-axes
+ glb_h, glb_w = math.ceil(h / loc_h), math.ceil(w / loc_w)
+ pad_h, pad_w = glb_h * loc_h - h, glb_w * loc_w - w
+ if pad_h > 0 or pad_w > 0: # pad if the size is not divisible
+ padding = (pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
+ pad_h - pad_h // 2)
+ x = F.pad(x, padding)
+
+ # global relation
+ x = x.view(n, c, glb_h, loc_h, glb_w, loc_w)
+ # do permutation to gather global group
+ x = x.permute(0, 3, 5, 1, 2, 4) # (n, loc_h, loc_w, c, glb_h, glb_w)
+ x = x.reshape(-1, c, glb_h, glb_w)
+ # apply attention within each global group
+ x = self.global_relation(x) # (n * loc_h * loc_w, c, glb_h, glb_w)
+
+ # local relation
+ x = x.view(n, loc_h, loc_w, c, glb_h, glb_w)
+ # do permutation to gather local group
+ x = x.permute(0, 4, 5, 3, 1, 2) # (n, glb_h, glb_w, c, loc_h, loc_w)
+ x = x.reshape(-1, c, loc_h, loc_w)
+ # apply attention within each local group
+ x = self.local_relation(x) # (n * glb_h * glb_w, c, loc_h, loc_w)
+
+ # permute each pixel back to its original position
+ x = x.view(n, glb_h, glb_w, c, loc_h, loc_w)
+ x = x.permute(0, 3, 1, 4, 2, 5) # (n, c, glb_h, loc_h, glb_w, loc_w)
+ x = x.reshape(n, c, glb_h * loc_h, glb_w * loc_w)
+ if pad_h > 0 or pad_w > 0: # remove padding
+ x = x[:, :, pad_h // 2:pad_h // 2 + h, pad_w // 2:pad_w // 2 + w]
+
+ x = self.out_conv(torch.cat([x, residual], dim=1))
+ out = self.cls_seg(x)
+
+ return out
diff --git a/mmseg/models/decode_heads/lraspp_head.py b/mmseg/models/decode_heads/lraspp_head.py
new file mode 100644
index 0000000..c10ff0d
--- /dev/null
+++ b/mmseg/models/decode_heads/lraspp_head.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv import is_tuple_of
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class LRASPPHead(BaseDecodeHead):
+ """Lite R-ASPP (LRASPP) head is proposed in Searching for MobileNetV3.
+
+ This head is the improved implementation of `Searching for MobileNetV3
+ `_.
+
+ Args:
+ branch_channels (tuple[int]): The number of output channels in every
+ each branch. Default: (32, 64).
+ """
+
+ def __init__(self, branch_channels=(32, 64), **kwargs):
+ super(LRASPPHead, self).__init__(**kwargs)
+ if self.input_transform != 'multiple_select':
+ raise ValueError('in Lite R-ASPP (LRASPP) head, input_transform '
+ f'must be \'multiple_select\'. But received '
+ f'\'{self.input_transform}\'')
+ assert is_tuple_of(branch_channels, int)
+ assert len(branch_channels) == len(self.in_channels) - 1
+ self.branch_channels = branch_channels
+
+ self.convs = nn.Sequential()
+ self.conv_ups = nn.Sequential()
+ for i in range(len(branch_channels)):
+ self.convs.add_module(
+ f'conv{i}',
+ nn.Conv2d(
+ self.in_channels[i], branch_channels[i], 1, bias=False))
+ self.conv_ups.add_module(
+ f'conv_up{i}',
+ ConvModule(
+ self.channels + branch_channels[i],
+ self.channels,
+ 1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ bias=False))
+
+ self.conv_up_input = nn.Conv2d(self.channels, self.channels, 1)
+
+ self.aspp_conv = ConvModule(
+ self.in_channels[-1],
+ self.channels,
+ 1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ bias=False)
+ self.image_pool = nn.Sequential(
+ nn.AvgPool2d(kernel_size=49, stride=(16, 20)),
+ ConvModule(
+ self.in_channels[2],
+ self.channels,
+ 1,
+ act_cfg=dict(type='Sigmoid'),
+ bias=False))
+
+ def forward(self, inputs):
+ """Forward function."""
+ inputs = self._transform_inputs(inputs)
+
+ x = inputs[-1]
+
+ x = self.aspp_conv(x) * resize(
+ self.image_pool(x),
+ size=x.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = self.conv_up_input(x)
+
+ for i in range(len(self.branch_channels) - 1, -1, -1):
+ x = resize(
+ x,
+ size=inputs[i].size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ x = torch.cat([x, self.convs[i](inputs[i])], 1)
+ x = self.conv_ups[i](x)
+
+ return self.cls_seg(x)
diff --git a/mmseg/models/decode_heads/nl_head.py b/mmseg/models/decode_heads/nl_head.py
new file mode 100644
index 0000000..637517e
--- /dev/null
+++ b/mmseg/models/decode_heads/nl_head.py
@@ -0,0 +1,50 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import NonLocal2d
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+@HEADS.register_module()
+class NLHead(FCNHead):
+ """Non-local Neural Networks.
+
+ This head is the implementation of `NLNet
+ `_.
+
+ Args:
+ reduction (int): Reduction factor of projection transform. Default: 2.
+ use_scale (bool): Whether to scale pairwise_weight by
+ sqrt(1/inter_channels). Default: True.
+ mode (str): The nonlocal mode. Options are 'embedded_gaussian',
+ 'dot_product'. Default: 'embedded_gaussian.'.
+ """
+
+ def __init__(self,
+ reduction=2,
+ use_scale=True,
+ mode='embedded_gaussian',
+ **kwargs):
+ super(NLHead, self).__init__(num_convs=2, **kwargs)
+ self.reduction = reduction
+ self.use_scale = use_scale
+ self.mode = mode
+ self.nl_block = NonLocal2d(
+ in_channels=self.channels,
+ reduction=self.reduction,
+ use_scale=self.use_scale,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ mode=self.mode)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ output = self.convs[0](x)
+ output = self.nl_block(output)
+ output = self.convs[1](output)
+ if self.concat_input:
+ output = self.conv_cat(torch.cat([x, output], dim=1))
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/ocr_head.py b/mmseg/models/decode_heads/ocr_head.py
new file mode 100644
index 0000000..09eadfb
--- /dev/null
+++ b/mmseg/models/decode_heads/ocr_head.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from ..utils import SelfAttentionBlock as _SelfAttentionBlock
+from .cascade_decode_head import BaseCascadeDecodeHead
+
+
+class SpatialGatherModule(nn.Module):
+ """Aggregate the context features according to the initial predicted
+ probability distribution.
+
+ Employ the soft-weighted method to aggregate the context.
+ """
+
+ def __init__(self, scale):
+ super(SpatialGatherModule, self).__init__()
+ self.scale = scale
+
+ def forward(self, feats, probs):
+ """Forward function."""
+ batch_size, num_classes, height, width = probs.size()
+ channels = feats.size(1)
+ probs = probs.view(batch_size, num_classes, -1)
+ feats = feats.view(batch_size, channels, -1)
+ # [batch_size, height*width, num_classes]
+ feats = feats.permute(0, 2, 1)
+ # [batch_size, channels, height*width]
+ probs = F.softmax(self.scale * probs, dim=2)
+ # [batch_size, channels, num_classes]
+ ocr_context = torch.matmul(probs, feats)
+ ocr_context = ocr_context.permute(0, 2, 1).contiguous().unsqueeze(3)
+ return ocr_context
+
+
+class ObjectAttentionBlock(_SelfAttentionBlock):
+ """Make a OCR used SelfAttentionBlock."""
+
+ def __init__(self, in_channels, channels, scale, conv_cfg, norm_cfg,
+ act_cfg):
+ if scale > 1:
+ query_downsample = nn.MaxPool2d(kernel_size=scale)
+ else:
+ query_downsample = None
+ super(ObjectAttentionBlock, self).__init__(
+ key_in_channels=in_channels,
+ query_in_channels=in_channels,
+ channels=channels,
+ out_channels=in_channels,
+ share_key_query=False,
+ query_downsample=query_downsample,
+ key_downsample=None,
+ key_query_num_convs=2,
+ key_query_norm=True,
+ value_out_num_convs=1,
+ value_out_norm=True,
+ matmul_norm=True,
+ with_out=True,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.bottleneck = ConvModule(
+ in_channels * 2,
+ in_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, query_feats, key_feats):
+ """Forward function."""
+ context = super(ObjectAttentionBlock,
+ self).forward(query_feats, key_feats)
+ output = self.bottleneck(torch.cat([context, query_feats], dim=1))
+ if self.query_downsample is not None:
+ output = resize(query_feats)
+
+ return output
+
+
+@HEADS.register_module()
+class OCRHead(BaseCascadeDecodeHead):
+ """Object-Contextual Representations for Semantic Segmentation.
+
+ This head is the implementation of `OCRNet
+ `_.
+
+ Args:
+ ocr_channels (int): The intermediate channels of OCR block.
+ scale (int): The scale of probability map in SpatialGatherModule in
+ Default: 1.
+ """
+
+ def __init__(self, ocr_channels, scale=1, **kwargs):
+ super(OCRHead, self).__init__(**kwargs)
+ self.ocr_channels = ocr_channels
+ self.scale = scale
+ self.object_context_block = ObjectAttentionBlock(
+ self.channels,
+ self.ocr_channels,
+ self.scale,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.spatial_gather_module = SpatialGatherModule(self.scale)
+
+ self.bottleneck = ConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs, prev_output):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ feats = self.bottleneck(x)
+ context = self.spatial_gather_module(feats, prev_output)
+ object_context = self.object_context_block(feats, context)
+ output = self.cls_seg(object_context)
+
+ return output
diff --git a/mmseg/models/decode_heads/point_head.py b/mmseg/models/decode_heads/point_head.py
new file mode 100644
index 0000000..eb54bbc
--- /dev/null
+++ b/mmseg/models/decode_heads/point_head.py
@@ -0,0 +1,363 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Modified from https://github.com/facebookresearch/detectron2/tree/master/projects/PointRend/point_head/point_head.py # noqa
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+try:
+ from mmcv.ops import point_sample
+except ModuleNotFoundError:
+ point_sample = None
+
+from mmseg.models.builder import HEADS
+from mmseg.ops import resize
+from ..losses import accuracy
+from .cascade_decode_head import BaseCascadeDecodeHead
+
+
+def calculate_uncertainty(seg_logits):
+ """Estimate uncertainty based on seg logits.
+
+ For each location of the prediction ``seg_logits`` we estimate
+ uncertainty as the difference between top first and top second
+ predicted logits.
+
+ Args:
+ seg_logits (Tensor): Semantic segmentation logits,
+ shape (batch_size, num_classes, height, width).
+
+ Returns:
+ scores (Tensor): T uncertainty scores with the most uncertain
+ locations having the highest uncertainty score, shape (
+ batch_size, 1, height, width)
+ """
+ top2_scores = torch.topk(seg_logits, k=2, dim=1)[0]
+ return (top2_scores[:, 1] - top2_scores[:, 0]).unsqueeze(1)
+
+
+@HEADS.register_module()
+class PointHead(BaseCascadeDecodeHead):
+ """A mask point head use in PointRend.
+
+ This head is implemented of `PointRend: Image Segmentation as
+ Rendering `_.
+ ``PointHead`` use shared multi-layer perceptron (equivalent to
+ nn.Conv1d) to predict the logit of input points. The fine-grained feature
+ and coarse feature will be concatenate together for predication.
+
+ Args:
+ num_fcs (int): Number of fc layers in the head. Default: 3.
+ in_channels (int): Number of input channels. Default: 256.
+ fc_channels (int): Number of fc channels. Default: 256.
+ num_classes (int): Number of classes for logits. Default: 80.
+ class_agnostic (bool): Whether use class agnostic classification.
+ If so, the output channels of logits will be 1. Default: False.
+ coarse_pred_each_layer (bool): Whether concatenate coarse feature with
+ the output of each fc layer. Default: True.
+ conv_cfg (dict|None): Dictionary to construct and config conv layer.
+ Default: dict(type='Conv1d'))
+ norm_cfg (dict|None): Dictionary to construct and config norm layer.
+ Default: None.
+ loss_point (dict): Dictionary to construct and config loss layer of
+ point head. Default: dict(type='CrossEntropyLoss', use_mask=True,
+ loss_weight=1.0).
+ """
+
+ def __init__(self,
+ num_fcs=3,
+ coarse_pred_each_layer=True,
+ conv_cfg=dict(type='Conv1d'),
+ norm_cfg=None,
+ act_cfg=dict(type='ReLU', inplace=False),
+ **kwargs):
+ super(PointHead, self).__init__(
+ input_transform='multiple_select',
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ init_cfg=dict(
+ type='Normal', std=0.01, override=dict(name='fc_seg')),
+ **kwargs)
+ if point_sample is None:
+ raise RuntimeError('Please install mmcv-full for '
+ 'point_sample ops')
+
+ self.num_fcs = num_fcs
+ self.coarse_pred_each_layer = coarse_pred_each_layer
+
+ fc_in_channels = sum(self.in_channels) + self.num_classes
+ fc_channels = self.channels
+ self.fcs = nn.ModuleList()
+ for k in range(num_fcs):
+ fc = ConvModule(
+ fc_in_channels,
+ fc_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.fcs.append(fc)
+ fc_in_channels = fc_channels
+ fc_in_channels += self.num_classes if self.coarse_pred_each_layer \
+ else 0
+ self.fc_seg = nn.Conv1d(
+ fc_in_channels,
+ self.num_classes,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+ if self.dropout_ratio > 0:
+ self.dropout = nn.Dropout(self.dropout_ratio)
+ delattr(self, 'conv_seg')
+
+ def cls_seg(self, feat):
+ """Classify each pixel with fc."""
+ if self.dropout is not None:
+ feat = self.dropout(feat)
+ output = self.fc_seg(feat)
+ return output
+
+ def forward(self, fine_grained_point_feats, coarse_point_feats):
+ x = torch.cat([fine_grained_point_feats, coarse_point_feats], dim=1)
+ for fc in self.fcs:
+ x = fc(x)
+ if self.coarse_pred_each_layer:
+ x = torch.cat((x, coarse_point_feats), dim=1)
+ return self.cls_seg(x)
+
+ def _get_fine_grained_point_feats(self, x, points):
+ """Sample from fine grained features.
+
+ Args:
+ x (list[Tensor]): Feature pyramid from by neck or backbone.
+ points (Tensor): Point coordinates, shape (batch_size,
+ num_points, 2).
+
+ Returns:
+ fine_grained_feats (Tensor): Sampled fine grained feature,
+ shape (batch_size, sum(channels of x), num_points).
+ """
+
+ fine_grained_feats_list = [
+ point_sample(_, points, align_corners=self.align_corners)
+ for _ in x
+ ]
+ if len(fine_grained_feats_list) > 1:
+ fine_grained_feats = torch.cat(fine_grained_feats_list, dim=1)
+ else:
+ fine_grained_feats = fine_grained_feats_list[0]
+
+ return fine_grained_feats
+
+ def _get_coarse_point_feats(self, prev_output, points):
+ """Sample from fine grained features.
+
+ Args:
+ prev_output (list[Tensor]): Prediction of previous decode head.
+ points (Tensor): Point coordinates, shape (batch_size,
+ num_points, 2).
+
+ Returns:
+ coarse_feats (Tensor): Sampled coarse feature, shape (batch_size,
+ num_classes, num_points).
+ """
+
+ coarse_feats = point_sample(
+ prev_output, points, align_corners=self.align_corners)
+
+ return coarse_feats
+
+ def forward_train(self, inputs, prev_output, img_metas, gt_semantic_seg,
+ train_cfg):
+ """Forward function for training.
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ prev_output (Tensor): The output of previous decode head.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ gt_semantic_seg (Tensor): Semantic segmentation masks
+ used if the architecture supports semantic segmentation task.
+ train_cfg (dict): The training config.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ x = self._transform_inputs(inputs)
+ with torch.no_grad():
+ points = self.get_points_train(
+ prev_output, calculate_uncertainty, cfg=train_cfg)
+ fine_grained_point_feats = self._get_fine_grained_point_feats(
+ x, points)
+ coarse_point_feats = self._get_coarse_point_feats(prev_output, points)
+ point_logits = self.forward(fine_grained_point_feats,
+ coarse_point_feats)
+ point_label = point_sample(
+ gt_semantic_seg.float(),
+ points,
+ mode='nearest',
+ align_corners=self.align_corners)
+ point_label = point_label.squeeze(1).long()
+
+ losses = self.losses(point_logits, point_label)
+
+ return losses
+
+ def forward_test(self, inputs, prev_output, img_metas, test_cfg):
+ """Forward function for testing.
+
+ Args:
+ inputs (list[Tensor]): List of multi-level img features.
+ prev_output (Tensor): The output of previous decode head.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ test_cfg (dict): The testing config.
+
+ Returns:
+ Tensor: Output segmentation map.
+ """
+
+ x = self._transform_inputs(inputs)
+ refined_seg_logits = prev_output.clone()
+ for _ in range(test_cfg.subdivision_steps):
+ refined_seg_logits = resize(
+ refined_seg_logits,
+ scale_factor=test_cfg.scale_factor,
+ mode='bilinear',
+ align_corners=self.align_corners)
+ batch_size, channels, height, width = refined_seg_logits.shape
+ point_indices, points = self.get_points_test(
+ refined_seg_logits, calculate_uncertainty, cfg=test_cfg)
+ fine_grained_point_feats = self._get_fine_grained_point_feats(
+ x, points)
+ coarse_point_feats = self._get_coarse_point_feats(
+ prev_output, points)
+ point_logits = self.forward(fine_grained_point_feats,
+ coarse_point_feats)
+
+ point_indices = point_indices.unsqueeze(1).expand(-1, channels, -1)
+ refined_seg_logits = refined_seg_logits.reshape(
+ batch_size, channels, height * width)
+ refined_seg_logits = refined_seg_logits.scatter_(
+ 2, point_indices, point_logits)
+ refined_seg_logits = refined_seg_logits.view(
+ batch_size, channels, height, width)
+
+ return refined_seg_logits
+
+ def losses(self, point_logits, point_label):
+ """Compute segmentation loss."""
+ loss = dict()
+ if not isinstance(self.loss_decode, nn.ModuleList):
+ losses_decode = [self.loss_decode]
+ else:
+ losses_decode = self.loss_decode
+ for loss_module in losses_decode:
+ loss['point' + loss_module.loss_name] = loss_module(
+ point_logits, point_label, ignore_index=self.ignore_index)
+
+ loss['acc_point'] = accuracy(point_logits, point_label)
+ return loss
+
+ def get_points_train(self, seg_logits, uncertainty_func, cfg):
+ """Sample points for training.
+
+ Sample points in [0, 1] x [0, 1] coordinate space based on their
+ uncertainty. The uncertainties are calculated for each point using
+ 'uncertainty_func' function that takes point's logit prediction as
+ input.
+
+ Args:
+ seg_logits (Tensor): Semantic segmentation logits, shape (
+ batch_size, num_classes, height, width).
+ uncertainty_func (func): uncertainty calculation function.
+ cfg (dict): Training config of point head.
+
+ Returns:
+ point_coords (Tensor): A tensor of shape (batch_size, num_points,
+ 2) that contains the coordinates of ``num_points`` sampled
+ points.
+ """
+ num_points = cfg.num_points
+ oversample_ratio = cfg.oversample_ratio
+ importance_sample_ratio = cfg.importance_sample_ratio
+ assert oversample_ratio >= 1
+ assert 0 <= importance_sample_ratio <= 1
+ batch_size = seg_logits.shape[0]
+ num_sampled = int(num_points * oversample_ratio)
+ point_coords = torch.rand(
+ batch_size, num_sampled, 2, device=seg_logits.device)
+ point_logits = point_sample(seg_logits, point_coords)
+ # It is crucial to calculate uncertainty based on the sampled
+ # prediction value for the points. Calculating uncertainties of the
+ # coarse predictions first and sampling them for points leads to
+ # incorrect results. To illustrate this: assume uncertainty func(
+ # logits)=-abs(logits), a sampled point between two coarse
+ # predictions with -1 and 1 logits has 0 logits, and therefore 0
+ # uncertainty value. However, if we calculate uncertainties for the
+ # coarse predictions first, both will have -1 uncertainty,
+ # and sampled point will get -1 uncertainty.
+ point_uncertainties = uncertainty_func(point_logits)
+ num_uncertain_points = int(importance_sample_ratio * num_points)
+ num_random_points = num_points - num_uncertain_points
+ idx = torch.topk(
+ point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1]
+ shift = num_sampled * torch.arange(
+ batch_size, dtype=torch.long, device=seg_logits.device)
+ idx += shift[:, None]
+ point_coords = point_coords.view(-1, 2)[idx.view(-1), :].view(
+ batch_size, num_uncertain_points, 2)
+ if num_random_points > 0:
+ rand_point_coords = torch.rand(
+ batch_size, num_random_points, 2, device=seg_logits.device)
+ point_coords = torch.cat((point_coords, rand_point_coords), dim=1)
+ return point_coords
+
+ def get_points_test(self, seg_logits, uncertainty_func, cfg):
+ """Sample points for testing.
+
+ Find ``num_points`` most uncertain points from ``uncertainty_map``.
+
+ Args:
+ seg_logits (Tensor): A tensor of shape (batch_size, num_classes,
+ height, width) for class-specific or class-agnostic prediction.
+ uncertainty_func (func): uncertainty calculation function.
+ cfg (dict): Testing config of point head.
+
+ Returns:
+ point_indices (Tensor): A tensor of shape (batch_size, num_points)
+ that contains indices from [0, height x width) of the most
+ uncertain points.
+ point_coords (Tensor): A tensor of shape (batch_size, num_points,
+ 2) that contains [0, 1] x [0, 1] normalized coordinates of the
+ most uncertain points from the ``height x width`` grid .
+ """
+
+ num_points = cfg.subdivision_num_points
+ uncertainty_map = uncertainty_func(seg_logits)
+ batch_size, _, height, width = uncertainty_map.shape
+ h_step = 1.0 / height
+ w_step = 1.0 / width
+
+ uncertainty_map = uncertainty_map.view(batch_size, height * width)
+ num_points = min(height * width, num_points)
+ point_indices = uncertainty_map.topk(num_points, dim=1)[1]
+ point_coords = torch.zeros(
+ batch_size,
+ num_points,
+ 2,
+ dtype=torch.float,
+ device=seg_logits.device)
+ point_coords[:, :, 0] = w_step / 2.0 + (point_indices %
+ width).float() * w_step
+ point_coords[:, :, 1] = h_step / 2.0 + (point_indices //
+ width).float() * h_step
+ return point_indices, point_coords
diff --git a/mmseg/models/decode_heads/psa_head.py b/mmseg/models/decode_heads/psa_head.py
new file mode 100644
index 0000000..df7593c
--- /dev/null
+++ b/mmseg/models/decode_heads/psa_head.py
@@ -0,0 +1,197 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+try:
+ from mmcv.ops import PSAMask
+except ModuleNotFoundError:
+ PSAMask = None
+
+
+@HEADS.register_module()
+class PSAHead(BaseDecodeHead):
+ """Point-wise Spatial Attention Network for Scene Parsing.
+
+ This head is the implementation of `PSANet
+ `_.
+
+ Args:
+ mask_size (tuple[int]): The PSA mask size. It usually equals input
+ size.
+ psa_type (str): The type of psa module. Options are 'collect',
+ 'distribute', 'bi-direction'. Default: 'bi-direction'
+ compact (bool): Whether use compact map for 'collect' mode.
+ Default: True.
+ shrink_factor (int): The downsample factors of psa mask. Default: 2.
+ normalization_factor (float): The normalize factor of attention.
+ psa_softmax (bool): Whether use softmax for attention.
+ """
+
+ def __init__(self,
+ mask_size,
+ psa_type='bi-direction',
+ compact=False,
+ shrink_factor=2,
+ normalization_factor=1.0,
+ psa_softmax=True,
+ **kwargs):
+ if PSAMask is None:
+ raise RuntimeError('Please install mmcv-full for PSAMask ops')
+ super(PSAHead, self).__init__(**kwargs)
+ assert psa_type in ['collect', 'distribute', 'bi-direction']
+ self.psa_type = psa_type
+ self.compact = compact
+ self.shrink_factor = shrink_factor
+ self.mask_size = mask_size
+ mask_h, mask_w = mask_size
+ self.psa_softmax = psa_softmax
+ if normalization_factor is None:
+ normalization_factor = mask_h * mask_w
+ self.normalization_factor = normalization_factor
+
+ self.reduce = ConvModule(
+ self.in_channels,
+ self.channels,
+ kernel_size=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.attention = nn.Sequential(
+ ConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ nn.Conv2d(
+ self.channels, mask_h * mask_w, kernel_size=1, bias=False))
+ if psa_type == 'bi-direction':
+ self.reduce_p = ConvModule(
+ self.in_channels,
+ self.channels,
+ kernel_size=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.attention_p = nn.Sequential(
+ ConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ nn.Conv2d(
+ self.channels, mask_h * mask_w, kernel_size=1, bias=False))
+ self.psamask_collect = PSAMask('collect', mask_size)
+ self.psamask_distribute = PSAMask('distribute', mask_size)
+ else:
+ self.psamask = PSAMask(psa_type, mask_size)
+ self.proj = ConvModule(
+ self.channels * (2 if psa_type == 'bi-direction' else 1),
+ self.in_channels,
+ kernel_size=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.bottleneck = ConvModule(
+ self.in_channels * 2,
+ self.channels,
+ kernel_size=3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ identity = x
+ align_corners = self.align_corners
+ if self.psa_type in ['collect', 'distribute']:
+ out = self.reduce(x)
+ n, c, h, w = out.size()
+ if self.shrink_factor != 1:
+ if h % self.shrink_factor and w % self.shrink_factor:
+ h = (h - 1) // self.shrink_factor + 1
+ w = (w - 1) // self.shrink_factor + 1
+ align_corners = True
+ else:
+ h = h // self.shrink_factor
+ w = w // self.shrink_factor
+ align_corners = False
+ out = resize(
+ out,
+ size=(h, w),
+ mode='bilinear',
+ align_corners=align_corners)
+ y = self.attention(out)
+ if self.compact:
+ if self.psa_type == 'collect':
+ y = y.view(n, h * w,
+ h * w).transpose(1, 2).view(n, h * w, h, w)
+ else:
+ y = self.psamask(y)
+ if self.psa_softmax:
+ y = F.softmax(y, dim=1)
+ out = torch.bmm(
+ out.view(n, c, h * w), y.view(n, h * w, h * w)).view(
+ n, c, h, w) * (1.0 / self.normalization_factor)
+ else:
+ x_col = self.reduce(x)
+ x_dis = self.reduce_p(x)
+ n, c, h, w = x_col.size()
+ if self.shrink_factor != 1:
+ if h % self.shrink_factor and w % self.shrink_factor:
+ h = (h - 1) // self.shrink_factor + 1
+ w = (w - 1) // self.shrink_factor + 1
+ align_corners = True
+ else:
+ h = h // self.shrink_factor
+ w = w // self.shrink_factor
+ align_corners = False
+ x_col = resize(
+ x_col,
+ size=(h, w),
+ mode='bilinear',
+ align_corners=align_corners)
+ x_dis = resize(
+ x_dis,
+ size=(h, w),
+ mode='bilinear',
+ align_corners=align_corners)
+ y_col = self.attention(x_col)
+ y_dis = self.attention_p(x_dis)
+ if self.compact:
+ y_dis = y_dis.view(n, h * w,
+ h * w).transpose(1, 2).view(n, h * w, h, w)
+ else:
+ y_col = self.psamask_collect(y_col)
+ y_dis = self.psamask_distribute(y_dis)
+ if self.psa_softmax:
+ y_col = F.softmax(y_col, dim=1)
+ y_dis = F.softmax(y_dis, dim=1)
+ x_col = torch.bmm(
+ x_col.view(n, c, h * w), y_col.view(n, h * w, h * w)).view(
+ n, c, h, w) * (1.0 / self.normalization_factor)
+ x_dis = torch.bmm(
+ x_dis.view(n, c, h * w), y_dis.view(n, h * w, h * w)).view(
+ n, c, h, w) * (1.0 / self.normalization_factor)
+ out = torch.cat([x_col, x_dis], 1)
+ out = self.proj(out)
+ out = resize(
+ out,
+ size=identity.shape[2:],
+ mode='bilinear',
+ align_corners=align_corners)
+ out = self.bottleneck(torch.cat((identity, out), dim=1))
+ out = self.cls_seg(out)
+ return out
diff --git a/mmseg/models/decode_heads/psp_head.py b/mmseg/models/decode_heads/psp_head.py
new file mode 100644
index 0000000..a27ae4b
--- /dev/null
+++ b/mmseg/models/decode_heads/psp_head.py
@@ -0,0 +1,103 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+class PPM(nn.ModuleList):
+ """Pooling Pyramid Module used in PSPNet.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module.
+ in_channels (int): Input channels.
+ channels (int): Channels after modules, before conv_seg.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict): Config of activation layers.
+ align_corners (bool): align_corners argument of F.interpolate.
+ """
+
+ def __init__(self, pool_scales, in_channels, channels, conv_cfg, norm_cfg,
+ act_cfg, align_corners, **kwargs):
+ super(PPM, self).__init__()
+ self.pool_scales = pool_scales
+ self.align_corners = align_corners
+ self.in_channels = in_channels
+ self.channels = channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ for pool_scale in pool_scales:
+ self.append(
+ nn.Sequential(
+ nn.AdaptiveAvgPool2d(pool_scale),
+ ConvModule(
+ self.in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ **kwargs)))
+
+ def forward(self, x):
+ """Forward function."""
+ ppm_outs = []
+ for ppm in self:
+ ppm_out = ppm(x)
+ upsampled_ppm_out = resize(
+ ppm_out,
+ size=x.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ ppm_outs.append(upsampled_ppm_out)
+ return ppm_outs
+
+
+@HEADS.register_module()
+class PSPHead(BaseDecodeHead):
+ """Pyramid Scene Parsing Network.
+
+ This head is the implementation of
+ `PSPNet `_.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module. Default: (1, 2, 3, 6).
+ """
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
+ super(PSPHead, self).__init__(**kwargs)
+ assert isinstance(pool_scales, (list, tuple))
+ self.pool_scales = pool_scales
+ self.psp_modules = PPM(
+ self.pool_scales,
+ self.in_channels,
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+ self.bottleneck = ConvModule(
+ self.in_channels + len(pool_scales) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ psp_outs = [x]
+ psp_outs.extend(self.psp_modules(x))
+ psp_outs = torch.cat(psp_outs, dim=1)
+ output = self.bottleneck(psp_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/segformer_head.py b/mmseg/models/decode_heads/segformer_head.py
new file mode 100644
index 0000000..2e75d50
--- /dev/null
+++ b/mmseg/models/decode_heads/segformer_head.py
@@ -0,0 +1,66 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.models.builder import HEADS
+from mmseg.models.decode_heads.decode_head import BaseDecodeHead
+from mmseg.ops import resize
+
+
+@HEADS.register_module()
+class SegformerHead(BaseDecodeHead):
+ """The all mlp Head of segformer.
+
+ This head is the implementation of
+ `Segformer ` _.
+
+ Args:
+ interpolate_mode: The interpolate mode of MLP head upsample operation.
+ Default: 'bilinear'.
+ """
+
+ def __init__(self, interpolate_mode='bilinear', **kwargs):
+ super().__init__(input_transform='multiple_select', **kwargs)
+
+ self.interpolate_mode = interpolate_mode
+ num_inputs = len(self.in_channels)
+
+ assert num_inputs == len(self.in_index)
+
+ self.convs = nn.ModuleList()
+ for i in range(num_inputs):
+ self.convs.append(
+ ConvModule(
+ in_channels=self.in_channels[i],
+ out_channels=self.channels,
+ kernel_size=1,
+ stride=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+
+ self.fusion_conv = ConvModule(
+ in_channels=self.channels * num_inputs,
+ out_channels=self.channels,
+ kernel_size=1,
+ norm_cfg=self.norm_cfg)
+
+ def forward(self, inputs):
+ # Receive 4 stage backbone feature map: 1/4, 1/8, 1/16, 1/32
+ inputs = self._transform_inputs(inputs)
+ outs = []
+ for idx in range(len(inputs)):
+ x = inputs[idx]
+ conv = self.convs[idx]
+ outs.append(
+ resize(
+ input=conv(x),
+ size=inputs[0].shape[2:],
+ mode=self.interpolate_mode,
+ align_corners=self.align_corners))
+
+ out = self.fusion_conv(torch.cat(outs, dim=1))
+
+ out = self.cls_seg(out)
+
+ return out
diff --git a/mmseg/models/decode_heads/segmenter_mask_head.py b/mmseg/models/decode_heads/segmenter_mask_head.py
new file mode 100644
index 0000000..6a9b3d4
--- /dev/null
+++ b/mmseg/models/decode_heads/segmenter_mask_head.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.utils.weight_init import (constant_init, trunc_normal_,
+ trunc_normal_init)
+from mmcv.runner import ModuleList
+
+from mmseg.models.backbones.vit import TransformerEncoderLayer
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class SegmenterMaskTransformerHead(BaseDecodeHead):
+ """Segmenter: Transformer for Semantic Segmentation.
+
+ This head is the implementation of
+ `Segmenter: `_.
+
+ Args:
+ backbone_cfg:(dict): Config of backbone of
+ Context Path.
+ in_channels (int): The number of channels of input image.
+ num_layers (int): The depth of transformer.
+ num_heads (int): The number of attention heads.
+ embed_dims (int): The number of embedding dimension.
+ mlp_ratio (int): ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ drop_path_rate (float): stochastic depth rate. Default 0.1.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.0
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ init_std (float): The value of std in weight initialization.
+ Default: 0.02.
+ """
+
+ def __init__(
+ self,
+ in_channels,
+ num_layers,
+ num_heads,
+ embed_dims,
+ mlp_ratio=4,
+ drop_path_rate=0.1,
+ drop_rate=0.0,
+ attn_drop_rate=0.0,
+ num_fcs=2,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ init_std=0.02,
+ **kwargs,
+ ):
+ super(SegmenterMaskTransformerHead, self).__init__(
+ in_channels=in_channels, **kwargs)
+
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, num_layers)]
+ self.layers = ModuleList()
+ for i in range(num_layers):
+ self.layers.append(
+ TransformerEncoderLayer(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ feedforward_channels=mlp_ratio * embed_dims,
+ attn_drop_rate=attn_drop_rate,
+ drop_rate=drop_rate,
+ drop_path_rate=dpr[i],
+ num_fcs=num_fcs,
+ qkv_bias=qkv_bias,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ batch_first=True,
+ ))
+
+ self.dec_proj = nn.Linear(in_channels, embed_dims)
+
+ self.cls_emb = nn.Parameter(
+ torch.randn(1, self.num_classes, embed_dims))
+ self.patch_proj = nn.Linear(embed_dims, embed_dims, bias=False)
+ self.classes_proj = nn.Linear(embed_dims, embed_dims, bias=False)
+
+ self.decoder_norm = build_norm_layer(
+ norm_cfg, embed_dims, postfix=1)[1]
+ self.mask_norm = build_norm_layer(
+ norm_cfg, self.num_classes, postfix=2)[1]
+
+ self.init_std = init_std
+
+ delattr(self, 'conv_seg')
+
+ def init_weights(self):
+ trunc_normal_(self.cls_emb, std=self.init_std)
+ trunc_normal_init(self.patch_proj, std=self.init_std)
+ trunc_normal_init(self.classes_proj, std=self.init_std)
+ for n, m in self.named_modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=self.init_std, bias=0)
+ elif isinstance(m, nn.LayerNorm):
+ constant_init(m, val=1.0, bias=0.0)
+
+ def forward(self, inputs):
+ x = self._transform_inputs(inputs)
+ b, c, h, w = x.shape
+ x = x.permute(0, 2, 3, 1).contiguous().view(b, -1, c)
+
+ x = self.dec_proj(x)
+ cls_emb = self.cls_emb.expand(x.size(0), -1, -1)
+ x = torch.cat((x, cls_emb), 1)
+ for layer in self.layers:
+ x = layer(x)
+ x = self.decoder_norm(x)
+
+ patches = self.patch_proj(x[:, :-self.num_classes])
+ cls_seg_feat = self.classes_proj(x[:, -self.num_classes:])
+
+ patches = F.normalize(patches, dim=2, p=2)
+ cls_seg_feat = F.normalize(cls_seg_feat, dim=2, p=2)
+
+ masks = patches @ cls_seg_feat.transpose(1, 2)
+ masks = self.mask_norm(masks)
+ masks = masks.permute(0, 2, 1).contiguous().view(b, -1, h, w)
+
+ return masks
diff --git a/mmseg/models/decode_heads/sep_aspp_head.py b/mmseg/models/decode_heads/sep_aspp_head.py
new file mode 100644
index 0000000..4e894e2
--- /dev/null
+++ b/mmseg/models/decode_heads/sep_aspp_head.py
@@ -0,0 +1,102 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .aspp_head import ASPPHead, ASPPModule
+
+
+class DepthwiseSeparableASPPModule(ASPPModule):
+ """Atrous Spatial Pyramid Pooling (ASPP) Module with depthwise separable
+ conv."""
+
+ def __init__(self, **kwargs):
+ super(DepthwiseSeparableASPPModule, self).__init__(**kwargs)
+ for i, dilation in enumerate(self.dilations):
+ if dilation > 1:
+ self[i] = DepthwiseSeparableConvModule(
+ self.in_channels,
+ self.channels,
+ 3,
+ dilation=dilation,
+ padding=dilation,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+
+@HEADS.register_module()
+class DepthwiseSeparableASPPHead(ASPPHead):
+ """Encoder-Decoder with Atrous Separable Convolution for Semantic Image
+ Segmentation.
+
+ This head is the implementation of `DeepLabV3+
+ `_.
+
+ Args:
+ c1_in_channels (int): The input channels of c1 decoder. If is 0,
+ the no decoder will be used.
+ c1_channels (int): The intermediate channels of c1 decoder.
+ """
+
+ def __init__(self, c1_in_channels, c1_channels, **kwargs):
+ super(DepthwiseSeparableASPPHead, self).__init__(**kwargs)
+ assert c1_in_channels >= 0
+ self.aspp_modules = DepthwiseSeparableASPPModule(
+ dilations=self.dilations,
+ in_channels=self.in_channels,
+ channels=self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ if c1_in_channels > 0:
+ self.c1_bottleneck = ConvModule(
+ c1_in_channels,
+ c1_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ else:
+ self.c1_bottleneck = None
+ self.sep_bottleneck = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ self.channels + c1_channels,
+ self.channels,
+ 3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ DepthwiseSeparableConvModule(
+ self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+
+ def forward(self, inputs):
+ """Forward function."""
+ x = self._transform_inputs(inputs)
+ aspp_outs = [
+ resize(
+ self.image_pool(x),
+ size=x.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ ]
+ aspp_outs.extend(self.aspp_modules(x))
+ aspp_outs = torch.cat(aspp_outs, dim=1)
+ output = self.bottleneck(aspp_outs)
+ if self.c1_bottleneck is not None:
+ c1_output = self.c1_bottleneck(inputs[0])
+ output = resize(
+ input=output,
+ size=c1_output.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ output = torch.cat([output, c1_output], dim=1)
+ output = self.sep_bottleneck(output)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/decode_heads/sep_fcn_head.py b/mmseg/models/decode_heads/sep_fcn_head.py
new file mode 100644
index 0000000..7f9658e
--- /dev/null
+++ b/mmseg/models/decode_heads/sep_fcn_head.py
@@ -0,0 +1,60 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import DepthwiseSeparableConvModule
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+@HEADS.register_module()
+class DepthwiseSeparableFCNHead(FCNHead):
+ """Depthwise-Separable Fully Convolutional Network for Semantic
+ Segmentation.
+
+ This head is implemented according to `Fast-SCNN: Fast Semantic
+ Segmentation Network `_.
+
+ Args:
+ in_channels(int): Number of output channels of FFM.
+ channels(int): Number of middle-stage channels in the decode head.
+ concat_input(bool): Whether to concatenate original decode input into
+ the result of several consecutive convolution layers.
+ Default: True.
+ num_classes(int): Used to determine the dimension of
+ final prediction tensor.
+ in_index(int): Correspond with 'out_indices' in FastSCNN backbone.
+ norm_cfg (dict | None): Config of norm layers.
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ loss_decode(dict): Config of loss type and some
+ relevant additional options.
+ dw_act_cfg (dict):Activation config of depthwise ConvModule. If it is
+ 'default', it will be the same as `act_cfg`. Default: None.
+ """
+
+ def __init__(self, dw_act_cfg=None, **kwargs):
+ super(DepthwiseSeparableFCNHead, self).__init__(**kwargs)
+ self.convs[0] = DepthwiseSeparableConvModule(
+ self.in_channels,
+ self.channels,
+ kernel_size=self.kernel_size,
+ padding=self.kernel_size // 2,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=dw_act_cfg)
+
+ for i in range(1, self.num_convs):
+ self.convs[i] = DepthwiseSeparableConvModule(
+ self.channels,
+ self.channels,
+ kernel_size=self.kernel_size,
+ padding=self.kernel_size // 2,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=dw_act_cfg)
+
+ if self.concat_input:
+ self.conv_cat = DepthwiseSeparableConvModule(
+ self.in_channels + self.channels,
+ self.channels,
+ kernel_size=self.kernel_size,
+ padding=self.kernel_size // 2,
+ norm_cfg=self.norm_cfg,
+ dw_act_cfg=dw_act_cfg)
diff --git a/mmseg/models/decode_heads/setr_mla_head.py b/mmseg/models/decode_heads/setr_mla_head.py
new file mode 100644
index 0000000..6bb94ae
--- /dev/null
+++ b/mmseg/models/decode_heads/setr_mla_head.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import Upsample
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class SETRMLAHead(BaseDecodeHead):
+ """Multi level feature aggretation head of SETR.
+
+ MLA head of `SETR `_.
+
+ Args:
+ mlahead_channels (int): Channels of conv-conv-4x of multi-level feature
+ aggregation. Default: 128.
+ up_scale (int): The scale factor of interpolate. Default:4.
+ """
+
+ def __init__(self, mla_channels=128, up_scale=4, **kwargs):
+ super(SETRMLAHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ self.mla_channels = mla_channels
+
+ num_inputs = len(self.in_channels)
+
+ # Refer to self.cls_seg settings of BaseDecodeHead
+ assert self.channels == num_inputs * mla_channels
+
+ self.up_convs = nn.ModuleList()
+ for i in range(num_inputs):
+ self.up_convs.append(
+ nn.Sequential(
+ ConvModule(
+ in_channels=self.in_channels[i],
+ out_channels=mla_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ ConvModule(
+ in_channels=mla_channels,
+ out_channels=mla_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ Upsample(
+ scale_factor=up_scale,
+ mode='bilinear',
+ align_corners=self.align_corners)))
+
+ def forward(self, inputs):
+ inputs = self._transform_inputs(inputs)
+ outs = []
+ for x, up_conv in zip(inputs, self.up_convs):
+ outs.append(up_conv(x))
+ out = torch.cat(outs, dim=1)
+ out = self.cls_seg(out)
+ return out
diff --git a/mmseg/models/decode_heads/setr_up_head.py b/mmseg/models/decode_heads/setr_up_head.py
new file mode 100644
index 0000000..87e7ea7
--- /dev/null
+++ b/mmseg/models/decode_heads/setr_up_head.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule, build_norm_layer
+
+from mmseg.ops import Upsample
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+
+
+@HEADS.register_module()
+class SETRUPHead(BaseDecodeHead):
+ """Naive upsampling head and Progressive upsampling head of SETR.
+
+ Naive or PUP head of `SETR `_.
+
+ Args:
+ norm_layer (dict): Config dict for input normalization.
+ Default: norm_layer=dict(type='LN', eps=1e-6, requires_grad=True).
+ num_convs (int): Number of decoder convolutions. Default: 1.
+ up_scale (int): The scale factor of interpolate. Default:4.
+ kernel_size (int): The kernel size of convolution when decoding
+ feature information from backbone. Default: 3.
+ init_cfg (dict | list[dict] | None): Initialization config dict.
+ Default: dict(
+ type='Constant', val=1.0, bias=0, layer='LayerNorm').
+ """
+
+ def __init__(self,
+ norm_layer=dict(type='LN', eps=1e-6, requires_grad=True),
+ num_convs=1,
+ up_scale=4,
+ kernel_size=3,
+ init_cfg=[
+ dict(type='Constant', val=1.0, bias=0, layer='LayerNorm'),
+ dict(
+ type='Normal',
+ std=0.01,
+ override=dict(name='conv_seg'))
+ ],
+ **kwargs):
+
+ assert kernel_size in [1, 3], 'kernel_size must be 1 or 3.'
+
+ super(SETRUPHead, self).__init__(init_cfg=init_cfg, **kwargs)
+
+ assert isinstance(self.in_channels, int)
+
+ _, self.norm = build_norm_layer(norm_layer, self.in_channels)
+
+ self.up_convs = nn.ModuleList()
+ in_channels = self.in_channels
+ out_channels = self.channels
+ for _ in range(num_convs):
+ self.up_convs.append(
+ nn.Sequential(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=1,
+ padding=int(kernel_size - 1) // 2,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg),
+ Upsample(
+ scale_factor=up_scale,
+ mode='bilinear',
+ align_corners=self.align_corners)))
+ in_channels = out_channels
+
+ def forward(self, x):
+ x = self._transform_inputs(x)
+
+ n, c, h, w = x.shape
+ x = x.reshape(n, c, h * w).transpose(2, 1).contiguous()
+ x = self.norm(x)
+ x = x.transpose(1, 2).reshape(n, c, h, w).contiguous()
+
+ for up_conv in self.up_convs:
+ x = up_conv(x)
+ out = self.cls_seg(x)
+ return out
diff --git a/mmseg/models/decode_heads/stdc_head.py b/mmseg/models/decode_heads/stdc_head.py
new file mode 100644
index 0000000..1e678ac
--- /dev/null
+++ b/mmseg/models/decode_heads/stdc_head.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+@HEADS.register_module()
+class STDCHead(FCNHead):
+ """This head is the implementation of `Rethinking BiSeNet For Real-time
+ Semantic Segmentation `_.
+
+ Args:
+ boundary_threshold (float): The threshold of calculating boundary.
+ Default: 0.1.
+ """
+
+ def __init__(self, boundary_threshold=0.1, **kwargs):
+ super(STDCHead, self).__init__(**kwargs)
+ self.boundary_threshold = boundary_threshold
+ # Using register buffer to make laplacian kernel on the same
+ # device of `seg_label`.
+ self.register_buffer(
+ 'laplacian_kernel',
+ torch.tensor([-1, -1, -1, -1, 8, -1, -1, -1, -1],
+ dtype=torch.float32,
+ requires_grad=False).reshape((1, 1, 3, 3)))
+ self.fusion_kernel = torch.nn.Parameter(
+ torch.tensor([[6. / 10], [3. / 10], [1. / 10]],
+ dtype=torch.float32).reshape(1, 3, 1, 1),
+ requires_grad=False)
+
+ def losses(self, seg_logit, seg_label):
+ """Compute Detail Aggregation Loss."""
+ # Note: The paper claims `fusion_kernel` is a trainable 1x1 conv
+ # parameters. However, it is a constant in original repo and other
+ # codebase because it would not be added into computation graph
+ # after threshold operation.
+ seg_label = seg_label.float()
+ boundary_targets = F.conv2d(
+ seg_label, self.laplacian_kernel, padding=1)
+ boundary_targets = boundary_targets.clamp(min=0)
+ boundary_targets[boundary_targets > self.boundary_threshold] = 1
+ boundary_targets[boundary_targets <= self.boundary_threshold] = 0
+
+ boundary_targets_x2 = F.conv2d(
+ seg_label, self.laplacian_kernel, stride=2, padding=1)
+ boundary_targets_x2 = boundary_targets_x2.clamp(min=0)
+
+ boundary_targets_x4 = F.conv2d(
+ seg_label, self.laplacian_kernel, stride=4, padding=1)
+ boundary_targets_x4 = boundary_targets_x4.clamp(min=0)
+
+ boundary_targets_x4_up = F.interpolate(
+ boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')
+ boundary_targets_x2_up = F.interpolate(
+ boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')
+
+ boundary_targets_x2_up[
+ boundary_targets_x2_up > self.boundary_threshold] = 1
+ boundary_targets_x2_up[
+ boundary_targets_x2_up <= self.boundary_threshold] = 0
+
+ boundary_targets_x4_up[
+ boundary_targets_x4_up > self.boundary_threshold] = 1
+ boundary_targets_x4_up[
+ boundary_targets_x4_up <= self.boundary_threshold] = 0
+
+ boudary_targets_pyramids = torch.stack(
+ (boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up),
+ dim=1)
+
+ boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)
+ boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids,
+ self.fusion_kernel)
+
+ boudary_targets_pyramid[
+ boudary_targets_pyramid > self.boundary_threshold] = 1
+ boudary_targets_pyramid[
+ boudary_targets_pyramid <= self.boundary_threshold] = 0
+
+ loss = super(STDCHead, self).losses(seg_logit,
+ boudary_targets_pyramid.long())
+ return loss
diff --git a/mmseg/models/decode_heads/uper_head.py b/mmseg/models/decode_heads/uper_head.py
new file mode 100644
index 0000000..57d80be
--- /dev/null
+++ b/mmseg/models/decode_heads/uper_head.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmseg.ops import resize
+from ..builder import HEADS
+from .decode_head import BaseDecodeHead
+from .psp_head import PPM
+
+
+@HEADS.register_module()
+class UPerHead(BaseDecodeHead):
+ """Unified Perceptual Parsing for Scene Understanding.
+
+ This head is the implementation of `UPerNet
+ `_.
+
+ Args:
+ pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
+ Module applied on the last feature. Default: (1, 2, 3, 6).
+ """
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
+ super(UPerHead, self).__init__(
+ input_transform='multiple_select', **kwargs)
+ # PSP Module
+ self.psp_modules = PPM(
+ pool_scales,
+ self.in_channels[-1],
+ self.channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+ self.bottleneck = ConvModule(
+ self.in_channels[-1] + len(pool_scales) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ # FPN Module
+ self.lateral_convs = nn.ModuleList()
+ self.fpn_convs = nn.ModuleList()
+ for in_channels in self.in_channels[:-1]: # skip the top layer
+ l_conv = ConvModule(
+ in_channels,
+ self.channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ inplace=False)
+ fpn_conv = ConvModule(
+ self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ inplace=False)
+ self.lateral_convs.append(l_conv)
+ self.fpn_convs.append(fpn_conv)
+
+ self.fpn_bottleneck = ConvModule(
+ len(self.in_channels) * self.channels,
+ self.channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def psp_forward(self, inputs):
+ """Forward function of PSP module."""
+ x = inputs[-1]
+ psp_outs = [x]
+ psp_outs.extend(self.psp_modules(x))
+ psp_outs = torch.cat(psp_outs, dim=1)
+ output = self.bottleneck(psp_outs)
+
+ return output
+
+ def forward(self, inputs):
+ """Forward function."""
+
+ inputs = self._transform_inputs(inputs)
+
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+
+ laterals.append(self.psp_forward(inputs))
+
+ # build top-down path
+ used_backbone_levels = len(laterals)
+ for i in range(used_backbone_levels - 1, 0, -1):
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] = laterals[i - 1] + resize(
+ laterals[i],
+ size=prev_shape,
+ mode='bilinear',
+ align_corners=self.align_corners)
+
+ # build outputs
+ fpn_outs = [
+ self.fpn_convs[i](laterals[i])
+ for i in range(used_backbone_levels - 1)
+ ]
+ # append psp feature
+ fpn_outs.append(laterals[-1])
+
+ for i in range(used_backbone_levels - 1, 0, -1):
+ fpn_outs[i] = resize(
+ fpn_outs[i],
+ size=fpn_outs[0].shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ fpn_outs = torch.cat(fpn_outs, dim=1)
+ output = self.fpn_bottleneck(fpn_outs)
+ output = self.cls_seg(output)
+ return output
diff --git a/mmseg/models/losses/__init__.py b/mmseg/models/losses/__init__.py
new file mode 100644
index 0000000..fbc5b2d
--- /dev/null
+++ b/mmseg/models/losses/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .accuracy import Accuracy, accuracy
+from .cross_entropy_loss import (CrossEntropyLoss, binary_cross_entropy,
+ cross_entropy, mask_cross_entropy)
+from .dice_loss import DiceLoss
+from .focal_loss import FocalLoss
+from .lovasz_loss import LovaszLoss
+from .utils import reduce_loss, weight_reduce_loss, weighted_loss
+
+__all__ = [
+ 'accuracy', 'Accuracy', 'cross_entropy', 'binary_cross_entropy',
+ 'mask_cross_entropy', 'CrossEntropyLoss', 'reduce_loss',
+ 'weight_reduce_loss', 'weighted_loss', 'LovaszLoss', 'DiceLoss',
+ 'FocalLoss'
+]
diff --git a/mmseg/models/losses/accuracy.py b/mmseg/models/losses/accuracy.py
new file mode 100644
index 0000000..f2cd16b
--- /dev/null
+++ b/mmseg/models/losses/accuracy.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+
+def accuracy(pred, target, topk=1, thresh=None):
+ """Calculate accuracy according to the prediction and target.
+
+ Args:
+ pred (torch.Tensor): The model prediction, shape (N, num_class, ...)
+ target (torch.Tensor): The target of each prediction, shape (N, , ...)
+ topk (int | tuple[int], optional): If the predictions in ``topk``
+ matches the target, the predictions will be regarded as
+ correct ones. Defaults to 1.
+ thresh (float, optional): If not None, predictions with scores under
+ this threshold are considered incorrect. Default to None.
+
+ Returns:
+ float | tuple[float]: If the input ``topk`` is a single integer,
+ the function will return a single float as accuracy. If
+ ``topk`` is a tuple containing multiple integers, the
+ function will return a tuple containing accuracies of
+ each ``topk`` number.
+ """
+ assert isinstance(topk, (int, tuple))
+ if isinstance(topk, int):
+ topk = (topk, )
+ return_single = True
+ else:
+ return_single = False
+
+ maxk = max(topk)
+ if pred.size(0) == 0:
+ accu = [pred.new_tensor(0.) for i in range(len(topk))]
+ return accu[0] if return_single else accu
+ assert pred.ndim == target.ndim + 1
+ assert pred.size(0) == target.size(0)
+ assert maxk <= pred.size(1), \
+ f'maxk {maxk} exceeds pred dimension {pred.size(1)}'
+ pred_value, pred_label = pred.topk(maxk, dim=1)
+ # transpose to shape (maxk, N, ...)
+ pred_label = pred_label.transpose(0, 1)
+ correct = pred_label.eq(target.unsqueeze(0).expand_as(pred_label))
+ if thresh is not None:
+ # Only prediction values larger than thresh are counted as correct
+ correct = correct & (pred_value > thresh).t()
+ res = []
+ for k in topk:
+ correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
+ res.append(correct_k.mul_(100.0 / target.numel()))
+ return res[0] if return_single else res
+
+
+class Accuracy(nn.Module):
+ """Accuracy calculation module."""
+
+ def __init__(self, topk=(1, ), thresh=None):
+ """Module to calculate the accuracy.
+
+ Args:
+ topk (tuple, optional): The criterion used to calculate the
+ accuracy. Defaults to (1,).
+ thresh (float, optional): If not None, predictions with scores
+ under this threshold are considered incorrect. Default to None.
+ """
+ super().__init__()
+ self.topk = topk
+ self.thresh = thresh
+
+ def forward(self, pred, target):
+ """Forward function to calculate accuracy.
+
+ Args:
+ pred (torch.Tensor): Prediction of models.
+ target (torch.Tensor): Target for each prediction.
+
+ Returns:
+ tuple[float]: The accuracies under different topk criterions.
+ """
+ return accuracy(pred, target, self.topk, self.thresh)
diff --git a/mmseg/models/losses/cross_entropy_loss.py b/mmseg/models/losses/cross_entropy_loss.py
new file mode 100644
index 0000000..ee489a8
--- /dev/null
+++ b/mmseg/models/losses/cross_entropy_loss.py
@@ -0,0 +1,218 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..builder import LOSSES
+from .utils import get_class_weight, weight_reduce_loss
+
+
+def cross_entropy(pred,
+ label,
+ weight=None,
+ class_weight=None,
+ reduction='mean',
+ avg_factor=None,
+ ignore_index=-100):
+ """The wrapper function for :func:`F.cross_entropy`"""
+ # class_weight is a manual rescaling weight given to each class.
+ # If given, has to be a Tensor of size C element-wise losses
+ loss = F.cross_entropy(
+ pred,
+ label,
+ weight=class_weight,
+ reduction='none',
+ ignore_index=ignore_index)
+
+ # apply weights and do the reduction
+ if weight is not None:
+ weight = weight.float()
+ loss = weight_reduce_loss(
+ loss, weight=weight, reduction=reduction, avg_factor=avg_factor)
+
+ return loss
+
+
+def _expand_onehot_labels(labels, label_weights, target_shape, ignore_index):
+ """Expand onehot labels to match the size of prediction."""
+ bin_labels = labels.new_zeros(target_shape)
+ valid_mask = (labels >= 0) & (labels != ignore_index)
+ inds = torch.nonzero(valid_mask, as_tuple=True)
+
+ if inds[0].numel() > 0:
+ if labels.dim() == 3:
+ bin_labels[inds[0], labels[valid_mask], inds[1], inds[2]] = 1
+ else:
+ bin_labels[inds[0], labels[valid_mask]] = 1
+
+ valid_mask = valid_mask.unsqueeze(1).expand(target_shape).float()
+ if label_weights is None:
+ bin_label_weights = valid_mask
+ else:
+ bin_label_weights = label_weights.unsqueeze(1).expand(target_shape)
+ bin_label_weights *= valid_mask
+
+ return bin_labels, bin_label_weights
+
+
+def binary_cross_entropy(pred,
+ label,
+ weight=None,
+ reduction='mean',
+ avg_factor=None,
+ class_weight=None,
+ ignore_index=255):
+ """Calculate the binary CrossEntropy loss.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, 1).
+ label (torch.Tensor): The learning label of the prediction.
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ reduction (str, optional): The method used to reduce the loss.
+ Options are "none", "mean" and "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ class_weight (list[float], optional): The weight for each class.
+ ignore_index (int | None): The label index to be ignored. Default: 255
+
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ if pred.dim() != label.dim():
+ assert (pred.dim() == 2 and label.dim() == 1) or (
+ pred.dim() == 4 and label.dim() == 3), \
+ 'Only pred shape [N, C], label shape [N] or pred shape [N, C, ' \
+ 'H, W], label shape [N, H, W] are supported'
+ label, weight = _expand_onehot_labels(label, weight, pred.shape,
+ ignore_index)
+
+ # weighted element-wise losses
+ if weight is not None:
+ weight = weight.float()
+ loss = F.binary_cross_entropy_with_logits(
+ pred, label.float(), pos_weight=class_weight, reduction='none')
+ # do the reduction for the weighted loss
+ loss = weight_reduce_loss(
+ loss, weight, reduction=reduction, avg_factor=avg_factor)
+
+ return loss
+
+
+def mask_cross_entropy(pred,
+ target,
+ label,
+ reduction='mean',
+ avg_factor=None,
+ class_weight=None,
+ ignore_index=None):
+ """Calculate the CrossEntropy loss for masks.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the number
+ of classes.
+ target (torch.Tensor): The learning label of the prediction.
+ label (torch.Tensor): ``label`` indicates the class label of the mask'
+ corresponding object. This will be used to select the mask in the
+ of the class which the object belongs to when the mask prediction
+ if not class-agnostic.
+ reduction (str, optional): The method used to reduce the loss.
+ Options are "none", "mean" and "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ class_weight (list[float], optional): The weight for each class.
+ ignore_index (None): Placeholder, to be consistent with other loss.
+ Default: None.
+
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ assert ignore_index is None, 'BCE loss does not support ignore_index'
+ # TODO: handle these two reserved arguments
+ assert reduction == 'mean' and avg_factor is None
+ num_rois = pred.size()[0]
+ inds = torch.arange(0, num_rois, dtype=torch.long, device=pred.device)
+ pred_slice = pred[inds, label].squeeze(1)
+ return F.binary_cross_entropy_with_logits(
+ pred_slice, target, weight=class_weight, reduction='mean')[None]
+
+
+@LOSSES.register_module()
+class CrossEntropyLoss(nn.Module):
+ """CrossEntropyLoss.
+
+ Args:
+ use_sigmoid (bool, optional): Whether the prediction uses sigmoid
+ of softmax. Defaults to False.
+ use_mask (bool, optional): Whether to use mask cross entropy loss.
+ Defaults to False.
+ reduction (str, optional): . Defaults to 'mean'.
+ Options are "none", "mean" and "sum".
+ class_weight (list[float] | str, optional): Weight of each class. If in
+ str format, read them from a file. Defaults to None.
+ loss_weight (float, optional): Weight of the loss. Defaults to 1.0.
+ loss_name (str, optional): Name of the loss item. If you want this loss
+ item to be included into the backward graph, `loss_` must be the
+ prefix of the name. Defaults to 'loss_ce'.
+ """
+
+ def __init__(self,
+ use_sigmoid=False,
+ use_mask=False,
+ reduction='mean',
+ class_weight=None,
+ loss_weight=1.0,
+ loss_name='loss_ce'):
+ super(CrossEntropyLoss, self).__init__()
+ assert (use_sigmoid is False) or (use_mask is False)
+ self.use_sigmoid = use_sigmoid
+ self.use_mask = use_mask
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.class_weight = get_class_weight(class_weight)
+
+ if self.use_sigmoid:
+ self.cls_criterion = binary_cross_entropy
+ elif self.use_mask:
+ self.cls_criterion = mask_cross_entropy
+ else:
+ self.cls_criterion = cross_entropy
+ self._loss_name = loss_name
+
+ def forward(self,
+ cls_score,
+ label,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None,
+ **kwargs):
+ """Forward function."""
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.class_weight is not None:
+ class_weight = cls_score.new_tensor(self.class_weight)
+ else:
+ class_weight = None
+ loss_cls = self.loss_weight * self.cls_criterion(
+ cls_score,
+ label,
+ weight,
+ class_weight=class_weight,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss_cls
+
+ @property
+ def loss_name(self):
+ """Loss Name.
+
+ This function must be implemented and will return the name of this
+ loss function. This name will be used to combine different loss items
+ by simple sum operation. In addition, if you want this loss item to be
+ included into the backward graph, `loss_` must be the prefix of the
+ name.
+ Returns:
+ str: The name of this loss item.
+ """
+ return self._loss_name
diff --git a/mmseg/models/losses/dice_loss.py b/mmseg/models/losses/dice_loss.py
new file mode 100644
index 0000000..79a3abf
--- /dev/null
+++ b/mmseg/models/losses/dice_loss.py
@@ -0,0 +1,137 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Modified from https://github.com/LikeLy-Journey/SegmenTron/blob/master/
+segmentron/solver/loss.py (Apache-2.0 License)"""
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..builder import LOSSES
+from .utils import get_class_weight, weighted_loss
+
+
+@weighted_loss
+def dice_loss(pred,
+ target,
+ valid_mask,
+ smooth=1,
+ exponent=2,
+ class_weight=None,
+ ignore_index=255):
+ assert pred.shape[0] == target.shape[0]
+ total_loss = 0
+ num_classes = pred.shape[1]
+ for i in range(num_classes):
+ if i != ignore_index:
+ dice_loss = binary_dice_loss(
+ pred[:, i],
+ target[..., i],
+ valid_mask=valid_mask,
+ smooth=smooth,
+ exponent=exponent)
+ if class_weight is not None:
+ dice_loss *= class_weight[i]
+ total_loss += dice_loss
+ return total_loss / num_classes
+
+
+@weighted_loss
+def binary_dice_loss(pred, target, valid_mask, smooth=1, exponent=2, **kwards):
+ assert pred.shape[0] == target.shape[0]
+ pred = pred.reshape(pred.shape[0], -1)
+ target = target.reshape(target.shape[0], -1)
+ valid_mask = valid_mask.reshape(valid_mask.shape[0], -1)
+
+ num = torch.sum(torch.mul(pred, target) * valid_mask, dim=1) * 2 + smooth
+ den = torch.sum(pred.pow(exponent) + target.pow(exponent), dim=1) + smooth
+
+ return 1 - num / den
+
+
+@LOSSES.register_module()
+class DiceLoss(nn.Module):
+ """DiceLoss.
+
+ This loss is proposed in `V-Net: Fully Convolutional Neural Networks for
+ Volumetric Medical Image Segmentation `_.
+
+ Args:
+ smooth (float): A float number to smooth loss, and avoid NaN error.
+ Default: 1
+ exponent (float): An float number to calculate denominator
+ value: \\sum{x^exponent} + \\sum{y^exponent}. Default: 2.
+ reduction (str, optional): The method used to reduce the loss. Options
+ are "none", "mean" and "sum". This parameter only works when
+ per_image is True. Default: 'mean'.
+ class_weight (list[float] | str, optional): Weight of each class. If in
+ str format, read them from a file. Defaults to None.
+ loss_weight (float, optional): Weight of the loss. Default to 1.0.
+ ignore_index (int | None): The label index to be ignored. Default: 255.
+ loss_name (str, optional): Name of the loss item. If you want this loss
+ item to be included into the backward graph, `loss_` must be the
+ prefix of the name. Defaults to 'loss_dice'.
+ """
+
+ def __init__(self,
+ smooth=1,
+ exponent=2,
+ reduction='mean',
+ class_weight=None,
+ loss_weight=1.0,
+ ignore_index=255,
+ loss_name='loss_dice',
+ **kwards):
+ super(DiceLoss, self).__init__()
+ self.smooth = smooth
+ self.exponent = exponent
+ self.reduction = reduction
+ self.class_weight = get_class_weight(class_weight)
+ self.loss_weight = loss_weight
+ self.ignore_index = ignore_index
+ self._loss_name = loss_name
+
+ def forward(self,
+ pred,
+ target,
+ avg_factor=None,
+ reduction_override=None,
+ **kwards):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.class_weight is not None:
+ class_weight = pred.new_tensor(self.class_weight)
+ else:
+ class_weight = None
+
+ pred = F.softmax(pred, dim=1)
+ num_classes = pred.shape[1]
+ one_hot_target = F.one_hot(
+ torch.clamp(target.long(), 0, num_classes - 1),
+ num_classes=num_classes)
+ valid_mask = (target != self.ignore_index).long()
+
+ loss = self.loss_weight * dice_loss(
+ pred,
+ one_hot_target,
+ valid_mask=valid_mask,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ smooth=self.smooth,
+ exponent=self.exponent,
+ class_weight=class_weight,
+ ignore_index=self.ignore_index)
+ return loss
+
+ @property
+ def loss_name(self):
+ """Loss Name.
+
+ This function must be implemented and will return the name of this
+ loss function. This name will be used to combine different loss items
+ by simple sum operation. In addition, if you want this loss item to be
+ included into the backward graph, `loss_` must be the prefix of the
+ name.
+ Returns:
+ str: The name of this loss item.
+ """
+ return self._loss_name
diff --git a/mmseg/models/losses/focal_loss.py b/mmseg/models/losses/focal_loss.py
new file mode 100644
index 0000000..af1c711
--- /dev/null
+++ b/mmseg/models/losses/focal_loss.py
@@ -0,0 +1,327 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Modified from https://github.com/open-mmlab/mmdetection
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.ops import sigmoid_focal_loss as _sigmoid_focal_loss
+
+from ..builder import LOSSES
+from .utils import weight_reduce_loss
+
+
+# This method is used when cuda is not available
+def py_sigmoid_focal_loss(pred,
+ target,
+ one_hot_target=None,
+ weight=None,
+ gamma=2.0,
+ alpha=0.5,
+ class_weight=None,
+ valid_mask=None,
+ reduction='mean',
+ avg_factor=None):
+ """PyTorch version of `Focal Loss `_.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the
+ number of classes
+ target (torch.Tensor): The learning label of the prediction with
+ shape (N, C)
+ one_hot_target (None): Placeholder. It should be None.
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float | list[float], optional): A balanced form for Focal Loss.
+ Defaults to 0.5.
+ class_weight (list[float], optional): Weight of each class.
+ Defaults to None.
+ valid_mask (torch.Tensor, optional): A mask uses 1 to mark the valid
+ samples and uses 0 to mark the ignored samples. Default: None.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ """
+ if isinstance(alpha, list):
+ alpha = pred.new_tensor(alpha)
+ pred_sigmoid = pred.sigmoid()
+ target = target.type_as(pred)
+ one_minus_pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)
+ focal_weight = (alpha * target + (1 - alpha) *
+ (1 - target)) * one_minus_pt.pow(gamma)
+
+ loss = F.binary_cross_entropy_with_logits(
+ pred, target, reduction='none') * focal_weight
+ final_weight = torch.ones(1, pred.size(1)).type_as(loss)
+ if weight is not None:
+ if weight.shape != loss.shape and weight.size(0) == loss.size(0):
+ # For most cases, weight is of shape (N, ),
+ # which means it does not have the second axis num_class
+ weight = weight.view(-1, 1)
+ assert weight.dim() == loss.dim()
+ final_weight = final_weight * weight
+ if class_weight is not None:
+ final_weight = final_weight * pred.new_tensor(class_weight)
+ if valid_mask is not None:
+ final_weight = final_weight * valid_mask
+ loss = weight_reduce_loss(loss, final_weight, reduction, avg_factor)
+ return loss
+
+
+def sigmoid_focal_loss(pred,
+ target,
+ one_hot_target,
+ weight=None,
+ gamma=2.0,
+ alpha=0.5,
+ class_weight=None,
+ valid_mask=None,
+ reduction='mean',
+ avg_factor=None):
+ r"""A warpper of cuda version `Focal Loss
+ `_.
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the number
+ of classes.
+ target (torch.Tensor): The learning label of the prediction. It's shape
+ should be (N, )
+ one_hot_target (torch.Tensor): The learning label with shape (N, C)
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float | list[float], optional): A balanced form for Focal Loss.
+ Defaults to 0.5.
+ class_weight (list[float], optional): Weight of each class.
+ Defaults to None.
+ valid_mask (torch.Tensor, optional): A mask uses 1 to mark the valid
+ samples and uses 0 to mark the ignored samples. Default: None.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'. Options are "none", "mean" and "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ """
+ # Function.apply does not accept keyword arguments, so the decorator
+ # "weighted_loss" is not applicable
+ final_weight = torch.ones(1, pred.size(1)).type_as(pred)
+ if isinstance(alpha, list):
+ # _sigmoid_focal_loss doesn't accept alpha of list type. Therefore, if
+ # a list is given, we set the input alpha as 0.5. This means setting
+ # equal weight for foreground class and background class. By
+ # multiplying the loss by 2, the effect of setting alpha as 0.5 is
+ # undone. The alpha of type list is used to regulate the loss in the
+ # post-processing process.
+ loss = _sigmoid_focal_loss(pred.contiguous(), target.contiguous(),
+ gamma, 0.5, None, 'none') * 2
+ alpha = pred.new_tensor(alpha)
+ final_weight = final_weight * (
+ alpha * one_hot_target + (1 - alpha) * (1 - one_hot_target))
+ else:
+ loss = _sigmoid_focal_loss(pred.contiguous(), target.contiguous(),
+ gamma, alpha, None, 'none')
+ if weight is not None:
+ if weight.shape != loss.shape and weight.size(0) == loss.size(0):
+ # For most cases, weight is of shape (N, ),
+ # which means it does not have the second axis num_class
+ weight = weight.view(-1, 1)
+ assert weight.dim() == loss.dim()
+ final_weight = final_weight * weight
+ if class_weight is not None:
+ final_weight = final_weight * pred.new_tensor(class_weight)
+ if valid_mask is not None:
+ final_weight = final_weight * valid_mask
+ loss = weight_reduce_loss(loss, final_weight, reduction, avg_factor)
+ return loss
+
+
+@LOSSES.register_module()
+class FocalLoss(nn.Module):
+
+ def __init__(self,
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.5,
+ reduction='mean',
+ class_weight=None,
+ loss_weight=1.0,
+ loss_name='loss_focal'):
+ """`Focal Loss `_
+ Args:
+ use_sigmoid (bool, optional): Whether to the prediction is
+ used for sigmoid or softmax. Defaults to True.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float | list[float], optional): A balanced form for Focal
+ Loss. Defaults to 0.5. When a list is provided, the length
+ of the list should be equal to the number of classes.
+ Please be careful that this parameter is not the
+ class-wise weight but the weight of a binary classification
+ problem. This binary classification problem regards the
+ pixels which belong to one class as the foreground
+ and the other pixels as the background, each element in
+ the list is the weight of the corresponding foreground class.
+ The value of alpha or each element of alpha should be a float
+ in the interval [0, 1]. If you want to specify the class-wise
+ weight, please use `class_weight` parameter.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'. Options are "none", "mean" and
+ "sum".
+ class_weight (list[float], optional): Weight of each class.
+ Defaults to None.
+ loss_weight (float, optional): Weight of loss. Defaults to 1.0.
+ loss_name (str, optional): Name of the loss item. If you want this
+ loss item to be included into the backward graph, `loss_` must
+ be the prefix of the name. Defaults to 'loss_focal'.
+ """
+ super(FocalLoss, self).__init__()
+ assert use_sigmoid is True, \
+ 'AssertionError: Only sigmoid focal loss supported now.'
+ assert reduction in ('none', 'mean', 'sum'), \
+ "AssertionError: reduction should be 'none', 'mean' or " \
+ "'sum'"
+ assert isinstance(alpha, (float, list)), \
+ 'AssertionError: alpha should be of type float'
+ assert isinstance(gamma, float), \
+ 'AssertionError: gamma should be of type float'
+ assert isinstance(loss_weight, float), \
+ 'AssertionError: loss_weight should be of type float'
+ assert isinstance(loss_name, str), \
+ 'AssertionError: loss_name should be of type str'
+ assert isinstance(class_weight, list) or class_weight is None, \
+ 'AssertionError: class_weight must be None or of type list'
+ self.use_sigmoid = use_sigmoid
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = reduction
+ self.class_weight = class_weight
+ self.loss_weight = loss_weight
+ self._loss_name = loss_name
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None,
+ ignore_index=255,
+ **kwargs):
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape
+ (N, C) where C = number of classes, or
+ (N, C, d_1, d_2, ..., d_K) with K≥1 in the
+ case of K-dimensional loss.
+ target (torch.Tensor): The ground truth. If containing class
+ indices, shape (N) where each value is 0≤targets[i]≤C−1,
+ or (N, d_1, d_2, ..., d_K) with K≥1 in the case of
+ K-dimensional loss. If containing class probabilities,
+ same shape as the input.
+ weight (torch.Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to
+ average the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used
+ to override the original reduction method of the loss.
+ Options are "none", "mean" and "sum".
+ ignore_index (int, optional): The label index to be ignored.
+ Default: 255
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ assert isinstance(ignore_index, int), \
+ 'ignore_index must be of type int'
+ assert reduction_override in (None, 'none', 'mean', 'sum'), \
+ "AssertionError: reduction should be 'none', 'mean' or " \
+ "'sum'"
+ assert pred.shape == target.shape or \
+ (pred.size(0) == target.size(0) and
+ pred.shape[2:] == target.shape[1:]), \
+ "The shape of pred doesn't match the shape of target"
+
+ original_shape = pred.shape
+
+ # [B, C, d_1, d_2, ..., d_k] -> [C, B, d_1, d_2, ..., d_k]
+ pred = pred.transpose(0, 1)
+ # [C, B, d_1, d_2, ..., d_k] -> [C, N]
+ pred = pred.reshape(pred.size(0), -1)
+ # [C, N] -> [N, C]
+ pred = pred.transpose(0, 1).contiguous()
+
+ if original_shape == target.shape:
+ # target with shape [B, C, d_1, d_2, ...]
+ # transform it's shape into [N, C]
+ # [B, C, d_1, d_2, ...] -> [C, B, d_1, d_2, ..., d_k]
+ target = target.transpose(0, 1)
+ # [C, B, d_1, d_2, ..., d_k] -> [C, N]
+ target = target.reshape(target.size(0), -1)
+ # [C, N] -> [N, C]
+ target = target.transpose(0, 1).contiguous()
+ else:
+ # target with shape [B, d_1, d_2, ...]
+ # transform it's shape into [N, ]
+ target = target.view(-1).contiguous()
+ valid_mask = (target != ignore_index).view(-1, 1)
+ # avoid raising error when using F.one_hot()
+ target = torch.where(target == ignore_index, target.new_tensor(0),
+ target)
+
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.use_sigmoid:
+ num_classes = pred.size(1)
+ if torch.cuda.is_available() and pred.is_cuda:
+ if target.dim() == 1:
+ one_hot_target = F.one_hot(target, num_classes=num_classes)
+ else:
+ one_hot_target = target
+ target = target.argmax(dim=1)
+ valid_mask = (target != ignore_index).view(-1, 1)
+ calculate_loss_func = sigmoid_focal_loss
+ else:
+ one_hot_target = None
+ if target.dim() == 1:
+ target = F.one_hot(target, num_classes=num_classes)
+ else:
+ valid_mask = (target.argmax(dim=1) != ignore_index).view(
+ -1, 1)
+ calculate_loss_func = py_sigmoid_focal_loss
+
+ loss_cls = self.loss_weight * calculate_loss_func(
+ pred,
+ target,
+ one_hot_target,
+ weight,
+ gamma=self.gamma,
+ alpha=self.alpha,
+ class_weight=self.class_weight,
+ valid_mask=valid_mask,
+ reduction=reduction,
+ avg_factor=avg_factor)
+
+ if reduction == 'none':
+ # [N, C] -> [C, N]
+ loss_cls = loss_cls.transpose(0, 1)
+ # [C, N] -> [C, B, d1, d2, ...]
+ # original_shape: [B, C, d1, d2, ...]
+ loss_cls = loss_cls.reshape(original_shape[1],
+ original_shape[0],
+ *original_shape[2:])
+ # [C, B, d1, d2, ...] -> [B, C, d1, d2, ...]
+ loss_cls = loss_cls.transpose(0, 1).contiguous()
+ else:
+ raise NotImplementedError
+ return loss_cls
+
+ @property
+ def loss_name(self):
+ """Loss Name.
+
+ This function must be implemented and will return the name of this
+ loss function. This name will be used to combine different loss items
+ by simple sum operation. In addition, if you want this loss item to be
+ included into the backward graph, `loss_` must be the prefix of the
+ name.
+ Returns:
+ str: The name of this loss item.
+ """
+ return self._loss_name
diff --git a/mmseg/models/losses/lovasz_loss.py b/mmseg/models/losses/lovasz_loss.py
new file mode 100644
index 0000000..2bb0fad
--- /dev/null
+++ b/mmseg/models/losses/lovasz_loss.py
@@ -0,0 +1,323 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Modified from https://github.com/bermanmaxim/LovaszSoftmax/blob/master/pytor
+ch/lovasz_losses.py Lovasz-Softmax and Jaccard hinge loss in PyTorch Maxim
+Berman 2018 ESAT-PSI KU Leuven (MIT License)"""
+
+import mmcv
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..builder import LOSSES
+from .utils import get_class_weight, weight_reduce_loss
+
+
+def lovasz_grad(gt_sorted):
+ """Computes gradient of the Lovasz extension w.r.t sorted errors.
+
+ See Alg. 1 in paper.
+ """
+ p = len(gt_sorted)
+ gts = gt_sorted.sum()
+ intersection = gts - gt_sorted.float().cumsum(0)
+ union = gts + (1 - gt_sorted).float().cumsum(0)
+ jaccard = 1. - intersection / union
+ if p > 1: # cover 1-pixel case
+ jaccard[1:p] = jaccard[1:p] - jaccard[0:-1]
+ return jaccard
+
+
+def flatten_binary_logits(logits, labels, ignore_index=None):
+ """Flattens predictions in the batch (binary case) Remove labels equal to
+ 'ignore_index'."""
+ logits = logits.view(-1)
+ labels = labels.view(-1)
+ if ignore_index is None:
+ return logits, labels
+ valid = (labels != ignore_index)
+ vlogits = logits[valid]
+ vlabels = labels[valid]
+ return vlogits, vlabels
+
+
+def flatten_probs(probs, labels, ignore_index=None):
+ """Flattens predictions in the batch."""
+ if probs.dim() == 3:
+ # assumes output of a sigmoid layer
+ B, H, W = probs.size()
+ probs = probs.view(B, 1, H, W)
+ B, C, H, W = probs.size()
+ probs = probs.permute(0, 2, 3, 1).contiguous().view(-1, C) # B*H*W, C=P,C
+ labels = labels.view(-1)
+ if ignore_index is None:
+ return probs, labels
+ valid = (labels != ignore_index)
+ vprobs = probs[valid.nonzero().squeeze()]
+ vlabels = labels[valid]
+ return vprobs, vlabels
+
+
+def lovasz_hinge_flat(logits, labels):
+ """Binary Lovasz hinge loss.
+
+ Args:
+ logits (torch.Tensor): [P], logits at each prediction
+ (between -infty and +infty).
+ labels (torch.Tensor): [P], binary ground truth labels (0 or 1).
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+ if len(labels) == 0:
+ # only void pixels, the gradients should be 0
+ return logits.sum() * 0.
+ signs = 2. * labels.float() - 1.
+ errors = (1. - logits * signs)
+ errors_sorted, perm = torch.sort(errors, dim=0, descending=True)
+ perm = perm.data
+ gt_sorted = labels[perm]
+ grad = lovasz_grad(gt_sorted)
+ loss = torch.dot(F.relu(errors_sorted), grad)
+ return loss
+
+
+def lovasz_hinge(logits,
+ labels,
+ classes='present',
+ per_image=False,
+ class_weight=None,
+ reduction='mean',
+ avg_factor=None,
+ ignore_index=255):
+ """Binary Lovasz hinge loss.
+
+ Args:
+ logits (torch.Tensor): [B, H, W], logits at each pixel
+ (between -infty and +infty).
+ labels (torch.Tensor): [B, H, W], binary ground truth masks (0 or 1).
+ classes (str | list[int], optional): Placeholder, to be consistent with
+ other loss. Default: None.
+ per_image (bool, optional): If per_image is True, compute the loss per
+ image instead of per batch. Default: False.
+ class_weight (list[float], optional): Placeholder, to be consistent
+ with other loss. Default: None.
+ reduction (str, optional): The method used to reduce the loss. Options
+ are "none", "mean" and "sum". This parameter only works when
+ per_image is True. Default: 'mean'.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. This parameter only works when per_image is True.
+ Default: None.
+ ignore_index (int | None): The label index to be ignored. Default: 255.
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+ if per_image:
+ loss = [
+ lovasz_hinge_flat(*flatten_binary_logits(
+ logit.unsqueeze(0), label.unsqueeze(0), ignore_index))
+ for logit, label in zip(logits, labels)
+ ]
+ loss = weight_reduce_loss(
+ torch.stack(loss), None, reduction, avg_factor)
+ else:
+ loss = lovasz_hinge_flat(
+ *flatten_binary_logits(logits, labels, ignore_index))
+ return loss
+
+
+def lovasz_softmax_flat(probs, labels, classes='present', class_weight=None):
+ """Multi-class Lovasz-Softmax loss.
+
+ Args:
+ probs (torch.Tensor): [P, C], class probabilities at each prediction
+ (between 0 and 1).
+ labels (torch.Tensor): [P], ground truth labels (between 0 and C - 1).
+ classes (str | list[int], optional): Classes chosen to calculate loss.
+ 'all' for all classes, 'present' for classes present in labels, or
+ a list of classes to average. Default: 'present'.
+ class_weight (list[float], optional): The weight for each class.
+ Default: None.
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+ if probs.numel() == 0:
+ # only void pixels, the gradients should be 0
+ return probs * 0.
+ C = probs.size(1)
+ losses = []
+ class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
+ for c in class_to_sum:
+ fg = (labels == c).float() # foreground for class c
+ if (classes == 'present' and fg.sum() == 0):
+ continue
+ if C == 1:
+ if len(classes) > 1:
+ raise ValueError('Sigmoid output possible only with 1 class')
+ class_pred = probs[:, 0]
+ else:
+ class_pred = probs[:, c]
+ errors = (fg - class_pred).abs()
+ errors_sorted, perm = torch.sort(errors, 0, descending=True)
+ perm = perm.data
+ fg_sorted = fg[perm]
+ loss = torch.dot(errors_sorted, lovasz_grad(fg_sorted))
+ if class_weight is not None:
+ loss *= class_weight[c]
+ losses.append(loss)
+ return torch.stack(losses).mean()
+
+
+def lovasz_softmax(probs,
+ labels,
+ classes='present',
+ per_image=False,
+ class_weight=None,
+ reduction='mean',
+ avg_factor=None,
+ ignore_index=255):
+ """Multi-class Lovasz-Softmax loss.
+
+ Args:
+ probs (torch.Tensor): [B, C, H, W], class probabilities at each
+ prediction (between 0 and 1).
+ labels (torch.Tensor): [B, H, W], ground truth labels (between 0 and
+ C - 1).
+ classes (str | list[int], optional): Classes chosen to calculate loss.
+ 'all' for all classes, 'present' for classes present in labels, or
+ a list of classes to average. Default: 'present'.
+ per_image (bool, optional): If per_image is True, compute the loss per
+ image instead of per batch. Default: False.
+ class_weight (list[float], optional): The weight for each class.
+ Default: None.
+ reduction (str, optional): The method used to reduce the loss. Options
+ are "none", "mean" and "sum". This parameter only works when
+ per_image is True. Default: 'mean'.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. This parameter only works when per_image is True.
+ Default: None.
+ ignore_index (int | None): The label index to be ignored. Default: 255.
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+
+ if per_image:
+ loss = [
+ lovasz_softmax_flat(
+ *flatten_probs(
+ prob.unsqueeze(0), label.unsqueeze(0), ignore_index),
+ classes=classes,
+ class_weight=class_weight)
+ for prob, label in zip(probs, labels)
+ ]
+ loss = weight_reduce_loss(
+ torch.stack(loss), None, reduction, avg_factor)
+ else:
+ loss = lovasz_softmax_flat(
+ *flatten_probs(probs, labels, ignore_index),
+ classes=classes,
+ class_weight=class_weight)
+ return loss
+
+
+@LOSSES.register_module()
+class LovaszLoss(nn.Module):
+ """LovaszLoss.
+
+ This loss is proposed in `The Lovasz-Softmax loss: A tractable surrogate
+ for the optimization of the intersection-over-union measure in neural
+ networks `_.
+
+ Args:
+ loss_type (str, optional): Binary or multi-class loss.
+ Default: 'multi_class'. Options are "binary" and "multi_class".
+ classes (str | list[int], optional): Classes chosen to calculate loss.
+ 'all' for all classes, 'present' for classes present in labels, or
+ a list of classes to average. Default: 'present'.
+ per_image (bool, optional): If per_image is True, compute the loss per
+ image instead of per batch. Default: False.
+ reduction (str, optional): The method used to reduce the loss. Options
+ are "none", "mean" and "sum". This parameter only works when
+ per_image is True. Default: 'mean'.
+ class_weight (list[float] | str, optional): Weight of each class. If in
+ str format, read them from a file. Defaults to None.
+ loss_weight (float, optional): Weight of the loss. Defaults to 1.0.
+ loss_name (str, optional): Name of the loss item. If you want this loss
+ item to be included into the backward graph, `loss_` must be the
+ prefix of the name. Defaults to 'loss_lovasz'.
+ """
+
+ def __init__(self,
+ loss_type='multi_class',
+ classes='present',
+ per_image=False,
+ reduction='mean',
+ class_weight=None,
+ loss_weight=1.0,
+ loss_name='loss_lovasz'):
+ super(LovaszLoss, self).__init__()
+ assert loss_type in ('binary', 'multi_class'), "loss_type should be \
+ 'binary' or 'multi_class'."
+
+ if loss_type == 'binary':
+ self.cls_criterion = lovasz_hinge
+ else:
+ self.cls_criterion = lovasz_softmax
+ assert classes in ('all', 'present') or mmcv.is_list_of(classes, int)
+ if not per_image:
+ assert reduction == 'none', "reduction should be 'none' when \
+ per_image is False."
+
+ self.classes = classes
+ self.per_image = per_image
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.class_weight = get_class_weight(class_weight)
+ self._loss_name = loss_name
+
+ def forward(self,
+ cls_score,
+ label,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None,
+ **kwargs):
+ """Forward function."""
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.class_weight is not None:
+ class_weight = cls_score.new_tensor(self.class_weight)
+ else:
+ class_weight = None
+
+ # if multi-class loss, transform logits to probs
+ if self.cls_criterion == lovasz_softmax:
+ cls_score = F.softmax(cls_score, dim=1)
+
+ loss_cls = self.loss_weight * self.cls_criterion(
+ cls_score,
+ label,
+ self.classes,
+ self.per_image,
+ class_weight=class_weight,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss_cls
+
+ @property
+ def loss_name(self):
+ """Loss Name.
+
+ This function must be implemented and will return the name of this
+ loss function. This name will be used to combine different loss items
+ by simple sum operation. In addition, if you want this loss item to be
+ included into the backward graph, `loss_` must be the prefix of the
+ name.
+ Returns:
+ str: The name of this loss item.
+ """
+ return self._loss_name
diff --git a/mmseg/models/losses/utils.py b/mmseg/models/losses/utils.py
new file mode 100644
index 0000000..c37875f
--- /dev/null
+++ b/mmseg/models/losses/utils.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools
+
+import mmcv
+import numpy as np
+import torch.nn.functional as F
+
+
+def get_class_weight(class_weight):
+ """Get class weight for loss function.
+
+ Args:
+ class_weight (list[float] | str | None): If class_weight is a str,
+ take it as a file name and read from it.
+ """
+ if isinstance(class_weight, str):
+ # take it as a file path
+ if class_weight.endswith('.npy'):
+ class_weight = np.load(class_weight)
+ else:
+ # pkl, json or yaml
+ class_weight = mmcv.load(class_weight)
+
+ return class_weight
+
+
+def reduce_loss(loss, reduction):
+ """Reduce loss as specified.
+
+ Args:
+ loss (Tensor): Elementwise loss tensor.
+ reduction (str): Options are "none", "mean" and "sum".
+
+ Return:
+ Tensor: Reduced loss tensor.
+ """
+ reduction_enum = F._Reduction.get_enum(reduction)
+ # none: 0, elementwise_mean:1, sum: 2
+ if reduction_enum == 0:
+ return loss
+ elif reduction_enum == 1:
+ return loss.mean()
+ elif reduction_enum == 2:
+ return loss.sum()
+
+
+def weight_reduce_loss(loss, weight=None, reduction='mean', avg_factor=None):
+ """Apply element-wise weight and reduce loss.
+
+ Args:
+ loss (Tensor): Element-wise loss.
+ weight (Tensor): Element-wise weights.
+ reduction (str): Same as built-in losses of PyTorch.
+ avg_factor (float): Average factor when computing the mean of losses.
+
+ Returns:
+ Tensor: Processed loss values.
+ """
+ # if weight is specified, apply element-wise weight
+ if weight is not None:
+ assert weight.dim() == loss.dim()
+ if weight.dim() > 1:
+ assert weight.size(1) == 1 or weight.size(1) == loss.size(1)
+ loss = loss * weight
+
+ # if avg_factor is not specified, just reduce the loss
+ if avg_factor is None:
+ loss = reduce_loss(loss, reduction)
+ else:
+ # if reduction is mean, then average the loss by avg_factor
+ if reduction == 'mean':
+ loss = loss.sum() / avg_factor
+ # if reduction is 'none', then do nothing, otherwise raise an error
+ elif reduction != 'none':
+ raise ValueError('avg_factor can not be used with reduction="sum"')
+ return loss
+
+
+def weighted_loss(loss_func):
+ """Create a weighted version of a given loss function.
+
+ To use this decorator, the loss function must have the signature like
+ `loss_func(pred, target, **kwargs)`. The function only needs to compute
+ element-wise loss without any reduction. This decorator will add weight
+ and reduction arguments to the function. The decorated function will have
+ the signature like `loss_func(pred, target, weight=None, reduction='mean',
+ avg_factor=None, **kwargs)`.
+
+ :Example:
+
+ >>> import torch
+ >>> @weighted_loss
+ >>> def l1_loss(pred, target):
+ >>> return (pred - target).abs()
+
+ >>> pred = torch.Tensor([0, 2, 3])
+ >>> target = torch.Tensor([1, 1, 1])
+ >>> weight = torch.Tensor([1, 0, 1])
+
+ >>> l1_loss(pred, target)
+ tensor(1.3333)
+ >>> l1_loss(pred, target, weight)
+ tensor(1.)
+ >>> l1_loss(pred, target, reduction='none')
+ tensor([1., 1., 2.])
+ >>> l1_loss(pred, target, weight, avg_factor=2)
+ tensor(1.5000)
+ """
+
+ @functools.wraps(loss_func)
+ def wrapper(pred,
+ target,
+ weight=None,
+ reduction='mean',
+ avg_factor=None,
+ **kwargs):
+ # get element-wise loss
+ loss = loss_func(pred, target, **kwargs)
+ loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
+ return loss
+
+ return wrapper
diff --git a/mmseg/models/necks/__init__.py b/mmseg/models/necks/__init__.py
new file mode 100644
index 0000000..aba73f1
--- /dev/null
+++ b/mmseg/models/necks/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .fpn import FPN
+from .ic_neck import ICNeck
+from .jpu import JPU
+from .mla_neck import MLANeck
+from .multilevel_neck import MultiLevelNeck
+
+__all__ = ['FPN', 'MultiLevelNeck', 'MLANeck', 'ICNeck', 'JPU']
diff --git a/mmseg/models/necks/fpn.py b/mmseg/models/necks/fpn.py
new file mode 100644
index 0000000..975a48e
--- /dev/null
+++ b/mmseg/models/necks/fpn.py
@@ -0,0 +1,213 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule, auto_fp16
+
+from mmseg.ops import resize
+from ..builder import NECKS
+
+
+@NECKS.register_module()
+class FPN(BaseModule):
+ """Feature Pyramid Network.
+
+ This neck is the implementation of `Feature Pyramid Networks for Object
+ Detection `_.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ num_outs (int): Number of output scales.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Default: 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Default: -1, which means the last level.
+ add_extra_convs (bool | str): If bool, it decides whether to add conv
+ layers on top of the original feature maps. Default to False.
+ If True, its actual mode is specified by `extra_convs_on_inputs`.
+ If str, it specifies the source feature map of the extra convs.
+ Only the following options are allowed
+
+ - 'on_input': Last feat map of neck inputs (i.e. backbone feature).
+ - 'on_lateral': Last feature map after lateral convs.
+ - 'on_output': The last output feature map after fpn convs.
+ extra_convs_on_inputs (bool, deprecated): Whether to apply extra convs
+ on the original feature from the backbone. If True,
+ it is equivalent to `add_extra_convs='on_input'`. If False, it is
+ equivalent to set `add_extra_convs='on_output'`. Default to True.
+ relu_before_extra_convs (bool): Whether to apply relu before the extra
+ conv. Default: False.
+ no_norm_on_lateral (bool): Whether to apply norm on lateral.
+ Default: False.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (str): Config dict for activation layer in ConvModule.
+ Default: None.
+ upsample_cfg (dict): Config dict for interpolate layer.
+ Default: `dict(mode='nearest')`
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+
+ Example:
+ >>> import torch
+ >>> in_channels = [2, 3, 5, 7]
+ >>> scales = [340, 170, 84, 43]
+ >>> inputs = [torch.rand(1, c, s, s)
+ ... for c, s in zip(in_channels, scales)]
+ >>> self = FPN(in_channels, 11, len(in_channels)).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 11, 340, 340])
+ outputs[1].shape = torch.Size([1, 11, 170, 170])
+ outputs[2].shape = torch.Size([1, 11, 84, 84])
+ outputs[3].shape = torch.Size([1, 11, 43, 43])
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level=0,
+ end_level=-1,
+ add_extra_convs=False,
+ extra_convs_on_inputs=False,
+ relu_before_extra_convs=False,
+ no_norm_on_lateral=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=None,
+ upsample_cfg=dict(mode='nearest'),
+ init_cfg=dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')):
+ super(FPN, self).__init__(init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.num_outs = num_outs
+ self.relu_before_extra_convs = relu_before_extra_convs
+ self.no_norm_on_lateral = no_norm_on_lateral
+ self.fp16_enabled = False
+ self.upsample_cfg = upsample_cfg.copy()
+
+ if end_level == -1:
+ self.backbone_end_level = self.num_ins
+ assert num_outs >= self.num_ins - start_level
+ else:
+ # if end_level < inputs, no extra level is allowed
+ self.backbone_end_level = end_level
+ assert end_level <= len(in_channels)
+ assert num_outs == end_level - start_level
+ self.start_level = start_level
+ self.end_level = end_level
+ self.add_extra_convs = add_extra_convs
+ assert isinstance(add_extra_convs, (str, bool))
+ if isinstance(add_extra_convs, str):
+ # Extra_convs_source choices: 'on_input', 'on_lateral', 'on_output'
+ assert add_extra_convs in ('on_input', 'on_lateral', 'on_output')
+ elif add_extra_convs: # True
+ if extra_convs_on_inputs:
+ # For compatibility with previous release
+ # TODO: deprecate `extra_convs_on_inputs`
+ self.add_extra_convs = 'on_input'
+ else:
+ self.add_extra_convs = 'on_output'
+
+ self.lateral_convs = nn.ModuleList()
+ self.fpn_convs = nn.ModuleList()
+
+ for i in range(self.start_level, self.backbone_end_level):
+ l_conv = ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg if not self.no_norm_on_lateral else None,
+ act_cfg=act_cfg,
+ inplace=False)
+ fpn_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ self.lateral_convs.append(l_conv)
+ self.fpn_convs.append(fpn_conv)
+
+ # add extra conv layers (e.g., RetinaNet)
+ extra_levels = num_outs - self.backbone_end_level + self.start_level
+ if self.add_extra_convs and extra_levels >= 1:
+ for i in range(extra_levels):
+ if i == 0 and self.add_extra_convs == 'on_input':
+ in_channels = self.in_channels[self.backbone_end_level - 1]
+ else:
+ in_channels = out_channels
+ extra_fpn_conv = ConvModule(
+ in_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ self.fpn_convs.append(extra_fpn_conv)
+
+ @auto_fp16()
+ def forward(self, inputs):
+ assert len(inputs) == len(self.in_channels)
+
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i + self.start_level])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+
+ # build top-down path
+ used_backbone_levels = len(laterals)
+ for i in range(used_backbone_levels - 1, 0, -1):
+ # In some cases, fixing `scale factor` (e.g. 2) is preferred, but
+ # it cannot co-exist with `size` in `F.interpolate`.
+ if 'scale_factor' in self.upsample_cfg:
+ laterals[i - 1] = laterals[i - 1] + resize(
+ laterals[i], **self.upsample_cfg)
+ else:
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] = laterals[i - 1] + resize(
+ laterals[i], size=prev_shape, **self.upsample_cfg)
+
+ # build outputs
+ # part 1: from original levels
+ outs = [
+ self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
+ ]
+ # part 2: add extra levels
+ if self.num_outs > len(outs):
+ # use max pool to get more levels on top of outputs
+ # (e.g., Faster R-CNN, Mask R-CNN)
+ if not self.add_extra_convs:
+ for i in range(self.num_outs - used_backbone_levels):
+ outs.append(F.max_pool2d(outs[-1], 1, stride=2))
+ # add conv layers on top of original feature maps (RetinaNet)
+ else:
+ if self.add_extra_convs == 'on_input':
+ extra_source = inputs[self.backbone_end_level - 1]
+ elif self.add_extra_convs == 'on_lateral':
+ extra_source = laterals[-1]
+ elif self.add_extra_convs == 'on_output':
+ extra_source = outs[-1]
+ else:
+ raise NotImplementedError
+ outs.append(self.fpn_convs[used_backbone_levels](extra_source))
+ for i in range(used_backbone_levels + 1, self.num_outs):
+ if self.relu_before_extra_convs:
+ outs.append(self.fpn_convs[i](F.relu(outs[-1])))
+ else:
+ outs.append(self.fpn_convs[i](outs[-1]))
+ return tuple(outs)
diff --git a/mmseg/models/necks/ic_neck.py b/mmseg/models/necks/ic_neck.py
new file mode 100644
index 0000000..d836a6b
--- /dev/null
+++ b/mmseg/models/necks/ic_neck.py
@@ -0,0 +1,147 @@
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import NECKS
+
+
+class CascadeFeatureFusion(BaseModule):
+ """Cascade Feature Fusion Unit in ICNet.
+
+ Args:
+ low_channels (int): The number of input channels for
+ low resolution feature map.
+ high_channels (int): The number of input channels for
+ high resolution feature map.
+ out_channels (int): The number of output channels.
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Dictionary to construct and config act layer.
+ Default: dict(type='ReLU').
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Returns:
+ x (Tensor): The output tensor of shape (N, out_channels, H, W).
+ x_low (Tensor): The output tensor of shape (N, out_channels, H, W)
+ for Cascade Label Guidance in auxiliary heads.
+ """
+
+ def __init__(self,
+ low_channels,
+ high_channels,
+ out_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ init_cfg=None):
+ super(CascadeFeatureFusion, self).__init__(init_cfg=init_cfg)
+ self.align_corners = align_corners
+ self.conv_low = ConvModule(
+ low_channels,
+ out_channels,
+ 3,
+ padding=2,
+ dilation=2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv_high = ConvModule(
+ high_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x_low, x_high):
+ x_low = resize(
+ x_low,
+ size=x_high.size()[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ # Note: Different from original paper, `x_low` is underwent
+ # `self.conv_low` rather than another 1x1 conv classifier
+ # before being used for auxiliary head.
+ x_low = self.conv_low(x_low)
+ x_high = self.conv_high(x_high)
+ x = x_low + x_high
+ x = F.relu(x, inplace=True)
+ return x, x_low
+
+
+@NECKS.register_module()
+class ICNeck(BaseModule):
+ """ICNet for Real-Time Semantic Segmentation on High-Resolution Images.
+
+ This head is the implementation of `ICHead
+ `_.
+
+ Args:
+ in_channels (int): The number of input image channels. Default: 3.
+ out_channels (int): The numbers of output feature channels.
+ Default: 128.
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Dictionary to construct and config act layer.
+ Default: dict(type='ReLU').
+ align_corners (bool): align_corners argument of F.interpolate.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=(64, 256, 256),
+ out_channels=128,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ init_cfg=None):
+ super(ICNeck, self).__init__(init_cfg=init_cfg)
+ assert len(in_channels) == 3, 'Length of input channels \
+ must be 3!'
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.align_corners = align_corners
+ self.cff_24 = CascadeFeatureFusion(
+ self.in_channels[2],
+ self.in_channels[1],
+ self.out_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+
+ self.cff_12 = CascadeFeatureFusion(
+ self.out_channels,
+ self.in_channels[0],
+ self.out_channels,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ align_corners=self.align_corners)
+
+ def forward(self, inputs):
+ assert len(inputs) == 3, 'Length of input feature \
+ maps must be 3!'
+
+ x_sub1, x_sub2, x_sub4 = inputs
+ x_cff_24, x_24 = self.cff_24(x_sub4, x_sub2)
+ x_cff_12, x_12 = self.cff_12(x_cff_24, x_sub1)
+ # Note: `x_cff_12` is used for decode_head,
+ # `x_24` and `x_12` are used for auxiliary head.
+ return x_24, x_12, x_cff_12
diff --git a/mmseg/models/necks/jpu.py b/mmseg/models/necks/jpu.py
new file mode 100644
index 0000000..3cc6b9f
--- /dev/null
+++ b/mmseg/models/necks/jpu.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmcv.runner import BaseModule
+
+from mmseg.ops import resize
+from ..builder import NECKS
+
+
+@NECKS.register_module()
+class JPU(BaseModule):
+ """FastFCN: Rethinking Dilated Convolution in the Backbone
+ for Semantic Segmentation.
+
+ This Joint Pyramid Upsampling (JPU) neck is the implementation of
+ `FastFCN `_.
+
+ Args:
+ in_channels (Tuple[int], optional): The number of input channels
+ for each convolution operations before upsampling.
+ Default: (512, 1024, 2048).
+ mid_channels (int): The number of output channels of JPU.
+ Default: 512.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Default: 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Default: -1, which means the last level.
+ dilations (tuple[int]): Dilation rate of each Depthwise
+ Separable ConvModule. Default: (1, 2, 4, 8).
+ align_corners (bool, optional): The align_corners argument of
+ resize operation. Default: False.
+ conv_cfg (dict | None): Config of conv layers.
+ Default: None.
+ norm_cfg (dict | None): Config of norm layers.
+ Default: dict(type='BN').
+ act_cfg (dict): Config of activation layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=(512, 1024, 2048),
+ mid_channels=512,
+ start_level=0,
+ end_level=-1,
+ dilations=(1, 2, 4, 8),
+ align_corners=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(JPU, self).__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, tuple)
+ assert isinstance(dilations, tuple)
+ self.in_channels = in_channels
+ self.mid_channels = mid_channels
+ self.start_level = start_level
+ self.num_ins = len(in_channels)
+ if end_level == -1:
+ self.backbone_end_level = self.num_ins
+ else:
+ self.backbone_end_level = end_level
+ assert end_level <= len(in_channels)
+
+ self.dilations = dilations
+ self.align_corners = align_corners
+
+ self.conv_layers = nn.ModuleList()
+ self.dilation_layers = nn.ModuleList()
+ for i in range(self.start_level, self.backbone_end_level):
+ conv_layer = nn.Sequential(
+ ConvModule(
+ self.in_channels[i],
+ self.mid_channels,
+ kernel_size=3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.conv_layers.append(conv_layer)
+ for i in range(len(dilations)):
+ dilation_layer = nn.Sequential(
+ DepthwiseSeparableConvModule(
+ in_channels=(self.backbone_end_level - self.start_level) *
+ self.mid_channels,
+ out_channels=self.mid_channels,
+ kernel_size=3,
+ stride=1,
+ padding=dilations[i],
+ dilation=dilations[i],
+ dw_norm_cfg=norm_cfg,
+ dw_act_cfg=None,
+ pw_norm_cfg=norm_cfg,
+ pw_act_cfg=act_cfg))
+ self.dilation_layers.append(dilation_layer)
+
+ def forward(self, inputs):
+ """Forward function."""
+ assert len(inputs) == len(self.in_channels), 'Length of inputs must \
+ be the same with self.in_channels!'
+
+ feats = [
+ self.conv_layers[i - self.start_level](inputs[i])
+ for i in range(self.start_level, self.backbone_end_level)
+ ]
+
+ h, w = feats[0].shape[2:]
+ for i in range(1, len(feats)):
+ feats[i] = resize(
+ feats[i],
+ size=(h, w),
+ mode='bilinear',
+ align_corners=self.align_corners)
+
+ feat = torch.cat(feats, dim=1)
+ concat_feat = torch.cat([
+ self.dilation_layers[i](feat) for i in range(len(self.dilations))
+ ],
+ dim=1)
+
+ outs = []
+
+ # Default: outs[2] is the output of JPU for decoder head, outs[1] is
+ # the feature map from backbone for auxiliary head. Additionally,
+ # outs[0] can also be used for auxiliary head.
+ for i in range(self.start_level, self.backbone_end_level - 1):
+ outs.append(inputs[i])
+ outs.append(concat_feat)
+ return tuple(outs)
diff --git a/mmseg/models/necks/mla_neck.py b/mmseg/models/necks/mla_neck.py
new file mode 100644
index 0000000..1513e29
--- /dev/null
+++ b/mmseg/models/necks/mla_neck.py
@@ -0,0 +1,118 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule, build_norm_layer
+
+from ..builder import NECKS
+
+
+class MLAModule(nn.Module):
+
+ def __init__(self,
+ in_channels=[1024, 1024, 1024, 1024],
+ out_channels=256,
+ norm_cfg=None,
+ act_cfg=None):
+ super(MLAModule, self).__init__()
+ self.channel_proj = nn.ModuleList()
+ for i in range(len(in_channels)):
+ self.channel_proj.append(
+ ConvModule(
+ in_channels=in_channels[i],
+ out_channels=out_channels,
+ kernel_size=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.feat_extract = nn.ModuleList()
+ for i in range(len(in_channels)):
+ self.feat_extract.append(
+ ConvModule(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs):
+
+ # feat_list -> [p2, p3, p4, p5]
+ feat_list = []
+ for x, conv in zip(inputs, self.channel_proj):
+ feat_list.append(conv(x))
+
+ # feat_list -> [p5, p4, p3, p2]
+ # mid_list -> [m5, m4, m3, m2]
+ feat_list = feat_list[::-1]
+ mid_list = []
+ for feat in feat_list:
+ if len(mid_list) == 0:
+ mid_list.append(feat)
+ else:
+ mid_list.append(mid_list[-1] + feat)
+
+ # mid_list -> [m5, m4, m3, m2]
+ # out_list -> [o2, o3, o4, o5]
+ out_list = []
+ for mid, conv in zip(mid_list, self.feat_extract):
+ out_list.append(conv(mid))
+
+ return tuple(out_list)
+
+
+@NECKS.register_module()
+class MLANeck(nn.Module):
+ """Multi-level Feature Aggregation.
+
+ This neck is `The Multi-level Feature Aggregation construction of
+ SETR `_.
+
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ norm_layer (dict): Config dict for input normalization.
+ Default: norm_layer=dict(type='LN', eps=1e-6, requires_grad=True).
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (dict): Config dict for activation layer in ConvModule.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ norm_layer=dict(type='LN', eps=1e-6, requires_grad=True),
+ norm_cfg=None,
+ act_cfg=None):
+ super(MLANeck, self).__init__()
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ # In order to build general vision transformer backbone, we have to
+ # move MLA to neck.
+ self.norm = nn.ModuleList([
+ build_norm_layer(norm_layer, in_channels[i])[1]
+ for i in range(len(in_channels))
+ ])
+
+ self.mla = MLAModule(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, inputs):
+ assert len(inputs) == len(self.in_channels)
+
+ # Convert from nchw to nlc
+ outs = []
+ for i in range(len(inputs)):
+ x = inputs[i]
+ n, c, h, w = x.shape
+ x = x.reshape(n, c, h * w).transpose(2, 1).contiguous()
+ x = self.norm[i](x)
+ x = x.transpose(1, 2).reshape(n, c, h, w).contiguous()
+ outs.append(x)
+
+ outs = self.mla(outs)
+ return tuple(outs)
diff --git a/mmseg/models/necks/multilevel_neck.py b/mmseg/models/necks/multilevel_neck.py
new file mode 100644
index 0000000..5151f87
--- /dev/null
+++ b/mmseg/models/necks/multilevel_neck.py
@@ -0,0 +1,78 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule, xavier_init
+
+from mmseg.ops import resize
+from ..builder import NECKS
+
+
+@NECKS.register_module()
+class MultiLevelNeck(nn.Module):
+ """MultiLevelNeck.
+
+ A neck structure connect vit backbone and decoder_heads.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ scales (List[float]): Scale factors for each input feature map.
+ Default: [0.5, 1, 2, 4]
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (dict): Config dict for activation layer in ConvModule.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ scales=[0.5, 1, 2, 4],
+ norm_cfg=None,
+ act_cfg=None):
+ super(MultiLevelNeck, self).__init__()
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.scales = scales
+ self.num_outs = len(scales)
+ self.lateral_convs = nn.ModuleList()
+ self.convs = nn.ModuleList()
+ for in_channel in in_channels:
+ self.lateral_convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ kernel_size=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ for _ in range(self.num_outs):
+ self.convs.append(
+ ConvModule(
+ out_channels,
+ out_channels,
+ kernel_size=3,
+ padding=1,
+ stride=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ # default init_weights for conv(msra) and norm in ConvModule
+ def init_weights(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ xavier_init(m, distribution='uniform')
+
+ def forward(self, inputs):
+ assert len(inputs) == len(self.in_channels)
+ inputs = [
+ lateral_conv(inputs[i])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+ # for len(inputs) not equal to self.num_outs
+ if len(inputs) == 1:
+ inputs = [inputs[0] for _ in range(self.num_outs)]
+ outs = []
+ for i in range(self.num_outs):
+ x_resize = resize(
+ inputs[i], scale_factor=self.scales[i], mode='bilinear')
+ outs.append(self.convs[i](x_resize))
+ return tuple(outs)
diff --git a/mmseg/models/segmentors/__init__.py b/mmseg/models/segmentors/__init__.py
new file mode 100644
index 0000000..c294a9e
--- /dev/null
+++ b/mmseg/models/segmentors/__init__.py
@@ -0,0 +1,12 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BaseSegmentor, ONNXRuntimeSegmentorKN
+from .cascade_encoder_decoder import CascadeEncoderDecoder
+from .encoder_decoder import EncoderDecoder
+
+__all__ = [
+ 'BaseSegmentor',
+ 'ONNXRuntimeSegmentorKN',
+ 'EncoderDecoder',
+ 'CascadeEncoderDecoder'
+]
diff --git a/mmseg/models/segmentors/base.py b/mmseg/models/segmentors/base.py
new file mode 100644
index 0000000..3778c4d
--- /dev/null
+++ b/mmseg/models/segmentors/base.py
@@ -0,0 +1,453 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from abc import ABCMeta, abstractmethod
+from collections import OrderedDict
+from typing import Any, Iterable, Union
+from os import path as osp
+
+import mmcv
+import numpy as np
+import torch
+import torch.distributed as dist
+from mmcv.runner import BaseModule, auto_fp16
+from mmseg.core import get_classes, get_palette
+from mmseg.ops import resize
+
+
+class BaseSegmentor(BaseModule, metaclass=ABCMeta):
+ """Base class for segmentors."""
+
+ def __init__(self, init_cfg=None):
+ super(BaseSegmentor, self).__init__(init_cfg)
+ self.fp16_enabled = False
+
+ @property
+ def with_neck(self):
+ """bool: whether the segmentor has neck"""
+ return hasattr(self, 'neck') and self.neck is not None
+
+ @property
+ def with_auxiliary_head(self):
+ """bool: whether the segmentor has auxiliary head"""
+ return hasattr(self,
+ 'auxiliary_head') and self.auxiliary_head is not None
+
+ @property
+ def with_decode_head(self):
+ """bool: whether the segmentor has decode head"""
+ return hasattr(self, 'decode_head') and self.decode_head is not None
+
+ @abstractmethod
+ def extract_feat(self, imgs):
+ """Placeholder for extract features from images."""
+ pass
+
+ @abstractmethod
+ def encode_decode(self, img, img_metas):
+ """Placeholder for encode images with backbone and decode into a
+ semantic segmentation map of the same size as input."""
+ pass
+
+ @abstractmethod
+ def forward_train(self, imgs, img_metas, **kwargs):
+ """Placeholder for Forward function for training."""
+ pass
+
+ @abstractmethod
+ def simple_test(self, img, img_meta, **kwargs):
+ """Placeholder for single image test."""
+ pass
+
+ @abstractmethod
+ def aug_test(self, imgs, img_metas, **kwargs):
+ """Placeholder for augmentation test."""
+ pass
+
+ def forward_test(self, imgs, img_metas, **kwargs):
+ """
+ Args:
+ imgs (List[Tensor]): the outer list indicates test-time
+ augmentations and inner Tensor should have a shape NxCxHxW,
+ which contains all images in the batch.
+ img_metas (List[List[dict]]): the outer list indicates test-time
+ augs (multiscale, flip, etc.) and the inner list indicates
+ images in a batch.
+ """
+ for var, name in [(imgs, 'imgs'), (img_metas, 'img_metas')]:
+ if not isinstance(var, list):
+ raise TypeError(f'{name} must be a list, but got '
+ f'{type(var)}')
+
+ num_augs = len(imgs)
+ if num_augs != len(img_metas):
+ raise ValueError(f'num of augmentations ({len(imgs)}) != '
+ f'num of image meta ({len(img_metas)})')
+ # all images in the same aug batch all of the same ori_shape and pad
+ # shape
+ for img_meta in img_metas:
+ ori_shapes = [_['ori_shape'] for _ in img_meta]
+ assert all(shape == ori_shapes[0] for shape in ori_shapes)
+ img_shapes = [_['img_shape'] for _ in img_meta]
+ assert all(shape == img_shapes[0] for shape in img_shapes)
+ pad_shapes = [_['pad_shape'] for _ in img_meta]
+ assert all(shape == pad_shapes[0] for shape in pad_shapes)
+
+ if num_augs == 1:
+ return self.simple_test(imgs[0], img_metas[0], **kwargs)
+ else:
+ return self.aug_test(imgs, img_metas, **kwargs)
+
+ @auto_fp16(apply_to=('img', ))
+ def forward(self, img, img_metas, return_loss=True, **kwargs):
+ """Calls either :func:`forward_train` or :func:`forward_test` depending
+ on whether ``return_loss`` is ``True``.
+
+ Note this setting will change the expected inputs. When
+ ``return_loss=True``, img and img_meta are single-nested (i.e. Tensor
+ and List[dict]), and when ``resturn_loss=False``, img and img_meta
+ should be double nested (i.e. List[Tensor], List[List[dict]]), with
+ the outer list indicating test time augmentations.
+ """
+ if return_loss:
+ return self.forward_train(img, img_metas, **kwargs)
+ else:
+ return self.forward_test(img, img_metas, **kwargs)
+
+ def train_step(self, data_batch, optimizer, **kwargs):
+ """The iteration step during training.
+
+ This method defines an iteration step during training, except for the
+ back propagation and optimizer updating, which are done in an optimizer
+ hook. Note that in some complicated cases or models, the whole process
+ including back propagation and optimizer updating is also defined in
+ this method, such as GAN.
+
+ Args:
+ data (dict): The output of dataloader.
+ optimizer (:obj:`torch.optim.Optimizer` | dict): The optimizer of
+ runner is passed to ``train_step()``. This argument is unused
+ and reserved.
+
+ Returns:
+ dict: It should contain at least 3 keys: ``loss``, ``log_vars``,
+ ``num_samples``.
+ ``loss`` is a tensor for back propagation, which can be a
+ weighted sum of multiple losses.
+ ``log_vars`` contains all the variables to be sent to the
+ logger.
+ ``num_samples`` indicates the batch size (when the model is
+ DDP, it means the batch size on each GPU), which is used for
+ averaging the logs.
+ """
+ losses = self(**data_batch)
+ loss, log_vars = self._parse_losses(losses)
+
+ outputs = dict(
+ loss=loss,
+ log_vars=log_vars,
+ num_samples=len(data_batch['img_metas']))
+
+ return outputs
+
+ def val_step(self, data_batch, optimizer=None, **kwargs):
+ """The iteration step during validation.
+
+ This method shares the same signature as :func:`train_step`, but used
+ during val epochs. Note that the evaluation after training epochs is
+ not implemented with this method, but an evaluation hook.
+ """
+ losses = self(**data_batch)
+ loss, log_vars = self._parse_losses(losses)
+
+ outputs = dict(
+ loss=loss,
+ log_vars=log_vars,
+ num_samples=len(data_batch['img_metas']))
+
+ return outputs
+
+ @staticmethod
+ def _parse_losses(losses):
+ """Parse the raw outputs (losses) of the network.
+
+ Args:
+ losses (dict): Raw output of the network, which usually contain
+ losses and other necessary information.
+
+ Returns:
+ tuple[Tensor, dict]: (loss, log_vars), loss is the loss tensor
+ which may be a weighted sum of all losses, log_vars contains
+ all the variables to be sent to the logger.
+ """
+ log_vars = OrderedDict()
+ for loss_name, loss_value in losses.items():
+ if isinstance(loss_value, torch.Tensor):
+ log_vars[loss_name] = loss_value.mean()
+ elif isinstance(loss_value, list):
+ log_vars[loss_name] = sum(_loss.mean() for _loss in loss_value)
+ else:
+ raise TypeError(
+ f'{loss_name} is not a tensor or list of tensors')
+
+ loss = sum(_value for _key, _value in log_vars.items()
+ if 'loss' in _key)
+
+ # If the loss_vars has different length, raise assertion error
+ # to prevent GPUs from infinite waiting.
+ if dist.is_available() and dist.is_initialized():
+ log_var_length = torch.tensor(len(log_vars), device=loss.device)
+ dist.all_reduce(log_var_length)
+ message = (f'rank {dist.get_rank()}' +
+ f' len(log_vars): {len(log_vars)}' + ' keys: ' +
+ ','.join(log_vars.keys()) + '\n')
+ assert log_var_length == len(log_vars) * dist.get_world_size(), \
+ 'loss log variables are different across GPUs!\n' + message
+
+ log_vars['loss'] = loss
+ for loss_name, loss_value in log_vars.items():
+ # reduce loss when distributed training
+ if dist.is_available() and dist.is_initialized():
+ loss_value = loss_value.data.clone()
+ dist.all_reduce(loss_value.div_(dist.get_world_size()))
+ log_vars[loss_name] = loss_value.item()
+
+ return loss, log_vars
+
+ def show_result(self,
+ img,
+ result,
+ palette=None,
+ win_name='',
+ show=False,
+ wait_time=0,
+ out_file=None,
+ opacity=0.5):
+ """Draw `result` over `img`.
+
+ Args:
+ img (str or Tensor): The image to be displayed.
+ result (Tensor): The semantic segmentation results to draw over
+ `img`.
+ palette (list[list[int]]] | np.ndarray | None): The palette of
+ segmentation map. If None is given, random palette will be
+ generated. Default: None
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ Default: 0.
+ show (bool): Whether to show the image.
+ Default: False.
+ out_file (str or None): The filename to write the image.
+ Default: None.
+ opacity(float): Opacity of painted segmentation map.
+ Default 0.5.
+ Must be in (0, 1] range.
+ Returns:
+ img (Tensor): Only if not `show` or `out_file`
+ """
+ img = mmcv.imread(img)
+ img = img.copy()
+ seg = result[0]
+ if palette is None:
+ if self.PALETTE is None:
+ # Get random state before set seed,
+ # and restore random state later.
+ # It will prevent loss of randomness, as the palette
+ # may be different in each iteration if not specified.
+ # See: https://github.com/open-mmlab/mmdetection/issues/5844
+ state = np.random.get_state()
+ np.random.seed(42)
+ # random palette
+ palette = np.random.randint(
+ 0, 255, size=(len(self.CLASSES), 3))
+ np.random.set_state(state)
+ else:
+ palette = self.PALETTE
+ palette = np.array(palette)
+ assert palette.shape[0] == len(self.CLASSES)
+ assert palette.shape[1] == 3
+ assert len(palette.shape) == 2
+ assert 0 < opacity <= 1.0
+ color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
+ for label, color in enumerate(palette):
+ color_seg[seg == label, :] = color
+ # convert to BGR
+ color_seg = color_seg[..., ::-1]
+
+ img = img * (1 - opacity) + color_seg * opacity
+ img = img.astype(np.uint8)
+ # if out_file specified, do not show image in window
+ if out_file is not None:
+ show = False
+
+ if show:
+ mmcv.imshow(img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(img, out_file)
+
+ if not (show or out_file):
+ warnings.warn('show==False and out_file is not specified, only '
+ 'result image will be returned')
+ return img
+
+
+class ONNXRuntimeSegmentorKN(BaseSegmentor):
+
+ def __init__(
+ self,
+ onnx_file: str,
+ cfg: Any,
+ device_id: Union[int, None] = 0):
+ super(ONNXRuntimeSegmentorKN, self).__init__()
+ import onnxruntime as ort
+
+ # get the custom op path
+ ort_custom_op_path = ''
+ try:
+ from mmcv.ops import get_onnxruntime_op_path
+ ort_custom_op_path = get_onnxruntime_op_path()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn(
+ 'If input model has custom op from mmcv, you may '
+ 'have to build mmcv with ONNXRuntime from source.')
+ session_options = ort.SessionOptions()
+ # register custom op for onnxruntime
+ if osp.exists(ort_custom_op_path):
+ session_options.register_custom_ops_library(ort_custom_op_path)
+ providers = ['CPUExecutionProvider']
+ provider_options = [{}]
+ is_cuda_available = (
+ ort.get_device() == 'GPU' and torch.cuda.is_available()
+ )
+ if is_cuda_available:
+ providers.insert(0, 'CUDAExecutionProvider')
+ device_id = device_id or 0
+ provider_options.insert(0, {'device_id': device_id})
+ sess = ort.InferenceSession(
+ onnx_file, session_options, providers, provider_options
+ )
+ self.sess = sess
+ sess_inputs = sess.get_inputs()
+ assert len(sess_inputs) == 1, "Only onnx with 1 input is supported"
+ self.input_name = sess_inputs[0].name
+ sess_outputs = sess.get_outputs()
+ self.num_classes = sess_outputs[0].shape[1]
+ assert len(sess_outputs) == 1, "Only onnx with 1 output is supported"
+ self.output_name_list = [sess_outputs[0].name]
+ self.cfg = cfg # TODO: necessary?
+ self.test_cfg = cfg.model.test_cfg
+ self.test_mode = self.test_cfg.mode # NOTE: either 'whole' or 'slide'
+ self.is_cuda_available = is_cuda_available
+ self.count_mat = None
+ try:
+ if 'test' in cfg.data:
+ dataset_name = cfg.data.test['type']
+ else:
+ dataset_name = cfg.data.train['type']
+ dataset_name = dataset_name.lower()[:-7]
+ self.CLASSES = get_classes(dataset_name)
+ self.PALETTE = get_palette(dataset_name)
+ except (AttributeError, KeyError):
+ warnings.warn(
+ "Failed to fetch dataset name from config; no CLASSES "
+ "and PALETTE for this ONNX model"
+ )
+ except ValueError:
+ warnings.warn(
+ "Failed to fetch CLASSES and PALETTE from dataset "
+ f"{dataset_name}; no CLASSES and PALETTE for this "
+ "ONNX MODEL."
+ )
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def encode_decode(self, img, img_metas):
+ raise NotImplementedError('This method is not implemented.')
+
+ def forward_train(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def forward_test(self, imgs, img_metas, **kwargs):
+ return super().forward_test(imgs, img_metas[0].data, **kwargs)
+
+ def simple_slide_inference(
+ self,
+ img: np.ndarray,
+ img_meta: Union[Iterable, None] = None):
+ h_stride, w_stride = self.test_cfg.stride
+ h_crop, w_crop = self.test_cfg.crop_size
+ _, _, h_img, w_img = img.shape
+ num_classes = self.num_classes
+ h_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1
+ w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1
+ preds = np.zeros((1, num_classes, h_img, w_img), dtype=np.float32)
+ # NOTE: count_mat should be invariant since
+ # input shape of kneron's onnx is fixed
+ if self.count_mat is None:
+ count_mat = np.zeros((1, 1, h_img, w_img), dtype=np.float32)
+ for h_idx in range(h_grids):
+ for w_idx in range(w_grids):
+ y1 = h_idx * h_stride
+ x1 = w_idx * w_stride
+ y2 = min(y1 + h_crop, h_img)
+ x2 = min(x1 + w_crop, w_img)
+ y1 = max(y2 - h_crop, 0)
+ x1 = max(x2 - w_crop, 0)
+ crop_img = img[:, :, y1:y2, x1:x2]
+ crop_seg_logit = self.sess.run(
+ self.output_name_list,
+ {self.input_name: crop_img}
+ )[0]
+ preds += np.pad(
+ crop_seg_logit,
+ ([0, 0],
+ [0, 0],
+ [int(y1), int(preds.shape[2] - y2)],
+ [int(x1), int(preds.shape[3] - x2)]),
+ )
+ if self.count_mat is None:
+ count_mat[:, :, y1:y2, x1:x2] += 1
+ if self.count_mat is None:
+ assert (count_mat == 0).sum() == 0
+ self.count_mat = count_mat
+ preds /= self.count_mat
+ return preds
+
+ @property
+ def module(self):
+ return self
+
+ @torch.no_grad()
+ def simple_test(
+ self,
+ img: torch.Tensor,
+ img_meta: Union[Iterable, None] = None,
+ **kwargs) -> list:
+ img = img.cpu().numpy()
+ # NOTE: not using run_with_iobinding since some ort versions
+ # generate wrong results when inferencing with CUDA
+ if self.test_mode == 'slide':
+ seg_pred = self.simple_slide_inference(img, img_meta)
+ else:
+ seg_pred = self.sess.run(
+ self.output_name_list, {self.input_name: img}
+ )[0]
+ if img_meta is not None:
+ ori_shape = img_meta[0]['ori_shape']
+ if not (ori_shape[0] == seg_pred.shape[-2]
+ and ori_shape[1] == seg_pred.shape[-1]):
+ seg_pred = torch.from_numpy(seg_pred).float()
+ seg_pred = resize(
+ seg_pred, size=tuple(ori_shape[:2]), mode='bilinear')
+ seg_pred = seg_pred.numpy()
+ elif img.shape[2:] != seg_pred.shape[2:]:
+ seg_pred = torch.from_numpy(seg_pred).float()
+ seg_pred = resize(
+ seg_pred, size=(img.shape[3], img.shape[2]), mode='bilinear')
+ seg_pred = seg_pred.numpy()
+ seg_pred = seg_pred.argmax(1)
+ return list(seg_pred)
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
diff --git a/mmseg/models/segmentors/cascade_encoder_decoder.py b/mmseg/models/segmentors/cascade_encoder_decoder.py
new file mode 100644
index 0000000..7f9f900
--- /dev/null
+++ b/mmseg/models/segmentors/cascade_encoder_decoder.py
@@ -0,0 +1,84 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from torch import nn
+
+from mmseg.core import add_prefix
+from mmseg.ops import resize
+from .. import builder
+from ..builder import SEGMENTORS
+from .encoder_decoder import EncoderDecoder
+
+
+@SEGMENTORS.register_module()
+class CascadeEncoderDecoder(EncoderDecoder):
+ """Cascade Encoder Decoder segmentors.
+
+ CascadeEncoderDecoder almost the same as EncoderDecoder, while decoders of
+ CascadeEncoderDecoder are cascaded. The output of previous decoder_head
+ will be the input of next decoder_head.
+ """
+
+ def __init__(self,
+ num_stages,
+ backbone,
+ decode_head,
+ neck=None,
+ auxiliary_head=None,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ init_cfg=None):
+ self.num_stages = num_stages
+ super(CascadeEncoderDecoder, self).__init__(
+ backbone=backbone,
+ decode_head=decode_head,
+ neck=neck,
+ auxiliary_head=auxiliary_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ pretrained=pretrained,
+ init_cfg=init_cfg)
+
+ def _init_decode_head(self, decode_head):
+ """Initialize ``decode_head``"""
+ assert isinstance(decode_head, list)
+ assert len(decode_head) == self.num_stages
+ self.decode_head = nn.ModuleList()
+ for i in range(self.num_stages):
+ self.decode_head.append(builder.build_head(decode_head[i]))
+ self.align_corners = self.decode_head[-1].align_corners
+ self.num_classes = self.decode_head[-1].num_classes
+
+ def encode_decode(self, img, img_metas):
+ """Encode images with backbone and decode into a semantic segmentation
+ map of the same size as input."""
+ x = self.extract_feat(img)
+ out = self.decode_head[0].forward_test(x, img_metas, self.test_cfg)
+ for i in range(1, self.num_stages):
+ out = self.decode_head[i].forward_test(x, out, img_metas,
+ self.test_cfg)
+ out = resize(
+ input=out,
+ size=img.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ return out
+
+ def _decode_head_forward_train(self, x, img_metas, gt_semantic_seg):
+ """Run forward function and calculate loss for decode head in
+ training."""
+ losses = dict()
+
+ loss_decode = self.decode_head[0].forward_train(
+ x, img_metas, gt_semantic_seg, self.train_cfg)
+
+ losses.update(add_prefix(loss_decode, 'decode_0'))
+
+ for i in range(1, self.num_stages):
+ # forward test again, maybe unnecessary for most methods.
+ prev_outputs = self.decode_head[i - 1].forward_test(
+ x, img_metas, self.test_cfg)
+ loss_decode = self.decode_head[i].forward_train(
+ x, prev_outputs, img_metas, gt_semantic_seg, self.train_cfg)
+ losses.update(add_prefix(loss_decode, f'decode_{i}'))
+
+ return losses
diff --git a/mmseg/models/segmentors/encoder_decoder.py b/mmseg/models/segmentors/encoder_decoder.py
new file mode 100644
index 0000000..a15c883
--- /dev/null
+++ b/mmseg/models/segmentors/encoder_decoder.py
@@ -0,0 +1,286 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmseg.core import add_prefix
+from mmseg.ops import resize
+from .. import builder
+from ..builder import SEGMENTORS
+from .base import BaseSegmentor
+
+
+@SEGMENTORS.register_module()
+class EncoderDecoder(BaseSegmentor):
+ """Encoder Decoder segmentors.
+
+ EncoderDecoder typically consists of backbone, decode_head, auxiliary_head.
+ Note that auxiliary_head is only used for deep supervision during training,
+ which could be dumped during inference.
+ """
+
+ def __init__(self,
+ backbone,
+ decode_head,
+ neck=None,
+ auxiliary_head=None,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ init_cfg=None):
+ super(EncoderDecoder, self).__init__(init_cfg)
+ if pretrained is not None:
+ assert backbone.get('pretrained') is None, \
+ 'both backbone and segmentor set pretrained weight'
+ backbone.pretrained = pretrained
+ self.backbone = builder.build_backbone(backbone)
+ if neck is not None:
+ self.neck = builder.build_neck(neck)
+ self._init_decode_head(decode_head)
+ self._init_auxiliary_head(auxiliary_head)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ assert self.with_decode_head
+
+ def _init_decode_head(self, decode_head):
+ """Initialize ``decode_head``"""
+ self.decode_head = builder.build_head(decode_head)
+ self.align_corners = self.decode_head.align_corners
+ self.num_classes = self.decode_head.num_classes
+
+ def _init_auxiliary_head(self, auxiliary_head):
+ """Initialize ``auxiliary_head``"""
+ if auxiliary_head is not None:
+ if isinstance(auxiliary_head, list):
+ self.auxiliary_head = nn.ModuleList()
+ for head_cfg in auxiliary_head:
+ self.auxiliary_head.append(builder.build_head(head_cfg))
+ else:
+ self.auxiliary_head = builder.build_head(auxiliary_head)
+
+ def extract_feat(self, img):
+ """Extract features from images."""
+ x = self.backbone(img)
+ if self.with_neck:
+ x = self.neck(x)
+ return x
+
+ def encode_decode(self, img, img_metas):
+ """Encode images with backbone and decode into a semantic segmentation
+ map of the same size as input."""
+ x = self.extract_feat(img)
+ out = self._decode_head_forward_test(x, img_metas)
+ out = resize(
+ input=out,
+ size=img.shape[2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ return out
+
+ def _decode_head_forward_train(self, x, img_metas, gt_semantic_seg):
+ """Run forward function and calculate loss for decode head in
+ training."""
+ losses = dict()
+ loss_decode = self.decode_head.forward_train(x, img_metas,
+ gt_semantic_seg,
+ self.train_cfg)
+
+ losses.update(add_prefix(loss_decode, 'decode'))
+ return losses
+
+ def _decode_head_forward_test(self, x, img_metas):
+ """Run forward function and calculate loss for decode head in
+ inference."""
+ seg_logits = self.decode_head.forward_test(x, img_metas, self.test_cfg)
+ return seg_logits
+
+ def _auxiliary_head_forward_train(self, x, img_metas, gt_semantic_seg):
+ """Run forward function and calculate loss for auxiliary head in
+ training."""
+ losses = dict()
+ if isinstance(self.auxiliary_head, nn.ModuleList):
+ for idx, aux_head in enumerate(self.auxiliary_head):
+ loss_aux = aux_head.forward_train(x, img_metas,
+ gt_semantic_seg,
+ self.train_cfg)
+ losses.update(add_prefix(loss_aux, f'aux_{idx}'))
+ else:
+ loss_aux = self.auxiliary_head.forward_train(
+ x, img_metas, gt_semantic_seg, self.train_cfg)
+ losses.update(add_prefix(loss_aux, 'aux'))
+
+ return losses
+
+ def forward_dummy(self, img):
+ """Dummy forward function."""
+ seg_logit = self.extract_feat(img)
+ seg_logit = self._decode_head_forward_test(seg_logit, None)
+
+ return seg_logit
+
+ def forward_train(self, img, img_metas, gt_semantic_seg):
+ """Forward function for training.
+
+ Args:
+ img (Tensor): Input images.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ gt_semantic_seg (Tensor): Semantic segmentation masks
+ used if the architecture supports semantic segmentation task.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+
+ x = self.extract_feat(img)
+
+ losses = dict()
+
+ loss_decode = self._decode_head_forward_train(x, img_metas,
+ gt_semantic_seg)
+ losses.update(loss_decode)
+
+ if self.with_auxiliary_head:
+ loss_aux = self._auxiliary_head_forward_train(
+ x, img_metas, gt_semantic_seg)
+ losses.update(loss_aux)
+
+ return losses
+
+ # TODO refactor
+ def slide_inference(self, img, img_meta, rescale):
+ """Inference by sliding-window with overlap.
+
+ If h_crop > h_img or w_crop > w_img, the small patch will be used to
+ decode without padding.
+ """
+
+ h_stride, w_stride = self.test_cfg.stride
+ h_crop, w_crop = self.test_cfg.crop_size
+ batch_size, _, h_img, w_img = img.size()
+ num_classes = self.num_classes
+ h_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1
+ w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1
+ preds = img.new_zeros((batch_size, num_classes, h_img, w_img))
+ count_mat = img.new_zeros((batch_size, 1, h_img, w_img))
+ for h_idx in range(h_grids):
+ for w_idx in range(w_grids):
+ y1 = h_idx * h_stride
+ x1 = w_idx * w_stride
+ y2 = min(y1 + h_crop, h_img)
+ x2 = min(x1 + w_crop, w_img)
+ y1 = max(y2 - h_crop, 0)
+ x1 = max(x2 - w_crop, 0)
+ crop_img = img[:, :, y1:y2, x1:x2]
+ crop_seg_logit = self.encode_decode(crop_img, img_meta)
+ preds += F.pad(crop_seg_logit,
+ (int(x1), int(preds.shape[3] - x2), int(y1),
+ int(preds.shape[2] - y2)))
+
+ count_mat[:, :, y1:y2, x1:x2] += 1
+ assert (count_mat == 0).sum() == 0
+ if torch.onnx.is_in_onnx_export():
+ # cast count_mat to constant while exporting to ONNX
+ count_mat = torch.from_numpy(
+ count_mat.cpu().detach().numpy()).to(device=img.device)
+ preds = preds / count_mat
+ if rescale:
+ preds = resize(
+ preds,
+ size=img_meta[0]['ori_shape'][:2],
+ mode='bilinear',
+ align_corners=self.align_corners,
+ warning=False)
+ return preds
+
+ def whole_inference(self, img, img_meta, rescale):
+ """Inference with full image."""
+
+ seg_logit = self.encode_decode(img, img_meta)
+ if rescale:
+ # support dynamic shape for onnx
+ if torch.onnx.is_in_onnx_export():
+ size = img.shape[2:]
+ else:
+ size = img_meta[0]['ori_shape'][:2]
+ seg_logit = resize(
+ seg_logit,
+ size=size,
+ mode='bilinear',
+ align_corners=self.align_corners,
+ warning=False)
+
+ return seg_logit
+
+ def inference(self, img, img_meta, rescale):
+ """Inference with slide/whole style.
+
+ Args:
+ img (Tensor): The input image of shape (N, 3, H, W).
+ img_meta (dict): Image info dict where each dict has: 'img_shape',
+ 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmseg/datasets/pipelines/formatting.py:Collect`.
+ rescale (bool): Whether rescale back to original shape.
+
+ Returns:
+ Tensor: The output segmentation map.
+ """
+
+ assert self.test_cfg.mode in ['slide', 'whole']
+ ori_shape = img_meta[0]['ori_shape']
+ assert all(_['ori_shape'] == ori_shape for _ in img_meta)
+ if self.test_cfg.mode == 'slide':
+ seg_logit = self.slide_inference(img, img_meta, rescale)
+ else:
+ seg_logit = self.whole_inference(img, img_meta, rescale)
+ output = F.softmax(seg_logit, dim=1)
+ flip = img_meta[0]['flip']
+ if flip:
+ flip_direction = img_meta[0]['flip_direction']
+ assert flip_direction in ['horizontal', 'vertical']
+ if flip_direction == 'horizontal':
+ output = output.flip(dims=(3, ))
+ elif flip_direction == 'vertical':
+ output = output.flip(dims=(2, ))
+
+ return output
+
+ def simple_test(self, img, img_meta, rescale=True):
+ """Simple test with single image."""
+ seg_logit = self.inference(img, img_meta, rescale)
+ seg_pred = seg_logit.argmax(dim=1)
+ if torch.onnx.is_in_onnx_export():
+ # our inference backend only support 4D output
+ seg_pred = seg_pred.unsqueeze(0)
+ return seg_pred
+ seg_pred = seg_pred.cpu().numpy()
+ # unravel batch dim
+ seg_pred = list(seg_pred)
+ return seg_pred
+
+ def aug_test(self, imgs, img_metas, rescale=True):
+ """Test with augmentations.
+
+ Only rescale=True is supported.
+ """
+ # aug_test rescale all imgs back to ori_shape for now
+ assert rescale
+ # to save memory, we get augmented seg logit inplace
+ seg_logit = self.inference(imgs[0], img_metas[0], rescale)
+ for i in range(1, len(imgs)):
+ cur_seg_logit = self.inference(imgs[i], img_metas[i], rescale)
+ seg_logit += cur_seg_logit
+ seg_logit /= len(imgs)
+ seg_pred = seg_logit.argmax(dim=1)
+ seg_pred = seg_pred.cpu().numpy()
+ # unravel batch dim
+ seg_pred = list(seg_pred)
+ return seg_pred
diff --git a/mmseg/models/utils/__init__.py b/mmseg/models/utils/__init__.py
new file mode 100644
index 0000000..2417c51
--- /dev/null
+++ b/mmseg/models/utils/__init__.py
@@ -0,0 +1,14 @@
+from .embed import PatchEmbed
+from .inverted_residual import InvertedResidual, InvertedResidualV3
+from .make_divisible import make_divisible
+from .res_layer import ResLayer
+from .se_layer import SELayer
+from .self_attention_block import SelfAttentionBlock
+from .shape_convert import nchw_to_nlc, nlc_to_nchw
+from .up_conv_block import UpConvBlock
+
+__all__ = [
+ 'ResLayer', 'SelfAttentionBlock', 'make_divisible', 'InvertedResidual',
+ 'UpConvBlock', 'InvertedResidualV3', 'SELayer', 'PatchEmbed',
+ 'nchw_to_nlc', 'nlc_to_nchw'
+]
diff --git a/mmseg/models/utils/embed.py b/mmseg/models/utils/embed.py
new file mode 100644
index 0000000..1515675
--- /dev/null
+++ b/mmseg/models/utils/embed.py
@@ -0,0 +1,330 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Sequence
+
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmcv.runner.base_module import BaseModule
+from mmcv.utils import to_2tuple
+
+
+class AdaptivePadding(nn.Module):
+ """Applies padding to input (if needed) so that input can get fully covered
+ by filter you specified. It support two modes "same" and "corner". The
+ "same" mode is same with "SAME" padding mode in TensorFlow, pad zero around
+ input. The "corner" mode would pad zero to bottom right.
+
+ Args:
+ kernel_size (int | tuple): Size of the kernel:
+ stride (int | tuple): Stride of the filter. Default: 1:
+ dilation (int | tuple): Spacing between kernel elements.
+ Default: 1.
+ padding (str): Support "same" and "corner", "corner" mode
+ would pad zero to bottom right, and "same" mode would
+ pad zero around input. Default: "corner".
+ Example:
+ >>> kernel_size = 16
+ >>> stride = 16
+ >>> dilation = 1
+ >>> input = torch.rand(1, 1, 15, 17)
+ >>> adap_pad = AdaptivePadding(
+ >>> kernel_size=kernel_size,
+ >>> stride=stride,
+ >>> dilation=dilation,
+ >>> padding="corner")
+ >>> out = adap_pad(input)
+ >>> assert (out.shape[2], out.shape[3]) == (16, 32)
+ >>> input = torch.rand(1, 1, 16, 17)
+ >>> out = adap_pad(input)
+ >>> assert (out.shape[2], out.shape[3]) == (16, 32)
+ """
+
+ def __init__(self, kernel_size=1, stride=1, dilation=1, padding='corner'):
+
+ super(AdaptivePadding, self).__init__()
+
+ assert padding in ('same', 'corner')
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ self.padding = padding
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.dilation = dilation
+
+ def get_pad_shape(self, input_shape):
+ input_h, input_w = input_shape
+ kernel_h, kernel_w = self.kernel_size
+ stride_h, stride_w = self.stride
+ output_h = math.ceil(input_h / stride_h)
+ output_w = math.ceil(input_w / stride_w)
+ pad_h = max((output_h - 1) * stride_h +
+ (kernel_h - 1) * self.dilation[0] + 1 - input_h, 0)
+ pad_w = max((output_w - 1) * stride_w +
+ (kernel_w - 1) * self.dilation[1] + 1 - input_w, 0)
+ return pad_h, pad_w
+
+ def forward(self, x):
+ pad_h, pad_w = self.get_pad_shape(x.size()[-2:])
+ if pad_h > 0 or pad_w > 0:
+ if self.padding == 'corner':
+ x = F.pad(x, [0, pad_w, 0, pad_h])
+ elif self.padding == 'same':
+ x = F.pad(x, [
+ pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
+ pad_h - pad_h // 2
+ ])
+ return x
+
+
+class PatchEmbed(BaseModule):
+ """Image to Patch Embedding.
+
+ We use a conv layer to implement PatchEmbed.
+
+ Args:
+ in_channels (int): The num of input channels. Default: 3
+ embed_dims (int): The dimensions of embedding. Default: 768
+ conv_type (str): The config dict for embedding
+ conv layer type selection. Default: "Conv2d".
+ kernel_size (int): The kernel_size of embedding conv. Default: 16.
+ stride (int, optional): The slide stride of embedding conv.
+ Default: None (Would be set as `kernel_size`).
+ padding (int | tuple | string ): The padding length of
+ embedding conv. When it is a string, it means the mode
+ of adaptive padding, support "same" and "corner" now.
+ Default: "corner".
+ dilation (int): The dilation rate of embedding conv. Default: 1.
+ bias (bool): Bias of embed conv. Default: True.
+ norm_cfg (dict, optional): Config dict for normalization layer.
+ Default: None.
+ input_size (int | tuple | None): The size of input, which will be
+ used to calculate the out size. Only work when `dynamic_size`
+ is False. Default: None.
+ init_cfg (`mmcv.ConfigDict`, optional): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=768,
+ conv_type='Conv2d',
+ kernel_size=16,
+ stride=None,
+ padding='corner',
+ dilation=1,
+ bias=True,
+ norm_cfg=None,
+ input_size=None,
+ init_cfg=None):
+ super(PatchEmbed, self).__init__(init_cfg=init_cfg)
+
+ self.embed_dims = embed_dims
+ if stride is None:
+ stride = kernel_size
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ if isinstance(padding, str):
+ self.adap_padding = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ # disable the padding of conv
+ padding = 0
+ else:
+ self.adap_padding = None
+ padding = to_2tuple(padding)
+
+ self.projection = build_conv_layer(
+ dict(type=conv_type),
+ in_channels=in_channels,
+ out_channels=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ if norm_cfg is not None:
+ self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
+ else:
+ self.norm = None
+
+ if input_size:
+ input_size = to_2tuple(input_size)
+ # `init_out_size` would be used outside to
+ # calculate the num_patches
+ # when `use_abs_pos_embed` outside
+ self.init_input_size = input_size
+ if self.adap_padding:
+ pad_h, pad_w = self.adap_padding.get_pad_shape(input_size)
+ input_h, input_w = input_size
+ input_h = input_h + pad_h
+ input_w = input_w + pad_w
+ input_size = (input_h, input_w)
+
+ # https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
+ h_out = (input_size[0] + 2 * padding[0] - dilation[0] *
+ (kernel_size[0] - 1) - 1) // stride[0] + 1
+ w_out = (input_size[1] + 2 * padding[1] - dilation[1] *
+ (kernel_size[1] - 1) - 1) // stride[1] + 1
+ self.init_out_size = (h_out, w_out)
+ else:
+ self.init_input_size = None
+ self.init_out_size = None
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Has shape (B, C, H, W). In most case, C is 3.
+
+ Returns:
+ tuple: Contains merged results and its spatial shape.
+
+ - x (Tensor): Has shape (B, out_h * out_w, embed_dims)
+ - out_size (tuple[int]): Spatial shape of x, arrange as
+ (out_h, out_w).
+ """
+
+ if self.adap_padding:
+ x = self.adap_padding(x)
+
+ x = self.projection(x)
+ out_size = (x.shape[2], x.shape[3])
+ x = x.flatten(2).transpose(1, 2)
+ if self.norm is not None:
+ x = self.norm(x)
+ return x, out_size
+
+
+class PatchMerging(BaseModule):
+ """Merge patch feature map.
+
+ This layer groups feature map by kernel_size, and applies norm and linear
+ layers to the grouped feature map. Our implementation uses `nn.Unfold` to
+ merge patch, which is about 25% faster than original implementation.
+ Instead, we need to modify pretrained models for compatibility.
+
+ Args:
+ in_channels (int): The num of input channels.
+ out_channels (int): The num of output channels.
+ kernel_size (int | tuple, optional): the kernel size in the unfold
+ layer. Defaults to 2.
+ stride (int | tuple, optional): the stride of the sliding blocks in the
+ unfold layer. Default: None. (Would be set as `kernel_size`)
+ padding (int | tuple | string ): The padding length of
+ embedding conv. When it is a string, it means the mode
+ of adaptive padding, support "same" and "corner" now.
+ Default: "corner".
+ dilation (int | tuple, optional): dilation parameter in the unfold
+ layer. Default: 1.
+ bias (bool, optional): Whether to add bias in linear layer or not.
+ Defaults: False.
+ norm_cfg (dict, optional): Config dict for normalization layer.
+ Default: dict(type='LN').
+ init_cfg (dict, optional): The extra config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=2,
+ stride=None,
+ padding='corner',
+ dilation=1,
+ bias=False,
+ norm_cfg=dict(type='LN'),
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ if stride:
+ stride = stride
+ else:
+ stride = kernel_size
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ if isinstance(padding, str):
+ self.adap_padding = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ # disable the padding of unfold
+ padding = 0
+ else:
+ self.adap_padding = None
+
+ padding = to_2tuple(padding)
+ self.sampler = nn.Unfold(
+ kernel_size=kernel_size,
+ dilation=dilation,
+ padding=padding,
+ stride=stride)
+
+ sample_dim = kernel_size[0] * kernel_size[1] * in_channels
+
+ if norm_cfg is not None:
+ self.norm = build_norm_layer(norm_cfg, sample_dim)[1]
+ else:
+ self.norm = None
+
+ self.reduction = nn.Linear(sample_dim, out_channels, bias=bias)
+
+ def forward(self, x, input_size):
+ """
+ Args:
+ x (Tensor): Has shape (B, H*W, C_in).
+ input_size (tuple[int]): The spatial shape of x, arrange as (H, W).
+ Default: None.
+
+ Returns:
+ tuple: Contains merged results and its spatial shape.
+
+ - x (Tensor): Has shape (B, Merged_H * Merged_W, C_out)
+ - out_size (tuple[int]): Spatial shape of x, arrange as
+ (Merged_H, Merged_W).
+ """
+ B, L, C = x.shape
+ assert isinstance(input_size, Sequence), f'Expect ' \
+ f'input_size is ' \
+ f'`Sequence` ' \
+ f'but get {input_size}'
+
+ H, W = input_size
+ assert L == H * W, 'input feature has wrong size'
+
+ x = x.view(B, H, W, C).permute([0, 3, 1, 2]) # B, C, H, W
+ # Use nn.Unfold to merge patch. About 25% faster than original method,
+ # but need to modify pretrained model for compatibility
+
+ if self.adap_padding:
+ x = self.adap_padding(x)
+ H, W = x.shape[-2:]
+
+ x = self.sampler(x)
+ # if kernel_size=2 and stride=2, x should has shape (B, 4*C, H/2*W/2)
+
+ out_h = (H + 2 * self.sampler.padding[0] - self.sampler.dilation[0] *
+ (self.sampler.kernel_size[0] - 1) -
+ 1) // self.sampler.stride[0] + 1
+ out_w = (W + 2 * self.sampler.padding[1] - self.sampler.dilation[1] *
+ (self.sampler.kernel_size[1] - 1) -
+ 1) // self.sampler.stride[1] + 1
+
+ output_size = (out_h, out_w)
+ x = x.transpose(1, 2) # B, H/2*W/2, 4*C
+ x = self.norm(x) if self.norm else x
+ x = self.reduction(x)
+ return x, output_size
diff --git a/mmseg/models/utils/inverted_residual.py b/mmseg/models/utils/inverted_residual.py
new file mode 100644
index 0000000..c9cda76
--- /dev/null
+++ b/mmseg/models/utils/inverted_residual.py
@@ -0,0 +1,213 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import ConvModule
+from torch import nn
+from torch.utils import checkpoint as cp
+
+from .se_layer import SELayer
+
+
+class InvertedResidual(nn.Module):
+ """InvertedResidual block for MobileNetV2.
+
+ Args:
+ in_channels (int): The input channels of the InvertedResidual block.
+ out_channels (int): The output channels of the InvertedResidual block.
+ stride (int): Stride of the middle (first) 3x3 convolution.
+ expand_ratio (int): Adjusts number of channels of the hidden layer
+ in InvertedResidual by this amount.
+ dilation (int): Dilation rate of depthwise conv. Default: 1
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU6').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+
+ Returns:
+ Tensor: The output tensor.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride,
+ expand_ratio,
+ dilation=1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU6'),
+ with_cp=False,
+ **kwargs):
+ super(InvertedResidual, self).__init__()
+ self.stride = stride
+ assert stride in [1, 2], f'stride must in [1, 2]. ' \
+ f'But received {stride}.'
+ self.with_cp = with_cp
+ self.use_res_connect = self.stride == 1 and in_channels == out_channels
+ hidden_dim = int(round(in_channels * expand_ratio))
+
+ layers = []
+ if expand_ratio != 1:
+ layers.append(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=hidden_dim,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ **kwargs))
+ layers.extend([
+ ConvModule(
+ in_channels=hidden_dim,
+ out_channels=hidden_dim,
+ kernel_size=3,
+ stride=stride,
+ padding=dilation,
+ dilation=dilation,
+ groups=hidden_dim,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ **kwargs),
+ ConvModule(
+ in_channels=hidden_dim,
+ out_channels=out_channels,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None,
+ **kwargs)
+ ])
+ self.conv = nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ if self.use_res_connect:
+ return x + self.conv(x)
+ else:
+ return self.conv(x)
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class InvertedResidualV3(nn.Module):
+ """Inverted Residual Block for MobileNetV3.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ mid_channels (int): The input channels of the depthwise convolution.
+ kernel_size (int): The kernel size of the depthwise convolution.
+ Default: 3.
+ stride (int): The stride of the depthwise convolution. Default: 1.
+ se_cfg (dict): Config dict for se layer. Default: None, which means no
+ se layer.
+ with_expand_conv (bool): Use expand conv or not. If set False,
+ mid_channels must be the same with in_channels. Default: True.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+
+ Returns:
+ Tensor: The output tensor.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ mid_channels,
+ kernel_size=3,
+ stride=1,
+ se_cfg=None,
+ with_expand_conv=True,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ with_cp=False):
+ super(InvertedResidualV3, self).__init__()
+ self.with_res_shortcut = (stride == 1 and in_channels == out_channels)
+ assert stride in [1, 2]
+ self.with_cp = with_cp
+ self.with_se = se_cfg is not None
+ self.with_expand_conv = with_expand_conv
+
+ if self.with_se:
+ assert isinstance(se_cfg, dict)
+ if not self.with_expand_conv:
+ assert mid_channels == in_channels
+
+ if self.with_expand_conv:
+ self.expand_conv = ConvModule(
+ in_channels=in_channels,
+ out_channels=mid_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.depthwise_conv = ConvModule(
+ in_channels=mid_channels,
+ out_channels=mid_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=kernel_size // 2,
+ groups=mid_channels,
+ conv_cfg=dict(
+ type='Conv2dAdaptivePadding') if stride == 2 else conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ if self.with_se:
+ self.se = SELayer(**se_cfg)
+
+ self.linear_conv = ConvModule(
+ in_channels=mid_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ out = x
+
+ if self.with_expand_conv:
+ out = self.expand_conv(out)
+
+ out = self.depthwise_conv(out)
+
+ if self.with_se:
+ out = self.se(out)
+
+ out = self.linear_conv(out)
+
+ if self.with_res_shortcut:
+ return x + out
+ else:
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
diff --git a/mmseg/models/utils/make_divisible.py b/mmseg/models/utils/make_divisible.py
new file mode 100644
index 0000000..ed42c2e
--- /dev/null
+++ b/mmseg/models/utils/make_divisible.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def make_divisible(value, divisor, min_value=None, min_ratio=0.9):
+ """Make divisible function.
+
+ This function rounds the channel number to the nearest value that can be
+ divisible by the divisor. It is taken from the original tf repo. It ensures
+ that all layers have a channel number that is divisible by divisor. It can
+ be seen here: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py # noqa
+
+ Args:
+ value (int): The original channel number.
+ divisor (int): The divisor to fully divide the channel number.
+ min_value (int): The minimum value of the output channel.
+ Default: None, means that the minimum value equal to the divisor.
+ min_ratio (float): The minimum ratio of the rounded channel number to
+ the original channel number. Default: 0.9.
+
+ Returns:
+ int: The modified output channel number.
+ """
+
+ if min_value is None:
+ min_value = divisor
+ new_value = max(min_value, int(value + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than (1-min_ratio).
+ if new_value < min_ratio * value:
+ new_value += divisor
+ return new_value
diff --git a/mmseg/models/utils/res_layer.py b/mmseg/models/utils/res_layer.py
new file mode 100644
index 0000000..190a0c5
--- /dev/null
+++ b/mmseg/models/utils/res_layer.py
@@ -0,0 +1,96 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmcv.runner import Sequential
+from torch import nn as nn
+
+
+class ResLayer(Sequential):
+ """ResLayer to build ResNet style backbone.
+
+ Args:
+ block (nn.Module): block used to build ResLayer.
+ inplanes (int): inplanes of block.
+ planes (int): planes of block.
+ num_blocks (int): number of blocks.
+ stride (int): stride of the first block. Default: 1
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ multi_grid (int | None): Multi grid dilation rates of last
+ stage. Default: None
+ contract_dilation (bool): Whether contract first dilation of each layer
+ Default: False
+ """
+
+ def __init__(self,
+ block,
+ inplanes,
+ planes,
+ num_blocks,
+ stride=1,
+ dilation=1,
+ avg_down=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ multi_grid=None,
+ contract_dilation=False,
+ **kwargs):
+ self.block = block
+
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = []
+ conv_stride = stride
+ if avg_down:
+ conv_stride = 1
+ downsample.append(
+ nn.AvgPool2d(
+ kernel_size=stride,
+ stride=stride,
+ ceil_mode=True,
+ count_include_pad=False))
+ downsample.extend([
+ build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=conv_stride,
+ bias=False),
+ build_norm_layer(norm_cfg, planes * block.expansion)[1]
+ ])
+ downsample = nn.Sequential(*downsample)
+
+ layers = []
+ if multi_grid is None:
+ if dilation > 1 and contract_dilation:
+ first_dilation = dilation // 2
+ else:
+ first_dilation = dilation
+ else:
+ first_dilation = multi_grid[0]
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=stride,
+ dilation=first_dilation,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ inplanes = planes * block.expansion
+ for i in range(1, num_blocks):
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=1,
+ dilation=dilation if multi_grid is None else multi_grid[i],
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ super(ResLayer, self).__init__(*layers)
diff --git a/mmseg/models/utils/se_layer.py b/mmseg/models/utils/se_layer.py
new file mode 100644
index 0000000..16f52aa
--- /dev/null
+++ b/mmseg/models/utils/se_layer.py
@@ -0,0 +1,58 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from .make_divisible import make_divisible
+
+
+class SELayer(nn.Module):
+ """Squeeze-and-Excitation Module.
+
+ Args:
+ channels (int): The input (and output) channels of the SE layer.
+ ratio (int): Squeeze ratio in SELayer, the intermediate channel will be
+ ``int(channels/ratio)``. Default: 16.
+ conv_cfg (None or dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ act_cfg (dict or Sequence[dict]): Config dict for activation layer.
+ If act_cfg is a dict, two activation layers will be configured
+ by this dict. If act_cfg is a sequence of dicts, the first
+ activation layer will be configured by the first dict and the
+ second activation layer will be configured by the second dict.
+ Default: (dict(type='ReLU'), dict(type='HSigmoid', bias=3.0,
+ divisor=6.0)).
+ """
+
+ def __init__(self,
+ channels,
+ ratio=16,
+ conv_cfg=None,
+ act_cfg=(dict(type='ReLU'),
+ dict(type='HSigmoid', bias=3.0, divisor=6.0))):
+ super(SELayer, self).__init__()
+ if isinstance(act_cfg, dict):
+ act_cfg = (act_cfg, act_cfg)
+ assert len(act_cfg) == 2
+ assert mmcv.is_tuple_of(act_cfg, dict)
+ self.global_avgpool = nn.AdaptiveAvgPool2d(1)
+ self.conv1 = ConvModule(
+ in_channels=channels,
+ out_channels=make_divisible(channels // ratio, 8),
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[0])
+ self.conv2 = ConvModule(
+ in_channels=make_divisible(channels // ratio, 8),
+ out_channels=channels,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[1])
+
+ def forward(self, x):
+ out = self.global_avgpool(x)
+ out = self.conv1(out)
+ out = self.conv2(out)
+ return x * out
diff --git a/mmseg/models/utils/self_attention_block.py b/mmseg/models/utils/self_attention_block.py
new file mode 100644
index 0000000..c945fa7
--- /dev/null
+++ b/mmseg/models/utils/self_attention_block.py
@@ -0,0 +1,160 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import ConvModule, constant_init
+from torch import nn as nn
+from torch.nn import functional as F
+
+
+class SelfAttentionBlock(nn.Module):
+ """General self-attention block/non-local block.
+
+ Please refer to https://arxiv.org/abs/1706.03762 for details about key,
+ query and value.
+
+ Args:
+ key_in_channels (int): Input channels of key feature.
+ query_in_channels (int): Input channels of query feature.
+ channels (int): Output channels of key/query transform.
+ out_channels (int): Output channels.
+ share_key_query (bool): Whether share projection weight between key
+ and query projection.
+ query_downsample (nn.Module): Query downsample module.
+ key_downsample (nn.Module): Key downsample module.
+ key_query_num_convs (int): Number of convs for key/query projection.
+ value_num_convs (int): Number of convs for value projection.
+ matmul_norm (bool): Whether normalize attention map with sqrt of
+ channels
+ with_out (bool): Whether use out projection.
+ conv_cfg (dict|None): Config of conv layers.
+ norm_cfg (dict|None): Config of norm layers.
+ act_cfg (dict|None): Config of activation layers.
+ """
+
+ def __init__(self, key_in_channels, query_in_channels, channels,
+ out_channels, share_key_query, query_downsample,
+ key_downsample, key_query_num_convs, value_out_num_convs,
+ key_query_norm, value_out_norm, matmul_norm, with_out,
+ conv_cfg, norm_cfg, act_cfg):
+ super(SelfAttentionBlock, self).__init__()
+ if share_key_query:
+ assert key_in_channels == query_in_channels
+ self.key_in_channels = key_in_channels
+ self.query_in_channels = query_in_channels
+ self.out_channels = out_channels
+ self.channels = channels
+ self.share_key_query = share_key_query
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.key_project = self.build_project(
+ key_in_channels,
+ channels,
+ num_convs=key_query_num_convs,
+ use_conv_module=key_query_norm,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ if share_key_query:
+ self.query_project = self.key_project
+ else:
+ self.query_project = self.build_project(
+ query_in_channels,
+ channels,
+ num_convs=key_query_num_convs,
+ use_conv_module=key_query_norm,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.value_project = self.build_project(
+ key_in_channels,
+ channels if with_out else out_channels,
+ num_convs=value_out_num_convs,
+ use_conv_module=value_out_norm,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ if with_out:
+ self.out_project = self.build_project(
+ channels,
+ out_channels,
+ num_convs=value_out_num_convs,
+ use_conv_module=value_out_norm,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ else:
+ self.out_project = None
+
+ self.query_downsample = query_downsample
+ self.key_downsample = key_downsample
+ self.matmul_norm = matmul_norm
+
+ self.init_weights()
+
+ def init_weights(self):
+ """Initialize weight of later layer."""
+ if self.out_project is not None:
+ if not isinstance(self.out_project, ConvModule):
+ constant_init(self.out_project, 0)
+
+ def build_project(self, in_channels, channels, num_convs, use_conv_module,
+ conv_cfg, norm_cfg, act_cfg):
+ """Build projection layer for key/query/value/out."""
+ if use_conv_module:
+ convs = [
+ ConvModule(
+ in_channels,
+ channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ ]
+ for _ in range(num_convs - 1):
+ convs.append(
+ ConvModule(
+ channels,
+ channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ else:
+ convs = [nn.Conv2d(in_channels, channels, 1)]
+ for _ in range(num_convs - 1):
+ convs.append(nn.Conv2d(channels, channels, 1))
+ if len(convs) > 1:
+ convs = nn.Sequential(*convs)
+ else:
+ convs = convs[0]
+ return convs
+
+ def forward(self, query_feats, key_feats):
+ """Forward function."""
+ batch_size = query_feats.size(0)
+ query = self.query_project(query_feats)
+ if self.query_downsample is not None:
+ query = self.query_downsample(query)
+ query = query.reshape(*query.shape[:2], -1)
+ query = query.permute(0, 2, 1).contiguous()
+
+ key = self.key_project(key_feats)
+ value = self.value_project(key_feats)
+ if self.key_downsample is not None:
+ key = self.key_downsample(key)
+ value = self.key_downsample(value)
+ key = key.reshape(*key.shape[:2], -1)
+ value = value.reshape(*value.shape[:2], -1)
+ value = value.permute(0, 2, 1).contiguous()
+
+ sim_map = torch.matmul(query, key)
+ if self.matmul_norm:
+ sim_map = (self.channels**-.5) * sim_map
+ sim_map = F.softmax(sim_map, dim=-1)
+
+ context = torch.matmul(sim_map, value)
+ context = context.permute(0, 2, 1).contiguous()
+ context = context.reshape(batch_size, -1, *query_feats.shape[2:])
+ if self.out_project is not None:
+ context = self.out_project(context)
+ return context
diff --git a/mmseg/models/utils/shape_convert.py b/mmseg/models/utils/shape_convert.py
new file mode 100644
index 0000000..0677348
--- /dev/null
+++ b/mmseg/models/utils/shape_convert.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def nlc_to_nchw(x, hw_shape):
+ """Convert [N, L, C] shape tensor to [N, C, H, W] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, L, C] before conversion.
+ hw_shape (Sequence[int]): The height and width of output feature map.
+
+ Returns:
+ Tensor: The output tensor of shape [N, C, H, W] after conversion.
+ """
+ H, W = hw_shape
+ assert len(x.shape) == 3
+ B, L, C = x.shape
+ assert L == H * W, 'The seq_len doesn\'t match H, W'
+ return x.transpose(1, 2).reshape(B, C, H, W)
+
+
+def nchw_to_nlc(x):
+ """Flatten [N, C, H, W] shape tensor to [N, L, C] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, C, H, W] before conversion.
+
+ Returns:
+ Tensor: The output tensor of shape [N, L, C] after conversion.
+ """
+ assert len(x.shape) == 4
+ return x.flatten(2).transpose(1, 2).contiguous()
diff --git a/mmseg/models/utils/up_conv_block.py b/mmseg/models/utils/up_conv_block.py
new file mode 100644
index 0000000..d8396d9
--- /dev/null
+++ b/mmseg/models/utils/up_conv_block.py
@@ -0,0 +1,102 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, build_upsample_layer
+
+
+class UpConvBlock(nn.Module):
+ """Upsample convolution block in decoder for UNet.
+
+ This upsample convolution block consists of one upsample module
+ followed by one convolution block. The upsample module expands the
+ high-level low-resolution feature map and the convolution block fuses
+ the upsampled high-level low-resolution feature map and the low-level
+ high-resolution feature map from encoder.
+
+ Args:
+ conv_block (nn.Sequential): Sequential of convolutional layers.
+ in_channels (int): Number of input channels of the high-level
+ skip_channels (int): Number of input channels of the low-level
+ high-resolution feature map from encoder.
+ out_channels (int): Number of output channels.
+ num_convs (int): Number of convolutional layers in the conv_block.
+ Default: 2.
+ stride (int): Stride of convolutional layer in conv_block. Default: 1.
+ dilation (int): Dilation rate of convolutional layer in conv_block.
+ Default: 1.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ upsample_cfg (dict): The upsample config of the upsample module in
+ decoder. Default: dict(type='InterpConv'). If the size of
+ high-level feature map is the same as that of skip feature map
+ (low-level feature map from encoder), it does not need upsample the
+ high-level feature map and the upsample_cfg is None.
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ """
+
+ def __init__(self,
+ conv_block,
+ in_channels,
+ skip_channels,
+ out_channels,
+ num_convs=2,
+ stride=1,
+ dilation=1,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ dcn=None,
+ plugins=None):
+ super(UpConvBlock, self).__init__()
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.conv_block = conv_block(
+ in_channels=2 * skip_channels,
+ out_channels=out_channels,
+ num_convs=num_convs,
+ stride=stride,
+ dilation=dilation,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dcn=None,
+ plugins=None)
+ if upsample_cfg is not None:
+ self.upsample = build_upsample_layer(
+ cfg=upsample_cfg,
+ in_channels=in_channels,
+ out_channels=skip_channels,
+ with_cp=with_cp,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ else:
+ self.upsample = ConvModule(
+ in_channels,
+ skip_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, skip, x):
+ """Forward function."""
+
+ x = self.upsample(x)
+ out = torch.cat([skip, x], dim=1)
+ out = self.conv_block(out)
+
+ return out
diff --git a/mmseg/ops/__init__.py b/mmseg/ops/__init__.py
new file mode 100644
index 0000000..bc075cd
--- /dev/null
+++ b/mmseg/ops/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .encoding import Encoding
+from .wrappers import Upsample, resize
+
+__all__ = ['Upsample', 'resize', 'Encoding']
diff --git a/mmseg/ops/encoding.py b/mmseg/ops/encoding.py
new file mode 100644
index 0000000..f397cc5
--- /dev/null
+++ b/mmseg/ops/encoding.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+
+class Encoding(nn.Module):
+ """Encoding Layer: a learnable residual encoder.
+
+ Input is of shape (batch_size, channels, height, width).
+ Output is of shape (batch_size, num_codes, channels).
+
+ Args:
+ channels: dimension of the features or feature channels
+ num_codes: number of code words
+ """
+
+ def __init__(self, channels, num_codes):
+ super(Encoding, self).__init__()
+ # init codewords and smoothing factor
+ self.channels, self.num_codes = channels, num_codes
+ std = 1. / ((num_codes * channels)**0.5)
+ # [num_codes, channels]
+ self.codewords = nn.Parameter(
+ torch.empty(num_codes, channels,
+ dtype=torch.float).uniform_(-std, std),
+ requires_grad=True)
+ # [num_codes]
+ self.scale = nn.Parameter(
+ torch.empty(num_codes, dtype=torch.float).uniform_(-1, 0),
+ requires_grad=True)
+
+ @staticmethod
+ def scaled_l2(x, codewords, scale):
+ num_codes, channels = codewords.size()
+ batch_size = x.size(0)
+ reshaped_scale = scale.view((1, 1, num_codes))
+ expanded_x = x.unsqueeze(2).expand(
+ (batch_size, x.size(1), num_codes, channels))
+ reshaped_codewords = codewords.view((1, 1, num_codes, channels))
+
+ scaled_l2_norm = reshaped_scale * (
+ expanded_x - reshaped_codewords).pow(2).sum(dim=3)
+ return scaled_l2_norm
+
+ @staticmethod
+ def aggregate(assignment_weights, x, codewords):
+ num_codes, channels = codewords.size()
+ reshaped_codewords = codewords.view((1, 1, num_codes, channels))
+ batch_size = x.size(0)
+
+ expanded_x = x.unsqueeze(2).expand(
+ (batch_size, x.size(1), num_codes, channels))
+ encoded_feat = (assignment_weights.unsqueeze(3) *
+ (expanded_x - reshaped_codewords)).sum(dim=1)
+ return encoded_feat
+
+ def forward(self, x):
+ assert x.dim() == 4 and x.size(1) == self.channels
+ # [batch_size, channels, height, width]
+ batch_size = x.size(0)
+ # [batch_size, height x width, channels]
+ x = x.view(batch_size, self.channels, -1).transpose(1, 2).contiguous()
+ # assignment_weights: [batch_size, channels, num_codes]
+ assignment_weights = F.softmax(
+ self.scaled_l2(x, self.codewords, self.scale), dim=2)
+ # aggregate
+ encoded_feat = self.aggregate(assignment_weights, x, self.codewords)
+ return encoded_feat
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(Nx{self.channels}xHxW =>Nx{self.num_codes}' \
+ f'x{self.channels})'
+ return repr_str
diff --git a/mmseg/ops/wrappers.py b/mmseg/ops/wrappers.py
new file mode 100644
index 0000000..ce67e4b
--- /dev/null
+++ b/mmseg/ops/wrappers.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+def resize(input,
+ size=None,
+ scale_factor=None,
+ mode='nearest',
+ align_corners=None,
+ warning=True):
+ if warning:
+ if size is not None and align_corners:
+ input_h, input_w = tuple(int(x) for x in input.shape[2:])
+ output_h, output_w = tuple(int(x) for x in size)
+ if output_h > input_h or output_w > output_h:
+ if ((output_h > 1 and output_w > 1 and input_h > 1
+ and input_w > 1) and (output_h - 1) % (input_h - 1)
+ and (output_w - 1) % (input_w - 1)):
+ warnings.warn(
+ f'When align_corners={align_corners}, '
+ 'the output would more aligned if '
+ f'input size {(input_h, input_w)} is `x+1` and '
+ f'out size {(output_h, output_w)} is `nx+1`')
+ return F.interpolate(input, size, scale_factor, mode, align_corners)
+
+
+class Upsample(nn.Module):
+
+ def __init__(self,
+ size=None,
+ scale_factor=None,
+ mode='nearest',
+ align_corners=None):
+ super(Upsample, self).__init__()
+ self.size = size
+ if isinstance(scale_factor, tuple):
+ self.scale_factor = tuple(float(factor) for factor in scale_factor)
+ else:
+ self.scale_factor = float(scale_factor) if scale_factor else None
+ self.mode = mode
+ self.align_corners = align_corners
+
+ def forward(self, x):
+ if not self.size:
+ size = [int(t * self.scale_factor) for t in x.shape[-2:]]
+ else:
+ size = self.size
+ return resize(x, size, None, self.mode, self.align_corners)
diff --git a/mmseg/utils/__init__.py b/mmseg/utils/__init__.py
new file mode 100644
index 0000000..ed002c7
--- /dev/null
+++ b/mmseg/utils/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .collect_env import collect_env
+from .logger import get_root_logger
+from .misc import find_latest_checkpoint
+from .set_env import setup_multi_processes
+
+__all__ = [
+ 'get_root_logger', 'collect_env', 'find_latest_checkpoint',
+ 'setup_multi_processes'
+]
diff --git a/mmseg/utils/collect_env.py b/mmseg/utils/collect_env.py
new file mode 100644
index 0000000..3379ecb
--- /dev/null
+++ b/mmseg/utils/collect_env.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.utils import collect_env as collect_base_env
+from mmcv.utils import get_git_hash
+
+import mmseg
+
+
+def collect_env():
+ """Collect the information of the running environments."""
+ env_info = collect_base_env()
+ env_info['MMSegmentation'] = f'{mmseg.__version__}+{get_git_hash()[:7]}'
+
+ return env_info
+
+
+if __name__ == '__main__':
+ for name, val in collect_env().items():
+ print('{}: {}'.format(name, val))
diff --git a/mmseg/utils/logger.py b/mmseg/utils/logger.py
new file mode 100644
index 0000000..0cb3c78
--- /dev/null
+++ b/mmseg/utils/logger.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+
+from mmcv.utils import get_logger
+
+
+def get_root_logger(log_file=None, log_level=logging.INFO):
+ """Get the root logger.
+
+ The logger will be initialized if it has not been initialized. By default a
+ StreamHandler will be added. If `log_file` is specified, a FileHandler will
+ also be added. The name of the root logger is the top-level package name,
+ e.g., "mmseg".
+
+ Args:
+ log_file (str | None): The log filename. If specified, a FileHandler
+ will be added to the root logger.
+ log_level (int): The root logger level. Note that only the process of
+ rank 0 is affected, while other processes will set the level to
+ "Error" and be silent most of the time.
+
+ Returns:
+ logging.Logger: The root logger.
+ """
+
+ logger = get_logger(name='mmseg', log_file=log_file, log_level=log_level)
+
+ return logger
diff --git a/mmseg/utils/misc.py b/mmseg/utils/misc.py
new file mode 100644
index 0000000..bd1b6b1
--- /dev/null
+++ b/mmseg/utils/misc.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import glob
+import os.path as osp
+import warnings
+
+
+def find_latest_checkpoint(path, suffix='pth'):
+ """This function is for finding the latest checkpoint.
+
+ It will be used when automatically resume, modified from
+ https://github.com/open-mmlab/mmdetection/blob/dev-v2.20.0/mmdet/utils/misc.py
+
+ Args:
+ path (str): The path to find checkpoints.
+ suffix (str): File extension for the checkpoint. Defaults to pth.
+
+ Returns:
+ latest_path(str | None): File path of the latest checkpoint.
+ """
+ if not osp.exists(path):
+ warnings.warn("The path of the checkpoints doesn't exist.")
+ return None
+ if osp.exists(osp.join(path, f'latest.{suffix}')):
+ return osp.join(path, f'latest.{suffix}')
+
+ checkpoints = glob.glob(osp.join(path, f'*.{suffix}'))
+ if len(checkpoints) == 0:
+ warnings.warn('The are no checkpoints in the path')
+ return None
+ latest = -1
+ latest_path = ''
+ for checkpoint in checkpoints:
+ if len(checkpoint) < len(latest_path):
+ continue
+ # `count` is iteration number, as checkpoints are saved as
+ # 'iter_xx.pth' or 'epoch_xx.pth' and xx is iteration number.
+ count = int(osp.basename(checkpoint).split('_')[-1].split('.')[0])
+ if count > latest:
+ latest = count
+ latest_path = checkpoint
+ return latest_path
diff --git a/mmseg/utils/set_env.py b/mmseg/utils/set_env.py
new file mode 100644
index 0000000..b2d3aaf
--- /dev/null
+++ b/mmseg/utils/set_env.py
@@ -0,0 +1,55 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import platform
+
+import cv2
+import torch.multiprocessing as mp
+
+from ..utils import get_root_logger
+
+
+def setup_multi_processes(cfg):
+ """Setup multi-processing environment variables."""
+ logger = get_root_logger()
+
+ # set multi-process start method
+ if platform.system() != 'Windows':
+ mp_start_method = cfg.get('mp_start_method', None)
+ current_method = mp.get_start_method(allow_none=True)
+ if mp_start_method in ('fork', 'spawn', 'forkserver'):
+ logger.info(
+ f'Multi-processing start method `{mp_start_method}` is '
+ f'different from the previous setting `{current_method}`.'
+ f'It will be force set to `{mp_start_method}`.')
+ mp.set_start_method(mp_start_method, force=True)
+ else:
+ logger.info(
+ f'Multi-processing start method is `{mp_start_method}`')
+
+ # disable opencv multithreading to avoid system being overloaded
+ opencv_num_threads = cfg.get('opencv_num_threads', None)
+ if isinstance(opencv_num_threads, int):
+ logger.info(f'OpenCV num_threads is `{opencv_num_threads}`')
+ cv2.setNumThreads(opencv_num_threads)
+ else:
+ logger.info(f'OpenCV num_threads is `{cv2.getNumThreads}')
+
+ if cfg.data.workers_per_gpu > 1:
+ # setup OMP threads
+ # This code is referred from https://github.com/pytorch/pytorch/blob/master/torch/distributed/run.py # noqa
+ omp_num_threads = cfg.get('omp_num_threads', None)
+ if 'OMP_NUM_THREADS' not in os.environ:
+ if isinstance(omp_num_threads, int):
+ logger.info(f'OMP num threads is {omp_num_threads}')
+ os.environ['OMP_NUM_THREADS'] = str(omp_num_threads)
+ else:
+ logger.info(f'OMP num threads is {os.environ["OMP_NUM_THREADS"] }')
+
+ # setup MKL threads
+ if 'MKL_NUM_THREADS' not in os.environ:
+ mkl_num_threads = cfg.get('mkl_num_threads', None)
+ if isinstance(mkl_num_threads, int):
+ logger.info(f'MKL num threads is {mkl_num_threads}')
+ os.environ['MKL_NUM_THREADS'] = str(mkl_num_threads)
+ else:
+ logger.info(f'MKL num threads is {os.environ["MKL_NUM_THREADS"]}')
diff --git a/mmseg/version.py b/mmseg/version.py
new file mode 100644
index 0000000..43cc13a
--- /dev/null
+++ b/mmseg/version.py
@@ -0,0 +1,18 @@
+# Copyright (c) Open-MMLab. All rights reserved.
+
+__version__ = '0.21.1'
+
+
+def parse_version_info(version_str):
+ version_info = []
+ for x in version_str.split('.'):
+ if x.isdigit():
+ version_info.append(int(x))
+ elif x.find('rc') != -1:
+ patch_version = x.split('rc')
+ version_info.append(int(patch_version[0]))
+ version_info.append(f'rc{patch_version[1]}')
+ return tuple(version_info)
+
+
+version_info = parse_version_info(__version__)
diff --git a/model-index.yml b/model-index.yml
new file mode 100644
index 0000000..1a491d9
--- /dev/null
+++ b/model-index.yml
@@ -0,0 +1,41 @@
+Import:
+- configs/ann/ann.yml
+- configs/apcnet/apcnet.yml
+- configs/bisenetv1/bisenetv1.yml
+- configs/bisenetv2/bisenetv2.yml
+- configs/ccnet/ccnet.yml
+- configs/cgnet/cgnet.yml
+- configs/danet/danet.yml
+- configs/deeplabv3/deeplabv3.yml
+- configs/deeplabv3plus/deeplabv3plus.yml
+- configs/dmnet/dmnet.yml
+- configs/dnlnet/dnlnet.yml
+- configs/dpt/dpt.yml
+- configs/emanet/emanet.yml
+- configs/encnet/encnet.yml
+- configs/erfnet/erfnet.yml
+- configs/fastfcn/fastfcn.yml
+- configs/fastscnn/fastscnn.yml
+- configs/fcn/fcn.yml
+- configs/gcnet/gcnet.yml
+- configs/hrnet/hrnet.yml
+- configs/icnet/icnet.yml
+- configs/isanet/isanet.yml
+- configs/mobilenet_v2/mobilenet_v2.yml
+- configs/mobilenet_v3/mobilenet_v3.yml
+- configs/nonlocal_net/nonlocal_net.yml
+- configs/ocrnet/ocrnet.yml
+- configs/point_rend/point_rend.yml
+- configs/psanet/psanet.yml
+- configs/pspnet/pspnet.yml
+- configs/resnest/resnest.yml
+- configs/segformer/segformer.yml
+- configs/segmenter/segmenter.yml
+- configs/sem_fpn/sem_fpn.yml
+- configs/setr/setr.yml
+- configs/stdc/stdc.yml
+- configs/swin/swin.yml
+- configs/twins/twins.yml
+- configs/unet/unet.yml
+- configs/upernet/upernet.yml
+- configs/vit/vit.yml
diff --git a/pytest.ini b/pytest.ini
new file mode 100644
index 0000000..9796e87
--- /dev/null
+++ b/pytest.ini
@@ -0,0 +1,7 @@
+[pytest]
+addopts = --xdoctest --xdoctest-style=auto
+norecursedirs = .git ignore build __pycache__ data docker docs .eggs
+
+filterwarnings= default
+ ignore:.*No cfgstr given in Cacher constructor or call.*:Warning
+ ignore:.*Define the __nice__ method for.*:Warning
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000..6da5ade
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,3 @@
+-r requirements/optional.txt
+-r requirements/runtime.txt
+-r requirements/tests.txt
diff --git a/requirements/docs.txt b/requirements/docs.txt
new file mode 100644
index 0000000..2017084
--- /dev/null
+++ b/requirements/docs.txt
@@ -0,0 +1,6 @@
+docutils==0.16.0
+myst-parser
+-e git+https://github.com/gaotongxiao/pytorch_sphinx_theme.git#egg=pytorch_sphinx_theme
+sphinx==4.0.2
+sphinx_copybutton
+sphinx_markdown_tables
diff --git a/requirements/mminstall.txt b/requirements/mminstall.txt
new file mode 100644
index 0000000..b1c42eb
--- /dev/null
+++ b/requirements/mminstall.txt
@@ -0,0 +1 @@
+mmcv-full>=1.3.1,<=1.4.0
diff --git a/requirements/onnx.txt b/requirements/onnx.txt
new file mode 100644
index 0000000..7944fcb
--- /dev/null
+++ b/requirements/onnx.txt
@@ -0,0 +1,3 @@
+onnx>=1.6.0
+onnxruntime
+onnxoptimizer
diff --git a/requirements/optional.txt b/requirements/optional.txt
new file mode 100644
index 0000000..47fa593
--- /dev/null
+++ b/requirements/optional.txt
@@ -0,0 +1 @@
+cityscapesscripts
diff --git a/requirements/readthedocs.txt b/requirements/readthedocs.txt
new file mode 100644
index 0000000..22a894b
--- /dev/null
+++ b/requirements/readthedocs.txt
@@ -0,0 +1,4 @@
+mmcv
+prettytable
+torch
+torchvision
diff --git a/requirements/runtime.txt b/requirements/runtime.txt
new file mode 100644
index 0000000..2712f50
--- /dev/null
+++ b/requirements/runtime.txt
@@ -0,0 +1,4 @@
+matplotlib
+numpy
+packaging
+prettytable
diff --git a/requirements/tests.txt b/requirements/tests.txt
new file mode 100644
index 0000000..991fd71
--- /dev/null
+++ b/requirements/tests.txt
@@ -0,0 +1,7 @@
+codecov
+flake8
+interrogate
+isort==4.3.21
+pytest
+xdoctest>=0.10.0
+yapf
diff --git a/requirements_kneron.txt b/requirements_kneron.txt
new file mode 100644
index 0000000..d188261
--- /dev/null
+++ b/requirements_kneron.txt
@@ -0,0 +1,2 @@
+-r requirements.txt
+-r requirements/onnx.txt
diff --git a/resources/3dogs.jpg b/resources/3dogs.jpg
new file mode 100644
index 0000000..02ef6fc
Binary files /dev/null and b/resources/3dogs.jpg differ
diff --git a/resources/3dogs_mask.png b/resources/3dogs_mask.png
new file mode 100644
index 0000000..339c2f5
Binary files /dev/null and b/resources/3dogs_mask.png differ
diff --git a/resources/mmseg-logo.png b/resources/mmseg-logo.png
new file mode 100644
index 0000000..009083a
Binary files /dev/null and b/resources/mmseg-logo.png differ
diff --git a/resources/seg_demo.gif b/resources/seg_demo.gif
new file mode 100644
index 0000000..2f0760f
Binary files /dev/null and b/resources/seg_demo.gif differ
diff --git a/setup.cfg b/setup.cfg
new file mode 100644
index 0000000..4839120
--- /dev/null
+++ b/setup.cfg
@@ -0,0 +1,19 @@
+[yapf]
+based_on_style = pep8
+blank_line_before_nested_class_or_def = true
+split_before_expression_after_opening_paren = true
+
+[isort]
+line_length = 79
+multi_line_output = 0
+extra_standard_library = setuptools
+known_first_party = mmseg
+known_third_party = PIL,cityscapesscripts,cv2,detail,matplotlib,mmcv,numpy,onnxruntime,packaging,prettytable,pytest,pytorch_sphinx_theme,requests,scipy,seaborn,torch,ts
+no_lines_before = STDLIB,LOCALFOLDER
+default_section = THIRDPARTY
+
+[codespell]
+skip = *.po,*.ts,*.ipynb
+count =
+quiet-level = 3
+ignore-words-list = formating,sur,hist
diff --git a/setup.py b/setup.py
new file mode 100755
index 0000000..dc758e2
--- /dev/null
+++ b/setup.py
@@ -0,0 +1,203 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import platform
+import shutil
+import sys
+import warnings
+from setuptools import find_packages, setup
+
+
+def readme():
+ with open('README.md', encoding='utf-8') as f:
+ content = f.read()
+ return content
+
+
+version_file = 'mmseg/version.py'
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+def parse_requirements(fname='requirements.txt', with_version=True):
+ """Parse the package dependencies listed in a requirements file but strips
+ specific versioning information.
+
+ Args:
+ fname (str): path to requirements file
+ with_version (bool, default=False): if True include version specs
+
+ Returns:
+ List[str]: list of requirements items
+
+ CommandLine:
+ python -c "import setup; print(setup.parse_requirements())"
+ """
+ import re
+ import sys
+ from os.path import exists
+ require_fpath = fname
+
+ def parse_line(line):
+ """Parse information from a line in a requirements text file."""
+ if line.startswith('-r '):
+ # Allow specifying requirements in other files
+ target = line.split(' ')[1]
+ for info in parse_require_file(target):
+ yield info
+ else:
+ info = {'line': line}
+ if line.startswith('-e '):
+ info['package'] = line.split('#egg=')[1]
+ else:
+ # Remove versioning from the package
+ pat = '(' + '|'.join(['>=', '==', '>']) + ')'
+ parts = re.split(pat, line, maxsplit=1)
+ parts = [p.strip() for p in parts]
+
+ info['package'] = parts[0]
+ if len(parts) > 1:
+ op, rest = parts[1:]
+ if ';' in rest:
+ # Handle platform specific dependencies
+ # http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
+ version, platform_deps = map(str.strip,
+ rest.split(';'))
+ info['platform_deps'] = platform_deps
+ else:
+ version = rest # NOQA
+ info['version'] = (op, version)
+ yield info
+
+ def parse_require_file(fpath):
+ with open(fpath, 'r') as f:
+ for line in f.readlines():
+ line = line.strip()
+ if line and not line.startswith('#'):
+ for info in parse_line(line):
+ yield info
+
+ def gen_packages_items():
+ if exists(require_fpath):
+ for info in parse_require_file(require_fpath):
+ parts = [info['package']]
+ if with_version and 'version' in info:
+ parts.extend(info['version'])
+ if not sys.version.startswith('3.4'):
+ # apparently package_deps are broken in 3.4
+ platform_deps = info.get('platform_deps')
+ if platform_deps is not None:
+ parts.append(';' + platform_deps)
+ item = ''.join(parts)
+ yield item
+
+ packages = list(gen_packages_items())
+ return packages
+
+
+def add_mim_extension():
+ """Add extra files that are required to support MIM into the package.
+
+ These files will be added by creating a symlink to the originals if the
+ package is installed in `editable` mode (e.g. pip install -e .), or by
+ copying from the originals otherwise.
+ """
+
+ # parse installment mode
+ if 'develop' in sys.argv:
+ # installed by `pip install -e .`
+ if platform.system() == 'Windows':
+ # set `copy` mode here since symlink fails on Windows.
+ mode = 'copy'
+ else:
+ mode = 'symlink'
+ elif 'sdist' in sys.argv or 'bdist_wheel' in sys.argv or \
+ platform.system() == 'Windows':
+ # installed by `pip install .`
+ # or create source distribution by `python setup.py sdist`
+ # set `copy` mode here since symlink fails with WinError on Windows.
+ mode = 'copy'
+ else:
+ return
+
+ filenames = ['tools', 'configs', 'model-index.yml']
+ repo_path = osp.dirname(__file__)
+ mim_path = osp.join(repo_path, 'mmseg', '.mim')
+ os.makedirs(mim_path, exist_ok=True)
+
+ for filename in filenames:
+ if osp.exists(filename):
+ src_path = osp.join(repo_path, filename)
+ tar_path = osp.join(mim_path, filename)
+
+ if osp.isfile(tar_path) or osp.islink(tar_path):
+ os.remove(tar_path)
+ elif osp.isdir(tar_path):
+ shutil.rmtree(tar_path)
+
+ if mode == 'symlink':
+ src_relpath = osp.relpath(src_path, osp.dirname(tar_path))
+ try:
+ os.symlink(src_relpath, tar_path)
+ except OSError:
+ # Creating a symbolic link on windows may raise an
+ # `OSError: [WinError 1314]` due to privilege. If
+ # the error happens, the src file will be copied
+ mode = 'copy'
+ warnings.warn(
+ f'Failed to create a symbolic link for {src_relpath}, '
+ f'and it will be copied to {tar_path}')
+ else:
+ continue
+
+ if mode == 'copy':
+ if osp.isfile(src_path):
+ shutil.copyfile(src_path, tar_path)
+ elif osp.isdir(src_path):
+ shutil.copytree(src_path, tar_path)
+ else:
+ warnings.warn(f'Cannot copy file {src_path}.')
+ else:
+ raise ValueError(f'Invalid mode {mode}')
+
+
+if __name__ == '__main__':
+ add_mim_extension()
+ setup(
+ name='mmsegmentation',
+ version=get_version(),
+ description='Open MMLab Semantic Segmentation Toolbox '
+ 'and Benchmark (Kneron Edition)',
+ long_description=readme(),
+ long_description_content_type='text/markdown',
+ author='MMSegmentation Contributors and Kneron',
+ author_email='',
+ keywords='computer vision, semantic segmentation',
+ url='http://github.com/kneron/MMSegmentationKN',
+ packages=find_packages(exclude=('configs', 'tools', 'demo')),
+ include_package_data=True,
+ classifiers=[
+ 'Development Status :: 4 - Beta',
+ 'License :: OSI Approved :: Apache Software License',
+ 'Operating System :: OS Independent',
+ 'Programming Language :: Python :: 3.6',
+ 'Programming Language :: Python :: 3.7',
+ 'Programming Language :: Python :: 3.8',
+ 'Programming Language :: Python :: 3.9',
+ ],
+ license='Apache License 2.0',
+ install_requires=parse_requirements('requirements/runtime.txt'),
+ extras_require={
+ 'all': parse_requirements('requirements_kneron.txt'),
+ 'tests': parse_requirements('requirements/tests.txt'),
+ 'build': parse_requirements('requirements/build.txt'),
+ 'optional': parse_requirements('requirements/optional.txt'),
+ 'onnx': parse_requirements('requirements/onnx.txt'),
+ },
+ ext_modules=[],
+ zip_safe=False)
diff --git a/tests/__init__.py b/tests/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/data/color.jpg b/tests/data/color.jpg
new file mode 100644
index 0000000..05d62b8
Binary files /dev/null and b/tests/data/color.jpg differ
diff --git a/tests/data/gray.jpg b/tests/data/gray.jpg
new file mode 100644
index 0000000..94edd73
Binary files /dev/null and b/tests/data/gray.jpg differ
diff --git a/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_instanceIds.png b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_instanceIds.png
new file mode 100644
index 0000000..dfe7aea
Binary files /dev/null and b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_instanceIds.png differ
diff --git a/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelIds.png b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelIds.png
new file mode 100644
index 0000000..faab6f5
Binary files /dev/null and b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelIds.png differ
diff --git a/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelTrainIds.png b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelTrainIds.png
new file mode 100644
index 0000000..659229b
Binary files /dev/null and b/tests/data/pseudo_cityscapes_dataset/gtFine/frankfurt_000000_000294_gtFine_labelTrainIds.png differ
diff --git a/tests/data/pseudo_cityscapes_dataset/leftImg8bit/frankfurt_000000_000294_leftImg8bit.png b/tests/data/pseudo_cityscapes_dataset/leftImg8bit/frankfurt_000000_000294_leftImg8bit.png
new file mode 100644
index 0000000..2c83ee4
Binary files /dev/null and b/tests/data/pseudo_cityscapes_dataset/leftImg8bit/frankfurt_000000_000294_leftImg8bit.png differ
diff --git a/tests/data/pseudo_dataset/gts/00000_gt.png b/tests/data/pseudo_dataset/gts/00000_gt.png
new file mode 100644
index 0000000..48fc125
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00000_gt.png differ
diff --git a/tests/data/pseudo_dataset/gts/00001_gt.png b/tests/data/pseudo_dataset/gts/00001_gt.png
new file mode 100644
index 0000000..ccb49b0
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00001_gt.png differ
diff --git a/tests/data/pseudo_dataset/gts/00002_gt.png b/tests/data/pseudo_dataset/gts/00002_gt.png
new file mode 100644
index 0000000..db7250c
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00002_gt.png differ
diff --git a/tests/data/pseudo_dataset/gts/00003_gt.png b/tests/data/pseudo_dataset/gts/00003_gt.png
new file mode 100644
index 0000000..f96a1be
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00003_gt.png differ
diff --git a/tests/data/pseudo_dataset/gts/00004_gt.png b/tests/data/pseudo_dataset/gts/00004_gt.png
new file mode 100644
index 0000000..35b1cad
Binary files /dev/null and b/tests/data/pseudo_dataset/gts/00004_gt.png differ
diff --git a/tests/data/pseudo_dataset/imgs/00000_img.jpg b/tests/data/pseudo_dataset/imgs/00000_img.jpg
new file mode 100644
index 0000000..33ab8e2
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00000_img.jpg differ
diff --git a/tests/data/pseudo_dataset/imgs/00001_img.jpg b/tests/data/pseudo_dataset/imgs/00001_img.jpg
new file mode 100644
index 0000000..49c2229
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00001_img.jpg differ
diff --git a/tests/data/pseudo_dataset/imgs/00002_img.jpg b/tests/data/pseudo_dataset/imgs/00002_img.jpg
new file mode 100644
index 0000000..6baeb5f
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00002_img.jpg differ
diff --git a/tests/data/pseudo_dataset/imgs/00003_img.jpg b/tests/data/pseudo_dataset/imgs/00003_img.jpg
new file mode 100644
index 0000000..6e889d7
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00003_img.jpg differ
diff --git a/tests/data/pseudo_dataset/imgs/00004_img.jpg b/tests/data/pseudo_dataset/imgs/00004_img.jpg
new file mode 100644
index 0000000..474c915
Binary files /dev/null and b/tests/data/pseudo_dataset/imgs/00004_img.jpg differ
diff --git a/tests/data/pseudo_dataset/splits/train.txt b/tests/data/pseudo_dataset/splits/train.txt
new file mode 100644
index 0000000..9e25ab0
--- /dev/null
+++ b/tests/data/pseudo_dataset/splits/train.txt
@@ -0,0 +1,4 @@
+00000
+00001
+00002
+00003
diff --git a/tests/data/pseudo_dataset/splits/val.txt b/tests/data/pseudo_dataset/splits/val.txt
new file mode 100644
index 0000000..59dd536
--- /dev/null
+++ b/tests/data/pseudo_dataset/splits/val.txt
@@ -0,0 +1 @@
+00004
diff --git a/tests/data/pseudo_loveda_dataset/ann_dir/0.png b/tests/data/pseudo_loveda_dataset/ann_dir/0.png
new file mode 100644
index 0000000..7823fd6
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/ann_dir/0.png differ
diff --git a/tests/data/pseudo_loveda_dataset/ann_dir/1.png b/tests/data/pseudo_loveda_dataset/ann_dir/1.png
new file mode 100644
index 0000000..bc50ac1
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/ann_dir/1.png differ
diff --git a/tests/data/pseudo_loveda_dataset/ann_dir/2.png b/tests/data/pseudo_loveda_dataset/ann_dir/2.png
new file mode 100644
index 0000000..c182838
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/ann_dir/2.png differ
diff --git a/tests/data/pseudo_loveda_dataset/img_dir/0.png b/tests/data/pseudo_loveda_dataset/img_dir/0.png
new file mode 100644
index 0000000..03a0652
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/img_dir/0.png differ
diff --git a/tests/data/pseudo_loveda_dataset/img_dir/1.png b/tests/data/pseudo_loveda_dataset/img_dir/1.png
new file mode 100644
index 0000000..2fe837f
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/img_dir/1.png differ
diff --git a/tests/data/pseudo_loveda_dataset/img_dir/2.png b/tests/data/pseudo_loveda_dataset/img_dir/2.png
new file mode 100644
index 0000000..b824499
Binary files /dev/null and b/tests/data/pseudo_loveda_dataset/img_dir/2.png differ
diff --git a/tests/data/pseudo_potsdam_dataset/ann_dir/2_10_0_0_512_512.png b/tests/data/pseudo_potsdam_dataset/ann_dir/2_10_0_0_512_512.png
new file mode 100644
index 0000000..6f22278
Binary files /dev/null and b/tests/data/pseudo_potsdam_dataset/ann_dir/2_10_0_0_512_512.png differ
diff --git a/tests/data/pseudo_potsdam_dataset/img_dir/2_10_0_0_512_512.png b/tests/data/pseudo_potsdam_dataset/img_dir/2_10_0_0_512_512.png
new file mode 100644
index 0000000..7821a18
Binary files /dev/null and b/tests/data/pseudo_potsdam_dataset/img_dir/2_10_0_0_512_512.png differ
diff --git a/tests/data/pseudo_vaihingen_dataset/ann_dir/area1_0_0_512_512.png b/tests/data/pseudo_vaihingen_dataset/ann_dir/area1_0_0_512_512.png
new file mode 100644
index 0000000..f58e187
Binary files /dev/null and b/tests/data/pseudo_vaihingen_dataset/ann_dir/area1_0_0_512_512.png differ
diff --git a/tests/data/pseudo_vaihingen_dataset/img_dir/area1_0_0_512_512.png b/tests/data/pseudo_vaihingen_dataset/img_dir/area1_0_0_512_512.png
new file mode 100644
index 0000000..648be0b
Binary files /dev/null and b/tests/data/pseudo_vaihingen_dataset/img_dir/area1_0_0_512_512.png differ
diff --git a/tests/data/seg.png b/tests/data/seg.png
new file mode 100644
index 0000000..f23a499
Binary files /dev/null and b/tests/data/seg.png differ
diff --git a/tests/test_apis/test_single_gpu.py b/tests/test_apis/test_single_gpu.py
new file mode 100644
index 0000000..b741896
--- /dev/null
+++ b/tests/test_apis/test_single_gpu.py
@@ -0,0 +1,72 @@
+import shutil
+from unittest.mock import MagicMock
+
+import numpy as np
+import pytest
+import torch
+import torch.nn as nn
+from torch.utils.data import DataLoader, Dataset, dataloader
+
+from mmseg.apis import single_gpu_test
+
+
+class ExampleDataset(Dataset):
+
+ def __getitem__(self, idx):
+ results = dict(img=torch.tensor([1]), img_metas=dict())
+ return results
+
+ def __len__(self):
+ return 1
+
+
+class ExampleModel(nn.Module):
+
+ def __init__(self):
+ super(ExampleModel, self).__init__()
+ self.test_cfg = None
+ self.conv = nn.Conv2d(3, 3, 3)
+
+ def forward(self, img, img_metas, return_loss=False, **kwargs):
+ return img
+
+
+def test_single_gpu():
+ test_dataset = ExampleDataset()
+ data_loader = DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_workers=0,
+ shuffle=False,
+ )
+ model = ExampleModel()
+
+ # Test efficient test compatibility (will be deprecated)
+ results = single_gpu_test(model, data_loader, efficient_test=True)
+ assert len(results) == 1
+ pred = np.load(results[0])
+ assert isinstance(pred, np.ndarray)
+ assert pred.shape == (1, )
+ assert pred[0] == 1
+
+ shutil.rmtree('.efficient_test')
+
+ # Test pre_eval
+ test_dataset.pre_eval = MagicMock(return_value=['success'])
+ results = single_gpu_test(model, data_loader, pre_eval=True)
+ assert results == ['success']
+
+ # Test format_only
+ test_dataset.format_results = MagicMock(return_value=['success'])
+ results = single_gpu_test(model, data_loader, format_only=True)
+ assert results == ['success']
+
+ # efficient_test, pre_eval and format_only are mutually exclusive
+ with pytest.raises(AssertionError):
+ single_gpu_test(
+ model,
+ dataloader,
+ efficient_test=True,
+ format_only=True,
+ pre_eval=True)
diff --git a/tests/test_config.py b/tests/test_config.py
new file mode 100644
index 0000000..2482144
--- /dev/null
+++ b/tests/test_config.py
@@ -0,0 +1,162 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import glob
+import os
+from os.path import dirname, exists, isdir, join, relpath
+
+from mmcv import Config
+from torch import nn
+
+from mmseg.models import build_segmentor
+
+
+def _get_config_directory():
+ """Find the predefined segmentor config directory."""
+ try:
+ # Assume we are running in the source mmsegmentation repo
+ repo_dpath = dirname(dirname(__file__))
+ except NameError:
+ # For IPython development when this __file__ is not defined
+ import mmseg
+ repo_dpath = dirname(dirname(mmseg.__file__))
+ config_dpath = join(repo_dpath, 'configs')
+ if not exists(config_dpath):
+ raise Exception('Cannot find config path')
+ return config_dpath
+
+
+def test_config_build_segmentor():
+ """Test that all segmentation models defined in the configs can be
+ initialized."""
+ config_dpath = _get_config_directory()
+ print('Found config_dpath = {!r}'.format(config_dpath))
+
+ config_fpaths = []
+ # one config each sub folder
+ for sub_folder in os.listdir(config_dpath):
+ if isdir(sub_folder):
+ config_fpaths.append(
+ list(glob.glob(join(config_dpath, sub_folder, '*.py')))[0])
+ config_fpaths = [p for p in config_fpaths if p.find('_base_') == -1]
+ config_names = [relpath(p, config_dpath) for p in config_fpaths]
+
+ print('Using {} config files'.format(len(config_names)))
+
+ for config_fname in config_names:
+ config_fpath = join(config_dpath, config_fname)
+ config_mod = Config.fromfile(config_fpath)
+
+ config_mod.model
+ print('Building segmentor, config_fpath = {!r}'.format(config_fpath))
+
+ # Remove pretrained keys to allow for testing in an offline environment
+ if 'pretrained' in config_mod.model:
+ config_mod.model['pretrained'] = None
+
+ print('building {}'.format(config_fname))
+ segmentor = build_segmentor(config_mod.model)
+ assert segmentor is not None
+
+ head_config = config_mod.model['decode_head']
+ _check_decode_head(head_config, segmentor.decode_head)
+
+
+def test_config_data_pipeline():
+ """Test whether the data pipeline is valid and can process corner cases.
+
+ CommandLine:
+ xdoctest -m tests/test_config.py test_config_build_data_pipeline
+ """
+ import numpy as np
+ from mmcv import Config
+
+ from mmseg.datasets.pipelines import Compose
+
+ config_dpath = _get_config_directory()
+ print('Found config_dpath = {!r}'.format(config_dpath))
+
+ import glob
+ config_fpaths = list(glob.glob(join(config_dpath, '**', '*.py')))
+ config_fpaths = [p for p in config_fpaths if p.find('_base_') == -1]
+ config_names = [relpath(p, config_dpath) for p in config_fpaths]
+
+ print('Using {} config files'.format(len(config_names)))
+
+ for config_fname in config_names:
+ config_fpath = join(config_dpath, config_fname)
+ print(
+ 'Building data pipeline, config_fpath = {!r}'.format(config_fpath))
+ config_mod = Config.fromfile(config_fpath)
+
+ # remove loading pipeline
+ load_img_pipeline = config_mod.train_pipeline.pop(0)
+ to_float32 = load_img_pipeline.get('to_float32', False)
+ config_mod.train_pipeline.pop(0)
+ config_mod.test_pipeline.pop(0)
+
+ train_pipeline = Compose(config_mod.train_pipeline)
+ test_pipeline = Compose(config_mod.test_pipeline)
+
+ img = np.random.randint(0, 255, size=(1024, 2048, 3), dtype=np.uint8)
+ if to_float32:
+ img = img.astype(np.float32)
+ seg = np.random.randint(0, 255, size=(1024, 2048, 1), dtype=np.uint8)
+
+ results = dict(
+ filename='test_img.png',
+ ori_filename='test_img.png',
+ img=img,
+ img_shape=img.shape,
+ ori_shape=img.shape,
+ gt_semantic_seg=seg)
+ results['seg_fields'] = ['gt_semantic_seg']
+
+ print('Test training data pipeline: \n{!r}'.format(train_pipeline))
+ output_results = train_pipeline(results)
+ assert output_results is not None
+
+ results = dict(
+ filename='test_img.png',
+ ori_filename='test_img.png',
+ img=img,
+ img_shape=img.shape,
+ ori_shape=img.shape,
+ )
+ print('Test testing data pipeline: \n{!r}'.format(test_pipeline))
+ output_results = test_pipeline(results)
+ assert output_results is not None
+
+
+def _check_decode_head(decode_head_cfg, decode_head):
+ if isinstance(decode_head_cfg, list):
+ assert isinstance(decode_head, nn.ModuleList)
+ assert len(decode_head_cfg) == len(decode_head)
+ num_heads = len(decode_head)
+ for i in range(num_heads):
+ _check_decode_head(decode_head_cfg[i], decode_head[i])
+ return
+ # check consistency between head_config and roi_head
+ assert decode_head_cfg['type'] == decode_head.__class__.__name__
+
+ assert decode_head_cfg['type'] == decode_head.__class__.__name__
+
+ in_channels = decode_head_cfg.in_channels
+ input_transform = decode_head.input_transform
+ assert input_transform in ['resize_concat', 'multiple_select', None]
+ if input_transform is not None:
+ assert isinstance(in_channels, (list, tuple))
+ assert isinstance(decode_head.in_index, (list, tuple))
+ assert len(in_channels) == len(decode_head.in_index)
+ elif input_transform == 'resize_concat':
+ assert sum(in_channels) == decode_head.in_channels
+ else:
+ assert isinstance(in_channels, int)
+ assert in_channels == decode_head.in_channels
+ assert isinstance(decode_head.in_index, int)
+
+ if decode_head_cfg['type'] == 'PointHead':
+ assert decode_head_cfg.channels+decode_head_cfg.num_classes == \
+ decode_head.fc_seg.in_channels
+ assert decode_head.fc_seg.out_channels == decode_head_cfg.num_classes
+ else:
+ assert decode_head_cfg.channels == decode_head.conv_seg.in_channels
+ assert decode_head.conv_seg.out_channels == decode_head_cfg.num_classes
diff --git a/tests/test_data/test_dataset.py b/tests/test_data/test_dataset.py
new file mode 100644
index 0000000..3d4c40a
--- /dev/null
+++ b/tests/test_data/test_dataset.py
@@ -0,0 +1,828 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import shutil
+import tempfile
+from typing import Generator
+from unittest.mock import MagicMock, patch
+
+import numpy as np
+import pytest
+import torch
+from PIL import Image
+
+from mmseg.core.evaluation import get_classes, get_palette
+from mmseg.datasets import (DATASETS, ADE20KDataset, CityscapesDataset,
+ COCOStuffDataset, ConcatDataset, CustomDataset,
+ ISPRSDataset, LoveDADataset, MultiImageMixDataset,
+ PascalVOCDataset, PotsdamDataset, RepeatDataset,
+ build_dataset)
+
+
+def test_classes():
+ assert list(CityscapesDataset.CLASSES) == get_classes('cityscapes')
+ assert list(PascalVOCDataset.CLASSES) == get_classes('voc') == get_classes(
+ 'pascal_voc')
+ assert list(
+ ADE20KDataset.CLASSES) == get_classes('ade') == get_classes('ade20k')
+ assert list(LoveDADataset.CLASSES) == get_classes('loveda')
+ assert list(PotsdamDataset.CLASSES) == get_classes('potsdam')
+ assert list(ISPRSDataset.CLASSES) == get_classes('vaihingen')
+ assert list(COCOStuffDataset.CLASSES) == get_classes('cocostuff')
+
+ with pytest.raises(ValueError):
+ get_classes('unsupported')
+
+
+def test_classes_file_path():
+ tmp_file = tempfile.NamedTemporaryFile()
+ classes_path = f'{tmp_file.name}.txt'
+ train_pipeline = [dict(type='LoadImageFromFile')]
+ kwargs = dict(pipeline=train_pipeline, img_dir='./', classes=classes_path)
+
+ # classes.txt with full categories
+ categories = get_classes('cityscapes')
+ with open(classes_path, 'w') as f:
+ f.write('\n'.join(categories))
+ assert list(CityscapesDataset(**kwargs).CLASSES) == categories
+
+ # classes.txt with sub categories
+ categories = ['road', 'sidewalk', 'building']
+ with open(classes_path, 'w') as f:
+ f.write('\n'.join(categories))
+ assert list(CityscapesDataset(**kwargs).CLASSES) == categories
+
+ # classes.txt with unknown categories
+ categories = ['road', 'sidewalk', 'unknown']
+ with open(classes_path, 'w') as f:
+ f.write('\n'.join(categories))
+
+ with pytest.raises(ValueError):
+ CityscapesDataset(**kwargs)
+
+ tmp_file.close()
+ os.remove(classes_path)
+ assert not osp.exists(classes_path)
+
+
+def test_palette():
+ assert CityscapesDataset.PALETTE == get_palette('cityscapes')
+ assert PascalVOCDataset.PALETTE == get_palette('voc') == get_palette(
+ 'pascal_voc')
+ assert ADE20KDataset.PALETTE == get_palette('ade') == get_palette('ade20k')
+ assert LoveDADataset.PALETTE == get_palette('loveda')
+ assert PotsdamDataset.PALETTE == get_palette('potsdam')
+ assert COCOStuffDataset.PALETTE == get_palette('cocostuff')
+
+ with pytest.raises(ValueError):
+ get_palette('unsupported')
+
+
+@patch('mmseg.datasets.CustomDataset.load_annotations', MagicMock)
+@patch('mmseg.datasets.CustomDataset.__getitem__',
+ MagicMock(side_effect=lambda idx: idx))
+def test_dataset_wrapper():
+ # CustomDataset.load_annotations = MagicMock()
+ # CustomDataset.__getitem__ = MagicMock(side_effect=lambda idx: idx)
+ dataset_a = CustomDataset(img_dir=MagicMock(), pipeline=[])
+ len_a = 10
+ dataset_a.img_infos = MagicMock()
+ dataset_a.img_infos.__len__.return_value = len_a
+ dataset_b = CustomDataset(img_dir=MagicMock(), pipeline=[])
+ len_b = 20
+ dataset_b.img_infos = MagicMock()
+ dataset_b.img_infos.__len__.return_value = len_b
+
+ concat_dataset = ConcatDataset([dataset_a, dataset_b])
+ assert concat_dataset[5] == 5
+ assert concat_dataset[25] == 15
+ assert len(concat_dataset) == len(dataset_a) + len(dataset_b)
+
+ repeat_dataset = RepeatDataset(dataset_a, 10)
+ assert repeat_dataset[5] == 5
+ assert repeat_dataset[15] == 5
+ assert repeat_dataset[27] == 7
+ assert len(repeat_dataset) == 10 * len(dataset_a)
+
+ img_scale = (60, 60)
+ pipeline = [
+ dict(type='RandomMosaic', prob=1, img_scale=img_scale),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Resize', img_scale=img_scale, keep_ratio=False),
+ ]
+
+ CustomDataset.load_annotations = MagicMock()
+ results = []
+ for _ in range(2):
+ height = np.random.randint(10, 30)
+ weight = np.random.randint(10, 30)
+ img = np.ones((height, weight, 3))
+ gt_semantic_seg = np.random.randint(5, size=(height, weight))
+ results.append(dict(gt_semantic_seg=gt_semantic_seg, img=img))
+
+ classes = ['0', '1', '2', '3', '4']
+ palette = [(0, 0, 0), (1, 1, 1), (2, 2, 2), (3, 3, 3), (4, 4, 4)]
+ CustomDataset.__getitem__ = MagicMock(side_effect=lambda idx: results[idx])
+ dataset_a = CustomDataset(
+ img_dir=MagicMock(),
+ pipeline=[],
+ test_mode=True,
+ classes=classes,
+ palette=palette)
+ len_a = 2
+ dataset_a.img_infos = MagicMock()
+ dataset_a.img_infos.__len__.return_value = len_a
+
+ multi_image_mix_dataset = MultiImageMixDataset(dataset_a, pipeline)
+ assert len(multi_image_mix_dataset) == len(dataset_a)
+
+ for idx in range(len_a):
+ results_ = multi_image_mix_dataset[idx]
+
+ # test skip_type_keys
+ multi_image_mix_dataset = MultiImageMixDataset(
+ dataset_a, pipeline, skip_type_keys=('RandomFlip'))
+ for idx in range(len_a):
+ results_ = multi_image_mix_dataset[idx]
+ assert results_['img'].shape == (img_scale[0], img_scale[1], 3)
+
+ skip_type_keys = ('RandomFlip', 'Resize')
+ multi_image_mix_dataset.update_skip_type_keys(skip_type_keys)
+ for idx in range(len_a):
+ results_ = multi_image_mix_dataset[idx]
+ assert results_['img'].shape[:2] != img_scale
+
+ # test pipeline
+ with pytest.raises(TypeError):
+ pipeline = [['Resize']]
+ multi_image_mix_dataset = MultiImageMixDataset(dataset_a, pipeline)
+
+
+def test_custom_dataset():
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True)
+ crop_size = (512, 1024)
+ train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(128, 256), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+ ]
+ test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(128, 256),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+ ]
+
+ # with img_dir and ann_dir
+ train_dataset = CustomDataset(
+ train_pipeline,
+ data_root=osp.join(osp.dirname(__file__), '../data/pseudo_dataset'),
+ img_dir='imgs/',
+ ann_dir='gts/',
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png')
+ assert len(train_dataset) == 5
+
+ # with img_dir, ann_dir, split
+ train_dataset = CustomDataset(
+ train_pipeline,
+ data_root=osp.join(osp.dirname(__file__), '../data/pseudo_dataset'),
+ img_dir='imgs/',
+ ann_dir='gts/',
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png',
+ split='splits/train.txt')
+ assert len(train_dataset) == 4
+
+ # no data_root
+ train_dataset = CustomDataset(
+ train_pipeline,
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'),
+ ann_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/gts'),
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png')
+ assert len(train_dataset) == 5
+
+ # with data_root but img_dir/ann_dir are abs path
+ train_dataset = CustomDataset(
+ train_pipeline,
+ data_root=osp.join(osp.dirname(__file__), '../data/pseudo_dataset'),
+ img_dir=osp.abspath(
+ osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs')),
+ ann_dir=osp.abspath(
+ osp.join(osp.dirname(__file__), '../data/pseudo_dataset/gts')),
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png')
+ assert len(train_dataset) == 5
+
+ # test_mode=True
+ test_dataset = CustomDataset(
+ test_pipeline,
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'),
+ img_suffix='img.jpg',
+ test_mode=True,
+ classes=('pseudo_class', ))
+ assert len(test_dataset) == 5
+
+ # training data get
+ train_data = train_dataset[0]
+ assert isinstance(train_data, dict)
+
+ # test data get
+ test_data = test_dataset[0]
+ assert isinstance(test_data, dict)
+
+ # get gt seg map
+ gt_seg_maps = train_dataset.get_gt_seg_maps(efficient_test=True)
+ assert isinstance(gt_seg_maps, Generator)
+ gt_seg_maps = list(gt_seg_maps)
+ assert len(gt_seg_maps) == 5
+
+ # format_results not implemented
+ with pytest.raises(NotImplementedError):
+ test_dataset.format_results([], '')
+
+ pseudo_results = []
+ for gt_seg_map in gt_seg_maps:
+ h, w = gt_seg_map.shape
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+
+ # test past evaluation without CLASSES
+ with pytest.raises(TypeError):
+ eval_results = train_dataset.evaluate(pseudo_results, metric=['mIoU'])
+
+ with pytest.raises(TypeError):
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mDice')
+
+ with pytest.raises(TypeError):
+ eval_results = train_dataset.evaluate(
+ pseudo_results, metric=['mDice', 'mIoU'])
+
+ # test past evaluation with CLASSES
+ train_dataset.CLASSES = tuple(['a'] * 7)
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mIoU')
+ assert isinstance(eval_results, dict)
+ assert 'mIoU' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mDice')
+ assert isinstance(eval_results, dict)
+ assert 'mDice' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mFscore')
+ assert isinstance(eval_results, dict)
+ assert 'mRecall' in eval_results
+ assert 'mPrecision' in eval_results
+ assert 'mFscore' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(
+ pseudo_results, metric=['mIoU', 'mDice', 'mFscore'])
+ assert isinstance(eval_results, dict)
+ assert 'mIoU' in eval_results
+ assert 'mDice' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+ assert 'mFscore' in eval_results
+ assert 'mPrecision' in eval_results
+ assert 'mRecall' in eval_results
+
+ assert not np.isnan(eval_results['mIoU'])
+ assert not np.isnan(eval_results['mDice'])
+ assert not np.isnan(eval_results['mAcc'])
+ assert not np.isnan(eval_results['aAcc'])
+ assert not np.isnan(eval_results['mFscore'])
+ assert not np.isnan(eval_results['mPrecision'])
+ assert not np.isnan(eval_results['mRecall'])
+
+ # test evaluation with pre-eval and the dataset.CLASSES is necessary
+ train_dataset.CLASSES = tuple(['a'] * 7)
+ pseudo_results = []
+ for idx in range(len(train_dataset)):
+ h, w = gt_seg_maps[idx].shape
+ pseudo_result = np.random.randint(low=0, high=7, size=(h, w))
+ pseudo_results.extend(train_dataset.pre_eval(pseudo_result, idx))
+ eval_results = train_dataset.evaluate(pseudo_results, metric=['mIoU'])
+ assert isinstance(eval_results, dict)
+ assert 'mIoU' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mDice')
+ assert isinstance(eval_results, dict)
+ assert 'mDice' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(pseudo_results, metric='mFscore')
+ assert isinstance(eval_results, dict)
+ assert 'mRecall' in eval_results
+ assert 'mPrecision' in eval_results
+ assert 'mFscore' in eval_results
+ assert 'aAcc' in eval_results
+
+ eval_results = train_dataset.evaluate(
+ pseudo_results, metric=['mIoU', 'mDice', 'mFscore'])
+ assert isinstance(eval_results, dict)
+ assert 'mIoU' in eval_results
+ assert 'mDice' in eval_results
+ assert 'mAcc' in eval_results
+ assert 'aAcc' in eval_results
+ assert 'mFscore' in eval_results
+ assert 'mPrecision' in eval_results
+ assert 'mRecall' in eval_results
+
+ assert not np.isnan(eval_results['mIoU'])
+ assert not np.isnan(eval_results['mDice'])
+ assert not np.isnan(eval_results['mAcc'])
+ assert not np.isnan(eval_results['aAcc'])
+ assert not np.isnan(eval_results['mFscore'])
+ assert not np.isnan(eval_results['mPrecision'])
+ assert not np.isnan(eval_results['mRecall'])
+
+
+@pytest.mark.parametrize('separate_eval', [True, False])
+def test_eval_concat_custom_dataset(separate_eval):
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True)
+ test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(128, 256),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+ ]
+ data_root = osp.join(osp.dirname(__file__), '../data/pseudo_dataset')
+ img_dir = 'imgs/'
+ ann_dir = 'gts/'
+
+ cfg1 = dict(
+ type='CustomDataset',
+ pipeline=test_pipeline,
+ data_root=data_root,
+ img_dir=img_dir,
+ ann_dir=ann_dir,
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png',
+ classes=tuple(['a'] * 7))
+ dataset1 = build_dataset(cfg1)
+ assert len(dataset1) == 5
+ # get gt seg map
+ gt_seg_maps = dataset1.get_gt_seg_maps(efficient_test=True)
+ assert isinstance(gt_seg_maps, Generator)
+ gt_seg_maps = list(gt_seg_maps)
+ assert len(gt_seg_maps) == 5
+
+ # test past evaluation
+ pseudo_results = []
+ for gt_seg_map in gt_seg_maps:
+ h, w = gt_seg_map.shape
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+ eval_results1 = dataset1.evaluate(
+ pseudo_results, metric=['mIoU', 'mDice', 'mFscore'])
+
+ # We use same dir twice for simplicity
+ # with ann_dir
+ cfg2 = dict(
+ type='CustomDataset',
+ pipeline=test_pipeline,
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ ann_dir=[ann_dir, ann_dir],
+ img_suffix='img.jpg',
+ seg_map_suffix='gt.png',
+ classes=tuple(['a'] * 7),
+ separate_eval=separate_eval)
+ dataset2 = build_dataset(cfg2)
+ assert isinstance(dataset2, ConcatDataset)
+ assert len(dataset2) == 10
+
+ eval_results2 = dataset2.evaluate(
+ pseudo_results * 2, metric=['mIoU', 'mDice', 'mFscore'])
+
+ if separate_eval:
+ assert eval_results1['mIoU'] == eval_results2[
+ '0_mIoU'] == eval_results2['1_mIoU']
+ assert eval_results1['mDice'] == eval_results2[
+ '0_mDice'] == eval_results2['1_mDice']
+ assert eval_results1['mAcc'] == eval_results2[
+ '0_mAcc'] == eval_results2['1_mAcc']
+ assert eval_results1['aAcc'] == eval_results2[
+ '0_aAcc'] == eval_results2['1_aAcc']
+ assert eval_results1['mFscore'] == eval_results2[
+ '0_mFscore'] == eval_results2['1_mFscore']
+ assert eval_results1['mPrecision'] == eval_results2[
+ '0_mPrecision'] == eval_results2['1_mPrecision']
+ assert eval_results1['mRecall'] == eval_results2[
+ '0_mRecall'] == eval_results2['1_mRecall']
+ else:
+ assert eval_results1['mIoU'] == eval_results2['mIoU']
+ assert eval_results1['mDice'] == eval_results2['mDice']
+ assert eval_results1['mAcc'] == eval_results2['mAcc']
+ assert eval_results1['aAcc'] == eval_results2['aAcc']
+ assert eval_results1['mFscore'] == eval_results2['mFscore']
+ assert eval_results1['mPrecision'] == eval_results2['mPrecision']
+ assert eval_results1['mRecall'] == eval_results2['mRecall']
+
+ # test get dataset_idx and sample_idx from ConcateDataset
+ dataset_idx, sample_idx = dataset2.get_dataset_idx_and_sample_idx(3)
+ assert dataset_idx == 0
+ assert sample_idx == 3
+
+ dataset_idx, sample_idx = dataset2.get_dataset_idx_and_sample_idx(7)
+ assert dataset_idx == 1
+ assert sample_idx == 2
+
+ dataset_idx, sample_idx = dataset2.get_dataset_idx_and_sample_idx(-7)
+ assert dataset_idx == 0
+ assert sample_idx == 3
+
+ # test negative indice exceed length of dataset
+ with pytest.raises(ValueError):
+ dataset_idx, sample_idx = dataset2.get_dataset_idx_and_sample_idx(-11)
+
+ # test negative indice value
+ indice = -6
+ dataset_idx1, sample_idx1 = dataset2.get_dataset_idx_and_sample_idx(indice)
+ dataset_idx2, sample_idx2 = dataset2.get_dataset_idx_and_sample_idx(
+ len(dataset2) + indice)
+ assert dataset_idx1 == dataset_idx2
+ assert sample_idx1 == sample_idx2
+
+ # test evaluation with pre-eval and the dataset.CLASSES is necessary
+ pseudo_results = []
+ eval_results1 = []
+ for idx in range(len(dataset1)):
+ h, w = gt_seg_maps[idx].shape
+ pseudo_result = np.random.randint(low=0, high=7, size=(h, w))
+ pseudo_results.append(pseudo_result)
+ eval_results1.extend(dataset1.pre_eval(pseudo_result, idx))
+
+ assert len(eval_results1) == len(dataset1)
+ assert isinstance(eval_results1[0], tuple)
+ assert len(eval_results1[0]) == 4
+ assert isinstance(eval_results1[0][0], torch.Tensor)
+
+ eval_results1 = dataset1.evaluate(
+ eval_results1, metric=['mIoU', 'mDice', 'mFscore'])
+
+ pseudo_results = pseudo_results * 2
+ eval_results2 = []
+ for idx in range(len(dataset2)):
+ eval_results2.extend(dataset2.pre_eval(pseudo_results[idx], idx))
+
+ assert len(eval_results2) == len(dataset2)
+ assert isinstance(eval_results2[0], tuple)
+ assert len(eval_results2[0]) == 4
+ assert isinstance(eval_results2[0][0], torch.Tensor)
+
+ eval_results2 = dataset2.evaluate(
+ eval_results2, metric=['mIoU', 'mDice', 'mFscore'])
+
+ if separate_eval:
+ assert eval_results1['mIoU'] == eval_results2[
+ '0_mIoU'] == eval_results2['1_mIoU']
+ assert eval_results1['mDice'] == eval_results2[
+ '0_mDice'] == eval_results2['1_mDice']
+ assert eval_results1['mAcc'] == eval_results2[
+ '0_mAcc'] == eval_results2['1_mAcc']
+ assert eval_results1['aAcc'] == eval_results2[
+ '0_aAcc'] == eval_results2['1_aAcc']
+ assert eval_results1['mFscore'] == eval_results2[
+ '0_mFscore'] == eval_results2['1_mFscore']
+ assert eval_results1['mPrecision'] == eval_results2[
+ '0_mPrecision'] == eval_results2['1_mPrecision']
+ assert eval_results1['mRecall'] == eval_results2[
+ '0_mRecall'] == eval_results2['1_mRecall']
+ else:
+ assert eval_results1['mIoU'] == eval_results2['mIoU']
+ assert eval_results1['mDice'] == eval_results2['mDice']
+ assert eval_results1['mAcc'] == eval_results2['mAcc']
+ assert eval_results1['aAcc'] == eval_results2['aAcc']
+ assert eval_results1['mFscore'] == eval_results2['mFscore']
+ assert eval_results1['mPrecision'] == eval_results2['mPrecision']
+ assert eval_results1['mRecall'] == eval_results2['mRecall']
+
+ # test batch_indices for pre eval
+ eval_results2 = dataset2.pre_eval(pseudo_results,
+ list(range(len(pseudo_results))))
+
+ assert len(eval_results2) == len(dataset2)
+ assert isinstance(eval_results2[0], tuple)
+ assert len(eval_results2[0]) == 4
+ assert isinstance(eval_results2[0][0], torch.Tensor)
+
+ eval_results2 = dataset2.evaluate(
+ eval_results2, metric=['mIoU', 'mDice', 'mFscore'])
+
+ if separate_eval:
+ assert eval_results1['mIoU'] == eval_results2[
+ '0_mIoU'] == eval_results2['1_mIoU']
+ assert eval_results1['mDice'] == eval_results2[
+ '0_mDice'] == eval_results2['1_mDice']
+ assert eval_results1['mAcc'] == eval_results2[
+ '0_mAcc'] == eval_results2['1_mAcc']
+ assert eval_results1['aAcc'] == eval_results2[
+ '0_aAcc'] == eval_results2['1_aAcc']
+ assert eval_results1['mFscore'] == eval_results2[
+ '0_mFscore'] == eval_results2['1_mFscore']
+ assert eval_results1['mPrecision'] == eval_results2[
+ '0_mPrecision'] == eval_results2['1_mPrecision']
+ assert eval_results1['mRecall'] == eval_results2[
+ '0_mRecall'] == eval_results2['1_mRecall']
+ else:
+ assert eval_results1['mIoU'] == eval_results2['mIoU']
+ assert eval_results1['mDice'] == eval_results2['mDice']
+ assert eval_results1['mAcc'] == eval_results2['mAcc']
+ assert eval_results1['aAcc'] == eval_results2['aAcc']
+ assert eval_results1['mFscore'] == eval_results2['mFscore']
+ assert eval_results1['mPrecision'] == eval_results2['mPrecision']
+ assert eval_results1['mRecall'] == eval_results2['mRecall']
+
+
+def test_ade():
+ test_dataset = ADE20KDataset(
+ pipeline=[],
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'))
+ assert len(test_dataset) == 5
+
+ # Test format_results
+ pseudo_results = []
+ for _ in range(len(test_dataset)):
+ h, w = (2, 2)
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+
+ file_paths = test_dataset.format_results(pseudo_results, '.format_ade')
+ assert len(file_paths) == len(test_dataset)
+ temp = np.array(Image.open(file_paths[0]))
+ assert np.allclose(temp, pseudo_results[0] + 1)
+
+ shutil.rmtree('.format_ade')
+
+
+@pytest.mark.parametrize('separate_eval', [True, False])
+def test_concat_ade(separate_eval):
+ test_dataset = ADE20KDataset(
+ pipeline=[],
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'))
+ assert len(test_dataset) == 5
+
+ concat_dataset = ConcatDataset([test_dataset, test_dataset],
+ separate_eval=separate_eval)
+ assert len(concat_dataset) == 10
+ # Test format_results
+ pseudo_results = []
+ for _ in range(len(concat_dataset)):
+ h, w = (2, 2)
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+
+ # test format per image
+ file_paths = []
+ for i in range(len(pseudo_results)):
+ file_paths.extend(
+ concat_dataset.format_results([pseudo_results[i]],
+ '.format_ade',
+ indices=[i]))
+ assert len(file_paths) == len(concat_dataset)
+ temp = np.array(Image.open(file_paths[0]))
+ assert np.allclose(temp, pseudo_results[0] + 1)
+
+ shutil.rmtree('.format_ade')
+
+ # test default argument
+ file_paths = concat_dataset.format_results(pseudo_results, '.format_ade')
+ assert len(file_paths) == len(concat_dataset)
+ temp = np.array(Image.open(file_paths[0]))
+ assert np.allclose(temp, pseudo_results[0] + 1)
+
+ shutil.rmtree('.format_ade')
+
+
+def test_cityscapes():
+ test_dataset = CityscapesDataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__),
+ '../data/pseudo_cityscapes_dataset/leftImg8bit'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_cityscapes_dataset/gtFine'))
+ assert len(test_dataset) == 1
+
+ gt_seg_maps = list(test_dataset.get_gt_seg_maps())
+
+ # Test format_results
+ pseudo_results = []
+ for idx in range(len(test_dataset)):
+ h, w = gt_seg_maps[idx].shape
+ pseudo_results.append(np.random.randint(low=0, high=19, size=(h, w)))
+
+ file_paths = test_dataset.format_results(pseudo_results, '.format_city')
+ assert len(file_paths) == len(test_dataset)
+ temp = np.array(Image.open(file_paths[0]))
+ assert np.allclose(temp,
+ test_dataset._convert_to_label_id(pseudo_results[0]))
+
+ # Test cityscapes evaluate
+
+ test_dataset.evaluate(
+ pseudo_results, metric='cityscapes', imgfile_prefix='.format_city')
+
+ shutil.rmtree('.format_city')
+
+
+@pytest.mark.parametrize('separate_eval', [True, False])
+def test_concat_cityscapes(separate_eval):
+ cityscape_dataset = CityscapesDataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__),
+ '../data/pseudo_cityscapes_dataset/leftImg8bit'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_cityscapes_dataset/gtFine'))
+ assert len(cityscape_dataset) == 1
+ with pytest.raises(NotImplementedError):
+ _ = ConcatDataset([cityscape_dataset, cityscape_dataset],
+ separate_eval=separate_eval)
+ ade_dataset = ADE20KDataset(
+ pipeline=[],
+ img_dir=osp.join(osp.dirname(__file__), '../data/pseudo_dataset/imgs'))
+ assert len(ade_dataset) == 5
+ with pytest.raises(NotImplementedError):
+ _ = ConcatDataset([cityscape_dataset, ade_dataset],
+ separate_eval=separate_eval)
+
+
+def test_loveda():
+ test_dataset = LoveDADataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_loveda_dataset/img_dir'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_loveda_dataset/ann_dir'))
+ assert len(test_dataset) == 3
+
+ gt_seg_maps = list(test_dataset.get_gt_seg_maps())
+
+ # Test format_results
+ pseudo_results = []
+ for idx in range(len(test_dataset)):
+ h, w = gt_seg_maps[idx].shape
+ pseudo_results.append(np.random.randint(low=0, high=7, size=(h, w)))
+ file_paths = test_dataset.format_results(pseudo_results, '.format_loveda')
+ assert len(file_paths) == len(test_dataset)
+ # Test loveda evaluate
+
+ test_dataset.evaluate(
+ pseudo_results, metric='mIoU', imgfile_prefix='.format_loveda')
+
+ shutil.rmtree('.format_loveda')
+
+
+def test_potsdam():
+ test_dataset = PotsdamDataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_potsdam_dataset/img_dir'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_potsdam_dataset/ann_dir'))
+ assert len(test_dataset) == 1
+
+
+def test_vaihingen():
+ test_dataset = ISPRSDataset(
+ pipeline=[],
+ img_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_vaihingen_dataset/img_dir'),
+ ann_dir=osp.join(
+ osp.dirname(__file__), '../data/pseudo_vaihingen_dataset/ann_dir'))
+ assert len(test_dataset) == 1
+
+
+@patch('mmseg.datasets.CustomDataset.load_annotations', MagicMock)
+@patch('mmseg.datasets.CustomDataset.__getitem__',
+ MagicMock(side_effect=lambda idx: idx))
+@pytest.mark.parametrize('dataset, classes', [
+ ('ADE20KDataset', ('wall', 'building')),
+ ('CityscapesDataset', ('road', 'sidewalk')),
+ ('CustomDataset', ('bus', 'car')),
+ ('PascalVOCDataset', ('aeroplane', 'bicycle')),
+])
+def test_custom_classes_override_default(dataset, classes):
+
+ dataset_class = DATASETS.get(dataset)
+
+ original_classes = dataset_class.CLASSES
+
+ # Test setting classes as a tuple
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=classes,
+ test_mode=True)
+
+ assert custom_dataset.CLASSES != original_classes
+ assert custom_dataset.CLASSES == classes
+
+ # Test setting classes as a list
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=list(classes),
+ test_mode=True)
+
+ assert custom_dataset.CLASSES != original_classes
+ assert custom_dataset.CLASSES == list(classes)
+
+ # Test overriding not a subset
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=[classes[0]],
+ test_mode=True)
+
+ assert custom_dataset.CLASSES != original_classes
+ assert custom_dataset.CLASSES == [classes[0]]
+
+ # Test default behavior
+ if dataset_class is CustomDataset:
+ with pytest.raises(AssertionError):
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=None,
+ test_mode=True)
+ else:
+ custom_dataset = dataset_class(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=None,
+ test_mode=True)
+
+ assert custom_dataset.CLASSES == original_classes
+
+
+@patch('mmseg.datasets.CustomDataset.load_annotations', MagicMock)
+@patch('mmseg.datasets.CustomDataset.__getitem__',
+ MagicMock(side_effect=lambda idx: idx))
+def test_custom_dataset_random_palette_is_generated():
+ dataset = CustomDataset(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=('bus', 'car'),
+ test_mode=True)
+ assert len(dataset.PALETTE) == 2
+ for class_color in dataset.PALETTE:
+ assert len(class_color) == 3
+ assert all(x >= 0 and x <= 255 for x in class_color)
+
+
+@patch('mmseg.datasets.CustomDataset.load_annotations', MagicMock)
+@patch('mmseg.datasets.CustomDataset.__getitem__',
+ MagicMock(side_effect=lambda idx: idx))
+def test_custom_dataset_custom_palette():
+ dataset = CustomDataset(
+ pipeline=[],
+ img_dir=MagicMock(),
+ split=MagicMock(),
+ classes=('bus', 'car'),
+ palette=[[100, 100, 100], [200, 200, 200]],
+ test_mode=True)
+ assert tuple(dataset.PALETTE) == tuple([[100, 100, 100], [200, 200, 200]])
diff --git a/tests/test_data/test_dataset_builder.py b/tests/test_data/test_dataset_builder.py
new file mode 100644
index 0000000..30910b0
--- /dev/null
+++ b/tests/test_data/test_dataset_builder.py
@@ -0,0 +1,200 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import os.path as osp
+
+import pytest
+from torch.utils.data import (DistributedSampler, RandomSampler,
+ SequentialSampler)
+
+from mmseg.datasets import (DATASETS, ConcatDataset, MultiImageMixDataset,
+ build_dataloader, build_dataset)
+
+
+@DATASETS.register_module()
+class ToyDataset(object):
+
+ def __init__(self, cnt=0):
+ self.cnt = cnt
+
+ def __item__(self, idx):
+ return idx
+
+ def __len__(self):
+ return 100
+
+
+def test_build_dataset():
+ cfg = dict(type='ToyDataset')
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ToyDataset)
+ assert dataset.cnt == 0
+ dataset = build_dataset(cfg, default_args=dict(cnt=1))
+ assert isinstance(dataset, ToyDataset)
+ assert dataset.cnt == 1
+
+ data_root = osp.join(osp.dirname(__file__), '../data/pseudo_dataset')
+ img_dir = 'imgs/'
+ ann_dir = 'gts/'
+
+ # We use same dir twice for simplicity
+ # with ann_dir
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ ann_dir=[ann_dir, ann_dir])
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 10
+
+ cfg = dict(type='MultiImageMixDataset', dataset=cfg, pipeline=[])
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, MultiImageMixDataset)
+ assert len(dataset) == 10
+
+ # with ann_dir, split
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=img_dir,
+ ann_dir=ann_dir,
+ split=['splits/train.txt', 'splits/val.txt'])
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 5
+
+ # with ann_dir, split
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=img_dir,
+ ann_dir=[ann_dir, ann_dir],
+ split=['splits/train.txt', 'splits/val.txt'])
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 5
+
+ # test mode
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ test_mode=True,
+ classes=('pseudo_class', ))
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 10
+
+ # test mode with splits
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ split=['splits/val.txt', 'splits/val.txt'],
+ test_mode=True,
+ classes=('pseudo_class', ))
+ dataset = build_dataset(cfg)
+ assert isinstance(dataset, ConcatDataset)
+ assert len(dataset) == 2
+
+ # len(ann_dir) should be zero or len(img_dir) when len(img_dir) > 1
+ with pytest.raises(AssertionError):
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ ann_dir=[ann_dir, ann_dir, ann_dir])
+ build_dataset(cfg)
+
+ # len(splits) should be zero or len(img_dir) when len(img_dir) > 1
+ with pytest.raises(AssertionError):
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=[img_dir, img_dir],
+ split=['splits/val.txt', 'splits/val.txt', 'splits/val.txt'])
+ build_dataset(cfg)
+
+ # len(splits) == len(ann_dir) when only len(img_dir) == 1 and len(
+ # ann_dir) > 1
+ with pytest.raises(AssertionError):
+ cfg = dict(
+ type='CustomDataset',
+ pipeline=[],
+ data_root=data_root,
+ img_dir=img_dir,
+ ann_dir=[ann_dir, ann_dir],
+ split=['splits/val.txt', 'splits/val.txt', 'splits/val.txt'])
+ build_dataset(cfg)
+
+
+def test_build_dataloader():
+ dataset = ToyDataset()
+ samples_per_gpu = 3
+ # dist=True, shuffle=True, 1GPU
+ dataloader = build_dataloader(
+ dataset, samples_per_gpu=samples_per_gpu, workers_per_gpu=2)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert isinstance(dataloader.sampler, DistributedSampler)
+ assert dataloader.sampler.shuffle
+
+ # dist=True, shuffle=False, 1GPU
+ dataloader = build_dataloader(
+ dataset,
+ samples_per_gpu=samples_per_gpu,
+ workers_per_gpu=2,
+ shuffle=False)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert isinstance(dataloader.sampler, DistributedSampler)
+ assert not dataloader.sampler.shuffle
+
+ # dist=True, shuffle=True, 8GPU
+ dataloader = build_dataloader(
+ dataset,
+ samples_per_gpu=samples_per_gpu,
+ workers_per_gpu=2,
+ num_gpus=8)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert dataloader.num_workers == 2
+
+ # dist=False, shuffle=True, 1GPU
+ dataloader = build_dataloader(
+ dataset,
+ samples_per_gpu=samples_per_gpu,
+ workers_per_gpu=2,
+ dist=False)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert isinstance(dataloader.sampler, RandomSampler)
+ assert dataloader.num_workers == 2
+
+ # dist=False, shuffle=False, 1GPU
+ dataloader = build_dataloader(
+ dataset,
+ samples_per_gpu=3,
+ workers_per_gpu=2,
+ shuffle=False,
+ dist=False)
+ assert dataloader.batch_size == samples_per_gpu
+ assert len(dataloader) == int(math.ceil(len(dataset) / samples_per_gpu))
+ assert isinstance(dataloader.sampler, SequentialSampler)
+ assert dataloader.num_workers == 2
+
+ # dist=False, shuffle=True, 8GPU
+ dataloader = build_dataloader(
+ dataset, samples_per_gpu=3, workers_per_gpu=2, num_gpus=8, dist=False)
+ assert dataloader.batch_size == samples_per_gpu * 8
+ assert len(dataloader) == int(
+ math.ceil(len(dataset) / samples_per_gpu / 8))
+ assert isinstance(dataloader.sampler, RandomSampler)
+ assert dataloader.num_workers == 16
diff --git a/tests/test_data/test_loading.py b/tests/test_data/test_loading.py
new file mode 100644
index 0000000..fdda93e
--- /dev/null
+++ b/tests/test_data/test_loading.py
@@ -0,0 +1,199 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+import tempfile
+
+import mmcv
+import numpy as np
+
+from mmseg.datasets.pipelines import LoadAnnotations, LoadImageFromFile
+
+
+class TestLoading(object):
+
+ @classmethod
+ def setup_class(cls):
+ cls.data_prefix = osp.join(osp.dirname(__file__), '../data')
+
+ def test_load_img(self):
+ results = dict(
+ img_prefix=self.data_prefix, img_info=dict(filename='color.jpg'))
+ transform = LoadImageFromFile()
+ results = transform(copy.deepcopy(results))
+ assert results['filename'] == osp.join(self.data_prefix, 'color.jpg')
+ assert results['ori_filename'] == 'color.jpg'
+ assert results['img'].shape == (288, 512, 3)
+ assert results['img'].dtype == np.uint8
+ assert results['img_shape'] == (288, 512, 3)
+ assert results['ori_shape'] == (288, 512, 3)
+ assert results['pad_shape'] == (288, 512, 3)
+ assert results['scale_factor'] == 1.0
+ np.testing.assert_equal(results['img_norm_cfg']['mean'],
+ np.zeros(3, dtype=np.float32))
+ assert repr(transform) == transform.__class__.__name__ + \
+ "(to_float32=False,color_type='color',imdecode_backend='cv2')"
+
+ # no img_prefix
+ results = dict(
+ img_prefix=None, img_info=dict(filename='tests/data/color.jpg'))
+ transform = LoadImageFromFile()
+ results = transform(copy.deepcopy(results))
+ assert results['filename'] == 'tests/data/color.jpg'
+ assert results['ori_filename'] == 'tests/data/color.jpg'
+ assert results['img'].shape == (288, 512, 3)
+
+ # to_float32
+ transform = LoadImageFromFile(to_float32=True)
+ results = transform(copy.deepcopy(results))
+ assert results['img'].dtype == np.float32
+
+ # gray image
+ results = dict(
+ img_prefix=self.data_prefix, img_info=dict(filename='gray.jpg'))
+ transform = LoadImageFromFile()
+ results = transform(copy.deepcopy(results))
+ assert results['img'].shape == (288, 512, 3)
+ assert results['img'].dtype == np.uint8
+
+ transform = LoadImageFromFile(color_type='unchanged')
+ results = transform(copy.deepcopy(results))
+ assert results['img'].shape == (288, 512)
+ assert results['img'].dtype == np.uint8
+ np.testing.assert_equal(results['img_norm_cfg']['mean'],
+ np.zeros(1, dtype=np.float32))
+
+ def test_load_seg(self):
+ results = dict(
+ seg_prefix=self.data_prefix,
+ ann_info=dict(seg_map='seg.png'),
+ seg_fields=[])
+ transform = LoadAnnotations()
+ results = transform(copy.deepcopy(results))
+ assert results['seg_fields'] == ['gt_semantic_seg']
+ assert results['gt_semantic_seg'].shape == (288, 512)
+ assert results['gt_semantic_seg'].dtype == np.uint8
+ assert repr(transform) == transform.__class__.__name__ + \
+ "(reduce_zero_label=False,imdecode_backend='pillow')"
+
+ # no img_prefix
+ results = dict(
+ seg_prefix=None,
+ ann_info=dict(seg_map='tests/data/seg.png'),
+ seg_fields=[])
+ transform = LoadAnnotations()
+ results = transform(copy.deepcopy(results))
+ assert results['gt_semantic_seg'].shape == (288, 512)
+ assert results['gt_semantic_seg'].dtype == np.uint8
+
+ # reduce_zero_label
+ transform = LoadAnnotations(reduce_zero_label=True)
+ results = transform(copy.deepcopy(results))
+ assert results['gt_semantic_seg'].shape == (288, 512)
+ assert results['gt_semantic_seg'].dtype == np.uint8
+
+ # mmcv backend
+ results = dict(
+ seg_prefix=self.data_prefix,
+ ann_info=dict(seg_map='seg.png'),
+ seg_fields=[])
+ transform = LoadAnnotations(imdecode_backend='pillow')
+ results = transform(copy.deepcopy(results))
+ # this image is saved by PIL
+ assert results['gt_semantic_seg'].shape == (288, 512)
+ assert results['gt_semantic_seg'].dtype == np.uint8
+
+ def test_load_seg_custom_classes(self):
+
+ test_img = np.random.rand(10, 10)
+ test_gt = np.zeros_like(test_img)
+ test_gt[2:4, 2:4] = 1
+ test_gt[2:4, 6:8] = 2
+ test_gt[6:8, 2:4] = 3
+ test_gt[6:8, 6:8] = 4
+
+ tmp_dir = tempfile.TemporaryDirectory()
+ img_path = osp.join(tmp_dir.name, 'img.jpg')
+ gt_path = osp.join(tmp_dir.name, 'gt.png')
+
+ mmcv.imwrite(test_img, img_path)
+ mmcv.imwrite(test_gt, gt_path)
+
+ # test only train with label with id 3
+ results = dict(
+ img_info=dict(filename=img_path),
+ ann_info=dict(seg_map=gt_path),
+ label_map={
+ 0: 0,
+ 1: 0,
+ 2: 0,
+ 3: 1,
+ 4: 0
+ },
+ seg_fields=[])
+
+ load_imgs = LoadImageFromFile()
+ results = load_imgs(copy.deepcopy(results))
+
+ load_anns = LoadAnnotations()
+ results = load_anns(copy.deepcopy(results))
+
+ gt_array = results['gt_semantic_seg']
+
+ true_mask = np.zeros_like(gt_array)
+ true_mask[6:8, 2:4] = 1
+
+ assert results['seg_fields'] == ['gt_semantic_seg']
+ assert gt_array.shape == (10, 10)
+ assert gt_array.dtype == np.uint8
+ np.testing.assert_array_equal(gt_array, true_mask)
+
+ # test only train with label with id 4 and 3
+ results = dict(
+ img_info=dict(filename=img_path),
+ ann_info=dict(seg_map=gt_path),
+ label_map={
+ 0: 0,
+ 1: 0,
+ 2: 0,
+ 3: 2,
+ 4: 1
+ },
+ seg_fields=[])
+
+ load_imgs = LoadImageFromFile()
+ results = load_imgs(copy.deepcopy(results))
+
+ load_anns = LoadAnnotations()
+ results = load_anns(copy.deepcopy(results))
+
+ gt_array = results['gt_semantic_seg']
+
+ true_mask = np.zeros_like(gt_array)
+ true_mask[6:8, 2:4] = 2
+ true_mask[6:8, 6:8] = 1
+
+ assert results['seg_fields'] == ['gt_semantic_seg']
+ assert gt_array.shape == (10, 10)
+ assert gt_array.dtype == np.uint8
+ np.testing.assert_array_equal(gt_array, true_mask)
+
+ # test no custom classes
+ results = dict(
+ img_info=dict(filename=img_path),
+ ann_info=dict(seg_map=gt_path),
+ seg_fields=[])
+
+ load_imgs = LoadImageFromFile()
+ results = load_imgs(copy.deepcopy(results))
+
+ load_anns = LoadAnnotations()
+ results = load_anns(copy.deepcopy(results))
+
+ gt_array = results['gt_semantic_seg']
+
+ assert results['seg_fields'] == ['gt_semantic_seg']
+ assert gt_array.shape == (10, 10)
+ assert gt_array.dtype == np.uint8
+ np.testing.assert_array_equal(gt_array, test_gt)
+
+ tmp_dir.cleanup()
diff --git a/tests/test_data/test_transform.py b/tests/test_data/test_transform.py
new file mode 100644
index 0000000..e9aa1d7
--- /dev/null
+++ b/tests/test_data/test_transform.py
@@ -0,0 +1,665 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+
+import mmcv
+import numpy as np
+import pytest
+from mmcv.utils import build_from_cfg
+from PIL import Image
+
+from mmseg.datasets.builder import PIPELINES
+
+
+def test_resize_to_multiple():
+ transform = dict(type='ResizeToMultiple', size_divisor=32)
+ transform = build_from_cfg(transform, PIPELINES)
+
+ img = np.random.randn(213, 232, 3)
+ seg = np.random.randint(0, 19, (213, 232))
+ results = dict()
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['pad_shape'] = img.shape
+
+ results = transform(results)
+ assert results['img'].shape == (224, 256, 3)
+ assert results['gt_semantic_seg'].shape == (224, 256)
+ assert results['img_shape'] == (224, 256, 3)
+ assert results['pad_shape'] == (224, 256, 3)
+
+
+def test_resize():
+ # test assertion if img_scale is a list
+ with pytest.raises(AssertionError):
+ transform = dict(type='Resize', img_scale=[1333, 800], keep_ratio=True)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if len(img_scale) while ratio_range is not None
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='Resize',
+ img_scale=[(1333, 800), (1333, 600)],
+ ratio_range=(0.9, 1.1),
+ keep_ratio=True)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion for invalid multiscale_mode
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='Resize',
+ img_scale=[(1333, 800), (1333, 600)],
+ keep_ratio=True,
+ multiscale_mode='2333')
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='Resize', img_scale=(1333, 800), keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ # (288, 512, 3)
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ resized_results = resize_module(results.copy())
+ assert resized_results['img_shape'] == (750, 1333, 3)
+
+ # test keep_ratio=False
+ transform = dict(
+ type='Resize',
+ img_scale=(1280, 800),
+ multiscale_mode='value',
+ keep_ratio=False)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert resized_results['img_shape'] == (800, 1280, 3)
+
+ # test multiscale_mode='range'
+ transform = dict(
+ type='Resize',
+ img_scale=[(1333, 400), (1333, 1200)],
+ multiscale_mode='range',
+ keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert max(resized_results['img_shape'][:2]) <= 1333
+ assert min(resized_results['img_shape'][:2]) >= 400
+ assert min(resized_results['img_shape'][:2]) <= 1200
+
+ # test multiscale_mode='value'
+ transform = dict(
+ type='Resize',
+ img_scale=[(1333, 800), (1333, 400)],
+ multiscale_mode='value',
+ keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert resized_results['img_shape'] in [(750, 1333, 3), (400, 711, 3)]
+
+ # test multiscale_mode='range'
+ transform = dict(
+ type='Resize',
+ img_scale=(1333, 800),
+ ratio_range=(0.9, 1.1),
+ keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert max(resized_results['img_shape'][:2]) <= 1333 * 1.1
+
+ # test img_scale=None and ratio_range is tuple.
+ # img shape: (288, 512, 3)
+ transform = dict(
+ type='Resize', img_scale=None, ratio_range=(0.5, 2.0), keep_ratio=True)
+ resize_module = build_from_cfg(transform, PIPELINES)
+ resized_results = resize_module(results.copy())
+ assert int(288 * 0.5) <= resized_results['img_shape'][0] <= 288 * 2.0
+ assert int(512 * 0.5) <= resized_results['img_shape'][1] <= 512 * 2.0
+
+
+def test_flip():
+ # test assertion for invalid prob
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomFlip', prob=1.5)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion for invalid direction
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomFlip', prob=1, direction='horizonta')
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='RandomFlip', prob=1)
+ flip_module = build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ original_seg = copy.deepcopy(seg)
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = flip_module(results)
+
+ flip_module = build_from_cfg(transform, PIPELINES)
+ results = flip_module(results)
+ assert np.equal(original_img, results['img']).all()
+ assert np.equal(original_seg, results['gt_semantic_seg']).all()
+
+
+def test_random_crop():
+ # test assertion for invalid random crop
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomCrop', crop_size=(-1, 0))
+ build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ h, w, _ = img.shape
+ transform = dict(type='RandomCrop', crop_size=(h - 20, w - 20))
+ crop_module = build_from_cfg(transform, PIPELINES)
+ results = crop_module(results)
+ assert results['img'].shape[:2] == (h - 20, w - 20)
+ assert results['img_shape'][:2] == (h - 20, w - 20)
+ assert results['gt_semantic_seg'].shape[:2] == (h - 20, w - 20)
+
+
+def test_pad():
+ # test assertion if both size_divisor and size is None
+ with pytest.raises(AssertionError):
+ transform = dict(type='Pad')
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='Pad', size_divisor=32)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+ # original img already divisible by 32
+ assert np.equal(results['img'], original_img).all()
+ img_shape = results['img'].shape
+ assert img_shape[0] % 32 == 0
+ assert img_shape[1] % 32 == 0
+
+ resize_transform = dict(
+ type='Resize', img_scale=(1333, 800), keep_ratio=True)
+ resize_module = build_from_cfg(resize_transform, PIPELINES)
+ results = resize_module(results)
+ results = transform(results)
+ img_shape = results['img'].shape
+ assert img_shape[0] % 32 == 0
+ assert img_shape[1] % 32 == 0
+
+
+def test_rotate():
+ # test assertion degree should be tuple[float] or float
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomRotate', prob=0.5, degree=-10)
+ build_from_cfg(transform, PIPELINES)
+ # test assertion degree should be tuple[float] or float
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomRotate', prob=0.5, degree=(10., 20., 30.))
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='RandomRotate', degree=10., prob=1.)
+ transform = build_from_cfg(transform, PIPELINES)
+
+ assert str(transform) == f'RandomRotate(' \
+ f'prob={1.}, ' \
+ f'degree=({-10.}, {10.}), ' \
+ f'pad_val={0}, ' \
+ f'seg_pad_val={255}, ' \
+ f'center={None}, ' \
+ f'auto_bound={False})'
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ h, w, _ = img.shape
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+ assert results['img'].shape[:2] == (h, w)
+ assert results['gt_semantic_seg'].shape[:2] == (h, w)
+
+
+def test_normalize():
+ img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True)
+ transform = dict(type='Normalize', **img_norm_cfg)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+
+ mean = np.array(img_norm_cfg['mean'])
+ std = np.array(img_norm_cfg['std'])
+ converted_img = (original_img[..., ::-1] - mean) / std
+ assert np.allclose(results['img'], converted_img)
+
+
+def test_rgb2gray():
+ # test assertion out_channels should be greater than 0
+ with pytest.raises(AssertionError):
+ transform = dict(type='RGB2Gray', out_channels=-1)
+ build_from_cfg(transform, PIPELINES)
+ # test assertion weights should be tuple[float]
+ with pytest.raises(AssertionError):
+ transform = dict(type='RGB2Gray', out_channels=1, weights=1.1)
+ build_from_cfg(transform, PIPELINES)
+
+ # test out_channels is None
+ transform = dict(type='RGB2Gray')
+ transform = build_from_cfg(transform, PIPELINES)
+
+ assert str(transform) == f'RGB2Gray(' \
+ f'out_channels={None}, ' \
+ f'weights={(0.299, 0.587, 0.114)})'
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ h, w, c = img.shape
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+ assert results['img'].shape == (h, w, c)
+ assert results['img_shape'] == (h, w, c)
+ assert results['ori_shape'] == (h, w, c)
+
+ # test out_channels = 2
+ transform = dict(type='RGB2Gray', out_channels=2)
+ transform = build_from_cfg(transform, PIPELINES)
+
+ assert str(transform) == f'RGB2Gray(' \
+ f'out_channels={2}, ' \
+ f'weights={(0.299, 0.587, 0.114)})'
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ h, w, c = img.shape
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+ assert results['img'].shape == (h, w, 2)
+ assert results['img_shape'] == (h, w, 2)
+ assert results['ori_shape'] == (h, w, c)
+
+
+def test_adjust_gamma():
+ # test assertion if gamma <= 0
+ with pytest.raises(AssertionError):
+ transform = dict(type='AdjustGamma', gamma=0)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if gamma is list
+ with pytest.raises(AssertionError):
+ transform = dict(type='AdjustGamma', gamma=[1.2])
+ build_from_cfg(transform, PIPELINES)
+
+ # test with gamma = 1.2
+ transform = dict(type='AdjustGamma', gamma=1.2)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+
+ inv_gamma = 1.0 / 1.2
+ table = np.array([((i / 255.0)**inv_gamma) * 255
+ for i in np.arange(0, 256)]).astype('uint8')
+ converted_img = mmcv.lut_transform(
+ np.array(original_img, dtype=np.uint8), table)
+ assert np.allclose(results['img'], converted_img)
+ assert str(transform) == f'AdjustGamma(gamma={1.2})'
+
+
+def test_rerange():
+ # test assertion if min_value or max_value is illegal
+ with pytest.raises(AssertionError):
+ transform = dict(type='Rerange', min_value=[0], max_value=[255])
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if min_value >= max_value
+ with pytest.raises(AssertionError):
+ transform = dict(type='Rerange', min_value=1, max_value=1)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if img_min_value == img_max_value
+ with pytest.raises(AssertionError):
+ transform = dict(type='Rerange', min_value=0, max_value=1)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ results['img'] = np.array([[1, 1], [1, 1]])
+ transform(results)
+
+ img_rerange_cfg = dict()
+ transform = dict(type='Rerange', **img_rerange_cfg)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+
+ min_value = np.min(original_img)
+ max_value = np.max(original_img)
+ converted_img = (original_img - min_value) / (max_value - min_value) * 255
+
+ assert np.allclose(results['img'], converted_img)
+ assert str(transform) == f'Rerange(min_value={0}, max_value={255})'
+
+
+def test_CLAHE():
+ # test assertion if clip_limit is None
+ with pytest.raises(AssertionError):
+ transform = dict(type='CLAHE', clip_limit=None)
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if tile_grid_size is illegal
+ with pytest.raises(AssertionError):
+ transform = dict(type='CLAHE', tile_grid_size=(8.0, 8.0))
+ build_from_cfg(transform, PIPELINES)
+
+ # test assertion if tile_grid_size is illegal
+ with pytest.raises(AssertionError):
+ transform = dict(type='CLAHE', tile_grid_size=(9, 9, 9))
+ build_from_cfg(transform, PIPELINES)
+
+ transform = dict(type='CLAHE', clip_limit=2)
+ transform = build_from_cfg(transform, PIPELINES)
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ original_img = copy.deepcopy(img)
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ results = transform(results)
+
+ converted_img = np.empty(original_img.shape)
+ for i in range(original_img.shape[2]):
+ converted_img[:, :, i] = mmcv.clahe(
+ np.array(original_img[:, :, i], dtype=np.uint8), 2, (8, 8))
+
+ assert np.allclose(results['img'], converted_img)
+ assert str(transform) == f'CLAHE(clip_limit={2}, tile_grid_size={(8, 8)})'
+
+
+def test_seg_rescale():
+ results = dict()
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ h, w = seg.shape
+
+ transform = dict(type='SegRescale', scale_factor=1. / 2)
+ rescale_module = build_from_cfg(transform, PIPELINES)
+ rescale_results = rescale_module(results.copy())
+ assert rescale_results['gt_semantic_seg'].shape == (h // 2, w // 2)
+
+ transform = dict(type='SegRescale', scale_factor=1)
+ rescale_module = build_from_cfg(transform, PIPELINES)
+ rescale_results = rescale_module(results.copy())
+ assert rescale_results['gt_semantic_seg'].shape == (h, w)
+
+
+def test_cutout():
+ # test prob
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomCutOut', prob=1.5, n_holes=1)
+ build_from_cfg(transform, PIPELINES)
+ # test n_holes
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut', prob=0.5, n_holes=(5, 3), cutout_shape=(8, 8))
+ build_from_cfg(transform, PIPELINES)
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut',
+ prob=0.5,
+ n_holes=(3, 4, 5),
+ cutout_shape=(8, 8))
+ build_from_cfg(transform, PIPELINES)
+ # test cutout_shape and cutout_ratio
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut', prob=0.5, n_holes=1, cutout_shape=8)
+ build_from_cfg(transform, PIPELINES)
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut', prob=0.5, n_holes=1, cutout_ratio=0.2)
+ build_from_cfg(transform, PIPELINES)
+ # either of cutout_shape and cutout_ratio should be given
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomCutOut', prob=0.5, n_holes=1)
+ build_from_cfg(transform, PIPELINES)
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut',
+ prob=0.5,
+ n_holes=1,
+ cutout_shape=(2, 2),
+ cutout_ratio=(0.4, 0.4))
+ build_from_cfg(transform, PIPELINES)
+ # test seg_fill_in
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut',
+ prob=0.5,
+ n_holes=1,
+ cutout_shape=(8, 8),
+ seg_fill_in='a')
+ build_from_cfg(transform, PIPELINES)
+ with pytest.raises(AssertionError):
+ transform = dict(
+ type='RandomCutOut',
+ prob=0.5,
+ n_holes=1,
+ cutout_shape=(8, 8),
+ seg_fill_in=256)
+ build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ results['pad_shape'] = img.shape
+ results['img_fields'] = ['img']
+
+ transform = dict(
+ type='RandomCutOut', prob=1, n_holes=1, cutout_shape=(10, 10))
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ assert 'cutout_shape' in repr(cutout_module)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() < img.sum()
+
+ transform = dict(
+ type='RandomCutOut', prob=1, n_holes=1, cutout_ratio=(0.8, 0.8))
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ assert 'cutout_ratio' in repr(cutout_module)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() < img.sum()
+
+ transform = dict(
+ type='RandomCutOut', prob=0, n_holes=1, cutout_ratio=(0.8, 0.8))
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() == img.sum()
+ assert cutout_result['gt_semantic_seg'].sum() == seg.sum()
+
+ transform = dict(
+ type='RandomCutOut',
+ prob=1,
+ n_holes=(2, 4),
+ cutout_shape=[(10, 10), (15, 15)],
+ fill_in=(255, 255, 255),
+ seg_fill_in=None)
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() > img.sum()
+ assert cutout_result['gt_semantic_seg'].sum() == seg.sum()
+
+ transform = dict(
+ type='RandomCutOut',
+ prob=1,
+ n_holes=1,
+ cutout_ratio=(0.8, 0.8),
+ fill_in=(255, 255, 255),
+ seg_fill_in=255)
+ cutout_module = build_from_cfg(transform, PIPELINES)
+ cutout_result = cutout_module(copy.deepcopy(results))
+ assert cutout_result['img'].sum() > img.sum()
+ assert cutout_result['gt_semantic_seg'].sum() > seg.sum()
+
+
+def test_mosaic():
+ # test prob
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomMosaic', prob=1.5)
+ build_from_cfg(transform, PIPELINES)
+ # test assertion for invalid img_scale
+ with pytest.raises(AssertionError):
+ transform = dict(type='RandomMosaic', prob=1, img_scale=640)
+ build_from_cfg(transform, PIPELINES)
+
+ results = dict()
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ seg = np.array(
+ Image.open(osp.join(osp.dirname(__file__), '../data/seg.png')))
+
+ results['img'] = img
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+
+ transform = dict(type='RandomMosaic', prob=1, img_scale=(10, 12))
+ mosaic_module = build_from_cfg(transform, PIPELINES)
+ assert 'Mosaic' in repr(mosaic_module)
+
+ # test assertion for invalid mix_results
+ with pytest.raises(AssertionError):
+ mosaic_module(results)
+
+ results['mix_results'] = [copy.deepcopy(results)] * 3
+ results = mosaic_module(results)
+ assert results['img'].shape[:2] == (20, 24)
+
+ results = dict()
+ results['img'] = img[:, :, 0]
+ results['gt_semantic_seg'] = seg
+ results['seg_fields'] = ['gt_semantic_seg']
+
+ transform = dict(type='RandomMosaic', prob=0, img_scale=(10, 12))
+ mosaic_module = build_from_cfg(transform, PIPELINES)
+ results['mix_results'] = [copy.deepcopy(results)] * 3
+ results = mosaic_module(results)
+ assert results['img'].shape[:2] == img.shape[:2]
+
+ transform = dict(type='RandomMosaic', prob=1, img_scale=(10, 12))
+ mosaic_module = build_from_cfg(transform, PIPELINES)
+ results = mosaic_module(results)
+ assert results['img'].shape[:2] == (20, 24)
diff --git a/tests/test_data/test_tta.py b/tests/test_data/test_tta.py
new file mode 100644
index 0000000..d61af27
--- /dev/null
+++ b/tests/test_data/test_tta.py
@@ -0,0 +1,151 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import pytest
+from mmcv.utils import build_from_cfg
+
+from mmseg.datasets.builder import PIPELINES
+
+
+def test_multi_scale_flip_aug():
+ # test assertion if img_scale=None, img_ratios=1 (not float).
+ with pytest.raises(AssertionError):
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=None,
+ img_ratios=1,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ build_from_cfg(tta_transform, PIPELINES)
+
+ # test assertion if img_scale=None, img_ratios=None.
+ with pytest.raises(AssertionError):
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=None,
+ img_ratios=None,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ build_from_cfg(tta_transform, PIPELINES)
+
+ # test assertion if img_scale=(512, 512), img_ratios=1 (not float).
+ with pytest.raises(AssertionError):
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=1,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ build_from_cfg(tta_transform, PIPELINES)
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=[0.5, 1.0, 2.0],
+ flip=False,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+
+ results = dict()
+ # (288, 512, 3)
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), '../data/color.jpg'), 'color')
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ # Set initial values for default meta_keys
+ results['pad_shape'] = img.shape
+ results['scale_factor'] = 1.0
+
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 256), (512, 512), (1024, 1024)]
+ assert tta_results['flip'] == [False, False, False]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=[0.5, 1.0, 2.0],
+ flip=True,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 256), (256, 256), (512, 512),
+ (512, 512), (1024, 1024), (1024, 1024)]
+ assert tta_results['flip'] == [False, True, False, True, False, True]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=1.0,
+ flip=False,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(512, 512)]
+ assert tta_results['flip'] == [False]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=(512, 512),
+ img_ratios=1.0,
+ flip=True,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(512, 512), (512, 512)]
+ assert tta_results['flip'] == [False, True]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=None,
+ img_ratios=[0.5, 1.0, 2.0],
+ flip=False,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 144), (512, 288), (1024, 576)]
+ assert tta_results['flip'] == [False, False, False]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=None,
+ img_ratios=[0.5, 1.0, 2.0],
+ flip=True,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 144), (256, 144), (512, 288),
+ (512, 288), (1024, 576), (1024, 576)]
+ assert tta_results['flip'] == [False, True, False, True, False, True]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=[(256, 256), (512, 512), (1024, 1024)],
+ img_ratios=None,
+ flip=False,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 256), (512, 512), (1024, 1024)]
+ assert tta_results['flip'] == [False, False, False]
+
+ tta_transform = dict(
+ type='MultiScaleFlipAug',
+ img_scale=[(256, 256), (512, 512), (1024, 1024)],
+ img_ratios=None,
+ flip=True,
+ transforms=[dict(type='Resize', keep_ratio=False)],
+ )
+ tta_module = build_from_cfg(tta_transform, PIPELINES)
+ tta_results = tta_module(results.copy())
+ assert tta_results['scale'] == [(256, 256), (256, 256), (512, 512),
+ (512, 512), (1024, 1024), (1024, 1024)]
+ assert tta_results['flip'] == [False, True, False, True, False, True]
diff --git a/tests/test_digit_version.py b/tests/test_digit_version.py
new file mode 100644
index 0000000..45daf09
--- /dev/null
+++ b/tests/test_digit_version.py
@@ -0,0 +1,21 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmseg import digit_version
+
+
+def test_digit_version():
+ assert digit_version('0.2.16') == (0, 2, 16, 0, 0, 0)
+ assert digit_version('1.2.3') == (1, 2, 3, 0, 0, 0)
+ assert digit_version('1.2.3rc0') == (1, 2, 3, 0, -1, 0)
+ assert digit_version('1.2.3rc1') == (1, 2, 3, 0, -1, 1)
+ assert digit_version('1.0rc0') == (1, 0, 0, 0, -1, 0)
+ assert digit_version('1.0') == digit_version('1.0.0')
+ assert digit_version('1.5.0+cuda90_cudnn7.6.3_lms') == digit_version('1.5')
+ assert digit_version('1.0.0dev') < digit_version('1.0.0a')
+ assert digit_version('1.0.0a') < digit_version('1.0.0a1')
+ assert digit_version('1.0.0a') < digit_version('1.0.0b')
+ assert digit_version('1.0.0b') < digit_version('1.0.0rc')
+ assert digit_version('1.0.0rc1') < digit_version('1.0.0')
+ assert digit_version('1.0.0') < digit_version('1.0.0post')
+ assert digit_version('1.0.0post') < digit_version('1.0.0post1')
+ assert digit_version('v1') == (1, 0, 0, 0, 0, 0)
+ assert digit_version('v1.1.5') == (1, 1, 5, 0, 0, 0)
diff --git a/tests/test_eval_hook.py b/tests/test_eval_hook.py
new file mode 100644
index 0000000..5267438
--- /dev/null
+++ b/tests/test_eval_hook.py
@@ -0,0 +1,204 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+import tempfile
+from unittest.mock import MagicMock, patch
+
+import mmcv.runner
+import pytest
+import torch
+import torch.nn as nn
+from mmcv.runner import obj_from_dict
+from torch.utils.data import DataLoader, Dataset
+
+from mmseg.apis import single_gpu_test
+from mmseg.core import DistEvalHook, EvalHook
+
+
+class ExampleDataset(Dataset):
+
+ def __getitem__(self, idx):
+ results = dict(img=torch.tensor([1]), img_metas=dict())
+ return results
+
+ def __len__(self):
+ return 1
+
+
+class ExampleModel(nn.Module):
+
+ def __init__(self):
+ super(ExampleModel, self).__init__()
+ self.test_cfg = None
+ self.conv = nn.Conv2d(3, 3, 3)
+
+ def forward(self, img, img_metas, test_mode=False, **kwargs):
+ return img
+
+ def train_step(self, data_batch, optimizer):
+ loss = self.forward(**data_batch)
+ return dict(loss=loss)
+
+
+def test_iter_eval_hook():
+ with pytest.raises(TypeError):
+ test_dataset = ExampleModel()
+ data_loader = [
+ DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_worker=0,
+ shuffle=False)
+ ]
+ EvalHook(data_loader)
+
+ test_dataset = ExampleDataset()
+ test_dataset.pre_eval = MagicMock(return_value=[torch.tensor([1])])
+ test_dataset.evaluate = MagicMock(return_value=dict(test='success'))
+ loader = DataLoader(test_dataset, batch_size=1)
+ model = ExampleModel()
+ data_loader = DataLoader(
+ test_dataset, batch_size=1, sampler=None, num_workers=0, shuffle=False)
+ optim_cfg = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+ optimizer = obj_from_dict(optim_cfg, torch.optim,
+ dict(params=model.parameters()))
+
+ # test EvalHook
+ with tempfile.TemporaryDirectory() as tmpdir:
+ eval_hook = EvalHook(data_loader, by_epoch=False, efficient_test=True)
+ runner = mmcv.runner.IterBasedRunner(
+ model=model,
+ optimizer=optimizer,
+ work_dir=tmpdir,
+ logger=logging.getLogger())
+ runner.register_hook(eval_hook)
+ runner.run([loader], [('train', 1)], 1)
+ test_dataset.evaluate.assert_called_with([torch.tensor([1])],
+ logger=runner.logger)
+
+
+def test_epoch_eval_hook():
+ with pytest.raises(TypeError):
+ test_dataset = ExampleModel()
+ data_loader = [
+ DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_worker=0,
+ shuffle=False)
+ ]
+ EvalHook(data_loader, by_epoch=True)
+
+ test_dataset = ExampleDataset()
+ test_dataset.pre_eval = MagicMock(return_value=[torch.tensor([1])])
+ test_dataset.evaluate = MagicMock(return_value=dict(test='success'))
+ loader = DataLoader(test_dataset, batch_size=1)
+ model = ExampleModel()
+ data_loader = DataLoader(
+ test_dataset, batch_size=1, sampler=None, num_workers=0, shuffle=False)
+ optim_cfg = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+ optimizer = obj_from_dict(optim_cfg, torch.optim,
+ dict(params=model.parameters()))
+
+ # test EvalHook with interval
+ with tempfile.TemporaryDirectory() as tmpdir:
+ eval_hook = EvalHook(data_loader, by_epoch=True, interval=2)
+ runner = mmcv.runner.EpochBasedRunner(
+ model=model,
+ optimizer=optimizer,
+ work_dir=tmpdir,
+ logger=logging.getLogger())
+ runner.register_hook(eval_hook)
+ runner.run([loader], [('train', 1)], 2)
+ test_dataset.evaluate.assert_called_once_with([torch.tensor([1])],
+ logger=runner.logger)
+
+
+def multi_gpu_test(model,
+ data_loader,
+ tmpdir=None,
+ gpu_collect=False,
+ pre_eval=False):
+ # Pre eval is set by default when training.
+ results = single_gpu_test(model, data_loader, pre_eval=True)
+ return results
+
+
+@patch('mmseg.apis.multi_gpu_test', multi_gpu_test)
+def test_dist_eval_hook():
+ with pytest.raises(TypeError):
+ test_dataset = ExampleModel()
+ data_loader = [
+ DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_worker=0,
+ shuffle=False)
+ ]
+ DistEvalHook(data_loader)
+
+ test_dataset = ExampleDataset()
+ test_dataset.pre_eval = MagicMock(return_value=[torch.tensor([1])])
+ test_dataset.evaluate = MagicMock(return_value=dict(test='success'))
+ loader = DataLoader(test_dataset, batch_size=1)
+ model = ExampleModel()
+ data_loader = DataLoader(
+ test_dataset, batch_size=1, sampler=None, num_workers=0, shuffle=False)
+ optim_cfg = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+ optimizer = obj_from_dict(optim_cfg, torch.optim,
+ dict(params=model.parameters()))
+
+ # test DistEvalHook
+ with tempfile.TemporaryDirectory() as tmpdir:
+ eval_hook = DistEvalHook(
+ data_loader, by_epoch=False, efficient_test=True)
+ runner = mmcv.runner.IterBasedRunner(
+ model=model,
+ optimizer=optimizer,
+ work_dir=tmpdir,
+ logger=logging.getLogger())
+ runner.register_hook(eval_hook)
+ runner.run([loader], [('train', 1)], 1)
+ test_dataset.evaluate.assert_called_with([torch.tensor([1])],
+ logger=runner.logger)
+
+
+@patch('mmseg.apis.multi_gpu_test', multi_gpu_test)
+def test_dist_eval_hook_epoch():
+ with pytest.raises(TypeError):
+ test_dataset = ExampleModel()
+ data_loader = [
+ DataLoader(
+ test_dataset,
+ batch_size=1,
+ sampler=None,
+ num_worker=0,
+ shuffle=False)
+ ]
+ DistEvalHook(data_loader)
+
+ test_dataset = ExampleDataset()
+ test_dataset.pre_eval = MagicMock(return_value=[torch.tensor([1])])
+ test_dataset.evaluate = MagicMock(return_value=dict(test='success'))
+ loader = DataLoader(test_dataset, batch_size=1)
+ model = ExampleModel()
+ data_loader = DataLoader(
+ test_dataset, batch_size=1, sampler=None, num_workers=0, shuffle=False)
+ optim_cfg = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+ optimizer = obj_from_dict(optim_cfg, torch.optim,
+ dict(params=model.parameters()))
+
+ # test DistEvalHook
+ with tempfile.TemporaryDirectory() as tmpdir:
+ eval_hook = DistEvalHook(data_loader, by_epoch=True, interval=2)
+ runner = mmcv.runner.EpochBasedRunner(
+ model=model,
+ optimizer=optimizer,
+ work_dir=tmpdir,
+ logger=logging.getLogger())
+ runner.register_hook(eval_hook)
+ runner.run([loader], [('train', 1)], 2)
+ test_dataset.evaluate.assert_called_with([torch.tensor([1])],
+ logger=runner.logger)
diff --git a/tests/test_inference.py b/tests/test_inference.py
new file mode 100644
index 0000000..f71a7ea
--- /dev/null
+++ b/tests/test_inference.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+
+from mmseg.apis import inference_segmentor, init_segmentor
+
+
+def test_test_time_augmentation_on_cpu():
+ config_file = 'configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py'
+ config = mmcv.Config.fromfile(config_file)
+
+ # Remove pretrain model download for testing
+ config.model.pretrained = None
+ # Replace SyncBN with BN to inference on CPU
+ norm_cfg = dict(type='BN', requires_grad=True)
+ config.model.backbone.norm_cfg = norm_cfg
+ config.model.decode_head.norm_cfg = norm_cfg
+ config.model.auxiliary_head.norm_cfg = norm_cfg
+
+ # Enable test time augmentation
+ config.data.test.pipeline[1].flip = True
+
+ checkpoint_file = None
+ model = init_segmentor(config, checkpoint_file, device='cpu')
+
+ img = mmcv.imread(
+ osp.join(osp.dirname(__file__), 'data/color.jpg'), 'color')
+ result = inference_segmentor(model, img)
+ assert result[0].shape == (288, 512)
diff --git a/tests/test_metrics.py b/tests/test_metrics.py
new file mode 100644
index 0000000..51ad1f3
--- /dev/null
+++ b/tests/test_metrics.py
@@ -0,0 +1,351 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+from mmseg.core.evaluation import (eval_metrics, mean_dice, mean_fscore,
+ mean_iou)
+from mmseg.core.evaluation.metrics import f_score
+
+
+def get_confusion_matrix(pred_label, label, num_classes, ignore_index):
+ """Intersection over Union
+ Args:
+ pred_label (np.ndarray): 2D predict map
+ label (np.ndarray): label 2D label map
+ num_classes (int): number of categories
+ ignore_index (int): index ignore in evaluation
+ """
+
+ mask = (label != ignore_index)
+ pred_label = pred_label[mask]
+ label = label[mask]
+
+ n = num_classes
+ inds = n * label + pred_label
+
+ mat = np.bincount(inds, minlength=n**2).reshape(n, n)
+
+ return mat
+
+
+# This func is deprecated since it's not memory efficient
+def legacy_mean_iou(results, gt_seg_maps, num_classes, ignore_index):
+ num_imgs = len(results)
+ assert len(gt_seg_maps) == num_imgs
+ total_mat = np.zeros((num_classes, num_classes), dtype=np.float)
+ for i in range(num_imgs):
+ mat = get_confusion_matrix(
+ results[i], gt_seg_maps[i], num_classes, ignore_index=ignore_index)
+ total_mat += mat
+ all_acc = np.diag(total_mat).sum() / total_mat.sum()
+ acc = np.diag(total_mat) / total_mat.sum(axis=1)
+ iou = np.diag(total_mat) / (
+ total_mat.sum(axis=1) + total_mat.sum(axis=0) - np.diag(total_mat))
+
+ return all_acc, acc, iou
+
+
+# This func is deprecated since it's not memory efficient
+def legacy_mean_dice(results, gt_seg_maps, num_classes, ignore_index):
+ num_imgs = len(results)
+ assert len(gt_seg_maps) == num_imgs
+ total_mat = np.zeros((num_classes, num_classes), dtype=np.float)
+ for i in range(num_imgs):
+ mat = get_confusion_matrix(
+ results[i], gt_seg_maps[i], num_classes, ignore_index=ignore_index)
+ total_mat += mat
+ all_acc = np.diag(total_mat).sum() / total_mat.sum()
+ acc = np.diag(total_mat) / total_mat.sum(axis=1)
+ dice = 2 * np.diag(total_mat) / (
+ total_mat.sum(axis=1) + total_mat.sum(axis=0))
+
+ return all_acc, acc, dice
+
+
+# This func is deprecated since it's not memory efficient
+def legacy_mean_fscore(results,
+ gt_seg_maps,
+ num_classes,
+ ignore_index,
+ beta=1):
+ num_imgs = len(results)
+ assert len(gt_seg_maps) == num_imgs
+ total_mat = np.zeros((num_classes, num_classes), dtype=np.float)
+ for i in range(num_imgs):
+ mat = get_confusion_matrix(
+ results[i], gt_seg_maps[i], num_classes, ignore_index=ignore_index)
+ total_mat += mat
+ all_acc = np.diag(total_mat).sum() / total_mat.sum()
+ recall = np.diag(total_mat) / total_mat.sum(axis=1)
+ precision = np.diag(total_mat) / total_mat.sum(axis=0)
+ fv = np.vectorize(f_score)
+ fscore = fv(precision, recall, beta=beta)
+
+ return all_acc, recall, precision, fscore
+
+
+def test_metrics():
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ label = np.random.randint(0, num_classes, size=pred_size)
+
+ # Test the availability of arg: ignore_index.
+ label[:, 2, 5:10] = ignore_index
+
+ # Test the correctness of the implementation of mIoU calculation.
+ ret_metrics = eval_metrics(
+ results, label, num_classes, ignore_index, metrics='mIoU')
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ all_acc_l, acc_l, iou_l = legacy_mean_iou(results, label, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, iou_l)
+ # Test the correctness of the implementation of mDice calculation.
+ ret_metrics = eval_metrics(
+ results, label, num_classes, ignore_index, metrics='mDice')
+ all_acc, acc, dice = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'Dice']
+ all_acc_l, acc_l, dice_l = legacy_mean_dice(results, label, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(dice, dice_l)
+ # Test the correctness of the implementation of mDice calculation.
+ ret_metrics = eval_metrics(
+ results, label, num_classes, ignore_index, metrics='mFscore')
+ all_acc, recall, precision, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Recall'], ret_metrics['Precision'], ret_metrics['Fscore']
+ all_acc_l, recall_l, precision_l, fscore_l = legacy_mean_fscore(
+ results, label, num_classes, ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(recall, recall_l)
+ assert np.allclose(precision, precision_l)
+ assert np.allclose(fscore, fscore_l)
+ # Test the correctness of the implementation of joint calculation.
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index,
+ metrics=['mIoU', 'mDice', 'mFscore'])
+ all_acc, acc, iou, dice, precision, recall, fscore = ret_metrics[
+ 'aAcc'], ret_metrics['Acc'], ret_metrics['IoU'], ret_metrics[
+ 'Dice'], ret_metrics['Precision'], ret_metrics[
+ 'Recall'], ret_metrics['Fscore']
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, iou_l)
+ assert np.allclose(dice, dice_l)
+ assert np.allclose(precision, precision_l)
+ assert np.allclose(recall, recall_l)
+ assert np.allclose(fscore, fscore_l)
+
+ # Test the correctness of calculation when arg: num_classes is larger
+ # than the maximum value of input maps.
+ results = np.random.randint(0, 5, size=pred_size)
+ label = np.random.randint(0, 4, size=pred_size)
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index=255,
+ metrics='mIoU',
+ nan_to_num=-1)
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ assert acc[-1] == -1
+ assert iou[-1] == -1
+
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index=255,
+ metrics='mDice',
+ nan_to_num=-1)
+ all_acc, acc, dice = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'Dice']
+ assert acc[-1] == -1
+ assert dice[-1] == -1
+
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index=255,
+ metrics='mFscore',
+ nan_to_num=-1)
+ all_acc, precision, recall, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Precision'], ret_metrics['Recall'], ret_metrics['Fscore']
+ assert precision[-1] == -1
+ assert recall[-1] == -1
+ assert fscore[-1] == -1
+
+ ret_metrics = eval_metrics(
+ results,
+ label,
+ num_classes,
+ ignore_index=255,
+ metrics=['mDice', 'mIoU', 'mFscore'],
+ nan_to_num=-1)
+ all_acc, acc, iou, dice, precision, recall, fscore = ret_metrics[
+ 'aAcc'], ret_metrics['Acc'], ret_metrics['IoU'], ret_metrics[
+ 'Dice'], ret_metrics['Precision'], ret_metrics[
+ 'Recall'], ret_metrics['Fscore']
+ assert acc[-1] == -1
+ assert dice[-1] == -1
+ assert iou[-1] == -1
+ assert precision[-1] == -1
+ assert recall[-1] == -1
+ assert fscore[-1] == -1
+
+ # Test the bug which is caused by torch.histc.
+ # torch.histc: https://pytorch.org/docs/stable/generated/torch.histc.html
+ # When the arg:bins is set to be same as arg:max,
+ # some channels of mIoU may be nan.
+ results = np.array([np.repeat(31, 59)])
+ label = np.array([np.arange(59)])
+ num_classes = 59
+ ret_metrics = eval_metrics(
+ results, label, num_classes, ignore_index=255, metrics='mIoU')
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ assert not np.any(np.isnan(iou))
+
+
+def test_mean_iou():
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ label = np.random.randint(0, num_classes, size=pred_size)
+ label[:, 2, 5:10] = ignore_index
+ ret_metrics = mean_iou(results, label, num_classes, ignore_index)
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ all_acc_l, acc_l, iou_l = legacy_mean_iou(results, label, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, iou_l)
+
+ results = np.random.randint(0, 5, size=pred_size)
+ label = np.random.randint(0, 4, size=pred_size)
+ ret_metrics = mean_iou(
+ results, label, num_classes, ignore_index=255, nan_to_num=-1)
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'IoU']
+ assert acc[-1] == -1
+ assert acc[-1] == -1
+
+
+def test_mean_dice():
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ label = np.random.randint(0, num_classes, size=pred_size)
+ label[:, 2, 5:10] = ignore_index
+ ret_metrics = mean_dice(results, label, num_classes, ignore_index)
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'Dice']
+ all_acc_l, acc_l, dice_l = legacy_mean_dice(results, label, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, dice_l)
+
+ results = np.random.randint(0, 5, size=pred_size)
+ label = np.random.randint(0, 4, size=pred_size)
+ ret_metrics = mean_dice(
+ results, label, num_classes, ignore_index=255, nan_to_num=-1)
+ all_acc, acc, dice = ret_metrics['aAcc'], ret_metrics['Acc'], ret_metrics[
+ 'Dice']
+ assert acc[-1] == -1
+ assert dice[-1] == -1
+
+
+def test_mean_fscore():
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ label = np.random.randint(0, num_classes, size=pred_size)
+ label[:, 2, 5:10] = ignore_index
+ ret_metrics = mean_fscore(results, label, num_classes, ignore_index)
+ all_acc, recall, precision, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Recall'], ret_metrics['Precision'], ret_metrics['Fscore']
+ all_acc_l, recall_l, precision_l, fscore_l = legacy_mean_fscore(
+ results, label, num_classes, ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(recall, recall_l)
+ assert np.allclose(precision, precision_l)
+ assert np.allclose(fscore, fscore_l)
+
+ ret_metrics = mean_fscore(
+ results, label, num_classes, ignore_index, beta=2)
+ all_acc, recall, precision, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Recall'], ret_metrics['Precision'], ret_metrics['Fscore']
+ all_acc_l, recall_l, precision_l, fscore_l = legacy_mean_fscore(
+ results, label, num_classes, ignore_index, beta=2)
+ assert all_acc == all_acc_l
+ assert np.allclose(recall, recall_l)
+ assert np.allclose(precision, precision_l)
+ assert np.allclose(fscore, fscore_l)
+
+ results = np.random.randint(0, 5, size=pred_size)
+ label = np.random.randint(0, 4, size=pred_size)
+ ret_metrics = mean_fscore(
+ results, label, num_classes, ignore_index=255, nan_to_num=-1)
+ all_acc, recall, precision, fscore = ret_metrics['aAcc'], ret_metrics[
+ 'Recall'], ret_metrics['Precision'], ret_metrics['Fscore']
+ assert recall[-1] == -1
+ assert precision[-1] == -1
+ assert fscore[-1] == -1
+
+
+def test_filename_inputs():
+ import tempfile
+
+ import cv2
+
+ def save_arr(input_arrays: list, title: str, is_image: bool, dir: str):
+ filenames = []
+ SUFFIX = '.png' if is_image else '.npy'
+ for idx, arr in enumerate(input_arrays):
+ filename = '{}/{}-{}{}'.format(dir, title, idx, SUFFIX)
+ if is_image:
+ cv2.imwrite(filename, arr)
+ else:
+ np.save(filename, arr)
+ filenames.append(filename)
+ return filenames
+
+ pred_size = (10, 30, 30)
+ num_classes = 19
+ ignore_index = 255
+ results = np.random.randint(0, num_classes, size=pred_size)
+ labels = np.random.randint(0, num_classes, size=pred_size)
+ labels[:, 2, 5:10] = ignore_index
+
+ with tempfile.TemporaryDirectory() as temp_dir:
+
+ result_files = save_arr(results, 'pred', False, temp_dir)
+ label_files = save_arr(labels, 'label', True, temp_dir)
+
+ ret_metrics = eval_metrics(
+ result_files,
+ label_files,
+ num_classes,
+ ignore_index,
+ metrics='mIoU')
+ all_acc, acc, iou = ret_metrics['aAcc'], ret_metrics[
+ 'Acc'], ret_metrics['IoU']
+ all_acc_l, acc_l, iou_l = legacy_mean_iou(results, labels, num_classes,
+ ignore_index)
+ assert all_acc == all_acc_l
+ assert np.allclose(acc, acc_l)
+ assert np.allclose(iou, iou_l)
diff --git a/tests/test_models/__init__.py b/tests/test_models/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_backbones/__init__.py b/tests/test_models/test_backbones/__init__.py
new file mode 100644
index 0000000..8b673fa
--- /dev/null
+++ b/tests/test_models/test_backbones/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .utils import all_zeros, check_norm_state, is_block, is_norm
+
+__all__ = ['is_norm', 'is_block', 'all_zeros', 'check_norm_state']
diff --git a/tests/test_models/test_backbones/test_bisenetv1.py b/tests/test_models/test_backbones/test_bisenetv1.py
new file mode 100644
index 0000000..c067749
--- /dev/null
+++ b/tests/test_models/test_backbones/test_bisenetv1.py
@@ -0,0 +1,109 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import BiSeNetV1
+from mmseg.models.backbones.bisenetv1 import (AttentionRefinementModule,
+ ContextPath, FeatureFusionModule,
+ SpatialPath)
+
+
+def test_bisenetv1_backbone():
+ # Test BiSeNetV1 Standard Forward
+ backbone_cfg = dict(
+ type='ResNet',
+ in_channels=3,
+ depth=18,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 1, 1),
+ strides=(1, 2, 2, 2),
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True)
+ model = BiSeNetV1(in_channels=3, backbone_cfg=backbone_cfg)
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 64, 128)
+ feat = model(imgs)
+
+ assert len(feat) == 3
+ # output for segment Head
+ assert feat[0].shape == torch.Size([batch_size, 256, 8, 16])
+ # for auxiliary head 1
+ assert feat[1].shape == torch.Size([batch_size, 128, 8, 16])
+ # for auxiliary head 2
+ assert feat[2].shape == torch.Size([batch_size, 128, 4, 8])
+
+ # Test input with rare shape
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 95, 27)
+ feat = model(imgs)
+ assert len(feat) == 3
+
+ with pytest.raises(AssertionError):
+ # BiSeNetV1 spatial path channel constraints.
+ BiSeNetV1(
+ backbone_cfg=backbone_cfg,
+ in_channels=3,
+ spatial_channels=(16, 16, 16))
+
+ with pytest.raises(AssertionError):
+ # BiSeNetV1 context path constraints.
+ BiSeNetV1(
+ backbone_cfg=backbone_cfg,
+ in_channels=3,
+ context_channels=(16, 32, 64, 128))
+
+
+def test_bisenetv1_spatial_path():
+ with pytest.raises(AssertionError):
+ # BiSeNetV1 spatial path channel constraints.
+ SpatialPath(num_channels=(16, 16, 16), in_channels=3)
+
+
+def test_bisenetv1_context_path():
+ backbone_cfg = dict(
+ type='ResNet',
+ in_channels=3,
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 1, 1),
+ strides=(1, 2, 2, 2),
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True)
+
+ with pytest.raises(AssertionError):
+ # BiSeNetV1 context path constraints.
+ ContextPath(
+ backbone_cfg=backbone_cfg, context_channels=(16, 32, 64, 128))
+
+
+def test_bisenetv1_attention_refinement_module():
+ x_arm = AttentionRefinementModule(32, 8)
+ assert x_arm.conv_layer.in_channels == 32
+ assert x_arm.conv_layer.out_channels == 8
+ assert x_arm.conv_layer.kernel_size == (3, 3)
+ x = torch.randn(2, 32, 8, 16)
+ x_out = x_arm(x)
+ assert x_out.shape == torch.Size([2, 8, 8, 16])
+
+
+def test_bisenetv1_feature_fusion_module():
+ ffm = FeatureFusionModule(16, 32)
+ assert ffm.conv1.in_channels == 16
+ assert ffm.conv1.out_channels == 32
+ assert ffm.conv1.kernel_size == (1, 1)
+ assert ffm.gap.output_size == (1, 1)
+ assert ffm.conv_atten[0].in_channels == 32
+ assert ffm.conv_atten[0].out_channels == 32
+ assert ffm.conv_atten[0].kernel_size == (1, 1)
+
+ ffm = FeatureFusionModule(16, 16)
+ x1 = torch.randn(2, 8, 8, 16)
+ x2 = torch.randn(2, 8, 8, 16)
+ x_out = ffm(x1, x2)
+ assert x_out.shape == torch.Size([2, 16, 8, 16])
diff --git a/tests/test_models/test_backbones/test_bisenetv2.py b/tests/test_models/test_backbones/test_bisenetv2.py
new file mode 100644
index 0000000..cf2dfb3
--- /dev/null
+++ b/tests/test_models/test_backbones/test_bisenetv2.py
@@ -0,0 +1,57 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import ConvModule
+
+from mmseg.models.backbones import BiSeNetV2
+from mmseg.models.backbones.bisenetv2 import (BGALayer, DetailBranch,
+ SemanticBranch)
+
+
+def test_bisenetv2_backbone():
+ # Test BiSeNetV2 Standard Forward
+ model = BiSeNetV2()
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 128, 256)
+ feat = model(imgs)
+
+ assert len(feat) == 5
+ # output for segment Head
+ assert feat[0].shape == torch.Size([batch_size, 128, 16, 32])
+ # for auxiliary head 1
+ assert feat[1].shape == torch.Size([batch_size, 16, 32, 64])
+ # for auxiliary head 2
+ assert feat[2].shape == torch.Size([batch_size, 32, 16, 32])
+ # for auxiliary head 3
+ assert feat[3].shape == torch.Size([batch_size, 64, 8, 16])
+ # for auxiliary head 4
+ assert feat[4].shape == torch.Size([batch_size, 128, 4, 8])
+
+ # Test input with rare shape
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 95, 27)
+ feat = model(imgs)
+ assert len(feat) == 5
+
+
+def test_bisenetv2_DetailBranch():
+ x = torch.randn(1, 3, 32, 64)
+ detail_branch = DetailBranch(detail_channels=(64, 16, 32))
+ assert isinstance(detail_branch.detail_branch[0][0], ConvModule)
+ x_out = detail_branch(x)
+ assert x_out.shape == torch.Size([1, 32, 4, 8])
+
+
+def test_bisenetv2_SemanticBranch():
+ semantic_branch = SemanticBranch(semantic_channels=(16, 32, 64, 128))
+ assert semantic_branch.stage1.pool.stride == 2
+
+
+def test_bisenetv2_BGALayer():
+ x_a = torch.randn(1, 8, 8, 16)
+ x_b = torch.randn(1, 8, 2, 4)
+ bga = BGALayer(out_channels=8)
+ assert isinstance(bga.conv, ConvModule)
+ x_out = bga(x_a, x_b)
+ assert x_out.shape == torch.Size([1, 8, 8, 16])
diff --git a/tests/test_models/test_backbones/test_blocks.py b/tests/test_models/test_backbones/test_blocks.py
new file mode 100644
index 0000000..ad3ad2d
--- /dev/null
+++ b/tests/test_models/test_backbones/test_blocks.py
@@ -0,0 +1,170 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+import pytest
+import torch
+
+from mmseg.models.utils import (InvertedResidual, InvertedResidualV3, SELayer,
+ make_divisible)
+
+
+def test_make_divisible():
+ # test with min_value = None
+ assert make_divisible(10, 4) == 12
+ assert make_divisible(9, 4) == 12
+ assert make_divisible(1, 4) == 4
+
+ # test with min_value = 8
+ assert make_divisible(10, 4, 8) == 12
+ assert make_divisible(9, 4, 8) == 12
+ assert make_divisible(1, 4, 8) == 8
+
+
+def test_inv_residual():
+ with pytest.raises(AssertionError):
+ # test stride assertion.
+ InvertedResidual(32, 32, 3, 4)
+
+ # test default config with res connection.
+ # set expand_ratio = 4, stride = 1 and inp=oup.
+ inv_module = InvertedResidual(32, 32, 1, 4)
+ assert inv_module.use_res_connect
+ assert inv_module.conv[0].kernel_size == (1, 1)
+ assert inv_module.conv[0].padding == 0
+ assert inv_module.conv[1].kernel_size == (3, 3)
+ assert inv_module.conv[1].padding == 1
+ assert inv_module.conv[0].with_norm
+ assert inv_module.conv[1].with_norm
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 64, 64)
+
+ # test inv_residual module without res connection.
+ # set expand_ratio = 4, stride = 2.
+ inv_module = InvertedResidual(32, 32, 2, 4)
+ assert not inv_module.use_res_connect
+ assert inv_module.conv[0].kernel_size == (1, 1)
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 32, 32)
+
+ # test expand_ratio == 1
+ inv_module = InvertedResidual(32, 32, 1, 1)
+ assert inv_module.conv[0].kernel_size == (3, 3)
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 64, 64)
+
+ # test with checkpoint forward
+ inv_module = InvertedResidual(32, 32, 1, 1, with_cp=True)
+ assert inv_module.with_cp
+ x = torch.rand(1, 32, 64, 64, requires_grad=True)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 64, 64)
+
+
+def test_inv_residualv3():
+ with pytest.raises(AssertionError):
+ # test stride assertion.
+ InvertedResidualV3(32, 32, 16, stride=3)
+
+ with pytest.raises(AssertionError):
+ # test assertion.
+ InvertedResidualV3(32, 32, 16, with_expand_conv=False)
+
+ # test with se_cfg=None, with_expand_conv=False
+ inv_module = InvertedResidualV3(32, 32, 32, with_expand_conv=False)
+
+ assert inv_module.with_res_shortcut is True
+ assert inv_module.with_se is False
+ assert inv_module.with_expand_conv is False
+ assert not hasattr(inv_module, 'expand_conv')
+ assert isinstance(inv_module.depthwise_conv.conv, torch.nn.Conv2d)
+ assert inv_module.depthwise_conv.conv.kernel_size == (3, 3)
+ assert inv_module.depthwise_conv.conv.stride == (1, 1)
+ assert inv_module.depthwise_conv.conv.padding == (1, 1)
+ assert isinstance(inv_module.depthwise_conv.bn, torch.nn.BatchNorm2d)
+ assert isinstance(inv_module.depthwise_conv.activate, torch.nn.ReLU)
+ assert inv_module.linear_conv.conv.kernel_size == (1, 1)
+ assert inv_module.linear_conv.conv.stride == (1, 1)
+ assert inv_module.linear_conv.conv.padding == (0, 0)
+ assert isinstance(inv_module.linear_conv.bn, torch.nn.BatchNorm2d)
+
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 32, 64, 64)
+
+ # test with se_cfg and with_expand_conv
+ se_cfg = dict(
+ channels=16,
+ ratio=4,
+ act_cfg=(dict(type='ReLU'),
+ dict(type='HSigmoid', bias=3.0, divisor=6.0)))
+ act_cfg = dict(type='HSwish')
+ inv_module = InvertedResidualV3(
+ 32, 40, 16, 3, 2, se_cfg=se_cfg, act_cfg=act_cfg)
+ assert inv_module.with_res_shortcut is False
+ assert inv_module.with_se is True
+ assert inv_module.with_expand_conv is True
+ assert inv_module.expand_conv.conv.kernel_size == (1, 1)
+ assert inv_module.expand_conv.conv.stride == (1, 1)
+ assert inv_module.expand_conv.conv.padding == (0, 0)
+ assert isinstance(inv_module.expand_conv.activate, mmcv.cnn.HSwish)
+
+ assert isinstance(inv_module.depthwise_conv.conv,
+ mmcv.cnn.bricks.Conv2dAdaptivePadding)
+ assert inv_module.depthwise_conv.conv.kernel_size == (3, 3)
+ assert inv_module.depthwise_conv.conv.stride == (2, 2)
+ assert inv_module.depthwise_conv.conv.padding == (0, 0)
+ assert isinstance(inv_module.depthwise_conv.bn, torch.nn.BatchNorm2d)
+ assert isinstance(inv_module.depthwise_conv.activate, mmcv.cnn.HSwish)
+ assert inv_module.linear_conv.conv.kernel_size == (1, 1)
+ assert inv_module.linear_conv.conv.stride == (1, 1)
+ assert inv_module.linear_conv.conv.padding == (0, 0)
+ assert isinstance(inv_module.linear_conv.bn, torch.nn.BatchNorm2d)
+ x = torch.rand(1, 32, 64, 64)
+ output = inv_module(x)
+ assert output.shape == (1, 40, 32, 32)
+
+ # test with checkpoint forward
+ inv_module = InvertedResidualV3(
+ 32, 40, 16, 3, 2, se_cfg=se_cfg, act_cfg=act_cfg, with_cp=True)
+ assert inv_module.with_cp
+ x = torch.randn(2, 32, 64, 64, requires_grad=True)
+ output = inv_module(x)
+ assert output.shape == (2, 40, 32, 32)
+
+
+def test_se_layer():
+ with pytest.raises(AssertionError):
+ # test act_cfg assertion.
+ SELayer(32, act_cfg=(dict(type='ReLU'), ))
+
+ # test config with channels = 16.
+ se_layer = SELayer(16)
+ assert se_layer.conv1.conv.kernel_size == (1, 1)
+ assert se_layer.conv1.conv.stride == (1, 1)
+ assert se_layer.conv1.conv.padding == (0, 0)
+ assert isinstance(se_layer.conv1.activate, torch.nn.ReLU)
+ assert se_layer.conv2.conv.kernel_size == (1, 1)
+ assert se_layer.conv2.conv.stride == (1, 1)
+ assert se_layer.conv2.conv.padding == (0, 0)
+ assert isinstance(se_layer.conv2.activate, mmcv.cnn.HSigmoid)
+
+ x = torch.rand(1, 16, 64, 64)
+ output = se_layer(x)
+ assert output.shape == (1, 16, 64, 64)
+
+ # test config with channels = 16, act_cfg = dict(type='ReLU').
+ se_layer = SELayer(16, act_cfg=dict(type='ReLU'))
+ assert se_layer.conv1.conv.kernel_size == (1, 1)
+ assert se_layer.conv1.conv.stride == (1, 1)
+ assert se_layer.conv1.conv.padding == (0, 0)
+ assert isinstance(se_layer.conv1.activate, torch.nn.ReLU)
+ assert se_layer.conv2.conv.kernel_size == (1, 1)
+ assert se_layer.conv2.conv.stride == (1, 1)
+ assert se_layer.conv2.conv.padding == (0, 0)
+ assert isinstance(se_layer.conv2.activate, torch.nn.ReLU)
+
+ x = torch.rand(1, 16, 64, 64)
+ output = se_layer(x)
+ assert output.shape == (1, 16, 64, 64)
diff --git a/tests/test_models/test_backbones/test_cgnet.py b/tests/test_models/test_backbones/test_cgnet.py
new file mode 100644
index 0000000..f938525
--- /dev/null
+++ b/tests/test_models/test_backbones/test_cgnet.py
@@ -0,0 +1,151 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import CGNet
+from mmseg.models.backbones.cgnet import (ContextGuidedBlock,
+ GlobalContextExtractor)
+
+
+def test_cgnet_GlobalContextExtractor():
+ block = GlobalContextExtractor(16, 16, with_cp=True)
+ x = torch.randn(2, 16, 64, 64, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([2, 16, 64, 64])
+
+
+def test_cgnet_context_guided_block():
+ with pytest.raises(AssertionError):
+ # cgnet ContextGuidedBlock GlobalContextExtractor channel and reduction
+ # constraints.
+ ContextGuidedBlock(8, 8)
+
+ # test cgnet ContextGuidedBlock with checkpoint forward
+ block = ContextGuidedBlock(
+ 16, 16, act_cfg=dict(type='PReLU'), with_cp=True)
+ assert block.with_cp
+ x = torch.randn(2, 16, 64, 64, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([2, 16, 64, 64])
+
+ # test cgnet ContextGuidedBlock without checkpoint forward
+ block = ContextGuidedBlock(32, 32)
+ assert not block.with_cp
+ x = torch.randn(3, 32, 32, 32)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([3, 32, 32, 32])
+
+ # test cgnet ContextGuidedBlock with down sampling
+ block = ContextGuidedBlock(32, 32, downsample=True)
+ assert block.conv1x1.conv.in_channels == 32
+ assert block.conv1x1.conv.out_channels == 32
+ assert block.conv1x1.conv.kernel_size == (3, 3)
+ assert block.conv1x1.conv.stride == (2, 2)
+ assert block.conv1x1.conv.padding == (1, 1)
+
+ assert block.f_loc.in_channels == 32
+ assert block.f_loc.out_channels == 32
+ assert block.f_loc.kernel_size == (3, 3)
+ assert block.f_loc.stride == (1, 1)
+ assert block.f_loc.padding == (1, 1)
+ assert block.f_loc.groups == 32
+ assert block.f_loc.dilation == (1, 1)
+ assert block.f_loc.bias is None
+
+ assert block.f_sur.in_channels == 32
+ assert block.f_sur.out_channels == 32
+ assert block.f_sur.kernel_size == (3, 3)
+ assert block.f_sur.stride == (1, 1)
+ assert block.f_sur.padding == (2, 2)
+ assert block.f_sur.groups == 32
+ assert block.f_sur.dilation == (2, 2)
+ assert block.f_sur.bias is None
+
+ assert block.bottleneck.in_channels == 64
+ assert block.bottleneck.out_channels == 32
+ assert block.bottleneck.kernel_size == (1, 1)
+ assert block.bottleneck.stride == (1, 1)
+ assert block.bottleneck.bias is None
+
+ x = torch.randn(1, 32, 32, 32)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 16, 16])
+
+ # test cgnet ContextGuidedBlock without down sampling
+ block = ContextGuidedBlock(32, 32, downsample=False)
+ assert block.conv1x1.conv.in_channels == 32
+ assert block.conv1x1.conv.out_channels == 16
+ assert block.conv1x1.conv.kernel_size == (1, 1)
+ assert block.conv1x1.conv.stride == (1, 1)
+ assert block.conv1x1.conv.padding == (0, 0)
+
+ assert block.f_loc.in_channels == 16
+ assert block.f_loc.out_channels == 16
+ assert block.f_loc.kernel_size == (3, 3)
+ assert block.f_loc.stride == (1, 1)
+ assert block.f_loc.padding == (1, 1)
+ assert block.f_loc.groups == 16
+ assert block.f_loc.dilation == (1, 1)
+ assert block.f_loc.bias is None
+
+ assert block.f_sur.in_channels == 16
+ assert block.f_sur.out_channels == 16
+ assert block.f_sur.kernel_size == (3, 3)
+ assert block.f_sur.stride == (1, 1)
+ assert block.f_sur.padding == (2, 2)
+ assert block.f_sur.groups == 16
+ assert block.f_sur.dilation == (2, 2)
+ assert block.f_sur.bias is None
+
+ x = torch.randn(1, 32, 32, 32)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 32, 32])
+
+
+def test_cgnet_backbone():
+ with pytest.raises(AssertionError):
+ # check invalid num_channels
+ CGNet(num_channels=(32, 64, 128, 256))
+
+ with pytest.raises(AssertionError):
+ # check invalid num_blocks
+ CGNet(num_blocks=(3, 21, 3))
+
+ with pytest.raises(AssertionError):
+ # check invalid dilation
+ CGNet(num_blocks=2)
+
+ with pytest.raises(AssertionError):
+ # check invalid reduction
+ CGNet(reductions=16)
+
+ with pytest.raises(AssertionError):
+ # check invalid num_channels and reduction
+ CGNet(num_channels=(32, 64, 128), reductions=(64, 129))
+
+ # Test CGNet with default settings
+ model = CGNet()
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([2, 35, 112, 112])
+ assert feat[1].shape == torch.Size([2, 131, 56, 56])
+ assert feat[2].shape == torch.Size([2, 256, 28, 28])
+
+ # Test CGNet with norm_eval True and with_cp True
+ model = CGNet(norm_eval=True, with_cp=True)
+ with pytest.raises(TypeError):
+ # check invalid pretrained
+ model.init_weights(pretrained=8)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([2, 35, 112, 112])
+ assert feat[1].shape == torch.Size([2, 131, 56, 56])
+ assert feat[2].shape == torch.Size([2, 256, 28, 28])
diff --git a/tests/test_models/test_backbones/test_erfnet.py b/tests/test_models/test_backbones/test_erfnet.py
new file mode 100644
index 0000000..6ae7345
--- /dev/null
+++ b/tests/test_models/test_backbones/test_erfnet.py
@@ -0,0 +1,146 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import ERFNet
+from mmseg.models.backbones.erfnet import (DownsamplerBlock, NonBottleneck1d,
+ UpsamplerBlock)
+
+
+def test_erfnet_backbone():
+ # Test ERFNet Standard Forward.
+ model = ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 256, 512)
+ output = model(imgs)
+
+ # output for segment Head
+ assert output[0].shape == torch.Size([batch_size, 16, 128, 256])
+
+ # Test input with rare shape
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 527, 279)
+ output = model(imgs)
+ assert len(output[0]) == batch_size
+
+ with pytest.raises(AssertionError):
+ # Number of encoder downsample block and decoder upsample block.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(128, 64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ with pytest.raises(AssertionError):
+ # Number of encoder downsample block and encoder Non-bottleneck block.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8, 10),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ with pytest.raises(AssertionError):
+ # Number of encoder downsample block and
+ # channels of encoder Non-bottleneck block.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128, 256),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+
+ with pytest.raises(AssertionError):
+ # Number of encoder Non-bottleneck block and number of its channels.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8, 3),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ with pytest.raises(AssertionError):
+ # Number of decoder upsample block and decoder Non-bottleneck block.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2, 3),
+ dec_non_bottleneck_channels=(64, 16),
+ dropout_ratio=0.1,
+ )
+ with pytest.raises(AssertionError):
+ # Number of decoder Non-bottleneck block and number of its channels.
+ ERFNet(
+ in_channels=3,
+ enc_downsample_channels=(16, 64, 128),
+ enc_stage_non_bottlenecks=(5, 8),
+ enc_non_bottleneck_dilations=(2, 4, 8, 16),
+ enc_non_bottleneck_channels=(64, 128),
+ dec_upsample_channels=(64, 16),
+ dec_stages_non_bottleneck=(2, 2),
+ dec_non_bottleneck_channels=(64, 16, 8),
+ dropout_ratio=0.1,
+ )
+
+
+def test_erfnet_downsampler_block():
+ x_db = DownsamplerBlock(16, 64)
+ assert x_db.conv.in_channels == 16
+ assert x_db.conv.out_channels == 48
+ assert len(x_db.bn.weight) == 64
+ assert x_db.pool.kernel_size == 2
+ assert x_db.pool.stride == 2
+
+
+def test_erfnet_non_bottleneck_1d():
+ x_nb1d = NonBottleneck1d(16, 0, 1)
+ assert x_nb1d.convs_layers[0].in_channels == 16
+ assert x_nb1d.convs_layers[0].out_channels == 16
+ assert x_nb1d.convs_layers[2].in_channels == 16
+ assert x_nb1d.convs_layers[2].out_channels == 16
+ assert x_nb1d.convs_layers[5].in_channels == 16
+ assert x_nb1d.convs_layers[5].out_channels == 16
+ assert x_nb1d.convs_layers[7].in_channels == 16
+ assert x_nb1d.convs_layers[7].out_channels == 16
+ assert x_nb1d.convs_layers[9].p == 0
+
+
+def test_erfnet_upsampler_block():
+ x_ub = UpsamplerBlock(64, 16)
+ assert x_ub.conv.in_channels == 64
+ assert x_ub.conv.out_channels == 16
+ assert len(x_ub.bn.weight) == 16
diff --git a/tests/test_models/test_backbones/test_fast_scnn.py b/tests/test_models/test_backbones/test_fast_scnn.py
new file mode 100644
index 0000000..7ee638b
--- /dev/null
+++ b/tests/test_models/test_backbones/test_fast_scnn.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import FastSCNN
+
+
+def test_fastscnn_backbone():
+ with pytest.raises(AssertionError):
+ # Fast-SCNN channel constraints.
+ FastSCNN(
+ 3, (32, 48),
+ 64, (64, 96, 128), (2, 2, 1),
+ global_out_channels=127,
+ higher_in_channels=64,
+ lower_in_channels=128)
+
+ # Test FastSCNN Standard Forward
+ model = FastSCNN(
+ in_channels=3,
+ downsample_dw_channels=(4, 6),
+ global_in_channels=8,
+ global_block_channels=(8, 12, 16),
+ global_block_strides=(2, 2, 1),
+ global_out_channels=16,
+ higher_in_channels=8,
+ lower_in_channels=16,
+ fusion_out_channels=16,
+ )
+ model.init_weights()
+ model.train()
+ batch_size = 4
+ imgs = torch.randn(batch_size, 3, 64, 128)
+ feat = model(imgs)
+
+ assert len(feat) == 3
+ # higher-res
+ assert feat[0].shape == torch.Size([batch_size, 8, 8, 16])
+ # lower-res
+ assert feat[1].shape == torch.Size([batch_size, 16, 2, 4])
+ # FFM output
+ assert feat[2].shape == torch.Size([batch_size, 16, 8, 16])
diff --git a/tests/test_models/test_backbones/test_hrnet.py b/tests/test_models/test_backbones/test_hrnet.py
new file mode 100644
index 0000000..8329c84
--- /dev/null
+++ b/tests/test_models/test_backbones/test_hrnet.py
@@ -0,0 +1,144 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from mmseg.models.backbones.hrnet import HRModule, HRNet
+from mmseg.models.backbones.resnet import BasicBlock, Bottleneck
+
+
+@pytest.mark.parametrize('block', [BasicBlock, Bottleneck])
+def test_hrmodule(block):
+ # Test multiscale forward
+ num_channles = (32, 64)
+ in_channels = [c * block.expansion for c in num_channles]
+ hrmodule = HRModule(
+ num_branches=2,
+ blocks=block,
+ in_channels=in_channels,
+ num_blocks=(4, 4),
+ num_channels=num_channles,
+ )
+
+ feats = [
+ torch.randn(1, in_channels[0], 64, 64),
+ torch.randn(1, in_channels[1], 32, 32)
+ ]
+ feats = hrmodule(feats)
+
+ assert len(feats) == 2
+ assert feats[0].shape == torch.Size([1, in_channels[0], 64, 64])
+ assert feats[1].shape == torch.Size([1, in_channels[1], 32, 32])
+
+ # Test single scale forward
+ num_channles = (32, 64)
+ in_channels = [c * block.expansion for c in num_channles]
+ hrmodule = HRModule(
+ num_branches=2,
+ blocks=block,
+ in_channels=in_channels,
+ num_blocks=(4, 4),
+ num_channels=num_channles,
+ multiscale_output=False,
+ )
+
+ feats = [
+ torch.randn(1, in_channels[0], 64, 64),
+ torch.randn(1, in_channels[1], 32, 32)
+ ]
+ feats = hrmodule(feats)
+
+ assert len(feats) == 1
+ assert feats[0].shape == torch.Size([1, in_channels[0], 64, 64])
+
+
+def test_hrnet_backbone():
+ # only have 3 stages
+ extra = dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)))
+
+ with pytest.raises(AssertionError):
+ # HRNet now only support 4 stages
+ HRNet(extra=extra)
+ extra['stage4'] = dict(
+ num_modules=3,
+ num_branches=3, # should be 4
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))
+
+ with pytest.raises(AssertionError):
+ # len(num_blocks) should equal num_branches
+ HRNet(extra=extra)
+
+ extra['stage4']['num_branches'] = 4
+
+ # Test hrnetv2p_w32
+ model = HRNet(extra=extra)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 64, 64)
+ feats = model(imgs)
+ assert len(feats) == 4
+ assert feats[0].shape == torch.Size([1, 32, 16, 16])
+ assert feats[3].shape == torch.Size([1, 256, 2, 2])
+
+ # Test single scale output
+ model = HRNet(extra=extra, multiscale_output=False)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 64, 64)
+ feats = model(imgs)
+ assert len(feats) == 1
+ assert feats[0].shape == torch.Size([1, 32, 16, 16])
+
+ # Test HRNET with two stage frozen
+ frozen_stages = 2
+ model = HRNet(extra, frozen_stages=frozen_stages)
+ model.init_weights()
+ model.train()
+ assert model.norm1.training is False
+
+ for layer in [model.conv1, model.norm1]:
+ for param in layer.parameters():
+ assert param.requires_grad is False
+ for i in range(1, frozen_stages + 1):
+ if i == 1:
+ layer = getattr(model, f'layer{i}')
+ transition = getattr(model, f'transition{i}')
+ elif i == 4:
+ layer = getattr(model, f'stage{i}')
+ else:
+ layer = getattr(model, f'stage{i}')
+ transition = getattr(model, f'transition{i}')
+
+ for mod in layer.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in layer.parameters():
+ assert param.requires_grad is False
+
+ for mod in transition.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in transition.parameters():
+ assert param.requires_grad is False
diff --git a/tests/test_models/test_backbones/test_icnet.py b/tests/test_models/test_backbones/test_icnet.py
new file mode 100644
index 0000000..a96d8d8
--- /dev/null
+++ b/tests/test_models/test_backbones/test_icnet.py
@@ -0,0 +1,50 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import ICNet
+
+
+def test_icnet_backbone():
+ with pytest.raises(TypeError):
+ # Must give backbone dict in config file.
+ ICNet(
+ in_channels=3,
+ layer_channels=(128, 512),
+ light_branch_middle_channels=8,
+ psp_out_channels=128,
+ out_channels=(16, 128, 128),
+ backbone_cfg=None)
+
+ # Test ICNet Standard Forward
+ model = ICNet(
+ layer_channels=(128, 512),
+ backbone_cfg=dict(
+ type='ResNetV1c',
+ in_channels=3,
+ depth=18,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ )
+ assert hasattr(model.backbone,
+ 'maxpool') and model.backbone.maxpool.ceil_mode is True
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 32, 64)
+ feat = model(imgs)
+
+ assert model.psp_modules[0][0].output_size == 1
+ assert model.psp_modules[1][0].output_size == 2
+ assert model.psp_modules[2][0].output_size == 3
+ assert model.psp_bottleneck.padding == 1
+ assert model.conv_sub1[0].padding == 1
+
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([batch_size, 64, 4, 8])
diff --git a/tests/test_models/test_backbones/test_mit.py b/tests/test_models/test_backbones/test_mit.py
new file mode 100644
index 0000000..9eec1fa
--- /dev/null
+++ b/tests/test_models/test_backbones/test_mit.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import MixVisionTransformer
+from mmseg.models.backbones.mit import EfficientMultiheadAttention, MixFFN
+
+
+def test_mit():
+ with pytest.raises(TypeError):
+ # Pretrained represents pretrain url and must be str or None.
+ MixVisionTransformer(pretrained=123)
+
+ # Test normal input
+ H, W = (224, 224)
+ temp = torch.randn((1, 3, H, W))
+ model = MixVisionTransformer(
+ embed_dims=32, num_heads=[1, 2, 5, 8], out_indices=(0, 1, 2, 3))
+ model.init_weights()
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 160, H // 16, W // 16)
+ assert outs[3].shape == (1, 256, H // 32, W // 32)
+
+ # Test non-squared input
+ H, W = (224, 256)
+ temp = torch.randn((1, 3, H, W))
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 160, H // 16, W // 16)
+ assert outs[3].shape == (1, 256, H // 32, W // 32)
+
+ # Test MixFFN
+ FFN = MixFFN(64, 128)
+ hw_shape = (32, 32)
+ token_len = 32 * 32
+ temp = torch.randn((1, token_len, 64))
+ # Self identity
+ out = FFN(temp, hw_shape)
+ assert out.shape == (1, token_len, 64)
+ # Out identity
+ outs = FFN(temp, hw_shape, temp)
+ assert out.shape == (1, token_len, 64)
+
+ # Test EfficientMHA
+ MHA = EfficientMultiheadAttention(64, 2)
+ hw_shape = (32, 32)
+ token_len = 32 * 32
+ temp = torch.randn((1, token_len, 64))
+ # Self identity
+ out = MHA(temp, hw_shape)
+ assert out.shape == (1, token_len, 64)
+ # Out identity
+ outs = MHA(temp, hw_shape, temp)
+ assert out.shape == (1, token_len, 64)
+
+
+def test_mit_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = MixVisionTransformer(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = MixVisionTransformer(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = MixVisionTransformer(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = MixVisionTransformer(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ MixVisionTransformer(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ MixVisionTransformer(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ MixVisionTransformer(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ MixVisionTransformer(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ MixVisionTransformer(pretrained=123, init_cfg=123)
diff --git a/tests/test_models/test_backbones/test_mobilenet_v3.py b/tests/test_models/test_backbones/test_mobilenet_v3.py
new file mode 100644
index 0000000..769ee14
--- /dev/null
+++ b/tests/test_models/test_backbones/test_mobilenet_v3.py
@@ -0,0 +1,67 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import MobileNetV3
+
+
+def test_mobilenet_v3():
+ with pytest.raises(AssertionError):
+ # check invalid arch
+ MobileNetV3('big')
+
+ with pytest.raises(AssertionError):
+ # check invalid reduction_factor
+ MobileNetV3(reduction_factor=0)
+
+ with pytest.raises(ValueError):
+ # check invalid out_indices
+ MobileNetV3(out_indices=(0, 1, 15))
+
+ with pytest.raises(ValueError):
+ # check invalid frozen_stages
+ MobileNetV3(frozen_stages=15)
+
+ with pytest.raises(TypeError):
+ # check invalid pretrained
+ model = MobileNetV3()
+ model.init_weights(pretrained=8)
+
+ # Test MobileNetV3 with default settings
+ model = MobileNetV3()
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 56, 56)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == (2, 16, 28, 28)
+ assert feat[1].shape == (2, 16, 14, 14)
+ assert feat[2].shape == (2, 576, 7, 7)
+
+ # Test MobileNetV3 with arch = 'large'
+ model = MobileNetV3(arch='large', out_indices=(1, 3, 16))
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 56, 56)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == (2, 16, 28, 28)
+ assert feat[1].shape == (2, 24, 14, 14)
+ assert feat[2].shape == (2, 960, 7, 7)
+
+ # Test MobileNetV3 with norm_eval True, with_cp True and frozen_stages=5
+ model = MobileNetV3(norm_eval=True, with_cp=True, frozen_stages=5)
+ with pytest.raises(TypeError):
+ # check invalid pretrained
+ model.init_weights(pretrained=8)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 56, 56)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == (2, 16, 28, 28)
+ assert feat[1].shape == (2, 16, 14, 14)
+ assert feat[2].shape == (2, 576, 7, 7)
diff --git a/tests/test_models/test_backbones/test_resnest.py b/tests/test_models/test_backbones/test_resnest.py
new file mode 100644
index 0000000..3013f34
--- /dev/null
+++ b/tests/test_models/test_backbones/test_resnest.py
@@ -0,0 +1,44 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import ResNeSt
+from mmseg.models.backbones.resnest import Bottleneck as BottleneckS
+
+
+def test_resnest_bottleneck():
+ with pytest.raises(AssertionError):
+ # Style must be in ['pytorch', 'caffe']
+ BottleneckS(64, 64, radix=2, reduction_factor=4, style='tensorflow')
+
+ # Test ResNeSt Bottleneck structure
+ block = BottleneckS(
+ 64, 256, radix=2, reduction_factor=4, stride=2, style='pytorch')
+ assert block.avd_layer.stride == 2
+ assert block.conv2.channels == 256
+
+ # Test ResNeSt Bottleneck forward
+ block = BottleneckS(64, 16, radix=2, reduction_factor=4)
+ x = torch.randn(2, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([2, 64, 56, 56])
+
+
+def test_resnest_backbone():
+ with pytest.raises(KeyError):
+ # ResNeSt depth should be in [50, 101, 152, 200]
+ ResNeSt(depth=18)
+
+ # Test ResNeSt with radix 2, reduction_factor 4
+ model = ResNeSt(
+ depth=50, radix=2, reduction_factor=4, out_indices=(0, 1, 2, 3))
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(2, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([2, 256, 56, 56])
+ assert feat[1].shape == torch.Size([2, 512, 28, 28])
+ assert feat[2].shape == torch.Size([2, 1024, 14, 14])
+ assert feat[3].shape == torch.Size([2, 2048, 7, 7])
diff --git a/tests/test_models/test_backbones/test_resnet.py b/tests/test_models/test_backbones/test_resnet.py
new file mode 100644
index 0000000..fa632f5
--- /dev/null
+++ b/tests/test_models/test_backbones/test_resnet.py
@@ -0,0 +1,575 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+from mmcv.ops import DeformConv2dPack
+from mmcv.utils.parrots_wrapper import _BatchNorm
+from torch.nn.modules import AvgPool2d, GroupNorm
+
+from mmseg.models.backbones import ResNet, ResNetV1d
+from mmseg.models.backbones.resnet import BasicBlock, Bottleneck
+from mmseg.models.utils import ResLayer
+from .utils import all_zeros, check_norm_state, is_block, is_norm
+
+
+def test_resnet_basic_block():
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ BasicBlock(64, 64, dcn=dcn)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ BasicBlock(64, 64, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ BasicBlock(64, 64, plugins=plugins)
+
+ # Test BasicBlock with checkpoint forward
+ block = BasicBlock(16, 16, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 16, 28, 28)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 16, 28, 28])
+
+ # test BasicBlock structure and forward
+ block = BasicBlock(32, 32)
+ assert block.conv1.in_channels == 32
+ assert block.conv1.out_channels == 32
+ assert block.conv1.kernel_size == (3, 3)
+ assert block.conv2.in_channels == 32
+ assert block.conv2.out_channels == 32
+ assert block.conv2.kernel_size == (3, 3)
+ x = torch.randn(1, 32, 28, 28)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 28, 28])
+
+
+def test_resnet_bottleneck():
+ with pytest.raises(AssertionError):
+ # Style must be in ['pytorch', 'caffe']
+ Bottleneck(64, 64, style='tensorflow')
+
+ with pytest.raises(AssertionError):
+ # Allowed positions are 'after_conv1', 'after_conv2', 'after_conv3'
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv4')
+ ]
+ Bottleneck(64, 16, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Need to specify different postfix to avoid duplicate plugin name
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ Bottleneck(64, 16, plugins=plugins)
+
+ with pytest.raises(KeyError):
+ # Plugin type is not supported
+ plugins = [dict(cfg=dict(type='WrongPlugin'), position='after_conv3')]
+ Bottleneck(64, 16, plugins=plugins)
+
+ # Test Bottleneck with checkpoint forward
+ block = Bottleneck(64, 16, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck style
+ block = Bottleneck(64, 64, stride=2, style='pytorch')
+ assert block.conv1.stride == (1, 1)
+ assert block.conv2.stride == (2, 2)
+ block = Bottleneck(64, 64, stride=2, style='caffe')
+ assert block.conv1.stride == (2, 2)
+ assert block.conv2.stride == (1, 1)
+
+ # Test Bottleneck DCN
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ with pytest.raises(AssertionError):
+ Bottleneck(64, 64, dcn=dcn, conv_cfg=dict(type='Conv'))
+ block = Bottleneck(64, 64, dcn=dcn)
+ assert isinstance(block.conv2, DeformConv2dPack)
+
+ # Test Bottleneck forward
+ block = Bottleneck(64, 16)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck with 1 ContextBlock after conv3
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ block = Bottleneck(64, 16, plugins=plugins)
+ assert block.context_block.in_channels == 64
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck with 1 GeneralizedAttention after conv2
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ block = Bottleneck(64, 16, plugins=plugins)
+ assert block.gen_attention_block.in_channels == 16
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck with 1 GeneralizedAttention after conv2, 1 NonLocal2d
+ # after conv2, 1 ContextBlock after conv3
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2'),
+ dict(cfg=dict(type='NonLocal2d'), position='after_conv2'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ block = Bottleneck(64, 16, plugins=plugins)
+ assert block.gen_attention_block.in_channels == 16
+ assert block.nonlocal_block.in_channels == 16
+ assert block.context_block.in_channels == 64
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test Bottleneck with 1 ContextBlock after conv2, 2 ContextBlock after
+ # conv3
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=1),
+ position='after_conv2'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=2),
+ position='after_conv3'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=3),
+ position='after_conv3')
+ ]
+ block = Bottleneck(64, 16, plugins=plugins)
+ assert block.context_block1.in_channels == 16
+ assert block.context_block2.in_channels == 64
+ assert block.context_block3.in_channels == 64
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+
+def test_resnet_res_layer():
+ # Test ResLayer of 3 Bottleneck w\o downsample
+ layer = ResLayer(Bottleneck, 64, 16, 3)
+ assert len(layer) == 3
+ assert layer[0].conv1.in_channels == 64
+ assert layer[0].conv1.out_channels == 16
+ for i in range(1, len(layer)):
+ assert layer[i].conv1.in_channels == 64
+ assert layer[i].conv1.out_channels == 16
+ for i in range(len(layer)):
+ assert layer[i].downsample is None
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test ResLayer of 3 Bottleneck with downsample
+ layer = ResLayer(Bottleneck, 64, 64, 3)
+ assert layer[0].downsample[0].out_channels == 256
+ for i in range(1, len(layer)):
+ assert layer[i].downsample is None
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 256, 56, 56])
+
+ # Test ResLayer of 3 Bottleneck with stride=2
+ layer = ResLayer(Bottleneck, 64, 64, 3, stride=2)
+ assert layer[0].downsample[0].out_channels == 256
+ assert layer[0].downsample[0].stride == (2, 2)
+ for i in range(1, len(layer)):
+ assert layer[i].downsample is None
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 256, 28, 28])
+
+ # Test ResLayer of 3 Bottleneck with stride=2 and average downsample
+ layer = ResLayer(Bottleneck, 64, 64, 3, stride=2, avg_down=True)
+ assert isinstance(layer[0].downsample[0], AvgPool2d)
+ assert layer[0].downsample[1].out_channels == 256
+ assert layer[0].downsample[1].stride == (1, 1)
+ for i in range(1, len(layer)):
+ assert layer[i].downsample is None
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 256, 28, 28])
+
+ # Test ResLayer of 3 Bottleneck with dilation=2
+ layer = ResLayer(Bottleneck, 64, 16, 3, dilation=2)
+ for i in range(len(layer)):
+ assert layer[i].conv2.dilation == (2, 2)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test ResLayer of 3 Bottleneck with dilation=2, contract_dilation=True
+ layer = ResLayer(Bottleneck, 64, 16, 3, dilation=2, contract_dilation=True)
+ assert layer[0].conv2.dilation == (1, 1)
+ for i in range(1, len(layer)):
+ assert layer[i].conv2.dilation == (2, 2)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+ # Test ResLayer of 3 Bottleneck with dilation=2, multi_grid
+ layer = ResLayer(Bottleneck, 64, 16, 3, dilation=2, multi_grid=(1, 2, 4))
+ assert layer[0].conv2.dilation == (1, 1)
+ assert layer[1].conv2.dilation == (2, 2)
+ assert layer[2].conv2.dilation == (4, 4)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = layer(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+
+def test_resnet_backbone():
+ """Test resnet backbone."""
+ with pytest.raises(KeyError):
+ # ResNet depth should be in [18, 34, 50, 101, 152]
+ ResNet(20)
+
+ with pytest.raises(AssertionError):
+ # In ResNet: 1 <= num_stages <= 4
+ ResNet(50, num_stages=0)
+
+ with pytest.raises(AssertionError):
+ # len(stage_with_dcn) == num_stages
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ ResNet(50, dcn=dcn, stage_with_dcn=(True, ))
+
+ with pytest.raises(AssertionError):
+ # len(stage_with_plugin) == num_stages
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ stages=(False, True, True),
+ position='after_conv3')
+ ]
+ ResNet(50, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # In ResNet: 1 <= num_stages <= 4
+ ResNet(18, num_stages=5)
+
+ with pytest.raises(AssertionError):
+ # len(strides) == len(dilations) == num_stages
+ ResNet(18, strides=(1, ), dilations=(1, 1), num_stages=3)
+
+ with pytest.raises(TypeError):
+ # pretrained must be a string path
+ model = ResNet(18, pretrained=0)
+ model.init_weights()
+
+ with pytest.raises(AssertionError):
+ # Style must be in ['pytorch', 'caffe']
+ ResNet(50, style='tensorflow')
+
+ # Test ResNet18 norm_eval=True
+ model = ResNet(18, norm_eval=True)
+ model.init_weights()
+ model.train()
+ assert check_norm_state(model.modules(), False)
+
+ # Test ResNet18 with torchvision pretrained weight
+ model = ResNet(
+ depth=18, norm_eval=True, pretrained='torchvision://resnet18')
+ model.init_weights()
+ model.train()
+ assert check_norm_state(model.modules(), False)
+
+ # Test ResNet18 with first stage frozen
+ frozen_stages = 1
+ model = ResNet(18, frozen_stages=frozen_stages)
+ model.init_weights()
+ model.train()
+ assert model.norm1.training is False
+ for layer in [model.conv1, model.norm1]:
+ for param in layer.parameters():
+ assert param.requires_grad is False
+ for i in range(1, frozen_stages + 1):
+ layer = getattr(model, 'layer{}'.format(i))
+ for mod in layer.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in layer.parameters():
+ assert param.requires_grad is False
+
+ # Test ResNet18V1d with first stage frozen
+ model = ResNetV1d(depth=18, frozen_stages=frozen_stages)
+ assert len(model.stem) == 9
+ model.init_weights()
+ model.train()
+ check_norm_state(model.stem, False)
+ for param in model.stem.parameters():
+ assert param.requires_grad is False
+ for i in range(1, frozen_stages + 1):
+ layer = getattr(model, 'layer{}'.format(i))
+ for mod in layer.modules():
+ if isinstance(mod, _BatchNorm):
+ assert mod.training is False
+ for param in layer.parameters():
+ assert param.requires_grad is False
+
+ # Test ResNet18 forward
+ model = ResNet(18)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet18 with BatchNorm forward
+ model = ResNet(18)
+ for m in model.modules():
+ if is_norm(m):
+ assert isinstance(m, _BatchNorm)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet18 with layers 1, 2, 3 out forward
+ model = ResNet(18, out_indices=(0, 1, 2))
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 112, 112)
+ feat = model(imgs)
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([1, 64, 28, 28])
+ assert feat[1].shape == torch.Size([1, 128, 14, 14])
+ assert feat[2].shape == torch.Size([1, 256, 7, 7])
+
+ # Test ResNet18 with checkpoint forward
+ model = ResNet(18, with_cp=True)
+ for m in model.modules():
+ if is_block(m):
+ assert m.with_cp
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet18 with checkpoint forward
+ model = ResNet(18, with_cp=True)
+ for m in model.modules():
+ if is_block(m):
+ assert m.with_cp
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet18 with GroupNorm forward
+ model = ResNet(
+ 18, norm_cfg=dict(type='GN', num_groups=32, requires_grad=True))
+ for m in model.modules():
+ if is_norm(m):
+ assert isinstance(m, GroupNorm)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNet50 with 1 GeneralizedAttention after conv2, 1 NonLocal2d
+ # after conv2, 1 ContextBlock after conv3 in layers 2, 3, 4
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ stages=(False, True, True, True),
+ position='after_conv2'),
+ dict(cfg=dict(type='NonLocal2d'), position='after_conv2'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ stages=(False, True, True, False),
+ position='after_conv3')
+ ]
+ model = ResNet(50, plugins=plugins)
+ for m in model.layer1.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert not hasattr(m, 'gen_attention_block')
+ assert m.nonlocal_block.in_channels == 64
+ for m in model.layer2.modules():
+ if is_block(m):
+ assert m.nonlocal_block.in_channels == 128
+ assert m.gen_attention_block.in_channels == 128
+ assert m.context_block.in_channels == 512
+
+ for m in model.layer3.modules():
+ if is_block(m):
+ assert m.nonlocal_block.in_channels == 256
+ assert m.gen_attention_block.in_channels == 256
+ assert m.context_block.in_channels == 1024
+
+ for m in model.layer4.modules():
+ if is_block(m):
+ assert m.nonlocal_block.in_channels == 512
+ assert m.gen_attention_block.in_channels == 512
+ assert not hasattr(m, 'context_block')
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 256, 56, 56])
+ assert feat[1].shape == torch.Size([1, 512, 28, 28])
+ assert feat[2].shape == torch.Size([1, 1024, 14, 14])
+ assert feat[3].shape == torch.Size([1, 2048, 7, 7])
+
+ # Test ResNet50 with 1 ContextBlock after conv2, 1 ContextBlock after
+ # conv3 in layers 2, 3, 4
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=1),
+ stages=(False, True, True, False),
+ position='after_conv3'),
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16, postfix=2),
+ stages=(False, True, True, False),
+ position='after_conv3')
+ ]
+
+ model = ResNet(50, plugins=plugins)
+ for m in model.layer1.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert not hasattr(m, 'context_block1')
+ assert not hasattr(m, 'context_block2')
+ for m in model.layer2.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert m.context_block1.in_channels == 512
+ assert m.context_block2.in_channels == 512
+
+ for m in model.layer3.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert m.context_block1.in_channels == 1024
+ assert m.context_block2.in_channels == 1024
+
+ for m in model.layer4.modules():
+ if is_block(m):
+ assert not hasattr(m, 'context_block')
+ assert not hasattr(m, 'context_block1')
+ assert not hasattr(m, 'context_block2')
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 256, 56, 56])
+ assert feat[1].shape == torch.Size([1, 512, 28, 28])
+ assert feat[2].shape == torch.Size([1, 1024, 14, 14])
+ assert feat[3].shape == torch.Size([1, 2048, 7, 7])
+
+ # Test ResNet18 zero initialization of residual
+ model = ResNet(18, zero_init_residual=True)
+ model.init_weights()
+ for m in model.modules():
+ if isinstance(m, Bottleneck):
+ assert all_zeros(m.norm3)
+ elif isinstance(m, BasicBlock):
+ assert all_zeros(m.norm2)
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
+
+ # Test ResNetV1d forward
+ model = ResNetV1d(depth=18)
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 64, 56, 56])
+ assert feat[1].shape == torch.Size([1, 128, 28, 28])
+ assert feat[2].shape == torch.Size([1, 256, 14, 14])
+ assert feat[3].shape == torch.Size([1, 512, 7, 7])
diff --git a/tests/test_models/test_backbones/test_resnext.py b/tests/test_models/test_backbones/test_resnext.py
new file mode 100644
index 0000000..2aecaf0
--- /dev/null
+++ b/tests/test_models/test_backbones/test_resnext.py
@@ -0,0 +1,62 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import ResNeXt
+from mmseg.models.backbones.resnext import Bottleneck as BottleneckX
+from .utils import is_block
+
+
+def test_renext_bottleneck():
+ with pytest.raises(AssertionError):
+ # Style must be in ['pytorch', 'caffe']
+ BottleneckX(64, 64, groups=32, base_width=4, style='tensorflow')
+
+ # Test ResNeXt Bottleneck structure
+ block = BottleneckX(
+ 64, 64, groups=32, base_width=4, stride=2, style='pytorch')
+ assert block.conv2.stride == (2, 2)
+ assert block.conv2.groups == 32
+ assert block.conv2.out_channels == 128
+
+ # Test ResNeXt Bottleneck with DCN
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ with pytest.raises(AssertionError):
+ # conv_cfg must be None if dcn is not None
+ BottleneckX(
+ 64,
+ 64,
+ groups=32,
+ base_width=4,
+ dcn=dcn,
+ conv_cfg=dict(type='Conv'))
+ BottleneckX(64, 64, dcn=dcn)
+
+ # Test ResNeXt Bottleneck forward
+ block = BottleneckX(64, 16, groups=32, base_width=4)
+ x = torch.randn(1, 64, 56, 56)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 64, 56, 56])
+
+
+def test_resnext_backbone():
+ with pytest.raises(KeyError):
+ # ResNeXt depth should be in [50, 101, 152]
+ ResNeXt(depth=18)
+
+ # Test ResNeXt with group 32, base_width 4
+ model = ResNeXt(depth=50, groups=32, base_width=4)
+ print(model)
+ for m in model.modules():
+ if is_block(m):
+ assert m.conv2.groups == 32
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert len(feat) == 4
+ assert feat[0].shape == torch.Size([1, 256, 56, 56])
+ assert feat[1].shape == torch.Size([1, 512, 28, 28])
+ assert feat[2].shape == torch.Size([1, 1024, 14, 14])
+ assert feat[3].shape == torch.Size([1, 2048, 7, 7])
diff --git a/tests/test_models/test_backbones/test_stdc.py b/tests/test_models/test_backbones/test_stdc.py
new file mode 100644
index 0000000..1e3862b
--- /dev/null
+++ b/tests/test_models/test_backbones/test_stdc.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import STDCContextPathNet
+from mmseg.models.backbones.stdc import (AttentionRefinementModule,
+ FeatureFusionModule, STDCModule,
+ STDCNet)
+
+
+def test_stdc_context_path_net():
+ # Test STDCContextPathNet Standard Forward
+ model = STDCContextPathNet(
+ backbone_cfg=dict(
+ type='STDCNet',
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=True),
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(in_channels=384, out_channels=256, scale_factor=4))
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 256, 512)
+ feat = model(imgs)
+
+ assert len(feat) == 4
+ # output for segment Head
+ assert feat[0].shape == torch.Size([batch_size, 256, 32, 64])
+ # for auxiliary head 1
+ assert feat[1].shape == torch.Size([batch_size, 128, 16, 32])
+ # for auxiliary head 2
+ assert feat[2].shape == torch.Size([batch_size, 128, 32, 64])
+ # for auxiliary head 3
+ assert feat[3].shape == torch.Size([batch_size, 256, 32, 64])
+
+ # Test input with rare shape
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 527, 279)
+ model = STDCContextPathNet(
+ backbone_cfg=dict(
+ type='STDCNet',
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='add',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False),
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(in_channels=384, out_channels=256, scale_factor=4))
+ model.init_weights()
+ model.train()
+ feat = model(imgs)
+ assert len(feat) == 4
+
+
+def test_stdcnet():
+ with pytest.raises(AssertionError):
+ # STDC backbone constraints.
+ STDCNet(
+ stdc_type='STDCNet3',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False)
+
+ with pytest.raises(AssertionError):
+ # STDC bottleneck type constraints.
+ STDCNet(
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='dog',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False)
+
+ with pytest.raises(AssertionError):
+ # STDC channels length constraints.
+ STDCNet(
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(16, 32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False)
+
+
+def test_feature_fusion_module():
+ x_ffm = FeatureFusionModule(in_channels=64, out_channels=32)
+ assert x_ffm.conv0.in_channels == 64
+ assert x_ffm.attention[1].in_channels == 32
+ assert x_ffm.attention[2].in_channels == 8
+ assert x_ffm.attention[2].out_channels == 32
+ x1 = torch.randn(2, 32, 32, 64)
+ x2 = torch.randn(2, 32, 32, 64)
+ x_out = x_ffm(x1, x2)
+ assert x_out.shape == torch.Size([2, 32, 32, 64])
+
+
+def test_attention_refinement_module():
+ x_arm = AttentionRefinementModule(128, 32)
+ assert x_arm.conv_layer.in_channels == 128
+ assert x_arm.atten_conv_layer[1].conv.out_channels == 32
+ x = torch.randn(2, 128, 32, 64)
+ x_out = x_arm(x)
+ assert x_out.shape == torch.Size([2, 32, 32, 64])
+
+
+def test_stdc_module():
+ x_stdc = STDCModule(in_channels=32, out_channels=32, stride=4)
+ assert x_stdc.layers[0].conv.in_channels == 32
+ assert x_stdc.layers[3].conv.out_channels == 4
+ x = torch.randn(2, 32, 32, 64)
+ x_out = x_stdc(x)
+ assert x_out.shape == torch.Size([2, 32, 32, 64])
diff --git a/tests/test_models/test_backbones/test_swin.py b/tests/test_models/test_backbones/test_swin.py
new file mode 100644
index 0000000..4690001
--- /dev/null
+++ b/tests/test_models/test_backbones/test_swin.py
@@ -0,0 +1,99 @@
+import pytest
+import torch
+
+from mmseg.models.backbones.swin import SwinBlock, SwinTransformer
+
+
+def test_swin_block():
+ # test SwinBlock structure and forward
+ block = SwinBlock(embed_dims=32, num_heads=4, feedforward_channels=128)
+ assert block.ffn.embed_dims == 32
+ assert block.attn.w_msa.num_heads == 4
+ assert block.ffn.feedforward_channels == 128
+ x = torch.randn(1, 56 * 56, 32)
+ x_out = block(x, (56, 56))
+ assert x_out.shape == torch.Size([1, 56 * 56, 32])
+
+ # Test BasicBlock with checkpoint forward
+ block = SwinBlock(
+ embed_dims=64, num_heads=4, feedforward_channels=256, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 56 * 56, 64)
+ x_out = block(x, (56, 56))
+ assert x_out.shape == torch.Size([1, 56 * 56, 64])
+
+
+def test_swin_transformer():
+ """Test Swin Transformer backbone."""
+
+ with pytest.raises(TypeError):
+ # Pretrained arg must be str or None.
+ SwinTransformer(pretrained=123)
+
+ with pytest.raises(AssertionError):
+ # Because swin uses non-overlapping patch embed, so the stride of patch
+ # embed must be equal to patch size.
+ SwinTransformer(strides=(2, 2, 2, 2), patch_size=4)
+
+ # test pretrained image size
+ with pytest.raises(AssertionError):
+ SwinTransformer(pretrain_img_size=(112, 112, 112))
+
+ # Test absolute position embedding
+ temp = torch.randn((1, 3, 112, 112))
+ model = SwinTransformer(pretrain_img_size=112, use_abs_pos_embed=True)
+ model.init_weights()
+ model(temp)
+
+ # Test patch norm
+ model = SwinTransformer(patch_norm=False)
+ model(temp)
+
+ # Test normal inference
+ temp = torch.randn((1, 3, 256, 256))
+ model = SwinTransformer()
+ outs = model(temp)
+ assert outs[0].shape == (1, 96, 64, 64)
+ assert outs[1].shape == (1, 192, 32, 32)
+ assert outs[2].shape == (1, 384, 16, 16)
+ assert outs[3].shape == (1, 768, 8, 8)
+
+ # Test abnormal inference size
+ temp = torch.randn((1, 3, 255, 255))
+ model = SwinTransformer()
+ outs = model(temp)
+ assert outs[0].shape == (1, 96, 64, 64)
+ assert outs[1].shape == (1, 192, 32, 32)
+ assert outs[2].shape == (1, 384, 16, 16)
+ assert outs[3].shape == (1, 768, 8, 8)
+
+ # Test abnormal inference size
+ temp = torch.randn((1, 3, 112, 137))
+ model = SwinTransformer()
+ outs = model(temp)
+ assert outs[0].shape == (1, 96, 28, 35)
+ assert outs[1].shape == (1, 192, 14, 18)
+ assert outs[2].shape == (1, 384, 7, 9)
+ assert outs[3].shape == (1, 768, 4, 5)
+
+ # Test frozen
+ model = SwinTransformer(frozen_stages=4)
+ model.train()
+ for p in model.parameters():
+ assert not p.requires_grad
+
+ # Test absolute position embedding frozen
+ model = SwinTransformer(frozen_stages=4, use_abs_pos_embed=True)
+ model.train()
+ for p in model.parameters():
+ assert not p.requires_grad
+
+ # Test Swin with checkpoint forward
+ temp = torch.randn((1, 3, 56, 56))
+ model = SwinTransformer(with_cp=True)
+ for m in model.modules():
+ if isinstance(m, SwinBlock):
+ assert m.with_cp
+ model.init_weights()
+ model.train()
+ model(temp)
diff --git a/tests/test_models/test_backbones/test_timm_backbone.py b/tests/test_models/test_backbones/test_timm_backbone.py
new file mode 100644
index 0000000..85ef9aa
--- /dev/null
+++ b/tests/test_models/test_backbones/test_timm_backbone.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import TIMMBackbone
+from .utils import check_norm_state
+
+
+def test_timm_backbone():
+ with pytest.raises(TypeError):
+ # pretrained must be a string path
+ model = TIMMBackbone()
+ model.init_weights(pretrained=0)
+
+ # Test different norm_layer, can be: 'SyncBN', 'BN2d', 'GN', 'LN', 'IN'
+ # Test resnet18 from timm, norm_layer='BN2d'
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=32,
+ norm_layer='BN2d')
+
+ # Test resnet18 from timm, norm_layer='SyncBN'
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=32,
+ norm_layer='SyncBN')
+
+ # Test resnet18 from timm, features_only=True, output_stride=32
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=32)
+ model.init_weights()
+ model.train()
+ assert check_norm_state(model.modules(), True)
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 112, 112))
+ assert feats[1] == torch.Size((1, 64, 56, 56))
+ assert feats[2] == torch.Size((1, 128, 28, 28))
+ assert feats[3] == torch.Size((1, 256, 14, 14))
+ assert feats[4] == torch.Size((1, 512, 7, 7))
+
+ # Test resnet18 from timm, features_only=True, output_stride=16
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=16)
+ imgs = torch.randn(1, 3, 224, 224)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 112, 112))
+ assert feats[1] == torch.Size((1, 64, 56, 56))
+ assert feats[2] == torch.Size((1, 128, 28, 28))
+ assert feats[3] == torch.Size((1, 256, 14, 14))
+ assert feats[4] == torch.Size((1, 512, 14, 14))
+
+ # Test resnet18 from timm, features_only=True, output_stride=8
+ model = TIMMBackbone(
+ model_name='resnet18',
+ features_only=True,
+ pretrained=False,
+ output_stride=8)
+ imgs = torch.randn(1, 3, 224, 224)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 112, 112))
+ assert feats[1] == torch.Size((1, 64, 56, 56))
+ assert feats[2] == torch.Size((1, 128, 28, 28))
+ assert feats[3] == torch.Size((1, 256, 28, 28))
+ assert feats[4] == torch.Size((1, 512, 28, 28))
+
+ # Test efficientnet_b1 with pretrained weights
+ model = TIMMBackbone(model_name='efficientnet_b1', pretrained=True)
+
+ # Test resnetv2_50x1_bitm from timm, features_only=True, output_stride=8
+ model = TIMMBackbone(
+ model_name='resnetv2_50x1_bitm',
+ features_only=True,
+ pretrained=False,
+ output_stride=8)
+ imgs = torch.randn(1, 3, 8, 8)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 4, 4))
+ assert feats[1] == torch.Size((1, 256, 2, 2))
+ assert feats[2] == torch.Size((1, 512, 1, 1))
+ assert feats[3] == torch.Size((1, 1024, 1, 1))
+ assert feats[4] == torch.Size((1, 2048, 1, 1))
+
+ # Test resnetv2_50x3_bitm from timm, features_only=True, output_stride=8
+ model = TIMMBackbone(
+ model_name='resnetv2_50x3_bitm',
+ features_only=True,
+ pretrained=False,
+ output_stride=8)
+ imgs = torch.randn(1, 3, 8, 8)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 192, 4, 4))
+ assert feats[1] == torch.Size((1, 768, 2, 2))
+ assert feats[2] == torch.Size((1, 1536, 1, 1))
+ assert feats[3] == torch.Size((1, 3072, 1, 1))
+ assert feats[4] == torch.Size((1, 6144, 1, 1))
+
+ # Test resnetv2_101x1_bitm from timm, features_only=True, output_stride=8
+ model = TIMMBackbone(
+ model_name='resnetv2_101x1_bitm',
+ features_only=True,
+ pretrained=False,
+ output_stride=8)
+ imgs = torch.randn(1, 3, 8, 8)
+ feats = model(imgs)
+ feats = [feat.shape for feat in feats]
+ assert len(feats) == 5
+ assert feats[0] == torch.Size((1, 64, 4, 4))
+ assert feats[1] == torch.Size((1, 256, 2, 2))
+ assert feats[2] == torch.Size((1, 512, 1, 1))
+ assert feats[3] == torch.Size((1, 1024, 1, 1))
+ assert feats[4] == torch.Size((1, 2048, 1, 1))
diff --git a/tests/test_models/test_backbones/test_twins.py b/tests/test_models/test_backbones/test_twins.py
new file mode 100644
index 0000000..c7d4a8e
--- /dev/null
+++ b/tests/test_models/test_backbones/test_twins.py
@@ -0,0 +1,170 @@
+import pytest
+import torch
+
+from mmseg.models.backbones.twins import (PCPVT, SVT,
+ ConditionalPositionEncoding,
+ LocallyGroupedSelfAttention)
+
+
+def test_pcpvt():
+ # Test normal input
+ H, W = (224, 224)
+ temp = torch.randn((1, 3, H, W))
+ model = PCPVT(
+ embed_dims=[32, 64, 160, 256],
+ num_heads=[1, 2, 5, 8],
+ mlp_ratios=[8, 8, 4, 4],
+ qkv_bias=True,
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False)
+ model.init_weights()
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 160, H // 16, W // 16)
+ assert outs[3].shape == (1, 256, H // 32, W // 32)
+
+
+def test_svt():
+ # Test normal input
+ H, W = (224, 224)
+ temp = torch.randn((1, 3, H, W))
+ model = SVT(
+ embed_dims=[32, 64, 128],
+ num_heads=[1, 2, 4],
+ mlp_ratios=[4, 4, 4],
+ qkv_bias=False,
+ depths=[4, 4, 4],
+ windiow_sizes=[7, 7, 7],
+ norm_after_stage=True)
+
+ model.init_weights()
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 128, H // 16, W // 16)
+
+
+def test_svt_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = SVT(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = SVT(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = SVT(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = SVT(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = SVT(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ model = SVT(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ model = SVT(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = SVT(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ model = SVT(pretrained=123, init_cfg=123)
+
+
+def test_pcpvt_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = PCPVT(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = PCPVT(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = PCPVT(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = PCPVT(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = PCPVT(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ model = PCPVT(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ model = PCPVT(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = PCPVT(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ model = PCPVT(pretrained=123, init_cfg=123)
+
+
+def test_locallygrouped_self_attention_module():
+ LSA = LocallyGroupedSelfAttention(embed_dims=32, window_size=3)
+ outs = LSA(torch.randn(1, 3136, 32), (56, 56))
+ assert outs.shape == torch.Size([1, 3136, 32])
+
+
+def test_conditional_position_encoding_module():
+ CPE = ConditionalPositionEncoding(in_channels=32, embed_dims=32, stride=2)
+ outs = CPE(torch.randn(1, 3136, 32), (56, 56))
+ assert outs.shape == torch.Size([1, 784, 32])
diff --git a/tests/test_models/test_backbones/test_unet.py b/tests/test_models/test_backbones/test_unet.py
new file mode 100644
index 0000000..9beb727
--- /dev/null
+++ b/tests/test_models/test_backbones/test_unet.py
@@ -0,0 +1,822 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+from mmcv.cnn import ConvModule
+
+from mmseg.models.backbones.unet import (BasicConvBlock, DeconvModule,
+ InterpConv, UNet, UpConvBlock)
+from mmseg.ops import Upsample
+from .utils import check_norm_state
+
+
+def test_unet_basic_conv_block():
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ BasicConvBlock(64, 64, dcn=dcn)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ BasicConvBlock(64, 64, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ BasicConvBlock(64, 64, plugins=plugins)
+
+ # test BasicConvBlock with checkpoint forward
+ block = BasicConvBlock(16, 16, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 16, 64, 64, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 16, 64, 64])
+
+ block = BasicConvBlock(16, 16, with_cp=False)
+ assert not block.with_cp
+ x = torch.randn(1, 16, 64, 64)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 16, 64, 64])
+
+ # test BasicConvBlock with stride convolution to downsample
+ block = BasicConvBlock(16, 16, stride=2)
+ x = torch.randn(1, 16, 64, 64)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 16, 32, 32])
+
+ # test BasicConvBlock structure and forward
+ block = BasicConvBlock(16, 64, num_convs=3, dilation=3)
+ assert block.convs[0].conv.in_channels == 16
+ assert block.convs[0].conv.out_channels == 64
+ assert block.convs[0].conv.kernel_size == (3, 3)
+ assert block.convs[0].conv.dilation == (1, 1)
+ assert block.convs[0].conv.padding == (1, 1)
+
+ assert block.convs[1].conv.in_channels == 64
+ assert block.convs[1].conv.out_channels == 64
+ assert block.convs[1].conv.kernel_size == (3, 3)
+ assert block.convs[1].conv.dilation == (3, 3)
+ assert block.convs[1].conv.padding == (3, 3)
+
+ assert block.convs[2].conv.in_channels == 64
+ assert block.convs[2].conv.out_channels == 64
+ assert block.convs[2].conv.kernel_size == (3, 3)
+ assert block.convs[2].conv.dilation == (3, 3)
+ assert block.convs[2].conv.padding == (3, 3)
+
+
+def test_deconv_module():
+ with pytest.raises(AssertionError):
+ # kernel_size should be greater than or equal to scale_factor and
+ # (kernel_size - scale_factor) should be even numbers
+ DeconvModule(64, 32, kernel_size=1, scale_factor=2)
+
+ with pytest.raises(AssertionError):
+ # kernel_size should be greater than or equal to scale_factor and
+ # (kernel_size - scale_factor) should be even numbers
+ DeconvModule(64, 32, kernel_size=3, scale_factor=2)
+
+ with pytest.raises(AssertionError):
+ # kernel_size should be greater than or equal to scale_factor and
+ # (kernel_size - scale_factor) should be even numbers
+ DeconvModule(64, 32, kernel_size=5, scale_factor=4)
+
+ # test DeconvModule with checkpoint forward and upsample 2X.
+ block = DeconvModule(64, 32, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 64, 128, 128, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ block = DeconvModule(64, 32, with_cp=False)
+ assert not block.with_cp
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test DeconvModule with different kernel size for upsample 2X.
+ x = torch.randn(1, 64, 64, 64)
+ block = DeconvModule(64, 32, kernel_size=2, scale_factor=2)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 128, 128])
+
+ block = DeconvModule(64, 32, kernel_size=6, scale_factor=2)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 128, 128])
+
+ # test DeconvModule with different kernel size for upsample 4X.
+ x = torch.randn(1, 64, 64, 64)
+ block = DeconvModule(64, 32, kernel_size=4, scale_factor=4)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ block = DeconvModule(64, 32, kernel_size=6, scale_factor=4)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+
+def test_interp_conv():
+ # test InterpConv with checkpoint forward and upsample 2X.
+ block = InterpConv(64, 32, with_cp=True)
+ assert block.with_cp
+ x = torch.randn(1, 64, 128, 128, requires_grad=True)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ block = InterpConv(64, 32, with_cp=False)
+ assert not block.with_cp
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test InterpConv with conv_first=False for upsample 2X.
+ block = InterpConv(64, 32, conv_first=False)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert isinstance(block.interp_upsample[0], Upsample)
+ assert isinstance(block.interp_upsample[1], ConvModule)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test InterpConv with conv_first=True for upsample 2X.
+ block = InterpConv(64, 32, conv_first=True)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert isinstance(block.interp_upsample[0], ConvModule)
+ assert isinstance(block.interp_upsample[1], Upsample)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test InterpConv with bilinear upsample for upsample 2X.
+ block = InterpConv(
+ 64,
+ 32,
+ conv_first=False,
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False))
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert isinstance(block.interp_upsample[0], Upsample)
+ assert isinstance(block.interp_upsample[1], ConvModule)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+ assert block.interp_upsample[0].mode == 'bilinear'
+
+ # test InterpConv with nearest upsample for upsample 2X.
+ block = InterpConv(
+ 64,
+ 32,
+ conv_first=False,
+ upsample_cfg=dict(scale_factor=2, mode='nearest'))
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(x)
+ assert isinstance(block.interp_upsample[0], Upsample)
+ assert isinstance(block.interp_upsample[1], ConvModule)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+ assert block.interp_upsample[0].mode == 'nearest'
+
+
+def test_up_conv_block():
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ UpConvBlock(BasicConvBlock, 64, 32, 32, dcn=dcn)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ UpConvBlock(BasicConvBlock, 64, 32, 32, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ UpConvBlock(BasicConvBlock, 64, 32, 32, plugins=plugins)
+
+ # test UpConvBlock with checkpoint forward and upsample 2X.
+ block = UpConvBlock(BasicConvBlock, 64, 32, 32, with_cp=True)
+ skip_x = torch.randn(1, 32, 256, 256, requires_grad=True)
+ x = torch.randn(1, 64, 128, 128, requires_grad=True)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test UpConvBlock with upsample=True for upsample 2X. The spatial size of
+ # skip_x is 2X larger than x.
+ block = UpConvBlock(
+ BasicConvBlock, 64, 32, 32, upsample_cfg=dict(type='InterpConv'))
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test UpConvBlock with upsample=False for upsample 2X. The spatial size of
+ # skip_x is the same as that of x.
+ block = UpConvBlock(BasicConvBlock, 64, 32, 32, upsample_cfg=None)
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 256, 256)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test UpConvBlock with different upsample method for upsample 2X.
+ # The upsample method is interpolation upsample (bilinear or nearest).
+ block = UpConvBlock(
+ BasicConvBlock,
+ 64,
+ 32,
+ 32,
+ upsample_cfg=dict(
+ type='InterpConv',
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False)))
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test UpConvBlock with different upsample method for upsample 2X.
+ # The upsample method is deconvolution upsample.
+ block = UpConvBlock(
+ BasicConvBlock,
+ 64,
+ 32,
+ 32,
+ upsample_cfg=dict(type='DeconvModule', kernel_size=4, scale_factor=2))
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ # test BasicConvBlock structure and forward
+ block = UpConvBlock(
+ conv_block=BasicConvBlock,
+ in_channels=64,
+ skip_channels=32,
+ out_channels=32,
+ num_convs=3,
+ dilation=3,
+ upsample_cfg=dict(
+ type='InterpConv',
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False)))
+ skip_x = torch.randn(1, 32, 256, 256)
+ x = torch.randn(1, 64, 128, 128)
+ x_out = block(skip_x, x)
+ assert x_out.shape == torch.Size([1, 32, 256, 256])
+
+ assert block.conv_block.convs[0].conv.in_channels == 64
+ assert block.conv_block.convs[0].conv.out_channels == 32
+ assert block.conv_block.convs[0].conv.kernel_size == (3, 3)
+ assert block.conv_block.convs[0].conv.dilation == (1, 1)
+ assert block.conv_block.convs[0].conv.padding == (1, 1)
+
+ assert block.conv_block.convs[1].conv.in_channels == 32
+ assert block.conv_block.convs[1].conv.out_channels == 32
+ assert block.conv_block.convs[1].conv.kernel_size == (3, 3)
+ assert block.conv_block.convs[1].conv.dilation == (3, 3)
+ assert block.conv_block.convs[1].conv.padding == (3, 3)
+
+ assert block.conv_block.convs[2].conv.in_channels == 32
+ assert block.conv_block.convs[2].conv.out_channels == 32
+ assert block.conv_block.convs[2].conv.kernel_size == (3, 3)
+ assert block.conv_block.convs[2].conv.dilation == (3, 3)
+ assert block.conv_block.convs[2].conv.padding == (3, 3)
+
+ assert block.upsample.interp_upsample[1].conv.in_channels == 64
+ assert block.upsample.interp_upsample[1].conv.out_channels == 32
+ assert block.upsample.interp_upsample[1].conv.kernel_size == (1, 1)
+ assert block.upsample.interp_upsample[1].conv.dilation == (1, 1)
+ assert block.upsample.interp_upsample[1].conv.padding == (0, 0)
+
+
+def test_unet():
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ dcn = dict(type='DCN', deform_groups=1, fallback_on_stride=False)
+ UNet(3, 64, 5, dcn=dcn)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet.
+ plugins = [
+ dict(
+ cfg=dict(type='ContextBlock', ratio=1. / 16),
+ position='after_conv3')
+ ]
+ UNet(3, 64, 5, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Not implemented yet
+ plugins = [
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0010',
+ kv_stride=2),
+ position='after_conv2')
+ ]
+ UNet(3, 64, 5, plugins=plugins)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=4,
+ strides=(1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2),
+ downsamples=(True, True, True),
+ enc_dilations=(1, 1, 1, 1),
+ dec_dilations=(1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 16.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 2, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check whether the input image size can be divisible by the whole
+ # downsample rate of the encoder. The whole downsample rate of this
+ # case is 32.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=6,
+ strides=(1, 1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2, 2),
+ downsamples=(True, True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1, 1))
+ x = torch.randn(2, 3, 65, 65)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(strides)=num_stages
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(enc_num_convs)=num_stages
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(dec_num_convs)=num_stages-1
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(downsamples)=num_stages-1
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(enc_dilations)=num_stages
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ with pytest.raises(AssertionError):
+ # Check if num_stages matches strides, len(dec_dilations)=num_stages-1
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1, 1))
+ x = torch.randn(2, 3, 64, 64)
+ unet(x)
+
+ # test UNet norm_eval=True
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ norm_eval=True)
+ unet.train()
+ assert check_norm_state(unet.modules(), False)
+
+ # test UNet norm_eval=False
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ norm_eval=False)
+ unet.train()
+ assert check_norm_state(unet.modules(), True)
+
+ # test UNet forward and outputs. The whole downsample rate is 16.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 8, 8])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 2, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 4.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 4.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 4.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 2.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, False, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 64, 64])
+ assert x_outs[1].shape == torch.Size([2, 32, 64, 64])
+ assert x_outs[2].shape == torch.Size([2, 16, 64, 64])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 1.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(False, False, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 128, 128])
+ assert x_outs[1].shape == torch.Size([2, 32, 128, 128])
+ assert x_outs[2].shape == torch.Size([2, 16, 128, 128])
+ assert x_outs[3].shape == torch.Size([2, 8, 128, 128])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 16.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 8, 8])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 8.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 2, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 16, 16])
+ assert x_outs[1].shape == torch.Size([2, 32, 16, 16])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet forward and outputs. The whole downsample rate is 4.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1))
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
+
+ # test UNet init_weights method.
+ unet = UNet(
+ in_channels=3,
+ base_channels=4,
+ num_stages=5,
+ strides=(1, 2, 2, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, False, False),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ pretrained=None)
+ unet.init_weights()
+ x = torch.randn(2, 3, 128, 128)
+ x_outs = unet(x)
+ assert x_outs[0].shape == torch.Size([2, 64, 32, 32])
+ assert x_outs[1].shape == torch.Size([2, 32, 32, 32])
+ assert x_outs[2].shape == torch.Size([2, 16, 32, 32])
+ assert x_outs[3].shape == torch.Size([2, 8, 64, 64])
+ assert x_outs[4].shape == torch.Size([2, 4, 128, 128])
diff --git a/tests/test_models/test_backbones/test_vit.py b/tests/test_models/test_backbones/test_vit.py
new file mode 100644
index 0000000..4ce860c
--- /dev/null
+++ b/tests/test_models/test_backbones/test_vit.py
@@ -0,0 +1,176 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones.vit import VisionTransformer
+from .utils import check_norm_state
+
+
+def test_vit_backbone():
+ with pytest.raises(TypeError):
+ # pretrained must be a string path
+ model = VisionTransformer()
+ model.init_weights(pretrained=0)
+
+ with pytest.raises(TypeError):
+ # img_size must be int or tuple
+ model = VisionTransformer(img_size=512.0)
+
+ with pytest.raises(TypeError):
+ # out_indices must be int ,list or tuple
+ model = VisionTransformer(out_indices=1.)
+
+ with pytest.raises(TypeError):
+ # test upsample_pos_embed function
+ x = torch.randn(1, 196)
+ VisionTransformer.resize_pos_embed(x, 512, 512, 224, 224, 'bilinear')
+
+ with pytest.raises(AssertionError):
+ # The length of img_size tuple must be lower than 3.
+ VisionTransformer(img_size=(224, 224, 224))
+
+ with pytest.raises(TypeError):
+ # Pretrained must be None or Str.
+ VisionTransformer(pretrained=123)
+
+ with pytest.raises(AssertionError):
+ # with_cls_token must be True when output_cls_token == True
+ VisionTransformer(with_cls_token=False, output_cls_token=True)
+
+ # Test img_size isinstance tuple
+ imgs = torch.randn(1, 3, 224, 224)
+ model = VisionTransformer(img_size=(224, ))
+ model.init_weights()
+ model(imgs)
+
+ # Test img_size isinstance tuple
+ imgs = torch.randn(1, 3, 224, 224)
+ model = VisionTransformer(img_size=(224, 224))
+ model(imgs)
+
+ # Test norm_eval = True
+ model = VisionTransformer(norm_eval=True)
+ model.train()
+
+ # Test ViT backbone with input size of 224 and patch size of 16
+ model = VisionTransformer()
+ model.init_weights()
+ model.train()
+
+ assert check_norm_state(model.modules(), True)
+
+ # Test normal size input image
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test large size input image
+ imgs = torch.randn(1, 3, 256, 256)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 16, 16)
+
+ # Test small size input image
+ imgs = torch.randn(1, 3, 32, 32)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 2, 2)
+
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test unbalanced size input image
+ imgs = torch.randn(1, 3, 112, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 7, 14)
+
+ # Test irregular input image
+ imgs = torch.randn(1, 3, 234, 345)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 15, 22)
+
+ # Test with_cp=True
+ model = VisionTransformer(with_cp=True)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test with_cls_token=False
+ model = VisionTransformer(with_cls_token=False)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test final norm
+ model = VisionTransformer(final_norm=True)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test patch norm
+ model = VisionTransformer(patch_norm=True)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[-1].shape == (1, 768, 14, 14)
+
+ # Test output_cls_token
+ model = VisionTransformer(with_cls_token=True, output_cls_token=True)
+ imgs = torch.randn(1, 3, 224, 224)
+ feat = model(imgs)
+ assert feat[0][0].shape == (1, 768, 14, 14)
+ assert feat[0][1].shape == (1, 768)
+
+
+def test_vit_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = VisionTransformer(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = VisionTransformer(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = VisionTransformer(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = VisionTransformer(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = VisionTransformer(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ model = VisionTransformer(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ model = VisionTransformer(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = VisionTransformer(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ model = VisionTransformer(pretrained=123, init_cfg=123)
diff --git a/tests/test_models/test_backbones/utils.py b/tests/test_models/test_backbones/utils.py
new file mode 100644
index 0000000..54b6404
--- /dev/null
+++ b/tests/test_models/test_backbones/utils.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from torch.nn.modules import GroupNorm
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmseg.models.backbones.resnet import BasicBlock, Bottleneck
+from mmseg.models.backbones.resnext import Bottleneck as BottleneckX
+
+
+def is_block(modules):
+ """Check if is ResNet building block."""
+ if isinstance(modules, (BasicBlock, Bottleneck, BottleneckX)):
+ return True
+ return False
+
+
+def is_norm(modules):
+ """Check if is one of the norms."""
+ if isinstance(modules, (GroupNorm, _BatchNorm)):
+ return True
+ return False
+
+
+def all_zeros(modules):
+ """Check if the weight(and bias) is all zero."""
+ weight_zero = torch.allclose(modules.weight.data,
+ torch.zeros_like(modules.weight.data))
+ if hasattr(modules, 'bias'):
+ bias_zero = torch.allclose(modules.bias.data,
+ torch.zeros_like(modules.bias.data))
+ else:
+ bias_zero = True
+
+ return weight_zero and bias_zero
+
+
+def check_norm_state(modules, train_state):
+ """Check if norm layer is in correct train state."""
+ for mod in modules:
+ if isinstance(mod, _BatchNorm):
+ if mod.training != train_state:
+ return False
+ return True
diff --git a/tests/test_models/test_forward.py b/tests/test_models/test_forward.py
new file mode 100644
index 0000000..ee707b3
--- /dev/null
+++ b/tests/test_models/test_forward.py
@@ -0,0 +1,235 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""pytest tests/test_forward.py."""
+import copy
+from os.path import dirname, exists, join
+from unittest.mock import patch
+
+import numpy as np
+import pytest
+import torch
+import torch.nn as nn
+from mmcv.cnn.utils import revert_sync_batchnorm
+
+
+def _demo_mm_inputs(input_shape=(2, 3, 8, 16), num_classes=10):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+
+ rng = np.random.RandomState(0)
+
+ imgs = rng.rand(*input_shape)
+ segs = rng.randint(
+ low=0, high=num_classes - 1, size=(N, 1, H, W)).astype(np.uint8)
+
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': 1.0,
+ 'flip': False,
+ 'flip_direction': 'horizontal'
+ } for _ in range(N)]
+
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs),
+ 'img_metas': img_metas,
+ 'gt_semantic_seg': torch.LongTensor(segs)
+ }
+ return mm_inputs
+
+
+def _get_config_directory():
+ """Find the predefined segmentor config directory."""
+ try:
+ # Assume we are running in the source mmsegmentation repo
+ repo_dpath = dirname(dirname(dirname(__file__)))
+ except NameError:
+ # For IPython development when this __file__ is not defined
+ import mmseg
+ repo_dpath = dirname(dirname(dirname(mmseg.__file__)))
+ config_dpath = join(repo_dpath, 'configs')
+ if not exists(config_dpath):
+ raise Exception('Cannot find config path')
+ return config_dpath
+
+
+def _get_config_module(fname):
+ """Load a configuration as a python module."""
+ from mmcv import Config
+ config_dpath = _get_config_directory()
+ config_fpath = join(config_dpath, fname)
+ config_mod = Config.fromfile(config_fpath)
+ return config_mod
+
+
+def _get_segmentor_cfg(fname):
+ """Grab configs necessary to create a segmentor.
+
+ These are deep copied to allow for safe modification of parameters without
+ influencing other tests.
+ """
+ config = _get_config_module(fname)
+ model = copy.deepcopy(config.model)
+ return model
+
+
+def test_pspnet_forward():
+ _test_encoder_decoder_forward(
+ 'pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_fcn_forward():
+ _test_encoder_decoder_forward('fcn/fcn_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_deeplabv3_forward():
+ _test_encoder_decoder_forward(
+ 'deeplabv3/deeplabv3_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_deeplabv3plus_forward():
+ _test_encoder_decoder_forward(
+ 'deeplabv3plus/deeplabv3plus_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_gcnet_forward():
+ _test_encoder_decoder_forward(
+ 'gcnet/gcnet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_ann_forward():
+ _test_encoder_decoder_forward('ann/ann_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_ccnet_forward():
+ if not torch.cuda.is_available():
+ pytest.skip('CCNet requires CUDA')
+ _test_encoder_decoder_forward(
+ 'ccnet/ccnet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_danet_forward():
+ _test_encoder_decoder_forward(
+ 'danet/danet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_nonlocal_net_forward():
+ _test_encoder_decoder_forward(
+ 'nonlocal_net/nonlocal_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_upernet_forward():
+ _test_encoder_decoder_forward(
+ 'upernet/upernet_r50_512x1024_40k_cityscapes.py')
+
+
+def test_hrnet_forward():
+ _test_encoder_decoder_forward('hrnet/fcn_hr18s_512x1024_40k_cityscapes.py')
+
+
+def test_ocrnet_forward():
+ _test_encoder_decoder_forward(
+ 'ocrnet/ocrnet_hr18s_512x1024_40k_cityscapes.py')
+
+
+def test_psanet_forward():
+ _test_encoder_decoder_forward(
+ 'psanet/psanet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_encnet_forward():
+ _test_encoder_decoder_forward(
+ 'encnet/encnet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_sem_fpn_forward():
+ _test_encoder_decoder_forward('sem_fpn/fpn_r50_512x1024_80k_cityscapes.py')
+
+
+def test_point_rend_forward():
+ _test_encoder_decoder_forward(
+ 'point_rend/pointrend_r50_512x1024_80k_cityscapes.py')
+
+
+def test_mobilenet_v2_forward():
+ _test_encoder_decoder_forward(
+ 'mobilenet_v2/pspnet_m-v2-d8_512x1024_80k_cityscapes.py')
+
+
+def test_dnlnet_forward():
+ _test_encoder_decoder_forward(
+ 'dnlnet/dnl_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def test_emanet_forward():
+ _test_encoder_decoder_forward(
+ 'emanet/emanet_r50-d8_512x1024_80k_cityscapes.py')
+
+
+def test_isanet_forward():
+ _test_encoder_decoder_forward(
+ 'isanet/isanet_r50-d8_512x1024_40k_cityscapes.py')
+
+
+def get_world_size(process_group):
+
+ return 1
+
+
+def _check_input_dim(self, inputs):
+ pass
+
+
+@patch('torch.nn.modules.batchnorm._BatchNorm._check_input_dim',
+ _check_input_dim)
+@patch('torch.distributed.get_world_size', get_world_size)
+def _test_encoder_decoder_forward(cfg_file):
+ model = _get_segmentor_cfg(cfg_file)
+ model['pretrained'] = None
+ model['test_cfg']['mode'] = 'whole'
+
+ from mmseg.models import build_segmentor
+ segmentor = build_segmentor(model)
+ segmentor.init_weights()
+
+ if isinstance(segmentor.decode_head, nn.ModuleList):
+ num_classes = segmentor.decode_head[-1].num_classes
+ else:
+ num_classes = segmentor.decode_head.num_classes
+ # batch_size=2 for BatchNorm
+ input_shape = (2, 3, 32, 32)
+ mm_inputs = _demo_mm_inputs(input_shape, num_classes=num_classes)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ gt_semantic_seg = mm_inputs['gt_semantic_seg']
+
+ # convert to cuda Tensor if applicable
+ if torch.cuda.is_available():
+ segmentor = segmentor.cuda()
+ imgs = imgs.cuda()
+ gt_semantic_seg = gt_semantic_seg.cuda()
+ else:
+ segmentor = revert_sync_batchnorm(segmentor)
+
+ # Test forward train
+ losses = segmentor.forward(
+ imgs, img_metas, gt_semantic_seg=gt_semantic_seg, return_loss=True)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ with torch.no_grad():
+ segmentor.eval()
+ # pack into lists
+ img_list = [img[None, :] for img in imgs]
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ segmentor.forward(img_list, img_meta_list, return_loss=False)
diff --git a/tests/test_models/test_heads/__init__.py b/tests/test_models/test_heads/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/test_heads/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_heads/test_ann_head.py b/tests/test_models/test_heads/test_ann_head.py
new file mode 100644
index 0000000..c1e44bc
--- /dev/null
+++ b/tests/test_models/test_heads/test_ann_head.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import ANNHead
+from .utils import to_cuda
+
+
+def test_ann_head():
+
+ inputs = [torch.randn(1, 4, 45, 45), torch.randn(1, 8, 21, 21)]
+ head = ANNHead(
+ in_channels=[4, 8],
+ channels=2,
+ num_classes=19,
+ in_index=[-2, -1],
+ project_channels=8)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 21, 21)
diff --git a/tests/test_models/test_heads/test_apc_head.py b/tests/test_models/test_heads/test_apc_head.py
new file mode 100644
index 0000000..dc55ccc
--- /dev/null
+++ b/tests/test_models/test_heads/test_apc_head.py
@@ -0,0 +1,59 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import APCHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_apc_head():
+
+ with pytest.raises(AssertionError):
+ # pool_scales must be list|tuple
+ APCHead(in_channels=8, channels=2, num_classes=19, pool_scales=1)
+
+ # test no norm_cfg
+ head = APCHead(in_channels=8, channels=2, num_classes=19)
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = APCHead(
+ in_channels=8,
+ channels=2,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ # fusion=True
+ inputs = [torch.randn(1, 8, 45, 45)]
+ head = APCHead(
+ in_channels=8,
+ channels=2,
+ num_classes=19,
+ pool_scales=(1, 2, 3),
+ fusion=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.fusion is True
+ assert head.acm_modules[0].pool_scale == 1
+ assert head.acm_modules[1].pool_scale == 2
+ assert head.acm_modules[2].pool_scale == 3
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
+
+ # fusion=False
+ inputs = [torch.randn(1, 8, 45, 45)]
+ head = APCHead(
+ in_channels=8,
+ channels=2,
+ num_classes=19,
+ pool_scales=(1, 2, 3),
+ fusion=False)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.fusion is False
+ assert head.acm_modules[0].pool_scale == 1
+ assert head.acm_modules[1].pool_scale == 2
+ assert head.acm_modules[2].pool_scale == 3
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
diff --git a/tests/test_models/test_heads/test_aspp_head.py b/tests/test_models/test_heads/test_aspp_head.py
new file mode 100644
index 0000000..db9e893
--- /dev/null
+++ b/tests/test_models/test_heads/test_aspp_head.py
@@ -0,0 +1,76 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import ASPPHead, DepthwiseSeparableASPPHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_aspp_head():
+
+ with pytest.raises(AssertionError):
+ # pool_scales must be list|tuple
+ ASPPHead(in_channels=8, channels=4, num_classes=19, dilations=1)
+
+ # test no norm_cfg
+ head = ASPPHead(in_channels=8, channels=4, num_classes=19)
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = ASPPHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ inputs = [torch.randn(1, 8, 45, 45)]
+ head = ASPPHead(
+ in_channels=8, channels=4, num_classes=19, dilations=(1, 12, 24))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.aspp_modules[0].conv.dilation == (1, 1)
+ assert head.aspp_modules[1].conv.dilation == (12, 12)
+ assert head.aspp_modules[2].conv.dilation == (24, 24)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
+
+
+def test_dw_aspp_head():
+
+ # test w.o. c1
+ inputs = [torch.randn(1, 8, 45, 45)]
+ head = DepthwiseSeparableASPPHead(
+ c1_in_channels=0,
+ c1_channels=0,
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ dilations=(1, 12, 24))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.c1_bottleneck is None
+ assert head.aspp_modules[0].conv.dilation == (1, 1)
+ assert head.aspp_modules[1].depthwise_conv.dilation == (12, 12)
+ assert head.aspp_modules[2].depthwise_conv.dilation == (24, 24)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
+
+ # test with c1
+ inputs = [torch.randn(1, 4, 45, 45), torch.randn(1, 16, 21, 21)]
+ head = DepthwiseSeparableASPPHead(
+ c1_in_channels=4,
+ c1_channels=2,
+ in_channels=16,
+ channels=8,
+ num_classes=19,
+ dilations=(1, 12, 24))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.c1_bottleneck.in_channels == 4
+ assert head.c1_bottleneck.out_channels == 2
+ assert head.aspp_modules[0].conv.dilation == (1, 1)
+ assert head.aspp_modules[1].depthwise_conv.dilation == (12, 12)
+ assert head.aspp_modules[2].depthwise_conv.dilation == (24, 24)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
diff --git a/tests/test_models/test_heads/test_cc_head.py b/tests/test_models/test_heads/test_cc_head.py
new file mode 100644
index 0000000..0630417
--- /dev/null
+++ b/tests/test_models/test_heads/test_cc_head.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import CCHead
+from .utils import to_cuda
+
+
+def test_cc_head():
+ head = CCHead(in_channels=16, channels=8, num_classes=19)
+ assert len(head.convs) == 2
+ assert hasattr(head, 'cca')
+ if not torch.cuda.is_available():
+ pytest.skip('CCHead requires CUDA')
+ inputs = [torch.randn(1, 16, 23, 23)]
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_da_head.py b/tests/test_models/test_heads/test_da_head.py
new file mode 100644
index 0000000..7ab4a96
--- /dev/null
+++ b/tests/test_models/test_heads/test_da_head.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import DAHead
+from .utils import to_cuda
+
+
+def test_da_head():
+
+ inputs = [torch.randn(1, 16, 23, 23)]
+ head = DAHead(in_channels=16, channels=8, num_classes=19, pam_channels=8)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert isinstance(outputs, tuple) and len(outputs) == 3
+ for output in outputs:
+ assert output.shape == (1, head.num_classes, 23, 23)
+ test_output = head.forward_test(inputs, None, None)
+ assert test_output.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_decode_head.py b/tests/test_models/test_heads/test_decode_head.py
new file mode 100644
index 0000000..cb9ab97
--- /dev/null
+++ b/tests/test_models/test_heads/test_decode_head.py
@@ -0,0 +1,165 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest.mock import patch
+
+import pytest
+import torch
+
+from mmseg.models.decode_heads.decode_head import BaseDecodeHead
+from .utils import to_cuda
+
+
+@patch.multiple(BaseDecodeHead, __abstractmethods__=set())
+def test_decode_head():
+
+ with pytest.raises(AssertionError):
+ # default input_transform doesn't accept multiple inputs
+ BaseDecodeHead([32, 16], 16, num_classes=19)
+
+ with pytest.raises(AssertionError):
+ # default input_transform doesn't accept multiple inputs
+ BaseDecodeHead(32, 16, num_classes=19, in_index=[-1, -2])
+
+ with pytest.raises(AssertionError):
+ # supported mode is resize_concat only
+ BaseDecodeHead(32, 16, num_classes=19, input_transform='concat')
+
+ with pytest.raises(AssertionError):
+ # in_channels should be list|tuple
+ BaseDecodeHead(32, 16, num_classes=19, input_transform='resize_concat')
+
+ with pytest.raises(AssertionError):
+ # in_index should be list|tuple
+ BaseDecodeHead([32],
+ 16,
+ in_index=-1,
+ num_classes=19,
+ input_transform='resize_concat')
+
+ with pytest.raises(AssertionError):
+ # len(in_index) should equal len(in_channels)
+ BaseDecodeHead([32, 16],
+ 16,
+ num_classes=19,
+ in_index=[-1],
+ input_transform='resize_concat')
+
+ # test default dropout
+ head = BaseDecodeHead(32, 16, num_classes=19)
+ assert hasattr(head, 'dropout') and head.dropout.p == 0.1
+
+ # test set dropout
+ head = BaseDecodeHead(32, 16, num_classes=19, dropout_ratio=0.2)
+ assert hasattr(head, 'dropout') and head.dropout.p == 0.2
+
+ # test no input_transform
+ inputs = [torch.randn(1, 32, 45, 45)]
+ head = BaseDecodeHead(32, 16, num_classes=19)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.in_channels == 32
+ assert head.input_transform is None
+ transformed_inputs = head._transform_inputs(inputs)
+ assert transformed_inputs.shape == (1, 32, 45, 45)
+
+ # test input_transform = resize_concat
+ inputs = [torch.randn(1, 32, 45, 45), torch.randn(1, 16, 21, 21)]
+ head = BaseDecodeHead([32, 16],
+ 16,
+ num_classes=19,
+ in_index=[0, 1],
+ input_transform='resize_concat')
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.in_channels == 48
+ assert head.input_transform == 'resize_concat'
+ transformed_inputs = head._transform_inputs(inputs)
+ assert transformed_inputs.shape == (1, 48, 45, 45)
+
+ # test multi-loss, loss_decode is dict
+ with pytest.raises(TypeError):
+ # loss_decode must be a dict or sequence of dict.
+ BaseDecodeHead(3, 16, num_classes=19, loss_decode=['CrossEntropyLoss'])
+
+ inputs = torch.randn(2, 19, 8, 8).float()
+ target = torch.ones(2, 1, 64, 64).long()
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss = head.losses(seg_logit=inputs, seg_label=target)
+ assert 'loss_ce' in loss
+
+ # test multi-loss, loss_decode is list of dict
+ inputs = torch.randn(2, 19, 8, 8).float()
+ target = torch.ones(2, 1, 64, 64).long()
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2')
+ ])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss = head.losses(seg_logit=inputs, seg_label=target)
+ assert 'loss_1' in loss
+ assert 'loss_2' in loss
+
+ # 'loss_decode' must be a dict or sequence of dict
+ with pytest.raises(TypeError):
+ BaseDecodeHead(3, 16, num_classes=19, loss_decode=['CrossEntropyLoss'])
+ with pytest.raises(TypeError):
+ BaseDecodeHead(3, 16, num_classes=19, loss_decode=0)
+
+ # test multi-loss, loss_decode is list of dict
+ inputs = torch.randn(2, 19, 8, 8).float()
+ target = torch.ones(2, 1, 64, 64).long()
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=(dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2'),
+ dict(type='CrossEntropyLoss', loss_name='loss_3')))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss = head.losses(seg_logit=inputs, seg_label=target)
+ assert 'loss_1' in loss
+ assert 'loss_2' in loss
+ assert 'loss_3' in loss
+
+ # test multi-loss, loss_decode is list of dict, names of them are identical
+ inputs = torch.randn(2, 19, 8, 8).float()
+ target = torch.ones(2, 1, 64, 64).long()
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=(dict(type='CrossEntropyLoss', loss_name='loss_ce'),
+ dict(type='CrossEntropyLoss', loss_name='loss_ce'),
+ dict(type='CrossEntropyLoss', loss_name='loss_ce')))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss_3 = head.losses(seg_logit=inputs, seg_label=target)
+
+ head = BaseDecodeHead(
+ 3,
+ 16,
+ num_classes=19,
+ loss_decode=(dict(type='CrossEntropyLoss', loss_name='loss_ce')))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ head, target = to_cuda(head, target)
+ loss = head.losses(seg_logit=inputs, seg_label=target)
+ assert 'loss_ce' in loss
+ assert 'loss_ce' in loss_3
+ assert loss_3['loss_ce'] == 3 * loss['loss_ce']
diff --git a/tests/test_models/test_heads/test_dm_head.py b/tests/test_models/test_heads/test_dm_head.py
new file mode 100644
index 0000000..a922ff7
--- /dev/null
+++ b/tests/test_models/test_heads/test_dm_head.py
@@ -0,0 +1,59 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import DMHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_dm_head():
+
+ with pytest.raises(AssertionError):
+ # filter_sizes must be list|tuple
+ DMHead(in_channels=8, channels=4, num_classes=19, filter_sizes=1)
+
+ # test no norm_cfg
+ head = DMHead(in_channels=8, channels=4, num_classes=19)
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = DMHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ # fusion=True
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = DMHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ filter_sizes=(1, 3, 5),
+ fusion=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.fusion is True
+ assert head.dcm_modules[0].filter_size == 1
+ assert head.dcm_modules[1].filter_size == 3
+ assert head.dcm_modules[2].filter_size == 5
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # fusion=False
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = DMHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ filter_sizes=(1, 3, 5),
+ fusion=False)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.fusion is False
+ assert head.dcm_modules[0].filter_size == 1
+ assert head.dcm_modules[1].filter_size == 3
+ assert head.dcm_modules[2].filter_size == 5
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_dnl_head.py b/tests/test_models/test_heads/test_dnl_head.py
new file mode 100644
index 0000000..720cb07
--- /dev/null
+++ b/tests/test_models/test_heads/test_dnl_head.py
@@ -0,0 +1,44 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import DNLHead
+from .utils import to_cuda
+
+
+def test_dnl_head():
+ # DNL with 'embedded_gaussian' mode
+ head = DNLHead(in_channels=8, channels=4, num_classes=19)
+ assert len(head.convs) == 2
+ assert hasattr(head, 'dnl_block')
+ assert head.dnl_block.temperature == 0.05
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # NonLocal2d with 'dot_product' mode
+ head = DNLHead(
+ in_channels=8, channels=4, num_classes=19, mode='dot_product')
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # NonLocal2d with 'gaussian' mode
+ head = DNLHead(in_channels=8, channels=4, num_classes=19, mode='gaussian')
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # NonLocal2d with 'concatenation' mode
+ head = DNLHead(
+ in_channels=8, channels=4, num_classes=19, mode='concatenation')
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_dpt_head.py b/tests/test_models/test_heads/test_dpt_head.py
new file mode 100644
index 0000000..d8cd8b0
--- /dev/null
+++ b/tests/test_models/test_heads/test_dpt_head.py
@@ -0,0 +1,48 @@
+import pytest
+import torch
+
+from mmseg.models.decode_heads import DPTHead
+
+
+def test_dpt_head():
+
+ with pytest.raises(AssertionError):
+ # input_transform must be 'multiple_select'
+ head = DPTHead(
+ in_channels=[768, 768, 768, 768],
+ channels=4,
+ num_classes=19,
+ in_index=[0, 1, 2, 3])
+
+ head = DPTHead(
+ in_channels=[768, 768, 768, 768],
+ channels=4,
+ num_classes=19,
+ in_index=[0, 1, 2, 3],
+ input_transform='multiple_select')
+
+ inputs = [[torch.randn(4, 768, 2, 2),
+ torch.randn(4, 768)] for _ in range(4)]
+ output = head(inputs)
+ assert output.shape == torch.Size((4, 19, 16, 16))
+
+ # test readout operation
+ head = DPTHead(
+ in_channels=[768, 768, 768, 768],
+ channels=4,
+ num_classes=19,
+ in_index=[0, 1, 2, 3],
+ input_transform='multiple_select',
+ readout_type='add')
+ output = head(inputs)
+ assert output.shape == torch.Size((4, 19, 16, 16))
+
+ head = DPTHead(
+ in_channels=[768, 768, 768, 768],
+ channels=4,
+ num_classes=19,
+ in_index=[0, 1, 2, 3],
+ input_transform='multiple_select',
+ readout_type='project')
+ output = head(inputs)
+ assert output.shape == torch.Size((4, 19, 16, 16))
diff --git a/tests/test_models/test_heads/test_ema_head.py b/tests/test_models/test_heads/test_ema_head.py
new file mode 100644
index 0000000..1811cd2
--- /dev/null
+++ b/tests/test_models/test_heads/test_ema_head.py
@@ -0,0 +1,23 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import EMAHead
+from .utils import to_cuda
+
+
+def test_emanet_head():
+ head = EMAHead(
+ in_channels=4,
+ ema_channels=3,
+ channels=2,
+ num_stages=3,
+ num_bases=2,
+ num_classes=19)
+ for param in head.ema_mid_conv.parameters():
+ assert not param.requires_grad
+ assert hasattr(head, 'ema_module')
+ inputs = [torch.randn(1, 4, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_enc_head.py b/tests/test_models/test_heads/test_enc_head.py
new file mode 100644
index 0000000..9c84c75
--- /dev/null
+++ b/tests/test_models/test_heads/test_enc_head.py
@@ -0,0 +1,47 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import EncHead
+from .utils import to_cuda
+
+
+def test_enc_head():
+ # with se_loss, w.o. lateral
+ inputs = [torch.randn(1, 8, 21, 21)]
+ head = EncHead(in_channels=[8], channels=4, num_classes=19, in_index=[-1])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert isinstance(outputs, tuple) and len(outputs) == 2
+ assert outputs[0].shape == (1, head.num_classes, 21, 21)
+ assert outputs[1].shape == (1, head.num_classes)
+
+ # w.o se_loss, w.o. lateral
+ inputs = [torch.randn(1, 8, 21, 21)]
+ head = EncHead(
+ in_channels=[8],
+ channels=4,
+ use_se_loss=False,
+ num_classes=19,
+ in_index=[-1])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 21, 21)
+
+ # with se_loss, with lateral
+ inputs = [torch.randn(1, 4, 45, 45), torch.randn(1, 8, 21, 21)]
+ head = EncHead(
+ in_channels=[4, 8],
+ channels=4,
+ add_lateral=True,
+ num_classes=19,
+ in_index=[-2, -1])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert isinstance(outputs, tuple) and len(outputs) == 2
+ assert outputs[0].shape == (1, head.num_classes, 21, 21)
+ assert outputs[1].shape == (1, head.num_classes)
+ test_output = head.forward_test(inputs, None, None)
+ assert test_output.shape == (1, head.num_classes, 21, 21)
diff --git a/tests/test_models/test_heads/test_fcn_head.py b/tests/test_models/test_heads/test_fcn_head.py
new file mode 100644
index 0000000..4e633fb
--- /dev/null
+++ b/tests/test_models/test_heads/test_fcn_head.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmcv.utils.parrots_wrapper import SyncBatchNorm
+
+from mmseg.models.decode_heads import DepthwiseSeparableFCNHead, FCNHead
+from .utils import to_cuda
+
+
+def test_fcn_head():
+
+ with pytest.raises(AssertionError):
+ # num_convs must be not less than 0
+ FCNHead(num_classes=19, num_convs=-1)
+
+ # test no norm_cfg
+ head = FCNHead(in_channels=8, channels=4, num_classes=19)
+ for m in head.modules():
+ if isinstance(m, ConvModule):
+ assert not m.with_norm
+
+ # test with norm_cfg
+ head = FCNHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ for m in head.modules():
+ if isinstance(m, ConvModule):
+ assert m.with_norm and isinstance(m.bn, SyncBatchNorm)
+
+ # test concat_input=False
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(
+ in_channels=8, channels=4, num_classes=19, concat_input=False)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert len(head.convs) == 2
+ assert not head.concat_input and not hasattr(head, 'conv_cat')
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test concat_input=True
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(
+ in_channels=8, channels=4, num_classes=19, concat_input=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert len(head.convs) == 2
+ assert head.concat_input
+ assert head.conv_cat.in_channels == 12
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test kernel_size=3
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(in_channels=8, channels=4, num_classes=19)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ for i in range(len(head.convs)):
+ assert head.convs[i].kernel_size == (3, 3)
+ assert head.convs[i].padding == 1
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test kernel_size=1
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(in_channels=8, channels=4, num_classes=19, kernel_size=1)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ for i in range(len(head.convs)):
+ assert head.convs[i].kernel_size == (1, 1)
+ assert head.convs[i].padding == 0
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test num_conv
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(in_channels=8, channels=4, num_classes=19, num_convs=1)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert len(head.convs) == 1
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+ # test num_conv = 0
+ inputs = [torch.randn(1, 8, 23, 23)]
+ head = FCNHead(
+ in_channels=8,
+ channels=8,
+ num_classes=19,
+ num_convs=0,
+ concat_input=False)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert isinstance(head.convs, torch.nn.Identity)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
+
+
+def test_sep_fcn_head():
+ # test sep_fcn_head with concat_input=False
+ head = DepthwiseSeparableFCNHead(
+ in_channels=128,
+ channels=128,
+ concat_input=False,
+ num_classes=19,
+ in_index=-1,
+ norm_cfg=dict(type='BN', requires_grad=True, momentum=0.01))
+ x = [torch.rand(2, 128, 8, 8)]
+ output = head(x)
+ assert output.shape == (2, head.num_classes, 8, 8)
+ assert not head.concat_input
+ assert isinstance(head.convs[0], DepthwiseSeparableConvModule)
+ assert isinstance(head.convs[1], DepthwiseSeparableConvModule)
+ assert head.conv_seg.kernel_size == (1, 1)
+
+ head = DepthwiseSeparableFCNHead(
+ in_channels=64,
+ channels=64,
+ concat_input=True,
+ num_classes=19,
+ in_index=-1,
+ norm_cfg=dict(type='BN', requires_grad=True, momentum=0.01))
+ x = [torch.rand(3, 64, 8, 8)]
+ output = head(x)
+ assert output.shape == (3, head.num_classes, 8, 8)
+ assert head.concat_input
+ assert isinstance(head.convs[0], DepthwiseSeparableConvModule)
+ assert isinstance(head.convs[1], DepthwiseSeparableConvModule)
diff --git a/tests/test_models/test_heads/test_gc_head.py b/tests/test_models/test_heads/test_gc_head.py
new file mode 100644
index 0000000..c62ac9a
--- /dev/null
+++ b/tests/test_models/test_heads/test_gc_head.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import GCHead
+from .utils import to_cuda
+
+
+def test_gc_head():
+ head = GCHead(in_channels=4, channels=4, num_classes=19)
+ assert len(head.convs) == 2
+ assert hasattr(head, 'gc_block')
+ inputs = [torch.randn(1, 4, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_isa_head.py b/tests/test_models/test_heads/test_isa_head.py
new file mode 100644
index 0000000..b177f6d
--- /dev/null
+++ b/tests/test_models/test_heads/test_isa_head.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import ISAHead
+from .utils import to_cuda
+
+
+def test_isa_head():
+
+ inputs = [torch.randn(1, 8, 23, 23)]
+ isa_head = ISAHead(
+ in_channels=8,
+ channels=4,
+ num_classes=19,
+ isa_channels=4,
+ down_factor=(8, 8))
+ if torch.cuda.is_available():
+ isa_head, inputs = to_cuda(isa_head, inputs)
+ output = isa_head(inputs)
+ assert output.shape == (1, isa_head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_lraspp_head.py b/tests/test_models/test_heads/test_lraspp_head.py
new file mode 100644
index 0000000..a46e6a1
--- /dev/null
+++ b/tests/test_models/test_heads/test_lraspp_head.py
@@ -0,0 +1,68 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import LRASPPHead
+
+
+def test_lraspp_head():
+ with pytest.raises(ValueError):
+ # check invalid input_transform
+ LRASPPHead(
+ in_channels=(4, 4, 123),
+ in_index=(0, 1, 2),
+ channels=32,
+ input_transform='resize_concat',
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+
+ with pytest.raises(AssertionError):
+ # check invalid branch_channels
+ LRASPPHead(
+ in_channels=(4, 4, 123),
+ in_index=(0, 1, 2),
+ channels=32,
+ branch_channels=64,
+ input_transform='multiple_select',
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+
+ # test with default settings
+ lraspp_head = LRASPPHead(
+ in_channels=(4, 4, 123),
+ in_index=(0, 1, 2),
+ channels=32,
+ input_transform='multiple_select',
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
+ inputs = [
+ torch.randn(2, 4, 45, 45),
+ torch.randn(2, 4, 28, 28),
+ torch.randn(2, 123, 14, 14)
+ ]
+ with pytest.raises(RuntimeError):
+ # check invalid inputs
+ output = lraspp_head(inputs)
+
+ inputs = [
+ torch.randn(2, 4, 111, 111),
+ torch.randn(2, 4, 77, 77),
+ torch.randn(2, 123, 55, 55)
+ ]
+ output = lraspp_head(inputs)
+ assert output.shape == (2, 19, 111, 111)
diff --git a/tests/test_models/test_heads/test_nl_head.py b/tests/test_models/test_heads/test_nl_head.py
new file mode 100644
index 0000000..d4ef0b9
--- /dev/null
+++ b/tests/test_models/test_heads/test_nl_head.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import NLHead
+from .utils import to_cuda
+
+
+def test_nl_head():
+ head = NLHead(in_channels=8, channels=4, num_classes=19)
+ assert len(head.convs) == 2
+ assert hasattr(head, 'nl_block')
+ inputs = [torch.randn(1, 8, 23, 23)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_ocr_head.py b/tests/test_models/test_heads/test_ocr_head.py
new file mode 100644
index 0000000..5e5d669
--- /dev/null
+++ b/tests/test_models/test_heads/test_ocr_head.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import FCNHead, OCRHead
+from .utils import to_cuda
+
+
+def test_ocr_head():
+
+ inputs = [torch.randn(1, 8, 23, 23)]
+ ocr_head = OCRHead(
+ in_channels=8, channels=4, num_classes=19, ocr_channels=8)
+ fcn_head = FCNHead(in_channels=8, channels=4, num_classes=19)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(ocr_head, inputs)
+ head, inputs = to_cuda(fcn_head, inputs)
+ prev_output = fcn_head(inputs)
+ output = ocr_head(inputs, prev_output)
+ assert output.shape == (1, ocr_head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_point_head.py b/tests/test_models/test_heads/test_point_head.py
new file mode 100644
index 0000000..142ab16
--- /dev/null
+++ b/tests/test_models/test_heads/test_point_head.py
@@ -0,0 +1,61 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.utils import ConfigDict
+
+from mmseg.models.decode_heads import FCNHead, PointHead
+from .utils import to_cuda
+
+
+def test_point_head():
+
+ inputs = [torch.randn(1, 32, 45, 45)]
+ point_head = PointHead(
+ in_channels=[32], in_index=[0], channels=16, num_classes=19)
+ assert len(point_head.fcs) == 3
+ fcn_head = FCNHead(in_channels=32, channels=16, num_classes=19)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(point_head, inputs)
+ head, inputs = to_cuda(fcn_head, inputs)
+ prev_output = fcn_head(inputs)
+ test_cfg = ConfigDict(
+ subdivision_steps=2, subdivision_num_points=8196, scale_factor=2)
+ output = point_head.forward_test(inputs, prev_output, None, test_cfg)
+ assert output.shape == (1, point_head.num_classes, 180, 180)
+
+ # test multiple losses case
+ inputs = [torch.randn(1, 32, 45, 45)]
+ point_head_multiple_losses = PointHead(
+ in_channels=[32],
+ in_index=[0],
+ channels=16,
+ num_classes=19,
+ loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2')
+ ])
+ assert len(point_head_multiple_losses.fcs) == 3
+ fcn_head_multiple_losses = FCNHead(
+ in_channels=32,
+ channels=16,
+ num_classes=19,
+ loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2')
+ ])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(point_head_multiple_losses, inputs)
+ head, inputs = to_cuda(fcn_head_multiple_losses, inputs)
+ prev_output = fcn_head_multiple_losses(inputs)
+ test_cfg = ConfigDict(
+ subdivision_steps=2, subdivision_num_points=8196, scale_factor=2)
+ output = point_head_multiple_losses.forward_test(inputs, prev_output, None,
+ test_cfg)
+ assert output.shape == (1, point_head.num_classes, 180, 180)
+
+ fake_label = torch.ones([1, 180, 180], dtype=torch.long)
+
+ if torch.cuda.is_available():
+ fake_label = fake_label.cuda()
+ loss = point_head_multiple_losses.losses(output, fake_label)
+ assert 'pointloss_1' in loss
+ assert 'pointloss_2' in loss
diff --git a/tests/test_models/test_heads/test_psa_head.py b/tests/test_models/test_heads/test_psa_head.py
new file mode 100644
index 0000000..34f592b
--- /dev/null
+++ b/tests/test_models/test_heads/test_psa_head.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import PSAHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_psa_head():
+
+ with pytest.raises(AssertionError):
+ # psa_type must be in 'bi-direction', 'collect', 'distribute'
+ PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_type='gather')
+
+ # test no norm_cfg
+ head = PSAHead(
+ in_channels=4, channels=2, num_classes=19, mask_size=(13, 13))
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ # test 'bi-direction' psa_type
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4, channels=2, num_classes=19, mask_size=(13, 13))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'bi-direction' psa_type, shrink_factor=1
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ shrink_factor=1)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'bi-direction' psa_type with soft_max
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_softmax=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'collect' psa_type
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_type='collect')
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'collect' psa_type, shrink_factor=1
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ shrink_factor=1,
+ psa_type='collect')
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'collect' psa_type, shrink_factor=1, compact=True
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_type='collect',
+ shrink_factor=1,
+ compact=True)
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
+
+ # test 'distribute' psa_type
+ inputs = [torch.randn(1, 4, 13, 13)]
+ head = PSAHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ mask_size=(13, 13),
+ psa_type='distribute')
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 13, 13)
diff --git a/tests/test_models/test_heads/test_psp_head.py b/tests/test_models/test_heads/test_psp_head.py
new file mode 100644
index 0000000..fde4087
--- /dev/null
+++ b/tests/test_models/test_heads/test_psp_head.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import PSPHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_psp_head():
+
+ with pytest.raises(AssertionError):
+ # pool_scales must be list|tuple
+ PSPHead(in_channels=4, channels=2, num_classes=19, pool_scales=1)
+
+ # test no norm_cfg
+ head = PSPHead(in_channels=4, channels=2, num_classes=19)
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = PSPHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'))
+ assert _conv_has_norm(head, sync_bn=True)
+
+ inputs = [torch.randn(1, 4, 23, 23)]
+ head = PSPHead(
+ in_channels=4, channels=2, num_classes=19, pool_scales=(1, 2, 3))
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ assert head.psp_modules[0][0].output_size == 1
+ assert head.psp_modules[1][0].output_size == 2
+ assert head.psp_modules[2][0].output_size == 3
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 23, 23)
diff --git a/tests/test_models/test_heads/test_segformer_head.py b/tests/test_models/test_heads/test_segformer_head.py
new file mode 100644
index 0000000..73afaba
--- /dev/null
+++ b/tests/test_models/test_heads/test_segformer_head.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import SegformerHead
+
+
+def test_segformer_head():
+ with pytest.raises(AssertionError):
+ # `in_channels` must have same length as `in_index`
+ SegformerHead(
+ in_channels=(1, 2, 3), in_index=(0, 1), channels=5, num_classes=2)
+
+ H, W = (64, 64)
+ in_channels = (32, 64, 160, 256)
+ shapes = [(H // 2**(i + 2), W // 2**(i + 2))
+ for i in range(len(in_channels))]
+ model = SegformerHead(
+ in_channels=in_channels,
+ in_index=[0, 1, 2, 3],
+ channels=256,
+ num_classes=19)
+
+ with pytest.raises(IndexError):
+ # in_index must match the input feature maps.
+ inputs = [
+ torch.randn((1, in_channel, *shape))
+ for in_channel, shape in zip(in_channels, shapes)
+ ][:3]
+ temp = model(inputs)
+
+ # Normal Input
+ # ((1, 32, 16, 16), (1, 64, 8, 8), (1, 160, 4, 4), (1, 256, 2, 2)
+ inputs = [
+ torch.randn((1, in_channel, *shape))
+ for in_channel, shape in zip(in_channels, shapes)
+ ]
+ temp = model(inputs)
+
+ assert temp.shape == (1, 19, H // 4, W // 4)
diff --git a/tests/test_models/test_heads/test_segmenter_mask_head.py b/tests/test_models/test_heads/test_segmenter_mask_head.py
new file mode 100644
index 0000000..7b681ac
--- /dev/null
+++ b/tests/test_models/test_heads/test_segmenter_mask_head.py
@@ -0,0 +1,24 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import SegmenterMaskTransformerHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_segmenter_mask_transformer_head():
+ head = SegmenterMaskTransformerHead(
+ in_channels=2,
+ channels=2,
+ num_classes=150,
+ num_layers=2,
+ num_heads=3,
+ embed_dims=192,
+ dropout_ratio=0.0)
+ assert _conv_has_norm(head, sync_bn=True)
+ head.init_weights()
+
+ inputs = [torch.randn(1, 2, 32, 32)]
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 32, 32)
diff --git a/tests/test_models/test_heads/test_setr_mla_head.py b/tests/test_models/test_heads/test_setr_mla_head.py
new file mode 100644
index 0000000..301bc0b
--- /dev/null
+++ b/tests/test_models/test_heads/test_setr_mla_head.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import SETRMLAHead
+from .utils import to_cuda
+
+
+def test_setr_mla_head(capsys):
+
+ with pytest.raises(AssertionError):
+ # MLA requires input multiple stage feature information.
+ SETRMLAHead(in_channels=8, channels=4, num_classes=19, in_index=1)
+
+ with pytest.raises(AssertionError):
+ # multiple in_indexs requires multiple in_channels.
+ SETRMLAHead(
+ in_channels=8, channels=4, num_classes=19, in_index=(0, 1, 2, 3))
+
+ with pytest.raises(AssertionError):
+ # channels should be len(in_channels) * mla_channels
+ SETRMLAHead(
+ in_channels=(8, 8, 8, 8),
+ channels=8,
+ mla_channels=4,
+ in_index=(0, 1, 2, 3),
+ num_classes=19)
+
+ # test inference of MLA head
+ img_size = (8, 8)
+ patch_size = 4
+ head = SETRMLAHead(
+ in_channels=(8, 8, 8, 8),
+ channels=16,
+ mla_channels=4,
+ in_index=(0, 1, 2, 3),
+ num_classes=19,
+ norm_cfg=dict(type='BN'))
+
+ h, w = img_size[0] // patch_size, img_size[1] // patch_size
+ # Input square NCHW format feature information
+ x = [
+ torch.randn(1, 8, h, w),
+ torch.randn(1, 8, h, w),
+ torch.randn(1, 8, h, w),
+ torch.randn(1, 8, h, w)
+ ]
+ if torch.cuda.is_available():
+ head, x = to_cuda(head, x)
+ out = head(x)
+ assert out.shape == (1, head.num_classes, h * 4, w * 4)
+
+ # Input non-square NCHW format feature information
+ x = [
+ torch.randn(1, 8, h, w * 2),
+ torch.randn(1, 8, h, w * 2),
+ torch.randn(1, 8, h, w * 2),
+ torch.randn(1, 8, h, w * 2)
+ ]
+ if torch.cuda.is_available():
+ head, x = to_cuda(head, x)
+ out = head(x)
+ assert out.shape == (1, head.num_classes, h * 4, w * 8)
diff --git a/tests/test_models/test_heads/test_setr_up_head.py b/tests/test_models/test_heads/test_setr_up_head.py
new file mode 100644
index 0000000..a051922
--- /dev/null
+++ b/tests/test_models/test_heads/test_setr_up_head.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import SETRUPHead
+from .utils import to_cuda
+
+
+def test_setr_up_head(capsys):
+
+ with pytest.raises(AssertionError):
+ # kernel_size must be [1/3]
+ SETRUPHead(num_classes=19, kernel_size=2)
+
+ with pytest.raises(AssertionError):
+ # in_channels must be int type and in_channels must be same
+ # as embed_dim.
+ SETRUPHead(in_channels=(4, 4), channels=2, num_classes=19)
+
+ # test init_cfg of head
+ head = SETRUPHead(
+ in_channels=4,
+ channels=2,
+ norm_cfg=dict(type='SyncBN'),
+ num_classes=19,
+ init_cfg=dict(type='Kaiming'))
+ super(SETRUPHead, head).init_weights()
+
+ # test inference of Naive head
+ # the auxiliary head of Naive head is same as Naive head
+ img_size = (4, 4)
+ patch_size = 2
+ head = SETRUPHead(
+ in_channels=4,
+ channels=2,
+ num_classes=19,
+ num_convs=1,
+ up_scale=4,
+ kernel_size=1,
+ norm_cfg=dict(type='BN'))
+
+ h, w = img_size[0] // patch_size, img_size[1] // patch_size
+
+ # Input square NCHW format feature information
+ x = [torch.randn(1, 4, h, w)]
+ if torch.cuda.is_available():
+ head, x = to_cuda(head, x)
+ out = head(x)
+ assert out.shape == (1, head.num_classes, h * 4, w * 4)
+
+ # Input non-square NCHW format feature information
+ x = [torch.randn(1, 4, h, w * 2)]
+ if torch.cuda.is_available():
+ head, x = to_cuda(head, x)
+ out = head(x)
+ assert out.shape == (1, head.num_classes, h * 4, w * 8)
diff --git a/tests/test_models/test_heads/test_stdc_head.py b/tests/test_models/test_heads/test_stdc_head.py
new file mode 100644
index 0000000..1628209
--- /dev/null
+++ b/tests/test_models/test_heads/test_stdc_head.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import STDCHead
+from .utils import to_cuda
+
+
+def test_stdc_head():
+ inputs = [torch.randn(1, 32, 21, 21)]
+ head = STDCHead(
+ in_channels=32,
+ channels=8,
+ num_convs=1,
+ num_classes=2,
+ in_index=-1,
+ loss_decode=[
+ dict(
+ type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=1.0)
+ ])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert isinstance(outputs, torch.Tensor) and len(outputs) == 1
+ assert outputs.shape == torch.Size([1, head.num_classes, 21, 21])
+
+ fake_label = torch.ones_like(
+ outputs[:, 0:1, :, :], dtype=torch.int16).long()
+ loss = head.losses(seg_logit=outputs, seg_label=fake_label)
+ assert loss['loss_ce'] != torch.zeros_like(loss['loss_ce'])
+ assert loss['loss_dice'] != torch.zeros_like(loss['loss_dice'])
diff --git a/tests/test_models/test_heads/test_uper_head.py b/tests/test_models/test_heads/test_uper_head.py
new file mode 100644
index 0000000..09456a8
--- /dev/null
+++ b/tests/test_models/test_heads/test_uper_head.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.decode_heads import UPerHead
+from .utils import _conv_has_norm, to_cuda
+
+
+def test_uper_head():
+
+ with pytest.raises(AssertionError):
+ # fpn_in_channels must be list|tuple
+ UPerHead(in_channels=4, channels=2, num_classes=19)
+
+ # test no norm_cfg
+ head = UPerHead(
+ in_channels=[4, 2], channels=2, num_classes=19, in_index=[-2, -1])
+ assert not _conv_has_norm(head, sync_bn=False)
+
+ # test with norm_cfg
+ head = UPerHead(
+ in_channels=[4, 2],
+ channels=2,
+ num_classes=19,
+ norm_cfg=dict(type='SyncBN'),
+ in_index=[-2, -1])
+ assert _conv_has_norm(head, sync_bn=True)
+
+ inputs = [torch.randn(1, 4, 45, 45), torch.randn(1, 2, 21, 21)]
+ head = UPerHead(
+ in_channels=[4, 2], channels=2, num_classes=19, in_index=[-2, -1])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert outputs.shape == (1, head.num_classes, 45, 45)
diff --git a/tests/test_models/test_heads/utils.py b/tests/test_models/test_heads/utils.py
new file mode 100644
index 0000000..675241c
--- /dev/null
+++ b/tests/test_models/test_heads/utils.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import ConvModule
+from mmcv.utils.parrots_wrapper import SyncBatchNorm
+
+
+def _conv_has_norm(module, sync_bn):
+ for m in module.modules():
+ if isinstance(m, ConvModule):
+ if not m.with_norm:
+ return False
+ if sync_bn:
+ if not isinstance(m.bn, SyncBatchNorm):
+ return False
+ return True
+
+
+def to_cuda(module, data):
+ module = module.cuda()
+ if isinstance(data, list):
+ for i in range(len(data)):
+ data[i] = data[i].cuda()
+ return module, data
diff --git a/tests/test_models/test_losses/__init__.py b/tests/test_models/test_losses/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/test_losses/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_losses/test_ce_loss.py b/tests/test_models/test_losses/test_ce_loss.py
new file mode 100644
index 0000000..2fe5c2e
--- /dev/null
+++ b/tests/test_models/test_losses/test_ce_loss.py
@@ -0,0 +1,89 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+
+def test_ce_loss():
+ from mmseg.models import build_loss
+
+ # use_mask and use_sigmoid cannot be true at the same time
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(
+ type='CrossEntropyLoss',
+ use_mask=True,
+ use_sigmoid=True,
+ loss_weight=1.0)
+ build_loss(loss_cfg)
+
+ # test loss with class weights
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ class_weight=[0.8, 0.2],
+ loss_weight=1.0,
+ loss_name='loss_ce')
+ loss_cls = build_loss(loss_cls_cfg)
+ fake_pred = torch.Tensor([[100, -100]])
+ fake_label = torch.Tensor([1]).long()
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(40.))
+
+ # test loss with class weights from file
+ import os
+ import tempfile
+
+ import mmcv
+ import numpy as np
+ tmp_file = tempfile.NamedTemporaryFile()
+
+ mmcv.dump([0.8, 0.2], f'{tmp_file.name}.pkl', 'pkl') # from pkl file
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ class_weight=f'{tmp_file.name}.pkl',
+ loss_weight=1.0,
+ loss_name='loss_ce')
+ loss_cls = build_loss(loss_cls_cfg)
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(40.))
+
+ np.save(f'{tmp_file.name}.npy', np.array([0.8, 0.2])) # from npy file
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ class_weight=f'{tmp_file.name}.npy',
+ loss_weight=1.0,
+ loss_name='loss_ce')
+ loss_cls = build_loss(loss_cls_cfg)
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(40.))
+ tmp_file.close()
+ os.remove(f'{tmp_file.name}.pkl')
+ os.remove(f'{tmp_file.name}.npy')
+
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)
+ loss_cls = build_loss(loss_cls_cfg)
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(200.))
+
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)
+ loss_cls = build_loss(loss_cls_cfg)
+ assert torch.allclose(loss_cls(fake_pred, fake_label), torch.tensor(100.))
+
+ fake_pred = torch.full(size=(2, 21, 8, 8), fill_value=0.5)
+ fake_label = torch.ones(2, 8, 8).long()
+ assert torch.allclose(
+ loss_cls(fake_pred, fake_label), torch.tensor(0.9503), atol=1e-4)
+ fake_label[:, 0, 0] = 255
+ assert torch.allclose(
+ loss_cls(fake_pred, fake_label, ignore_index=255),
+ torch.tensor(0.9354),
+ atol=1e-4)
+
+ # test cross entropy loss has name `loss_ce`
+ loss_cls_cfg = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0,
+ loss_name='loss_ce')
+ loss_cls = build_loss(loss_cls_cfg)
+ assert loss_cls.loss_name == 'loss_ce'
+ # TODO test use_mask
diff --git a/tests/test_models/test_losses/test_dice_loss.py b/tests/test_models/test_losses/test_dice_loss.py
new file mode 100644
index 0000000..3936f5d
--- /dev/null
+++ b/tests/test_models/test_losses/test_dice_loss.py
@@ -0,0 +1,78 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+
+def test_dice_lose():
+ from mmseg.models import build_loss
+
+ # test dice loss with loss_type = 'multi_class'
+ loss_cfg = dict(
+ type='DiceLoss',
+ reduction='none',
+ class_weight=[1.0, 2.0, 3.0],
+ loss_weight=1.0,
+ ignore_index=1,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ logits = torch.rand(8, 3, 4, 4)
+ labels = (torch.rand(8, 4, 4) * 3).long()
+ dice_loss(logits, labels)
+
+ # test loss with class weights from file
+ import os
+ import tempfile
+
+ import mmcv
+ import numpy as np
+ tmp_file = tempfile.NamedTemporaryFile()
+
+ mmcv.dump([1.0, 2.0, 3.0], f'{tmp_file.name}.pkl', 'pkl') # from pkl file
+ loss_cfg = dict(
+ type='DiceLoss',
+ reduction='none',
+ class_weight=f'{tmp_file.name}.pkl',
+ loss_weight=1.0,
+ ignore_index=1,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ dice_loss(logits, labels, ignore_index=None)
+
+ np.save(f'{tmp_file.name}.npy', np.array([1.0, 2.0, 3.0])) # from npy file
+ loss_cfg = dict(
+ type='DiceLoss',
+ reduction='none',
+ class_weight=f'{tmp_file.name}.pkl',
+ loss_weight=1.0,
+ ignore_index=1,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ dice_loss(logits, labels, ignore_index=None)
+ tmp_file.close()
+ os.remove(f'{tmp_file.name}.pkl')
+ os.remove(f'{tmp_file.name}.npy')
+
+ # test dice loss with loss_type = 'binary'
+ loss_cfg = dict(
+ type='DiceLoss',
+ smooth=2,
+ exponent=3,
+ reduction='sum',
+ loss_weight=1.0,
+ ignore_index=0,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ logits = torch.rand(8, 2, 4, 4)
+ labels = (torch.rand(8, 4, 4) * 2).long()
+ dice_loss(logits, labels)
+
+ # test dice loss has name `loss_dice`
+ loss_cfg = dict(
+ type='DiceLoss',
+ smooth=2,
+ exponent=3,
+ reduction='sum',
+ loss_weight=1.0,
+ ignore_index=0,
+ loss_name='loss_dice')
+ dice_loss = build_loss(loss_cfg)
+ assert dice_loss.loss_name == 'loss_dice'
diff --git a/tests/test_models/test_losses/test_focal_loss.py b/tests/test_models/test_losses/test_focal_loss.py
new file mode 100644
index 0000000..687312b
--- /dev/null
+++ b/tests/test_models/test_losses/test_focal_loss.py
@@ -0,0 +1,216 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+import torch.nn.functional as F
+
+from mmseg.models import build_loss
+
+
+# test focal loss with use_sigmoid=False
+def test_use_sigmoid():
+ # can't init with use_sigmoid=True
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', use_sigmoid=False)
+ build_loss(loss_cfg)
+
+ # can't forward with use_sigmoid=True
+ with pytest.raises(NotImplementedError):
+ loss_cfg = dict(type='FocalLoss', use_sigmoid=True)
+ focal_loss = build_loss(loss_cfg)
+ focal_loss.use_sigmoid = False
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ focal_loss(fake_pred, fake_target)
+
+
+# reduction type must be 'none', 'mean' or 'sum'
+def test_wrong_reduction_type():
+ # can't init with wrong reduction
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', reduction='test')
+ build_loss(loss_cfg)
+
+ # can't forward with wrong reduction override
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ focal_loss(fake_pred, fake_target, reduction_override='test')
+
+
+# test focal loss can handle input parameters with
+# unacceptable types
+def test_unacceptable_parameters():
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', gamma='test')
+ build_loss(loss_cfg)
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', alpha='test')
+ build_loss(loss_cfg)
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', class_weight='test')
+ build_loss(loss_cfg)
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', loss_weight='test')
+ build_loss(loss_cfg)
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(type='FocalLoss', loss_name=123)
+ build_loss(loss_cfg)
+
+
+# test if focal loss can be correctly initialize
+def test_init_focal_loss():
+ loss_cfg = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=3.0,
+ alpha=3.0,
+ class_weight=[1, 2, 3, 4],
+ reduction='sum')
+ focal_loss = build_loss(loss_cfg)
+ assert focal_loss.use_sigmoid is True
+ assert focal_loss.gamma == 3.0
+ assert focal_loss.alpha == 3.0
+ assert focal_loss.reduction == 'sum'
+ assert focal_loss.class_weight == [1, 2, 3, 4]
+ assert focal_loss.loss_weight == 1.0
+ assert focal_loss.loss_name == 'loss_focal'
+
+
+# test reduction override
+def test_reduction_override():
+ loss_cfg = dict(type='FocalLoss', reduction='mean')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss = focal_loss(fake_pred, fake_target, reduction_override='none')
+ assert loss.shape == fake_pred.shape
+
+
+# test wrong pred and target shape
+def test_wrong_pred_and_target_shape():
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 2, 2))
+ fake_target = F.one_hot(fake_target, num_classes=4)
+ fake_target = fake_target.permute(0, 3, 1, 2)
+ with pytest.raises(AssertionError):
+ focal_loss(fake_pred, fake_target)
+
+
+# test forward with different shape of target
+def test_forward_with_different_shape_of_target():
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss1 = focal_loss(fake_pred, fake_target)
+
+ fake_target = F.one_hot(fake_target, num_classes=4)
+ fake_target = fake_target.permute(0, 3, 1, 2)
+ loss2 = focal_loss(fake_pred, fake_target)
+ assert loss1 == loss2
+
+
+# test forward with weight
+def test_forward_with_weight():
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ weight = torch.rand(3 * 5 * 6, 1)
+ loss1 = focal_loss(fake_pred, fake_target, weight=weight)
+
+ weight2 = weight.view(-1)
+ loss2 = focal_loss(fake_pred, fake_target, weight=weight2)
+
+ weight3 = weight.expand(3 * 5 * 6, 4)
+ loss3 = focal_loss(fake_pred, fake_target, weight=weight3)
+ assert loss1 == loss2 == loss3
+
+
+# test none reduction type
+def test_none_reduction_type():
+ loss_cfg = dict(type='FocalLoss', reduction='none')
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss = focal_loss(fake_pred, fake_target)
+ assert loss.shape == fake_pred.shape
+
+
+# test the usage of class weight
+def test_class_weight():
+ loss_cfg_cw = dict(
+ type='FocalLoss', reduction='none', class_weight=[1.0, 2.0, 3.0, 4.0])
+ loss_cfg = dict(type='FocalLoss', reduction='none')
+ focal_loss_cw = build_loss(loss_cfg_cw)
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss_cw = focal_loss_cw(fake_pred, fake_target)
+ loss = focal_loss(fake_pred, fake_target)
+ weight = torch.tensor([1, 2, 3, 4]).view(1, 4, 1, 1)
+ assert (loss * weight == loss_cw).all()
+
+
+# test ignore index
+def test_ignore_index():
+ loss_cfg = dict(type='FocalLoss', reduction='none')
+ # ignore_index within C classes
+ focal_loss = build_loss(loss_cfg)
+ fake_pred = torch.rand(3, 5, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ dim1 = torch.randint(0, 3, (4, ))
+ dim2 = torch.randint(0, 5, (4, ))
+ dim3 = torch.randint(0, 6, (4, ))
+ fake_target[dim1, dim2, dim3] = 4
+ loss1 = focal_loss(fake_pred, fake_target, ignore_index=4)
+ one_hot_target = F.one_hot(fake_target, num_classes=5)
+ one_hot_target = one_hot_target.permute(0, 3, 1, 2)
+ loss2 = focal_loss(fake_pred, one_hot_target, ignore_index=4)
+ assert (loss1 == loss2).all()
+ assert (loss1[dim1, :, dim2, dim3] == 0).all()
+ assert (loss2[dim1, :, dim2, dim3] == 0).all()
+
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ loss1 = focal_loss(fake_pred, fake_target, ignore_index=2)
+ one_hot_target = F.one_hot(fake_target, num_classes=4)
+ one_hot_target = one_hot_target.permute(0, 3, 1, 2)
+ loss2 = focal_loss(fake_pred, one_hot_target, ignore_index=2)
+ ignore_mask = one_hot_target == 2
+ assert (loss1 == loss2).all()
+ assert torch.sum(loss1 * ignore_mask) == 0
+ assert torch.sum(loss2 * ignore_mask) == 0
+
+ # ignore index is not in prediction's classes
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ dim1 = torch.randint(0, 3, (4, ))
+ dim2 = torch.randint(0, 5, (4, ))
+ dim3 = torch.randint(0, 6, (4, ))
+ fake_target[dim1, dim2, dim3] = 255
+ loss1 = focal_loss(fake_pred, fake_target, ignore_index=255)
+ assert (loss1[dim1, :, dim2, dim3] == 0).all()
+
+
+# test list alpha
+def test_alpha():
+ loss_cfg = dict(type='FocalLoss')
+ focal_loss = build_loss(loss_cfg)
+ alpha_float = 0.4
+ alpha = [0.4, 0.4, 0.4, 0.4]
+ alpha2 = [0.1, 0.3, 0.2, 0.1]
+ fake_pred = torch.rand(3, 4, 5, 6)
+ fake_target = torch.randint(0, 4, (3, 5, 6))
+ focal_loss.alpha = alpha_float
+ loss1 = focal_loss(fake_pred, fake_target)
+ focal_loss.alpha = alpha
+ loss2 = focal_loss(fake_pred, fake_target)
+ assert loss1 == loss2
+ focal_loss.alpha = alpha2
+ focal_loss(fake_pred, fake_target)
diff --git a/tests/test_models/test_losses/test_lovasz_loss.py b/tests/test_models/test_losses/test_lovasz_loss.py
new file mode 100644
index 0000000..bea3f4b
--- /dev/null
+++ b/tests/test_models/test_losses/test_lovasz_loss.py
@@ -0,0 +1,118 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+
+def test_lovasz_loss():
+ from mmseg.models import build_loss
+
+ # loss_type should be 'binary' or 'multi_class'
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='Binary',
+ reduction='none',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ build_loss(loss_cfg)
+
+ # reduction should be 'none' when per_image is False.
+ with pytest.raises(AssertionError):
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='multi_class',
+ loss_name='loss_lovasz')
+ build_loss(loss_cfg)
+
+ # test lovasz loss with loss_type = 'multi_class' and per_image = False
+ loss_cfg = dict(
+ type='LovaszLoss',
+ reduction='none',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ logits = torch.rand(1, 3, 4, 4)
+ labels = (torch.rand(1, 4, 4) * 2).long()
+ lovasz_loss(logits, labels)
+
+ # test lovasz loss with loss_type = 'multi_class' and per_image = True
+ loss_cfg = dict(
+ type='LovaszLoss',
+ per_image=True,
+ reduction='mean',
+ class_weight=[1.0, 2.0, 3.0],
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ logits = torch.rand(1, 3, 4, 4)
+ labels = (torch.rand(1, 4, 4) * 2).long()
+ lovasz_loss(logits, labels, ignore_index=None)
+
+ # test loss with class weights from file
+ import os
+ import tempfile
+
+ import mmcv
+ import numpy as np
+ tmp_file = tempfile.NamedTemporaryFile()
+
+ mmcv.dump([1.0, 2.0, 3.0], f'{tmp_file.name}.pkl', 'pkl') # from pkl file
+ loss_cfg = dict(
+ type='LovaszLoss',
+ per_image=True,
+ reduction='mean',
+ class_weight=f'{tmp_file.name}.pkl',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ lovasz_loss(logits, labels, ignore_index=None)
+
+ np.save(f'{tmp_file.name}.npy', np.array([1.0, 2.0, 3.0])) # from npy file
+ loss_cfg = dict(
+ type='LovaszLoss',
+ per_image=True,
+ reduction='mean',
+ class_weight=f'{tmp_file.name}.npy',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ lovasz_loss(logits, labels, ignore_index=None)
+ tmp_file.close()
+ os.remove(f'{tmp_file.name}.pkl')
+ os.remove(f'{tmp_file.name}.npy')
+
+ # test lovasz loss with loss_type = 'binary' and per_image = False
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='binary',
+ reduction='none',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ logits = torch.rand(2, 4, 4)
+ labels = (torch.rand(2, 4, 4)).long()
+ lovasz_loss(logits, labels)
+
+ # test lovasz loss with loss_type = 'binary' and per_image = True
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='binary',
+ per_image=True,
+ reduction='mean',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ logits = torch.rand(2, 4, 4)
+ labels = (torch.rand(2, 4, 4)).long()
+ lovasz_loss(logits, labels, ignore_index=None)
+
+ # test lovasz loss has name `loss_lovasz`
+ loss_cfg = dict(
+ type='LovaszLoss',
+ loss_type='binary',
+ per_image=True,
+ reduction='mean',
+ loss_weight=1.0,
+ loss_name='loss_lovasz')
+ lovasz_loss = build_loss(loss_cfg)
+ assert lovasz_loss.loss_name == 'loss_lovasz'
diff --git a/tests/test_models/test_losses/test_utils.py b/tests/test_models/test_losses/test_utils.py
new file mode 100644
index 0000000..1d94387
--- /dev/null
+++ b/tests/test_models/test_losses/test_utils.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import pytest
+import torch
+
+from mmseg.models.losses import Accuracy, reduce_loss, weight_reduce_loss
+
+
+def test_weight_reduce_loss():
+ loss = torch.rand(1, 3, 4, 4)
+ weight = torch.zeros(1, 3, 4, 4)
+ weight[:, :, :2, :2] = 1
+
+ # test reduce_loss()
+ reduced = reduce_loss(loss, 'none')
+ assert reduced is loss
+
+ reduced = reduce_loss(loss, 'mean')
+ np.testing.assert_almost_equal(reduced.numpy(), loss.mean())
+
+ reduced = reduce_loss(loss, 'sum')
+ np.testing.assert_almost_equal(reduced.numpy(), loss.sum())
+
+ # test weight_reduce_loss()
+ reduced = weight_reduce_loss(loss, weight=None, reduction='none')
+ assert reduced is loss
+
+ reduced = weight_reduce_loss(loss, weight=weight, reduction='mean')
+ target = (loss * weight).mean()
+ np.testing.assert_almost_equal(reduced.numpy(), target)
+
+ reduced = weight_reduce_loss(loss, weight=weight, reduction='sum')
+ np.testing.assert_almost_equal(reduced.numpy(), (loss * weight).sum())
+
+ with pytest.raises(AssertionError):
+ weight_wrong = weight[0, 0, ...]
+ weight_reduce_loss(loss, weight=weight_wrong, reduction='mean')
+
+ with pytest.raises(AssertionError):
+ weight_wrong = weight[:, 0:2, ...]
+ weight_reduce_loss(loss, weight=weight_wrong, reduction='mean')
+
+
+def test_accuracy():
+ # test for empty pred
+ pred = torch.empty(0, 4)
+ label = torch.empty(0)
+ accuracy = Accuracy(topk=1)
+ acc = accuracy(pred, label)
+ assert acc.item() == 0
+
+ pred = torch.Tensor([[0.2, 0.3, 0.6, 0.5], [0.1, 0.1, 0.2, 0.6],
+ [0.9, 0.0, 0.0, 0.1], [0.4, 0.7, 0.1, 0.1],
+ [0.0, 0.0, 0.99, 0]])
+ # test for top1
+ true_label = torch.Tensor([2, 3, 0, 1, 2]).long()
+ accuracy = Accuracy(topk=1)
+ acc = accuracy(pred, true_label)
+ assert acc.item() == 100
+
+ # test for top1 with score thresh=0.8
+ true_label = torch.Tensor([2, 3, 0, 1, 2]).long()
+ accuracy = Accuracy(topk=1, thresh=0.8)
+ acc = accuracy(pred, true_label)
+ assert acc.item() == 40
+
+ # test for top2
+ accuracy = Accuracy(topk=2)
+ label = torch.Tensor([3, 2, 0, 0, 2]).long()
+ acc = accuracy(pred, label)
+ assert acc.item() == 100
+
+ # test for both top1 and top2
+ accuracy = Accuracy(topk=(1, 2))
+ true_label = torch.Tensor([2, 3, 0, 1, 2]).long()
+ acc = accuracy(pred, true_label)
+ for a in acc:
+ assert a.item() == 100
+
+ # topk is larger than pred class number
+ with pytest.raises(AssertionError):
+ accuracy = Accuracy(topk=5)
+ accuracy(pred, true_label)
+
+ # wrong topk type
+ with pytest.raises(AssertionError):
+ accuracy = Accuracy(topk='wrong type')
+ accuracy(pred, true_label)
+
+ # label size is larger than required
+ with pytest.raises(AssertionError):
+ label = torch.Tensor([2, 3, 0, 1, 2, 0]).long() # size mismatch
+ accuracy = Accuracy()
+ accuracy(pred, label)
+
+ # wrong pred dimension
+ with pytest.raises(AssertionError):
+ accuracy = Accuracy()
+ accuracy(pred[:, :, None], true_label)
diff --git a/tests/test_models/test_necks/__init__.py b/tests/test_models/test_necks/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/test_necks/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_necks/test_fpn.py b/tests/test_models/test_necks/test_fpn.py
new file mode 100644
index 0000000..c294006
--- /dev/null
+++ b/tests/test_models/test_necks/test_fpn.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models import FPN
+
+
+def test_fpn():
+ in_channels = [64, 128, 256, 512]
+ inputs = [
+ torch.randn(1, c, 56 // 2**i, 56 // 2**i)
+ for i, c in enumerate(in_channels)
+ ]
+
+ fpn = FPN(in_channels, 64, len(in_channels))
+ outputs = fpn(inputs)
+ assert outputs[0].shape == torch.Size([1, 64, 56, 56])
+ assert outputs[1].shape == torch.Size([1, 64, 28, 28])
+ assert outputs[2].shape == torch.Size([1, 64, 14, 14])
+ assert outputs[3].shape == torch.Size([1, 64, 7, 7])
+
+ fpn = FPN(
+ in_channels,
+ 64,
+ len(in_channels),
+ upsample_cfg=dict(mode='nearest', scale_factor=2.0))
+ outputs = fpn(inputs)
+ assert outputs[0].shape == torch.Size([1, 64, 56, 56])
+ assert outputs[1].shape == torch.Size([1, 64, 28, 28])
+ assert outputs[2].shape == torch.Size([1, 64, 14, 14])
+ assert outputs[3].shape == torch.Size([1, 64, 7, 7])
diff --git a/tests/test_models/test_necks/test_ic_neck.py b/tests/test_models/test_necks/test_ic_neck.py
new file mode 100644
index 0000000..3d13008
--- /dev/null
+++ b/tests/test_models/test_necks/test_ic_neck.py
@@ -0,0 +1,53 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.necks import ICNeck
+from mmseg.models.necks.ic_neck import CascadeFeatureFusion
+from ..test_heads.utils import _conv_has_norm, to_cuda
+
+
+def test_ic_neck():
+ # test with norm_cfg
+ neck = ICNeck(
+ in_channels=(4, 16, 16),
+ out_channels=8,
+ norm_cfg=dict(type='SyncBN'),
+ align_corners=False)
+ assert _conv_has_norm(neck, sync_bn=True)
+
+ inputs = [
+ torch.randn(1, 4, 32, 64),
+ torch.randn(1, 16, 16, 32),
+ torch.randn(1, 16, 8, 16)
+ ]
+ neck = ICNeck(
+ in_channels=(4, 16, 16),
+ out_channels=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ align_corners=False)
+ if torch.cuda.is_available():
+ neck, inputs = to_cuda(neck, inputs)
+
+ outputs = neck(inputs)
+ assert outputs[0].shape == (1, 4, 16, 32)
+ assert outputs[1].shape == (1, 4, 32, 64)
+ assert outputs[1].shape == (1, 4, 32, 64)
+
+
+def test_ic_neck_cascade_feature_fusion():
+ cff = CascadeFeatureFusion(64, 64, 32)
+ assert cff.conv_low.in_channels == 64
+ assert cff.conv_low.out_channels == 32
+ assert cff.conv_high.in_channels == 64
+ assert cff.conv_high.out_channels == 32
+
+
+def test_ic_neck_input_channels():
+ with pytest.raises(AssertionError):
+ # ICNet Neck input channel constraints.
+ ICNeck(
+ in_channels=(16, 64, 64, 64),
+ out_channels=32,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ align_corners=False)
diff --git a/tests/test_models/test_necks/test_jpu.py b/tests/test_models/test_necks/test_jpu.py
new file mode 100644
index 0000000..4c3fa9f
--- /dev/null
+++ b/tests/test_models/test_necks/test_jpu.py
@@ -0,0 +1,46 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.necks import JPU
+
+
+def test_fastfcn_neck():
+ # Test FastFCN Standard Forward
+ model = JPU(
+ in_channels=(64, 128, 256),
+ mid_channels=64,
+ start_level=0,
+ end_level=-1,
+ dilations=(1, 2, 4, 8),
+ )
+ model.init_weights()
+ model.train()
+ batch_size = 1
+ input = [
+ torch.randn(batch_size, 64, 64, 128),
+ torch.randn(batch_size, 128, 32, 64),
+ torch.randn(batch_size, 256, 16, 32)
+ ]
+ feat = model(input)
+
+ assert len(feat) == 3
+ assert feat[0].shape == torch.Size([batch_size, 64, 64, 128])
+ assert feat[1].shape == torch.Size([batch_size, 128, 32, 64])
+ assert feat[2].shape == torch.Size([batch_size, 256, 64, 128])
+
+ with pytest.raises(AssertionError):
+ # FastFCN input and in_channels constraints.
+ JPU(in_channels=(256, 64, 128), start_level=0, end_level=5)
+
+ # Test not default start_level
+ model = JPU(in_channels=(64, 128, 256), start_level=1, end_level=-1)
+ input = [
+ torch.randn(batch_size, 64, 64, 128),
+ torch.randn(batch_size, 128, 32, 64),
+ torch.randn(batch_size, 256, 16, 32)
+ ]
+ feat = model(input)
+ assert len(feat) == 2
+ assert feat[0].shape == torch.Size([batch_size, 128, 32, 64])
+ assert feat[1].shape == torch.Size([batch_size, 2048, 32, 64])
diff --git a/tests/test_models/test_necks/test_mla_neck.py b/tests/test_models/test_necks/test_mla_neck.py
new file mode 100644
index 0000000..e385418
--- /dev/null
+++ b/tests/test_models/test_necks/test_mla_neck.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models import MLANeck
+
+
+def test_mla():
+ in_channels = [4, 4, 4, 4]
+ mla = MLANeck(in_channels, 32)
+
+ inputs = [torch.randn(1, c, 12, 12) for i, c in enumerate(in_channels)]
+ outputs = mla(inputs)
+ assert outputs[0].shape == torch.Size([1, 32, 12, 12])
+ assert outputs[1].shape == torch.Size([1, 32, 12, 12])
+ assert outputs[2].shape == torch.Size([1, 32, 12, 12])
+ assert outputs[3].shape == torch.Size([1, 32, 12, 12])
diff --git a/tests/test_models/test_necks/test_multilevel_neck.py b/tests/test_models/test_necks/test_multilevel_neck.py
new file mode 100644
index 0000000..9c71d51
--- /dev/null
+++ b/tests/test_models/test_necks/test_multilevel_neck.py
@@ -0,0 +1,32 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models import MultiLevelNeck
+
+
+def test_multilevel_neck():
+
+ # Test init_weights
+ MultiLevelNeck([266], 32).init_weights()
+
+ # Test multi feature maps
+ in_channels = [32, 64, 128, 256]
+ inputs = [torch.randn(1, c, 14, 14) for i, c in enumerate(in_channels)]
+
+ neck = MultiLevelNeck(in_channels, 32)
+ outputs = neck(inputs)
+ assert outputs[0].shape == torch.Size([1, 32, 7, 7])
+ assert outputs[1].shape == torch.Size([1, 32, 14, 14])
+ assert outputs[2].shape == torch.Size([1, 32, 28, 28])
+ assert outputs[3].shape == torch.Size([1, 32, 56, 56])
+
+ # Test one feature map
+ in_channels = [768]
+ inputs = [torch.randn(1, 768, 14, 14)]
+
+ neck = MultiLevelNeck(in_channels, 32)
+ outputs = neck(inputs)
+ assert outputs[0].shape == torch.Size([1, 32, 7, 7])
+ assert outputs[1].shape == torch.Size([1, 32, 14, 14])
+ assert outputs[2].shape == torch.Size([1, 32, 28, 28])
+ assert outputs[3].shape == torch.Size([1, 32, 56, 56])
diff --git a/tests/test_models/test_segmentors/__init__.py b/tests/test_models/test_segmentors/__init__.py
new file mode 100644
index 0000000..ef101fe
--- /dev/null
+++ b/tests/test_models/test_segmentors/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) OpenMMLab. All rights reserved.
diff --git a/tests/test_models/test_segmentors/test_cascade_encoder_decoder.py b/tests/test_models/test_segmentors/test_cascade_encoder_decoder.py
new file mode 100644
index 0000000..07ad5c3
--- /dev/null
+++ b/tests/test_models/test_segmentors/test_cascade_encoder_decoder.py
@@ -0,0 +1,57 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv import ConfigDict
+
+from mmseg.models import build_segmentor
+from .utils import _segmentor_forward_train_test
+
+
+def test_cascade_encoder_decoder():
+
+ # test 1 decode head, w.o. aux head
+ cfg = ConfigDict(
+ type='CascadeEncoderDecoder',
+ num_stages=2,
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleCascadeDecodeHead')
+ ])
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test slide mode
+ cfg.test_cfg = ConfigDict(mode='slide', crop_size=(3, 3), stride=(2, 2))
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test 1 decode head, 1 aux head
+ cfg = ConfigDict(
+ type='CascadeEncoderDecoder',
+ num_stages=2,
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleCascadeDecodeHead')
+ ],
+ auxiliary_head=dict(type='ExampleDecodeHead'))
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test 1 decode head, 2 aux head
+ cfg = ConfigDict(
+ type='CascadeEncoderDecoder',
+ num_stages=2,
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleCascadeDecodeHead')
+ ],
+ auxiliary_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleDecodeHead')
+ ])
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
diff --git a/tests/test_models/test_segmentors/test_encoder_decoder.py b/tests/test_models/test_segmentors/test_encoder_decoder.py
new file mode 100644
index 0000000..4ed1437
--- /dev/null
+++ b/tests/test_models/test_segmentors/test_encoder_decoder.py
@@ -0,0 +1,47 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv import ConfigDict
+
+from mmseg.models import build_segmentor
+from .utils import _segmentor_forward_train_test
+
+
+def test_encoder_decoder():
+
+ # test 1 decode head, w.o. aux head
+
+ cfg = ConfigDict(
+ type='EncoderDecoder',
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=dict(type='ExampleDecodeHead'),
+ train_cfg=None,
+ test_cfg=dict(mode='whole'))
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test slide mode
+ cfg.test_cfg = ConfigDict(mode='slide', crop_size=(3, 3), stride=(2, 2))
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test 1 decode head, 1 aux head
+ cfg = ConfigDict(
+ type='EncoderDecoder',
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=dict(type='ExampleDecodeHead'),
+ auxiliary_head=dict(type='ExampleDecodeHead'))
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
+
+ # test 1 decode head, 2 aux head
+ cfg = ConfigDict(
+ type='EncoderDecoder',
+ backbone=dict(type='ExampleBackbone'),
+ decode_head=dict(type='ExampleDecodeHead'),
+ auxiliary_head=[
+ dict(type='ExampleDecodeHead'),
+ dict(type='ExampleDecodeHead')
+ ])
+ cfg.test_cfg = ConfigDict(mode='whole')
+ segmentor = build_segmentor(cfg)
+ _segmentor_forward_train_test(segmentor)
diff --git a/tests/test_models/test_segmentors/utils.py b/tests/test_models/test_segmentors/utils.py
new file mode 100644
index 0000000..1826dbf
--- /dev/null
+++ b/tests/test_models/test_segmentors/utils.py
@@ -0,0 +1,140 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+from torch import nn
+
+from mmseg.models import BACKBONES, HEADS
+from mmseg.models.decode_heads.cascade_decode_head import BaseCascadeDecodeHead
+from mmseg.models.decode_heads.decode_head import BaseDecodeHead
+
+
+def _demo_mm_inputs(input_shape=(1, 3, 8, 16), num_classes=10):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+
+ rng = np.random.RandomState(0)
+
+ imgs = rng.rand(*input_shape)
+ segs = rng.randint(
+ low=0, high=num_classes - 1, size=(N, 1, H, W)).astype(np.uint8)
+
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': 1.0,
+ 'flip': False,
+ 'flip_direction': 'horizontal'
+ } for _ in range(N)]
+
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs),
+ 'img_metas': img_metas,
+ 'gt_semantic_seg': torch.LongTensor(segs)
+ }
+ return mm_inputs
+
+
+@BACKBONES.register_module()
+class ExampleBackbone(nn.Module):
+
+ def __init__(self):
+ super(ExampleBackbone, self).__init__()
+ self.conv = nn.Conv2d(3, 3, 3)
+
+ def init_weights(self, pretrained=None):
+ pass
+
+ def forward(self, x):
+ return [self.conv(x)]
+
+
+@HEADS.register_module()
+class ExampleDecodeHead(BaseDecodeHead):
+
+ def __init__(self):
+ super(ExampleDecodeHead, self).__init__(3, 3, num_classes=19)
+
+ def forward(self, inputs):
+ return self.cls_seg(inputs[0])
+
+
+@HEADS.register_module()
+class ExampleCascadeDecodeHead(BaseCascadeDecodeHead):
+
+ def __init__(self):
+ super(ExampleCascadeDecodeHead, self).__init__(3, 3, num_classes=19)
+
+ def forward(self, inputs, prev_out):
+ return self.cls_seg(inputs[0])
+
+
+def _segmentor_forward_train_test(segmentor):
+ if isinstance(segmentor.decode_head, nn.ModuleList):
+ num_classes = segmentor.decode_head[-1].num_classes
+ else:
+ num_classes = segmentor.decode_head.num_classes
+ # batch_size=2 for BatchNorm
+ mm_inputs = _demo_mm_inputs(num_classes=num_classes)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ gt_semantic_seg = mm_inputs['gt_semantic_seg']
+
+ # convert to cuda Tensor if applicable
+ if torch.cuda.is_available():
+ segmentor = segmentor.cuda()
+ imgs = imgs.cuda()
+ gt_semantic_seg = gt_semantic_seg.cuda()
+
+ # Test forward train
+ losses = segmentor.forward(
+ imgs, img_metas, gt_semantic_seg=gt_semantic_seg, return_loss=True)
+ assert isinstance(losses, dict)
+
+ # Test train_step
+ data_batch = dict(
+ img=imgs, img_metas=img_metas, gt_semantic_seg=gt_semantic_seg)
+ outputs = segmentor.train_step(data_batch, None)
+ assert isinstance(outputs, dict)
+ assert 'loss' in outputs
+ assert 'log_vars' in outputs
+ assert 'num_samples' in outputs
+
+ # Test val_step
+ with torch.no_grad():
+ segmentor.eval()
+ data_batch = dict(
+ img=imgs, img_metas=img_metas, gt_semantic_seg=gt_semantic_seg)
+ outputs = segmentor.val_step(data_batch, None)
+ assert isinstance(outputs, dict)
+ assert 'loss' in outputs
+ assert 'log_vars' in outputs
+ assert 'num_samples' in outputs
+
+ # Test forward simple test
+ with torch.no_grad():
+ segmentor.eval()
+ # pack into lists
+ img_list = [img[None, :] for img in imgs]
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ segmentor.forward(img_list, img_meta_list, return_loss=False)
+
+ # Test forward aug test
+ with torch.no_grad():
+ segmentor.eval()
+ # pack into lists
+ img_list = [img[None, :] for img in imgs]
+ img_list = img_list + img_list
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ img_meta_list = img_meta_list + img_meta_list
+ segmentor.forward(img_list, img_meta_list, return_loss=False)
diff --git a/tests/test_models/test_utils/__init__.py b/tests/test_models/test_utils/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/tests/test_models/test_utils/test_embed.py b/tests/test_models/test_utils/test_embed.py
new file mode 100644
index 0000000..be20c97
--- /dev/null
+++ b/tests/test_models/test_utils/test_embed.py
@@ -0,0 +1,461 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.utils.embed import AdaptivePadding, PatchEmbed, PatchMerging
+
+
+def test_adaptive_padding():
+
+ for padding in ('same', 'corner'):
+ kernel_size = 16
+ stride = 16
+ dilation = 1
+ input = torch.rand(1, 1, 15, 17)
+ adap_pool = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ out = adap_pool(input)
+ # padding to divisible by 16
+ assert (out.shape[2], out.shape[3]) == (16, 32)
+ input = torch.rand(1, 1, 16, 17)
+ out = adap_pool(input)
+ # padding to divisible by 16
+ assert (out.shape[2], out.shape[3]) == (16, 32)
+
+ kernel_size = (2, 2)
+ stride = (2, 2)
+ dilation = (1, 1)
+
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ input = torch.rand(1, 1, 11, 13)
+ out = adap_pad(input)
+ # padding to divisible by 2
+ assert (out.shape[2], out.shape[3]) == (12, 14)
+
+ kernel_size = (2, 2)
+ stride = (10, 10)
+ dilation = (1, 1)
+
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ input = torch.rand(1, 1, 10, 13)
+ out = adap_pad(input)
+ # no padding
+ assert (out.shape[2], out.shape[3]) == (10, 13)
+
+ kernel_size = (11, 11)
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ input = torch.rand(1, 1, 11, 13)
+ out = adap_pad(input)
+ # all padding
+ assert (out.shape[2], out.shape[3]) == (21, 21)
+
+ # test padding as kernel is (7,9)
+ input = torch.rand(1, 1, 11, 13)
+ stride = (3, 4)
+ kernel_size = (4, 5)
+ dilation = (2, 2)
+ # actually (7, 9)
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ dilation_out = adap_pad(input)
+ assert (dilation_out.shape[2], dilation_out.shape[3]) == (16, 21)
+ kernel_size = (7, 9)
+ dilation = (1, 1)
+ adap_pad = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ kernel79_out = adap_pad(input)
+ assert (kernel79_out.shape[2], kernel79_out.shape[3]) == (16, 21)
+ assert kernel79_out.shape == dilation_out.shape
+
+ # assert only support "same" "corner"
+ with pytest.raises(AssertionError):
+ AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=1)
+
+
+def test_patch_embed():
+ B = 2
+ H = 3
+ W = 4
+ C = 3
+ embed_dims = 10
+ kernel_size = 3
+ stride = 1
+ dummy_input = torch.rand(B, C, H, W)
+ patch_merge_1 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=1,
+ norm_cfg=None)
+
+ x1, shape = patch_merge_1(dummy_input)
+ # test out shape
+ assert x1.shape == (2, 2, 10)
+ # test outsize is correct
+ assert shape == (1, 2)
+ # test L = out_h * out_w
+ assert shape[0] * shape[1] == x1.shape[1]
+
+ B = 2
+ H = 10
+ W = 10
+ C = 3
+ embed_dims = 10
+ kernel_size = 5
+ stride = 2
+ dummy_input = torch.rand(B, C, H, W)
+ # test dilation
+ patch_merge_2 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=2,
+ norm_cfg=None,
+ )
+
+ x2, shape = patch_merge_2(dummy_input)
+ # test out shape
+ assert x2.shape == (2, 1, 10)
+ # test outsize is correct
+ assert shape == (1, 1)
+ # test L = out_h * out_w
+ assert shape[0] * shape[1] == x2.shape[1]
+
+ stride = 2
+ input_size = (10, 10)
+
+ dummy_input = torch.rand(B, C, H, W)
+ # test stride and norm
+ patch_merge_3 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=2,
+ norm_cfg=dict(type='LN'),
+ input_size=input_size)
+
+ x3, shape = patch_merge_3(dummy_input)
+ # test out shape
+ assert x3.shape == (2, 1, 10)
+ # test outsize is correct
+ assert shape == (1, 1)
+ # test L = out_h * out_w
+ assert shape[0] * shape[1] == x3.shape[1]
+
+ # test the init_out_size with nn.Unfold
+ assert patch_merge_3.init_out_size[1] == (input_size[0] - 2 * 4 -
+ 1) // 2 + 1
+ assert patch_merge_3.init_out_size[0] == (input_size[0] - 2 * 4 -
+ 1) // 2 + 1
+ H = 11
+ W = 12
+ input_size = (H, W)
+ dummy_input = torch.rand(B, C, H, W)
+ # test stride and norm
+ patch_merge_3 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=2,
+ norm_cfg=dict(type='LN'),
+ input_size=input_size)
+
+ _, shape = patch_merge_3(dummy_input)
+ # when input_size equal to real input
+ # the out_size should be equal to `init_out_size`
+ assert shape == patch_merge_3.init_out_size
+
+ input_size = (H, W)
+ dummy_input = torch.rand(B, C, H, W)
+ # test stride and norm
+ patch_merge_3 = PatchEmbed(
+ in_channels=C,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=0,
+ dilation=2,
+ norm_cfg=dict(type='LN'),
+ input_size=input_size)
+
+ _, shape = patch_merge_3(dummy_input)
+ # when input_size equal to real input
+ # the out_size should be equal to `init_out_size`
+ assert shape == patch_merge_3.init_out_size
+
+ # test adap padding
+ for padding in ('same', 'corner'):
+ in_c = 2
+ embed_dims = 3
+ B = 2
+
+ # test stride is 1
+ input_size = (5, 5)
+ kernel_size = (5, 5)
+ stride = (1, 1)
+ dilation = 1
+ bias = False
+
+ x = torch.rand(B, in_c, *input_size)
+ patch_embed = PatchEmbed(
+ in_channels=in_c,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_embed(x)
+ assert x_out.size() == (B, 25, 3)
+ assert out_size == (5, 5)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test kernel_size == stride
+ input_size = (5, 5)
+ kernel_size = (5, 5)
+ stride = (5, 5)
+ dilation = 1
+ bias = False
+
+ x = torch.rand(B, in_c, *input_size)
+ patch_embed = PatchEmbed(
+ in_channels=in_c,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_embed(x)
+ assert x_out.size() == (B, 1, 3)
+ assert out_size == (1, 1)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test kernel_size == stride
+ input_size = (6, 5)
+ kernel_size = (5, 5)
+ stride = (5, 5)
+ dilation = 1
+ bias = False
+
+ x = torch.rand(B, in_c, *input_size)
+ patch_embed = PatchEmbed(
+ in_channels=in_c,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_embed(x)
+ assert x_out.size() == (B, 2, 3)
+ assert out_size == (2, 1)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test different kernel_size with different stride
+ input_size = (6, 5)
+ kernel_size = (6, 2)
+ stride = (6, 2)
+ dilation = 1
+ bias = False
+
+ x = torch.rand(B, in_c, *input_size)
+ patch_embed = PatchEmbed(
+ in_channels=in_c,
+ embed_dims=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_embed(x)
+ assert x_out.size() == (B, 3, 3)
+ assert out_size == (1, 3)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+
+def test_patch_merging():
+
+ # Test the model with int padding
+ in_c = 3
+ out_c = 4
+ kernel_size = 3
+ stride = 3
+ padding = 1
+ dilation = 1
+ bias = False
+ # test the case `pad_to_stride` is False
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+ B, L, C = 1, 100, 3
+ input_size = (10, 10)
+ x = torch.rand(B, L, C)
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (1, 16, 4)
+ assert out_size == (4, 4)
+ # assert out size is consistent with real output
+ assert x_out.size(1) == out_size[0] * out_size[1]
+ in_c = 4
+ out_c = 5
+ kernel_size = 6
+ stride = 3
+ padding = 2
+ dilation = 2
+ bias = False
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+ B, L, C = 1, 100, 4
+ input_size = (10, 10)
+ x = torch.rand(B, L, C)
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (1, 4, 5)
+ assert out_size == (2, 2)
+ # assert out size is consistent with real output
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # Test with adaptive padding
+ for padding in ('same', 'corner'):
+ in_c = 2
+ out_c = 3
+ B = 2
+
+ # test stride is 1
+ input_size = (5, 5)
+ kernel_size = (5, 5)
+ stride = (1, 1)
+ dilation = 1
+ bias = False
+ L = input_size[0] * input_size[1]
+
+ x = torch.rand(B, L, in_c)
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (B, 25, 3)
+ assert out_size == (5, 5)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test kernel_size == stride
+ input_size = (5, 5)
+ kernel_size = (5, 5)
+ stride = (5, 5)
+ dilation = 1
+ bias = False
+ L = input_size[0] * input_size[1]
+
+ x = torch.rand(B, L, in_c)
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (B, 1, 3)
+ assert out_size == (1, 1)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test kernel_size == stride
+ input_size = (6, 5)
+ kernel_size = (5, 5)
+ stride = (5, 5)
+ dilation = 1
+ bias = False
+ L = input_size[0] * input_size[1]
+
+ x = torch.rand(B, L, in_c)
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (B, 2, 3)
+ assert out_size == (2, 1)
+ assert x_out.size(1) == out_size[0] * out_size[1]
+
+ # test different kernel_size with different stride
+ input_size = (6, 5)
+ kernel_size = (6, 2)
+ stride = (6, 2)
+ dilation = 1
+ bias = False
+ L = input_size[0] * input_size[1]
+
+ x = torch.rand(B, L, in_c)
+ patch_merge = PatchMerging(
+ in_channels=in_c,
+ out_channels=out_c,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ x_out, out_size = patch_merge(x, input_size)
+ assert x_out.size() == (B, 3, 3)
+ assert out_size == (1, 3)
+ assert x_out.size(1) == out_size[0] * out_size[1]
diff --git a/tests/test_sampler.py b/tests/test_sampler.py
new file mode 100644
index 0000000..1409224
--- /dev/null
+++ b/tests/test_sampler.py
@@ -0,0 +1,78 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.core import OHEMPixelSampler
+from mmseg.models.decode_heads import FCNHead
+
+
+def _context_for_ohem():
+ return FCNHead(in_channels=32, channels=16, num_classes=19)
+
+
+def _context_for_ohem_multiple_loss():
+ return FCNHead(
+ in_channels=32,
+ channels=16,
+ num_classes=19,
+ loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_1'),
+ dict(type='CrossEntropyLoss', loss_name='loss_2')
+ ])
+
+
+def test_ohem_sampler():
+
+ with pytest.raises(AssertionError):
+ # seg_logit and seg_label must be of the same size
+ sampler = OHEMPixelSampler(context=_context_for_ohem())
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 89, 89))
+ sampler.sample(seg_logit, seg_label)
+
+ # test with thresh
+ sampler = OHEMPixelSampler(
+ context=_context_for_ohem(), thresh=0.7, min_kept=200)
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 45, 45))
+ seg_weight = sampler.sample(seg_logit, seg_label)
+ assert seg_weight.shape[0] == seg_logit.shape[0]
+ assert seg_weight.shape[1:] == seg_logit.shape[2:]
+ assert seg_weight.sum() > 200
+
+ # test w.o thresh
+ sampler = OHEMPixelSampler(context=_context_for_ohem(), min_kept=200)
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 45, 45))
+ seg_weight = sampler.sample(seg_logit, seg_label)
+ assert seg_weight.shape[0] == seg_logit.shape[0]
+ assert seg_weight.shape[1:] == seg_logit.shape[2:]
+ assert seg_weight.sum() == 200
+
+ # test multiple losses case
+ with pytest.raises(AssertionError):
+ # seg_logit and seg_label must be of the same size
+ sampler = OHEMPixelSampler(context=_context_for_ohem_multiple_loss())
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 89, 89))
+ sampler.sample(seg_logit, seg_label)
+
+ # test with thresh in multiple losses case
+ sampler = OHEMPixelSampler(
+ context=_context_for_ohem_multiple_loss(), thresh=0.7, min_kept=200)
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 45, 45))
+ seg_weight = sampler.sample(seg_logit, seg_label)
+ assert seg_weight.shape[0] == seg_logit.shape[0]
+ assert seg_weight.shape[1:] == seg_logit.shape[2:]
+ assert seg_weight.sum() > 200
+
+ # test w.o thresh in multiple losses case
+ sampler = OHEMPixelSampler(
+ context=_context_for_ohem_multiple_loss(), min_kept=200)
+ seg_logit = torch.randn(1, 19, 45, 45)
+ seg_label = torch.randint(0, 19, size=(1, 1, 45, 45))
+ seg_weight = sampler.sample(seg_logit, seg_label)
+ assert seg_weight.shape[0] == seg_logit.shape[0]
+ assert seg_weight.shape[1:] == seg_logit.shape[2:]
+ assert seg_weight.sum() == 200
diff --git a/tests/test_utils/test_misc.py b/tests/test_utils/test_misc.py
new file mode 100644
index 0000000..7ce1fa6
--- /dev/null
+++ b/tests/test_utils/test_misc.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+
+from mmseg.utils import find_latest_checkpoint
+
+
+def test_find_latest_checkpoint():
+ with tempfile.TemporaryDirectory() as tempdir:
+ # no checkpoints in the path
+ path = tempdir
+ latest = find_latest_checkpoint(path)
+ assert latest is None
+
+ # The path doesn't exist
+ path = osp.join(tempdir, 'none')
+ latest = find_latest_checkpoint(path)
+ assert latest is None
+
+ # test when latest.pth exists
+ with tempfile.TemporaryDirectory() as tempdir:
+ with open(osp.join(tempdir, 'latest.pth'), 'w') as f:
+ f.write('latest')
+ path = tempdir
+ latest = find_latest_checkpoint(path)
+ assert latest == osp.join(tempdir, 'latest.pth')
+
+ with tempfile.TemporaryDirectory() as tempdir:
+ for iter in range(1600, 160001, 1600):
+ with open(osp.join(tempdir, f'iter_{iter}.pth'), 'w') as f:
+ f.write(f'iter_{iter}.pth')
+ latest = find_latest_checkpoint(tempdir)
+ assert latest == osp.join(tempdir, 'iter_160000.pth')
+
+ with tempfile.TemporaryDirectory() as tempdir:
+ for epoch in range(1, 21):
+ with open(osp.join(tempdir, f'epoch_{epoch}.pth'), 'w') as f:
+ f.write(f'epoch_{epoch}.pth')
+ latest = find_latest_checkpoint(tempdir)
+ assert latest == osp.join(tempdir, 'epoch_20.pth')
diff --git a/tests/test_utils/test_set_env.py b/tests/test_utils/test_set_env.py
new file mode 100644
index 0000000..0af4424
--- /dev/null
+++ b/tests/test_utils/test_set_env.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import multiprocessing as mp
+import os
+import platform
+
+import cv2
+import pytest
+from mmcv import Config
+
+from mmseg.utils import setup_multi_processes
+
+
+@pytest.mark.parametrize('workers_per_gpu', (0, 2))
+@pytest.mark.parametrize(('valid', 'env_cfg'), [(True,
+ dict(
+ mp_start_method='fork',
+ opencv_num_threads=0,
+ omp_num_threads=1,
+ mkl_num_threads=1)),
+ (False,
+ dict(
+ mp_start_method=1,
+ opencv_num_threads=0.1,
+ omp_num_threads='s',
+ mkl_num_threads='1'))])
+def test_setup_multi_processes(workers_per_gpu, valid, env_cfg):
+ # temp save system setting
+ sys_start_mehod = mp.get_start_method(allow_none=True)
+ sys_cv_threads = cv2.getNumThreads()
+ # pop and temp save system env vars
+ sys_omp_threads = os.environ.pop('OMP_NUM_THREADS', default=None)
+ sys_mkl_threads = os.environ.pop('MKL_NUM_THREADS', default=None)
+
+ config = dict(data=dict(workers_per_gpu=workers_per_gpu))
+ config.update(env_cfg)
+ cfg = Config(config)
+ setup_multi_processes(cfg)
+
+ # test when cfg is valid and workers_per_gpu > 0
+ # setup_multi_processes will work
+ if valid and workers_per_gpu > 0:
+ # test config without setting env
+
+ assert os.getenv('OMP_NUM_THREADS') == str(env_cfg['omp_num_threads'])
+ assert os.getenv('MKL_NUM_THREADS') == str(env_cfg['mkl_num_threads'])
+ # when set to 0, the num threads will be 1
+ assert cv2.getNumThreads() == env_cfg[
+ 'opencv_num_threads'] if env_cfg['opencv_num_threads'] > 0 else 1
+ if platform.system() != 'Windows':
+ assert mp.get_start_method() == env_cfg['mp_start_method']
+
+ # revert setting to avoid affecting other programs
+ if sys_start_mehod:
+ mp.set_start_method(sys_start_mehod, force=True)
+ cv2.setNumThreads(sys_cv_threads)
+ if sys_omp_threads:
+ os.environ['OMP_NUM_THREADS'] = sys_omp_threads
+ else:
+ os.environ.pop('OMP_NUM_THREADS')
+ if sys_mkl_threads:
+ os.environ['MKL_NUM_THREADS'] = sys_mkl_threads
+ else:
+ os.environ.pop('MKL_NUM_THREADS')
+
+ elif valid and workers_per_gpu == 0:
+
+ if platform.system() != 'Windows':
+ assert mp.get_start_method() == env_cfg['mp_start_method']
+ assert cv2.getNumThreads() == env_cfg[
+ 'opencv_num_threads'] if env_cfg['opencv_num_threads'] > 0 else 1
+ assert 'OMP_NUM_THREADS' not in os.environ
+ assert 'MKL_NUM_THREADS' not in os.environ
+ if sys_start_mehod:
+ mp.set_start_method(sys_start_mehod, force=True)
+ cv2.setNumThreads(sys_cv_threads)
+ if sys_omp_threads:
+ os.environ['OMP_NUM_THREADS'] = sys_omp_threads
+ if sys_mkl_threads:
+ os.environ['MKL_NUM_THREADS'] = sys_mkl_threads
+
+ else:
+ assert mp.get_start_method() == sys_start_mehod
+ assert cv2.getNumThreads() == sys_cv_threads
+ assert 'OMP_NUM_THREADS' not in os.environ
+ assert 'MKL_NUM_THREADS' not in os.environ
diff --git a/tools/analyze_logs.py b/tools/analyze_logs.py
new file mode 100644
index 0000000..8c62a34
--- /dev/null
+++ b/tools/analyze_logs.py
@@ -0,0 +1,130 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Modified from https://github.com/open-
+mmlab/mmdetection/blob/master/tools/analysis_tools/analyze_logs.py."""
+import argparse
+import json
+from collections import defaultdict
+
+import matplotlib.pyplot as plt
+import seaborn as sns
+
+
+def plot_curve(log_dicts, args):
+ if args.backend is not None:
+ plt.switch_backend(args.backend)
+ sns.set_style(args.style)
+ # if legend is None, use {filename}_{key} as legend
+ legend = args.legend
+ if legend is None:
+ legend = []
+ for json_log in args.json_logs:
+ for metric in args.keys:
+ legend.append(f'{json_log}_{metric}')
+ assert len(legend) == (len(args.json_logs) * len(args.keys))
+ metrics = args.keys
+
+ num_metrics = len(metrics)
+ for i, log_dict in enumerate(log_dicts):
+ epochs = list(log_dict.keys())
+ for j, metric in enumerate(metrics):
+ print(f'plot curve of {args.json_logs[i]}, metric is {metric}')
+ plot_epochs = []
+ plot_iters = []
+ plot_values = []
+ # In some log files, iters number is not correct, `pre_iter` is
+ # used to prevent generate wrong lines.
+ pre_iter = -1
+ for epoch in epochs:
+ epoch_logs = log_dict[epoch]
+ if metric not in epoch_logs.keys():
+ continue
+ if metric in ['mIoU', 'mAcc', 'aAcc']:
+ plot_epochs.append(epoch)
+ plot_values.append(epoch_logs[metric][0])
+ else:
+ for idx in range(len(epoch_logs[metric])):
+ if pre_iter > epoch_logs['iter'][idx]:
+ continue
+ pre_iter = epoch_logs['iter'][idx]
+ plot_iters.append(epoch_logs['iter'][idx])
+ plot_values.append(epoch_logs[metric][idx])
+ ax = plt.gca()
+ label = legend[i * num_metrics + j]
+ if metric in ['mIoU', 'mAcc', 'aAcc']:
+ ax.set_xticks(plot_epochs)
+ plt.xlabel('epoch')
+ plt.plot(plot_epochs, plot_values, label=label, marker='o')
+ else:
+ plt.xlabel('iter')
+ plt.plot(plot_iters, plot_values, label=label, linewidth=0.5)
+ plt.legend()
+ if args.title is not None:
+ plt.title(args.title)
+ if args.out is None:
+ plt.show()
+ else:
+ print(f'save curve to: {args.out}')
+ plt.savefig(args.out)
+ plt.cla()
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Analyze Json Log')
+ parser.add_argument(
+ 'json_logs',
+ type=str,
+ nargs='+',
+ help='path of train log in json format')
+ parser.add_argument(
+ '--keys',
+ type=str,
+ nargs='+',
+ default=['mIoU'],
+ help='the metric that you want to plot')
+ parser.add_argument('--title', type=str, help='title of figure')
+ parser.add_argument(
+ '--legend',
+ type=str,
+ nargs='+',
+ default=None,
+ help='legend of each plot')
+ parser.add_argument(
+ '--backend', type=str, default=None, help='backend of plt')
+ parser.add_argument(
+ '--style', type=str, default='dark', help='style of plt')
+ parser.add_argument('--out', type=str, default=None)
+ args = parser.parse_args()
+ return args
+
+
+def load_json_logs(json_logs):
+ # load and convert json_logs to log_dict, key is epoch, value is a sub dict
+ # keys of sub dict is different metrics
+ # value of sub dict is a list of corresponding values of all iterations
+ log_dicts = [dict() for _ in json_logs]
+ for json_log, log_dict in zip(json_logs, log_dicts):
+ with open(json_log, 'r') as log_file:
+ for line in log_file:
+ log = json.loads(line.strip())
+ # skip lines without `epoch` field
+ if 'epoch' not in log:
+ continue
+ epoch = log.pop('epoch')
+ if epoch not in log_dict:
+ log_dict[epoch] = defaultdict(list)
+ for k, v in log.items():
+ log_dict[epoch][k].append(v)
+ return log_dicts
+
+
+def main():
+ args = parse_args()
+ json_logs = args.json_logs
+ for json_log in json_logs:
+ assert json_log.endswith('.json')
+ log_dicts = load_json_logs(json_logs)
+ plot_curve(log_dicts, args)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/benchmark.py b/tools/benchmark.py
new file mode 100644
index 0000000..f6d6888
--- /dev/null
+++ b/tools/benchmark.py
@@ -0,0 +1,120 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+import time
+
+import mmcv
+import numpy as np
+import torch
+from mmcv import Config
+from mmcv.parallel import MMDataParallel
+from mmcv.runner import load_checkpoint, wrap_fp16_model
+
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.models import build_segmentor
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMSeg benchmark a model')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('checkpoint', help='checkpoint file')
+ parser.add_argument(
+ '--log-interval', type=int, default=50, help='interval of logging')
+ parser.add_argument(
+ '--work-dir',
+ help=('if specified, the results will be dumped '
+ 'into the directory as json'))
+ parser.add_argument('--repeat-times', type=int, default=1)
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ if args.work_dir is not None:
+ mmcv.mkdir_or_exist(osp.abspath(args.work_dir))
+ json_file = osp.join(args.work_dir, f'fps_{timestamp}.json')
+ else:
+ # use config filename as default work_dir if cfg.work_dir is None
+ work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ mmcv.mkdir_or_exist(osp.abspath(work_dir))
+ json_file = osp.join(work_dir, f'fps_{timestamp}.json')
+
+ repeat_times = args.repeat_times
+ # set cudnn_benchmark
+ torch.backends.cudnn.benchmark = False
+ cfg.model.pretrained = None
+ cfg.data.test.test_mode = True
+
+ benchmark_dict = dict(config=args.config, unit='img / s')
+ overall_fps_list = []
+ for time_index in range(repeat_times):
+ print(f'Run {time_index + 1}:')
+ # build the dataloader
+ # TODO: support multiple images per gpu (only minor changes are needed)
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=False,
+ shuffle=False)
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ model = build_segmentor(cfg.model, test_cfg=cfg.get('test_cfg'))
+ fp16_cfg = cfg.get('fp16', None)
+ if fp16_cfg is not None:
+ wrap_fp16_model(model)
+ if 'checkpoint' in args and osp.exists(args.checkpoint):
+ load_checkpoint(model, args.checkpoint, map_location='cpu')
+
+ model = MMDataParallel(model, device_ids=[0])
+
+ model.eval()
+
+ # the first several iterations may be very slow so skip them
+ num_warmup = 5
+ pure_inf_time = 0
+ total_iters = 200
+
+ # benchmark with 200 image and take the average
+ for i, data in enumerate(data_loader):
+
+ torch.cuda.synchronize()
+ start_time = time.perf_counter()
+
+ with torch.no_grad():
+ model(return_loss=False, rescale=True, **data)
+
+ torch.cuda.synchronize()
+ elapsed = time.perf_counter() - start_time
+
+ if i >= num_warmup:
+ pure_inf_time += elapsed
+ if (i + 1) % args.log_interval == 0:
+ fps = (i + 1 - num_warmup) / pure_inf_time
+ print(f'Done image [{i + 1:<3}/ {total_iters}], '
+ f'fps: {fps:.2f} img / s')
+
+ if (i + 1) == total_iters:
+ fps = (i + 1 - num_warmup) / pure_inf_time
+ print(f'Overall fps: {fps:.2f} img / s\n')
+ benchmark_dict[f'overall_fps_{time_index + 1}'] = round(fps, 2)
+ overall_fps_list.append(fps)
+ break
+ benchmark_dict['average_fps'] = round(np.mean(overall_fps_list), 2)
+ benchmark_dict['fps_variance'] = round(np.var(overall_fps_list), 4)
+ print(f'Average fps of {repeat_times} evaluations: '
+ f'{benchmark_dict["average_fps"]}')
+ print(f'The variance of {repeat_times} evaluations: '
+ f'{benchmark_dict["fps_variance"]}')
+ mmcv.dump(benchmark_dict, json_file, indent=4)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/browse_dataset.py b/tools/browse_dataset.py
new file mode 100644
index 0000000..d46487b
--- /dev/null
+++ b/tools/browse_dataset.py
@@ -0,0 +1,181 @@
+import argparse
+import os
+import warnings
+from pathlib import Path
+
+import mmcv
+import numpy as np
+from mmcv import Config, DictAction
+
+from mmseg.datasets.builder import build_dataset
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Browse a dataset')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument(
+ '--show-origin',
+ default=False,
+ action='store_true',
+ help='if True, omit all augmentation in pipeline,'
+ ' show origin image and seg map')
+ parser.add_argument(
+ '--skip-type',
+ type=str,
+ nargs='+',
+ default=['DefaultFormatBundle', 'Normalize', 'Collect'],
+ help='skip some useless pipeline,if `show-origin` is true, '
+ 'all pipeline except `Load` will be skipped')
+ parser.add_argument(
+ '--output-dir',
+ default='./output',
+ type=str,
+ help='If there is no display interface, you can save it')
+ parser.add_argument('--show', default=False, action='store_true')
+ parser.add_argument(
+ '--show-interval',
+ type=int,
+ default=999,
+ help='the interval of show (ms)')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='the opacity of semantic map')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def imshow_semantic(img,
+ seg,
+ class_names,
+ palette=None,
+ win_name='',
+ show=False,
+ wait_time=0,
+ out_file=None,
+ opacity=0.5):
+ """Draw `result` over `img`.
+
+ Args:
+ img (str or Tensor): The image to be displayed.
+ seg (Tensor): The semantic segmentation results to draw over
+ `img`.
+ class_names (list[str]): Names of each classes.
+ palette (list[list[int]]] | np.ndarray | None): The palette of
+ segmentation map. If None is given, random palette will be
+ generated. Default: None
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ Default: 0.
+ show (bool): Whether to show the image.
+ Default: False.
+ out_file (str or None): The filename to write the image.
+ Default: None.
+ opacity(float): Opacity of painted segmentation map.
+ Default 0.5.
+ Must be in (0, 1] range.
+ Returns:
+ img (Tensor): Only if not `show` or `out_file`
+ """
+ img = mmcv.imread(img)
+ img = img.copy()
+ if palette is None:
+ palette = np.random.randint(0, 255, size=(len(class_names), 3))
+ palette = np.array(palette)
+ assert palette.shape[0] == len(class_names)
+ assert palette.shape[1] == 3
+ assert len(palette.shape) == 2
+ assert 0 < opacity <= 1.0
+ color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
+ for label, color in enumerate(palette):
+ color_seg[seg == label, :] = color
+ # convert to BGR
+ color_seg = color_seg[..., ::-1]
+
+ img = img * (1 - opacity) + color_seg * opacity
+ img = img.astype(np.uint8)
+ # if out_file specified, do not show image in window
+ if out_file is not None:
+ show = False
+
+ if show:
+ mmcv.imshow(img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(img, out_file)
+
+ if not (show or out_file):
+ warnings.warn('show==False and out_file is not specified, only '
+ 'result image will be returned')
+ return img
+
+
+def _retrieve_data_cfg(_data_cfg, skip_type, show_origin):
+ if show_origin is True:
+ # only keep pipeline of Loading data and ann
+ _data_cfg['pipeline'] = [
+ x for x in _data_cfg.pipeline if 'Load' in x['type']
+ ]
+ else:
+ _data_cfg['pipeline'] = [
+ x for x in _data_cfg.pipeline if x['type'] not in skip_type
+ ]
+
+
+def retrieve_data_cfg(config_path, skip_type, cfg_options, show_origin=False):
+ cfg = Config.fromfile(config_path)
+ if cfg_options is not None:
+ cfg.merge_from_dict(cfg_options)
+ train_data_cfg = cfg.data.train
+ if isinstance(train_data_cfg, list):
+ for _data_cfg in train_data_cfg:
+ while 'dataset' in _data_cfg and _data_cfg[
+ 'type'] != 'MultiImageMixDataset':
+ _data_cfg = _data_cfg['dataset']
+ if 'pipeline' in _data_cfg:
+ _retrieve_data_cfg(_data_cfg, skip_type, show_origin)
+ else:
+ raise ValueError
+ else:
+ while 'dataset' in train_data_cfg and train_data_cfg[
+ 'type'] != 'MultiImageMixDataset':
+ train_data_cfg = train_data_cfg['dataset']
+ _retrieve_data_cfg(train_data_cfg, skip_type, show_origin)
+ return cfg
+
+
+def main():
+ args = parse_args()
+ cfg = retrieve_data_cfg(args.config, args.skip_type, args.cfg_options,
+ args.show_origin)
+ dataset = build_dataset(cfg.data.train)
+ progress_bar = mmcv.ProgressBar(len(dataset))
+ for item in dataset:
+ filename = os.path.join(args.output_dir,
+ Path(item['filename']).name
+ ) if args.output_dir is not None else None
+ imshow_semantic(
+ item['img'],
+ item['gt_semantic_seg'],
+ dataset.CLASSES,
+ dataset.PALETTE,
+ show=args.show,
+ wait_time=args.show_interval,
+ out_file=filename,
+ opacity=args.opacity,
+ )
+ progress_bar.update()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/chase_db1.py b/tools/convert_datasets/chase_db1.py
new file mode 100644
index 0000000..580e6e7
--- /dev/null
+++ b/tools/convert_datasets/chase_db1.py
@@ -0,0 +1,88 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import mmcv
+
+CHASE_DB1_LEN = 28 * 3
+TRAINING_LEN = 60
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert CHASE_DB1 dataset to mmsegmentation format')
+ parser.add_argument('dataset_path', help='path of CHASEDB1.zip')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ dataset_path = args.dataset_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'CHASE_DB1')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'validation'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'validation'))
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ print('Extracting CHASEDB1.zip...')
+ zip_file = zipfile.ZipFile(dataset_path)
+ zip_file.extractall(tmp_dir)
+
+ print('Generating training dataset...')
+
+ assert len(os.listdir(tmp_dir)) == CHASE_DB1_LEN, \
+ 'len(os.listdir(tmp_dir)) != {}'.format(CHASE_DB1_LEN)
+
+ for img_name in sorted(os.listdir(tmp_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(tmp_dir, img_name))
+ if osp.splitext(img_name)[1] == '.jpg':
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'training',
+ osp.splitext(img_name)[0] + '.png'))
+ else:
+ # The annotation img should be divided by 128, because some of
+ # the annotation imgs are not standard. We should set a
+ # threshold to convert the nonstandard annotation imgs. The
+ # value divided by 128 is equivalent to '1 if value >= 128
+ # else 0'
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(img_name)[0] + '.png'))
+
+ for img_name in sorted(os.listdir(tmp_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(tmp_dir, img_name))
+ if osp.splitext(img_name)[1] == '.jpg':
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'validation',
+ osp.splitext(img_name)[0] + '.png'))
+ else:
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(img_name)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/cityscapes.py b/tools/convert_datasets/cityscapes.py
new file mode 100644
index 0000000..17b6168
--- /dev/null
+++ b/tools/convert_datasets/cityscapes.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+import mmcv
+from cityscapesscripts.preparation.json2labelImg import json2labelImg
+
+
+def convert_json_to_label(json_file):
+ label_file = json_file.replace('_polygons.json', '_labelTrainIds.png')
+ json2labelImg(json_file, label_file, 'trainIds')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert Cityscapes annotations to TrainIds')
+ parser.add_argument('cityscapes_path', help='cityscapes data path')
+ parser.add_argument('--gt-dir', default='gtFine', type=str)
+ parser.add_argument('-o', '--out-dir', help='output path')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ cityscapes_path = args.cityscapes_path
+ out_dir = args.out_dir if args.out_dir else cityscapes_path
+ mmcv.mkdir_or_exist(out_dir)
+
+ gt_dir = osp.join(cityscapes_path, args.gt_dir)
+
+ poly_files = []
+ for poly in mmcv.scandir(gt_dir, '_polygons.json', recursive=True):
+ poly_file = osp.join(gt_dir, poly)
+ poly_files.append(poly_file)
+ if args.nproc > 1:
+ mmcv.track_parallel_progress(convert_json_to_label, poly_files,
+ args.nproc)
+ else:
+ mmcv.track_progress(convert_json_to_label, poly_files)
+
+ split_names = ['train', 'val', 'test']
+
+ for split in split_names:
+ filenames = []
+ for poly in mmcv.scandir(
+ osp.join(gt_dir, split), '_polygons.json', recursive=True):
+ filenames.append(poly.replace('_gtFine_polygons.json', ''))
+ with open(osp.join(out_dir, f'{split}.txt'), 'w') as f:
+ f.writelines(f + '\n' for f in filenames)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/coco_stuff10k.py b/tools/convert_datasets/coco_stuff10k.py
new file mode 100644
index 0000000..4f0fd53
--- /dev/null
+++ b/tools/convert_datasets/coco_stuff10k.py
@@ -0,0 +1,306 @@
+import argparse
+import os.path as osp
+import shutil
+from functools import partial
+
+import mmcv
+import numpy as np
+from PIL import Image
+from scipy.io import loadmat
+
+COCO_LEN = 10000
+
+clsID_to_trID = {
+ 0: 0,
+ 1: 1,
+ 2: 2,
+ 3: 3,
+ 4: 4,
+ 5: 5,
+ 6: 6,
+ 7: 7,
+ 8: 8,
+ 9: 9,
+ 10: 10,
+ 11: 11,
+ 13: 12,
+ 14: 13,
+ 15: 14,
+ 16: 15,
+ 17: 16,
+ 18: 17,
+ 19: 18,
+ 20: 19,
+ 21: 20,
+ 22: 21,
+ 23: 22,
+ 24: 23,
+ 25: 24,
+ 27: 25,
+ 28: 26,
+ 31: 27,
+ 32: 28,
+ 33: 29,
+ 34: 30,
+ 35: 31,
+ 36: 32,
+ 37: 33,
+ 38: 34,
+ 39: 35,
+ 40: 36,
+ 41: 37,
+ 42: 38,
+ 43: 39,
+ 44: 40,
+ 46: 41,
+ 47: 42,
+ 48: 43,
+ 49: 44,
+ 50: 45,
+ 51: 46,
+ 52: 47,
+ 53: 48,
+ 54: 49,
+ 55: 50,
+ 56: 51,
+ 57: 52,
+ 58: 53,
+ 59: 54,
+ 60: 55,
+ 61: 56,
+ 62: 57,
+ 63: 58,
+ 64: 59,
+ 65: 60,
+ 67: 61,
+ 70: 62,
+ 72: 63,
+ 73: 64,
+ 74: 65,
+ 75: 66,
+ 76: 67,
+ 77: 68,
+ 78: 69,
+ 79: 70,
+ 80: 71,
+ 81: 72,
+ 82: 73,
+ 84: 74,
+ 85: 75,
+ 86: 76,
+ 87: 77,
+ 88: 78,
+ 89: 79,
+ 90: 80,
+ 92: 81,
+ 93: 82,
+ 94: 83,
+ 95: 84,
+ 96: 85,
+ 97: 86,
+ 98: 87,
+ 99: 88,
+ 100: 89,
+ 101: 90,
+ 102: 91,
+ 103: 92,
+ 104: 93,
+ 105: 94,
+ 106: 95,
+ 107: 96,
+ 108: 97,
+ 109: 98,
+ 110: 99,
+ 111: 100,
+ 112: 101,
+ 113: 102,
+ 114: 103,
+ 115: 104,
+ 116: 105,
+ 117: 106,
+ 118: 107,
+ 119: 108,
+ 120: 109,
+ 121: 110,
+ 122: 111,
+ 123: 112,
+ 124: 113,
+ 125: 114,
+ 126: 115,
+ 127: 116,
+ 128: 117,
+ 129: 118,
+ 130: 119,
+ 131: 120,
+ 132: 121,
+ 133: 122,
+ 134: 123,
+ 135: 124,
+ 136: 125,
+ 137: 126,
+ 138: 127,
+ 139: 128,
+ 140: 129,
+ 141: 130,
+ 142: 131,
+ 143: 132,
+ 144: 133,
+ 145: 134,
+ 146: 135,
+ 147: 136,
+ 148: 137,
+ 149: 138,
+ 150: 139,
+ 151: 140,
+ 152: 141,
+ 153: 142,
+ 154: 143,
+ 155: 144,
+ 156: 145,
+ 157: 146,
+ 158: 147,
+ 159: 148,
+ 160: 149,
+ 161: 150,
+ 162: 151,
+ 163: 152,
+ 164: 153,
+ 165: 154,
+ 166: 155,
+ 167: 156,
+ 168: 157,
+ 169: 158,
+ 170: 159,
+ 171: 160,
+ 172: 161,
+ 173: 162,
+ 174: 163,
+ 175: 164,
+ 176: 165,
+ 177: 166,
+ 178: 167,
+ 179: 168,
+ 180: 169,
+ 181: 170,
+ 182: 171
+}
+
+
+def convert_to_trainID(tuple_path, in_img_dir, in_ann_dir, out_img_dir,
+ out_mask_dir, is_train):
+ imgpath, maskpath = tuple_path
+ shutil.copyfile(
+ osp.join(in_img_dir, imgpath),
+ osp.join(out_img_dir, 'train2014', imgpath) if is_train else osp.join(
+ out_img_dir, 'test2014', imgpath))
+ annotate = loadmat(osp.join(in_ann_dir, maskpath))
+ mask = annotate['S'].astype(np.uint8)
+ mask_copy = mask.copy()
+ for clsID, trID in clsID_to_trID.items():
+ mask_copy[mask == clsID] = trID
+ seg_filename = osp.join(out_mask_dir, 'train2014',
+ maskpath.split('.')[0] +
+ '_labelTrainIds.png') if is_train else osp.join(
+ out_mask_dir, 'test2014',
+ maskpath.split('.')[0] + '_labelTrainIds.png')
+ Image.fromarray(mask_copy).save(seg_filename, 'PNG')
+
+
+def generate_coco_list(folder):
+ train_list = osp.join(folder, 'imageLists', 'train.txt')
+ test_list = osp.join(folder, 'imageLists', 'test.txt')
+ train_paths = []
+ test_paths = []
+
+ with open(train_list) as f:
+ for filename in f:
+ basename = filename.strip()
+ imgpath = basename + '.jpg'
+ maskpath = basename + '.mat'
+ train_paths.append((imgpath, maskpath))
+
+ with open(test_list) as f:
+ for filename in f:
+ basename = filename.strip()
+ imgpath = basename + '.jpg'
+ maskpath = basename + '.mat'
+ test_paths.append((imgpath, maskpath))
+
+ return train_paths, test_paths
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description=\
+ 'Convert COCO Stuff 10k annotations to mmsegmentation format') # noqa
+ parser.add_argument('coco_path', help='coco stuff path')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--nproc', default=16, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ coco_path = args.coco_path
+ nproc = args.nproc
+
+ out_dir = args.out_dir or coco_path
+ out_img_dir = osp.join(out_dir, 'images')
+ out_mask_dir = osp.join(out_dir, 'annotations')
+
+ mmcv.mkdir_or_exist(osp.join(out_img_dir, 'train2014'))
+ mmcv.mkdir_or_exist(osp.join(out_img_dir, 'test2014'))
+ mmcv.mkdir_or_exist(osp.join(out_mask_dir, 'train2014'))
+ mmcv.mkdir_or_exist(osp.join(out_mask_dir, 'test2014'))
+
+ train_list, test_list = generate_coco_list(coco_path)
+ assert (len(train_list) +
+ len(test_list)) == COCO_LEN, 'Wrong length of list {} & {}'.format(
+ len(train_list), len(test_list))
+
+ if args.nproc > 1:
+ mmcv.track_parallel_progress(
+ partial(
+ convert_to_trainID,
+ in_img_dir=osp.join(coco_path, 'images'),
+ in_ann_dir=osp.join(coco_path, 'annotations'),
+ out_img_dir=out_img_dir,
+ out_mask_dir=out_mask_dir,
+ is_train=True),
+ train_list,
+ nproc=nproc)
+ mmcv.track_parallel_progress(
+ partial(
+ convert_to_trainID,
+ in_img_dir=osp.join(coco_path, 'images'),
+ in_ann_dir=osp.join(coco_path, 'annotations'),
+ out_img_dir=out_img_dir,
+ out_mask_dir=out_mask_dir,
+ is_train=False),
+ test_list,
+ nproc=nproc)
+ else:
+ mmcv.track_progress(
+ partial(
+ convert_to_trainID,
+ in_img_dir=osp.join(coco_path, 'images'),
+ in_ann_dir=osp.join(coco_path, 'annotations'),
+ out_img_dir=out_img_dir,
+ out_mask_dir=out_mask_dir,
+ is_train=True), train_list)
+ mmcv.track_progress(
+ partial(
+ convert_to_trainID,
+ in_img_dir=osp.join(coco_path, 'images'),
+ in_ann_dir=osp.join(coco_path, 'annotations'),
+ out_img_dir=out_img_dir,
+ out_mask_dir=out_mask_dir,
+ is_train=False), test_list)
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/coco_stuff164k.py b/tools/convert_datasets/coco_stuff164k.py
new file mode 100644
index 0000000..4533bf5
--- /dev/null
+++ b/tools/convert_datasets/coco_stuff164k.py
@@ -0,0 +1,263 @@
+import argparse
+import os.path as osp
+import shutil
+from functools import partial
+from glob import glob
+
+import mmcv
+import numpy as np
+from PIL import Image
+
+COCO_LEN = 123287
+
+clsID_to_trID = {
+ 0: 0,
+ 1: 1,
+ 2: 2,
+ 3: 3,
+ 4: 4,
+ 5: 5,
+ 6: 6,
+ 7: 7,
+ 8: 8,
+ 9: 9,
+ 10: 10,
+ 12: 11,
+ 13: 12,
+ 14: 13,
+ 15: 14,
+ 16: 15,
+ 17: 16,
+ 18: 17,
+ 19: 18,
+ 20: 19,
+ 21: 20,
+ 22: 21,
+ 23: 22,
+ 24: 23,
+ 26: 24,
+ 27: 25,
+ 30: 26,
+ 31: 27,
+ 32: 28,
+ 33: 29,
+ 34: 30,
+ 35: 31,
+ 36: 32,
+ 37: 33,
+ 38: 34,
+ 39: 35,
+ 40: 36,
+ 41: 37,
+ 42: 38,
+ 43: 39,
+ 45: 40,
+ 46: 41,
+ 47: 42,
+ 48: 43,
+ 49: 44,
+ 50: 45,
+ 51: 46,
+ 52: 47,
+ 53: 48,
+ 54: 49,
+ 55: 50,
+ 56: 51,
+ 57: 52,
+ 58: 53,
+ 59: 54,
+ 60: 55,
+ 61: 56,
+ 62: 57,
+ 63: 58,
+ 64: 59,
+ 66: 60,
+ 69: 61,
+ 71: 62,
+ 72: 63,
+ 73: 64,
+ 74: 65,
+ 75: 66,
+ 76: 67,
+ 77: 68,
+ 78: 69,
+ 79: 70,
+ 80: 71,
+ 81: 72,
+ 83: 73,
+ 84: 74,
+ 85: 75,
+ 86: 76,
+ 87: 77,
+ 88: 78,
+ 89: 79,
+ 91: 80,
+ 92: 81,
+ 93: 82,
+ 94: 83,
+ 95: 84,
+ 96: 85,
+ 97: 86,
+ 98: 87,
+ 99: 88,
+ 100: 89,
+ 101: 90,
+ 102: 91,
+ 103: 92,
+ 104: 93,
+ 105: 94,
+ 106: 95,
+ 107: 96,
+ 108: 97,
+ 109: 98,
+ 110: 99,
+ 111: 100,
+ 112: 101,
+ 113: 102,
+ 114: 103,
+ 115: 104,
+ 116: 105,
+ 117: 106,
+ 118: 107,
+ 119: 108,
+ 120: 109,
+ 121: 110,
+ 122: 111,
+ 123: 112,
+ 124: 113,
+ 125: 114,
+ 126: 115,
+ 127: 116,
+ 128: 117,
+ 129: 118,
+ 130: 119,
+ 131: 120,
+ 132: 121,
+ 133: 122,
+ 134: 123,
+ 135: 124,
+ 136: 125,
+ 137: 126,
+ 138: 127,
+ 139: 128,
+ 140: 129,
+ 141: 130,
+ 142: 131,
+ 143: 132,
+ 144: 133,
+ 145: 134,
+ 146: 135,
+ 147: 136,
+ 148: 137,
+ 149: 138,
+ 150: 139,
+ 151: 140,
+ 152: 141,
+ 153: 142,
+ 154: 143,
+ 155: 144,
+ 156: 145,
+ 157: 146,
+ 158: 147,
+ 159: 148,
+ 160: 149,
+ 161: 150,
+ 162: 151,
+ 163: 152,
+ 164: 153,
+ 165: 154,
+ 166: 155,
+ 167: 156,
+ 168: 157,
+ 169: 158,
+ 170: 159,
+ 171: 160,
+ 172: 161,
+ 173: 162,
+ 174: 163,
+ 175: 164,
+ 176: 165,
+ 177: 166,
+ 178: 167,
+ 179: 168,
+ 180: 169,
+ 181: 170,
+ 255: 255
+}
+
+
+def convert_to_trainID(maskpath, out_mask_dir, is_train):
+ mask = np.array(Image.open(maskpath))
+ mask_copy = mask.copy()
+ for clsID, trID in clsID_to_trID.items():
+ mask_copy[mask == clsID] = trID
+ seg_filename = osp.join(
+ out_mask_dir, 'train2017',
+ osp.basename(maskpath).split('.')[0] +
+ '_labelTrainIds.png') if is_train else osp.join(
+ out_mask_dir, 'val2017',
+ osp.basename(maskpath).split('.')[0] + '_labelTrainIds.png')
+ Image.fromarray(mask_copy).save(seg_filename, 'PNG')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description=\
+ 'Convert COCO Stuff 164k annotations to mmsegmentation format') # noqa
+ parser.add_argument('coco_path', help='coco stuff path')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--nproc', default=16, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ coco_path = args.coco_path
+ nproc = args.nproc
+
+ out_dir = args.out_dir or coco_path
+ out_img_dir = osp.join(out_dir, 'images')
+ out_mask_dir = osp.join(out_dir, 'annotations')
+
+ mmcv.mkdir_or_exist(osp.join(out_mask_dir, 'train2017'))
+ mmcv.mkdir_or_exist(osp.join(out_mask_dir, 'val2017'))
+
+ if out_dir != coco_path:
+ shutil.copytree(osp.join(coco_path, 'images'), out_img_dir)
+
+ train_list = glob(osp.join(coco_path, 'annotations', 'train2017', '*.png'))
+ train_list = [file for file in train_list if '_labelTrainIds' not in file]
+ test_list = glob(osp.join(coco_path, 'annotations', 'val2017', '*.png'))
+ test_list = [file for file in test_list if '_labelTrainIds' not in file]
+ assert (len(train_list) +
+ len(test_list)) == COCO_LEN, 'Wrong length of list {} & {}'.format(
+ len(train_list), len(test_list))
+
+ if args.nproc > 1:
+ mmcv.track_parallel_progress(
+ partial(
+ convert_to_trainID, out_mask_dir=out_mask_dir, is_train=True),
+ train_list,
+ nproc=nproc)
+ mmcv.track_parallel_progress(
+ partial(
+ convert_to_trainID, out_mask_dir=out_mask_dir, is_train=False),
+ test_list,
+ nproc=nproc)
+ else:
+ mmcv.track_progress(
+ partial(
+ convert_to_trainID, out_mask_dir=out_mask_dir, is_train=True),
+ train_list)
+ mmcv.track_progress(
+ partial(
+ convert_to_trainID, out_mask_dir=out_mask_dir, is_train=False),
+ test_list)
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/drive.py b/tools/convert_datasets/drive.py
new file mode 100644
index 0000000..f547579
--- /dev/null
+++ b/tools/convert_datasets/drive.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import cv2
+import mmcv
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert DRIVE dataset to mmsegmentation format')
+ parser.add_argument(
+ 'training_path', help='the training part of DRIVE dataset')
+ parser.add_argument(
+ 'testing_path', help='the testing part of DRIVE dataset')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ training_path = args.training_path
+ testing_path = args.testing_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'DRIVE')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'validation'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'validation'))
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ print('Extracting training.zip...')
+ zip_file = zipfile.ZipFile(training_path)
+ zip_file.extractall(tmp_dir)
+
+ print('Generating training dataset...')
+ now_dir = osp.join(tmp_dir, 'training', 'images')
+ for img_name in os.listdir(now_dir):
+ img = mmcv.imread(osp.join(now_dir, img_name))
+ mmcv.imwrite(
+ img,
+ osp.join(
+ out_dir, 'images', 'training',
+ osp.splitext(img_name)[0].replace('_training', '') +
+ '.png'))
+
+ now_dir = osp.join(tmp_dir, 'training', '1st_manual')
+ for img_name in os.listdir(now_dir):
+ cap = cv2.VideoCapture(osp.join(now_dir, img_name))
+ ret, img = cap.read()
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(img_name)[0] + '.png'))
+
+ print('Extracting test.zip...')
+ zip_file = zipfile.ZipFile(testing_path)
+ zip_file.extractall(tmp_dir)
+
+ print('Generating validation dataset...')
+ now_dir = osp.join(tmp_dir, 'test', 'images')
+ for img_name in os.listdir(now_dir):
+ img = mmcv.imread(osp.join(now_dir, img_name))
+ mmcv.imwrite(
+ img,
+ osp.join(
+ out_dir, 'images', 'validation',
+ osp.splitext(img_name)[0].replace('_test', '') + '.png'))
+
+ now_dir = osp.join(tmp_dir, 'test', '1st_manual')
+ if osp.exists(now_dir):
+ for img_name in os.listdir(now_dir):
+ cap = cv2.VideoCapture(osp.join(now_dir, img_name))
+ ret, img = cap.read()
+ # The annotation img should be divided by 128, because some of
+ # the annotation imgs are not standard. We should set a
+ # threshold to convert the nonstandard annotation imgs. The
+ # value divided by 128 is equivalent to '1 if value >= 128
+ # else 0'
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(img_name)[0] + '.png'))
+
+ now_dir = osp.join(tmp_dir, 'test', '2nd_manual')
+ if osp.exists(now_dir):
+ for img_name in os.listdir(now_dir):
+ cap = cv2.VideoCapture(osp.join(now_dir, img_name))
+ ret, img = cap.read()
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(img_name)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/hrf.py b/tools/convert_datasets/hrf.py
new file mode 100644
index 0000000..5e016e3
--- /dev/null
+++ b/tools/convert_datasets/hrf.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import mmcv
+
+HRF_LEN = 15
+TRAINING_LEN = 5
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert HRF dataset to mmsegmentation format')
+ parser.add_argument('healthy_path', help='the path of healthy.zip')
+ parser.add_argument(
+ 'healthy_manualsegm_path', help='the path of healthy_manualsegm.zip')
+ parser.add_argument('glaucoma_path', help='the path of glaucoma.zip')
+ parser.add_argument(
+ 'glaucoma_manualsegm_path', help='the path of glaucoma_manualsegm.zip')
+ parser.add_argument(
+ 'diabetic_retinopathy_path',
+ help='the path of diabetic_retinopathy.zip')
+ parser.add_argument(
+ 'diabetic_retinopathy_manualsegm_path',
+ help='the path of diabetic_retinopathy_manualsegm.zip')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ images_path = [
+ args.healthy_path, args.glaucoma_path, args.diabetic_retinopathy_path
+ ]
+ annotations_path = [
+ args.healthy_manualsegm_path, args.glaucoma_manualsegm_path,
+ args.diabetic_retinopathy_manualsegm_path
+ ]
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'HRF')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'validation'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'validation'))
+
+ print('Generating images...')
+ for now_path in images_path:
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ zip_file = zipfile.ZipFile(now_path)
+ zip_file.extractall(tmp_dir)
+
+ assert len(os.listdir(tmp_dir)) == HRF_LEN, \
+ 'len(os.listdir(tmp_dir)) != {}'.format(HRF_LEN)
+
+ for filename in sorted(os.listdir(tmp_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(tmp_dir, filename))
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'training',
+ osp.splitext(filename)[0] + '.png'))
+ for filename in sorted(os.listdir(tmp_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(tmp_dir, filename))
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Generating annotations...')
+ for now_path in annotations_path:
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ zip_file = zipfile.ZipFile(now_path)
+ zip_file.extractall(tmp_dir)
+
+ assert len(os.listdir(tmp_dir)) == HRF_LEN, \
+ 'len(os.listdir(tmp_dir)) != {}'.format(HRF_LEN)
+
+ for filename in sorted(os.listdir(tmp_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(tmp_dir, filename))
+ # The annotation img should be divided by 128, because some of
+ # the annotation imgs are not standard. We should set a
+ # threshold to convert the nonstandard annotation imgs. The
+ # value divided by 128 is equivalent to '1 if value >= 128
+ # else 0'
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(filename)[0] + '.png'))
+ for filename in sorted(os.listdir(tmp_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(tmp_dir, filename))
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/loveda.py b/tools/convert_datasets/loveda.py
new file mode 100644
index 0000000..3a06268
--- /dev/null
+++ b/tools/convert_datasets/loveda.py
@@ -0,0 +1,73 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import shutil
+import tempfile
+import zipfile
+
+import mmcv
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert LoveDA dataset to mmsegmentation format')
+ parser.add_argument('dataset_path', help='LoveDA folder path')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ dataset_path = args.dataset_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'loveDA')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'test'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
+
+ assert 'Train.zip' in os.listdir(dataset_path), \
+ 'Train.zip is not in {}'.format(dataset_path)
+ assert 'Val.zip' in os.listdir(dataset_path), \
+ 'Val.zip is not in {}'.format(dataset_path)
+ assert 'Test.zip' in os.listdir(dataset_path), \
+ 'Test.zip is not in {}'.format(dataset_path)
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ for dataset in ['Train', 'Val', 'Test']:
+ zip_file = zipfile.ZipFile(
+ os.path.join(dataset_path, dataset + '.zip'))
+ zip_file.extractall(tmp_dir)
+ data_type = dataset.lower()
+ for location in ['Rural', 'Urban']:
+ for image_type in ['images_png', 'masks_png']:
+ if image_type == 'images_png':
+ dst = osp.join(out_dir, 'img_dir', data_type)
+ else:
+ dst = osp.join(out_dir, 'ann_dir', data_type)
+ if dataset == 'Test' and image_type == 'masks_png':
+ continue
+ else:
+ src_dir = osp.join(tmp_dir, dataset, location,
+ image_type)
+ src_lst = os.listdir(src_dir)
+ for file in src_lst:
+ shutil.move(osp.join(src_dir, file), dst)
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/pascal_context.py b/tools/convert_datasets/pascal_context.py
new file mode 100644
index 0000000..03b79d5
--- /dev/null
+++ b/tools/convert_datasets/pascal_context.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from functools import partial
+
+import mmcv
+import numpy as np
+from detail import Detail
+from PIL import Image
+
+_mapping = np.sort(
+ np.array([
+ 0, 2, 259, 260, 415, 324, 9, 258, 144, 18, 19, 22, 23, 397, 25, 284,
+ 158, 159, 416, 33, 162, 420, 454, 295, 296, 427, 44, 45, 46, 308, 59,
+ 440, 445, 31, 232, 65, 354, 424, 68, 326, 72, 458, 34, 207, 80, 355,
+ 85, 347, 220, 349, 360, 98, 187, 104, 105, 366, 189, 368, 113, 115
+ ]))
+_key = np.array(range(len(_mapping))).astype('uint8')
+
+
+def generate_labels(img_id, detail, out_dir):
+
+ def _class_to_index(mask, _mapping, _key):
+ # assert the values
+ values = np.unique(mask)
+ for i in range(len(values)):
+ assert (values[i] in _mapping)
+ index = np.digitize(mask.ravel(), _mapping, right=True)
+ return _key[index].reshape(mask.shape)
+
+ mask = Image.fromarray(
+ _class_to_index(detail.getMask(img_id), _mapping=_mapping, _key=_key))
+ filename = img_id['file_name']
+ mask.save(osp.join(out_dir, filename.replace('jpg', 'png')))
+ return osp.splitext(osp.basename(filename))[0]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert PASCAL VOC annotations to mmsegmentation format')
+ parser.add_argument('devkit_path', help='pascal voc devkit path')
+ parser.add_argument('json_path', help='annoation json filepath')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ devkit_path = args.devkit_path
+ if args.out_dir is None:
+ out_dir = osp.join(devkit_path, 'VOC2010', 'SegmentationClassContext')
+ else:
+ out_dir = args.out_dir
+ json_path = args.json_path
+ mmcv.mkdir_or_exist(out_dir)
+ img_dir = osp.join(devkit_path, 'VOC2010', 'JPEGImages')
+
+ train_detail = Detail(json_path, img_dir, 'train')
+ train_ids = train_detail.getImgs()
+
+ val_detail = Detail(json_path, img_dir, 'val')
+ val_ids = val_detail.getImgs()
+
+ mmcv.mkdir_or_exist(
+ osp.join(devkit_path, 'VOC2010/ImageSets/SegmentationContext'))
+
+ train_list = mmcv.track_progress(
+ partial(generate_labels, detail=train_detail, out_dir=out_dir),
+ train_ids)
+ with open(
+ osp.join(devkit_path, 'VOC2010/ImageSets/SegmentationContext',
+ 'train.txt'), 'w') as f:
+ f.writelines(line + '\n' for line in sorted(train_list))
+
+ val_list = mmcv.track_progress(
+ partial(generate_labels, detail=val_detail, out_dir=out_dir), val_ids)
+ with open(
+ osp.join(devkit_path, 'VOC2010/ImageSets/SegmentationContext',
+ 'val.txt'), 'w') as f:
+ f.writelines(line + '\n' for line in sorted(val_list))
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/potsdam.py b/tools/convert_datasets/potsdam.py
new file mode 100644
index 0000000..95a97f6
--- /dev/null
+++ b/tools/convert_datasets/potsdam.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import math
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import mmcv
+import numpy as np
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert potsdam dataset to mmsegmentation format')
+ parser.add_argument('dataset_path', help='potsdam folder path')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--clip_size',
+ type=int,
+ help='clipped size of image after preparation',
+ default=512)
+ parser.add_argument(
+ '--stride_size',
+ type=int,
+ help='stride of clipping original images',
+ default=256)
+ args = parser.parse_args()
+ return args
+
+
+def clip_big_image(image_path, clip_save_dir, args, to_label=False):
+ # Original image of Potsdam dataset is very large, thus pre-processing
+ # of them is adopted. Given fixed clip size and stride size to generate
+ # clipped image, the intersection of width and height is determined.
+ # For example, given one 5120 x 5120 original image, the clip size is
+ # 512 and stride size is 256, thus it would generate 20x20 = 400 images
+ # whose size are all 512x512.
+ image = mmcv.imread(image_path)
+
+ h, w, c = image.shape
+ clip_size = args.clip_size
+ stride_size = args.stride_size
+
+ num_rows = math.ceil((h - clip_size) / stride_size) if math.ceil(
+ (h - clip_size) /
+ stride_size) * stride_size + clip_size >= h else math.ceil(
+ (h - clip_size) / stride_size) + 1
+ num_cols = math.ceil((w - clip_size) / stride_size) if math.ceil(
+ (w - clip_size) /
+ stride_size) * stride_size + clip_size >= w else math.ceil(
+ (w - clip_size) / stride_size) + 1
+
+ x, y = np.meshgrid(np.arange(num_cols + 1), np.arange(num_rows + 1))
+ xmin = x * clip_size
+ ymin = y * clip_size
+
+ xmin = xmin.ravel()
+ ymin = ymin.ravel()
+ xmin_offset = np.where(xmin + clip_size > w, w - xmin - clip_size,
+ np.zeros_like(xmin))
+ ymin_offset = np.where(ymin + clip_size > h, h - ymin - clip_size,
+ np.zeros_like(ymin))
+ boxes = np.stack([
+ xmin + xmin_offset, ymin + ymin_offset,
+ np.minimum(xmin + clip_size, w),
+ np.minimum(ymin + clip_size, h)
+ ],
+ axis=1)
+
+ if to_label:
+ color_map = np.array([[0, 0, 0], [255, 255, 255], [255, 0, 0],
+ [255, 255, 0], [0, 255, 0], [0, 255, 255],
+ [0, 0, 255]])
+ flatten_v = np.matmul(
+ image.reshape(-1, c),
+ np.array([2, 3, 4]).reshape(3, 1))
+ out = np.zeros_like(flatten_v)
+ for idx, class_color in enumerate(color_map):
+ value_idx = np.matmul(class_color,
+ np.array([2, 3, 4]).reshape(3, 1))
+ out[flatten_v == value_idx] = idx
+ image = out.reshape(h, w)
+
+ for box in boxes:
+ start_x, start_y, end_x, end_y = box
+ clipped_image = image[start_y:end_y,
+ start_x:end_x] if to_label else image[
+ start_y:end_y, start_x:end_x, :]
+ idx_i, idx_j = osp.basename(image_path).split('_')[2:4]
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(
+ clip_save_dir,
+ f'{idx_i}_{idx_j}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+
+
+def main():
+ args = parse_args()
+ splits = {
+ 'train': [
+ '2_10', '2_11', '2_12', '3_10', '3_11', '3_12', '4_10', '4_11',
+ '4_12', '5_10', '5_11', '5_12', '6_10', '6_11', '6_12', '6_7',
+ '6_8', '6_9', '7_10', '7_11', '7_12', '7_7', '7_8', '7_9'
+ ],
+ 'val': [
+ '5_15', '6_15', '6_13', '3_13', '4_14', '6_14', '5_14', '2_13',
+ '4_15', '2_14', '5_13', '4_13', '3_14', '7_13'
+ ]
+ }
+
+ dataset_path = args.dataset_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'potsdam')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
+
+ zipp_list = glob.glob(os.path.join(dataset_path, '*.zip'))
+ print('Find the data', zipp_list)
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ for zipp in zipp_list:
+ zip_file = zipfile.ZipFile(zipp)
+ zip_file.extractall(tmp_dir)
+ src_path_list = glob.glob(os.path.join(tmp_dir, '*.tif'))
+ if not len(src_path_list):
+ sub_tmp_dir = os.path.join(tmp_dir, os.listdir(tmp_dir)[0])
+ src_path_list = glob.glob(os.path.join(sub_tmp_dir, '*.tif'))
+
+ prog_bar = mmcv.ProgressBar(len(src_path_list))
+ for i, src_path in enumerate(src_path_list):
+ idx_i, idx_j = osp.basename(src_path).split('_')[2:4]
+ data_type = 'train' if f'{idx_i}_{idx_j}' in splits[
+ 'train'] else 'val'
+ if 'label' in src_path:
+ dst_dir = osp.join(out_dir, 'ann_dir', data_type)
+ clip_big_image(src_path, dst_dir, args, to_label=True)
+ else:
+ dst_dir = osp.join(out_dir, 'img_dir', data_type)
+ clip_big_image(src_path, dst_dir, args, to_label=False)
+ prog_bar.update()
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/stare.py b/tools/convert_datasets/stare.py
new file mode 100644
index 0000000..29b78c0
--- /dev/null
+++ b/tools/convert_datasets/stare.py
@@ -0,0 +1,166 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import gzip
+import os
+import os.path as osp
+import tarfile
+import tempfile
+
+import mmcv
+
+STARE_LEN = 20
+TRAINING_LEN = 10
+
+
+def un_gz(src, dst):
+ g_file = gzip.GzipFile(src)
+ with open(dst, 'wb+') as f:
+ f.write(g_file.read())
+ g_file.close()
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert STARE dataset to mmsegmentation format')
+ parser.add_argument('image_path', help='the path of stare-images.tar')
+ parser.add_argument('labels_ah', help='the path of labels-ah.tar')
+ parser.add_argument('labels_vk', help='the path of labels-vk.tar')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ image_path = args.image_path
+ labels_ah = args.labels_ah
+ labels_vk = args.labels_vk
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'STARE')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(out_dir)
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'images', 'validation'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'training'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'annotations', 'validation'))
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'gz'))
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'files'))
+
+ print('Extracting stare-images.tar...')
+ with tarfile.open(image_path) as f:
+ f.extractall(osp.join(tmp_dir, 'gz'))
+
+ for filename in os.listdir(osp.join(tmp_dir, 'gz')):
+ un_gz(
+ osp.join(tmp_dir, 'gz', filename),
+ osp.join(tmp_dir, 'files',
+ osp.splitext(filename)[0]))
+
+ now_dir = osp.join(tmp_dir, 'files')
+
+ assert len(os.listdir(now_dir)) == STARE_LEN, \
+ 'len(os.listdir(now_dir)) != {}'.format(STARE_LEN)
+
+ for filename in sorted(os.listdir(now_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'training',
+ osp.splitext(filename)[0] + '.png'))
+
+ for filename in sorted(os.listdir(now_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img,
+ osp.join(out_dir, 'images', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'gz'))
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'files'))
+
+ print('Extracting labels-ah.tar...')
+ with tarfile.open(labels_ah) as f:
+ f.extractall(osp.join(tmp_dir, 'gz'))
+
+ for filename in os.listdir(osp.join(tmp_dir, 'gz')):
+ un_gz(
+ osp.join(tmp_dir, 'gz', filename),
+ osp.join(tmp_dir, 'files',
+ osp.splitext(filename)[0]))
+
+ now_dir = osp.join(tmp_dir, 'files')
+
+ assert len(os.listdir(now_dir)) == STARE_LEN, \
+ 'len(os.listdir(now_dir)) != {}'.format(STARE_LEN)
+
+ for filename in sorted(os.listdir(now_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ # The annotation img should be divided by 128, because some of
+ # the annotation imgs are not standard. We should set a threshold
+ # to convert the nonstandard annotation imgs. The value divided by
+ # 128 equivalent to '1 if value >= 128 else 0'
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(filename)[0] + '.png'))
+
+ for filename in sorted(os.listdir(now_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'gz'))
+ mmcv.mkdir_or_exist(osp.join(tmp_dir, 'files'))
+
+ print('Extracting labels-vk.tar...')
+ with tarfile.open(labels_vk) as f:
+ f.extractall(osp.join(tmp_dir, 'gz'))
+
+ for filename in os.listdir(osp.join(tmp_dir, 'gz')):
+ un_gz(
+ osp.join(tmp_dir, 'gz', filename),
+ osp.join(tmp_dir, 'files',
+ osp.splitext(filename)[0]))
+
+ now_dir = osp.join(tmp_dir, 'files')
+
+ assert len(os.listdir(now_dir)) == STARE_LEN, \
+ 'len(os.listdir(now_dir)) != {}'.format(STARE_LEN)
+
+ for filename in sorted(os.listdir(now_dir))[:TRAINING_LEN]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'training',
+ osp.splitext(filename)[0] + '.png'))
+
+ for filename in sorted(os.listdir(now_dir))[TRAINING_LEN:]:
+ img = mmcv.imread(osp.join(now_dir, filename))
+ mmcv.imwrite(
+ img[:, :, 0] // 128,
+ osp.join(out_dir, 'annotations', 'validation',
+ osp.splitext(filename)[0] + '.png'))
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/convert_datasets/vaihingen.py b/tools/convert_datasets/vaihingen.py
new file mode 100644
index 0000000..b025ae5
--- /dev/null
+++ b/tools/convert_datasets/vaihingen.py
@@ -0,0 +1,155 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import math
+import os
+import os.path as osp
+import tempfile
+import zipfile
+
+import mmcv
+import numpy as np
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert vaihingen dataset to mmsegmentation format')
+ parser.add_argument('dataset_path', help='vaihingen folder path')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--clip_size',
+ type=int,
+ help='clipped size of image after preparation',
+ default=512)
+ parser.add_argument(
+ '--stride_size',
+ type=int,
+ help='stride of clipping original images',
+ default=256)
+ args = parser.parse_args()
+ return args
+
+
+def clip_big_image(image_path, clip_save_dir, to_label=False):
+ # Original image of Vaihingen dataset is very large, thus pre-processing
+ # of them is adopted. Given fixed clip size and stride size to generate
+ # clipped image, the intersection of width and height is determined.
+ # For example, given one 5120 x 5120 original image, the clip size is
+ # 512 and stride size is 256, thus it would generate 20x20 = 400 images
+ # whose size are all 512x512.
+ image = mmcv.imread(image_path)
+
+ h, w, c = image.shape
+ cs = args.clip_size
+ ss = args.stride_size
+
+ num_rows = math.ceil((h - cs) / ss) if math.ceil(
+ (h - cs) / ss) * ss + cs >= h else math.ceil((h - cs) / ss) + 1
+ num_cols = math.ceil((w - cs) / ss) if math.ceil(
+ (w - cs) / ss) * ss + cs >= w else math.ceil((w - cs) / ss) + 1
+
+ x, y = np.meshgrid(np.arange(num_cols + 1), np.arange(num_rows + 1))
+ xmin = x * cs
+ ymin = y * cs
+
+ xmin = xmin.ravel()
+ ymin = ymin.ravel()
+ xmin_offset = np.where(xmin + cs > w, w - xmin - cs, np.zeros_like(xmin))
+ ymin_offset = np.where(ymin + cs > h, h - ymin - cs, np.zeros_like(ymin))
+ boxes = np.stack([
+ xmin + xmin_offset, ymin + ymin_offset,
+ np.minimum(xmin + cs, w),
+ np.minimum(ymin + cs, h)
+ ],
+ axis=1)
+
+ if to_label:
+ color_map = np.array([[0, 0, 0], [255, 255, 255], [255, 0, 0],
+ [255, 255, 0], [0, 255, 0], [0, 255, 255],
+ [0, 0, 255]])
+ flatten_v = np.matmul(
+ image.reshape(-1, c),
+ np.array([2, 3, 4]).reshape(3, 1))
+ out = np.zeros_like(flatten_v)
+ for idx, class_color in enumerate(color_map):
+ value_idx = np.matmul(class_color,
+ np.array([2, 3, 4]).reshape(3, 1))
+ out[flatten_v == value_idx] = idx
+ image = out.reshape(h, w)
+
+ for box in boxes:
+ start_x, start_y, end_x, end_y = box
+ clipped_image = image[start_y:end_y,
+ start_x:end_x] if to_label else image[
+ start_y:end_y, start_x:end_x, :]
+ area_idx = osp.basename(image_path).split('_')[3].strip('.tif')
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(clip_save_dir,
+ f'{area_idx}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+
+
+def main():
+ splits = {
+ 'train': [
+ 'area1', 'area11', 'area13', 'area15', 'area17', 'area21',
+ 'area23', 'area26', 'area28', 'area3', 'area30', 'area32',
+ 'area34', 'area37', 'area5', 'area7'
+ ],
+ 'val': [
+ 'area6', 'area24', 'area35', 'area16', 'area14', 'area22',
+ 'area10', 'area4', 'area2', 'area20', 'area8', 'area31', 'area33',
+ 'area27', 'area38', 'area12', 'area29'
+ ],
+ }
+
+ dataset_path = args.dataset_path
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'vaihingen')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
+ mmcv.mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
+
+ zipp_list = glob.glob(os.path.join(dataset_path, '*.zip'))
+ print('Find the data', zipp_list)
+
+ with tempfile.TemporaryDirectory(dir=args.tmp_dir) as tmp_dir:
+ for zipp in zipp_list:
+ zip_file = zipfile.ZipFile(zipp)
+ zip_file.extractall(tmp_dir)
+ src_path_list = glob.glob(os.path.join(tmp_dir, '*.tif'))
+ if 'ISPRS_semantic_labeling_Vaihingen' in zipp:
+ src_path_list = glob.glob(
+ os.path.join(os.path.join(tmp_dir, 'top'), '*.tif'))
+ if 'ISPRS_semantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE' in zipp: # noqa
+ src_path_list = glob.glob(os.path.join(tmp_dir, '*.tif'))
+ # delete unused area9 ground truth
+ for area_ann in src_path_list:
+ if 'area9' in area_ann:
+ src_path_list.remove(area_ann)
+ prog_bar = mmcv.ProgressBar(len(src_path_list))
+ for i, src_path in enumerate(src_path_list):
+ area_idx = osp.basename(src_path).split('_')[3].strip('.tif')
+ data_type = 'train' if area_idx in splits['train'] else 'val'
+ if 'noBoundary' in src_path:
+ dst_dir = osp.join(out_dir, 'ann_dir', data_type)
+ clip_big_image(src_path, dst_dir, to_label=True)
+ else:
+ dst_dir = osp.join(out_dir, 'img_dir', data_type)
+ clip_big_image(src_path, dst_dir, to_label=False)
+ prog_bar.update()
+
+ print('Removing the temporary files...')
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ main()
diff --git a/tools/convert_datasets/voc_aug.py b/tools/convert_datasets/voc_aug.py
new file mode 100644
index 0000000..1d42c27
--- /dev/null
+++ b/tools/convert_datasets/voc_aug.py
@@ -0,0 +1,92 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from functools import partial
+
+import mmcv
+import numpy as np
+from PIL import Image
+from scipy.io import loadmat
+
+AUG_LEN = 10582
+
+
+def convert_mat(mat_file, in_dir, out_dir):
+ data = loadmat(osp.join(in_dir, mat_file))
+ mask = data['GTcls'][0]['Segmentation'][0].astype(np.uint8)
+ seg_filename = osp.join(out_dir, mat_file.replace('.mat', '.png'))
+ Image.fromarray(mask).save(seg_filename, 'PNG')
+
+
+def generate_aug_list(merged_list, excluded_list):
+ return list(set(merged_list) - set(excluded_list))
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert PASCAL VOC annotations to mmsegmentation format')
+ parser.add_argument('devkit_path', help='pascal voc devkit path')
+ parser.add_argument('aug_path', help='pascal voc aug path')
+ parser.add_argument('-o', '--out_dir', help='output path')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ devkit_path = args.devkit_path
+ aug_path = args.aug_path
+ nproc = args.nproc
+ if args.out_dir is None:
+ out_dir = osp.join(devkit_path, 'VOC2012', 'SegmentationClassAug')
+ else:
+ out_dir = args.out_dir
+ mmcv.mkdir_or_exist(out_dir)
+ in_dir = osp.join(aug_path, 'dataset', 'cls')
+
+ mmcv.track_parallel_progress(
+ partial(convert_mat, in_dir=in_dir, out_dir=out_dir),
+ list(mmcv.scandir(in_dir, suffix='.mat')),
+ nproc=nproc)
+
+ full_aug_list = []
+ with open(osp.join(aug_path, 'dataset', 'train.txt')) as f:
+ full_aug_list += [line.strip() for line in f]
+ with open(osp.join(aug_path, 'dataset', 'val.txt')) as f:
+ full_aug_list += [line.strip() for line in f]
+
+ with open(
+ osp.join(devkit_path, 'VOC2012/ImageSets/Segmentation',
+ 'train.txt')) as f:
+ ori_train_list = [line.strip() for line in f]
+ with open(
+ osp.join(devkit_path, 'VOC2012/ImageSets/Segmentation',
+ 'val.txt')) as f:
+ val_list = [line.strip() for line in f]
+
+ aug_train_list = generate_aug_list(ori_train_list + full_aug_list,
+ val_list)
+ assert len(aug_train_list) == AUG_LEN, 'len(aug_train_list) != {}'.format(
+ AUG_LEN)
+
+ with open(
+ osp.join(devkit_path, 'VOC2012/ImageSets/Segmentation',
+ 'trainaug.txt'), 'w') as f:
+ f.writelines(line + '\n' for line in aug_train_list)
+
+ aug_list = generate_aug_list(full_aug_list, ori_train_list + val_list)
+ assert len(aug_list) == AUG_LEN - len(
+ ori_train_list), 'len(aug_list) != {}'.format(AUG_LEN -
+ len(ori_train_list))
+ with open(
+ osp.join(devkit_path, 'VOC2012/ImageSets/Segmentation', 'aug.txt'),
+ 'w') as f:
+ f.writelines(line + '\n' for line in aug_list)
+
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/deploy_test.py b/tools/deploy_test.py
new file mode 100644
index 0000000..fedd645
--- /dev/null
+++ b/tools/deploy_test.py
@@ -0,0 +1,326 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import shutil
+import warnings
+from typing import Any, Iterable
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.parallel import MMDataParallel
+from mmcv.runner import get_dist_info
+from mmcv.utils import DictAction
+
+from mmseg.apis import single_gpu_test
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.models.segmentors.base import BaseSegmentor
+from mmseg.ops import resize
+
+
+class ONNXRuntimeSegmentor(BaseSegmentor):
+
+ def __init__(self, onnx_file: str, cfg: Any, device_id: int):
+ super(ONNXRuntimeSegmentor, self).__init__()
+ import onnxruntime as ort
+
+ # get the custom op path
+ ort_custom_op_path = ''
+ try:
+ from mmcv.ops import get_onnxruntime_op_path
+ ort_custom_op_path = get_onnxruntime_op_path()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn('If input model has custom op from mmcv, \
+ you may have to build mmcv with ONNXRuntime from source.')
+ session_options = ort.SessionOptions()
+ # register custom op for onnxruntime
+ if osp.exists(ort_custom_op_path):
+ session_options.register_custom_ops_library(ort_custom_op_path)
+ sess = ort.InferenceSession(onnx_file, session_options)
+ providers = ['CPUExecutionProvider']
+ options = [{}]
+ is_cuda_available = ort.get_device() == 'GPU'
+ if is_cuda_available:
+ providers.insert(0, 'CUDAExecutionProvider')
+ options.insert(0, {'device_id': device_id})
+
+ sess.set_providers(providers, options)
+
+ self.sess = sess
+ self.device_id = device_id
+ self.io_binding = sess.io_binding()
+ self.output_names = [_.name for _ in sess.get_outputs()]
+ for name in self.output_names:
+ self.io_binding.bind_output(name)
+ self.cfg = cfg
+ self.test_mode = cfg.model.test_cfg.mode
+ self.is_cuda_available = is_cuda_available
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def encode_decode(self, img, img_metas):
+ raise NotImplementedError('This method is not implemented.')
+
+ def forward_train(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def simple_test(self, img: torch.Tensor, img_meta: Iterable,
+ **kwargs) -> list:
+ if not self.is_cuda_available:
+ img = img.detach().cpu()
+ elif self.device_id >= 0:
+ img = img.cuda(self.device_id)
+ device_type = img.device.type
+ self.io_binding.bind_input(
+ name='input',
+ device_type=device_type,
+ device_id=self.device_id,
+ element_type=np.float32,
+ shape=img.shape,
+ buffer_ptr=img.data_ptr())
+ self.sess.run_with_iobinding(self.io_binding)
+ seg_pred = self.io_binding.copy_outputs_to_cpu()[0]
+ # whole might support dynamic reshape
+ ori_shape = img_meta[0]['ori_shape']
+ if not (ori_shape[0] == seg_pred.shape[-2]
+ and ori_shape[1] == seg_pred.shape[-1]):
+ seg_pred = torch.from_numpy(seg_pred).float()
+ seg_pred = resize(
+ seg_pred, size=tuple(ori_shape[:2]), mode='nearest')
+ seg_pred = seg_pred.long().detach().cpu().numpy()
+ seg_pred = seg_pred[0]
+ seg_pred = list(seg_pred)
+ return seg_pred
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+
+class TensorRTSegmentor(BaseSegmentor):
+
+ def __init__(self, trt_file: str, cfg: Any, device_id: int):
+ super(TensorRTSegmentor, self).__init__()
+ from mmcv.tensorrt import TRTWraper, load_tensorrt_plugin
+ try:
+ load_tensorrt_plugin()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn('If input model has custom op from mmcv, \
+ you may have to build mmcv with TensorRT from source.')
+ model = TRTWraper(
+ trt_file, input_names=['input'], output_names=['output'])
+
+ self.model = model
+ self.device_id = device_id
+ self.cfg = cfg
+ self.test_mode = cfg.model.test_cfg.mode
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def encode_decode(self, img, img_metas):
+ raise NotImplementedError('This method is not implemented.')
+
+ def forward_train(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def simple_test(self, img: torch.Tensor, img_meta: Iterable,
+ **kwargs) -> list:
+ with torch.cuda.device(self.device_id), torch.no_grad():
+ seg_pred = self.model({'input': img})['output']
+ seg_pred = seg_pred.detach().cpu().numpy()
+ # whole might support dynamic reshape
+ ori_shape = img_meta[0]['ori_shape']
+ if not (ori_shape[0] == seg_pred.shape[-2]
+ and ori_shape[1] == seg_pred.shape[-1]):
+ seg_pred = torch.from_numpy(seg_pred).float()
+ seg_pred = resize(
+ seg_pred, size=tuple(ori_shape[:2]), mode='nearest')
+ seg_pred = seg_pred.long().detach().cpu().numpy()
+ seg_pred = seg_pred[0]
+ seg_pred = list(seg_pred)
+ return seg_pred
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+
+def parse_args() -> argparse.Namespace:
+ parser = argparse.ArgumentParser(
+ description='mmseg backend test (and eval)')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('model', help='Input model file')
+ parser.add_argument(
+ '--backend',
+ help='Backend of the model.',
+ choices=['onnxruntime', 'tensorrt'])
+ parser.add_argument('--out', help='output result file in pickle format')
+ parser.add_argument(
+ '--format-only',
+ action='store_true',
+ help='Format the output results without perform evaluation. It is'
+ 'useful when you want to format the result to a specific format and '
+ 'submit it to the test server')
+ parser.add_argument(
+ '--eval',
+ type=str,
+ nargs='+',
+ help='evaluation metrics, which depends on the dataset, e.g., "mIoU"'
+ ' for generic datasets, and "cityscapes" for Cityscapes')
+ parser.add_argument('--show', action='store_true', help='show results')
+ parser.add_argument(
+ '--show-dir', help='directory where painted images will be saved')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--eval-options',
+ nargs='+',
+ action=DictAction,
+ help='custom options for evaluation')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ assert args.out or args.eval or args.format_only or args.show \
+ or args.show_dir, \
+ ('Please specify at least one operation (save/eval/format/show the '
+ 'results / save the results) with the argument "--out", "--eval"'
+ ', "--format-only", "--show" or "--show-dir"')
+
+ if args.eval and args.format_only:
+ raise ValueError('--eval and --format_only cannot be both specified')
+
+ if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):
+ raise ValueError('The output file must be a pkl file.')
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ cfg.model.pretrained = None
+ cfg.data.test.test_mode = True
+
+ # init distributed env first, since logger depends on the dist info.
+ distributed = False
+
+ # build the dataloader
+ # TODO: support multiple images per gpu (only minor changes are needed)
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=distributed,
+ shuffle=False)
+
+ # load onnx config and meta
+ cfg.model.train_cfg = None
+
+ if args.backend == 'onnxruntime':
+ model = ONNXRuntimeSegmentor(args.model, cfg=cfg, device_id=0)
+ elif args.backend == 'tensorrt':
+ model = TensorRTSegmentor(args.model, cfg=cfg, device_id=0)
+
+ model.CLASSES = dataset.CLASSES
+ model.PALETTE = dataset.PALETTE
+
+ # clean gpu memory when starting a new evaluation.
+ torch.cuda.empty_cache()
+ eval_kwargs = {} if args.eval_options is None else args.eval_options
+
+ # Deprecated
+ efficient_test = eval_kwargs.get('efficient_test', False)
+ if efficient_test:
+ warnings.warn(
+ '``efficient_test=True`` does not have effect in tools/test.py, '
+ 'the evaluation and format results are CPU memory efficient by '
+ 'default')
+
+ eval_on_format_results = (
+ args.eval is not None and 'cityscapes' in args.eval)
+ if eval_on_format_results:
+ assert len(args.eval) == 1, 'eval on format results is not ' \
+ 'applicable for metrics other than ' \
+ 'cityscapes'
+ if args.format_only or eval_on_format_results:
+ if 'imgfile_prefix' in eval_kwargs:
+ tmpdir = eval_kwargs['imgfile_prefix']
+ else:
+ tmpdir = '.format_cityscapes'
+ eval_kwargs.setdefault('imgfile_prefix', tmpdir)
+ mmcv.mkdir_or_exist(tmpdir)
+ else:
+ tmpdir = None
+
+ model = MMDataParallel(model, device_ids=[0])
+ results = single_gpu_test(
+ model,
+ data_loader,
+ args.show,
+ args.show_dir,
+ False,
+ args.opacity,
+ pre_eval=args.eval is not None and not eval_on_format_results,
+ format_only=args.format_only or eval_on_format_results,
+ format_args=eval_kwargs)
+
+ rank, _ = get_dist_info()
+ if rank == 0:
+ if args.out:
+ warnings.warn(
+ 'The behavior of ``args.out`` has been changed since MMSeg '
+ 'v0.16, the pickled outputs could be seg map as type of '
+ 'np.array, pre-eval results or file paths for '
+ '``dataset.format_results()``.')
+ print(f'\nwriting results to {args.out}')
+ mmcv.dump(results, args.out)
+ if args.eval:
+ dataset.evaluate(results, args.eval, **eval_kwargs)
+ if tmpdir is not None and eval_on_format_results:
+ # remove tmp dir when cityscapes evaluation
+ shutil.rmtree(tmpdir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/deploy_test_kneron.py b/tools/deploy_test_kneron.py
new file mode 100644
index 0000000..5be25a5
--- /dev/null
+++ b/tools/deploy_test_kneron.py
@@ -0,0 +1,215 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import shutil
+import warnings
+
+import mmcv
+import torch
+from mmcv.runner import get_dist_info
+from mmcv.utils import DictAction
+
+from mmseg.apis import single_gpu_test
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.models.segmentors.base import ONNXRuntimeSegmentorKN
+
+
+def parse_args() -> argparse.Namespace:
+ parser = argparse.ArgumentParser(
+ description='mmseg backend test (and eval)')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('model', help='Input model file (onnx only)')
+ parser.add_argument('--out', help='output result file in pickle format')
+ parser.add_argument(
+ '--format-only',
+ action='store_true',
+ help='Format the output results without perform evaluation. It is'
+ 'useful when you want to format the result to a specific format and '
+ 'submit it to the test server')
+ parser.add_argument(
+ '--eval',
+ type=str,
+ nargs='+',
+ help='evaluation metrics, which depends on the dataset, e.g., "mIoU"'
+ ' for generic datasets, and "cityscapes" for Cityscapes')
+ parser.add_argument('--show', action='store_true', help='show results')
+ parser.add_argument(
+ '--show-dir', help='directory where painted images will be saved')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--eval-options',
+ nargs='+',
+ action=DictAction,
+ help='custom options for evaluation')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=None,
+ help='input image height and width.')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ assert args.out or args.eval or args.format_only or args.show \
+ or args.show_dir, \
+ ('Please specify at least one operation (save/eval/format/show the '
+ 'results / save the results) with the argument "--out", "--eval"'
+ ', "--format-only", "--show" or "--show-dir"')
+
+ if args.eval and args.format_only:
+ raise ValueError('--eval and --format_only cannot be both specified')
+
+ if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):
+ raise ValueError('The output file must be a pkl file.')
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ cfg.model.pretrained = None
+ cfg.data.test.test_mode = True
+ if args.shape is not None:
+
+ if len(args.shape) == 1:
+ shape = (args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ shape = (args.shape[1], args.shape[0])
+ else:
+ raise ValueError('invalid input shape')
+
+ test_mode = cfg.model.test_cfg.mode
+ if test_mode == 'slide':
+ warnings.warn(
+ "We suggest you NOT assigning shape when exporting "
+ "slide-mode models. Assigning shape to slide-mode models "
+ "may result in unexpected results. To see which mode the "
+ "model is using, check cfg.model.test_cfg.mode, which "
+ "should be either 'whole' or 'slide'."
+ )
+ cfg.model.test_cfg['crop_size'] = shape
+ else:
+ cfg.test_pipeline[1]['img_scale'] = shape
+ cfg.data.test['pipeline'][1]['img_scale'] = shape
+
+ # init distributed env first, since logger depends on the dist info.
+ distributed = False
+
+ # build the dataloader
+ # TODO: support multiple images per gpu (only minor changes are needed)
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=distributed,
+ shuffle=False)
+
+ # load onnx config and meta
+ cfg.model.train_cfg = None
+
+ model = ONNXRuntimeSegmentorKN(args.model, cfg=cfg, device_id=0)
+
+ model.CLASSES = dataset.CLASSES
+ model.PALETTE = dataset.PALETTE
+
+ # clean gpu memory when starting a new evaluation.
+ torch.cuda.empty_cache()
+ eval_kwargs = {} if args.eval_options is None else args.eval_options
+
+ # Deprecated
+ efficient_test = eval_kwargs.get('efficient_test', False)
+ if efficient_test:
+ warnings.warn(
+ '"efficient_test=True" does not have effect in '
+ 'tools/test_kneron.py, the evaluation and format '
+ 'results are CPU memory efficient by default')
+
+ eval_on_format_results = (
+ args.eval is not None and 'cityscapes' in args.eval)
+ if eval_on_format_results:
+ assert len(args.eval) == 1, 'eval on format results is not ' \
+ 'applicable for metrics other than ' \
+ 'cityscapes'
+ if args.format_only or eval_on_format_results:
+ if 'imgfile_prefix' in eval_kwargs:
+ tmpdir = eval_kwargs['imgfile_prefix']
+ else:
+ tmpdir = '.format_cityscapes'
+ eval_kwargs.setdefault('imgfile_prefix', tmpdir)
+ mmcv.mkdir_or_exist(tmpdir)
+ else:
+ tmpdir = None
+
+ results = single_gpu_test(
+ model,
+ data_loader,
+ args.show,
+ args.show_dir,
+ False,
+ args.opacity,
+ pre_eval=args.eval is not None and not eval_on_format_results,
+ format_only=args.format_only or eval_on_format_results,
+ format_args=eval_kwargs)
+
+ rank, _ = get_dist_info()
+ if rank == 0:
+ if args.out:
+ warnings.warn(
+ 'The behavior of ``args.out`` has been changed since MMSeg '
+ 'v0.16, the pickled outputs could be seg map as type of '
+ 'np.array, pre-eval results or file paths for '
+ '``dataset.format_results()``.')
+ print(f'\nwriting results to {args.out}')
+ mmcv.dump(results, args.out)
+ if args.eval:
+ dataset.evaluate(results, args.eval, **eval_kwargs)
+ if tmpdir is not None and eval_on_format_results:
+ # remove tmp dir when cityscapes evaluation
+ shutil.rmtree(tmpdir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dist_test.sh b/tools/dist_test.sh
new file mode 100755
index 0000000..34fb465
--- /dev/null
+++ b/tools/dist_test.sh
@@ -0,0 +1,9 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+CHECKPOINT=$2
+GPUS=$3
+PORT=${PORT:-29500}
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
+ $(dirname "$0")/test.py $CONFIG $CHECKPOINT --launcher pytorch ${@:4}
diff --git a/tools/dist_train.sh b/tools/dist_train.sh
new file mode 100755
index 0000000..5b43fff
--- /dev/null
+++ b/tools/dist_train.sh
@@ -0,0 +1,9 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+GPUS=$2
+PORT=${PORT:-29500}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
+ $(dirname "$0")/train.py $CONFIG --launcher pytorch ${@:3}
diff --git a/tools/get_flops.py b/tools/get_flops.py
new file mode 100644
index 0000000..83dea0a
--- /dev/null
+++ b/tools/get_flops.py
@@ -0,0 +1,59 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+from mmcv import Config
+from mmcv.cnn import get_model_complexity_info
+
+from mmseg.models import build_segmentor
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a segmentor')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=[2048, 1024],
+ help='input image size')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+
+ args = parse_args()
+
+ if len(args.shape) == 1:
+ input_shape = (3, args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ input_shape = (3, ) + tuple(args.shape)
+ else:
+ raise ValueError('invalid input shape')
+
+ cfg = Config.fromfile(args.config)
+ cfg.model.pretrained = None
+ model = build_segmentor(
+ cfg.model,
+ train_cfg=cfg.get('train_cfg'),
+ test_cfg=cfg.get('test_cfg')).cuda()
+ model.eval()
+
+ if hasattr(model, 'forward_dummy'):
+ model.forward = model.forward_dummy
+ else:
+ raise NotImplementedError(
+ 'FLOPs counter is currently not currently supported with {}'.
+ format(model.__class__.__name__))
+
+ flops, params = get_model_complexity_info(model, input_shape)
+ split_line = '=' * 30
+ print('{0}\nInput shape: {1}\nFlops: {2}\nParams: {3}\n{0}'.format(
+ split_line, input_shape, flops, params))
+ print('!!!Please be cautious if you use the results in papers. '
+ 'You may need to check if all ops are supported and verify that the '
+ 'flops computation is correct.')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/mit2mmseg.py b/tools/model_converters/mit2mmseg.py
new file mode 100644
index 0000000..2eff1f7
--- /dev/null
+++ b/tools/model_converters/mit2mmseg.py
@@ -0,0 +1,82 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from collections import OrderedDict
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_mit(ckpt):
+ new_ckpt = OrderedDict()
+ # Process the concat between q linear weights and kv linear weights
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ # patch embedding conversion
+ elif k.startswith('patch_embed'):
+ stage_i = int(k.split('.')[0].replace('patch_embed', ''))
+ new_k = k.replace(f'patch_embed{stage_i}', f'layers.{stage_i-1}.0')
+ new_v = v
+ if 'proj.' in new_k:
+ new_k = new_k.replace('proj.', 'projection.')
+ # transformer encoder layer conversion
+ elif k.startswith('block'):
+ stage_i = int(k.split('.')[0].replace('block', ''))
+ new_k = k.replace(f'block{stage_i}', f'layers.{stage_i-1}.1')
+ new_v = v
+ if 'attn.q.' in new_k:
+ sub_item_k = k.replace('q.', 'kv.')
+ new_k = new_k.replace('q.', 'attn.in_proj_')
+ new_v = torch.cat([v, ckpt[sub_item_k]], dim=0)
+ elif 'attn.kv.' in new_k:
+ continue
+ elif 'attn.proj.' in new_k:
+ new_k = new_k.replace('proj.', 'attn.out_proj.')
+ elif 'attn.sr.' in new_k:
+ new_k = new_k.replace('sr.', 'sr.')
+ elif 'mlp.' in new_k:
+ string = f'{new_k}-'
+ new_k = new_k.replace('mlp.', 'ffn.layers.')
+ if 'fc1.weight' in new_k or 'fc2.weight' in new_k:
+ new_v = v.reshape((*v.shape, 1, 1))
+ new_k = new_k.replace('fc1.', '0.')
+ new_k = new_k.replace('dwconv.dwconv.', '1.')
+ new_k = new_k.replace('fc2.', '4.')
+ string += f'{new_k} {v.shape}-{new_v.shape}'
+ # norm layer conversion
+ elif k.startswith('norm'):
+ stage_i = int(k.split('.')[0].replace('norm', ''))
+ new_k = k.replace(f'norm{stage_i}', f'layers.{stage_i-1}.2')
+ new_v = v
+ else:
+ new_k = k
+ new_v = v
+ new_ckpt[new_k] = new_v
+ return new_ckpt
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in official pretrained segformer to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+ weight = convert_mit(state_dict)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/stdc2mmseg.py b/tools/model_converters/stdc2mmseg.py
new file mode 100644
index 0000000..9241f86
--- /dev/null
+++ b/tools/model_converters/stdc2mmseg.py
@@ -0,0 +1,71 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_stdc(ckpt, stdc_type):
+ new_state_dict = {}
+ if stdc_type == 'STDC1':
+ stage_lst = ['0', '1', '2.0', '2.1', '3.0', '3.1', '4.0', '4.1']
+ else:
+ stage_lst = [
+ '0', '1', '2.0', '2.1', '2.2', '2.3', '3.0', '3.1', '3.2', '3.3',
+ '3.4', '4.0', '4.1', '4.2'
+ ]
+ for k, v in ckpt.items():
+ ori_k = k
+ flag = False
+ if 'cp.' in k:
+ k = k.replace('cp.', '')
+ if 'features.' in k:
+ num_layer = int(k.split('.')[1])
+ feature_key_lst = 'features.' + str(num_layer) + '.'
+ stages_key_lst = 'stages.' + stage_lst[num_layer] + '.'
+ k = k.replace(feature_key_lst, stages_key_lst)
+ flag = True
+ if 'conv_list' in k:
+ k = k.replace('conv_list', 'layers')
+ flag = True
+ if 'avd_layer.' in k:
+ if 'avd_layer.0' in k:
+ k = k.replace('avd_layer.0', 'downsample.conv')
+ elif 'avd_layer.1' in k:
+ k = k.replace('avd_layer.1', 'downsample.bn')
+ flag = True
+ if flag:
+ new_state_dict[k] = ckpt[ori_k]
+
+ return new_state_dict
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in official pretrained STDC1/2 to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ parser.add_argument('type', help='model type: STDC1 or STDC2')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+
+ assert args.type in ['STDC1',
+ 'STDC2'], 'STD type should be STDC1 or STDC2!'
+ weight = convert_stdc(state_dict, args.type)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/swin2mmseg.py b/tools/model_converters/swin2mmseg.py
new file mode 100644
index 0000000..03b24ce
--- /dev/null
+++ b/tools/model_converters/swin2mmseg.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from collections import OrderedDict
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_swin(ckpt):
+ new_ckpt = OrderedDict()
+
+ def correct_unfold_reduction_order(x):
+ out_channel, in_channel = x.shape
+ x = x.reshape(out_channel, 4, in_channel // 4)
+ x = x[:, [0, 2, 1, 3], :].transpose(1,
+ 2).reshape(out_channel, in_channel)
+ return x
+
+ def correct_unfold_norm_order(x):
+ in_channel = x.shape[0]
+ x = x.reshape(4, in_channel // 4)
+ x = x[[0, 2, 1, 3], :].transpose(0, 1).reshape(in_channel)
+ return x
+
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ elif k.startswith('layers'):
+ new_v = v
+ if 'attn.' in k:
+ new_k = k.replace('attn.', 'attn.w_msa.')
+ elif 'mlp.' in k:
+ if 'mlp.fc1.' in k:
+ new_k = k.replace('mlp.fc1.', 'ffn.layers.0.0.')
+ elif 'mlp.fc2.' in k:
+ new_k = k.replace('mlp.fc2.', 'ffn.layers.1.')
+ else:
+ new_k = k.replace('mlp.', 'ffn.')
+ elif 'downsample' in k:
+ new_k = k
+ if 'reduction.' in k:
+ new_v = correct_unfold_reduction_order(v)
+ elif 'norm.' in k:
+ new_v = correct_unfold_norm_order(v)
+ else:
+ new_k = k
+ new_k = new_k.replace('layers', 'stages', 1)
+ elif k.startswith('patch_embed'):
+ new_v = v
+ if 'proj' in k:
+ new_k = k.replace('proj', 'projection')
+ else:
+ new_k = k
+ else:
+ new_v = v
+ new_k = k
+
+ new_ckpt[new_k] = new_v
+
+ return new_ckpt
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in official pretrained swin models to'
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+ weight = convert_swin(state_dict)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/twins2mmseg.py b/tools/model_converters/twins2mmseg.py
new file mode 100644
index 0000000..ab64aa5
--- /dev/null
+++ b/tools/model_converters/twins2mmseg.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from collections import OrderedDict
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_twins(args, ckpt):
+
+ new_ckpt = OrderedDict()
+
+ for k, v in list(ckpt.items()):
+ new_v = v
+ if k.startswith('head'):
+ continue
+ elif k.startswith('patch_embeds'):
+ if 'proj.' in k:
+ new_k = k.replace('proj.', 'projection.')
+ else:
+ new_k = k
+ elif k.startswith('blocks'):
+ # Union
+ if 'attn.q.' in k:
+ new_k = k.replace('q.', 'attn.in_proj_')
+ new_v = torch.cat([v, ckpt[k.replace('attn.q.', 'attn.kv.')]],
+ dim=0)
+ elif 'mlp.fc1' in k:
+ new_k = k.replace('mlp.fc1', 'ffn.layers.0.0')
+ elif 'mlp.fc2' in k:
+ new_k = k.replace('mlp.fc2', 'ffn.layers.1')
+ # Only pcpvt
+ elif args.model == 'pcpvt':
+ if 'attn.proj.' in k:
+ new_k = k.replace('proj.', 'attn.out_proj.')
+ else:
+ new_k = k
+
+ # Only svt
+ else:
+ if 'attn.proj.' in k:
+ k_lst = k.split('.')
+ if int(k_lst[2]) % 2 == 1:
+ new_k = k.replace('proj.', 'attn.out_proj.')
+ else:
+ new_k = k
+ else:
+ new_k = k
+ new_k = new_k.replace('blocks.', 'layers.')
+ elif k.startswith('pos_block'):
+ new_k = k.replace('pos_block', 'position_encodings')
+ if 'proj.0.' in new_k:
+ new_k = new_k.replace('proj.0.', 'proj.')
+ else:
+ new_k = k
+ if 'attn.kv.' not in k:
+ new_ckpt[new_k] = new_v
+ return new_ckpt
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in timm pretrained vit models to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ parser.add_argument('model', help='model: pcpvt or svt')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+
+ if 'state_dict' in checkpoint:
+ # timm checkpoint
+ state_dict = checkpoint['state_dict']
+ else:
+ state_dict = checkpoint
+
+ weight = convert_twins(args, state_dict)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/vit2mmseg.py b/tools/model_converters/vit2mmseg.py
new file mode 100644
index 0000000..bc18ebe
--- /dev/null
+++ b/tools/model_converters/vit2mmseg.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from collections import OrderedDict
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_vit(ckpt):
+
+ new_ckpt = OrderedDict()
+
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ if k.startswith('norm'):
+ new_k = k.replace('norm.', 'ln1.')
+ elif k.startswith('patch_embed'):
+ if 'proj' in k:
+ new_k = k.replace('proj', 'projection')
+ else:
+ new_k = k
+ elif k.startswith('blocks'):
+ if 'norm' in k:
+ new_k = k.replace('norm', 'ln')
+ elif 'mlp.fc1' in k:
+ new_k = k.replace('mlp.fc1', 'ffn.layers.0.0')
+ elif 'mlp.fc2' in k:
+ new_k = k.replace('mlp.fc2', 'ffn.layers.1')
+ elif 'attn.qkv' in k:
+ new_k = k.replace('attn.qkv.', 'attn.attn.in_proj_')
+ elif 'attn.proj' in k:
+ new_k = k.replace('attn.proj', 'attn.attn.out_proj')
+ else:
+ new_k = k
+ new_k = new_k.replace('blocks.', 'layers.')
+ else:
+ new_k = k
+ new_ckpt[new_k] = v
+
+ return new_ckpt
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in timm pretrained vit models to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+ if 'state_dict' in checkpoint:
+ # timm checkpoint
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ # deit checkpoint
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+ weight = convert_vit(state_dict)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/vitjax2mmseg.py b/tools/model_converters/vitjax2mmseg.py
new file mode 100644
index 0000000..e3a0986
--- /dev/null
+++ b/tools/model_converters/vitjax2mmseg.py
@@ -0,0 +1,122 @@
+import argparse
+import os.path as osp
+
+import mmcv
+import numpy as np
+import torch
+
+
+def vit_jax_to_torch(jax_weights, num_layer=12):
+ torch_weights = dict()
+
+ # patch embedding
+ conv_filters = jax_weights['embedding/kernel']
+ conv_filters = conv_filters.permute(3, 2, 0, 1)
+ torch_weights['patch_embed.projection.weight'] = conv_filters
+ torch_weights['patch_embed.projection.bias'] = jax_weights[
+ 'embedding/bias']
+
+ # pos embedding
+ torch_weights['pos_embed'] = jax_weights[
+ 'Transformer/posembed_input/pos_embedding']
+
+ # cls token
+ torch_weights['cls_token'] = jax_weights['cls']
+
+ # head
+ torch_weights['ln1.weight'] = jax_weights['Transformer/encoder_norm/scale']
+ torch_weights['ln1.bias'] = jax_weights['Transformer/encoder_norm/bias']
+
+ # transformer blocks
+ for i in range(num_layer):
+ jax_block = f'Transformer/encoderblock_{i}'
+ torch_block = f'layers.{i}'
+
+ # attention norm
+ torch_weights[f'{torch_block}.ln1.weight'] = jax_weights[
+ f'{jax_block}/LayerNorm_0/scale']
+ torch_weights[f'{torch_block}.ln1.bias'] = jax_weights[
+ f'{jax_block}/LayerNorm_0/bias']
+
+ # attention
+ query_weight = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/query/kernel']
+ query_bias = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/query/bias']
+ key_weight = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/key/kernel']
+ key_bias = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/key/bias']
+ value_weight = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/value/kernel']
+ value_bias = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/value/bias']
+
+ qkv_weight = torch.from_numpy(
+ np.stack((query_weight, key_weight, value_weight), 1))
+ qkv_weight = torch.flatten(qkv_weight, start_dim=1)
+ qkv_bias = torch.from_numpy(
+ np.stack((query_bias, key_bias, value_bias), 0))
+ qkv_bias = torch.flatten(qkv_bias, start_dim=0)
+
+ torch_weights[f'{torch_block}.attn.attn.in_proj_weight'] = qkv_weight
+ torch_weights[f'{torch_block}.attn.attn.in_proj_bias'] = qkv_bias
+ to_out_weight = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/out/kernel']
+ to_out_weight = torch.flatten(to_out_weight, start_dim=0, end_dim=1)
+ torch_weights[
+ f'{torch_block}.attn.attn.out_proj.weight'] = to_out_weight
+ torch_weights[f'{torch_block}.attn.attn.out_proj.bias'] = jax_weights[
+ f'{jax_block}/MultiHeadDotProductAttention_1/out/bias']
+
+ # mlp norm
+ torch_weights[f'{torch_block}.ln2.weight'] = jax_weights[
+ f'{jax_block}/LayerNorm_2/scale']
+ torch_weights[f'{torch_block}.ln2.bias'] = jax_weights[
+ f'{jax_block}/LayerNorm_2/bias']
+
+ # mlp
+ torch_weights[f'{torch_block}.ffn.layers.0.0.weight'] = jax_weights[
+ f'{jax_block}/MlpBlock_3/Dense_0/kernel']
+ torch_weights[f'{torch_block}.ffn.layers.0.0.bias'] = jax_weights[
+ f'{jax_block}/MlpBlock_3/Dense_0/bias']
+ torch_weights[f'{torch_block}.ffn.layers.1.weight'] = jax_weights[
+ f'{jax_block}/MlpBlock_3/Dense_1/kernel']
+ torch_weights[f'{torch_block}.ffn.layers.1.bias'] = jax_weights[
+ f'{jax_block}/MlpBlock_3/Dense_1/bias']
+
+ # transpose weights
+ for k, v in torch_weights.items():
+ if 'weight' in k and 'patch_embed' not in k and 'ln' not in k:
+ v = v.permute(1, 0)
+ torch_weights[k] = v
+
+ return torch_weights
+
+
+def main():
+ # stole refactoring code from Robin Strudel, thanks
+ parser = argparse.ArgumentParser(
+ description='Convert keys from jax official pretrained vit models to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ args = parser.parse_args()
+
+ jax_weights = np.load(args.src)
+ jax_weights_tensor = {}
+ for key in jax_weights.files:
+ value = torch.from_numpy(jax_weights[key])
+ jax_weights_tensor[key] = value
+ if 'L_16-i21k' in args.src:
+ num_layer = 24
+ else:
+ num_layer = 12
+ torch_weights = vit_jax_to_torch(jax_weights_tensor, num_layer)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(torch_weights, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/onnx2tensorrt.py b/tools/onnx2tensorrt.py
new file mode 100644
index 0000000..f8a258f
--- /dev/null
+++ b/tools/onnx2tensorrt.py
@@ -0,0 +1,276 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+from typing import Iterable, Optional, Union
+
+import matplotlib.pyplot as plt
+import mmcv
+import numpy as np
+import onnxruntime as ort
+import torch
+from mmcv.ops import get_onnxruntime_op_path
+from mmcv.tensorrt import (TRTWraper, is_tensorrt_plugin_loaded, onnx2trt,
+ save_trt_engine)
+
+from mmseg.apis.inference import LoadImage
+from mmseg.datasets import DATASETS
+from mmseg.datasets.pipelines import Compose
+
+
+def get_GiB(x: int):
+ """return x GiB."""
+ return x * (1 << 30)
+
+
+def _prepare_input_img(img_path: str,
+ test_pipeline: Iterable[dict],
+ shape: Optional[Iterable] = None,
+ rescale_shape: Optional[Iterable] = None) -> dict:
+ # build the data pipeline
+ if shape is not None:
+ test_pipeline[1]['img_scale'] = (shape[1], shape[0])
+ test_pipeline[1]['transforms'][0]['keep_ratio'] = False
+ test_pipeline = [LoadImage()] + test_pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ # prepare data
+ data = dict(img=img_path)
+ data = test_pipeline(data)
+ imgs = data['img']
+ img_metas = [i.data for i in data['img_metas']]
+
+ if rescale_shape is not None:
+ for img_meta in img_metas:
+ img_meta['ori_shape'] = tuple(rescale_shape) + (3, )
+
+ mm_inputs = {'imgs': imgs, 'img_metas': img_metas}
+
+ return mm_inputs
+
+
+def _update_input_img(img_list: Iterable, img_meta_list: Iterable):
+ # update img and its meta list
+ N = img_list[0].size(0)
+ img_meta = img_meta_list[0][0]
+ img_shape = img_meta['img_shape']
+ ori_shape = img_meta['ori_shape']
+ pad_shape = img_meta['pad_shape']
+ new_img_meta_list = [[{
+ 'img_shape':
+ img_shape,
+ 'ori_shape':
+ ori_shape,
+ 'pad_shape':
+ pad_shape,
+ 'filename':
+ img_meta['filename'],
+ 'scale_factor':
+ (img_shape[1] / ori_shape[1], img_shape[0] / ori_shape[0]) * 2,
+ 'flip':
+ False,
+ } for _ in range(N)]]
+
+ return img_list, new_img_meta_list
+
+
+def show_result_pyplot(img: Union[str, np.ndarray],
+ result: np.ndarray,
+ palette: Optional[Iterable] = None,
+ fig_size: Iterable[int] = (15, 10),
+ opacity: float = 0.5,
+ title: str = '',
+ block: bool = True):
+ img = mmcv.imread(img)
+ img = img.copy()
+ seg = result[0]
+ seg = mmcv.imresize(seg, img.shape[:2][::-1])
+ palette = np.array(palette)
+ assert palette.shape[1] == 3
+ assert len(palette.shape) == 2
+ assert 0 < opacity <= 1.0
+ color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
+ for label, color in enumerate(palette):
+ color_seg[seg == label, :] = color
+ # convert to BGR
+ color_seg = color_seg[..., ::-1]
+
+ img = img * (1 - opacity) + color_seg * opacity
+ img = img.astype(np.uint8)
+
+ plt.figure(figsize=fig_size)
+ plt.imshow(mmcv.bgr2rgb(img))
+ plt.title(title)
+ plt.tight_layout()
+ plt.show(block=block)
+
+
+def onnx2tensorrt(onnx_file: str,
+ trt_file: str,
+ config: dict,
+ input_config: dict,
+ fp16: bool = False,
+ verify: bool = False,
+ show: bool = False,
+ dataset: str = 'CityscapesDataset',
+ workspace_size: int = 1,
+ verbose: bool = False):
+ import tensorrt as trt
+ min_shape = input_config['min_shape']
+ max_shape = input_config['max_shape']
+ # create trt engine and wrapper
+ opt_shape_dict = {'input': [min_shape, min_shape, max_shape]}
+ max_workspace_size = get_GiB(workspace_size)
+ trt_engine = onnx2trt(
+ onnx_file,
+ opt_shape_dict,
+ log_level=trt.Logger.VERBOSE if verbose else trt.Logger.ERROR,
+ fp16_mode=fp16,
+ max_workspace_size=max_workspace_size)
+ save_dir, _ = osp.split(trt_file)
+ if save_dir:
+ os.makedirs(save_dir, exist_ok=True)
+ save_trt_engine(trt_engine, trt_file)
+ print(f'Successfully created TensorRT engine: {trt_file}')
+
+ if verify:
+ inputs = _prepare_input_img(
+ input_config['input_path'],
+ config.data.test.pipeline,
+ shape=min_shape[2:])
+
+ imgs = inputs['imgs']
+ img_metas = inputs['img_metas']
+ img_list = [img[None, :] for img in imgs]
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ # update img_meta
+ img_list, img_meta_list = _update_input_img(img_list, img_meta_list)
+
+ if max_shape[0] > 1:
+ # concate flip image for batch test
+ flip_img_list = [_.flip(-1) for _ in img_list]
+ img_list = [
+ torch.cat((ori_img, flip_img), 0)
+ for ori_img, flip_img in zip(img_list, flip_img_list)
+ ]
+
+ # Get results from ONNXRuntime
+ ort_custom_op_path = get_onnxruntime_op_path()
+ session_options = ort.SessionOptions()
+ if osp.exists(ort_custom_op_path):
+ session_options.register_custom_ops_library(ort_custom_op_path)
+ sess = ort.InferenceSession(onnx_file, session_options)
+ sess.set_providers(['CPUExecutionProvider'], [{}]) # use cpu mode
+ onnx_output = sess.run(['output'],
+ {'input': img_list[0].detach().numpy()})[0][0]
+
+ # Get results from TensorRT
+ trt_model = TRTWraper(trt_file, ['input'], ['output'])
+ with torch.no_grad():
+ trt_outputs = trt_model({'input': img_list[0].contiguous().cuda()})
+ trt_output = trt_outputs['output'][0].cpu().detach().numpy()
+
+ if show:
+ dataset = DATASETS.get(dataset)
+ assert dataset is not None
+ palette = dataset.PALETTE
+
+ show_result_pyplot(
+ input_config['input_path'],
+ (onnx_output[0].astype(np.uint8), ),
+ palette=palette,
+ title='ONNXRuntime',
+ block=False)
+ show_result_pyplot(
+ input_config['input_path'], (trt_output[0].astype(np.uint8), ),
+ palette=palette,
+ title='TensorRT')
+
+ np.testing.assert_allclose(
+ onnx_output, trt_output, rtol=1e-03, atol=1e-05)
+ print('TensorRT and ONNXRuntime output all close.')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert MMSegmentation models from ONNX to TensorRT')
+ parser.add_argument('config', help='Config file of the model')
+ parser.add_argument('model', help='Path to the input ONNX model')
+ parser.add_argument(
+ '--trt-file', type=str, help='Path to the output TensorRT engine')
+ parser.add_argument(
+ '--max-shape',
+ type=int,
+ nargs=4,
+ default=[1, 3, 400, 600],
+ help='Maximum shape of model input.')
+ parser.add_argument(
+ '--min-shape',
+ type=int,
+ nargs=4,
+ default=[1, 3, 400, 600],
+ help='Minimum shape of model input.')
+ parser.add_argument('--fp16', action='store_true', help='Enable fp16 mode')
+ parser.add_argument(
+ '--workspace-size',
+ type=int,
+ default=1,
+ help='Max workspace size in GiB')
+ parser.add_argument(
+ '--input-img', type=str, default='', help='Image for test')
+ parser.add_argument(
+ '--show', action='store_true', help='Whether to show output results')
+ parser.add_argument(
+ '--dataset',
+ type=str,
+ default='CityscapesDataset',
+ help='Dataset name')
+ parser.add_argument(
+ '--verify',
+ action='store_true',
+ help='Verify the outputs of ONNXRuntime and TensorRT')
+ parser.add_argument(
+ '--verbose',
+ action='store_true',
+ help='Whether to verbose logging messages while creating \
+ TensorRT engine.')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+
+ assert is_tensorrt_plugin_loaded(), 'TensorRT plugin should be compiled.'
+ args = parse_args()
+
+ if not args.input_img:
+ args.input_img = osp.join(osp.dirname(__file__), '../demo/demo.png')
+
+ # check arguments
+ assert osp.exists(args.config), 'Config {} not found.'.format(args.config)
+ assert osp.exists(args.model), \
+ 'ONNX model {} not found.'.format(args.model)
+ assert args.workspace_size >= 0, 'Workspace size less than 0.'
+ assert DATASETS.get(args.dataset) is not None, \
+ 'Dataset {} does not found.'.format(args.dataset)
+ for max_value, min_value in zip(args.max_shape, args.min_shape):
+ assert max_value >= min_value, \
+ 'max_shape should be larger than min shape'
+
+ input_config = {
+ 'min_shape': args.min_shape,
+ 'max_shape': args.max_shape,
+ 'input_path': args.input_img
+ }
+
+ cfg = mmcv.Config.fromfile(args.config)
+ onnx2tensorrt(
+ args.model,
+ args.trt_file,
+ cfg,
+ input_config,
+ fp16=args.fp16,
+ verify=args.verify,
+ show=args.show,
+ dataset=args.dataset,
+ workspace_size=args.workspace_size,
+ verbose=args.verbose)
diff --git a/tools/optimizer_scripts/.clang-format b/tools/optimizer_scripts/.clang-format
new file mode 100644
index 0000000..2593ef5
--- /dev/null
+++ b/tools/optimizer_scripts/.clang-format
@@ -0,0 +1 @@
+BasedOnStyle: Google
\ No newline at end of file
diff --git a/tools/optimizer_scripts/.gitignore b/tools/optimizer_scripts/.gitignore
new file mode 100644
index 0000000..991fd07
--- /dev/null
+++ b/tools/optimizer_scripts/.gitignore
@@ -0,0 +1,7 @@
+__pycache__
+.vscode
+*.pyc
+models.py
+temp.py
+.ssh/
+docker/test_models/
\ No newline at end of file
diff --git a/tools/optimizer_scripts/README.md b/tools/optimizer_scripts/README.md
new file mode 100644
index 0000000..cac99c5
--- /dev/null
+++ b/tools/optimizer_scripts/README.md
@@ -0,0 +1,189 @@
+# Converter Scripts
+
+[](http://192.168.200.1:8088/jiyuan/converter_scripts/commits/master)
+
+This project collects various optimization scripts and converter scritps for
+Kneron toolchain. This collection does not include the Keras to ONNX converter
+and the Caffe to ONNX converter. They are in seperate projects.
+
+**The scripts not listed below are used as libraries and cannot be used
+directly.**
+
+## onnx2onnx.py
+
+### 1.1. Description
+
+General optimizations on ONNX model for Kneron toolchain. Though Kneron
+toolchains are designed to take ONNX models as input, they have some
+restrictions on the models (e.g. inferenced shapes for all value_info). Thus, we
+have this tool to do some general optimization and conversion on ONNX models.
+**Notice that this script should take an valid ONNX model as input.** It cannot
+turn an invalid ONNX model into a valid one.
+
+### 1.2. Basic Usage
+
+```bash
+python onnx2onnx.py input.onnx -o output.onnx
+```
+
+### 1.3. Optimizations Included
+
+* Fusing BN into Conv.
+* Fusing BN into Gemm.
+* Fusing consecutive Gemm.
+* Eliminating Identify layers and Dropout layers.
+* Eliminating last shape changing nodes.
+* Replacing initializers into Constant nodes.
+* Replacing global AveragePool with GAP.
+* Replacing Squeeze and Unsqueeze with Reshape.
+* Replacing 1x1 depthwise with BN.
+* Inferencing Upsample shapes.
+* Transposing B in Gemm.
+
+## pytorch2onnx.py
+
+### 2.1. Description
+
+Convert Pytorch models or Pytorch generated ONNX models into Kneron toolchain
+compatible ONNX files. This script include most of the optimizations in
+`onnx2onnx.py`. It also includes some optimizations for Pytorch model only.
+
+### 2.2. Basic Usage
+
+```bash
+# Take Pytorch model name, input channel number, input height, input width
+python pytorch2onnx.py input.pth output.onnx --input-size 3 224 224
+# Or take Pytorch exported ONNX.
+python pytorch2onnx.py input.onnx output.onnx
+```
+
+### 2.3. Optimizations Included
+
+* Adding name to nodes.
+* Unsqueeze nodes constant folding.
+* Reshape nodes constant folding.
+* Optimizations in `onnx2onnx.py`.
+
+## editor.py
+
+### 3.1. Description
+
+This is an simple ONNX editor which achieves the following functions:
+
+* Add nop BN or Conv nodes.
+* Delete specific nodes or inputs.
+* Cut the graph from certain node (Delete all the nodes following the node).
+* Reshape inputs and outputs
+
+### 3.2 Usage
+
+```
+usage: editor.py [-h] [-c CUT_NODE [CUT_NODE ...]]
+ [--cut-type CUT_TYPE [CUT_TYPE ...]]
+ [-d DELETE_NODE [DELETE_NODE ...]]
+ [--delete-input DELETE_INPUT [DELETE_INPUT ...]]
+ [-i INPUT_CHANGE [INPUT_CHANGE ...]]
+ [-o OUTPUT_CHANGE [OUTPUT_CHANGE ...]]
+ [--add-conv ADD_CONV [ADD_CONV ...]]
+ [--add-bn ADD_BN [ADD_BN ...]]
+ in_file out_file
+
+Edit an ONNX model. The processing sequense is 'delete nodes/values' -> 'add
+nodes' -> 'change shapes'. Cutting cannot be done with other operations
+together
+
+positional arguments:
+ in_file input ONNX FILE
+ out_file ouput ONNX FILE
+
+optional arguments:
+ -h, --help show this help message and exit
+ -c CUT_NODE [CUT_NODE ...], --cut CUT_NODE [CUT_NODE ...]
+ remove nodes from the given nodes(inclusive)
+ --cut-type CUT_TYPE [CUT_TYPE ...]
+ remove nodes by type from the given nodes(inclusive)
+ -d DELETE_NODE [DELETE_NODE ...], --delete DELETE_NODE [DELETE_NODE ...]
+ delete nodes by names and only those nodes
+ --delete-input DELETE_INPUT [DELETE_INPUT ...]
+ delete inputs by names
+ -i INPUT_CHANGE [INPUT_CHANGE ...], --input INPUT_CHANGE [INPUT_CHANGE ...]
+ change input shape (e.g. -i 'input_0 1 3 224 224')
+ -o OUTPUT_CHANGE [OUTPUT_CHANGE ...], --output OUTPUT_CHANGE [OUTPUT_CHANGE ...]
+ change output shape (e.g. -o 'input_0 1 3 224 224')
+ --add-conv ADD_CONV [ADD_CONV ...]
+ add nop conv using specific input
+ --add-bn ADD_BN [ADD_BN ...]
+ add nop bn using specific input
+```
+
+### 3.3. Example
+
+Here is an example of when and how to use the editor.py.
+
+```bash
+# In the `res` folder, there is a vdsr model from tensorflow.
+# We need to convert this model firstly.
+./tf2onnx.sh res/vdsr_41_20layer_1.pb res/tmp.onnx images:0 output:0
+# This onnx file seems valid. But, it's channel last for the input and output.
+# It is using Traspose to convert to channel first, affacting the performance.
+# Thus, here we use the editor to delete these Transpose and reset the shapes.
+python editor.py debug.onnx new.onnx -d Conv2D__6 Conv2D_19__84 -i 'images:0 1 3 41 41' -o 'output:0 1 3 41 41'
+# Now, it has no Transpose and take channel first inputs directly.
+```
+
+## test_models_opt.py
+
+### 4.1. Description
+Compare all original and optimized onnx models under a specified directory.
+Using different endings to locate original and optimized model paths. Apply
+onnxruntime inference to the models, and compare the results from original
+and optimized models. Calculate basic statistics and store to a csv file.
+
+### 4.2. Usage
+
+```bash
+python DIR ending1 ending2 csv_out_file -p=Y/N
+
+# csv_out_file is file path for the stats data.
+# -p --plot is the plot option, if Y, stats plots will be generated.
+```
+
+### 4.3. Statistics
+* max_rel_diff
+* max_abs_diff
+* mean_rel_diff
+* mean_abs_diff
+* std_rel_diff
+* std_abs_diff
+* acc_with_diff_precision
+* percentile
+
+### 4.4. Plots
+* Max Relative Difference Histogram
+* Max Absolute Difference Histogram
+* Rel_diff Percentiles of Raw and Optimized Models
+* Abs_diff Percentiles of Raw and Optimized Models
+* Accuracies with Different Precisions
+
+## tensorflow2onnx.py
+
+### 5.1. Description
+Convert and optimize tensorflow models. If input file is frozen tensorflow .pb model,
+convert to onnx model and do the custmized optimization afterwards. If input model is already
+onnx model, apply optimization and save optimized model.
+
+### 5.2 Dependency
+
+This scripts depends on the tensorflow-onnx project. Please [check and install it](https://github.com/onnx/tensorflow-onnx/tree/r1.5) before using this script. We currently support up to version 1.5.5. For other versions, you may need to try it our yourself.
+
+### 5.3. Basic Usage
+```bash
+python tensorflow2onnx.py in_file out_file -t=True/False
+
+# -t --test, is the option for test mode, if True, shape change after input will not be eliminated.
+```
+
+### 5.4. Model Save Paths
+`in_file` is the input model path, `out_file` specifies output optimized model path.
+If input file is `.pb` model, an unoptimized onnx model will be saved to the output directory as well.
+
diff --git a/tools/optimizer_scripts/consecutive_conv_opt.py b/tools/optimizer_scripts/consecutive_conv_opt.py
new file mode 100644
index 0000000..0ed4a28
--- /dev/null
+++ b/tools/optimizer_scripts/consecutive_conv_opt.py
@@ -0,0 +1,85 @@
+import numpy as np
+import onnx
+import sys
+
+from tools.other import topological_sort
+from tools import helper
+
+
+def fuse_bias_in_consecutive_1x1_conv(g):
+ for second in g.node:
+ # Find two conv
+ if second.op_type != "Conv":
+ continue
+ first = helper.find_node_by_output_name(g, second.input[0])
+ if first is None or first.op_type != "Conv":
+ continue
+ # Check if the first one has only one folloing node
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, first.output[0]
+ )
+ )
+ != 1
+ ):
+ continue
+ # If first node has no bias, continue
+ if len(first.input) == 2:
+ continue
+ # Check their kernel size
+ first_kernel_shape = helper.get_list_attribute_by_name(
+ first, "kernel_shape", "int"
+ )
+ second_kernel_shape = helper.get_list_attribute_by_name(
+ second, "kernel_shape", "int"
+ )
+ prod = (
+ first_kernel_shape[0]
+ * first_kernel_shape[1]
+ * second_kernel_shape[0]
+ * second_kernel_shape[1]
+ )
+ if prod != 1:
+ continue
+ print("Found: ", first.name, " ", second.name)
+ # Get bias of the nodes
+ first_bias_node = helper.find_node_by_output_name(g, first.input[2])
+ second_weight_node = helper.find_node_by_output_name(
+ g, second.input[1]
+ )
+ second_bias_node = helper.find_node_by_output_name(g, second.input[2])
+ first_bias = helper.constant_to_numpy(first_bias_node)
+ second_weight = helper.constant_to_numpy(second_weight_node)
+ second_bias = helper.constant_to_numpy(second_bias_node)
+ # Calculate the weight for second node
+ first_bias = np.reshape(first_bias, (1, first_bias.size))
+ second_weight = np.reshape(
+ second_weight, (second_weight.shape[0], second_weight.shape[1])
+ )
+ second_weight = np.transpose(second_weight)
+ new_second_bias = second_bias + np.matmul(first_bias, second_weight)
+ new_second_bias = np.reshape(new_second_bias, (new_second_bias.size,))
+ # Generate new weight
+ new_first_bias = np.reshape(first_bias, (first_bias.size,))
+ for i in range(new_first_bias.shape[0]):
+ new_first_bias[i] = 0.0
+ new_first_bias_node = helper.numpy_to_constant(
+ first_bias_node.output[0], new_first_bias
+ )
+ new_second_bias_node = helper.numpy_to_constant(
+ second_bias_node.output[0], new_second_bias
+ )
+ # Delete old weight and add new weights
+ g.node.remove(first_bias_node)
+ g.node.remove(second_bias_node)
+ g.node.extend([new_first_bias_node, new_second_bias_node])
+ topological_sort(g)
+
+
+if __name__ == "__main__":
+ if len(sys.argv) != 3:
+ exit(1)
+ m = onnx.load(sys.argv[1])
+ fuse_bias_in_consecutive_1x1_conv(m.graph)
+ onnx.save(m, sys.argv[2])
diff --git a/tools/optimizer_scripts/docker/Dockerfile b/tools/optimizer_scripts/docker/Dockerfile
new file mode 100644
index 0000000..bb62f7f
--- /dev/null
+++ b/tools/optimizer_scripts/docker/Dockerfile
@@ -0,0 +1,24 @@
+FROM continuumio/miniconda3:latest
+LABEL maintainer="jiyuan@kneron.us"
+
+# Install python packages
+RUN conda update -y conda && \
+conda install -y python=3.6 && \
+conda install -y -c intel caffe && \
+conda install -y -c pytorch pytorch=1.3.1 torchvision=0.4.2 cpuonly && \
+conda install -y -c conda-forge tensorflow=1.5.1 keras=2.2.4 && \
+pip install onnx==1.4.1 onnxruntime==1.1.0 tf2onnx==1.5.4 && \
+ln -s /opt/conda/lib/libgflags.so.2.2.2 /opt/conda/lib/libgflags.so.2
+
+# Install git lfs packages
+RUN apt-get update && apt-get install -y curl apt-utils && \
+curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash && \
+apt-get install -y git-lfs
+
+RUN conda clean -a -y && rm -rf /var/lib/apt/lists/*
+
+# copy the test data
+COPY ./test_models /test_models
+
+# Clean the environment and finalize the process
+WORKDIR /root
\ No newline at end of file
diff --git a/tools/optimizer_scripts/editor.py b/tools/optimizer_scripts/editor.py
new file mode 100644
index 0000000..b04183c
--- /dev/null
+++ b/tools/optimizer_scripts/editor.py
@@ -0,0 +1,235 @@
+import onnx
+import onnx.utils
+
+try:
+ from onnx import optimizer
+except ImportError:
+ import onnxoptimizer as optimizer
+import argparse
+
+import tools.modhelper as helper
+import tools.other as other
+import tools.replacing as replacing
+
+# Main process
+# Argument parser
+parser = argparse.ArgumentParser(
+ description="Edit an ONNX model.\nThe processing sequense is 'delete "
+ "nodes/values' -> 'add nodes' -> 'change shapes'.\nCutting "
+ "cannot be done with other operations together"
+)
+parser.add_argument("in_file", type=str, help="input ONNX FILE")
+parser.add_argument("out_file", type=str, help="ouput ONNX FILE")
+parser.add_argument(
+ "-c",
+ "--cut",
+ dest="cut_node",
+ type=str,
+ nargs="+",
+ help="remove nodes from the given nodes(inclusive)",
+)
+parser.add_argument(
+ "--cut-type",
+ dest="cut_type",
+ type=str,
+ nargs="+",
+ help="remove nodes by type from the given nodes(inclusive)",
+)
+parser.add_argument(
+ "-d",
+ "--delete",
+ dest="delete_node",
+ type=str,
+ nargs="+",
+ help="delete nodes by names and only those nodes",
+)
+parser.add_argument(
+ "--delete-input",
+ dest="delete_input",
+ type=str,
+ nargs="+",
+ help="delete inputs by names",
+)
+parser.add_argument(
+ "--delete-output",
+ dest="delete_output",
+ type=str,
+ nargs="+",
+ help="delete outputs by names",
+)
+parser.add_argument(
+ "-i",
+ "--input",
+ dest="input_change",
+ type=str,
+ nargs="+",
+ help="change input shape (e.g. -i 'input_0 1 3 224 224')",
+)
+parser.add_argument(
+ "-o",
+ "--output",
+ dest="output_change",
+ type=str,
+ nargs="+",
+ help="change output shape (e.g. -o 'input_0 1 3 224 224')",
+)
+parser.add_argument(
+ "--add-conv",
+ dest="add_conv",
+ type=str,
+ nargs="+",
+ help="add nop conv using specific input",
+)
+parser.add_argument(
+ "--add-bn",
+ dest="add_bn",
+ type=str,
+ nargs="+",
+ help="add nop bn using specific input",
+)
+parser.add_argument(
+ "--rename-output",
+ dest="rename_output",
+ type=str,
+ nargs="+",
+ help="Rename the specific output(e.g. --rename-output old_name new_name)",
+)
+parser.add_argument(
+ "--pixel-bias-value",
+ dest="pixel_bias_value",
+ type=str,
+ nargs="+",
+ help='(per channel) set pixel value bias bn layer at model front for '
+ 'normalization( e.g. --pixel_bias_value "[104.0, 117.0, 123.0]" )',
+)
+parser.add_argument(
+ "--pixel-scale-value",
+ dest="pixel_scale_value",
+ type=str,
+ nargs="+",
+ help='(per channel) set pixel value scale bn layer at model front for '
+ 'normalization( e.g. --pixel_scale_value '
+ '"[0.0078125, 0.0078125, 0.0078125]" )',
+)
+
+args = parser.parse_args()
+
+# Load model and polish
+m = onnx.load(args.in_file)
+m = other.polish_model(m)
+g = m.graph
+replacing.replace_initializer_with_Constant(g)
+other.topological_sort(g)
+
+# Remove nodes according to the given arguments.
+if args.delete_node is not None:
+ helper.delete_nodes(g, args.delete_node)
+
+if args.delete_input is not None:
+ helper.delete_input(g, args.delete_input)
+
+if args.delete_output is not None:
+ helper.delete_output(g, args.delete_output)
+
+# Add do-nothing Conv node
+if args.add_conv is not None:
+ other.add_nop_conv_after(g, args.add_conv)
+ other.topological_sort(g)
+
+# Add do-nothing BN node
+if args.add_bn is not None:
+ other.add_nop_bn_after(g, args.add_bn)
+ other.topological_sort(g)
+
+# Add bias scale BN node
+if args.pixel_bias_value is not None or args.pixel_scale_value is not None:
+
+ if len(g.input) > 1:
+ raise ValueError(
+ " '--pixel-bias-value' and '--pixel-scale-value' "
+ "only support one input node model currently"
+ )
+
+ i_n = g.input[0]
+
+ pixel_bias_value = [0] * i_n.type.tensor_type.shape.dim[1].dim_value
+ pixel_scale_value = [1] * i_n.type.tensor_type.shape.dim[1].dim_value
+
+ if args.pixel_bias_value is not None and len(args.pixel_bias_value) == 1:
+ pixel_bias_value = [
+ float(n)
+ for n in args.pixel_bias_value[0]
+ .replace("[", "")
+ .replace("]", "")
+ .split(",")
+ ]
+
+ if args.pixel_scale_value is not None and len(args.pixel_scale_value) == 1:
+ pixel_scale_value = [
+ float(n)
+ for n in args.pixel_scale_value[0]
+ .replace("[", "")
+ .replace("]", "")
+ .split(",")
+ ]
+
+ if i_n.type.tensor_type.shape.dim[1].dim_value != len(
+ pixel_bias_value
+ ) or i_n.type.tensor_type.shape.dim[1].dim_value != len(pixel_scale_value):
+ raise ValueError(
+ "--pixel-bias-value ("
+ + str(pixel_bias_value)
+ + ") and --pixel-scale-value ("
+ + str(pixel_scale_value)
+ + ") should be same as input dimension:"
+ + str(i_n.type.tensor_type.shape.dim[1].dim_value)
+ )
+ other.add_bias_scale_bn_after(
+ g, i_n.name, pixel_bias_value, pixel_scale_value
+ )
+
+# Change input and output shapes as requested
+if args.input_change is not None:
+ other.change_input_shape(g, args.input_change)
+if args.output_change is not None:
+ other.change_output_shape(g, args.output_change)
+
+# Cutting nodes according to the given arguments.
+if args.cut_node is not None or args.cut_type is not None:
+ if args.cut_node is None:
+ other.remove_nodes(g, cut_types=args.cut_type)
+ elif args.cut_type is None:
+ other.remove_nodes(g, cut_nodes=args.cut_node)
+ else:
+ other.remove_nodes(g, cut_nodes=args.cut_node, cut_types=args.cut_type)
+ other.topological_sort(g)
+
+# Rename nodes
+if args.rename_output:
+ if len(args.rename_output) % 2 != 0:
+ print("Rename output should be paires of names.")
+ else:
+ for i in range(0, len(args.rename_output), 2):
+ other.rename_output_name(
+ g, args.rename_output[i], args.rename_output[i + 1]
+ )
+
+# Remove useless nodes
+if (
+ args.delete_node
+ or args.delete_input
+ or args.input_change
+ or args.output_change
+):
+ # If shape changed during the modification, redo shape inference.
+ while len(g.value_info) > 0:
+ g.value_info.pop()
+passes = ["extract_constant_to_initializer"]
+m = optimizer.optimize(m, passes)
+g = m.graph
+replacing.replace_initializer_with_Constant(g)
+other.topological_sort(g)
+# Polish and output
+m = other.polish_model(m)
+other.add_output_to_value_info(m.graph)
+onnx.save(m, args.out_file)
diff --git a/tools/optimizer_scripts/norm_on_scaled_onnx.py b/tools/optimizer_scripts/norm_on_scaled_onnx.py
new file mode 100644
index 0000000..7d462c2
--- /dev/null
+++ b/tools/optimizer_scripts/norm_on_scaled_onnx.py
@@ -0,0 +1,54 @@
+import onnx
+import sys
+import json
+
+from tools import special
+
+if len(sys.argv) != 3:
+ print("python norm_on_scaled_onnx.py input.onnx input.json")
+ exit(1)
+
+# Modify onnx
+m = onnx.load(sys.argv[1])
+special.add_0_5_to_normalized_input(m)
+onnx.save(m, sys.argv[1][:-4] + "norm.onnx")
+
+# Change input node
+origin_file = open(sys.argv[2], "r")
+origin_json = json.load(origin_file)
+origin_json["input_node"]["output_datapath_radix"] = [8]
+new_json_str = json.dumps(origin_json)
+
+# Modify json
+file = open(sys.argv[1][:-4] + "norm.onnx" + ".json", "w")
+s = """{{
+ \"{0}\" :
+ {{
+ \"bias_bitwidth\" : 16,
+ \"{0}_bias\" : [15],
+ \"{0}_weight\" : [3,3,3],
+ \"conv_coarse_shift\" : [-4,-4,-4],
+ \"conv_fine_shift\" : [0,0,0],
+ \"conv_total_shift\" : [-4,-4,-4],
+ \"cpu_mode\" : false,
+ \"delta_input_bitwidth\" : [0],
+ \"delta_output_bitwidth\" : 8,
+ \"flag_radix_bias_eq_output\" : true,
+ \"input_scale\" : [[1.0,1.0,1.0]],
+ \"output_scale\" : [1.0, 1.0, 1.0],
+ \"psum_bitwidth\" : 16,
+ \"weight_bitwidth\" : 8,
+ \"input_datapath_bitwidth\" : [8],
+ \"input_datapath_radix\" : [8],
+ \"working_input_bitwidth\" : 8,
+ \"working_input_radix\" : [8],
+ \"working_output_bitwidth\" : 16,
+ \"working_output_radix\" : 15,
+ \"output_datapath_bitwidth\" : 8,
+ \"output_datapath_radix\" : 7
+ }},\n""".format(
+ "input_norm"
+)
+file.write(s + new_json_str[1:])
+file.close()
+origin_file.close()
diff --git a/tools/optimizer_scripts/onnx1_3to1_4.py b/tools/optimizer_scripts/onnx1_3to1_4.py
new file mode 100644
index 0000000..6c6613f
--- /dev/null
+++ b/tools/optimizer_scripts/onnx1_3to1_4.py
@@ -0,0 +1,144 @@
+# ref http://192.168.200.1:8088/jiyuan/converter_scripts.git
+
+import sys
+import onnx
+from tools import other, helper
+
+"""
+Change onnx model from version 1.3 to version 1.4.
+- Modify the BN node by removing the spatial attribute
+- Modify the Upsample node by removing the 'scales' attribute,
+ and adding a constant node instead.
+- Model's ir_version and opset_import are updated.
+"""
+
+
+def remove_BN_spatial(g):
+ for node in g.node:
+ if node.op_type != "BatchNormalization":
+ continue
+ for att in node.attribute:
+ if att.name == "spatial":
+ node.attribute.remove(att)
+
+
+def upsample_attribute_to_const(g):
+ for node in g.node:
+ if node.op_type != "Upsample":
+ continue
+ scales_exist = False
+ for att in node.attribute:
+ if att.name == "scales":
+ scales_exist = True
+ break
+ if not scales_exist:
+ continue
+
+ shape = [len(att.floats)]
+ node.attribute.remove(att)
+ new_node = helper.list_to_constant(
+ node.name + "_input", shape, att.floats
+ )
+
+ g.node.extend([new_node])
+ value_info = onnx.helper.make_tensor_value_info(
+ node.name + "_input", onnx.TensorProto.FLOAT, shape
+ )
+ node.input.extend([node.name + "_input"])
+ g.value_info.extend([value_info])
+
+
+def relu6_to_clip(g):
+ for node in g.node:
+ if node.op_type != "Relu":
+ continue
+ max_val = helper.get_var_attribute_by_name(node, "max", "float")
+ if max_val is None:
+ continue
+ new_node = onnx.helper.make_node(
+ "Clip",
+ node.input,
+ node.output,
+ name=node.name,
+ max=max_val,
+ min=0.0,
+ )
+ g.node.remove(node)
+ g.node.extend([new_node])
+
+
+def PRelu_weight_reshape(g):
+ # For PRelu with single dimension weight. Expand it to 1, x, 1, 1
+ for node in g.node:
+ if node.op_type != "PRelu":
+ continue
+ slope = helper.find_node_by_output_name(g, node.input[1])
+ if slope is not None:
+ # Constant node
+ if len(slope.attribute[0].t.dims) != 1:
+ continue
+ slope.attribute[0].t.dims.append(slope.attribute[0].t.dims[0])
+ slope.attribute[0].t.dims[0] = 1
+ slope.attribute[0].t.dims.append(1)
+ slope.attribute[0].t.dims.append(1)
+ else:
+ # Initializer
+ for i in g.initializer:
+ if i.name == node.input[1]:
+ slope = i
+ break
+ if len(slope.dims) != 1:
+ continue
+ slope.dims.append(slope.dims[0])
+ slope.dims[0] = 1
+ slope.dims.append(1)
+ slope.dims.append(1)
+ input_value = helper.find_input_by_name(g, node.input[1])
+ new_input = onnx.helper.make_tensor_value_info(
+ node.input[1],
+ input_value.type.tensor_type.elem_type,
+ (1, slope.dims[1], 1, 1),
+ )
+ g.input.remove(input_value)
+ g.input.append(new_input)
+ value_info = helper.find_value_by_name(g, node.input[1])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+
+
+def do_convert(m):
+ graph = m.graph
+
+ # Modify the nodes.
+ remove_BN_spatial(graph)
+ upsample_attribute_to_const(graph)
+ relu6_to_clip(graph)
+ PRelu_weight_reshape(graph)
+ other.topological_sort(graph)
+
+ # Change model properties.
+ m.ir_version = 4
+ m.opset_import[0].version = 9
+ return m
+
+
+if __name__ == "__main__":
+ if len(sys.argv) != 3:
+ print("Usage:{} file_in file_out".format(sys.argv[0]))
+ exit(1)
+
+ model = onnx.load(sys.argv[1])
+ graph = model.graph
+
+ # Modify the nodes.
+ remove_BN_spatial(graph)
+ upsample_attribute_to_const(graph)
+ relu6_to_clip(graph)
+ PRelu_weight_reshape(graph)
+ other.topological_sort(graph)
+
+ # Change model properties.
+ model.ir_version = 4
+ model.opset_import[0].version = 9
+
+ onnx.save(model, sys.argv[2])
diff --git a/tools/optimizer_scripts/onnx1_4to1_6.py b/tools/optimizer_scripts/onnx1_4to1_6.py
new file mode 100644
index 0000000..caa5540
--- /dev/null
+++ b/tools/optimizer_scripts/onnx1_4to1_6.py
@@ -0,0 +1,211 @@
+# ref http://192.168.200.1:8088/jiyuan/converter_scripts.git
+
+import sys
+import onnx
+import onnx.utils
+from tools import other, helper, replacing
+
+"""
+Change onnx model from version 1.4 to version 1.6.
+"""
+
+
+def replace_all_attribute_to_const_node_in_pad_node(g):
+ node_to_remove = []
+ node_to_extend = []
+ for node in g.node:
+ if node.op_type != "Pad":
+ continue
+
+ pad_loc_node = None # must have
+ pad_mode = "constant"
+ pad_value_node = helper.list_to_constant(
+ node.name + "_pad_value", [], [0.0]
+ ) # need scalar
+ for att in node.attribute:
+ if att.name == "mode":
+ pad_mode = helper.get_var_attribute_by_name(
+ node, "mode", "string"
+ )
+ if att.name == "pads":
+ pad_loc_node = helper.list_to_constant(
+ node.name + "_pad_loc", [len(att.ints)], att.ints
+ )
+ if att.name == "value":
+ pad_value_node = helper.list_to_constant(
+ node.name + "_pad_value", [], [att.f]
+ )
+
+ new_node = onnx.helper.make_node(
+ "Pad",
+ [node.input[0], pad_loc_node.name, pad_value_node.name],
+ [node.output[0]],
+ name=node.output[0],
+ mode=pad_mode,
+ )
+ node_to_remove.append(node)
+ node_to_extend.append(new_node)
+ node_to_extend.append(pad_loc_node)
+ node_to_extend.append(pad_value_node)
+
+ for node in node_to_remove:
+ g.node.remove(node)
+ for node in node_to_extend:
+ g.node.extend([node])
+
+
+def upsampling_to_resize(g):
+ for node in g.node:
+ if node.op_type != "Upsample":
+ continue
+ upsampling_mode = helper.get_var_attribute_by_name(
+ node, "mode", "string"
+ )
+
+ scale_value_node = helper.find_node_by_output_name(g, node.input[1])
+ if scale_value_node.op_type != "Constant":
+ raise TypeError(
+ 'seems there is a dynamic "scales" param in Upsampling node: '
+ + node.name
+ + " , you might need to do constant folding first"
+ )
+
+ roi_node = helper.list_to_constant(node.name + "_roi_value", [0], [])
+
+ new_node = onnx.helper.make_node(
+ "Resize",
+ [node.input[0], roi_node.name, scale_value_node.name],
+ [node.output[0]],
+ name=node.output[0],
+ mode=upsampling_mode,
+ coordinate_transformation_mode="asymmetric",
+ )
+
+ g.node.remove(node)
+ g.node.extend([new_node])
+ g.node.extend([roi_node])
+
+
+def replace_all_attribute_to_const_node_in_slice_node(g):
+ for node in g.node:
+ if node.op_type != "Slice":
+ continue
+
+ axes_const_node = None
+ ends_const_node = None
+ starts_const_node = None
+ steps_const_node = None
+ for att in node.attribute:
+ if att.name == "axes":
+ axes_const_node = helper.list_to_constant(
+ node.name + "_axes_value", [len(att.ints)], att.ints
+ )
+
+ if att.name == "ends":
+ ends_const_node = helper.list_to_constant(
+ node.name + "_ends_value", [len(att.ints)], att.ints
+ )
+
+ if att.name == "starts":
+ starts_const_node = helper.list_to_constant(
+ node.name + "_starts_value", [len(att.ints)], att.ints
+ )
+
+ if att.name == "steps":
+ steps_const_node = helper.list_to_constant(
+ node.name + "_steps_value", [len(att.ints)], att.ints
+ )
+
+ # pop out from back
+ attr_len = len(node.attribute)
+ for i in range(attr_len):
+ node.attribute.remove(node.attribute[attr_len - 1 - i])
+
+ # according the spec, we need to add node in specific order
+ if starts_const_node is not None:
+ g.node.extend([starts_const_node])
+ node.input.extend([starts_const_node.name])
+ if ends_const_node is not None:
+ g.node.extend([ends_const_node])
+ node.input.extend([ends_const_node.name])
+ if axes_const_node is not None:
+ g.node.extend([axes_const_node])
+ node.input.extend([axes_const_node.name])
+ if steps_const_node is not None:
+ g.node.extend([steps_const_node])
+ node.input.extend([steps_const_node.name])
+
+
+def replace_min_max_attribute_to_const_node_in_clip_node(g):
+ for node in g.node:
+ if node.op_type != "Clip":
+ continue
+
+ max_const_node = None
+ min_const_node = None
+ for att in node.attribute:
+ if att.name == "max":
+ max_const_node = helper.list_to_constant(
+ node.name + "_max_value", [], [att.f]
+ )
+
+ if att.name == "min":
+ min_const_node = helper.list_to_constant(
+ node.name + "_min_value", [], [att.f]
+ )
+
+ # pop out from back
+ node.attribute.remove(node.attribute[1])
+ node.attribute.remove(node.attribute[0])
+
+ # according the spec, we need to add node in specific order
+ g.node.extend([min_const_node])
+ g.node.extend([max_const_node])
+ node.input.extend([min_const_node.name])
+ node.input.extend([max_const_node.name])
+
+
+def onnx1_4to1_6(model: onnx.ModelProto) -> onnx.ModelProto:
+ """Update ir_version from 4 to 6 and update opset from 9 to 11.
+
+ Args:
+ model (onnx.ModelProto): input onnx model.
+
+ Returns:
+ onnx.ModelProto: updated onnx model.
+ """
+ graph = model.graph
+
+ if model.opset_import[0].version == 11:
+ print("(Stop) the input model is already opset 11, no need to upgrade")
+ exit(1)
+
+ # deal with empty node name issue
+ other.add_name_to_node(graph)
+ # simplify the node param type from initializer to constant
+ replacing.replace_initializer_with_Constant(graph)
+
+ # Modify the nodes.
+ replace_min_max_attribute_to_const_node_in_clip_node(graph)
+ replace_all_attribute_to_const_node_in_slice_node(graph)
+ replace_all_attribute_to_const_node_in_pad_node(graph)
+ upsampling_to_resize(graph)
+ other.topological_sort(graph)
+
+ # Change model properties.
+ model.ir_version = 6
+ model.opset_import[0].version = 11
+
+ model = other.polish_model(model)
+ return model
+
+
+if __name__ == "__main__":
+ if len(sys.argv) != 3:
+ print("Usage:{} file_in file_out".format(sys.argv[0]))
+ exit(1)
+
+ model = onnx.load(sys.argv[1])
+ model = onnx1_4to1_6(model)
+
+ onnx.save(model, sys.argv[2])
diff --git a/tools/optimizer_scripts/onnx2onnx.py b/tools/optimizer_scripts/onnx2onnx.py
new file mode 100644
index 0000000..884dd2b
--- /dev/null
+++ b/tools/optimizer_scripts/onnx2onnx.py
@@ -0,0 +1,208 @@
+import onnx
+import onnx.utils
+
+import argparse
+import logging
+
+from tools import eliminating
+from tools import other
+from tools import special
+from tools import combo
+
+# from tools import temp
+
+
+def onnx2onnx_flow(
+ m: onnx.ModelProto,
+ disable_fuse_bn=False,
+ bn_on_skip=False,
+ bn_before_add=False,
+ bgr=False,
+ norm=False,
+ rgba2yynn=False,
+ eliminate_tail=False,
+ opt_matmul=False,
+ duplicate_shared_weights=True,
+) -> onnx.ModelProto:
+ """Optimize the onnx.
+
+ Args:
+ m (ModelProto): the input onnx ModelProto
+ disable_fuse_bn (bool, optional): do not fuse BN into Conv.
+ Defaults to False.
+ bn_on_skip (bool, optional): add BN operator on skip branches.
+ Defaults to False.
+ bn_before_add (bool, optional): add BN before Add node on every branch.
+ Defaults to False.
+ bgr (bool, optional): add an Conv layer to convert rgb input to bgr.
+ Defaults to False.
+ norm (bool, optional): add an Conv layer to add 0.5 tp the input.
+ Defaults to False.
+ rgba2yynn (bool, optional): add an Conv layer to convert rgb to yynn.
+ Defaults to False.
+ eliminate_tail (bool, optional): remove trailing NPU unsupported nodes.
+ Defaults to False.
+ opt_matmul(bool, optional): optimize MatMul layers due to NPU limit.
+ Defaults to False.
+ duplicate_shared_weights(bool, optional): duplicate shared weights.
+ Defaults to True.
+
+ Returns:
+ ModelProto: the optimized onnx model object.
+ """
+ # temp.weight_broadcast(m.graph)
+ m = combo.preprocess(m, disable_fuse_bn, duplicate_shared_weights)
+ # temp.fuse_bias_in_consecutive_1x1_conv(m.graph)
+
+ # Add BN on skip branch
+ if bn_on_skip:
+ other.add_bn_on_skip_branch(m.graph)
+ elif bn_before_add:
+ other.add_bn_before_add(m.graph)
+ other.add_bn_before_activation(m.graph)
+
+ # My optimization
+ m = combo.common_optimization(m)
+ # Special options
+ if bgr:
+ special.change_input_from_bgr_to_rgb(m)
+ if norm:
+ special.add_0_5_to_normalized_input(m)
+ if rgba2yynn:
+ special.add_rgb2yynn_node(m)
+
+ # Remove useless last node
+ if eliminate_tail:
+ eliminating.remove_useless_last_nodes(m.graph)
+
+ # Postprocessing
+ m = combo.postprocess(m)
+
+ # Put matmul after postprocess to avoid transpose moving downwards
+ if opt_matmul:
+ special.special_MatMul_process(m.graph)
+ m = other.polish_model(m)
+
+ return m
+
+
+# Main process
+if __name__ == "__main__":
+ # Argument parser
+ parser = argparse.ArgumentParser(
+ description="Optimize an ONNX model for Kneron compiler"
+ )
+ parser.add_argument("in_file", help="input ONNX FILE")
+ parser.add_argument(
+ "-o", "--output", dest="out_file", type=str, help="ouput ONNX FILE"
+ )
+ parser.add_argument("--log", default="i", type=str, help="set log level")
+ parser.add_argument(
+ "--bgr",
+ action="store_true",
+ default=False,
+ help="set if the model is trained in BGR mode",
+ )
+ parser.add_argument(
+ "--norm",
+ action="store_true",
+ default=False,
+ help="set if you have the input -0.5~0.5",
+ )
+ parser.add_argument(
+ "--rgba2yynn",
+ action="store_true",
+ default=False,
+ help="set if the model has yynn input but you want "
+ "to take rgba images",
+ )
+ parser.add_argument(
+ "--add-bn-on-skip",
+ dest="bn_on_skip",
+ action="store_true",
+ default=False,
+ help="set if you only want to add BN on skip branches",
+ )
+ parser.add_argument(
+ "--add-bn",
+ dest="bn_before_add",
+ action="store_true",
+ default=False,
+ help="set if you want to add BN before Add",
+ )
+ parser.add_argument(
+ "-t",
+ "--eliminate-tail-unsupported",
+ dest="eliminate_tail",
+ action="store_true",
+ default=False,
+ help="whether remove the last unsupported node for hardware",
+ )
+ parser.add_argument(
+ "--no-bn-fusion",
+ dest="disable_fuse_bn",
+ action="store_true",
+ default=False,
+ help="set if you have met errors which related to inferenced "
+ "shape mismatch. This option will prevent fusing "
+ "BatchNormalization into Conv.",
+ )
+ parser.add_argument(
+ "--opt-matmul",
+ dest="opt_matmul",
+ action="store_true",
+ default=False,
+ help="set if you want to optimize MatMul operations "
+ "for kneron hardware.",
+ )
+ parser.add_argument(
+ "--no-duplicate-shared-weights",
+ dest="no_duplicate_shared_weights",
+ action="store_true",
+ default=False,
+ help="do not duplicate shared weights. Defaults to False.",
+ )
+ args = parser.parse_args()
+
+ if args.out_file is None:
+ outfile = args.in_file[:-5] + "_polished.onnx"
+ else:
+ outfile = args.out_file
+
+ if args.log == "w":
+ logging.basicConfig(level=logging.WARN)
+ elif args.log == "d":
+ logging.basicConfig(level=logging.DEBUG)
+ elif args.log == "e":
+ logging.basicConfig(level=logging.ERROR)
+ else:
+ logging.basicConfig(level=logging.INFO)
+
+ # onnx Polish model includes:
+ # -- nop
+ # -- eliminate_identity
+ # -- eliminate_nop_transpose
+ # -- eliminate_nop_pad
+ # -- eliminate_unused_initializer
+ # -- fuse_consecutive_squeezes
+ # -- fuse_consecutive_transposes
+ # -- fuse_add_bias_into_conv
+ # -- fuse_transpose_into_gemm
+
+ # Basic model organize
+ m = onnx.load(args.in_file)
+
+ m = onnx2onnx_flow(
+ m,
+ args.disable_fuse_bn,
+ args.bn_on_skip,
+ args.bn_before_add,
+ args.bgr,
+ args.norm,
+ args.rgba2yynn,
+ args.eliminate_tail,
+ args.opt_matmul,
+ not args.no_duplicate_shared_weights,
+ )
+
+ onnx.save(m, outfile)
diff --git a/tools/optimizer_scripts/onnx_vs_onnx.py b/tools/optimizer_scripts/onnx_vs_onnx.py
new file mode 100644
index 0000000..d416045
--- /dev/null
+++ b/tools/optimizer_scripts/onnx_vs_onnx.py
@@ -0,0 +1,181 @@
+import onnxruntime
+import onnx
+import argparse
+import numpy as np
+from tools import helper
+
+
+onnx2np_dtype = {
+ 0: "float",
+ 1: "float32",
+ 2: "uint8",
+ 3: "int8",
+ 4: "uint16",
+ 5: "int16",
+ 6: "int32",
+ 7: "int64",
+ 8: "str",
+ 9: "bool",
+ 10: "float16",
+ 11: "double",
+ 12: "uint32",
+ 13: "uint64",
+ 14: "complex64",
+ 15: "complex128",
+ 16: "float",
+}
+
+
+def onnx_model_results(path_a, path_b, total_times=10):
+ """using onnxruntime to inference two onnx models' ouputs
+
+ :onnx model paths: two model paths
+ :total_times: inference times, default to be 10
+ :returns: inference results of two models
+ """
+ # load model a and model b to runtime
+ session_a = onnxruntime.InferenceSession(path_a, None)
+ session_b = onnxruntime.InferenceSession(path_b, None)
+ outputs_a = session_a.get_outputs()
+ outputs_b = session_b.get_outputs()
+
+ # check outputs
+ assert len(outputs_a) == len(
+ outputs_b
+ ), "Two models have different output numbers."
+ for i in range(len(outputs_a)):
+ out_shape_a, out_shape_b = outputs_a[i].shape, outputs_b[i].shape
+ out_shape_a = list(
+ map(lambda x: x if isinstance(x, int) else 1, out_shape_a)
+ )
+ out_shape_b = list(
+ map(lambda x: x if isinstance(x, int) else 1, out_shape_b)
+ )
+ assert (
+ out_shape_a == out_shape_b
+ ), "Output {} has unmatched shapes".format(i)
+
+ # load onnx graph_a and graph_b, to find the initializer and inputs
+ # then compare to remove the items in the inputs which will be initialized
+ model_a, model_b = onnx.load(path_a), onnx.load(path_b)
+ graph_a, graph_b = model_a.graph, model_b.graph
+ inputs_a, inputs_b = graph_a.input, graph_b.input
+ init_a, init_b = graph_a.initializer, graph_b.initializer
+
+ # remove initializer from raw inputs
+ input_names_a, input_names_b = set([ele.name for ele in inputs_a]), set(
+ [ele.name for ele in inputs_b]
+ )
+ init_names_a, init_names_b = set([ele.name for ele in init_a]), set(
+ [ele.name for ele in init_b]
+ )
+ real_inputs_names_a, real_inputs_names_b = (
+ input_names_a - init_names_a,
+ input_names_b - init_names_b,
+ )
+
+ # prepare and figure out matching of real inputs a and real inputs b
+ # try to keep original orders of each inputs
+ real_inputs_a, real_inputs_b = [], []
+ for item in inputs_a:
+ if item.name in real_inputs_names_a:
+ real_inputs_a.append(item)
+ for item in inputs_b:
+ if item.name in real_inputs_names_b:
+ real_inputs_b.append(item)
+
+ # suppose there's only one real single input tensor for each model
+ # find the real single inputs for model_a and model_b
+ real_single_input_a = None
+ real_single_input_b = None
+ size_a, size_b = 0, 0
+ shape_a, shape_b = [], []
+ for item_a in real_inputs_a:
+ size, shape = helper.find_size_shape_from_value(item_a)
+ if size:
+ assert (
+ real_single_input_a is None
+ ), "Multiple inputs of first model, single input expected."
+ real_single_input_a = item_a
+ size_a, shape_a = size, shape
+ for item_b in real_inputs_b:
+ size, shape = helper.find_size_shape_from_value(item_b)
+ if size:
+ assert (
+ real_single_input_b is None
+ ), "Multiple inputs of second model, single input expected."
+ real_single_input_b = item_b
+ size_b, shape_b = size, shape
+ assert size_a == size_b, "Sizes of two models do not match."
+
+ # construct inputs tensors
+ input_data_type_a = real_single_input_a.type.tensor_type.elem_type
+ input_data_type_b = real_single_input_b.type.tensor_type.elem_type
+ input_data_type_a = onnx2np_dtype[input_data_type_a]
+ input_data_type_b = onnx2np_dtype[input_data_type_b]
+
+ # run inference
+ times = 0
+ results_a = [[] for i in range(len(outputs_a))]
+ results_b = [[] for i in range(len(outputs_b))]
+ while times < total_times:
+ # initialize inputs by random data, default to be uniform
+ data = np.random.random(size_a)
+ input_a = np.reshape(data, shape_a).astype(input_data_type_a)
+ input_b = np.reshape(data, shape_b).astype(input_data_type_b)
+
+ input_dict_a = {}
+ input_dict_b = {}
+ for item_a in real_inputs_a:
+ item_type_a = onnx2np_dtype[item_a.type.tensor_type.elem_type]
+ input_dict_a[item_a.name] = (
+ np.array([]).astype(item_type_a)
+ if item_a.name != real_single_input_a.name
+ else input_a
+ )
+ for item_b in real_inputs_b:
+ item_type_b = onnx2np_dtype[item_b.type.tensor_type.elem_type]
+ input_dict_b[item_b.name] = (
+ np.array([]).astype(item_type_b)
+ if item_b.name != real_single_input_b.name
+ else input_b
+ )
+
+ ra = session_a.run([], input_dict_a)
+ rb = session_b.run([], input_dict_b)
+ for i in range(len(outputs_a)):
+ results_a[i].append(ra[i])
+ results_b[i].append(rb[i])
+ times += 1
+
+ return results_a, results_b
+
+
+if __name__ == "__main__":
+ # Argument parser.
+ parser = argparse.ArgumentParser(
+ description="Compare two ONNX models to check if "
+ "they have the same output."
+ )
+ parser.add_argument("in_file_a", help="input ONNX file a")
+ parser.add_argument("in_file_b", help="input ONNX file b")
+
+ args = parser.parse_args()
+
+ results_a, results_b = onnx_model_results(
+ args.in_file_a, args.in_file_b, total_times=10
+ )
+ ra_flat = helper.flatten_with_depth(results_a, 0)
+ rb_flat = helper.flatten_with_depth(results_b, 0)
+ shape_a = [item[1] for item in ra_flat]
+ shape_b = [item[1] for item in rb_flat]
+ assert shape_a == shape_b, "two results data shape doesn't match"
+ ra_raw = [item[0] for item in ra_flat]
+ rb_raw = [item[0] for item in rb_flat]
+
+ try:
+ np.testing.assert_almost_equal(ra_raw, rb_raw, 4)
+ print("Two models have the same behaviour.")
+ except Exception as mismatch:
+ print(mismatch)
+ exit(1)
diff --git a/tools/optimizer_scripts/onnx_vs_onnx_opt.py b/tools/optimizer_scripts/onnx_vs_onnx_opt.py
new file mode 100644
index 0000000..5ac4e6b
--- /dev/null
+++ b/tools/optimizer_scripts/onnx_vs_onnx_opt.py
@@ -0,0 +1,248 @@
+import argparse
+import glob
+import csv
+import numpy as np
+import matplotlib.pyplot as plt
+
+from tools import helper
+import onnx_vs_onnx as onnx_tester
+
+
+def compare_results(results_a, results_b):
+ """compare onnx model inference results
+ calculate basic statistical values
+ results: results from inference multiple times
+ returns: list of basic statistical values
+ """
+ # input results data can be of nonuniform shape
+ # get flatten data to compare
+ ra_flat = helper.flatten_with_depth(results_a, 0)
+ rb_flat = helper.flatten_with_depth(results_b, 0)
+ shape_a = [item[1] for item in ra_flat]
+ shape_b = [item[1] for item in rb_flat]
+ assert shape_a == shape_b, "two results data shape doesn't match"
+ ra_raw = [item[0] for item in ra_flat]
+ rb_raw = [item[0] for item in rb_flat]
+
+ # the statistical values
+ max_rel_diff = (
+ 0 # defined to be max( { abs(diff)/max(abs(ra), abs(rb) ) } )
+ )
+ max_abs_diff = 0 # defined to be max( { abs(ra-rb) } )
+ mean_rel_diff = 0
+ mean_abs_diff = 0
+ std_rel_diff = 0
+ std_abs_diff = 0
+ acc_with_diff_precision = []
+ rel_diff = []
+ abs_diff_percentiles = [] # rel_diff percentiles
+ rel_diff_percentiles = [] # abs_diff precentiles
+
+ raw_diff = [ra_raw[i] - rb_raw[i] for i in range(len(ra_raw))]
+ abs_diff = [abs(num) for num in raw_diff]
+ for i in range(len(ra_raw)):
+ divider = max([abs(ra_raw[i]), abs(rb_raw[i])])
+ val = abs_diff[i] / divider if divider != 0 else 0
+ rel_diff.append(val)
+
+ max_rel_diff = max(rel_diff)
+ max_abs_diff = max(abs_diff)
+ mean_rel_diff = np.average(rel_diff)
+ mean_abs_diff = np.average(abs_diff)
+ std_rel_diff = np.std(rel_diff)
+ std_abs_diff = np.std(abs_diff)
+
+ # calculate accuracy with different precison
+ for digit in range(8):
+ correct = 0
+ for i in range(len(ra_raw)):
+ if format(ra_raw[i], "." + str(digit) + "f") == format(
+ rb_raw[i], "." + str(digit) + "f"
+ ):
+ correct += 1
+ acc_with_diff_precision.append(
+ [digit, float(format(correct / len(ra_raw), ".3f"))]
+ )
+
+ # analyze rel_diff distribution
+ rel_diff.sort()
+ abs_diff.sort()
+ for i in range(20):
+ rel_diff_percentiles.append(
+ ["{}%".format(i * 5), rel_diff[int((i / 20) * len(rel_diff))]]
+ )
+ abs_diff_percentiles.append(
+ ["{}%".format(i * 5), abs_diff[int((i / 20) * len(abs_diff))]]
+ )
+
+ results = [
+ ["max_rel_diff", max_rel_diff],
+ ["max_abs_diff", max_abs_diff],
+ ["mean_rel_diff", mean_rel_diff],
+ ["mean_abs_diff", mean_abs_diff],
+ ["std_rel_diff", std_rel_diff],
+ ["std_abs_diff", std_abs_diff],
+ ["acc_with_diff_precision", acc_with_diff_precision],
+ ["rel_diff_percentiles", rel_diff_percentiles],
+ ["abs_diff_percentiles", abs_diff_percentiles],
+ ]
+
+ return results
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ description="test model optimization results"
+ )
+
+ parser.add_argument(
+ "dir", type=str, help="the directory that stores onnx models"
+ )
+ parser.add_argument(
+ "ending1", type=str, help="model file name ending(eg, .onnx)"
+ )
+ parser.add_argument(
+ "ending2", type=str, help="opt model file name ending(eg. _opt.onnx)"
+ )
+ parser.add_argument("out_file", type=str, help="output csv file name")
+ parser.add_argument("-p", "--plot", default="N", help="get plots (Y/N)")
+ parser.add_argument(
+ "-i", "--iter_times", default=10, type=int, help="inference times"
+ )
+
+ args = parser.parse_args()
+
+ old_models_paths = glob.glob(args.dir + "*" + args.ending1)
+ new_models_paths = glob.glob(args.dir + "*" + args.ending2)
+
+ stats_table = [
+ [
+ "Model",
+ "max_rel_diff",
+ "max_abs_diff",
+ "mean_rel_diff",
+ "mean_abs_diff",
+ "std_rel_diff",
+ "std_abs_diff",
+ "acc_with_diff_precision",
+ "rel_diff_percentiles",
+ "abs_diff_percentiles",
+ ]
+ ]
+
+ for new_model_path in new_models_paths:
+ old_model_path = new_model_path[: -len(args.ending2)] + args.ending1
+ if old_model_path not in old_models_paths:
+ continue
+
+ # run inference
+ results_a, results_b = onnx_tester.onnx_model_results(
+ old_model_path, new_model_path, total_times=args.iter_times
+ )
+
+ # compare inference results
+ comparision = compare_results(results_a, results_b)
+
+ new_line = [old_model_path.split("/")[-1]]
+ for item in comparision:
+ new_line.append(item[1])
+
+ stats_table.append(new_line)
+
+ # try to read existing file
+ old_stats_table = []
+ try:
+ old_file = open(args.out_file, "r")
+ reader = csv.reader(old_file)
+ old_header = reader.__next__()
+ for row in reader:
+ old_stats_table.append(row)
+ old_file.close()
+ except Exception:
+ pass
+
+ # compare and merge possible old stat data file with new stat data file
+ header = stats_table[0]
+ stats_table = stats_table[1:]
+ new_model_names = set([item[0] for item in stats_table])
+ for row in old_stats_table:
+ if row[0] not in new_model_names:
+ stats_table.append(row)
+ stats_table.insert(0, header)
+
+ # write a new stat data file, overwrite old file
+ new_file = open(args.out_file, "w", newline="")
+ writer = csv.writer(new_file)
+ for row in stats_table:
+ writer.writerow(row)
+ new_file.close()
+
+ # make some plots
+ if args.plot == "Y":
+ if len(stats_table) < 2:
+ exit(0)
+
+ sample_table = (
+ stats_table[1:] if len(stats_table) < 6 else stats_table[1:6]
+ )
+
+ max_rel_diffs = [round(float(item[1]), 2) for item in stats_table[1:]]
+ plt.hist(max_rel_diffs, bins=15)
+ plt.title("Max Relavtive Difference Histogram")
+ plt.xlabel("Max Relative Difference")
+ plt.ylabel("Counts")
+ plt.savefig("max_rel_diff_hist.png")
+ plt.close()
+
+ max_abs_diffs = [round(float(item[2]), 2) for item in stats_table[1:]]
+ plt.hist(max_abs_diffs, bins=15)
+ plt.title("Max Absolute Difference Histogram")
+ plt.xlabel("Max Absolute Difference")
+ plt.ylabel("Counts")
+ plt.savefig("max_abs_diff_hist.png")
+ plt.close()
+
+ for line in sample_table:
+ model_name = line[0]
+ percentiles = line[-2]
+ x = [
+ round(i * (1 / len(percentiles)), 2)
+ for i in range(len(percentiles))
+ ]
+ y = [ele[1] for ele in percentiles]
+ plt.plot(x, y, label=model_name)
+ plt.title("Rel_diff Percentiles of Raw and Optimized Models")
+ plt.xlabel("percentage")
+ plt.ylabel("relative difference")
+ plt.legend()
+ plt.savefig("rel_diff_percentiles.png")
+ plt.close()
+
+ for line in sample_table:
+ model_name = line[0]
+ percentiles = line[-1]
+ x = [
+ round(i * (1 / len(percentiles)), 2)
+ for i in range(len(percentiles))
+ ]
+ y = [ele[1] for ele in percentiles]
+ plt.plot(x, y, label=model_name)
+ plt.title("Abs_diff Percentiles of Raw and Optimized Models")
+ plt.xlabel("percentage")
+ plt.ylabel("absolute difference")
+ plt.legend()
+ plt.savefig("abs_diff_percentiles.png")
+ plt.close()
+
+ for line in sample_table:
+ model_name = line[0]
+ accuracies = line[-3]
+ x = [acc[0] for acc in accuracies]
+ y = [acc[1] for acc in accuracies]
+ plt.plot(x, y, label=model_name)
+ plt.title("Accuracies with Different Precisions")
+ plt.xlabel("Decimals")
+ plt.ylabel("Precision")
+ plt.legend()
+ plt.savefig("precisions.png")
+ plt.close()
diff --git a/tools/optimizer_scripts/pytorch2onnx.py b/tools/optimizer_scripts/pytorch2onnx.py
new file mode 100644
index 0000000..9dd79ec
--- /dev/null
+++ b/tools/optimizer_scripts/pytorch2onnx.py
@@ -0,0 +1,93 @@
+import onnx
+import onnx.utils
+
+import sys
+import logging
+import argparse
+
+from pytorch_exported_onnx_preprocess import torch_exported_onnx_flow
+
+# Debug use
+# logging.basicConfig(level=logging.DEBUG)
+
+######################################
+# Generate a prototype onnx #
+######################################
+
+parser = argparse.ArgumentParser(
+ description="Optimize a Pytorch generated model for Kneron compiler"
+)
+parser.add_argument("in_file", help="input ONNX or PTH FILE")
+parser.add_argument("out_file", help="ouput ONNX FILE")
+parser.add_argument(
+ "--input-size",
+ dest="input_size",
+ nargs=3,
+ help="if you using pth, please use this argument to set up the input "
+ "size of the model. It should be in 'CH H W' format, "
+ "e.g. '--input-size 3 256 512'.",
+)
+parser.add_argument(
+ "--no-bn-fusion",
+ dest="disable_fuse_bn",
+ action="store_true",
+ default=False,
+ help="set if you have met errors which related to inferenced shape "
+ "mismatch. This option will prevent fusing BatchNormalization "
+ "into Conv.",
+)
+
+args = parser.parse_args()
+
+if len(args.in_file) <= 4:
+ # When the filename is too short.
+ logging.error("Invalid input file: {}".format(args.in_file))
+ exit(1)
+elif args.in_file[-4:] == ".pth":
+ # Pytorch pth case
+ logging.warning("Converting from pth to onnx is not recommended.")
+ onnx_in = args.out_file
+ # Import pytorch libraries
+ from torch.autograd import Variable
+ import torch
+ import torch.onnx
+
+ # import torchvision
+ # Standard ImageNet input - 3 channels, 224x224.
+ # Values don't matter as we care about network structure.
+ # But they can also be real inputs.
+ if args.input_size is None:
+ logging.error("'--input-size' is required for the pth input file.")
+ exit(1)
+ dummy_input = Variable(
+ torch.randn(
+ 1,
+ int(args.input_size[0]),
+ int(args.input_size[1]),
+ int(args.input_size[2]),
+ )
+ )
+ # Obtain your model, it can be also constructed in your script explicitly.
+ model = torch.load(sys.argv[1], map_location="cpu")
+ # model = torchvision.models.resnet34(pretrained=True)
+ # Invoke export.
+ # torch.save(model, "resnet34.pth")
+ torch.onnx.export(model, dummy_input, args.out_file, opset_version=11)
+elif args.in_file[-4:] == "onnx":
+ onnx_in = args.in_file
+else:
+ # When the file is neither an onnx or a pytorch pth.
+ logging.error("Invalid input file: {}".format(args.in_file))
+ exit(1)
+
+onnx_out = args.out_file
+
+######################################
+# Optimize onnx #
+######################################
+
+m = onnx.load(onnx_in)
+
+m = torch_exported_onnx_flow(m, args.disable_fuse_bn)
+
+onnx.save(m, onnx_out)
diff --git a/tools/optimizer_scripts/pytorch_exported_onnx_preprocess.py b/tools/optimizer_scripts/pytorch_exported_onnx_preprocess.py
new file mode 100644
index 0000000..356f0e3
--- /dev/null
+++ b/tools/optimizer_scripts/pytorch_exported_onnx_preprocess.py
@@ -0,0 +1,82 @@
+import onnx
+import onnx.utils
+
+import logging
+import argparse
+
+from .tools import combo
+
+
+# Define general pytorch exported onnx optimize process
+def torch_exported_onnx_flow(
+ m: onnx.ModelProto, disable_fuse_bn=False
+) -> onnx.ModelProto:
+ """Optimize the Pytorch exported onnx.
+
+ Args:
+ m (ModelProto): the input onnx model
+ disable_fuse_bn (bool, optional): do not fuse BN into Conv.
+ Defaults to False.
+
+ Returns:
+ ModelProto: the optimized onnx model
+ """
+ m = combo.preprocess(m, disable_fuse_bn)
+ m = combo.pytorch_constant_folding(m)
+ m = combo.common_optimization(m)
+ m = combo.postprocess(m)
+
+ return m
+
+
+# Main Process
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ description="Optimize a Pytorch generated model for Kneron compiler"
+ )
+ parser.add_argument("in_file", help="input ONNX")
+ parser.add_argument("out_file", help="ouput ONNX FILE")
+ parser.add_argument("--log", default="i", type=str, help="set log level")
+ parser.add_argument(
+ "--no-bn-fusion",
+ dest="disable_fuse_bn",
+ action="store_true",
+ default=False,
+ help="set if you have met errors which related to inferenced shape "
+ "mismatch. This option will prevent fusing BatchNormalization "
+ "into Conv.",
+ )
+
+ args = parser.parse_args()
+
+ if args.log == "w":
+ logging.basicConfig(level=logging.WARN)
+ elif args.log == "d":
+ logging.basicConfig(level=logging.DEBUG)
+ elif args.log == "e":
+ logging.basicConfig(level=logging.ERROR)
+ else:
+ logging.basicConfig(level=logging.INFO)
+
+ if len(args.in_file) <= 4:
+ # When the filename is too short.
+ logging.error("Invalid input file: {}".format(args.in_file))
+ exit(1)
+ elif args.in_file[-4:] == "onnx":
+ onnx_in = args.in_file
+ else:
+ # When the file is not an onnx file.
+ logging.error("Invalid input file: {}".format(args.in_file))
+ exit(1)
+
+ onnx_out = args.out_file
+
+ ######################################
+ # Optimize onnx #
+ ######################################
+
+ m = onnx.load(onnx_in)
+
+ m = torch_exported_onnx_flow(m, args.disable_fuse_bn)
+
+ onnx.save(m, onnx_out)
diff --git a/tools/optimizer_scripts/res/first_insert_layer.json b/tools/optimizer_scripts/res/first_insert_layer.json
new file mode 100644
index 0000000..4fe3f59
--- /dev/null
+++ b/tools/optimizer_scripts/res/first_insert_layer.json
@@ -0,0 +1,27 @@
+{
+ "LAYERNAME" :
+ {
+ "bias_bitwidth" : 16,
+ "LAYERNAME_bias" : [15],
+ "LAYERNAME_weight" : [3,3,3],
+ "conv_coarse_shift" : [-4,-4,-4],
+ "conv_fine_shift" : [0,0,0],
+ "conv_total_shift" : [-4,-4,-4],
+ "cpu_mode" : false,
+ "delta_input_bitwidth" : [0],
+ "delta_output_bitwidth" : 8,
+ "flag_radix_bias_eq_output" : true,
+ "input_scale" : [[1.0,1.0,1.0]],
+ "output_scale" : [1.0, 1.0, 1.0],
+ "psum_bitwidth" : 16,
+ "weight_bitwidth" : 8,
+ "input_datapath_bitwidth" : [8],
+ "input_datapath_radix" : [7],
+ "working_input_bitwidth" : 8,
+ "working_input_radix" : [7],
+ "working_output_bitwidth" : 16,
+ "working_output_radix" : 15,
+ "output_datapath_bitwidth" : 8,
+ "output_datapath_radix" : 7
+ }
+}
diff --git a/tools/optimizer_scripts/res/test_onnx_tester_on_difference.sh b/tools/optimizer_scripts/res/test_onnx_tester_on_difference.sh
new file mode 100644
index 0000000..342b198
--- /dev/null
+++ b/tools/optimizer_scripts/res/test_onnx_tester_on_difference.sh
@@ -0,0 +1,9 @@
+#!/bin/bash
+
+python onnx_tester.py /test_models/mobilenet_v2_224.onnx /test_models/mobilenet_v2_224.cut.onnx
+if [ $? -eq 0 ]; then
+ echo "Those two model results should be different!"
+ exit 1
+fi
+
+exit 0
diff --git a/tools/optimizer_scripts/res/vdsr_41_20layer_1.pb b/tools/optimizer_scripts/res/vdsr_41_20layer_1.pb
new file mode 100644
index 0000000..81096de
Binary files /dev/null and b/tools/optimizer_scripts/res/vdsr_41_20layer_1.pb differ
diff --git a/tools/optimizer_scripts/tensorflow2onnx.py b/tools/optimizer_scripts/tensorflow2onnx.py
new file mode 100644
index 0000000..44b8667
--- /dev/null
+++ b/tools/optimizer_scripts/tensorflow2onnx.py
@@ -0,0 +1,180 @@
+import tensorflow as tf
+import tf2onnx
+import argparse
+import logging
+import sys
+import onnx
+import onnx.utils
+from tensorflow.python.platform import gfile
+from tools import combo, eliminating, replacing, other
+
+
+def tf2onnx_flow(pb_path: str, test_mode=False) -> onnx.ModelProto:
+ """Convert frozen graph pb file into onnx
+
+ Args:
+ pb_path (str): input pb file path
+ test_mode (bool, optional): test mode. Defaults to False.
+
+ Raises:
+ Exception: invalid input file
+
+ Returns:
+ onnx.ModelProto: converted onnx
+ """
+ TF2ONNX_VERSION = int(tf2onnx.version.version.replace(".", ""))
+
+ if 160 <= TF2ONNX_VERSION:
+ from tf2onnx import tf_loader
+ else:
+ from tf2onnx import loader as tf_loader
+
+ if pb_path[-3:] == ".pb":
+ model_name = pb_path.split("/")[-1][:-3]
+
+ # always reset tensorflow session at begin
+ tf.reset_default_graph()
+
+ with tf.Session() as sess:
+ with gfile.FastGFile(pb_path, "rb") as f:
+ graph_def = tf.GraphDef()
+ graph_def.ParseFromString(f.read())
+ sess.graph.as_default()
+ tf.import_graph_def(graph_def, name="")
+
+ if 160 <= int(tf2onnx.version.version.replace(".", "")):
+ (
+ onnx_nodes,
+ op_cnt,
+ attr_cnt,
+ output_shapes,
+ dtypes,
+ functions,
+ ) = tf2onnx.tf_utils.tflist_to_onnx(sess.graph, {})
+ else:
+ (
+ onnx_nodes,
+ op_cnt,
+ attr_cnt,
+ output_shapes,
+ dtypes,
+ ) = tf2onnx.tfonnx.tflist_to_onnx(
+ sess.graph.get_operations(), {}
+ )
+
+ for n in onnx_nodes:
+ if len(n.output) == 0:
+ onnx_nodes.remove(n)
+
+ # find inputs and outputs of graph
+ nodes_inputs = set()
+ nodes_outputs = set()
+
+ for n in onnx_nodes:
+ if n.op_type == "Placeholder":
+ continue
+ for input in n.input:
+ nodes_inputs.add(input)
+ for output in n.output:
+ nodes_outputs.add(output)
+
+ graph_input_names = set()
+ for input_name in nodes_inputs:
+ if input_name not in nodes_outputs:
+ graph_input_names.add(input_name)
+
+ graph_output_names = set()
+ for n in onnx_nodes:
+ if n.input and n.input[0] not in nodes_outputs:
+ continue
+ if len(n.output) == 0:
+ n.output.append(n.name + ":0")
+ graph_output_names.add(n.output[0])
+ else:
+ output_name = n.output[0]
+ if (output_name not in nodes_inputs) and (
+ 0 < len(n.input)
+ ):
+ graph_output_names.add(output_name)
+
+ logging.info("Model Inputs: %s", str(list(graph_input_names)))
+ logging.info("Model Outputs: %s", str(list(graph_output_names)))
+
+ graph_def, inputs, outputs = tf_loader.from_graphdef(
+ model_path=pb_path,
+ input_names=list(graph_input_names),
+ output_names=list(graph_output_names),
+ )
+
+ with tf.Graph().as_default() as tf_graph:
+ tf.import_graph_def(graph_def, name="")
+
+ if 160 <= TF2ONNX_VERSION:
+ with tf_loader.tf_session(graph=tf_graph):
+ onnx_graph = tf2onnx.tfonnx.process_tf_graph(
+ tf_graph=tf_graph,
+ input_names=inputs,
+ output_names=outputs,
+ opset=11,
+ )
+ else:
+ with tf.Session(graph=tf_graph):
+ onnx_graph = tf2onnx.tfonnx.process_tf_graph(
+ tf_graph=tf_graph,
+ input_names=inputs,
+ output_names=outputs,
+ opset=11,
+ )
+
+ # Optimize with tf2onnx.optimizer
+ onnx_graph = tf2onnx.optimizer.optimize_graph(onnx_graph)
+ model_proto = onnx_graph.make_model(model_name)
+
+ # Make tf2onnx output compatible with the spec. of other.polish_model
+ replacing.replace_initializer_with_Constant(model_proto.graph)
+ model_proto = other.polish_model(model_proto)
+
+ else:
+ raise Exception(
+ 'expect .pb file as input, but got "' + str(pb_path) + '"'
+ )
+
+ # rename
+ m = model_proto
+
+ m = combo.preprocess(m)
+ m = combo.common_optimization(m)
+ m = combo.tensorflow_optimization(m)
+ m = combo.postprocess(m)
+
+ if not test_mode:
+ g = m.graph
+ eliminating.eliminate_shape_changing_after_input(g)
+
+ m = other.polish_model(m)
+ return m
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ description="Convert tensorflow pb file to onnx file and optimized "
+ "onnx file. Or just optimize tensorflow onnx file."
+ )
+ parser.add_argument("in_file", help="input file")
+ parser.add_argument("out_file", help="output optimized model file")
+ parser.add_argument(
+ "-t",
+ "--test_mode",
+ default=False,
+ help="test mode will not eliminate shape changes after input",
+ )
+
+ args = parser.parse_args()
+ logging.basicConfig(
+ stream=sys.stdout,
+ format="[%(asctime)s] %(levelname)s: %(message)s",
+ level=logging.INFO,
+ )
+ m = tf2onnx_flow(args.in_file, args.test_mode)
+ onnx.save(m, args.out_file)
+ logging.info("Save Optimized ONNX: %s", args.out_file)
diff --git a/tools/optimizer_scripts/tflite_vs_onnx.py b/tools/optimizer_scripts/tflite_vs_onnx.py
new file mode 100644
index 0000000..e8405cf
--- /dev/null
+++ b/tools/optimizer_scripts/tflite_vs_onnx.py
@@ -0,0 +1,85 @@
+import argparse
+import numpy as np
+import tensorflow as tf
+import onnx
+import onnxruntime
+
+from tools import helper
+
+
+def compare_tflite_and_onnx(tflite_file, onnx_file, total_times=10):
+ # Setup onnx session and get meta data
+ onnx_session = onnxruntime.InferenceSession(onnx_file, None)
+ onnx_outputs = onnx_session.get_outputs()
+ assert len(onnx_outputs) == 1, "The onnx model has more than one output"
+ onnx_model = onnx.load(onnx_file)
+ onnx_graph = onnx_model.graph
+ onnx_inputs = onnx_graph.input
+ assert len(onnx_inputs) == 1, "The onnx model has more than one input"
+ _, onnx_input_shape = helper.find_size_shape_from_value(onnx_inputs[0])
+ # Setup TFLite sessio and get meta data
+ tflite_session = tf.lite.Interpreter(model_path=tflite_file)
+ tflite_session.allocate_tensors()
+ tflite_inputs = tflite_session.get_input_details()
+ tflite_outputs = tflite_session.get_output_details()
+ tflite_input_shape = tflite_inputs[0]["shape"]
+ # Compare input shape
+ assert len(onnx_input_shape) == len(
+ tflite_input_shape
+ ), "TFLite and ONNX shape unmatch."
+ assert onnx_input_shape == [
+ tflite_input_shape[0],
+ tflite_input_shape[3],
+ tflite_input_shape[1],
+ tflite_input_shape[2],
+ ], "TFLite and ONNX shape unmatch."
+ # Generate random number and run
+ tflite_results = []
+ onnx_results = []
+ for _ in range(total_times):
+ # Generate input
+ tflite_input_data = np.array(
+ np.random.random_sample(tflite_input_shape), dtype=np.float32
+ )
+ onnx_input_data = np.transpose(tflite_input_data, [0, 3, 1, 2])
+ # Run tflite
+ tflite_session.set_tensor(tflite_inputs[0]["index"], tflite_input_data)
+ tflite_session.invoke()
+ tflite_results.append(
+ tflite_session.get_tensor(tflite_outputs[0]["index"])
+ )
+ # Run onnx
+ onnx_input_dict = {onnx_inputs[0].name: onnx_input_data}
+ onnx_results.append(onnx_session.run([], onnx_input_dict)[0])
+
+ return tflite_results, onnx_results
+
+
+if __name__ == "__main__":
+ # Argument parser.
+ parser = argparse.ArgumentParser(
+ description="Compare a TFLite model and an ONNX model to check "
+ "if they have the same output."
+ )
+ parser.add_argument("tflite_file", help="input tflite file")
+ parser.add_argument("onnx_file", help="input ONNX file")
+
+ args = parser.parse_args()
+
+ results_a, results_b = compare_tflite_and_onnx(
+ args.tflite_file, args.onnx_file, total_times=10
+ )
+ ra_flat = helper.flatten_with_depth(results_a, 0)
+ rb_flat = helper.flatten_with_depth(results_b, 0)
+ shape_a = [item[1] for item in ra_flat]
+ shape_b = [item[1] for item in rb_flat]
+ assert shape_a == shape_b, "two results data shape doesn't match"
+ ra_raw = [item[0] for item in ra_flat]
+ rb_raw = [item[0] for item in rb_flat]
+
+ try:
+ np.testing.assert_almost_equal(ra_raw, rb_raw, 8)
+ print("Two models have the same behaviour.")
+ except Exception as mismatch:
+ print(mismatch)
+ exit(1)
diff --git a/tools/optimizer_scripts/tools/__init__.py b/tools/optimizer_scripts/tools/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/tools/optimizer_scripts/tools/combo.py b/tools/optimizer_scripts/tools/combo.py
new file mode 100644
index 0000000..1a20ebb
--- /dev/null
+++ b/tools/optimizer_scripts/tools/combo.py
@@ -0,0 +1,267 @@
+"""Combo functions that are usually called together.
+"""
+
+import logging
+
+try:
+ from onnx import optimizer
+except ImportError:
+ import onnxoptimizer as optimizer
+
+from . import helper
+from . import other
+from . import replacing
+from . import eliminating
+from . import fusing
+from . import constant_folding
+from . import removing_transpose
+from .common_pattern import torch_pattern_match, tf_pattern_match
+from .helper import logger
+
+
+def preprocess(
+ model_proto, disable_fuse_bn=False, duplicate_shared_weights=True
+):
+ """The most common used functions before other processing.
+
+ Args:
+ model_proto: the original model input
+ duplicate_shared_weights(bool, optional): duplicate shared weights.
+ Defaults to True.
+
+ Return:
+ the new model after preprocessing
+
+ It includes:
+
+ - inference shapes
+ - optimize model by ONNX library
+ - give names to the nodes
+ - replace initializer with Constant node
+ - replace -1 batch size with 1
+ - eliminate dropout and identity
+ - eliminate no children inputs
+ - topological sort
+
+ The optimizations provided by ONNX:
+
+ - eliminate_identity
+ - eliminate_nop_dropout
+ - eliminate_nop_transpose
+ - eliminate_nop_pad
+ - eliminate_unused_initializer
+ - eliminate_deadend
+ - fuse_consecutive_squeezes
+ - fuse_consecutive_transposes
+ - fuse_add_bias_into_conv
+ - fuse_transpose_into_gemm
+ - fuse_matmul_add_bias_into_gemm
+ - fuse_bn_into_conv
+ - fuse_pad_into_conv
+
+ """
+ logger.info("Preprocessing the model...")
+ helper.setup_current_opset_version(model_proto)
+ eliminating.eliminate_empty_value_infos(model_proto.graph)
+ other.add_name_to_node(model_proto.graph)
+ other.rename_all_node_name(model_proto.graph)
+ replacing.replace_initializer_with_Constant(model_proto.graph)
+ other.topological_sort(model_proto.graph)
+ m = other.polish_model(model_proto)
+ passes = [
+ "extract_constant_to_initializer",
+ "eliminate_nop_dropout",
+ "eliminate_deadend",
+ "fuse_matmul_add_bias_into_gemm",
+ "fuse_pad_into_conv",
+ ]
+ if not disable_fuse_bn:
+ passes.append("fuse_bn_into_conv")
+ m = optimizer.optimize(m, passes)
+ g = m.graph
+ # Add name again since onnx optimizer higher than 1.7 may remove node names
+ other.add_name_to_node(g)
+ if duplicate_shared_weights:
+ replacing.replace_initializer_with_Constant(
+ g, duplicate_shared_weights=True
+ )
+ other.duplicate_param_shared_constant(g)
+ else:
+ replacing.replace_initializer_with_Constant(
+ g, duplicate_shared_weights=False
+ )
+ other.topological_sort(g)
+ m = other.polish_model(m)
+ g = m.graph
+ eliminating.eliminate_consecutive_Cast(m.graph)
+ eliminating.eliminate_Cast_after_input(m.graph)
+ eliminating.eliminate_nop_pads(g)
+ eliminating.eliminate_nop_cast(g)
+ eliminating.eliminate_Identify_and_Dropout(g)
+ eliminating.eliminate_trivial_maxpool(g)
+ eliminating.eliminate_no_children_input(g)
+ other.format_value_info_shape(g)
+ other.topological_sort(g)
+ m = other.inference_shapes(m)
+ g = m.graph
+ replacing.replace_split_with_slices(g)
+ other.topological_sort(g)
+
+ return m
+
+
+def common_optimization(m):
+ """Common optimizations can be used in most cases.
+
+ :param m: the original model input\\
+ :return: the new model after preprocessing
+
+ It includes:
+
+ - transpose B in Gemm
+ - fuse BN into Gemm
+ - fuse consecutive Gemm
+ - replace AveragePool with GAP
+ - replace Squeeze/Unsqueeze with Reshape
+ - replace Reshape with Flatten
+ """
+ logger.info("Doing nodes fusion and replacement... ")
+ m = other.polish_model(m)
+ g = m.graph
+ other.transpose_B_in_Gemm(g)
+ fusing.fuse_BN_into_Gemm(g)
+ fusing.fuse_BN_with_Reshape_into_Gemm(g)
+ fusing.fuse_Gemm_into_Gemm(g)
+ fusing.fuse_consecutive_reducemean(g)
+ fusing.fuse_slice_nodes_into_conv(g)
+ fusing.fuse_relu_min_into_clip(g)
+ other.duplicate_shared_Flatten(g)
+ replacing.replace_average_pool_with_GAP(g)
+
+ m = other.polish_model(m)
+ g = m.graph
+
+ replacing.replace_Squeeze_with_Reshape(g)
+ replacing.replace_Unsqueeze_with_Reshape(g)
+ replacing.replace_Reshape_with_Flatten(g)
+ replacing.replace_ReduceMean_with_GlobalAveragePool(g)
+ replacing.replace_Sum_with_Adds(g)
+ replacing.replace_constant_input_concat_with_pad(g)
+ other.topological_sort(g)
+ return m
+
+
+def pytorch_constant_folding(m):
+ """Constant folding needed by Pytorch exported models. It should be done
+ before using onnx optimizers since the dynamic shape structure may affect
+ the optimizations.
+
+ :param m: the original model input\\
+ :return: the new model after preprocessing
+ """
+ logger.info("Working on constant folding.")
+ replacing.replace_shape_with_constant(m.graph)
+ replacing.replace_ConstantOfShape_with_constant(m.graph)
+
+ # constant_folding
+ m = other.inference_shapes(m)
+ while constant_folding.constant_folding(m.graph):
+ logging.debug("After constant folding jobs.")
+ other.topological_sort(m.graph)
+ while len(m.graph.value_info) != 0:
+ m.graph.value_info.pop()
+
+ m = other.inference_shapes(m)
+ replacing.replace_shape_with_constant(m.graph)
+ other.topological_sort(m.graph)
+ m = torch_pattern_match(m)
+ m = optimizer.optimize(m, ["eliminate_deadend"])
+ return m
+
+
+def tensorflow_optimization(m):
+ """Optimizations for tf models can be used in most cases.
+
+ :param m: the original model input\\
+ :return: the new model after preprocessing
+
+ It includes:
+
+ - eliminate shape change after input
+ - eliminate Reshape cast
+ - eliminate Squeeze before Reshape
+ - fuse Transpose into Constant
+ - replace Shape with Constant
+ """
+
+ fusing.fuse_Transpose_into_Constant(m.graph)
+ fusing.fuse_MatMul_and_Add_into_Gemm(m.graph)
+ other.topological_sort(m.graph)
+
+ m = other.polish_model(m)
+
+ # constant folding
+ replacing.replace_shape_with_constant(m.graph)
+
+ # constant_folding
+ m = other.inference_shapes(m)
+ while constant_folding.constant_folding(m.graph):
+ logging.debug("After constant folding jobs.")
+ other.topological_sort(m.graph)
+ while len(m.graph.value_info) != 0:
+ m.graph.value_info.pop()
+
+ m = other.inference_shapes(m)
+ replacing.replace_shape_with_constant(m.graph)
+ other.topological_sort(m.graph)
+ m = tf_pattern_match(m)
+ m = optimizer.optimize(m, ["eliminate_deadend"])
+
+ eliminating.eliminate_consecutive_reshape(m.graph)
+ eliminating.eliminate_Squeeze_before_Reshape(m.graph)
+ other.topological_sort(m.graph)
+ return m
+
+
+def postprocess(m):
+ """Inference the shape and prepare for export.
+
+ :param m: the original model input\\
+ :return: the new model after preprocessing
+ """
+ logger.info("Postprocessing the model...")
+ while len(m.graph.value_info) > 0:
+ m.graph.value_info.pop()
+ m = other.polish_model(m)
+ eliminating.eliminate_single_input_Concat(m.graph)
+ eliminating.eliminate_nop_Maxpool_and_AveragePool(m.graph)
+ eliminating.eliminate_trivial_elementwise_calculation(m.graph)
+ m = other.polish_model(m)
+
+ replacing.replace_depthwise_1x1_with_bn(m.graph)
+ m = other.polish_model(m)
+
+ # removing transpose
+ m = removing_transpose.eliminate_transposes(m)
+ m = other.polish_model(m)
+ removing_transpose.remove_trivial_transpose(m.graph)
+ removing_transpose.fuse_Transpose_into_Gemm_weight(m.graph)
+
+ # fuse some nodes
+ fusing.fuse_mul_and_add_into_bn(m.graph)
+ m = other.polish_model(m)
+ fusing.fuse_mul_and_add_into_gemm(m.graph)
+ m = other.polish_model(m)
+ fusing.fuse_conv_and_add_into_conv(m.graph)
+ m = other.polish_model(m)
+ replacing.replace_mul_to_bn(m.graph)
+ replacing.replace_div_to_bn(m.graph)
+ replacing.replace_add_to_bn(m.graph)
+ replacing.replace_sub_to_bn(m.graph)
+ replacing.replace_sub_with_bn_and_add(m.graph)
+ m = other.polish_model(m)
+
+ other.add_output_to_value_info(m.graph)
+ m = optimizer.optimize(m, ["eliminate_deadend"])
+ m.producer_name = "kneron_formatter"
+ return m
diff --git a/tools/optimizer_scripts/tools/common_pattern.py b/tools/optimizer_scripts/tools/common_pattern.py
new file mode 100644
index 0000000..19d4b35
--- /dev/null
+++ b/tools/optimizer_scripts/tools/common_pattern.py
@@ -0,0 +1,177 @@
+from collections import defaultdict
+import numpy as np
+import onnx.helper
+import onnx.utils
+
+from . import helper
+from . import other
+
+
+def torch_pattern_match(m):
+ # Create a map from optype to the nodes.
+ optype2node = defaultdict(list)
+ for node in m.graph.node:
+ optype2node[node.op_type].append(node)
+ for matmul_node in optype2node["MatMul"]:
+ pattern_matmul_mul_add(m.graph, matmul_node)
+ for resize_node in optype2node["Resize"]:
+ # torch nn.UpsamplingBilinear2d will be given us 4 input:
+ # "X, roi, scales, sizes"
+ if len(resize_node.input) != 4:
+ continue
+ make_UpsamplingBilinear2d_value_info(m.graph, resize_node.name)
+ m = onnx.shape_inference.infer_shapes(m)
+ polish_RESIZE_input_param_node(m.graph, resize_node.name)
+ m = other.polish_model(m)
+ return m
+
+
+def tf_pattern_match(m):
+ # Create a map from optype to the nodes.
+ optype2node = defaultdict(list)
+ for node in m.graph.node:
+ optype2node[node.op_type].append(node)
+ for matmul_node in optype2node["MatMul"]:
+ pattern_matmul_mul_add(m.graph, matmul_node)
+ for resize_node in optype2node["Resize"]:
+ # In tensorflow2onnx, ReizeXXX will be given us 4 input:
+ # "X, roi, scales, sizes"
+ # and node output name will be given the "node name + :0"
+ if len(resize_node.input) != 4:
+ continue
+ make_UpsamplingBilinear2d_value_info(m.graph, resize_node.name)
+ m = onnx.shape_inference.infer_shapes(m)
+ polish_RESIZE_input_param_node(m.graph, resize_node.name)
+ m = other.polish_model(m)
+ return m
+
+
+def pattern_matmul_mul_add(g, matmul_node):
+ # Check node match - Mul node
+ next_nodes = helper.find_nodes_by_input_name(g, matmul_node.output[0])
+ if len(next_nodes) != 1:
+ return
+ if next_nodes[0].op_type != "Mul":
+ return
+ mul_node = next_nodes[0]
+ # Check node match - Add node
+ next_nodes = helper.find_nodes_by_input_name(g, mul_node.output[0])
+ if len(next_nodes) != 1:
+ return
+ if next_nodes[0].op_type != "Add":
+ return
+ add_node = next_nodes[0]
+ # Check Mul weight
+ mul_weight_node = helper.find_node_by_output_name(g, mul_node.input[1])
+ if mul_weight_node.op_type != "Constant":
+ return
+ weight_size, mul_weight = helper.constant_to_list(mul_weight_node)
+ for i in mul_weight:
+ if i != 1:
+ return
+ channel = weight_size[0]
+ # Check Add weight
+ add_weight_node = helper.find_node_by_output_name(g, add_node.input[1])
+ if add_weight_node.op_type != "Constant":
+ return
+ # Check MatMul weight to see if it need weight broadcast
+ matmul_weight_node = helper.find_node_by_output_name(
+ g, matmul_node.input[1]
+ )
+ matmul_weight = helper.constant_to_numpy(matmul_weight_node)
+ if matmul_weight.shape[1] == 1:
+ # Weight broadcast
+ new_matmul_weight = np.tile(matmul_weight, channel)
+ new_matmul_weight_node = helper.numpy_to_constant(
+ matmul_weight_node.name, new_matmul_weight
+ )
+ g.node.remove(matmul_weight_node)
+ g.node.extend([new_matmul_weight_node])
+ value = helper.find_value_by_name(g, matmul_weight_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ # Remove Mul node
+ g.node.remove(mul_weight_node)
+ value = helper.find_value_by_name(g, mul_weight_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ g.node.remove(mul_node)
+ value = helper.find_value_by_name(g, mul_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ # Fuse Matmul and Add
+ gemm_node = onnx.helper.make_node(
+ "Gemm",
+ [matmul_node.input[0], matmul_node.input[1], add_node.input[1]],
+ [add_node.output[0]],
+ name=matmul_node.name,
+ alpha=1.0,
+ beta=1.0,
+ transA=0,
+ transB=0,
+ )
+ g.node.extend([gemm_node])
+ # Clean up
+ g.node.remove(matmul_node)
+ g.node.remove(add_node)
+ value = helper.find_value_by_name(g, matmul_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ other.topological_sort(g)
+
+
+def make_UpsamplingBilinear2d_value_info(g, resize_node_name):
+ resize_node = helper.find_node_by_node_name(g, resize_node_name)
+
+ shape_data_node = helper.find_node_by_output_name(g, resize_node.input[3])
+ shape_data = helper.constant_to_numpy(shape_data_node).astype(int)
+ l_shape_data = list(shape_data)
+ if l_shape_data[0] == 0:
+ l_shape_data[0] = 1 + l_shape_data[0]
+ shape_data = np.array(l_shape_data)
+
+ new_output_value_info = onnx.helper.make_tensor_value_info(
+ resize_node.output[0],
+ onnx.helper.TensorProto.FLOAT,
+ shape_data.tolist(),
+ )
+
+ g.value_info.extend([new_output_value_info])
+
+
+def polish_RESIZE_input_param_node(g, resize_node_name):
+ resize_node = helper.find_node_by_node_name(g, resize_node_name)
+
+ shape_data_node = helper.find_node_by_output_name(g, resize_node.input[3])
+ shape_data = helper.constant_to_numpy(shape_data_node).astype(int)
+
+ # handle 0 batch size which is invalid
+ if shape_data[0] == 0:
+ shape_data[0] = 1
+
+ pre_node_output_value_info = helper.find_value_by_name(
+ g, resize_node.input[0]
+ )
+ ori_shape = np.array(
+ [
+ pre_node_output_value_info.type.tensor_type.shape.dim[0].dim_value,
+ pre_node_output_value_info.type.tensor_type.shape.dim[1].dim_value,
+ pre_node_output_value_info.type.tensor_type.shape.dim[2].dim_value,
+ pre_node_output_value_info.type.tensor_type.shape.dim[3].dim_value,
+ ]
+ )
+
+ resize_node.input.remove(resize_node.input[3])
+
+ resize_scales = np.array(shape_data / ori_shape).astype(float)
+ resize_scale_node = helper.list_to_constant(
+ "resize_scales_node_" + resize_node.name,
+ resize_scales.shape,
+ resize_scales,
+ data_type=onnx.helper.TensorProto.FLOAT,
+ )
+
+ resize_node.input[2] = resize_scale_node.name
+ g.node.extend([resize_scale_node])
+
+ other.topological_sort(g)
diff --git a/tools/optimizer_scripts/tools/constant_folding.py b/tools/optimizer_scripts/tools/constant_folding.py
new file mode 100644
index 0000000..45ef674
--- /dev/null
+++ b/tools/optimizer_scripts/tools/constant_folding.py
@@ -0,0 +1,973 @@
+import onnx.utils
+import onnx
+import numpy as np
+import logging
+import traceback
+
+from . import helper
+from .other import topological_sort
+from .helper import logger
+
+
+def are_all_inputs_Constant_with_one_child(g, node):
+ for input_name in node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ if input_node is None or input_node.op_type != "Constant":
+ return False
+ relative_outputs = helper.find_nodes_by_input_name(g, input_name)
+ if len(relative_outputs) > 1:
+ return False
+ return True
+
+
+def constant_folding(g):
+ """ Do constant folding until nothing more can be done.
+
+ :param g: The onnx GraphProto\\
+ :return: If any node is folded, return True. Otherwise, return False.
+ """
+ keep_folding = True # Keep the while loop
+ folded = False # Return value
+ try:
+ # Before constant folding, duplicate the constant nodes.
+ duplicate_constant_node(g)
+ while keep_folding:
+ keep_folding = False
+ for node in g.node:
+ # Check if the node is foldable
+ if node.op_type not in constant_folding_nodes.keys():
+ continue
+ # Check if parents of the node are all
+ # single follower constant node.
+ if not are_all_inputs_Constant_with_one_child(g, node):
+ continue
+ # Constant folding for the specific node
+ if constant_folding_nodes[node.op_type](g, node):
+ logging.debug(
+ "Constant nodes and %s %s are folded.",
+ node.op_type,
+ node.name,
+ )
+ folded = True
+ keep_folding = True
+ else:
+ logging.debug(
+ "Constant nodes and %s %s are skipped.",
+ node.op_type,
+ node.name,
+ )
+ except Exception:
+ logger.error("An exception is raised while constant folding.")
+ logger.error(traceback.format_exc())
+ return folded
+
+
+def duplicate_constant_node(g):
+ """
+ Duplicate the constant node if its following nodes contain
+ constant folding nodes. Create and link the new constant nodes
+ to the constant folding nodes.
+ """
+ for node in g.node:
+ # Find a valid constant node
+ if node.op_type != "Constant":
+ continue
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+ if output_val_info is None:
+ print(
+ "Cannot inference the shape of Const node output: "
+ + node.output[0]
+ )
+ exit(1)
+ data_shape = helper.get_shape_from_value_info(output_val_info)
+ output_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+
+ # For constant that has only one following node, no need to duplicate
+ if len(output_nodes) < 2:
+ continue
+
+ # Check if its following nodes are foldable
+ foldable_output_nodes = list(
+ filter(
+ lambda n: n.op_type in constant_folding_nodes.keys(),
+ output_nodes,
+ )
+ )
+ if not foldable_output_nodes:
+ continue
+
+ # Duplicate the node needed by foldable nodes
+ for i in range(len(foldable_output_nodes)):
+ logging.debug(
+ f"Found constant {node.name} and "
+ f"{foldable_output_nodes[i].op_type} "
+ f"{foldable_output_nodes[i].name} are availble for folding. "
+ "Duplicate constant.",
+ )
+ output_name = node.output[0] + "_dup_" + str(i)
+ new_constant_node = onnx.helper.make_node(
+ "Constant",
+ [],
+ [output_name],
+ name=output_name,
+ value=node.attribute[0].t,
+ )
+ new_val_info = onnx.helper.make_tensor_value_info(
+ output_name, node.attribute[0].t.data_type, data_shape
+ )
+ input_ind = list(foldable_output_nodes[i].input).index(
+ node.output[0]
+ )
+ foldable_output_nodes[i].input[input_ind] = output_name
+
+ g.node.extend([new_constant_node])
+ g.value_info.extend([new_val_info])
+
+ # If all following nodes are foldable node, delete the original node.
+ if len(foldable_output_nodes) == len(output_nodes):
+ g.node.remove(node)
+ g.value_info.remove(output_val_info)
+
+ topological_sort(g)
+
+ return
+
+
+def slice_constant_folding(g, node):
+ op_version = helper.get_current_opset_version()
+ # only support opset 9 & 11
+ if op_version == 11:
+ return slice_constant_folding_Opset_11(g, node)
+ elif op_version == 9:
+ return slice_constant_folding_Opset_9(g, node)
+
+
+def slice_constant_folding_Opset_11(g, node):
+ """Fold constant and slice nodes to a single constant node."""
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_shape, data_list = helper.constant_to_list(pre_node)
+
+ starts_node = helper.find_node_by_output_name(g, node.input[1])
+ _, starts = helper.constant_to_list(starts_node)
+
+ ends_node = helper.find_node_by_output_name(g, node.input[2])
+ _, ends = helper.constant_to_list(ends_node)
+
+ axes_node = (
+ None
+ if len(node.input) <= 3
+ else helper.find_node_by_output_name(g, node.input[3])
+ )
+ if not axes_node:
+ axes = list(range(len(helper.get_shape(data_list))))
+ else:
+ _, axes = helper.constant_to_list(axes_node)
+
+ steps_node = (
+ None
+ if len(node.input) <= 4
+ else helper.find_node_by_output_name(g, node.input[4])
+ )
+ if not steps_node:
+ steps = [1] * len(helper.get_shape(data_list))
+ else:
+ _, steps = helper.constant_to_list(steps_node)
+
+ data_list = list(map(int, data_list))
+ starts = list(map(int, starts))
+ ends = list(map(int, ends))
+ axes = list(map(int, axes))
+ steps = list(map(int, steps))
+
+ data_list = np.reshape(data_list, pre_shape)
+
+ new_data = None
+ for idx, _ in enumerate(axes):
+ new_data = np.apply_along_axis(
+ lambda x: x[starts[idx]:ends[idx]:steps[idx]], idx, data_list
+ )
+
+ new_node = helper.list_to_constant(
+ node.output[0],
+ helper.get_shape(new_data),
+ helper.flatten_to_list(new_data),
+ )
+ g.node.extend([new_node])
+ value_info = helper.find_value_by_name(g, pre_node.output[0])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ g.node.remove(node)
+ g.node.remove(pre_node)
+
+ return True
+
+
+def slice_constant_folding_Opset_9(g, node):
+ """Fold constant and slice nodes to a single constant node."""
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_shape, data_list = helper.constant_to_list(pre_node)
+
+ data_list = np.reshape(data_list, pre_shape)
+ axes = helper.get_attribute_by_name(node, "axes")
+ ends = list(helper.get_attribute_by_name(node, "ends").ints)
+ starts = list(helper.get_attribute_by_name(node, "starts").ints)
+
+ if not axes:
+ axes = list(range(len(helper.get_shape(data_list))))
+ else:
+ axes = list(axes.ints)
+
+ new_data = helper.slice_data(data_list, starts, ends, axes)
+ new_node = helper.list_to_constant(
+ node.output[0],
+ helper.get_shape(new_data),
+ helper.flatten_to_list(new_data),
+ )
+ g.node.extend([new_node])
+ value_info = helper.find_value_by_name(g, pre_node.output[0])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ g.node.remove(node)
+ g.node.remove(pre_node)
+
+ return True
+
+
+def cast_constant_folding(g, node):
+ """Fold constant and cast node to a single constant node."""
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ data_type = node.attribute[0].i
+ if data_type in (6, 7):
+ data = list(map(int, data))
+ elif data_type == onnx.helper.TensorProto.FLOAT:
+ data = list(map(float, data))
+ else:
+ raise RuntimeError("data type not supported")
+
+ if shape == 1:
+ tensor = onnx.helper.make_tensor(
+ name=pre_node.attribute[0].name,
+ data_type=data_type,
+ dims=[],
+ vals=data,
+ )
+ else:
+ tensor = onnx.helper.make_tensor(
+ name=pre_node.attribute[0].name,
+ data_type=data_type,
+ dims=shape,
+ vals=helper.flatten_to_list(data),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=tensor
+ )
+ g.node.extend([new_node])
+
+ value_info = helper.find_value_by_name(g, pre_node.output[0])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ value_info = helper.find_value_by_name(g, node.output[0])
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ g.node.remove(pre_node)
+ g.node.remove(node)
+
+ return True
+
+
+def reduceprod_constant_folding(g, node):
+ """Fold constant and reduceprod nodes to a single constant node."""
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data_set = helper.constant_to_list(pre_node)
+ tensor = pre_node.attribute[0].t
+
+ data_set = np.reshape(data_set, shape)
+ for att in node.attribute:
+ if att.name == "axes":
+ axes = list(att.ints)
+ else:
+ keepdims = int(att.i)
+
+ new_data = np.prod(data_set, axis=tuple(axes), keepdims=keepdims == 1)
+ new_shape = helper.get_shape(new_data)
+ new_flat_data = helper.flatten_to_list(new_data)
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0],
+ data_type=tensor.data_type,
+ dims=new_shape,
+ vals=new_flat_data,
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.node.extend([new_node])
+ value_info = None
+ for item in g.value_info:
+ if item.name == pre_node.output[0]:
+ value_info = item
+ if value_info is not None:
+ g.value_info.remove(value_info)
+ g.node.remove(pre_node)
+ g.node.remove(node)
+
+ return True
+
+
+def reshape_constant_input_folding(g, node):
+ """Fold constant and reshape nodes to a single constant node."""
+ pre_data_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_shape_node = helper.find_node_by_output_name(g, node.input[1])
+
+ data = helper.constant_to_numpy(pre_data_node)
+ _, shape = helper.constant_to_list(pre_shape_node)
+ new_data = np.reshape(data, shape)
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0],
+ data_type=pre_data_node.attribute[0].t.data_type,
+ dims=new_data.shape,
+ vals=helper.flatten_to_list(new_data),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+ g.node.extend([new_node])
+
+ data_val_info = helper.find_value_by_name(g, pre_data_node.output[0])
+ shape_val_info = helper.find_value_by_name(g, pre_shape_node.output[0])
+
+ g.value_info.remove(data_val_info)
+ g.value_info.remove(shape_val_info)
+
+ g.node.remove(node)
+ g.node.remove(pre_data_node)
+ g.node.remove(pre_shape_node)
+
+ return True
+
+
+def concat_constant_folding(g, node):
+ """Fold constant and concat nodes to a single constant node."""
+ node_to_del = []
+ valid_inputs = True
+ for input_name in node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ input_node_output = helper.find_nodes_by_input_name(g, input_name)
+ if len(input_node_output) > 1:
+ valid_inputs = False
+ break
+ if input_node.op_type != "Constant":
+ valid_inputs = False
+ break
+
+ if not valid_inputs:
+ return False
+
+ input_data = []
+ input_shapes = []
+ for input_name in node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ s, d = helper.constant_to_list(input_node)
+ d = np.reshape(d, s)
+ input_data.append(d)
+ input_shapes.append(s)
+ node_to_del.append(input_node)
+
+ concat_data = np.concatenate(input_data, axis=node.attribute[0].i)
+ node_data_type = input_node.attribute[0].t.data_type
+ if concat_data.dtype in [np.int32, np.int64]:
+ node_data_type = onnx.helper.TensorProto.INT64
+ elif concat_data.dtype in [np.float32, np.float64]:
+ node_data_type = onnx.helper.TensorProto.FLOAT
+
+ new_node = helper.list_to_constant(
+ node.output[0],
+ helper.get_shape(concat_data),
+ helper.flatten_to_list(concat_data),
+ data_type=node_data_type,
+ )
+ g.node.extend([new_node])
+ node_to_del.append(node)
+
+ for input_name in node.input:
+ val_info = helper.find_value_by_name(g, input_name)
+ if val_info:
+ g.value_info.remove(val_info)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def transpose_constant_folding(g, node):
+ """Fold constant and transpose nodes to a single constant node."""
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ np_data = np.reshape(data, shape)
+ permutation = list(node.attribute[0].ints)
+
+ new_data = np.transpose(np_data, permutation)
+ new_shape = new_data.shape
+ new_node = helper.list_to_constant(
+ node.output[0],
+ new_shape,
+ new_data.flatten().tolist(),
+ data_type=pre_node.attribute[0].t.data_type,
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([node, pre_node])
+
+ pre_val_info = helper.find_value_by_name(g, node.input[0])
+ g.value_info.remove(pre_val_info)
+
+ next_val_info = helper.find_value_by_name(g, node.output[0])
+ g.value_info.remove(next_val_info)
+
+ new_val_info = onnx.helper.make_tensor_value_info(
+ node.output[0], pre_node.attribute[0].t.data_type, new_shape
+ )
+ g.value_info.extend([new_val_info])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+ folded = True
+
+ return folded
+
+
+def unsqueeze_constant_folding(g, node):
+ """Fold constant and unsqueeze nodes to a single constant node."""
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ if type(shape) == int:
+ np_data = data[0]
+ else:
+ np_data = np.reshape(data, shape)
+ axes = list(node.attribute[0].ints)
+ axes.sort()
+
+ for dim in axes:
+ np_data = np.expand_dims(np_data, axis=dim)
+ new_shape = np_data.shape
+ new_node = helper.list_to_constant(
+ node.output[0],
+ new_shape,
+ np_data.flatten().tolist(),
+ data_type=pre_node.attribute[0].t.data_type,
+ )
+ g.node.extend([new_node])
+ node_to_del.extend([node, pre_node])
+
+ pre_val_info = helper.find_value_by_name(g, node.input[0])
+ next_val_info = helper.find_value_by_name(g, node.output[0])
+ if pre_val_info is not None:
+ g.value_info.remove(pre_val_info)
+ else:
+ print(node.name)
+ if next_val_info is not None:
+ g.value_info.remove(next_val_info)
+
+ new_val_info = onnx.helper.make_tensor_value_info(
+ node.output[0], pre_node.attribute[0].t.data_type, new_shape
+ )
+ g.value_info.extend([new_val_info])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def gather_constant_folding(g, node):
+ """Fold constant and gather nodes to a single constant node."""
+ node_to_del = []
+
+ pre_data_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_indices_node = helper.find_node_by_output_name(g, node.input[1])
+
+ shape, data = helper.constant_to_list(pre_data_node)
+ indice_shape, indices = helper.constant_to_list(pre_indices_node)
+ if type(indice_shape) == int:
+ indices = indices[0]
+
+ np_data = np.reshape(data, shape)
+ if len(node.attribute) < 1:
+ axis = 0
+ else:
+ axis = node.attribute[0].i
+
+ new_data = np.take(np_data, indices, axis=axis)
+ new_shape = new_data.shape
+ new_node = helper.list_to_constant(
+ node.output[0],
+ new_shape,
+ new_data.flatten().tolist(),
+ data_type=pre_data_node.attribute[0].t.data_type,
+ )
+
+ node_to_del.extend([node, pre_data_node, pre_indices_node])
+ g.node.extend([new_node])
+
+ val_info_1 = helper.find_value_by_name(g, node.input[0])
+ val_info_2 = helper.find_value_by_name(g, node.input[1])
+ val_info_3 = helper.find_value_by_name(g, node.output[0])
+ new_val_info = onnx.helper.make_tensor_value_info(
+ new_node.output[0], pre_data_node.attribute[0].t.data_type, new_shape
+ )
+
+ if val_info_1 is not None:
+ g.value_info.remove(val_info_1)
+ if val_info_2 is not None:
+ g.value_info.remove(val_info_2)
+ if val_info_3 is not None:
+ g.value_info.remove(val_info_3)
+ g.value_info.extend([new_val_info])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def add_constant_folding(g, node):
+ """Fold constant and add nodes to a single constant node."""
+ node_to_del = []
+ pre_node_1 = helper.find_node_by_output_name(g, node.input[0])
+ pre_node_2 = helper.find_node_by_output_name(g, node.input[1])
+ if not pre_node_1 or not pre_node_2:
+ return False
+
+ shape1, data1 = helper.constant_to_list(pre_node_1)
+ shape2, data2 = helper.constant_to_list(pre_node_2)
+ np_data1 = np.reshape(data1, shape1)
+ np_data2 = np.reshape(data2, shape2)
+ try:
+ new_data = np.add(np_data1, np_data2)
+ except Exception:
+ raise RuntimeError("can't broadcast and add two data sets")
+
+ new_node = helper.list_to_constant(
+ node.output[0],
+ new_data.shape,
+ new_data.flatten().tolist(),
+ data_type=pre_node_1.attribute[0].t.data_type,
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([node, pre_node_1, pre_node_2])
+ g.value_info.remove(helper.find_value_by_name(g, pre_node_1.output[0]))
+ g.value_info.remove(helper.find_value_by_name(g, pre_node_2.output[0]))
+ folded = True
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return folded
+
+
+def sqrt_constant_folding(g, node):
+ """Fold constant and sqrt nodes to a single node."""
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ np_data = np.sqrt(np.reshape(data, shape))
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+ input_val_info = helper.find_value_by_name(g, node.input[0])
+ data_type = output_val_info.type.tensor_type.elem_type
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=data_type,
+ dims=shape,
+ vals=np_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.value_info.remove(input_val_info)
+ node_to_del.extend([pre_node, node])
+ g.node.extend([new_node])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def reciprocal_constant_folding(g, node):
+ """Fold constant and reciprocal nodes to a single constant node."""
+ node_to_del = []
+
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ shape, data = helper.constant_to_list(pre_node)
+ data = list(map(lambda x: x if abs(x) > 1.0e-8 else 1.0e-8, data))
+ np_data = np.reshape(data, shape)
+ np_data = np.reciprocal(np_data)
+
+ input_val_info = helper.find_value_by_name(g, node.input[0])
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+ data_type = output_val_info.type.tensor_type.elem_type
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=data_type,
+ dims=shape,
+ vals=np_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ node_to_del.extend([node, pre_node])
+ g.node.extend([new_node])
+
+ g.value_info.remove(input_val_info)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def mul_constant_folding(g, node):
+ """Fold constant and mul nodes to a single constant node."""
+ node_to_del = []
+ pre_node_1 = helper.find_node_by_output_name(g, node.input[0])
+ pre_node_2 = helper.find_node_by_output_name(g, node.input[1])
+
+ pre_value_info1 = helper.find_value_by_name(g, node.input[0])
+ pre_value_info2 = helper.find_value_by_name(g, node.input[1])
+ if pre_value_info1 is None or pre_value_info2 is None:
+ return False
+
+ shape1, data1 = helper.constant_to_list(pre_node_1)
+ shape2, data2 = helper.constant_to_list(pre_node_2)
+ np_data1 = np.reshape(data1, shape1)
+ np_data2 = np.reshape(data2, shape2)
+
+ try:
+ new_data = np.multiply(np_data1, np_data2)
+ except Exception:
+ raise RuntimeError("can not broadcast and multiply two data sets")
+
+ # Special shape for single element.
+ if shape1 == 1 and shape2 == 1:
+ new_shape = []
+ else:
+ new_shape = new_data.shape
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=pre_node_1.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=new_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ node_to_del.extend([node, pre_node_1, pre_node_2])
+ g.node.extend([new_node])
+
+ g.value_info.remove(pre_value_info1)
+ g.value_info.remove(pre_value_info2)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def div_constant_folding(g, node):
+ """Fold constant and mul nodes to a single constant node."""
+ node_to_del = []
+ pre_node_1 = helper.find_node_by_output_name(g, node.input[0])
+ pre_node_2 = helper.find_node_by_output_name(g, node.input[1])
+
+ pre_value_info1 = helper.find_value_by_name(g, node.input[0])
+ pre_value_info2 = helper.find_value_by_name(g, node.input[1])
+ if pre_value_info1 is None or pre_value_info2 is None:
+ return False
+
+ shape1, data1 = helper.constant_to_list(pre_node_1)
+ shape2, data2 = helper.constant_to_list(pre_node_2)
+ np_data1 = np.reshape(data1, shape1)
+ np_data2 = np.reshape(data2, shape2)
+
+ try:
+ new_data = np.divide(np_data1, np_data2)
+ except Exception:
+ raise RuntimeError("can not broadcast and multiply two data sets")
+
+ # Special shape for single element.
+ if shape1 == 1 and shape2 == 1:
+ new_shape = []
+ else:
+ new_shape = new_data.shape
+
+ # Check data type if it is int
+ if pre_node_1.attribute[0].t.data_type == 7:
+ new_data = new_data.astype("int64")
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=pre_node_1.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=new_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ node_to_del.extend([node, pre_node_1, pre_node_2])
+ g.node.extend([new_node])
+
+ g.value_info.remove(pre_value_info1)
+ g.value_info.remove(pre_value_info2)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def sub_constant_folding(g, node):
+ """Fold constant and sub nodes to a single node."""
+ node_to_del = []
+ pre_node_1 = helper.find_node_by_output_name(g, node.input[0])
+ pre_node_2 = helper.find_node_by_output_name(g, node.input[1])
+ pre_val_info_1 = helper.find_value_by_name(g, node.input[0])
+ pre_val_info_2 = helper.find_value_by_name(g, node.input[1])
+
+ shape1, data1 = helper.constant_to_list(pre_node_1)
+ shape2, data2 = helper.constant_to_list(pre_node_2)
+
+ new_data = np.subtract(data1, data2)
+ # Special shape for single element.
+ if shape1 == 1 and shape2 == 1:
+ new_shape = []
+ else:
+ new_shape = new_data.shape
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=pre_node_1.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=helper.flatten_to_list(new_data),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([node, pre_node_1, pre_node_2])
+
+ g.value_info.remove(pre_val_info_1)
+ g.value_info.remove(pre_val_info_2)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def neg_constant_folding(g, node):
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+
+ shape, data_list = helper.constant_to_list(pre_node)
+ new_data_list = [-num for num in data_list]
+
+ new_tensor = onnx.helper.make_tensor(
+ name=pre_node.name + "_neg_tensor",
+ data_type=pre_node.attribute[0].t.data_type,
+ dims=shape,
+ vals=new_data_list,
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([pre_node, node])
+ g.value_info.remove(helper.find_value_by_name(g, node.input[0]))
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ return True
+
+
+def floor_constant_folding(g, node):
+ node_to_del = []
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+
+ shape, data = helper.constant_to_list(pre_node)
+ new_data = np.floor(data).flatten().tolist()
+
+ if shape == 1:
+ new_shape = []
+ else:
+ new_shape = shape
+
+ new_tensor = onnx.helper.make_tensor(
+ name=node.output[0] + "_data",
+ data_type=pre_node.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=helper.flatten_to_list(new_data),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant", [], [node.output[0]], name=node.output[0], value=new_tensor
+ )
+
+ g.node.extend([new_node])
+ node_to_del.extend([pre_node, node])
+ old_value = helper.find_value_by_name(g, node.input[0])
+ if old_value is not None:
+ g.value_info.remove(old_value)
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ return True
+
+
+def bn_constant_folding(g, node):
+ """Fold constant and mul nodes to a single constant node."""
+ # Prepare data
+ node_to_del = []
+ input_node = helper.find_node_by_output_name(g, node.input[0])
+ scale_node = helper.find_node_by_output_name(g, node.input[1])
+ bias_node = helper.find_node_by_output_name(g, node.input[2])
+ mean_node = helper.find_node_by_output_name(g, node.input[3])
+ var_node = helper.find_node_by_output_name(g, node.input[4])
+
+ input_value_info = []
+ for i in range(5):
+ input_value_info.append(helper.find_value_by_name(g, node.input[i]))
+
+ if input_value_info[0] is None:
+ return False
+
+ input_data = helper.constant_to_numpy(input_node)
+ scale_data = helper.constant_to_numpy(scale_node)
+ bias_data = helper.constant_to_numpy(bias_node)
+ mean_data = helper.constant_to_numpy(mean_node)
+ var_data = helper.constant_to_numpy(var_node)
+
+ epsilon = helper.get_var_attribute_by_name(node, "epsilon", "float")
+ if epsilon is None:
+ epsilon = 0.00001
+
+ # Calculate new node
+ new_data = (
+ scale_data * (input_data - mean_data) / np.sqrt(var_data + epsilon)
+ + bias_data
+ )
+
+ new_node = helper.numpy_to_constant(node.output[0], new_data)
+
+ # Reconnect the graph
+ node_to_del.extend(
+ [node, input_node, scale_node, bias_node, mean_node, var_node]
+ )
+ g.node.extend([new_node])
+
+ for value in input_value_info:
+ if value is not None:
+ g.value_info.remove(value)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+def DequantizeLinear_constant_folding(g, node):
+ """Fold constant and mul nodes to a single constant node."""
+ # Prepare data
+ node_to_del = []
+ x_node = helper.find_node_by_output_name(g, node.input[0])
+ x_scale_node = helper.find_node_by_output_name(g, node.input[1])
+ if len(node.input) > 2:
+ x_zero_point_node = helper.find_node_by_output_name(g, node.input[2])
+ else:
+ x_zero_point_node = None
+
+ input_value_info = []
+ for i in range(len(node.input)):
+ input_value_info.append(helper.find_value_by_name(g, node.input[i]))
+
+ if input_value_info[0] is None:
+ return False
+
+ x_data = helper.constant_to_numpy(x_node)
+ x_scale_data = helper.constant_to_numpy(x_scale_node)
+ if x_zero_point_node is not None:
+ x_zero_point_data = helper.constant_to_numpy(x_zero_point_node)
+ else:
+ x_zero_point_data = np.array([0.0])
+
+ # Calculate new node
+ new_data = (
+ x_data.astype(np.float32) - x_zero_point_data.astype(np.float32)
+ ) * x_scale_data
+
+ new_node = helper.numpy_to_constant(node.output[0], new_data)
+
+ # Reconnect the graph
+ node_to_del.extend([node, x_node, x_scale_node])
+ if x_zero_point_node is not None:
+ node_to_del.append(x_zero_point_node)
+ g.node.extend([new_node])
+
+ for value in input_value_info:
+ if value is not None:
+ g.value_info.remove(value)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return True
+
+
+# Available constant folding names to function map.
+constant_folding_nodes = {
+ "Add": add_constant_folding,
+ "BatchNormalization": bn_constant_folding,
+ "Cast": cast_constant_folding,
+ "Concat": concat_constant_folding,
+ "DequantizeLinear": DequantizeLinear_constant_folding,
+ "Div": div_constant_folding,
+ "Floor": floor_constant_folding,
+ "Gather": gather_constant_folding,
+ "Mul": mul_constant_folding,
+ "Reciprocal": reciprocal_constant_folding,
+ "ReduceProd": reduceprod_constant_folding,
+ "Reshape": reshape_constant_input_folding,
+ "Slice": slice_constant_folding,
+ "Sqrt": sqrt_constant_folding,
+ "Transpose": transpose_constant_folding,
+ "Unsqueeze": unsqueeze_constant_folding,
+ "Sub": sub_constant_folding,
+ "Neg": neg_constant_folding,
+}
diff --git a/tools/optimizer_scripts/tools/eliminating.py b/tools/optimizer_scripts/tools/eliminating.py
new file mode 100644
index 0000000..7871665
--- /dev/null
+++ b/tools/optimizer_scripts/tools/eliminating.py
@@ -0,0 +1,751 @@
+import collections
+import struct
+import onnx
+import numpy as np
+from . import other
+from . import helper
+from . import modhelper
+from .general_graph import Graph
+
+
+def eliminate_Identify_and_Dropout(g):
+ """
+ Eliminate Identify layers
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Identity" and node.op_type != "Dropout":
+ continue
+ # If this node is the last, leave it to `eliminate_useless_last node`
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ continue
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ try:
+ g.value_info.remove(value_between)
+ except Exception:
+ print("No value info to delete while eliminating identity layers.")
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+# Remove last useless nodes
+def remove_useless_last_nodes(g):
+ """Remove useless nodes from the tail of the graph"""
+ USELESS = [
+ "Reshape",
+ "Identity",
+ "Transpose",
+ "Flatten",
+ "Dropout",
+ "Mystery",
+ "Constant",
+ "Squeeze",
+ "Unsqueeze",
+ "Softmax",
+ ]
+ graph = Graph(g)
+ todo = collections.deque()
+ for node in graph.output_nodes:
+ if len(node.children) == 0:
+ todo.append(node)
+ node_to_remove = []
+ while todo:
+ # BFS find nodes to remove
+ cur_node = todo.popleft()
+ if cur_node.proto is None:
+ continue
+ if cur_node.proto.op_type not in USELESS:
+ continue
+ # Find the output
+ cur_node_output = helper.find_output_by_name(
+ g, cur_node.proto.output[0]
+ )
+ for cur_input in cur_node.parents:
+ cur_input.children.remove(cur_node)
+ if len(cur_input.children) == 0:
+ todo.append(cur_input)
+ if cur_node_output is not None:
+ cur_input_output = helper.find_value_by_name(
+ g, cur_input.proto.output[0]
+ )
+ cur_input_output_in_output = helper.find_output_by_name(
+ g, cur_input.proto.output[0]
+ )
+ if (
+ cur_input_output is not None
+ and cur_input_output_in_output is None
+ ):
+ g.output.extend([cur_input_output])
+ node_to_remove.append(cur_node.proto)
+ try:
+ g.value_info.remove(
+ helper.find_value_by_name(g, cur_node.proto.output[0])
+ )
+ except ValueError:
+ pass
+ if cur_node_output is not None:
+ g.output.remove(cur_node_output)
+ cur_node.proto = None
+ cur_node.parents.clear()
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+######################################
+# TF only optimization passes #
+######################################
+
+
+def eliminate_shape_changing_after_input(g):
+ """
+ Eliminate the Reshape node after input and reshape the input
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ REMOVE_LIST = [
+ "Reshape",
+ "Transpose",
+ "Flatten",
+ "Dropout",
+ "Squeeze",
+ "Unsqueeze",
+ ]
+ for node in g.node:
+ # Find an input and the shape node
+ if node.op_type not in REMOVE_LIST:
+ continue
+ old_input = helper.find_input_by_name(g, node.input[0])
+ if old_input is None:
+ continue
+ # If the input is used by multiple nodes, skip.
+ counter = 0
+ for tnode in g.node:
+ if old_input.name in tnode.input:
+ counter += 1
+ if counter > 1:
+ continue
+ # Remove Weight if any.
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+
+ if node.op_type == "Reshape":
+ shape_node = helper.find_node_by_output_name(g, node.input[1])
+ if shape_node.op_type != "Constant":
+ continue
+
+ # manuelly set the input shape
+ shape_info = helper.find_value_by_name(g, shape_node.output[0])
+ old_size, old_shape = helper.find_size_shape_from_value(shape_info)
+
+ _, new_shape = helper.constant_to_list(shape_node)
+ for i in range(len(new_shape)):
+ if new_shape[i] == -1:
+ dim = int(old_size // np.prod(new_shape) * (-1))
+ new_shape[i] = dim
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+
+ node_to_remove.append(node)
+
+ shape_outputs = helper.find_nodes_by_input_name(
+ g, shape_node.output[0]
+ )
+ if len(shape_outputs) == 1:
+ node_to_remove.append(shape_node)
+ g.value_info.remove(
+ helper.find_value_by_name(g, shape_node.output[0])
+ )
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ elif node.op_type == "Transpose":
+ permutation = list(node.attribute[0].ints)
+ pre_shape = helper.get_shape_from_value_info(old_input)
+ new_shape = [pre_shape[i] for i in permutation]
+
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+
+ node_to_remove.append(node)
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ elif node.op_type == "Flatten":
+ axis = node.attribute[0].int
+ pre_shape = helper.get_shape_from_value_info(old_input)
+ dim_1, dim_2 = 1, 1
+ if axis == 0:
+ dim_1 = 1
+ dim_2 = np.prod(pre_shape)
+ else:
+ dim_1 = np.prod(pre_shape[:axis]).astype(int)
+ dim_2 = np.prod(pre_shape[axis:]).astype(int)
+ new_shape = [dim_1, dim_2]
+
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+
+ node_to_remove.append(node)
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ elif node.op_type == "Dropout":
+ g.input.remove(old_input)
+ g.input.extend([output_val_info])
+ g.value_info.remove(output_val_info)
+
+ node_to_remove.append(node)
+ elif node.op_type == "Squeeze":
+ axis = list(node.attribute[0].ints)
+ pre_shape = helper.get_shape_from_value_info(old_input)
+ for pos in sorted(axis)[::-1]:
+ if pre_shape[pos] != 1:
+ raise RuntimeError("invalid axis for squeeze")
+ else:
+ pre_shape.pop(pos)
+ new_shape = pre_shape
+
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+
+ node_to_remove.append(node)
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ elif node.op_type == "Unsqueeze":
+ axis = list(node.attribute[0].ints)
+ pre_shape = helper.get_shape_from_value_info(old_input)
+ new_shape = pre_shape
+ for pos in axis:
+ new_shape.insert(pos, 1)
+ new_input = onnx.helper.make_tensor_value_info(
+ output_val_info.name,
+ output_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+ node_to_remove.append(node)
+
+ g.input.remove(old_input)
+ g.input.extend([new_input])
+ g.value_info.remove(output_val_info)
+ else:
+ pass
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+ other.topological_sort(g)
+
+
+def eliminate_Reshape_Cast(g):
+ """Eliminate the cast layer for shape of Reshape layer
+
+ :param g: the onnx graph
+ """
+ # Find all reshape layers
+ for node in g.node:
+ if node.op_type != "Reshape":
+ continue
+ prev_node = helper.find_node_by_output_name(g, node.input[1])
+ if prev_node.op_type != "Cast":
+ continue
+ reshape_node = node
+ cast_node = prev_node
+ weight_node = helper.find_node_by_output_name(g, cast_node.input[0])
+ if weight_node is None:
+ raise RuntimeError("Unexpected None before Cast-Reshape.")
+ weight_node.attribute[0].t.data_type = 7
+ if weight_node.attribute[0].t.raw_data:
+ raw_data = weight_node.attribute[0].t.raw_data
+ int_data = [i[0] for i in struct.iter_unpack("i", raw_data)]
+ raw_data = struct.pack("q" * len(int_data), *int_data)
+ elif (
+ len(weight_node.attribute[0].t.int64_data) > 0
+ or len(weight_node.attribute[0].t.int32_data) > 0
+ ):
+ # It's already int. Do nothing
+ pass
+ else:
+ raise NotImplementedError()
+ # Change Value info
+ origin_weight_out = helper.find_value_by_name(g, weight_node.output[0])
+ weight_node.output.pop()
+ weight_node.output.extend([reshape_node.input[1]])
+ # Delete
+ g.value_info.remove(origin_weight_out)
+ g.node.remove(cast_node)
+
+
+def eliminate_Cast_after_input(g):
+ """Eliminate the cast layer right after the input
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Cast":
+ continue
+ old_input = helper.find_input_by_name(g, node.input[0])
+ if old_input is None:
+ continue
+ next_val_info = helper.find_value_by_name(g, node.output[0])
+ shape = helper.get_shape_from_value_info(next_val_info)
+ new_val_info = onnx.helper.make_tensor_value_info(
+ next_val_info.name, node.attribute[0].i, shape
+ )
+ # Delete old value_info
+ g.input.remove(old_input)
+ g.value_info.remove(next_val_info)
+ # Append nodes to node_to_remove
+ node_to_remove.append(node)
+ # Add new input
+ g.input.extend([new_val_info])
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_consecutive_Cast(g):
+ """If two cast is next to each other, remove the first cast
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Cast":
+ continue
+ first_node = helper.find_node_by_output_name(g, node.input[0])
+ if first_node is None or first_node.op_type != "Cast":
+ continue
+ # Here we have two consecutive Cast Node
+ # Reset the input of the later node
+ node.input[0] = first_node.input[0]
+ # Remove the first node and its output value info
+ node_to_remove.append(first_node)
+ first_output = helper.find_value_by_name(g, first_node.output[0])
+ g.value_info.remove(first_output)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_Squeeze_before_Reshape(g):
+ """If Squeeze and Reshape is next to each other, remove the first node
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Reshape":
+ continue
+ first_node = helper.find_node_by_output_name(g, node.input[0])
+ if not first_node:
+ continue
+ if first_node.op_type != "Squeeze":
+ continue
+ # Here we have two consecutive Cast Node
+ # Reset the input of the later node
+ node.input[0] = first_node.input[0]
+ # Remove the first node and its output value info
+ node_to_remove.append(first_node)
+ first_output = helper.find_value_by_name(g, first_node.output[0])
+ g.value_info.remove(first_output)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_no_children_input(g):
+ """Eliminate inputs with no children at all."""
+ # Create a set of input names
+ input_names = set([i.name for i in g.input])
+ # If a name is used in any node, remove this name from the set.
+ for n in g.node:
+ for i in n.input:
+ input_names.discard(i)
+ # Remove the inputs with the left names.
+ for i in input_names:
+ info = helper.find_input_by_name(g, i)
+ g.input.remove(info)
+
+
+def eliminate_consecutive_reshape(g):
+ """Replace consecutive reshape nodes by a single node."""
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Reshape":
+ continue
+ pre_data_node = helper.find_node_by_output_name(g, node.input[0])
+ pre_shape_node = helper.find_node_by_output_name(g, node.input[1])
+ if not pre_data_node or not pre_shape_node:
+ continue
+ if pre_shape_node.op_type != "Constant":
+ continue
+ if pre_data_node.op_type != "Reshape":
+ continue
+
+ pre_pre_shape_node = helper.find_node_by_output_name(
+ g, pre_data_node.input[1]
+ )
+ if pre_pre_shape_node.op_type != "Constant":
+ continue
+
+ new_reshape_node = onnx.helper.make_node(
+ "Reshape",
+ [pre_data_node.input[0], node.input[1]],
+ [node.output[0]],
+ name=node.output[0],
+ )
+
+ g.node.extend([new_reshape_node])
+ node_to_del.append(node)
+ node_to_del.append(pre_data_node)
+ node_to_del.append(pre_pre_shape_node)
+
+ val_info_to_del1 = helper.find_value_by_name(g, node.input[0])
+ val_info_to_del2 = helper.find_value_by_name(g, pre_data_node.input[1])
+ g.value_info.remove(val_info_to_del1)
+ g.value_info.remove(val_info_to_del2)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+
+def eliminate_single_input_Concat(g):
+ """
+ Eliminate single input Concat layers
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Concat":
+ continue
+ # If this node has more than 1 input, continue.
+ if len(node.input) > 1:
+ continue
+ # If this node is output node, set its previous node as output nodes.
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ g.output.remove(todel_output)
+ g.output.extend([the_input_value])
+ node_to_remove.append(node)
+ continue
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ try:
+ g.value_info.remove(value_between)
+ except Exception:
+ print("No value info to delete while eliminating identity layers.")
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_nop_Maxpool_and_AveragePool(g):
+ """
+ Eliminate do nothing MaxPool and AveragePool layers.
+ Those layers have valid padding, 1x1 kernel and [1,1] strides.
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "MaxPool" and node.op_type != "AveragePool":
+ continue
+ # If this node is actually working, continue.
+ kernel = helper.get_list_attribute_by_name(node, "kernel_shape", "int")
+ pads = helper.get_list_attribute_by_name(node, "pads", "int")
+ strides = helper.get_list_attribute_by_name(node, "strides", "int")
+ if kernel != [1, 1] or pads != [0, 0, 0, 0] or strides != [1, 1]:
+ continue
+ # If this node is the output, set its previous node as output nodes.
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ g.output.remove(todel_output)
+ g.output.extend([the_input_value])
+ node_to_remove.append(node)
+ continue
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ try:
+ g.value_info.remove(value_between)
+ except Exception:
+ print("No value info to delete while eliminating identity layers.")
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_trivial_maxpool(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "MaxPool":
+ continue
+ pads = None
+ strides = None
+ dilation = None
+ kernel_shape = None
+ for att in node.attribute:
+ if att.name == "pads":
+ pads = list(att.ints)
+ elif att.name == "strides":
+ strides = list(att.ints)
+ elif att.name == "kernel_shape":
+ kernel_shape = list(att.ints)
+ elif att.name == "dilation":
+ dilation = list(att.ints)
+ else:
+ pass
+ if pads and any([pad != 0 for pad in pads]):
+ continue
+ if strides and any([stride != 1 for stride in strides]):
+ continue
+ if dilation and any([dila != 1 for dila in dilation]):
+ continue
+ if any([dim != 1 for dim in kernel_shape]):
+ continue
+
+ node_to_del.append(node)
+
+ next_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+
+ if next_nodes[0] is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if not output_value:
+ continue
+ else:
+ pre_val_info = helper.find_value_by_name(g, node.input[0])
+ g.output.extend([pre_val_info])
+ g.output.remove(output_value)
+
+ for next_node in next_nodes:
+ modhelper.replace_node_input(
+ next_node, node.output[0], node.input[0]
+ )
+
+ next_val_info = helper.find_value_by_name(g, node.output[0])
+ g.value_info.remove(next_val_info)
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ other.topological_sort(g)
+
+
+def eliminate_empty_value_infos(g):
+ to_remove = []
+ for value_info in g.value_info:
+ if len(value_info.type.tensor_type.shape.dim) == 0:
+ to_remove.append(value_info)
+ for value_info in to_remove:
+ g.value_info.remove(value_info)
+
+
+def eliminate_nop_pads(g):
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Pad":
+ continue
+ # Check if the Pad is empty or not
+ pads_node = helper.find_node_by_output_name(g, node.input[1])
+ pads_np = helper.constant_to_numpy(pads_node)
+ all_zero = True
+ for value in pads_np:
+ if value != 0:
+ all_zero = False
+ if not all_zero:
+ continue
+ # If this node is the output, set its previous node as output nodes.
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ g.output.remove(todel_output)
+ if helper.find_output_by_name(g, node.input[0]) is None:
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ if the_input_value is not None:
+ g.output.extend([the_input_value])
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ try:
+ g.value_info.remove(value_between)
+ except Exception:
+ helper.logger.info(
+ "No value info to delete while eliminating identity layers."
+ )
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_trivial_elementwise_calculation(g):
+ """Eliminate Add, Sub, Mul, Sub nodes which do nothing."""
+ node_to_remove = []
+ for node in g.node:
+ weight_node = None
+ if node.op_type == "Add" or node.op_type == "Sub":
+ # For add and sub, check if the weights are 0s.
+ weight_node = helper.find_node_by_output_name(g, node.input[1])
+ if weight_node is None or weight_node.op_type != "Constant":
+ continue
+ weight_np = helper.constant_to_numpy(weight_node)
+ if np.any(weight_np):
+ continue
+ elif node.op_type == "Mul" or node.op_type == "Div":
+ # For Mul and Div, check if the weights are 1s.
+ weight_node = helper.find_node_by_output_name(g, node.input[1])
+ if weight_node is None or weight_node.op_type != "Constant":
+ continue
+ weight_np = helper.constant_to_numpy(weight_node)
+ weight_np = weight_np - 1
+ if np.any(weight_np):
+ continue
+ else:
+ # For other nodes, just skip
+ continue
+ # Remove the node
+ node_to_remove.append(node)
+ output_value_info = helper.find_value_by_name(g, node.output[0])
+ if output_value_info is not None:
+ g.value_info.remove(output_value_info)
+ # Replace next node input if any.
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ if todel_output is not None:
+ g.output.remove(todel_output)
+ previous_output = helper.find_output_by_name(g, node.input[0])
+ if previous_output is None:
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ g.output.extend([the_input_value])
+ # Delete the constant node if it is not used by other nodes
+ constant_following_nodes = (
+ helper.find_following_nodes_by_input_value_name(
+ g, weight_node.output[0]
+ )
+ )
+ if len(constant_following_nodes) == 1:
+ node_to_remove.append(weight_node)
+ output_value_info = helper.find_value_by_name(
+ g, weight_node.output[0]
+ )
+ if output_value_info is not None:
+ g.value_info.remove(output_value_info)
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def eliminate_nop_cast(g):
+ """Eliminate do nothing Cast nodes."""
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Cast":
+ continue
+ # Get input value_info
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ helper.logger.debug(
+ f"Cannot find the input value_info for Cast node {node.name}. "
+ "Skip elimination check."
+ )
+ continue
+ # Get output value_info
+ output_value = helper.find_value_by_name(g, node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if output_value is None:
+ helper.logger.debug(
+ f"Cannot find the output value_info for Cast node {node.name}."
+ " Skip elimination check."
+ )
+ continue
+ # Compare the type.
+ if (
+ input_value.type.tensor_type.elem_type
+ != output_value.type.tensor_type.elem_type
+ ):
+ continue
+ # If this node is the output, set its previous node as output nodes.
+ if helper.find_output_by_name(g, node.output[0]) is not None:
+ todel_output = helper.find_output_by_name(g, node.output[0])
+ g.output.remove(todel_output)
+ if helper.find_output_by_name(g, node.input[0]) is None:
+ the_input_value = helper.find_value_by_name(g, node.input[0])
+ if the_input_value is not None:
+ g.output.extend([the_input_value])
+ # Replace the parents in all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ # Delete value info
+ value_between = helper.find_value_by_name(g, node.output[0])
+ if value_between is not None:
+ g.value_info.remove(value_between)
+ # Node is waiting for elimination
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
diff --git a/tools/optimizer_scripts/tools/fusing.py b/tools/optimizer_scripts/tools/fusing.py
new file mode 100644
index 0000000..e19ca94
--- /dev/null
+++ b/tools/optimizer_scripts/tools/fusing.py
@@ -0,0 +1,1201 @@
+import onnx.helper
+import numpy as np
+from . import helper
+from .other import topological_sort
+from .modhelper import delete_value_with_name_if_exists, replace_node_input
+
+
+def fuse_Transpose_into_Constant(g):
+ """
+ Fuse Transpose layers into the Constant layers before
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ prev_node = helper.find_node_by_output_name(g, node.input[0])
+ if prev_node is None or prev_node.op_type != "Constant":
+ continue
+
+ pre_shape, data_list = helper.constant_to_list(prev_node)
+ w = np.reshape(data_list, pre_shape)
+ w = w.transpose(node.attribute[0].ints)
+ new_shape = w.shape
+ w = w.flatten()
+
+ new_tensor = onnx.helper.make_tensor(
+ name=prev_node.name + "_data",
+ data_type=prev_node.attribute[0].t.data_type,
+ dims=new_shape,
+ vals=w.tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant",
+ [],
+ [node.output[0]],
+ name=node.output[0],
+ value=new_tensor,
+ )
+
+ value_between = helper.find_value_by_name(g, prev_node.output[0])
+ value_type = value_between.type.tensor_type.elem_type
+ g.value_info.remove(value_between)
+
+ g.node.extend([new_node])
+ node_to_remove.append(node)
+ node_to_remove.append(prev_node)
+
+ if new_node.output[0] not in [i.name for i in g.value_info]:
+ new_value = onnx.helper.make_tensor_value_info(
+ name=new_node.output[0], elem_type=value_type, shape=new_shape
+ )
+ g.value_info.extend([new_value])
+ if new_node.output[0]:
+ val_info_to_del = helper.find_value_by_name(
+ g, new_node.output[0]
+ )
+ g.value_info.remove(val_info_to_del)
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+ topological_sort(g)
+
+
+def fuse_Add_into_Conv(g):
+ """
+ Fuse Transpose layers into the Constant layers before
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Add":
+ continue
+ conv_node = helper.find_node_by_output_name(g, node.input[0])
+ cons_node = helper.find_node_by_output_name(g, node.input[1])
+ if conv_node is None or cons_node is None:
+ continue
+ if conv_node.op_type != "Conv" or cons_node.op_type != "Constant":
+ continue
+ if len(conv_node.input) > 2:
+ continue
+ # This layer should be fused. Connect constant node into convolution.
+ add_node = node
+ conv_node.input.extend([cons_node.output[0]])
+ old_value = helper.find_value_by_name(g, conv_node.output[0])
+ conv_node.output[0] = add_node.output[0]
+ # Remove origin conv_node_output
+ g.value_info.remove(old_value)
+ # Remove current node
+ node_to_remove.append(add_node)
+ # Apply changes to the model
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def fuse_BN_into_Gemm(g):
+ """Fuse the following BN into the previous Gemm.
+
+ :param g: the graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check for BN and Gemm
+ if node.op_type != "BatchNormalization":
+ continue
+ gemm_node = helper.find_node_by_output_name(g, node.input[0])
+ if gemm_node is None:
+ continue
+ if gemm_node.op_type != "Gemm":
+ continue
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, gemm_node.output[0]
+ )
+ )
+ > 1
+ ):
+ continue
+ bn_node = node
+ # Get original weights
+ gemm_b_node = helper.find_node_by_output_name(g, gemm_node.input[1])
+ gemm_b = helper.constant_to_numpy(gemm_b_node)
+ gemm_c_node = helper.find_node_by_output_name(g, gemm_node.input[2])
+ gemm_c = helper.constant_to_numpy(gemm_c_node)
+ bn_scale_node = helper.find_node_by_output_name(g, bn_node.input[1])
+ bn_scale = helper.constant_to_numpy(bn_scale_node)
+ bn_bias_node = helper.find_node_by_output_name(g, bn_node.input[2])
+ bn_bias = helper.constant_to_numpy(bn_bias_node)
+ bn_mean_node = helper.find_node_by_output_name(g, bn_node.input[3])
+ bn_mean = helper.constant_to_numpy(bn_mean_node)
+ bn_var_node = helper.find_node_by_output_name(g, bn_node.input[4])
+ bn_var = helper.constant_to_numpy(bn_var_node)
+ # Apply attributes
+ # epsilon
+ epsilon = helper.get_attribute_by_name(bn_node, "epsilon")
+ if epsilon is None:
+ epsilon = 0.00001
+ else:
+ epsilon = epsilon.f
+ bn_var = bn_var + epsilon
+ # alpha
+ alpha = helper.get_attribute_by_name(gemm_node, "alpha")
+ if alpha is None:
+ alpha = 1
+ else:
+ alpha = alpha.f
+ gemm_b = gemm_b * alpha
+ # beta
+ beta = helper.get_attribute_by_name(gemm_node, "beta")
+ if beta is None:
+ beta = 1
+ else:
+ beta = beta.f
+ gemm_c = gemm_c * beta
+ # transA
+ transA = helper.get_attribute_by_name(gemm_node, "transA")
+ if transA is not None and transA.i == 1:
+ raise RuntimeError("Do not support transA")
+ # transB
+ transB = helper.get_attribute_by_name(gemm_node, "transB")
+ if transB is not None and transB.i == 1:
+ gemm_b = gemm_b.transpose()
+ # Calculate new weights
+ new_gemm_b = gemm_b * bn_scale / np.sqrt(bn_var)
+ new_gemm_c = (gemm_c - bn_mean) * bn_scale / np.sqrt(bn_var) + bn_bias
+ # Replace original weights
+ new_gemm_b_node = helper.numpy_to_constant(
+ gemm_b_node.name + "_fused", new_gemm_b
+ )
+ new_gemm_c_node = helper.numpy_to_constant(
+ gemm_c_node.name + "_fused", new_gemm_c
+ )
+ g.node.extend([new_gemm_b_node, new_gemm_c_node])
+ node_to_remove.extend(
+ [
+ gemm_b_node,
+ gemm_c_node,
+ bn_node,
+ bn_scale_node,
+ bn_bias_node,
+ bn_mean_node,
+ bn_var_node,
+ ]
+ )
+ # Modify attributes
+ # alpha
+ alpha = helper.get_attribute_by_name(gemm_node, "alpha")
+ if alpha is not None:
+ alpha.f = 1.0
+ # beta
+ beta = helper.get_attribute_by_name(gemm_node, "beta")
+ if beta is not None:
+ beta.f = 1.0
+ # transB
+ transB = helper.get_attribute_by_name(gemm_node, "transB")
+ if transB is not None:
+ transB.i = 0
+ # Connect the new graph
+ gemm_node.input[1] = new_gemm_b_node.output[0]
+ gemm_node.input[2] = new_gemm_c_node.output[0]
+ gemm_b_value = helper.find_value_by_name(g, gemm_b_node.output[0])
+ gemm_c_value = helper.find_value_by_name(g, gemm_c_node.output[0])
+ gemm_b_value.name = new_gemm_b_node.output[0]
+ gemm_c_value.name = new_gemm_c_node.output[0]
+ gemm_value = helper.find_value_by_name(g, gemm_node.output[0])
+ g.value_info.remove(gemm_value)
+ gemm_node.output[0] = bn_node.output[0]
+ for i in range(1, 5):
+ value = helper.find_value_by_name(g, bn_node.input[i])
+ g.value_info.remove(value)
+ # Remove useless nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def fuse_BN_with_Reshape_into_Gemm(g):
+ """Fuse the following BN into the previous Gemm, even with Reshape or \\
+ Squeeze and Unsqueeze surrounding.
+
+ :param g: the graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check for BN and Gemm pattern: Gemm A BN B
+ # Find BatchNorm Node
+ if node.op_type != "BatchNormalization":
+ continue
+ bn_node = node
+ # Find A Node
+ a_node = helper.find_node_by_output_name(g, node.input[0])
+ if a_node is None or len(a_node.input) == 0:
+ continue
+ # Find Gemm Node
+ gemm_node = helper.find_node_by_output_name(g, a_node.input[0])
+ if gemm_node is None or gemm_node.op_type != "Gemm":
+ continue
+ # Find B Node
+ b_node_list = helper.find_following_nodes_by_input_value_name(
+ g, bn_node.output[0]
+ )
+ if len(b_node_list) == 0:
+ the_output = helper.find_output_by_name(g, bn_node.output[0])
+ if the_output is None:
+ continue
+ b_node = None
+ elif len(b_node_list) > 1:
+ continue
+ else:
+ b_node = b_node_list[0]
+ # Check for branches
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, gemm_node.output[0]
+ )
+ )
+ > 1
+ ):
+ continue
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, a_node.output[0]
+ )
+ )
+ > 1
+ ):
+ continue
+ # Check type of A
+ if a_node.op_type == "Unsqueeze":
+ axes = helper.get_attribute_by_name(a_node, "axes")
+ if axes.ints != [2]:
+ continue
+ elif a_node.op_type == "Reshape":
+ a = helper.constant_to_list(
+ helper.find_node_by_output_name(g, a_node.input[1])
+ )[1]
+ if len(a) != 3 or a[2] != 1:
+ continue
+ else:
+ continue
+ # Check type of B
+ if b_node is None:
+ pass
+ elif b_node.op_type == "Flatten":
+ pass
+ elif b_node.op_type == "Squeeze":
+ axes = helper.get_attribute_by_name(a_node, "axes")
+ if axes.ints != [2]:
+ continue
+ elif b_node.op_type == "Reshape":
+ a = helper.constant_to_list(
+ helper.find_node_by_output_name(g, b_node.input[1])
+ )[1]
+ if len(a) != 2:
+ continue
+ else:
+ continue
+ # Construct new Nodes
+ # Get original weights
+ gemm_b_node = helper.find_node_by_output_name(g, gemm_node.input[1])
+ gemm_b = helper.constant_to_numpy(gemm_b_node)
+ gemm_c_node = helper.find_node_by_output_name(g, gemm_node.input[2])
+ gemm_c = helper.constant_to_numpy(gemm_c_node)
+ bn_scale_node = helper.find_node_by_output_name(g, bn_node.input[1])
+ bn_scale = helper.constant_to_numpy(bn_scale_node)
+ bn_bias_node = helper.find_node_by_output_name(g, bn_node.input[2])
+ bn_bias = helper.constant_to_numpy(bn_bias_node)
+ bn_mean_node = helper.find_node_by_output_name(g, bn_node.input[3])
+ bn_mean = helper.constant_to_numpy(bn_mean_node)
+ bn_var_node = helper.find_node_by_output_name(g, bn_node.input[4])
+ bn_var = helper.constant_to_numpy(bn_var_node)
+ # Apply attributes
+ # epsilon
+ epsilon = helper.get_attribute_by_name(bn_node, "epsilon")
+ if epsilon is None:
+ epsilon = 0.00001
+ else:
+ epsilon = epsilon.f
+ bn_var = bn_var + epsilon
+ # alpha
+ alpha = helper.get_attribute_by_name(gemm_node, "alpha")
+ if alpha is None:
+ alpha = 1
+ else:
+ alpha = alpha.f
+ gemm_b = gemm_b * alpha
+ # beta
+ beta = helper.get_attribute_by_name(gemm_node, "beta")
+ if beta is None:
+ beta = 1
+ else:
+ beta = beta.f
+ gemm_c = gemm_c * beta
+ # transA
+ transA = helper.get_attribute_by_name(gemm_node, "transA")
+ if transA is not None and transA.i == 1:
+ raise RuntimeError("Do not support transA")
+ # transB
+ transB = helper.get_attribute_by_name(gemm_node, "transB")
+ if transB is not None and transB.i == 1:
+ gemm_b = gemm_b.transpose()
+ # Calculate new weights
+ new_gemm_b = gemm_b * bn_scale / np.sqrt(bn_var)
+ new_gemm_c = (gemm_c - bn_mean) * bn_scale / np.sqrt(bn_var) + bn_bias
+ # Replace original weights
+ new_gemm_b_node = helper.numpy_to_constant(
+ gemm_b_node.name + "_fused", new_gemm_b
+ )
+ new_gemm_c_node = helper.numpy_to_constant(
+ gemm_c_node.name + "_fused", new_gemm_c
+ )
+ g.node.extend([new_gemm_b_node, new_gemm_c_node])
+ # Modify attributes
+ # alpha
+ alpha = helper.get_attribute_by_name(gemm_node, "alpha")
+ if alpha is not None:
+ alpha.f = 1.0
+ # beta
+ beta = helper.get_attribute_by_name(gemm_node, "beta")
+ if beta is not None:
+ beta.f = 1.0
+ # transB
+ transB = helper.get_attribute_by_name(gemm_node, "transB")
+ if transB is not None:
+ transB.i = 0
+ # Remove useless nodes
+ node_to_remove.extend(
+ [
+ gemm_b_node,
+ gemm_c_node,
+ bn_node,
+ bn_scale_node,
+ bn_bias_node,
+ bn_mean_node,
+ bn_var_node,
+ a_node,
+ ]
+ )
+ if a_node.op_type == "Reshape":
+ node_to_remove.append(
+ helper.find_node_by_output_name(g, a_node.input[1])
+ )
+ if b_node is not None:
+ node_to_remove.append(b_node)
+ if b_node.op_type == "Reshape":
+ node_to_remove.append(
+ helper.find_node_by_output_name(g, b_node.input[1])
+ )
+ # Delete useless value infos
+ value = helper.find_value_by_name(g, a_node.output[0])
+ g.value_info.remove(value)
+ if a_node.op_type == "Reshape":
+ value = helper.find_value_by_name(g, a_node.input[1])
+ g.value_info.remove(value)
+ for i in range(1, 5):
+ value = helper.find_value_by_name(g, bn_node.input[i])
+ g.value_info.remove(value)
+ value = helper.find_value_by_name(g, bn_node.output[0])
+ if value is not None:
+ g.value_info.remove(value)
+ if b_node is not None:
+ value = helper.find_value_by_name(g, gemm_node.output[0])
+ g.value_info.remove(value)
+ if b_node.op_type == "Reshape":
+ value = helper.find_value_by_name(g, b_node.input[1])
+ g.value_info.remove(value)
+ # Connect the new graph
+ # Connect Gemm new weights
+ gemm_node.input[1] = new_gemm_b_node.output[0]
+ gemm_node.input[2] = new_gemm_c_node.output[0]
+ gemm_b_value = helper.find_value_by_name(g, gemm_b_node.output[0])
+ gemm_c_value = helper.find_value_by_name(g, gemm_c_node.output[0])
+ gemm_b_value.name = new_gemm_b_node.output[0]
+ gemm_b_value.type.tensor_type.shape.dim[
+ 0
+ ].dim_value = new_gemm_b.shape[0]
+ gemm_b_value.type.tensor_type.shape.dim[
+ 1
+ ].dim_value = new_gemm_b.shape[1]
+ gemm_c_value.name = new_gemm_c_node.output[0]
+ if b_node is None:
+ # If b node is None, set the Gemm output as the graph output
+ output_value = helper.find_output_by_name(g, bn_node.output[0])
+ g.output.remove(output_value)
+ g.output.extend(
+ [helper.find_value_by_name(g, gemm_node.output[0])]
+ )
+ else:
+ # Else, set node B output as gemm output
+ gemm_node.output[0] = b_node.output[0]
+ # Remove useless nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def fuse_Gemm_into_Gemm(g):
+ """Fuse the previous Gemm into the following Gemm.
+
+ :param g: the graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check for Gemm and Gemm
+ if node.op_type != "Gemm":
+ continue
+ prev_node = helper.find_node_by_output_name(g, node.input[0])
+ if prev_node is None:
+ continue
+ if prev_node.op_type != "Gemm":
+ continue
+ # Get original weights
+ prev_b_node = helper.find_node_by_output_name(g, prev_node.input[1])
+ prev_b = helper.constant_to_numpy(prev_b_node)
+ prev_c_node = helper.find_node_by_output_name(g, prev_node.input[2])
+ prev_c = helper.constant_to_numpy(prev_c_node)
+ b_node = helper.find_node_by_output_name(g, node.input[1])
+ b = helper.constant_to_numpy(b_node)
+ c_node = helper.find_node_by_output_name(g, node.input[2])
+ c = helper.constant_to_numpy(c_node)
+ # Apply attributes
+ # alpha
+ alpha = helper.get_attribute_by_name(node, "alpha")
+ if alpha is None:
+ alpha = 1
+ else:
+ alpha = alpha.f
+ b = b * alpha
+ alpha = helper.get_attribute_by_name(prev_node, "alpha")
+ if alpha is None:
+ alpha = 1
+ else:
+ alpha = alpha.f
+ prev_b = prev_b * alpha
+ # beta
+ beta = helper.get_attribute_by_name(node, "beta")
+ if beta is None:
+ beta = 1
+ else:
+ beta = beta.f
+ c = c * beta
+ beta = helper.get_attribute_by_name(prev_node, "beta")
+ if beta is None:
+ beta = 1
+ else:
+ beta = beta.f
+ prev_c = prev_c * beta
+ # transA
+ transA = helper.get_attribute_by_name(node, "transA")
+ if transA is not None and transA.i == 1:
+ raise RuntimeError("Do not support transA")
+ transA = helper.get_attribute_by_name(prev_node, "transA")
+ if transA is not None and transA.i == 1:
+ raise RuntimeError("Do not support transA")
+ # transB
+ transB = helper.get_attribute_by_name(node, "transB")
+ if transB is not None and transB.i == 1:
+ b = b.transpose()
+ transB = helper.get_attribute_by_name(prev_node, "transB")
+ if transB is not None and transB.i == 1:
+ prev_b = prev_b.transpose()
+ # Calculate new weights
+ new_b = prev_b.dot(b)
+ new_c = prev_c.dot(b) + c
+ # Replace original weights
+ new_b_node = helper.numpy_to_constant(b_node.name + "_fused", new_b)
+ new_c_node = helper.numpy_to_constant(c_node.name + "_fused", new_c)
+ g.node.extend([new_b_node, new_c_node])
+ node_to_remove.extend(
+ [b_node, c_node, prev_b_node, prev_c_node, prev_node]
+ )
+ # Modify attributes
+ # alpha
+ alpha = helper.get_attribute_by_name(node, "alpha")
+ if alpha is not None:
+ alpha.f = 1.0
+ # beta
+ beta = helper.get_attribute_by_name(node, "beta")
+ if beta is not None:
+ beta.f = 1.0
+ # transB
+ transB = helper.get_attribute_by_name(node, "transB")
+ if transB is not None:
+ transB.i = 0
+ # Connect the new graph
+ node.input[0] = prev_node.input[0]
+ delete_value_with_name_if_exists(g, prev_node.output[0])
+ for i in range(1, 3):
+ delete_value_with_name_if_exists(g, prev_node.input[i])
+ delete_value_with_name_if_exists(g, node.input[i])
+ node.input[1] = new_b_node.output[0]
+ node.input[2] = new_c_node.output[0]
+ # Remove useless nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def fuse_MatMul_and_Add_into_Gemm(g):
+ """
+ Fuse MatMul and Add layers into a new Gemm layers.
+
+ :param g: the onnx graph
+ :raises ValueError: MatMul must be followed by an Add node
+ """
+ node_to_remove = []
+ node_to_add = []
+ for node in g.node:
+ if node.op_type != "MatMul":
+ continue
+ add_node = None
+ for i in g.node:
+ if not i.input:
+ continue
+ if i.input[0] == node.output[0]:
+ add_node = i
+ break
+ value_to_remove = helper.find_value_by_name(g, node.output[0])
+ if (
+ add_node is None
+ or value_to_remove is None
+ or add_node.op_type != "Add"
+ ):
+ continue
+ input_list = node.input
+ input_list.append(add_node.input[1]),
+ new_node = onnx.helper.make_node(
+ "Gemm",
+ input_list,
+ add_node.output,
+ name=node.name,
+ alpha=1.0,
+ beta=1.0,
+ transA=0,
+ transB=0,
+ )
+ node_to_add.append(new_node)
+ node_to_remove.append(node)
+ node_to_remove.append(add_node)
+ g.value_info.remove(value_to_remove)
+ for node in node_to_remove:
+ g.node.remove(node)
+ g.node.extend(node_to_add)
+
+
+def fuse_consecutive_transposes(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ if pre_node.op_type != "Transpose":
+ continue
+
+ pre_permutation = list(pre_node.attribute[0].ints)
+ cur_permutation = list(node.attribute[0].ints)
+ if len(pre_permutation) != len(cur_permutation):
+ continue
+
+ new_permutation = []
+ for ind in cur_permutation:
+ new_permutation.append(pre_permutation[ind])
+
+ new_trans_node = onnx.helper.make_node(
+ "Transpose",
+ [pre_node.input[0]],
+ [node.output[0]],
+ name=node.name,
+ perm=new_permutation,
+ )
+
+ g.node.extend([new_trans_node])
+ node_to_del.extend([pre_node, node])
+
+ mid_val_info = helper.find_value_by_name(g, node.input[0])
+ if mid_val_info:
+ g.value_info.remove(mid_val_info)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ topological_sort(g)
+
+
+def fuse_mul_and_add_into_bn(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Add":
+ continue
+ add_node = node
+ input_nodes_add = [
+ helper.find_node_by_output_name(g, input_name)
+ for input_name in add_node.input
+ ]
+ if any([n is None for n in input_nodes_add]):
+ continue
+ mul_node, const_add = None, None
+ for input_node_add in input_nodes_add:
+ if input_node_add.op_type == "Mul":
+ mul_node = input_node_add
+ elif input_node_add.op_type == "Constant":
+ const_add = input_node_add
+ else:
+ pass
+ if not mul_node or not const_add:
+ continue
+ data_input_name, const_mul = None, None
+ for input_name in mul_node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ if not input_node:
+ data_input_name = input_name
+ elif input_node.op_type == "Constant":
+ if not const_mul:
+ const_mul = input_node
+ else:
+ data_input_name = input_name
+ else:
+ data_input_name = input_name
+
+ if not const_mul:
+ continue
+
+ scale_shape, scale_data = helper.constant_to_list(const_mul)
+ bias_shape, __ = helper.constant_to_list(const_add)
+ c_dim = len(scale_data)
+ if scale_shape != bias_shape:
+ continue
+
+ data_input_value = helper.find_value_by_name(g, data_input_name)
+ if data_input_value is None:
+ data_input_value = helper.find_input_by_name(g, data_input_name)
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ data_input_value
+ )
+ # only allow 4 dim data input due to the hardware limitation
+ if (
+ previous_node_output_shape is None
+ or len(previous_node_output_shape) != 4
+ ):
+ continue
+
+ # check if mul's dim and input channel dimension are matched
+ if previous_node_output_shape[1] != c_dim:
+ continue
+
+ if scale_shape == [1, c_dim, 1, 1]:
+ # remove all '1'
+ for _ in range(3):
+ const_add.attribute[0].t.dims.remove(1)
+ const_mul.attribute[0].t.dims.remove(1)
+ elif scale_shape == [1, c_dim]:
+ # remove all '1'
+ const_add.attribute[0].t.dims.remove(1)
+ const_mul.attribute[0].t.dims.remove(1)
+ elif scale_shape == 1 and c_dim == 1:
+ # Single value weight
+ const_add.attribute[0].t.dims.append(1)
+ const_mul.attribute[0].t.dims.append(1)
+ else:
+ continue
+
+ bn_name = add_node.output[0]
+ const_mean = helper.list_to_constant(
+ bn_name + "_mean", [c_dim], [0.0 for _ in range(c_dim)]
+ )
+ const_var = helper.list_to_constant(
+ bn_name + "_var", [c_dim], [1.0 for _ in range(c_dim)]
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ data_input_name,
+ const_mul.output[0],
+ const_add.output[0],
+ const_mean.output[0],
+ const_var.output[0],
+ ],
+ [add_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ mid_val_info = helper.find_value_by_name(g, mul_node.output[0])
+ scale_val_info = helper.find_value_by_name(g, const_mul.output[0])
+ bais_val_info = helper.find_value_by_name(g, const_add.output[0])
+ g.value_info.remove(mid_val_info)
+ g.value_info.remove(scale_val_info)
+ g.value_info.remove(bais_val_info)
+
+ new_scale_val_info = onnx.helper.make_tensor_value_info(
+ const_mul.output[0], const_mul.attribute[0].t.data_type, [c_dim]
+ )
+ new_bais_val_info = onnx.helper.make_tensor_value_info(
+ const_add.output[0], const_add.attribute[0].t.data_type, [c_dim]
+ )
+ mean_val_info = onnx.helper.make_tensor_value_info(
+ const_mean.output[0], const_mean.attribute[0].t.data_type, [c_dim]
+ )
+ var_val_info = onnx.helper.make_tensor_value_info(
+ const_var.output[0], const_var.attribute[0].t.data_type, [c_dim]
+ )
+
+ g.value_info.extend([new_scale_val_info])
+ g.value_info.extend([new_bais_val_info])
+ g.value_info.extend([mean_val_info])
+ g.value_info.extend([var_val_info])
+ g.node.extend([bn_node])
+ g.node.extend([const_mean])
+ g.node.extend([const_var])
+ node_to_del.extend([mul_node, add_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def fuse_mul_and_add_into_gemm(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Add":
+ continue
+ add_node = node
+ mul_node = helper.find_node_by_output_name(g, add_node.input[0])
+ if not mul_node or mul_node.op_type != "Mul":
+ continue
+ mul_const = helper.find_node_by_output_name(g, mul_node.input[1])
+ if not mul_const or mul_const.op_type != "Constant":
+ continue
+ add_const = helper.find_node_by_output_name(g, add_node.input[1])
+ if not add_const or add_const.op_type != "Constant":
+ continue
+
+ input_val = helper.find_value_by_name(g, mul_node.input[0])
+ if not input_val:
+ input_val = helper.find_input_by_name(g, mul_node.input[0])
+ if not input_val:
+ continue
+
+ _, input_shape = helper.find_size_shape_from_value(input_val)
+ if not input_shape:
+ continue
+
+ dim = int(np.prod(input_shape))
+ if input_shape != [1, dim]:
+ continue
+
+ mul_const_shape, mul_const_data = helper.constant_to_list(mul_const)
+ add_const_shape, __ = helper.constant_to_list(add_const)
+
+ if len(mul_const_shape) != 1 or mul_const_shape[0] != dim:
+ continue
+ if len(add_const_shape) != 1 or add_const_shape[0] != dim:
+ continue
+
+ b_data = np.zeros([dim, dim])
+ for i in range(dim):
+ b_data[i][i] = mul_const_data[i]
+ b_data = b_data.flatten().tolist()
+ b_tensor = onnx.helper.make_tensor(
+ name=mul_const.name + "_tensor",
+ data_type=mul_const.attribute[0].t.data_type,
+ dims=[dim, dim],
+ vals=b_data,
+ )
+ b_const_node = onnx.helper.make_node(
+ "Constant",
+ [],
+ [mul_const.output[0]],
+ value=b_tensor,
+ name=mul_const.output[0],
+ )
+
+ add_const.attribute[0].t.dims.insert(0, 1)
+
+ gemm_node = onnx.helper.make_node(
+ "Gemm",
+ [mul_node.input[0], b_const_node.output[0], add_const.output[0]],
+ [add_node.output[0]],
+ name=add_node.output[0],
+ )
+
+ g.node.extend([gemm_node, b_const_node])
+ node_to_del.extend([mul_const, mul_node, add_node])
+
+ val_info_mid = helper.find_value_by_name(g, mul_node.output[0])
+ val_info_mul_const = helper.find_value_by_name(g, mul_const.output[0])
+ val_info_add_const = helper.find_value_by_name(g, add_const.output[0])
+ if val_info_mid:
+ g.value_info.remove(val_info_mid)
+ if val_info_mul_const:
+ g.value_info.remove(val_info_mul_const)
+ if val_info_add_const:
+ g.value_info.remove(val_info_add_const)
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def fuse_conv_and_add_into_conv(g):
+ node_to_del = []
+ for node in g.node:
+ # Check if two nodes can be fused
+ if node.op_type != "Add":
+ continue
+ add_node = node
+ add_const = helper.find_node_by_output_name(g, add_node.input[1])
+ if not add_const or add_const.op_type != "Constant":
+ continue
+
+ conv_node = helper.find_node_by_output_name(g, add_node.input[0])
+ if not conv_node or conv_node.op_type != "Conv":
+ continue
+ weight_node = helper.find_node_by_output_name(g, conv_node.input[1])
+ if not weight_node or weight_node.op_type != "Constant":
+ continue
+
+ m_dim = weight_node.attribute[0].t.dims[0]
+ if add_const.attribute[0].t.dims != [1, m_dim, 1, 1]:
+ continue
+ for _ in range(3):
+ add_const.attribute[0].t.dims.remove(1)
+
+ # Link the add weight to constant.
+ conv_node.input.extend([add_const.output[0]])
+
+ # Remove the node
+ node_to_del.append(node)
+ output_value_info = helper.find_value_by_name(g, add_node.output[0])
+ if output_value_info is not None:
+ g.value_info.remove(output_value_info)
+ add_weight_value_info = helper.find_value_by_name(
+ g, add_const.output[0]
+ )
+ if add_weight_value_info is not None:
+ g.value_info.remove(add_weight_value_info)
+ # Replace next node input if any.
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, add_node.output[0]
+ )
+ for following_node in following_nodes:
+ replace_node_input(
+ following_node, add_node.output[0], add_node.input[0]
+ )
+ # Replace output if any
+ todel_output = helper.find_output_by_name(g, add_node.output[0])
+ if todel_output is not None:
+ g.output.remove(todel_output)
+ previous_output = helper.find_output_by_name(g, add_node.input[0])
+ if previous_output is None:
+ the_input_value = helper.find_value_by_name(
+ g, add_node.input[0]
+ )
+ g.output.extend([the_input_value])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def fuse_consecutive_reducemean(g):
+ node_to_del = []
+ for node in g.node:
+ # Find consecutive ReduceMean
+ if node.op_type != "ReduceMean":
+ continue
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ if pre_node is None or pre_node.op_type != "ReduceMean":
+ continue
+ # Check attributes
+ pre_keepdims = helper.get_var_attribute_by_name(
+ pre_node, "keepdims", "int"
+ )
+ pre_axes = helper.get_list_attribute_by_name(pre_node, "axes", "int")
+ cur_keepdims = helper.get_var_attribute_by_name(
+ node, "keepdims", "int"
+ )
+ cur_axes = helper.get_list_attribute_by_name(node, "axes", "int")
+ if pre_keepdims != 0 or cur_keepdims != 0:
+ continue
+ axes = sorted(pre_axes + cur_axes)
+ if axes != [2, 3]:
+ continue
+ # Merge two ReduceMean into GlobalAveragePool.
+ new_gap_node = onnx.helper.make_node(
+ "GlobalAveragePool",
+ [pre_node.input[0]],
+ [node.output[0] + "_intermedia"],
+ name=node.name + "_gap",
+ )
+ new_flatten_node = onnx.helper.make_node(
+ "Flatten",
+ [node.output[0] + "_intermedia"],
+ [node.output[0]],
+ name=node.name + "_flatten",
+ axis=1,
+ )
+
+ # Clean up
+ g.node.extend([new_gap_node, new_flatten_node])
+ node_to_del.extend([pre_node, node])
+ mid_val_info = helper.find_value_by_name(g, node.input[0])
+ if mid_val_info:
+ g.value_info.remove(mid_val_info)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ topological_sort(g)
+
+
+def fuse_slice_nodes_into_conv(g):
+ # define pattern checker
+ def check_is_slice(node):
+ if node.op_type == "Concat":
+ return True
+ if node.op_type != "Slice":
+ return False
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ if len(following_nodes) != 1:
+ return False
+ # also check attributes
+ if len(node.input) != 5:
+ return False
+ # starts should be 0 or 1
+ starts_node = helper.find_node_by_output_name(g, node.input[1])
+ if starts_node.op_type != "Constant":
+ return False
+ _, starts_list = helper.constant_to_list(starts_node)
+ for num in starts_list:
+ if num != 0 and num != 1:
+ return False
+ # ends
+ ends_node = helper.find_node_by_output_name(g, node.input[2])
+ if ends_node.op_type != "Constant":
+ return False
+ # axes should be 2 or 3
+ axes_node = helper.find_node_by_output_name(g, node.input[3])
+ if axes_node.op_type != "Constant":
+ return False
+ _, axes_list = helper.constant_to_list(axes_node)
+ for num in axes_list:
+ if num != 2 and num != 3:
+ return False
+ # Steps can only be 2
+ steps_node = helper.find_node_by_output_name(g, node.input[4])
+ if steps_node.op_type != "Constant":
+ return False
+ _, steps_list = helper.constant_to_list(steps_node)
+ for num in steps_list:
+ if num != 2:
+ return False
+ # Recursion
+ return check_is_slice(following_nodes[0])
+
+ # defind concat finder
+ def find_concat_node(node):
+ while node.op_type != "Concat":
+ node = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )[0]
+ return node
+
+ # define remove node function.
+ def remove_nodes(input_name):
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, input_name
+ )
+ # Remove concat directly
+ if (
+ len(following_nodes) == 1
+ and following_nodes[0].op_type == "Concat"
+ ):
+ g.node.remove(following_nodes[0])
+ return
+ for following_node in following_nodes:
+ # Recursion first
+ remove_nodes(following_node.output[0])
+ # Remove weights
+ for i in range(1, len(following_node.input)):
+ if (
+ len(
+ helper.find_following_nodes_by_input_value_name(
+ g, following_node.input[i]
+ )
+ )
+ > 1
+ ):
+ # More than one following nodes. Skip.
+ continue
+ input_weight = helper.find_node_by_output_name(
+ g, following_node.input[i]
+ )
+ g.node.remove(input_weight)
+ # Remove Slice nodes
+ g.node.remove(following_node)
+
+ # define remove value_info function
+ def remove_value_infos(input_name):
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, input_name
+ )
+ if following_nodes[0].op_type == "Concat":
+ return
+ for following_node in following_nodes:
+ output_value = helper.find_value_by_name(
+ g, following_node.output[0]
+ )
+ # Remove output values
+ if output_value is not None:
+ g.value_info.remove(output_value)
+ # Remove weight values
+ for i in range(1, len(following_node.input)):
+ input_value = helper.find_value_by_name(
+ g, following_node.input[i]
+ )
+ if input_value is not None:
+ g.value_info.remove(input_value)
+ # Recursion
+ remove_value_infos(following_node.output[0])
+
+ # define get slice position
+ def get_slice_position(final_slice_output):
+ slice_position = [0, 0]
+ prev_node = helper.find_node_by_output_name(g, final_slice_output)
+ while prev_node is not None:
+ starts_np = helper.constant_to_numpy(
+ helper.find_node_by_output_name(g, prev_node.input[1])
+ )
+ axes_np = helper.constant_to_numpy(
+ helper.find_node_by_output_name(g, prev_node.input[3])
+ )
+ for i in range(len(axes_np)):
+ if axes_np[i] == 2:
+ slice_position[0] = starts_np[i]
+ elif axes_np[i] == 3:
+ slice_position[1] = starts_np[i]
+ prev_node = helper.find_node_by_output_name(g, prev_node.input[0])
+ return slice_position
+
+ # Check pattern from each input
+ for input_value in g.input:
+ nodes_after_input = helper.find_following_nodes_by_input_value_name(
+ g, input_value.name
+ )
+ pattern_matched = True
+ for following_node in nodes_after_input:
+ if following_node.op_type != "Slice":
+ pattern_matched = False
+ break
+ else:
+ pattern_matched = check_is_slice(following_node)
+ if not pattern_matched:
+ continue
+ # Pattern found. Check limitation
+ # Currently only support 2D
+ if len(nodes_after_input) != 4:
+ continue
+ # Get the concat node
+ concat_node = find_concat_node(nodes_after_input[0])
+ # Get basic information
+ input_shape = helper.get_shape_from_value_info(input_value)
+ channel_num = input_shape[1]
+ # Construct weight
+ weight_np = np.zeros(
+ (input_shape[1] * 4, input_shape[1], 3, 3), dtype=np.float32
+ )
+ for i in range(4):
+ # Check each branch
+ slice_position = get_slice_position(concat_node.input[i])
+ for j in range(channel_num):
+ weight_np[
+ i * channel_num + j,
+ j,
+ slice_position[0],
+ slice_position[1],
+ ] = 1
+ weight_node = helper.numpy_to_constant(
+ concat_node.name + "_weight", weight_np
+ )
+ # Construct Conv node
+ new_conv = onnx.helper.make_node(
+ "Conv",
+ [input_value.name, concat_node.name + "_weight"],
+ [concat_node.output[0]],
+ name=concat_node.name + "_fused",
+ dilations=[1, 1],
+ group=1,
+ kernel_shape=[3, 3],
+ strides=[2, 2],
+ pads=[0, 0, 2, 2],
+ )
+ # Delete old nodes, weights and value_infos
+ remove_value_infos(input_value.name)
+ remove_nodes(input_value.name)
+ # Replace node
+ g.node.append(weight_node)
+ g.node.append(new_conv)
+
+
+def fuse_relu_min_into_clip(g):
+ node_to_del = []
+ for node in g.node:
+ # Check Min node
+ if node.op_type != "Min":
+ continue
+ min_node = node
+ # Check Constant node
+ min_const = helper.find_node_by_output_name(g, min_node.input[1])
+ if not min_const or min_const.op_type != "Constant":
+ continue
+ min_shape, min_value = helper.constant_to_list(min_const)
+ if min_shape != 1:
+ continue
+ # Check Relu node
+ relu_node = helper.find_node_by_output_name(g, min_node.input[0])
+ if not relu_node or relu_node.op_type != "Relu":
+ continue
+
+ # Create Clip node
+ relu_min_const_node = helper.list_to_constant(
+ relu_node.name + "_min_value", [], [0.0]
+ )
+ clip_node = onnx.helper.make_node(
+ "Clip",
+ [
+ relu_node.input[0],
+ relu_min_const_node.output[0],
+ min_const.output[0],
+ ],
+ [min_node.output[0]],
+ name=min_node.name,
+ )
+
+ node_to_del.extend([relu_node, min_node])
+
+ old_relu_const_val_info = helper.find_value_by_name(
+ g, min_node.input[0]
+ )
+ if old_relu_const_val_info:
+ g.value_info.remove(old_relu_const_val_info)
+ g.node.extend([relu_min_const_node, clip_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
diff --git a/tools/optimizer_scripts/tools/general_graph.py b/tools/optimizer_scripts/tools/general_graph.py
new file mode 100644
index 0000000..f9904f2
--- /dev/null
+++ b/tools/optimizer_scripts/tools/general_graph.py
@@ -0,0 +1,85 @@
+from collections import deque
+
+
+class Node:
+ """A Node which maps a node proto. It has pointers to its parents and
+ children.
+ """
+
+ def __init__(self, onnx_node):
+ """Initialize a node. This initialization only set up the mapping to
+ node proto. The pointers should be set up by outside.
+ """
+ self.name = None
+ self.parents = []
+ self.children = []
+ self.proto = None
+ self.output_value = None
+ if onnx_node is not None:
+ self.name = onnx_node.name
+ self.proto = onnx_node
+
+
+class Graph:
+ """A graph which is constructed from the onnx proto."""
+
+ def __init__(self, onnx_graph):
+ """Construct the graph from onnx."""
+ self.input_nodes = []
+ self.output_nodes = []
+ self.name2node = {}
+ self.output2node = {}
+ self.proto = onnx_graph
+ # Add input nodes
+ for value in onnx_graph.input:
+ input_node = Node(None)
+ input_node.name = "Input_" + value.name
+ input_node.output_value = value
+ self.name2node[input_node.name] = input_node
+ self.output2node[value.name] = input_node
+ self.input_nodes.append(input_node)
+ output_value_names = [value.name for value in onnx_graph.output]
+ # Add regular nodes
+ for onnx_node in onnx_graph.node:
+ node = Node(onnx_node)
+ self.name2node[node.name] = node
+ self.output2node[onnx_node.output[0]] = node
+ for value_name in onnx_node.input:
+ node.parents.append(self.output2node[value_name])
+ self.output2node[value_name].children.append(node)
+ if onnx_node.output[0] in output_value_names:
+ self.output_nodes.append(node)
+ # Add value infos
+ for value in onnx_graph.value_info:
+ node = self.output2node[value.name]
+ node.output_value = value
+
+ def get_sorted_node_list(self):
+ """Return a node list in topological order."""
+ visited = set()
+ todo = deque()
+ result = []
+ for node in self.input_nodes:
+ todo.append(node)
+ visited.add(node)
+ for onnx_node in self.proto.node:
+ if onnx_node.op_type == "Constant":
+ node = self.name2node[onnx_node.name]
+ todo.append(node)
+ visited.add(node)
+ while todo:
+ node = todo.popleft()
+ result.append(node)
+ for child in node.children:
+ if child in visited:
+ continue
+ ready = True
+ for child_parent in child.parents:
+ if child_parent in visited:
+ continue
+ ready = False
+ break
+ if ready:
+ todo.append(child)
+ visited.add(child)
+ return result
diff --git a/tools/optimizer_scripts/tools/helper.py b/tools/optimizer_scripts/tools/helper.py
new file mode 100644
index 0000000..02da09d
--- /dev/null
+++ b/tools/optimizer_scripts/tools/helper.py
@@ -0,0 +1,642 @@
+"""This module contains helper functions that do not modify the graph.
+"""
+import onnx
+import onnx.helper
+import struct
+import numpy as np
+import logging
+
+__ONNX_VERSION__ = -1
+
+logger = logging.getLogger("optimizer_scripts")
+
+
+def setup_current_opset_version(m):
+ global __ONNX_VERSION__
+ __ONNX_VERSION__ = m.opset_import[0].version
+ if __ONNX_VERSION__ not in [11]:
+ raise RuntimeError(
+ "Only support opset 11, but got " + str(__ONNX_VERSION__)
+ )
+
+
+def get_current_opset_version():
+ if __ONNX_VERSION__ == -1:
+ raise RuntimeError("do setup_current_opset_version first please")
+ return __ONNX_VERSION__
+
+
+def find_nodes_by_input_name(g, name):
+ nodes = []
+ for node in g.node:
+ if name in node.input:
+ nodes.append(node)
+ return nodes
+
+
+def find_node_by_output_name(g, name):
+ """
+ Find a node in the graph by its output name
+
+ :param g: the onnx graph\\
+ :param name: the target node output name\\
+ :returns: the node find by name
+ """
+ for i in g.node:
+ if name in i.output:
+ return i
+ return None
+
+
+def find_node_by_node_name(g, name):
+ """
+ Find a node in the graph by its output name
+
+ :param g: the onnx graph\\
+ :param name: the target node output name\\
+ :returns: the node find by name
+ """
+ for i in g.node:
+ if i.name == name:
+ return i
+ return None
+
+
+def find_following_nodes_by_input_value_name(g, name):
+ """ Find the following nodes of a specific value.
+
+ :param g: the onnx graph. \\
+ :param name: the value name. \\
+ :return: a list of following nodes.
+ """
+ return find_nodes_by_input_name(g, name)
+
+
+def find_value_by_name(g, name):
+ """
+ Find a value_info in the graph by name
+
+ :param g: the onnx graph\\
+ :param name: the target value_info name\\
+ :returns: the value_info find by name
+ """
+ for i in g.value_info:
+ if i.name == name:
+ return i
+ return None
+
+
+def find_output_by_name(g, name):
+ """
+ Find a value_info in the graph by name
+
+ :param g: the onnx graph\\
+ :param name: the target value_info name\\
+ :returns: the value_info find by name
+ """
+ for i in g.output:
+ if i.name == name:
+ return i
+ return None
+
+
+def find_input_by_name(g, name):
+ """
+ Find a input in the graph by name
+
+ :param g: the onnx graph\\
+ :param name: the target input name\\
+ :returns: the input find by name
+ """
+ for i in g.input:
+ if i.name == name:
+ return i
+ return None
+
+
+def list_to_constant(name, shape, data, data_type=None):
+ """Generate a constant node using the given infomation.
+
+ :name: the node name and the output value name\\
+ :shape: the data shape\\
+ :data: the data itself\\
+ :returns: the generated onnx constant node
+ """
+ if not data_type:
+ if isinstance(data, int):
+ data_type = onnx.helper.TensorProto.INT64
+ elif isinstance(data, float):
+ data_type = onnx.helper.TensorProto.FLOAT
+ elif len(data) > 0 and isinstance(data[0], int):
+ data_type = onnx.helper.TensorProto.INT64
+ else:
+ data_type = onnx.helper.TensorProto.FLOAT
+ tensor = onnx.helper.make_tensor(name, data_type, shape, data)
+ new_w_node = onnx.helper.make_node(
+ "Constant", [], [name], name=name, value=tensor
+ )
+ return new_w_node
+
+
+def scaler_to_constant(name, data, data_type=None):
+ """Generate a constant node using the given infomation.
+
+ :name: the node name and the output value name\\
+ :shape: the data shape\\
+ :data: the data itself\\
+ :returns: the generated onnx constant node
+ """
+ if not data_type:
+ if isinstance(data, int):
+ data_type = onnx.helper.TensorProto.INT64
+ elif isinstance(data, float):
+ data_type = onnx.helper.TensorProto.FLOAT
+ else:
+ logger.error("Cannot create scaler constant with a list.")
+ exit(1)
+ tensor = onnx.helper.make_tensor(name, data_type, None, [data])
+ new_w_node = onnx.helper.make_node(
+ "Constant", [], [name], name=name, value=tensor
+ )
+ return new_w_node
+
+
+def numpy_to_constant(name, np_array):
+ return list_to_constant(name, np_array.shape, np_array.flatten().tolist())
+
+
+def constant_to_list(node):
+ """Generate a list from the constant node
+
+ :node: the Constant node\\
+ :returns: the shape of the constant node, the data of the constant node
+ """
+ tensor = node.attribute[0].t
+ # 1. check data type
+ # 2. get data from raw or data
+ # 3. get shape from dim
+ if tensor.data_type == onnx.helper.TensorProto.INT32:
+ if len(tensor.int32_data) != 0:
+ data = list(tensor.int32_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("i", tensor.raw_data)]
+ elif tensor.data_type == onnx.helper.TensorProto.INT64:
+ if len(tensor.int64_data) != 0:
+ data = list(tensor.int64_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("q", tensor.raw_data)]
+ elif tensor.data_type == onnx.helper.TensorProto.INT8:
+ if len(tensor.int32_data) != 0:
+ data = list(tensor.int32_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("b", tensor.raw_data)]
+ elif tensor.data_type == onnx.helper.TensorProto.FLOAT:
+ if len(tensor.float_data) != 0:
+ data = list(tensor.float_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("f", tensor.raw_data)]
+ elif tensor.data_type == onnx.helper.TensorProto.DOUBLE:
+ if len(tensor.double_data) != 0:
+ data = list(tensor.double_data)
+ else:
+ data = [i[0] for i in struct.iter_unpack("d", tensor.raw_data)]
+ else:
+ print("Not supported data type {}".format(tensor.data_type))
+ raise RuntimeError
+ if len(tensor.dims) == 0:
+ shape = len(data)
+ else:
+ shape = list(tensor.dims)
+ return shape, data
+
+
+def constant_to_numpy(node):
+ """Generate a numpy array from the constant node
+
+ :node: the Constant node\\
+ :returns: the numpy array
+ """
+ shape, data = constant_to_list(node)
+ return np.array(data).reshape(shape)
+
+
+def all_constant_input(node):
+ """Find the inputs of the given node. If the inputs of this node are all\\
+ constant nodes, return True. Otherwise, return False.
+
+ :param node: the input node which has a Node structure\\
+ :return: whether the node of this node are all constant
+ """
+ if node.proto is None:
+ return False
+ isConstant = True
+ for parent in node.parents:
+ if parent.proto is None or parent.proto.op_type != "Constant":
+ isConstant = False
+ break
+ return isConstant
+
+
+def get_padding(size, kernel_size, strides):
+ """ Calculate the padding array for same padding in the Tensorflow fashion.\\
+ See https://www.tensorflow.org/api_guides/python/nn#Convolution for more.
+ """
+ if size[0] % strides[0] == 0:
+ pad_h = max(kernel_size[0] - strides[0], 0)
+ else:
+ pad_h = max(kernel_size[0] - (size[0] % strides[0]), 0)
+ if size[1] % strides[1] == 0:
+ pad_w = max(kernel_size[1] - strides[1], 0)
+ else:
+ pad_w = max(kernel_size[1] - (size[1] % strides[1]), 0)
+ return [pad_h // 2, pad_w // 2, pad_h - pad_h // 2, pad_w - pad_w // 2]
+
+
+def get_shape_from_value_info(value):
+ """Get shape from a value info.
+
+ :param value: the value_info proto\\
+ :return: list of the shape
+ """
+ return [d.dim_value for d in value.type.tensor_type.shape.dim]
+
+
+def find_size_shape_from_value(value):
+ """
+ Find the size of data within the value_info object.
+ :param value: value_info
+ :return: int size and list shape of the data in the value_info
+ """
+ if not value:
+ return None, None
+ if not value.type.tensor_type.shape.dim:
+ return 0, []
+ size = 1
+ shape = []
+ for i in range(len(value.type.tensor_type.shape.dim)):
+ size *= max(1, value.type.tensor_type.shape.dim[i].dim_value)
+ shape.append(max(1, value.type.tensor_type.shape.dim[i].dim_value))
+
+ return size, shape
+
+
+def get_attribute_by_name(node, attr_name):
+ """Get attribute proto with specific name in the given node proto.
+
+ :param node: the node proto.\\
+ :param attr_name: a str for the name of the target.\\
+ :return: if found, return the attribute_proto. Else, return None.
+ """
+ for attr in node.attribute:
+ if attr.name == attr_name:
+ return attr
+ return None
+
+
+def get_list_attribute_by_name(node, attr_name: str, attr_type: str):
+ """Get list attribute with specific name in the given node proto.
+
+ :param node: the node proto.\\
+ :param attr_name: a str for the name of the target.\\
+ :param attr_type: a str which should be "float" or "int".\\
+ :return: if found, return the list. Else, return None.
+ """
+ attr_proto = get_attribute_by_name(node, attr_name)
+ if attr_proto is None:
+ return None
+ if attr_type == "int":
+ if len(attr_proto.ints) == 0:
+ return None
+ else:
+ return list(attr_proto.ints)
+ elif attr_type == "float":
+ if len(attr_proto.ints) == 0:
+ return None
+ else:
+ return list(attr_proto.floats)
+ else:
+ print("Warning: undefined type for list attribute extraction")
+ return None
+
+
+def get_var_attribute_by_name(node, attr_name: str, attr_type: str):
+ """Get variable attribute with specific name in the given node proto.
+
+ :param node: the node proto.
+ :param attr_name: str for the name of the target.
+ :param attr_type: str which should be "float", "int", "string" or "tensor".
+ :return: if found, return the variable. Else, return None.
+ """
+ attr_proto = get_attribute_by_name(node, attr_name)
+ if attr_proto is None:
+ return None
+ if attr_type == "int":
+ return attr_proto.i
+ elif attr_type == "float":
+ return attr_proto.f
+ elif attr_type == "string":
+ if isinstance(attr_proto.s, bytes):
+ return attr_proto.s.decode("utf-8")
+ else:
+ return attr_proto.s
+ elif attr_type == "tensor":
+ return attr_proto.t
+ else:
+ print("Warning: undefined type for variable attribute extraction")
+ return None
+
+
+def flatten_with_depth(data, depth):
+ output = []
+ if type(data) not in [type(np.array([1])), type([1])]:
+ return [[data, 0]]
+ for item in data:
+ if type(item) not in [type(np.array([1])), type([1])]:
+ output.append([item, depth + 1])
+ else:
+ output += flatten_with_depth(item, depth + 1)
+ return output
+
+
+def flatten_to_list(data):
+ flatten_depth = flatten_with_depth(data, 0)
+ flat_data = [item[0] for item in flatten_depth]
+ return flat_data
+
+
+def get_shape(data):
+ shape = []
+ if type(data) not in [type(np.array([1])), type([1])]:
+ return []
+ sub_data = data[0]
+ shape.append(len(data))
+ while type(sub_data) in [type(np.array([1])), type([1])]:
+ shape.append(len(sub_data))
+ sub_data = sub_data[0]
+ return shape
+
+
+def slice_data(data, starts, ends, axes):
+ flat_data = [item[0] for item in flatten_with_depth(data, 0)]
+ shape = get_shape(data)
+
+ starts_updated = []
+ ends_updated = []
+ for i in range(len(starts)):
+ start_updated = min(starts[i], shape[i] - 1) % shape[i]
+ starts_updated.append(start_updated)
+ for j in range(len(starts)):
+ if ends[j] >= shape[j]:
+ end_updated = shape[j]
+ else:
+ end_updated = min(ends[j], shape[j]) % shape[j]
+ ends_updated.append(end_updated)
+
+ index_slices = []
+ for i in range(len(shape)):
+ if i not in axes:
+ index_slices.append(list(range(shape[i])))
+ else:
+ axe_ind = axes.index(i)
+ index_slices.append(
+ list(range(starts_updated[axe_ind], ends_updated[axe_ind]))
+ )
+
+ indices = [1]
+ for i in range(len(shape) - 1, -1, -1):
+ step = np.prod(shape[i + 1:])
+ temp_pos = indices
+ new_indices = []
+ for n in index_slices[i]:
+ for pos in temp_pos:
+ new_indices.append(int(n * step + pos))
+ indices = new_indices
+
+ sliced_data = [flat_data[k - 1] for k in indices]
+
+ # reshape to correct shape.
+ new_shape = []
+ for i in range(len(shape)):
+ if i not in axes:
+ new_shape.append(shape[i])
+ else:
+ axe_ind = axes.index(i)
+ new_shape.append(ends_updated[axe_ind] - starts_updated[axe_ind])
+ if any([dim < 1 for dim in new_shape]):
+ raise RuntimeError("Invalid starts ends.")
+
+ sliced_data = np.reshape(sliced_data, new_shape)
+
+ return sliced_data
+
+
+def concatenate(data_sets, axis):
+ # check shapes
+ shapes = []
+ shapes_ = []
+ for data_set in data_sets:
+ shape = get_shape(data_set)
+ shapes.append(list(shape))
+ shape.pop(axis)
+ shapes_.append(shape)
+ if not all([s == shapes_[0] for s in shapes_]):
+ raise RuntimeError("data sets shapes do not match")
+
+ new_dim = sum([s[axis] for s in shapes])
+ new_shape = list(shapes[0])
+ new_shape[axis] = new_dim
+
+ flat_data_sets = []
+ for data_set in data_sets:
+ flat_data_sets.append(flatten_to_list(data_set))
+
+ sub_block_size = 1
+ for i in range(axis + 1, len(shapes[0])):
+ sub_block_size *= shapes[0][i]
+
+ split_num = 1
+ for i in range(axis):
+ split_num *= shapes[0][i]
+
+ total_flat_data = []
+ for i in range(split_num):
+ for j in range(len(shapes)):
+ block_size = sub_block_size * shapes[j][axis]
+ total_flat_data.extend(
+ flat_data_sets[j][i * block_size:(i + 1) * block_size]
+ )
+
+ new_data = np.reshape(total_flat_data, new_shape)
+
+ return new_data
+
+
+def broadcast_data_sets(data_set_1, data_set_2):
+ shape1 = get_shape(data_set_1)
+ shape2 = get_shape(data_set_2)
+
+ # compare shapes and get broadcasted shape
+ list_a, list_b = (
+ (shape1, shape2) if len(shape1) > len(shape2) else (shape2, shape1)
+ )
+ while len(list_a) > len(list_b):
+ list_b.insert(0, 0)
+ broadcasted_shape = []
+ for i in range(len(list_a)):
+ if list_b[i] == 0:
+ broadcasted_shape.append(list_a[i])
+ elif list_b[i] == 1:
+ broadcasted_shape.append(list_a[i])
+ elif list_a[i] == 1:
+ broadcasted_shape.append(list_b[i])
+ elif list_a[i] == list_b[i]:
+ broadcasted_shape.append(list_a[i])
+ else:
+ raise RuntimeError("Can not broadcast two data sets")
+
+ # prepare data for broadcasting.
+ shape1 = list(map(lambda x: x if x != 0 else 1, shape1))
+ shape2 = list(map(lambda x: x if x != 0 else 1, shape2))
+ data_1 = np.reshape(data_set_1, shape1)
+ data_2 = np.reshape(data_set_2, shape2)
+
+ for i in range(len(shape1)):
+ if shape1[i] != broadcasted_shape[i]:
+ new_data_total = [
+ list(data_1) for _ in range(broadcasted_shape[i])
+ ]
+ data_1 = concatenate(new_data_total, axis=i)
+ for i in range(len(shape2)):
+ if shape2[i] != broadcasted_shape[i]:
+ new_data_total = [
+ list(data_2) for _ in range(broadcasted_shape[i])
+ ]
+ data_2 = concatenate(new_data_total, axis=i)
+
+ return data_1, data_2
+
+
+def add(data_set_1, data_set_2):
+ broadcasted_data_1, broadcasted_data_2 = broadcast_data_sets(
+ data_set_1, data_set_2
+ )
+
+ flat_data_1 = flatten_to_list(broadcasted_data_1)
+ flat_data_2 = flatten_to_list(broadcasted_data_2)
+ shape = get_shape(broadcasted_data_1)
+ res = []
+ for i in range(len(flat_data_1)):
+ res.append(flat_data_1[i] + flat_data_2[i])
+
+ res = np.reshape(res, shape)
+
+ return res
+
+
+def reduceprod(data_set, axis, keepdims=1):
+ flat_data = flatten_to_list(data_set)
+ old_shape = get_shape(data_set)
+
+ temp_shape = old_shape
+ temp_flat_data = flat_data
+ for ax in axis:
+ split_num = 1
+ step = 1
+ for i in range(ax):
+ split_num *= temp_shape[i]
+ for i in range(ax + 1, len(temp_shape)):
+ step *= temp_shape[i]
+
+ block_size = len(temp_flat_data) // split_num
+ new_flat_data = []
+ for j in range(split_num):
+ block_data = temp_flat_data[j * block_size:(j + 1) * block_size]
+ reduced_block_data = []
+ for k in range(step):
+ val = block_data[k]
+ for li in range(1, block_size // step):
+ val *= block_data[k + li * step]
+ reduced_block_data.append(val)
+ new_flat_data.extend(reduced_block_data)
+ temp_flat_data = new_flat_data
+ temp_shape[ax] = 1
+
+ new_flat_data = temp_flat_data
+ new_shape = temp_shape
+ if not keepdims:
+ axis = sorted(list(axis))
+ for pos in axis[::-1]:
+ new_shape.pop(pos)
+
+ return np.reshape(new_flat_data, new_shape)
+
+
+def transpose(data_set, permutation):
+ # find series of local swaps
+ data_set = list(data_set)
+ perm = list(permutation)
+ shape = get_shape(data_set)
+ flat_data = flatten_to_list(data_set)
+ assert set(perm) == set(range(len(shape))), "invalid permutation"
+
+ new_shape = [shape[i] for i in perm]
+ swaps = []
+ bubbled = True
+ while bubbled:
+ bubbled = False
+ for i in range(len(new_shape) - 1):
+ if perm[i] > perm[i + 1]:
+ swaps.append([i, i + 1])
+ p_1, p_2 = perm[i], perm[i + 1]
+ perm[i], perm[i + 1] = p_2, p_1
+ bubbled = True
+
+ # apply local swaps
+ current_shape = list(shape)
+ temp_flat_data = flat_data
+
+ for swap in swaps[::-1]:
+ ind_1, ind_2 = swap[0], swap[1]
+ dim_1 = current_shape[ind_1]
+ dim_2 = current_shape[ind_2]
+ split_num = 1
+ block_size = 1
+
+ for i in range(ind_1):
+ split_num *= current_shape[i]
+ for i in range(ind_2 + 1, len(current_shape)):
+ block_size *= current_shape[i]
+
+ data_blocks = np.reshape(temp_flat_data, [-1, block_size])
+ flat_data_1 = []
+ for k in range(split_num):
+ block = []
+ for m in range(dim_2):
+ for n in range(dim_1):
+ block_pos = k * dim_1 * dim_2 + n * dim_2 + m
+ block.extend(data_blocks[block_pos])
+ flat_data_1.extend(block)
+
+ temp_flat_data = flat_data_1
+ current_shape[ind_1] = dim_2
+ current_shape[ind_2] = dim_1
+
+ return np.reshape(temp_flat_data, current_shape)
+
+
+def subtract(data_set_1, data_set_2):
+ broadcasted_data_1, broadcasted_data_2 = broadcast_data_sets(
+ data_set_1, data_set_2
+ )
+
+ shape = get_shape(broadcasted_data_1)
+ flat_data_1 = flatten_to_list(broadcasted_data_1)
+ flat_data_2 = flatten_to_list(broadcasted_data_2)
+
+ substracted_data = [
+ flat_data_1[i] - flat_data_2[i] for i in range(len(flat_data_1))
+ ]
+
+ new_data = np.reshape(substracted_data, shape)
+
+ return new_data
diff --git a/tools/optimizer_scripts/tools/modhelper.py b/tools/optimizer_scripts/tools/modhelper.py
new file mode 100644
index 0000000..ca5e040
--- /dev/null
+++ b/tools/optimizer_scripts/tools/modhelper.py
@@ -0,0 +1,96 @@
+"""
+This module contains helper functions that do graph modifications.
+"""
+
+from . import helper
+
+
+def replace_node_input(node, old_input, new_input):
+ for i, input_name in enumerate(node.input):
+ if input_name == old_input:
+ node.input[i] = new_input
+
+
+def delete_nodes(g, node_list):
+ node_to_delete = []
+ # Find target nodes
+ for node in g.node:
+ if node.name not in node_list:
+ continue
+ else:
+ node_to_delete.append(node)
+ if len(node_list) != len(node_to_delete):
+ print("Some nodes do not exist in the graph. Skipping them.")
+ for node in node_to_delete:
+ # Check the node whether if it is valid to delete
+ if len(node.input) == 0:
+ print(
+ "Deleting an Constant node. "
+ "Please make sure you also delete all its following nodes"
+ )
+ elif len(node.input) > 1:
+ print(
+ f"Warning: Node {node.name} has more than one input. "
+ "This script cannot delete merge nodes."
+ )
+ # Connect the nodes around the target node.
+ # Set the following node input as the previous node output.
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ if len(node.input) == 0:
+ for following_node in following_nodes:
+ following_node.input.remove(node.output[0])
+ elif (
+ len(following_nodes) > 0
+ and len(node.input) == 1
+ and helper.find_input_by_name(g, node.input[0]) is not None
+ ):
+ # The node input is an input
+ new_input = helper.find_value_by_name(g, node.output[0])
+ g.input.append(new_input)
+ g.input.remove(helper.find_input_by_name(g, node.input[0]))
+ g.value_info.remove(new_input)
+ elif len(following_nodes) > 0:
+ for following_node in following_nodes:
+ replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ else:
+ # If the node is the output, replace it with previous input.
+ value = helper.find_value_by_name(g, node.input[0])
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name == node.output[0]:
+ g.output.extend([value])
+ else:
+ g.output.extend([output_value])
+ # Remove the node and value info.
+ g.node.remove(node)
+
+
+def delete_input(g, target_list):
+ for name in target_list:
+ input_value = helper.find_input_by_name(g, name)
+ if input_value is None:
+ print("Cannot find input {}".format(name))
+ continue
+ g.input.remove(input_value)
+
+
+def delete_output(g, target_list):
+ for name in target_list:
+ output_value = helper.find_output_by_name(g, name)
+ if output_value is None:
+ print("Cannot find output {}".format(name))
+ continue
+ g.output.remove(output_value)
+
+
+def delete_value_with_name_if_exists(g, name):
+ value = helper.find_value_by_name(g, name)
+ if value is not None:
+ g.value_info.remove(value)
diff --git a/tools/optimizer_scripts/tools/other.py b/tools/optimizer_scripts/tools/other.py
new file mode 100644
index 0000000..b003fbb
--- /dev/null
+++ b/tools/optimizer_scripts/tools/other.py
@@ -0,0 +1,1451 @@
+"""
+Optimization functions that are not fusing, eliminating or replacing.
+In most cases, these are the modifications on the original nodes.
+"""
+import struct
+import collections
+import numpy as np
+import onnx.helper
+import onnxoptimizer as optimizer
+import math
+import logging
+from . import helper
+from .modhelper import replace_node_input
+import copy
+from .helper import logger
+
+
+def polish_model(model):
+ """
+ This function combines several useful utility functions together.
+ """
+ onnx.checker.check_model(model)
+ onnx.helper.strip_doc_string(model)
+ model = onnx.shape_inference.infer_shapes(model)
+ model = optimizer.optimize(model)
+ onnx.checker.check_model(model)
+ return model
+
+
+def format_value_info_shape(g):
+ """
+ Replace -1 and 0 batch size in value info
+
+ :param g: the onnx graph
+ """
+ for value in g.input:
+ if len(value.type.tensor_type.shape.dim) > 0 and (
+ value.type.tensor_type.shape.dim[0].dim_value <= 0
+ or not isinstance(
+ value.type.tensor_type.shape.dim[0].dim_value, int
+ )
+ ):
+ value.type.tensor_type.shape.dim[0].dim_value = 1
+ for value in g.output:
+ if len(value.type.tensor_type.shape.dim) > 0 and (
+ value.type.tensor_type.shape.dim[0].dim_value <= 0
+ or not isinstance(
+ value.type.tensor_type.shape.dim[0].dim_value, int
+ )
+ ):
+ value.type.tensor_type.shape.dim[0].dim_value = 1
+ for value in g.value_info:
+ if len(value.type.tensor_type.shape.dim) > 0 and (
+ value.type.tensor_type.shape.dim[0].dim_value < 0
+ or not isinstance(
+ value.type.tensor_type.shape.dim[0].dim_value, int
+ )
+ ):
+ value.type.tensor_type.shape.dim[0].dim_value = 1
+
+
+def add_name_to_node(g):
+ """
+ If no name presents, give a name based on output name.
+
+ :param g: the onnx graph
+ """
+ for node in g.node:
+ if len(node.name) == 0:
+ node.name = node.output[0]
+
+
+def rename_all_node_name(g):
+ """
+ rename all nodes if the node name is a number:
+
+ new_name = old_name + "_kn"
+
+ :param g: the onnx graph
+ """
+
+ for node in g.node:
+ if not node.name.isdigit():
+ # Skip not number names
+ continue
+ new_node_name = node.name + "_kn"
+ new_node_output0_name = node.output[0] + "_kn"
+
+ # in order to keep same output node name, skip if it is output node.
+ output_value_info = helper.find_output_by_name(g, node.output[0])
+ if output_value_info is not None:
+ continue
+
+ # rename the input of all the following nodes
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ replace_node_input(
+ following_node, node.output[0], new_node_output0_name
+ )
+
+ # rename value info
+ value_info = helper.find_value_by_name(g, node.output[0])
+ if value_info is not None:
+ value_info.name = new_node_output0_name
+
+ # rename node
+ node.output[0] = new_node_output0_name
+ node.name = new_node_name
+
+
+def add_output_to_value_info(g):
+ """
+ If output does not present in value_info, copy one
+
+ :param g: the onnx graph
+ """
+ for output in g.output:
+ if helper.find_value_by_name(g, output.name) is None:
+ g.value_info.extend([output])
+
+
+def find_first_sequential_output(g, node):
+ for value_name in node.output:
+ value = helper.find_output_by_name(g, value_name)
+ if value is not None:
+ return value
+ next_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ if len(next_nodes) == 0:
+ # No following nodes
+ return None
+ return find_first_sequential_output(g, next_nodes[0])
+
+
+def remove_nodes(g, cut_nodes=[], cut_types=[]):
+ node_to_delete = []
+ # Find target nodes
+ for node in g.node:
+ if node.name not in cut_nodes and node.op_type not in cut_types:
+ continue
+ else:
+ node_to_delete.append(node)
+ # Mapping originnal outputs to new outputs.
+ # This mapping is to keep the output order.
+ output_mapping = {}
+ new_output = set()
+ for node in node_to_delete:
+ original_output = find_first_sequential_output(g, node)
+ if original_output.name not in output_mapping:
+ output_mapping[original_output.name] = []
+ for input_name in node.input:
+ value = helper.find_value_by_name(g, input_name)
+ if (
+ value is not None
+ and helper.find_output_by_name(g, input_name) is None
+ and value.name not in new_output
+ ):
+ output_mapping[original_output.name].append(value)
+ new_output.add(value.name)
+ # Remove them
+ while node_to_delete:
+ g.node.remove(node_to_delete.pop())
+ # Remove unreachable nodes
+ visited_values = set()
+ unused_constant_map = {}
+ for input_value in g.input:
+ visited_values.add(input_value.name)
+ for node in g.node:
+ if node.op_type == "Constant":
+ visited_values.add(node.output[0])
+ unused_constant_map[node.output[0]] = node
+ continue
+ can_reach = True
+ for input_name in node.input:
+ if input_name not in visited_values:
+ can_reach = False
+ break
+ if can_reach:
+ for output_name in node.output:
+ visited_values.add(output_name)
+ else:
+ node_to_delete.append(node)
+ # Mapping outputs again
+ for node in node_to_delete:
+ original_output = find_first_sequential_output(g, node)
+ if original_output is None:
+ continue
+ if original_output.name not in output_mapping:
+ output_mapping[original_output.name] = []
+ for input_name in node.input:
+ value = helper.find_value_by_name(g, input_name)
+ if (
+ value is not None
+ and helper.find_output_by_name(g, input_name) is None
+ and value.name not in new_output
+ ):
+ output_mapping[original_output.name].append(value)
+ new_output.add(value.name)
+ # Remove them
+ while node_to_delete:
+ g.node.remove(node_to_delete.pop())
+ # Remove unused constants
+ for node in g.node:
+ for input_name in node.input:
+ if input_name in unused_constant_map:
+ del unused_constant_map[input_name]
+ for node in unused_constant_map.values():
+ g.node.remove(node)
+ # Remove unreachable value infos
+ reachable_values = set()
+ for input_value in g.input:
+ reachable_values.add(input_value.name)
+ for node in g.node:
+ for input_name in node.input:
+ reachable_values.add(input_name)
+ for output_name in node.output:
+ reachable_values.add(output_name)
+ value_to_remove = []
+ for value_info in g.value_info:
+ if value_info.name not in reachable_values:
+ value_to_remove.append(value_info)
+ while value_to_remove:
+ value_info = value_to_remove.pop()
+ g.value_info.remove(value_info)
+ # Reorder output
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name in reachable_values:
+ logger.info("Keep output {}".format(output_value.name))
+ g.output.extend([output_value])
+ elif output_value.name in output_mapping:
+ real_outputs = [
+ i
+ for i in output_mapping[output_value.name]
+ if i.name in reachable_values
+ ]
+ logger.info(
+ "Replace output {} with {}".format(
+ output_value.name, [i.name for i in real_outputs]
+ )
+ )
+ g.output.extend(real_outputs)
+ else:
+ logger.info("Abandon output {}".format(output_value.name))
+ continue
+
+
+def transpose_B_in_Gemm(g):
+ """
+ If transB is set in Gemm, transpose it
+
+ :param g: the onnx graph
+ """
+ for node in g.node:
+ if node.op_type != "Gemm":
+ continue
+ do_it = False
+ for attr in node.attribute:
+ if attr.name == "transB":
+ if attr.i == 1:
+ attr.i = 0
+ do_it = True
+ break
+ if not do_it:
+ continue
+ # Transpose the weight and its output value
+ w_node = helper.find_node_by_output_name(g, node.input[1])
+ w_output = helper.find_value_by_name(g, node.input[1])
+ dim_0 = w_output.type.tensor_type.shape.dim[0].dim_value
+ dim_1 = w_output.type.tensor_type.shape.dim[1].dim_value
+ w_output.type.tensor_type.shape.dim[0].dim_value = dim_1
+ w_output.type.tensor_type.shape.dim[1].dim_value = dim_0
+ w_node.attribute[0].t.dims[0] = dim_1
+ w_node.attribute[0].t.dims[1] = dim_0
+ if w_node.attribute[0].t.raw_data:
+ raw_data = w_node.attribute[0].t.raw_data
+ fl_data = [i[0] for i in struct.iter_unpack("f", raw_data)]
+ else:
+ fl_data = w_node.attribute[0].t.float_data
+ w = np.reshape(fl_data, (dim_0, dim_1))
+ w = w.transpose((1, 0)).flatten()
+ if w_node.attribute[0].t.raw_data:
+ buf = struct.pack("%sf" % len(w), *w)
+ w_node.attribute[0].t.raw_data = buf
+ else:
+ for i in range(len(fl_data)):
+ w_node.attribute[0].t.float_data[i] = w[i]
+
+
+def topological_sort(g):
+ """
+ Topological sort all the layers.
+ Assume a node do not take the same value as more than one inputs.
+
+ :param g: the onnx graph
+ """
+ # TODO: Topological sort on the same branch
+ # Map from node name to its input degree
+ in_degree = {}
+ # Map from value info name to the nodes using it as input
+ output_nodes = collections.defaultdict(list)
+ # Map from node name to node object
+ node_map = {}
+ to_add = collections.deque()
+ # init
+ length = len(g.node)
+ for _ in range(length):
+ node = g.node.pop()
+ node_map[node.name] = node
+ if len([i for i in node.input if i != ""]) == 0:
+ to_add.append(node.name)
+ else:
+ in_degree[node.name] = len([i for i in node.input if i != ""])
+ for input_name in node.input:
+ if input_name == "":
+ continue
+ output_nodes[input_name].append(node.name)
+ # sort
+ # deal with input first
+ for value_info in g.input:
+ input_name = value_info.name
+ for node_name in output_nodes[input_name]:
+ in_degree[node_name] -= 1
+ if in_degree[node_name] == 0:
+ to_add.append(node_name)
+ del in_degree[node_name]
+ # main sort loop
+ sorted_nodes = []
+ while to_add:
+ node_name = to_add.pop()
+ node = node_map[node_name]
+ del node_map[node_name]
+ sorted_nodes.append(node)
+ # Expect only one output name for each node
+ next_node_names = []
+ for output_name in node.output:
+ next_node_names.extend(output_nodes[output_name])
+ for next_node_name in next_node_names:
+ in_degree[next_node_name] -= 1
+ if in_degree[next_node_name] == 0:
+ to_add.append(next_node_name)
+ del in_degree[next_node_name]
+ g.node.extend(sorted_nodes)
+ if in_degree:
+ raise RuntimeError(
+ "Unreachable nodes exist: {}".format(in_degree.keys())
+ )
+ if node_map:
+ raise RuntimeError("Unused nodes exist: {}".format(node_map.keys()))
+
+
+def remove_zero_value_info(g):
+ value_info_list = list(g.value_info)
+ for vi in value_info_list:
+ if not vi.type.tensor_type.shape.dim:
+ g.value_info.remove(vi)
+
+ for dim in vi.type.tensor_type.shape.dim:
+ if dim.dim_value == 0:
+ g.value_info.remove(vi)
+ break
+
+
+def inference_shapes(m):
+ while len(m.graph.value_info) > 0:
+ m.graph.value_info.pop()
+ g = m.graph
+ inferencing_shapes = True
+ while inferencing_shapes:
+ inferencing_shapes = False
+ if inference_cov_shape(g):
+ inferencing_shapes = True
+ if inference_upsample_shape(g):
+ inferencing_shapes = True
+ if inference_resize_shape(g):
+ inferencing_shapes = True
+ if inference_split_shape(g):
+ inferencing_shapes = True
+ if inferencing_shapes:
+ topological_sort(g)
+ m = polish_model(m)
+ g = m.graph
+ remove_zero_value_info(g)
+ m = polish_model(m)
+ return m
+
+
+def inference_resize_shape(g):
+ for node in g.node:
+ if node.op_type != "Resize":
+ continue
+
+ output_value = helper.find_value_by_name(g, node.output[0])
+ output_value = (
+ helper.find_output_by_name(g, node.output[0])
+ if output_value is None
+ else output_value
+ )
+ if output_value is not None:
+ continue
+
+ if len(node.input) == 4: # input: X, roi, scales, sizes
+ shape_node = helper.find_node_by_output_name(g, node.input[3])
+ if shape_node.op_type != "Constant":
+ continue
+
+ _, shape_value = helper.constant_to_list(shape_node)
+ output_value = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ onnx.TensorProto.FLOAT,
+ [int(v) for v in shape_value],
+ )
+ g.value_info.extend([output_value])
+ return True
+ else:
+ # If output shape is not given, inference from scales
+ # Get the input shape
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ continue
+ shape_value = helper.get_shape_from_value_info(input_value)
+ scales_node = helper.find_node_by_output_name(g, node.input[2])
+ if scales_node.op_type != "Constant":
+ continue
+ _, scales_value = helper.constant_to_list(scales_node)
+ for i in range(len(shape_value)):
+ shape_value[i] *= scales_value[i]
+ output_value = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ onnx.TensorProto.FLOAT,
+ [int(v) for v in shape_value],
+ )
+ g.value_info.extend([output_value])
+ return True
+ return False
+
+
+def inference_upsample_shape(g):
+ """For onnx v1.4.1+, onnx cannot inference upsample output shape. Let's\\
+ do it ourselves. This function only inference the next upsample without\\
+ output shape each time.
+
+ :param g: the graph\\
+ :return: True if any Upsample shape is generated. Otherwise, False.
+ """
+ for node in g.node:
+ if node.op_type != "Upsample":
+ continue
+ output_value = helper.find_value_by_name(g, node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if output_value and helper.get_shape_from_value_info(output_value):
+ continue
+ # Get input shape
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ continue
+ if not helper.get_shape_from_value_info(input_value):
+ continue
+ input_shape = helper.get_shape_from_value_info(input_value)
+ # Get upsample weight
+ weight_node = helper.find_node_by_output_name(g, node.input[1])
+ weight_shape, weight = helper.constant_to_list(weight_node)
+ if len(input_shape) != weight_shape[0]:
+ raise RuntimeError(
+ "Unmatch input shape and weight shape: {} vs {}".format(
+ input_shape, weight_shape
+ )
+ )
+ # Calculate shape
+ output_shape = list(input_shape)
+ for i in range(len(output_shape)):
+ output_shape[i] = int(input_shape[i] * weight[i])
+ output_value = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ input_value.type.tensor_type.elem_type,
+ output_shape,
+ )
+ g.value_info.extend([output_value])
+ return True
+ return False
+
+
+def inference_cov_shape(g):
+ processed = False
+ for node in g.node:
+ # Check for Conv output shape need to be inferrenced.
+ if node.op_type != "Conv":
+ continue
+ # Input shape is not ready yet. Skip.
+ input_value_info = helper.find_value_by_name(g, node.input[0])
+ if not input_value_info:
+ input_value_info = helper.find_input_by_name(g, node.input[0])
+ if not input_value_info:
+ continue
+ _, input_shape = helper.find_size_shape_from_value(input_value_info)
+ if not input_shape:
+ continue
+ # Output shape is already there. Skip.
+ output_value_info = helper.find_value_by_name(g, node.output[0])
+ if not output_value_info:
+ output_value_info = helper.find_output_by_name(g, node.output[0])
+ if output_value_info and helper.get_shape_from_value_info(
+ output_value_info
+ ):
+ continue
+
+ # Now start the inference.
+ # Check kernel shape
+ kernel_value_info = helper.find_value_by_name(g, node.input[1])
+ _, kernel_shape = helper.find_size_shape_from_value(kernel_value_info)
+ if not kernel_shape:
+ continue
+ # If auto_pad is set, use the auto_pad.
+ auto_pad = helper.get_var_attribute_by_name(node, "auto_pad", "string")
+ pads = None
+ if auto_pad is not None and auto_pad != "NOTSET":
+ if auto_pad == "SAME_LOWER" or auto_pad == "SAME_UPPER":
+ new_output_value_info = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ input_value_info.type.tensor_type.elem_type,
+ [
+ input_shape[0],
+ kernel_shape[0],
+ input_shape[2],
+ input_shape[3],
+ ],
+ )
+ if output_value_info:
+ g.value_info.remove(output_value_info)
+ g.value_info.extend([new_output_value_info])
+ processed = True
+ continue
+ elif auto_pad == "VALID":
+ pads = [0, 0, 0, 0]
+ else:
+ logger.error("Unrecognized auto_pad value: " + str(auto_pad))
+ exit(1)
+
+ strides = helper.get_attribute_by_name(node, "strides").ints
+ if not pads:
+ pads = helper.get_attribute_by_name(node, "pads").ints
+ dilation = helper.get_attribute_by_name(node, "dilations").ints
+
+ # Pytorch model has the case where strides only have one number
+ if len(strides) == 1:
+ strides.append(strides[0])
+ if len(dilation) == 1:
+ dilation.append(dilation[0])
+
+ H = math.floor(
+ (
+ input_shape[2]
+ + pads[0]
+ + pads[2]
+ - dilation[0] * (kernel_shape[2] - 1)
+ - 1
+ )
+ / strides[0]
+ + 1
+ )
+ W = math.floor(
+ (
+ input_shape[3]
+ + pads[1]
+ + pads[3]
+ - dilation[1] * (kernel_shape[3] - 1)
+ - 1
+ )
+ / strides[1]
+ + 1
+ )
+ output_shape = [input_shape[0], kernel_shape[0], H, W]
+
+ new_output_value_info = onnx.helper.make_tensor_value_info(
+ node.output[0],
+ input_value_info.type.tensor_type.elem_type,
+ output_shape,
+ )
+
+ processed = True
+
+ if output_value_info:
+ g.value_info.remove(output_value_info)
+ g.value_info.extend([new_output_value_info])
+
+ return processed
+
+
+def inference_split_shape(g):
+ processed = False
+ for node in g.node:
+ if node.op_type != "Split":
+ continue
+
+ input_val_info = helper.find_value_by_name(g, node.input[0])
+ if not input_val_info:
+ input_val_info = helper.find_input_by_name(g, node.input[0])
+ if not input_val_info:
+ continue
+
+ _, input_shape = helper.find_size_shape_from_value(input_val_info)
+ if not input_shape:
+ continue
+
+ output_val_names = list(node.output)
+ output_vals = [
+ helper.find_value_by_name(g, val_name)
+ for val_name in output_val_names
+ ]
+
+ output_shapes = [
+ helper.find_size_shape_from_value(output_val)[1]
+ for output_val in output_vals
+ ]
+ if not any([len(s) == 0 for s in output_shapes]):
+ continue
+
+ for att in node.attribute:
+ if att.name == "axis":
+ axis = att.i
+ else:
+ split = list(att.ints)
+
+ new_output_vals = []
+ for i in range(len(output_val_names)):
+ new_shape = list(input_shape)
+ new_shape[axis] = split[i]
+ new_output_val = onnx.helper.make_tensor_value_info(
+ output_val_names[i],
+ input_val_info.type.tensor_type.elem_type,
+ new_shape,
+ )
+ new_output_vals.append(new_output_val)
+
+ for val in output_vals:
+ if val is not None:
+ g.value_info.remove(val)
+ g.value_info.extend(new_output_vals)
+
+ processed = True
+
+ return processed
+
+
+def parse_shape_change_input(s: str):
+ """The input should be like 'input 1 1 224 224'."""
+ s_list = s.split(" ")
+ if len(s_list) < 2:
+ print("Cannot parse the shape change input: {}".format(s))
+ return None
+ shape = []
+ for i in range(1, len(s_list)):
+ shape.append(int(s_list[i]))
+ return s_list[0], shape
+
+
+def change_input_shape(g, target_list):
+ for target in target_list:
+ try:
+ name, shape = parse_shape_change_input(target)
+ input_value = helper.find_input_by_name(g, name)
+ if input_value is None:
+ print("Cannot find input {}".format(name))
+ continue
+ if len(shape) != len(input_value.type.tensor_type.shape.dim):
+ print("The dimension doesn't match for input {}".format(name))
+ continue
+ for i in range(len(shape)):
+ input_value.type.tensor_type.shape.dim[i].dim_value = shape[i]
+ except TypeError:
+ # This happens when the parser function returns None.
+ continue
+ except ValueError:
+ # This happens when the input cannot be converter into int
+ print("Cannot parse {} into name and int".format(target))
+ continue
+
+
+def change_output_shape(g, target_list):
+ for target in target_list:
+ try:
+ name, shape = parse_shape_change_input(target)
+ output_value = helper.find_output_by_name(g, name)
+ if output_value is None:
+ print("Cannot find output {}".format(name))
+ continue
+ if len(shape) != len(output_value.type.tensor_type.shape.dim):
+ print("The dimension doesn't match for output {}".format(name))
+ continue
+ for i in range(len(shape)):
+ output_value.type.tensor_type.shape.dim[i].dim_value = shape[i]
+ except TypeError:
+ # This happens when the parser function returns None.
+ continue
+ except ValueError:
+ # This happens when the input cannot be converter into int
+ print("Cannot parse {} into name and int".format(target))
+ continue
+
+
+def add_nop_conv_after(g, value_names):
+ """Add do-nothing depthwise Conv nodes after the given value info. It will\\
+ take the given names as the inputs of the new node and replace the inputs\\
+ of the following nodes.
+
+ :param g: the graph\\
+ :param value_names: a list of string which are the names of value_info.
+ """
+ for value_name in value_names:
+ # Find the value first
+ value = helper.find_value_by_name(g, value_name)
+ if value is None:
+ value = helper.find_input_by_name(g, value_name)
+ if value is None:
+ value = helper.find_output_by_name(g, value_name)
+ if value is None:
+ print("Cannot find an value_info named {}".format(value_name))
+ continue
+ # Get the channel number from value info
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_conv"
+ ones = [1.0] * channel
+ weight_node = helper.list_to_constant(
+ node_name + "_weight", [channel, 1, 1, 1], ones
+ )
+ # Construct BN node
+ conv_node = onnx.helper.make_node(
+ "Conv",
+ [value_name, weight_node.output[0]],
+ [node_name],
+ name=node_name,
+ dilations=[1, 1],
+ group=channel,
+ kernel_shape=[1, 1],
+ pads=[0, 0, 0, 0],
+ strides=[1, 1],
+ )
+ # Reconnect the graph
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, value_name
+ )
+ if len(following_nodes) > 0:
+ for following_node in following_nodes:
+ replace_node_input(following_node, value_name, node_name)
+ else:
+ new_value = onnx.helper.make_tensor_value_info(
+ node_name, value.type.tensor_type.elem_type, shape
+ )
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name == value_name:
+ g.output.extend([new_value])
+ else:
+ g.output.extend([output_value])
+ # Add node to the graph
+ g.node.extend([conv_node, weight_node])
+ topological_sort(g)
+
+
+def add_nop_bn_after(g, value_names):
+ """Add do-nothing BatchNormalization nodes after the given value info.
+ It will take the given names as the inputs of the new node and replace
+ the inputs of the following nodes.
+
+ :param g: the graph
+ :param value_names: a list of string which are the names of value_info.
+ """
+ for value_name in value_names:
+ # Find the value first
+ value = helper.find_value_by_name(g, value_name)
+ if value is None:
+ value = helper.find_input_by_name(g, value_name)
+ if value is None:
+ value = helper.find_output_by_name(g, value_name)
+ if value is None:
+ print("Cannot find an value_info named {}".format(value_name))
+ continue
+ # Get the channel number from value info
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [channel], ones
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [channel], zeros
+ )
+ mean_node = helper.list_to_constant(
+ node_name + "_mean", [channel], zeros
+ )
+ var_node = helper.list_to_constant(node_name + "_var", [channel], ones)
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ )
+ # Reconnect the graph
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, value_name
+ )
+ if len(following_nodes) > 0:
+ for following_node in following_nodes:
+ replace_node_input(following_node, value_name, node_name)
+ else:
+ new_value = onnx.helper.make_tensor_value_info(
+ node_name, value.type.tensor_type.elem_type, shape
+ )
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name == value_name:
+ g.output.extend([new_value])
+ else:
+ g.output.extend([output_value])
+ # Add node to the graph
+ g.node.extend([bn_node, scale_node, bias_node, mean_node, var_node])
+ topological_sort(g)
+
+
+def add_bias_scale_bn_after(g, value_name, channel_bias, channel_scale):
+ """
+ Add do-nothing BatchNormalization nodes after the given value info.
+ It will take the given names as the inputs of the new node and replace
+ the inputs of the following nodes.
+
+ :param g: the graph
+ :param value_name: a list of string which are the name of value_info.
+ """
+ # Find the value first
+ value = helper.find_value_by_name(g, value_name)
+ if value is None:
+ value = helper.find_input_by_name(g, value_name)
+ if value is None:
+ value = helper.find_output_by_name(g, value_name)
+ if value is None:
+ print("Cannot find an value_info named {}".format(value_name))
+ return
+ # Get the channel number from value info
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_scale_shift_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [len(channel_scale)], channel_scale
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [len(channel_bias)], channel_bias
+ )
+ mean_node = helper.list_to_constant(node_name + "_mean", [channel], zeros)
+ var_node = helper.list_to_constant(node_name + "_var", [channel], ones)
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ )
+ # Reconnect the graph
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, value_name
+ )
+ if len(following_nodes) > 0:
+ for following_node in following_nodes:
+ replace_node_input(following_node, value_name, node_name)
+ else:
+ new_value = onnx.helper.make_tensor_value_info(
+ node_name, value.type.tensor_type.elem_type, shape
+ )
+ output_values = []
+ while len(g.output):
+ output_values.append(g.output.pop())
+ while output_values:
+ output_value = output_values.pop()
+ if output_value.name == value_name:
+ g.output.extend([new_value])
+ else:
+ g.output.extend([output_value])
+ # Add node to the graph
+ g.node.extend([bn_node, scale_node, bias_node, mean_node, var_node])
+ topological_sort(g)
+
+
+def duplicate_shared_Flatten(g):
+ """To feed our compiler, bind Flatten with Gemm. If the output of one\\
+ Flatten goes to two Gemm nodes, duplicate the Flatten.
+
+ :param g: the graph
+ """
+ for node in g.node:
+ # Find a Flatten node
+ if node.op_type != "Flatten":
+ continue
+ # Check Flatten outputs. Get following Gemm
+ output_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ if len(output_nodes) < 2:
+ continue
+ gemm_nodes = []
+ for output_node in output_nodes:
+ if output_node.op_type == "Gemm":
+ gemm_nodes.append(output_node)
+ if len(gemm_nodes) < 2:
+ continue
+ # Process all the Gemm nodes except for the first one.
+ for i in range(1, len(gemm_nodes)):
+ # Duplicate
+ new_flatten_name = node.name + "_copy" + str(i)
+ new_flatten_node = onnx.helper.make_node(
+ "Flatten",
+ node.input,
+ [new_flatten_name],
+ name=new_flatten_name,
+ axis=1,
+ )
+ # Connect new graph
+ replace_node_input(gemm_nodes[i], node.output[0], new_flatten_name)
+ g.node.extend([new_flatten_node])
+ topological_sort(g)
+
+
+def deconv_to_conv_info_extraction(input_size, node_proto):
+ """Extract the information needed for deconv split.
+
+ :param input_size: input shape of the deconv node.\\
+ :param node_proto: the deconv node proto.\\
+ :return: a dictionary of extracted params.
+ """
+ attr = dict()
+ # Get attributes from Deconv node
+ attr["auto_pad"] = helper.get_var_attribute_by_name(
+ node_proto, "auto_pad", "string"
+ )
+ attr["dilations"] = helper.get_list_attribute_by_name(
+ node_proto, "dilations", "int"
+ )
+ attr["group"] = helper.get_var_attribute_by_name(
+ node_proto, "group", "int"
+ )
+ attr["kernel_shape"] = helper.get_list_attribute_by_name(
+ node_proto, "kernel_shape", "int"
+ )
+ attr["output_padding"] = helper.get_list_attribute_by_name(
+ node_proto, "output_padding", "int"
+ )
+ attr["pads"] = helper.get_list_attribute_by_name(node_proto, "pads", "int")
+ attr["strides"] = helper.get_list_attribute_by_name(
+ node_proto, "strides", "int"
+ )
+ # Get output_padding
+ if attr["output_padding"] is None:
+ if (
+ attr["auto_pad"] == "SAME_LOWER"
+ or attr["auto_pad"] == "SAME_UPPER"
+ ):
+ attr["output_padding"] = [
+ attr["strides"][0] - 1,
+ attr["strides"][1],
+ ]
+ else:
+ attr["output_padding"] = [
+ max(attr["strides"][0] - attr["kernel_shape"][0], 0),
+ max(attr["strides"][1] - attr["kernel_shape"][1], 0),
+ ]
+ # Calculate conv_padding
+ if attr["auto_pad"] == "SAME_LOWER" or attr["auto_pad"] == "SAME_UPPER":
+ pad1_h = (
+ attr["kernel_shape"][0] - (attr["kernel_shape"][0] - 1) // 2 - 1
+ )
+ pad1_w = (
+ attr["kernel_shape"][1] - (attr["kernel_shape"][1] - 1) // 2 - 1
+ )
+ head_h = min(
+ attr["kernel_shape"][0] // 2, (attr["output_padding"][0] + 1) // 2
+ )
+ head_w = min(
+ attr["kernel_shape"][1] // 2, (attr["output_padding"][1] + 1) // 2
+ )
+ tail_h = attr["output_padding"][0] - head_h
+ tail_w = attr["output_padding"][1] - head_w
+ attr["conv_pads"] = [
+ pad1_h + head_h,
+ pad1_w + head_w,
+ pad1_h + tail_h,
+ pad1_w + tail_w,
+ ]
+ elif attr["pads"] is not None:
+ sum_of_pads = sum(attr["pads"])
+ if sum_of_pads == 0:
+ # Valid padding
+ pad1_h = attr["kernel_shape"][0] - 0 - 1
+ pad1_w = attr["kernel_shape"][1] - 0 - 1
+ head_h = 0
+ head_w = 0
+ tail_h = attr["output_padding"][0] - head_h
+ tail_w = attr["output_padding"][1] - head_w
+ attr["conv_pads"] = [
+ pad1_h + head_h,
+ pad1_w + head_w,
+ pad1_h + tail_h,
+ pad1_w + tail_w,
+ ]
+ else:
+ # Calculate output shape
+ tmp_output_shape = [0, 0]
+ tmp_output_shape[0] = (
+ attr["strides"][0] * (input_size[2] - 1)
+ + attr["output_padding"][0]
+ + attr["kernel_shape"][0]
+ - attr["pads"][0]
+ - attr["pads"][2]
+ )
+ tmp_output_shape[1] = (
+ attr["strides"][1] * (input_size[3] - 1)
+ + attr["output_padding"][1]
+ + attr["kernel_shape"][1]
+ - attr["pads"][1]
+ - attr["pads"][3]
+ )
+ # Calculate real conv output shape
+ tmp_center_shape = [0, 0]
+ tmp_center_shape[0] = (input_size[2] - 1) * attr["strides"][0] + 1
+ tmp_center_shape[1] = (input_size[3] - 1) * attr["strides"][1] + 1
+ # Calculate padding
+ total_padding = [0, 0]
+ total_padding[0] = (
+ tmp_output_shape[0]
+ - tmp_center_shape[0]
+ + attr["kernel_shape"][0]
+ - 1
+ )
+ total_padding[1] = (
+ tmp_output_shape[1]
+ - tmp_center_shape[1]
+ + attr["kernel_shape"][1]
+ - 1
+ )
+ if total_padding[0] < 0 or total_padding[1] < 0:
+ raise RuntimeError(
+ node_proto.name + " cannot infer conv padding."
+ )
+ conv_pads_ = [0] * 4
+ conv_pads_[0] = total_padding[0] // 2
+ conv_pads_[1] = total_padding[1] // 2
+ conv_pads_[2] = total_padding[0] - total_padding[0] // 2
+ conv_pads_[3] = total_padding[1] - total_padding[1] // 2
+ attr["conv_pads"] = conv_pads_
+ else:
+ pad1_h = attr["kernel_shape"][0] - 0 - 1
+ pad1_w = attr["kernel_shape"][1] - 0 - 1
+ head_h = 0
+ head_w = 0
+ tail_h = attr["output_padding"][0] - head_h
+ tail_w = attr["output_padding"][1] - head_w
+ attr["conv_pads"] = [
+ pad1_h + head_h,
+ pad1_w + head_w,
+ pad1_h + tail_h,
+ pad1_w + tail_w,
+ ]
+ return attr
+
+
+def split_ConvTranspose(model):
+ """To feed our compiler, split ConvTranspose into Upsample and Conv.
+
+ :param model: the model
+ """
+ node_to_delete = []
+ # Change model properties for upsample.
+ if model.ir_version < 3:
+ print("Warning: Current model IR version is not fully supported.")
+ model.ir_version = 4
+ model.opset_import[0].version = 9
+ g = model.graph
+ # Get a Convtranspose layer
+ for node in g.node:
+ # Find a Flatten node
+ if node.op_type != "ConvTranspose":
+ continue
+ # Check auto_pad
+ auto_pad_proto = helper.get_attribute_by_name(node, "auto_pad")
+ if auto_pad_proto is not None:
+ print("Currently not split auto_pad ConvTranspose")
+ continue
+ # Check output_shape
+ output_shape_proto = helper.get_attribute_by_name(node, "output_shape")
+ if output_shape_proto is not None:
+ print("Currently not split output_shape ConvTranspose")
+ continue
+ # Get input shape
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ input_value = helper.find_input_by_name(g, node.input[0])
+ if input_value is None:
+ print("Cannot get value info named {}.".format(node.input[0]))
+ exit(1)
+ input_shape = helper.get_shape_from_value_info(input_value)
+ # Get attrbutes
+ attr = deconv_to_conv_info_extraction(input_shape, node)
+ # Generate Upsample scales
+ upsample_output_shape = list(input_shape)
+ upsample_output_shape[2] = (input_shape[2] - 1) * attr["strides"][
+ 0
+ ] + 1
+ upsample_output_shape[3] = (input_shape[3] - 1) * attr["strides"][
+ 1
+ ] + 1
+ upsample_node_name = node.name + "_inner_upsample"
+ upsample_scale_name = upsample_node_name + "_scales"
+ scales_np = np.ones([4]).astype("float32")
+ scales_np[2] = float(upsample_output_shape[2]) / input_shape[2]
+ scales_np[3] = float(upsample_output_shape[3]) / input_shape[3]
+ scales_node = helper.numpy_to_constant(upsample_scale_name, scales_np)
+ # Generate a Upsample layer and an internal value info
+ upsample_node = onnx.helper.make_node(
+ "Upsample",
+ [node.input[0], upsample_scale_name],
+ [upsample_node_name],
+ name=upsample_node_name,
+ mode="zeros",
+ )
+ upsample_value_info = onnx.helper.make_tensor_value_info(
+ upsample_node_name,
+ input_value.type.tensor_type.elem_type,
+ upsample_output_shape,
+ )
+ # Check the weight layer, it may need a transpose
+ if attr["group"] != input_shape[1]:
+ weight_node = helper.find_node_by_output_name(g, node.input[1])
+ weight_np = helper.constant_to_numpy(weight_node)
+ new_weight_np = np.transpose(weight_np, [1, 0, 2, 3])
+ new_weight_node = helper.numpy_to_constant(
+ node.input[1], new_weight_np
+ )
+ node_to_delete.append(weight_node)
+ g.node.extend([new_weight_node])
+ value = helper.find_value_by_name(g, node.input[1])
+ g.value_info.remove(value)
+ # Generate a Conv layer
+ conv_node_name = node.name + "_inner_conv"
+ conv_node_input = [upsample_node_name]
+ conv_node_input.extend(node.input[1:])
+ conv_node = onnx.helper.make_node(
+ "Conv",
+ conv_node_input,
+ [node.output[0]],
+ name=conv_node_name,
+ pads=[int(i) for i in attr["conv_pads"]],
+ dilations=[int(i) for i in attr["dilations"]],
+ group=int(attr["group"]),
+ kernel_shape=[int(i) for i in attr["kernel_shape"]],
+ strides=[int(1), int(1)],
+ )
+ # Reconnect the graph
+ g.node.extend([scales_node, upsample_node, conv_node])
+ g.value_info.extend([upsample_value_info])
+ node_to_delete.append(node)
+ # Delete useless nodes
+ for node in node_to_delete:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def add_bn_on_skip_branch(g):
+ for n in g.node:
+ # Find merge node (Add)
+ if n.op_type != "Add":
+ continue
+ if len(n.input) != 2:
+ continue
+ # TODO: Still need to consider more cases
+ # Check if skip branch exist
+ input_node_a = helper.find_node_by_output_name(g, n.input[0])
+ output_of_input_node_a = helper.find_nodes_by_input_name(
+ g, input_node_a.output[0]
+ )
+ input_node_b = helper.find_node_by_output_name(g, n.input[1])
+ output_of_input_node_b = helper.find_nodes_by_input_name(
+ g, input_node_b.output[0]
+ )
+ if (
+ len(output_of_input_node_a) == 1
+ and len(output_of_input_node_b) == 1
+ ):
+ continue
+ if len(output_of_input_node_a) == 2:
+ split_node = input_node_a
+ elif len(output_of_input_node_b) == 2:
+ split_node = input_node_b
+ else:
+ continue
+ # Get the channel number from value info
+ value_name = split_node.output[0]
+ value = helper.find_value_by_name(g, value_name)
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [channel], ones
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [channel], zeros
+ )
+ mean_node = helper.list_to_constant(
+ node_name + "_mean", [channel], zeros
+ )
+ var_node = helper.list_to_constant(node_name + "_var", [channel], ones)
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ )
+ # Reconnect the graph
+ replace_node_input(n, value_name, node_name)
+ # Add node to the graph
+ g.node.extend([bn_node, scale_node, bias_node, mean_node, var_node])
+ topological_sort(g)
+
+
+def add_bn_before_add(g):
+ for n in g.node:
+ # Find merge node (Add)
+ if n.op_type != "Add":
+ continue
+ if len(n.input) != 2:
+ continue
+ # Get two inputs
+ input_node_a = helper.find_node_by_output_name(g, n.input[0])
+ input_node_b = helper.find_node_by_output_name(g, n.input[1])
+ # Skip constant input add
+ if input_node_a is None or input_node_a.op_type == "Constant":
+ continue
+ if input_node_b is None or input_node_b.op_type == "Constant":
+ continue
+
+ def add_bn_after(prev_node):
+ # Get the channel number from value info
+ value_name = prev_node.output[0]
+ value = helper.find_value_by_name(g, value_name)
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [channel], ones
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [channel], zeros
+ )
+ mean_node = helper.list_to_constant(
+ node_name + "_mean", [channel], zeros
+ )
+ var_node = helper.list_to_constant(
+ node_name + "_var", [channel], ones
+ )
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ epsilon=0.00000001,
+ )
+ # Reconnect the graph
+ replace_node_input(n, value_name, node_name)
+ # Add node to the graph
+ g.node.extend(
+ [bn_node, scale_node, bias_node, mean_node, var_node]
+ )
+
+ if (
+ not input_node_a.op_type == "BatchNormalization"
+ or len(
+ helper.find_following_nodes_by_input_value_name(
+ g, input_node_a.output[0]
+ )
+ )
+ > 1
+ ):
+ add_bn_after(input_node_a)
+ if (
+ not input_node_b.op_type == "BatchNormalization"
+ or len(
+ helper.find_following_nodes_by_input_value_name(
+ g, input_node_b.output[0]
+ )
+ )
+ > 1
+ ):
+ add_bn_after(input_node_b)
+ topological_sort(g)
+
+
+def add_bn_before_activation(g):
+ activation_nodes = set(["Relu", "Clip", "PRelu", "LeakyRelu"])
+ previous_nodes = set(["Conv", "BatchNormalization"])
+ for n in g.node:
+ # Find activation node
+ if n.op_type not in activation_nodes:
+ continue
+ # Get input
+ input_node = helper.find_node_by_output_name(g, n.input[0])
+ if input_node is None or input_node.op_type in previous_nodes:
+ continue
+
+ def add_bn_after(prev_node):
+ # Get the channel number from value info
+ value_name = prev_node.output[0]
+ value = helper.find_value_by_name(g, value_name)
+ shape = helper.get_shape_from_value_info(value)
+ channel = shape[1]
+ # Construct 4 weights
+ node_name = value_name + "_nop_bn"
+ ones = [1.0] * channel
+ zeros = [0.0] * channel
+ scale_node = helper.list_to_constant(
+ node_name + "_scale", [channel], ones
+ )
+ bias_node = helper.list_to_constant(
+ node_name + "_bias", [channel], zeros
+ )
+ mean_node = helper.list_to_constant(
+ node_name + "_mean", [channel], zeros
+ )
+ var_node = helper.list_to_constant(
+ node_name + "_var", [channel], ones
+ )
+ # Construct BN node
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ value_name,
+ scale_node.output[0],
+ bias_node.output[0],
+ mean_node.output[0],
+ var_node.output[0],
+ ],
+ [node_name],
+ name=node_name,
+ epsilon=0.00000001,
+ )
+ # Reconnect the graph
+ replace_node_input(n, value_name, node_name)
+ # Add node to the graph
+ g.node.extend(
+ [bn_node, scale_node, bias_node, mean_node, var_node]
+ )
+
+ add_bn_after(input_node)
+ topological_sort(g)
+
+
+def rename_output_name(g, original_name, new_name):
+ # Output
+ output_value = helper.find_output_by_name(g, original_name)
+ if output_value is None:
+ logging.error("Cannot find output value named " + original_name)
+ return
+ output_value.name = new_name
+ # Value Info
+ value_info = helper.find_value_by_name(g, original_name)
+ if value_info is not None:
+ value_info.name = new_name
+ # Node output
+ node = helper.find_node_by_output_name(g, original_name)
+ node.output[0] = new_name
+ # Node input
+ nodes = helper.find_nodes_by_input_name(g, original_name)
+ for node in nodes:
+ replace_node_input(node, original_name, new_name)
+
+
+def duplicate_param_shared_constant(g):
+ for node in g.node:
+ input_names = set()
+ for n, input_node_name in enumerate(node.input):
+ param_data_node = helper.find_node_by_output_name(
+ g, input_node_name
+ )
+ if (
+ param_data_node is None
+ or param_data_node.op_type != "Constant"
+ ):
+ continue
+ if param_data_node.name not in input_names:
+ input_names.add(input_node_name)
+ continue
+
+ new_node_name = param_data_node.name + "_" + str(n)
+ helper.logger.debug(
+ f"Duplicating weight: {param_data_node.name} -> "
+ f"{new_node_name}"
+ )
+ duplicated_node = copy.deepcopy(param_data_node)
+
+ duplicated_node.name = new_node_name
+ duplicated_node.output[0] = new_node_name
+
+ node.input[n] = new_node_name
+ g.node.extend([duplicated_node])
diff --git a/tools/optimizer_scripts/tools/removing_transpose.py b/tools/optimizer_scripts/tools/removing_transpose.py
new file mode 100644
index 0000000..89f772b
--- /dev/null
+++ b/tools/optimizer_scripts/tools/removing_transpose.py
@@ -0,0 +1,368 @@
+from . import helper
+from . import other
+from . import modhelper
+import numpy as np
+import onnx
+import onnx.utils
+
+
+def eliminate_transposes(m):
+ g = m.graph
+ keep_eliminating = True
+ while keep_eliminating:
+ while swap_transpose_with_single_next_node(g):
+ pass
+ splitted = split_transpose_for_multiple_next_nodes(g)
+ annihilated = annihilate_transposes(g)
+ multiple_trans_swapped = swap_multiple_transposes_with_node(g)
+ keep_eliminating = splitted or annihilated or multiple_trans_swapped
+
+ if keep_eliminating:
+ m = other.polish_model(m)
+ g = m.graph
+
+ return m
+
+
+def swap_transpose_with_single_next_node(g):
+ swapped = False
+ passable_nodes = set(
+ [
+ "Relu",
+ "Neg",
+ "LeakyRelu",
+ "Sqrt",
+ "Reciprocal",
+ "Add",
+ "Mul",
+ "Tanh",
+ ]
+ )
+ for node in g.node:
+ trans_node = node
+ # Check for transpose node
+ if trans_node.op_type != "Transpose":
+ continue
+ next_nodes = helper.find_nodes_by_input_name(g, trans_node.output[0])
+ if len(next_nodes) != 1:
+ continue
+ next_node = next_nodes[0]
+ # Check if the next node is the type can be swapped
+ if next_node.op_type not in passable_nodes:
+ continue
+
+ input_nodes = [
+ helper.find_node_by_output_name(g, input_name)
+ for input_name in next_node.input
+ ]
+
+ # Check if the node has nonconstant input
+ # other than the Transpose node itself
+ nonconstant_input = False
+ for input_node in input_nodes:
+ if input_node is None:
+ nonconstant_input = True
+ break
+ if input_node.name == trans_node.name:
+ continue
+ elif input_node.op_type == "Constant":
+ continue
+ else:
+ nonconstant_input = True
+ break
+ if nonconstant_input:
+ continue
+
+ for input_node in input_nodes:
+ if input_node.name == trans_node.name:
+ # if the input is just the transpose node
+ next_value_info = helper.find_value_by_name(
+ g, next_node.output[0]
+ )
+ mid_value_info = helper.find_value_by_name(
+ g, trans_node.output[0]
+ )
+
+ output_nodes = helper.find_nodes_by_input_name(
+ g, next_node.output[0]
+ )
+ for out_node in output_nodes:
+ modhelper.replace_node_input(
+ out_node, next_node.output[0], trans_node.name
+ )
+
+ next_node.input[0] = trans_node.input[0]
+ next_node.output[0] = next_node.name
+ trans_node.input[0] = next_node.name
+ trans_node.output[0] = trans_node.name
+
+ if next_value_info:
+ next_value_info.name = trans_node.name
+ if mid_value_info:
+ g.value_info.remove(mid_value_info)
+ else:
+ # if the input is a constant node
+ old_tensor = input_node.attribute[0].t
+ old_shape, data = helper.constant_to_list(input_node)
+ # If the constant node is a scaler, no action is needed
+ if type(old_shape) == int:
+ old_shape = [old_shape]
+ permutation = list(trans_node.attribute[0].ints)
+ while len(old_shape) < len(permutation):
+ old_shape.insert(0, 1)
+ np_data = np.reshape(data, old_shape)
+ reverse_perm = []
+ for i in range(len(permutation)):
+ reverse_perm.append(permutation.index(i))
+ np_data = np.transpose(np_data, reverse_perm)
+ new_shape = np_data.shape
+ new_tensor = onnx.helper.make_tensor(
+ name=old_tensor.name,
+ data_type=old_tensor.data_type,
+ dims=new_shape,
+ vals=np_data.flatten().tolist(),
+ )
+ new_node = onnx.helper.make_node(
+ "Constant",
+ [],
+ [input_node.output[0]],
+ name=input_node.name,
+ value=new_tensor,
+ )
+ g.node.extend([new_node])
+
+ g.value_info.remove(
+ helper.find_value_by_name(g, input_node.output[0])
+ )
+ g.node.remove(input_node)
+
+ swapped = True
+
+ other.topological_sort(g)
+ return swapped
+
+
+def swap_multiple_transposes_with_node(g):
+ # here only consider same input transposes
+ swapped = False
+ passable_nodes = set(["Add", "Mul"])
+ node_to_del = []
+ for node in g.node:
+ if node.op_type not in passable_nodes:
+ continue
+ input_nodes = [
+ helper.find_node_by_output_name(g, input_name)
+ for input_name in node.input
+ ]
+ if any([input_node is None for input_node in input_nodes]):
+ continue
+ if any(
+ [input_node.op_type != "Transpose" for input_node in input_nodes]
+ ):
+ continue
+
+ permutation = list(input_nodes[0].attribute[0].ints)
+ if any(
+ [
+ list(input_node.attribute[0].ints) != permutation
+ for input_node in input_nodes
+ ]
+ ):
+ continue
+
+ for input_name in node.input:
+ input_node = helper.find_node_by_output_name(g, input_name)
+ modhelper.replace_node_input(node, input_name, input_node.input[0])
+
+ node_to_del.extend(input_nodes)
+ for input_node in input_nodes:
+ input_val_info = helper.find_value_by_name(g, input_node.output[0])
+ if input_val_info is not None:
+ g.value_info.remove(input_val_info)
+ output_val_info = helper.find_value_by_name(g, node.output[0])
+ if output_val_info is not None:
+ g.value_info.remove(output_val_info)
+
+ output_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ for i in range(len(output_nodes)):
+ new_trans_node_name = node.name + "_trans_" + str(i)
+ new_trans_node = onnx.helper.make_node(
+ "Transpose",
+ [node.output[0]],
+ [new_trans_node_name],
+ name=new_trans_node_name,
+ perm=permutation,
+ )
+ modhelper.replace_node_input(
+ output_nodes[i], node.output[0], new_trans_node_name
+ )
+
+ g.node.extend([new_trans_node])
+
+ swapped = True
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ other.topological_sort(g)
+ return swapped
+
+
+def annihilate_transposes(g):
+ node_to_del = []
+ annihilated = False
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ if not pre_node or pre_node.op_type != "Transpose":
+ continue
+ nodes_from_top_transpose = helper.find_nodes_by_input_name(
+ g, pre_node.output[0]
+ )
+ if len(nodes_from_top_transpose) > 1:
+ continue
+
+ perm_1 = list(pre_node.attribute[0].ints)
+ perm_2 = list(node.attribute[0].ints)
+ if perm_1 != perm_2:
+ continue
+
+ out_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ for out_node in out_nodes:
+ modhelper.replace_node_input(
+ out_node, node.output[0], pre_node.input[0]
+ )
+
+ node_to_del.extend([node, pre_node])
+ mid_value_info = helper.find_value_by_name(g, pre_node.output[0])
+ out_value_info = helper.find_value_by_name(g, node.output[0])
+ g.value_info.remove(mid_value_info)
+ g.value_info.remove(out_value_info)
+
+ annihilated = True
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ return annihilated
+
+
+def split_transpose_for_multiple_next_nodes(g):
+ splitted = False
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ output_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ if len(output_nodes) < 2:
+ continue
+ for i in range(len(output_nodes)):
+ output_node = output_nodes[i]
+ new_trans_node_name = node.name + "_" + str(i)
+ new_trans_node = onnx.helper.make_node(
+ "Transpose",
+ [node.input[0]],
+ [new_trans_node_name],
+ name=new_trans_node_name,
+ perm=list(node.attribute[0].ints),
+ )
+ modhelper.replace_node_input(
+ output_node, node.output[0], new_trans_node.output[0]
+ )
+ g.node.extend([new_trans_node])
+
+ node_to_del.append(node)
+ val_info = helper.find_value_by_name(g, node.output[0])
+ g.value_info.remove(val_info)
+
+ splitted = True
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ other.topological_sort(g)
+ return splitted
+
+
+def remove_trivial_transpose(g):
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Transpose":
+ continue
+ permutation = list(node.attribute[0].ints)
+ if permutation != list(range(len(permutation))):
+ continue
+
+ next_nodes = helper.find_nodes_by_input_name(g, node.output[0])
+ if not next_nodes:
+ input_val_info = helper.find_value_by_name(g, node.input[0])
+ out_val_info = helper.find_output_by_name(g, node.output[0])
+ if not input_val_info:
+ input_val_info = helper.find_input_by_name(g, node.input[0])
+ g.output.remove(out_val_info)
+ g.output.extend([input_val_info])
+ else:
+ out_val_info = helper.find_value_by_name(g, node.output[0])
+ for next_node in next_nodes:
+ modhelper.replace_node_input(
+ next_node, node.output[0], node.input[0]
+ )
+ g.value_info.remove(out_val_info)
+
+ node_to_del.append(node)
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ other.topological_sort(g)
+
+
+def fuse_Transpose_into_Gemm_weight(g):
+ node_to_del = []
+ for node in g.node:
+ # Check pattern
+ if node.op_type != "Gemm":
+ continue
+ prev_node = helper.find_node_by_output_name(g, node.input[0])
+ if prev_node is None or prev_node.op_type != "Flatten":
+ continue
+ transpose_node = helper.find_node_by_output_name(g, prev_node.input[0])
+ if transpose_node.op_type != "Transpose":
+ continue
+ # Check attribute
+ perm = helper.get_list_attribute_by_name(transpose_node, "perm", "int")
+ if perm != [0, 2, 3, 1]:
+ continue
+ transB = helper.get_var_attribute_by_name(node, "transB", "int")
+ if transB is not None and transB == 1:
+ continue
+ # Get the original weight
+ origin_weight = helper.find_node_by_output_name(g, node.input[1])
+ origin_np = helper.constant_to_numpy(origin_weight)
+ # Calculate a new weight
+ shape = helper.get_shape_from_value_info(
+ helper.find_value_by_name(g, prev_node.input[0])
+ )
+ shape.append(-1)
+ new_np = np.reshape(origin_np, shape)
+ new_np = np.transpose(new_np, [0, 3, 1, 2, 4])
+ new_np = np.reshape(new_np, [-1, new_np.shape[-1]])
+ new_weight = helper.numpy_to_constant(origin_weight.output[0], new_np)
+ # Replace and eliminate
+ prev_node.input[0] = transpose_node.input[0]
+ node_to_del.append(transpose_node)
+ node_to_del.append(origin_weight)
+ g.value_info.remove(
+ helper.find_value_by_name(g, transpose_node.output[0])
+ )
+ g.node.extend([new_weight])
+
+ while node_to_del:
+ node = node_to_del.pop()
+ g.node.remove(node)
+
+ other.topological_sort(g)
diff --git a/tools/optimizer_scripts/tools/replacing.py b/tools/optimizer_scripts/tools/replacing.py
new file mode 100644
index 0000000..fdbaa62
--- /dev/null
+++ b/tools/optimizer_scripts/tools/replacing.py
@@ -0,0 +1,1367 @@
+"""
+Optimizations that replace one node with another.
+"""
+import struct
+import copy
+import logging
+import onnx.helper
+import numpy as np
+from . import helper
+from . import modhelper
+from .other import topological_sort
+
+
+def replace_initializer_with_Constant(g, duplicate_shared_weights=True):
+ """
+ Replace initializers with Constant and a corresponding value_info
+ If the initializer has related input, remove it.
+
+ :param g: the onnx graph
+ """
+
+ input_map = {i.name: i for i in g.input}
+ for tensor in g.initializer:
+ # Check for the initializer related input and remove it
+ if tensor.name in input_map:
+ value_info = input_map[tensor.name]
+ g.input.remove(value_info)
+ following_nodes = helper.find_nodes_by_input_name(g, tensor.name)
+ if duplicate_shared_weights and len(following_nodes) >= 2:
+ for i, node in enumerate(following_nodes):
+ new_name = (
+ tensor.name + "_duplicated_No" + str(i)
+ if i > 0
+ else tensor.name
+ )
+ helper.logger.debug(
+ f"Duplicating weight: {tensor.name} -> {new_name}"
+ )
+ modhelper.replace_node_input(node, tensor.name, new_name)
+ new_node = onnx.helper.make_node(
+ "Constant", [], [new_name], name=new_name, value=tensor
+ )
+ # Add node to lists
+ g.node.extend([new_node])
+ else:
+ new_name = tensor.name
+ new_node = onnx.helper.make_node(
+ "Constant", [], [new_name], name=new_name, value=tensor
+ )
+ # Add node to lists
+ g.node.extend([new_node])
+
+ # if value info already exists, remove it as well.
+ value_info = helper.find_value_by_name(g, tensor.name)
+ if value_info is not None:
+ g.value_info.remove(value_info)
+
+ # Remove original initializer
+ while len(g.initializer) != 0:
+ g.initializer.pop()
+
+ topological_sort(g)
+
+
+def replace_Reshape_with_Flatten(g):
+ """
+ Replace Reshape node into Flatten node if applicable.
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ if node.op_type != "Reshape":
+ continue
+ found_Gemm = False
+ # Flatten could be followed by Gemm
+ for i in g.node:
+ if len(i.input) == 0 or i.input[0] != node.output[0]:
+ continue
+ if i.op_type == "Gemm":
+ break
+ # Check weight
+ shape_node = helper.find_node_by_output_name(g, node.input[1])
+ if shape_node.op_type != "Constant":
+ continue
+ shape_value = helper.constant_to_numpy(shape_node)
+ if (shape_value.size != 2 or shape_value[0] != 1) and not found_Gemm:
+ continue
+ # Replace it
+ node.op_type = "Flatten"
+ for _ in range(len(node.attribute)):
+ node.attribute.pop()
+ shape_value = helper.find_value_by_name(g, shape_node.output[0])
+ node.input.pop()
+ node_to_remove.append(shape_node)
+ # If found shape value_info, remove it
+ if shape_value is not None:
+ g.value_info.remove(shape_value)
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def replace_Squeeze_with_Reshape(g):
+ """
+ Replace Squeeze nodes with Reshape node.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find Squeeze node
+ if node.op_type != "Squeeze":
+ continue
+ # Get the shape and Construct the shape
+ output_value = helper.find_value_by_name(g, node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if output_value is None:
+ raise RuntimeError("Cannot get shape for Squeeze")
+ shape = [
+ dim.dim_value for dim in output_value.type.tensor_type.shape.dim
+ ]
+ const_node = helper.list_to_constant(
+ node.name + "_shape", [len(shape)], shape
+ )
+ # Construct the Reshape layer with same input, output and name.
+ new_node = onnx.helper.make_node(
+ "Reshape",
+ [node.input[0], node.name + "_shape"],
+ node.output,
+ name=node.name,
+ )
+ # Append constructed nodes and append old node to remove_list
+ g.node.extend([const_node, new_node])
+ node_to_remove.append(node)
+ # Remove old nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ # Topological sort
+ topological_sort(g)
+
+
+def replace_Unsqueeze_with_Reshape(g):
+ """
+ Replace Unsqueeze nodes with Reshape node.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find Squeeze node
+ if node.op_type != "Unsqueeze":
+ continue
+ # Get the shape and Construct the shape
+ output_value = helper.find_value_by_name(g, node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(g, node.output[0])
+ if output_value is None:
+ raise RuntimeError("Cannot get shape for Unsqueeze")
+ shape = [
+ dim.dim_value for dim in output_value.type.tensor_type.shape.dim
+ ]
+
+ const_node = helper.list_to_constant(
+ node.name + "_shape", [len(shape)], shape
+ )
+ # Construct the Reshape layer with same input, output and name.
+ new_node = onnx.helper.make_node(
+ "Reshape",
+ [node.input[0], node.name + "_shape"],
+ node.output,
+ name=node.name,
+ )
+ # Append constructed nodes and append old node to remove_list
+ g.node.extend([const_node, new_node])
+ node_to_remove.append(node)
+ # Remove old nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+ # Topological sort
+ topological_sort(g)
+
+
+def replace_average_pool_with_GAP(g):
+ """
+ Replace AveragePool nodes with GlobalAveragePool node when available.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a average pool layer
+ if node.op_type != "AveragePool":
+ continue
+ # Check attributes
+ not_replace = False
+ for attr in node.attribute:
+ if attr.name == "pads":
+ if list(attr.ints) != [0, 0, 0, 0]:
+ not_replace = True
+ break
+ if attr.name == "kernel_shape":
+ kernel_shape = list(attr.ints)
+ value_info = helper.find_value_by_name(g, node.input[0])
+ if value_info is None:
+ not_replace = True
+ break
+ input_shape = []
+ for dim in value_info.type.tensor_type.shape.dim:
+ input_shape.append(dim.dim_value)
+ if input_shape[-2:] != kernel_shape:
+ not_replace = True
+ break
+ if not_replace:
+ continue
+ # Replace it with GlobalAveragePool
+ new_node = onnx.helper.make_node(
+ "GlobalAveragePool", node.input, node.output, name=node.name
+ )
+ g.node.extend([new_node])
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def replace_dilated_conv(g):
+ """
+ If the dilation of a convolution is not (1, 1), replace it with a regular
+ convolution with an expanded kernel.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check if this is a conv layer
+ if node.op_type != "Conv":
+ continue
+ # Check if this has dilation
+ has_dilations = False
+ has_strides = False
+ for attr in node.attribute:
+ if attr.name == "dilations":
+ dilations = list(attr.ints)
+ if dilations != [1, 1]:
+ has_dilations = True
+ if attr.name == "strides":
+ strides = list(attr.ints)
+ if strides != [1, 1]:
+ has_strides = True
+ if has_dilations and has_strides:
+ print("Warning: Both strides and dilations are set in ", node.name)
+ continue
+ if not has_dilations:
+ continue
+ # Construct new kernel
+ w_node = helper.find_node_by_output_name(g, node.input[1])
+ w_output = helper.find_value_by_name(g, node.input[1])
+ shape = list(w_node.attribute[0].t.dims)
+ # get original weight from float_data or raw data
+ weight = list(w_node.attribute[0].t.float_data)
+ if len(weight) == 0:
+ # Unpack from raw data
+ raw_data = w_node.attribute[0].t.raw_data
+ weight = [i[0] for i in struct.iter_unpack("f", raw_data)]
+ weight = np.array(weight)
+ weight = np.reshape(weight, shape)
+ new_shape = copy.copy(shape)
+ new_shape[2] = 1 + (shape[2] - 1) * dilations[0]
+ new_shape[3] = 1 + (shape[3] - 1) * dilations[1]
+ new_weight = np.zeros(new_shape)
+ for batch in range(shape[0]):
+ for ch in range(shape[1]):
+ for h in range(shape[2]):
+ nh = h * dilations[0]
+ for w in range(shape[3]):
+ nw = w * dilations[1]
+ new_weight[batch, ch, nh, nw] = weight[batch, ch, h, w]
+ tensor = onnx.helper.make_tensor(
+ w_node.attribute[0].t.name,
+ w_node.attribute[0].t.data_type,
+ new_shape,
+ new_weight.ravel(),
+ )
+ new_w_node = onnx.helper.make_node(
+ "Constant", [], list(w_node.output), name=w_node.name, value=tensor
+ )
+ g.node.extend([new_w_node])
+ node_to_remove.append(w_node)
+ # Modify attributes and value info shapes
+ w_output.type.tensor_type.shape.dim[2].dim_value = new_shape[2]
+ w_output.type.tensor_type.shape.dim[3].dim_value = new_shape[3]
+ for attr in node.attribute:
+ if attr.name == "kernel_shape":
+ attr.ints[0] = new_shape[2]
+ attr.ints[1] = new_shape[3]
+ if attr.name == "dilations":
+ attr.ints[0] = 1
+ attr.ints[1] = 1
+ # Remove old weight nodes
+ for node in node_to_remove:
+ g.node.remove(node)
+
+
+def replace_depthwise_1x1_with_bn(g):
+ """Replace 1x1 DepthwiseConv node into BN node if applicable.
+
+ :param g: the onnx graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Check op_type
+ if node.op_type != "Conv":
+ continue
+ # Check attributes
+ attr_map = {attr.name: attr for attr in node.attribute}
+ if "group" not in attr_map or attr_map["group"].i == 1:
+ continue
+ if (
+ attr_map["kernel_shape"].ints[0] != 1
+ or attr_map["kernel_shape"].ints[1] != 1
+ ):
+ continue
+ if "pads" in attr_map and sum(attr_map["pads"].ints) != 0:
+ continue
+ # Check scale
+ scale_node = helper.find_node_by_output_name(g, node.input[1])
+ if scale_node is None or scale_node.attribute[0].t.dims[1] != 1:
+ continue
+ scale_node.attribute[0].t.dims.pop()
+ scale_node.attribute[0].t.dims.pop()
+ scale_node.attribute[0].t.dims.pop()
+ scale_info = helper.find_value_by_name(g, node.input[1])
+ if scale_info is not None:
+ scale_info.type.tensor_type.shape.dim.pop()
+ scale_info.type.tensor_type.shape.dim.pop()
+ scale_info.type.tensor_type.shape.dim.pop()
+ # Check bias
+ if len(node.input) == 3:
+ bias_name = node.input[2]
+ else:
+ bias_name = node.name + "_bias"
+ bias_node = helper.list_to_constant(
+ bias_name, [attr_map["group"].i], [0.0] * attr_map["group"].i
+ )
+ g.node.extend([bias_node])
+ # Construct mean and vars
+ mean_name = node.name + "_mean"
+ mean_node = helper.list_to_constant(
+ mean_name, [attr_map["group"].i], [0.0] * attr_map["group"].i
+ )
+ var_name = node.name + "_var"
+ var_node = helper.list_to_constant(
+ var_name, [attr_map["group"].i], [1.0] * attr_map["group"].i
+ )
+ g.node.extend([mean_node, var_node])
+ # Convert
+ bn_node = onnx.helper.make_node(
+ op_type="BatchNormalization",
+ inputs=[
+ node.input[0],
+ node.input[1],
+ bias_name,
+ mean_name,
+ var_name,
+ ],
+ outputs=node.output,
+ name=node.name,
+ epsilon=0.00001,
+ momentum=0.9,
+ )
+ g.node.extend([bn_node])
+ node_to_remove.append(node)
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def replace_shape_with_constant(g):
+ """Replace Shape with Constant.\\
+ This is the first step of reshape constant folding.
+
+ :param g: the input graph\\
+ :return: if anything modified, return true.
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a Shape
+ if node.op_type != "Shape":
+ continue
+ # Check its input
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ input_value = helper.find_input_by_name(g, node.input[0])
+ if (
+ input_value is None
+ or len(input_value.type.tensor_type.shape.dim) == 0
+ ):
+ continue
+ # Check for case where dimension could be 0 or -1
+ tmp = True
+ for d in input_value.type.tensor_type.shape.dim:
+ tmp = tmp and (d.dim_value > 0)
+ if not tmp:
+ continue
+ # Repalce it
+ input_shape = [
+ d.dim_value for d in input_value.type.tensor_type.shape.dim
+ ]
+ node_name = node.output[0]
+ new_node = helper.list_to_constant(
+ node_name, [len(input_shape)], input_shape
+ )
+ g.node.extend([new_node])
+ node_to_remove.append(node)
+
+ # if the input value_info is not used by other node
+ # delete this input value_info
+ val_info_used = sum(
+ [input_value.name in node.input for node in g.node]
+ )
+ if val_info_used == 1:
+ g.value_info.remove(input_value)
+
+ replaced = True if len(node_to_remove) > 0 else False
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+ topological_sort(g)
+
+ return replaced
+
+
+def replace_ConstantOfShape_with_constant(g):
+ """Replace Shape with Constant.\\
+ This is the first step of reshape constant folding.
+
+ :param g: the input graph\\
+ :return: if anything modified, return true.
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a Shape
+ if node.op_type != "ConstantOfShape":
+ continue
+ # Check input
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if input_value is None:
+ input_value = helper.find_input_by_name(g, node.input[0])
+ if (
+ input_value is None
+ or len(input_value.type.tensor_type.shape.dim) == 0
+ ):
+ continue
+
+ # Replace to constant node
+ pre_node = helper.find_node_by_output_name(g, node.input[0])
+ _, target_shape = helper.constant_to_list(pre_node)
+
+ value = helper.get_attribute_by_name(node, "value").i
+
+ node_name = node.output[0]
+ new_node = helper.list_to_constant(
+ node_name, [target_shape[0]], [value] * target_shape[0]
+ )
+
+ g.node.extend([new_node])
+
+ # remove old node
+ node_to_remove.append(node)
+
+ # delete value_info
+ val_info_used = sum(
+ [input_value.name in node.input for node in g.node]
+ )
+ if val_info_used == 1:
+ g.value_info.remove(input_value)
+
+ replaced = True if len(node_to_remove) > 0 else False
+
+ for node in node_to_remove:
+ g.node.remove(node)
+
+ topological_sort(g)
+
+ return replaced
+
+
+def replace_split_with_slices(g):
+ """Replace split node with slice nodes.
+ :param g: input graph.
+ :return:
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a Split
+ if node.op_type != "Split":
+ continue
+
+ input_value = helper.find_value_by_name(g, node.input[0])
+ if not input_value:
+ input_value = helper.find_input_by_name(g, node.input[0])
+ _, shape = helper.find_size_shape_from_value(input_value)
+ if len(shape) == 0:
+ continue
+
+ output_val_names = list(node.output)
+
+ axis = 0
+ split = []
+ for item in node.attribute:
+ if item.name == "axis":
+ axis = item.i
+ if item.name == "split":
+ split = item.ints
+
+ # For opset 11, axis could be negative.
+ if axis < 0:
+ axis = len(shape) + axis
+
+ length = input_value.type.tensor_type.shape.dim[axis].dim_value
+ if len(split) > 0:
+ n_out = len(split)
+ pos = 0
+ for i in range(n_out):
+ pos += split[i]
+ new_node_name = output_val_names[i]
+ # Construct starts, ends, axes
+ starts_name = new_node_name + "_starts_" + str(i)
+ ends_name = new_node_name + "_ends_" + str(i)
+ axes_name = new_node_name + "_axes_" + str(i)
+ starts_node = helper.list_to_constant(
+ starts_name, (1,), [int(pos - split[i])]
+ )
+ ends_node = helper.list_to_constant(
+ ends_name, (1,), [int(pos)]
+ )
+ axes_node = helper.list_to_constant(
+ axes_name, (1,), [int(axis)]
+ )
+ # Construtc node
+ new_node = onnx.helper.make_node(
+ op_type="Slice",
+ inputs=[node.input[0], starts_name, ends_name, axes_name],
+ outputs=[node.output[i]],
+ name=new_node_name,
+ )
+ g.node.extend([starts_node, ends_node, axes_node, new_node])
+ node_to_remove.append(node)
+ else:
+ n_out = len(output_val_names)
+ width = length // n_out
+ for i in range(n_out):
+ new_node_name = output_val_names[i]
+ # Construct starts, ends, axes
+ starts_name = new_node_name + "_starts_" + str(i)
+ ends_name = new_node_name + "_ends_" + str(i)
+ axes_name = new_node_name + "_axes_" + str(i)
+ starts_node = helper.list_to_constant(
+ starts_name, (1,), [int(i * width)]
+ )
+ ends_node = helper.list_to_constant(
+ ends_name, (1,), [int((1 + i) * width)]
+ )
+ axes_node = helper.list_to_constant(
+ axes_name, (1,), [int(axis)]
+ )
+ # Construtc node
+ new_node = onnx.helper.make_node(
+ op_type="Slice",
+ inputs=[node.input[0], starts_name, ends_name, axes_name],
+ outputs=[node.output[i]],
+ name=new_node_name,
+ )
+ g.node.extend([starts_node, ends_node, axes_node, new_node])
+ node_to_remove.append(node)
+
+ for old_node in node_to_remove:
+ g.node.remove(old_node)
+ topological_sort(g)
+
+
+def replace_ReduceMean_with_GlobalAveragePool(g):
+ """
+ Replace ReduceMean with GlobalAveragePool node when available.
+
+ If there is preceeded Transpose, check the Transpose and the ReduceMean
+ together. If the keep_dims is set to 0, add a Flatten.
+
+ :param g: the input graph
+ """
+ node_to_remove = []
+ for node in g.node:
+ # Find a ReduceMean layer
+ if node.op_type != "ReduceMean":
+ continue
+ # Find if it have previous Transpose and its attribute meet the need.
+ prev_node = helper.find_node_by_output_name(g, node.input[0])
+ if prev_node is not None and prev_node.op_type != "Transpose":
+ prev_node = None
+ if prev_node is not None:
+ perm = helper.get_list_attribute_by_name(prev_node, "perm", "int")
+ if perm != [0, 2, 3, 1]:
+ prev_node = None
+ # Check attributes
+ axes = helper.get_list_attribute_by_name(node, "axes", "int")
+ keepdims = helper.get_var_attribute_by_name(node, "keepdims", "int")
+ if axes is None:
+ continue
+ if prev_node is None and axes != [2, 3]:
+ continue
+ if prev_node is not None and axes != [1, 2]:
+ continue
+ if keepdims is None:
+ keepdims = 1
+ # Replace it with GlobalAveragePool
+ if prev_node:
+ input_list = prev_node.input
+ else:
+ input_list = node.input
+ if keepdims == 1:
+ output_list = node.output
+ else:
+ output_list = [node.output[0] + "_before_flatten"]
+ flatten_node = onnx.helper.make_node(
+ "Flatten",
+ output_list,
+ node.output,
+ name=node.name + "_flatten",
+ axis=1,
+ )
+ g.node.extend([flatten_node])
+ new_node = onnx.helper.make_node(
+ "GlobalAveragePool", input_list, output_list, name=node.name
+ )
+ g.node.extend([new_node])
+ node_to_remove.append(node)
+ if prev_node:
+ value = helper.find_value_by_name(g, prev_node.output[0])
+ if value:
+ g.value_info.remove(value)
+ node_to_remove.append(prev_node)
+ for node in node_to_remove:
+ g.node.remove(node)
+ topological_sort(g)
+
+
+def replace_mul_to_bn(g):
+ """Replace single Mul node with Batchnorm node.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Mul":
+ continue
+
+ mul_op_node = node
+
+ # only support one input node
+ if len(mul_op_node.input) != 2: # OP node and value node
+ continue
+
+ input_op_node_name = mul_op_node.input[0]
+ mul_value_node = helper.find_node_by_output_name(
+ g, mul_op_node.input[1]
+ )
+ if not mul_value_node or mul_value_node.op_type != "Constant":
+ continue
+
+ prev_shape_value_info = helper.find_value_by_name(
+ g, input_op_node_name
+ )
+ prev_shape_value_info = (
+ helper.find_input_by_name(g, input_op_node_name)
+ if prev_shape_value_info is None
+ else prev_shape_value_info
+ )
+ if prev_shape_value_info is None:
+ continue
+
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ prev_shape_value_info
+ )
+ scale_shape, scale_data = helper.constant_to_list(mul_value_node)
+
+ # channel dimension
+ c_dim = (
+ previous_node_output_shape[1]
+ if len(previous_node_output_shape) > 1
+ else 1
+ )
+
+ # only allow channelwise mul or const mul
+ if scale_shape == [1, c_dim, 1, 1]:
+ muls = scale_data
+ elif scale_shape == [c_dim, 1, 1]:
+ muls = scale_data
+ elif scale_shape == 1:
+ muls = scale_data * c_dim
+ else:
+ continue
+
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ bn_name = mul_op_node.output[0]
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ bias_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(zeros).shape, zeros
+ )
+ new_mul_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(muls).shape, muls
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ input_op_node_name,
+ new_mul_value_node.output[0],
+ bias_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [mul_op_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ scale_val_info = helper.find_value_by_name(g, mul_value_node.output[0])
+ g.value_info.remove(scale_val_info)
+
+ g.node.extend([bn_node])
+ g.node.extend([mean_value_node])
+ g.node.extend([variance_value_node])
+ g.node.extend([bias_value_node])
+ g.node.extend([new_mul_value_node])
+
+ node_to_del.extend([mul_op_node])
+ node_to_del.extend([mul_value_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_div_to_bn(g):
+ """Replace single Div node with Batchnorm node.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Div":
+ continue
+
+ div_op_node = node
+
+ # only support one input node
+ if len(div_op_node.input) != 2: # OP node and value node
+ continue
+
+ input_op_node_name = div_op_node.input[0]
+ div_value_node = helper.find_node_by_output_name(
+ g, div_op_node.input[1]
+ )
+ if not div_value_node or div_value_node.op_type != "Constant":
+ continue
+
+ prev_shape_value_info = helper.find_value_by_name(
+ g, input_op_node_name
+ )
+ prev_shape_value_info = (
+ helper.find_input_by_name(g, input_op_node_name)
+ if prev_shape_value_info is None
+ else prev_shape_value_info
+ )
+ if prev_shape_value_info is None:
+ continue
+
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ prev_shape_value_info
+ )
+ scale_shape, scale_data = helper.constant_to_list(div_value_node)
+
+ # channel dimension
+ c_dim = (
+ previous_node_output_shape[1]
+ if len(previous_node_output_shape) > 1
+ else 1
+ )
+
+ # only allow channelwise div or const div
+ if scale_shape == [1, c_dim, 1, 1]:
+ muls = scale_data
+ elif scale_shape == [c_dim, 1, 1]:
+ muls = scale_data
+ elif scale_shape == 1:
+ muls = scale_data * c_dim
+ else:
+ continue
+
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ muls = (1 / np.array(muls)).tolist()
+ bn_name = div_op_node.output[0]
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ bias_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(zeros).shape, zeros
+ )
+ new_mul_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(muls).shape, muls
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ input_op_node_name,
+ new_mul_value_node.output[0],
+ bias_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [div_op_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ scale_val_info = helper.find_value_by_name(g, div_value_node.output[0])
+ g.value_info.remove(scale_val_info)
+
+ g.node.extend([bn_node])
+ g.node.extend([mean_value_node])
+ g.node.extend([variance_value_node])
+ g.node.extend([bias_value_node])
+ g.node.extend([new_mul_value_node])
+
+ node_to_del.extend([div_op_node])
+ node_to_del.extend([div_value_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_add_to_bn(g):
+ """Replace single Add node with Batchnorm node.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Add":
+ continue
+
+ add_op_node = node
+
+ # only support one input node
+ if len(add_op_node.input) != 2: # OP node and value node
+ continue
+
+ input_op_node_name = add_op_node.input[0]
+ add_value_node = helper.find_node_by_output_name(
+ g, add_op_node.input[1]
+ )
+ if not add_value_node or add_value_node.op_type != "Constant":
+ continue
+
+ prev_shape_value_info = helper.find_value_by_name(
+ g, input_op_node_name
+ )
+ prev_shape_value_info = (
+ helper.find_input_by_name(g, input_op_node_name)
+ if prev_shape_value_info is None
+ else prev_shape_value_info
+ )
+ if prev_shape_value_info is None:
+ continue
+
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ prev_shape_value_info
+ )
+ bias_shape, bias_data = helper.constant_to_list(add_value_node)
+
+ # channel dimension
+ c_dim = (
+ previous_node_output_shape[1]
+ if len(previous_node_output_shape) > 1
+ else 1
+ )
+
+ # only allow channelwise add or const add
+ if bias_shape == [1, c_dim, 1, 1]:
+ bias = bias_data
+ elif bias_shape == [c_dim, 1, 1]:
+ bias = bias_data
+ elif bias_shape == 1:
+ bias = bias_data * c_dim
+ else:
+ continue
+
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ bn_name = add_op_node.output[0]
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ scale_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(ones).shape, ones
+ )
+ new_add_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(bias).shape, bias
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ input_op_node_name,
+ scale_value_node.output[0],
+ new_add_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [add_op_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ add_val_info = helper.find_value_by_name(g, add_value_node.output[0])
+ g.value_info.remove(add_val_info)
+
+ g.node.extend([bn_node])
+ g.node.extend([mean_value_node])
+ g.node.extend([variance_value_node])
+ g.node.extend([scale_value_node])
+ g.node.extend([new_add_value_node])
+
+ node_to_del.extend([add_op_node])
+ node_to_del.extend([add_value_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_sub_to_bn(g):
+ """Replace single Sub node with BatchNorm node.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ if node.op_type != "Sub":
+ continue
+
+ sub_op_node = node
+
+ # only support one input node
+ if len(sub_op_node.input) != 2: # OP node and value node
+ continue
+
+ # Check the input type
+ input_1st_name = sub_op_node.input[0]
+ input_2nd_name = sub_op_node.input[1]
+ input_1st_node = helper.find_node_by_output_name(g, input_1st_name)
+ input_2nd_node = helper.find_node_by_output_name(g, input_2nd_name)
+ if input_1st_node is not None and input_1st_node.op_type == "Constant":
+ real_input_name = input_2nd_name
+ reverse = True
+ constant_node = input_1st_node
+ elif (
+ input_2nd_node is not None and input_2nd_node.op_type == "Constant"
+ ):
+ real_input_name = input_1st_name
+ reverse = False
+ constant_node = input_2nd_node
+ else:
+ continue
+
+ # Get shapes
+ prev_shape_value_info = helper.find_value_by_name(g, real_input_name)
+ prev_shape_value_info = (
+ helper.find_input_by_name(g, real_input_name)
+ if prev_shape_value_info is None
+ else prev_shape_value_info
+ )
+ if prev_shape_value_info is None:
+ continue
+
+ _, previous_node_output_shape = helper.find_size_shape_from_value(
+ prev_shape_value_info
+ )
+ bias_shape, bias_data = helper.constant_to_list(constant_node)
+
+ # channel dimension
+ c_dim = (
+ previous_node_output_shape[1]
+ if len(previous_node_output_shape) > 1
+ else 1
+ )
+
+ # only allow channelwise sub or const sub
+ if bias_shape == [1, c_dim, 1, 1]:
+ bias = bias_data
+ elif bias_shape == [c_dim, 1, 1]:
+ bias = bias_data
+ elif bias_shape == 1:
+ bias = bias_data * c_dim
+ else:
+ continue
+
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ # If reversed provide special scaler
+ if reverse:
+ scale = [-1.0] * c_dim
+ else:
+ scale = ones
+ bias *= -1
+ bn_name = sub_op_node.output[0]
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ scale_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(scale).shape, scale
+ )
+ new_add_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(bias).shape, bias
+ )
+
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ real_input_name,
+ scale_value_node.output[0],
+ new_add_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [sub_op_node.output[0]],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ add_val_info = helper.find_value_by_name(g, constant_node.output[0])
+ g.value_info.remove(add_val_info)
+
+ g.node.extend([bn_node])
+ g.node.extend([mean_value_node])
+ g.node.extend([variance_value_node])
+ g.node.extend([scale_value_node])
+ g.node.extend([new_add_value_node])
+
+ node_to_del.extend([sub_op_node])
+ node_to_del.extend([constant_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_sub_with_bn_and_add(g):
+ """Replace two input Sub node with BN and Add: A - B = A + (-1) * B
+ :param g: input graph.
+ :return:
+ """
+ for node in g.node:
+ if node.op_type != "Sub":
+ continue
+
+ sub_op_node = node
+
+ # only support one input node
+ if len(sub_op_node.input) != 2: # OP node and value node
+ continue
+
+ # Check the input type
+ input_1st_name = sub_op_node.input[0]
+ input_2nd_name = sub_op_node.input[1]
+ input_1st_node = helper.find_node_by_output_name(g, input_1st_name)
+ input_2nd_node = helper.find_node_by_output_name(g, input_2nd_name)
+ if input_1st_node is not None and input_1st_node.op_type == "Constant":
+ continue
+ elif (
+ input_2nd_node is not None and input_2nd_node.op_type == "Constant"
+ ):
+ continue
+
+ # Get shapes
+ input_2nd_value_info = helper.find_value_by_name(g, input_2nd_name)
+ if input_2nd_value_info is None:
+ input_2nd_value_info = helper.find_input_by_name(g, input_2nd_name)
+ if input_2nd_value_info is None:
+ continue
+
+ # Get channel dimension
+ _, input_2nd_shape = helper.find_size_shape_from_value(
+ input_2nd_value_info
+ )
+ if len(input_2nd_shape) < 2:
+ helper.logger.debug(
+ f"{sub_op_node.name} cannot be replaced "
+ "due to the input shape."
+ )
+ c_dim = input_2nd_shape[1]
+
+ # Create * -1 bn node.
+ ones = [1.0] * c_dim
+ zeros = [0.0] * c_dim
+ scale = [-1.0] * c_dim
+ bn_name = input_2nd_name + "_neg_for_" + node.name
+ mean_value_node = helper.list_to_constant(
+ bn_name + "_mean", np.array(zeros).shape, zeros
+ )
+ variance_value_node = helper.list_to_constant(
+ bn_name + "_var", np.array(ones).shape, ones
+ )
+ scale_value_node = helper.list_to_constant(
+ bn_name + "_mul", np.array(scale).shape, scale
+ )
+ bias_value_node = helper.list_to_constant(
+ bn_name + "_add", np.array(zeros).shape, zeros
+ )
+ bn_node = onnx.helper.make_node(
+ "BatchNormalization",
+ [
+ input_2nd_name,
+ scale_value_node.output[0],
+ bias_value_node.output[0],
+ mean_value_node.output[0],
+ variance_value_node.output[0],
+ ],
+ [bn_name],
+ name=bn_name,
+ epsilon=0.00000001,
+ )
+
+ # Change sub to add
+ sub_op_node.op_type = "Add"
+ # Replace add input
+ modhelper.replace_node_input(sub_op_node, input_2nd_name, bn_name)
+
+ g.node.extend(
+ [
+ scale_value_node,
+ bias_value_node,
+ mean_value_node,
+ variance_value_node,
+ bn_node,
+ ]
+ )
+
+ topological_sort(g)
+
+
+def replace_Sum_with_Adds(g):
+ node_to_del = []
+
+ for node in g.node:
+ # Check for sum
+ if node.op_type != "Sum":
+ continue
+ # Check for input number
+ if len(node.input) == 1:
+ # If input number is 1, delete the sum node.
+ following_nodes = helper.find_following_nodes_by_input_value_name(
+ g, node.output[0]
+ )
+ for following_node in following_nodes:
+ modhelper.replace_node_input(
+ following_node, node.output[0], node.input[0]
+ )
+ node_to_del.append(node)
+ if helper.find_value_by_name(node.output[0]) is not None:
+ g.value_info.remove(helper.find_value_by_name(node.output[0]))
+ elif len(node.input) == 2:
+ # If input number is 2, replace it with add.
+ node.op_type = "Add"
+ continue
+ elif len(node.input) > 2:
+ # If input number is larger than 2, replace it with n-1 add.
+ input_count = len(node.input)
+ # First node has 2 inputs
+ first_node = onnx.helper.make_node(
+ "Add",
+ [node.input[0], node.input[1]],
+ [node.output[0] + "_replacement_1"],
+ name=node.name + "_replacement_1",
+ )
+ # Last node has the same output as the original sum node
+ last_node = onnx.helper.make_node(
+ "Add",
+ [
+ node.output[0] + "_replacement_" + str(input_count - 2),
+ node.input[input_count - 1],
+ ],
+ [node.output[0]],
+ name=node.name,
+ )
+ g.node.extend([first_node, last_node])
+ for i in range(2, input_count - 1):
+ new_node = onnx.helper.make_node(
+ "Add",
+ [
+ node.output[0] + "_replacement_" + str(i - 1),
+ node.input[i],
+ ],
+ [node.output[0] + "_replacement_" + str(i)],
+ name=node.name + "_replacement_" + str(i),
+ )
+ g.node.extend([new_node])
+ node_to_del.append(node)
+ else:
+ logging.error("Sum node must have at least 1 input.")
+ quit(1)
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
+
+
+def replace_constant_input_concat_with_pad(g):
+ """
+ If single input is concating with constant node of same number.
+ Replace it with pad. Currently only support 2-3 inputs.
+ :param g: input graph.
+ :return:
+ """
+ node_to_del = []
+ for node in g.node:
+ # Check for Concat node
+ if node.op_type != "Concat":
+ continue
+
+ # Check concat node input
+ mode = None
+ value = 0
+ real_input_name = None
+ if len(node.input) == 2:
+ input_1st_node = helper.find_node_by_output_name(g, node.input[0])
+ input_2nd_node = helper.find_node_by_output_name(g, node.input[1])
+ if (
+ input_1st_node is not None
+ and input_1st_node.op_type == "Constant"
+ ):
+ mode = "left"
+ constant_value = helper.constant_to_numpy(input_1st_node)
+ real_input_name = node.input[1]
+ value = constant_value.flatten()[0]
+ # Check if the values are all the same.
+ if np.any(constant_value - value):
+ continue
+ elif (
+ input_2nd_node is not None
+ and input_2nd_node.op_type == "Constant"
+ ):
+ mode = "right"
+ constant_value = helper.constant_to_numpy(input_2nd_node)
+ real_input_name = node.input[0]
+ value = constant_value.flatten()[0]
+ # Check if the values are all the same.
+ if np.any(constant_value - value):
+ continue
+ else:
+ # No constant input case
+ continue
+ elif len(node.input) == 3:
+ # For 3 inputs concat node, the 1st and the 3rd input should be
+ # constant with the same value.
+ input_1st_node = helper.find_node_by_output_name(g, node.input[0])
+ input_2nd_node = helper.find_node_by_output_name(g, node.input[1])
+ input_3rd_node = helper.find_node_by_output_name(g, node.input[2])
+ if (
+ input_1st_node is None
+ or input_1st_node.op_type != "Constant"
+ or input_3rd_node is None
+ or input_3rd_node.op_type != "Constant"
+ ):
+ continue
+ mode = "both"
+ real_input_name = node.input[1]
+ input_1st_value = helper.constant_to_numpy(input_1st_node)
+ input_3rd_value = helper.constant_to_numpy(input_3rd_node)
+ value = input_1st_value.flatten()[0]
+ # Check if all the values are all the same
+ if np.any(input_1st_value - value):
+ continue
+ elif np.any(input_3rd_value - value):
+ continue
+ else:
+ # Too many inputs case.
+ continue
+ # Make weight nodes
+ input_value_info = helper.find_value_by_name(g, real_input_name)
+ input_shape = helper.get_shape_from_value_info(input_value_info)
+ pads = [0] * (len(input_shape) * 2)
+ axis = helper.get_var_attribute_by_name(node, "axis", "int")
+ if axis < 0:
+ axis = len(input_shape) - axis
+ if mode == "left":
+ left_value_info = helper.find_value_by_name(g, node.input[0])
+ left_input_shape = helper.get_shape_from_value_info(
+ left_value_info
+ )
+ pads[axis] = left_input_shape[axis]
+ elif mode == "right":
+ right_value_info = helper.find_value_by_name(g, node.input[1])
+ right_input_shape = helper.get_shape_from_value_info(
+ right_value_info
+ )
+ pads[axis + len(input_shape)] = right_input_shape[axis]
+ else:
+ # mode shoule be both
+ left_value_info = helper.find_value_by_name(g, node.input[0])
+ left_input_shape = helper.get_shape_from_value_info(
+ left_value_info
+ )
+ pads[axis] = left_input_shape[axis]
+ right_value_info = helper.find_value_by_name(g, node.input[2])
+ right_input_shape = helper.get_shape_from_value_info(
+ right_value_info
+ )
+ pads[axis + len(input_shape)] = right_input_shape[axis]
+ pads_node = helper.list_to_constant(
+ node.name + "_pads", (len(pads),), pads
+ )
+ constant_value_node = helper.scaler_to_constant(
+ node.name + "_constant_value", value
+ )
+ # Create new Pad node
+ new_pad_node = onnx.helper.make_node(
+ "Pad",
+ [real_input_name, pads_node.name, constant_value_node.name],
+ [node.output[0]],
+ name=node.name,
+ mode="constant",
+ )
+ # Replace
+ node_to_del.append(node)
+ g.node.extend([pads_node, constant_value_node, new_pad_node])
+
+ while node_to_del:
+ g.node.remove(node_to_del.pop())
+
+ topological_sort(g)
diff --git a/tools/optimizer_scripts/tools/special.py b/tools/optimizer_scripts/tools/special.py
new file mode 100644
index 0000000..275f8c5
--- /dev/null
+++ b/tools/optimizer_scripts/tools/special.py
@@ -0,0 +1,489 @@
+"""Special operations on model.
+"""
+import onnx.helper
+import numpy as np
+from . import helper
+from . import other
+
+
+def change_first_conv_from_bgr_to_rgb(m):
+ """For input channel format BGR model, use this function to change the first
+ conv weight to adapt the input into RGB.
+
+ :param m: the model proto
+ """
+ # Check for first node.
+ g = m.graph
+ input_name = g.input[0].name
+ first_nodes = helper.find_following_nodes_by_input_value_name(
+ g, input_name
+ )
+ if len(first_nodes) > 1:
+ return False
+ first_node = first_nodes[0]
+ # Now we have the first node. Check this first node.
+ if first_node.op_type != "Conv":
+ return False
+ weight_value = helper.find_value_by_name(g, first_node.input[1])
+ weight_shape = helper.get_shape_from_value_info(weight_value)
+ if weight_shape[1] != 3:
+ return False
+ # Do weight shuffle
+ weight_node = helper.find_node_by_output_name(g, weight_value.name)
+ weight_np = helper.constant_to_numpy(weight_node)
+ b_channel = np.expand_dims(weight_np[:, 0, :, :], axis=1)
+ g_channel = np.expand_dims(weight_np[:, 1, :, :], axis=1)
+ r_channel = np.expand_dims(weight_np[:, 2, :, :], axis=1)
+ new_np = np.concatenate((r_channel, g_channel, b_channel), axis=1)
+ new_node = helper.numpy_to_constant(weight_value.name, new_np)
+ # Replace the weight and topological sort
+ g.node.remove(weight_node)
+ g.node.extend([new_node])
+ other.topological_sort(g)
+ return True
+
+
+def change_input_from_bgr_to_rgb(m):
+ """
+ For input channel format BGR model, use this function to modify the model
+ to accepct RGB image.If the first node is a non-group Conv.
+ Modify weight to adapt the input into RGB. Otherwise create a new node.
+
+ :param m: the model proto
+ """
+ g = m.graph
+ if len(g.input) > 1:
+ print("This model has multiple inputs. Cannot change to RGB input.")
+ return
+ input_shape = helper.get_shape_from_value_info(g.input[0])
+ if len(input_shape) != 4 or input_shape[1] != 3:
+ print("The input shape is invalid for bgr conversion.")
+ return
+ # Try change conv weight first
+ if change_first_conv_from_bgr_to_rgb(m):
+ return
+ # Otherwise, create a special conv node and replace the input
+ # Construct weight
+ weight_np = np.zeros((3, 3, 3, 3)).astype("float32")
+ weight_np[0, 2, 1, 1] = 1.0
+ weight_np[1, 1, 1, 1] = 1.0
+ weight_np[2, 0, 1, 1] = 1.0
+ new_weight = helper.numpy_to_constant("bgr_shuffle_weight", weight_np)
+ # Construct Conv
+ new_conv = onnx.helper.make_node(
+ "Conv",
+ ["rgb_input", "bgr_shuffle_weight"],
+ [g.input[0].name],
+ name="bgr_shuffle",
+ dilations=[1, 1],
+ kernel_shape=[3, 3],
+ pads=[1, 1, 1, 1],
+ strides=[1, 1],
+ )
+ # Connect the graph
+ old_input_value = g.input.pop()
+ new_input_value = onnx.helper.make_tensor_value_info(
+ "rgb_input", old_input_value.type.tensor_type.elem_type, input_shape
+ )
+ g.input.extend([new_input_value])
+ g.node.extend([new_weight, new_conv])
+ # topological sort
+ other.topological_sort(g)
+
+
+def add_0_5_to_normalized_input(m):
+ """For normalized input between -0.5 ~ 0.5, add 0.5 to the input to keep it
+ between 0 ~ 1.
+
+ :param m: the model proto
+ """
+ g = m.graph
+ if len(g.input) > 1:
+ print("This model has multiple inputs. Cannot normalize input.")
+ return
+ input_shape = helper.get_shape_from_value_info(g.input[0])
+ if len(input_shape) != 4:
+ print("The input shape is not BCHW. Cannot normalize input.")
+ return
+ # Construct weight
+ ch = input_shape[1]
+ weight_np = np.zeros((ch, ch, 3, 3)).astype("float32")
+ for i in range(ch):
+ weight_np[i, i, 1, 1] = 1.0
+ new_weight = helper.numpy_to_constant("input_norm_weight", weight_np)
+ # Construct bias
+ bias_np = np.array([0.5] * ch).astype("float32")
+ new_bias = helper.numpy_to_constant("input_norm_bias", bias_np)
+ # Construct Conv
+ new_conv = onnx.helper.make_node(
+ "Conv",
+ ["origin_input", "input_norm_weight", "input_norm_bias"],
+ [g.input[0].name],
+ name="input_norm",
+ dilations=[1, 1],
+ kernel_shape=[3, 3],
+ pads=[1, 1, 1, 1],
+ strides=[1, 1],
+ )
+ # Construct value_infos
+ old_input_value = g.input.pop()
+ weight_value = onnx.helper.make_tensor_value_info(
+ "input_norm_weight",
+ old_input_value.type.tensor_type.elem_type,
+ [3, 3, 3, 3],
+ )
+ bias_value = onnx.helper.make_tensor_value_info(
+ "input_norm_bias", old_input_value.type.tensor_type.elem_type, [3]
+ )
+ # Connect the graph
+ new_input_value = onnx.helper.make_tensor_value_info(
+ "origin_input", old_input_value.type.tensor_type.elem_type, input_shape
+ )
+ g.input.extend([new_input_value])
+ g.node.extend([new_weight, new_bias, new_conv])
+ g.value_info.extend([weight_value, bias_value, old_input_value])
+ # topological sort
+ other.topological_sort(g)
+
+
+def add_rgb2yynn_node(m):
+ """Add a conv layer which can convert rgb to yynn input."""
+ g = m.graph
+ if len(g.input) > 1:
+ print("This model has multiple inputs. Cannot change to rgb input.")
+ return
+ input_shape = helper.get_shape_from_value_info(g.input[0])
+ if len(input_shape) != 4:
+ print("The input shape is not BCHW. Cannot normalize input.")
+ return
+ # Construct weight
+ weight_np = np.zeros((3, 3, 4, 4)).astype("float32")
+ weight_np[1, 1, :3, :2] = np.array([[[[0.299], [0.587], [0.114]]]])
+ weight_np[1, 1, 3, 2:] = 1.0
+ weight_np = np.transpose(weight_np, (3, 2, 0, 1))
+ new_weight = helper.numpy_to_constant("input_rgb2yynn_weight", weight_np)
+ # Construct conv node
+ new_conv = onnx.helper.make_node(
+ "Conv",
+ ["new_input", "input_rgb2yynn_weight"],
+ [g.input[0].name],
+ name="input_rgba2yynn",
+ dilations=[1, 1],
+ kernel_shape=[3, 3],
+ pads=[1, 1, 1, 1],
+ strides=[1, 1],
+ )
+ # Construct value_infos
+ old_input_value = g.input.pop()
+ weight_value = onnx.helper.make_tensor_value_info(
+ "input_rgb2yynn_weight",
+ old_input_value.type.tensor_type.elem_type,
+ [4, 4, 3, 3],
+ )
+ # Connect the graph
+ new_input_value = onnx.helper.make_tensor_value_info(
+ "new_input", old_input_value.type.tensor_type.elem_type, input_shape
+ )
+ g.input.extend([new_input_value])
+ g.node.extend([new_weight, new_conv])
+ g.value_info.extend([weight_value, old_input_value])
+ # topological sort
+ other.topological_sort(g)
+
+
+def swap_MatMul_inputs(g, original_matmul_node):
+ # Create Transpose nodes
+ input_a_value = helper.find_value_by_name(g, original_matmul_node.input[0])
+ input_a_shape = helper.get_shape_from_value_info(input_a_value)
+ if len(input_a_shape) == 2:
+ perm = [1, 0]
+ else:
+ perm = [0, 2, 1]
+ new_input_b_node = onnx.helper.make_node(
+ "Transpose",
+ inputs=[input_a_value.name],
+ outputs=[input_a_value.name + "_transposed"],
+ name=f"{input_a_value.name}_transposed_for_"
+ f"{original_matmul_node.name}",
+ perm=perm,
+ )
+ input_b_value = helper.find_value_by_name(g, original_matmul_node.input[1])
+ input_b_shape = helper.get_shape_from_value_info(input_b_value)
+ if len(input_b_shape) == 3:
+ perm = [0, 2, 1]
+ else:
+ perm = [0, 1, 3, 2]
+ new_input_a_node = onnx.helper.make_node(
+ "Transpose",
+ inputs=[input_b_value.name],
+ outputs=[input_b_value.name + "_transposed"],
+ name=f"{input_b_value.name}_transposed_for_"
+ f"{original_matmul_node.name}",
+ perm=perm,
+ )
+ # Create new MatMul node
+ new_matmul_node = onnx.helper.make_node(
+ "MatMul",
+ inputs=[new_input_a_node.output[0], new_input_b_node.output[0]],
+ outputs=[original_matmul_node.output[0] + "_transposed"],
+ name=original_matmul_node.name + "_transposed",
+ )
+ # Create final Transpose node
+ output_value = helper.find_value_by_name(g, original_matmul_node.output[0])
+ output_shape = helper.get_shape_from_value_info(output_value)
+ if len(output_shape) == 3:
+ perm = [0, 2, 1]
+ else:
+ perm = [0, 1, 3, 2]
+ new_final_transpose_node = onnx.helper.make_node(
+ "Transpose",
+ inputs=[new_matmul_node.output[0]],
+ outputs=[original_matmul_node.output[0]],
+ name=original_matmul_node.name + "_final_transpose",
+ perm=perm,
+ )
+ # Add new nodes
+ g.node.extend(
+ [
+ new_input_a_node,
+ new_input_b_node,
+ new_matmul_node,
+ new_final_transpose_node,
+ ]
+ )
+ # Delete original nodes
+ g.node.remove(original_matmul_node)
+
+
+def split_MatMul_batch_then_concat(g, original_matmul_node):
+ new_nodes = []
+ final_concat_inputs = []
+ # Get the batch count
+ input_a_value = helper.find_value_by_name(g, original_matmul_node.input[0])
+ input_a_shape = helper.get_shape_from_value_info(input_a_value)
+ input_b_value = helper.find_value_by_name(g, original_matmul_node.input[1])
+ input_b_shape = helper.get_shape_from_value_info(input_b_value)
+ if len(input_a_shape) == 3:
+ batch_count = input_a_shape[0]
+ else:
+ batch_count = input_a_shape[1]
+ for i in range(batch_count):
+ # Create Split nodes for input A
+ starts_node = helper.list_to_constant(
+ f"{input_a_value.name}_sliced_{i}_starts", (1,), [i]
+ )
+ ends_node = helper.list_to_constant(
+ f"{input_a_value.name}_sliced_{i}_ends", (1,), [i + 1]
+ )
+ axes_node = helper.list_to_constant(
+ f"{input_a_value.name}_sliced_{i}_axes",
+ (1,),
+ [len(input_a_shape) - 3],
+ )
+ new_sliced_a_node = onnx.helper.make_node(
+ "Slice",
+ inputs=[
+ input_a_value.name,
+ starts_node.output[0],
+ ends_node.output[0],
+ axes_node.output[0],
+ ],
+ outputs=[f"{input_a_value.name}_sliced_{i}"],
+ name=f"{input_a_value.name}_sliced_{i}_for_"
+ f"{original_matmul_node.name}",
+ )
+ new_nodes.extend(
+ [starts_node, ends_node, axes_node, new_sliced_a_node]
+ )
+ # Create Split nodes for input B
+ starts_node = helper.list_to_constant(
+ f"{input_b_value.name}_sliced_{i}_starts", (1,), [i]
+ )
+ ends_node = helper.list_to_constant(
+ f"{input_b_value.name}_sliced_{i}_ends", (1,), [i + 1]
+ )
+ axes_node = helper.list_to_constant(
+ f"{input_b_value.name}_sliced_{i}_axes",
+ (1,),
+ [len(input_b_shape) - 3],
+ )
+ new_sliced_b_node = onnx.helper.make_node(
+ "Slice",
+ inputs=[
+ input_b_value.name,
+ starts_node.output[0],
+ ends_node.output[0],
+ axes_node.output[0],
+ ],
+ outputs=[f"{input_b_value.name}_sliced_{i}"],
+ name=f"{input_b_value.name}_sliced_{i}_for_"
+ f"{original_matmul_node.name}",
+ )
+ new_nodes.extend(
+ [starts_node, ends_node, axes_node, new_sliced_b_node]
+ )
+ # Create MatMul nodes
+ new_matmul_node = onnx.helper.make_node(
+ "MatMul",
+ inputs=[new_sliced_a_node.output[0], new_sliced_b_node.output[0]],
+ outputs=[f"{original_matmul_node.output[0]}_sliced_{i}"],
+ name=f"{original_matmul_node.name}_sliced_{i}",
+ )
+ new_nodes.append(new_matmul_node)
+ final_concat_inputs.append(new_matmul_node.output[0])
+ # Create Concat nodes
+ output_value = helper.find_value_by_name(g, original_matmul_node.output[0])
+ if output_value is None:
+ output_value = helper.find_output_by_name(
+ g, original_matmul_node.output[0]
+ )
+ if output_value is None:
+ helper.logger.error(
+ f"Cannot find value_info for {original_matmul_node.output[0]}"
+ )
+ output_shape = helper.get_shape_from_value_info(output_value)
+ new_concat_node = onnx.helper.make_node(
+ "Concat",
+ inputs=final_concat_inputs,
+ outputs=[original_matmul_node.output[0]],
+ name=f"{original_matmul_node.name}_final_concat",
+ axis=len(output_shape) - 3,
+ )
+ new_nodes.append(new_concat_node)
+ # Add new nodes
+ g.node.extend(new_nodes)
+ # Delete original nodes
+ g.node.remove(original_matmul_node)
+
+
+def split_MatMul_Constant_input_then_concat(g, original_matmul_node):
+ new_nodes = []
+ final_concat_inputs = []
+ # Get the batch count
+ input_b_node = helper.find_node_by_output_name(
+ g, original_matmul_node.input[1]
+ )
+ input_b_np = helper.constant_to_numpy(input_b_node)
+ if len(input_b_np.shape) == 3:
+ batch_count = input_b_np.shape[0]
+ else:
+ batch_count = input_b_np.shape[1]
+ for i in range(batch_count):
+ # Create new constant node
+ if len(input_b_np.shape) == 3:
+ new_np = input_b_np[i:i + 1, ...]
+ else:
+ new_np = input_b_np[:, i:i + 1, ...]
+ new_weight = helper.numpy_to_constant(
+ f"{input_b_node.name}_sliced_{i}", new_np
+ )
+ new_nodes.append(new_weight)
+ # Create MatMul nodes
+ new_matmul_node = onnx.helper.make_node(
+ "MatMul",
+ inputs=[original_matmul_node.input[0], new_weight.output[0]],
+ outputs=[f"{original_matmul_node.output[0]}_sliced_{i}"],
+ name=f"{original_matmul_node.name}_sliced_{i}",
+ )
+ new_nodes.append(new_matmul_node)
+ final_concat_inputs.append(new_matmul_node.output[0])
+ # Create Concat nodes
+ output_value = helper.find_value_by_name(g, original_matmul_node.output[0])
+ output_shape = helper.get_shape_from_value_info(output_value)
+ new_concat_node = onnx.helper.make_node(
+ "Concat",
+ inputs=final_concat_inputs,
+ outputs=[original_matmul_node.output[0]],
+ name=f"{original_matmul_node.name}_final_concat",
+ axis=len(output_shape) - 3,
+ )
+ new_nodes.append(new_concat_node)
+ # Add new nodes
+ g.node.extend(new_nodes)
+ # Delete original value info
+ input_b_value = helper.find_value_by_name(g, original_matmul_node.input[1])
+ if input_b_value is not None:
+ g.value_info.remove(input_b_value)
+ # Delete original nodes
+ g.node.remove(original_matmul_node)
+ g.node.remove(input_b_node)
+
+
+def special_MatMul_process(g):
+ for node in g.node:
+ if node.op_type != "MatMul":
+ continue
+ input_a_name = node.input[0]
+ input_a_value = helper.find_value_by_name(g, input_a_name)
+ input_b_name = node.input[1]
+ input_b_value = helper.find_value_by_name(g, input_b_name)
+ if input_a_value is None or input_b_value is None:
+ continue
+ input_a_shape = helper.get_shape_from_value_info(input_a_value)
+ input_b_shape = helper.get_shape_from_value_info(input_b_value)
+ # Check shapes and choose the process
+ # Normal case, Skip
+ if len(input_b_shape) == 2:
+ continue
+ # Too many dimensions or too few dimensions. Not supported. Skip
+ if len(input_a_shape) > 4 or len(input_b_shape) > 4:
+ helper.logger.warning(
+ f"Cannot optimize MatMul {node.name}: "
+ "inputs have too many dimensions."
+ )
+ continue
+ if len(input_a_shape) < 2 or len(input_b_shape) < 2:
+ helper.logger.warning(
+ f"Cannot optimize MatMul {node.name}: "
+ "inputs have two few dimensions."
+ )
+ continue
+ # For 4 dimension, check the first dimension (should be 1)
+ # and treated as 3 dimensions.
+ extra_dim = None
+ if len(input_a_shape) == 4:
+ extra_dim = input_a_shape[0]
+ input_a_shape = input_a_shape[1:]
+ if len(input_b_shape) == 4:
+ if input_b_shape[0] != extra_dim:
+ helper.logger.warning(
+ f"Cannot optimize MatMul {node.name}: "
+ "input dimension batch sizes does not match "
+ f"({extra_dim} vs {input_b_shape[0]})."
+ )
+ continue
+ input_b_shape = input_b_shape[1:]
+ # Check input B dimension
+ # If B is 1 x W x V, it is the same as normal case.
+ if input_b_shape[0] == 1:
+ continue
+ # If B is B x W x V, but B is a constant.
+ input_b_node = helper.find_node_by_output_name(g, input_b_name)
+ if input_b_node is not None and input_b_node.op_type == "Constant":
+ # Constant input
+ helper.logger.debug(
+ f"Optimizing MatMul node {node.name}: split constant input."
+ )
+ split_MatMul_Constant_input_then_concat(g, node)
+ # If B is B x W x V and A is 1 x H x W, do the swap.
+ elif len(input_a_shape) == 2 or (
+ input_a_shape[0] == 1 and (extra_dim is None or extra_dim == 1)
+ ):
+ helper.logger.debug(
+ f"Optimizing MatMul node {node.name}: swap input."
+ )
+ swap_MatMul_inputs(g, node)
+ # If B is B x W x V and A is B x H x W, do the split.
+ elif input_b_shape[0] == input_a_shape[0]:
+ helper.logger.debug(
+ f"Optimizing MatMul node {node.name}: split input batch."
+ )
+ split_MatMul_batch_then_concat(g, node)
+ # Other cases are not supported: If B is B x W x V but A is X x H x W.
+ else:
+ helper.logger.warning(
+ f"Cannot optimize MatMul {node.name}: "
+ "unknown reason. Might be shape mismatch."
+ )
+ continue
+ other.topological_sort(g)
diff --git a/tools/print_config.py b/tools/print_config.py
new file mode 100644
index 0000000..3f9c08d
--- /dev/null
+++ b/tools/print_config.py
@@ -0,0 +1,69 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import warnings
+
+from mmcv import Config, DictAction
+
+from mmseg.apis import init_segmentor
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Print the whole config')
+ parser.add_argument('config', help='config file path')
+ parser.add_argument(
+ '--graph', action='store_true', help='print the models graph')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options, '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ print(f'Config:\n{cfg.pretty_text}')
+ # dump config
+ cfg.dump('example.py')
+ # dump models graph
+ if args.graph:
+ model = init_segmentor(args.config, device='cpu')
+ print(f'Model graph:\n{str(model)}')
+ with open('example-graph.txt', 'w') as f:
+ f.writelines(str(model))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/publish_model.py b/tools/publish_model.py
new file mode 100644
index 0000000..e266057
--- /dev/null
+++ b/tools/publish_model.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import subprocess
+
+import torch
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Process a checkpoint to be published')
+ parser.add_argument('in_file', help='input checkpoint filename')
+ parser.add_argument('out_file', help='output checkpoint filename')
+ args = parser.parse_args()
+ return args
+
+
+def process_checkpoint(in_file, out_file):
+ checkpoint = torch.load(in_file, map_location='cpu')
+ # remove optimizer for smaller file size
+ if 'optimizer' in checkpoint:
+ del checkpoint['optimizer']
+ # if it is necessary to remove some sensitive data in checkpoint['meta'],
+ # add the code here.
+ torch.save(checkpoint, out_file)
+ sha = subprocess.check_output(['sha256sum', out_file]).decode()
+ final_file = out_file.rstrip('.pth') + '-{}.pth'.format(sha[:8])
+ subprocess.Popen(['mv', out_file, final_file])
+
+
+def main():
+ args = parse_args()
+ process_checkpoint(args.in_file, args.out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/pytorch2onnx.py b/tools/pytorch2onnx.py
new file mode 100644
index 0000000..9de3404
--- /dev/null
+++ b/tools/pytorch2onnx.py
@@ -0,0 +1,392 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+from functools import partial
+
+import mmcv
+import numpy as np
+import onnxruntime as rt
+import torch
+import torch._C
+import torch.serialization
+from mmcv import DictAction
+from mmcv.onnx import register_extra_symbolics
+from mmcv.runner import load_checkpoint
+from torch import nn
+
+from mmseg.apis import show_result_pyplot
+from mmseg.apis.inference import LoadImage
+from mmseg.datasets.pipelines import Compose
+from mmseg.models import build_segmentor
+from mmseg.ops import resize
+
+torch.manual_seed(3)
+
+
+def _convert_batchnorm(module):
+ module_output = module
+ if isinstance(module, torch.nn.SyncBatchNorm):
+ module_output = torch.nn.BatchNorm2d(module.num_features, module.eps,
+ module.momentum, module.affine,
+ module.track_running_stats)
+ if module.affine:
+ module_output.weight.data = module.weight.data.clone().detach()
+ module_output.bias.data = module.bias.data.clone().detach()
+ # keep requires_grad unchanged
+ module_output.weight.requires_grad = module.weight.requires_grad
+ module_output.bias.requires_grad = module.bias.requires_grad
+ module_output.running_mean = module.running_mean
+ module_output.running_var = module.running_var
+ module_output.num_batches_tracked = module.num_batches_tracked
+ for name, child in module.named_children():
+ module_output.add_module(name, _convert_batchnorm(child))
+ del module
+ return module_output
+
+
+def _demo_mm_inputs(input_shape, num_classes):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+ rng = np.random.RandomState(0)
+ imgs = rng.rand(*input_shape)
+ segs = rng.randint(
+ low=0, high=num_classes - 1, size=(N, 1, H, W)).astype(np.uint8)
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': 1.0,
+ 'flip': False,
+ } for _ in range(N)]
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs).requires_grad_(True),
+ 'img_metas': img_metas,
+ 'gt_semantic_seg': torch.LongTensor(segs)
+ }
+ return mm_inputs
+
+
+def _prepare_input_img(img_path,
+ test_pipeline,
+ shape=None,
+ rescale_shape=None):
+ # build the data pipeline
+ if shape is not None:
+ test_pipeline[1]['img_scale'] = (shape[1], shape[0])
+ test_pipeline[1]['transforms'][0]['keep_ratio'] = False
+ test_pipeline = [LoadImage()] + test_pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ # prepare data
+ data = dict(img=img_path)
+ data = test_pipeline(data)
+ imgs = data['img']
+ img_metas = [i.data for i in data['img_metas']]
+
+ if rescale_shape is not None:
+ for img_meta in img_metas:
+ img_meta['ori_shape'] = tuple(rescale_shape) + (3, )
+
+ mm_inputs = {'imgs': imgs, 'img_metas': img_metas}
+
+ return mm_inputs
+
+
+def _update_input_img(img_list, img_meta_list, update_ori_shape=False):
+ # update img and its meta list
+ N, C, H, W = img_list[0].shape
+ img_meta = img_meta_list[0][0]
+ img_shape = (H, W, C)
+ if update_ori_shape:
+ ori_shape = img_shape
+ else:
+ ori_shape = img_meta['ori_shape']
+ pad_shape = img_shape
+ new_img_meta_list = [[{
+ 'img_shape':
+ img_shape,
+ 'ori_shape':
+ ori_shape,
+ 'pad_shape':
+ pad_shape,
+ 'filename':
+ img_meta['filename'],
+ 'scale_factor':
+ (img_shape[1] / ori_shape[1], img_shape[0] / ori_shape[0]) * 2,
+ 'flip':
+ False,
+ } for _ in range(N)]]
+
+ return img_list, new_img_meta_list
+
+
+def pytorch2onnx(model,
+ mm_inputs,
+ opset_version=11,
+ show=False,
+ output_file='tmp.onnx',
+ verify=False,
+ dynamic_export=False):
+ """Export Pytorch model to ONNX model and verify the outputs are same
+ between Pytorch and ONNX.
+
+ Args:
+ model (nn.Module): Pytorch model we want to export.
+ mm_inputs (dict): Contain the input tensors and img_metas information.
+ opset_version (int): The onnx op version. Default: 11.
+ show (bool): Whether print the computation graph. Default: False.
+ output_file (string): The path to where we store the output ONNX model.
+ Default: `tmp.onnx`.
+ verify (bool): Whether compare the outputs between Pytorch and ONNX.
+ Default: False.
+ dynamic_export (bool): Whether to export ONNX with dynamic axis.
+ Default: False.
+ """
+ model.cpu().eval()
+ test_mode = model.test_cfg.mode
+
+ if isinstance(model.decode_head, nn.ModuleList):
+ num_classes = model.decode_head[-1].num_classes
+ else:
+ num_classes = model.decode_head.num_classes
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+
+ img_list = [img[None, :] for img in imgs]
+ img_meta_list = [[img_meta] for img_meta in img_metas]
+ # update img_meta
+ img_list, img_meta_list = _update_input_img(img_list, img_meta_list)
+
+ # replace original forward function
+ origin_forward = model.forward
+ model.forward = partial(
+ model.forward,
+ img_metas=img_meta_list,
+ return_loss=False,
+ rescale=True)
+ dynamic_axes = None
+ if dynamic_export:
+ if test_mode == 'slide':
+ dynamic_axes = {'input': {0: 'batch'}, 'output': {1: 'batch'}}
+ else:
+ dynamic_axes = {
+ 'input': {
+ 0: 'batch',
+ 2: 'height',
+ 3: 'width'
+ },
+ 'output': {
+ 1: 'batch',
+ 2: 'height',
+ 3: 'width'
+ }
+ }
+
+ register_extra_symbolics(opset_version)
+ with torch.no_grad():
+ torch.onnx.export(
+ model, (img_list, ),
+ output_file,
+ input_names=['input'],
+ output_names=['output'],
+ export_params=True,
+ keep_initializers_as_inputs=False,
+ verbose=show,
+ opset_version=opset_version,
+ dynamic_axes=dynamic_axes)
+ print(f'Successfully exported ONNX model: {output_file}')
+ model.forward = origin_forward
+
+ if verify:
+ # check by onnx
+ import onnx
+ onnx_model = onnx.load(output_file)
+ onnx.checker.check_model(onnx_model)
+
+ if dynamic_export and test_mode == 'whole':
+ # scale image for dynamic shape test
+ img_list = [resize(_, scale_factor=1.5) for _ in img_list]
+ # concate flip image for batch test
+ flip_img_list = [_.flip(-1) for _ in img_list]
+ img_list = [
+ torch.cat((ori_img, flip_img), 0)
+ for ori_img, flip_img in zip(img_list, flip_img_list)
+ ]
+
+ # update img_meta
+ img_list, img_meta_list = _update_input_img(
+ img_list, img_meta_list, test_mode == 'whole')
+
+ # check the numerical value
+ # get pytorch output
+ with torch.no_grad():
+ pytorch_result = model(img_list, img_meta_list, return_loss=False)
+ pytorch_result = np.stack(pytorch_result, 0)
+
+ # get onnx output
+ input_all = [node.name for node in onnx_model.graph.input]
+ input_initializer = [
+ node.name for node in onnx_model.graph.initializer
+ ]
+ net_feed_input = list(set(input_all) - set(input_initializer))
+ assert (len(net_feed_input) == 1)
+ sess = rt.InferenceSession(output_file)
+ onnx_result = sess.run(
+ None, {net_feed_input[0]: img_list[0].detach().numpy()})[0][0]
+ # show segmentation results
+ if show:
+ import os.path as osp
+
+ import cv2
+ img = img_meta_list[0][0]['filename']
+ if not osp.exists(img):
+ img = imgs[0][:3, ...].permute(1, 2, 0) * 255
+ img = img.detach().numpy().astype(np.uint8)
+ ori_shape = img.shape[:2]
+ else:
+ ori_shape = LoadImage()({'img': img})['ori_shape']
+
+ # resize onnx_result to ori_shape
+ onnx_result_ = cv2.resize(onnx_result[0].astype(np.uint8),
+ (ori_shape[1], ori_shape[0]))
+ show_result_pyplot(
+ model,
+ img, (onnx_result_, ),
+ palette=model.PALETTE,
+ block=False,
+ title='ONNXRuntime',
+ opacity=0.5)
+
+ # resize pytorch_result to ori_shape
+ pytorch_result_ = cv2.resize(pytorch_result[0].astype(np.uint8),
+ (ori_shape[1], ori_shape[0]))
+ show_result_pyplot(
+ model,
+ img, (pytorch_result_, ),
+ title='PyTorch',
+ palette=model.PALETTE,
+ opacity=0.5)
+ # compare results
+ np.testing.assert_allclose(
+ pytorch_result.astype(np.float32) / num_classes,
+ onnx_result.astype(np.float32) / num_classes,
+ rtol=1e-5,
+ atol=1e-5,
+ err_msg='The outputs are different between Pytorch and ONNX')
+ print('The outputs are same between Pytorch and ONNX')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Convert MMSeg to ONNX')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('--checkpoint', help='checkpoint file', default=None)
+ parser.add_argument(
+ '--input-img', type=str, help='Images for input', default=None)
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ help='show onnx graph and segmentation results')
+ parser.add_argument(
+ '--verify', action='store_true', help='verify the onnx model')
+ parser.add_argument('--output-file', type=str, default='tmp.onnx')
+ parser.add_argument('--opset-version', type=int, default=11)
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=None,
+ help='input image height and width.')
+ parser.add_argument(
+ '--rescale_shape',
+ type=int,
+ nargs='+',
+ default=None,
+ help='output image rescale height and width, work for slide mode.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--dynamic-export',
+ action='store_true',
+ help='Whether to export onnx with dynamic axis.')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ cfg.model.pretrained = None
+
+ if args.shape is None:
+ img_scale = cfg.test_pipeline[1]['img_scale']
+ input_shape = (1, 3, img_scale[1], img_scale[0])
+ elif len(args.shape) == 1:
+ input_shape = (1, 3, args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ input_shape = (
+ 1,
+ 3,
+ ) + tuple(args.shape)
+ else:
+ raise ValueError('invalid input shape')
+
+ test_mode = cfg.model.test_cfg.mode
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ segmentor = build_segmentor(
+ cfg.model, train_cfg=None, test_cfg=cfg.get('test_cfg'))
+ # convert SyncBN to BN
+ segmentor = _convert_batchnorm(segmentor)
+
+ if args.checkpoint:
+ checkpoint = load_checkpoint(
+ segmentor, args.checkpoint, map_location='cpu')
+ segmentor.CLASSES = checkpoint['meta']['CLASSES']
+ segmentor.PALETTE = checkpoint['meta']['PALETTE']
+
+ # read input or create dummpy input
+ if args.input_img is not None:
+ preprocess_shape = (input_shape[2], input_shape[3])
+ rescale_shape = None
+ if args.rescale_shape is not None:
+ rescale_shape = [args.rescale_shape[0], args.rescale_shape[1]]
+ mm_inputs = _prepare_input_img(
+ args.input_img,
+ cfg.data.test.pipeline,
+ shape=preprocess_shape,
+ rescale_shape=rescale_shape)
+ else:
+ if isinstance(segmentor.decode_head, nn.ModuleList):
+ num_classes = segmentor.decode_head[-1].num_classes
+ else:
+ num_classes = segmentor.decode_head.num_classes
+ mm_inputs = _demo_mm_inputs(input_shape, num_classes)
+
+ # convert model to onnx file
+ pytorch2onnx(
+ segmentor,
+ mm_inputs,
+ opset_version=args.opset_version,
+ show=args.show,
+ output_file=args.output_file,
+ verify=args.verify,
+ dynamic_export=args.dynamic_export)
diff --git a/tools/pytorch2onnx_kneron.py b/tools/pytorch2onnx_kneron.py
new file mode 100644
index 0000000..f93b873
--- /dev/null
+++ b/tools/pytorch2onnx_kneron.py
@@ -0,0 +1,354 @@
+# All modification made by Kneron Corp.: Copyright (c) 2022 Kneron Corp.
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import warnings
+import os
+import onnx
+import mmcv
+import numpy as np
+import onnxruntime as rt
+import torch
+import torch._C
+import torch.serialization
+from mmcv import DictAction
+from mmcv.onnx import register_extra_symbolics
+from mmcv.runner import load_checkpoint
+from torch import nn
+
+from mmseg.apis import show_result_pyplot
+from mmseg.apis.inference import LoadImage
+from mmseg.datasets.pipelines import Compose
+from mmseg.models import build_segmentor
+
+from optimizer_scripts.tools import other
+from optimizer_scripts.pytorch_exported_onnx_preprocess import (
+ torch_exported_onnx_flow,
+)
+
+torch.manual_seed(3)
+
+
+def _parse_normalize_cfg(test_pipeline):
+ transforms = None
+ for pipeline in test_pipeline:
+ if 'transforms' in pipeline:
+ transforms = pipeline['transforms']
+ break
+ assert transforms is not None, 'Failed to find `transforms`'
+ norm_config_li = [_ for _ in transforms if _['type'] == 'Normalize']
+ assert len(norm_config_li) == 1, '`norm_config` should only have one'
+ norm_config = norm_config_li[0]
+ return norm_config
+
+
+def _convert_batchnorm(module):
+ module_output = module
+ if isinstance(module, torch.nn.SyncBatchNorm):
+ module_output = torch.nn.BatchNorm2d(module.num_features, module.eps,
+ module.momentum, module.affine,
+ module.track_running_stats)
+ if module.affine:
+ module_output.weight.data = module.weight.data.clone().detach()
+ module_output.bias.data = module.bias.data.clone().detach()
+ # keep requires_grad unchanged
+ module_output.weight.requires_grad = module.weight.requires_grad
+ module_output.bias.requires_grad = module.bias.requires_grad
+ module_output.running_mean = module.running_mean
+ module_output.running_var = module.running_var
+ module_output.num_batches_tracked = module.num_batches_tracked
+ for name, child in module.named_children():
+ module_output.add_module(name, _convert_batchnorm(child))
+ del module
+ return module_output
+
+
+def _demo_mm_inputs(input_shape):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+ rng = np.random.RandomState(0)
+ img = torch.FloatTensor(rng.rand(*input_shape))
+ return img
+
+
+def _prepare_input_img(img_path,
+ test_pipeline,
+ shape=None):
+ # build the data pipeline
+ if shape is not None:
+ test_pipeline[1]['img_scale'] = (shape[1], shape[0])
+ test_pipeline[1]['transforms'][0]['keep_ratio'] = False
+ test_pipeline = [LoadImage()] + test_pipeline[1:]
+ test_pipeline = Compose(test_pipeline)
+ # prepare data
+ data = dict(img=img_path)
+ data = test_pipeline(data)
+ img = torch.FloatTensor(data['img']).unsqueeze_(0)
+ return img
+
+
+def pytorch2onnx(model,
+ img,
+ norm_cfg=None,
+ opset_version=11,
+ show=False,
+ output_file='tmp.onnx',
+ verify=False):
+ """Export Pytorch model to ONNX model and verify the outputs are same
+ between Pytorch and ONNX.
+
+ Args:
+ model (nn.Module): Pytorch model we want to export.
+ img (dict): Input tensor (1xCxHxW)
+ opset_version (int): The onnx op version. Default: 11.
+ show (bool): Whether print the computation graph. Default: False.
+ output_file (string): The path to where we store the output ONNX model.
+ Default: `tmp.onnx`.
+ verify (bool): Whether compare the outputs between Pytorch and ONNX.
+ Default: False.
+ """
+ model.cpu().eval()
+
+ if isinstance(model.decode_head, nn.ModuleList):
+ num_classes = model.decode_head[-1].num_classes
+ else:
+ num_classes = model.decode_head.num_classes
+
+ # replace original forward function
+ model.forward = model.forward_dummy
+ origin_forward = model.forward
+
+ register_extra_symbolics(opset_version)
+ with torch.no_grad():
+ torch.onnx.export(
+ model, img,
+ output_file,
+ input_names=['input'],
+ output_names=['output'],
+ export_params=True,
+ keep_initializers_as_inputs=False,
+ verbose=show,
+ opset_version=opset_version,
+ dynamic_axes=None)
+ print(f'Successfully exported ONNX model: {output_file}')
+ model.forward = origin_forward
+ # NOTE: optimizing onnx for kneron inference
+ m = onnx.load(output_file)
+ # NOTE: PyTorch 1.10.x exports onnx ir_version == 7 for opset 11,
+ # but should be ir_version == 6
+ if opset_version == 11:
+ m.ir_version = 6
+ m = torch_exported_onnx_flow(m, disable_fuse_bn=False)
+ onnx.save(m, output_file)
+ print(f'{output_file} optimized by KNERON successfully.')
+
+ if verify:
+ onnx_model = onnx.load(output_file)
+ onnx.checker.check_model(onnx_model)
+
+ # check the numerical value
+ # get pytorch output
+ with torch.no_grad():
+ pytorch_result = model(img).numpy()
+
+ # get onnx output
+ input_all = [node.name for node in onnx_model.graph.input]
+ input_initializer = [
+ node.name for node in onnx_model.graph.initializer
+ ]
+ net_feed_input = list(set(input_all) - set(input_initializer))
+ assert (len(net_feed_input) == 1)
+ sess = rt.InferenceSession(
+ output_file, providers=['CPUExecutionProvider']
+ )
+ onnx_result = sess.run(
+ None, {net_feed_input[0]: img.detach().numpy()})[0]
+ # show segmentation results
+ if show:
+ import cv2
+ img = img[0][:3, ...].permute(1, 2, 0) * 255
+ img = img.detach().numpy().astype(np.uint8)
+ ori_shape = img.shape[:2]
+
+ # resize onnx_result to ori_shape
+ onnx_result_ = onnx_result[0].argmax(0)
+ onnx_result_ = cv2.resize(onnx_result_.astype(np.uint8),
+ (ori_shape[1], ori_shape[0]))
+ show_result_pyplot(
+ model,
+ img, (onnx_result_, ),
+ palette=model.PALETTE,
+ block=False,
+ title='ONNXRuntime',
+ opacity=0.5)
+
+ # resize pytorch_result to ori_shape
+ pytorch_result_ = pytorch_result.squeeze().argmax(0)
+ pytorch_result_ = cv2.resize(pytorch_result_.astype(np.uint8),
+ (ori_shape[1], ori_shape[0]))
+ show_result_pyplot(
+ model,
+ img, (pytorch_result_, ),
+ title='PyTorch',
+ palette=model.PALETTE,
+ opacity=0.5)
+ # compare results
+ np.testing.assert_allclose(
+ pytorch_result.astype(np.float32) / num_classes,
+ onnx_result.astype(np.float32) / num_classes,
+ rtol=1e-5,
+ atol=1e-5,
+ err_msg='The outputs are different between Pytorch and ONNX')
+ print('The outputs are same between Pytorch and ONNX')
+
+ if norm_cfg is not None:
+ print("Prepending BatchNorm layer to ONNX as data normalization...")
+ mean = norm_cfg['mean']
+ std = norm_cfg['std']
+ i_n = m.graph.input[0]
+ if (
+ i_n.type.tensor_type.shape.dim[1].dim_value != len(mean)
+ or i_n.type.tensor_type.shape.dim[1].dim_value != len(std)
+ ):
+ raise ValueError(
+ f"--pixel-bias-value ({mean}) and --pixel-scale-value "
+ f"({std}) should be same as input dimension: "
+ f"{i_n.type.tensor_type.shape.dim[1].dim_value}"
+ )
+ norm_bn_bias = [-1 * cm / cs + 128. / cs for cm, cs in zip(mean, std)]
+ norm_bn_scale = [1 / cs for cs in std]
+ other.add_bias_scale_bn_after(
+ m.graph, i_n.name, norm_bn_bias, norm_bn_scale
+ )
+ m = other.polish_model(m)
+ bn_outf = os.path.splitext(output_file)[0] + "_bn_prepended.onnx"
+ onnx.save(m, bn_outf)
+ print(f"BN-Prepended ONNX saved to {bn_outf}")
+
+ return
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Convert MMSeg to ONNX')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('--checkpoint', help='checkpoint file', default=None)
+ parser.add_argument(
+ '--input-img', type=str, help='Images for input', default=None)
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ help='show onnx graph and segmentation results')
+ parser.add_argument(
+ '--verify', action='store_true', help='verify the onnx model')
+ parser.add_argument('--output-file', type=str, default='tmp.onnx')
+ parser.add_argument('--opset-version', type=int, default=11)
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=None,
+ help='input image height and width.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--normalization-in-onnx',
+ action='store_true',
+ help='Prepend BatchNorm layer to onnx model as a role of data '
+ 'normalization according to the mean and std value in the given'
+ 'cfg file.'
+ )
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ assert args.opset_version == 11, (
+ "kneron_toolchain currently only supports opset 11"
+ )
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ cfg.model.pretrained = None
+
+ test_mode = cfg.model.test_cfg.mode
+
+ if args.shape is None:
+ if test_mode == 'slide':
+ crop_size = cfg.model.test_cfg['crop_size']
+ input_shape = (1, 3, crop_size[1], crop_size[0])
+ else:
+ img_scale = cfg.test_pipeline[1]['img_scale']
+ input_shape = (1, 3, img_scale[1], img_scale[0])
+ else:
+ if test_mode == 'slide':
+ warnings.warn(
+ "We suggest you NOT assigning shape when exporting "
+ "slide-mode models. Assigning shape to slide-mode models "
+ "may result in unexpected results. To see which mode the "
+ "model is using, check cfg.model.test_cfg.mode, which "
+ "should be either 'whole' or 'slide'."
+ )
+ if len(args.shape) == 1:
+ input_shape = (1, 3, args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ input_shape = (
+ 1,
+ 3,
+ ) + tuple(args.shape)
+ else:
+ raise ValueError('invalid input shape')
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ segmentor = build_segmentor(
+ cfg.model, train_cfg=None, test_cfg=cfg.get('test_cfg'))
+ # convert SyncBN to BN
+ segmentor = _convert_batchnorm(segmentor)
+
+ if args.checkpoint:
+ checkpoint = load_checkpoint(
+ segmentor, args.checkpoint, map_location='cpu')
+ segmentor.CLASSES = checkpoint['meta']['CLASSES']
+ segmentor.PALETTE = checkpoint['meta']['PALETTE']
+
+ # read input or create dummpy input
+ if args.input_img is not None:
+ preprocess_shape = (input_shape[2], input_shape[3])
+ img = _prepare_input_img(
+ args.input_img,
+ cfg.data.test.pipeline,
+ shape=preprocess_shape)
+ else:
+ img = _demo_mm_inputs(input_shape)
+
+ if args.normalization_in_onnx:
+ norm_cfg = _parse_normalize_cfg(cfg.test_pipeline)
+ else:
+ norm_cfg = None
+ # convert model to onnx file
+ pytorch2onnx(
+ segmentor,
+ img,
+ norm_cfg=norm_cfg,
+ opset_version=args.opset_version,
+ show=args.show,
+ output_file=args.output_file,
+ verify=args.verify,
+ )
diff --git a/tools/pytorch2torchscript.py b/tools/pytorch2torchscript.py
new file mode 100644
index 0000000..d76f5ec
--- /dev/null
+++ b/tools/pytorch2torchscript.py
@@ -0,0 +1,185 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import mmcv
+import numpy as np
+import torch
+import torch._C
+import torch.serialization
+from mmcv.runner import load_checkpoint
+from torch import nn
+
+from mmseg.models import build_segmentor
+
+torch.manual_seed(3)
+
+
+def digit_version(version_str):
+ digit_version = []
+ for x in version_str.split('.'):
+ if x.isdigit():
+ digit_version.append(int(x))
+ elif x.find('rc') != -1:
+ patch_version = x.split('rc')
+ digit_version.append(int(patch_version[0]) - 1)
+ digit_version.append(int(patch_version[1]))
+ return digit_version
+
+
+def check_torch_version():
+ torch_minimum_version = '1.8.0'
+ torch_version = digit_version(torch.__version__)
+
+ assert (torch_version >= digit_version(torch_minimum_version)), \
+ f'Torch=={torch.__version__} is not support for converting to ' \
+ f'torchscript. Please install pytorch>={torch_minimum_version}.'
+
+
+def _convert_batchnorm(module):
+ module_output = module
+ if isinstance(module, torch.nn.SyncBatchNorm):
+ module_output = torch.nn.BatchNorm2d(module.num_features, module.eps,
+ module.momentum, module.affine,
+ module.track_running_stats)
+ if module.affine:
+ module_output.weight.data = module.weight.data.clone().detach()
+ module_output.bias.data = module.bias.data.clone().detach()
+ # keep requires_grad unchanged
+ module_output.weight.requires_grad = module.weight.requires_grad
+ module_output.bias.requires_grad = module.bias.requires_grad
+ module_output.running_mean = module.running_mean
+ module_output.running_var = module.running_var
+ module_output.num_batches_tracked = module.num_batches_tracked
+ for name, child in module.named_children():
+ module_output.add_module(name, _convert_batchnorm(child))
+ del module
+ return module_output
+
+
+def _demo_mm_inputs(input_shape, num_classes):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple):
+ input batch dimensions
+ num_classes (int):
+ number of semantic classes
+ """
+ (N, C, H, W) = input_shape
+ rng = np.random.RandomState(0)
+ imgs = rng.rand(*input_shape)
+ segs = rng.randint(
+ low=0, high=num_classes - 1, size=(N, 1, H, W)).astype(np.uint8)
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': 1.0,
+ 'flip': False,
+ } for _ in range(N)]
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs).requires_grad_(True),
+ 'img_metas': img_metas,
+ 'gt_semantic_seg': torch.LongTensor(segs)
+ }
+ return mm_inputs
+
+
+def pytorch2libtorch(model,
+ input_shape,
+ show=False,
+ output_file='tmp.pt',
+ verify=False):
+ """Export Pytorch model to TorchScript model and verify the outputs are
+ same between Pytorch and TorchScript.
+
+ Args:
+ model (nn.Module): Pytorch model we want to export.
+ input_shape (tuple): Use this input shape to construct
+ the corresponding dummy input and execute the model.
+ show (bool): Whether print the computation graph. Default: False.
+ output_file (string): The path to where we store the
+ output TorchScript model. Default: `tmp.pt`.
+ verify (bool): Whether compare the outputs between
+ Pytorch and TorchScript. Default: False.
+ """
+ if isinstance(model.decode_head, nn.ModuleList):
+ num_classes = model.decode_head[-1].num_classes
+ else:
+ num_classes = model.decode_head.num_classes
+
+ mm_inputs = _demo_mm_inputs(input_shape, num_classes)
+
+ imgs = mm_inputs.pop('imgs')
+
+ # replace the original forword with forward_dummy
+ model.forward = model.forward_dummy
+ model.eval()
+ traced_model = torch.jit.trace(
+ model,
+ example_inputs=imgs,
+ check_trace=verify,
+ )
+
+ if show:
+ print(traced_model.graph)
+
+ traced_model.save(output_file)
+ print('Successfully exported TorchScript model: {}'.format(output_file))
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert MMSeg to TorchScript')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('--checkpoint', help='checkpoint file', default=None)
+ parser.add_argument(
+ '--show', action='store_true', help='show TorchScript graph')
+ parser.add_argument(
+ '--verify', action='store_true', help='verify the TorchScript model')
+ parser.add_argument('--output-file', type=str, default='tmp.pt')
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=[512, 512],
+ help='input image size (height, width)')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ check_torch_version()
+
+ if len(args.shape) == 1:
+ input_shape = (1, 3, args.shape[0], args.shape[0])
+ elif len(args.shape) == 2:
+ input_shape = (
+ 1,
+ 3,
+ ) + tuple(args.shape)
+ else:
+ raise ValueError('invalid input shape')
+
+ cfg = mmcv.Config.fromfile(args.config)
+ cfg.model.pretrained = None
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ segmentor = build_segmentor(
+ cfg.model, train_cfg=None, test_cfg=cfg.get('test_cfg'))
+ # convert SyncBN to BN
+ segmentor = _convert_batchnorm(segmentor)
+
+ if args.checkpoint:
+ load_checkpoint(segmentor, args.checkpoint, map_location='cpu')
+
+ # convert the PyTorch model to LibTorch model
+ pytorch2libtorch(
+ segmentor,
+ input_shape,
+ show=args.show,
+ output_file=args.output_file,
+ verify=args.verify)
diff --git a/tools/slurm_test.sh b/tools/slurm_test.sh
new file mode 100755
index 0000000..4e6f7bf
--- /dev/null
+++ b/tools/slurm_test.sh
@@ -0,0 +1,24 @@
+#!/usr/bin/env bash
+
+set -x
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+CHECKPOINT=$4
+GPUS=${GPUS:-4}
+GPUS_PER_NODE=${GPUS_PER_NODE:-4}
+CPUS_PER_TASK=${CPUS_PER_TASK:-5}
+PY_ARGS=${@:5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --cpus-per-task=${CPUS_PER_TASK} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/test.py ${CONFIG} ${CHECKPOINT} --launcher="slurm" ${PY_ARGS}
diff --git a/tools/slurm_train.sh b/tools/slurm_train.sh
new file mode 100755
index 0000000..ab23210
--- /dev/null
+++ b/tools/slurm_train.sh
@@ -0,0 +1,23 @@
+#!/usr/bin/env bash
+
+set -x
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+GPUS=${GPUS:-4}
+GPUS_PER_NODE=${GPUS_PER_NODE:-4}
+CPUS_PER_TASK=${CPUS_PER_TASK:-5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+PY_ARGS=${@:4}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --cpus-per-task=${CPUS_PER_TASK} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/train.py ${CONFIG} --launcher="slurm" ${PY_ARGS}
diff --git a/tools/test.py b/tools/test.py
new file mode 100644
index 0000000..d5dc0d5
--- /dev/null
+++ b/tools/test.py
@@ -0,0 +1,303 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import shutil
+import time
+import warnings
+
+import mmcv
+import torch
+from mmcv.cnn.utils import revert_sync_batchnorm
+from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
+from mmcv.runner import (get_dist_info, init_dist, load_checkpoint,
+ wrap_fp16_model)
+from mmcv.utils import DictAction
+
+from mmseg import digit_version
+from mmseg.apis import multi_gpu_test, single_gpu_test
+from mmseg.datasets import build_dataloader, build_dataset
+from mmseg.models import build_segmentor
+from mmseg.utils import setup_multi_processes
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='mmseg test (and eval) a model')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('checkpoint', help='checkpoint file')
+ parser.add_argument(
+ '--work-dir',
+ help=('if specified, the evaluation metric results will be dumped'
+ 'into the directory as json'))
+ parser.add_argument(
+ '--aug-test', action='store_true', help='Use Flip and Multi scale aug')
+ parser.add_argument('--out', help='output result file in pickle format')
+ parser.add_argument(
+ '--format-only',
+ action='store_true',
+ help='Format the output results without perform evaluation. It is'
+ 'useful when you want to format the result to a specific format and '
+ 'submit it to the test server')
+ parser.add_argument(
+ '--eval',
+ type=str,
+ nargs='+',
+ help='evaluation metrics, which depends on the dataset, e.g., "mIoU"'
+ ' for generic datasets, and "cityscapes" for Cityscapes')
+ parser.add_argument('--show', action='store_true', help='show results')
+ parser.add_argument(
+ '--show-dir', help='directory where painted images will be saved')
+ parser.add_argument(
+ '--gpu-collect',
+ action='store_true',
+ help='whether to use gpu to collect results.')
+ parser.add_argument(
+ '--gpu-id',
+ type=int,
+ default=0,
+ help='id of gpu to use '
+ '(only applicable to non-distributed testing)')
+ parser.add_argument(
+ '--tmpdir',
+ help='tmp directory used for collecting results from multiple '
+ 'workers, available when gpu_collect is not specified')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--eval-options',
+ nargs='+',
+ action=DictAction,
+ help='custom options for evaluation')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+ assert args.out or args.eval or args.format_only or args.show \
+ or args.show_dir, \
+ ('Please specify at least one operation (save/eval/format/show the '
+ 'results / save the results) with the argument "--out", "--eval"'
+ ', "--format-only", "--show" or "--show-dir"')
+
+ if args.eval and args.format_only:
+ raise ValueError('--eval and --format_only cannot be both specified')
+
+ if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):
+ raise ValueError('The output file must be a pkl file.')
+
+ cfg = mmcv.Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # set multi-process settings
+ setup_multi_processes(cfg)
+
+ # set cudnn_benchmark
+ if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+ if args.aug_test:
+ # hard code index
+ cfg.data.test.pipeline[1].img_ratios = [
+ 0.5, 0.75, 1.0, 1.25, 1.5, 1.75
+ ]
+ cfg.data.test.pipeline[1].flip = True
+ cfg.model.pretrained = None
+ cfg.data.test.test_mode = True
+
+ if args.gpu_id is not None:
+ cfg.gpu_ids = [args.gpu_id]
+
+ # init distributed env first, since logger depends on the dist info.
+ if args.launcher == 'none':
+ cfg.gpu_ids = [args.gpu_id]
+ distributed = False
+ if len(cfg.gpu_ids) > 1:
+ warnings.warn(f'The gpu-ids is reset from {cfg.gpu_ids} to '
+ f'{cfg.gpu_ids[0:1]} to avoid potential error in '
+ 'non-distribute testing time.')
+ cfg.gpu_ids = cfg.gpu_ids[0:1]
+ else:
+ distributed = True
+ init_dist(args.launcher, **cfg.dist_params)
+
+ rank, _ = get_dist_info()
+ # allows not to create
+ if args.work_dir is not None and rank == 0:
+ mmcv.mkdir_or_exist(osp.abspath(args.work_dir))
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ if args.aug_test:
+ json_file = osp.join(args.work_dir,
+ f'eval_multi_scale_{timestamp}.json')
+ else:
+ json_file = osp.join(args.work_dir,
+ f'eval_single_scale_{timestamp}.json')
+ elif rank == 0:
+ work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ mmcv.mkdir_or_exist(osp.abspath(work_dir))
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ if args.aug_test:
+ json_file = osp.join(work_dir,
+ f'eval_multi_scale_{timestamp}.json')
+ else:
+ json_file = osp.join(work_dir,
+ f'eval_single_scale_{timestamp}.json')
+
+ # build the dataloader
+ # TODO: support multiple images per gpu (only minor changes are needed)
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=distributed,
+ shuffle=False)
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ model = build_segmentor(cfg.model, test_cfg=cfg.get('test_cfg'))
+ fp16_cfg = cfg.get('fp16', None)
+ if fp16_cfg is not None:
+ wrap_fp16_model(model)
+ checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu')
+ if 'CLASSES' in checkpoint.get('meta', {}):
+ model.CLASSES = checkpoint['meta']['CLASSES']
+ else:
+ print('"CLASSES" not found in meta, use dataset.CLASSES instead')
+ model.CLASSES = dataset.CLASSES
+ if 'PALETTE' in checkpoint.get('meta', {}):
+ model.PALETTE = checkpoint['meta']['PALETTE']
+ else:
+ print('"PALETTE" not found in meta, use dataset.PALETTE instead')
+ model.PALETTE = dataset.PALETTE
+
+ # clean gpu memory when starting a new evaluation.
+ torch.cuda.empty_cache()
+ eval_kwargs = {} if args.eval_options is None else args.eval_options
+
+ # Deprecated
+ efficient_test = eval_kwargs.get('efficient_test', False)
+ if efficient_test:
+ warnings.warn(
+ '``efficient_test=True`` does not have effect in tools/test.py, '
+ 'the evaluation and format results are CPU memory efficient by '
+ 'default')
+
+ eval_on_format_results = (
+ args.eval is not None and 'cityscapes' in args.eval)
+ if eval_on_format_results:
+ assert len(args.eval) == 1, 'eval on format results is not ' \
+ 'applicable for metrics other than ' \
+ 'cityscapes'
+ if args.format_only or eval_on_format_results:
+ if 'imgfile_prefix' in eval_kwargs:
+ tmpdir = eval_kwargs['imgfile_prefix']
+ else:
+ tmpdir = '.format_cityscapes'
+ eval_kwargs.setdefault('imgfile_prefix', tmpdir)
+ mmcv.mkdir_or_exist(tmpdir)
+ else:
+ tmpdir = None
+
+ if not distributed:
+ warnings.warn(
+ 'SyncBN is only supported with DDP. To be compatible with DP, '
+ 'we convert SyncBN to BN. Please use dist_train.sh which can '
+ 'avoid this error.')
+ if not torch.cuda.is_available():
+ assert digit_version(mmcv.__version__) >= digit_version('1.4.4'), \
+ 'Please use MMCV >= 1.4.4 for CPU training!'
+ model = revert_sync_batchnorm(model)
+ model = MMDataParallel(model, device_ids=cfg.gpu_ids)
+ results = single_gpu_test(
+ model,
+ data_loader,
+ args.show,
+ args.show_dir,
+ False,
+ args.opacity,
+ pre_eval=args.eval is not None and not eval_on_format_results,
+ format_only=args.format_only or eval_on_format_results,
+ format_args=eval_kwargs)
+ else:
+ model = MMDistributedDataParallel(
+ model.cuda(),
+ device_ids=[torch.cuda.current_device()],
+ broadcast_buffers=False)
+ results = multi_gpu_test(
+ model,
+ data_loader,
+ args.tmpdir,
+ args.gpu_collect,
+ False,
+ pre_eval=args.eval is not None and not eval_on_format_results,
+ format_only=args.format_only or eval_on_format_results,
+ format_args=eval_kwargs)
+
+ rank, _ = get_dist_info()
+ if rank == 0:
+ if args.out:
+ warnings.warn(
+ 'The behavior of ``args.out`` has been changed since MMSeg '
+ 'v0.16, the pickled outputs could be seg map as type of '
+ 'np.array, pre-eval results or file paths for '
+ '``dataset.format_results()``.')
+ print(f'\nwriting results to {args.out}')
+ mmcv.dump(results, args.out)
+ if args.eval:
+ eval_kwargs.update(metric=args.eval)
+ metric = dataset.evaluate(results, **eval_kwargs)
+ metric_dict = dict(config=args.config, metric=metric)
+ mmcv.dump(metric_dict, json_file, indent=4)
+ if tmpdir is not None and eval_on_format_results:
+ # remove tmp dir when cityscapes evaluation
+ shutil.rmtree(tmpdir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/torchserve/mmseg2torchserve.py b/tools/torchserve/mmseg2torchserve.py
new file mode 100644
index 0000000..9063634
--- /dev/null
+++ b/tools/torchserve/mmseg2torchserve.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser, Namespace
+from pathlib import Path
+from tempfile import TemporaryDirectory
+
+import mmcv
+
+try:
+ from model_archiver.model_packaging import package_model
+ from model_archiver.model_packaging_utils import ModelExportUtils
+except ImportError:
+ package_model = None
+
+
+def mmseg2torchserve(
+ config_file: str,
+ checkpoint_file: str,
+ output_folder: str,
+ model_name: str,
+ model_version: str = '1.0',
+ force: bool = False,
+):
+ """Converts mmsegmentation model (config + checkpoint) to TorchServe
+ `.mar`.
+
+ Args:
+ config_file:
+ In MMSegmentation config format.
+ The contents vary for each task repository.
+ checkpoint_file:
+ In MMSegmentation checkpoint format.
+ The contents vary for each task repository.
+ output_folder:
+ Folder where `{model_name}.mar` will be created.
+ The file created will be in TorchServe archive format.
+ model_name:
+ If not None, used for naming the `{model_name}.mar` file
+ that will be created under `output_folder`.
+ If None, `{Path(checkpoint_file).stem}` will be used.
+ model_version:
+ Model's version.
+ force:
+ If True, if there is an existing `{model_name}.mar`
+ file under `output_folder` it will be overwritten.
+ """
+ mmcv.mkdir_or_exist(output_folder)
+
+ config = mmcv.Config.fromfile(config_file)
+
+ with TemporaryDirectory() as tmpdir:
+ config.dump(f'{tmpdir}/config.py')
+
+ args = Namespace(
+ **{
+ 'model_file': f'{tmpdir}/config.py',
+ 'serialized_file': checkpoint_file,
+ 'handler': f'{Path(__file__).parent}/mmseg_handler.py',
+ 'model_name': model_name or Path(checkpoint_file).stem,
+ 'version': model_version,
+ 'export_path': output_folder,
+ 'force': force,
+ 'requirements_file': None,
+ 'extra_files': None,
+ 'runtime': 'python',
+ 'archive_format': 'default'
+ })
+ manifest = ModelExportUtils.generate_manifest_json(args)
+ package_model(args, manifest)
+
+
+def parse_args():
+ parser = ArgumentParser(
+ description='Convert mmseg models to TorchServe `.mar` format.')
+ parser.add_argument('config', type=str, help='config file path')
+ parser.add_argument('checkpoint', type=str, help='checkpoint file path')
+ parser.add_argument(
+ '--output-folder',
+ type=str,
+ required=True,
+ help='Folder where `{model_name}.mar` will be created.')
+ parser.add_argument(
+ '--model-name',
+ type=str,
+ default=None,
+ help='If not None, used for naming the `{model_name}.mar`'
+ 'file that will be created under `output_folder`.'
+ 'If None, `{Path(checkpoint_file).stem}` will be used.')
+ parser.add_argument(
+ '--model-version',
+ type=str,
+ default='1.0',
+ help='Number used for versioning.')
+ parser.add_argument(
+ '-f',
+ '--force',
+ action='store_true',
+ help='overwrite the existing `{model_name}.mar`')
+ args = parser.parse_args()
+
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ if package_model is None:
+ raise ImportError('`torch-model-archiver` is required.'
+ 'Try: pip install torch-model-archiver')
+
+ mmseg2torchserve(args.config, args.checkpoint, args.output_folder,
+ args.model_name, args.model_version, args.force)
diff --git a/tools/torchserve/mmseg_handler.py b/tools/torchserve/mmseg_handler.py
new file mode 100644
index 0000000..28fe501
--- /dev/null
+++ b/tools/torchserve/mmseg_handler.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import base64
+import os
+
+import cv2
+import mmcv
+import torch
+from mmcv.cnn.utils.sync_bn import revert_sync_batchnorm
+from ts.torch_handler.base_handler import BaseHandler
+
+from mmseg.apis import inference_segmentor, init_segmentor
+
+
+class MMsegHandler(BaseHandler):
+
+ def initialize(self, context):
+ properties = context.system_properties
+ self.map_location = 'cuda' if torch.cuda.is_available() else 'cpu'
+ self.device = torch.device(self.map_location + ':' +
+ str(properties.get('gpu_id')) if torch.cuda.
+ is_available() else self.map_location)
+ self.manifest = context.manifest
+
+ model_dir = properties.get('model_dir')
+ serialized_file = self.manifest['model']['serializedFile']
+ checkpoint = os.path.join(model_dir, serialized_file)
+ self.config_file = os.path.join(model_dir, 'config.py')
+
+ self.model = init_segmentor(self.config_file, checkpoint, self.device)
+ self.model = revert_sync_batchnorm(self.model)
+ self.initialized = True
+
+ def preprocess(self, data):
+ images = []
+
+ for row in data:
+ image = row.get('data') or row.get('body')
+ if isinstance(image, str):
+ image = base64.b64decode(image)
+ image = mmcv.imfrombytes(image)
+ images.append(image)
+
+ return images
+
+ def inference(self, data, *args, **kwargs):
+ results = [inference_segmentor(self.model, img) for img in data]
+ return results
+
+ def postprocess(self, data):
+ output = []
+
+ for image_result in data:
+ _, buffer = cv2.imencode('.png', image_result[0].astype('uint8'))
+ content = buffer.tobytes()
+ output.append(content)
+ return output
diff --git a/tools/torchserve/test_torchserve.py b/tools/torchserve/test_torchserve.py
new file mode 100644
index 0000000..5975285
--- /dev/null
+++ b/tools/torchserve/test_torchserve.py
@@ -0,0 +1,57 @@
+from argparse import ArgumentParser
+from io import BytesIO
+
+import matplotlib.pyplot as plt
+import mmcv
+import requests
+
+from mmseg.apis import inference_segmentor, init_segmentor
+
+
+def parse_args():
+ parser = ArgumentParser(
+ description='Compare result of torchserve and pytorch,'
+ 'and visualize them.')
+ parser.add_argument('img', help='Image file')
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument('model_name', help='The model name in the server')
+ parser.add_argument(
+ '--inference-addr',
+ default='127.0.0.1:8080',
+ help='Address and port of the inference server')
+ parser.add_argument(
+ '--result-image',
+ type=str,
+ default=None,
+ help='save server output in result-image')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+
+ args = parser.parse_args()
+ return args
+
+
+def main(args):
+ url = 'http://' + args.inference_addr + '/predictions/' + args.model_name
+ with open(args.img, 'rb') as image:
+ tmp_res = requests.post(url, image)
+ content = tmp_res.content
+ if args.result_image:
+ with open(args.result_image, 'wb') as out_image:
+ out_image.write(content)
+ plt.imshow(mmcv.imread(args.result_image, 'grayscale'))
+ plt.show()
+ else:
+ plt.imshow(plt.imread(BytesIO(content)))
+ plt.show()
+ model = init_segmentor(args.config, args.checkpoint, args.device)
+ image = mmcv.imread(args.img)
+ result = inference_segmentor(model, image)
+ plt.imshow(result[0])
+ plt.show()
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ main(args)
diff --git a/tools/train.py b/tools/train.py
new file mode 100644
index 0000000..1e1d01a
--- /dev/null
+++ b/tools/train.py
@@ -0,0 +1,234 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import copy
+import os
+import os.path as osp
+import time
+import warnings
+
+import mmcv
+import torch
+from mmcv.cnn.utils import revert_sync_batchnorm
+from mmcv.runner import get_dist_info, init_dist
+from mmcv.utils import Config, DictAction, get_git_hash
+
+from mmseg import __version__
+from mmseg.apis import init_random_seed, set_random_seed, train_segmentor
+from mmseg.datasets import build_dataset
+from mmseg.models import build_segmentor
+from mmseg.utils import collect_env, get_root_logger, setup_multi_processes
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a segmentor')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument('--work-dir', help='the dir to save logs and models')
+ parser.add_argument(
+ '--load-from', help='the checkpoint file to load weights from')
+ parser.add_argument(
+ '--resume-from', help='the checkpoint file to resume from')
+ parser.add_argument(
+ '--no-validate',
+ action='store_true',
+ help='whether not to evaluate the checkpoint during training')
+ group_gpus = parser.add_mutually_exclusive_group()
+ group_gpus.add_argument(
+ '--gpus',
+ type=int,
+ help='(Deprecated, please use --gpu-id) number of gpus to use '
+ '(only applicable to non-distributed training)')
+ group_gpus.add_argument(
+ '--gpu-ids',
+ type=int,
+ nargs='+',
+ help='(Deprecated, please use --gpu-id) ids of gpus to use '
+ '(only applicable to non-distributed training)')
+ group_gpus.add_argument(
+ '--gpu-id',
+ type=int,
+ default=0,
+ help='id of gpu to use '
+ '(only applicable to non-distributed training)')
+ parser.add_argument('--seed', type=int, default=None, help='random seed')
+ parser.add_argument(
+ '--deterministic',
+ action='store_true',
+ help='whether to set deterministic options for CUDNN backend.')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', type=int, default=0)
+ parser.add_argument(
+ '--auto-resume',
+ action='store_true',
+ help='resume from the latest checkpoint automatically.')
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # set cudnn_benchmark
+ if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ if args.load_from is not None:
+ cfg.load_from = args.load_from
+ if args.resume_from is not None:
+ cfg.resume_from = args.resume_from
+ if args.gpus is not None:
+ cfg.gpu_ids = range(1)
+ warnings.warn('`--gpus` is deprecated because we only support '
+ 'single GPU mode in non-distributed training. '
+ 'Use `gpus=1` now.')
+ if args.gpu_ids is not None:
+ cfg.gpu_ids = args.gpu_ids[0:1]
+ warnings.warn('`--gpu-ids` is deprecated, please use `--gpu-id`. '
+ 'Because we only support single GPU mode in '
+ 'non-distributed training. Use the first GPU '
+ 'in `gpu_ids` now.')
+ if args.gpus is None and args.gpu_ids is None:
+ cfg.gpu_ids = [args.gpu_id]
+
+ cfg.auto_resume = args.auto_resume
+
+ # init distributed env first, since logger depends on the dist info.
+ if args.launcher == 'none':
+ distributed = False
+ else:
+ distributed = True
+ init_dist(args.launcher, **cfg.dist_params)
+ # gpu_ids is used to calculate iter when resuming checkpoint
+ _, world_size = get_dist_info()
+ cfg.gpu_ids = range(world_size)
+
+ # create work_dir
+ mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
+ # dump config
+ cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
+ # init the logger before other steps
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ log_file = osp.join(cfg.work_dir, f'{timestamp}.log')
+ logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
+
+ # set multi-process settings
+ setup_multi_processes(cfg)
+
+ # init the meta dict to record some important information such as
+ # environment info and seed, which will be logged
+ meta = dict()
+ # log env info
+ env_info_dict = collect_env()
+ env_info = '\n'.join([f'{k}: {v}' for k, v in env_info_dict.items()])
+ dash_line = '-' * 60 + '\n'
+ logger.info('Environment info:\n' + dash_line + env_info + '\n' +
+ dash_line)
+ meta['env_info'] = env_info
+
+ # log some basic info
+ logger.info(f'Distributed training: {distributed}')
+ logger.info(f'Config:\n{cfg.pretty_text}')
+
+ # set random seeds
+ seed = init_random_seed(args.seed)
+ logger.info(f'Set random seed to {seed}, '
+ f'deterministic: {args.deterministic}')
+ set_random_seed(seed, deterministic=args.deterministic)
+ cfg.seed = seed
+ meta['seed'] = seed
+ meta['exp_name'] = osp.basename(args.config)
+
+ model = build_segmentor(
+ cfg.model,
+ train_cfg=cfg.get('train_cfg'),
+ test_cfg=cfg.get('test_cfg'))
+ model.init_weights()
+
+ # SyncBN is not support for DP
+ if not distributed:
+ warnings.warn(
+ 'SyncBN is only supported with DDP. To be compatible with DP, '
+ 'we convert SyncBN to BN. Please use dist_train.sh which can '
+ 'avoid this error.')
+ model = revert_sync_batchnorm(model)
+
+ logger.info(model)
+
+ datasets = [build_dataset(cfg.data.train)]
+ if len(cfg.workflow) == 2:
+ val_dataset = copy.deepcopy(cfg.data.val)
+ val_dataset.pipeline = cfg.data.train.pipeline
+ datasets.append(build_dataset(val_dataset))
+ if cfg.checkpoint_config is not None:
+ # save mmseg version, config file content and class names in
+ # checkpoints as meta data
+ cfg.checkpoint_config.meta = dict(
+ mmseg_version=f'{__version__}+{get_git_hash()[:7]}',
+ config=cfg.pretty_text,
+ CLASSES=datasets[0].CLASSES,
+ PALETTE=datasets[0].PALETTE)
+ # add an attribute for visualization convenience
+ model.CLASSES = datasets[0].CLASSES
+ # passing checkpoint meta for saving best checkpoint
+ meta.update(cfg.checkpoint_config.meta)
+ train_segmentor(
+ model,
+ datasets,
+ cfg,
+ distributed=distributed,
+ validate=(not args.no_validate),
+ timestamp=timestamp,
+ meta=meta)
+
+
+if __name__ == '__main__':
+ main()